Среднее геометрическое
значение (xg)
используется для вычисления центральной
тенденции при прогрессивно возрастающих
квантилях (когда распределение значений
переменной имеет выраженную положительную
(правостороннюю) асимметрию).
Формула среднего
геометрического:
![]()
(4.5)
Для
вычислений можно использовать
логарифмирование каждой переменной по
основанию е:
![]()
(4.6)
Переход
от ln xg
к xg
осуществляется с помощью операции
антилогарифмирования:
![]()
(4.7)
З а д а ч и п о
т е м е
Задача
4.1
Условие задачи
У 50 школьников выпускных классов
исследовался коэффициент интеллекта
(IQ). Получен следующий вариационный ряд
(см. табл.).
|
№№ |
IQ |
№№ |
IQ |
№№ |
IQ |
№№ |
IQ |
№№ |
IQ |
|
1 |
119 |
11 |
104 |
21 |
111 |
31 |
103 |
41 |
107 |
|
2 |
86 |
12 |
88 |
22 |
98 |
32 |
88 |
42 |
92 |
|
3 |
100 |
13 |
113 |
23 |
84 |
33 |
108 |
43 |
105 |
|
4 |
93 |
14 |
89 |
24 |
102 |
34 |
70 |
44 |
89 |
|
5 |
108 |
15 |
103 |
25 |
92 |
35 |
113 |
45 |
95 |
|
6 |
117 |
16 |
107 |
26 |
88 |
36 |
83 |
46 |
110 |
|
7 |
82 |
17 |
78 |
27 |
104 |
37 |
91 |
47 |
101 |
|
8 |
100 |
18 |
110 |
28 |
127 |
38 |
97 |
48 |
85 |
|
9 |
86 |
19 |
98 |
29 |
103 |
39 |
87 |
49 |
114 |
|
10 |
129 |
20 |
84 |
30 |
112 |
40 |
101 |
50 |
102 |
Задание
1. Построить
ранжированный ряд IQ.
2. Построить таблицу
сгруппированных частот для 7 ¸
8-классового распределения.
3. Построить
графическое выражение IQ в виде полигона
распределения или столбчатой диаграммы.
4. Определить 1-й,
2-й и 3-й квартили, моду, медиану и среднее
арифметическое значение коэффициента
интеллектуальности для выборки в 50
испытуемых.
Задача
4.2
Условие задачи
В трех выпускных
классах средней школы подсчитывался
средний балл успеваемости. Получены
следующие результаты:
|
11-а класс |
11-б класс |
11-в класс |
||||
|
Пол |
Число учащихся |
Балл |
Число учащихся |
Балл |
Число учащихся |
Балл |
|
Девочки |
18 |
3,62 |
15 |
3,90 |
17 |
3,75 |
|
Мальчики |
12 |
3,44 |
13 |
3,58 |
13 |
3,70 |
Задание
Вычислить средний
балл успеваемости у девочек и мальчиков
всех выпускных классов.
Задача
4.
3
Имеется следующая
совокупность экспериментальных данных:
1,00; 1,26; 1,58; 2,00; 2,51; 3,16; 3,98; 5,01; 6,31; 7,94.
Задание
Вычислить среднее
геометрическое значение данной
совокупности двумя способами:
а) вычислением
произведения значений и возведения в
соответствующую степень;
б) путем
логарифмирования по основанию e.
________________________________________________________________________________
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
There are two ways to calculate the geometric mean in Python:
Method 1: Calculate Geometric Mean Using SciPy
from scipy.stats import gmean #calculate geometric mean gmean([value1, value2, value3, ...])
Method 2: Calculate Geometric Mean Using NumPy
import numpy as np
#define custom function
def g_mean(x):
a = np.log(x)
return np.exp(a.mean())
#calculate geometric mean
g_mean([value1, value2, value3, ...])
Both methods will return the exact same results.
The following examples show how to use each of these methods in practice.
Example 1: Calculate Geometric Mean Using SciPy
The following code shows how to use the gmean() function from the SciPy library to calculate the geometric mean of an array of values:
from scipy.stats import gmean #calculate geometric mean gmean([1, 4, 7, 6, 6, 4, 8, 9]) 4.81788719702029
The geometric mean turns out to be 4.8179.
Example 2: Calculate Geometric Mean Using NumPy
The following code shows how to write a custom function to calculate a geometric mean using built-in functions from the NumPy library:
import numpy as np
#define custom function
def g_mean(x):
a = np.log(x)
return np.exp(a.mean())
#calculate geometric mean
g_mean([1, 4, 7, 6, 6, 4, 8, 9])
4.81788719702029
The geometric mean turns out to be 4.8179, which matches the result from the previous example.
How to Handle Zeros
Note that both methods will return a zero if there are any zeros in the array that you’re working with.
Thus, you can use the following bit of code to remove any zeros from an array before calculating the geometric mean:
#create array with some zeros
x = [1, 0, 0, 6, 6, 0, 8, 9]
#remove zeros from array
x_new = [i for i in x if i != 0]
#view updated array
print(x_new)
[1, 6, 6, 8, 9]
Additional Resources
How to Calculate Mean Squared Error (MSE) in Python
How to Calculate Mean Absolute Error in Python
Иллюстрированный самоучитель по MathCAD 12
В Mathcad имеется ряд встроенных функций для расчетов числовых статистических характеристик рядов случайных данных:
- mean(x) – выборочное среднее значение;
- median (х) – выборочная медиана (median) – значение аргумента, которое делит гистограмму плотности вероятностей на две равные части;
- var (х) – выборочная дисперсия (variance);
- stdev(x) – среднеквадратичное (или стандартное) отклонение (standard deviation);
- max(x),min(x) – максимальное и минимальное значения выборки;
- mode(x) – наиболее часто встречающееся значение выборки;
- var(х),stdev(x) – выборочная дисперсия и среднеквадратичное отклонение в другой нормировке:
- х – вектор (или матрица) с выборкой случайных данных.
Пример использования первых четырех функций приведен в листинге 12.10.
Листинг 12.10. Расчет числовых характеристик случайного вектора:
Определение статистических характеристик случайных величин приведено в листинге 12.11 на еще одном примере обработки выборки малого объема (по пяти данным). В том же листинге иллюстрируется применение еще двух функций, которые имеют смысл дисперсии и стандартного отклонения в несколько другой нормировке. Сравнивая различные выражения, вы без труда освоите связь между встроенными функциями.
Внимание!
Осторожно относитесь к написанию первой литеры в этих функциях, особенно при обработке малых выборок (листинг 12.11).Листинг 12.11. К определению статических характеристик:
Иногда в статистике встречаются и иные функции, например, помимо арифметического среднего, применяются другие средние значения:
- gmean(x) – геометрическое среднее выборки случайных чисел;
- hmean(x) – гармоническое среднее выборки случайных чисел.
Математическое определение этих функций и пример их использования в Mathcad приведены в листинге 12.12.
Маткад как найти среднее значение функции
Встроенные функции и ключевые слова
В этом приложении дан список основных встроенных функций Mathcad. В приведенных ниже функциях для систем класса Mathcad используются следующие обозначения:
- х и у – вещественные числа;
- z – вещественное либо комплексное число;
- m, n, i, j и k – целые числа;
- v, u и все имена, начинающиеся с v – векторы;
- А и B – матрицы либо векторы;
- М и N – квадратные матрицы;
- F – вектор-функция;
- file – либо имя файла, либо файловая переменная, присоединенная к имени файла.
Все углы в тригонометрических функциях выражены в радианах. Многозначные функции и функции с комплексным аргументом всегда возвращают главное значение. Имена приведенных функций нечувствительны к шрифту, но чувствительны к регистру – их следует вводить с клавиатуры в точности, как они приведены. Все функции возвращают указанное для них значение
Как найти максимум функции в маткаде
MathCAD позволяет находить экстремумы функций, которые имеют конечное количество экстремумов. Для нахождения экстремума используются функции Minimize и Maximize .
На рис.14 показан пример использования функции нахождения минимума. Нахождение максимума происходит аналогично, за исключением того, что функцию Minimize необходимо заменить на Maximize . В данном примере показан случай, когда максимум функции не может быть найден.
8.6.1. Экстремум функции одной переменной
Поиск экстремума функции включает в себя задачи нахождения локального и глобального экстремума. Последние называют еще задачами оптимизации. Рассмотрим конкретный пример функции f(x), показанной графиком на рис. 8.8 на интервале (-2,5). Она имеет глобальный максимум на левой границе интервала, глобальный минимум, локальный максимум, локальный минимум и локальный максимум на правой границе интервала (в порядке слева направо).
В Mathcad с помощью встроенных функций решается только задача поиска локального экстремума. Чтобы найти глобальный максимум (или минимум), требуется либо сначала вычислить все их локальные значения и потом выбрать из них наибольший (наименьший), либо предварительно просканиро-вать с некоторым шагом рассматриваемую область, чтобы выделить из нее подобласть наибольших (наименьших) значений функции и осуществить поиск глобального экстремума, уже находясь в его окрестности. Последний путь таит в себе некоторую опасность уйти в зону другого локального экстремума, но часто может быть предпочтительнее из соображений экономии времени.
Рис. 8.8. График функции f(х)=х 4 +5х 3 -10х
Для поиска локальных экстремумов имеются две встроенные функции, которые могут применяться как в пределах вычислительного блока, так и автономно.
- Minimize (f, x1, . ,хм) — вектор значений аргументов, при которых функция f достигает минимума;
- Maximize (f, х1, . ,хм) — вектор значений аргументов, при которых функция f достигает максимума;
- f (x1, . , хм. ) — функция;
- x1, . , xм — аргументы, по которым производится минимизация (максимизация).
Всем аргументам функции f предварительно следует присвоить некоторые значения, причем для тех переменных, по которым производится минимизация, они будут восприниматься как начальные приближения. Примеры вычисления экстремума функции одной переменной (рис. 8.8) без дополнительных условий показаны в листингах 8.11- 8.12. Поскольку никаких дополнительных условий в них не вводится, поиск экстремумов выполняется для любых значений.
Листинг 8.11. Минимум функции одной переменной
Листинг 8.12. Максимум функции одной переменной
Как видно из листингов, существенное влияние на результат оказывает выбор начального приближения, в зависимости от чего в качестве ответа выдаются различные локальные экстремумы. В последнем случае численный метод вообще не справляется с задачей, поскольку начальное приближение х=-10 выбрано далеко от области локального максимума, и поиск решения уходит в сторону увеличения f (х).
1. Поиск экстремума функции
Задачи поиска экстремума функции означают нахождение ее максимума (наибольшего значения) или минимума (наименьшего значения) в некоторой области определения ее аргументов. Ограничения значений аргументов, задающих эту область, как и прочие дополнительные условия, должны быть определены в виде системы неравенств и (или) уравнений. В таком случае говорят о задаче на условный экстремум.
Для решения задач поиска максимума и минимума в Mathcad имеются встроенные функции Minerr, Minimize и Maximize. Все они используют те же градиентные численные методы, что и функция Find для решения уравнений.
2. Экстремум функции одной переменной
Поиск экстремума функции включает в себя задачи нахождения локального и глобального экстремума. Последние называют еще задачами оптимизации. Рассмотрим конкретный пример функции f(x), показанной графиком на рис.2 на интервале (-2,5). Она имеет глобальный максимум на левой границе интервала, глобальный минимум, локальный максимум, локальный минимум и локальный максимум на правой границе интервала (в порядке слева направо).
В Mathcad с помощью встроенных функций решается только задача поиска локального экстремума. Чтобы найти глобальный максимум (или минимум), требуется либо сначала вычислить все их локальные значения и потом выбрать из них наибольший (наименьший), либо предварительно просканировать с некоторым шагом рассматриваемую область, чтобы выделить из нее подобласть наибольших (наименьших) значений функции и осуществить поиск глобального экстремума, уже находясь в его окрестности. Последний путь таит в себе некоторую опасность уйти в зону другого локального экстремума, но часто может быть предпочтительнее из соображений экономии времени.
 Рис. 1. График функции f(х)=х 4 +5х 3 -10х
Рис. 1. График функции f(х)=х 4 +5х 3 -10хПостроим график заданной функции (рис.1). По графику видны участки локальных экстремумов функции.
Для поиска локальных экстремумов имеются две встроенные функции, которые могут применяться как в пределах вычислительного блока, так и автономно.
· Minimize (f, x1, … ,хм) — вектор значений аргументов, при которых функция f достигает минимума;
· Maximize (f, х1, … ,хм) — вектор значений аргументов, при которых функция f достигает максимума;
Всем аргументам функции f предварительно следует присвоить некоторые значения, причем для тех переменных, по которым производится минимизация, они будут восприниматься как начальные приближения. Примеры вычисления экстремума функции одной переменной (рис.1) без дополнительных условий показаны в листинге на рис.2. Поскольку никаких дополнительных условий в них не вводится, поиск экстремумов выполняется для любых значений.
Рис.2. Поиск локальных экстремумов функции одной переменнойКак видно из листинга, существенное влияние на результат оказывает выбор начального приближения, в зависимости от чего в качестве ответа выдаются локальные различные экстремумы. В последнем случае численный метод вообще не справляется с задачей, поскольку начальное приближение х=-10 выбрано далеко от области локального максимума, и поиск решения уходит в сторону увеличения f (х).
3. Условный экстремум
В задачах на условный экстремум функции минимизации и максимизации должны быть включены в вычислительный блок, т. е. им должно предшествовать ключевое слово Given. В промежутке между Given и функцией поиска экстремума с помощью булевых операторов записываются логические выражения (неравенства, уравнения), задающие ограничения на значения аргументов минимизируемой функции. На рис.3 показаны примеры поиска условного экстремума на различных интервалах, определенных неравенствами. Сравните результаты работы этого листинга с двумя предыдущими.
Рис. 3. Три примера поиска условного экстремума функции
Не забывайте о важности выбора правильного начального приближения и в случае задач на условный экстремум. Например, если вместо условия — 3 Скачать пример
Александр Малыгин
Объект обсуждения – программное обеспечение для выполнения автоматизированного конструкторского и технологического проектирования, разработки управляющих программ, вопросы, связанные с разработкой прикладных САПР.
2 Комментарии “ Оптимизация функций одной и нескольких переменных в PTC MathCAD ”
Спасибо, очень информативано! Скажите, а для 9 переменных такая же функция и такой же принцип используется?
Функция будет другая. Вы сами подбираете вид функции, остальное аналогично.
 Рис. 1. График функции f(х)=х 4 +5х 3 -10х
Рис. 1. График функции f(х)=х 4 +5х 3 -10х

 Рис.2. Поиск локальных экстремумов функции одной переменной
Рис.2. Поиск локальных экстремумов функции одной переменной


Способы представления числовых и категорийных данных в виде таблиц и диаграмм являются существенной, но не основной частью анализа данных. Ведущая роль принадлежит методам исследования числовых данных и их свойств. В этой заметке рассмотрены способы определения среднего значения, вариации и формы распределения генеральной совокупности. [1]
В большинстве случаев данные концентрируются вокруг некоей центральной точки. Таким образом, чтобы описать любой набор данных, достаточно указать средне значение. Рассмотрим последовательно три числовые характеристики, которые используются для оценки среднего значения распределения: среднее арифметическое, медиана и мода.
Среднее арифметическое
Среднее арифметическое (часто называемое просто средним) — наиболее распространенная оценка среднего значения распределения. Она является результатом деления суммы всех наблюдаемых числовых величин на их количество. Для выборки, состоящей из чисел Х1, Х2, …, Хn, выборочное среднее (обозначаемое символом ![]() ) равно
) равно ![]() = (Х1 + Х2 + … + Хn) / n, или
= (Х1 + Х2 + … + Хn) / n, или

где ![]() — выборочное среднее, n — объем выборки, Xi – i-й элемент выборки.
— выборочное среднее, n — объем выборки, Xi – i-й элемент выборки.
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Рассмотрим вычисление среднего арифметического значения пятилетней среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска (рис. 1).

Рис. 1. Среднегодовая доходность 15 взаимных фондов с очень высоким уровнем риска
Выборочное среднее вычисляется следующим образом:

Это хороший доход, особенно по сравнению с 3–4% дохода, который получили вкладчики банков или кредитных союзов за тот же период времени. Если упорядочить значения доходности, то легко заметить, что восемь фондов имеют доходность выше, а семь — ниже среднего значения. Среднее арифметическое играет роль точки равновесия, так что фонды с низкими доходами уравновешивают фонды с высокими доходами. В вычислении среднего задействованы все элементы выборки. Ни одна из других оценок среднего значения распределения не обладает этим свойством.
Когда следует вычислять среднее арифметическое. Поскольку среднее арифметическое зависит от всех элементов выборки, наличие экстремальных значений значительно влияет на результат. В таких ситуациях среднее арифметическое может исказить смысл числовых данных. Следовательно, описывая набор данных, содержащий экстремальные значения, необходимо указывать медиану либо среднее арифметическое и медиану. Например, если удалить из выборки доходность фонда RS Emerging Growth, выборочное среднее доходности 14 фондов уменьшится почти на 1% и составит 5,19%.
Медиана
Медиана представляет собой срединное значение упорядоченного массива чисел. Если массив не содержит повторяющихся чисел, то половина его элементов окажется меньше, а половина — больше медианы. Если выборка содержит экстремальные значения, для оценки среднего значения лучше использовать не среднее арифметическое, а медиану. Чтобы вычислить медиану выборки, ее сначала необходимо упорядочить.

Эта формула неоднозначна. Ее результат зависит от четности или нечетности числа n:
- Если выборка содержит нечетное количество элементов, медиана равна (n+1)/2-му элементу.
- Если выборка содержит четное количество элементов, медиана лежит между двумя средними элементами выборки и равна среднему арифметическому, вычисленному по этим двум элементам.
Чтобы вычислить медиану выборки, содержащей данные о доходности 15 взаимных фондов с очень высокий уровнем риска, сначала необходимо упорядочить исходные данные (рис. 2). Тогда медиана будет напротив номера среднего элемента выборки; в нашем примере №8. В Excel есть специальная функция =МЕДИАНА(), которая работает и с неупорядоченными массивами тоже.

Рис. 2. Медиана 15 фондов
Таким образом, медиана равна 6,5. Это означает, что доходность одной половины фондов с очень высоким уровнем риска не превышает 6,5, а доходность второй половины — превышает ее. Обратите внимание на то, что медиана, равная 6,5, ненамного больше среднего значения, равного 6,08.
Если удалить из выборки доходность фонда RS Emerging Growth, то медиана оставшихся 14 фондов уменьшится до 6,2%, то есть не так значительно, как среднее арифметическое (рис. 3).

Рис. 3. Медиана 14 фондов
Мода
Термин был впервые введен Пирсоном в 1894 г. Мода — это число, которое чаще других встречается в выборке (наиболее модное). Мода хорошо описывает, например, типичную реакцию водителей на сигнал светофора о прекращении движения. Классический пример использования моды — выбор размера выпускаемой партии обуви или цвета обоев. Если распределение имеет несколько мод, то говорят, что оно мультимодально или многомодально (имеет два или более «пика»). Мультимодальность распределения дает важную информацию о природе исследуемой переменной. Например, в социологических опросах, если переменная представляет собой предпочтение или отношение к чему-то, то мультимодальность может означать, что существуют несколько определенно различных мнений. Мультимодальность также служит индикатором того, что выборка не является однородной и наблюдения, возможно, порождены двумя или более «наложенными» распределениями. В отличие от среднего арифметического, выбросы на моду не влияют. Для непрерывно распределенных случайных величин, например, для показателей среднегодовой доходности взаимных фондов, мода иногда вообще не существует (или не имеет смысла). Поскольку эти показатели могут принимать самые разные значения, повторяющиеся величины встречаются крайне редко.
Квартили
Квартили — это показатели, которые чаще всего используются для оценки распределения данных при описании свойств больших числовых выборок. В то время как медиана разделяет упорядоченный массив пополам (50% элементов массива меньше медианы и 50% — больше), квартили разбивают упорядоченный набор данных на четыре части. Величины Q1, медиана и Q3 являются 25-м, 50-м и 75-м перцентилем соответственно. Первый квартиль Q1 — это число, разделяющее выборку на две части: 25% элементов меньше, а 75% — больше первого квартиля.

Третий квартиль Q3 — это число, разделяющее выборку также на две части: 75% элементов меньше, а 25% — больше третьего квартиля.

Для расчета квартилей в версиях Excel до 2007 г. использовалась функция =КВАРТИЛЬ(массив;часть). Начиная с версии Excel2010 применяются две функции: [2]
- =КВАРТИЛЬ.ВКЛ(массив;часть)
- =КВАРТИЛЬ.ИСКЛ(массив;часть)
Эти две функции дают немного различные значения (рис. 4). Например, при вычислении квартилей выборки, содержащей данные о среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска Q1 = 1,8 или –0,7 для КВАРТИЛЬ.ВКЛ и КВАРТИЛЬ.ИСКЛ, соответственно. Кстати функция КВАРТИЛЬ, использовавшаяся ранее соответствует современной функции КВАРТИЛЬ.ВКЛ. Для расчета квартилей в Excel с помощью вышеприведенных формул массив данных можно не упорядочивать.

Рис. 4. Вычисление квартилей в Excel
Подчеркнем еще раз. Excel умеет рассчитывать квартили для одномерного дискретного ряда, содержащего значения случайной величины. Расчет квартилей для распределения на основе частот приведен ниже в разделе Вычисление описательных статистик для распределения на основе частот.
Среднее геометрическое
В отличие от среднего арифметического среднее геометрическое позволяет оценить степень изменения переменной с течением времени. Среднее геометрическое — это корень n-й степени из произведения n величин (в Excel используется функция =СРГЕОМ):
![]() G = (X1 * X2 * … * Xn)1/n
G = (X1 * X2 * … * Xn)1/n
Похожий параметр – среднее геометрическое значение нормы прибыли – определяется формулой:
![]() G = [(1 + R1) * (1 + R2) * … * (1 + Rn)]1/n – 1,
G = [(1 + R1) * (1 + R2) * … * (1 + Rn)]1/n – 1,
где Ri – норма прибыли за i-й период времени.
Например, предположим, что объем вложенных средств в исходный момент времени равен 100 000 долл. К концу первого года он падает до уровня 50 000 долл., а к концу второго года восстанавливается до исходной отметки 100 000 долл. Норма прибыли этой инвестиции за двухлетний период равна 0, поскольку первоначальный и финальный объем средств равны между собой. Однако среднее арифметическое годовых норм прибыли равно ![]() = (–0,5 + 1) / 2 = 0,25 или 25%, поскольку норма прибыли в первый год R1 = (50 000 – 100 000) / 100 000 = –0,5, а во второй R2 = (100 000 – 50 000) / 50 000 = 1. В то же время, среднее геометрическое значение нормы прибыли за два года равно:
= (–0,5 + 1) / 2 = 0,25 или 25%, поскольку норма прибыли в первый год R1 = (50 000 – 100 000) / 100 000 = –0,5, а во второй R2 = (100 000 – 50 000) / 50 000 = 1. В то же время, среднее геометрическое значение нормы прибыли за два года равно: ![]() G = [(1–0,5) * (1+1)]1/2 – 1 = [0,5*2,0] ½ – 1 = 1 – 1 = 0. Таким образом, среднее геометрическое точнее отражает изменение (точнее, отсутствие изменений) объема инвестиций за двухлетний период, чем среднее арифметическое.
G = [(1–0,5) * (1+1)]1/2 – 1 = [0,5*2,0] ½ – 1 = 1 – 1 = 0. Таким образом, среднее геометрическое точнее отражает изменение (точнее, отсутствие изменений) объема инвестиций за двухлетний период, чем среднее арифметическое.
Интересные факты. Во-первых, среднее геометрическое всегда будет меньше среднего арифметического тех же чисел. За исключением случая, когда все взятые числа равны друг другу. Во-вторых, рассмотрев свойства прямоугольного треугольника, можно понять, почему среднее называется геометрическим. Высота прямоугольного треугольника, опущенная на гипотенузу, есть среднее пропорциональное между проекциями катетов на гипотенузу, а каждый катет есть среднее пропорциональное между гипотенузой и его проекцией на гипотенузу (рис. 5). Это даёт геометрический способ построения среднего геометрического двух (длин) отрезков: нужно построить окружность на сумме этих двух отрезков как на диаметре, тогда высота, восставленная из точки их соединения до пересечения с окружностью, даст искомую величину: ![]()

Рис. 5. Геометрическая природа среднего геометрического (рисунок из Википедии)
* * *
Второе важное свойство числовых данных — их вариация, характеризующая степень дисперсии данных. Две разные выборки могут отличаться как средними значениями, так и вариациями. Однако, как показано на рис. 6 и 7, две выборки могут иметь одинаковые вариации, но разные средние значения, либо одинаковые средние значения и совершенно разные вариации. Данные, которым соответствует полигон В на рис. 7, изменяются намного меньше, чем данные, по которым построен полигон А.

Рис. 6. Два симметричных распределения колоколообразной формы с одинаковым разбросом и разными средними значениями

Рис. 7. Два симметричных распределения колоколообразной формы с одинаковыми средними значениями и разным разбросом
Существует пять оценок вариации данных:
- размах,
- межквартильный размах,
- дисперсия,
- стандартное отклонение,
- коэффициент вариации.
Размах
Размахом называется разность между наибольшим и наименьшим элементами выборки:
Размах = ХMax – ХMin
Размах выборки, содержащей данные о среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска, можно вычислить, используя упорядоченный массив (см. рис. 4): Размах = 18,5 – (–6,1) = 24,6. Это значит, что разница между наибольшей и наименьшей среднегодовой доходностью фондов с очень высоким уровнем риска равна 24,6% .
Размах позволяет измерить общий разброс данных. Хотя размах выборки является весьма простой оценкой общего разброса данных, его слабость заключается в том, что он никак не учитывает, как именно распределены данные между минимальным и максимальным элементами. Этот эффект хорошо прослеживается на рис. 8, который иллюстрирует выборки, имеющие одинаковый размах. Шкала В демонстрирует, что если выборка содержит хотя бы одно экстремальное значение, размах выборки оказывается весьма неточной оценкой разброса данных.

Рис. 8. Сравнение трех выборок, имеющих одинаковый размах; треугольник символизирует опору весов, и его расположение соответствует среднему значению выборки
Межквартильный размах
Межквартильный, или средний, размах — это разность между третьим и первым квартилями выборки:
Межквартильный размах = Q3 – Q1
Эта величина позволяет оценить разброс 50% элементов и не учитывать влияние экстремальных элементов. Межквартильный размах выборки, содержащей данные о среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска, можно вычислить, используя данные на рис. 4 (например, для функции КВАРТИЛЬ.ИСКЛ): Межквартильный размах = 9,8 – (–0,7) = 10,5. Интервал, ограниченный числами 9,8 и –0,7, часто называют средней половиной.
Следует отметить, что величины Q1 и Q3, а значит, и межквартильный размах, не зависят от наличия выбросов, поскольку при их вычислении не учитывается ни одна величина, которая была бы меньше Q1 или больше Q3. Суммарные количественные характеристики, такие как медиана, первый и третий квартили, а также межквартильный размах, на которые не влияют выбросы, называются устойчивыми показателями.
Дисперсия и стандартное отклонение
Хотя размах и межквартильный размах позволяют оценить общий и средний разброс выборки соответственно, ни одна из этих оценок не учитывает, как именно распределены данные. Дисперсия и стандартное отклонение лишены этого недостатка. Эти показатели позволяют оценить степень колебания данных вокруг среднего значения. Выборочная дисперсия является приближением среднего арифметического, вычисленного на основе квадратов разностей между каждым элементом выборки и выборочным средним. Для выборки Х1, Х2, … Хn выборочная дисперсия (обозначаемая символом S2 задается следующей формулой:

В общем случае выборочная дисперсия — это сумма квадратов разностей между элементами выборки и выборочным средним, деленная на величину, равную объему выборки минус один:

где ![]() — арифметическое среднее, n — объем выборки, Xi — i-й элемент выборки X. В Excel до версии 2007 для расчета выборочной дисперсии использовалась функция =ДИСП(), с версии 2010 используется функция =ДИСП.В().
— арифметическое среднее, n — объем выборки, Xi — i-й элемент выборки X. В Excel до версии 2007 для расчета выборочной дисперсии использовалась функция =ДИСП(), с версии 2010 используется функция =ДИСП.В().
Наиболее практичной и широко распространенной оценкой разброса данных является стандартное выборочное отклонение. Этот показатель обозначается символом S и равен квадратному корню из выборочной дисперсии:

В Excel до версии 2007 для расчета стандартного выборочного отклонения использовалась функция =СТАНДОТКЛОН(), с версии 2010 используется функция =СТАНДОТКЛОН.В(). Для расчета этих функций массив данных может быть неупорядоченным.
Ни выборочная дисперсия, ни стандартное выборочное отклонение не могут быть отрицательными. Единственная ситуация, в которой показатели S2 и S могут быть нулевыми, — если все элементы выборки равны между собой. В этом совершенно невероятном случае размах и межквартильный размах также равны нулю.
Числовые данные по своей природе изменчивы. Любая переменная может принимать множество разных значений. Например, разные взаимные фонды имеют разные показатели доходности и убытков. Вследствие изменчивости числовых данных очень важно изучать не только оценки среднего значения, которые по своей природе являются суммарными, но и оценки дисперсии, характеризующие разброс данных.
Дисперсия и стандартное отклонение позволяют оценить разброс данных вокруг среднего значения, иначе говоря, определить, сколько элементов выборки меньше среднего, а сколько — больше. Дисперсия обладает некоторыми ценными математическими свойствами. Однако ее величина представляет собой квадрат единицы измерения — квадратный процент, квадратный доллар, квадратный дюйм и т.п. Следовательно, естественной оценкой дисперсии является стандартное отклонение, которое выражается в обычных единицах измерений — процентах дохода, долларах или дюймах.
Стандартное отклонение позволяет оценить величину колебаний элементов выборки вокруг среднего значения. Практически во всех ситуациях основное количество наблюдаемых величин лежит в интервале плюс-минус одно стандартное отклонение от среднего значения. Следовательно, зная среднее арифметическое элементов выборки и стандартное выборочное отклонение, можно определить интервал, которому принадлежит основная масса данных.
Стандартное отклонение доходности 15 взаимных фондов с очень высоким уровнем риска равно 6,6 (рис. 9). Это значит, что доходность основной массы фондов отличается от среднего значения не более чем на 6,6% (т.е. колеблется в интервале от ![]() – S = 6,2 – 6,6 = –0,4 до
– S = 6,2 – 6,6 = –0,4 до ![]() + S = 12,8). Фактически в этом интервале лежит пятилетняя среднегодовая доходность 53,3% (8 из 15) фондов.
+ S = 12,8). Фактически в этом интервале лежит пятилетняя среднегодовая доходность 53,3% (8 из 15) фондов.

Рис. 9. Стандартное выборочное отклонение
Обратите внимание на то, что в процессе суммирования квадратов разностей элементы выборки, лежащие дальше от среднего значения, приобретают больший вес, чем элементы, лежащие ближе. Это свойство является основной причиной того, что для оценки среднего значения распределения чаще всего используется среднее арифметическое значение.
Коэффициент вариации
В отличие от предыдущих оценок разброса, коэффициент вариации является относительной оценкой. Он всегда измеряется в процентах, а не в единицах измерения исходных данных. Коэффициент вариации, обозначаемый символами CV, измеряет рассеивание данных относительно среднего значения. Коэффициент вариации равен стандартному отклонению, деленному на среднее арифметическое и умноженному на 100%:

где S — стандартное выборочное отклонение, ![]() — выборочное среднее.
— выборочное среднее.
Коэффициент вариации позволяет сравнить две выборки, элементы которых выражаются в разных единицах измерения. Например, управляющий службы доставки корреспонденции намеревается обновить парк грузовиков. При погрузке пакетов следует учитывать два вида ограничений: вес (в фунтах) и объем (в кубических футах) каждого пакета. Предположим, что в выборке, содержащей 200 пакетов, средний вес равен 26,0 фунтов, стандартное отклонение веса 3,9 фунтов, средний объем пакета 8,8 кубических футов, а стандартное отклонение объема 2,2 кубических фута. Как сравнить разброс веса и объема пакетов?
Поскольку единицы измерения веса и объема отличаются друг от друга, управляющий должен сравнить относительный разброс этих величин. Коэффициент вариации веса равен CVW = 3,9 / 26,0 * 100% = 15%, а коэффициент вариации объема CVV = 2,2 / 8,8 * 100% = 25% . Таким образом, относительный разброс объема пакетов намного больше относительного разброса их веса.
Форма распределения
Третье важное свойство выборки — форма ее распределения. Это распределение может быть симметричным или асимметричным. Чтобы описать форму распределения, необходимо вычислить его среднее значение и медиану. Если эти два показателя совпадают, переменная считается симметрично распределенной. Если среднее значение переменной больше медианы, ее распределение имеет положительную асимметрию (рис. 10). Если медиана больше среднего значения, распределение переменной имеет отрицательную асимметрию. Положительная асимметрия возникает, когда среднее значение увеличивается до необычайно высоких значений. Отрицательная асимметрия возникает, когда среднее значение уменьшается до необычайно малых значений. Переменная является симметрично распределенной, если она не принимает никаких экстремальных значений ни в одном из направлений, так что большие и малые значения переменной уравновешивают друг друга.

Рис. 10. Три вида распределений
Данные, изображенные на шкале А, имеют отрицательную асимметрию. На этом рисунке виден длинный хвост и перекос влево, вызванные наличием необычно малых значений. Эти крайне малые величины смещают среднее значение влево, и оно становится меньше медианы. Данные, изображенные на шкале Б, распределены симметрично. Левая и правая половины распределения являются своими зеркальными отражениями. Большие и малые величины уравновешивают друг друга, а среднее значение и медиана равны между собой. Данные, изображенные на шкале В, имеют положительную асимметрию. На этом рисунке виден длинный хвост и перекос вправо, вызванные наличием необычайно высоких значений. Эти слишком большие величины смещают среднее значение вправо, и оно становится больше медианы.
В Excel описательные статистики можно получить с помощью надстройки Пакет анализа. Пройдите по меню Данные → Анализ данных, в открывшемся окне выберите строку Описательная статистика и кликните Ok. В окне Описательная статистика обязательно укажите Входной интервал (рис. 11). Если вы хотите увидеть описательные статистики на том же листе, что и исходные данные, выберите переключатель Выходной интервал и укажите ячейку, куда следует поместить левый верхний угол выводимых статистик (в нашем примере $C$1). Если вы хотите вывести данные на новый лист или в новую книгу, достаточно просто выбрать соответствующий переключатель. Поставьте галочку напротив Итоговая статистика. По желанию также можно выбрать Уровень сложности, k-й наименьший и k-й наибольший.
Если на вкладе Данные в области Анализ у вас не отображается пиктограмма Анализ данных, нужно предварительно установить надстройку Пакет анализа (см., например, Представление числовых данных в виде таблиц и диаграмм).

Рис. 11. Описательные статистики пятилетней среднегодовой доходности фондов с очень высоким уровнями риска, вычисленные с помощью надстройки Анализ данных программы Excel
Excel вычисляет целый ряд статистик, рассмотренных выше: среднее, медиану, моду, стандартное отклонение, дисперсию, размах (интервал), минимум, максимум и объем выборки (счет). Кроме того, Excel вычисляет некоторые новые для нас статистики: стандартную ошибку, эксцесс и асимметричность. Стандартная ошибка равна стандартному отклонению, деленному на квадратный корень объема выборки. Асимметричность характеризует отклонение от симметричности распределения и является функцией, зависящей от куба разностей между элементами выборки и средним значением. Эксцесс представляет собой меру относительной концентрации данных вокруг среднего значения по сравнению с хвостами распределения и зависит от разностей между элементами выборки и средним значением, возведенных в четвертую степень.
Вычисление описательных статистик для генеральной совокупности
Среднее значение, разброс и форма распределения, рассмотренные выше, представляют собой характеристики, определяемые по выборке. Однако, если набор данных содержит числовые измерения всей генеральной совокупности, можно вычислить ее параметры. К числу таких параметров относятся математическое ожидание, дисперсия и стандартное отклонение генеральной совокупности.
Математическое ожидание равно сумме всех значений генеральной совокупности, деленной на объем генеральной совокупности:

где µ — математическое ожидание, Xi — i-е наблюдение переменной X, N — объем генеральной совокупности. В Excel для вычисления математического ожидания используется та же функция, что и для среднего арифметического: =СРЗНАЧ().
Дисперсия генеральной совокупности равна сумме квадратов разностей между элементами генеральной совокупности и мат. ожиданием, деленной на объем генеральной совокупности:

где σ2 – дисперсия генеральной совокупности. В Excel до версии 2007 для вычисления дисперсии генеральной совокупности используется функция =ДИСПР(), начиная с версии 2010 =ДИСП.Г().
Стандартное отклонение генеральной совокупности равно квадратному корню, извлеченному из дисперсии генеральной совокупности:

В Excel до версии 2007 для вычисления стандартного отклонения генеральной совокупности используется функция =СТАНДОТКЛОНП(), начиная с версии 2010 =СТАНДОТКЛОН.Г(). Обратите внимание на то, что формулы для дисперсии и стандартного отклонения генеральной совокупности отличаются от формул для вычисления выборочной дисперсии и стандартного отклонения. При вычислении выборочных статистик S2 и S знаменатель дроби равен n – 1, а при вычислении параметров σ2 и σ — объему генеральной совокупности N.
Эмпирическое правило
В большинстве ситуаций крупная доля наблюдений концентрируется вокруг медианы, образуя кластер. В наборах данных, имеющих положительную асимметрию, этот кластер расположен левее (т.е. ниже) математического ожидания, а в наборах, имеющих отрицательную асимметрию, этот кластер расположен правее (т.е. выше) математического ожидания. У симметричных данных математическое ожидание и медиана совпадают, а наблюдения концентрируются вокруг математического ожидания, формируя колоколообразное распределение. Если распределение не имеет ярко выраженной асимметрии, а данные концентрируются вокруг некоего центра тяжести, для оценки изменчивости можно применять эмпирическое правило, которое гласит: если данные имеют колоколообразное распределение, то приблизительно 68% наблюдений отстоят от математического ожидания не более чем на одно стандартное отклонение, приблизительно 95% наблюдений отстоят от математического ожидания не более чем на два стандартных отклонения и 99,7% наблюдений отстоят от математического ожидания не более чем на три стандартных отклонения.
Таким образом, стандартное отклонение, представляющее собой оценку среднего колебания вокруг математического ожидания, помогает понять, как распределены наблюдения, и идентифицировать выбросы. Из эмпирического правила следует, что для колоколообразных распределений лишь одно значение из двадцати отличается от математического ожидания больше, чем на два стандартных отклонения. Следовательно, значения, лежащие за пределами интервала µ ± 2σ, можно считать выбросами. Кроме того, только три из 1000 наблюдений отличаются от математического ожидания больше чем на три стандартных отклонения. Таким образом, значения, лежащие за пределами интервала µ ± 3σ практически всегда являются выбросами. Для распределений, имеющих сильную асимметрию или не имеющих колоколообразной формы, можно применять эмпирическое правило Бьенамэ-Чебышева.
Более ста лет назад математики Бьенамэ и Чебышев независимо друг от друга открыли полезное свойство стандартного отклонения. Они обнаружили, что для любого набора данных, независимо от формы распределения, процент наблюдений, лежащих на расстоянии не превышающем k стандартных отклонений от математического ожидания, не меньше (1 – 1/k2)*100%.
Например, если k = 2, правило Бьенамэ-Чебышева гласит, что как минимум (1 – (1/2)2) х 100% = 75% наблюдений должно лежать в интервале µ ± 2σ. Это правило справедливо для любого k, превышающего единицу. Правило Бьенамэ-Чебышева носит весьма общий характер и справедливо для распределений любого вида. Оно указывает минимальное количество наблюдений, расстояние от которых до математического ожидания не превышает заданной величины. Однако, если распределение имеет колоколообразную форму, эмпирическое правило более точно оценивает концентрацию данных вокруг математического ожидания.
Вычисление описательных статистик для распределения на основе частот
Если исходные данные недоступны, единственным источником информации становится распределение частот. В таких ситуациях можно вычислить приближенные значения количественных показателей распределения, таких как среднее арифметическое, стандартное отклонение, квартили.
Если выборочные данные представлены в виде распределения частот, приближенное значение среднего арифметического можно вычислить, предполагая, что все значения внутри каждого класса сосредоточены в средней точке класса:

где ![]() — выборочное среднее, n — количество наблюдений, или объем выборки, с — количество классов в распределении частот, mj — средняя точка j-гo класса, fj — частота, соответствующая j-му классу.
— выборочное среднее, n — количество наблюдений, или объем выборки, с — количество классов в распределении частот, mj — средняя точка j-гo класса, fj — частота, соответствующая j-му классу.
Для вычисления стандартного отклонения по распределению частот также предполагается, что все значения внутри каждого класса сосредоточены в средней точке класса.

Чтобы понять, как определяются квартили ряда на основе частот, рассмотрим расчет нижнего квартиля на основе данных за 2013 г. о распределении населения России по величине среднедушевых денежных доходов (рис. 12).

Рис. 12. Доля населения России со среднедушевыми денежными доходами в среднем за месяц, рублей
Для расчета первого квартиля интервального вариационного ряда можно воспользоваться формулой: [3]

где Q1 – величина первого квартиля, хQ1 – нижняя граница интервала, содержащего первый квартиль (интервал определяется по накопленной частоте, первой превышающей 25%); i – величина интервала; Σf – сумма частот всей выборки; наверное, всегда равна 100%; SQ1–1 – накопленная частота интервала, предшествующего интервалу, содержащему нижний квартиль; fQ1 – частота интервала, содержащего нижний квартиль. Формула для третьего квартиля отличается тем, что во всех местах вместо Q1 нужно использовать Q3, а вместо ¼ подставить ¾.
В нашем примере (рис. 12) нижний квартиль находится в интервале 7000,1 – 10 000, накопленная частота которого равна 26,4%. Нижняя граница этого интервала – 7000 руб., величина интервала – 3000 руб., накопленная частота интервала, предшествующего интервалу, содержащему нижний квартиль – 13,4%, частота интервала, содержащего нижний квартиль – 13,0%. Таким образом: Q1 = 7000 + 3000 * (¼ * 100 – 13,4) / 13 = 9677 руб.
Ловушки, связанные с описательными статистиками
В этой заметке мы рассмотрели, как описать набор данных с помощью различных статистик, оценивающих его среднее значение, разброс и вид распределения. Следующим этапом является анализ и интерпретация данных. До сих пор мы изучали объективные свойства данных, а теперь переходим к их субъективной трактовке. Исследователя подстерегают две ошибки: неверно выбранный предмет анализа и неправильная интерпретация результатов.
Анализ доходности 15 взаимных фондов с очень высоким уровнем риска является вполне беспристрастным. Он привел к совершенно объективным выводам: все взаимные фонды имеют разную доходность, разброс доходности фондов колеблется от –6,1 до 18,5, а средняя доходность равна 6,08. Объективность анализа данных обеспечивается правильным выбором суммарных количественных показателей распределения. Было рассмотрено несколько способов оценки среднего значения и разброса данных, указаны их преимущества и недостатки. Как же выбрать правильную статистику, обеспечивающую объективный и беспристрастный анализ? Если распределение данных имеет небольшую асимметрию, следует ли выбирать медиану, а не среднее арифметическое? Какой показатель более точно характеризует разброс данных: стандартное отклонение или размах? Следует ли указывать на положительную асимметрию распределения?
С другой стороны, интерпретация данных является субъективным процессом. Разные люди приходят к разным выводам, истолковывая одни и те же результаты. У каждого своя точка зрения. Кто-то считает суммарные показатели среднегодовой доходности 15 фондов с очень высоким уровнем риска хорошими и вполне доволен полученным доходом. Другим может показаться, что эти фонды имеют слишком низкую доходность. Таким образом, субъективность следует компенсировать честностью, нейтральностью и ясностью выводов.
Этические проблемы
Анализ данных неразрывно связан с этическими вопросами. Следует критически относиться к информации, распространяемой газетами, радио, телевидением и Интернетом. Со временем вы научитесь скептически относиться не только к результатам, но и к целям, предмету и объективности исследований. Лучше всего об этом сказал известный британский политик Бенджамин Дизраэли: «Существуют три вида лжи: ложь, наглая ложь и статистика».
Как было отмечено в заметке Искусство графического представления данных этические проблемы возникают при выборе результатов, которые следует привести в отчете. Следует публиковать как положительные, так и отрицательные результаты. Кроме того, делая доклад или письменный отчет, результаты необходимо излагать честно, нейтрально и объективно. Следует различать неудачную и нечестную презентации. Для этого необходимо определить, каковы были намерения докладчика. Иногда важную информацию докладчик пропускает по невежеству, а иногда — умышленно (например, если он применяет среднее арифметическое для оценки среднего значения явно асимметричных данных, чтобы получить желаемый результат). Нечестно также замалчивать результаты, которые не соответствуют точке зрения исследователя.
Предыдущая заметка Искусство графического представления данных
Следующая заметка Анализ данных. Пять базовых показателей распределения случайной величины
К оглавлению Статистика для менеджеров с использованием Microsoft Excel
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 178–209
[2] Функция КВАРТИЛЬ оставлена для совмещения с более ранними версиями Excel
[3] Используются материалы Структурные характеристики вариационного ряда распределения
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функции СРГЕОМ в Microsoft Excel.
Описание
Возвращает среднее геометрическое значений массива или интервала положительных чисел. Например, функцией СРГЕОМ можно воспользоваться для вычисления средних темпов роста, если задан составной доход с переменными ставками.
Синтаксис
СРГЕОМ(число1;[число2];…)
Аргументы функции СРГЕОМ описаны ниже.
-
Число1, число2,… — от 1 до 255 аргументов, для которых вычисляется среднее геометрическое. «Число1» обязательно, последующие числа — нет. Вместо аргументов, разделенных точками с запятой, можно использовать один массив или ссылку на массив.
Замечания
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, то такие значения пропускаются; однако ячейки, которые содержат нулевые значения, учитываются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Если любая точка данных ≤ 0, то geoMEAN возвращает #NUM! значение ошибки #ЗНАЧ!.
-
Уравнение для среднего геометрического имеет следующий вид:
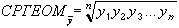
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
4 |
||
|
5 |
||
|
8 |
||
|
7 |
||
|
11 |
||
|
4 |
||
|
3 |
||
|
Формула |
Описание |
Результат |
|
=СРГЕОМ(A2:A8) |
Среднее геометрическое набора данных в ячейках A2:A8. |
5,476987 |
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.