Средняя зарплата… Средняя продолжительность жизни… Практически каждый день мы с вами слышим эти словосочетания, используемые для описания множества одним единственным числом. Но как ни странно, «среднее значение» — достаточно коварное понятие, часто вводящее в заблуждение обычного, неискушенного в математической статистике, человека.
В чем проблема?
Под средним значением чаще всего подразумевается среднее арифметическое, которое очень сильно варьируется под воздействием единичных фактов или событий. И вы не получите реального представления о том, как именно распределены значения, которые вы изучаете.
Давайте обратимся к классическому примеру со средней зарплатой.
В какой-то абстрактной компании работает десять сотрудников. Девять из них получают зарплату около 50 000 рублей, а один 1 500 000 рублей (по странному совпадению он же является генеральным директором этой компании).

Средним значением в данном случае будет 195 150 рублей, что согласитесь, неправильно.
Какие способы вычисления среднего бывают?
Первым способом является вычисление уже упомянутого среднего арифметического, являющегося суммой всех значений, деленной на их количество.
Формула:
![]()
- x – среднее арифметическое;
- xn – конкретное значение;
- n – количество значений.
Плюсы:
- Хорошо работает при нормальном распределении значений в выборке;
- Легко вычислить;
- Интуитивно понятно.
Минусы:
- Не дает реального представления о распределении значений;
- Неустойчивая величина легко поддающаяся выбросам (как в случае с генеральным директором).
Вторым способом является вычисление моды, то есть наиболее часто встречающегося значения.
Формула:
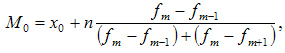
- M0 – мода;
- x0 – нижняя граница интервала, который содержит моду;
- n – величина интервала;
- fm– частота (сколько раз в ряду встречается то или иное значение);
- fm-1 – частота интервала предшествующего модальному;
- fm+1 – частота интервала следующего за модальным.
Плюсы:
- Прекрасно подходит для получения представления об общественном мнении;
- Хорошо подходит для нечисловых данных (цвета сезона, хиты продаж, рейтинги);
- Проста для понимания.
Минусы:
- Моды может просто не быть (нет повторов);
- Мод может быть несколько (многомодальное распределение).
Третий способ — это вычисление медианы, то есть значения, которое делит упорядоченную выборку на две половины и находится между ними. А если такого значения нет, то за медиану принимается среднее арифметическое между границами половин выборки.
Формула:

- Me – медиана;
- x0 – нижняя граница интервала, который содержит медиану;
- h – величина интервала;
- f i – частота (сколько раз в ряду встречается то или иное значение);
- Sm-1 – сумма частот интервалов предшествующих медианному;
- fm – число значений в медианном интервале (его частота).
Плюсы:
- Дает самую реалистичную и репрезентативную оценку;
- Устойчива к выбросам.
Минусы:
- Сложнее вычислить, так как перед вычислением выборку нужно упорядочить.
Мы рассмотрели основные методы нахождения среднего значения, называющиеся мерами центральной тенденции (на самом деле их больше, но это наиболее популярные).
А теперь давайте вернемся к нашему примеру и посчитаем все три варианта среднего при помощи специальных функций Excel:
СРЗНАЧ(число1;[число2];…)— функция для определения среднего арифметического;МОДА.ОДН(число1;[число2];...)— функция моды (в более старых версиях Excel использоваласьМОДА(число1;[число2];...));МЕДИАНА(число1;[число2];...)— функция для поиска медианы.
И вот какие значения у нас получились:

В данном случае мода и медиана гораздо лучше характеризуют среднюю зарплату в компании.
Но что делать, когда в выборке не 10 значений, как в примере, а миллионы? В Excel это не посчитать, а вот в базе данных где хранятся ваши данные, без проблем.
Вычисляем среднее арифметическое на SQL
Тут все достаточно просто, так как в SQL предусмотрена специальная агрегатная функция AVG.
И чтобы ее использовать достаточно написать вот такой запрос:
/* Здесь и далее salary - столбец с зарплатами, а employees - таблица сотрудников в нашей базе данных */ SELECT AVG(salary) AS 'Средняя зарплата' FROM employees
Вычисляем моду на SQL
В SQL нет отдельной функции для нахождения моды, но ее легко и быстро можно написать самостоятельно. Для этого нам необходимо узнать, какая из зарплат чаще всего повторяется и выбрать наиболее популярную.
Напишем запрос:
/* WITH TIES необходимо добавлять к TOP() если множество многомодально, то есть у множества несколько мод */ SELECT TOP(1) WITH TIES salary AS 'Мода зарплаты' FROM employees GROUP BY salary ORDER BY COUNT(*) DESC
Вычисляем медиану на SQL
Как и в случае с модой, в SQL нет встроенной функции для вычисления медианы, зато есть универсальная функция для вычисления процентилей PERCENTILE_CONT.
Выглядит все это так:
/* В данном случае процентиль 0.5 и будет являться медианой */
SELECT TOP(1) PERCENTILE_CONT(0.5)
WITHIN GROUP (ORDER BY salary)
OVER() AS 'Медианная зарплата'
FROM employees
Подробнее о работе функции PERCENTILE_CONT лучше почитать в справке Microsoft и Google BigQuery.
Какой способ все-таки использовать?
Из сказанного выше следует, что медиана лучший способ для вычисления среднего значения.
Но это не всегда так. Если вы работаете со средним, то остерегайтесь многомодального распределения:

На графике представлено бимодальное распределение с двумя пиками. Такая ситуация может возникнуть, например, при голосовании на выборах.
В данном случае среднее арифметическое и медиана — это значения, находящиеся где-то посередине и они ничего не скажут о том, что происходит на самом деле и лучше сразу признать, что вы имеете дело с бимодальным распределением, сообщив о двух модах.
А еще лучше разделить выборку на две группы и собрать статистические данные для каждой.
Вывод:
При выборе метода нахождения среднего нужно учитывать наличие выбросов, а также нормальность распределения значений в выборке.
Окончательный выбор меры центральной тенденции всегда лежит на аналитике.
Полезные ссылки:
- SQL и теория вероятностей (YouTube)
- Анализ нормальности распределения данных (YouTube)
- Меры центральной тенденции
- Об авторе
- Свежие записи

В поисках средних значений: разбираемся со средним арифметическим, медианой и модой

В поисках средних значений: разбираемся со средним арифметическим, медианой и модой

Иногда при работе с данными нужно описать множество значений каким-то одним числом. Например, при исследовании эффективности сотрудников, уровня вовлеченности в аккаунте, KPI или времени ответа на сообщения клиентов. В таких случаях используют меры центральной тенденции. Их можно называть проще — средние значения.
Но в зависимости от вводных данных, находить среднее значение нужно по-разному. Основной набор задач закрывается с использованием среднего арифметического, медианы и моды. Но если выбрать неверный способ — выводы будут необъективны, а результаты исследования нельзя будет признать действительными. Чтобы не допустить ошибку, нужно понимать особенности разных способов нахождения средних значений.

Cтратег, аналитик и контент-продюсер. Работает с агентством «Палиндром».

Как считать среднее арифметическое
Использовать среднее арифметическое стоит тогда, когда множество значений распределяются нормально ― это значит, что значения расположены симметрично относительно центра. Как выглядит нормальное распределение на графике и в таблице, можно посмотреть на примере:
![]()

Если данные распределяются как в примерах — вам повезло. Можно без лишних заморочек считать среднее арифметическое и быть уверенным, что выводы будут объективны. Однако, нормальное распределение на практике встречается крайне редко, поэтому среднее арифметическое в большинстве случаев лучше не использовать.
Как рассчитать
Сумму значений нужно поделить на их количество. Например, вы хотите узнать средний ER за 4 дня при нормальном распределении значений и без аномальных выбросов. Для этого считаем среднее арифметическое: складываем ER всех дней и делим полученное число на количество дней.

Если хотите автоматизировать вычисления и узнать среднее арифметическое для большого числа показателей — используйте Google Таблицы:
- Заполните таблицу данными.
- Щелкните по пустой ячейке, в которую хотите записать среднее арифметическое.
- Введите «=AVERAGE(» и выделите ряд чисел, для которых нужно вычислить среднее арифметическое. Нажмите «Enter» после ввода формулы.

Когда можно не использовать
Если данные распределены ненормально, то наши расчеты не будут отражать реальную картину. На ненормальность распределения указывают:
- Отсутствие симметрии в расположении значений.
- Наличие ярко выраженных выбросов.
Как пример ненормального распределения (с выбросами) можно рассматривать среднее время ответа на комментарии по неделям:

Если посчитать среднее значение для такого набора данных с помощью среднего арифметического, то получится завышенное число. В итоге наши выводы будут более позитивными, чем реальное положение дел. Еще стоит учитывать, что выбросы могут не только завышать среднее значение, но и занижать его. В таком случае вы получите более скромный показатель, который не будет соответствовать реальности.
Например, в группе «Золотое Яблоко» во ВКонтакте иногда публикуют конкурсные посты. Они набирают более высокие показатели вовлеченности чем обычные публикации. Если посчитать средний ER с учетом конкурсов, мы получим 0,37%, а без учета конкурсов — только 0,29%. Аналогичная ситуация с числом комментариев. С конкурсами в среднем получаем 917 комментариев, а без конкурсов — всего лишь 503. Очевидно, что из-за розыгрышей средние показатели вовлеченности завышаются. В этом случае конкурсные посты следует исключить из анализа, чтобы объективно оценить эффективность контента в группе.

Еще часто бывает так, что данных очень много, заметны явные выбросы, но на их обработку и исключение аномальных значений не хватит ни времени, ни терпения. Тем более нет гарантий, что исключив выбросы, вы получите нормальное распределение. В таком случае лучше подсчитать средние значения, используя медиану.
Как найти медиану и когда ее применять
Если вы имеете дело с ненормальным распределением или замечаете значительные выбросы — используйте медиану. Так можно получить более адекватное среднее значение, чем при использовании среднего арифметического. Чтобы понять, как работать с медианой, рассмотрим аналогичный пример с ненормальным распределением времени ответов на комментарии.
Ниже в таблице уже введены данные из графика и рассчитано среднее время ответа с помощью среднего арифметического и медианы. Из расчетов видна наглядная разница между средним арифметическим и медианой ― она составляет 17 минут. Такое различие появляется из-за низкого темпа работы на выходных и в нестандартных ситуациях, когда к ответу на сообщения нужно относиться с особой ответственностью (события конца февраля). Подобные выбросы сильно завышают среднее арифметическое, а вот на медиану они практически не влияют. Поэтому если хотите посчитать среднее значение избегая влияния выбросов, — используйте медиану. Такие данные будут без искажений.

Как рассчитать
Разберем на примере. В аккаунте опубликовали семь постов и они набрали разное количество комментариев: 35, 105, 2, 15, 2, 31, 1. Чтобы вычислить медиану, нужно пройти два этапа:
- Расположите числа в порядке возрастания. Итоговый ряд будет выглядеть так: 1, 2, 2, 15, 31, 35, 105.
- Найдите середину сформированного ряда. В центре стоит число 15 — его и нужно считать медианой.
Немного сложнее найти медиану, если вы работаете с четным количеством чисел. Например, вы собрали количество лайков на последних шести постах: 32, 48, 36, 201, 52, 12. Чтобы найти медиану, выполните три действия:
- Расставьте числа по возрастанию: 12, 32, 36, 48, 52, 201.
- Возьмите два из них, наиболее близких к центру. В нашем случае — это 36 и 48.
- Сложите два этих числа и разделите на два: (36 + 48) / 2 = 42. Результат и есть медиана.
Чтобы вычислять медиану быстрее и обрабатывать большие объемы данных — используйте Google Таблицы:
- Внесите данные в таблицу.
- Щелкните по свободной ячейке, в которую хотите записать медиану.
- Введите формулу «=MEDIAN(» и выделите ряд чисел, для которых нужно рассчитать медиану. Нажмите «Enter», чтобы все посчиталось.

Когда можно не использовать
Если данные распределены нормально и вы не видите заметных выбросов — медиану можно не использовать. В этом случае значение среднего арифметического будет очень близким к медиане. Можете выбрать любой способ нахождения среднего, с которым вам работать проще. Результат от этого сильно не изменится.
Что такое мода и где ее использовать
Мода ― это самое популярное/часто встречающееся значение. Например, стоит задача узнать, сколько комментариев чаще всего набирают посты в аккаунте. В этом случае можно не высчитывать среднее арифметическое или медиану ― лучше и проще использовать моду.
Еще пример. Нужно узнать, в какое время аудитория чаще всего взаимодействует с публикациями. Для этого можно посчитать данные вручную или использовать готовую таблицу из LiveDune (вкладка «Вовлеченность» ― таблица «Лучшее время для поста»). По ее данным ― больше всего реакций пользователи оставляют в среду в 16 часов. Это время и есть мода. Таким образом, если вам нужно найти самое популярное значение, а не классическое среднее — проще использовать моду.

Как рассчитать
Чтобы найти наиболее часто встречающееся значение в наборе данных, нужно посмотреть, какое число встречается в ряду чаще всех. Например, для ряда 5, 4, 2, 4, 7 ― модой будет число 4.
Иногда в ряде значений встречается несколько мод. Например, ряду 7, 7, 21, 2, 5, 5 свойственны две моды — 7 и 5. В этом случае совокупность чисел называется мультимодальной. Также поиск моды можно упростить с помощью Google Таблиц:
- Внесите значения в таблицу.
- Щелкните по ячейке, в которую хотите записать моду.
- Введите формулу «=MODE(» и выделите ряд чисел, для которых нужно вычислить моду. Нажмите «Enter».

Однако важно иметь в виду, что табличная функция выдает только самую меньшую моду. Поэтому будьте внимательны — можно упустить из виду несколько мод.
Когда использовать не стоит
Моду нет смысла использовать, если вас не просят найти самое популярное значение. Там, где надо найти классическое среднее значение, про моду лучше забыть.
Памятка по использованию
Среднее арифметическое
Как находим: сумма чисел / количество чисел.
Используем: если данные распределены нормально и нет ярких выбросов.
Не используем: если видим явные выбросы или ненормальное распределение.
Медиана
Как находим: располагаем числа в порядке возрастания и находим середину сформированного ряда.
Используем: если работаем с ненормальным распределением или видим выбросы.
Не используем: если выбросов нет и распределение нормальное.
Мода
Как находим: определяем значение, которое чаще всего встречается в ряду чисел.
Используем: если нужно найти не среднее, а самое популярное значение.
Не используем: если нужно найти классическое среднее значение.
Только важные новости в ежемесячной рассылке
Нажимая на кнопку, вы даете согласие на обработку персональных данных.

Подписывайся сейчас и получи гайд аудита Instagram аккаунта
Маркетинговые продукты LiveDune — 7 дней бесплатно
Наши продукты помогают оптимизировать работу в соцсетях и улучшать аккаунты с помощью глубокой аналитики
![]()
Анализ своих и чужих аккаунтов по 50+ метрикам в 6 соцсетях.
Оптимизация обработки сообщений: операторы, статистика, теги и др.
Автоматические отчеты по 6 соцсетям. Выгрузка в PDF, Excel, Google Slides.
Контроль за прогрессом выполнения KPI для аккаунтов Инстаграм.
Аудит Инстаграм аккаунтов с понятными выводами и советами.
Поможем отобрать «чистых» блогеров для эффективного сотрудничества.
|
найти среднее значение за период до указанной даты |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |
||||||||
Ответить |









Поговорим о средних показателях
Время на прочтение
4 мин
Количество просмотров 1.5K

Возможно, самая важная часть нашей работы — это осмысление данных, в первую очередь чисел. Как правило, мы смотрим на показатели, которые получаем благодаря инструментам нагрузочного тестирования, мониторингу серверов и приложений, логам или запросам к базе данных.
Цель состоит в том, чтобы понять поведение системы, но иногда получаемая информация вводит нас в заблуждение.
Сырые данные против сводных
Возьмем для примера простой нагрузочный тест. Скажем, мы запускаем короткий тест, который запрашивает одну веб-страницу 100 раз. Сырыми можно назвать данные, которые были записаны для каждого из этих 100 запросов (ключевым показателем является время ответа). Сырые данные можно нанести на точечный график, и мне кажется, что на это следует обращать внимание в первую очередь всякий раз при анализе каких-либо данных, связанных с производительностью.
Возьмем в качестве примера график, на котором показано время ответа для 100 запросов:
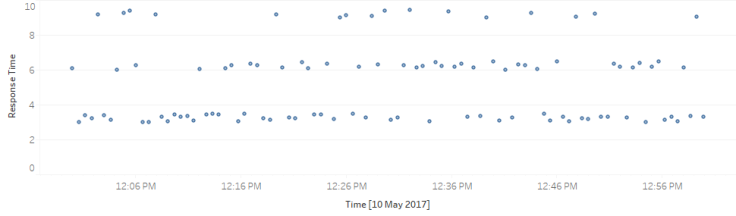
Ключевое наблюдение заключается в том, что есть три горизонтальные «полосы» времени отклика около 3, 6 и 9 секунд. Гипотетически это может быть вызвано таймаутом или переповторами.
Теперь давайте возьмем те же данные и построим график среднего времени отклика с периодом выборки в одну минуту:

Мы по-прежнему видим, что время отклика колеблется от 3 до 9 секунд, но мы потеряли видимость закономерности — теперь мы хуже понимаем поведение тестируемой системы. А что произойдет, если мы увеличим период выборки до пяти минут?
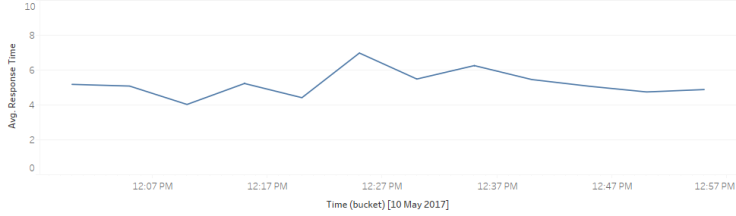
Теперь у нас создается ложное впечатление, что время отклика составляет около 5 секунд, хотя на самом деле во время нашего теста время отклика от 5 до 6 секунд вообще отсутствовало.
Это относится не только к средним значениям (которые вызывают много критики), но и к любым совокупным показателям, включая процентили и медианы.
Вот еще один распространенный пример. Скажем, у нас есть конкретный запрос, который занимает более минуты в 5% случаев, но в остальное время отвечает быстро. Если мы нанесем необработанное время отклика на график (график слева), то сразу станет ясно, что происходит, но просмотр среднего значения тех же данных (график справа) дает нам ложное впечатление, что время отклика равно около 4-5 секунд:
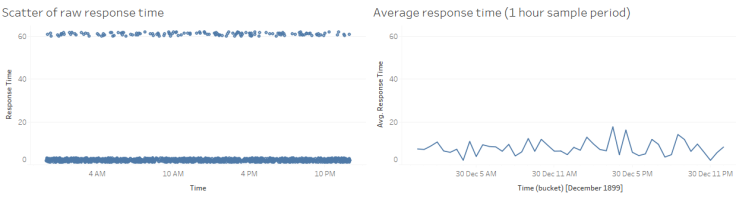
Период выборки
Период выборки — это то, как часто вы собираете замеры данных. Например, можно сделать снимок использования памяти за пятиминутные периоды.
Одна из наиболее распространенных ситуаций, когда периоды выборки влияют на мою работу, связана с интерпретацией показателей процента загрузки CPU (тема, достойная отдельного поста). Недавно я получил данные об использовании ресурсов продакшн-сервера, усредненные за период выборки в один час. За это время средняя загрузка процессора не превышала 40%:

Однако это вовсе не означает, что CPU не был загружен в течение марта. В течение любого заданного периода в один час может быть 10 минут, когда CPU постоянно достигает 100%, 50 минут, когда CPU находится на уровне 10%, а среднее значение будет составлять около 25% — что, опять-таки, не показывает истинного поведения системы.
Объем выборки
Если набор данных невелик, будьте осторожны со сводными показателями. Чем меньше объем выборки, тем меньше и уверенности в том, что мы наблюдаем. Если мы запускаем короткие тесты, которые выполняют только десятки или несколько сотен запросов, сводные показатели будут сильно колебаться между запусками теста.
Я часто сталкиваюсь с проблемой использования процентилей, когда объем выборки меньше сотни. «90-й процентиль» некоторых данных о времени отклика говорит нам, что «90% времени отклика заняло столько времени или меньше» (50-й процентиль — это медиана).
Если объем выборки всего из десяти записей, то «95-й процентиль» не является значимой метрикой. В этой ситуации 90-й, 95-й и 99-й процентили будут равны. Сводные показатели сообщают нам полезную информацию только тогда, когда объем выборки достаточно велик. Я все еще в поиске инструмента, который предупреждает или адаптируется к такого рода ситуациям.
Ограничение точечных графиков
Мы не можем с помощью точечных графиков узнать все. Во-первых, они не говорят о плотности данных. Взгляните на один экстремальный пример:
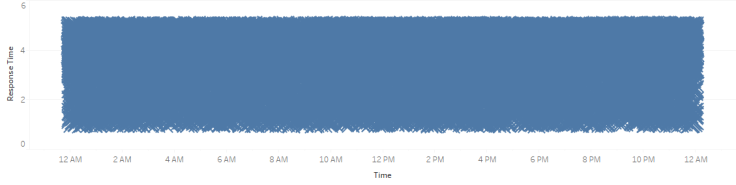
Здесь мы видим сплошной блок результатов времени отклика в диапазоне от 1 до 5 секунд. Однако мы не понимаем, что между 3 и 5 секундами в четыре раза больше записей, чем между 1 и 3. Даже если я скорректирую график, чтобы мы могли увидеть разницу:

… мы все еще не видим масштаба разницы между количеством 3-5 секунд и 1-3 секундами времени отклика.
Чтобы увидеть плотность, можно разбить данные на группы — так мы узнаем, сколько записей было сделано для каждой группы. Ниже я сгруппировал одни и те же данные о времени отклика в «сегменты» по 200 миллисекунд и отобразил количество запросов для каждого из них. Теперь масштаб разницы можно увидеть между двумя полосами времени отклика:

Таким образом, мы можем использовать сводные показатели, чтобы получить более полное представление о необработанных данных.
Чем еще хороши сводные показатели?
При помощи сводных показателей удобно отслеживать изменения с течением времени. Учитывая проблему плотности, может быть трудно понять, имеет ли место общая деградация с течением времени, просто глядя на необработанные данные.
Сводные показатели также могут дать нам общее представление о производительности в нужной ситуации. Например, если время отклика определенного ресурса постоянно занимает около 2 секунд без каких-либо выбросов или значительных отклонений, то в этом конкретном случае среднее значение является достаточно точным представлением пользовательского опыта.
Заключение
Цель этой статьи состоит не в том, чтобы отговорить вас от использования сводных данных. Важно понимать ограничения данных, которые мы предоставляем клиентам. Спросите себя:
-
О чем мне говорят эти данные?
-
О чем они не говорят?
-
Что (как кажется) показывают эти данные, хотя это может привести к неверным выводам?
Если вы будете продолжать задавать себе эти вопросы, вы повысите не только ценность, поставляемую клиентам, но и целостность индустрии тестирования производительности.
Всех желающих приглашаем на открытое занятие онлайн-курса «Нагрузочное тестирование», на котором ассмотрим инструменты shift left performance testing, и сравним два наиболее популярных из них: Gatling и k6. Регистрация открыта по ссылке.
17 авг. 2022 г.
читать 1 мин
Вы можете использовать следующую формулу для расчета среднего значения в Excel только для ячеек, попадающих между двумя конкретными датами:
=AVERAGEIFS( B2:B11 , A2:A11 , "<=1/15/2022", A2:A11 , ">=1/5/2022")
Эта конкретная формула вычисляет среднее значение ячеек в диапазоне B2:B11 , где дата в диапазоне A2:A11 находится между 05.01.2022 и 15.01.2022.
В следующем примере показано, как использовать эту формулу на практике.
Пример: вычислить среднее значение между двумя датами
Предположим, у нас есть следующий набор данных, показывающий общий объем продаж какой-либо компании в разные даты:
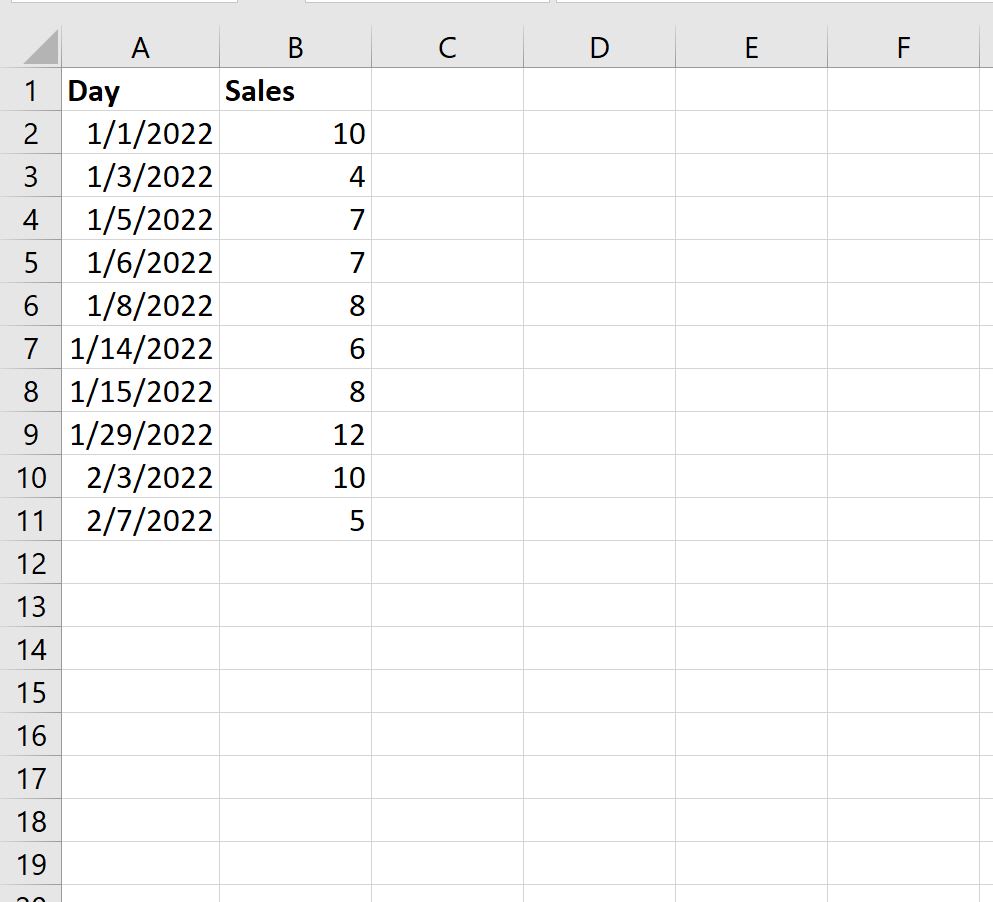
Мы можем использовать следующую формулу для расчета среднего дневного объема продаж между 05.01.2022 и 15.01.2022:
=AVERAGEIFS( B2:B11 , A2:A11 , "<=1/15/2022", A2:A11 , ">=1/5/2022")
На следующем снимке экрана показано, как использовать эту формулу на практике:
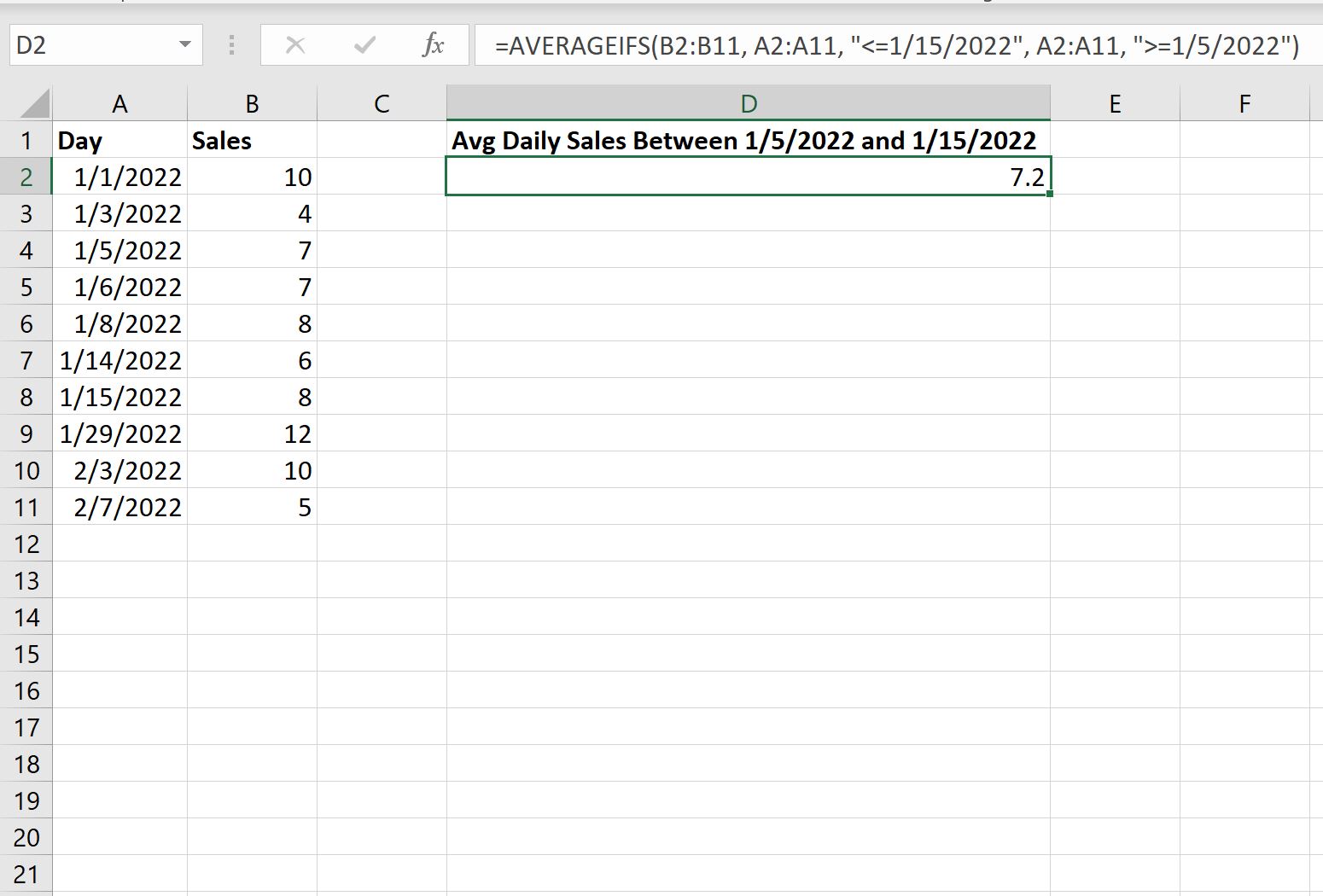
Среднедневные продажи в период с 05.01.2022 по 15.01.2022 составляют 7,2 .
Мы можем вручную проверить, что это правильно:
Среднедневные продажи = (7 + 7 + 8 + 6 +  / 5 = 7,2 .
/ 5 = 7,2 .
Примечание.Полную документацию по функции СРЗНАЧЕСЛИМН можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в Excel:
Как рассчитать среднее значение между двумя значениями в Excel
Как рассчитать среднее значение, если ячейка содержит текст в Excel
Как рассчитать кумулятивное среднее в Excel
Как найти взвешенные скользящие средние в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.