Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
Оценивает дисперсию по выборке.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция ДИСП.В.
Синтаксис
ДИСП(число1;[число2];…)
Аргументы функции ДИСП описаны ниже.
-
Число1 Обязательный. Первый числовой аргумент, соответствующий выборке из генеральной совокупности.
-
Число2… Необязательный. Числовые аргументы 2—255, соответствующие выборке из генеральной совокупности.
Замечания
-
В функции ДИСП предполагается, что аргументы являются только выборкой из генеральной совокупности. Если данные представляют всю генеральную совокупность, для вычисления дисперсии следует использовать функцию ДИСПР.
-
Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками.
-
Учитываются логические значения и текстовые представления чисел, которые непосредственно введены в список аргументов.
-
Если аргумент является массивом или ссылкой, то учитываются только числа. Пустые ячейки, логические значения, текст и значения ошибок в массиве или ссылке игнорируются.
-
Аргументы, которые представляют собой значения ошибок или текст, не преобразуемый в числа, вызывают ошибку.
-
Чтобы включить логические значения и текстовые представления чисел в ссылку как часть вычисления, используйте функцию ДИСПА.
-
Функция ДИСП вычисляется по следующей формуле:

где x — выборочное среднее СРЗНАЧ(число1,число2,…), а n — размер выборки.
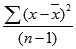
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Прочность |
||
|
1345 |
||
|
1301 |
||
|
1368 |
||
|
1322 |
||
|
1310 |
||
|
1370 |
||
|
1318 |
||
|
1350 |
||
|
1303 |
||
|
1299 |
||
|
Формула |
Описание |
Результат |
|
=ДИСП(A2:A11) |
Дисперсия предела прочности для всех протестированных инструментов. |
754,2667 |
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Вычислим в
MS
EXCEL
дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим
дисперсию
, затем
стандартное отклонение
.
Дисперсия выборки
Дисперсия выборки
(
выборочная дисперсия,
sample
variance
) характеризует разброс значений в массиве относительно
среднего
.
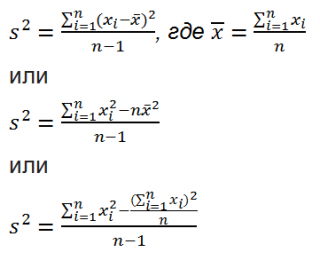
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
Для вычисления дисперсии выборки нужно:
- вычислить среднее значение выборки;
-
вычислить «расстояния» от каждого значения до среднего (x
i
-x
ср.
); - возвести «расстояния» в квадрат, чтобы отклонения в разные стороны от среднего не компенсировали друг друга;
- вычислить среднее значение квадратов «расстояний»)
Примечание
: в знаменателе формулы стоит n-1, а не n т.к. дисперсия выборки — это оценка дисперсии случайной величины (вычитаем 1, чтобы оценка была несмещенной).
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии
выборки
используется функция
ДИСП()
, англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
ДИСП.В()
, англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция
ДИСП.Г(),
англ. название VARP, т.е. Population VARiance, которая вычисляет
дисперсию
для
генеральной совокупности
. Все отличие сводится к знаменателю: вместо n-1 как у
ДИСП.В()
, у
ДИСП.Г()
в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция
ДИСПР()
.
Дисперсию выборки
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
)
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
. Обычно, чем больше величина
дисперсии
, тем больше разброс значений в массиве.
Дисперсия выборки
является точечной оценкой
дисперсии
распределения случайной величины, из которой была сделана
выборка
. О построении
доверительных интервалов
при оценке
дисперсии
можно прочитать в статье
Доверительный интервал для оценки дисперсии в MS EXCEL
.
Дисперсия случайной величины
Чтобы вычислить
дисперсию
случайной величины, необходимо знать ее
функцию распределения
.
Для
дисперсии
случайной величины Х часто используют обозначение Var(Х).
Дисперсия
равна
математическому ожиданию
квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X))
2
]
Если случайная величина имеет
дискретное распределение
, то
дисперсия
вычисляется по формуле:
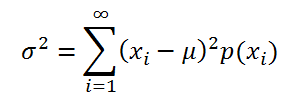
где x
i
– значение, которое может принимать случайная величина, а μ – среднее значение (
математическое ожидание случайной величины
), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет
непрерывное распределение
, то
дисперсия
вычисляется по формуле:
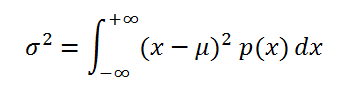
где р(x) –
плотность вероятности
.
Для распределений, представленных в MS EXCEL
,
дисперсию
можно вычислить аналитически, как функцию от параметров распределения. Например, для
Биномиального распределения
дисперсия
равна произведению его параметров: n*p*q.
Примечание
:
Дисперсия,
является
вторым центральным моментом
, обозначается D[X], VAR(х), V(x). Второй центральный момент — числовая характеристика распределения случайной величины, которая является мерой разброса случайной величины относительно
математического ожидания
.
Примечание
: О распределениях в MS EXCEL можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии
–
стандартное отклонение
.
Некоторые свойства
дисперсии
:
Var(Х+a)=Var(Х), где Х — случайная величина, а — константа.
Var(aХ)=a
2
Var(X)
Var(Х)=E[(X-E(X))
2
]=E[X
2
-2*X*E(X)+(E(X))
2
]=E(X
2
)-E(2*X*E(X))+(E(X))
2
=E(X
2
)-2*E(X)*E(X)+(E(X))
2
=E(X
2
)-(E(X))
2
Это свойство дисперсии используется в
статье про линейную регрессию
.
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y — случайные величины, Cov(Х;Y) — ковариация этих случайных величин.
Если случайные величины независимы (independent), то их
ковариация
равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе
стандартной ошибки среднего
.
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1)
2
Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения
доверительного интервала для разницы 2х средних
.
Примечание
: квадратный корень из дисперсии случайной величины называется Среднеквадратическое отклонение (или другие названия — среднее квадратическое отклонение, среднеквадратичное отклонение, квадратичное отклонение, стандартное отклонение, стандартный разброс).
Стандартное отклонение выборки
Стандартное отклонение выборки
— это мера того, насколько широко разбросаны значения в выборке относительно их
среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
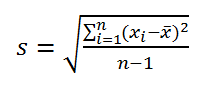
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется
Коэффициент вариации
(Coefficient of Variation, CV) — отношение
Стандартного отклонения
к среднему
арифметическому
, выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
=СТАНДОТКЛОН()
, англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
=СТАНДОТКЛОН.В()
, англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция
СТАНДОТКЛОН.Г()
, англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет
стандартное отклонение
для
генеральной совокупности
. Все отличие сводится к знаменателю: вместо n-1 как у
СТАНДОТКЛОН.В()
, у
СТАНДОТКЛОН.Г()
в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция
КВАДРОТКЛ()
вычисляет с умму квадратов отклонений значений от их
среднего
. Эта функция вернет тот же результат, что и формула
=ДИСП.Г(
Выборка
)*СЧЁТ(
Выборка
)
, где
Выборка
— ссылка на диапазон, содержащий массив значений выборки (
именованный диапазон
). Вычисления в функции
КВАДРОТКЛ()
производятся по формуле:
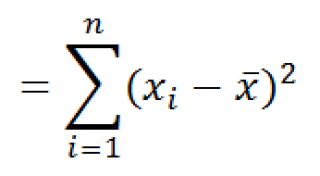
Функция
СРОТКЛ()
является также мерой разброса множества данных. Функция
СРОТКЛ()
вычисляет среднее абсолютных значений отклонений значений от
среднего
. Эта функция вернет тот же результат, что и формула
=СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка)
, где
Выборка
— ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции
СРОТКЛ
()
производятся по формуле:
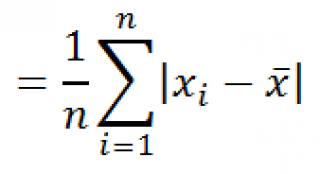

Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
где:
s2 – дисперсия выборки;
xср — среднее значение выборки;
n — размер выборки (количество значений данных),
(xi – xср) — отклонение от средней величины для каждого значения набора данных.
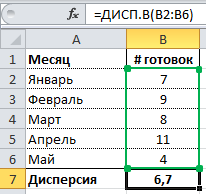
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
![]()
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.
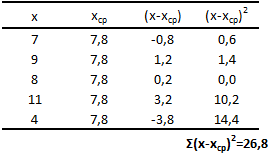
Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
![]()
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.
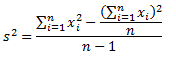
где:
![]() — сумма каждого значения данных после возведения в квадрат,
— сумма каждого значения данных после возведения в квадрат,
![]() — квадрат суммы всех значений данных.
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.
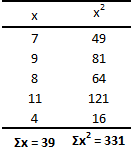
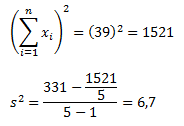
Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
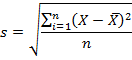
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях:
В этом уроке мы рассмотрим, как проводить дисперсионный анализ в Excel и какие формулы использовать для нахождения дисперсии выборки и генеральной совокупности.
Дисперсия — один из самых полезных инструментов в теории вероятностей и статистике. В науке он описывает, насколько далеко каждое число в наборе данных от среднего. На практике это часто показывает, насколько сильно что-то меняется. Например, температура вблизи экватора имеет меньшую дисперсию, чем в других климатических зонах. В этой статье мы проанализируем различные методы расчета дисперсии в Excel.
Что такое дисперсия?
Дисперсия — это мера изменчивости набора данных, которая указывает, насколько далеко разбросаны разные значения. Математически он определяется как среднее квадратов отличий от среднего.
Чтобы лучше понять, что вы на самом деле рассчитываете с помощью дисперсии, рассмотрите этот простой пример.
Предположим, в вашем местном зоопарке есть 5 тигров в возрасте 14, 10, 8, 6 и 2 лет.
Чтобы найти дисперсию, выполните следующие простые шаги:
- Вычислите среднее (простое среднее) пяти чисел:
- Из каждого числа вычтите среднее значение, чтобы найти различия. Для наглядности нанесем различия на график:
- Сократите каждую разницу.
- Вычислите среднее квадратов разностей.
Итак, дисперсия равна 16. Но что на самом деле означает это число?
По правде говоря, дисперсия просто дает вам очень общее представление о дисперсии набора данных. Значение 0 означает отсутствие изменчивости, т. е. все числа в наборе данных одинаковы. Чем больше число, тем больше разбросаны данные.
Этот пример для дисперсия населения (т.е. 5 тигров — это вся интересующая вас группа). Если ваши данные являются выборкой из большей совокупности, вам необходимо рассчитать выборочная дисперсия по несколько иной формуле.
В Excel есть 6 встроенных функций для расчета дисперсии: VAR, VAR.S, VARP, VAR.P, VARA и VARPA.
Ваш выбор формулы дисперсии определяется следующими факторами:
- Версия Excel, которую вы используете.
- Независимо от того, рассчитываете ли вы выборку или дисперсию населения.
- Хотите ли вы оценивать или игнорировать текст и логические значения.
Функции дисперсии Excel
В таблице ниже представлен обзор функций вариации, доступных в Excel, которые помогут вам выбрать формулу, наиболее подходящую для ваших нужд.
Название Версия Excel Тип данных Текст и логика
БЫЛ
2000 — 2019 Образец игнорируется
ЧЬЯ
2010 — 2019 Образец игнорируется
БЫТЬ
2000 — 2019 Образец Оценка
ПОСЛЕДНИЙ
2000–2019 гг. Население не учитывается
ДА
2010–2019 гг. Население не учитывается
БРОСАТЬ
2000 — 2019 Оценка населения
ВАР.С против. ВАРА и ВАР.П vs. ДЕФОРМАЦИЯ
VARA и VARPA отличаются от других функций дисперсии только тем, как они обрабатывают логические и текстовые значения в ссылках. В следующей таблице приведены сводные данные о том, как оцениваются текстовые представления чисел и логических значений.
Тип аргумента VAR, VAR.S, VARP, VAR.P VARA и VARPA Логические значения в массивах и ссылках Игнорируется Оценивается
(TRUE=1, FALSE=0) Текстовые представления чисел в массивах и ссылках Игнорируется Оценивается как ноль Логические значения и текстовые представления чисел, вводимые непосредственно в аргументы Оцениваются
(TRUE=1, FALSE=0) Пустые ячейки Игнорируются
Как рассчитать выборочную дисперсию в Excel
Выборка представляет собой набор данных, извлеченных из всего населения. А дисперсия, рассчитанная по выборке, называется выборочной дисперсией.
Например, если вы хотите узнать, как меняется рост людей, для вас будет технически невозможно измерить каждого человека на земле. Решение состоит в том, чтобы взять выборку населения, скажем, 1000 человек, и оценить рост всего населения на основе этой выборки.
Выборочная дисперсия рассчитывается по следующей формуле:
Где:
- x̄ — среднее (простое среднее) значений выборки.
- n — размер выборки, т. е. количество значений в выборке.
В Excel есть 3 функции для нахождения выборочной дисперсии: VAR, VAR.S и VARA.
Функция ВАР в Excel
Это самая старая функция Excel для оценки дисперсии на основе выборки. Функция VAR доступна во всех версиях Excel с 2000 по 2019.
ВАР(число1, [number2]…)
Примечание. В Excel 2010 функция VAR была заменена функцией VAR.S, которая обеспечивает повышенную точность. Хотя VAR по-прежнему доступен для обратной совместимости, рекомендуется использовать VAR.S в текущих версиях Excel.
Функция VAR.S в Excel
Это современный аналог функции Excel VAR. Используйте функцию VAR.S, чтобы найти выборочную дисперсию в Excel 2010 и более поздних версиях.
ВАР.С(число1, [number2]…)
Функция ВАРА в Excel
Функция Excel VARA возвращает примерную дисперсию на основе набора чисел, текста и логических значений, как показано на рис. этот стол.
БЫТЬ(значение1, [value2]…)
Пример формулы отклонения в Excel
При работе с числовым набором данных вы можете использовать любую из вышеперечисленных функций для расчета выборочной дисперсии в Excel.
В качестве примера найдем дисперсию выборки, состоящей из 6 элементов (B2:B7). Для этого можно использовать одну из следующих формул:
= ПЕРЕМ(B2:B7)
=ПЕР.С(B2:B7)
=ВАРА(B2:B7)
Как показано на скриншоте, все формулы возвращают один и тот же результат (округленный до 2 знаков после запятой):
Чтобы проверить результат, произведем расчет var вручную:
- Найдите среднее значение с помощью функции СРЗНАЧ:
=СРЕДНЕЕ(B2:B7)Среднее значение идет в любую пустую ячейку, скажем, B8.
- Вычтите среднее значение из каждого числа в выборке:
=B2-$B$8Различия идут в столбец C, начиная с C2.
- Возведите в квадрат каждую разницу и поместите результаты в столбец D, начиная с D2:
=С2^2 - Сложите квадраты разностей и разделите результат на количество элементов в выборке минус 1:
=СУММ(D2:D7)/(6-1)
Как видите, результат нашего ручного вычисления var точно такой же, как число, возвращаемое встроенными функциями Excel:
Если ваш набор данных содержит логические и/или текстовые значения, функция VARA вернет другой результат. Причина в том, что VAR и VAR.S игнорируют любые значения, отличные от чисел, в ссылках, в то время как VARA оценивает текстовые значения как нули, TRUE как 1 и FALSE как 0. Поэтому, пожалуйста, тщательно выбирайте функцию дисперсии для своих расчетов в зависимости от того, хотите обработать или игнорировать текст и логические операции.
Как рассчитать дисперсию населения в Excel
Совокупность – это все члены данной группы, т. е. все наблюдения в области исследования. Дисперсия населения описывает, как распределены точки данных во всей совокупности.
Дисперсию населения можно найти по следующей формуле:
Где:
- x̄ — среднее значение населения.
- n — размер совокупности, т. е. общее количество значений в совокупности.
В Excel есть 3 функции для расчета дисперсии генеральной совокупности: VARP, VAR.P и VARPA.
Функция VARP в Excel
Функция Excel VARP возвращает дисперсию генеральной совокупности на основе всего набора чисел. Он доступен во всех версиях Excel с 2000 по 2019.
ВАРП(число1, [number2]…)
Примечание. В Excel 2010 VARP был заменен на VAR.P, но по-прежнему сохранен для обратной совместимости. В текущих версиях Excel рекомендуется использовать ДИСП.П, поскольку нет гарантии, что функция ДИСП будет доступна в будущих версиях Excel.
Функция VAR.P в Excel
Это улучшенная версия функции VARP, доступная в Excel 2010 и более поздних версиях.
ВАР.П(число1, [number2]…)
Функция ДСПСП в Excel
Функция VARPA вычисляет дисперсию генеральной совокупности на основе всего набора чисел, текста и логических значений. Он доступен во всех версиях Excel с 2000 по 2019.
БЫТЬ(значение1, [value2]…)
Формула дисперсии населения в Excel
в пример расчета переменной, мы обнаружили расхождение в 5 экзаменационных баллов, предполагая, что эти баллы были выбраны из большей группы студентов. Если вы соберете данные обо всех учащихся в группе, эти данные будут представлять все население, и вы рассчитаете дисперсию населения, используя вышеуказанные функции.
Допустим, у нас есть экзаменационные баллы группы из 10 студентов (B2:B11). Баллы составляют всю совокупность, поэтому мы будем делать дисперсию с этими формулами:
=СКОРБКА(B2:B11)
=ПЕР.П(B2:B11)
=ТОЭ(B2:B11)
И все формулы вернут одинаковый результат:
Чтобы убедиться, что Excel правильно рассчитал дисперсию, вы можете проверить ее с помощью формулы ручного расчета var, показанной на снимке экрана ниже:
Если кто-то из студентов не сдавал экзамен и вместо количества баллов указано N/A, функция VARPA вернет другой результат. Причина в том, что VARPA оценивает текстовые значения как нули, в то время как VARP и VAR.P игнорируют текстовые и логические значения в ссылках. Посмотри пожалуйста VAR.P vs. БЫЛ НА для получения полной информации.
Формула дисперсии в Excel — примечания по использованию
Чтобы правильно провести дисперсионный анализ в Excel, следуйте простым правилам:
- Предоставляйте аргументы в виде значений, массивов или ссылок на ячейки.
- В Excel 2007 и более поздних версиях можно указать до 255 аргументов, соответствующих выборке или генеральной совокупности; в Excel 2003 и старше — до 30 аргументов.
- Чтобы оценить только числа в ссылках, игнорируя пустые ячейки, текст и логические значения, используйте функцию VAR или VAR.S для расчета выборочной дисперсии и VARP или VAR.P для нахождения дисперсии генеральной совокупности.
- Для оценки логических и текстовых значений в ссылках используйте функцию VARA или VARPA.
- Укажите не менее двух числовых значений для формула выборочной дисперсии и по крайней мере одно числовое значение для формула дисперсии населения в Excel, иначе #DIV/0! возникает ошибка.
- Аргументы, содержащие текст, который нельзя интерпретировать как числа, приводят к ошибке #ЗНАЧ! ошибки.
Дисперсия по сравнению со стандартным отклонением в Excel
Дисперсия, несомненно, полезная концепция в науке, но она дает очень мало практической информации. Например, мы нашли возраст популяции тигров в местном зоопарке и рассчитал дисперсиючто равно 16. Вопрос в том, как на самом деле мы можем использовать это число?
Вы можете использовать дисперсию для определения стандартного отклонения, которое является гораздо лучшей мерой количества вариаций в наборе данных.
Стандартное отклонение рассчитывается как квадратный корень из дисперсии. Итак, мы берем квадратный корень из 16 и получаем стандартное отклонение 4.
В сочетании со средним значением стандартное отклонение может сказать вам, сколько лет большинству тигров. Например, если среднее значение равно 8, а стандартное отклонение равно 4, возраст большинства тигров в зоопарке составляет от 4 (8 — 4) до 12 лет (8 + 4).
Microsoft Excel имеет специальные функции для расчета стандартного отклонения выборки и генеральной совокупности. Подробное объяснение всех функций можно найти в этом руководстве: Как рассчитать стандартное отклонение в Excel.
Вот как сделать дисперсию в Excel. Чтобы поближе познакомиться с формулами, обсуждаемыми в этом руководстве, вы можете загрузить наш образец рабочей книги в конце этого поста. Я благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе!
Практическая рабочая тетрадь
Вычислить дисперсию в Excel — примеры (файл .xlsx)