Доброго времени суток, Друзья. Сегодня, я решил поднять тему, которая должна быть интересной практически всем, кто, так или иначе, связан с созданием сайтов.
Ни для кого, ни секрет, что скачав бесплатно шаблон, для своего сайта, независимо от движка, который используется, для управления контентом. Мы можем столкнуться с проблемой исходящих ссылок, которые ставятся различными вебмастерами, необязательно авторами. Парочку ссылок может оставить автор шаблона, затем еще парочку могут оставить те кто, например, перевел шаблон, те, кто выложил… И в общем итоге, исходящих ссылок может быть довольно солидное количество.

Я не буду поднимать тему, стоит ли оставлять ссылки автора шаблона или нет. Принимать решение только Вам. Порой шаблоны настолько заспамлены ссылками, что довольно остро встает вопрос, как удалить исходящие ссылки с сайта. Но прежде, чем удалять ссылки, их необходимо найти.
Как найти внешние ссылки в исходном коде?
Способов поиска, я думаю не мало. Можно искать исходящие ссылки, с помощью различных сервисов, плагинов или модулей для движков. Например, как написано в этой статье. Но самый простой и точный способ — это поиск исходящих ссылок вручную. Возможно, у Вас появилось чувство, что руками искать придется довольно долго. Или что данный процесс довольно трудоемкий, нежели воспользоваться каким-либо сервисом или утилитой. Но на самом деле, все очень просто, а надежность данного метода ни сравнима, ни с чем.
И, кроме того, у нас есть ни один вариант поиска. Сначала рассмотрим вариант поиска, с помощью исходного кода. В данном случае, необходимо хотя бы образно понимать структуру используемого шаблона. То есть, из каких основных файлов состоит шаблон. К примеру, wordpress, состоит из главной страницы index.php или home.php, файла полной новости single.php, файла страниц page.php футера, хэдера и сайдбара. Зачем это нужно?
Это нужно для того, чтобы понять, где проверить сайт на исходящие ссылки. Например, если мы проверим главную страницу сайта — это не даст нам гарантии, что ссылок на сайте нет, так как, проверив главную страницу, мы проверим только файлы: index.php, header.php, footer.php и sidebar.php. Однако ссылки могут быть спрятаны в записи или на страницах, то есть в файлах single.php и page.php.
Отсюда можно сделать вывод, что стоит проверить как минимум три страницы: главную, страницу с записью и обычную страницу с какой-либо информацией, например, «О сайте».
Теперь, разберем, как найти внешние ссылки? Заходим на страницу сайта и нажимаем сочетание клавиш Ctrl+U. Откроется новая вкладка с исходным кодом сайта. Вот в нем-то мы наверняка сможем найти исходящую ссылку, даже если в файле, она зашифрована. Для того, чтобы найти, достаточно нажать сочетание клавиш Ctrl+F, после чего появится форма поиска. И в поле формы написать начало любого адреса в сети интернет, это протокол. То есть, пишем http и жмем «Enter». После этого, абсолютно все ссылки на сайте будут подсвечены в коде.
А дальше дело за малым — вычислить ссылки, которые не были установлены нами. И удалить их в файлах. Чтобы найти, в каком файле они запрятаны, достаточно воспользоваться следующим вариантом поиска внешних ссылок.
Как найти ссылку на сайте?
Следующий вариант — это поиск ссылок в самих файлах сайта. Допустим, мы скачали шаблон для сайта, и сразу его можно проверить на наличие исходящих ссылок. Для этого, можно воспользоваться текстовым редактором NotePad++.
Чтобы найти ссылку на сайте, открываем редактор. В верхнем меню нажимаем на кнопку поиск, и из выпавшего списка выбираем «Найти в файлах». Дальше уже дело техники. Вводим в поле «Найти» протокол, используемый гиперссылками — http. И в поле «Папка» выбираем местонахождение шаблона на компьютере. После чего, нажимаем на кнопку «Найти все». Затем, программа выведет результаты поиска в нижней части окна. Где просмотрев ссылки, мы можем вычислить те, которые явно не относятся к шаблону.
Но у данного варианта, в отличие от первого, есть один большой недостаток, если ссылка зашифрована, то найти по протоколу ее не удастся. Хотя можно поменять цель поиска. И вместо http попробовать найти нечто подобное: base64. Довольно часто закодированные ссылки содержат такой кусок кода. Но все же данный вариант менее надежный, в отличии от первого.
Также, стоит отметить, что закодированные ссылки могут повлиять на работу шаблона, после удаления кода. Поэтому, перед удалением, следует cделать резервную копию сайта или файлов.
Оба способа могут показаться не такими уж понятными для начинающих, так как найдя ссылку, мы не всегда можем сразу определить ее точное местонахождение в файлах шаблона, модуля или плагина. Однако, при хорошем понимании структуры шаблона и методов подключения дополнительных файлов, довольно просто найти исходящие ссылки с сайта.
А как ищите Вы исходящие ссылки на сайте? Хотелось бы узнать методы, которыми пользуетесь Вы.
А у меня на этом все. Удачи!
![]() Как извлечь все ссылки с веб-страницы? Задался я вопросом когда возникла необходимость пакетной загрузки большого числа файлов по ссылкам с веб-страницы публичного ФТП серванта.
Как извлечь все ссылки с веб-страницы? Задался я вопросом когда возникла необходимость пакетной загрузки большого числа файлов по ссылкам с веб-страницы публичного ФТП серванта.
Туда-сюда из браузера в менеджер загрузки тыкать заколебёт, а файлы потребно скачать все и разом…
Искать сторонний спец.софт не вариант, нужно уметь обойтись стандартным набором инструментов входящих Дебиан Линух репозиторий или в сам браузер.
Подумалось сначала извлечь все ссылки с веб-страницы путём парсинга curl запроса, но на это не было времени и побежал я анонировать поиском, и наанонировал вот такой кусок JavaScript кода:
var x = document.querySelectorAll("a"); var myarray = [] for (var i=0; i<x.length; i++){ var nametext = x[i].textContent; var cleantext = nametext.replace(/s+/g, ' ').trim(); var cleanlink = x[i].href; myarray.push([cleantext,cleanlink]); }; function make_table() { var table = '<table><thead><th>Name</th><th>Links</th></thead><tbody>'; for (var i=0; i<myarray.length; i++) { table += '<tr><td>'+ myarray[i][0] + '</td><td>'+myarray[i][1]+'</td></tr>'; }; var w = window.open(""); w.document.write(table); } make_table()
Куда его вставлять? В «Инструменты разработчика» браузера, открываем комбинацией на клаве «CTRL + SHIFT + i». На вкладке «Console» в левом нижнем углу окна браузера есть неприметные две синие стрелки указывающие на узкую строку — ото туды и вставляем весь тот код, жмём/давим ENTER. В новой вкладке (всплывающие/выползающие окна нужно будет разрешить) появится список ссылок:




В данном примере извлекались ссылки с веб-страницы ФТП-серванта download.mapsforge.org для пакетной загрузки карт оффлайн-навигации. Можно также использовать для пакетной загрузки голых сисек/писек или кому чего угодно.
Для насквозь мобилизированных киборгов/челоботов/андроидов, т.е. для мобильных юзеров, данный метод извлечения ссылок с веб-страницы наверно не вариант ибо могут возникнуть проблемы с комбинацией на клаве «CTRL + SHIFT + i» — тогда смотрим в сторону дополнений/плагинов к браузерам.
Дале хрен знает шо то за плагины и как они арбайтен, афтор не в курсе и тупо нарыл их по поисковому запросу «extract links plugin for browser» — сами ставьте, юзайте, пишите в комменты шо то за хрень такая и какая от них польза.
Для сатанинского шпионского гугляцкого Chrome:
- Link Klipper — Extract all links — Chrome Web Store
Extract all links on a webpage and export them to a file.
Для браузера Firefox:
- Link Gopher – Get this Extension for Firefox (en-US)
Extracts all links from web page, sorts them, removes duplicates, and displays them in a new tab for inspection or copy and paste into other systems.
Извлечение ссылок через онлайн сервисы — это ещё тот квэст!
Куча сайто-говно-кодеров развелось, клепающих монструозные говно-сайты фреймворком «хуяк-хуяк» + конченная reCaptcha, и в продакшын. На такие «хуяк-хуяк-сервисы» уходит десятки МБ траффика, ресурсов железа, и хороший пучок нервов на пробивание пиЗЕ!данутой reCaptcha и часто + завал окна рекламой. В последнее время у меня впечатление, что кроме reCaptcha никакой иной на всей Планете уже нигде не осталось!
Но, местами нормальные онлайн сервисы извлечения ссылок попадаются (нарыто по запросу «Online Tool to Extract Links»):
- URL Extractor, Free Online Links Extractor, Extract HTML Links
На момент публикации был реально рабочий вариант онлайн сервиса для извлечения ссылок с веб-страницы
Через что ещё можно извлекать веб-ссылки? Через «питона»? Через «Ц», через «Ц++» или может через «Ж»? Вам через что бы ещё хотелося? В комменты пишите письма.
Пока усё, дасвидос/допобачендос/гудбай/аухфидерзейн.
1 ) Скачиваешь и устанавливаешь Python. ( ставишь галочку для PATH )https://www.python.org/downloads/
2) Win+R -> pip install requests > OK
3) Win+R -> pip install bs4 > OK
4) Создаешь папку на рабочем столе.
5) Создаешь два фаила в папке.
5.1) Первый фаил например get_links.py , туда вставляешь этот
КОД
import requests
from bs4 import BeautifulSoup
main_url = 'https://uristhome.ru'
docs_url = "https://uristhome.ru/document"
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
down_link = []
r = requests.get(docs_url, headers=headers)
soup = BeautifulSoup(r.content, 'html.parser')
for doc in soup.find("ul",{"class": "y_articles-document-list"}):
down_link.append(main_url+doc.find("a").attrs['href'])
with open('download_link.txt', 'a') as nf:
nf.writelines('n'.join(docs)) потом сохраняешь фаил.
5.2) Создаешь второй фаил например download_links.py туда вставляешь уже этот
КОД
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
down_link = open('download_links.txt', 'r')
docs = []
counter = 0
for links in down_link.readlines():
try:
r = requests.get(links, headers=headers)
soup = BeautifulSoup(r.content, 'html.parser')
x = soup.find("div",{"class": "filefield-file"}).find("a").attrs['href']
counter += 1
print(counter)
print(x)
docs.append(x)
except:
pass
with open('documents_link.txt', 'a') as nf:
nf.writelines('n'.join(docs))Как это работает:
1) открываешь get_links.py в папке создается текстовой файл с ссылками на документы
2) отрываешь download_links.py он будет обрабатывать тот текстовой файл. по окончанию создаст еще 1 текстовой файл documents_link.txt с ссылками на документы.
На заре интернета, если бы вы захотели создать свой сайт, скорее всего, заниматься версткой вам бы пришлось самостоятельно. В этом есть свой плюс, а именно четкое понимание работы своего сайта и полный контроль над кодом. Сегодня, когда сайты стали намного сложнее, для их создания вебмастера чаще всего используют готовые решения — CMS-системы и шаблоны, среди которых наибольшее распространение получили темы для Joomla и WordPress.
Такой подход к сайтостроению экономит массу времени и сил, но он может таить в себе скрытую опасность.
Учитывая количество доступных для скачивания бесплатных шаблонов, плагинов и модулей для популярных CMS, должно показаться странным, что их разработчики и распространители делятся ими исключительно по доброте душевной. Или всё же здесь есть нечто такое, о чём мы не знаем? Всё верно, ибо видимая бесплатность может оказаться лишь прикрытием, и заплатить вам таки придется, хоть и по-иному — в лучшем случае генерированием вашим сайтом рекламного трафика, а в худшем — подпадением его под фильтры поисковых систем.
Чем опасны скрытые ссылки
В чём же подвох? В том, что очень часто в код бесплатных шаблонов и компонентов их авторы вставляют ведущие на «левые» ресурсы скрытые ссылки, среди которых могут быть и явно фишинговые или содержащие вирусы, а это прямая дорога к бану от Google или Яндекс. Однако не нужно считать, что подобными грязными манипуляциями грешат поголовно все разработчики тем и ПО для CMS. Предлагая вебмастерам бесплатные решения, уважающие себя разработчики вполне открыто декларируют свои намерения, указывая на наличие копирайта или ограничений функциональности продукта.

Одна внешняя ссылка на тот же сайт разработчика вряд ли нанесет вред вашему ресурсу, иное дело если таких ссылок окажется много и проставлены они будут на многих страницах. А это уже ссылочный спам, за который полагаются санкции — фильтры Панда или Пингвин от того же Google. Поэтому, если вы всё же решите использовать бесплатные шаблоны, модули или компоненты, обязательно проверяйте свой сайт на предмет внешних ссылок. Увы, такая проверка может оказаться нетривиальной задачей, поскольку ссылки нередко кодируются или подгружаются скриптами с внешних источников.
Как узнать, есть ли на сайте внешние ссылки
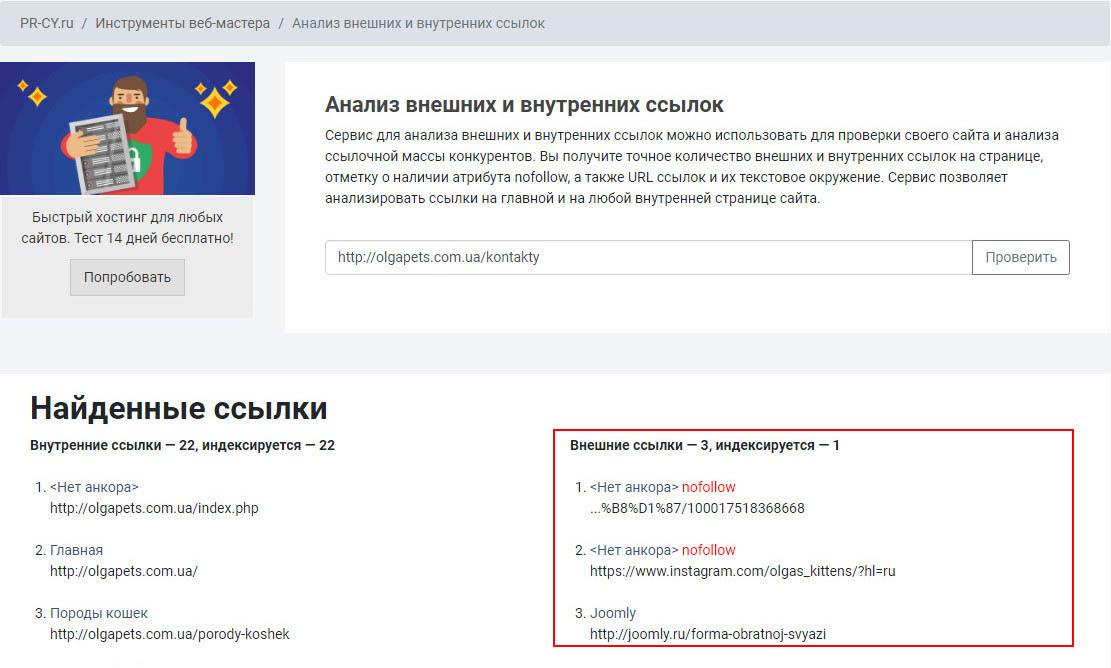
Установить наличие внешних ссылок можно как вручную, найдя в коде загруженной в браузере веб-страницы теги с HTTP, так и с помощью специальных приложений и скриптов — онлайновых и десктопных. Одним из них является PR-CY.ru — сервис для анализа и оптимизации сайтов.
Вбив на странице pr-cy.ru/link_extractor URL проверяемой страницы, можно вывести все внутренние и внешние ссылки, в том числе неиндексируемые.
Для анализа всего сайта лучше использовать программу Xenu Link Sleuth, предназначенную для аудита внутренних и внешних ссылок веб-ресурсов.
Запустив приложение, выберите в меню «File» опцию «Check URL», введите в поле адрес вашего сайта, отметьте, если не отмечен, чекбокс «Check external links» и нажмите «OK».
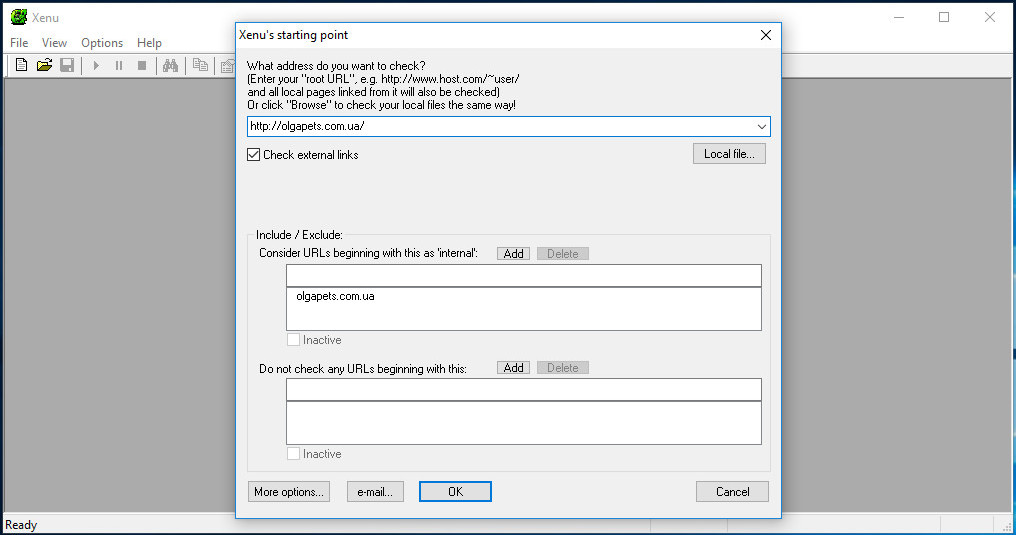
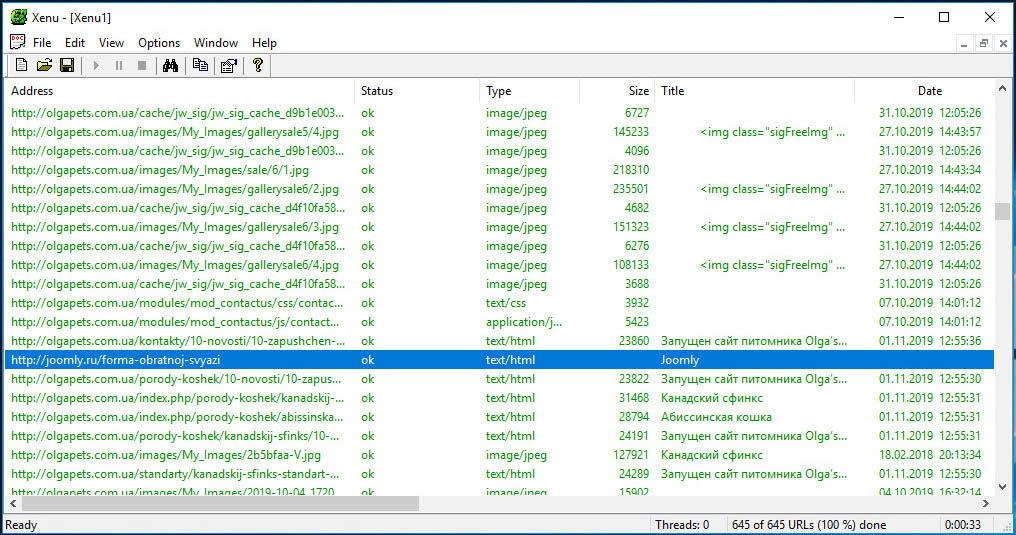
Готово, останется только внимательно изучить список найденных ссылок, отсортировав их по доступным параметрам.
Другой способ проверить сайт на предмет «левых» ссылок — воспользоваться скриптом Find-Link, ссылку на который вы найдете в конце статьи.
Положите скрипт в корень вашего сайта и обратитесь к нему напрямую, вот так: вашсайт.com/find-link.php. Скрипт выведет все внешние ссылки, включая те, которые доступны из панели управления CMS. Также будут выведены пути и имена файлов, в которых прописана ссылка, благодаря чему вы тут же можете их открыть и отредактировать.

Скрипт Find-Link не работает на локальном сервере, использовать его есть смысл после того как сайт будет залит на сервер.
Как удалить внешние ссылки сайта
В наиболее очевидных случаях ссылки на внешние ресурсы вставляются прямо в код главной страницы шаблона index.php. Избавиться от них проще всего, вы просто открываете шаблон Notepad++ и удаляете тег «a href» или содержащий его блок, после чего сохраняете страницу.
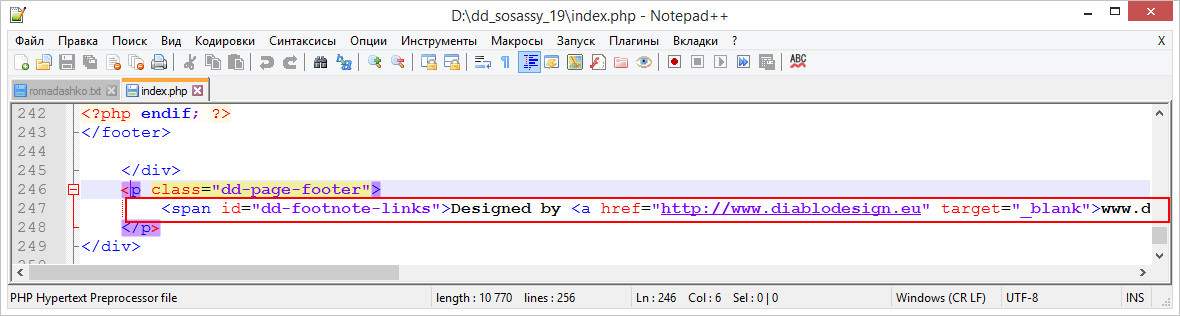
Если ссылка прячется где-то в дополнительных файлах, придется немного повозиться. Искать ссылки удобнее всего в Total Commander. Открываем файловый менеджер, переходим в каталог, в котором предположительно находится содержащий ссылку файл и жмем Alt + F7.
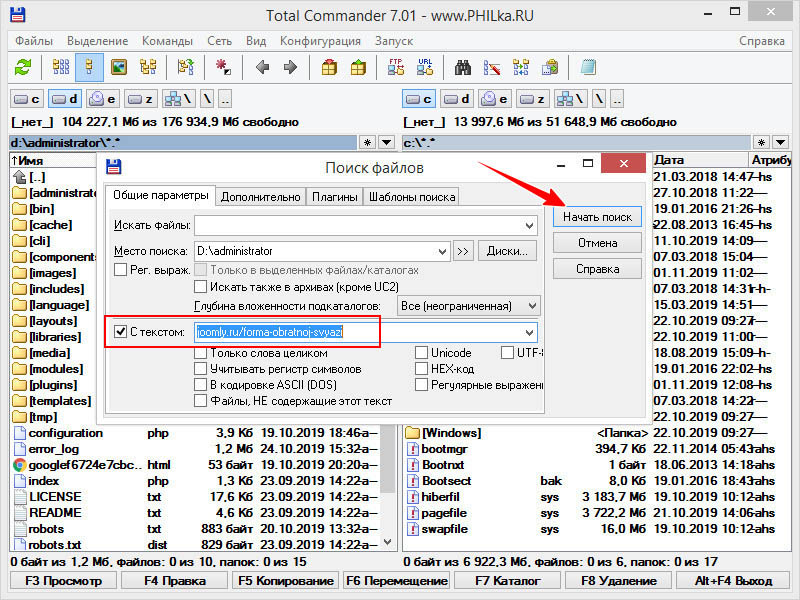
В открывшемся окошке поиска файлов отмечаем галкой пункт «С текстом», вводим в поле поиска искомую ссылку и жмем «Начать поиск». Менеджер прочтет файлы кода и выведет их имена и пути, если ссылка будет найдена. В нашем примере Total Commander нашел ссылку в конфигурационных INI-файлах.
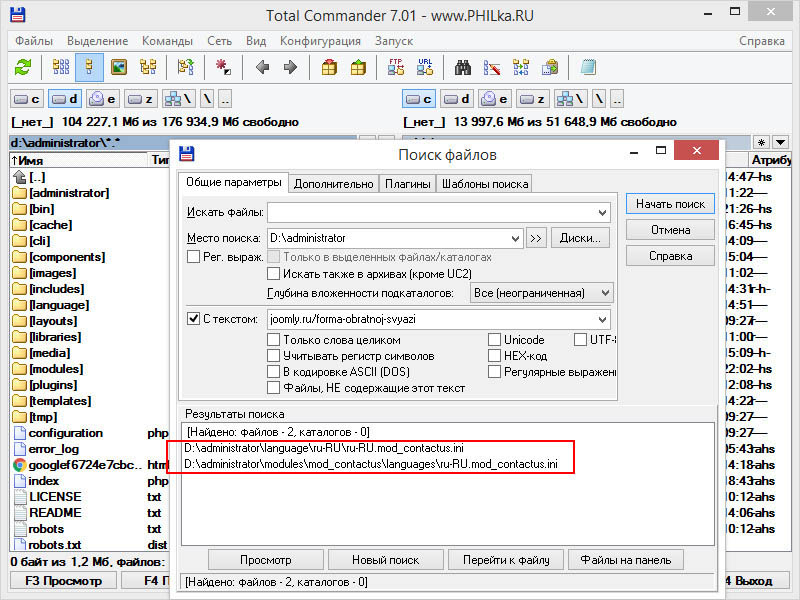
Далее всё просто, открываем найденные файлы Notepad++ и удаляем ссылки.

Естественно, работу с файлами выполняем на локальном компьютере во избежание случайных ошибок.
Увы, не все ссылки можно обнаружить таким способом.
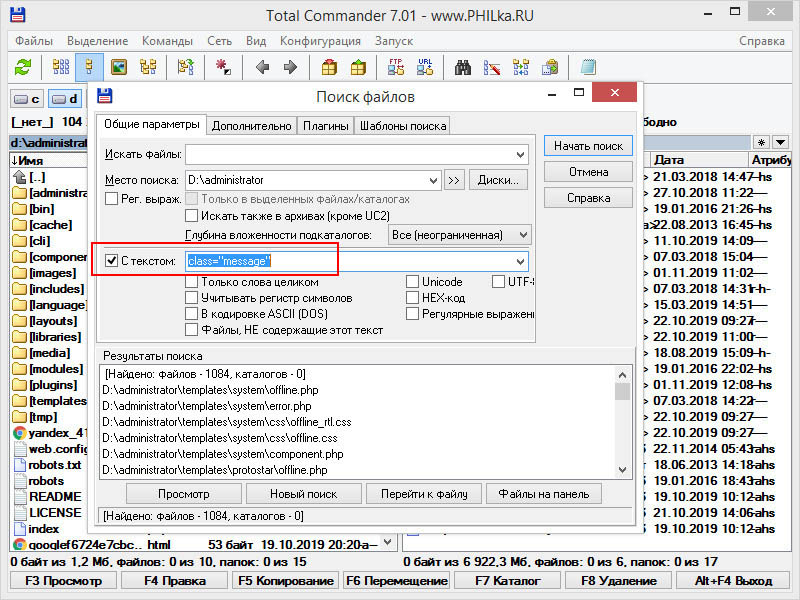
Если ссылка закодирована md5 или base64 либо она подгружается с внешнего ресурса, поиск по URL не принесет результатов. В этом случае лучше всего искать по ID или CSS-классу HTML-элемента, в котором выводится ссылка. Способ тем хорош, что избавляет от необходимости расшифровывать ссылку, вы находите и удаляете содержимое блока HTML. В приведенном ниже примере поиск выполнен по классу блока DIV — class=»message».
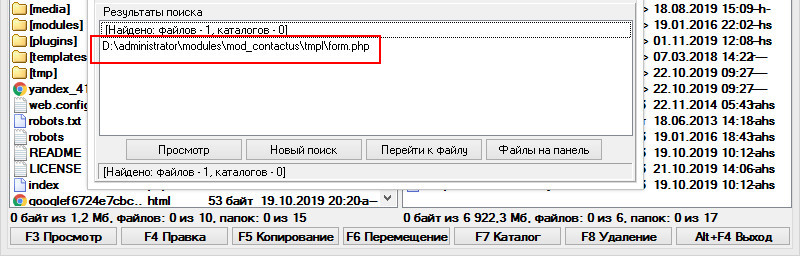
В результате чего был обнаружен вывод содержащей ссылку переменной методом JText в PHP-файле.

Меры предосторожности
В действительности, всё может быть сложнее. Особо хитрые авторы шаблонов или компонентов прописывают условия проверки наличия ссылки, при несоблюдении которых функционал или вывод последних нарушается. К сожалению, без знаний языков программирования наладить правильную работу скрипта не получится, ищите шаблон или компонент, чистка которого от ссылок не нарушает его работу или обращайтесь за помощью к специалистам.
Как вариант, скрытые ссылки можно закрыть от индексации, добавив в исходный код значение атрибута rel nofollow, но не факт, что после такой модификации всё будет работать. А вообще, чтобы было меньше хлопот и головной боли, скачивайте шаблоны, компоненты и плагины с официальных сайтов разработчиков, по крайней мере, так вы убережете свой сайт от совершенно левых добавок, которые столь часто встречаются в ПО, выложенном на варезных ресурсах.
Find-Link: yadi.sk/d/1yc087GHoR0u7Q
Xenu Link Sleuth: home.snafu.de/tilman/xenulink.html#Download
![]() Загрузка…
Загрузка…
Здравствуйте, уважаемые коллеги!
В этой статье мы с вами поговорим о скрытых исходящих ссылках на сайте (никто не застрахован от этой напасти), научимся их находить и безболезненно для себя удалять.
Не очень давно, я уже писал о проблематике исходящих ссылок в этой статье. Там же рассмотрены способы их закрытия метатегами и java скриптом.
Но как быть с паразитами, которые пробрались на сайт обманом, скрыты от глаз человека, откуда они вообще берутся, как их найти и ликвидировать.

Чаще всего, эта беда внедряется в бесплатные темы, плагины и модули своими шибко хитрыми разработчиками. Кроме высасывания жизненной силы, такие ссылки почти наверняка не совпадают с тематикой донора — будут иметь коммерческий характер или даже adult направленность. Согласитесь, за такое безобразие поисковики сайт не похвалят.
У вас наверное уже чешутся руки побыстрее приступить к поиску скрытой напасти (или убедиться в ее отсутствии) на сайте и, ликуя, уничтожить пакость. Весь вопрос в том, как это сделать. Для начала узнаем врага поближе.
Какие бывают скрытые ссылки
Рассмотрим и разберем самые распространенные способы сокрытия кровососов, их всего два.
1 С применением стиля «display:none»
Стиль display:none делает ссылку на странице невидимой для посетителей, но не для поисковых роботов в исходном коде — <a style=»display: none;» href=»https://wordpress-book.ru»>Учебник WordPress</a>

2 С дополнительным кодированием в «base64»
В этом случае ссылку, кроме того что она уже невидима, еще и кодируют.
В браузере ее не видно, но только не в исходном коде как и в первом случае. А в одном из сотен файлов, куда ссылка установлена, она будет состоять из такой пугающей конструкции:
<!--?php $str='PGEgc3R5bGU9ImRpc3BsYXk6IG5vbmU7IiBocmVmPSJodHRwczovL3dvcmRwcmVzcy1ib29rLnJ1Ij7Qo9GH0LXQsdC90LjQuiBXb3JkUHJlc3M8L2E+'; echo base64_decode($str); ?-->
Я вставил вышеуказанный код в footer.php этого блога и вот что получилось:

Делается это для того, чтобы максимально затруднить администратору ресурса обнаружение и поиск гидры.
Чтобы узнать, во что трансформируется такая абракадабра в браузере, можно воспользоваться любым, специальным для этого сервисом по кодировке, например этим — https://www.base64encode.org/.
Просто скопируйте код, заключенный в одинарные кавычки, вставьте его в верхнее окошко формы и нажмите на зеленую кнопку <DECODE>.

Сервис умеет не только раскодировать, но и кодировать ссылки (вкладка Encode).
Черному оптимизатору останется только такую конструкцию вставить в любой элемент распространяемого шаблона, плагина, модуля и т.д.
Между прочим, тем кто защищает контент от копирования посредством скрипта, встраивающего в конец скопированного текста ссылку на источник (в комментариях к статье «Как защитить контент от воровства» я приводил этот скрипт), есть пища для размышлений. Теперь вы знаете как защитить свою ссылку от удаления в скопированном контенте кем-то или чем-то. Не на 100% защита конечно, но лучше чем ничего.
Как найти скрытые исходящие ссылки
Начнем с небольшого предисловия. Когда-то на wordpress-book.ru стоял плагин, выводящий красивое облако меток в сайдбаре. Давным-давно это было очень модно.
Плагин был переведен на русский язык одним деятелем и им же была вставлена ссылка на свой АГС в файл расширения. Пиявка в блоке облака терялась среди множества меток и ее с удовольствием индексировали поисковые машины. Я же обнаружил вампира тогда случайно с помощью одного сервиса (ссылку не привожу, сдал сервис в последнее время). Вот старый скриншот:

А вот повествование давно минувших дней, как я эту ссылку удалял.
Как видим, на блог без приглашения пробрались 3 ссылки, одна из них полностью открыта для индексации.
И следующей задачей будет найти и удалить паразитов. Для этого в вашем файл менеджере (рекомендую Total Commander) нужно перейти в корень сайта (более подробно я писал об этом в статье- Доступ к сайту через ftp.

- Вызвать окно поиска файлов нажатием кнопки «Поиск файлов» на панели инструментов.
- В поле «Искать файлы» наберите *.*.
- Место поиска пропишется автоматически, это будет корень сайта.
- В поле «С текстом» вставьте текст ссылки, которую нужно найти.
- Нажмите на кнопку «Начать поиск«.
- В поле «Результаты поиска» появится список файлов с адресом их расположения, где была найдена искомая ссылка.
- Нажмите на кнопку «Перейти к файлу«.

В открывшемся файле зловредную ссылку с радостью удаляем.
Невидимые или закодированные ссылки вы найдете точно также, как в примере выше. Только в строку для поиска (пункт 4) вставьте другой искомый текст, в нашем случае display:none или base64.
Следует заметить, что не все найденные конструкции кода, включающие в себя display:none или base64 следует вносить в черный список.
Технологии кодировки в base64 и невидимость при помощи стиля display:none вполне легальны. Их используют разработчики расширений для всех СМС. К примеру, популярный в России плагин «Социальный замок» скрывает контент от посетителя при помощи base64. Будьте внимательны и не нарубите дров в азарте.
С помощью бесплатной программы «Xenu Link Sleuth», вы найдете вообще все ссылки, присутствующие на сайте. Полезно для решения широкого спектра задач по внутренней оптимизации. Ссылка для скачивания и основной функционал программы изложен в статье «Xenu Link Sleuth — Программа для поиска ссылок на сайте«.
Делитесь своими успехами или неудачами в комментариях, буду рад помочь. Желаю удачи!