-

1
Look at your data set. This is a crucial step in any type of statistical calculation, even if it is a simple figure like the mean or median.[2]
- Know how many numbers are in your sample.
- Do the numbers vary across a large range? Or are the differences between the numbers small, such as just a few decimal places?
- Know what type of data you are looking at. What do your numbers in your sample represent? this could be something like test scores, heart rate readings, height, weight etc.
- For example, a set of test scores is 10, 8, 10, 8, 8, and 4.
-
2
Gather all of your data. You will need every number in your sample to calculate the mean.[3]
- The mean is the average of all your data points.
- This is calculated by adding all of the numbers in your sample, then dividing this figure by the how many numbers there are in your sample (n).
- In the sample of test scores (10, 8, 10, 8, 8, 4) there are 6 numbers in the sample. Therefore n = 6.
Advertisement
-
3
Add the numbers in your sample together. This is the first part of calculating a mathematical average or mean.[4]
- For example, use the data set of quiz scores: 10, 8, 10, 8, 8, and 4.
- 10 + 8 + 10 + 8 + 8 + 4 = 48. This is the sum of all the numbers in the data set or sample.
- Add the numbers a second time to check your answer.
-
4
Divide the sum by how many numbers there are in your sample (n). This will provide the average or mean of the data.[5]
- In the sample of test scores (10, 8, 10, 8, 8, and 4) there are six numbers, so n = 6.
- The sum of the test scores in the example was 48. So you would divide 48 by n to figure out the mean.
- 48 / 6 = 8
- The mean test score in the sample is 8.




Advertisement
-
1
Find the variance. The variance is a figure that represents how far the data in your sample is clustered around the mean.[6]
- This figure will give you an idea of how far your data is spread out.
- Samples with low variance have data that is clustered closely about the mean.
- Samples with high variance have data that is clustered far from the mean.
- Variance is often used to compare the distribution of two data sets.
-
2
Subtract the mean from each of your numbers in your sample. This will give you a figure of how much each data point differs from the mean.[7]
- For example, in our sample of test scores (10, 8, 10, 8, 8, and 4) the mean or mathematical average was 8.
- 10 — 8 = 2; 8 — 8 = 0, 10 — 8 = 2, 8 — 8 = 0, 8 — 8 = 0, and 4 — 8 = -4.
- Do this procedure again to check each answer. It is very important you have each of these figures correct as you will need them for the next step.
-
3
Square all of the numbers from each of the subtractions you just did. You will need each of these figures to find out the variance in your sample.[8]
- Remember, in our sample we subtracted the mean (8) from each of the numbers in the sample (10, 8, 10, 8, 8, and 4) and came up with the following: 2, 0, 2, 0, 0 and -4.
- To do the next calculation in figuring out variance you would perform the following: 22, 02, 22, 02, 02, and (-4)2 = 4, 0, 4, 0, 0, and 16.
- Check your answers before proceeding to the next step.
-
4
Add the squared numbers together. This figure is called the sum of squares.[9]
- In our example of test scores, the squares were as follows: 4, 0, 4, 0, 0, and 16.
- Remember, in the example of test scores we started by subtracting the mean from each of the scores and squaring these figures: (10-8)^2 + (8-8)^2 + (10-8)^2 + (8-8)^2 + (8-8)^2 + (4-8)^2
- 4 + 0 + 4 + 0 + 0 + 16 = 24.
- The sum of squares is 24.
-
5
Divide the sum of squares by (n-1). Remember, n is how many numbers are in your sample. Doing this step will provide the variance. The reason to use n-1 is to have sample variance and population variance unbiased. [10]
- In our sample of test scores (10, 8, 10, 8, 8, and 4) there are 6 numbers. Therefore, n = 6.
- n-1 = 5.
- Remember the sum of squares for this sample was 24.
- 24 / 5 = 4.8
- The variance in this sample is thus 4.8.





Advertisement
-
1
Find your variance figure. You will need this to find the standard deviation for your sample.[11]
- Remember, variance is how spread out your data is from the mean or mathematical average.
- Standard deviation is a similar figure, which represents how spread out your data is in your sample.
- In our example sample of test scores, the variance was 4.8.
-
2
Take the square root of the variance. This figure is the standard deviation.[12]
- Usually, at least 68% of all the samples will fall inside one standard deviation from the mean.
- Remember in our sample of test scores, the variance was 4.8.
- √4.8 = 2.19. The standard deviation in our sample of test scores is therefore 2.19.
- 5 out of 6 (83%) of our sample of test scores (10, 8, 10, 8, 8, and 4) is within one standard deviation (2.19) from the mean (8).
-
3
Go through finding the mean, variance and standard deviation again. This will allow you to check your answer.[13]
- It is important that you write down all steps to your problem when you are doing calculations by hand or with a calculator.
- If you come up with a different figure the second time around, check your work.
- If you cannot find where you made a mistake, start over a third time to compare your work.



Advertisement
Practice Problems and Answers
Add New Question
-
Question
What is the standard deviation of 10 samples with a mean of 29.05?

Depends on the 10 samples of data. If all ten numbers were 29.05 then the standard deviation would be zero. Standard deviation is a measure of how much the data deviates from the mean.
-
Question
How do I calculate the standard deviation of 5 samples with the mean of 26?
You take the average of 26 and 5, divide by b squared and multiply by deviation equation constant.
-
Question
How do I find the standard deviation of 10 samples with a mean of 29.05?
Take each sample and subract the mean. Next, square each result, getting rid of the negative. Add the 10 results and divide the sun by 10 — 1 or 9. That is the standard deviation.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
Thanks for submitting a tip for review!
References
About This Article
Article SummaryX
To calculate standard deviation, start by calculating the mean, or average, of your data set. Then, subtract the mean from all of the numbers in your data set, and square each of the differences. Next, add all the squared numbers together, and divide the sum by n minus 1, where n equals how many numbers are in your data set. Finally, take the square root of that number to find the standard deviation. To learn how to find standard deviation with the help of example problems, keep reading!
Did this summary help you?
Thanks to all authors for creating a page that has been read 2,561,041 times.
Reader Success Stories
-

«This article was the best statistics instructor I have ever been taught by. I have learned more from this little…» more
Did this article help you?
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
- среднеквадратическое отклонение,
- среднее квадратическое отклонение,
- среднеквадратичное отклонение,
- квадратичное отклонение,
- стандартный разброс.
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
- в финансах в качестве меры волатильности,
- в социологии в опросах общественного мнения — оно помогает в расчёте погрешности.
Пример:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
- А -> (19 + 21 + 19+ 21) / 4 = 20
- Б -> (15 + 26 + 15+ 24) / 4 = 20
Однако, глядя на цифры, можно заметить:
- в компании A количество товара всех четырёх дней очень близко находится к этому среднему значению 20 (колеблется лишь между 19 ед. и 21 ед.),
- в компании Б существует большая разница со средним количеством товара (колеблется между 15 ед. и 26 ед.).
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
- стандартное отклонение компании A = 1,
- стандартное отклонение компании Б ≈ 5.
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения

σ — стандартное отклонение,
xi — величина отдельного значения выборки,
μ — среднее арифметическое выборки,
n — размер выборки.
Эта формула применяется, когда анализируются все значения выборки.

S — стандартное отклонение,
n — размер выборки,
xi — величина отдельного значения выборки,
xср — среднее арифметическое выборки.
Эта формула применяется, когда присутствует очень большой размер выборки, поэтому на анализ обычно берётся только её часть.
Единственная разница с предыдущей формулой: “n — 1” вместо “n”, и обозначение «xср» вместо «μ».
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
- только её часть – используется формула S (с «n–1»),
- полностью все данные – используется формула σ (с «n»).
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
x1 — μ = 15 — 20 = -5
x2 — μ = 26 — 20 = 6
x3 — μ = 15 — 20 = -5
x4 — μ = 24 — 20 = 4
3. Каждую полученную разницу возвести в квадрат:
(x1 — μ)² = (-5)² = 25
(x2 — μ)² = 6² = 36
(x3 — μ)² = (-5)² = 25
(x4 — μ)² = 4² = 16
4. Сделать сумму полученных значений:
Σ (xi — μ)² = 25 + 36+ 25+ 16 = 102
5. Поделить на размер выборки (т.е. на n):
(Σ (xi — μ)²)/n = 102 / 4 = 25,5
6. Найти квадратный корень:
√((Σ (xi — μ)²)/n) = √ 25,5 ≈ 5,0498
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
(X1 – Xср)² = (2,5)² = 6,25
(X2 – Xср)² = (–4,5)² = 20,25
(X3 – Xср)² = (–1,5)² = 2,25
(X4 – Xср)² = (–2,5)² = 6,25
(X5 – Xср)² = 5,5² = 30,25
(X6 – Xср)² = 0,5² = 0,25
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
- Вычесть среднее значение из каждого числа
- Возвести каждый результат в квадрат (так получатся квадраты разностей)
- Найти среднее значение квадратов разностей.
Ещё расчёт дисперсии можно сделать по этой формуле:

S² — выборочная дисперсия,
Xi — величина отдельного значения выборки,
Xср (может появляться как X̅) — среднее арифметическое выборки,
n — размер выборки.
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
- одного среднеквадратического отклонения заключаются 68,26% значений (Xср ± 1σ или μ ± 1σ),
- двух стандартных отклонений — 95,44% (Xср ± 2σ или μ ± 2σ),
- трёх стандартных отклонений — 99,72% (Xср ± 3σ или μ ± 3σ).
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
- при <10% выборка слабо вариабельна,
- при 10% – 20 % — средне вариабельна,
- при >20 % — выборка сильно вариабельна.
Узнайте также про:
- Корреляции,
- Метод Крамера,
- Метод наименьших квадратов,
- Теорию вероятностей
- Интегралы.
Среднее абсолютное отклонение позволяет решить проблему, заключающуюся в том, что сумма отклонений от среднего равна нулю. Для этого при расчете среднего используется абсолютное значение отклонений.
Второй подход к расчету отклонений состоит в их возведении в квадрат.
Дисперсия и стандартное отклонение, основанные на квадрате отклонений, являются двумя наиболее широко используемыми мерами дисперсии:
- Дисперсия определяется как среднее квадратов отклонений от среднего значения.
- Стандартное отклонение — это положительный квадратный корень дисперсии.
Далее обсуждается расчет и использования дисперсии и стандартного отклонения.
Дисперсия генеральной совокупности.
Если нам известен каждый элемент генеральной совокупности, мы можем вычислить дисперсию генеральной совокупности или просто дисперсию (англ. ‘population variance’).
Она обозначается символом (sigma^2)[сигма] и представляет собой среднее арифметическое квадратов отклонений от среднего значения.
Формула дисперсии генеральной совокупности.
( Large
sigma^2 = { dsum_{i=1}^{N} ( X_i — mu )^2 over N } ) (Формула 11)
где
- (mu) [мю] — это среднее генеральной совокупности, а
- (N) — размер генеральной совокупности.
Зная среднее значение μ, мы можем использовать Формулу 11 для вычисления суммы квадратов отклонений от среднего с учетом всех (N) элементов в генеральной совокупности, а затем для определения среднего квадратов отклонений путем деления этой суммы на (N).
Независимо от того, является ли отклонение от среднего положительным или отрицательным, возведение в квадрат этой разности дает положительное число.
Таким образом, дисперсия решает проблему отрицательных отклонений от среднего значения, устраняя их посредством операции возведения в квадрат этих отклонений.
Рассмотрим пример.
Прибыль в процентах от выручки для оптовых клубов BJ’s Wholesale Club, Costco и Walmart за 2012 год составляла 0.9%, 1.6% и 3.5% соответственно. Мы рассчитали среднюю прибыль в процентах от выручки как 2.0%.
Следовательно, дисперсия прибыли в процентах от выручки составляет:
(1/3)[(0.9 — 2.0)2 + (1.6 — 2.0)2 + (3.5 — 2.0)2]
= (1/3)(-1.12 + -0.42 + 1.52)
= (1/3)(1.21 + 0.16 + 2.25) = (1/3)(3.62) = 1.21
Стандартное отклонение генеральной совокупности.
Поскольку дисперсия измеряется в квадратах, нам нужен способ вернуться к исходным единицам. Мы можем решить эту проблему, используя стандартное отклонение, т.е. квадратный корень из дисперсии.
Стандартное отклонение легче интерпретировать, чем дисперсию, поскольку стандартное отклонение выражается в той же единице измерения, что и наблюдения.
Формула стандартного отклонения генеральной совокупности.
Стандартное отклонение генеральной совокупности (или просто стандартное отклонение, а также среднеквадратическое отклонение, от англ. ‘population standard deviation’), определяемое как положительный квадратный корень из дисперсии генеральной совокупности, составляет:
( Large dst
sigma = sqrt{sum_{i=1}^{N} ( X_i — mu )^2 over N} ) (Формула 12)
где
- (mu) [мю] — это среднее генеральной совокупности, а
- (N) — размер генеральной совокупности.
Используя пример прибыли в процентах от выручки для оптовых клубов BJ’s Wholesale Club, Costco и Walmart за 2012 год, в соответствии с Формулой 12, мы вычислим дисперсию 1.21, а затем возьмем квадратный корень: ( sqrt{1.21} ) = 1.10.
Как дисперсия, так и стандартное отклонение являются примерами параметров распределения. В последующих чтениях мы введем понятие дисперсии и стандартного отклонения как меры риска.
Занимаясь инвестициями, мы часто не знаем среднего значения интересующей совокупности, обычно потому, что мы не можем практически идентифицировать или провести измерения для каждого элемента генеральной совокупности.
Поэтому мы рассчитываем среднее значение по генеральной совокупности и среднее выборки, взятой из совокупности, и вычисляем выборочную дисперсию или стандартное отклонение выборки, используя формулы, немного отличающиеся от Формул 11 и 12.
Мы обсудим эти вычисления далее.
Однако в инвестициях у нас иногда есть определенная группа, которую мы можем считать генеральной совокупностью. Для четко определенных групп наблюдений мы используем Формулы 11 и 12, как в следующем примере.
Пример расчета стандартного отклонения для генеральной совокупности.
В Таблице 20 представлен годовой оборот портфеля из 12 фондов акций США, которые вошли в список Forbes Magazine Honor Roll 2013 года.
Журнал Forbes ежегодно выбирает американские взаимные фонды, отвечающие определенным критериям для своего почетного списка Honor Roll.
Критериями являются:
- сохранение капитала (эффективность на медвежьем рынке),
- непрерывность управления (у фонда должен управлять менеджер непрерывно, в течение не менее 6 лет), диверсификация портфелей,
- доступность (дисквалификация фондов, которые закрыты для новых инвесторов), и
- долгосрочные показатели эффективности после уплаты налогов.
Оборачиваемость или оборот портфеля, показатель торговой активности, является меньшим значением из стоимости продаж или покупок за год, деленным на среднюю чистую стоимость активов за год. Количество и состав списка Forbes Honor Roll меняются из года в год.
|
Фонд |
Годовой оборот портфеля (%) |
|---|---|
|
Bruce Fund (BRUFX) |
10 |
|
CGM Focus Fund (CGMFX) |
360 |
|
Hotchkis And Wiley Small Cap Value A Fund (HWSAX) |
37 |
|
Aegis Value Fund (AVALX) |
20 |
|
Delafield Fund (DEFIX) |
49 |
|
Homestead Small Company Stock Fund (HSCSX) |
1 |
|
Robeco Boston Partners Small Cap Value II Fund (BPSCX) |
32 |
|
Hotchkis And Wiley Mid Cap Value A Fund (HWMAX) |
72 |
|
T Rowe Price Small Cap Value Fund (PRSVX) |
9 |
|
Guggenheim Mid Cap Value Fund Class A (SEVAX) |
19 |
|
Wells Fargo Advantage Small Cap Value Fund (SSMVX) |
16 |
|
Stratton Small-Cap Value Fund (STSCX) |
11 |
Источник: Forbes (2013).
Основываясь на данных из таблицы 20, сделайте следующее:
- Рассчитайте среднее по совокупности для оборота портфеля за период, используя данные для 12 фондов из Honor Roll.
- Рассчитайте дисперсию и стандартное отклонение совокупности для оборота портфеля.
- Объясните использование формул в этом примере.
Решение для части 1:
(mu) = (10 + 360 + 37 + 20 + 49 + 1 + 32 + 72 + 9 + 19 + 16 + 11)/12
= 636 /12 = 53%.
Решение для части 2:
Установив, что (mu) = 53%, мы можем вычислить дисперсию
( sigma^2 = { sum_{i=1}^{N} ( X_i — mu )^2 over N } ), сначала рассчитав числитель, а затем разделив результат на (N) = 12.
Числитель (сумма квадратов отклонений от среднего) равен:
(10 — 53)2 + (360 — 53)2 + (37 — 53)2 + (20 — 53)2 +
(49 — 53)2 + (1 — 53)2 + (32 — 53)2 + (72 — 53)2 +
(9 — 53)2 + (19 — 53)2 + (16 — 53)2 + (11 — 53)2 = 107,190
Таким образом,
( sigma^2 ) = 107,190/12 = 8,932.50.
Для расчета стандартного отклонения находим квадратный корень:
( sigma = sqrt{ 8,932.50 } ) = 94.51%.
Единицей измерения дисперсии является процент в квадрате, поэтому единицей измерения стандартного отклонения также является процент.
Решение для части 3:
Если генеральная совокупность четко определена как фонды Forbes Honor Roll за один конкретный год (2013 г.), и если под оборотом портфеля понимается конкретный одногодичный период, о котором отчитывается Forbes, то применение формул генеральной совокупности для дисперсии и стандартного отклонения уместно.
Результаты 8,932.50 и 94.51 представляют собой, соответственно, перекрестную дисперсию и стандартное отклонение годового оборота портфеля для фондов Forbes Honor Roll за 2013 год.
Фактически, мы не могли должным образом использовать фонды Honor Roll для оценки дисперсии оборота портфеля (например) любой другой по-разному определенной генеральной совокупности, потому что фонды Honor Roll не являются случайной выборкой из какой-либо большей генеральной совокупности взаимных фондов США.
Выборочная дисперсия.
Во многих случаях в управлении инвестициями подгруппа или выборка из генеральной совокупности — это все, что мы можем наблюдать. Когда мы имеем дело с выборками, сводные показатели называются статистикой.
Статистика, которая измеряет дисперсию по выборке, называется выборочной дисперсией или дисперсией выборки (англ. ‘sample variance’).
В приведенном ниже обсуждении обратите внимание на использование латинских букв вместо греческих для обозначения объема выборки.
Формула выборочной дисперсии.
( Large
s^2 = { dsum_{i=1}^{n} ( X_i — overline X )^2 over n-1 } ) (Формула 13)
где
- ( overline X ) — среднее значение выборки, а
- (n) — количество наблюдений в выборке.
Формула 13 предписывает нам предпринять следующие шаги для вычисления выборочной дисперсии:
- Рассчитать выборочное среднее значение, ( overline X ).
- Рассчитать квадратичное отклонение каждого наблюдения от среднего значения по выборке, ( ( X_i — overline X )^2 )
- Найти сумму квадратов отклонений от среднего: ( sum_{i=1}^{n} ( X_i — overline X )^2 ).
- Разделить сумму квадратов отклонений от среднего на ( (n — 1)).
Мы проиллюстрируем расчет выборочной дисперсии и выборочного стандартного отклонения на примере ниже.
Отличие выборочной дисперсии от дисперсии генеральной совокупности.
Мы используем обозначение ( s^2 ) для выборочной дисперсии, чтобы отличить ее от дисперсии генеральной совокупности ( sigma^2 ).
Формула для выборочной дисперсии почти такая же, как и для дисперсии генеральной совокупности, за исключением использования среднего значения выборки ( overline X ) вместо среднего значения генеральной совокупности μ и другого делителя.
В случае дисперсии генеральной совокупности мы делим числитель на размер совокупности (N). Однако для дисперсии выборки мы делим ее на размер выборки минус 1 или (n — 1). Используя (n — 1) (а не (n)) в качестве делителя мы улучшаем статистические свойства выборочной дисперсии.
В статистических терминах выборочная дисперсия, определенная в Формуле 13, является несмещенной оценкой (англ. ‘unbiased estimator ‘) дисперсии генеральной совокупности ( sigma^2 ).
Мы обсудим эту концепцию далее в чтении о выборке.
Величина (n — 1) также называется числом степеней свободы (англ. ‘number of degrees of freedom’) при оценке дисперсии генеральной совокупности.
Чтобы оценить дисперсию ( s^2 ), мы должны сначала вычислить среднее. После того как мы вычислили среднее значение выборки, существует только (n — 1) независимых отклонений от него.
Стандартное отклонение выборки.
Для стандартного отклонения генеральной совокупности мы аналогичным образом можем вычислить стандартное отклонение выборки, взяв квадратный корень из положительной дисперсии выборки.
Формула стандартного отклонения выборки.
Стандартное отклонение выборки (выборочное стандартное отклонение, выборочное среднеквадратическое отклонение, англ. ‘sample standard deviation’), обозначается символом (s) и рассчитывается следующим образом:
( Large dst
s = sqrt{ sum_{i=1}^{n} ( X_i — overline X )^2 over n-1 } ) (Формула 14)
где
- ( overline X ) — среднее значение выборки, а
- (n) — количество наблюдений в выборке.
Чтобы рассчитать стандартное отклонение выборки, мы сначала вычисляем дисперсию выборки, используя приведенные выше шаги. Затем мы берем квадратный корень из выборочной дисперсии.
Пример, приведенный ниже, иллюстрирует расчет выборочной дисперсии и стандартного отклонения выборки для двух взаимных фондов, представленных ранее.
Пример расчета выборочной дисперсии и стандартного отклонения выборки.
После расчета геометрических и арифметических средних доходностей двух взаимных фондов в Примере (1) мы вычислили две меры дисперсии для этих фондов, размах и среднее абсолютное отклонение доходности (см. Пример расчета размаха и среднего абсолютного отклонения для оценки риска).
Теперь мы вычислим выборочную дисперсию и стандартное отклонение выборки для доходности тех же двух фондов.
|
Год |
Фонд Selected |
Фонд T. Rowe Price |
|---|---|---|
|
2008 |
-39.44% |
-35.75% |
|
2009 |
31.64 |
25.62 |
|
2010 |
12.53 |
15.15 |
|
2011 |
-4.35 |
-0.72 |
|
2012 |
12.82 |
17.25 |
Источник: performance.morningstar.com.
На основании приведенных выше данных сделайте следующее:
- Рассчитайте выборочную дисперсию доходности для (A) SLASX и (B) PRFDX.
- Рассчитайте выборочное стандартное отклонение доходности для (A) SLASX и (B) PRFDX.
- Сравните дисперсию доходности, измеренную стандартным отклонением доходности и средним абсолютным отклонением доходности для каждого из двух фондов.
Решение для части 1:
Чтобы вычислить выборочную дисперсию, мы используем Формулу 13 (значения отклонений приведены в процентах).
А. SLASX:
1. Среднее значение выборки:
( overline R ) = (-39.44 + 31.64 + 12.53 — 4.35 +12.82)/ 5 =
13.20/5 = 2.64%.
2. Квадратичные отклонения от среднего значения:
(-39.44 — 2.64)2 = (-42.08)2 = 1,770.73
(31.64 — 2.64)2 = (29.00)2 = 841.00
(12.53 — 2.64)2 = (9.89)2 = 97.81
(-4.35 — 2.64)2 = (-6.99)2 = 48.86
(12.82 — 2.64)2 = (10.18)2 = 103.63
3. Сумма квадратов отклонений от среднего составляет:
1,770.73 + 841.00 + 97.81 + 48.86 + 103.63 = 2,862.03.
4. Разделим сумму квадратов отклонений от среднего на (n — 1):
2,862.03 / (5 — 1) = 2,862.03 / 4 = 715.51
B. PRFDX:
1. Среднее значение выборки:
( overline R ) = (-35.75 + 25.62 + 15.15 — 0.72 + 17.25)/5 = 21.55/5 = 4.31%.
2. Квадратичные отклонения от среднего значения:
(-35.75 — 4.31)2 = (-40.06)2 = 1,604.80
(25.62 — 4.31)2 = (21.31)2 = 454.12
(15.15 — 4.31)2 = (10.84)2 = 117.51
(-0.72 — 4.31)2 = (-5.03)2 = 25.30
(17.25 — 4.31)2 = (12.94)2 = 167.44
3. Сумма квадратов отклонений от среднего составляет:
1,604.80 + 454.12 + 117.51 + 25.30 + 167.44 = 2,369.17.
4. Разделим сумму квадратов отклонений от среднего на ((n — 1)):
2,369.17/4 = 592.29
Решение для части 2:
Чтобы найти стандартное отклонение, мы берем положительный квадратный корень из дисперсии.
A. Для SLASX, s = ( sqrt {715.51} ) = 26.7%.
B. Для PRFDX, s = ( sqrt {592.29} ) = 24.3%.
Решение для части 3:
Таблица 21 суммирует результаты части 2 для стандартного отклонения и включает результаты для MAD из Примера расчета размаха и среднего абсолютного отклонения для оценки риска.
|
Фонд |
Стандартное |
Среднее |
|---|---|---|
|
SLASX |
26.7 |
19.6 |
|
PRFDX |
24.3 |
18.0 |
Обратите внимание, что среднее абсолютное отклонение меньше стандартного отклонения. Среднее абсолютное отклонение всегда будет меньше или равно стандартному отклонению, потому что стандартное отклонение придает больший вес большим отклонениям, чем маленьким (помните, что отклонения возводятся в квадрат).
Поскольку стандартное отклонение является мерой дисперсии относительно среднего арифметического, мы обычно представляем среднее арифметическое и стандартное отклонение вместе при анализе данных.
Когда мы имеем дело с данными, которые представляют собой временной ряд процентных изменений, представление геометрического среднего, представляющего собой сложную ставку скорости роста, также очень полезно.
В Таблице 22 представлены исторические геометрические и арифметические средние доходности, а также историческое стандартное отклонение доходности для годовой и месячной доходности S&P 500.
Мы представляем эту статистику для номинальной (без поправки на инфляцию) доходности, чтобы мы могли наблюдать первоначальные величины доходности.
|
Ставка доходности |
Геометрическое |
Среднее |
Стандартное отклонение |
|---|---|---|---|
|
S&P 500 (Годовая) |
9.84 |
11.82 |
20.18 |
|
S&P 500 (Месячная) |
0.79 |
0.94 |
5.50 |
Источник: Ibbotson.
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом  (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее  мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
![[ begin{array}{l} 1: 600-394 = 206 \ 2: 470-394 = 76 \ 3: 170-394 = -224\ 4: 430-394 = 36\ 5: 300-394 = -94 end{array} ]](https://yourtutor.info/wp-content/ql-cache/quicklatex.com-3916a3ccd97d909589dfe1dabb970af0_l3.png "Rendered by QuickLaTeX.com")
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия  мм2.
мм2.
Таким образом, дисперсия составляет 21704 мм2.
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть  значений, то:
значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм2.
мм2.
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
 .
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Определение 2.13
Стандартным отклонением выборки x1, x2, …, xn называется число S, которое вычисляется по формуле:
![]() .
.
Таким образом, выборочное стандартное отклонение
равно квадратному корню из выборочной дисперсии, следовательно, справедливы
формулы:
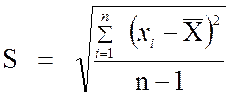 либо
либо 
Пример 2.21 В течение пяти
дней студент Ковалев записывал стоимость обедов в студенческой столовой: 3,2;
4,8; 5,6; 4,5; 5,4. Найдем выборочную дисперсию и стандартное отклонение.
Сначала определим среднее:
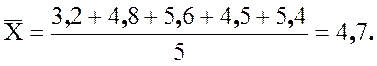
Вычислим дисперсию:
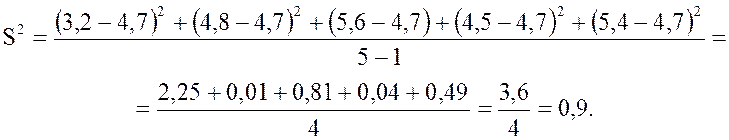
Найдем стандартное отклонение:
![]()
Округлим полученное значение: S =
0,95 условных рублей.
■
Определение 2.14 Выборочной
дисперсией вариационного ряда x1, x2, …, xn с
соответствующими частотами ![]() называется число
называется число ![]() , определяемое формулой:
, определяемое формулой:
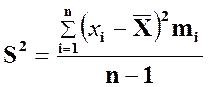 или
или 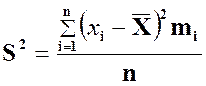
соответственно, при малом и большом значении n,где ![]() .
.
Пример
2.22 Для социологического
исследования были собраны данные о количественном составе 20 семей, приведенные
в следующей таблице.
Таблица 2.16 – Количественный
состав семей
|
Количество членов семьи |
1 2 3 |
|
|
2 3 8 |
Найдем среднее, дисперсию и стандартное отклонение:
n = 2 + 3 + 8 + 5 + 1 + 1 = 20;
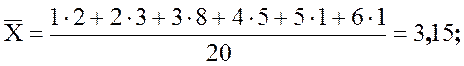
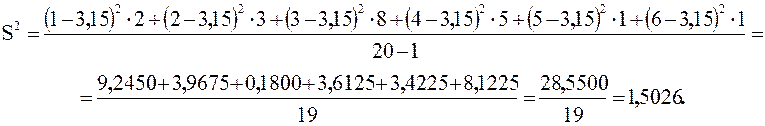
![]() .
.
Округлим S2 = 1,50 и S = 1,23. Итак, ![]() – это среднее число членов семьи, S = 1,23 – это стандартное
– это среднее число членов семьи, S = 1,23 – это стандартное
отклонение от среднего.
■
Определение 2.15 Выборочной
дисперсией статистического ряда, состоящего из k
интервалов с соответствующими интервальными средними ![]() и
и
интервальными частотами ![]() , называется число
, называется число ![]() , равное:
, равное:
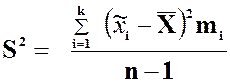 или
или 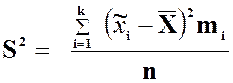 ,
,
соответственно, при малом и большом значении n,
где ![]() .
.
Пример
2.23 Результаты экзамена по высшей
математике пятидесяти студентов представлены следующим статистическим рядом.
Используется десятибалльная система оценок. Найдем среднее и стандартное
отклонение.
Таблица 2.17 – Итоги экзамена по высшей математике
|
Оценка |
0–2 |
2–4 |
4–6 |
6–8 |
8–1 |
|
|
3 |
9 |
16 |
14 |
8 |
Итак, ![]()
Найдем интервальные средние:
![]()
Вычислим среднее:
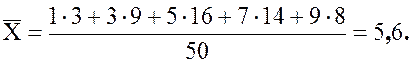
Найдем
дисперсию данной выборки:
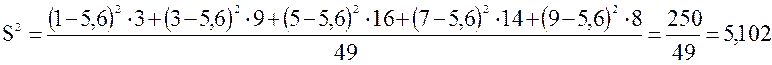 Определим значение
Определим значение
стандартного отклонения:
![]() .
.
Итак, средняя оценка студентов I
курса составляет 5,6 баллов. Стандартное отклонение ![]() баллов
баллов
показывает, что оценки большинства студентов отличаются от среднего не более,
чем на 2,26 баллов.
■
Таким образом, для вычисления
выборочной дисперсии необходимо найти значение среднего ![]() , вычислить
, вычислить
сумму квадратов отклонений выборочный значений от среднего и разделить ее на n –
1, где n – число всех наблюдений. Извлечение квадратного корня
при нахождении стандартного отклонения возвращает к первоначальному масштабу
единицы измерения.
Обработка и анализ статических
данных требует кропотливой и нелегкой вычислительной работы. Для организации
вычислений в математической статистике часто используются специальные таблицы.
Пример 2.24 Найдем среднее и стандартное
отклонение для статистического ряда из примера 1.4 о высоте городских зданий.
Все необходимые вычисления будем записывать в таблицу 2.18.
Из таблицы 2.18
берем необходимые промежуточные результаты:
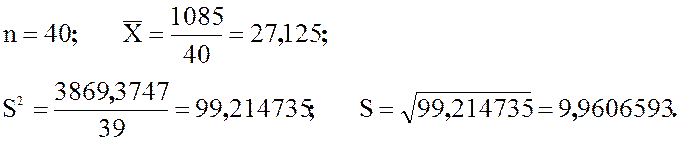
Итак, среднее высоты зданий равно 27,12
метров, а стандартное отклонение ![]() равно 9,96 метров.
равно 9,96 метров.
Таблица 2.18 – Вычисление среднего и
стандартного отклонения высоты зданий
|
Высота |
Интервальное среднее |
Частота
|
|
|
|
|
|
5–10 10–15 15–20 20–25 25–30 30–35 35–40 40–45 35–50 |
7,5 12,5 17,5 22,5 27,5 32,5 37,5 42,5 47,5 |
2 3 5 6 8 7 5 3 1 |
15 37,5 87,5 135 220 227,5 187,5 127,5 47,5 |
-19,625 -14,625 -9,625 -4,625 0,375 5,375 10,375 15,375 20,375 |
385,14062 213,89062 92,64065 21,390625 0,140625 28,890625 107,64062 236,39062 415,14062 |
770,28124 641,67186 463,20312 128,34375 1,12500 202,23437 538,20310 709,17186 415,14062 |
|
Сумма |
40 |
1085 |
3869,3447 |
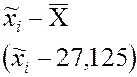
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.