Оценка достоверности результатов статистического исследования
Задачей
статистического исследования является
выявление закономерностей, лежащих в
природе исследуемых явлений. Показатели
и средние величины должны служить
отображением действительности, для
чего необходимо определять степень их
достоверности. Правильное отображение
выборочной совокупностью генеральной
совокупности называется репрезентативностью.
Мерой
точности и достоверности выборочных
статистических величин являются средние
ошибки представительности
(репрезентативности), которые зависят
от численности выборки и степени
разнообразия выборочной совокупности
по исследуемому признаку.
Поэтому
для определения степени достоверности
результатов статистического исследования
необходимо для каждой относительной и
средней величины вычислить соответствующую
среднюю ошибку. Средняя ошибка показателя
mp
вычисляется по формуле:
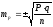
При числе наблюдений
менее 30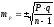 ,
,
где
P — величина
показателя в процентах, промилле и т.д.
q
— дополнение этого показателя до 100,
если он в процентах, до 1000, если %0
и т.д. (т.е. q
= 100–P, 1000–P и т.д.)
Например, известно,
что в районе в течение года заболело
дизентерией 224 человека. Численность
населения ― 33000. Показатель заболеваемости
дизентерией на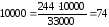
Средняя ошибка
этого показателя

Для решения вопроса
о степени достоверности показателя
определяют доверительный
коэффициент (t), который равен отношению
показателя к его средней ошибке, т.е.
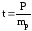
В нашем примере
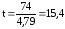
Чем выше t, тем
больше степень достоверности. При t=1,
вероятность достоверности показателя
равна 68,3%, при t=2 ― 95,5%, при t=3 ― 99,7%. В
медико-статистических исследованиях
обычно используют доверительную
вероятность (надежность), равную
95,5%–99,0%, а в наиболее ответственных
случаях – 99,7%. Таким образом в нашем
примере показатель заболеваемости
достоверен.
При числе наблюдений
менее 30, значение критерия определяется
по таблице Стьюдента. Если полученная
величина будет выше или равна табличной
― показатель достоверен. Если ниже ―
не достоверен.
При необходимости
сравнения двух однородных показателей
достоверность их различий определяется
по формуле:
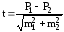 (от большего числа
(от большего числа
отнимают меньшее),
где P1–P2
― разность двух сравниваемых показателей,
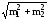 ― средняя ошибка разности двух
― средняя ошибка разности двух
показателей.
Например,
в районе Б в течении года заболело
дизентерией 270 человек. Население района
― 45000. Отсюда заболеваемость дизентерией:
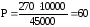
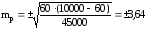
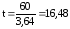 т.е. показатель
т.е. показатель
заболеваемости достоверен.
Как видно,
заболеваемость в районе Б ниже, чем в
районе А. Определяем по формуле
достоверность разницы двух показателей:
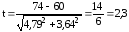
При наличии
большого числа наблюдений (более 30)
разность показателей является
статистически достоверной, если t = 2 или
больше. Таким образом, в нашем примере
заболеваемость в районе А достоверно
выше, т.к. доверительный коэффициент
(t)
больше 2.
Зная величину
средней ошибки показателя, можно
определить доверительные границы этого
показателя в зависимости от влияния
причин случайного характера. Доверительные
границы определяются по формуле:
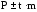 ,
,
где
P ― показатель;
m ― его средняя
ошибка;
t ― доверительный
коэффициент выбирается в зависимости
от требуемой величины надежности: t=1
соответствует надежности результата
в 68,3% случаев, t=2
– 95,5%, t=2,6
– 99%, t=3
– 99,7%, t=3,3
– 99,9Величина
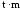 называется
называется
предельной ошибкой.
Например, в
районе Б показатель заболеваемости
дизентерией с точностью до 99,79%
может колебаться в связи со случайными
факторами в пределах
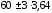 т.е. от 49,1 до 70,9 .
т.е. от 49,1 до 70,9 .
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
13.02.2016142.85 Кб219.doc
- #
- #
- #
В практической и научно-практической работе
врачи обобщают результаты, полученные как правило на выборочных
совокупностях.
Для более широкого распространения и применения полученных при изучении
репрезентативной выборочной совокупности данных и выводов
надо уметь по части явления судить о явлении и его закономерностях в
целом.
Учитывая, что врачи, как правило, проводят исследования на
выборочных совокупностях, теория статистики позволяет с помощью
математического аппарата (формул) переносить данные с выборочного
исследования на генеральную совокупность. При этом врач должен
уметь не только воспользоваться математической формулой, но сделать
вывод, соответствующий каждому способу оценки достоверности
полученных данных. С этой целью врач должен знать способы оценки
достоверности.
Применяя метод оценки достоверности результатов исследования для изучения общественного здоровья и деятельности учреждений
здравоохранения, а также в своей научной деятельности, исследователь должен уметь правильно выбрать способ данного метода.
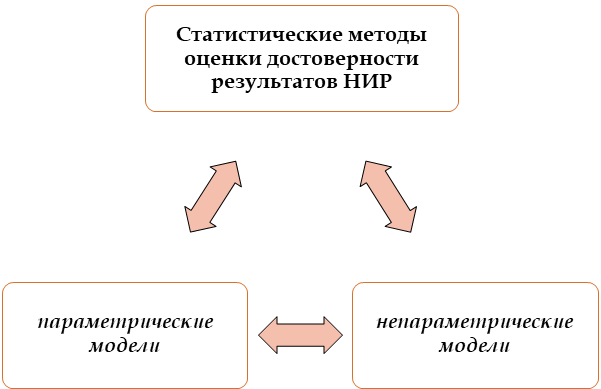
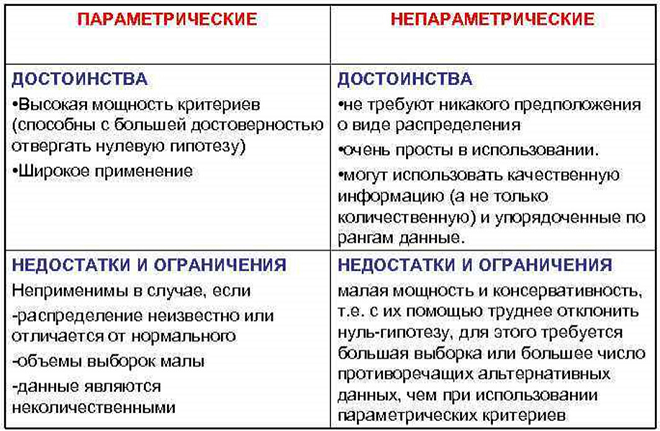
Среди методов оценки достоверности различают параметрические и непараметрические.
Параметрическими называют количественные методы статистической обработки данных, применение которых требует обязательного
знания закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Непараметрическими являются количественные методы статистической обработки данных, применение которых не требует знания
закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Как параметрические, так и непараметрические методы, используемые
для сравнения результатов исследований, т.е. для сравнения
выборочных совокупностей, заключаются в применении определенных формул и
расчете определенных показателей в соответствии с
предписанными алгоритмами. В конечном результате высчитывается
определенная числовая величина, которую сравнивают с табличными
пороговыми значениями. Критерием достоверности будет результат сравнения
полученной величины и табличного значения при данном числе
наблюдений (или степеней свободы) и при заданном уровне безошибочного
прогноза.
Таким образом, в статистической процедуре оценки основное
значение имеет полученный критерий достоверности, поэтому сам способ
оценки достоверности в целом иногда называют тем или иным критерием по
фамилии автора, предложившего его в качестве основы метода.
Применение параметрических методов
При проведении выборочных исследований полученный результат не обязательно совпадает с результатом, который мог бы быть получен
при исследовании всей генеральной совокупности. Между этими величинами существует определенная разница, называемая ошибкой
репрезентативности, т.е. это погрешность, обусловленная переносом результатов выборочного исследования на всю генеральную
совокупность.
Определение доверительных границ средних
и относительных величин
Формулы определения доверительных границ представлены следующим образом:
- для средних величин (М): Мген = Мвыб ± tm
- для относительных показателей (Р): Рген = Рвыб ± tm
где Мген и Рген — соответственно, значения средней величины и относительного показателя генеральной
совокупности;
Мвы6 и Рвы6 — значения средней величины и относительного показателя выборочной совокупности;
m — ошибка репрезентативности;
t — критерий достоверности (доверительный коэффициент).
Данный способ применяется в тех случаях, когда по результатам выборочной совокупности необходимо судить о размерах изучаемого
явления (или признака) в генеральной совокупности.
Обязательным условием для применения способа является репрезентативность выборочной совокупности. Для переноса результатов,
полученных при выборочных исследованиях, на генеральную совокупность необходима степень вероятности безошибочного прогноза (Р),
показывающая, в каком проценте случаев результаты выборочных исследований по изучаемому признаку (явлению) будут иметь место в
генеральной совокупности.
При определении доверительных границ средней величины или относительного показателя генеральной совокупности, исследователь сам
задает определенную (необходимую) степень вероятности безошибочного прогноза (Р).
Для большинства медико-биологических исследований считается
достаточной степень вероятности безошибочного прогноза, равная 95%,
а число случаев генеральной совокупности, в котором могут наблюдаться
отклонения от закономерностей, установленных при выборочном
исследовании, не будут превышать 5%. При ряде исследований, связанных,
например, с применением высокотоксичных веществ, вакцин,
оперативного лечения и т.п., в результате чего возможны тяжелые
заболевания, осложнения, летальные исходы, применяется степень
вероятности Р = 99,7%, т.е. не более чем у 1% случаев генеральной
совокупности возможны отклонения от закономерностей,
установленных в выборочной совокупности.
Заданной степени вероятности (Р) безошибочного прогноза соответствует определенное, подставляемое в формулу, значение критерия
t, зависящее также и от числа наблюдений.
При n>30 степени вероятности безошибочного прогноза Р = 99,7% — соответствует значение t = 3, а при Р = 95,5% — значение
t = 2.
При п<30 величина t при соответствующей степени вероятности безошибочного прогноза определяется по специальной таблице
(Н.А. Плохинского).
на определение ошибок репрезентативности (m) и доверительных границ средней величины генеральной совокупности (Мген)
при числе наблюдений больше 30
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у 36 обследованных водителей сельскохозяйственных машин через 1 ч работы составила 80
ударов в 1 минуту; σ = ± 6 ударов в минуту.
Задание: определить ошибку репрезентативности (mM) и доверительные границы средней величины генеральной
совокупности (Мген).
Решение.
- Вычисление средней ошибки средней арифметической (ошибки репрезентативности) (m):
m = σ / √n =
6 / √36 =
±1 удар в минуту - Вычисление доверительных границ средней величины генеральной совокупности (Мген). Для этого необходимо:
- а) задать степень вероятности безошибочного прогноза (Р = 95 %);
- б) определить величину критерия t. При заданной степени вероятности (Р=95%) и числе наблюдений меньше 30 величина критерия t,
определяемого по таблице, равна 2 (t = 2). Тогда Мген = Мвыб ± tm = 80 ± 2×1 = 80 ± 2
удара в минуту.
Вывод. Установлено с вероятностью безошибочного прогноза Р =
95%, что средняя частота пульса в генеральной совокупности,
т.е. у всех водителей сельскохозяйственных машин, через 1 ч работы в
аналогичных условиях будет находиться в пределах от 78 до 82
ударов в минуту, т.е. средняя частота пульса менее 78 и более 82 ударов в
минуту возможна не более, чем у 5% случаев генеральной
совокупности.
на определение ошибок репрезентативности (m) и доверительных границ относительного показателя генеральной совокупности
(Рген)
Условие задачи: при медицинском осмотре 164 детей 3 летнего возраста, проживающих в одном из районов городе Н., в 18%
случаев обнаружено нарушение осанки функционального характера.
Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя
генеральной совокупности (Рген).
Решение.
- Вычисление ошибки репрезентативности относительного показателя:
m = √P x q / n =
√18 x (100 — 18) / 164 =
± 3% - Вычисление доверительных границ средней величины генеральной совокупности (Рген) производится следующим образом:
- необходимо задать степень вероятности безошибочного прогноза (Р=95%);
- при заданной степени вероятности и числе наблюдений больше 30, величина критерия t равна 2 (t = 2).
Тогда Рген = Рвыб± tm = 18% ± 2 х 3 = 18% ± 6%.
Вывод. Установлено с вероятностью безошибочного прогноза Р=95%, что частота нарушения осанки функционального характера у
детей 3 летнего возраста, проживающих в городе Н., будет находиться в пределах от 12 до 24% случаев.
Оценка достоверности разности результатов исследования
Данный способ применяется в тех случаях, когда необходимо определить, случайны или достоверны (существенны), т.е. обусловлены
какой-то причиной, различия между двумя средними величинами или относительными показателями.
Обязательным условием для применения данного способа является репрезентативность выборочных совокупностей, а также наличие
причинно-следственной связи между сравниваемыми величинами (показателями) и факторами, влияющими на них.
Формулы определения достоверности разности представлены следующим образом:
Если вычисленный критерий t более или равен 2 (t ≥ 2), что соответствует вероятности безошибочного прогноза Р равном или
более 95% (Р ≥ 95%), то разность следует считать достоверной (существенной), т.е. обусловленной влиянием какого-то фактора, что
будет иметь место и в генеральной совокупности.
При t < 2, вероятность безошибочного прогноза Р < 95%, это означает, что разность недостоверна, случайна, т.е. не
обусловлена какой-то закономерностью (не обусловлена влиянием какого-то фактора).
Поэтому полученный критерий должен всегда оцениваться по отношению к конкретной цели исследования.
на оценку достоверности разности средних величин
Условие задачи: при изучении комбинированного воздействия шума
и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у водителей сельскохозяйственных
машин через 1 ч после начала работы составила 80 ударов в
минуту; m = ± 1 удар в мин. Средняя частота пульса у этой же группы
водителей до начала работы равнялась 75 ударам в минуту;
m = ± 1 удар в минуту.
Задание: оценить достоверность различий средних значений пульса у водителей сельскохозяйственных машин до и после 1 ч
работы.
Решение.
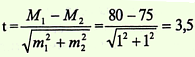
Вывод. Значение критерия t = 3,5 соответствует вероятности безошибочного прогноза Р > 99,7%, следовательно можно
утверждать, что различия в средних значениях пульса у водителей сельскохозяйственных машин до и после 1 ч работы не случайно, а
достоверно, существенно, т.е. обусловлено влиянием воздействия шума и низкочастотной вибрации.
на оценку достоверности разности относительных показателей
Условие задачи: при медицинском осмотре детей 3 летнего возраста в 18% (m = ± 3%) случаях обнаружено нарушение
осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 4-летнего возраста составила 24%
(m = ± 2,64%).
Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп.
Решение.
![]()
Вывод. Значение критерия t=1,5 соответствует вероятности безошибочного прогноза Р<95%. Следовательно, различие в
частоте нарушений осанки среди детей, сравниваемых возрастных групп случайно, недостоверно, несущественно, т.е. не обусловлено
влиянием возраста детей.
Типичные ошибки, допускаемые исследователями при
применении способа оценки достоверности разности результатов исследования
- При оценке достоверности разности результатов исследования по критерию t часто делается вывод о достоверности (или
недостоверности) самих результатов исследования. В действительности же этот способ позволяет судить только о достоверности
(существенности) или случайности различий между результатами исследования. - При полученном значении критерия t<2 часто делается вывод о необходимости увеличения числа наблюдений. Если же
выборочные совокупности репрезентативны, то нельзя делать вывод о необходимости увеличения числа наблюдений, т.к. в данном
случае значение критерия t<2 свидетельствует о случайности, недостоверности различия между двумя сравниваемыми результатами
исследования.
Применение методов статистического анализа для изучения общественного здоровья и здравоохранения.
Под ред. чл.-корр. РАМН, проф. В.З.Кучеренко. М., «Гэотар-Медиа», 2007, учебное пособие для вузов
- Власов В.В. Эпидемиология. — М.: ГЭОТАР-МЕД, 2004. — 464 с.
- Лисицын Ю.П. Общественное здоровье и здравоохранение. Учебник для вузов. — М.: ГЭОТАР-МЕД, 2007. — 512 с.
- Медик В.А., Юрьев В.К. Курс лекций по общественному здоровью
и здравоохранению: Часть 1. Общественное здоровье. — М.: Медицина,
2003. — 368 с. - Миняев В.А., Вишняков Н.И. и др. Социальная медицина и организация здравоохранения (Руководство в 2 томах). — СПб, 1998. -528 с.
- Кучеренко В.З., Агарков Н.М. и др.Социальная гигиена и организация здравоохранения (Учебное пособие) — Москва, 2000. — 432 с.
- С. Гланц. Медико-биологическая статистика. Пер с англ. — М., Практика, 1998. — 459 с.

Выполнение любого исследования сопровождается различными нюансами, сложностями, порождающими небольшую погрешность. Несмотря на это, каждый исследователь стремится получить максимально точные и надежные результаты научной работы. Но чтобы обосновать свою позицию и правоту, доказать состоятельность выдвинутой гипотезы, важно убедиться в качестве и достоверности изыскания. В этом деле на помощь приходит статистическая оценка достоверности НИР.
Что это такое?
Статистическое подтверждение достоверности исследования представляет собой «проверочный этап», призванный убедиться в корректности и правильности полученных результатов, возможности их дальнейшего применения. Как уже стало ясно из определения, он реализуется после проведения изыскания и получения конкретных финальных данных.
Для начала давайте разберемся с такими важными понятиями, как достоверность и обоснованность. Указанные категории взаимосвязаны и важны для каждого автора. Под достоверностью следует понимать степень соответствия полученных результатов с действительностью, реальными условиями и параметрами. То есть это то самое сравнение «ощущение и реальность», но в научном русле.

Обоснованность исследования предполагает наличие четкой и точной доказательной базы, подчеркивающей конкретную тенденцию или симптоматику.
Оценка достоверности научной работы предполагает определение перспектив и ответ на такие вопросы, как:
- Насколько точны результаты исследования?
- Можно ли полагаться на них в перспективе, как и где применять?
- Можно ли расширить «спектр действия» полученных результатов, то есть расширить масштабы результативности с рассмотренной узкой плоскости на более значимую выборку или всю совокупность в целом?
Таким образом, показатель достоверности позволяет судить о корректности реализованной научной работы и возможности применения полученных результатов в дальнейшем. Миссия столь важного этапа состоит в определении следующего момента: возможно ли судить по части исследования (выборке) о всем явлении в целом?
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!

Проверка НИР на достоверность позволяет автору убедиться в отсутствии грубейших ошибок и нарушений существующих научных канонов, норм и минимизировать риск дальнейших ошибок и сомнений. Чем выше уровень достоверности, тем выше качество проекта и степень компетентности исследователя.
Среди ключевых признаков достоверности научного исследования (и его результатов) можно отметить:
- Полученные результаты должны быть сугубо однозначными и обоснованными с научной точки зрения;
- Итоги научной работы должны оценить конкретную проблему и тему, т есть соответствовать критериям валидности и адекватности, целенаправленности;
- Результаты исследования должны быть нейтральными и оценивать явление с одного ракурса, позиции , при одинаковых или максимально схожих условиях (для большей точности и убедительности);
- Итоги научной мысли должны полностью охватывать все намеченные задачи и наиболее важные характеристики, соответствовать научному аппарату и в целом изучаемому процессу.
Таким образом, достоверность результатов научной работы проявляется в таких принципах, как точность, актуальность, целенаправленность и однозначность (однонаправленность).
Способы проверки достоверности исследования
Оценить степень достоверности научной работы не так просто. Существуем масса вариантов для проведения столь важной проверки. Студенты чаще всего прибегают к следующим видам:
- Сравнительный или содержательный анализ. В данном случае автору или эксперту предстоит внимательно изучить текст научной работы и констатировать значимые показатели, тенденции, а затем сравнить с аналогичными исследованиями. Согласитесь, если суждение верно или наблюдается од на и та же проблема-тенденция, то и результаты будут как минимум схожими, очерчивать тот же характер. В данном случае на выручку исследователю приходят актуальные аналогичные изыскания, реализованные иными авторами, то есть достаточно оценить степень разработанности тем, сопоставить результаты и понять: чем отличаются проекты, в чем их сходства, о чем свидетельствуют общие результаты (тенденция и пр.).
Обратите внимание, что точных совпадений в целом быть не должно. Главное, чтобы совпадали общие моменты, тенденции, характер доказательной базы и изменений и пр. Но даже если некоторые моменты кардинально разнятся, это не означает, что что-то выполнено неверно. Важно взять данный момент на заметку и учесть в дальнейшем;
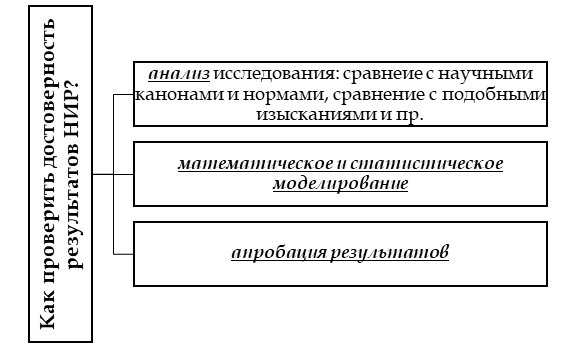
- Аналитический метод. В данном случае автор исследования или квалифицированный эксперт анализирует полученные результаты и сравнивает их с общепринятыми нормами, устоявшимися научными фактами и законами, отраслевыми показателями и правовыми регламентами, результатами аналогичных исследований и пр. Чем больше совпадений (по характеру), тем выше точность итогов.
- Апробация результатов. Данный прием считается самым надежным и достоверным, позволяющим оценить полученные результаты, рекомендации и выводы на практике. В данном случае предстоит провести повторно эксперимент или проследовать по описанному автором пути и сравнить полученные результаты, а заодно оценить посильность, корректность и достоверность исследования;
- Статистическая проверка данных. Данный метод предполагает проведение ряда математических операций с целью определения наличия отклонений, наличие случайных моментов и отклонений, стабильных показателей и пр. О данной комбинации приемов мы поговорим подробнее.
Последняя группа методов по проверке результатов научного исследования на достоверность в целом может заменить (по роли и значимости, корректности и объективности) апробация результатов. Предлагаем рассмотреть ее детальнее.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Специфика статистической оценки достоверности результатов научно-исследовательской работы
Статистические приемы по проверке результатов НИР на объективность, обоснованность и достоверность применимы преимущественно к прикладным изысканиям. Также допустимо использовать их в отношении тех проектов которые можно преобразовать в математическую, статистическую или иную числовую модель, то есть оценить с количественной стороны посредством применения простейших математических операций, специальных методик и формул.
Статистические методы по проверке достоверности результатов НИР применимы преимущественно к прикладным или экспериментальным изысканиям, где явление или проблема оценивалась в рамках конкретной выборки. Чтобы распространить действие полученного результата на «проблему в целом» (то есть вынести за пределы выборки), важно убедиться в достоверности итогов (то есть совпадении данных с реальностью).
На практике применяют два вида статистической оценки достоверности изыскания: параметрические и непараметрические. К первой группе относят специфические приемы, основанные на законах распределения и предполагают изучение всего механизма в целом с выделением основных признаков из общей совокупности. Ко второй – методы, не требующие понимания и владения законом распределения. То есть ключевое отличие между данными приемами будут формулы и порядок расчета, учета отдельных показателей. Без математических и статистических подходов в этом деле не обойтись.
Применение параметрических и непараметрических методов статистической оценки достоверности исследования предполагает расчет определенных показателей и выведение единого (самого важного) коэффициента, который будет сравниваться с существующими нормами. Если итоговое значение выпадает на «допустимый диапазон», где отклонение незначительно, то НИР считается достоверной.
Основные параметрические показатели, необходимые для оценки достоверности исследования
На практике действует два основных параметра, позволяющих определить возможности использования результаты реализованного исследования. К ним относят среднее значение и дисперсию. Именно эти показатели лежат в основе самых популярных и признанных среди исследователей методик, о которых мы писали ранее: критерий Стьюдента и критерий Фишера.
Оценивание достоверности исследования на базе указанных подходов основывается на таких показателях, как:
- Средние ошибки средних арифметических и относительных величин (ошибка репрезентативности). Данный показатель позволяет установить тот самый промежуток действия результатов при заданном количестве наблюдений. Этот параметр всегда точен и способствует установлению конкретных границ для переноса частных результатов на всю совокупность в целом. Показатель рассчитывается в тех случаях, когда проблема оценивалась по частям, а для общей оценки необходимо убедиться в корректности и достоверности итогов, их общего действия. С помощью ошибок репрезентативности можно установить, на сколько отличаются результаты выборочного исследования от результатов, полученных при реализации сплошного изыскания.

- Оценка достоверности разности результатов исследования. Данный подход уместен при оценке возникновения проблемного фактора: результаты случайны или достоверны. В это деле на подмогу приходит сравнение средних и относительных показателей. Для использования данного приема важно соблюдение конкретных условий: выборка должна быть репрезентативной, наличие причинно-следственных связей между основными сравниваемыми данными, понимание провоцирующих изменения факторов.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Непараметрические подходы к оценке достоверности результатов исследования
Непараметрические критерии действуют в отношении таких ситуаций, когда исследователь не имеет четких представлений или фактов относительно изучаемого явления, проблемы. В данном случае не требуется расчет средних или стандартных отклонений для описания исследуемого явления или величины.
Непараметрические методики применимы в отношении исследований, где действует небольшая выборка и нет четких данных в отношении изучаемой проблемы. Для использования данной группы приемов полагаются на следующий принцип: в отношении любого параметрического критерия можно подобрать аналогичный непараметрический аналог, который будет относиться к одной из категорий:
- Критерии различия между независимыми выборками. В этом случае уместны описанные нами ранее U-методика Манна-Уитни, критерий Краскела-Уоллиса, тест Спирмена и пр.;
- Критерии различия между зависимыми выборками. Наиболее популярными подходами данного плана выступают критерий Вилкоксона, анализ Фридмана, Q-критерий Кохрена и пр.
Как выбрать статистический способ проверки достоверности результатов исследования: параметрический или непараметрический?
Непараметрические приемы по оценке степени достоверности результатов научного исследования применимы лишь к тем работам, где исследуется небольшая по численности выборка. Если исследуется большая совокупность данных и критериев, то подключают параметрические методики (считающиеся более обоснованными и точными).
Параметрические подходы предполагают установление конкретных границ и точек соприкосновения, зависимостей. Поэтому здесь преобладают более точные расчеты, необходимо соблюдение конкретных правил и законов и пр. Все это требуется для проверки конкретной гипотезы или предположений о характере или особенностях распределения полученных данных.
В любом случае применение статистической оценки результатов исследования будет основываться на проведении конкретных математических расчетов и аналитических операций, сопоставлений, владении научными канонами, критическом мышлении автора и его представлениями по теме (как он ее понимает и видит). Притом изобретать велосипед для перепроверки итогов НИР не потребуется: достаточно лишь воспользоваться уже ранее утвержденным алгоритмом, грамотно подставив в него имеющиеся параметры и сравнив их с измерительной шкалой.
Как обеспечить достоверность проводимого исследования?
Статистические способы проверки достоверности результатов исследования считаются одними из точных. Но чтобы повысить эффективность проводимого изыскания и расширить спектр применения полученных итогов можно позаботиться об обеспечении достоверности НИР следующим образом:
- Важно установить четкие границы исследования и утвердить максимально точный научный аппарат: что автор будет исследовать, какие факторы учитывать, по возможности конкретизировать все нюансы;
- Подходить к подбору данных с максимальной ответственностью и вниманием: учитывать научные законы и ограничения, возможности и особенности объекта, обосновывать каждый шаг и пр.;
- В идеале исследователю следует полагаться только на апробированный материал, то есть не просто данные полученные в ходе первичного эксперимента. Чтобы исследование было более точным и достоверным, следует убедиться в корректности и эффективности итогов. Нередко в этом случае приходится пользоваться повторным проведением эксперимента или апробацией (для сопоставления итогов и анализа данных, определения погрешностей, общего направления и характера результатов и пр.);
- Важно грамотно сочетать теоретические моменты и категории с программой исследования, в ходе реализации эксперимента. Для этого автору НИР предстоит разобраться в правилах, терминах, научных законах и подходах, а затем на основе располагаемых данных (относительно выборки или исследуемом объекте) правильно использовать их. То есть еще на начальном этапе (в ходе планирования исследования) важно уточнить уместность, целесообразность и посильность намеченного подхода, пути.
В целом, при проведении научных исследований экспериментального характера важно убедиться в правильности суждений, точности полученных результатов и возможностей их применения в перспективе. В этом деле на помощь приходит классический принцип «доверяй, но проверяй» на основе математических и статистических моделей.
Применение методов статистической оценки достоверности НИР основывается математических (порой сложных) операциях: расчеты в рамках конкретных формул, корреляция, дисперсия, разница величин (относительных и абсолютных) и пр. Чтобы успешно ими пользоваться, автору изыскания важно владеть основными категориями и понятиями, хорошо знать математические законы и быть предельно внимательным (во избежание банальных «расчетных» ошибок).
Статистическая оценка достоверности результатов исследования позволяет перепроверить и обосновать авторскую позицию, повысить точность полученных итогов, сделать проект более аргументированным и приближенным к реалиям, определить возможности использования полученных итогов в больших масштабах или иных сферах деятельности. При проведении подобной поверки важно учитывать все нюансы, характер изыскания и располагаемые автором данные, их достаточность и надежность.
Ведение статистики, тестирование различных вариантов данных с отслеживанием эффективности изменений имеет огромное значение в отношении выбора той или иной концепции развития. Однако для анализа важно выбрать только значимые для статистики данные. В этой статье разберемся с понятием статистическая значимость в целом и в A/B тестах, а также рассмотрим, как ее оценивать и рассчитывать.
Что такое статистическая значимость
В процессе любого исследования стоит задача выявить связи между переменными, которые, как правило, характеризуются направлением, силой и надежностью. Чем выше вероятность повторного обнаружения связи, тем она надежнее.
Для проверки гипотез при проведении различных тестов применяется методика статистического анализа. Результатом оценки уровня надежности связи и проверки гипотезы выступает статистическая значимость (statistical significance). Чем меньше вероятность, тем надежнее будет связь.
Статистическая значимость – это параметр, который подтверждает, что результаты исследования были достигнуты не случайно.

Аналитик делает такое заключение, используя метод статистической проверки гипотез. По итогам теста определяется p-значение или значение уровня значимости. Чем оно меньше, тем больше будет статистическая значимость.
Обратите внимание! Слово «значимость» в данном контексте отличается по смыслу от общепринятого. Статистически значимые значения не обязательно являются значимыми или важными. Если же уровень значимости низкий, это не говорит о том, что итоги эксперимента не имеют ценности на практике.
Говоря о статистической значимости, стоит иметь ввиду:
- уровень значимости дает понять, что связь между переменными не случайна;
- уровень значимости в статистике может служить доказательством правдоподобности нулевой гипотезы;
- в ходе проверки получаем информацию о том, что результат эксперимента является или не является статистически значимым.
Значимость статистического критерия применяют при испытаниях вакцин, эффекта новых лекарственных препаратов, изучении болезней, а также при определении, насколько успешна и эффективна работа компании, при A/B тестировании сайтов в маркетинге, а также в различных областях науки, психологии.
История понятия уровня значимости
Статистика помогает решать задачи в различных сферах много веков, однако о статистической значимости заговорили лишь в начале XX столетия. Ввел это понятие в 1925 году британский генетик и статистик сэр Рональд Фишер, который работал над методикой проверки гипотез.

В процессе анализа любого процесса есть вероятность, что произойдут те или иные явления. Итоги эксперимента, которые имели высокую вероятность стать действительными, Фишер описывал словом «значимость» (в переводе с английского significance).
Если данные были недостаточно конкретные для проверки, возникала проблема нулевой гипотезы. Для таких систем в качестве удобной для отклонения нулевой гипотезы выборки исследователем было предложено считать вероятность событий как 5%.
Как оценить статистическую значимость
Для проверки гипотезы используют статистический анализ, при этом уровень значимости определяется с помощью p-значения. Последнее показывает вероятность события, если предположить, что определенная нулевая гипотеза верна.
Весь процесс оценивания уровня значимости можно разделить на 3 стадии, которые, в свою очередь, включают следующие промежуточные этапы.
Постановка эксперимента
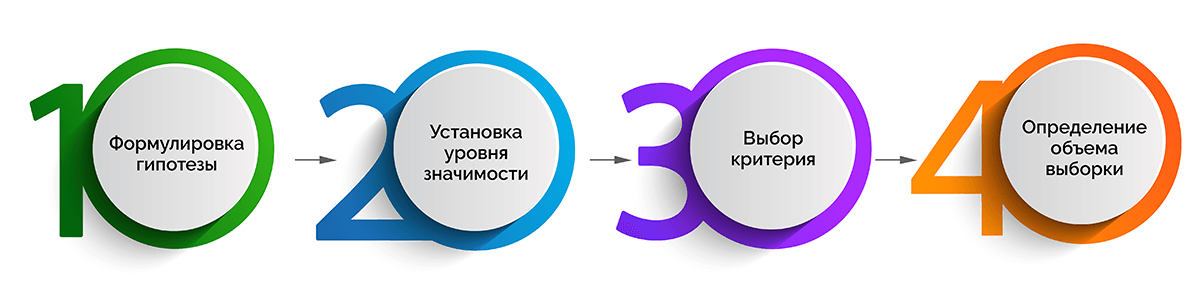
- Формулировка гипотезы.
- Установка уровня значимости, который поможет определить отклонение в распределении данных для идентификации значимого результата.
Если р-значение меньше или равно уровню значимости, данные можно считать статистически значимыми.
- Выбор критерия – одностороннего или двустороннего.
Первый подходит для случаев, когда известно, в какую сторону от нормального значения могут отклониться данные. Второй критерий лучше выбирать, если трудно понять возможное направление отклонения данных от контрольной группы значений. - Определение объема выборки с использованием статистической мощности. Она показывает вероятность того, что при заданной выборке будет получен именно ожидаемый результат. Зачастую пороговая (критическая) цифра мощности – 80%.
Вычисление стандартного отклонения

- Расчет стандартного отклонения, которое показывает величину разброса данных на заданной выборке.
- Поиск среднего значения в каждой исследуемой группе. Для этого осуществляют сложение всех значений, а сумму делят на их количество.
- Определение стандартного отклонения (xi – µ). Разница вычисляется путем вычитания каждого полученного значения из средней величины.
- Возведение полученных величин в квадрат и их суммирование. На данном этапе все числа со знаком «минус» должны исчезнуть.
- Деление суммы на общий объем выборки минус 1. Единица – это генеральная совокупность, которая не учитывается в расчете.
- Извлечение корня квадратного.
Определение значимости
- Определение дисперсии между двумя группами данных по формуле:

sd = √((s1/N1) + (s2/N2)), где:
s1 – стандартной отклонение в первой группе;
s2 – стандартное отклонение во второй группе;
N1 – объем выборки в первой группе;
N2 – объем выборки во 2-й группе. - Поиск t-оценки данных. С ее помощью можно переводить данные в такую форму, которая позволит использовать их в сравнении с другими значениями. T-оценка рассчитывается по формуле:
t = (µ1 – µ2)/sd, где:
µ1 – среднее значение для 1-й группы;
µ2 – среднее значение для 2-й группы;
sd – дисперсия между двумя группами. - Определение степени свободы выборки. Для этого объемы двух выборок складывают и вычитают 2.
- Оценка значимости. Ее осуществляют по таблице значений t-критерия (критерия Стьюдента).
- Повышение уверенности в достоверности выводов путем проведения дальнейшего исследования.


Статистическая значимость и гипотезы
Гипотеза – это теория, предположение. Если требуется проверка гипотез, всегда используется статистическая значимость. Предположение же называется гипотезой до тех пор, пока это утверждение не будет опровергнуто или доказано.

Гипотезы бывают двух типов:
- нулевая гипотеза – теория, не требующая доказательств. Согласно нее, при внесении изменений ничего не произойдет, т. е. стоит задача не доказать это, а опровергнуть;
- альтернативная гипотеза (исследовательская) – теория, в пользу которой нужно отклонить нулевую гипотезу, т. е. предстоит доказать, что одно решение лучше другого.
Рассмотрим, как статистическая значимость влияет на подтверждение или опровержение альтернативной гипотезы на простом примере.
У компании запущена реклама, которая стала давать меньше конверсий и продаж, чем месяц назад. По мнению маркетолога, причина кроется в рекламных креативах, которые приелись аудитории и требуют замены. Специалист предлагает заменить текстовый материал объявления. Гипотеза состоит в том, что после внесенных изменений будет достигнута главная цель эксперимента: клиенты, пришедшие на сайт с рекламы, станут покупать больше. Теперь маркетологу нужно проводить A/B тестирование обоих креативов, чтобы выяснить, какой текст объявления лучше работает. При высоком уровне достоверности данные условия позволят учитывать результаты такого тестирования.
Проверка статистических гипотез
В случаях, когда информация говорит о незначительных изменениях в сравнении с предыдущими значениями, требуется проверка гипотез. Она позволяет определить, действительно ли происходят изменения или это всего лишь результат неточности измерений.
Для этого принимают или отвергают нулевую гипотезу. Задача решается на основании соотношения p-уровня (общей статистической значимости) и α (уровня значимости).
- p-уровень < α – нулевая гипотеза отвергается;
- p-уровень > α – нулевая гипотеза принимается.
Чем меньше значение p-уровня, тем больше шансов, что тестовая статистика актуальна.
Критерии оценки
Уровень значимости для определения степени правдивости полученных результатов обычно устанавливается на отметке 0,05. Таким образом, интервал вероятности между разными вариантами составляет 5%.
После этого необходимо найти подходящий критерий, по которому будут оцениваться выдвинутые гипотезы: односторонний или двусторонний. Для этого применяют разные методы расчета:

- t-критерий Стьюдента;
- u-критерий Манна-Уитни;
- w-критерий Уилкоксона;
- критерий хи-квадрата Пирсона.
T-критерий Стьюдента
предполагает сравнение данных по двум вариантам исследования и позволяет делать выводы о том, по каким параметрам они отличаются. Метод актуален, когда есть сомнения, что данные располагаются ниже или выше относительно нормального распределения.
Установить, все ли данные лежат в заданном пределе, можно с помощью специальной таблицы значений. Но чаще применяют автоматический расчет t-критерия Стьюдента. Существует много калькуляторов, которые работают по схожему принципу:
- Указываем вид расчета (связанные выборки или несвязанные).
- Вносим данные о первой выборке в первую колонку, о второй – во вторую. В одну строку вписываем одно значение, без пропусков и пробелов. Для отделения дробной части от основной используется точка.
- После заполнения обеих колонок, нажимаем кнопку запуска.
Преимущество коэффициента Стьюдента в том, что он применим для любой сферы деятельности, поэтому является самым популярным и используется на практике чаще всего.
Критерий Манна-Уитни
Рассчитывается по иному алгоритму, но предполагает использование аналогичных исходных данных. Его также зачастую рассчитывают онлайн с помощью специальных сервисов.
При расчете критерия Манна-Уитни есть особенности. Показатель применим для малых выборок или выборок с большими выбросами данных. Чем меньше совпадающих значений в выборках, тем корректнее будет работать критерий.
W-критерий Уилкоксона
Непараметрический аналог t-критерия Стьюдента для сравнения показателей до и после эксперимента, основанный на рангах. Его принцип заключается в том, что для каждого участника определяется величина изменения признака. Затем все значения упорядочиваются по абсолютной величине, рангам присваивается знак изменения, после чего «знаковые ранги» суммируются. Данный критерий применяется в медицинской статистике для сравнения показателей пациентов до лечения и после его завершения.
Критерий хи-квадрата Пирсона
Еще один непараметрический метод для оценки уровня значимости двух и более относительных показателей. Применяется для анализа таблиц сопряженности, в которых приведены данные о частотах различных исходов с учетом фактора риска.
Проблема множественного тестирования гипотез
Если сравнивать группы по различным срезам аудитории или метрикам, может возникать проблема множественного тестирования. Дело в том, что учесть абсолютно все проверки достаточно сложно. Это связано со сложностью предварительного прогнозирования их количества. К тому же, зачастую они всё равно не независимы.

Не существует универсального рецепта решения проблемы множественного тестирования гипотез. Аналитики рекомендуют руководствоваться здравым смыслом. Если протестировать много срезов по различным метрикам, любое исследование может показать якобы значимый для статистики результат. Это означает, итоги тестирования следует читать и интерпретировать с осторожностью.
Вычисление объема выборки и стандартного отклонения
После вычисления критерия оценки (критерия Стьюдента или Манна-Уитни) можно определить, какого оптимального объема должна быть выборка. При этом условии должно быть достаточное для признания достоверности результатов исследования количество людей в фокус-группах, на которых будут проверяться разные варианты.
Недостаточное количество участников эксперимента может стать причиной нехватки выборочных данных для того, чтобы сделать статистически значимый вывод и привести к повышению риска получения случайных результатов.
Объем выборки определяют с помощью статистической мощности (распространенный порог находится на уровне 80%). Этот показатель рассчитывают обычно с помощью специального калькулятора.
Затем можно переходить к вычислению уровня стандартного отклонения, по которому можно узнать величину разброса данных. Его рассчитывают по формуле:

s = √∑((xi – µ)2/(N – 1)), где:
xi – i-е значение или полученный результат эксперимента;
µ – среднее значение для конкретной исследуемой группы;
N – общее количество данных.
Для упрощения расчетов также используют онлайн-калькуляторы.
Значение p-уровня
Имея две гипотезы – нулевую и альтернативную, необходимо доказать одну из них (истинную) и опровергнуть другую (ложную).
Для этого основатель теории статистической значимости доктор Рональд Фишер создал определитель, с помощью которого можно было оценить, был эксперимент удачным или нет. Такой определитель получил название индекс достоверности или p-уровень (p-value).
P-уровень или уровень статистической значимости результатов – это показатель, который находится в обратной зависимости от истинного результата и отражает вероятность его ошибочной интерпретации.
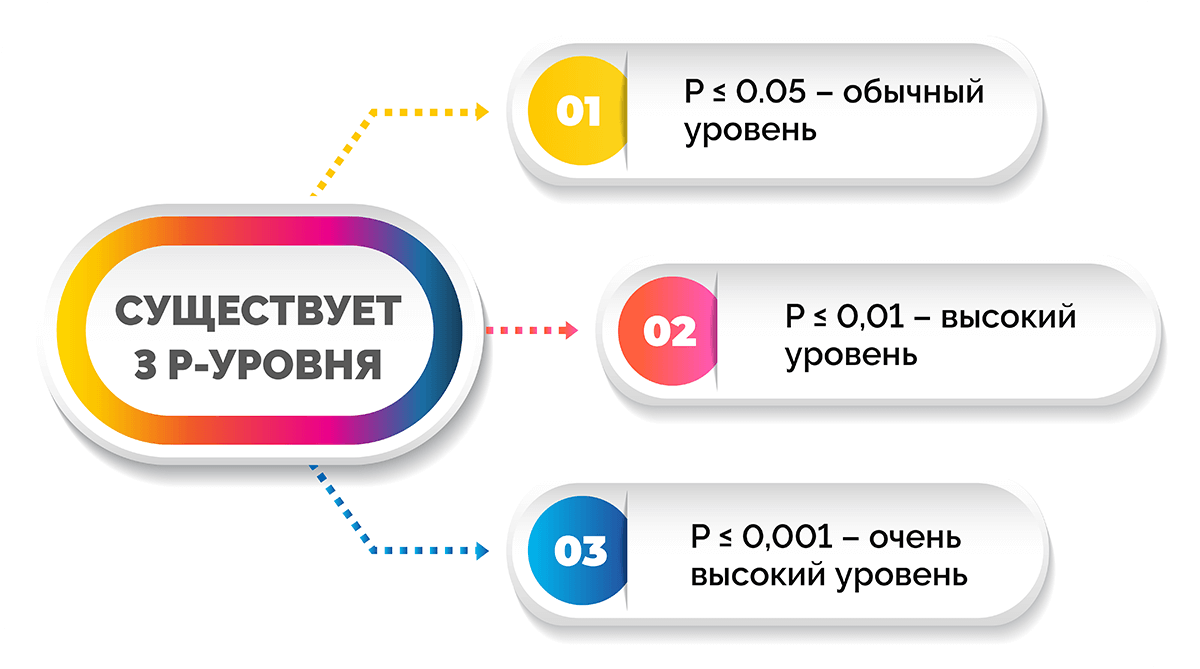
Существует 3 p-уровня.
- P ≤ 0,05 – обычный уровень, т. е. получен статистически значимый результат.
- P ≤ 0,01 – высокий уровень, т. е. выявлена выраженная закономерность.
- P ≤ 0,001 – очень высокий уровень.
Есть и другие значения статистической значимости. Например, уровень p ≥ 0,1 свидетельствует о том, что итог эксперимента не является статистически значимым.
Приближенные к статистически значимым результаты с уровнями p = 0,06 ÷ 0,09 говорят о том, что есть тенденция к существованию искомой закономерности.
Говоря проще, чем ниже значение p-уровня, тем более статистически значимым будет результат эксперимента и тем ниже вероятность ошибки.
Расчет статистической значимости
Выше в статье мы рассматривали порядок оценки уровня статистической значимости. Что касается расчета, то вручную он выполняется редко. Большинство аналитиков определяют уровень значимости с помощью онлайн-калькулятора.
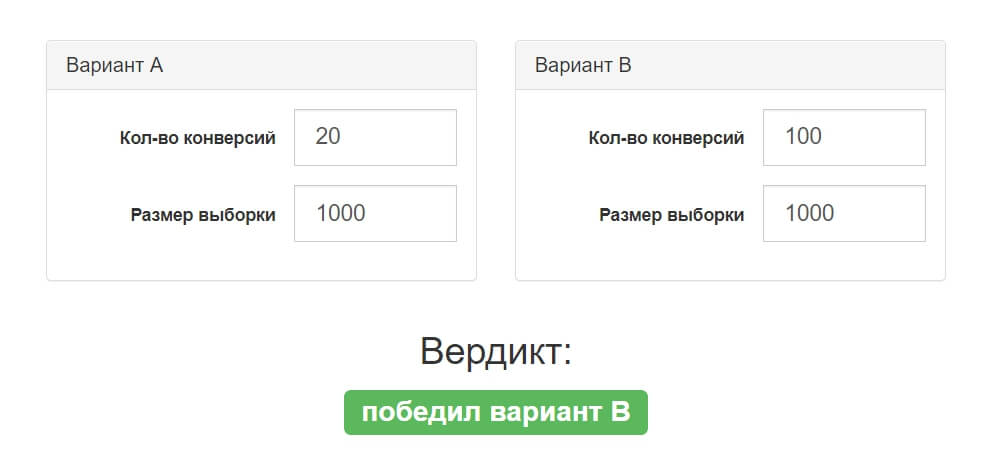
В анализе участвуют две гипотезы, для каждой из которых необходимо задать количество конверсий и размер выборки. Сервис автоматически рассчитывает показатель и определяет уровень значимости результата.
Порог вероятности
Основа статистической значимости – это вероятность получения нужного значения, если принять как факт, что нулевая гипотеза верна. Если предположить, что в процессе эксперимента было получено некое число Х, то при помощи функции плотности вероятности можно узнать, будет ли вероятность получить значение Х или любое другое значение с меньшей вероятностью, чем Х.
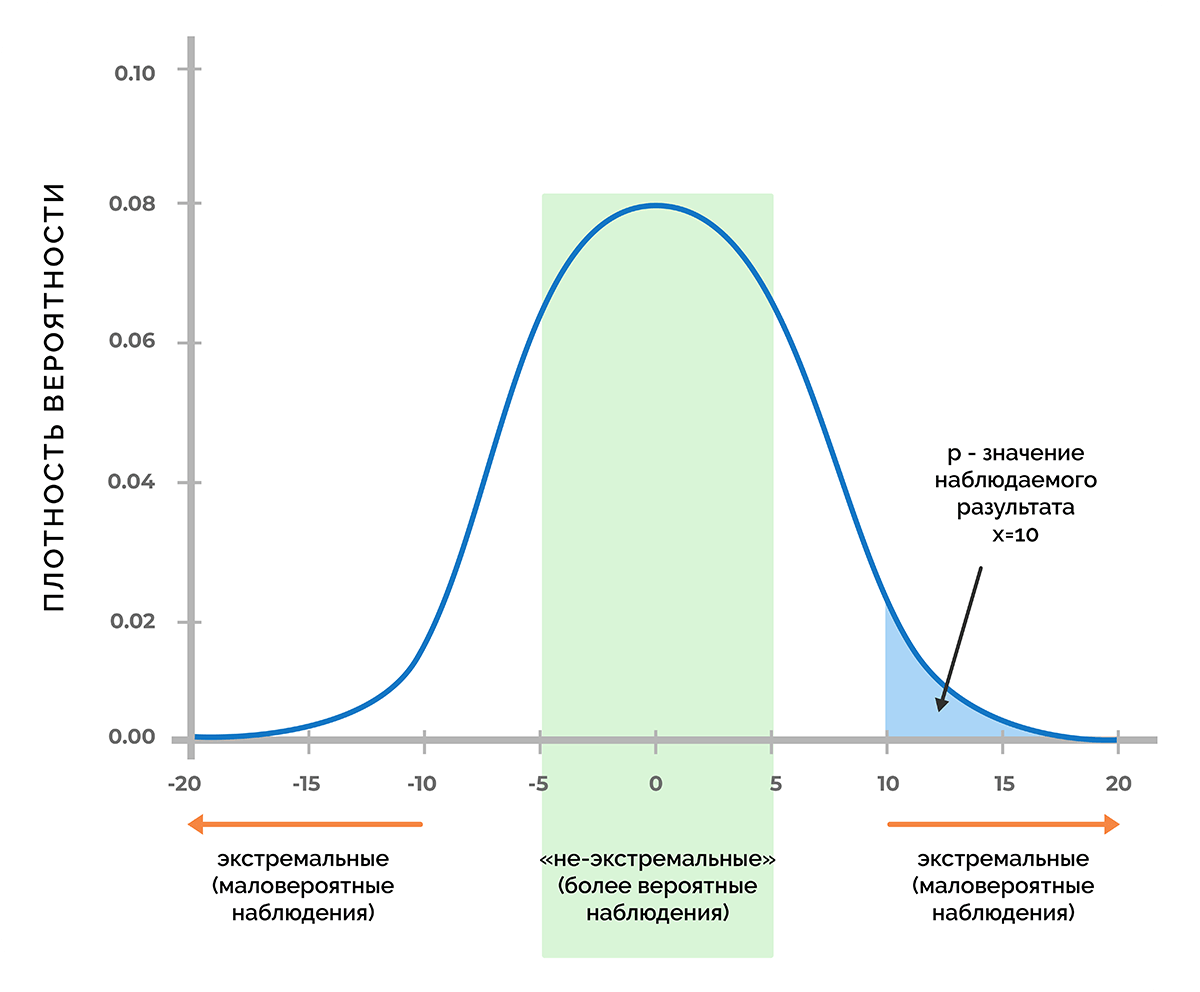
На рисунке изображена кривая Гаусса, соответствующая функции плотности вероятности, которая отвечает распределению значений показателя, при котором верна нулевая гипотеза.
При достаточно низком значении p-уровня не имеет смысла продолжать считать, что переменные не связаны друг с другом. Это позволяет отвергнуть нулевую гипотезу и принять факт того, что связь существует.
Пороги значимости в разных областях могут значительно отличаться. Так, при исследовании вероятности существования бозона Хиггса p-значение равно 1/3,5 млн, в сфере исследования геномов его уровень может достигать 5×10-8.
Статистическая значимость в A/B тестах
Одной из сфер широкого применения статистической значимости является маркетинг. Аналитики используют исследования для поиска оптимальных путей развития бизнеса, интернет-маркетологи оценивают эффективность рекламных кампаний и посещаемость ресурсов.
A/B тестирование – самый распространенный способ оптимизации страниц сайтов. Его результат невозможно предугадать, можно лишь строить алгоритм работы так, чтобы в конце тестирования получить максимальное количество данных, которые позволят сделать вывод о самом удачном варианте.
Важно, чтобы A/B тестирование длилось минимум 7 дней. Это позволит учесть колебания уровней конверсии и других показателей в разные дни.
Процедура A/B тестирования кажется довольно простой:
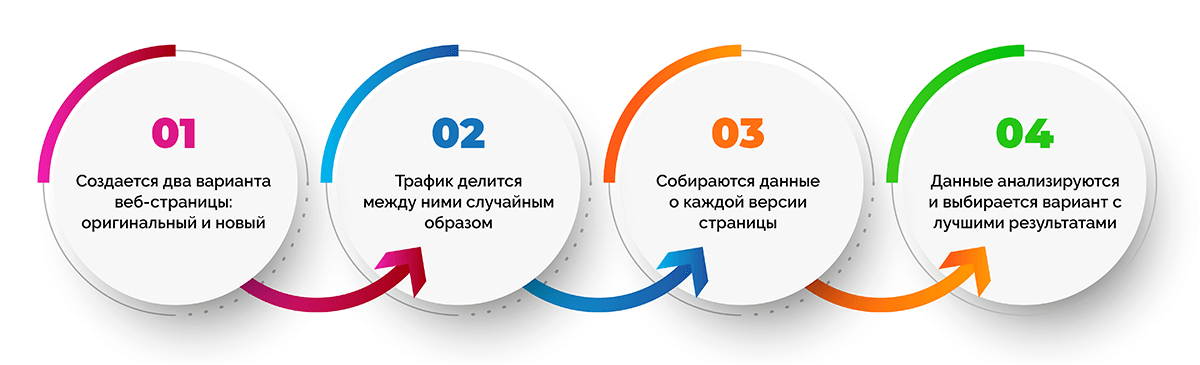
- Создается две веб-страницы (оригинальная и новая).
- Трафик делится между двумя версиями веб-страницы случайным образом.
- Собираются данные о каждой версии страницы.
- Данные анализируются и выбирается вариант с лучшими показателями, а второй отключается.
Важно, чтобы тестирование было достоверным, в противном случае неверное решение может привести к негативным последствиям для сайта.
В данном случае гипотезой считается достижение нужной достоверности. Сама достоверность будет статистической значимостью. Для тестирования гипотезы нужно сформулировать нулевую гипотезу и оценить возможность ее отклонения из-за малой вероятности.
Возможные ошибки
На этапе оценки результатов тестирования можно допустить два типа ошибок:
- ошибка первого рода (type I error) – ложноположительный итог, когда кажется, что различия между показателями двух тестируемых страниц есть, на самом же деле их нет;
- ошибка второго рода (type II error) – ложноотрицательный итог, когда существенная разница между тестируемыми страницами не заметна, но на самом деле она есть, при этом в тестировании видимое ее отсутствие является случайностью.
Как избежать ошибок
Избежать обоих типов ошибок можно, устанавливая при тестировании правильный размер выборки. Чтобы его определить, предстоит в настройках теста задать несколько параметров.
- Чтобы исключить ложноположительные результаты, понадобится указать уровень значимости. Обычно задают значение 0,05, которое будет гарантировать достоверность, превышающую 95%.
- Чтобы избежать ложноотрицательных результатов потребуется минимальная разница в ответах и вероятность обнаружить эту разницу, т. е. статистическая мощность. Последнюю по умолчанию устанавливают на уровне 80%.
Этого достаточно, чтобы вычислить требуемый размер выборки. Обычно расчеты проводятся с помощью спец. калькуляторов.
Можно ли доверять результатам на 100%
К сожалению, даже при правильно проведенной проверке гипотез могут быть допущены ошибки. Это связано с человеческим фактором, а точнее – со скрытыми предположениями, которые зачастую не имеют ничего общего с реальностью.
Вот распространенные предположения, которые приводят к ошибкам:
- посетители сайта, которые просматривают разные варианты веб-страницы, не связаны друг с другом;
- для всех посетителей вероятность конверсии одинакова;
- показатели, которые измеряются в процессе тестирования, имеют нормальное распределение.
На что обратить внимание
Без A/B теста сложно представить развитие современного интернет-продукта. Однако, несмотря на кажущийся простым инструмент, специалисты порой на практике встречаются с подводными камнями. Если знать о них заранее, можно повысить точность тестирования.

Первый узкий момент – проблема подглядывания. Наблюдение за итогами тестирования в реальном времени выступает в качестве соблазна для активных действий, предпринимаемых раньше времени. Обработка «сырых» данных неизменно приводит к статистической погрешности. Чем чаще смотреть на промежуточные результаты A/B теста, тем больше вероятность обнаружить разницу, которой в действительности нет:
- 2 подглядывания с желанием завершить тестирование повышают p-значение в 2 раза;
- 5 подглядывания – в 3,2 раза;
- 10 000 подглядываний – в 12 раз и более.
Решить проблему подглядывания можно тремя способами:
- Заблаговременно фиксировать размер выборки и не смотреть итоги теста до его окончания.
- С помощью математических методов: комбинация Sequential experiment design и байесовского подхода к A/B-тесту.
- С помощью продуктового метода, который предполагает предварительную оценку размера выборки, обеспечивающего эффективность тестирования, и принятие во внимание природы проблемы подглядывания в процессе промежуточных проверок.
Еще один подводный камень заключается в том, что от выигравшей гипотезы ожидают слишком многого. На самом деле в долгосрочной перспективе показатели победителя могут быть менее выдающимися, чем те, которые выдал тест.
Пример статистической значимости
Предположим, разработчики онлайн-игры тестируют два дизайна интерфейса. При A/B тестировании было привлечено 2000 новых игроков: по 1000 пользователей в каждую версию.
В первый день тестирования первая версия дизайна получила 370 возвратов пользователей, вторая – 510.
Как видно, вторая версия дизайна показала лучший результат возвратов. Но разработчики не были уверены, действительно ли это произошло из-за изменения продукта, а не стало следствием случайной погрешности.
Чтобы выяснить это, было принято решение рассчитать уровень значимости для наблюдаемой разницы. Поскольку метрика является простой, можно воспользоваться онлайн-сервисом и вычислить статистическую значимость автоматически.

P-значение < 0,001 в нашем примере свидетельствует о том, что при одинаковых тестовых группах вероятность увидеть наблюдаемую разницу чрезвычайно мала. Это говорит о том, что рост возвратов в первый день с высокой долей вероятности зависит от изменений продукта.
Часто задаваемые вопросы
Маркетинговые исследования статистики чаще всего проводятся путем A/B тестирования. О нем мы рассказали в одном из предыдущих разделов статьи. Однако при тестировании могут возникать некоторые трудности. Например, некорректное определение статистически значимого различия или невозможность определить, чем обусловлено различие. Решить подобные проблемы позволяет увеличение выборки и вариантов.
Оценка необходимости ранжирования данных статистики исключительно на основании статистической значимости может привести к серьезным ошибкам. Предпочтение лишь «значимых» результатов повышает риск искажения фактов.
В процессе тестирования регулярная проверка показателей с готовностью принять решение о завершении теста при обнаружении существенной разницы приводит к кумулятивному накоплению вероятных случайных моментов, при которых разница покидает пределы диапазона. В результате этого каждая новая проверка приводит к росту p-значения.
Заключение
Статистическая значимость является важным методом в ходе проведения экспериментов и исследований несмотря на риск ее неправильной интерпретации. При грамотном подходе погрешность можно свести к минимуму, используя значение в целях повышения достоверности результатов.

Олег Вершинин
Специалист по продукту
Все статьи автора
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter
Моя программа делает выборки от 1 до 30000 значений из базы данных, каждое из которых может быть случайно с определенной долей вероятности.
Например вчера рыбаки ловили рыбу.
Первый поймал 10 рыб.
Второй — 50 рыб
Третий -20 рыб
И так далее.
У меня есть различные входными показатели погоды, условий, возраста и так далее.
Я делаю различные выборки из базы с разными входными показателями, но если выборка будет всего несколько ситуаций, то высока вероятность того, что рыбакам просто везло и никакой зависимости между входными данными и уловом нет, если взять слишком много ситуаций, то я найду слишком мало взаимосвязей.
Как определить золотую середину?
Я хочу чтобы найденные мной взаимосвязи имели отклонения не более 3-4% в связи со случайными данными, но не знаю как это грамотно называется.
То есть я нашел, что у рыбаков от 50 лет и при времени улова до 12:00 часов дня, улов превышает средний на 80%.
Так вот я хочу, чтобы эти найденные мной 80% были случайными не более,чем на 3-4%, надеюсь я понятно выразил мысль.
Подскажите как это называется и как мне посчитать достаточное количество случаев для моей задачи?
-
Вопрос заданболее трёх лет назад
-
150 просмотров