Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
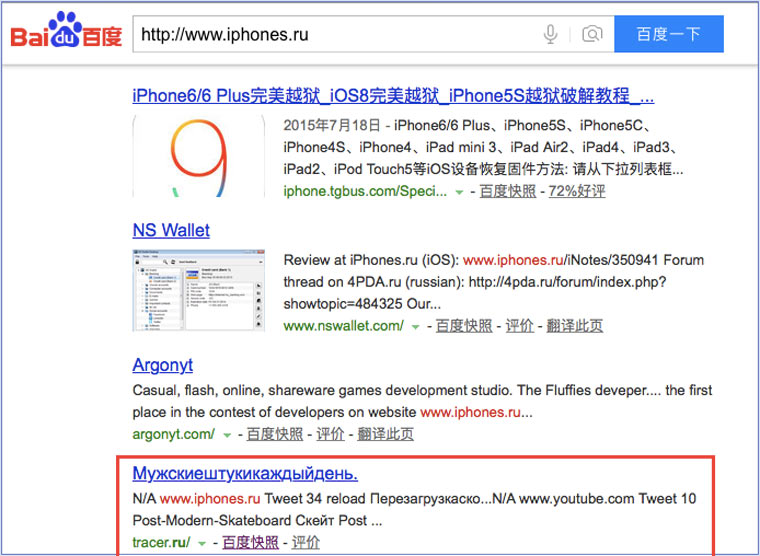
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
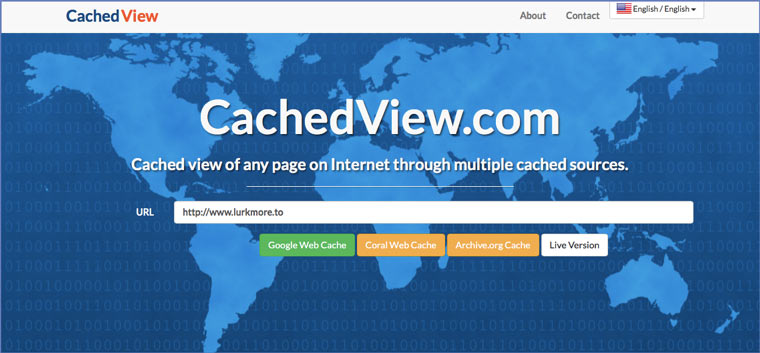
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
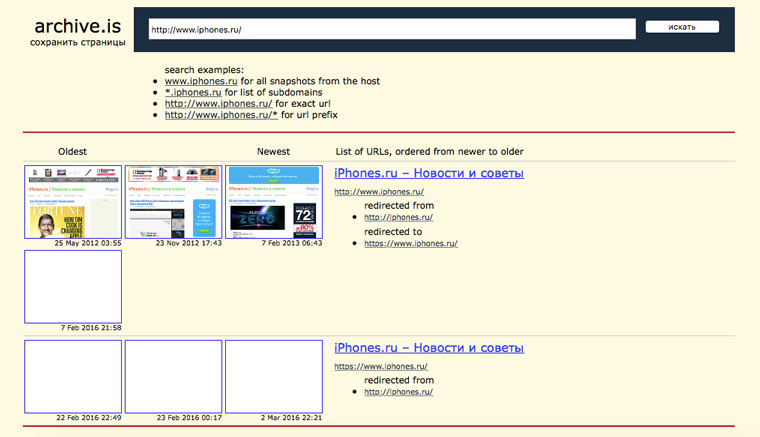
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
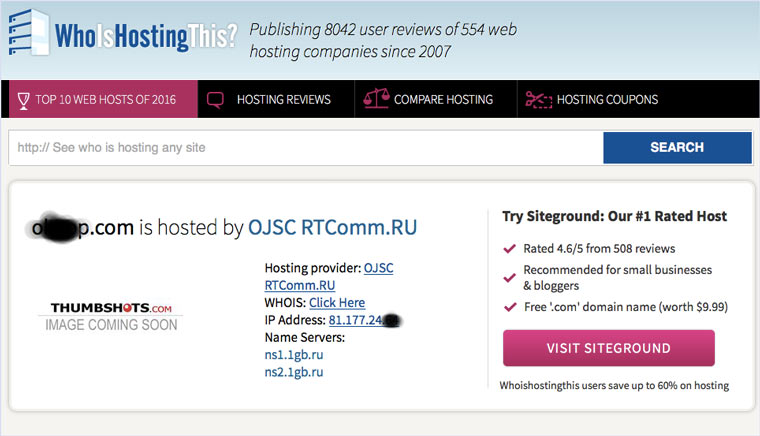
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
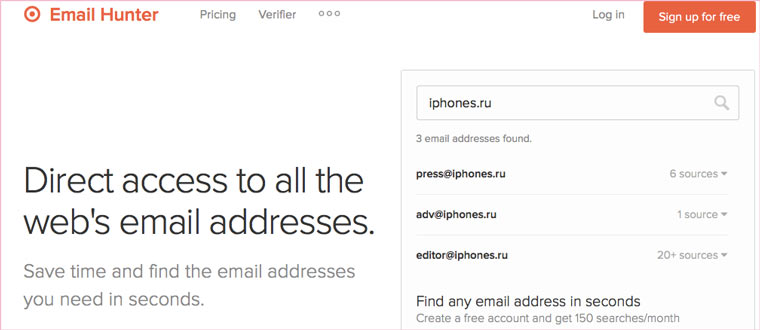
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Я добавил в закладки страницу сайту, но теперь она недоступна. Я пытался в течение 2 дней, но нечего не работает даже сайт не загружается. Похоже, весь сайт был удален. Есть ли способ просмотреть удаленную страницу?
Интернет это динамичная среда. Все меняется очень быстро — старые страницы удаляются, а новые добавляются. Как правило, когда страницы модифицируются или у них изменяется адрес, разработчики используют методы перенаправления. Редирект (перенаправление) позволяет перенаправить посетителя со старого адреса страницы на новый.
Но если весь сайт будет закрыт и не будет работать в течение многих дней, маловероятно, что он восстановит работу. В этой статье я покажу как просмотреть удаленную страницу или зайти на неработающий или уже несуществующий сайт.
Содержание
- Как просмотреть удаленную страницу
- Просмотр удаленных сайтов / страниц с помощью Wayback Machine
- Просмотр удаленных сайтов / страниц с помощью кеша Гугл
Как просмотреть удаленную страницу
Для просмотра удаленных страниц или сайтов я использую два сервиса:
- Кэш Google.
- Архив сайтов Wayback Machine.
Удаленная страница, вероятно будет доступна на одном из них. Имейте ввиду. Далеко не все сайты попадают в архив интернета. Если сайт молодой, новая страница может быть не проиндексирована сайтом.
РЕКОМЕНДУЕМ:
Как включить темную тему в Gmail
Просмотр удаленных сайтов / страниц с помощью Wayback Machine
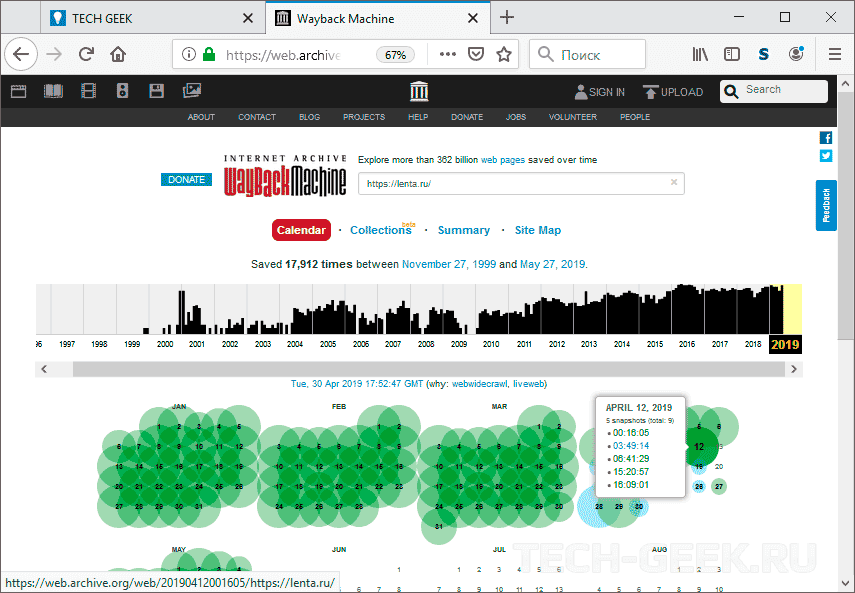
Архив интернета Wayback Machine позволяет просматривать весь сайт. Страница результатов довольно информативна, поскольку показывает, когда сайт был впервые доступен, и изменения, которые он претерпел за последние годы.
Шаг 1: Зайдите на сайт архива интернета и в верхней части экрана введите адрес удаленной страницы или неработающего сайта.

Шаг 2: Если сайт находиться в архиве будет отображена история. Выбрав необходимую дату вы сможете открыть открыть сайт и просмотреть страницу.
Теперь рассмотрим другой способ просмотра удаленных страниц и неработающих сайтов.
Просмотр удаленных сайтов / страниц с помощью кеша Гугл
Поисковая система Google хранит старый контент с веб-сайтов в кеше. Они доступны по ссылке «Сохраненная копия» рядом со списком страниц на странице результатов поиска Google.

В кеше Google находятся страницы которые были удаленны недавно. Если сайт не работает продолжительное время (пару-тройку месяцев и больше), тогда эта страница будет удалена из индекса Google, и в этом случае единственный способ просмотреть удаленную страницу — архив интернета Wayback Machine.
РЕКОМЕНДУЕМ:
Как найти похожие сайты с помощью оператора Google
Google индексирует страницы быстрее, чем Wayback Machine, кэшированные страницы могут предоставлять более свежую версию. Но могут быть проблемы с отображением изображений и другого встроенного в страницу медиа-контента.
На этом все. Теперь вы знаете как зайти на неработающий сайт и просмотреть удаленную страницу.


 (8 оценок, среднее: 3,88 из 5)
(8 оценок, среднее: 3,88 из 5)
![]() Загрузка…
Загрузка…
Что такое веб-архив?
Организатор и идейный вдохновитель веб-архива сайтов — американец Брюстер Кейл. Internet Archive («Архив интернета») — некоммерческий проект, его цель — сохранить мировое культурное и интеллектуальное наследие. По данным Википедии, этот сервис был создан в 1996 году. Во всемирном архиве интернета хранятся литературные произведения, видеозаписи, изображения, которые свободно публикуются в Сети. Это один из разделов огромного сервиса archive.org.
Боты постоянно сканируют всемирный интернет и пополняют библиотеку. Роботам помогают живые сотрудники и партнеры. Добавить копии страничек в веб-архив интернета может любой желающий. Конечно, в библиотеке невозможно найти абсолютно все страницы, которые когда-то были созданы. Но их там очень много — более 580 миллиардов.
Просмотреть архив «машины времени» («Wayback Machine» — второе название web-архива сайтов) можно бесплатно. При этом пользователям предлагают перейти по ссылке «Пожертвовать» и перевести создателям уникального сервиса посильную сумму.
Возможности сервиса
Для вебмастера и SEO-специалиста бесплатные всемирные архивы открывают ряд полезных возможностей.
- Если планируется купить домен или интернет-проект, важно посмотреть историю сайта. В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
- Архив веб-страниц поможет при выборе дроп-домена. В сервисе можно посмотреть бесплатно, какой проект на нем располагался (коммерческий, информационный) и как он выглядел.
- Можно узнать историю конкурентов. Сравнивая архивы сайтов с их современной версией, легко понять, как менялась ниша, как трансформировались проекты.
- Есть возможность проследить и проанализировать изменения на собственном сайте и даже восстановить измененный по ошибке URL.
- С помощью дополнительных сервисов можно восстановить удаленный ресурс или отдельные страницы.
- А также найти контент по интересующей теме, которого уже нет в глобальной сети.
Как посмотреть архивные страницы?
Откройте в браузере https://web.archive.org/. В строке для поиска укажите URL главной или любой другой страницы нужного сайта.
Сервис покажет график сохранений и календарь, в котором обведены даты сканирований. Эти даты не связаны с датами обновления контента. Боты работают по собственному графику.
Если кликнуть на нужный год и дату, сервис покажет web-версию старых страниц. Обычно сохраняется не весь контент, часть документов недоступна, отображаются не все фотографии и картинки. Часть ссылок кликабельны, можно погулять по интернет-площадке, перейти в другие разделы.
Если вы не знаете точный адрес нужного ресурса или хотите изучить целую нишу, нужно набрать в поисковой строке главные ключевые слова. Архив бесплатно найдет сайты нужной тематики. Перейдите по ссылкам этого списка и изучайте историю интересующего проекта.
Существует приложение Wayback Machine («Машина времени») для iOS и Android. Приложение скачивают на мобильное устройство. В нем заложен тот же функционал, что и в десктопной версии.
Как добавить страницу в сервис?
Боты обходят интернет по собственному графику. Не все проекты попадают в историю «Машины времени». Молодые площадки с небольшим трафиком редко оказываются в библиотеке. А если и попадают туда, то частота сканирований очень низкая — раз в несколько месяцев.
Сохранять копии сайта в WebArchive можно самостоятельно. Для этого нужно открыть сервис, найти поле «Сохранить страницу» и добавить туда URL. Снимки появятся в библиотеке через пару минут.
Эту операцию можно периодически повторять.
В будущем эти копии будут полезны, чтобы отслеживать изменения в дизайне, структуре, контенте. Если страницы будут по ошибке удалены, а бэкапы не делались или были утеряны, архивные снимки помогут восстановить документ.
Как удалить копии страниц своего проекта?
Не всем и не всегда хочется выкладывать историю своей веб-площадки на всеобщее обозрение. Например, на сайте могла быть выложена ошибочная, некорректная или противозаконная информация. Даже если удалить страницу или файл, они сохранятся в библиотеке.
Архивом страниц могут заинтересоваться конкуренты и недоброжелатели. Поэтому многим хочется удалить копии веб-документов из сервиса.
Раньше вебмастера вписывали в robots.txt запрещающую директиву для ботов. Но сейчас это уже не работает.
Убрать страницы из библиотеки можно только через саппорт. Для этого нужно написать письмо на info@archive.org. Писать нужно по-английски, с указанием реальных имени, фамилии, физического адреса. Чтобы подтвердить, что вы владелец ресурса, отправлять письмо лучшего с почтового ящика, указанного на сайте. Еще один способ подтвердить свои права — написать через регистратора домена или через хостинг. Иногда саппорт просит прислать копию паспорта.
Через поддержку можно навсегда запретить делать копии своего проекта.
Как восстановить сайт из архива?
Если вы сами загрузили копию страницы, ее можно найти в своем аккаунте в разделе «Мой архив».

Чтобы скачать страницу, найдите ее в списке, кликните по виджету справа и сохраните документ в виде html-файла.

С чужими сайтами действуют примерно так же: открывают копию в архиве, через панель разработчика копируют html-код, стили, изображения.
Файлы заливаются по FTP в корневую директорию домена на хостинге.
Но ручной способ слишком долгий и трудоемкий. Автоматизировать процесс можно через платные онлайн сервисы: Archivarix, waybackmachinedownloader, r-tools, rush-analytics и другие. Здесь можно не только скачать файлы, но и оптимизировать их: убрать битые ссылки, неработающие скрипты и так далее. Некоторые сервисы умеют импортировать файлы в WordPress.
Другие полезные опции
WebArchive умеет не только сохранять копии и показывать старую версию страниц сайта. Здесь есть несколько полезных инструментов аналитики.
- Сводка. Сервис показывает, какие данные содержит сайт: сколько на нем текстов, изображений, приложений. Можно открыть и просмотреть список всех URL.
- Изменения. Инструмент поможет выявить изменения в URL-адресах. Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.
- Карта сайта. Группирует данные по годам и строит карту в виде круговой диаграммы для каждого года.

В центре диаграммы корень сайта, а кольца — это разделы и страницы. Диаграмма кликабельна, она позволяет перейти на копию нужного URL.
Читайте на Askusers
Как быстро и правильно провести A/B-тестирование в маркетинге и SEO? Что можно тестировать, какие инструменты использовать и как замерять результат?
Что такое коммерческие факторы ранжирования, как они влияют на трафик и конверсию и как их улучшить?
Если страницы выпали из индекса поисковых систем — это тревожный признак, надо срочно искать причину. Подробный алгоритм проверки.
Иногда, зайдя на одну из ранее посещаемых страниц в сети Интернет, мы получаем 404 ошибку – страница не найдена. Возможно, что эта страница была удалена, возможно, что сайт на данный момент не доступен и т.д., но нам от этого не тепло и не холодно. Возникает закономерный вопрос: как просмотреть удалённую страницу? В данной статье я попробую дать ответ на этот вопрос и предложить Вам четыре готовых варианта решения данной задачи. Приступим?
Вариант 1: автономный режим браузера
Для экономии трафика и увеличения скорости загрузки страниц, многие современные браузеры используют, так называемый, кэш. Что это такое? Кэш (от англ. cache) – это дисковое пространство на Вашем компьютере, выделенное специально под временные файлы, к которым относятся и веб-страницы.
Так что если страница удалена или Интернет Вам не доступен, Вы можете воспользоваться данными из кэша браузера. Для этого Вам нужно перейти в, так называемый, автономный режим работы браузера. Как это сделать?
Примечание: для просмотра удалённой страницы в автономном режиме, она должна присутствовать в кэше браузера. Это происходит только в том случае, если Вы ранее уже посещали эту страницу. Но нужно помнить, что кэш периодически подчищается самим браузером. Многое здесь зависит от выделенного под кэш дискового пространства в настройках браузера.
Как включить автономный режим работы браузера?
Для браузером на движке Chromium, а это Google Chrome, Яндекс.Браузер, браузерИнтернет от Mail.ru, Рамблер Браузер и др., автономного режима не существует. Точнее он есть, но только в качестве эксперимента. Для его активизации перейдите на системную страницу: chrome://flags/ — и найдите там «Автономный режим кеша», а потом кликните в нём ссылку «Включить».

Включение и выключение автономного режима в браузере Google Chrome
В браузере Firefox (версия 29 и старше) нужно открыть меню (кликнув по кнопке с тремя полосками, она обычно находится в верхнем правом углу окна браузера) и кликнуть в нём пункт «Разработка» (в виде гаечного ключа), а потом пункт «Работать автономно».
Включение и выключение автономного режима в браузере Firefox
В браузере Opera кликните кнопку «Opera», найдите в меню пункт «Настройки», а потом кликните пункт «Работать автономно».
Как включить или отключить автономный режим в Opera?
В Internet Explorer нужно нажать кнопку Alt, выбрать пункт «Файл» (в появившемся меню) и кликнуть пункт меню «Автономный режим».
Как выключить или выключить автономный режим в Internet Explorer?
Как отключить автономный режим в Internet Explorer 11?
Стоит уточнить, что в IE 11 разработчики удалили возможность включения и отключения автономного режима. Здесь возникает другая проблема: как отключить автономный режим в Internet Explorer 11? Тут проделать обратные действия не получится, нужно сбрасывать настройки браузера.
Для этого закройте все приложения, в том числе и браузер. Дальше нажмите комбинацию клавиш Win+R и введите: inetcpl.cpl – в открывшемся окне «Выполнить», нажмите кнопку Enter. В открывшемся окне «Свойства: Интернет» перейдите на вкладку «Дополнительно». На открывшейся вкладке найдите и кликните кнопку «Восстановить дополнительные параметры», а потом и появившуюся кнопку «Сброс…». В окне подтверждения установите галочку «Удалить личные настройки» и нажмите кнопку «Сброс».
Вариант 2: копии страниц в поисковых системах
Я уже как-то отмечал, что пользователям поисковых систем нет смысла заходить на сайты, ведь можно просматривать копии их страниц в самой поисковой системе. Так или иначе, но это хороший способ просмотреть удалённую страницу.
В случае с поисковой системой Google, Вы можете использовать оператор поискового запроса info:, с указанием нужного URL-адреса, например:
Просмотр копии страницы в кэше поисковой системы Google
Здесь нам нужно кликнуть ссылку «сохраненную в Google версию» и мы получим последнюю сохранённую в Google версию удалённой страницы.
В случае с поисковой системой Яндекс, Вы можете использовать оператор поискового запроса url:, с указанием нужного URL-адреса, например:
Просмотр копии удаленной веб-страницы в индексе поисковой системы Яндекс
Здесь нам нужно навести курсор мыши на (зелёный) URL-адресс в сниппете, а потом кликнуть появившуюся ссылку «копия» и мы получим последнюю сохранённую в Яндекс версию удалённой страницы.
Проблема в том, что поисковые системы хранят только последние проиндексированные копии страниц. В том случае если страница была удалена, со временем она может стать недоступной и в кэше поисковых систем.
Вариант 3: WayBack Machine
Есть в сети Интернет и такой замечательный сервис, как WayBack Machine, рекомендую взять его на заметку. Фактически, это целый Интернет архив, который содержит историю существования многих сайтов.
Просмотр истории сайта на WayBack Machine
Суть его проста. Вы вводите нужный вам URL-адрес, а сервис пытается найти его копии в своей базе с привязкой к дате. К сожалению, сервис индексирует далеко не все сайты и тем более их страницы, но тем не менее. Это реальный способ восстановить ранее удалённую страницу.
Вариант 4: Archive.today
Достаточно простым и (к сожалению) пассивным сервис для создания копий веб-страниц сайтов является сервис Archive.today. Другими словами, для того, чтобы получить доступ к удалённой странице, нужно чтобы ранее она была кем-то скопирована в сервис. Для этого нужно ввести URL-адрес в первую (красную) форму и нажать кнопку «submit url».
Добавление и поиск копий веб-страниц на сайте Archive.today
После этого вы можете попробовать найти нужную страницу, используя вторую (синюю) форму. В результате Вы увидите имеющиеся в архиве копии страниц.
Просмотр копий страни на сайте Archive.today
Возможно, что существуют и другие варианты решения поставленной задачи с просмотром удаленных страниц, но думаю и того, что было сказано будет вполне достаточно. На этом у меня всё. Спасибо за внимание. Удачи!
Короткая ссылка: http://goo.gl/M0atyn