Дата обновления: 06.02.2023
Время чтения: 11 мин.
![]()

Марат Исрафилов
ЭКСПЕРТ
Совладелец и директор агентства интернет-рекламы Юла Group. Более 15 лет опыта на рынке.
Основная деятельность:
— SEO Продвижение сайтов в …
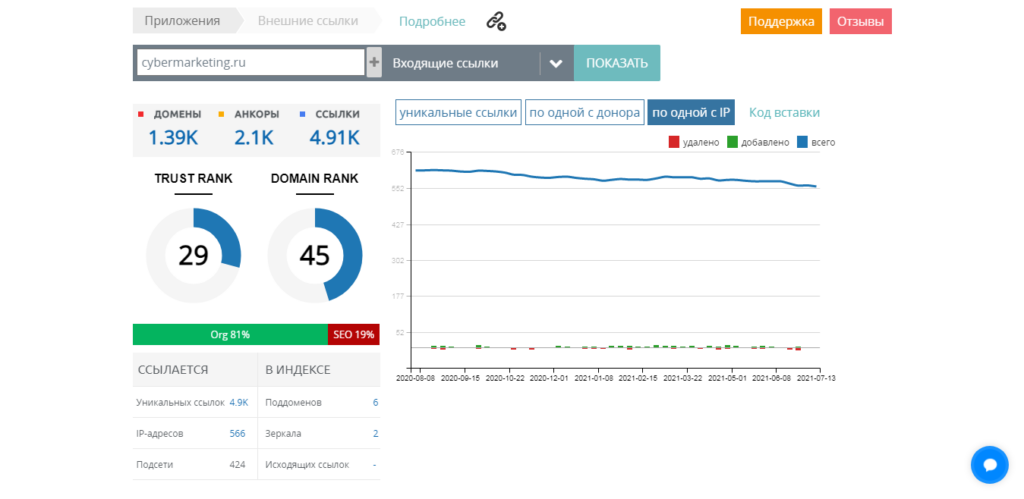
Бэклинки или, как их ещё называют, обратные или входящие ссылки – это внешние ссылки на ваш сайт, которые размещены на сторонних ресурсах.
Они влияют на ранжирование сайта в поисковых системах. И если раньше поисковики оценивали только количество ссылок, то сейчас нужно следить и за их качеством. Некорректные бэклинки только навредят вашему проекту, поэтому нужно время от времени их анализировать.
Продвижение в Stories у блогеров: надёжно и эффективно

InstaJet.in — сервис интеграций с блогерами в Stories. Только проверенные блогеры, готовые к сотрудничеству!
- Выбирайте лучших: в открытом каталоге можно подобрать блогеров самостоятельно или с помощью менеджера.
- Контролируйте процесс: интеграции размещаются точно в срок и в том виде, в котором их согласует заказчик.
- Анализируйте результаты: сервис предоставляет готовые отчёты по кампаниям в удобных таблицах.
Платформа работает с юридическими лицами и предоставляет все необходимые документы.
Для чего нужно проверять бэклинки на сайт
Линкбилдинг, или построение ссылочной массы для вашего проекта – важная часть в SEO-продвижении сайта. Хорошие бэклинки помогают выйти на первые позиции в выдаче поиска. Даже если ваш сайт хорошо оптимизирован, без входящих ссылок результата не будет.
Отличное видео из уроков Школы SEO, в котором доступно рассказано, на что влияют бэклинки:
Не стоит думать, что другие сайты начнут сами по себе на безвозмездной основе оставлять ссылки на вас и приводить трафик. Это, конечно, возможно, если у вас действительно крутой и полезный контент. Но вряд ли все ссылки будут хорошего качества (почему это важно, расскажем ниже). Поэтому нужно самостоятельно работать с бэклинками.
Проверяя внешние ссылки, вы сможете решить ряд задач:
- Узнаете, кто и как отзывается о вашем проекте. Это могут быть как качественные статьи, подборки полезных сервисов, так и негативные отзывы или заказные материалы конкурентов. Увидев вовремя такие бэклинки, сможете оперативно реагировать на них. Так вы не допустите падения вашего сервиса в поисковой выдаче.
- Обнаружите ссылки на сомнительных сайтах, которые также могут оставлять конкуренты. От них нужно обязательно избавляться, ведь такие бэклинки могут привести к блокировке вашего сервиса.
- Проверите контекст, в котором употребляется ссылка и её правильность. Например, если к бэклинку применили атрибут nofollow (т.е. скрыли ссылку от индексации), от неё будет мало пользы.
- Проанализируете ссылочную массу конкурентов и узнаете, почему их сайт находится в поиске выше.
- Исключите плохие и некачественные бэклинки.
Как узнать, кто ссылается на сайт
Вручную найти бэклинки сложно или даже невозможно. Но есть сервисы, благодаря которым вы сможете узнать, кто и как ссылается на вас.
Есть как бесплатные сервисы, так и платные. Расскажем про 6 самых популярных, которые помогают найти и проанализировать входящие ссылки.
Бесплатные сервисы
У бесплатных сервисов для проверки обратных ссылок есть очевидный плюс – чтобы ими пользоваться, не нужно платить. Но есть и ряд минусов:
- представленный в них функционал, не так широк, как в платных;
- часто есть ограничения по количеству ссылок, которые можно изучить;
- они не всегда корректны.
Мы подобрали 2 бесплатных сервиса с широким функционалом и подробно расскажем о каждом из них.
XTool
Сначала нужно зарегистрироваться. Затем на почту приходит пароль, который можно поменять на свой в настройках.
Для проверки бэклинков необходим только адрес сайта. Вводим его в соответствующее окно и нажимаем «Найти».
.jpg)
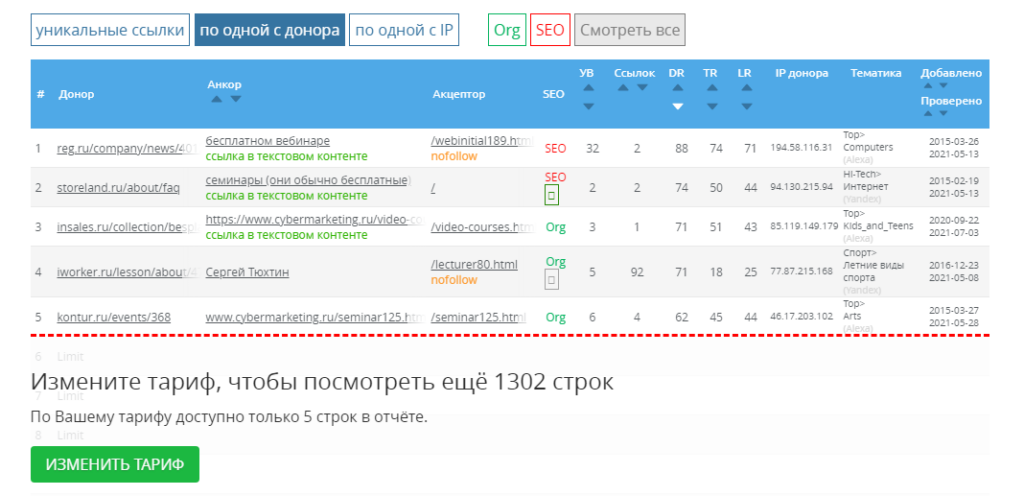
Бесплатно сервис ищет до 1000 ссылок, которые формирует в таблицу. Там можно увидеть номер ссылки, донор (ссылающийся сайт), акцептор (страница сайта, на которую ведет ссылка), ТИЦ (тематический индекс цитирования), уровень, анкор и состояние ссылки. Отметим, что ТИЦ сейчас не поддерживается Яндексом. Ссылки можно отсортировать по показателю параметра.
.jpg)
Помимо списка бэклинков на странице выводятся таблицы с популярными акцепторами и анкорами.
.jpg)
Данные по обратным ссылкам можно выгрузить в Excel или CSV для более удобной работы.
Backlink Watch
Очень простой в использовании сервис. В нем даже не надо регистрироваться. Чтобы найти бэклинки, нужно ввести адрес сайта, подтвердить, что вы не робот и нажать кнопку Check Backlinks. Он выдаёт не все ссылки, а список из 1000 штук. Но этого достаточно, чтобы проверить качество внешних ссылок.

Отметим, что сервис может работать некорректно. При проверке нашего сайта он выдал информацию, что никаких внешних ссылок нет и посоветовал создать их.

Поэтому для демонстрации работы сервиса мы проверили сам сайт backlinkwatch.com. После нажатия на кнопку проверки появляется плашка с количеством обработанных и необработанных ссылок. По мере готовности они появляются в таблице. На то, чтобы обработать 1000 обратных ссылок, ушло 30 минут.
В таблице выводится номер ссылки, URL бэклинка, текст (при наличии), рейтинг страницы, количество внешних ссылок на странице и атрибут nofollow (если есть).
.jpg)
Есть возможность отсортировать бэклинки по имеющимся параметрам, щёлкнув по плашке с категорией.
Платные инструменты
Платные сервисы более функциональны, поэтому для серьёзной работы с бэклинками лучше отдавать предпочтение им. Расскажем о 5 платформах для анализа входящих ссылок. Чтобы пользоваться ими, нужна регистрация.
MegaIndex
После регистрации автоматически активизируется бесплатный тариф, который позволяет увидеть информацию:
- Типы ссылок
- Тематику сайтов
- Типы доменов
- Популярные страницы
- Популярные анкоры
- 5 ссылающихся сайтов

Чтобы посмотреть больше информации, необходимо подключить платный тариф.
Сколько стоит использование сайта? Есть несколько тарифных планов, которые отличаются по цене и функционалу:
- Начальный – 2990 р. в месяц
- Стандартный – 5990 р. в месяц
- Премиум – 23980 р. в месяц
Если оплачивать на несколько месяцев вперёд, можно получить скидку.
Важное уточнение для сервисов, которые приведем ниже! С марта 2022 года из-за санкций платежных систем Visa и MasterCard эти сервисы не принимают российские банковские карты. Можно оплатить только через карты, выпущенные за рубежом.
Majestic
На платформе можно изучить количество и качество входящих ссылок, посмотреть, сколько действующих и удалённых бэклинков, наглядные диаграммы, историю ссылок и многое другое.
.jpg)
Стоимость использования платформы за месяц:
- Lite – 49,99 $
- Pro – 99,99 $
- API – 399,99 $
При подключении первых двух тарифов можно вернуть деньги в течение 7 дней, если что-то не понравилось.
Moz
Сервис показывает информацию по внешним ссылкам:
- Потерянные и актуальные бэклинки
- Самые популярные ссылки
- Лучшие ссылающиеся сайты
- Анкорный текст и др.
Бесплатно доступно 10 проверок на месяц, посмотреть можно 5 популярных позиций.

Есть 4 тарифа с ежемесячной платой:
- Standard – 99 $
- Medium – 179 $
- Large – 299 $
- Premium – 599 $
Перед оформлением подписки можно активировать пробный 30-дневный период.
Будьте внимательны! При оформлении нужно ввести номер своей карты, по истечении срока с вас спишут деньги.
У платных сервисов для проверки бэклинков есть один минус – они платные. Но в остальном они обходят бесплатные инструменты. У них шире функционал, больше точность, больше возможностей.
Для сервисов Ahrefs и Serpstat: кроме проблем с оплатой, они не работают через российские IP, сильно ограничен функционал и даже есть риск блокировки аккаунта. Поэтому их можно полноценно использовать только с ВПН.
Ahrefs
Один из самых удобных и точных инструментов, который помогает находить обратные ссылки свои и конкурентов. База данных обновляется каждые 20-30 минут. В таблице выводятся:
- Ссылающаяся страница
- Текст анкора
- Трафик
- Дата создания бэклинка
Для анализа ссылок сначала переходим в Site Explorer:

Далее прописываем нужный домен и жмем на поиск:

Высветится общая информация по беклинкам, где в левом меню выбираем Backlinks:

Отобразится полный список ссылок, которые можно отсортировать или отфильтровать, как вам нужно:

Отметим, что у сервиса нет пробной бесплатной проверки, при регистрации нужно оплатить один из тарифов:
- Lite – 89 €
- Standard – 179 €
- Advanced – 369 €
- Enterprise – 899 €
Serpstat
На этом сайте можно ознакомиться с анализом ссылок:
- Суммарный отчёт, в котором собраны все данные, которые мы перечислим ниже;
- Ссылающиеся домены;
- Вредоносные сайты;
- Входящие ссылки;
- Исходящие ссылки;
- Исходящие домены;
- Анкоры ссылок.
Во вкладке «Входящие ссылки» можно увидеть количество активных и потерянных ссылок. В бесплатной версии можно ознакомиться с 10 популярными бэклинками.

Чтобы получить больше информации, нужно подключить платный тариф. Один месяц использования стоит 69$. Если оплачивать на несколько месяцев вперёд, получите скидку.
Больше аналогичных сервисов можно найти здесь.
Где искать входящие ссылки онлайн в Google и Яндекс
Кроме платных и бесплатных инструментов, есть специальные сервисы от Google и Яндекс, которые анализируют информацию по бэклинкам в своих поисковиках – Google Search Console, Яндекс.Вебмастер.
В них не получится анализировать внешние ссылки конкурентов, потому что для доступа к аналитике необходимо подтвердить, что вы являетесь владельцем сайта.
Как работать с этими сервисами? Нужно, чтобы у вас был аккаунт почты Google и Яндекс, соответственно. Зайдите на выбранную платформу и введите адрес своего сайта. Затем вам предложат варианты для подтверждения владения сайтом.
В Google Search Console:
- Через HTML-файл
- Через метатег
- Через аккаунт Google Analytics
- Через Диспетчер тегов Google
- Через DNS-запись
После подтверждения вы попадёте в аккаунт со всей информацией о сайте. В анализе по внешним ссылкам можно найти страницы, на которые чаще всего ссылаются, сайты, ссылающиеся на вас и многое другое.
Инструмент бесплатный, показывает множество нужных для аналитики параметров, можно выгрузить данные в Гугл Таблицу. Показывает статистику именно по своей поисковой системе Googl, что логично.
В панели слева нужно зайти в Ссылки, затем выбираем Внешние ссылки и появляется информация о сайтах, которые больше всего ссылаются на выбранный домен. Здесь показано общее количество бэклинков на сайт:

Можно проверить конкретную страницу, на скриншоте показали данные по главной нашего сайта:

В Яндекс.Вебмастер подтвердить владение доменом можно:
- Через HTML-файл
- Через метатег
- Через DNS-запись
Важный момент: с января 2021 года Вебмастер не обновляет статистику. Так что сейчас для поиска актуальных данных этот инструмент недоступен. На скриншоте видны даты последнего обновления сайта:

Как анализировать внешние ссылки
Расскажем на примере, как проводить аналитику по внешним ссылкам. Будем использовать сервис XTool.
1. Регистрируемся на выбранном сайте. Вводим email, получаем письмо с паролем и входим.
2. Нажимаем «Обратные ссылки» и вводим адрес сайта, затем – «Найти».
.png)
3. Появится таблица с ссылками и данными по ним.
4. Нажать на кнопку «Проверить позиции текущих ссылок».
.png)
5. Дожидаемся окончания проверки и нажимаем «Перенести ссылки в массовую проверку».
6. Нажимаем «Проверить».

После проверки скачиваем файл, нажав на его название.

Чтобы улучшить показатели ссылок, нужно решить проблемы с плохими и увеличить количество хороших.

Главное, что нужно помнить при анализе имеющихся ссылок и создании новых – это качество. Чем меньше спама на доноре и больше траста, тем лучше сайт и больше доверия к нему.
Как работать с бэклинками и где их получать
После того, как вы найдёте обратные ссылки и проанализируете их, нужно уменьшить потери и увеличить их качество и количество.
Как уменьшить потери по бэклинкам?
- Исправьте битые ссылки
- Проанализируйте популярные материалы
Рассмотрим каждый пункт подробнее.
Исправление битых ссылок
Обратные ссылки на ваш сайт могут оказаться некорректными, например, если страница была изменена. При переходе по таким ссылкам пользователи попадают на страницу с ошибкой. Соответственно, они не попадают на ваш сайт, соответственно, такие ссылки не ранжируются.
Во многих сервисах есть возможность отфильтровать бэклинки, выявив именно битые. В отчёте покажут, какие ссылки некорректны и на каком сайте. Чтобы их исправить, нужно попросить владельцев сайта заменить ссылку на работающую или настроить на нее 301 редирект.
Как исправить битые ссылки, смотрите в видео:
Анализ популярных материалов
Для чего это нужно? Узнав, на какие ваши материалы ссылаются чаще всего, вы поймёте, как создавать популярные статьи. Не нужно проверять свою интуицию, лучше довериться статистике.
В сервисе для поиска бэклинков можно отсортировать страницы по популярности. Сделайте это и посмотрите, какой контент привлёк читателей и они ссылались на ваш сайт. Возможно, это какое-то исследование, интервью с экспертом, привлекательные иллюстрации к статье. Учитывайте это в будущем, при составлении контент-плана и создания материалов.
Как получать больше входящих ссылок? Для этого есть несколько способов:
- Покупка внешних ссылок
- Продвижение статьями
- Крауд-маркетинг
Расскажем о каждом способе подробнее.
Покупка внешних ссылок
Этот способ используется чаще всего. Приобретать их можно на биржах или автоматизированных сервисах, таких как Gogetlinks и Rotapost.
Как выбрать сайт-донор:
- Проверьте трафик и его качество. Важно, чтобы это был естественный, а не искусственный трафик.
- Важна и тематика сайта, она должна быть релевантной вашей. Если у вас сайт про садоводство, будет глупо полагать, что на него перейдут с сайта про компьютерные игры.
- У площадки должен быть высокий рейтинг траста и небольшая заспамленность.
Этот способ увеличения ссылочной массы экономит время и предлагает большой выбор площадок. Конечно, минусом станет трата денег, но если подойти к вопросу с умом, то она окупится.
Продвижение статьями
Это один из способов получения естественных внешних ссылок. Он эффективен, но требует времени и ресурсов. Для этого нужно:
- Написать качественный материал с ссылкой в нём;
- Найти подходящий сайт для публикации – с релевантной аудиторией, заинтересованностью, возможностью размещения материала с ссылкой на ресурс (на некоторых сайтах запрещается оставлять ссылки);
- Договориться о публикации на безвозмездной основе, либо за плату.
Плюс этого метода в том, что всего один качественный материал может привести на ваш сайт хороший трафик. Один из изестных сервисов для продвижения статьями – Miralinks.
Крауд-маркетинг
Этот способ похож на предыдущий, но всё же имеет отличия. Как это работает:
- Сначала нужно найти обсуждение или статью с подходящей для вас целевой аудиторией;
- Затем написать текст на обсуждаемую тему;
- Опубликовать текст с прикреплением ссылки.
Главное условие – нужно писать естественным языком, без явной рекламы. Лучше всего подойдёт для раскручивания конкретных страниц на сайтах – с товарами или услугами.
Крауд-маркетинг привлечёт естественный трафик, улучшит видимость в поисковиках. Есть и минусы – нужно время чтобы найти подходящую площадку, написать хороший текст и дождаться результатов размещения. Хорошие сервисы для крауд-маркетинга: Linkum и Zenlink.
Более детально тему крауд-ссылок разбирают в этом видео:
Чтобы успешно наращивать ссылочную массу, нужно сначала избавиться от битых и некорректных ссылок, а уже потом распространять «правильные». Не забывайте делать это регулярно.
Как найти бэклинки у конкурентов
Найти бэклинки конкурентов можно с помощью бесплатных или платных сервисов, которые не требуют подтверждения, что вы владелец сайта. То есть все платформы, о которых мы рассказали, кроме Google Search Console и Яндекс.Вебмастер.
Зачем нужно искать и анализировать внешние ссылки конкурентов?
- Это поможет усовершенствовать вашу собственную стратегию продвижения.
- Вы сможете обнаружить новые возможности маркетинга, поймёте свои ошибки.
- Если сайт конкурента отображается в поиске выше, чем ваш, вы сможете увидеть, какие методы применяет он и использовать в своих целях.
Перед тем, как начать анализ внешних ссылок конкурентов, определите, что это за компании. Это очень важно. Если вы выявите соперников, с которыми на самом деле не конкурируете, анализ окажется бесполезным.

Как определить конкурентов:
- Работают в том же сегменте, что и вы.
- Продают похожие товары, услуги.
- Работают в той же ценовой категории.
- Работают в вашем городе/области/стране.
Если все пункты совпадают, значит, это ваш ключевой конкурент. Когда вы определились с конкретной компанией, можно приступать к анализу её бэклинков.
Покажем на примере сайта XTool.
- Введите в окошко адрес сайта конкурента, который хотите проверить.
- Нажмите «Найти».
- Выведется таблица, в которой можно увидеть сайты-доноры, акцептор, анкор и др.
Те же действия повторите для каждого своего конкурента.
В первую очередь обращайте внимание на ссылки с высоким уровнем, перейдите по ним, посмотрите, что зацепило читателей в материале. Так изучите самые популярные позиции.
После изучения поймёте, что привлекает клиентов, почему они переходят на сайт вашего конкурента.
Заключение
Бэклинки – это неотъемлемый инструмент в SEO-продвижении сайта и бренда. Чем качественнее они будут, тем лучше поведенческие и выше позиции. Регулярно проверяйте внешние ссылки, чтобы исправлять плохие и создавать новые, хорошие.
Вам понравилась статья?
![]()
1
![]()
1
Те, кто давно занимается поисковой оптимизацией, хорошо знают об операторах расширенного поиска Google. Например, почти все знают об операторе site:, который ограничивает поисковую выдачу одним сайтом.
Большинство операторов легко запомнить, это короткие команды. Но уметь эффективно их использовать — совсем другая история. Многие специалисты знают основы, но немногие по-настоящему овладели этими командами.
В этой статье я поделюсь советами, которые помогут освоить поисковые операторы для 15 конкретных задач.
- Поиск ошибок индексации
- Поиск незащищённых страниц (не https)
- Поиск дубликатов контента
- Поиск нежелательных файлов и страниц на своём сайте
- Поиск возможностей для гостевой публикации
- Поиск страниц со списками ресурсов
- Поиск сайтов с примерами инфографики… так что можно предложить свою
- Поиск сайтов для размещения своих ссылок… и проверки, насколько они подходят
- Поиск профилей в социальных сетях
- Поиск возможностей для внутренних ссылок
- Поиск упоминаний конкурентов для своего пиара
- Поиск возможностей для спонсорских постов
- Поиск тем Q+A, связанных с вашим контентом
- Проверка, как часто конкуренты публикуют новый контент
- Поиск сайтов со ссылками на конкурентов
Сначала полный список всех поисковых операторов Google и их функций.
Операторы поиска Google: полный список
Вы знали, что Google постоянно удаляет полезные операторы? Именно поэтому большинство существующих списков устарели и неточны. Для этой статьи я лично проверил каждый оператор, что смог найти.
Вот полный список всех рабочих, частично рабочих и сломанных операторов расширенного поиска Google по состоянию на 2018 год.
Рабочие операторы
“поисковый запрос”
Принудительный поиск точного совпадения. Используйте его для уточнения неоднозначных результатов поиска или исключения синонимов при поиске отдельных слов.
Пример: “steve jobs”
OR
Поиск по X или Y. Вернёт результаты, связанные с X или Y, или и то, и другое. Вместо него можно использовать оператор (|).
Примеры: jobs OR gates / jobs | gates
AND
Поиск по X и Y. Вернёт только результаты, связанные как с X, так и с Y. Примечание: в реальности не имеет значения для обычного поиска, потому что Google по умолчанию вставляет AND. Но очень полезен в сочетании с другими операторами.
Пример: jobs AND gates
—
Исключение термина или фразы. В нашем примере все страницы будут упоминать Джобса, но не с Apple (компанией).
Пример: jobs -apple
*
Действует как подстановочный знак для произвольного слова или фразы.
Пример: steve * apple
( )
Группировка нескольких терминов или операторов, чтобы контролировать выдачу.
Пример: (ipad OR iphone) apple
$
Поиск цен. Также работает для евро (€), но не для британского фунта (£).
Пример: ipad $329
define:
По сути, это встроенный в Google словарь. Показывает значение слова.
Пример: define:entrepreneur
cache:
Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно).
Пример: cache:apple.com
filetype:
Ограничивает результаты файлами определённого формата, например, pdf, docx, txt, ppt и т. д. Примечание: аналогично оператору “ext:”.
Пример: apple filetype:pdf / apple ext:pdf
site:
Результаты для определённого домена.
Пример: site:apple.com
related:
Поиск сайтов, связанных с данным доменом.
Пример: related:apple.com
intitle:
Найти страницы с определённым словом (или словами) в заголовке страницы. В нашем примере возвратятся все результаты со словом [apple] в теге title.
Пример: intitle:apple
allintitle:
Аналогично “intitle», но будут возвращает результаты, содержащие все указанные слова в теге title.
Пример: allintitle:apple iphone
inurl:
Найти страницы с определённым словом (или словами) в URL. В этом примере будут возвращены все результаты, содержащие слово [apple] в URL.
Пример: inurl:apple
allinurl:
Аналогично “inurl», но возвращает результаты со всеми указанными словами в URL.
Пример: allinurl:apple iphone
intext:
Найти страницы, содержащие определённое слово (или слова) где-то в содержании. В примере будут возвращены все результаты, содержащие слово [apple] на странице.
Пример: intext:apple
allintext:
Аналогично “intext», но возвращает результаты со всеми указанными словами на странице.
Пример: allintext:apple iphone
AROUND(X)
Поиск поблизости. Страницы, содержащие два слова или фразы на расстоянии X слов друг от друга. В этом примере слова [apple] и [iphone] должны присутствовать в тексте на расстоянии не более четырёх слов друг от друга.
Пример: apple AROUND(4) iphone
weather:
Найти погоду для конкретного места. Отображается в погодном сниппете, но также возвращает результаты с других метеорологических сайтов.
Пример: weather:san francisco
stocks:
Биржевая информация (т. е., цена и т. д.) для любой акции по биржевому тикеру.
Пример: stocks:aapl
map:
Результаты поиска по картам.
Пример: map:silicon valley
movie:
Найти информацию о конкретном фильме. Также находит расписание сеансов, если фильм сейчас показывают недалеко от вас.
Пример: movie:steve jobs
in
Преобразует одну единицы измерения в другую. Работает с валютами, весами, температурой, расстояниями и т. д.
Пример: $329 in GBP
source:
Найти новостные результаты из определённого источника в Google News.
Пример: apple source:the_verge
_
Не совсем оператор поиска, но действует как подстановочный знак для автодополнения.
Пример: apple CEO _ jobs
Частично рабочие операторы
Вот операторы, которые не всегда дают желательный результат:
#..#
Поиск диапазона чисел. В приведённом примере возвращаются результаты [видео WWDC] за 2010-2014 годы, но не за 2015 год и последующие годы.
Пример: wwdc video 2010..2014
inanchor:
Поиск страниц, связанных с определённым текстом в ссылке. В этом примере будут возвращены все страницы, на которые есть ссылки со словами [apple] или [iphone].
Пример: inanchor:apple iphone
allinanchor:
Аналогично inanchor, но возвращает результаты, содержащие все указанные слова во входящих ссылках.
Пример: allinanchor:apple iphone
blogurl:
Поиск URL блога в определённом домене. Использовался в поиске Google по блогам, но кое-как работает и в обычном поиске.
Пример: blogurl:microsoft.com
Примечание. Поиск Google по блогам закрыт в 2011 году.
loc:placename
Найти результаты из заданного места.
Пример: loc:”san francisco” apple
Примечание. Официально не закрыт, но результаты противоречивы.
location:
Найти результаты из заданного места в Google News.
Пример: location:”san francisco” apple
Примечание. Официально не закрыт, но результаты противоречивы.
Сломанные операторы
Операторы поиска Google, которые удалены и больше не работают.
+
Принудительный поиск по одному слову или фразе.
Пример: jobs +apple
Примечание. То же самое делается с помощью кавычек.
~
Включить синонимы. Не работает, потому что Google теперь включает синонимы по умолчанию. (Подсказка: для исключения синонимов используйте двойные кавычки).
Пример: ~apple
inpostauthor:
Найти сообщения в блоге, написанные конкретным автором. Работало только в поиске по блогам.
Пример: inpostauthor:”steve jobs”
Примечание. Поиск Google по блогам закрыт в 2011 году.
allinpostauthor:
Аналогично предыдущему, но устраняет необходимость в кавычках (если вы хотите найти конкретного автора, включая фамилию).
Пример: allinpostauthor:steve jobs
inposttitle:
Найти сообщения в блоге с конкретными словами в названии. Больше не работает, так как этот оператор был уникальным для поиска по блогам.
Пример: inposttitle:apple iphone
link:
Поиск страниц, которые ссылаются на определённый домен или URL. Google убила этот оператор в 2017 году, но он по-прежнему возвращает некоторые результаты — вероятно, не особо точные (поддержка прекращена в 2017 году)
Пример: link:apple.com
info:
Найти информацию о конкретной странице, включая время последнего кэширования, похожие страницы и т. д. (поддержка завершена в 2017 году). Примечание: идентичен оператору id:.
Примечание. Хотя изначальная функциональность этого оператора устарела, он по-прежнему полезен для поиска канонической индексированной версии. Благодарю @glenngabe за информацию!
Пример: info:apple.com / id:apple.com
daterange:
Найти результаты по определённому диапазону дат. Почему-то использует юлианский формат даты.
Пример: daterange:11278–13278
Примечание. Официально не закрыт, но, похоже, не работает.
phonebook:
Найди чей-то номер телефона (поддержка прекращена в 2010 году).
Пример: phonebook:tim cook
#
Поиск по хэштегу. Появился вместе с Google+, теперь устарел.
Пример: #apple
15 вариантов использования операторов поиска Google
Теперь рассмотрим несколько способов эффективного применения этих операторов, в том числе в сочетании друг с другом. Не стесняйтесь отклоняться от приведённых примеров, можете найти что-то новое.
Поехали!
1. Поиск ошибок индексации
На большинстве сайтов есть страницы, которые Google проиндексирвоал некорректно. Возможно, какой-то страницы нет в индексе или наоборот, там присутствует что-то лишнее. Воспользуемся оператором site:, чтобы узнать количество проиндексированных страниц на моём сайте.

Около 1040.
Примечание. Google здесь даёт примерное количество. Точную информацию см. в Google Search Console.
Но сколько из них являются статьями в блоге?
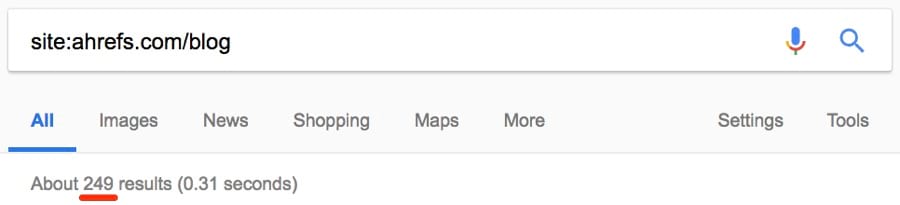
Примерно четверть: около 249.
Я отлично знаю свой блог, поэтому уверен, что у меня статей реально меньше.
Исследуем дальше.

Кажется, проиндексировано несколько странных страниц.
(Это даже не реальная страница — она выдаёт 404)
Такие страницы следует удалить из индекса. Сузим поиск до поддоменов и посмотрим, что получится.
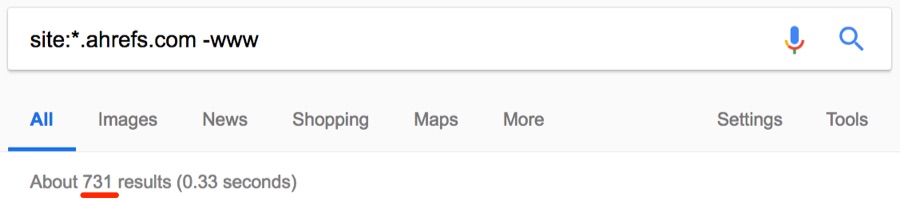
Примечание. Здесь мы используем подстановочный знак (*), чтобы найти все поддомены, принадлежащие домену, в сочетании с оператором исключения (-), чтобы исключить обычные результаты www.
Примерно 731 результат.
Вот страница на поддомене, которая определённо не должна индексироваться. Она сразу выдаёт 404.

Есть несколько других способов выявить ошибки индексации:
site:yourblog.com/category— найти страницы рубрик в блоге WordPress;site:yourblog.com inurl:tag— найти странице тегов в блоге WordPress.
2. Поиск незащищённых страниц (не https)
HTTPS в наше время стал обязательным требованием, особенно для сайтов электронной коммерции. Но вы знали, что с помощью оператора site: можно найти незащищённые страницы? Проверим на примере asos.com.
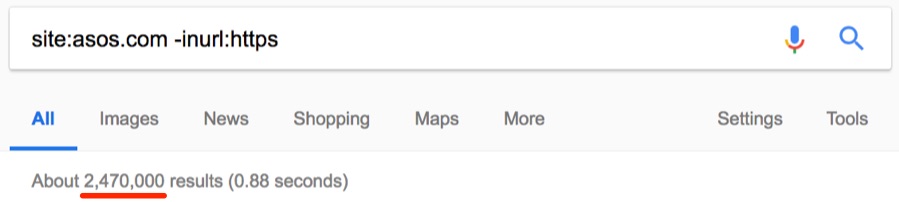
О боже, около 2,47 млн незащищённых страниц.
Похоже, что Asos вообще не используют SSL — невероятно для такого большого сайта.

Примечание. Клиентам Asos волноваться не стоит — страницы оформления заказа безопасны.
Но вот ещё одна вещь: Asos доступен в версиях https и http.
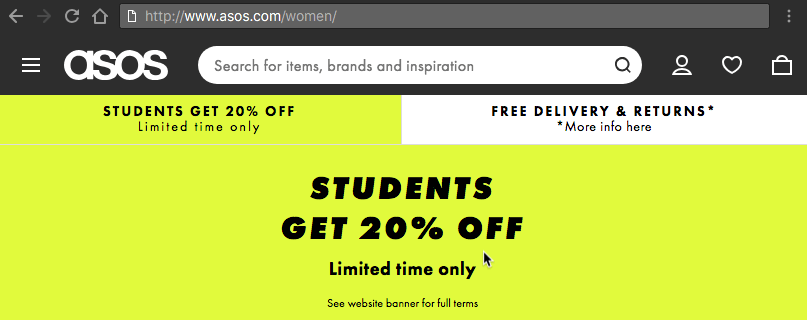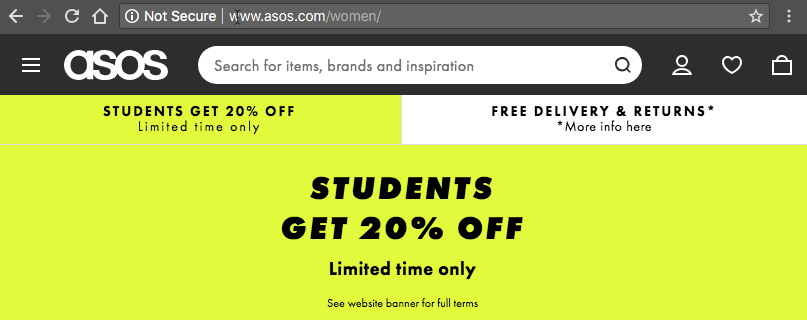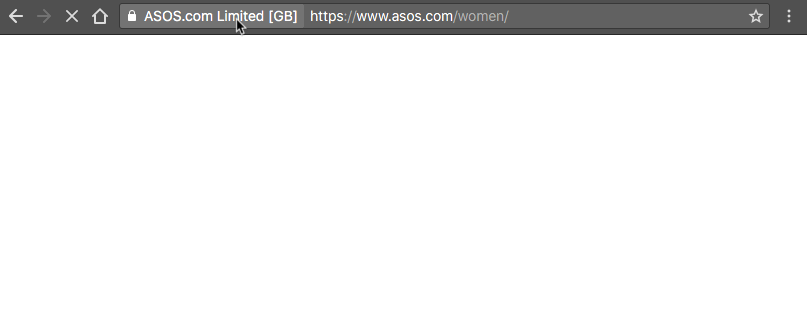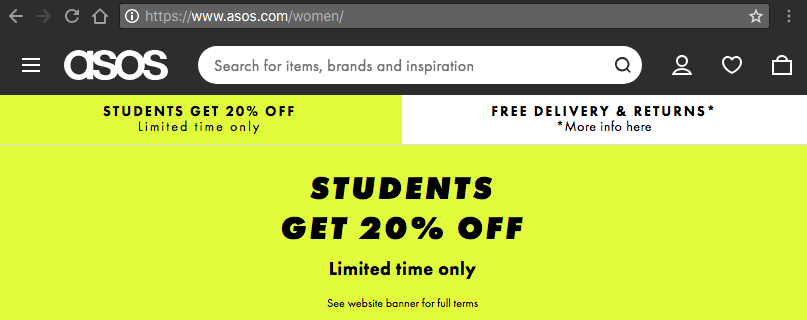
И мы узнали это с помощью простого оператора site:!
Примечание. Иногда страницы индексируются без https, но после перехода по ссылке происходит редирект на версию https.
3. Поиск дубликатов контента
Дубликаты — это плохо. Вот пара джинсов Abercrombie & Fitch на сайте Asos со стандартным описанием:

Стандартные описания сторонних брендов часто дублируются на других сайтах. Но интересно, сколько раз текст встречается на asos.com.
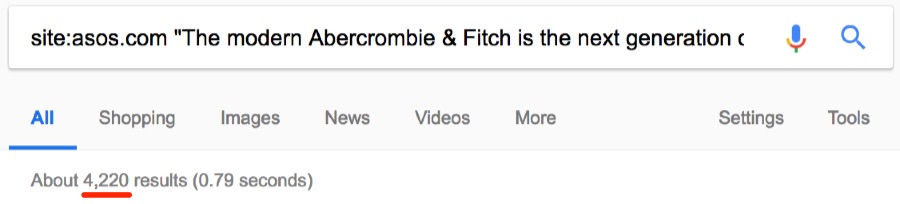
Примерно 4200 раз.
Теперь интересно, является ли текст уникальным для Asos. Проверим.

Нет, он не уникален. Есть 15 других сайтов с точно таким же текстом, то есть дублированным контентом. Иногда дубли присутствуют на страницах с похожими товарами. Например, аналогичные продукты или тот же товар в упаковках с разным количеством. Вот пример на сайте Asos:
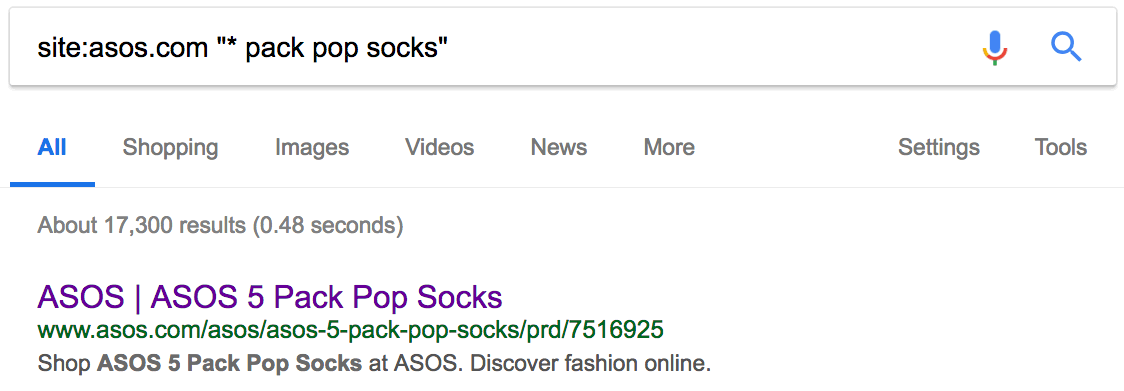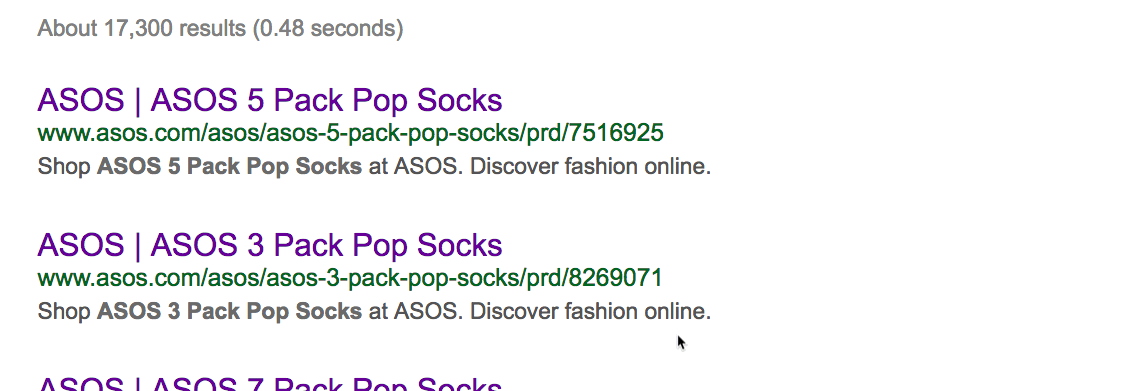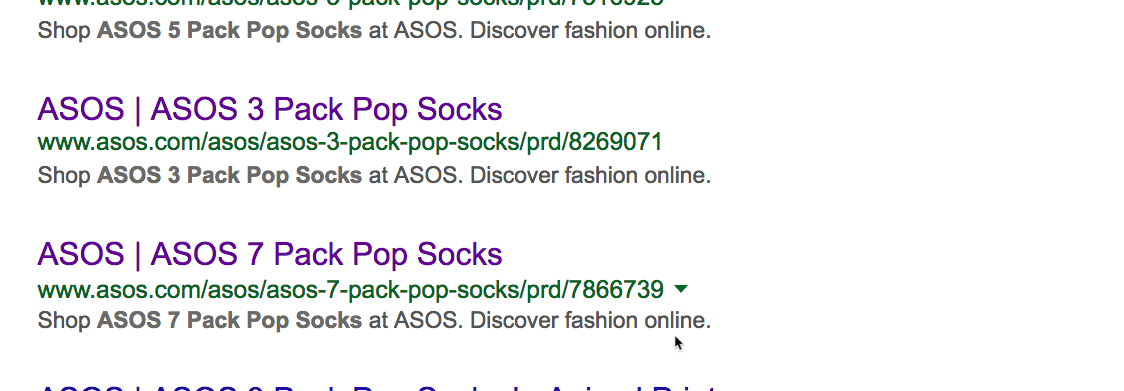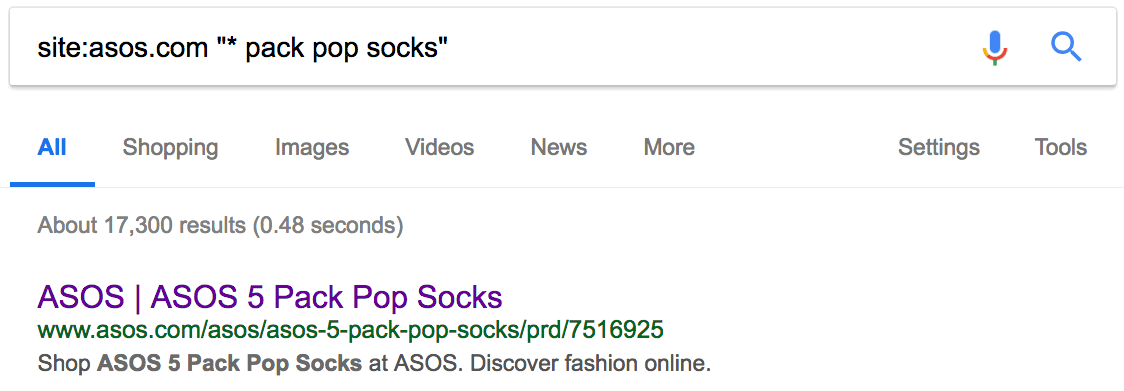
Как видим, за исключением количества, страницы одинаковые. Но дубликаты встречаются не только на сайтах электронной коммерции. Если у вас есть блог, то люди могут красть и публиковать ваш контент без надлежащей ссылки. Посмотрим, может кто-то украл и опубликовал наш список советов по SEO.
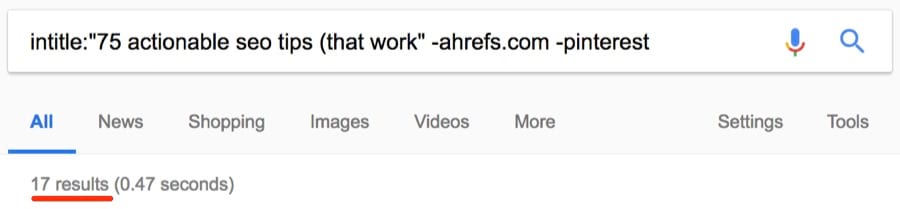
Около 17 результатов.
Примечание. Как видите, я исключил ahrefs.com из результатов с помощью оператора исключения (-), а также исключил слово [pinterest], потому что по запросу выдаётся много результатов с сайта Pinterest, которые не имеют отношения к нашей задаче. Можно было исключить только pinterest.com (-pinterest.com), но у него много доменов, так что это не особо поможет. Исключение слова [pinterest] оказалось лучшим способом очистки результатов.
Большинство страниц, наверное, созданы в результате синдикации. Всё-таки стоит проверить, что они ссылаются на вас.
4. Поиск нежелательных файлов и страниц на своём сайте (о которых вы могли забыть)
Трудно уследить за всем на большом сайте, поэтому легко забыть о каких-то старых загруженных файлах: PDF, документы Word, презентации PowerPoint, текстовые файлы и т. д. Оператор filetype: поможет их найти.
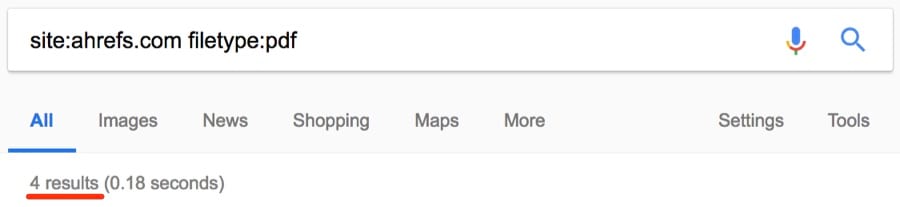
Примечание. Помните, что аналогичная функциональность у оператора ext:.
Вот одна находка:

Никогда раньше не видел этой статьи, а вы? Комбинируя несколько операторов, можно одновременно выводить результаты для разных типов файлов.

Примечание. Этот оператор также поддерживает .asp, .php, .html и др.
Важно удалить или деиндексировать их, чтобы они не попадались людям на глаза.
5. Поиск возможностей для гостевой публикации
Возможность публикации на других сайтах… есть много способов найти такие ресурсы:

Но вы уже знали об этом методе, верно!? 
Примечание. Этот метод находит страницы с предложением написать статью. Такие страницы создают многие сайты, которые ищут авторов.
Так что применим более творческий подход. Во-первых: не ограничивайтесь одной фразой. Также можете использовать такие поисковые запросы:
[become a contributor][contribute to][write for me](да, есть отдельные блогеры, которые тоже приглашают авторов!)[guest post guidelines]inurl:guest-postinurl:guest-contributor-guidelines- и др.
Многие забывают один классный совет: можно искать всё сразу.

Примечание. На этот раз я использую оператор (“|”) вместо AND, он делает то же самое.
Можно даже искать эти фразу с учётом тематики.

Нужна конкретная страна? Просто добавьте оператор site:.tld .

Вот ещё один метод: если знаете конкретного блоггера в своей нише, попробуйте такой способ:
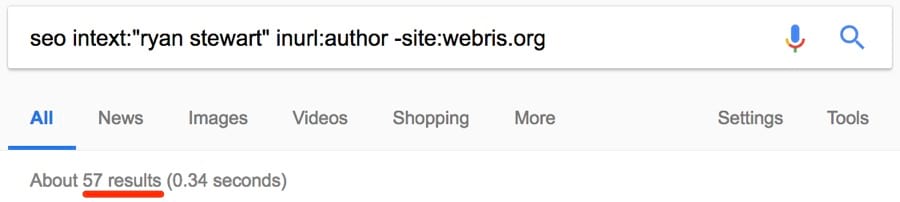
Так найдутся все сайты, где публиковался этот автор.
Примечание. Не забудьте исключить его сайт из выдачи, чтобы сохранить чистоту результатов!
Наконец, если вам интересно, принимает ли конкретный сайт статьи от сторонних авторов, попробуйте это:
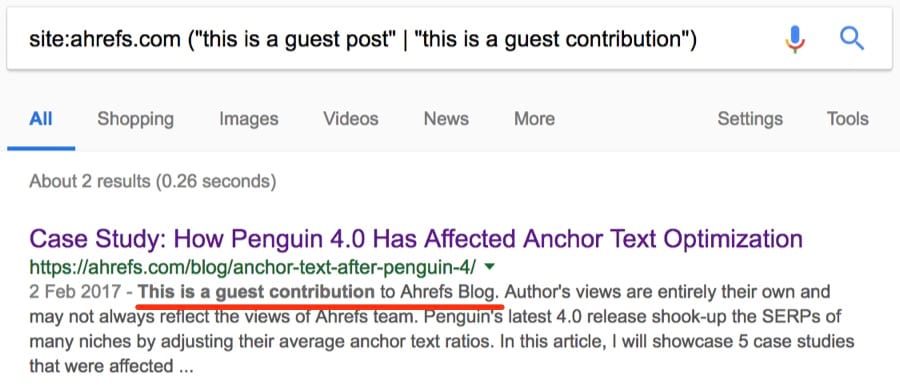
Примечание. В список можно добавить много других фраз.
6. Поиск страниц со списками ресурсов
Такие страницы собирают списки ресурсов по определённой теме.

Всё это — ссылки на сторонние ресурсы. По иронии, учитывая тему этой конкретной страницы — многие ссылки там не работают.
Так что если у вас есть крутой ресурс, можно найти соответствующие «ресурсные» страницы и подать заявку на добавление туда своей ссылки.
Вот один из способов найти их:

Но это может вернуть много мусора. Сужаем поиск:

Ещё больше сужаем:

Примечание. Здесь allintitle: гарантирует, что тег title содержит слова [fitness] и [resources], а также число от 5 до 15.
Примечание об операторе #..#
Я знаю, о чем вы думаете: почему бы вместо этой длинной последовательности чисел не использовать оператор
#..#. Хорошая мысль, попробуем:
Странно, да? Дело в том, что этот оператор плохо сочетается с большинством других операторов. Да и вообще не всегда работает. Поэтому я рекомендую использовать последовательность чисел с оператором OR или вертикальной чертой (“|”). Это немного трудоёмкая процедура, зато работает.
7. Поиск сайтов с примерами инфографики… так что можно предложить свою
У инфографики плохая репутация. Скорее всего, потому что многие создают некачественную, дешёвую инфографику, которая не служит никакой реальной цели… кроме как «привлекать ссылки». Но не вся инфографика такая.
Кому вы можете предложить свою инфографику? Любым известным сайтам в своей нише?
НЕТ.
Надо обратиться к сайтам, которые действительно захотят её опубликовать. Лучший способ — найти сайты, где уже публиковались такие материалы:

Примечание. Есть смысл поискать в пределах диапазона недавних дат, например, за последние три месяца. Если сайт публиковал инфографику два года назад, это не означает, что они таким занимаются до сих пор. Но если сайт публиковал её в последние несколько месяцев, то есть вероятность, что примет и вашу. Поскольку оператор daterange: больше не работает, придётся указать диапазон дат во встроенном фильтре поиска Google.
Но опять же, придётся отфильтровать мусор.
Вот быстрый трюк:
- использовать вышеуказанный запрос для поиска качественной инфографики по заданной теме;
- найти, где она размещалась.
Пример:

Нашлось два результата за последние три месяца. И более 450 результатов за всё время. Проведите такой поиск для нескольких конкретных иллюстраций — и получите хороший список.
8. Поиск сайтов для размещения своих ссылок… и проверки, насколько они подходят
Предположим, вы нашли сайт, где хотите разместить ссылку. Вручную проверили актуальность… всё выглядит хорошо. Вот как найти список похожих сайтов или страниц:

Получаем около 49 результатов, все похожие.
Примечание. В приведённом примере мы ищем сайты, похожие именно на блог Ahrefs, а не на весь сайт Ahrefs.
Вот один из результатов: yoast.com/seo-blog.
Я хорошо знаю Yoast, поэтому уверен, что это подходящий сайт для наших целей. Но предположим, что я ничего не знаю об этом сайте, Как проверить, что он подходит? Вот как:
- запустить
site:domain.comнайдите и записать количество результатов; - запустить
site:domain.com [niche], опять записать количество результатов; - делим второе число на первое: если оно выше 0,5, это подходящий вариант; если выше 0.75, то это просто супер.
Попробуем на примере yoast.com. Вот количество результатов для простого поиска:
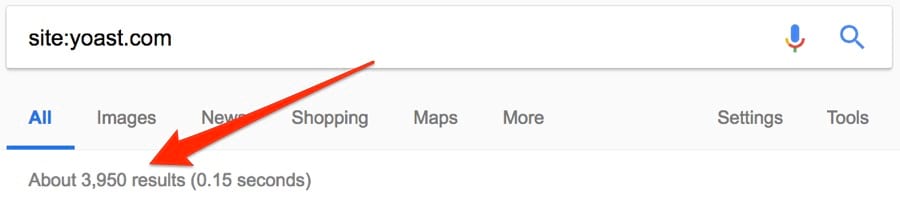
И site: [niche]:

Итак, 3950 / 3330 = ~0,84. Отличный результат.
Теперь проверим на сайтах, которые точно нам не подходят.
Количество результатов для поиска site:greatist.com: ~18,000
Количество результатов для поиска site:greatist.com SEO: ~7
(18000 / 7 = ~0,0004 = совершенно нерелевантный сайт)
Важно! Это отличный способ быстро устранить крайне нерелевантные результаты, но он не всегда надёжно работает. Конечно же, это не замена ручной проверке потенциального кандидата: их всегда следует просматривать вручную, прежде чем обращаться с предложением. Иначе вы начнёте генерировать спам.
9. Поиск профилей в социальных сетях
Хотите с кем-то связаться? Попробуйте найти контактную информацию таким способом:

Примечание. Имя человека обычно легко найти, а вот контактную информацию сложно.
Четыре лучших результата:
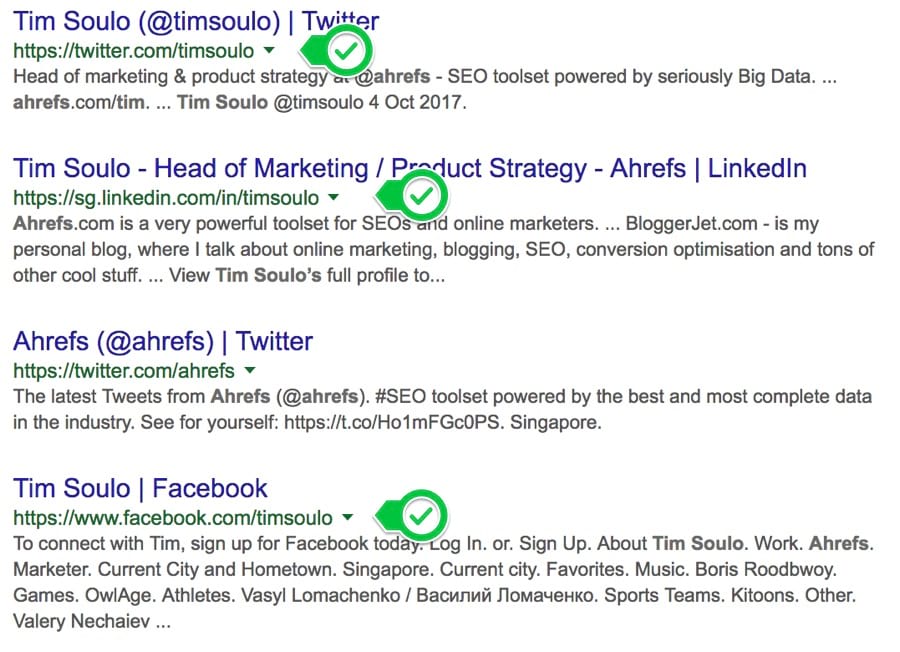
БИНГО.
Затем можете связаться с человеком напрямую через социальные медиа. Или воспользуйтесь советами 4 и 6 из этой статьи для поиска адреса электронной почты.
10. Поиск возможностей для внутренних ссылок
Внутренние ссылки очень важны. Они помогают в навигации посетителей по вашему сайту, а также полезны для SEO (при разумном использовании). Но нужно убедиться, что вы добавляете внутренние ссылки только там, где это уместно. Допустим, вы только опубликовали большой список советов по SEO. Разве не здорово добавить внутреннюю ссылку на эту статью со всех страниц, где упоминаются советы по SEO?
Определённо.
Но не так легко найти соответствующие места для добавления этих ссылок, особенно на больших сайтах. Вот быстрый трюк:

Для тех, кто ещё не освоил операторы поиска, здесь мы делаем следующее:
- Ограничиваем поиск определённым сайтом.
- Исключаем страницу/публикацию, на которую требуется создать внутренние ссылки.
- Ищем определённое слово или фразу в тексте.
Вот одна из подходящих страниц, которую я нашёл таким запросом:

Поиск занял три секунды.
11. Поиск упоминаний конкурентов для своего пиара
Вот страница, на которой упоминается наш конкурент — Moz.

Найдено с помощью такого расширенного поиска:

Но почему нет упоминания блогов Ahrefs? 
С помощью site: и intext: я вижу, что этот сайт раньше упоминал нас пару раз.
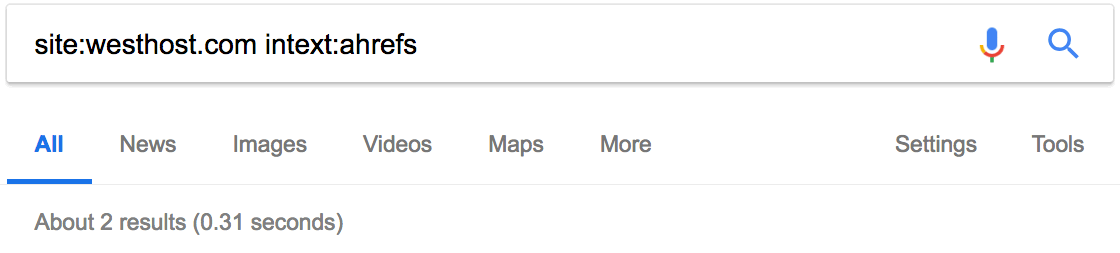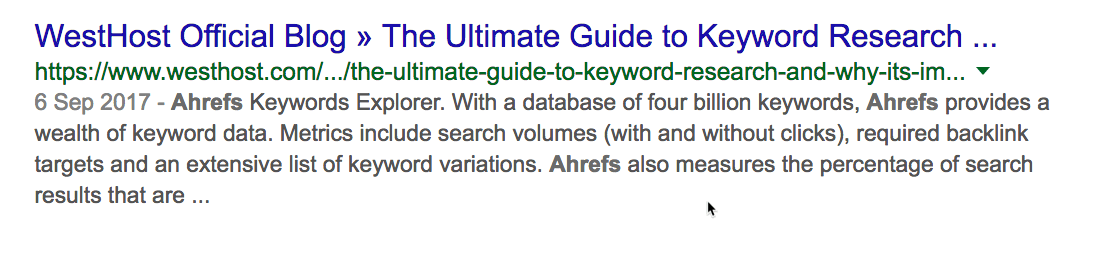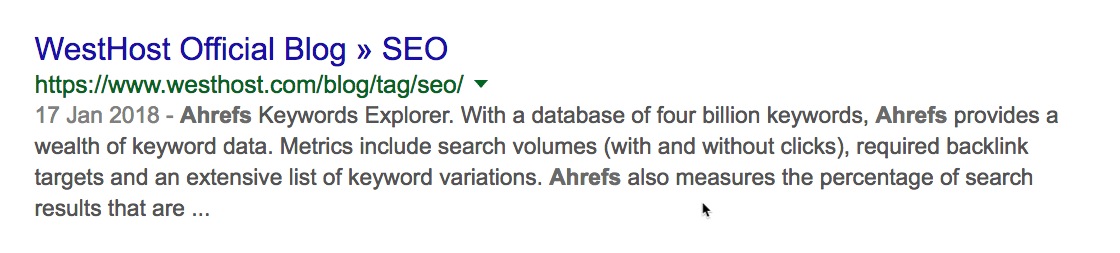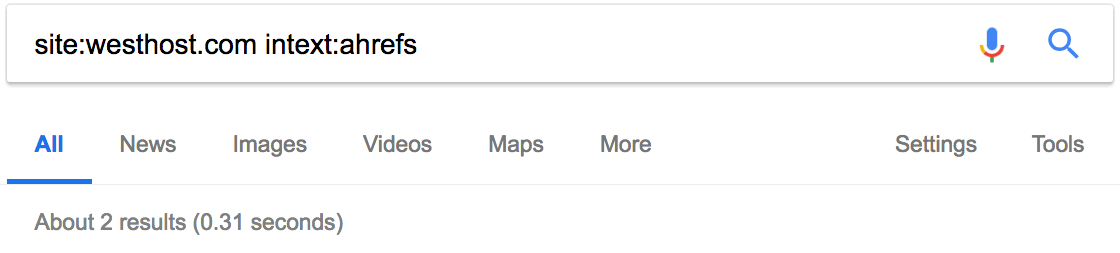
Но они не разместили никакой статьи с обзором наших инструментов, как в случае с Moz. Это даёт возможность. Свяжитесь с ними, пообщайтесь. Возможно, они напишут также про Ahrefs.
Вот ещё один классный запрос, который можно использовать для поиска отзывов о конкурентах:

Примечание. Поскольку мы используем [allintitle], а не [intitle], то получим результаты со словом [review] и названием одного из конкурентов в теге заголовка.
Можете пообщаться с этими людьми, чтобы они повторно рассмотрели ваш товар/услугу.
Вот ещё один совет. Оператор daterange: устарел, но на странице поиска можно добавить фильтр для дат, чтобы найти последние упоминания конкурентов. Просто используйте этот встроенный фильтр.
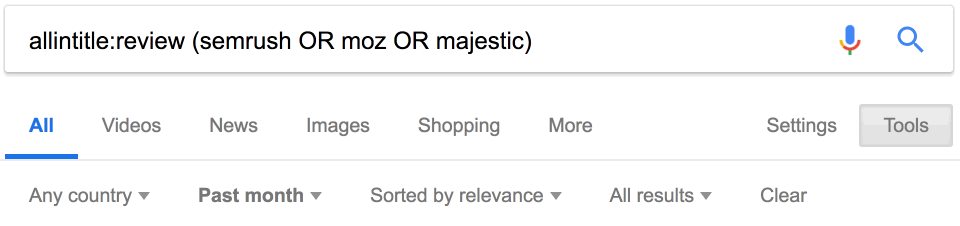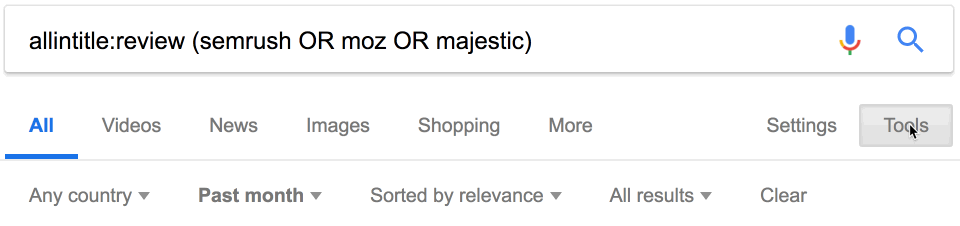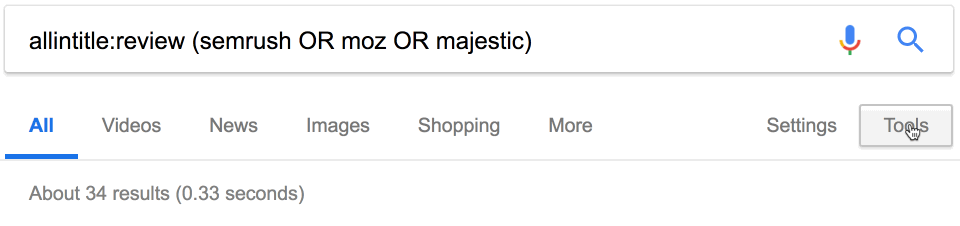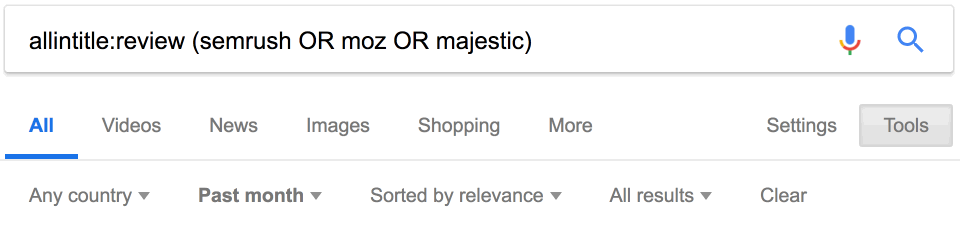
Похоже, за последний месяц опубликовано 34 отзыва о наших конкурентах.
12. Поиск возможностей для спонсорских постов
Спонсорские посты — это платные статьи, продвигающие ваш бренд, продукт или услугу. Такой вариант не предназначен для размещения ссылок.
В руководстве Google явно запрещено:
Покупка или продажа ссылок, которые передают PageRank. Это включает в себя передачу денег на ссылки или сообщения, содержащие ссылки; передачу товаров или услуг в обмен на ссылки; отправку кому-то «бесплатного» продукта в обмен на то, что они напишут о нём и поставят ссылку.
Вот почему вы всегда должны следить за ссылками в спонсорских статьях.
Но истинная ценность этих статей всё равно не сводится к ссылкам. Это пиар, то есть демонстрация свого бренда перед нужными людьми. Вот один из способов найти возможности для спонсорских публикаций с помощью операторов поиска Google:
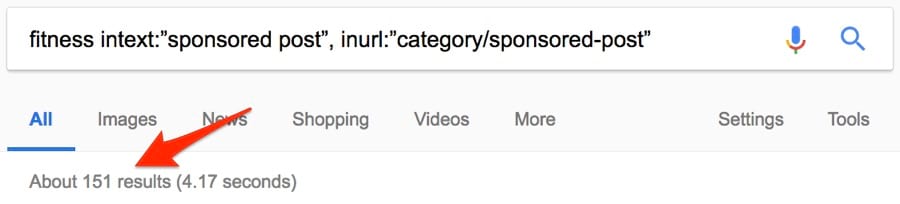
Примерно 151 результат. Неплохо.
Несколько других комбинаций операторов:
[niche] intext:”this is a sponsored post by”[niche] intext:”this post was sponsored by”[niche] intitle:”sponsored post”[niche] intitle:”sponsored post archives” inurl:”category/sponsored-post”“sponsored” AROUND(3) “post”
Примечание. Приведённые примеры — именно примеры. Почти наверняка эти сообщения можно найти по другим фразам. Не бойтесь проверять различные идеи.
13. Поиск тем Q+A, связанных с вашим контентом
Форумы, а также сайты с вопросами и ответами отлично подходят для продвижения контента.
Примечание. Продвижение != спам. Не заходите на эти сайты только для того, чтобы добавить свои ссылки. Публикуйте ценную информацию, а по ходу дела иногда — уместные ссылки.
На ум приходит Quora, которая разрешает публиковать в своих ответах релевантные ссылки.
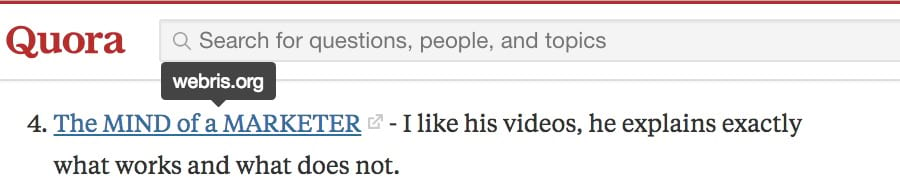
Ответ в Quora со ссылкой на SEO-блог
Правда, этим ссылкам проставляется тег nofollow. Но мы не пытаемся здесь строить базу ссылок, это пиар! Вот один из способов найти подходящие темы:

Это можно сделать на любом форуме или сайте с вопросами и ответами. Такой же поиск для Warrior Forum:

Я знаю, что там есть раздел о поисковой оптимизации. У каждой темы в этом разделе в URL указано .com/search‐engine‐optimization/. Так что я могу ещё больше уточнить запрос с помощью оператора inurl:.

Такие операторы даже лучше находят темы на форуме, чем встроенный поиск на сайте.
14. Проверка, как часто конкуренты публикуют новый контент
Большинство блогов находятся в подпапке или поддомене, например:
ahrefs.com/blogblog.hubspot.comblog.kissmetrics.com
Это позволяет легко проверить, насколько регулярно конкуренты публикуют новый контент. Проверим на одном из наших конкурентов: SEMrush.
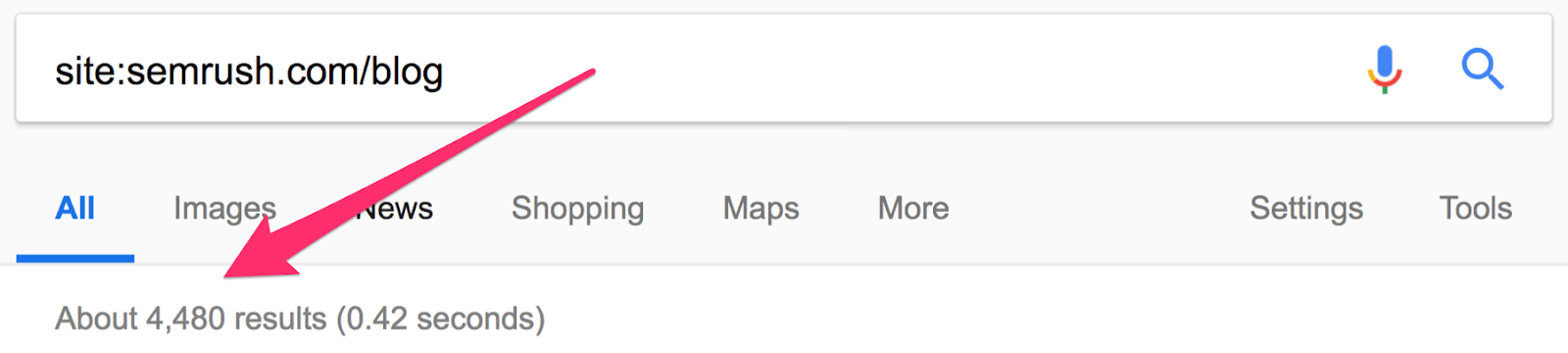
Похоже, у них уже около 4500 статей. Но это не совсем так. Сюда входят версии блога на разных языках, которые находятся на поддоменах.
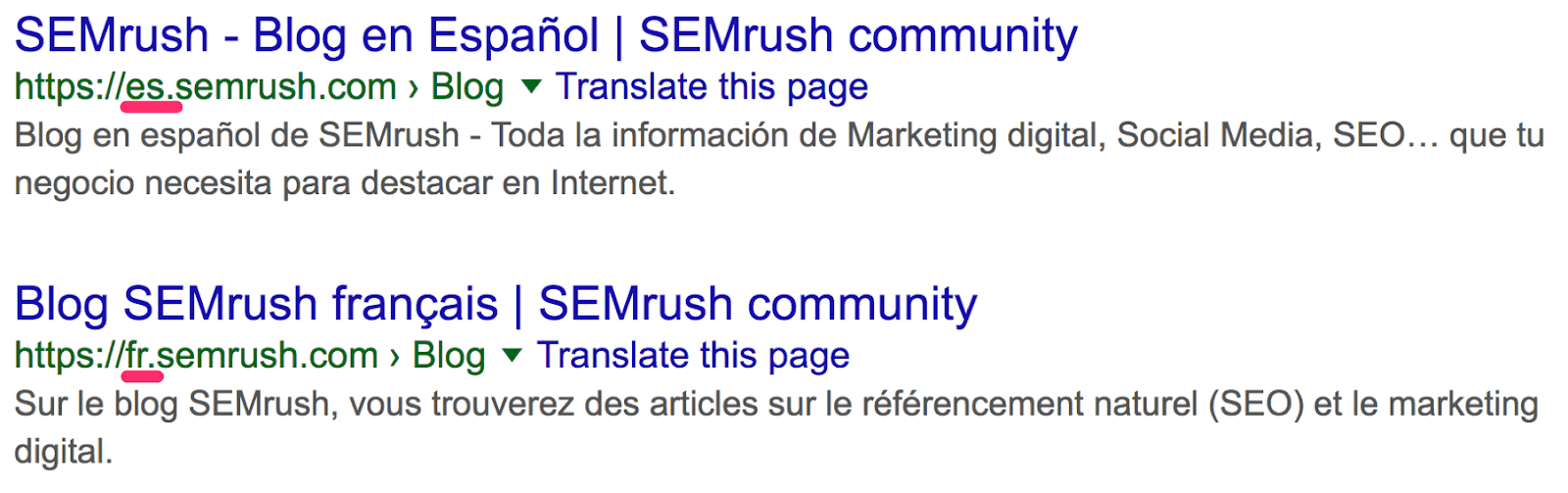
Отфильтруем их.
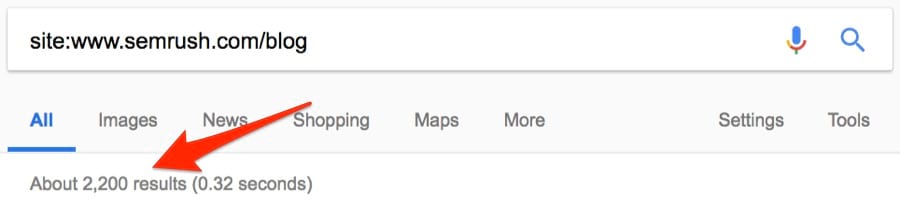
Это больше похоже на правду: около 2200 постов. Посмотрим, сколько опубликовано за последний месяц. Поскольку оператор daterange: больше не работает, используем встроенный фильтр Google.

Примечание. Можно указать любой диапазон дат. Просто выберите “Custom”.
Около 29 постов. Интересно. Это примерно вчетверо больше, чем у нас. И у них в целом примерно в 15 раз больше постов, чем у нас. Но мы всё равно получаем больше трафика… с двукратным превосходством по ценности.

Качество важнее количества, верно!?
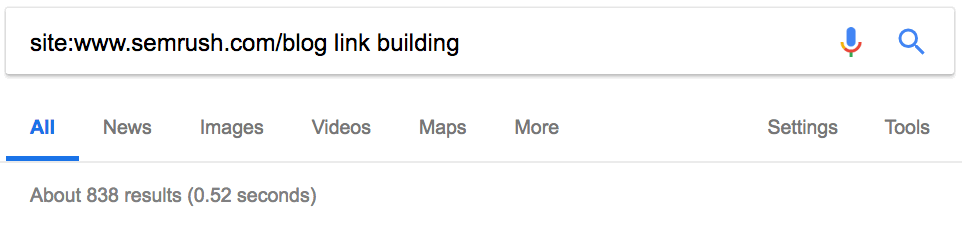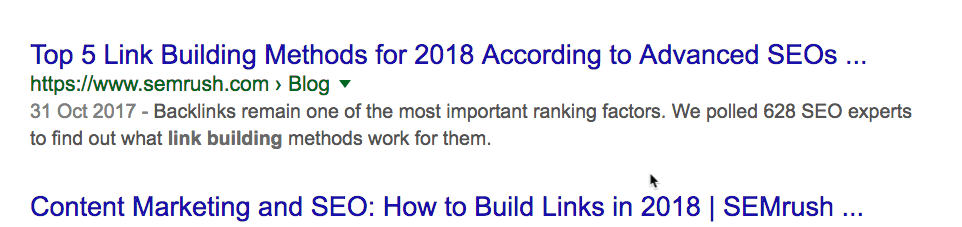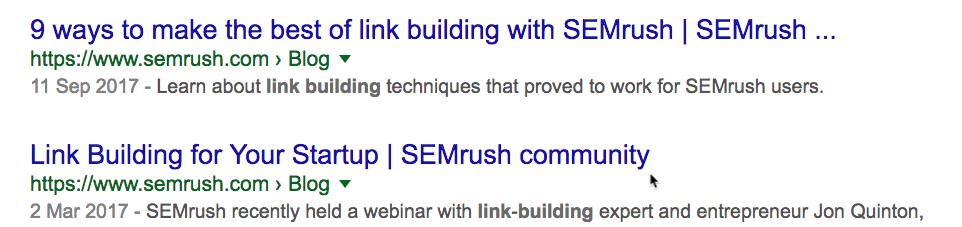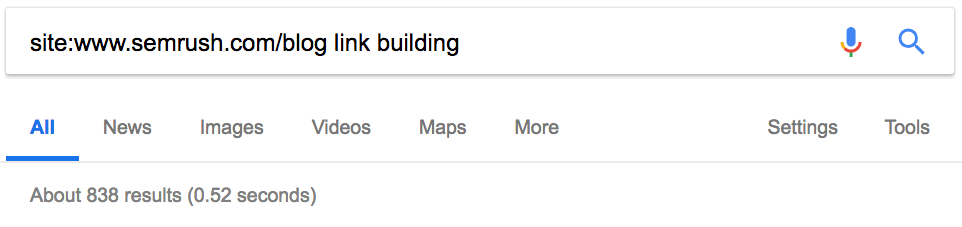
Оператор site: в сочетании с поисковым запросом покажет, сколько статей конкурент опубликовал по определённой теме.
15. Поиск сайтов со ссылками на конкурентов
На конкурентов ставят ссылки? Может быть, мы тоже можем их получить? Google прекратил поддержку оператора link в 2017 году, но он по-прежнему возвращает некоторые результаты.
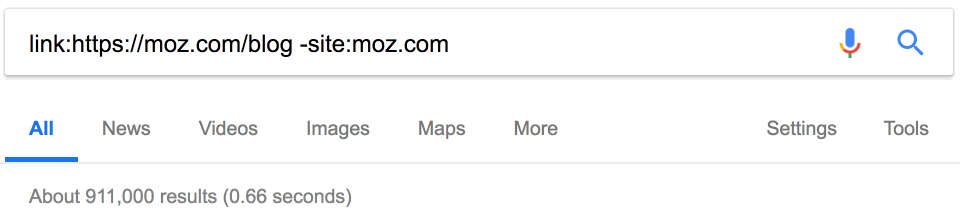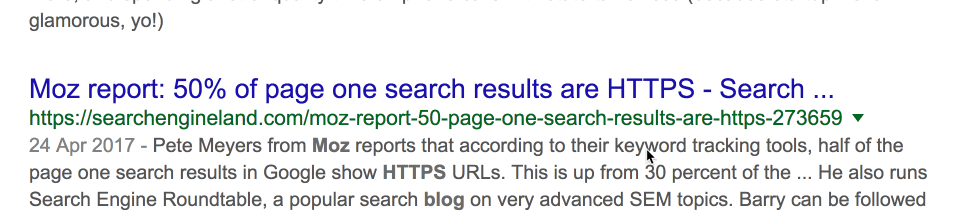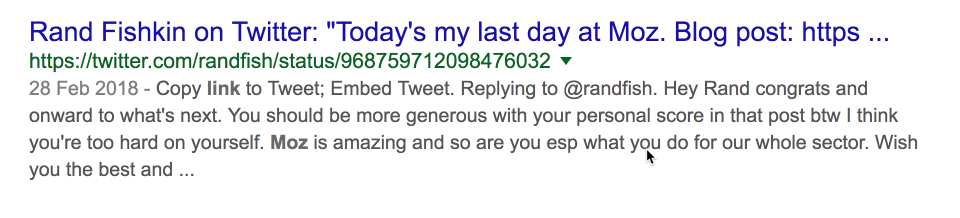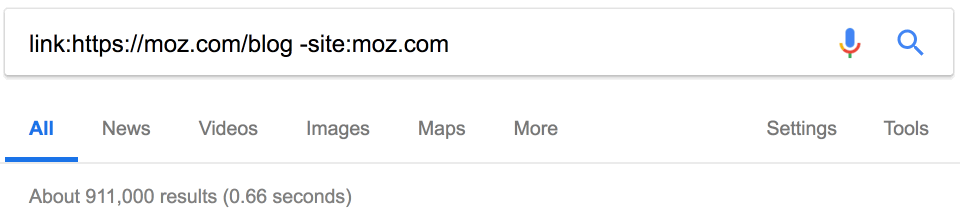
Примечание. Обязательно исключайте сайт конкурента, чтобы отфильтровать внутренние ссылки.
Около 900 тыс. ссылок. Здесь тоже пригодится фильтр по дате. Например, за последний месяц на Moz поставили 18 тыс. новых ссылок.
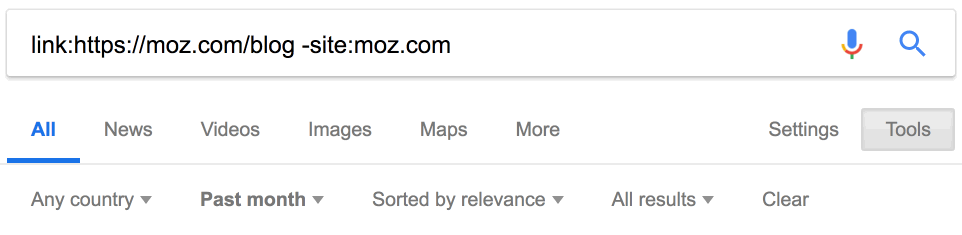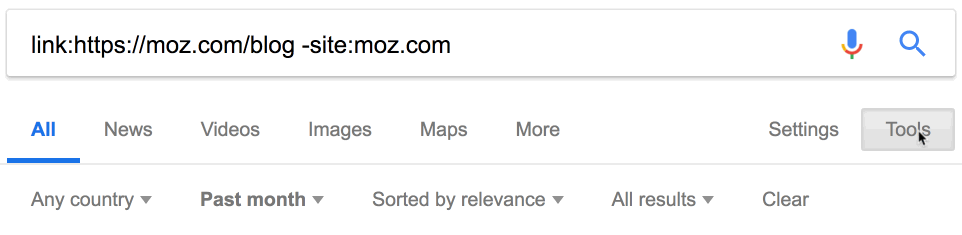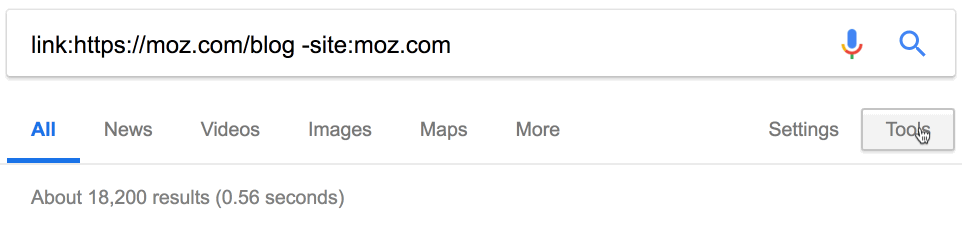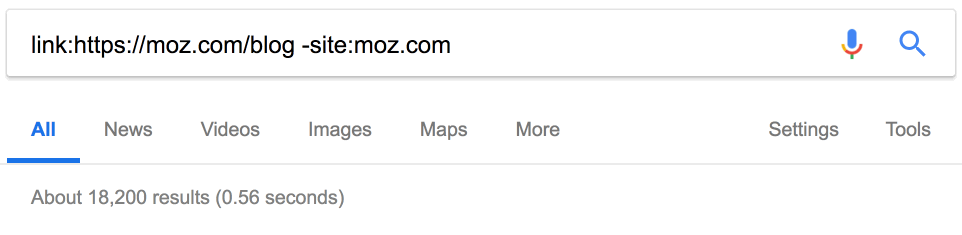
Очень полезная информация. Но эти данные тоже могут быть неточными.
Заключение
Операторы расширенного поиска Google безумно мощные. Просто надо знать, как их использовать. Но я должен признать, что некоторые полезнее других, особенно в поисковой оптимизации. Я практически ежедневно использую site:, intitle:, intext: и inurl:, но очень редко прибегаю к помощи AROUND(X), allintitle: и многих других более мутных операторов.
Я бы ещё добавил, что многие операторы бесполезны, если не применяются в сочетании с другим оператором… или двумя-тремя. Так что поиграйте с ними и напишите, как ещё их можно использовать. Я с радостью добавлю в статью любые полезные комбинации, какие вы найдёте.
Is it possible to find all the pages and links on ANY given website? I’d like to enter a URL and produce a directory tree of all links from that site?
I’ve looked at HTTrack but that downloads the whole site and I simply need the directory tree.
![]()
Davidmh
3,77718 silver badges35 bronze badges
asked Sep 17, 2009 at 14:43
![]()
Jonathan LyonJonathan Lyon
3,8027 gold badges39 silver badges52 bronze badges
1
Check out linkchecker—it will crawl the site (while obeying robots.txt) and generate a report. From there, you can script up a solution for creating the directory tree.
![]()
answered Sep 17, 2009 at 14:51
![]()
10
If you have the developer console (JavaScript) in your browser, you can type this code in:
urls = document.querySelectorAll('a'); for (url in urls) console.log(urls[url].href);
Shortened:
n=$$('a');for(u in n)console.log(n[u].href)
answered Jan 5, 2015 at 22:03
![]()
ElectroBitElectroBit
1,15211 silver badges16 bronze badges
7
Another alternative might be
Array.from(document.querySelectorAll("a")).map(x => x.href)
With your $$( its even shorter
Array.from($$("a")).map(x => x.href)
answered Mar 1, 2020 at 19:00
![]()
SebSeb
88812 silver badges20 bronze badges
1
If this is a programming question, then I would suggest you write your own regular expression to parse all the retrieved contents. Target tags are IMG and A for standard HTML. For JAVA,
final String openingTags = "(<a [^>]*href=['"]?|<img[^> ]* src=['"]?)";
this along with Pattern and Matcher classes should detect the beginning of the tags. Add LINK tag if you also want CSS.
However, it is not as easy as you may have intially thought. Many web pages are not well-formed. Extracting all the links programmatically that human being can «recognize» is really difficult if you need to take into account all the irregular expressions.
Good luck!
answered Sep 17, 2009 at 15:17
![]()
mizubashomizubasho
911 silver badge7 bronze badges
1
function getalllinks($url) {
$links = array();
if ($fp = fopen($url, 'r')) {
$content = '';
while ($line = fread($fp, 1024)) {
$content. = $line;
}
}
$textLen = strlen($content);
if ($textLen > 10) {
$startPos = 0;
$valid = true;
while ($valid) {
$spos = strpos($content, '<a ', $startPos);
if ($spos < $startPos) $valid = false;
$spos = strpos($content, 'href', $spos);
$spos = strpos($content, '"', $spos) + 1;
$epos = strpos($content, '"', $spos);
$startPos = $epos;
$link = substr($content, $spos, $epos - $spos);
if (strpos($link, 'http://') !== false) $links[] = $link;
}
}
return $links;
}
try this code….
![]()
Morgoth
4,8658 gold badges39 silver badges66 bronze badges
answered Dec 3, 2014 at 7:42
![]()
3
Внешние ссылки – один из важнейших факторов ранжирования сайта в поисковых системах. Поэтому, когда речь идёт о SEO, линкбилдингу следует уделять особое внимание.
Так как не все бэклинки одинаково полезны, — а некоторые даже вредны, — нужно следить за качеством ссылочного профиля, чтобы тот действительно помогал сайту продвигаться в поиске.
В этом материале 10 бесплатных сервисов, которые помогут проверить внешние ссылки и получить общее представление о ссылочном профиле ресурса.
Больше о SEO и других важных направлениях диджитал-маркетинга — PPC, SMM, веб-аналитике, арбитраже трафика, созданию сайтов — в обучающем центре CyberMarketing. Статьи, вебинары, видеокурсы, интенсивы от экспертов Click.ru, Promopult и др.
Google Search Console
В консоли для вебмастера Google можно посмотреть все бэклинки на ваш сайт. Для этого в левом меню нажмите на соответствующий пункт.
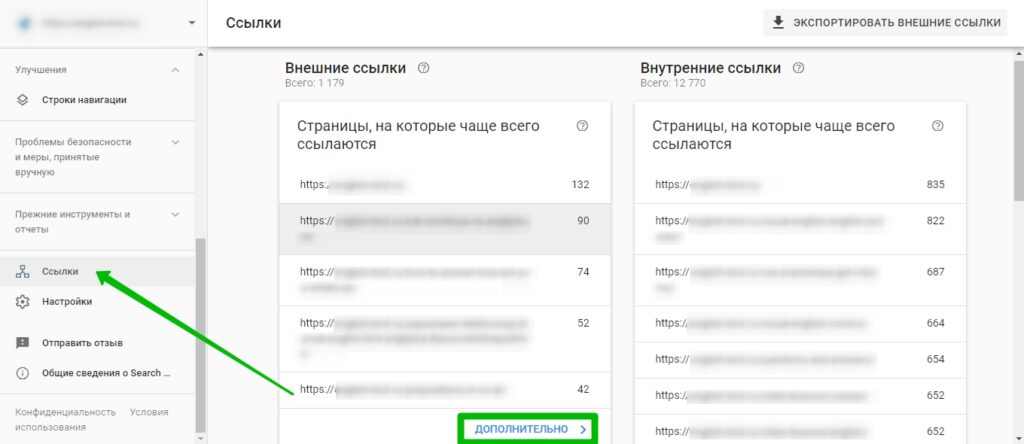 Кликните на «Дополнительно», чтобы посмотреть все страницы с внешними ссылками
Кликните на «Дополнительно», чтобы посмотреть все страницы с внешними ссылками
Если нажать на конкретный URL, появится список всех ссылающихся на эту страницу доменов. Щёлкните на домен, чтобы посмотреть все ссылки с этого сайта на вашу страницу.
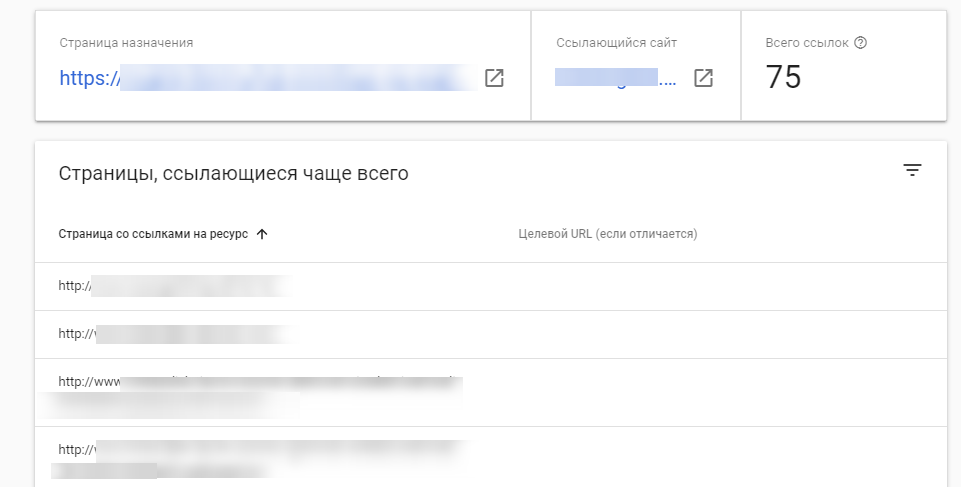 Здесь отображаются все ссылки с конкретного домена, которые ведут на выбранную страницу
Здесь отображаются все ссылки с конкретного домена, которые ведут на выбранную страницу
Сервис показывает как внутренние, так и внешние ссылки на сайт. Можно смотреть анкоры и ссылающиеся домены. Если щёлкнуть по заголовку колонки «Входящие ссылки», элементы списка будут отсортированы по возрастанию или убыванию количества ссылок.
В правом углу есть фильтр, с помощью которого также можно сортировать элементы списка по конкретным критериям.
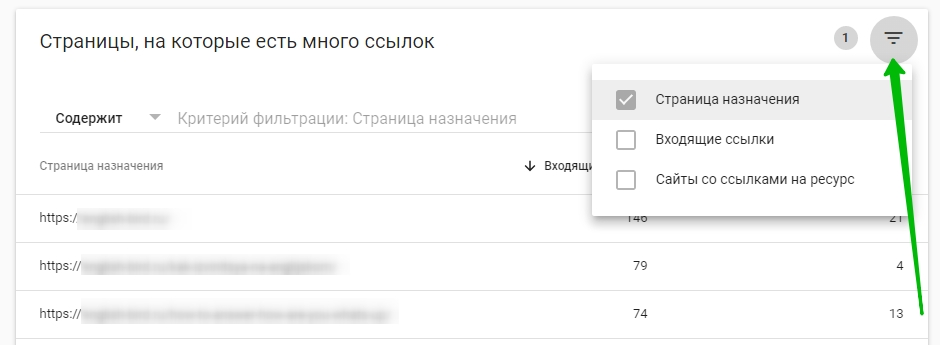 Можно, к примеру, отфильтровать страницы по количеству входящих ссылок – чтобы показывались только те, у которых это значение больше, меньше или равно заданному
Можно, к примеру, отфильтровать страницы по количеству входящих ссылок – чтобы показывались только те, у которых это значение больше, меньше или равно заданному
«Яндекс.Вебмастер»
«Яндекс.Вебмастер» предлагает владельцам сайтов похожий инструмент, который можно найти в меню «Ссылки». Но отчёт здесь выглядит по-другому.
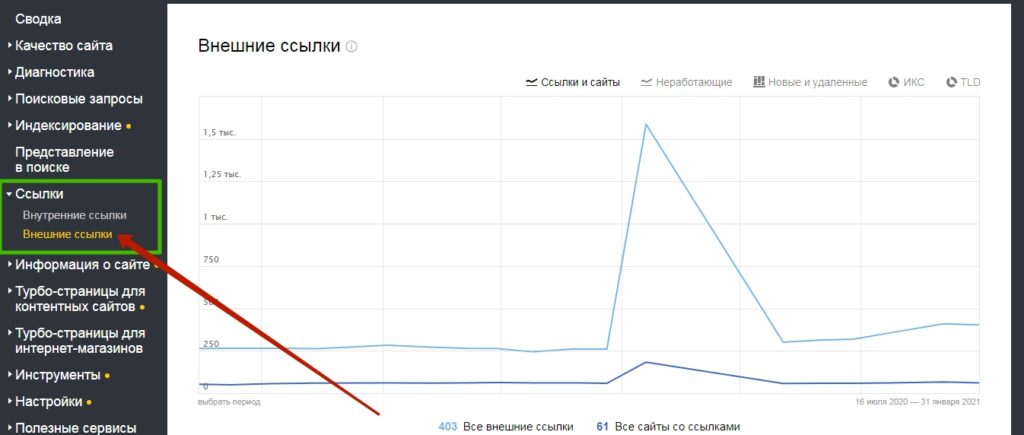 Помимо внешних, здесь тоже можно посмотреть внутренние ссылки
Помимо внешних, здесь тоже можно посмотреть внутренние ссылки
В верхней части отчёта показан график, по которому можно проследить, как менялась ссылочная масса сайта в течение года. Ниже – список всех ссылок, начинающийся с самых новых. В отдельной колонке показан ИКС каждого сайта, чтобы можно было примерно оценить качество донора.
Ссылки можно группировать по сайтам. Для этого поставьте галочку напротив соответствующего пункта. После этого в списке будут показаны все домены, ссылающиеся на ваш сайт.
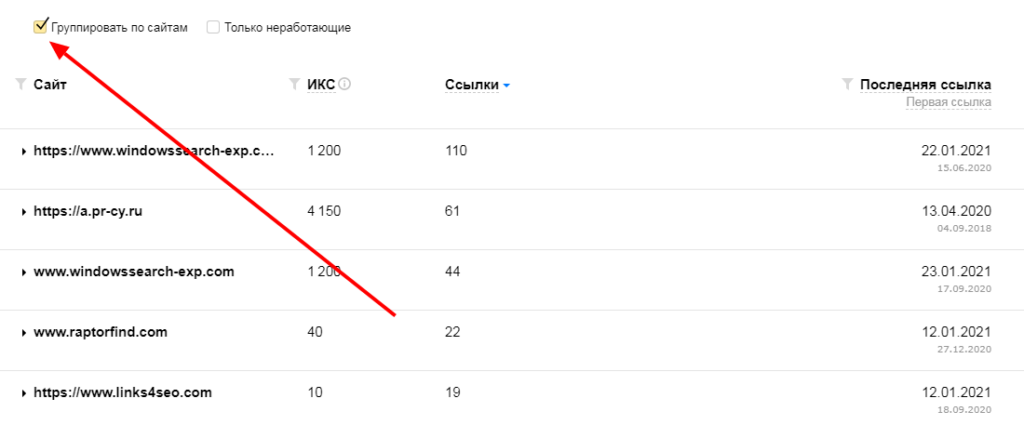 Чтобы список начинался с доменов, которые ссылаются чаще всего, нажмите на колонку «Ссылки» – результаты отсортируются в порядке убывания количества ссылок
Чтобы список начинался с доменов, которые ссылаются чаще всего, нажмите на колонку «Ссылки» – результаты отсортируются в порядке убывания количества ссылок
Также в панели от «Яндекса» есть возможность фильтровать данные списка по разным параметрам. Для это нужно нажать на соответствующий значок рядом с названием колонки и ввести нужные значения.
 Такой значок есть у каждой колонки
Такой значок есть у каждой колонки
Как и Google Search Console, «Яндекс.Вебмастер» не подходит для анализа бэклинков конкурентов, но для проверки ссылок на собственный сайт это, пожалуй, лучший бесплатный инструмент. Помимо анализа, он позволяет также экспортировать данные в электронные таблицы. Кроме того, сервисы поисковых систем выигрывают у сторонних инструментов тем, что предоставляют актуальную информацию.
Читайте также: 11 способов проверки битых ссылок на сайте
LinkPad
Сервис позволяет получить подробную информацию о внешних ссылках, но просмотр и экспорт данных в бесплатной версии ограничен – доступно лишь 100 строк (чего вполне достаточно для небольших сайтов). Для начала работы необходимо зарегистрироваться.
 После ввода адреса сайта и клика по кнопке «Найти ссылки» появится форма для регистрации
После ввода адреса сайта и клика по кнопке «Найти ссылки» появится форма для регистрации
На графике сверху можно проследить динамику основных показателей: внешние ссылки, количество ссылающихся сайтов/IP/подсетей и рейтинг ресурса в LinkPad. Большой плюс – возможность выбрать временной период (от 1 до 5 лет).
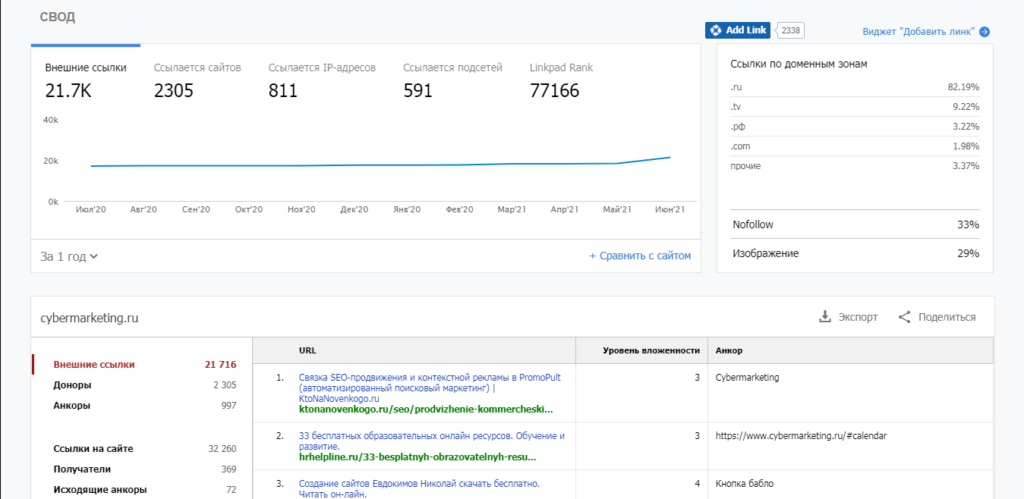 Под графиком есть кнопка «Сравнить с сайтом», которую можно использовать для анализа динамики бэклинков ресурса в сравнении с конкурентами
Под графиком есть кнопка «Сравнить с сайтом», которую можно использовать для анализа динамики бэклинков ресурса в сравнении с конкурентами
LinkPad показывает долю nofollow-ссылок в общей массе, а также процент бэклинков в виде изображений.
Nofollow-ссылки получили своё название из-за атрибута rel=»nofollow», который указывает роботам не переходить по ссылке. Значит, странице, на которую ведет такая ссылка, не передается так называемый ссылочный вес.
Как-либо отсортировать ссылки в списке не получится. Но можно открыть вкладку «Доноры» и посмотреть все ссылающиеся на сайт домены (во второй колонке показано, на какие страницы ссылается каждый из них).
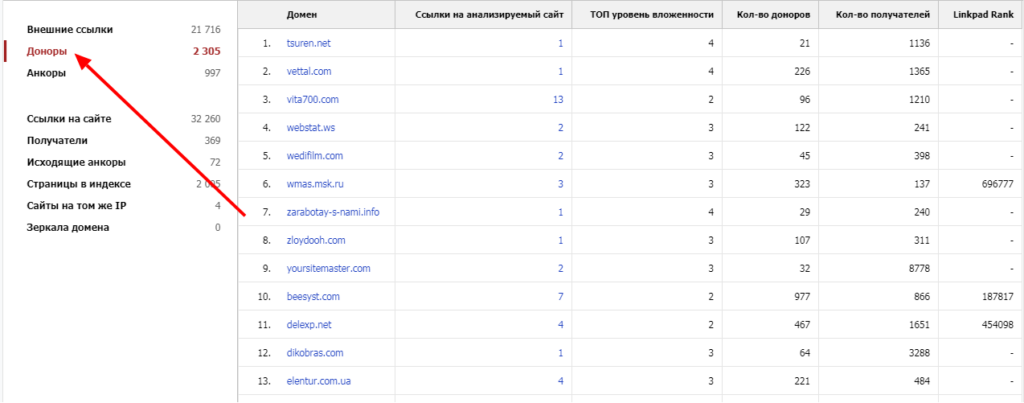 Также можно узнать анкоры входящих ссылок (соответствующая вкладка ниже)
Также можно узнать анкоры входящих ссылок (соответствующая вкладка ниже)
Megaindex
Megaindex предлагает большое количество SEO-инструментов, один из которых позволяет проверить бэклинки. Чтобы воспользоваться сервисом, нужно зарегистрироваться. После создания учётной записи перейдите в приложение «Внешние ссылки», введите имя домена и нажмите «Показать».
 По ссылке «Подробнее» можно почитать инструкцию и посмотреть обзор сервиса
По ссылке «Подробнее» можно почитать инструкцию и посмотреть обзор сервиса
Бесплатная версия приложения очень ограничена, но здесь можно получить общее представление о ссылочном профиле сайта: суммарное количество бэклинков, ссылающихся доменов, анкоров, соотношение естественных и SEO-ссылок, популярные страницы, типы ссылок и т. д.
 Также можно посмотреть динамику ссылок за последний год
Также можно посмотреть динамику ссылок за последний год
Все ссылки посмотреть не получится – доступна информация только о пяти самых «жирных» бэклинках. Для полного доступа к инструменту необходимо перейти на платный тариф, самый дешёвый из которых стоит 2 990 рублей в месяц.
 По каждой ссылке показывается подробная информация: анкорный текст, наличие атрибута nofollow, уровень вложенности, траст донора и пр.
По каждой ссылке показывается подробная информация: анкорный текст, наличие атрибута nofollow, уровень вложенности, траст донора и пр.
У Megaindex есть также приложение «Сравнение доноров», которое позволяет узнать, какие источники ссылок являются общими для трёх любых ресурсов. Так можно сравнить объём ссылочной массы собственного сайта с конкурентами, а еще найти ресурсы-доноры, с которых получают ссылки сайты в вашей нише.
Backlink Watch
Англоязычный сервис, позволяющий проверить до 1 000 обратных ссылок бесплатно. Главный минус – Backlink Watch выгружает все бэклинки на одной странице и делает это довольно долго.
Чтобы получить список ссылок, введите адрес сайта и нажмите «Check Backlinks».
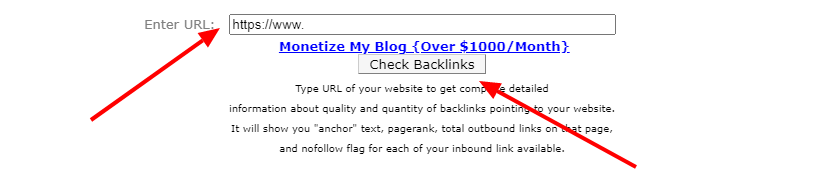 На сайте много рекламы, поэтому поле для ввода домена можно заметить не сразу
На сайте много рекламы, поэтому поле для ввода домена можно заметить не сразу
В верхней части страницы отображается прогресс: сколько ссылок уже обработано и сколько осталось.
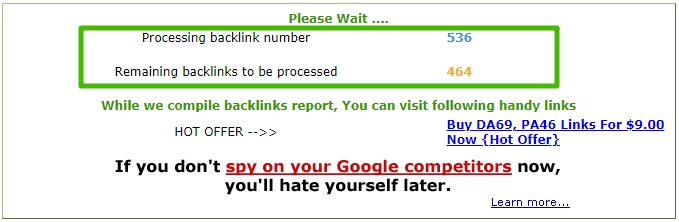 Прежде чем отобразятся все ссылки, может пройти несколько минут
Прежде чем отобразятся все ссылки, может пройти несколько минут
По мере проверки в таблице ниже будут появляться URL ссылающихся страниц. В колонке Anchor Text отображается текст ссылки (при наличии), OBL – общее количество внешних ссылок на ссылающейся странице. Если бэклинк имеет атрибут nofollow, это отобразится в последней колонке.
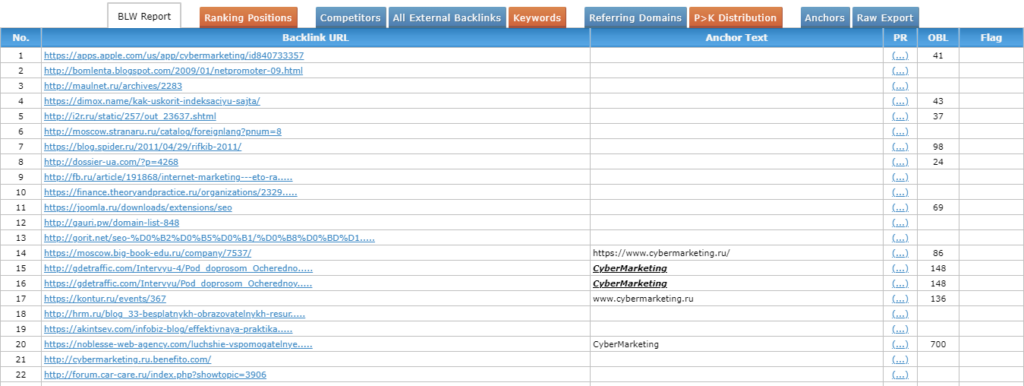 Есть также колонка PR (PageRank), но информация в ней больше не показывается
Есть также колонка PR (PageRank), но информация в ней больше не показывается
Читайте также: 20 инструментов для проверки позиций сайта в поисковых системах
XTool
Простой условно-бесплатный инструмент для быстрой проверки ссылок. Без оплаты можно посмотреть 500 бэклинков и общую информацию о ссылочном профиле (соотношение анкорных и безанкорных ссылок, соотношение nofollow/dofollow, уровень вложенности ссылающихся страниц, популярные акцепторы и анкоры).
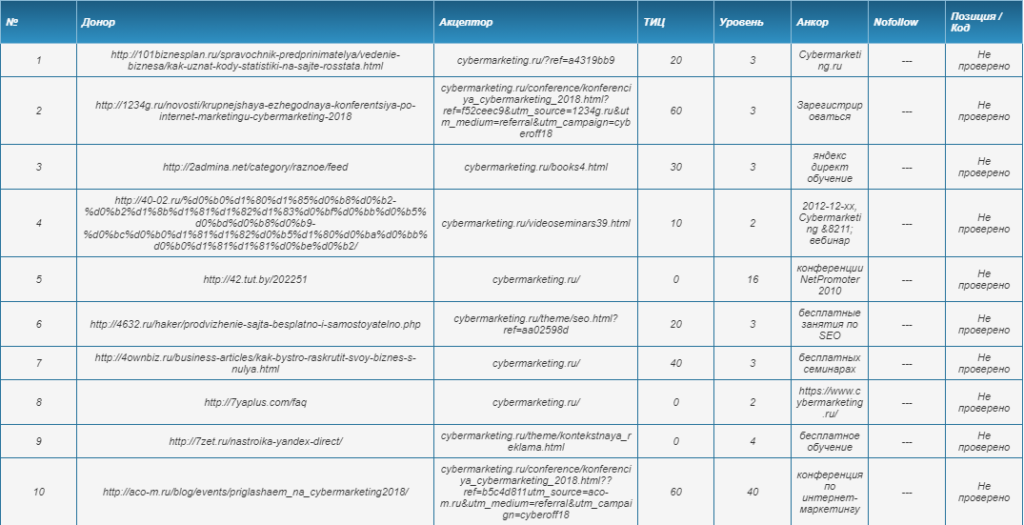 По каждой ссылке дана информация об уровне вложенности и анкорном тексте
По каждой ссылке дана информация об уровне вложенности и анкорном тексте
Если зарегистрироваться, станет доступна функция выгрузки данных в таблицы. Каждая дополнительная ссылка свыше 500 бесплатных стоит 0,01 руб.
Serpstat
Serpstat – мощный SEO-инструмент, который позволяет в том числе анализировать и входящие ссылки. Все возможности доступны только после оплаты подписки, но суммарный отчёт по бэклинкам доступен в бесплатной версии сервиса уже после регистрации.
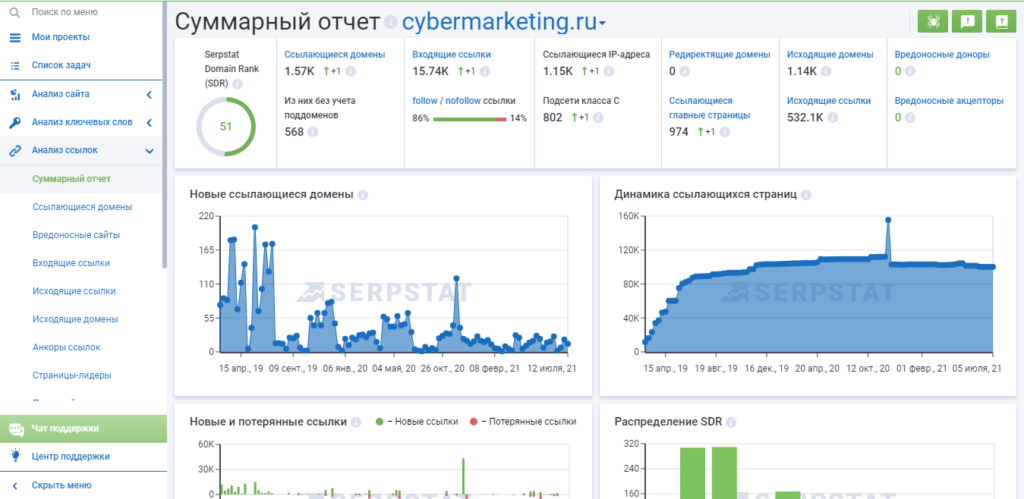 В разделах «Входящие ссылки» и «Ссылающиеся домены» отображаются только 10 элементов списка, остальное – после оплаты тарифа
В разделах «Входящие ссылки» и «Ссылающиеся домены» отображаются только 10 элементов списка, остальное – после оплаты тарифа
Сервис даёт много подробных данных по бэклинкам. Здесь можно отследить динамику ссылающихся страниц, новых ссылающихся доменов и добавленных/удалённых ссылок за 2,5 года, а также узнать, какую долю в общей массе составляют текстовые, редиректные и прочие типы ссылок.
Карта доменов – отчёт, полезный для мультиязычных сайтов, продвигаемых в разных странах. Он позволяет узнать, с площадок каких стран чаще ссылаются на анализируемый ресурс.
В Serpstat много полезных инструментов для SEO, он даёт гораздо больше информации, чем любой другой бесплатный ресурс (например, здесь есть данные о редиректных ссылках). Но пользоваться им полноценно можно только после оплаты подписки. Один месяц обойдётся в 69$.
SE Ranking
Ещё один комплексный SEO-комбайн, включающий в себя функцию анализа ссылок. Чтобы посмотреть все доступные в бесплатном режиме данные, необходимо создать учётную запись.
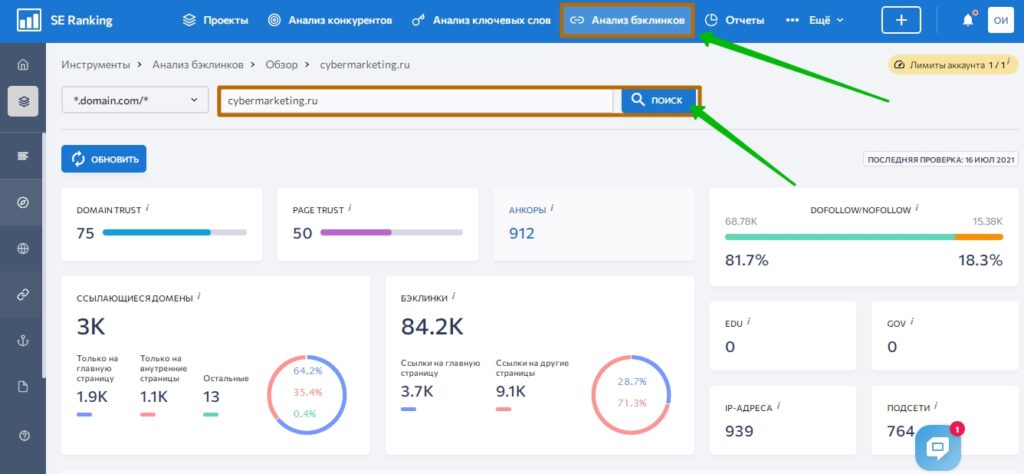 После регистрации перейдите в раздел «Анализ бэклинков», введите адрес сайта и нажмите «Поиск»
После регистрации перейдите в раздел «Анализ бэклинков», введите адрес сайта и нажмите «Поиск»
Без ограничений можно просматривать до 100 тысяч ссылок, но за каждый анализируемый сайт придётся платить по 50 рублей. Ежедневно можно проверять один сайт бесплатно.
По полноте данных сервис может конкурировать с Serpstat. Отчёты сервисов очень похожи, хотя показатели в динамике здесь можно просматривать за период не более года. Однако по количеству анализируемых ссылок в бесплатном режиме SE Ranking заметно превосходит конкурента. С другой стороны, если проверять ежедневно нужно большое количество сайтов, Serpstat может оказаться выгоднее.
По каждой ссылке в таблице можно посмотреть основные данные, которые включают показатель ИКС в «Яндексе», Alexa Rank и т. д. По этим и другим (целевой URL, тип ссылки, анкор, дата проверки) показателям бэклинки можно фильтровать.
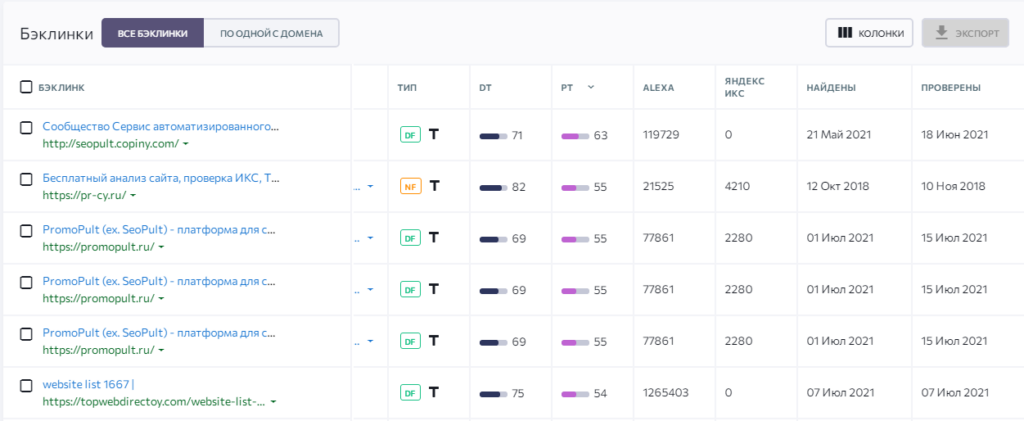 Также можно отключать определённые колонки в таблице, если они не нужны
Также можно отключать определённые колонки в таблице, если они не нужны
Каждый отчёт по бэклинкам хранится в аккаунте, поэтому его можно посмотреть в любое время.
Ahrefs’ Backlink Checker
Бесплатный инструмент англоязычного сервиса Ahrefs для проверки ссылок. Интерфейс на русском языке.
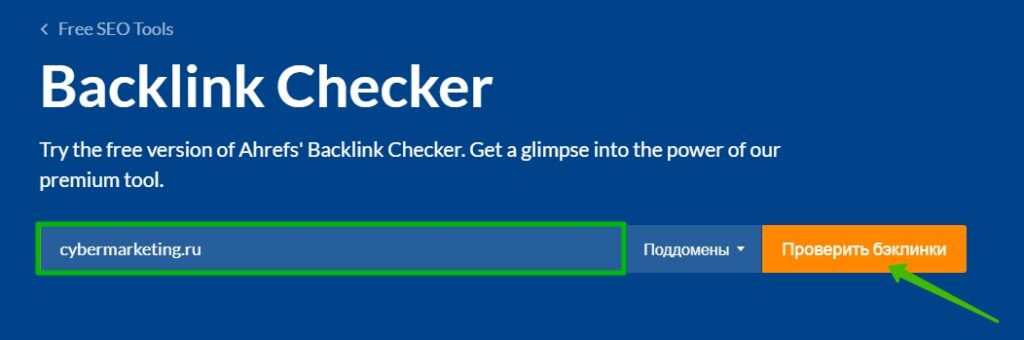 Введите имя домена, нажмите «Проверить бэклинки» и пройдите проверку на роботов
Введите имя домена, нажмите «Проверить бэклинки» и пройдите проверку на роботов
Через несколько секунд отобразятся топ-100 ссылок на сайт (отсортированы по рейтингу, который присваивает сервис в зависимости от авторитетности ресурса), анкорный текст, а также примерные данные по трафику с этих ссылок.
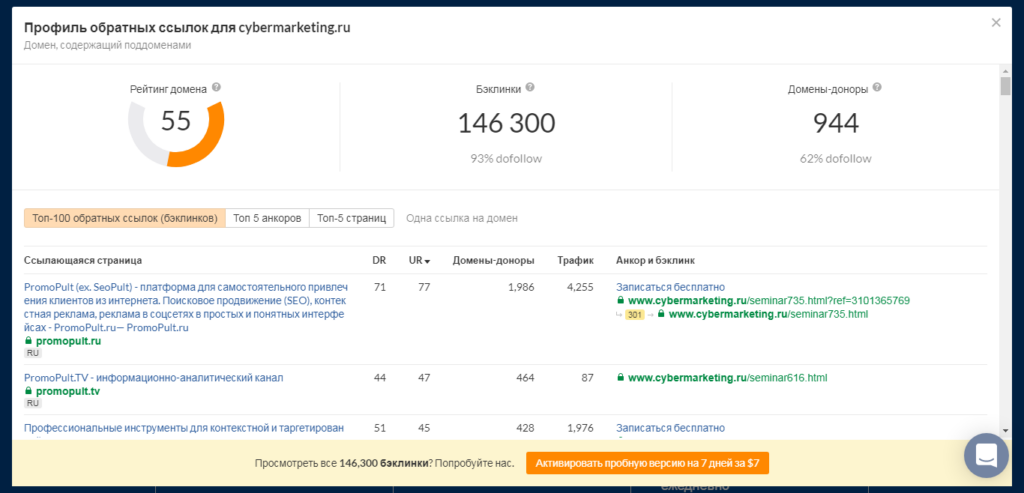 Ещё можно посмотреть 5 самых популярных анкоров и 5 страниц с наибольшим количеством входящих ссылок
Ещё можно посмотреть 5 самых популярных анкоров и 5 страниц с наибольшим количеством входящих ссылок
Также Ahrefs показывает общее количество бэклинков и доноров, и какой процент из них имеет атрибут dofollow. Посмотреть все ссылки можно только при оплате тарифа (пробная недельная версия стоит 7$).
Читайте также: 25+ YouTube-каналов для самостоятельного изучения SEO
CheckTrust
Сервис для экспресс-аудита сайта. Оценивает ресурсы в первую очередь с точки зрения траста (степени доверия поисковых систем), в том числе показывая примерное количество бэклинков. Данные о ссылках CheckTrust берёт из сервисов LinkPad, Majestic и SEOkicks.
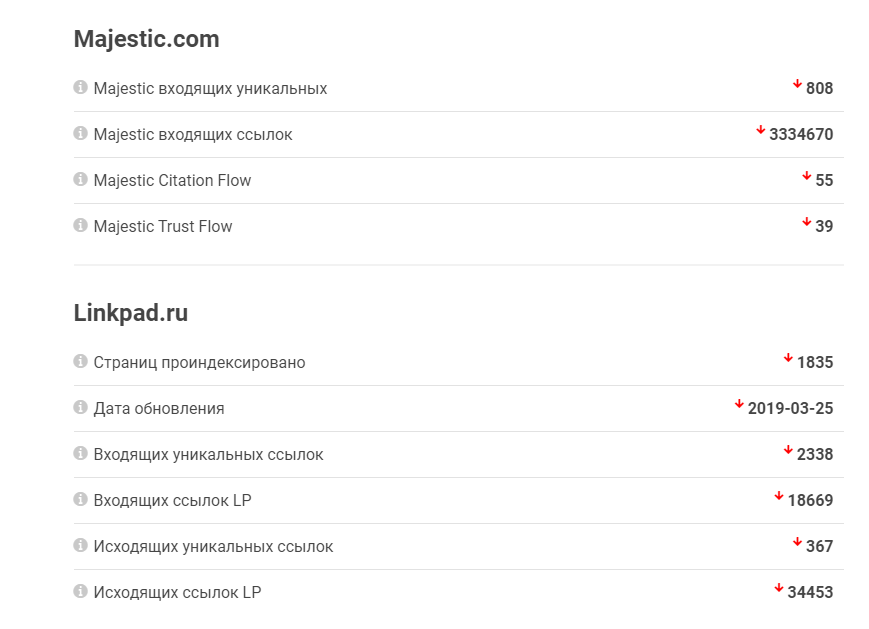 Здесь можно быстро посмотреть данные о ссылках сразу по трём сервисам (так как алгоритмы у них разные, то и количество ссылок может сильно отличаться)
Здесь можно быстро посмотреть данные о ссылках сразу по трём сервисам (так как алгоритмы у них разные, то и количество ссылок может сильно отличаться)
Ещё один полезный инструмент для линкбилдинга от CheckTrust – Backlinks Checker. С его помощью можно выявить некачественные ссылки. Для этого нужно ввести список в специальное поле или загрузить файл (если бэклинков очень много). Инструмент платный, но после регистрации доступно 500 баллов, которых хватит на несколько проверок.
Moz
MOZ предлагает набор условно-бесплатных инструментов для проверки ссылок. Основной из них – Overview, с помощью которого вы можете получить общую информацию о ссылочном профиле сайта.
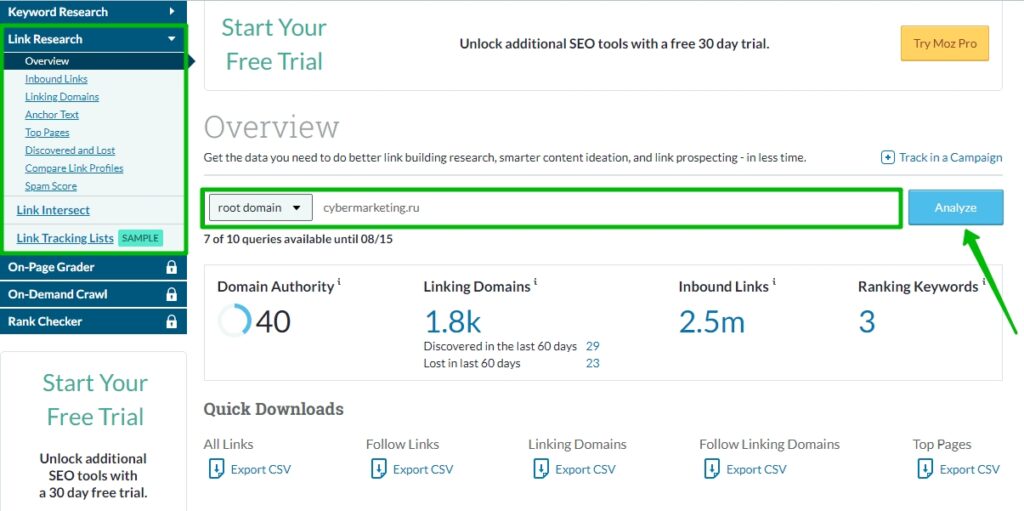 В левом меню раздела Link Research можно найти и другие инструменты
В левом меню раздела Link Research можно найти и другие инструменты
Сведения здесь, в принципе, не сильно отличаются от того, что можно узнать в других сервисах. Но есть, к примеру, полезный отчёт Spam Score, в котором можно узнать о некачественных бэклинках. А с помощью инструмента Compare Link Profiles можно сравнить ссылочный профиль своего сайта с конкурентами.
Чтобы посмотреть входящие ссылки, выберите пункт Inbound Links. В бесплатном режиме доступно только 50 ссылок. Но есть удобный фильтр, с помощью которого можно отсортировать ссылки по типам или конкретным доменам.
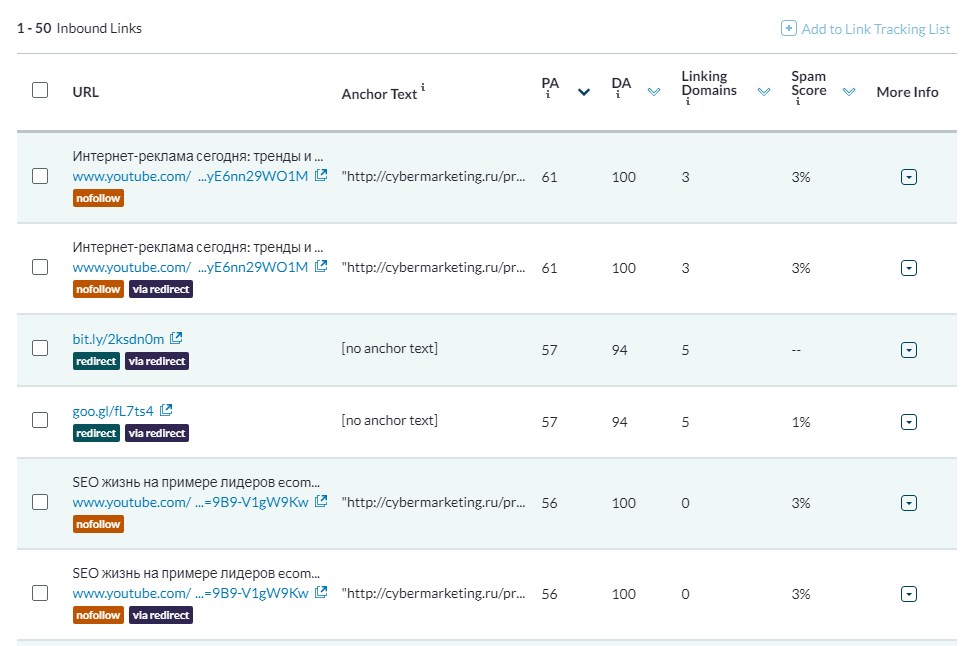 Чем больше ссылка будет напоминать спамную, тем выше будет показатель Spam Score в таблице
Чем больше ссылка будет напоминать спамную, тем выше будет показатель Spam Score в таблице
Расширенная версия Moz Pro стоит 179$ в месяц. Также пользователи могут воспользоваться бесплатной 30-дневной версией.
P. S.
Учитывайте, что ни один из перечисленных инструментов не идеален, поэтому сайты лучше проверять несколькими сервисами одновременно. Так вы получите более точные и актуальные данные о ссылочном профиле. Воспользуйтесь одним из платных инструментов, если необходимо, чтобы информация о бэклинках была максимально полной. Правда, это может быть невыгодно, если у вас мало сайтов и вы не оказываете услуги по SEO.
А если вы уже освоили базу и стремитесь познать все глубины поисковой оптимизации, у CyberMarketing есть продвинутый курс по SEO. Узнайте, как оптимизировать структуру и контент сайта, устранять технические ошибки, улучшать юзабилити сайта и его «продающие» способности. Отдельное внимание — эффективному линкбилдингу: какие ссылки получать и как оценивать их эффективность.
Ниже вы найдете обновленное руководство о том, как SEO-специалисты, профессионалы контекстной рекламы и эксперты по цифровому маркетингу могут использовать краулер Screaming Frog (также называемый поисковым роботом, пауком или ботом) для оптимизации своего рабочего процесса.
Оглавление статьи
- 1 Основы краулинга
- 1.1 Как сканировать весь сайт
- 1.2 Как сканировать один подкаталог
- 1.3 Как сканировать определенный набор поддоменов или подкаталогов
- 1.4 Я хочу получить список всех страниц моего сайта
- 1.5 Я хочу получить список всех страниц в определенном подкаталоге
- 1.6 Как найти все поддомены на сайте и проверить внутренние ссылки.
- 1.7 Как сканировать сайт электронной коммерции или другой крупный сайт
- 1.8 Как сканировать сайт, расположенный на старом сервере — или как просканировать сайт, не положив его
- 1.9 Как просмотреть сайт, на котором используются файлы cookie
- 1.10 Как сканировать, используя другой пользовательский агент
- 1.11 Как сканировать страницы, требующие аутентификации
- 2 Внутренние ссылки
- 2.1 Мне нужна информация обо всех внутренних и внешних ссылках на моем сайте (якорный текст, директивы, ссылки на страницу и т.д.).
- 2.2 Как найти неработающие внутренние ссылки на странице или сайте
- 2.3 Как найти неработающие исходящие ссылки на странице или сайте (или все исходящие ссылки в целом)
- 2.4 Как найти ссылки, которые перенаправляются
- 3 Контент сайта
- 3.1 Как определить страницы с “тонким” контентом
- 3.2 Мне нужен список ссылок на изображения на определенной странице
- 3.3 Как найти изображения, у которых отсутствует alt-текст, или изображения, у которых alt-текст длинный
- 3.4 Как найти все CSS файлы на моем сайте
- 3.5 Как найти каждый файл JavaScript на моем сайте
- 3.6 Как определить все плагины jQuery, используемые на сайте, и на каких страницах они используются
- 3.7 Как найти, где на сайте внедрен flash
- 3.8 Как найти все внутренние PDF файлы, на которые есть ссылки на сайте
- 3.9 Как понять сегментацию контента внутри сайта или группы страниц
- 3.10 Как найти страницы, на которых есть кнопки поделиться в соцсетях
- 3.11 Как найти страницы, использующие iframes
- 3.12 Как найти страницы, содержащие встроенное видео или аудио содержимое
- 4 Мета-данные и директивы
- 4.1 Как определить страницы с длинными заголовками, мета-описаниями или URL-адресами
- 4.2 Как найти дублирующиеся заголовки страниц, мета-описания или URL-адреса
- 4.3 Как найти дублированный контент и/или URL, которые необходимо переписать/перенаправить/канонизировать
- 4.4 Как определить все страницы, которые включают мета-директивы, например: nofollow/noindex/noodp/canonical и т.д.
- 4.5 Как проверить, что мой файл robots.txt работает так, как нужно
- 4.6 Как найти или проверить разметку Schema или другие микроданные на моем сайте
- 5 Sitemap
- 5.1 Как создать XML Sitemap
- 5.2 Создание карты сайта XML путем загрузки URL-адресов
- 5.3 Как проверить существующий XML Sitemap
- 6 Устранение общих неполадок
- 6.1 Как определить, почему определенные разделы моего сайта не индексируются или не ранжируются
- 6.2 Как проверить, была ли миграция/редизайн моего сайта успешной
- 6.3 Как найти медленно загружающиеся страницы на моем сайте
- 6.4 Как найти вредоносное ПО или спам на моем сайте
- 7 PPC и аналитика
- 7.1 Как проверить, что мой код Google Analytics находится на каждой странице или на определенном наборе страниц моего сайта
- 7.2 Как проверить список PPC URLs в массовом порядке
- 8 Скраппинг
- 8.1 Как произвести скраппинг метаданных для списка страниц
- 8.2 Как найти на сайте все страницы, содержащие определенное посадочное место
- 9 Переписывание URL
- 9.1 Как найти и удалить идентификатор сеанса или другие параметры из моих просмотренных URL
- 9.2 Как переписать URL (например: заменить .com на .co.uk, или писать все URL в нижнем регистре)
- 10 Исследование ключевых слов
- 10.1 Как узнать, какие страницы наиболее ценны для моих конкурентов
- 10.2 Как узнать, какой анкорный текст используют мои конкуренты для внутренней перелинковки
- 10.3 Как узнать, какие мета ключевые слова (если таковые имеются) добавили мои конкуренты на свои страницы
- 11 Линкбилдинг
- 11.1 Как проанализировать список перспективных мест размещения ссылок
- 11.2 Как найти неработающие ссылки, чтобы использовать их для аутрич-возможностей
- 11.3 Как проверить мои обратные ссылки и просмотреть анкорный текст
- 11.4 Я нахожусь в процессе очистки своих обратных ссылок и мне нужно проверить, что ссылки удаляются в соответствии с запросом
- 11.5 Бонусный раунд
- 11.6 Как редактировать метаданные
- 11.7 Как просканировать сайт с JavaScript
- 12 Просмотр оригинального HTML и рендеринга HTML
- 12.1 Заключительные замечания
Основы краулинга
Как сканировать весь сайт
До начала краулинга сайта будет полезным оценить, какую информацию вы хотите получить, насколько велик сайт и какую часть сайта вам нужно сканировать, чтобы получить представление обо всем сайте. Иногда на больших сайтах лучше ограничить работу краулера только некоторыми URL-адресами, чтобы получить репрезентативную выборку данных. В этом случае размеры файлов и экспорт данных становятся более управляемыми. Подробнее об этом мы расскажем ниже. Для сканирования всего сайта, включая все поддомены, вам потребуется внести небольшие изменения в конфигурацию паука, чтобы начать работу.
По умолчанию Screaming Frog сканирует только тот поддомен, который вы указали. Любые дополнительные поддомены, которые встречает паук, будут рассматриваться как внешние ссылки. Для того чтобы просканировать дополнительные поддомены, необходимо изменить настройки в меню Configuration паука. Установив флажок ‘Crawl All Subdomains’, вы убедитесь, что паук просматривает все ссылки на другие поддомены вашего сайта, которые он встречает.
Шаг 1:
Шаг 2:
Кроме того, если вы начинаете поиск из определенной подпапки или подкаталога, но при этом хотите, чтобы Screaming Frog просмотрел весь сайт, установите флажок «Crawl Outside of Start Folder».
По умолчанию SEO Spider настроен на краулинг только той подпапки или поддиректории, из которой вы начинаете сканирование. Если вы хотите сканировать весь сайт и начинать с определенного подкаталога, убедитесь, что в конфигурации установлен режим просмотра за пределами начальной папки.
Профессиональный совет:
Чтобы сэкономить время и дисковое пространство, не забывайте о ресурсах, которые могут не понадобиться в процессе сканирования. Веб-сайты содержат ссылки не только на страницы. Снимите флажки с Изображений, CSS, JavaScript и SWF ресурсов, чтобы уменьшить размер краулинга.
Как сканировать один подкаталог
Если вы хотите ограничить краулинг одной папкой, просто введите URL и нажмите старт, не изменяя никаких настроек по умолчанию. Если вы переписали исходные настройки по умолчанию, сбросьте их в меню ‘File’.
Если вы хотите начать поиск в определенной папке, но продолжить поиск по остальной части поддомена, обязательно выберите «Crawl Outside Of Start Folder» в настройках конфигурации паука перед вводом конкретного начального URL.
Как сканировать определенный набор поддоменов или подкаталогов
Если вы хотите ограничить краулинг определенным набором поддоменов или подкаталогов, вы можете использовать RegEx, чтобы установить эти правила в настройках Include или Exclude в меню Configuration.
Исключение:
В этом примере мы сканировали все страницы на сайте seerinteractive.com, исключая страницы «О сайте» на каждом поддомене.
Шаг 1:
Перейдите в меню Configuration > Exclude (Конфигурация > Исключить); используйте регулярное выражение с подстановочным знаком, чтобы определить URL-адреса или параметры, которые вы хотите исключить.
Шаг 2:
Проверьте регулярное выражение, чтобы убедиться, что оно исключает те страницы, которые вы ожидали исключить, прежде чем начать сканирование:
Включение:
В приведенном ниже примере мы хотели просканировать только подпапку «Команда» на сайте seerinteractive.com. Снова используйте вкладку «Тест» для проверки нескольких URL-адресов и убедитесь, что RegEx правильно настроен для вашего правила включения.
Это отличный способ краулинга по большим сайтам; на самом деле, Screaming Frog рекомендует этот метод, если вам нужно разделить и подчинить себе краулинг по большому домену.
Я хочу получить список всех страниц моего сайта
По умолчанию Screaming Frog настроен на сканирование всех изображений, JavaScript, CSS и флеш-файлов, которые встречаются пауку. Чтобы проверять только HTML, вам нужно снять флажки ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ и ‘Check SWF’ в меню Spider Configuration.
Запуск паука с этими настройками без галочек, по сути, предоставит вам список всех страниц вашего сайта, на которые ведут внутренние ссылки.
После завершения сканирования перейдите на вкладку ‘Internal’ («Внутренние») и отфильтруйте результаты по «HTML». Нажмите «Экспорт», и вы получите полный список в формате CSV.
Совет профессионала:
Если вы склонны использовать одни и те же настройки для каждого краулинга, Screaming Frog теперь позволяет сохранять параметры конфигурации:
Я хочу получить список всех страниц в определенном подкаталоге
В дополнение к снятию флажков ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ и ‘Check SWF’, вы также должны снять флажок ‘Check Links Outside Folder’ в настройках конфигурации паука. Запуск паука с этими настройками без галочки даст вам список всех страниц в вашей начальной папке (если они не являются страницами-сиротами) Примечание: страницы-сироты — это страницы, которые не связаны ни с одной другой страницей / разделом сайта, поэтому если пользователь попал на неё, он не сможет перейти с этой страницы на другую.
Как найти все поддомены на сайте и проверить внутренние ссылки.
Существует несколько различных способов найти все поддомены на сайте.
Способ 1:
Используйте Screaming Frog для определения всех поддоменов на данном сайте. Перейдите в раздел Configuration > Spider и убедитесь, что выбрана опция «Crawl all Subdomains». Как и при описанном выше сканировании всего сайта, это поможет сканировать все поддомены, на которые есть ссылки на сайте. Однако это не поможет найти поддомены, которые являются “сиротливыми” или на которые нет ссылок.
Метод 2:
Используйте Google для определения всех проиндексированных поддоменов.
С помощью расширения Scraper Chrome и некоторых операторов расширенного поиска можно найти все индексируемые поддомены для данного домена.
Шаг 1:
Начните с использования оператора поиска site: в Google, чтобы ограничить результаты конкретным доменом. Затем используйте оператор поиска -inurl, чтобы сузить результаты поиска, удалив основной домен. Вы должны увидеть список субдоменов, которые были проиндексированы в Google и не содержат основного домена.
Шаг 2:
Используйте расширение Scraper, чтобы извлечь все результаты в лист Google. Просто щелкните правой кнопкой мыши URL в поисковой выдаче, нажмите «Scrape Similar» и экспортируйте в Google Doc.
Шаг 3:
В Google Doc используйте следующую функцию, чтобы обрезать URL до поддомена:
=LEFT(A2,SEARCH(«/»,A2,9))
По сути, приведенная выше формула должна помочь отсечь любые подкаталоги, страницы или имена файлов в конце сайта. Эта формула, по сути, говорит sheets или Excel возвращать то, что находится слева от косой черты. Начальное число 9 является важным, потому что мы просим начать поиск косой черты после 9-го символа. Это учитывает протокол: https://, длина которого составляет 8 символов.
Дедублируйте список и загрузите его в Screaming Frog в режиме списка — вы можете вставить список доменов вручную, использовать функцию вставки или загрузить CSV.
Способ 3:
Введите URL корневого домена в инструменты, помогающие искать сайты, которые могут существовать на том же IP, или в поисковые системы, созданные специально для поиска поддоменов, например FindSubdomains. Создайте бесплатную учетную запись, чтобы войти в систему и экспортировать список поддоменов. Затем загрузите список в Screaming Frog с помощью режима списка.
После завершения работы паука вы сможете увидеть коды состояния, а также все ссылки на домашних страницах поддоменов, якорный текст и дублирующиеся заголовки страниц.
Как сканировать сайт электронной коммерции или другой крупный сайт
Изначально Screaming Frog не был создан для просмотра сотен тысяч страниц, но благодаря обновлениям он становится все ближе к этому.
В версии 11.0 Screaming Frog позволил пользователям сохранять все данные на диске в базе данных, а не просто хранить их в оперативной памяти. Это впервые открыло возможность обхода очень больших сайтов.
В версии 12.0 краулер автоматически сохраняет данные в базе данных. Это позволяет получить к ним доступ и открыть их с помощью команды «File > Crawls» в меню верхнего уровня — на случай, если вы запаникуете и задумаетесь, куда делась команда open!
Хотя использование базы данных краулинга помогает Screaming Frog лучше управлять большими сканами, это, конечно, не единственный способ краулить большой сайт.
Во-первых, вы можете увеличить объем памяти, выделяемой пауку.
Во-вторых, вы можете разбить краулинг по подкаталогам или сканировать только определенные части сайта с помощью настроек Include/Exclude («Включить/Исключить»).
В-третьих, вы можете отказаться от просмотра изображений, JavaScript, CSS и flash. Отменив выбор этих опций в меню Конфигурация, вы можете сэкономить память, выполняя сканирование только HTML.
Профессиональный совет:
До недавнего времени Screaming Frog SEO Spider мог приостановиться или упасть при просмотре большого сайта. Теперь, когда хранение базы данных установлено по умолчанию, вы можете восстановить краулинг, чтобы продолжить работу с того места, на котором остановились. Кроме того, вы можете получить доступ к URL-адресам, поставленным в очередь. Это может дать вам представление о дополнительных параметрах или правилах, которые необходимо исключить при краулинге большого сайта.
Как сканировать сайт, расположенный на старом сервере — или как просканировать сайт, не положив его
В некоторых случаях старые серверы могут быть не в состоянии обрабатывать стандартное количество запросов URL в секунду. На самом деле, мы рекомендуем на всякий случай включить ограничение на количество URL-адресов для просмотра в секунду, чтобы проявить уважение к серверу сайта. Лучше всего сообщить клиенту о том, что вы планируете провести сканирование сайта, на всякий случай, если у него есть защита от неизвестных пользовательских агентов. С одной стороны, им может понадобиться внести ваш IP или User Agent в белый список до того, как вы пройдете по сайту. Худший сценарий может заключаться в том, что вы посылаете слишком много запросов на сервер и непреднамеренно разрушаете сайт.
Чтобы изменить скорость краулинга, выберите «Speed» в меню «Configuration» и во всплывающем окне выберите максимальное количество потоков, которые должны работать одновременно. В этом же меню вы можете выбрать максимальное количество URL-адресов, запрашиваемых в секунду.
Профессиональный совет:
Если вы обнаружите, что в результате вашей проверки возникает много ошибок сервера, перейдите на вкладку ‘Advanced’ в меню Spider Configuration и увеличьте значение ‘Response Timeout’ и ‘5xx Response Retries’, чтобы получить лучшие результаты.
Как просмотреть сайт, на котором используются файлы cookie
Хотя поисковые боты не принимают cookies, если вы сканируете сайт и вам нужно разрешить cookies, просто выберите ‘Allow Cookies’ во вкладке ‘Advanced’ в меню Spider Configuration.
Как сканировать, используя другой пользовательский агент
Чтобы выполнить поиск с использованием другого агента пользователя, выберите ‘User Agent’ в меню ‘Configuration’, затем выберите поискового бота из выпадающего списка или введите желаемые строки агента пользователя.
Поскольку Google теперь ориентируется на мобильные устройства, попробуйте просмотреть сайт под именем Googlebot Smartphone или измените User-Agent, чтобы он имитировал Googlebot Smartphone. Это важно по двум разным причинам:
- Краулинг, имитирующий пользовательский агент Googlebot Smartphone, может помочь определить любые проблемы, возникающие у Google при краулинге и рендеринге содержимого вашего сайта.
- Использование модифицированной версии агента Googlebot Smartphone поможет вам отличить ваши краулинги от краулингов Google при анализе журналов сервера.
Как сканировать страницы, требующие аутентификации
Когда паук Screaming Frog наткнется на страницу, защищенную паролем, появится всплывающее окно, в котором вы сможете ввести имя пользователя и пароль.
Аутентификация на основе форм — очень мощная функция, и для ее эффективной работы может потребоваться рендеринг JavaScript. Примечание: Аутентификация на основе форм должна использоваться редко и только опытными пользователями. Краулер запрограммирован на переход по каждой ссылке на странице, поэтому потенциально это может привести к ссылкам на выход из системы, создание сообщений или даже удаление данных.
Чтобы управлять аутентификацией, перейдите в раздел Configuration > Authentication.
Чтобы отключить запросы на аутентификацию, отмените выбор ‘Standards Based Authentication’ в окне ‘Authentication’ в меню Configuration.
Внутренние ссылки
Мне нужна информация обо всех внутренних и внешних ссылках на моем сайте (якорный текст, директивы, ссылки на страницу и т.д.).
Если вам не нужно проверять изображения, JavaScript, flash или CSS на сайте, отмените выбор этих опций в меню Spider Configuration, чтобы сэкономить время обработки и память.
После того как паук закончит проверку, воспользуйтесь меню Bulk Export, чтобы экспортировать CSV ‘All Links’. Это позволит вам получить все местоположения ссылок, а также соответствующий якорный текст, директивы и т.д.
Все ссылки могут быть большим отчетом. Помните об этом при экспорте. Для большого сайта этот экспорт может занять несколько минут.
Чтобы быстро подсчитать количество ссылок на каждой странице, перейдите на вкладку «Internal» и отсортируйте по «Outlinks». Все, что превышает 100, может потребовать пересмотра.
Как найти неработающие внутренние ссылки на странице или сайте
Если вам не нужно проверять изображения, JavaScript, flash или CSS сайта, снимите выделение этих опций в меню конфигурации паука, чтобы сэкономить время обработки и память.
После того как паук закончит сканирование, отсортируйте результаты на вкладке «Internal» по «Status Code». Любые 404, 301 или другие коды статуса будут легко просматриваться.
При нажатии на любой отдельный URL-адрес в результатах сканирования вы увидите изменение информации в нижнем окне программы. Перейдя на вкладку ‘In Links’ в нижнем окне, вы увидите список страниц, которые ссылаются на выбранный URL, а также якорный текст и директивы, используемые в этих ссылках. Вы можете использовать эту функцию для выявления страниц, на которых необходимо обновить внутренние ссылки.
Чтобы экспортировать полный список страниц, содержащих неработающие или перенаправленные ссылки, выберите «Redirection (3xx) In Links» или «Client Error (4xx) In Links» или «Server Error (5xx) In Links» в меню «Advanced Export», и вы получите экспорт данных в формате CSV.
Чтобы экспортировать полный список страниц, содержащих неработающие или перенаправленные ссылки, зайдите в меню Bulk Export. Прокрутите вниз до кодов ответов и просмотрите следующие отчеты:
- No Response Inlinks (Входящие ссылки без ответа)
- Redirection (3xx) Inlinks (Перенаправление (3xx) Входящие ссылки)
- Redirection (JavaScript) Inlinks (Перенаправление (JavaScript) Внутренние ссылки)
- Redirection (Meta Refresh) Inlinks (Перенаправление (Meta Refresh) Входящие ссылки)
- Client Error (4xx) Inlinks (Ошибка клиента (4xx) Входящие ссылки)
- Server Error (5xx) Inlinks (Ошибка сервера (5xx) Ссылки)
Просмотр всех этих отчетов должен дать нам адекватное представление о том, какие внутренние ссылки должны быть обновлены, чтобы они указывали на каноническую версию URL и эффективно распределяли ссылочный капитал.
Как найти неработающие исходящие ссылки на странице или сайте (или все исходящие ссылки в целом)
После удаления выбора ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ и ‘Check SWF’ в настройках конфигурации паука, убедитесь, что ‘Check External Links’ остается выбранным.
После того как паук закончит сканирование, перейдите на вкладку ‘External’ в верхнем окне, отсортируйте по ‘Status Code’ и вы легко сможете найти URL с кодами состояния, отличными от 200. Если щелкнуть на любом отдельном URL-адресе в результатах сканирования, а затем перейти на вкладку ‘In Links’ в нижнем окне, вы найдете список страниц, которые указывают на выбранный URL-адрес. Вы можете использовать эту функцию для определения страниц, на которых необходимо обновить исходящие ссылки.
Чтобы экспортировать полный список исходящих ссылок, нажмите «Внешние ссылки» на вкладке «Массовый экспорт».
Для получения полного списка всех местоположений и якорного текста исходящих ссылок выберите ‘All Outlinks’ в меню ‘Bulk Export’. Отчет «All Outlinks» будет включать исходящие ссылки на ваши поддомены; если вы хотите исключить ваш домен, перейдите к отчету «External Links», о котором говорилось выше.
Как найти ссылки, которые перенаправляются
После того, как паук закончил сканирование, выберите вкладку ‘Response Codes’ в главном пользовательском интерфейсе и отфильтруйте по Status Code. Поскольку Screaming Frog использует регулярные выражения для поиска, используйте следующие критерии в качестве фильтра: 301|302|307. Это должно дать вам довольно солидный список всех ссылок, которые вернулись с каким-либо перенаправлением, независимо от того, был ли контент постоянно перемещен, найден и перенаправлен, или временно перенаправлен из-за настроек HSTS (это вероятная причина 307 перенаправления в Screaming Frog). Отсортируйте по ‘Status Code’, и вы сможете разбить результаты по типам. Перейдите на вкладку ‘In Links’ в нижнем окне, чтобы просмотреть все страницы, на которых используется перенаправляющая ссылка.
Если вы экспортируете данные непосредственно с этой вкладки, вы увидите только те данные, которые показаны в верхнем окне (исходный URL, код состояния и место, куда перенаправляет ссылка).
Чтобы экспортировать полный список страниц, включающих перенаправляющие ссылки, вам нужно выбрать ‘Redirection (3xx) In Links’ в меню ‘Advanced Export’. В результате вы получите CSV, содержащий расположение всех ваших перенаправленных ссылок. Чтобы показать только внутренние перенаправления, отфильтруйте столбец ‘Destination’ в CSV, чтобы включить только ваш домен.
Совет:
Используйте VLOOKUP между двумя вышеуказанными экспортными файлами, чтобы сопоставить столбцы Source и Destination с окончательным местоположением URL.
Пример формулы:
=VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,FALSE)
(Где ‘response_codes_redirection_(3xx).csv’ — CSV файл, содержащий URL перенаправления, а ’50’ — количество строк в этом файле).
Контент сайта
Как определить страницы с “тонким” контентом
После того, как паук закончил сканирование, перейдите на вкладку ‘Internal’, отфильтруйте по HTML, затем прокрутите страницу вправо до столбца ‘Word Count’. Отсортируйте столбец ‘Word Count’ от низкого к высокому, чтобы найти страницы с низким содержанием текста. Вы можете перетащить столбец ‘Word Count’ влево, чтобы лучше сопоставить низкие значения количества слов с соответствующими URL-адресами. Нажмите кнопку «Export» на вкладке «Internal», если вы предпочитаете работать с данными в формате CSV.
Мне нужен список ссылок на изображения на определенной странице
Если вы уже просканировали весь сайт или подкаталог, просто выберите страницу в верхнем окне, затем нажмите на вкладку ‘Image Info’ в нижнем окне, чтобы просмотреть все изображения, которые были найдены на этой странице. Изображения будут перечислены в столбце «To».
Совет профессионала:
Щелкните правой кнопкой мыши на любой записи в нижнем окне, чтобы скопировать или открыть URL-адрес.
Кроме того, вы можете просмотреть изображения на одной странице, выполнив поиск только по этому URL. Убедитесь, что глубина просмотра установлена на ‘1’ в настройках конфигурации паука, затем, когда страница будет просмотрена, перейдите на вкладку ‘Images’, и вы увидите все изображения, которые нашел паук.
Как найти изображения, у которых отсутствует alt-текст, или изображения, у которых alt-текст длинный
Во-первых, вы должны убедиться, что опция ‘Check Images’ выбрана в меню Spider Configuration. После того, как паук закончит поиск, перейдите на вкладку ‘Images’ и отфильтруйте изображения по ‘Missing Alt Text’ или ‘Alt Text Over 100 Characters’. Вы можете найти страницы, на которых находится любое изображение, нажав на вкладку ‘Image Info’ в нижнем окне. Страницы будут перечислены в колонке ‘From’.
Наконец, если вы предпочитаете CSV, используйте меню ‘Bulk Export’ для экспорта ‘All Images’ или ‘Images Missing Alt Text Inlinks’, чтобы увидеть полный список изображений, где они расположены и любой связанный с ними alt text или проблемы с alt text.
Кроме того, используйте правую боковую панель для перехода к разделу «Images»; здесь вы можете легко экспортировать список всех изображений с отсутствующим alt-текстом.
Как найти все CSS файлы на моем сайте
В меню Spider Configuration выберите ‘Crawl’ и ‘Store’ CSS перед просмотром, затем, когда просмотр будет завершен, отфильтруйте результаты во вкладке ‘Internal’ по ‘CSS’.
Как найти каждый файл JavaScript на моем сайте
В меню Spider Configuration выберите ‘Check JavaScript’ перед просмотром, затем, когда просмотр будет завершен, отфильтруйте результаты во вкладке ‘Internal’ по ‘JavaScript’.
Как определить все плагины jQuery, используемые на сайте, и на каких страницах они используются
Во-первых, убедитесь, что опция ‘Check JavaScript’ выбрана в меню Spider Configuration. После того как паук закончит поиск, отфильтруйте вкладку ‘Internal’ по ‘JavaScript’, а затем выполните поиск по ‘jquery’. В результате вы получите список файлов плагинов. При необходимости отсортируйте список по ‘Address’ для более удобного просмотра, затем просмотрите ‘InLinks’ в нижнем окне или экспортируйте данные в CSV, чтобы найти страницы, на которых используется файл. Они будут находиться в колонке ‘From’.
Также вы можете использовать меню ‘Advanced Export’ для экспорта CSV ‘All Links’ и отфильтровать столбец ‘Destination’, чтобы показать только URL-адреса с ‘jquery’.
Профессиональный совет:
Не все плагины jQuery вредны для SEO. Если вы видите, что на сайте используется jQuery, лучше всего убедиться, что контент, который вы хотите проиндексировать, включен в исходный текст страницы и передается при ее загрузке, а не после. Если вы все еще не уверены, погуглите плагин, чтобы получить больше информации о том, как он работает.
Как найти, где на сайте внедрен flash
В меню Spider Configuration выберите ‘Check SWF’ перед началом сканирования, затем, когда сканирование будет завершено, отфильтруйте результаты на вкладке ‘Internal’ по ‘Flash’.
Это становится все более важным для поиска и идентификации содержимого, передаваемого с помощью Flash, и предложения альтернативного кода для этого содержимого. Chrome находится в процессе повсеместного отказа от Flash; это действительно то, что следует использовать для выявления проблем с критическим содержимым и Flash на сайте.
Примечание: Этот метод позволяет найти только файлы .SWF, связанные со страницей. Если Flash подтягивается через JavaScript, вам нужно будет использовать специальный фильтр.
Как найти все внутренние PDF файлы, на которые есть ссылки на сайте
После того, как паук закончил поиск, отфильтруйте результаты во вкладке ‘Internal’ по ‘PDF’.
Как понять сегментацию контента внутри сайта или группы страниц
Если вы хотите найти страницы вашего сайта, содержащие определенный тип контента, установите пользовательский фильтр для отпечатка HTML, уникального для данной страницы. Это нужно сделать *до* запуска паука.
Как найти страницы, на которых есть кнопки поделиться в соцсетях
Чтобы найти страницы, содержащие кнопки поделиться в соцсетях, вам нужно установить пользовательский фильтр перед запуском паука. Чтобы установить пользовательский фильтр, перейдите в меню Конфигурация и нажмите ‘Custom’. Оттуда введите любой фрагмент кода из источника страницы.
В приведенном выше примере я хотел найти страницы, содержащие кнопку Facebook «Мне нравится», поэтому я создал фильтр для facebook.com/plugins/like.php.
Как найти страницы, использующие iframes
Чтобы найти страницы, использующие iframe, установите пользовательский фильтр для <iframe перед запуском паука.
Как найти страницы, содержащие встроенное видео или аудио содержимое
Чтобы найти страницы, содержащие встроенное видео или аудио содержимое, установите пользовательский фильтр для фрагмента кода вставки для Youtube или любого другого медиаплеера, который используется на сайте.
Мета-данные и директивы
Как определить страницы с длинными заголовками, мета-описаниями или URL-адресами
После того, как паук закончил сканирование, перейдите на вкладку ‘Page Titles’ и отфильтруйте их по ‘Over 60 Characters’, чтобы увидеть слишком длинные заголовки страниц. То же самое можно сделать на вкладке ‘Meta Description’ или на вкладке ‘URI’.
Как найти дублирующиеся заголовки страниц, мета-описания или URL-адреса
После того, как паук закончил поиск, перейдите на вкладку ‘Page Titles’, затем отфильтруйте их по ‘Duplicate’. То же самое можно сделать на вкладках ‘Meta Description’ или ‘URI’.
Как найти дублированный контент и/или URL, которые необходимо переписать/перенаправить/канонизировать
После того, как паук закончил поиск, перейдите на вкладку ‘URI’, затем отфильтруйте по ‘Underscores’, ‘Uppercase’ или ‘Non ASCII Characters’ для просмотра URL, которые потенциально могут быть переписаны в более стандартную структуру. Отфильтруйте по ‘Duplicate’ и вы увидите все страницы, которые имеют несколько версий URL. Фильтр по ‘Параметрам’ позволяет увидеть URL-адреса, содержащие параметры.
Кроме того, если вы перейдете на вкладку ‘Internal’, отфильтруете по ‘HTML’ и прокрутите колонку ‘Hash’ в крайнем правом углу, вы увидите уникальную серию букв и цифр для каждой страницы. Если вы нажмете кнопку «Экспорт», вы сможете использовать условное форматирование в Excel, чтобы выделить дублирующиеся значения в этом столбце, что в конечном итоге покажет вам страницы, которые идентичны и требуют внимания.
Как определить все страницы, которые включают мета-директивы, например: nofollow/noindex/noodp/canonical и т.д.
После того, как паук закончил сканирование, перейдите на вкладку ‘Directives’. Чтобы увидеть тип директивы, просто прокрутите страницу вправо и посмотрите, какие столбцы заполнены, или воспользуйтесь фильтром, чтобы найти любой из следующих тегов:
- index
- noindex
- follow
- nofollow
- noarchive
- nosnippet
- noodp
- noydir
- noimageindex
- notranslate
- unavailable_after
- refresh
Как проверить, что мой файл robots.txt работает так, как нужно
По умолчанию, Screaming Frog будет соблюдать инструкции robots.txt. В первую очередь, он будет следовать директивам, сделанным специально для пользовательского агента Screaming Frog. Если нет директив специально для агента пользователя Screaming Frog, то паук будет следовать любым директивам для Googlebot, а если нет специальных директив для Googlebot, то паук будет следовать глобальным директивам для всех агентов пользователя. Паук будет следовать только одному набору директив, поэтому если есть правила, установленные специально для Screaming Frog, он будет следовать только этим правилам, а не правилам для Googlebot или любым глобальным правилам. Если вы хотите заблокировать определенные части сайта от паука, используйте обычный синтаксис robots.txt с агентом пользователя ‘Screaming Frog SEO Spider’. Если вы хотите игнорировать robots.txt, просто выберите эту опцию в настройках конфигурации паука.
Configuration > Robots.txt > Settings
Как найти или проверить разметку Schema или другие микроданные на моем сайте
Чтобы найти каждую страницу, которая содержит разметку Schema или любые другие микроданные, вам необходимо использовать пользовательские фильтры. Просто нажмите на ‘Custom’ → ‘Search’ в меню конфигурации и введите искомый след.
Чтобы найти каждую страницу, содержащую разметку Schema, просто добавьте следующий фрагмент кода в пользовательский фильтр: itemtype=http://schema.org
Чтобы найти определенный тип разметки, вам придется уточнить его. Например, используя пользовательский фильтр для ‘span itemprop=»ratingValue»‘, вы получите все страницы, содержащие разметку Schema для оценок.
Начиная с версии Screaming Frog 11.0, SEO-паук также предлагает нам возможность сканировать, извлекать и проверять структурированные данные непосредственно из краулинга. Проверяйте любые структурированные данные JSON-LD, Microdata или RDFa в соответствии с рекомендациями Schema.org и спецификациями Google в режиме реального времени по мере сканирования. Чтобы получить доступ к инструментам проверки структурированных данных, выберите опции в разделе «Config > Spider > Advanced».
В главном интерфейсе появится вкладка «Структурированные данные» (Structured Data), которая позволяет переключаться между страницами, содержащими структурированные данные, отсутствующими структурированными данными, а также страницами с ошибками проверки или предупреждениями:
Вы также можете экспортировать проблемы со структурированными данными в массовом порядке, посетив раздел «Reports > Structured Data > Validation Errors & Warnings.».
Sitemap
Как создать XML Sitemap
После того, как паук закончил сканирование вашего сайта, нажмите на меню «Sitemaps» и выберите «XML Sitemap».
Открыв настройки конфигурации XML Sitemap, вы сможете включить или исключить страницы по кодам ответа, последним изменениям, приоритету, частоте изменений, изображениям и т.д. По умолчанию Screaming Frog включает только URL-адреса 2xx, но это хорошее правило — всегда перепроверять.
В идеале, ваша XML sitemap должна включать только единственную, предпочтительную (каноническую) версию каждого URL со статусом 200, без параметров или других дублирующих факторов. После внесения всех изменений нажмите кнопку OK. Файл XML sitemap загрузится на ваше устройство, и вы сможете отредактировать соглашение об именовании по своему усмотрению.
Создание карты сайта XML путем загрузки URL-адресов
Вы также можете создать XML sitemap, загрузив URL-адреса из существующего файла или вставив их вручную в Screaming Frog.
Измените «Режим» с «Паук» на «Список» и нажмите на выпадающий список «Загрузить», чтобы выбрать любой из вариантов.
Нажмите кнопку «Старт», и Screaming Frog начнет просматривать загруженные URL-адреса. После того, как URL будут просмотрены, вы будете следовать тому же процессу, что и выше.
Как проверить существующий XML Sitemap
Вы можете легко загрузить существующую XML карту сайта или индекс карты сайта, чтобы проверить ее на наличие ошибок или несоответствий.
Перейдите в меню ‘Mode’ в Screaming Frog и выберите ‘List’. Затем нажмите «Upload» в верхней части экрана, выберите «Download Sitemap» или «Download Sitemap Index», введите URL-адрес карты сайта и начните сканирование. После того как паук закончит сканирование, вы сможете найти любые перенаправления, ошибки 404, дублированные URL и многое другое. Вы можете легко экспортировать выявленные ошибки.
Выявление отсутствующих страниц в XML Sitemap
Вы можете настроить параметры краулинга для обнаружения и сравнения URL-адресов в XML-карте сайта с URL-адресами в краулинге сайта.
Перейдите в ‘Configuration’ -> ‘Spider’ в главной навигации и внизу есть несколько опций для XML sitemaps — автоматическое обнаружение XML sitemaps через файл robots.txt или ручной ввод ссылки XML sitemap в поле. *Важное замечание — если ваш файл robots.txt не содержит надлежащих ссылок назначения на все XML sitemap, которые вы хотите получить, вы должны ввести их вручную.
После обновления настроек краулинга XML Sitemap перейдите к разделу «Crawl Analysis» в навигации, затем нажмите «Configure» и убедитесь, что кнопка Sitemaps отмечена. Сначала необходимо выполнить полное сканирование сайта, затем вернуться в «Crawl Analysis» и нажать кнопку Start.
После завершения Crawl Analysis вы сможете увидеть любые несоответствия, например, URL-адреса, которые были обнаружены в ходе полного обхода сайта и отсутствуют в XML sitemap.
Устранение общих неполадок
Как определить, почему определенные разделы моего сайта не индексируются или не ранжируются
Интересуетесь, почему определенные страницы не индексируются? Во-первых, убедитесь, что они не были случайно помещены в robots.txt или помечены как noindex. Затем необходимо убедиться, что пауки могут добраться до страниц, проверив внутренние ссылки. Страница, на которую нет внутренней ссылки на вашем сайте, часто называется «сиротской”.
Для того чтобы определить все подобные страницы, выполните следующие действия:
- Перейдите в ‘Configuration’ -> ‘Spider’ в главной навигации, там внизу есть несколько опций для XML sitemap — Автоматическое обнаружение XML sitemap через ваш файл robots.txt или ручной ввод ссылки XML sitemap в поле. *Важное замечание — если ваш файл robots.txt не содержит надлежащих ссылок назначения на все XML sitemap, которые вы хотите получить, вам следует ввести их вручную.
- Перейдите в раздел ‘Configuration → API Access’ → ‘Google Analytics’ — с помощью API вы можете получить данные аналитики для определенного аккаунта и вида. Чтобы найти страницы-«сироты» из органического поиска, убедитесь, что проведена сегментация по ‘Organic Traffic’
- Вы также можете зайти в General → ‘Crawl New URLs Discovered In Google Analytics’, если хотите, чтобы URLs, обнаруженные в GA, были включены в полный обход сайта. Если эта функция не включена, вы сможете просматривать новые URL, полученные из GA, только в отчете Orphaned Pages (“сиротским” страницам).
- Перейдите в раздел ‘Configuration → API Access’ → ‘Google Search Console’ — с помощью API вы можете получить данные GSC для определенного аккаунта и вида. Чтобы найти страницы-«сироты», вы можете искать URL-адреса, получающие клики и впечатления, которые не включены в ваш краулинг.
- Вы также можете зайти в General → ‘Crawl New URLs Discovered In Google Search Console’, если хотите, чтобы URLs, обнаруженные в GSC, были включены в полный обход сайта. Если эта функция не включена, вы сможете просматривать новые URL-адреса, полученные из GSC, только в отчете Orphaned Pages.
- Выполните сканирование всего сайта. После завершения обхода перейдите в меню ‘Crawl Analysis –> Start’ и дождитесь его завершения.
- Просмотрите “сиротские” URL-адреса на каждой из вкладок или экспортируйте все осиротевшие URL-адреса оптом, перейдя в Reports → Orphan Pages.
Если у вас нет доступа к Google Analytics или GSC, вы можете экспортировать список внутренних URL в файл .CSV, используя фильтр ‘HTML’ на вкладке ‘Internal’.
Откройте CSV-файл и на втором листе вставьте список URL, которые не индексируются или плохо ранжируются. Используйте VLOOKUP, чтобы проверить, были ли URL из вашего списка на втором листе найдены в ходе сканирования.
Как проверить, была ли миграция/редизайн моего сайта успешной
У @ipullrank есть отличный Whiteboard Friday на эту тему, но общая идея в том, что вы можете использовать Screaming Frog для проверки того, перенаправляются ли старые URL, используя режим ‘List’ для проверки кодов состояния. Если старые URL-адреса выдают 404, то вы будете знать, какие URL-адреса еще нужно перенаправить.
Как найти медленно загружающиеся страницы на моем сайте
После того, как паук закончил сканирование, перейдите на вкладку ‘Response Codes’ и отсортируйте по столбцу ‘Response Time’ от высокого к низкому, чтобы найти страницы, которые могут страдать от низкой скорости загрузки.
Как найти вредоносное ПО или спам на моем сайте
Во-первых, вам нужно определить посадочное место вредоносного ПО или спама. Далее, в меню Конфигурация, нажмите на ‘Custom’ → ‘Search’ и введите посадочное место, которое вы ищете.
Вы можете ввести до 10 различных посадочных мест для каждого сканирования. Наконец, нажмите OK и перейдите к просмотру сайта или списка страниц.
Когда паук закончит сканирование, выберите вкладку «Custom» в верхнем окне, чтобы просмотреть все страницы, содержащие ваши посадочные места. Если вы ввели более одного пользовательского фильтра, вы можете просмотреть каждый из них, изменив фильтр на результатах.
PPC и аналитика
Как проверить, что мой код Google Analytics находится на каждой странице или на определенном наборе страниц моего сайта
Начните с выбора Пользовательских фильтров в разделе Конфигурация.
Определите, что вы хотите искать в фильтрах. Обычно один фильтр показывает страницы, содержащие нужную информацию, а другой — страницы, не содержащие ее. Например, фильтры 1 и 2 обычно представляют собой страницы, содержащие или не содержащие номер UA.
Для примера ниже использован номер UA компании SEER: UA-11852503-1.
Если сайт использует кросс-доменное отслеживание, поскольку он охватывает несколько доменов или субдоменов, возьмите строку кода для кросс-доменного отслеживания и поместите ее в фильтры 3 и 4. Сделайте один фильтр Contains, а другой — Does Not Contain.
Для примера ниже использованы setDomainName’, ‘seerinteractive.com.
Для фильтра 5 попробуйте добавить фрагмент из второй части кода GA. Я был удивлен количеством сайтов, которые отбрасывают вторую часть и сохраняют только верхнюю часть кода.
Для примера ниже использован google-analytics.com/ga.js.
После того как все настройки выполнены, введите URL-адрес в Screaming Frog и нажмите кнопку Start.
Оттуда перейдите на вкладку Custom. Данные, которые отображаются, будут относиться к любому из ваших фильтров. Вы можете быстро проверить данные фильтров на наличие проблем или экспортировать данные из каждого фильтра в CSV для дальнейшего анализа или отправки клиенту.
Как проверить список PPC URLs в массовом порядке
Сохраните ваш список в формате .txt или .csv, затем измените настройки ‘Mode’ на ‘List’.
Затем выберите файл для загрузки и нажмите ‘Start’ или вставьте список вручную в Screaming Frog. Посмотрите код состояния каждой страницы на вкладке «Internal».
Скраппинг
Как произвести скраппинг метаданных для списка страниц
Итак, вы собрали кучу URL, но вам нужно больше информации о них? Установите режим ‘List’, затем загрузите список URL в формате .txt или .csv. После того, как паук закончит работу, вы сможете увидеть коды статуса, исходящие ссылки, количество слов и, конечно же, метаданные для каждой страницы из вашего списка.
Как найти на сайте все страницы, содержащие определенное посадочное место
Сначала вам нужно определить посадочное место. Далее, в меню Конфигурация, нажмите на ‘Custom’ → ‘Search’ или ‘Extraction’ и введите посадочное место, которое вы ищете.
Вы можете ввести до 10 различных посадочных мест для каждого краулинга. Наконец, нажмите OK и приступайте к краулингу сайта или списка страниц. В приведенном ниже примере я хотел найти все страницы, на которых в разделе цен написано «Пожалуйста, позвоните», поэтому я нашел и скопировал HTML-код из источника страницы.
Когда паук закончит краулинг, выберите вкладку «Custom» в верхнем окне, чтобы просмотреть все страницы, содержащие ваше посадочное место. Если вы ввели более одного пользовательского фильтра, вы можете просмотреть каждый из них, изменив фильтр в результатах.
Ниже приведены дополнительные общие посадочные места, которые вы можете соскраппить с веб-сайтов и которые могут быть полезны для вашего SEO-аудита:
- http://schema.org — Поиск страниц, содержащих schema.org
- youtube.com/embed/|youtu.be|<video|player.vimeo.com/video/|wistia.(com|net)/embed|sproutvideo.com/embed/|view.vzaar.com|dailymotion.com/embed/|players.brightcove.net/|play.vidyard.com/|kaltura.com/(p|kwidget)/ — Поиск страниц, содержащих видеоконтент.
Профессиональный совет:
Если вы извлекаете данные о продуктах с сайта клиента, вы можете сэкономить себе время, попросив клиента извлечь данные непосредственно из его базы данных. Приведенный выше метод предназначен для сайтов, к которым у вас нет прямого доступа.
Переписывание URL
Как найти и удалить идентификатор сеанса или другие параметры из моих просмотренных URL
Чтобы определить URL с идентификатором сессии или другими параметрами, просто выполните сканирование вашего сайта с настройками по умолчанию. Когда паук закончит работу, перейдите на вкладку «URI» и отфильтруйте «Parameters», чтобы просмотреть все URL-адреса, содержащие параметры.
Чтобы убрать параметры из URL, которые вы сканируете, выберите в меню конфигурации ‘URL Rewriting’, затем на вкладке ‘Remove Parameters’ нажмите ‘Add’, чтобы добавить параметры, которые вы хотите убрать из URL, и нажмите ‘OK’. Вам придется запустить паука снова с этими настройками, чтобы переписывание произошло.
Как переписать URL (например: заменить .com на .co.uk, или писать все URL в нижнем регистре)
Чтобы переписать любой URL, выберите ‘URL Rewriting’ в меню Configuration, затем во вкладке ‘Regex Replace’ нажмите ‘Add’, чтобы добавить RegEx для того, что вы хотите заменить.
После добавления всех необходимых правил вы можете протестировать правила на вкладке ‘Тест’, введя тестовый URL в поле ‘URL before rewriting’. ‘URL after rewriting’ будет автоматически обновлен в соответствии с вашими правилами.
Если вы хотите установить правило, чтобы все URL возвращались в нижнем регистре, просто выберите ‘Lowercase discovered URLs’ на вкладке ‘Options’. Это устранит дублирование URL с заглавными буквами.
Помните, что вам придется запустить паука с этими настройками, чтобы произошло переписывание URL.
Исследование ключевых слов
Как узнать, какие страницы наиболее ценны для моих конкурентов
Как правило, конкуренты пытаются увеличить популярность ссылок и привлечь трафик на свои наиболее ценные страницы, размещая на них внутренние ссылки. Любой SEO-мыслящий конкурент, вероятно, также будет ссылаться на важные страницы из своего блога. Чтобы найти ценные страницы конкурентов, просмотрите их сайт, а затем отсортируйте вкладку «Internal» по столбцу «Inlinks» от наибольшего к наименьшему, чтобы увидеть, на каких страницах больше всего внутренних ссылок.
Чтобы просмотреть страницы, на которые ведут ссылки из блога конкурента, снимите флажок ‘Check links outside folder’ («Проверять ссылки вне папки») в меню «Конфигурация паука» и просмотрите папку/поддомен блога. Затем на вкладке ‘External’ отфильтруйте результаты, используя поиск по URL-адресу основного домена. Прокрутите список вправо и отсортируйте его по колонке ‘Inlinks’, чтобы увидеть, на какие страницы чаще всего ссылаются.
Профессиональный совет:
Перетаскивайте столбцы влево или вправо, чтобы улучшить вид данных.
Как узнать, какой анкорный текст используют мои конкуренты для внутренней перелинковки
В меню ‘Bulk Export’ выберите ‘All Anchor Text’, чтобы экспортировать CSV, содержащий весь анкорный текст на сайте, где он используется и на что он ссылается.
Как узнать, какие мета ключевые слова (если таковые имеются) добавили мои конкуренты на свои страницы
После того, как паук закончил работу, посмотрите на вкладку ‘Meta Keywords’, чтобы увидеть все мета ключевые слова, найденные для каждой страницы. Отсортируйте по столбцу ‘Meta Keyword 1’, чтобы упорядочить список по алфавиту и визуально отделить пустые записи, или просто экспортируйте весь список.
Линкбилдинг
Как проанализировать список перспективных мест размещения ссылок
Если вы провели скраппинг или иным образом составили список URL, которые необходимо проверить, вы можете загрузить и просмотреть их в режиме ‘List’, чтобы собрать больше информации о страницах. Когда паук закончит сканирование, проверьте коды состояния на вкладке «Response Codes» и просмотрите исходящие ссылки, типы ссылок, якорный текст и директивы nofollow на вкладке «Outlinks» в нижнем окне. Это даст вам представление о том, на какие сайты и как ссылаются эти страницы. Чтобы просмотреть вкладку «Outlinks», убедитесь, что интересующий вас URL выбран в верхнем окне.
Конечно, вы захотите использовать пользовательский фильтр, чтобы определить, ссылаются ли эти страницы уже на вас.
Вы также можете экспортировать полный список внешних ссылок, нажав на «All Outlinks» в «Bulk Export Menu». Это не только покажет вам ссылки на внешние сайты, но и покажет все внутренние ссылки на отдельных страницах в вашем списке.
Как найти неработающие ссылки, чтобы использовать их для аутрич-возможностей
Итак, вы нашли сайт, с которого вы хотели бы получить ссылку? Используйте Screaming Frog для поиска битых ссылок на нужной странице или на сайте в целом, затем свяжитесь с владельцем сайта, предложите свой сайт в качестве замены битой ссылки, если это возможно, или просто предложите битую ссылку в знак доброй воли.
Как проверить мои обратные ссылки и просмотреть анкорный текст
Загрузите список обратных ссылок и запустите паука в режиме ‘List’. Затем экспортируйте полный список исходящих ссылок, нажав на ‘All Out Links’ в ‘Advanced Export Menu’. В результате вы получите URL-адреса и якорный текст/alt-текст для всех ссылок на этих страницах. Затем вы можете использовать фильтр в столбце ‘Destination’ в CSV, чтобы определить, есть ли на вашем сайте ссылки и какой якорный текст/alt текст включен.
Я нахожусь в процессе очистки своих обратных ссылок и мне нужно проверить, что ссылки удаляются в соответствии с запросом
Установите пользовательский фильтр, содержащий URL вашего корневого домена, затем загрузите список обратных ссылок и запустите паука в режиме ‘List’. Когда паук закончит сканирование, выберите вкладку ‘Custom’, чтобы просмотреть все страницы, которые все еще ссылаются на вас.
Бонусный раунд
Знаете ли вы, что, щелкнув правой кнопкой мыши на любом URL в верхнем окне результатов, вы можете сделать любое из следующих действий?
- Скопировать или открыть URL
- Повторно просканировать URL или удалить его из просмотра
- Экспортировать информацию об URL, входящие ссылки, исходящие ссылки или информацию об изображении для этой страницы.
- Проверить индексацию страницы в Google, Bing и Yahoo
- Проверить обратные ссылки страницы в Majestic, OSE, Ahrefs и Blekko
- Посмотреть кэшированную версию/дату кэширования страницы
- Посмотреть более старые версии страницы
- Проверить валидность HTML страницы
- Открsnm robots.txt для домена, на котором расположена страница
- Искать другие домены на том же IP
Аналогично, в нижнем окне, щелкнув правой кнопкой мыши, вы можете:
- Скопировать или открыть URL-адрес в столбце «To» или «From» для выбранной строки.
Как редактировать метаданные
Режим SERP Mode позволяет просматривать сниппеты поисковой выдачи по устройствам, чтобы наглядно показать, как ваши метаданные будут отображаться в результатах поиска.
- Загрузите URL, заголовки и метаописания в Screaming Frog с помощью документа .CSV или Excel
- Если вы уже выполнили сканирование своего сайта, вы можете экспортировать URL-адреса, перейдя в раздел ‘Reports → SERP Summary’. Это позволит легко отформатировать URL-адреса и мета-описания, которые вы хотите повторно загрузить и отредактировать.
- Mode → SERP → Upload File
- Редактирование метаданных в Screaming Frog
- Массовый экспорт обновленных метаданных для отправки непосредственно разработчикам для обновления
Как просканировать сайт с JavaScript
Все чаще сайты строятся с использованием JavaScript-фреймворков, таких как Angular, React и т. д. Google настоятельно рекомендует использовать решение для рендеринга, поскольку Googlebot все еще с трудом справляется с содержимым на javascript. Если вы обнаружили сайт, построенный с использованием javascript, следуйте приведенным ниже инструкциям, чтобы сканировать его.
- ‘Configuration → Spider → Rendering → JavaScript
- Измените настройки рендеринга в зависимости от того, что вы ищете. Вы можете настроить время ожидания, размер окна (мобильное, планшетное, настольное и т.д.).
- Нажмите OK и сканируйте сайт.
В нижней навигации перейдите на вкладку Rendered Page («Рендеринг страницы»), чтобы посмотреть, как отображается страница. Если страница отображается некорректно, проверьте наличие заблокированных ресурсов или увеличьте лимит тайм-аута в настройках конфигурации. Если ни один из этих способов не помогает решить проблему рендеринга страницы, возможно, необходимо выявить более серьезную проблему.
Вы можете просмотреть и экспортировать в массовом порядке все заблокированные ресурсы, которые могут влиять на краулинг и рендеринг вашего сайта, перейдя в раздел ‘Bulk Export’ → ‘Response Codes’.
Просмотр оригинального HTML и рендеринга HTML
Если вы хотите сравнить исходный HTML и рендеринг HTML, чтобы выявить любые несоответствия или убедиться, что важное содержимое находится в DOM, перейдите в ‘Configuration’ → ‘Spider’ -> ‘Advanced’ и нажмите store HTML & store rendered HTML.
В нижнем окне вы сможете увидеть необработанный и преобразованный HTML. Это может помочь выявить проблемы с тем, как ваше содержимое отображается и просматривается краулерами.
Заключительные замечания
В заключение, я надеюсь, что это руководство даст вам лучшее представление о том, что Screaming Frog может сделать для вас. Оно сэкономило мне бесчисленное количество часов, поэтому я надеюсь, что оно поможет и вам!
Кстати, я не связан со Screaming Frog; я просто считаю, что это потрясающий инструмент.
Источник: https://www.seerinteractive.com/blog/screaming-frog-guide/