
When you’re working with a Python program, you might need to search for and locate a specific string inside another string.
This is where Python’s built-in string methods come in handy.
In this article, you will learn how to use Python’s built-in find() string method to help you search for a substring inside a string.
Here is what we will cover:
- Syntax of the
find()method- How to use
find()with no start and end parameters example - How to use
find()with start and end parameters example - Substring not found example
- Is the
find()method case-sensitive?
- How to use
find()vsinkeywordfind()vsindex()
The find() Method — A Syntax Overview
The find() string method is built into Python’s standard library.
It takes a substring as input and finds its index — that is, the position of the substring inside the string you call the method on.
The general syntax for the find() method looks something like this:
string_object.find("substring", start_index_number, end_index_number)
Let’s break it down:
string_objectis the original string you are working with and the string you will call thefind()method on. This could be any word you want to search through.- The
find()method takes three parameters – one required and two optional. "substring"is the first required parameter. This is the substring you are trying to find insidestring_object. Make sure to include quotation marks.start_index_numberis the second parameter and it’s optional. It specifies the starting index and the position from which the search will start. The default value is0.end_index_numberis the third parameter and it’s also optional. It specifies the end index and where the search will stop. The default is the length of the string.- Both the
start_index_numberand theend_index_numberspecify the range over which the search will take place and they narrow the search down to a particular section.
The return value of the find() method is an integer value.
If the substring is present in the string, find() returns the index, or the character position, of the first occurrence of the specified substring from that given string.
If the substring you are searching for is not present in the string, then find() will return -1. It will not throw an exception.
How to Use find() with No Start and End Parameters Example
The following examples illustrate how to use the find() method using the only required parameter – the substring you want to search.
You can take a single word and search to find the index number of a specific letter:
fave_phrase = "Hello world!"
# find the index of the letter 'w'
search_fave_phrase = fave_phrase.find("w")
print(search_fave_phrase)
#output
# 6
I created a variable named fave_phrase and stored the string Hello world!.
I called the find() method on the variable containing the string and searched for the letter ‘w’ inside Hello world!.
I stored the result of the operation in a variable named search_fave_phrase and then printed its contents to the console.
The return value was the index of w which in this case was the integer 6.
Keep in mind that indexing in programming and Computer Science in general always starts at 0 and not 1.
How to Use find() with Start and End Parameters Example
Using the start and end parameters with the find() method lets you limit your search.
For example, if you wanted to find the index of the letter ‘w’ and start the search from position 3 and not earlier, you would do the following:
fave_phrase = "Hello world!"
# find the index of the letter 'w' starting from position 3
search_fave_phrase = fave_phrase.find("w",3)
print(search_fave_phrase)
#output
# 6
Since the search starts at position 3, the return value will be the first instance of the string containing ‘w’ from that position and onwards.
You can also narrow down the search even more and be more specific with your search with the end parameter:
fave_phrase = "Hello world!"
# find the index of the letter 'w' between the positions 3 and 8
search_fave_phrase = fave_phrase.find("w",3,8)
print(search_fave_phrase)
#output
# 6
Substring Not Found Example
As mentioned earlier, if the substring you specify with find() is not present in the string, then the output will be -1 and not an exception.
fave_phrase = "Hello world!"
# search for the index of the letter 'a' in "Hello world"
search_fave_phrase = fave_phrase.find("a")
print(search_fave_phrase)
# -1
Is the find() Method Case-Sensitive?
What happens if you search for a letter in a different case?
fave_phrase = "Hello world!"
#search for the index of the letter 'W' capitalized
search_fave_phrase = fave_phrase.find("W")
print(search_fave_phrase)
#output
# -1
In an earlier example, I searched for the index of the letter w in the phrase «Hello world!» and the find() method returned its position.
In this case, searching for the letter W capitalized returns -1 – meaning the letter is not present in the string.
So, when searching for a substring with the find() method, remember that the search will be case-sensitive.
The find() Method vs the in Keyword – What’s the Difference?
Use the in keyword to check if the substring is present in the string in the first place.
The general syntax for the in keyword is the following:
substring in string
The in keyword returns a Boolean value – a value that is either True or False.
>>> "w" in "Hello world!"
True
The in operator returns True when the substring is present in the string.
And if the substring is not present, it returns False:
>>> "a" in "Hello world!"
False
Using the in keyword is a helpful first step before using the find() method.
You first check to see if a string contains a substring, and then you can use find() to find the position of the substring. That way, you know for sure that the substring is present.
So, use find() to find the index position of a substring inside a string and not to look if the substring is present in the string.
The find() Method vs the index() Method – What’s the Difference?
Similar to the find() method, the index() method is a string method used for finding the index of a substring inside a string.
So, both methods work in the same way.
The difference between the two methods is that the index() method raises an exception when the substring is not present in the string, in contrast to the find() method that returns the -1 value.
fave_phrase = "Hello world!"
# search for the index of the letter 'a' in 'Hello world!'
search_fave_phrase = fave_phrase.index("a")
print(search_fave_phrase)
#output
# Traceback (most recent call last):
# File "/Users/dionysialemonaki/python_article/demopython.py", line 4, in <module>
# search_fave_phrase = fave_phrase.index("a")
# ValueError: substring not found
The example above shows that index() throws a ValueError when the substring is not present.
You may want to use find() over index() when you don’t want to deal with catching and handling any exceptions in your programs.
Conclusion
And there you have it! You now know how to search for a substring in a string using the find() method.
I hope you found this tutorial helpful.
To learn more about the Python programming language, check out freeCodeCamp’s Python certification.
You’ll start from the basics and learn in an interactive and beginner-friendly way. You’ll also build five projects at the end to put into practice and help reinforce your understanding of the concepts you learned.
Thank you for reading, and happy coding!
Happy coding!
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Текстовые переменные str в Питоне
Строковый тип str в Python используют для работы с любыми текстовыми данными. Python автоматически определяет тип str по кавычкам – одинарным или двойным:
>>> stroka = 'Python'
>>> type(stroka)
<class 'str'>
>>> stroka2 = "code"
>>> type(stroka2)
<class 'str'>
Для решения многих задач строковую переменную нужно объявить заранее, до начала исполнения основной части программы. Создать пустую переменную str просто:
stroka = ''
Или:
stroka2 = ""
Если в самой строке нужно использовать кавычки – например, для названия книги – то один вид кавычек используют для строки, второй – для выделения названия:
>>> print("'Самоучитель Python' - возможно, лучший справочник по Питону.")
'Самоучитель Python' - возможно, лучший справочник по Питону.
>>> print('"Самоучитель Python" - возможно, лучший справочник по Питону.')
"Самоучитель Python" - возможно, лучший справочник по Питону.
Использование одного и того же вида кавычек внутри и снаружи строки вызовет ошибку:
>>> print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
File "<pyshell>", line 1
print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
^
SyntaxError: invalid syntax
Кроме двойных " и одинарных кавычек ', в Python используются и тройные ''' – в них заключают текст, состоящий из нескольких строк, или программный код:
>>> print('''В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.''')
В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.
Длина строки len в Python
Для определения длины строки используется встроенная функция len(). Она подсчитывает общее количество символов в строке, включая пробелы:
>>> stroka = 'python'
>>> print(len(stroka))
6
>>> stroka1 = ' '
>>> print(len(stroka1))
1
Преобразование других типов данных в строку
Целые и вещественные числа преобразуются в строки одинаково:
>>> number1 = 55
>>> number2 = 55.5
>>> stroka1 = str(number1)
>>> stroka2 = str(number2)
>>> print(type(stroka1))
<class 'str'>
>>> print(type(stroka2))
<class 'str'>
Решение многих задач значительно упрощается, если работать с числами в строковом формате. Особенно это касается заданий, где нужно разделять числа на разряды – сотни, десятки и единицы.
Сложение и умножение строк
Как уже упоминалось в предыдущей главе, строки можно складывать – эта операция также известна как конкатенация:
>>> str1 = 'Python'
>>> str2 = ' - '
>>> str3 = 'самый гибкий язык программирования'
>>> print(str1 + str2 + str3)
Python - самый гибкий язык программирования
При необходимости строку можно умножить на целое число – эта операция называется репликацией:
>>> stroka = '*** '
>>> print(stroka * 5)
*** *** *** *** ***
Подстроки
Подстрокой называется фрагмент определенной строки. Например, ‘abra’ является подстрокой ‘abrakadabra’. Чтобы определить, входит ли какая-то определенная подстрока в строку, используют оператор in:
>>> stroka = 'abrakadabra'
>>> print('abra' in stroka)
True
>>> print('zebra' in stroka)
False
Для обращения к определенному символу строки используют индекс – порядковый номер элемента. Python поддерживает два типа индексации – положительную, при которой отсчет элементов начинается с 0 и с начала строки, и отрицательную, при которой отсчет начинается с -1 и с конца:
| Положительные индексы | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Пример строки | P | r | o | g | l | i | b |
| Отрицательные индексы | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Чтобы получить определенный элемент строки, нужно указать его индекс в квадратных скобках:
>>> stroka = 'программирование'
>>> print(stroka[7])
м
>>> print(stroka[-1])
е
Срезы строк в Python
Индексы позволяют работать с отдельными элементами строк. Для работы с подстроками используют срезы, в которых задается нужный диапазон:
>>> stroka = 'программирование'
>>> print(stroka[7:10])
мир
Диапазон среза [a:b] начинается с первого указанного элемента а включительно, и заканчивается на последнем, не включая b в результат:
>>> stroka = 'программa'
>>> print(stroka[3:8])
грамм
Если не указать первый элемент диапазона [:b], срез будет выполнен с начала строки до позиции второго элемента b:
>>> stroka = 'программa'
>>> print(stroka[:4])
прог
В случае отсутствия второго элемента [a:] срез будет сделан с позиции первого символа и до конца строки:
>>> stroka = 'программa'
>>> print(stroka[3:])
граммa
Если не указана ни стартовая, ни финальная позиция среза, он будет равен исходной строке:
>>> stroka = 'позиции не заданы'
>>> print(stroka[:])
позиции не заданы
Шаг среза
Помимо диапазона, можно задавать шаг среза. В приведенном ниже примере выбирается символ из стартовой позиции среза, а затем каждая 3-я буква из диапазона:
>>> stroka = 'Python лучше всего подходит для новичков.'
>>> print(stroka[1:15:3])
yoлшв
Шаг может быть отрицательным – в этом случае символы будут выбираться, начиная с конца строки:
>>> stroka = 'это пример отрицательного шага'
>>> print(stroka[-1:-15:-4])
а нт
Срез [::-1] может оказаться очень полезным при решении задач, связанных с палиндромами:
>>> stroka = 'А роза упала на лапу Азора'
>>> print(stroka[::-1])
арозА упал ан алапу азор А
Замена символа в строке
Строки в Python относятся к неизменяемым типам данных. По этой причине попытка замены символа по индексу обречена на провал:
>>> stroka = 'mall'
>>> stroka[0] = 'b'
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Но заменить любой символ все-таки можно – для этого придется воспользоваться срезами и конкатенацией. Результатом станет новая строка:
>>> stroka = 'mall'
>>> stroka = 'b' + stroka[1:]
>>> print(stroka)
ball
Более простой способ «замены» символа или подстроки – использование метода replace(), который мы рассмотрим ниже.
Полезные методы строк
Python предоставляет множество методов для работы с текстовыми данными. Все методы можно сгруппировать в четыре категории:
- Преобразование строк.
- Оценка и классификация строк.
- Конвертация регистра.
- Поиск, подсчет и замена символов.
Рассмотрим эти методы подробнее.
Преобразование строк
Три самых используемых метода из этой группы – join(), split() и partition(). Метод join() незаменим, если нужно преобразовать список или кортеж в строку:
>>> spisok = ['Я', 'изучаю', 'Python']
>>> stroka = ' '.join(spisok)
>>> print(stroka)
Я изучаю Python
При объединении списка или кортежа в строку можно использовать любые разделители:
>>> kort = ('Я', 'изучаю', 'Django')
>>> stroka = '***'.join(kort)
>>> print(stroka)
Я***изучаю***Django
Метод split() используется для обратной манипуляции – преобразования строки в список:
>>> text = 'это пример текста для преобразования в список'
>>> spisok = text.split()
>>> print(spisok)
['это', 'пример', 'текста', 'для', 'преобразования', 'в', 'список']
По умолчанию split() разбивает строку по пробелам. Но можно указать любой другой символ – и на практике это часто требуется:
>>> text = 'цвет: синий; вес: 1 кг; размер: 30х30х50; материал: картон'
>>> spisok = text.split(';')
>>> print(spisok)
['цвет: синий', ' вес: 1 кг', ' размер: 30х30х50', ' материал: картон']
Метод partition() поможет преобразовать строку в кортеж:
>>> text = 'Python - простой и понятный язык'
>>> kort = text.partition('и')
>>> print(kort)
('Python - простой ', 'и', ' понятный язык')
В отличие от split(), partition() учитывает только первое вхождение элемента-разделителя (и добавляет его в итоговый кортеж).
Оценка и классификация строк
В Python много встроенных методов для оценки и классификации текстовых данных. Некоторые из этих методов работают только со строками, в то время как другие универсальны. К последним относятся, например, функции min() и max():
>>> text = '12345'
>>> print(min(text))
1
>>> print(max(text))
5
В Python есть специальные методы для определения типа символов. Например, isalnum() оценивает, состоит ли строка из букв и цифр, либо в ней есть какие-то другие символы:
>>> text = 'abracadabra123456'
>>> print(text.isalnum())
True
>>> text1 = 'a*b$ra cadabra'
>>> print(text1.isalnum())
False
Метод isalpha() поможет определить, состоит ли строка только из букв, или включает специальные символы, пробелы и цифры:
>>> text = 'программирование'
>>> print(text.isalpha())
True
>>> text2 = 'password123'
>>> print(text2.isalpha())
False
С помощью метода isdigit() можно определить, входят ли в строку только цифры, или там есть и другие символы:
>>> text = '1234567890'
>>> print(text.isdigit())
True
>>> text2 = '123456789o'
>>> print(text2.isdigit())
False
Поскольку вещественные числа содержат точку, а отрицательные – знак минуса, выявить их этим методом не получится:
>>> text = '5.55'
>>> print(text.isdigit())
False
>>> text1 = '-5'
>>> print(text1.isdigit())
False
Если нужно определить наличие в строке дробей или римских цифр, подойдет метод isnumeric():
>>> text = '½⅓¼⅕⅙'
>>> print(text.isdigit())
False
>>> print(text.isnumeric())
True
Методы islower() и isupper() определяют регистр, в котором находятся буквы. Эти методы игнорируют небуквенные символы:
>>> text = 'abracadabra'
>>> print(text.islower())
True
>>> text2 = 'Python bytes'
>>> print(text2.islower())
False
>>> text3 = 'PYTHON'
>>> print(text3.isupper())
True
Метод isspace() определяет, состоит ли анализируемая строка из одних пробелов, или содержит что-нибудь еще:
>>> stroka = ' '
>>> print(stroka.isspace())
True
>>> stroka2 = ' a '
>>> print(stroka2.isspace())
False
Конвертация регистра
Как уже говорилось выше, строки относятся к неизменяемым типам данных, поэтому результатом любых манипуляций, связанных с преобразованием регистра или удалением (заменой) символов будет новая строка.
Из всех методов, связанных с конвертацией регистра, наиболее часто используются на практике два – lower() и upper(). Они преобразуют все символы в нижний и верхний регистр соответственно:
>>> text = 'этот текст надо написать заглавными буквами'
>>> print(text.upper())
ЭТОТ ТЕКСТ НАДО НАПИСАТЬ ЗАГЛАВНЫМИ БУКВАМИ
>>> text = 'зДесь ВСе букВы рАзныЕ, а НУжнЫ проПИСНыЕ'
>>> print(text.lower())
здесь все буквы разные, а нужны прописные
Иногда требуется преобразовать текст так, чтобы с заглавной буквы начиналось только первое слово предложения:
>>> text = 'предложение должно начинаться с ЗАГЛАВНОЙ буквы.'
>>> print(text.capitalize())
Предложение должно начинаться с заглавной буквы.
Методы swapcase() и title() используются реже. Первый заменяет исходный регистр на противоположный, а второй – начинает каждое слово с заглавной буквы:
>>> text = 'пРИМЕР иСПОЛЬЗОВАНИЯ swapcase'
>>> print(text.swapcase())
Пример Использования SWAPCASE
>>> text2 = 'тот случай, когда нужен метод title'
>>> print(text2.title())
Тот Случай, Когда Нужен Метод Title
Поиск, подсчет и замена символов
Методы find() и rfind() возвращают индекс стартовой позиции искомой подстроки. Оба метода учитывают только первое вхождение подстроки. Разница между ними заключается в том, что find() ищет первое вхождение подстроки с начала текста, а rfind() – с конца:
>>> text = 'пример текста, в котором нужно найти текстовую подстроку'
>>> print(text.find('текст'))
7
>>> print(text.rfind('текст'))
37
Такие же результаты можно получить при использовании методов index() и rindex() – правда, придется предусмотреть обработку ошибок, если искомая подстрока не будет обнаружена:
>>> text = 'Съешь еще этих мягких французских булок!'
>>> print(text.index('еще'))
6
>>> print(text.rindex('чаю'))
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
ValueError: substring not found
Если нужно определить, начинается ли строка с определенной подстроки, поможет метод startswith():
>>> text = 'Жила-была курочка Ряба'
>>> print(text.startswith('Жила'))
True
Чтобы проверить, заканчивается ли строка на нужное окончание, используют endswith():
>>> text = 'В конце всех ждал хэппи-енд'
>>> print(text.endswith('енд'))
True
Для подсчета числа вхождений определенного символа или подстроки применяют метод count() – он помогает подсчитать как общее число вхождений в тексте, так и вхождения в указанном диапазоне:
>>> text = 'Съешь еще этих мягких французских булок, да выпей же чаю!'
>>> print(text.count('е'))
5
>>> print(text.count('е', 5, 25))
2
Методы strip(), lstrip() и rstrip() предназначены для удаления пробелов. Метод strip() удаляет пробелы в начале и конце строки, lstrip() – только слева, rstrip() – только справа:
>>> text = ' здесь есть пробелы и слева, и справа '
>>> print('***', text.strip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.lstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.rstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
Метод replace() используют для замены символов или подстрок. Можно указать нужное количество замен, а сам символ можно заменить на пустую подстроку – проще говоря, удалить:
>>> text = 'В этой строчке нужно заменить только одну "ч"'
>>> print(text.replace('ч', '', 1))
В этой строке нужно заменить только одну "ч"
Стоит заметить, что метод replace() подходит лишь для самых простых вариантов замены и удаления подстрок. В более сложных случаях необходимо использование регулярных выражений, которые мы будем изучать позже.
Практика
Задание 1
Напишите программу, которая получает на вход строку и выводит:
- количество символов, содержащихся в тексте;
- True или False в зависимости от того, являются ли все символы буквами и цифрами.
Решение:
text = input()
print(len(text))
print(text.isalpha())
Задание 2
Напишите программу, которая получает на вход слово и выводит True, если слово является палиндромом, или False в противном случае. Примечание: для сравнения в Python используется оператор ==.
Решение:
text = input().lower()
print(text == text[::-1])
Задание 3
Напишите программу, которая получает строку с именем, отчеством и фамилией, написанными в произвольном регистре, и выводит данные в правильном формате. Например, строка алеКСандр СЕРГЕЕВИЧ ПушкиН должна быть преобразована в Александр Сергеевич Пушкин.
Решение:
text = input()
print(text.title())
Задание 4
Имеется строка 12361573928167047230472012. Напишите программу, которая преобразует строку в текст один236один573928один670472304720один2.
Решение:
text = '12361573928167047230472012'
print(text.replace('1', 'один'))
Задание 5
Напишите программу, которая последовательно получает на вход имя, отчество, фамилию и должность сотрудника, а затем преобразует имя и отчество в инициалы, добавляя должность после запятой.
Пример ввода:
Алексей
Константинович
Романов
бухгалтер
Вывод:
А. К. Романов, бухгалтер
Решение:
first_name, patronymic, last_name, position = input(), input(), input(), input()
print(first_name[0] + '.', patronymic[0] + '.', last_name + ',', position)
Задание 6
Напишите программу, которая получает на вход строку текста и букву, а затем определяет, встречается ли данная буква (в любом регистре) в тексте. В качестве ответа программа должна выводить True или False.
Пример ввода:
ЗонтИК
к
Вывод:
True
Решение:
text = input().lower()
letter = input()
print(letter in text)
Задание 7
Напишите программу, которая определяет, является ли введенная пользователем буква гласной. В качестве ответа программы выводит True или False, буквы могут быть как в верхнем, так и в нижнем регистре.
Решение:
vowels = 'аиеёоуыэюя'
letter = input().lower()
print(letter in vowels)
Задание 8
Напишите программу, которая принимает на вход строку текста и подстроку, а затем выводит индексы первого вхождения подстроки с начала и с конца строки (без учета регистра).
Пример ввода:
Шесть шустрых мышат в камышах шуршат
ша
Вывод:
16 33
Решение:
text, letter = input().lower(), input()
print(text.find(letter), text.rfind(letter))
Задание 9
Напишите программу для подсчета количества пробелов и непробельных символов в введенной пользователем строке.
Пример ввода:
В роще, травы шевеля, мы нащиплем щавеля
Вывод:
Количество пробелов: 6, количество других символов: 34
Решение:
text = input()
nospace = text.replace(' ', '')
print(f"Количество пробелов: {text.count(' ')}, количество других символов: {len(nospace)}")
Задание 10
Напишите программу, которая принимает строку и две подстроки start и end, а затем определяет, начинается ли строка с фрагмента start, и заканчивается ли подстрокой end. Регистр не учитывать.
Пример ввода:
Программирование на Python - лучшее хобби
про
про
Вывод:
True
False
Решение:
text, start, end = input().lower(), input(), input()
print(text.startswith(start))
print(text.endswith(end))
Подведем итоги
В этой части мы рассмотрели самые популярные методы работы со строками – они пригодятся для решения тренировочных задач и в разработке реальных проектов. В следующей статье будем разбирать методы работы со списками.
***
📖 Содержание самоучителя
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
- Регулярные выражения
- Основы скрапинга и парсинга
- Основы ООП: инкапсуляция и наследование
- Основы ООП – абстракция и полиморфизм
- Графический интерфейс на Tkinter
***
Материалы по теме
- ТОП-15 трюков в Python 3, делающих код понятнее и быстрее
In this Python tutorial, you’ll learn to search a string in a text file. Also, we’ll see how to search a string in a file and print its line and line number.
After reading this article, you’ll learn the following cases.
- If a file is small, read it into a string and use the
find()method to check if a string or word is present in a file. (easier and faster than reading and checking line per line) - If a file is large, use the mmap to search a string in a file. We don’t need to read the whole file in memory, which will make our solution memory efficient.
- Search a string in multiple files
- Search file for a list of strings
We will see each solution one by one.
Table of contents
- How to Search for a String in Text File
- Example to search for a string in text file
- Search file for a string and Print its line and line number
- Efficient way to search string in a large text file
- mmap to search for a string in text file
- Search string in multiple files
- Search file for a list of strings
How to Search for a String in Text File
Use the file read() method and string class find() method to search for a string in a text file. Here are the steps.
- Open file in a read mode
Open a file by setting a file path and access mode to the
open()function. The access mode specifies the operation you wanted to perform on the file, such as reading or writing. For example, r is for reading.fp= open(r'file_path', 'r') - Read content from a file
Once opened, read all content of a file using the
read()method. Theread()method returns the entire file content in string format. - Search for a string in a file
Use the
find()method of a str class to check the given string or word present in the result returned by theread()method. Thefind()method. The find() method will return -1 if the given text is not present in a file - Print line and line number
If you need line and line numbers, use the
readlines() method instead ofread()method. Use the for loop andreadlines()method to iterate each line from a file. Next, In each iteration of a loop, use the if condition to check if a string is present in a current line and print the current line and line number
Example to search for a string in text file
I have a ‘sales.txt’ file that contains monthly sales data of items. I want the sales data of a specific item. Let’s see how to search particular item data in a sales file.
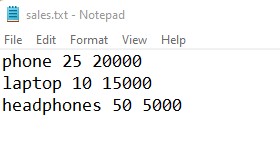
def search_str(file_path, word):
with open(file_path, 'r') as file:
# read all content of a file
content = file.read()
# check if string present in a file
if word in content:
print('string exist in a file')
else:
print('string does not exist in a file')
search_str(r'E:demosfiles_demosaccountsales.txt', 'laptop')Output:
string exists in a file
Search file for a string and Print its line and line number
Use the following steps if you are searching a particular text or a word in a file, and you want to print a line number and line in which it is present.
- Open a file in a read mode.
- Next, use the
readlines()method to get all lines from a file in the form of a list object. - Next, use a loop to iterate each line from a file.
- Next, In each iteration of a loop, use the if condition to check if a string is present in a current line and print the current line and line number.
Example: In this example, we’ll search the string ‘laptop’ in a file, print its line along with the line number.
# string to search in file
word = 'laptop'
with open(r'E:demosfiles_demosaccountsales.txt', 'r') as fp:
# read all lines in a list
lines = fp.readlines()
for line in lines:
# check if string present on a current line
if line.find(word) != -1:
print(word, 'string exists in file')
print('Line Number:', lines.index(line))
print('Line:', line)Output:
laptop string exists in a file line: laptop 10 15000 line number: 1
Note: You can also use the readline() method instead of readlines() to read a file line by line, stop when you’ve gotten to the lines you want. Using this technique, we don’t need to read the entire file.
Efficient way to search string in a large text file
All above way read the entire file in memory. If the file is large, reading the whole file in memory is not ideal.
In this section, we’ll see the fastest and most memory-efficient way to search a string in a large text file.
- Open a file in read mode
- Use for loop with
enumerate()function to get a line and its number. Theenumerate()function adds a counter to an iterable and returns it in enumerate object. Pass the file pointer returned by theopen()function to theenumerate(). - We can use this enumerate object with a for loop to access the each line and line number.
Note: The enumerate(file_pointer) doesn’t load the entire file in memory, so this is an efficient solution.
Example:
with open(r"E:demosfiles_demosaccountsales.txt", 'r') as fp:
for l_no, line in enumerate(fp):
# search string
if 'laptop' in line:
print('string found in a file')
print('Line Number:', l_no)
print('Line:', line)
# don't look for next lines
breakExample:
string found in a file Line Number: 1 Line: laptop 10 15000
mmap to search for a string in text file
In this section, we’ll see the fastest and most memory-efficient way to search a string in a large text file.
Also, you can use the mmap module to find a string in a huge file. The mmap.mmap() method creates a bytearray object that checks the underlying file instead of reading the whole file in memory.
Example:
import mmap
with open(r'E:demosfiles_demosaccountsales.txt', 'rb', 0) as file:
s = mmap.mmap(file.fileno(), 0, access=mmap.ACCESS_READ)
if s.find(b'laptop') != -1:
print('string exist in a file')Output:
string exist in a file
Search string in multiple files
Sometimes you want to search a string in multiple files present in a directory. Use the below steps to search a text in all files of a directory.
- List all files of a directory
- Read each file one by one
- Next, search for a word in the given file. If found, stop reading the files.
Example:
import os
dir_path = r'E:demosfiles_demosaccount'
# iterate each file in a directory
for file in os.listdir(dir_path):
cur_path = os.path.join(dir_path, file)
# check if it is a file
if os.path.isfile(cur_path):
with open(cur_path, 'r') as file:
# read all content of a file and search string
if 'laptop' in file.read():
print('string found')
breakOutput:
string found
Search file for a list of strings
Sometimes you want to search a file for multiple strings. The below example shows how to search a text file for any words in a list.
Example:
words = ['laptop', 'phone']
with open(r'E:demosfiles_demosaccountsales.txt', 'r') as f:
content = f.read()
# Iterate list to find each word
for word in words:
if word in content:
print('string exist in a file')Output:
string exist in a file
Python Exercises and Quizzes
Free coding exercises and quizzes cover Python basics, data structure, data analytics, and more.
- 15+ Topic-specific Exercises and Quizzes
- Each Exercise contains 10 questions
- Each Quiz contains 12-15 MCQ
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, we are going to see how to search for a string in text files using Python
Example:
string = “GEEK FOR GEEKS”
Input: “FOR”
Output: Yes, FOR is present in the given string.
Text File for demonstration:

myfile.txt
Finding the index of the string in the text file using readline()
In this method, we are using the readline() function, and checking with the find() function, this method returns -1 if the value is not found and if found it returns 0.
Python3
with open(r'myfile.txt', 'r') as fp:
lines = fp.readlines()
for row in lines:
word = 'Line 3'
if row.find(word) != -1:
print('string exists in file')
print('line Number:', lines.index(row))
Output:
string exists in file line Number: 2
Finding string in a text file using read()
we are going to search string line by line if the string is found then we will print that string and line number using the read() function.
Python3
with open(r'myfile.txt', 'r') as file:
content = file.read()
if 'Line 8' in content:
print('string exist')
else:
print('string does not exist')
Output:
string does not exist
Search for a String in Text Files using enumerate()
We are just finding string is present in the file or not using the enumerate() in Python.
Python3
with open(r"myfile.txt", 'r') as f:
for index, line in enumerate(f):
if 'Line 3y' in line:
print('string found in a file')
break
print('string does not exist in a file')
Output:
string does not exist in a file
Last Updated :
14 Mar, 2023
Like Article
Save Article
В уроке по присвоению типа переменной в Python вы могли узнать, как определять строки: объекты, состоящие из последовательности символьных данных. Обработка строк неотъемлемая частью программирования на python. Крайне редко приложение, не использует строковые типы данных.
Из этого урока вы узнаете: Python предоставляет большую коллекцию операторов, функций и методов для работы со строками. Когда вы закончите изучение этой документации, узнаете, как получить доступ и извлечь часть строки, а также познакомитесь с методами, которые доступны для манипулирования и изменения строковых данных.
Ниже рассмотрим операторы, методы и функции, доступные для работы с текстом.
Строковые операторы
Вы уже видели операторы + и * в применении их к числовым значениям в уроке по операторам в Python . Эти два оператора применяются и к строкам.
Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из других строк, как показано здесь:
>>> s = 'py'
>>> t = 'th'
>>> u = 'on'
>>> s + t
'pyth'
>>> s + t + u
'python'
>>> print('Привет, ' + 'Мир!')
Go team!!!
Оператор умножения строк *
* — оператор создает несколько копий строки. Если s это строка, а n целое число, любое из следующих выражений возвращает строку, состоящую из n объединенных копий s:
s * n
n * s
Вот примеры умножения строк:
>>> s = 'py.'
>>> s * 4
'py.py.py.py.'
>>> 4 * s
'py.py.py.py.'
Значение множителя n должно быть целым положительным числом. Оно может быть нулем или отрицательным, но этом случае результатом будет пустая строка:
>>> 'py' * -6
''
Если вы создадите строковую переменную и превратите ее в пустую строку, с помощью 'py' * -6, кто-нибудь будет справедливо считать вас немного глупым. Но это сработает.
Оператор принадлежности подстроки in
Python также предоставляет оператор принадлежности, который можно использоваться для манипуляций со строками. Оператор in возвращает True, если подстрока входит в строку, и False, если нет:
>>> s = 'Python'
>>> s in 'I love Python.'
True
>>> s in 'I love Java.'
False
Есть также оператор not in, у которого обратная логика:
>>> 'z' not in 'abc'
True
>>> 'z' not in 'xyz'
False
Python предоставляет множество функций, которые встроены в интерпретатор. Вот несколько, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Изменяет тип объекта на string |
Более подробно о них ниже.
Функция ord(c) возвращает числовое значение для заданного символа.
На базовом уровне компьютеры хранят всю информацию в виде цифр. Для представления символьных данных используется схема перевода, которая содержит каждый символ с его репрезентативным номером.
Самая простая схема в повседневном использовании называется ASCII . Она охватывает латинские символы, с которыми мы чаще работает. Для этих символов ord(c) возвращает значение ASCII для символа c:
>>> ord('a')
97
>>> ord('#')
35
ASCII прекрасен, но есть много других языков в мире, которые часто встречаются. Полный набор символов, которые потенциально могут быть представлены в коде, намного больше обычных латинских букв, цифр и символом.
Unicode — это современный стандарт, который пытается предоставить числовой код для всех возможных символов, на всех возможных языках, на каждой возможной платформе. Python 3 поддерживает Unicode, в том числе позволяет использовать символы Unicode в строках.
Функция ord() также возвращает числовые значения для символов Юникода:
>>> ord('€')
8364
>>> ord('∑')
8721
Функция chr(n) возвращает символьное значение для данного целого числа.
chr() действует обратно ord(). Если задано числовое значение n, chr(n) возвращает строку, представляющую символ n:
>>> chr(97)
'a'
>>> chr(35)
'#'
chr() также обрабатывает символы Юникода:
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
Функция len(s) возвращает длину строки.
len(s) возвращает количество символов в строке s:
>>> s = 'Простоя строка.'
>>> len(s)
15
Функция str(obj) возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен как строка. str(obj) возвращает строковое представление объекта obj:
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('py')
'py'
Индексация строк
Часто в языках программирования, отдельные элементы в упорядоченном наборе данных могут быть доступны с помощью числового индекса или ключа. Этот процесс называется индексация.
В Python строки являются упорядоченными последовательностями символьных данных и могут быть проиндексированы. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках [].
Индексация строк начинается с нуля: у первого символа индекс 0, следующего 1 и так далее. Индекс последнего символа в python — ‘‘длина строки минус один’’.
Например, схематическое представление индексов строки 'foobar' выглядит следующим образом:

Отдельные символы доступны по индексу следующим образом:
>>> s = 'foobar'
>>> s[0]
'f'
>>> s[1]
'o'
>>> s[3]
'b'
>>> s[5]
'r'
Попытка обращения по индексу большему чем len(s) - 1, приводит к ошибке IndexError:
>>> s[6]
Traceback (most recent call last):
File "", line 1, in <module>
s[6]
IndexError: string index out of range
Индексы строк также могут быть указаны отрицательными числами. В этом случае индексирование начинается с конца строки: -1 относится к последнему символу, -2 к предпоследнему и так далее. Вот такая же диаграмма, показывающая как положительные, так и отрицательные индексы строки 'foobar':

Вот несколько примеров отрицательного индексирования:
>>> s = 'foobar'
>>> s[-1]
'r'
>>> s[-2]
'a'
>>> len(s)
6
>>> s[-len(s)] # отрицательная индексация начинается с -1
'f'
Попытка обращения по индексу меньшему чем -len(s), приводит к ошибке IndexError:
>>> s[-7]
Traceback (most recent call last):
File "", line 1, in <module>
s[-7]
IndexError: string index out of range
Для любой непустой строки s, код s[len(s)-1] и s[-1] возвращают последний символ. Нет индекса, который применим к пустой строке.
Срезы строк
Python также допускает возможность извлечения подстроки из строки, известную как ‘‘string slice’’. Если s это строка, выражение формы s[m:n] возвращает часть s, начинающуюся с позиции m, и до позиции n, но не включая позицию:
>>> s = 'python'
>>> s[2:5]
'tho'
Помните: индексы строк в python начинаются с нуля. Первый символ в строке имеет индекс
0. Это относится и к срезу.
Опять же, второй индекс указывает символ, который не включен в результат. Символ 'n' в приведенном выше примере. Это может показаться немного не интуитивным, но дает результат: выражение s[m:n] вернет подстроку, которая является разницей n - m, в данном случае 5 - 2 = 3.
Если пропустить первый индекс, срез начинается с начала строки. Таким образом, s[:m] = s[0:m]:
>>> s = 'python'
>>> s[:4]
'pyth'
>>> s[0:4]
'pyth'
Аналогично, если опустить второй индекс s[n:], срез длится от первого индекса до конца строки. Это хорошая, лаконичная альтернатива более громоздкой s[n:len(s)]:
>>> s = 'python'
>>> s[2:]
'thon'
>>> s[2:len(s)]
'thon'
Для любой строки s и любого целого n числа (0 ≤ n ≤ len(s)), s[:n] + s[n:]будет s:
>>> s = 'python'
>>> s[:4] + s[4:]
'python'
>>> s[:4] + s[4:] == s
True
Пропуск обоих индексов возвращает исходную строку. Это не копия, это ссылка на исходную строку:
>>> s = 'python'
>>> t = s[:]
>>> id(s)
59598496
>>> id(t)
59598496
>>> s is t
True
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
>>> s[2:2]
''
>>> s[4:2]
''
Отрицательные индексы можно использовать и со срезами. Вот пример кода Python:
>>> s = 'python'
>>> s[-5:-2]
'yth'
>>> s[1:4]
'yth'
>>> s[-5:-2] == s[1:4]
True
Шаг для среза строки
Существует еще один вариант синтаксиса среза, о котором стоит упомянуть. Добавление дополнительного : и третьего индекса означает шаг, который указывает, сколько символов следует пропустить после извлечения каждого символа в срезе.
Например , для строки 'python' срез 0:6:2 начинается с первого символа и заканчивается последним символом (всей строкой), каждый второй символ пропускается. Это показано на следующей схеме:

Иллюстративный код показан здесь:
>>> s = 'foobar'
>>> s[0:6:2]
'foa'
>>> s[1:6:2]
'obr'
Как и в случае с простым срезом, первый и второй индексы могут быть пропущены:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::5]
'11111'
>>> s[4::5]
'55555'
Вы также можете указать отрицательное значение шага, в этом случае Python идет с конца строки. Начальный/первый индекс должен быть больше конечного/второго индекса:
>>> s = 'python'
>>> s[5:0:-2]
'nhy'
В приведенном выше примере, 5:0:-2 означает «начать с последнего символа и делать два шага назад, но не включая первый символ.”
Когда вы идете назад, если первый и второй индексы пропущены, значения по умолчанию применяются так: первый индекс — конец строки, а второй индекс — начало. Вот пример:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::-5]
'55555'
Это общая парадигма для разворота (reverse) строки:
>>> s = 'Если так говорит товарищ Наполеон, значит, так оно и есть.'
>>> s[::-1]
'.ьтсе и оно кат ,тичанз ,ноелопаН щиравот тировог кат илсЕ'
Форматирование строки
В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Возможности форматирования строк огромны и не будут подробно описана здесь.
Одной простой особенностью f-строк, которые вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале (f'string'), и python заменит имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Это можно сделать с помощью простого print() и оператора ,, разделяющего числовые значения и строковые:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print('Произведение', n, 'на', m, 'равно', prod)
Произведение 20 на 25 равно 500
Но это громоздко. Чтобы выполнить то же самое с помощью f-строки:
- Напишите
fилиFперед кавычками строки. Это укажет python, что это f-строка вместо стандартной. - Укажите любые переменные для воспроизведения в фигурных скобках (
{}).
Код с использованием f-string, приведенный ниже выглядит намного чище:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'Произведение {n} на {m} равно {prod}')
Произведение 20 на 25 равно 500
Любой из трех типов кавычек в python можно использовать для f-строки:
>>> var = 'Гав'
>>> print(f'Собака говорит {var}!')
Собака говорит Гав!
>>> print(f"Собака говорит {var}!")
Собака говорит Гав!
>>> print(f'''Собака говорит {var}!''')
Собака говорит Гав!
Изменение строк
Строки — один из типов данных, которые Python считает неизменяемыми, что означает невозможность их изменять. Как вы ниже увидите, python дает возможность изменять (заменять и перезаписывать) строки.
Такой синтаксис приведет к ошибке TypeError:
>>> s = 'python'
>>> s[3] = 't'
Traceback (most recent call last):
File "", line 1, in <module>
s[3] = 't'
TypeError: 'str' object does not support item assignment
На самом деле нет особой необходимости изменять строки. Обычно вы можете легко сгенерировать копию исходной строки с необходимыми изменениями. Есть минимум 2 способа сделать это в python. Вот первый:
>>> s = s[:3] + 't' + s[4:]
>>> s
'pytton'
Есть встроенный метод string.replace(x, y):
>>> s = 'python'
>>> s = s.replace('h', 't')
>>> s
'pytton'
Читайте дальше о встроенных методах строк!
Встроенные методы строк в python
В руководстве по типам переменных в python вы узнали, что Python — это объектно-ориентированный язык. Каждый элемент данных в программе python является объектом.
Вы также знакомы с функциями: самостоятельными блоками кода, которые вы можете вызывать для выполнения определенных задач.
Методы похожи на функции. Метод — специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается только вместе с определенным объектом и знает о нем во время выполнения.
Синтаксис для вызова метода объекта выглядит следующим образом:
obj.foo(<args>)
Этот код вызывает метод .foo() объекта obj. — аргументы, передаваемые методу (если есть).
Вы узнаете намного больше об определении и вызове методов позже в статьях про объектно-ориентированное программирование. Сейчас цель усвоить часто используемые встроенные методы, которые есть в python для работы со строками.
В приведенных методах аргументы, указанные в квадратных скобках ([]), являются необязательными.
Изменение регистра строки
Методы этой группы выполняют преобразование регистра строки.
string.capitalize() приводит первую букву в верхний регистр, остальные в нижний.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и остальными символами, преобразованными в нижний регистр:
>>> s = 'everyTHing yoU Can IMaGine is rEAl'
>>> s.capitalize()
'Everything you can imagine is real'
Не алфавитные символы не изменяются:
>>> s = 'follow us @PYTHON'
>>> s.capitalize()
'Follow us @python'
string.lower() преобразует все буквенные символы в строчные.
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
>>> 'everyTHing yoU Can IMaGine is rEAl'.lower()
'everything you can imagine is real'
string.swapcase() меняет регистр буквенных символов на противоположный.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
>>> 'everyTHing yoU Can IMaGine is rEAl'.swapcase()
'EVERYthING YOu cAN imAgINE IS ReaL'
string.title() преобразует первые буквы всех слов в заглавные
s.title() возвращает копию, s в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы — в нижний регистр:
>>> 'the sun also rises'.title()
'The Sun Also Rises'
Этот метод использует довольно простой алгоритм. Он не пытается различить важные и неважные слова и не обрабатывает апострофы, имена или аббревиатуры:
>>> 'follow us @PYTHON'.title()
'Follow Us @Python'
string.upper() преобразует все буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами в верхнем регистре:
>>> 'follow us @PYTHON'.upper()
'FOLLOW US @PYTHON'
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы и аргументы. Они задают диапазон поиска: действие метода ограничено частью целевой строки, начинающейся в позиции символа и продолжающейся вплоть до позиции символа , но не включая его. Если указано, а нет, метод применяется к части строки от конца.
string.count([, [, ]]) подсчитывает количество вхождений подстроки в строку.
s.count() возвращает количество точных вхождений подстроки в s:
>>> 'foo goo moo'.count('oo')
3
Количество вхождений изменится, если указать и :
>>> 'foo goo moo'.count('oo', 0, 8)
2
string.endswith([, [, ]]) определяет, заканчивается ли строка заданной подстрокой.
s.endswith() возвращает, True если s заканчивается указанным и False если нет:
>>> 'python'.endswith('on')
True
>>> 'python'.endswith('or')
False
Сравнение ограничено подстрокой, между и , если они указаны:
>>> 'python'.endswith('yt', 0, 4)
True
>>> 'python'.endswith('yt', 2, 4)
False
string.find([, [, ]]) ищет в строке заданную подстроку.
s.find() возвращает первый индекс в s который соответствует началу строки :
>>> 'Follow Us @Python'.find('Us')
7
Этот метод возвращает, -1 если указанная подстрока не найдена:
>>> 'Follow Us @Python'.find('you')
-1
Поиск в строке ограничивается подстрокой, между и , если они указаны:
>>> 'Follow Us @Python'.find('Us', 4)
7
>>> 'Follow Us @Python'.find('Us', 4, 7)
-1
string.index([, [, ]]) ищет в строке заданную подстроку.
Этот метод идентичен .find(), за исключением того, что он вызывает исключение ValueError, если не найден:
>>> 'Follow Us @Python'.index('you')
Traceback (most recent call last):
File "", line 1, in <module>
'Follow Us @Python'.index('you')
ValueError: substring not found
string.rfind([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
s.rfind() возвращает индекс последнего вхождения подстроки в s, который соответствует началу :
>>> 'Follow Us @Python'.rfind('o')
15
Как и в .find(), если подстрока не найдена, возвращается -1:
>>> 'Follow Us @Python'.rfind('a')
-1
Поиск в строке ограничивается подстрокой, между и , если они указаны:
>>> 'Follow Us @Python'.rfind('Us', 0, 14)
7
>>> 'Follow Us @Python'.rfind('Us', 9, 14)
-1
string.rindex([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
Этот метод идентичен .rfind(), за исключением того, что он вызывает исключение ValueError, если не найден:
>>> 'Follow Us @Python'.rindex('you')
Traceback (most recent call last):
File "", line 1, in <module>
'Follow Us @Python'.rindex('you')
ValueError: substring not found
string.startswith([, [, ]]) определяет, начинается ли строка с заданной подстроки.
s.startswith() возвращает, True если s начинается с указанного и False если нет:
>>> 'Follow Us @Python'.startswith('Fol')
True
>>> 'Follow Us @Python'.startswith('Go')
False
Сравнение ограничено подстрокой, между и , если они указаны:
>>> 'Follow Us @Python'.startswith('Us', 7)
True
>>> 'Follow Us @Python'.startswith('Us', 8, 16)
False
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
string.isalnum() определяет, состоит ли строка из букв и цифр.
s.isalnum() возвращает True, если строка s не пустая, а все ее символы буквенно-цифровые (либо буква, либо цифра). В другом случае False :
>>> 'abc123'.isalnum()
True
>>> 'abc$123'.isalnum()
False
>>> ''.isalnum()
False
string.isalpha() определяет, состоит ли строка только из букв.
s.isalpha() возвращает True, если строка s не пустая, а все ее символы буквенные. В другом случае False:
>>> 'ABCabc'.isalpha()
True
>>> 'abc123'.isalpha()
False
string.isdigit() определяет, состоит ли строка из цифр (проверка на число).
s.digit() возвращает True когда строка s не пустая и все ее символы являются цифрами, а в False если нет:
>>> '123'.isdigit()
True
>>> '123abc'.isdigit()
False
string.isidentifier() определяет, является ли строка допустимым идентификатором Python.
s.isidentifier() возвращает True, если s валидный идентификатор (название переменной, функции, класса и т.д.) python, а в False если нет:
>>> 'foo32'.isidentifier()
True
>>> '32foo'.isidentifier()
False
>>> 'foo$32'.isidentifier()
False
Важно: .isidentifier() вернет True для строки, которая соответствует зарезервированному ключевому слову python, даже если его нельзя использовать:
>>> 'and'.isidentifier()
True
Вы можете проверить, является ли строка ключевым словом Python, используя функцию iskeyword(), которая находится в модуле keyword. Один из возможных способов сделать это:
>>> from keyword import iskeyword
>>> iskeyword('and')
True
Если вы действительно хотите убедиться, что строку можно использовать как идентификатор python, вы должны проверить, что .isidentifier() = True и iskeyword() = False.
string.islower() определяет, являются ли буквенные символы строки строчными.
s.islower() возвращает True, если строка s не пустая, и все содержащиеся в нем буквенные символы строчные, а False если нет. Не алфавитные символы игнорируются:
>>> 'abc'.islower()
True
>>> 'abc1$d'.islower()
True
>>> 'Abc1$D'.islower()
False
string.isprintable() определяет, состоит ли строка только из печатаемых символов.
s.isprintable() возвращает, True если строка s пустая или все буквенные символы которые она содержит можно вывести на экран. Возвращает, False если s содержит хотя бы один специальный символ. Не алфавитные символы игнорируются:
>>> 'atb'.isprintable() # t - символ табуляции
False
>>> 'a b'.isprintable()
True
>>> ''.isprintable()
True
>>> 'anb'.isprintable() # n - символ перевода строки
False
Важно: Это единственный .is****() метод, который возвращает True, если s пустая строка. Все остальные возвращаются False.
string.isspace() определяет, состоит ли строка только из пробельных символов.
s.isspace() возвращает True, если s не пустая строка, и все символы являются пробельными, а False, если нет.
Наиболее часто встречающиеся пробельные символы — это пробел ' ', табуляция 't' и новая строка 'n':
>>> ' t n '.isspace()
True
>>> ' a '.isspace()
False
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
>>> 'fu2005r'.isspace()
True
'f' и 'r' являются escape-последовательностями для символов ASCII; 'u2005' это escape-последовательность для Unicode.
string.istitle() определяет, начинаются ли слова строки с заглавной буквы.
s.istitle() возвращает True когда s не пустая строка и первый алфавитный символ каждого слова в верхнем регистре, а все остальные буквенные символы в каждом слове строчные. Возвращает False, если нет:
>>> 'This Is A Title'.istitle()
True
>>> 'This is a title'.istitle()
False
>>> 'Give Me The #$#@ Ball!'.istitle()
True
string.isupper() определяет, являются ли буквенные символы строки заглавными.
s.isupper() возвращает True, если строка s не пустая, и все содержащиеся в ней буквенные символы являются заглавными, и в False, если нет. Не алфавитные символы игнорируются:
>>> 'ABC'.isupper()
True
>>> 'ABC1$D'.isupper()
True
>>> 'Abc1$D'.isupper()
False
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
string.center([, ]) выравнивает строку по центру.
s.center() возвращает строку, состоящую из s выровненной по ширине . По умолчанию отступ состоит из пробела ASCII:
>>> 'py'.center(10)
' py '
Если указан необязательный аргумент , он используется как символ заполнения:
>>> 'py'.center(10, '-')
'----py----'
Если s больше или равна , строка возвращается без изменений:
>>> 'python'.center(2)
'python'
string.expandtabs(tabsize=8) заменяет табуляции на пробелы
s.expandtabs() заменяет каждый символ табуляции ('t') пробелами. По умолчанию табуляция заменяются на 8 пробелов:
>>> 'atbtc'.expandtabs()
'a b c'
>>> 'aaatbbbtc'.expandtabs()
'aaa bbb c'
tabsize необязательный параметр, задающий количество пробелов:
>>> 'atbtc'.expandtabs(4)
'a b c'
>>> 'aaatbbbtc'.expandtabs(tabsize=4)
'aaa bbb c'
string.ljust([, ]) выравнивание по левому краю строки в поле.
s.ljust() возвращает строку s, выравненную по левому краю в поле шириной . По умолчанию отступ состоит из пробела ASCII:
>>> 'python'.ljust(10)
'python '
Если указан аргумент , он используется как символ заполнения:
>>> 'python'.ljust(10, '-')
'python----'
Если s больше или равна , строка возвращается без изменений:
>>> 'python'.ljust(2)
'python'
string.lstrip([]) обрезает пробельные символы слева
s.lstrip()возвращает копию s в которой все пробельные символы с левого края удалены:
>>> ' foo bar baz '.lstrip()
'foo bar baz '
>>> 'tnfootnbartnbaz'.lstrip()
'footnbartnbaz'
Необязательный аргумент , определяет набор символов, которые будут удалены:
>>> 'https://www.pythonru.com'.lstrip('/:pths')
'www.pythonru.com'
string.replace(, [, ]) заменяет вхождения подстроки в строке.
s.replace(, ) возвращает копию s где все вхождения подстроки , заменены на :
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love')
'I love python! I love python! I love python!'
Если указан необязательный аргумент , выполняется количество замен:
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love', 2)
'I love python! I love python! I hate python!'
string.rjust([, ]) выравнивание по правому краю строки в поле.
s.rjust() возвращает строку s, выравненную по правому краю в поле шириной . По умолчанию отступ состоит из пробела ASCII:
>>> 'python'.rjust(10)
' python'
Если указан аргумент , он используется как символ заполнения:
>>> 'python'.rjust(10, '-')
'----python'
Если s больше или равна , строка возвращается без изменений:
>>> 'python'.rjust(2)
'python'
string.rstrip([]) обрезает пробельные символы справа
s.rstrip() возвращает копию s без пробельных символов, удаленных с правого края:
>>> ' foo bar baz '.rstrip()
' foo bar baz'
>>> 'footnbartnbaztn'.rstrip()
'footnbartnbaz'
Необязательный аргумент , определяет набор символов, которые будут удалены:
>>> 'foo.$$$;'.rstrip(';$.')
'foo'
string.strip([]) удаляет символы с левого и правого края строки.
s.strip() эквивалентно последовательному вызову s.lstrip()и s.rstrip(). Без аргумента метод удаляет пробелы в начале и в конце:
>>> s = ' foo bar bazttt'
>>> s = s.lstrip()
>>> s = s.rstrip()
>>> s
'foo bar baz'
Как в .lstrip() и .rstrip(), необязательный аргумент определяет набор символов, которые будут удалены:
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
>>> ' foo bar bazttt'.lstrip().rstrip()
'foo bar baz'
>>> ' foo bar bazttt'.strip()
'foo bar baz'
>>> 'www.pythonru.com'.lstrip('w.').rstrip('.moc')
'pythonru'
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
string.zfill() дополняет строку нулями слева.
s.zfill() возвращает копию s дополненную '0' слева для достижения длины строки указанной в :
>>> '42'.zfill(5)
'00042'
Если s содержит знак перед цифрами, он остается слева строки:
>>> '+42'.zfill(8)
'+0000042'
>>> '-42'.zfill(8)
'-0000042'
Если s больше или равна , строка возвращается без изменений:
>>> '-42'.zfill(3)
'-42'
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если в ней нет чисел:
>>> 'foo'.zfill(6)
'000foo'
Методы преобразование строки в список
Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Эти методы возвращают или принимают итерируемые объекты — термин Python для последовательного набора объектов.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих типа данных, которые являются прототипами примеров итераций в python. Список заключен в квадратные скобки ( []), а кортеж заключен в простые (()).
Теперь давайте посмотрим на последнюю группу строковых методов.
string.join() объединяет список в строку.
s.join() возвращает строку, которая является результатом конкатенации объекта с разделителем s.
Обратите внимание, что .join() вызывается строка-разделитель s . должна быть последовательностью строковых объектов.
Примеры кода помогут вникнуть. В первом примере разделителем s является строка ', ', а список строк:
>>> ', '.join(['foo', 'bar', 'baz', 'qux'])
'foo, bar, baz, qux'
В результате получается одна строка, состоящая из списка объектов, разделенных запятыми.
В следующем примере указывается как одно строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
>>> list('corge')
['c', 'o', 'r', 'g', 'e']
>>> ':'.join('corge')
'c:o:r:g:e'
Таким образом, результатом ':'.join('corge') является строка, состоящая из каждого символа в 'corge', разделенного символом ':'.
Этот пример завершается с ошибкой TypeError, потому что один из объектов в не является строкой:
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
Это можно исправить так:
>>> '---'.join(['foo', str(23), 'bar'])
'foo---23---bar'
Как вы скоро увидите, многие объекты в Python можно итерировать, и .join() особенно полезен для создания из них строк.
string.partition() делит строку на основе разделителя.
s.partition() отделяет от s подстроку длиной от начала до первого вхождения . Возвращаемое значение представляет собой кортеж из трех частей:
- Часть
sдо - Разделитель
- Часть
sпосле
Вот пара примеров .partition()в работе:
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
Если не найден в s, возвращаемый кортеж содержит s и две пустые строки:
>>> 'foo.bar'.partition('@@')
('foo.bar', '', '')
s.rpartition() делит строку на основе разделителя, начиная с конца.
s.rpartition() работает как s.partition(), за исключением того, что s делится при последнем вхождении вместо первого:
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок.
Без аргументов s.rsplit() делит s на подстроки, разделенные любой последовательностью пробелов, и возвращает список:
>>> 'foo bar baz qux'.rsplit()
['foo', 'bar', 'baz', 'qux']
>>> 'foontbar bazrfqux'.rsplit()
['foo', 'bar', 'baz', 'qux']
Если указан, он используется в качестве разделителя:
>>> 'foo.bar.baz.qux'.rsplit(sep='.')
['foo', 'bar', 'baz', 'qux']
Если = None, строка разделяется пробелами, как если бы не был указан вообще.
Когда явно указан в качестве разделителя s, последовательные повторы разделителя будут возвращены как пустые строки:
>>> 'foo...bar'.rsplit(sep='.')
['foo', '', '', 'bar']
Это не работает, когда не указан. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
>>> 'footttbar'.rsplit()
['foo', 'bar']
Если указан необязательный параметр , выполняется максимальное количество разделений, начиная с правого края s:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=1)
['www.pythonru', 'com']
Значение по умолчанию для — -1. Это значит, что все возможные разделения должны быть выполнены:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=-1)
['www', 'pythonru', 'com']
>>> 'www.pythonru.com'.rsplit(sep='.')
['www', 'pythonru', 'com']
string.split(sep=None, maxsplit=-1) делит строку на список из подстрок.
s.split() ведет себя как s.rsplit(), за исключением того, что при указании , деление начинается с левого края s:
>>> 'www.pythonru.com'.split('.', maxsplit=1)
['www', 'pythonru.com']
>>> 'www.pythonru.com'.rsplit('.', maxsplit=1)
['www.pythonru', 'com']
Если не указано, между .rsplit() и .split() в python разницы нет.
string.splitlines([]) делит текст на список строк.
s.splitlines() делит s на строки и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
|---|---|
| n | Новая строка |
| r | Возврат каретки |
| rn | Возврат каретки + перевод строки |
| v или же x0b | Таблицы строк |
| f или же x0c | Подача формы |
| x1c | Разделитель файлов |
| x1d | Разделитель групп |
| x1e | Разделитель записей |
| x85 | Следующая строка |
| u2028 | Новая строка (Unicode) |
| u2029 | Новый абзац (Unicode) |
Вот пример использования нескольких различных разделителей строк:
>>> 'foonbarrnbazfquxu2028quux'.splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
Если в строке присутствуют последовательные символы границы строки, они появятся в списке результатов, как пустые строки:
>>> 'foofffbar'.splitlines()
['foo', '', '', 'bar']
Если необязательный аргумент указан и его булевое значение True, то символы границы строк сохраняются в списке подстрок:
>>> 'foonbarnbaznqux'.splitlines(True)
['foon', 'barn', 'bazn', 'qux']
>>> 'foonbarnbaznqux'.splitlines(8)
['foon', 'barn', 'bazn', 'qux']
Заключение
В этом руководстве было подробно рассмотрено множество различных механизмов, которые Python предоставляет для работы со строками, включая операторы, встроенные функции, индексирование, срезы и встроенные методы.
Python есть другие встроенные типы данных. В этих урока вы изучите два наиболее часто используемых:
- Списки python
- Кортежи (tuple)