Мини-задача на разогрев: являются ли две строки анаграммами?
Как проверить, содержит ли строка Python другую строку?
Проверка, содержит ли строка какую-нибудь другую строку, это одна из самых распространенных операций, осуществляемых разработчиками.
Если вы раньше (до перехода на Python) писали код, скажем, на Java, для подобной проверки вы могли использовать метод contains.
В Python есть два способа достичь той же
цели.
1. Использование оператора
in
Самый простой способ проверить, содержится ли в строке другая строка, это использовать оператор Python in.
Давайте рассмотрим пример.
>>> str = "Messi is the best soccer player" >>> "soccer" in str True >>> "football" in str False
Как видите, оператор in возвращает True, если указанная подстрока является частью строки. В противном случае он возвращает False.
Этот метод очень простой, понятный,
читаемый и идиоматичный.
2. Использование метода find
Также для проверки вхождения одной строки в другую можно использовать строковый метод find.
В отличие от оператора, возвращающего булево значение, метод find возвращает целое число.
Это число является по сути индексом начала подстроки, если она есть в указанной строке. Если этой подстроки в строке не содержится, метод возвращает -1.
Давайте посмотрим, как работает метод find.
>>> str = "Messi is the best soccer player"
>>> str.find("soccer")
18
>>> str.find("Ronaldo")
-1
>>> str.find("Messi")
0
Что особенно хорошо в применении этого
метода — вы можете при желании ограничить
пределы поиска, указав начальный и
конечный индекс.
Например:
>>> str = "Messi is the best soccer player"
>>> str.find("soccer", 5, 25)
18
>>> str.find("Messi", 5, 25)
-1
Обратите внимание, что для подстроки «Messi» метод вернул -1. Это произошло потому, что мы ограничили поиск в строке промежутком символов с индексами от 5-го до 25-го.
Более сложные способы
Представьте на минутку, что в Python нет
никаких встроенных функций или методов,
позволяющих проверить, входит ли одна
строка в другую. Как бы вы написали
функцию для этой цели?
Можно использовать брутфорс-подход
и на каждой возможной позиции в строке
проверять, начинается ли там искомая
подстрока. Но для длинных строк этот
процесс будет очень медленным.
Есть лучшие алгоритмы поиска строк. Если вы хотите углубиться в эту тему, можем порекомендовать статью «Rabin-Karp and Knuth-Morris-Pratt Algorithms». Также вам может пригодиться статья «Поиск подстроки» в Википедии.
Если вы прочитаете указанные статьи,
у вас может родиться закономерный
вопрос: так какой же алгоритм используется
в Python?
Для поиска ответов на подобные вопросы практически всегда нужно углубиться в исходный код. В этом плане вам повезло: Python это технология с открытым кодом. Давайте же в него заглянем.
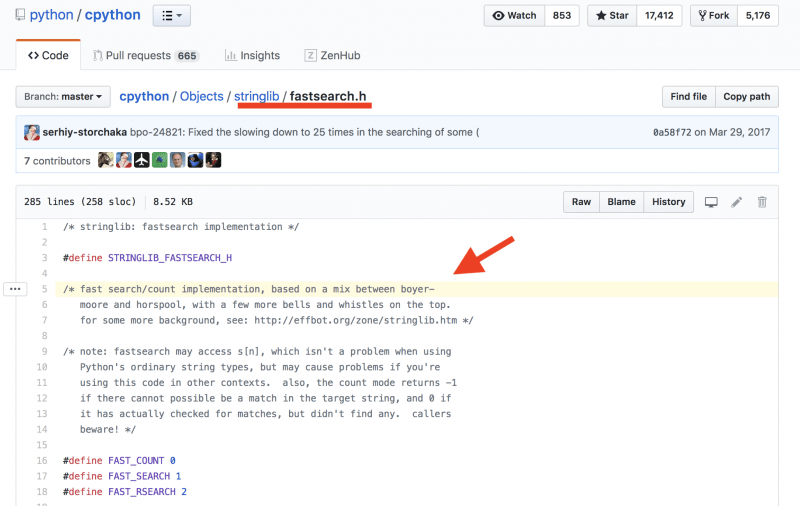
Как удачно, что разработчики прокомментировали свой код! Теперь нам совершенно ясно, что метод find использует смесь алгоритмов Бойера-Мура и Бойера-Мура-Хорспула.
Заключение
Для проверки, содержится ли указанная строка в другой строке, в Python можно использовать оператор in или метод find.
Оператор in возвращает True, если указанная подстрока является частью другой строки. В противном случае он возвращает False.
Метод find возвращает индекс начала подстроки в строке, если эта подстрока там есть, или -1 — если подстрока не найдена.
str.find() and str.index() are nearly identical. the biggest difference is that when a string is not found, str.index() throws an error, like the one you got, while str.find() returns -1 as others’ have posted.
there are 2 sister methods called str.rfind() and str.rindex() which start the search from the end of the string and work their way towards the beginning.
in addition, as others have already shown, the in operator (as well as not in) are perfectly valid as well.
finally, if you’re trying to look for patterns within strings, you may consider regular expressions, although i think too many people use them when they’re overkill. in other (famous) words, «now you have two problems.»
that’s it as far as all the info i have for now. however, if you are learning Python and/or learning programming, one highly useful exercise i give to my students is to try and build *find() and *index() in Python code yourself, or even in and not in (although as functions). you’ll get good practice traversing through strings, and you’ll have a better understanding as far as how the existing string methods work.
good luck!
Я начал вести список наиболее часто используемых функций, решая алгоритмические задачи на LeetCode и HackerRank.
Быть хорошим программистом — это не значит помнить все встроенные функции некоего языка. Но это не означает и того, что их запоминание — бесполезное дело. Особенно — если речь идёт о подготовке к собеседованию.
Хочу сегодня поделиться со всеми желающими моей шпаргалкой по работе со строками в Python. Я оформил её в виде списка вопросов, который использую для самопроверки. Хотя эти вопросы и не тянут на полноценные задачи, которые предлагаются на собеседованиях, их освоение поможет вам в решении реальных задач по программированию.

1. Как проверить два объекта на идентичность?
Оператор is возвращает True в том случае, если в две переменные записана ссылка на одну и ту же область памяти. Именно об этом идёт речь при разговоре об «идентичности объектов».
Не стоит путать is и ==. Оператор == проверяет лишь равенство объектов.
animals = ['python','gopher']
more_animals = animals
print(animals == more_animals) #=> True
print(animals is more_animals) #=> True
even_more_animals = ['python','gopher']
print(animals == even_more_animals) #=> True
print(animals is even_more_animals) #=> False
Обратите внимание на то, что animals и even_more_animals не идентичны, хотя и равны друг другу.
Кроме того, существует функция id(), которая возвращает идентификатор адреса памяти, связанного с именем переменной. При вызове этой функции для двух идентичных объектов будет выдан один и тот же идентификатор.
name = 'object'
id(name)
#=> 4408718312
2. Как проверить то, что каждое слово в строке начинается с заглавной буквы?
Существует строковый метод istitle(), который проверяет, начинается ли каждое слово в строке с заглавной буквы.
print( 'The Hilton'.istitle() ) #=> True
print( 'The dog'.istitle() ) #=> False
print( 'sticky rice'.istitle() ) #=> False
3. Как проверить строку на вхождение в неё другой строки?
Существует оператор in, который вернёт True в том случае, если строка содержит искомую подстроку.
print( 'plane' in 'The worlds fastest plane' ) #=> True
print( 'car' in 'The worlds fastest plane' ) #=> False
4. Как найти индекс первого вхождения подстроки в строку?
Есть два метода, возвращающих индекс первого вхождения подстроки в строку. Это — find() и index(). У каждого из них есть определённые особенности.
Метод find() возвращает -1 в том случае, если искомая подстрока в строке не найдена.
'The worlds fastest plane'.find('plane') #=> 19
'The worlds fastest plane'.find('car') #=> -1
Метод index() в подобной ситуации выбрасывает ошибку ValueError.
'The worlds fastest plane'.index('plane') #=> 19
'The worlds fastest plane'.index('car') #=> ValueError: substring not found
5. Как подсчитать количество символов в строке?
Функция len() возвращает длину строки.
len('The first president of the organization..') #=> 41
6. Как подсчитать то, сколько раз определённый символ встречается в строке?
Ответить на этот вопрос нам поможет метод count(), который возвращает количество вхождений в строку заданного символа.
'The first president of the organization..'.count('o') #=> 3
7. Как сделать первый символ строки заглавной буквой?
Для того чтобы это сделать, можно воспользоваться методом capitalize().
'florida dolphins'.capitalize() #=> 'Florida dolphins'
8. Что такое f-строки и как ими пользоваться?
В Python 3.6 появилась новая возможность — так называемые «f-строки». Их применение чрезвычайно упрощает интерполяцию строк. Использование f-строк напоминает применение метода format().
При объявлении f-строк перед открывающей кавычкой пишется буква f.
name = 'Chris'
food = 'creme brulee'
f'Hello. My name is {name} and I like {food}.'
#=> 'Hello. My name is Chris and I like creme brulee'
9. Как найти подстроку в заданной части строки?
Метод index() можно вызывать, передавая ему необязательные аргументы, представляющие индекс начального и конечного фрагмента строки, в пределах которых и нужно осуществлять поиск подстроки.
'the happiest person in the whole wide world.'.index('the',10,44)
#=> 23
Обратите внимание на то, что вышеприведённая конструкция возвращает 23, а не 0, как было бы, не ограничь мы поиск.
'the happiest person in the whole wide world.'.index('the')
#=> 0
10. Как вставить содержимое переменной в строку, воспользовавшись методом format()?
Метод format() позволяет добиваться результатов, сходных с теми, которые можно получить, применяя f-строки. Правда, я полагаю, что использовать format() не так удобно, так как все переменные приходится указывать в качестве аргументов format().
difficulty = 'easy'
thing = 'exam'
'That {} was {}!'.format(thing, difficulty)
#=> 'That exam was easy!'
11. Как узнать о том, что в строке содержатся только цифры?
Существует метод isnumeric(), который возвращает True в том случае, если все символы, входящие в строку, являются цифрами.
'80000'.isnumeric() #=> True
Используя этот метод, учитывайте то, что знаки препинания он цифрами не считает.
'1.0'.isnumeric() #=> False
12. Как разделить строку по заданному символу?
Здесь нам поможет метод split(), который разбивает строку по заданному символу или по нескольким символам.
'This is great'.split(' ')
#=> ['This', 'is', 'great']
'not--so--great'.split('--')
#=> ['not', 'so', 'great']
13. Как проверить строку на то, что она составлена только из строчных букв?
Метод islower() возвращает True только в том случае, если строка составлена исключительно из строчных букв.
'all lower case'.islower() #=> True
'not aLL lowercase'.islower() # False
14. Как проверить то, что строка начинается со строчной буквы?
Сделать это можно, вызвав вышеописанный метод islower() для первого символа строки.
'aPPLE'[0].islower() #=> True
15. Можно ли в Python прибавить целое число к строке?
В некоторых языках это возможно, но Python при попытке выполнения подобной операции будет выдана ошибка TypeError.
'Ten' + 10 #=> TypeError
16. Как «перевернуть» строку?
Для того чтобы «перевернуть» строку, её можно разбить, представив в виде списка символов, «перевернуть» список, и, объединив его элементы, сформировать новую строку.
''.join(reversed("hello world"))
#=> 'dlrow olleh'
17. Как объединить список строк в одну строку, элементы которой разделены дефисами?
Метод join() умеет объединять элементы списков в строки, разделяя отдельные строки с использованием заданного символа.
'-'.join(['a','b','c'])
#=> 'a-b-c'
18. Как узнать о том, что все символы строки входят в ASCII?
Метод isascii() возвращает True в том случае, если все символы, имеющиеся в строке, входят в ASCII.
print( 'Â'.isascii() ) #=> False
print( 'A'.isascii() ) #=> True
19. Как привести всю строку к верхнему или нижнему регистру?
Для решения этих задач можно воспользоваться методами upper() и lower(), которые, соответственно, приводят все символы строк к верхнему и нижнему регистрам.
sentence = 'The Cat in the Hat'
sentence.upper() #=> 'THE CAT IN THE HAT'
sentence.lower() #=> 'the cat in the hat'
20. Как преобразовать первый и последний символы строки к верхнему регистру?
Тут, как и в одном из предыдущих примеров, мы будем обращаться к символам строки по индексам. Строки в Python иммутабельны, поэтому мы будем заниматься сборкой новой строки на основе существующей.
animal = 'fish'
animal[0].upper() + animal[1:-1] + animal[-1].upper()
#=> 'FisH'
21. Как проверить строку на то, что она составлена только из прописных букв?
Имеется метод isupper(), который похож на уже рассмотренный islower(). Но isupper() возвращает True только в том случае, если вся строка состоит из прописных букв.
'Toronto'.isupper() #=> False
'TORONTO'.isupper() #= True
22. В какой ситуации вы воспользовались бы методом splitlines()?
Метод splitlines() разделяет строки по символам разрыва строки.
sentence = "It was a stormy nightnThe house creekednThe wind blew."
sentence.splitlines()
#=> ['It was a stormy night', 'The house creeked', 'The wind blew.']
23. Как получить срез строки?
Для получения среза строки используется синтаксическая конструкция следующего вида:
string[start_index:end_index:step]
Здесь step — это шаг, с которым будут возвращаться символы строки из диапазона start_index:end_index. Значение step, равное 3, указывает на то, что возвращён будет каждый третий символ.
string = 'I like to eat apples'
string[:6] #=> 'I like'
string[7:13] #=> 'to eat'
string[0:-1:2] #=> 'Ilk oetape' (каждый 2-й символ)
24. Как преобразовать целое число в строку?
Для преобразования числа в строку можно воспользоваться конструктором str().
str(5) #=> '5'
25. Как узнать о том, что строка содержит только алфавитные символы?
Метод isalpha() возвращает True в том случае, если все символы в строке являются буквами.
'One1'.isalpha() #=> False
'One'.isalpha() #=> True
26. Как в заданной строке заменить на что-либо все вхождения некоей подстроки?
Если обойтись без экспорта модуля, позволяющего работать с регулярными выражениями, то для решения этой задачи можно воспользоваться методом replace().
sentence = 'Sally sells sea shells by the sea shore'
sentence.replace('sea', 'mountain')
#=> 'Sally sells mountain shells by the mountain shore'
27. Как вернуть символ строки с минимальным ASCII-кодом?
Если взглянуть на ASCII-коды элементов, то окажется, например, что прописные буквы имеют меньшие коды, чем строчные. Функция min() возвращает символ строки, имеющий наименьший код.
min('strings') #=> 'g'
28. Как проверить строку на то, что в ней содержатся только алфавитно-цифровые символы?
В состав алфавитно-цифровых символов входят буквы и цифры. Для ответа на этот вопрос можно воспользоваться методом isalnum().
'Ten10'.isalnum() #=> True
'Ten10.'.isalnum() #=> False
29. Как удалить пробелы из начала строки (из её левой части), из её конца (из правой части), или с обеих сторон строки?
Здесь нам пригодятся, соответственно, методы lstrip(), rstrip() и strip().
string = ' string of whitespace '
string.lstrip() #=> 'string of whitespace '
string.rstrip() #=> ' string of whitespace'
string.strip() #=> 'string of whitespace'
30. Как проверить то, что строка начинается с заданной последовательности символов, или заканчивается заданной последовательностью символов?
Для ответа на этот вопрос можно прибегнуть, соответственно, к методам startswith() и endswith().
city = 'New York'
city.startswith('New') #=> True
city.endswith('N') #=> False
31. Как закодировать строку в ASCII?
Метод encode() позволяет кодировать строки с использованием заданной кодировки. По умолчанию используется кодировка utf-8. Если некий символ не может быть представлен с использованием заданной кодировки, будет выдана ошибка UnicodeEncodeError.
'Fresh Tuna'.encode('ascii')
#=> b'Fresh Tuna'
'Fresh Tuna Â'.encode('ascii')
#=> UnicodeEncodeError: 'ascii' codec can't encode character 'xc2' in position 11: ordinal not in range(128)
32. Как узнать о том, что строка включает в себя только пробелы?
Есть метод isspace(), который возвращает True только в том случае, если строка состоит исключительно из пробелов.
''.isspace() #=> False
' '.isspace() #=> True
' '.isspace() #=> True
' the '.isspace() #=> False
33. Что случится, если умножить некую строку на 3?
Будет создана новая строка, представляющая собой исходную строку, повторённую три раза.
'dog' * 3
# 'dogdogdog'
34. Как привести к верхнему регистру первый символ каждого слова в строке?
Существует метод title(), приводящий к верхнему регистру первую букву каждого слова в строке.
'once upon a time'.title() #=> 'Once Upon A Time'
35. Как объединить две строки?
Для объединения строк можно воспользоваться оператором +.
'string one' + ' ' + 'string two'
#=> 'string one string two'
36. Как пользоваться методом partition()?
Метод partition() разбивает строку по заданной подстроке. После этого результат возвращается в виде кортежа. При этом подстрока, по которой осуществлялась разбивка, тоже входит в кортеж.
sentence = "If you want to be a ninja"
print(sentence.partition(' want '))
#=> ('If you', ' want ', 'to be a ninja')
37. Строки в Python иммутабельны. Что это значит?
То, что строки иммутабельны, говорит о том, что после того, как создан объект строки, он не может быть изменён. При «модификации» строк исходные строки не меняются. Вместо этого в памяти создаются совершенно новые объекты. Доказать это можно, воспользовавшись функцией id().
proverb = 'Rise each day before the sun'
print( id(proverb) )
#=> 4441962336
proverb_two = 'Rise each day before the sun' + ' if its a weekday'
print( id(proverb_two) )
#=> 4442287440
При конкатенации 'Rise each day before the sun' и ' if its a weekday' в памяти создаётся новый объект, имеющий новый идентификатор. Если бы исходный объект менялся бы, тогда у объектов был бы один и тот же идентификатор.
38. Если объявить одну и ту же строку дважды (записав её в 2 разные переменные) — сколько объектов будет создано в памяти? 1 или 2?
В качестве примера подобной работы со строками можно привести такой фрагмент кода:
animal = 'dog'
pet = 'dog'
При таком подходе в памяти создаётся лишь один объект. Когда я столкнулся с этим в первый раз, мне это не показалось интуитивно понятным. Но этот механизм помогает Python экономить память при работе с длинными строками.
Доказать это можно, прибегнув к функции id().
animal = 'dog'
print( id(animal) )
#=> 4441985688
pet = 'dog'
print( id(pet) )
#=> 4441985688
39. Как пользоваться методами maketrans() и translate()?
Метод maketrans() позволяет описать отображение одних символов на другие, возвращая таблицу преобразования.
Метод translate() позволяет применить заданную таблицу для преобразования строки.
# создаём отображение
mapping = str.maketrans("abcs", "123S")
# преобразуем строку
"abc are the first three letters".translate(mapping)
#=> '123 1re the firSt three letterS'
Обратите внимание на то, что в строке произведена замена символов a, b, c и s, соответственно, на символы 1, 2, 3 и S.
40. Как убрать из строки гласные буквы?
Один из ответов на этот вопрос заключается в том, что символы строки перебирают, пользуясь механизмом List Comprehension. Символы проверяют, сравнивая с кортежем, содержащим гласные буквы. Если символ не входит в кортеж — он присоединяется к новой строке.
string = 'Hello 1 World 2'
vowels = ('a','e','i','o','u')
''.join([c for c in string if c not in vowels])
#=> 'Hll 1 Wrld 2'
41. В каких ситуациях пользуются методом rfind()?
Метод rfind() похож на метод find(), но он, в отличие от find(), просматривает строку не слева направо, а справа налево, возвращая индекс первого найденного вхождения искомой подстроки.
story = 'The price is right said Bob. The price is right.'
story.rfind('is')
#=> 39
Итоги
Я часто объясняю одному продакт-менеджеру, человеку в возрасте, что разработчики — это не словари, хранящие описания методов объектов. Но чем больше методов помнит разработчик — тем меньше ему придётся гуглить, и тем быстрее и приятнее ему будет работаться. Надеюсь, теперь вы без труда ответите на рассмотренные здесь вопросы.
Уважаемые читатели! Что, касающееся обработки строк в Python, вы посоветовали бы изучить тем, кто готовится к собеседованию?


В этой статье поговорим про строки в Python, особенности поиска, а также о том, как искать подстроку или символ в строке.

Но сначала давайте вспомним основные методы для обработки строк в Python:
• isalpha(str): если строка в Python включает в себя лишь алфавитные символы, возвращается True;
• islower(str): True возвращается, если строка включает лишь символы в нижнем регистре;
• isupper(str): True, если символы строки в Python находятся в верхнем регистре;
• startswith(str): True, когда строка начинается с подстроки str;
• isdigit(str): True, когда каждый символ строки — цифра;
• endswith(str): True, когда строка в Python заканчивается на подстроку str;
• upper(): строка переводится в верхний регистр;
• lower(): строка переводится в нижний регистр;
• title(): для перевода начальных символов всех слов в строке в верхний регистр;
• capitalize(): для перевода первой буквы самого первого слова строки в верхний регистр;
• lstrip(): из строки в Python удаляются начальные пробелы;
• rstrip(): из строки в Python удаляются конечные пробелы;
• strip(): из строки в Python удаляются и начальные, и конечные пробелы;
• rjust(width): когда длина строки меньше, чем параметр width, слева добавляются пробелы, строка выравнивается по правому краю;
• ljust(width): когда длина строки в Python меньше, чем параметр width, справа от неё добавляются пробелы для дополнения значения width, при этом происходит выравнивание строки по левому краю;
• find(str[, start [, end]): происходит возвращение индекса подстроки в строку в Python. В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
Обрабатываем строку в Python
Представим, что ожидается ввод числа с клавиатуры. Перед преобразованием введенной нами строки в число можно легко проверить, введено ли действительно число. Если это так, выполнится операция преобразования. Для обработки строки используем такой метод в Python, как isnumeric():
string = input("Введите какое-нибудь число: ") if string.isnumeric(): number = int(string) print(number)Следующий пример позволяет удалять пробелы в конце и начале строки:
string = " привет мир! " string = string.strip() print(string) # привет мир!Так можно дополнить строку пробелами и выполнить выравнивание:
print("iPhone 7:", "52000".rjust(10)) print("Huawei P10:", "36000".rjust(10))В консоли Python будет выведено следующее:
iPhone 7: 52000 Huawei P10: 36000Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!" index = welcome.find("wor") print(index) # 6 # ищем с десятого индекса index = welcome.find("wor",10) print(index) # 21 # ищем с 10-го по 15-й индекс index = welcome.find("wor",10,15) print(index) # -1Замена в строке
Чтобы в Python заменить в строке одну подстроку на другую, применяют метод replace():
• replace(old, new): подстрока old заменяется на new;
• replace(old, new, num): параметр num показывает, сколько вхождений подстроки old требуется заменить на new.Пример замены в строке в Python:
phone = "+1-234-567-89-10" # дефисы меняются на пробелы edited_phone = phone.replace("-", " ") print(edited_phone) # +1 234 567 89 10 # дефисы удаляются edited_phone = phone.replace("-", "") print(edited_phone) # +12345678910 # меняется только первый дефис edited_phone = phone.replace("-", "", 1) print(edited_phone) # +1234-567-89-10Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter;
• split(delimeter, num): параметром num указывается, какое количество вхождений delimeter применяется для разделения. При этом оставшаяся часть строки добавляется в перечень без разделения на подстроки.Соединение строк в Python
Рассматривая простейшие операции со строками, мы увидели, как объединяются строки через операцию сложения. Однако есть и другая возможность для соединения строк — метод join():, объединяющий списки строк. В качестве разделителя используется текущая строка, у которой вызывается этот метод:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # символ разделителя - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # символ разделителя - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | EnglishА если вместо списка в метод join передать простую строку, разделитель будет вставляться уже между символами:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o

(PHP 4, PHP 5, PHP 7, PHP 
strpos — Find the position of the first occurrence of a substring in a string
Description
strpos(string $haystack, string $needle, int $offset = 0): int|false
Parameters
-
haystack -
The string to search in.
-
needle -
Prior to PHP 8.0.0, if
needleis not a string, it is converted
to an integer and applied as the ordinal value of a character.
This behavior is deprecated as of PHP 7.3.0, and relying on it is highly
discouraged. Depending on the intended behavior, the
needleshould either be explicitly cast to string,
or an explicit call to chr() should be performed. -
offset -
If specified, search will start this number of characters counted from
the beginning of the string. If the offset is negative, the search will start
this number of characters counted from the end of the string.
Return Values
Returns the position of where the needle exists relative to the beginning of
the haystack string (independent of offset).
Also note that string positions start at 0, and not 1.
Returns false if the needle was not found.
Warning
This function may
return Boolean false, but may also return a non-Boolean value which
evaluates to false. Please read the section on Booleans for more
information. Use the ===
operator for testing the return value of this
function.
Changelog
| Version | Description |
|---|---|
| 8.0.0 |
Passing an int as needle is no longer supported.
|
| 7.3.0 |
Passing an int as needle has been deprecated.
|
| 7.1.0 |
Support for negative offsets has been added.
|
Examples
Example #1 Using ===
<?php
$mystring = 'abc';
$findme = 'a';
$pos = strpos($mystring, $findme);// Note our use of ===. Simply == would not work as expected
// because the position of 'a' was the 0th (first) character.
if ($pos === false) {
echo "The string '$findme' was not found in the string '$mystring'";
} else {
echo "The string '$findme' was found in the string '$mystring'";
echo " and exists at position $pos";
}
?>
Example #2 Using !==
<?php
$mystring = 'abc';
$findme = 'a';
$pos = strpos($mystring, $findme);// The !== operator can also be used. Using != would not work as expected
// because the position of 'a' is 0. The statement (0 != false) evaluates
// to false.
if ($pos !== false) {
echo "The string '$findme' was found in the string '$mystring'";
echo " and exists at position $pos";
} else {
echo "The string '$findme' was not found in the string '$mystring'";
}
?>
Example #3 Using an offset
<?php
// We can search for the character, ignoring anything before the offset
$newstring = 'abcdef abcdef';
$pos = strpos($newstring, 'a', 1); // $pos = 7, not 0
?>
Notes
Note: This function is
binary-safe.
See Also
- stripos() — Find the position of the first occurrence of a case-insensitive substring in a string
- str_contains() — Determine if a string contains a given substring
- str_ends_with() — Checks if a string ends with a given substring
- str_starts_with() — Checks if a string starts with a given substring
- strrpos() — Find the position of the last occurrence of a substring in a string
- strripos() — Find the position of the last occurrence of a case-insensitive substring in a string
- strstr() — Find the first occurrence of a string
- strpbrk() — Search a string for any of a set of characters
- substr() — Return part of a string
- preg_match() — Perform a regular expression match
Suggested re-write for pink WARNING box ¶
15 years ago
WARNING
As strpos may return either FALSE (substring absent) or 0 (substring at start of string), strict versus loose equivalency operators must be used very carefully.
To know that a substring is absent, you must use:
=== FALSE
To know that a substring is present (in any position including 0), you can use either of:
!== FALSE (recommended)
> -1 (note: or greater than any negative number)
To know that a substring is at the start of the string, you must use:
=== 0
To know that a substring is in any position other than the start, you can use any of:
> 0 (recommended)
!= 0 (note: but not !== 0 which also equates to FALSE)
!= FALSE (disrecommended as highly confusing)
Also note that you cannot compare a value of "" to the returned value of strpos. With a loose equivalence operator (== or !=) it will return results which don't distinguish between the substring's presence versus position. With a strict equivalence operator (=== or !==) it will always return false.
martijn at martijnfrazer dot nl ¶
11 years ago
This is a function I wrote to find all occurrences of a string, using strpos recursively.
<?php
function strpos_recursive($haystack, $needle, $offset = 0, &$results = array()) {
$offset = strpos($haystack, $needle, $offset);
if($offset === false) {
return $results;
} else {
$results[] = $offset;
return strpos_recursive($haystack, $needle, ($offset + 1), $results);
}
}
?>
This is how you use it:
<?php
$string = 'This is some string';
$search = 'a';
$found = strpos_recursive($string, $search);
if(
$found) {
foreach($found as $pos) {
echo 'Found "'.$search.'" in string "'.$string.'" at position <b>'.$pos.'</b><br />';
}
} else {
echo '"'.$search.'" not found in "'.$string.'"';
}
?>
fabio at naoimporta dot com ¶
7 years ago
It is interesting to be aware of the behavior when the treatment of strings with characters using different encodings.
<?php
# Works like expected. There is no accent
var_dump(strpos("Fabio", 'b'));
#int(2)
# The "á" letter is occupying two positions
var_dump(strpos("Fábio", 'b')) ;
#int(3)
# Now, encoding the string "Fábio" to utf8, we get some "unexpected" outputs. Every letter that is no in regular ASCII table, will use 4 positions(bytes). The starting point remains like before.
# We cant find the characted, because the haystack string is now encoded.
var_dump(strpos(utf8_encode("Fábio"), 'á'));
#bool(false)
# To get the expected result, we need to encode the needle too
var_dump(strpos(utf8_encode("Fábio"), utf8_encode('á')));
#int(1)
# And, like said before, "á" occupies 4 positions(bytes)
var_dump(strpos(utf8_encode("Fábio"), 'b'));
#int(5)
mtroy dot student at gmail dot com ¶
11 years ago
when you want to know how much of substring occurrences, you'll use "substr_count".
But, retrieve their positions, will be harder.
So, you can do it by starting with the last occurrence :
function strpos_r($haystack, $needle)
{
if(strlen($needle) > strlen($haystack))
trigger_error(sprintf("%s: length of argument 2 must be <= argument 1", __FUNCTION__), E_USER_WARNING);
$seeks = array();
while($seek = strrpos($haystack, $needle))
{
array_push($seeks, $seek);
$haystack = substr($haystack, 0, $seek);
}
return $seeks;
}
it will return an array of all occurrences a the substring in the string
Example :
$test = "this is a test for testing a test function... blah blah";
var_dump(strpos_r($test, "test"));
// output
array(3) {
[0]=>
int(29)
[1]=>
int(19)
[2]=>
int(10)
}
Paul-antoine
Malézieux.
rjeggens at ijskoud dot org ¶
11 years ago
I lost an hour before I noticed that strpos only returns FALSE as a boolean, never TRUE.. This means that
strpos() !== false
is a different beast then:
strpos() === true
since the latter will never be true. After I found out, The warning in the documentation made a lot more sense.
m.m.j.kronenburg ¶
6 years ago
<?php/**
* Find the position of the first occurrence of one or more substrings in a
* string.
*
* This function is simulair to function strpos() except that it allows to
* search for multiple needles at once.
*
* @param string $haystack The string to search in.
* @param mixed $needles Array containing needles or string containing
* needle.
* @param integer $offset If specified, search will start this number of
* characters counted from the beginning of the
* string.
* @param boolean $last If TRUE then the farthest position from the start
* of one of the needles is returned.
* If FALSE then the smallest position from start of
* one of the needles is returned.
**/
function mstrpos($haystack, $needles, $offset = 0, $last = false)
{
if(!is_array($needles)) { $needles = array($needles); }
$found = false;
foreach($needles as $needle)
{
$position = strpos($haystack, (string)$needle, $offset);
if($position === false) { continue; }
$exp = $last ? ($found === false || $position > $found) :
($found === false || $position < $found);
if($exp) { $found = $position; }
}
return $found;
}/**
* Find the position of the first (partially) occurrence of a substring in a
* string.
*
* This function is simulair to function strpos() except that it wil return a
* position when the substring is partially located at the end of the string.
*
* @param string $haystack The string to search in.
* @param mixed $needle The needle to search for.
* @param integer $offset If specified, search will start this number of
* characters counted from the beginning of the
* string.
**/
function pstrpos($haystack, $needle, $offset = 0)
{
$position = strpos($haystack, $needle, $offset);
if($position !== false) { return $position; }
for(
$i = strlen($needle); $i > 0; $i--)
{
if(substr($needle, 0, $i) == substr($haystack, -$i))
{ return strlen($haystack) - $i; }
}
return false;
}/**
* Find the position of the first (partially) occurrence of one or more
* substrings in a string.
*
* This function is simulair to function strpos() except that it allows to
* search for multiple needles at once and it wil return a position when one of
* the substrings is partially located at the end of the string.
*
* @param string $haystack The string to search in.
* @param mixed $needles Array containing needles or string containing
* needle.
* @param integer $offset If specified, search will start this number of
* characters counted from the beginning of the
* string.
* @param boolean $last If TRUE then the farthest position from the start
* of one of the needles is returned.
* If FALSE then the smallest position from start of
* one of the needles is returned.
**/
function mpstrpos($haystack, $needles, $offset = 0, $last = false)
{
if(!is_array($needles)) { $needles = array($needles); }
$found = false;
foreach($needles as $needle)
{
$position = pstrpos($haystack, (string)$needle, $offset);
if($position === false) { continue; }
$exp = $last ? ($found === false || $position > $found) :
($found === false || $position < $found);
if($exp) { $found = $position; }
}
return $found;
}?>
jexy dot ru at gmail dot com ¶
6 years ago
Docs are missing that WARNING is issued if needle is '' (empty string).
In case of empty haystack it just return false:
For example:
<?php
var_dump(strpos('foo', ''));var_dump(strpos('', 'foo'));var_dump(strpos('', ''));
?>
will output:
Warning: strpos(): Empty needle in /in/lADCh on line 3
bool(false)
bool(false)
Warning: strpos(): Empty needle in /in/lADCh on line 7
bool(false)
Note also that warning text may differ depending on php version, see https://3v4l.org/lADCh
greg at spotx dot net ¶
5 years ago
Warning:
this is not unicode safe
strpos($word,'?') in e?ez-> 1
strpos($word,'?') in è?ent-> 2
usulaco at gmail dot com ¶
12 years ago
Parse strings between two others in to array.
<?php
function g($string,$start,$end){
preg_match_all('/' . preg_quote($start, '/') . '(.*?)'. preg_quote($end, '/').'/i', $string, $m);
$out = array();
foreach(
$m[1] as $key => $value){
$type = explode('::',$value);
if(sizeof($type)>1){
if(!is_array($out[$type[0]]))
$out[$type[0]] = array();
$out[$type[0]][] = $type[1];
} else {
$out[] = $value;
}
}
return $out;
}
print_r(g('Sample text, [/text to extract/] Rest of sample text [/WEB::http://google.com/] bla bla bla. ','[/','/]'));
?>
results:
Array
(
[0] => text to extract
[WEB] => Array
(
[0] => http://google.com
)
)
Can be helpfull to custom parsing :)
akarmenia at gmail dot com ¶
12 years ago
My version of strpos with needles as an array. Also allows for a string, or an array inside an array.
<?php
function strpos_array($haystack, $needles) {
if ( is_array($needles) ) {
foreach ($needles as $str) {
if ( is_array($str) ) {
$pos = strpos_array($haystack, $str);
} else {
$pos = strpos($haystack, $str);
}
if ($pos !== FALSE) {
return $pos;
}
}
} else {
return strpos($haystack, $needles);
}
}// Test
echo strpos_array('This is a test', array('test', 'drive')); // Output is 10?>
eef dot vreeland at gmail dot com ¶
6 years ago
To prevent others from staring at the text, note that the wording of the 'Return Values' section is ambiguous.
Let's say you have a string $myString containing 50 'a's except on position 3 and 43, they contain 'b'.
And for this moment, forget that counting starts from 0.
strpos($myString, 'b', 40) returns 43, great.
And now the text: "Returns the position of where the needle exists relative to the beginning of the haystack string (independent of offset)."
So it doesn't really matter what offset I specify; I'll get the REAL position of the first occurrence in return, which is 3?
... no ...
"independent of offset" means, you will get the REAL positions, thus, not relative to your starting point (offset).
Substract your offset from strpos()'s answer, then you have the position relative to YOUR offset.
ohcc at 163 dot com ¶
8 years ago
Be careful when the $haystack or $needle parameter is an integer.
If you are not sure of its type, you should convert it into a string.
<?php
var_dump(strpos(12345,1));//false
var_dump(strpos(12345,'1'));//0
var_dump(strpos('12345',1));//false
var_dump(strpos('12345','1'));//0
$a = 12345;
$b = 1;
var_dump(strpos(strval($a),strval($b)));//0
var_dump(strpos((string)$a,(string)$b));//0
?>
ilaymyhat-rem0ve at yahoo dot com ¶
15 years ago
This might be useful.
<?php
class String{
//Look for a $needle in $haystack in any position
public static function contains(&$haystack, &$needle, &$offset)
{
$result = strpos($haystack, $needle, $offset);
return $result !== FALSE;
}
//intuitive implementation .. if not found returns -1.
public static function strpos(&$haystack, &$needle, &$offset)
{
$result = strpos($haystack, $needle, $offset);
if ($result === FALSE )
{
return -1;
}
return $result;
}
}
//String
?>
yasindagli at gmail dot com ¶
13 years ago
This function finds postion of nth occurence of a letter starting from offset.
<?php
function nth_position($str, $letter, $n, $offset = 0){
$str_arr = str_split($str);
$letter_size = array_count_values(str_split(substr($str, $offset)));
if( !isset($letter_size[$letter])){
trigger_error('letter "' . $letter . '" does not exist in ' . $str . ' after ' . $offset . '. position', E_USER_WARNING);
return false;
} else if($letter_size[$letter] < $n) {
trigger_error('letter "' . $letter . '" does not exist ' . $n .' times in ' . $str . ' after ' . $offset . '. position', E_USER_WARNING);
return false;
}
for($i = $offset, $x = 0, $count = (count($str_arr) - $offset); $i < $count, $x != $n; $i++){
if($str_arr[$i] == $letter){
$x++;
}
}
return $i - 1;
}
echo
nth_position('foobarbaz', 'a', 2); //7
echo nth_position('foobarbaz', 'b', 1, 4); //6
?>
bishop ¶
19 years ago
Code like this:
<?php
if (strpos('this is a test', 'is') !== false) {
echo "found it";
}
?>
gets repetitive, is not very self-explanatory, and most people handle it incorrectly anyway. Make your life easier:
<?php
function str_contains($haystack, $needle, $ignoreCase = false) {
if ($ignoreCase) {
$haystack = strtolower($haystack);
$needle = strtolower($needle);
}
$needlePos = strpos($haystack, $needle);
return ($needlePos === false ? false : ($needlePos+1));
}
?>
Then, you may do:
<?php
// simplest use
if (str_contains('this is a test', 'is')) {
echo "Found it";
}// when you need the position, as well whether it's present
$needlePos = str_contains('this is a test', 'is');
if ($needlePos) {
echo 'Found it at position ' . ($needlePos-1);
}// you may also ignore case
$needlePos = str_contains('this is a test', 'IS', true);
if ($needlePos) {
echo 'Found it at position ' . ($needlePos-1);
}
?>
Jean ¶
4 years ago
When a value can be of "unknow" type, I find this conversion trick usefull and more readable than a formal casting (for php7.3+):
<?php
$time = time();
$string = 'This is a test: ' . $time;
echo (strpos($string, $time) !== false ? 'found' : 'not found');
echo (strpos($string, "$time") !== false ? 'found' : 'not found');
?>
Anonymous ¶
10 years ago
The most straightforward way to prevent this function from returning 0 is:
strpos('x'.$haystack, $needle, 1)
The 'x' is simply a garbage character which is only there to move everything 1 position.
The number 1 is there to make sure that this 'x' is ignored in the search.
This way, if $haystack starts with $needle, then the function returns 1 (rather than 0).
marvin_elia at web dot de ¶
5 years ago
Find position of nth occurrence of a string:
function strpos_occurrence(string $string, string $needle, int $occurrence, int $offset = null) {
if((0 < $occurrence) && ($length = strlen($needle))) {
do {
} while ((false !== $offset = strpos($string, $needle, $offset)) && --$occurrence && ($offset += $length));
return $offset;
}
return false;
}
digitalpbk [at] gmail.com ¶
13 years ago
This function raises a warning if the offset is not between 0 and the length of string:
Warning: strpos(): Offset not contained in string in %s on line %d
Achintya ¶
13 years ago
A function I made to find the first occurrence of a particular needle not enclosed in quotes(single or double). Works for simple nesting (no backslashed nesting allowed).
<?php
function strposq($haystack, $needle, $offset = 0){
$len = strlen($haystack);
$charlen = strlen($needle);
$flag1 = false;
$flag2 = false;
for($i = $offset; $i < $len; $i++){
if(substr($haystack, $i, 1) == "'"){
$flag1 = !$flag1 && !$flag2 ? true : false;
}
if(substr($haystack, $i, 1) == '"'){
$flag2 = !$flag1 && !$flag2 ? true : false;
}
if(substr($haystack, $i, $charlen) == $needle && !$flag1 && !$flag2){
return $i;
}
}
return false;
}
echo
strposq("he'llo'character;"'som"e;crap", ";"); //16
?>
spinicrus at gmail dot com ¶
16 years ago
if you want to get the position of a substring relative to a substring of your string, BUT in REVERSE way:
<?phpfunction strpos_reverse_way($string,$charToFind,$relativeChar) {
//
$relativePos = strpos($string,$relativeChar);
$searchPos = $relativePos;
$searchChar = '';
//
while ($searchChar != $charToFind) {
$newPos = $searchPos-1;
$searchChar = substr($string,$newPos,strlen($charToFind));
$searchPos = $newPos;
}
//
if (!empty($searchChar)) {
//
return $searchPos;
return TRUE;
}
else {
return FALSE;
}
//
}?>
lairdshaw at yahoo dot com dot au ¶
8 years ago
<?php
/*
* A strpos variant that accepts an array of $needles - or just a string,
* so that it can be used as a drop-in replacement for the standard strpos,
* and in which case it simply wraps around strpos and stripos so as not
* to reduce performance.
*
* The "m" in "strposm" indicates that it accepts *m*ultiple needles.
*
* Finds the earliest match of *all* needles. Returns the position of this match
* or false if none found, as does the standard strpos. Optionally also returns
* via $match either the matching needle as a string (by default) or the index
* into $needles of the matching needle (if the STRPOSM_MATCH_AS_INDEX flag is
* set).
*
* Case-insensitive searching can be specified via the STRPOSM_CI flag.
* Note that for case-insensitive searches, if the STRPOSM_MATCH_AS_INDEX is
* not set, then $match will be in the haystack's case, not the needle's case,
* unless the STRPOSM_NC flag is also set.
*
* Flags can be combined using the bitwise or operator,
* e.g. $flags = STRPOSM_CI|STRPOSM_NC
*/
define('STRPOSM_CI' , 1); // CI => "case insensitive".
define('STRPOSM_NC' , 2); // NC => "needle case".
define('STRPOSM_MATCH_AS_INDEX', 4);
function strposm($haystack, $needles, $offset = 0, &$match = null, $flags = 0) {
// In the special case where $needles is not an array, simply wrap
// strpos and stripos for performance reasons.
if (!is_array($needles)) {
$func = $flags & STRPOSM_CI ? 'stripos' : 'strpos';
$pos = $func($haystack, $needles, $offset);
if ($pos !== false) {
$match = (($flags & STRPOSM_MATCH_AS_INDEX)
? 0
: (($flags & STRPOSM_NC)
? $needles
: substr($haystack, $pos, strlen($needles))
)
);
return $pos;
} else goto strposm_no_match;
}// $needles is an array. Proceed appropriately, initially by...
// ...escaping regular expression meta characters in the needles.
$needles_esc = array_map('preg_quote', $needles);
// If either of the "needle case" or "match as index" flags are set,
// then create a sub-match for each escaped needle by enclosing it in
// parentheses. We use these later to find the index of the matching
// needle.
if (($flags & STRPOSM_NC) || ($flags & STRPOSM_MATCH_AS_INDEX)) {
$needles_esc = array_map(
function($needle) {return '('.$needle.')';},
$needles_esc
);
}
// Create the regular expression pattern to search for all needles.
$pattern = '('.implode('|', $needles_esc).')';
// If the "case insensitive" flag is set, then modify the regular
// expression with "i", meaning that the match is "caseless".
if ($flags & STRPOSM_CI) $pattern .= 'i';
// Find the first match, including its offset.
if (preg_match($pattern, $haystack, $matches, PREG_OFFSET_CAPTURE, $offset)) {
// Pull the first entry, the overall match, out of the matches array.
$found = array_shift($matches);
// If we need the index of the matching needle, then...
if (($flags & STRPOSM_NC) || ($flags & STRPOSM_MATCH_AS_INDEX)) {
// ...find the index of the sub-match that is identical
// to the overall match that we just pulled out.
// Because sub-matches are in the same order as needles,
// this is also the index into $needles of the matching
// needle.
$index = array_search($found, $matches);
}
// If the "match as index" flag is set, then return in $match
// the matching needle's index, otherwise...
$match = (($flags & STRPOSM_MATCH_AS_INDEX)
? $index
// ...if the "needle case" flag is set, then index into
// $needles using the previously-determined index to return
// in $match the matching needle in needle case, otherwise...
: (($flags & STRPOSM_NC)
? $needles[$index]
// ...by default, return in $match the matching needle in
// haystack case.
: $found[0]
)
);
// Return the captured offset.
return $found[1];
}strposm_no_match:
// Nothing matched. Set appropriate return values.
$match = ($flags & STRPOSM_MATCH_AS_INDEX) ? false : null;
return false;
}
?>
qrworld.net ¶
8 years ago
I found a function in this post http://softontherocks.blogspot.com/2014/11/buscar-multiples-textos-en-un-texto-con.html
that implements the search in both ways, case sensitive or case insensitive, depending on an input parameter.
The function is:
function getMultiPos($haystack, $needles, $sensitive=true, $offset=0){
foreach($needles as $needle) {
$result[$needle] = ($sensitive) ? strpos($haystack, $needle, $offset) : stripos($haystack, $needle, $offset);
}
return $result;
}
It was very useful for me.
Lurvik ¶
9 years ago
Don't know if already posted this, but if I did this is an improvement.
This function will check if a string contains a needle. It _will_ work with arrays and multidimensional arrays (I've tried with a > 16 dimensional array and had no problem).
<?php
function str_contains($haystack, $needles)
{
//If needles is an array
if(is_array($needles))
{
//go trough all the elements
foreach($needles as $needle)
{
//if the needle is also an array (ie needles is a multidimensional array)
if(is_array($needle))
{
//call this function again
if(str_contains($haystack, $needle))
{
//Will break out of loop and function.
return true;
}
return
false;
}//when the needle is NOT an array:
//Check if haystack contains the needle, will ignore case and check for whole words only
elseif(preg_match("/b$needleb/i", $haystack) !== 0)
{
return true;
}
}
}
//if $needles is not an array...
else
{
if(preg_match("/b$needlesb/i", $haystack) !== 0)
{
return true;
}
}
return
false;
}
?>
gambajaja at yahoo dot com ¶
12 years ago
<?php
$my_array = array ('100,101', '200,201', '300,301');
$check_me_in = array ('100','200','300','400');
foreach ($check_me_in as $value_cmi){
$is_in=FALSE; #asume that $check_me_in isn't in $my_array
foreach ($my_array as $value_my){
$pos = strpos($value_my, $value_cmi);
if ($pos===0)
$pos++;
if ($pos==TRUE){
$is_in=TRUE;
$value_my2=$value_my;
}
}
if ($is_in) echo "ID $value_cmi in $check_me_in I found in value '$value_my2' n";
}
?>
The above example will output
ID 100 in $check_me_in I found in value '100,101'
ID 200 in $check_me_in I found in value '200,201'
ID 300 in $check_me_in I found in value '300,301'
ah dot d at hotmail dot com ¶
13 years ago
A strpos modification to return an array of all the positions of a needle in the haystack
<?php
function strallpos($haystack,$needle,$offset = 0){
$result = array();
for($i = $offset; $i<strlen($haystack); $i++){
$pos = strpos($haystack,$needle,$i);
if($pos !== FALSE){
$offset = $pos;
if($offset >= $i){
$i = $offset;
$result[] = $offset;
}
}
}
return $result;
}
?>
example:-
<?php
$haystack = "ASD is trying to get out of the ASDs cube but the other ASDs told him that his behavior will destroy the ASDs world";
$needle = "ASD";
print_r(strallpos($haystack,$needle));
//getting all the positions starting from a specified position
print_r(strallpos($haystack,$needle,34));
?>
teddanzig at yahoo dot com ¶
14 years ago
routine to return -1 if there is no match for strpos
<?php
//instr function to mimic vb instr fucntion
function InStr($haystack, $needle)
{
$pos=strpos($haystack, $needle);
if ($pos !== false)
{
return $pos;
}
else
{
return -1;
}
}
?>
Tim ¶
14 years ago
If you would like to find all occurences of a needle inside a haystack you could use this function strposall($haystack,$needle);. It will return an array with all the strpos's.
<?php
/**
* strposall
*
* Find all occurrences of a needle in a haystack
*
* @param string $haystack
* @param string $needle
* @return array or false
*/
function strposall($haystack,$needle){
$s=0;
$i=0;
while (
is_integer($i)){
$i = strpos($haystack,$needle,$s);
if (
is_integer($i)) {
$aStrPos[] = $i;
$s = $i+strlen($needle);
}
}
if (isset($aStrPos)) {
return $aStrPos;
}
else {
return false;
}
}
?>
user at nomail dot com ¶
16 years ago
This is a bit more useful when scanning a large string for all occurances between 'tags'.
<?php
function getStrsBetween($s,$s1,$s2=false,$offset=0) {
/*====================================================================
Function to scan a string for items encapsulated within a pair of tags
getStrsBetween(string, tag1, <tag2>, <offset>
If no second tag is specified, then match between identical tags
Returns an array indexed with the encapsulated text, which is in turn
a sub-array, containing the position of each item.
Notes:
strpos($needle,$haystack,$offset)
substr($string,$start,$length)
====================================================================*/
if( $s2 === false ) { $s2 = $s1; }
$result = array();
$L1 = strlen($s1);
$L2 = strlen($s2);
if(
$L1==0 || $L2==0 ) {
return false;
}
do {
$pos1 = strpos($s,$s1,$offset);
if(
$pos1 !== false ) {
$pos1 += $L1;$pos2 = strpos($s,$s2,$pos1);
if(
$pos2 !== false ) {
$key_len = $pos2 - $pos1;$this_key = substr($s,$pos1,$key_len);
if( !
array_key_exists($this_key,$result) ) {
$result[$this_key] = array();
}$result[$this_key][] = $pos1;$offset = $pos2 + $L2;
} else {
$pos1 = false;
}
}
} while($pos1 !== false );
return
$result;
}
?>
philip ¶
18 years ago
Many people look for in_string which does not exist in PHP, so, here's the most efficient form of in_string() (that works in both PHP 4/5) that I can think of:
<?php
function in_string($needle, $haystack, $insensitive = false) {
if ($insensitive) {
return false !== stristr($haystack, $needle);
} else {
return false !== strpos($haystack, $needle);
}
}
?>
Lhenry ¶
5 years ago
note that strpos( "8 june 1970" , 1970 ) returns FALSE..
add quotes to the needle
gjh42 — simonokewode at hotmail dot com ¶
11 years ago
A pair of functions to replace every nth occurrence of a string with another string, starting at any position in the haystack. The first works on a string and the second works on a single-level array of strings, treating it as a single string for replacement purposes (any needles split over two array elements are ignored).
Can be used for formatting dynamically-generated HTML output without touching the original generator: e.g. add a newLine class tag to every third item in a floated list, starting with the fourth item.
<?php
/* String Replace at Intervals by Glenn Herbert (gjh42) 2010-12-17
*/
//(basic locator by someone else - name unknown)
//strnposr() - Find the position of nth needle in haystack.
function strnposr($haystack, $needle, $occurrence, $pos = 0) {
return ($occurrence<2)?strpos($haystack, $needle, $pos):strnposr($haystack,$needle,$occurrence-1,strpos($haystack, $needle, $pos) + 1);
}//gjh42
//replace every nth occurrence of $needle with $repl, starting from any position
function str_replace_int($needle, $repl, $haystack, $interval, $first=1, $pos=0) {
if ($pos >= strlen($haystack) or substr_count($haystack, $needle, $pos) < $first) return $haystack;
$firstpos = strnposr($haystack, $needle, $first, $pos);
$nl = strlen($needle);
$qty = floor(substr_count($haystack, $needle, $firstpos + 1)/$interval);
do { //in reverse order
$nextpos = strnposr($haystack, $needle, ($qty * $interval) + 1, $firstpos);
$qty--;
$haystack = substr_replace($haystack, $repl, $nextpos, $nl);
} while ($nextpos > $firstpos);
return $haystack;
}
//$needle = string to find
//$repl = string to replace needle
//$haystack = string to do replacing in
//$interval = number of needles in loop
//$first=1 = first occurrence of needle to replace (defaults to first)
//$pos=0 = position in haystack string to start from (defaults to first)
//replace every nth occurrence of $needle with $repl, starting from any position, in a single-level array
function arr_replace_int($needle, $repl, $arr, $interval, $first=1, $pos=0, $glue='|+|') {
if (!is_array($arr)) return $arr;
foreach($arr as $key=>$value){
if (is_array($arr[$key])) return $arr;
}
$haystack = implode($glue, $arr);
$haystack = str_replace_int($needle, $repl, $haystack, $interval, $first, $pos);
$tarr = explode($glue, $haystack);
$i = 0;
foreach($arr as $key=>$value){
$arr[$key] = $tarr[$i];
$i++;
}
return $arr;
}
?>
If $arr is not an array, or a multilevel array, it is returned unchanged.
amolocaleb at gmail dot com ¶
4 years ago
Note that strpos() is case sensitive,so when doing a case insensitive search,use stripos() instead..If the latter is not available,subject the string to strlower() first,otherwise you may end up in this situation..
<?php
//say we are matching url routes and calling access control middleware depending on the route$registered_route = '/admin' ;
//now suppose we want to call the authorization middleware before accessing the admin route
if(strpos($path->url(),$registered_route) === 0){
$middleware->call('Auth','login');
}
?>
and the auth middleware is as follows
<?php
class Auth{
function
login(){
if(!loggedIn()){
return redirect("path/to/login.php");
}
return true;
}
}//Now suppose:
$user_url = '/admin';
//this will go to the Auth middleware for checks and redirect accordingly
//But:
$user_url = '/Admin';
//this will make the strpos function return false since the 'A' in admin is upper case and user will be taken directly to admin dashboard authentication and authorization notwithstanding
?>
Simple fixes:
<?php
//use stripos() as from php 5
if(stripos($path->url(),$registered_route) === 0){
$middleware->call('Auth','login');
}
//for those with php 4
if(stripos(strtolower($path->url()),$registered_route) === 0){
$middleware->call('Auth','login');
}
//make sure the $registered_route is also lowercase.Or JUST UPGRADE to PHP 5>
ds at kala-it dot de ¶
3 years ago
Note this code example below in PHP 7.3
<?php
$str = "17,25";
if(
FALSE !== strpos($str, 25)){
echo "25 is inside of str";
} else {
echo "25 is NOT inside of str";
}
?>
Will output "25 is NOT inside of str" and will throw out a deprication message, that non string needles will be interpreted as strings in the future.
This just gave me some headache since the value I am checking against comes from the database as an integer.
sunmacet at gmail dot com ¶
2 years ago
To check that a substring is present.
Confusing check if position is not false:
if ( strpos ( $haystack , $needle ) !== FALSE )
Logical check if there is position:
if ( is_int ( strpos ( $haystack , $needle ) ) )
binodluitel at hotmail dot com ¶
9 years ago
This function will return 0 if the string that you are searching matches i.e. needle matches the haystack
{code}
echo strpos('bla', 'bla');
{code}
Output: 0
hu60 dot cn at gmail dot com ¶
3 years ago
A more accurate imitation of the PHP function session_start().
Function my_session_start() does something similar to session_start() that has the default configure, and the session files generated by the two are binary compatible.
The code may help people increase their understanding of the principles of the PHP session.
<?php
error_reporting(E_ALL);
ini_set('display_errors', true);
ini_set('session.save_path', __DIR__);my_session_start();
echo
'<p>session id: '.my_session_id().'</p>';
echo
'<code><pre>';
var_dump($_SESSION);
echo '</pre></code>';$now = date('H:i:s');
if (isset($_SESSION['last_visit_time'])) {
echo '<p>Last Visit Time: '.$_SESSION['last_visit_time'].'</p>';
}
echo '<p>Current Time: '.$now.'</p>';$_SESSION['last_visit_time'] = $now;
function
my_session_start() {
global $phpsessid, $sessfile;
if (!isset(
$_COOKIE['PHPSESSID']) || empty($_COOKIE['PHPSESSID'])) {
$phpsessid = my_base32_encode(my_random_bytes(16));
setcookie('PHPSESSID', $phpsessid, ini_get('session.cookie_lifetime'), ini_get('session.cookie_path'), ini_get('session.cookie_domain'), ini_get('session.cookie_secure'), ini_get('session.cookie_httponly'));
} else {
$phpsessid = substr(preg_replace('/[^a-z0-9]/', '', $_COOKIE['PHPSESSID']), 0, 26);
}$sessfile = ini_get('session.save_path').'/sess_'.$phpsessid;
if (is_file($sessfile)) {
$_SESSION = my_unserialize(file_get_contents($sessfile));
} else {
$_SESSION = array();
}
register_shutdown_function('my_session_save');
}
function
my_session_save() {
global $sessfile;file_put_contents($sessfile, my_serialize($_SESSION));
}
function
my_session_id() {
global $phpsessid;
return $phpsessid;
}
function
my_serialize($data) {
$text = '';
foreach ($data as $k=>$v) {
// key cannot contains '|'
if (strpos($k, '|') !== false) {
continue;
}
$text.=$k.'|'.serialize($v)."n";
}
return $text;
}
function
my_unserialize($text) {
$data = [];
$text = explode("n", $text);
foreach ($text as $line) {
$pos = strpos($line, '|');
if ($pos === false) {
continue;
}
$data[substr($line, 0, $pos)] = unserialize(substr($line, $pos + 1));
}
return $data;
}
function
my_random_bytes($length) {
if (function_exists('random_bytes')) {
return random_bytes($length);
}
$randomString = '';
for ($i = 0; $i < $length; $i++) {
$randomString .= chr(rand(0, 255));
}
return $randomString;
}
function
my_base32_encode($input) {
$BASE32_ALPHABET = 'abcdefghijklmnopqrstuvwxyz234567';
$output = '';
$v = 0;
$vbits = 0;
for ($i = 0, $j = strlen($input); $i < $j; $i++) {
$v <<= 8;
$v += ord($input[$i]);
$vbits += 8;
while ($vbits >= 5) {
$vbits -= 5;
$output .= $BASE32_ALPHABET[$v >> $vbits];
$v &= ((1 << $vbits) - 1);
}
}
if ($vbits > 0) {
$v <<= (5 - $vbits);
$output .= $BASE32_ALPHABET[$v];
}
return $output;
}
msegit post pl ¶
4 years ago
This might be useful, I often use for parsing file paths etc.
(Some examples inside https://gist.github.com/msegu/bf7160257037ec3e301e7e9c8b05b00a )
<?php
/**
* Function 'strpos_' finds the position of the first or last occurrence of a substring in a string, ignoring number of characters
*
* Function 'strpos_' is similar to 'str[r]pos()', except:
* 1. fourth (last, optional) param tells, what to return if str[r]pos()===false
* 2. third (optional) param $offset tells as of str[r]pos(), BUT if negative (<0) search starts -$offset characters counted from the end AND skips (ignore!, not as 'strpos' and 'strrpos') -$offset-1 characters from the end AND search backwards
*
* @param string $haystack Where to search
* @param string $needle What to find
* @param int $offset (optional) Number of characters to skip from the beginning (if 0, >0) or from the end (if <0) of $haystack
* @param mixed $resultIfFalse (optional) Result, if not found
* Example:
* positive $offset - like strpos:
* strpos_('abcaba','ab',1)==strpos('abcaba','ab',1)==3, strpos('abcaba','ab',4)===false, strpos_('abcaba','ab',4,'Not found')==='Not found'
* negative $offset - similar to strrpos:
* strpos_('abcaba','ab',-1)==strpos('abcaba','ab',-1)==3, strrpos('abcaba','ab',-3)==3 BUT strpos_('abcaba','ab',-3)===0 (omits 2 characters from the end, because -2-1=-3, means search in 'abca'!)
*
* @result int $offset Returns offset (or false), or $resultIfFalse
*/
function strpos_($haystack, $needle, $offset = 0, $resultIfFalse = false) {
$haystack=((string)$haystack); // (string) to avoid errors with int, float...
$needle=((string)$needle);
if ($offset>=0) {
$offset=strpos($haystack, $needle, $offset);
return (($offset===false)? $resultIfFalse : $offset);
} else {
$haystack=strrev($haystack);
$needle=strrev($needle);
$offset=strpos($haystack,$needle,-$offset-1);
return (($offset===false)? $resultIfFalse : strlen($haystack)-$offset-strlen($needle));
}
}
?>