Как найти строку в тексте
Иногда пользователю требуется найти определенную строку или слово в документе. Было бы крайне неудобно перечитывать для этого весь текст, поэтому многие программы оснащены инструментом для поиска.

Инструкция
В приложении Microsoft Office Word поиск конкретной строки можно произвести несколькими способами: по ее порядковому номеру (если вы его знаете) или по содержимому, то есть словам, которые должны содержаться в строке.
Чтобы осуществить поиск строки по ее порядковому номеру, у вас должно быть корректно настроено отображение строки состояния. Она находится в нижней части окна программы сразу под рабочей областью документа.
Кликните по строке состояния правой кнопкой мыши. В контекстном меню отметьте маркером пункт «Номер строки». Теперь вы сможете увидеть в левом нижнем углу количество строк, содержащихся в документе, и получить сведения о том, на какой по счету строке установлен курсор в текущий момент.
Для того чтобы задать параметры поиска, кликните левой кнопкой мыши по кнопке-ссылке «Строка: [номер той строки, где стоит курсор]» на строке состояния. Откроется новое диалоговое окно. На вкладке «Перейти» отметьте левой кнопкой мыши пункт «Строка», в соответствующем поле введите номер нужной вам строки и нажмите клавишу Enter или кнопку «Далее». Курсор будет перемещен в тексте в начало указанной вами строки.
Данное диалоговое окно не мешает редактировать текст, поэтому его можно не закрывать до тех пор, пока вы не найдете все нужные вам строки. Чтобы перейти от текущего положения на заданное количество строк вверх или вниз, используйте знаки «+» и «-» перед порядковым номером искомой строки.
В приложении Word и практически во всех других программах для поиска строки по ее содержимому (заданному слову или словосочетанию) инструмент поиска вызывается сочетанием клавиш Ctrl и F. Также он доступен в меню «Правка» через команду «Найти», а в некоторых программах вынесен на панель инструментов. В MS Word – вкладка «Главная», блок «Редактирование», кнопка «Найти».
Пользоваться этим инструментом следует так же, как и в случае поиска строки по ее номеру. Введите в предназначенное для поиска поле нужное вам слово и нажмите на кнопку «Далее», «Найти» или клавишу Enter на клавиатуре.
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Самый простой способ выполнить поиск на странице в браузере — комбинация клавиш, позволяющие быстро вызвать интересующий инструмент. С помощью такого метода можно в течение двух-трех секунд найти требуемый текст на странице или отыскать определенное слово. Это удобно, когда у пользователя перед глазами большой объем информации, а поиск необходимо осуществить в сжатые сроки.
Горячие клавиши для поиска на странице для браузеров
Лучший помощники в вопросе поиска в браузере — горячие клавиши. С их помощью можно быстро решить поставленную задачу, не прибегая к сбору требуемой информации через настройки или иными доступным способами. Рассмотрим решения для популярных веб-обозревателей.
Internet Explorer
Пользователи Internet Explorer могут выполнить поиск по тексту с помощью комбинации клавиш Ctrl+ F. В появившемся окне необходимо ввести интересующую фразу, букву или словосочетание.
Google Chrome
Зная комбинацию клавиш, можно осуществить быстрый поиск текста в браузере на странице. Это актуально для всех веб-проводников, в том числе Google Chrome. Чтобы найти какую-либо информацию на страничке, необходимо нажать комбинацию клавиш Ctrl+F.

Mozilla Firefox
Для поиска какой-либо информации на странице жмите комбинацию клавиш Ctrl+F. В нижней части веб-обозревателя появляется поисковая строка. В нее можно ввести фразу или предложение, которое будет подсвечено в тексте на странице. Если необходимо найти ссылку через панель быстрого поиска, нужно войти в упомянутую панель, прописать символ в виде одиночной кавычки и нажать комбинацию клавиш Ctrl+G.
Opera
Теперь рассмотрим особенности поиска на странице в браузере Опера (сочетание клавиш). Для нахождения нужной информации необходимо нажать на Ctrl+F. Чтобы найти следующее значение, используется комбинация клавиш Ctrl+G, а предыдущее — Ctrl+Shift+G.

Yandex
Для поиска какой-либо информации через браузер Яндекс, необходимо нажать комбинацию клавиш Ctrl+F. После этого появляется окно, с помощью которого осуществляется поиск слова или фразы. При вводе система находит все слова с одинаковым или похожим корнем. Чтобы увидеть точные совпадения по запросу, нужно поставить отметку в поле «Точное совпадение».
Safari
Теперь рассмотрим, как открыть в браузере Сафари поиск по словам на странице. Для решения задачи жмите на комбинацию клавиш Command+F. В этом случае появляется окно, в которое нужно ввести искомое слово или словосочетание. Для перехода к следующему вхождению жмите на кнопку Далее с левой стороны.

Промежуточный вывод
Как видно из рассмотренной выше информации, в большинстве веб-проводников комбинации клавиш для вызова поиска идентична. После появления поискового окна необходимо прописать слово или нужную фразу, а далее перемещаться между подсвеченными элементами. Принципы управления немного отличаются в зависимости от программы, но в целом ситуация похожа для всех программ.
Как найти слова или фразы через настройки в разных браузерах?
Если под рукой нет информации по комбинациям клавиш, нужно знать, как включить поиск в браузере по словам через меню. Здесь также имеются свои особенности для каждого из веб-проводников.
Google Chrome
Чтобы осуществить поиск какого-либо слова или фразы на странице, можно использовать комбинацию клавиш (об этом мы говорили выше) или воспользоваться функцией меню. Для поиска на странице сделайте такие шаги:
- откройте Гугл Хром;
- жмите значок Еще (три точки справа вверху);
- выберите раздел Найти;

- введите запрос и жмите на Ввод;
- совпадения отображаются желтой заливкой (в случае прокрутки страницы эта особенность сохраняется).

Если нужно в браузере открыть строку поиска, найти картинку или фразу, сделайте такие шаги:
- откройте веб-проводник;
- выделите фразу, слово или картинку;
- жмите на выделенную область правой кнопкой мышки;
- осуществите поиск по умолчанию (выберите Найти в Гугл или Найти это изображение).

Применение этих инструментов позволяет быстро отыскать требуемые сведения.
Обратите внимание, что искать можно таким образом и в обычной вкладе и перейдя в режим инкогнито в Хроме.
Mozilla Firefox
Чтобы в браузере найти слово или фразу, можно задействовать комбинацию клавиш (об этом упоминалось выше) или использовать функционал меню. Для поиска текста сделайте следующее:
- жмите на три горизонтальные полоски;
- кликните на ссылку Найти на этой странице;
- введите поисковую фразу в появившееся поле (система сразу подсвечивает искомые варианты);
- выберите одно из доступных действий — Х (Закрыть поисковую панель), Следующее или Предыдущее (стрелки), Подсветить все (указываются интересующие вхождения), С учетом регистра (поиск становится чувствительным к регистру) или Только слова целиком (указывается те варианты, которые полностью соответствуют заданным).
Если браузер не находит ни одного варианта, он выдает ответ Фраза не найдена.
Выше мы рассмотрели, как найти нужный текст на странице в браузере Mozilla Firefox. Но бывают ситуации, когда требуется отыскать только ссылку на странице. В таком случае сделайте следующее:
- наберите символ одиночной кавычки, которая открывает панель быстрого поиска ссылок;
- укажите нужную фразу в поле Быстрый поиск (выбирается первая ссылка, содержащая нужную фразу);
- жмите комбинацию клавиш Ctrl+G для подсветки очередной ссылки с поисковой фразы.
Чтобы закрыть указанную панель, выждите некоторое время, а после жмите на кнопку Esc на клавиатуре или жмите на любое место в браузере.
Возможности Firefox позволяют осуществлять поиск на странице в браузере по мере набора фразы. Здесь комбинация клавиш не предусмотрена, но можно использовать внутренние возможности веб-проводника. Для начала нужно включить эту функцию. Сделайте следующее:
- жмите на три горизонтальные полоски и выберите Настройки;
- войдите в панель Общие;
- перейдите к Просмотру сайтов;
- поставьте отметку в поле Искать текст на странице по мере набора;
- закройте страничку.
Теперь рассмотрим, как искать в браузере по словам в процессе ввода. Для этого:
- наберите поисковую фразу при просмотре сайта;
- обратите внимание, что первое совпадение выделится;
- жмите Ctrl+G для получения следующего совпадения.
Закрытие строки поиска происходит по рассмотренному выше принципу — путем нажатия F3 или комбинации клавиш Ctrl+G.
Opera
Если нужно что-то найти на странице, которая открыта в Опере, можно воспользоваться комбинацией клавиш или кликнуть на значок «О» слева вверху. Во втором случае появится список разделов, в котором необходимо выбрать Найти. Появится поле, куда нужно ввести слово или фразу для поиска. По мере ввода система сразу осуществляет поиск, показывает число совпадений и подсвечивает их. Для перемещения между выявленными словами необходимо нажимать стрелочки влево или вправо.
Yandex
Иногда бывают ситуации, когда нужен поиск по буквам, словам или фразам в браузере Yandex. В таком случае также можно воспользоваться комбинацией клавиш или встроенными возможностями. Сделайте такие шаги:
- жмите на три горизонтальные полоски;
- войдите в раздел Дополнительно;
- выберите Найти.

В появившемся поле введите информацию, которую нужно отыскать. Если не устанавливать дополнительные настройки, система находит грамматические формы искомого слова. Для получения точного совпадения нужно поставить отметку в соответствующем поле. Браузер Яндекс может переключать раскладку поискового запроса в автоматическом режиме. Если он не выполняет этих действий, сделайте следующее:
- жмите на три горизонтальные полоски;
- войдите в Настройки;

- перейдите в Инструменты;
- жмите на Поиск на странице;
- проверьте факт включения интересующей опции (поиск набранного запроса в другой раскладке, если поиск не дал результатов).

Safari
В этом браузере доступна опция умного поиска. Достаточно ввести одну или несколько букв в специальном поле, чтобы система отыскала нужные фрагменты.
Итоги
Владея рассмотренными знаниями, можно скачать любой браузер и выполнить поиск нужного слова на странице. Наиболее удобный путь — использование комбинации клавиш, но при желании всегда можно использовать внутренние возможности веб-проводника.
Отличного Вам дня!
Поиск подстроки и смежные вопросы
Время на прочтение
13 мин
Количество просмотров 112K
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная статья о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил восполнить данный пробел и описать хотя бы парочку тех, которые потенциально можно запомнить. Те, кто еще помнит курс алгоритмов из института, не найдут, видимо, ничего нового для себя.
Сначала хотел бы предотвратить вопрос «на кой это надо? все уже и так написано». Да, написано. Но во-первых, полезно знать как работает используемые тобой иструменты на более низком уровне чтобы лучше понимать их ограничения, а во-вторых, есть достаточно большие смежные области, где работающей из коробочки функции strstr() окажется недостаточно. Ну и в-третьих, вам может неповезти и придется разрабатывать под мобильную платформу с неполноценным runtime, а тогда лучше знать на что подписываетесь, если решитесь самостоятельно его дополнять (чтобы убедиться, что это не сферическая проблема в вакууме, достаточно попробовать wcslen() и wcsstr() из Android NDK).
А разве просто поискать нельзя?
Дело в том, что очевидный способ, который все формулирует как «взять и поискать», является отнюдь не самым эффективным, а для такой низкоуровневой и сравнительно частовызываемой функции это немаловажно. Итак, план такой:
- Постановка задачи: здесь перечислены определения и условные обозначения.
- Решение «в лоб»: здесь будет описано, как делать не надо и почему.
- Z-функция: простейший вариант правильной реализации поиска подстроки.
- Алгоритм Кнута-Морриса-Пратта: еще один вариант правильного поиска.
- Другие задачи поиска: вкратце пробегусь по ним без подробного описания.
Постановка задачи
Канонический вариант задачи выглядит так: есть у нас строка A (текст). Необходимо проверить, есть ли в ней подстрока X (образец), и если есть, то где она начинается. То есть именно то, что делает функция strstr() в C. Дополнительно к этому можно еще попросить найти все вхождения образца. Очевидно, что задача имеет смысл только если X не длинее A.
Для простоты дальнейшего объяснения введу сразу пару понятий. Что такое строка все, наверное, понимают — это последовательность символов, возможно пустая. Символы, или буквы, принадлежат некоторому множеству, которое называют алфавитом (данный алфавит, вообще говоря, может не иметь ничего общего с алфавитом в бытовом понимании). Длина строки |A| — это, очевидно, количество символов в ней. Префикс строки A[..i] — это строка из i первых символов строки A. Суффикс строки A[j..] — это строка из |A|-j+1 последних символов. Подстроку из A будем обозначать как A[i..j], а A[i] — i-ый символ строки. Вопрос про пустые суффиксы и префиксы и т.д. не трогаем — с ними разобраться не сложно по месту. Еще есть такое понятие как сентинел — некий уникальный символ, не встречающийся в алфавите. Его обозначают значком $ и дополняют допустимый алфавит таким символом (это в теории, на практике проще применить дополнительные проверки, чем придумать такой символ, которого не могло бы оказаться во входных строках).
В выкладках будем считать символы в строке с первой позиции. Код писать традиционно проще отсчитывая от нуля. Переход от одного к другому не составляет трудностей.
Решение «в лоб»
Прямой поиск, или, как еще часто говорят, «просто взять и поискать»- это Первое решение, которое приходит в голову неискушенному программисту. Суть проста: идти по проверяемой строке A и искать в ней вхождение первого символа искомой строки X. Когда находим, делаем гипотезу, что это и есть то самое искомое вхождение. Затем остается проверять по очереди все последующие символы шаблона на совпадение с соответствующими символами строки A. Если они все совпали — значит вот оно, прямо перед нами. Но вот если какой-то из символов не совпал, то ничего не остается, как признать нашу гипотезу неверной, что возвращает нас к символу, следующему за вхождением первого символа из X.
Многие люди ошибаются в этом пункте, считая, что не надо возвращаться назад, а можно продолжать обработку строки A с текущей позиции. Почему это не так легко продемонстрировать на примере поиска X=«AAAB» в A=«AAAAB». Первая гипотеза нас приведет к четвертому символу A: «AAAAB», где мы обнаружим несоответствие. Если не откатиться назад, то вхождение мы так и не обнаружим, хотя оно есть.
Неправильные гипотезы неизбежны, а из-за таких откатываний назад при плохом стечении обстоятельств может оказаться, что мы каждый символ в A проверили около |X| раз. То есть вычислительная сложность сложность алгоритма O(|X||A|). Так поиск фразы в параграфе может и затянуться…
Справедливости ради следует отметить, что если строки невелики, то такой алгоритм может работать быстрее «правильных» алгоритмов за счет более предсказуемого с точки зрения процессора поведения.
Z-функция
Одна из категорий правильных способов поиска строки сводится к вычислению в каком-то смысле корреляции двух строк. Сначала отметим, что задача сравнения начал двух строк проста и понятна: сравниваем соответствующие буквы, пока не найдем несоответствие либо какая-нибудь из строк закончится. Рассмотрим множество всех суффиксов строки A: A[|A|..] A[|A|-1..],… A[1..]. Будем сравнивать начало самой строки с каждым из ее суффиксов. Сравнение может дойти до конца суффикса, либо оборваться на каком-то символе ввиду несовпадения. Длину совпавшей части и назовем компонентой Z-функции для данного суффикса.
То есть Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. Ух! Отличная фраза, когда надо кого-то запутать или самоутвердиться, а чтобы понять что же это такое, лучше рассмотреть пример.
Исходная строка «ababcaba». Сравнивая каждый суффикс с самой строкой получим табличку для Z-функции:
| суффикс | строка | Z | |
|---|---|---|---|
| ababcaba | ababcaba | -> | 8 |
| babcaba | ababcaba | -> | 0 |
| abcaba | ababcaba | -> | 2 |
| bcaba | ababcaba | -> | 0 |
| caba | ababcaba | -> | 0 |
| aba | ababcaba | -> | 3 |
| ba | ababcaba | -> | 0 |
| a | ababcaba | -> | 1 |
Префикс суффикса это ничто иное, как подстрока, а Z-функция — длины подстрок, которые встречаются одновременно в начале и в середине. Рассматривая все значения компонент Z-функции, можно заметить некоторые закономерности. Во-первых, очевидно, что значение Z-функции не превышает длины строки и совпадает с ней только для «полного» суффикса A[1..] (и поэтому это значение нас не интересует — мы его будем опускать в своих рассуждениях). Во-вторых, если в строке есть некий символ в единственном экземпляре, то совпасть он может только с самим собой, и значит он делит строку на две части, а значение Z-функции нигде не может превысить длины более короткой части.
Использовать эти наблюдения предлагается следующим образом. Допустим в строке «ababcabсacab» мы хотим поискать «abca». Берем эти строчки и конкатенируем, вставляя между ними сентинел: «abca$ababcabсacab». Вектор Z-функции выглядит для такой строки так:
| a b c a $ a b a b c a b с a c a b |
| 17 0 0 1 0 2 0 4 0 0 4 0 0 1 0 2 0 |
Если отбросить значение для полного суффикса, то наличие сентинела ограничивает Zi длиной искомого фрагмента (он является меньшей половиной строки по смыслу задачи). Но вот если этот максимум и достигается, то только в позициях вхождения подстроки. В нашем примере четверками отмечены
все
позиции вхождения искомой строки (отметьте, что найденные участки расположены внахлест друг с другом, но все-равно наши рассуждения остаются верны).
Ну, значит если мы сможем быстро строить вектор Z-функции, то поиск с его помощью всех вхождений строки сводится к поиску в нем значения ее длины. Вот только если вычислять Z-функцию для каждого суффикса, то будет это явно не быстрее, чем решение «в лоб». Выручает нас то, что значение очередного элемента вектора можно узнать опираясь на предыдущие элементы.
Допустим, мы каким-то образом посчитали значения Z-функции вплоть до соответствующего i-1-ому символу. Рассмотрм некую позицию r<i, где мы уже знаем Zr.
Значит Zr символов начиная с этой позиции точно такие же, как и в начале строки. Они образуют так называемый Z-блок. Нас будет интересовать самый правый Z-блок, то-есть тот, кто заканчивается дальше всех (самый первый не в счет). В некоторых случаях самый правый блок может быть нулевой длины (когда никакой из непустых блоков не покрывает i-1, то самым правым будет i-1-ый, даже если Zi-1= 0).
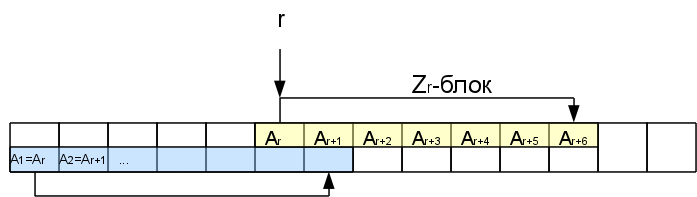
Когда мы будем рассматривать последующие символы внутри этого Z-блока, сравнивать очередной суффикс с самого начала не имеет смысла, так как часть этого суфикса уже встречалась в начале строки, а значит уже была обработана. Можно будет сразу пропускать символы аж до конца Z-блока.
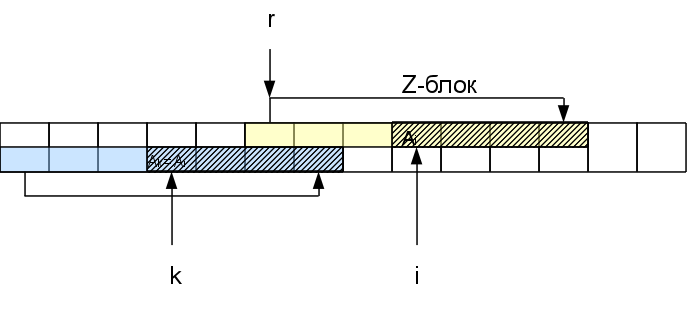
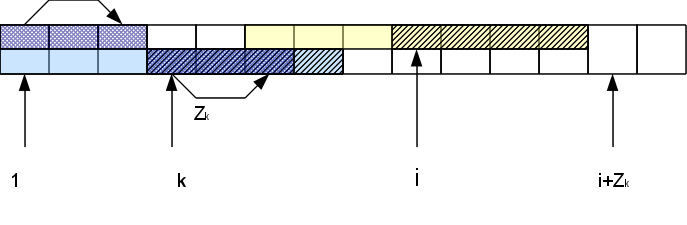
А именно, если мы рассматриваем i-й символ, находящийся в Zr-блоке, то есть соответствующий символ в начале строки на позиции k=i-r+1. Функция Zk нам уже известна. Если она меньше, чем оставшееся до конца Z-блока расстояние Zr-(i-r), то сразу можем быть уверены, что вся область совпадения для этого символа лежит внутри r-того Z-блока и значит результат будет тот же, что и в начале строки: Zi=Zk. Если же Zk >= Zr-(i-r), то Zi тоже больше или равна Zr-(i-r). Чтобы узнать насколько именно она больше, нам надо будет проверять следующие за Z-блоком символы. При этом в случае совпадения h этих символов с соответствующими им в начале строки, Zi увеличивается на h: Zi=Zk + h. В результате у нас может появиться новый самый правый Z-блок (если h>0).
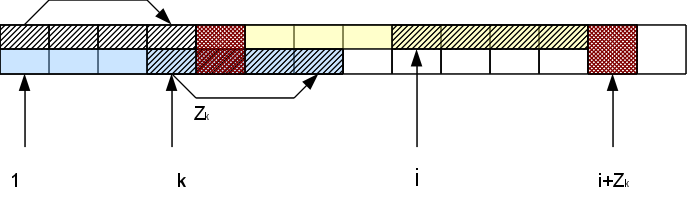
Таким образом, сравнивать символы нам приходится только правее самого правого Z-блока, причем за счет успешных сравнений блок «продвигается» правее, а неуспешные сообщают, что вычисление для данной позиции окончено. Это обеспечивает нам построение всего вектора Z-функции за линейное по длине строки время.
Применив этот алгоритм для поиска подстроки получим сложность по времени O(|A|+|X|), что значительно лучше, чем произведение, которое было в первом варианте. Правда, нам пришлось хранить вектор для Z-функции, на что уйдет дополнительной памяти порядка O(|A|+|X|). На самом деле, если не нужно находить все вхождения, а достаточно только одного, то можно обойтись и O(|X|) памяти, так как длина Z-блока все-равно не может быть больше чем |X|, кроме этого можно не продолжать обработку строки после обнаружения первого вхождения.
Напоследок, пример функции, вычисляющей Z-функцию. Просто модельный вариант без каких либо хитростей.
void z_preprocess(vector<int> & Z, const string & str)
{
const size_t len = str.size();
Z.clear();
Z.resize(len);
if (0 == len)
return;
Z[0] = len;
for (size_t curr = 1, left = 0, right = 1; curr < len; ++curr)
{
if (curr >= right)
{
size_t off = 0;
while ( curr + off < len && str[curr + off] == str[off] )
++off;
Z[curr] = off;
right = curr + Z[curr];
left = curr;
}
else
{
const size_t equiv = curr - left;
if (Z[equiv] < right - curr)
Z[curr] = Z[equiv];
else
{
size_t off = 0;
while ( right + off < len && str[right - curr + off] == str[right + off] )
++off;
Z[curr] = right - curr + off;
right += off;
left = curr;
}
}
}
}
Алгоритм Кнута-Морриса-Пратта (КМП)
Не смотря на логическую простоту предыдущего метода, более популярным является другой алгоритм, который в некотором смысле обратный Z-функции — алгоритм Кнута-Морриса-Пратта (КМП). Введем понятие префикс-функции. Префикс-функция для i-ой позиции — это длина максимального префикса строки, который короче i и который совпадает с суффиксом префикса длины i. Если определение Z-функции не сразило оппонента наповал, то уж этим комбо вам точно удастся поставить его на место  А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
| префикс | префикс | p |
|---|---|---|
| a | a | 0 |
| ab | ab | 0 |
| aba | aba | 1 |
| abab | abab | 2 |
| ababc | ababc | 0 |
| ababca | ababca | 1 |
| ababcab | ababcab | 2 |
| ababcaba | ababcaba | 3 |
Опять же наблюдаем ряд свойств префикс-функции. Во-первых, значения ограничены сверху своим номером, что следует прямо из определения — длина префикса должна быть больше префикс-функции. Во-вторых, уникальный символ точно так же делит строку на две части и ограничивает максимальное значение префикс-функции длиной меньшей из частей — потому что все, что длиннее, будет содержать уникальный, ничему другому не равный символ.
Отсюда получается интересующий нас вывод. Допустим, мы таки достигли в каком-то элементе этого теоретического потолка. Это значит, что здесь закончился такой префикс, что начальная часть совпадает с конечной и одна из них представляет «полную» половинку. Понятно, что в префиксе полная половинка обязана быть спереди, а значит при таком допущении это должна быть более короткая половинка, максимума же мы достигаем на более длинной половинке.
Таким образом, если мы, как и в предыдущей части, конкатенируем искомую строчку с той, в которой ищем, через сентинел, то точка вхождения длины искомой подстроки в компоненту префикс-функции будет соответствовать месту окончания вхождения. Возьмем наш пример: в строке «ababcabсacab» мы ищем «abca». Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:
| a b c a $ a b a b c a b с a c a b |
| 0 0 0 1 0 1 2 1 2 3 4 2 3 4 0 1 2 |
Снова мы нашли все вхождения подстроки одним махом — они оканчиваются на позициях четверок. Осталось понять как же эффективно посчитать эту префикс-функцию. Идея алгоритма незначительно отличается от идеи построения Z-функции.

Самое первое значение префикс-функции, очевидно, 0. Пусть мы посчитали префикс-функцию до i-ой позиции включительно. Рассмотрим i+1-ый символ. Если значение префикс-функции в i-й позиции Pi, то значит префикс A[..Pi] совпадает с подстрокой A[i-Pi+1..i]. Если символ A[Pi+1] совпадет с A[i+1], то можем спокойно записать, что Pi+1=Pi+1. Но вот если нет, то значение может быть либо меньше, либо такое же. Конечно, при Pi=0 сильно некуда уменьшаться, так что в этом случае Pi+1=0. Допустим, что Pi>0. Тогда есть в строке префикс A[..Pi], который эквивалентен подстроке A[i-Pi+1..i]. Искомая префикс-функция формируется в пределах этих эквивалентных участков плюс обрабатываемый символ, а значит нам можно забыть о всей строке после префикса и оставить только данный префикс и i+1-ый символ — ситуация будет идентичной.
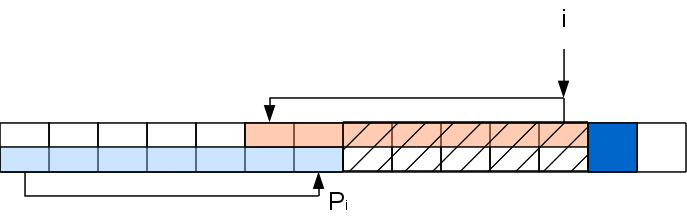
Задача на данном шаге свелась к задаче для строки с вырезанной серединкой: A[..Pi]A[i+1], которую можно решать рекурсивно таким же способом (хотя хвостовая рекурсия и не рекурсия вовсе, а цикл). То есть если A[PPi+1] совпадет с A[i+1], то Pi+1=PPi+1, а иначе снова выкидываем из рассмотрения часть строки и т.д. Повторяем процедуру пока не найдем совпадение либо не дойдем до 0.
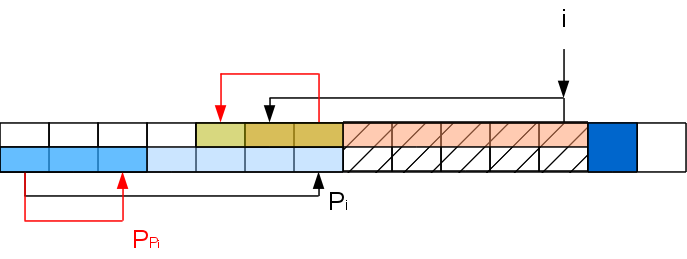
Повторение этих операций должно насторожить — казалось бы получается два вложенных цикла. Но это не так. Дело в том, что вложенный цикл длиной в k итераций уменьшает префикс-функцию в i+1-й позиции хотя бы на k-1, а для того, чтобы нарастить префикс-функцию до такого значения, нужно хотя бы k-1 раз успешно сопоставить буквы, обработав k-1 символов. То есть длина цикла соответствует промежутку между выполнением таких циклов и поэтому сложность алгоритма по прежнему линейна по длине обрабатываемой строки. С памятью тут такая-же ситуация, как и с Z-функцией — линейная по длине строки, но есть способ сэкономить. Кроме этого есть удобный факт, что символы обрабатываются последовательно, то есть мы не обязаны обрабатывать всю строку, если первое вхождение мы уже получили.
Ну и для примера фрагмент кода:
void calc_prefix_function(vector<int> & prefix_func, const string & str)
{
const size_t str_length = str.size();
prefix_func.clear();
prefix_func.resize(str_length);
if (0 == str_length)
return;
prefix_func[0] = 0;
for (size_t current = 1; current < str_length; ++current)
{
size_t matched_prefix = current - 1;
size_t candidate = prefix_func[matched_prefix];
while (candidate != 0 && str[current] != str[candidate])
{
matched_prefix = prefix_func[matched_prefix] - 1;
candidate = prefix_func[matched_prefix];
}
if (candidate == 0)
prefix_func[current] = str[current] == str[0] ? 1 : 0;
else
prefix_func[current] = candidate + 1;
}
}
Не смотря на то, что алгоритм более замысловат, реализация его даже проще, чем для Z-функции.
Другие задачи поиска
Дальше пойдет просто много букв о том, что этим задачи поиска строк не ограничиваются и что есть другие задачи и другие способы решения, так что если кому не интересно, то дальше можно не читать. Эта информация просто для ознакомления, чтобы в случае необходимости хотя бы осознавать, что «все уже украдено до нас» и не переизобретать велосипед.
Хоть вышеописанные алгоритмы и гарантируют линейное время выполнения, звание «алгоритма по умолчанию» получил алгоритм Бойера-Мура. В среднем он тоже дает линейное время, но еще и имеет лучше константу при этой линейной функции, но это в среднем. Бывают «плохие» данные, на которых он оказываются не лучше простейшего сравнения «в лоб» (ну прямо как с qsort). Он на редкость запутан и рассматривать его не будем — все-равно не упомнить. Есть еще ряд экзотических алгоритмов, которые ориентированы на обработку текстов на естественном языке и опираются в своих оптимизациях на статистические свойства слов языка.
Ну ладно, есть у нас алгоритм, который так или иначе за O(|X|+|A|) ищет подстроку в строке. А теперь представим, что мы пишем движок для гостевой книги. Есть у нас список запрещенных матерных слов (понятно, что так не поможет, но задача просто для примера). Мы собираемся фильтровать сообщения. Будем каждое из запрещенных слов искать в сообщении и… на это у нас уйдет O(|X1|+|X2|+…+|Xn|+n|A|). Как-то так себе, особенно если словарь «могучих выражений» «великого и могучего» очень «могуч». Для этого случая есть способ так предобработать словарь искомых строк, что поиск будет занимать только O(|X1|+|X2|+…+|Xn|+|A|), а это может быть существенно меньше, особенно если сообщения длинные.
Такая предобработка сводится к построению бора (trie) из словаря: дерево начинается в некотором фиктивном корне, узлы соответствует буквам слов в словаре, глубина узла дерева соответствует номеру буквы в слове. Узлы, в которых заканчивается слово из словаря называются терминальными и помечены неким образом (красным цветом на рисунке).
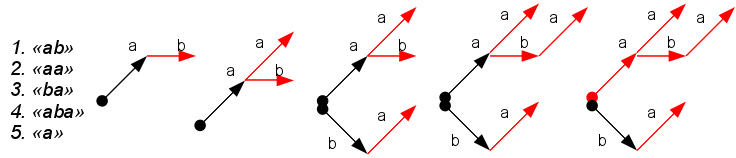
Полученное дерево является аналогом префикс-функции алгоритма КМП. С его помощью можно найти все вхождения всех слов словаря в фразе. Надо идти по дереву, проверяя наличие очередного символа в виде узла дерева, попутно отмечая встречающиеся терминальные вершины — это вхождения слов. Если соответствующего узла в дереве нет, то как и в КМП, происходит откат выше по дереву по специальным ссылкам. Данный алгоритм носит название алгоритма Ахо-Корасика. Такую же схему можно применять для поиска во время ввода и предсказания следующего символа в электронных словарях.
В данном примере построение бора несложно: просто добавляем в бор слова по очереди (нюансы только с дополнительными ссылками для «откатов»). Есть ряд оптимизаций, направленный на сокращение использования памяти этим деревом (т.н. сжатие бора — пропуск участков без ветвлений). На практике эти оптимизации чуть ли не обязательны. Недостатком данного алгоритма является его алфавитозависимость: время на обработку узла и занимаемая память зависят от количества потенциально возможных детей, которое равно размеру алфавита. Для больших алфавитов это серьезная проблема (представляете себе набор символов юникода?). Подробнее про это все можно почитать в этом хабратопике или воспользовавшись гуглояндексом — благо инфы по этомоу вопросу много.
Теперь посмотрим на другую задачу. Если в предыдущей мы знали заранее, что мы должны будем найти в поступающих потом данных, то здесь с точностью до наоборот: нам заранее выдали строчку, в которой будут искать, но что будут искать — неизвестно, а искать будут много. Типичный пример — поисковик. Документ, в котором ищется слово, известен заранее, а вот слова, которые там ищут, сыпятся на ходу. Вопрос, опять же, как вместо O(|X1|+|X2|+…+|Xn|+n|A|) получить O(|X1|+|X2|+…+|Xn|+|A|)?
Предлагается построить бор, в котором будут все возможные суффиксы имеющейся строки. Тогда поиск шаблона сведется к проверки наличия пути в дереве, соответствующего искомому шаблону. Если строить такой бор перебором всех суффиксов, то эта процедура может занять O(|A|2) времени, да и по памяти много. Но, к счастью, существуют алгоритмы, которые позволяют построить такое дерево сразу в сжатом виде — суффиксное дерево, причем сделать это за O(|A|). Недавно на Хабре была по этому поводу статья, так что интересующиеся могут прочитать про алгоритм Укконена там.
Плохо в суффиксном дереве, как обычно, две вещи: то, что это дерево, и то, что узлы дерева алфавитозависимы. От этих недостатков избавлен суффиксный массив. Суть суффиксного массива заключается в том, что если все суффиксы строки отсортировать, то поиск подстроки сведется к поиску группы расположенных рядом суффиксов по первой букве искомого образца и дальнейшего уточнения диапазона по последующим. При этом сами суффиксы в отсортированном виде хранить незачем, достаточно хранить позиции, в которых они начинаются в исходных данных. Правда, временные зависимости у данной структуры несколько хуже: единичный поиск будет обходиться O(|X| + log|A|) если подумать и сделать все аккуратно, и O(|X|log|A|) если не заморачиваться. Для сравнения в дереве для фиксированного алфавита O(|X|). Но зато то, что это массив, а не дерево, может улучшить ситуацию с кэшированием памяти и облегчить задачу предсказателю переходов процессора. Строится суффиксный массив за линейное время с помощью алгоритма Kärkkäinen-Sanders (уж извините, но плохо представляю как это должно звучать на русском). Нынче это один из самых популярных методов индексирования строк.
Вопросов приближенного поиска строк и анализа степени похожести мы тут касаться не будем совсем — слишком большая область для того, чтобы запихнуть в эту статью. Просто упомяну, что там люди зря хлеб не ели и придумали много всяких подходов, поэтому если столкнетесь с подобной задачей — найдите и почитайте. Весьма возможно такая задача уже решена.
Спасибо тем, кто читал! А тем, кто дочитал досюда, спасибо особенное!
UPD: Добавил ссылку на содержательную статью про бор (он же луч, он же префиксное дерево, он же нагруженное дерево, он же trie).
Содержание
- Комбинация клавиш для поиска в тексте и на странице
- Поиск по тексту в Ворде
- Поиск по словам и фразам через панель «Навигация»
- Расширенный поиск в Ворде
- Метод 1: Вкладка «Главная»
- Метод 2: Через окно «Навигация»
- Как найти слово в тексте Word
- Поиск слов в документе Word
- Замена слов по всему документу Word
- Поиск по тексту в Ворде
- Самый простой поиск в Word – кнопка «Найти»
- Расширенный поиск в Ворде
- Как в Word найти слово в тексте – Расширенный поиск
- Направление поиска
- Поиск с учетом регистра
- Поиск по целым словам
- Подстановочные знаки
- Поиск омофонов
- Поиск по тексту без учета знаков препинания
- Поиск слов без учета пробелов
- Поиск текста по формату
- Специальный поиск от Ворд
- Опции, которые не приносят пользы
- Как в Ворде в тексте быстро найти нужное слово
- Окно Навигация
- Расширенный поиск
Комбинация клавиш для поиска в тексте и на странице
Очень часто возникает необходимость найти какую-нибудь строчку, слово или абзац в длинном-длинном тексте на странице сайта, в текстовом документе, файле Word или таблице Excel. Можно, конечно, полазить по менюшкам и найти нужный пункт для вызова поискового диалогового окна. Но есть способ быстрее и удобнее — это специальная комбинация клавиш для поиска. В веб-браузерах, текстовых редакторах и офисных программах это — сочетание клавиш CTRL+F.

Нажав этим кнопки Вы вызовите стандартную для этого приложения форму поиска в тексте и на странице.
Причём комбинация клавиш поиска не зависит от версии программы или операционной системы — это общепринятый стандарт и от него практически никто не отходит!
Для того, чтобы найти что-то нужное через проводник Windows — необходимо воспользоваться несколько иной комбинацией клавиш для поиска — Win+F. Она относится к основным горячим клавишам Виндовс.
Для новичков поясню: кнопка Win — это специальная клавиша с логотипом Windows, расположенная в нижнем ряду кнопок клавиатуры компьютера. Она используется для вызова ряда функций Windows, в том числе и для поиска.
Источник
Поиск по тексту в Ворде
Бывают такие ситуации, когда в огромной статье нужно найти определённый символ или слово. Перечитывать весь текст – не вариант, необходимо воспользоваться быстрым способом – открыть поиск в Ворде. Существует несколько способов, с помощью которых можно легко совершать поиск по документу.
Поиск по словам и фразам через панель «Навигация»
Чтобы найти какую-либо фразу или слово в документе Ворд, надо открыть окно «Навигация». Найти данное окно можно с помощью шагов ниже:
Примечание. Поиск будет выдавать как точный вариант запроса фразы, так и производный. Наглядно можно увидеть на примере ниже.

Внимание. Если выделить определённое слово в тексте и нажать «Ctrl+F», то сработает поиск по данному слову. Причем в области поиска искомое слово уже будет написано.
Если случайно закрыли окно поиска, то нажмите сочетание клавиш «Ctrl+Alt+Y». Ворд повторно начнет искать последнюю искомую фразу.
Расширенный поиск в Ворде
Если понадобилось разыскать какой-то символ в определенном отрывке статьи, к примеру, знак неразрывного пробела или сноску, то в помощь расширенный поиск.
Метод 1: Вкладка «Главная»
Найти расширенный поиск можно нажав по стрелке на кнопке «Найти» во вкладке «Главная».

В новом окне в разделе «Найти» нужно кликнуть по кнопке «Больше». Тогда раскроется полный функционал данного поиска.

В поле «Найти» напишите искомую фразу или перейдите к кнопке «Специальный» и укажите нужный вариант для поиска.

Далее поставьте соответствующий вид документа, нажав по кнопке «Найти в», если нужно совершить поиск по всему документу то «Основной документ».

Когда надо совершить поиск по какому-то фрагменту в статье, изначально нужно его выделить и указать «Текущий фрагмент».

В окне «Найти и заменить» всплывет уведомление сколько элементов найдено Вордом.

Метод 2: Через окно «Навигация»
Открыть расширенный поиск можно через панель «Навигация».

Рядом со значком «Лупа» есть маленький треугольник, нужно нажать по нему и выбрать «Расширенный поиск».

Источник
Как найти слово в тексте Word
Word – одна из самых популярных программ для работы с текстом. Здесь пользователю доступны все возможные инструменты, которые только могут понадобиться при работе с текстовыми документами.
Одним из таких инструментов является поиск. В этой небольшой статье мы расскажем о том, как найти слово в тексте Word и при необходимости выполнить его замену по всему тексту. Статья будет актуальной для всех современных версий Word, включая Word 2007, 2010, 2013, 2016 и 2019.
Поиск слов в документе Word
Для того чтобы найти слово в тексте Word нужно перейти на вкладку « Главная » и нажать на кнопку « Найти » (в правом верхнем углу окна) или нажать комбинацию клавиш CTRL-F (F от английского Find).
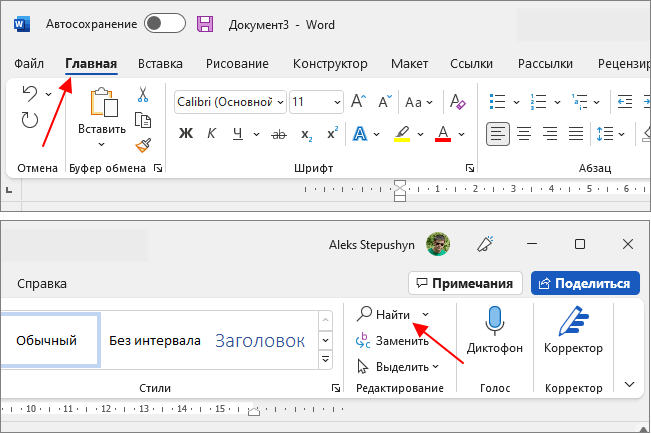
В результате откроется боковое меню « Навигация ». Здесь нужно ввести слово, которое вам нужно найти в тексте, и оно автоматически будет подсвечено в документе Word.
Также можно сначала выделить нужное слово в тексте и потом нажать на кнопку « Найти ». В этом случае выделенное слово сразу будет подставлено в поисковую строку.
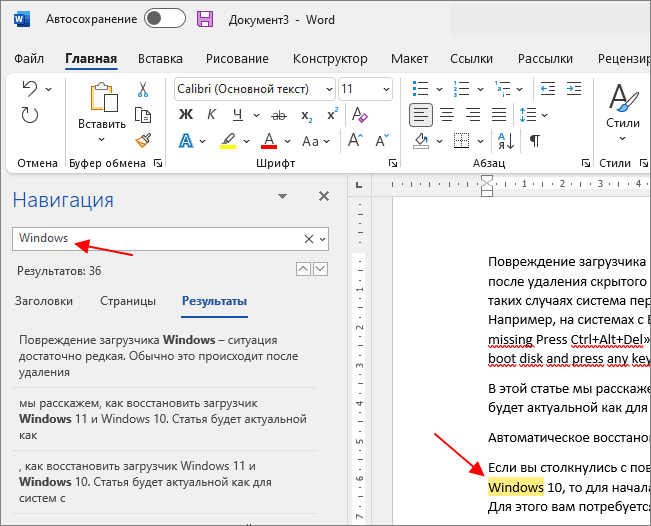
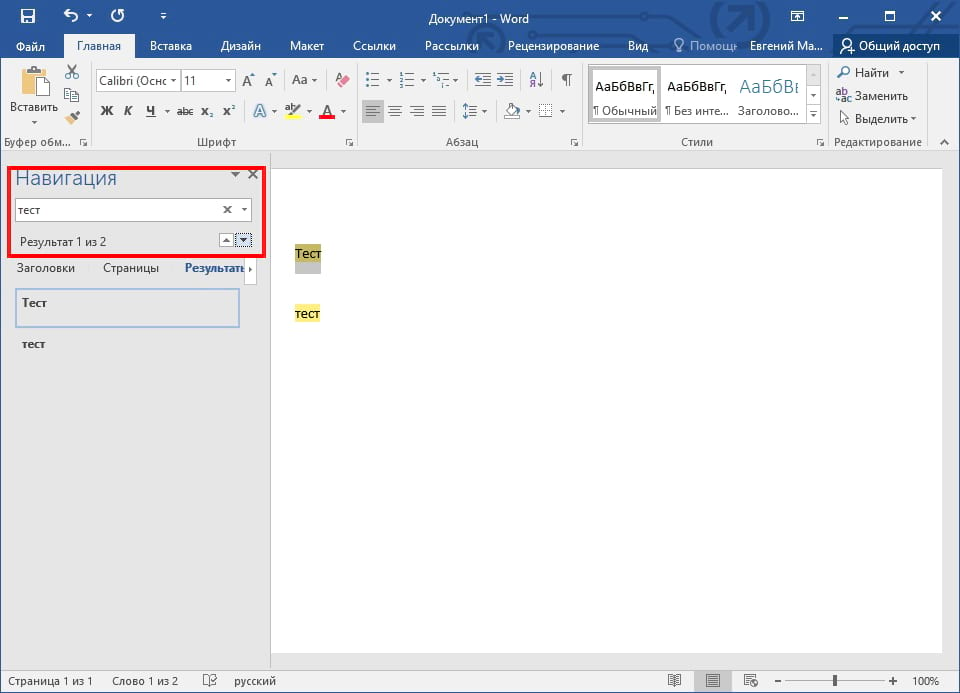
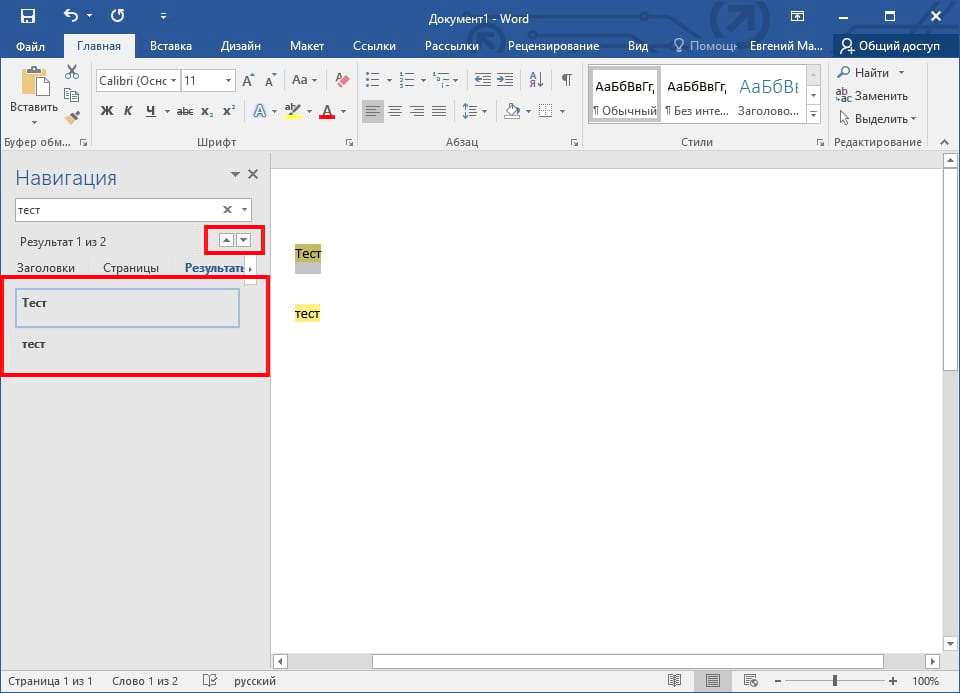
При этом в меню « Навигация » в блоке « Результаты » будет выведен список из отрывков текста, в которых было найдено введенное в поиск слово. Кликнув по найденному отрывку текста, вы сразу переместитесь к данному месту документа. Также для перемещения между найденными словами можно использовать небольшие стрелки под строкой поиска.
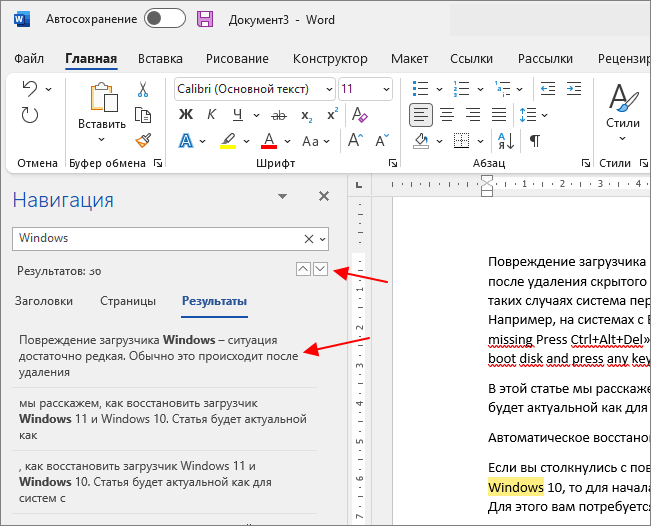
Для того чтобы закончить поиск достаточно просто закрыть меню « Навигация ».
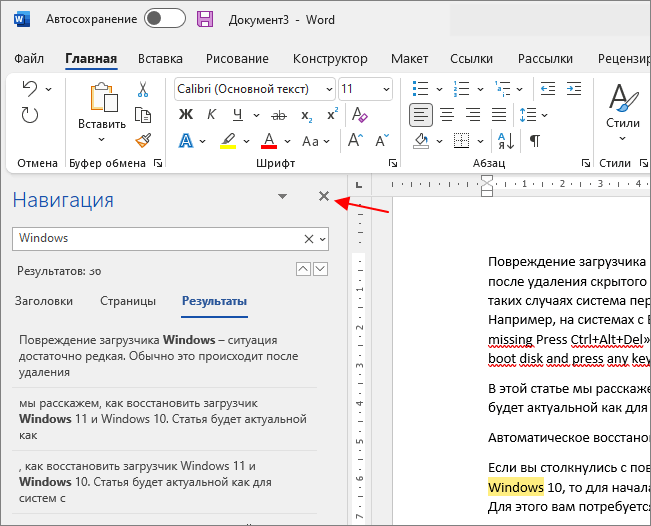
В старых версиях программы Word при нажатии на кнопку « Найти » или использовании комбинации клавиш CTRL-F будет появляться всплывающее окно « Найти и заменить ».
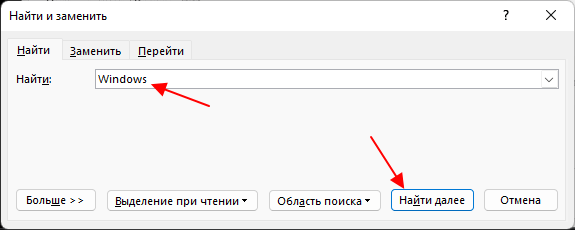
В этом случае нужно на вкладке « Найти » ввести искомое слово в поисковую строку и нажимать на кнопку « Найти далее » для того, чтобы перемещаться между найденными в документе словами.
Замена слов по всему документу Word
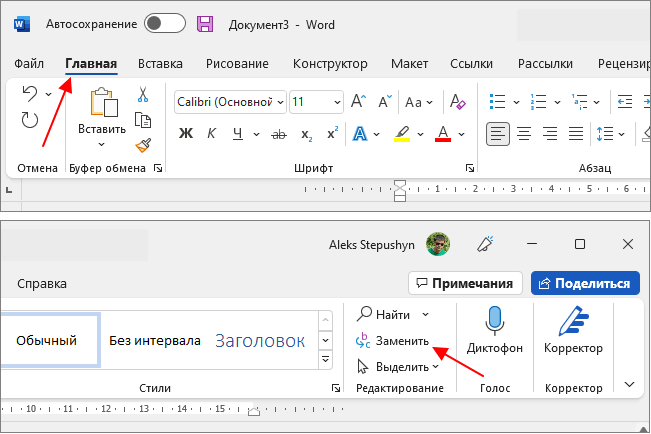
В результате откроется всплывающее окно « Найти и заменить ». Здесь на вкладке « Заменить » можно искать слова и автоматически заменять их на другие.
Для этого нужно ввести исходный текст в строку « Найти » и новый текст в строку « Заменить на ». После этого для замены нужно нажимать на кнопку « Заменить », если вы уверены и хотите заменить сразу все найденные отрывки текста, то можно нажать на кнопку « Заменить все ».
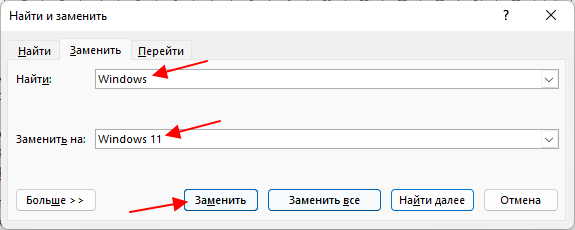
Если нажать на кнопку «Больше», то появятся дополнительные настройки замены текста.
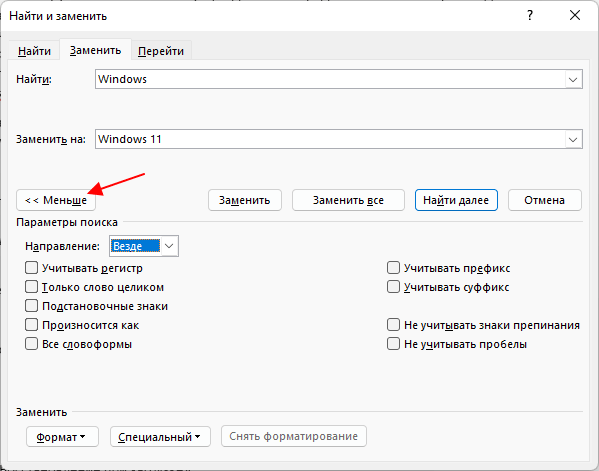
Здесь можно выбрать направление поиска, включить учет регистра (большие и маленькие буквы) и т. д.
Более подробно о поиске и замене в отдельной статье:
Источник
Поиск по тексту в Ворде
Работая с текстом, особенно с большими объемами, зачастую необходимо найти слово или кусок текста. Для этого можно воспользоваться поиском по тексту в Ворде. Существует несколько вариантов поиска в Word:
Самый простой поиск в Word – кнопка «Найти»
Самый простой поиск в ворде – это через кнопку «Найти». Эта кнопка расположена во вкладке «Главная» в самом правом углу.
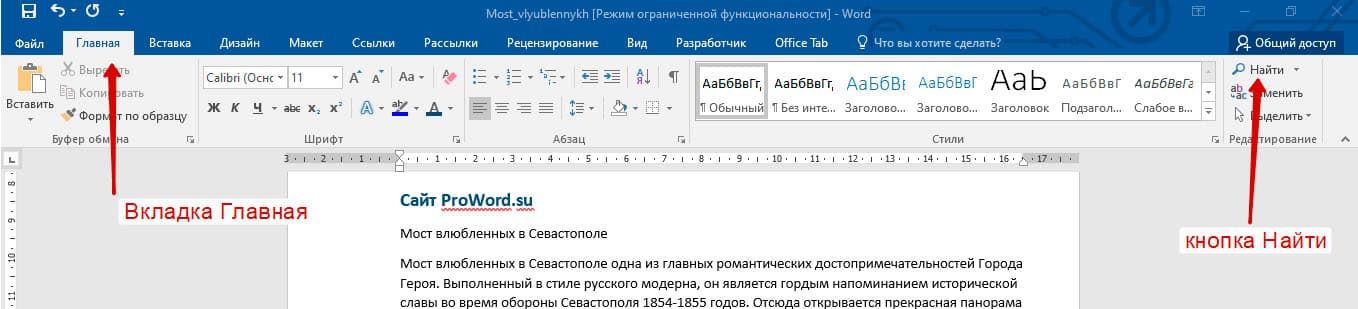
! Для ускорения работы, для поиска в Ворде воспользуйтесь комбинацией клавишей: CRL+F
После нажатия кнопки или сочетания клавишей откроется окно Навигации, где можно будет вводить слова для поиска.

! Это самый простой и быстрый способ поиска по документу Word.
Для обычного пользователя большего и не нужно. Но если ваша деятельность, вынуждает Вас искать более сложные фрагменты текста (например, нужно найти текст с синим цветом), то необходимо воспользоваться расширенной формой поиска.
Расширенный поиск в Ворде
Часто возникает необходимость поиска слов в Ворде, которое отличается по формату. Например, все слова, выделенные жирным. В этом как рас и поможет расширенный поиск.
Существует 3 варианта вызова расширенного поиска:
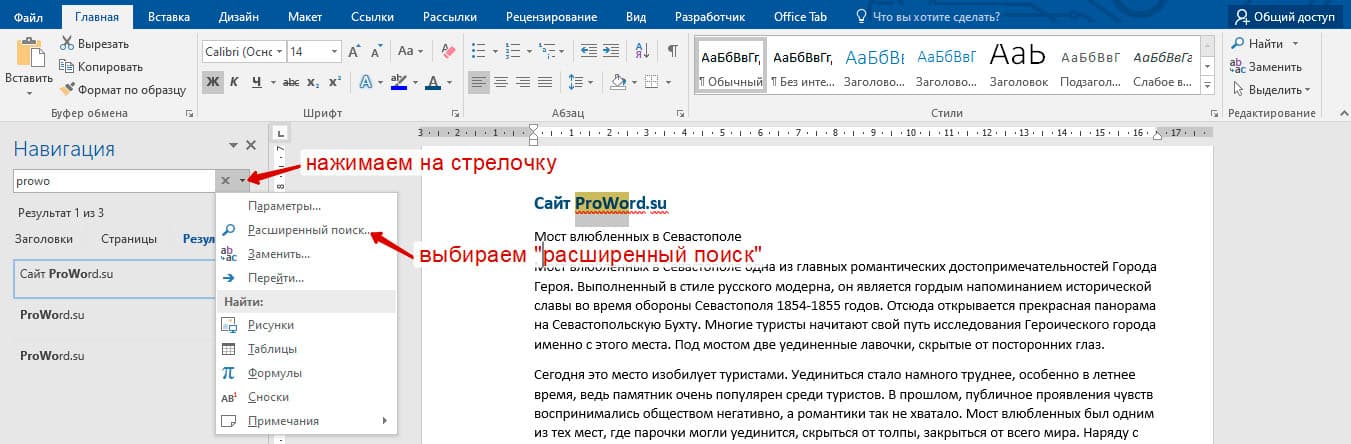
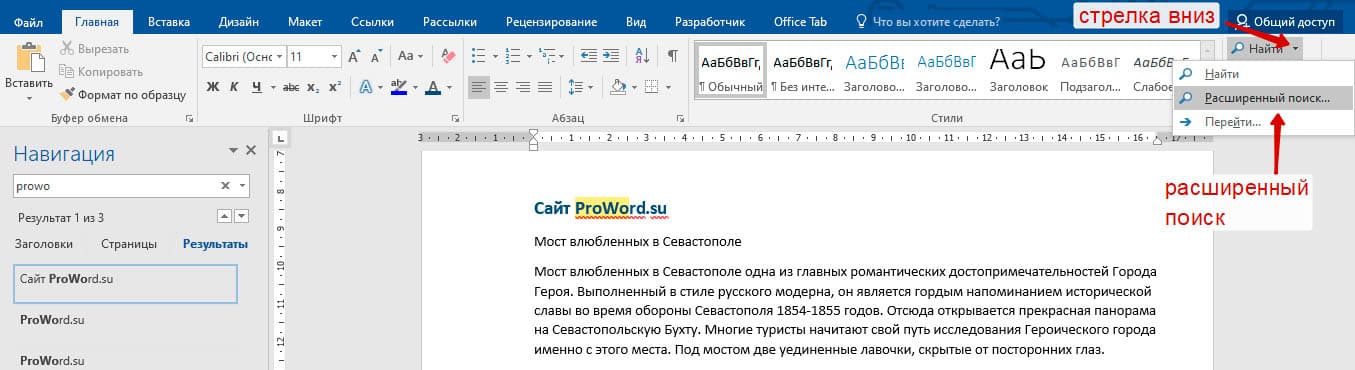
В любом случае все 3 варианта ведут к одной форме – «Расширенному поиску».
Как в Word найти слово в тексте – Расширенный поиск
После открытия отдельного диалогового окна, нужно нажать на кнопку «Больше»
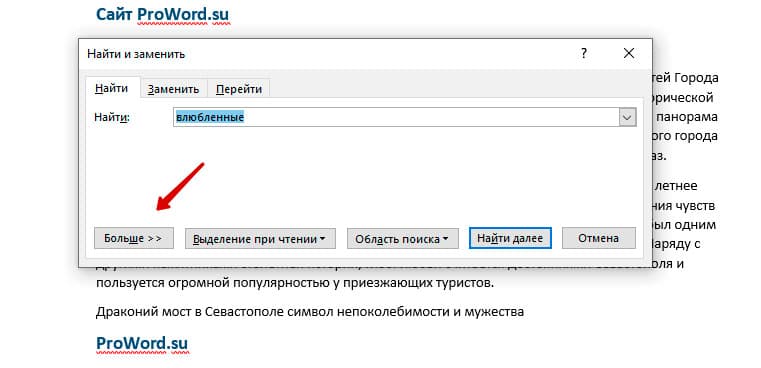
После нажатия кнопки диалоговое окно увеличится
Перед нами высветилось большое количество настроек. Рассмотрим самые важные:
Направление поиска
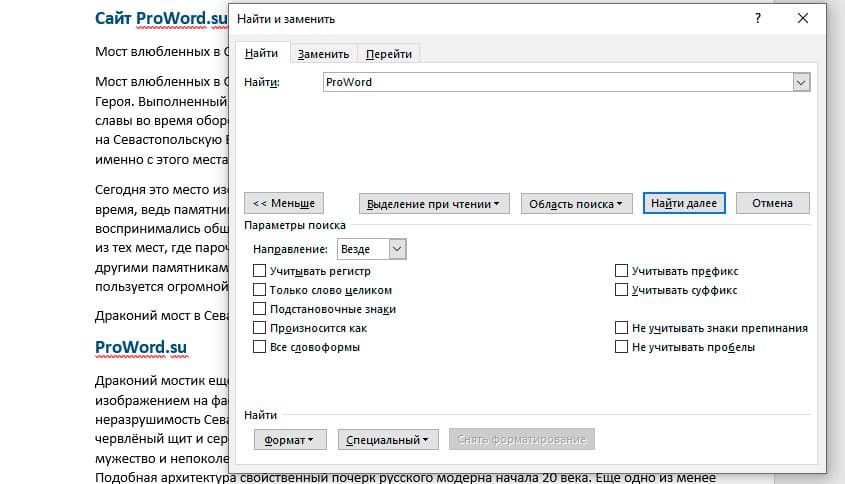
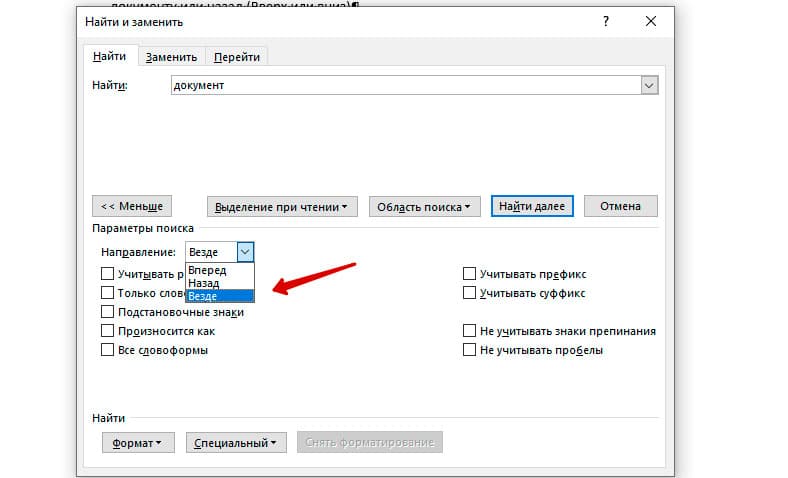
В настройках можно задать Направление поиска. Рекомендовано оставлять пункт «Везде». Так найти слово в тексте будет более реально, потому что поиск пройдет по всему файлу. Еще существуют режимы «Назад» и «Вперед». В этом режиме поиск начинается от курсора и идет вперед по документу или назад (Вверх или вниз)
Поиск с учетом регистра
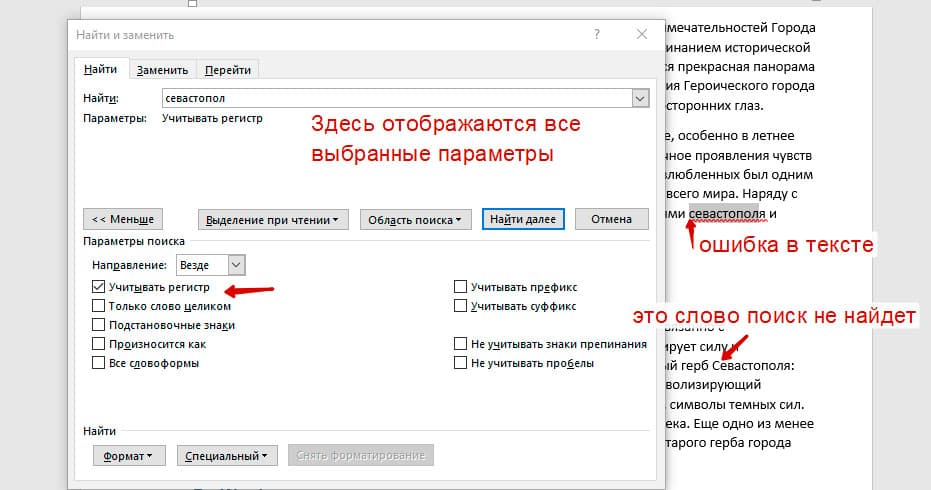
Поиск с учетом регистра позволяет искать слова с заданным регистром. Например, города пишутся с большой буквы, но журналист где-то мог неосознанно написать название города с маленькой буквы. Что бы облегчить поиск и проверку, необходимо воспользоваться этой конфигурацией:
Поиск по целым словам
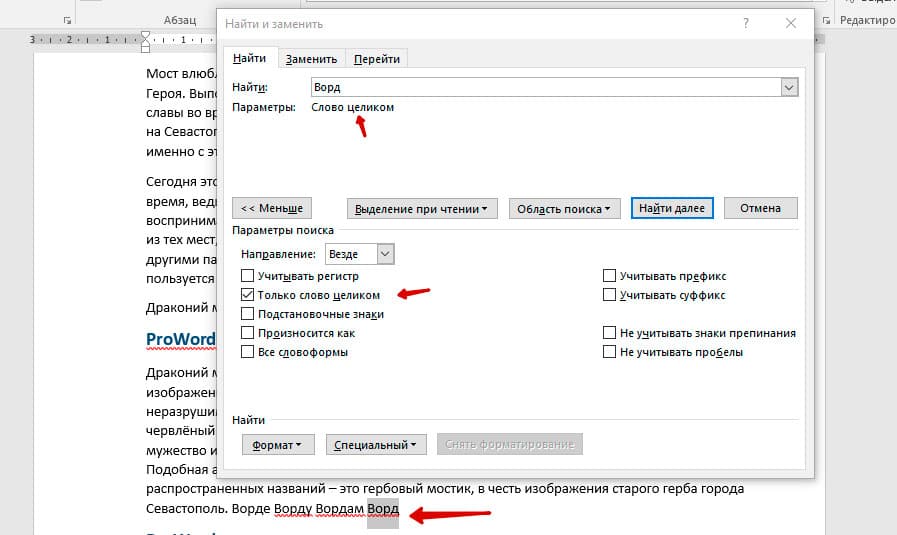
Если нажать на вторую галочку, «Только слово целиком», то поиск будет искать не по символам, а по целым словам. Т.е. если вбить в поиск только часть слова, то он его не найдет. Напимер, необходимо найти слово Ворд, при обычном поиске будут найдены все слова с разными окончаниями (Ворде, Ворду), но при нажатой галочке «Только слова целиком» этого не произойдет.
Подстановочные знаки
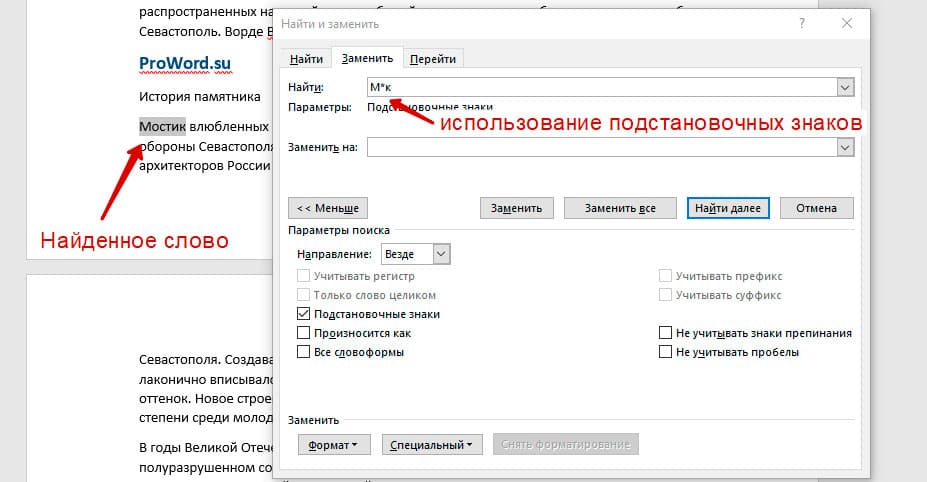
Более тяжелый элемент, это подстановочные знаки. Например, нам нужно найти все слова, которые начинаются с буквы м и заканчиваются буквой к. Для этого в диалоговом окне поиска нажимаем галочку «Подстановочные знаки», и нажимаем на кнопку «Специальный», в открывающемся списке выбираем нужный знак:
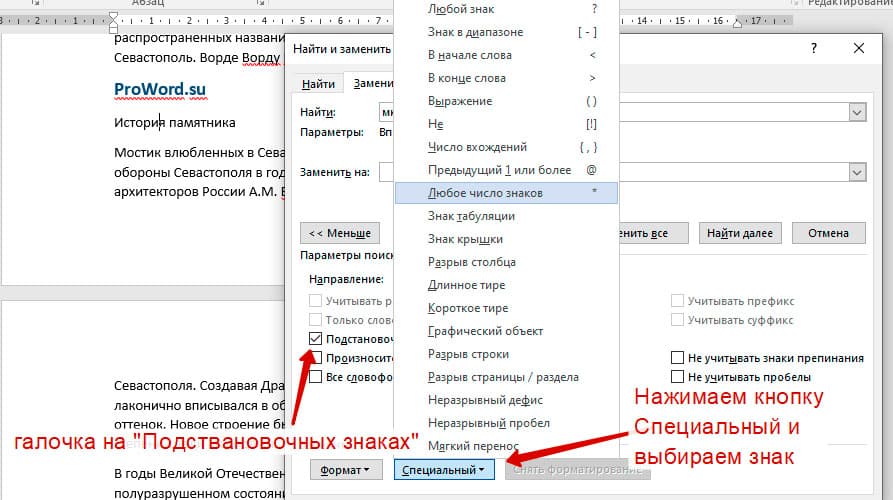
В результате Word найдет вот такое значение:
Поиск омофонов
Microsoft Word реализовал поиск омофонов, но только на английском языке, для этого необходимо выбрать пункт «Произносится как». Вообще, омофоны — это слова, которые произносятся одинаково, но пишутся и имеют значение разное. Для такого поиска необходимо нажать «Произносится как». Например, английское слово cell (клетка) произносится так же, как слово sell (продавать).
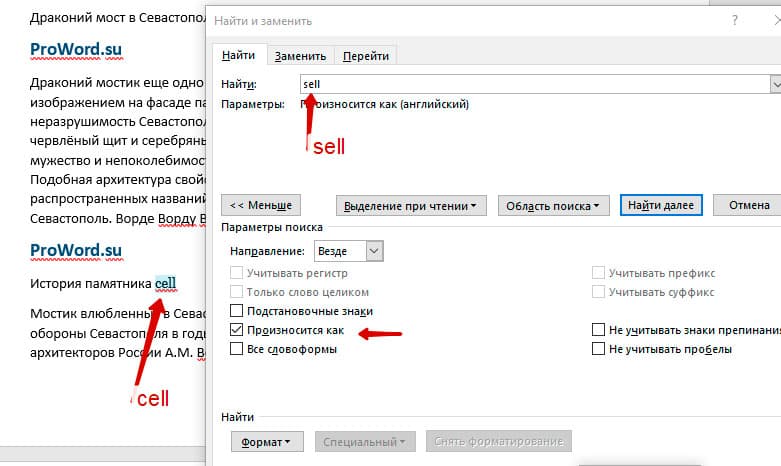
! из-за не поддержания русского языка, эффективность от данной опции на нуле
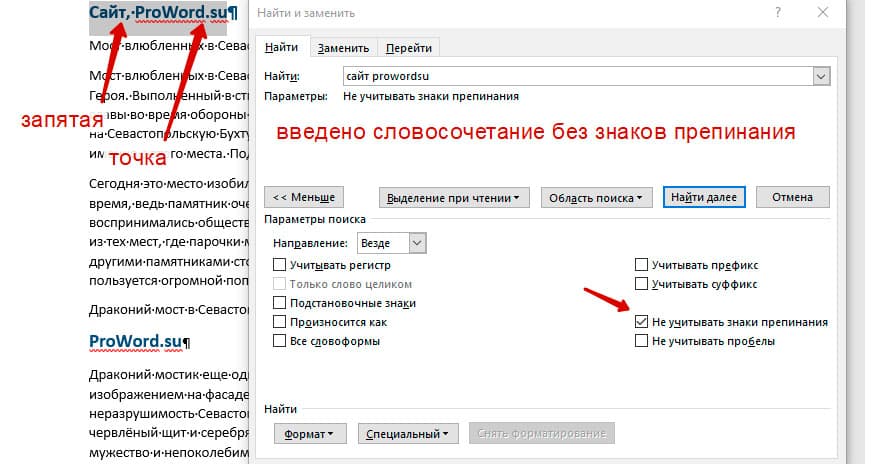
Поиск по тексту без учета знаков препинания
Очень полезная опция «Не учитывать знаки препинания». Она позволяет проводить поиск без учета знаков препинания, особенно хорошо, когда нужно найти словосочетание в тексте.
Поиск слов без учета пробелов
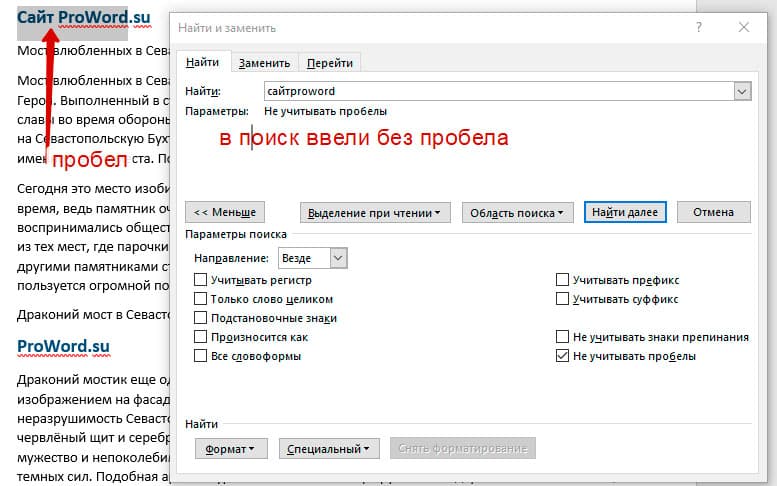
Включенная галочка «Не учитывать пробелы» позволяет находить словосочетания, в которых есть пробел, но алгоритм поиска Word как бы проглатывает его.
Поиск текста по формату
Очень удобный функционал, когда нужно найти текст с определенным форматированием. Для поиска необходимо нажать кнопку Формат, потом у Вас откроется большой выбор форматов:

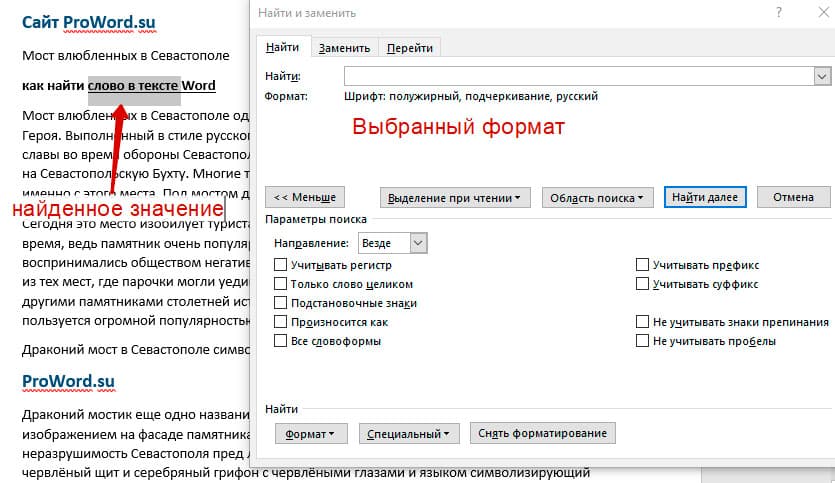
Для примера в тексте я выделил Жирным текст «как найти слово в тексте Word». Весть текст выделен полужирным, а кусок текста «слово в тексте Word» сделал подчернутым.
В формате я выбрал полужирный, подчеркивание, и русский язык. В итоге Ворд наше только фрагмент «слово в тексте». Только он был и жирным и подчеркнутым и на русском языке.
После проделанных манипуляция не забудьте нажать кнопку «Снять форматирование». Кнопка находится правее от кнопки «Формат».
Специальный поиск от Ворд
Правее от кнопки формат есть кнопка «Специальный». Там существует огромное количество элементов для поиска
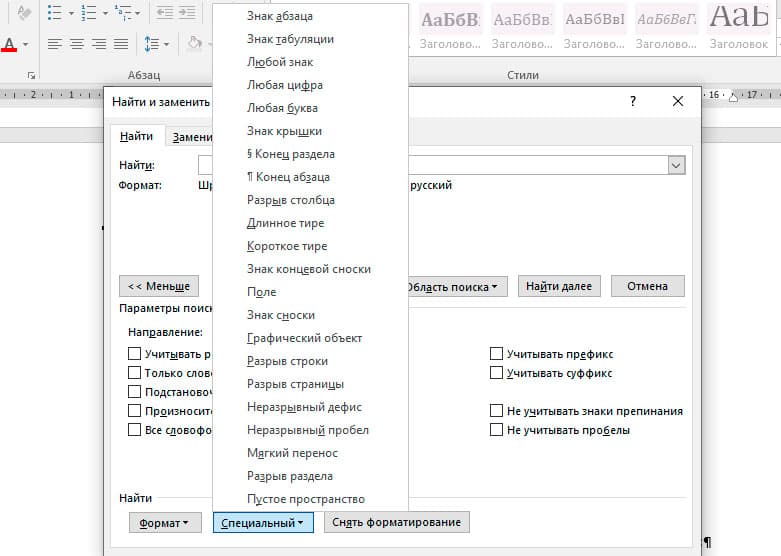
Через этот элемент можно искать:
Опции, которые не приносят пользы
!Это мое субъективное мнение, если у вас есть другие взгляды, то можете писать в комментариях.
Источник
Как в Ворде в тексте быстро найти нужное слово
После написания объемной статьи возникает необходимость найти неудачное слово или символ. Перечитывать весь документ достаточно трудоемкий процесс, который требует повышенного внимания и концентрации. Однако текстовый редактор Microsoft Office Word обладает функцией поиска. Данная статья о том, как в ворде найти слово в тексте.
Окно Навигация
Чтобы начать искать слова в тексте необходимо открыть панель навигации. Сделать это можно следующим образом:



В ворде запрограммированы горячие клавиши для быстрого вызова панели Навигация. Для этого необходимо одновременно нажать Ctrl+F.
Совет! Чтобы сразу найти повторяющиеся слова, выделяете одно и нажимаете сочетание кнопок Ctrl+F. Оно автоматически будет вписано в строку поиска.
Расширенный поиск
Расширенные поиск в ворде позволяет искать в тексте не только отрывки предложений, но и специальные знаки, а также скрытые символы форматирования.
Существует два способа вызова данной функции: через Найти во вкладке Главная или используя панель Навигация.
В первом случае необходимо выполнить следующие действия:



Во втором случае, в верхней строке нажимаете стрелку рядом со значком лупы и выбираете Расширенный поиск. Остальные действия аналогичны описанным в первом методе.

Совет! Для того, чтобы найти картинки, формулы или таблицы, рекомендуем использовать расширенный поиск из панели Навигации.
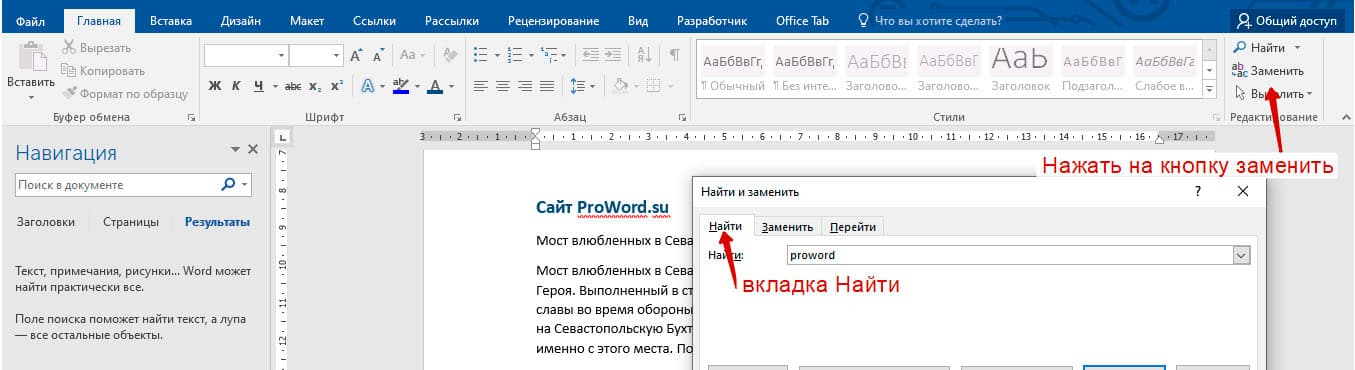
Дополнительно стоит отметить возможность в текстовом редакторе найти нужное слово и заменить его другим. Во вкладке Главная есть отдельная кнопка Заменить.

Меню выглядит следующим образом:

Заполняете нужные поля и нажимаете Заменить. Если предварительно хотите просмотреть искомые слова, то нажимаете на Найти далее и прорабатываете весь файл. Используя эту функцию можно за один раз поменять одинаковые слова на другие, что ускоряет процесс работы с документом.
Как видите, функция поиска слов и символов в ворд очень полезна и удобна. С ней легко справится даже новичок. Также этот инструмент позволяет искать ключевые слова в документе. А для более специфических условий рекомендуем использовать расширенный поиск, который позволяет искать специальные знаки, а также таблицы, рисунки и формулы.
Поделись с друзьями в соц.сети!
Источник
Как искать текст в Word

M icrosoft Word предоставляет функцию, которая позволяет Вам искать текст в документе. Вы также можете использовать расширенные настройки, чтобы сделать поиск более конкретным, например, сопоставление регистра или игнорирование знаков препинания. Вот как это использовать.
Поиск текста в документе Word
Для поиска текста в Word Вам потребуется доступ к панели «Навигация». Это можно сделать, выбрав «Найти» в группе «Редактирование» на вкладке «Главная».
Альтернативный способ доступа к этой панели — использование сочетания клавиш Ctrl + F в Windows или Command + F в Mac.
Открыв панель «Навигация», введите текст, который хотите найти. Будет отображено количество экземпляров этого текста в документе.
Вы можете перемещаться по результатам поиска, нажимая стрелки вверх и вниз, расположенные под окном поиска, или щелкая непосредственно по фрагменту результата на панели навигации.
Настройка функций расширенного поиска
Минус основной функции поиска состоит в том, что она не учитывает многие вещи, такие как регистр букв в тексте. Это проблема, если Вы ищете в документе, который содержит много контента, например, книгу или диссертацию.
Вы можете настроить это, перейдя в группу «Редактирование» на вкладке «Главная», выбрав стрелку рядом с «Найти» и выбрав «Расширенный поиск» в раскрывающемся списке.
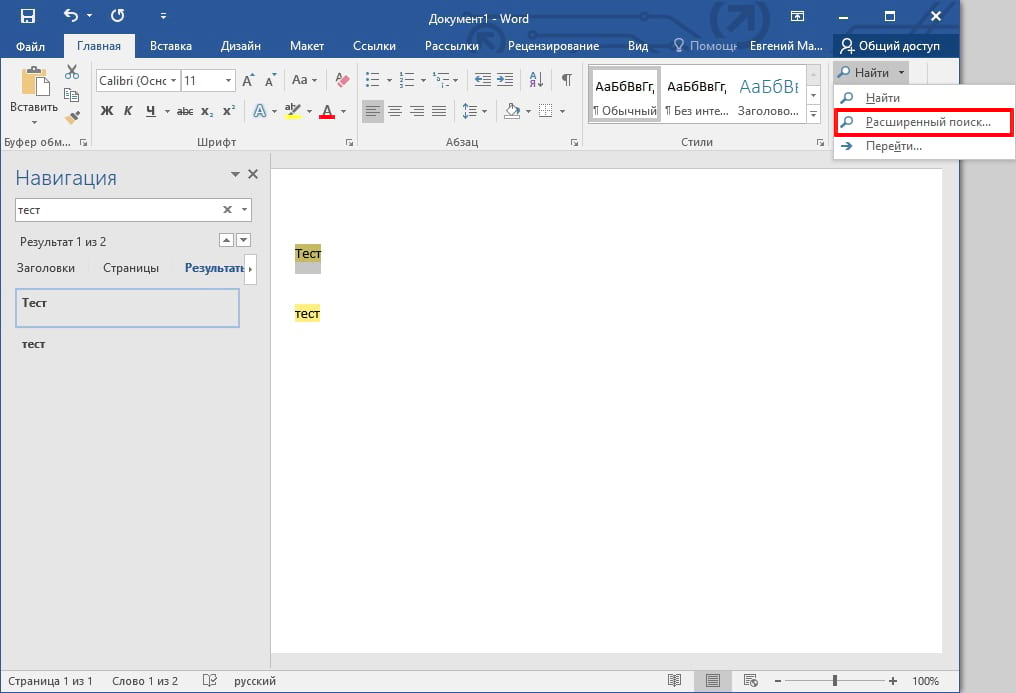
Откроется окно «Найти и заменить». Выберите «Больше».

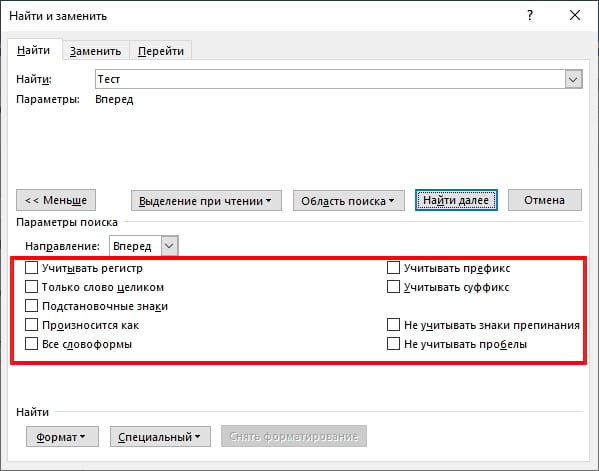
В группе «Параметры поиска» установите флажок рядом с параметрами, которые хотите включить.
Теперь при следующем поиске текста в Word поиск будет работать с выбранными дополнительными параметрами.
Как найти слово в тексте документа Word Online
Удобный в использовании и бесплатный для всех пользователей, редактор Word Online приобретает все большую популярность. С его помощью создаются документы любого объема и любого назначения. Часто возникают ситуации, когда в тексте необходимо найти конкретное выражение или слово, для того чтобы уточнить или заменить его. Как найти в Word Online слово в тексте и использовать возможности настройки поиска – в данной публикации.

Как найти в Word Online слово в тексте
Поиск конкретного слова в документе, имеющем большой размер, может занять много времени. Но с помощью Ворд Онлайн можно использовать вариант быстрого поиска слова, причем как на компьютере, так и на смартфоне. Для поиска слова в документе Word выполните следующую инструкцию:
- Откройте требуемый текст;
- В строке верхнего меню найдите блок «Правка»;
- В предложенном перечне выберите нижнюю строку «Найти и заменить»;
- Откроется диалоговое окно, в котором используйте поле «Найти», доступное для ввода текста;
- Напечатайте слово, которое необходимо найти в документе;
- Нажмите кнопку «Далее».
Если слова в тексте найдутся, они будут подсвечены зеленым цветом.
Поиск в документе Word Online можно применять не только для отдельных слов, но и для целых предложений.

Как применить настройки поиска слова
Если документ имеет большой размер и область поиска нужно сузить, применяется настройка поиска:
- Для того чтобы найти слова с прописной буквой, например, имя, фамилию или название города, установите флажок около параметра «Учитывать регистр»;
- Обратите внимание, что в этом случае в строку «Найти» необходимо вставить слово, содержащее данную прописную букву;
- При нажатии кнопки «Далее» будут найдены слова точным вхождением прописной буквы.
Если текст содержит много различных международных символов, имеет смысл установить флажок около параметра «Игнорировать диакритические знаки в латинице», в этом случае такие обозначения при поиске учитываться не будут.
Вызвать диалоговое окно поиска можно с применением горячих клавиш, для чего используйте комбинацию «Ctrl + H».

Функция замены слова в Word Online
Если нужное слово найдено и требуется произвести его замену, используйте функцию «Заменить на»:
- Откройте системное окно «Найти и заменить»;
- В строке «Заменить на» напечатайте то слово, которое подлежит исправлению.
В редакторе Ворд Онлайн предусмотрено два варианта замены слов. Используйте первый способ при помощи следующего алгоритма:
- Если требуется заменить одно конкретное слово, выделите его в тексте курсором;
- После указания слова, которое хотите заменить, в строке «Заменить на» нажмите кнопку «Заменить» — произойдет замена только данного варианта.

Второй способ применяется ко всему документу целиком:
- Если требуется осуществить замену какого-либо слова во всем документе, выделите весь документ полностью;
- В диалоговом окне нажмите кнопку «Заменить все». В этом случае замена будет произведена во всем документе.
Все параметры, применяемые для простого поиска, можно использовать и для функции «Заменить».

Поиск слов по документу Word Online с мобильного устройства
Поиск слов в Word Online на смартфоне или планшете практически ничем не отличается от компьютерной версии. Меню раскрывается нажатием трех горизонтальных полос в правом верхнем углу, в предложенном списке нужно выбрать уже знакомое «Найти и заменить». Предусмотрен вариант как простого поиска, так и последующей замены слов или фраз.
Функция поиска – одна из основных, которую применяют пользователи при создании документов в Ворд Онлайн. Простота и скорость, с которой можно решить задачи по редактированию текста, несомненно, позволяют из всех текстовых редакторов остановить свой выбор на Word Online.
Поиск текста в файлах через командную строку Windows
 Недавно мы рассматривали поиск файлов через командную строку Windows. Сегодня поговорим о том, как найти внутри файлов нужный нам текст. Сделать это можно при помощи команды FIND.
Недавно мы рассматривали поиск файлов через командную строку Windows. Сегодня поговорим о том, как найти внутри файлов нужный нам текст. Сделать это можно при помощи команды FIND.
Команда find сообщает имена файлов, в которых был найден искомый файл, и выводит строки, в которых он содержится.
Синтаксис команды find :
FIND [/V] [/C] [/N] [/I] [/OFF[LINE]] «искомый_текст» [путь_к_файлу]
V — вывод всех строк, НЕ содержащих искомый текст;
C — вывод только общего числа строк, содержащих искомый текст;
N — вывод номеров строк;
I — поиск без учёта регистра символов;
OFF[LINE] — не пропускать файлы с атрибутом «автономный».
Для примера проверим все текстовые файлы в каталоге C:test на наличие слова «текст».
Если посмотреть на скриншот ниже, то можно подумать, что ни один из файлов не содержит слова «текст». Конечно, это вполне допустимый вариант. Но есть и другое объяснение.

Дело в том, что по умолчанию текст в командной строке Windows отображается согласно кодовой странице CP866, а в файлах он в кодовой странице CP1251. Поэтому нам достаточно сменить кодовую страницу в текущем окне командной строки. О том, как это сделать, можно прочитать в статье по этой ссылке.
Теперь мы видим, что слово «текст» встречается во всех трёх файлах.

Теперь посмотрим на строки, в которых нет слова «текст»:
Такие оказались только в файле FILE_1.TXT.

Помните, что команда find по умолчанию учитывает регистр. Поэтому, написав в ней «Текст», мы не найдём подобного слова в файлах. Но регистр можно и проигнорировать:
На скриншоте ниже хорошо видно, что сперва команда не нашла слова «Текст» в файлах, так как в них оно записано без заглавных букв. Добавив /i , мы это исправили.

Допустим, нам нужно знать порядковые номера строк, в которых отсутствует слово «текст»:

Если мы захотим знать число строк, в которых присутствует искомое слово, тогда выполним команду:
А если нам нужно знать число строк, где это слово отсутствует, тогда пример команды такой:

Хотя до этого в примерах мы искали отдельное слово, find спокойно ищет и выражения:

Особенностью команды find является то, что искомый текст обязательно нужно заключать в кавычки. Это приводит к трудностям, если в пути к файлам (и в именах файлов) содержится пробел. В таком случае нужно воспользоваться перенаправлением ввода, но только если мы ищем в конкретном файле.
Как видите, наличие пробела в имени каталога C:test test не помешало осуществить поиск. Но это что касается поиска в файле file_1.txt. А вот попытка поискать сразу во всех файлах привела к ошибке.

В таком случае можно воспользоваться циклическое обработкой, к примеру, командой for :

Помните, что в этом случае в командной строке нужно использовать конструкции вида %a, а в файлах .bat и .cmd вида %%a.
До этого в примерах мы всегда указывали в каких файлах искать. Если этого не сделать, то команда find выполняет поиск в тексте консоли или в тексте, который был передан по конвейеру другой командой.
Для следующего примера вернём кодовую страницу CP866. После этого отсортируем вывод команды ipconfig /all — оставим только те строки, где содержится слово «Состояние»:

Здесь мы лишь пробежались по вершинам, но возможности команды find гораздо больше. Особенно, если использовать её в комплексе с другими командами.