Время на прочтение
6 мин
Количество просмотров 479K
Продолжение.
Предыдущие части: 1-3, 4-6
7. Связь один-ко-многим.
Я уже показал вам как данные из разных таблиц могут быть связаны при помощи связи по внешнему ключу. Вы видели как заказы связываются с клиентами путем помещения customer_id в качестве внешнего ключа в таблице заказов.
Другой пример связи один-ко-многим – это связь, которая существует между матерью и ее детьми. Мать может иметь множество детей, но каждый ребенок может иметь только одну мать.
(Технически лучше говорить о женщине и ее детях вместо матери и ее детях потому, что, в контексте связи один-ко-многим, мать может иметь 0, 1 или множество потомков, но мать с 0 детей не может считаться матерью. Но давайте закроем на это глаза, хорошо?)
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
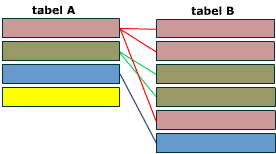
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
1) Сколько объектов и B могут относится к объекту A?
2) Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Примеры.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
В данном случае все настолько просто, что только поэтому может оказаться трудным понимание. Возьмем последний пример с домами. На улице ведь действительно может быть любое количество домов, но у каждого дома именно на этой улице может быть только одна улица (не берем дома, которые на практике принадлежат разным улицам, возьмем, к примеру, дом в центре улицы). Ведь не может конкретно этот дом быть одновременно в двух местах, на двух разных улицах, а мы говорим не про какой-то абстрактный дом вообще, а про конкретный.
8. Связь многие-ко-многим.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Связь между поставщиком пива и пивом, которое они поставляют – это тоже связь многие-ко-многим. Поставщик, во многих случаях, предоставляет более одного вида пива, а каждый вид пива может быть предоставлен множеством поставщиков.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но… Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
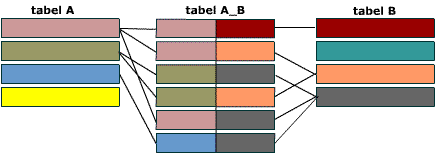
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
Таблицы “о пиве”.
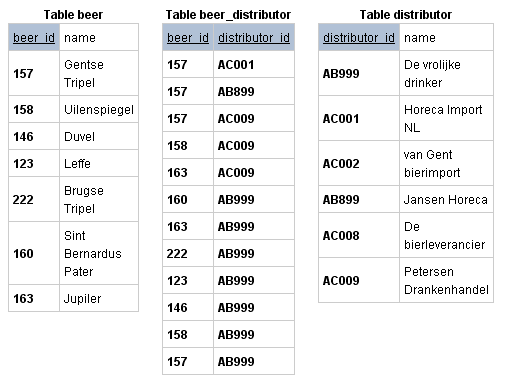

Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво ‘Gentse Tripel’ (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь на которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
Другой пример связи многие-ко-многим: заказ билетов в отеле.
В качестве последнего примера позвольте мне показать как бы могла быть смоделирована таблица заказов номеров гостиницы посетителями.

Соединительная таблица связи многие-ко-многим имеет дополнительные поля.
В этом примере вы видите, что между таблицами гостей и комнат существует связь многие-ко-многим. Одна комната может быть заказана многими гостями с течением времени и с течением времени гость может заказывать многие комнаты в отеле. Соединительная таблица в данном случае является не классической соединительной таблицей, которая состоит только из двух внешних ключей. Она является отдельной сущностью, которая имеет связи с двумя другими сущностями.
Вы часто будете сталкиваться с такими ситуациями, когда совокупность двух сущностей будет являться новой сущностью.
9. Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
В одной таблице.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В отдельных таблицах.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Примеры связи один-к-одному.
- Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.

Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”. В следующих частях я покажу как нормализовать вашу базу данных.
Какой же вид связи вам нужен?
Примеры связей таблиц на практике. Когда какие-то данные являются уникальными для конкретного объекта, например, человек и номера его паспортов, то имеем дело со связью один-ко-многим. Т.е. в одной таблице мы имеем список неких людей, а в другой таблице у нас есть перечисление номеров паспортов этого человека (напр., паспорт страны проживания и загранпаспорт). И эта комбинация данных уникальная для каждого человека. Т.е. у каждого человека может быть несколько номеров паспортов, но у каждого паспорта может быть только один владелец. Итого: нужны две таблицы.
А если есть некие данные, которые могу быть присвоены любому человеку, то имеем дело со связью многие-ко-многим. Например, есть таблица со списком людей и мы хотим хранить информацию о том, какие страны посетил каждый человек. В данном случае имеется две сущности: люди и страны. Любой человек может посетить любое количество стран равно, как и любая страна может быть посещена любым человеком. Т.е., в данном случае, страна не является уникальными данными для конкретного человека и может использоваться повторно.
В таких случаях использование связи многие-ко-многим с использованием трех таблиц и с хранением общей информации централизованно очень удобно. Ведь если общие данные меняются, то для того, чтобы информация в базе данных соответствовала действительности достаточно подправить ее только в одном месте, т.к. хранится она только в одном месте (таблице), в остальных таблицах имеются лишь ссылки на нее.
А когда у вас есть набор уникальных данных, которые имеют отношение только друг к другу, то храните все в одной таблице. Ваш выбор – связь один-к-одному. Например, у вас есть небольшая коллекция автомобилей и вы хотите хранить информацию о них (цвет, марка, год выпуска и пр.).
Внешние ключи и связи
Последнее обновление: 02.07.2017
Базы данных могут содержать таблицы, которые связаны между собой различными связями. Связь (relationship) представляет ассоциацию между
сущностями разных типов.
При выделении связи выделяют главную или родительскую таблицу (primary key table / master table) и зависимую, дочернюю таблицу (foreign key table / child table).
Дочерняя таблица зависит от родительской.
Для организации связи используются внешние ключи. Внешний ключ представляет один или несколько столбцов из одной таблицы,
который одновременно является потенциальным ключом из другой таблицы. Внешний ключ необязательно должен соответствовать первичному ключу из главной таблицы. Хотя, как правило,
внешний ключ из зависимой таблицы указывает на первичный ключ из главной таблицы.
Связи между таблицами бывают следующих типов:
-
Один к одному (One to one)
-
Один к многим (One to many)
-
Многие ко многим (Many to many)
Связь один к одному
Данный тип связей встречает не часто. В этом случае объекту одной сущности можно сопоставить только один объект другой сущности. Например,
на некоторых сайтах пользователь может иметь только один блог. То есть возникает отношение один пользователь — один блог.
Нередко этот тип связей предполагает разбиение одной большой таблицы на несколько маленьких. Основная родительская таблица в
этом случае продолжает содержать часто используемые данные, а дочерняя зависимая таблица обычно хранит данные, которые используются реже.
В этом отношении первичный ключ зависимой таблицы в то же время является внешним ключом, который ссылается на первичный ключ из главной таблицы.
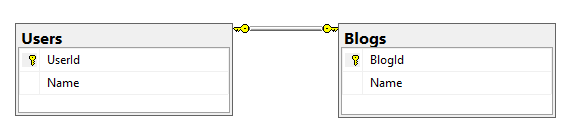
Например, таблица Users представляет пользователей и имеет следующие столбцы:
-
UserId (идентификатор, первичный ключ)
-
Name (имя пользователя)
И таблица Blogs представляет блоги пользователей и имеет следующие столбцы:
-
BlogId (идентификатор, первичный и внешний ключ)
-
Name (название блога)
В этом случае столбец BlogId будет хранить значение из столбца UserId из таблицы пользователей. То есть столбец BlogId будет выступать одновременно первичным и внешним ключом.
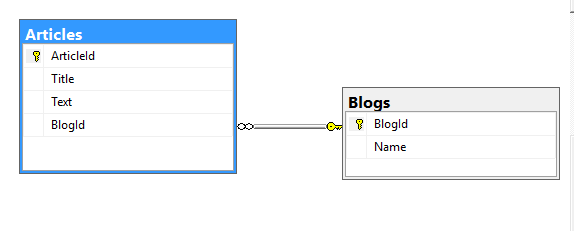
Связь один ко многим
Это наиболее часто встречаемый тип связей. В этом типе связей несколько строк из дочерний таблицы зависят от одной строки в
родительской таблице. Например, в одном блоге может быть несколько статей. В этом случае таблица блогов является родительской, а таблица статей — дочерней.
То есть один блог — много статей. Или другой пример, в футбольной команде может играть несколько футболистов. И в то же время один футболист одновременно
может играть только в одной команде. То есть одна команда — много футболистов.
К примеру, пусть будет таблица Articles, которая представляет статьи блога и которая имеет следующие столбцы:
-
ArticleId (идентификатор, первичный ключ)
-
BlogId (внешний ключ)
-
Title (название статьи)
-
Text (текст статьи)
В этом случае столбец BlogId из таблицы статей будет хранить значение из столбца BlogId из таблицы блогов.
Связь многие ко многим
При этом типе связей одна строка из таблицы А может быть связана с множеством строк из таблицы В. В свою очередь одна строка из таблицы В может быть связана с множеством строк
из таблицы А. Типичный пример — студенты и курсы: один студент может посещать несколько курсов, и соответственно на один курс могут записаться несколько студентов.
Другой пример — статьи и теги: для одной статьи можно определить несколько тегов, а один тег может быть определен для нескольких статей.
Но в SQL Server на уровне базы данных мы не можем установить прямую связь многие ко многим между двумя таблицами. Это делается посредством
вспомогательной промежуточной таблицы. Иногда данные из этой промежуточной таблицы представляют отдельную сущность.
Например, в случае со статьями и тегами пусть будет таблица Tags, которая имеет два столбца:
-
TagId (идентификатор, первичный ключ)
-
Text (текст тега)
Также пусть будет промежуточная таблица ArticleTags со следующими полями:
-
TagId (идентификатор, первичный и внешний ключ)
-
ArticleIdId (идентификатор, первичный и внешний ключ)
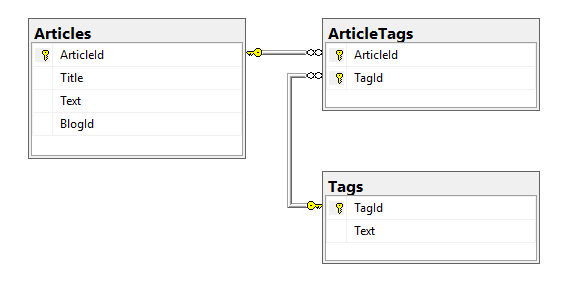
Технически мы получим две связи один-ко-многим. Столбец TagId из таблицы ArticleTags будет ссылаться на столбец TagId из таблицы Tags.
А столбец ArticleId из таблицы ArticleTags будет ссылаться
на столбец ArticleId из таблицы Articles. То есть столбцы TagId и ArticleId в таблице ArticleTags представляют составной первичный ключ и
одновременно являются внешними ключами для связи с таблицами Articles и Tags.
Ссылочная целостность данных
При изменении первичных и внешних ключей следует соблюдать такой аспект как ссылочная целостность данных (referential integrity).
Ее основная идея состоит в том, чтобы две таблице в базе данных, которые хранят одни и те же данные, поддерживали их согласованность.
Целостность данных представляет правильно выстроенные отношения между таблицами с корректной установкой ссылок между ними. В каких случаях целостность данных может нарушаться:
-
Аномалия удаления (deletion anomaly). Возникает при удалении строки из главной таблицы.
В этом случае внешний ключ из зависимой таблицы продолжает ссылаться на удаленную строку из главной таблицы -
Аномалия вставки (insertion anomaly). Возникает при вставке строки в зависимую таблицу.
В этом случае внешний ключ из зависимой таблицы не соответствует первичному ключу ни одной из строк из главной таблицы. -
Аномалии обновления (update anomaly). При подобной аномалии несколько строк одной таблицы могут содержать данные, которые принадлежат одному и
тому же объекту. При изменении данных в одной строке они могу прийти в противоречие с данными из другой строки.
Аномалия удаления
Для решения аномалии удаления для внешнего ключа следует устанавливать одно из двух ограничений:
-
Если строка из зависимой таблицы обязательно требует наличия строки из главной таблицы,
то для внешнего ключа устанавливается каскадное удаление. То есть при удалении строки из главной таблицы происходит удаление связанной строки (строк) из
зависимой таблицы. -
Если строка из зависимой таблицы допускает отсутствие связи со строкой из главной таблицы (то есть такая связь необязательна),
то для внешнего ключа при удалении связанной строки из главной таблицы задается установка значения NULL. При этом столбец внешнего ключа должен допускать
значение NULL.
Аномалия вставки
Для решения аномалии вставки при добавлении в зависимую таблицу данных столбец, который представляет внешний ключ, должен допускать значение NULL.
И таким образом, если добавляемый объект не имеет связи с главной таблицей, то в столбце внешнего ключа будет стоять значение NULL.
Аномалии обновления
Для решения проблемы аномалии обновления применяется нормализация, которая будет рассмотрена далее.
Следует
еще раз отметить, что связь один к одному
в рассмотренном примере нелогична.
Связь такого типа оправдана, например,
для связывания таблиц с личными данными
студента и его успеваемостью.
В
нашем случае более логично сформировать
связь один ко многим: ведь каждое
издательство может издавать множество
книг.
Формирование
и описание такой связи реализуется по
аналогии с предыдущим примером. Только
теперь связываются первичный ключ «Код
издательства» таблицы «Издательства»
и внешний ключ «Код издательства»
таблицы «Книги» (рисунок 2.19):

Рис.
2.19. Формирование
связи один ко многим
В
этом случае автоматически формируется
связь один ко многим, что видно из
комментария в нижней части окна.
Установленные
флажки имеют тот же смысл, что и в
предыдущем примере. Они означают, что
при формировании записи о книге допустимо
ссылаться только на существующее (ранее
описанное) издательство; при изменении
«Кода издательства» в таблице
«Издательства» автоматически изменяются
ссылки на издательства в таблице «Книги»;
при удалении записи из таблицы
«Издательства» удаляются записи обо
всех книгах, которые изданы в данном
издательстве, из таблицы «Книги».
Внешний
вид связи, как и в предыдущем случае,
зависит от флажка «Обеспечение целостности
данных» и параметров объединения.
Единственное отличие заключается в
появлении условного знака бесконечности
на конце связи со стороны «многие», что
видно из рисунка 2.20:
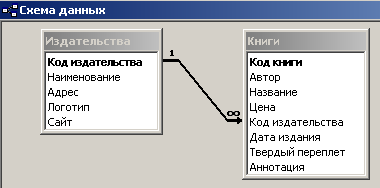
Рис.
2.20. Связь между
таблицами один ко многим
Связь
такого рода обычно предусматривается
– в таблицах описываются соответствующие
поля.
2.5.4. Связь многие ко многим
Для
БД «Издательства-Книги» более логична
связь многие ко многим. Действительно,
различные издательства могут издавать
одни и те же книги. И наоборот – одна и
та же книга может издаваться в различных
издательствах.
Для
формирования связей такого типа вводится
третья таблица, в которой задействованы
первичные ключи первых двух таблиц.
Если есть необходимость, в эту таблицу
вводятся и другие поля. На рисунке 2.21
представлена такая связующая таблица
в режиме конструктора.
Поля
лучше назвать так же, как и в связываемых
таблицах. Типы данных полей в нашем
случае должны быть числовыми, их размер
– длинное целое (как у счетчика). В
свойствах полей «Индексированное поле»
необходимо выбрать «Да (Допускаются
совпадения)». Это связано с тем, что в
таблице «Связи»
значения данных полей могут повторяться
– связь многие ко многим.

Рис.
2.21. Таблица
«Связи» в режиме конструктора
После
описания таблицы «Связи»
ее следует
включить в схему данных. Для этого
необходимо загрузить схему данных,
выбрать из контекстного меню команду
«Добавить таблицу» и добавить таблицу
«Связи»
в схему данных. В результате появится
окно, представленное на рисунке 2.22:

Рис.
2.22. Три таблицы
для формирования связи многие ко многим
Теперь осталось
сформировать связь один ко многим между
таблицами «Издательства» и «Связи» и
такую же связь – между таблицами «Книги»
и «Связи». В результате получится схема
данных, приведенная на рисунке 2.23:
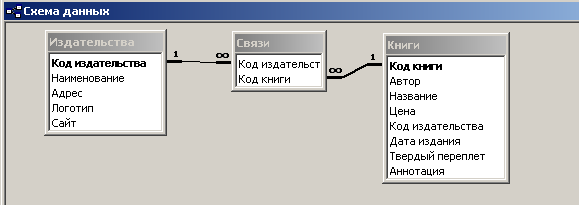
Рис.
2.23. Схема данных
со связью многие ко многим
между таблицами
«Издательства» и «Книги»
Итак, между таблицами
«Издательства» и «Книги» сформирована
связь многие ко многим. При построении
запроса на основе этой схемы данных
можно просмотреть все издательства и
книги, которые ими изданы.
Соседние файлы в папке Книги
- #
- #
- #
Russian (Pусский) translation by Yuri Yuriev (you can also view the original English article)
Сегодня мы продолжаем наше путешествие в мир SQL и связанных баз данных. В третьей части этой серии мы узнаем, как работать с несколькими таблицами, которые имеют отношения друг с другом. Во-первых, мы рассмотрим некоторые базовые концепции, а затем начнем работать с JOIN queries в SQL.
Вы также можете увидеть базы данных SQL в действии, просмотрев SQL scripts, apps and add-ons на рынке Envato.
Напоминание
- SQL for Beginners: Part 1
- SQL for Beginners: Part 2
Введение
При создании базы данных здравый смысл подсказывает, что мы используем отдельные таблицы для разных типов сущностей. Например: клиенты, заказы, предметы, сообщения… Но нам также нужно иметь отношения между этими таблицами. Например, клиенты делают заказы, а заказы содержат предметы. Эти отношения должны быть представлены в базе данных. Кроме того, при получении данных с помощью SQL нам нужно использовать определённые типы запросов JOIN, чтобы получить то, что нам нужно.
Существует несколько типов отношений базы данных. Сегодня мы рассмотрим следующее:
- Отношения один к одному
- Отношения «один ко многим» и «многие к одному»
- «Многие ко многим» отношения
- Самостоятельные ссылки
При выборе данных из нескольких таблиц с отношениями мы будем использовать запрос JOIN. Существует несколько типов JOIN, и мы собираемся узнать следующее:
- Перекрестные соединения
- Обычные соединения
- Внутренние соединения
- Левые (внешние) соединения
- Правые (внешние) соединения
Мы также узнаем об оговорках ON и USING.
Отношения один к одному
Предположим, у вас есть таблица для клиентов:


Мы можем поместить информацию об адресе клиента в отдельную таблицу:


Теперь мы имеем отношение между таблицей Customers и таблицей Addresses. Если каждый адрес может принадлежать только одному клиенту, это отношение «Один к одному». Имейте в виду, что такого рода отношения не очень распространены. Наша начальная таблица, которая включала адрес вместе с клиентом, в большинстве случаев могла работать нормально.
Обратите внимание: теперь в таблице Customers есть поле с именем «address_id», которое ссылается на запись соответствия в таблице Address. Это называется «Foreign Key» и используется для всех видов отношений баз данных. Мы рассмотрим этот вопрос позже.
Мы можем показать отношения между клиентскими и адресными записями следующим образом:


Обратите внимание, что существование отношений может быть необязательным, например, есть запись клиента, у которой нет связанной записи адреса.
Отношения «один ко многим» и «многие к одному»
Это наиболее часто используемый тип отношений. Рассмотрим веб-сайт e-commerce со следующим:
- Клиенты могут делать много заказов.
- Заказы могут содержать много позиций.
- Позиции могут иметь описания на многих языках.
В этих случаях нам необходимо создать отношения «один ко многим». Вот пример:

У каждого клиента может быть ноль, один или несколько заказов. Но заказ может принадлежать только одному клиенту.


Отношения «многие ко многим»
В некоторых случаях вам может потребоваться несколько экземпляров с обеих сторон. Например, каждый заказ может содержать несколько элементов. И каждый элемент также может быть в нескольких заказах.
Для этих отношений нам нужно создать дополнительную таблицу:


Таблица Items_Orders имеет только одну цель, а именно, чтобы создать отношение «многие ко многим» между элементами и заказами.
Вот картинка таких отношений:


Если вы хотите включить записи items_orders в график, это может выглядеть так:


Самостоятельные ссылки
Это используется, когда таблица должна иметь отношения с самой собой. Например, у вас есть реферальная программа. Клиенты могут направлять других клиентов на ваш веб-сайт. Таблица может выглядеть так:


Клиенты 102 и 103 были переданы клиентом 101.
На самом деле это может быть похоже на отношение «один ко многим», поскольку один клиент может ссылаться на нескольких клиентов. Также он может выглядеть, как древовидная структура:


Один клиент может ссылаться на ноль, одного или несколько клиентов. К каждому клиенту может обращаться только один клиент, или вообще никто.
Если вы хотите создать самостоятельную ссылку «многие ко многим», вам понадобится дополнительная таблица, вроде той, что мы говорили в предыдущем разделе.
Foreign Keys
До сих пор мы узнали только о некоторых концепциях. Теперь пришло время воплотить их в жизнь с помощью SQL. Для этой части нам нужно понять, что такое Foreign Keys.
В приведённых выше примерах отношений мы всегда имели эти поля «**** _ id», которые ссылались на столбец в другой таблице. В этом примере столбец customer_id в таблице Orders является столбцом Foreign Key:
В базе данных типа MySQL есть два способа создания столбцов внешних ключей:
Чёткое определение Foreign Key
Давайте создадим простую таблицу клиентов:
1 |
CREATE TABLE customers ( |
2 |
customer_id INT AUTO_INCREMENT PRIMARY KEY, |
3 |
customer_name VARCHAR(100) |
4 |
); |
Теперь таблицу заказов, в которой будет Foreign Key:
1 |
CREATE TABLE orders ( |
2 |
order_id INT AUTO_INCREMENT PRIMARY KEY, |
3 |
customer_id INT, |
4 |
amount DOUBLE, |
5 |
FOREIGN KEY (customer_id) REFERENCES customers(customer_id) |
6 |
); |
Оба столбца (customers.customer_id и orders.customer_id) должны иметь одинаковую структуру данных. Если один является INT, другой не должен быть BIGINT, например.
Обратите внимание, что в MySQL только механизм InnoDB имеет полную поддержку Foreign Keys. Но другие механизмы хранения данных по-прежнему позволят вам указывать их без каких-либо ошибок. Кроме того, столбец Foreign Key индексируется автоматически, если не указать для него другой индекс.
Без явной декларации
Та же таблица заказов может быть создана без явного объявления столбца customer_id как Foreign Key:
1 |
CREATE TABLE orders ( |
2 |
order_id INT AUTO_INCREMENT PRIMARY KEY, |
3 |
customer_id INT, |
4 |
amount DOUBLE, |
5 |
INDEX (customer_id) |
6 |
); |
При получении данных с помощью запроса JOIN вы всё равно можете рассматривать этот столбец как Foreign Key , хотя механизм базы данных не знает об этом отношении.
1 |
SELECT * FROM orders |
2 |
JOIN customers USING(customer_id) |
Далее мы собираемся узнать о JOIN-запросах.
Визуализация отношений
Моим любимым программным обеспечением для проектирования баз данных и визуализации отношений Foreign Key является MySQL Workbench.


После разработки базы данных вы можете экспортировать SQL и запустить его на своем сервере. Это очень удобно для больших и сложных баз данных.


JOIN Queries
Для извлечения данных из базы, имеющей отношения, нам часто приходится использовать JOIN queries.
Прежде чем начать, давайте создадим таблицы и некоторые образцы данных для работы.
1 |
CREATE TABLE customers ( |
2 |
customer_id INT AUTO_INCREMENT PRIMARY KEY, |
3 |
customer_name VARCHAR(100) |
4 |
); |
5 |
|
6 |
CREATE TABLE orders ( |
7 |
order_id INT AUTO_INCREMENT PRIMARY KEY, |
8 |
customer_id INT, |
9 |
amount DOUBLE, |
10 |
FOREIGN KEY (customer_id) REFERENCES customers(customer_id) |
11 |
); |
12 |
|
13 |
INSERT INTO `customers` (`customer_id`, `customer_name`) VALUES |
14 |
(1, 'Adam'), |
15 |
(2, 'Andy'), |
16 |
(3, 'Joe'), |
17 |
(4, 'Sandy'); |
18 |
|
19 |
INSERT INTO `orders` (`order_id`, `customer_id`, `amount`) VALUES |
20 |
(1, 1, 19.99), |
21 |
(2, 1, 35.15), |
22 |
(3, 3, 17.56), |
23 |
(4, 4, 12.34); |
У нас 4 клиента. У одного клиента два заказа, у двух клиентов по одному заказу, а у одного клиента нет заказа. Теперь давайте посмотрим различные виды JOIN queries, которые мы можем запустить в этих таблицах.
Перекрестное соединение
Это тип JOIN query по умолчанию, если условие не указано.


Результатом является так называемый «Cartesian product» таблиц. Это означает, что каждая строка из первой таблицы сопоставляется с каждой строкой второй таблицы. Так как каждая таблица имела 4 строки, мы получили результат из 16 строк.
Ключевое слово JOIN может быть опционально заменено запятой.


Конечно, такой результат не очень полезен. Давайте посмотрим на другие типы соединений.
Обычное соединение
При таком типе JOIN query таблицы должны иметь имя соответствующего столбца. В нашем случае обе таблицы имеют столбец customer_id. Таким образом, MySQL будет присоединяться к записям только тогда, когда значение этого столбца соответствует двум записям.


Как вы можете видеть, столбец customer_id отображается только один раз, потому что ядро базы данных рассматривает это как общий столбец. Мы видим два заказа Адама, а два других — Джо и Сэнди. Наконец, мы получаем некоторую полезную информацию.
Внутреннее соединение
Когда указано условие соединения, выполняется Inner Join. В этом случае было бы неплохо иметь поле customer_id в обеих таблицах. Результаты должны быть похожими на Natural Join.


Результаты те же, за исключением небольшой разницы. Столбец customer_id повторяется дважды, один раз для каждой таблицы. Причина в том, что мы просто попросили базу данных соответствовать значениям этих двух столбцов. Но сами они не знают, что представляют одну и ту же информацию.
Давайте добавим еще несколько условий в запрос.


На этот раз мы получили заказы на сумму более $15.
ON Clause
Прежде чем перейти к другим типам соединений, нам нужно посмотреть ON clause. Это полезно для помещения условий JOIN в отдельное предложение.


Теперь мы можем отличить условие JOIN от условий WHERE. Но есть и небольшая разница в функциональности. Мы увидим это в примерах LEFT JOIN.
USING Clause
USING clause похоже на предложение ON, но оно короче. Если столбец имеет одинаковое имя в обеих таблицах, мы можем указать его здесь.


На самом деле это похоже на NATURAL JOIN, поэтому столбец join (customer_id) не повторяется дважды в результатах.
Левое (внешнее) соединение
LEFT JOIN — это тип внешнего соединения. В этих запросах, если во второй таблице не найдено совпадений, запись из первой таблицы по-прежнему отображается.


Хотя у Энди нет заказов, его запись все ещё отображается. Значения под столбцами второй таблицы имеют значение NULL.
Это полезно для поиска записей, которые не имеют отношений. Например, мы можем искать клиентов, которые не разместили какие-либо заказы.


Всё, что мы сделали, это нашли NULL для order_id.
Также обратите внимание, что ключевое слово OUTER является необязательным. Вы можете просто использовать LEFT JOIN вместо LEFT OUTER JOIN.
Условия
Теперь давайте рассмотрим запрос с условием.


Так что случилось с Энди и Сэнди? LEFT JOIN должен был вернуть клиентов без соответствующих заказов. Проблема в том, что предложение WHERE блокирует эти результаты. Чтобы их получить, мы можем попытаться включить условие NULL.


У нас Энди, но нет Сэнди. Тем не менее это выглядит не так. Чтобы получить то, что мы хотим, нам нужно использовать ON clause.


Теперь у нас есть все, и все заказы выше $ 15. Как я уже говорил, ON clause иногда имеет несколько иную функциональность, чем WHERE clause. В условии Outer Join , таком как этот, строки включаются, даже если они не соответствуют условиям ON clause.
Правое (внешнее) соединение
RIGHT OUTER JOIN работает точно так же, но порядок таблиц обратный.


На этот раз у нас нет результатов NULL, потому что каждый заказ имеет соответствующую запись клиента. Мы можем изменить порядок таблиц и получить те же результаты, что и в LEFT OUTER JOIN.


Теперь у нас есть эти значения NULL, потому что таблица Customers находится на правой стороне соединения.
Заключение
Спасибо, что прочитали статью. Надеюсь, вам понравилось! Пожалуйста, оставляйте свои комментарии и вопросы, и хорошего дня!
Не забудьте проверить SQL scripts, apps and add-ons на рынке Envato. Вы получите представление о возможностях баз данных SQL, и сможете найти идеальное решение, которое поможет вам в текущем проекте разработки.
Следуйте за нами на Twitter или подпишитесь на Nettuts + RSS Feed для получения лучших обучающих материалов по веб-разработке в Интернете.
Связи между таблицами MS SQL: обзор основных отношений и типов соединения
Связи между таблицами в базе данных — основа хранения данных в СУБД.
Связи в базе данных MS SQL позволяют нормализировать БД, настроить отношение между данными таблиц и сделать эффективные выборки данных. Главное — понять, как настраивать и использовать связи между таблицами MS SQL. Это необходимое условие для работы с любой БД.
Ниже рассмотрим основные концепции связей: Foreign Key и JOINs.
Foreign Key
Создание связей MS SQL между таблицами происходит через внешний ключ (foreign key). Данный ключ связывает поле (значение) исходной таблицы с Primary Key внешней таблицы. Через внешний ключ можно не только производить выборку данных, но и контролировать удаление данных в главной таблице:
- NO ACTION — не производит никаких действий;
- SET NULL — зависимые данные установятся в NULL при удалении записи из главной таблицы (primary table);
- CASCADE — удаляются зависимые данные. Опасная операция. В реальной жизни используется редко.
Шаблон «Как добавить внешний ключ» — ([]link](https://docs.microsoft.com/en-us/sql/relational-databases/tables/create-foreign-key-relationships?view=sql-server-ver16))
ALTER TABLE <table_name> ADD CONSTRAINT FK_<primary_table_name>_<primary_table_column> FOREIGN KEY (<primary_table_column>) REFERENCES <ref_table_name>(<table_pk>) ON UPDATE <type> ON UPDATE <type>
Типы соединения JOINs
Когда отношения между таблицами установлены, можно делать выборки данных из этих связанных таблиц.
Существует несколько механизмов соединения двух таблиц в запросе: это основные типы JOINs для MS SQL SERVER. И они практически всегда совпадают для всех реляционных СУБД.
Рассмотрим основные типы JOINs. Будем считать, что у нас есть левая и правая таблицы, которые соединяем через JOIN. *Левая и правая относительно слова JOIN.
Есть несколько механизмов соединения двух таблиц в запросе. Например, Oracle содержит Natural Join, который соединяет колонки с одинаковыми именами в таблицах. Используется крайне редко.
LEFT (OUTER) JOIN
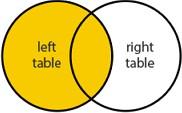
Всегда выводите данные по левой таблице. Если правая таблица не содержит связанных данных, то выводите NULL для этих значений.
select * from A left join B on A.ID = B.A_ID
RIGHT (OUTER) JOIN
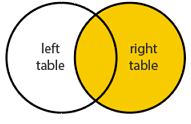
Обратное от Left Join. Используют редко. Всегда можно переписать на Left Join — тогда запрос легче читать. В частных случаях бывает, что Right Join дает лучшую статистику выполнения и оптимизирует запрос.
A left join B = B right join A:
select * from B right join A on A.ID = B.A_ID

Аналитик данных: новая работа через 5 месяцев
Получится, даже если у вас нет опыта в IT
Узнать больше
INNER JOIN
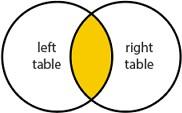
Выводите значения для строки из левой таблицы, только если есть связанные данные в правой таблице. Часто используют, чтобы отфильтровать данные левой таблицы и выводить только те записи, по которым есть значения в правой.
select * from A inner join B on A.ID = B.A_ID -- аналог запроса на left join select * from A left join B on A.ID = B.A_ID where B.ID is not null
CROSS JOIN
Это пересечение всех строк из левой таблицы со всеми строками правой таблицы.
select * from A cross join B
FULL JOIN
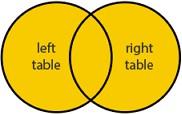
Представьте, что это смешанное сочетание Left Join и Right Join. Вначале выводятся значения левой таблицы, а правой заполняются NULL, затем — наоборот.
Запрос выводит пересечение значений. Если нет пересечений, то выводит значения по A и B c NULL:
select * from A full join B on A.ID = B.A_ID
| A1 | B1 |
| A2 | B2 |
| A3 | NULL |
| NULL | B4 |
Типы отношений между таблицами
Используем Foreign Key и JOINs и создадим реальный пример бизнес-задачи. А еще рассмотрим настройку связей между таблицами.
Введем сущности Clinics, Doctors, Patients и Appointments.
- Доктор работает или не работает только в одной клинике.
- У доктора может быть вышестоящий менеджер.
- Пациент может обращаться в разные клиники к разным докторам.
Создадим таблицы БД, пока без связей с сурогатными Primary Keys:
CREATE TABLE dbo.Clinics ( ID int, Name varchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, CONSTRAINT Clinics_PK PRIMARY KEY (ID) ); CREATE TABLE dbo.Patients ( ID int, Name varchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, CONSTRAINT Patients_PK PRIMARY KEY (ID) ); CREATE TABLE dbo.Doctors ( ID int, Name varchar(100) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, Clinic_ID int NULL, Manager_ID int NULL, CONSTRAINT Doctors_PK PRIMARY KEY (ID) ); CREATE TABLE dbo.Appointments ( ID int, [Date] datetime2(0) NOT NULL, Patient_ID int NOT NULL, Doctor_ID int NOT NULL, CONSTRAINT Appointments_PK PRIMARY KEY (ID) );
Фейковые данные:
insert into dbo.Clinics values (1, 'First Clinic'), (2, 'Second Clinic') insert into dbo.Doctors values (10, 'Doctor', 1, NULL), (11, 'Assistent Doctor', 1, 10), (12, 'Another Doctor', 2, NULL), (13, 'Retired Doctor', NULL, NULL), (15, 'Assist 2 Doctor', 1, 11) insert into dbo.Patients values (100, 'First Patient'), (101, 'Second Patient') insert into dbo.Appointments values (1000, GETDATE(), 100, 10), (1001, GETDATE(), 101, 10), (1002, GETDATE(), 100, 12)
Отношения «один к одному»
Используйте данную связь, когда значению из таблицы соответствует только одна запись из внешней таблицы. «Доктор может работать только в одной клинике». Можем предположить, что связь между Clinics и Doctors будет «один к одному»:
ALTER TABLE dbo.Doctors ADD CONSTRAINT FK_Doctors_ClinicID FOREIGN KEY (Clinic_ID) REFERENCES dbo.Clinics(ID);
select d.Name, c.Name from dbo.Doctors d left join dbo.Clinics c on c.ID = d.Clinic_ID;
Отношение «один ко многим»
Одной записи из таблицы соответствуют несколько записей из внешней. Данный тип связи очень распространен при построении схемы БД.
«Хотя доктор может принадлежать только одной клинике, клиники, в свою очередь, содержат штат докторов». Это отношение «один ко многим»:
select c.Name, d.Name from dbo.Clinics c inner join dbo.Doctors d on d.Clinic_ID = c.ID;
| CLINIC | DOCTOR |
| First Clinic | Doctor |
| First Clinic | Assistent Doctor |
| First Clinic | Assist 2 Doctor |
| Second Clinic | Another Doctor |
Отношение «многие ко многим»
Организуется через промежуточную таблицу, в которой есть внешние ключи на разные таблицы.
В таблице Appointments есть связь на таблицы Doctors и Patients. Таким образом, организована связь между пациентами и докторами: пациент может посещать нескольких докторов, а доктора — принимать нескольких пациентов.
ALTER TABLE dbo.Appointments ADD CONSTRAINT FK_Appointments_DoctorID FOREIGN KEY (Doctor_ID) REFERENCES dbo.Doctors(ID); ALTER TABLE dbo.Appointments ADD CONSTRAINT FK_Appointments_PatientID FOREIGN KEY (Patient_ID) REFERENCES dbo.Patients(ID);
Это довольно распространенный вопрос на собеседовании для SQL-разработчика. Если программист может на примере объяснить, как строится связь «многие ко многим», — это уже хороший показатель для интервьюера.
Как получить список посещений пользователя с указанием клиники и докторов:
select p.Name, a.[Date], d.Name, c.Name from dbo.Patients p inner join dbo.Appointments a on a.Patient_ID = p.ID inner join dbo.Doctors d on d.ID = a.Doctor_ID inner join dbo.Clinics c on c.ID = d.Clinic_ID where p.ID = 100;
| PATIENT | DATE | DOCTOR | CLINIC |
| First Patient | 2022-08-06 07:41:45.000 | Doctor | First Clinic |
| First Patient | 2022-08-06 07:41:45.000 | Another Doctor | Second Clinic |
Связь с самим собой
Такой тип связи называется рекурсивным, или иерархическим: связывание строки со строкой из той же таблицы. Полезно при отображении древовидной структуры.
Таблица Doctors содержит колонку Manager, в которой указано, кто из докторов является менеджером текущего доктора. Здесь связь на строку из той же таблицы докторов.
Как рекурсивно получить список докторов, у которых определенный доктор является вышестоящим менеджером:
with cte as ( select d.ID, d.Name from dbo.Doctors d where d.ID = 10 union all select d2.ID, d2.Name from dbo.Doctors d2 inner join cte on cte.ID = d2.Manager_ID ) select * from cte
Выводы
Таблицы БД без связей — это просто набор данных, который ограничен в своем применении. Без связей нельзя сделать эффективный запрос на выборку значений.
Обычно индексы строят по тем колонкам, через которые построена связь между таблицами. Тогда JOINs работают максимально эффективно при выборке данных. Но построение индексов — уже другая большая тема для рассмотрения.
Еще связи контролируют сохранность и консистентность данных. Правильно построенные связи между таблицами MS SQL во многом описывают бизнес-модель на уровне хранения данных и очень важны для построения всего ПО.