Как найти границы на клиенте и сервере
Время на прочтение
8 мин
Количество просмотров 30K
Как обычно тестировщик ищет границы в поле? Если в ТЗ есть ограничения, то тестирует их. А если их нет? С нижней границей все понятно — это пустое поле. А как найти верхнюю? Вставляем большую строку и смотрим, сколько символов сохранится. И всё…
Но если у нас клиент-серверное приложение, то границы разработчик может поставить на каждом звене!

И тестировщик должен проверить их все. Почему? Потому что когда мы одно значение дублируем несколько раз в разных местах, велик шанс ошибиться. При этом границу на клиенте очень легко снять. Что будет, если пользователь обойдет границу на клиенте? Не сломает ли он нам сайт большой строкой?
В этой статье я расскажу, как искать границы для поля в веб-формочке. Возьмем для примера форму редактирования пользователя в бесплатной системе Users.
Содержание
- 1. Границы на клиенте
- Maxlength
- Ошибки в консоли JS
- Изменение поведения
- Итого по границе на клиенте
- 2. Границы на сервере
- 3. Границы в БД
- Итого: чек-лист поиска границ
1. Границы на клиенте
Maxlength
Ограничение по длине строки на клиенте прописывают в параметре maxlength поля.
Чтобы его найти, вам нужно:
- Открыть панель разработчика — нажать f12.
- Нажать самую левую кнопку и навести курсор на элемент на странице.
Вуаля! Для поля «имя1» у нас стоит ограничение в 10 символов.
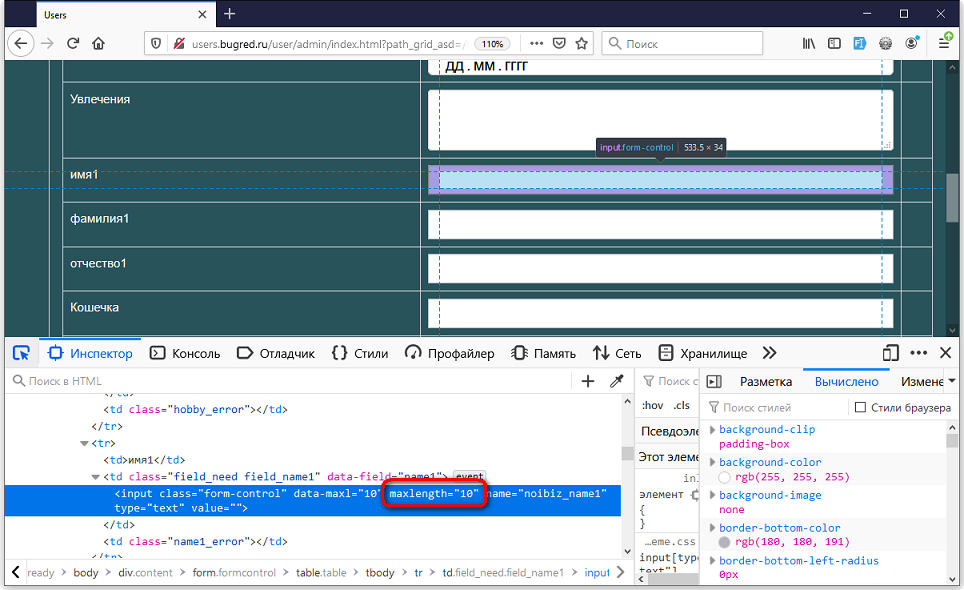
См также:
Что тестировщику надо знать про панель разработчика
Проверяем ограничение — пытаемся ввести больше 10 символов. Но вводится ровно 10, больше не дает. Печатаешь на клавиатуре, а система просто не реагирует:
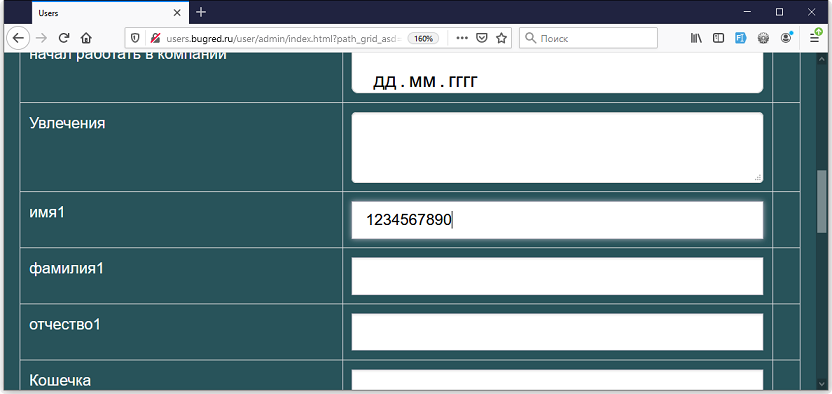
Это — граница! Граница на клиенте, мы ее нашли, ура.
Но это не значит, что за сим надо успокоиться. Границы на клиенте снимаются очень легко, поэтому важно поставить проверку на сервере тоже. А нам, как тестировщикам — проверить, есть ли защита на сервере.
Поэтому мы границу снимаем. Для этого прямо в DOM-модели (это структура нашей страницы, по которой мы искали инспектором) исправляем строчку с параметром. Да, оно меняется. Дважды кликаем на параметр maxlength и меняем значение. Вуаля! Теперь можно ввести намного больше символов, чем раньше!
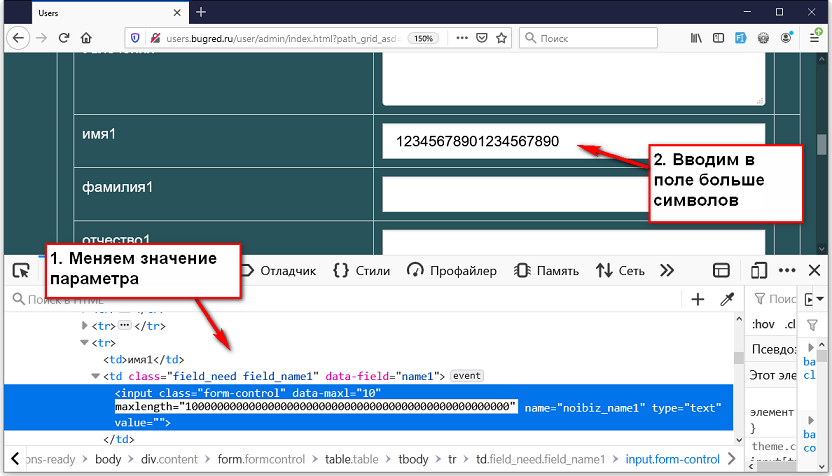
Обратите внимание — символы можно вводить сразу, без обновления страницы. Более того, если вы обновите страницу, то ваши изменения пропадут. Ведь при обновлении страницы HTML-код запрашивается с сервера, а там ваших изменений нет. Так что балуйтесь сколько хотите, не бойтесь что-то сломать =)
В принципе для проверки границы на сервере можно сначала поменять значение с 10 на 1000. Но если вы хотите поискать именно технологическую границу, то лучше выбрать значение побольше. Или вовсе удалить параметр. Выделить и удалить!

Найдя элемент в инспекторе, вы можете увидеть и другие цифры, кроме maxlength. Например, «data-max» или «data-jsmax», или какие-то еще. Можно ли считать их границами? Только если вы умеете читать код и найдете в нем их значение.
Разработчик может написать HTML так, как ему нравится. Он может указать любые атрибуты для тега, с любыми названиями. Совершенно не факт, что это будет какая-то граница.
Это может быть «легаси»-элемент, то есть он вообще никак не обрабатывается и не используется. Просто забыли удалить. Или он может использоваться для CSS — «если у нас такое-то значение, то пишем белым цветом, если сякое, то черным».
А вот maxlength — стандартный атрибут. И если он установлен, то он ограничивает пользователя — пользователь не может ввести в input-поле больше символов, чем указано в maxlength. Поэтому это граница.
А всё остальное — надо проверять, ограничивает нас как-то, или нет. Как проверять? Включить консоль!
Ошибки в консоли JS
При тестировании веба нужно обязательно включить консоль:
F12 → Консоль
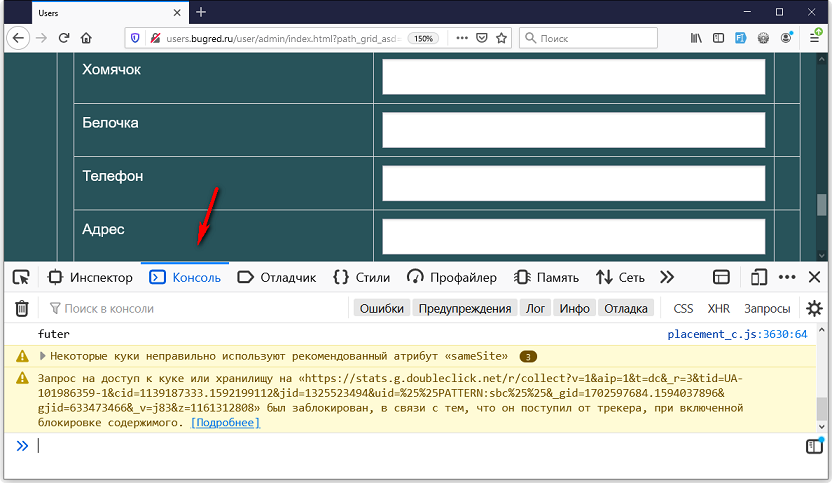
И следить за ней краем глаза. А иначе можно пропустить ошибку!
Бывает, что система никак не проявляет проблему — в самом интерфейсе ничего не меняется. Вводим данные в поля? Ничего красным не подсвечивается, но в консоли появляется ошибка. Тыкаем на кнопку? Загружается отчет, вроде всё нормально, но в консоли ошибка.
Если в консоли появляется ошибка — это ненормально. И с этим надо разобраться. Ошибка может нести в себе отложенный эффект, а может, вы просто не заметили ее проявление. Например, при загрузке отчета одна ячейка посчиталась неправильно, потому что не смогла подгрузить данные, о чем и написала в консоль. При этом отчет загрузился и вроде как данные внутри есть, выглядит нормально. Но ошибка есть.
Итак, открываем консоль и начинаем заполнять поля пользователя. Вот, например, вбиваем данные в поле «хомячок». Сняли границу на клиенте (maxlength) и печатаем. И тут замечаем, что в консоли появилась ошибка!
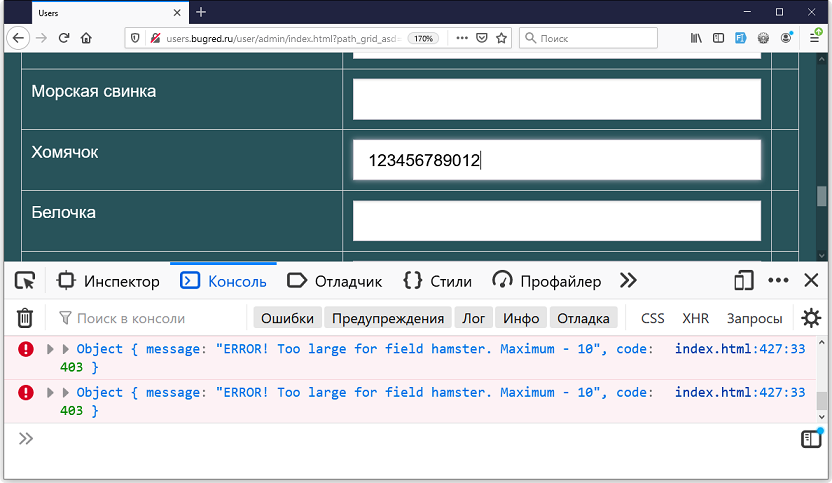
Оказывается, разработчик поставил дополнительную защиту на поле. Помимо maxlength прописал ограничение в коде. Возможно, это сообщение должно было выводиться в интерфейсе, чтобы пользователь видел, что что-то делает не так, но разработчик напутал и выводит в консоль.
В случае с Users разработчик ничего не путал, у него по ТЗ стояло выводить такое сообщение в консоль =)) Потому что наша задача была просто показать ситуацию, когда в интерфейсе все хорошо, а в консоли есть ошибки.
Но где граница? Судя по сообщению об ошибке «Maximum — 10». Значит, граница 10 символов. Да? Ни фига! Граница — это когда у нас до нее поведение системы одно (ошибок нет), а после другое.

Помните, что сообщения об ошибках — это тоже код. Который тоже надо тестировать. Разработчик может ошибиться и написать сообщение неправильно. Поэтому давайте проверим, где реакция системы на ввод изменится.
Начинаем вводить символы медленно, следя за консолью:
- 10 — нет ошибки
- 11 — нет ошибки
- 12 — ошибочка!
Ага, значит, граница по JS у нас не 10, а 11 символов! До 11 все хорошо, а после сыпятся ошибки. А сообщение об ошибке, как оказалось, врет. Так что «доверяй, но проверяй» =)
Это тоже граница на клиенте. Таким образом, у поля «хомячок» есть две границы на клиенте:
- maxlength = 10 символов
- js = 11 символов
А вот в поле «имя 1» одна граница на клиенте: maxlength = 10 символов. Ошибок в консоли при вводе символов там нет.
Изменение поведения
Хочется еще раз подчеркнуть, что граница — это не только когда в консоли ошибки сыпятся. Это может быть и видимое пользователю изменение поведения системы.
Например, аналитик решил, что имя должно быть не короче 3 букв. Поэтому, когда пользователь ставит курсор на поле с именем, вокруг него появляется красная рамка и снизу подпись «Имя не должно быть короче 3 букв». Ввел 1-2 буквы — ничего не изменилось. Ввел 3 — рамка с подписью исчезли. Или рамка поменяла цвет с красной на зеленую.

В Users таких границ нет, поэтому я просто взяла картинку из интернета =)
Это нижняя граница, установленная по ТЗ. И сделанная на клиенте. Аналогично можно оформить и верхнюю границу — ввел больше 10 символов? Вокруг поля появляется красная рамочка. Значит, это тоже граница.
Итого по границе на клиенте
Граница на клиенте — это значение атрибута «maxlength» в поле ввода символов. Больше этого значения ввести нельзя, система просто не даст этого сделать.
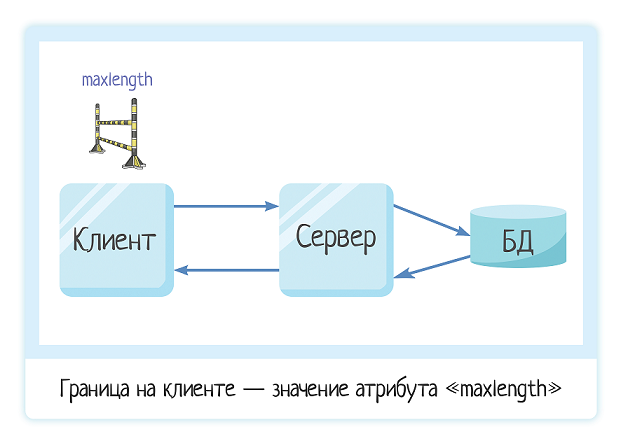
Это ограничение легко снять через панель разработчика — Как снять maxlength со всех полей формы.
Это может быть не единственной границей. Границу разработчик может также прописать в код. Чтобы ее найти, следим за системой. Если она меняет своё поведение — мы нашли границу:
- Вводишь символы и у поля появляется красная рамка и подпись «слишком большая длина» — граница! Помимо «maxlength» разработчик добавил проверку
- Вводишь символы и появляются ошибки в консоли — тоже граница!
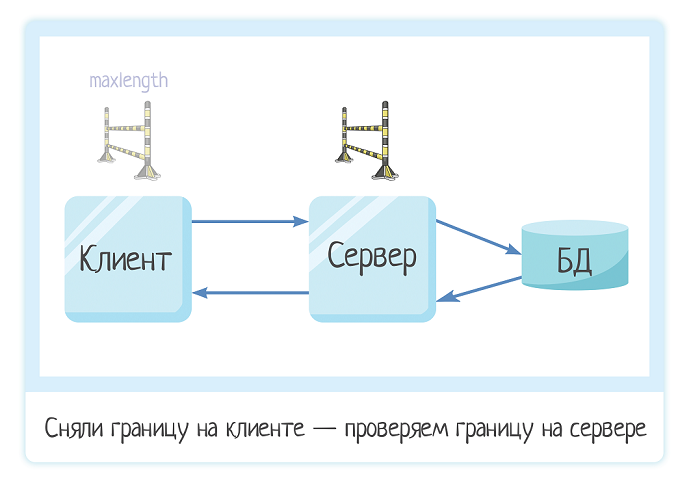
2. Граница на сервере
Граница на сервере — это сколько символов мы можем сохранить в системе. По идее, она должна совпадать с границей на клиенте =) Но всякое бывает. Когда нам надо одно значение прописать в разных местах, всегда есть шанс ошибиться.
Так как границу на клиенте легко обойти, нам во время тестирования обязательно нужно это сделать. И посмотреть, есть ли границы на сервере. И если да, то какие.
Давайте снимем в Users ограничение maxlength = 10 с поля «имя1», введем туда длинную строку и попробуем сохранить. При сохранении система выдает ошибку:
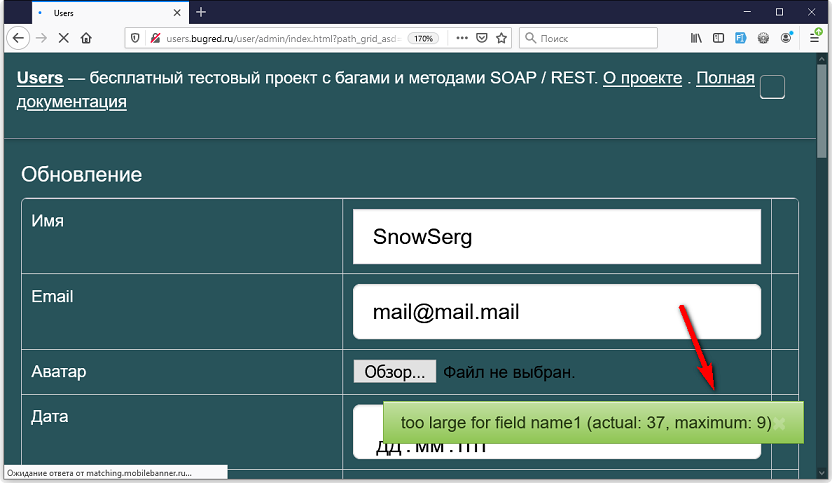
Вот это — граница на сервере. Клиент передал серверу запрос, тот его отработал и вернул фидбек.
Осталось понять, где граница то. Конечно, в этом нам помогает сообщение об ошибке: «actual: 37, maximum: 9». По идее, на сервере стоит ограничение в 9 символов. Но мы то с вами уже знаем, что это надо проверить!
Проверяем:
- Вводим 9 символов, сохраняем — сохранилось!
- Вводим 10 символов — сохранилось.
- Вводим 11 символов — при сохранении ошибка.
Значит, реально граница 10 символов на сервере. Совпадает с границей на клиенте, это хорошо.
А теперь давайте проверим поле «хомячок».
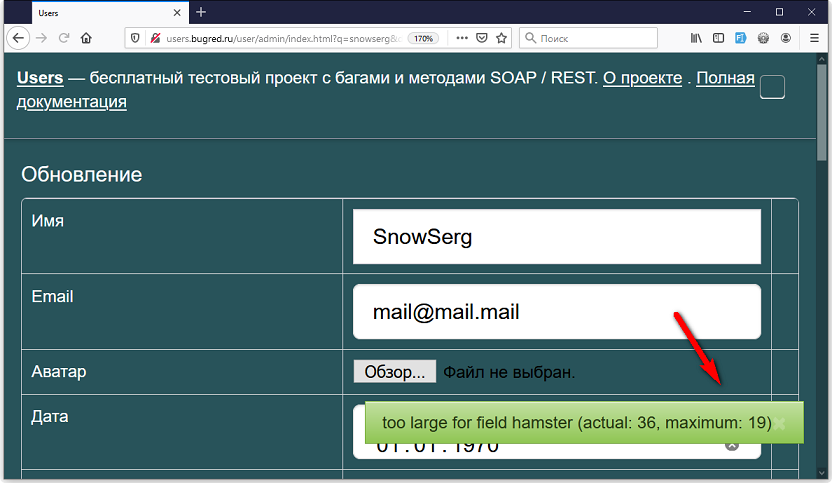
Ага, тут граница другая. В сообщении 19, но мы помним, что оно врет. Проверяем — граница 20 символов. А на клиенте то 10 было, в maxlength! Значит, границы отличаются.
В целом, это повод поставить баг, потому что границы должны совпадать. Правда, его могут закрыть как «won`t fix», ну сохранил чуть больше, и ладно. Намного хуже, когда разработчик ошибается в другую сторону:
- Сервер — 10 символов
- Клиент — 20 символов
В итоге на клиенте ввести 20 символов можно, а при сохранении огребаем ошибку. Нехорошо!
После проверки верхней границы в «адекватных» пределах стоит поискать технологическую границу. Сняли ограничение на клиенте, ввели несколько миллионов символов. Это очень легко сделать. Берем любой инструмент из статьи «Как сгенерить большую строку, инструменты», подставляем, сохраняем.
Если система выдала ровно такую же ошибку, как и раньше, то ок. Значит, технологической границы нет. Ну и славненько. Главное, что мы попытались поискать =)
Зачем это нужно делать? Потому что система может не просто сохранять данные, а как-то их предварительно обрабатывать. Проверять по условию, или как-то еще. И тогда небольшую строку система осилит, а огромную уже нет.
См также:
Технологическая граница в подсказках по ЮЛ — если ввести 1000 символов, ничего не случится, а вот если «войну и мир»…
3. Граница в БД
Граница в БД — это сколько символов влезет в базу. Создавая базу, мы указываем размерность каждого поля. Вот пример из folks:
- surname — VARCHAR(255)
- name — VARCHAR(100)
- city — VARCHAR(20)
Это значит, что в поле «фамилия» мы можем сохранить 255 символов, в имя 100, а в город — 20. При попытке запихать туда строку большего размера система выдаст ошибку из серии «ORA-06502: PL/SQL: numeric or value error: character string buffer too small».
Важно понимать, что мы увидим границу БД только в том случае, если нет границы на сервере. Путь поиска границы не меняется:
- Сняли границу на клиенте
- Запихали большую строку
- Пытаемся сохранить

Так вот, если разработчик поставил границу на сервере, то мы увидим обработанную ошибку — красиво (или не очень) отрисованную, с вполне осмысленным текстом. Потому что его писал разработчик и он про наше приложение.
А если границы на сервере нет, то мы увидим необработанную ошибку. Это может быть ошибка вида «ORA-06502:..», или стректрейс кода — куча непонятных простому пользователю символов.
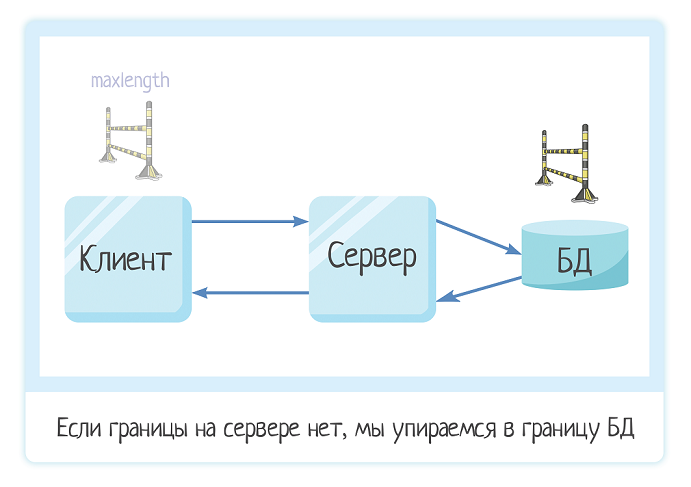
Конечно, может быть и другая ситуация — когда на сервере граница больше, чем в БД:
- Сервер — 20 символов
- БД — 10 символов
И тогда получается забавная ситуация. Да, от вставки «войны и мир» мы защитились. Вводишь 25 символов или 25 млн символов — получаешь осмысленную ошибку. А вот если вводишь 11 символов, то ой! Большой и страшный стектрейс во весь экран.
Поэтому при тестировании черного ящика не стремитесь сразу фигачить МНОГО символов. Для начала попробуйте осмысленное значение. А если вы сняли ограничение на клиенте, стоит попробовать пограничное значение к нему. Было maxlength = 10? Попробуйте 11 символов. А потом уже 55, а потом уже 55 млн.
Итого: чек-лист поиска границ
В клиент-серверном приложении границы могут быть в каждом звене. И в идеале они должны совпадать. Но мы должны это проверить!
Границ может быть больше. На клиенте разработчик может навесить сразу несколько границ: и maxlength, и изменение поведения при пересечении некой черты (js-код).
Границ может быть меньше. Из серии «да не будет пользователь глупости вводить», и в итоге на клиенте и сервере вообще без ограничений. Но размерность полей в БД остается.
Как искать границы:
1. Проверить, есть ли на поле maxlength — это самая очевидная граница на клиенте.
2. Снять это ограничение.
3. Включить консоль JS (а куда же без нее?).
4. Начать вбивать символы, около 50-100 в каждое поле. Следить за:
- консолью — не появились ли ошибки?
- поведением самой системы — не изменилось ли поведение?
Если поведение системы меняется, или появляются ошибки в консоли — это также граница на клиенте. Но другая, в js-коде.
5. Попробовать сохранить эти 50-100 символов. Так мы ищем границу на сервере и / или в базе.
Если система выдаст осмысленную ошибку вида «Слишком длинное поле» — это ошибка на сервере. Если ошибка необработанная — скорее всего, на сервере границы нет, и вы нашли границу в базе.
Найти точное значение границы можно с помощью метода бисекционного деления. Ну или с помощью логов / текста сообщения об ошибке.
6. Ввести 100 млн символов (инструменты) и попробовать их сохранить для поиска технологической границы.
В процессе статьи мы проверили по этому чек-листу в системе Users поля «имя1» и «хомячок». Результаты:
Поле «имя1»:
- maxlength — 10 символов
- сервер — 10 символов
Поле «хомячок»:
- maxlength — 10 символов
- js — 11 символов
- сервер — 20 символов
Для имени все хорошо, границы совпадают. А вот при исследовании «хомячка» мы обнаружили сразу 2 проблемы — разница границ клиент-сервер (10 и 20), а также ошибка в консоли. Можно ставить баги!
Автор: Ольга Назина (Киселёва)
Я посмотрела, как тестируют поиск начинающие тестировщики, и решила написать этот чит-лист проверок. Это такая серебряная пуля, которую можно применить на любом проекте, лишь немного варьируя под себя, под свой проект.
Поиск — он же есть практически в каждой системе. Поэтому здорово, когда есть шпаргалка «какие вопросы задать аналитику» и «какие проверки провести». Именно это мы в статье и обсудим. Сначала я дам чек-лист, а потом разберу каждый пункт отдельно.
-
Что надо узнать
-
Что надо проверить
-
Поиск ищет по всем полям, указанным в ТЗ
-
Поиск НЕ ищет по тем полям, которые НЕ указаны в ТЗ
-
Релевантность выдачи
-
Контекст поиска
-
Регистронезависимость поиска
-
Ищет ли по включению или полному соответствию
-
Два слова из одного поля
-
Два слова из разных полей
-
Опечатки
-
Неправильная раскладка
-
Другой язык
-
Спецсимволы
-
Эмоджи
-
Тримаются ли открывающие и закрывающие пробелы
-
Пустое поле
-
Пробелы в поле
-
Нижняя граница
-
Верхняя произвольная граница
-
Верхняя граница на выходе
-
Поиск технологической границы
-
А дальше что?
-
-
Итого
Что надо узнать
-
По каким полям поиск должен работать / по каким нет
-
Ищет по включению или полному соответствию?
-
Регистрозависимый ли поиск?
-
Какая максимальная длина поисковой строки?
-
А если длина превышена, запрос обрезается?
-
Как работает поиск при пустом запросе?
Что надо проверить
Повторю список, немного прокомментировав каждый пункт, чтобы вы могли пользоваться именно им в дальнейшем. Что надо проверить, тестируя поиск:
-
Поиск ищет по всем полям, указанным в ТЗ
-
Поиск НЕ ищет по тем полям, которые НЕ указаны в ТЗ
-
Релевантность выдачи — то, что я ищу, в начале списка, или в конце?
-
Учитывается ли контекст поиска — ищу я по всему сайту или только разделу игрушек
-
Регистронезависимость поиска — найдет ли «Платье», если я ввела «платье»?
-
Ищет ли по включению или полному соответствию — «ту» найдет мне «туфли»?
-
Найдет ли 2 слова из одного поля? В любом порядке введенные?
-
Найдет ли 2 слова из разных полей?
-
Ошибка в вводе (исправляются ли опечатки, ищет ли похожее)
-
Исправляет ли система неправильную раскладку?
-
Ищет ли на разных языках? А если сразу на двух попробовать?
-
Поиск со спецсимволами работает?
-
А с эмоджи? Не упадет система при вводе какашки?
-
Тримаются ли открывающие и закрывающие пробелы
-
Пустое поле / только пробелы в поле
-
Нижнюю границу (от скольких символов ищет)
-
Верхнюю произвольную границу — указанную в ТЗ
-
Верхнюю границу на выходе
-
Поиск технологической границы — ввести «войну и мир», 100 млн символов
Давайте пройдемся по каждому пункту и выясним, как и зачем его проверять.
1. Поиск ищет по всем полям, указанным в ТЗ
Вроде бы капитан очевидность, но с чего только новички не начинают свой чек-лист:
-
Оставить поле пустым
-
Вбить кириллицу / латиницу
-
Большую строку
-
Всяко потыкать поиск по названию (а если часть названия указать, а если с опечаткой, а если…)
Если надо выбирать, то последний вариант выглядит наиболее логичным. Он по крайней мере не абстрактная серебряная пуля про любое текстовое поле. Он про поиск.
Но ведь чтобы всяко-разно издеваться над названием, надо сначала убедиться, что по названию вообще ищет, верно? Так что пишем в названии слово «Тест» (или любое другое, но одно, без спецсимволов и прочего), его же вводим в строку поиска. Так мы понимаем, что поиск по названию в принципе работает. Значит, можно будет дальше над ним изгаляться =)
Но сначала надо проверить основное — то, что поиск вообще работает. Что он ищет по всем тем полям, по которым должен.

Иначе сами представьте, идет у нас чек-лист на 30 проверок по названию, а потом уже «что поиск работает по описанию, категории товара, бренду…». А времени на тестирование нет, и выделяется буквально 5-10 минут.
В итоге тестировщик провел первые 20 тестов и гордо говорит:
— Всё отлично! Поиск работает! А если всякую чухню в него вбить, не падает!
При этом поиск работает по 1 полю из 10 обязательных. И пользователи пытаются искать, а у них ничего не получается, потому что ищут не по названию. Нехорошо…

В любом чек-листе надо думать о приоритетах. Сначала — самое важное. Как в чек-листе в целом, так и внутри каждого блока проверок, постепенно идем от важного к неважному. От позитива к негативу.
Чтобы при ограниченном времени не пытаться в спешке понять, что в чек-листе важно, прыгая глазами туда-сюда и ища эти пункты.
А что самое важное в поиске? Для этого думаем, зачем его вообще делают. Чтобы искать. По чему? По каким-то полям / признакам. По каким? Узнаем и проверяем, ищет он по ним или нет.
2. Поиск НЕ ищет по тем полям, которые НЕ указаны в ТЗ
Если прошлый пункт ещё очевиден новичкам, то этот не особо. Поэтому давайте сначала подумаем — а зачем тестировать то, что поиск не работает по полям, по которым не должен? Может, ну их, эти поля? Не должен же искать, чего проверять то?
А теперь представьте себе ситуации:
1. Я ищу в интернет-магазине «белая майка», а система вываливает всё, что угодно:
-
Черная майка
-
Зеленый топ
-
Красные штаны
-
…
И если разобраться, то найдем слова «белая» и «майка» где-то внутри этих товаров. Например, в комментариях.
2. Я операционист банка. Пришла клиентка «Ольга Гагарина», я ищу её в системе, а в ответ получаю:
-
Ольга Морозова (у которой адрес прописки на ул Гагарина)
-
Иван Иванов (жена Ольга, в адресе тоже есть Гагарина)
-
Петр Забубенов (в комментарии к адресу «арендодатель Ольга», в любимых певицах Гагарина)
-
…

Ведь не зря же делают поиск по конкретным полям, а не «ищи по всему, что видишь». Как раз для того, чтобы результат был более релевантным. И если не тестировать, что поиск НЕ ищет там, где не должен, то в поисковую выборку может попасть вообще не то, что хотелось.
Поэтому проверять «поиск по полю НЕ ищет» тоже надо. А как? Вот тестируют у меня студенты Folks. Читаем ТЗ:
Фолкс найдет человека по следующим признакам: ФИО, предпочтительному имени, дате рождения(дд.мм.гггг), компании, модели девайса, его OS, автору изменений
Первая попытка — проверяют только перечисленные поля в чек-листе. Убеждаются, что поиск по ним работает. Обсуждаем, зачем тестировать «негатив», выясняем. Следующая попытка — проводится один дополнительный тест, что по одному из оставшихся полей карточки поиск НЕ работает. И всё.
Обсуждаем на кошках: допустим, в системе есть 100 полей. Поиск работает только по 10 из них. Что проверяем?
— Что по каждому из этих полей ищет. И одно любое другое, что по нему НЕ ищет.
Моя коллега Ольга Алифанова придумала такую аналогию для этой ситуации:
У нас огромный гипермаркет, в нем сто отделов
В десяти из этих отделов продавщицы Клава, Маня, Муся, Света, Ира, Ната, Дина, Раиса, Тамара и Галя никогда не должны обвешивать никого. В 90 оставшихся отделах продавщицы обвешивают всех.
Достаточно ли нам убедиться, что Муся дает точный вес, чтобы сказать, что Света и Раиса тоже не обманывают покупателей?

Если мы проверили одно поле, мы знаем ровно то, что именно по этому полю система НЕ ищет. Но мы ничего не знаем про оставшиеся 89 полей. И не узнаем, пока не проверим.
А проверять надо, потому что иначе мы рискуем получить нерелевантный поиск, который работает по абсолютно рандомным полям системы.
Но тогда возникает другой вопрос. Сколько это тестов?
-
Поиск ищет по всем полям, указанным в ТЗ
-
Поиск НЕ ищет по тем полям, которые НЕ указаны в ТЗ
Нужно ли нам писать отдельный тест на каждое поле? Или их можно объединить? Не получится ли кейс «я надену всё лучшее сразу» и при падении теста будет совершенно непонятно, на чем именно сломалось?

См также:
В тестировании всегда начинаем с простого — чем плох принцип «надену всё лучшее сразу»
Смотрите, допустим, что у нас по полю с именем искать система должна, а по фамилии — не должна. Я пишу тест:
В строку поиска вбить: Тест
В системе подготовить карточки с данными:
1. Имя = Тест
2. Фамилия = Тест
ОР: 1
Давайте предположим, что в системе баг и по фамилии она тоже ищет. Какой будет ФР?
ФР: 1, 2
Вернулись обе карточки. Можно ли на основании этого сделать вывод, из-за чего именно поиск сломался? Из-за какого конкретно поля? Можно! Мы четко понимаем из такого ФР, что:
-
Поиск по имени работает правильно
-
А вот с фамилией косяк
И наоборот, если у нас будет такой результат:
ФР: (пусто)
Мы тоже вполне четко понимаем, что:
-
С именем косяк
-
Фамилия работает как надо
Получается, мы можем объединить тесты без потери простоты локализации при падении! Даже если полей будет 100, а не 2.

А дальше уже встает вопрос простоты проведения =) Вернемся к примеру про 100 полей, из которых поиск работает только по 10.
Вот смотрите, если мы делаем автоматизированный тест, то делаем «сразу хорошо». Один раз заполнили 100 карточек, в каждой 1 поле (каждый раз разное).
А вот если мы проводим тест вручную, то тут надо понимать, что заполнение каждой карточки — это затраты времени. Нажал «создать», заполнил поле, нажал «Сохранить» и система чуток подумала при сохранении. И так 100 раз? Грустновато получается.

Вообще в этом случае идеальный вариант — полуавтоматизация. Например, REST-метод создания карточки. Тогда создали в постмане коллекцию для создания 100 карточек один раз — а потом один щелчок кнопки, и все карточки готовы!
Или может, разработчик поможет написать утилитку для заполнения базы. Вот как пример у меня было на одном из проектов: заполняешь табличку экселя значениями, одна команда — и они уже в базе! И снова всё просто. Один раз табличку подготовили, потом используем.
А вот если у нас только графический интерфейс, тогда уже начинаем думать, что можно совместить без потери «качества».
Можно ли ввести искомое слово во все 10 полей одной карточки? Нет, потому что когда система её найдет, мы не будем знать, по какому из 10 полей она сработала. И информацию от такого теста мы получим лишь “по какому-то полю из 10 обязательных поиск работает”. Не совсем то, что надо. Значит, позитив объединить нельзя, создаем 10 карточек.
А как насчет негатива? Поиск НЕ должен сработать по 90 полям. Значит, мы можем заполнить все 90 полей одним значением в одной карточке. И поискать по нему. В идеале система ничего не найдет.

Конечно, если в системе есть баг и карточка нашлась, ошибку придется локализовывать. И тогда уже или заполнять 90 разных карточек, или использовать метод бисеционного деления.
А как правильно заполнить наши поля? Каким-то одним значением. Оно должно быть простое, без излишеств, без принципа «надену всё лучшее сразу». То есть не надо сразу класть туда спецсимволы, эмоджи, разные алфавиты и регистры, комбинацию слов через пробел… Написали везде «тест» или «котик», и всё.
Потому что сейчас мы проверяем самое важно — что поиск вообще работает. А вот как он работает и обрабатывает всяко-разный ввод — проверим чуть позже. А иначе если поиск не сработает на «%#$**», как понять, он вообще не работает по полю, или не ищет спецсимволы?

3. Релевантность выдачи
Здесь важно проверить приоритет поисковой выдачи. Понятно, что туда может попасть что-то «не то». Чем больше у нас данных и чем больше полей, по которым поиск возможен, тем больше вариантов на каждый запрос.
Вот, допустим, пытаюсь я найти однотонное платье в интернет-магазине. Что я могу задать в поиске? «Желтое платье». Что я получаю в выборке?
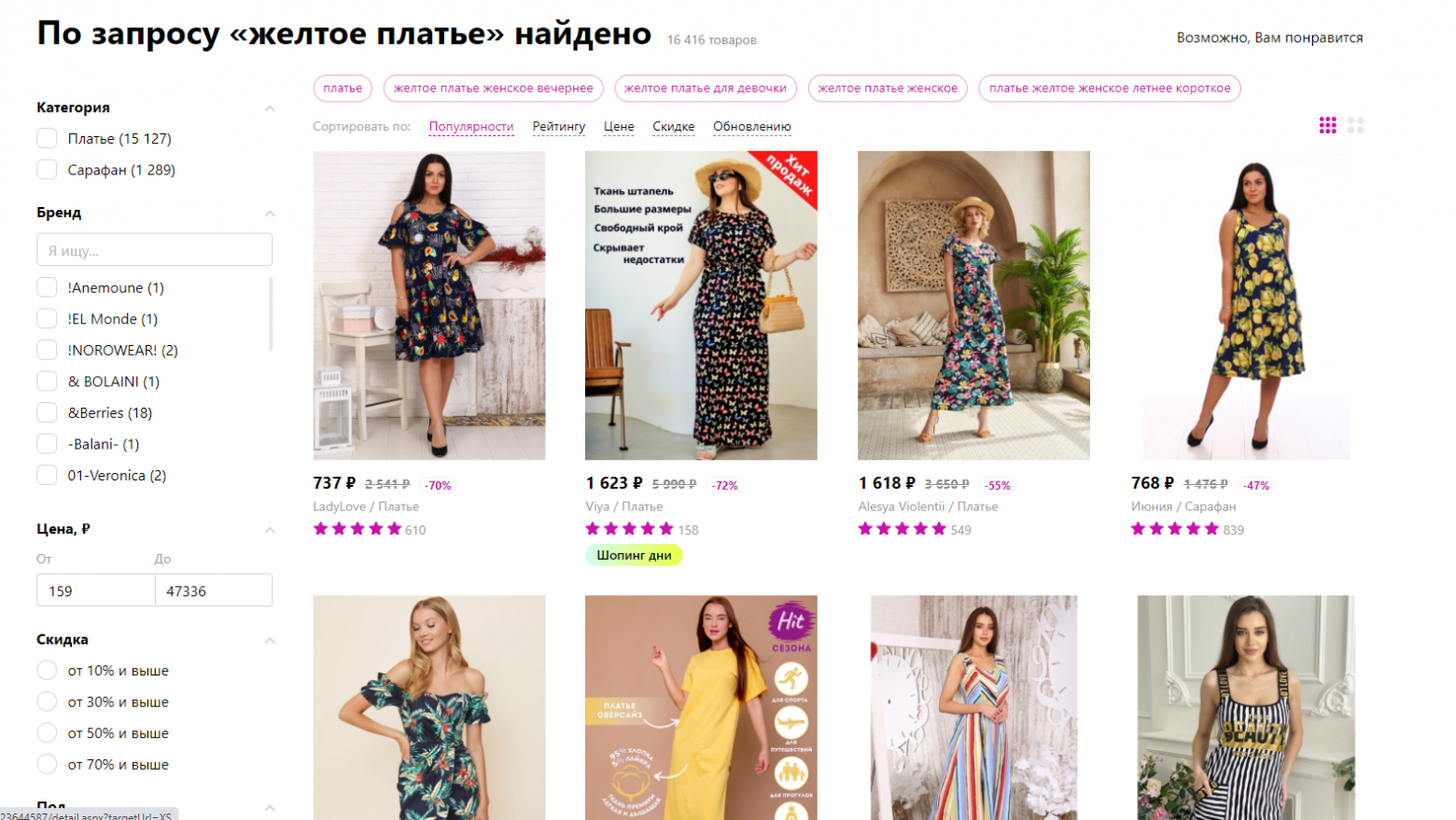
Целиком желтое платье на ШЕСТОМ месте. После 5 черных с вкраплениями желтого цвета.
С одной стороны, это логично. Ведь на других платьях желтый цвет тоже есть, поэтому его добавили в параметр «цвета». Ищем по параметрам:
-
Платье — да, тут платья
-
Желтый цвет — да, в блоке «цвета» есть слово «желтый» у каждого.
И как раз в силу большого ассортимента товаров мы получаем то, что получаем. Можно ли как-то на эту выборку повлиять?
Можно. Причем можно даже разные варианты придумать:
-
Можно добавить в систему галочку «однотонная вещь». И проставлять её при заполнении товаров. А потом уже по запросу вещи конкретного цвета выводить сначала вещи с этой галочкой, а потом уже все остальные.
При этом можно даже в фильтры вывести такую галку, чтобы пользователь мог выбрать “только однотонные”, и получить только вещи нужного ему цвета.
-
Можно фильтр настроить так:
-
Сначала вещи, у которых только один цвет
-
Потом все остальные (многоцветные)
В этом случае также можно сделать галку для пользователя “только однотонные”, которая будет выводить только вещи, в которых указан один цвет.
-
-
Можно при заполнении цветов вещи добавить галку «основной», если они выбираются из списка. Или, если их вводят вручную (что вряд ли) ориентироваться на порядок цветов. Какой идет первым — он приоритетный.
И тогда уже при выдаче результатов сначала отдаем вещи, у которых запрошенный пользователем — приоритетный.
А вот другой пример. Исходный запрос — «красная майка женская»:
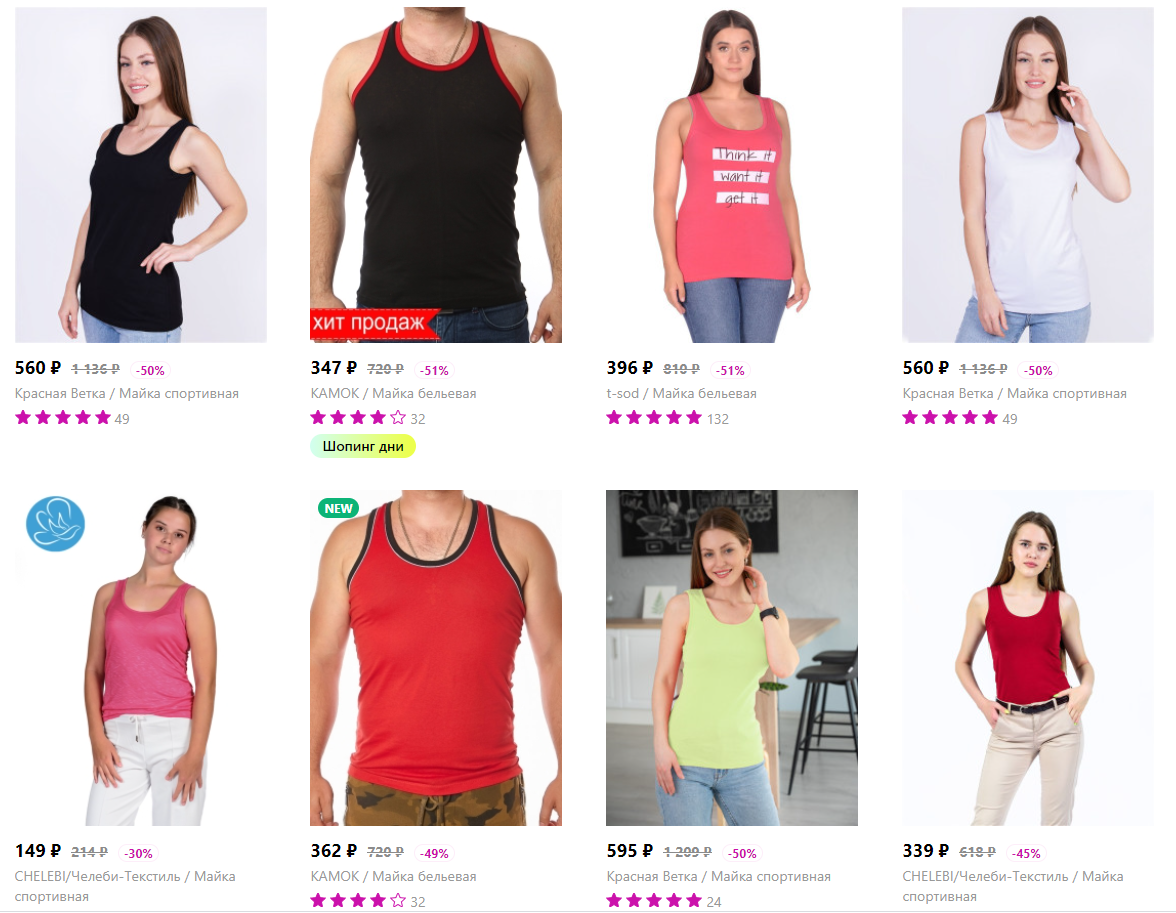
Что вернула система:
-
Черная майка
-
Мужская майка
-
Розовая с белым
-
Белая майка
-
…
А то, что нам нужно, аж на 8-ом месте. Почему так? А снова приоритеты. Где-то мелькнуло слово «красный», вон на мужских майках то каемка красная, то майка. Где-то просто ошиблись цветом при заполнении данных (и такое бывает), где-то в комментариях или другом описании было написано ключевое слово (что-то типа «подойдет и мужчинам, и женщинам, унисекс!»).
Но в результате — нерелевантная выборка. И если большой интернет-магазин с его оборотами может себе это позволить (и так найдут), то маленький, пытающийся завоевать доверие пользователей — нет. Впрочем, это уже выбор хозяина продукта.
Тут хотелось бы добавить, что поиск может быть не только в интернет-магазине. Искать можно среди данных: ФИО, адресов, телефонов… Например, если у нас система с клиентскими данными типа Users. Или подсказки Дадаты, ведь они работают по своим справочникам, но приоритезируют информацию:

Имена бывают самые разные, но если вместо Александра и Алексея система предложит Алладина, Алана и Алмаза, то толку от такой системы? Проще руками ввести…
4. Контекст поиска
Откуда я вызываю поиск? С главной страницы сайта или из конкретного раздела?
Скажем, если на Озоне попробовать поискать «котенок» на главной странице, он поищет везде: в книжках, игрушках, чашках, воздушных шариках…
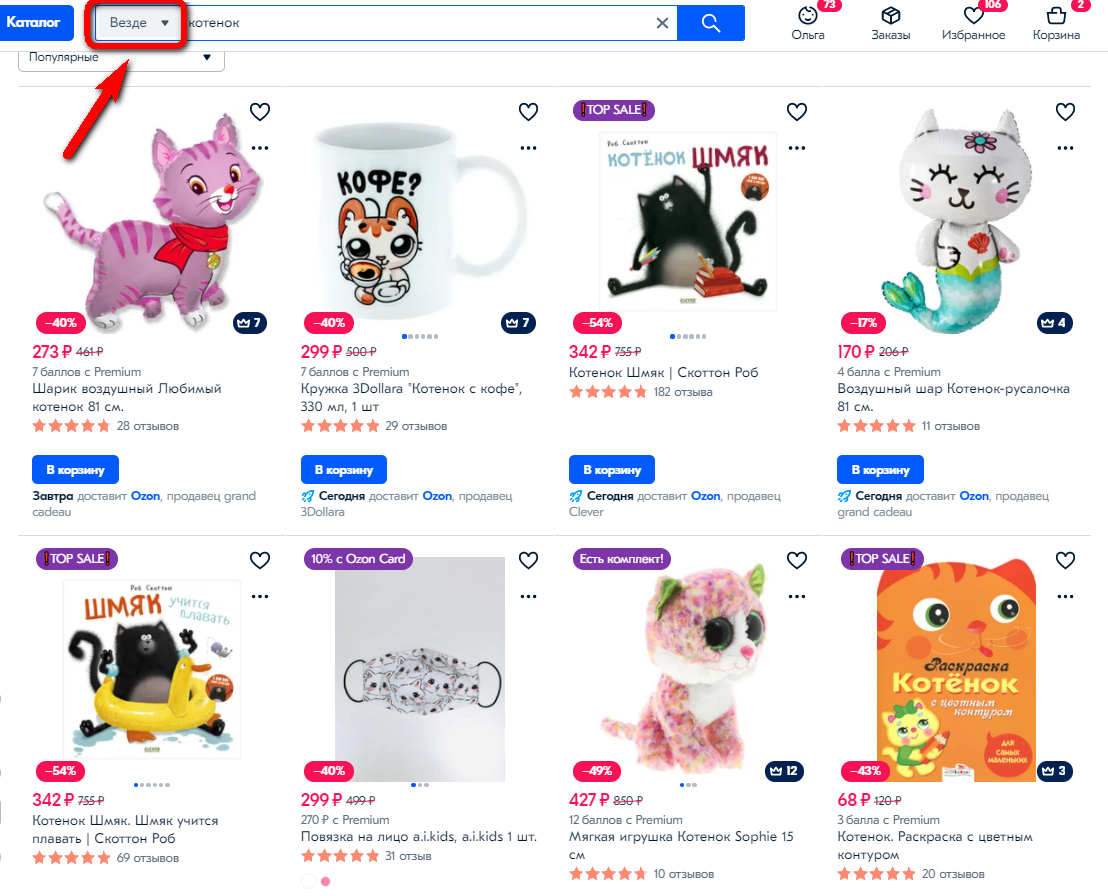
А вот если я буду искать в разделе книг, то буду ожидать только книги про котят, не игрушки:

В интернет-магазинах обычно куча разных товаров, поэтому контекст поиска очень важен, чтобы выдавать релевантные товары.
А ещё контекст очень важен в мессенджерах. Искать вообще везде, во всех 100500 чатах, или только в одном? Будет очень плохо, если я запущу поиск по диалогу с мамой, а система выдаст мне кучу рабочих чатиков, где нашла совпадение…
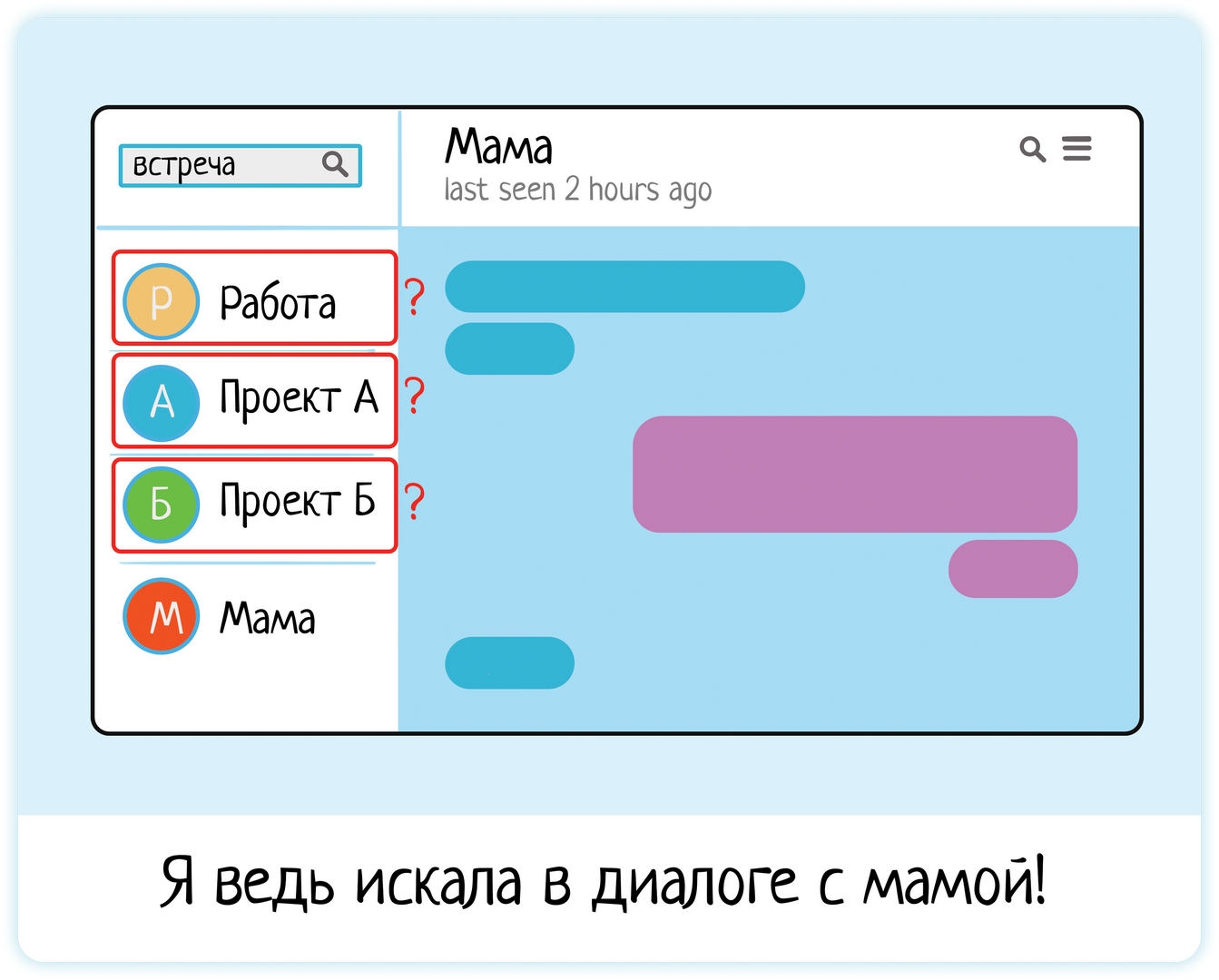
5. Регистронезависимость поиска
Обычно поиск регистронезависимый, и это логично. Представьте, что я ввожу:
Женское платье
А система ничего не находит, ведь у неё есть только «Платье» (первая заглавная, а у нас в запросе — нет)… Но пользователь же не в курсе, что надо немного изменить запрос, он будет думать, что платья тут просто не продаются…
Так что проверяем:
-
нижний регистр
-
ВЕРХНИЙ РЕГИСТР
-
ЗоЛоТую СеРеДиНу
.
6. Ищет ли по включению или полному соответствию
Поиск по включению — это когда можно ввести только часть слова. Например, «ко» вместо «котик». Это очень удобно во всяких чатах. Вот, например, я помню, что Ольга рассказывала историю про баг, связанный с кораблем. Но в каком падеже она говорила?
На корабле…
У корабля…
Есть корабль…
Если поиск работает по полному совпадению, то нужно перебирать все падежи. Если он работает по включению, мне достаточно написать «корабл».
Бывает, что сам поиск работает по полному совпадению, но при вводе подсказывает варианты:
Ту → туфли / тушь / туника

При этом если выбрал подсказку — показались товары. А если не выбрал, то сам себе злобная чебурашка.

Впрочем, некоторые магазины всё равно предлагают товары. Или которые включают в себя введенный текст, или какие-то вариации (Озон мне на «ту» выдал товары с «Two» в названии!)
В любом случае, нужно уточнить — как должно работать? А потом проверить:
-
Поиск по полному соответствию в одном слове
-
Поиск по частичному соответствию в одном слове — совпадение в начале слова / середине / конце (вспоминаем про классы эквивалентности и граничные значения)
.
7. Два слова из одного поля
А что будет, если у нас не одно слово, а два или более? Причем 2 слова у нас может быть:
-
В искомом поле
-
В поисковом запросе
И это будут разные тесты! Например, название товара: «Игровой набор». Тесты при этом:
-
Игровой → то есть в поле несколько слов, а мы ввели одно из них, найдётся?
-
Игровой набор → в поиске тоже несколько слов
Но что будет, если в поиске мы изменим порядок слов?
-
Набор игровой → найдется ли он в таком формате? Или нужно прям четкое совпадение?

8. Два слова из разных полей
Если мы проверяем несколько слов в поиске, то тут тоже возможны варианты:
-
Они все из разных полей — например, мы ищем по цвету + названию + полу: «красная майка женская».
-
Они из одного поля — как выше с игровым набором. И в этом случае намного интереснее изменить порядок слов и проверить поведение системы =)
Важно понимать, что это разные тесты. И стоит проверить и тот вариант, и другой.
.
9. Опечатки
Как система работает с опечатками? Найдет ли похожее слово?
Краный галстук → Красный галстук
Если система работает с опечатками, то как:
-
1 неправильную букву исправит / 2 и более
-
1 пропущенную букву исправит / 2 и более
Это, конечно, зависит от длины искомого слова, но тогда исправляются ли опечатки в коротких словах? Тут, главное, не увлечься, и не побежать ставить баг «система не исправила хлеб на пиво» =))

10. Неправильная раскладка
Типичный пример опечатки — пользователь забыл изменить раскладку на клавиатуре и напечатал английскими символами русский текст. Ищем «котик» но вводим «rjnbr».
Озон понимает, что мы ошиблись и ненавязчиво исправляет ошибку, подсказывая варианты по котикам:

Если нажать энтер, то увидим, что система исправила раскладку прямо в поисковой строке, но на всякий случай уточняет, правильно ли сделала:

Это — хороший тон. Если система русскоязычная и пользователь ввел данные на английском, по которым ничего не ищется, надо проверить — не забыл ли он переключить раскладку? Если по переключенной раскладке поиск работает, показываем эти результаты.
Всегда лучше ненавязчиво исправить ошибку пользователя, чем гневно тыкать ему под нос «По такому запросу ничего не найдено!!»
.
11. Другой язык
Что, если в системе есть данные и на русском, и на английском? Или даже смешанный вариант: «Сухой корм Purina ONE». Найдет ли система и по русскому алфавиту, и по английскому?
А ещё интересный кейс, если в системе можно изменить язык! Что будет, если я изменю язык сайта на английский, а поищу по русскому названию, или наоборот?

12. Спецсимволы
Это стандартная серебряная пуля для всех текстовых полей:
-
Русский алфавит
-
Английский
-
Спецсимволы
-
Эмоджи
-
Перемешал
И поэтому приоритет у таких проверок не супер-важный. Ведь проверить “английский, русский, спецсимволы, перемешал” может любой человек, даже робот. А тестировщик отталкивается от того, что он вообще тестирует. Что это за поле, для чего оно нужно? Сначала особенность приложения, потом серебряная пуля.
Но проверять этот мини чек-лист для любого текстового поля тоже надо. Ведь нам надо предоставить информацию о том, как система себя поведет в том или ином случае. А спецсимволы попасть в поле вполне себе могут, причем по разным причинам.
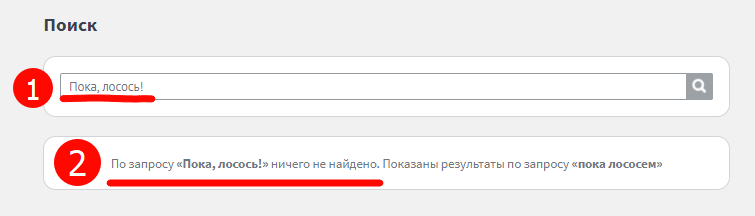
1. Спецсимвол есть в искомом поле. Вот буквально на днях студентка завела такой интересный баг на одном из сайтов поиска книг — если в запросе есть восклицательный знак, поиск не срабатывает:
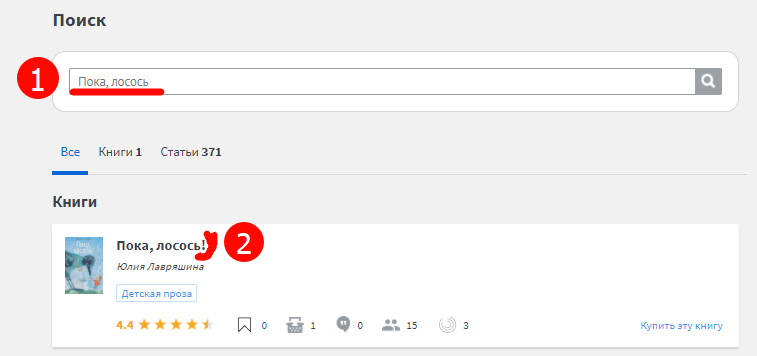
При том, что сама книга на сайте есть:
И система умеет работать со спецсимволами. Скажем, по вопросительному знаку она ищет:
Поэтому проверить нужно все спецсимволы. Я обычно делаю это примерно так: создаю товар / искомый объект сразу с набором спецсимволов:
~!@#$%^&*()_+{}|:”>?<Ё!”№;%:?*()_+/Ъ,/.,;’[]|
И по нему ищу. А вот если не срабатывает, тогда уже разбираюсь, с каким именно символом проблема.
2. Пользователь может забыть переключить раскладку и вот уже вместо «Хлеб» он вводит «{kt,»
3. Пользователь может случайно вкопипастить в поле какой-то текст со спецсимволами. Ошибки тоже надо предусмотреть, и уж точно не падать на этом =)
.
13. Эмоджи
Я специально вынесла их в отдельный пункт, чтобы вы не забыли проверить. Потому что эмоджи — это даже не совсем спецсимвол. Система может не искать по спецсимволам, но при этом падать на эмоджи. Получается, классы эквивалентности разные!
Так что в любую текстовую строку, в том числе строку поиска, обязательно вводим какую-нибудь эмоджи. Например, отсюда:
????.
14. Тримаются ли открывающие и закрывающие пробелы
Метод trim() удаляет пробельные символы с начала и конца строки.
То есть вводим « тест », а система преобразует строку в «тест» и потом уже передаёт дальше, в нашем случае — функцие поиска.
Надо признать, что проверка на трим более логична при заполнении и сохранении полей — ввела случайно « Ольга» в имя, а потом поиск не находит, требуя точного совпадения. И тогда логично системе перед сохранением сделать трим.
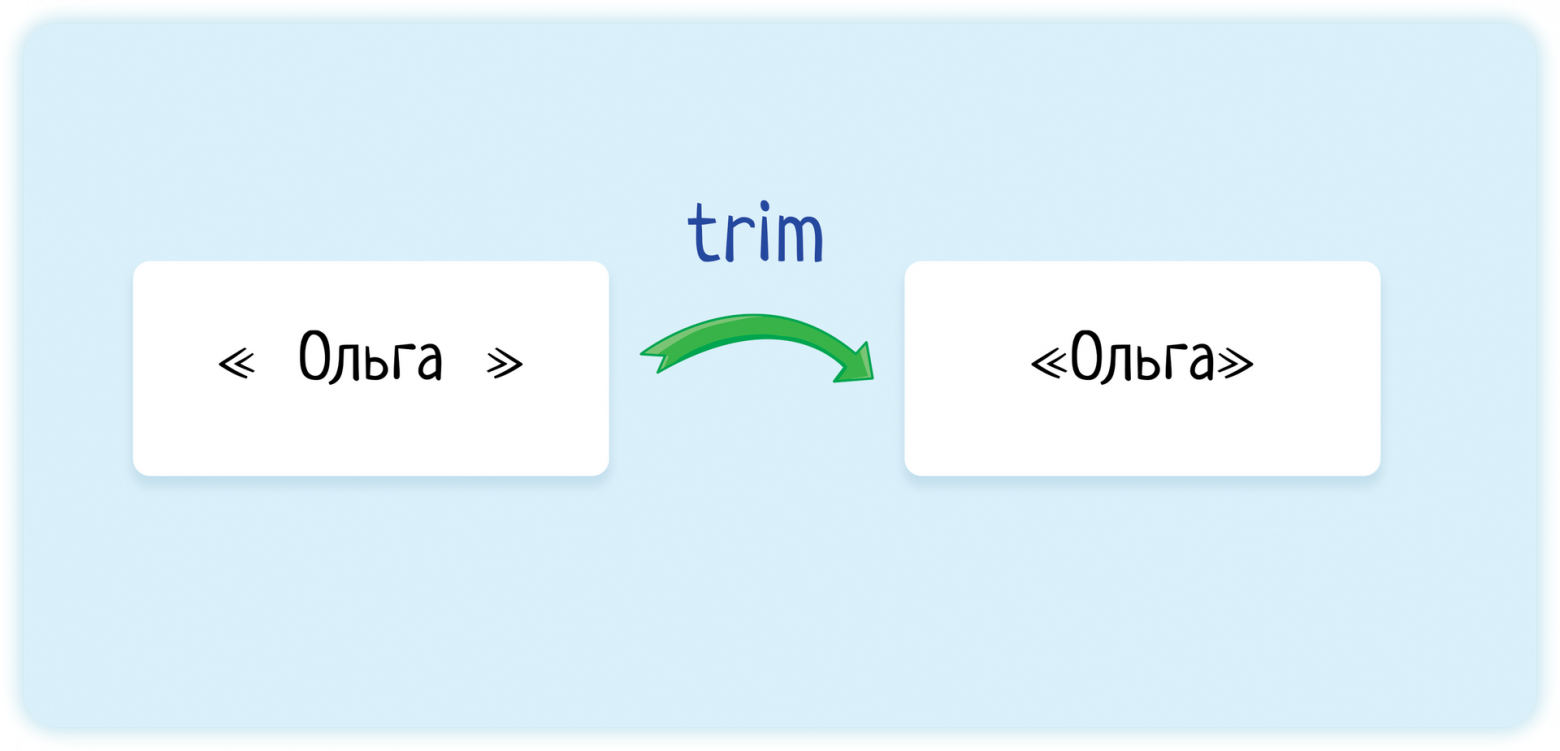
В поиске обычно пробелы используются как разделители слов. Поэтому пробелом больше, пробелом меньше — системе неважно.
Хотя лидирующий пробел всегда интересно проверить — а что, если система посчитает « майка» за пустую строку, так как обнаружила в первом поле пробел и посчитала строку мусорной?
.
15. Пустое поле
Фактически это проверка на ноль. А ноль — это отдельный класс эквивалентности, который часто приносит баги, поэтому его надо проверять!
См также:
Класс эквивалентности «Ноль-не ноль» — подробнее о нуле

Если мы оставили поисковую строку пустой, то есть варианты:
-
Система выводит всю базу
-
Система выводит пустоту
-
Кнопка поиска просто не срабатывает / вообще заблокирована до ввода символов (что сомнительно, впрочем, да и зачем?)
.
16. Пробелы в поле
Ещё один вариант тестирования нуля — ввести в поле ТОЛЬКО пробелы. Как система их обработает?
По идее также, как и пустую строку. Но может быть так, что при пустой строке выводится вообще всё, а вот если ты начал что-то вводить — начинается поиск. И хотя пробел наверняка встречается в искомых полях, найдет ли система хоть что-то?
Впрочем, в данном тесте мы просто собираем информацию о том, как работает система. Потому что почти любое поведение (разве что кроме ошибки) можно считать нормальным.
.
17. Нижняя граница
Пустое поле (ноль) — мы уже проверили. А дальше думаем, какая у наших данных будет нижняя граница?
Важно подобрать её осознанно, а не просто ввести одну букву и потом заводить баг, что вы ожидали что-то другое (и обязательно при этом добавить «если не исправите, пользователи обидятся и уйдут!»)
Павел Абдюшев в своем докладе «Есть фича. Помогите протестировать!» привел замечательный пример с писателем и поэтом Эдгаром ПО. Это пример короткой реальной фамилии, по которой могут искать.
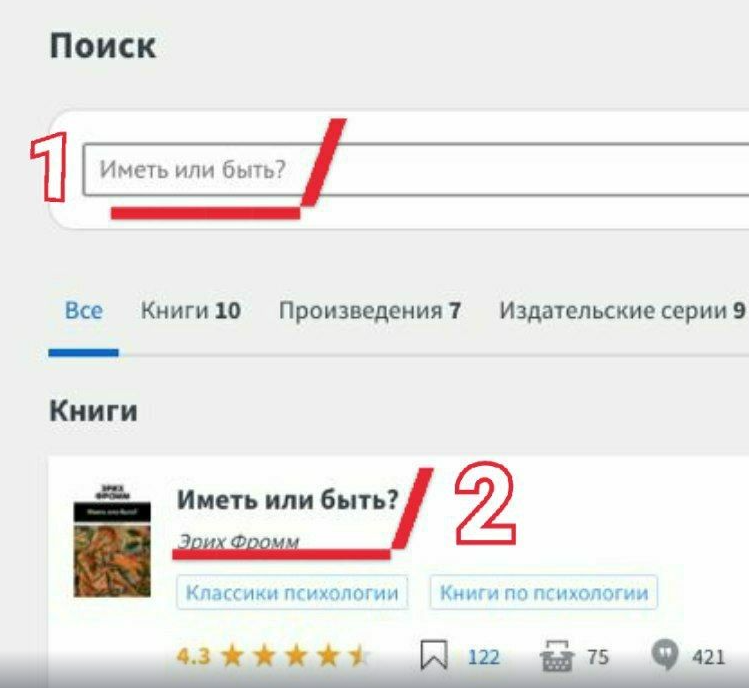
А теперь пойдем на OZON, который раньше, на минуточку, только книги и продавал, и попробуем найти там книгу «Ворон».
Сначала пробуем по фамилии:
ПО

Хммм, нет, даже среди вариантов не предлагает, думаем, что мы ввели начало слова. Ладно, попробуем с названием книги:
ПО ворон
Теперь Озон нашел нужную книгу, вот только я могу её не заметить, так как над ней аж 7 рекламных пункта:
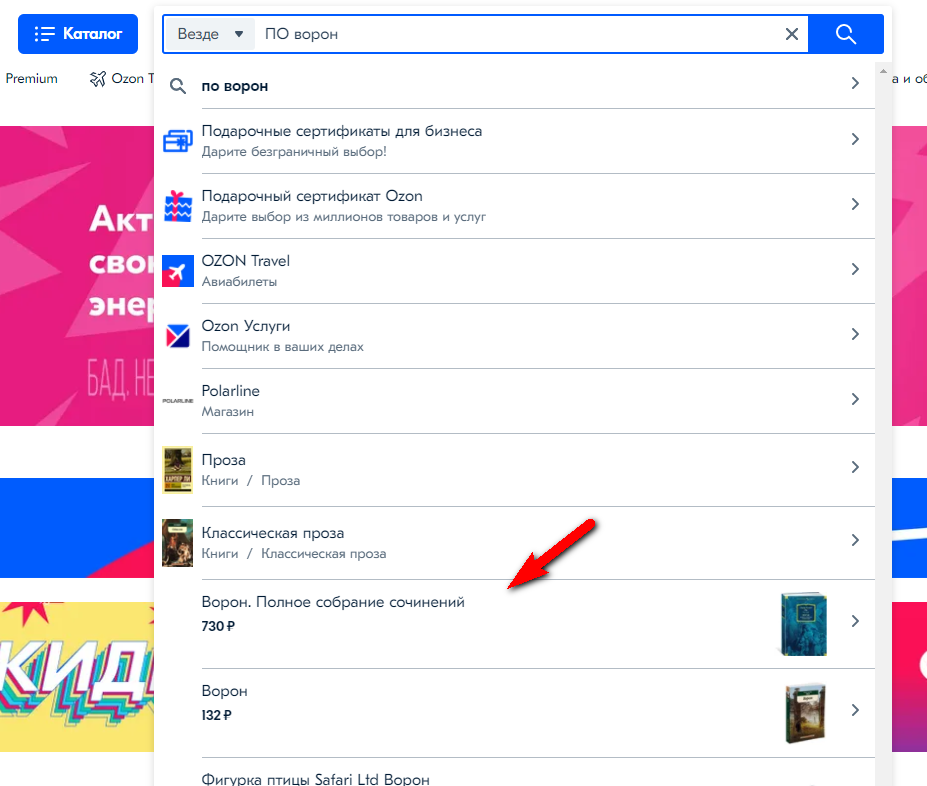
Пожалуй, нажму «энтер», чтобы перейти на страницу результатов поиска. Нашлась!

Так что Озон с задачей справился. Но это Озон, а как поведет себя другой магазин с книгами, мы не знаем, пока не проверим.
Если книги автора найти не получается — то проблемы с приоритетами в выборке. Поиск по ФИО автора должен быть более релевантным, чем совпадение какого-то слова в описании.
.
18. Верхняя произвольная граница
Есть ли ограничение в строке поиска? Если есть, то оно обычно в разумных пределах — 100 / 500 / 1000 символов. И если пользователь вводит больше, то значение обрезается до максимального.
И это разумно. Всегда лучше не дать ошибиться (не дать ввести больше N, обрезать запрос самостоятельно), чем ругаться на пользователя «да ты дурак, куда так много вводишь!».

Начинающие тестировщики, прочитав в ТЗ про границу в 1000 символов, записывают в свои чек-листы ожидаемый результат «при вводе больше система выдает ошибку». Но зачем выводить ошибку там, где можно обойтись без неё? Если системы ещё нет и вы пишете чек-лист заранее, просто уточните, как она будет работать.
Иногда верхнюю границу просто не ставят. И это тоже нормально, это не баг, который надо срочно исправить. Просто верхней произвольной границы у нас не будет.
.
19. Верхняя граница на выходе
Прошлый пункт — о том, как подать много на вход. А что будет, если «много» не на входе, а на выходе? Или «где-то посередине», то есть там, где поиск идёт?
-
Вернулось много данных по поиску (распространенный запрос)
-
Много данных находится в самой системе / базе данных
Сколько времени займет поиск? И пройдет ли он вообще? А то может на поиск установлен тайм-аут в 1 минуту. И при плохом интернете / большом объеме данных он будет просто висеть-тупить, а потом отваливаться.

20. Поиск технологической границы
Для поиска технологической границы мы вбиваем в строку поиска ОЧЕНЬ БОЛЬШОЕ значение. Тут хочется напомнить, что мы живем в 21 веке, поэтому 1000 символов — не поиск технологической границы. И даже 10 000, или 100 000.
Введите миллионов символов или главу «Войны и мира». Есть куча инструментов, которые помогут вам в этом.
См также:
Как сгенерить большую строку, инструменты
Генератор текста нужной длины
Зачем такой тест нужен? Казалось бы, ну даже если выдаст тебе система не слишком красивую ошибку, ну сам ведь балбес, хлам ввел. Однако иногда такой тест приводит к зависанию сервера. А вот это уже серьезно.
Мы столкнулись с этим на тестовом стенде подсказок Дадаты — ввели в подсказки по организациям большой текст и подвесили систему.

Поиск там работал по условию OR → то есть механизм брал каждое слово и искал его в справочнике так:
Слушай, у тебя есть слово 1 ИЛИ слово 2 ИЛИ слово 3 ИЛИ слово 4…?
Если слов много → то и комбинаций получается много → вот он и зависал, все их перебирая… При этом зависал сервер, то есть подсказок бы никто не увидел, если бы баг дошел до продакшена. А это уже нехорошо =)
Поэтому мой вам совет при тестировании поиска — когда исследуете технологические границы, генерируйте ТЕКСТ, а не строку. То есть кучу слов с пробелами. А то вдруг ваша система тоже не выдержит много комбинаций?
Это можно сделать и через perlclip. Просто задайте условие вида
«x xxx xx » x 9999999999
.
21. А дальше что?
Это чек-лист конкретного функционала — поиска. Но стоит ли останавливаться на проверке того, что «товар найден / не найден»?
Послушайте доклад Павла Абдюшева «Есть фича. Помогите протестировать!». Он там показывает, как выйти за рамки тестирования функционала. Как посмотреть на него с разных сторон. Что ещё стоит проверить и включить в план тестирования.
Как подключить связанный функционал — например, на что обратить внимание в результатах поиска, есть ли там сразу кнопка “купить”.
.
Итого
Помните, что мы всегда начинаем тестировать с самого важного. Поиск нужен для чего? Чтобы искать по каким-то полям. Поэтому в первую очередь проверяем:
-
что поиск ищет по всем полям, указанным в ТЗ
-
что он НЕ ищет по тем полям, которые НЕ указаны в ТЗ
А потом уже начинаем проверять регистр, включение, опечатки и прочая. И идём от простого к сложному, потому что если в одном тесте проверять сразу всё, то потом очень сложно будет понять, из-за чего конкретно поиск не сработал.

Также не забывайте про стандартные тесты для любого текстового поля. Это проверка на длину:
-
Разный регистр / язык / спецсимволы / эмоджи
-
Пустое поле / поле из пробелов
-
Нижняя граница — есть ли у вас адекватные, но короткие данные, ищет система по ним?
-
Верхняя произвольная граница — если она есть
-
Поиск технологической границы — вводим МНОГО слов, желательно с пробелами.
Но помните, что это серебряная пуля для любой текстовой строки. А, значит, она явно менее приоритетна тестов именно на ваш функционал — в данном случае на поиск. А тестировать надо начинать с самого главного!
Обсудить в форуме
Чек-лист для тестирования числового поля +9
Тестирование веб-сервисов, Тестирование IT-систем, Тестирование мобильных приложений
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/
При тестировании встречаются как интересные задачки с замудреной логикой, так и простые, вроде проверки простой строки или числового поля. Для простых полей можно один раз написать чек-лист проверок, а потом переиспользовать, лишь немного меняя под «своё» поле.
Сегодня мы разберем чек-лист для числового поля. Сначала я напишу общий чек-лист, потом пройдемся по каждому пункту и разберемся, зачем он нужен, а в конце напишем чек-лист по этому шаблону.
Итак, у нас есть некое поле, куда нужно вводить число. Например, поле «возраст» при регистрации:

При этом на сайте нельзя регистрироваться до 18 лет, есть запрещённый контент.
Какие проверки тут можно провести:
- Корректные значения
- Некорректные значения (за пределами валидных диапазонов или нелогичные: 200 лет, 88 секунд…)
- Граничные значения
- Пограничные значения
- Дробное число — формат (через запятую и через точку)
- Дробное число — округление (с кучей знаков после запятой)
- Ноль
- Один
- Пустое поле
- Очень большое число (поиск технологической границы)
- Отрицательное число
- Нечисловые и «не совсем числовые» значения
Соединяем все вместе — Пример: чек-лист для возраста.
Ну и куда же практики — Попробуй сам!
Корректные значения
Представьте, что у вас буквально 5 минут на проверку функционала. И вы успеваете провести только первые несколько тестов из чек-листа. А чек-лист у вас:
- Пустое поле
- 0
- -1
В итоге эти проверки провели и считаете, что система работает нормально (ну ругается же!). А она всегда ругается, даже на корректное значение! Нехорошо… Поэтому запоминаем правило:
ВСЕГДА сначала позитив, потом негатив!

См также:
Позитивное и негативное тестирование — подробнее о том, с чего начинать
Для поля с возрастом какие у нас будут корректные значения? Все, что выше 18 лет:
- 18
- 25
- 38
- 45
- …

Тут надо понимать, что мы выбираем какое-то ОДНО значение. Просто каждый раз разное, для избежания эффекта пестицида.
Также важно понимать, что у нас может быть не одно корректное значение. Это когда у нас есть несколько диапазонов, и разные условия на каждом.
Например, тот же возраст:
- если до 18 лет — показать в магазине все товары, кроме сигарет и алкоголя
- если больше 18 лет — показать вообще все товары
Тогда мы понимаем, что у нас есть уже два «валидных» диапазона. Значит, нам нужно взять значение из каждого. Например, 16 и 26.

Или если у нас идет расчет страховки в зависимости от стажа вождения:
- 0 — 1 год — 1000 руб
- 1 — 3 года — 800 руб
- 3-5 лет — 600 руб
- 5-10 лет — 500 руб
- 10+ лет — 300 руб
Получается 5 интервалов. И нам надо взять по одному значению из каждого. Например: 0.5, 2, 4, 6, 15.

Каждый раз берем разные значения, но в этом пункте смысл один — взять корректные значения из ТЗ.
Некорректные значения
Тут есть разные варианты. Что значит некорректное значение?
- за пределами валидных диапазонов
- корректное с точки зрения компьютера (число), но лишенное смысла (200 лет)
Вернемся к примеру с возрастом. Корректное значение — старше 18 лет. Значит, мы должны задать вопрос:
— А что будет, если мы возьмем значение из «неправильного» диапазона? Что, если мне меньше 18 лет? Ну, скажем, 10.

Потом внимательно смотрим на выбранный интервал:
— Хммммм, но ведь возраст не может быть меньше 0. То есть у нас есть логическая граница, разделяющая два разных класса эквивалентности:
- Возможный физически, но невалидный по ТЗ (0 — 17 лет)
- Невозможный физически (0 и менее)
Так что надо взять значение из каждого диапазона. Тогда получается 10 и «-5»:

Думаем дальше:
— Если у нас есть некая логическая граница снизу, должна быть и сверху. Какой максимально возможный возраст у регистрирующихся на нашем сайте? Скорее всего, это около 55-65 лет, потому что более старшее поколение не любит компьютеры. Но можно заложить и условные 100-110 лет долгожителей.
Получаем еще один интервал с неявной границей. Но в любом случае, значения 25 и 145 будут различаться — одно реалистичное, а другое нет. Значит, стоит его тоже попробовать!

А дальше снова эффект пестицида. Один раз берем 145, а другой — 6666666.
Тут мы можем столкнуться с тем, что в поле нельзя ввести больше 2-3 символов. Разработчик перестраховался «от дурака». Это не повод опускать руки и отказываться от своей проверки. Потому что скорее всего разработчик просто установил maxlength на поле, а он легко обходится!
См также:
Как снять maxlength со всех полей формы — несколько способов на заметку ?
Граничные значения
Граничные значения отделяют один интервал от другого. Их обязательно надо тестировать!!! Потому что именно на границах чаще всего встречаются баги. Почему? Да потому что попадают в оба диапазона, или не попадают ни в один.
В нашем примере в ТЗ есть условие «регистрация только для лиц старше 18 лет». Это значит, что разработчик должен сделать в коде программы логику вида:
- ЕСЛИ x > 18 ТО регистрируем
- ЕСЛИ x <=18 ТО выдаем ошибку
Если разработчик забыл добавить значение 18 в один из диапазонов, это может и не привести к ошибке. Потому что в таких случаях обычно используется конструкция if else. И разработчик ставит последний «else» на всякий случай — то есть если ВДРУГ вводимое значение не попало ни в одно из условий выше:
- if x > 18 …
- elseif x < 18 …
- else …
А вот если разработчик добавил значение 18 сразу в несколько диапазонов:
- if x => 18 …
- elseif x <= 18 …
То программа растеряется, что же ей выбрать? И вполне может упасть!
В общем, на границах баги встречаются чаще, чем внутри интервала. Поэтому обязательно исследуйте их! В нашем ТЗ есть четкая граница «больше 18 лет». Значит, тестируем число 18:

Если по ТЗ у нас есть несколько интервалов, проверяем каждую границу отдельно. Это произвольные границы — которые накладывает ТЗ.
Но границы бывают разных типов:
- Произвольные
- Логические
- Технологические
Произвольные проверили? Едем дальше. Логические — это все о, что подчиняется логике (в минуте 60 секунд, человеку не может быть «минус один годик», и т.д.). Применим к нашему примеру.
Граница снизу:
— Логично, что возраст не может быть меньше нуля. Так что 0 — это граница. Тестируем!

Граница сверху:
— Нуууу… Врядли возраст будет больше 35 лет. Хотя что мешает бабушке зайти на сайт? Может быть, 65? 88?
Здесь границу найти сложно. Вот взять значение из диапазона «не слишком верится в это» легко, а конкретной границы нету. Значит, и тестировать нечего. Сверху логической границы нет.
Поиск технологической границы я вынесла в отдельный пункт, так что вернемся к нему чуть позже. В любом случае это менее важно, чем выверить валидные границы, которые есть в ТЗ.
См также:
Типы границ на примере стиральной машинки
Зачем тестировать граничные значенияКак найти границы на клиенте и сервере
Мнемоника БМВ для поиска граничных значений
Пограничные значения
Если у нас есть граница, то есть и пограничные значения. И их тоже надо проверять!
В примере с возрастом граница — 18. Значит, пограничные значения — 17 и 19.

Зачем проверять пограничные значения? Да затем, что разработчик мог ошибиться в коде и указать границу немного не там.
if x > 18 …
v
if x > 17 …Если у нас граница сдвинута, а мы не тестируем пограничные значения, то можем легко пропустить этот баг. Ведь мы проверили:
- границу — 18. 18 > 17, так что все работает
- недопустимое значение из диапазона слева — 10. 10 < 17, так что выдало ошибку.
Делаем вывод, что всё работает правильно, хотя это не так! Так что обязательно проверяем пограничные значение.
Но нужно ли тестировать пограничные значения в обеих сторон? С 17 разобрались, нужно. А 19? Допустим, разработчик опечатался в другую сторону:
if x > 18 …
v
if x > 19 …Мы найдем этот баг проверкой граничного значения 18. А если на 18 работает и на числе внутри диапазона (например, 26) работает — значит, код написан верно. То есть чтобы в коде был баг, это как надо извратиться то, написать что-то типа:
if (x == 18 or x > 21) …Такое только специально можно сделать)) Ну а если рассчитывать на разработчика-дурака со злыми шутками в виде таких пасхалок, то остается только полный перебор делать. Так что давайте считать коллег адекватными людьми.
Но! Что, если разработчик описывает работу кода для нескольких интервалов? Тогда при опечатке диапазоны идут внахлест:
if x <= 19 (ОПЕЧАТКА) …
if (x > 18 and x < 55) …Число 18 ошибку уже не поймает, ведь 18 <= 19, а во второй диапазон уже не попадает. Вот и будет ситуация, что на границе работает, внутри диапазона — работает, а на пограничном значении — нет.
Так что если нет доступа к коду, стоит проверить пограничные с обеих сторон, а то мало ли, где там опечатка закралась?
Дело становится еще интереснее, если в поле можно ввести не только целое число, но и дробное. Что тогда будет пограничным значением? Стоит начать с одного знака после запятой. В нашем примере это 17.9 и 18.1:

Хорошо, допустим, проверили:
- Целые границы — 17 и 19
- Дробные границы — 17.9 и 18.1
Но если такие значения округляются нормально, значит ли это, что и другие тоже будут округляться хорошо? Что будет, если ввести значение 17.99999999999 (после запятой 11 девяток, а результатом округления является попадание на границу)?
Это разные классы эквивалентности, если мы говорим о дробях, которые будут округляться:
- Один знак после запятой
- Много знаков
И стоит проверить оба! Так что добавляем новые тесты: 17.99999999999 и 18.00000000001

Дробное число (формат)
Если система позволяет вводить дробные значения, то мы проверяем их ещё в пункте 1, при тестировании корректных значений. Просто разбиваем понятие «корректное число»:
- Целое
- Дробное
А пункт «дробное» разбиваем дальше. Ведь дробное число можно записать через:
- точку — 6.9
- запятую — 6,9
Если работает один из способов, это совсем не значит, что будет работать второй! У меня даже есть пример двух калькуляторов, которые работают с дробными числами по-разному — http://bugred.ru/calc/.
См также:
Не пишите в баге «Ввести 6,9»! — разбор багов в калькуляторе
Значит, нам нужно убедиться, что работают оба способа. По крайней мере если они должны работать. Если должен работать только один, потому что стандарты запрещают использовать другой — проверяем, что второй возвращает ошибку!
В случае с возрастом прикидываем, что будет позитивным дробным значением? Скорее всего, половинка — например, 20.5 лет:

Проверили? Работает? Тогда смотрим через запятую — 20,5:

То, что дробные в принципе работают — проверили. Хорошо.
Дробное число (округление)
Особый интерес представляют значения, близкие к граничным, а не любые дробные значения. При приближении к границе на расстояние, меньшее точности вычислений, мы можем попасть в ситуацию, когда проверки значения на допустимость успешно проходят, но вычисления завершаются неуспешно.
Так что если у вас можно вводить нецелое число, обязательно попробуйте много девяток после запятой, приближенной к границе значение (мы это уже сделали пунктом выше):
При этом нет смысла проверять округление и через точку, и через запятую. Это будет лишнее дублирование тестов. Проверяем отдельно:
- формат — через точку или запятую
- округление — когда один или много знаков после запятой
См также:
В тестировании всегда начинаем с простого! — почему не надо смешивать проверки
Ноль
Ноль мы тестируем всегда. И везде. Просто запомните это как аксиому. Просто потому, что в нуле часто встречаются баги.
Потому, что это обычно граница. Она может быть явной (прописанной в ТЗ) или неявной (в ТЗ не написано, но и так понятно, что возраст отрицательным быть не может).
Если мы говорим именно про числовое поле, то пробуем ввести число 0. Хотя, конечно «ноль» в тестировании выходит за рамки простого числа.

См также:
Класс эквивалентности «Ноль-не ноль» — подробнее о тестировании нуля, и не только в числовых полях!
Один
Так как мы всегда проверяем ноль, то не забываем и о приграничном значении — единице.
Фактически это обычно «минимально возможное значение», если мы не говорим о дробных значениях:
— Логично, что если мы делаем заказ, то покупаем хотя бы 1 книжку, или 1 платьюшко, или 1 кг муки…
— Минимальный возраст — 1 день / месяц / год
— Минимальное количество времени — 1 секунда
— Минимальное количество трудового стажа — 1 день / месяц / год
— …
Так что единица не менее магическое число, чем ноль. Проверяем и её!
Пустое поле
Фактически это тоже тест на ноль. Только уже не на число «ноль», а на ноль в длине вводимой строки.
Ведь если мы вводим «0», это получается
один
символ.
А если мы изучаем длину строки, стоит проверить не только один, но и
ноль
.
Не забудьте, что ноль — это не только число. Даже в числовом поле у нас будет минимум два нуля — пустая строка и число «0». Может быть и больше нулей — не забывайте про ноль на выходе. Но в нашем примере с возрастом его нет.
Очень большое число
Для поиска технологической границы нужно ввести очень большое число. Например, 9999999999999999.

Мы пытаемся зайти так далеко, как только это возможно. Но не слишком упарываясь — это должен быть один тест, ну два.
Сначала можно оттолкнуться от значения integer — чаще всего для числового поля выбирают именно такой тип данных. Если получилось его превысить, просто проверяем 25 или 45 девяток в поле. Не упало? Ну и чудненько. Технологической границы нет, но мы хотя бы попытались ее найти.
См также:
Как сгенерить большую строку, инструменты — не обязательно делать это руками))
Технологическая граница в подсказках по ЮЛ — пример реального бага
Если поле допускает ввод отрицательных значений, то проверяем «много девяток» как со знаком плюс, так и со знаком минус, проводя два теста:
- 99999999999999999999999
- -99999999999999999999999
Напоминаю — если в поле нельзя ввести много символов, это не повод опускать руки и говорить «технологическую границу проверить нельзя!». Потому что если в поле нельзя вводить много символов — там скорее всего стоит maxlength на поле, который легко обходится. Сняли ограничение на клиенте и убедились, что на сервере защита от дурака тоже есть.
См также:
Как снять maxlength со всех полей формы
Как найти границы на клиенте и сервере
Отрицательное число
Когда у нас есть число, то всегда помним, что оно может быть:
- положительное
- отрицательное
При этом по опыту проводимых мною собеседований могу точно сказать, что немногие додумываются до проверки «а если ввести отрицательное значение». А ведь система может работать по разному:
- выдавать ошибку «такого возраста / количества товара не существует, введите положительное число»;
- отсекать знак минус и работать с отрицательным числом как с положительным.
Это помимо того, что отрицательное число может быть вполне нормальным для поля (например, если мы сохраняем доходы / расходы).
Что тестируем в этом разделе?
- Что будет, если ввести отрицательное число, которое по модулю будет корректным: -26 в нашем примере
- Попытка найти технологическую границу: -99999999999999999999999
Нечисловые и «не совсем числовые» значения
Если вы думаете, что для проверки нечислового значения достаточно вбить любую строку типа «привет», то вы ошибаетесь )))
Строки тоже бывают разные, и их можно разбить на:
- множество строк, которые программа интерпретирует как числа;
- множество строк, которые программа не может интерпретировать как числа.
Очень хорошо тесты для «не совсем числовых» значений рассмотрены в этой статье: Классы эквивалентности для строки, которая обозначает число
Я не буду ее полностью переписывать, просто дополню список проверок для нашего примера. Что мы еще не смотрели:
- Точно не число — «Тест»
- Лидирующий ноль — «025»
- Пробел перед числом — « 25»
- Пробел внутри числа — «2 5»
- Запись через е — «1.2e+2»
- Шестнадцатеричное значение — «0xba»
- Boolean — TRUE / FALSE (может интерпретироваться как 0 / 1)
- Infinity (да, прям так текстом и пишем)
- NaN
В нашем случае с корректным значением возраста от 18 лет пункт «пробел внутри числа» становится интереснее. Тут ведь зависит от логики работы системы. Тут есть разные варианты:
- Ругаться, если введено несколько слов
- Отсекать всё, что идет после первого пробела — «2 5» > «2»
- Убирать пробел и делать вид, что его не было (воспринимать как опечатку в цифре) — «2 5» > «25»
Аналогично с буквами. Система может ругаться, увидев их, а может просто выкинуть. Так что посмотрим новые варианты тестов:
- до пробела меньше 18 лет — 2 5
- до пробела больше 18 лет — 25 6
- после пробела текста — 25 тест
- до пробела текст — тест 25
При этом учтите — в интерфейсе мы просто вводим какое-то значение, не указывая тип данных. А вот если мы тестируем REST API и json-сообщение в нем, то обязательно стоит попробовать передать число строкой:
- number: 3
- number: “3”
Это разные значения. Если значение без кавычек — это число. Если в кавычках — строка, даже если выглядит как число. Может быть, разработчик сделает приведение типов в коде и «примет» второй вариант, а может, и нет. В любом случае, проверить стоит!
Соединяем все вместе: чек-лист для возраста
Идеи для проверок записали, обсудили каждую. Теперь давайте соединим все пункты вместе и напишем чек-лист для нашего примера.
Напомню условие — у нас есть поле «возраст» при регистрации. При этом на сайте нельзя регистрироваться до 18 лет, запрещённый контент есть.
При составлении чек-листа учитываем все пункты, которые обсудили выше. Но не забываем о приоритетах. Начинаем всегда с основных проверок, а не с «вбили ноль, отрицательное число и вообще всячески попытались сломать».
* Если работает 18.000000000001, то проверять целое число 19 смысла нет. Если дробные не принимаются системой, тогда да, проверяем на 19
Конечно, проверки из блока «нецелые числа» не супер-важны. Иногда на них можно и нужно забить. Особенно если мы знаем, что система не должна ничего анализировать, убирать пробелы, выкидывать текст и прочая… Тогда достаточно взять одно значение из этого списка. А остальные использовать для эффекта пестицида, то есть каждый раз новый вариант «не числа».
Но ведь для того, чтобы отсекать лишнее, надо сначала научиться генерировать много идей! Вот в этом мы с вами сегодня и потренировались =)
См также:
Читлист для числового поля в Ситечке (нужно авторизоваться)
Где брать идеи для тестов (подборка полезных ссылок)
Попробуй сам
Напишите чек-лист проверок для поля «Стаж вождения». В зависимости от стажа идёт расчет страховки. У всех интервалов слева число «включительно», а справа — нет.
- 0-3 года — 1000 руб
- 3-6 лет — 700 руб
- 6-10 лет — 500 руб
- 10+ лет — 300 руб
Форма не дает вводить ничего, кроме цифр (это ограничение стоит на клиенте). Дробные значения недопустимы, сколько полных лет стажа есть, столько и пишем.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
При тестировании встречаются как интересные
задачки с замудреной логикой, так и простые, вроде проверки простой
строки или числового поля. Для простых полей можно один раз
написать чек-лист проверок, а потом переиспользовать, лишь немного
меняя под своё поле.
Сегодня мы разберем чек-лист для числового поля. Сначала я напишу
общий чек-лист, потом пройдемся по каждому пункту и разберемся,
зачем он нужен, а в конце напишем чек-лист по этому шаблону.
Итак, у нас есть некое поле, куда нужно вводить число. Например,
поле возраст при регистрации:

При этом на сайте нельзя регистрироваться до 18 лет, есть
запрещённый контент.
Какие проверки тут можно провести:
- Корректные значения
- Некорректные значения (за пределами
валидных диапазонов или нелогичные: 200 лет, 88 секунд…) - Граничные значения
- Пограничные значения
- Дробное число формат (через
запятую и через точку) - Дробное число округление (с кучей
знаков после запятой) - Ноль
- Один
- Пустое поле
- Очень большое число (поиск
технологической границы) - Отрицательное число
- Нечисловые и не совсем
числовые значения
Соединяем все вместе Пример: чек-лист для
возраста.
Ну и куда же практики Попробуй сам!
Корректные значения
Представьте, что у вас буквально 5 минут на проверку функционала. И
вы успеваете провести только первые несколько тестов из чек-листа.
А чек-лист у вас:
- Пустое поле
- 0
- -1
В итоге эти проверки провели и считаете, что система работает
нормально (ну ругается же!). А она всегда ругается, даже на
корректное значение! Нехорошо Поэтому запоминаем правило:
ВСЕГДА сначала позитив, потом
негатив!

См также:
Позитивное и негативное тестирование подробнее о
том, с чего начинать
Для поля с возрастом какие у нас будут корректные значения? Все,
что выше 18 лет:
- 18
- 25
- 38
- 45

Тут надо понимать, что мы выбираем какое-то ОДНО значение.
Просто каждый раз разное, для избежания эффекта пестицида.
Также важно понимать, что у нас может быть не одно корректное
значение. Это когда у нас есть несколько диапазонов, и разные
условия на каждом.
Например, тот же возраст:
- если до 18 лет показать в магазине все товары, кроме сигарет и
алкоголя - если больше 18 лет показать вообще все товары
Тогда мы понимаем, что у нас есть уже два валидных диапазона.
Значит, нам нужно взять значение из каждого. Например, 16 и 26.

Или если у нас идет расчет страховки в зависимости от стажа
вождения:
- 0 1 год 1000 руб
- 1 3 года 800 руб
- 3-5 лет 600 руб
- 5-10 лет 500 руб
- 10+ лет 300 руб
Получается 5 интервалов. И нам надо взять по одному значению из
каждого. Например: 0.5, 2, 4, 6, 15.

Каждый раз берем разные значения, но в этом пункте смысл один взять
корректные значения из ТЗ.
Некорректные значения
Тут есть разные варианты. Что значит некорректное значение?
- за пределами валидных диапазонов
- корректное с точки зрения компьютера (число), но лишенное
смысла (200 лет)
Вернемся к примеру с возрастом. Корректное значение старше 18 лет.
Значит, мы должны задать вопрос:
А что будет, если мы возьмем значение из неправильного диапазона?
Что, если мне меньше 18 лет? Ну, скажем, 10.

Потом внимательно смотрим на выбранный интервал:
Хммммм, но ведь возраст не может быть меньше 0. То есть у нас есть
логическая граница, разделяющая два разных класса
эквивалентности:
- Возможный физически, но невалидный по ТЗ (0 17 лет)
- Невозможный физически (0 и менее)
Так что надо взять значение из каждого диапазона. Тогда получается
10 и -5:

Думаем дальше:
Если у нас есть некая логическая граница снизу, должна быть и
сверху. Какой максимально возможный возраст у регистрирующихся на
нашем сайте? Скорее всего, это около 55-65 лет, потому что более
старшее поколение не любит компьютеры. Но можно заложить и условные
100-110 лет долгожителей.
Получаем еще один интервал с неявной границей. Но в любом случае,
значения 25 и 145 будут различаться одно реалистичное, а другое
нет. Значит, стоит его тоже попробовать!

А дальше снова эффект пестицида. Один раз берем 145, а другой
6666666.
Тут мы можем столкнуться с тем, что в поле нельзя ввести больше 2-3
символов. Разработчик перестраховался от дурака. Это не повод
опускать руки и отказываться от своей проверки. Потому что скорее
всего разработчик просто установил maxlength на поле, а он
легко обходится!
См также:
Как снять maxlength со всех полей формы
несколько способов на заметку
Граничные значения
Граничные значения отделяют один интервал от другого. Их
обязательно надо тестировать!!! Потому что именно на границах чаще
всего встречаются баги. Почему? Да потому что попадают в оба
диапазона, или не попадают ни в один.
В нашем примере в ТЗ есть условие регистрация только для лиц старше
18 лет. Это значит, что разработчик должен сделать в коде программы
логику вида:
- ЕСЛИ x < 18 ТО регистрируем
- ЕСЛИ x >=18 ТО выдаем ошибку
Если разработчик забыл добавить значение 18 в один из диапазонов,
это может и не привести к ошибке. Потому что в таких случаях обычно
используется конструкция if else. И разработчик ставит последний
else на всякий случай то есть если ВДРУГ вводимое значение не
попало ни в одно из условий выше:
- if x > 18
- elseif x < 18
- else
А вот если разработчик добавил значение 18 сразу в несколько
диапазонов:
- if x => 18
- elseif x <= 18
То программа растеряется, что же ей выбрать? И вполне может
упасть!
В общем, на границах баги встречаются чаще, чем внутри интервала.
Поэтому обязательно исследуйте их! В нашем ТЗ есть четкая граница
больше 18 лет. Значит, тестируем число 18:

Если по ТЗ у нас есть несколько интервалов, проверяем каждую
границу отдельно. Это произвольные границы которые накладывает
ТЗ.
Но границы бывают разных типов:
- Произвольные
- Логические
- Технологические
Произвольные проверили? Едем дальше. Логические это все о, что
подчиняется логике (в минуте 60 секунд, человеку не может быть
минус один годик, и т.д.). Применим к нашему примеру.
Граница снизу:
Логично, что возраст не может быть меньше нуля. Так что 0 это
граница. Тестируем!

Граница сверху:
Нуууу Врядли возраст будет больше 35 лет. Хотя что мешает бабушке
зайти на сайт? Может быть, 65? 88?
Здесь границу найти сложно. Вот взять значение из диапазона не
слишком верится в это легко, а конкретной границы нету. Значит, и
тестировать нечего. Сверху логической границы нет.
Поиск технологической границы я вынесла в отдельный пункт, так что
вернемся к нему чуть позже. В любом случае это менее важно, чем
выверить валидные границы, которые есть в ТЗ.
См также:
Типы границ на примере стиральной машинки
Зачем тестировать граничные значенияКак найти границы на клиенте и сервере
Мнемоника БМВ для поиска граничных значений
Пограничные значения
Если у нас есть граница, то есть и пограничные значения. И их тоже
надо проверять!
В примере с возрастом граница 18. Значит, пограничные значения 17 и
19.

Зачем проверять пограничные значения? Да затем, что разработчик мог
ошибиться в коде и указать границу немного не там.
if x > 18 if x > 17
Если у нас граница сдвинута, а мы не тестируем пограничные
значения, то можем легко пропустить этот баг. Ведь мы
проверили:
- границу 18. 18 > 17, так что все работает
- недопустимое значение из диапазона слева 10. 10 < 17, так
что выдало ошибку.
Делаем вывод, что всё работает правильно, хотя это не так! Так что
обязательно проверяем пограничные значение.
Но нужно ли тестировать пограничные значения в обеих сторон? С 17
разобрались, нужно. А 19? Допустим, разработчик опечатался в другую
сторону:
if x > 18 if x > 19
Мы найдем этот баг проверкой граничного значения 18. А если на 18
работает и на числе внутри диапазона (например, 26) работает
значит, код написан верно. То есть чтобы в коде был баг, это как
надо извратиться то, написать что-то типа:
if (x == 18 or x > 21)
Такое только специально можно сделать)) Ну а если рассчитывать на
разработчика-дурака со злыми шутками в виде таких пасхалок, то
остается только полный перебор делать. Так что давайте считать
коллег адекватными людьми.
Но! Что, если разработчик описывает работу кода для нескольких
интервалов? Тогда при опечатке диапазоны идут внахлест:
if x <= 19 (ОПЕЧАТКА) if (x > 18 and x < 55)
Число 18 ошибку уже не поймает, ведь 18 <= 19, а во второй
диапазон уже не попадает. Вот и будет ситуация, что на границе
работает, внутри диапазона работает, а на пограничном значении
нет.
Так что если нет доступа к коду, стоит проверить пограничные с
обеих сторон, а то мало ли, где там опечатка закралась?
Дело становится еще интереснее, если в поле можно ввести не только
целое число, но и дробное. Что тогда будет пограничным значением?
Стоит начать с одного знака после запятой. В нашем примере это 17.9
и 18.1:

Хорошо, допустим, проверили:
- Целые границы 17 и 19
- Дробные границы 17.9 и 18.1
Но если такие значения округляются нормально, значит ли это, что и
другие тоже будут округляться хорошо? Что будет, если ввести
значение 17.99999999999 (после запятой 11 девяток, а результатом
округления является попадание на границу)?
Это разные классы эквивалентности, если мы говорим о дробях,
которые будут округляться:
- Один знак после запятой
- Много знаков
И стоит проверить оба! Так что добавляем новые тесты:
17.99999999999 и 18.00000000001

Дробное число (формат)
Если система позволяет вводить дробные значения, то мы проверяем их
ещё в пункте 1, при тестировании корректных значений. Просто
разбиваем понятие корректное число:
- Целое
- Дробное
А пункт дробное разбиваем дальше. Ведь дробное число можно записать
через:
- точку 6.9
- запятую 6,9
Если работает один из способов, это совсем не значит, что будет
работать второй! У меня даже есть пример двух калькуляторов,
которые работают с дробными числами по-разному http://bugred.ru/calc/.
См также:
Не пишите в баге Ввести 6,9! разбор багов в
калькуляторе
Значит, нам нужно убедиться, что работают оба способа. По крайней
мере если они должны работать. Если должен работать только один,
потому что стандарты запрещают использовать другой проверяем, что
второй возвращает ошибку!
В случае с возрастом прикидываем, что будет позитивным дробным
значением? Скорее всего, половинка например, 20.5 лет:

Проверили? Работает? Тогда смотрим через запятую 20,5:

То, что дробные в принципе работают проверили. Хорошо.
Дробное число (округление)
Особый интерес представляют значения, близкие к граничным, а не
любые дробные значения. При приближении к границе на расстояние,
меньшее точности вычислений, мы можем попасть в ситуацию, когда
проверки значения на допустимость успешно проходят, но вычисления
завершаются неуспешно.
Так что если у вас можно вводить нецелое число, обязательно
попробуйте много девяток после запятой, приближенной к границе
значение (мы это уже сделали пунктом выше):
При этом нет смысла проверять округление и через точку, и через
запятую. Это будет лишнее дублирование тестов. Проверяем
отдельно:
- формат через точку или запятую
- округление когда один или много знаков после запятой
См также:
В тестировании всегда начинаем с простого!
почему не надо смешивать проверки
Ноль
Ноль мы тестируем всегда. И везде. Просто запомните это как
аксиому. Просто потому, что в нуле часто встречаются баги.
Потому, что это обычно граница. Она может быть явной (прописанной в
ТЗ) или неявной (в ТЗ не написано, но и так понятно, что возраст
отрицательным быть не может).
Если мы говорим именно про числовое поле, то пробуем ввести число
0. Хотя, конечно ноль в тестировании выходит за рамки простого
числа.

См также:
Класс эквивалентности Ноль-не ноль подробнее о
тестировании нуля, и не только в числовых полях!
Один
Так как мы всегда проверяем ноль, то не забываем и о приграничном
значении единице.
Фактически это обычно минимально возможное значение, если мы не
говорим о дробных значениях:
Логично, что если мы делаем заказ, то покупаем хотя бы 1 книжку,
или 1 платьюшко, или 1 кг муки
Минимальный возраст 1 день / месяц / год
Минимальное количество времени 1 секунда
Минимальное количество трудового стажа 1 день / месяц / год
Так что единица не менее магическое число, чем ноль. Проверяем и
её!
Пустое поле
Фактически это тоже тест на ноль. Только уже не на число ноль, а на
ноль в длине вводимой строки.
Ведь если мы вводим 0, это получается
один
символ.
А если мы изучаем длину строки, стоит проверить не только один, но
и
ноль
.
Не забудьте, что ноль это не только число. Даже в числовом поле у
нас будет минимум два нуля пустая строка и число 0. Может быть и
больше нулей не забывайте про ноль на выходе. Но в нашем примере с
возрастом его нет.
Очень большое число
Для поиска технологической границы нужно ввести очень большое
число. Например, 9999999999999999.

Мы пытаемся зайти так далеко, как только это возможно. Но не
слишком упарываясь это должен быть один тест, ну два.
Сначала можно оттолкнуться от значения integer чаще всего
для числового поля выбирают именно такой тип данных. Если
получилось его превысить, просто проверяем 25 или 45 девяток в
поле. Не упало? Ну и чудненько. Технологической границы нет, но мы
хотя бы попытались ее найти.
См также:
Как сгенерить большую строку, инструменты не
обязательно делать это руками))
Технологическая граница в подсказках по ЮЛ
пример реального бага
Если поле допускает ввод отрицательных значений, то проверяем много
девяток как со знаком плюс, так и со знаком минус, проводя два
теста:
- 99999999999999999999999
- -99999999999999999999999
Напоминаю если в поле нельзя ввести много символов, это не повод
опускать руки и говорить технологическую границу проверить нельзя!.
Потому что если в поле нельзя вводить много символов там скорее
всего стоит maxlength на поле, который легко обходится.
Сняли ограничение на клиенте и убедились, что на сервере защита от
дурака тоже есть.
См также:
Как снять maxlength со всех полей формы
Как найти границы на клиенте и сервере
Отрицательное число
Когда у нас есть число, то всегда помним, что оно может быть:
- положительное
- отрицательное
При этом по опыту проводимых мною собеседований могу точно сказать,
что немногие додумываются до проверки а если ввести отрицательное
значение. А ведь система может работать по разному:
- выдавать ошибку такого возраста / количества товара не
существует, введите положительное число; - отсекать знак минус и работать с отрицательным числом как с
положительным.
Это помимо того, что отрицательное число может быть вполне
нормальным для поля (например, если мы сохраняем доходы /
расходы).
Что тестируем в этом разделе?
- Что будет, если ввести отрицательное число, которое по модулю
будет корректным: -26 в нашем примере - Попытка найти технологическую границу:
-99999999999999999999999
Нечисловые и не совсем числовые значения
Если вы думаете, что для проверки нечислового значения достаточно
вбить любую строку типа привет, то вы ошибаетесь )))
Строки тоже бывают разные, и их можно разбить на:
- множество строк, которые программа интерпретирует как
числа; - множество строк, которые программа не может интерпретировать
как числа.
Очень хорошо тесты для не совсем числовых значений рассмотрены в
этой статье: Классы эквивалентности для строки, которая
обозначает число
Я не буду ее полностью переписывать, просто дополню список проверок
для нашего примера. Что мы еще не смотрели:
- Точно не число Тест
- Лидирующий ноль 025
- Пробел перед числом 25
- Пробел внутри числа 2 5
- Запись через е 1.2e+2
- Шестнадцатеричное значение 0xba
- Infinity (да, прям так текстом и пишем)
- NaN
В нашем случае с корректным значением возраста от 18 лет пункт
пробел внутри числа становится интереснее. Тут ведь зависит от
логики работы системы. Тут есть разные варианты:
- Ругаться, если введено несколько слов
- Отсекать всё, что идет после первого пробела 2 5 2
- Убирать пробел и делать вид, что его не было (воспринимать как
опечатку в цифре) 2 5 25
Аналогично с буквами. Система может ругаться, увидев их, а может
просто выкинуть. Так что посмотрим новые варианты тестов:
- до пробела меньше 18 лет 2 5
- до пробела больше 18 лет 25 6
- после пробела текста 25 тест
- до пробела текст тест 25
При этом учтите в интерфейсе мы просто вводим какое-то значение, не
указывая тип данных. А вот если мы тестируем REST API и
json-сообщение в нем, то обязательно стоит попробовать передать
число строкой:
- number: 3
- number: 3
Это разные значения. Если значение без кавычек это число. Если в
кавычках строка, даже если выглядит как число. Может быть,
разработчик сделает приведение типов в коде и примет второй
вариант, а может, и нет. В любом случае, проверить стоит!
Соединяем все вместе: чек-лист для возраста
Идеи для проверок записали, обсудили каждую. Теперь давайте
соединим все пункты вместе и напишем чек-лист для нашего
примера.
Напомню условие у нас есть поле возраст при регистрации. При этом
на сайте нельзя регистрироваться до 18 лет, запрещённый контент
есть.
При составлении чек-листа учитываем все пункты, которые обсудили
выше. Но не забываем о приоритетах. Начинаем всегда с основных
проверок, а не с вбили ноль, отрицательное число и вообще всячески
попытались сломать.
* Если работает 18.000000000001, то проверять целое число 19 смысла
нет. Если дробные не принимаются системой, тогда да, проверяем на
19
Конечно, проверки из блока нецелые числа не супер-важны. Иногда на
них можно и нужно забить. Особенно если мы знаем, что система не
должна ничего анализировать, убирать пробелы, выкидывать текст и
прочая Тогда достаточно взять одно значение из этого списка. А
остальные использовать для эффекта пестицида, то есть каждый раз
новый вариант не числа.
Но ведь для того, чтобы отсекать лишнее, надо сначала научиться
генерировать много идей! Вот в этом мы с вами сегодня и
потренировались =)
См также:
Читлист для числового поля в Ситечке (нужно
авторизоваться)
Где брать идеи для тестов (подборка полезных
ссылок)
Попробуй сам
Напишите чек-лист проверок для поля Стаж вождения. В зависимости от
стажа идёт расчет страховки. У всех интервалов слева число
включительно, а справа нет.
- 0-3 года 1000 руб
- 3-6 лет 700 руб
- 6-10 лет 500 руб
- 10+ лет 300 руб
Форма не дает вводить ничего, кроме цифр (это ограничение стоит на
клиенте). Дробные значения недопустимы, сколько полных лет стажа
есть, столько и пишем.
Зачастую на проектах, вы будете писать не тест-кейсы, а чек-листы. Они пишутся либо в специфическом софте, например HP ALM (HP QC), Zephyr for JARA, либо, самое популярное — Google drive, Excel. Определенного формата создания чек-листов не существует. Каждая команда сама для себя решает, как им удобнее хранить и описывать тесты, и насколько детально всё описывать.
Введение в чек-листы
Чек-лист (checklist) — документ, описывающий набор (список) проверок или идей.
Люди используют список проверок в повседневной жизни, как в быту, так и на рабочем месте для организации деятельности и процессов. Особенно актуально и важно в сферах, требующих повышенного внимания и нетривиальных задач. Помогает не упустить наиболее сложные моменты в больших проектах.
В тестировании списки проверок называются чек-листами. Чек-листы создаются QA инженерами на основе заявленных требований, опыта и знания тестировщиков системы. Частым явлением стало тестирование на основе чек-листов в проектах.
Преимущества чек-листов в сравнении с тест-кейсами:
- оперативное написание и легче поддерживать;
- гибкость в модификации полей и действий тестировщика;
- списки проверок выстроены в порядке приоритета;
- наглядное отслеживание выполненных проверок тестировщиком;
- удобен при отсутствии требований и спецификаций к проекту;
- разбивает задачу на множество подзадач, упрощая и акцентируя внимание на деталях;
- предотвращает «эффект пестицида», так как каждый тестировщик вводит свои данные;
- экономит средства фирмы.
«Эффект пестицида» — постоянное повторение одних и тех же шагов тест-кейса приводит к снижению его эффективности, так как при регулярном прогоне тестовых сценариев дефекты перестают находиться.
Чек-лист – отличный мотиватор для продуктивности и мотивации тестировщика, понимающий и видящий свой прогресс тестирования.
Необходимо учитывать некоторые нюансы чек-листов:
- поддерживать логичность и последовательность чек-листа;
- формировать взаимосвязанные проверки для тестирования;
- учитывать приоритеты проверок;
- в первую очередь проводить тесты по позитивным сценариям, в конце по негативным.
Статусы проверки чек-листа:
- passed — проверено, соответствует ожидаемому результаты, работает согласно заявленным требованиям. Комментарий необязателен.
- failed — поведение системы не соответствует ожидаемым требованиям, найден дефект. Пишется комментарий, желательно указывается ИД бага в багтрекенговой системе.
- blocked — выполнить проверку невозможно, имеются обстоятельства (дефект, модуль, компонент), которые блокируют дальнейшую проверку. В комментарии указывается причина.
- skipped — тест пропущен. Возможно, отсутствует необходимый модуль для проверки, который будет не реализован. В комментарии указывается причина пропуска.
- draft — тест пропущен, либо не начат. Отсутствует объект тестирования, который будет реализован позже. Комментарий не обязателен.
Правила составления чек листов
- Каждый пункт – одна процедура
Пункт чек-листа – это один законченный цикл процедуры. Регистрация на сайте, авторизация на сайте, покупка товаров, открыть документацию о чек листах, скачать книгу – это атомарно разбитые процессы. Разделение на конкретные пункты зависит от проекта, требований, обстановки и предпочтений команды тестировщиков.
В чек лист добавляют отдельными позициями:

- Позиции в чек листе желательно писать в утвердительной форме
Данный пункт на личное усмотрение тестировщика и команды. Зависит от договоренностей и удобства. Жестких рамок и критериев нет, в случае написания «Зарегистрироваться на сайте», либо «Регистрация на сайте» общей роли не играет. Многие рекомендуют и предпочитают оформлять чек лист в утвердительной форме «Куплен товар», а не «Купить товар». В статье приводим примеры чек листов разного характера, чтобы вы для себя решили наиболее предпочтительный вариант.
- Определиться с целесообразным количеством позиций в чек листе
На разных интернет ресурсах и книгах советуют, что для оптимального чек листа достаточно до 20 пунктов. Мы не совсем согласны с схожими мнениями. Временами необходимо разбить чек лист и до 50 пунктов, в случае с проверкой страниц сайта, кнопок, ссылок. Неуместно создавать 5 индивидуальных чек-листов взамен одному. Далее по оглавлению приводим пример аналогичного списка проверок.
Примеры различных видов чек-листов
Четких критериев для создания чек-листа не существует. Количество столбцов, значения, строки зависят от конкретной специфики реализуемого проекта или устоявшиеся порядки в команде тестировщиков.
1. Минимальный чек-лист состоит из 3-х столбцов ID («Номер»), Tester Actions («Проверка», «Действия тестировщика»), Actual Result («Результат»):

По необходимости в чек-лист добавляется поле Comment («Комментарий»):

2. Чек-лист может быть разбит на более детализированные задачи:

3. Чек-лист расширяется при необходимости проводить тестирование в различных тестовых средах:

4. Чек-листы используются для различных версий проекта, системы, модуля. Для удобства, используется несколько вариантов, либо создается новый файл в каталоге с именем версионности, либо добавляется новое поле:

5. Чек-лист может содержать порядок действий(инструкций) для тестировщика по необходимости:

6. Зачастую будете сталкиваться с чек-листами, содержащими поле Expected Result («Ожидаемый результат»):

Пример чек-листа проверки страниц на сайте

Материалы для скачивания:
- Скачать готовые чек-листы
Заключение
Создание чек-листов в тестировании очень полезный навык для QA инженера. Даже, если на вашем проекте он не предусмотрен, старайтесь применять для своей выгоды и собственных целей. Спустя время, вы убедитесь, насколько он помогает в проведении тестировании, особенно при написании тестов и регрессе.
Чтобы попрактиковаться в составлении чек-листов в виде доски Kanban, советуем ознакомиться с продуктом от atlassian под названием «Trello»:
— реализация в веб-версии, мобильном приложении;
— абсолютно бесплатен для нескольких пользователей;
— возможна интеграция с Jira и Confluence;
Линейка продуктов atlassian очень популярна в сфере разработки и тестирования приложений. Рекомендуем начинать изучение и практику, как тестировщику, именно в ней.
Что подразумевается под чек листами в тестировании? Чек-лист тестирования сайта — это список проверок, которые выполняет тестировщик при тестировании веб-сайта. В данной статье рассмотрим, как составить чек лист тестирования, а также приведем список готовых чек листов тестирования.
В статье будут рассмотрены чек листы, связанные только с веб-тестированием (чек листы для тестирования АПИ или чек листы для тестирования мобильных приложений здесь рассматриваться не будут).
Многие тестировщики (и не только) задаются вопросами: как выглядит чек лист тестирования? Как написать чек лист для тестирования веб-сайта? Как писать чек-лист тестирования сайта? Как правильно его составить? В этой статье мы постараемся ответить на все эти вопросы и дадим примеры (образцы, шаблоны) готовых чек-листов тестирования сайта с готовым оформлением и структурой.
➀ Составление чек листа
Давайте поговорим о том, как правильно составить чек лист для тестирования сайта. Сначала нужно определиться с объектом тестирования. Например, у нас объектом тестирования может быть сам сайт. Разделяем сайт на несколько областей. К примеру, разделить можно следующим образом: меню, основная часть сайта и подвал сайта. И начинаем писать чек лист. После того, как мы написали чек лист, можно его оформить в виде списка, таблицы, определить структуру, нумерацию, как он будет выглядеть. Таким образом мы можем составить чек лист тестирования сайта.
Ниже мы рассмотрим на шаблоны (образцы), как могут выглядеть чек листы тестирования сайта на разные случаи жизни, иногда даже пробуют проводить тестирование на основе чек листов.
➁ Готовые чек листы тестирования
➁.➀ Чек лист функционального тестирования
☑ Сайт открывается и доступен.
☑ При попытке повторно открыть сайт, он открывается и доступен.
☑ Все кнопки на сайте нажимаются.
☑ Все ссылки на сайте открываются.
☑ На сайте нет битых ссылок.
☑ Проверить все формы на сайте.
☑ Проверить валидацию всех обязательных полей.
☑ Знак звездочки есть у всех обязательных полей.
☑ Проверить валидацию для всех необязательных полей.
☑ Проверить основные элементы сайта.
☑ Проверить работу меню.
☑ Проверить, что загруженные документы открываются правильно.
☑ Отправка форм работает корректно.
☑ Проверить, что будет, если удалить куки, находясь на сайте.
☑ Проверить, что будет, если удалить куки после посещения сайта.
☑ Все данные в списках в хронологическом порядке.
➁.➁ Чек лист тестирования верстки
☑ Кодировка UTF-8.
☑ Шрифты прогружаются и работают.
☑ Нет ошибок HTML и CSS.
☑ Проверить элементы на разных разрешениях экранов.
☑ Проверить кнопки на разных страницах.
☑ Формы при сворачивании окна.
☑ Проверить верстку в разных браузерах.
☑ Проверить, что нет больших комментариев в коде.
☑ Есть favicon на сайте.
➁.➂ Чек лист смоук тестирования
☑ Сайт открывается и доступен.
☑ Основные элементы сайта работают корректно.
☑ Нет ошибок в консоли.
☑ Нет битых ссылок.
☑ Основные страницы сайта открываются и работают.
☑ Нет видимых ошибок на главной странице.
➁.➃ Чек лист формы регистрации (логина, пароля)
☑ Можно заполнить поля формы.
☑ После нажатия на кнопку отправить происходит отправка формы.
☑ Письмо отправляется на почту после регистрации.
☑ Поля передаются в запросе.
☑ Проверить валидацию обязательных полей.
☑ Проверить валидацию необязательных полей.
➁.➄ Чек лист интернет магазина
☑ Наличие кнопок Купить, Заказать.
☑ Можно положить товар в корзину.
☑ После заказа приходит письмо на почту.
☑ Есть фильтры для поиска товаров.
☑ Есть форма обратной связи.
☑ Есть раздел с контактами.
☑ Есть ссылки на социальные сети.
☑ Строка поиска находится на видном месте.
☑ Присутствуют хлебные крошки.
☑ Отсутствуют опечатки.
☑ Проверка возможностей личного кабинета.
☑ Легко найти нужный товар.
☑ Нет дублирующихся товаров.
➁.⑥ Тестирование мобильной версии
☑ Сайт открывается в мобильной версии сайта.
☑ Пройтись по пунктам «Чек лист функционального тестирования».
☑ Пройтись по пунктам «Чек лист тестирования верстки».
☑ Пройтись по пунктам «Чек лист смоук тестирования».
☑ Пройтись по пунктам «Чек лист формы регистрации».
☑ Если интернет-магазин: пройтись по пунктам «Чек лист интернет-магазина».
☑ Проверить мобильную версию с поворотом экрана (горизонтальный и вертикальный вид экрана).
☑ Проверить в разных браузерах телефона.
☑ Проверить на разных телефонах.
➁.⑦ SEO чек лист
☑ Проверить, что нет запрета индексации в файле robots.txt.
☑ На всех страницах есть ровно один тег H1.
☑ Сайт на протоколе HTTPS.
☑ На сайте есть favicon.
☑ На сайте есть sitemap.
☑ Нет дублирующихся страниц.
☑ Есть хлебные крошки.
☑ Настроены ЧПУ.
Список чек листов представлен в ознакомительных целях. Готовые чек листы могут помочь при тестировании сайтов, а также служить источником вдохновения для новых идей.
Чек-лист для тестирования числового поля +9
Тестирование веб-сервисов, Тестирование IT-систем, Тестирование мобильных приложений

При тестировании встречаются как интересные задачки с замудреной логикой, так и простые, вроде проверки простой строки или числового поля. Для простых полей можно один раз написать чек-лист проверок, а потом переиспользовать, лишь немного меняя под «своё» поле.
Сегодня мы разберем чек-лист для числового поля. Сначала я напишу общий чек-лист, потом пройдемся по каждому пункту и разберемся, зачем он нужен, а в конце напишем чек-лист по этому шаблону.
Итак, у нас есть некое поле, куда нужно вводить число. Например, поле «возраст» при регистрации:
При этом на сайте нельзя регистрироваться до 18 лет, есть запрещённый контент.
Какие проверки тут можно провести:
- Корректные значения
- Некорректные значения (за пределами валидных диапазонов или нелогичные: 200 лет, 88 секунд…)
- Граничные значения
- Пограничные значения
- Дробное число — формат (через запятую и через точку)
- Дробное число — округление (с кучей знаков после запятой)
- Ноль
- Один
- Пустое поле
- Очень большое число (поиск технологической границы)
- Отрицательное число
- Нечисловые и «не совсем числовые» значения
Соединяем все вместе — Пример: чек-лист для возраста.
Ну и куда же практики — Попробуй сам!
Корректные значения
Представьте, что у вас буквально 5 минут на проверку функционала. И вы успеваете провести только первые несколько тестов из чек-листа. А чек-лист у вас:
- Пустое поле
- 0
- -1
В итоге эти проверки провели и считаете, что система работает нормально (ну ругается же!). А она всегда ругается, даже на корректное значение! Нехорошо… Поэтому запоминаем правило:
ВСЕГДА сначала позитив, потом негатив!
См также:
Позитивное и негативное тестирование — подробнее о том, с чего начинать
Для поля с возрастом какие у нас будут корректные значения? Все, что выше 18 лет:
- 18
- 25
- 38
- 45
- …
Тут надо понимать, что мы выбираем какое-то ОДНО значение. Просто каждый раз разное, для избежания эффекта пестицида.
Также важно понимать, что у нас может быть не одно корректное значение. Это когда у нас есть несколько диапазонов, и разные условия на каждом.
Например, тот же возраст:
- если до 18 лет — показать в магазине все товары, кроме сигарет и алкоголя
- если больше 18 лет — показать вообще все товары
Тогда мы понимаем, что у нас есть уже два «валидных» диапазона. Значит, нам нужно взять значение из каждого. Например, 16 и 26.
Или если у нас идет расчет страховки в зависимости от стажа вождения:
- 0 — 1 год — 1000 руб
- 1 — 3 года — 800 руб
- 3-5 лет — 600 руб
- 5-10 лет — 500 руб
- 10+ лет — 300 руб
Получается 5 интервалов. И нам надо взять по одному значению из каждого. Например: 0.5, 2, 4, 6, 15.
Каждый раз берем разные значения, но в этом пункте смысл один — взять корректные значения из ТЗ.
Некорректные значения
Тут есть разные варианты. Что значит некорректное значение?
- за пределами валидных диапазонов
- корректное с точки зрения компьютера (число), но лишенное смысла (200 лет)
Вернемся к примеру с возрастом. Корректное значение — старше 18 лет. Значит, мы должны задать вопрос:
— А что будет, если мы возьмем значение из «неправильного» диапазона? Что, если мне меньше 18 лет? Ну, скажем, 10.
Потом внимательно смотрим на выбранный интервал:
— Хммммм, но ведь возраст не может быть меньше 0. То есть у нас есть логическая граница, разделяющая два разных класса эквивалентности:
- Возможный физически, но невалидный по ТЗ (0 — 17 лет)
- Невозможный физически (0 и менее)
Так что надо взять значение из каждого диапазона. Тогда получается 10 и «-5»:
Думаем дальше:
— Если у нас есть некая логическая граница снизу, должна быть и сверху. Какой максимально возможный возраст у регистрирующихся на нашем сайте? Скорее всего, это около 55-65 лет, потому что более старшее поколение не любит компьютеры. Но можно заложить и условные 100-110 лет долгожителей.
Получаем еще один интервал с неявной границей. Но в любом случае, значения 25 и 145 будут различаться — одно реалистичное, а другое нет. Значит, стоит его тоже попробовать!
А дальше снова эффект пестицида. Один раз берем 145, а другой — 6666666.
Тут мы можем столкнуться с тем, что в поле нельзя ввести больше 2-3 символов. Разработчик перестраховался «от дурака». Это не повод опускать руки и отказываться от своей проверки. Потому что скорее всего разработчик просто установил maxlength на поле, а он легко обходится!
См также:
Как снять maxlength со всех полей формы — несколько способов на заметку ?
Граничные значения
Граничные значения отделяют один интервал от другого. Их обязательно надо тестировать!!! Потому что именно на границах чаще всего встречаются баги. Почему? Да потому что попадают в оба диапазона, или не попадают ни в один.
В нашем примере в ТЗ есть условие «регистрация только для лиц старше 18 лет». Это значит, что разработчик должен сделать в коде программы логику вида:
- ЕСЛИ x > 18 ТО регистрируем
- ЕСЛИ x <=18 ТО выдаем ошибку
Если разработчик забыл добавить значение 18 в один из диапазонов, это может и не привести к ошибке. Потому что в таких случаях обычно используется конструкция if else. И разработчик ставит последний «else» на всякий случай — то есть если ВДРУГ вводимое значение не попало ни в одно из условий выше:
- if x > 18 …
- elseif x < 18 …
- else …
А вот если разработчик добавил значение 18 сразу в несколько диапазонов:
- if x => 18 …
- elseif x <= 18 …
То программа растеряется, что же ей выбрать? И вполне может упасть!
В общем, на границах баги встречаются чаще, чем внутри интервала. Поэтому обязательно исследуйте их! В нашем ТЗ есть четкая граница «больше 18 лет». Значит, тестируем число 18:
Если по ТЗ у нас есть несколько интервалов, проверяем каждую границу отдельно. Это произвольные границы — которые накладывает ТЗ.
Но границы бывают разных типов:
- Произвольные
- Логические
- Технологические
Произвольные проверили? Едем дальше. Логические — это все о, что подчиняется логике (в минуте 60 секунд, человеку не может быть «минус один годик», и т.д.). Применим к нашему примеру.
Граница снизу:
— Логично, что возраст не может быть меньше нуля. Так что 0 — это граница. Тестируем!
Граница сверху:
— Нуууу… Врядли возраст будет больше 35 лет. Хотя что мешает бабушке зайти на сайт? Может быть, 65? 88?
Здесь границу найти сложно. Вот взять значение из диапазона «не слишком верится в это» легко, а конкретной границы нету. Значит, и тестировать нечего. Сверху логической границы нет.
Поиск технологической границы я вынесла в отдельный пункт, так что вернемся к нему чуть позже. В любом случае это менее важно, чем выверить валидные границы, которые есть в ТЗ.
См также:
Типы границ на примере стиральной машинки
Зачем тестировать граничные значенияКак найти границы на клиенте и сервере
Мнемоника БМВ для поиска граничных значений
Пограничные значения
Если у нас есть граница, то есть и пограничные значения. И их тоже надо проверять!
В примере с возрастом граница — 18. Значит, пограничные значения — 17 и 19.
Зачем проверять пограничные значения? Да затем, что разработчик мог ошибиться в коде и указать границу немного не там.
if x > 18 …
v
if x > 17 …Если у нас граница сдвинута, а мы не тестируем пограничные значения, то можем легко пропустить этот баг. Ведь мы проверили:
- границу — 18. 18 > 17, так что все работает
- недопустимое значение из диапазона слева — 10. 10 < 17, так что выдало ошибку.
Делаем вывод, что всё работает правильно, хотя это не так! Так что обязательно проверяем пограничные значение.
Но нужно ли тестировать пограничные значения в обеих сторон? С 17 разобрались, нужно. А 19? Допустим, разработчик опечатался в другую сторону:
if x > 18 …
v
if x > 19 …Мы найдем этот баг проверкой граничного значения 18. А если на 18 работает и на числе внутри диапазона (например, 26) работает — значит, код написан верно. То есть чтобы в коде был баг, это как надо извратиться то, написать что-то типа:
if (x == 18 or x > 21) …Такое только специально можно сделать)) Ну а если рассчитывать на разработчика-дурака со злыми шутками в виде таких пасхалок, то остается только полный перебор делать. Так что давайте считать коллег адекватными людьми.
Но! Что, если разработчик описывает работу кода для нескольких интервалов? Тогда при опечатке диапазоны идут внахлест:
if x <= 19 (ОПЕЧАТКА) …
if (x > 18 and x < 55) …Число 18 ошибку уже не поймает, ведь 18 <= 19, а во второй диапазон уже не попадает. Вот и будет ситуация, что на границе работает, внутри диапазона — работает, а на пограничном значении — нет.
Так что если нет доступа к коду, стоит проверить пограничные с обеих сторон, а то мало ли, где там опечатка закралась?
Дело становится еще интереснее, если в поле можно ввести не только целое число, но и дробное. Что тогда будет пограничным значением? Стоит начать с одного знака после запятой. В нашем примере это 17.9 и 18.1:
Хорошо, допустим, проверили:
- Целые границы — 17 и 19
- Дробные границы — 17.9 и 18.1
Но если такие значения округляются нормально, значит ли это, что и другие тоже будут округляться хорошо? Что будет, если ввести значение 17.99999999999 (после запятой 11 девяток, а результатом округления является попадание на границу)?
Это разные классы эквивалентности, если мы говорим о дробях, которые будут округляться:
- Один знак после запятой
- Много знаков
И стоит проверить оба! Так что добавляем новые тесты: 17.99999999999 и 18.00000000001
Дробное число (формат)
Если система позволяет вводить дробные значения, то мы проверяем их ещё в пункте 1, при тестировании корректных значений. Просто разбиваем понятие «корректное число»:
- Целое
- Дробное
А пункт «дробное» разбиваем дальше. Ведь дробное число можно записать через:
- точку — 6.9
- запятую — 6,9
Если работает один из способов, это совсем не значит, что будет работать второй! У меня даже есть пример двух калькуляторов, которые работают с дробными числами по-разному — http://bugred.ru/calc/.
См также:
Не пишите в баге «Ввести 6,9»! — разбор багов в калькуляторе
Значит, нам нужно убедиться, что работают оба способа. По крайней мере если они должны работать. Если должен работать только один, потому что стандарты запрещают использовать другой — проверяем, что второй возвращает ошибку!
В случае с возрастом прикидываем, что будет позитивным дробным значением? Скорее всего, половинка — например, 20.5 лет:
Проверили? Работает? Тогда смотрим через запятую — 20,5:
То, что дробные в принципе работают — проверили. Хорошо.
Дробное число (округление)
Особый интерес представляют значения, близкие к граничным, а не любые дробные значения. При приближении к границе на расстояние, меньшее точности вычислений, мы можем попасть в ситуацию, когда проверки значения на допустимость успешно проходят, но вычисления завершаются неуспешно.
Так что если у вас можно вводить нецелое число, обязательно попробуйте много девяток после запятой, приближенной к границе значение (мы это уже сделали пунктом выше):
При этом нет смысла проверять округление и через точку, и через запятую. Это будет лишнее дублирование тестов. Проверяем отдельно:
- формат — через точку или запятую
- округление — когда один или много знаков после запятой
См также:
В тестировании всегда начинаем с простого! — почему не надо смешивать проверки
Ноль
Ноль мы тестируем всегда. И везде. Просто запомните это как аксиому. Просто потому, что в нуле часто встречаются баги.
Потому, что это обычно граница. Она может быть явной (прописанной в ТЗ) или неявной (в ТЗ не написано, но и так понятно, что возраст отрицательным быть не может).
Если мы говорим именно про числовое поле, то пробуем ввести число 0. Хотя, конечно «ноль» в тестировании выходит за рамки простого числа.
См также:
Класс эквивалентности «Ноль-не ноль» — подробнее о тестировании нуля, и не только в числовых полях!
Один
Так как мы всегда проверяем ноль, то не забываем и о приграничном значении — единице.
Фактически это обычно «минимально возможное значение», если мы не говорим о дробных значениях:
— Логично, что если мы делаем заказ, то покупаем хотя бы 1 книжку, или 1 платьюшко, или 1 кг муки…
— Минимальный возраст — 1 день / месяц / год
— Минимальное количество времени — 1 секунда
— Минимальное количество трудового стажа — 1 день / месяц / год
— …
Так что единица не менее магическое число, чем ноль. Проверяем и её!
Пустое поле
Фактически это тоже тест на ноль. Только уже не на число «ноль», а на ноль в длине вводимой строки.
Ведь если мы вводим «0», это получается
один
символ.
А если мы изучаем длину строки, стоит проверить не только один, но и
ноль
.
Не забудьте, что ноль — это не только число. Даже в числовом поле у нас будет минимум два нуля — пустая строка и число «0». Может быть и больше нулей — не забывайте про ноль на выходе. Но в нашем примере с возрастом его нет.
Очень большое число
Для поиска технологической границы нужно ввести очень большое число. Например, 9999999999999999.
Мы пытаемся зайти так далеко, как только это возможно. Но не слишком упарываясь — это должен быть один тест, ну два.
Сначала можно оттолкнуться от значения integer — чаще всего для числового поля выбирают именно такой тип данных. Если получилось его превысить, просто проверяем 25 или 45 девяток в поле. Не упало? Ну и чудненько. Технологической границы нет, но мы хотя бы попытались ее найти.
См также:
Как сгенерить большую строку, инструменты — не обязательно делать это руками))
Технологическая граница в подсказках по ЮЛ — пример реального бага
Если поле допускает ввод отрицательных значений, то проверяем «много девяток» как со знаком плюс, так и со знаком минус, проводя два теста:
- 99999999999999999999999
- -99999999999999999999999
Напоминаю — если в поле нельзя ввести много символов, это не повод опускать руки и говорить «технологическую границу проверить нельзя!». Потому что если в поле нельзя вводить много символов — там скорее всего стоит maxlength на поле, который легко обходится. Сняли ограничение на клиенте и убедились, что на сервере защита от дурака тоже есть.
См также:
Как снять maxlength со всех полей формы
Как найти границы на клиенте и сервере
Отрицательное число
Когда у нас есть число, то всегда помним, что оно может быть:
- положительное
- отрицательное
При этом по опыту проводимых мною собеседований могу точно сказать, что немногие додумываются до проверки «а если ввести отрицательное значение». А ведь система может работать по разному:
- выдавать ошибку «такого возраста / количества товара не существует, введите положительное число»;
- отсекать знак минус и работать с отрицательным числом как с положительным.
Это помимо того, что отрицательное число может быть вполне нормальным для поля (например, если мы сохраняем доходы / расходы).
Что тестируем в этом разделе?
- Что будет, если ввести отрицательное число, которое по модулю будет корректным: -26 в нашем примере
- Попытка найти технологическую границу: -99999999999999999999999
Нечисловые и «не совсем числовые» значения
Если вы думаете, что для проверки нечислового значения достаточно вбить любую строку типа «привет», то вы ошибаетесь )))
Строки тоже бывают разные, и их можно разбить на:
- множество строк, которые программа интерпретирует как числа;
- множество строк, которые программа не может интерпретировать как числа.
Очень хорошо тесты для «не совсем числовых» значений рассмотрены в этой статье: Классы эквивалентности для строки, которая обозначает число
Я не буду ее полностью переписывать, просто дополню список проверок для нашего примера. Что мы еще не смотрели:
- Точно не число — «Тест»
- Лидирующий ноль — «025»
- Пробел перед числом — « 25»
- Пробел внутри числа — «2 5»
- Запись через е — «1.2e+2»
- Шестнадцатеричное значение — «0xba»
- Boolean — TRUE / FALSE (может интерпретироваться как 0 / 1)
- Infinity (да, прям так текстом и пишем)
- NaN
В нашем случае с корректным значением возраста от 18 лет пункт «пробел внутри числа» становится интереснее. Тут ведь зависит от логики работы системы. Тут есть разные варианты:
- Ругаться, если введено несколько слов
- Отсекать всё, что идет после первого пробела — «2 5» > «2»
- Убирать пробел и делать вид, что его не было (воспринимать как опечатку в цифре) — «2 5» > «25»
Аналогично с буквами. Система может ругаться, увидев их, а может просто выкинуть. Так что посмотрим новые варианты тестов:
- до пробела меньше 18 лет — 2 5
- до пробела больше 18 лет — 25 6
- после пробела текста — 25 тест
- до пробела текст — тест 25
При этом учтите — в интерфейсе мы просто вводим какое-то значение, не указывая тип данных. А вот если мы тестируем REST API и json-сообщение в нем, то обязательно стоит попробовать передать число строкой:
- number: 3
- number: “3”
Это разные значения. Если значение без кавычек — это число. Если в кавычках — строка, даже если выглядит как число. Может быть, разработчик сделает приведение типов в коде и «примет» второй вариант, а может, и нет. В любом случае, проверить стоит!
Соединяем все вместе: чек-лист для возраста
Идеи для проверок записали, обсудили каждую. Теперь давайте соединим все пункты вместе и напишем чек-лист для нашего примера.
Напомню условие — у нас есть поле «возраст» при регистрации. При этом на сайте нельзя регистрироваться до 18 лет, запрещённый контент есть.
При составлении чек-листа учитываем все пункты, которые обсудили выше. Но не забываем о приоритетах. Начинаем всегда с основных проверок, а не с «вбили ноль, отрицательное число и вообще всячески попытались сломать».
* Если работает 18.000000000001, то проверять целое число 19 смысла нет. Если дробные не принимаются системой, тогда да, проверяем на 19
Конечно, проверки из блока «нецелые числа» не супер-важны. Иногда на них можно и нужно забить. Особенно если мы знаем, что система не должна ничего анализировать, убирать пробелы, выкидывать текст и прочая… Тогда достаточно взять одно значение из этого списка. А остальные использовать для эффекта пестицида, то есть каждый раз новый вариант «не числа».
Но ведь для того, чтобы отсекать лишнее, надо сначала научиться генерировать много идей! Вот в этом мы с вами сегодня и потренировались =)
См также:
Читлист для числового поля в Ситечке (нужно авторизоваться)
Где брать идеи для тестов (подборка полезных ссылок)
Попробуй сам
Напишите чек-лист проверок для поля «Стаж вождения». В зависимости от стажа идёт расчет страховки. У всех интервалов слева число «включительно», а справа — нет.
- 0-3 года — 1000 руб
- 3-6 лет — 700 руб
- 6-10 лет — 500 руб
- 10+ лет — 300 руб
Форма не дает вводить ничего, кроме цифр (это ограничение стоит на клиенте). Дробные значения недопустимы, сколько полных лет стажа есть, столько и пишем.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
При тестировании встречаются как интересные задачки с замудреной логикой, так и простые, вроде проверки простой строки или числового поля. Для простых полей можно один раз написать чек-лист проверок, а потом переиспользовать, лишь немного меняя под «своё» поле.
Сегодня мы разберем чек-лист для числового поля. Сначала я напишу общий чек-лист, потом пройдемся по каждому пункту и разберемся, зачем он нужен, а в конце напишем чек-лист по этому шаблону.
Итак, у нас есть некое поле, куда нужно вводить число. Например, поле «возраст» при регистрации:

При этом на сайте нельзя регистрироваться до 18 лет, есть запрещённый контент.
Какие проверки тут можно провести:
- Корректные значения
- Некорректные значения (за пределами валидных диапазонов или нелогичные: 200 лет, 88 секунд…)
- Граничные значения
- Пограничные значения
- Дробное число — формат (через запятую и через точку)
- Дробное число — округление (с кучей знаков после запятой)
- Ноль
- Один
- Пустое поле
- Очень большое число (поиск технологической границы)
- Отрицательное число
- Нечисловые и «не совсем числовые» значения
Соединяем все вместе — Пример: чек-лист для возраста.
Ну и куда же практики — Попробуй сам!
Корректные значения
Представьте, что у вас буквально 5 минут на проверку функционала. И вы успеваете провести только первые несколько тестов из чек-листа. А чек-лист у вас:
- Пустое поле
- 0
- -1
В итоге эти проверки провели и считаете, что система работает нормально (ну ругается же!). А она всегда ругается, даже на корректное значение! Нехорошо… Поэтому запоминаем правило:
ВСЕГДА сначала позитив, потом негатив!

См также:
Позитивное и негативное тестирование — подробнее о том, с чего начинать
Для поля с возрастом какие у нас будут корректные значения? Все, что выше 18 лет:
- 18
- 25
- 38
- 45
- …

Тут надо понимать, что мы выбираем какое-то ОДНО значение. Просто каждый раз разное, для избежания эффекта пестицида.
Также важно понимать, что у нас может быть не одно корректное значение. Это когда у нас есть несколько диапазонов, и разные условия на каждом.
Например, тот же возраст:
- если до 18 лет — показать в магазине все товары, кроме сигарет и алкоголя
- если больше 18 лет — показать вообще все товары
Тогда мы понимаем, что у нас есть уже два «валидных» диапазона. Значит, нам нужно взять значение из каждого. Например, 16 и 26.

Или если у нас идет расчет страховки в зависимости от стажа вождения:
- 0 — 1 год — 1000 руб
- 1 — 3 года — 800 руб
- 3-5 лет — 600 руб
- 5-10 лет — 500 руб
- 10+ лет — 300 руб
Получается 5 интервалов. И нам надо взять по одному значению из каждого. Например: 0.5, 2, 4, 6, 15.

Каждый раз берем разные значения, но в этом пункте смысл один — взять корректные значения из ТЗ.
Некорректные значения
Тут есть разные варианты. Что значит некорректное значение?
- за пределами валидных диапазонов
- корректное с точки зрения компьютера (число), но лишенное смысла (200 лет)
Вернемся к примеру с возрастом. Корректное значение — старше 18 лет. Значит, мы должны задать вопрос:
— А что будет, если мы возьмем значение из «неправильного» диапазона? Что, если мне меньше 18 лет? Ну, скажем, 10.

Потом внимательно смотрим на выбранный интервал:
— Хммммм, но ведь возраст не может быть меньше 0. То есть у нас есть логическая граница, разделяющая два разных класса эквивалентности:
- Возможный физически, но невалидный по ТЗ (0 — 17 лет)
- Невозможный физически (0 и менее)
Так что надо взять значение из каждого диапазона. Тогда получается 10 и «-5»:

Думаем дальше:
— Если у нас есть некая логическая граница снизу, должна быть и сверху. Какой максимально возможный возраст у регистрирующихся на нашем сайте? Скорее всего, это около 55-65 лет, потому что более старшее поколение не любит компьютеры. Но можно заложить и условные 100-110 лет долгожителей.
Получаем еще один интервал с неявной границей. Но в любом случае, значения 25 и 145 будут различаться — одно реалистичное, а другое нет. Значит, стоит его тоже попробовать!

А дальше снова эффект пестицида. Один раз берем 145, а другой — 6666666.
Тут мы можем столкнуться с тем, что в поле нельзя ввести больше 2-3 символов. Разработчик перестраховался «от дурака». Это не повод опускать руки и отказываться от своей проверки. Потому что скорее всего разработчик просто установил maxlength на поле, а он легко обходится!
См также:
Как снять maxlength со всех полей формы — несколько способов на заметку ツ
Граничные значения
Граничные значения отделяют один интервал от другого. Их обязательно надо тестировать!!! Потому что именно на границах чаще всего встречаются баги. Почему? Да потому что попадают в оба диапазона, или не попадают ни в один.
В нашем примере в ТЗ есть условие «регистрация только для лиц старше 18 лет». Это значит, что разработчик должен сделать в коде программы логику вида:
- ЕСЛИ x > 18 ТО регистрируем
- ЕСЛИ x <=18 ТО выдаем ошибку
Если разработчик забыл добавить значение 18 в один из диапазонов, это может и не привести к ошибке. Потому что в таких случаях обычно используется конструкция if else. И разработчик ставит последний «else» на всякий случай — то есть если ВДРУГ вводимое значение не попало ни в одно из условий выше:
- if x > 18 …
- elseif x < 18 …
- else …
А вот если разработчик добавил значение 18 сразу в несколько диапазонов:
- if x => 18 …
- elseif x <= 18 …
То программа растеряется, что же ей выбрать? И вполне может упасть!
В общем, на границах баги встречаются чаще, чем внутри интервала. Поэтому обязательно исследуйте их! В нашем ТЗ есть четкая граница «больше 18 лет». Значит, тестируем число 18:

Если по ТЗ у нас есть несколько интервалов, проверяем каждую границу отдельно. Это произвольные границы — которые накладывает ТЗ.
Но границы бывают разных типов:
- Произвольные
- Логические
- Технологические
Произвольные проверили? Едем дальше. Логические — это все то, что подчиняется логике (в минуте 60 секунд, человеку не может быть «минус один годик», и т.д.). Применим к нашему примеру.
Граница снизу:
— Логично, что возраст не может быть меньше нуля. Так что 0 — это граница. Тестируем!

Граница сверху:
— Нуууу… Врядли возраст будет больше 35 лет. Хотя что мешает бабушке зайти на сайт? Может быть, 65? 88?
Здесь границу найти сложно. Вот взять значение из диапазона «не слишком верится в это» легко, а конкретной границы нету. Значит, и тестировать нечего. Сверху логической границы нет.
Поиск технологической границы я вынесла в отдельный пункт, так что вернемся к нему чуть позже. В любом случае это менее важно, чем выверить валидные границы, которые есть в ТЗ.
См также:
Типы границ на примере стиральной машинки
Зачем тестировать граничные значенияКак найти границы на клиенте и сервере
Мнемоника БМВ для поиска граничных значений
Пограничные значения
Если у нас есть граница, то есть и пограничные значения. И их тоже надо проверять!
В примере с возрастом граница — 18. Значит, пограничные значения — 17 и 19.

Зачем проверять пограничные значения? Да затем, что разработчик мог ошибиться в коде и указать границу немного не там.
if x > 18 …
↓
if x > 17 …Если у нас граница сдвинута, а мы не тестируем пограничные значения, то можем легко пропустить этот баг. Ведь мы проверили:
- границу — 18. 18 > 17, так что все работает
- недопустимое значение из диапазона слева — 10. 10 < 17, так что выдало ошибку.
Делаем вывод, что всё работает правильно, хотя это не так! Так что обязательно проверяем пограничные значение.
Но нужно ли тестировать пограничные значения в обеих сторон? С 17 разобрались, нужно. А 19? Допустим, разработчик опечатался в другую сторону:
if x > 18 …
↓
if x > 19 …Мы найдем этот баг проверкой граничного значения 18. А если на 18 работает и на числе внутри диапазона (например, 26) работает — значит, код написан верно. То есть чтобы в коде был баг, это как надо извратиться то, написать что-то типа:
if (x == 18 or x > 21) …Такое только специально можно сделать)) Ну а если рассчитывать на разработчика-дурака со злыми шутками в виде таких пасхалок, то остается только полный перебор делать. Так что давайте считать коллег адекватными людьми.
Но! Что, если разработчик описывает работу кода для нескольких интервалов? Тогда при опечатке диапазоны идут внахлест:
if x <= 19 (ОПЕЧАТКА) …
if (x > 18 and x < 55) …Число 18 ошибку уже не поймает, ведь 18 <= 19, а во второй диапазон уже не попадает. Вот и будет ситуация, что на границе работает, внутри диапазона — работает, а на пограничном значении — нет.
Так что если нет доступа к коду, стоит проверить пограничные с обеих сторон, а то мало ли, где там опечатка закралась?
Дело становится еще интереснее, если в поле можно ввести не только целое число, но и дробное. Что тогда будет пограничным значением? Стоит начать с одного знака после запятой. В нашем примере это 17.9 и 18.1:

Хорошо, допустим, проверили:
- Целые границы — 17 и 19
- Дробные границы — 17.9 и 18.1
Но если такие значения округляются нормально, значит ли это, что и другие тоже будут округляться хорошо? Что будет, если ввести значение 17.99999999999 (после запятой 11 девяток, а результатом округления является попадание на границу)?
Это разные классы эквивалентности, если мы говорим о дробях, которые будут округляться:
- Один знак после запятой
- Много знаков
И стоит проверить оба! Так что добавляем новые тесты: 17.99999999999 и 18.00000000001

Дробное число (формат)
Если система позволяет вводить дробные значения, то мы проверяем их ещё в пункте 1, при тестировании корректных значений. Просто разбиваем понятие «корректное число»:
- Целое
- Дробное
А пункт «дробное» разбиваем дальше. Ведь дробное число можно записать через:
- точку — 6.9
- запятую — 6,9
Если работает один из способов, это совсем не значит, что будет работать второй! У меня даже есть пример двух калькуляторов, которые работают с дробными числами по-разному — http://bugred.ru/calc/.
См также:
Не пишите в баге «Ввести 6,9»! — разбор багов в калькуляторе
Значит, нам нужно убедиться, что работают оба способа. По крайней мере если они должны работать. Если должен работать только один, потому что стандарты запрещают использовать другой — проверяем, что второй возвращает ошибку!
В случае с возрастом прикидываем, что будет позитивным дробным значением? Скорее всего, половинка — например, 20.5 лет:

Проверили? Работает? Тогда смотрим через запятую — 20,5:

То, что дробные в принципе работают — проверили. Хорошо.
Дробное число (округление)
Особый интерес представляют значения, близкие к граничным, а не любые дробные значения. При приближении к границе на расстояние, меньшее точности вычислений, мы можем попасть в ситуацию, когда проверки значения на допустимость успешно проходят, но вычисления завершаются неуспешно.
Так что если у вас можно вводить нецелое число, обязательно попробуйте много девяток после запятой, приближенной к границе значение (мы это уже сделали пунктом выше):
При этом нет смысла проверять округление и через точку, и через запятую. Это будет лишнее дублирование тестов. Проверяем отдельно:
- формат — через точку или запятую
- округление — когда один или много знаков после запятой
См также:
В тестировании всегда начинаем с простого! — почему не надо смешивать проверки
Ноль
Ноль мы тестируем всегда. И везде. Просто запомните это как аксиому. Просто потому, что в нуле часто встречаются баги.
Потому, что это обычно граница. Она может быть явной (прописанной в ТЗ) или неявной (в ТЗ не написано, но и так понятно, что возраст отрицательным быть не может).
Если мы говорим именно про числовое поле, то пробуем ввести число 0. Хотя, конечно «ноль» в тестировании выходит за рамки простого числа.

См также:
Класс эквивалентности «Ноль-не ноль» — подробнее о тестировании нуля, и не только в числовых полях!
Один
Так как мы всегда проверяем ноль, то не забываем и о приграничном значении — единице.
Фактически это обычно «минимально возможное значение», если мы не говорим о дробных значениях:
— Логично, что если мы делаем заказ, то покупаем хотя бы 1 книжку, или 1 платьюшко, или 1 кг муки…
— Минимальный возраст — 1 день / месяц / год
— Минимальное количество времени — 1 секунда
— Минимальное количество трудового стажа — 1 день / месяц / год
— …
Так что единица не менее магическое число, чем ноль. Проверяем и её!
Пустое поле
Фактически это тоже тест на ноль. Только уже не на число «ноль», а на ноль в длине вводимой строки.
Ведь если мы вводим «0», это получается
один
символ.
А если мы изучаем длину строки, стоит проверить не только один, но и
ноль
.
Не забудьте, что ноль — это не только число. Даже в числовом поле у нас будет минимум два нуля — пустая строка и число «0». Может быть и больше нулей — не забывайте про ноль на выходе. Но в нашем примере с возрастом его нет.
Очень большое число
Для поиска технологической границы нужно ввести очень большое число. Например, 9999999999999999.

Мы пытаемся зайти так далеко, как только это возможно. Но не слишком упарываясь — это должен быть один тест, ну два.
Сначала можно оттолкнуться от значения integer — чаще всего для числового поля выбирают именно такой тип данных. Если получилось его превысить, просто проверяем 25 или 45 девяток в поле. Не упало? Ну и чудненько. Технологической границы нет, но мы хотя бы попытались ее найти.
См также:
Как сгенерить большую строку, инструменты — не обязательно делать это руками))
Технологическая граница в подсказках по ЮЛ — пример реального бага
Если поле допускает ввод отрицательных значений, то проверяем «много девяток» как со знаком плюс, так и со знаком минус, проводя два теста:
- 99999999999999999999999
- -99999999999999999999999
Напоминаю — если в поле нельзя ввести много символов, это не повод опускать руки и говорить «технологическую границу проверить нельзя!». Потому что если в поле нельзя вводить много символов — там скорее всего стоит maxlength на поле, который легко обходится. Сняли ограничение на клиенте и убедились, что на сервере защита от дурака тоже есть.
См также:
Как снять maxlength со всех полей формы
Как найти границы на клиенте и сервере
Отрицательное число
Когда у нас есть число, то всегда помним, что оно может быть:
- положительное
- отрицательное
При этом по опыту проводимых мною собеседований могу точно сказать, что немногие додумываются до проверки «а если ввести отрицательное значение». А ведь система может работать по разному:
- выдавать ошибку «такого возраста / количества товара не существует, введите положительное число»;
- отсекать знак минус и работать с отрицательным числом как с положительным.
Это помимо того, что отрицательное число может быть вполне нормальным для поля (например, если мы сохраняем доходы / расходы).
Что тестируем в этом разделе?
- Что будет, если ввести отрицательное число, которое по модулю будет корректным: -26 в нашем примере
- Попытка найти технологическую границу: -99999999999999999999999
Нечисловые и «не совсем числовые» значения
Если вы думаете, что для проверки нечислового значения достаточно вбить любую строку типа «привет», то вы ошибаетесь )))
Строки тоже бывают разные, и их можно разбить на:
- множество строк, которые программа интерпретирует как числа;
- множество строк, которые программа не может интерпретировать как числа.
Очень хорошо тесты для «не совсем числовых» значений рассмотрены в этой статье: Классы эквивалентности для строки, которая обозначает число
Я не буду ее полностью переписывать, просто дополню список проверок для нашего примера. Что мы еще не смотрели:
- Точно не число — «Тест»
- Лидирующий ноль — «025»
- Пробел перед числом — « 25»
- Пробел внутри числа — «2 5»
- Запись через е — «1.2e+2»
- Шестнадцатеричное значение — «0xba»
- Boolean — TRUE / FALSE (может интерпретироваться как 0 / 1)
- Infinity (да, прям так текстом и пишем)
- NaN
В нашем случае с корректным значением возраста от 18 лет пункт «пробел внутри числа» становится интереснее. Тут ведь зависит от логики работы системы. Тут есть разные варианты:
- Ругаться, если введено несколько слов
- Отсекать всё, что идет после первого пробела — «2 5» → «2»
- Убирать пробел и делать вид, что его не было (воспринимать как опечатку в цифре) — «2 5» → «25»
Аналогично с буквами. Система может ругаться, увидев их, а может просто выкинуть. Так что посмотрим новые варианты тестов:
- до пробела меньше 18 лет — 2 5
- до пробела больше 18 лет — 25 6
- после пробела текста — 25 тест
- до пробела текст — тест 25
При этом учтите — в интерфейсе мы просто вводим какое-то значение, не указывая тип данных. А вот если мы тестируем REST API и json-сообщение в нем, то обязательно стоит попробовать передать число строкой:
- number: 3
- number: “3”
Это разные значения. Если значение без кавычек — это число. Если в кавычках — строка, даже если выглядит как число. Может быть, разработчик сделает приведение типов в коде и «примет» второй вариант, а может, и нет. В любом случае, проверить стоит!
Соединяем все вместе: чек-лист для возраста
Идеи для проверок записали, обсудили каждую. Теперь давайте соединим все пункты вместе и напишем чек-лист для нашего примера.
Напомню условие — у нас есть поле «возраст» при регистрации. При этом на сайте нельзя регистрироваться до 18 лет, запрещённый контент есть.
При составлении чек-листа учитываем все пункты, которые обсудили выше. Но не забываем о приоритетах. Начинаем всегда с основных проверок, а не с «вбили ноль, отрицательное число и вообще всячески попытались сломать».
* Если работает 18.000000000001, то проверять целое число 19 смысла нет. Если дробные не принимаются системой, тогда да, проверяем на 19
Конечно, проверки из блока «нецелые числа» не супер-важны. Иногда на них можно и нужно забить. Особенно если мы знаем, что система не должна ничего анализировать, убирать пробелы, выкидывать текст и прочая… Тогда достаточно взять одно значение из этого списка. А остальные использовать для эффекта пестицида, то есть каждый раз новый вариант «не числа».
Но ведь для того, чтобы отсекать лишнее, надо сначала научиться генерировать много идей! Вот в этом мы с вами сегодня и потренировались =)
См также:
Читлист для числового поля в Ситечке (нужно авторизоваться)
Где брать идеи для тестов (подборка полезных ссылок)
Попробуй сам
Напишите чек-лист проверок для поля «Стаж вождения». В зависимости от стажа идёт расчет страховки. У всех интервалов слева число «включительно», а справа — нет.
- 0-3 года — 1000 руб
- 3-6 лет — 700 руб
- 6-10 лет — 500 руб
- 10+ лет — 300 руб
Форма не дает вводить ничего, кроме цифр (это ограничение стоит на клиенте). Дробные значения недопустимы, сколько полных лет стажа есть, столько и пишем.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
1. Введение: задача о технологической границе. Сегодня, как, впрочем, и в обозримой ретроспективе, мир разделен на две группы стран – страны ядра (страны первой группы), достигшие высокого уровня технологического развития, и страны периферии и полупериферии (страны второй группы), которые находятся в роли технологических аутсайдеров, пытающихся догнать лидеров. Для сокращения своего технологического отставания страны могут в разных пропорциях использовать стратегии создания и заимствования новых технологий. Первый способ иногда называют инновационной деятельностью, второй – имитационной. Несмотря на кажущуюся простоту указанной стратегии, лишь немногие страны смогли перейти из первой группы во вторую.
Сложность в проведении правильной инновационной политики определяется многими факторами, в том числе незнанием так называемой технологической границы (ТГ). Задача о ТГ состоит в определении того критического уровня технологического развития страны, измеряемого, как правило, с помощью относительной производительности труда (относительно страны-лидера), до которого целесообразно заимствование чужих технологий, а после которого следует переходить к собственным разработкам. На практике недоучет ТГ порождает две проблемы. При продолжении заимствования технологий после превышения ТГ возникает так называемая ловушка технологического заимствования с присущим ей торможением экономического развития [Дементьев, 2006]. Попытка проводить масштабные исследования и разработки при нахождении национальной экономики существенно ниже ТГ приводит к неоправданным, а во многих случаях холостым затратам в силу невостребованности производителями передовых технологий.
Задача статьи состоит в разработке алгоритма идентификации ТГ на базе международной статистики. Знание данного параметра может оказать значимую помощь правительству при разработке и реализации технологической политики для правильного определения момента разворота имитационной стратегии на инновационную.
2. Понятие технологической границы: дайджест идей. В экономической литературе концепция ТГ возникла в рамках теорий эндогенного экономического роста и находится в тесной связи с термином совокупная или общая факторная производительность (ОФП). Данный термин, фигурирующий иногда в качестве остатка Солоу, обозначает оценку уровня технологического прогресса в экономике и исчисляется путем вычитания из темпов прироста выпуска взвешенных темпов прироста остальных факторов производства [Solow, 1956]. К таковым в канонических моделях относятся труд и капитал, а в усложненных модификациях добавляются человеческий капитал, качество институтов и инфраструктуры и т.п. В классической модели Солоу принят ряд предпосылок: 1) постоянная отдача от масштаба; 2) условия совершенной конкуренции; 3) оперирование фирм на границе производственных возможностей. Для устранения указанных постулатов были предложены так называемые «граничные» способы оценки технологического прогресса: непараметрические методы огибающих (линейное программирование) и модели стохастической границы производственных возможностей (панельные данные) [Мамонов и др., 2015]. Оба метода ориентированы на получение оценки величины технологического прогресса на основе моделирования производственной границы посредством поиска предельной эффективности технологического фактора. В ряде исследований эта граница называется технологической (например, [Caselli et al., 2006; Апокин, Ипатова, 2007]). Однако при таком понимании ТГ речь идет о потенциально возможных технологических возможностях экономики и несет в себе расширенную коннотацию указанного понятия.
Подобное понимание ТГ является довольно сложным, ибо подразумевает совокупность всех наиболее эффективных способов производства, доступных при определенных условиях (для фирмы, отрасли или страны) [Sato, 1974]. Причем, в английском языке данное понятие несет двойную коннотацию. С одной стороны, пограничная или передовая технология (frontier technology) – это технология, которая способна кардинально трансформировать устоявшиеся экономические или социальные процессы. К их числу относятся, например, возобновляемая энергия, искусственный интеллект, электромобили и т.д. [UNCTAD, 2018]. С другой стороны, совокупность таких технологий, действующих на рынке, образует технологическую границу (technology или technological frontier) в смысле некоторого предела технологических возможностей.
Расширительное понимание ТГ отождествляет ее с технологическим фактором в самом широком смысле слова, тогда как в естественных и технических науках ТГ понимается в более узком смысле – это пороговая величина (например, температура), при которой наблюдаемый объект или процесс принципиально меняет свои свойства (например, температура плавления). Именно такое понимание все чаще используется экономистами при моделировании поведения фирмы или страны при переключении режима инвестиций в зарубежные технологии (имитация) на режим проведения собственных разработок (инновации).
Первые попытки моделирования поведения фирмы в условиях смены режимов были предприняты в 1960-х годах [Scherer, 1967; Baldwin, Childs, 1969]. В основу модели был заложен затратный подход: расходы на покупку технологии (имитацию) имеют преимущество в силу быстрой окупаемости, но прибыль, получаемая вследствие внедрения приобретенной технологии, достаточно быстро угасает из-за того, что фирма теряет долю рынка. Затраты на собственные разработки, наоборот, менее привлекательны в краткосрочном периоде, но в долгосрочном – оправдываются с избытком. Таким образом, с учетом особенностей рынка фирма всегда находится перед выбором: имитировать или заниматься инновациями. На наш взгляд, это очень плодотворный подход, однако несколько усложненный фактором межвременного соизмерения альтернативных эффектов.
В дальнейшем такой подход был перенесен на макроуровень. Для внутреннего рынка была получена модель с представлением отрасли в качестве конкурентного поля фирм–инноваторов и фирм–имитаторов; по сути, авторы смоделировали влияние стратегий фирм на экономический рост и эффективность государственных субсидий НИОКР [Segerstrom, 1991]. В дальнейшем разбиение стран на технологических лидеров и последователей позволило обозначить основные векторы государственной политики, обеспечивающей максимальные темпы экономического роста для каждой группы государств [Sala–i–Martin, Barro, 1995]. Данный подход позволил ввести дихотомию не только в отношении технологического режима компании (страны), но и в отношении множества участников рынка, что стало основой для будущих эмпирических исследований.
Хотя в указанных работах термин ТГ не был напрямую введен в научный обиход, именно они создали предпосылки для формулирования его нового понимания. В 2002 г. в одной из работ было сформулировано простое правило: «Прорывные инновации (т.е. переход к технологической границе) становятся выгодными, когда присутствует растущая отдача от успешных достижений в области технологии и рост стоимости НИОКР перекрывается масштабом инновации» [Paulson Gjerde et al., 2002]. Хотя это правило изначально относилось к отдельным фирмам, оно легко переносится на отрасли и страны. В частности, это было сделано Д. Аджемоглу с соавторами, выявившими генеральную закономерность – страны с отсталой экономикой предпочитают имитационный путь развития, а инновационную стратегию выбирают экономически более развитые государства; мерой зрелости экономики служит расстояние до мировой технологической границы [Acemoglu et al., 2006]. Очевидно, переключение режимов происходит относительно плавно, когда возможно сосуществование обоих способов технологического обновления. Это связано с тем, что по мере приближения к технологической границе вырастает сложность заимствуемых технологий, а также растет значение собственных инноваций, которые опираются на внутренний человеческий капитал и научно–технологические заделы [Acemoglu, 1997]. При этом инновации появляются в отраслях (экономиках), которые находятся на ТГ или в непосредственной близости от нее, а потребность в заимствовании технологий тем больше, чем ниже параметры отрасли (экономика) мировой ТГ [Полтерович, 2009]. Тем самым в оборот была введена идея смешанной стратегии, когда одновременно имеют место процессы заимствования и разработки новых технологий, а динамика развития выступает в форме увеличения доли режима генерирования инноваций.
В целом расширенное понимание ТГ объясняется высоким динамизмом самих технологических изменений. Например, коммерциализация одной из «пограничных» технологий способна существенно переместить ТГ во всем мире. Вместе с тем Е. Ясин и М. Снеговая справедливо отмечают, что существует «…важное различие между инновациями «для себя», реализуемыми в том числе при заимствовании технологий, и инновациями для рынка – подлинными инновациями: их покупают, значит, они признаются рынком и в какой-то мере отодвигают технологическую границу» [Ясин, Снеговая, 2018]. Таким образом, расширительная трактовка ТГ, с одной стороны, более абстрактна и сложнее верифицируема, с другой – способна содержательно объяснить траектории развития фирм или целых стран, а также служить элементом в системе проектирования дальнейшего развития.
3. Практика количественной оценки технологической границы. Рассмотрим некоторые подходы к идентификации ТГ.
1. Определение ТГ как ОФП в традиционных производственных функциях [Бессонова, 2007]: , где Y – совокупный выпуск; K – капитал; L – труд; α – параметр эластичности; A – параметр совокупной производительности факторов, который трактуется как ТГ. Как уже было отмечено, более сложные и реалистичные модификации достигаются путем введения дополнительных факторов или дезагрегировании базовых факторов (например, труда на квалифицированный и неквалифицированный) [Caselli et al., 2006]. Основным преимуществом данного подхода выглядит возможность введения двух категорий ТГ: 1) расстояние страны относительно ее условной границы, то есть ее максимально достижимым уровнем производительности; 2) мера дистанции между условной границей страны и мировой границей [Filippetti, Peyrache, 2017]. Второй подход доказал свою применимость и плодотворность с точки зрения объяснения темпов экономического роста с учетом величины технологического отставания страны [например, Battisti et al., 2018; Rabe, 2016]. Вместе такой подход все-таки ориентирован на абстрактный маржинальный технический потенциал страны, выраженный в безразмерных единицах.
2. Понимание ТГ как отношение производительности труда в рассматриваемой стране к стране–лидеру (обычно к США) с учетом паритета покупательной способности [Aghion et al., 2005], что позволяет воспринимать эту величину в качестве разделительной полосы между режимами имитации и создания инноваций. Часто значение ТГ вводится в уравнения, содержащие другие макроэкономические переменные – добавленную стоимость, затраты на НИОКР, стоимость промежуточной продукции и т.д. Аналогичная схема используется и на микроуровне с той лишь разницей, что в систему уравнений вводятся один или несколько компаний-конкурентов, что позволяет рассчитать рентабельность выбора инновационного режима, а ТГ оказывается равной максимальной производительности среди всех фирм [Benhabib et al., 2017]. Тем самым в указанных исследованиях само понятие ТГ фактически подменяется показателем относительной производительности труда, в результате чего учитывается дистанция от технологического лидера, но точка смены режима с заимствования на создание инноваций, строго говоря, не определяется.
Если на уровне стран или отраслей эмпирические данные обычно собираются национальными статистическими ведомствами, то для оценки ТГ отдельных компаний применяются социологические исследования. Так, на основе опроса испанских фирм удалось смоделировать влияние удаленности от технологического уровня компании-лидера на выбор между инновациями и заимствованием для отдельных предприятий; при этом ТГ была представлена через ОФП [Gombau, Segarra, 2011]. Похожий опрос был выполнен и для африканских стран, однако ТГ не рассматривалась в контексте имитации/генерации инноваций [Cirera et al., 2017]; на примере португальских предприятий было исследовано влияние структурных реформ на изменение дистанции от ТГ [Gouveia, Santos, Goncalves, 2017]. Имеется опыт оценки эффективности издержек на НИОКР в зависимости от близости к ТГ на базе опросных данных о компаниях, имеющих самые высокие затраты на НИОКР в мире (почти 550 фирм) [Andrade et al., 2018]. Из сказанного очевидно, что и здесь в качестве ТГ используется не слишком прозрачная конструкция – относительная ОФП. Кроме того, определение величины ТГ является относительно простым, а основной вычислительный прием состоит опять–таки в определении разрыва между максимальным (граничным) и фактическим уровнем ОФП для множества фирм–участников рынка
3. Идентификация ТГ на основе качественных ответов от участвующих в опросах компаниях. В его основе лежит закрытый вопрос (с заданными вариантами ответа) об оценочном уровне технологий, используемых фирмой (более продвинутые по сравнению с конкурентами; примерно идентичные; отстающие) [Alder, 2010]. Подобный опрос проводился Всемирным банком с 2002 по 2008 г. и охватил более 9 тыс. предприятий. Другой вариант вопроса был сформулирован в социологическом исследовании корейских компаний: «какова цель внедрения инноваций?»; предлагаемые ответы позволяют классифицировать фирмы и используемые ими технологические стратегии: 1) открытие нового рынка (уровень ТГ); 2) увеличение рыночной доли или диверсификация линейки продуктов (фирмы–последователи); 3) изменение формы (дизайна) продукции (фирмы–аутсайдеры) [No, Seo, 2014]. Основной проблемой этого подхода квантификации ТГ следует признать нерегулярность проведения подобных социологических исследований, отсутствие международной сопоставимости результатов и разделение рынка на три группы фирм по нерепрезентативной выборке.
4. Косвенная оценка ТГ на основе коэффициента Тобина (соотношение рыночной стоимости фирмы и балансовой стоимости активов) [Coad, 2008]. Данный подход позволяет оперативно идентифицировать смену паттерна поведения фирмы в зависимости от ее производительности за счет оперативности данных фондового рынка. Вместе с тем данный метод имеет очень ограниченное применение из-за своего недостатка, состоящего в том, что увеличение коэффициента Тобина далеко не всегда является следствием роста технологического уровня компании.
Таким образом, в мировой научной литературе представлены различные методы «оцифровки» ТГ. Каждый из них имеет свои сильные и слабые стороны, которые детерминируются контекстом анализа и которые мы указали выше. В российской научной мысли термин «технологическая граница» употребляется исключительно в описательном контексте, и случаев его количественной интерпретации, а, следовательно, включения в макроэкономические модели обнаружить не удается.
В рамках наиболее перспективного подхода к пониманию ТГ в работах [Polterovich, Tonis, 2003; Polterovich, Tonis, 2005] была предложена теория перехода от заимствования к разработке новых технологий; указанные авторы трактовали ТГ как относительную ПТ (база сравнения – США), превышение которой делает экономически оправданными собственные разработки страны. Более того, авторами были получены две эконометрические зависимости, которые описывают затраты на имитацию и инновации. В статье [Балацкий, 2012] данные эконометрические зависимости были использованы для непосредственного расчета ТГ и тем самым была продемонстрирована принципиальная возможность простого аналитического решения подобной задачи. Насколько нам известно, других попыток количественно оценить ТГ в современном понимании точки переключения с одного режима на другой в России не было. Вместе с тем исходные данные и метод расчета в указанной работе были относительно грубыми и нуждаются в серьезных уточнениях, а, следовательно, сама задача о ТГ предполагает более тонкие методические аранжировки. Например, остается открытым вопрос о том, насколько универсальна технологическая граница – в пространстве и во времени. Не ясно, например, насколько сильно различается ТГ по группам государств, находящихся на разных уровнях экономического развития, а также направление, в котором она дрейфует с течением времени. На эти вопросы призваны ответить последующие построения.
4. Теоретическая модель рынка инноваций. Продолжая линию, начатую в работах [Polterovich, Tonis, 2003; Polterovich, Tonis, 2005; Балацкий, 2012], рассмотрим две стороны рынка инноваций. Однако сразу оговоримся, что здесь возможны две интерпретации рыночных взаимодействий – микро– (затратная) и макроэкономическая (рыночная). Остановимся сначала на первой, которая была развита в указанных работах и является более традиционной.
Пусть S – удельные расходы страны на закупку на открытом рынке технологий (сальдо роялти), D – удельные затраты страны на исследования и разработки технологических инноваций. Тогда основное предположение состоит в том, что данные издержки являются функциями производительности труда P. Вполне резонно предположить, что с ростом технологического уровня страны (относительной производительности труда; как правило, относительно относительного лидера – США) происходит снижение удельных затрат на исследования и разработки и, наоборот, рост производительности ведет к росту издержек на заимствование из-за необходимости покупать все более современные и дорогие технологии. Тогда задача выбора страной инновационной стратегии может быть описана обобщенной функцией удельных издержек W, которая представляет собой смесь двух типов затрат с весовым коэффициентом ζ:
 (1)
(1)
Тогда оптимизация смеси (1) по весовому коэффициенту дает простейшее условие:
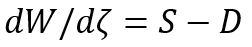 (2)
(2)
Отсюда вытекает, что оптимум достигается при равенстве двух видов удельных издержек, причем рациональная стратегия государства состоит не в выборе правильной пропорции между двумя видами издержек и следованию так называемой смешанной стратегии, а в выборе чистой стратегии согласно простому правилу: если D>S, то dW/dζ<0 и страна осуществляет преимущественно собственные исследования и разработки; в противном случае она осуществляет массовое заимствование технологий. Разумеется, это теоретическая идеализация; на практике всегда применяется смешанная стратегия с явным доминированием одного типа затрат. Для нас важен указанный момент доминирования одной из чистых инновационных стратегий.
Для простоты, как и во многих предыдущих работах, будем полагать, что зависимости издержек описываются простейшими линейными функциями производительности труда:
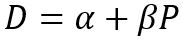 (3)
(3)
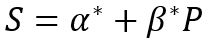 (4)
(4)
где α, α*, β и β* – параметры. Тогда равновесное значение производительности труда P* при S=D будет выступать в качестве искомой технологической границы:
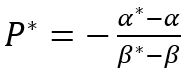 (5)
(5)
Вторая – рыночная (макроэкономическая) – интерпретация предполагает, что уравнение (3) описывает спрос на технологические ноу–хау, тогда как уравнение (4) – предложение технологических инноваций. Здесь также вполне резонно предположить, что спрос (потребности страны в инновациях) убывает по мере роста производительности труда, а предложение (ее возможности по созданию роялти) – возрастает. Тогда равновесие на рынке роялти возникает при равенстве спроса и предложения, что и дает технологическую границу (5).
Несмотря на чрезвычайную простоту предложенной модели рынка инноваций, она дает содержательные и хорошо верифицируемые результаты. Ниже мы рассмотрим возможность эконометрической проверки данной модели, для чего достаточно построить регрессии вида (3) и (4).
5. Исходные данные и их калибровка. Для прикладных расчетов в целях идентификации ТГ использовались статистические данные базы World Development Indicators [1] за период 1996–2017 гг. (22 наблюдения). Использовались следующие переменные: P – относительная производительность труда (объем ВВП к численности занятых); значение производительности каждой страны относилось к аналогичному показателю США, которые были выбраны в качестве базы (эталона); D – доля внутренних затрат на исследования и разработки в ВВП (прокси-переменная для удельных затрат на создание инноваций); C – доля инвестиций в основной капитал в ВВП (gross fixed capital formation); S – отношение разницы поступлений (экспорт технологий) и платежей (импорт технологий) за использование интеллектуальной собственности к ВВП (прокси–переменная для удельных затрат на заимствование технологий). Выбор прокси-переменных основывается на распространенной практике моделирования инновационной (затраты на НИОКР) и имитационной (покупка готовых технологий) стратегии фирм или национальных экономик (например, [Schewe, 1996; Slivko, Theilen, 2014]).
Все показатели усреднялись на исследуемом интервале методом среднего геометрического, кроме S, который усреднялся методом среднего арифметического из-за наличия отрицательных значений. Окончательно в статистическую выборку попали страны, по которым имелись данные хотя бы по 11 наблюдениям по каждой из переменных (пропущенные значения восстанавливались как среднее от двух соседних точек, в нескольких случаях усреднение происходило по неполному временному ряду); итоговый массив составил 61 страну. Соответственно эконометрические зависимости строились на базе пространственной выборки, т.к. анализ панельных данных не соответствует цели идентификации общей зависимости на определенном временном срезе с последующим сравнением ТГ во времени; кроме того, на длительных временных участках имеет место высокая волатильность S.
Ко всем показателям за исключением доли инвестиций в основной капитал применялась процедура стандартной нормировки переменной x: xn=(x–xvin)/(xmax–xmin) в рамках всей выборки или соответствующего кластера.
6. Кластеризация стран. Для корректных расчетов предварительно необходимо определить, какие страны подпадают под задачу о ТГ, а для каких государств она не имеет смысла. Для этого необходимо осуществить кластеризацию исходного массива стран, чтобы в дальнейшем для полученных групп государств строить отдельные регрессионные зависимости. Очевидно, что для разных групп стран разного уровня развития будут неодинаковые зависимости; универсальная модель для всей выборки, скорее всего, будет давать либо завышенные, либо заниженные оценки. В данном пункте мы уточняем модели, которые использовались в [Polterovich, Tonis, 2003; Polterovich, Tonis, 2005] для единого массива стран. Кроме того, мы используем более свежие данные, что также вносит свои корректировки относительно ранее полученных оценок.
Стратегически задача кластирования состоит в выделении двух эшелонов стран – передовых и догоняющих. Для этого использовалась двухшаговая процедура.
Первый этап – использование машинных методов кластеризации для первичной идентификации нескольких эшелонов государств. Для этого наиболее часто используются следующие методы определения расстояния между кластерами: метод одиночной связи (single); метод полной связи (complete); метод средней связи (average); центроидный метод (centroid); метод Уорда (ward.D). Наибольшую корреляцию с другими методами демонстрирует центроидный метод, а уникальность – метод Уорда. Более того, все подходы кроме метода Уорда генерируют варианты кластирования с одним непропорционально большим кластером и несколькими небольшими. Такой результат является неудовлетворительным, так как слишком малые выборки не позволяют строить статистически значимые регрессии. Однако уже на этом этапе первичная закономерность все-таки просматривается: при любых методах кластирования в первый эшелон попадают в основном страны с долей затрат на исследования и разработки в ВВП больше 1,5%. Таким образом, по результатам предварительного кластирования сформировались две группы стран, для которых ключевым признаком стала величина затрат на исследования и разработки. Однако в дальнейшем значимых регрессий для полученных кластеров получить не удалось, хотя связь между переменными явно просматривается.
Второй этап – калибровка машинной кластеризации, которая предполагает три последовательные операции: сортировка стран по убыванию показателя D; расчет коэффициентов корреляции между D и P (последовательная оценка корреляции для верхних двух стран, трех стран, четырех и т.д.); поиск пороговых точек, в которых происходит изменение знака коэффициента корреляции, а также «горбов», сигнализирующих об изменениях силы связи (рис.1). За исключением Южной Кореи, на рис.1 четко просматривается разделение стран по характеру связи между показателями D и P. В связи с этим в первый кластер отнесены все страны выше Чехии, так как начиная с этой страны коэффициент корреляции становится по модулю меньше 0,2, что говорит об относительно слабой связи. Примечательно, что 16 из 18 стран первого кластера соответствуют первому кластеру, полученному машинным методом. Выделение суб–кластеров в эшелоне догоняющих стран не дало положительного результата. Причем повторение процедуры ручной калибровки второго кластера с использованием скользящих коэффициентов корреляции показало, что для него параметр D не является определяющим, равно как и S. Однако сортировка второго кластера по показателю P дала положительный результат, хотя такой явной синусоиды, как в первом кластере, не просматривается. Окончательное число стран второго кластера – 43.
Рис 1. Скользящие коэффициенты корреляции между показателями D и P.
7. Эмпирическое определение технологической границы. Исходной гипотезой дальнейших расчетов выступает тезис о том, что для различных страновых кластеров характерны разные значения ТГ. Окончательная проверка сформулированной гипотезы и правильности проведенного кластирования стран состоит в построении двух эконометрических зависимостей: если модели строятся по каждому кластеру, имеют хорошие статистические характеристики и дают непротиворечивые результаты, то можно полагать, что и кластеры идентифицированы верно; в противном случае кластирование выполнено неудачно и следует использовать иные процедуры группировки стран. Различия значений ТГ для двух кластеров должны подтвердить гетерогенность данного параметра для мировой экономики.
Для первого кластера, включающего передовые страны мира, получена следующая пара эконометрических зависимостей:
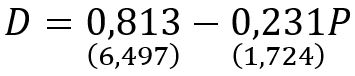 (6)
(6)
N=18; R2=0,157; BP=2,18 (уровень значимости – 0,14); GQ=0,18 (0,99).
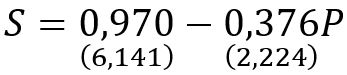 (7)
(7)
N=18; R2=0,236; BP=0,01 (0,96); GQ=3,29 (0,07).
Построенные модели (6) и (7) имеют удовлетворительные статистические характеристики; уровень значимости коэффициента β в модели (6) является значимым на 11–процентном уровне, что можно считать вполне допустимым для используемой выборки с усредненным значениями на длительном временном интервале; отсутствие гетероскедастичности проверено при помощи тестов Бройша–Пагана (BP) и Голдфелда–Куандта (GQ) – для обеих моделей получены удовлетворительные результаты. Более тщательная верификация модели (5)–(6) не проводилась, т.к. ее результаты используются для прикладных расчетов носящей иллюстративный (вспомогательный) характер «виртуальной» ТГ (см. ниже).
С учетом средней величины доли инвестиций в ВВП по первой группе стран в 22,6% расчет ТГ для моделей (6) и (7) дает величину Р*=108,2%, что выходит за область допустимых значений. Иными словами, эконометрические расчеты подтвердили, что для кластера передовых стран задача о ТГ не имеет смысла, а сама ТГ становится «виртуальной». Данный факт требует комментария с точки зрения структуры моделей (6) и (7). Дело в том, что для традиционной ситуации, как правило, действуют два эффекта – обучения применительно к сфере исследований и разработок (β<0) и удорожания заимствуемых технологий (β*>0). Однако для передовых стран эффект удорожания технологий претерпевает инверсию (β*<0), что имеет довольно прозрачную интерпретацию: для государств, которые сами поставляют на рынок передовые технологии, рост производительности труда делает доступность технологий для них еще больше, а сами технологии дешевле. Таким образом, для стран–лидеров обе кривые спроса и предложения становятся убывающими; их пересечение происходит за пределами отметки в 100%, так как на всей области определения оси абсцисс удельные издержки создания «своих» новых технологий для них ниже удельной стоимости «чужого» оборудования (рис.2).
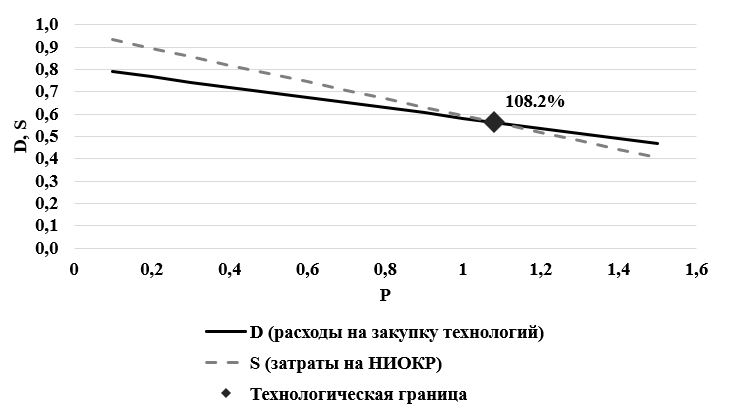
Рис.2. Кривые спроса и предложения ноу–хау для группы передовых стран.
Для второго кластера, включающего догоняющие страны, получена следующая пара эконометрических зависимостей:
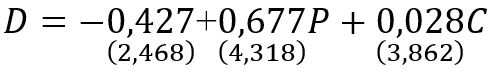 (8)
(8)
N=43; R2=0,448; BP=0,31 (0,86); GQ=0,33 (0,99); Chow=1,01 (0,40).
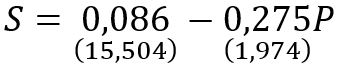 (9)
(9)
N=43; R2=0,087; BP=1,27 (0,26); GQ=2,75 (0,02), BPwt=1,51 (0,47); Chow=1,84 (0,17).
Построенные модели (8) и (9) также имеют удовлетворительные статистические характеристики; уровень значимости коэффициента β* в модели (9) является значимым на 6–процентном уровне, что практически никак не снижает достоверность полученных оценок; признаки гетероскедастичности обнаружены в модели (9) по одному из тестов, но дополнительный тест Уайта (BPwt) указывает на ее отсутствие. Верификация моделей для второго кластера стран была проведена при помощи теста Чоу (Chow) – в отношении обоих уравнений получены удовлетворительные результаты, что говорит об устойчивости полученных зависимостей.
Так как доля инвестиций в ВВП по второй группе стран составляет 21,8%, то расчет ТГ для моделей (8) и (9) дает величину Р*=71,7%. Тем самым для стран второго эшелона, реализующих догоняющую стратегию, задача о ТГ имеет самое непосредственное значение. Эффекты обучения и удорожания для государств данного кластера действуют в своем классическом виде, а кривые спроса и предложения (8) и (9) являются разнонаправленными (рис.3). Более того, полученная величина ставит очень серьезный инновационный барьер для развивающихся стран. Фактически это означает, что прежде чем начинать собственные разработки, догоняющие страны должны нарастить производительность труда более чем в 2/3 от уровня США, в том числе за счет заимствования и внедрения иностранных технологий; лишь после этого имеет смысл разворачивать национальные инициативы по разработке собственных оригинальных технологических решений.
Рис.3. Кривые спроса и предложения ноу–хау для группы догоняющих стран.
Достаточно интересными и неожиданными являются два аспекта полученного результата.
Во-первых, с течением времени величина ТГ имеет тенденцию к росту. Так, в более ранней работе [Балацкий, 2012] была получена «грубая» оценка ТЗ на уровне 61,5%, тогда как приведенные выше более «свежие» расчеты дают величину в 71,7%, т.е. на 10 п.п. больше. Если не списывать всю эту разницу на тонкие различия в алгоритмах получения двух оценок, то она заставляет предположить следующее: странам позднего старта становится все труднее переходить к активной инновационной политике. Фактически «ловушка заимствования» становится все более глубокой и прочной – опоздавшие страны вынуждены надолго оставаться в качестве пользователей чужих технологий. Чтобы вырваться из пресловутой технологической ловушки заимствования, догоняющим экономикам нужно не просто сократить дистанцию со страной-лидером, но очень близко приблизиться к ней по показателю производительности труда.
Во-вторых, фактором, понижающим величину ТГ, выступает инвестиционная активность. Проведенные расчеты показывают, что рост доли инвестиций в основной капитал с 21% до 30% позволяет сократить технологическую границу с 71,7% до 47,5%. Тем самым ловушка технологического заимствования отнюдь не фатальна: если страны позднего старта стремятся ее преодолеть, то они должны на какое-то время сознательно отказаться от потребительской идеологии в пользу высокой инвестиционной активности. Этим путем в свое время шел СССР, этой же стратегии придерживались Южная Корея и Китай. В противном случае период преследования может растянуться бесконечно.
8. Иллюстрация значимости ТГ: успешные и неудачные стратегии. Наличие такого индикатора, как ТГ, имеет большое значение для догоняющих стран для того, чтобы избежать двух типов ошибок – отставания в реализации технологических программ относительно реального положения дел в экономике и неправомерного опережения подобной политики, когда для этого нет никакой базы. Попытка откладывания создания собственной развитой национальной инновационной системы (НИС) при наличии соответствующих технологических предпосылок также губительна, как и попытка создания таковой в условиях отсутствия достаточно развитой экономики. Многие страны уже прошли тот путь, когда можно говорить о реальных примерах указанных ошибок или, наоборот, успехов. Для контрастности роли фактора ТГ в инновационной политике очень коротко рассмотрим два успешных примера – Южная Корея и Китай – и один негативный – Россия.
Китай. Еще в 1980-х годах китайская экономика была довольно архаична и претендовать на глобальные технологические успехи не могла. В связи с этим китайские компании начали с имитации – копирования и незначительного улучшения – зарубежной продукции от модных аксессуаров до телефонов [Yip, McKern, 2016, p.13]. Чуть позже Китай начал проводить политику встраивания китайских компаний, дислоцированных на его территории, в транснациональные цепочки добавленной стоимости в ИКТ–отраслях. Именно сотрудничество с такими глобальными компаниями как Intel, Google, MediaTek создало предпосылку для масштабной технологической диффузии и формирования национальных предприятий, производящих высокотехнологичную продукцию под китайскими брендами. Со второй половины 2004 г. началась работа по созданию собственных инноваций и расширение сферы НИОКР [König et al., 2018]. Позднее в стране началась систематическая работа по локальной генерации новых технологий; продвижение инновационной деятельности по широкому фронту было невозможно из-за того, что выход на ТГ так и не состоялся, однако устойчивый рост доли затрат на НИОКР в ВВП позволяет Китаю уверенно идти к данной отметке (табл.1). Осуществление политики имитации, дополненной локальными инновациями, дало впечатляющий результат: в 2018 г. в первую сотню компаний мира по уровню затрат на НИОКР вошли 9 китайских предприятий, специализирующиеся в передовых областях экономики [2].
Таблица 1. Производительность труда стран относительно США (по ППС), %
|
Год |
Китай |
Южная Корея |
Россия |
|
1975 |
н/д |
9.4* |
н/д |
|
1985 |
1.5* |
16.5* |
н/д |
|
1992 |
4.1 |
37.8 |
43.9 |
|
1995 |
5.5 |
43.4 |
35.8 |
|
2000 |
7.0 |
48.2 |
34.1 |
|
2005 |
9.9 |
51.0 |
39.4 |
|
2010 |
15.6 |
57.3 |
43.4 |
|
2015 |
21.7 |
59.3 |
45.2 |
|
2017 |
24.5 |
61.4 |
46.0 |
* без учета ППС.
Южная Корея. По мнению аналитиков, Южная Корея прошла технологический путь, который условно можно разделить на четыре этапа [El Fakir, 2008]. При этом на первых двух этапах страна активно приобретала зарубежные технологии: в период с 1962 по 1982 гг. было совершено более 2000 закупочных сделок, суммарная стоимость которых соответствовала почти половине объема всех прямых инвестиций за этот период [Бойкова, Салазкин, 2007]; не игнорировался и потенциал протекционистских мер по отношению к местным корпорациям (чеболям) [Коргун, 2007]. На третьем этапе (1980–1990-е гг.) началось постепенное переключение на режим генерации инноваций, результатом чего стало увеличение объема внутренних НИОКР и появление высокотехнологичных производств. Четвертый этап (конец 1990–х гг. по н/в) ознаменовался кластерным подходом в управлении развитием национальной промышленности и поддержкой чеболей как мировых лидеров в соответствующих отраслях, для чего территория Кореи была поделена на зоны по принципу ведущих базовых отраслей; стимулирование инноваций велось с учетом особенностей каждой из них [Абдурасулова, 2009]. К настоящему моменту Южная Корея приблизилась к ТГ (табл.1), радикально увеличила внутренние затраты на НИОКР, а в 2018 г. 4 корейских чеболя вошли в число глобальных компаний–лидеров по уровню затрат на НИОКР [3].
Таким образом, и Южная Корея, и Китай проводили последовательную инновационную политику – от заимствования иностранных технологий до создания инноваций в ограниченном числе перспективных отраслей экономики (высокотехнологичных кластерах). Тотальное освоение рынка высоких технологий данные государства не осуществляют, т.к. их руководство понимает, что они до этого еще не «дозрели» – ТГ ими пока не преодолена.
Россия. Опыт Российской Федерации по созданию инновационной экономики в отличие от Китая и Кореи представляет собой явный случай неудачи. Начиная с 1992 г., когда начались масштабные экономические реформы, в стране было принято огромное количество стратегических документов, направленных на развитие сферы инноваций. Однако реальных изменений в повышении уровня технологичности производства так и не произошло. Как поясняют Л.М.Гохберг и И.А.Кузнецова, «это обусловлено не только макроэкономическими условиями, структурой рынков и качеством корпоративного управления, но в значительной степени – неэффективностью национальной инновационной системы и неадекватностью ее институтов требованиям инновационного развития» [Гохберг, Кузнецова, 2009]. По мнению Ю. Симачева, инновационный путь развития оказался невозможен в силу целого ряда причин (например, опора на госкорпорации в инновационном развитии имеет неустранимые недостатки [Симачев и др., 2014]). По нашему мнению, главная причина провала всех планов российских властей на построение высокотехнологичного сектора экономики состоит в попытке «перепрыгивания» этапа имитации к этапу разработки оригинальных инноваций. В результате такой политики по показателю производительности труда Россия не смогла заметно улучшить свои мировые позиции и по-прежнему далека от ТГ (табл.1).
На микроуровне патовая ситуация в России проявлялась в отторжении российским бизнесом массы внутренних и внешних технологических инноваций из-за их невостребованности. Фактически бизнес нуждался в простых, но более продуктивных технологиях, тогда как разработчики предлагали ему чрезмерно сложные и непроверенные технологические решения. Непосредственным результатом подобной непоследовательной политики явилась стагнация затрат на НИОКР и отсутствие национальных глобальных высокотехнологических компаний: в рейтинге 2018 г. компаний–лидеров по затратам на НИОКР на 448 месте присутствует только российский «Газпром».
Не заостряя внимания на тактических ошибках российской инновационной политики, укажем лишь на то, что вряд ли будет преувеличением тезис, что главная проблема модернизации экономики состоит в отсутствии внутренних и внешних механизмов диффузии технологий. Сегодня опыт даже отечественных преуспевающих предприятий не перенимается компаниями этого же производственного профиля. Внешние механизмы заимствования технологий не только до конца не выстроены, но теперь во многом осложняются международными санкциями.
9. Обсуждение результатов. Рассмотренная выше трактовка ТГ и алгоритм ее количественного определения пополняют арсенал полезных аналитических инструментов в экономике. Сначала остановимся на тех новых возможностях, которые дает данный индикатор.
Во-первых, идентификация ТГ позволяет довольно точно определить тот «клуб» стран, в который входит конкретное государство: если фактическая относительная производительность труда намного ниже ТГ, то речь идет о технологически отсталой державе; в противном случае она попадает в разряд технологически развитых. При этом подтвердилась наша гипотеза, согласно которой для технологически развитых стран само понятие ТГ как пороговое значение не имеет смысла, ибо они уже находятся на инновационной стадии развития экономики. Для развивающихся стран ТГ, наоборот, имеет огромное значение для определения их места в мировой экономической системе.
Во-вторых, понимание положения страны относительно ТГ позволяет определить, какой вид технологической политики для нее является приоритетным – заимствование или создание инноваций. Приведенные в предыдущем разделе страновые примеры показывают, что учет данного обстоятельства позволяет выстроить адекватную технологическую политику и довольно быстро осуществить модернизацию национальной экономики, тогда как игнорирование существующего технологического барьера приводит к дезориентации властей, несбалансированности научно–производственной стратегии, хаотичному экспериментированию с разными инновационными институтами и неправильному определению приоритетов в финансировании и организации производств.
Вместе с тем следует указать и те моменты относительно ТГ, которые не позволяют пользоваться ею автоматически и шаблонно. Наоборот, данное понятие и алгоритм ее определения требуют чрезвычайно аккуратного ее использования в практических целях.
Во-первых, оценку ТГ нельзя абсолютизировать, т.к. эконометрический аппарат, несмотря на свои возможности, все–таки не может гарантировать слишком высокой точности такого непростого индикатора. На наш взгляд, реальное значение ТГ находится в радиусе ±3 п.п. от ее идентифицированного значения. Эту погрешность следует учитывать и не абсолютизировать конкретные цифры.
Во-вторых, определенная нами ТГ носит макроэкономический характер, т.е. для всей национальной экономики. Вместе с тем во многих странах, включая Россию, различия в производительности труда между отраслями могут отличаться в разы, а различия между компаниями внутри одной отрасли и регионами – в десятки раз (Балацкий, Екимова, 2020). В связи с этим макрооценка ТГ показывает общий ориентир для экономики в проведении технологической политики. Параллельно необходим отраслевой и региональный анализ, который бы позволил определить соответственно отраслевые и региональные зоны, где целесообразно заимствование технологий, а где – их создание. Более того, в идеале ТГ должна определяться отдельно по каждой отрасли экономики для того, чтобы обеспечить сопоставимость исходных данных, однако в настоящее время для этого не хватает статистических данных, в связи с чем можно ограничиться хотя бы общим правилом относительно критической величины ОПТ.
В-третьих, предложенная теоретическая схема является крайне упрощенной, в связи с чем она оперирует чистыми стратегиями – либо заимствование, либо разработка новых технологий. Однако в реальности многие страны придерживаются смешанных стратегий, когда для определенных, наиболее отсталых, сегментов экономики используется режим заимствования, а для других – режим разработки. Это заведомо отрицает бинарный характер экономической и технологической политики. Это означает, что ТГ указывает на доминирующий режим модернизации экономики, а селекция зон на два режима является прерогативой более тщательного анализа национальной экономики и ее технического оснащения.
В-четвертых, даже очень точное и корректное определение ТГ для всей экономики или ее отдельного сектора ничего не говорит о том, как должно происходить заимствование/разработка новых технологий. Разработка и реализация таких механизмов является искусством и определяется компетентностью государственного менеджмента. Иными словами, ТГ позволяет на качественном уровне понять, как надо осуществлять технологический прогресс – преимущественно за счет имитации или создания собственных инноваций.
Сказанное выше позволяет сформулировать тезис о целесообразности использования инструмента ТГ в технологической политике российских властей с учетом всех указанных нюансов и ограничений. Вместе с тем проведенные расчеты показывают, что в России процесс заимствования новых технологий осуществлялся крайне неэффективно. В качестве критериев эффективности процесса заимствования выступают степень приближения к ТГ и скорость этого приближения. Так, в 2017 г. Южную Корею от ТГ отделяло всего 10 п.п., тогда как Россию – более 25. Скорость приближения к ТГ на временном интервале 1992–2017 гг. у Южной Кореи была в 11,2 раза выше, чем у России; в последние годы ситуация в России улучшилась, но по-прежнему оставляет желать лучшего (табл. 1). Еще ярче данные критерии проявлялись в обрабатывающих производствах, в которых ПТ России по отношению к США составляла 16,7%, а Южной Кореи – 71,2% (уровень ТГ!) [4]. Подобное положение дел подтверждается и интенсивностью закупки промышленных роботов: по данным Международной федерации робототехники, плотность роботизации промышленности в Южной Корее в 2018 г. составила 774 (ед./10 тыс. занятых), а в России – 5 [5].
Надо сказать, что в нормативных документах страны, касающихся научно–технического развития экономики, не ставится задача об организации продуманного заимствования зарубежных и отечественных инноваций. Между тем это главное, на что ориентирует идентификация ТГ. Именно на этом пути у России имеется недоиспользованный регулятивный резерв в модернизации экономики и именно в этом направлении может быть плодотворно использован новый индикатор [6].
10. Заключение. Выполненные построения показывают, что шумпетерианский анализ инновационной сферы по-прежнему продуктивен и способен давать новые интересные результаты. В частности, использование такого понятия, как ТГ в узком понимании порогового значения ОПТ, позволяет существенно углубить концепцию Й. Шумпетера о двух фазах технологического развития – имитации (заимствовании) и инновации (создания) технологий. Как оказывается, для стран догоняющего развития, к числу которых относится и Россия, эффективный переход от одной фазы развития к другой предполагает свои закономерности и условия. Одно из них состоит в достижении развивающимся государством ТГ. Нарушение этого принципа приводит к холостым затратам и торможению развития.
Несмотря на простоту концепции ТГ, на практике она может непреднамеренно нарушаться. Причины подобных действий могут быть разными. Например, Россия после распада СССР и потери промышленного потенциала перешла в разряд догоняющих стран, однако в силу институциональной инерции за три десятилетия так и не создала эффективных механизмов широкого заимствования технологий. Однако Россия не является уникальной в этом отношении – сегодня имеется множество стран, которые стремятся обрести независимость и больший международный вес благодаря наращиванию сектора НИОКР при недостаточном технологическом уровне национальной экономики. По всей видимости, к разряду таких стран можно отнести Пакистан, Иран и Нигерию. Как было сказано, подобные стратегии тормозят развитие, но, помимо всего прочего, провоцируют различного рода экономические дисбалансы и социальную напряженность.
Библиография
Абдурасулова Д. (2009). Республика Корея: промышленная политика в условиях глобализации // Мировая экономика и международные отношения. №. 5. С. 100–107.
Апокин А.Ю., Ипатова И.Б. (2017). Компоненты совокупной факторной производительности экономики России относительно других стран мира: роль технической эффективности // Проблемы прогнозирования. №. 1. С. 22–29.
Балацкий Е.В. (2012). Технологическая диффузия и инвестиционные решения // Журнал Новой экономической ассоциации. Т. 15. №3. С.10–34.
Балацкий Е.В., Екимова Н.А. (2020). Внутренние источники роста производительности труда в России // Мир новой экономики. Т. 14. № 2. С.32–43.
Бессонова Е.В. (2007). Оценка эффективности производства российских промышленных предприятий // Прикладная эконометрика. №. 2. С. 13–35.
Бойкова М.В., Салазкин М.Г. (2007). Корея: опережающие стратегии // Форсайт. Т. 1. № 4. С. 52–63.
Гохберг Л.М., Кузнецова И.А. (2009). Инновации в российской экономике: стагнация в преддверии кризиса? // Форсайт. Т. 3. № 2. С. 28–46.
Дементьев В.Е. (2006). Ловушка технологических заимствований и условия ее преодоления в двухсекторной модели экономики // Экономика и математические методы. Т. 42. № 4. С. 17–32.
Казакова М.В., Любимов И.Л., Нестерова К.В. (2016). Гарантирует ли успех отдельной реформы ускорение экономического роста? Недостаточно развитые институты как причина провала реформ // Экономический журнал Высшей школы экономики. Т. 20. №. 4. С. 624–654.
Коргун И.А. (2007). Политика поддержки промышленного экспорта в Республике Корея // Вестник Санкт–Петербургского университета. Экономика. №. 4. С. 170–174.
Мамонов М.Е., Пестова А.А., Сабельникова Е.М., Апокин А.Ю. (2015). Подходы к оценке факторов производства и технологического развития национальных экономик: обзор мировой практики // Проблемы прогнозирования. Т. 153. № 6. С. 45–57.
Полтерович В. М. (2009). Проблема формирования национальной инновационной системы // Экономика и математические методы. Т. 45. №. 2. С. 3–18.
Полтерович В.М. (2006). Стратегии институциональных реформ. Китай и Россия // Экономика и математические методы. 2006. Т. 42. № 2. С. 3–18.
Симачев Ю.В., Кузык М.Г., Фейгина В.В. (2014). Государственная поддержка инноваций в России: что можно сказать о воздействии на компании налоговых и финансовых механизмов? // Российский журнал менеджмента. Т. 12. № 1. С. 7–38.
Ясин Е.Г., Снеговая М.В. (2018). Роль инноваций в развитии мировой экономики // Вопросы экономики. №. 9. С. 15–31.
Acemoglu D. (1997). Training and innovation in an imperfect labour market // The Review of Economic Studies. Vol. 64. №. 3. P. 445–464.
Acemoglu D., Aghion P., Zilibotti F. (2006). Distance to frontier, selection, and economic growth // Journal of the European Economic association. Vol. 4. №. 1. P. 37–74.
Acemoglu D., Aghion P., Zilibotti F. (2003). Vertical integration and distance to frontier // Journal of the European Economic Association. Vol. 1. №. 2–3. P. 630–638.
Aghion P., Howitt P., Mayer-Foulkes D. (2005). The effect of financial development on convergence: Theory and evidence // The Quarterly Journal of Economics. Vol. 120. №. 1. P. 173–222.
Alder S. (2010). Competition and innovation: does the distance to the technology frontier matter? Available at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1635789, accessed 15.02.2020.
Baldwin W.L., Childs G.L. (1969). The fast second and rivalry in research and development // Southern Economic Journal. P. 18–24.
Battisti M., Del Gatto M., Parmeter C.F. (2018). Labor productivity growth: disentangling technology and capital accumulation // Journal of Economic Growth. Vol. 23. №. 1. P. 111–143.
Benhabib J., Perla J., Tonetti C. (2017). Reconciling models of diffusion and innovation: a theory of the productivity distribution and technology frontier. National Bureau of Economic Research. №. w23095.
Caselli F., Coleman I. I., John W. (2006). The world technology frontier // American Economic Review. Vol. 96. №. 3. P. 499–522.
Cirera X., Fattal Jaef R.N., Maemir H.B. (2017). Taxing the good? distortions, misallocation, and productivity in Sub–Saharan Africa. The World Bank. Available at: http://documents.worldbank.org/curated/en/492891485178180375/Taxing-the-good-distortions-misallocation-and-productivity-in-Sub-Saharan-Africa, accessed 15.02.2020.
Coad A. (2008). Distance to frontier and appropriate business strategy. Papers on economics and evolution. №. 0807. Available at: https://www.econstor.eu/bitstream/10419/31801/1/572410638.pdf, accessed 15.02.2020.
El Fakir A. (2008). South korean system of innovation: from imitation to frontiers of technology, successes and limitations // Management of Technology Innovation and Value Creation: Selected Papers from the 16th International Conference on Management of Technology. P. 275–292.
Filippetti A., Peyrache A. (2017). Productivity growth and catching up: a technology gap explanation // International Review of Applied Economics. Vol. 31. №. 3. P. 283–303.
Gombau V., Segarra A. (2011). The Innovation and Imitation Dichotomy in Spanish Firms: Do Absorptive Capacity and the Technological Frontier Matter? Working Paper. XREAP 2011–22. Available at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1973790, accessed 15.02.2020.
Gouveia A.F., Santos S., Goncalves I. (2017). The impact of structural reforms on productivity: The role of the distance to the technological frontier. OECD Productivity working papers. № 8. Available at: https://www.oecd-ilibrary.org/economics/the-impact-of-structural-reforms-on-productivity_6e4a4bf7-en;jsessionid=ocD4z8zimAYXeuT-JLPtgBRG.ip-10-240-5-160, accessed 15.02.2020.
König M., Storesletten K., Song Z., Zilibotti F. (2018). From Imitation to Innovation? Where Is All That Chinese R&D. Going? Available at: https://economics.stanford.edu/sites/g/files/sbiybj9386/f/kssz_180403_webpage.pdf, accessed 15.02.2020.
Lee M., Son B., Om K. (1996). Evaluation of national R&D projects in Korea // Research Policy. Vol. 25. №. 5. P. 805–818.
No J.Y.A., Seo B. (2014). Innovation and Competition // Korea and the World Economy. Vol. 15. №. 2. P. 155–183.
Paulson Gjerde K.A., Slotnick S.A., Sobel M.J. (2002). New product innovation with multiple features and technology constraints // Management Science. Vol. 48. №. 10. P. 1268–1284.
Polterovich V., Tonis A. (2003). Innovation and Imitation at Various Stages of Development // NES Working Paper. Available at: https://www.researchgate.net/publication/41020311_Innovation_and_Imitation_at_Various_Stages_of_Development, accessed 15.02.2020.
Polterovich V., Tonis A. (2005). Innovation and Imitation at Various Stages of Development: A Model with Capital // NES Working Paper. Available at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1753531, accessed 15.02.2020.
Rabe C. (2016). Capital controls, competitive depreciation, and the technological frontier // Journal of International Money and Finance. Vol. 68. P. 74–102.
Rocha L.A., Cárdenas L.Q., Oliveira F.S. D., Lopes F.D., Fernandes K.C. (20180. The Impact of R&D Investments on Performance of Firms in Different Degrees of Proximity to the Technological Frontier // Economics Bulletin. Vol. 38. №. 2. P. 1156–1170.
Sala-i-Martin X.X., Barro R.J. (1995). Technological diffusion, convergence, and growth // Center Discussion Paper. №. 735. Available at: https://www.econstor.eu/bitstream/10419/160652/1/cdp735.pdf, accessed 15.02.2020.
Sato K. (1974). The neoclassical postulate and the technology frontier in capital theory // The Quarterly Journal of Economics. Vol. 88. №. 3. P. 353–384.
Scherer F.M. (1967). Research and development resource allocation under rivalry // The Quarterly Journal of Economics. Vol. 81. №. 3. P. 359–394.
Schewe, G. (1996). Imitation as a strategic option for external acquisition of technology // Journal of Engineering and Technology Management. Vol. 13. №. 1. P. 55–82.
Segerstrom P.S. (1991). Innovation, imitation, and economic growth // Journal of political economy. Vol. 99. №. 4. P. 807–827.
Slivko O., Theilen B. (2014). Innovation or imitation? The effect of spillovers and competitive pressure on firms’ R&D strategy choice // Journal of Economics. Vol. 112. №. 3. P. 253–282.
Solow R.M. (1956). A contribution to the theory of economic growth // The quarterly journal of economics. Vol. 70. №. 1. P. 65–94.
UNCTAD. (2018). The Technology and Innovation Report 2018: Harnessing Frontier Technologies for Sustainable Development. Available at: https://unctad.org/en/PublicationsLibrary/tir2018_en.pdf, accessed 15.02.2020.
Yip G.S., McKern B. (2016). China’s next strategic advantage: From imitation to innovation. MIT Press. 304 pp.
[1] https://datacatalog.worldbank.org/dataset/world-development-indicators
[2] https://www.strategyand.pwc.com/innovation1000#VisualTabs1
[3] https://www.strategyand.pwc.com/innovation1000#VisualTabs1
[4] В расчетах использовалась статистика по валовой добавленной стоимости (http://data.un.org/Data.aspx?q=Gross+Value+Added+by+Kind+of+Economic+Activity&d=SNAAMA&f=grID:202;currID:USD;pcFlag:0) и численности занятых (https://www.ilo.org/shinyapps/bulkexplorer29/?lang=en&segment=indicator&id=EMP_TEMP_SEX_ECO_NB_A)
[5] https://roscongress.org/en/materials/perspektivnye-napravleniya-primeneniya-robototekhniki-v-biznese/
[6] Конкретные механизмы заимствования могут быть сколь угодно разнообразными. Например, создание налоговых льгот зарубежным компаниям на территории страны, поощрение отечественных предприятий на закупку и внедрение современного оборудования путем введения инвестиционных вычетов из прибыли и т.п. Однако этот практический вопрос является темой отдельного обсуждения и выходит за рамки данной статьи, которая носит преимущественно инструментальный характер.
Официальная ссылка на статью:
Балацкий Е.В. Идентификация технологического фронтира // «Форсайт», Т. 15, №3, 2021. С. 23–34.