
Наверное, многие когда-нибудь задумывались, как сделать поиск на сайте? Безусловно, для крупных сайтов с большим количеством контента поиск является просто незаменимой вещью. В большинстве случаев пользователь, впервые посетив Ваш сайт в поисках чего-либо важного, не станет разбираться в навигационных панелях, выпадающих меню и прочих элементах навигации, а в спешке попытается найти что-нибудь похожее на поисковую строку. И если такой роскоши на сайте не окажется, либо он не справится с поисковым запросом, то посетитель просто закроет вкладку. Но статья не о значении поиска для сайта и не о психологии посетителей. Я расскажу, как реализовать небольшой алгоритм полнотекстового поиска, который, надеюсь, избавит начинающих разработчиков от головной боли.
У читателя может возникнуть вопрос: зачем писать все с нуля, если все уже давно написано? Да, у крупных поисковиков есть API, есть такие клевые проекты, как Sphinx и Apache Solr. Но у каждого из этих решений есть свои преимущества и недостатки. Пользуясь услугами поисковиков, типа Google и Яндекс, Вы получите множество плюшек, таких как мощный морфологический анализ, исправление опечаток и ошибок в запросе, распознавание неверной раскладки клавиатуры, однако без ложки дегтя тут не обойдется. Во первых, такой поиск не интегрируется в структуру сайта — он внешний, и Вы не сможете указать ему, какие данные наиболее важны, а какие не очень. Во вторых, содержимое сайта индексируется только с определенным интервалом, который зависит от выбранного поисковика, так что если на сайте что-нибудь обновится, придется дожидаться момента, когда эти изменения попадут в индекс и станут доступными в поиске. У Sphinx и Apache Solr дела с интеграцией и индексированием гораздо лучше, но не каждый хостинг позволит из запустить.
Ничто не мешает написать поисковый механизм самостоятельно. Предполагается, что сайт работает на PHP в связке с каким-нибудь сервером баз данных, например MySQL. Давайте сначала определимся, что требуется от поиска на сайте?
- Поиск с учетом языковой морфологии. Независимо от падежа, окончания и
других прелестей великого и могучего языка поиск должен находить то, что нужно
пользователю. Другими словами, «яблок», «яблока», «яблоки» — это формы одного и того
же слова «яблоко», что нужно учитывать в поисковом алгоритме. Одним из способов
достижения данной цели является приведение каждого слова поискового запроса и слов
содержимого сайта к базовой форме. - Возможность указать контекст поиска. То есть, возможность самостоятельно выбрать
контент сайта, в пределах которого будет работать поисковый алгоритм, а также определить
значимость для каждого из пределов. Например, рассмотрим интернет-магазин. Предполагается,
что поисковый запрос чаще всего будет содержать название искомой продукции, поэтому поиск по
названиям товара будет иметь наивысший приоритет. В качестве следующего приоритета можно
выбрать поиск по свойствам товаров, затем поиск по описанию. - Индексирование содержимого сайта. Представьте ситуацию: одновременно около 30 человек
выполняют поисковые запросы. Сервер принимает каждое соединение, управление потоком
передается интерпретатору PHP. При каждом запросе заново инициализируется поисковый
движок, заново перерывается содержимое сайта… Сложно сказать, сколько времени и
ресурсов потребуется, чтобы обработать все эти запросы. Именно для того, чтобы не
делать одну и ту же работу по сто раз, была придумана технология индексирования.
Индексирование выполняется только при изменении или добавлении содержимого сайта,
а поиск выполняется уже по индексу, а не по содержимому. - Механизм ранжирования. Ранжирование результатов поиска — это сортировка результатов поиска, выполняемая на основе оценки значимости найденных данных. Например, в каком-нибудь блоге выполняется поисковый запрос «космос». Данное слово содержится в двух статьях: в первой 16 раз, во второй — 5 раз. Вероятнее всего, первая статья будет иметь большее значение для инициатора поиска. Также каждой разновидности содержимого сайта при индексировании задается определенный коэффициент, который будет влиять на его позиции в поисковой выдаче.
Теперь пару слов о том, что нам предстоит реализовать:
- морфологический анализатор,
- алгоритм ранжирования,
- алгоритм индексирования,
- алгоритм поиска.
В конце статьи будет показан пример реализации поиска на примере простого интернет-магазина. Тем, кому лень все это изучать и просто нужен готовый поисковик, можно смело забирать движок из репозитория GitHub FireWind.
Принцип работы
Со стороны бэкенда поиск работает так:
- содержимое сайта индексируется,
- пользователь присылает запрос,
- из запроса исключаются служебные части речи,
- получившаяся строка разбивается на массив слов, переведенных в базовую форму,
- поиск каждого слова полученного массива осуществляется в индексе,
- результаты поиска ранжируются, сортируются и отдаются пользователю.
Подготовка
Задача поставлена, теперь можно перейти к делу. Я использую Linux в качестве рабочей ОС, однако постараюсь не использовать ее экзотических возможностей, чтобы любители Windows смогли «собрать» поисковый движок по аналогии. Все, что Вам нужно — это знание основ PHP и умение обращаться с MySQL. Поехали!
Наш проект будет состоять из ядра, где будут собраны все жизненно необходимые функции, а также модуля морфологического анализа и обработки текста. Для начала создадим корневую папку проекта firewind, а в ней создадим файл core.php — он и будет ядром.
$ mkdir firewind
$ cd firewind
$ touch core.php
Теперь вооружаемся своим любимым текстовым редактором и подготавливаем каркас:
<?php
class firewind {
public $VERSION = "1.0.0";
function __construct() {
// Инициализатор //
}
}
?>
Тут мы создали основной класс, который можно будет использовать на Ваших сайтах. На этом подготовительная часть заканчивается, пора двигаться дальше.
Морфологический анализатор
Русский язык — довольно сложная штука, которая радует своим разнообразием и шокирует иностранцев конструкциями, типа «да нет, наверное». Научить машину понимать его, да и любой другой язык, — довольно непростая задача. Наиболее успешны в этом плане поисковые компании, типа Google и Яндекс, которые постоянно улучшают свои алгоритмы и держат их в секрете. Придется нам сделать что-то свое, попроще. К счастью, колесо изобретать не придется — все уже сделано за нас. Встречайте, phpMorphy — морфологический анализатор, поддерживающий русский, английский и немецкий языки. Более подробную информацию можно получить тут, однако нас интересуют только две его возможности: лемматизация, то есть получение базовой формы слова, и получение грамматической информации о слове (род, число, падеж, часть речи и т.д.).
Нужна библиотека и словарь для нее. Все это добро можно найти тут. Библиотека находится в одноименной папке «phpmorphy», словари расположены в «phpmorphy-dictionaries». Скачиваем последние версии в корневую папку проекта и распаковываем:
# Распаковываем библиотеку
$ unzip phpmorphy-0.3.7.zip
$ mv phpmorphy-0.3.7 phpmorphy
# Распаковываем словарь в phpmorphy/dicts
$ unzip morphy-0.3.x-ru_RU-withjo-utf-8.zip -d phpmorphy/dicts/
# Удаляем исходные архивы
$ rm phpmorphy-0.3.7.zip morphy-0.3.x-ru_RU-withjo-utf-8.zip
Отлично! Библиотека готова к использованию. Пришло время написать «оболочку», которая абстрагирует работу с phpMorphy. Для этого создадим еще один файл morphyus.php в корневой директории:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
function __construct() {
$directory = __DIR__.'/phpmorphy/dicts';
$language = 'ru_RU';
$options[ 'storage' ] = PHPMORPHY_STORAGE_FILE;
// Инициализация библиотеки //
$this->phpmorphy = new phpMorphy( $directory, $language, $options );
}
/**
* Разбивает текст на массив слов
*
* @param {string} content Исходный текст для выделения слов
* @param {boolean} filter Активирует фильтрацию HTML-тегов и сущностей
* @return {array} Результирующий массив
*/
public function get_words( $content, $filter=true ) {
// Фильтрация HTML-тегов и HTML-сущностей //
if ( $filter ) {
$content = strip_tags( $content );
$content = preg_replace( $this->regexp_entity, ' ', $content );
}
// Перевод в верхний регистр //
$content = mb_strtoupper( $content, 'UTF-8' );
// Замена ё на е //
$content = str_ireplace( 'Ё', 'Е', $content );
// Выделение слов из контекста //
preg_match_all( $this->regexp_word, $content, $words_src );
return $words_src[ 1 ];
}
/**
* Находит леммы слова
*
* @param {string} word Исходное слово
* @param {array|boolean} Массив возможных лемм слова, либо false
*/
public function lemmatize( $word ) {
// Получение базовой формы слова //
$lemmas = $this->phpmorphy->lemmatize( $word );
return $lemmas;
}
}
?>
Пока реализовано только два метода. get_words разбивает текст на массив слов, фильтруя при этом HTML-теги и сущности типа « ». Метод lemmatize возвращает массив лемм слова, либо false, если таковых не нашлось.
Механизм ранжирования на уровне морфологии
Давайте остановимся на такой единице языка, как предложение. Наиболее важной частью предложения является основа в виде подлежащего и/или сказуемого. Чаще всего подлежащее выражается существительным, а сказуемое глаголом. Второстепенные члены в основном употребляются для уточнения смысла основы. В разных предложениях одни и те же части речи порой имеют совершенно разное значение, и наиболее точно оценить это значение в контексте текста сегодня может только человек. Однако программно оценить значение какого-либо слова все-таки можно, хоть и не так точно. При этом алгоритм ранжирования должен опираться на так называемый профиль текста, который определяется его автором. Профиль представляет из себя ассоциативный массив, ключами которого являются части речи, а значениями соответственно ранг (или вес) каждой из них. Пример профиля я покажу в заключении, а пока попробуем перевести эти размышления на язык PHP, добавив еще один метод к классу morphyus:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
// ... //
/**
* Оценивает значимость слова
*
* @param {string} word Исходное слово
* @param {array} profile Профиль текста
* @return {integer} Оценка значимости от 0 до 5
*/
public function weigh( $word, $profile=false ) {
// Попытка определения части речи //
$partsOfSpeech = $this->phpmorphy->getPartOfSpeech( $word );
// Профиль по умолчанию //
if ( !$profile ) {
$profile = [
// Служебные части речи //
'ПРЕДЛ' => 0,
'СОЮЗ' => 0,
'МЕЖД' => 0,
'ВВОДН' => 0,
'ЧАСТ' => 0,
'МС' => 0,
// Наиболее значимые части речи //
'С' => 5,
'Г' => 5,
'П' => 3,
'Н' => 3,
// Остальные части речи //
'DEFAULT' => 1
];
}
// Если не удалось определить возможные части речи //
if ( !$partsOfSpeech ) {
return $profile[ 'DEFAULT' ];
}
// Определение ранга //
for ( $i = 0; $i < count( $partsOfSpeech ); $i++ ) {
if ( isset( $profile[ $partsOfSpeech[ $i ] ] ) ) {
$range[] = $profile[ $partsOfSpeech[ $i ] ];
} else {
$range[] = $profile[ 'DEFAULT' ];
}
}
return max( $range );
}
}
?>
Индексирование содержимого сайта

Как уже говорилось выше, индексирование заметно ускоряет выполнение поискового запроса, так как поисковому движку не нужно обрабатывать контент каждый раз заново — поиск выполняется по индексу. Но что же все-таки происходит при индексировании? Если по порядку, то:
- Сначала из текста формируется массив слов, и делается это с помощью метода get_words.
- Согласно профилю, из текста отбрасываются незначимые части речи.
- Значимые оцениваются по пятибальной шкале, с помощью метода weigh.
- Для каждого сова выполняется поиск лемм, иначе говоря базовых форм.
- Рассчитывается количество повторений каждого слова и суммарный ранг.
- Все данные записываются в объект и в виде JSON записываются в базу данных.
В результате получается объект следующего формата:
{
"range" : "<коэффициент значимости индексируемых данных>",
"words" : [
// Одно из слов //
{
"source" : "<базовая версия слова>",
"range" : "<суммарный ранг>",
"count" : "<количество повторений данного слова в тексте>",
"weight" : "<ранг на основе части речи>",
"basic" : [
// Варианты лемм слова //
]
}
]
}
Пишем инициализатор и первый метод ядра поискового движка:
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
function __construct() {
$this->morphyus = new morphyus;
}
/**
* Выполняет индексирование текста
*
* @param {string} content Текст для индексирования
* @param {integer} [range] Коэффициент значимости индексируемых данных
* @return {object} Результат индексирования
*/
public function make_index( $content, $range=1 ) {
$index = new stdClass;
$index->range = $range;
$index->words = [];
// Выделение слов из текста //
$words = $this->morphyus->get_words( $content );
foreach ( $words as $word ) {
// Оценка значимости слова //
$weight = $this->morphyus->weigh( $word );
if ( $weight > 0 ) {
// Количество слов в индексе //
$length = count( $index->words );
// Проверка существования исходного слова в индексе //
for ( $i = 0; $i < $length; $i++ ) {
if ( $index->words[ $i ]->source === $word ) {
// Исходное слово уже есть в индексе //
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
// Если исходного слова еще нет в индексе //
$lemma = $this->morphyus->lemmatize( $word );
if ( $lemma ) {
// Проверка наличия лемм в индексе //
for ( $i = 0; $i < $length; $i++ ) {
// Если у сравниваемого слова есть леммы //
if ( $index->words[ $i ]->basic ) {
$difference = count(
array_diff( $lemma, $index->words[ $i ]->basic )
);
// Если сравниваемое слово имеет менее двух отличных лемм //
if ( $difference === 0 ) {
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
}
}
// Если в индексе нет ни лемм, ни исходного слова, //
// значит пора добавить его //
$node = new stdClass;
$node->source = $word;
$node->count = 1;
$node->range = $range * $weight;
$node->weight = $weight;
$node->basic = $lemma;
$index->words[] = $node;
}
}
return $index;
}
}
?>
Теперь при добавлении или изменении данных в таблицах достаточно просто вызвать данную функцию, чтобы проиндексировать их, но это не обязательно: индексирование может быть и отложенным. Первым аргументом метода make_index является исходный текст, вторым — коэффициент значимости индексируемых данных. Ранг каждого слова, кстати, расчитывается по формуле:
<?php
$range = <коэффициент значимости> * <ранг на основе части речи> * <количество повторений>;
// В коде это выглядит так: //
$index->words[ $i ]->range = $range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
?>
Хранение индексированных данных
Очевидно, что индекс нужно где-нибудь хранить, да еще и привязать к исходным данным. Наиболее подходящим местом для них будет база данных. Если индексируется содержимое файлов, то можно создать отдельную таблицу в базе данных, которая будет содержать индекс название каждого файла, а для содержимого, которое уже хранится в базе, можно добавить еще одно поле типа в структуру таблиц. Такой подход позволит разделять типы содержимого при поиске, например, названия и описание статей в случае блога.
Нерешенным остался лишь вопрос формата индексированного содержимого, ведь make_index возвращает объект, и так просто в базу данных или файл его не запишешь. Можно использовать JSON и хранить его в полях типа LONGTEXT, можно BSON или CBOR, используя тип данных LONGBLOB. Два последних формата позволяют представлять данные в более компактном виде, чем первый.
Как говорится, «хозяин — барин», так-что решать, где и как все будет храниться, Вам.
Benchmark
Давайте проверим, что у нас получилось. Я взял текст своей любимой статьи «Темная материя интернета», а именно содержимое узла #content html_format и сохранил его в отдельный файл.
<?php
require_once '../src/core.php';
$firewind = new firewind;
// Читаем исходный текст //
$source = file_get_contents( './source.html' );
// Засекаем время начала //
$begin_time = microtime( true );
echo "Indexing started: $begin_timen";
// Индексирование //
$index = $firewind->make_index( $source );
// Засекаем время конца //
$finish_time = microtime( true );
echo "Indexing finished: $finish_timen";
// Результаты //
$total_time = $finish_time - $begin_time;
echo "Total time: $total_timen";
?>
На моей машине с конфигурацией:
CPU: Intel Core i7-4510U @ 2.00GHz, 4M Cache
RAM: 2×4096 Mb
OS: Ubuntu 14.04.1 LTS, x64
PHP: 5.5.9-1ubuntu4.5
Индексирование заняло около секунды:
$ php benchmark.php
Indexing started: 1417343592.3094
Indexing finished: 1417343593.5604
Total time: 1.2510349750519
Думаю, вполне неплохой результат.
Реализация поиска
Остался последний и самый главный метод, метод поиска. В качестве первого аргумента метод принимает индекс поискового запроса, в качестве второго — индекс содержимого, в котором выполняется поиск. В результате выполнения возвращается суммарный ранг, рассчитанный на основе ранга найденных слов, либо 0, если ничего не нашлось. Это позволит сортировать поисковую выдачу.
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
// ... //
/**
* Выполняет поиск слов одного индексного объекта в другом
*
* @param {object} target Искомые данные
* @param {object} source Данные, в которых выполняется поиск
* @return {integer} Суммарный ранг на основе найденных данных
*/
public function search( $target, $index ) {
$total_range = 0;
// Перебор слов запроса //
foreach ( $target->words as $target_word ) {
// Перебор слов индекса //
foreach ( $index->words as $index_word ) {
if ( $index_word->source === $target_word->source ) {
$total_range += $index_word->range;
} else if ( $index_word->basic && $target_word->basic ) {
// Если у искомого и индексированного слов есть леммы //
$index_count = count( $index_word ->basic );
$target_count = count( $target_word ->basic );
for ( $i = 0; $i < $target_count; $i++ ) {
for ( $j = 0; $j < $index_count; $j++ ) {
if ( $index_word->basic[ $j ] === $target_word->basic[ $i ] ) {
$total_range += $index_word->range;
continue 2;
}
}
}
}
}
}
return $total_range;
}
}
?>
Все! Поисковый движок готов к использованию. Но есть одно но… На самом деле это не джин-волшебник, и просто закинув его на свой сайт Вы не получите ничего. Его нужно интегрировать, причем этот процесс во многом зависит от архитектуры Вашего сайта. Рассмотрим этот процесс на примере небольшого интернет магазина.
Реализация поиска на примере интернет-магазина
Допустим, информация о продаваемой продукции хранится в таблице production:
CREATE TABLE `production` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`name` VARCHAR(45) NOT NULL, -- Название продукта
`manufacturer` VARCHAR(45) NOT NULL, -- Производитель
`price` INT NOT NULL, -- Стоимость продукта
`keywords` TEXT NULL, -- Индекс ключевых слов
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `production`;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| name | varchar(45) | NO | | NULL | |
| manufacturer | varchar(45) | NO | | NULL | |
| price | int(11) | NO | | NULL | |
| keywords | text | YES | | NULL | |
+--------------+-------------+------+-----+---------+-------+
А описание в таблице description:
CREATE TABLE `description` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`fid` INT NOT NULL, -- Внешний ключ для привязки описания к продукту
`description` LONGTEXT NOT NULL, -- Само описание
`index` TEXT NULL, -- Индексированное описание
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `description`;
+-------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| fid | int(11) | NO | | NULL | |
| description | longtext | NO | | NULL | |
| index | text | YES | | NULL | |
+-------------+----------+------+-----+---------+-------+
Поле production.keywords будет содержать индекс ключевых слов продукта, description.index будет содержать индексированное описание. И все это будут храниться в формате JSON.
Вот пример функции добавления нового продукта:
<?php
require_once 'firewind/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
function add_product( $name, $manufacturer, $price, $description, $keywords ) {
global $firewind, $connection;
// Индексирование описания продукта //
$description_index = $firewind->make_index( $description );
$description_index = json_encode( $description_index );
// Индексирование ключевых слов //
$keywords_index = $firewind->make_index( $keywords, 2 );
$keywords_index = json_encode( $keywords_index );
// Подготовка запросов //
$production_query = $connection->prepare(
"INSERT INTO `production` ( `name`, `manufacturer`, `price`, `keywords` )
VALUES ( ?, ?, ?, ? )"
);
$description_query = $connection->prepare(
"INSERT INTO `description` ( `fid`, `description`, `index` )
VALUES ( LAST_INSERT_ID(), ?, ? )"
);
if ( !$production_query || !$description_query ) {
die( "Cannot prepare requests!n" );
}
if (
// Биндинг параметров //
$production_query -> bind_param( 'ssis', $name, $manufacturer, $price, $keywords_index ) &&
$description_query -> bind_param( 'ss', $description, $description_index ) &&
// Выполнение запросов //
$production_query -> execute() &&
$description_query -> execute()
) {
// Если запросы выполнились успешно //
echo( "Product successfully added!n" );
// Завершение запросов //
$production_query -> close();
$description_query -> close();
return true;
} else {
die( "An error occurred while executing query...n" );
}
}
?>
Здесь поисковый механизм был интегрирован в функцию добавления нового продукта магазина. А теперь обработчик поисковых запросов:
<?php
require_once '../src/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
// Поисковый запрос //
$query = isset( $_GET[ 'query' ] ) ? trim( $_GET[ 'query' ] ) : false;
if ( $query ) {
// Обработка поискового запроса //
$query_index = $firewind->make_index( $query );
// Получение данных //
$production = $connection->query("
SELECT p.`uid`, p.`name`, p.`keywords`, d.`index`
FROM `production` p, `description` d
WHERE p.`uid` = d.`uid`
");
if ( !$production ) {
die( "Cannot get production info.n" );
}
// Выполнение поиска //
while ( $product = $production->fetch_assoc() ) {
// Распаковка индекса //
$keywords = json_decode( $product[ 'keywords' ] );
$index = json_decode( $product[ 'index' ] );
$range = $firewind->search( $query_index, $keywords );
$range += $firewind->search( $query_index, $index );
if ( $range > 0 ) {
$result[ $product[ 'uid' ] ] = $range;
}
}
// Если что-нибудь нашлось //
if ( isset( $result ) ) {
// Сортировка по убыванию //
arsort( $result );
// Вывод результатов //
$i = 1;
foreach ( $result as $uid => $range ) {
printf(
"#%d. Found product with id %d and range %d.n",
$i++,
$uid,
$range
);
}
} else {
echo( "Sorry, no results found.n" );
}
} else {
echo( "Query cannot be empty. Try again.n" );
}
?>
Данный сценарий принимает поисковый запрос в виде GET-параметра query и выполняет поиск. В результате выводятся найденные продукты магазина.
Заключение
В статье был описан один из вариантов реализации поиска для сайта. Это самая первая его версия, поэтому буду только рад узнать Ваши замечания, мнения и пожелания. Присоединяйтесь к моему проекту на Github: https://github.com/axilirator/firewind. В планах добавить туда еще кучу всяких возможностей, вроде кэширования поисковых запросов, подсказок при вводе поискового запроса и алгоритма побуквенного сравнения, который поможет бороться с опечатками.
Всем спасибо за внимание, ну и с днем информационной безопасности!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какой поиск для сайта предпочитаете Вы?
23.17%
Своя реализация
174
5.99%
Попробую FireWind
45
12.25%
Не использую поиск для сайта
92
Проголосовал 751 пользователь.
Воздержались 287 пользователей.
Задача. На сайте необходимо заменить определенный текст. Проблема заключается в том, что это непопулярная CMS Zikula, в которой сложно разобраться где что находится. Сначала пробовали искать и заменять текст в базе данных. Но во многих местах оставался старый текст. Значит, скорей всего, этот текст в каких-то шаблонах страниц. Нужно найти этот текст в файлах.
Решение. Чтобы найти конкретный текст в файлах сайта на сервере можно воспользоваться Total Commander:
- Открыть Total Commander.
- Нажать кнопку FTP (иконка вверху на панели).
- Ввести данные для подключения к ресурсу (Хост, порт, логин, пароль) по FTP и соединиться.
- Перейти в корень сайта.
- Нажать кнопку «Поиск» (иконка бинокля вверху в панели).
- В появившемся окне Поиска файлов включить «С текстом» и в текстовом поле указать искомый текст.

Поиск текста в файлах в Total Commander
Вы часами пытались найти строку кода на своем сайте WordPress? Это может быть неприятно, если после тщательного ручного поиска вы не добьетесь успеха. Попробуйте некоторые из бесплатных инструментов, которые сделают задачу проще и точнее.
Иногда случается, что вы добавили код настройки и теперь не можете его отследить. Другая возможность заключается в том, что вы внесли много изменений на свой сайт. Это может включать в себя фрагмент кода с ошибками, который не является ошибочным, но может давать нежелательный результат. После нескольких дней добавления этого кода, когда вы поймете, что результат не такой, как ожидалось, вы можете захотеть его изменить. Затем вам нужно будет отследить источник и исправить его. Теперь вы не можете найти строку кода на своем веб-сайте. Ручной поиск может работать, а может и не работать постоянно. В этой статье, здесь Templatetoaster WordPress сайте застройщика, мы рассмотрим несколько простых в использовании методов для автоматизации процесса, чтобы найти строку кода в веб – сайте.
Ручные методы поиска строк кода
1. Найдите строку кода на веб-сайте с помощью PHP / текстового редактора.
Вы можете использовать любой текстовый редактор, например Notepad ++, чтобы использовать расширенные функции поиска. Notepad ++ – лучший и самый популярный редактор файлов PHP, работающий как для Windows, так и для Mac. После того, как вы скачали файлы PHP WordPress, вы можете использовать Notepad ++, чтобы найти строку кода в файле веб-сайта.
Если вам известен файл, в котором отображается ошибка, вы можете просто загрузить этот файл и найти в нем код. Вы также можете искать строки кода в своем каталоге WordPress, используя расширенные функции поиска редактора.
2. Найдите строку кода на веб-сайте в системах Unix / Linux / MacOS
Команда grep позволяет искать текстовые шаблоны в файле. Используйте вариант использования приведенной ниже команды, чтобы найти строку кода в файлах вашего веб-сайта для сервера Linux / Unix. Прежде всего, вам необходимо войти на сервер через терминал с помощью Putty или Bitvise. Перейдите в каталог установки WordPress и выполните команду ниже:
grep $search-term file.phpПримечание: вам может потребоваться ssh-доступ к веб-серверу, если вы не являетесь администратором.
3. Поиск по строке кода на веб-сайте на компьютерах с Windows
В Windows вы можете установить Cygwin, а затем использовать grep для поиска определенного текста или текста, соответствующего регулярным выражениям. Вы также можете использовать команду findstr для поиска файлов, содержащих строки кода, которые точно соответствуют указанной строке или соответствуют регулярному выражению.
Автоматические инструменты для поиска строк кода
Утилиты и инструменты, такие как Agent Ransack, позволяют найти строку кода в файлах веб-сайта. Сначала вам нужно загрузить файлы кода веб-сайта на локальный компьютер, а затем запустить инструмент для загруженных файлов.
Агент Рэнсак
Agent Ransack – это инструмент для быстрого и эффективного поиска файлов с определенным текстом. Это позволяет искать в содержимом файлов код или текст. Агент Ransack отображает текстовые результаты, и вы можете просматривать результаты, не открывая каждый файл. Agent Ransack также предоставляет мастер для построения регулярных выражений, которые создают более сложные поисковые запросы.
С помощью Agent Ransack вы можете указать выражение имени файла для поиска, строку кода для поиска и каталог для поиска. Вы также можете искать двоичные файлы, но не файлы .zip или другие архивы.
Agent Ransack или FileLocator Lite (для корпоративных сред) – это «облегченная» версия инструмента FileLocator Pro, которая хорошо работает для новичков. Для опытных программистов, которым требуется расширенный поиск большего количества файлов, FileLocator Pro предоставляет дополнительные функции.
Альтернативные варианты для Agent Ransack
Давайте теперь рассмотрим некоторые другие популярные и бесплатные альтернативы Agent Ransack для Windows, Linux, Mac, BSD, Self-Hosted и других сред. Вы можете попробовать эти утилиты для поиска строк кода в файлах вашего сайта.
1. DocFetcher
Портативное настольное приложение для поиска с открытым исходным кодом. Вы можете использовать этот инструмент для поиска содержимого файлов, чтобы найти строку кода на веб-сайте, который вы ищете.
2. FileSearchy
Это служебная программа для поиска файлов, обеспечивающая эффективный поиск по содержимому файла. Он выделяет найденный текст в содержимом файла.
3. Восстановить
Позволяет искать содержимое ваших файлов, как поисковая система. Вы можете быстро искать в больших объемах данных с помощью поискового индекса. Regain незаметно просматривает файлы или веб-страницы, извлекая весь текст и добавляя его в индекс интеллектуального поиска. Вы можете сразу же получить результаты поиска по своей неотслеживаемой строке кода.
4. AstroGrep
Утилита поиска файлов с графическим интерфейсом пользователя Microsoft Windows, которую можно использовать для поиска совпадений регулярного выражения в исходном коде. Вы можете использовать это, чтобы найти совпадающие строки кода в файлах вашего веб-сайта.
5. SearchMonkey
Это поисковая система в реальном времени для отображения совпадений регулярных выражений в содержимом файлов и в нескольких каталогах.
6. SearchMyFiles
Это точный вариант поиска Windows, который позволяет легко искать файлы по содержимому файла, которое может быть текстовым или двоичным.
Строки поиска на HTML-сайтах
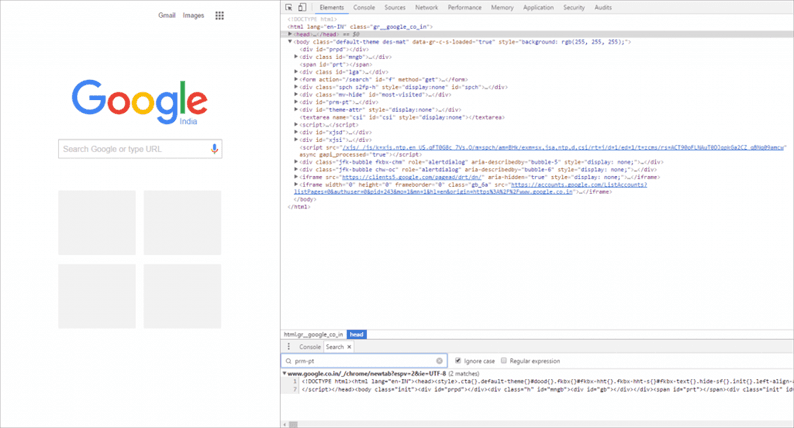
Веб-сайт может содержать код HTML, Javascript и CSS. Возможно, вы захотите найти строку кода в исходном коде своего веб-сайта. Каждый браузер позволяет вам просматривать источник просматриваемого веб-сайта. Вы можете щелкнуть правой кнопкой мыши «Просмотр источника страницы», чтобы открыть исходный код страницы. Вы можете найти строку кода в исходном коде с помощью инструментов, предоставляемых браузером.
Вы также можете выполнять поиск по всем ресурсам веб-сайта, таким как HTML, CSS, JavaScript и т.д. В случае браузера Chrome вы можете использовать инструменты разработчика для выполнения поиска. На любой панели откройте панель поиска (Win: Ctrl + Shift + f, Mac: Cmd + Opt + f). Введите строку кода или имя класса для поиска на текущей HTML-странице. Все результаты поиска с номерами строк будут отображены на панели.
Плагины WordPress для поиска строки кода на веб-сайте
Иногда при создании веб-сайта вы можете застрять, пытаясь выяснить, какой шаблон используется на конкретной странице. Вы можете поискать строки кода на страницах своего веб-сайта. Могут быть фрагменты неотслеживаемого текста, исходный код которых невозможно. Есть несколько доступных плагинов WordPress, которые помогут вам с этими проблемами.
1. Что за файл
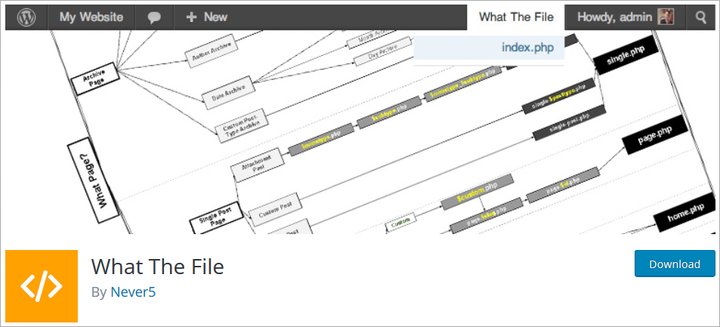
Плагин «What The File» позволяет добавить на панель инструментов параметр, отображающий файл и шаблоны, используемые для отображения просматриваемой в данный момент страницы. Вы можете напрямую просматривать, находить строку кода на веб-сайте и редактировать файл через редактор темы. Затем вы можете искать строки кода внутри этих файлов.
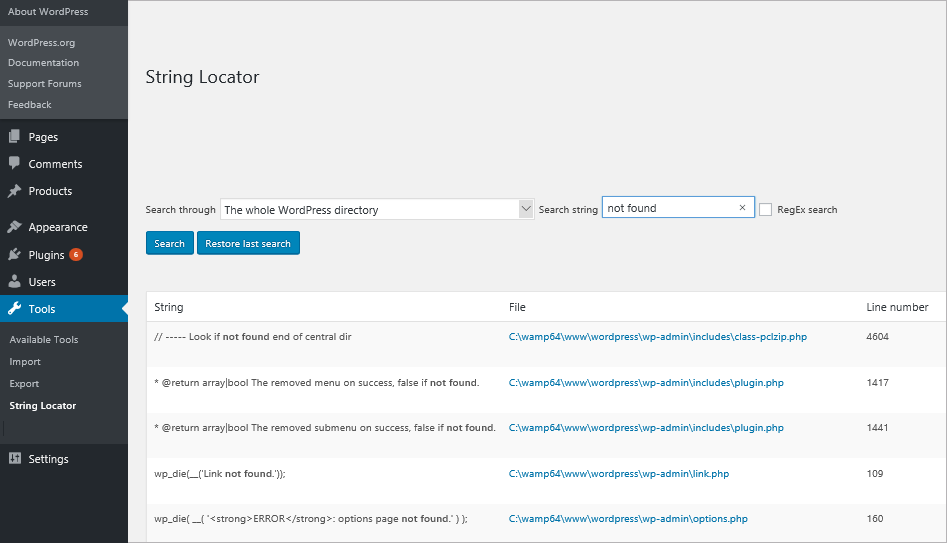
2. Локатор строк

При работе с темами и плагинами вы можете увидеть фрагмент текста, который выглядит так, как будто он жестко закодирован в файлах. Возможно, вам придется изменить его, но вы не можете найти строку кода в файлах темы. С помощью плагина «String Locator» вы можете искать темы, плагины или основные файлы WordPress. Плагин представляет результаты в виде списка файлов, совпадающего текста и строки файла, который соответствовал поиску.
Вывод
Поиск, ручной или автоматический, не всегда может дать вам наилучшие результаты. Вы можете бесконечно пытаться найти строку кода на веб-сайте вручную, но это приведет к разочарованию только в том случае, если поисковый контент большой. Автоматические инструменты, утилиты и плагины WordPress помогут значительно сократить усилия, но при этом будут более точными. Инструмент TemplateToaster для создания веб-сайтов также прост в использовании. TemplateToaster, программа для веб-дизайна, поддерживает все плагины WordPress и помогает создавать расширенные темы и шаблоны страниц. Он не требует кодирования и автоматически генерирует код. С помощью конструктора веб- сайтов TemplateToaster и конструктора тем WordPress вам больше не нужно будет самостоятельно создавать, искать и устранять неполадки любого кода настройки.
Источник записи: https://blog.templatetoaster.com
Содержание статьи
- Панели поиска в браузерах
- Поиск текста в Google Chrome
- Поиск текста в Mozilla Firefox
- Поиск текста в Яндекс Браузере
Каждому юзеру приходится искать-либо на страницах сайтов. Это может быть не статья или новость целиком, а конкретный абзац или отрывок текста, где находится ключевое слово или фраза. Если на странице много текста, а нужен только кусок с искомым описанием, то юзаем поиск слов в браузере. Это функция, идентичная с поиском в Ворде, Экселе или PDF-редакторах.
Панели поиска в браузерах
В каждом браузере есть своя панель поиска. Чтобы вызвать ее, следует нажать Ctrl+F. Рассмотрим панели поиска таких браузеров как Хром, Firefox и Яндекс Браузер.
Поиск текста в Google Chrome
Открыть панель в Хроме можно другим способом, нажав на меню и выбрав функцию «Найти…».

Находясь на любой странице, набираем интересующее слово или фразу и нажимаем enter. Как видно на скриншоте, найденное слово подсвечено оранжевым. На панели указано количество найденных слов. С помощью стрелок осуществляется переход от одного результата к другому.

Поиск текста в Mozilla Firefox
В Firefox панель поиска более продвинутая и удобная. Обладает следующими опциями:
- подсветить все;
- с учетом регистра;
- только слова целиком.

«Подсветить все», как вы догадались, позволяет увидеть все нужные слова в документе.

Функция «С учетом регистра» придает поиску чувствительность к большим и маленьким буквам. Например, если вы напечатали слово «нефть», то есть слово с маленькой буквы, то в качестве совпадений варианты «Нефть» или «НЕФТЬ» учитываться не будут.

Поиск при помощи опции «Только слова целиком» отсеивает слова со склонениями и окончаниями. Вобъем персидское слово «нефт», чтобы проверить результат.

Поиск текста в Яндекс Браузере
Браузер Яндекса имеет аналогичную с Хромом панель поиска текста, однако обладает крутой лингвистической системой. Известно, что Яндекс как поисковик лучше любой другой системы понимает русский язык. Именно это преимущество дает пользователю возможность находить среди текста на странице нужный фрагмент или отдельные предложения с максимальным количеством вариантов. Алгоритм поиска текста учитывает падежи, склонения, число, род, часть речи.

Однажды мы рассказывали, как утащить что угодно с любого сайта, — написали свой парсер и забрали с чужого сайта заголовки статей. Теперь сделаем круче — покажем на примере нашего сайта, как можно спарсить вообще весь текст всех статей.
Парсинг — это когда вы забираете какую-то конкретную информацию с сайта в автоматическом режиме. Для этого пишется софт (скрипт или отдельная программа), софт настраивается под конкретный сайт, и дальше он ходит по нужным страницам и всё оттуда забирает.
После парсинга полученный текст можно передать в другие программы — например подстроить свои цены под цены конкурентов, обновить информацию на своём сайте, проанализировать текст постов или собрать бигдату для тренировки нейросетей.
Что делаем
Сегодня мы спарсим все статьи «Кода» кроме новостей и задач, причём сделаем всё так:
- Научимся обрабатывать одну страницу.
- Сделаем из этого удобную функцию для обработки.
- Найдём все адреса всех нужных страниц.
- Выберем нужные нам рубрики.
- Для каждой рубрики создадим отдельный файл, в который добавим всё текстовое содержимое всех статей в этой рубрике.
Чтобы потом можно было нормально работать с текстом, мы не будем парсить вставки с примерами кода, а ещё постараемся избавиться от титров, рекламных баннеров и плашек.
Будем работать поэтапно: сначала научимся разбирать контент на одной странице, а потом подгрузим в скрипт все остальные статьи.
Выбираем страницу для отладки
Технически самый простой парсинг делается двумя командами в Python, одна из которых — подключение сторонней библиотеки. Но этот код не слишком полезен для нашей задачи, сейчас объясним.
from urllib.request import urlopen
inner_html_code = str(urlopen('АДРЕС СТРАНИЦЫ').read(),'utf-8')Когда мы заберём таким образом страницу, мы получим сырой код, в котором будет всё: метаданные, шапка, подвал и т. д. А нам нужно не только достать информацию из самой статьи (а не всей страницы), а ещё и очистить её от ненужной информации.
Чтобы скрипт научился отбрасывать ненужное, придётся ему прописать, что именно отбрасывать. А для этого нужно знать, что нам не нужно. А значит, нам нужно взять какую-то старую статью, в которой будут все ненужные элементы, и на этой одной странице всё объяснить.
Для настройки скрипта мы возьмём нашу старую статью. В ней есть всё нужное для отладки:
- текст статьи,
- подзаголовки,
- боковые ссылки,
- кат с кодом,
- просто вставки кода в текст,
- титры,
- рекламный баннер.
Получаем сырой текст
Вот что мы сейчас сделаем:
- Подключим библиотеку urlopen для обработки адресов страниц.
- Подключим библиотеку BeautifulSoup для разбора исходного кода страницы на теги.
- Получим исходный код страницы по её адресу.
- Распарсим его по тегам.
- Выведем текстовое содержимое распарсенной страницы.
На языке Python это выглядит так:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSoup
from bs4 import BeautifulSoup
# получаем исходный код страницы
inner_html_code = str(urlopen('https://thecode.media/parsing/').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# выводим содержимое страницы
print(inner_soup.get_text())Если посмотреть на результат, то видно, что в вывод пошло всё: и программный код из примеров, и текст статьи, и служебные плашки, и баннер, и ссылки с рекомендациями. Такой мусорный текст не годится для дальнейшего анализа:
Чистим текст
Так как нам требуется только сама статья, найдём раздел, в котором она лежит. Для этого посмотрим исходный код страницы, нажав Ctrl+U или ⌘+⌥+U. Видно, что содержимое статьи лежит в блоке <div class="article-content line-numbers">, причём такой блок на странице один.

Чтобы из всего исходного кода оставить только этот блок, используем команду find() с параметром 'div', {"class": 'article-content'} — она найдёт нужный нам блок, у которого есть характерный признак класса.
Добавим эту команду перед выводом текста на экран:
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
Стало лучше: нет мусора до и после статьи, но в тексте всё ещё много лишнего — содержимое ката с кодом, преформатированный код (вот такой), вставки с кодом, титры и рекламный баннер.
Чтобы избавиться и от этого, нам нужно знать, в каких тегах или блоках это лежит. Для этого нам снова понадобится заглянуть в исходный код страницы. Логика будет такая: находим фрагмент текста → смотрим код, который за него отвечает, → удаляем этот код из нашей переменной.Например, если мы хотим убрать титры, то находим блок, где они лежат, а потом в цикле удаляем его командой decompose().

Сделаем функцию, которая очистит наш код от любых разделов и тегов, которые мы укажем в качестве параметра:
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()А теперь добавим такой код перед выводом содержимого:
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
Точно так же проанализируем исходный код и добавим циклы для удаления остального мусора:
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры, перебирая все их возможные индексы в цикле (потому что баннеры в коде имеют номера от 1 до 99)
for i in range(99):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')Теперь всё в порядке: у нас есть только текст статьи, без внешнего обвеса, лишнего кода и ссылок. Можно переходить к массовой обработке.
Собираем функцию
У нас есть скрипт, который берёт одну конкретную ссылку, идёт по ней, чистит контент и получает очищенный текст. Сделаем из этого функцию — на вход она будет получать адрес страницы, а на выходе будет давать обработанный и очищенный текст. Это нам пригодится на следующем шаге, когда будем обрабатывать сразу много ссылок.
Если запустить этот скрипт, получим тот же результат, что и в предыдущем разделе.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.get_text())
print(clear_text('https://thecode.media/parsing/'))Получаем адреса всех страниц
Одна из самых сложных вещей в парсинге — получить список адресов всех нужных страниц. Для этого можно использовать:
- карту сайта,
- внутренние рубрикаторы,
- разделы на сайте,
- готовые страницы со всеми ссылками.
В нашем случае мы воспользуемся готовой страницей — там собраны все статьи с разбивкой по рубрикам: https://thecode.media/all. Но даже в этом случае нам нужно написать код, который обработает эту страницу и заберёт оттуда только адреса статей. Ещё нужно предусмотреть, что нам не нужны ссылки из новостей и задач.
Идём в исходный код общей страницы и видим, что все ссылки лежат внутри списка:

При этом каждая категория статей лежит в своём разделе — именно это мы и будем использовать, чтобы обработать только нужные нам категории. Например, вот как рубрика «Ахах» выглядит на странице:
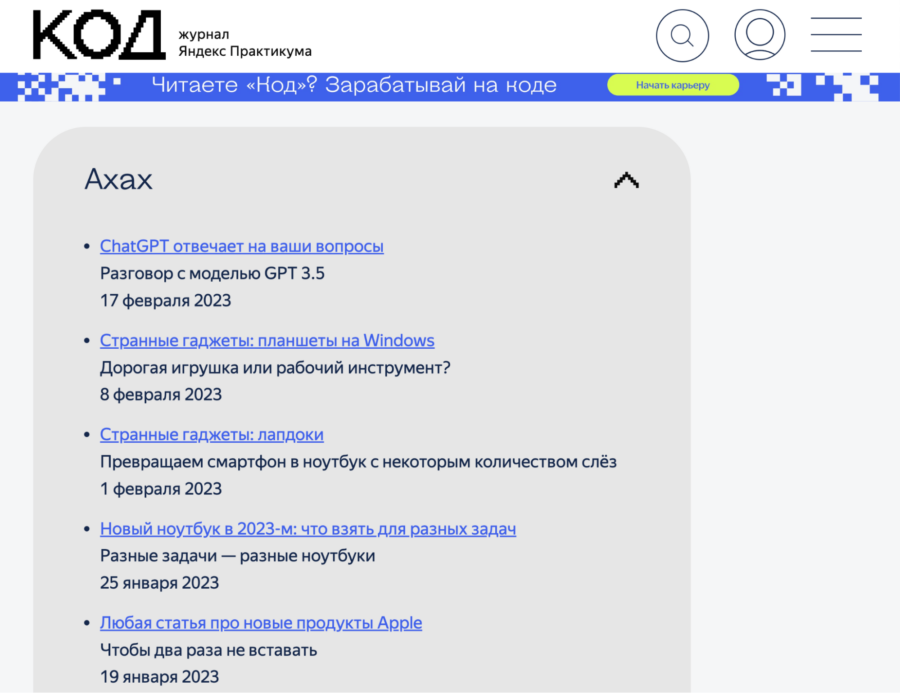
А вот она же — но в исходном коде. По названию легко понять, какой блок за неё отвечает:
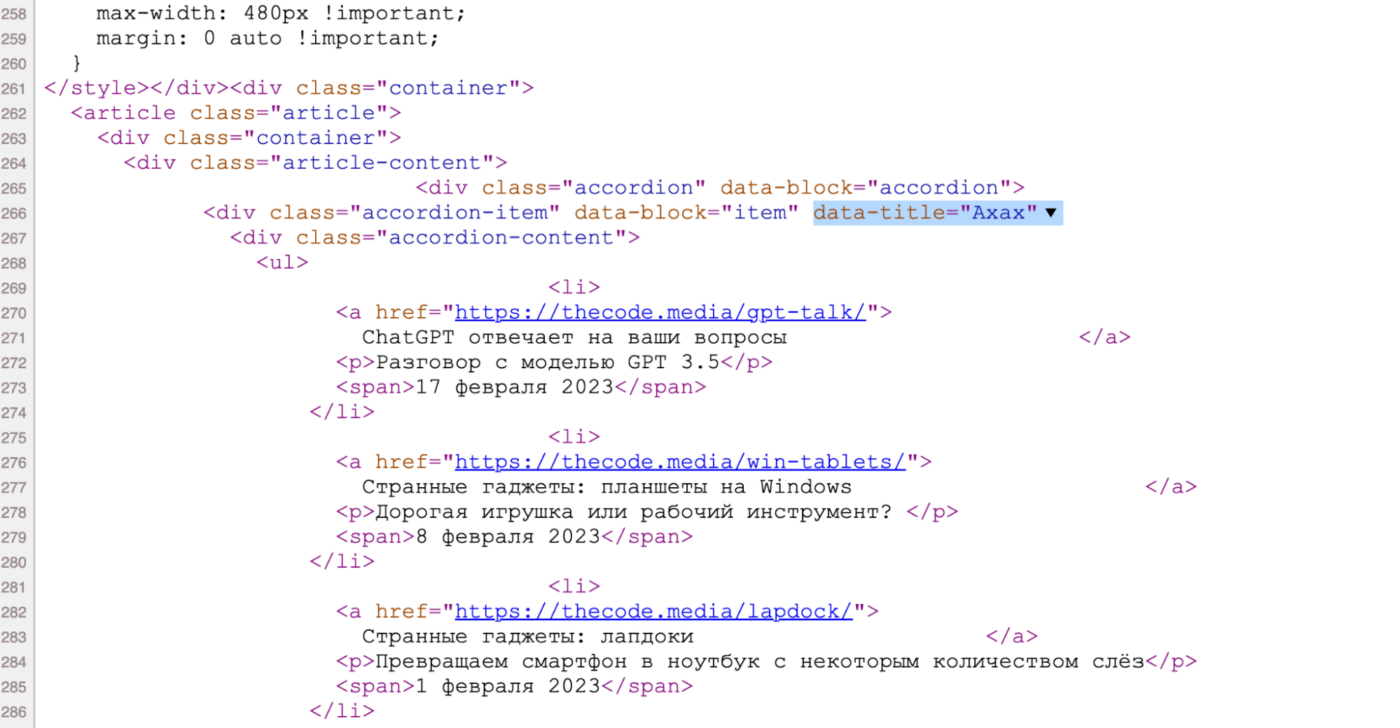
Чтобы найти раздел в коде по атрибуту, используем команду find() с параметром attrs — в нём мы укажем название рубрики. А чтобы найти адрес в ссылке — используем команду select(), в которой укажем, что ссылка должна лежать внутри элемента списка.
Теперь логика будет такая:
- Создаём список с названиями нужных нам рубрик.
- Делаем функцию, куда будем передавать эти названия.
- Внутри функции находим рубрику по атрибуту.
- Перебираем все элементы списка со ссылками.
- Находим там адреса и записываем в переменную.
- Для проверки — выводим переменную с адресами на экран.
def get_all_url(data_title):
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# выводим найденные адреса
print(url)
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)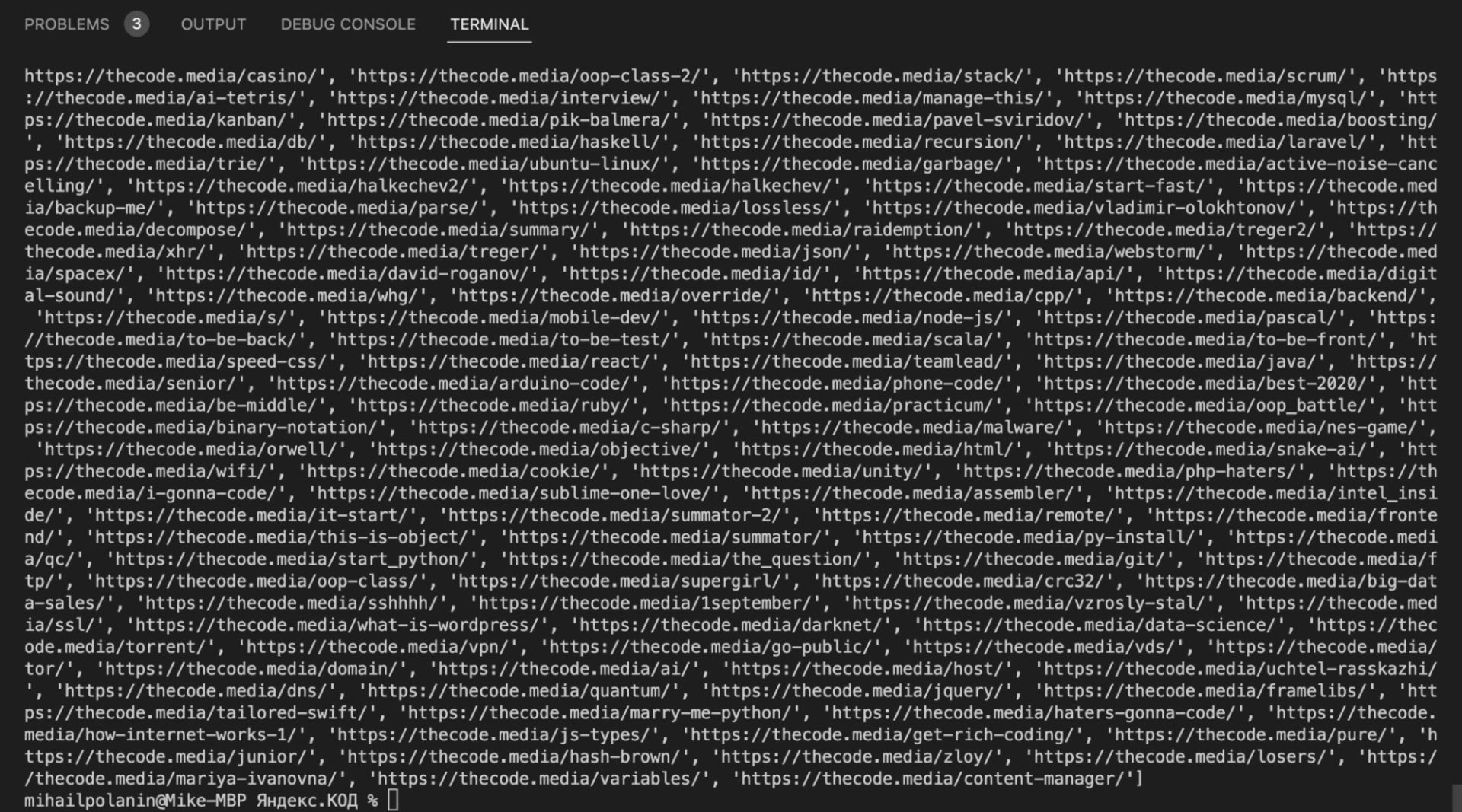
На выходе у нас все адреса страниц из нужных рубрик. Теперь объединим обе функции и научим их сохранять текст в файл.
Сохраняем текст в файл
Единственное, чего нам сейчас не хватает, — это сохранения в файл. Чтобы каждая рубрика хранилась в своём файле, привяжем имя файла к названию рубрики. Дальше логика будет такая:
- Берём функцию get_all_url(), которая формирует список всех адресов для каждой рубрики.
- В конец этой функции добавляем команду создания файла с нужным названием.
- Открываем файл для записи.
- Перебираем в цикле все найденные адреса и тут же отправляем каждый адрес в функцию clear_text().
- Результат работы этой функции — готовый контент — записываем в файл и переходим к следующему.
Так у нас за один прогон сформируются адреса, и мы получим содержимое страницы, которые сразу запишем в файл. Читайте комментарии, чтобы разобраться в коде:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.get_text())
# формируем список адресов для указанной рубрики
def get_all_url(data_title):
# считываем страницу со всеми адресами
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# имя файла для содержимого каждой рубрики
content_file_name = data_title + '_content.txt'
# открываем файл и стираем всё, что там было
file = open(content_file_name, "w")
# перебираем все адреса из списка
for x in url:
# сохраняем обработанный текст в файле и переносим курсор на новую строку
file.write(clear_text(x) + 'n')
# закрываем файл
file.close()
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)
Что дальше
Теперь у нас есть все тексты всех статей. Как-нибудь проанализируем частотность слов в них (как в проекте с текстами Льва Толстого) или научим нейросеть писать новые статьи на основе старых.
Вёрстка:
Кирилл Климентьев