При создании контента, большое значение имеет использование ключей, или предполагаемых запросов, с помощью которых пользователь быстрее найдет нужную информацию. Внедрив в текст ключевики, автор статьи тем самым значительно увеличивает шансы, что среди большого разнообразия материалов в сети интернет его работа найдет своего читателя. Однако, работать с ними нужно аккуратно, чтобы написанное выглядело органично. Для этого следует разобраться, что собой представляет прямое, точное и другие варианты вхождения ключевых слов, а также другие нюансы этой темы.
- Что это такое и как работает
-
Виды вхождений ключевых слов
- Точное вхождение ключевого слова: что это
- Чистое
- Прямое вхождение ключа: что это такое
- Разбавленное вхождение ключа: подробнее об этом
- Морфологическое
- Синонимическое
- Обратное
- Сложное
- С опечаткой
-
Правила подбора
- Вручную
- С помощью сервисов
- Особенности использования
- Чем опасно перенасыщение
- Допустимое количество
- Что важно запомнить
- Заключение

Что это такое и как работает
Ключевиками называют словосочетания, которые пользователь вводит в поисковую строку, чтобы быстрее получить нужную информацию. Робот-поисковик на основе этого анализирует все страницы в интернете и выдает наиболее подходящие.
Приведем пример. Человеку нужен ведущий на мероприятие. Именно это он введет в строке. Дополнительно может указываться название города, где будет проходить праздник, что нужно именно «заказать» или «купить» услугу и прочие уточняющие детали. На основе этого в выдаче появится страница с доступными ссылками, где высокие места будут занимать сайты, тексты которых содержат указанные в поисковой строке запросы.
Разделение ключей происходит на основе нескольких параметров. Одним из них является частота ввода конкретного словосочетания. В указанной категории выделяют следующие типы ключевиков:
- Низкочастотные. Используются редко, как правило, они связаны с узкой тематикой. Их запрашивают не чаще 200 раз в месяц. подходят для продвижения непопулярных услуг, товаров в небольших населенных пунктах.
- Среднечастотные. Их количество ежемесячно может достигать 1 000. Они более длинные, подробные. Могут включать до 6 единиц.
- Высокочастотные. Запрашиваются тысячами пользователей постоянно. Может возникать в поиске больше 500 000 раз за 30 дней. ВЧ применяются для изделий, на которые существует стабильный спрос.
Виды вхождений ключевых слов
Существует несколько вариантов добавления ключей в текст, каждый из которых отличается формой написания ключевика. В таблице ниже приведены примеры, как могут внедряться запросы в текстовый материал.
| Тип | Особенности изменений | Например |
| Прямое | Появляются предлоги, знаки препинания | Аренда офиса в краснодаре |
| Точное вхождение запроса | Без смены | Аренда офиса краснодар |
| Разбавленное | Прибавляются допы | Аренда офиса в центре краснодара |
| Морфологическое | Различные склонения, спряжения | Условия аренды офиса в краснодаре |
| Синонимическое | Частично используются синонимы | Аренда офисного помещения в краснодаре |
На практике видно, как меняется фраза в зависимости от конкретного вида ключа. При создании каждого из них важно учитывать определенные нюансы, чтобы не допустить ошибок. В противном случае продвигать сайт будет достаточно сложно – поисковики не будут выводить его на высокие позиции.

Точное вхождение ключевого слова: что это
Особенность этого запроса в том, что словосочетание внедряется в заданном формате, без каких-либо изменений. Нельзя менять окончания, что-то добавлять. Например: «свадебные букеты» – именно в таком виде и нужно вписывать фразу в тексте.
Чистое
Не отличается от предыдущего варианта. При написании также не должно быть никаких знаков препинания, нельзя добавлять ничего лишнего, особенно дополнительные словосочетания, местоимения и прочие части речи, не рекомендуется изменять порядок словесной конструкции.

Заспамленность текста: что это такое, значение нормы
Сегодня мы расскажем о заспамленности текста, а также что означает такой параметр, как тошнота, в чем суть и значение этих показателей для seo-оптимизации сайта, как можно их снизить, чтобы избежать негативных последствий при продвижении страниц. Узнаем, под какие санкции попадают статьи с переспамом и с помощью каких действий получится миновать фильтры поисковых систем Яндекс и Google. Общее представление Термин «спам» появился в сети 30 лет назад. Изначально это слово связывалось исключительно с бесконечными рекламными рассылками, основное назначение которых было склонить…
Прямое вхождение ключа: что это такое
Данный вариант также схож с предыдущими двумя. Однако имеет одно отличие: при написании можно использовать знаки препинания. Это позволяет добиться естественности, особенно, если изначальное словосочетание кажется слишком нелогичным.
Например, ключевик «свадебные букеты купить» можно написать в предложении, разделив конструкцию запятой или другими символами: «В нашем салоне представлены к продаже роскошные свадебные букеты, купить которые вы можете по самой выгодной цене».

Разбавленное вхождение ключа: подробнее об этом
Отличительной особенностью этого написания является возможность использовать дополнительные слова. Исключением являются случаи, когда запрос состоит из одной словарной единицы. Этот тип добавления ключевиков позволяет добиться естественности в тексте. Например, словосочетание «свадебные букеты купить» мы можем прописать уже следующим образом: «Заказывайте роскошные свадебные букеты в Пензе – купить цветочную композицию можно в нашем салоне по адресу.».
Морфологическое
Позволяет менять склонение или спряжение. Чем длиннее изначальная фраза, тем больше возможностей для ее трансформации. Приведем пример. Словосочетание «доставка свадебных букетов» при написании может выглядеть так: «Закажите быструю доставку свадебных букетов на нашем сайте».

Синонимическое
Из названия понятно, что некоторые части словосочетания можно заменить близкими по значению, то есть синонимами. Так, «работать» возможно поменять на «трудиться» – кроме того, такой подход позволяет избежать тавтологии в содержании статьи.
Обратное
Особенность написания заключается в возможности менять местами слова во фразе, при этом одно из них может изменить окончание. В качестве примера возьмем словосочетание «свадебные букеты доставка». Перефразировав, получаем «Срочная доставка свадебных букетов».
Морфологическое разбавленное вхождение ключа
Этот тип внедрения в текст ключевиков интересен тем, что позволяет употреблять их в различной форме, а также разбавлять дополнительными словесными единицами. Например, «составление свадебных букетов» будет выглядеть так: «В нашем салоне вы можете заказать не только составление цветочных композиций, но готовые свадебные букеты».
Сложное
Когда в одной фразе используется сразу несколько приемов. Например, переставляются единицы, меняется их форма и добавляются местоимения, наречия и другие части речи.
Вернемся к запросу «доставка свадебных букетов». При сложном написании она будет выглядеть следующим образом: «Роскошные свадебные букеты мы можем доставить не только в городе, но и по области».

С опечаткой
В некоторых случаях автор совершается намеренную ошибку. Но в современном seo к подобному приему практически уже не прибегают. Это связано с тем, что от такого написания можно получить больше вреда, чем пользы. Не стоит писать, например, «свадёбные букеты» вместо «свадебные букеты».
Правила подбора
Выше мы говорили, что подобные запросы должны положительно отражаться на статистике сайта. Чтобы вхождение ключевых фраз и слов в текст приносило нужный результат, важно знать, как грамотно их подбирать, какие вообще словосочетания подходят.

Вручную
Суть метода заключается в самостоятельном отборе подходящих ключевиков. Необходимо подумать, как пользователь будет формулировать вопрос, чтобы найти конкретную услугу или товар в интернете. Например:
заказать свадебные букеты
букеты пенза
доставка свадебных букетов пенза
роскошные свадебные букеты
букеты на свадьбу красивые
купить срочно свадебный букет
Затем создать список и отметить в нем простые и более детальные запросы.
С помощью сервисов
Метод помогает автоматизировать процесс и ускорить его. Для этого используют специальные программы, которые подбирают нужные фразы самостоятельно. При выборе системы необходимо учитывать, что за функции они предлагают, на какие поисковики ориентированы. Кроме того, есть сервисы платные (Serpstat, Rush Analytics) и бесплатные, например, The SEO Tools.
Особенности использования
Вхождение ключевых слов в текст необходимо совершать определенным образом. Их можно добавлять в любые разделы сайта, заголовки статей. Важно, чтобы они равномерно распределялись по всему материалу, а не скапливались в одной его области. Несколько схожих ключевиков не должны находиться близко. Используют только уместные запросы в подходящих точках контента.

Чем опасно перенасыщение
Проблемы возникнут не только с поисковой оптимизацией, но и потенциальной аудиторией. Избыток ключей поисковики давно научились распознавать. И находя такие порталы, они намеренно понижают их в выдаче.
Дополнительно контент становится неестественным, читать его сложно. А пользователи охотнее реагируют на качественные статьи.
Допустимое количество
Нет установленных стандартов того, сколько точных или других типов вхождений должно присутствовать в материале. Рекомендуется, чтобы их было около 5% от общего объема. Это позволит добиться хорошего уровня оптимизации, избежав перенасыщения. Главное, чтобы выбранные ключевики являлись средне- и высокочастотными.

Как быстро собрать семантическое ядро для интернет-магазина
Что значит СЯ Если говорить просто, семантика – это список запросов пользователей, по которым они ищут какую-то информацию в интернете. В нашем случае фразы, забитые в строку поисковика, ведут покупателя на страницу, где можно купить, заказать, оформить доставку или узнать цену конкретного продукта. Собирая эти ключевики и вписывая их в H1, Title, Description и текстовые блоки, мы можем привлекать потенциальных клиентов на наш сайт. Особенности сбора семантического ядра для интернет-магазина Так как в ИМ размещено много разных страниц, СЯ для…
Что важно запомнить
Резюмируем вышесказанное. Для качественной работы стоит помнить следующие нюансы:
- Ключевые слова позволяют системе ранжировать сайт, согласно вводимой пользователем информации.
- При небольшом объеме работы, например, когда товар или услуга только одна, оптимизацией можно заниматься вручную. Для более крупных сайтов рекомендуется использовать специальные сервисы.
- Точное вхождение фразы позволяет вносить словосочетания в неизменном виде. Существуют и другие типы ключевиков, позволяющих менять окончание, добавлять знаки препинания и прочее.
- В зависимости от популярности ключа, его подразделяют на низко- средне- и высокочастотный.

Заключение
Чем выше расположен сайт в выдаче, тем больше вероятность, что пользователи посетят его. Один из способов получить большое количество посетителей на ваш ресурс – сделать оптимизацию контента под ключевые запросы. Однако, важно уметь добавлять их грамотно – в противном случае, контент будет признан поисковой системой неестественным и вряд ли когда-либо попадет в ТОП.
Текст с ключевыми словами. Виды вхождений и секреты эффективного использования ключей
Подбор, определение плотности и видов вхождений ключевых слов в тексты – это вотчина SЕО-специалистов. Итог их работы выливается в техническое задание, порой сбивающее с толку даже опытных копирайтеров.
В данной статье вы узнаете, что такое ключевые слова и какие виды вхождений существуют. В качестве бонуса – несколько полезных фишек по органичному использованию ключевиков в текстах.
Что такое ключевые слова, виды их вхождений в тексты
Ключевые слова (ключевики, keywords, SEO-ключи) – это запросы, органично вписанные в текст определенное количество раз, влияющие на ранжирование страницы в поисковой выдаче.
Проще говоря, это отдельные слова или словосочетания, которые пользователи пишут в поисковой строке для получения необходимой информации. Также ключи используются поисковыми системами для обеспечения максимально точного соответствия результатов выдачи, чтобы человек с запросом [купить холодильник] попадал на сайт магазина бытовой техники, а не туристического снаряжения.

Чаще всего ключи определяют содержание статьи, но бывает, что авторам приходится использовать в тексте слова, далекие от основной темы.
Какие виды вхождений ключевых слов существуют?
- Точное/чистое вхождение подразумевает использование фразы в тексте без изменений: с таким же порядком слов, без знаков препинания и в такой же словоформе, как указано в техническом задании: «Предлагаем купить холодильник в магазине N».
- Прямое вхождение. Формулировка ключа не всегда позволяет красиво вписать его в предложение без знаков препинания. Словоформа, как и в первом случае, сохраняется, но фраза может быть разбита знаком препинания: «По бонусной программе, действующей для постоянных клиентов, можно купить: холодильник, микроволновую печь и электрочайник».
Прямые и точные вхождения больше используются в контекстной рекламе, в качестве текста-анкора для ссылок, а также в заголовках, подзаголовках второго и третьего уровня и метатегах. Их любят поисковики, но оптимизированный заголовок должен обязательно отражать содержание абзаца.
- Разбавленное вхождение. Это ключевые фразы, разбавленные дополнительными словами: «Купить двухкамерный холодильник можно со скидкой 10 %».
- Морфологическое вхождение. Слова из ключевой фразы при таком варианте вхождения используются в разных словоформах: «Купив холодильник в период с 1 по 10 сентября, вы получаете 3 формочки для льда в подарок».
- Морфологическое разбавленное, или сложное, вхождение. Ключевую фразу можно использовать в любой словоформе и разбавить дополнительными словами: «Купив два холодильника в одном чеке, вы автоматически становитесь участником в розыгрыше ноутбука».
- Обратное вхождение. Данная форма подразумевает прямое вхождение ключа, слова в котором поменяны местами: «Нужен новый холодильник? Купить технику, не выходя из дома, можно у нас».
Техническое задание составляет SЕО-специалист и указывает, в какой форме и сколько раз должна встречаться каждая ключевая фраза в тексте.

Какими еще бывают вхождения ключей?
- С опечатками или ошибками. Иногда пользователи набирают запрос с опечатками, и такие ключи также попадают в статистику «Яндекс» и Google. Чаще всего ошибочно пишут заимствования иностранных слов: «блоггер/блогер», «Твиттер/Твитер».
- С аббревиатурами. РБ, РФ и другие официальные сокращения воспринимаются поисковиками как полноценные фразы, но такая форма помогает разнообразить текст и избежать переспама.
- Синонимическими. Это слова/фразы, близкие по значению основному запросу (купить – приобрести) или уточняющие, дополняющие его (купить холодильник Атлант, купить однокамерный холодильник). Такие ключи являются основой LSI-копирайтинга.
Обещанный бонус
- Как вписать в текст большое количество однотипных ключей?
Если по техническому заданию не требуется точное вхождение запросов, их можно объединять, склонять и разбавлять. Это повысит читабельность статьи без повышения плотности вхождения запросов, при этом поисковые роботы все равно «узнают» ключи.
Ключевые фразы [купить холодильник], [холодильник Минск], [холодильник по низкой цене купить] можно объединить следующим образом: Купить холодильник по низкой цене в Минске можно в интернет-магазине N.
- Как органично вписать нечитаемый ключ в текст без изменений?
Если точный ключ совсем «кривой» и нечитаемый, его можно сделать органичным, не меняя сути.
Хороший пример: «Купить холодильник, цена которого ниже средней по региону минимум на 10 %, можно в интернет-магазине N».
Плохой пример: «Если ввести в поисковой строке «купить холодильник цена», вы увидите список сайтов с предложениями товара».
- Как правильно распределять ключи по тексту?
Запросы, особенно коммерческие (со словами «заказать», «купить», «цена», «стоимость» и другими), должны быть равномерно распределены по тексту с промежутком в 250–300 знаков, а не вписаны в первые предложения с надеждой, что таким образом статья быстрее выйдет в топ поисковой выдачи. С большой долей вероятности страница попадет под фильтр и будет исключена из индекса.
- Что лучше: прямое или разбавленное вхождение ключа?
Лучше – органичное, естественное вхождение, чтобы самый придирчивый читатель не смог «споткнуться» о ключ при чтении статьи. Ключи можно и нужно менять, не боясь разбавлять слова знаками препинания или предлогами, которые поисковые системы чаще всего игнорируют. Естественность текста определяет доверие пользователя к ресурсу и напрямую влияет на поведенческие факторы сайта.
Кроме того, ключевые фразы должны быть релевантными, соответствующими тематике статьи, а не вписанными в текст «между прочим», пусть даже красиво и естественно. Поэтому качественный SЕО-текст – это золотая середина, удовлетворяющая требованиям поисковиков (как минимум, Яндекс и Google) и привлекательная для пользователей. Только грамотный тандем SЕО-специалиста и копирайтера позволяет получить хороший текст, привлекательный для людей и поисковых роботов.
Авторы компании ProText пишут до 15 миллионов знаков в год, и большую часть контента – по техническим заданиям SЕО-специалистов. Наши тексты хорошо ранжируются поисковиками и вызывают доверие у посетителей ресурса. Если вы заинтересованы в качественных и уникальных текстах с грамотно вписанными ключами – заполните форму на сайте и станьте клиентом ProText.
Татьяна Сабук
5.09.2019.
- Текст
- URL
Количество символов 0 (от 200 до 100000 символов)
Не учитывать текст в теге noindex
Укажите ключевые слова по одному в строке. Одна фраза — одно вхождение.
В круглых скобках укажите требуемое количество вхождений.
В квадратных скобках укажите требуемое количество вхождений.
После запятой укажите требуемое количество вхождений.
После тире укажите требуемое количество вхождений.
Точное и другие
точное вхождение
чистое вхождение
прямое вхождение
Разбавленное и другие
разбавленное вхождение
морфологическое вхождение
морфологическое разбавленное
обратное вхождение
обратное разбавленное вхождение
сложное вхождение
Любое вхождение
точное вхождение
чистое вхождение
прямое вхождение
разбавленное вхождение
морфологическое вхождение
морфологическое разбавленное
обратное вхождение
обратное разбавленное вхождение
сложное вхождение
Как искать слова
Разовые вхождения.
Если в части текста найдена фраза, то в рамках одного типа поиска по этой части текста поиск больше не производится. В рамках другого типа поиска в этой части текста снова может быть найдена фраза.Пересечение вхождений.
Фраза может быть найдена даже в той части текста, где уже ранее была найдена другая фраза.Уникальные вхождения.
Если фраза один раз найдена, то поиск по этой части текста больше не ведется.
Сначала алгоритм ищет длинные фразы, а потом короткие. Рекомендуем выбирать режим “Разовые вхождения”, чтобы алгоритм правильно, с точки зрения SEO, считал вхождения и давал корректные рекомендации. Используйте другие режимы только если знаете, что делаете. Сравнение алгоритмов.
Текст
Сначала надо выбрать автомобиль, потом найти автомобиль, а потом купить автомобиль.
Что надо найти
Точное и другие:
- сначала (1)
Разбавленное и другие:
- найти автомобиль (1)
- выбрать автомобиль (1)
Любое вхождение:
- купить автомобиль (1)
- автомобиль (3)
Результат
| Фраза | Вхождение фразы | Разовые вхождения | Пересечение вхождений | Уникальные вхождения |
|---|---|---|---|---|
| сначала (1) | Точное | найдено (1) | найдено (1) | найдено (1) |
| найти автомобиль (1) | Разбавленное | найдено (1) | найдено (1) | найдено (1) |
| выбрать автомобиль (1) | Разбавленное | найдено (1) | найдено (1) | найдено (1) |
| купить автомобиль (1) | Любое | найдено (1) | найдено (1) | найдено (1) |
| автомобиль (3) | Любое | найдено (2) | найдено (3) | не найдено |
Разовые вхождения. Алгоритм сначала будет искать все точные вхождения и найдет фразу “сначала”. Потом будет искать разбавленные вхождения и найдет фразы “найти автомобиль” и “выбрать автомобиль”. А потом будет искать любые вхождения, найдет “купить автомобиль”, а также вместо трех найдет два вхождения слова “автомобиль”, т.к. в части текста “купить автомобиль” поиск уже производился.
Пересечение вхождений. Алгоритм сначала будет искать все точные вхождения и найдет фразу “сначала”. Потом будет искать разбавленные вхождения и найдет фразы “найти автомобиль” и “выбрать автомобиль”. А потом будет искать любые вхождения, найдет “купить автомобиль” и три вхождения слова “автомобиль”.
Уникальные вхождения. Алгоритм сначала будет искать все точные вхождения и найдет фразу “сначала”. Потом будет искать разбавленные вхождения и найдет фразы “найти автомобиль” и “выбрать автомобиль”. А потом будет искать любые вхождения, найдет “купить автомобиль”. А вот слово “автомобиль” не найдет, т.к. в той части текста уже был поиск, а в другой части текста такого слова нет.
Частично материал был взят из статьи Сергея Кокшарова про классификацию вхождений ключевых слов, но немного видоизменен.
- Добавляйте ссылку на инструмент в свое ТЗ, чтобы авторы сразу понимали, как их будут проверять.
- Отправьте ссылку на полученный результат, чтобы человек сам увидел каких ключевых фраз еще нет в тексте.
- Высказывайте свои пожелания, чтобы сделать инструмент еще удобнее конкретно для ваших задач: help@miratext.ru.
Шаблоны ключевых слов
Существует много сервисов для сбора семантики. Они предоставляют результаты в разных форматах. Чтобы их было удобно использовать мы создали разные шаблоны обработки ключевых слов. В зависимости от выбранного шаблона алгоритм будет по-разному искать ключевые фразы.
Шаблон: ключевая фраза. Пример:
- купить автомобиль
- купить автомобиль
- купить трактор
Инструмент будет искать каждую ключевую фразу минимум один раз, даже если они одинаковые.
Шаблон: ключевая фраза (3). Пример:
- купить автомобиль (2)
- купить трактор
Инструмент будет искать ключевую фразу “купить автомобиль” минимум два раза и “купить трактор” минимум один раз.
Шаблон: ключевая фраза [3]. Пример:
- купить автомобиль [2]
- купить трактор
Отличается от предыдущего только квадратными скобками. Инструмент будет искать ключевую фразу “купить автомобиль” минимум два раза и “купить трактор” минимум один раз.
Шаблон: ключевая фраза — 2*. Пример:
- купить автомобиль — 2
- купить мопед — 2+
- купить трактор — 3 раза
- купить самолет
Звездочка (*) означает, что при наличии тире и цифры “- 2” весь дальнейший текст будет игнорироваться.
Инструмент будет искать ключевую фразу “купить автомобиль” минимум два раза, “купить мопед” минимум два раза, “купить трактор” минимум три раза, “купить самолет” минимум один раз.
Шаблон: ключевая фраза,2*. Пример:
- купить автомобиль,2
- купить трактор,3 раза
- купить самолет
Звездочка (*) означает, что при наличии запятой и цифры “,2” весь дальнейший текст будет игнорироваться.
Инструмент будет искать ключевую фразу “купить автомобиль” минимум два раза, “купить трактор” минимум три раза, “купить самолет” минимум один раз.
Если вам необходим индивидуальный шаблон для обработки ключевых фраз, напишите нам на help@miratext.ru.
Точное вхождение
Ключевая фраза встречается в тексте в неизменном виде. Регистр и последовательность слов важны.
Пример для фразы “брачное агентство”:
Готового рецепта счастья не существует, но один из способов найти свое – обратиться в брачное агентство.
Чистое вхождение
То же самое, что и точное. Регистр не важен. Последовательность слов важна.
Пример для фразы “nokia купить”:
У официальных представителей Nokia купить телефон надежнее, чем у других продавцов.
Прямое вхождение
Почти то же самое, что и чистое, за исключением того, что между ключевыми фразами могут встречаться некоторые знаки препинания в рамках одного предложения.
Пример для фразы “nokia купить”:
Телефоны Nokia, купить которые можно у нас, пользуются большим спросом.
Разбавленное вхождение
Фраза может быть разбавлена дополнительными словами и знаками препинания в рамках одного предложения. Регистр не важен. Последовательность слов важна.
Примеры для фразы “пакеты оптом”:
Приобретайте наши пакеты полиэтиленовые оптом и в розницу.
Каждый месяц мы покупаем пакеты для мусора, оптом брать не хотим.
Морфологическое вхождение
Одно или несколько слов из ключевой фразы изменены по форме с помощью склонения или спряжения. Регистр не важен. Последовательность слов важна.
Примеры для фразы “доставка грузов”:
Как доставить груз в пункт назначения как можно быстрее?
Срочная доставка груза позволяет сохранить качество скоропортящейся продукции.
Морфологическое разбавленное вхождение
Говорит само за себя. Означает изменение формы слов (склонение, спряжение) с возможным разбавлением дополнительными словами и знаками препинания в рамках одного предложения.
Пример для фразы “доставка грузов”:
Курьерская служба обеспечит доставку документов и выдачу грузов.
Обратное вхождение
Это прямое вхождение только с проверкой последовательности слов в ключевой фразе от последнего слова к первому в рамках одного предложения. Регистр не важен.
Пример для фразы “смартфон купить”:
Купить смартфон проще, чем вы думаете.
Обратное разбавленное вхождение
Обратное вхождение с возможным разбавлением дополнительными словами и знаками препинания в рамках одного предложения. Регистр не важен.
Пример для фразы “смартфон купить”:
Купить новый смартфон проще, чем вы думаете.
Сложное вхождение
Любое вхождение в любой последовательности. Регистр не важен. Последовательность слов не важна.
Пример для фразы “российская премьер лига чемпион”:
Единственный их шанс – это возможная ничья, стать чемпионом российской премьер-лиги команде вряд ли удастся.
- Как правильно искать в Яндексе
- Что учитывается в запросе
- Синтаксис поиска
- Символы для поиска
- Не используйте устаревшие знаки
- Документные операторы Яндекс.Поиска
- Поиск по всему сайту и поддоменам site:
- Поиск по начальному адресу url:
- Поиск по страницам главного зеркала сайта host:
- Поиск по хосту наоборот rhost:
- Поиск по сайтам на домене или в доменной зоне domain:
- Фильтры расширенного поиска
- Фильтрация поиска по документам определённого формата mime:
- Фильтрация поиска документов по языку lang:
- Фильтрация страниц по дате изменения date:
- Бонус: как узнать дату первой индексации страницы в Яндексе
- Выводы
Язык поисковых запросов Яндекса включает в себя специальные символы и операторы поиска, которые можно использовать для уточнения или фильтрации результатов.

Стоит отметить, что язык Яндекса отличается не только от языка других поисковых систем (Google, Bing), но и внутри собственных сервисов (Поиск, Вордстат, Директ). Это значит, что операторы или спецсимволы, которые работают в одном сервисе, могут не функционировать в другом. Например, круглые скобки ( ) для группировки сложных запросов в Поиске не работают, но широко применяются в Wordstat и Директе.
Сегодня мы покажем на примерах полезные команды именно для точного Яндекс.Поиска. Правильно используя язык запросов, вы сможете легко искать страницы с точным вхождением слов, фильтровать результаты выдачи по региону или дате, а также находить технические проблемы на своём сайте.
Как правильно искать в Яндексе
Что учитывается в запросе
По умолчанию поиск в Яндексе работает согласно таким правилам:
- Учитывается морфология: все формы ключевых слов запроса (падеж, род, число, склонение) и то, к какой части речи они относятся (существительное, прилагательное, глагол).
То есть он может искать по склонённому слову и его синонимам, но не ищет по однокоренным словам. Например, он считает похожими запросы «охладить квартиру» и «охлаждение квартиры», но не «охладитель квартиры».

7 совпадений в выдаче — значит, эти запросы Яндекс считает похожими.

2 совпадения, одно из которых Яндекс.Дзен — мы бы засомневались в близости этих запросов.
- Автоматически исправляются ошибки, опечатки или нетипичные слова.
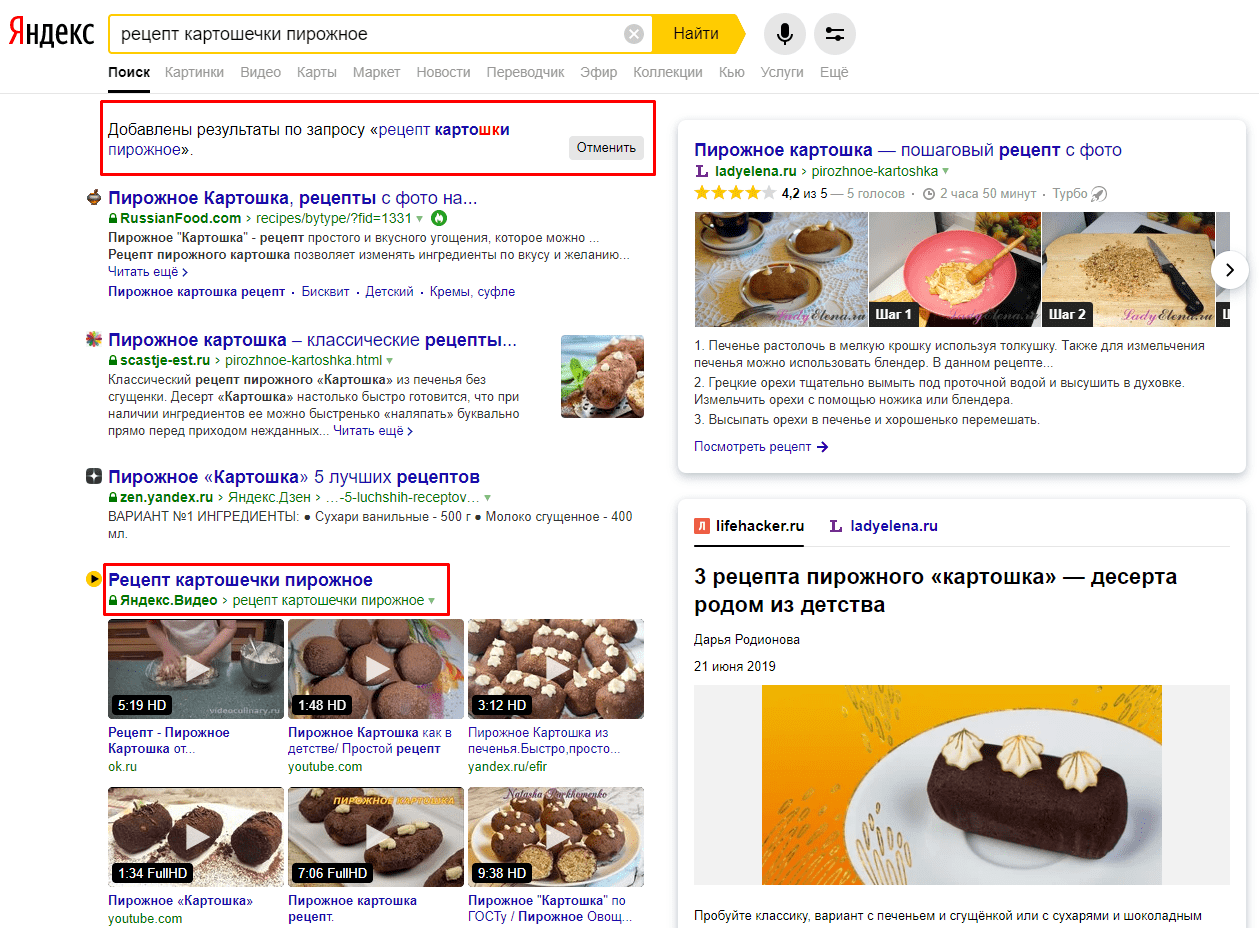
Например, запрос «рецепт картошечки пирожное» Яндекс исправляет на «рецепт картошки пирожное» и ищет информацию в документах со склонёнными по падежам и числам словами:
- Пирожное картошка, рецепты с фото.
- 3 рецепта пирожного картошка.
- Как правильно готовить пирожное картошку, 5 лучших рецептов.
Синтаксис поиска
Бывает, что вам нужен конкретный результат (без синонимов, с определённым порядком слов и т. д.), тогда вы можете использовать поисковые команды.
Основные правила поиска такие:
- Сначала впишите текст запроса (ключевые слова).
- После них через пробел можете написать один или несколько поисковых операторов или фильтров. Между операторами тоже должны быть пробелы.

Рекомендации по каждой из поисковых команд мы приведём ниже.
Символы для поиска
В таблице приведены все специальные символы, которые на данный момент работают в морфологии Яндекса.
| Символ | Синтаксис | Для чего используется |
|---|---|---|
| Восклицательный знак ! | !слово
слово и !другие !слова !фразы |
Фиксирует слово в заданной форме, позволяя искать без учёта других падежей, числа, времён. Например, по запросу купить билет в !Париж:
|
| Плюс + | +слово
слова +с предлогом |
Фиксирует слова, которые обязательно должны содержаться на странице. Обычно Яндекс убирает малозначимые служебные части речи, местоимения и другие слова без дополнительного смысла.
Например, по запросу работа +на дому:
|
| Минус — | -слово
фраза без -слова |
Минус позволяет исключить из поиска слова, а вернее, документы, в которых содержится выделенное минусом слово.
Например, по запросу уроки живописи -начинающий:
|
| Кавычки “ ” | “слово”
слово и “все слова фразы” |
Фиксирует количество слов в заданной фразе, не показывая расширенные варианты. Но разные словоформы разрешены. Кавычки используются для поиска по точной цитате.
Например, по запросу “домик в аренду на двоих”:
|
| Звёздочка * | “слово1 * слово3” | Поиск документов, которые содержат цитату с пропущенным словом или словами. Одна звёздочка заменяет одно слово.
Важно! Используется только при поиске цитат, то есть внутри кавычек. Например, по запросу «у лукоморья * * златая»:
|
| Вертикальная черта | | слово1 | слово2
фраза с одним | другим | третьим |
Поиск документов, которые содержат хотя бы одно из слов, размеченных вертикальной чертой.
По нашим наблюдениям, предпочтение отдаётся документам, которые содержат оба запроса, а в таком случае выдача бывает непредсказуемой. Например, по запросу заказать еду роллы | пицца:
|
Чтобы найти самое точное совпадение по словам фразы, нужно использовать вместе кавычки и восклицательные знаки: “!все !слова !запроса”.
Данные знаки можно комбинировать с операторами и фильтрами, составляя сложные поисковые команды под свои нужды.
Не используйте устаревшие знаки
В 2017 году Яндекс убрал довольно много символов из Поиска, а именно:
- & — использовался для поиска документов, в которых слова запроса, объединённые оператором, встречаются в одном предложении;
- && и << — искали заданные слова в пределах документа;
- ~ — использовался для поиска документов, в которых заданное слово не содержится в одном предложении со словом, указанным до оператора;
- () — применялись для группировки слов при сложных запросах;
- !! — выполнял поиск слова, начальная форма которого указана в запросе.
Теперь они не работают в поисковике, и использовать их там бессмысленно.
Документные операторы Яндекс.Поиска
Поиск по всему сайту и поддоменам site:
Позволяет искать документы по всем страницам главного домена и поддоменов сайта.
Как применять:
Поиск по начальному адресу url:
С помощью него можно искать информацию на конкретной странице или в категории. Регистр букв в урле не учитывается.
Важно! Если URL содержит один из следующих символов: одинарные или двойные кавычки ‘ «, круглые скобки () или нижнее подчёркивание _, то его следует заключить в кавычки.
Как применять:
Важно! При использовании операторов url, host и rhost нужно вписывать только главное зеркало сайта. Например, host:example.com, а не host:www.example.com.
Поиск по страницам главного зеркала сайта host:
Позволяет искать информацию по хосту (главному зеркалу сайта).
По сути,host:www.example.com идентичен оператору url:www.example.com/* и применяется так же.
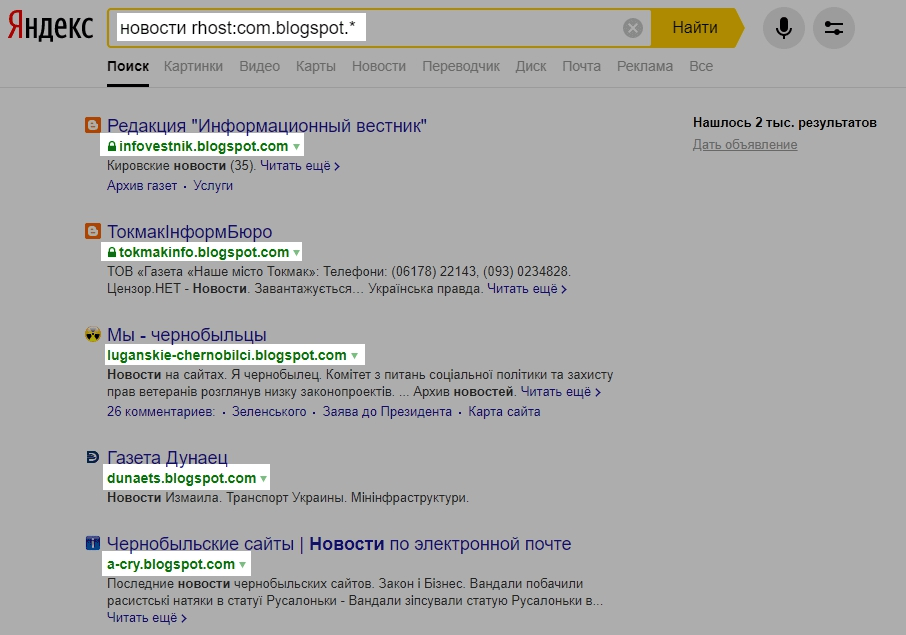
Поиск по хосту наоборот rhost:
Оператор действует так же, как и host, но адрес записывается в обратном порядке.
Как применять:
- Поиск по определённому поддомену — запрос rhost:com.example.www
- Искать информацию на всех поддоменах — запрос rhost:com.example.*
Поиск по сайтам на домене или в доменной зоне domain:
Работает только с зонами, состоящими из одного уровня вроде ua, ru, com (но не с длинными od.ua, msk.ru).
Как применять:
Фильтры расширенного поиска
Справа от поисковой строки находится иконка расширенного поиска. Он позволяет применять фильтры по городу, времени публикации и языку страницы.

У Яндекса есть поисковые операторы, которые тоже позволяют фильтровать выдачу.
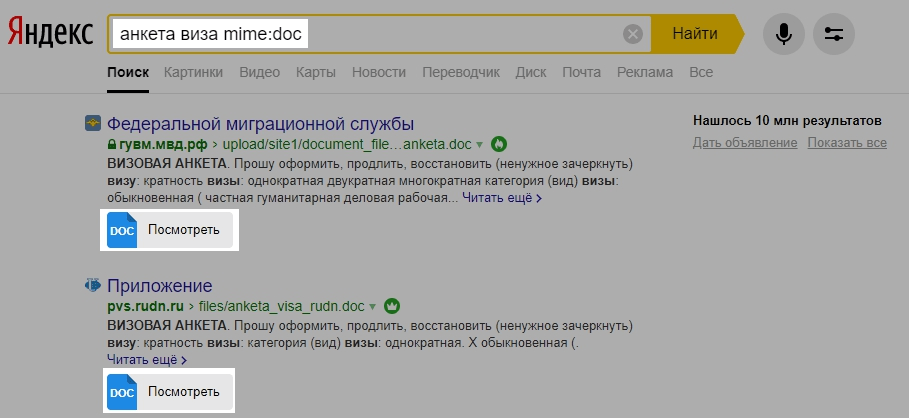
Фильтрация поиска по документам определённого формата mime:
Оператор позволяет найти ключевые слова в файлах следующих форматов: pdf, rtf, swf, doc, xls, ppt, odt, ods, odp, odg.
Синтаксис простой — запрос mime:doc
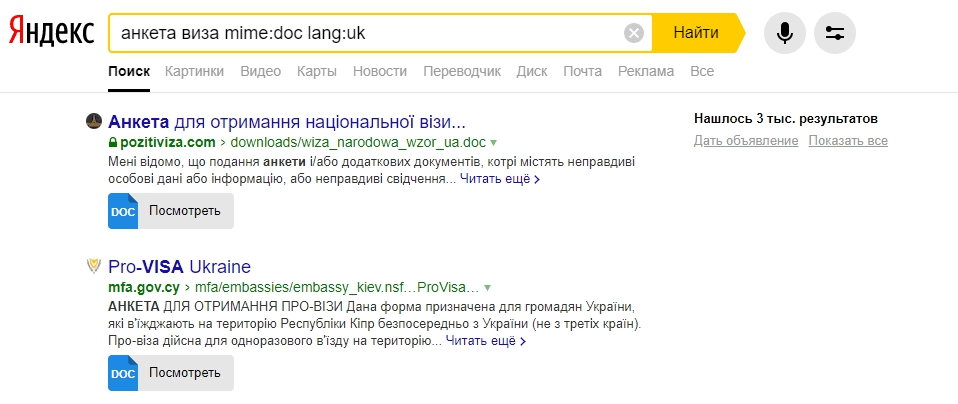
Фильтрация поиска документов по языку lang:
Позволяет быстро найти сайты и документы на нужном языке. Код языка указывается по стандарту ISO 639-1 (первый столбик в таблице на Википедии), например:
- ru — русский;
- en — английский;
- uk — украинский.
Синтаксис — запрос lang:ru
Фильтрация страниц по дате изменения date:
Оператор позволяет увидеть только свежие результаты или за определённую дату. Формат даты:
- Точная дата date:ГГГГММДД
- Раньше или позже даты (можно использовать символы <, <=, >, >=) date:<ГГГГММДД
- Между датами date:ГГГГММДД..ГГГГММДД
- В определённом месяце date:ГГГГММ* или году date:ГГГГ*.
Стоит отметить, что оператор учитывает именно дату последнего изменения, поэтому найти какие-то новости за период может быть сложно, если страница была обновлена.
Таким образом можно искать на своём сайте страницы, которые давно пора улучшить.
Бонус: как узнать дату первой индексации страницы в Яндексе
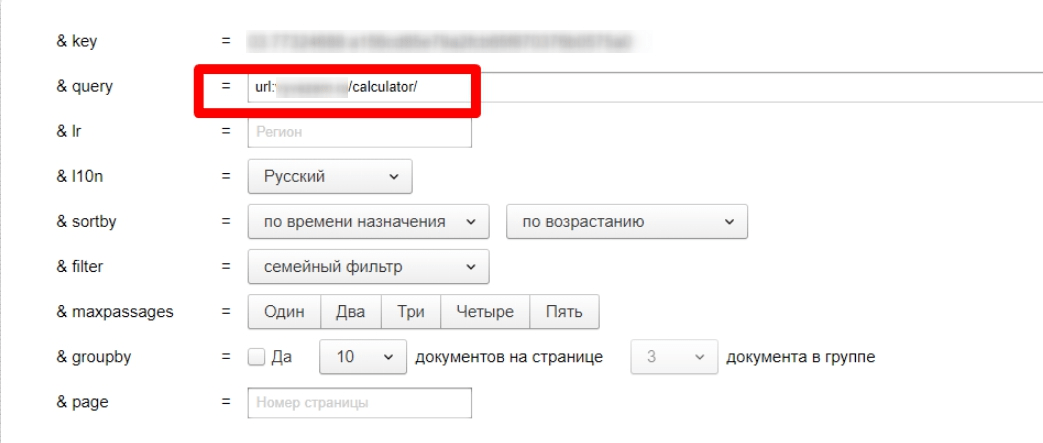
Для этого у вас должны быть лимиты XML Яндекса.
- Заходим на https://xml.yandex.ru/test/.
- Указываем URL интересующей страницы в поле query:

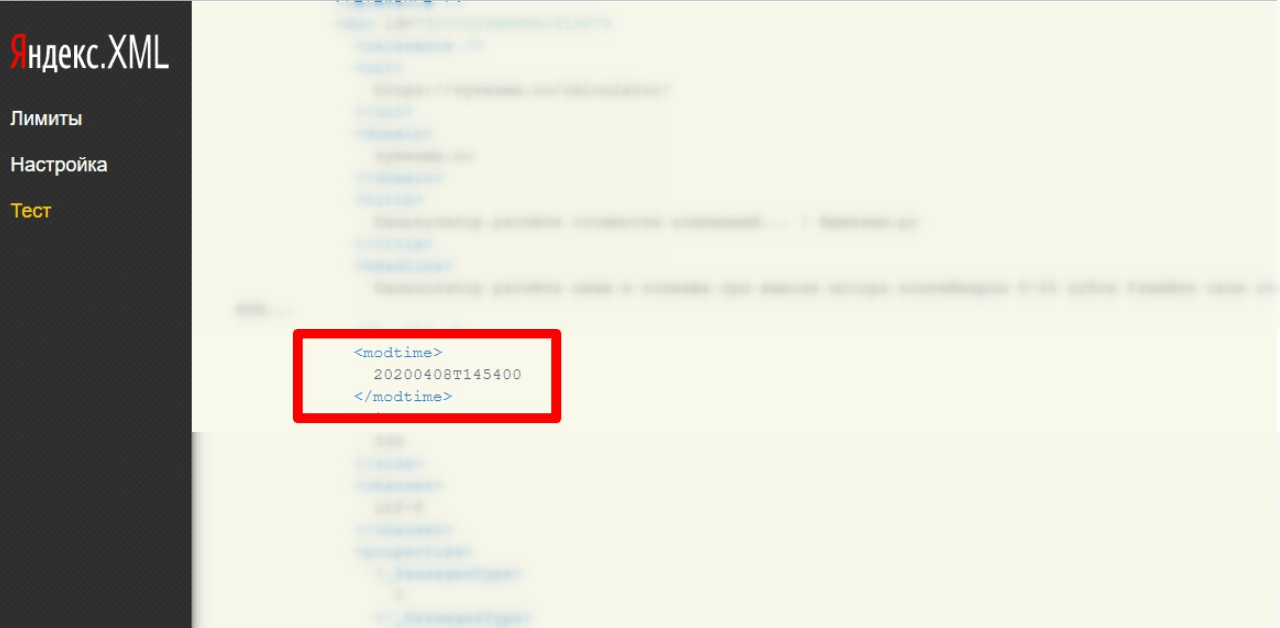
- Смотрим modtime — это и есть дата, когда страница была впервые проиндексирована Яндексом.

Выводы
Все вышеперечисленные операторы и символы Яндекс сам рекомендует к использованию в справке, и они позволяют найти нужные фразы и документы гораздо быстрее. SEO-специалисты любят упоминать, что существуют недокументированные операторы, которые никогда нигде не публиковались. Но ручная проверка показывает, что ни один из них сейчас не работает стабильно.
Возникли трудности с более глубоким анализом текущего состояния сайта? Обращайтесь к нам!
Заказать аудит сайта
Еще по теме:
- Сравнительный обзор бесплатного SiteAnalyzer с аналогичными платными сервисами
- Парсим сайт при помощи XPath
- Новый функционал SEOlib превосходит все ожидания?
- Новая версия Google Search Console – обзор доступных инструментов. Январь 2019
- 12 фичей Seolib, о которых вы, возможно, не знали
Что может SiteAnalyzer? Простота в использование инструмента Генерация sitemap.xml в один клик Перекрестный анализ сайтов Постраничная скорость загрузки сайта Тонкие настройки парсера Все ведь любят…
Что такое XPath Терминология XPath и отношение узлов Синтаксис Предикаты Как парсить данные с помощью Google Spreadsheets Синтаксис XPath-запроса для Google Spreadsheets Распространённые выражения Разметка…
Сегодня подробно поговорим про новую функцию анализа топов одного из самых популярных сервисов на просторах SEO. Как это выглядит Как добавить функцию «Анализ ТОП(а)» Отчет…
Мы планировали сделать обзор новой версии Google Search Console, когда её обновление будет полностью закончено, и в новой панели будут доступны все инструменты. Но прошёл…
Введение Турбо и AMP-страницы Релевантные и ранжируемые страницы Отчёт по конкурентам Визуализация процента и количества запросов в ТОП-10, ТОП-11–50 Мониторинг ТОПов Синонимы по запросам Геозависимость…

SEO-аналитик
Получив диплом предпринимателя, успела уже побывать оценщиком и иллюстратором. Теперь держу руку на пульсе SEO-трендов.
Люблю постигать новое и делиться этим с другими.
Увлекаюсь супергероикой, фантастикой и своей кошкой.
Девиз: Теоретически возможно всё
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
Найти подстроку в строке
Время на прочтение
6 мин
Количество просмотров 20K
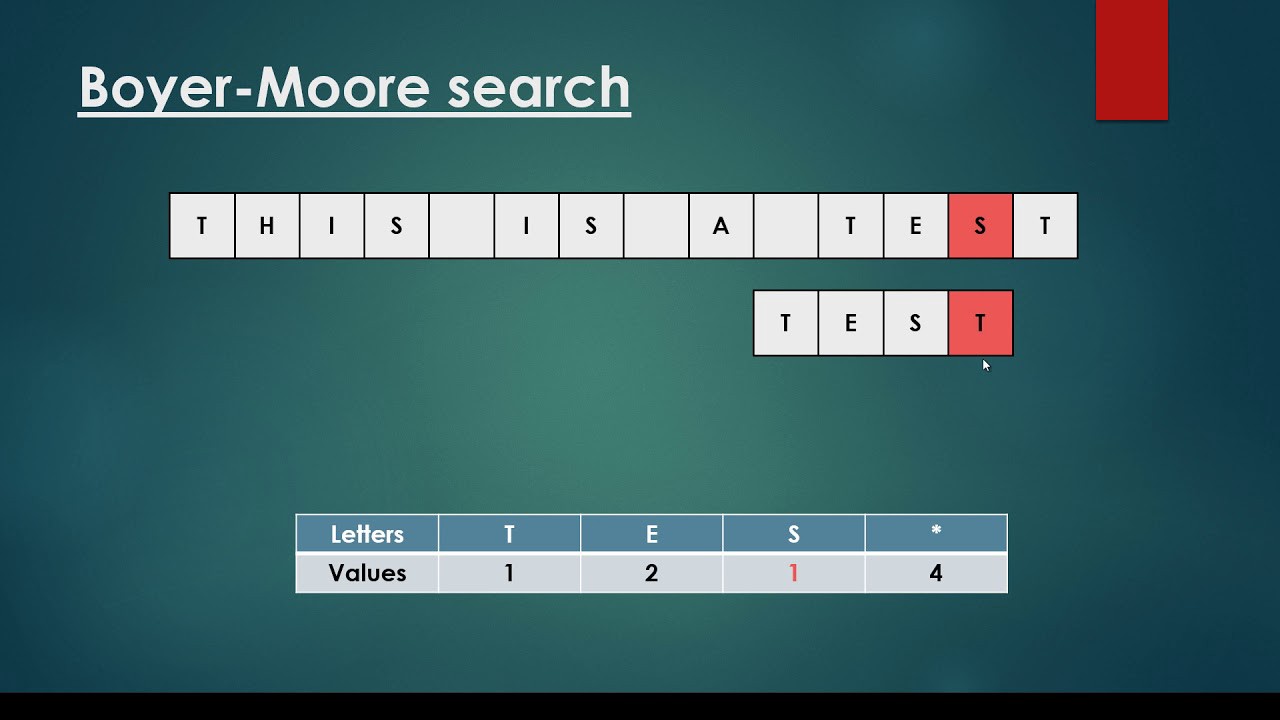
Алгоритм поиска строки Бойера — Мура — алгоритм общего назначения, предназначенный для поиска подстроки в строке.
Давайте попробуем найти вхождение подстроки в строку.
Наш исходный текст будет:
Text: somestringИ паттерн, который мы будем искать
Pattern: stringДавайте расставим индексы в нашем тексте, чтобы видеть на каком индексе находится какая буква.
0 1 2 3 4 5 6 7 8 9
s o m e s t r i n gНапишем метод, который определяет, находится ли шаблон в строке. Метод будет возвращать индекс откуда шаблон входит в строку.
int find (string text, string pattern){}В нашем примере должно будет вернуться 4.
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
pattern: s t r i n gЕсли ответ не найден, мы будем возвращать -1
int find (string text, string pattern) {
int t = 0; создадим индекс для прохода по тексту.
int last = pattern.length — 1; это индекс последнего элемента в шаблонеСоздадим цикл для прохода по тексту.
while (t < text.length — last)Почему именно такое условие? Потому что если останется символов меньше чем длина нашего паттерна, нам уже нет смысла проверять дальше. Наш паттерн точно не входит в строку.
В нашем примере:
last = 5 (Последний индекс паттерна string равен 5)
Длина текста равна 10 (somestring)
Это значит что text.length — last = 10–5 = 5;
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
pattern: s t r i n g Можно заметить, что если мы стоим на 5м индексе в строке, а 4й не подошел, то наш паттерн не входит в строку, например
0 1 2 3 4 5 6 7 8 9
text: s o m e X t r i n g
^
pattern: s t r i n gПолучится что длина паттерна, больше чем длина оставшейся строки.
На данный момент у нас есть код вида :
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last){
}
}Теперь введем переменную int p = 0, которая будет двигаться по нашему паттерну.
И запустим внутренний цикл
while( p <= last && text[ t + p ] == pattern[p] ){
}p <= last — пока меньше или равно последнему индексу символа шаблона
text[ t + p ] = pattern[p] — пока очередной сивмол текста совпадает с символом в шаблоне.
Давайте детальнее разберем, что значит text[ t + p ] = pattern[p]
Допустим мы в тексте стоим на индексе 4
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
^
pattern: s t r i n gПолучается t = 4, p = 0; text[ t + p ] = text[ 4 + 0 ] = s, pattern[0] = s, значит условие цикла выполняется.
Код на текущий момент:
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = 0;
while( p <= last && text[ t + p ] = pattren[p] ){
Если условие цикла выполняется, сдвигаем p вперед.
p ++;
}
В результате если p == pattern.length
мы можем вернуть индекс на котором паттерн входит в текст.
if (p == pattern.length){
return t;
}
В противном случае идем к следующему индексу в строке.
t ++;
}
}Получается мы имеем такой метод:
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = 0;
while( p <= last && text[ t + p ] == pattern[p] ) {
p ++;
}
if (p == pattern.length) {
return t;
}
t ++;
}
return — 1;
}Как можно ускорить этот алгоритм? Какие есть варианты?
Представим что у нас в тексте есть символ, которого нет в паттерне.
text: some*string , то на сколько можно сдвигать паттерн?
А если есть повторяющиеся символы?
Например можно начать бежать с конца паттерна, то есть
text: somestring
^
pattern: string
^Начинаем бежать с конца паттерна. Если символы не совпадают, на сколько можно сдвинуть паттерн?
Если символ из текста есть в нашем паттерне, то можно сразу сдвинуть до этого символа.
text: somestring
pattern: stringСдвигаем на длину паттерна минус индекс символа на котором мы стоим в тексте.
То есть в данном случае
text: somestring
^
pattern: string
^Когда мы начинаем бежать по паттерну с конца у нас pattern[i] = ‘g’, а text[i] = ’t’,
мы можем сдвинуть наш паттерн на pattern.length — индекс ’t’ в паттерне.
Индекс ’t’ в паттерне = 1, получается 5–1 = 4, сдвигаем паттерн на 4 символа вперед.
text: somestring
^
pattern: >>>>string
^Мы можем предварительно создать таблицу для нашего паттерна.
Посчитаем позицию каждого символа в паттерне, чтобы знать на сколько сдвигаться.
Составляем таблицу смещений, для каждого символа алфавита. Я буду в примере использовать символ * чтобы не расписывать весь алфавит.
Таблица смещений:
s 0
t 1
r 2
i 3
n 4
g 5
* -1Давайте возьмем другой паттерн, чтобы символы повторялись и было ясно, на сколько нужно двигать паттерн, если символы повторяются:
pattern: колокол
к 4
л 2 — если символ последний в строке, то оставляем его первый вход
м -1
н -1
о 5Мы сдвигаем на последние вхождение символа, потому что если сдвигать на первое, то можно упустить часть входа паттерна в строку.
Попробуем реализовать эту часть алгоритма:
int[] createOffsetTable(string pattern) {
int[] offset = new int[128]; // количество символов зависит от
// алфавита с которым мы работаем
for (int i = 0; i < offset.length; i++){
offset[i] = -1; // заполняем базовыми значениями
}
for (int i = 0; i < pattern.length; i++){
offset[pattern[i]] = i;
}
return offset;
}Добавим таблицу смещений в алгоритм поиска, что мы написали выше:
int find (string text, string pattern) {
int[] offset = createOffsetTable(pattern);
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last){
int p = last; // начнем двигаться с конца паттерна
//Чуть чуть меняем условие цикла,
//так как теперь мы двигаемся с конца
while( p >= 0 && text[ t + p ] == pattern[p] ){
p — ;
}
if (p == -1){
return t;
}
t += last — offset[ text[ t + last ] ];
}
return — 1;
}Почему t + last ? Смотрим на каком символе стоим в тексте и прибавляем длину шаблона. Если при поиске входа, какая то часть не совпала, то мы должны сдвинуться на символ текста в котором стоим + длина шаблона.
Например:
Таблица смещений для колокол:
к = 4
л = 2
о = 5Шаг 1:
0 1 2 3 4 5 6 7 8 9 10
text: а а к о л о л о к о л о к о л
pattern: к о л о к о л
last = 7;
t += last — offset[text[t + last]]
t += last — offset[text[0 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 2;Шаг 2:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > к о л о к о л
t = 2;
t += last — offset[text[t + last]]
t += last — offset[text[2 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 4;Шаг 3:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > > > к о л о к о л
t = 4;
t += last — offset[text[t + last]]
t += last — offset[text[4 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 6;Шаг 4:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > > > > > к о л о к о л
t = 6;
t += last — offset[text[t + last]]
t += last — offset[text[6 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 8;Шаг 5:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > > > > > > > к о л о к о лСовпадение найдено.
На этом разбор упрощенного алгоритма Бойера-Мура закончен.
Пока мы отталкивались только от крайних символов. Но возможно ли как то использовать информацию по уже пройденным символам?
Допустим есть строка
abcdadcd
Как составить таблицу смещений мы уже знаем. Теперь составим таблицу суффиксов.
Когда мы стоим на символе d, на сколько можно сдвинуть паттерн? Сдвигаем на на расстояние до ближайшего такого же символа. В примере ниже у нас есть 2 символа d с расстояниями 2 и 4. Мы выберем 2 потому что оно меньше.
4
-----—
| 2
| ---
| | |
abcdadcd
^Дальше рассмотрим суффикс cd. Для d мы уже записали 2.
2
abcdadcd
У нас есть только один суффикс cd, это значит что можно
-- сдвинуться на 4 символа.
Запишем для с = 4.
842
abcdadcd
Далее dcd. dcd в тексте больше нигде не встречается.
--- Двигаем на длину шаблона = 8И для всех остальных символов пишем 8, потому что суффиксы не будут совпадать.
Теперь вернемся к нашему паттерну колокол.
колокол* В конце всегда будет *, еcли символ не совпал, сдвинем на 1.
1
колокол*
—
41
колокол*
-—
441
колокол*
--—
4441
колокол*
---—
4441
колокол*
----Для окол мы тоже запишем 4. Потому что у нас префикс совпадает с суффиксом.
Попробуем написать код для этого
createSuffix(string pattern){
int[] suffix = new int[pattern.length + 1]; // +1 для символа звездочки
for(int i = 0; i < pattern.length; i ++){
suffix[i] = pattern.length; // изначальное значение,
//длина шаблона. на сколько сдвигать если нет совпадения суффиксов
}
suffix[pattern.length] = 1; // для звездочки ставим 1
//Сначала создадим переменную, которая идет справа на лево.
for (int i = pattern.length — 1; i >= 0; i — ) {
for (int at = i; at < pattern.lenth; at ++){
string s = pattern.substring(at); // с какого символа берем подстрокуНапример колокол с чем сравниваем?
--—
колокол
--—
---
---
---
кол мы сравним с око, лок, оло, кол
for (int j = at — 1; j >= 0; j — ) {
string p = pattern.substring(j, s.length); // берем подстроку той же длинны
//что и суффикс
if (p.equals(s)) {
suffix[j] = at — i;
break;
}
}
}
}
return suffix;}Существует более оптимальный алгоритм, но дальше индивидуально.
Какой код у нас есть на данный момент?
int[] createSuffix (string pattern) {
int[] suffix = new int[pattern.length + 1];
for (int i = 0; i < pattern.length; i ++){
suffix[i] = pattern.length;
}
suffix[pattern.length] = 1;
for (int i = pattern.length — 1; i >=0; i — ){
for(int at = i; i < pattern.length; i ++){
string s = pattern.substring(at);
for (int j = at — 1; j >= 0; j — ){
string p = pattern.substring(j, s.length);
if (p == s) {
suffix[i] = at — 1;
at = pattern.length;
break;
}
}
}
}
return suffix;
}
int find(string text, string pattern) {
int[] offset = createOffset(pattern);
int[] suffix = createSuffix(pattern);
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = last;
while (p >= 0 && text[t + p] == pattern[p]) {
p — ;
}
if (p == -1) {
return t;
}
t += Math.max (p — offset[text[t + p]], suffix[p + 1]);
}
return -1;
}p — prefix[text[t + p]] — последний символ, который нашли и под него подстроить сдвиг нашего шаблона
suffix[p + 1] — значение суффикса для последнего элемента, который был сравнен.
И двигаем на максимальное значение, чтобы двигаться максимально быстро.
На этом разбор алгоритма Бойера-Мура закончен. Спасибо за внимание! =)