К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Что такое веб-архив?
Организатор и идейный вдохновитель веб-архива сайтов — американец Брюстер Кейл. Internet Archive («Архив интернета») — некоммерческий проект, его цель — сохранить мировое культурное и интеллектуальное наследие. По данным Википедии, этот сервис был создан в 1996 году. Во всемирном архиве интернета хранятся литературные произведения, видеозаписи, изображения, которые свободно публикуются в Сети. Это один из разделов огромного сервиса archive.org.
Боты постоянно сканируют всемирный интернет и пополняют библиотеку. Роботам помогают живые сотрудники и партнеры. Добавить копии страничек в веб-архив интернета может любой желающий. Конечно, в библиотеке невозможно найти абсолютно все страницы, которые когда-то были созданы. Но их там очень много — более 580 миллиардов.
Просмотреть архив «машины времени» («Wayback Machine» — второе название web-архива сайтов) можно бесплатно. При этом пользователям предлагают перейти по ссылке «Пожертвовать» и перевести создателям уникального сервиса посильную сумму.
Возможности сервиса
Для вебмастера и SEO-специалиста бесплатные всемирные архивы открывают ряд полезных возможностей.
- Если планируется купить домен или интернет-проект, важно посмотреть историю сайта. В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
- Архив веб-страниц поможет при выборе дроп-домена. В сервисе можно посмотреть бесплатно, какой проект на нем располагался (коммерческий, информационный) и как он выглядел.
- Можно узнать историю конкурентов. Сравнивая архивы сайтов с их современной версией, легко понять, как менялась ниша, как трансформировались проекты.
- Есть возможность проследить и проанализировать изменения на собственном сайте и даже восстановить измененный по ошибке URL.
- С помощью дополнительных сервисов можно восстановить удаленный ресурс или отдельные страницы.
- А также найти контент по интересующей теме, которого уже нет в глобальной сети.
Как посмотреть архивные страницы?
Откройте в браузере https://web.archive.org/. В строке для поиска укажите URL главной или любой другой страницы нужного сайта.
Сервис покажет график сохранений и календарь, в котором обведены даты сканирований. Эти даты не связаны с датами обновления контента. Боты работают по собственному графику.
Если кликнуть на нужный год и дату, сервис покажет web-версию старых страниц. Обычно сохраняется не весь контент, часть документов недоступна, отображаются не все фотографии и картинки. Часть ссылок кликабельны, можно погулять по интернет-площадке, перейти в другие разделы.
Если вы не знаете точный адрес нужного ресурса или хотите изучить целую нишу, нужно набрать в поисковой строке главные ключевые слова. Архив бесплатно найдет сайты нужной тематики. Перейдите по ссылкам этого списка и изучайте историю интересующего проекта.
Существует приложение Wayback Machine («Машина времени») для iOS и Android. Приложение скачивают на мобильное устройство. В нем заложен тот же функционал, что и в десктопной версии.
Как добавить страницу в сервис?
Боты обходят интернет по собственному графику. Не все проекты попадают в историю «Машины времени». Молодые площадки с небольшим трафиком редко оказываются в библиотеке. А если и попадают туда, то частота сканирований очень низкая — раз в несколько месяцев.
Сохранять копии сайта в WebArchive можно самостоятельно. Для этого нужно открыть сервис, найти поле «Сохранить страницу» и добавить туда URL. Снимки появятся в библиотеке через пару минут.
Эту операцию можно периодически повторять.
В будущем эти копии будут полезны, чтобы отслеживать изменения в дизайне, структуре, контенте. Если страницы будут по ошибке удалены, а бэкапы не делались или были утеряны, архивные снимки помогут восстановить документ.
Как удалить копии страниц своего проекта?
Не всем и не всегда хочется выкладывать историю своей веб-площадки на всеобщее обозрение. Например, на сайте могла быть выложена ошибочная, некорректная или противозаконная информация. Даже если удалить страницу или файл, они сохранятся в библиотеке.
Архивом страниц могут заинтересоваться конкуренты и недоброжелатели. Поэтому многим хочется удалить копии веб-документов из сервиса.
Раньше вебмастера вписывали в robots.txt запрещающую директиву для ботов. Но сейчас это уже не работает.
Убрать страницы из библиотеки можно только через саппорт. Для этого нужно написать письмо на info@archive.org. Писать нужно по-английски, с указанием реальных имени, фамилии, физического адреса. Чтобы подтвердить, что вы владелец ресурса, отправлять письмо лучшего с почтового ящика, указанного на сайте. Еще один способ подтвердить свои права — написать через регистратора домена или через хостинг. Иногда саппорт просит прислать копию паспорта.
Через поддержку можно навсегда запретить делать копии своего проекта.
Как восстановить сайт из архива?
Если вы сами загрузили копию страницы, ее можно найти в своем аккаунте в разделе «Мой архив».

Чтобы скачать страницу, найдите ее в списке, кликните по виджету справа и сохраните документ в виде html-файла.

С чужими сайтами действуют примерно так же: открывают копию в архиве, через панель разработчика копируют html-код, стили, изображения.
Файлы заливаются по FTP в корневую директорию домена на хостинге.
Но ручной способ слишком долгий и трудоемкий. Автоматизировать процесс можно через платные онлайн сервисы: Archivarix, waybackmachinedownloader, r-tools, rush-analytics и другие. Здесь можно не только скачать файлы, но и оптимизировать их: убрать битые ссылки, неработающие скрипты и так далее. Некоторые сервисы умеют импортировать файлы в WordPress.
Другие полезные опции
WebArchive умеет не только сохранять копии и показывать старую версию страниц сайта. Здесь есть несколько полезных инструментов аналитики.
- Сводка. Сервис показывает, какие данные содержит сайт: сколько на нем текстов, изображений, приложений. Можно открыть и просмотреть список всех URL.
- Изменения. Инструмент поможет выявить изменения в URL-адресах. Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.
- Карта сайта. Группирует данные по годам и строит карту в виде круговой диаграммы для каждого года.

В центре диаграммы корень сайта, а кольца — это разделы и страницы. Диаграмма кликабельна, она позволяет перейти на копию нужного URL.
Читайте на Askusers
Как быстро и правильно провести A/B-тестирование в маркетинге и SEO? Что можно тестировать, какие инструменты использовать и как замерять результат?
Что такое коммерческие факторы ранжирования, как они влияют на трафик и конверсию и как их улучшить?
Если страницы выпали из индекса поисковых систем — это тревожный признак, надо срочно искать причину. Подробный алгоритм проверки.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
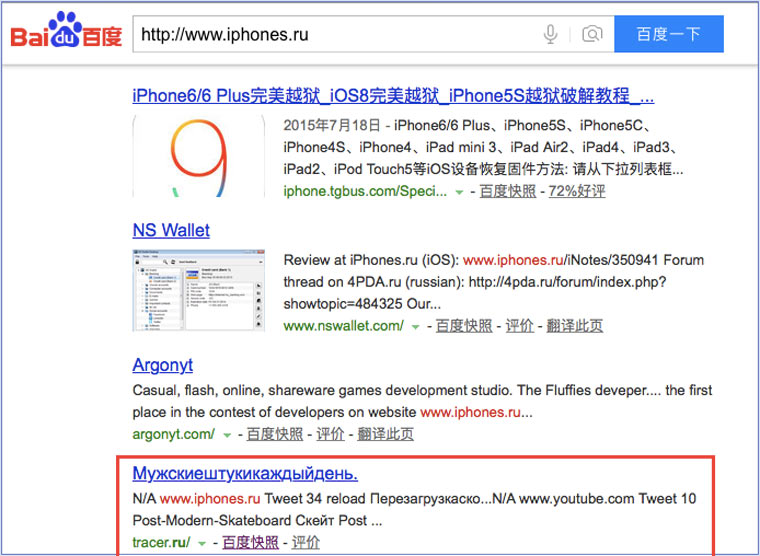
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
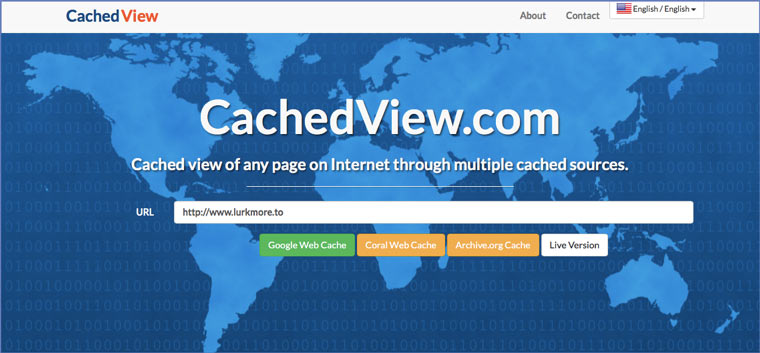
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
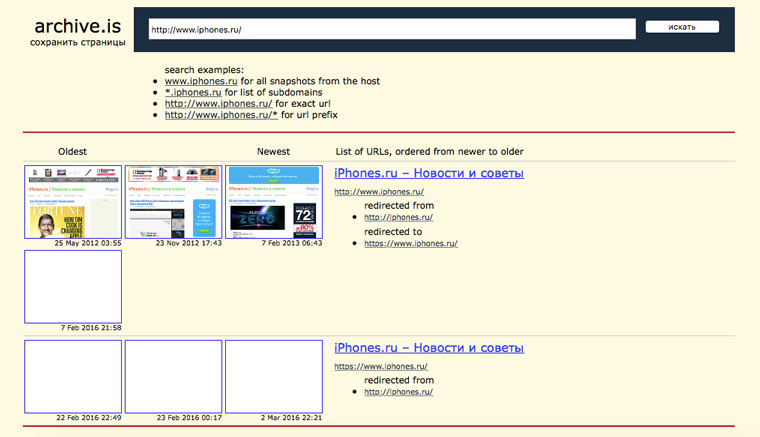
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
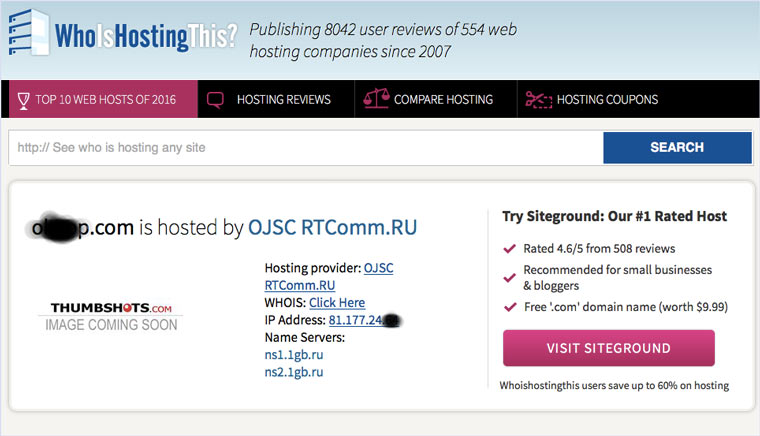
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
Представьте себе библиотеку с каталогом. Чтобы найти нужную книгу, достаточно в каталоге посмотреть, в каком ряду и на какой полке она стоит. Если из каталога убрать карточку, то книгу найти будет невозможно. Всё, нет такой книги! Вот же каталог — видите? Нету! Хотя с полки её никто и не убирал…
С файлами то же самое. Что в компьютере, что в интернете. Когда вы смотрите список файлов на диске или на сайте, вам показывают каталог. Список файлов. Если из этого списка убрать ссылку на файл, то система его найти не сможет и выдаст сообщение «Файл не найден» (для интернет-страницы это может быть «ошибка 404»). При этом физически файл вовсе не обязательно будет стёрт — если только на то же место не запишут другой файл.
Так что удалённые файлы вовсе не обязательно куда-то деваются, они просто становятся недоступными. По крайней мере недоступными снаружи.
Но даже и тут есть трюк: веб-архив, из которых наиболее известен веб-архив Гугла. Поисковый механизм этого сервиса регулярно делает мгновенный снимок сайта — и складывает его в архив. Для одного и того же сайта может скопиться огромное число таких снимков, соответствующих разным моментам времени. И если в какой-то день Х вот этот файл был с сайта удалён, то на снимке, соответствующем дню Х-1, его ещё запросто можно будет найти.
Достаём потерянные статьи из сетевых хранилищ
Время на прочтение
4 мин
Количество просмотров 299K
Решение рассматривается (пока) только для одного сайта — того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, что это решение будет работать лишь частично, но полного решения пока не существует. Можно повысить вероятность нахождения копии выбором результата из нескольких сервисов. Этим стал заниматься скрипт HabrAjax (наряду с 3 десятками других функций). Теперь (с версии 0.859), если пользователь увидел полупустую страницу, с которой можно перейти лишь на главную, в личную страницу автора (если повезёт) и назад, юзерскрипт предоставляет несколько альтернативных ссылок, в которых можно попытаться найти потерю. И тут начинается самое интересное, потому что ни один сервис не заточен на качественное архивирование одного сайта.
Кстати, статья и исследования порождены интересным опросом А вас раздражает постоянное «Доступ к публикации закрыт»? и скриптом пользователя dotneter — комментарий habrahabr.ru/post/146070/#comment_4914947.
Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы — чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
Кеш Гугла
В отличие от кеша Яндекса, к нему имеется прямой доступ по ссылке, не надо просить пользователя «затем нажать кнопку „копия“». Однако, все кеширователи, как и известный archive.org, имеют ряд ненужных особенностей.
1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
2) далее, возникает такая смешная особенность, что они могут чуть позже закешировать пустую страницу, говорящую о том, что «доступ закрыт».
3) поэтому результат кеширования — как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Кеш archive.org
Он работает на весь интернет с мощностями, меньшими, чем у поисковиков, поэтому обходит страницы какого-то далёкого русскоязычного сайта редко. Частоту можно увидеть здесь: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
Да и цель сайта — запечатлеть фрагменты истории веба, а не все события на каждом сайте. Поэтому мы редко будем попадать на полезную информацию.
Кеш Яндекса
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).
Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков. Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Yahoo Pipes
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 и прочие.
Довольно интересное решение. Те, кто умеет их настраивать, возможно, полноценно решат задачу архивирования RSS. Из имеющегося, я не нашёл пайпов с поиском статьи по её номеру, поэтому пока нет прямой ссылки на такие сохранённые полные статьи. (Кто умеет с ним работать — прошу изготовить такую ссылку для скрипта.)
Многочисленные клонировщики
Все из них болеют тем, что не дают ссылки на статью по её номеру, не приводят полный текст статьи, а некоторые вообще ограничиваются «захабренным» или «настолько ленивы», что копируют редко (к примеру, раз в день), что актуально не всегда. Однако, если хотя бы один автор копировщика подкрутит движок на сохранение полноценного и актуального контента, он окажет неоценимую услугу интернету, и его сервис займёт главное место в скрипте HabrAjax.
Из живых я нашёл пока что 4, некоторые давно существовавшие (itgator) на данный момент не работали. В общем, пока что они почти бесполезны, потому что заставляют искать статью по названию или ключевым словам, а не по адресу, по которому пользователь пришёл на закрытую страницу (а по словам отлично ищет Яндекс и не только по одному их сайту). Приведены в скрипте для какой-нибудь полезной информации.
Задача
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).
В настоящее время неполное решение её, как описано выше, выглядит так:
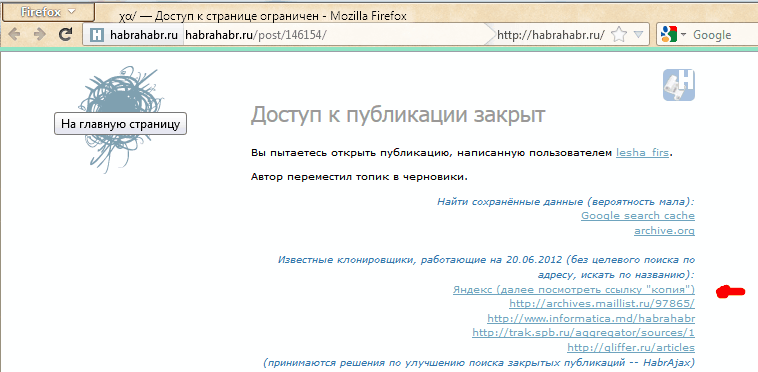
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):

Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
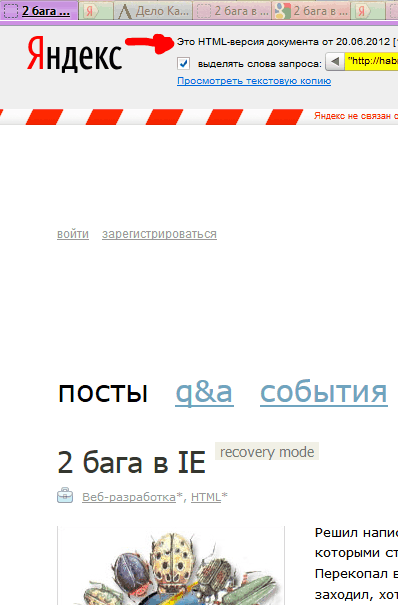
В Гугле несколько проще — сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.
Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):

Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных — на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
UPD 23:00: опытным путём для mail.ru было выяснено строение прямой ссылки на кеш:
'http://hl.mailru.su/gcached?q=cache:'+ window.location
Знатоки или инсайдеры, расскажите, что это за ссылка, насколько она стабильна (не изменится ли, например, домен 3-го уровня), что значит приставка «g»-cached? Значит ли это кеш Гугла или это кеш движка Gogo? Пример.
Добавил ссылки мейла и ВК в обновление скрипта (habrAjax) (0.861), теперь там — на 2 строчки больше.