Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
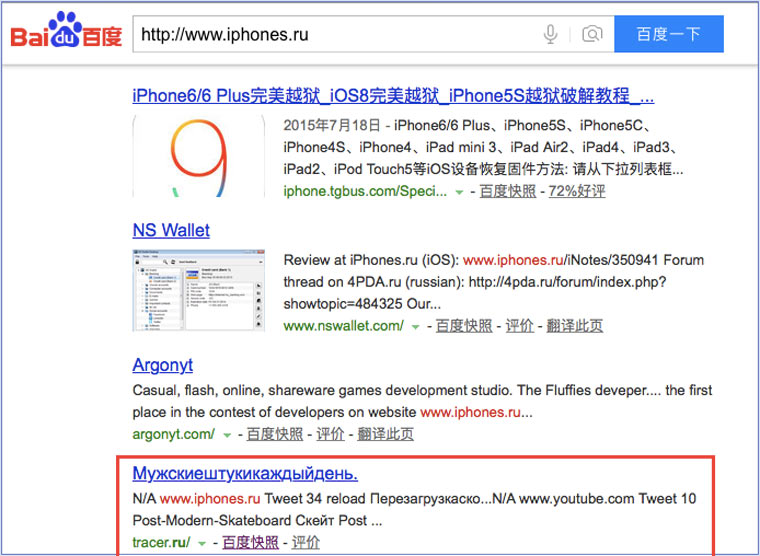
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
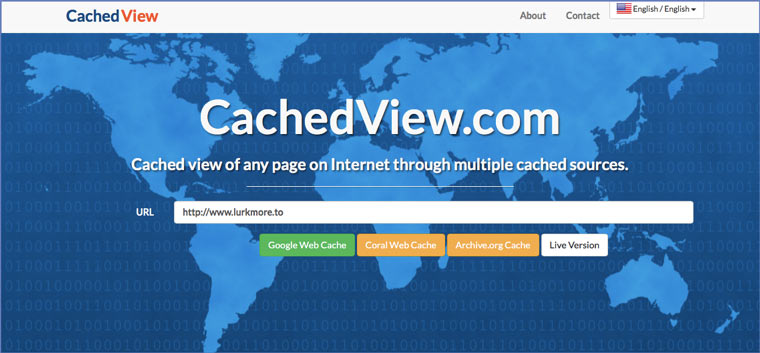
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
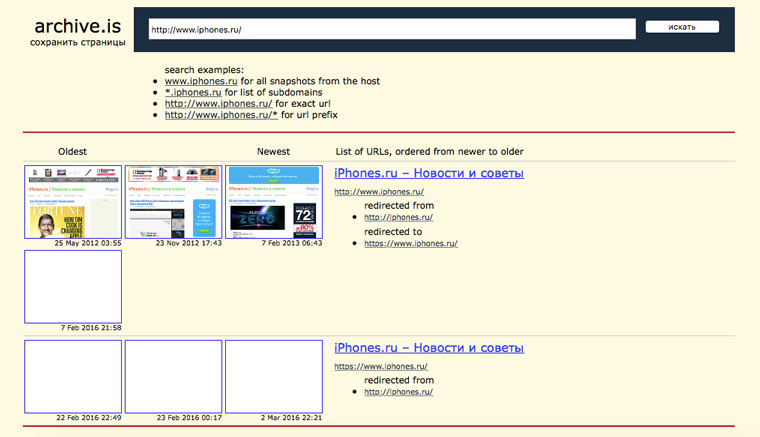
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
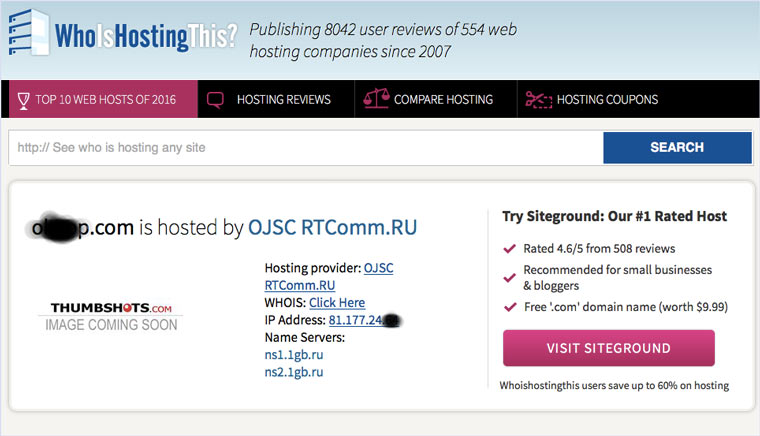
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Я добавил в закладки страницу сайту, но теперь она недоступна. Я пытался в течение 2 дней, но нечего не работает даже сайт не загружается. Похоже, весь сайт был удален. Есть ли способ просмотреть удаленную страницу?
Интернет это динамичная среда. Все меняется очень быстро — старые страницы удаляются, а новые добавляются. Как правило, когда страницы модифицируются или у них изменяется адрес, разработчики используют методы перенаправления. Редирект (перенаправление) позволяет перенаправить посетителя со старого адреса страницы на новый.
Но если весь сайт будет закрыт и не будет работать в течение многих дней, маловероятно, что он восстановит работу. В этой статье я покажу как просмотреть удаленную страницу или зайти на неработающий или уже несуществующий сайт.
Содержание
- Как просмотреть удаленную страницу
- Просмотр удаленных сайтов / страниц с помощью Wayback Machine
- Просмотр удаленных сайтов / страниц с помощью кеша Гугл
Как просмотреть удаленную страницу
Для просмотра удаленных страниц или сайтов я использую два сервиса:
- Кэш Google.
- Архив сайтов Wayback Machine.
Удаленная страница, вероятно будет доступна на одном из них. Имейте ввиду. Далеко не все сайты попадают в архив интернета. Если сайт молодой, новая страница может быть не проиндексирована сайтом.
РЕКОМЕНДУЕМ:
Как включить темную тему в Gmail
Просмотр удаленных сайтов / страниц с помощью Wayback Machine
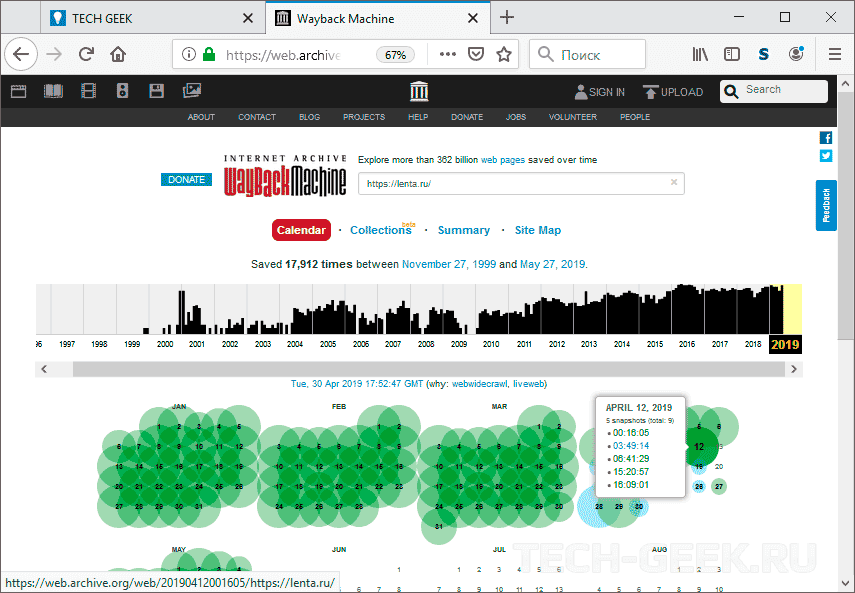
Архив интернета Wayback Machine позволяет просматривать весь сайт. Страница результатов довольно информативна, поскольку показывает, когда сайт был впервые доступен, и изменения, которые он претерпел за последние годы.
Шаг 1: Зайдите на сайт архива интернета и в верхней части экрана введите адрес удаленной страницы или неработающего сайта.

Шаг 2: Если сайт находиться в архиве будет отображена история. Выбрав необходимую дату вы сможете открыть открыть сайт и просмотреть страницу.
Теперь рассмотрим другой способ просмотра удаленных страниц и неработающих сайтов.
Просмотр удаленных сайтов / страниц с помощью кеша Гугл
Поисковая система Google хранит старый контент с веб-сайтов в кеше. Они доступны по ссылке «Сохраненная копия» рядом со списком страниц на странице результатов поиска Google.

В кеше Google находятся страницы которые были удаленны недавно. Если сайт не работает продолжительное время (пару-тройку месяцев и больше), тогда эта страница будет удалена из индекса Google, и в этом случае единственный способ просмотреть удаленную страницу — архив интернета Wayback Machine.
РЕКОМЕНДУЕМ:
Как найти похожие сайты с помощью оператора Google
Google индексирует страницы быстрее, чем Wayback Machine, кэшированные страницы могут предоставлять более свежую версию. Но могут быть проблемы с отображением изображений и другого встроенного в страницу медиа-контента.
На этом все. Теперь вы знаете как зайти на неработающий сайт и просмотреть удаленную страницу.


 (8 оценок, среднее: 3,88 из 5)
(8 оценок, среднее: 3,88 из 5)
![]() Загрузка…
Загрузка…
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета.
У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
Источник: https://www.iphones.ru/iNotes/562838

0

19
9 способов найти удаленный сайт или страницу
 В закладки
В закладки

Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет
К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
В закладки
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
- https://web.archive.org/
- http://archive.md/ (также использует домены http://archive.ph/ и http://archive.today/)
- http://web-arhive.ru/
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
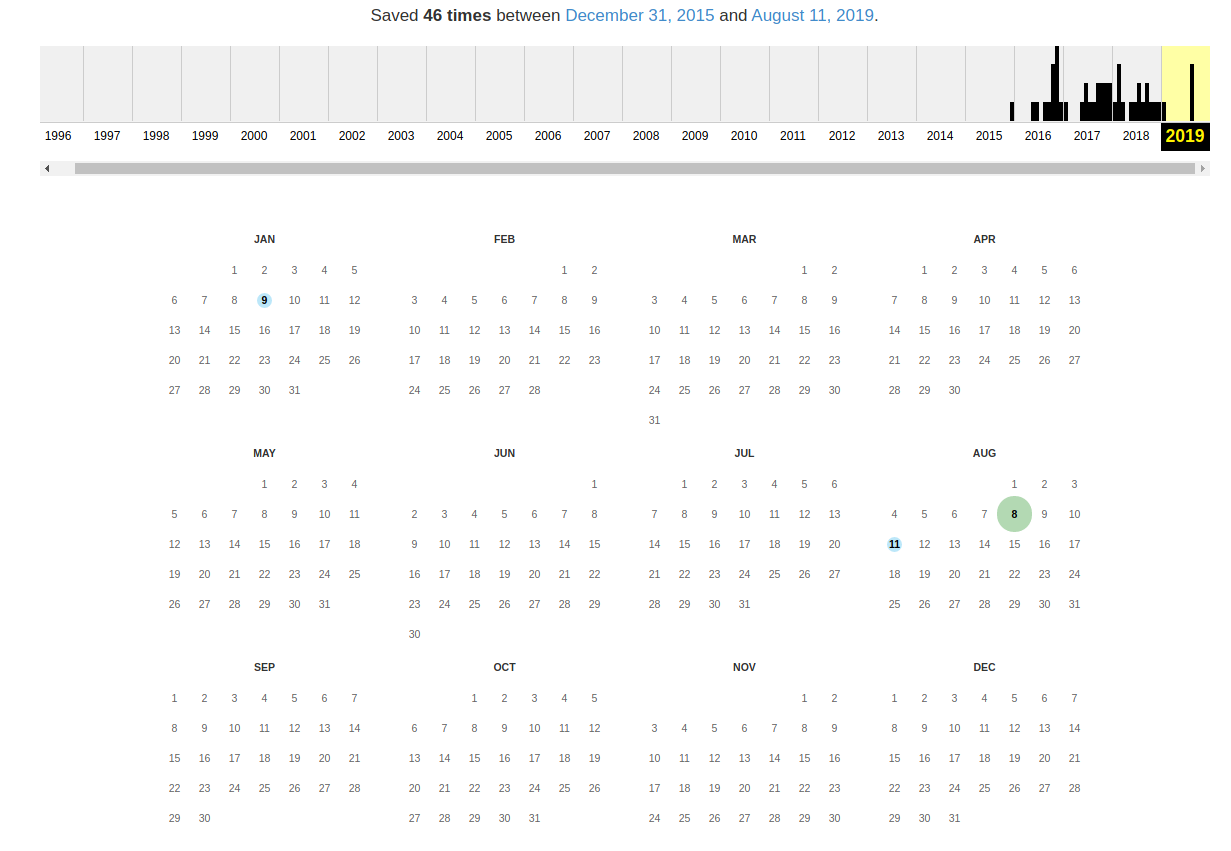
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.

При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:

Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
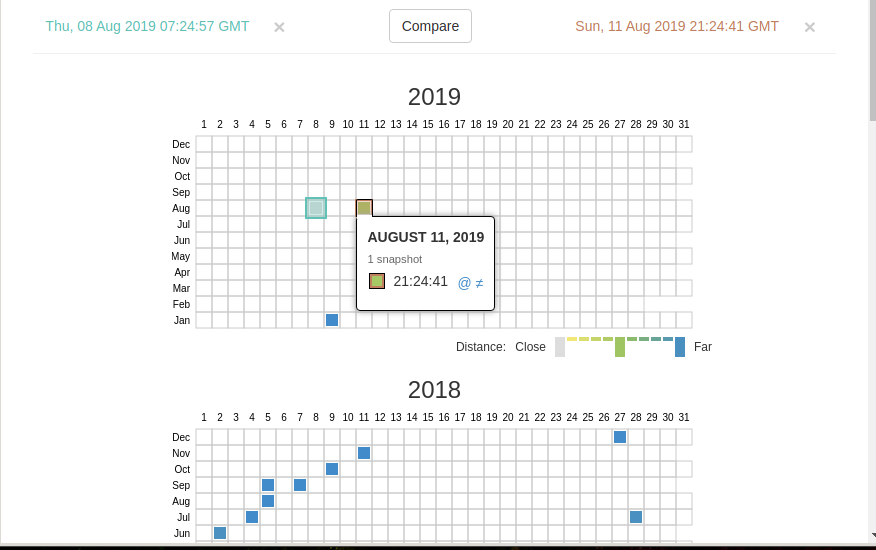
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
Summary
В этой вкладке статистика о количестве изменений MIME-типов.
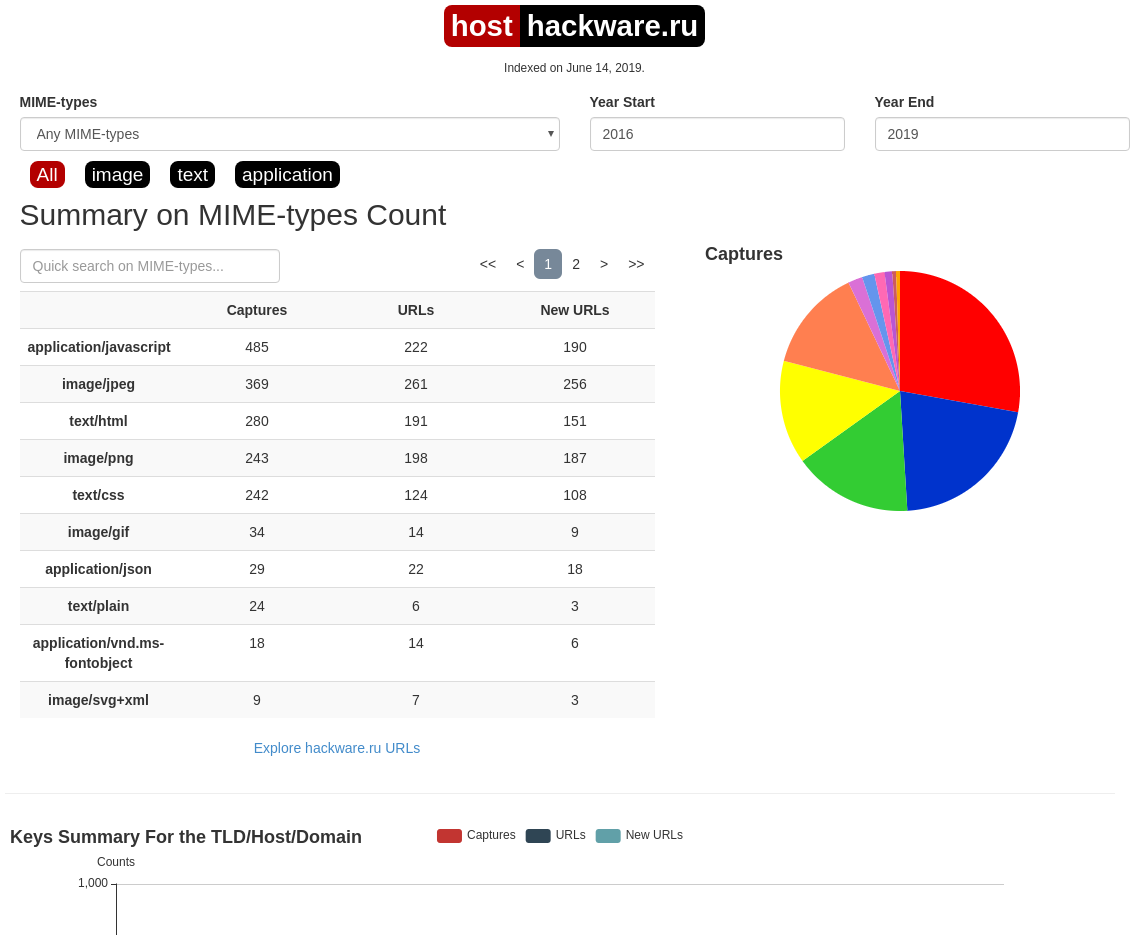
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
- http://archive.md
- http://archive.ph/
- http://archive.today/
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- http://twitter.com/burgerkingfor покажет архив данного url (поиск чувствителен к регистру)
- http://twitter.com/burg* поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
- http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
- http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
- http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например, http://archive.md/dva4n#95%
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например, http://archive.is/FWVL#selection-1493.0-1493.53
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
web-arhive.ru
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
Как полностью скачать сайт из веб-архива
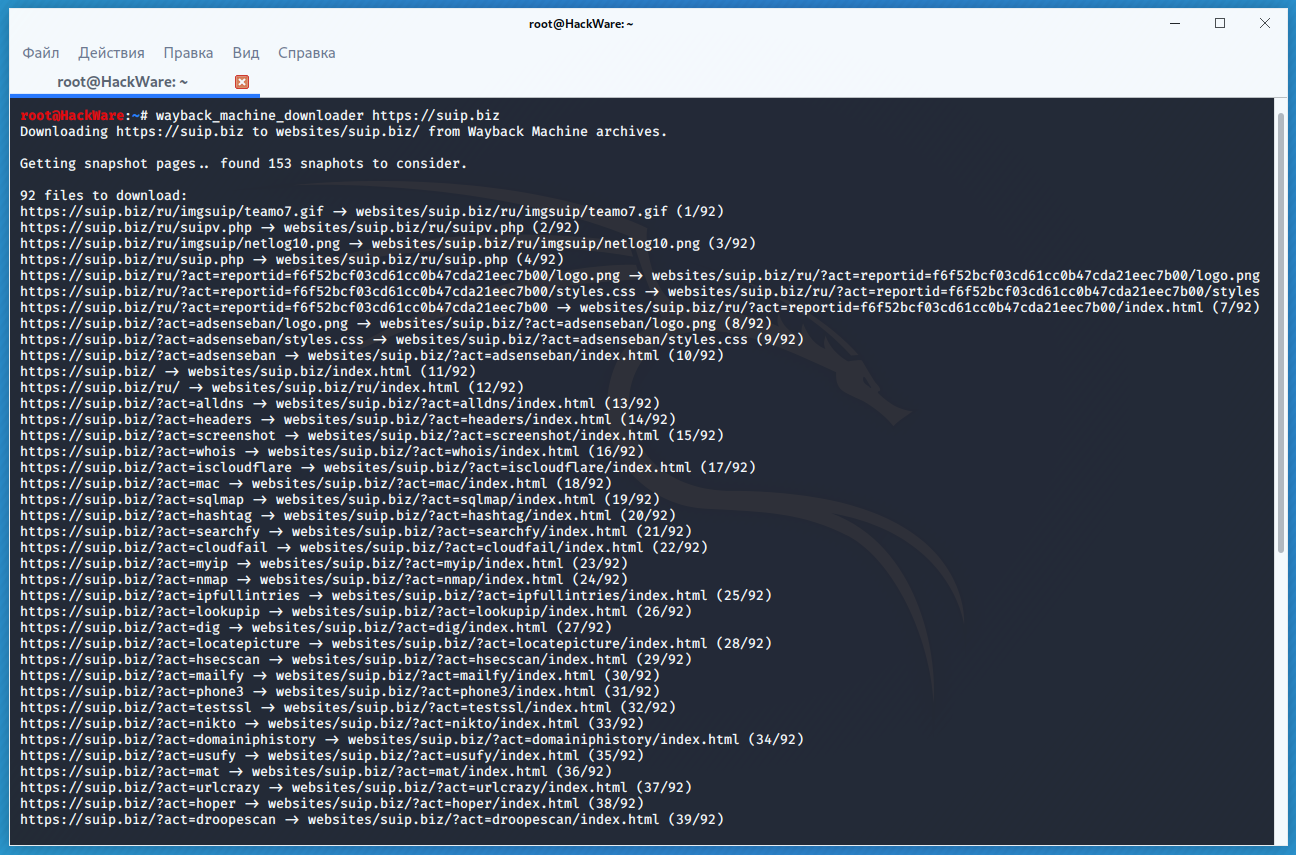
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
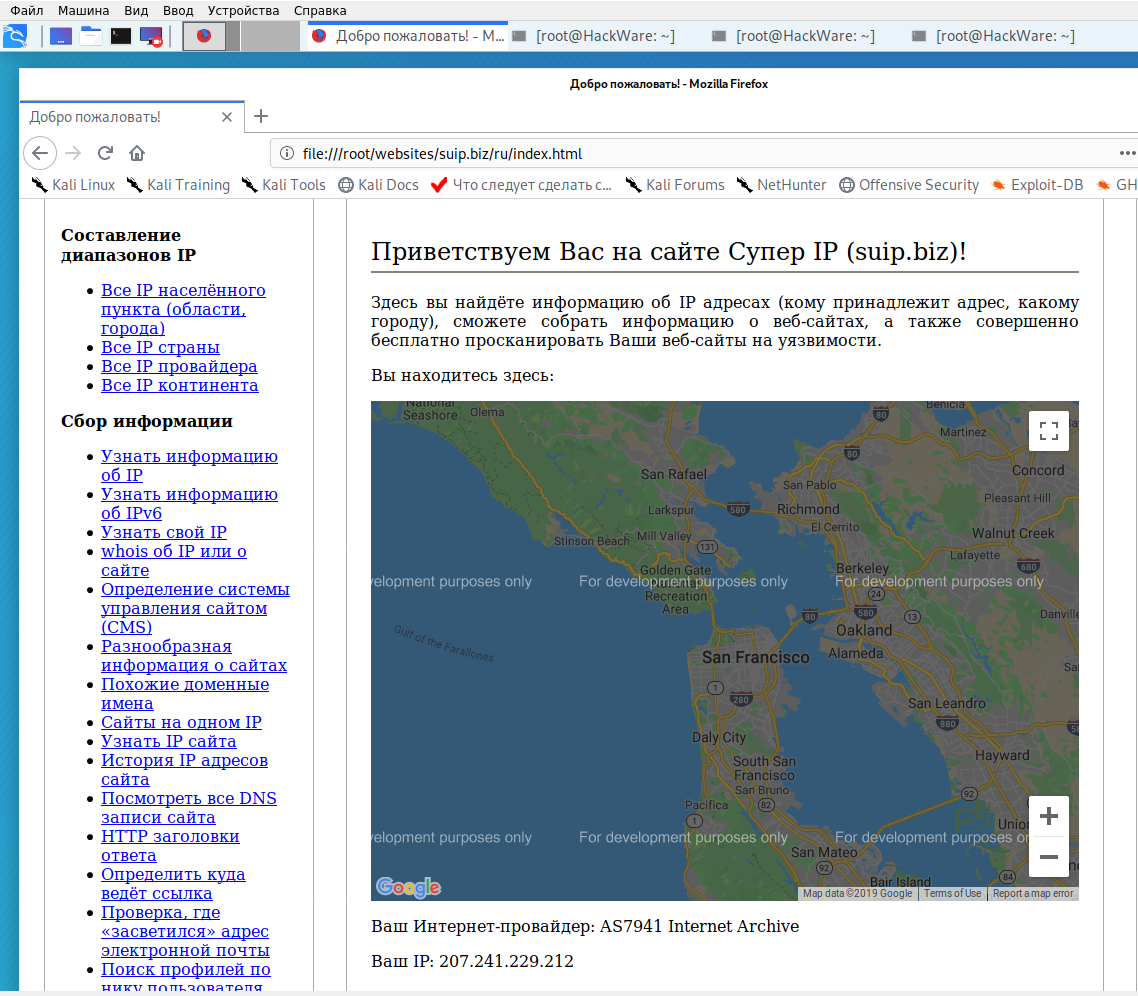
Пример скачивания полной копии сайта suip.biz из веб-архива:
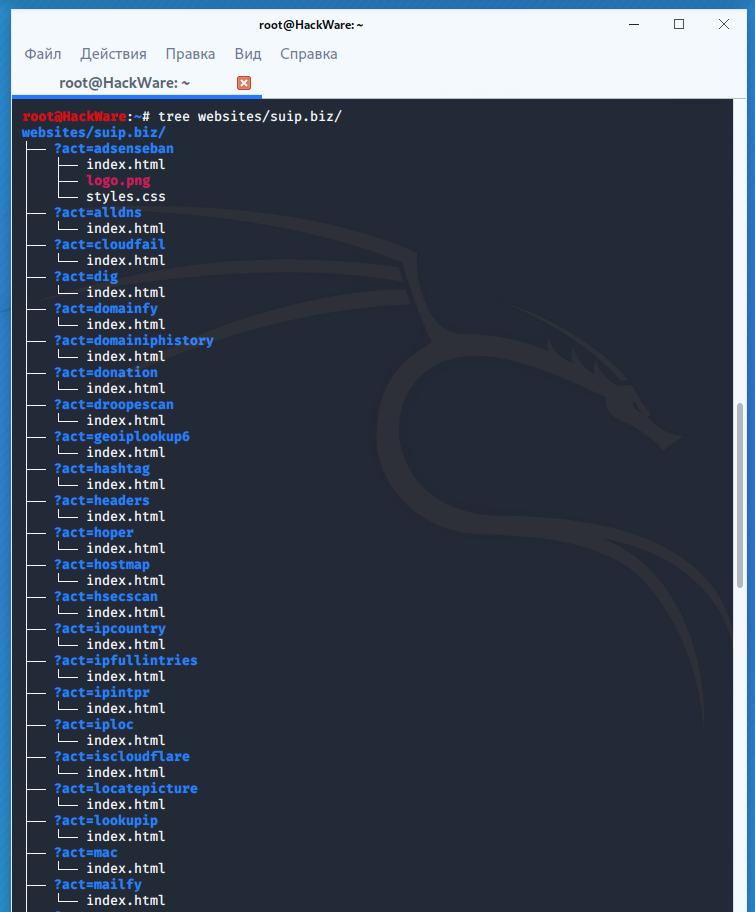
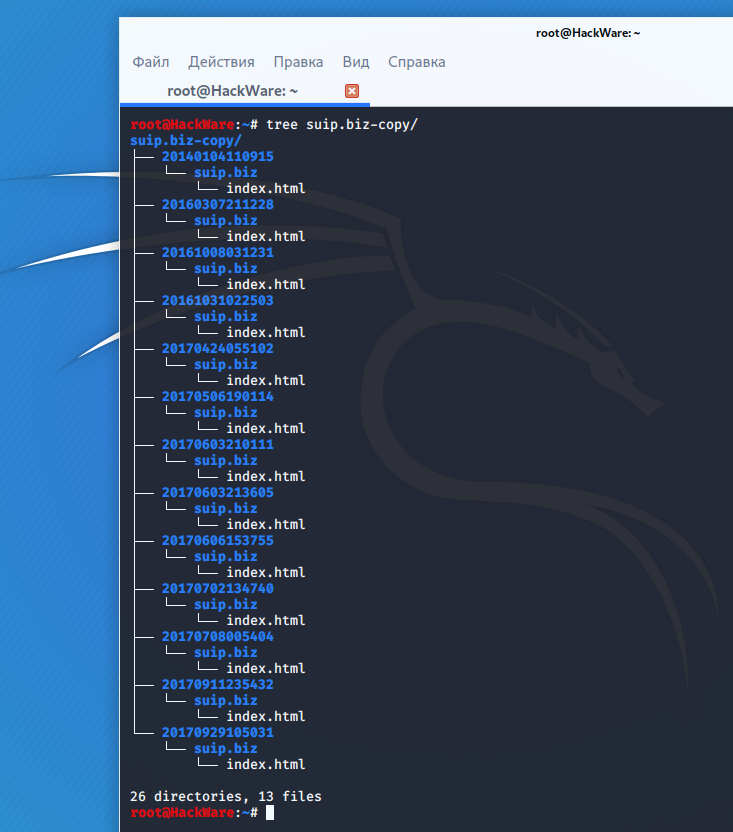
Структура скаченных файлов:
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:
Как скачать все изменения страницы из веб-архива
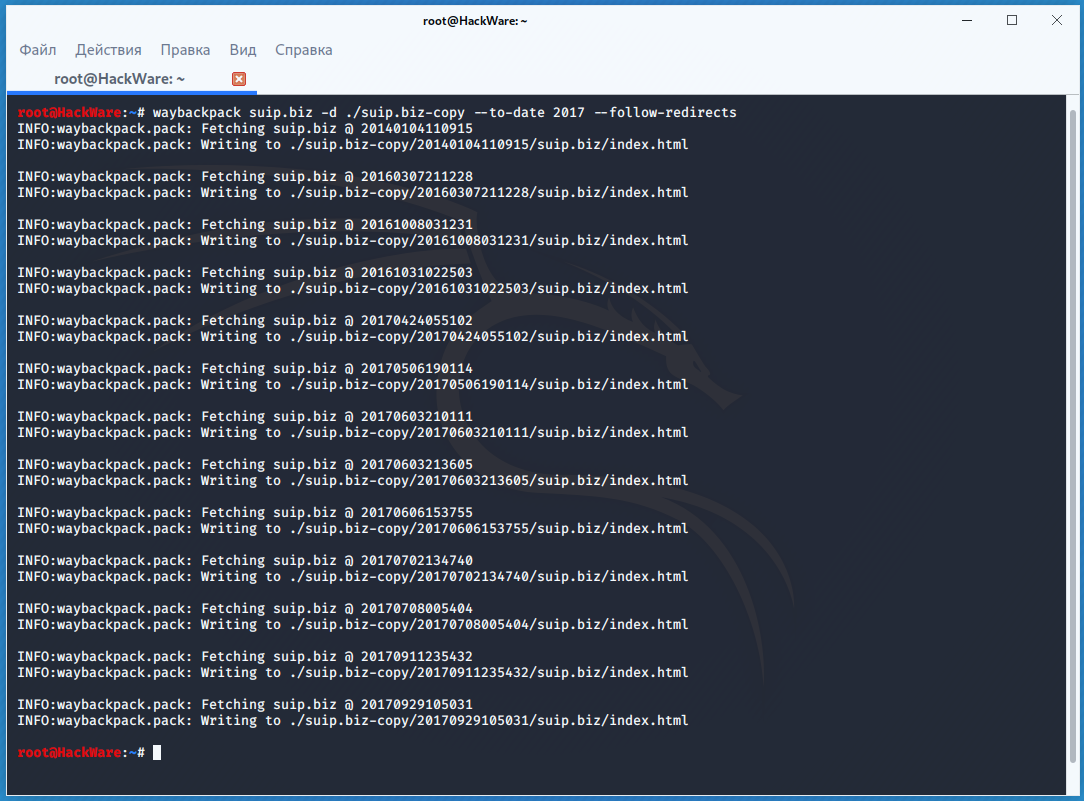
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz:
Заключение
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Как просматривать закрывшиеся сайты / удалённые файлы и предотвратить их бесследное исчезновение
Но 24 года назад, лишь в 1996 году Брюстером Кейлом была организована некоммерческая организация Internet Arсhive, собирающая копии веб-сайтов, с 2001 года предоставившая публичный доступ к своей Waybackmachine (накопилось свыше 50 петабайт данных и число перевалило за полтриллиона страниц).
Но, к сожалению, материалы за около 5 лет, когда сайты были, а архива не было, фактически потеряны.
Распадаются страны (например, домен .yu — Югославия), упраздняются организации, прекращают работу сайты, следовательно сведения бесследно исчезают.
Информация — это история и культура.
Например, сайт прекратившей работу компании, создавшей один из первых интернет-браузеров:
«Существует два типа людей: 1) которые ещё не делают резервное копирование и 2) которое уже делают.»
Лучшие практики того,
как можно вручную сохранить ценную информацию [почти] навечно (на примере Пикабу).
Чтобы сохранить АДРЕС_СТРАНИЦЫ, нужно прописать:
Чтобы найти АДРЕС_СТРАНИЦЫ потом:
1) Web-страницы публично открытых сайтов (когда waybackmachine срабатывает).
Стандартно. «Скармливать» ему лучше чистую ссылку (например, https://pikabu.ru/story/_7676787, без заголовка в URL). Чтобы потом проще было найти в архиве, если статья исчезнет.
2) Текстовая информация.
Сохранить текст, большой текст можно в pastebin.com (должно хранить вечно, но кто знает).
А потом дополнительно для спокойствия сохраняем в Waybackmachine.
Обе ссылки можно дать, например, в комментарии.
3.1) Файлы по ссылкам.
Стандартно. Упомянутый Архив Интернета сохраняет файлы, если дать на них прямую ссылку.
В комментариях можно дать ссылку на резервную копию файла.
3.2) Файлы по ссылкам, когда waybackmachine не сработал, ИЛИ же закрытые файлы.
Во-первых, применимо, когда сохранение не проходит из-за настроек сервера.
Во-вторых, применимо, когда у вас есть свой файл, который хочется опубликовать и сделать так, чтобы ссылка на него была доступна в комментариях и в будущем, навсегда.
Тогда файл стоит «перезалить», сохранить и дать на него ссылку.
Последовательность действий моя:
— загружаем файл через https://leopard.hosting.pecon.us/ (даёт прямые ссылки; утверждает, что хранит файл вечно; до 100 мегабайтов);
— дополнительно сохраняем полученную ссылку в Waybackmachine;
— в комментариях к странице даём обе ссылки;
— опционно: сохраняем в waybackmachine ещё и статью с комментариями (где будут эти ссылки).
Критерии хостинга: без регистрации, получается прямая ссылка (которая сохранится в Waybackmachine), а бонусом идёт вечное хранение (как утверждается). Но если и не вечное, то зеркало будет в Архиве Интернета.
Если у вас есть подпадающие под эти критерии хостинги — кидайте в комментарии.
4.1) Web-страницы публично открытых сайтов, когда waybackmachine не сработал, ИЛИ же закрытые страницы.
Во-первых, применимо, когда сохранение конкретной страницы не проходит опять-таки из-за настроек сервера (например, сайт подгружает информацию по нажатию мыши).
Во-вторых, применимо, когда есть информация, которая доступна после авторизации, а давать логин-пароль не рационально.
С первым примером всё ясно.
Типичный пример второго — та же Лепра, или страница с закрытого паблика соцсети, или страница с электронной почты. Сделать копию HTML, не давая доступа к учётной записи, чтобы показать, можно.
В своё время для этого использовался созданный в 2009 году сайт peeep.us , который бонусом был ещё и удобным сокращателем ссылок. Но он увы канул в Лету. Ничто не вечно.
Доступный аналог (к сожалению, в отличие от исчезнувшего сервиса ссылки не сокращает и хранит информацию у себя не вечно, хотя с первостепенной задачей справляется):
— зайти на сайт, скопировать букмарклет себе в браузер (или быть готовым запустить скрипт, например, через консоль);
— зайти на нужную страницу;
— запустить букмарклет, чтобы осуществить копирование страницы. Учтите, она пропадёт в скором времени!
— дополнительно сохранить её с помощью в waybackmachine навечно;
— в комментарии к странице даём обе ссылки;
— опционно: сохраняем в waybackmachine ещё и статью с комментариями (где будут эти ссылки).
4.2) Страницы закрытых сайтов (исправленные).
Как и в peeep.us , разумеется, если вам дали страницу, полностью доверять содержимому на ней нельзя: перед загрузкой страницы её можно отредактировать и отправить на сервер отредактированную (подменённую) версию.
Как подменить:
После изменения HTML страницы данный код позволяет отправить страницу, как её видит пользователь:
Типичные примеры спасения файлов, когда ссылка в посте больше не работает, и иное:
1. Пикабу: Векторные дома в изометри, раздаю бесплатно:) (с сайта, указанного в посте, не грузится, но Архив Интернета скопировал).
2. Голосовое управление офисной оргтехникой (по ссылке в посте не грузится, но файл залит на хостинг, а потом сохранён в Архив Интернета).
3. Сайт peeep.us больше не работает, пропал и их javascript, но код сохранён в 2017 году.
4. Аналогичный файл javascript сайта-аналога, не был сохранён. А был сохранён позавчера мной, и я был первым. Если что с сайтом случится, файл останется.

Web-технологии
295 постов 4.9K подписчиков
Правила сообщества
1. Не оскорблять других пользователей
2. Не пытаться продвигать свои услуги под видом тематических постов
3. Не заниматься рекламой
4. Никакой табличной верстки
5. Тег сообщества(не обязателен) pikaweb
Ниче не понял. Оставил комент чтоб потом зайти почитать, что умные люди скажут.
Полезная вещь. На archive.org находил драйвер и прошивку на очень старое устройство давно разорившегося производителя.
Спасибо за пост. А можно сохранить весь сайт целиком с файлами? Например, есть сайт на сервере, по какой — то причине сервер вышел из строя, снэпшота ос нет. Можно сделать полную резервную копию сайта, чтобы потом на заново устаенленной ос на сервере можно было восстановить полноценный рабочий сайт?
Хм. А как можно вытащить с Wayback Machine сайт, который там уже есть, но целиком, со всем флешем?
Через простое сохранение страницы — не выходит, внутренние элементы флеша не сохраняются. Но в самом архиве всё работает, даже файлы скачать можно.
Не волнуйтесь, в Америке весь интернет копирует АНБ. Так что всегда можно написать им и восстановить:)
Кстати, если кто внезапно захочет перепостить / использовать для своих целей, можете это делать свободно: лицензия на текст поста, код и скрины: CC0 ( https://creativecommons.org/publicdomain/zero/1.0/deed.ru ). В принципе и на мои личные комментарии тоже, если очень нужны.
использую diigo. Умеет сохранять все кешируя
А вдруг кто-нибудь знает, как скопировать и заархивировать свой блог на ЖЖ?
Как быстро написать слайдер на JS?
Во многих сайтах и программах уже давным — давно используются такие элементы взаимодейтсвия пользователем, как «Слайдер», по сути это одна большая фотография которую можно переключать с помощью стрелочек или по нажатию на клавиши. Удобно когда на экране мало места, а показать множество фотографий нужно.



Как же создать вот такой слайдер?
Слайдер будет состоять из кусков кода HTML, CSS, JS, писать будем в Codepen.io но это только для удобства, можете перенести к себе на сайт, веб-приложение или в удобное для вас место.
1. Пишем структуру
4. Заполняем объект
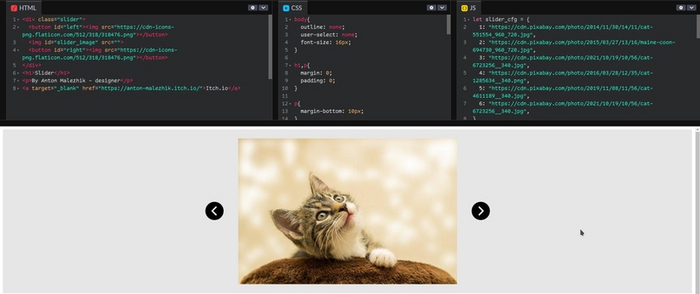
Пишем структуру
Наша структура будет состоять из объекта с классом «slider», внутри которого будет две кнопки для переключения, одна с индификатором «left», другая с «right». По середине будет большая фотография с индификатором «slider_image».
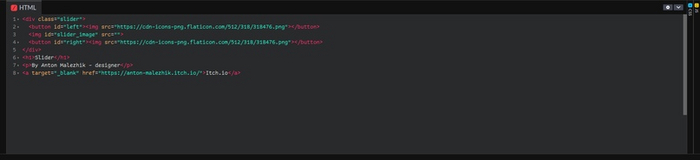
Пишем стили
Обнуляем лишние стили и пишем свои для наших элементов, контейнеров, кнопочек и фотографий.

Пишем скрипт
Для начала создадим объект, внутри которого будет хранить фотографии для слайдера, а именно ссылки на них для вписывания в будущем их в атрибут «src» на главной фотографии с индификатором «slider_image». После ищем все нужные элементы на странице через вставку «document.querySelector» и «document.getElementById». Создаем функции такие как «update()» которые будут отвечать за обновление главной фотографии, дальше будем писать ещё две функции для переключения главной фотографии. При старте страницы нужно вызвать функцию обновления, для подстраивания картинки при старте.
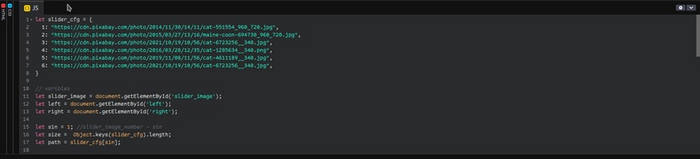
Заполняем объект
Внутри объекта «slider_cfg», пишем номер картинки от 1 до бесконечности, он сам подстроит и сам определит количество, главное соблюдать индификатор, но можно написать и без индификатора по номеру и просто перебирать их. Ещё легче было бы написать в массиве. После указания номера картинки, после «:» пишем ссылку на картинку в скобочках « ‘ ‘ », не забудьте поставить «висячую запятую», то есть как на скриншоте, после каждой записи ставить запятую в конце, даже если запись окончена.

У нас есть рабочий и очень простенький слайдер для переключения фотографий, которые мы заполняем в объект. Все это работает без сбоев и хорошо.

Панические атаки, антидепрессанты и обучение по 16 часов в день. Как я пытаюсь стать программистом

Интернет пестрит рекламными баннерами в духе «Изучи programmingLanguageName (подставьте название любого популярного языка) с нуля за 3 месяца и устройся на работу с зп от 100 000 вечнодеревянных». Предложение, конечно, заманчивое, но вряд ли осуществимое на практике для среднего человека без опыта разработки и не являющегося гением. Попытаюсь рассказать о своём пути в IT.
Программирование я открыл для себя совершенно случайно. Началось всё с того, что полтора года назад мне пришлось кое-что поправить в HTML разметке сайта компании в которой я на тот момент работал. С помощью Гугла удалось решить эту задачу. HTML мне показался весьма интересной штукой, к тому же я узнал, что существует ещё более интересный CSS. На Ютубе были найдены видео с вёрсткой примитивных лендингов. Сначала я тупо повторял за спикером и параллельно гуглил все непонятные моменты, потом начал верстать самостоятельно. Через пару месяцев пришло время JavaScript. Идея обучаться на платных курсах была отброшена почти сразу по нескольким причинам: 1. Множество негативных комментариев от программистов о качестве выпускников таких курсов. 2. Все платные курсы открывают часть уроков, чтобы заманить клиентов. Меня не удовлетворила полнота информации, предоставляемая в бесплатных уроках. 3. Не было цели как можно быстрее получить работу. Мне просто нравилось учить JS.
В апреле мой работодатель решил закрыть бизнес и я оказался на улице. Было принято окончательное решение стать разработчиком. К этому моменту у меня за плечами был опыт изучения JS примерно полгода и примерно месяц изучения React. Я решил, что смогу за пару месяцев подтянуть знания до уровня, позволяющего претендовать на позицию junior frontend-developer. Следующие 2 месяца я начинал занятия в 10-11 часов утра и заканчивал в 2-3 ночи. Без праздников и выходных. Оказалось, что кроме HTML, CSS и JavaScript нужно знать ещё кучу разных технологий и библиотек вроде Redux, Webpack, Material-UI, formik, axios, да тысячи их. Также было сделано открытие: знать синтаксис языка, писать ToDo и решать задачи на codewars !== быть программистом.
В общем, список того, что нужно изучить в процессе только разрастался. Я начал переживать, что ошибся в оценке сроков, нужных для трудоустройства. Деньги заканчивались. Рассылка резюме не давала нужных результатов. Я не получал даже приглашения на интервью. Думаю, что это в совокупности с ещё рядом факторов спровоцировали первую паническую атаку. Букет, состоящий из высокого давления, головокружения, нехватки воздуха и дикого страха смерти прямо здесь и сейчас даёт весьма интересные ощущения. Терапевты из платной и бесплатной клиник поставили диагноз гипертония. На мой вопрос почему у меня развилась гипертония в 27 лет был дан ответ: «Что вы хотите, — возраст. Даже железо стареет». Сначала панические атаки были раз в неделю, спустя некоторое время они стали возникать каждый день. Нормально учиться стало невозможно. В таком состоянии я пробыл около 3 месяцев, пока наконец не попал к неврологу, который выписал антидепрессанты. Я вернулся к учёбе.
На данный момент прошло 1,5 года с момента, как я впервые встретился с HTML. До сих пор не получилось устроиться на работу. Программирование мне очень нравится и, думаю, что я его не брошу, даже если ничего не выйдет с работой. Идея окунуться в омут с головой, не имея солидной финансовой подушки, была весьма авантюрной. О решении не идти на платные курсы, готовящие профессиональных разработчиков за срок от недели до 3 месяцев не жалею, поскольку до сих пор не вижу их преимуществ перед самообучением.