Каждый узел однонаправленного (односвязного) линейного списка (ОЛС) содержит одно поле указателя на следующий узел. Поле указателя последнего узла содержит нулевое значение (указывает на NULL).

Узел ОЛС можно представить в виде структуры
struct list
{
int field; // поле данных
struct list *ptr; // указатель на следующий элемент
};
Основные действия, производимые над элементами ОЛС:
- Инициализация списка
- Добавление узла в список
- Удаление узла из списка
- Удаление корня списка
- Вывод элементов списка
- Взаимообмен двух узлов списка
Инициализация ОЛС
Инициализация списка предназначена для создания корневого узла списка, у которого поле указателя на следующий элемент содержит нулевое значение.

1
2
3
4
5
6
7
8
9
struct list * init(int a) // а- значение первого узла
{
struct list *lst;
// выделение памяти под корень списка
lst = (struct list*)malloc(sizeof(struct list));
lst->field = a;
lst->ptr = NULL; // это последний узел списка
return(lst);
}
Добавление узла в ОЛС
Функция добавления узла в список принимает два аргумента:
- Указатель на узел, после которого происходит добавление
- Данные для добавляемого узла.
Процедуру добавления узла можно отобразить следующей схемой:

Добавление узла в ОЛС включает в себя следующие этапы:
- создание добавляемого узла и заполнение его поля данных;
- переустановка указателя узла, предшествующего добавляемому, на добавляемый узел;
- установка указателя добавляемого узла на следующий узел (тот, на который указывал предшествующий узел).
Таким образом, функция добавления узла в ОЛС имеет вид:
1
2
3
4
5
6
7
8
9
10
struct list * addelem(list *lst, int number)
{
struct list *temp, *p;
temp = (struct list*)malloc(sizeof(list));
p = lst->ptr; // сохранение указателя на следующий узел
lst->ptr = temp; // предыдущий узел указывает на создаваемый
temp->field = number; // сохранение поля данных добавляемого узла
temp->ptr = p; // созданный узел указывает на следующий элемент
return(temp);
}
Возвращаемым значением функции является адрес добавленного узла.
Удаление узла ОЛС
В качестве аргументов функции удаления элемента ОЛС передаются указатель на удаляемый узел, а также указатель на корень списка.
Функция возвращает указатель на узел, следующий за удаляемым.
Удаление узла может быть представлено следующей схемой:

Удаление узла ОЛС включает в себя следующие этапы:
- установка указателя предыдущего узла на узел, следующий за удаляемым;
- освобождение памяти удаляемого узла.
1
2
3
4
5
6
7
8
9
10
11
12
struct list * deletelem(list *lst, list *root)
{
struct list *temp;
temp = root;
while (temp->ptr != lst) // просматриваем список начиная с корня
{ // пока не найдем узел, предшествующий lst
temp = temp->ptr;
}
temp->ptr = lst->ptr; // переставляем указатель
free(lst); // освобождаем память удаляемого узла
return(temp);
}
Удаление корня списка
Функция удаления корня списка в качестве аргумента получает указатель на текущий корень списка. Возвращаемым значением будет новый корень списка — тот узел, на который указывает удаляемый корень.
1
2
3
4
5
6
7
struct list * deletehead(list *root)
{
struct list *temp;
temp = root->ptr;
free(root); // освобождение памяти текущего корня
return(temp); // новый корень списка
}
Вывод элементов списка
В качестве аргумента в функцию вывода элементов передается указатель на корень списка.
Функция осуществляет последовательный обход всех узлов с выводом их значений.
1
2
3
4
5
6
7
8
9
void listprint(list *lst)
{
struct list *p;
p = lst;
do {
printf(«%d «, p->field); // вывод значения элемента p
p = p->ptr; // переход к следующему узлу
} while (p != NULL);
}
Взаимообмен узлов ОЛС
В качестве аргументов функция взаимообмена ОЛС принимает два указателя на обмениваемые узлы, а также указатель на корень списка. Функция возвращает адрес корневого элемента списка.
Взаимообмен узлов списка осуществляется путем переустановки указателей. Для этого необходимо определить предшествующий и последующий узлы для каждого заменяемого. При этом возможны две ситуации:
- заменяемые узлы являются соседями;
- заменяемые узлы не являются соседями, то есть между ними имеется хотя бы один элемент.
При замене соседних узлов переустановка указателей выглядит следующим образом:

При замене узлов, не являющихся соседними переустановка указателей выглядит следующим образом:

При переустановке указателей необходима также проверка, является ли какой-либо из заменяемых узлов корнем списка, поскольку в этом случае не существует узла, предшествующего корневому.
Функция взаимообмена узлов списка выглядит следующим образом:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
struct list * swap(struct list *lst1, struct list *lst2, struct list *head)
{
// Возвращает новый корень списка
struct list *prev1, *prev2, *next1, *next2;
prev1 = head;
prev2 = head;
if (prev1 == lst1)
prev1 = NULL;
else
while (prev1->ptr != lst1) // поиск узла предшествующего lst1
prev1 = prev1->ptr;
if (prev2 == lst2)
prev2 = NULL;
else
while (prev2->ptr != lst2) // поиск узла предшествующего lst2
prev2 = prev2->ptr;
next1 = lst1->ptr; // узел следующий за lst1
next2 = lst2->ptr; // узел следующий за lst2
if (lst2 == next1)
{ // обмениваются соседние узлы
lst2->ptr = lst1;
lst1->ptr = next2;
if (lst1 != head)
prev1->ptr = lst2;
}
else
if (lst1 == next2)
{
// обмениваются соседние узлы
lst1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst2;
}
else
{
// обмениваются отстоящие узлы
if (lst1 != head)
prev1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst1;
lst1->ptr = next2;
}
if (lst1 == head)
return(lst2);
if (lst2 == head)
return(lst1);
return(head);
}
Назад: Структуры данных
Мы представили структуру данных связанного списка в предыдущий пост и обсудили различные типы связанных списков. Мы также рассмотрели применение структуры данных связанного списка и ее плюсы и минусы в отношении массивов. В этом посте мы подробно обсудим различные методы реализации связанных списков и создадим односвязный список на языке программирования C.
Начнем с обсуждения структуры узла связанного списка. Каждый узел связанного списка содержит один элемент данных и указатель на следующий узел в списке.
|
// Узел связанного списка struct Node { int data; // целочисленные данные struct Node* next; // указатель на следующий узел }; |
Распределение памяти узлов связанного списка
Узлы, которые составят тело списка, размещаются в куче памяти. Мы можем выделить динамическую память в C, используя malloc() или же calloc() функция. malloc() принимает один аргумент (количество выделяемой памяти в байтах). Наоборот, calloc() требуется два аргумента (общее количество переменных для размещения в памяти и размер одной переменной в байтах). malloc() не инициализирует выделенную память, а calloc() гарантирует, что все байты выделенного блока памяти были инициализированы 0. Чтобы освободить выделенную память, мы можем использовать free().
|
// Вспомогательная функция в C для возврата нового узла связанного списка из кучи struct Node* newNode(int data) { // выделяем новый узел в куче с помощью `malloc()` и устанавливаем его данные struct Node* node = (struct Node*)malloc(sizeof(struct Node)); node->data = data; // устанавливаем указатель `.next` нового узла так, чтобы он указывал на ноль node->next = NULL; return node; } |
Создание связанного списка
В этом разделе рассматриваются различные методы построения связанного списка.
1. Наивный метод
Наивное решение состоит в том, чтобы сначала построить отдельные узлы связанного списка, а затем переставить их указатели, чтобы построить список.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
#include <stdio.h> #include <stdlib.h> // Структура данных для хранения узла связанного списка struct Node { int data; struct Node* next; }; // Вспомогательная функция для возврата нового узла связанного списка из кучи struct Node* newNode(int data) { // выделяем новый узел в куче и устанавливаем его данные struct Node* node = (struct Node*)malloc(sizeof(struct Node)); node->data = data; // `.next` указатель нового узла ни на что не указывает node->next = NULL; return node; } // Наивная функция для реализации связанного списка, содержащего три узла struct Node* constructList() { // строим три узла связанного списка struct Node* first = newNode(1); struct Node* second = newNode(2); struct Node* third = newNode(3); // переставляем указатели для построения списка struct Node* head = first; first->next = second; second->next = third; // возвращаем указатель на первый узел в списке return head; } // Вспомогательная функция для печати связанного списка void printList(struct Node* head) { struct Node* ptr = head; while (ptr) { printf(«%d -> «, ptr->data); ptr = ptr->next; } printf(«NULL»); } int main(void) { // `head` указывает на первый узел (также известный как головной узел) связанного списка struct Node* head = constructList(); // распечатать связанный список printList(head); return 0; } |
Скачать Выполнить код
2. Одна линия
Приведенный выше код можно переписать в одну строку, передав следующий узел в качестве аргумента функции newNode() функция:

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
#include <stdio.h> #include <stdlib.h> // Структура данных для хранения узла связанного списка struct Node { int data; struct Node* next; }; // Вспомогательная функция для возврата нового узла связанного списка из кучи struct Node* newNode(int data, struct Node* nextNode) { // выделяем новый узел в куче и устанавливаем его данные struct Node* node = (struct Node*)malloc(sizeof(struct Node)); node->data = data; // устанавливаем указатель `.next` нового узла так, чтобы он указывал на текущий // первый узел списка. node->next = nextNode; return node; } // Наивная функция для реализации связанного списка, содержащего три узла struct Node* constructList() { struct Node* head = newNode(1, newNode(2, newNode(3, NULL))); return head; } // Вспомогательная функция для печати связанного списка void printList(struct Node* head) { struct Node* ptr = head; while (ptr) { printf(«%d -> «, ptr->data); ptr = ptr->next; } printf(«NULL»); } int main(void) { // `head` указывает на первый узел (также известный как головной узел) связанного списка struct Node* head = constructList(); // распечатать связанный список printList(head); return 0; } |
Скачать Выполнить код
3. Общий метод
Обсужденные выше методы станут проблемой, если общее количество требуемых узлов в связанном списке огромно. Мы можем легко построить связанный список, используя итерацию, если ключи заданы в виде массива или любой другой структуры данных (используя ее итератор). Далее реализация идеи:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
#include <stdio.h> #include <stdlib.h> // Структура данных для хранения узла связанного списка struct Node { int data; struct Node* next; }; // Вспомогательная функция для возврата нового узла связанного списка из кучи struct Node* newNode(int data, struct Node* nextNode) { // выделяем новый узел в куче и устанавливаем его данные struct Node* node = (struct Node*)malloc(sizeof(struct Node)); node->data = data; // устанавливаем указатель `.next` нового узла так, чтобы он указывал на текущий // первый узел списка. node->next = nextNode; return node; } // Функция реализации связанного списка из заданного набора ключей struct Node* constructList(int keys[], int n) { struct Node *head = NULL, *node = NULL; // начинаем с конца массива for (int i = n — 1; i >= 0; i—) { node = newNode(keys[i], node); head = node; } return head; } // Вспомогательная функция для печати связанного списка void printList(struct Node* head) { struct Node* ptr = head; while (ptr) { printf(«%d -> «, ptr->data); ptr = ptr->next; } printf(«NULL»); } int main(void) { // ключи ввода int keys[] = {1, 2, 3, 4}; int n = sizeof(keys)/sizeof(keys[0]); // `head` указывает на первый узел (также известный как головной узел) связанного списка struct Node* head = constructList(keys, n); // распечатать связанный список printList(head); return 0; } |
Скачать Выполнить код
4. Стандартное решение
Стандартная функция добавляет один узел в начало любого списка. Эта функция называется push() так как мы добавляем ссылку в головной конец, делая список немного похожим на stack. По другому его можно назвать InsertAtFront().
Рассмотрим следующий фрагмент:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
#include <stdio.h> #include <stdlib.h> // Структура данных для хранения узла связанного списка struct Node { int data; struct Node* next; }; void push(struct Node* head, int data) { // выделяем новый узел в куче и устанавливаем его данные struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; // устанавливаем указатель `.next` нового узла так, чтобы он указывал на текущий // первый узел (головной узел) списка. newNode->next = head; // изменяем указатель головы, чтобы он указывал на новый узел, так что // теперь первый узел в списке. head = newNode; // Нет, эта строка не работает! (Почему?) } // Функция реализации связанного списка из заданного набора ключей struct Node* constructList(int keys[], int n) { struct Node* head = NULL; // начинаем с конца массива for (int i = n — 1; i >= 0; i—) { push(head, keys[i]); // пытаемся нажать клавишу впереди — не работает } return head; } // Вспомогательная функция для печати заданного связанного списка void printList(struct Node* head) { struct Node* ptr = head; while (ptr) { printf(«%d -> «, ptr->data); ptr = ptr->next; } printf(«NULL»); } int main(void) { // ключи ввода int keys[] = {1, 2, 3, 4}; int n = sizeof(keys)/sizeof(keys[0]); // заголовок указывает на первый узел (также называемый головным узлом) связанного списка struct Node* head = constructList(keys, n); // распечатать связанный список printList(head); return 0; } |
Скачать Выполнить код
Приведенный выше код не работает, так как изменения локальных параметров никогда не отражаются в памяти вызывающего объекта. Традиционный метод, позволяющий функции изменять память вызывающего объекта, заключается в передаче указателя на память вызывающего объекта вместо копии. Итак, в C, чтобы изменить int в вызывающей программе, передайте int* вместо. В общем, менять X, мы проходим X*. Итак, в этом случае значение, которое мы хотим изменить, равно struct Node*, поэтому мы передаем struct Node** вместо этого, т. е. тип указателя головы — “указатель на узел структуры”, и чтобы изменить этот указатель, нам нужно передать ему указатель, который будет “указателем на указатель на узел структуры”.
Правильный push() код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
/* push(): принимает список и значение данных, создает новую ссылку с заданным данные и помещает их в начало списка. Его головной указатель не проходит в списке. Вместо этого список передается как «reference» указатель. к указателю на голову — это позволяет нам модифицировать память вызывающего объекта. В параметре есть слово «ref» как напоминание о том, что это «reference». (struct Node**) указатель на головной указатель вместо обычного (struct Node*) копия указателя заголовка. */ void push(struct Node** headRef, int data) { // выделяем новый узел в куче и устанавливаем его данные struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; // устанавливаем указатель `.next` нового узла так, чтобы он указывал на текущий // первый узел списка. newNode->next = *headRef; // ‘*’ для разыменования обратно к настоящей голове // изменяем указатель головы, чтобы он указывал на новый узел, так что // теперь первый узел в списке. *headRef = newNode; } // Функция реализации связанного списка из заданного набора ключей struct Node* constructList(int keys[], int n) { struct Node* head = NULL; // начинаем с конца массива for (int i = n — 1; i >= 0; i—) { push(&head, keys[i]); } return head; } |
Скачать Выполнить код
5. Сделайте указатель головы глобальным
Этот подход не рекомендуется, поскольку глобальные переменные обычно считаются плохой практикой именно из-за их нелокальности: глобальные переменные потенциально могут быть изменены откуда угодно (если только они не находятся в защищенной памяти или иным образом не отображаются только для чтения), и любая часть программы может зависеть от этого. Следовательно, глобальная переменная имеет неограниченный потенциал для создания взаимных зависимостей, а добавление взаимных зависимостей увеличивает сложность. Глобальные переменные также усложняют интеграцию модулей, поскольку другие могут использовать те же самые глобальные имена, если имена не зарезервированы соглашением или соглашением об именах.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
#include <stdio.h> #include <stdlib.h> // Узел связанного списка struct Node { int data; struct Node* next; }; // Глобальный указатель головы struct Node* head = NULL; // Берет список и значение данных, создает новую ссылку с заданным // данные и помещаем их в начало списка void push(int data) { // выделяем новый узел в куче и устанавливаем его данные struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; // устанавливаем указатель `.next` нового узла так, чтобы он указывал на текущий // головной узел списка. newNode->next = head; // изменяем указатель головы, чтобы он указывал на новый узел, так что // теперь первый узел в списке. head = newNode; } // Функция реализации связанного списка из заданного набора ключей void constructList(int keys[], int n) { // начинаем с конца массива for (int i = n — 1; i >= 0; i—) { push(keys[i]); } } // Вспомогательная функция для печати глобального связанного списка `head` void printList() { struct Node* ptr = head; while (ptr) { printf(«%d -> «, ptr->data); ptr = ptr->next; } printf(«NULL»); } int main(void) { // ключи ввода int keys[] = {1, 2, 3, 4}; int n = sizeof(keys)/sizeof(keys[0]); // `head` указывает на первый узел (также известный как головной узел) связанного списка constructList(keys, n); // распечатать связанный список printList(); return 0; } |
Скачать Выполнить код
6. Возврат головы из push() функция
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
#include <stdio.h> #include <stdlib.h> // Структура данных для хранения узла связанного списка struct Node { int data; struct Node* next; }; /* Принимает список и значение данных, создает новую ссылку с заданными данными и помещает его в начало списка */ struct Node* push(struct Node* head, int data) { // выделяем новый узел в куче и устанавливаем его данные struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = data; // устанавливаем указатель `.next` нового узла так, чтобы он указывал на текущий // первый узел списка. newNode->next = head; // вернуть новый узел, чтобы он стал первым узлом в списке return newNode; } // Функция реализации связанного списка из заданного набора ключей struct Node* constructList(int keys[], int n) { struct Node* head = NULL; // начинаем с конца массива for (int i = n — 1; i >= 0; i—) { head = push(head, keys[i]); // обновить заголовок здесь } return head; } // Вспомогательная функция для печати связанного списка void printList(struct Node* head) { struct Node* ptr = head; while (ptr) { printf(«%d -> «, ptr->data); ptr = ptr->next; } printf(«NULL»); } int main(void) { // ключи ввода int keys[] = {1, 2, 3, 4}; int n = sizeof(keys)/sizeof(keys[0]); // `head` указывает на первый узел (также известный как головной узел) связанного списка struct Node* head = constructList(keys, n); // распечатать связанный список printList(head); return 0; } |
Скачать Выполнить код
Упражнение: Изменить push() функция добавления узлов в хвост списка.
(Подсказка — найдите последний узел в списке, а затем измените его .next поле из NULL чтобы указать на новый узел, или поддерживать хвостовой указатель вместе с головным указателем для выполнения вставки за постоянное время.)
Продолжить чтение:
Связанный список – вставка в конце | Реализация C, Java и Python
Также см:
Реализация связанного списка в C++
Реализация связанного списка в Java
Реализация связанного списка в Python
Использованная литература: http://cslibrary.stanford.edu/103/LinkedListBasics.pdf
Односвязный список – это динамическая структура данных, элементы которой содержат ссылку на следующий элемент. Последний элемент имеет в качестве ссылки NULL. Для доступа к списку используется указатель на первый элемент.
- Работа со списком занимает гораздо меньше времени, чем с массивом
- Списки можно нарисовать на бумаге, тем самым наглядно понять механизм работы
- Списки можно определить рекурсивно
Односвязный список состоит из узлов. Каждый узел содержит в себе указатель на следующий узел (элемент списка) и хранимое значение. Узлы представляются в качестве структуры:
typedef struct Node
{
int value;
struct Node *next;
} Spisok;
- Используем typedef для создания нового типа, чтобы в дальнейшем не писать слово struct.
- int value — хранимое значение, может быть любого типа.
- struct Node *next — указатель на следующий узел списка.
- Spisok — название структуры.
Инициализируем список
Spisok *create(int data)
{
// Выделение памяти под корень списка
Spisok *tmp = (Spisok*)malloc(sizeof(Spisok));
// Присваивание значения узлу
tmp -> value = data;
// Присваивание указателю на следующий элемент значения NULL
tmp -> next = NULL;
return(tmp);
}
Мы инициализируем список отдельной функцией для того, чтобы облегчить процесс добавления звеньев в список. Другими словами, мы создаем заглавное звено списка.
Добавим узел в начало списка
Spisok *add_element_start(int data, Spisok *head)
{
// Выделение памяти под узел списка
Spisok *tmp = (Spisok*)malloc(sizeof(Spisok));
// Присваивание значения узлу
tmp -> value = data;
// Присваивание указателю на следующий элемент значения указателя на «голову»
// первоначального списка
tmp -> next = head;
return(tmp);
}
Добавим узел в конец списка
void add_element_end(int data, Spisok *head)
{
// Выделение памяти под корень списка
Spisok *tmp = (Spisok*)malloc(sizeof(Spisok));
// Присваивание значения узлу
tmp -> value = data;
// Присваивание указателю на следующий элемент значения NULL
tmp -> next = NULL;
// Присваивание новому указателю указателя head.
// Присваивание выполняется для того, чтобы не потерять указатель на «голову» списка
Spisok *p = head;
// Сдвиг указателя p в самый конец первоначального списка
while (p -> next != NULL)
p = p -> next;
// Присваивание указателю p -> next значения указателя tmp (созданный новый узел)
p -> next = tmp;
}
- p -> next имеет значение NULL, так как указатель p расположен в конце списка. Указатель tmp ссылается на только что созданный узел, который мы хотим добавить в конец списка. Следовательно, нужно сделать так, чтобы последний элемент текущего списка ссылался на добавляемый узел (а не на NULL). Именно для этого используется строчка p -> next = tmp.
- Мы не проверяем список на пустоту, так как ранее список был инициализирован (имеется заглавное звено).
Добавим узел в определенное место списка
Spisok *add_element_n_position(int data, int n, Spisok *head)
{
// Присваивание новому указателю указателя head.
// Присваивание выполняется для того, чтобы не потерять указатель на «голову» списка
Spisok *p = head;
// Счетчик
int count = 1;
// Поиск позиции n
while (count < n - 1 && p -> next != NULL)
{
p = p -> next;
count++;
}
// Выделение памяти под узел списка
Spisok *tmp = (Spisok*)malloc(sizeof(Spisok));
// Присваивание значения узлу
tmp -> value = data;
// Присваивание указателю tmp -> next значения указателя p -> next
// (созданный новый узел)
tmp -> next = p -> next;
// Присваивание указателю p -> next значения указателя tmp (созданный новый узел)
p -> next = tmp;
return head;
}
- Рассмотрим пример для того, чтобы лучше понять принцип работы данной функции. Имеем следующий список: 1 2 3 4 5 6 7 8 9. Например, нам нужно в пятую позицию добавить элемент 10. Сдвигаем указатель p до 4 элемента (это выполняется в цикле while). Указателю на следующий элемент для нового узла присваиваем значение p -> next [строчка tmp -> next = p -> next] (после четвертого элемента идет пятый, но мы на 5 позицию вставляем новый узел списка, он должен ссылаться на «старый» пятый элемент, чтобы «цепочка» из указателей не прерывалась после вставки нового элемента).
- Мы «соединили» новый узел с элементами, которые следуют после пятой позиции, то есть имеем следующие: 10 5 6 7 8 9. Однако нам нужно «присоединить» предшествующие элементы. Для этого указателю на следующий элемент для четвертого узла присваиваем значение tmp. То есть теперь p -> next [строчка p -> next = tmp] ссылается не на элемент со значением 5, а на новый узел с параметром 10. А узел со значением 10 (то есть узел, который мы добавляем в список), в свою очередь, ссылается на элемент c параметром 5, который ссылается на элемент со значением 6 и так далее.
Удалим весь список
Spisok *remove_all(Spisok *head)
{
// Сдвиг указателя head в самый конец первоначального списка
while (head != NULL)
{
// Присваивание новому указателю указателя head
Spisok *p = head;
head = head -> next;
// Освобождение памяти для указателя p
free(p);
}
return NULL;
}
Данная функция полностью «уничтожает» список, рассмотрим случай когда нужно удалить только определенный элемент из списка.
Удалим определенный узел списка
Spisok *remove_element(int data, Spisok *head)
{
// Присваивание новому указателю tmp указателя head, p - NULL
Spisok *tmp = head, *p = NULL;
// Проверка списка на пустоту
if (head == NULL)
return NULL;
// Если список не пуст, поиск указателя на искомый элемент
while (tmp && tmp -> value != data)
{
p = tmp;
tmp = tmp -> next;
}
// Если удаляемый элемент первый
if (tmp == head)
{
free(head);
return tmp -> next;
}
// Если в списке нет искомого элемента, то возвращаем первоначальный список
if (!tmp)
return head;
// Присваивание новому указателю указателя tmp
p -> next = tmp -> next;
// Освобождение памяти для указателя tmp
free(tmp);
return head;
}
В данной функции используется принцип функции удаления всего списка и добавления нового элемента в n-ую позицию (конечно, никакого добавления нового узла нет, но здесь мы связываем элемент до удаляемого узла с элементом, расположенным после удаляемого узла).
Вывод элементов списка
Рассмотрим простейший способ вывода элементов списка:
while (tmp != NULL)
{
// Вывод значения узла
printf("%d ", tmp -> value);
// Сдвиг указателя к следующему узлу
tmp = tmp -> next;
}
В данной статье мы рассмотрели основные функции, которые предназначены для работы с односвязными списками. Если у Вас остались вопросы, то просьба писать их в комментариях.
Подписывайтесь на T4S.TECH в Telegram, чтобы оставаться в курсе самых интересных новостей из мира технологий и не только.
Structuri dinamice de date
1.ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
2.ЛИНЕЙНЫЙ СПИСОК
3.СОЗДАНИЕ ЭЛЕМЕНТА СПИСКА
4.ДОБАВЛЕНИЕ УЗЛА
5.ПРОХОД ПО СПИСКУ
6.ПОИСК УЗЛА В СПИСКЕ
7.УДАЛЕНИЕ УЗЛА
8.ДВУСВЯЗНЫЙ СПИСОК
9.ОПЕРАЦИИ С ДВУСВЯЗНЫМ СПИСКОМ
10.ЦИКЛИЧЕСКИЕ СПИСКИ
11.СТЕК
1. Динамические структуры данных.
Часто в серьезных программах надо использовать данные,
размер и структура которых должны меняться в процессе работы. Динамические
массивы здесь не выручают, поскольку заранее нельзя сказать, сколько памяти
надо выделить – это выясняется только в процессе работы. Например, надо
проанализировать текст и определить, какие слова и в каком количество в нем
встречаются, причем эти слова нужно расставить по алфавиту.

В таких случаях применяют данные особой структуры, которые представляют
собой отдельные элементы, связанные с помощью ссылок. Каждый элемент (узел) состоит из двух областей
памяти: поля данных и ссылок. Ссылки – это адреса других узлов этого же типа, с
которыми данный элемент логически связан. В языке Си для организации ссылок
используются переменные- указатели. При добавлении нового узла в такую
структуру выделяется новый блок памяти и устанавливаются связи этого элемента с
уже существующими. Для обозначения конечного элемента в цепи используются
нулевые ссылки (NULL).
2. Линейный список.
2. Линейный список.
В простейшем случае каждый узел содержит всего одну ссылку.
Для определенности будем считать, что решается задача частотного анализа текста
– определения всех слов, встречающихся в тексте и их количества. В этом случае
область данных элемента включает строку (длиной не более 40 символов) и целое
число.

Каждый элемент
содержит также ссылку на следующий за ним элемент. У последнего в списке элемента
поле ссылки содержит NULL. Чтобы не потерять список, мы должны где-то (в переменной)
хранить адрес его первого узла – он называется «головой» списка. В программе
надо объявить два новых типа данных – узел списка Node и указатель на него
PNode. Узел представляет собой структуру, которая содержит три поля — строку,
целое число и указатель на та-кой же узел. Правилами языка Си допускается объявление:

В дальнейшем мы будем
считать, что указатель Head указывает на начало списка, то есть, объявлен в
виде:

Первая буква «P» в
названии типа PNode происходит от слова pointer – указатель (англ.) В начале
работы в списке нет ни одного элемента, поэтому в указатель Head записывается
нулевой адрес NULL.
3. Создание элемента списка
3. Создание элемента списка
Для того, чтобы добавить узел к списку, необходимо создать
его, то есть выделить память под узел и запомнить адрес выделенного блока.
Будем считать, что надо добавить к списку узел, соответствующий новому слову,
которое записано в переменной NewWord. Составим функцию, которая создает новый
узел в памяти и возвращает его адрес. Обратите внимание, что при записи данных
в узел используется обращение к полям структуры через указатель.

После этого узел надо
добавить к списку (в начало, в конец или в середину).
4. Добавление узла
4. Добавление узла
4.1. Добавление узла в начало списка
При добавлении нового узла
NewNode в начало списка надо 1) установить ссылку узла NewNode на голову
существующего списка и 2) установить голову списка на новый узел.
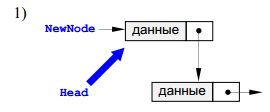
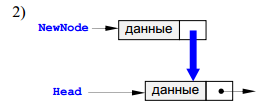
По такой схеме
работает процедура AddFirst. Предполагается, что адрес начала списка хранится
в Head. Важно, что здесь и далее адрес начала списка передается по ссылке, так
как при добавлении нового узла он изменяется внутри процедуры.
4.2. Добавление узла после заданного.
Дан адрес NewNode
нового узла и адрес p одного из существующих узлов в списке. Тре-буется
вставить в список новый узел после узла с адресом p. Эта операция выполняется в
два этапа: 1) установить ссылку нового узла на узел, следующий за данным; 2)
установить ссылку данного узла p на NewNode.

Последовательность операций менять
нельзя, потому что если сначала поменять ссылку у узла p, будет потерян адрес
следующего узла.
4.3. Добавление узла перед заданным.
Эта схема добавления самая сложная. Проблема заключается в том, что в простейшем линейном списке (он называется односвязным, потому что связи направлены только в одну сторону) для того, чтобы получить адрес предыдущего узла, нужно пройти весь список сначала. Задача сведется либо к вставке узла в начало списка (если заданный узел – первый), либо к вставке после заданного узла.
Такая процедура обеспечивает «защиту от дурака»: если задан узел, не присутствующий в списке, то в конце цикла указатель q равен NULL и ничего не происходит. Существует еще один интересный прием: если надо вставить новый узел NewNode до заданного узла p, вставляют узел после этого узла, а потом выполняется обмен данными между узлами NewNode и p. Таким образом, по адресу p в самом деле будет расположен узел с новыми данными, а по адресу NewNode – с теми данными, которые были в узле p, то есть мы решили задачу. Этот прием не сработает, если адрес нового узла NewNode запоминается где-то в программе и потом используется, поскольку по этому адресу будут находиться другие данные.
4.4. Добавление узла в конец списка.
Для решения задачи надо сначала найти последний узел, у которого ссылка равна NULL, а затем воспользоваться процедурой вставки после заданного узла. Отдельно надо обработать случай, когда список пуст.

5. Проход по списку.
Для того, чтобы пройти весь список и сделать что-либо с каждым его элементом, надо начать с головы и, используя указатель next, продвигаться к следующему узлу.

6. Поиск узла в списке.
6. Поиск узла в списке.
Часто требуется найти в списке нужный элемент (его адрес или данные). Надо учесть, что требуемого элемента может и не быть, тогда просмотр заканчивается при достижении конца списка. Такой подход приводит к следующему алгоритму: 1) начать с головы списка; 2) пока текущий элемент существует (указатель – не NULL), проверить нужное условие и перейти к следующему элементу; 3) закончить, когда найден требуемый элемент или все элементы списка просмотрены. Например, следующая функция ищет в списке элемент, соответствующий заданному слову (для которого поле word совпадает с заданной строкой NewWord), и возвращает его адрес или NULL, если такого узла нет.
Вернемся к задаче построения алфавитно-частотного словаря. Для того, чтобы добавить новое слово в нужное место (в алфавитном порядке), требуется найти адрес узла, перед которым надо вставить новое слово. Это будет первый от начала списка узел, для которого «его» слово окажется «больше», чем новое слово. Поэтому достаточно просто изменить условие в цикле while в функции Find., учитывая, что функция strcmp возвращает «разность» первого и второго слова.
Эта функция вернет адрес узла, перед которым надо вставить новое слово (когда функция strcmp вернет положительное значение), или NULL, если слово надо добавить в конец списка.
7.Удаление узла.
7.Удаление узла.
Удаление узла Эта процедура также связана с поиском заданного узла по всему списку, так как нам надо поменять ссылку у предыдущего узла, а перейти к нему непосредственно невозможно. Если мы нашли узел, за которым идет удаляемый узел, надо просто переставить ссылку.
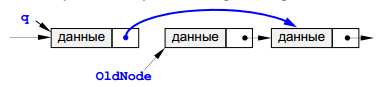
Отдельно обрабатывается случай, когда удаляется первый элемент списка. При удалении узла освобождается память, которую он занимал. Отдельно рассматриваем случай, когда удаляется первый элемент списка. В этом случае адрес удаляемого узла совпадает с адресом головы списка Head и надо просто записать в Head адрес следующего элемента.
8.Двусвязный список.
8.Двусвязный список.
Многие проблемы при работе с односвязным списком вызваны тем, что в них невозможно перейти к предыдущему элементу. Возникает естественная идея – хранить в памяти ссылку не только на следующий, но и на предыдущий элемент списка. Для доступа к списку используется не одна переменная-указатель, а две – ссылка на «голову» списка (Head) и на «хвост» — последний элемент (Tail).
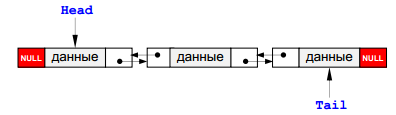
Каждый узел содержит (кроме полезных данных) также ссылку на следующий за ним узел (поле next) и предыдущий (поле prev). Поле next у последнего элемента и поле prev у первого содержат NULL.
В дальнейшем мы будем считать, что указатель Head указывает на начало списка, а указатель Tail – на конец списка:

Для пустого списка оба указателя равны NULL.
9. Операции с двусвязным списком.
9. Операции с двусвязным списком.
9.1. Добавление узла в начало списка.
При добавлении нового узла NewNode в начало списка надо:
1) установить ссылку next узла NewNode на голову существующего списка и его ссылку prev в NULL;
2) установить ссылку prev бывшего первого узла (если он существовал) на NewNode;3) установить голову списка на новый узел;
4) если в списке не было ни одного элемента, хвост списка также устанавливается на новый узел.

9.2. Добавление узла в конец списка.
Благодаря симметрии добавление нового узла NewNode в конец списка проходит совершенно аналогично, в процедуре надо везде заменить Head на Tail и наоборот, а также поменять prev и next.
9.3. Добавление узла после заданного.
Дан адрес NewNode нового узла и адрес p одного из существующих узлов в списке. Требуется вставить в список новый узел после p. Если узел p является последним, то операция сводится к добавлению в конец списка.
Если узел p – не последний, то операция вставки выполняется в два этапа:
1) установить ссылки нового узла на следующий за данным (next) и предшествующий ему (prev);
2) установить ссылки соседних узлов так, чтобы включить NewNode в список.

Такой метод реализует приведенная ниже процедура (она учитывает также возможность вставки элемента в конец списка, именно для этого в параметрах передаются ссылки на голову и хвост списка).
Добавление узла перед заданным выполняется аналогично.
9.4. Поиск узла в списке.
Проход по двусвязному списку может выполняться в двух направлениях – от головы к хвосту (как для односвязного) или от хвоста к голове.
9.5. Удаление узла.
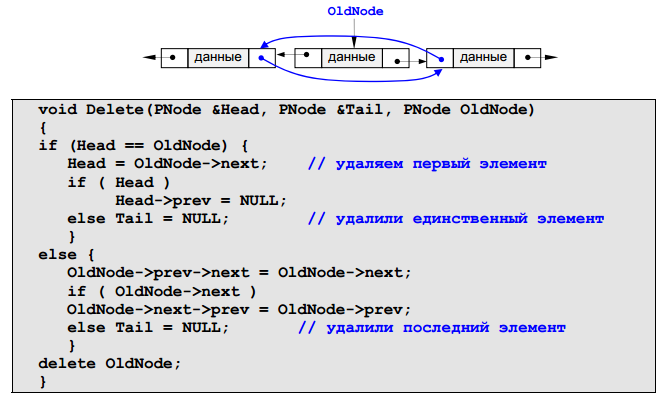 Эта процедура также требует ссылки на голову и хвост списка, поскольку они могут измениться при удалении крайнего элемента списка. На первом этапе устанавливаются ссылки соседних узлов (если они есть) так, как если бы удаляемого узла не было бы. Затем узел удаляется и память, которую он занимает, освобождается. Эти этапы показаны на рисунке внизу. Отдельно проверяется, не является ли удаляемый узел первым или последним узлом списка.
Эта процедура также требует ссылки на голову и хвост списка, поскольку они могут измениться при удалении крайнего элемента списка. На первом этапе устанавливаются ссылки соседних узлов (если они есть) так, как если бы удаляемого узла не было бы. Затем узел удаляется и память, которую он занимает, освобождается. Эти этапы показаны на рисунке внизу. Отдельно проверяется, не является ли удаляемый узел первым или последним узлом списка.
10. Циклические списки.
10. Циклические списки.
Иногда список (односвязный или двусвязный) замыкают в кольцо, то есть указатель next последнего элемента указывает на первый элемент, и (для двусвязных списков) указатель prev первого элемента указывает на последний. В таких списках понятие «хвоста» списка не имеет смысла, для работы с ним надо использовать указатель на «голову», причем «головой» можно считать любой элемент.
11. Стек
11. Стек
Стек — динамическая структура данных, представляющая из себя упорядоченный набор элементов, в которой добавление новых элементов и удаление существующих производится с одного конца, называемого вершиной стека.
По определению, элементы извлекаются из стека в порядке, обратном их добавлению в эту структуру, т.е. действует принцип «последний пришёл — первый ушёл».
Наиболее наглядным примером организации стека служит детская пирамидка, где добавление и снятие колец осуществляется как раз согласно определению стека.
Стек можно организовать на базе любой структуры данных, где возможно хранение нескольких однотипных элементов и где можно реализовать определение стека: линейный массив, типизированный файл, однонаправленный или двунаправленный список. В нашем случае наиболее подходящим для реализации стека является однонаправленный список, причём в качестве вершины стека выберем начало этого списка.
Выделим типовые операции над стеком и его элементами:
- добавление элемента в стек;
- удаление элемента из стека;
- проверка, пуст ли стек;
- просмотр элемента в вершине стека без удаления;
- очистка стека.
Чтобы привести этот код к классическому пониманию стека, достаточно заменить мои temp -переменные на (*MyList) и тогда даже при простом просмотре просмотренные данные будут сразу теряться. Удаляться не будут, но связь потеряется. И если так сделаете, то будут паразитировать эти призраки стека и пожирать вашу память отныне и вовеки веков. При работе с динамическими данными надо быть очень внимательным к памяти и не нужно этого забывать.
Стек можно просмотреть с противоположной стороны голове, но это требует очень много с точки зрения затрат памяти, потому что каждый раз придется проходить от головы до последнего (который последний текущий) ровно столько раз сколько в стеке элементов. Это чтобы два элемента считать, надо два раза по стеку пройтись.
Для стека можно выполнить и другие нетипичные для него операции, но кроме как для лучшего понимания материала это вряд ли стоит делать
В данном примере стек был построен на основе линейного связного списка, но стеки могут реализовываться на различных структурах данных: на одномерных статических и динамических массивах, на линейных списках, с помощью файлов. Стек можно реализовать на любой структуре, в которой есть возможность хранить несколько элементов и если есть то, куда можно сохранять данные.
Всем привет! Сегодня я расскажу как реализовать, наверное, самую популярную структуру данных — односвязный список. Подразумевается, что вы уже знаете такие темы, как указатели, функции и конструкторы.
Односвязный список — это динамическая структура данных, состоящая из узлов. Каждый узел будет иметь какое-то значение (я буду использовать строку) и указатель на следующий узел.

Эта картинка демонстрирует, как будет выглядеть односвязный список.
Реализация узла
struct Node {
string val;
Node* next;
Node(string _val) : val(_val), next(nullptr){}
};В этом узле есть:
-
Значение, которое будет задавать пользователь
-
Указатель на следующий элемент (по умолчанию nullptr)
-
Конструктор
Реализация односвязного списка
В списке будет:
-
Указатель на первый узел
-
Указатель на последний узел
-
Конструктор
-
Функция проверки наличия узлов в списке
-
Функция добавления элемента в конец списка
-
Функция печати всего списка
-
Функция поиска узла в списке по заданному значению
-
Функция удаления первого узла
-
Функция удаления последнего узла
-
Функция удаления узла по заданному значению значению
-
Функция обращения к узлу по индексу (дополнительная функция)
Реализация 1-3 пункта
struct list {
Node* first;
Node* last;
list() : first(nullptr), last(nullptr) {}
};Функция проверки наличия узлов в списке
Это однострочная функция, в которой надо проверить является ли первый узел — пустым
bool is_empty() {
return first == nullptr;
}Функция добавления элемента в конец списка
Здесь надо рассмотреть два случая:
-
Список — пустой
-
Список не пустой
В обоих случаях надо создать сам узел со значением, которое мы передали в эту функцию.
void push_back(string _val) {
Node* p = new Node(_val);
}Первый случай:
Здесь нам как раз пригодиться функция проверки наличия узлов. Если список пустой, тогда мы присваиваем указателю на первый узел и последний узел указатель на новый узел и выходим из функции.
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
}Второй случай:
Нам уже не нужно проверка наличия узлов в списке, так как если первый случай не происходит, то в списке есть узлы. Раз мы добавляем в конец, надо указать, что новый узел стоит после последнего узла. Затем мы меняем значения указателя last.
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
last->next = p;
last = p;
}Теперь в список можно добавлять элементы.
Функция печати всего списка
Начинаем функцию с проверки is_empty(). Далее создаём указатель p на первый узел и выводим значение узла, пока p не пустой, при каждой итерации обновляем значение p на следующий узел.
void print() {
if (is_empty()) return;
while (p) { // p != nullptr
cout << p->val << " ";
p = p->next;
}
cout << endl;
}Тест уже написанных функций
Код который мы написали:
#include <iostream>
using namespace std;
struct Node {
string val;
Node* next;
Node(string _val) : val(_val), next(nullptr) {}
};
struct list {
Node* first;
Node* last;
list() : first(nullptr), last(nullptr) {}
bool is_empty() {
return first == nullptr;
}
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
last->next = p;
last = p;
}
void print() {
if (is_empty()) return;
Node* p = first;
while (p) {
cout << p->val << " ";
p = p->next;
}
cout << endl;
}
}
int main() {
list l;
cout << l.is_empty() << endl;
l.push_back("3");
l.push_back("123") l.push_back("8");
cout << l.is_empty() << endl;
l.print();
return 0;
}[Output]
1
3 123 8
0Функция поиска узла в списке по заданному значению
Также делаем проверку is_empty() и создаём указатель p на первый узел
if (is_empty()) return;
Node* p = first;Обходим список, пока указатель p не пустой и пока значение узла p не равно заданному значению. После цикла возвращаем наш узел
while (p && p->val != _val) p = p->next;
return p ? p : nullptr;Весь код функции:
Node* find(string _val) {
Node* p = first;
while (p && p->val != _val) p = p->next;
return (p && p->val == _val) ? p : nullptr;
}Функция удаления первого узла
Делаем проверку is_empty(). Далее создаём указатель p на первый узел списка. Меняем значение первого узла на следующий и удаляем узел p;
void remove_first() {
if (is_empty()) return;
Node* p = first;
first = p->next;
delete p;
}Функция удаления последнего узла
Это функция сложнее функции удаления первого узла. Сначала также делаем проверку is_empty(). А теперь надо надо рассмотреть два случая:
-
Конец списка одновременно и начало
-
Когда размер списка больше одного
Первый случай:
Сравниваем указатель на первый узел и указатель на последний узел, если они равны, то вызываем функцию удаления первого узла.
Второй случай:
Создаём указатель p на первый узел и обходим список, пока следующий узел не равен последнему. Убираем у указателя p следующий узел и удаляем p.
Код функции:
void remove_last() {
if (is_empty()) return;
if (first == last) {
remove_first();
return;
}
Node* p = first;
while (p->next != last) p = p->next;
p->next = nullptr;
delete last;
last = p;
}Функция удаления узла по заданному значению значению
Делаем проверку is_empty(). И рассматриваем уже три случая:
-
Узел, который нам нужен, равен первому
-
Узел, который нам нужен, равен последнему
-
Когда не первый и не второй случаи
Первый случай:
Сравниваем значение первого узла с заданным значением, если значения совпадают, тогда вызываем функцию удаления первого узла.
Второй случай:
Сравниваем значение последнего узла с заданным значением, если значения совпадают, тогда вызываем функцию удаления последнего узла.
Третий случай:
Создаём указатели slow, равный первому узлу, и fast, равный следующему узлу после первого. Затем пока fast не пустой и пока значения узла fast не равно заданному значению, при каждой итерации обновляем значения slow и fast на следующий после них узел. Далее делаем проверку, что указатель fast пустой, если это так, тогда мы выводим ошибку, иначе просто удаляем узел fast.
Код функции:
void remove(string _val) {
if (is_empty()) return;
if (first->val == _val) {
remove_first();
return;
}
else if (last->val == _val) {
remove_last();
return;
}
Node* slow = first;
Node* fast = first->next;
while (fast && fast->val != _val) {
fast = fast->next;
slow = slow->next;
}
if (!fast) {
cout << "This element does not exist" << endl;
return;
}
slow->next = fast->next;
delete fast;
}Функция обращения к узлу по индексу
Для этой функции надо перегрузить оператор []
Node* operator[] (const int index)Дальше делаем проверку is_empty(). Создадим указатель p на первый узел списка. С помощью цикла for будем обновлять значение указателя p на следующий указатель, также делаем проверку на пустоту указателя p. В конце возвращаем узел p.
Node* operator[] (const int index) {
if (is_empty()) return nullptr;
Node* p = first;
for (int i = 0; i < index; i++) {
p = p->next;
if (!p) return nullptr;
}
return p;
}Тест программы
Весь код:
#include <iostream>
using namespace std;
struct Node {
string val;
Node* next;
Node(string _val) : val(_val), next(nullptr) {}
};
struct list {
Node* first;
Node* last;
list() : first(nullptr), last(nullptr) {}
bool is_empty() {
return first == nullptr;
}
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
last->next = p;
last = p;
}
void print() {
if (is_empty()) return;
Node* p = first;
while (p) {
cout << p->val << " ";
p = p->next;
}
cout << endl;
}
Node* find(string _val) {
Node* p = first;
while (p && p->val != _val) p = p->next;
return (p && p->val == _val) ? p : nullptr;
}
void remove_first() {
if (is_empty()) return;
Node* p = first;
first = p->next;
delete p;
}
void remove_last() {
if (is_empty()) return;
if (first == last) {
remove_first();
return;
}
Node* p = first;
while (p->next != last) p = p->next;
p->next = nullptr;
delete last;
last = p;
}
void remove(string _val) {
if (is_empty()) return;
if (first->val == _val) {
remove_first();
return;
}
else if (last->val == _val) {
remove_last();
return;
}
Node* slow = first;
Node* fast = first->next;
while (fast && fast->val != _val) {
fast = fast->next;
slow = slow->next;
}
if (!fast) {
cout << "This element does not exist" << endl;
return;
}
slow->next = fast->next;
delete fast;
}
Node* operator[] (const int index) {
if (is_empty()) return nullptr;
Node* p = first;
for (int i = 0; i < index; i++) {
p = p->next;
if (!p) return nullptr;
}
return p;
}
};
int main()
{
list l;
cout << l.is_empty() << endl;
l.push_back("3");
l.push_back("123");
l.push_back("8");
l.print();
cout << l.is_empty() << endl;
l.remove("123");
l.print();
l.push_back("1234");
l.remove_first();
l.print();
l.remove_last();
l.print();
cout << l[0]->val << endl;
return 0;
}
[Output]
1
3 123 8
0
3 8
8 1234
8
8Заключение
Вот Вы и научились реализовывать односвязный список, и, надеюсь, стали лучше его понимать.