Товарищи знатоки. Прошу помощи, чтобы разобраться и понять, где узкое место на моем сервере. Есть несколько разных серверов. Туда залит проект на php: кое-какая api. При работе 1 человека с апи — все ок, когда их становиться много — сразу начинает лагать и респонса клиент может и не дождаться.
Вот конфигурация одного из серверов: это бесплатный инстантс амазона. ОС — какая-то версия амазоновская, наверно основанная на убунту или дебиан. Процессор с 1 ядром, 600 мб оперативной памяти. Понимаю, что это понты, но сервера с более мощной конфигурацией испытывают такие же проблемы, хотя на мой взгляд работать они должны при бо’льших нагрузках. На сервере используется php 5.4, mysql 5, nginx. Работы с бд почти нет, тк раз 2 часа все данные апи кешируются с помощью memcached и всегда отдаются из кеша.
Так вот я запускаю тест загрузки от сайта loader.io, который имитирует 30 клиентов в минуту, каждый клиент делает запросы на 6 разных енпоинтов апи. Каждый ендпоинт в общем отдает закешированные данные + кое-какие мелкие действия в бд типа обновить дату доступа. При таком конфиге и 30 клиентов в минуту тест крашится из-за большого кол-ва таймаутов. Я не могу понять, в чем беда. Загрузка процессора — 100 почти всегда. Занимает почти все — пхп. Но почему он так грузит проц, если там работы-то на пару секунд…
Может кто описать кратко инструкцию по определению узкого места на сервере: в nginx что-то(может настрока неверная), или я как-то пхп неверно конфигурю, или с бд что-то не так. В настройке я полный 0, хотелось бы услышать советов людей, которые имеют опыт. Спасибо!
П.С. вот один из графиков, на нем видно, как сервере исправно обрабатывает запросы, но потом резко начинает педалить и загибается: 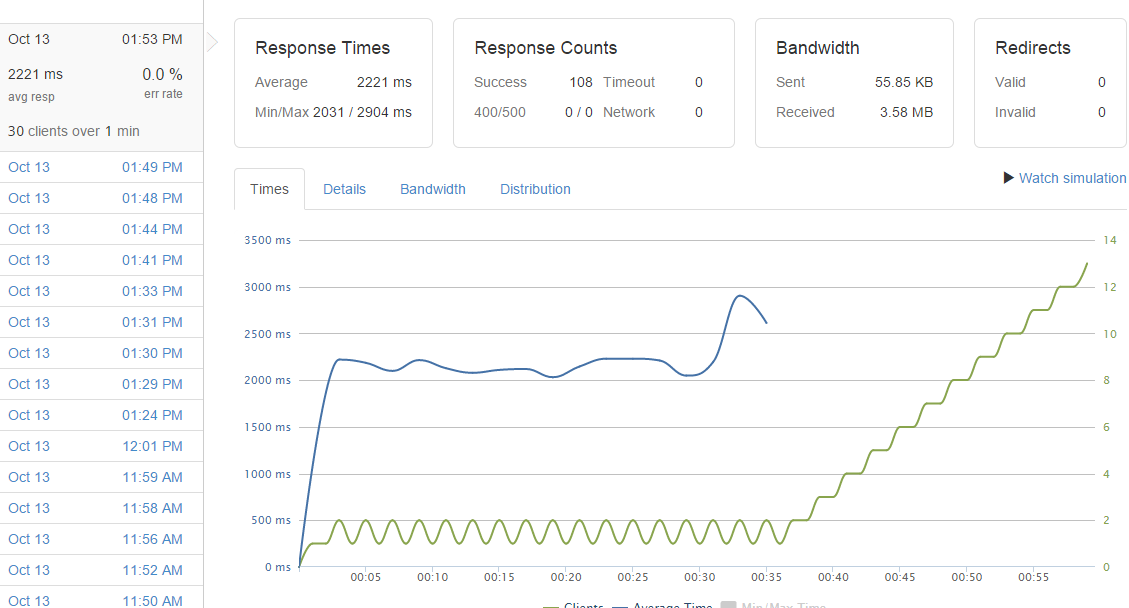 upd: результаты профайлера
upd: результаты профайлера
 Настоящим переворотом в мире PHP стал PHPUnit, который вышел в 2004 году (появилась версия 1.0). До появления этого инструмента тестировать по сути приходилось вручную, каждый раз проверяя, что ничего не поломалось. В такой схеме баги непреднамеренно появлялись на production серверах.
Настоящим переворотом в мире PHP стал PHPUnit, который вышел в 2004 году (появилась версия 1.0). До появления этого инструмента тестировать по сути приходилось вручную, каждый раз проверяя, что ничего не поломалось. В такой схеме баги непреднамеренно появлялись на production серверах.
В настоящее время помимо PHPUnit существуют другие фреймворки для тестирования, такие как PHPSpec, Behat, Codeception.
С производительностью же (а точнее с написанием тестов по ее оценке) дела обстоят гораздо хуже. Большинство разработчиков этим просто не занимается. В больших компаниях есть целые отделы, чья работа как раз заключается в поиске различных багов, а также оценке производительности приложения. Может у разработчиков просто не хватает инструментов для анализа своих приложений, либо нужно долго изучать то, чем по сути занимаются тестировщики?
Производительность тем не менее оказывает не меньшее (а иногда и большее) влияние на восприятие пользователя при работе с приложением, чем пресловутые баги.
Вот пример того, как Амазон увеличил свои доходы, улучшив производительность. А вот – опыт Google, Yahoo, AOL, Shopzilla.
Если багам разработчики стараются уделять большое внимание, то о производительности (в малых компаниях) мало кто из них по-настоящему задумывается.
Каким образом можно оценить скорость выполнения своего кода. Самый простой и старый метод заключается в замере времени выполнения некоего куска кода при помощи функции
microtime(true);Понятно, что с таким подходом далеко не уедешь. Один замер какого-либо куска кода по-сути не может объективно ответить ни на один из интересующих вопросов для разработчика. Для более адекватной оценки код следует прогнать в цикле n-раз. Для этого существует множество утилит, одна из них phpbench. Но даже используя phpbench, вы не сможете протестировать свой код в реальных условиях под нагрузкой.
Но решение есть, для мира PHP существует инструмент, который позволяет в короткие сроки протестировать код в любых условиях, в dev окружении, либо на production сервере с минимальным влиянием на пользователя. Этот инструмент – Blackfire.
Он позволяет понять, почему ваше приложение работает медленно.
CPU, память, сетевое взаимодействие, работа дисков. Все это влияет на ваше приложение, и каждый параметр нужно просматривать отдельно для более четкой картины работы приложения. И Blackfire в этом помогает. Также он показывает сколько раз была вызвана та или иная функция, сколько времени потребовалось на это, общее количество SQL запросов.
Blackfire оказывает незначительный overhead на ваше приложение во время замеров. Он позволяет находить узкие места в работе приложения. Его можно интегрировать с текущим CI решением, что позволяет автоматизировать процесс поиска слабых мест и избежать регрессии. Blackfire выполняет несколько замеров во время выполнения кода, что позволяет получить более адекватный результат.
Изначально инструмент появился в качестве форка XHProf, но потом был переписан. Для установки перейдите на официальную страницу и следуйте инструкциям. Для работы вам понадобятся агент (работает в качестве сервиса, где вы регистрируйте id и токен сервера для работы с Blackfire API), установленное расширение для PHP, и клиент, которым по сути и будете пользоваться.
Также перед началом работ нужно будет создать аккаунт на Blackfire.io. Далее рекомендую поставить Blackfire companion – расширения для Chrome. С его помощью будете одной кнопкой запускать профайлинг. Также профайлинг можно запускать вручную при помощи клиента. Если при запуске клиента что-то пойдет не так, то можно посмотреть логи в
/var/log/blackfire/agent.logКак все это выглядит можете посмотреть ниже.
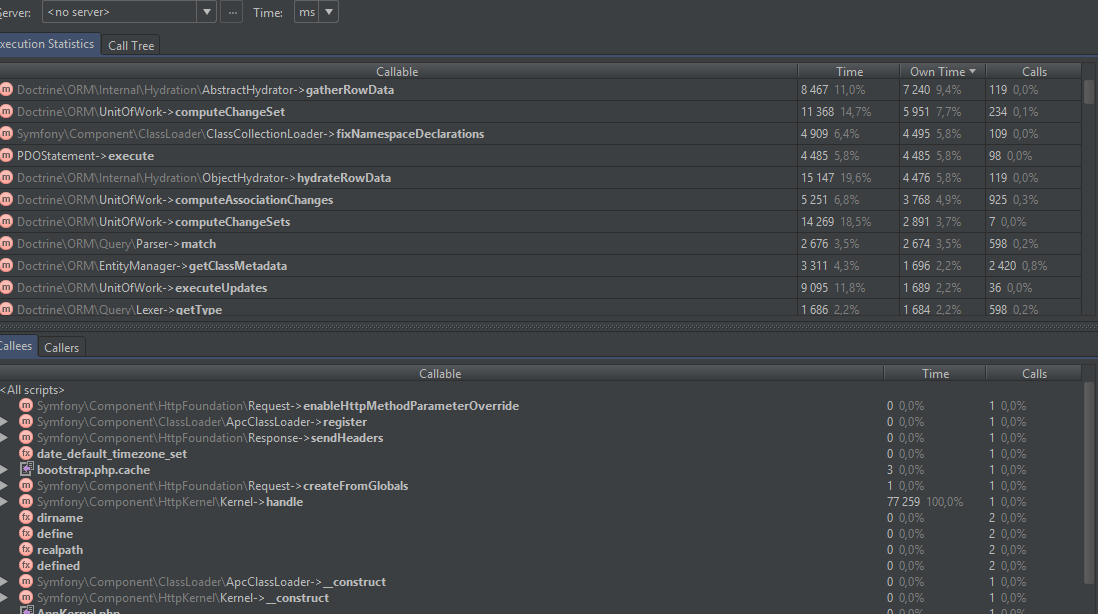
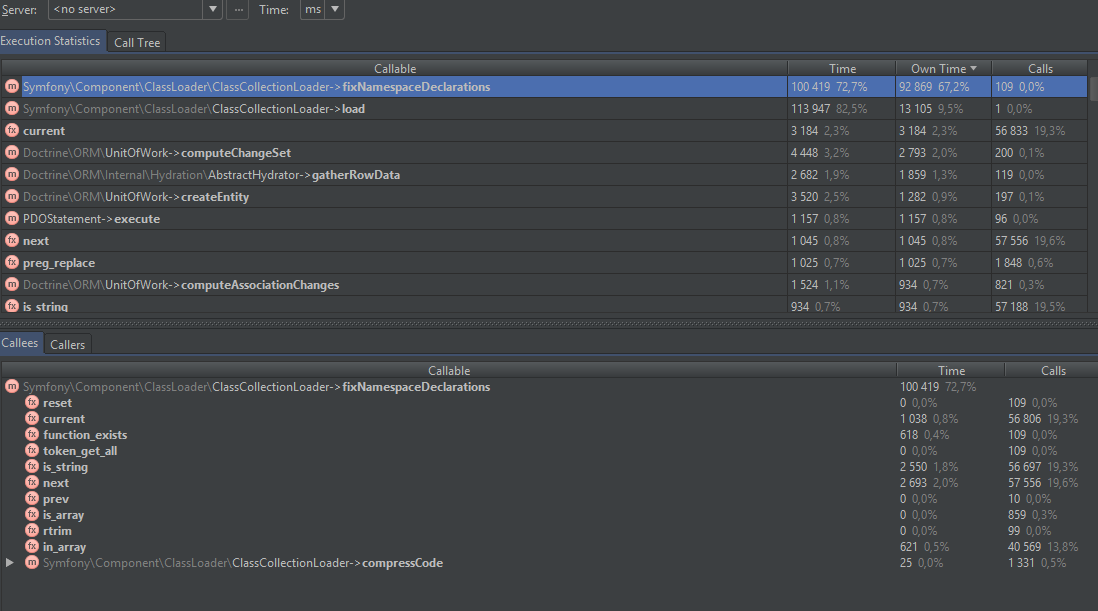
В моем примере включены модули xdebug и xhprof. Вообще их рекомендуется выключать во время профайлинга, чтобы убрать оверхед, который эти инструменты накладывают. Но в качестве демонстрации я их оставил. В моем примере рассматривается приложение на Symfony. На примере видно, что много времени тратится на парсинг yml файлов, а также получение метаданных классов для Doctrine. По-умолчанию, сверху располагаются вызовы функций, которые отнимают больше всего времени. На них-то и стоит смотреть в первую очередь. На диаграмме очень наглядно отражается поток выполнения программы.
Если переключиться на граф, показывающий потребление памяти, то можно увидеть, что большую часть у приложения отнимает загрузка классов и сборка контейнера.
Для устранения этих проблем можно включить APC кэширование, оптимизировать загрузку классов через composer, включить кэш для доктрины. После этого можно запустить профайлинг заново и сравнить с предыдущими результатами. Сравнение – это одна из лучших фич blackfire, которая отсутствует у многих инструментов для профилирования. Вот пример из официальной документации, как это выглядит.
При выполнении повторного профайлинга можно выбрать reference profile, тогда Blackfire пометит такой профайл звездочкой и при клике на него автоматически перенаправит вас на страницу сравнения с предыдущим профайлом.
Обычно при анализе в первую очередь смотрят на время. Blackfire предоставляет для времени несколько метрик.
Во-первых, это Wall Clock Time или Wall Time (общее время) – это настоящее время выполнения кода. Если говорить о функции, то это время отсчитывается от момента, когда интерпретатор вошел в функцию, и до выхода из функции, т.е. считается непосредственно само тело функции. Это время зависит от того, сколько инструкций потратил CPU на вычисления, сколько памяти было использовано, сколько операции чтения с диска было произведено и сколько пакетов по сети отослано. Упрощая, можно выделить две основных пункта: это CPU time и I/O time.
Не помешает также различать inclusive (включающее) и exclusive (исключающее) время.
Распределение времени является достаточно сложной вещью. Давайте посмотрим на примере, как это происходит.
function foo()
{
$a = new Bar();
$count = $a->getCount();
$str = '';
for ($i = 0; $i < $count; $i++) { $str .= str_repeat('foo', 10); } $str = $a->sanitizeString($str);
return $str;
}При вызове метода foo() соответствующая нода будет добавлена на граф вызовов. Inclusive time – это время, которое потребовалось на выполнение всех строк кода внутри метода. Во время выполнения функции вызываются методы sanitizeString, getCount и функция str_repeat. Эти три вызова будут представлены дочерними узлами функции foo() на графе. Таким образом у foo() есть три вызываемых метода (callees), а sanitizeString имеет вызывающий метод (caller).
Inclusive time позволяет находить критические места в приложении.
Exclusive time – это время, потраченное на выполнение самой функций без вызовов дочерних узлов.
function foo()
{
$a = new Bar();
$count =
$a->getCount();
$str = '';
for ($i = 0; $i < $count; $i++) {
$str .=
str_repeat('foo', 10);
}
$str =
$a->sanitizeString($str);
return $str;
}
Exclusive time позволяет найти функции, которые сами потребляют много ресурсов.
До этого мы рассмотрели пример профайлинга GET запроса. Но Blackfire позволяет профилировать POST, PUT, DELETE запросы, AJAX вызовы, а также консольные скрипты. Для этого понадобится CLI команда blackfire.
Выполните следующую команду и убедитесь, что client-id и client-token соответствуют вашему аккаунту.
blackfire config --dumpДля теста можете выполнить
blackfire curl http://gitlist.demo.blackfire.io/и посмотреть результат.
Вывод будет примерно следующим
Profiling: [########################################] 10/10
Blackfire cURL completed
Graph URL https://blackfire.io/profiles/f8dadabc-ce36-4512-b7fd-a61819655ef6/graph
No tests! Create some now https://blackfire.io/docs/cookbooks/tests
No recommendations
Wall Time 17.8ms
CPU Time n/a
I/O Time n/a
Memory 1.4MB
Network n/a n/a -
SQL n/a -Затем можно перейти по ссылке и посмотреть результаты более подробно.
Для профилировки скриптов можно использовать команду run.
blackfire run php -r 'echo "Hello World!";'Можно сказать blackfire, чтоб он прогнал код несколько раз для получения усредненной оценки.
blackfire --samples=3 run php -r 'echo "Hello World!";'Как же на самом деле работает Blackfire? Основная задача расширения Chrome либо клиента командной строки это добавить специальный флаг во время выполнения профайлинга. Для HTTP запроса это заголовок X-Blackfire-Query, для командной строки – это переменная окружения BLACKFIRE_QUERY. В этой переменной или заголовке запроса содержится сгенерированная цифровая подпись, которая затем проверяется расширением blackfire. Подпись может быть невалидна, либо пользователю не разрешено запускать профайлинг на этой машине, тогда blackfire не позволяет выполнить дальнейшую работу.
Теперь вы можете самостоятельно составить запрос, используя стандартные инструменты
# замена blackfire curl
blackfire run sh -c 'curl -H "X-Blackfire-Query: $BLACKFIRE_QUERY" http://example.com/ > /dev/null'
# wget вместо cURL
blackfire run sh -c 'wget --header="X-Blackfire-Query: $BLACKFIRE_QUERY" http://example.com/ > /dev/null'Для httpie можно сделать так
blackfire run sh -c 'http --json PUT example.org name=Fabien "X-Blackfire-Query:$BLACKFIRE_QUERY" > /dev/null'Blackfire поддерживает работу с окружениями. При помощи окружений можно
- разграничить права доступа отдельным пользователям
- изолировать профили, т.е. делать сравнения отдельно для разных машин (dev, staging, production)
- различные настройки для разных машин. Например, какие-то уведомления для production серверов.
Эта фича доступна только в платной версии, как и анализ SQL запросов, профайлинг HTTP запросов и многое другое.
Blackfire позволяет вам писать произвольные утверждения для анализа производительности приложения. Вот пример из документации
tests:
"All pages are fast":
path: "/.*"
assertions:
- main.wall_time < 50ms
- main.memory < 2MbЭти утверждения пишутся в файле .blackfire.yml. В примере выше говорится, что на всех страницах время работы должно быть менее 50 миллисекунд и потребление памяти менее 2 Mb. Утверждения объединяются в группы, называемые метриками. Сами утверждения представляют собой некую характеристику заданной метрики. Список доступных метрик можно посмотреть на этой странице. Можно писать свои кастомные метрики, отслеживать сколько раз был вызван тот или иной метод, сколько памяти он израсходовал. Список доступных характеристик для метрик приведен ниже:
- count
- wall_time
- cpu_time
- memory
- peak_memory
- io
- network_in
- network_out
Выглядит все это таким образом

Таким образом можно легко, например, проверить, что кэш работает на production системе, а на dev он отключен.
Но не стоит всегда ориентироваться на время в своих метриках. Медленное выполнение кода это причина какой-либо проблемы. Например, чем больше http запросов вы имеете, тем больше времени потребуется на их выполнение.
Для контроля таких ситуаций существуют специальные метрики
- metrics.symfony.processes.count < 10
- metrics.http.requests.count < 5
- metrics.parses.count == metrics.cache_driver.count
- metrics.sql.queries.count < 10
- metrics.sql.connections.count <= 1
- metrics.redis.connections.count <= 1
- metrics.amqp.connections.count <= 1 Другим полезным приемом будет проверка утверждений при определенных условиях.
# убираем компиляцию Twig/Smarty
- is_dev() or metrics.twig.compile.count == 0
- is_dev() or metrics.smarty.compile.count == 0
# нет проверки метаданных
- is_dev() or metrics.symfony.config_check.count == 0
# нет парсинга Doctrine
- is_dev() or (metrics.doctrine.annotations.parsed.count + metrics.doctrine.annotations.read.count + metrics.doctrine.dql.parsed.count + metrics.doctrine.entities.metadata.count + metrics.doctrine.proxies.generated.count) == 0
# YAML не загружается
- is_dev() or metrics.symfony.yaml.reads.count == 0
# Assetic controller не должен быть вызван
- is_dev() or metrics.assetic.controller.calls.count == 0Еще одна тема, которую стоит осветить – это профилирование скриптов-демонов. Для этих случаев blackfire предоставляет SDK. Наберите следующую команду.
composer require blackfire/php-sdkВот пример скрипта из документации
require_once DIR.'/vendor/autoload.php';
use BlackfireClient;
function consume()
{
echo "Message consumed!n";
}
$blackfire = new Client();
for (;;) {
$probe = $blackfire->createProbe();
consume(); $profile = $blackfire->endProbe($probe); print $profile->getUrl()."n"; usleep(10000);
}Тут наш код мы оборачиваем методами createProbe и endProbe. Можно не снимать показания каждый раз, а делать это раз в n итераций. Для этого существует класс LoopClient. Для достижения максимальной гибкости blackfire предусматривает использование сигналов. Можно из какого-нибудь скрипта слать сигнал blackfire, а тот в свою очередь произведет снятие метрики. Более подробно можно посмотреть в документации.
Также SDK можно использовать для написания своих тестов, используя PHPUnit.
Например, можно померить Wall Time прямо в тесте
use BlackfireProfileConfiguration;
public function testIsWallTimeOk()
{
$config = new ProfileConfiguration();
$config->assert('main.wall_time < 50ms', 'Wall Time is too high'); $this->assertBlackfire($config, function () {
doSomething();
});
}Еще одним отличным инструментом blackfire является плеер. Можно создать файл gitlist.yml примерно такого содержания
scenario:
options:
title: GitList Scenario
endpoint: http://gitlist.demo.blackfire.io/
steps:
- title: "Homepage"
visit: url('/')
expect:
- status_code() == 200
- header('content_type') matches '/html/'
- css('footer').text() matches '/Powered by GitList/'Затем запустить указанные шаги при помощи команды
blackfire-player run gitlist.yml -vvЭтот инструмент поможет вам при выполнении интеграционного тестирования. Последним шагом использования blackfire является его интеграция в CI систему. При помощи системы вебхуков можно очень гибко управлять оценкой производительности приложения. В ряде случаев это поможет избежать регрессии вашего кода.
Blackfire – это отличный инструмент, который позволит оценить производительность приложения на каждом этапе жизненного цикла.
I’m trying to figure out the bottleneck(s) in a web application on a production server. There are about 80 sites running on ColdFusion 10 with the latest Java 8, Tomcat 7, IIS 8.5 on Windows Server 2012 R2. Requests randomly peak from average 500-1000 ms to up to 30 seconds, meaning 9 out of 10 requests of the same page are completed within 1000 ms and one takes 20-30 seconds. It can happen on pretty much every page/template with code, it seems.
Web app characteristics:
- lots of regular expressions and string manipulation
- lots of data transformation (list to array, recreating arrays, randomizing data order, generating structs)
- lightweight SQL queries (dedicated SQL server in the same network)
- no outgoing connections (
<cfhttp>)
I’m monitoring using FusionReactor and I observed the following things:
- the server has very low traffic (6 requests per second on average, 50 at best)
- requests are not queued
- average 60 JDBC queries per second between 1-2 ms, highest is 250 JDBC queries per second, worst total time is around 300 ms
- heap is at 10 GB at best (most of it being cache/old gen, eden space being collected at around 2 GB, survivor space less than 200 MB)
- GC young collection runs every 40 seconds around 20 ms on average, worst time is 140 ms
- disk read/write is less than 200 Kb/s on average, highest reads at 2 Mb/s, highest writes at 4 Mb/s
- network IO: 200 b/s TX, 400 b/s RX on average
- CPU runs from 20% to 60% load
- whenever the 20-30 seconds peaks occur, the JIT Time graph shows spikes
Stacktrace of a slow request
Note: This is just an example. Other hanging requests show the gap in other functions. There doesn’t seem to be a pattern, sometimes it’s a function that contains a query, sometimes it’s just a <cfinclude>, sometimes it’s just plain output.

Thread CPU Time is 2500 ms while execution time is 29727 ms. TTFB and TTLB is 29726 ms, stream opened 2 ms before and closed 1 ms after. Query Total Time was 76 ms (19 queries).
Notice how funcCONSTRUCTFOOTER.getAccess is actually just a single line Java function return 0; (returning the access attribute of the <cffunction> tag), so I really doubt that the execution of this function took 23 seconds. I don’t see any lock/wait either though.
More examples:



JVM (Java HotSpot(TM) 64-Bit Server VM, 1.8.0_121)
-server
-Xms24G
-Xmx48G
-Xss4m
-XX:MaxMetaspaceSize=2G
-XX:+TieredCompilation
-XX:ReservedCodeCacheSize=2G
-XX:+UseCompressedOops
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-Xbatch
ColdFusion (10.0.22.283922, Update 22)
Maximum number of simultaneous Template requests: 40
Maximum number of cached templates: 40000 (~14500 cached according to monitor)
Trusted cache: true
Cache template in request: true
Component cache: true
Save class files: true
Connector
<Connector port="8012" protocol="AJP/1.3" redirectPort="8445" tomcatAuthentication="false" maxThreads="500" connectionTimeout="60000" />
worker.list=cfusion
worker.cfusion.type=ajp13
worker.cfusion.host=localhost
worker.cfusion.port=8012
worker.cfusion.connection_pool_size=500
worker.cfusion.max_reuse_connections=250
worker.cfusion.connection_pool_timeout=60
Average in metrics.log ranges from 35 to 75 threads. Busy count is about 90% of the value, e.g. Max threads: 500 Current thread count: 70 Current thread busy: 64.
Hardware
- HyperV VM on Intel Xeon E5-2650
- 4 physical cores assigned, 8 logical cores
- 64 GB RAM assigned
What could be the reason? How can I inspect the issue further?
Что касается узких мест на сервере приложений, вы можете использовать инструмент профилирования, чтобы узнать, сколько времени потрачено на каждую часть вашего кода, как используется много памяти и т.д. Для PHP webgrind кажется популярным способом профилирования на основе графического интерфейса. Что-то вроде dotTrace будет делать то же самое для приложения ASP.NET. Обратите внимание, что когда дело доходит до баз данных, такие инструменты профилирования будут показывать только те запросы баз данных, которые медленны, а не почему они медленны. Для этого вам нужно будет изучить профилирование базы данных…
Еще один аспект узких мест в веб-приложениях — это то, сколько времени на самом деле занимает браузер, чтобы сбрасывать все (импорт и импорт CSS и JavaScript, изображения и т.д.) и отображать страницу. Есть несколько компаний, таких как Keynote, у которых есть боты, которые попадут на ваш сайт со всего мира, проанализируют производительность и дадут вам рекомендации относительно изменения, которые вы можете сделать, чтобы получить выход вашего приложения в браузер и отобразиться как можно быстрее (например, «использовать сжатие gzip и разместить свой JavaScript в конце страницы вместо головы» и т.д.). Разумеется, вы также можете сделать это самостоятельно. Например, плагины Firefox, такие как Jiffy и YSlow будут выполняйте эту работу.
Clint Harris
05 фев. 2009, в 07:39
Поделиться
Для любого веб-приложения вы можете попробовать использовать расширение Firebug вместе с расширением Yahoo YSlow (Firebug). Очень полезно в производительности страницы.
http://developer.yahoo.com/yslow/
Mark Unwin
05 фев. 2009, в 07:44
Поделиться
Трассировка — отличное начало
kd7
05 фев. 2009, в 05:58
Поделиться
Fiddler — хороший инструмент для ведения журнала трафика и мониторинга. Он работает на клиенте, и вы можете видеть, какие запросы и ответы идут между клиентом и веб-сервером. Вы можете легко анализировать медленные страницы и определять причины (для многих запросов, большой страницы,…)
В частности, для ASP.Net существует механизм трассировки, который может создавать подробный журнал для веб-приложений. Журнал показывает информацию о времени, и вы можете найти длинные функции. (Статья MSDN: Обзор трассировки ASP.NET
zendar
05 фев. 2009, в 12:11
Поделиться
попробуйте использовать некоторые тестовые механизмы, такие как PHPUnit, чтобы подчеркнуть ваше приложение и использовать оболочку, чтобы узнать, какой процесс требует больше времени для решения.
в Unix/Linux вы можете использовать команду «top»
в Windows используйте диспетчер задач (расширенный)
perrohunter
05 фев. 2009, в 17:05
Поделиться
Если вам нужен общий способ поиска узких мест, попробуйте использовать инструмент мониторинга HTTP. Это позволяет вам видеть, какие типы запросов занимают больше времени, или если они возвращают сообщения об ошибках. Затем вы можете использовать инструмент профилирования для платформы с нулевым значением в определенных областях вашего приложения на основе данных из этого инструмента.
Мне нравится использовать HTTP-прокси-инструмент, например Charles, чтобы выполнить этот тип анализа.
Flynn81
05 фев. 2009, в 18:55
Поделиться
Включите функцию трассировки, trace = true, если это веб-приложение, и введите инструкции трассировки в начале и конце ваших методов, которые срабатывают. Это даст вам очень подробное считывание тиков в системе и, следовательно, сколько времени каждая часть будет выполнять.
Если у вас есть библиотека, которая вызывается, вы также можете сделать трассировку в ней, используя httpcontext.Current.Trace.Write, чтобы вывести то, что вам нужно посмотреть. Альтернативно, если ваше приложение действительно тонкое, вы можете написать свою собственную функцию для хранения операторов трассировки в общей переменной и записать ее в БД или другой механизм после запуска script.
Middletone
05 фев. 2009, в 16:52
Поделиться
Patrick Cuff
05 фев. 2009, в 11:27
Поделиться
Не могли бы вы более подробно рассказать о платформе (XP, Vista, Server 2000, 2003, 2008) и методе запуска приложения (IIS, Windows Service). Как упоминалось выше, трассировка является хорошим началом, но есть и другие инструменты, зависящие от среды, в которой также настроено веб-приложение.
HMS_Matteo
05 фев. 2009, в 05:25
Поделиться
Первый шаг — быстрый и грязный. Попробуйте это на iPhone, ноутбуке с 3G-соединением, ПК со спутниковым интернет-соединением и мобильным КПК для Windows. Если это сработает, все готово. Если нет, триангуляция.
Stephan Eggermont
05 фев. 2009, в 13:54
Поделиться
Ещё вопросы
- 0Разбор HTML от определенной начальной точки до определенной конечной точки?
- 0Асинхронный обратный вызов не был вызван в течение тайм-аута — модульное тестирование службы Typescript & Angular $ http
- 1D3 v4, перемещая и круг, и текст одновременно
- 1Конвертировать категорические признаки (Enum) в H2o в Boolean
- 1Исключение с 64-битным модульным тестом в Visual Studio 2008 Professional
- 0jQuery не работает в .load ()
- 1Типы предупреждений в Python и MATLAB
- 0Ошибка: «Ответ» не был объявлен в этой области
- 1Загрузка изображений с помощью Express
- 0Почему десятичные поля принимают буквы в предложении where?
- 1Вставьте оператор в базу данных SQL Server
- 1MusicPlayer повтор музыки «X» [дубликаты]
- 0Microsoft Visual Studio C ++ 2010 Exp — Компиляция в порядке, но не работает
- 1Тема Splashscreen отображается при каждом предварительном просмотре в Android Studio
- 1Получите <a href= людямhttps://www.google.se/ Обработанной> html пакет аджилити ширины адреса
- 0Как использовать угловой контроллер JS дважды
- 0Выберите следующее «свободное» целое число на основе ввода
- 1Android-байт-код JAVA отсутствует после обновления инструментов Gradle и Build
- 0Magento — показать комментарии заказа на phtml
- 0Подключите локальный хост Mysql из ядра Docker .net
- 0Сравните время Python с форматом времени MySQL
- 1Замена «*» в фрейме данных панд
- 0Оператор MySQL NOT IN
- 1оператор if, включая hover () и ширину окна
- 0Могу ли я сделать этот PDO короче
- 1Использование заполнителя в StringBuilder
- 1Office 365 надстройка Javascript — синтез речи
- 1Android — Kotlin: сделать GET или PUT запрос на отправку JWT
- 0т.е. ответный текст не завершен
- 0Btn-group, накладывающаяся на изменение размера окна (меньше)
- 0Как добавить начальный ноль в jQueryUI Datepicker (внутри кода, не выводится)
- 0Установка переменной в число на основе результата производной таблицы
- 0Как преодолеть недостаток дружбы в C #?
- 0Итерация по векторному столбцу C ++
- 1Определение CultureInfo свойства с помощью DataAnnotation
- 1Почему текст Snackbar исчезает, если текст слишком длинный?
- 1Синтаксическая ошибка при реализации API Google Map Javascript с помощью Smarty
- 1Bukkit Плагин Minecraft Сундуки заполнить и построить из класса с INT в списке
- 1Android ViewPager предварительно загружает слишком много фрагментов
- 0Передача пользовательских функций в объекты jquery
- 0дополнительные элементы данных в объединенной структуре
- 0синтаксическая ошибка в моих SQL-запросах
- 1Проблема с отображением приложения Android Studio
- 1EF: Должен ли я включать идентификаторы внешнего ключа в мои объекты?
- 0Почему я получаю сообщение об ошибке для последней строки кода?
- 1Динамическая последовательность точек GPS вдоль дороги
- 1Java JComboBox внешний вид
- 0Фронт-контроллер PHP и .htaccess с XAMPP и Windows
- 1Каким будет путь к пакету служб SSIS?
- 0При использовании Angular с SignalR, как я могу уведомить контроллер, когда в объект вносится изменение?
Как понять, что происходит на сервере +94
Системное администрирование, *nix, Серверное администрирование, Серверная оптимизация, Блог компании Конференции Олега Бунина (Онтико)
Рекомендация: подборка платных и бесплатных курсов таргетированной рекламе — https://katalog-kursov.ru/

Александр Крижановский ( krizhanovsky, NatSys Lab.)
По Сети уже давно бегает эта картинка, по крайней мере, я ее часто видел на Фейсбуке, и появилась идея рассказать про нее:

Я набрал в Google, оказалось, что человек, который ее создал, занимается оптимизацией производительности Linux’а, и у него есть замечательный блог. Там не только презентация, где эта картинка присутствует, там порядка трех презентаций, есть какая-то еще документация. Призываю сходить на этот блог, там хорошо рассказывается про все утилиты, которые перечислены на этой картинке. Мне не хотелось заниматься пересказом, поэтому я даю ссылку на презентацию – http://www.brendangregg.com/linuxperf.html.
С другой стороны, у него в презентации очень сжатый поток, там часовая презентация, о каждой из этих утилит понемногу — просто, что она делает, по сути, то же самое, что вы можете найти в man’е, либо просто набрав название каждой из этих утилит в Google. Мне захотелось сделать пару примеров о том, как можно найти узкое место и понять, что происходит.
Gregg дает методологии, начиная с рассмотрения того, как найти узкое место, пять вопросов «зачем» и т.д. Я ни разу не использовал какие-то методологии, просто смотрю, что-то делаю и хочу показать, что можно делать.

К сожалению, когда я готовил презентацию, у меня под рукой не было стенда с установленным софтом, бенчмарками, т.е. я не мог повторить весь сценарий. Я пытался собрать какие-то логи, которые у меня были, чаты, плюс воспроизводил какие-то сценарии у себя на ноутбуке, на виртуалках, поэтому если какие-то циферки вам покажутся подозрительными, они действительно подозрительные, и давайте смотреть на них немного сквозь пальцы. Нам будет больше важна идея о порядке цифр и о том, как их посмотреть, как их узнать.
Первый и основной пример — это то, что у нас было кастомное приложение, был модуль nginx, очень тяжелый модуль, но прикладную логику мы не будем рассматривать. Там была проблема в том, что людям хотелось очень много коннектов, но много коннектов не получалось, там остановилось все. Входной трафик был порядка 250 Мб в секунду, очень много параллельных соединений на таком достаточно скромном трафике. У нас полностью выжирались ресурсы, и ничего не происходило, т.е. новые коннекты, новые запросы просто отбрасывались.
Посмотрели. Первое, что мы делаем — это смотрим в netstat, делаем grep, делаем еще один grep. В netstat’е больше 20 тыс. соединений, и у нас там вот эти потоки. Понятно, что когда происходят проблемы с производительностью, система чувствует себя очень плохо. И когда мы запускаем netstat, он висит очень долго с grep’ом, поэтому, если есть возможность, лучше работать с proc’ом, она на самом деле всегда есть, и написать awk скрипт, который будет не пайпами работать, а сразу прочитает одну строку из proc, разберет ее и выдаст вам результат, как посчитает. Будет немного быстрее, комфортнее работать.
Второе, что делаем для понимания, что происходит — это просто посчитать входящие пакеты. Здесь я не пользовался какими-то сложными вещами, я просто беру счетчики пакетов, счетчики байтов. Собственно, как получены эти цифры — делаю sleep на 10 секунд, чтобы нивелировать какие-то флуктуации, и потом вычитаю одного из другого и делю на 10.

Далее запускаем Top обычный. В Top’е какая-то картинка, в целом, в ней ничего криминального нет, т.е. nginx не 100% процессора ест, average тоже в принципе нормальный. Подозрительно то, что системное время 33% и софтинтерраптное (si — software Interrupts) — 52%. Т.е. фактически у нас nginx мало что делает, но у нас много что делает ядро ОС. Также мы видим, что у нас есть две нитки ksoftirqd — это я воспроизводил у себя внутри виртуальной машины, и там всего два ядра было, т.е. два сетевых потока обработчика поднялись в Top.

Есть полезная кнопка в Top’е — это нужно нажать «1». Она вам покажет не суммарную статистику по процессорам, а для каждого процессора индивидуально. Здесь мы видим хорошую картинку, в целом, процессоры работают равномерно. Если один процессор выкручивается на 100%, а другие лежат, у нас явно проблема с распределением нагрузки. Если пакеты идут, в основном, на одно ядро, на одно прерывание, то остальные отдыхают. Здесь у нас распределение неплохое было.

Я люблю этим пользоваться. Это нехорошо, это крестьянский метод, но в целом GDB дает очень мощный интерфейс. Вы в цикле можете задать скрипт для GDB по всем вашим процессам nginx’а и посмотреть, что с ними делается. Здесь мы смотрим просто верхушку стека — первую и вторую функции, но, в принципе, вы можете сделать более интересные вещи, вы можете не только бэктрейсы собирать, вы можете какие-то переменные распечатывать и т.д. Это достаточно мощный механизм для того, чтобы в реал тайме заглянуть внутрь сервера, посмотреть, что с ним делается, его состояние, но при этом сильно не останавливать его. Этот скрипт, как бы, тормозит, понятное дело, что nginx’у становится еще хуже, но, в целом, оно работает, можно это делать в реал тайме.
Если запустить этот скрипт несколько раз, то, в целом, даже просто по нескольким процессам, нескольким потокам можно видеть, что какие-то потоки в большинстве своем проводят время в одной-двух функциях — этот как раз наш bottle-neck будет. Если у вас будет всего один поток или процесс, который вас интересует, просто несколько раз запустите и сможете понять, что это вот такое простое сэмплирование.
Еще не сказал, что в данном случае мы видим здесь просто epoll. Epoll — это не очень интересно, гораздо интересней, если бы мы увидели user space код. В том случае, с которого мы начинали, был user space код, там были регулярные выражения, которые мы обрабатывали, там был bottle-neck.
Следующее, что мы делаем, поскольку мы видим, что проблема не в nginx, а проблема в системе, мы идем в систему. Смотрим, как чувствует себя ОС. Т.е. на данный момент мы уже отсекли, поделили зону поиска и уже ищем в ОС.

Есть удобная утилита perf top — это трейсер ядра, он может показать все ваши процессы в системе, конкретный процессор, конкретный процесс, его call_trace. Вот, здесь мы видим, что основное время у нас тратится в nf_conntrack. В целом, не очень понятно, т.е. видно, что последние две строчки — это nginx. Мы понимаем, что там какой-то прикладной код, он для нас не интересен, потому что мы знаем, что nginx уже не наш bottle-neck. То, что мы ищем, мы ищем внутри ОС, и нас интересуют первые три вызова.
Первый. Для того чтобы найти что такое nf_ct_tuple_equal опять же удобно иметь исходники ядра под рукой. Я не говорю о том, что всем нужно разбираться внутри него, но просто сделав grep внутри ядра — то, что я сделал — вы можете достаточно легко понять, либо можете просто набрав в Google вызов, который вы видите в perf’e. Он может быть сначала непонятным, но достаточно быстро можно найти, что это за подсистемы. Не нужно знать точно, что делает этот системный вызов, эта функция ядра, просто понимать, что это за подсистема, в какой подсистеме у нас тормозит ядро.
Просто делаем grep. Я сделал общий рекурсивный grep внутри директорий, нашел Kconfig, где он лежит, и там есть человеческое описание — то, что вам выводится в конфигурации ядра, что делает эта подсистема. Дальше мы идем в Google, смотрим, что такое conntrack’и видим достаточно много сообщений о том, что conntrack’и тормозят систему, на входной трафик они не имеют смысла, в частности, для htp-сервера, мы их можем отключить.
Для того чтобы убедиться в том, что все сошлось, все наши данные, мы распечатываем количество соединений, которое сейчас пасут conntrack’и, и видим там примерно то же самое число, что и число установленных соединений. Сonntrack’и в Linux’е — это подсистема firewall’а, который отслеживает наши соединения, т.е. яркий пример FTP, когда у нас идет одно соединение, по нему отдается порт и firewall должен пасти и первое, и второе соединение, связать их. И у этой подсистемы есть достаточно медленная функция, которая начинает матчить все соединения, она просто работает вхолостую, она ничего не делает, поэтому мы ее можем отключить.
С первым bottle-neck‘ом разобрались, давайте посмотрим на следующий.

Intel_idle. Честно говоря, в первый раз я подумал, что это от Intel’овской карты. Опять же делаем grep внутри ядра. Уже в Kconfig’e ничего нет, потому что это все всегда включено, но зато разработчики Intel позаботились, чтобы сделать хороший комментарий внутри исходника, и мы видим, что время, которое наш процессор тратит впустую, он тратит его внутри этого потока. Этот поток хороший, это значит, что у нас простаивает процессор какое-то время, и мы с ним ничего не делаем.
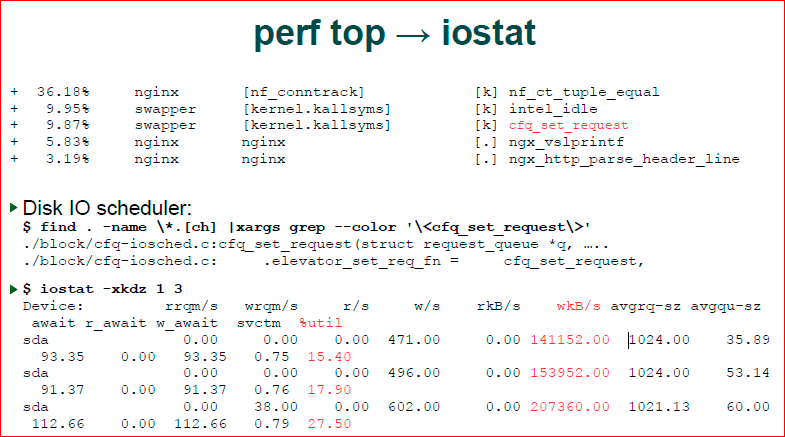
Следующая точка. Вновь делаем grep, мы видим, что у нас ./block/cfq-io планировщик, и мы понимаем, что мы имеем дело с планировщиком ввода-вывода. Значит, наверное, nginx что-то вводит-выводит. При этом block IO — это значит, что у нас файловая система, а не сетевая часть, т.е. сетевая часть находится в net.
Если так происходит, мы хотим посмотреть статистику ввода-вывода, iostat помогает нам это сделать. Мы видим, что у нас идет массивная запись, и что диск как-то там используется на 15-20%. Не очень много, но там тратится время.
Дальше, когда мы посмотрели perf top, мы на самом деле видели, что это ОС проводит в вводе-выводе. Это не значит, что nginx это делает, это может быть kswapd что-то выводит, это может быть какой-то демон Updatedb поднялся у нас по cron’у, который запускает какое-то обновление баз данных, может быть у нас там package менеджер обновляется и т.д. По-хорошему, когда мы видим, что у нас в системе происходит нагрузка на ввод-вывод, нам все-таки хорошо бы посмотреть, кто этим занимается.
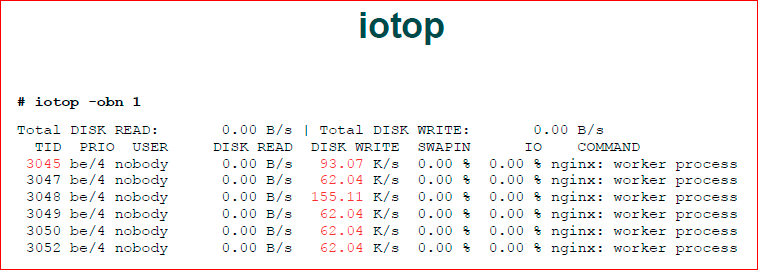
И у нас есть iotop — аналог обычного top’a, но для ввода-вывода. Он нам, как раз, показывает, кто нам генерирует такой ввод-вывод. Видим, что nginx.
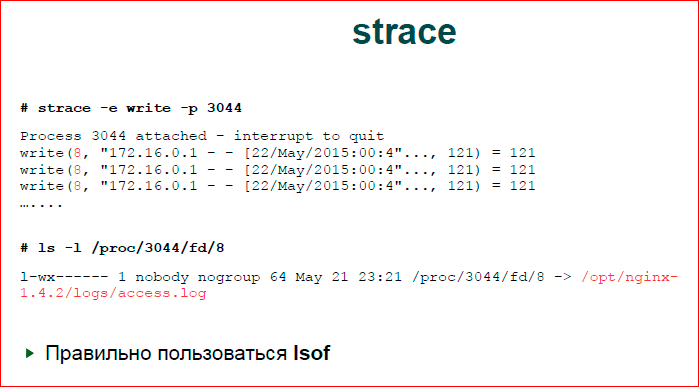
Следующее, что мы делаем — смотрим, что же nginx делает с вводом-выводом. Есть прикладная утилита strace, которая находится на стыке между ОС и прикладным процессом. Она выводит хуки на все системные вызовы. Я догадался, что у нас будет write и поставил write. Я до этого специально ничего не делал, просто получилось. На самом деле, у нас системных вызовов не так много, т.е. здесь правильно было — «-e write, write w» и, наверное, все. Т.е. если мы знаем, что файл ввод-вывод тормозит, то нас будет интересовать достаточно небольшое количество системных вызовов.
Второй вариант. Здесь мне подфартило, у меня чистый вывод. У меня действительно было там очень много таких write’ов. В реальности у вас может быть очень плохая ситуация, когда вы увидите просто мешанину системных вызовов, там будет epoll, обязательно там будет какой-то read из сокета, там будет write иногда, и, в целом, тяжело понять, что это такое.
Можно так же запустить strace. Мы strace откладываем в файл, потом этот файл обрабатываем скриптом, который нам строит статистику по системным вызовам. Понимаем, какой системный вызов у нас в Top’е, и, соответственно, в Top’е системных вызовов ищем системный вызов записей, и это будет write. По write мы видим, что у нас первым аргументом write идет файловый дескриптор 8.
Правильно пользоваться lsof, но я им так и не научился пользоваться, я пользуюсь docfs. Я иду в директорию fd, смотрю, что находится в 8-ом дескрипторе. Это access.log — не удивительно.

Последний сценарий — это, что делать, если у нас Top молчит, если он нам показывает хорошие цифры, что у нас, в целом, в системе все хорошо, но мы знаем, что у нас нехорошо.
Такой пример. Я просто взял свой бенчмарк — это бенчмарк, который нагружает очередь синхронизации в мьютексах, и посмотрел, что говорит Top. Top говорит, что у нас очень большой idle, и если мы не выводим per-CPU статистику, то у нас будет порядка 130% использования процессора при том, что у нас должно быть 400. Т.е. видим, что статистика вся хороша, но бенчмарк по своей идеологии должен полностью утилизировать все ресурсы, он этого не делает.
Давайте посмотрим, что происходит.

Здесь мы делаем снова strace, но мы зовем уже с -p и –с; -с позволяет нам собрать статистику по системным вызовам.
Почему мы этого не сделали для nginx, почему я сказал, что нужно брать какой-то скрипт и парсить вывод из strace? Дело в том, что strace генерирует эту статистику по завершении программы, которую он пасет, которую он трассирует, и если у вас работает nginx, а вы не хотите его прерывать, то вы не получите этой статистики, статистику надо собирать самому.
Здесь strace нам показывает трассу, какие системные вызовы у нас чаще зовутся, время внутри этих системных вызовов, и мы видим, что у нас futex. Если мы наберем man futex, то увидим, что это механизм ОC, который используется для синхронизации user space, а это мьютаксы наши. И pathRead lock’и, условные переменные используют как раз единый этот вызов futex — это значит, что у нас проблема с pathRead синхронизацией.
Вообще говоря, если вы видите такую картину, что у вас ввод-вывод хороший, процессоры хорошие, у вас, вообще, все хорошо, и с памятью хорошо, но количества RPS’ов вы не достигаете, как правило, это значит lock contention, что и, как раз, эта цифра 130% — она не случайна. Т.е. во время lock contention, когда у вас четыре процессора дерутся за одну блокировку, у вас в каждый момент времени только один процессор может что-то делать. Т.е., по сути, вы из четырех процессоров получаете один. И мы получаем еще дополнительные 30% только за счет дополнительных расходов на планировщик и еще на что-то, что дает нам чуть больше 100%, но эта такая природа у contention.
Контакты
» ak@natsys-lab.com
» Александр на Хабре: krizhanovsky
» Блог компании NatSys Lab.
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior. Александра обязательно вновь позовём в докладчики