Что такое веб-архив?
Организатор и идейный вдохновитель веб-архива сайтов — американец Брюстер Кейл. Internet Archive («Архив интернета») — некоммерческий проект, его цель — сохранить мировое культурное и интеллектуальное наследие. По данным Википедии, этот сервис был создан в 1996 году. Во всемирном архиве интернета хранятся литературные произведения, видеозаписи, изображения, которые свободно публикуются в Сети. Это один из разделов огромного сервиса archive.org.
Боты постоянно сканируют всемирный интернет и пополняют библиотеку. Роботам помогают живые сотрудники и партнеры. Добавить копии страничек в веб-архив интернета может любой желающий. Конечно, в библиотеке невозможно найти абсолютно все страницы, которые когда-то были созданы. Но их там очень много — более 580 миллиардов.
Просмотреть архив «машины времени» («Wayback Machine» — второе название web-архива сайтов) можно бесплатно. При этом пользователям предлагают перейти по ссылке «Пожертвовать» и перевести создателям уникального сервиса посильную сумму.
Возможности сервиса
Для вебмастера и SEO-специалиста бесплатные всемирные архивы открывают ряд полезных возможностей.
- Если планируется купить домен или интернет-проект, важно посмотреть историю сайта. В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
- Архив веб-страниц поможет при выборе дроп-домена. В сервисе можно посмотреть бесплатно, какой проект на нем располагался (коммерческий, информационный) и как он выглядел.
- Можно узнать историю конкурентов. Сравнивая архивы сайтов с их современной версией, легко понять, как менялась ниша, как трансформировались проекты.
- Есть возможность проследить и проанализировать изменения на собственном сайте и даже восстановить измененный по ошибке URL.
- С помощью дополнительных сервисов можно восстановить удаленный ресурс или отдельные страницы.
- А также найти контент по интересующей теме, которого уже нет в глобальной сети.
Как посмотреть архивные страницы?
Откройте в браузере https://web.archive.org/. В строке для поиска укажите URL главной или любой другой страницы нужного сайта.
Сервис покажет график сохранений и календарь, в котором обведены даты сканирований. Эти даты не связаны с датами обновления контента. Боты работают по собственному графику.
Если кликнуть на нужный год и дату, сервис покажет web-версию старых страниц. Обычно сохраняется не весь контент, часть документов недоступна, отображаются не все фотографии и картинки. Часть ссылок кликабельны, можно погулять по интернет-площадке, перейти в другие разделы.
Если вы не знаете точный адрес нужного ресурса или хотите изучить целую нишу, нужно набрать в поисковой строке главные ключевые слова. Архив бесплатно найдет сайты нужной тематики. Перейдите по ссылкам этого списка и изучайте историю интересующего проекта.
Существует приложение Wayback Machine («Машина времени») для iOS и Android. Приложение скачивают на мобильное устройство. В нем заложен тот же функционал, что и в десктопной версии.
Как добавить страницу в сервис?
Боты обходят интернет по собственному графику. Не все проекты попадают в историю «Машины времени». Молодые площадки с небольшим трафиком редко оказываются в библиотеке. А если и попадают туда, то частота сканирований очень низкая — раз в несколько месяцев.
Сохранять копии сайта в WebArchive можно самостоятельно. Для этого нужно открыть сервис, найти поле «Сохранить страницу» и добавить туда URL. Снимки появятся в библиотеке через пару минут.
Эту операцию можно периодически повторять.
В будущем эти копии будут полезны, чтобы отслеживать изменения в дизайне, структуре, контенте. Если страницы будут по ошибке удалены, а бэкапы не делались или были утеряны, архивные снимки помогут восстановить документ.
Как удалить копии страниц своего проекта?
Не всем и не всегда хочется выкладывать историю своей веб-площадки на всеобщее обозрение. Например, на сайте могла быть выложена ошибочная, некорректная или противозаконная информация. Даже если удалить страницу или файл, они сохранятся в библиотеке.
Архивом страниц могут заинтересоваться конкуренты и недоброжелатели. Поэтому многим хочется удалить копии веб-документов из сервиса.
Раньше вебмастера вписывали в robots.txt запрещающую директиву для ботов. Но сейчас это уже не работает.
Убрать страницы из библиотеки можно только через саппорт. Для этого нужно написать письмо на info@archive.org. Писать нужно по-английски, с указанием реальных имени, фамилии, физического адреса. Чтобы подтвердить, что вы владелец ресурса, отправлять письмо лучшего с почтового ящика, указанного на сайте. Еще один способ подтвердить свои права — написать через регистратора домена или через хостинг. Иногда саппорт просит прислать копию паспорта.
Через поддержку можно навсегда запретить делать копии своего проекта.
Как восстановить сайт из архива?
Если вы сами загрузили копию страницы, ее можно найти в своем аккаунте в разделе «Мой архив».

Чтобы скачать страницу, найдите ее в списке, кликните по виджету справа и сохраните документ в виде html-файла.

С чужими сайтами действуют примерно так же: открывают копию в архиве, через панель разработчика копируют html-код, стили, изображения.
Файлы заливаются по FTP в корневую директорию домена на хостинге.
Но ручной способ слишком долгий и трудоемкий. Автоматизировать процесс можно через платные онлайн сервисы: Archivarix, waybackmachinedownloader, r-tools, rush-analytics и другие. Здесь можно не только скачать файлы, но и оптимизировать их: убрать битые ссылки, неработающие скрипты и так далее. Некоторые сервисы умеют импортировать файлы в WordPress.
Другие полезные опции
WebArchive умеет не только сохранять копии и показывать старую версию страниц сайта. Здесь есть несколько полезных инструментов аналитики.
- Сводка. Сервис показывает, какие данные содержит сайт: сколько на нем текстов, изображений, приложений. Можно открыть и просмотреть список всех URL.
- Изменения. Инструмент поможет выявить изменения в URL-адресах. Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.
- Карта сайта. Группирует данные по годам и строит карту в виде круговой диаграммы для каждого года.

В центре диаграммы корень сайта, а кольца — это разделы и страницы. Диаграмма кликабельна, она позволяет перейти на копию нужного URL.
Читайте на Askusers
Как быстро и правильно провести A/B-тестирование в маркетинге и SEO? Что можно тестировать, какие инструменты использовать и как замерять результат?
Что такое коммерческие факторы ранжирования, как они влияют на трафик и конверсию и как их улучшить?
Если страницы выпали из индекса поисковых систем — это тревожный признак, надо срочно искать причину. Подробный алгоритм проверки.
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
История хранит множество загадок и тайн. Большая их часть известна узкому кругу людей, имеющих доступ к секретным данным.
Но рано или поздно все становится явным, срок хранения секретов заканчивается и уникальные свидетельства исторических событий открывают для всех.
Без цензуры или правок — как есть, как было составлено, записано и сохранено. Где же искать рассекреченные разными государствами документы?
Попробуем разобраться: где и как искать ставшие доступными ранее секретные документы России, СНГ и других стран, и как получить к ним доступ.
Основные проблемы поиска

В интернете чаще всего можно встретить рассекреченные документы из государственных архивов, реже — личные записи, относящиеся к государтсвенной тайне.
Любая гостайна хотя и является защищенной от лишних глаз, имеет заранее оговоренный срок хранения.
Для большинства документов срок варьируется от 5 до 75 лет. Другая часть хранится до указания о списании руководящего органа управления.
Третья – предполагает открытие доступа только при прямом указании правительства или ведомств, к которым относится хранимая информация.

Ввиду большого объема рассекреченных бумажных документов, даже важные исторические документы не всегда оцифровываются, хотя в интернете можно найти, где они хранятся.
Некоторые архивные источники имеют ветхое состояние и предполагают только личное обращение. Интернет в данном случае может помочь разыскать место хранения и составить предварительную заявку на доступ.
Да, вы правильно поняли — ввиду определенного установленного режима обращения, отдельные виды рассекреченных документов могут быть доступны только по паспорту.
Еще 2 проблемы — безумная фрагментация и колоссальное количество информации. Как секретные, так и несекретные документы хранятся архивными органами власти.
Как устроено хранение архивов в России

Все существующие в России архивы делятся на 2 категории: общие и ведомственные. Ведомственные хранят документы тех или иных государственных служб в течении оговоренного срока, потом по специальному приказу передают их в общий фонд.
Все операции с межведомственными и переданными из ведомств документами ведет Архивный фонд Российской Федерации (подробно о его структуре можно узнать здесь), находящийся под управлением Федерального архивного агентства «Росархив».
В свою очередь, «Росархив» является не библиотекой, а федеральным органом исполнительной власти, находящимся в ведении Президента Российской Федерации.

Архивный фонд только хранит документы, архивное агенство их выпускает, каталогизирует, устанавливает права и порядки обращения, а так же определяет порядок обращения даже в силовых структурах.
При создании особо важного документа, закона, договора — он сразу попадает в каталог Росархива с оформленной копией.
Объем Архивного фонда Российской Федерации составляет более 500 млн. единиц хранения на различных носителях, или более 8,5 тыс. км архивных полок.
Документы Архивного фонда Российской Федерации в законодательно определенном порядке хранятся:
постоянно в
- федеральных государственных архивах,
- государственных архивах субъектов Российской Федерации,
- муниципальных архивах, федеральных и других государственных и муниципальных библиотеках и музеях,
- организациях Российской академии наук;
временно в
- государственных органах,
- государственных организациях,
- муниципальных архивах,
- на депозитарном хранении в ряде федеральных органов исполнительной власти и федеральных организаций.
Последний пункт как раз чаще всего относится к ведомственным засекреченным архивам. Перечень таких организаций можно узнать в постановлении Правительства Российской Федерации № 808 от 27 декабря 2006 г.
Важно: ведомственные архивы спецслужб не входят в подчинение Росархива, но передают ему или его подразделениям рассекреченные документы на ответственное хранение, каталогизацию и публикацию.
Как найти секретный документ в России

Любой запрос при поиске архивного документа в России имеет смысл начинать с сайта Росархива.
Здесь есть все нормативные документы и полный перечень архивных ведомств на данный момент. Кроме того, Росархив предоставляет возможность электронных письменных и устных запросов, а так же подробных телефонных консультаций.
Правила составления запросов на поиск можно найти на сайте в соответствующем разделе, либо пройти предварительную консультацию.
В том случае, если документ находится в подведомственном Росархиву учреждении, организация даёт подробный ответ о возможности, месте и сроке получения.

Если документ засекречен, о нём расскажут тоже самое без упоминания содержания и пояснят — какие права либо процедура потребуется для подробного изучения материала.
Так же существует специальный поисковый инструмент: Справочно-информационный центр федеральных государственных архивов (сайт).
Здесь можно составить запрос в удобной форме и получить подробную консультацию — где и как искать необходимую информацию.
Архивные источники официальных документов

С порядком создания, архивирования и рассекречивания определились. Если есть интерес к старым историческим документам — вперед, в главный государственный архив.
Теперь попробуем определиться, какие ресурсы в интернете хранят рассекреченные документы.
Рассматривать все подведомственные Росархиву объединения не имеет смысла — при необходимости на них можно перейти через специальные структурные подразделения головной организации.
База данных рассекреченных дел и документов федеральных государственных архивов
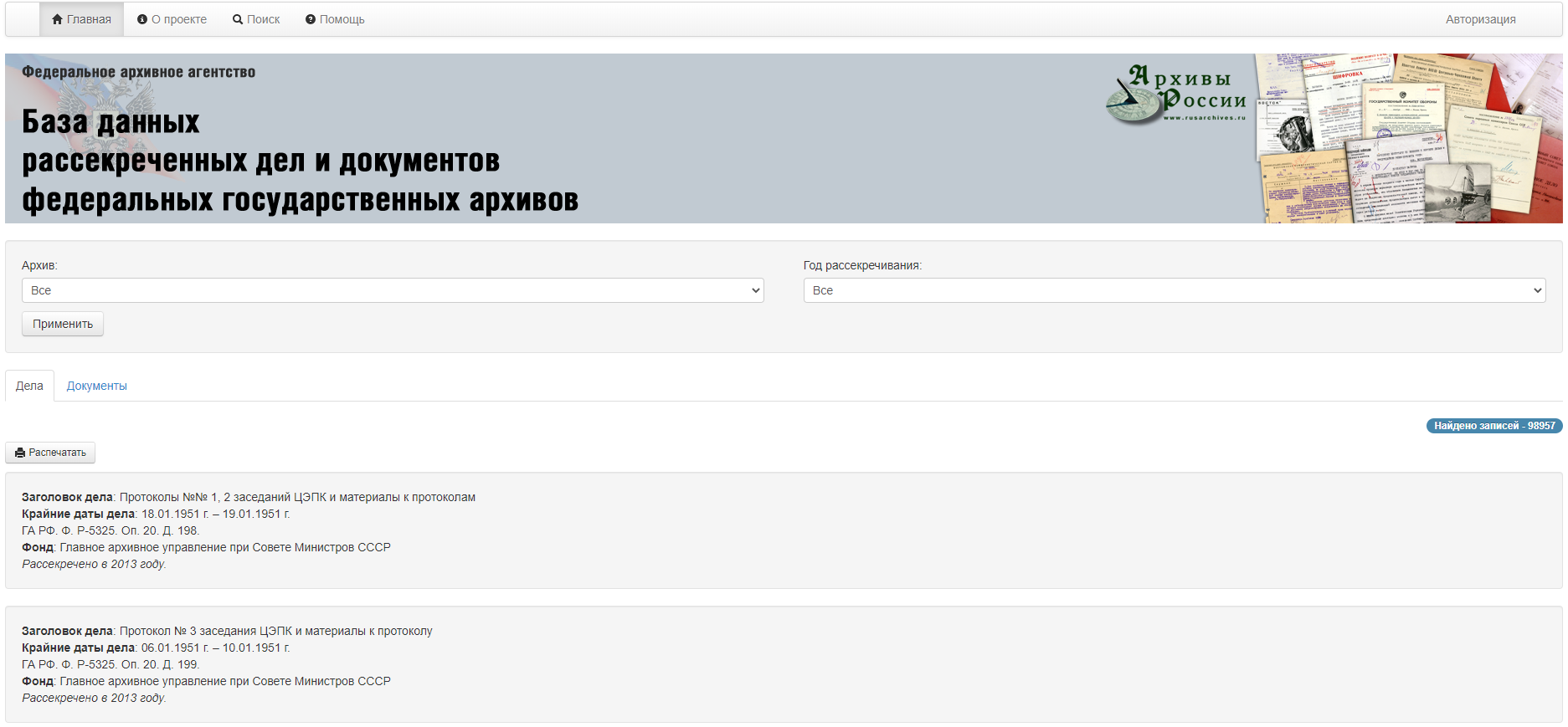
Эта огромная база с довольно скромным оформлением есть ни что иное, как официальный ресурс Росархива, который публикует подробную сводку по рассекреченным в стране документам.
Получается что-то вроде новостного дайджеста, из которого можно узнать о появлении в открытом доступе тех или иных данных.
Часть из них оцифровывается и появляется для ознакомления на страницах базы. Для ознакомления с другими оцифровками придется посетить ссылки, представленные на другие архивные ресурсы.
Основную часть информационной сводки составляют перечисления доступных в архивах рассекреченных документов, доступных в «живом» и оцифрованном виде через запрос с ресурсов Росархива.
Посетить Базу рассекреченных дел
Архив Министерства обороны

Центральный архив Министерства обороны хранит все документы органов военного управления, соединений, частей и учреждений Министерства обороны с 1941 года по настоящее время.
Именно здесь прячутся военные тайны, стратегические планы и карты личного состава, включая наградные листы. Чертежей и донесений разведки, правда, не найти — такого рода старые документы находятся в управлении соответствующих ведомств.
Документы государственной важности из архива Минобороны передаются в Росархив на ответственное хранение и оцифровку. Тем не менее, ряд материалов можно найти прямо на официальном сайте самого ведомства.
Посетить Архив Минобороны
Раздел с рассекреченными документами
Ассоциация «Российское историческое общество»

Создана в качестве правопреемницы Императорского Русского исторического общества, в 1866–1917 годах, собиравшего, обрабатывавшего и публиковавшего материалы и документы, связанные с историей государства.
Современная организация занимается преимущественно сбором и обработкой дореволюционных материалов, публикуя их в удобоваримом виде подборок/коллекций с комментариями и описанием.
Участники Российского исторического сообщества ввиду высокого статуса имеют доступ к гостайне и право на на работу с соответствующими материалами с последующей публикацией.
Посетить официальный сайт
Зарубежные источники рассекреченных документов
Аналогично российскому устроено хранение архивов в США, Великобритании и странах ЕС — поэтому они так же доступны в сети.
Все эти государства имеют централизованную систему хранения архивов, в которую государственные ведомства и спецслужбы обязаны сдавать документы по истечении срока хранения.
Благодаря чему можно найти множество интересных исторических, военных и юридических документов. Многие из них касаются России и её взаимоотношений с другими государствами.
База рассекреченных документов CREST

По закону Freedom of Information Act Центральное разведывательное управление с 31 декабря 2006 года обязано снимать гриф секретности с документов старше 25 лет и обеспечивать свободный доступ к ним.
Благодаря этому появилась база рассекреченных документов CREST (CIA Records Search Tool) с полным «свободным» доступом, который заметно удобнее российских вариантов, правда нет информационных дайджестов.
Доступен полнотекстовый поиск, все материалы оцифрованы, текст на них распознан и доступен полнотекстовый поиск. Доступны практически все материалы ЦРУ, касающиеся ведомства и политики государства.
Посетить официальный сайт
Воспользоваться поиском
Национальное управление архивов и документации

Национальные архивы (National Archives and Records Administration, NARA) официально ответственны за ведение и публикацию юридически достоверных и авторитетных копий актов Конгресса США, президентских обращений и распоряжений, также ведает федеральными нормами.
Кроме того, именно здесь публикуют рассекреченные документы ФБР (FBI), разведка (NSA) и различные подразделения армии США, а так же ряд научных и промышленных организаций, включая NASA.
Большинство документов доступно в оцифрованном и распознанном виде. Так же публикуются подробные дайджесты рассекреченных документов. Отсутствующее всегда можно запросить прямо на сайте.
Посетить официальный сайт
Национальный архив Великобритании

Национальный архив (The National Archive) содержит, как и Росархив, все рассекреченные документы государственного или исторического значения, переданные ведомствами на ответственное хранение.
Кроме того, учреждение собирает, каталогизирует и публикует основные документы об управлении государством, судебные документы и домовые книги, корреспонденцию ведомств и их приказы и многое другое.
Фактически, является наиболее полным и структурированным архивом среди перечисленных: на базе блокчейна они хранят сводку за 1000 лет. Другие источники по Великобритании, скорее всего, не потребуется.
Все самое важное уже оцифровано и опубликовано в свободном доступе, а при необходимости — оцифруют по запросу.
Посетить National Archive
Федеральный архив Германии

Федеральный архив Германии (Bundesarchiv) содержит документы, относящихся к Западной Германии времён до объединения и к современной Германии, а также из документов, относящихся к имперскому прошлому Германии и к ГДР.
Помимо государственных документов, в архиве хранятся материалы, относящиеся к деятельности политических партий и общественных организаций, а также исторические коллекции.
Есть текстовые документы, фотографии, фильмы, плакаты, а также материалы в электронном виде. Однако, основной доступ организован в оффлайн-виде.
Посетить Федеральный архив
Раздел с электронными коллекциями
Высокоточные спутниковые снимки

Основной пробел большинства вышеописанных служб и архивов — полное отсутствие карт и географических данных. Более того, в России с некоторых пор старые карты и вовсе «засекретились обратно».
С учетом изменчивости ландшафта и постоянных геологических процессов, а так же отсутствия точных официальных карт некоторых регионов этот факт составляет большую проблему.
Исправить ситуацию вызвалось Американское геологическое сообщество (U.S. Geological Survey), публикующее точные спутниковые карты с отображением изменений в «реальном времени» (по геологическим меркам).
Министерство обороны США, в свою очередь, для исторических работ рассекретило и открыло публичных доступ к базе данных спутниковых снимков высокого разрешения Corona.

Ещё большую точность дают картографические материалы базы SRTM (Shuttle Radar Topography Mission), рассекреченные и опубликованные Белым домом (США): здесь точность составляет 1 угловую секунду (30 метров).
Посетить Американское геологическое сообщество
Посетить Базу спутниковых снимков Corona
Посетить SRTM
«Краденые» данные, опубликованные в сети

Неофициально рассекреченные данные, утечки и «ворованные» документы в сети тоже встречаются. Вопреки всем опасностям, связанным с подобной работой.
Основным общественным источником рассекреченных документов разведок и правительств мира является сетевой проект WikiLeaks Джулиана Ассанжа, на данный момент находящегося в британской тюрьме.
Публикации WikiLeaks ответственны за множество серьезных политических скандалов. С осени 2019 года сайт перестал обновляться, но ранние публикации доступны для чтения — вероятно, причиной стал суд над Ассанжем.
Череда скандалов и серьезное противодействие со стороны властей, обеспокоенных публикацией секретной документации (прежде всего перепиской официальных лиц и дипломатов), привела к появлению множества аналогичных проектов.

К сожалению, до 2020 года не дожил ни один из крупных аналогов WikiLeaks. Работоспособны только
1. SportsLeaks.com, посвященный допинговым и договорным скандалам в профессиональном спорте,
2. Distributed Denial of Secrets («DDOS»), посвященный прочим утечкам.
SportsLeaks предлагает участникам делиться подтвержденными данными о нарушениях в спортивной этике. На данный момент документы не публикуются.
DDOS содержит огромные частные коллекции документов, посвященных глобальным вопросам в разнообразных сферах жизни. Ядерные программы, корпоративная этика.
Большой пул данных составляют утечки российских спецслужб, либо добытые ими (по заявлениям создателей сайта) в результате хакерских атак.
Кратко подведем итог: где искать?

Еще раз повторим: как только секретные данные официально рассекречиваются, они попадают в архив. Так происходит в России, США, Великобритании и странах ЕС.
Документы государственной важности при этом передаются государственными ведомствами и спецслужбами в центральную архивную службу:
- в России — отделение Росархива,
- в США — Национальный архив,
- в Великобритании — Национальный архив,
- в Германии — Федеральный архив.

Ведомственные документы рангом ниже публикуются прямо на сайте конкретной службы: Минобороны РФ, ЦРУ, NASA.
Узнать об официально снятом грифе «секретно» можно на:
- сайте ведомства,
- на сайте главного архивного управления государства.
При необходимости в единую государственную службу можно направить официальный запрос и получить конкретный ответ об интересующем документе и необходимых для работы с ним правах/документах/процедурах.
P.S. Добавляйте в комментариях интересные источники, актуальные платформы. А в следующей статье обсудим – как на практике составить поисковый запрос в архивы и найти что-то полезное.

 (11 голосов, общий рейтинг: 4.73 из 5)
(11 голосов, общий рейтинг: 4.73 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Удивительные тайны уже ждут.
- Это интересно
![]()
Николай Маслов
@nicmaslov
Не инженер, радиофизик и музыкант. Рассказываю о технике простым языком.
Как найти информацию в Интернете, которую не отображают такие продвинутые поисковые системы как Google или Яндекс? Можно ли найти сайты, которые когда-то существовали в сети, но уже не работают, удалены или же заменены новыми? На эти вопросы мы постараемся дать ответ в этой статье.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Как скачать сайт из веб архива
Если вы желаете восстановить сайт из веб-архива, то вам в этом поможет программа Web Archive Downloader 6.0
Веб-архив: импортозамещение
Время на прочтение
3 мин
Количество просмотров 29K
Понадобилось найти старую версию одного сайта. В Wayback Machine (https://archive.org/web/) версии от нужной даты не оказалось, и я решил поискать альтернативные архивы интернетов. В основном находились сервисы, реализующие идею «вы нам дайте URL, а мы его заархивируем» (типа уважаемого мной http://archive.md), то есть совсем не то, что было нужно в данный момент.
И тут вдруг находится искомое — http://web-arhive.ru/ Сначала порадовался за соотечественников, сделавших полезный сервис, но через несколько минут меня начали терзать смутные сомнения…
При внимательном рассмотрении даты создания снимков на archive.org и на web-arhive.ru оказались полностью совпадающими. Поковырявшись ещё, я сделал вывод, что web-arhive.ru представляет собой прокси: получает запрос, пересылает его на archive.org, парсит ответ, вычищает из него интерфейсные куски и все упоминания о Wayback Machine, меняет URL ссылок внутри на свои, заворачивает в собственный интерфейс и отдаёт ничего не подозревающему пользователю.
Интересно, как к этому отнесётся archive.org, когда узнает? Во втором абзаце правил использования сказано: «Access to the Archive’s Collections is provided at no cost to you and is granted for scholarship and research purposes only.»
Сайт выглядит так (с отключённым блокировщиком рекламы):
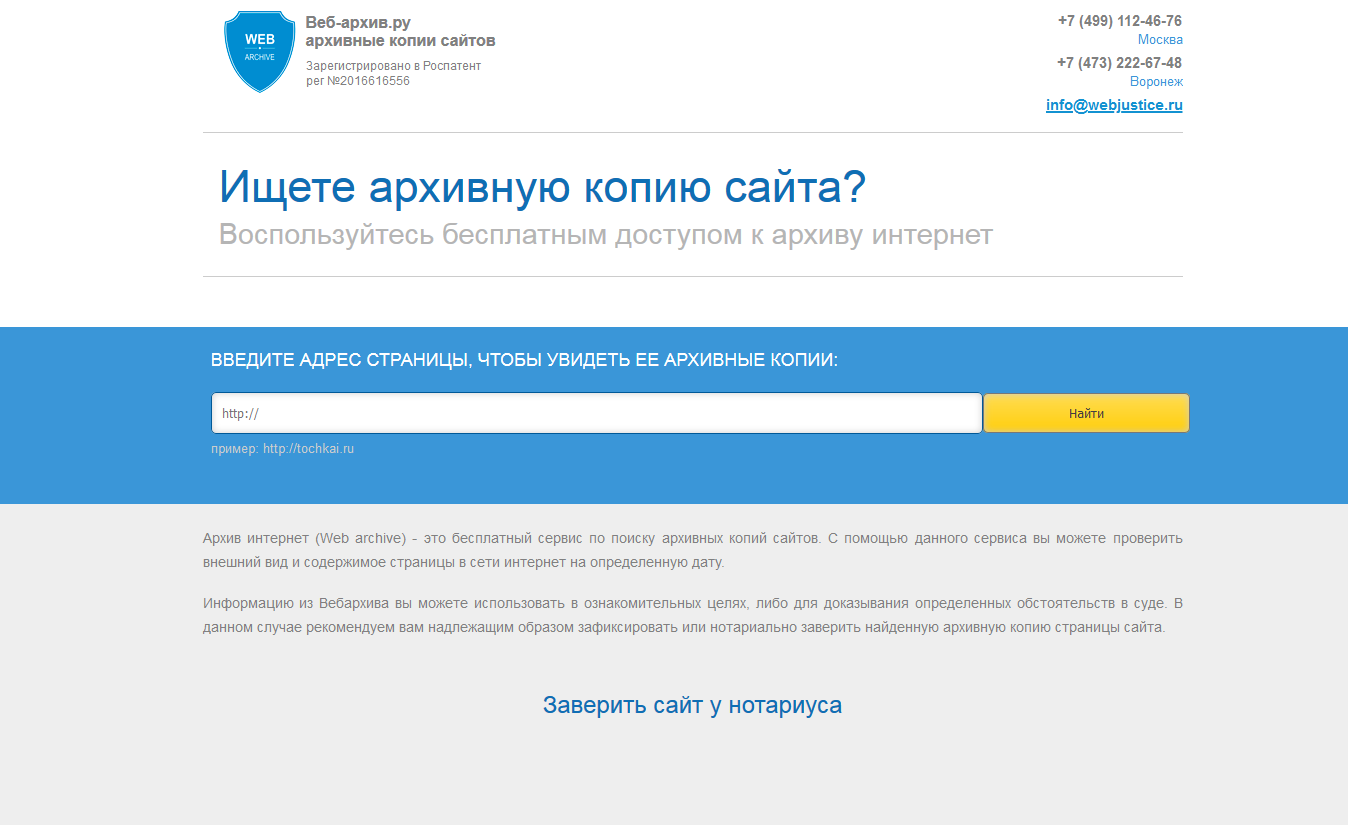
Смысл его существования, видимо, сводится к ссылке «Заверить сайт у нотариуса».
Также в глаза бросается нажористый шильдик «Зарегистрировано в Роспатент, рег №2016616556».
Стало любопытно почитать, что же там зарегистрировано, и…
http://patinfo.ru/files/fips/pevm2016/_TXT/2016616556.txt
РОССИЙСКАЯ ФЕДЕРАЦИЯ
ФЕДЕРАЛЬНАЯ СЛУЖБА ПО ИНТЕЛЛЕКТУАЛЬНОЙ СОБСТВЕННОСТИ
ГОСУДАРСТВЕННАЯ РЕГИСТРАЦИЯ ПРОГРАММЫ ДЛЯ ЭВМНомер регистрации (свидетельства): 2016616556
Дата регистрации: 15.06.2016
Номер и дата поступления заявки: 2016612809 29.03.2016
Дата публикации: 20.07.2016
Контактные реквизиты:
(8-473)222-67-48, bastionvrn@yandex.ruАвторы:
Седых Евгений Николаевич,
Дубинин Сергей ВикторовичПравообладатель:
Седых Евгений НиколаевичНазвание программы для ЭВМ:
Программный комплекс по доступу к архивным копиям сайтов в сети Интернет «Веб-архив.ру» версия 1.0Реферат:
Программный комплекс предназначен для доступа к архивным копиям страниц (сайтов) в сети Интернет, хранящимся в архиве Интернет, в том числе текста, фотоизображений, графических изображений, размещенных на страницах сайтов. Программный комплекс обеспечивает выполнение следующих функций: направление запроса к архиву Интернет в отношении архивной копии страницы, адрес которой задается пользователем в интерфейсе программного комплекса; получение ответа от архива Интернет о количестве, дате и времени архивных копий страницы, адрес которой задан пользователем; отображение архивной копии страницы в сети Интернет в интерфейсе браузера в том виде, в котором данная страница существовала на дату, выбранную пользователем из доступных дат; инициирование процедуры автоматической фиксации информации, отображаемой на архивной копии заданной страницы в виде графического образа (скриншота) заданной страницы.Тип реализующей ЭВМ: Сервер
Язык программирования: РНР
Вид и версия операционной системы: FreeBSD 8.3-STABLE
Объем программы для ЭВМ: 355 Мб
В принципе, всё честно написано про это чудо-ПО (вернее даже, целый программный комплекс, это вам не хрен собачий!) Ах, да, они ещё и скриншотик умеют делать. Ладно, хоть что-то новое от себя привнесли.
Можно было бы и не докапываться особо до них, но:
— они на первых местах в Гугле и Яндексе по запросам типа «веб архив», «архив сайтов», «архив интернета» (где-то сразу под archive.org, а где-то и вообще на первом месте),
— люди воспринимают web-arhive.ru как самостоятельный сервис (например, https://qna.habr.com/q/440257) и публикуют ссылки на архивные страницы на нём,
— разные SEO-информационные сайты говорят про от 600 до 2300 уникальных посетителей в день.
То есть, это не маргинальная фиговина в дальнем углу интернета, а что-то, путающееся у людей под ногами.
Так-то!
UPD
В комментариях жалуются на слово «импортозамещение» в заголовке.
Не воспринимайте его как «по заказу государства». Оно имелось в виду в ироничном смысле. Как по мне, один в один тот случай, когда на мониторах логотипы переклеивали.