Как найти что-то в тексте
Время на прочтение
8 мин
Количество просмотров 5.5K
Найти объект или распознать понятие в тексте — с этого начинается решение большинства NLP задач. Если вы проектируете поисковую систему, создаете голосового помощника или классифицируете пользовательские запросы, прежде всего вы должны разобрать входной текст и попытаться найти в нем именованные сущности, которые могут быть универсальными, такими как даты, страны и города, или специфичными для конкретной модели. Обратите внимание, мы сейчас говорим лишь о тех видах задач, для которых заранее известно, что именно вы ищете или что может встретиться в тексте.
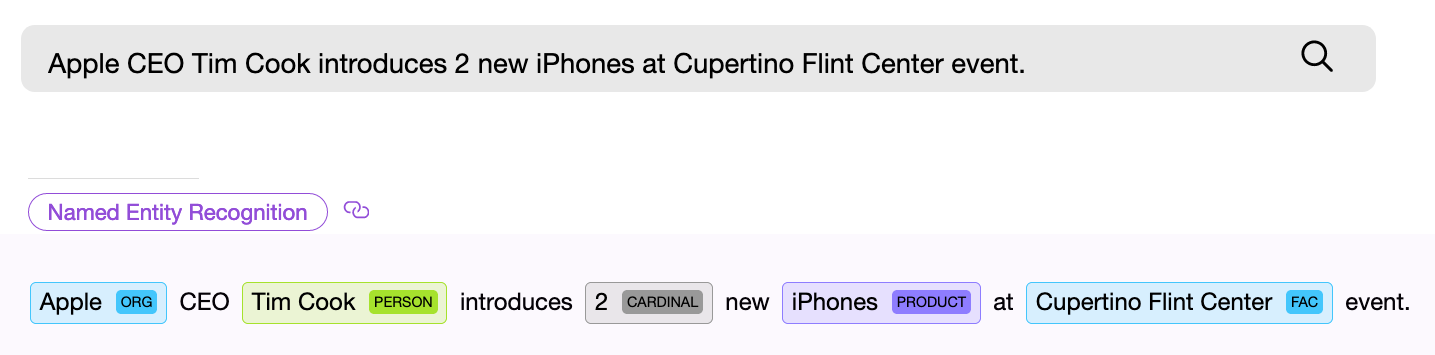
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.
Провайдеры NER компонентов
Apache OpenNlp
Apache OpenNlp предоставляет для английского языка достаточно стандартный набор NER компонентов, работающих с датами, временем, географией, организациями, числовыми процентами и персонами. Имеется небольшой набор и для других языков (испанский, голландский).
Поставка:
Java библиотека. Apache OpenNlp не поставляет модели вместе с основным проектом. Они доступны для скачивания отдельно.
Плюсы:
Apache лицензия. Модели протестированы на множестве внедрений.
Минусы:
Судя по всему, модели недаром вынесены из основного проекта. Складывается впечатление, что работа над ними или остановлена или идет в удручающе неторопливом темпе, так как новых моделей или изменений в существующих не видно уже довольно давно. Так как пользователи Apache OpenNlp могут создавать и тренировать свои собственные модели, возможно эта задача фактически полностью переложена на них.
Stanford Nlp
Stanford NLP — живой, постоянно развивающийся продукт отличного качества и широких возможностей. Для английского языка добавлена поддержка распознавания следующих сущностей: person, location, organization, misc, money, number, ordinal, percent, date, time, duration, set. Кроме того встроенный Regex NER компонент позволяет находить с высокой степенью точности такие сущности как: email, url, city, state_or_province, country, nationality, religion, (job) title, ideology, criminal_charge, cause_of_death, handle. Подробнее по ссылке. Заявлена поддержка ограниченного набора NER для немецкого, испанского и китайского языков. Качество распознавания можно попробовать с помощью онлайн демо.
Поставка:
Java библиотека. Модели можно загрузить из мавен вместе с проектом.
Я нигде не нашел перечня и детального описания NER компонентов для языков отличных от английского. По ссылкам 1, 2 — приведены примеры процесса тренировки собственных NER компонентов для разных языков. Проще говоря, возможность использовать другие языки заявлена, но придется повозиться.
Плюсы:
Ощущение от работы с проектом в целом и с готовыми моделями самое позитивное, проект живет и развивается, качество распознавания хорошее (”хорошее” — понятие условное, существуют метрики, характеризующие качество распознавания NER компонентов, но данный вопрос выходит за рамки статьи).
Минусы:
Помимо некоторого хаоса с документаций, они небольшие. Кому это важно, обратите внимание на лицензию. GNU General Public License отличается от Apache, так, например, вы не можете добавить продукт с данной лицензией в продукты, лицензируемые под Apache и т. д.
Google Language API
Google language API для английского языка поддерживает следующий список сущностей: person, location, organization, event, work_of_art, consumer_good, other, phone_number, address, date, number, price.
Платформа:
REST API, SaaS. Доступны готовые клиентские библиотеки над REST (Java, C#, Python, Go и т. д.).
Плюсы:
Большой набор NER компонентов, развитие и качество обеспечивается всем известным интернет гигантом.
Минусы:
Начиная с определенных объемов, использование платное.
Spacy
Данная библиотека предоставляет один из наиболее широких наборов поддерживаемых для распознавания сущностей, по ссылке список поддерживаемых.
Платформа:
Python.
К сожалению отсутствие личного опыта промышленного использования не позволяет мне добавить реальное описание плюсов и минусов данной библиотеки. К тому же подробный обзор питоновских NLP решений уже опубликован на habr.
Все вышеперечисленные библиотеки позволяют обучать собственные модели. Также все из них (кроме Apache OpenNlp) позволяют извлекать нормализованные значения из найденных сущностей, то есть, например, получить число “173“ из найденной в запросе числовой сущности “сто семьдесят три“.
Как мы видим вариантов решения задачи нахождения именованных сущностей представлено множество, направление их развития очевидно — расширение списка поддерживаемых языков и набора распознаваемых сущностей, улучшение качества распознавания.
Ниже описано, что привнес проект Apache NlpCraft в данную, уже широко проработанную область.
Дополнительные возможности предоставляемые NlpCraft
- Собственные NER компоненты для новых сущностей, улучшенные варианты решения для некоторых уже существующих.
- Интеграция NER компонентов всех вышеперечисленных библиотек в рамках использования продукта.
- Поддержка “составных сущностей“, что дает пользователям простую возможность создания новых собственных компонентов на основе уже имеющихся.
Теперь обо всем этом чуть подробнее.
Собственные NER компоненты
Собственные NER компоненты Apache NlpCraft — это компоненты распознавания дат, чисел, географии, координат, сортировки и сопоставления разных сущностей. Часть из них уникальна, часть — лишь улучшенная реализация существующих решений (повышена точность распознавания, добавлены дополнительные поля значений и т. д.).
Интеграция существующих решений
Все перечисленные выше решения интегрированы для использования в Apache NlpCraft.
При работе с проектом пользователю достаточно подключить нужный модуль и указать в конфигурации какие именно NER компоненты должны быть задействованы при поиске сущностей конкретной модели.
Ниже приведен пример конфигурации, для которой при поиске в тексте используется четыре различных NER компонента от двух провайдеров:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Подробнее об использовании Apache NlpCraft написано здесь. Для использования Google Language API необходим действующий Google developer account.
Поддержка составных сущностей
Поддержка составных сущностей — самая интересная из вышеперечисленных возможностей, остановимся на ней немного подробнее.
Составная сущность — это сущность определенная на основе другой. Рассмотрим пример. Пусть вы разрабатываете NLP систему управления, основанную на интентах (см. Alexa, Google Dialogflow, Алиса, Apache NlpСraft и т. д.), и пусть ваша модель работает с географией, но только для США. Вы можете взять любой компонент для поиска географии, например ”nlpcraft:city”, и использовать его напрямую.
Далее, при срабатывании интента, вы в соответствующей ему функции (callback), должны проверить значение поля ”country”, и если оно не удовлетворяет требуемым условиям, завершить работу функции, предотвращая ложное срабатывание. Далее вы должны вернуться к матчингу и попытаться выбрать другую, более подходящую функцию.
Что не так в данном подходе:
- Вы значительно усложняете работу с вызываемыми функциями, передавая управление из них в основной рабочий поток и обратно. Кроме того стоит учесть, что подобным функционалом передачи управления обладают далеко не все диалоговые системы.
- Вы размазываете логику матчинга между интентом и кодом исполняемого метода.
Хорошо… Вы можете с нуля создать свой собственный NER компонент по поиску американских городов, но эта задача решается не за пять минут.
Попробуем иначе. Вы можете усложнить интент (в тех системах где это возможно) и искать города, дополнительно отфильтрованные по стране. Но, повторюсь, возможность сложной фильтрации по полям элементов предоставляют далеко не все системы, кроме того вы усложняете интенты, которые должны быть максимально понятными и простыми, особенно если их много в проекте.
Apache NlpCraft предлагает механизм определения собственных NER компонентов на основе уже существующих. Ниже приведен пример конфигурации (полный синтаксис DSL доступен по ссылке, пример создания элементов — тут):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы описываем новую именованную сущность “американский город“ — “custom:city:usa”, основанную на уже существующей “nlpcraft:city”, отфильтрованной по определенному критерию.
Теперь вы можете создавать интенты, опирающиеся на созданный новый элемент, а встреченные в тексте города за пределами США не вызовут нежелательного срабатывания ваших интентов.
Еще пример:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы определили именованную сущность “городской аэропорт в США“ — “custom:airport:usa”. При определении этого элемента мы не только отфильтровали города по признаку принадлежности к государству, но и задали дополнительное правило, по которому названию города должен предшествовать какой-либо синоним, определяющий понятие “аэропорт”. (Подробнее о создании синонимов элементов через макросы — тут).
Составные элементы могут быть определены с любой степенью вложенности, то есть при необходимости вы можете спроектировать новые элементы на базе только что созданного “custom:airport:usa”. Также обратите внимание на то, что все нормализованные значения родительских сущностей, в данном случае базового элемента “nlpcraft:city”, доступны также в элементе “custom:airport:usa”, и могут быть использованы в теле функции сработавшего интента.
Разумеется, “составные элементы“ можно определять не только для всех поддерживаемых стандартных компонентов от OpenNlp, Stanford, Google, Spacy и NlpCraft, но и для пользовательских NER компонентов, расширяя их возможности и позволяя переиспользовать уже имеющиеся программные наработки.
Обратите внимание, фактически вы не плодите новые компоненты для каждой новой задачи, а просто конфигурируете их или “подмешиваете” их функционал в собственные элементы.
Таким образом, используя “составные сущности“ разработчик может:
- Значительно упростить логику построения интентов путем ее частичного переноса в переиспользуемые составные элементы.
- С помощью изменений конфигурации получить NER компоненты с новым поведением без обучения моделей или кодирования.
- Переиспользовать уже готовые решения с ожидаемым качеством, опираясь на существующие тесты или метрики.
Заключение
Надеюсь, что краткий обзор плюсов и минусов существующих NER компонентов будет полезен читателям, а понимание того, как с помощью Apache NlpCraft можно существенно расширить их возможности и адаптировать имеющиеся решения для новых задач, ускорит процесс разработки ваших проектов.
Как найти нужное слово в тексте в ворде или интернете?

Просмотров 6.7к. Опубликовано 20.06.2017 Обновлено 20.06.2017
Доброго всем времени суток, мои дорогие друзья и гости моего блога. С вами как обычно Дмитрий Костин, и сегодня я хотел бы рассказать вам, как найти нужное слово в тексте в интернете, либо в ворде. Мне постоянно приходится искать определенные части в тексте статей, и если бы не было простых методов, как это сделать, а пришлось бы пробегаться по всему тексту вручную, то я бы наверное сошел с ума. Ну, давайте приступим к делу.
Ищем слово в документе Word
Когда вы уже открыли документ, то убедитесь, что вы находитесь на вкладке «Главная» в меню. После этого ищите в правой верхнем углу слово «Найти», после чего жмите на него. Но я бы, для экономии времени, предлагал бы воспользоваться комбинацией клавиш CTRL+F.

Вам откроется боковая панель навигации. Именно там вы и должны будете вводить то слово, которое собираетесь найти. Как только вы вобьете первую букву, то редактор уже покажет вам количество слов, в которых есть данная буква. Естественно, чем больше вы вводите букв, тем более узким становится круг подозреваемых…т.е. тем меньше становится слов, которые содержат данный символов.

Допустим, что вы нашли 5 слов, которые содержат именно ту комбинацию символов. Дальше вам остается найти их в самом документе. Это делается элементарно, так как все слова в тексте автоматически выделяются желтым цветом, что существенно облегчает сам поиск.
Поиск слова в интернете
Ну а если вы вдруг захотели обнаружить какой-либо отрывок в статье, что находится в интернете, то это еще легче.
Для этого вам всего лишь надо открыть меню в браузере (у меня показано для Google Chrome, но в остальных браузерах всё действует аналогично), после чего выбрать пункт «Найти», либо же по классике нажать комбинацию клавиш CTRL+F.
Когда вы будете писать искомые слова, то найденные комбинации букв также будут выделены желтым цветом. И что еще удобно, в отличие от ворда, на боковой полосе прокрутки будет отмечено, в каком месте текста находится нужное вам словечко.

Как видите, ничего в этом сложного нет. Так что справитесь.
Ну а если статья была для вас полезной, то не забудьте подписаться на обновления моего блога, чтобы всегда быть в курсе самой интересной и полезной информации. Ну а я с вами на сегодня прощаюсь. Удачи вам. Пока-пока!
С уважением, Дмитрий Костин.
![]()
Всем привет! Меня зовут Дмитрий Костин. Я автор и создатель данного блога. Первые шаги к заработку в интернете я начал делать еще в 2013 году, а данный проект я завел в 2015 году, еще когда работал IT-шником. Ну а с 2017 года я полностью ушел в интернет-заработок.
На данный момент моим основным источником дохода являются трафиковые проекты, среди которых сайты, ютуб-канал, каналы в Яндекс Дзен и Mail Пульс, телеграм канал и паблики в социальных сетях. На своем блоге я стараюсь делиться своими знаниями в сфере интернет-заработка, работе в интернете, а также разоблачаю мошеннические проекты.
Доброго времени суток всем, дорогие друзья и гости моего блога. Дмитрий Костин, как всегда, с вами, и сегодня я хотел бы рассказать вам, как найти нужное слово в тексте в Интернете или в слове. Мне постоянно приходится искать какие-то части в тексте статей, и если бы не было простых способов сделать это, а приходилось бы вручную просматривать весь текст, я бы, наверное, сошел с ума. Что ж, приступим к делу.
Когда вы уже открыли документ, убедитесь, что вы находитесь на вкладке «Главная» в меню. Затем найдите слово «Найти» в правом верхнем углу и щелкните по нему. Но, чтобы сэкономить время, я бы предложил использовать комбинацию клавиш CTRL + F.
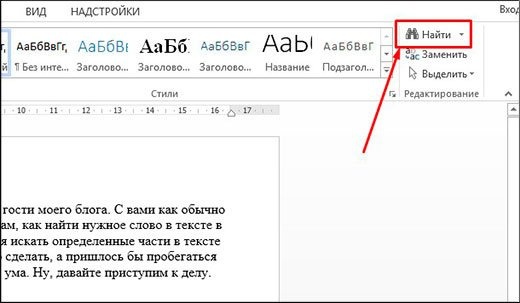
Это откроет боковую панель навигации. Здесь вам нужно будет ввести слово, которое вы собираетесь найти. Как только вы наберете первую букву, редактор уже покажет вам количество слов, содержащих эту букву. Конечно, чем больше букв вы вставляете, тем уже становится круг подозреваемых… то есть тем меньше становится слов, содержащих этот символ.
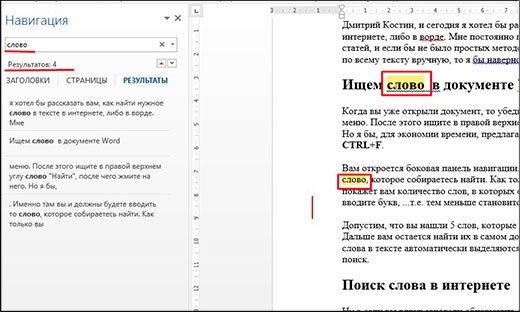
Допустим, вы нашли 5 слов, которые содержат именно такую комбинацию символов. Так что вам просто нужно найти их в самом документе. Делается это элементарно, так как все слова в тексте автоматически выделяются желтым цветом, что значительно облегчает сам поиск.
Поиск слова в интернете
Ну а если вдруг захотелось найти отрывок в статье, которая есть в Интернете, то это еще проще.
Для этого просто откройте меню в браузере (у меня оно отображается для Google Chrome, но в других браузерах все работает так же), затем выберите пункт «Найти» или, согласно классике, нажмите клавишу CTRL комбинация + F.
Когда вы вводите поисковые слова, найденные комбинации букв также выделяются желтым цветом. И что удобнее, в отличие от слова, боковая полоса прокрутки укажет, где в тексте находится нужное вам слово.
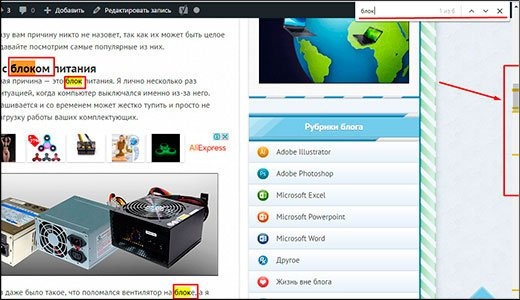
Как видите, ничего сложного в этом нет. Так что ты справишься.
Что ж, если статья была вам полезна, не забудьте подписаться на обновления моего блога, чтобы всегда быть в курсе самой интересной и полезной информации. Что ж, приветствую вас на сегодня.
Ниже вставьте или введите текст:
Искомое слово встречается в тексте -x
Где в тексте находится искомое слово?
Вам нужно найти в тексте любого типа определенный символ, букву, число, слово или целое предложение? В таком случае вам точно подойдет наш бесплатный онлайн поисковик слов, в который достаточно просто ввести или скопировать текст, затем задать искомое слово или символ, которые он в тексте найдет и выделит цветом.
По сравнению с поиском слов в текстовом документе Word, Open Office или непосредственно на веб-сайте наш поисковик более понятен, и, кроме того, он позволяет сразу же редактировать слова и символы.
Если найденных букв или слов будет больше одного, их количество будет отображено на экране. Это весьма удобно во многих ситуациях. Например, вы пишете статью, которая фокусируется на определенных словах. Однако таких слов в ней не должно быть ни много, ни мало. Именно наша поисковая система проверит весь ваш текст и поможет определить количество слов и их расположение.
Поиск слова происходит в режиме реального времени, поэтому при вводе его по буквам данные буквы в проверяемом тексте отмечаются, и отображается их
количество. Это удобно в ситуациях, когда вы ищете определенное слово, которое может иметь разные окончания. В таком случае достаточно написать только часть слова и при необходимости добавлять или удалять символы.
Как найти слово в тексте?
- Сначала введите или вставьте текст, в котором вы хотите осуществить поиск.
- Чтобы скопировать текст из любого места, выделите его и используйте сочетание клавиш Ctrl + C.
- Чтобы вставить текст, переместите курсор мыши в выделенное поле и используйте сочетание клавиш Ctrl + V.
- В выделенное поле введите буквы, цифры, символы или слова, которые вы хотите найти.
- Вы можете редактировать, удалять, переписывать и копировать исходный текст.
![]()
Поиск по текстам книг
Ищет среди доступных текстов в открытых российских и зарубежных библиотеках.
- Для поиска точной словоформы или цитаты возьмите её «в кавычки».
- Исключите книги, содержащие определённые слова, поместив их в конец запроса -со ‑знаком ‑минус.
Для чего может понадобиться подобный поисковый механизм?
Подбирать примеры словоупотребления из классики
Изучаете ли вы русский язык или уже профессор – если есть сомнения в уклюжести словесной конструкции, спроситесь у мэтров. Можно им – позволено и вам!
Нужно больше примеров? Загляните в ruscorpora, крупнейший сборник русскоязычных текстов.
Найти обалденный рассказ, который вы читали давным‐давно в детстве, но запомнили только пару имён и отдельные детали сюжета:

Этого более чем достаточно, чтобы найти книгу. Но выдача обычного яндекса забита совсем другими вещами:
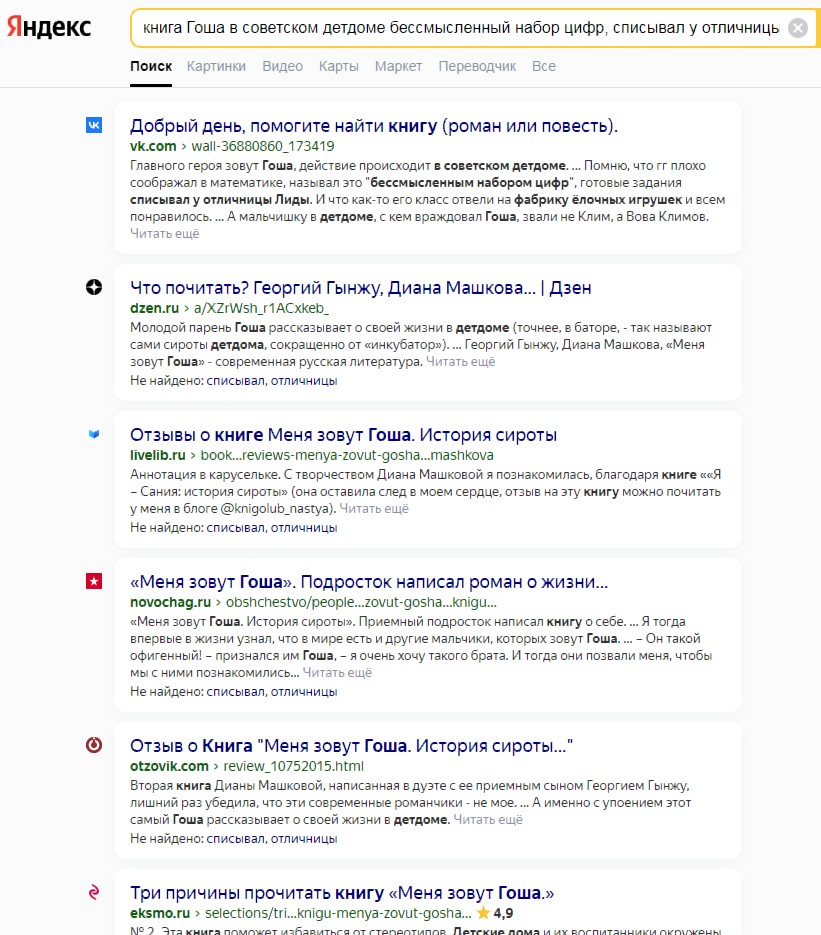
Попробуем книжный поиск с теми же ключевыми словами:
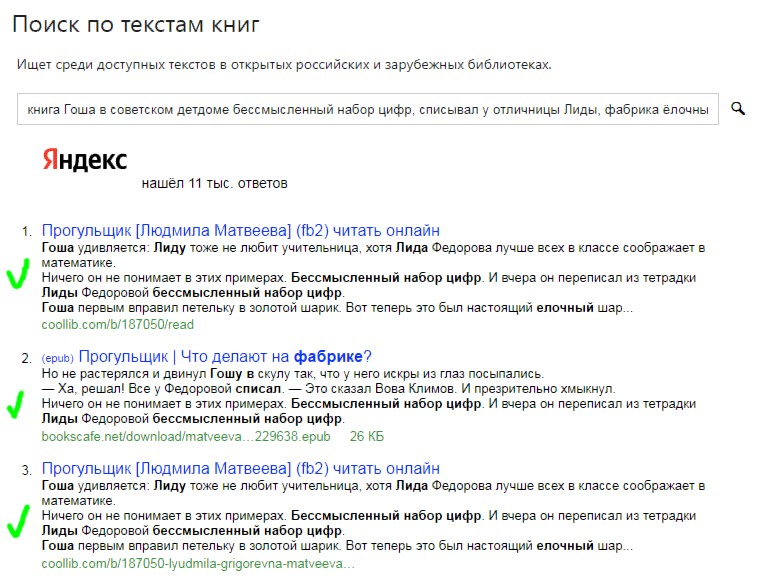
Да, это действительно «Прогульщик» Людмилы Матвеевой.
Чтобы отделить книги от посторонних текстов и искать только среди проверенного содержимого (фактчекинг).
Попробуем выяснить, кому из классиков принадлежит известное «Спокойно, Маша! Я – Дубровский». Сначала спросим Яндекс:

Ой ли? А теперь – книжный поиск:

Видим, что это кто угодно, но только не Пушкин. Ни в одном издании «Дубровского» ни в одной библиотеке подобного нет. Что логично, ведь это фраза из фильма «Дубровский» 1988 года.
Выберите движок:
Яндекс
Google
Где ещё поискать?
- Совет: используйте переключатель под строкой ввода, чтобы сменить поисковый движок. С точными формулировками и редкими словами лучше справляется Google. А вот найти книгу по памяти, имея туманное описание сюжета и героев – это к Яндексу.
- Поищите в книгах, оцифрованных Google. В его базе, в отличие от этой, есть в том числе книги, защищённым авторским правом.
- Поищите в RusCorpora, крупнейшем сборнике русскоязычных текстов.
- Спросите на книжном форуме.
Смотрите также: как искать по нескольким выбранным сайтам.