1
ЭНТРОПИЯ
Задание 1. Рассчитать энтропию события – бросание игральной кости с шестью гранями при равновероятных исходах.
Решение. Если все варианты равновероятны, то
H(X) = log2 (6) = 2,585 (бит).
Задание 2. Рассчитать энтропию при разных вероятностях выпадения сторон игральной кости:
Р(1) = 0,5; Р(6) = 0,06; Р(2) = Р(3) = Р(4) = Р(5) = 0,11.
Решение. Средняя энтропия всех исходов равна:
H(X) = – [0,5 * log2 0,5 + 4 * (0,11 * log2 0,11) + 0,06 * log2 0,06]. H(X) = 2,344 (бит).
Задание 3. Определить энтропию сообщения из 5 букв, если общее число букв в алфавите равно 32 и все сообщения равновероятны.
Решение. Общее число пятибуквенных сообщений : n = 325. Энтропия равновероятных событий:
Н(Х) = log2 (n) = 5 log2 (32) = 25 (бит).
Задание 4: Определить минимальное количество взвешиваний, которое необходимо произвести на уравновешивающих весах (аптечных), чтобы среди 27 внешне неотличимых монет найти одну фальшивую, более легкую.
Решение. При случайном поиске монеты общая неопределенность одного опыта:
H(X) = log 27 = log 33 = 3 * log 3.
Одно взвешивание имеет 3 исхода: левая чаша легче, правая чаша легче, весы находятся в равновесии. Поэтому после одного взвешивания равномерного количества монет неопределенность уменьшится на величину:
H(X1) = log 3.
Из этих равенств следует, что для снятия полной неопределенности потребуется 3 взвешивания.
Задание 5 : для двух событий X и Y приведены вероятности совместных событий P(X,Y):
|
X1 |
X2 |
X3 |
|
|
Y1 |
0.1 |
0.2 |
0.3 |
|
Y2 |
0.25 |
0 |
0.15 |
Определить: энтропию сообщений H(X) и H(Y);
2
энтропию совместного события H(X,Y); условные энтропии H(X/Y), H(Y/X).
Решение: P(X1) = 0,1 + 0,25 = 0,35;
P(X2) = 0,2;
P(X3) = 0,3 + 0,15 =0,45;
P(Y1) = 0,1 + 0,2 + 0,3 = 0,6;
P(Y2) = 0,25 + 0,15 = 0,4.
Энтропии отдельных событий:
3
H(X) P(Xi) logP(Xi ) 1,512 (бит);
i 1
2
H(Y) P(Yi ) logP(Yi) 0,917 (бит).
i 1
Энтропия совместного события:
3 2
H(X,Y) P(Xi,Yj ) logP(Xi,Yj ) 2,228 (бит).
i 1 j 1
Условные энтропии:
H(Y/X) H(X,Y) H(X) 2.228 1.512 0.716 (бит);
H(X/Y) H(X,Y) H(Y) 2.228 0.971 1.257 (бит).
Задание 6. Измеряемая величина имеет равновероятное распределение в пределах от х0 до х0 + а. Найти дифференциальную энтропию данной величины.
Решение. Закон равновероятного распределения:
1
(X) a при хo Х хo а,0 приостальных Х.
Формула дифференциальной энтропии:
h(X) (X) log (X)dX .
2
|
h(X) |
1 |
xo a |
log |
1 |
dX log a(бит). |
|
2 a |
|||||
|
a |
x |
2 |
|||
|
o |
Задание 7. Сигнал формируется в виде двоичного кода с вероятностями появления символов: р(х0) = 0,6; р(х1) = 0,4. Появление любого из символов взаимосвязаны условными вероятностями:
3
р(х0/х0) = 0,1 – вероятность того, что после 0 будет 0; р(х1/х0) = 0,9 – вероятность того, что после 0 будет 1; р(х1/х1) = 0,1 – вероятность того, что после 1 будет 1; р(х0/х1) = 0,9 – вероятность того, что после 1 будет 0. Найти энтропию сигналов.
Решение.
|
1 |
1 |
p(xi/xj) log2 p(xj/xi) |
|
H(X) p(xi) |
||
|
i 0 |
j 0 |
= – (0,1 log2 0,1 + 0,9 log2 0,9) (0,6 + 0,4) = 0,467 (бит).
Задание 8. Вероятности появления четырех событий равны:
Р(х1) = 0,5; Р(х2) = 0,25; Р(х3) = Р(х4) = 0,125.
Между событиями имеются корреляционные связи, описанные в таблице. Найти энтропию событий.
|
xi, xj |
P(xi, xj) |
P(xi/xj) |
xi, xj |
P(xi, xj) |
P(xi/xj) |
||||||||
|
x1,x1 |
13/32 |
13/16 |
x3,x1 |
0 |
0 |
||||||||
|
x1,x2 |
3/64 |
3/16 |
x3,x2 |
0 |
0 |
||||||||
|
x1,x3 |
0 |
0 |
x3,x3 |
0 |
0 |
||||||||
|
x1,x4 |
0 |
0 |
x3,x4 |
1/8 |
1 |
||||||||
|
x2,x1 |
1/16 |
1/8 |
x4,x1 |
1/4 |
1/2 |
||||||||
|
x2,x2 |
1/8 |
1/2 |
x4,x2 |
1/16 |
1/4 |
||||||||
|
x2,x3 |
3/64 |
3/8 |
x4,x3 |
1/32 |
1/4 |
||||||||
|
x2,x4 |
0 |
0 |
x4,x3 |
0 |
0 |
||||||||
|
Решение. Для зависимых событий (между которыми имеются |
|||||||||||||
|
корреляционные связи) энтропия рассчитывается по формуле: |
|||||||||||||
|
4 |
4 |
||||||||||||
|
H(X) |
p(xi,xj) log2 p(xi/xj) = –13/32 log2 13/16 – 3/64 log2 3/16 – |
||||||||||||
|
i 1j 1 |
|||||||||||||
|
1/64 log2 3/16 – 1/16 log2 1/8 – 1/8 log2 1/2 – 3/64 log2 3/8 – 1/4 log2 1/2 – |
|||||||||||||
|
1/16 log2 1/4 – 2/32 log2 1/4 = 0,886 (бит) |
|||||||||||||
|
Задание |
9. |
Передаваемые сигналы |
р(y0/x0) |
||||||||||
|
могут иметь два значения с равными |
х0 |
y0 |
|||||||||||
|
вероятностями: р(х0) = р(х1) = 0,5. |
|||||||||||||
|
р(y0/x1)=0,01 |
|||||||||||||
|
Вследствие наличия шумов принятые сигналы |
|||||||||||||
|
могут |
быть |
зарегистрированы, |
как |
р(y1/x0)=0,01 |
|||||||||
|
противоположные с вероятностью р(y1/х0) = |
|||||||||||||
|
х1 |
y1 |
||||||||||||
|
р(y0/х1) = 0,01. Определить количество |
р(y1/x1) |
||||||||||||
|
информации после приема одного сигнала. |
4
Решение. Количество получаемой информации при неполной достоверности переданных сигналов будет равно разности начальной и остаточной энтропии:
I(Y,X) = H(X) – H(X/Y) =
|
1 |
p(x ) log |
p(x ) |
1 |
p(y |
1 |
p(x /y |
) log |
p(x /y |
). |
|||||
|
) |
||||||||||||||
|
i 0 |
i |
2 |
i |
j 0 |
j |
i 0 |
i |
j |
2 |
i |
j |
Начальная энтропия:
H(X) = – p(x0) log2 p(x0) – p(x1) log2 p(x1) = 2 * 0,5 * log2 0,5 = 1 (бит)
Для определения условной энтропии H(X/Y) необходимо знать вероятности
p(yj), p(xi/yj).
Вероятности p(yj) вычисляем по формуле полной вероятности:
p(yj) i p(xi) p(yj /xi).
p(y0) = p(x0) p(y0/x0) + p(x1) p(y0/x1)= 0,5 * 0,99 + 0,5 * 0,01 = 0,5; p(y1) = p(x0) p(y1/x0) + p(x1) p(y1/x1) = 0,5 *0,01 + 0,5 * 0,99 = 0,5.
Условные вероятности p(xi/yj) вычисляем по теореме Байеса:
|
p(x /y |
) |
p(xi) p(yj /xi) |
. |
|||||
|
i |
j |
p(yj) |
||||||
|
p(x0 |
/ y1) |
p(x0) p(y1 /x0) |
0,5 0,01 |
0,01; |
||||
|
p(y1) |
0,5 |
|||||||
|
p(x1 |
/ y0) |
p(x1) p(y0 /x1) |
0,5 0,01 |
0,01. |
||||
|
p(y0) |
0,5 |
Тогда: p(x0/y0) = 1 – p(x1/y0) = 1 – 0,01 = 0,99; p(x1/y1) = 1 – p(x0/y1) = 1 – 0,01 = 0,99.
Таким образом, условная энтропия равна:
H(X/Y) = – 0,5 (0,99 * log2 0,99 + 0,01 * log2 0,01) – 0,5 (0,01 * log2 0,01 + +0,99 * log2 0,99) = 0,081 (бит).
Окончательно получаем:
I(Y,X) = 1 – 0,081 = 0,919 (бит).
Содержание
Для понимания материалов настоящего раздела рекомендуется ознакомиться с разделом ТЕОРИЯ ВЕРОЯТНОСТЕЙ.
.
Статус документа: черновик.
Теория информации по Шеннону
Энтропия
Пусть случайное событие заключается в осуществлении одного из несовместимых состояний $ S_{1},dots,S_n $, вероятности появления которых даются таблицей
$$
begin{array}{l|l|l|l}
S_1 & S_2 & dots & S_n \
hline
P_1 & P_2 & dots & P_n
end{array} quad mbox{ при } quad P_1+P_2+dots+P_n=1.
$$
Эти вероятности известны, но это — все, что нам известно относительно того какое состояние осуществится. Можно ли найти «меру» насколько велик выбор из такого набора состояний и сколь неопределено для нас событие?
Если наше событие (опыт) состоит в определении цвета первой встретившейся нам вороны, то мы можем почти с полной уверенностью рассчитывать, что
этот цвет будет черным. Несколько менее определено событие (опыт), состоящее в выяснении того, окажется ли первый встреченный нами человек левшой или нет — здесь тоже предсказать результаты опыта можно, почти не колеблясь, но опасения в относительно правильности этого предсказания будут более обоснованны, чем в предыдущем случае. Значительно труднее предсказать заранее пол первого встретившегося нам на улице человека. Но и этот опыт имеет относительно небольшую степень неопределенности по сравнению, например с попыткой определить победителя в чемпионате страны по футболу с участием двадцати совершенно незнакомых нам команд.
Для практики важно уметь численно оценивать степень неопределенности самых разнообразных случайных событий (опытов), чтобы иметь возможность сравнивать их с этой стороны. Искомая численная характеристика должна быть функцией числа $ n_{} $ возможных состояний. Некоторые свойства этой функции $ f(n) $ определяются соображениями здравого смысла. При $ n_{}=1 $ событие вообще не является случайным, т.е. следует положить $ f(1)=0 $. При возрастании числа $ n_{} $ возможных состояний эта функция должна возрастать поскольку увеличение количества возможных исходов опыта увеличивает неопределенность в предсказании его результатов.
Идем далее: рассмотрим два независимых события $ A_{} $ и $ B_{} $. Пусть событие $ A_{} $ имеет $ k_{} $ равновероятных исходов, а событие $ B_{} $ имеет $ ell_{} $ равновероятных исходов. Рассмотрим событие, состоящее в произведении (совместном осуществлении) событий $ A_{} $ и $ B_{} $, обозначим это событие $ AB_{} $. Например, если событие $ A_{} $ заключается в появлении масти карты — бубновой
♦
, червовой
♥
, трефовой
♣
или пиковой
♠
—
при выборе ее из колоды в $ 36_{} $ карт, а событие $ B_{} $
заключается в появлении достоинства карты — шестерки,семерки, восьмерки, девятки, десятки, валета, дамы, короля или туза — при выборе ее из той же колоды, то событие $ AB_{} $ заключается в появлении конкретной карты колоды. Очевидно, что неопределенность события $ AB_{} $ больше неопределенности события $ A_{} $, так как к неопределенности $ A_{} $ добавляется неопределенность события $ B_{} $. Естественно потребовать, чтобы мера неопределенности события $ AB_{} $ была равна сумме неопределенностей, характеризующих события $ A_{} $ и $ B_{} $. Это требование обеспечивается следующим следующим свойством функции $ f_{} $:
$$
f(kell)=f(k)+f(ell) ,
$$
имеющего тот смысл, что число $ kell $ как раз и дает число возможных исходов события $ AB_{} $.
Последнее равенство наталкивает на мысль принять за меру неопределенности опыта, имеющего $ n_{} $ равновероятных исходов, число $ log n $. Можно доказать, что логарифмическая функция является единственной непрерывной функцией аргумента $ nin mathbb R $, удовлетворяющей такому функциональному уравнению. При этом выбор основания системы логарифмов несуществен, так как, в силу известной формулы $ log_b n = log_b a cdot log_a n $, переход от одной системы логарифмов к другой сводится лишь к умножению функции $ f(n)=log n $ на постоянный множитель $ log_b a $, т.е. равносилен простому изменению единицы измерения степени неопределенности. Единственным ограничением является естественное требование, чтобы основание было большим $ 1 $: число $ log_b n $ должно быть положительным
Как правило, в дальнейшем будем пользоваться логарифмом по основанию $ 2_{} $; такой выбор в одном из последующих пунктов будет подкреплен некоторыми дополнительными «бонусами». В ближайших же пунктах будем просто писать $ log $ без указания основания.
Таблица вероятностей события, имеющего $ n_{} $ равновероятных состояний, имеет вид
$$
begin{array}{l|l|l|l}
S_1 & S_2 & dots & S_n \
hline
1/n & 1/n & dots & 1/n
end{array}
$$
Так как общая неопределенность события по нашему условию равна $ log n $, то можно считать, что каждое в отдельности состояние вносит неопределенность равную $ frac{1}{n} log n = — frac{1}{n} log frac{1}{n} $. Но тогда естественно считать, что в событие, таблица вероятностей состояний которого имеет вид
$$
begin{array}{l|l|l}
S_1 & S_2 & S_3 \
hline
1/2 & 1/3 & 1/6
end{array}
$$
состояние $ S_1 $ вносит неопределенность, равную $ left( — frac{1}{2} log frac{1}{2} right) $, состояние $ S_2 $ — неопределенность, равную $ left( — frac{1}{3} log frac{1}{3} right) $, а состояние $ S_3 $ — неопределенность, равную
$ left( — frac{1}{6} log frac{1}{6} right) $, так что суммарная неопределенность события равна
$$
— frac{1}{2} log frac{1}{2} — frac{1}{3} log frac{1}{3} — frac{1}{6} log frac{1}{6} .
$$
Аналогично этому можно положить, что для события $ A_{} $ с таблицей вероятностей
$$
begin{array}{l|l|l|l}
S_1 & S_2 & dots & S_n \
hline
P_1 & P_2 & dots & P_n
end{array} quad mbox{ при } quad P_1+P_2+dots+P_n=1
$$
мера его неопределенности равна
$$
-sum_{j=1}^n P_j log P_j = — P_1 log P_1 — P_2 log P_2 — dots — P_n log P_n = log frac{1}{P_1^{P_1} P_2^{P_2}times
dots times P_n^{P_n}} .
$$
Это число будем называть энтропией события $ A_{} $ и обозначать либо $ H(A) $ либо $ H(P_1,P_2,dots,P_n) $. Величина энтропии зависит от выбранного основания логарифмической функции; в случае основания $ 2_{} $ единицу измерения энтропии называют «бит», в случае основания $ 10_{} $ — «дит», в случае основания $ e=2.718281828459045dots $ — «нат».
В случае, когда $ P_j=0 $ при каком-то значении $ j_{} $, полагают $ P_j log P_j=0 $ (на основании известного из мат.анализа факта $ displaystyle lim_{xto +0} x log x = 0 $).
Можно проверить, что функция $ H(P_1,P_2,dots,P_n) $ симметрична относительно своих переменных; этот факт имеет тот
смысл, что мера неопределенности события не зависит от способа нумерации его возможных состояний. Кроме того эта функция
обладает следующими свойствами.
1.
$ H_{} $ непрерывна по каждой своей переменной;
2.
Если все вероятности одинаковы: $ P_1=1/n,P_2=1/n,dots,P_n=1/n $, то $ H_{} $ монотонно возрастающая функцией по $ n_{} $:
$$H bigg(underbrace{frac{1}{n},dots,frac{1}{n}}_n bigg)<Hbigg(underbrace{frac{1}{n+1},frac{1}{n+1},dots,frac{1}{n+1}}_{n+1}bigg) $$
(при равновероятности состояний, неопределенность события тем больше, чем больше количество этих состояний).
3.
При распадении какого-то события на два последовательных, величина $ H_{} $ должна вычисляться как взвешенная сумма составляющих значений $ H_{} $. Иллюстрирую на примере, который беру у Шеннона, но при этом излагаю в русском фольклорном стиле.
П
Пример. Предположим, что найденная Иваном-царевичем лягушка в течение минуты либо
-
превращается в бабу-Ягу с вероятностью $ 1/3 $;
-
превращается в красавицу Василису Премудрую с вероятностью $ 1/6 $;
-
остается лягушкой, и вероятность этого события равна $ 1/2 $.
Мера неопределенности этого события $ H(1/3,1/6,1/2) $. Теперь посчитаем меру неопределенности по-другому, объединив сначала первые два состояния в одно. Лягушка в течение минуты
-
превращается в женщину с вероятностью $ 1/2 $;
-
остается лягушкой с вероятностью $ 1/2 $.
Кроме того известно, что если лягушка точно превратилась в женщину, то ( условная ) вероятность того, что она стала бабой-Ягой равна $ 2/3 $, и, следовательно, вероятность появления Василисы Премудрой оказывается равной $ 1/3 $. В результате получаем два значения для функции $ H_{} $, именно $ H(1/2,1/2 ) $ и $ H(2/3 , 1/3 ) $.
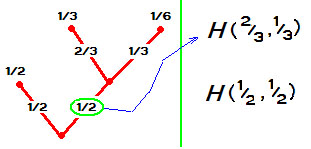
Как должны быть связаны эти новые величины со старой — с $ H(1/3,1/6,1/2) $? Конечный результат у обоих событий одинаков, во втором случае мы просто искусственно «вставили» одно промежуточное событие. Так вот, имеет место равенство:
$$H(1/3,1/6,1/2)=H(1/2,1/2 )+frac{1}{2} H(2/3 , 1/3 ) , $$
здесь весовой множитель $ 1/2 $ в составе второго слагаемого возникает из-за того, что ситуация второго события происходит только в половине случаев.
♦
Формализуем: утверждается, что функция $ H_{} $ удовлетворяет условию
$$
H(P_1,P_2,P_3,dots,P_n)=H(P_1+P_2,P_3,dots,P_n)+(P_1+P_2)Hleft(frac{P_1}{P_1+P_2}, frac{P_2}{P_1+P_2} right) ;
$$
а уж из последнего можно вывести и еще более общее:
$$
H(P_1,dots,P_n)=H(P_1+dots+P_m,P_{m+1},dots,P_n)+
$$
$$
+(P_1+dots+P_m)Hleft(frac{P_1}{P_1+dots+P_m}, frac{P_2}{P_1+dots+P_m},dots,
frac{P_m}{P_1+dots+P_m} right)
$$
при $ forall min {2,dots,n-1} $.
Перечисленные свойства
1
—
3
оказываются настолько «жесткими», что будучи формально наложенными на произвольную функцию $ H_{} $, задают ее, фактически,
однозначно:
Т
Теорема [Шеннон]. Единственной функцией, удовлетворяющей условиям
1
—
3
,
является функция
$$ H=- K sum_{j=1}^n P_j log P_j . $$
Здесь $ K_{} $ — положительная константа, а логарифм берется по произвольному основанию большему $ 1_{} $.
Можно сказать, что свойства
1
—
3
являются определяющими свойствами энтропии — по аналогии с определяющими свойствами определителя как функции столбцов (или строк) матрицы.
После приведения этой формулировки, Шеннон пишет:
Эта теорема, равно как и необходимые для ее доказательства условия, не являются необходимыми для собственно излагаемой теории. Она приведена, главным образом, для придания правдоподобия1) некоторым последующим определениям. Действительное же обоснование этих определений, однако, остается за их применениями.
Образно говоря, следующее определение энтропии как меры неопределенности само в себе имеет некоторую меру неопределенности ![]()
И
Происхождение слова «энтропия»
☞
ЗДЕСЬ.
В дальнейшем, если не оговаривается особо, будем считать энтропию при логарифмической функции, взятой по основанию $ 2_{} $, и этот индекс при написании будем часто опускать.
П
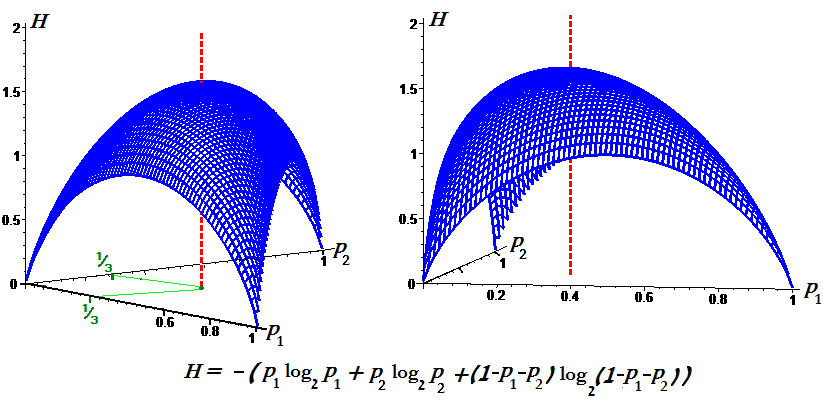
Пример. Графики энтропии для $ n_{}=2 $
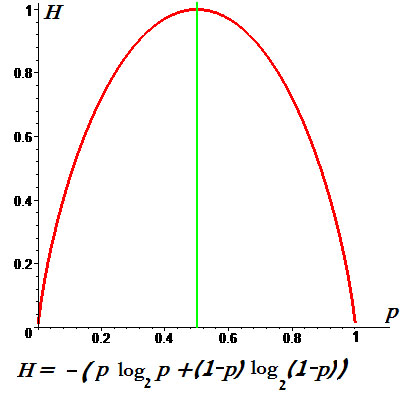
и для $ n_{}=3 $:
Формула для энтропии была получена в XIX веке Больцманом в его работах по статистической физике. Больцман показал, что если в газе, состоящем из большого числа молекул, вероятности состояний отдельных молекул равны $ P_1,dots,P_n $, то энтропия системы определяется соотношением
$$ H=- c sum_{j=1}^n P_j ln P_j , $$
где $ c_{} $ — некоторая константа. Можно считать, что энтропия системы является мерой неопределенности состояния молекул, составляющих эту систему. Эта интерпретация позволяет понять, почему Шеннон использовал ту же формулу в теории информации. Информация — это убыль неопределенности. До осуществления случайного события мы пребываем в полной неопределенности относительно того, какое из своих состояний оно может принять. После осуществления события, неопределенность устраняется. В одном из следующих пунктов мы покажем, что величина энтропии $ H_{} $ может быть интерпретирована как количество информации, содержащейся в событии.
Свойства энтропии
Проанализируем теперь формулу для энтропии.
Т
Теорема 1. $ H=0 $ тогда и только тогда, когда одна из вероятностей равна $ 1_{} $ при всех остальных, равных нулю (мера недостоверности наверняка осуществимого события равна $ 0_{} $).
Т
Теорема 2. При фиксированном $ n_{} $ максимум функции $ H_{} $ достигается при всех вероятностях одинаковых:
$$ max_{P_1+dots+P_n=1} H(P_1,dots,P_n)=Hleft(frac{1}{n},dots,frac{1}{n} right) = log n $$
(при равновероятности состояний предсказание об осуществимости какого-то конкретного из них максимально недостоверно).
Т
Теорема 3. Пусть случайные события $ A_{} $ и $ B_{} $ независимы. Тогда энтропия произведения (совместного осуществления) событий $ A cdot B $ равна сумме энтропий перемножаемых событий:
$$ H ( A cdot B) = H(A) + H(B) . $$
Доказательство. Пусть случайное событие $ A_{} $ может находиться в состояниях $ S_1,dots,S_n $ с вероятностями, заданными таблицей
$$
begin{array}{l|l|l|l}
S_1 & S_2 & dots & S_n \
hline
P_1 & P_2 & dots & P_n
end{array} quad mbox{ при } quad P_1+P_2+dots+P_n=1,
$$
а случайная величина $ B_{} $ может находиться в состояниях $ U_1,dots,U_m $ с вероятностями, заданными таблицей
$$
begin{array}{l|l|l|l}
U_1 & U_2 & dots & U_m \
hline
Q_1 & Q_2 & dots & Q_m
end{array} quad mbox{ при } quad Q_1+Q_2+dots+Q_m=1.
$$
Тогда случайная величина $ Acdot B $ может находиться в состояниях
$$ { S_jU_k mid quad jin {1,dots,n}, kin {1,dots,m } } ; $$
здесь $ S_jU_k $ означает такое состояние «сложного» события, которое заключается в одновременном выполнении двух условий: событие $ A_{} $ находится в состоянии $ S_j $, a событие $ B_{} $ — в состоянии $ U_k $. Поскольку, по предположению, события $ A_{} $ и $ B_{} $ независимы, то вероятность такого состояния равна $ P_jQ_k $.
Тогда
$$ H(Acdot B)= sum_{j=1}^n sum_{k=1}^{m} P_jQ_k log frac{1}{P_jQ_k}=
sum_{j=1}^n sum_{k=1}^{m} P_jQ_k left( log frac{1}{P_j} + log frac{1}{Q_k}right)=
$$
$$
= underbrace{left( sum_{k=1}^{m} Q_k right)}_{=1} sum_{j=1}^n P_j log frac{1}{P_j} +
underbrace{left( sum_{j=1}^{n} P_j right)}_{=1}
sum_{k=1}^{m} Q_klog frac{1}{Q_k}= H(A) + H(B) .
$$
♦
=>
Для любых случайных событий $ A_{} $ и $ B_{} $ энтропия их произведения (совместного появления) $ A cdot B $ не превосходит суммы энтропий перемножаемых событий:
$$ H ( A cdot B) le H(A) + H(B) . $$
Условная энтропия
Предположим теперь, что события $ A_{} $ и $ B_{} $ не являются независимыми. Выясним, чему равна энтропия произведения этих событий.
Общая формула для энтропии дает
$$
H(AB)=-sum_{j=1}^n sum_{k=1}^{m} P(S_jU_k) log P(S_jU_k) .
$$
В общем случае уже нельзя заменить вероятность $ P(S_jU_k) $ на произведение соответствующих вероятностей; в соответствии с теоремой из пункта
☞
УСЛОВНЫЕ ВЕРОЯТНОСТИ имеет место равенство
$$ P(S_jU_k)=P(S_j)P_{S_j}(U_k)=P_j P_{S_j}(U_k) , $$
где $ P_{S_j}(U_k) $ означает условную вероятность состояния $ U_k $ при условии нахождения события $ A_{} $ в состоянии $ S_j $. Каждое слагаемое под знаком суммы в выражении для энтропии представляется тогда в виде
$$
P(S_jU_k) log P(S_jU_k)=P_j P_{S_j}(U_k) left( log P_j + log P_{S_j}(U_k) right) .
$$
Тогда
$$
H(AB)=-sum_{j=1}^n P_j log P_j left( sum_{k=1}^{m} P_{S_j}(U_k) right)- sum_{j=1}^n P_j left( sum_{k=1}^m P_{S_j}(U_k) log P_{S_j}(U_k) right) .
$$
Сумма
$$
sum_{k=1}^{m} P_{S_j}(U_k)=P_{S_j}(U_1+U_2+dots+U_k)=1 ,
$$
поскольку событие $ U_1+U_2+dots+U_k $ — достоверное (какое-то из состояний $ U_1,U_2,dots,U_k $ событие $ B_{} $ принимает). Поэтому первое слагаемое в правой части формулы для $ H(AB) $ равно просто $ H(A_{}) $. Во втором слагаемом сумма
$$
— sum_{k=1}^m P_{S_j}(U_k) log P_{S_j}(U_k)
$$
представляет собой энтропию события $ B_{} $ при условии, что событие $ A_{} $ оказалось в состоянии $ S_{j} $. Эта энтропия называется условной энтропией события $ B_{} $ при условии нахождения события $ A_{} $ в состоянии $ S_{j} $ (или частной условной энтропией) и обозначается $ H_{S_j}(B) $ или $ H(B mid S_j) $. Тогда сумму
$$
sum_{j=1}^n P_j H_{S_j}(B)
$$
естественно считать средней условной энтропией события $ B_{} $ при условии выполнения события $ A_{} $; эту величину называют условной энтропией $ B_{} $ при условии выполнения $ A_{} $ и обозначается $ H_A(B) $ или $ H(B mid A) $.
Перепишем теперь все эти определения с использованием матричного формализма. Если обозначить
$$ P_{jk}=P_{S_j}(U_k) , $$
т.е. условную вероятность состояния $ U_k $ при условии $ S_{j} $, то из этих вероятностей можно составить матрицу
$$ mathfrak P=left[ P_{jk} right]_{j=1,dots,n atop k=1,dots,m} $$
по следующей схеме
$$
begin{array}{c}
\
S_1 \
dots \
S_n
end{array}
begin{array}{c}
begin{array}{llll}
U_1 & U_2 & dots & U_m
end{array} \
left( begin{array}{llll}
P_{11} & P_{12} & dots & P_{1m} \
dots &&& dots \
P_{n1} & P_{n2} & dots & P_{nm}
end{array} right) .
end{array}
$$
В одном из следующих ПУНКТОВ эта матрица получит специальное название и обозначение, а пока подчеркну только, что элементы этой матрицы неотрицательны и сумма их в каждой строке равна $ 1_{} $.
Введем в рассмотрение новую матрицу:
$$
tilde{mathfrak P}
=
left( begin{array}{llll}
P_{11} log P_{11} & P_{12} log P_{12} & dots & P_{1m} log P_{1m} \
dots &&& dots \
P_{n1} log P_{n1} & P_{n2} log P_{n2} & dots & P_{nm} log P_{nm}
end{array} right) .
$$
Тогда условная энтропия $ H_{S_j}(B) $ равна сумме элементов $ j_{} $-й строки этой матрицы. С использованием операции умножения матриц условные энтропии можно собрать в один столбец:
$$
left( begin{array}{c}
H_{S_1}(B) \
vdots \
H_{S_n}(B)
end{array}
right)= -tilde{mathfrak P}
left( begin{array}{c}
1 \
vdots \
1
end{array}
right) .
$$
Тогда условная энтропия $ B_{} $ при условии выполнения $ A_{} $ вычисляется по формуле
$$ H_A(B) = sum_{j=1}^n P_j H_{S_j}(B) = — (P_1,dots,P_n) tilde{mathfrak P}
left( begin{array}{c}
1 \
vdots \
1
end{array}
right) .
$$
Т
Теорема 4. Для энтропии произведения случайных событий $ A_{} $ и $ B_{} $ имеет место правило сложения энтропий:
$$ H(AB)=H(A)+ H_A(B) . $$
Проиллюстрируем результат теоремы на примере, который подробно будем разбирать во всех последующих пунктах. Источник приведенных в нем данных
☞
ЗДЕСЬ.
П
Пример. Пусть случайный процесс заключается в ежесекундном появлении на экране монитора одной буквы русского алфавита
в соответствии с приведенными ниже вероятностями
| и | м | о | т | пробел | |
|---|---|---|---|---|---|
| $ P_{} $ | 0.219 | 0.104 | 0.295 | 0.148 | 0.234 |
Таким образом, случайным событием $ A_{} $ является появление какой-то из указанных букв и
$$ H(A) = — sum_{j=1}^5 P_j log_2 P_j approx 2.237 quad mbox{ бит .} $$
Теперь предположим, что каждое следующее событие $ B_{} $ — появление на экране буквы — зависит от результата предыдущего по времени (но только от одного предыдущего). Условные вероятности, полученные в результате натурных экспериментов, соберем в матрицу
$$
mathfrak P= left[ P_{jk} right]_{j,k=1}^5=
left(
begin{array}{ccccc}
0.170 & 0.130 & 0.144 & 0.065 & 0.491 \
0.259 & 0.029 & 0.231 & 0.111 & 0.370 \
0.204 & 0.116 & 0.268 & 0.206 & 0.206 \
0.161 & 0.077 & 0.523 & 0.052 & 0.187 \
0.304 & 0.113 & 0.356 & 0.227 & 0
end{array} right)
.
$$
Так, значение $ P_{3,2}=0.116 $ означает, что если в данный момент времени на экране появилась буква о, то в следующий момент времени буква м появится примерно в $ 116 $ случаях из $ 1000 $. Выражение для матрицы $ tilde{mathfrak P} $ приведено в одном из последующих
☞
ПУНКТОВ. С ее помощью вычисляем условную энтропию события $ B_{} $ при условии события $ A_{} $:
$$ H_A(B)=
— (P_1,P_2,P_3,P_4,P_5) tilde{mathfrak P}
left( begin{array}{c}
1 \
1 \
1 \
1 \
1
end{array}
right) approx 2.036 quad mbox{ бит .}
$$
Теперь вычислим энтропию произведения событий $ A_{} $ и $ B_{} $, то есть события, заключающемся в последовательном появлении двух букв. Для этого нам потребуются вероятности появления каждой пары букв, приведенные ☞ ВСЁ ТАМ ЖЕ.
| ии | им | ио | ит | и_ | ми | мм | мо | мт | м_ | ои | ом | оо | от | о_ | ти | тм | то | тт | т_ | _и | _м | _o | _т | _ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $ hat P $ | 0.037 | 0.028 | 0.031 | 0.014 | 0.108 | 0.027 | 0.003 | 0.024 | 0.011 | 0.038 | 0.060 | 0.034 | 0.079 | 0.061 | 0.061 | 0.024 | 0.011 | 0.077 | 0.008 | 0.028 | 0.071 | 0.027 | 0.084 | 0.053 | 0.000 |
Имеем:
$$H(AB)=- sum_{j=1}^{25} hat P_j log_2 hat P_j approx 4.268 quad mbox{ бит .} $$
Проверка: $ H(A)+H_A(B)approx 4.273 $ бит.
♦
§
Пока мы только лишь формально осваиваем введенный математический аппарат, оставляя обсуждение лежащего под ним здравого смысла до следующих пунктов.
Т
Теорема 5. Для условной энтропии выполняются неравенства
$$ 0 le H_A(B) le H(B) . $$
Это утверждение хорошо согласуется со смыслом энтропии как меры неопределенности: предварительное осуществление события $ A_{} $ может лишь уменьшить степень неопределенности события $ B_{} $, но никак не может ее увеличить. Здесь необходимо отметить, что частная условная энтропия $ H_{S_j}(B) $ может быть и больше $ H(B) $, но усреднение всего набора частных энтропий по вероятностям всё-таки
приводит к ограничению типа $ le $.
Поскольку события $ AB_{} $ и $ BA_{} $ одинаковы, то
$$ H(AB)=H(A)+ H_A(B) =H(B)+H_B(A) . $$
Из последнего равенства можно определить и условную энтропию события $ A_{} $ при условии осуществления события $ B_{} $:
$$ H_B(A)=H(A)-H(B)+H_A(B) . $$
П
Пример. Пусть события $ A_{} $ и $ B_{} $ заключаются в извлечении одного шара из ящика, содержащего $ m_{} $ черных и
$ n-m $ белых шаров. Чему равны энтропии $ H(A), H(B), H_A(B), H_B(A) $?
Понятие об информации
Рассмотрим величину $ H(B) $, характеризующую степень неопределенности события $ B_{} $. Равенство этой величины нулю означает, что
состояние события $ B_{} $ заранее известно; большее или меньшее значение числа $ H(B) $ отвечает большей или меньшей неопределенности события. Какое-либо состояние события $ A_{} $, предшествующее событию $ B_{} $, может ограничить количество возможных состояний для события $ B_{} $ и тем самым уменьшить степень его неопределенности. Для того чтобы состояние события $ A_{} $ могло сказаться на последующем событии $ B_{} $, необходимо, чтобы это состояние не было известно заранее; поэтому $ A_{} $ можно рассматривать как вспомогательное событие, также имеющее несколько допустимых состояний. Тот факт, что осуществление $ A_{} $ уменьшает степень неопределенности $ B_{} $, находит свое отражение в том, что условная энтропия $ H_A(B) $ события $ B_{} $ при условии выполнения события
$ A_{} $ оказывается не больше первоначальной энтропии $ H(B) $ того же события. При этом, если событие $ B_{} $ не зависит от $ A_{} $,
то $ H_A(B)=H(B) $; если же состояние события $ A_{} $ полностью предопределяет событие $ B_{} $, то $ H_A(B)=0 $. Таким образом, разность
$$ I(A,B)=H(B)-H_A(B) $$
указывает, насколько осуществление события $ A_{} $ уменьшает неопределенность $ B_{} $, т.е. сколько нового мы узнаем о событии $ B_{} $, осуществив событие $ A_{} $. Эту разность называют количеством информации относительно события $ B_{} $, содержащимся в событии $ A_{} $.
Введенное таким образом определение можно «развернуть», определив энтропию $ H(B) $ события как информацию о событии $ B_{} $, содержащуюся в самом этом событии (поскольку осуществление события $ B_{} $ полностью определяет его исход и, следовательно, $ H_B(B)=0 $), или как наибольшую информацию относительно $ B_{} $, какую только можно иметь. Иными словами, энтропия $ H(B) $ события $ B_{} $ равна той информации, которую мы получаем при осуществлении этого события, т.е. средней информации, содержащейся в состояниях $ U_1,dots, U_m $ события $ B_{} $. Чем больше неопределенность какого-то события, тем бóльшую информацию дает определение его состояния.
Следует также иметь в виду, что информация относительно события $ B_{} $, содержащаяся в событии $ A_{} $, по определению представляет собой среднее значение (математическое ожидание) случайной величины $ { H(B)-H_{S_j}(B) }_{j=1}^n $, связанной с отдельными состояниями $ { S_{j} }_{j=1}^n $ события $ A_{} $; поэтому ее можно назвать средней информацией относительно $ B_{} $, содержащейся в $ A_{} $. Часто может случиться, что при определении состояния какого-либо события $ B_{} $ мы можем по-разному выбирать вспомогательные состояния (опыты, измерения, наблюдения) события $ A_{} $; так, например, при нахождении самого тяжелого груза из заданного набора грузов мы можем в разном порядке сравнивать отдельные грузы.
Информационная избыточность
Задача. Имея сообщение, записанное символами некоторого алфавита $ {S_1,dots,S_n} $, закодировать его наиболее выгодным способом.
Здесь кодирование понимается как процесс перехода от исходного алфавита к некоторому новому $ {U_1,dots,U_m} $, в котором каждому символу $ S_{j} $ однозначно сопоставляется последовательность символов $ (U_{j_1},dots, U_{j_k}) $.
Будем считать кодирование тем более выгодным, чем меньше элементарных сигналов приходится затратить на передачу данного сообщения.
Если считать, что коммуникация каждого из символов нового алфавита «стоит» одинакового количества ресурсов (энергии, времени), то наиболее выгодный код позволит сэкономить эти ресурсы.
П
Пример. Пусть $ n=10, m=2 $, т.е., к примеру, исходный алфавит, состоящий из цифр $ 0,1,dots, 9 $, мы кодируем двоичным кодом. Кодовая таблица
$$
begin{array}{c|c|c|c|c|c|c|c|c|c}
0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \
hline
0000 & 0001 & 0010 & 0011 & 0100 & 0101 & 0110 & 0111 & 1000 & 1001
end{array}
$$
фактически соответствует переводу десятичных чисел в двоичную систему счисления. С одним только различием: каждый блок кода состоит из $ 4 $-х цифр, разрядов2) , т.е. код является равномерным. Требование равномерности понятно: оно позволяет получателю закодированного сообщения однозначно выделить блоки, соответствующие закодированным символам. Заметим, что вопрос о количестве этих разрядов равносилен задаче о том сколько вопросов, имеющих ответы «да» или «нет» надо задать, чтобы отгадать задуманное целое число среди $ 0,1,dots, 9 $.
Рассмотрим теперь вопрос о выгодности (т.е. экономности) построенного кода. Каждая цифра числового сообщения, записанного в привычной десятичной системе счисления, может принимать одно из десяти значений, т.е. может содержать информацию, равную, самое большее, $ log_2 10 approx 3.32 $ бит. Следовательно, сообщение, состоящее из $ N_{} $ десятичных цифр, может содержать, самое большее, $ N log_2 10 approx 3.32 N $ бит. Каждый разряд закодированного сообщения может принимать одно из двух значений, т.е. может содержать информацию, равную, самое большее $ log_2 2=1 $ биту. Но при использовании рассмотренного нами двоичного кода мы затрачиваем на передачу одного символа алфавита $ 4_{} $ разряда, а на передачу сообщения из $ N_{} $ символов алфавита — $ 4, N $ разрядов. Однако с помощью $ 4, N $ двоичных разрядов можно было бы передать информацию, равную $ 4, N $ бит. Разность $ 4,N-3.32, N=0.68, N $ отражает величину неэкономичности нашего кода. Нетрудно также объяснить, почему предложенный код не будет наиболее экономичным: в нем значения $ 0_{} $ и $ 1_{} $ не являются равновероятными: если в кодируемом сообщении все цифры $ 0,1,dots, 9 $ равновероятны, то в закодированном сообщении $ 0_{} $ будет встречаться в $ 25/15=5/3 $ раз чаще, чем $ 1_{} $. Между тем для того, чтобы последовательность из определенного количества символов $ 0_{} $ и $ 1_{} $ содержала наибольшую информацию, требуется, чтобы все цифры этой последовательности принимали оба значения с одинаковой вероятностью (и были взаимно независимы).
Легко понять, как можно построить более выгодный двоичный код. Разобьем наше сообщение на последовательные пары цифр и будем переводить в двоичную систему счисления не отдельно каждую цифру, к каждое двузначное десятичное число разбиения. Число двоичных разрядов кодовых блоков, требуемое для записи всех двузначных чисел $ 00,01,dots,99 $ равно $ 7_{} $:
$$
begin{array}{c|c|c|c}
0 & 1 & dots & 99 \
hline
0000000 & 0000001 & dots & 1100011
end{array}
$$
При такой схеме кодирования на два символа исходного алфавита тратится $ 7_{} $ бит, а не $ 8_{} $ — как в первой схеме, т.е. для передачи числа из $ N_{} $ десятичных цифр надо передать $ 7, (N+1)/2 approx 3.5 N $ двоичных цифр.
Еще выгоднее было бы разбить передаваемое число на триплеты — блоки из трех цифр. В этом случае «стоимость» кодирования понижается до $ approx 3.33 N $ бит. Выгода от перехода к разбиению сообщения на еще более крупные блоки практически оказывается уже совсем небольшой.
При переходе от триплетов к квадруплетам (блокам из четырех цифр) экономность кодирования даже уменьшается: на передачу последних требуются $ 14 $-тиразрядные двоичные блоки. Тем не менее, применяя разбиение кодируемого $ N_{} $-значного числа на еще более крупные блоки, мы можем еще более «сжать» получаемый двоичный, подойдя максимально близко к значению $ N log_2 10 $.
♦
Эта последняя граница может быть получена и из других соображений — без использования понятия информации. Количество всевозможных
$ N_{} $-буквенных слов, составленных из букв алфавита $ { S_1,dots,S_n } $, равно $ n^N $, количество всевозможных $ k_{} $-разрядных двоичных блоков равно $ 2^k $. Для однозначности кодирования необходимо, чтобы $ 2^k ge n^N $.
Способ кодирования $ k_{} $-разрядными двоичными блоками фактически заключается в том, что мы разбиваем множество всевозможных $ k_{} $-значных чисел на две равные части и числам из одной части сопоставляем первую разрядную цифру равную $ 0_{} $, а числам из второй части — равную $ 1_{} $. Далее, каждая из половинок множества снова разбивается на две равные части, каждой из которых приписывается $ 0_{} $ или $ 1_{} $.
Т
Теорема [Хартли]. Если в заданном множестве $ mathbb S $, состоящем из $ mathfrak N $ элементов:
$$ operatorname{Card}(mathbb S) = mathfrak N $$
выделен какой-то элемент $ U_{} $, о котором заранее известно, лишь что $ U in mathbb S $, то, для того, чтобы найти $ U_{} $ необходимо получить информацию, равную $ log_2 mathfrak N $ бит.
На первый взгляд кажется, что если число букв в исходном алфавите равно $ n_{} $, а в кодирующем алфавите равно $ m_{} $, то число $ log_m n $ характеризует наиболее экономичный код. Однако это утверждение ошибочно. Разумеется, верно, что текст из $ N_{} $ букв $ n_{} $-буквенного алфавита может содержать информацию, самое большее равную $ N log_2 n $ бит, но в действительности такой текст, если только он является осмысленным, никогда такой информации не содержит. Это ясно из свойств энтропии: каждая буква текста может содержать наибольшую информацию $ log_2 n $ бит лишь в том случае, когда все буквы алфавита будут встречаться одинаково часто. Известно, однако, что частоты встречаемости букв o или е во много раз больше частот встречаемости букв ф или щ.
Частота встречаемости букв в обычном (неспециальном) тексте (без учета пробелов) [2]:
| a | б | в | г | д | е,ё | ж | з | и | й | к | л | м | н | о | п | р |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.075 | 0.017 | 0.046 | 0.016 | 0.030 | 0.087 | 0.009 | 0.018 | 0.075 | 0.012 | 0.034 | 0.042 | 0.031 | 0.065 | 0.110 | 0.028 | 0.048 |
| с | т | у | ф | х | ц | ч | ш | щ | ъ,ь | ы | э | ю | я | |||
| 0.055 | 0.065 | 0.025 | 0.002 | 0.011 | 0.005 | 0.015 | 0.007 | 0.004 | 0.017 | 0.019 | 0.003 | 0.007 | 0.022 |
Энтропия достигает своего максимума, если все символы алфавита $ {S_1,dots,S_n} $ независимы и генерируются источником с одинаковой вероятностью. Можно сказать, что в равновероятном алфавите все символы несут максимальную информационную нагрузку. Если же алфавит неравновероятен, то некоторые его символы будут иметь меньшую информационную нагрузку, чем другие. Так, если считать, что в русском алфавите $ 31_{} $ буква (отождествляем е и ё, а также ь и ъ) и все они равновероятны, то
$$ H_0= — sum_{j=1}^{31} 1/31 log_2 (1/31) = log_2 31 approx 4.954 mbox{ бит } . $$
Если учитывать частоты букв в соответствии с приведенной таблицей, то получим:
$$ H_1= — sum_{j=1}^{31} P_j log_2 (P_j) approx 4.460 mbox{ бит } , $$
т.е. средняя информация, приходящаяся на одну букву русского текста, заметно понижается.
Аналогичные результаты справедливы и для других языков.
Если латинский алфавит содержит $ 26_{} $ букв и, следовательно, $ H_0 = log_2 26 approx 4.700 $ бит,
то значения $ H_{1} $ для основных европейских языков приведены в таблице
| английский | французский | немецкий | |
|---|---|---|---|
| $ H_{1} $ | 4.126 | 3.986 | 4.096 |
Однако, даже с учетом частот появления букв в тексте языков, мы все равно получим значение средней удельной информации на единицу текста,
превосходящую фактическое значение этой величины. В самом деле, для русского алфавита, например, информация в $ 4.460 $ бит на одну букву получилась бы, если бы каждая буква текста определялась с помощью извлечения карточки из ящика с перемешанными $ 1000 $ карточками, среди которых на $ 110 $ карточках написана буква о, на $ 87 $ карточках — буква е, и т.д., на $ 2_{} $ карточках — буква ф. Энтропия каждого такого события (извлечения карточки) $ A_1 $ примерно равна $ 4.460 $ бит; если $ [A_1,A_2,dots,A_N] $ обозначают $ N_{} $ последовательных событий3), то
$$ H([A_1, A_2, dots , A_N])= sum_{ell=1}^N H(A_{ell}) approx N cdot 4.460 mbox{ бит } . $$
Однако, появление каждой буквы текста на «естественном» языке не является независимым событием: вероятности появления каждой буквы зависят от предыдущих букв. Так, например, в русском языке после появления гласной буквы, существенно увеличивается вероятность появления согласной; если последняя появившаяся буква ч, то следующей уже никак не может быть ы, ю, или я, а весьма вероятно появление одной из букв
и, е или т. Аналогичные закономерности имеются и во всех других языках. Поэтому, если $ [A_1,A_2] $ — сложное событие, состоящее в последовательном появлении двух, то информация, содержащаяся в этом событии, равна
$$ H([A_1,A_2])=H(A_1)+H_{A_1}(A_2) le H(A_1)+H(A_2) . $$
Среднюю информацию на одну букву следует вычислять как условную энтропию:
$$
H_2=H_{A_1}(A_2)=-sum_{j,ell=1}^n P([S_j,S_{ell}]) log_2 P_{jell} ,
$$
где $ n_{} $ — число букв алфавита, $ P_{jell}= P_{S_j}(S_{ell}) $
— условная вероятность появления буквы $ S_{ell} $, если известно, что непосредственно перед ней стоит буква $ S_{j} $,
а $ P([S_j,S_{ell}]) $ — вероятность появления двухбуквенного сочетания (диграммы) $ [S_j,S_{ell}] $.
Как правило, $ P([S_j,S_{ell}]) ne P([S_{ell},S_j]) $; сочетание ый встречается значительно чаще йы4).
Можно переписать последнюю формулу в матричном виде с использованием условных вероятностей.
По правилу умножения вероятностей:
$$
P([S_j,S_{ell}])=P(S_j)P_{S_j}(S_{ell})=P_j P_{jell} .
$$
Составим из условных вероятностей матрицу:
$$
mathfrak P =left[ P_{jk} right]_{j,k=1}^n
$$
— она называется матрицей условных (или переходных) **вероятностей. На ее основе построим матрицу
$$
tilde{mathfrak P}= left[P_{jk} log P_{jk} right]_{j,k=1}^n
left( begin{array}{llll}
P_{11} log P_{11} & P_{12} log P_{12} & dots & P_{1n} log P_{1n} \
dots &&& dots \
P_{n1} log P_{n1} & P_{n2} log P_{n2} & dots & P_{nn} log P_{nn}
end{array} right) ;
$$
В нашем случае — в отличие от общего случая пункта
☞
УСЛОВНАЯ ЭНТРОПИЯ — матрицы $ mathfrak P $ и $ tilde{mathfrak P} $ будут квадратными. В полном соответствии с пунктом
☞
УСЛОВНАЯ ЭНТРОПИЯ можем записать:
$$
H_2=
— (P_1,dots,P_n) tilde{mathfrak P}
left( begin{array}{c}
1 \
vdots \
1
end{array}
right) .
$$
П
Пример. Обратимся к примеру сокращенного русского языка из букв $ S_1= $и, $ S_2= $м, $ S_3= $о, $ S_4= $т и $ S_5= $пробел, рассмотренному
☞
ЗДЕСЬ. Сделаем сначала «привязку» к только что введенным обозначениям:
$$ P_1=0.219, P_2=0.104, P_3= 0.295, P_4=0.148, P_5=0.234 . $$
Матрица условных вероятностей:
$$
mathfrak P=left[P_{jk}right]_{j,k=1}^5 =
left(
begin{array}{ccccc}
0.170 & 0.130 & 0.144 & 0.065 & 0.491 \
0.259 & 0.029 & 0.231 & 0.111 & 0.370 \
0.204 & 0.116 & 0.268 & 0.206 & 0.206 \
0.161 & 0.077 & 0.523 & 0.052 & 0.187 \
0.304 & 0.113 & 0.356 & 0.227 & 0
end{array} right)
$$
Вычисляем матрицу
$$
tilde{mathfrak P}=left[P_{jk} log_2 P_{jk} right]_{j,k=1}^5 =
left(
begin{array}{ccccc}
-0.435 & -0.383 & -0.403 & -0.256 & -0.504 \
-0.505 & -0.148 & -0.488 & -0.352 & -0.530 \
-0.467 & -0.360 & -0.509 & -0.470 & -0.470 \
-0.424 & -0.285 & -0.489 & -0.222 & -0.452 \
-0.522 & -0.355 & -0.530 & -0.486 & 0
end{array} right) .
$$
Величины энтропий (в битах):
$$ H_0=log_2 5 approx 2.322, H_1=-sum_{j=1}^5 P_j log_2 P_j approx 2.237,
$$
$$
H_2 =
— (P_1,P_2,P_3,P_4,P_5) tilde{mathfrak P}
left( begin{array}{c}
1 \
1 \
1 \
1 \
1
end{array}
right) approx 2.036 . $$
♦
Продолжаем дальнейшее продвижение в намеченном направлении. Если учесть информацию о двух предыдущих буквах текста, то для средней информации на одну букву получается формула:
$$
H_3=H_{A_1A_2}(A_3)=- sum_{j,ell,r=1}^n P([S_j,S_{ell},S_r]) log_2 P_{[S_j,S_{ell}]}(S_r) ,
$$
где $ P([S_j,S_{ell},S_r]) $ — вероятность трехбуквенного сочетания (триграммы) $ [S_j,S_{ell},S_r] $, а
$ P_{[S_j,S_{ell}]}(S_r) $ — условная вероятность появления буквы $ S_r $ после появления биграммы $ [S_j,S_{ell}] $.
Нетрудно понять как строятся величины $ H_M $ при $ M> 3 $. Также понятно, что с возрастанием $ M_{} $ величины $ H_M $ будут убывать, приближаясь к некоторому предельному значению $ H_{infty} $, которое и можно считать теоретическим значением средней удельной информации при передаче длинного текста.
Значения $ H_{M} $ (в битах) для русского5) и английского языков6):
| $ M $ | $ 0_{} $ | $ 1_{} $ | $ 2_{} $ | $ 3_{} $ |
|---|---|---|---|---|
| русский | 5.000 | 4.348 | 3.521 | 3.006 |
| английский | 4.754 | 4.029 | 3.319 | 3.099 |
Учтя также и статистические данные о частотах появления различных слов в английском языке, Шеннон сумел приблизительно оценить и значения величин $ H_5 $ и $ H_8 $:
$$ H_{5} approx 2.1, H_{8} approx 1.9 . $$
П
Пример [обезьяна за клавиатурой]. Известна теорема о бесконечных обезьянах: абстрактная обезьяна, ударяя случайным образом по клавишам печатной машинки7) в течение неограниченно долгого времени, рано или поздно напечатает любой наперёд заданный текст (например «Войны и мира»). В указанной ссылке приводятся оценки времени наступления этого события. Следующие примеры  показывают, что может произойти, если обезьяна будет бить по клавиатуре специально сконструированной машинки, в которой клавиши соответствуют биграммам, триграммам и т.п. русского языка и при этом размеры клавиш пропорциональны частотам встречаемости в русском языке (а обезьяна будет чаще ударять по большим клавишам).
показывают, что может произойти, если обезьяна будет бить по клавиатуре специально сконструированной машинки, в которой клавиши соответствуют биграммам, триграммам и т.п. русского языка и при этом размеры клавиш пропорциональны частотам встречаемости в русском языке (а обезьяна будет чаще ударять по большим клавишам).
Картинка в тему
☞
ЗДЕСЬ
Приближения нулевого порядка (символы независимы и равновероятны):
ФЮНАЩРЪФЬНШЦЖЫКАПМЪНИФПЩМНЖЮЧГПМ ЮЮВСТШЖЕЩЭЮКЯПЛЧНЦШФОМЕЦЕЭДФБКТТР МЮЕТ
Приближение первого порядка (символы независимы, но с частотами, свойственными русскому языку):
ИВЯЫДТАОАДПИ САНЫАЦУЯСДУДЯЪЛЛЯ Л ПРЕЬЕ БАЕОВД ХНЕ АОЛЕТЛС И
Приближение второго порядка (частотность диграмм такая же как в русском языке):
ОТЕ ДОСТОРО ННЕДИЯРИТРКИЯ ПРНОПРОСЕБЫ НРЕТ ОСКАЛАСИВИ ОМ Р ВШЕРГУ П
Приближение третьего порядка (частотности триграмм такие же как в русском языке):
С ВОЗДРУНИТЕЛЫБКОТОРОЧЕНЯЛ МЕСЛОСТОЧЕМ МИ ДО
Вместо того, чтобы продолжить процесс приближения с помощью тетраграмм, пентаграмм и т.д., легче и лучше сразу перейти к словарным единицам. Приближение первого порядка на уровне слов9): cлова выбираются независимо, но с соответствующими им частотами.
СВОБОДНОЙ ДУШЕ ПРОТЯНУЛ КАК ГОВОРИТ ВСПОМНИТЬ МИЛОСТЬ КОМНАТАМ РАССКАЗА ЖЕНЩИНЫ МНЕ ТУДА ПОНЮХАВШЕГО КОНЦУ ИСКУСНО КАЖДОМУ РЯСАХ К ДРУГ ПЕРЕРЕЗАЛО ВИДНО ВСЕМ НАЧИНАЕТЕ НАД ДВУХ ЭТО СВЕТА ХОДУНОМ ЗЕЛЕНАЯ МУХА ЗВУК ОН БЫ ШЕЮ УТЕР БЕЗДАРНЫХ
Приближение второго порядка на уровне слов. Переходные вероятности от слова к слову соответствуют русскому языку,
но «более дальние» зависимости не учитываются:
ОБЩЕСТВО ИМЕЛО ВЫРАЖЕНИЕ МГНОВЕННОГО ОРУДИЯ К ДОСТИЖЕНИЮ ДОЛЖНОСТЕЙ ОДИН В РАСЧЕТЫ НА БЕЗНРАВСТВЕННОСТИ В ПОЭЗИИ РЕЗВИТЬСЯ ВСЕ ГРЫЗЕТ СВОИ БРАЗДЫ ПРАВЛЕНИЯ НАЧАЛА ЕГО ПОШЛОЙ
С каждым проделанным шагом сходство с обычным текстом заметно возрастает. До текста «Войны и мира» осталось совсем немного… ![]()
♦
Уменьшение информационной нагрузки на один символ алфавита вследствие неравновероятности, а также взаимозависимости появления, символов называют избыточностью языка10). Информационная избыточность рассчитывается по формуле
$$ R_{}= frac{H_0-H_{infty}}{H_0}=1-frac{H_{infty}}{log n} . $$
Величина $ H_0-H_{infty} $ называется недогруженностью алфавита, а отношение $ H_{infty}/H_0 = H_{infty}/log n $ — коэффициентом его оптимальности. Равенство избыточности величине $ 1/L_{} $ огрубленно эквивалентно утверждению о том, что каждая $ L_{} $-я буква алфавита является «лишней», однозначно восстанавливаемой по $ (L-1) $-й предыдущей. Избыточность наиболее распространенных европейских языков близка к $ 1/2 $, т.е., огрубляя, можно утверждать, что в тексте на одном из этих языков можно исключить до 50 % букв с тем, чтобы затем восстановить содержание текста по его оставшейся части.
Как определить величину $ H_M $ и оценить $ H_{infty} $ ? Для малых значений $ M_{} $ еще можно произвести частотный анализ, но вот уже для определения $ H_9 $ требуется знание вероятностей $ 32^9 approx 3.5 cdot 10^{13} $
всех девятибуквенных комбинаций. Шеннон предложил для оценки $ H_M $ использовать экспертное оценивание
☞
ЗДЕСЬ.
Явление избыточности влечет за собой как отрицательные, так и положительные последствия. Отрицательные последствия вызваны тем, что наличие «лишних» символов увеличивает затраты ресурсов при коммуникации. Положительный аспект избыточности заключается в повышении помехоустойчивости процесса коммуникации. Наличие высокой избыточности естественных языков позволяет понимать речь при значительных дефектах произношения, смене диалектов, а тексты — при лингвистических ошибках, сокращении слов и плохом почерке. См. также по этому поводу феномены Глокой куздры и Пушистых браздов.
Код Шеннона — Фано
Для понимания материалов настоящего пункта крайне желательно ознакомиться с материалами пункта
☞
ПРЕФИКСНЫЕ КОДЫ.
Для решения задачи наиболее экономичного кодирования приходится расширять алфавит. Поясню эту фразу. Если считать, что «исходный» алфавит состоит из символов $ S_1,dots,S_{n} $, то рассуждения из начала предыдущего пункта показывают, что уже переход к алфавиту, состоящему из набора биграмм $ {[S_j,S_{ell}]}_{j,ell=1}^n $ с последующим кодированием двоичным кодом может существенно снизить «стоимость» кодирования текста. А соображения предыдущего пункта позволят еще больше сэкономить — но, правда, при наличии дополнительной информации о новом алфавите — информации о частоте встречаемости каждой из биграмм в кодируемом тексте. Требование равномерности кода (одинакового количества разрядов в кодовых словах) снимается и в кодовую таблицу допускаются кодовые наборы с варьируемым количеством разрядов. Основным принципом кодирования становится:
чаще встречаемость — короче кодовая последовательность.
Реализация последнего принципа возможна различными способами. Исторически первым является кодирование по методу Шеннона-Фано. Чтобы не вводить новых обозначений, будем считать что алфавит состоит из «букв» $ S_1,dots,S_{n} $, при этом каждая «буква» может быть произвольным символом или набором символов, например: $ S_1 = $
в
, $ S_2 $=
о
с
, $ S_3 = 210 $ Д, $ S_4 = $
शब्द
, $ S_5=sqrt[3]{int_{3}^{-5} sin x^{2y} d, x} $,… лишь бы только алфавит был «полон» («покрывал» весь текст) и не «переполнен» (включенные в него символы реально в тексте присутствовали). И главное требование: частоты встречаемости «букв» в тексте должны быть нам известны. Для кодирования этих «букв» бинарным кодом ранжируем «буквы» по частоте встречаемости и разбиваем алфавит
$ {S_1,S_2,dots,S_n } $ на два подмножества, по возможности, равной вероятности. «Буквам» из одного подмножества ставим в соответствие $ 0_{} $, из второго — $ 1_{} $. Это — первые разряды соответствующих кодовых последовательностей. Далее процесс повторяется для каждого из подмножеств — производится деление их на подмножества по возможности равной вероятности с последующим присвоением им номера $ 0_{} $ или $ 1_{} $. Процесс заканчивается когда в каждом из образовавшихся подмножеств не останется ровно по одной «букве». В результате каждая из них получает свой индивидуальный бинарный «номер» — то есть, кодировку.
П
Пример. Рассмотрим пример с кодированием $ 10_{} $ букв русского алфавита с частотами, полученными на основании искусственного текста, созданного ☞ ЗДЕСЬ.
| е | и | а | в | д | к | з | б | г | ж | всего | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| количество | 236 | 231 | 195 | 111 | 94 | 94 | 46 | 42 | 40 | 30 | 1119 |
| вероятность | 0.211 | 0.206 | 0.174 | 0.099 | 0.084 | 0.084 | 0.041 | 0.038 | 0.036 | 0.027 |
Множество этих букв разобьем на два подмножества, (примерно) одинаковые по вероятности. Например, суммарная вероятность букв е,
и, д равна $ 0.51 $. Так что два образуемых подмножества: $ { mbox{ е, } mbox{ и, } mbox{ д } } $ и
$ { mbox{ а, } mbox{ б, } mbox{ г, } mbox{ в, } mbox{ ж, } mbox{ к, } mbox{ з } } $. Каждое из этих подмножеств снова разобьем на два подмножества (примерно) одинаковые по вероятности. Первое подмножество делится плохо, но что поделать — делим как получится! Продолжаем процесс деления пока не дойдем в таких разбиениях до отдельных букв. Последовательность построения схемы разбиения приведена на рисунке.
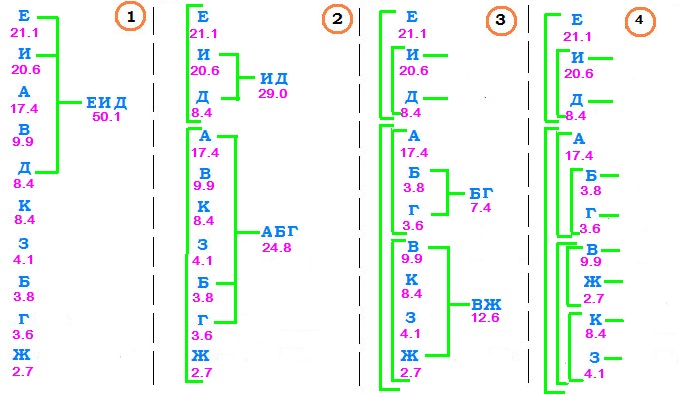
Оформляем эту схему в виде дерева и, идя от корня к листьям, нумеруем ветви после каждого узла (точки ветвления): верхней даем номер $ 0_{} $, а нижней — номер $ 1_{} $.
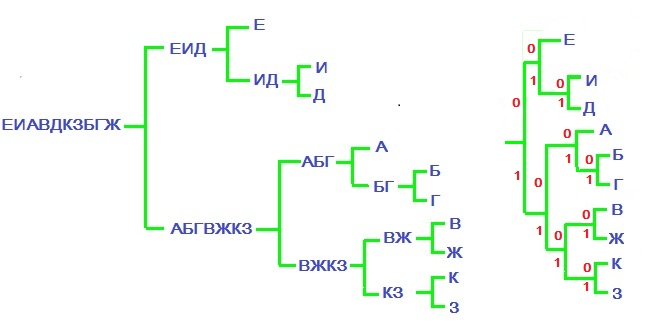
Результатом оказывается кодовая таблица
| е | и | д | а | б | г | в | ж | к | з |
|---|---|---|---|---|---|---|---|---|---|
| 00 | 010 | 011 | 100 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
Стоимость кодирования текста по такой таблице равна
$$ 236cdot 2+231cdot 3+94 cdot 3+195 cdot 3+42 cdot 4+40 cdot 4+111 cdot 4+30 cdot 4+94 cdot 4+46 cdot 4=3423 mbox{ бит, } $$
то есть, в среднем, $ 3.11_{} $ бит на букву. Это неплохое достижение, но оно всё-таки хуже полученного использованием кода Хаффмана, также основанного на частотном анализе букв алфавита.
♦
Сходство кода Шеннона-Фано с кодом Хаффмана проявляется и в алгоритмах построения обоих кодов, только направление построения кодового дерева меняется на противоположное: от корня к листьям. Так же как и код Хаффмана, код Шеннона-Фано относится к префиксным кодам: ни одно его кодовое слово не совпадает с начальным отрезком какого-то другого кодового слова. И при всех при этих сходствах, код Шеннона-Фано менее экономичен, чем код Хаффмана и поэтому практически не используется.
Алгоритм построения кода Шеннона-Фано основан на решении задачи из раздела computer science, известной как partition problem: для заданного конечного набора $ mathbb S $ чисел11) требуется найти такое разбиение его на два набора $ mathbb S_1 $ и $ mathbb S_2 $, чтобы разность между суммами чисел составляющих наборов была минимальной. Проблема известна как $ NP $-сложная.
А теперь перейдем к фундаментальному результату теории кодирования, связав код Шеннона-Фано с понятием энтропии.
Т
Теорема [Шеннон]. Сообщение из большого количества $ N_{} $ букв алфавита $ {S_1,dots,S_n} $, частоты встречаемости которых в сообщении заданы таблицей:
$$
begin{array}{l|l|l|l}
S_1 & S_2 & dots & S_n \
hline
P_1 & P_2 & dots & P_n
end{array} quad mbox{ при } quad P_1+P_2+dots+P_n=1,
$$
всегда можно закодировать бинарным кодом таким образом, чтобы количество двоичных разрядов в кодовой последовательности было сколь угодно близким к величине
$$Hcdot N quad mbox{ где } quad H=-sum_{j=1}^n P_j log_2 P_j ; $$
но никогда не меньшим ее.
Доказательство (совершенно нестрогое: очень сильная «выжимка» из рассуждений, приведенных в [2]; которые, в свою очередь, тоже не абсолютно строги). Пусть источник сообщений случайным образом генерирует символы из алфавита $ {S_1,dots,S_n} $. Пусть передаваемое сообщение состоит из достаточно большого числа $ N_{} $ символов. Рассмотрим подмножество $ mathbb S $ всевозможных сообщений длины $ N_{} $, в которых количества вхождений символов $ { S_j }_{j=1}^n $ примерно соответствуют указанным вероятностям. Именно, если $ N_j $ — количество вхождений символа $ S_j $, то $ N_j/N approx P_j $. Тогда вероятность вхождения в сообщение всех символов $ S_{j} $ в количестве $ N_{j} $ при $ jin {1,dots,n} $, в соответствии с теоремой об умножении вероятностей, равна
$$ P_1^{N_1} P_2^{N_2}times dots times P_n^{N_n} approx P_1^{N, P_1} P_2^{N,P_2}times dots times P_n^{N,P_n}=underbrace{left(P_1^{P_1}P_2^{P_2} times dots times P_n^{P_n} right)^N}_{=Q} . $$
Строго говоря, здесь надо сослаться на закон больших чисел, но пока не буду с этим заморачиваться.
Будем для простоты считать, что это — вероятность любого сообщения из подмножества $ mathbb S_{} $, т.е. количество элементов во множестве $ mathbb S_{} $ примерно совпадает с $ 1/Q $:
$$ mathfrak N = operatorname{Card} (mathbb S) approx 1/Q . $$
Сколько стоит найти один-единственный элемент этого множества: как найти во множестве $ mathbb S $ какое-то конкретное сообщение — не просто состоящее из нужных букв в требуемом количестве — но, например, определяющее осмысленный текст? В соответствии с теоремой Хартли, это число
$$ approx log_2 mathfrak N approx — N cdot left(P_1 log_2 P_1+P_2 log_2 P_2+dots+ P_n log_2 P_n right) mbox{ бит.} $$
♦
Теперь обсудим полученный результат. Итак, «на входе» имеем документ — самый произвольный, содержащий возможно осмысленный, но не обязательно нам понятный текст (он записан на неизвестном языке, содержит специфические символы из неизвестной нам научной отрасли и т.п.). Наша цель — закодировать его бинарным кодом, с тем, чтобы иметь возможность передать по каналу связи. Первое, что мы делаем — строим алфавит. Слово «алфавит» понимается в том смысле, что упомянут в начале пункта. Пытаемся, по-возможности, определять часто повторяющиеся блоки — их будем включать в состав алфавита целиком, как отдельные «буквы». Стоп.
Стоп!
— Что же получается: для каждого документа — делать свой отдельный алфавит?! ![]() — Вообще говоря, да12). Другое дело, что если этот документ не единствен, а предполагается коммуникация целой серии документов, и эти документы написаны на одном языке, и в них содержится разве лишь строго ограниченное количество специальных символов,… — и вот при всех при этих обстоятельствах имеет смысл предварительным анализом составить алфавит общий для всех документов. После того как алфавит создан, вычисляем частоты вхождений составляющих его букв в исходный документ. Кодируем по методу Шеннона-Фано. Кодовую таблицу храним в надежном файле и передаем адресату (на бумажном (электронном) носителе при личной встрече, курьером, по электронной почте и т.п.). И что у нас имеется для оценки стоимости кодирования нашего документа? — Оценка снизу для количества бит на букву: $ H_{} $. Что такое $ H_{} $? — Энтропия случайного события, состоящего в появлении в тексте букв алфавита при известных их вероятностях (т.е. как если бы случайный источник генерировал буквы алфавита независимо друг от друга, но с частотами, примерно соответствующими их вероятностям). Хорошо подобрали алфавит, каждый документ — достаточно длинный, этих документов много — тогда, в среднем, результаты нашего кодирования не должны слишком уж сильно превосходить этой величины. Сколько это: «слишком сильно»? — Решает заказчик. Если ему хочется улучшить результат — придется увеличивать алфавит. Но тогда решение одной проблемы приведет к появлению другой…
— Вообще говоря, да12). Другое дело, что если этот документ не единствен, а предполагается коммуникация целой серии документов, и эти документы написаны на одном языке, и в них содержится разве лишь строго ограниченное количество специальных символов,… — и вот при всех при этих обстоятельствах имеет смысл предварительным анализом составить алфавит общий для всех документов. После того как алфавит создан, вычисляем частоты вхождений составляющих его букв в исходный документ. Кодируем по методу Шеннона-Фано. Кодовую таблицу храним в надежном файле и передаем адресату (на бумажном (электронном) носителе при личной встрече, курьером, по электронной почте и т.п.). И что у нас имеется для оценки стоимости кодирования нашего документа? — Оценка снизу для количества бит на букву: $ H_{} $. Что такое $ H_{} $? — Энтропия случайного события, состоящего в появлении в тексте букв алфавита при известных их вероятностях (т.е. как если бы случайный источник генерировал буквы алфавита независимо друг от друга, но с частотами, примерно соответствующими их вероятностям). Хорошо подобрали алфавит, каждый документ — достаточно длинный, этих документов много — тогда, в среднем, результаты нашего кодирования не должны слишком уж сильно превосходить этой величины. Сколько это: «слишком сильно»? — Решает заказчик. Если ему хочется улучшить результат — придется увеличивать алфавит. Но тогда решение одной проблемы приведет к появлению другой…
П
Пример. Обратимся к рассмотренному
☞
ЗДЕСЬ примеру сокращенного русского языка
| и | м | о | т | пробел | |
|---|---|---|---|---|---|
| $ P_{} $ | 0.219 | 0.104 | 0.295 | 0.148 | 0.234 |
Для алфавита, состоящего из этих букв, с указанными в таблице вероятностями
величина энтропии $ H approx 2.237 $. Следовательно, кодирование приведенного ЗДЕСЬ текста из $ 1050 $ букв по теореме Шеннона оценивается в $ 2349 $ двоичных разряда. Код Шеннона-Фано для этого алфавита имеет вид
| и | м | о | т | пробел |
|---|---|---|---|---|
| 11 | 010 | 10 | 011 | 00 |
и точная стоимость кодирования — $ 2364 $ разряда.
Если же перейти к алфавиту, составленному из биграмм
| ии | им | ио | ит | и_ | ми | мм | мо | мт | м_ | ои | ом | оо | от | о_ | ти | тм | то | тт | т_ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $ hat P $ | 0.037 | 0.028 | 0.031 | 0.014 | 0.108 | 0.027 | 0.003 | 0.024 | 0.011 | 0.038 | 0.060 | 0.034 | 0.079 | 0.061 | 0.061 | 0.024 | 0.011 | 0.077 | 0.008 | 0.028 |
| _и | _м | _o | _т | __ | ||||||||||||||||
| $ hat P $ | 0.071 | 0.027 | 0.084 | 0.053 | 0.000 |
то код Хаффмана этого алфавита (уже из $ 25_{} $ «букв») имеет вид
| ии | им | ио | ит | и_ | ми | мм | мо | мт | м_ | ои | ом | оо | от | о_ | ти | тм | то | тт | т_ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11000 | 10001 | 10100 | 010001 | 000 | 01101 | 0010100 | 00100 | 010000 | 11001 | 0101 | 10101 | 1110 | 0111 | 1001 | 01001 | 001011 | 1101 | 0010101 | 10000 |
| _и | _м | _o | _т | ||||||||||||||||
| 1011 | 01100 | 1111 | 0011 |
и стоимость кодирования текста, разбитого на $ 525 $ биграмм по схеме
Ои
|
то
|
ми
|
и_
|
о_
|
им
|
и_
|
оо
|
ои
|
тм
|
и_
|
о_
|
о_
|
о_
|
оо
|
ии
|
им
|
то
|
ми
|
им
|
от
|
ои
|
м_
|
…
будет равна $ 2193 $ бит. Величина энтропии $ H approx 2.036 $ бит и теорема Шеннона дает оценку в $ 2138 $ двоичных разрядов.
♦
Пропускная способность канала связи
Рассуждения предыдущего пункта относились к случаю, когда процесс коммуникации происходит без искажений. Обратимся теперь от теории к реальности: помехи всегда будут.
Предполагаем, что по каналу связи передается последовательность бит (т.е. $ 0_{} $ или $ 1_{} $), задающая символы (или буквы некоторого алфавита) $ S_{1},dots, S_n $. Предполагается, что символ $ S_j $ представлен набором из $ t_{j} $ двоичных сигналов. На передачу по каналу связи каждого информационного двоичного сигнала тратится некоторая единица времени. Исходя из этого будем говорить о сигнале $ S_j $
как имеющем длительность $ t_{j} $.
П
Пример. Шеннон рассматривает пример из телеграфии, где имеется всего $ 4_{} $ «символа алфавита»:
-
точка, создаваемая замыканием линии на $ 1_{} $ единицу времени и последующим размыканием на $ 1_{} $ единицу времени;
-
тире, создаваемая замыканием на $ 3_{} $ единицы времени и последующим размыканием на $ 1_{} $ единицу;
-
пробел между буквами13), создаваемый размыканием линии на $ 3_{} $ единицы времени;
-
пробел между словами, создаваемый размыканием линии на $ 6_{} $ единиц времени.
Если заменить слова «замыкание линии» на $ 1_{} $, а «размыкание линии» — на $ 0_{} $, то получим двоичную кодировку алфавита
$ mathfrak C ( $
точка
$ )=10 $,
$ mathfrak C ( $
тире
$ )=1110 $,
$ mathfrak C ( $
пробел между буквами
$ )=000 $,
$ mathfrak C ( $
пробел между словами
$ )=000000 $.
Таким образом, используя в качестве вспомогательного алфавита для передачи латинских букв азбуку Морзе, получаем кодировку сообщения:
SOS
=
••• − − − •••
$ = 101010000111011101110000101010000000 $
Дополнительно вводятся ограничения на допустимые к передаче последовательности — например, запрет двух пробелов подряд между словами.
♦
Пропускная способность канала связи без помех задается формулой
$$ C=lim_{Tto infty} frac{log_2 N(T)}{T} . $$
Здесь $ N(T) $ — число сигналов длительности $ T_{} $. Очевидно, что $ N(T)le 2^T $.
Пусть все символы алфавита $ S_1,dots,S_n $ допустимы и имеют длительности $ t_1,dots,t_n $.
Если $ N(t) $ число сигналов длительности $ t_{} $, то справедлива следующая формула:
$$ N(t)=N(t-t_1)+N(t-t_2)+dots+N(t-t_n) . $$
Последняя формула представляет тот очевидный факт, что концом любого сигнала длительности $ t_{} $ должен быть один из символов множества $ {S_{j}}_{j=1}^n $ (или набор этих символов).
Эта формула определяет линейное разностное уравнение порядка
$$ tau= max_{jin {1,dots,n}} t_j . $$
Его общее решение может быть явно выражено через корни уравнения
$$ 1= lambda^{-t_1}+lambda^{-t_2}+dots+lambda^{-t_n} . $$
Это уравнение — домножением на $ lambda^{tau} $ — может быть преобразовано в характеристический полином разностного уравнения.
Предположив, для простоты рассуждений, что все корни этого полинома $ lambda_1,dots,lambda_{tau} $ различны, получим общее решение разностного уравнения в виде
$$ N(t)=C_1lambda_1^t+C_2lambda_2^t+dots+C_{tau}lambda_{tau}^t $$
при величинах $ C_1,C_2,dots,C_{tau} $, не зависящих от $ t_{} $.
Тогда если через $ lambda_{ast} $ обозначить максимальный по модулю корень полинома:
$$ | lambda_{ast} | =max_{jin{1,dots,tau}} | lambda_j | , $$
то
$$ lim_{Tto infty} frac{log_2 N(T)}{T} = lim_{Tto infty} frac{log_2 C_{ast} lambda_{ast}^T }{T} = log_2 lambda_{ast} . $$
Тут надо бы проверить несколько предположений, например, что максимальный по
модулю корень характеристического полинома единствен — тогда, хотя бы, он обязательно будет веществен. Пока могу с определенностью утверждать, что при $ nge 2 $ у этого полинома все корни по модулю не превосходят $ 2_{} $ (см. ☞ теорему Маклорена ),что существует единственный положительный вещественный корень (см. ☞ правило знаков Декарта ), и что этот корень лежит в интервале $ ]1,2[ $. Еще одно преположение, нуждающееся в обосновании: коэффициент $ C_{ast} $ не должен равняться нулю,… Но поскольку сам Шеннон не заморачивался такими мелочами, то и я пока не буду.
П
Пример. Для рассмотренного выше «телеграфного» примера имеем разностное уравнение в виде
$$ N(t)=N(t-2)+N(t-4)+N(t-5)+N(t-7)+N(t-8)+N(t-10) . $$
Это уравнение имеет порядок $ 10_{} $, его характеристический полином
$$ lambda^{10}=lambda^{8}+lambda^{6}+lambda^{5}+lambda^{3}+lambda^{2}+1 $$
имеет максимальный по модулю корень $ lambda_{ast} approx 1.453 $. Таким образом,
пропускная способность канала равна $ approx 0.539 $.
♦
Пусть символы алфавита имеют вероятности появления в любом месте сообщения, заданные таблицей
$$
begin{array}{l|l|l|l}
S_1 & S_2 & dots & S_n \
hline
P_1 & P_2 & dots & P_n
end{array} quad mbox{ при } quad P_1+P_2+dots+P_n=1.
$$
Тогда при отсутствии помех сообщение по линии связи может быть передано со скоростью сколь угодно близкой к
$$ v=C/H quad mbox{ букв } / mbox{ единица времени } , $$
где $ C_{} $ — пропускная способность линии связи, а $ H=-sum_{j=1}^n P_j log_2 P_i $ — энтропия одной буквы передаваемого сообщения; однако скорость передачи, превосходящая $ v_{} $ никогда не может быть достигнута.
При наличии помех в линии связи дело будет обстоять иначе. В этом случае только наличие избыточности в передаваемой последовательности сигналов может помочь нам точно восстановить переданное сообщение по принятым данным. Ясно, что использование кода, приводящего к наименьшей избыточности закодированного сообщения здесь уже нецелесообразно и скорость передачи сообщения должна быть уменьшена. Насколько уменьшена?
Для ответа на этот вопрос придется предварительно описать линию связи с помехами. Пусть линия связи использует $ m_{} $ различных элементраных сигналов $ A_1,A_2,dots,A_m $, но из-за наличия помех переданный сигнал $ A_j $ может оказаться по выходе из канала каким-то другим сигналом $ A_k $; пусть известна вероятность этого события $ hat P_{jk}^{} $. Из этих вероятностей можно составить квадратную матрицу
$$
hat{mathfrak P} =
left( begin{array}{llll}
hat P_{11} & hat P_{12} & dots & hat P_{1m} \
hat P_{21} & hat P_{22} & dots & hat P_{2m} \
dots & & & dots \
hat P_{m1} & hat P_{m2} & dots & hat P_{mm}
end{array}
right)
$$
Предположим, для простоты, что по линии связи передается два элементарных сигнала — $ A_1=0 $ и $ A_{2}=1 $ (и на выходе канала связи других сигналов быть не может). Предположим, что вероятность безошибочного приема любого из передаваемых сигналов равна $ 1-p_{} $, а вероятность ошибки равна $ p_{} $. Можно составить матрицу переходных вероятностей:
$$
begin{array}{l}
\
A_1 \
A_2
end{array}
begin{array}{l}
begin{array}{llll}
& & A_{1} & A_{2}
end{array} \
left(begin{array}{cc}
1-p & p \
p & 1-p
end{array}
right)
end{array}
$$
Пусть $ P(A_{j}) $ — вероятность того, что передаваемым сигналом является $ A_{j} $, имеем: $ P(A_1)+P(A_2)=1 $.
Опыт $ B_{} $, заключающийся в выяснении того, какой сигнал передается, будет иметь энтропию
$$ H(B)=-P(A_{1}) log P(A_1) — P(A_2) log P(A_{2}) . $$
Опыт $ A_{} $, заключающийся в выяснении того, какой именно сигнал при этом будет принят на выходе, является опытом
с двумя исходами, зависящими от опыта $ B_{} $. Условные энтропии
$$ H_{A_1}(B)=-(1-p) log (1-p)-p log p,quad H_{A_2}(B)=-p log p — (1-p) log (1-p) $$
оказываются одинаковыми и
$$ H_{A}(B)=P(A_1) H_{A_1}(B) + P(A_2) H_{A_2}(B)=-(1-p) log (1-p)-p log p_{} $$
независимо от величин вероятностей $ P(A_{1}), P(A_{2}) $.

Статья не закончена!
Источники
[1]. Шеннон К. Математическая теория связи. (Shannon C.E. A Mathematical Theory of Communication. Bell System Technical Journal. — 1948. — Т. 27. — С. 379-423, 623–656.)
[2]. Яглом А.М., Яглом И.М. Вероятность и информация. М. Наука. 1973.
.
«Системный анализ и проектирование»
Е. Н. Живицкая
Лекция 10: Энтропия и количество информации
Установив, что случайные процессы являются адекватной моделью сигналов, мы получаем возможность воспользоваться результатами и мощным аппаратом теории случайных процессов. Это не означает, что теория вероятностей и теория случайных процессов дают готовые ответы на все вопросы о сигналах: подход с новых позиций выдвигает такие вопросы, которые просто не возникали. Так и родилась теория информации, специально рассматривающая сигнальную специфику случайных процессов. При этом были построены принципиально новые понятия и получены новые, неожиданные результаты, имеющие характер научных открытий.
Понятие неопределенности
Первым специфическим понятием теории информации является понятие неопределенности случайного объекта, для которого удалось ввести количественную меру, названную энтропией. Начнем с простейшего примера — со случайного события. Пусть, например, некоторое событие может произойти с вероятностью 0,99 и не произойти с вероятностью 0,01, а другое событие имеет вероятности соответственно 0,5 и 0,5. Очевидно, что в первом случае результатом опыта «почти наверняка» является наступление события, во втором же случае неопределенность исхода так велика, что от прогноза разумнее воздержаться.
Для характеристики размытости распределения широко используется второй центральный момент (дисперсия) или доверительный интервал. Однако эти величины имеют смысл лишь для случайных числовых величин и не могут применяться к случайным объектам, состояния которых различаются качественно. Следовательно, мера неопределенности, связанной с распределением, должна быть некоторой его числовой характеристикой, функционалом от распределения, никак не связанным с тем, в какой шкале измеряются реализации случайного объекта.
Энтропия и ее свойства
Примем (пока без обоснования) в качестве меры неопределенности случайного объекта А с конечным множеством возможных состояний А1,…,Аn с соответствующими вероятностями P1,P2…Pn величину
H(A) = H({pi}) = -∑ pi⋅log(pi)
которую и называют энтропией случайного объекта А (или распределения { }. Убедимся, что этот функционал обладает свойствами, которые вполне естественны для меры неопределенности.
- Н(p1…pn)=0 в том и только в том случае, когда какое-нибудь одно из {pi } равно единице (а остальные — нули). Это соответствует случаю, когда исход опыта может быть предсказан с полной достоверностью, т.е. когда отсутствует всякая неопределенность. Во всех других случаях энтропия положительна. Это свойство проверяется непосредственно.
- Н(p1…pn) достигает наибольшего значения при p1=…pn=1/n т.е. в случае максимальной неопределенности. Действительно, вариация Н по pi при условии ∑pi = 1 дает pi = const = 1/n.
- Если А и В — независимые случайные объекты, то H(A∩B) = H({piqk}) = H({pi}) + H({qk}) = H(A) + H(B). Это свойство проверяется непосредственно.
- Если А и В — зависимые случайные объекты, то H(A∩B) = H(A) + H(B/A) = H(B) + H(A/B), где условная энтропия H(А/В) определяется как математическое ожидание энтропии условного распределения. Это свойство проверяется непосредственно.
- Имеет место неравенство Н(А) > Н(А/В), что согласуется с интуитивным предположением о том, что знание состояния объекта В может только уменьшить неопределенность объекта А, а если они независимы, то оставит ее неизменной.
Как видим, свойства функционала Н позволяют использовать его в качестве меры неопределенности.
Дифференциальная энтропия
Обобщение столь полезной меры неопределенности на непрерывные случайные величины наталкивается на ряд сложностей, которые, однако, преодолимы. Прямая аналогия
-∑pk⋅log(pk) → ∫p(x)⋅log(p(x))dx
не приводит к нужному результату: плотность p(x) является размерной величиной (размерность плотности p(x) обратно пропорциональна x а логарифм размерной величины не имеет смысла. Однако положение можно исправить, умножив p(x) под знаком логарифма на величину К, имеющую туже размерность, что и величина х:
-∑pk⋅log(pk) → ∫p(x)⋅log(K⋅p(x))dx
Теперь величину К можно принять равной единице измерения х, что приводит к функционалу
h(X) = -∫p(x)⋅log(p(x))dx,
который получил название «дифференциальной энтропии». Это аналог энтропии дискретной величины, но аналог условный, относительный: ведь единица измерения произвольна. Запись (3) означает, что мы как бы сравниваем неопределенность случайной величины, имеющей плотность p(x), с неопределенностью случайной величины, равномерно распределенной в единичном интервале. Поэтому величина h(X) в отличие от Н(Х) может быть не только положительной. Кроме того, h(X) изменяется при нелинейных преобразованиях шкалы х, что в дискретном случае не играет роли. Остальные свойства h(X) аналогичны свойствам Н(Х), что делает дифференциальную энтропию очень полезной мерой.
Пусть, например, задача состоит в том, чтобы, зная лишь некоторые ограничения на случайную величину (типа моментов, пределов области возможных значений и т.п.), задать для дальнейшего (каких-то расчетов или моделирования) конкретное распределение. Один из подходов к решению этой задачи дает «принцип максимума энтропии»: из всех распределений, отвечающих данным ограничениям, следует выбирать то, которое обладает максимальной дифференциальной энтропией. Смысл этого критерия состоит в том, что, выбирая максимальное по энтропии распределение, мы гарантируем наибольшую неопределенность, связанную с ним, т.е. имеем дело с наихудшим случаем при данных условиях.
Фундаментальное свойство энтропии случайного процесса
Особое значение энтропия приобретает в связи с тем, что она связана с очень глубокими, фундаментальными свойствами случайных процессов. Покажем это на примере процесса с дискретным временем и дискретным конечным множеством возможных состояний.
Назовем каждое такое состояние «символом», множество возможных состояний — «алфавитом», их число m — «объемом алфавита». Число возможных последовательностей длины n, очевидно, равно mn. Появление конкретной последовательности можно рассматривать как реализацию одного из mn возможных событий. Зная вероятности символов и условные вероятности появление следующего символа, если известен предыдущий (в случае их зависимости), можно вычислить вероятность P(C) для каждой последовательности С. Тогда энтропия множества {C}, по определению, равна
Hn = -∑P(C)⋅log(P(C)).
На множестве {C} можно задать любую числовую функцию fn(C), которая, очевидно, является случайной величиной. Определим fn(C) c помощью соотношения fn(C) = -[1/n]⋅logP(C).
Математическое ожидание этой функции
M{fn(C)} = ∑P(C)⋅fn(C) = -[1/n]∑P(C)⋅log(P(C)),
M{-[1/n]⋅log(P(C))} = Hn/n
lim(M){-[1/n]⋅log(P(C))} = H
Это соотношение является одним из проявлений более общего свойства дискретных эргодических процессов. Оказывается, что не только математическое ожидание величины fn(C) при n стремящемся к бесконечности имеет своим пределом H, но и сама эта величина fn(C) стремится к H при n стремящемся к бесконечности. Другими словами, как бы малы ни были e > 0 и s > 0, при достаточно большом n справедливо неравенство
P{|[1/n]⋅log(P(C))+H| > ε} < δ
т.е. близость fn(C) к H при больших n является почти достоверным событием.
Для большей наглядности сформулированное фундаментальное свойство случайных процессов обычно излагают следующим образом. Для любых заданных e > 0 и s > 0 можно найти такое no, что реализация любой длины n > no распадаются на два класса:
- группа реализаций, вероятность P(C) которых удовлетворяет неравенству |[1/n]⋅log(P(C))+H| < ε
- группа реализаций, вероятности которых этому неравенству не удовлетворяют.
Cуммарные вероятности этих групп равны соответственно 1-s и s, то первая группа называется «высоковероятной», а вторая — «маловероятной».
Это свойство эргодических процессов приводит к ряду важных следствий, из которых три заслуживают особого внимания.
- независимо от того, каковы вероятности символов и каковы статистические связи между ними, все реализации высоковероятной группы приблизительно равновероятны. Это следствие, в частности, означает, что при известной вероятности P(C) одной из реализаций высоковероятной группы можно оценить число N1 реализаций в этой группе: N1 = 1 / P(C).
- Энтропия Hn с высокой точностью равна логарифму числа реализаций в высоковероятной группе: Hn = n * H = log N1
- При больших n высоковероятная группа обычно охватывает лишь ничтожную долю всех возможных реализаций (за исключением случая равновероятных и независимых символов, когда все реализации равновероятны и и H = log m).
Действительно, из соотношения (9) имеем
N1 = αnH
Число N всех возможных реализаций есть
N = mn = σn⋅log(m)
Доля реализаций высоковероятной группы в общем числе реализаций выражается формулой
N1/N = σ-n⋅log(m-H)
и при H < logm эта доля неограниченно убывает с ростом n. Например, если a = 2, n = 100, H = 2,75, m = 8, то
N1/N = 2-25 = (3⋅107)-1
т.е. к высоковероятной группе относится лишь одна тридцати миллионная доля всех реализаций!
Строгое доказательство фундаментального свойства эргодических процессов здесь не приводится. Однако следует отметить, что в простейшем случае независимости символов это свойство является следствием закона больших чисел. Действительно, закон больших чисел утверждает, что с вероятностью, близкой к 1, в длиной реализации i-й символ, имеющий вероятность pi встретится примерно npi раз. Следовательно вероятность реализации высоковероятной группы есть
P(C) = ∏{pin⋅Pi}
-log(P(C)) = -n⋅∑pi⋅log(pi) = n⋅N
что и доказывает справедливость фундаментального свойства в этом случае.
Подведем итог
Связав понятие неопределенности дискретной величины с распределением вероятности по возможным состояниям и потребовав некоторых естественных свойств от количественной меры неопределенности, мы приходим к выводу, что такой мерой может служить только функционал (1), названный энтропией. С некоторыми трудностями энтропийный подход удалось обобщить на непрерывные случайные величины (введением дифференциальной энтропии) и на дискретные случайные процессы.
Количество информации
В основе всей теории информации лежит открытие, что «информация допускает количественную оценку». В простейшей форме эта идея была выдвинута еще в 1928г. Хартли, но завершенный и общий вид придал ее Шэннон в 1948г. Не останавливаясь на том, как развивалось и обобщалось понятие количества информации, дадим сразу ее современное толкование.
Количество информации как мера снятой неопределенности
Процесс получения информации можно интерпретировать как «изменение неопределенности в результате приема сигнала». Проиллюстрируем эту идею на примере достаточно простого случая, когда передача сигнала происходит при следующих условиях:
- полезный (передаваемый) сигнал является последовательностью статистически независимых символов с вероятностями p(xi),i = 1,m ;
- принимаемый сигнал является последовательностью символов Yk того же алфавита;
- если шумы (искажения) отсутствуют, то принимаемый сигнал совпадает с отправленным Yk=Xk ;
- если шум имеется, то его действие приводит к тому, что данный символ либо остается прежним (i-м), либо подменен любым другим (k-м) с вероятностью p(yk/xi) ;
- искажение данного символа является событием статистически независимым от того, что произошло с предыдущим символом.
Итак, до получения очередного символа ситуация характеризуется неопределенностью того, какой символ будет отправлен, т.е. априорной энтропией Н(Х). После получения символа yk неопределенность относительно того, какой символ был отправлен, меняется: в случае отсутствия шума она вообще исчезает (апостериорная энтропия равна нулю, поскольку точно известно, что был передан символ yk=xi), а при наличии шума мы не можем быть уверены, что принятый символ и есть переданный, т.е. возникает неопределенность, характеризуемая апостериорной энтропией H(X/yk)=H({p(xi/yk)})>0.
В среднем после получения очередного символа энтропия H(X/Y)=My{H(X/Yk)}
Определим теперь количество информации как меру снятой неопределенности: числовое значение количества информации о некотором объекте равно разности априорной и апостериорной энтропии этого объекта, т.е. I(X,Y) = H(X)-H(X/Y). (1)
Используя свойство 2 энтропии, легко получить, что I(X,Y) = H(Y) — H(Y/X) (2)
В явной форме равенство (1) запишется так:
I(X,Y) = H(X)-H(X/Y) = -∑p(xi)⋅(p(xi))+∑p(yk)⋅∑p(xi/yk)⋅log(p(xi/yk)) =
=-∑∑p(xi,yk)⋅log(p(xi))+∑∑p(xi,yk)⋅log(p(xi/yk)) =
= ∑∑p(xi,yk)⋅log{p(xi,yk)/p(xi)} (3)
а для равенства (2) имеем:
I(X,Y) = ∑∑p(xi,yk)⋅log{p(yk/xi)/p(yk)} (4)
Количество информации как мера соответствия случайных процессов
Представленным формулам легко придать полную симметричность: умножив и разделив логарифмируемое выражение в (3) на p(yk), а в (4) на p(xi) сразу получим, что
I(X,Y) = ∑∑p(xi,yk)⋅log{p(yk/xi)/[p(xi)⋅p(yk)]}
Эту симметрию можно интерпретировать так: «количество информации в объекте Х об объекте Y равно количеству информации в объекте Y об объекте Х. Таким образом, количество информации является не характеристикой одного из объектов, а характеристикой их связи, соответствия между их состояниями. Подчеркивая это, можно сформулировать еще одно определение: «среднее количество информации, вычисляемое по формуле (5), есть мера соответствия двух случайных объектов».
Это определение позволяет прояснить связь понятий информации и количества информации. Информация есть отражение одного объекта другим, проявляющееся в соответствии их состояний. Один объект может быть отражен с помощью нескольких других, часто какими-то лучше, чем остальными. Среднее количество информации и есть числовая характеристика степени отражения, степени соответствия. Подчеркнем, что при таком описании как отражаемый, так и отражающий объекты выступают совершенно равноправно. С одной стороны, это подчеркивает обоюдность отражения: каждый из них содержит информацию друг о друге. Это представляется естественным, поскольку отражение есть результат взаимодействия, т.е. взаимного, обоюдного изменения состояний. С другой стороны, фактически одно явление (или объект) всегда выступает как причина, другой — как следствие; это никак не учитывается при введенном количественном описании информации.
Формула (5) обобщается на непрерывные случайные величины, если в отношении (1) и (2) вместо Н подставить дифференциальную энтропию h; при этом исчезает зависимость от стандарта К и, значит, количество информации в непрерывном случае является столь же безотносительным к единицам измерения, как и в дискретном:
I(X,Y) = ∫∫p(x,y)⋅log{p(y/x)/[p(x)⋅p(y)]}dxdy
где р(x), p(y) и p(x,y) — соответствующие плотности вероятностей.
Свойства количества информации
Отметим некоторые важные свойства количества информации.
- Количество информации в случайном объекте Х относительно объекта Y равно количеству информации в Y относительно Х: I(X,Y) = I(Y,X)
- Количество информации неотрицательно: I(X,Y) > 0. Это можно доказать по-разному. Например, варьированием p(x,y) при фиксированных p(x) и p(y) можно показать, что минимум I, равный нулю, достигается при p(x,y) = p(x) p(y).
- Для дискретных Х справедливо равенство I(X,X) = H(X).
- Преобразование y (.) одной случайной величины не может увеличить содержание в ней информации о другой, связанной с ней, величине: I[y (X),Y] < I(X,Y) (9)
- Для независимых пар величин количество информации аддитивно: I({Xi,Yi}) = ∑ I(Xi,Yi)
Единицы измерения энтропии и количества информации
Рассмотрим теперь вопрос о единицах измерения количества информации и энтропии. Из определений I и H следует их безразмерность, а из линейности их связи — одинаковость их единиц. Поэтому будем для определенности говорить об энтропии. Начнем с дискретного случая. За единицу энтропии примем неопределенность случайного объекта, такого, что
H(X) = -∑pi⋅log(pi) = 1
Легко установить, что для однозначного определения единицы измерения энтропии необходимо конкретизировать число m состояний объекта и основание логарифма. Возьмем для определенности наименьшее число возможных состояний, при котором объект еще остается случайным, т.е. m=2, и в качестве основания логарифма также возьмем число 2. Тогда из равенства
-p1⋅log2(p2)-p2⋅log2(p2) = 1
вытекает, что p1=p2=1/2. Следовательно, единицей неопределенности служит энтропия объекта с двумя равновероятными состояниями. Эта единица получила название «бит». Бросание монеты дает количество информации в один бит. Другая единица «нит» получается, если использовать натуральные логарифмы. Обычно она употребляется для непрерывных величин.
Количество информации в индивидуальных событиях
Остановимся еще на одном важном моменте. До сих пор речь шла о среднем количестве информации, приходящемся на пару состояний (xi,yk) объектов X и Y. Эта характеристика естественна для рассмотрения особенностей стационарно функционирующих систем, когда в процессе функционирования принимают участие все возможные пары (xi,yk). Однако в ряде практических случаев оказывается необходимым рассмотреть информационное описание конкретной пары состояний, оценить содержание информации в конкретной реализации сигнала. Тот факт, что некоторые сигналы несут информации намного больше, чем другие, виден на примере того, как отбираются новости средствами массовой информации (о рождении шестерых близнецов сообщают практически все газеты мира, а о рождении двойни не пишут).
Допуская существование количественной меры информации (xi,yk), в конкретной паре (xi,yk) естественно потребовать, чтобы индивидуальное и среднее количество информации удовлетворяли соотношению
I(X,Y) — M{i(xi,yk)} = ∑p(xi,yk)⋅i(xi,yk) (5)
Хотя равенство имеет место не только при равенстве всех слагаемых, сравнение формул (5) и, например, (4) наталкивает на мысль, что мерой индивидуальной информации в дискретном случае может служить величина
i(xi,yk) = log{p(xi/yk)/p(xi)} = log{p(yk/xi)/p(yk)} = log{p(xi,yk)/[p(xi)⋅p(yk)]}. (6)
а в непрерывном — величина i(x,y) = ln{p(x/y) / p(x)} = ln{{p(y/x) / p(y)} = ln{p(x,y) / p(x)p(y)}, (7)
называемая «информационной плотностью». Свойства этих величин согласуются с интуитивными представлениями и, кроме того, доказана единственность меры, обладающей указанными свойствами. Полезность введения понятия индивидуального количества информации проиллюстрируем на следующем примере.
Пример
Пусть по выборке (т.е. совокупности наблюдений x=x1…xn требуется отдать предпочтение одной из конкурирующих гипотез (H или H1), если известны распределения наблюдений при каждой из них, т.е. p(x/H0) и p(x/H1). Как обработать выборку? Из теории известно, что никакая обработка не может увеличить количество информации, содержащегося в выборке x (см. формулу (9). Следовательно, выборке x следует поставить в соответствие число, содержащее всю полезную информацию, т.е. обработать выборку без потерь. Возникает мысль о том, чтобы вычислить индивидуальное количество информации в выборке x о каждой из гипотез и сравнить их:
σi = i(x,H1)-i(x,H0) = ln{p(x/H1)/p(x)}-ln{p(x/H0)/p(x)} = ln{p(x/H1)/p(x,H0)} (15)
Какой из гипотез теперь отдать предпочтение зависит теперь от величины 7d 0i и от того, какой порог сравнения мы назначим. Оказывается, что мы получили статистическую процедуру, оптимальность которой специально доказывается в математической статистике, — именно к этому сводится содержание фундаментальной леммы Неймана-Пирсона. Данный пример иллюстрирует эвристическую силу теоретико-информационных представлений.
Подведем итог
Для системного анализа теория информации имеет двоякое значение. Во-первых, ее конкретные методы позволяют провести ряд количественных исследований информационных потоков в изучаемой или проектируемой системе. Однако более важным является эвристическое значение основных понятий теории информации — неопределенности, энтропии, количество информации, избыточности, пропускной способности и пр. Их использование столь же важно для понимания системных процессов, как и использование понятий, связанных с временными, энергетическими процессами. Системный анализ неизбежно выходит на исследование ресурсов, которые потребуются для решения анализируемой проблемы. Информационные ресурсы играют далеко не последнюю роль наряду с остальными ресурсами — материальными, энергетическими, временными, кадровыми.
Пусть имеются две случайные величины X и Y. Если они зависимые, то значения, принимаемые одной из них, могут оказывать влияние на значения, принимаемые другой. Приведем простейший пример: пусть у нас есть урна с двумя шарами — белым и черным. Случайная величина X — цвет шара, вытащенного первым, случайная величина Y — цвет шара, вытащенного вторым. Понятно, что если мы ЗНАЕМ значение какой-либо одной из этих случайных величин, мы также точно знаем значение и второй. Для описания подобной зависимости и используется условная энтропия.
Для расчета условной энтропии нам нужны вероятности появления всех пар значений случайных величин X и Y. В поле ввода ниже нужно ввести матрицу, элемент которой на пересечении i-ой строки и j-ого столбца равен  — вероятности того, что X и Y примут значения , соответственно. Строки соответствуют значениям случайной величины X — а столбцы — случайной величины Y — .
— вероятности того, что X и Y примут значения , соответственно. Строки соответствуют значениям случайной величины X — а столбцы — случайной величины Y — .
Нажав кнопку «Детали расчета» вы сможете увидеть расчет средних условных энтропий. Формулы расчета в общем виде приведены под калькулятором.
![]()
Условная энтропия
Таблица вероятности состояний (X, Y) ~ p
Точность вычисления
Знаков после запятой: 2
Файл очень большой, при загрузке и создании может наблюдаться торможение браузера.
Формула условной энтропии
Частная условная энтропия — это количество информации, или энтропия, которая характеризует степень неопределенности значений случайной величины Y, остающуюся после того, как стало известно, что случайная величина X приняла значение .
Средняя или полная условная энтропия H(Y|X) — это количество информации, или энтропия, которая характеризует степень неопределенности значений случайной величины Y, остающуюся после того, как стало известно значение, принятое случайной величиной X.
Средняя условная энтропия Y по X определяется как
Предполагается что выражения вида и трактуются как ноль.
Значения для каждой строки вычисляются суммированием ячеек в этой строке, а — даны.
Эта формула, по факту, является взвешенным средним значением частных условных энтропий для каждого из возможных значений X.
Веса пропорциональны значению p(x), то есть