Содержание:
Ошибки измерения: Опыт убеждает, что измерения объектов не могут быть произведены абсолютно точно и каждое конкретное измерение дает лишь, как правило, приближенное значение величины явления, истинное значение которой (A) нам неизвестно. Ошибки измерения (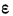
Рассмотрим такие измерения, которые производятся одним наблюдателем, одним и тем же инструментом, в одинаковых условиях, т. е. равноточные измерения.
Различают два вида ошибок измерения:
- систематические ошибки, т. е. такие, которые при данных условиях проведения измерения имеют вполне определенное значение (например, ошибка измерительного прибора);
- случайные — такие, которые являются результатом взаимодействия большого числа незначительных в отдельности факторов и имеют в каждом отдельном случае различные значения.
Задача математической статистики — предусмотреть возможность возникновения систематических ошибок и добиться их ликвидации или сведения к минимуму.
Случайные ошибки измерения обладают рядом свойств: при большом числе измерений крупные ошибки встречаются реже мелких и число положительных ошибок примерно равно числу отрицательных, вследствие чего сумма всех ошибок близка к нулю.
Если ошибки получаются весьма малыми по сравнению с величиной явления, то ими просто пренебрегают или считаются с наибольшей возможной ошибкой, чтобы обезопасить себя от влияния случайной неточности.
В теории ошибок изучаются те ошибки, которые, являясь, с одной стороны, ошибками случайного характера, по своему абсолютному значению настолько велики, что ими пренебречь нельзя, а с другой стороны, для них существует закон, позволяющий установить зависимость между величиной ошибки и вероятностью ее появления. Закон случайных ошибок, полученный Гауссом, состоит в том, что случайные ошибки подчиняются закону нормального распределения.
Средняя ошибка сводного результата измерения
Принимая за действительное значение измеряемой величины при равноточном измерении среднюю арифметическую из всех результатов n измерений, можно охарактеризовать точность одного измерения с помощью средней арифметической из абсолютных величин значений ошибок:
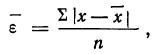
где n — число измерений, х — численное значение отдельных измерений, 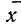 — средняя арифметическая из результатов измерений.
— средняя арифметическая из результатов измерений.
За меру точности соответствия принятой средней арифметической 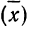 истинному значению измеряемой величины (A) принимают среднюю ошибку сводного результата измерения, вычисляемую по формуле:
истинному значению измеряемой величины (A) принимают среднюю ошибку сводного результата измерения, вычисляемую по формуле:
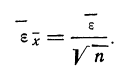
Пример 1. Произведено 10-кратное измерение размера детали (в мм), давшее следующие, расположенные в возрастающем порядке результаты: 138; 139; 140; 141; 141; 142; 142; 143; 144; 145.
Охарактеризуем сначала точность одного измерения, т. е. вычислим среднюю арифметическую из абсолютных значений ошибок. Для этой цели вычислим среднюю арифметическую из результатов измерений:
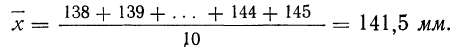
Найдем ошибки измерения:
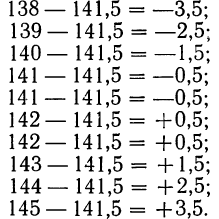
Следовательно:
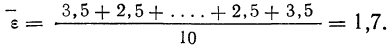
Теперь можно вычислить среднюю ошибку сводного результата измерения:
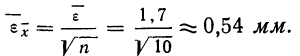
Значит, мерой точности соответствия 141,5 мм истинной величине размера детали является средняя ошибка, равная 0,54 мм.
Средняя квадратическая ошибка
Если в качестве меры точности одного измерения принять не среднюю арифметическую из абсолютных значений ошибок (средняя ошибка), а среднюю квадратическую из ошибок измерений, т. е.
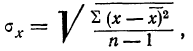
то средняя квадратическая ошибка найденной средней арифметической из ошибок измерения вычисляется по формуле:
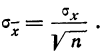
Между средней -квадратической ошибкой и средней ошибкой сводного результата измерения существует связь: 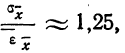 если случайные ошибки подчиняются Гауссову закону нормального распределения.
если случайные ошибки подчиняются Гауссову закону нормального распределения.
Пример 2. Используя данные предыдущего примера, находим меру точности одного измерения, т. е. среднюю квадратическую ошибку:
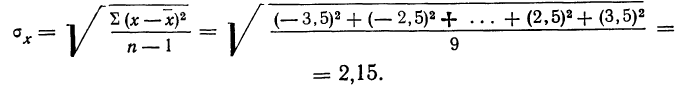
Затем исчисляем среднюю квадратическую ошибку найденной средней арифметической, равной 141,5 мм:
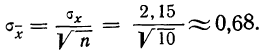
Сопоставляя среднюю квадратическую ошибку сводного результата измерения со средней ошибкой, получаем:
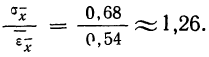
Вероятная ошибка
За меру точности одного измерения иногда принимают вероятную ошибку:
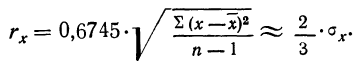
Тогда в качестве вероятной ошибки сводного результата измерения используют соотношение:
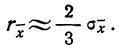
Пример 3. Используя данные предыдущих примеров, находим вероятную ошибку сводного результата измерения:
Наиболее вероятные границы сводных результатов измерения
Математическое ожидание случайной ошибки равно нулю. В качестве значения измеряемой величины применяется средняя арифметическая всех измерений (если они равноточны). Использование отклонений результатов измерений (х) от средней из них 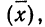 называемых в теории ошибок «кажущимися ошибками»
называемых в теории ошибок «кажущимися ошибками» 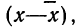 позволяет произвести оценку точности соответствия средней арифметической неизвестному истинному значению измеряемой величины (A).
позволяет произвести оценку точности соответствия средней арифметической неизвестному истинному значению измеряемой величины (A).
Для этой цели используют удвоенную или утроенную среднюю квадратическую ошибку сводного результата измерения или его вероятную ошибку и получают:
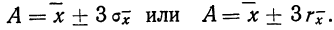
Найденные границы неизвестной истинной величины в случае, если ошибки подчинены нормальному закону распределения Гаусса (чаще всего так и бывает), соблюдаются с большой вероятностью (0,997 и 0,954).
Пример 4. По данным предыдущих примеров находим границы истинного значения размера детали 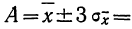
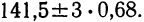 Значит, истинное значение размера детали находится в границах от 141,5—2,04 до 141,5+2,04.
Значит, истинное значение размера детали находится в границах от 141,5—2,04 до 141,5+2,04.
- Методы математической статистики
- Комбинаторика — правила, формулы и примеры
- Классическое определение вероятности
- Геометрические вероятности
- Законы распределения случайных величин
- Дисперсионный анализ
- Математическая обработка динамических рядов
- Корреляция — определение и вычисление
Теория ошибок
Теория ошибок
– дисциплина, которая изучает законы
возникновения и распределения ошибок
измерений, а также методы их обработки.
Виды измерений: 1)полученные непосредственно
из измерения (длина линии при изм. мерной
летной) и косвенным путем (неприступные
расстояния); 2) необходимые
(назыв.минимальное
кол-во измерений, которое нужно выполнить
для определения искомой величины) и
избыточные
(назыв измерения в которых для контроля
всегда выполняются дополнительные
измерения) вычисл. по формуле : r=n-k,
где n
– общее число изм., k
– необходим число изм.; 3) равноточные
(измерения выполненные одним и тем же
инструментом, при одинаковых внешних
условиях, по одной и той же методике,
наблюдателями одинаковой опытности) и
неравноточные (если хотя бы одно из
условий равноточности нарушается это
приводит к неравноточности).
Ошибки измерений
Теория ошибок делит
ошибки на: грубые(возникают
при просчетах и промахах, теор.ош. их не
изучает), систематические
( назыв ошибки МО которых отлично от
нуля. Н.ошибка компарирования), случайные
(ошибки
измерений которых имеют различные знаки
и их МО равно 0). Св-ва случайных ошибок:
1) их МО равно нулю; 2) Положит и отриц
ошибки появляются равновозможно; 3)
Малые по абсолютной величине ошибки
появляются чаще чем большие; 4) Ошибки
не превосходят определенной величины
равной 3m.
Истинная
ошибка
измерения: Δi=xi-X,
где xi
– результат измерения, Х – истинное
значение измеренной величины. Истинное
значение практически никогда не известно.
Средняя
квадратическая ошибка
Это МО квадрата
истинной ошибки, т.е. нач момент второго
порядка:
![]()
.
Истинная ошибка состоит из: Δ=Θ+с;
![]()
.
Т.е. любая СКО содержит случайную и
систематическую составляющую.
Систематической ошибкой можно пренебречь
если ее величина равна:![]()
,
Θ – случайная ошибка.
Равноточные
измерения
Условие: измерения
выполненные одним и тем же инструментом,
при одинаковых внешних условиях, по
одной и той же методике, наблюдателями
одинаковой опытности. Т.к. равноточность
подразумевает одинаковую точность
каждого измерения для хар-ки точности
любого одного измерения используют СКО
одного измерения. Наиболее надежным
значением из ряда равноточных измерений
будет среднее арифметическое, которое
вычисляется по формуле:
![]()
,
где х – результат измерения, n
– число изм.
Оценка точности
равноточных измерений
1) СКО одного
измерения.
Если известна истинная ошибка измерения
Δ, которая находиться по формуле: Δi=xi-X,
где xi
– результат измерения, Х – истинное
значение измеренной величины.
![]()
.СКО
одного измерения находим как: а) n>=30.
Формула Гаусса:
![]()
,
где
![]()
;
б) n<30.
Формула Бесселя:
![]()
.
2) При вычислении СКО удерживают две
значащих цифры. Для того чтобы убедиться
что этого достаточно вычислим СКО самой
СКО:
![]()
— если СКО вычислено по формулам Гаусса,
![]()
— -«»- по формулам Бесселя; 3) СКО среднего
арифметического: вычисляется по формулам:
![]()
,
где m
– CКО
одного измерения, n
– число измерений. 4) Кроме СКО для хар-ки
точности равн.измерний используют
среднюю и вероятную ошибку: Средняя
ошибка —
![]()
,
ν – уклонение ср.кв.значения. Для
вычисления вероятной ошибки r,
которая хар-ет середину ряда используют
или ряд истинных значений Δ, или уклонения
от среднего ν.
Эти величины берут по абсолютной величине
и выстраивают в порядке возвр. Вероятная
ошибка r
будет равна центральному значению из
полученного ряда если число измерений
нечетное или среднему из двух центральных
знач. при четном числе измерений.
Относительные
ошибки измерений Абсолютные
Абсолютными ошибками
назыв СКО, среднюю v,
вероятную r,
истинную Θ. Относительной ошибкой –
назыв. величину получаемую как отношение
ошибки измерения к результату измерения:
mx/x.
В геодезии принято представлять
относительную ошибку в виде простой
дроби: 1/(х/mx)
И округлять
до целых сотых. В зависимости от того
какую точечную оценку использовали для
хар-ки точности различают относит.
истинная ош. – Δ/х, относит ср.кв.ош –
ν/х, относит вер-я ош – r/x.
СКО функции.
Принцип равного влияния
Если представить
ф-ю F(x)=F(x1,
x2…xn),
которую оцениваем как ф-ю измеренных
величин, то СКО ф-ии для некоррелированных
измерений
будет найдена как:
![]()
,
где
![]()
— частная производная оцениваемой ф-ии
по i-му
измерению. Если измерения коллерированы:
![]()
,
mxi
mxj
– коэф.кореляц между i-м
j-м
измерениями. Для определения СКО
отдельных аргументов применяют принцип
равного влияния. Суть принципа в том
что влияние каждого источника ошибок
на конечный результат применяют
одинаковым:
![]()
1)СКО алгебраической
суммы: F=x1±x2±..±xn,
![]()
— для неравноточных. Частный случай
когда измерения равноточны:
![]()
.
В этом случае формула приобретает вид:
![]()
2)Как СКО ф-ии
получают и СКО арифметической середины:
![]()
,
Неравноточные
измерения
Неравноточными
назыв измерения в которых каждое
измерение будет иметь свою отличную от
других СКО. Вычислить ошибку каждого
неравноточного измерения сложно, поэтому
для хар-ки неравноточ измерений применяют
относительную меру точности, которую
назыв.весом. Веса измерений обратны
квадратам СКО:
![]()
,
mi
– ско соотв измерения, с – произвольная
постоянная для данного ряда измерений.
При выборе с стараются чтобы вычисленные
веса измерений были близки к 1.Зная вес
всегда можно определить величину СКО
измерения:
![]()
.
При оценке точности заменяют с=μ2.
Ошибка единицы
веса для ряда неравноточных измерений
играет ту же роль что и СКО одного
измерения для ряда равноточных:
![]()
.
Для вычисления ошибки единицы веса
используют формулу Гаусса:
![]()
— когда известно истинное значение,
![]()
— при n<30,
![]()
— при n>30.
Наиболее надежное
значение из ряда неравноточных измерений
и его оценка точности:
Наиболее надежным
будет ср.весовое
![]()
.
Эту величину так же назыв.общая
арифметич.середина. СКО среднего
весового:
![]()
.
Вес функции:
Формулы для
вычисления весов ф-ии получают из формул
для вычисления весов ф-ий разделив их
на μ2.
Для некоррелированных
измерений:
![]()
.
Для коррелированных:
![]()
Задача уравнивания
Наличие в сети
избыточных измерений приводит к
неоднозначности определения неизвестных,
а значит возникает задача ур-я, которая
Состоит в определении наиболее надежных
значений неизвестных параметров и их
оценки точности. Мы решали такую задачу
при обработке измерения одной величины
в теории ошибок. Принципиальное отличие
задачи в том что в обработку включаются
разнородные величины. Существует два
вида ур-я: параметрический и корелантный.
Параметрический
способ ур-я
Х – истинное
значение неизвестного параметра, У –
истинное значение измеренной величины,
у – измеренное значение. Результаты
измерений всегда можно связать с какой
то ф-ей. Т.к. в общем случае ур-е (1) нелинейно
приведем его у линейному виду разложив
в ряд Тейлора
Порядок уравнивания
параметрическим способом
1) Выберем неизвестные
и обозначим их xj.
2)Составим у-е связей между измеренными
значениями и неизвестными У=φ(х).
3) Составим параметрическое у-е поправок
А∆х+L=V.
4)Находим приближенное значение
неизвестных и вычисляем свободные члены
параметрических у-ий поправок: φ(х(0))-у=L.
5) Составим нормальное у-е R∆x+B=0,
R=ATA,
b=ATL.
6) Получим поправки из уравнивания
приближенным значением неизвестных
∆х=-R-1b.
7) Вычислим уравненные значения неизвестных
![]()
.
 Выполним оценку точности.
Выполним оценку точности.
Запись матричных
выражений в параметрич.способе
Параметрич.у-е
поправок
V=A∆x+L
Для каждого измерения
![]()
![]()
Матрица поправок
изм.знач.
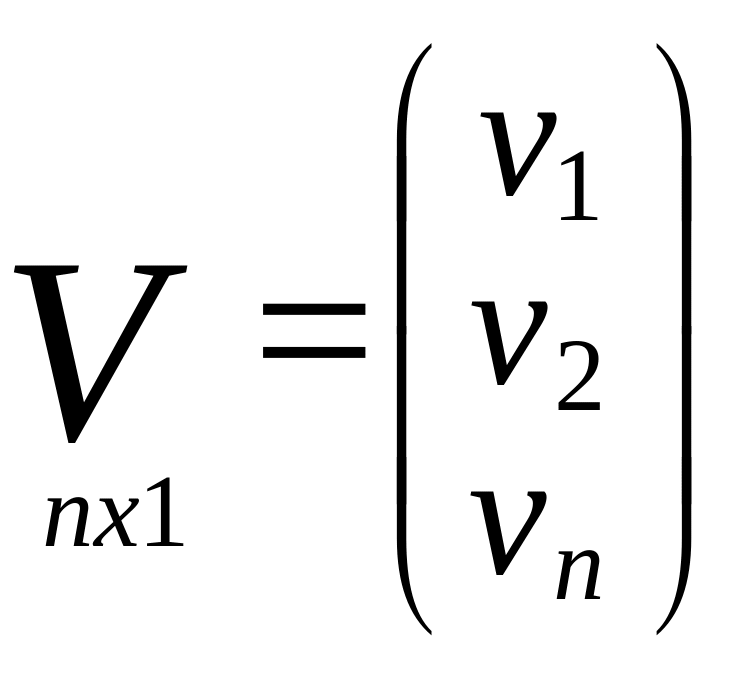
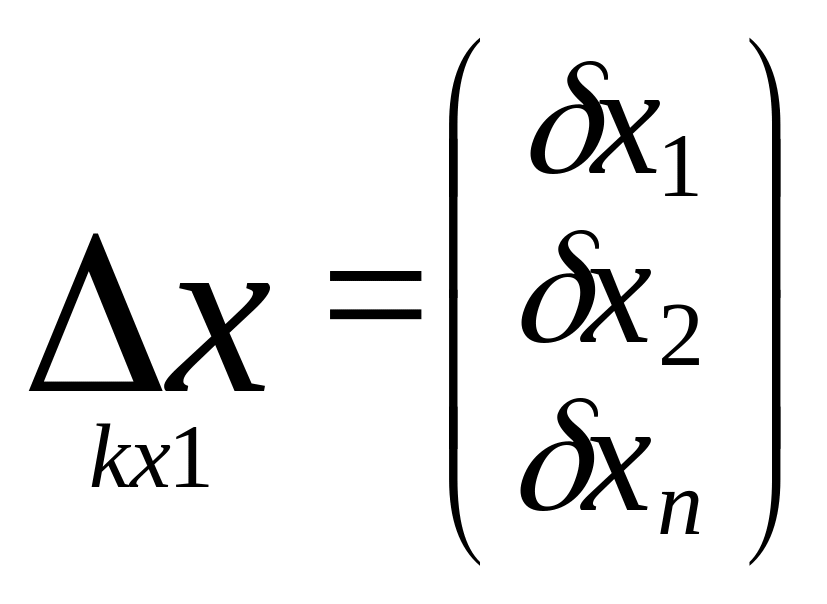
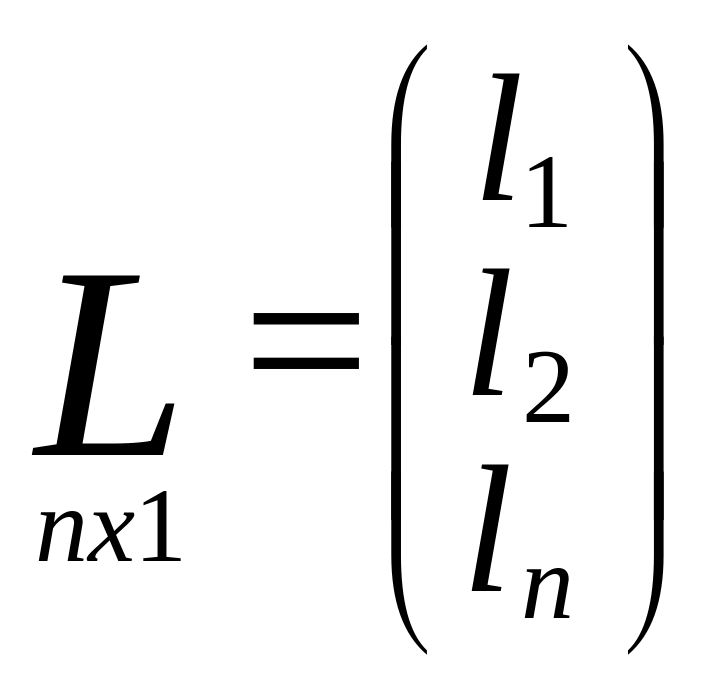
Матрица частных
произв.
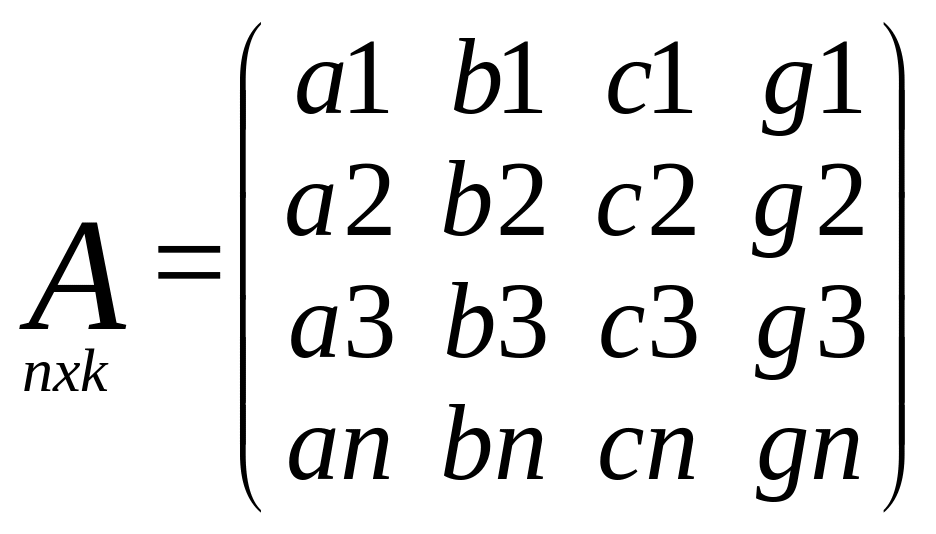
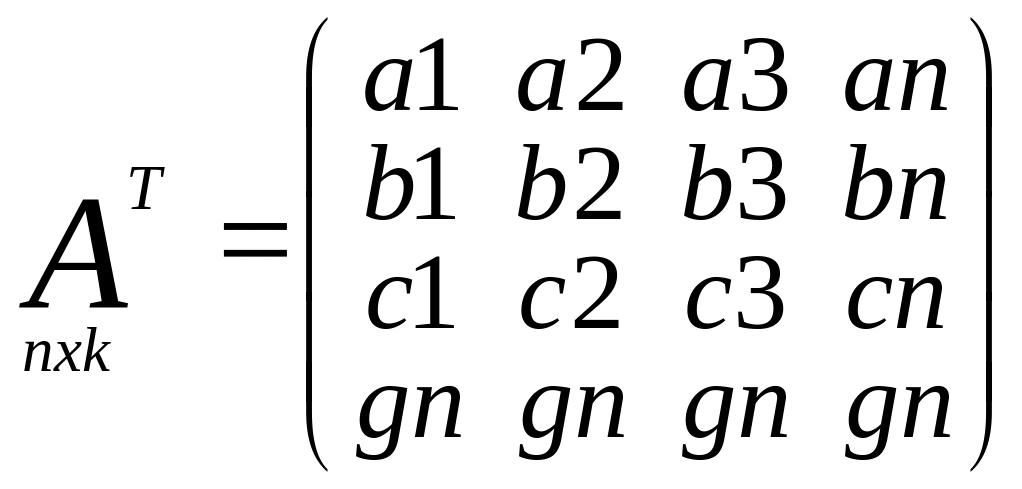
Матрица коэфиц.
норм.ур-й. Св-ва:
1) по диагонали стоят квадратичные коэф.,
они всегда положит. 2) не лиагональные
элементы симметричны относительно
главной диагонали.
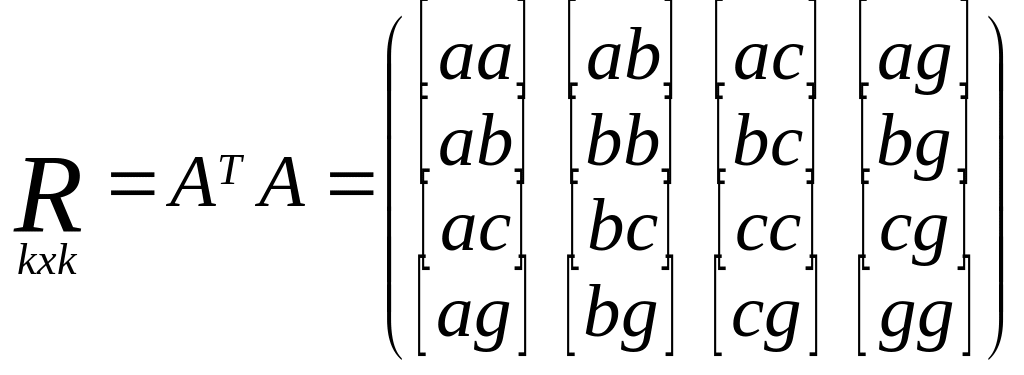
Матрица свободных
членов нормальных ур-ий
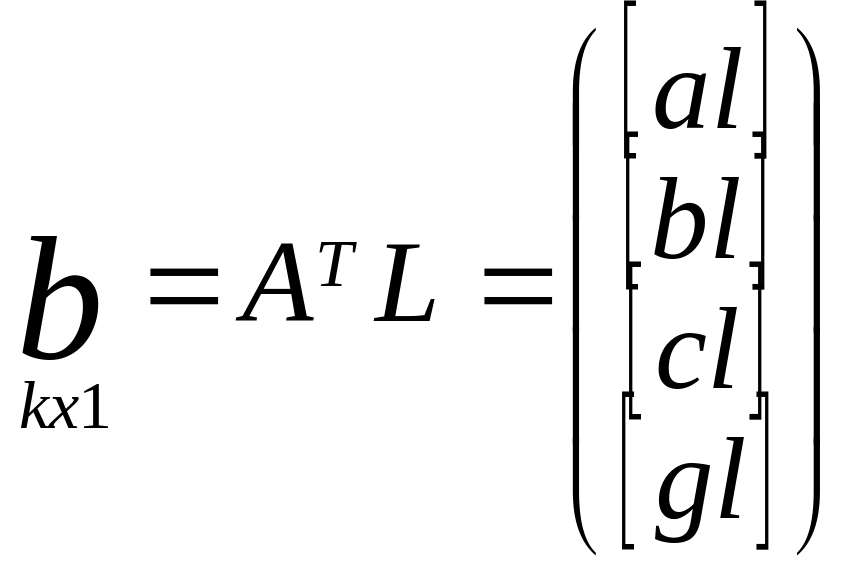
Номальные у-я для
4 неизвестных
R∆х+b=0
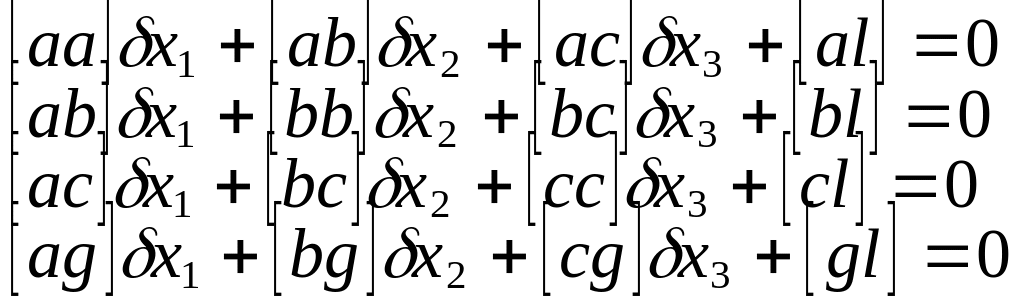
Способы решения
нормальных ур-ий
Прямой способ,
когда решения получают в виде: ax=b,
x=b/a.
При прямых способах мы можем заранее
указать кол-во операций. Приближенный
способ, когда решения получаем в виде:
ax+x-x-b=0,
xi=(1-a)xi-1-b,
т.е. в каждом последующем приближении
I
используется значение неизвестного
xi-1
полученное
в предыдущем приближении. В этом способе
мы заранее не можем описать кол-во
операций, но этот способ занимает меньше
памяти в ЭВМ.
Оценка точности
при параметрическом способе
а) оценка точности
неизвестных. Обратный вес уравненного
значения каждого неизвестного будет
равен соотв.диагональному элементу
обратной матрицы коэф.норм. ур-й![]()
.В
матрице Q
по диагонали стоят обратные веса
неизвестных ее так же назыв. весовой
матрицей.
б) вычисление ошибки
единицы веса. При параметр. способе
ошибки единицы веса вычисляются по
формуле:![]()
,
здесь v
может быть вычислено по формуле:
,
где n
– общее число изм., k
– число необходим изм., равное числу
определяемых неизвестных.
Ур-ие неравноточных
измерений
1)пусть измерения
неравноточны, чтобы привести их к
равноточному виду мы умножим их на
матрицу:
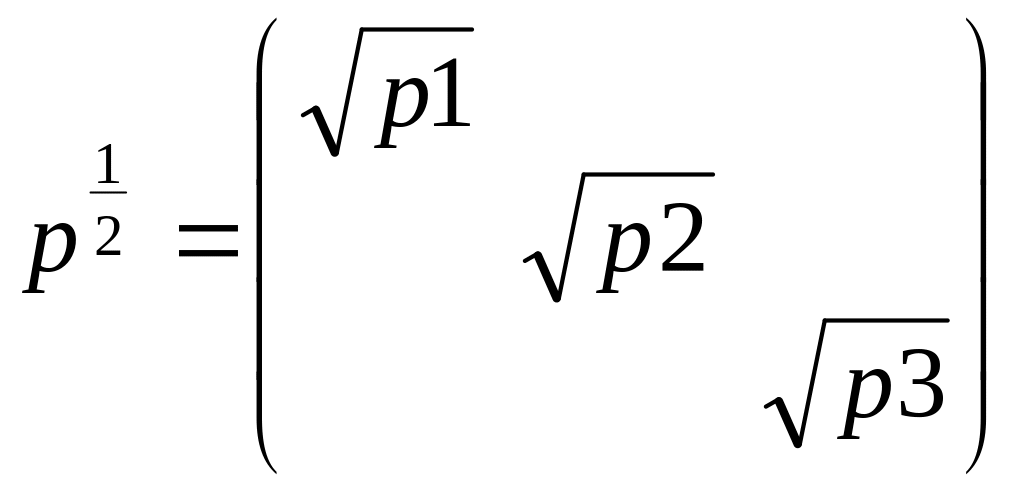
![]()
![]()
.
Получим у-е:
![]()
.
Решаем задачу также как и для равноточных
изм.: получим нормальное у-е и вектор
решения:
![]()
;
![]()
.
Из ур-я мы получим
![]()
,
чтобы получить величину V.
После ур-я разделим поправки:
![]()
2) для учета
неравноточных измерений во все алгоритмы
Гаусса ввести веса измерений и получит
алгоритмы в виде:
![]()
;
![]()
Коррелатный
способ ур-я
Сущность ур-я
коррелатным способом заключается в том
чт задачу нахождения минимума ф-ии
зависимых переменных [pv2]
решают способом Лагранжа, вводя
вспомогательные множители независимых
условных ур-ий. Приводит к тем же
результатам что и параметрический, но
иногда более выгоден.
Порядок ур-я
корелатным способом
1) Подсчитываем
число избыточных измерений в геод.сети.
Каждое избыточное измерение приводит
к возникновению независимого ксловного
у-я поправок. 2) Составляем у-е связей
между измеренными величинами которые
выражают какое-то математическое
соотношение: φ(У)=0;
3) Составляем условное у-е поправок:
BV+w=0;
4) Составляем нормальные у-я: Nk+w=0;
5)Получаем корелаты решив у-е любым
известным споcобом:
k=-N-1w;
6) вычисляем поправки к измеренным
величинам: V=p-1BTk;
7)Вычисляем уравненные значения измеренных
величин
![]()
;
По уравненным значениям измерений
вычисляем значения неизвестных; 9) Оценка
точности.
Подробная запись
матричных выражений
![]()
![]()
![]()
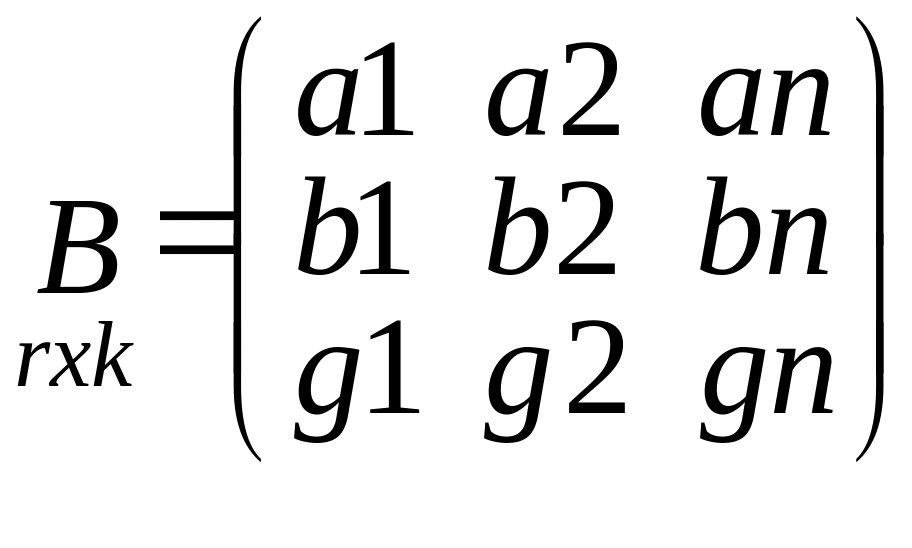
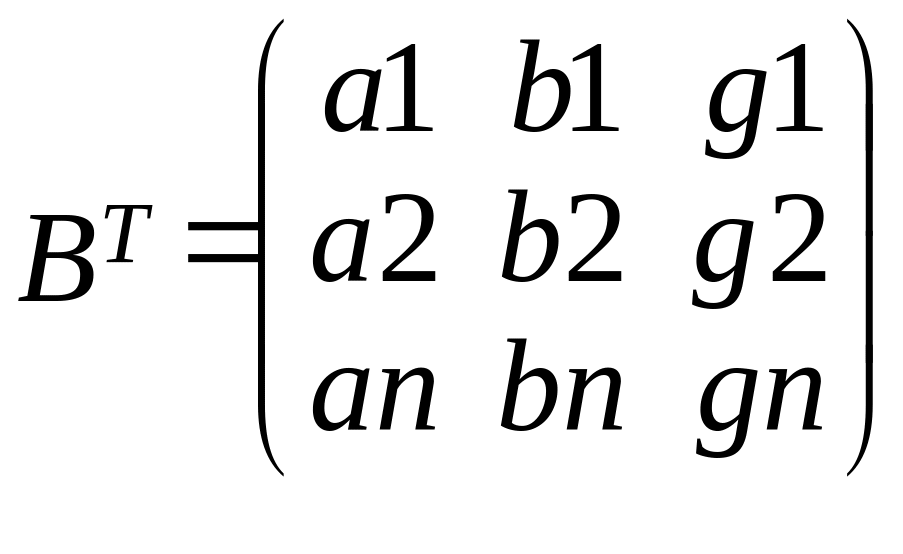
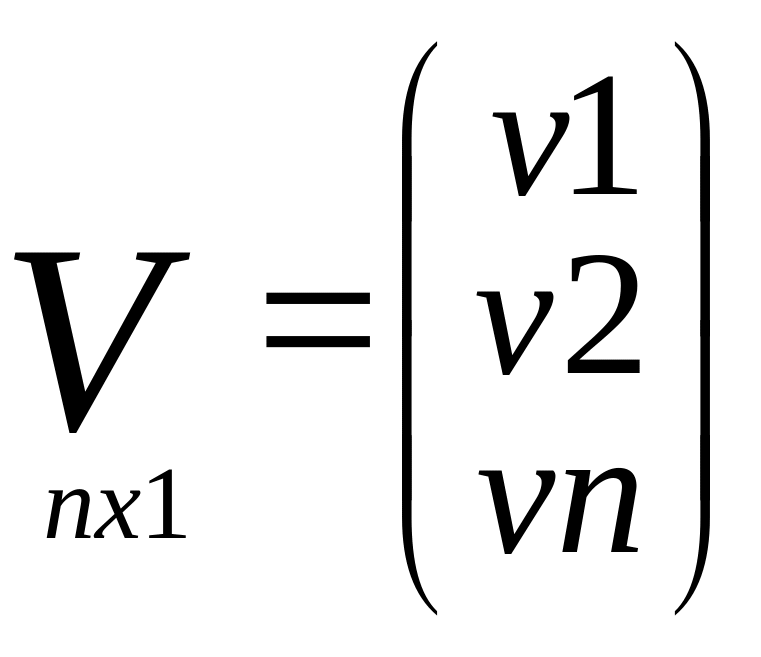
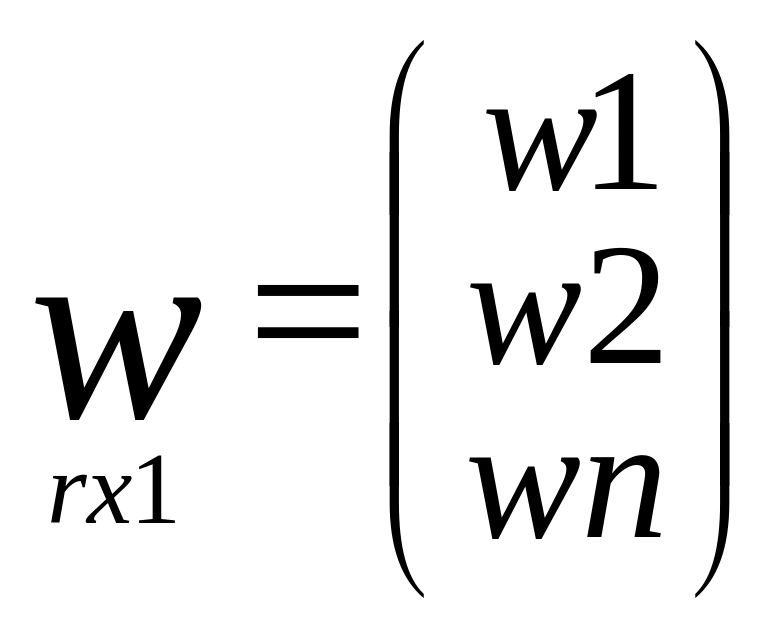
C
учетом у-я поправок:
![]()
Нормальные у-я в
подробной записи:
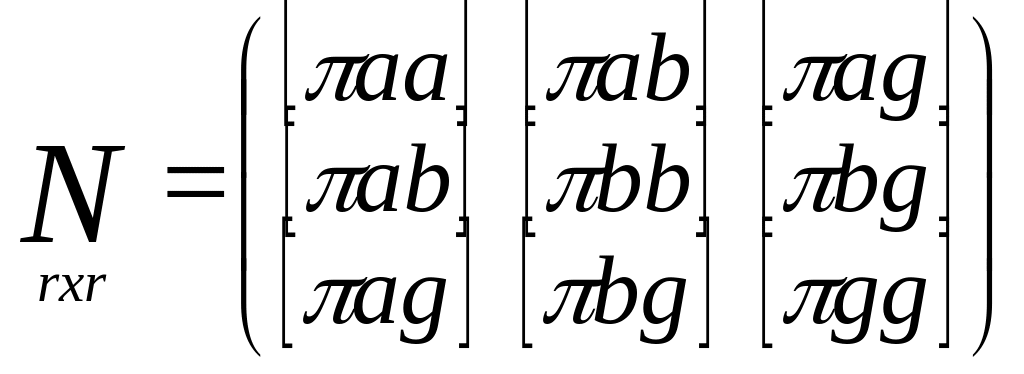
,
где
![]()
— обратный вес
Порядок обработки
ряда неравноточных измерений
1) Вычисляем общую
арифметич. середину:![]()
,
где εi=xi-x’,
x’=minxi
. 2)
Вычисялем уклонения vi=хо-хточн
и выполняем контроль
![]()
,
где ошибка округления при вычислении
![]()
будет![]()
.
3)Вычисляем [pv2]
с контролем:
![]()
.
4) Вычисляем μ, M,
mμ,
mM
b
и строим
доверительные интервалы![]()
Порядок обработки
ряда равноточных измерений
1.Вычисляем простую
арифметич. середину:![]()
,
где εi=xi-x’,
x’-
приближенное значение х (обычно
минимальное значение xi).
2) Вычисляем отклонения vi=
хi-xокр,
и выполняем контроль
![]()
,
где β – ошиюка округления х —
![]()
.
3) Вычисляем [v2]
с контролем:
![]()
.
4) Вычисляем m,
M,
mm.
5)Cтроим
доверительные интервалы
;![]()
;![]()
Число нормальных
ур-й в параметрическом и корелатном
способе
В параметрическом
способе: это определенная система из k
линейных уравнений с k
неизвестными: R∆х+b=0.
В корелатном: в системе нормальных
уравнений число уравнений r
равно числу неизвестных.
Алгоритм гаусса.
Эквивалентные ур-я.
Система эквивалентных
у-й имеет вид:
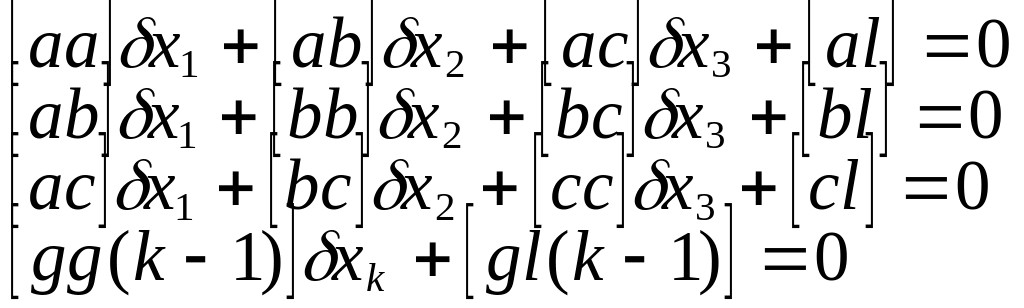
Алгоритм полученный
для вычисления коэффициентов в
экквивалентной системе, назыв алгоритмом
Гаусса. Первый сомножитель получается
как произведение первой буквы знаменателя
на первую букву раскрываемого алгоритма,
а второй как произведение второй буквы
знаменателя на его вторую букву
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Вероятная ошибка. — Bсе наши наблюдения и опытные исследования подвержены большим или меньшим ошибкам, причина которых заключается частью в несовершенстве наших чувств, частью в несовершенстве употребляемых нами инструментов. Ошибки эти делятся на постоянные (систематические) и случайные; постоянной ошибкой называется такая, которая при всех измерениях какой-либо величины или остается постоянной, или ее изменения следуют какому-либо определенному закону; случайной же называется ошибка, появляющаяся без определенного порядка и происходящая то в одну, то в другую сторону. Чтобы ослабить влияние случайных ошибок на результат, одни и те же наблюдения повторяют несколько раз, так что для наблюдаемой величины получается несколько более или менее отличных друг от друга результатов. Наиболее правдоподобным или наивероятнейшим значением определяемой величины, если все отдельные наблюдения равно благонадежны, считается среднее арифметическое из отдельных результатов. Разности между средним арифметическим и результатами каждого отдельного наблюдения принимаются за случайные ошибки (при этом предполагается, конечно, что влияние постоянных ошибок уже принято во внимание). Представим себе теперь, что имеется ряд измерений какой-нибудь величины и, следовательно, соответствующий этим измерениям ряд ошибок; та ошибка, численная величина которой такова, что число всех ошибок, меньших ее, равно числу ошибок, больших ее, называется, следуя Гауссу, вероятною (erreur moyenne à craindre); она дает возможность судить о достоинстве измерения какой-либо величины. Астрономы и геодезисты, измерения которых отличаются чрезвычайною точностью, сообщая результаты своих измерений, приводят обыкновенно и вероятную ошибку их. Вместо вероятной ошибки иногда дается средняя;средней называется такая ошибка, квадрат которой равен среднему арифметическому из квадратов всех ошибок рассматриваемого ряда наблюдений. В простейшем случае, когда для определения искомой величины произведен достаточно многочисленный ряд равно благонадежных измерений, средняя ошибка отдельного измерения вычисляется по формуле

а средняя ошибка результата (среднего арифметического) по формуле
 ,
,
где (Δ²) означает сумму квадратов всех уклонений отдельных измерений от среднего арифметического, а n — число измерений. Вероятная ошибка приблизительно в полтора раза менее средней. Величину вероятной ошибки можно найти еще следующим, хотя и грубым, способом, вытекающим из самого ее определения: из всего числа ошибок отобрать по порядку половину их, по численной величине наиболее близких к нулю; тогда ошибка, находящаяся на границе отобранных с остальными, и будет приблизительно равна В. ошибке отдельного измерения. В более общем случае, когда различные, не зависимые друг от друга выводы для искомой величины неодинаково благонадежны, при вычислении вероятнейшего значения искомой величины, а также вероятной и средней ошибки ее, принимают в расчет так наз. веса выводов; относительным весом наз. число, обратно пропорциональное квадрату средней ошибки разных выводов, причем единица веса произвольна. См. Gauss, «Theoria combinationis observationum erroribus minimis obnoxiae» (1821); Буняковский, «Теория вероятностей»; Савич, «Приложение теории вероятностей к вычислению наблюдений etc.».
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.