Определить
время блокирования эвакуационного пути
из лекционного
класса
учебно-методического цетра из предыдущего
примера:
тип
помещения — непроизводственное;
учреждение
высшего профессионального образования;
площадь
— 120 м2;
высота
— 6 м;
вероятность
ППО — 0;
время
начала эвакуации — 90 с;
время
эвакуации — 120 с;
Количество
смен — 1 смена;
Горючая
наргузка — здания I–II ст. огнест.; мебель
— ткани.
Д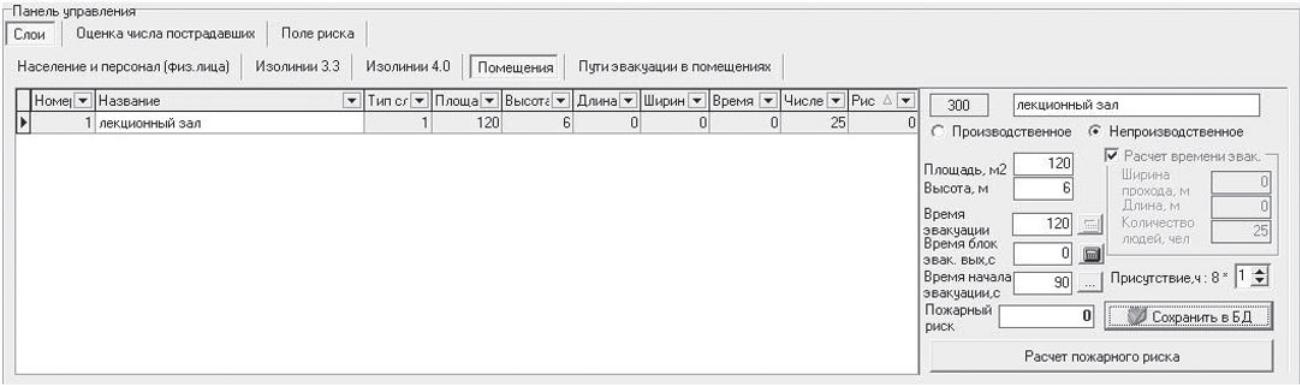
ля
расчета времени блокирования эвакуационных
путей задать тип слоя Помещение
в режиме Площадные
объекты
панели инструментов и задать на
ситуационном плане контуры помещений,
для которых будет проводиться расчет.
Переключившись на закладку Помещения
(рис.
29), следует задать для каждого из слоев
типа Помещения дополнительные параметры.
Рис.29
Рис.30
З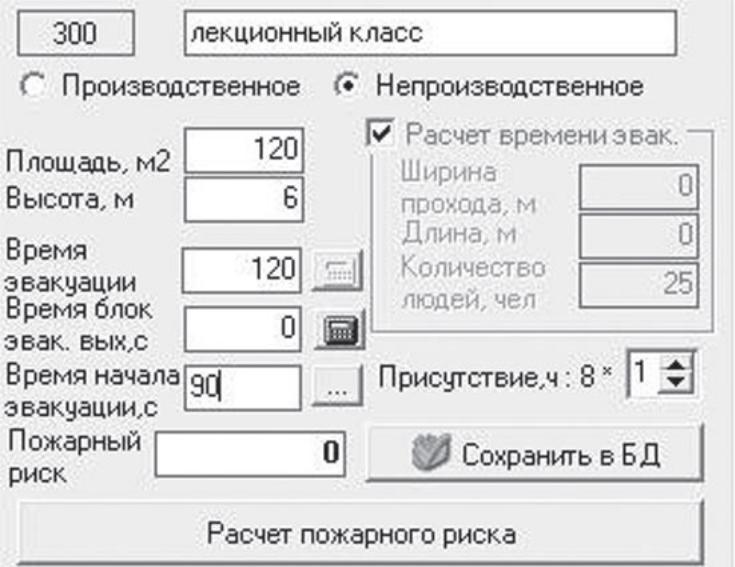
адать
исходные данные в соответствии в заданием
(рис. 30).
После
ввода основных характеристик для каждого
помещения следует выполнить расчет
времени блокировки путей эвакуации.
С
этой целью в программе имеется встроенный
калькулятор (рис. 31) для
расчета
времени блокировки эвакуационных путей.
Вызывается он нажатием на кнопку Расчет
времени блокирования эвакуационных
путей
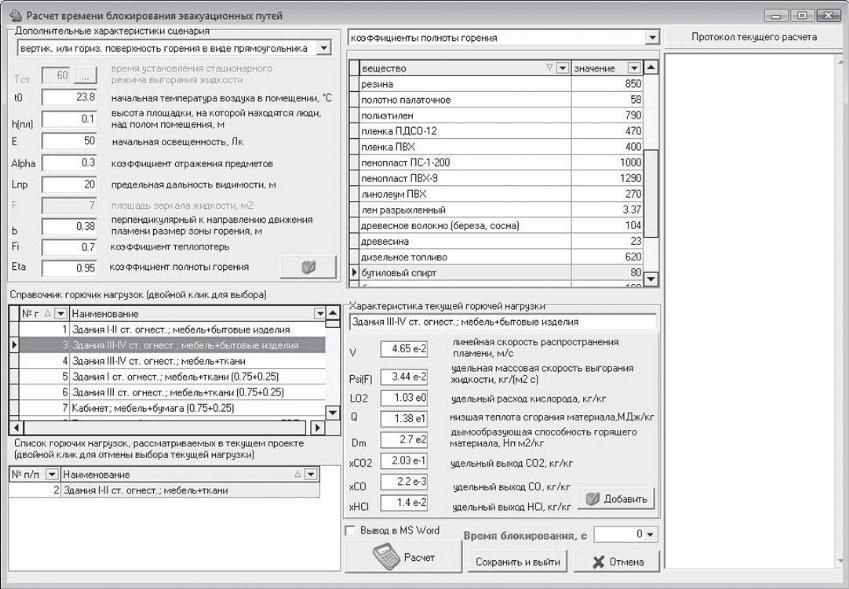
Рис.31
В
ыбрать
горючую нагрузку двойным нажатием левой
кнопки мыши по выбранной нагрузке в
Справочнике
горючих нагрузок —
здания I–II ст.огнест.; мебель — ткани.
После
нажатия на кнопку Расчет
программа
выполнит расчет времени блокирования
для заданного помещения. В поле Протокол
текущего расчета выводится
протокол проведенного расчета (рис.
32).
Нажать
кнопку Сохранить
и выйти для
того чтобы окно Расчет
времени блокирования эвакуационных
путей было
закрыто и в поле Время
блокирования на
вкладке Помещения
было
занесено рассчитанное значение.
Рис.32
6. Общие сведения о программе «Эколог-шум»
Программа
«Эколог-ШУМ»позволяет
проводить оценку звукового давления в
отдельных точках и на расчетных площадках.
Программа дает возможность разрабатывать
разделы «Оценка шумового воздействия»
в составе проектов организации
санитарно-защитных зон промышленных
предприятий.
В
основе программы два нормативных
документа:
-
СНиП
II-12-77 Нормы проектирования. Защита от
шума. Утверждены постановлением
государственного комитета Совета
Министров СССР по делам строительства
от 14 июня 1977 г. № 72 -
СНиП
23-03-2003 Защита от шума и акустика
Программный
продукт предназначен для выполнения
следующих задач:
• оценка
шумового воздействия на территориях,
прилегающих к промышленным предприятиям
и транспортным магистралям;
• разработка
и оценка эффективности шумозащитных
мероприятий; • определение санитарно-защитных
зон по фактору шума проектируемых и
существующих предприятий; • экологический
аудит промышленных, коммунальных и
транспортных предприятий по фактору
промышленного и транспортного шума.
К
программе «Эколог-Шум» бесплатно
поставляется электронный «Каталог
шумовых характеристик технологического
оборудования (к СНиП II-12-77)». Источники
шума наносятся прямо на карту. Для
каждого источника шума заносятся его
название, тип, нижняя и верхняя высота,
уровень мощности или звукового давления
в Дб (в зависимости от типа данных –
паспортные или измеренные) по октавным
полосам частот со среднегеометрическими
частотами от 31,5 Гц до 8000 Гц. Помимо
точечного и линейного, реализован
объёмный тип источника шума. Его
особенностью является возможность
задания шумящей стороны или сторон
источника. Координаты источников могут
быть откорректированы пользователем.
Программа
содержит заполненный справочник шумовых
характеристик, который может редактироваться
и пополняться пользователем.
Препятствия
для шума заносятся аналогичным способом
– рисуются на карте. Программа снабжена
справочником материалов препятствий,
в зависимости от которых меняется
коэффициент поглощения шума.
Отличительной
особенностью программы является то,
что она производит расчет как по точкам,
так и по полю (площадке) с заданным шагом,
так и по точкам на границе особых зон,
которые могут быть нанесены на карту с
последующими уточнениями координатами
в таблицах.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Использование статистики работы индекса и общие рекомендации для организации высокопроизводительной среды SQL Server
В первой статье серии, посвященной функции динамического управления dm_db_index_operational_stats, «Динамическое управление сбором статистики работы индекса» (опубликованной в Windows IT Pro/RE № 8 за 2016 год), я рассказал о том, как различное поведение запроса отражается на результатах, возвращаемых запросами, которые направляются к функции динамического управления (DMF). Кроме того, я представил типовой сценарий для запроса полной ширины столбцов из этой DMF и сравнения информации, которую можно получить из данного объекта, с информацией из родственного динамического административного представления (DMV): sys.dm_db_index_usage_stats. Во второй статье серии речь пойдет о том, как идентифицировать объекты, вызывающие больше всего проблем со временем ожидания блокировок (lock) и кратковременных блокировок (latch). Мы выясним, в каких случаях существует достаточно оснований, чтобы предпринять проверку на наличие конкуренции блокировок, и какие запросы следует выполнить, чтобы обнаружить основных виновников. В заключение я дам общие рекомендации по использованию собранной информации для устранения блокировок, мешающих организовать высокопроизводительную среду SQL Server.
Полностью основные сведения о функции sys.dm_db_index_operational_stats приведены в первой статье данной серии. Напоминание о том, как выполнять запрос к sys.dm_db_index_operational_stats и столбцам, вы можете найти в листинге 1.
Пользователям, незнакомым с параметрами шаблона в среде SQL Server Management Studio, программная конструкция может показаться странной. Тем, кто не представляет себе соответствующую концепцию параметров шаблона, рекомендуется познакомиться с первой статьей серии. Возможно, у вас нет времени читать длинную статью, поэтому приведу краткий вывод из нее: используйте комбинацию клавиш Ctl+Shift+M в среде SQL Server Management Studio (SSMS), чтобы подставить конкретные значения вместо заполнителей в синтаксисе вида <некоторый_параметр, описание, значение_по_умолчанию>.
Если оставить команду без изменений, она предоставит результаты, охватывающие все объекты (индексы и кучи) и все связанные индексы без учета ограничений до определенной секции. Конечно, таким образом вы получаете огромное количество информации, но ее ценность невелика из-за отсутствия контекста для результатов. Поэтому я всегда объединяю DMO индексации с другими системными представлениями, обеспечивающими контекст для результатов, а также фильтрацию возвращенных строк и столбцов, которые мне нужно увидеть. Системные представления для получения контекста следующие:
- sys.indexes — предоставляет информацию о ваших индексах SQL Server на уровне базы данных, охватывая имя, тип индекса (кластеризованный, некластеризованный), уникальность и т. д.
- sys.objects — можно использовать системную функцию OBJECT_NAME (object_id), чтобы возвратить имя таблицы или представления, связанного с object_id, выдаваемого sys.dm_db_index_operational_stats, но также необходимо фильтровать результаты, так как я заинтересован только в объектах пользователя, а не в системных таблицах и представлениях, используемых внутри SQL Server. Для этого требуется доступ к столбцу is_ms_shipped в sys.objects. При этом я могу возвратить имя объекта (имя столбца) и тип объекта (type_desc).
Таким образом мы получаем базовую структуру как в листинге 2.
Конечно, вы захотите сузить диапазон столбцов до sys.dm_db_index_operational_stats, а также предоставить некоторый уровень фильтрации путем использования предикатов поиска через предложение WHERE, но эта конструкция — хороший фундамент для дальнейшего роста. Дополнительные сведения о полном диапазоне столбцов в sys.dm_db_index_operational_stats и их предназначении можно найти в первой статье серии. А здесь мы рассмотрим sys.dm_db_index_operational_stats, блокировки и кратковременные блокировки.
Обзор блокировок и кратковременных блокировок
Один из самых важных выводов, которые можно сделать из sys.dm_db_index_operational_stats, касается того, какие объекты больше всего страдают от ожидания блокировок и кратковременных блокировок. Прежде чем продолжить рассказ о том, как идентифицировать причины снижения производительности, рассмотрим принципы действия блокировок и кратковременных блокировок в Microsoft SQL Server.
В реляционных базах данных блокировкам принадлежит огромная роль в обеспечении соответствия транзакций условиям атомарности, целостности данных, изолированности транзакций и надежности (ACID).
- Атомарность: транзакции должны завершить все действия или вернуться в исходное состояние.
- Целостность данных: поведение транзакций всегда единообразно.
- Изолированность транзакций: транзакции защищены от внешнего влияния до тех пор, пока они не будут завершены.
- Надежность: реляционная система управления базами данных ведет запись незафиксированных (то есть незавершенных) транзакций для восстановления в случае аварии.
Эти требования удовлетворяются с помощью сложных процессов блокировки, гарантирующих, что одновременные запросы от пользователей не взаимодействуют с результатами любых других запросов. Блокировки применяются к строкам и страницам, участвующим в открытых транзакциях, и снимаются после завершения или отмены этих транзакций. Блокировки также применяются к объектам, участвующим в изменениях схемы для этих объектов. Существует сложный набор правил и логики, определяющий поведение блокировок в Microsoft SQL Server, а также различные типы режимов блокировки, кратко описанные ниже.
- Общие Shared (S) блокировки: участвуют в операциях только для чтения, которые не изменяют данные.
- Блокировки изменения Update (U): используются в транзакциях UPDATE, чтобы предотвратить попытки нескольких транзакций обновить одну и ту же строку одновременно.
- Монопольные Exclusive (X) блокировки: ассоциируются с операциями, которые изменяют данные через запросы INSERT, UPDATE или DELETE, чтобы одна транзакция не пыталась изменить строку одновременно с другой транзакцией.
- Блокировки схемы Schema (Sch): назначаются, когда происходит изменение определения объекта, например если добавляется столбец к таблице.
- Блокировки намерения Intent (I): устанавливаются принудительно, чтобы определить «старшинство» блокировок. Блокировки намерения информируют внутренний механизм о том, что транзакция вводится в очередь, чтобы в конечном итоге применить следующую блокировку типа IS (коллективная блокировка намерения), IX (монопольная блокировка намерения) или SIX (коллективная, с монопольной блокировкой намерения).
- Блокировки массового обновления Bulk Update (BU): используются в определенных условиях, когда в ходе операции применяется массовое копирование и предоставляются указания блокировки.
- Блокировки диапазона ключа: вступают в действие, когда используется наиболее строгий уровень изоляции транзакций (сериализуемый). Этот тип блокировки защищает диапазон строк, а не единственную строку, участвующую в транзакции в качестве целевой.
Иногда поведение блокировки может меняться в зависимости от уровня изоляции, используемого для транзакции в Microsoft SQL Server. Уровень изоляции определяет степень, в которой транзакции изолированы друг от друга; например, какие типы блокировок мешают применять другие блокировки. Изоляция транзакций — гораздо более широкая тема, и не раскрывается здесь во всей полноте. Дополнительные сведения об уровнях изоляции в Microsoft SQL Server можно получить из официальной документации по адресу: http://msdn.microsoft.com/en-us/library/ms173763.aspx.
Кратковременные блокировки часто представляют как «блокировки SQL для памяти». В общем смысле это верно, но такое описание нельзя назвать точным. Кратковременные блокировки похожи на стандартные блокировки в том, что они обеспечивают управляемый доступ к строкам, страницам, представлениям и таблицам базы данных, наряду с другими объектами. Кратковременные блокировки, с другой стороны, предоставляют управляемый доступ к объектам, размещаемым в памяти SQL Server. Объекты, размещаемые в памяти, делятся на два класса: буферные объекты и небуферные объекты. В отличие от блокировок, кратковременные блокировки применяются и снимаются по мере необходимости и не сохраняются в ходе выполнения транзакции; несколько кратковременных блокировок могут оцениваться на одной странице.
Существуют различные режимы кратковременных блокировок.
- Кратковременная блокировка удаления Destroy (DT) применяется для удаления и исключения буфера из кэша.
- Монопольная кратковременная блокировка Exclusive (EX) обеспечивает монопольный доступ к записываемой странице. Не допускает других кратковременных блокировок на той же странице.
- Кратковременная блокировка сохранения Keep (KP) предназначена для целей, схожих с блокировкой намерения: учет порядка блокировок и размещение блокировки в буферном кэше при применении другой блокировки.
- Общая кратковременная блокировка Shared (SH) применяется, когда предоставляются права на чтение страницы.
- Кратковременная блокировка обновления Update (UP) аналогична, но не столь строга, как монопольная кратковременная блокировка, так как разрешает операции чтения страницы, но запрещает запись.
Кроме того, существуют две формы кратковременных блокировок: обычные и кратковременные блокировки ввода-вывода. В чистом виде кратковременная блокировка происходит, когда страница уже находится в памяти и требуется лишь применить новую или дополнительную кратковременную блокировку. Кратковременные блокировки ввода-вывода применяются, когда страница не существует в памяти и должна быть получена с диска и предоставлена в буферном кэше.
Ожидания SQL Server
В конечном итоге блокировки и кратковременные блокировки обеспечивают согласованность и упорядоченность в базе данных и объектах памяти, связанных с экземпляром SQL Server. Они являются регулировщиками трафика. Однако за поддерживаемый ими порядок приходится расплачиваться снижением производительности. В результате блокировок увеличивается время ответа для завершения транзакций. Огромное число факторов влияет на общую производительность базы данных: внутренние факторы (такие, как архитектура схемы, индексация, программный код хранимых процедур, структура запросов и уровень изоляции транзакций) и внешние (задержка сети, программный код приложения, аппаратные средства и т. д). Каждый раз, когда SQL Server приходится ожидать освобождения необходимого ресурса, чтобы выполнить запрос, сохраняются сведения о длительности ожидания, базовом ожидаемом ресурсе и объекте, на котором ожидалось освобождение ресурса. Эта информация называется статистикой ожидания SQL Server и может быть получена в динамических административных представлениях (DMV) sys.dm_os_wait_stats и sys.dm_os_waiting_tasks, а также sys.dm_exec_session_wait_stats (новшество SQL Server 2016). В каждом из этих DMV собрана разная информация об ожидании.
- dm_os_wait_stats: репозиторий для информации об ожидании, собранной после перезапуска службы SQL Server или ручного удаления статистики ожидания. Данные группируются по типу ожидания.
- dm_os_waiting_tasks: предоставляет информацию о задачах, в настоящее время ожидающих ресурсов. Данные группируются по типу ожидания.
- dm_exec_session_wait_stats: новейшее DMV для ожиданий. Статистика ожиданий накапливается в форме, аналогичной dm_os_wait_stats, но также добавляется идентификатор session_id в качестве уровня агрегирования, чтобы вы могли оценить типы ожидания, встречающиеся в каждом активном сеансе на экземпляре SQL.
В данной статье мы сосредоточимся на времени, когда запрос статистики ожидания (см. листинг 3) может принести самые полезные результаты с последующим запросом к dm_db_index_operational_stats (см. экран 1). Более подробно о статистике ожидания будет рассказано в следующей статье. Упомянутый выше запрос описан в статье «Полный запрос статистики ожидания SQL 2005-2016» (опубликованной в Windows IT Pro/RE № 2 за 2016 год).
 |
| Экран 1. Результаты запроса статистики ожидания |
Существует три вида ожиданий, связанных с блокировками и кратковременными блокировками: ожидания блокировок с префиксом «LCK_», ожидания блокировок ввода-вывода с префиксом «PAGEIOLATCH_» и ожидания кратковременных блокировок с префиксом «PAGELATCH_». Ожидания блокировок и кратковременных блокировок содержат тип блокировки в имени типа блокировки.
В случае с экземпляром SQL Server мы обнаруживаем высокий уровень ожиданий, связанных с блокировками и кратковременными блокировками, что можно наблюдать на примере показанных выше выделенных результатов. Однако это лишь часть картины. Она позволяет точнее выявить проблемы производительности, возникающие из-за блокировок и кратковременных блокировок, но не дает сведений об их источнике. Сделать это поможет sys.dm_db_index_operational_stats.
Учет блокировок и кратковременных блокировок в DMF статистики работы индекса
Мы рассмотрим следующие столбцы dm_db_index_operational_stats, связанные с блокировками и кратковременными блокировками в Microsoft SQL Server:
- row_lock_count;
- row_lock_wait_count;
- row_lock_wait_in_ms;
- page_lock_count;
- page_lock_wait_count;
- page_lock_wait_in_ms;
- index_lock_promotion_attempt_count;
- index_lock_promotion_count;
- page_latch_wait_count;
- page_latch_wait_in_ms;
- page_io_latch_wait_count;
- page_io_latch_wait_in_ms.
Выявление индексов, связанных с длительными ожиданиями блокировок и кратковременных блокировок, происходит по простому протоколу.
- Если выяснилось, что ожидания блокировок и кратковременных блокировок — одни из самых длительных по средней величине, то перейти к диагностике баз данных, участвующих в блокировках.
- Перейти к деталям объектов и индексов, участвующих в наиболее часто применяемых блокировках.
Шаг 1. Определение баз данных, участвующих в ожиданиях блокировок и кратковременных блокировок
Запрос в листинге 4 изолирует базы данных, объекты и индексы, с которыми связано больше всего блокировок. В этом примере встречаются в основном ожидания краткосрочных блокировок, поэтому мы используем краткосрочную блокировку ввода-вывода из трех приведенных ниже вариантов (в зависимости от самого большого типа ожидания для первоначального запроса статистики ожиданий).
Обратите внимание, что если вы заинтересованы в деталях только определенных столбцов, связанных с нужными ожиданиями, можно сократить список столбцов (см. листинг 5).
Использование последнего из трех запросов показывает, что я сосредоточился на идентификации объектов и индексов, задействованных в первом наборе столбцов, а также метрики для всех столбцов блокировок и кратковременных блокировок. Я хочу убедиться, что результаты ограничены исключительно строками с нужными блокировками, а затем, поскольку наиболее распространенным типом ожидания являются ожидания кратковременных блокировок, выполняется сортировка в порядке убывания по времени кратковременной блокировки. Полученные результаты показаны на экране 2.
|
|
| Экран 2. Получение метрик для всех столбцов блокировок и кратковременных блокировок |
Меня могут спросить, почему я выполняю первоначальное обнаружение просто для сужения результатов до базы данных. Это сделано потому, что для идентификации участвующих основных индексов я должен иметь возможность присоединить dm_db_index_operational_stats к sys.indexes. dm_db_index_operational_stats — значение уровня сервера, поэтому результаты пересекают границы баз данных; независимо от того, на какой базе данных выполняется запрос к DMF, результаты получаются одинаковые. Но того же нельзя сказать о запросах к sys.indexes. Это системное представление, уникальное для каждой базы данных. Возвращаются только результаты для индексов в базе данных, из которой вызвано представление. Чтобы объединить dm_db_index_operational_stats и sys.indexes, необходимо полностью определить sys.indexes с именем базы данных. И index_id, и object_id объединяют столбцы между этими объектами и не уникальны во всех базах данных. Это означает, что необходимо сначала идентифицировать базу данных, чтобы перейти к шагу 2, на котором мы получаем подробные сведения об индексе благодаря знанию имени базы данных.
Шаг 2. Обнаружение сведений об индексе для решения проблем блокировок и кратковременных блокировок
В зависимости от типа ожидания блокировок и кратковременных блокировок мы запускаем приведенный в листинге 6 запрос с одним из трех вариантов сортировки, чтобы получить дополнительные сведения об индексах (см. экран 3). Продолжим рассмотрение кратковременных блокировок — в частности, кратковременных блокировок ввода-вывода, с учетом того, что будем использовать любые другие диагностические запросы, относящиеся к ожиданиям блокировок или кратковременных блокировок, в зависимости от наиболее распространенного типа ожидания при анализе состояний ожидания для настройки производительности.
|
|
| Экран 3. Дополнительные сведения об индексах |
На данном этапе мы выяснили, что индекс lifeboat..Database_Files_History.PK_Database_Files_History_1 виновен в значительной доле ожиданий кратковременных блокировок ввода-вывода. Теперь необходима точная диагностика на уровне индекса. С помощью dm_db_index_operational_stats, благодаря применению ожиданий как инструмента настройки производительности, мы прошли путь от понимания, что ожидания кратковременной блокировки ввода-вывода являются главной проблемой, до выяснения, какие именно объекты порождают ее.
Выявление основных типов ожиданий — только часть задачи. Определение объектов, вносящих вклад в эти ожидания, с последующей целевой настройкой этих объектов — следующий, решающий шаг процесса настройки производительности. Благодаря информации, получаемой от dm_db_index_operational_stats, мы можем без труда определить вызывающие затруднения таблицы и индексы.
Листинг 1. запрос к sys.dm_db_index_operational_stats и столбцам
SELECT * FROM sys.dm_db_index_operational_stats ( DB_ID(), , , );
Листинг 2. Базовая структура запроса
SELECT O.name AS [object_name] , O.type_desc AS object_type , I.name AS index_name , I.type_desc AS index_type , ixO.* FROM sys.dm_db_index_operational_stats ( DB_ID(), , , ) AS ixO INNER JOIN sys.indexes I ON ixO.object_id = I.object_id AND ixO.index_id = I.index_id INNER JOIN sys.objects AS O ON O.object_id = ixO.object_id WHERE O.is_ms_shipped = 0;
Листинг 3. Запрос статистики ожидания
SET NOCOUNT ON;
IF OBJECT_ID('tempdb..#dm_os_wait_stats','U') IS NOT NULL
DROP TABLE #dm_os_wait_stats;
GO
SELECT wait_type
, (wait_time_ms - signal_wait_time_ms) / 1000. AS wait_time_s
, waiting_tasks_count
, CASE waiting_tasks_count
WHEN 0 THEN 0
ELSE (wait_time_ms - signal_wait_time_ms) / waiting_tasks_count
END AS avg_wait_ms
, 100. * (wait_time_ms - signal_wait_time_ms) / SUM
(wait_time_ms - signal_wait_time_ms) OVER ( ) AS pct
, ROW_NUMBER() OVER ( ORDER BY wait_time_ms DESC ) AS rn
INTO #dm_os_wait_stats
FROM sys.dm_os_wait_stats
WHERE wait_type NOT IN
(
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP',
N'BROKER_TO_FLUSH', N'BROKER_TRANSMITTER',
N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT',
N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE',
N'DBMIRRORING_CMD', N'DIRTY_PAGE_POLL',
N'DISPATCHER_QUEUE_SEMAPHORE',
N’EXECSYNC’, N’FSAGENT’, N’FT_IFTS_SCHEDULER_IDLE_WAIT’,
N’FT_IFTSHC_MUTEX’,
N’HADR_CLUSAPI_CALL’, N’HADR_FILESTREAM_IOMGR_
IOCOMPLETION’, N’HADR_LOGCAPTURE_WAIT’,
N’HADR_NOTIFICATION_DEQUEUE’, N’HADR_TIMER_TASK’,
N’HADR_WORK_QUEUE’,
N’KSOURCE_WAKEUP’, N’LAZYWRITER_SLEEP’,
N’LOGMGR_QUEUE’,
N’MEMORY_ALLOCATION_EXT’, N’ONDEMAND_TASK_QUEUE’,
N’PREEMPTIVE_OS_LIBRARYOPS’, N’PREEMPTIVE_OS_COMOPS’,
N’PREEMPTIVE_OS_CRYPTOPS’,
N’PREEMPTIVE_OS_PIPEOPS’, N’PREEMPTIVE_OS_
AUTHENTICATIONOPS’,
N’PREEMPTIVE_OS_GENERICOPS’, N’PREEMPTIVE_OS_
VERIFYTRUST’,
N’PREEMPTIVE_OS_FILEOPS’, N’PREEMPTIVE_OS_DEVICEOPS’,
N’PWAIT_ALL_COMPONENTS_INITIALIZED’, N’QDS_PERSIST_
TASK_MAIN_LOOP_SLEEP’,
N’QDS_ASYNC_QUEUE’,
N’QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP’,
N’REQUEST_FOR_DEADLOCK_SEARCH’,
N’RESOURCE_QUEUE’, N’SERVER_IDLE_CHECK’,
N’SLEEP_BPOOL_FLUSH’, N’SLEEP_DBSTARTUP’,
N’SLEEP_DCOMSTARTUP’, N’SLEEP_MASTERDBREADY’,
N’SLEEP_MASTERMDREADY’,
N’SLEEP_MASTERUPGRADED’, N’SLEEP_MSDBSTARTUP’,
N’SLEEP_SYSTEMTASK’, N’SLEEP_TASK’,
N’SLEEP_TEMPDBSTARTUP’, N’SNI_HTTP_ACCEPT’,
N’SP_SERVER_DIAGNOSTICS_SLEEP’,
N’SQLTRACE_BUFFER_FLUSH’, N’SQLTRACE_INCREMENTAL_
FLUSH_SLEEP’, N’SQLTRACE_WAIT_ENTRIES’,
N’WAIT_FOR_RESULTS’, N’WAITFOR’,
N’WAITFOR_TASKSHUTDOWN’, N’WAIT_XTP_HOST_WAIT’,
N’WAIT_XTP_OFFLINE_CKPT_NEW_LOG’,
N’WAIT_XTP_CKPT_CLOSE’, N’XE_DISPATCHER_JOIN’,
N’XE_DISPATCHER_WAIT’, N’XE_LIVE_TARGET_TVF’,
N’XE_TIMER_EVENT’,
N’PREEMPTIVE_SP_SERVER_DIAGNOSTICS’,
N’PREEMPTIVE_HADR_LEASE_MECHANISM’, N’TRACEWRITE’,
N’PREEMPTIVE_OS_WRITEFILEGATHER’,
N’PREEMPTIVE_OS_LOOKUPACCOUNTSID’, N’CXPACKET’);
WITH Waits AS
(
SELECT wait_type
, wait_time_s
, waiting_tasks_count
, avg_wait_ms
, pct
, rn
FROM #dm_os_wait_stats
)
SELECT W1.wait_type
, CAST(W1.wait_time_s AS DECIMAL(12, 1)) AS wait_time_s
, W1.waiting_tasks_count
, CAST(W1.avg_wait_ms AS DECIMAL(12, 1)) AS avg_wait_ms
, CAST(W1.pct AS DECIMAL(12, 1)) AS pct
, CAST(SUM(W2.pct) AS DECIMAL(12, 1)) AS running_pct
FROM Waits AS W1
INNER JOIN Waits AS W2
ON W2.rn <= W1.rn
GROUP BY W1.rn
, W1.wait_type
, W1.waiting_tasks_count
, W1.avg_wait_ms
, W1.wait_time_s
, W1.pct
HAVING SUM(W2.pct) - W1.pct < 95 /* процентный порог */
ORDER BY W1.pct DESC;
IF OBJECT_ID('tempdb..#dm_os_wait_stats','U') IS NOT NULL
DROP TABLE #dm_os_wait_stats;
GO
SET NOCOUNT OFF;
Листинг 4. Выбор объектов с наибольшим числом блокировок
SELECT TOP 10 DB_NAME(database_id) AS database_name , OBJECT_NAME(object_id, database_id) AS table_name , index_id , partition_number , row_lock_count , row_lock_wait_in_ms , CASE row_lock_wait_count WHEN 0 THEN row_lock_wait_in_ms ELSE row_lock_wait_in_ms / row_lock_wait_count END AS avg_row_lock_wait_in_ms , page_lock_count , page_lock_wait_in_ms , CASE page_lock_count WHEN 0 THEN page_lock_wait_in_ms ELSE page_lock_wait_in_ms / page_lock_count END AS avg_page_lock_wait_in_ms , page_latch_wait_count , page_latch_wait_in_ms , CASE page_latch_wait_count WHEN 0 THEN page_latch_wait_in_ms ELSE page_latch_wait_in_ms / page_latch_wait_count END AS avg_page_latch_wait_in_ms , page_io_latch_wait_count , page_io_latch_wait_in_ms , CASE page_io_latch_wait_count WHEN 0 THEN page_io_latch_wait_in_ms ELSE page_io_latch_wait_in_ms / page_io_latch_wait_count END AS avg_page_io_latch_wait_in_ms FROM sys.dm_db_index_operational_stats(NULL, NULL, NULL, NULL) WHERE row_lock_wait_in_ms > 0 OR page_lock_wait_in_ms > 0 OR page_latch_wait_in_ms > 0 OR page_io_latch_wait_in_ms > 0 AND database_id > 4 ORDER BY page_io_latch_wait_in_ms DESC; /* ИЛИ ВЫПОЛНИТЕ СОРТИРОВКУ ПО ОДНОМУ ИЗ СЛЕДУЮЩИХ КРИТЕРИЕВ: page_latch_wait_in_ms DESC -- когда PAGELATCH_% самое большое ожидание (row_lock_wait_in_ms + page_lock_wait_in_ms) DESC -- когда тип ожидания блокировки представляет самое большое ожидание */
Листинг 5. Укороченный запрос столбцов с блокировками
---LOCKING SELECT TOP 3 DB_NAME(database_id) AS database_name , OBJECT_NAME(object_id, database_id) AS table_name , index_id , partition_number , row_lock_count , row_lock_wait_in_ms , CASE row_lock_wait_count WHEN 0 THEN row_lock_wait_in_ms ELSE row_lock_wait_in_ms / row_lock_wait_count END AS avg_row_lock_wait_in_ms , page_lock_count , page_lock_wait_in_ms , CASE page_lock_count WHEN 0 THEN page_lock_wait_in_ms ELSE page_lock_wait_in_ms / page_lock_count END AS avg_page_lock_wait_in_ms FROM sys.dm_db_index_operational_stats(NULL, NULL, NULL, NULL) ORDER BY (row_lock_wait_in_ms + page_lock_wait_in_ms) DESC; --PAGELATCH SELECT TOP 3 DB_NAME(database_id) AS database_name , OBJECT_NAME(object_id, database_id) AS table_name , index_id , partition_number , page_latch_wait_count , page_latch_wait_in_ms , CASE page_latch_wait_count WHEN 0 THEN page_latch_wait_in_ms ELSE page_latch_wait_in_ms / page_latch_wait_count END AS avg_page_latch_wait_in_ms FROM sys.dm_db_index_operational_stats(NULL, NULL, NULL, NULL) ORDER BY page_latch_wait_in_ms DESC; --PAGEIOLATCH SELECT TOP 3 DB_NAME(database_id) AS database_name , OBJECT_NAME(object_id, database_id) AS table_name , index_id , partition_number , page_io_latch_wait_count , page_io_latch_wait_in_ms , CASE page_io_latch_wait_count WHEN 0 THEN page_io_latch_wait_in_ms ELSE page_io_latch_wait_in_ms / page_io_latch_wait_count END AS avg_page_io_latch_wait_in_ms FROM sys.dm_db_index_operational_stats(NULL, NULL, NULL, NULL) ORDER BY page_io_latch_wait_in_ms DESC;
Листинг 6. Дальнейшее уточнение имен объектов
--ДАЛЬНЕЙШЕЕ УТОЧНЕНИЕ ИМЕН ОБЪЕКТОВ SELECT TOP 4 DB_NAME(ixOS.database_id) AS database_name , OBJECT_NAME(ixOS.object_id, ixOS.database_id) AS table_name , I.name AS index_name , I.type_desc AS index_type , ixOS.partition_number , ixOS.page_io_latch_wait_count , ixOS.page_io_latch_wait_in_ms , CASE ixOS.page_io_latch_wait_count WHEN 0 THEN ixOS.page_io_latch_wait_in_ms ELSE ixOS.page_io_latch_wait_in_ms / ixOS.page_io_latch_wait_count END AS avg_page_io_latch_wait_in_ms FROM sys.dm_db_index_operational_stats(NULL, NULL, NULL, NULL) AS ixOS INNER JOIN lifeboat.sys.indexes AS I ON I.index_id = ixOS.index_id AND I.object_id = ixOS.object_id ORDER BY ixOS.page_io_latch_wait_in_ms DESC; /* ИЛИ ВЫПОЛНИТЕ СОРТИРОВКУ ПО ОДНОМУ ИЗ СЛЕДУЮЩИХ КРИТЕРИЕВ: page_latch_wait_in_ms DESC -- когда PAGELATCH_% самое большое ожидание (row_lock_wait_in_ms + page_lock_wait_in_ms) DESC -- когда тип ожидания блокировки представляет самое большое ожидание */
Время блокирования эвакуации людей при пожаре
Расчет времени блокирования путей эвакуации по полевой математической модели расчета газообмена в здании при пожаре
Фогард-НВ (полевая модель) для расчётов времени блокирования путей эвакуации при пожаре разработано совместно с Объединённым институтом высоких температур Российской Академии наук (ОИВТ РАН).
-
Для использования Программного комплекса ФОГАРД рекомендуется:
Расчет времени блокирования путей эвакуации по математической двухзонной модели пожара в здании.
Расчет времени блокирования путей эвакуации по интегральной математической модели расчета газообмена в здании, при пожаре.
Определение необходимого времени эвакуации людей при пожаре из помещений высотой не более 6 м.

С чего начать работу в программном комплексе Фогард? Четыре шага!

По каждой программе представлены видеоролики

Для расширения понимания расчета рисков,
использования программ, обмена опытом рекомендуем
ознакомиться со статьями.
Как снизить время блокировок с помощью кластеризации причин блокировок
3 шага, чтобы определить причины блокировок, систематизировать их и уменьшить время простоев в рабочем процессе

7 апр. 2023 г.
• 4 min read

Заблокированная задача — это задача, над которой сейчас невозможно работать. Нередко они тормозят весь рабочий процесс. Такие задачи выделяются на канбан-доске и остаются на своем месте до момента снятия блокировки. Блокировки могут быть как единичным, так и системным явлением в рабочем процессе. Чтобы найти их причины и снизить время нахождения задач в блоке, можно воспользоваться методом кластеризации блокировок.
Этот метод позволит вам найти самые частые причины блокировок, приоритизировать их и заниматься решением их первопричин, что позволит уменьшить время пребывания задач в блоке.
Шаг 1. Выделить заблокированные задачи и рассортировать их
Начиная кластеризацию причин блокировок, первым делом распределите заблокированные карточки по двум большим группам:
- внутренние факторы — трудности внутри команды;
- внешние факторы — независящие от команды трудности.
После этого сформулируйте кластеры причин блокировок и рассортируйте карточки по ним. Например, поводом для приостановки работы над задачей могут стать отсутствие фидбэка, ожидание тестирования, неправильно поставленное техзадание и т.д. Определите с командой список причин, по которым будут блокироваться задачи.
В Kaiten задачу можно заблокировать, если открыть карточку и выбрать соответствующую опцию. В развернувшейся строке напишите причину, по которой карточка была заблокирована. Чтобы сразу распределять задачи по кластерам, вписывайте в строку причины, которые были сформулированы вместе с командой.
Помимо этого, в Kaiten можно добавлять карточку-блокер — это задача, из-за которой блокируется выбранная карточка.
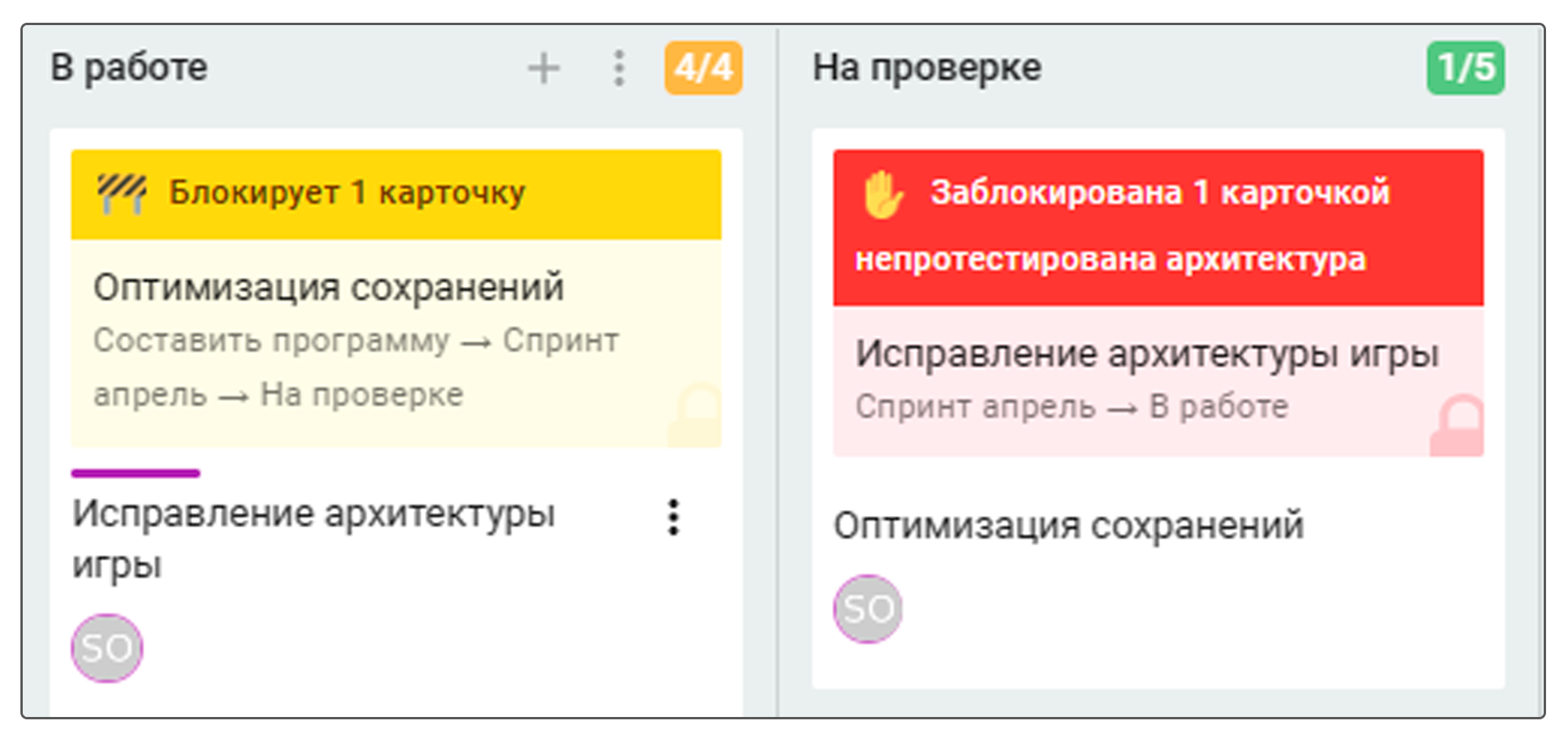
Шаг 2. Определить, какие блокировки отнимают у команды больше времени
После сортировки задач по группам причин блокировок выясните, на какие задачи команда тратит больше всего усилий. Для этого посчитайте время, которое уходит на заблокированные по разным причинам задачи.
Например, на задачи в кластере «отсутствие фидбэка» уходит 8 дней за выбранный промежуток времени, а блокеры с пометкой «ожидание тестирования» возвращаются в работу быстрее, и на них тратят в среднем 1 день.
В Кайтене есть специальный отчет по заблокированным карточкам — Время разрешения блокировок (Block resolution time). На графике видно, сколько времени карточки находились в блоке, и указана причина. Если задача блокировалась по двум разным причинам, она будет выделена двумя цветами.
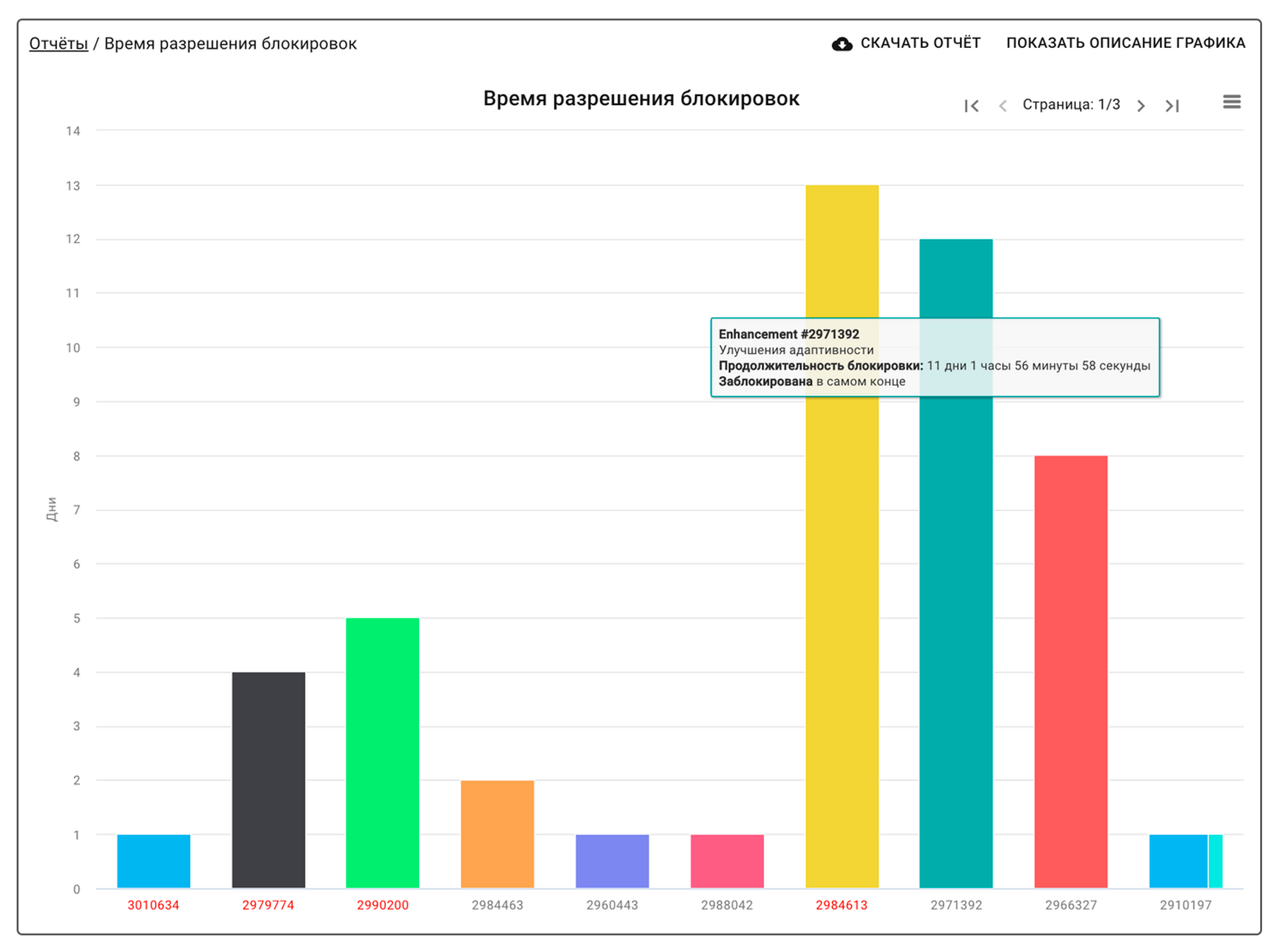
На графике можно увидеть, как долго и по какой причине были заблокированы карточки, после чего переходить к следующему шагу.
Шаг 3. Приоритизировать блокировки и выяснить их причину
Чтобы не оттягивать силы и внимание участников команды с актуальных задач по проекту, займитесь решением проблем блокировок постепенно. В первую очередь обратите внимание на те группы блокировок, которые больше остальных тормозят рабочий процесс.
После того как вы выбрали кластер, с которым предстоит работать, осталось выяснить причину возникновения кластеров блокировок. Чтобы добраться до корневой причины блокировки, воспользуйтесь методом «5 почему»: спросите «почему?» пять раз, уточняя причину с каждым новым вопросом.
Например. Кластер блокеров звучит так: «неверно поставленное техническое задание».
- Почему техзадание неверно поставлено? Потому что результат не соответствовал ожиданиям.
- Почему так? Потому что при составлении заданий были допущены ошибки.
- Почему? Потому что техзадания не были проверены владельцем продукта и заинтересованными лицами.
- Почему? Потому что владелец продукта и заинтересованные лица посчитали, что техзадания могут быть составлены по аналогии с техзаданиями предыдущего проекта и им не нужна дополнительная проверка.
- Почему? Потому что владельцем продукта и заинтересованными лицами не были учтены критичные отличия между двумя проектами.
Благодаря ответу в пятом пункте можно сделать вывод, что корневой причиной этого кластера стала попытка скопировать методы работы из предыдущего проекта чтобы ускорить прогресс текущего.
Выяснить причину возникновения группы блокеров гораздо полезнее, чем разбираться со всеми заблокированными задачами по отдельности. Если устранить первопричину, доработка таких задач больше не будет отнимать так много времени.
Каким будет результат
Вместо вороха заблокированных по разным причинам задач перед командой будет система, благодаря которой все участники смогут увидеть самые частые проблемы в проекте.
Кластеризация поможет упорядочить трудности и работать с каждой из них системно, а не с отдельными задачами. В итоге команда или устранит причину блокировки, или начнет справляться с ней быстрее. Что, в свою очередь, приведет к уменьшению времени нахождения задач в блоке и увеличению производительности.
Общее время блокировки (TBT) — это один из показателей, отслеживаемых в разделе Performance отчета Lighthouse. Каждый показатель отражает определенный аспект скорости загрузки страницы.
В отчете Lighthouse TBT отображается в миллисекундах:

Что такое TBT
TBT — это общее время, в течение которого страница не может отвечать на пользовательский ввод, такой как щелчки мыши, касания экрана или нажатия на клавиатуру. Сумма рассчитывается путем сложения блокирующей части всех длительных задач в промежутке между первой отрисовкой контента (FCP) и временем до интерактивности (TTI). Длительной задачей считается любая задача, которая выполняется более 50 мс. Время свыше 50 мс считается блокирующей частью. Например, если Lighthouse обнаруживает задачу длительностью в 70 мс, блокирующая часть будет составлять 20 мс.
Как Lighthouse рассчитывает оценку вашего TBT
Оценка TBT рассчитывается путем сравнения времени TBT при загрузке вашей страницы на мобильных устройствах с временем TBT миллионов реальных сайтов. О том, как определяются пороговые значения оценок Lighthouse, см. в статье Как определяются оценки показателей.
В этой таблице показано, как интерпретировать оценку TBT:
Как улучшить оценку TBT
Чтобы узнать, как при помощи панели «Производительность» в Chrome DevTools диагностировать основную причину появления длительных задач, см. статью В чем причина появления длительных задач?.
Вот наиболее распространенные причины появления длительных задач:
- Загрузка, обработка или выполнение ненужного JavaScript-кода. В ходе анализа кода при помощи панели «Производительность» может выясниться, что основной поток выполняет работу, которая на самом деле не требуется для загрузки страницы. Улучшить оценку TBT можно посредством сокращения полезной нагрузки JavaScript с помощью разделения кода, удаления неиспользуемого кода или эффективной загрузки стороннего JavaScript.
- Неэффективные JavaScript-инструкции. Например, предположим, что в ходе анализа кода при помощи панели «Производительность» вы обнаружили вызов
document.querySelectorAll('a'), возвращающий 2000 узлов. Чтобы улучшить оценку TBT, можно перестроить код, заменив селектор на более избирательный, возвращающий только 10 узлов.
На большинстве сайтов устранение загрузки, обработки или выполнения ненужного JavaScript-кода обычно позволяет добиться гораздо более серьезных улучшений.
How to improve your overall Performance score
Unless you have a specific reason for focusing on a particular metric, it’s usually better to focus on improving your overall Performance score.
Use the Opportunities section of your Lighthouse report to determine which improvements will have the most value for your page. The more significant the opportunity, the greater the effect it will have on your Performance score. For example, the Lighthouse screenshot below shows that eliminating render-blocking resources will yield the biggest improvement:

See the Performance audits landing page to learn how to address the opportunities identified in your Lighthouse report.
Ресурсы
- Исходный код проверки Total Blocking Time (общее время блокировки)
- Увеличено ли у вас время до интерактивности (TTI) из-за длительных JavaScript-задач?
- Оптимизация времени ожидания до первого взаимодействия с контентом (FID)
- Первая отрисовка контента (FCP)
- Время до интерактивности (TTI)
- Сокращение размера полезной нагрузки JavaScript за счет разделения кода
- Удаление неиспользуемого кода
- Эффективная загрузка сторонних ресурсов
Updated on пятница, 4 июня 2021 г. • Improve article