Секреты поиска. Как найти нужный документ .
 Всем привет, это следующий урок о том, как правильно искать информацию в сети с помощью Google. Есть одна хитрость, которая, впрочем как всегда, никаким секретом не является. Мало кто из нас задумывается, но логически это понимают все – интернет это далеко не только веб-страницы ресурсов. Это видео, фото и аудио файлы, это документы различных форматов и многое другое. Даже не всегда на том или ином ресурсе в силу каких-то обстоятельств (в том числе и по недосмотру владельца файла) мы имеем доступ к нему по прямой ссылке для скачивания. Но в сети они есть и Google их прекрасно видит. Файлы проиндексированы поисковой системой, а значит, они доступны и для нас. Так что найти нужный документ бывает проще, чем каждый из нас думает. Давайте найдём их.
Всем привет, это следующий урок о том, как правильно искать информацию в сети с помощью Google. Есть одна хитрость, которая, впрочем как всегда, никаким секретом не является. Мало кто из нас задумывается, но логически это понимают все – интернет это далеко не только веб-страницы ресурсов. Это видео, фото и аудио файлы, это документы различных форматов и многое другое. Даже не всегда на том или ином ресурсе в силу каких-то обстоятельств (в том числе и по недосмотру владельца файла) мы имеем доступ к нему по прямой ссылке для скачивания. Но в сети они есть и Google их прекрасно видит. Файлы проиндексированы поисковой системой, а значит, они доступны и для нас. Так что найти нужный документ бывает проще, чем каждый из нас думает. Давайте найдём их.
Перед тем, как перейти конкретно к поиску, стоит упомянуть о специальном сервисе Google, о котором, оказывается, мало кто знает. Это страница расширенного поиска:
https://www.google.com/advanced_search?hl=ru
Я нарочно оставлю это без комментариев, там всё по-русски. Изучайте и пользуйтесь. Это, скажем, страница продвинутого поиска без знания операторов Google.
У каждого из файлов есть своё расширение, которое определяет тип программы, с помощью которой ему положено открываться. По умолчанию тип сокрыт от глаз пользователя. Но не для Google. Даже не зная названия документа полностью, вы сможете (теоретически) попытаться найти нужный документ, зная, что он имеет вид, например, документа Word из набора Microsoft Office. Вобщем, Google понимает вот такие расширения:
Adobe Portable Document Format (PDF)
Adobe PostScript (PS)
MacWrite (MW)
Microsoft Excel (XLS)
Microsoft PowerPoint (PPT)
Microsoft Word (DOC)
Microsoft Works (WDB, WKS, WPS)
Microsoft Write (WRI)
Rich Text Format (RTF)
Text (ANS, TXT)
И некоторые другие, более специфичные. Если вы собираетесь найти нужный документ , например, обязательно в формате Word с расширением .docx, то можно попробовать задать этот параметр (без точки перед расширением) уже в поисковой строке. Это должно выглядеть так:
Название_документафайлафильмапесни filetype:тип_файла
Например:
Договор купли-продажи кактуса filetype:docx
По аналогии с известным вам исключением ненужной информации из поисковой выдачи, можно, наоборот, исключить из неё ненужные расширения и работать только с определёнными их типами. Используем, тем самым, оператор исключения «-». Например:
Договор купли-продажи кактуса -filetype:docx
Всё. В поисковой выдаче страниц с договором в формате Word не будет. Будут PDF, TXT, но не Word.
Как найти нужный документ на конкретном сайте или домене.
Нередко перед некоторыми пользователями ставится задача найти нужный документ или просто посмотреть некоторую информацию только на ресурсах, имеющих более высокую степень доверия по сравнению с остальными. Например, домены .com, .edu, .org принадлежат правительственным или образовательным учреждениям, которые имеют больший информационный вес. Или нам необходимо узнать информацию или новость из первоисточника. А про обрушение котировок на английской бирже лучше узнать не из израильского сайта, не так ли? Потому лучше было зондировать именно английские источники информации – это доменная зона британцев .uk. Или канадцев — .ca. Или французов – fr. И так далее.
Так вот, чтобы заняться поиском только по конкретной доменной зоне, укажите тип домена в поисковом запросе с помощью оператора “site:”. Например:
site:.edu (не забудьте точку перед названием домена)
И при наборе информации в определённой зоне:
Do it yourself.:ru
Google будет искать результаты только в русскоязычном интернете (рунете).
По аналогии с доменной зоной можно сократить место поиска до конкретного веб-сайта. Например, если нужно прочитать справку о том или ином событий в операционной системе Windows, есть смысл обратиться к первоисточнику. Ищите в пределах только официальной справки от Microsoft на официальном сайте. Для этого используйте тот же самый оператор в таком виде:
Ошибка 000240767 site:www.microsoft.com (точку перед адресом ставить нельзя!)
Все найденные результаты будут касаться только этого сайта.
Успехов
В общем случае такую информацию узнать нельзя, т.к. обычно выставлена защита на сайтах от перечисления папок и получения списка файлов. Только если включена возможность перечисления папок, что бывает редко, тогда можно набрать имя папки в браузере, например mysite.org/folder_name/, и возможно оно выдаст список файлов. Если список получать нельзя у папки, можно только перебирать возможные папки и имена и пытатьтся скачивать их.
Также можно попробовать поискать в гугле через «site:SITENAME filetype:txt» (например найти все TXT на archive.org), он вернёт список всех индексированных TXT файлов на заданном сайте, конечно если на них какая-то страница сайта где-то ссылалась, если ссылок на файлы нигде нет на страницах то и гугл не найдёт.

Эксперт + Директолог + Интернет маркетолог
179
27 подписчиков
Спросить
24 октября 2014
Как быстро найти и скачать любые документы и файлы в интернете
Что делать, если вам нужно быстро найти определенный тип файла в интернете и желательно скачать его без регистрации? К примеру, вам понадобилось для написания реферата или диплома найти таблицу с данными в формате Excel или книгу в текстовом формате TXT, или презентацию PowerPoint, или, например, музыканту срочно нужен MIDI-файл.

Значительно сократить время поиска документов и файлов вплоть до нескольких минут и даже секунд помогут некоторые полезные сервисы:
- Расширенный поиск Яндекса. Далеко не все в курсе, что у поисковых машин существует расширенные версии поиска. У Яндекса этот сервис располагается на этой странице: http://yandex.ru/search/advanced. Здесь, введя требуемый запрос, вы можете уточнить детали этого запроса. Например, язык документа, дату публикации, ну и, конечно же, необходимый вам формат. После нажатия на кнопку «Найти», поисковик выдаст вам список ссылок на документы требуемого формата. Вам остается только нажать на кнопку «Загрузить», и произойдет скачивание документа непосредственно с сервера, на котором документ или файл находится без всяких регистраций. Или можно вначале почитать содержимое документа без закачки, нажав на кнопку «Просмотреть», чтобы не перегружать компьютер ненужными файлами.
- Расширенный поиск Google. Google также предоставляет возможность найти файлы нужного формата. Вот страница, где это можно сделать: http://www.google.ru/advanced_search. В отличие от Яндекса, Google дает возможность осуществлять поиск по таким экзотическим форматам, как: Adobe PostScript (.ps), Autodesk DWF (.dwf), Shockwave Flash (.swf). На самом деле список форматов, по которым Google осуществляет поиск, намного шире. Если вы в конце поисковой фразы добавите так называемый оператор запроса filetype: и добавите за ним необходимый вам формат файла, то вы сможете без труда найти искомый файл. Например, если вам нужно найти MIDI-файл композитора Баха, то вы можете набрать Bach filetype:mid и вполне вероятно, что вы отыщете то, что вам было нужно.
- Еще один полезный сервис находится по этому адресу: http://wte.su/poisk.html. Это сервис поиска по документам различных форматов, в том числе и TXT, FB2, ODT, и даже RAR и ZIP. После ввода вашего запроса, вы можете быстро перемещаться по вкладкам, осуществляя поиск по конкретному типу файла. У сервиса 2 существенных преимущества — простота и скорость поиска. Единственный недочет — ссылки не всегда ведут на конечный файл. Там, где есть прямая ссылка на файл, вы увидите кнопку «Скачать».
- Также для поиска файлов можно воспользоваться сервисом поиска по FTP-серверам http://filemare.com/. Ведь иногда файлы выгружают на FTP-серверы с открытым доступом к внутренним папкам, а вот поисковые машины часто их не находят. После того как вы введете ваш запрос в строку поиска данного сервиса, вы увидите список найденных в интернете файлов и папок, которые содержат в своем имени или в пути к себе текст, введенный вами в поисковом запросе.
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Десктопные/облачные, платные/бесплатные, для SEO, для совместных покупок, для наполнения сайтов, для сбора цен… В обилии парсеров можно утонуть.
Мы разложили все по полочкам и собрали самые толковые инструменты парсинга — чтобы вы могли быстро и просто собрать открытую информацию с любого сайта.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
- Цены. Актуальная задача для интернет-магазинов. Например, с помощью парсинга вы можете регулярно отслеживать цены конкурентов по тем товарам, которые продаются у вас. Или актуализировать цены на своем сайте в соответствии с ценами поставщика (если у него есть свой сайт).
- Товарные позиции: названия, артикулы, описания, характеристики и фото. Например, если у вашего поставщика есть сайт с каталогом, но нет выгрузки для вашего магазина, вы можете спарсить все нужные позиции, а не добавлять их вручную. Это экономит время.
- Метаданные: SEO-специалисты могут парсить содержимое тегов title, description и другие метаданные.
- Анализ сайта. Так можно быстро находить страницы с ошибкой 404, редиректы, неработающие ссылки и т. д.
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Но если вы хотите собрать персональные данные пользователей и использовать их для email-рассылок или таргетированной рекламы, это уже будет незаконно (эти данные защищены законом о персональных данных).
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
- Import.io,
- Mozenda (доступна также десктопная версия парсера),
- Octoparce,
- ParseHub.
Из русскоязычных облачных парсеров можно привести такие:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
- Parsers;
- Scraper;
- Data Scraper;
- Kimono.
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Эти формулы: IMPORTXML и IMPORTHTML.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
IMPORTXML("https://site.com/catalog"; "//a/@href")Функция принимает два значения:
- ссылку на страницу или фид, из которого нужно получить данные;
- второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.

С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)Она принимает три значения:
- Ссылку на страницу, с которой необходимо собрать данные.
- Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
- Число — порядковый номер элемента в коде страницы.
Об использовании 16 функций Google Таблиц для целей SEO читайте в нашей статье. Здесь все очень подробно расписано, с примерами по каждой функции.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Парсеры цен конкурентов
Инструменты для интернет-магазинов, которые хотят регулярно отслеживать цены конкурентов на аналогичные товары. С помощью таких парсеров вы можете указать ссылки на ресурсы конкурентов, сопоставлять их цены с вашими и корректировать при необходимости.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Парсеры для SEO-специалистов
Отдельная категория парсеров — узко- или многофункциональные программы, созданные специально под решение задач SEO-специалистов. Такие парсеры предназначены для упрощения комплексного анализа оптимизации сайта. С их помощью можно:
- анализировать содержимое robots.txt и sitemap.xml;
- проверять наличие title и description на страницах сайта, анализировать их длину, собирать заголовки всех уровней (h1-h6);
- проверять коды ответа страниц;
- собирать и визуализировать структуру сайта;
- проверять наличие описаний изображений (атрибут alt);
- анализировать внутреннюю перелинковку и внешние ссылки;
- находить неработающие ссылки;
- и многое другое.
Пройдемся по нескольким популярным парсерам и рассмотрим их основные возможности и функционал.
Парсер метатегов и заголовков PromoPult
Стоимость: первые 500 запросов — бесплатно. Стоимость последующих запросов зависит от количества: до 1000 — 0,04 руб./запрос; от 10000 — 0,01 руб.
Возможности
С помощью парсера метатегов и заголовков можно собирать заголовки h1-h6, а также содержимое тегов title, description и keywords со своего или чужих сайтов.
Инструмент пригодится при оптимизации своего сайта. С его помощью можно обнаружить:
- страницы с пустыми метатегами;
- неинформативные заголовки или заголовки с ошибками;
- дубли метатегов и т.д.
Также парсер полезен при анализе SEO конкурентов. Вы можете проанализировать, под какие ключевые слова конкуренты оптимизируют страницы своих сайтов, что прописывают в title и description, как формируют заголовки.
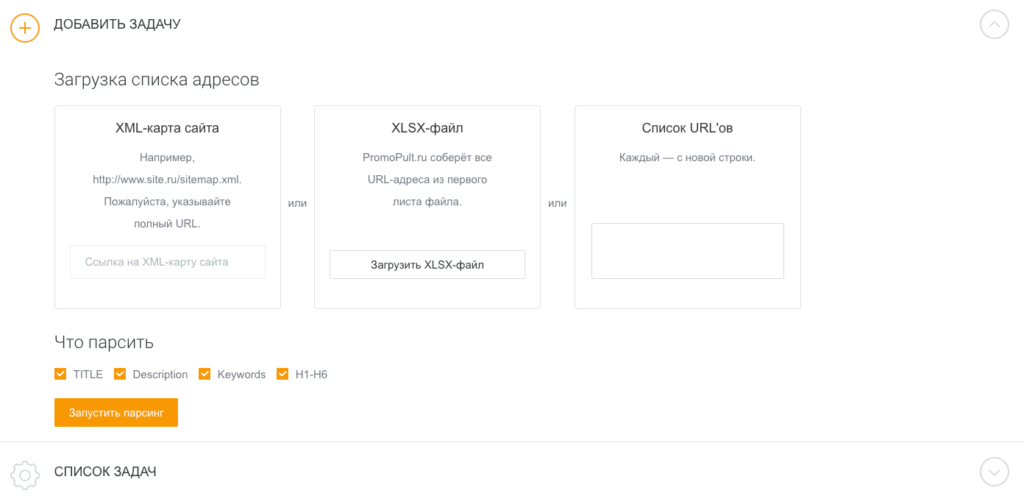
Сервис работает «в облаке». Для начала работы необходимо добавить список URL и указать, какие данные нужно спарсить. URL можно добавить вручную, загрузить XLSX-таблицу со списком адресов страниц, или вставить ссылку на карту сайта (sitemap.xml).
Работа с инструментом подробно описана в статье «Как в один клик собрать мета-теги и заголовки с любого сайта?».
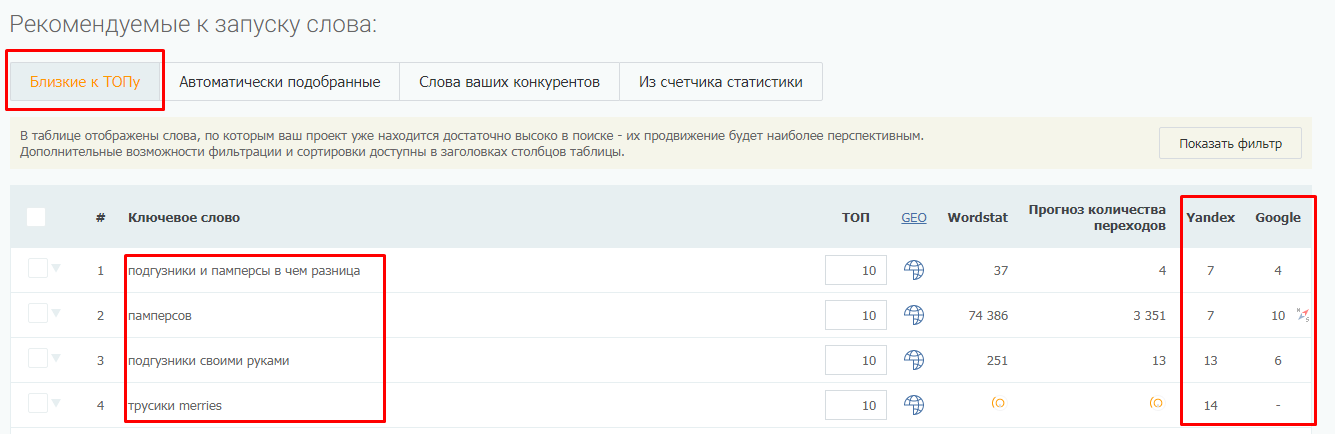
Парсер метатегов и заголовков — не единственный инструмент системы PromoPult для парсинга. В SEO-модуле системы можно бесплатно спарсить ключевые слова, по которым добавленный в систему сайт занимает ТОП-50 в Яндексе/Google.
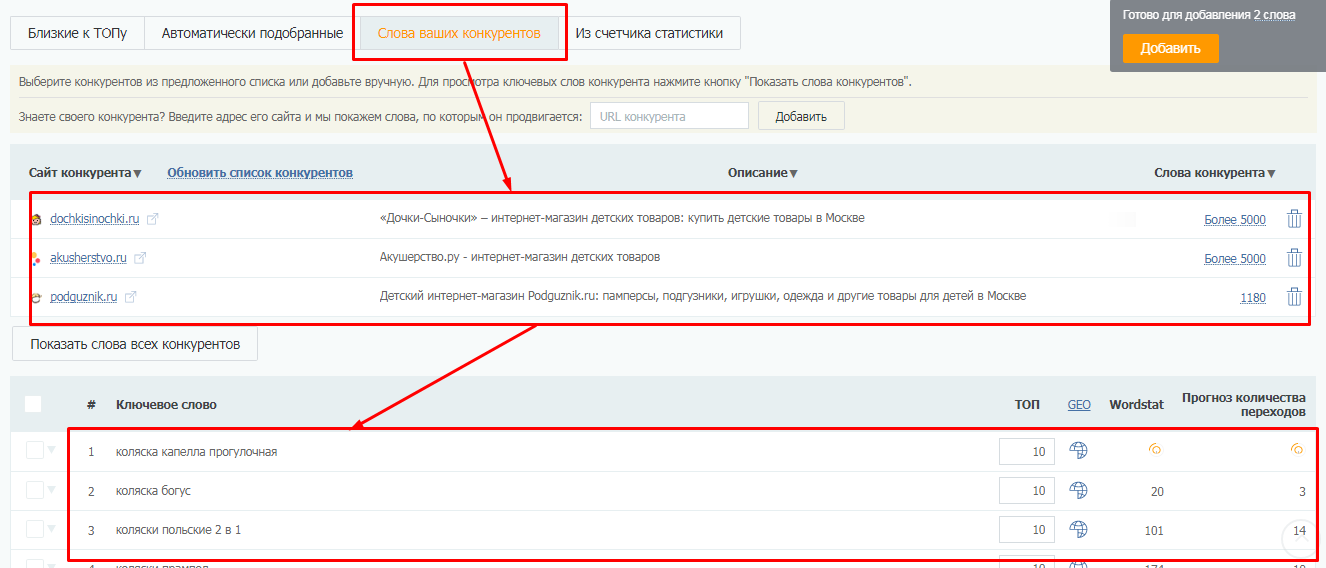
Здесь же на вкладке “Слова ваших конкурентов” вы можете выгрузить ключевые слова конкурентов (до 10 URL за один раз).
Подробно о работе с парсингом ключей в SEO-модуле PromoPult читайте здесь.
Netpeak Spider
Стоимость: от 19$ в месяц, есть 14-дневный пробный период.
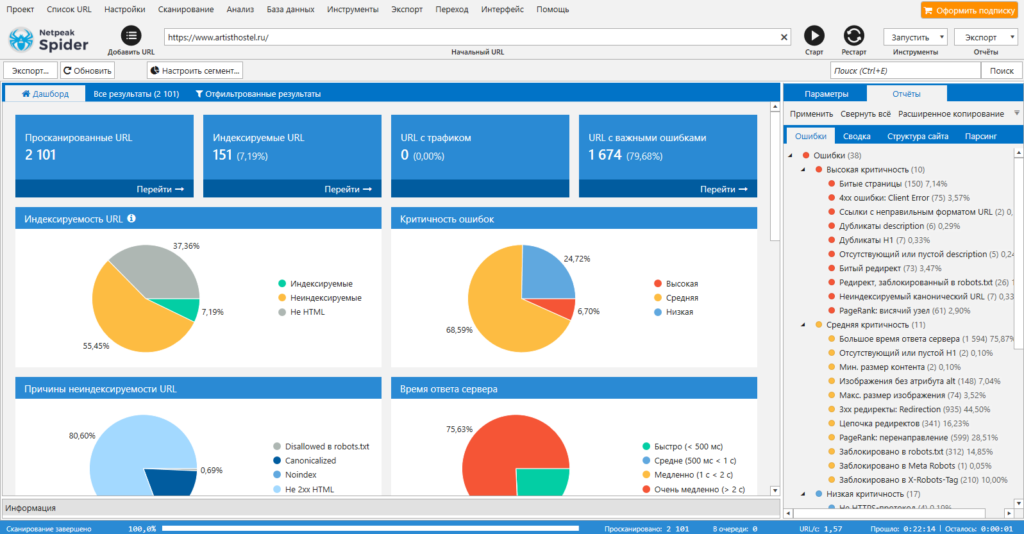
Парсер для комплексного анализа сайтов. С Netpeak Spider можно:
- провести технический аудит сайта (обнаружить битые ссылки, проверить коды ответа страниц, найти дубли и т.д.). Парсер позволяет находить более 80 ключевых ошибок внутренней оптимизации;
- проанализировать основные SEO-параметры (файл robots.txt, проанализировать структуру сайта, проверить редиректы);
- парсить данные с сайтов с помощью регулярных выражений, XPath-запросов и других методов;
- также Netpeak Spider может импортировать данные из Google Аналитики, Яндекс.Метрики и Google Search Console.
Screaming Frog SEO Spider
Стоимость: лицензия на год — 149 фунтов, есть бесплатная версия.
Многофункциональный инструмент для SEO-специалистов, подходит для решения практически любых SEO-задач:
- поиск битых ссылок, ошибок и редиректов;
- анализ мета-тегов страниц;
- поиск дублей страниц;
- генерация файлов sitemap.xml;
- визуализация структуры сайта;
- и многое другое.

В бесплатной версии доступен ограниченный функционал, а также есть лимиты на количество URL для парсинга (можно парсить всего 500 url). В платной версии таких лимитов нет, а также доступно больше возможностей. Например, можно парсить содержимое любых элементов страниц (цены, описания и т.д.).
Подробно том, как пользоваться Screaming Frog, мы писали в статье «Парсинг любого сайта «для чайников»: ни строчки программного кода».
ComparseR
Стоимость: 2000 рублей за 1 лицензию. Есть демо-версия с ограничениями.
Еще один десктопный парсер. С его помощью можно:
- проанализировать технические ошибки на сайте (ошибки 404, дубли title, внутренние редиректы, закрытые от индексации страницы и т.д.);
- узнать, какие страницы видит поисковой робот при сканировании сайта;
- основная фишка ComparseR — парсинг выдачи Яндекса и Google, позволяет выяснить, какие страницы находятся в индексе, а какие в него не попали.

Анализ сайта от PR-CY
Стоимость: платный сервис, минимальный тариф — 990 рублей в месяц. Есть 7-дневная пробная версия с полным доступом к функционалу.
Онлайн-сервис для SEO-анализа сайтов. Сервис анализирует сайт по подробному списку параметров (70+ пунктов) и формирует отчет, в котором указаны:
- обнаруженные ошибки;
- варианты исправления ошибок;
- SEO-чеклист и советы по улучшению оптимизации сайта.
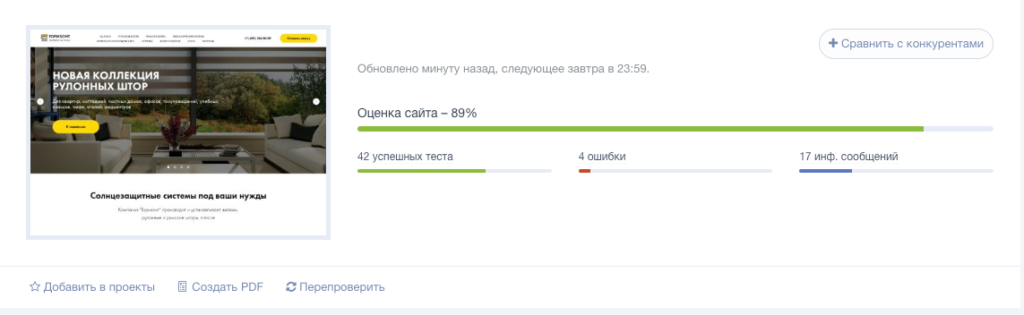
Анализ сайта от SE Ranking
Стоимость: платный облачный сервис. Доступно две модели оплаты: ежемесячная подписка или оплата за проверку.
Стоимость минимального тарифа — 7$ в месяц (при оплате годовой подписки).
Возможности:
- сканирование всех страниц сайта;
- анализ технических ошибок (настройки редиректов, корректность тегов canonical и hreflang, проверка дублей и т.д.);
- поиск страниц без мета-тегов title и description, определение страниц со слишком длинными тегами;
- проверка скорости загрузки страниц;
- анализ изображений (поиск неработающих картинок, проверка наличия заполненных атрибутов alt, поиск «тяжелых» изображений, которые замедляют загрузку страниц);
- анализ внутренних ссылок.

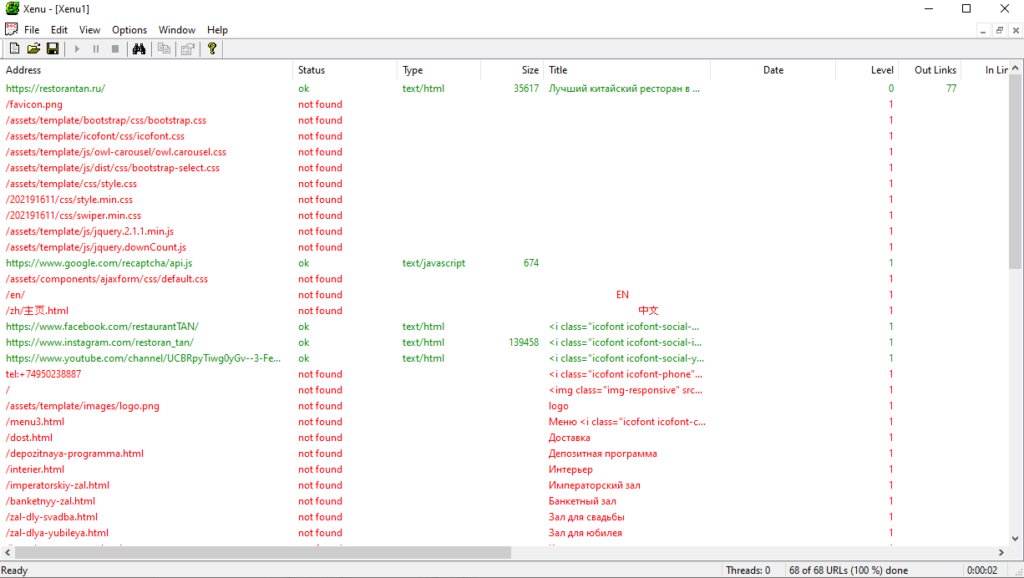
Xenu’s Link Sleuth
Стоимость: бесплатно.
Десктопный парсер для Windows. Используется для парсинга все url, которые есть на сайте:
- ссылки на внешние ресурсы;
- внутренние ссылки (перелинковка);
- ссылки на изображения, скрипты и другие внутренние ресурсы.
Часто применяется для поиска неработающих ссылок на сайте.
A-Parser
Стоимость: платная программа с пожизненной лицензией. Минимальный тарифный план — 119$, максимальный — 279$. Есть демо-версия.
Многофункциональный SEO-комбайн, объединяющий 70+ разных парсеров, заточенных под различные задачи:
- парсинг ключевых слов;
- парсинг данных с Яндекс и Google карт;
- мониторинг позиций сайтов в поисковых системах;
- парсинг контента (текст, изображения, видео) и т.д.
Кроме набора готовых инструментов, можно создать собственный парсер с помощью регулярных выражений, языка запросов XPath или Javascript. Есть доступ по API.

Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Открываем Google, пишем то, что нужно найти в специальную строку и жмем Enter. «Все просто, чему вы меня учить собрались», — думаете вы. Ага, не тут-то было, друзья.
После сегодняшней статьи большинство из вас поймет, что делали это неправильно. Но этот навык – один из самых важных для продуктивного сотрудника. Потому что в 2021 году дергать руководство по вопросам, которые, как оказалось, легко гуглятся, — моветон.
Ну и на форумах не даст вам упасть лицом в грязь, чего уж там.
Затягивать не будем, ниже вас ждут фишки, которые облегчат вам жизнь.
Кстати, вы замечали, что какую бы ты ни ввёл проблему в Google, это уже с кем-то было? Серьёзно, даже если ввести запрос: «Что делать, если мне кинули в лицо дикобраза?», то на каком-нибудь форуме будет сидеть мужик, который уже написал про это. Типа, у нас с женой в прошлом году была похожая ситуация.
Ваня Усович, Белорусский и российский стендап-комик и юморист
Фишка 1
Если вам нужно найти точную цитату, например, из книги, возьмите ее в кавычки. Ниже мы отыскали гениальную цитату из книги «Мастер и Маргарита».
Фишка 2
Бывает, что вы уже точно знаете, что хотите найти, но гугл цепляет что-то схожее с запросом. Это мешает и раздражает. Чтобы отсеять слова, которые вы не хотите видеть в выдаче, используйте знак «-» (минус).
Вот, например, поисковой запрос ненавистника песочного печенья:
Фишка 3
Подходит для тех, кто привык делать всё и сразу. Уже через несколько долей секунд вы научитесь вводить сразу несколько запросов.
*барабанная дробь*
Для этого нужна палочка-выручалочка «|». Например, вводите в поисковую строку «купить клавиатуру | компьютерную мышь» и получаете страницы, содержащие «купить клавиатуру» или «купить компьютерную мышь».
Совет: если вы тоже долго ищете, где находится эта кнопка, посмотрите над Enter.
Фишка 4
Выручит, если вы помните первое и последнее слово в словосочетании или предложении. А еще может помочь составить клевый заголовок. Короче, знак звездочка «*» как бы говорит гуглу: «Чувак, я не помню, какое слово должно там быть, но я надеюсь, ты справишься с задачей».
Фишка 5
Если вы хотите найти файл в конкретном формате, добавьте к запросу «filetype:» с указанием расширения файла: pdf, docx и т.д., например, нам нужно было отыскать PDF-файлы:
Фишка 6
Чтобы найти источник, в котором упоминаются сразу все ключевые слова, перед каждым словом добавьте знак «&». Слов может быть много, но чем их больше, тем сильнее сужается зона поиска.
Кстати, вы еще не захотели есть от наших примеров?
Фишка 7
Признавайтесь, что вы делаете, когда нужно найти значение слова. «ВВП что такое» или «Шерофобия это». Вот так пишете, да?
Гуглить значения слов теперь вам поможет оператор «define:». Сразу после него вбиваем интересующее нас слово и получаем результат.
— Ты сильный?!
— Я сильный!
— Ты матерый?!
— Я матерый!
— Ты даже не знаешь, что такое сдаваться?!
— Я даже не знаю, что такое «матерый»!
Фишка 8
Допустим, вам нужно найти статью не во всём Интернете, а на конкретном сайте. Для этого введите в поисковую строку «site:» и после двоеточия укажите адрес сайта и запрос. Вот так все просто.
Фишка 9
Часто заголовок полностью отображает суть статьи или материалов, которые вам нужны. Поэтому в некоторых случаях удобно пользоваться поиском по заголовку. Для этого введите «intitle:», а после него свой запрос. Получается примерно так:
Фишка 10
Чтобы расширить количество страниц в выдаче за счёт синонимов, указывайте перед запросом тильду «~». К примеру, загуглив «~cтранные имена», вы найдете сайты, где помимо слова «странные» будут и его синонимы: «необычные, невероятные, уникальные».
Ну и, конечно, не забывайте о расширенных инструментах, которые предлагает Google. Там вы можете установить точный временной промежуток для поиска, выбирать язык и даже регион, в которым был опубликован материал.
В комментариях делитесь, о каких функциях вы знали, а о каких услышали впервые 
Кстати, еще больше интересных фишек в области онлайн-образования, подборки с полезными ресурсами и т.д., вы найдете в нашем Telegram-канале. Присоединяйтесь!