Один из способов решения этой задачи — использовать словарь. Можно создать словарь, в котором каждому элементу списка соответствует количество его повторений, и в цикле перебрать элементы списка, добавляя их в словарь.
Вот пример такой функции:
def count_repeats(lst):
"""
Возвращает словарь, в котором каждому элементу списка lst соответствует
количество его повторений.
"""
repeats = {}
for item in lst:
if item in repeats:
repeats[item] += 1
else:
repeats[item] = 1
return repeats
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
repeats = count_repeats(lst)
print(repeats) # {10: 3, 123: 2}
Функция count_repeats принимает на вход список lst, перебирает его элементы и добавляет их в словарь repeats. Если элемент уже есть в словаре, то увеличивается значение соответствующей пары ключ-значение, если же элемента еще нет в словаре, то добавляется пара с ключом равным этому элементу и значением 1.
Вы можете использовать эту функцию, чтобы найти повторяющиеся элементы в списке и количество их повторений.
Вы также можете использовать функцию Counter из модуля collections, чтобы посчитать количество повторений элементов списка. Эта функция возвращает словарь, в котором каждому элементу списка соответствует количество его повторений.
Вот пример кода, который использует функцию Counter:
from collections import Counter
def count_repeats(lst):
"""
Возвращает словарь, в котором каждому элементу списка lst соответствует
количество его повторений.
"""
return Counter(lst)
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
repeats = count_repeats(lst)
print(repeats) # Counter({10: 3, 123: 2})
В этом коде сначала импортируется модуль collections и функция Counter, а затем определяется функция count_repeats, которая принимает список lst и возвращает результат вызова функции Counter на этом списке.
Вы также можете использовать функцию most_common из модуля collections, чтобы найти топ-N самых часто встречающихся элементов в списке. Эта функция принимает список и число N, и возвращает список кортежей, каждый из которых содержит элемент и количество его повторений.
Вот пример кода, который использует функцию most_common:
from collections import Counter
def find_top_repeats(lst, n):
"""
Возвращает топ-N самых часто встречающихся элементов в списке lst.
"""
return Counter(lst).most_common(n)
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
top_repeats = find_top_repeats(lst, 2)
print(top_repeats) # [(10, 3), (123, 2)]
В этом коде сначала импортируется модуль collections и функция Counter, а затем определяется функция find_top_repeats, которая принимает список lst и число n, и возвращает результат вызова функции most_common
Если вам нужно найти только уникальные элементы в списке, то можете использовать функцию set. Эта функция создает множество из элементов списка, удаляя повторяющиеся элементы. Множество не содержит повторяющихся элементов, поэтому вы можете использовать его, чтобы найти уникальные элементы в списке.
Вот пример кода, который использует функцию set:
def find_unique(lst):
"""
Возвращает список уникальных элементов в списке lst.
"""
return list(set(lst))
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
unique = find_unique(lst)
print(unique) # [66, 78, 10, 123, 23]
В этом коде определяется функция find_unique, которая принимает список lst и возвращает список уникальных элементов. Для этого список преобразуется в множество
Если вам нужно найти только уникальные элементы в списке и посчитать их количество, то можете соединить два предыдущих подхода: сначала использовать функцию set для нахождения уникальных элементов, а затем функцию count_repeats для подсчета их количества.
Вот пример кода, который реализует этот подход:
def count_unique(lst):
"""
Возвращает словарь, в котором каждому уникальному элементу списка lst соответствует
количество его повторений.
"""
repeats = {}
for item in set(lst):
repeats[item] = lst.count(item)
return repeats
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
unique_counts = count_unique(lst)
print(unique_counts) # {66: 1, 78: 1, 10: 3, 123: 2}
В этом коде определяется функция count_unique, которая принимает список lst и возвращает словарь, в котором каждому уникальному элементу списка
В этом посте мы обсудим, как найти все дубликаты в массиве в JavaScript.
1. Использование Array.prototype.indexOf() функция
Идея состоит в том, чтобы сравнить индекс всех элементов в массиве с индексом их первого появления. Если оба индекса не совпадают ни для одного элемента в массиве, можно сказать, что текущий элемент дублируется. Чтобы вернуть новый массив с дубликатами, используйте filter() метод.
В следующем примере кода показано, как реализовать это с помощью indexOf() метод:
|
const arr = [ 5, 3, 4, 2, 3, 7, 5, 6 ]; const findDuplicates = arr => arr.filter((item, index) => arr.indexOf(item) !== index) const duplicates = findDuplicates(arr); console.log(duplicates); /* результат: [ 3, 5 ] */ |
Скачать Выполнить код
Приведенное выше решение может привести к дублированию значений на выходе. Чтобы справиться с этим, вы можете преобразовать результат в Set, в котором хранятся уникальные значения.
|
function findDuplicates(arr) { const filtered = arr.filter((item, index) => arr.indexOf(item) !== index); return [...new Set(filtered)] } const arr = [ 5, 3, 4, 2, 3, 7, 5, 6 ]; const duplicates = findDuplicates(arr); console.log(duplicates); /* результат: [ 3, 5 ] */ |
Скачать Выполнить код
2. Использование Set.prototype.has() функция
Кроме того, для повышения производительности вы можете использовать ES6. Установить структуру данных для эффективной фильтрации массива.
Следующее решение находит и возвращает дубликаты, используя has() метод. Это работает, потому что каждое значение в наборе должно быть уникальным.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
function findDuplicates(arr) { const distinct = new Set(arr); // для повышения производительности const filtered = arr.filter(item => { // удаляем элемент из набора при первой же встрече if (distinct.has(item)) { distinct.delete(item); } // возвращаем элемент при последующих встречах else { return item; } }); return [...new Set(filtered)] } const arr = [ 5, 3, 4, 2, 3, 7, 5, 6 ]; const duplicates = findDuplicates(arr); console.log(duplicates); /* результат: [ 3, 5 ] */ |
Скачать Выполнить код
Это все о поиске всех дубликатов в массиве в JavaScript.
Спасибо за чтение.
Пожалуйста, используйте наш онлайн-компилятор размещать код в комментариях, используя C, C++, Java, Python, JavaScript, C#, PHP и многие другие популярные языки программирования.
Как мы? Порекомендуйте нас своим друзьям и помогите нам расти. Удачного кодирования 
Given an array of n integers. The task is to print the duplicates in the given array. If there are no duplicates then print -1.
Examples:
Input: {2, 10,10, 100, 2, 10, 11,2,11,2}
Output: 2 10 11
Input: {5, 40, 1, 40, 100000, 1, 5, 1}
Output: 5 40 1
Note: The duplicate elements can be printed in any order.
Simple Approach: The idea is to use nested loop and for each element check if the element is present in the array more than once or not. If present, then store it in a Hash-map. Otherwise, continue checking other elements.
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
void findDuplicates(int arr[], int len)
{
bool ifPresent = false;
vector<int> al;
for(int i = 0; i < len - 1; i++)
{
for(int j = i + 1; j < len; j++)
{
if (arr[i] == arr[j])
{
auto it = std::find(al.begin(),
al.end(), arr[i]);
if (it != al.end())
{
break;
}
else
{
al.push_back(arr[i]);
ifPresent = true;
}
}
}
}
if (ifPresent == true)
{
cout << "[" << al[0] << ", ";
for(int i = 1; i < al.size() - 1; i++)
{
cout << al[i] << ", ";
}
cout << al[al.size() - 1] << "]";
}
else
{
cout << "No duplicates present in arrays";
}
}
int main()
{
int arr[] = { 12, 11, 40, 12,
5, 6, 5, 12, 11 };
int n = sizeof(arr) / sizeof(arr[0]);
findDuplicates(arr, n);
return 0;
}
Java
import java.util.ArrayList;
public class GFG {
static void findDuplicates(
int arr[], int len)
{
boolean ifPresent = false;
ArrayList<Integer> al = new ArrayList<Integer>();
for (int i = 0; i < len - 1; i++) {
for (int j = i + 1; j < len; j++) {
if (arr[i] == arr[j]) {
if (al.contains(arr[i])) {
break;
}
else {
al.add(arr[i]);
ifPresent = true;
}
}
}
}
if (ifPresent == true) {
System.out.print(al + " ");
}
else {
System.out.print(
"No duplicates present in arrays");
}
}
public static void main(String[] args)
{
int arr[] = { 12, 11, 40, 12, 5, 6, 5, 12, 11 };
int n = arr.length;
findDuplicates(arr, n);
}
}
Python3
def findDuplicates(arr, Len):
ifPresent = False
a1 = []
for i in range(Len - 1):
for j in range(i + 1, Len):
if (arr[i] == arr[j]):
if arr[i] in a1:
break
else:
a1.append(arr[i])
ifPresent = True
if (ifPresent):
print(a1, end = " ")
else:
print("No duplicates present in arrays")
arr = [ 12, 11, 40, 12, 5, 6, 5, 12, 11 ]
n = len(arr)
findDuplicates(arr, n)
C#
using System;
using System.Collections.Generic;
class GFG{
static void findDuplicates(int[] arr, int len)
{
bool ifPresent = false;
List<int> al = new List<int>();
for(int i = 0; i < len - 1; i++)
{
for(int j = i + 1; j < len; j++)
{
if (arr[i] == arr[j])
{
if (al.Contains(arr[i]))
{
break;
}
else
{
al.Add(arr[i]);
ifPresent = true;
}
}
}
}
if (ifPresent == true)
{
Console.Write("[" + al[0] + ", ");
for(int i = 1; i < al.Count - 1; i++)
{
Console.Write(al[i] + ", ");
}
Console.Write(al[al.Count - 1] + "]");
}
else
{
Console.Write("No duplicates present in arrays");
}
}
static void Main()
{
int[] arr = { 12, 11, 40, 12,
5, 6, 5, 12, 11 };
int n = arr.Length;
findDuplicates(arr, n);
}
}
Javascript
<script>
function findDuplicates(arr, len) {
let ifPresent = false;
let al = new Array();
for (let i = 0; i < len - 1; i++) {
for (let j = i + 1; j < len; j++) {
if (arr[i] == arr[j]) {
if (al.includes(arr[i])) {
break;
}
else {
al.push(arr[i]);
ifPresent = true;
}
}
}
}
if (ifPresent == true) {
document.write(`[${al}]`);
}
else {
document.write("No duplicates present in arrays");
}
}
let arr = [12, 11, 40, 12, 5, 6, 5, 12, 11];
let n = arr.length;
findDuplicates(arr, n);
</script>
Time Complexity: O(N2)
Auxiliary Space: O(N)
Efficient Approach: Use unordered_map for hashing. Count frequency of occurrence of each element and the elements with frequency more than 1 is printed. unordered_map is used as range of integers is not known. For Python, Use Dictionary to store number as key and it’s frequency as value. Dictionary can be used as range of integers is not known.
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
usingnamespacestd;
voidprintDuplicates(intarr[],intn)
{
unordered_map<int,int> freq;
for(inti=0; i<n; i++)
freq[arr[i]]++;
booldup =false;
unordered_map<int,int>:: iterator itr;
for(itr=freq.begin(); itr!=freq.end(); itr++)
{
if(itr->second > 1)
{
cout << itr->first <<" ";
dup =true;
}
}
if(dup ==false)
cout <<"-1";
}
intmain()
{
intarr[] = {12, 11, 40, 12, 5, 6, 5, 12, 11};
intn =sizeof(arr) /sizeof(arr[0]);
printDuplicates(arr, n);
return0;
}Java
importjava.util.HashMap;
importjava.util.Map;
importjava.util.Map.Entry;
publicclassFindDuplicatedInArray
{
publicstaticvoidmain(String[] args)
{
intarr[] = {12,11,40,12,5,6,5,12,11};
intn = arr.length;
printDuplicates(arr, n);
}
privatestaticvoidprintDuplicates(int[] arr,intn)
{
Map<Integer,Integer> map =newHashMap<>();
intcount =0;
booleandup =false;
for(inti =0; i < n; i++){
if(map.containsKey(arr[i])){
count = map.get(arr[i]);
map.put(arr[i], count +1);
}
else{
map.put(arr[i],1);
}
}
for(Entry<Integer,Integer> entry : map.entrySet())
{
if(entry.getValue() >1){
System.out.print(entry.getKey()+" ");
dup =true;
}
}
if(!dup){
System.out.println("-1");
}
}
}Python3
defprintDuplicates(arr):
dict={}
foreleinarr:
try:
dict[ele]+=1
except:
dict[ele]=1
foritemindict:
if(dict[item] >1):
(item, end=" ")
("n")
if__name__=="__main__":
list=[12,11,40,12,
5,6,5,12,11]
printDuplicates(list)C#
usingSystem;
usingSystem.Collections.Generic;
classGFG
{
staticvoidprintDuplicates(int[] arr,intn)
{
Dictionary<int,
int> map =newDictionary<int,
int>();
intcount = 0;
booldup =false;
for(inti = 0; i < n; i++)
{
if(map.ContainsKey(arr[i]))
{
count = map[arr[i]];
map[arr[i]]++;
}
else
map.Add(arr[i], 1);
}
foreach(KeyValuePair<int,
int> entryinmap)
{
if(entry.Value > 1)
Console.Write(entry.Key +" ");
dup =true;
}
if(!dup)
Console.WriteLine("-1");
}
publicstaticvoidMain(String[] args)
{
int[] arr = { 12, 11, 40, 12,
5, 6, 5, 12, 11 };
intn = arr.Length;
printDuplicates(arr, n);
}
}Javascript
<script>
functionprintDuplicates(arr, n)
{
varfreq =newMap();
for(let i = 0; i < n; i++)
{
if(freq.has(arr[i]))
{
freq.set(arr[i], freq.get(arr[i]) + 1);
}
else
{
freq.set(arr[i], 1);
}
}
vardup =false;
for(let [key, value] of freq)
{
if(value > 1)
{
document.write(key +" ");
dup =true;
}
}
if(dup ==false)
document.write("-1");
}
vararr = [ 12, 11, 40, 12,
5, 6, 5, 12, 11 ];
varn = arr.length;
printDuplicates(arr, n);
</script>
Time Complexity: O(N)
Auxiliary Space: O(N)
Another Efficient Approach(Space optimization):
- First we will sort the array for binary search function.
- we will find index at which arr[i] occur first time lower_bound
- Then , we will find index at which arr[i] occur last time upper_bound
- Then check if diff=(last_index-first_index+1)>1
- If diff >1 means it occurs more than once and print
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
void printDuplicates(int arr[], int n)
{
sort(arr,arr+n);
cout<<"[";
for(int i = 0 ; i < n ;i++)
{
int first_index = lower_bound(arr,arr+n,arr[i])- arr;
int last_index = upper_bound(arr,arr+n,arr[i])- arr-1;
int occur_time = last_index-first_index+1;
if(occur_time > 1 )
{ i=last_index;
cout<<arr[i]<<", "; }
} cout<<"]";
}
int main()
{ int arr[] = {12, 11, 40, 12, 5, 6, 5, 12, 11};
int n = sizeof(arr) / sizeof(arr[0]);
printDuplicates(arr, n);
return 0;
}
Python3
def printDuplicates(arr, n):
arr.sort()
print("[", end="")
i = 0
while i < n:
first_index = arr.index(arr[i])
last_index = n - arr[::-1].index(arr[i]) - 1
occur_time = last_index - first_index + 1
if occur_time > 1:
i = last_index
print(arr[i], end=", ")
i += 1
print("]")
arr = [12, 11, 40, 12, 5, 6, 5, 12, 11]
n = len(arr)
printDuplicates(arr, n)
Java
import java.io.*;
import java.util.*;
class GFG {
public static int lowerBound(int[] arr, int target)
{
int lo = 0, hi = arr.length - 1;
int ans = -1;
while (lo <= hi) {
int mid = lo + (hi - lo) / 2;
if (arr[mid] >= target) {
ans = mid;
hi = mid - 1;
}
else {
lo = mid + 1;
}
}
return ans;
}
public static int upperBound(int[] arr, int target)
{
int lo = 0, hi = arr.length - 1;
int ans = -1;
while (lo <= hi) {
int mid = lo + (hi - lo) / 2;
if (arr[mid] <= target) {
ans = mid;
lo = mid + 1;
}
else {
hi = mid - 1;
}
}
return ans;
}
static void printDuplicates(int[] arr, int n)
{
Arrays.sort(arr);
System.out.print("[");
for (int i = 0; i < n; i++) {
int firstIndex = lowerBound(arr, arr[i]);
int lastIndex = upperBound(arr, arr[i]);
int occurTime = lastIndex - firstIndex
+ 1;
if (occurTime
> 1) {
i = lastIndex;
System.out.print(arr[i] + ", ");
}
}
System.out.println("]");
}
public static void main(String[] args)
{
int[] arr = { 12, 11, 40, 12, 5, 6, 5, 12, 11 };
int n = arr.length;
printDuplicates(arr, n);
}
}
Javascript
function printDuplicates(arr, n) {
arr.sort();
console.log("[");
for (let i = 0; i < n; i++)
{
let first_index = arr.indexOf(arr[i]);
let last_index = arr.lastIndexOf(arr[i]);
let occur_time = last_index - first_index + 1;
if (occur_time > 1) {
i = last_index;
console.log(arr[i] + ", ");
}
}
console.log("]");
}
let arr = [12, 11, 40, 12, 5, 6, 5, 12, 11];
let n = arr.length;
printDuplicates(arr, n);
C#
using System;
class MainClass {
static void printDuplicates(int[] arr, int n) {
Array.Sort(arr);
Console.Write("[");
for (int i = 0; i < n; i++) {
int first_index = Array.IndexOf(arr, arr[i]);
int last_index = Array.LastIndexOf(arr, arr[i]);
int occur_time = last_index - first_index + 1;
if (occur_time > 1) {
i = last_index;
Console.Write(arr[i] + ", ");
}
}
Console.Write("]");
}
static void Main() {
int[] arr = {12, 11, 40, 12, 5, 6, 5, 12, 11};
int n = arr.Length;
printDuplicates(arr, n);
}
}
Time Complexity: O(n*log2n)
Auxiliary Space: O(1)
Related Post :
Print All Distinct Elements of a given integer array
Find duplicates in O(n) time and O(1) extra space | Set 1
Duplicates in an array in O(n) and by using O(1) extra space | Set-2
Print all the duplicates in the input string
This article is contributed by Ayush Jauhari. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks main page and help other Geeks.
Last Updated :
18 Apr, 2023
Like Article
Save Article

Проблема
- Найти дубликат в массиве
Given an array of n + 1 integers between 1 and n, find one of the duplicates.
If there are multiple possible answers, return one of the duplicates.
If there is no duplicate, return -1.
Example:
Input: [1, 2, 2, 3]
Output: 2
Input: [3, 4, 1, 4, 1]
Output: 4 or 1Категория: массивы
Процесс решения задачи
Перед тем как вы увидите решение, давайте немного поговорим о самой проблеме. У нас есть: массив n + 1 элементов с целочисленными переменными в диапазоне от 1 до n.


Например: массив из пяти integers подразумевает, что каждый элемент будет иметь значение от 1 до 4 (включительно). Это автоматически означает, что будет по крайней мере один дубликат.
Единственное исключение — это массив размером 1. Это единственный случай, когда мы получим -1.
Brute Force
Метод Brute Force можно реализовать двумя вложенными циклами:
for i = 0; i < size(a); i++ {
for j = i+1; j < size(a); j++ {
if(a[i] == a[j]) return a[i]
}
}O(n²) — временная сложность и O(1) — пространственная сложность.
Count Iterations
Другой подход, это иметь структуру данных, в которой можно перечитать количество итераций каждого элемента integer. Такой метод подойдёт как для массивов, так и для хэш-таблиц.
Реализация на Java:
public int repeatedNumber(final List<Integer> list) {
if(list.size() <= 1) {
return -1;
}
int[] count = new int[list.size() - 1];
for (int i = 0; i < list.size(); i++) {
int n = list.get(i) - 1;
count[n]++;
if (count[n] > 1) {
return list.get(i);
}
}
return -1;
}Значение индекса i представляет число итераций i+1.
Временная сложность этого решения — O(n), но и пространственная — O(n), так как нам требуется дополнительная структура.
Sorted Array
Если мы применяем метод упрощения, то можно попытаться найти решение с отсортированным массивом.
В этом случае, нам нужно сравнить каждый элемент с его соседом справа.
Реализация на Java:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1) {
return -1;
}
Collections.sort(list);
for (int i = 0; i < list.size() - 1; i++) {
if (list.get(i) == list.get(i + 1)) {
return list.get(i);
}
}
return -1;
}Пространственная сложность O(1), но временная O(n log(n)), так как нам нужно отсортировать коллекцию.
Sum of the Elements
Ещё один способ — это суммирование элементов массива и их сравнение с помощью 1 + 2 + … + n.
Рассмотрим пример:
Input: [1, 4, 3, 3, 2, 5]
Sum = 18
As in this example, we have n = 5:
Sum of 1 to 5 = 1 + 2 + 3 + 4 + 5 = 15
=> 18 - 15 = 3 so 3 is the duplicateВ этом примере мы можем добиться результата временной сложности O(n) и пространственной O(1). Тем не менее, это решение работает только в случае, когда мы имеем один дубликат.
Нерабочий пример:
Input: [1, 2, 3, 2, 3, 4]
Sum = 15
As in this example we have n = 5,
Sum of 1 to 5 = 1 + 2 + 3 + 4 + 5 = 15
/! Not workingТакой способ приведёт в тупик. Но иногда, чтобы найти оптимальное решение, нужно перепробовать всё.
Marker
Кое-что интересное стоит упомянуть. Мы рассматривали решения, не учитывая условия, что диапазон значений integer может быть от 1 до n. Из-за этого примечательного условия каждое значение имеет свой собственный, соответствующий ему индекс в массиве.
Суть этого решения в том, чтобы рассматривать данный массив как список связей. То есть значение индекса указывает на его содержание.
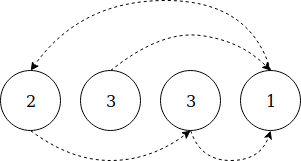
Мы проходим через каждый элемент и помечаем соответствующий индекс, прибавляя к нему знак минус. Элемент является дубликатом, если его индекс уже помечен минусом.
Давайте рассмотрим конкретный пример, шаг за шагом:
Input: [2, 3, 3, 1]
* Iteration 0:
Absolute value = 2
Put a minus sign to a[2] => [2, 3, -3, 1]
* Iteration 1:
Absolute value = 3
Put a minus sign to a[3] => [2, 3, -3, -1]
* Iteration 2:
Absolute value = 3
As a[3] is already negative, it means 3 is a duplicateРеализация на Java:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1) {
return -1;
}
for (int i = 0; i < list.size(); i++) {
if (list.get(Math.abs(list.get(i))) > 0) {
list.set(Math.abs(list.get(i)), -1 * list.get(Math.abs(list.get(i))));
} else {
return Math.abs(list.get(i));
}
}
return 0;
}Это решение даёт результат временной сложности O(n) и пространственной O(1). Тем не менее, потребуется изменять список ввода.
Runner Technique
Есть ещё один способ, который предполагает рассматривать массив как некий список связей (повторюсь, это возможно благодаря ограничению диапазона значений элементов).
Давайте проанализируем пример [1, 2, 3, 4, 2]:
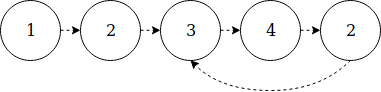
Такое представление даёт нам понять, что дубликат существует, когда есть цикл. Более того, дубликат проявляется на точке входа цикла (в этом случае, второй элемент).
Мы можем взять за основу алгоритм нахождения цикла по Флойду, тогда мы придём к следующему алгоритму:
- Инициировать два указателя
slowиfast - С каждым шагом: slow смещается на шаг со значением
slow = a[slow], fast смещается на два шага со значениемfast = a[a[fast]] - Когда
slow == fast― мы в цикле.
Можно ли считать этот алгоритм завершённым? Пока нет. Точка входа этого цикла будет обозначать дубликат. Нам нужно сбросить slow и двигать указатели шаг за шагом, пока они снова не станут равны.
Возможная реализация на Java:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1)
return -1;
int slow = list.get(0);
int fast = list.get(list.get(0));
while (fast != slow) {
slow = list.get(slow);
fast = list.get(list.get(fast));
}
slow = 0;
while (fast != slow) {
slow = list.get(slow);
fast = list.get(fast);
}
return slow;
}Это решение даёт результат временной сложности O(n) и пространственной O(1) и не требует изменения входящего списка.
Перевод статьи Teiva Harsanyi : Solving Algorithmic Problems: Find a Duplicate in an Array
Для нахождения одинаковых элементов можно использовать следующий алгоритм:
- Находим количество вхождений (сколько раз встречается в списке) для каждого элемента
- Выводим только те, у которых количество вхождений больше 1
Алгоритм можно реализовать с помощью цикла:
const numbers = [4, 3, 3, 1, 15, 7, 4, 19, 19]; // исходный массив
const countItems = {}; // здесь будет храниться промежуточный результат
// получаем объект в котором ключ - это элемент массива, а значение - сколько раз встречается элемент в списке
// например так будет выглядеть этот объект после цикла:
// {1: 1, 3: 2, 4: 2, 7: 1, 15: 1, 19: 2}
// 1 встречается в тексте 1 раз, 2 встречается 2 раза, 4 встречается 2 раза и так далее
for (const item of numbers) {
// если элемент уже был, то прибавляем 1, если нет - устанавливаем 1
countItems[item] = countItems[item] ? countItems[item] + 1 : 1;
}
// обрабатываем ключи объекта, отфильтровываем все, что меньше 1
const result = Object.keys(countItems).filter((item) => countItems[item] > 1);
console.dir(result); // => ['3', '4', '19']