Еще раз о поиске простых чисел
Время на прочтение
7 мин
Количество просмотров 220K
") В заметке обсуждаются алгоритмы решета для поиска простых чисел. Мы подробно рассмотрим классическое решето Эратосфена, особенности его реализации на популярных языках программирования, параллелизацию и оптимизацию, а затем опишем более современное и быстрое решето Аткина. Если материал о решете Эратосфена предназначен в первую очередь уберечь новичков от регулярного хождения по граблям, то алгоритм решета Аткина ранее на Хабрахабре не описывался.
В заметке обсуждаются алгоритмы решета для поиска простых чисел. Мы подробно рассмотрим классическое решето Эратосфена, особенности его реализации на популярных языках программирования, параллелизацию и оптимизацию, а затем опишем более современное и быстрое решето Аткина. Если материал о решете Эратосфена предназначен в первую очередь уберечь новичков от регулярного хождения по граблям, то алгоритм решета Аткина ранее на Хабрахабре не описывался.
На снимке — скульптура абстрактного экспрессиониста Марка Ди Суверо «Решето Эратосфена», установленная в кампусе Стэнфорского университета
Введение
Напомним, что число называется простым, если оно имеет ровно два различных делителя: единицу и самого себя. Числа, имеющие большее число делителей, называются составными. Таким образом, если мы умеем раскладывать числа на множители, то мы умеем и проверять числа на простоту. Например, как-то так:
function isprime(n){
if(n==1) // 1 - не простое число
return false;
// перебираем возможные делители от 2 до sqrt(n)
for(d=2; d*d<=n; d++){
// если разделилось нацело, то составное
if(n%d==0)
return false;
}
// если нет нетривиальных делителей, то простое
return true;
}
(Здесь и далее, если не оговорено иное, приводится JavaScript-подобный псевдокод)
Время работы такого теста, очевидно, есть O(n½), т. е. растет экспоненциально относительно битовой длины n. Этот тест называется проверкой перебором делителей.
Довольно неожиданно, что существует ряд способов проверить простоту числа, не находя его делителей. Если полиномиальный алгоритм разложения на множители пока остается недостижимой мечтой (на чем и основана стойкость шифрования RSA), то разработанный в 2004 году тест на простоту
AKS
[1] отрабатывает за полиномиальное время. С различными эффективными тестами на простоту можно ознакомиться по [2].
Если теперь нам нужно найти все простые на достаточно широком интервале, то первым побуждением, наверное, будет протестировать каждое число из интервала индивидуально. К счастью, если у нас достаточно памяти, можно использовать более быстрые (и простые) алгоритмы решета. В этой статье мы обсудим два из них: классическое решето Эратосфена, известное еще древним грекам, и решето Аткина, наиболее совершенный современный алгоритм этого семейства.
Решето Эратосфена
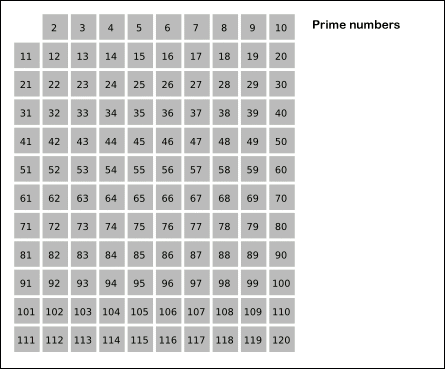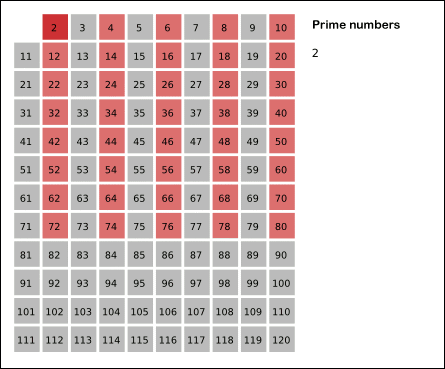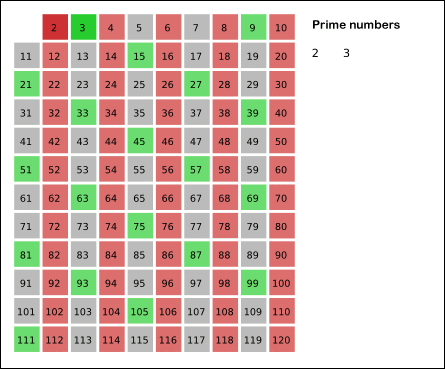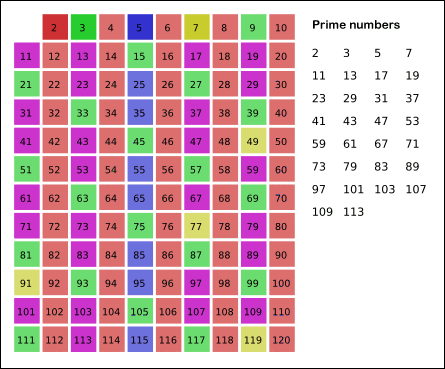
Древнегреческий математик Эратосфен предложил следующий алгоритм для нахождения всех простых, не превосходящих данного числа n. Возьмем массив S длины n и заполним его единицами (пометим как невычеркнутые). Теперь будем последовательно просматривать элементы S[k], начиная с k = 2. Если S[k] = 1, то заполним нулями (вычеркнем или высеем) все последующие ячейки, номера которых кратны k. В результате получим массив, в котором ячейки содержат 1 тогда и только тогда, когда номер ячейки — простое число.
Много времени можно сэкономить, если заметить, что, поскольку у составного числа, меньшего n, по крайней мере один из делителей не превосходит  , процесс высевания достаточно закончить на
, процесс высевания достаточно закончить на  . Вот анимация решета Эратосфена, взятая с Википедии:
. Вот анимация решета Эратосфена, взятая с Википедии:

Еще немного операций можно сэкономить, если — по той же причине — начинать вычеркивать кратные k, начиная не с 2k, а с номера k2.
Реализация примет следующий вид:
function sieve(n){
S = [];
S[1] = 0; // 1 - не простое число
// заполняем решето единицами
for(k=2; k<=n; k++)
S[k]=1;
for(k=2; k*k<=n; k++){
// если k - простое (не вычеркнуто)
if(S[k]==1){
// то вычеркнем кратные k
for(l=k*k; l<=n; l+=k){
S[l]=0;
}
}
}
return S;
}
Эффективность решета Эратосфена вызвана крайней простотой внутреннего цикла: он не содержит условных переходов, а также «тяжелых» операций вроде деления и умножения.
Оценим сложность алгоритма. Первое вычеркивание требует n/2 действий, второе — n/3, третье — n/5 и т. д. По формуле Мертенса
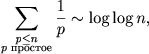
так что для решета Эратосфена потребуется O(n log log n) операций. Потребление памяти же составит O(n).
Оптимизация и параллелизация
Первую оптимизацию решета предложил сам Эратосфен: раз из всех четных чисел простым является только 2, то давайте сэкономим половину памяти и времени и будем выписывать и высеивать только нечетные числа. Реализация такой модификации алгоритма потребует лишь косметических изменений (код).
Более развитая оптимизация (т. н. wheel factorization) опирается на то, что все простые, кроме 2, 3 и 5, лежат в одной из восьми следующих арифметических прогрессий: 30k+1, 30k+7, 30k+11, 30k+13, 30k+17, 30k+19, 30k+23 и 30k+29. Чтобы найти все простые числа до n, вычислим предварительно (опять же при помощи решета) все простые до . Теперь составим восемь решет, в каждое из которых будут входить элементы соответствующей арифметической прогрессии, меньшие n, и высеем каждое из них в отдельном потоке. Все, можно пожинать плоды: мы не только понизили потребление памяти и нагрузку на процессор (в четыре раза по сравнению с базовым алгоритмом), но и распараллелили работу алгоритма.
Наращивая шаг прогрессии и количество решет (например, при шаге прогрессии 210 нам понадобится 48 решет, что сэкономит еще 4% ресурсов) параллельно росту n, удается увеличить скорость алгоритма в log log n раз.
Сегментация
Что же делать, если, несмотря на все наши ухищрения, оперативной памяти не хватает и алгоритм безбожно «свопится»? Можно заменить одно большое решето на последовательность маленьких ситечек и высевать каждое в отдельности. Как и выше, нам придется предварительно подготовить список простых до , что займет O(n½-ε) дополнительной памяти. Простые же, найденные в процессе высевание ситечек, нам хранить не нужно — будем сразу отдавать их в выходной поток.
Не надо делать ситечки слишком маленькими, меньше тех же O(n½-ε) элементов. Так вы ничего не выиграете в асимптотике потребления памяти, но из-за накладных расходов начнете все сильнее терять в производительности.
Решето Эратосфена и однострочники
На Хабрахабре ранее публиковалась большая подборка алгоритмов Эратосфена в одну строчку на разных языках программирования (однострочники №10). Интересно, что все они на самом деле решетом Эратосфена не являются и реализуют намного более медленные алгоритмы.
Дело в том, что фильтрация множества по условию (например,
primes = primes.select { |x| x == prime || x % prime != 0 } на Ruby) или использование генераторных списков aka list comprehensions (например,
let pgen (p:xs) = p : pgen [x|x <- xs, x `mod` p > 0] на Haskell) вызывают как раз то, избежать чего призван алгоритм решета, а именно поэлементную проверку делимости. В результате сложность алгоритма возрастает по крайней мере до 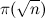 (это число фильтраций), умноженного на
(это число фильтраций), умноженного на 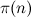 (минимальное число элементов фильтруемого множества), где
(минимальное число элементов фильтруемого множества), где 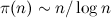 — число простых, не превосходящих n, т. е. до O(n3/2-ε) действий.
— число простых, не превосходящих n, т. е. до O(n3/2-ε) действий.
Однострочник
(n: Int) => (2 to n) |> (r => r.foldLeft(r.toSet)((ps, x) => if (ps(x)) ps -- (x * x to n by x) else ps))на Scala ближе к алгоритму Эратосфена тем, что избегает проверки на делимость. Однако сложность построения разности множеств пропорциональна размеру большего из них, так что в результате получаются те же O(n3/2-ε) операций.
Вообще решето Эратосфена тяжело эффективно реализовать в рамках функциональной парадигмы неизменяемых переменных. В случае, если функциональный язык (например, OСaml) позволяет, стоит нарушить нормы и завести изменяемый массив. В [3] обсуждается, как грамотно реализовать решето Эратосфена на Haskell при помощи техники ленивых вычеркиваний.
Решето Эратосфена и PHP
Запишем алгоритм Эратосфена на PHP. Получится примерно следующее:
define("LIMIT",1000000);
define("SQRT_LIMIT",floor(sqrt(LIMIT)));
$S = array_fill(2,LIMIT-1,true);
for($i=2;$i<=SQRT_LIMIT;$i++){
if($S[$i]===true){
for($j=$i*$i; $j<=LIMIT; $j+=$i){
$S[$j]=false;
}
}
}
Здесь есть две проблемы. Первая из них связана с системой типов данных и является характерной для многих современных языков. Дело в том, что наиболее эффективно решето Эратосфена реализуется в тех
ЯП
, где можно объявить гомогенный массив, последовательно расположенный в памяти. Тогда вычисление адреса ячейки S[i] займет всего пару команд процессора. Массив же в PHP — это на самом деле гетерогенный словарь, т. е. он индексируется произвольными строками или числами и может содержать данные различных типов. В таком случае нахождение S[i] становится куда более трудооемкой задачей.
Вторая проблема: массивы в PHP ужасны по накладным расходам памяти. У меня на 64-битной системе каждый элемент $S из кода выше съедает по 128 байт. Как обсуждалось выше, необязательно держать сразу все решето в памяти, можно обрабатывать его порционно, но все равно такие расходы дóлжно признать недопустимыми.
Для решения этих проблем достаточно выбрать более подходящий тип данных — строку!
define("LIMIT",1000000);
define("SQRT_LIMIT",floor(sqrt(LIMIT)));
$S = str_repeat("1", LIMIT+1);
for($i=2;$i<=SQRT_LIMIT;$i++){
if($S[$i]==="1"){
for($j=$i*$i; $j<=LIMIT; $j+=$i){
$S[$j]="";
}
}
}
Теперь каждый элемент занимает ровно 1 байт, а время работы уменьшилось примерно втрое. Скрипт для измерения скорости.
Решето Аткина
В 1999 году Аткин и Бернштейн предложили новый метод высеивания составных чисел, получивший название решета Аткина. Он основан на следующей теореме.
Теорема. Пусть n — натуральное число, которое не делится ни на какой полный квадрат. Тогда
- если n представимо в виде 4k+1, то оно просто тогда и только тогда, когда число натуральных решений уравнения 4x2+y2 = n нечетно.
- если n представимо в виде 6k+1, то оно просто тогда и только тогда, когда число натуральных решений уравнения 3x2+y2 = n нечетно.
- если n представимо в виде 12k-1, то оно просто тогда и только тогда, когда число натуральных решений уравнения 3x2−y2 = n, для которых x > y, нечетно.
C доказательством можно ознакомиться в [4].
Из элементарной теории чисел следует, что все простые, большие 3, имеют вид 12k+1 (случай 1), 12k+5 (снова 1), 12k+7 (случай 2) или 12k+11 (случай 3).
Для инициализации алгоритма заполним решето S нулями. Теперь для каждой пары (x, y), где 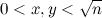 , инкрементируем значения в ячейках S[4x2+y2], S[3x2+y2], а также, если x > y, то и в S[3x2−y2]. В конце вычислений номера ячеек вида 6k±1, содержащие нечетные числа, — это или простые, или делятся на квадраты простых.
, инкрементируем значения в ячейках S[4x2+y2], S[3x2+y2], а также, если x > y, то и в S[3x2−y2]. В конце вычислений номера ячеек вида 6k±1, содержащие нечетные числа, — это или простые, или делятся на квадраты простых.
В качестве заключительного этапа пройдемся по предположительно простым номерам последовательно и вычеркнем кратные их квадратам.
Из описания видно, что сложность решета Аткина пропорциональна n, а не n log log n как у алгоритма Эратосфена.
Авторская, оптимизированная реализация на Си представлена в виде primegen, упрощенная версия — в Википедии. На Хабрахабре публиковалось решето Аткина на C#.
Как и в решете Эратосфена, при помощи wheel factorization и сегментации, можно снизить асимптотическую сложность в log log n раз, а потребление памяти — до O(n½+o(1)).
О логарифме логарифма
На самом деле множитель log log n растет крайне. медленно. Например, log log 1010000 ≈ 10. Поэтому с практической точки зрения его можно полагать константой, а сложность алгоритма Эратосфена — линейной. Если только поиск простых не является ключевой функцией в вашем проекте, можно использовать базовый вариант решета Эратосфена (разве что сэкономьте на четных числах) и не комплексовать по этому поводу. Однако при поиске простых на больших интервалах (от 232) игра стоит свеч, оптимизации и решето Аткина могут ощутимо повысить производительность.
P. S. В комментариях напомнили про решето Сундарама. К сожалению, оно является лишь математической диковинкой и всегда уступает либо решетам Эратосфена и Аткина, либо проверке перебором делителей.
Литература
[1] Agrawal M., Kayal N., Saxena N. PRIMES is in P. — Annals of Math. 160 (2), 2004. — P. 781–793.
[2] Василенко О. Н. Теоретико-числовые алгоритмы в криптографии. — М., МЦНМО, 2003. — 328 с.
[3] O’Neill M. E. The Genuine Sieve of Eratosthenes. — 2008.
[4] Atkin A. O. L., Bernstein D. J. Prime sieves using binary quadratic forms. — Math. Comp. 73 (246), 2003. — P. 1023-1030.
Простое число — это натуральное число, которое больше 1 и не имеет положительного делителя, кроме 1 и самого себя, например 2, 3, 5, 7, 11, 13 и так далее.
Пользователю даются два целых числа, нижнее значение и верхнее значение. Задача состоит в том, чтобы написать программу Python для вывода всех простых чисел в заданном интервале (или диапазоне).
Чтобы напечатать все простые числа в заданном интервале, пользователь должен выполнить следующие шаги:
- Шаг 1: Переберите все элементы в заданном диапазоне.
- Шаг 2: Проверьте для каждого числа, есть ли у него какой-либо множитель между 1 и самим собой.
- Шаг 3: Если да, то число не простое, и оно перейдет к следующему числу.
- Шаг 4: Если нет, то это простое число, и программа распечатает его и проверит следующее число.
- Шаг 5: Цикл прервется, когда будет достигнуто верхнее значение.
Пример: код Python для печати простого числа в заданном интервале.
# First, we will take the input:
lower_value = int(input("Please, Enter the Lowest Range Value: "))
upper_value = int(input("Please, Enter the Upper Range Value: "))
print("The Prime Numbers in the range are: ")
for number in range(lower_value, upper_value + 1):
if number > 1:
for i in range(2, number):
if(number % i) == 0:
break
else:
print(number)
Выход:
Please, Enter the Lowest Range Value: 14 Please, Enter the Upper Range Value: 97 The Prime Numbers in the range are: 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
Заключение
В этом уроке мы показали, как написать код для печати простых чисел в заданном диапазоне чисел.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Сайт переезжает. Большинство статей уже перенесено на новую версию.
Скоро добавим автоматические переходы, но пока обновленную версию этой статьи можно найти там.
Теория чисел
- Простые числа
- Разложение на простые множители
- Решето Эратосфена
- Линейное решето Эратосфена*
- НОД и НОК
- Алгоритм Евклида
- Расширенный алгоритм Евклида*
- Операции по модулю
- Быстрое возведение в степень
- Деление по простому модулю*
Простые числа
Простым называется натуральное число, которое делится только на единицу и на себя. Единица при этом простым числом не считается. Составным числом называют непростое число, которое еще и не единица.
Примеры простых чисел: (2), (3), (5), (179), (10^9+7), (10^9+9).
Примеры составных чисел: (4), (15), (2^{30}).
Еще одно определение простого числа: (N) — простое, если у (N) ровно два делителя. Эти делители при этом равны (1) и (N).
Проверка на простоту за линию
С точки зрения программирования интересно научиться проверять, является ли число (N) простым. Это очень легко сделать за (O(N)) — нужно просто проверить, делится ли оно хотя бы на одно из чисел (2, 3, 4, ldots, N-1) . (N > 1) является простым только в случае, если оно не делится на на одно из этих чисел.
def is_prime(n):
if n == 1:
return False
for i in range(2, n): # начинаем с 2, так как на 1 все делится; n не включается
if n % i == 0:
return False
return True
for i in range(1, 10):
print(i, is_prime(i))(1, False)
(2, True)
(3, True)
(4, False)
(5, True)
(6, False)
(7, True)
(8, False)
(9, False)Проверка на простоту за корень
Алгоритм можно ускорить с (O(N)) до (O(sqrt{N})).
Пусть (N = a times b), причем (a leq b). Тогда заметим, что (a leq sqrt N leq b).
Почему? Потому что если (a leq b < sqrt{N}), то (ab leq b^2 < N), но (ab = N). А если (sqrt{N} < a leq b), то (N < a^2 leq ab), но (ab = N).
Иными словами, если число (N) равно произведению двух других, то одно из них не больше корня из (N), а другое не меньше корня из (N).
Из этого следует, что если число (N) не делится ни на одно из чисел (2, 3, 4, ldots, lfloorsqrt{N}rfloor), то оно не делится и ни на одно из чисел (lceilsqrt{N}rceil + 1, ldots, N-2, N-1), так как если есть делитель больше корня (не равный (N)), то есть делитель и меньше корня (не равный 1). Поэтому в цикле for достаточно проверять числа не до (N), а до корня.
def is_prime(n):
if n == 1:
return False
# Удобно вместо for i in range(2, n ** 0.5) писать так:
i = 2
while i * i <= n:
if n % i == 0:
return False
i += 1
return True
for i in [1, 2, 3, 10, 11, 12, 10**9+6, 10**9+7]:
print(i, is_prime(i))(1, False)
(2, True)
(3, True)
(10, False)
(11, True)
(12, False)
(1000000006, False)
(1000000007, True)Разложение на простые множители
Любое натуральное число можно разложить на произведение простых, и с такой записью очень легко работать при решении задач. Разложение на простые множители еще называют факторизацией.
[11 = 11 = 11^1] [100 = 2 times 2 times 5 times 5 = 2^2 times 5^2] [126 = 2 times 3 times 3 times 7 = 2^1 times 3^2 times 7^1]
Рассмотрим, например, такую задачу:
Условие: Нужно разбить (N) людей на группы равного размера. Нам интересно, какие размеры это могут быть.
Решение: По сути нас просят найти число делителей (N). Нужно посмотреть на разложение числа (N) на простые множители, в общем виде оно выглядит так:
[N= p_1^{a_1} times p_2^{a_2} times ldots times p_k^{a_k}]
Теперь подумаем над этим выражением с точки зрения комбинаторики. Чтобы «сгенерировать» какой-нибудь делитель, нужно подставить в степень (i)-го простого число от 0 до (a_i) (то есть (a_i+1) различное значение), и так для каждого. То есть делитель (N) выглядит ровно так: [M= p_1^{b_1} times p_2^{b_2} times ldots times p_k^{b_k}, 0 leq b_i leq a_i] Значит, ответом будет произведение ((a_1+1) times (a_2+1) times ldots times (a_k + 1)).
Алгоритм разложения на простые множители
Применяя алгоритм проверки числа на простоту, мы умеем легко находить минимальный простой делитель числа N. Ясно, что как только мы нашли простой делитель числа (N), мы можем число (N) на него поделить и продолжить искать новый минимальный простой делитель.
Будем перебирать простой делитель от (2) до корня из (N) (как и раньше), но в случае, если (N) делится на этот делитель, будем просто на него делить. Причем, возможно, нам понадобится делить несколько раз ((N) может делиться на большую степень этого простого делителя). Так мы будем набирать простые делители и остановимся в тот момент, когда (N) стало либо (1), либо простым (и мы остановились, так как дошли до корня из него). Во втором случае надо еще само (N) добавить в ответ.
Напишем алгоритм факторизации:
def factorize(n):
factors = []
i = 2
while i * i <= n: # перебираем простой делитель
while n % i == 0: # пока N на него делится
n //= i # делим N на этот делитель
factors.append(i)
i += 1
# возможно, в конце N стало большим простым числом,
# у которого мы дошли до корня и поняли, что оно простое
# его тоже нужно добавить в разложение
if n > 1:
factors.append(n)
return factors
for i in [1, 2, 3, 10, 11, 12, 10**9+6, 10**9+7]:
print(i, '=', ' x '.join(str(x) for x in factorize(i)))1 =
2 = 2
3 = 3
10 = 2 x 5
11 = 11
12 = 2 x 2 x 3
1000000006 = 2 x 500000003
1000000007 = 1000000007Задание
За сколько работает этот алгоритм?
.
.
.
.
Решение
За те же самые (O(sqrt{N})). Итераций цикла while с перебором делителя будет не больше, чем (sqrt{N}). Причем ровно (sqrt{N}) операций будет только в том случае, если (N) — простое.
А итераций деления (N) на делители будет столько, сколько всего простых чисел в факторизации числа (N). Понятно, что это не больше, чем (O(log{N})).
Задание
Докажите, что число (N) имеет не больше, чем (O(log{N})) простых множителей в факторизации.
Разные свойства простых чисел*
Вообще, про простые числа известно много свойств, но почти все из них очень трудно доказать. Вот еще некоторые из них:
- Простых чисел, меньших (N), примерно (frac{N}{ln N}).
- N-ое простое число равно примерно (Nln N).
- Простые числа распределены более-менее равномерно. Например, если вам нужно найти какое-то простое число в промежутке, то можно их просто перебрать и проверить — через несколько сотен какое-нибудь найдется.
- Для любого (N ge 2) на интервале ((N, 2N)) всегда найдется простое число (Постулат Бертрана)
- Впрочем, существуют сколь угодно длинные отрезки, на которых простых чисел нет. Самый простой способ такой построить — это начать с (N! + 2).
- Есть алгоритмы, проверяющие число на простоту намного быстрее, чем за корень.
- Максимальное число делителей равно примерно (O(sqrt[3]{n})). Это не математический результат, а чисто эмпирический — не пишите его в асимптотиках.
- Максимальное число делителей у числа на отрезке ([1, 10^5]) — 128
- Максимальное число делителей у числа на отрекзке ([1, 10^9]) — 1344
- Максимальное число делителей у числа на отрезке ([1, 10^{18}]) — 103680
- Наука умеет факторизовать числа за (O(sqrt[4]{n})), но об этом как-нибудь в другой раз.
- Любое число больше трёх можно представить в виде суммы двух простых (гипотеза Гольдбаха), но это не доказано.
Решето Эратосфена
Часто нужно не проверять на простоту одно число, а найти все простые числа до (N). В этом случае наивный алгоритм будет работать за (O(Nsqrt N)), так как нужно проверить на простоту каждое число от 1 до (N).
Но древний грек Эратосфен предложил делать так:
Запишем ряд чисел от 1 до (N) и будем вычеркивать числа: * делящиеся на 2, кроме самого числа 2 * затем деляющиеся на 3, кроме самого числа 3 * затем на 5, затем на 7, и так далее и все остальные простые до n. Таким образом, все незачеркнутые числа будут простыми — «решето» оставит только их.
Красивая визуализация
Задание
Найдите этим способом на бумажке все простые числа до 50, потом проверьте с программой:
N = 50
prime = [1] * (N + 1)
prime[0], prime[1] = 0, 0
for i in range(2, N + 1): # можно и до sqrt(N)
if prime[i]:
for j in range(2 * i, N + 1, i): # идем с шагом i, можно начиная с i * i
prime[j] = 0
for i in range(1, N + 1):
if prime[i]:
print(i)2
3
5
7
11
13
17
19
23
29
31
37
41
43
47У этого алгоритма можно сразу заметить несколько ускорений.
Во-первых, число (i) имеет смысл перебирать только до корня из (N), потому что при зачеркивании составных чисел, делящихся на простое (i > sqrt N), мы ничего не зачеркнем. Почему? Пусть существует составное (M leq N), которое делится на %i%, и мы его не зачеркнули. Но тогда (i > sqrt N geq sqrt M), а значит по ранее нами доказанному утверждению (M) должно делиться и на простое число, которое меньше корня. Но это значит, что мы его уже вычеркнули.
Во-вторых, по этой же самое причине (j) имеет смысл перебирать только начиная с (i^2). Зачем вычеркивать (2i), (3i), (4i), …, ((i-1)i), если они все уже вычеркнуты, так как мы уже вычеркивали всё, что делится на (2), (3), (4), …, ((i-1)).
Асимптотика
Такой код будет работать за (O(N log log N)) по причинам, которые мы пока не хотим объяснять формально.
Гармонический ряд
Научимся оценивать асимптотику величины (1 + frac{1}{2} + ldots + frac{1}{N}), которая нередко встречается в задачах, где фигурирует делимость.
Возьмем (N) равное (2^i — 1) и запишем нашу сумму следующим образом: [left(frac{1}{1}right) + left(frac{1}{2} + frac{1}{3}right) + left(frac{1}{4} + ldots + frac{1}{7}right) + ldots + left(frac{1}{2^{i — 1}} + ldots + frac{1}{2^i — 1}right)]
Каждое из этих слагаемых имеет вид [frac{1}{2^j} + ldots + frac{1}{2^{j + 1} — 1} le frac{1}{2^j} + ldots + frac{1}{2^j} = 2^j frac{1}{2^j} = 1]
Таким образом, наша сумма не превосходит (1 + 1 + ldots + 1 = i le 2log_2(2^i — 1)). Тем самым, взяв любое (N) и дополнив до степени двойки, мы получили асимптотику (O(log N)).
Оценку снизу можно получить аналогичным образом, оценив каждое такое слагаемое снизу значением (frac{1}{2}).
Попытка объяснения асимптотики** (для старших классов)
Мы знаем, что гармонический ряд (1 + frac{1}{2} + frac{1}{3} + ldots + frac{1}{N}) это примерно (log N), а значит [N + frac{N}{2} + frac{N}{3} + ldots + frac{N}{N} sim N log N]
А что такое асимптотика решета Эратосфена? Мы как раз ровно (frac{N}{p}) раз зачеркиваем числа делящиеся на простое число (p). Если бы все числа были простыми, то мы бы как раз получили (N log N) из формули выше. Но у нас будут не все слагаемые оттуда, только с простым (p), поэтому посмотрим чуть более точно.
Известно, что простых чисел до (N) примерно (frac{N}{log N}), а значит допустим, что k-ое простое число примерно равно (k ln k). Тогда
[sum_{substack{2 leq p leq N \ text{p is prime}}} frac{N}{p} sim frac{1}{2} + sum_{k = 2}^{frac{N}{ln N}} frac{N}{k ln k} sim int_{2}^{frac{N}{ln N}} frac{N}{k ln k} dk =N(lnlnfrac{N}{ln N} — lnln 2) sim N(lnln N — lnlnln N) sim N lnln N]
Но вообще-то решето можно сделать и линейным.
Задание
Решите 5 первых задач из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34271
Линейное решето Эратосфена*
Наша цель — для каждого числа до (N) посчитать его минимальный простой делитель. Будем хранить его в массиве min_d. Параллельно будем хранить и список всех найденных простых чисел primes — это ровно те числа (x), у которых (min_d[x] = x).
Основное утверждение такое:
Пусть у числа (M) минимальный делитель равен (a). Тогда, если (M) составное, мы хотим вычеркнуть его ровно один раз при обработке числа (frac{M}{a}).
Мы также перебираем число (i) от (2) до (N). Если (min_d[i]) равно 0 (то есть мы не нашли ни один делитель у этого числа еще), значит оно простое — добавим в primes и сделаем (min_d[i] = i).
Далее мы хотим вычеркнуть все числа (i times k) такие, что (k) — это минимальный простой делитель этого числа. Из этого следует, что необходимо и достаточно перебрать (k) в массиве primes, и только до тех пор, пока (k < min_d[i]). Ну и перестать перебирать, если (i times k > N).
Алгоритм пометит все числа по одному разу, поэтому он корректен и работает за (O(N)).
N = 30
primes = []
min_d = [0] * (N + 1)
for i in range(2, N + 1):
if min_d[i] == 0:
min_d[i] = i
primes.append(i)
for p in primes:
if p > min_d[i] or i * p > N:
break
min_d[i * p] = p
print(i, min_d)
print(min_d)
print(primes)2 [0, 0, 2, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
3 [0, 0, 2, 3, 2, 0, 2, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
4 [0, 0, 2, 3, 2, 0, 2, 0, 2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
5 [0, 0, 2, 3, 2, 5, 2, 0, 2, 3, 2, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0]
6 [0, 0, 2, 3, 2, 5, 2, 0, 2, 3, 2, 0, 2, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0]
7 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 0, 0, 0, 0, 0, 3, 0, 0, 0, 5, 0, 0, 0, 0, 0]
8 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 0, 0, 0, 3, 0, 0, 0, 5, 0, 0, 0, 0, 0]
9 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 0, 0, 3, 0, 0, 0, 5, 0, 3, 0, 0, 0]
10 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 0, 2, 3, 0, 0, 0, 5, 0, 3, 0, 0, 0]
11 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 0, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 0, 5, 0, 3, 0, 0, 0]
12 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 0, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 0, 3, 0, 0, 0]
13 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 0, 0, 0]
14 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 0]
15 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
16 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
17 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
18 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
19 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
20 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
21 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
22 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
23 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
24 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
25 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
26 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
27 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
28 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
29 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 29, 2]
30 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 29, 2]
[0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 29, 2]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]Этот алгоритм работает асимптотически быстрее, чем обычное решето. Но на практике, если писать обычное решето Эратсфена с оптимизациями, то оно оказывается быстрее линейнего. Также линейное решето занимает гораздо больше памяти — ведь в обычном решете можно хранить просто (N) бит, а здесь нам нужно (N) чисел и еще массив primes.
Зато один из «побочных эффектов» алгоритма — он неявно вычисляет факторизацию всех чисел от (1) до (N). Ведь зная минимальный простой делитель любого числа от (1) до (N) можно легко поделить на это число, посмотреть на новый минимальный простой делитель и так далее.
НОД и НОК
Введем два определения.
Наибольший общий делитель (НОД) чисел (a_1, a_2, ldots, a_n) — это максимальное такое число (x), что все (a_i) делятся на (x).
Наименьшее общее кратное (НОК) чисел (a_1, a_2, ldots, a_n) — это минимальное такое число (x), что (x) делится на все (a_i).
Например, * НОД(18, 30) = 6 * НОД(60, 180, 315) = 15 * НОД(1, N) = 1 * НОК(12, 30) = 6 * НОК(1, 2, 3, 4) = 12 * НОК(1, (N)) = (N)
Зачем они нужны? Например, они часто возникают в задачах.
Условие: Есть (N) шестеренок, каждая (i)-ая зацеплена с ((i-1))-ой. (i)-ая шестеренка имеет (a_i) зубчиков. Сколько раз нужно повернуть полносьтю первую шестеренку, чтобы все остальные шестеренки тоже вернулись на изначальное место?
Решение: Когда одна шестеренка крутится на 1 зубчик, все остальные тоже крутятся на один зубчик. Нужно найти минимальное такое число зубчиков (x), что при повороте на него все шестеренки вернутся в изначальное положение, то есть (x) делится на все (a_i), то есть это НОК((a_1, a_2, ldots, a_N)). Ответом будет (frac{x}{a_1}).
Еще пример задачи на применение НОД и НОК:
Условие: Город — это прямоугольник (n) на (m), разделенный на квадраты единичного размера. Вертолет летит из нижнего левого угла в верхний правый по прямой. Вертолет будит людей в квартале, когда он пролетает строго над его внутренностью (границы не считаются). Сколько кварталов разбудит вертолёт?
Решение: Вертолет пересечет по вертикали ((m-1)) границу. С этим ничего не поделать — каждое считается как новое посещение какого-то квартала. По горизонтали то же самое — ((n-1)) переход в новую ячейку будет сделан.
Однако еще есть случай, когда он пересекает одновременно обе границы (то есть пролетает над каким-нибудь углом) — ровно тот случай, когда нового посещения квартала не происходит. Сколько таких будет? Ровно столько, сколько есть целых решений уравнения (frac{n}{m} = frac{x}{y}). Мы как бы составили уравнение движения вертолёта и ищем, в скольки целых точках оно выполняется.
Пусть (t = НОД(n, m)), тогда (n = at, m = bt).
Тогда (frac{n}{m} = frac{a}{b} = frac{x}{y}). Любая дробь с натуральными числителем и знаменателем имеет ровно одно представление в виде несократимой дроби, так что (x) должно делиться на (a), а (y) должно делиться на (b). А значит, как ответ подходят ((a, b), (2a, 2b), (3a, 3b), cdots, ((t-1)a, (t-1)b)). Таких ответов ровно (t = НОД(n, m))
Значит, итоговый ответ: ((n-1) + (m-1) — (t-1)).
Кстати, когда (НОД(a, b) = 1), говорят, что (a) и (b) взаимно просты.
Алгоритм Евклида
Осталось придумать, как искать НОД и НОК. Понятно, что их можно искать перебором, но мы хотим хороший быстрый способ.
Давайте для начала научимся искать (НОД(a, b)).
Мы можем воспользоваться следующим равенством: [НОД(a, b) = НОД(a, b — a), b > a]
Оно доказывается очень просто: надо заметить, что множества общих делителей у пар ((a, b)) и ((a, b — a)) совпадают. Почему? Потому что если (a) и (b) делятся на (x), то и (b-a) делится на (x). И наоборот, если (a) и (b-a) делятся на (x), то и (b) делится на (x). Раз множства общих делитей совпадают, то и максимальный делитель совпадает.
Из этого равенства сразу следует следующее равенство: [НОД(a, b) = НОД(a, b operatorname{%} a), b > a]
(так как (НОД(a, b) = НОД(a, b — a) = НОД(a, b — 2a) = НОД(a, b — 3a) = ldots = НОД(a, b operatorname{%} a)))
Это равенство дает идею следующего рекурсивного алгоритма:
[НОД(a, b) = НОД(b operatorname{%} a, a) = НОД(a operatorname{%} , (b operatorname{%} a), b operatorname{%} a) = ldots]
Например: [НОД(93, 36) = ] [= НОД(36, 93spaceoperatorname{%}36) = НОД(36, 21) = ] [= НОД(21, 15) = ] [= НОД(15, 6) = ] [= НОД(6, 3) = ] [= НОД(3, 0) = 3]
Задание:
Примените алгоритм Евклида и найдите НОД чисел: * 1 и 500000 * 10, 20 * 18, 60 * 55, 34 * 100, 250
По-английски наибольший общий делитель — greatest common divisor. Поэтому вместо НОД будем в коде писать gcd.
def gcd(a, b):
if b == 0:
return a
return gcd(b, a % b)
print(gcd(1, 500000))
print(gcd(10, 20))
print(gcd(18, 60))
print(gcd(55, 34))
print(gcd(100, 250))
print(gcd(2465473782, 12542367456))1
10
6
1
50
6Вообще, в C++ такая функция уже есть в компиляторе g++ — называется __gcd. Если у вас не Visual Studio, то, скорее всего, у вас g++. Вообще, там много всего интересного.
А за сколько оно вообще работает?
Задание
Докажите, что алгоритм Евклида для чисел (N), (M) работает за (O(log(N+M))).
Кстати, интересный факт: самыми плохими входными данными для алгоритма Евклида являются числа Фибоначчи. Именно там и достигается логарифм.
Как выразить НОК через НОД
(НОК(a, b) = frac{ab}{НОД(a, b)})
По этой формуле можно легко найти НОК двух чисел через их произведение и НОД. Почему она верна?
Посмотрим на разложения на простые множители чисел a, b, НОК(a, b), НОД(a, b).
[ a = p_1^{a_1}times p_2^{a_2}timesldotstimes p_n^{a_n} ] [ b = p_1^{b_1}times p_2^{b_2}timesldotstimes p_n^{b_n} ] [ ab = p_1^{a_1+b_1}times p_2^{a_2+b_2}timesldotstimes p_n^{a_n+b_n} ]
Из определений НОД и НОК следует, что их факторизации выглядят так: [ НОД(a, b) = p_1^{min(a_1, b_1)}times p_2^{min(a_2, b_2)}timesldotstimes p_n^{min(a_n, b_n)} ] [ НОК(a, b) = p_1^{max(a_1, b_1)}times p_2^{max(a_2, b_2)}timesldotstimes p_n^{max(a_n, b_n)} ]
Тогда посчитаем (НОД(a, b) times НОК(a, b)): [ НОД(a, b)НОК(a, b) = p_1^{min(a_1, b_1)+max(a_1, b_1)}times p_2^{min(a_2, b_2)+max(a_2, b_2)}timesldotstimes p_n^{min(a_n, b_n)+max(a_n, b_n)} =] [ = p_1^{a_1+b_1}times p_2^{a_2+b_2}timesldotstimes p_n^{a_n+b_n} = ab]
Формула доказана.
Как посчитать НОД/НОК от более чем 2 чисел
Для того, чтобы искать НОД или НОК у более чем двух чисел, достаточно считать их по цепочке:
(НОД(a, b, c, d, ldots) = НОД(НОД(a, b), c, d, ldots))
(НОК(a, b, c, d, ldots) = НОК(НОК(a, b), c, d, ldots))
Почему это верно?
Ну просто множество общих делителей (a) и (b) совпадает с множеством делителей (НОД(a, b)). Из этого следует, что и множество общих делителей (a), (b) и еще каких-то чисел совпадает с множеством общих делителей (НОД(a, b)) и этих же чисел. И раз совпадают множества общих делителей, то и наибольший из них совпадает.
С НОК то же самое, только фразу “множество общих делителей” надо заменить на “множество общих кратных”.
Задание
Решите задачи F, G, H, I из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34271
Расширенный алгоритм Евклида*
Очень важным для математики свойством наибольшего общего делителя является следующий факт:
Для любых целых (a, b) найдутся такие целые (x, y), что (ax + by = d), где (d = gcd(a, b)).
Из этого следует, что существует решение в целых числах, например, у таких уравнений: * (8x + 6y = 2) * (4x — 5y = 1) * (116x + 44y = 4) * (3x + 11y = -1)
Мы сейчас не только докажем, что решения у таких уравнений существуют, но и приведем быстрый алгоритм нахождения этих решений. Здесь нам вновь пригодится алгоритм Евклида.
Рассмотрим один шаг алгоритма Евклида, преобразующий пару ((a, b)) в пару ((b, a operatorname{%} b)). Обозначим (r = a operatorname{%} b), то есть запишем деление с остатком в виде (a = bq + r).
Предположим, что у нас есть решение данного уравнения для чисел (b) и (r) (их наибольший общий делитель, как известно, тоже равен (d)): [bx_0 + ry_0 = d]
Теперь сделаем в этом выражении замену (r = a — bq):
[bx_0 + ry_0 = bx_0 + (a — bq)y_0 = ay_0 + b(x_0 — qy_0)]
Tаким образом, можно взять (x = y_0), а (y = (x_0 — qy_0) = (x_0 — (a operatorname{/} b)y_0)) (здесь (/) обозначает целочисленное деление).
В конце алгоритма Евклида мы всегда получаем пару ((d, 0)). Для нее решение требуемого уравнения легко подбирается — (d * 1 + 0 * 0 = d). Теперь, используя вышесказанное, мы можем идти обратно, при вычислении заменяя пару ((x, y)) (решение для чисел (b) и (a operatorname{%} b)) на пару ((y, x — (a / b)y)) (решение для чисел (a) и (b)).
Это удобно реализовывать рекурсивно:
def extended_gcd(a, b):
if b == 0:
return a, 1, 0
d, x, y = extended_gcd(b, a % b)
return d, y, x - (a // b) * y
a, b = 3, 5
res = extended_gcd(a, b)
print("{3} * {1} + {4} * {2} = {0}".format(res[0], res[1], res[2], a, b))3 * 2 + 5 * -1 = 1Но также полезно и посмотреть, как будет работать расширенный алгоритм Евклида и на каком-нибудь конкретном примере. Пусть мы, например, хотим найти целочисленное решение такого уравнения: [116x + 44y = 4] [(2times44+28)x + 44y = 4] [44(2x+y) + 28x = 4] [44x_0 + 28y_0 = 4] Следовательно, [x = y_0, y = x_0 — 2y_0] Будем повторять такой шаг несколько раз, получим такие уравнения: [116x + 44y = 4] [44x_0 + 28y_0 = 4, x = y_0, y = x_0 — 2y_0] [28x_1 + 16y_1 = 4, x_0 = y_1, y_0 = x_1 — y_1] [16x_2 + 12y_2 = 4, x_1 = y_2, y_1 = x_2 — y_2] [12x_3 + 4y_3 = 4, x_2 = y_3, y_2 = x_3 — y_3] [4x_4 + 0y_4 = 4, x_3 = y_4, y_3 = x_4 — 3 y_4] А теперь свернем обратно: [x_4 = 1, y_4 = 0] [x_3 = 0, y_3 =1] [x_2 = 1, y_2 =-1] [x_1 = -1, y_1 =2] [x_0 = 2, y_0 =-3] [x = -3, y =8]
Действительно, (116times(-3) + 44times8 = 4)
Задание
Решите задачу J из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34273
Операции по модулю
Выражение (a equiv b pmod m) означает, что остатки от деления (a) на (m) и (b) на (m) равны. Это выражение читается как «(a) сравнимо (b) по модулю (m)».
Еще это можно опрделить так: (a) сравнимо c (b) по модулю (m), если ((a — b)) делится на (m).
Все целые числа можно разделить на классы эквивалентности — два числа лежат в одном классе, если они сравнимы по модулю (m). Говорят, что мы работаем в «кольце остатков по модулю (m)», и в нем ровно (m) элементов: (0, 1, 2, cdots, m-1).
Сложение, вычитение и умножение по модулю определяются довольно интуитивно — нужно выполнить соответствующую операцию и взять остаток от деления.
С делением намного сложнее — поделить и взять по модулю не работает. Об этом подробнее поговорим чуть дальше.
a = 30
b = 50
mod = 71
print('{} + {} = {} (mod {})'.format(a, b, (a + b) % mod, mod))
print('{} - {} = {} (mod {})'.format(a, b, (a - b) % mod, mod)) # на C++ это может не работать, так как модуль от отрицательного числа берется странно
print('{} - {} = {} (mod {})'.format(a, b, (a - b + mod) % mod, mod)) # на C++ надо писать так, чтобы брать модулю от гарантированно неотрицательного числа
print('{} * {} = {} (mod {})'.format(a, b, (a * b) % mod, mod))
# print((a / b) % mod) # а как писать это, пока неясно30 + 50 = 9 (mod 71)
30 - 50 = 51 (mod 71)
30 - 50 = 51 (mod 71)
30 * 50 = 9 (mod 71)Задание
Посчитайте: * (2 + 3 pmod 5) * (2 * 3 pmod 5) * (2 ^ 3 pmod 5) * (2 — 4 pmod 5) * (5 + 5 pmod 6) * (2 * 3 pmod 6) * (3 * 3 pmod 6)
Для умножения (в C++) нужно ещё учитывать следующий факт: при переполнении типа всё ломается (разве что если вы используете в качестве модуля степень двойки).
intвмещает до (2^{31} — 1 approx 2 cdot 10^9).long longвмещает до (2^{63} — 1 approx 8 cdot 10^{18}).long long longв плюсах нет, при попытке заиспользовать выдает ошибкуlong long long is too long.- Под некоторыми компиляторами и архитектурами доступен
int128, но не везде и не все функции его поддерживают (например, его нельзя вывести обычными методами).
Зачем нужно считать ответ по модулю
Очень часто в задаче нужно научиться считать число, которое в худшем случае гораздо больше, чем (10^{18}). Тогда, чтобы не заставлять вас писать длинную арифметику, автор задачи часто просит найти ответ по модулю большого числа, обычно (10^9 + 7)
Кстати, вместо того, чтобы писать (1000000007) удобно просто написать (1e9 + 7). (1e9) означает (1 times 10^9)
int mod = 1e9 + 7; # В C++
cout << mod;1000000007N = 1e9 + 7 # В питоне такое число становится float
print(N)
print(int(N))1000000007.0
1000000007Быстрое возведение в степень
Задача: > Даны натуральные числа (a, b, c < 10^9). Найдите (a^b) (mod (c)).
Мы хотим научиться возводить число в большую степень быстро, не просто умножая (a) на себя (b) раз. Требование на модуль здесь дано только для того, чтобы иметь возможность проверить правильность алгоритма для чисел, которые не влезают в int и long long.
Сам алгоритм довольно простой и рекурсивный, постарайтесь его придумать, решая вот такие примеры (прямо решать необязательно, но можно придумать, как посчитать значение этих чисел очень быстро):
- (3^2)
- (3^4)
- (3^8)
- (3^{16})
- (3^{32})
- (3^{33})
- (3^{66})
- (3^{132})
- (3^{133})
- (3^{266})
- (3^{532})
- (3^{533})
- (3^{1066})
Да, здесь специально приведена такая последовательность, в которой каждое следующее число легко считается через предыдущее: его либо нужно умножить на (a=3), либо возвести в квадрат. Так и получается рекурсивный алгоритм:
- (a^0 = 1)
- (a^{2k}=(a^{k})^2)
- (a^{2k+1}=a^{2k}times a)
Нужно только после каждой операции делать mod: * (a^0 pmod c = 1) * (a^{2k} pmod c = (a^{k} pmod c)^2 pmod c) * (a^{2k+1} pmod c = ((a^{2k}pmod c) times a) pmod c)
Этот алгоритм называется быстрое возведение в степень. Он имеет много применений: * в криптографии очень часто надо возводить число в большую степень по модулю * используется для деления по простому модулю (см. далее) * можно быстро перемножать не только числа, но еще и матрицы (используется для динамики, например)
Асимптотика этого алгоритма, очевидно, (O(log c)) — за каждые две итерации число уменьшается хотя бы в 2 раза.
Задание
Решите задачу K из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34271
Задание
Решите как можно больше задач из практического контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34273
Деление по модулю*
Давайте все-таки научимся не только умножать, но и делить по простому модулю. Вот только что это значит?
(a / b) = (a times b^{-1}), где (b^{-1}) — это обратный элемент к (b).
Определение: (b^{-1}) — это такое число, что (bb^{-1} = 1)
Утверждение: в кольце остатков по простому модулю (p) у каждого остатка (кроме 0) существует ровно один обратный элемент.
Например, обратный к (2) по модулю (5) это (3) ((2 times 3 = 1 pmod 5)))
Задание
Найдите обратный элемент к: * числу (3) по модулю (5) * числу (3) по модулю (7) * числу (1) по модулю (7) * числу (2) по модулю (3) * числу (9) по модулю (31)
Давайте докажем это утверждение: надо заметить, что если каждый ненулевой остаток (1, 2, ldots, (p-1)) умножить на ненулевой остаток (a), то получатся числа (a, 2a, ldots, (p-1)a) — и они все разные! Они разные, потому что если (xa = ya), то ((x-y)a = 0), а значит ((x — y) a) делится на (p), (a) — ненулевой остаток, а значит (x = y), и это не разные числа. И из того, что все числа получились разными, это все ненулевые, и их столько же, следует, что это ровно тот же набор чисел, просто в другом порядке!
Из этого следует, что среди этих чисел есть (1), причем ровно один раз. А значит существует ровно один обратный элемент (a^{-1}). Доказательство закончено.
Это здорово, но этот обратный элемент еще хочется быстро находить. Быстрее, чем за (O(p)).
Есть несколько способов это сделать.
Через малую теорему Ферма
Малая теорема Ферма: > (a^{p-1} = 1 pmod p), если (p) — простое, (a neq 0 pmod p)).
Доказательство: В предыдущем пункте мы выяснили, что множества чисел (1, 2, ldots, (p-1)) и (a, 2a, ldots, (p-1)a) совпадают. Из этого следует, что их произведения тоже совпадают по модулю: ((p-1)! = a^{p-1} (p-1)! pmod p).
((p-1)!neq 0 pmod p) а значит на него можно поделить (это мы кстати только в предыдущем пункте доказали, поделить на число — значит умножить на обратный к нему, который существует).
А значит, (a^{p — 1} = 1 pmod p).
Как это применить Осталось заметить, что из малой теоремы Ферма сразу следует, что (a^{p-2}) — это обратный элемент к (a), а значит мы свели задачу к возведению (a) в степень (p-2), что благодаря быстрому возведению в степень мы умеем делать за (O(log p)).
Обобщение У малой теоремы Ферма есть обобщение для составных (p):
Теорема Эйлера: > (a^{varphi(p)} = 1 pmod p), (a) — взаимно просто с (p), а (varphi(p)) — это функция Эйлера (количество чисел, меньших (p) и взаимно простых с (p)).
Доказывается теорема очень похоже, только вместо ненулевых остатков (1, 2, ldots, p-1) нужно брать остатки, взаимно простые с (p). Их как раз не (p-1), а (varphi(p)).
Для нахождения обратного по этой теореме достаточно посчитать функцию Эйлера (varphi(p)) и найти (a^{-1} = a^{varphi(p) — 1}).
Но с этим возникают большие проблемы: посчитать функцию Эйлера сложно. Более того, на предполагаемой невозможности быстро ее посчитать построены некоторые криптографические алгоритм типа RSA. Поэтому быстро делить по составному модулю этим способом не получится.
Через расширенный алгоритм Евклида
Этим способом легко получится делить по любому модулю! Рекомендую.
Пусть мы хотим найти (a^{-1} pmod p), (a) и (p) взаимно простые (а иначе обратного и не будет существовать).
Давайте найдем корни уравнения
[ax + py = 1]
Они есть и находятся расширенным алгоритмом Евклида за (O(log p)), так как (НОД(a, p) = 1), ведь они взаимно простые.
Тогда если взять остаток по модулю (p):
[ax = 1 pmod p]
А значит, найденный (x) и будет обратным элементом к (a).
То есть надо просто найти (x) из решения того уравнения по модулю (p). Можно брать по модулю прямо походу решения уравнения, чтобы случайно не переполниться.
Список простых чисел
Список всех простых чисел — сколько простых чисел в диапазоне
Калькулятор «Список простых чисел»
О калькуляторе «Список простых чисел»
Данный калькулятор покажет список простых чисел между заданными числами. Например, он может помочь узнать какие простые числа между 20 и 30? Выберите начальное число (например ’20’) и конечное число (например ’30’). После чего нажмите кнопку ‘Посчитать’.
Простые числа - это положительные целые числа, имеющие только два делителя - 1 и само себя.
Последние расчеты
Напишите программу, которая ищет среди целых чисел, принадлежащих числовому отрезку [2422000; 2422080], простые числа. Выведите все найденные простые числа в порядке возрастания, слева от каждого числа выведите его номер по порядку.
мой способ дает бесконечное выполнение программы
for x in range(2422000, 2422080):
a = []
for n in range(1,x):
if x%n==0 and (x==n or n==1):
a.append(n)
print(a)
![]()
Эникейщик
25.1k7 золотых знаков30 серебряных знаков46 бронзовых знаков
задан 19 дек 2020 в 21:39
![]()
4
По идее как то так
a = []
for x in range(2422000, 2422080):
d = 2
while x % d != 0:
d += 1
if d == x:
a.append(x)
print(a)
ответ дан 19 дек 2020 в 22:18
![]()
KersKers
3,1562 золотых знака7 серебряных знаков16 бронзовых знаков
Попробуйте так:
import math
def is_prime(i):
m = min(i, int(math.sqrt(b)))
l = range(2, m)
r = map(lambda x: i % x == 0, l)
return not any(r)
a = 2422000
b = 2422080
ls = range(a, b)
_list = list(filter(is_prime, ls))
print(*[ f'{i+1}: {v}' for i, v in enumerate(_list)], sep='n')
ответ дан 19 дек 2020 в 22:18
![]()
S. NickS. Nick
70.2k96 золотых знаков36 серебряных знаков55 бронзовых знаков
1
Под словами «номер по порядку» имеется в виду номер в списке (2422000, 2422080), или номер числа в списке простых чисел? Если первый вариант, то решение такое:
for i in range(2422000, 2422081):
for j in range(2, i // 2):
if i % j == 0: break
else: print(i - 2421999, i)
ответ дан 19 дек 2020 в 21:45
![]()
Попробуйте через списковую сборку, в первом списке поставьте нужный интервал в range(2, 1001)…, числа до 1000 поставил для примера,
вот:
print([x for x in range(2, 1001) if not [n for n in range(2, x) if not x % n]])
или
print([x for x in range(2, 1001) if all(x % t for t in range(2, int(math.sqrt(x))+1))])
ответ дан 13 июн 2021 в 19:39
![]()
PoMaXaPoMaXa
12 бронзовых знака
1
for i in range(2422000, 2422081):
deli=[]
for a in range(2,i+1):
if i%a==0:
deli.append(a)
if len(deli)>1:
break
if len(deli)==1:
print(deli)
ответ дан 23 июн 2021 в 10:14
![]()
1