Как найти в интернете информацию
Все, что можно найти в интернете (книги, музыку, фото, видео и другое), находится на сайтах. То есть интернет – это очень-очень-очень много сайтов. Чтобы попасть на какой-нибудь из них, нужно открыть программу для работы в интернете, которая называется браузер.
Браузер — это программа, через которую человек открывает интернет. Как правило, на компьютере таких программ несколько, но работает пользователь только в одной.
Самые популярные браузеры: Google Chrome, Opera, Mozilla Firefox, Yandex и Internet Explorer. В зависимости от того, какой значок Вы открываете, когда заходите в интернет, такой программой и пользуетесь.

Где искать сайты
Так как вся информация в интернете находится на сайтах, то для ее получения нужно открыть какой-то сайт.
У каждого из них есть собственный адрес. Например, у ресурса, на котором Вы сейчас находитесь, адрес neumeka.ru
Таких адресов миллиарды. На каждом — какая-то информация. На одном рецепты, на другом видео ролики, на третьем новости… Получается огромная куча адресов и каждый с каким-то своим наполнением.
И как среди них отыскать нужную информацию?! Помогут нам в этом поисковые системы. Или, по-простому, – поисковики. Это такие специальные сайты-справочники. Принцип работы прост: Вы открываете адрес сайта-поисковика, печатаете на нем то, что хотите найти в интернете, и нажимаете кнопку «Enter» на клавиатуре. Буквально через секунду поисковая система перероет весь интернет и покажет те сайты, где есть то, что Вы ищете.
То есть, чтобы работать в интернете (находить и скачивать информацию, общаться и т.д.), Вам нужно знать всего один-два адреса поисковых систем.
Яндекс (yandex.ru)
Начнем с поисковика Яндекс, так как это российский поисковик, ориентированный, в первую очередь, на русскоговорящих людей.
Чтобы его открыть, нужно напечатать английскими буквами адрес yandex.ru в верхней строке браузера и нажать на кнопку Enter на клавиатуре.

Откроется примерно такая страница.

Обратите внимание на желтую полоску посередине. Именно она отвечает за поиск в интернете.

Щелкните левой кнопкой мышки внутри этой полоски (по белой строчке) и напечатайте по-русски то, что хотите найти в интернете.
Кстати, можно напечатать и по-английски, и по-украински, и на других языках. Но если Вы никогда этого не делали, лучше начать с русского.
Допустим, я хочу найти биографию Леонардо Да Винчи. Что в этом случае нужно набрать?
Можно, конечно, так и напечатать: «хочу найти биографию Леонардо Да Винчи». Но это не самый лучший вариант. Потому что поисковик не человек. И «общаться» с ним следует несколько по-другому. Печатать нужно точно и ясно. В моем случае лучше набрать «леонардо да винчи биография».
Вводить запрос можно любыми буквами – и большими, и маленькими. Поисковику все равно. Даже если Вы напечатаете с ошибками он, скорее всего, их сам и исправит.
После ввода запроса нужно нажать на кнопку «Найти» в конце поисковой строки или кнопку «Enter» на клавиатуре.
Загрузится новая страница с результатами поиска.

Произошло следующее: я напечатал то, что хотел найти в интернете (по-научному это называется «ввел запрос»), нажал «Enter» – и Яндекс молниеносно «прогулялся» интернету и нашел сайты, на которых представлена интересующая меня информация.
Если вопрос касается каких-то общеизвестных явлений (популярные люди, фильмы и т.д.), то с правой стороны поисковик показывает основные сведения. В моем случае это краткая биография и известные работы художника.
А в центре Яндекс показывает сайты (а точнее, страницы сайтов) с информацией — их адреса и краткое содержание. Расскажу о них подробнее, так как это самая важная часть поиска.

Нашел их Яндекс очень и очень много. Но сначала поисковик показывает те, которые по определенным причинам считает лучшими. И чаще всего он не ошибается — остальные ресурсы, как правило, худшего качества.
Все это все небольшие анонсы. Каждый из них имеет заголовок сине-голубого цвета, после которого идет краткое описание (черного цвета). А над описанием находится адрес сайта в интернете (зеленого цвета). А если быть более точным, то адрес статьи сайта с нужной информацией.
Ведь на каждом сайте, как правило, не одна страница с информацией, а много. Например, одна статья о Леонардо Да Винчи, другая о Микеланджело, третья о Рембрандте и так далее. И у каждой из них есть свой собственный адрес в рамках адреса сайта.
Это как журнал, в котором много страниц и все они пронумерованы — у каждой свой номер.

Например, мне понравилось первое описание, и я хочу прочитать статью целиком. Для этого нужно навести курсор (стрелку) на заголовок. Курсор примет вид руки с вытянутым пальцем. Нужно нажать левой кнопкой мышки один раз.

Кстати, в интернете все нужно нажимать по одному разу, а не два, как в компьютере.
Нажав по заголовку анонса, откроется новая страница. Это и есть та страница сайта, про которую нам «рассказал» Яндекс. Теперь нужно пробежаться глазами по тексту. Если информация на этой странице не подходит, закрываем ее и возвращаемся к Яндексу с результатами поиска. Открываем другой анонс из предложенных.
Можно открыть не одну, а несколько страниц одновременно. Главное – в них не запутаться 
Все открытые сайты находятся вверху программы-браузера в виде закладок:

То есть, когда мы открываем какой-нибудь анонс, то получается, что у нас открыто два сайта. Первый – это Яндекс с результатами поиска, а второй – тот, который мы открыли из списка (один из результатов).
Но вернемся к поиску. Я уже говорил, что для начала Яндекс показывает те страницы, которые, по его мнению, лучшие. Все остальные (а их сотни и даже тысячи) находятся внизу.
Если опуститься в самый них страницы с результатами поиска, то там будут цифры.
Для этого нужно покрутить колесико на мышке или передвинуть ползунок с правой стороны браузера.

За ними прячутся другие страницы, которые нашел Яндекс. Нажмите на цифру «2». Загрузится страничка с анонсами уже других сайтов.
Значит, если не подошло то, что выдал Яндекс в самом начале, можно посмотреть другие анонсы (и сайты), которые прячутся под цифрами в самом низу результатов поиска.
Гугл (google.ru)
Второй поисковик, которым следует уметь пользоваться – Гугл (google.ru). Принцип тот же. Набираем в адресной строке браузера google.ru и нажимаете кнопку «Enter» на клавиатуре.

Загрузится очень простая по дизайну страница. В центре находится строка для печати запроса.

Напечатайте в эту строчку то, что хотите найти в интернете (поисковый запрос). После этого нажмите кнопку «Enter» на клавиатуре или же кнопку «Поиск в Google» на самом сайте.
Загрузится новая страничка с анонсами. Все очень похоже на то, что мы уже видели в Яндексе.

Так же, как и у Яндекса, – читаем анонс, и, если кажется, что он подходит, нажимаем на заголовок. Откроется сайт с информацией по нашей теме. Если это действительно то, что нужно, остаемся на этом сайте. А если данная информация не подходит, – закрываем и снова возвращаемся в Гугл.
И, как и в Яндексе, в самом конце страницы с результатами поиска есть цифры. Под этими цифрами прячутся другие анонсы сайтов по теме.

В этом уроке мы рассмотрели универсальный способ поиска информации. Зная всего два сайта – yandex.ru и google.ru, – Вы сможете найти в интернете что угодно.

13 марта 2017
Как узнать все сайты, на которых я зарегистрирован
Многие пользователи интернета хотя бы однажды спрашивали: «Как узнать все сайты, на которых я зарегистрирован?» Вспомнить, где была пройдена регистрация, может быть полезно, чтобы воспользоваться одним из различных онлайн сервисов, например, социальной сетью или интернет-банком.

Для начала постарайтесь вспомнить, какими интернет-ресурсами вы пользовались и в какое время. Например, человеку вполне под силу осознать, что, к примеру, 2-3 года назад он был постоянным пользователем определенной социальной сети, форума, трекера либо являлся клиентом того или иного банка. В таком случае остается лишь вспомнить название данного сайта. Сделать это можно, поинтересовавшись у знакомых или просто выполнив поиск через «Яндекс», Google либо другой поисковик по ключевым словам.
Что еще важно для того, чтобы узнать все сайты, на которых зарегистрирован? Конечно же, имя пользователя, то есть логин, который был указан во время регистрации. Допустим, вы какое-то время использовали для этого логин Super_Ivan1 или любой подобный. Попробуйте вновь выполнить поиск по этому логину через интернет-поисковики. Скорее всего, в результатах поиска отобразится большинство сайтов, где до сих пор сохранился ваш профиль под таким именем.
Многие люди хранят информацию о своей деятельности в интернете на своем компьютере. Это может быть текстовый документ со списком сайтов, а также логинов и паролей к ним, на которых зарегистрирован данный пользователь. Постарайтесь вспомнить, возможно, подобный документ хранится в одной из личных папок на вашем жестком диске. Можно также поинтересоваться об этом у близких друзей и родственников. Вероятно, кто-нибудь из них пользовался одними и теми же сайтами одновременно с вами. Обратите внимание, что некоторые организации, например, банки, электронные офисы и всевозможные фирмы обычно имеют физические офисы, куда можно обратиться, если вам нужно вернуть доступ к их интернет-ресурсам.
Если вы вспомнили все или хотя бы несколько сайтов, где зарегистрированы, остается лишь восстановить к ним доступ. Если вы не помните ваш логин или пароль, посмотрите, нет ли рядом с панелью входа кнопкой «восстановить логин (пароль)». Нажав на нее, вы запустите процедуры восстановления доступа. Важно, чтобы у вас оставалась в текущем пользовании электронная почта, через которую проходила регистрация на соответствующем сайте. Именно на нее придет информация с указаниями по дальнейшим действиям.
Получив письмо от сайта, просто последуйте его указаниям для восстановления логина и пароля к сайту. Если же у вас не получилось этого сделать, можно попытаться связаться с администрацией ресурса и поинтересоваться о способах восстановления на нем. Также нелишним будет изучить ваш почтовый ящик: возможно, здесь еще остались старые письма, в которых содержится информация о том, на каких еще сайтах вы зарегистрированы с указанием всех соответствующих регистрационных данных.
Источники:
- Что означает сообщение «Абонент в сети не зарегистрирован»?
Иногда оптимизатору нужно получить список всех страниц сайта, в том числе технических и не проиндексированных. Чтобы собрать их вручную, придется потратить не один час, особенно если сайт большой. Существуют сервисы, которые упрощают задачу. Чтобы при аудите ни один документ не потерялся, можно воспользоваться не одним, а сразу несколькими инструментами.
Расскажем, как найти все страницы сайта и какие сервисы для этого нужны.
Зачем нужна такая информация
Список страниц полезен для того, чтобы:
- Найти все страницы, которые не проиндексированы или выпали из индекса поисковой системы. Их нужно проанализировать. Возможно, причина в технических настройках (например, URL закрыт от роботов ПС) или в низком качестве документов. При необходимости их нужно доработать.
- Такой список — хорошая помощь, когда нужно найти причину проблем. Например, при резком падении трафика.
- Настроить перелинковку — проставить внутренние ссылки, правильно распределить ссылочный вес.
- Избавиться от «мусорных» документов, ошибок, дублей.
- Найти все страницы сайта с кодом ответа, отличным от 200 OK.
Почему для сбора данных одного инструмента мало
Выбор инструмента зависит от задачи. Если встал вопрос, как найти все проиндексированные документы или только те, на которые идет трафик, Вебмастера и Метрики будет достаточно. Если проводится технический аудит, подходит Screaming frog SEO spider.
Если нужен полный список страниц, удобнее воспользоваться сразу несколькими инструментами и объединить получившиеся списки. Если ограничиться только одним способом, перечень будет неполным. Например, если использовать только xml-карту, в списке не окажется «мусорных» файлов, сгенерированных из-за неправильных технических настроек. Яндекс.Вебмастер показывает только те документы, которые попали в поиск или выпали из него.
Пиксель Тулс
С помощью онлайн-инструмента «Анализ структуры проекта» можно узнать все страницы, проиндексированные поисковой системой Яндекс. Для анализа не нужен доступ к файлам сайта и Метрике. Можно получить список URL любого проекта, например, конкурента.
Введите домен в верхнюю строку и кликните на кнопку «Найти». Если выбрать опцию «Анализировать число документов только для разделов второго уровня», сервис подсчитает количество страниц в категориях и не будет определять объем подкатегорий.
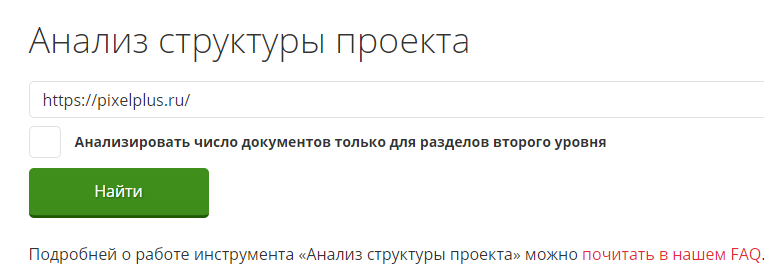
Инструмент строит подробную наглядную структуру (иерархию), подсчитывает количество документов в разделах и процент от общего объема проекта.
Яндекс.Вебмастер
Откройте подраздел «Страницы в поиске» в разделе «Индексирование».
Откройте вкладку «Все страницы» и скачайте таблицу в формате CSV или XLS.
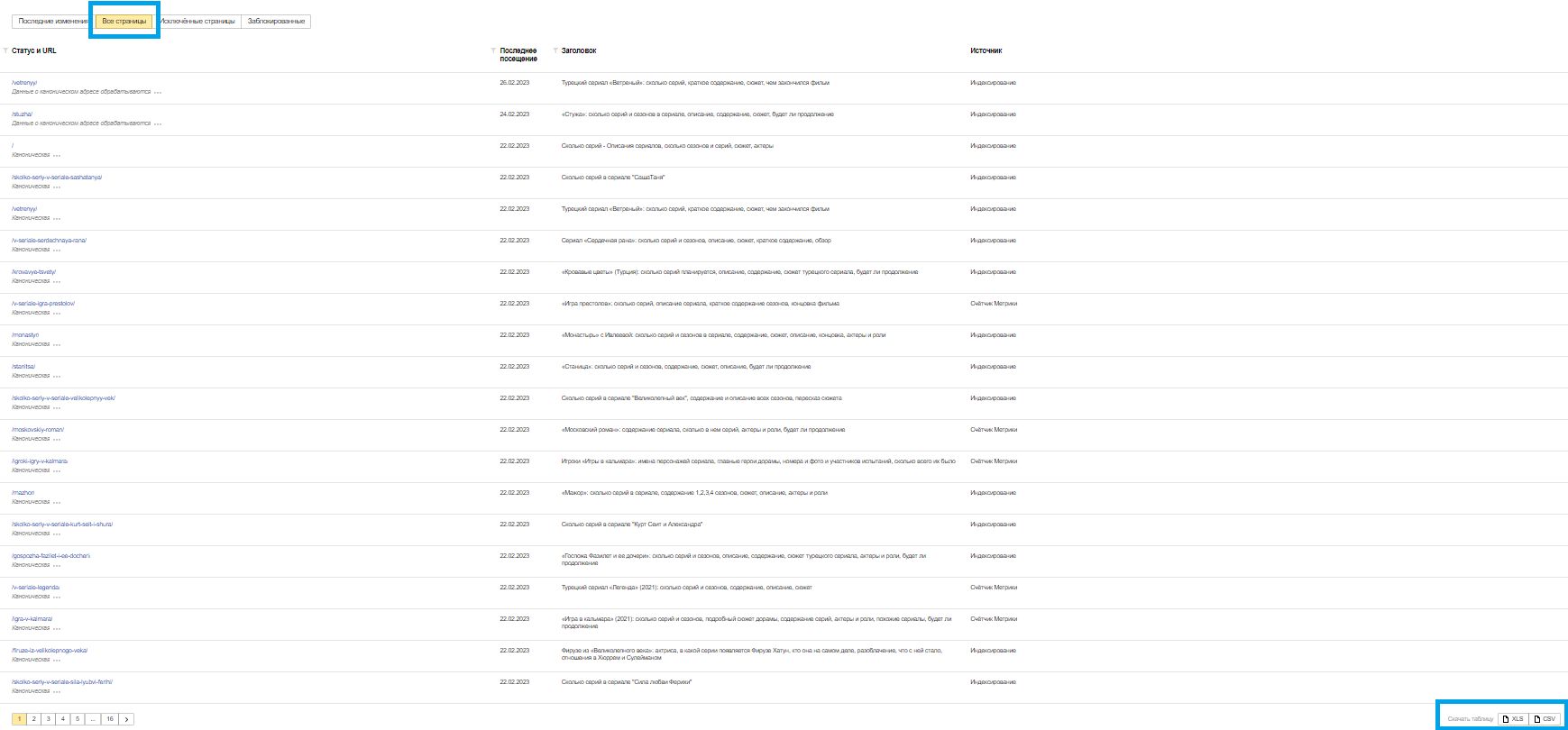
Чтобы получить перечень не попавших в индекс документов, нужно скачать таблицу в разделе «Исключенные страницы».
Яндекс.Метрика
Полный список страниц, на которые заходят пользователи, можно найти в Яндекс.Метрике. Для этого нужно выбрать большой период, например, год, и зайти в раздел «Адрес страницы».
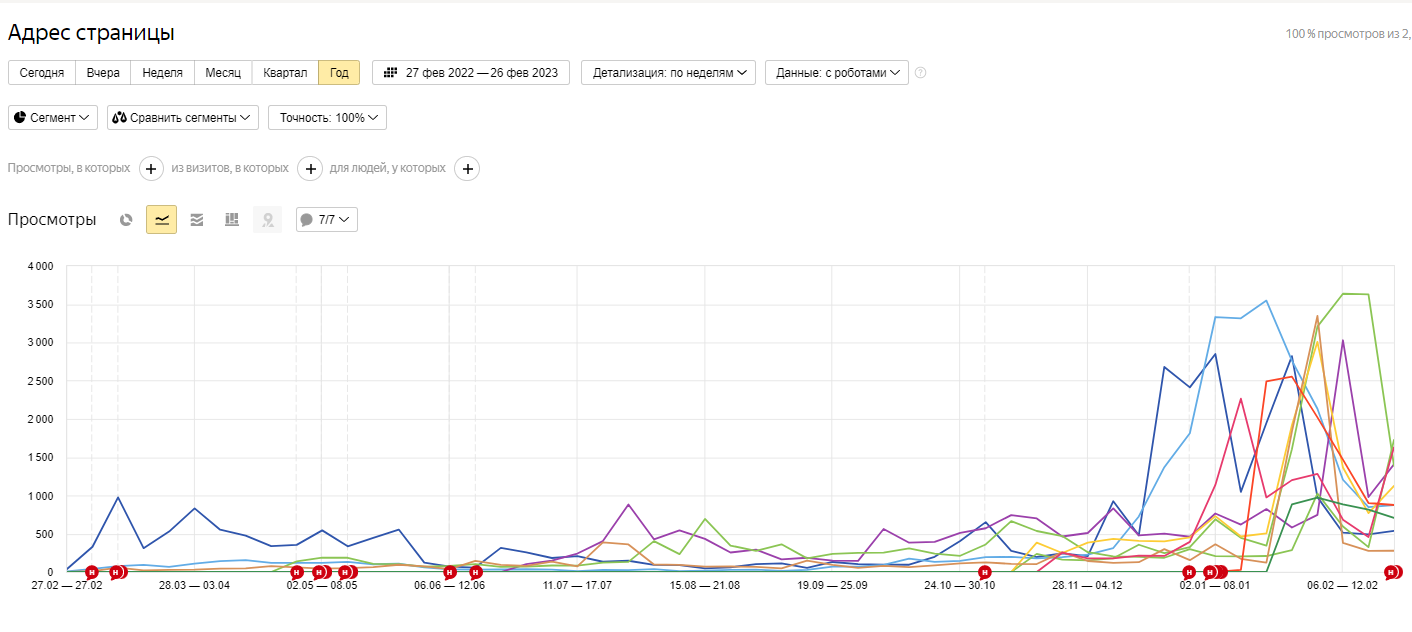
По умолчанию документы ранжируются по количеству просмотров.

В список попадают не только проиндексированные, но и неканонические документы: пагинационные, с результатами поиска и другие.
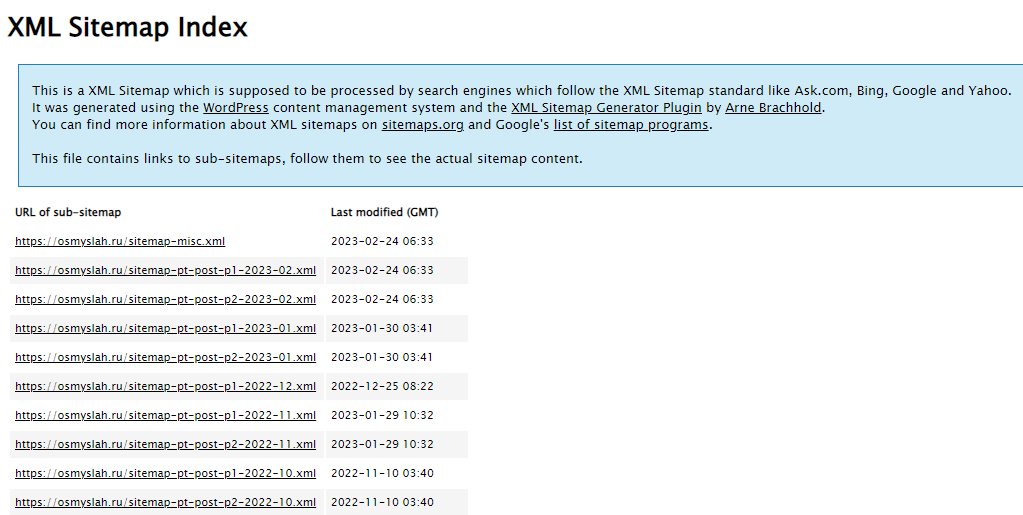
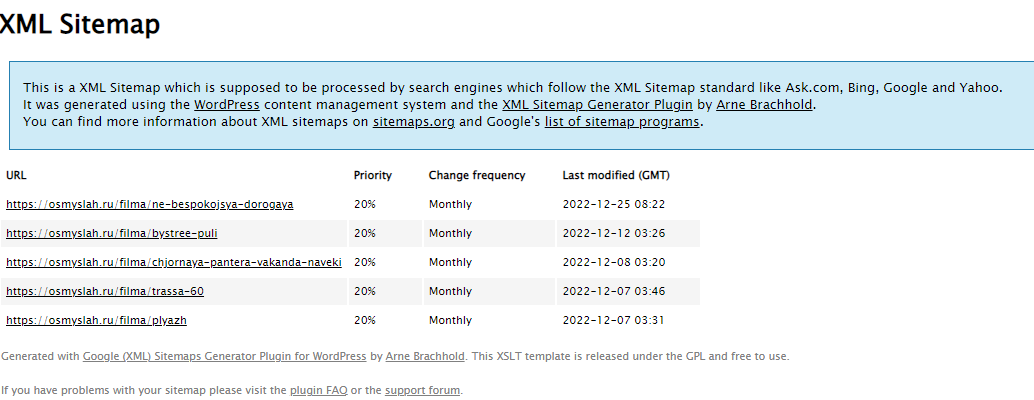
Xml-карта сайта
Обычно Xml-карта располагается по стандартному адресу site.ru/sitemap.xml, но может находиться и на другом URL. Иногда карта строится как список всех адресов, расположенных по датам индексации.
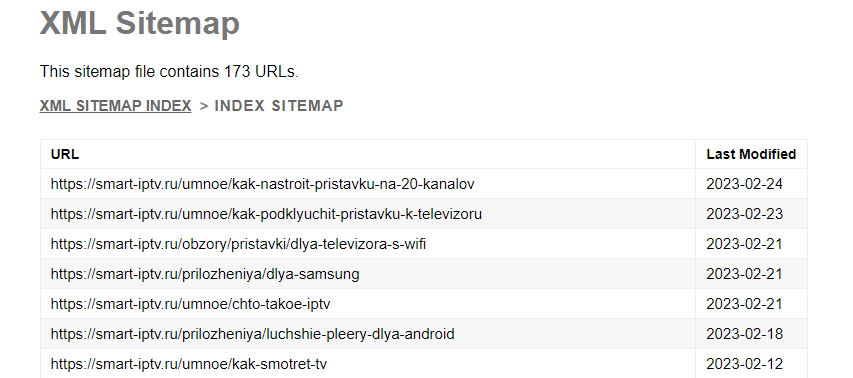
Карта может представлять собой набор файлов со ссылками. Чтобы получить полный список страниц, нужно открыть каждый файл и скопировать ссылки.
Google Analytics
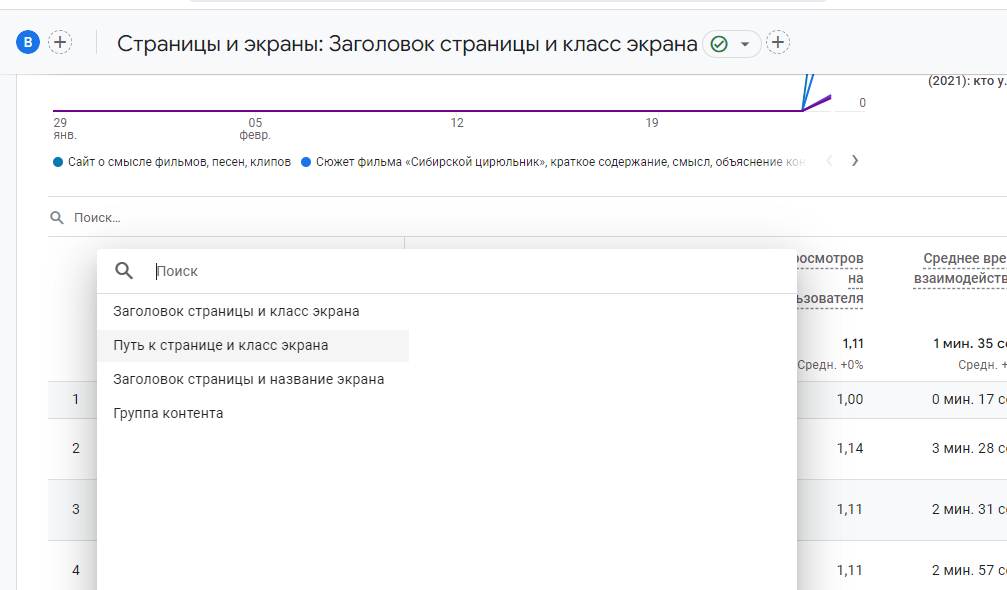
В счетчике Google Analytics, так же, как и в метрике, можно посмотреть все адреса, на которые есть заходы.
Откройте отчет «Страницы и экраны». Кликните на «Путь к странице и класс экрана».
Чтобы скачать результат, выберите опцию «Поделиться отчетом»-«Загрузить файл».
Google Search Console
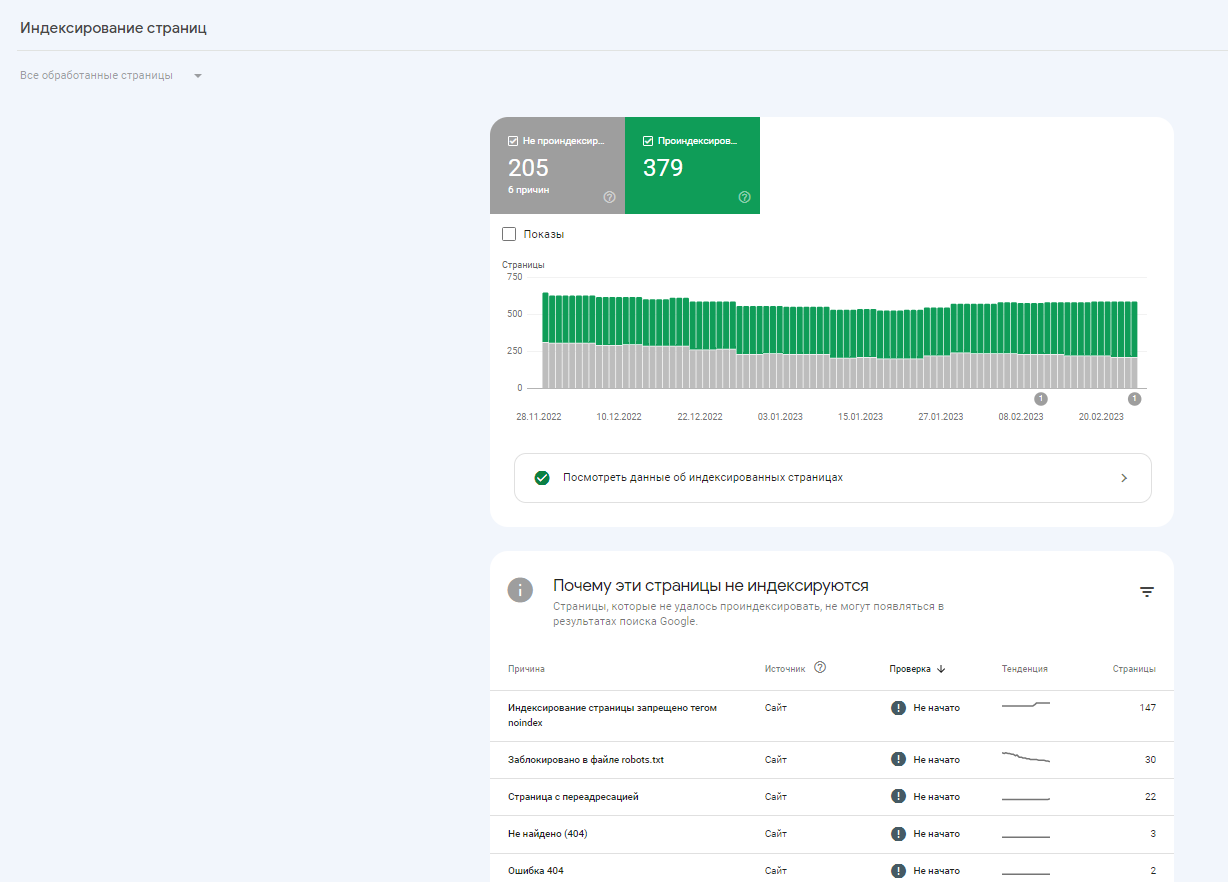
Еще один способ получить нужные данные — скачать их через консоль Google. В разделе «Индексирование» сформированы два перечня — проиндексированных и не проиндексированных документов. Здесь же показаны причины, почему документы не индексируются. Например, ошибка 404, переадресация, блокировка в файле robots.txt.
Чтобы скачать отчет, кликните «Экспортировать» в правом верхнем углу и выберите удобный формат.
Сканирование через Screaming frog SEO spider
Screaming Frog SEO Spider («Паук», «Лягушка») – десктопная платная программа, один из самых популярных и продвинутых парсеров. Умеет без доступа к файлам и админпанели сканировать любые сайты.
- Проверяет весь сайт или указанный раздел, файлы только основного домена или всех поддоменов.
- Находит все страницы сайта, проверяет коды ответа сервера.
- Составляет список битых ссылок.
- Находит все страницы с очень длинными заголовками, тегами или URL-адресами.
- Ищет изображения без тега alt.
- Вычисляет дубли SEO-тегов или URL.
- Проверяет орфографию.
- Находит документы с директивами nofollow, noindex, canonical.
- Проверяет файл robots.txt, микроразметку Schema.
- Выявляет все страницы без контента или с минимумом контента.
Иногда лучше ограничить парсинг только некоторыми разделами или типами документов. Чтобы уменьшить время сканирования и объем работы, можно снять галочки с Изображений, CSS, JavaScript и SWF ресурсов.
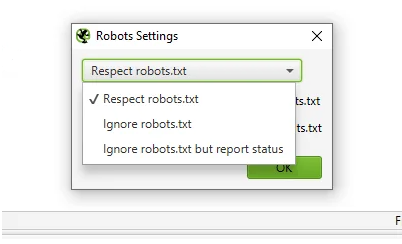
Во вкладке Settings можно настроить парсинг относительно правил robots.txt.
Respect robots.txt — сканируются только те файлы, которые открыты в файле robots.txt.
Ignore robots.txt — парятся все файлы домена, независимо от того, открыты ли они для индексирования.
Ignore robots.txt but report status — сканируются все файлы, но отдельно выводится информация, проиндексирован документ или нет.
Чтобы запустить сканирование, введите адрес сайта, выберите функцию Spider, кликните на кнопку Start.
Итоговый список страниц можно скачать на компьютер в удобном формате.
Заключение
Существуют сервисы, которые формируют списки документов сайта. Выбор инструмента зависит от задачи. Если нужно просканировать свой проект, возможно, будет достаточно Google Analytics, Яндекс.Метрики и Яндекс.Вебмастера. Если планируется глубокий технический аудит, с задачей справится Screaming frog SEO spider. Он же подходит для парсинга конкурентов. Также для анализа чужого сайта можно воспользоваться Xml-картой и инструментом «Анализ структуры проекта» от Пиксель Тулс.
Уследить за всеми страницами сайта сложно, особенно если сайт большой. Но иногда без полного списка страниц не обойтись. Например, если вы хотите создать xml карту сайта, удалить лишние страницы или настроить внутреннюю перелинковку.
С полным списком страниц вы сможете очистить сайт от мусора, исправить технические ошибки на страницах и улучшить ранжирование. Возникает логичный вопрос: как собрать такой список максимально быстро и просто.
Легче всего выгрузить все страницы из одного инструмента, но тогда ваш список может оказаться неполным. Чтобы собрать абсолютно все страницы, в том числе закрытые от поисковых роботов и страницы с техническими ошибками, придется потрудиться.
Почему для сбора данных одного инструмента мало
Собирать данные мы будем из трех инструментов:
- Из модуля «Аудит сайта» в SE Ranking выгрузим все страницы, открытые для поисковых роботов;
- В Google Analytics найдем все страницы, у которых есть просмотры;
- Из Google Search Console достанем оставшиеся закрытые от поисковых роботов страницы, у которых нет просмотров.
Сравнив все данные мы получим полный список страниц вашего сайта.
Проиндексированные URL-ы мы найдем еще на первом этапе. Но нам нужны не только они. У многих сайтов найдутся страницы, на которые не ведет ни одна внутренняя ссылка. Их называют страницами-сиротами.
Почему страницы оказываются «в изоляции»? Причины могут быть разные, к примеру:
- посадочные страницы создавались под конкретную кампанию;
- тестовые страницы создавались для сплит-тестирования;
- страницы убрали из системы внутренней перелинковки, но не удалили;
- страницы потерялись во время переноса сайта;
- была удалена страница категории товаров, а страницы товаров остались.
Такие страницы отрезаны от остального сайта, а значит поисковой робот не может их просканировать. Также кроулер не увидит страницы, закрытые от него через файл .htaccess. Ну, и наконец, часть страниц не индексируется из-за технических проблем.
С помощью разных инструментов мы найдем абсолютно все страницы. Но давайте по порядку. Для начала выгрузим список всех проиндексированных и корректно работающих страниц.
Ищем открытые для краулеров страницы в SE Ranking
Экспортировать страницы, открытые пользователям и краулерам, будем с помощью инструмента «Аудит сайта» SE Ranking.

Чтобы поисковый робот просканировал все необходимые страницы, выберем нужные параметры в настройках.
Заходим в Настройки → Источник страниц для анализа сайта и разрешаем системе сканировать Страницы сайта, Поддомены сайта и XML карту сайта. Так инструмент отследит все страницы сайта, включая поддомены.

Дальше переходим в раздел Правила сканирования страниц и разрешаем учитывать директивы robots.txt.

Осталось нажать кнопку Сохранить.
Затем переходим во вкладку Обзор и запускаем анализ — нажимаем кнопку Перезапустить аудит.

Когда анализ завершится, на главном дашборде нажимаем на зеленую линию в разделе Индексация страниц.

Вы увидите полный список страниц, открытых для поисковых роботов. Теперь можно выгрузить данные — нажимаем на кнопку Экспорт.

На следующем этапе мы будем сравнивать большие массивы данных. Если вам удобно это делать в Excel — оставляйте все как есть. Если вы предпочитаете Google таблицы, скопируйте оставшиеся строки и вставьте их в новую таблицу.
Через Google Analytics ищем все страницы с просмотрами
Поисковые роботы находят страницы переходя по внутренним ссылкам сайта. Поэтому если на страницу не ведет ни одна ссылка на сайте, кроулер ее не найдет.
Обнаружить их можно с помощью данных из Google Analytics — система хранит инфу о посещениях всех страниц. Одно плохо — GA не знает о тех просмотрах, которые были до того, как вы подключили аналитику к вашему сайту.
Просмотров у таких страниц будет немного, потому что с сайта на них перейти не получится. Находим их следующим образом.
Заходим в Поведение → Контент сайта → Все страницы. Если ваш сайт не молодой, стоит указать данные за какой период вы хотите получить. Это важно, так как Google Analytics применяет выборку данных — то есть анализирует не всю информацию, а только ее часть.

Дальше, кликаем на колонку Просмотры страниц, чтобы отсортировать список от меньшего к большему значению . В результате, вверху окажутся самые редко просматриваемые страницы — среди них-то и будут страницы-сироты.

Двигайтесь вниз по списку, пока не увидите страницы, у которых просмотров существенно больше. Это уже страницы с настроенной перелинковкой.
Собранные данные экспортируем в .csv файл.
Выделяем страницы-сироты
Наш следующий шаг — сравнить данные из SE Ranking и Google Analytics, чтобы понять, к каким страницам у поисковых роботов нет доступа.
Копируем данные из .csv файла, выгруженного из Google Analytics, и вставляем их в таблицу рядом с данными из SE Ranking.
Из Google Analytics мы выгрузили только окончания URL, а нам нужно, чтобы все данные были в одном формате. Поэтому в колонку B вставляем адрес главной страницы сайта как показано на скриншоте.

Далее, с помощью функции сцепить (concatenate) объединяем значения из колонок B и C в колонке D и протягиваем формулу вниз до конца списка.

А теперь самое интересное: будем сравнивать колонку «SE Ranking» и колонку «GA URLs», чтобы найти страницы-сироты.
На практике страниц будет намного больше, чем на скриншоте, поэтому анализировать их вручную пришлось бы бесконечно долго. К счастью, существует функция поискпоз (match), которая позволяет определить, какие значения из колонки «GA URLs» есть в колонке «SE Ranking». Вводим функцию в колонке E и протягиваем ее вниз до конца списка.
Результат должен выглядеть так:

В колонке E увидим, каких страниц из GA нет в колонке SE Ranking, там таблица выдаст ошибку (#N/A). В примере видно, что в ячейке E9 нет значения, потому что ячейка A11 — пустая.
Ваш список будет намного больше. Чтобы собрать все ошибки, отсортируйте данные в колонке E по алфавиту:

Теперь у вас есть полный список страниц, не связанных ссылками с сайтом. Перед тем, как двигаться дальше, изучите каждую одинокую страницу. Ваша цель — понять, что это за страница, какова ее роль, и почему на нее не ведет ни одна ссылка.
Дальше есть три варианта развития событий:
- Поставить на страницу внутреннюю ссылку. Для этого нужно определить ее место в структуре вашего сайта.
- Удалить страницу, настроив с нее 301 редирект, если это лишняя страница.
- Оставить все как есть, но присвоить странице тег <noindex>, если, например, страница создавалась под рекламную кампанию.
Поработав с изолированными страницами, можно еще раз выгрузить и сравнить списки из SE Ranking и GA. Так вы убедитесь, что ничего не упустили.
Ищем оставшиеся страницы через Google Search Console
Как найти страницы, не связанные ссылками с сайтом, разобрались. Приступим к остальным страницам, о которых знает Google, — будем анализировать данные Google Search Console.
Для начала откройте свой аккаунт и зайдите в раздел Покрытие. Убедитесь, что выбран режим отображения данных «Все обработанные страницы» и откройте вкладку «Страницы без ошибок».

Таким образом в список попадут Проиндексированные страницы, которых нет в карте сайта, а также Отправленные и проиндексированные страницы.

Кликните на список, чтобы развернуть его. Внимательно изучите данные: возможно в списке есть страницы, которые вы не видели в выгрузках из SE Ranking и GA. В таком случае убедитесь, что они должным образом выполняют свою роль в рамках вашего сайта.
Теперь перейдем во вкладку Исключено, чтобы отобразились только непроиндексированные страницы.

Чаще всего страницы из этой вкладки были намеренно заблокированы владельцами сайта — это страницы с переадресациями, закрытые тегом «noindex», заблокированные в файле robots.txt, и так далее. Также в этой вкладке можно выявить технические ошибки, которые нужно исправить.

Если обнаружите страницы, которые вам не встречались на предыдущих этапах, добавьте их в общий список. Таким образом, вы наконец получите список всех без исключения страниц вашего сайта.
В заключение
Если у вас есть доступ к необходимым инструментам, собрать все страницы сайта не сложно. Да, сделать все в два клика не получится, но в процессе сбора данных вы найдете страницы, о существовании которых могли и не догадываться.
Страницы, которые не видят ни поисковые роботы, ни пользователи, не приносят сайту никакой пользы. Так же как и страницы, которые не индексируются из-за технических ошибок. Если таких страниц на сайте много, это может негативно сказаться на результатах SEO.
Хотя бы один раз собрать все страницы сайта нужно обязательно, чтобы адекватно его оценивать и знать, откуда ждать проблем 🙂
Светлана — контент-маркетолог и редактор в SE Ranking. Светлана убеждена, что о сложных вещах можно писать просто и делится своими знаниями в области SEO и диджитал-маркетинга в блоге SE Ranking и других тематических медиа.
Вечера Светлана проводит, изучая новые языки, планируя увлекательные путешествия и играя с кошкой.
Открываем Google, пишем то, что нужно найти в специальную строку и жмем Enter. «Все просто, чему вы меня учить собрались», — думаете вы. Ага, не тут-то было, друзья.
После сегодняшней статьи большинство из вас поймет, что делали это неправильно. Но этот навык – один из самых важных для продуктивного сотрудника. Потому что в 2021 году дергать руководство по вопросам, которые, как оказалось, легко гуглятся, — моветон.
Ну и на форумах не даст вам упасть лицом в грязь, чего уж там.
Затягивать не будем, ниже вас ждут фишки, которые облегчат вам жизнь.
Кстати, вы замечали, что какую бы ты ни ввёл проблему в Google, это уже с кем-то было? Серьёзно, даже если ввести запрос: «Что делать, если мне кинули в лицо дикобраза?», то на каком-нибудь форуме будет сидеть мужик, который уже написал про это. Типа, у нас с женой в прошлом году была похожая ситуация.
Ваня Усович, Белорусский и российский стендап-комик и юморист
Фишка 1
Если вам нужно найти точную цитату, например, из книги, возьмите ее в кавычки. Ниже мы отыскали гениальную цитату из книги «Мастер и Маргарита».
Фишка 2
Бывает, что вы уже точно знаете, что хотите найти, но гугл цепляет что-то схожее с запросом. Это мешает и раздражает. Чтобы отсеять слова, которые вы не хотите видеть в выдаче, используйте знак «-» (минус).
Вот, например, поисковой запрос ненавистника песочного печенья:
Фишка 3
Подходит для тех, кто привык делать всё и сразу. Уже через несколько долей секунд вы научитесь вводить сразу несколько запросов.
*барабанная дробь*
Для этого нужна палочка-выручалочка «|». Например, вводите в поисковую строку «купить клавиатуру | компьютерную мышь» и получаете страницы, содержащие «купить клавиатуру» или «купить компьютерную мышь».
Совет: если вы тоже долго ищете, где находится эта кнопка, посмотрите над Enter.
Фишка 4
Выручит, если вы помните первое и последнее слово в словосочетании или предложении. А еще может помочь составить клевый заголовок. Короче, знак звездочка «*» как бы говорит гуглу: «Чувак, я не помню, какое слово должно там быть, но я надеюсь, ты справишься с задачей».
Фишка 5
Если вы хотите найти файл в конкретном формате, добавьте к запросу «filetype:» с указанием расширения файла: pdf, docx и т.д., например, нам нужно было отыскать PDF-файлы:
Фишка 6
Чтобы найти источник, в котором упоминаются сразу все ключевые слова, перед каждым словом добавьте знак «&». Слов может быть много, но чем их больше, тем сильнее сужается зона поиска.
Кстати, вы еще не захотели есть от наших примеров?
Фишка 7
Признавайтесь, что вы делаете, когда нужно найти значение слова. «ВВП что такое» или «Шерофобия это». Вот так пишете, да?
Гуглить значения слов теперь вам поможет оператор «define:». Сразу после него вбиваем интересующее нас слово и получаем результат.
— Ты сильный?!
— Я сильный!
— Ты матерый?!
— Я матерый!
— Ты даже не знаешь, что такое сдаваться?!
— Я даже не знаю, что такое «матерый»!
Фишка 8
Допустим, вам нужно найти статью не во всём Интернете, а на конкретном сайте. Для этого введите в поисковую строку «site:» и после двоеточия укажите адрес сайта и запрос. Вот так все просто.
Фишка 9
Часто заголовок полностью отображает суть статьи или материалов, которые вам нужны. Поэтому в некоторых случаях удобно пользоваться поиском по заголовку. Для этого введите «intitle:», а после него свой запрос. Получается примерно так:
Фишка 10
Чтобы расширить количество страниц в выдаче за счёт синонимов, указывайте перед запросом тильду «~». К примеру, загуглив «~cтранные имена», вы найдете сайты, где помимо слова «странные» будут и его синонимы: «необычные, невероятные, уникальные».
Ну и, конечно, не забывайте о расширенных инструментах, которые предлагает Google. Там вы можете установить точный временной промежуток для поиска, выбирать язык и даже регион, в которым был опубликован материал.
В комментариях делитесь, о каких функциях вы знали, а о каких услышали впервые
Кстати, еще больше интересных фишек в области онлайн-образования, подборки с полезными ресурсами и т.д., вы найдете в нашем Telegram-канале. Присоединяйтесь!