Для поиска сайтов по HTML-коду следует выполнить запрос с префиксом html=.
| Пример запроса | Результат поиска |
|---|---|
| html=»google analytics» «yandex metrika» |
Сайты, использующие счетчики посещаемости аналитических систем Google Analytics или Яндекс.Метрика |
| html=iframe |
Сайты, содержащие HTML-тег iframe |
| html=»meta name generator content Joomla» или html=»meta Joomla»~5 |
Сайты, использующие CMS Joomla |
| html=»generator content WordPress» |
Сайты, использующие CMS WordPress |
| html=»ca-pub-3598865760224321″ |
Сайты с Google AdSense ID 3598865760224321 |
| html=»UA-8487723″ |
Сайты с ID Google Ananlytics UA-8487723 |
| html=»_setAccount UA» «_getTracker UA» |
Все сайты с ID Google Ananlytics |
Примечание: в поиске по HTML-коду не участвуют сайты с нулевым ИКС (индекс качества сайтов).
Нет, к сожалению. Это поиск сайтов, использующих одни библиотеки или технологии. Искомому же сервису скармливаешь урл сайта и он выдает тебе список похожих сайтов. Сервис достаточно большой и развитый, у них свой паук, постоянно сканирующий сеть, свои базы данных. Вот только как он называется.. Я уже все изгуглил на предмет «similar web sites», «similar websites code», «searching sites with similar code» etc..
Написано
более трёх лет назад
U2
На сайте с 16.01.2012
Offline
18
26 января 2012, 10:19
14931
Подскажите рабочий сервис, позволяющий искать сайты по любым сигнатурам в исходных текстах страниц. В том числе в тэгах, яваскриптах, комментариях…
Например чтобы можно найти все сайты с определенным адсенс-айди или урчин-айди или построенные на одной версии какогото движка. Чтобы поиск был возможен вообще по любому куску текста.

На сайте с 17.11.2006
Offline
95
и чтобы можно было грабить корованы

На сайте с 02.03.2010
Offline
146
а чем гугл не подходит? составьте корректно поисковый запрос и-и-и вуаля!

На сайте с 15.06.2006
Offline
226
d4k:
а чем гугл не подходит? составьте корректно поисковый запрос и-и-и вуаля!
а можно пример запроса поиска по куску ява-скрипта?
M
На сайте с 07.06.2011
Offline
49
Врятли кроме поисковиков кто-то может обладать такими мощностями. Читайте мануалы по поиску, скорее всего что-то подобное есть
http://spicysales.ru (http://spicysales.ru) — заработок для тематических кулинарных сайтов.
B
На сайте с 02.05.2007
Offline
240
ничего нет и быть не может
но по урчинайди есть всякие сервисы слежки за конкурентами
конечно, по движкам они не ищут
U2
На сайте с 16.01.2012
Offline
18

На сайте с 20.10.2009
Offline
94
Интересная хрень, если она действительно хоть как-то работала.

На сайте с 25.11.2006
Offline
1690
Поисковики такого не позволяют, иначе можно было такой фигни натворить, мама не горю 

На сайте с 22.12.2006
Offline
54
mrcloud:
Врятли кроме поисковиков кто-то может обладать такими мощностями. Читайте мануалы по поиску, скорее всего что-то подобное есть
Даже поисковики не обладают мощностями для полнотекстового поиска. В том же Public WWW один запрос выполняется около 30 с. А там поиск всего лишь по 1 млн. страниц (ничто по сравнению с общим количеством страниц в интернете).
На сайте с 02.03.2010
Offline
146
28 января 2012, 00:52
#10
Sterh:
а можно пример запроса поиска по куску ява-скрипта?
По скриптам хз, а по сигнатурам разметки — легко… Так же и блоги, форумы и сетки сателлитов ищутся.
Привет! Сегодня расскажу, как определить сетку сайтов одного владельца и какие для этого нужно использовать сервисы и инструменты.
Стоит отметить, что чужие проекты можно найти не только используя платные сервисы, но и при помощи бесплатных инструментов. В данной статье я расскажу и про те и про другие.
Содержание статьи:
- Способы поиска сеток чужих сайтов
- Поисковая система Bing
- 2IP.ru
- Keys.so – платно и БЕСПЛАТНО
- Лайфхакерский метод спалить сетку в Кейс.со БЕСПЛАТНО
- Для чего это нужно?
Способы поиска сеток чужих сайтов
Для двух первых бесплатных способов вам потребуется узнать IP адрес того сайта, который вы хотите пробивать на предмет наличия целой сетки сайтов одного владельца.
Для того чтобы узнать IP-адрес сайта нужно зайти в «Командную строку» Windows и вбить команду:
ping site.ru

Винда любезно предоставит айпишник хостинга, на котором находится сайт.
Имея IP, переходим к двум способам, описанным ниже.
Поисковая система Bing
Самый простой, но при этом наименее информативный способ – это использовать команду в поисковике Bing.
Зная IP-адрес, вам необходимо вбить команду в Бинге вот таким образом:
ip:5.255.255.5
Получаем такую выдачу:

Т.е. на данном IP у Яндекса лежит 77 доменов/поддоменов/сайтов.
Стоит отметить, что подобным образом нельзя вычислить сайты одного владельца, если у него не выделенный сервер, а хостинг типа Beget или Hostenko или любой другой, т.к. на одном IP будут размещаться сотни других сайтов, которые могут не иметь никакого отношения к человеку, сетку которого вы ищите.
В этой связи подобный метод работает только, когда вы уверены, что у владельца все его сайты размещаются на выделенном серваке.
2IP.ru
По такому же принципу можно определить сетку с помощью сервиса 2ip.ru. Вот прямая ссылка на него.

Автор блога о SEO и заработке на сайтах — Vysokoff.ru. Продвигаю информационные и коммерческие сайты с 2013 года.
Задать вопрос
![]() Загрузка …
Загрузка …
Однако, сервис очень часто глючит и не ищет ничего, выдывая ошибку или находит далеко не все сайты. Вот, например, если в Bing мы нашли 77 результатов для IP Яндекса, то 2ИП выдал всего один домен:

Keys.so – платно и БЕСПЛАТНО
И наконец, 146%-ый способ найти все сайты, принадлежащие одному человек – это платный сервис Keys.so.
Сервис ищет сетки анализируя код Adsense и Google Analytics, а также Relap.io, Moevideo, Leadia, Leetero, но как правило все палятся на Адсенсе или Аналитиксе 🙂
Что нужно, чтобы определить сайты нашей жертвы? Оплатить Базовый тариф (4800 рублей за месяц) и вбить домен в строку. Для эксперимента взял первый попавшийся домен на Телдери:

Всё очень просто, переходим и радуемся находке 🙂
Лайфхакерский метод спалить сетку в Кейс.со БЕСПЛАТНО
Купить подписку и узнать все сайты “жертвы” – метод “для слабаков” 🙂 Есть вариант посмотреть максимальное количество чужих сайтов бесплатно. Что нужно сделать?
Вначале перейти в раздел – Сайты владельца:

В бесплатном режиме мы увидим только 2 сайта, однако, если поочерёдно кликать по параметрам фильтрации, список доменов будет меняться:

Вот так:

Таким образом можно увидеть довольно много (а зачастую и все) сайты одного владельца.
Для чего это нужно?
Зачем вообще палить чьи-то сайты? Лично я использую чужие сетки сайтов для анализа и выбора ниши.
Анализируя чужие проекты можно взять себе на вооружение какие-то новые или особенные фишки в оформление статей, в SEO в целом или монетизации.
Палево чужих сайтов незаменимый помощник при выборе ниши для запуска новых проектов. Лично у меня есть целый алгоритм действий поиска ниши и не последнее место в этом алгоритме занимает именно определение чужих сеток.
Иногда оптимизатору нужно получить список всех страниц сайта, в том числе технических и не проиндексированных. Чтобы собрать их вручную, придется потратить не один час, особенно если сайт большой. Существуют сервисы, которые упрощают задачу. Чтобы при аудите ни один документ не потерялся, можно воспользоваться не одним, а сразу несколькими инструментами.
Расскажем, как найти все страницы сайта и какие сервисы для этого нужны.
Зачем нужна такая информация
Список страниц полезен для того, чтобы:
- Найти все страницы, которые не проиндексированы или выпали из индекса поисковой системы. Их нужно проанализировать. Возможно, причина в технических настройках (например, URL закрыт от роботов ПС) или в низком качестве документов. При необходимости их нужно доработать.
- Такой список — хорошая помощь, когда нужно найти причину проблем. Например, при резком падении трафика.
- Настроить перелинковку — проставить внутренние ссылки, правильно распределить ссылочный вес.
- Избавиться от «мусорных» документов, ошибок, дублей.
- Найти все страницы сайта с кодом ответа, отличным от 200 OK.
Почему для сбора данных одного инструмента мало
Выбор инструмента зависит от задачи. Если встал вопрос, как найти все проиндексированные документы или только те, на которые идет трафик, Вебмастера и Метрики будет достаточно. Если проводится технический аудит, подходит Screaming frog SEO spider.
Если нужен полный список страниц, удобнее воспользоваться сразу несколькими инструментами и объединить получившиеся списки. Если ограничиться только одним способом, перечень будет неполным. Например, если использовать только xml-карту, в списке не окажется «мусорных» файлов, сгенерированных из-за неправильных технических настроек. Яндекс.Вебмастер показывает только те документы, которые попали в поиск или выпали из него.
Пиксель Тулс
С помощью онлайн-инструмента «Анализ структуры проекта» можно узнать все страницы, проиндексированные поисковой системой Яндекс. Для анализа не нужен доступ к файлам сайта и Метрике. Можно получить список URL любого проекта, например, конкурента.
Введите домен в верхнюю строку и кликните на кнопку «Найти». Если выбрать опцию «Анализировать число документов только для разделов второго уровня», сервис подсчитает количество страниц в категориях и не будет определять объем подкатегорий.
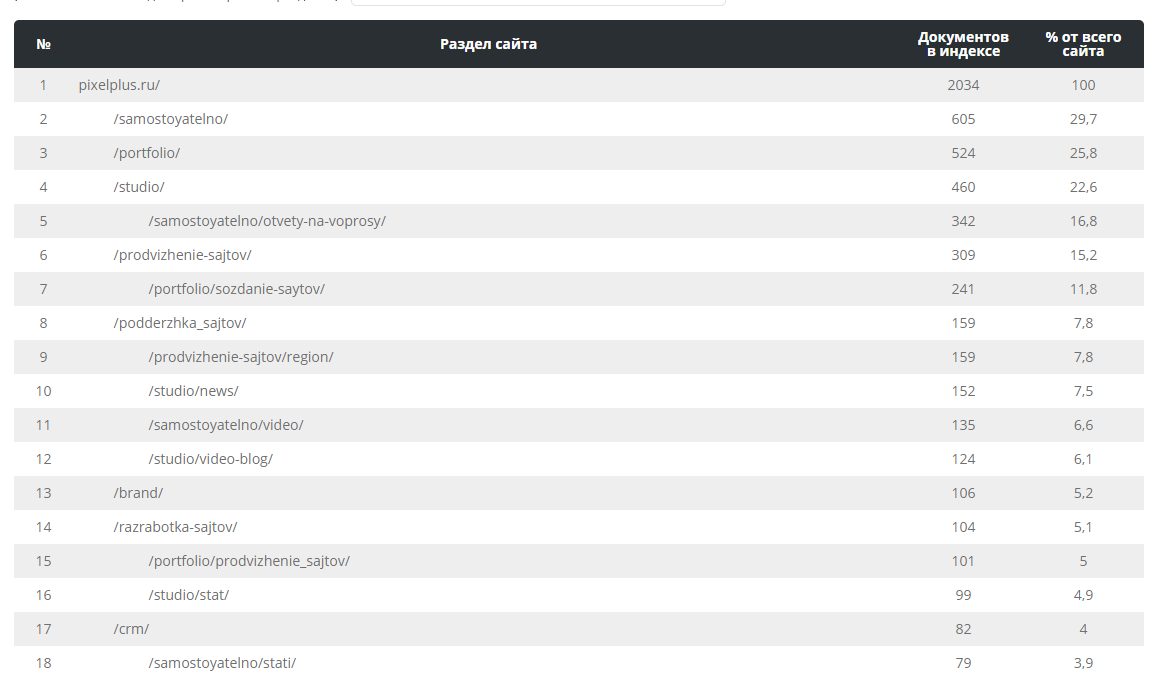
Инструмент строит подробную наглядную структуру (иерархию), подсчитывает количество документов в разделах и процент от общего объема проекта.
Яндекс.Вебмастер
Откройте подраздел «Страницы в поиске» в разделе «Индексирование».
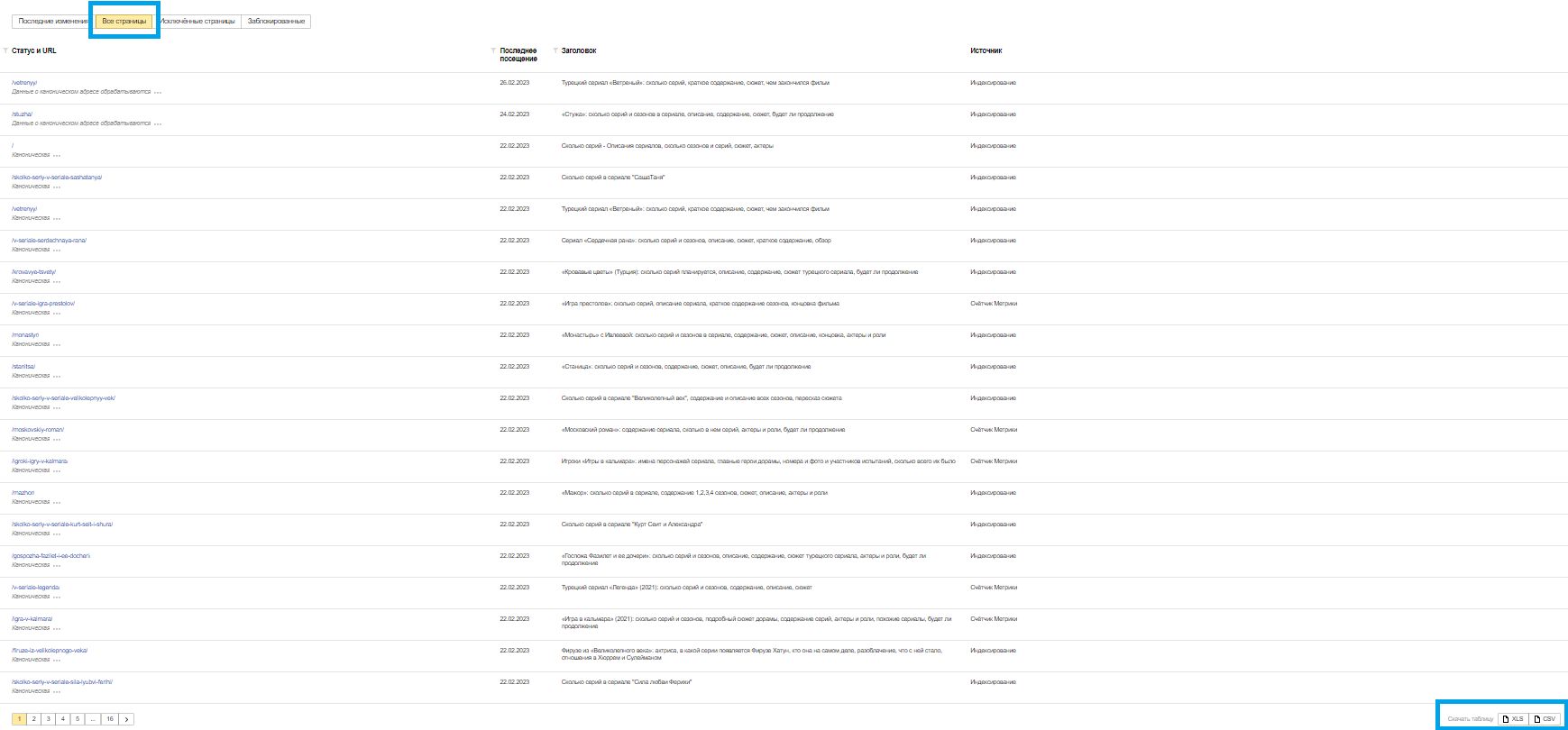
Откройте вкладку «Все страницы» и скачайте таблицу в формате CSV или XLS.
Чтобы получить перечень не попавших в индекс документов, нужно скачать таблицу в разделе «Исключенные страницы».
Яндекс.Метрика
Полный список страниц, на которые заходят пользователи, можно найти в Яндекс.Метрике. Для этого нужно выбрать большой период, например, год, и зайти в раздел «Адрес страницы».
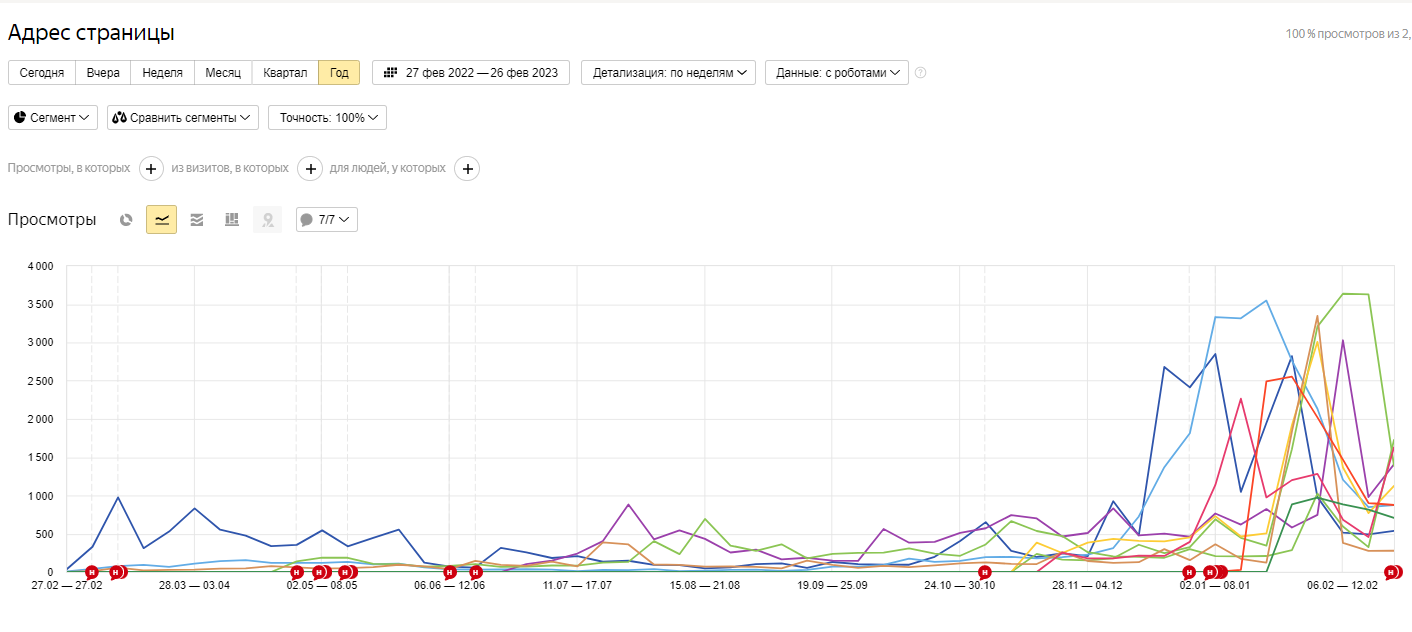
По умолчанию документы ранжируются по количеству просмотров.

В список попадают не только проиндексированные, но и неканонические документы: пагинационные, с результатами поиска и другие.
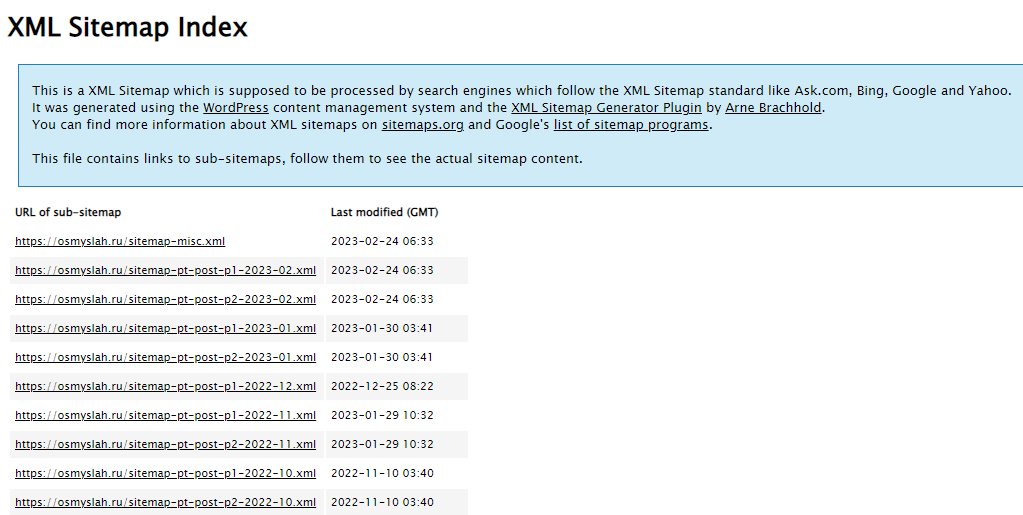
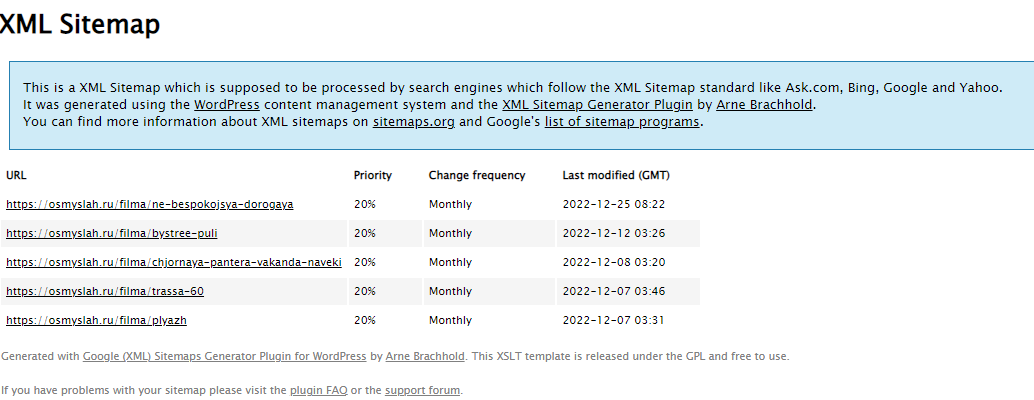
Xml-карта сайта
Обычно Xml-карта располагается по стандартному адресу site.ru/sitemap.xml, но может находиться и на другом URL. Иногда карта строится как список всех адресов, расположенных по датам индексации.
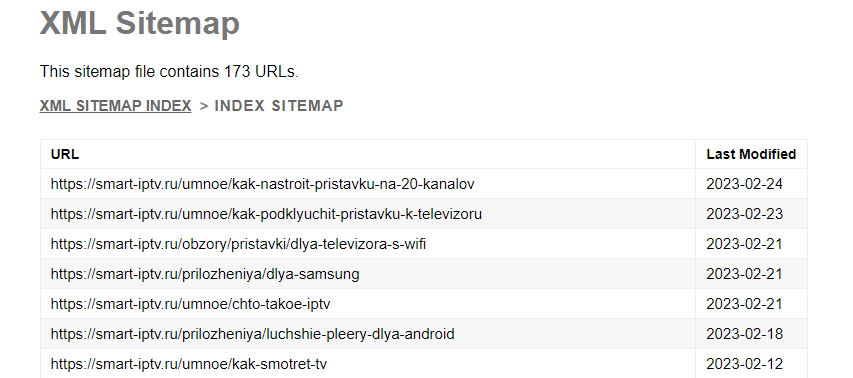
Карта может представлять собой набор файлов со ссылками. Чтобы получить полный список страниц, нужно открыть каждый файл и скопировать ссылки.
Google Analytics
В счетчике Google Analytics, так же, как и в метрике, можно посмотреть все адреса, на которые есть заходы.
Откройте отчет «Страницы и экраны». Кликните на «Путь к странице и класс экрана».
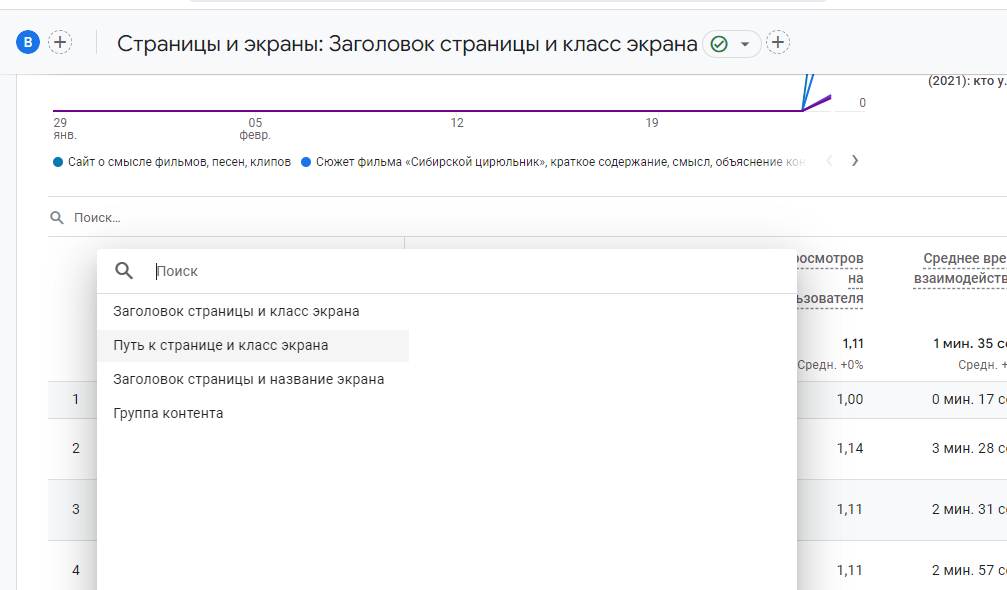
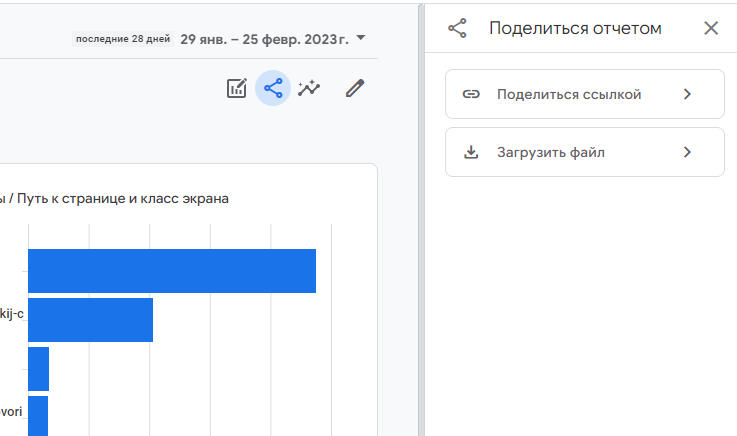
Чтобы скачать результат, выберите опцию «Поделиться отчетом»-«Загрузить файл».
Google Search Console
Еще один способ получить нужные данные — скачать их через консоль Google. В разделе «Индексирование» сформированы два перечня — проиндексированных и не проиндексированных документов. Здесь же показаны причины, почему документы не индексируются. Например, ошибка 404, переадресация, блокировка в файле robots.txt.
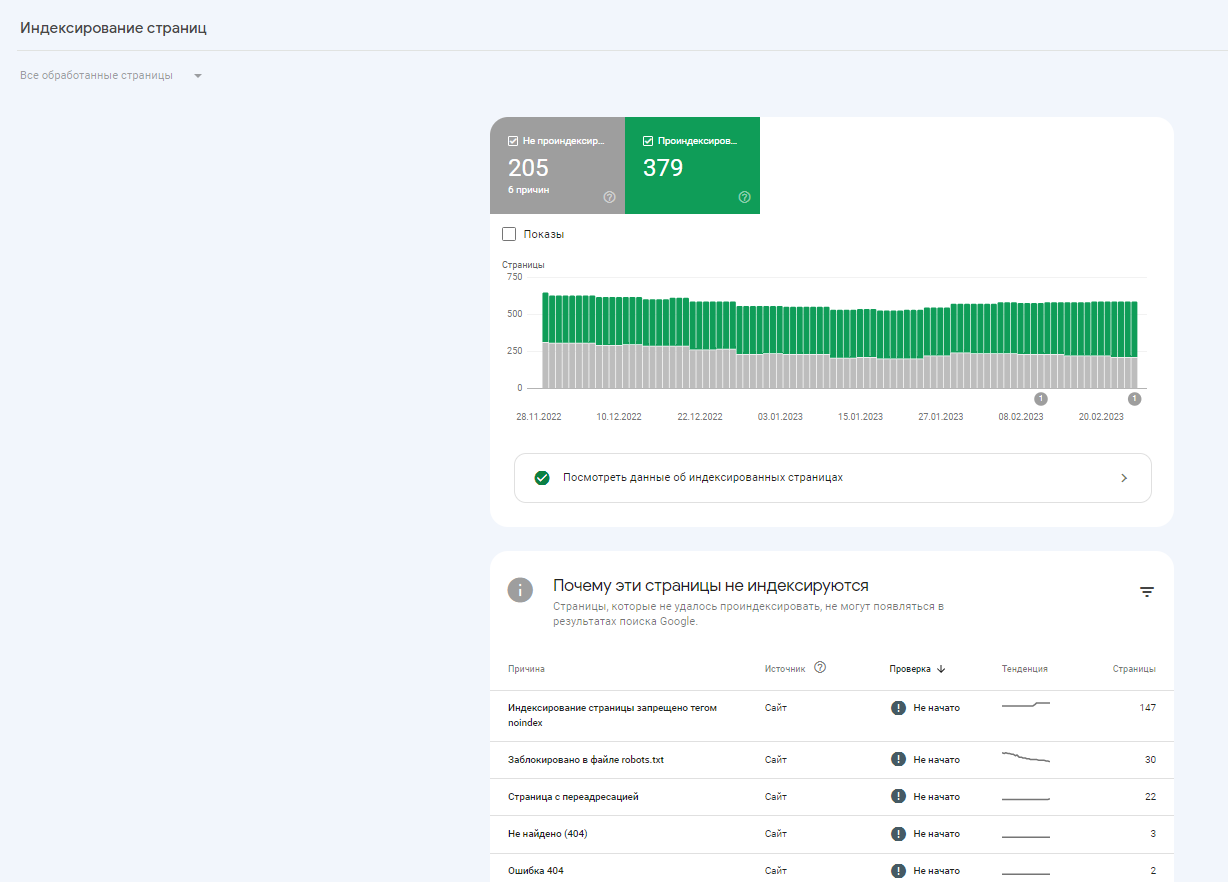
Чтобы скачать отчет, кликните «Экспортировать» в правом верхнем углу и выберите удобный формат.
Сканирование через Screaming frog SEO spider
Screaming Frog SEO Spider («Паук», «Лягушка») – десктопная платная программа, один из самых популярных и продвинутых парсеров. Умеет без доступа к файлам и админпанели сканировать любые сайты.
- Проверяет весь сайт или указанный раздел, файлы только основного домена или всех поддоменов.
- Находит все страницы сайта, проверяет коды ответа сервера.
- Составляет список битых ссылок.
- Находит все страницы с очень длинными заголовками, тегами или URL-адресами.
- Ищет изображения без тега alt.
- Вычисляет дубли SEO-тегов или URL.
- Проверяет орфографию.
- Находит документы с директивами nofollow, noindex, canonical.
- Проверяет файл robots.txt, микроразметку Schema.
- Выявляет все страницы без контента или с минимумом контента.
Иногда лучше ограничить парсинг только некоторыми разделами или типами документов. Чтобы уменьшить время сканирования и объем работы, можно снять галочки с Изображений, CSS, JavaScript и SWF ресурсов.
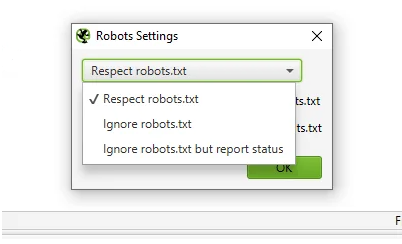
Во вкладке Settings можно настроить парсинг относительно правил robots.txt.
Respect robots.txt — сканируются только те файлы, которые открыты в файле robots.txt.
Ignore robots.txt — парятся все файлы домена, независимо от того, открыты ли они для индексирования.
Ignore robots.txt but report status — сканируются все файлы, но отдельно выводится информация, проиндексирован документ или нет.
Чтобы запустить сканирование, введите адрес сайта, выберите функцию Spider, кликните на кнопку Start.
Итоговый список страниц можно скачать на компьютер в удобном формате.
Заключение
Существуют сервисы, которые формируют списки документов сайта. Выбор инструмента зависит от задачи. Если нужно просканировать свой проект, возможно, будет достаточно Google Analytics, Яндекс.Метрики и Яндекс.Вебмастера. Если планируется глубокий технический аудит, с задачей справится Screaming frog SEO spider. Он же подходит для парсинга конкурентов. Также для анализа чужого сайта можно воспользоваться Xml-картой и инструментом «Анализ структуры проекта» от Пиксель Тулс.