We sometimes come through situations where we require to get all the words present in the string, this can be a tedious task done using the native method. Hence having shorthands to perform this task is always useful. Additionally, this article also includes the cases in which punctuation marks have to be ignored.
Method #1 : Using split()
Using the split function, we can split the string into a list of words and this is the most generic and recommended method if one wished to accomplish this particular task. But the drawback is that it fails in cases the string contains punctuation marks.
Python3
test_string = "Geeksforgeeks is best Computer Science Portal"
print ("The original string is : " + test_string)
res = test_string.split()
print ("The list of words is : " + str(res))
Output:
The original string is : Geeksforgeeks is best Computer Science Portal
The list of words is : [‘Geeksforgeeks’, ‘is’, ‘best’, ‘Computer’, ‘Science’, ‘Portal’]
Time Complexity: O(n)
Auxiliary Space: O(1)
Method #2 : Using regex( findall() )
In the cases which contain all the special characters and punctuation marks, as discussed above, the conventional method of finding words in string using split can fail and hence requires regular expressions to perform this task. findall function returns the list after filtering the string and extracting words ignoring punctuation marks.
Python3
import re
test_string = "Geeksforgeeks, is best @# Computer Science Portal.!!!"
print ("The original string is : " + test_string)
res = re.findall(r'w+', test_string)
print ("The list of words is : " + str(res))
Output:
The original string is : Geeksforgeeks, is best @# Computer Science Portal.!!!
The list of words is : [‘Geeksforgeeks’, ‘is’, ‘best’, ‘Computer’, ‘Science’, ‘Portal’]
Method #3 : Using regex() + string.punctuation
This method also used regular expressions, but string function of getting all the punctuations is used to ignore all the punctuation marks and get the filtered result string.
Python3
import re
import string
test_string = "Geeksforgeeks, is best @# Computer Science Portal.!!!"
print ("The original string is : " + test_string)
res = re.sub('['+string.punctuation+']', '', test_string).split()
print ("The list of words is : " + str(res))
Output:
The original string is : Geeksforgeeks, is best @# Computer Science Portal.!!!
The list of words is : [‘Geeksforgeeks’, ‘is’, ‘best’, ‘Computer’, ‘Science’, ‘Portal’]
Method #4: using a list comprehension and the isalnum() method:
- The string module is imported to get access to the punctuation characters.
- A test string is initialized with a string that contains punctuations, multiple spaces, and special characters.
- A list comprehension is used to extract the words from the test string. This list comprehension has the following components:
- a. word.strip(string.punctuation) – This method is called on each word after splitting the test string to remove any leading or trailing punctuation characters from the word.
- b. for word in test_string.split() – This splits the test string into a list of words.
- c. if word.strip(string.punctuation).isalnum() – This checks whether the word after removing punctuation characters contains only alphabets or numbers. If it is true, the word is added to the resulting list.
- The resulting list is stored in the variable res.
- Finally, the resulting list of words is printed with a message that says “The list of words is:”.
Python3
import string
test_string = "Geeksforgeeks, is best @# Computer Science Portal.!!!"
res = [word.strip(string.punctuation) for word in test_string.split() if word.strip(string.punctuation).isalnum()]
print("The list of words is:", res)
Output
The list of words is: ['Geeksforgeeks', 'is', 'best', 'Computer', 'Science', 'Portal']
The time complexity of the program is O(n), where n is the length of the test string.
The space complexity of the program is also O(n), where n is the length of the test string.
Last Updated :
22 Apr, 2023
Like Article
Save Article
Last updated: August 20, 2019
This implementation of Word Search was, in most part, an experiment—to observe how I utilize Python to try and solve the problem of implementing a basic word search solving algorithm.
Table of contents
- What is Word Search?
- How and where do we start?
- Which tool do we use?
- Python installation
- Windows
- Linux and Unix
- Pen and paper
- Onto the code!
- Implementing the algorithm
- matrixify
- coord_char
- convert_to_word
- find_base_match
- matched_neighbors
- complete_line
- complete_match
- find_matches
- wordsearch
- Implementing the algorithm
- Closing remarks
What is Word Search?
Word search is a puzzle we usually see in newspapers, and in some magazines, located along the crossword puzzles. They can be located sometimes in bookstores, around the trivia area, as a standalone puzzle book, in which the sole content is a grid of characters and a set of words per page.
How a traditional word search puzzle works is, for a given grid of different characters, you have to find the hidden words inside the grid. The word could be oriented vertically, horizontally, diagonally, and also inversely in the previously mentioned directions. After all the words are found, the remaining letters of the grid expose a secret message.
In some word search puzzles, a limitation exists in the length of the hidden words, in that it should contain more than 2 characters, and the grid should have a fixed size of 10 × 10, or an equivalent length and width proportion (which this python implementation doesn’t have).
How and where do we start?
Before going deeper into the computer side of the algorithm, let’s first clarify how we tend to solve a word search puzzle:
- We look at a hidden word and its first letter then we proceed to look for the first letter inside the grid of letters.
- Once we successfully find the first letter of the hidden word inside the grid, we then check the neighboring characters of that successful match and check whether the second letter of our word matches any of the neighbors of the successful match.
- After confirming a successful match for the second letter of the hidden word through its neighbors, we proceed to a much narrower step. After the successful matching of the second letter of the word in the successful second match’s neighbors, we then follow-through to a straight line from there, hoping to get a third match (and so on) of the hidden word’s letters.
Which tool do we use?
To realize this series of steps in solving a word search puzzle, we will utilize a programming language known for having a syntax similar to pseudo-code—Python.
There are two main versions of Python—versions 2.x and 3.x. For this project, we would be utilizing version 2.7.
To make this run under Python 3.X, replace all instances of xrange with range.
Python installation
For the installation part, we’ll be covering installation instructions for both Windows, Unix, and Linux.
Windows
First, determine whether you’re running a 32- or 64-bit operating system. To do that, click Start, right-click Computer, then click Properties. You should see whether you’re running on 32-bit or 64-bit under System type. If you’re running on 32-bit, click on this link then start the download; if you’re on 64-bit, click this one. Again, take note that we will be utilizing version 2.7 of Python.
Linux and Unix
Download this file then extract. After extraction, go inside the extracted directory then run the following:
$ ./configure
$ make
$ make install
In Linux/Unix, to make sure that we can actually run Python when we enter the python command in a terminal, let’s make sure that the installed Python files can be located by the system.
Type the following, then press Enter on your corresponding shell:
Bash, Sh, Zsh, Ash, or Ksh:
$ export PATH="$PATH:/usr/local/bin/python"Csh or Tcsh:
$ setenv PATH "$PATH:/usr/local/bin/python"Pen and paper
As problems go in software development or in programming in general, it is better to tackle the problem with a clear head—going at it with the problem statement and constraints clear in our minds. What we are going to do first is to outline the initial crucial steps in a word search puzzle.
First, write the word dog, then on the space immediately below it, draw a grid of characters on the paper, like the following:
dog
d o g g
o o g o
g o g d
To start the hunt, we look at the first letter of the word dog, which is the letter d. If, somehow, the first letter of dog doesn’t exist within the grid, it means that we won’t be able to find the word in it! If we successfully find a character match for the first letter of dog, we then proceed to look at the second letter of dog. This time, we are now restricted to look around among the adjacent letters of the first letter match. If the second letter of dog can’t be located around the adjacent letters of d inside the grid, this means that we have to proceed to the next occurrence of the letter d inside the grid.
If we find a successful match around the adjacent letters of the next occurrence of d inside the grid, then the next steps are literally straightforward. For example:
*
o
d
In the previous grid, the first letter d matched on the corner of the grid, and the word’s second letter o which is adjacent to d, also successfully matched. If that’s the case, the next location in the grid to check for the subsequent matches of the remaining letters of the word dog, will now be in a straight line with the direction drawn from the first letter to the second letter. In this case, we will check the letter directly above o for the third letter of the word dog, which is g. If instead of the asterisk, the grid showed:
d
o
d
This means that we don’t have a match, and we should be going to the next occurrence of the first letter, inside the grid. If the asterisk is replaced by the correct missing letter:
g
o
d
We have a match! However, for our version of word search, we will not stop there. Instead, we will count for all the adjacent letters of the letter d, then look for the matches of the letter o! For example, if we are presented with the following grid:
g g
o o
d
Then so far, for the word dog, we found 2 matches! After all the neighbors of the letter d have been checked for a possible match, we then move to the next occurrence of the letter in the grid.
Onto the code!
With the basic algorithm in mind, we can now start implementing the algorithm from the previous section.
Implementing the algorithm
matrixify
def matrixify(grid, separator='n'):
return grid.split(separator)The purpose of this function is to return a list whose elements are lines of string. This provides us the ability to index individual elements of the grid through accessing them by their row and column indices:
>>> grid = 'dogg oogo gogd'
>>> matrix = matrixify(grid, ' ')
['dogg', 'oogo', 'gogd']
>>> matrix[1][2]
'g'
coord_char
def coord_char(coord, matrix):
row_index, column_index = coord
return matrix[row_index][column_index]
Given a coordinate ((row_index, column_index) structure) and the matrix where this coordinate is supposedly located in, this function returns the element located at that row and column:
>>> matrix
['dogg', 'oogo', 'gogd']
>>> coord_char((0, 2), matrix)
'g'
convert_to_word
def convert_to_word(coord_matrix, matrix):
return ''.join([coord_char(coord, matrix)
for coord in coord_matrix])This function will run through a list of coordinates through a for loop and gets the single length strings using coord_char:
>>> [coord_char(coord, matrix) for coord in [(0, 0),(0, 1),(0, 2)]]
['d', 'o', 'g']and then uses the join() method of strings to return one single string. The '' before the join() method is the separator to use in between the strings, but in our case, we want one single word so we used an empty string separator.
find_base_match
def find_base_match(char, matrix):
base_matches = [(row_index, column_index)
for row_index, row in enumerate(matrix)
for column_index, column in enumerate(row)
if char == column]
return base_matches
The value of base_matches above is computed by a list comprehension. A list comprehension is just another way of constructing a list, albeit a more concise one. The above list comprehension is roughly equivalent to the following:
base_matches = []
for row_index, row in enumerate(matrix):
for column_index, column in enumerate(row):
if char == column:
base_matches.append((row_index, column_index))
I used the enumerate() function because it appends a counter to an iterable, and that is handy because the counter’s value could correspond to either the row or column indices of the matrix!
To show that the above code indeed scrolls through the individual characters of grid, let’s modify the body of our for loop in order to display the characters and their corresponding coordinates:
>>> for row_index, row in enumerate(matrix):
... for column_index, column in enumerate(row):
... print column, (row_index, column_index)
...
d (0, 0)
o (0, 1)
g (0, 2)
g (0, 3)
o (1, 0)
o (1, 1)
g (1, 2)
o (1, 3)
g (2, 0)
o (2, 1)
g (2, 2)
d (2, 3)
Giving our function find_base_match the arguments d and grid, respectively, we get the following:
>>> find_base_match('d', grid)
[(0, 0), (2, 3)]As you can see from the previous for loop output, the coordinates output by our function are indeed the coordinates where the character d matched!
By calling this function, we can determine whether or not to continue with the further steps. If we deliberately give find_base_match a character that is not inside grid, like c:
>>> find_base_match('c', grid)
[]The function returns an empty list! This means, that inside the encompassing function that will call find_base_match, one of the conditions could be:
if not find_base_match(char, grid):
passmatched_neighbors
def matched_neighbors(coord, char, matrix, row_length, col_length):
row_num, col_num = coord
neighbors_coords = [(row, column)
for row in xrange(row_num - 1,
row_num + 2)
for column in xrange(col_num - 1,
col_num + 2)
if row_length > row >= 0
and col_length > column >= 0
and coord_char((row,column),matrix) == char
and not (row, column) == coord]
return neighbors_coords
This function finds the adjacent coordinates of the given coordinate, wherein the character of that adjacent coordinate matches the char argument!
Inside neighbors_coords, we’re trying to create a list of all the coordinates adjacent the one we gave, but with some conditions to further filter the resulting coordinate:
[(row, column)
for row in xrange(row_num - 1,
row_num + 2)
for column in xrange(col_num - 1,
col_num + 2)
if row_length > row >= 0
and col_length > column >= 0
and coord_char((row, column),matrix) == char
and not (row, column) == coord]
In the above code snippet, we are creating a list of adjacent coordinates (through (row, column)). Because we want to get the immediate neighbors of a certain coordinate, we deduct 1 from our starting range then add 2 to our end range, so that, if given a row of 0, we will be iterating through xrange(-1, 2). Remember that the range() and xrange() functions is not inclusive of the end range, which means that it doesn’t include the end range in the iteration (hence, the 2 that we add at the end range, not only 1):
>>> list(xrange(-1, 2))
[-1, 0, 1]We do the same to the column variable, then later, we filter the contents of the final list through an if clause inside the list comprehension. We do that because we don’t want this function to return coordinates that are out of bounds of the matrix.
To further hit the nail in the coffin, we also give this function a character as its second argument. That is because we want to further filter the resulting coordinate. We only want a coordinate whose string equivalent matches the second character argument that we give the function!
If we want to get the neighbors of the coordinate (0, 0), whose adjacent character in the matrix should be c, call this function with (0, 0) as the first argument, the string c as the second, the matrix itself, and the matrix’s row length and column length, respectively:
>>> matched_neighbors((0, 0), 'c', matrix, 4, 3)
[]Notice that it returns an empty list, because in the neighbors of the coordinate (0, 0), there is no coordinate in there that has the string c as its string equivalent!
If we replace c with a:
>>> matched_neighbors((0, 0), 'a', matrix, 4, 3)
[(0, 1), (1, 0), (1, 1)]This function returns a list of the adjacent coordinates that match the given character.
complete_line
def complete_line(base_coord, targ_coord, word_len, row_length,
col_len):
if word_len == 2:
return base_coord, targ_coord
line = [base_coord, targ_coord]
diff_1, diff_2 = targ_coord[0] - base_coord[0],
targ_coord[1] - base_coord[1]
for _ in xrange(word_len - 2):
line += [(line[-1][0] + diff_1, line[-1][1] + diff_2)]
if 0 <= line[-1][0] < row_length
and 0 <= line[-1][1] < col_len:
return line
return []
We are now at the stage where functions seem a bit hairier to comprehend! I will attempt to discuss the thoughts I had before creating this function.
In the Pen and paper section, after matching the first and second letters of the word inside the matrix, I mentioned that the next matching steps become narrower. It becomes narrower in the sense that, after matching the first and second letters of the word, the only thing you need to do after that is to go straight in the direction that the first and second letters created.
For example:
o
d
In the above grid, once the letters d and o are found, one only need to go straight in a line from the first letter d to the second letter o, then take the direction that d took to get to o. In this case, we go upwards of o to check for the third letter match:
* <- Check this next.
o
d
Another example:
o
d
The direction that the above matches create is north-east. This means that we have to check the place north-east of ‘o’:
* <- This one.
o
d
With that being said, I wanted a function to give me all the coordinates forming a straight line, when given two coordinates.
The first problem I had to solve was—Given two coordinates, how do I compute the coordinate of the third one, which will later form a straight line in the matrix?
To solve this problem, I tried plotting all the expected goal coordinates, if for example, the first coordinate match is (1, 1) and the second coordinate match is (0, 0):
first (1, 1) (1, 1) (1, 1) (1, 1) (1, 1) (1, 1) (1, 1) (1, 1)
second (0, 0) (0, 1) (0, 2) (1, 2) (2, 2) (2, 1) (2, 0) (1, 0)
expected (-1,-1)(-1, 1)(-1, 3) (1, 3) (3, 3) (3, 1) (3,-1) (1,-1)
While looking at the above plot, an idea came into my mind. What I wanted to get was the amount of step needed to go from the second coordinate to the third. In hopes of achieving that, I tried subtracting the row and column values of the first from the second:
second (0, 0) (0, 1) (0, 2) (1, 2) (2, 2) (2, 1) (2, 0) (1, 0)
first (1, 1) (1, 1) (1, 1) (1, 1) (1, 1) (1, 1) (1, 1) (1, 1)
diff (-1,-1)(-1, 0)(-1, 1) (0, 1) (1, 1) (1, 0) (1,-1) (0,-1)
After that, I tried adding the values of the diff row to the values of second:
second (0, 0) (0, 1) (0, 2) (1, 2) (2, 2) (2, 1) (2, 0) (1, 0)
diff (-1,-1)(-1, 0)(-1, 1) (0, 1) (1, 1) (1, 0) (1,-1) (0,-1)
sum (-1,-1)(-1, 1)(-1, 3) (1, 3) (3, 3) (3, 1) (3,-1) (1,-1)
If you look closely, the values of the sum row match those of the expected row! To summarize, I get the difference by subtracting values of the first coordinate from the values of the second coordinate, then I add the difference to the second coordinate to arrive at the expected third!
Now, back to the function:
def complete_line(base_coord, targ_coord, word_len, row_length,
col_len):
if word_len == 2:
return base_coord, targ_coord
line = [base_coord, targ_coord]
diff_1, diff_2 = targ_coord[0] - base_coord[0],
targ_coord[1] - base_coord[1]
for _ in xrange(word_len - 2):
line += [(line[-1][0] + diff_1, line[-1][1] + diff_2)]
if 0 <= line[-1][0] <= row_length
and 0 <= line[-1][1] <= col_len:
return line
return []
For this function, I passed the length of the word as an argument for two main reasons—to check for words with a length of two, and for the length of the final list output. We check for double length words because with words that have lengths of 2, we no longer need to compute for a third coordinate because the word only needs two coordinates to be complete.
For the second reason, this serves as the quirk of my algorithm. Instead of checking the third coordinate for a match of the third character (and the subsequent ones), I instead create a list of coordinates, forming a straight line in the matrix, whose length is equal to the length of the word.
I first create the line variable which already contains the coordinates of the first match and the second match of the word. After that, I get the difference of the second coordinates values and the first. Finally, I create a for loop whose loop count is the length of the word minus 2 (because line already has two values inside). Inside the loop, I append to the line list variable a new coordinate by getting line’s last variable values then adding the difference of the second and first match coordinates.
Finally, to make sure that the created coordinate list can be found inside the matrix, I check the last coordinate of the line variable if it’s within the bounds of the matrix. If it is, I return the newly created coordinate list, and if not, I simply return an empty list.
Let’s say we want a complete line when given coordinate matches (0, 0) and (1, 1), and the length of our word is 3:
>>> core.complete_line((0, 0), (1, 1), 3, 4, 3)
[(0, 0), (1, 1), (2, 2)]If we give the function a word length of 4:
>>> core.complete_line((0, 0), (1, 1), 4, 4, 3)
[]it returns an empty list because the last coordinate of the created list went out of bounds.
complete_match
def complete_match(word, matrix, base_match, word_len, row_len,
col_len):
new = (complete_line(base, n, word_len, row_len, col_len)
for base in base_match
for n in matched_neighbors(base, word[1], matrix,
row_len, col_len))
return [ero for ero in new
if convert_to_word(ero, matrix) == word]
This is the complete_line function on steroids. The goal of this function is to apply complete_line to all the neighbors of the first match. After that, it creates a lists of coordinates whose word equivalent is the same as the word we’re trying to look for inside the matrix.
For the value of the new variable, I utilize a generator comprehension. These are like list comprehensions, except, they release their values one by one, only upon request, in contrast to list comprehensions which return all the contents of the list in one go.
To accomplish the application of complete_line to all the neighbors of the first match, I iterate through all the first matches:
for base in base_matchthen inside that for loop, I iterate through all the neighbors that matched_neighbors gave us:
for n in matched_neighbors(base, word[1], matrix, row_len, col_len)I then put the following statement in the first part of the generator comprehension:
complete_line(base, n, word_len, row_len, column_len)The above generator comprehension is roughly equivalent to:
for base in base_match:
for n in matched_neighbors(base, word[1], matrix, row_len,
col_len):
yield complete_line(base, n, word_len, row_len, col_len)
After the creation of the new variable, we now start going through its values one by one:
[ero for ero in new if convert_to_word(ero, matrix) == word]This list comprehension above will filter the new and the resulting list will only contain coordinates that, when converted to its word counterpart, match the original word we wanted to find.
Attempting to find the word dog inside our matrix returns a list of lists containing matched coordinates:
>>> base_match = find_base_match('dog'[0], matrix)
>>> core.complete_match('dog', matrix, base_match, 3, 3, 4)
[[(0, 0), (0, 1), (0, 2)], [(0, 0), (1, 0), (2, 0)],
[(0, 0), (1, 1), (2, 2)], [(2, 3), (1, 3), (0, 3)]]
find_matches
def find_matches(word, grid, separator='n'):
word_len = len(word)
matrix = matrixify(grid, separator)
row_len, column_len = len(matrix), len(matrix[0])
base_matches = find_base_match(word[0], matrix)
if column_len < word_len > row_len or not base_matches:
return []
elif word_len == 1:
return base_matches
return complete_match(word, matrix, base_matches, word_len,
row_len, column_len)
This function will serve as the helper of our main function. Its goal is to output a list containing the coordinates of all the possible matches of word inside grid. For general purposes, I defined four variables:
- The
word_lenvariable whose value is the length of thewordargument, which will generally be useful throughout the script - The
matrixvariable whose value we get through givinggridto ourmatrixifyfunction, which will allow us to later be able to index contents of the matrix through its row and column indices. - The
row_lenand thecolumn_lenvariable ofmatrix base_matcheswhich contain the coordinates of all the first letter matches ofword
After the variables, we will do some sanity checks:
if column_len < word_len > row_len or not base_matches:
return []
elif word_len == 1:
return base_matches
The above if elif statement will check if the length of word is longer than both the column_len and row_len and also checks if base_matches returns an empty list. If that condition is not satisfied, it means that word can fit inside the matrix, and base_matches found a match! However, if the length of word is 1, we simply return base_matches.
If the word is longer than 1, we then pass the local variables to complete_match for further processing.
Given dog, the string chain dogg oogo gogd, and the ' ' separator as arguments:
>>> find_matches('dog', 'dogg oogo gogd', ' ')
[[(0, 0), (0, 1), (0, 2)], [(0, 0), (1, 0), (2, 0)],
[(0, 0), (1, 1), (2, 2)], [(2, 3), (1, 3), (0, 3)]]
Voila! This is the list, which contain lists of coordinates where the word dog matched inside dogg oogo gogd!
wordsearch
def wordsearch(word, string_grid, separator='n'):
return len(find_matches(word, string_grid, separator))This function simply returns the number of matches of running
find_matches(word, string_grid, separator='n'):>>> wordsearch('dog', 'dogg oogo gogd', ' ')
4There are 4 matches of dog inside dogg oogo gogd!
Closing remarks
Remember, it’s never a bad idea to go back to using pen and paper to solve programming problems. Sometimes, we express ideas better using our bare hands, and to top it off, a good ol’ break from the monitor and from the walls of code could just be what you need for a breakthrough—just like when I got stuck thinking about how I should implement my complete_line function!
In this Python tutorial, you’ll learn to search a string in a text file. Also, we’ll see how to search a string in a file and print its line and line number.
After reading this article, you’ll learn the following cases.
- If a file is small, read it into a string and use the
find()method to check if a string or word is present in a file. (easier and faster than reading and checking line per line) - If a file is large, use the mmap to search a string in a file. We don’t need to read the whole file in memory, which will make our solution memory efficient.
- Search a string in multiple files
- Search file for a list of strings
We will see each solution one by one.
Table of contents
- How to Search for a String in Text File
- Example to search for a string in text file
- Search file for a string and Print its line and line number
- Efficient way to search string in a large text file
- mmap to search for a string in text file
- Search string in multiple files
- Search file for a list of strings
How to Search for a String in Text File
Use the file read() method and string class find() method to search for a string in a text file. Here are the steps.
- Open file in a read mode
Open a file by setting a file path and access mode to the
open()function. The access mode specifies the operation you wanted to perform on the file, such as reading or writing. For example, r is for reading.fp= open(r'file_path', 'r') - Read content from a file
Once opened, read all content of a file using the
read()method. Theread()method returns the entire file content in string format. - Search for a string in a file
Use the
find()method of a str class to check the given string or word present in the result returned by theread()method. Thefind()method. The find() method will return -1 if the given text is not present in a file - Print line and line number
If you need line and line numbers, use the
readlines() method instead ofread()method. Use the for loop andreadlines()method to iterate each line from a file. Next, In each iteration of a loop, use the if condition to check if a string is present in a current line and print the current line and line number
Example to search for a string in text file
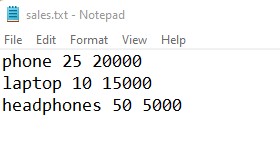
I have a ‘sales.txt’ file that contains monthly sales data of items. I want the sales data of a specific item. Let’s see how to search particular item data in a sales file.
def search_str(file_path, word):
with open(file_path, 'r') as file:
# read all content of a file
content = file.read()
# check if string present in a file
if word in content:
print('string exist in a file')
else:
print('string does not exist in a file')
search_str(r'E:demosfiles_demosaccountsales.txt', 'laptop')Output:
string exists in a file
Search file for a string and Print its line and line number
Use the following steps if you are searching a particular text or a word in a file, and you want to print a line number and line in which it is present.
- Open a file in a read mode.
- Next, use the
readlines()method to get all lines from a file in the form of a list object. - Next, use a loop to iterate each line from a file.
- Next, In each iteration of a loop, use the if condition to check if a string is present in a current line and print the current line and line number.
Example: In this example, we’ll search the string ‘laptop’ in a file, print its line along with the line number.
# string to search in file
word = 'laptop'
with open(r'E:demosfiles_demosaccountsales.txt', 'r') as fp:
# read all lines in a list
lines = fp.readlines()
for line in lines:
# check if string present on a current line
if line.find(word) != -1:
print(word, 'string exists in file')
print('Line Number:', lines.index(line))
print('Line:', line)Output:
laptop string exists in a file line: laptop 10 15000 line number: 1
Note: You can also use the readline() method instead of readlines() to read a file line by line, stop when you’ve gotten to the lines you want. Using this technique, we don’t need to read the entire file.
Efficient way to search string in a large text file
All above way read the entire file in memory. If the file is large, reading the whole file in memory is not ideal.
In this section, we’ll see the fastest and most memory-efficient way to search a string in a large text file.
- Open a file in read mode
- Use for loop with
enumerate()function to get a line and its number. Theenumerate()function adds a counter to an iterable and returns it in enumerate object. Pass the file pointer returned by theopen()function to theenumerate(). - We can use this enumerate object with a for loop to access the each line and line number.
Note: The enumerate(file_pointer) doesn’t load the entire file in memory, so this is an efficient solution.
Example:
with open(r"E:demosfiles_demosaccountsales.txt", 'r') as fp:
for l_no, line in enumerate(fp):
# search string
if 'laptop' in line:
print('string found in a file')
print('Line Number:', l_no)
print('Line:', line)
# don't look for next lines
breakExample:
string found in a file Line Number: 1 Line: laptop 10 15000
mmap to search for a string in text file
In this section, we’ll see the fastest and most memory-efficient way to search a string in a large text file.
Also, you can use the mmap module to find a string in a huge file. The mmap.mmap() method creates a bytearray object that checks the underlying file instead of reading the whole file in memory.
Example:
import mmap
with open(r'E:demosfiles_demosaccountsales.txt', 'rb', 0) as file:
s = mmap.mmap(file.fileno(), 0, access=mmap.ACCESS_READ)
if s.find(b'laptop') != -1:
print('string exist in a file')Output:
string exist in a file
Search string in multiple files
Sometimes you want to search a string in multiple files present in a directory. Use the below steps to search a text in all files of a directory.
- List all files of a directory
- Read each file one by one
- Next, search for a word in the given file. If found, stop reading the files.
Example:
import os
dir_path = r'E:demosfiles_demosaccount'
# iterate each file in a directory
for file in os.listdir(dir_path):
cur_path = os.path.join(dir_path, file)
# check if it is a file
if os.path.isfile(cur_path):
with open(cur_path, 'r') as file:
# read all content of a file and search string
if 'laptop' in file.read():
print('string found')
breakOutput:
string found
Search file for a list of strings
Sometimes you want to search a file for multiple strings. The below example shows how to search a text file for any words in a list.
Example:
words = ['laptop', 'phone']
with open(r'E:demosfiles_demosaccountsales.txt', 'r') as f:
content = f.read()
# Iterate list to find each word
for word in words:
if word in content:
print('string exist in a file')Output:
string exist in a file
Python Exercises and Quizzes
Free coding exercises and quizzes cover Python basics, data structure, data analytics, and more.
- 15+ Topic-specific Exercises and Quizzes
- Each Exercise contains 10 questions
- Each Quiz contains 12-15 MCQ
В прошлой статье я рассказывала, что составила для своего проекта словарь «Властелина Колец», причем для каждого англоязычного терма (слова/словосочетания) хранится перевод и список глав, в которых встречается это выражение. Все это составлено вручную. Однако мне не дает покоя, что многие вхождения термов могли быть пропущены.

В первой версии MVP я частично решила эту проблему обычным поиском по подстроке (b{term}, где b – граница слова), что позволило найти вхождения отдельных слов без учета морфологии или с некоторыми внешними флексиями (например, -s, -ed, -ing). Фактически это поиск подстроки с джокером на конце. Но для многословных выражений и неправильных глаголов, составляющих весомую долю моего словаря, этот способ не работал.
После пары безуспешных попыток установить Elasticsearch я, как типичный изобретатель велосипеда и вечного двигателя, решила писать свой код. Скудным словообразованием английского языка меня не запугать ввиду наличия опыта разработки полнотекстового поиска по документам на великом и могучем русском языке. Кроме того, для моей задачи часть вхождений уже все равно выбрана вручную и потому стопроцентная точность не требуется.
Подготовка словаря
Итак, дан словарь. Ну как дан – составлен руками за несколько месяцев упорного труда. Дан с точки зрения программиста. После прошлой статьи словарь подрос вдвое и теперь охватывает весь первый том («Братство Кольца»). В сыром виде состоит из 11.690 записей в формате «терм – перевод – номер главы». Хранится в Excel.
Как и в прошлый раз, я сгруппировала свой словарь по словарным гнездам с помощью функции pivot_table() из pandas. Осталось 5.404 записи, а после ручного редактирования — 5.354.
Больше всего меня беспокоили неправильные глаголы, поскольку в моем словаре они хранились в инфинитиве, а в романе чаще всего употреблялись в прошедшем времени. Ввиду так называемого аблаута (например, run – ran – run) установить инфинитив по словоформе прошедшего времени невозможно.
Я скачала словарь неправильных глаголов. Он насчитывал 294 штуки, многие из которых допускали два варианта. Пришлось проверить все вариации по тексту Толкиена, чтобы установить, какая форма характерна для его речи: например, cloven (p.p. от cleave) вместо cleft (что у него существительное). Оказалось, что многие неправильные глаголы у него правильные (например, burn), а leap даже существует в обеих версиях — leaped и leapt.
Теперь вариации неправильных глаголов унифицированы, а их список хранится в обычном текстовом файле:

Остается считать этот файл в датафрейм с помощью функции read_csv(), указав в качестве разделителей пробелы:
import pandas as pd
verb_data = pd.read_csv(pathlib.Path('c:/', 'ALL', 'LotR', 'неправильные глаголы.txt'),
sep=" ", header=None, names=["Inf", "Past", "PastParticiple"], index_col=0)Явно задаем index_col, чтобы сделать индексом первый столбец, хранящий инфинитивы глаголов, для удобства дальнейшего поиска.
Считаем наш главный словарь в другой датафрейм:
excel_data = pd.read_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'), dtype = str)
df = pd.DataFrame(excel_data, columns=['Word', 'Russian', 'Chapters'])Теперь объявим функцию, которая для каждого словарного терма проверит наличие в нем неправильного глагола и в зависимости от результата сгенерирует словоформы. Для простоты будем считать, что неправильный глагол всегда стоит на первом месте.
def check_irrverbs(word):
global verb_data
# берем часть выражения до первого пробела
arr = word.split(' ')
w, *tail = arr # = arr[0], arr[1:]
# запоминаем хвост
tail = " ".join(tail)
# проверяем, не является ли она неправильным глаголом
if w in verb_data.index:
# формируем формы Past и Past Participle
# если они одинаковые, то достаточно хранить одну форму
if verb_data.loc[w]["Past"] == verb_data.loc[w]["PastParticiple"]:
return verb_data.loc[w]["Past"] + " " + tail
return ", ".join([v + " " + tail for v in verb_data.loc[w].tolist()])
return ""Таким образом, для выражения make up one’s mind функция вернет made up one’s mind.
Применяем функцию к датафрейму, сохраняя результаты в новый столбец, и затем экспортируем результат в новый Excel-файл:
df['IrrVerb'] = df['Word'].apply(check_irrverbs)
df.to_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'))Теперь в Excel-таблице появился новый столбец, хранящий 2-ю (Past) и 3-ю (Past Participle) формы для всех неправильных глаголов, а для правильных столбец пуст.

Всего таких записей оказалось 662.
Спряжение потенциальных глаголов
Теперь сгенерируем все формы и для правильных, и для неправильных глаголов.
def generate_verbs(word, is_irrverb):
forms = []
# взять часть выражения до первого пробела
verb, tail = word, ""
pos = word.find(" ")
if pos >= 0:
verb = word[:pos]
tail = word[pos:]
consonant = "bcdfghjklmnpqrstvwxz"
last = verb[-1]
# глагол во 2 и 3 формах
if not is_irrverb:
if last in consonant:
forms.append(verb + last + "ed" + tail) # stop -> stopped
forms.append(verb + "ed" + tail) # и вариант без удвоения
elif last == "y":
if verb[-2] in consonant:
forms.append(verb[:-1] + "ied" + tail) # carry -> carried
else:
forms.append(verb + "ed" + tail) # play -> played
elif last == "e":
forms.append(verb + "d" + tail) # arrive -> arrived
else:
forms.append(verb + "ed" + tail)
# герундий, он же ing-овая форма глагола
if verb[-2:] == "ie":
forms.append(verb[:-2] + "ying" + tail) # lie -> lying
elif last == "e":
forms.append(verb[:-1] + "ing" + tail) # write -> writing
elif last in consonant:
forms.append(verb + last + "ing" + tail) # sit -> sitting
forms.append(verb + "ing" + tail) # sit -> sitting
else:
forms.append(verb + "ing" + tail)
return formsКак и прежде, для простоты будем считать глаголом часть выражения до первого пробела либо все выражение целиком, если оно не содержит пробелов. Посмотрим, на какую букву (переменная last) оканчивается предполагаемый глагол. Для этого нужен список либо гласных, либо согласных. Список гласных был бы короче, но так как нам понадобится проверять именно на согласную, то нагляднее будет хранить список consonant.
Для правильных глаголов вторая и третья формы создаются путем прибавления флексий -d, -ed, -ied в зависимости от последнего и предпоследнего звука. Так как учитывается еще и ударение, то проще всего сгенерировать оба варианта, из которых грамматически корректен будет только один. Для неправильных глаголов мы уже нашли обе формы и записали в отдельный столбец.
Герундий образуется одинаково для правильных и неправильных глаголов, но опять-таки надо учитывать последний символ и ударение, поэтому снова создаем оба варианта.
Все варианты записываются в список forms, который функция и возвращает.
Сложность заключается в том, что наш словарь не содержит информации о частях речи для каждого терма, да это и малоинформативно ввиду так называемой конверсии – одно и то же слово может быть и существительным, и глаголом в зависимости от места в предложении. Поэтому мы сейчас рассматриваем все хранящиеся в словаре выражения как потенциальные глаголы, так как перед нами не стоит задача построить грамматически корректную форму. Мы строим просто гипотезы. Если они не найдутся в тексте, то и не надо.
Подстановки
Кроме неправильных глаголов, словарь содержит еще один вид выражений, осложняющих полнотекстовый поиск, — подстановочные местоимения: притяжательное one’s, возвратное oneself и неопределенные somebody и something. В реальном тексте они должны заменяться на конкретные слова – соответственно, притяжательные местоимения (my, your, his и т.д.), возвратные местоимения (myself, yourself, himself и т.д.) и существительные. Поэтому надо сгенерировать все возможные формы с подстановками.
Начнем с one’s и oneself:
def replace_possessive_reflexive(word):
possessive = ["my", "mine", "your", "yours", "his", "her", "hers", "its", "our", "ours", "their", "theirs"]
reflexive = ["myself", "yourself", "himself", "herself", "itself", "ourselves", "yourselves", "themselves"]
# заменить one's на все варианты из possessive
if "one's" in word:
forms = list(map(lambda p: word.replace("one's", p), possessive))
elif "oneself" in word:
# заменить oneself на все варианты из reflexive
forms = list(map(lambda r: word.replace("oneself", r), reflexive))
else:
forms = [word]
return formsЗдесь мы для простоты предполагаем, что one’s и oneself не встречаются в одном выражении, а также не употребляются в реальном тексте. Если в терме есть одно из этих слов, то он интересует нас только с подстановками. В противном случае терм рассматривается как одна из форм самого себя, поэтому создается список, состоящий только из него.
Полный процесс замены обрабатывает также скобки и неопределенные местоимения:
def template_replace(word):
forms = []
forms = [word] if not "(" in word else [word.replace("(", "").replace(")", ""), re.sub("([^)]+)", "", word)]
forms = list(map(lambda f: f.replace("somebody", "S+").replace("something", "S+"), forms))
forms = list(map(replace_possessive_reflexive, forms))
return sum(forms, [])Замена происходит в три этапа, причем результат предыдущего подается на вход следующему.
-
Если терм содержит скобки, то рассматриваем два варианта – с их содержимым или без него: например, wild(ly) -> {wild, wildly}.
-
Что касается somebody и something, то они заменяются на S+ – группу любых непробельных символов, то есть на заготовку для будущего регулярного выражения.
-
Наконец вызываем рассмотренную выше функцию replace_possessive_reflexive() для обработки one’s и oneself.
В итоге получится многомерный список, который необходимо преобразовать в одномерный. В данном случае эта задача решается путем сложения с пустым списком.
Таким образом, основная идея данной реализации полнотекстового поиска – генерировать максимальное количество вариантов словоформ, чтобы затем искать их в тексте. Как велико это число? В простейшем случае, для термов, не содержащих неправильных глаголов и оканчивающихся на гласную, будет всего 3 формы – инфинитив, вторая/третья форма и герундий. Если терм кончается на согласную, то появляется второй вариант герундия. В худшем случае терм содержит скобки, притяжательное местоимение и неправильный глагол, оканчиваясь на согласную, тогда для первичного списка из 2 вариантов со скобками * 12 притяжательных местоимений будут сгенерированы по 24 формы инфинитива, двух вариантов герундия, а также прошедшего времени и причастия прошедшего времени, итого
![]()
Отдельной строкой, чтобы осознать масштаб этой цифры)
Впрочем, мой словарь не содержит настолько сложных случаев. Вот более характерный пример – hold one’s breath (сочетание неправильного глагола, оканчивающегося на гласную, и притяжательного местоимения). Из него будет сгенерировано 48 форм:
-
12 вариантов инфинитива: ‘hold my breath’, ‘hold mine breath’, ‘hold your breath’, ‘hold yours breath’, ‘hold his breath’, ‘hold her breath’, ‘hold hers breath’, ‘hold its breath’, ‘hold our breath’, ‘hold ours breath’, ‘hold their breath’, ‘hold theirs breath’
-
24 варианта герундия, с удвоенной согласной и с одинарной: ‘holdding my breath’, ‘holding my breath’, ‘holdding mine breath’, ‘holding mine breath’, ‘holdding your breath’, ‘holding your breath’, ‘holdding yours breath’, ‘holding yours breath’, ‘holdding his breath’, ‘holding his breath’, ‘holdding her breath’, ‘holding her breath’, ‘holdding hers breath’, ‘holding hers breath’, ‘holdding its breath’, ‘holding its breath’, ‘holdding our breath’, ‘holding our breath’, ‘holdding ours breath’, ‘holding ours breath’, ‘holdding their breath’, ‘holding their breath’, ‘holdding theirs breath’, ‘holding theirs breath’
-
12 вариантов прошедшего времени, совпадающего с past participle: ‘held my breath’, ‘held mine breath’, ‘held your breath’, ‘held yours breath’, ‘held his breath’, ‘held her breath’, ‘held hers breath’, ‘held its breath’, ‘held our breath’, ‘held ours breath’, ‘held their breath’, ‘held theirs breath’
Такие случаи довольно редки. Как уже говорилось, на весь 5-тысячный словарь нашлось всего 662 строки с неправильными глаголами. Что касается остальных сложных случаев, то в словаре 91 терм с притяжательными местоимениями, 31 – с подстановками somebody/something и 61 совмещает в себе и неправильный глагол, и какую-либо подстановку.
Поиск по тексту
Наконец приступаем к анализу оригинального текста, чтобы найти в нем пропущенные вхождения термов. Считаем датафрейм из Excel, не забывая, что заданные в списке columns заголовки столбцов должны фигурировать в первой строке листа Excel.
excel_data = pd.read_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'), dtype = str)
df = pd.DataFrame(excel_data, columns=['Word', 'Russian', 'Chapters', 'IrrVerb'])Прежде чем работать с текстом романа, возьмем на себя смелость слегка подправить великого автора, изменив нумерацию глав на сквозную. Вместо двух книг по 12 и 10 глав соответственно получится одна с 22-мя главами.
После этого откроем текст, удалим символы перевода строки и табуляции. Сразу заменим часто встречающееся в нем слово Mr., чтобы оно не мешало разбивать текст по предложениям.
f = open(pathlib.Path('c:/', 'ALL', 'LotR', 'Fellowship.txt'))
text = f.read().replace('n', ' ').replace('t', ' ').replace('r', ' ').replace('Mr. ', 'Mr') # учтет Mr.BagginsТеперь разобьем текст по главам.
lotr = []
text = re.split('Chaptersd+', text)Тогда в 0-м элементе списка будет предисловие, в 1-м — глава 1 и т.д., то есть индексы будут соответствовать реальным номерам глав, что очень удобно.

for chapter in text:
lotr.append(re.split('[.?!]', chapter))Теперь нас ждет главная функция, обрабатывающая строку датафрейма. Прежде всего получим старый список глав, в которых встречается данный терм. Он хранится в отдельном столбце таблицы. Наша задача — постараться дополнить этот список и в любом случае не забыть хотя бы отсортировать его.
ch = list(map(int, vec[0].split(',')))Если терм оканчивается восклицательным или вопросительным знаком, то это неизменяемое устойчивое выражение, например, междометие. Для него никаких словоформ искать не нужно.
word = vec[1]
if word[-1:] == "!" or word[-1:] == "?":
forms = [word]Для любого другого терма начнем с проверки, входит ли в него неправильный глагол, то есть заполнен ли соответствующий столбец (isnan()). Для неправильного глагола выделим 2-ю и 3-ю формы, которые могут различаться или совпадать.
else:
is_irrverb = False if isinstance(vec[2], float) and math.isnan(vec[2]) else True
if is_irrverb:
pos = vec[2].find(", ")
if pos >= 0:
past = vec[2][:pos]
past_participle = vec[2][pos + 2:]
else:
past = past_participle = vec[2]Произведем замены с помощью функции template_replace(), получим список словоформ. Проспрягаем каждый элемент этого списка.
forms = template_replace(word)
forms = forms + sum(list(map(lambda f: generate_verbs(f, is_irrverb), forms)), [])Для неправильных глаголов отдельно произведем замены для 2-й и 3-й форм.
if is_irrverb:
forms = forms + template_replace(past)
if past_participle != past:
forms = forms + template_replace(past_participle)Затем ищем каждую словоформу в каждой главе кроме ранее найденных глав, содержащихся в старом списке ch. Для этого используем функцию filter(), передав ей лямбда-функцию, которая будет обрабатывать каждое предложение. Поиск производится по регулярному выражению b{f}, где b — граница слова, а f — словоформа. Как уже говорилось, указание левой границы слова позволяет реализовать поиск с джокером на конце подстроки. Несмотря на весь написанный ранее код, мы все еще нуждаемся в этом нехитром приеме, так как флексии никто не отменял. Кроме того, от регулярного выражения мы никуда не денемся, так как ранее заменяли somebody/something на S+.
for f in forms:
for i in range(1, len(lotr)): # 0-ю главу (предисловие) пока пропускаем
if not i in ch:
match = list(filter(lambda sentence: re.search(rf'b{f}', sentence, flags=re.IGNORECASE), lotr[i]))
if match:
ch.append(i)Этот код ищет все вхождения терма в главу, хотя для поставленной задачи нужно найти только первое. Зато этот вариант облегчает тестирование программы.
Новые номера глав сохраняются в тот же список ch, который в конце концов сортируется и возвращается.
ch.sort()
return chПолный код функции check_chapters() выглядит следующим образом.
def check_chapters(vec):
global lotr
ch = list(map(int, vec[0].split(',')))
word = vec[1]
if word[-1:] == "!" or word[-1:] == "?":
forms = [word]
else:
is_irrverb = False if isinstance(vec[2], float) and math.isnan(vec[2]) else True
if is_irrverb:
pos = vec[2].find(", ")
if pos >= 0:
past = vec[2][:pos]
past_participle = vec[2][pos + 2:]
else:
past = past_participle = vec[2]
forms = template_replace(word)
forms = forms + sum(list(map(lambda f: generate_verbs(f, is_irrverb), forms)), [])
if is_irrverb:
forms = forms + template_replace(past)
if past_participle != past:
forms = forms + template_replace(past_participle)
for f in forms:
for i in range(1, len(lotr)): # 0-ю главу (предисловие) пока пропускаем
if not i in ch:
match = list(filter(lambda sentence: re.search(rf'b{f}', sentence, flags=re.IGNORECASE), lotr[i]))
if match:
ch.append(i)
ch.sort()
return chОсталось только применить эту функцию к датафрейму, сохранив результат в новый столбец New chapters:
df['New chapters'] = df[['Chapters', 'Word', 'IrrVerb']].apply(check_chapters, axis=1)
df.to_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'))Тестирование
Для тестирования была произведена выборка наиболее сложных термов – с неправильными глаголами и подстановками.
test = df[['Chapters', 'Word', 'IrrVerb']]
test = test[(test['IrrVerb'].str.len() > 0) & (test['Word'].str.contains("one's") | test['Word'].str.contains("something") | test['Word'].str.contains("somebody"))]
print(test.apply(check_chapters, axis=1))Вот термы, для которых было найдено более одного вхождения и которые поэтому являются самыми характерными (неупорядоченная нумерация сложилась потому, что поиск производился сначала по словоформам и лишь затем по главам):
|
Терм |
Найденные вхождения |
|
find one’s way |
Chapter 12: We could perhaps find our way through and come round to Rivendell from the north; but it would take too long, for I do not know the way, and our food would not last Chapter 2: He found his way into Mirkwood, as one would expect |
|
make one’s way |
Chapter 3: My plan was to leave the Shire secretly, and make my way to Rivendell; but now my footsteps are dogged, before ever I get to Buckland Chapter 16: Make your ways to places where you can find grass, and so come in time to Elrond’s house, or wherever you wish to go Chapter 6: Coming to the opening they found that they had made their way down through a cleft in a high sleep bank, almost a cliff Chapter 11: Merry’s ponies had escaped altogether, and eventually (having a good deal of sense) they made their way to the Downs in search of Fatty Lumpkin Chapter 12: They made their way slowly and cautiously round the south-western slopes of the hill, and came in a little while to the edge of the Road |
|
make up one’s mind |
Chapter 10: You must make up your mind Chapter 19: But before Sam could make up his mind what it was that he saw, the light faded; and now he thought he saw Frodo with a pale face lying fast asleep under a great dark cliff Chapter 16: The eastern arch will probably prove to be the way that we must take; but before we make up our minds we ought to look about us Chapter 22: ‘Yet we must needs make up our minds without his aid Chapter 4: I am leaving the Shire as soon as ever I can – in fact I have made up my mind now not even to wait a day at Crickhollow, if it can be helped Chapter 21: Sam had long ago made up his mind that, though boats were maybe not as dangerous as he had been brought up to believe, they were far more uncomfortable than even he had imagined |
|
one’s heart sink |
Chapter 11: ‘It is getting late, and I don’t like this hole: it makes my heart sink somehow Chapter 14: » ‘»The Shire,» I said; but my heart sank |
|
shake one’s head |
Chapter 2: ‘They are sailing, sailing, sailing over the Sea, they are going into the West and leaving us,’ said Sam, half chanting the words, shaking his head sadly and solemnly Chapter 4: Too near the River,’ he said, shaking his head Chapter 9: ‘ ‘There’s some mistake somewhere,’ said Butterbur, shaking his head Chapter 14: ‘ he said, shaking his head Chapter 16: ‘I am too weary to decide,’ he said, shaking his head Chapter 12: ‘ When he heard what Frodo had to tell, he became full of concern, and shook his head and sighed Chapter 15: Gimli looked up and shook his head Chapter 22: Sam, who had been watching his master with great concern, shook his head and muttered: ‘Plain as a pikestaff it is, but it’s no good Sam Gamgee putting in his spoke just now |
|
sleep on something |
Chapter 3: ‘Well, see you later – the day after tomorrow, if you don’t go to sleep on the way Chapter 13: His head seemed sunk in sleep on his breast, and a fold of his dark cloak was drawn over his face Chapter 18: I cannot sleep on a perch |
|
spring to one’s feet |
Chapter 2: ’ cried Gandalf, springing to his feet Chapter 11: ‘ asked Frodo, springing to his feet Chapter 14: ‘ cried Frodo in amazement, springing to his feet, as if he expected the Ring to be demanded at once Chapter 16: With a suddenness that startled them all the wizard sprang to his feet Chapter 8: The hobbits sprang to their feet in alarm, and ran to the western rim Chapter 9: The local hobbits stared in amazement, and then sprang to their feet and shouted for Barliman |
|
take one’s advice |
Chapter 3: If I take your advice I may not see Gandalf for a long while, and I ought to know what is the danger that pursues me Chapter 11: When they saw them they were glad that they had taken his advice: the windows had been forced open and were swinging, and the curtains were flapping; the beds were tossed about, and the bolsters slashed and flung upon the floor; the brown mat was torn to pieces |
Таким образом, в большинстве случаев словоформы обрабатываются корректно.
Итоги
Учитывая вышеприведенный расчет со 120 словоформами, порожденными одной строкой словаря, поиск всех вхождений вместо первого, наличие регулярных выражений и громоздкость решения в целом, я не ожидала от программы быстрых результатов. Однако на ноутбуке с 4-ядерным Intel i5-8265U и 8 Гб ОЗУ словарь из 5 тыс. строк был проработан за 1.187 секунд. В итоге найдены 3.330 новых вхождений в дополнение к прежним 10.482, записанным вручную.

Вот так несколько десятков строк кода показали вполне удовлетворительные результаты для полнотекстового поиска с поддержкой морфологии английского языка. Программа работает достаточно корректно и быстро. Конечно, она не лишена недостатков — не застрахована от ложных срабатываний, не учтет флексию в середине многословного терма (например, takes his advice). Однако с поставленной задачей успешно справилась.
Есть список слов, вида:
animalslist=['кот', 'собака', 'олень', 'тюлень']
длинною в 600+ слов
Имеется строка, введённая пользователем, вида:
message='Какой либо текст олень какой либо текст'
Как эффективнее всего можно узнать, имеются ли в строке слова из списка
Длина строки заранее не известна
задан 24 мар 2020 в 17:56
![]()
if set(animalslist) & set(message.split()):
print('В строке есть слова из списка')
ответ дан 24 мар 2020 в 18:01
![]()
Sergey GornostaevSergey Gornostaev
66.1k6 золотых знаков51 серебряный знак111 бронзовых знаков
2
Должно немного быстрее (если время в вашем случаем можно принять за критерий эффективности) работать, когда так (крутой вариант от vadim vaduxa):
animalslist = ['кот', 'собака', 'олень', 'тюлень']
message = 'Какой либо текст олень какой либо кот текст олень'.split()
sm = set(message)
print([f'{word} == {message.count(word)}' for word in animalslist if word in sm])
# ['кот == 1', 'олень == 2']
ответ дан 24 мар 2020 в 19:32
![]()
SerzhevSerzhev
971 золотой знак1 серебряный знак8 бронзовых знаков
animalslist = ['кот', 'собака', 'олень', 'тюлень']
message = 'Какой либо текст олень какой либо кот текст олень'.split()
sm = set(message)
# ['олень', 'кот']
print([a for a in sm if a in animalslist])
# ['кот=1', 'олень=2']
print([f'{a}={c}' for a, c in ([a, message.count(a)] for a in animalslist if a in sm) if c])
ответ дан 24 мар 2020 в 18:23
![]()
vadim vaduxavadim vaduxa
8,88714 серебряных знаков24 бронзовых знака
1