Способ номер 1 — Метод getElementsByTagName()
Получение HTMLCollection с объектами HTML-элементов <img>
document.getElementsByTagName("img")
Конвертируем коллекцию (HTMLCollection) в массив (Array)
[...document.getElementsByTagName("img")]
Проходим по каждому объекту в массиве и извлекаем значение свойства src. Получаем массив из строк
[...document.getElementsByTagName("img")].map(i => i.src)
Выводим результат на текущую открытую страницу браузера. Нужно для копирования в эксельку.
document.write([...document.getElementsByTagName("img")].map(i => i.src).join("<br>"))
Способ номер 2 — Получатель доступа images
Получение HTMLCollection с объектами HTML-элементов img
document.images
С выводом результатов на текущую страницу
document.write((Array.from(document.images).map(i =>i.src)).join("<br>"))
Куда вводить эту команду? Открываете HTML-страницу, с которой хотите получить все веб-ссылки. Включаете «Инструменты разработчика» в браузере (CTRL + SHIFT + i). Находите вкладку «Console«. Тыкаете курсор в белое поле справа от синей стрелочки. Вставляете команду. Жмёте клавишу ENTER.
Пошаговая инструкция
Стандарт HTML предусматривает быстрое получение всех элементов изображений <img>. Для этого используется JavaScript команда:
document.images

Все эти элементы лежат в массиво-подобном прототипе объекта HTMLCollection. Это значит, что мы можем обращаться к любому элементу коллекции по его индексу (как у массивов). Например:
document.images[0]
Мы обратились к первому элементу нашего прототипа объекта HTMLCollection.

В ответ мы получили элемент со всеми атрибутами. Мы видим, что ссылка на изображение хранится в атрибуте «src». То есть нам нужно пройти по всем элементам коллекции и извлечь значение этого атрибута — составить список ссылок. Как это сделать?
Дадим коллекции имя, чтобы взаимодействовать с переменной:
let a = document.images
Потом нам нужно преобразовать HTML коллекцию в массив:
let b = Array.from(a)
Далее мы должны «пробежаться» по каждому элементу коллекции и достать значение в атрибуте «src». Делаем это при помощи метода map(). В ответ нам вернётся новый массив со строковым типом данных.
let c = b.map(i => i.src)
Теперь можно соединить все элементы массива в одну строку с разделителем <br>. Мы генерируем HTML-разметку с переносами строк:
let d = c.join("<br>")
И вывести на текущую страницу:
document.write(d)

Список адресов на изображения со страницы успешно создан. Его можно скопировать и использовать в собственных задачах.
Способ номер 3 — Console Utilities API reference
Работает в браузерах на движке Chromium
$$("img")
Способ номер 4 — Console Utilities API reference
Работает в браузерах на движке Chromium
$x("//img")
Что нужно знать?
В этом списке будут ТОЛЬКО те изображения, которые находятся в самой разметке страницы — которые есть в элементах img. Это значит, что если система управления контентом сайта предусматривает загрузку изображений в стилях CSS, тогда таких фото не будет в этом списке.
Также может не быть фотографий, которые обрабатываются скриптами — например, фотографии из слайдеров, потому что это фоновая подгрузка элементов, которые изменяют структуру страницы в процессе взаимодействия, а не во время первичной загрузки документа. Это изменение DOM-дерева.
Ещё в список не попадут изображения, которые должны открываться по ссылке (например, в новой вкладке). Имеется ввиду HTML-элемент <a> и атрибут href. Получение изображения в этом случае описано в публикации «JavaScript | Как получить все ссылки на HTML-странице?»
Имейте это ввиду.
Информационные ссылки
Fetch | Как сохранить изображение на клиенте? | JavaScript
Узнайте как сохранить найденные изображения на ПК из клиента.
HTML — Living Standard — https://html.spec.whatwg.org/#dom-document-images
DOM — Living Standard — https://dom.spec.whatwg.org/#dom-element-getelementsbytagname
Console Utilities API reference — https://developer.chrome.com/docs/devtools/console/utilities/
Как найти похожую картинку, фотографию, изображение в интернет
12.07.2019
Допустим у Вас есть какое-то изображение (рисунок, картинка, фотография), и Вы хотите найти такое же (дубликат) или похожее в интернет. Это можно сделать при помощи специальных инструментов поисковиков Google и Яндекс, сервиса TinEye, а также потрясающего браузерного расширения PhotoTracker Lite, который объединяет все эти способы. Рассмотрим каждый из них.
Поиск по фото в Гугл
Тут всё очень просто. Переходим по ссылке https://www.google.ru/imghp и кликаем по иконке фотоаппарата:

Дальше выбираем один из вариантов поиска:
- Указываем ссылку на изображение в интернете
- Загружаем файл с компьютера
На открывшейся страничке кликаем по ссылке «Все размеры»:

В итоге получаем полный список похожих картинок по изображению, которое было выбрано в качестве образца:

Есть еще один хороший способ, работающий в браузере Chrome. Находясь на страничке с интересующей Вас картинкой, подведите к ней курсор мыши, кликните правой клавишей и в открывшейся подсказке выберите пункт «Найти картинку (Google)»:

Вы сразу переместитесь на страницу с результатами поиска!
Статья по теме: Поисковые сервисы Google, о которых Вы не знали!
Поиск по картинкам в Яндекс
У Яндекса всё не менее просто чем у Гугла  Переходите по ссылке https://yandex.by/images/ и нажимайте значок фотоаппарата в верхнем правом углу:
Переходите по ссылке https://yandex.by/images/ и нажимайте значок фотоаппарата в верхнем правом углу:

Укажите адрес картинки в сети интернет либо загрузите её с компьютера (можно простым перетаскиванием в специальную области в верхней части окна браузера):
![]()
Результат поиска выглядит таким образом:
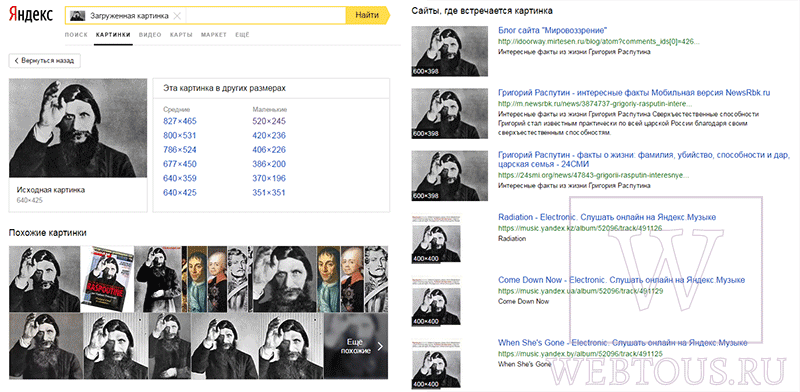
Вы мгновенно получаете доступ к следующей информации:
- Какие в сети есть размеры изображения, которое Вы загрузили в качестве образца для поиска
- Список сайтов, на которых оно встречается
- Похожие картинки (модифицированы на основе исходной либо по которым алгоритм принял решение об их смысловом сходстве)
Поиск похожих картинок в тинай
Многие наверняка уже слышали об онлайн сервисе TinEye, который русскоязычные пользователи часто называют Тинай. Он разработан экспертами в сфере машинного обучения и распознавания объектов. Как следствие всего этого, тинай отлично подходит не только для поиска похожих картинок и фотографий, но их составляющих.
Проиндексированная база изображений TinEye составляет более 10 миллиардов позиций, и является крупнейших во всем Интернет. «Здесь найдется всё» — это фраза как нельзя лучше характеризует сервис.

Переходите по ссылке https://www.tineye.com/, и, как и в случае Яндекс и Google, загрузите файл-образец для поиска либо ссылку на него в интернет.

На открывшейся страничке Вы получите точные данные о том, сколько раз картинка встречается в интернет, и ссылки на странички, где она была найдена.
PhotoTracker Lite – поиск 4в1
Расширение для браузера PhotoTracker Lite (работает в Google Chrome, Opera с версии 36, Яндекс.Браузере, Vivaldi) позволяет в один клик искать похожие фото не только в указанных выше источниках, но и по базе поисковика Bing (Bing Images)!
Скриншот интерфейса расширения:
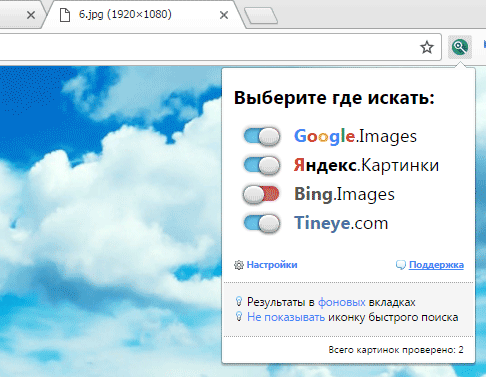
В настройках приложения укажите источники поиска, после чего кликайте правой кнопкой мыши на любое изображение в браузере и выбирайте опцию «Искать это изображение» PhotoTracker Lite:
![]()
Есть еще один способ поиска в один клик. По умолчанию в настройках приложения активирован пункт «Показывать иконку быстрого поиска». Когда Вы наводите на какое-то фото или картинку, всплывает круглая зеленая иконка, нажатие на которую запускает поиск похожих изображений – в новых вкладках автоматически откроются результаты поиска по Гугл, Яндекс, Тинай и Бинг.

Расширение создано нашим соотечественником, который по роду увлечений тесно связан с фотографией. Первоначально он создал этот инструмент, чтобы быстро находить свои фото на чужих сайтах.
Когда это может понадобиться
- Вы являетесь фотографом, выкладываете свои фото в интернет и хотите посмотреть на каких сайтах они используются и где возможно нарушаются Ваши авторские права.
- Вы являетесь блогером или копирайтером, пишите статьи и хотите подобрать к своему материалу «незаезженное» изображение.
- А вдруг кто-то использует Ваше фото из профиля Вконтакте или Фейсбук в качестве аватарки на форуме или фальшивой учетной записи в какой-либо социальной сети? А ведь такое более чем возможно!
- Вы нашли фотографию знакомого актера и хотите вспомнить как его зовут.
На самом деле, случаев, когда может пригодиться поиск по фотографии, огромное множество. Можно еще привести и такой пример…
Как найти оригинал заданного изображения
Например, у Вас есть какая-то фотография, возможно кадрированная, пожатая, либо отфотошопленная, а Вы хотите найти её оригинал, или вариант в лучшем качестве. Как это сделать? Проводите поиск в Яндекс и Гугл, как описано выше, либо средствами PhotoTracker Lite и получаете список всех найденных изображений. Далее руководствуетесь следующим:
- Оригинальное изображение, как правило имеет больший размер и лучшее качество по сравнению с измененной копией, полученной в результате кадрирования. Конечно можно в фотошопе выставить картинке любой размер, но при его увеличении относительно оригинала, всегда будут наблюдаться артефакты. Их можно легко заметить даже при беглом визуальном осмотре.
Статья в тему: Как изменить размер картинки без потери в качестве.
- Оригинальные фотографии часто имеют водяные знаки, обозначающие авторство снимка (фамилия, адрес сайта, название компании и пр.). Конечно водяной знак может добавить кто угодно на абсолютно на любое изображение, но в этом случае можно поискать образец фото на сайте или по фамилии автора, наверняка он где-то выкладывает своё портфолио онлайн.
- И наконец, совсем простой признак. Если Ваш образец фото черно-белый (сепия и пр.), а Вы нашли такую же, но полноцветную фотографию, то у Вас явно не оригинал. Добавить цветность ч/б фотографии гораздо более сложнее, чем перевести цветную фотографию в черно-белую

Уважаемые читатели, порекомендуйте данный материал своим друзьям в социальных сетях, а также задавайте свои вопросы в комментариях и делитесь своим мнением!
Похожие публикации:
- Data Recovery Wizard — легкое восстановление файлов, удаленных по ошибке
- Решение проблемы черного экрана при воспроизведении видео с Youtube
- Просто и понятно о VPN – с картинками и пояснениями
- Как отключить автоматическое создание групп вкладок в Chrome
- Как активировать режим «картинка в картинке» для видео в Хроме
Понравилось? Поделитесь с друзьями!

Сергей Сандаков, 42 года.
С 2011 г. пишу обзоры полезных онлайн сервисов и сайтов, программ для ПК.
Интересуюсь всем, что происходит в Интернет, и с удовольствием рассказываю об этом своим читателям.
 Есть ряд ситуаций, когда важно узнать, кем, где и когда было впервые опубликовано фото, найденное в сети. На первый взгляд это кажется нереальным, когда картинка растиражирована многочисленными пользователями и Интернет-ресурсами. Однако это возможно. Многие современные сервисы без проблем помогут найти ответ на вопрос: «Как найти первоисточник фотографии в Интернете?».
Есть ряд ситуаций, когда важно узнать, кем, где и когда было впервые опубликовано фото, найденное в сети. На первый взгляд это кажется нереальным, когда картинка растиражирована многочисленными пользователями и Интернет-ресурсами. Однако это возможно. Многие современные сервисы без проблем помогут найти ответ на вопрос: «Как найти первоисточник фотографии в Интернете?».
- Зачем искать первоисточник фотографии
- На что обращать внимание при поиске
- Сервисы для поиска по картинкам
- TinEye
- RevIMG
- Яндекс Картинки
- Google Картинки
Зачем искать первоисточник фотографии
Поиск может понадобиться для работы или в личных интересах. Самые распространенные причины, по которым ищут первоисточник:
- необходимость указать автора фотографии;
- проверка достоверности информации, найденной в Интернете;
- если нужно фото в максимальном разрешении.
Также сервисы по поиску первоисточника помогают найти свои картинки, без спроса взятые другими пользователями или сайтами. Найдя похитителей, можно напомнить им о законе об авторских правах и потребовать оплату.
На что обращать внимание при поиске
 Чтобы найти первоисточник изображения, важно учесть несколько моментов:
Чтобы найти первоисточник изображения, важно учесть несколько моментов:
- Первая фотография должна быть наивысшего разрешения. Это доказывает, что она использовалась в Интернете наименьшее количество раз;
- Если поисковый сервис выдал сразу несколько картинок одинакового разрешения, оригинал можно определить по большему размеру или наличию метаданных;
- Некоторые сервисы (например, Google) позволяют отбирать фотографии по дате публикации. Чтобы ее найти, следует перейти в меню «Инструменты поиска», а затем в папку «Время». Затем указать необходимый временной отрезок. Так будет нетрудно распознать оригинал. Такое фото будет опубликовано раньше других;
- Стоит обращать внимание и на сопроводительный текст к изображениям. К одинаковым картинкам может быть написан совершенно разный текст. Такие манипуляции часто используют в фейковых новостях, что полностью меняет отношение пользователей к снимкам;
- Чтобы помешать обнаружению первоисточника при создании неправдоподобных новостей, фотографии нередко зеркалят. То есть переворачивают изображение зеркально в фоторедакторе. Или кадрируют. Так что, когда обычный поиск не дает результат, можно также загрузить снимок в сервис в зеркальном виде, и попробовать вновь;
- Также порой обнаружению первоисточника способствует размытие картинки. Можно прибегнуть к этому способу, если четкий снимок не был найден. Когда изображение размыто, поисковые системы концентрируются не на деталях, а на общих контурах фотографии.
Если нужная фотография найдена в социальных сетях, и важно установить достоверность поста, следует изучить профиль пользователя. При этом стоит обратить внимание на следующие моменты:
- Время создания аккаунта. Если информация не отображается, можно посмотреть, когда пользователь опубликовал первую аватарку. Чаще всего, это время соответствует времени создания профиля. В Twitter и ВКонтакте есть специальные сервисы для проверки времени открытия аккаунта;
- Активность пользователя и взаимодействие с другими профилями;
- Связанность интересующего поста с фотографией с общей темой профиля;
- Указано ли реальное имя человека и связана ли страница с другими профилями в соцсетях;
- Есть ли информация о местонахождении владельца странички;
- Указана ли профессия.
Все это поможет найти автора и определить реальность фотографии и сопроводительного текста.
Сервисы для поиска по картинкам
Расскажем о нескольких сервисах, помогающих найти первоисточник фото.
TinEye
 Это один из первых ресурсов, который позволил использовать обратный поиск снимков в Интернете. Он действует с 2008 года и основан канадской компанией Idee Inc.
Это один из первых ресурсов, который позволил использовать обратный поиск снимков в Интернете. Он действует с 2008 года и основан канадской компанией Idee Inc.
В сервисе достаточно просто разобраться, несмотря на то, что он работает только на английском языке.
При использовании для личных целей с сервисом можно работать бесплатно.
Форма для загрузки и поиска картинки расположена в центре стартовой страницы сайта. Можно загрузить ее классическим способом или перетащить с винчестера. Здесь же можно попробовать отыскать автора фотографии, указав URL-адрес изображения, найденного в сети.
Сайт работает очень быстро и эффективно. Выдает огромное количество результатов и без погрешностей.
Если поиск первоисточника фото необходим часто, можно установить плагин этого сервиса. Он подойдет для любого из популярных браузеров.
Есть у этого ресурса и один минус. Чтобы понять, куда ведут отобразившиеся ссылки, необходимо нажать на них. При этом можно оказаться на сайтах других стран, язык которых будет непонятен пользователю. Так работа по поиску первоисточника изображения может занять много времени.
RevIMG
 Сервисом можно воспользоваться бесплатно. У него достаточно простой интерфейс, но язык английский.
Сервисом можно воспользоваться бесплатно. У него достаточно простой интерфейс, но язык английский.
Среди преимуществ этого поисковика картинок – возможность задать тему поиска, а не только загрузить фотографию и ее URL-адрес. Так удастся значительно сузить поиск. Сервис также позволяет выделять определенную часть изображения. Это актуально, когда искомое фото включено в коллаж.
У сервиса есть также приложение для Android.
При этом можно отметить несколько недостатков. Сайт работает медленнее и не так точно как конкуренты. Может выдавать меньшее количество результатов и делать ошибки. Например, отображать не искомое фото, а похожие на него по цветовой гамме.
Яндекс Картинки
 Этот сервис также помогает осуществлять обратный поиск фотографий. Можно выбрать интерфейс на русском.
Этот сервис также помогает осуществлять обратный поиск фотографий. Можно выбрать интерфейс на русском.
Позволяет искать как целое изображение, так и его фрагмент.
Можно выбрать фото в Интернете или на компьютере.
В результатах поиска отображаются идентичные фотографии и те, что немного отличаются от указанного снимка.
Эффективность поиска зависит от наличия или отсутствия указанной картинки в Интернете и ее индексации поисковой системой.
Чтобы отыскать первоисточник, понадобится:
- Зайти в сервис Яндекс картинки;
- Нажать на иконку фотокамеры в правой части поисковой строки;
- Выбрать файл, перетащить его или написать URL-адрес.
После этого система укажет все найденные результаты.
Google Картинки
 Сайт можно использовать бесплатно. Он очень простой, и язык можно выбрать на свое усмотрение. В том числе русский.
Сайт можно использовать бесплатно. Он очень простой, и язык можно выбрать на свое усмотрение. В том числе русский.
С поиском первоисточников картинок Google позволяет работать с 2011 года.
Дает быстрый и точный результат. Кроме идентичных фотографий в отдельной части страницы отображает снимки, похожие на заданный в поиске.
Удобно, что при выдаче результатов видна часть теста с ресурса, на который ведет ссылка.
Алгоритм действий для обратного поиска фото:
- Открыть Google Картинки;
- Нажать на значок с фотоаппаратом в правой части поисковой строки;
- Выбрать кнопку «Загрузить файл» или «Указать ссылку»;
- Ввести нужные данные или загрузить фото и нажать на кнопку «Выбрать».
Сервис моментально покажет все найденные результаты. Из них следует выбрать подходящий и перейти на нужный сайт. Вот и все.
Если пользователю нужно найти первоисточник фотографии, это не составит труда. Сервисы TinEye, RevIMG, Google Картинки, Яндекс Картинки и другие помогут сделать это в несколько кликов. Чтобы разобраться, где в выданных результатах сам первоисточник, следует обратить внимание на размер и разрешение снимка, наличие метаданных, время съемки. Так проще определить достоверность информации, найти автора фото или отследить плагиат своих фотографий.
Извлечение данных из фотохостинга
Время на прочтение
6 мин
Количество просмотров 20K
Наткнулся однажды на этот пост и мне подумалось — раз у нас есть такая прекрасная, полностью открытая галерея частных данных (Radikal.ru), не попытаться ли извлечь из нее эти данные в удобном для обработки виде? То есть:
- Скачать картинки;
- Распознать текст на них;
- Выделить из этого текста полезную информацию и классифицировать ее для дальнейшего анализа.
И в результате, после нескольких вечеров, работающий прототип был сделан. Много технических деталей:
Все делалось на C# в среде ASP MVC 5. Просто потому, что я там пишу постоянно и мне так удобнее.
Этап 1: Скачать картинку
Как следует посидев в исходном коде страниц галереи, я не нашел какой-то последовательности — значит придется скачивать каждую веб-страницу, и выдирать из кода ссылку на картинку. Хорошо хоть, что адрес страницы с картинкой поддается автоматическому формированию — это просто URL с порядковым номером картинки. Ок, берем HtmlAgilityPack, и пишем парсер, благо классов на странице с картинкой достаточно, и выдернуть нужный узел не сложно.
Вытаскиваем узел, смотрим — ссылки нет. Ссылка, оказывается генерируется посредством JavaScript, который у нас не был запущен. Это грустно, т.к. скрипты обфусцированы, и терпения разобраться в принципах их работы мне не хватило.
Ок, есть другой путь — открыть страницу в браузере, дождать выполнения скриптов, и получить ссылку из заполненной страницы. Благо для этого есть прекрасная связка в виде Selenium и PhantomJS (браузер без графической оболочки), потому как делать все через, к примеру, FireFox — и дольше по времени выполнения, и неудобнее. К сожалению, и это тоже очень медленно — вряд ли есть еще более медленный способ  Примерно по 1 секунде на картинку.
Примерно по 1 секунде на картинку.
Парсер:
public static string Parse_Radikal_ImagePage(IWebDriver wd, string Url)
{
wd.Url = Url;
wd.Navigate();
new WebDriverWait(wd, TimeSpan.FromSeconds(3));
HtmlDocument html = new HtmlDocument();
html.OptionOutputAsXml = true;
html.LoadHtml(wd.PageSource);
HtmlNodeCollection Blocks = html.DocumentNode.SelectNodes("//div[@class='show_pict']//div//a//img");
return Blocks[0].Attributes["src"].Value;
}
* Весь код сильно упрощен, убраны некритические детали. Подробнее в исходниках
Контроллер — обработчик:
IWebDriver wd = new PhantomJSDriver("C:\PhantomJS");
for (var imageCode = data.imgCode; imageCode > data.imgCode - data.imgCount; imageCode--)
{
if (ParserResult.Processed(imageCode)) continue;
var Url = "http://radikal.ru/Img/ShowGallery#aid=" + imageCode.ToString() + "&sm=true";
var imageUrl = Parser.Parse_Radikal_ImagePage(wd, Url);
if (imageUrl != null)
{
var image = Parser.GetImageFromUrl(imageUrl);
var Filename = TempFilesRepository.TempFilesDirectory() + "Radikal_" + imageCode.ToString() + "." + Parser.GetImageFormat(image);
image.Save(Filename);
}
}
wd.Quit();
Все это над где-то хранить и обрабатывать. Логично выбрать уже развернутый MS SQL Server, создать на нем небольшую базу и сложить туда ссылки на картинки и путь к скачанному файлу. Пишем маленький класс для хранения и записи результата парсинга картинки. Почему не хранить картинки в базе? Об этом ниже, в разделе про распознавание.
[Table(Name = "ParserResults")]
public class ParserResult
{
[Key]
[Column(Name = "id", IsPrimaryKey = true, IsDbGenerated=true)]
public long id { get; set; }
[Column(Name = "Url")]
public string Url { get; set; }
[Column(Name = "Code")]
public long Code { get; set; }
[Column(Name = "Filename")]
public string Filename { get; set; }
[Column(Name = "Date")]
public DateTime Date { get; set; }
[Column(Name = "Text")]
public string Text { get; set; }
[Column(Name = "Extracted")]
public bool Extracted { get; set; }
public ParserResult() { }
public ParserResult(string Url, long Code, string Filename, string Text)
{
this.Url = Url;
this.Code = Code;
this.Filename = Filename;
this.Date = DateTime.Now;
this.Text = Text;
this.Extracted = false;
DataContext Context = DataEngine.Context();
Context.GetTable<ParserResult>().InsertOnSubmit(this);
Context.SubmitChanges();
}
public static bool Processed(long imgCode)
{
return DataEngine.Data<ParserResult>().Where(x => x.Code == imgCode).Count() > 0;
}
}
Этап 2: Распознать текст
Тоже, казалось бы, не самая сложная задача. Берем Tesseract (точнее, обертку для него под .NET), качаем данные для русского языка, и… облом! Как выяснилось, для нормальной работы Tesseract с русским языком, необходимы условия близкие к идеальным — отличного качества скан, а не фотка документа на дрянной мобильник. Процент распознавания — хорошо если приближается к 10.
Вообще, всё приемлемое распознавание кириллицы представлено всего тремя продуктами: CuneiForm, Tesseract, FineReader. Чтение форумов и блогов укрепило в мысли, что CuneiForm пробовать смысла нет (многие пишут, что по качеству распознавания он недалеко ушел от Tesseract), и я решил сразу пробовать FineReader. Основной его минус — он платный, очень платный. К тому же под рукой не было Finereader Engine (который предоставляет API для распознавания), и пришлось делать ужасный велосипед: запускать Abbyy Hotfolder, которая смотрит в указанную папку, распознает появляющиеся там картинки, и кладет рядом одноименные текстовые файлы. Таким образом, выждав немного после скачивания картинок, мы можем взять готовые результаты распознавания и положить их в базу данных. Очень медленно, очень костыльно — но качество распознавания, я надеюсь, окупает эти затраты.
var data = DataEngine.Data<ParserResult>().Where(x => x.Text == null & x.Filename != null).ToList();
foreach (var result in data)
{
var textFilename = result.Filename.Replace(Path.GetExtension(result.Filename), ".txt");
if (System.IO.File.Exists(textFilename))
{
result.Text = System.IO.File.ReadAllText(textFilename, Encoding.Default).Trim();
result.Update();
}
}
Кстати, именно по причине таких костылей картинки храним не в БД — Abbyy Hotfolder с БД, к сожалению, не работает.
Этап 3: Извлечь из текста информацию
На удивление, этот этап оказался самым простым. Наверное, потому что я знал, что искать — год назад я прошел курс Natural Language Processing на Coursera.org, и представлял, как решаются такие задачи и какая терминология используется. В том числе поэтому я решил не писать очередные велосипеды, а недолго погуглив, взял библиотеку PullEnti, которая:
- заточена на работу с русским языком;
- сразу обернута для работы с C#;
- бесплатна для некоммерческого использования.
Выделить с помощью нее сущности оказалось очень просто:
public static List<Referent> ExtractEntities(string source)
{
// создаём экземпляр процессора
Processor processor = new Processor();
// запускаем на тексте
AnalysisResult result = processor.Process(new SourceOfAnalysis(source));
return result.Entities;
}
Выделенные сущности надо хранить и анализировать, для этого пишем их в простенькую табличку в БД: ID картинки / тип сущности / значение сущности. После парсинга получается что-то такое:
| DocID | EntityType | Value |
| 63 | Территориальное образование | город Уссурийск |
| 63 | Адрес | улица Дзер д.1; город Уссурийск |
| 63 | Дата | 17 ноября 2014 года |
PullEnti умеет выделять из текста (автоматически правя ошибки) довольно много таких сущностей: Банковские реквизиты, Территориальное образование, Улица, Адрес, URI, Дата, Период, Обозначение, Денежная сумма, Персона, Организация, etc… А дальше над полученными таблицами надо садиться и думать: выбирать документы по конкретному городу, искать конкретную организацию, и т.п. Главную задачу мы выполнили — данные извлекли и подготовили.
Результаты
Давайте посмотрим, что получилось на небольшой пробной выборке.
- Обработано страниц галереи — 2 263;
- Получено изображений — 1 972 (на остальных страницах изображения удалены либо закрыты настройками приватности);
- Выделен текст — 773 (на других изображениях FineReader не обнаружил ничего подоходящего для распознавания);
- Выделены сущности из текста — 293.
Правильные срабатывания — это последний показатель, т.к. довольно часто из картинки с насыщенной графикой выделяется текст в виде «^ЯА71 Г1/Г» и так далее. Получается, что годный для анализа текст мы находим, приблизительно, в каждом десятом изображении. Это неплохо для такого беспорядочного хранилища!
А вот, например, список извлеченных городов (довольно часто документы, из которых они извлечены — фотографии паспортов): Анкара, Бобруйск, Варшава, Златоуст, Казань, Киев, Красноярск, Минск, Москва, Омск, Санкт-Петербург, Сухум, Тверь, Уссурийск, Усть-Каменогорск, Челябинск, Шуя, Ярославль.
Итоги
- Задача решается; создан работающий прототип решения.
- Скорость работы этого прототипа пока что не выдерживает никакой критики Картинка в секунду — это очень медленно.
- И, конечно, есть ряд нерешенных проблем: например, аварийное завершение работы после того, как PhantomJS съест всю память.
Исходный код (проект для Visual Studio 2013) — скачать.
Back to Google (from Fotki.yandex.ru)
Получить URL-список фоток иа альбома на Google Photo. How to get list of public URL for photos stored in Google Photos public albums
Несколькими днями ранее мне открылось и я прозрел. Оказалось, что изображения залитые на Фотки.ру уже не всегда видны во всех-всех странах. Опуская лирику, констатирую: выругался я громко и многоэтажно по поводу введенной цензуры и после годичного перерыва снова предпринял попытку вернуться к гугловскому сервису для хранения фотографий, куда заливал фотки для жж с 2012 по 2016 год.
Потратил я несколько часов и нашел в этот раз (жаль год назад не свезло) более или менее устраивающую меня схему, в которой мне понравились:
1) Предположительная долговечность ссылок;
2) Легкость процесса извлечения ссылок;
3) Видимость фотографий по этим ссылкам во всех странах (Китай не в счет)
Ну и теперь решил своей находкой поделиться, поскольку совсем недавно читал у моих жж-френдов посты по теме фотохранилищ и было мною замечено, что люди в отдельных случаях готовы на «героические подвиги» — «выковыривать» по отдельности к каждой фотографии ссылки аццкой длины (примерно 666 знаков) и потом вставлять эти длиннющие ссылки в будущий пост поштучно. Надеюсь, что нижеописанный способ этим добрым людям понравится больше.
Читайте-смотрите ниже том, как в несколько простых шагов получить полный список ссылок приемлемой длины (111 символов плюс имя файла) к нужному количеству фотографий из альбома в google-аппликации Фото (Photos).
А вот вам картинка со стамбульским котэ для привлечения внимания.. Типа, вашим фоткам тоже нужен добротный домик))

Систэмные трэбования:
1.Google аккаунт и активированная для этого аккаунта апликация Фото (или Photos, если в настройках аккаунта выбран английский язык).
2.Также надо зарегать блог в(на) платформе Blogger. Это дело займет 2 мин. Найти обе этих аппликации очень легко в правом верхнем углу поисковика Google.
А теперь процесс получения ссылок пошагово:
1. Загрузить фото в альбом типа «Общий альбом» в google-аппликации Фото (photos.google.com).

2. После загрузки фото аппликация предложит вам дать имя альбому.

С последовательностью фотографий на этом этапе заморачиваться не надо — не даст результата. Порядок фотографий можно будет определить в самом конце процесса.
3. Следующим шагом аппликация предложит вам поделиться альбомом. Проще всего выбрать опцию «Получить ссылку».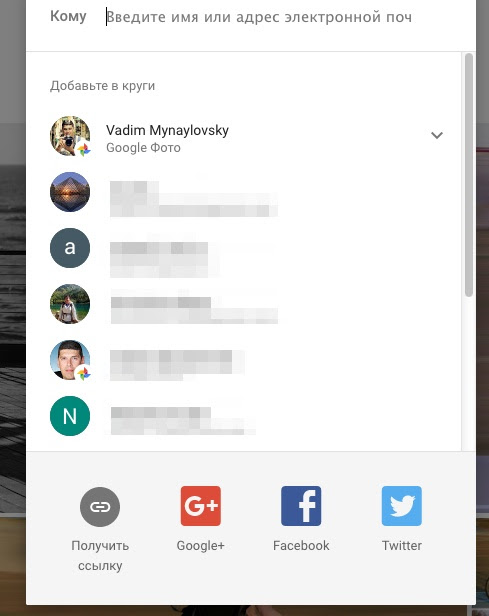
4. С аппликацией «Фото» закончили — идем в Blogger (blogger.com). Вы же помните, как в нее попасть? Правильно — нажать на символ кубик-рубик в правом-верхнем углу поисковика google или любой другой google-аппликации.
После того, как вы ответили на несколько простых вопросов и дали какое-нибудь вымышленное имя своему новому микроблогу (это нужно будет сделать только один раз) вы попадаете на страницу управления блогом. На панели слева нажмите кнопку «Страницы» и потом на кнопку «Создать страницу».

И тогда на экране появится текстовый редактор похожий на тот, что
пока что
мы видим в ЖЖ.
Важно
: нужно перейти в режим HTML. Очистите редактор — кликните внутри редактора, и нажмите последовательно Ctrl+A и Delete.

5. Теперь нажмите на кнопку с картинкой (справа от слова «Ссылка») и откроется окошко «Добавление фотографий». Жмите на «Из архива альбомов Google»

6. Отмечаем фотографии из альбома, который мы добавили в шагах 1-3. Если отмечать фотографии в той последовательности что вам нужно, то и получите список с ссылками в нужной последовательности. Возможно кому-то будет легче определить порядок фотографий в Обрамляторе. Закончив отбор жмем на кнопку «Добавить выбранные изображения».

7. После нажатия кнопки нужно будет в открывшемся окошке выбрать параметры загрузки. Выбирайте «Исходный размер» в правой колонке, а в левой можно оставить все как есть.
Я заранее делаю уменьшение размера фотографий до 1024рх по большой стороне и потом (в ЖЖ-редакторе) жестко задаю этот же размер — так резкость сохраняется наилучшим образом. А вы можете и не уменьшать, а только задать нужный вам размер в ЖЖ-редакторе

8. Получаем в редакторе такой текст и что важно (как для меня) с высотой и шириной как в оригинальном фото.

Копируем содержимое из редактора в Blogger и переносим в ЖЖ-редактор. В принципе, на этом уже можно перейти к написанию текста. Но пока что фотографии без номеров (что многих устраивает впрочем) и, что больше мешает, фотографии словно прилепились одна к другой — вы увидите один сплошной столбик из фотографий. Можно конечно вручную «разлепить» их, но я предлагаю проделать еще несколько простых манипуляций для получения идеального «тела поста» готового к добавлению текста.
9. Для этого в ЖЖ-редкторе надо перейти на режим «Визуальный редактор» и выделить все фотографии (кликните внутри редактора и нажмите Ctrl+A). Теперь надо нажать на кнопку со значком «ссылка» и нажать в открывшемся окошке красную кнопку «Удалить все выбранные ссылки». Переходим в режим редактор HTML и копируем весь текст.

А дальше идем в Обрамлятор и вставляем скопированный текст. Обрамлятор из этого текста «заглатывает» только ссылки
на фотографии. Если вы не выбрали еще в Блогере фотографии в нужном вам порядке, то можно подвигать их в Обрамляторе и добиться той последовательности, что вам нужна. И на выходе..

Копируем и вставляем в ЖЖ-редактор. Вуаля — осталось только написать текст.
На первый взгляд (возможно) процедура показалась вам длинной, но это не так. Сделайте все пошагово один-два раза и в следующий раз весь процесс займет у вас не больше двух минут.
К вопросу о долговечности ссылок.
Обратите внимание на то, как выглядит ссылка на фото, которое было вставлено 7 лет назад в пост блога на гугловской платформе (Blogger называется). Выглядит она точно также, как и ссылки полученные в вышепоказанной пошаговой объяснялке. Платформе Blogger прочат еще долгую жизнь, а если и нет — Google поддерживает ссылки сгенерированные в своих аппликациях-приложениях и после того, как их закрывает. Пример с Picasaweb: проект закрыли уж год как, а ссылки работают и по сей день. И дальше будут работать. Также будет и с Blogger. А вот «выковырянным вручную» ссылкам аццкой длины в 666 символов длинная жизнь совершенно не гарантирована IMHO.

| Мои Fb, G+, Tw, Ig, Rss. Кнопки активные. | |||||||||
 |
 |
 |
 |
 |
|||||
| Плюсуйтесь! Добавляйтесь! Stay tuned! |

Добавить в друзья в Facebook![]() Добавить в друзья в VKontakte
Добавить в друзья в VKontakte ![]() Группа моего блога в «Одноклассниках»
Группа моего блога в «Одноклассниках»