Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
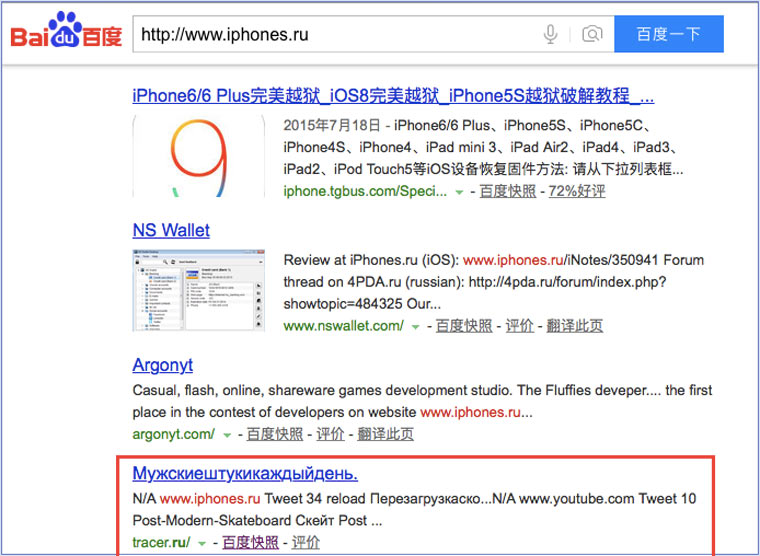
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
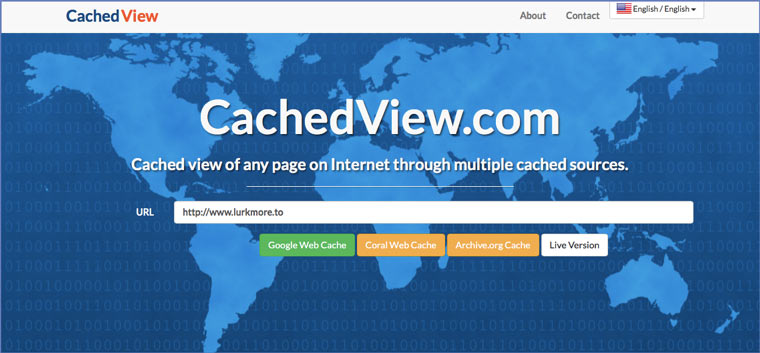
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
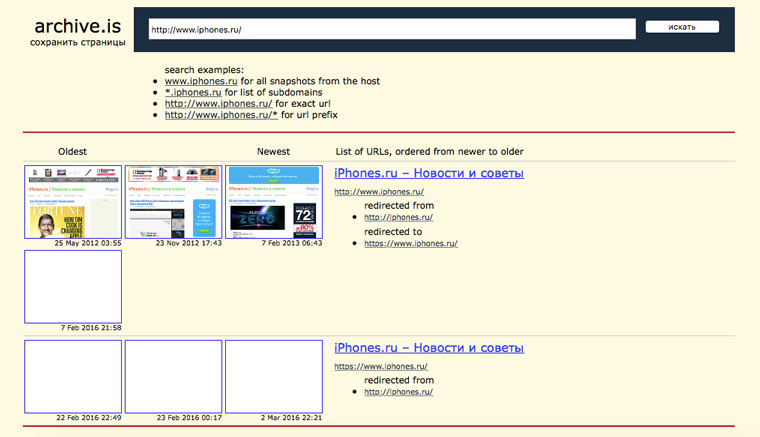
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
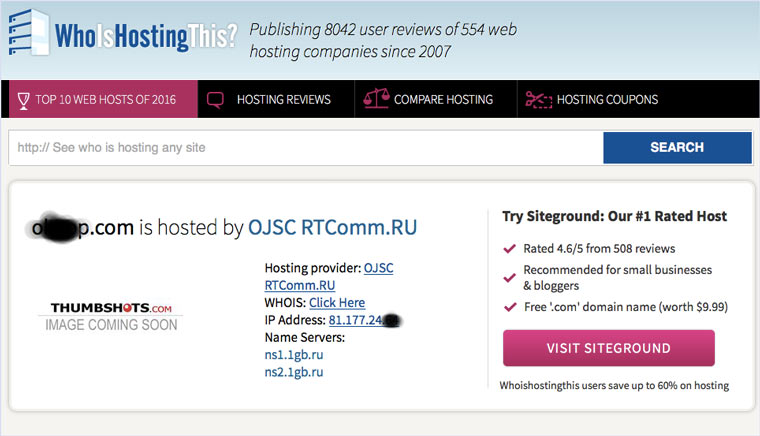
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
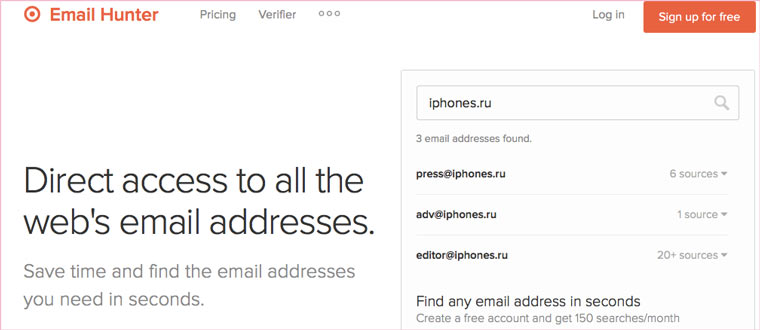
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
Всем читающим и следящим за моим блогом — Добрый День. После Апа PR, несколько человек на блоге спрашивало: «Как проверить все страницы большого сайта на PR?». Ведь большинство онлайн сервисов позволяют проверять только по 50 страниц, что очень не удобно, когда сайт имеет сотни или тысячи страниц. Давайте сегодня попробуем разобраться в этой проблеме.
Значение Page Rank многие не до оценивают и очень зря, ведь цены на ссылки, размещённых на страницах имеющих PR, вырастают в 2-3 раза. Например в бирже Get Good Links, ссылка со страницы которая имеет PR 1 стоит 8-10 долларов, PR 2 — 25$ и так далее в геометрической прогрессии.
Мой способ проверки PR
Чтобы массово проверить PR всех внутренних страниц, понадобиться две программы. Первая — которая получит все url страниц сайта. Вторая — позволяющая массово проверять PR страниц.
Парсим страницы сайта
По идеи, можно получить список страниц сайта, с файла sitemap.xml, но это будет не полный список, потому что в этих файлах не указываются — рубрики, теги, постраничные урлы (https://cospi.ru/page/2/) и.т.п. Поэтому берём бесплатную программу stgrabber, вписываем url сайта, обязательно с наклонным слешем в конце и нажимаем Пуск.
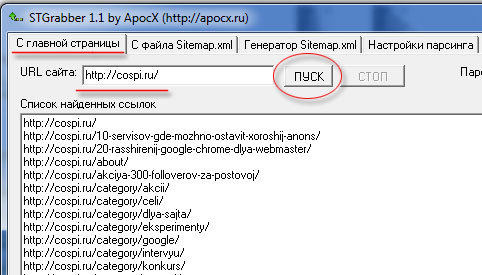
Ждём когда закончит работу программа и копируем список найденных ссылок в текстовый файл, который нам пригодиться для работу в другой программе. Я использую именно эту программу, потому, что у неё есть настройки парсинга (изъятия данных):
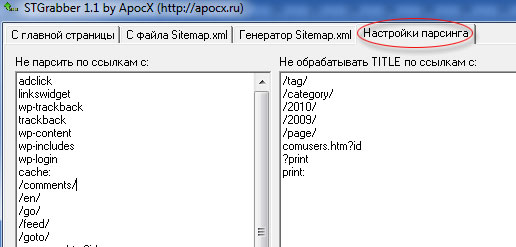
В полученный список ссылок, попадают только нужные страницы. В отличии от других программ, для генерации Sitemap, где сканируются все найденные ссылки. Не попадают в список ссылок:
- файлы (favicon например);
- ссылки на сообщения (?replytocom=);
- Системные страницы (?do=search, ?print и.т.п.).
Проверяем на PR
Для этого программу PaRaMeter, импортируем в неё ссылки сайта, которые мы сохранили в текстовом файлике:
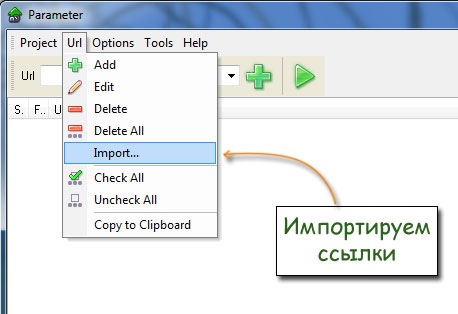
И запускаем проверку. Для наглядности я проверил 1500 страниц блога Димка:
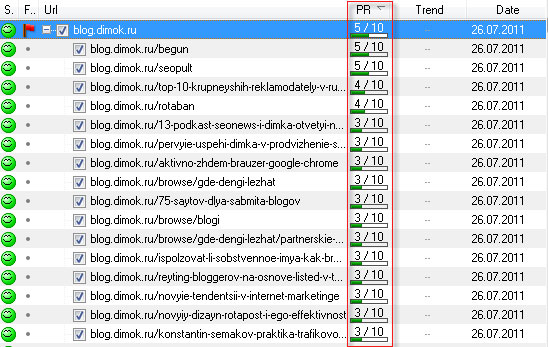
На проверку 1.5 тысячи страниц понадобилось минуты 2-3 примерно. После того, когда программа закончит свою работу, нажимаем кнопочку PR и в таблице все значения от сортируются по убыванию, чтобы удобно было анализировать список. Все обработанные данные можно экспортировать в Excel, для последующего использования. На этом всё, спасибо за внимание.
UPDATE 8.11.2011
Программа PaRaMeter уже не определяет PR, пользуйтесь сервисом, который я описал в статье — Проверка всех страниц сайта на Page Rank.

Александр Филиппов
Контент-менеджер. Отдел разработки
Каким образом можно получить все страницы сайта чтобы их спарсить?
Допустим я использую curl и хочу получить весь контент с каждой страницы сайта, но если я не знаю адрес этой страницы то и никак не получу его.
Я видел различный инструментарий для *nix систем, но можно ли как то это сделать на чистом php?
Понятно что можно получить все ссылки на странице и ходить по ним, но бывают страницы и без ссылок на другие страницы, редко но бывают, как быть?
-
Вопрос заданболее трёх лет назад
-
4796 просмотров
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Уследить за всеми страницами сайта сложно, особенно если сайт большой. Но иногда без полного списка страниц не обойтись. Например, если вы хотите создать xml карту сайта, удалить лишние страницы или настроить внутреннюю перелинковку.
С полным списком страниц вы сможете очистить сайт от мусора, исправить технические ошибки на страницах и улучшить ранжирование. Возникает логичный вопрос: как собрать такой список максимально быстро и просто.
Легче всего выгрузить все страницы из одного инструмента, но тогда ваш список может оказаться неполным. Чтобы собрать абсолютно все страницы, в том числе закрытые от поисковых роботов и страницы с техническими ошибками, придется потрудиться.
Почему для сбора данных одного инструмента мало
Собирать данные мы будем из трех инструментов:
- Из модуля «Аудит сайта» в SE Ranking выгрузим все страницы, открытые для поисковых роботов;
- В Google Analytics найдем все страницы, у которых есть просмотры;
- Из Google Search Console достанем оставшиеся закрытые от поисковых роботов страницы, у которых нет просмотров.
Сравнив все данные мы получим полный список страниц вашего сайта.
Проиндексированные URL-ы мы найдем еще на первом этапе. Но нам нужны не только они. У многих сайтов найдутся страницы, на которые не ведет ни одна внутренняя ссылка. Их называют страницами-сиротами.
Почему страницы оказываются «в изоляции»? Причины могут быть разные, к примеру:
- посадочные страницы создавались под конкретную кампанию;
- тестовые страницы создавались для сплит-тестирования;
- страницы убрали из системы внутренней перелинковки, но не удалили;
- страницы потерялись во время переноса сайта;
- была удалена страница категории товаров, а страницы товаров остались.
Такие страницы отрезаны от остального сайта, а значит поисковой робот не может их просканировать. Также кроулер не увидит страницы, закрытые от него через файл .htaccess. Ну, и наконец, часть страниц не индексируется из-за технических проблем.
С помощью разных инструментов мы найдем абсолютно все страницы. Но давайте по порядку. Для начала выгрузим список всех проиндексированных и корректно работающих страниц.
Ищем открытые для краулеров страницы в SE Ranking
Экспортировать страницы, открытые пользователям и краулерам, будем с помощью инструмента «Аудит сайта» SE Ranking.

Чтобы поисковый робот просканировал все необходимые страницы, выберем нужные параметры в настройках.
Заходим в Настройки → Источник страниц для анализа сайта и разрешаем системе сканировать Страницы сайта, Поддомены сайта и XML карту сайта. Так инструмент отследит все страницы сайта, включая поддомены.

Дальше переходим в раздел Правила сканирования страниц и разрешаем учитывать директивы robots.txt.

Осталось нажать кнопку Сохранить.
Затем переходим во вкладку Обзор и запускаем анализ — нажимаем кнопку Перезапустить аудит.

Когда анализ завершится, на главном дашборде нажимаем на зеленую линию в разделе Индексация страниц.

Вы увидите полный список страниц, открытых для поисковых роботов. Теперь можно выгрузить данные — нажимаем на кнопку Экспорт.

На следующем этапе мы будем сравнивать большие массивы данных. Если вам удобно это делать в Excel — оставляйте все как есть. Если вы предпочитаете Google таблицы, скопируйте оставшиеся строки и вставьте их в новую таблицу.
Через Google Analytics ищем все страницы с просмотрами
Поисковые роботы находят страницы переходя по внутренним ссылкам сайта. Поэтому если на страницу не ведет ни одна ссылка на сайте, кроулер ее не найдет.
Обнаружить их можно с помощью данных из Google Analytics — система хранит инфу о посещениях всех страниц. Одно плохо — GA не знает о тех просмотрах, которые были до того, как вы подключили аналитику к вашему сайту.
Просмотров у таких страниц будет немного, потому что с сайта на них перейти не получится. Находим их следующим образом.
Заходим в Поведение → Контент сайта → Все страницы. Если ваш сайт не молодой, стоит указать данные за какой период вы хотите получить. Это важно, так как Google Analytics применяет выборку данных — то есть анализирует не всю информацию, а только ее часть.

Дальше, кликаем на колонку Просмотры страниц, чтобы отсортировать список от меньшего к большему значению . В результате, вверху окажутся самые редко просматриваемые страницы — среди них-то и будут страницы-сироты.

Двигайтесь вниз по списку, пока не увидите страницы, у которых просмотров существенно больше. Это уже страницы с настроенной перелинковкой.
Собранные данные экспортируем в .csv файл.
Выделяем страницы-сироты
Наш следующий шаг — сравнить данные из SE Ranking и Google Analytics, чтобы понять, к каким страницам у поисковых роботов нет доступа.
Копируем данные из .csv файла, выгруженного из Google Analytics, и вставляем их в таблицу рядом с данными из SE Ranking.
Из Google Analytics мы выгрузили только окончания URL, а нам нужно, чтобы все данные были в одном формате. Поэтому в колонку B вставляем адрес главной страницы сайта как показано на скриншоте.

Далее, с помощью функции сцепить (concatenate) объединяем значения из колонок B и C в колонке D и протягиваем формулу вниз до конца списка.

А теперь самое интересное: будем сравнивать колонку «SE Ranking» и колонку «GA URLs», чтобы найти страницы-сироты.
На практике страниц будет намного больше, чем на скриншоте, поэтому анализировать их вручную пришлось бы бесконечно долго. К счастью, существует функция поискпоз (match), которая позволяет определить, какие значения из колонки «GA URLs» есть в колонке «SE Ranking». Вводим функцию в колонке E и протягиваем ее вниз до конца списка.
Результат должен выглядеть так:

В колонке E увидим, каких страниц из GA нет в колонке SE Ranking, там таблица выдаст ошибку (#N/A). В примере видно, что в ячейке E9 нет значения, потому что ячейка A11 — пустая.
Ваш список будет намного больше. Чтобы собрать все ошибки, отсортируйте данные в колонке E по алфавиту:

Теперь у вас есть полный список страниц, не связанных ссылками с сайтом. Перед тем, как двигаться дальше, изучите каждую одинокую страницу. Ваша цель — понять, что это за страница, какова ее роль, и почему на нее не ведет ни одна ссылка.
Дальше есть три варианта развития событий:
- Поставить на страницу внутреннюю ссылку. Для этого нужно определить ее место в структуре вашего сайта.
- Удалить страницу, настроив с нее 301 редирект, если это лишняя страница.
- Оставить все как есть, но присвоить странице тег <noindex>, если, например, страница создавалась под рекламную кампанию.
Поработав с изолированными страницами, можно еще раз выгрузить и сравнить списки из SE Ranking и GA. Так вы убедитесь, что ничего не упустили.
Ищем оставшиеся страницы через Google Search Console
Как найти страницы, не связанные ссылками с сайтом, разобрались. Приступим к остальным страницам, о которых знает Google, — будем анализировать данные Google Search Console.
Для начала откройте свой аккаунт и зайдите в раздел Покрытие. Убедитесь, что выбран режим отображения данных «Все обработанные страницы» и откройте вкладку «Страницы без ошибок».

Таким образом в список попадут Проиндексированные страницы, которых нет в карте сайта, а также Отправленные и проиндексированные страницы.

Кликните на список, чтобы развернуть его. Внимательно изучите данные: возможно в списке есть страницы, которые вы не видели в выгрузках из SE Ranking и GA. В таком случае убедитесь, что они должным образом выполняют свою роль в рамках вашего сайта.
Теперь перейдем во вкладку Исключено, чтобы отобразились только непроиндексированные страницы.

Чаще всего страницы из этой вкладки были намеренно заблокированы владельцами сайта — это страницы с переадресациями, закрытые тегом «noindex», заблокированные в файле robots.txt, и так далее. Также в этой вкладке можно выявить технические ошибки, которые нужно исправить.

Если обнаружите страницы, которые вам не встречались на предыдущих этапах, добавьте их в общий список. Таким образом, вы наконец получите список всех без исключения страниц вашего сайта.
В заключение
Если у вас есть доступ к необходимым инструментам, собрать все страницы сайта не сложно. Да, сделать все в два клика не получится, но в процессе сбора данных вы найдете страницы, о существовании которых могли и не догадываться.
Страницы, которые не видят ни поисковые роботы, ни пользователи, не приносят сайту никакой пользы. Так же как и страницы, которые не индексируются из-за технических ошибок. Если таких страниц на сайте много, это может негативно сказаться на результатах SEO.
Хотя бы один раз собрать все страницы сайта нужно обязательно, чтобы адекватно его оценивать и знать, откуда ждать проблем 🙂
Светлана — контент-маркетолог и редактор в SE Ranking. Светлана убеждена, что о сложных вещах можно писать просто и делится своими знаниями в области SEO и диджитал-маркетинга в блоге SE Ranking и других тематических медиа.
Вечера Светлана проводит, изучая новые языки, планируя увлекательные путешествия и играя с кошкой.