How to find all the relations between all MySQL tables? If for example, I want to know the relation of tables in a database of having around 100 tables.
Is there anyway to know this?
![]()
asked Dec 31, 2013 at 9:32
![]()
5
The better way, programmatically speaking, is gathering data from INFORMATION_SCHEMA.KEY_COLUMN_USAGE table as follows:
SELECT
`TABLE_SCHEMA`, -- Foreign key schema
`TABLE_NAME`, -- Foreign key table
`COLUMN_NAME`, -- Foreign key column
`REFERENCED_TABLE_SCHEMA`, -- Origin key schema
`REFERENCED_TABLE_NAME`, -- Origin key table
`REFERENCED_COLUMN_NAME` -- Origin key column
FROM
`INFORMATION_SCHEMA`.`KEY_COLUMN_USAGE` -- Will fail if user don't have privilege
WHERE
`TABLE_SCHEMA` = SCHEMA() -- Detect current schema in USE
AND `REFERENCED_TABLE_NAME` IS NOT NULL; -- Only tables with foreign keys
There are more columns info like ORDINAL_POSITION that could be useful depending your purpose.
More info: http://dev.mysql.com/doc/refman/5.1/en/key-column-usage-table.html
answered Nov 17, 2014 at 22:31
![]()
xudrexudre
2,7212 gold badges19 silver badges19 bronze badges
Try this:
select * from INFORMATION_SCHEMA.TABLE_CONSTRAINTS;
answered Dec 31, 2013 at 9:34
![]()
BaBL86BaBL86
2,5921 gold badge13 silver badges13 bronze badges
Try
SELECT
`TABLE_NAME`,
`COLUMN_NAME`,
`REFERENCED_TABLE_NAME`,
`REFERENCED_COLUMN_NAME`
FROM `information_schema`.`KEY_COLUMN_USAGE`
WHERE `CONSTRAINT_SCHEMA` = ‘YOUR_DATABASE_NAME’ AND
`REFERENCED_TABLE_SCHEMA` IS NOT NULL AND
`REFERENCED_TABLE_NAME` IS NOT NULL AND
`REFERENCED_COLUMN_NAME` IS NOT NULL
do not forget to replace YOUR_DATABASE_NAME with your database name!
answered Mar 15, 2015 at 12:19
![]()
Mostafa LavaeiMostafa Lavaei
1,9101 gold badge18 silver badges27 bronze badges
A quick method of visualizing relationships in MySQL is reverse engineering the database with MySQL Workbench.
This can be done using the reverse engineering too, which will result in an entity-relationship diagram much like the following (though you may have to organize it yourself, once it is generated):

![]()
Sculper
7562 gold badges12 silver badges24 bronze badges
answered Aug 27, 2015 at 16:05
![]()
2
SELECT
count(1) totalrelationships ,
c.table_name tablename,
CONCAT(' ',GROUP_CONCAT(c.column_name ORDER BY ordinal_position SEPARATOR ', ')) columnname,
CONCAT(' ',GROUP_CONCAT(c.column_type ORDER BY ordinal_position SEPARATOR ', ')) columntype
FROM
information_schema.columns c RIGHT JOIN
(SELECT column_name , column_type FROM information_schema.columns WHERE
-- column_key in ('PRI','MUL') AND -- uncomment this line if you want to see relations only with indexes
table_schema = DATABASE() AND table_name = 'YourTableName') AS p
USING (column_name,column_type)
WHERE
c.table_schema = DATABASE()
-- AND c.table_name != 'YourTableName'
GROUP BY tablename
-- HAVING (locate(' YourColumnName',columnname) > 0) -- uncomment this line to search for specific column
ORDER BY totalrelationships desc, columnname
;
answered Aug 12, 2015 at 17:43
![]()
1
1) Go into your database:
use DATABASE;
2) Show all the tables:
show tables;
3) Look at each column of the table to gather what it does and what it’s made of:
describe TABLENAME;
4) Describe is nice since you can figure out exactly what your table columns do, but if you would like an even closer look at the data itself:
select * from TABLENAME
If you have big tables, then each row usually has an id, in which case I like to do this to just get a few lines of data and not have the terminal overwhelmed:
select * from TABLENAME where id<5 — You can put any condition here you like.
This method give you more information than just doing select * from INFORMATION_SCHEMA.TABLE_CONSTRAINTS;, and it also provides you with more bite-sized information each time.
EDIT
As the comments suggested, the above WHERE id < 5 was a bad choice as a conditional placeholder. It is not a good idea to limit by ID number, especially since the id is usually not trustworthy to be sequential. Add LIMIT 5 at the end of the query instead.
answered Sep 17, 2015 at 13:47
![]()
RomanRoman
8,6468 gold badges62 silver badges100 bronze badges
3
Based on xudre’s answer, you can execute the following to see all the relations of a schema:
SELECT
`TABLE_SCHEMA`, -- Foreign key schema
`TABLE_NAME`, -- Foreign key table
`COLUMN_NAME`, -- Foreign key column
`REFERENCED_TABLE_SCHEMA`, -- Origin key schema
`REFERENCED_TABLE_NAME`, -- Origin key table
`REFERENCED_COLUMN_NAME` -- Origin key column
FROM `INFORMATION_SCHEMA`.`KEY_COLUMN_USAGE`
WHERE `TABLE_SCHEMA` = 'YourSchema'
AND `REFERENCED_TABLE_NAME` IS NOT NULL -- Only tables with foreign keys
What I want in most cases is to know all FKs that point to a specific table. In this case I run:
SELECT
`TABLE_SCHEMA`, -- Foreign key schema
`TABLE_NAME`, -- Foreign key table
`COLUMN_NAME` -- Foreign key column
FROM `INFORMATION_SCHEMA`.`KEY_COLUMN_USAGE`
WHERE `TABLE_SCHEMA` = 'YourSchema'
AND `REFERENCED_TABLE_NAME` = 'YourTableName'
answered Apr 28, 2020 at 13:54
![]()
One option is : You can do reverse engineering to understand it in diagrammatic way.
When you install MySQL, you will get MySQLWorkbench. You need to open it and choose the database you want to reverse engineer. Click on Reverse Engineer option somewhere you find under the tools or Database menu. It will ask you to choose the tables. Either you select the tables you want to understand or choose the entire DB. It will generate a diagram with relationships.
answered May 29, 2014 at 7:16
![]()
you can use:
SHOW CREATE TABLE table_name;
![]()
Arnab Nandy
6,4425 gold badges43 silver badges50 bronze badges
answered May 6, 2015 at 12:44
![]()
1
SELECT DISTINCT CONCAT(TABLE_SCHEMA,'.',TABLE_NAME) `table`
, CONCAT(REFERENCED_TABLE_SCHEMA,'.',REFERENCED_TABLE_NAME) ref_table
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE TABLE_SCHEMA='MyDataBase'
AND REFERENCED_TABLE_NAME IS NOT NULL;
А ещё лучше — аналогичный запрос к INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS:
SELECT CONCAT( CONSTRAINT_SCHEMA,
'.',
TABLE_NAME,
' REFERENCES ',
UNIQUE_CONSTRAINT_SCHEMA,
'.',
REFERENCED_TABLE_NAME,
' ON DELETE ',
DELETE_RULE,
' ON UPDATE ',
UPDATE_RULE
) `references`
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
WHERE CONSTRAINT_SCHEMA='MyDataBase';
Просмотр зависимостей таблицы
Зависимости таблицы в SQL Server можно просмотреть в среде SQL Server Management Studio или с помощью Transact-SQL.
В этом разделе
Перед началом работы
Просмотр зависимостей таблицы с помощью следующих средств:
Перед началом
безопасность
Permissions
Необходимо разрешение VIEW DEFINITION в базе данных и разрешение SELECT на представление sys.sql_expression_dependencies в базе данных. По умолчанию разрешение SELECT предоставляется только членам предопределенной роли базы данных db_owner. Если разрешения SELECT и VIEW DEFINITION предоставлены другому пользователю, он может просматривать все зависимости в базе данных.
Использование среды SQL Server Management Studio
Просмотр объектов, от которых зависит таблица
В Обозревателе объектов разверните узел Базы данных, разверните саму базу данных, а затем разверните узел Таблицы.
Щелкните таблицу правой кнопкой мыши и выберите Просмотр зависимостей.
В диалоговом окне Зависимости объектов <object name> выберите либо вариант Объекты, которые зависят от <object name> , либо вариант Объекты, от которых зависит <object name> .
Выберите объект в сетке Зависимости . Тип объекта (например, «Триггер» или «Хранимая процедура») появится в поле Тип .
Использование Transact-SQL
Просмотр объектов, зависящих от таблицы
В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить.
Просмотр зависимостей таблицы
В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
Связи между таблицами базы данных
Связи — это довольна важная тема, которую следует понимать при проектировании баз данных. По своему личному опыту скажу, что осознав связи, мне намного легче далось понимание нормализации базы данных.
1.1. Для кого эта статья?
Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. В ней я постарался рассказать на понятном языке, что это такое. Для лучшего понимания темы, я чередую теоретический материал с практическими примерами, представленными в виде диаграммы и запроса, создающего нужные нам таблицы. Я использую СУБД Microsoft SQL Server и запросы пишу на T-SQL. Написанный мною код должен работать и на других СУБД, поскольку запросы являются универсальными и не используют специфических конструкций языка T-SQL.
1.2. Как вы можете применить эти знания?
- Процесс создания баз данных станет для вас легче и понятнее.
- Понимание связей между таблицами поможет вам легче освоить нормализацию, что является очень важным при проектировании базы данных.
- Разобраться с чужой базой данных будет значительно проще.
- На собеседовании это будет очень хорошим плюсом.
2. Благодарности
Учтены были советы и критика авторов jobgemws, unfilled, firnind, Hamaruba.
Спасибо!
3.1. Как организовываются связи?
Связи создаются с помощью внешних ключей (foreign key).
Внешний ключ — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
3.2. Виды связей
Связи делятся на:
- Многие ко многим.
- Один ко многим.
- с обязательной связью;
- с необязательной связью;
- Один к одному.
- с обязательной связью;
- с необязательной связью;
4. Многие ко многим
Представим, что нам нужно написать БД, которая будет хранить работником IT-компании. При этом существует некий стандартный набор должностей. При этом:
- Работник может иметь одну и более должностей. Например, некий работник может быть и админом, и программистом.
- Должность может «владеть» одним и более работников. Например, админами является определенный набор работников. Другими словами, к админам относятся некие работники.
4.1. Как построить такие таблицы?
| EmployeeId | PositionId |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 3 |
Слева указаны работники (их id), справа — должности (их id). Работники и должности на этой таблице указываются с помощью id’шников.
На эту таблицу можно посмотреть с двух сторон:
- Таким образом, мы говорим, что работник с id 1 находится на должность с id 1. При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
- Мы также можем сказать, что должности с id 3 принадлежат пользователи с id 2 и 3. Т.е., каждой роли справа принадлежит некий работник слева.
4.2. Реализация
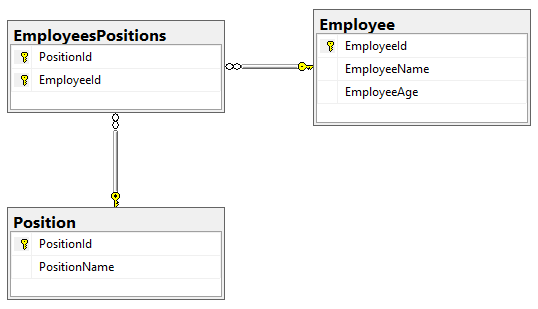
С помощью ограничения foreign key мы можем ссылаться на primary key или unique другой таблицы. В этом примере мы
- ссылаемся атрибутом PositionId таблицы EmployeesPositions на атрибут PositionId таблицы Position;
- атрибутом EmployeeId таблицы EmployeesPositions — на атрибут EmployeeId таблицы Employee;
4.3. Вывод
Для реализации связи многие ко многим нам нужен некий посредник между двумя рассматриваемыми таблицами. Он должен хранить два внешних ключа, первый из которых ссылается на первую таблицу, а второй — на вторую.
5. Один ко многим
Эта самая распространенная связь между базами данных. Мы рассматриваем ее после связи многие ко многим для сравнения.
Предположим, нам нужно реализовать некую БД, которая ведет учет данных о пользователях. У пользователя есть: имя, фамилия, возраст, номера телефонов. При этом у каждого пользователя может быть от одного и больше номеров телефонов (многие номера телефонов).
В этом случае мы наблюдаем следующее: пользователь может иметь многие номера телефонов, но нельзя сказать, что номеру телефона принадлежит определенный пользователь.
Другими словами, телефон принадлежит только одному пользователю. А пользователю могут принадлежать 1 и более телефонов (многие).
Как мы видим, это отношение один ко многим.
5.1. Как построить такие таблицы?
| PhoneId | PersonId | PhoneNumber |
|---|---|---|
| 1 | 5 | 11 091-10 |
| 2 | 5 | 19 124-66 |
| 3 | 17 | 21 972-02 |
Данная таблица представляет три номера телефона. При этом номера телефона с id 1 и 2 принадлежат пользователю с id 5. А вот номер с id 3 принадлежит пользователю с id 17.
Заметка. Если бы у таблицы «Phones» было бы больше атрибутов, то мы смело бы их добавляли в эту таблицу.
5.2. Почему мы не делаем тут таблицу-посредника?
Таблица-посредник нужна только в том случае, если мы имеем связь многие-ко-многим. По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
- Каждому работнику принадлежат несколько должностей (многие).
- Каждой должности принадлежит несколько работников (многие).
5.3. Реализация

6. Один к одному
Представим, что на работе вам дали задание написать БД для учета всех работников для HR. Начальник уверял, что компании нужно знать только об имени, возрасте и телефоне работника. Вы разработали такую БД и поместили в нее всю 1000 работников компании. И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
Более простым решением будет создать новую таблицу, назовем ее «DisabledEmployee». Она будет выглядеть так:
| DisabledPersonId | EmployeeId |
|---|---|
| 1 | 159 |
| 2 | 722 |
| 3 | 937 |
Но это еще не связь один к одному. Дело в том, что в такую таблицу работник может быть вписан более одного раза, соответственно, мы получили отношение один ко многим: работник может быть несколько раз инвалидом. Нужно сделать так, чтобы работник мог быть вписан в таблицу только один раз, соответственно, мог быть инвалидом только один раз. Для этого нам нужно указать, что столбец EmployeeId может хранить только уникальные значения. Нам нужно просто наложить на столбец EmloyeeId ограничение unique. Это ограничение сообщает, что атрибут может принимать только уникальные значения.
Выполнив это мы получили связь один к одному.
Заметка. Обратите внимание на то, что мы могли также наложить на атрибут EmloyeeId ограничение primary key. Оно отличается от ограничения unique лишь тем, что не может принимать значения null.
6.1. Вывод
Можно сказать, что отношение один к одному — это разделение одной и той же таблицы на две.
6.2. Реализация
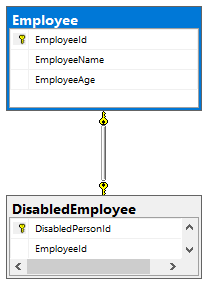
7. Обязательные и необязательные связи
Связи можно поделить на обязательные и необязательные.
7.1. Один ко многим
- Один ко многим с обязательной связью:
К одному полку относятся многие бойцы. Один боец относится только к одному полку. Обратите внимание, что любой солдат обязательно принадлежит к одному полку, а полк не может существовать без солдат. - Один ко многим с необязательной связью:
На планете Земля живут все люди. Каждый человек живет только на Земле. При этом планета может существовать и без человечества. Соответственно, нахождение нас на Земле не является обязательным
А) У женщины необязательно есть свои дети. Соответственно, связь необязательна.
Б) У ребенка обязательно есть только одна биологическая мать – в таком случае, связь обязательна.
7.2. Один к одному
- Один к одному с обязательной связью:
У одного гражданина определенной страны обязательно есть только один паспорт этой страны. У одного паспорта есть только один владелец. - Один к одному с необязательной связью:
У одной страны может быть только одна конституция. Одна конституция принадлежит только одной стране. Но конституция не является обязательной. У страны она может быть, а может и не быть, как, например, у Израиля и Великобритании.
А) Наличие загранпаспорта необязательно – его может и не быть у гражданина. Это необязательная связь.
Б) У загранпаспорта обязательно есть только один владелец. В этом случае, это уже обязательная связь.
7.3. Многие ко многим
А) Человек может вообще не инвестировать свои деньги в акции.
Б) Акции компании мог никто не купить.
8. Как читать диаграммы?
Выше я приводил диаграммы созданных нами таблиц. Но для того, чтобы их понимать, нужно знать, как их «читать». Разберемся в этом на примере диаграммы из пункта 5.3.
Мы видим отношение один ко многим. Одной персоне принадлежит много телефонов.
Сегодня мы продолжаем наше путешествие в мир SQL и связанных баз данных. В третьей части этой серии мы узнаем, как работать с несколькими таблицами, которые имеют отношения друг с другом. Во-первых, мы рассмотрим некоторые базовые концепции, а затем начнем работать с JOIN queries в SQL.
Вы также можете увидеть базы данных SQL в действии, просмотрев SQL scripts, apps and add-ons на рынке Envato.
Напоминание
Введение
При создании базы данных здравый смысл подсказывает, что мы используем отдельные таблицы для разных типов сущностей. Например: клиенты, заказы, предметы, сообщения. Но нам также нужно иметь отношения между этими таблицами. Например, клиенты делают заказы, а заказы содержат предметы. Эти отношения должны быть представлены в базе данных. Кроме того, при получении данных с помощью SQL нам нужно использовать определённые типы запросов JOIN, чтобы получить то, что нам нужно.
Существует несколько типов отношений базы данных. Сегодня мы рассмотрим следующее:
- Отношения один к одному
- Отношения «один ко многим» и «многие к одному»
- «Многие ко многим» отношения
- Самостоятельные ссылки
При выборе данных из нескольких таблиц с отношениями мы будем использовать запрос JOIN. Существует несколько типов JOIN, и мы собираемся узнать следующее:
- Перекрестные соединения
- Обычные соединения
- Внутренние соединения
- Левые (внешние) соединения
- Правые (внешние) соединения
Мы также узнаем об оговорках ON и USING.
Отношения один к одному
Предположим, у вас есть таблица для клиентов:


Мы можем поместить информацию об адресе клиента в отдельную таблицу:


Теперь мы имеем отношение между таблицей Customers и таблицей Addresses. Если каждый адрес может принадлежать только одному клиенту, это отношение «Один к одному». Имейте в виду, что такого рода отношения не очень распространены. Наша начальная таблица, которая включала адрес вместе с клиентом, в большинстве случаев могла работать нормально.
Обратите внимание: теперь в таблице Customers есть поле с именем «address_id», которое ссылается на запись соответствия в таблице Address. Это называется «Foreign Key» и используется для всех видов отношений баз данных. Мы рассмотрим этот вопрос позже.
Мы можем показать отношения между клиентскими и адресными записями следующим образом:


Обратите внимание, что существование отношений может быть необязательным, например, есть запись клиента, у которой нет связанной записи адреса.
Отношения «один ко многим» и «многие к одному»
Это наиболее часто используемый тип отношений. Рассмотрим веб-сайт e-commerce со следующим:
- Клиенты могут делать много заказов.
- Заказы могут содержать много позиций.
- Позиции могут иметь описания на многих языках.
В этих случаях нам необходимо создать отношения «один ко многим». Вот пример:

У каждого клиента может быть ноль, один или несколько заказов. Но заказ может принадлежать только одному клиенту.


Отношения «многие ко многим»
В некоторых случаях вам может потребоваться несколько экземпляров с обеих сторон. Например, каждый заказ может содержать несколько элементов. И каждый элемент также может быть в нескольких заказах.
Для этих отношений нам нужно создать дополнительную таблицу:


Таблица Items_Orders имеет только одну цель, а именно, чтобы создать отношение «многие ко многим» между элементами и заказами.
Вот картинка таких отношений:


Если вы хотите включить записи items_orders в график, это может выглядеть так:


Самостоятельные ссылки
Это используется, когда таблица должна иметь отношения с самой собой. Например, у вас есть реферальная программа. Клиенты могут направлять других клиентов на ваш веб-сайт. Таблица может выглядеть так:


Клиенты 102 и 103 были переданы клиентом 101.
На самом деле это может быть похоже на отношение «один ко многим», поскольку один клиент может ссылаться на нескольких клиентов. Также он может выглядеть, как древовидная структура:


Один клиент может ссылаться на ноль, одного или несколько клиентов. К каждому клиенту может обращаться только один клиент, или вообще никто.
Если вы хотите создать самостоятельную ссылку «многие ко многим», вам понадобится дополнительная таблица, вроде той, что мы говорили в предыдущем разделе.
Foreign Keys
До сих пор мы узнали только о некоторых концепциях. Теперь пришло время воплотить их в жизнь с помощью SQL. Для этой части нам нужно понять, что такое Foreign Keys.
В приведённых выше примерах отношений мы всегда имели эти поля «**** _ id», которые ссылались на столбец в другой таблице. В этом примере столбец customer_id в таблице Orders является столбцом Foreign Key:
В базе данных типа MySQL есть два способа создания столбцов внешних ключей:
Чёткое определение Foreign Key
Давайте создадим простую таблицу клиентов:
Теперь таблицу заказов, в которой будет Foreign Key:
Оба столбца (customers.customer_id и orders.customer_id) должны иметь одинаковую структуру данных. Если один является INT, другой не должен быть BIGINT, например.
Обратите внимание, что в MySQL только механизм InnoDB имеет полную поддержку Foreign Keys. Но другие механизмы хранения данных по-прежнему позволят вам указывать их без каких-либо ошибок. Кроме того, столбец Foreign Key индексируется автоматически, если не указать для него другой индекс.
Без явной декларации
Та же таблица заказов может быть создана без явного объявления столбца customer_id как Foreign Key:
При получении данных с помощью запроса JOIN вы всё равно можете рассматривать этот столбец как Foreign Key , хотя механизм базы данных не знает об этом отношении.
Далее мы собираемся узнать о JOIN-запросах.
Визуализация отношений
Моим любимым программным обеспечением для проектирования баз данных и визуализации отношений Foreign Key является MySQL Workbench.


После разработки базы данных вы можете экспортировать SQL и запустить его на своем сервере. Это очень удобно для больших и сложных баз данных.


JOIN Queries
Для извлечения данных из базы, имеющей отношения, нам часто приходится использовать JOIN queries.
Прежде чем начать, давайте создадим таблицы и некоторые образцы данных для работы.
У нас 4 клиента. У одного клиента два заказа, у двух клиентов по одному заказу, а у одного клиента нет заказа. Теперь давайте посмотрим различные виды JOIN queries, которые мы можем запустить в этих таблицах.
Перекрестное соединение
Это тип JOIN query по умолчанию, если условие не указано.


Результатом является так называемый «Cartesian product» таблиц. Это означает, что каждая строка из первой таблицы сопоставляется с каждой строкой второй таблицы. Так как каждая таблица имела 4 строки, мы получили результат из 16 строк.
Ключевое слово JOIN может быть опционально заменено запятой.


Конечно, такой результат не очень полезен. Давайте посмотрим на другие типы соединений.
Обычное соединение
При таком типе JOIN query таблицы должны иметь имя соответствующего столбца. В нашем случае обе таблицы имеют столбец customer_id. Таким образом, MySQL будет присоединяться к записям только тогда, когда значение этого столбца соответствует двум записям.


Как вы можете видеть, столбец customer_id отображается только один раз, потому что ядро базы данных рассматривает это как общий столбец. Мы видим два заказа Адама, а два других — Джо и Сэнди. Наконец, мы получаем некоторую полезную информацию.
Внутреннее соединение
Когда указано условие соединения, выполняется Inner Join. В этом случае было бы неплохо иметь поле customer_id в обеих таблицах. Результаты должны быть похожими на Natural Join.


Результаты те же, за исключением небольшой разницы. Столбец customer_id повторяется дважды, один раз для каждой таблицы. Причина в том, что мы просто попросили базу данных соответствовать значениям этих двух столбцов. Но сами они не знают, что представляют одну и ту же информацию.
Давайте добавим еще несколько условий в запрос.


На этот раз мы получили заказы на сумму более $15.
ON Clause
Прежде чем перейти к другим типам соединений, нам нужно посмотреть ON clause. Это полезно для помещения условий JOIN в отдельное предложение.


Теперь мы можем отличить условие JOIN от условий WHERE. Но есть и небольшая разница в функциональности. Мы увидим это в примерах LEFT JOIN.
USING Clause
USING clause похоже на предложение ON, но оно короче. Если столбец имеет одинаковое имя в обеих таблицах, мы можем указать его здесь.


На самом деле это похоже на NATURAL JOIN, поэтому столбец join (customer_id) не повторяется дважды в результатах.
Левое (внешнее) соединение
LEFT JOIN — это тип внешнего соединения. В этих запросах, если во второй таблице не найдено совпадений, запись из первой таблицы по-прежнему отображается.


Хотя у Энди нет заказов, его запись все ещё отображается. Значения под столбцами второй таблицы имеют значение NULL.
Это полезно для поиска записей, которые не имеют отношений. Например, мы можем искать клиентов, которые не разместили какие-либо заказы.


Всё, что мы сделали, это нашли NULL для order_id.
Также обратите внимание, что ключевое слово OUTER является необязательным. Вы можете просто использовать LEFT JOIN вместо LEFT OUTER JOIN.
Условия
Теперь давайте рассмотрим запрос с условием.


Так что случилось с Энди и Сэнди? LEFT JOIN должен был вернуть клиентов без соответствующих заказов. Проблема в том, что предложение WHERE блокирует эти результаты. Чтобы их получить, мы можем попытаться включить условие NULL.


У нас Энди, но нет Сэнди. Тем не менее это выглядит не так. Чтобы получить то, что мы хотим, нам нужно использовать ON clause.


Теперь у нас есть все, и все заказы выше $ 15. Как я уже говорил, ON clause иногда имеет несколько иную функциональность, чем WHERE clause. В условии Outer Join , таком как этот, строки включаются, даже если они не соответствуют условиям ON clause.
Правое (внешнее) соединение
RIGHT OUTER JOIN работает точно так же, но порядок таблиц обратный.


На этот раз у нас нет результатов NULL, потому что каждый заказ имеет соответствующую запись клиента. Мы можем изменить порядок таблиц и получить те же результаты, что и в LEFT OUTER JOIN.


Теперь у нас есть эти значения NULL, потому что таблица Customers находится на правой стороне соединения.
Заключение
Спасибо, что прочитали статью. Надеюсь, вам понравилось! Пожалуйста, оставляйте свои комментарии и вопросы, и хорошего дня!
Не забудьте проверить SQL scripts, apps and add-ons на рынке Envato. Вы получите представление о возможностях баз данных SQL, и сможете найти идеальное решение, которое поможет вам в текущем проекте разработки.
Следуйте за нами на Twitter или подпишитесь на Nettuts + RSS Feed для получения лучших обучающих материалов по веб-разработке в Интернете.
Как dba и консультант по оптимизации производительности SQL Server в Ambient Consulting, я часто сталкиваюсь с необходимостью анализа узких мест производительности на экземплярах SQL Server, которые вижу первый раз в жизни. Это может быть сложной задачей. Как правило, у большинства компаний нет документации по их базам данных. А если есть, то она устарела, или же её поиск занимает несколько дней.
В этой статье я поделюсь базовым набором скриптов, раскапывающим информацию о метаданных с помощью системных функций, хранимых процедур, таблиц, dmv. Вместе они раскрывают все секреты баз данных на нужном экземпляре – их размер, расположение файлов, их дизайн, включая столбцы, типы данных, значения по умолчанию, ключи и индексы.
Если вы когда-нибудь пытались получить часть этой информации, с помощью GUI, я думаю вы будете приятно удивлены количеством той информации, которая, с помощью этих скриптов, получается мнгновенно.
Как и с любыми скриптами, сначала проверьте их в тестовом окружении, прежде чем запускать в продакшене. Я бы рекомендовал вам погонять их на тестовых базах MS, таких как AdventureWorks или pubs.
Ну, хватит слов, давайте я покажу скрипты!
Изучаем сервера
Начнём с запросов, предоставляющих информацию о ваших серверах.
Базовая информация
Во-первых, несколько простых @@Функций, которые предоставят нам базовую информацию.
-- Имена сервера и экземпляра
Select @@SERVERNAME as [ServerInstance];
-- версия SQL Server
Select @@VERSION as SQLServerVersion;
-- экземпляр SQL Server
Select @@ServiceName AS ServiceInstance;
-- Текущая БД (БД, в контексте которой выполняется запрос)
Select DB_NAME() AS CurrentDB_Name;
Как долго ваш SQL Server работает после последнего перезапуска? Помните, что системная база данных tempdb пересоздаётся при каждом перезапуске SQL Server. Вот один из методов определения времени последнего перезапуска сервера.
SELECT @@Servername AS ServerName ,
create_date AS ServerStarted ,
DATEDIFF(s, create_date, GETDATE()) / 86400.0 AS DaysRunning ,
DATEDIFF(s, create_date, GETDATE()) AS SecondsRunnig
FROM sys.databases
WHERE name = 'tempdb';
GO
Связанные сервера
Связанные сервера – это соединения, позволяющие SQL Server’у обращаться к другим серверам с данными. Распределённые запросы могут быть запущенны на разных связанных серверах. Полезно знать – является ли ваш сервер баз данных изолированным от других, или он связан с другими серверами.
EXEC sp_helpserver;
--OR
EXEC sp_linkedservers;
--OR
SELECT @@SERVERNAME AS Server ,
Server_Id AS LinkedServerID ,
name AS LinkedServer ,
Product ,
Provider ,
Data_Source ,
Modify_Date
FROM sys.servers
ORDER BY name;
GO
Список всех баз данных
Во-первых, получим список всех баз данных на сервере. Помните, что на любом сервере есть четыре или пять системных баз данных (master, model, msdb, tempdb и distribution, если вы пользуетесь репликацией). Вы, вероятно, захотите исключить эти базы в следующих запросах. Очень просто увидеть список баз данных в SSMS, но, эти запросы будут нашими «строительными блоками» для более сложных запросов.
Есть несколько путей для получения списка всех БД на T-SQL и ниже вы увидите некоторые из них. Каждый метод возвращает похожий результат, но с некоторыми отличиями.
EXEC sp_helpdb;
--OR
EXEC sp_Databases;
--OR
SELECT @@SERVERNAME AS Server ,
name AS DBName ,
recovery_model_Desc AS RecoveryModel ,
Compatibility_level AS CompatiblityLevel ,
create_date ,
state_desc
FROM sys.databases
ORDER BY Name;
--OR
SELECT @@SERVERNAME AS Server ,
d.name AS DBName ,
create_date ,
compatibility_level ,
m.physical_name AS FileName
FROM sys.databases d
JOIN sys.master_files m ON d.database_id = m.database_id
WHERE m.[type] = 0 -- data files only
ORDER BY d.name;
GO
Последний бэкап?
Стоп! Прежде чем двигаться дальше, каждый хороший dba должен узнать есть ли у него свежий бэкап.
SELECT @@Servername AS ServerName ,
d.Name AS DBName ,
MAX(b.backup_finish_date) AS LastBackupCompleted
FROM sys.databases d
LEFT OUTER JOIN msdb..backupset b
ON b.database_name = d.name
AND b.[type] = 'D'
GROUP BY d.Name
ORDER BY d.Name;
Будет лучше, если вы сразу узнаете путь к файлу с последним бэкапом.
SELECT @@Servername AS ServerName ,
d.Name AS DBName ,
b.Backup_finish_date ,
bmf.Physical_Device_name
FROM sys.databases d
INNER JOIN msdb..backupset b ON b.database_name = d.name
AND b.[type] = 'D'
INNER JOIN msdb.dbo.backupmediafamily bmf ON b.media_set_id = bmf.media_set_id
ORDER BY d.NAME ,
b.Backup_finish_date DESC;
GO
Активные пользовательские соединения
Хорошо было бы понимать какие БД сейчас используются, особенно, если вы собираетесь разбираться с проблемами производительности.
Примечание переводчика: это будет работать только в SQL Server 2012 и выше, в предыдущих редакциях, в dmv sys.dm_exec_sessions отсутствовал столбец database_id. Чтобы узнать в каких БД в данный момент работают пользователи, можно воспользоваться sp_who.
-- Похожая информация, может быть получена с помощью sp_who
SELECT @@Servername AS Server ,
DB_NAME(database_id) AS DatabaseName ,
COUNT(database_id) AS Connections ,
Login_name AS LoginName ,
MIN(Login_Time) AS Login_Time ,
MIN(COALESCE(last_request_end_time, last_request_start_time))
AS Last_Batch
FROM sys.dm_exec_sessions
WHERE database_id > 0
AND DB_NAME(database_id) NOT IN ( 'master', 'msdb' )
GROUP BY database_id ,
login_name
ORDER BY DatabaseName;
Изучаем базы данных
Давайте заглянем поглубже и посмотрим, как мы можем собрать информацию об объектах во всех ваших БД, используя различные представления каталога и dmv. Большинство из запросов, представленных в этом разделе, смотрят «внутрь» только одной БД, поэтому не забывайте выбирать нужную БД в SSMS или с помощью команды use database. Также помните, что вы всегда можете посмотреть в контексте какой БД будет выполнен запрос, с помощью select db_name().
Системная таблица sys.objects одна из ключевых для сбора информации об объектах, составляющих вашу модель данных.
-- В примере U - таблицы
-- Попробуйте подставить другие значения type в WHERE
USE MyDatabase;
GO
SELECT *
FROM sys.objects
WHERE type = 'U';
Ниже представлен список типов объектов, информацию о которых мы можем получить (смотрите документацию на sys.objects в MSDN)
sys.objects.type
AF = статистическая функция (среда CLR);
C = ограничение CHECK;
D = DEFAULT (ограничение или изолированный);
F = ограничение FOREIGN KEY;
PK = ограничение PRIMARY KEY;
P = хранимая процедура SQL;
PC = хранимая процедура сборки (среда CLR);
FN = скалярная функция SQL;
FS = скалярная функция сборки (среда CLR);
FT = возвращающая табличное значение функция сборки (среда CLR);
R = правило (старый стиль, изолированный);
RF = процедура фильтра репликации;
S = системная базовая таблица;
SN = синоним;
SQ = очередь обслуживания;
TA = триггер DML сборки (среда CLR);
TR = триггер DML SQL;
IF = встроенная возвращающая табличное значение функция SQL;
TF = возвращающая табличное значение функция SQL;
U = таблица (пользовательская);
UQ = ограничение UNIQUE;
V = представление;
X = расширенная хранимая процедура;
IT = внутренняя таблица.
Другие представления каталога, такие как sys.tables и sys.views, обращаются к sys.objects и предоставляют информацию о конкретном типе объектов. С этими представлениями, плюс функцией OBJECTPROPERTY, мы можем получить огромное количество информации по каждому из объектов, составляющих нашу схему БД.
Расположение файлов баз данных
Физическое расположение выбранной БД, включая основной файл данных (mdf), и файл журнала транзакций (ldf), могут быть получены с помощью этих запросов.
EXEC sp_Helpfile;
--OR
SELECT @@Servername AS Server ,
DB_NAME() AS DB_Name ,
File_id ,
Type_desc ,
Name ,
LEFT(Physical_Name, 1) AS Drive ,
Physical_Name ,
RIGHT(physical_name, 3) AS Ext ,
Size ,
Growth
FROM sys.database_files
ORDER BY File_id;
GO
Таблицы
Конечно, Object Explorer в SSMS показывает полный список таблиц в выбранной БД, но часть информации с помощью GUI получить сложнее, чем с помощью скриптов. Стандарт ANSI предполагает обращение к представлениям INFORMATION_SCHEMA, но они не предоставят информацию об объектах, которые не являются частью стандарта (такие как триггеры, extended procedures и т.д.), поэтому лучше использовать представления каталога SQL Server.
EXEC sp_tables; -- Помните, что этот метод вернёт и таблицы, и представления
--OR
SELECT @@Servername AS ServerName ,
TABLE_CATALOG ,
TABLE_SCHEMA ,
TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
ORDER BY TABLE_NAME ;
--OR
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
o.name AS 'TableName' ,
o.[Type] ,
o.create_date
FROM sys.objects o
WHERE o.Type = 'U' -- User table
ORDER BY o.name;
--OR
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
t.Name AS TableName,
t.[Type],
t.create_date
FROM sys.tables t
ORDER BY t.Name;
GO
Количество записей в таблице
Если вы ничего не знаете о таблице, то все таблицы одинаково важны. Чем больше вы узнаёте о таблицах, тем больше вы их разделяете на условно более важные и условно менее важные. В целом, таблицы с огромным количеством записей чаще оказывают серьёзное влияние на производительность.
В SSMS мы можем нажать правой кнопкой мыши на любую таблицу, открыть свойства на вкладке Storage и увидеть количество записей в таблице.
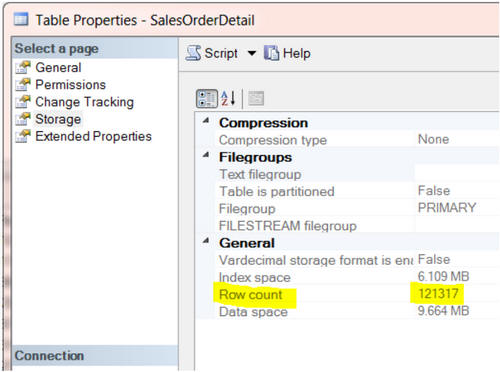
Довольно тяжело собрать вручную эту информацию обо всех таблицах. Опять же, если мы будем писать SELECT COUNT(*) FROM TABLENAME для каждой таблицы, нам придётся очень много печатать.
Намного удобнее использовать T-SQL для генерирования скрипта. Скрипт, приведённый ниже, сгенерирует набор инструкций T-SQL для получения количества строк в каждой таблице текущей базы данных. Просто выполните его, скопируйте результат в новое окно и запустите.
SELECT 'Select ''' + DB_NAME() + '.' + SCHEMA_NAME(SCHEMA_ID) + '.'
+ LEFT(o.name, 128) + ''' as DBName, count(*) as Count From ' + o.name
+ ';' AS ' Script generator to get counts for all tables'
FROM sys.objects o
WHERE o.[type] = 'U'
ORDER BY o.name;
GO

Примечание переводчика: у меня запрос не работал, добавил схему к имени таблицы.
SELECT 'Select ''' + DB_NAME() + '.' + SCHEMA_NAME(SCHEMA_ID) + '.'
+ LEFT(o.name, 128) + ''' as DBName, count(*) as Count From ' + SCHEMA_NAME(SCHEMA_ID) + '.' + o.name
+ ';' AS ' Script generator to get counts for all tables'
FROM sys.objects o
WHERE o.[type] = 'U'
ORDER BY o.name;
sp_msForEachTable
Sp_msforeachtable – это недокументированная функция, которая «проходит» по всем таблицам в БД и выполняет запрос, подставляя вместо ‘?’ имя текущей таблицы. Так же существует похожая функция sp_msforeachdb, работающая на уровне баз данных.
Известно несколько проблем с этой недокументированной функцией, например, использование спецсимволов в именах объектов. Т.е. если имя таблицы или базы данных содержит знак ‘-‘, хранимая процедура, листинг которой ниже, завершится с ошибкой.
CREATE TABLE #rowcount
( Tablename VARCHAR(128) ,
Rowcnt INT );
EXEC sp_MSforeachtable 'insert into #rowcount select ''?'', count(*) from ?'
SELECT *
FROM #rowcount
ORDER BY Tablename ,
Rowcnt;
DROP TABLE #rowcount;
Самый быстрый способ получения количества записей – кластерный индекс
Все предыдущие метода использовали COUNT(*), который медленно отрабатывает, если в таблице больше чем 500K записей.
Самый быстрый способ получения количества записей в таблице – получать количество записей в кластерном индексе или куче. Помните, что хоть этот метод и самый быстрый, MS говорит, что информация о количестве записей индекса и реальное количество строк в таблице может не совпадать, из-за того, что на обновление информации требуется хоть и небольшое, но время. В большинстве же случаев, эти значения или одинаковы, или очень-очень близки и вскоре станут одинаковыми.
-- Самый быстрый путь получения количества записей
-- Hint: получайте из индекса, а не таблицы
SELECT @@ServerName AS Server ,
DB_NAME() AS DBName ,
OBJECT_SCHEMA_NAME(p.object_id) AS SchemaName ,
OBJECT_NAME(p.object_id) AS TableName ,
i.Type_Desc ,
i.Name AS IndexUsedForCounts ,
SUM(p.Rows) AS Rows
FROM sys.partitions p
JOIN sys.indexes i ON i.object_id = p.object_id
AND i.index_id = p.index_id
WHERE i.type_desc IN ( 'CLUSTERED', 'HEAP' )
-- This is key (1 index per table)
AND OBJECT_SCHEMA_NAME(p.object_id) <> 'sys'
GROUP BY p.object_id ,
i.type_desc ,
i.Name
ORDER BY SchemaName ,
TableName;
-- OR
-- Похожий метод получения количества записей, но с использованием DMV dm_db_partition_stats
SELECT @@ServerName AS ServerName ,
DB_NAME() AS DBName ,
OBJECT_SCHEMA_NAME(ddps.object_id) AS SchemaName ,
OBJECT_NAME(ddps.object_id) AS TableName ,
i.Type_Desc ,
i.Name AS IndexUsedForCounts ,
SUM(ddps.row_count) AS Rows
FROM sys.dm_db_partition_stats ddps
JOIN sys.indexes i ON i.object_id = ddps.object_id
AND i.index_id = ddps.index_id
WHERE i.type_desc IN ( 'CLUSTERED', 'HEAP' )
-- This is key (1 index per table)
AND OBJECT_SCHEMA_NAME(ddps.object_id) <> 'sys'
GROUP BY ddps.object_id ,
i.type_desc ,
i.Name
ORDER BY SchemaName ,
TableName;
GO
Поиск куч (таблиц без кластерных индексов)
Работа с кучами – это как работа с плоским файлом, вместо базы данных. Если вы хотите гарантированно получать полное сканирование таблицы при выполнении любого запроса, используйте кучи. Обычно я рекомендую добавлять primary key ко всем таблицам-кучам.
-- Кучи (метод 1)
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
t.Name AS HeapTable ,
t.Create_Date
FROM sys.tables t
INNER JOIN sys.indexes i ON t.object_id = i.object_id
AND i.type_desc = 'HEAP'
ORDER BY t.Name
--OR
-- Кучи (Метод 2)
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
t.Name AS HeapTable ,
t.Create_Date
FROM sys.tables t
WHERE OBJECTPROPERTY(OBJECT_ID, 'TableHasClustIndex') = 0
ORDER BY t.Name;
--OR
-- Кучи (Метод 3) + количество записей
SELECT @@ServerName AS Server ,
DB_NAME() AS DBName ,
OBJECT_SCHEMA_NAME(ddps.object_id) AS SchemaName ,
OBJECT_NAME(ddps.object_id) AS TableName ,
i.Type_Desc ,
SUM(ddps.row_count) AS Rows
FROM sys.dm_db_partition_stats AS ddps
JOIN sys.indexes i ON i.object_id = ddps.object_id
AND i.index_id = ddps.index_id
WHERE i.type_desc = 'HEAP'
AND OBJECT_SCHEMA_NAME(ddps.object_id) <> 'sys'
GROUP BY ddps.object_id ,
i.type_desc
ORDER BY TableName;
Разбираемся с активностью в таблице
При работах по оптимизации производительности, очень важно знать какие таблицы активно читаются, а в какие идёт активная запись. Ранее мы узнали сколько записей в наших таблицах, сейчас посмотрим как часто в них пишут и читают.
Помните, что эта информация из dmv, очищается при каждом перезапуске SQL Server. Чем дольше сервер работает, тем более надёжна статистика. Я чувствую себя намного более уверенно со статистикой, собранной за 30 дней, чем со статистикой, собранной за неделю.
-- Чтение/запись таблицы
-- Кучи не рассматриваются, у них нет индексов
-- Только те таблицы, к которым обращались после запуска SQL Server
SELECT @@ServerName AS ServerName ,
DB_NAME() AS DBName ,
OBJECT_NAME(ddius.object_id) AS TableName ,
SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups)
AS Reads ,
SUM(ddius.user_updates) AS Writes ,
SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups
+ ddius.user_updates) AS [Reads&Writes] ,
( SELECT DATEDIFF(s, create_date, GETDATE()) / 86400.0
FROM master.sys.databases
WHERE name = 'tempdb'
) AS SampleDays ,
( SELECT DATEDIFF(s, create_date, GETDATE()) AS SecoundsRunnig
FROM master.sys.databases
WHERE name = 'tempdb'
) AS SampleSeconds
FROM sys.dm_db_index_usage_stats ddius
INNER JOIN sys.indexes i ON ddius.object_id = i.object_id
AND i.index_id = ddius.index_id
WHERE OBJECTPROPERTY(ddius.object_id, 'IsUserTable') = 1
AND ddius.database_id = DB_ID()
GROUP BY OBJECT_NAME(ddius.object_id)
ORDER BY [Reads&Writes] DESC;
GO
Намного более продвинутая версия этого запроса представлена курсором, собирающим информацию по всем таблицам всех баз данных на сервере. Вообще, я не фанат курсоров из-за их невысокой производительности, но перемещение по разным базам данных – это отличное применение для них.
-- Операции чтения и записи
-- Кучи пропущены, у них нет индексов
-- Только таблицы, использовавшиеся после перезапуска SQL Server
-- В запросе используется курсор для получения информации во всех БД
-- Единый отчёт, хранится в tempdb
DECLARE DBNameCursor CURSOR
FOR
SELECT Name
FROM sys.databases
WHERE Name NOT IN ( 'master', 'model', 'msdb', 'tempdb',
'distribution' )
ORDER BY Name;
DECLARE @DBName NVARCHAR(128)
DECLARE @cmd VARCHAR(4000)
IF OBJECT_ID(N'tempdb..TempResults') IS NOT NULL
BEGIN
DROP TABLE tempdb..TempResults
END
CREATE TABLE tempdb..TempResults
(
ServerName NVARCHAR(128) ,
DBName NVARCHAR(128) ,
TableName NVARCHAR(128) ,
Reads INT ,
Writes INT ,
ReadsWrites INT ,
SampleDays DECIMAL(18, 8) ,
SampleSeconds INT
)
OPEN DBNameCursor
FETCH NEXT FROM DBNameCursor INTO @DBName
WHILE @@fetch_status = 0
BEGIN
----------------------------------------------------
-- Print @DBName
SELECT @cmd = 'Use ' + @DBName + '; '
SELECT @cmd = @cmd + ' Insert Into tempdb..TempResults
SELECT @@ServerName AS ServerName,
DB_NAME() AS DBName,
object_name(ddius.object_id) AS TableName ,
SUM(ddius.user_seeks
+ ddius.user_scans
+ ddius.user_lookups) AS Reads,
SUM(ddius.user_updates) as Writes,
SUM(ddius.user_seeks
+ ddius.user_scans
+ ddius.user_lookups
+ ddius.user_updates) as ReadsWrites,
(SELECT datediff(s,create_date, GETDATE()) / 86400.0
FROM sys.databases WHERE name = ''tempdb'') AS SampleDays,
(SELECT datediff(s,create_date, GETDATE())
FROM sys.databases WHERE name = ''tempdb'') as SampleSeconds
FROM sys.dm_db_index_usage_stats ddius
INNER JOIN sys.indexes i
ON ddius.object_id = i.object_id
AND i.index_id = ddius.index_id
WHERE objectproperty(ddius.object_id,''IsUserTable'') = 1 --True
AND ddius.database_id = db_id()
GROUP BY object_name(ddius.object_id)
ORDER BY ReadsWrites DESC;'
--PRINT @cmd
EXECUTE (@cmd)
-----------------------------------------------------
FETCH NEXT FROM DBNameCursor INTO @DBName
END
CLOSE DBNameCursor
DEALLOCATE DBNameCursor
SELECT *
FROM tempdb..TempResults
ORDER BY DBName ,
TableName;
--DROP TABLE tempdb..TempResults;
Примечание переводчика: курсор не отработает, если у вас в списке есть базы данных с состоянием, отличным от ONLINE.
Представления
Представления – это, условно говоря, запросы, хранящиеся в БД. Вы можете думать о них, как о виртуальных таблицах. Данные не хранятся в представлениях, но в наших запросах мы ссылаемся на них точно так же, как и на таблицы.
В SQL Server, в некоторых случаях, мы можем обновлять данные с использованием представления. Чтобы получить представление «только для чтения», можно использовать SELECT DISTINCT при его создании. Данные «через» представление можно менять только в том случае, если каждой строке представления соответствует только одна строка в «базовой» таблице. Любое представление, не отвечающее этому критерию, т.е. построенное на нескольких таблицах, или с использованием группировок, агрегатных функций и вычислений, будет доступно только для чтения.
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
o.name AS ViewName ,
o.[Type] ,
o.create_date
FROM sys.objects o
WHERE o.[Type] = 'V' -- View
ORDER BY o.NAME
--OR
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
Name AS ViewName ,
create_date
FROM sys.Views
ORDER BY Name
--OR
SELECT @@Servername AS ServerName ,
TABLE_CATALOG ,
TABLE_SCHEMA ,
TABLE_NAME ,
TABLE_TYPE
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'VIEW'
ORDER BY TABLE_NAME
--OR
-- CREATE VIEW Code
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
o.name AS 'ViewName' ,
o.Type ,
o.create_date ,
sm.[DEFINITION] AS 'View script'
FROM sys.objects o
INNER JOIN sys.sql_modules sm ON o.object_id = sm.OBJECT_ID
WHERE o.Type = 'V' -- View
ORDER BY o.NAME;
GO
Синонимы
Несколько раз в моей карьере я сталкивался с ситуацией, когда не мог понять к какой же таблице обращается запрос. Представьте простой запрос SELECT * FROM Client. Я ищу таблицу под именем Client, но я не могу найти её. Хорошо, думаю я, должно быть это представление, ищу представление с именем Client и всё равно не могу найти. Может быть я ошибся базой данных? В итоге выясняется, что Client – это синоним для покупателей и таблица, на самом деле, называется Customer. Отдел маркетинга хотел обращаться к этой таблице как к Client и из-за этого был создан синоним. К счастью, использование синонимов – это редкость, но разбирательства могут вызвать определённые затруднения, если вы к ним не готовы.
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
o.name AS ViewName ,
o.Type ,
o.create_date
FROM sys.objects o
WHERE o.[Type] = 'SN' -- Synonym
ORDER BY o.NAME;
--OR
-- дополнительная информация о синонимах
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
s.name AS synonyms ,
s.create_date ,
s.base_object_name
FROM sys.synonyms s
ORDER BY s.name;
GO
Хранимые процедуры
Хранимые процедуры – это группа скриптов, которые компилируются в единственный план выполнения. Мы можем использовать представления каталога, чтобы определить какие ХП созданы, какие действия они выполняют и над какими таблицами.
-- Хранимые процедуры
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
o.name AS StoredProcedureName ,
o.[Type] ,
o.create_date
FROM sys.objects o
WHERE o.[Type] = 'P' -- Stored Procedures
ORDER BY o.name
--OR
-- Дополнительная информация о ХП
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
o.name AS 'ViewName' ,
o.[type] ,
o.Create_date ,
sm.[definition] AS 'Stored Procedure script'
FROM sys.objects o
INNER JOIN sys.sql_modules sm ON o.object_id = sm.object_id
WHERE o.[type] = 'P' -- Stored Procedures
-- AND sm.[definition] LIKE '%insert%'
-- AND sm.[definition] LIKE '%update%'
-- AND sm.[definition] LIKE '%delete%'
-- AND sm.[definition] LIKE '%tablename%'
ORDER BY o.name;
GO
Добавив простое условие в WHERE мы можем получить информацию только о тех хранимых процедурах, которые, например, выполняют операции INSERT.
WHERE o.[type] = 'P' -- Stored Procedures
AND sm.definition LIKE '%insert%'
ORDER BY o.name
…
Немного модифицировав условие в WHERE, мы можем собрать информацию о ХП, производящих обновление, удаление или же обращающихся к определённым таблицам.
Функции
Функции хранятся в SQL Server, принимают какие-либо параметры и выполняют определённые действия, либо вычисления, после чего возвращают результат.
-- Функции
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
o.name AS 'Functions' ,
o.[Type] ,
o.create_date
FROM sys.objects o
WHERE o.Type = 'FN' -- Function
ORDER BY o.NAME;
--OR
-- Дополнительная информация о функциях
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
o.name AS 'FunctionName' ,
o.[type] ,
o.create_date ,
sm.[DEFINITION] AS 'Function script'
FROM sys.objects o
INNER JOIN sys.sql_modules sm ON o.object_id = sm.OBJECT_ID
WHERE o.[Type] = 'FN' -- Function
ORDER BY o.NAME;
GO
Триггеры
Триггер – это что-то вроде хранимой процедуры, которая выполняется в ответ на определённые действия с той таблицей, которой этот триггер принадлежит. Например, мы можем создать INSERT, UPDATE и DELETE триггеры.
-- Триггеры
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
parent.name AS TableName ,
o.name AS TriggerName ,
o.[Type] ,
o.create_date
FROM sys.objects o
INNER JOIN sys.objects parent ON o.parent_object_id = parent.object_id
WHERE o.Type = 'TR' -- Triggers
ORDER BY parent.name ,
o.NAME
--OR
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
Parent_id ,
name AS TriggerName ,
create_date
FROM sys.triggers
WHERE parent_class = 1
ORDER BY name;
--OR
-- Дополнительная информация о триггерах
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
OBJECT_NAME(Parent_object_id) AS TableName ,
o.name AS 'TriggerName' ,
o.Type ,
o.create_date ,
sm.[DEFINITION] AS 'Trigger script'
FROM sys.objects o
INNER JOIN sys.sql_modules sm ON o.object_id = sm.OBJECT_ID
WHERE o.Type = 'TR' -- Triggers
ORDER BY o.NAME;
GO
CHECK-ограничения
CHECK-ограничения – это неплохое средство для реализации бизнес-логики в базе данных. Например, некоторые поля должны быть положительными, или отрицательными, или дата в одном столбце должна быть больше даты в другом.
-- Check Constraints
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
parent.name AS 'TableName' ,
o.name AS 'Constraints' ,
o.[Type] ,
o.create_date
FROM sys.objects o
INNER JOIN sys.objects parent
ON o.parent_object_id = parent.object_id
WHERE o.Type = 'C' -- Check Constraints
ORDER BY parent.name ,
o.name
--OR
--CHECK constriant definitions
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
OBJECT_SCHEMA_NAME(parent_object_id) AS SchemaName ,
OBJECT_NAME(parent_object_id) AS TableName ,
parent_column_id AS Column_NBR ,
Name AS CheckConstraintName ,
type ,
type_desc ,
create_date ,
OBJECT_DEFINITION(object_id) AS CheckConstraintDefinition
FROM sys.Check_constraints
ORDER BY TableName ,
SchemaName ,
Column_NBR
GO
Углубляемся в модель данных
Ранее, мы использовали скрипты, которые дали нам представление о «верхнем уровне» объектов, составляющих нашу базу данных. Иногда нам нужно получить больше данных о таблице, включая столбцы, их типы данных, какие значения по умолчанию заданы, какие ключи и индексы существуют (или должны существовать) и т.д.
Запросы, представленные в этом разделе, предоставляют средства почти что реверс-инжиниринга существующей модели данных.
Столбцы
Следующий скрипт описывает таблицы и столбцы из всей базы данных. Результат этого запроса, можно скопировать в Excel, где можно настроить фильтры и сортировку и хорошо разобраться с типами данных, использующимися в БД. Так же, обратите внимание на столбцы с одинаковыми именами, но разными типами данных.
SELECT @@Servername AS Server ,
DB_NAME() AS DBName ,
isc.Table_Name AS TableName ,
isc.Table_Schema AS SchemaName ,
Ordinal_Position AS Ord ,
Column_Name ,
Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length AS LEN , -- -1 means MAX like Varchar(MAX)
Is_Nullable ,
Column_Default ,
Table_Type
FROM INFORMATION_SCHEMA.COLUMNS isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
-- WHERE Table_Type = 'BASE TABLE' -- 'Base Table' or 'View'
ORDER BY DBName ,
TableName ,
SchemaName ,
Ordinal_position;
-- Имена столбцов и количество повторов
-- Используется для поиска одноимённых столбцов с разными типами данных/длиной
SELECT @@Servername AS Server ,
DB_NAME() AS DBName ,
Column_Name ,
Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length ,
COUNT(*) AS Count
FROM information_schema.columns isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
WHERE Table_type = 'BASE TABLE'
GROUP BY Column_Name ,
Data_Type ,
Numeric_Precision ,
Numeric_Scale ,
Character_Maximum_Length;
-- Информация по используемым типам данных
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length AS [Length] ,
COUNT(*) AS COUNT
FROM information_schema.columns isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
WHERE Table_type = 'BASE TABLE'
GROUP BY Data_Type ,
Numeric_Precision ,
Numeric_Scale ,
Character_Maximum_Length
ORDER BY Data_Type ,
Numeric_Precision ,
Numeric_Scale ,
Character_Maximum_Length
-- Large object data types or Binary Large Objects(BLOBs)
-- Помните, что индексы по этим таблицам не могут быть перестроены в режиме "online"
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
isc.Table_Name ,
Ordinal_Position AS Ord ,
Column_Name ,
Data_Type AS BLOB_Data_Type ,
Numeric_Precision AS Prec ,
Numeric_Scale AS Scale ,
Character_Maximum_Length AS [Length]
FROM information_schema.columns isc
INNER JOIN information_schema.tables ist
ON isc.table_name = ist.table_name
WHERE Table_type = 'BASE TABLE'
AND ( Data_Type IN ( 'text', 'ntext', 'image', 'XML' )
OR ( Data_Type IN ( 'varchar', 'nvarchar', 'varbinary' )
AND Character_Maximum_Length = -1
)
) -- varchar(max), nvarchar(max), varbinary(max)
ORDER BY isc.Table_Name ,
Ordinal_position;
Значения по умолчанию
Значение по умолчанию – это значение, которое будет сохранено, если никакого значения для столбца не будет задано при вставке. Зачастую, для столбцов хранящих дату ставят get_date(). Также, значения по умолчанию используются для аудита – вставляется system_user для определения учётной записи пользователя, совершившего определённое действие.
-- Table Defaults
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
parent.name AS TableName ,
o.name AS Defaults ,
o.[Type] ,
o.Create_date
FROM sys.objects o
INNER JOIN sys.objects parent
ON o.parent_object_id = parent.object_id
WHERE o.[Type] = 'D' -- Defaults
ORDER BY parent.name ,
o.NAME
--OR
-- Column Defaults
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
OBJECT_SCHEMA_NAME(parent_object_id) AS SchemaName ,
OBJECT_NAME(parent_object_id) AS TableName ,
parent_column_id AS Column_NBR ,
Name AS DefaultName ,
[type] ,
type_desc ,
create_date ,
OBJECT_DEFINITION(object_id) AS Defaults
FROM sys.default_constraints
ORDER BY TableName ,
Column_NBR
--OR
-- Column Defaults
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
OBJECT_SCHEMA_NAME(t.object_id) AS SchemaName ,
t.Name AS TableName ,
c.Column_ID AS Ord ,
c.Name AS Column_Name ,
OBJECT_NAME(default_object_id) AS DefaultName ,
OBJECT_DEFINITION(default_object_id) AS Defaults
FROM sys.Tables t
INNER JOIN sys.columns c ON t.object_id = c.object_id
WHERE default_object_id <> 0
ORDER BY TableName ,
SchemaName ,
c.Column_ID
GO
Вычисляемые столбцы
Вычисляемые столбцы – это столбцы, значения в которых вычисляются на основании, как правило, значений в других столбцах таблицы.
-- Вычисляемые столбцы
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
OBJECT_SCHEMA_NAME(object_id) AS SchemaName ,
OBJECT_NAME(object_id) AS Tablename ,
Column_id ,
Name AS Computed_Column ,
[Definition] ,
is_persisted
FROM sys.computed_columns
ORDER BY SchemaName ,
Tablename ,
[Definition];
--Or
-- Computed Columns
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
OBJECT_SCHEMA_NAME(t.object_id) AS SchemaName,
t.Name AS TableName ,
c.Column_ID AS Ord ,
c.Name AS Computed_Column
FROM sys.Tables t
INNER JOIN sys.Columns c ON t.object_id = c.object_id
WHERE is_computed = 1
ORDER BY t.Name ,
SchemaName ,
c.Column_ID
GO
Столбцы identity
Столбцы IDENTITY автоматически заполняются системой уникальными значениями. Обычно используются для хранения порядкового номера записи в таблице.
SELECT @@Servername AS ServerName ,
DB_NAME() AS DBName ,
OBJECT_SCHEMA_NAME(object_id) AS SchemaName ,
OBJECT_NAME(object_id) AS TableName ,
Column_id ,
Name AS IdentityColumn ,
Seed_Value ,
Last_Value
FROM sys.identity_columns
ORDER BY SchemaName ,
TableName ,
Column_id;
GO
Ключи и индексы
Как я писал ранее, наличие первичного ключа и соответствующего индекса у таблицы – это одна из best practice. Ещё одна best practice заключается в том, что внешние ключи так же должны иметь индекс, построенный по столбцам, входящим во внешний ключ. Индексы, построенные «по внешним ключам» отлично подходят для соединения таблиц. Эти индексы так же хорошо сказываются на производительности при удалении записей.
Какие индексы у нас есть?
Скрипт для поиска всех индексов во всех таблицах текущей БД.
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
o.Name AS TableName ,
i.Name AS IndexName
FROM sys.objects o
INNER JOIN sys.indexes i ON o.object_id = i.object_id
WHERE o.Type = 'U' -- User table
AND LEFT(i.Name, 1) <> '_' -- Remove hypothetical indexes
ORDER BY o.NAME ,
i.name;
GO
Каких индексов не хватает?
На основании ранее исполнявшихся запросов, SQL Server предоставляет информацию об отсутствующих индексах в БД, создание которых может увеличить производительность.
Не добавляйте эти индексы вслепую. Я бы подумал о каждом из предложенных индексов. Использование включенных столбцов, например, может аукнуться серьёзным увеличением объёмов.
-- Отсутствующие индексы из DMV
SELECT @@ServerName AS ServerName ,
DB_NAME() AS DBName ,
t.name AS 'Affected_table' ,
( LEN(ISNULL(ddmid.equality_columns, N'')
+ CASE WHEN ddmid.equality_columns IS NOT NULL
AND ddmid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END) - LEN(REPLACE(ISNULL(ddmid.equality_columns, N'')
+ CASE WHEN ddmid.equality_columns
IS NOT NULL
AND ddmid.inequality_columns
IS NOT NULL
THEN ','
ELSE ''
END, ',', '')) ) + 1 AS K ,
COALESCE(ddmid.equality_columns, '')
+ CASE WHEN ddmid.equality_columns IS NOT NULL
AND ddmid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + COALESCE(ddmid.inequality_columns, '') AS Keys ,
COALESCE(ddmid.included_columns, '') AS [include] ,
'Create NonClustered Index IX_' + t.name + '_missing_'
+ CAST(ddmid.index_handle AS VARCHAR(20))
+ ' On ' + ddmid.[statement] COLLATE database_default
+ ' (' + ISNULL(ddmid.equality_columns, '')
+ CASE WHEN ddmid.equality_columns IS NOT NULL
AND ddmid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL(ddmid.inequality_columns, '') + ')'
+ ISNULL(' Include (' + ddmid.included_columns + ');', ';')
AS sql_statement ,
ddmigs.user_seeks ,
ddmigs.user_scans ,
CAST(( ddmigs.user_seeks + ddmigs.user_scans )
* ddmigs.avg_user_impact AS BIGINT) AS 'est_impact' ,
avg_user_impact ,
ddmigs.last_user_seek ,
( SELECT DATEDIFF(Second, create_date, GETDATE()) Seconds
FROM sys.databases
WHERE name = 'tempdb'
) SecondsUptime
FROM sys.dm_db_missing_index_groups ddmig
INNER JOIN sys.dm_db_missing_index_group_stats ddmigs
ON ddmigs.group_handle = ddmig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details ddmid
ON ddmig.index_handle = ddmid.index_handle
INNER JOIN sys.tables t ON ddmid.OBJECT_ID = t.OBJECT_ID
WHERE ddmid.database_id = DB_ID()
ORDER BY est_impact DESC;
GO
Внешние ключи
Внешние ключи определяют связь между таблицами и используются для контроля ссылочной целостности. На диаграмме сущность-связь линии между таблицами обозначают внешние ключи.
-- Foreign Keys
SELECT @@Servername AS ServerName ,
DB_NAME() AS DB_Name ,
parent.name AS 'TableName' ,
o.name AS 'ForeignKey' ,
o.[Type] ,
o.Create_date
FROM sys.objects o
INNER JOIN sys.objects parent ON o.parent_object_id = parent.object_id
WHERE o.[Type] = 'F' -- Foreign Keys
ORDER BY parent.name ,
o.name
--OR
SELECT f.name AS ForeignKey ,
SCHEMA_NAME(f.SCHEMA_ID) AS SchemaName ,
OBJECT_NAME(f.parent_object_id) AS TableName ,
COL_NAME(fc.parent_object_id, fc.parent_column_id) AS ColumnName ,
SCHEMA_NAME(o.SCHEMA_ID) ReferenceSchemaName ,
OBJECT_NAME(f.referenced_object_id) AS ReferenceTableName ,
COL_NAME(fc.referenced_object_id, fc.referenced_column_id)
AS ReferenceColumnName
FROM sys.foreign_keys AS f
INNER JOIN sys.foreign_key_columns AS fc
ON f.OBJECT_ID = fc.constraint_object_id
INNER JOIN sys.objects AS o ON o.OBJECT_ID = fc.referenced_object_id
ORDER BY TableName ,
ReferenceTableName;
GO
Пропущенные индексы по внешним ключам
Как я уже говорил, желательно иметь индекс, построенный по столбцам, входящим во внешний ключ. Это значительно ускоряет соединения таблиц, которые, обычно, всё равно соединяются по внешнему ключу. Эти индексы так же значительно ускоряют операции удаления. Если такого индекса нет, SQL Server будет производить table scan связанной таблицы, при каждом удалении записи из «первой» таблицы.
-- Foreign Keys missing indexes
-- Помните, что этот скрипт работает только для создания индексов по одному столбцу
-- Внешние ключи, состоящие более чем из одного столбца, не отслеживаются
SELECT DB_NAME() AS DBName ,
rc.Constraint_Name AS FK_Constraint ,
-- rc.Constraint_Catalog AS FK_Database,
-- rc.Constraint_Schema AS FKSch,
ccu.Table_Name AS FK_Table ,
ccu.Column_Name AS FK_Column ,
ccu2.Table_Name AS ParentTable ,
ccu2.Column_Name AS ParentColumn ,
I.Name AS IndexName ,
CASE WHEN I.Name IS NULL
THEN 'IF NOT EXISTS (SELECT * FROM sys.indexes
WHERE object_id = OBJECT_ID(N'''
+ RC.Constraint_Schema + '.' + ccu.Table_Name
+ ''') AND name = N''IX_' + ccu.Table_Name + '_'
+ ccu.Column_Name + ''') '
+ 'CREATE NONCLUSTERED INDEX IX_' + ccu.Table_Name + '_'
+ ccu.Column_Name + ' ON ' + rc.Constraint_Schema + '.'
+ ccu.Table_Name + '( ' + ccu.Column_Name
+ ' ASC ) WITH (PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = ON, IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF, ONLINE = ON);'
ELSE ''
END AS SQL
FROM information_schema.referential_constraints RC
JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE ccu
ON rc.CONSTRAINT_NAME = ccu.CONSTRAINT_NAME
JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE ccu2
ON rc.UNIQUE_CONSTRAINT_NAME = ccu2.CONSTRAINT_NAME
LEFT JOIN sys.columns c ON ccu.Column_Name = C.name
AND ccu.Table_Name = OBJECT_NAME(C.OBJECT_ID)
LEFT JOIN sys.index_columns ic ON C.OBJECT_ID = IC.OBJECT_ID
AND c.column_id = ic.column_id
AND index_column_id = 1
-- index found has the foreign key
-- as the first column
LEFT JOIN sys.indexes i ON IC.OBJECT_ID = i.OBJECT_ID
AND ic.index_Id = i.index_Id
WHERE I.name IS NULL
ORDER BY FK_table ,
ParentTable ,
ParentColumn;
GO
Зависимости
Это зависит… Я уверен, вы слышали это выражение раньше. Я рассмотрю три разных метода для «реверс-инжиниринга» зависимостей в БД. Первый метода – использовать хранимую процедуру sp_msdependecies. Второй – системные таблицы, связанные со внешними ключами. Третий метод – использовать CTE.
sp_msdependencies
Sp_msdependencies – это недокументированная хранимая процедура, которая может быть очень полезна для разбора сложных взаимозависимостей таблиц.
EXEC sp_msdependencies '?' -- Displays Help
sp_MSobject_dependencies name = NULL, type = NULL, flags = 0x01fd
name: name or null (all objects of type)
type: type number (see below) or null
if both null, get all objects in database
flags is a bitmask of the following values:
0x10000 = return multiple parent/child rows per object
0x20000 = descending return order
0x40000 = return children instead of parents
0x80000 = Include input object in output result set
0x100000 = return only firstlevel (immediate) parents/children
0x200000 = return only DRI dependencies
power(2, object type number(s)) to return in results set:
0 (1 - 0x0001) - UDF
1 (2 - 0x0002) - system tables or MS-internal objects
2 (4 - 0x0004) - view
3 (8 - 0x0008) - user table
4 (16 - 0x0010) - procedure
5 (32 - 0x0020) - log
6 (64 - 0x0040) - default
7 (128 - 0x0080) - rule
8 (256 - 0x0100) - trigger
12 (1024 - 0x0400) - uddt
shortcuts:
29 (0x011c) - trig, view, user table, procedure
448 (0x00c1) - rule, default, datatype
4606 (0x11fd) - all but systables/objects
4607 (0x11ff) – all
Если мы выведем все зависимости, используя sp_msdependencies, мы получим четыре столбца: Type, ObjName, Owner(Schema), Sequence.
Обратите внимание на номер последовательности (Sequence) – он начинается с 1 и последовательно увеличивается. Sequence – это «порядковый номер» зависимости.
Я несколько раз использовал этот метод, когда мне нужно было выполнить архивирование или удаление на очень большой БД. Если вы знаете зависимости таблицы, значит у вас есть «дорожная карта» — в каком порядке вам нужно архивировать или удалять данные. Начните с таблицы с самым большим значение в столбце Sequence и двигайтесь от него в обратном порядке – от большего к меньшему. Таблицы с одинаковым значением Sequence могут быть удалены одновременно. Этот метод не нарушает ни одного из ограничений внешних ключей и позволяет перенести/удалить записи без временного удаления и перестроения ограничений (constraints).
EXEC sp_msdependencies NULL -- Все зависимости в БД
EXEC sp_msdependencies NULL, 3 -- Зависимости определённой таблицы

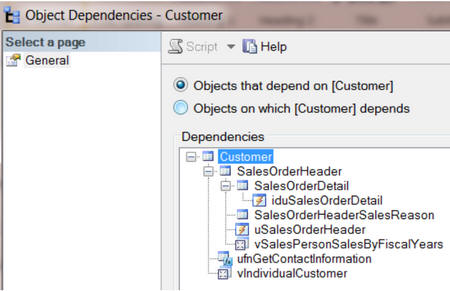
В SSMS, если вы нажмёте правой кнопкой мыши на имя таблицы, вы сможете выбрать «View Dependencies» и «Объекты, которые зависят от TABLENAME»:
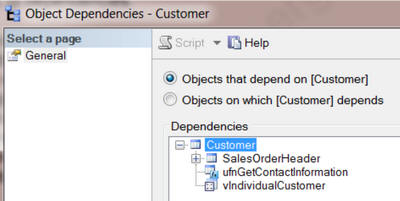
Мы также можем получить эту информацию следующим способом:
-- sp_MSdependencies — Только верхний уровень
-- Объекты, которые зависят от указанного объекта
EXEC sp_msdependencies N'Sales.Customer',null, 1315327 -- Change Table Name
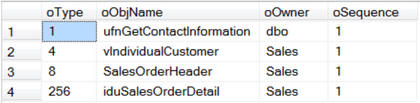
Если в SSMS, в окне просмотра зависимостей, выбрать «Объекты которые зависят от TABLENAME», а затем раскрыть все уровни, мы увидим следующее:
Ту же самую информацию вернёт sp_msdependencies.
-- sp_MSdependencies - Все уровни
-- Объекты, которые зависят от указанного объекта
EXEC sp_MSdependencies N'Sales.Customer', NULL, 266751 -- Change Table Name
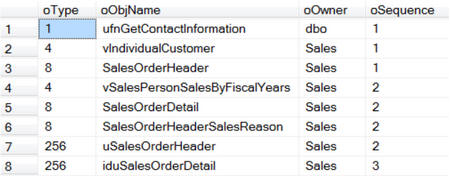
Так же, в SSMS, мы можем увидеть от каких объектов зависит выбранная таблица.
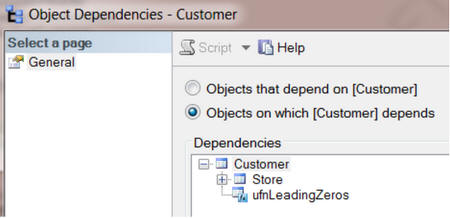
Следующий запрос, с использованием msdependencies, вернёт ту же самую информацию.
-- Объекты, от которых зависит указанный объект
EXEC sp_MSdependencies N'Sales.Customer', null, 1053183 -- Change Table
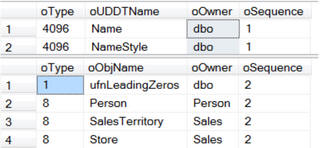
Если вы хотите получить список зависимостей таблиц, вы можете использовать временную таблицу, чтобы отфильтровать зависимости по типу.
CREATE TABLE #TempTable1
(
Type INT ,
ObjName VARCHAR(256) ,
Owner VARCHAR(25) ,
Sequence INT
);
INSERT INTO #TempTable1
EXEC sp_MSdependencies NULL
SELECT *
FROM #TempTable1
WHERE Type = 8 --Tables
ORDER BY Sequence ,
ObjName
DROP TABLE #TempTable1;
Запросы к системным представлениям каталога
Второй метод «реверс-инжиниринга» зависимостей в вашей БД – это запросы к системным представлениям каталога, связанным со внешними ключами.
--Independent tables
SELECT Name AS InDependentTables
FROM sys.tables
WHERE object_id NOT IN ( SELECT referenced_object_id
FROM sys.foreign_key_columns )
-- Check for parents
AND object_id NOT IN ( SELECT parent_object_id
FROM sys.foreign_key_columns )
-- Check for Dependents
ORDER BY Name
-- Tables with dependencies.
SELECT DISTINCT
OBJECT_NAME(referenced_object_id) AS ParentTable ,
OBJECT_NAME(parent_object_id) AS DependentTable ,
OBJECT_NAME(constraint_object_id) AS ForeignKeyName
FROM sys.foreign_key_columns
ORDER BY ParentTable ,
DependentTable
-- Top level of the pyramid tables. Tables with no parents.
SELECT DISTINCT
OBJECT_NAME(referenced_object_id) AS TablesWithNoParent
FROM sys.foreign_key_columns
WHERE referenced_object_id NOT IN ( SELECT parent_object_id
FROM sys.foreign_key_columns )
ORDER BY 1
-- Bottom level of the pyramid tables.
-- Tables with no dependents. (These are the leaves on a tree.)
SELECT DISTINCT
OBJECT_NAME(parent_object_id) AS TablesWithNoDependents
FROM sys.foreign_key_columns
WHERE parent_object_id NOT IN ( SELECT referenced_object_id
FROM sys.foreign_key_columns )
ORDER BY 1
-- Tables with both parents and dependents.
-- Tables in the middle of the hierarchy
SELECT DISTINCT
OBJECT_NAME(referenced_object_id) AS MiddleTables
FROM sys.foreign_key_columns
WHERE referenced_object_id IN ( SELECT parent_object_id
FROM sys.foreign_key_columns )
AND parent_object_id NOT IN ( SELECT referenced_object_id
FROM sys.foreign_key_columns )
ORDER BY 1;
-- in rare cases, you might find a self-referencing dependent table.
-- Recursive (self) referencing table dependencies.
SELECT DISTINCT
OBJECT_NAME(referenced_object_id) AS ParentTable ,
OBJECT_NAME(parent_object_id) AS ChildTable ,
OBJECT_NAME(constraint_object_id) AS ForeignKeyName
FROM sys.foreign_key_columns
WHERE referenced_object_id = parent_object_id
ORDER BY 1 ,
2;
Использование CTE
Третий метод, для получения иерархии зависимостей – использование рекурсивного CTE.
-- How to find the hierarchical dependencies
-- Solve recursive queries using Common Table Expressions (CTE)
WITH TableHierarchy ( ParentTable, DependentTable, Level )
AS (
-- Anchor member definition (First level group to start the process)
SELECT DISTINCT
CAST(NULL AS INT) AS ParentTable ,
e.referenced_object_id AS DependentTable ,
0 AS Level
FROM sys.foreign_key_columns AS e
WHERE e.referenced_object_id NOT IN (
SELECT parent_object_id
FROM sys.foreign_key_columns )
-- Add filter dependents of only one parent table
-- AND Object_Name(e.referenced_object_id) = 'User'
UNION ALL
-- Recursive member definition (Find all the layers of dependents)
SELECT --Distinct
e.referenced_object_id AS ParentTable ,
e.parent_object_id AS DependentTable ,
Level + 1
FROM sys.foreign_key_columns AS e
INNER JOIN TableHierarchy AS d
ON ( e.referenced_object_id ) =
d.DependentTable
)
-- Statement that executes the CTE
SELECT DISTINCT
OBJECT_NAME(ParentTable) AS ParentTable ,
OBJECT_NAME(DependentTable) AS DependentTable ,
Level
FROM TableHierarchy
ORDER BY Level ,
ParentTable ,
DependentTable;
Заключение
Таким образом, за час или два, можно получить неплохое представление о внутренностях любой базы данных, используя методы «реверс-инжиниринга», описанные выше.
Примечание переводчика: все запросы в тексте (за исключением одного, в тексте он отмечен) будут работать на SQL Server 2005 SP3 и в более поздних редакциях. Текст достаточно объёмный, я старался как мог его вычитать и найти свои ошибки (стилистические, синтаксические, смысловые и прочие), но, наверняка что-то не заметил, напишите мне в личку, пожалуйста, если что-то будет резать глаз.
1) Зайдите в свою базу данных: use DATABASE;
2) Показать все таблицы: show tables;
3) Посмотрите на каждый столбец таблицы, чтобы собрать, что он делает и что он сделал: describe TABLENAME;
4) Опишите хорошо, поскольку вы можете точно определить, что делают ваши столбцы таблицы, но если вы хотите еще более внимательно рассмотреть сами данные:
select * from TABLENAME
Если у вас большие таблицы, то каждая строка обычно имеет id, и в этом случае мне нравится делать это, чтобы просто получить несколько строк данных и не перегружать терминал: select * from TABLENAME where id<5 — Вы можете поместить любое условие, которое вам нравится.
Этот метод дает вам больше информации, чем просто делать select * from INFORMATION_SCHEMA.TABLE_CONSTRAINTS;, а также предоставляет вам дополнительную информацию об размеру укуса каждый раз.
ИЗМЕНИТЬ
Как и предполагалось, вышеприведенный WHERE id < 5 был плохим выбором в качестве условного заполнителя. Не рекомендуется ограничивать идентификационный номер, тем более, что идентификатор обычно не заслуживает доверия, чтобы быть последовательным. Вместо этого добавьте LIMIT 5 в конце запроса.