КОНСПЕКТ 15
15.1
ПРЕДВАРИТЕЛЬНЫЕ СВЕДЕНИЯ
Математическая
статистика возникла (XVIII в.) и создавалась
параллельно с теорией вероятностей.
Дальнейшее развитие этой дисциплины
(начало 20в.) обязано, в первую очередь,
П.Л. Чебышеву, А.А. Маркову, А.М. Ляпунову.
Основные результаты, ставшие в настоящее
время классическими, были получены
учеными англо – американской школы –
К. Пирсон, Р.Фишер, Ю.Нейман, А.Вальд,
В.Феллер и др. и российскими математиками
–В.И.Романовский, Е.Е.Слуцкий, А.Н.
Колмогоров, Н.В.Смирнов. Годом рождения
современной математической статистики
следует считать 1933 г. – год опубликования
работы академика А.Н.Колмогорова
«Основные понятия
теории
вероятностей». Именно в это время
математическую статистику выделили из
теории вероятностей в отдельную
дисциплину.
В теории
вероятностей, если мы изучаем случайную
величину X, ее закон распределения
считается заданным, и мы можем достоверно
ответить на любой вопрос, касающийся
данной случайной величины. В математической
статистике ситуация прямо противоположная
– мы ничего не знаем о законе распределения
изучаемой случайной величины X. У нас
имеются только некоторые ее наблюдения
или измерения.
Понятно, что
по конечному числу наблюдений невозможно
достоверно сделать какие-либо выводы
об изучаемой случайной величине. Ясно
также, что чем больше таких наблюдений,
тем более надежными будут наши приближенные
выводы. В этом состоит основная особенность
математической статистики – она не
определяет достоверно закономерности
поведения изучаемых случайной явлений,
а оценивает их с той или иной степенью
достоверности.
Но при неограниченном увеличении числа
наблюдений
выводы математической статистики
становятся практически
достоверными.
Поэтому содержание этой дисциплины –
как и сколько сделать
наблюдений
и как их обработать, чтобы ответить на
интересующий нас вопрос
о
случайном явлении с требуемой степенью
достоверности.
Итак,
установление закономерностей, которым
подчинены массовые
случайные
явления основано на изучении статистических
данных – результатах наблюдений.
Математическая
статистика решает две главные задачи:
указать
способы
сбора и группировки (если данных очень
много) статистических
сведений
(результатов наблюдений) и разработать
методы анализа собранных
статистических
данных в зависимости от целей исследования.
Пусть требуется
изучить совокупность однородных объектов
относительно качественного или
количественного признака, характеризующего
эти объекты.
15.2 ХАРАКТЕРИСТИКИ
ВАРИАЦИОННОГО РЯДА
Некоторое
предприятие выпускает партию одинаковых
деталей. Если контролируют детали по
размеру – это количественный признак.
Можно производить этот контроль сплошным
обследованием, то есть измерять каждый
из объектов совокупности. Но на практике
сплошное обследование применяется
редко:
а) из-за очень
большого числа объектов;
б) из-за того,
что иногда обследование заключается в
физическом уничтожении, например,
проверяем взрываемость гранат или
проверяем на крепость произведенную
посуду и т.д.
В таких случаях
производится случайный отбор ограниченного
(небольшого) числа объектов, которые и
подвергают изучению.
Выборочной совокупностью
(выборкой)
называется совокупность случайно
отобранных однородных объектов.
Генеральной совокупностью
называется
совокупность всех однородных объектов,
из которых производится выборка.
Объемом
совокупности
(выборочной или генеральной) называется
число объектов этой совокупности.
При наборе
выборки можно поступать двояко: после
того, как объект отобран и над ним
произведено наблюдение, он может быть
возвращен либо не возвращен в генеральную
совокупность. В связи с этим выборки
подразделяются на повторные и бесповторные.
Для того,
чтобы по данным выборки можно было
достаточно уверенно судить об интересующем
нас признаке генеральной совокупности,
необходимо, чтобы объекты выборки
правильно его представляли. Это требование
коротко формулируется так: выборка
должна быть репрезентативной
(представительной).
Способы
отбора выборки:
1. Отбор, не
требующий расчленения генеральной
совокупности на части:
а) простой
случайный бесповторный;
б) простой
случайный повторный.
2. Отбор, при
котором генеральная совокупность
разбивается на части (если объем
генеральной совокупности слишком
большой):
а) типический
отбор. Объекты отбираются не из всей
генеральной совокупности, а из ее
«типичных» частей. Например, цех из
тридцати станков
производит
одну и ту же деталь. Тогда отбор делается
по одной или по две детали с каждого
станка в случайные моменты времени;
б) механический
отбор. Например, если нужно выбрать 5%
деталей, то выбирают не случайно, а
каждую двадцатую деталь;
в) серийный
отбор. Объекты выбирают не по одному, а
сериями.
Итак, пусть
из генеральной совокупности значений
некоторого количественного признака
произведена выборка объема N:
X =
{ x1
, x
2
, x
3
,…, x
N
}.
Таблица вида
1.1
|
№ |
1 |
2 |
3 |
… |
N |
|
x |
x1 |
x2 |
x3 |
… |
xN |
называется
простым статистическим рядом, являющимся
первичной формой представления
статистического материала.
Из данных
табл. 1.1 находят xmin
и xmax
, соответственно наименьшее и наибольшее
значения выборки. Затем данные табл.
1.1 называемые вариантами, располагают
в порядке возрастания. Тогда выборка
X =
{
x1
, x
2
, x
3
,…, x
N
}, записанная
в порядке возрастания, называется
вариационным
рядом.
Размах выборки
– это длина основного интервала
[xmin
; xmax]
, в который попадают все значения выборки.
Пусть из
генеральной совокупности извлечена
выборка, причем x1,
наблюдалось
n1
раз,
x2
– соответственно
n2
раз, xk
— nk
раз и сумма всех
ni
и есть
объем выборки:
![]() .
.
Наблюдаемые значения![]() называют
называют
вариантами, а последовательностьвариант,
записанных в порядке возрастания, —вариационным
рядом. Числа
наблюдений называют частотами, а их
отношения к объему выборки
![]() —относительными
—относительными
частотами.
Статистическим
распределением выборки называют перечень
вариант и соответствующих им частот
или относительных частот. Статистическое
распределение можно записать также в
виде последовательности интервалов и
соответствующих им частот (в качестве
частоты, соответствующей интервалу,
принимают сумму частот, попавших в этот
интервал).
Заметим, что
в теории вероятностей под распределением
понимают соответствие между возможными
значениями случайной величины и их
вероятностями, а в математической
статистике – соответствие между
наблюдаемыми вариантами и их частотами,
или относительными частотами.
ПРИМЕР
Задано
распределение частот выборки объёма n
= 20
xi 2 6 12
ni 3 10 7
Написать
распределение относительных частот.
РЕШЕНИЕ.
Найдём относительные частоты, для чего
разделим частоты на объем выборки:
W1
= 3/20 = 0,15, W2
= 10/20 = 0,50, W3
= 7/20 = 0,35.
Напишем
распределение относительных частот:
xi 2 6 12
Wi 0,15 0,50 0,35
КОНТРОЛЬ:
0,15 + 0,50 + 0,35 = 1.
ПРАКТИКУМ 15
ЗАДАНИЕ N 1Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «1» − 5 раз,
значение «2» − 11 раз,
значение «3» − 29 раз и
значение «4» − 15 раз. Тогда
![]() объем
объем
выборки.
ЗАДАНИЕ N 2Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
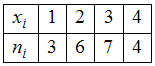 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «1» − 3 раза,
значение «2» − 6 раз,
значение «3» − 7 раз и
значение «4» − 4 раза. Тогда
![]() объем
объем
выборки.
ЗАДАНИЕ N 3Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда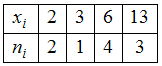 равно …
равно …
Решение:Выборочным средним
называется среднее арифметическое всех
значений выборки:![]() Значение «2»
Значение «2»
некоторая случайная величина
принимает 2 раза, значение «3» – 1 раз,
значение «6» – 4 раза и
значение «13» − 3 раза. Тогда
среднее арифметическое всех значений
выборки равно![]()
ЗАДАНИЕ N 4Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
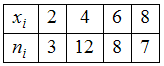 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «2» − 3 раза,
значение «4» − 12 раз,
значение «6» − 8 раз и
значение «8» − 7 раз. Тогда
![]() объем
объем
выборки.
ЗАДАНИЕ N 5Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда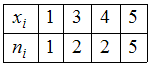 равно …
равно …
Решение:Выборочным средним
называется среднее арифметическое всех
значений выборки:![]() Значение «1»
Значение «1»
некоторая случайная величина
принимает 1 раз,
значение «3» – 2 раза,
значение «4» – 2 раза и
значение «5» − 5 раз. Тогда
среднее арифметическое всех значений
выборки равно![]()
ЗАДАНИЕ N 6Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «1» − 15 раз,
значение «2» − 5 раз,
значение «3» − 20 раз и
значение «4» − 10 раз.
Тогда
![]() объем
объем
выборки.
ЗАДАНИЕ N 7Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда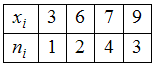 равно …
равно …
Решение:Выборочным средним
называется среднее арифметическое всех
значений выборки:![]() Обращаем
Обращаем
внимание, что значение «3» некоторая
случайная величина
принимает 1 раз,
значение «6» – 2 раза,
значение «7» – 4 раза и
значение «9» − 3 раза. Тогда
среднее арифметическое всех значений
выборки равно![]()
САМОСТОЯТЕЛЬНАЯ РАБОТА 15
ЗАДАНИЕ N 1Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда
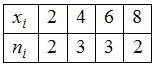 равно …
равно …
ЗАДАНИЕ N 2Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда
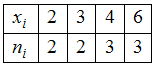 равно …
равно …
ЗАДАНИЕ N 3
Тема: Характеристики вариационного
ряда. Выборочное среднееВыборочное
среднее для вариационного ряда
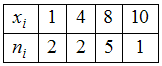 равно …
равно …
ЗАДАНИЕ N 4Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
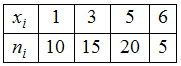 ,
,
равен …
ЗАДАНИЕ N 5Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
ЗАДАНИЕ N 6Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
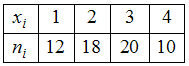 ,
,
равен …
ЗАДАНИЕ N 7
Тема: Объем выборкиОбъем
выборки, заданной статистическим
распределением
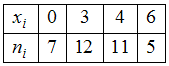 ,
,
равен …
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Сейчас Вы научитесь находить числовые характеристики статистического распределения выборки. Примеры подобраны на основании индивидуальных заданий по теории вероятностей, которые задавали студентам ЛНУ им. И. Франка. Ответы послужат для студентов математических дисциплин хорошей инструкцией на экзаменах и тестах. Подобные решения точно используют в обучении экономисты , поскольку именно им задавали все что приведено ниже. ВУЗы Киева, Одессы, Харькова и других городов Украины имеют подобную систему обучения поэтому много полезного для себя должен взять каждый студент. Задачи различной тематики связаны между собой линками в конце статьи, поэтому можете найти то, что Вам нужно.
Индивидуальное задание 1
Вариант 11
Задача 1. Построить статистическое распределение выборки, записать эмпирическую функцию распределения и вычислить такие числовые характеристики:
- выборочное среднее;
- выборочную дисперсию;;
- подправленную дисперсию;
- выборочное среднее квадратичное отклонение;
- подправленное среднее квадратичное отклонение;
- размах выборки;
- медиану;
- моду;
- квантильное отклонение;
- коэффициент вариации;
- коэффициент асимметрии;
- эксцесс для выборки:
Выборка задана рядом 11, 9, 8, 7, 8, 11, 10, 9, 12, 7, 6, 11, 8, 7, 10, 9, 11, 8, 13, 8.
Решение:
Запишем выборку в виде вариационного ряда (в порядке возрастания):
6; 7; 7; 7; 8; 8; 8; 8; 8; 9; 9; 9; 10; 10; 11; 11; 11; 11; 12; 13.
Далее записываем статистическое распределение выборки в виде дискретного статистического распределения частот:
![]()
Эмпирическую функцию распределения определим по формуле
![]()
Здесь nx – количество элементов выборки которые меньше х. Используя таблицу и учитывая что объем выборки равен n = 20, запишем эмпирическую функцию распределения:

Далее вычислим числовые характеристики статистического распределения выборки.
Выборочное среднее вычисляем по формуле
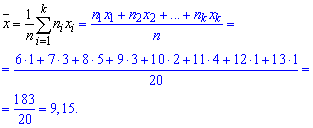
Выборочную дисперсию находим по формуле
![]()
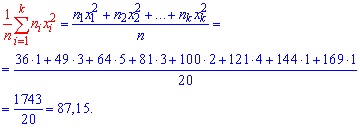
Выборочное среднее, что фигурирует в формуле дисперсии в квадрате найдено выше. Остается все подставить в формулу
![]()
Подправленную дисперсию вычисляем согласно формулы
![]()
Выборочное среднее квадратичное отклонение вычисляем по формуле
![]()
Подправленное среднее квадратичное отклонение вычисляем как корень из подправленной дисперсии
![]()
Размах выборки вычисляем как разность между наибольшим и наименьшим значениями вариант, то есть:
![]()
Медиану находим по 2 формулам:
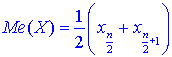 если число n — четное;
если число n — четное;
![]() если число n — нечетное.
если число n — нечетное.
Здесь берем индексы в xi согласно нумерации варианта в вариационном ряду.
В нашем случае n = 20, поэтому
![]()
Мода – это варианта которая в вариационном ряду случается чаще всего, то есть
![]()
Квантильное отклонение находят по формуле
![]()
где ![]() – первый квантиль,
– первый квантиль, ![]() – третий квантиль.
– третий квантиль.
Квантили получаем при разбивке вариационного ряда на 4 равные части.
Для заданного статистического распределения квантильное отклонения примет значение
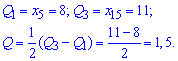
Коэффициент вариации равный процентному отношению подправленного среднего квадратичного к выборочному среднему
![]()
Коэффициент асимметрии находим по формуле
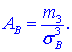
Здесь 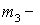 центральный эмпирический момент 3-го порядка,
центральный эмпирический момент 3-го порядка,
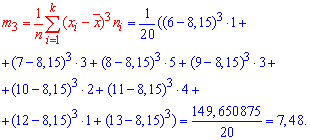
Подставляем в формулу коэффициента асимметрии
![]()
Эксцессом ![]() статистического распределения выборки называется число, которое вычисляют по формуле:
статистического распределения выборки называется число, которое вычисляют по формуле:
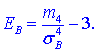
Здесь m4 центральный эмпирический момент 4-го порядка. Находим момент
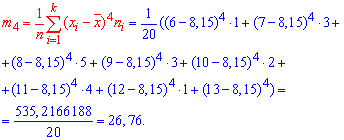
а далее эксцесс![]()
Теперь Вы имеете все необходимые формулы чтобы найти числовые характеристики статистического распределения. Как найти моду, медиану и дисперсию должен знать каждый студент, который изучает теорию вероятностей.
Готовые решения по теории вероятностей
- Следующая статья — Построение уравнения прямой регрессии Y на X
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k — число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) — это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) — середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) — нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) — соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) — нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) — середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) — результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | — |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).

Эксперт по предмету «Математика»
Задать вопрос автору статьи
Генеральная средняя
Пусть нам дана генеральная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность — совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная средняя — среднее арифметическое значений вариант генеральной совокупности.
Пусть значения вариант $x_1, x_2,dots ,x_k$ имеют, соответственно, частоты $n_1, n_2,dots ,n_k$. Тогда генеральная средняя вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1, x_2,dots ,x_k$ различны. В этом случае $n_1, n_2,dots ,n_k=1$. Получаем, что в этом случае генеральная средняя вычисляется по формуле:
Выборочная средняя
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 3
Выборочная совокупность — часть отобранных объектов из генеральной совокупности.
Определение 4
Выборочная средняя — среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1, x_2,dots ,x_k$ имеют, соответственно, частоты $n_1, n_2,dots ,n_k$. Тогда выборочная средняя вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1, x_2,dots ,x_k$ различны. В этом случае $n_1, n_2,dots ,n_k=1$. Получаем, что в этом случае выборочная средняя вычисляется по формуле:
«Средняя выборки: генеральная, выборочная» 👇
!!! В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной средних значений за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Примеры задач на нахождение средней выборки
Пример 1
В магазин завезли 10 видов шоколадных конфет. По ним проведена следующая выборка по цене за килограмм: 70, 65, 97, 83, 120, 107, 77, 88, 100, 86. Построить ряд распределения данной генеральной совокупности и найти её генеральное среднее.
Решение.
Видим, что все значения вариант различны, поэтому частоты равны единице. Ряд распределения можно записать следующим образом, перечислив значения вариант в порядке возрастания:
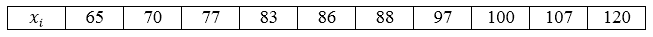
Рисунок 1.
Так как наша совокупность является генеральной и все варианты различны, то мы будем пользоваться следующей формулой:
[overline{x_г}=frac{sumlimits^k_{i=1}{x_i}}{n}]
Получим:
[overline{x_г}=frac{65+70+77+83+86+88+97+100+107+120}{10}=89,3]
Ответ: 89,3.
Пример 2
Выборочная совокупность задана следующей таблицей распределения:

Рисунок 2.
Найти среднее выборочное данной совокупности.
Решение.
Для нахождения значения выборочной средней будем пользоваться следующей формулой:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}]
Обычно, для наглядности и удобности вычислений составляется расчетная таблица, в которую входят необходимые промежуточные вычисления. В нашем случае составим таблицу со следующей «шапкой»:
Рисунок 3.
Внизу таблицы также добавляется строка «итог», в которой подсчитывается сумма по всем значениям столбцов. Проведя необходимые вычисления, получим следующую расчетную таблицу:

Рисунок 4.
Используя формулу, получим:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}=frac{305}{20}=15,25]
Ответ: 15,25.
Пример 3
Проводится социальный опрос среди 100 пенсионеров об уровне их пенсии. Получена следующая таблица распределения результатов опроса (размер пенсии указан в тысячах рублей):

Рисунок 5.
Найти среднее выборочное данной совокупности.
Данная совокупность является выборочной, поэтому будем пользоваться следующей формулой:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}]
Составим, для начала, расчетную таблицу.
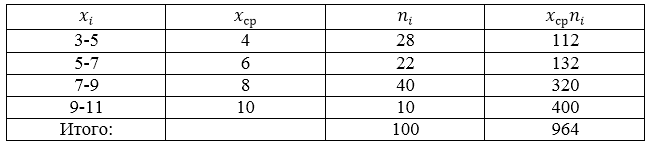
Рисунок 6.
Получаем:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}=frac{964}{100}=9,64]
Ответ: 9,64.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
3.1. Показатели центральной тенденции
Простейший пример такого показателя нам уже встречался – это среднее арифметическое значение. Но средней
дело не ограничивается, впрочем, обо всём по порядку:
3.1.1. Генеральная и выборочная средняя
Пусть исследуется некоторая генеральная совокупность объёма ![]() , а именно её числовая характеристика
, а именно её числовая характеристика ![]() , не важно, дискретная или непрерывная.
, не важно, дискретная или непрерывная.
Генеральной средней называют среднее арифметическое всех значений этой совокупности:
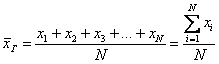
Если среди чисел ![]() есть одинаковые (что
есть одинаковые (что
характерно для дискретного ряда), то формулу можно записать в более компактном
виде:
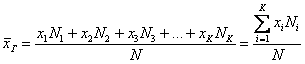 , где:
, где:
варианта ![]() повторяется
повторяется ![]() раз;
раз;
варианта ![]() –
– ![]() раз;
раз;
варианта ![]() –
– ![]() раз;
раз;
…
варианта ![]() –
– ![]() раз.
раз.
Живой пример вычисления генеральной средней встретился в Примере 2, но чтобы не занудничать, я даже не буду
напоминать его содержание. Далее.
Как мы помним, обработка всей генеральной совокупности часто затруднена либо невозможна, и поэтому из неё организуют представительную выборку объема ![]() , и на основании исследования этой выборки делают вывод обо всей совокупности.
, и на основании исследования этой выборки делают вывод обо всей совокупности.
Выборочной средней называется среднее арифметическое всех значений выборки:
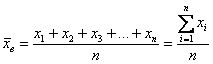
и при наличии одинаковых вариант формула запишется компактнее:
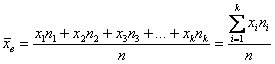 – как сумма произведений вариант
– как сумма произведений вариант ![]() на соответствующие частоты
на соответствующие частоты ![]() , делённая на объём совокупности
, делённая на объём совокупности ![]() .
.
Выборочная средняя ![]() позволяет достаточно
позволяет достаточно
точно оценить истинное значение ![]() , при этом, чем
, при этом, чем
больше выборка, тем точнее будет эта оценка.
Практику начнём с дискретного вариационного ряда и знакомого условия:
Пример 8
По результатам выборочного исследования ![]() рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4,
рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4,
4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
Это числа из Примера 4, но теперь нам требуется: вычислить выборочную среднюю, и, не отходя от станка, найти моду
и медиану.
Как решать задачу? Если нам даны первичные данные (конкретные варианты ![]() ), то их можно тупо просуммировать и разделить результат на объём
), то их можно тупо просуммировать и разделить результат на объём
выборки:
![]() – средний квалификационный разряд рабочих
– средний квалификационный разряд рабочих
цеха.
Но здесь удобнее составить вариационный ряд:
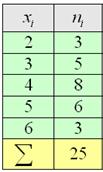
и использовать «цивилизованную» формулу:
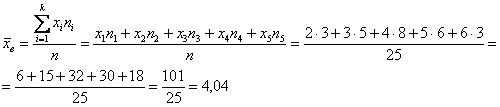
 3.1.2. Мода
3.1.2. Мода
 3. Основные показатели статистической совокупности
3. Основные показатели статистической совокупности
| Оглавление |