 Поэзия — та же добыча радия.
Поэзия — та же добыча радия.
В грамм добыча, в годы труды.
Изводишь единого слова ради
Тысячи тонн словесной руды.
Но как испепеляюще слов этих жжение
Рядом с тлением слова-сырца.
Эти слова приводят в движение
Тысячи лет миллионов сердца.
Владимир Маяковский
Напомню, что наша ближайшая задача — показать алгоритм универсального обобщения. Такое обобщение должно удовлетворять всем требованиям, сформулированным ранее в десятой части. Кроме того, оно должно быть свободно от традиционных для многих методов машинного обучения недостатков (комбинаторный взрыв, переобучение, схождение к локальному минимуму, дилемма стабильности-пластичности и тому подобное). При этом механизм такого обобщения должен не противоречить нашим знаниям о работе реальных нейронов живого мозга.
Сделаем еще один шаг в сторону универсального обобщения. Опишем идею комбинаторного пространства и то, как это пространство помогает искать закономерности и тем самым решать задачу обучения с учителем.
Задача контекстного сдвига текстовой строки
Сейчас мы покажем, как очень сложно решить очень простую задачу. Мы научимся сдвигать на одну позицию произвольную текстовую строку.
Предположим, что у нас есть длинный текст. Мы последовательно читаем его от начала к концу. За один шаг чтения мы смещаемся на один символ. Предположим, что у нас есть скользящее окно шириной N символов и в каждый момент времени нам доступен только фрагмент текста, помещающийся в это окно. Введем циклический идентификатор позиции (описан в конце четвертой части), указывающий на позицию символов в тексте. Период идентификатора обозначим K. Пример текста с наложенным идентификатором позиции и сканирующим окном приведен на рисунке ниже.

Фрагмент текста. Числами обозначен циклический идентификатор позиции. Период идентификатора K=10. Вертикальными линиями выделено одно из положений скользящего окна. Размер окна N=6
Основная идея такого представления в том, что если размер окна N меньше периода идентификатора K, то набор пар «буква — идентификатор позиции» позволяет однозначно записать строку внутри скользящего окна. Ранее похожий метод записи мы упоминали, когда говорили о том, как можно закодировать звуковую информацию. Подставьте вместо букв коды неких условных фонем, и вы получите запись звукового фрагмента.
Введем систему понятий, позволяющую описать все, что появляется в скользящем окне. Для простоты не будем делать разницы между заглавными и строчными буквами и не будем учитывать знаки препинания. Так как потенциально любая буква может встретиться нам в любой позиции, то нам понадобятся все возможные сочетания букв и позиций, то есть 26 x K понятий. Условно эти понятия можно обозначить как
{a0,a1⋯a(K-1),b0,b1⋯b(K-1),z0,z1⋯z(K-1)}
Мы можем записать любое состояние скользящего окна как перечисление соответствующих понятий. Так для окна, показанного на рисунке выше, это будет
{s1,w3,e4,d6}
Сопоставим каждому понятию некий разреженный бинарный код. Например, если взять длину кода в 256 бит и отвести 8 бит для кодирования одного понятия, то кодирование буквы «a» в различных позициях будет выглядеть как показано на рисунке ниже. Напомню, что коды выбираются случайным образом, и биты у них могут повторяться, то есть одни и те же биты могут быть общими для нескольких кодов.

Пример кодов буквы a в позициях от 0 до 9. Бинарные вектора показаны вертикально, единицы выделены горизонтальными светлыми линиями
Создадим бинарный код фрагмента логическим сложением кодов составляющих его понятий. Как уже писалось ранее, такой бинарный код фрагмента будет обладать свойствами фильтра Блума. Если разрядность бинарного массива достаточна высока, то с достаточно высокой точностью можно выполнить обратное преобразование и получить из кода фрагмента набор исходных понятий.
На рисунке ниже приведен пример того, как будут выглядеть коды понятий и суммарный код фрагмента для предыдущего примера.

Пример сложения бинарных кодов понятий в код фрагмента
Описание, составленное таким образом, хранит не только набор букв фрагмента текста, но и их последовательность. Однако и набор понятий, и суммарный код этой последовательности зависит от того, в какой позиции находился циклический идентификатор на момент, когда последовательность появилась в тексте. На рисунке ниже приведен пример того, как описание одного и того же фрагмента текста зависит от начального положения циклического идентификатора.

Изменение кодировки текста при разном начальном смещении
Первому случаю будет соответствовать описание
{s1,w3,e4,d6}
Второй случай будет записан, как
{s9,w1,e2,d4}
В результате текст один и тот же, но совсем другой набор понятий и, соответственно, совсем другой описывающий его бинарный код.
Тут мы приходим к тому, о чем так много говорили в предыдущих частях. Варианты, получаемые при смещении текста, – это возможные трактовки одной и той же информации. При этом контекстами выступают все возможные варианты смещения. И хотя суть информации неизменна, ее внешняя форма, то есть описание через набор понятий или через его бинарное представление, меняется от контекста к контексту, то есть, в нашем случае, при каждом изменении начальной позиции.
Чтобы иметь возможность сравнивать фрагменты текста инвариантно к их смещению, надо ввести пространство контекстов смещений. Для этого понадобится K контекстов. Каждый контекст будет соответствовать одному из вариантов возможного начального смещения.
Напомню, что контексты определяются правилами контекстных преобразований. В каждом контексте задается набор правил относительно того, как меняются понятия в этом контексте.
Контекстными преобразованиями в случае с текстом будут правила изменения понятий при переходе к соответствующему контексту смещению. Так, например, для контекста с нулевым смещением правила переходов будут переходами сами в себя
a0→a0, a2→a2⋯z(K-1)→z(K-1)
Для контекста со смещением на 8 позиций при длине кольцевого идентификатора K=10, что соответствует нижней строке примера с рисунка выше, правила будут иметь вид
a0→a8, a1→a9, a2→a0⋯z9→z7
При таких правилах в контексте со смещением 8 описание окна из первой строки примера перейдет в описание окна из второй строки, что, собственно, вполне очевидно и без долгих пояснений
{s1,w3,e4,d6}→{s9,w1,e2,d4}
В нашем случае контексты, по сути, выполняют вариацию смещения текстовой строки по всем возможным позициям кольцевого идентификатора. В результате если две строки совпадают или похожи друг на друга, но сдвинуты одна относительно другой, то всегда найдется контекст, который нивелирует это смещение.
Позже мы подробно разовьем мысль о контекстах, сейчас же нас будет интересовать один частный, но при этом очень важный вопрос: как изменяются бинарные коды описаний при переходе от одного контекста к другому?
В нашем примере мы имеем текст и знаем позиции букв. Задав требуемое смещение, мы всегда можем пересчитать позиции букв и получить новое описание. Не представляет труда вычислить бинарные коды для исходного и смещенного состояния. Например, на рисунке ниже показано, как будет выглядеть код строки «arkad» в нулевом смещении и код той же строки при смещении на одну позицию вправо.

Код исходной строки и ее смещения
Так как у нас есть алгоритм пересчета описаний, мы без труда можем для любой строки получить ее исходный бинарный код (в нулевом контексте) и код в смещении на одну позицию (в контексте «1»). Взяв длинный текст, мы можем создать сколь угодно много таких примеров, относящихся к одному смещению.
А теперь возьмем сгенерированные примеры и представим, что перед нами черный ящик. Есть бинарное описание на входе, есть бинарное описание на выходе, но нам ничего не известно ни про природу входного описания, ни про правила, по которым происходит преобразование. Можем ли мы воспроизвести работу этого черного ящика?
Мы пришли к классической задаче обучения с учителем. Есть обучающая выборка и по ней требуется воспроизвести внутреннюю логику, связывающую входные и выходные данные.
Такая постановка задачи типична для ситуаций, с которыми часто сталкивается мозг, решая вопросы контекстных преобразований. Например, в прошлой части было описано, как сетчатка глаза формирует бинарные коды, соответствующие зрительной картинке. Микродвижения глаз постоянно создают обучающие примеры. Так как движения очень быстрые, то можно считать, что мы видим одну и ту же сцену, но только в разных контекстах смещения. Таким образом мозг получает исходный код изображения и код, в который это изображение переходит в контексте проделанного глазом смещения. Задача обучения зрительных контекстов – это вычисление правил, которым подчиняются зрительные трансформации. Знание этих правил позволяет получать трактовки одного и того же изображения одновременно в различных вариантах смещений без необходимости глазу физически эти смещения совершать.
В чем сложность?
Когда я учился в институте, у нас была очень популярна игра «Быки и коровы». Один игрок загадывает четырехзначное число без повторов, другой пытается его угадать. Тот, кто пытается, называет некие числа, а загадавший сообщает, сколько в них быков, то есть угаданных цифр, стоящих на своем месте, и сколько коров, цифр, которые есть в загаданном числе, но стоят не там, где им положено. Вся соль игры в том, что ответы загадавшего не дают однозначной информации, а создают множество допустимых вариантов. Каждая попытка порождает такую неоднозначную информацию. Однако совокупность попыток позволяет найти единственно верный ответ.
Что-то похожее есть и в нашей задаче. Выходные биты не случайны, каждый из них зависит от определенного сочетания входных битов. Но так как во входном векторе может содержаться несколько понятий, то неизвестно, какие именно биты отвечают за срабатывание конкретного выходного бита.
Так как в кодах понятий биты могут повторяться, то один входной бит ничего не говорит о выходе. Чтобы судить о выходе, требуется анализировать сочетание нескольких входных битов.
Поскольку один и тот же выходной бит может относиться к кодам разным понятий, то срабатывание выходного бита еще не говорит о том, что на входе появилось то же сочетание бит, которое заставило этот выходной бит сработать ранее.
Иначе говоря, получается достаточно сильная неопределенность, как со стороны входа, так и со стороны выхода. Эта неопределенность оказывается серьезной помехой и затрудняет слишком простое решение. Одна неопределенность перемножается на другую неопределенность, что в результате приводит к комбинаторному взрыву.
Для борьбы с комбинаторным взрывом требуется «комбинаторный лом». Есть два инструмента, позволяющие на практике решать сложные комбинаторные задачи. Первый – это массовое распараллеливание вычислений. И тут важно не только иметь большое количество параллельных процессоров, но и подобрать такой алгоритм, который позволяет распараллелить задачу и загрузить все доступные вычислительные мощности.
Второй инструмент – это принцип ограниченности. Основной метод, использующий принцип ограниченности – это метод «случайных подпространств». Иногда комбинаторные задачи допускают сильное ограничение исходных условий и при этом сохраняют надежду, что и после этих ограничений в данных сохранится достаточно информации, чтобы можно было найти требуемое решение. Вариантов того, как можно ограничить исходные условия, может быть много. Не все из них могут быть удачными. Но если, все же, вероятность, что удачные варианты ограничений есть, то тогда сложная задача может быть разбита на большое количество ограниченных задач, каждая из которых решается значительно проще исходной.
Комбинируя эти два принципа, можно построить решение и нашей задачи.
Комбинаторное пространство
Возьмем входной битовый вектор и пронумеруем его биты. Создадим комбинаторные «точки». В каждую точку сведем несколько случайных битов входного вектора (рисунок ниже). Наблюдая за входом, каждая из этих точек будет видеть не всю картину, а только ее малую часть, определяемую тем, какие биты сошлись в выбранной точке. Так на рисунке ниже крайняя слева точка с индексом 0 следит только за битами 1, 6, 10 и 21 исходного входного сигнала. Создадим таких точек достаточно много и назовем их набор комбинаторным пространством.

Комбинаторное пространство
В чем смысл этого пространства? Мы предполагаем, что входной сигнал не случаен, а содержит определенные закономерности. Закономерности могут быть двух основных типов. Что-то во входном описании может появляться несколько чаще чем другое. Например, в нашем случае отдельные буквы появляются чаще чем их сочетания. При битовом кодировании это означает, что определенные комбинации битов встречаются, чаще чем другие.
Другой тип закономерностей – это когда кроме входного сигнала есть сопутствующий ему сигнал обучения и что-то, содержащееся во входном сигнале, оказывается связано с чем-то, что содержится в сигнале обучения. В нашем случае активные выходные биты – это реакция на комбинацию определенных входных битов.
Если искать закономерности «в лоб», то есть глядя на весь входной и весь выходной векторы, то не очень понятно, что делать и куда двигаться. Если начинать строить гипотезы на предмет того, что от чего может зависеть, то моментально наступает комбинаторный взрыв. Количество возможных гипотез оказывается чудовищно.
Классический метод, широко используемый в нейронных сетях, — градиентный спуск. Для него важно понять, в какую сторону двигаться. Обычно это несложно, когда выходная цель одна. Например, если мы хотим обучить нейронную сеть написанию цифр, мы показываем ей изображения цифр и указываем, что за цифру она при этом видит. Сети понятно «как и куда спускаться». Если мы будем показывать картинки сразу с несколькими цифрами и называть все эти цифры одновременно, не указывая, где что, то ситуация становится значительно сложнее.
Когда создаются точки комбинаторного пространства с сильно ограниченным «обзором» (случайные подпространства), то оказывается, что некоторым точкам может повезти и они увидят закономерность если не совсем чистой, то, по крайней мере, в значительно очищенном виде. Такой ограниченный взгляд позволит, например, провести градиентный спуск и получить уже чистую закономерность. Вероятность для отдельной точки наткнуться на закономерность может быть не очень высока, но всегда можно подобрать такое количество точек, чтобы гарантировать себе, что всякая закономерность «где-то да всплывет».
Конечно, если делать размеры точек слишком узкими, то есть количество битов в точках выбирать приблизительно равным тому, сколько битов ожидается в закономерности, то размеры комбинаторного пространства начнут стремиться к количеству вариантов полного перебора возможных гипотез, что возвращает нас к комбинаторному взрыву. Но, к счастью, можно увеличивать обзор точек, снижая их общее количество. Это снижение не дается бесплатно, комбинаторика «переносится в точки», но до определенного момента это не смертельно.
Создадим выходной вектор. Просто сведем в каждый бит выхода несколько точек комбинаторного пространства. Какие это будут точки выберем случайным образом. Количество точек, попадающих в один бит, будет соответствовать тому, во сколько раз мы хотим уменьшить комбинаторное пространство. Такой вектор выхода будет хэш-функцией для вектора состояния комбинаторного пространства. О том, как это состояние считается, мы поговорим чуть позже.
В общем случае, например, как показано на рисунке выше, размер входа и выхода могут быть различны. В нашем примере с перекодированием строк эти размеры совпадают.
Кластеры рецепторов
Как искать закономерности в комбинаторном пространстве? Каждая точка видит свой фрагмент входного вектора. Если в том, что она видит, оказывается достаточно много активных битов, то можно предположить, что то, что она видит, и есть какая-либо закономерность. То есть, набор активных битов, попадающий в точку, можно назвать гипотезой о наличии закономерности. Запомним такую гипотезу, то есть зафиксируем набор активных битов, видимых в точке. В ситуации, показанной на рисунке ниже, видно, что в точке 0 надо зафиксировать биты 1, 6 и 21.

Фиксация битов в кластере
Будем называть запись номера одного бита рецептором к этому биту. Это подразумевает, что рецептор следит за состоянием соответствующего бита входного вектора и реагирует, когда там появляется единица.
Набор рецепторов будем называть кластером рецепторов или рецептивным кластером. Когда предъявляется входной вектор, рецепторы кластера реагируют, если в соответствующих позициях вектора стоят единицы. Для кластера можно подсчитать количество сработавших рецепторов.
Так как информация у нас кодируется не отдельными битами, а кодом, то от того, сколько битов мы возьмем в кластер, зависит точность, с которой мы сформулируем гипотезу. К статье приложен текст программы, решающий задачу с перекодировкой строк. По умолчанию в программе заданы следующие настройки:
- длина входного вектора — 256 бит;
- длина выходного вектора – 256 бит;
- отдельная буква кодируется 8 битами;
- длина строки — 5 символов;
- количество контекстов смещения — 10;
- размер комбинаторного пространства – 60000;
- количество битов, пересекающихся в точке – 32;
- порог создания кластера – 6;
- порог частичной активации кластера — 4.
При таких настройках практически каждый бит, который есть в коде одной буквы, повторяется в коде другой буквы, а то и в кодах нескольких букв. Поэтому одиночный рецептор не может надежно указать на закономерность. Два рецептора указывают на букву значительно лучше, но и они могут указывать на сочетание совсем других букв. Можно ввести некий порог длины, начиная с которого можно достаточно достоверно судить о том, есть ли в кластере нужный нам фрагмент кода.
Введем минимальный порог по количеству рецепторов, необходимых для формирования гипотезы (в примере он равен 6). Приступим к обучению. Будем подавать исходный код и код, который мы хотим получить на выходе. Для исходного кода легко подсчитать, сколько активных битов попадает в каждую из точек комбинаторного пространства. Выберем только те точки, которые подключены к активным битам выходного кода и у которых количество попавших в нее активных битов входного кода окажется не меньше порога создания кластера. В таких точках создадим кластеры рецепторов с соответствующими наборами битов. Сохраним эти кластеры именно в тех точках, где они были созданы. Чтобы не создавать дубликаты, предварительно проверим, что эти кластеры уникальны для этих точек и точки еще не содержат точно таких же кластеров.
Скажем то же другими словами. По выходному вектору мы знаем, какие биты должны быть активны. Соответственно, мы можем выбрать связанные с ними точки комбинаторного пространства. Для каждой такой точки мы можем сформулировать гипотезу о том, что то, что она сейчас видит на входном векторе, – это и есть закономерность, которая отвечает за активность того бита, к которому эта точка подключена. Мы не можем сказать по одному примеру, верна или нет эта гипотеза, но выдвинуть предположение нам никто не мешает.
Обучение. Консолидация памяти
В процессе обучения каждый новый пример создает огромное количество гипотез, большинство из которых неверны. От нас требуется проверить все эти гипотезы и отсеять ложные. Это мы можем сделать, наблюдая за тем, подтвердятся ли эти гипотезы на последующих примерах. Кроме того, создавая новый кластер, мы запоминаем все биты, которые видит точка, а это, даже если там и содержится закономерность, еще и случайные биты, которые попали туда от других понятий, не влияющих на наш выход, и которые в нашем случае являются шумом. Соответственно, требуется не только подтвердить или опровергнуть, что в запомненной комбинации битов содержится нужная закономерность, но и очистить эту комбинацию от шума, оставив только «чистое» правило.
Возможны разные подходы к решению поставленной задачи. Опишу один из них, не утверждая, что он лучший. Я перебрал множество вариантов, этот подкупил меня качеством работы и простотой, но это не значит, что его нельзя улучшить.
Удобно воспринимать кластеры, как автономные вычислители. Если каждый кластер может проверять свою гипотезу и принимать решения независимо от остальных, то это очень хорошо для потенциального распараллеливания вычислений. Каждый кластер рецепторов после создания начинает самостоятельную жизнь. Он следит за поступающими сигналами, накапливает опыт, меняет себя и принимает если необходимо решение о самоликвидации.
Кластер – это набор битов, про который мы предположили, что внутри него сидит закономерность, связанная со срабатыванием того выходного бита, к которому подключена точка, содержащая этот кластер. Если закономерность есть, то скорее всего она затрагивает только часть битов, причем мы заранее не знаем, какую. Поэтому будем фиксировать все моменты, когда в кластере срабатывает существенное количество рецепторов (в примере не менее 4). Возможно, что в эти моменты закономерность, если она есть, проявляет себя. Когда накопится определенная статистика, мы сможем попробовать определить, есть ли в таких частичных срабатываниях кластера что-то закономерное или нет.
Пример статистики показан на рисунке ниже. Плюс в начале строки показывает, что в момент частичного срабатывания кластера выходной бит также был активен. Биты кластера сформированы из соответствующих битов входного вектора.
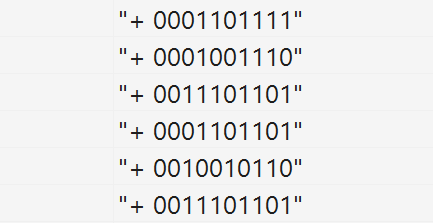
Хроника частичного срабатывания кластера рецепторов
Что нас должно интересовать в этой статистике? Нам важно, какие биты чаще других срабатывают совместно. Не спутайте это с самыми частыми битами. Если посчитать для каждого бита частоту его появления и взять самые распространенные биты, то это будет усреднение, которое совсем не то, что нам надо. Если в точке сошлись несколько устойчивых закономерностей, то при усреднении получится средняя между ними «не закономерность». В нашем примере, видно, что 1,2 и 4 строки похожи между собой, также похожи 3,4 и 6 строки. Нам надо выбрать одну из этих закономерностей, желательно самую сильную, и очистить ее от лишних битов.
Наиболее распространенная комбинация, которая проявляется как совместное срабатывание определенных битов, является для этой статистики первой главной компонентой. Чтобы вычислить главную компоненту, можно воспользоваться фильтром Хебба. Для этого можно задать вектор с единичными начальными весами. Затем получать активность кластера, перемножая вектор весов на текущее состояние кластера. А затем сдвигать веса в сторону текущего состояния тем сильнее, чем выше эта активность. Чтобы веса не росли бесконтрольно, после изменения весов их надо нормировать, например, на максимальное значение из вектора весов.
Такая процедура повторяется для всех имеющихся примеров. В результате вектор весов все больше приближается к главной компоненте. Если тех примеров, что есть, не хватает, чтобы сойтись, то можно несколько раз повторить процесс на тех же примерах, постепенно уменьшая скорость обучения.
Основная идея в том, что по мере приближения к главной компоненте кластер начинает все сильнее реагировать на образцы, похожие на нее и все меньше на остальные, за счет этого обучение в нужную сторону идет быстрее, чем «плохие» примеры пытаются его испортить. Результат работы такого алгоритма после нескольких итераций показан ниже.

Результат, полученный после нескольких итераций выделения первой главной компоненты
Если теперь подрезать кластер, то есть оставить только те рецепторы, у которых высокие веса (например, выше 0.75), то мы получим закономерность, очищенную от лишних шумовых битов. Эту процедуру можно повторить несколько раз по мере накопления статистики. В результате можно понять, есть ли в кластере какая-либо закономерность, или мы собрали вместе случайный набор битов. Если закономерности нет, то в результате подрезания кластера останется слишком короткий фрагмент. В этом случае такой кластер можно удалить как несостоявшуюся гипотезу.
Кроме подрезки кластера надо следить за тем, чтобы была поймана именно нужная закономерность. В исходной строке смешаны коды нескольких букв, каждый из них является закономерностью. Любой из этих кодов может быть «пойман» кластером. Но нас интересует код только той буквы, которая влияет на формирование выходного бита. По этой причине большинство гипотез будут ложными и их необходимо отвергнуть. Это можно сделать по тем критериям, что частичное или даже полное срабатывание кластера слишком часто будет не совпадать с активностью нужного выходного бита. Такие кластеры подлежат удалению. Процесс такого контроля и удаления лишних кластеров вместе с их «подрезкой» можно назвать консолидацией памяти.
Процесс накопления новых кластеров достаточно быстрый, каждый новый опыт формирует несколько тысяч новых кластеров-гипотез. Обучение целесообразно проводить этапами с перерывом на «сон». Когда кластеров создается критически много, требуется перейти в режим «холостой» работы. В этом режиме прокручивается ранее запомненный опыт. Но при этом не создается новых гипотез, а только идет проверка старых. В результате «сна» удается удалить огромный процент ложных гипотез и оставить только гипотезы, прошедшие проверку. После «сна» комбинаторное пространство не только оказывается очищено и готово к приему новой информации, но и гораздо увереннее ориентируется в том, что было выучено «вчера».
Выход комбинаторного пространства
По мере того, как кластеры будут накапливать статистику и проходить консолидацию, будут появляться кластеры, достаточно похожие на то, что их гипотеза либо верна, либо близка к истине. Будем брать такие кластеры и следить за тем, когда они будут полностью активироваться, то есть когда будут активны все рецепторы кластера.
Далее из этой активности сформируем выход как хеш комбинаторного пространства. При этом будем учитывать, что чем длиннее кластер, тем выше шанс, что мы поймали закономерность. Для коротких кластеров есть вероятность, что сочетание битов возникло случайно как комбинация других понятий. Для повышения помехоустойчивости воспользуемся идеей бустинга, то есть будем требовать, чтобы для коротких кластеров активация выходного бита происходила только когда таких срабатываний будет несколько. В случае же длинных кластеров будем считать, что достаточно и единичного срабатывания. Это можно представить через потенциал, который возникает при срабатывании кластеров. Этот потенциал тем выше, чем длиннее кластер. Потенциалы точек, подключенных к одному выходному биту, складываются. Если итоговый потенциал превышает определенный порог, то бит активируется.
После некоторого обучения на выходе начинает воспроизводиться часть, совпадающая с тем, что мы хотим получить (рисунок ниже).

Пример работы комбинаторного пространства в процессе обучения (порядка 200 шагов). Сверху исходный код, в середине требуемый код, снизу код, предсказанный комбинаторным пространством
Постепенно выход комбинаторного пространства начинает все лучше воспроизводить требуемый код выхода. После нескольких тысяч шагов обучения выход воспроизводится с достаточно высокой точностью (рисунок ниже).

Пример работы обученного комбинаторного пространства. Сверху исходный код, в середине требуемый код, снизу код, предсказанный комбинаторным пространством
Чтобы наглядно представить, как это все работает, я записал видео с процессом обучения. Кроме того, возможно, мои пояснения помогут лучше разобраться во всей этой кухне.
Усиление правил
Для выявления более сложных закономерностей можно использовать тормозные рецепторы. То есть вводить закономерности, блокирующие срабатывание некоторых утвердительных правил при появлении некой комбинации входных битов. Это выглядит как создание при определенных условиях кластера рецепторов с тормозными свойствами. При срабатывании такого кластера он будет не увеличивать, а уменьшать потенциал точки.
Несложно придумать правила проверки тормозных гипотез и запустить консолидацию тормозных рецептивных кластеров.
Так как тормозные кластеры создаются в конкретных точках, то они влияют не на блокировку выходного бита вообще, а на блокировку его срабатывания от правил, обнаруженных именно в этой точке. Можно усложнить архитектуру связей и ввести тормозные правила, общие для группы точек или для всех точек, подключенных к выходному биту. Похоже, что можно придумать еще много чего интересного, но пока остановимся на описанной простой модели.
Случайный лес
Описанный механизм позволяет найти закономерности, которые в Data Mining принято называть правилами типа «if-then». Соответственно, можно найти что-то общее между нашей моделью и всеми теми методами, что традиционно используются для решения таких задач. Пожалуй, наиболее близок к нам «random forest».
Этот метод начинается с идеи «случайных подпространств». Если в исходных данных слишком много переменных и эти переменные слабо, но коррелированы, то на полном объеме данных становится трудно вычленить отдельные закономерности. В таком случае можно создать подпространства, в которых будут ограничены как используемые переменные, так и обучающие примеры. То есть каждое подпространство будет содержать только часть входных данных, и эти данные будут представлены не всеми переменными, а их случайным ограниченным набором. Для некоторых из этих подпространств шансы обнаружить закономерность, плохо видимую на полном объеме данных, значительно повышаются.
Затем в каждом подпространстве на ограниченном наборе переменных и обучающих примеров производится обучение решающего дерева. Решающее дерево – это древовидная структура (рисунок ниже), в узлах которой происходит проверка входных переменных (атрибутов). По результатам проверки условий в узлах определяется путь от вершины к терминальному узлу, который принято называть листом дерева. В листе дерева находится результат, который может быть значением какой-либо величины или номером класса.

Пример дерева принятия решений
Для решающих деревьев существуют различные алгоритмы обучения, которые позволяют построить дерево с более-менее оптимальными атрибутами в его узлах.
На завершающем этапе применяется идея бустинга. Решающие деревья формируют комитет для голосования. На основании коллективного мнения создается наиболее правдоподобный ответ. Главное достоинство бустинга – это возможность при объединении множества «плохих» алгоритмов (результат которых лишь немного лучше случайного) получить сколь угодно «хороший» итоговый результат.
В нашем алгоритме, эксплуатирующем комбинаторное пространство и кластеры рецепторов, используются те же фундаментальные идеи, что и в методе случайного леса. Поэтому нет ничего удивительного, что наш алгоритм работает и выдает неплохой результат.
Биология обучения
Собственно, в этой статье описана программная реализация тех механизмов, которые были описаны в предыдущих частях цикла. Поэтому не будем повторять все с самого начала, отметим лишь основное. Если вы забыли о том, как работает нейрон, то можно перечитать вторую часть цикла.
На мембране нейрона располагается множество различных рецепторов. Большинство этих рецепторов находится в «свободном плавании». Мембрана создает для рецепторов среду, в которой они могут свободно перемещаться, легко меняя свое положение на поверхности нейрона (Sheng, M., Nakagawa, T., 2002) (Tovar K. R.,Westbrook G. L., 2002).
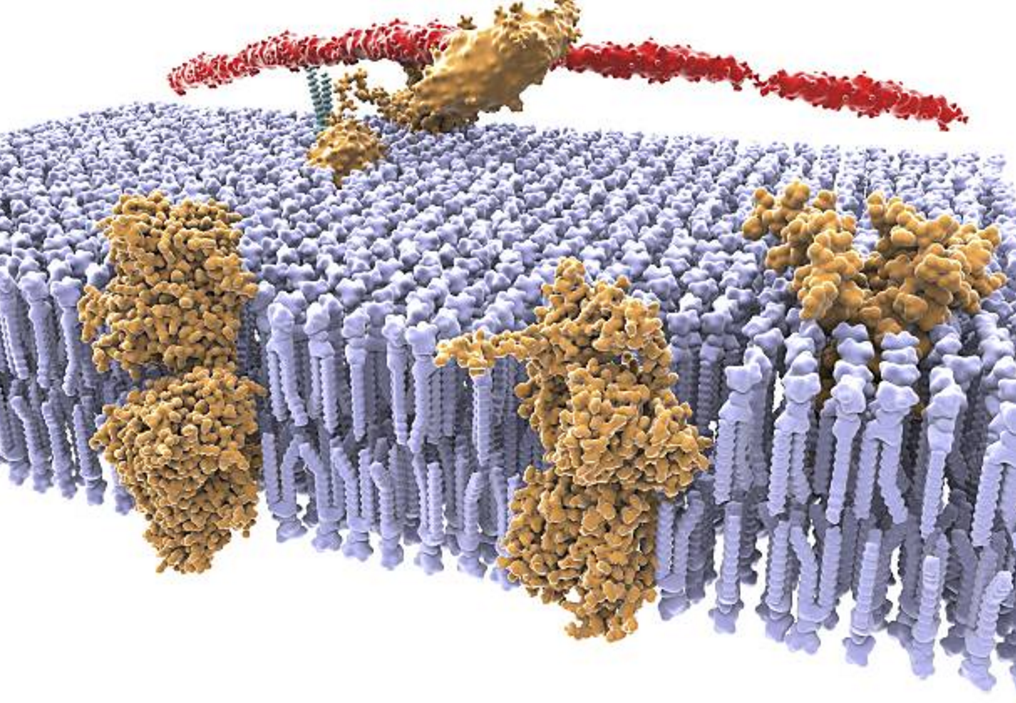
Мембрана и рецепторы
В классическом подходе на причинах такой «свободы» рецепторов обычно акцент не делается. Когда синапс усиливает свою чувствительность, это сопровождается перемещением рецепторов из внесинаптического пространства в синаптическую щель (Malenka R.C., Nicoll R.A., 1999). Этот факт негласно воспринимается как оправдание подвижности рецепторов.
В нашей модели можно предположить, что основная причина подвижности рецепторов – это необходимость «на лету» формировать из них кластеры. То есть картина выглядит следующим образом. По мембране свободно дрейфуют самые разные рецепторы, чувствительные к различным нейромедиаторам. Информационный сигнал, возникший в миниколонке, вызывает выброс нейромедиаторов аксонными окончаниями нейронов и астроцитами. В каждом синапсе, где испускаются нейромедиаторы, кроме основного нейромедиатора присутствует своя уникальная добавка, которая идентифицирует именно этот синапс. Нейромедиаторы выплескиваются из синаптических щелей в окружающее пространство, за счет чего в каждом месте дендрита (точках комбинаторного пространства) возникает специфический коктейль нейромедиаторов (ингредиенты коктейля указывают на биты, попадающие в точку). Те свободно блуждающие рецепторы, которые находят в этот момент свой нейромедиатор в этом коктейле (рецепторы конкретных битов входного сигнала), переходят в новое состояние – состояние поиска. В этом состоянии у них есть небольшое время (до того момента, пока не наступит следующий такт), за которое они могут встретить другие «активные» рецепторы и создать общий кластер (кластер рецепторов, чувствительных к определенному сочетанию битов).
Метаботропные рецепторы, а речь идет о них, имеют достаточно сложную форму (рисунок ниже). Они состоят из семи трансмембранных доменов, которые соединены петлями. Кроме того, у них есть два свободных конца. За счет разных по знаку электростатических зарядов свободные концы могут через мембрану «залипать» друг на друга. За счет таких соединений рецепторы и объединяются в кластеры.
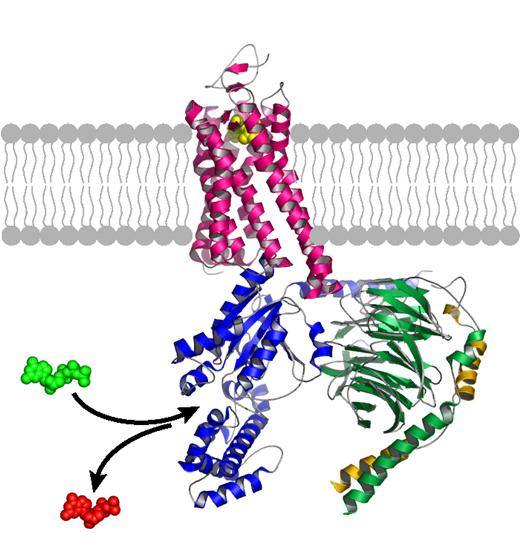
Одиночный метаботропный рецептор
После объединения начинается совместная жизнь рецепторов в кластере. Можно предположить, что положение рецепторов относительно друг друга может меняться в широких пределах и кластер может принимать причудливые формы. Если допустить, что рецепторы, срабатывающие совместно, будут стремиться занять место ближе друг к другу, например, за счет электростатических сил, то получится интересное следствие. Чем ближе будут оказываться такие «совместные» рецепторы, тем сильнее будет их совместное притяжение. Сблизившись они начнут усиливать влияние друг друга. Такое поведение воспроизводит поведение фильтра Хебба, который выделяет первую главную компоненту. Чем точнее фильтр настраивается на главную компоненту, тем сильнее оказывается его реакция, когда она появляется в примере. Таким образом, если после ряда итераций совместно срабатывающие рецепторы окажутся вместе в условном «центре» кластера, а «лишние» рецепторы на удалении, на его краях, то, в принципе, такие «лишние» рецепторы могут в какой-то момент самоликвидироваться, то есть просто оторваться от кластера. И тогда мы получим поведение кластера, аналогичное тому, что описано выше в нашей вычислительной модели.
Кластеры, которые прошли консолидацию, могут переместиться куда-нибудь «в тихую гавань», например, в синаптическую щель. Там существует постсинаптическое уплотнение, за которое кластеры рецепторов могут якориться, теряя уже ненужную им подвижность. Поблизости от них будут находиться ионные каналы, которыми они смогут управлять через G-белки. Теперь эти рецепторы начнут влиять на формирование локального постсинаптического потенциала (потенциала точки).
Локальный потенциал складывается из совместного влияния расположенных рядом активирующих и тормозящих рецепторов. В нашем подходе активирующие отвечают за узнавание закономерностей, призывающих активировать выходной бит, тормозящие за определение закономерностей, которые блокируют действие локальных правил.
Синапсы (точки) расположены на дендритном дереве. Если где-то на этом дереве находится место, где на небольшом участке срабатывает сразу несколько активирующих рецепторов и это не блокируется тормозными рецепторами, то возникает дендритный спайк, который распространяется до тела нейрона и, дойдя до аксонного холмика, вызывает спайк самого нейрона. Дендритное дерево объединяет множество синапсов, замыкая их на один нейрон, что очень похоже на формирование выходного бита комбинаторного пространства.
Объединение сигналов с разных синапсов одного дендритного дерева может быть не простым логическим сложением, а быть сложнее и реализовывать какой-нибудь алгоритм хитрого бустинга.
Напомню, что базовый элемент коры – это кортикальная миниколонка. В миниколонке около ста нейронов расположены друг под другом. При этом они плотно окутаны связями, которые гораздо обильнее внутри миниколонки, чем связи, идущие к соседним миниколонкам. Вся кора мозга – это пространство таких миниколонок. Один нейрон миниколонки может соответствовать одному выходному биту, все нейроны одной кортикальной миниколонки могут быть аналогом выходного бинарного вектора.
Кластеры рецепторов, описанные в этой главе, создают память, ответственную за поиск закономерностей. Ранее мы описывали, как с помощью кластеров рецепторов создать голографическую событийную память. Это два разных типа памяти, выполняющие разные функции, хотя и основанные на общих механизмах.
Сон
У здорового человека сон начинается с первой стадии медленного сна, которая длится 5-10 минут. Затем наступает вторая стадия, которая продолжается около 20 минут. Еще 30-45 минут приходится на периоды третей и четвертой стадий. После этого спящий снова возвращается во вторую стадию медленного сна, после которой возникает первый эпизод быстрого сна, который имеет короткую продолжительность — около 5 минут. Во время быстрого сна глазные яблоки очень часто и периодически совершают быстрые движения под сомкнутыми веками. Если в это время разбудить спящего, то в 90% случаев можно услышать рассказ о ярком сновидении. Вся эта последовательность называется циклом. Первый цикл имеет длительность 90-100 минут. Затем циклы повторяются, при этом уменьшается доля медленного сна и постепенно нарастает доля быстрого сна, последний эпизод которого в отдельных случаях может достигать 1 часа. В среднем при полноценном здоровом сне отмечается пять полных циклов.
Можно предположить, что во сне происходит основная работа по расчистке кластеров рецепторов, накопившихся за день. В вычислительной модели мы описали процедуру «холостого» обучения. Старый опыт предъявляется мозгу, не вызывая формирования новых кластеров. Цель – проверка уже существующих гипотез. Такая проверка состоит из двух этапов. Первый — вычисление главной компоненты закономерности и проверка того, что количество битов, отвечающих за нее, достаточно для четкой идентификации. Второй – проверка истинности гипотезы, то есть того, что закономерность оказалась в нужной точке, связанной с нужным выходным битом. Можно предположить, что часть стадий ночного сна связана с такими процедурами.
Все процессы, связанные с изменениями в клетках, сопровождаются экспрессией определенных белков и транскрипционных факторов. Есть белки и факторы про которые показано, что они участвут в формировании нового опыта. Так вот, оказывается, что их количество сильно увеличивается во время бодрствования и резко уменьшается во время сна.
Увидеть и оценить концентрацию белков можно через окрашивание среза мозговой ткани красителем, избирательно реагирующим на требуемый белок. Подобные наблюдения показали, что наиболее масштабные изменения для белков, связанных с памятью, происходят именно во время сна (Chiara Cirelli, Giulio Tononi, 1998) (Cirelli, 2002) (рисунки ниже).

Распределение белка Arc в теменной коре крысы после трех часов сна (S) и после трех часов спонтанного бодрствования (W) (Cirelli, 2002)

Распределение транскрипционного фактора P-CREB в корональных участках теменной коры крысы после трех часов сна (S) и в случае лишения сна на три часа (SD) (Cirelli, 2002)
В такие рассуждения о роли сна хорошо укладывается известная каждому особенность – «утро вечера мудренее». Утром мы гораздо лучше ориентируемся в том, что еще вчера было не особо понятно. Все становится четче и очевиднее. Возможно, что этим мы обязаны именно масштабной расчистке кластеров рецепторов, произошедшей во время сна. Удаляются ложные и сомнительные гипотезы, достоверные проходят консолидацию и начинают активнее участвовать в информационных процессах.
При моделировании было видно, что количество ложных гипотез во многие тысячи раз превышает количество истинных. Так как отличить одни от других можно только временем и опытом, то мозгу не остается ничего другого, кроме как копить всю эту информационную руду в надежде найти в ней со временем граммы радия. При получении нового опыта количество кластеров с гипотезами, требующими проверки, постоянно растет. Количество кластеров, формирующихся за день и содержащих руду, которую еще предстоит обработать, может превышать количество кластеров, отвечающих за кодирование накопленного за всю предыдущую жизнь проверенного опыта. Ресурс мозга по хранению сырых гипотез, требующих проверки должен быть ограничен. Похоже, что за 16 часов дневного бодрствования кластерами рецепторов практически полностью забивается все доступное пространство. Когда наступает этот момент, мозг начинает принуждать нас перейти в режим сна, чтобы позволить ему выполнить консолидацию и расчистить свободное место. Видимо, процесс полной расчистки занимает около 8 часов. Если разбудить нас раньше, то часть кластеров останется необработанной. Отсюда происходит феномен того, что усталость накапливается. Если несколько дней недосыпать, то потом придется наверстывать упущенный сон. В противном случае мозг начинает «аварийно» удалять кластеры, что ни к чему хорошему не приводит, так как лишает нас возможности почерпнуть знания из полученного опыта. Событийная память скорее всего сохранится, но закономерности останутся невыявленными.
Кстати, мой личный совет: не пренебрегайте качественным сном, особенно если вы учитесь. Не пытайтесь сэкономить на сне, чтобы больше успеть. Сон не менее важен в обучении, чем посещение лекций и повтор материала на практических занятиях. Недаром дети в те периоды развития, когда накопление и обобщение информации идет наиболее активно, большую часть времени проводят во сне.
Быстродействие мозга
Предположение о роли рецептивных кластеров позволяет по-новому взглянуть на вопрос быстродействия мозга. Ранее мы говорили, что каждая миниколонка коры, состоящая из сотни нейронов – это самостоятельный вычислительный модуль, который рассматривает трактовку поступающей информации в отдельном контексте. Это позволяет одной зоне коры рассматривать до миллиона возможных вариантов трактовки одновременно.
Теперь можно предположить, что каждый кластер рецепторов может работать как автономный вычислительный элемент, выполняя весь цикл вычислений по проверке своей гипотезы. Таких кластеров в одной только кортикальной колонке может быть сотни миллионов. Это значит, что, хотя частоты, с которыми работает мозг, далеки от частот, на которых работают современные компьютеры, тревожиться о быстродействии мозга не стоит. Сотни миллионов кластеров рецепторов, работающих параллельно в каждой миниколонке коры, позволяют успешно решать сложные задачи, находящиеся на границе с комбинаторным взрывом. Чудес не бывет. Но можно научиться ходить по грани.
Текст приведенной программы доступен на GitHub. В коде оставлено достаточно много отладочных фрагментов, я не стал их удалять, а только закомментировал на случай, если кому-то захочется самостоятельно поэкспериментировать.
Алексей Редозубов
Логика сознания. Часть 1. Волны в клеточном автомате
Логика сознания. Часть 2. Дендритные волны
Логика сознания. Часть 3. Голографическая память в клеточном автомате
Логика сознания. Часть 4. Секрет памяти мозга
Логика сознания. Часть 5. Смысловой подход к анализу информации
Логика сознания. Часть 6. Кора мозга как пространство вычисления смыслов
Логика сознания. Часть 7. Самоорганизация пространства контекстов
Логика сознания. Пояснение «на пальцах»
Логика сознания. Часть 8. Пространственные карты коры мозга
Логика сознания. Часть 9. Искусственные нейронные сети и миниколонки реальной коры
Логика сознания. Часть 10. Задача обобщения
Логика сознания. Часть 11. Естественное кодирование зрительной и звуковой информации
Логика сознания. Часть 12. Поиск закономерностей. Комбинаторное пространство
Логика сознания. Часть 13. Мозг, смысл и конец света
Закономерность — это регулярные устойчивые взаимосвязи в количествах, свойствах и явлениях объектов. В математической закономерности нужно найти алгоритм, согласно которому в цепочке чисел происходит их повторение, изменение или замещение в соответствии с установленным правилом.
В чем смысл игры?
Игры такого рода развивают умение выделять закономерности в последовательном ряде элементов. Для этого сначала нужно внимательно рассмотреть задание: сравнить соседние объекты и попробовать определить правило закономерности.
Решить задачу можно с помощью простого счета, обобщения по какому-либо признаку или простого анализа рисунка, текста или схемы.
Как научить ребенка находить закономерности?
Маленьким детям, для решения задач на поиски закономерностей, понадобится только смекалка и воображение. Достаточно лишь объяснить, как можно установить закономерность между звеньями ряда. Если задачу решить не получается, то вместо прямых подсказок следует задать дополнительные вопросы, не раскрывая решение задачи полностью.
В любом случае, пользы будет больше, если ребенок решит, хотя бы одну задачу самостоятельно, нежели взрослый просто расскажет, как её решать.
Рассмотрим способы, которые помогут ребенку понять закономерности и последовательности в заданиях.
Инструкция по решению числовых последовательностей:
- Найти разницу между двумя рядом стоящими числами
- Определить алгоритм построения последовательности
- Применить алгоритм к следующей паре чисел
- Использовать алгоритм для определения следующего числа в ряду
Инструкция по нахождению закономерностей в заданиях с геометрическими фигурами:
- Рассмотреть фигуры и разделить их, на повторяющиеся группы
- Определить какой элемент изменился в группе
- Решить, какая именно фигура отсутствует или является лишней.
Задания для 1 класса
Задание 1
Раскрась дорожки для зайчика и белочки, сохраняя закономерность.
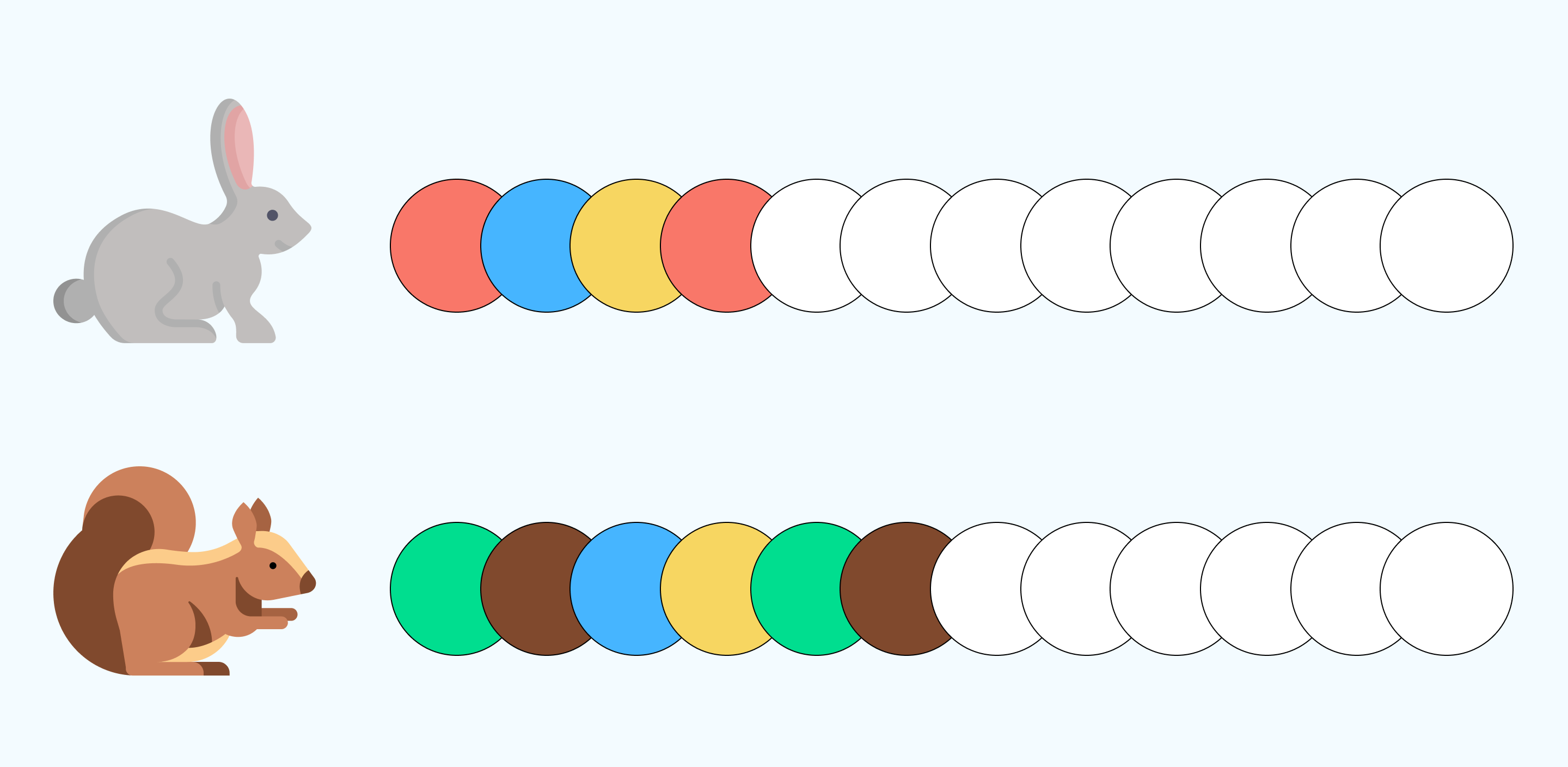
Решение: Белочка и зайчик бегут по разным дорожкам. У каждой дорожки есть своя закономерность. У зайчика повторяется 3 цвета на дорожке: красный, голубой, жёлтый, а у белочки 4: зеленый, коричневый, фиолетовый, жёлтый.
В этом задании можно обратить внимание на то, что обе дорожки состоят из 12 кругов. Но количество повторяющихся цветов разное.
Задание 2
Найди закономерность в ряду геометрических фигур.

Решение: В этом ряду нужно обратить внимание на размеры фигур, а не на цвет и форму. Сначала идет одна большая фигура, а за ней две маленькие, далее они повторяются.
Задание 3
Нарисуйте в четвертом квадрате правильный ответ.
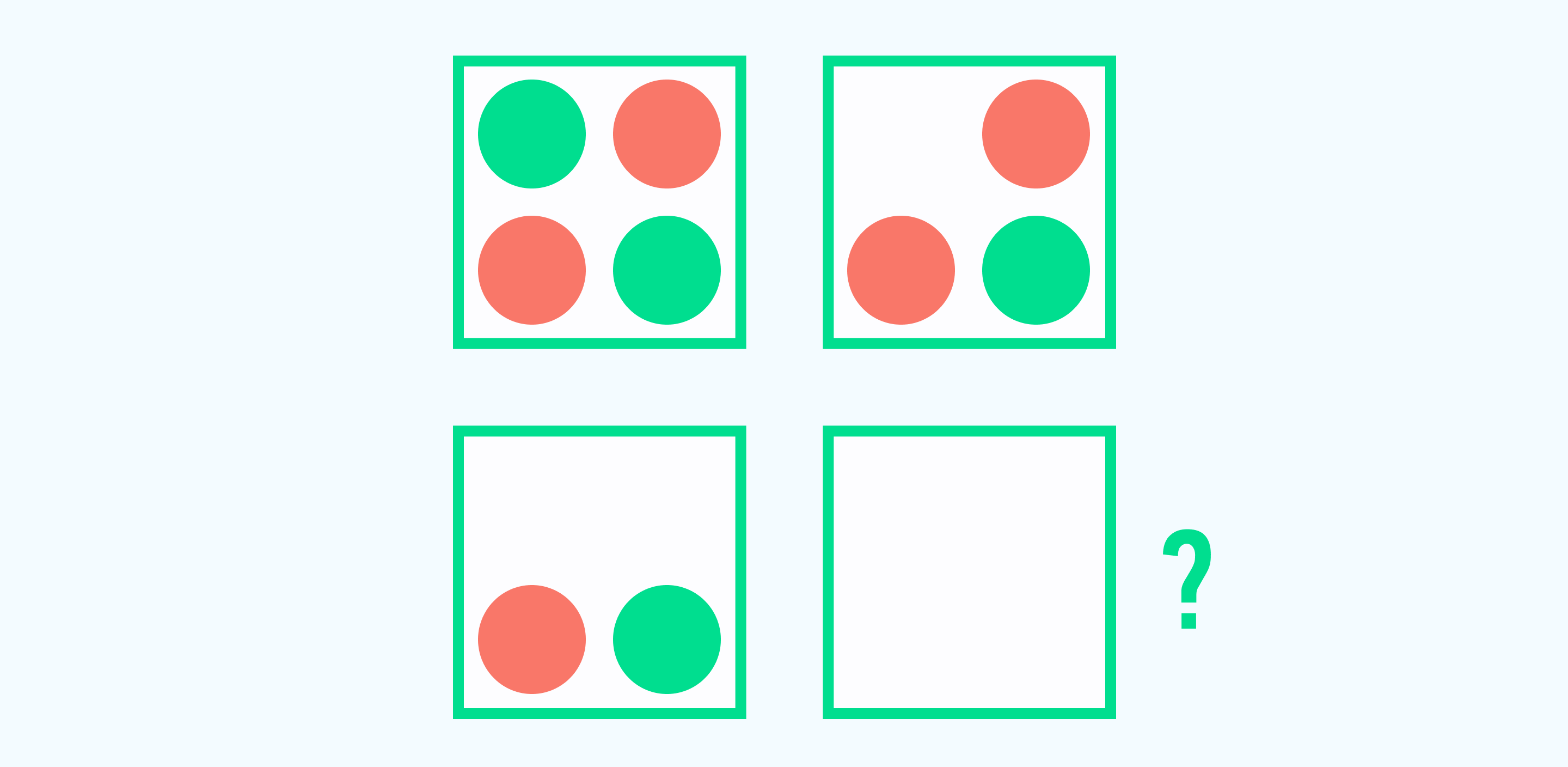
Решение: Рассмотрев внимательно рисунок, мы увидим, что круги в квадратах исчезают по одному, против часовой стрелки. В этой задаче имеет значение только расположение кругов квадрате. Таким образом, в последний квадрат мы должны нарисовать один синий круг в нижнем левом углу.
Задание 4
Соблюдая закономерность, продолжи ряд чисел до 10. Сформулируй правило, которое действует в этой закономерности. Используя это правило, придумай свою закономерность.
- 2, 4, 6,…
Решение: В этом ряду каждая цифра увеличивается на 2 относительно предыдущей – мы вычислили правило для данной закономерности. Значит, чтобы продолжить ряд, мы прибавим к каждой следующей цифре по 2. Ответ будет выглядеть так: 2,4,6,8,10.
Чтобы придумать подобную закономерность, нужно использовать сформулированное выше правило: например, 1,3,5,7,9.
Задания для 2 класса
Задание 1
Найди закономерность и в пустом квадрате нарисуй нужное количество кругов.
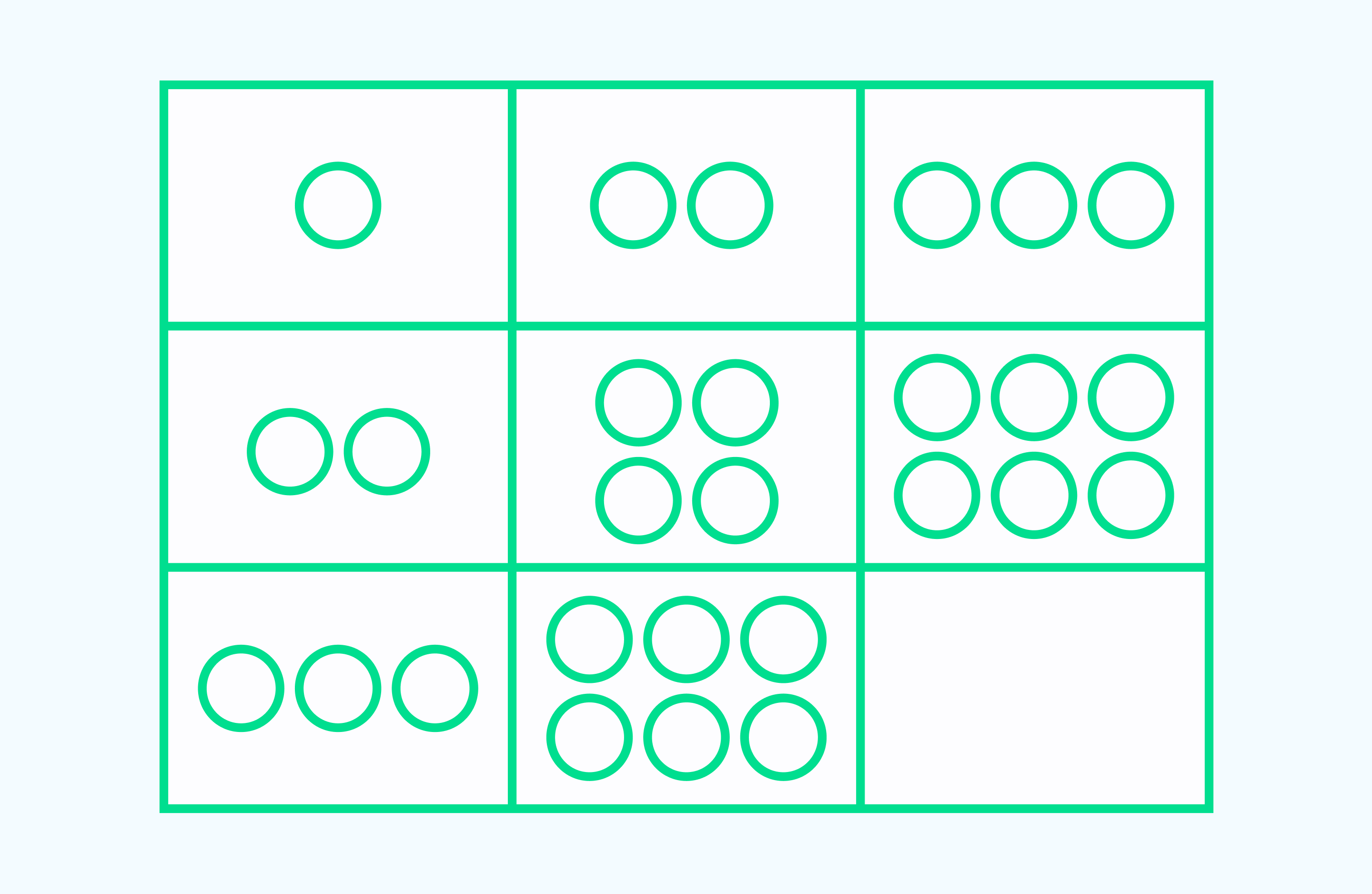
Решение: В таблице в первом горизонтальном ряду количество кругов увеличивается на 1. Во втором ряду увеличивается на 2. Таким образом, можно предположить, что в третьем ряду количество кругов будет увеличиваться на 3 и ответ будет 9. Можно заметить, что и в вертикальных рядах эта закономерность повторяется.
Задание 2
В цепочке чисел найди закономерность и вставь пропущенные числа
- 95, 90, 85, 80, 75,_, 65,_, _,50
Решение: В цепочке чисел можно выделить пары: 95 -90, 85 – 80 и далее. Каждый раз, в паре, число уменьшается на 5. Значит, после 75 запишем 70, после 65 — 60, а затем 55 .
Задание 3
Найди закономерность и продолжи последовательность.
- 2, 3, 5, 8, …, …, …, …
Решение: В этой цепочке чисел к каждому последующему числу прибавляется предыдущее. 2+3=5+3=8+5=13+8=21+13=34 и далее.
Задание 4
В поезде едут геометрические фигуры. Нарисуйте фигуры, в четвёртом вагоне, соблюдая закономерность их расположения.
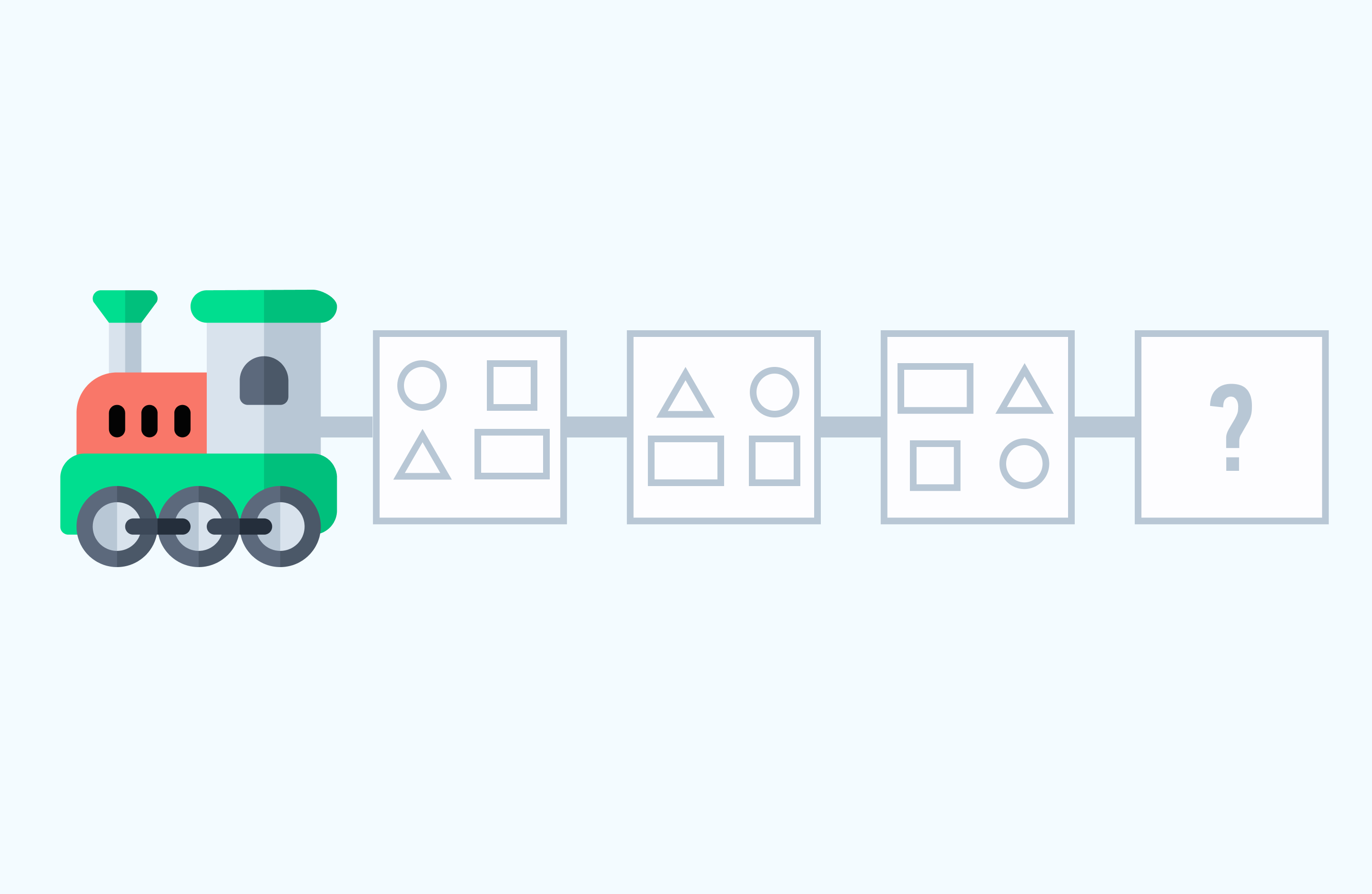
Решение: В поезде едут геометрические фигуры: квадрат, треугольник, прямоугольник и круг. В трёх вагонах все места заняты фигурами, в определённом порядке. Расставим их и в четвертом вагоне: Круг в нём будет располагаться в нижнем левом углу, квадрат в верхнем левом, треугольник поедет в правом нижнем, а прямоугольник – в левом верхнем углу.
Задания для 3 класса
Задание 1
Рассмотрите картинку и найдите закономерность в задаче.
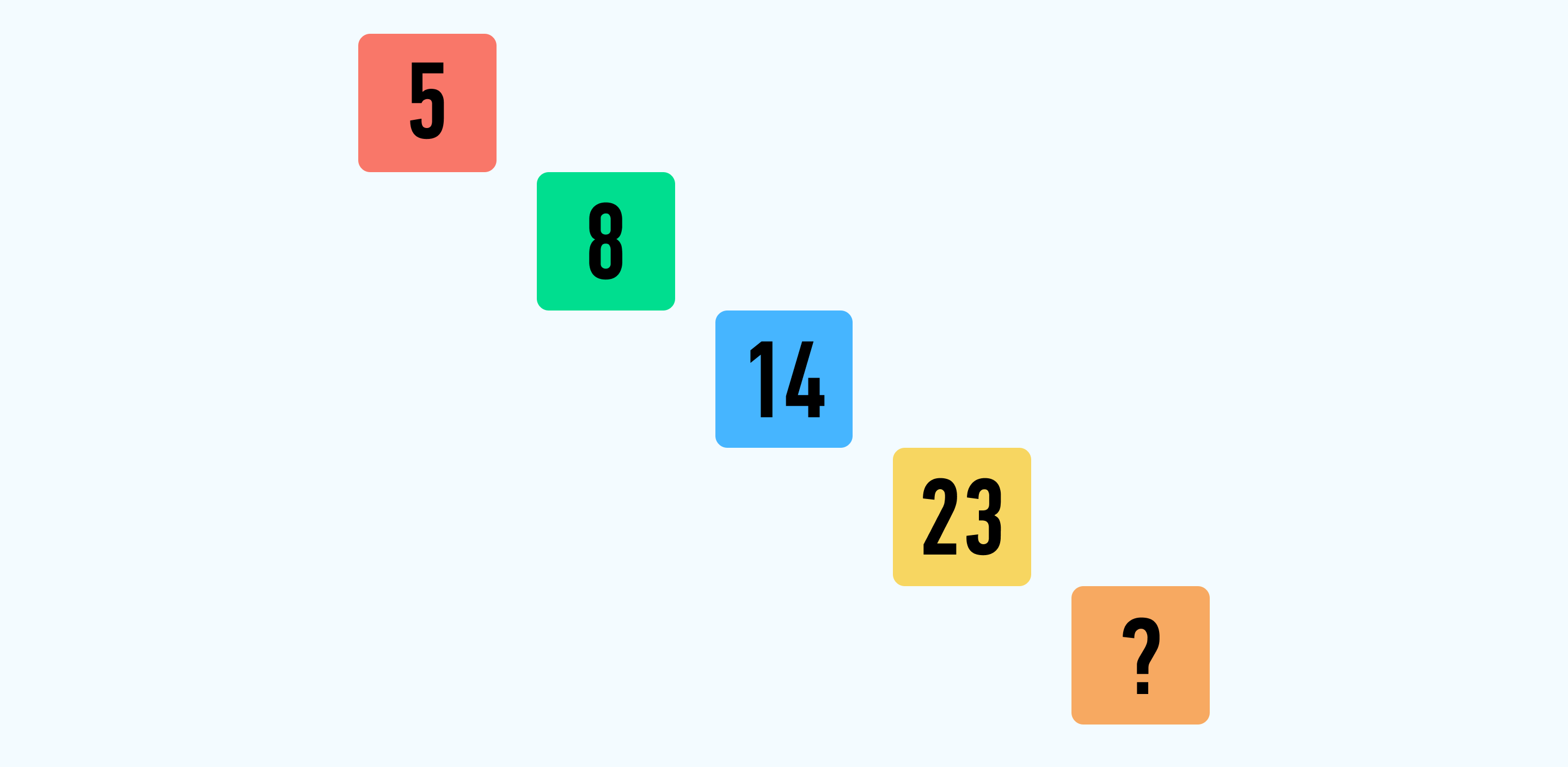
Решение: В таблице мы увидим такую закономерность:
8-5=3, то есть число увеличилось на 3; далее 14-8=6, соответственно, число увеличилось на 6. В последней связке 23-14=9 число увеличилось на 9. Мы делаем вывод, что каждое следующее число увеличивается на предыдущее значение+3. Таким образом, следующее число увеличивается на 9+3=12. 23 + 12 = 35. Ответ: 35.
Задание 2
В пустые клетки вставьте геометрические фигуры, сохраняя закономерность.
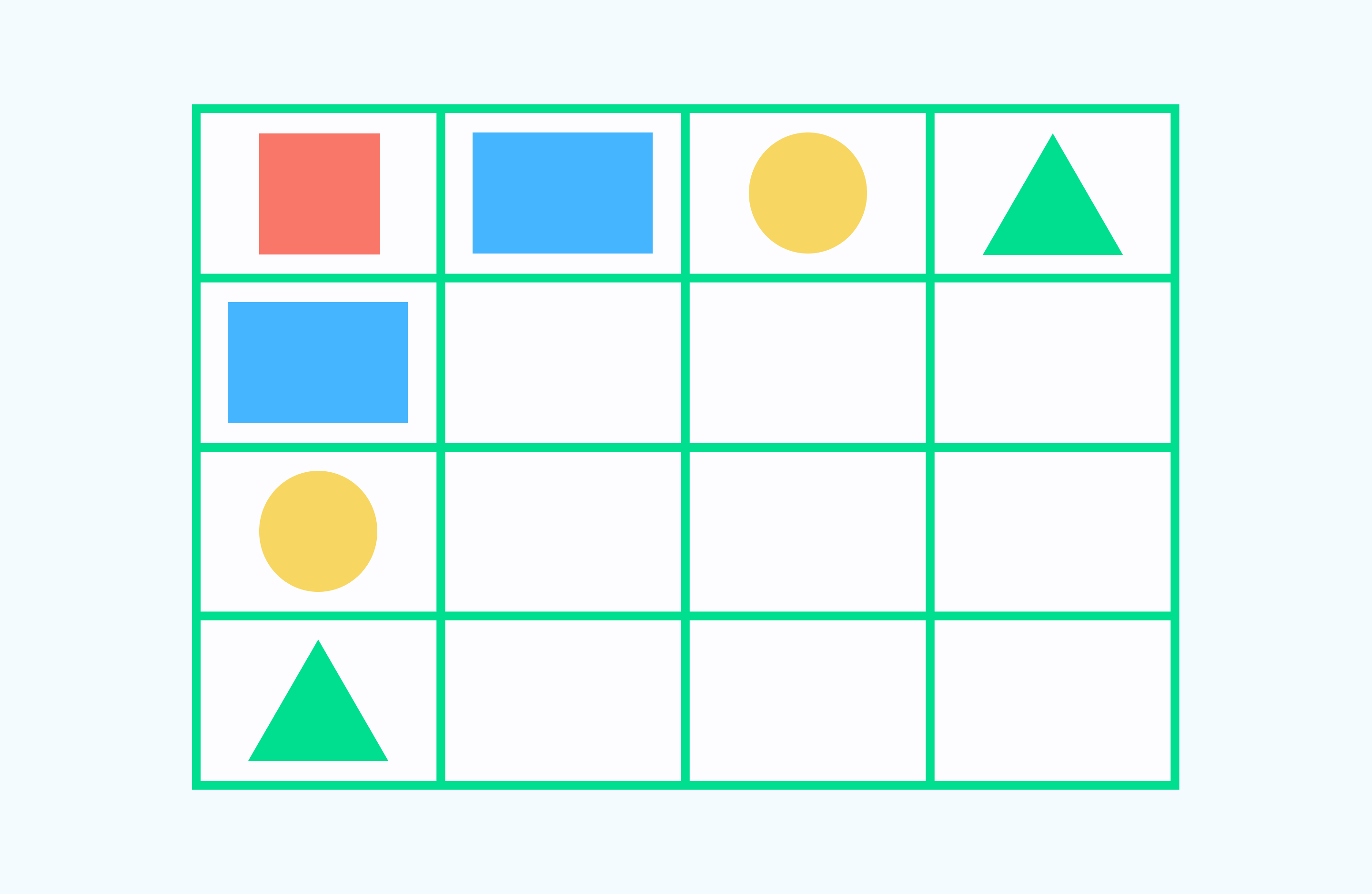
Решение: Чтобы выполнить задание, нужно фигуры расставить по порядку, друг за другом, соблюдая последовательность. Значит, после прямоугольника стоит круг, треугольник и квадрат и т. д.
Задание 3
Найди закономерность и продолжи ряды:
- 12, 23, 34, 45, 56…
- 13, 24, 35, 46…
Решение: В этой задаче каждая последующая цифра увеличивается так: десятки на один десяток и единицы на одну единицу. 12=10+2, 23=20+3, 34=30+5 и т. д.
Задание 4
Продолжи ряд, сохраняя закономерность.
- 12, 36, 13, 39, 14, 42, 15,…
Решение: В числовой цепочке выделяем пары чисел. Первая пара:12 и 36. 12×3=36, далее по порядку: 13×3=39. Умножая каждый раз на 3, цифры, следующие по порядку (12,13,14,15…), мы продолжаем последовательный ряд. Ответ: 45.
Задания для 4 класса
Задание 1
Найди ошибку в бусах.

Решение: В первых бусах повторяются квадрат и круг, значит лишний шестой круг. Во вторых бусах, повторяется закономерность: круг, два треугольника, два круга, лишний – восьмой, по счету, круг.
Задание 2
Определите закономерность. Найдите лишнее число.
- 8, 16, 20, 24, 32, 40, 48, 56, 64, 72.
Решение: В этом числовом ряду таблица умножения на 8. Ответ: число 20 – лишнее.
Задание 3
Каких геометрических фигур не хватает? Дорисуй их, соблюдая закономерность в таблице:
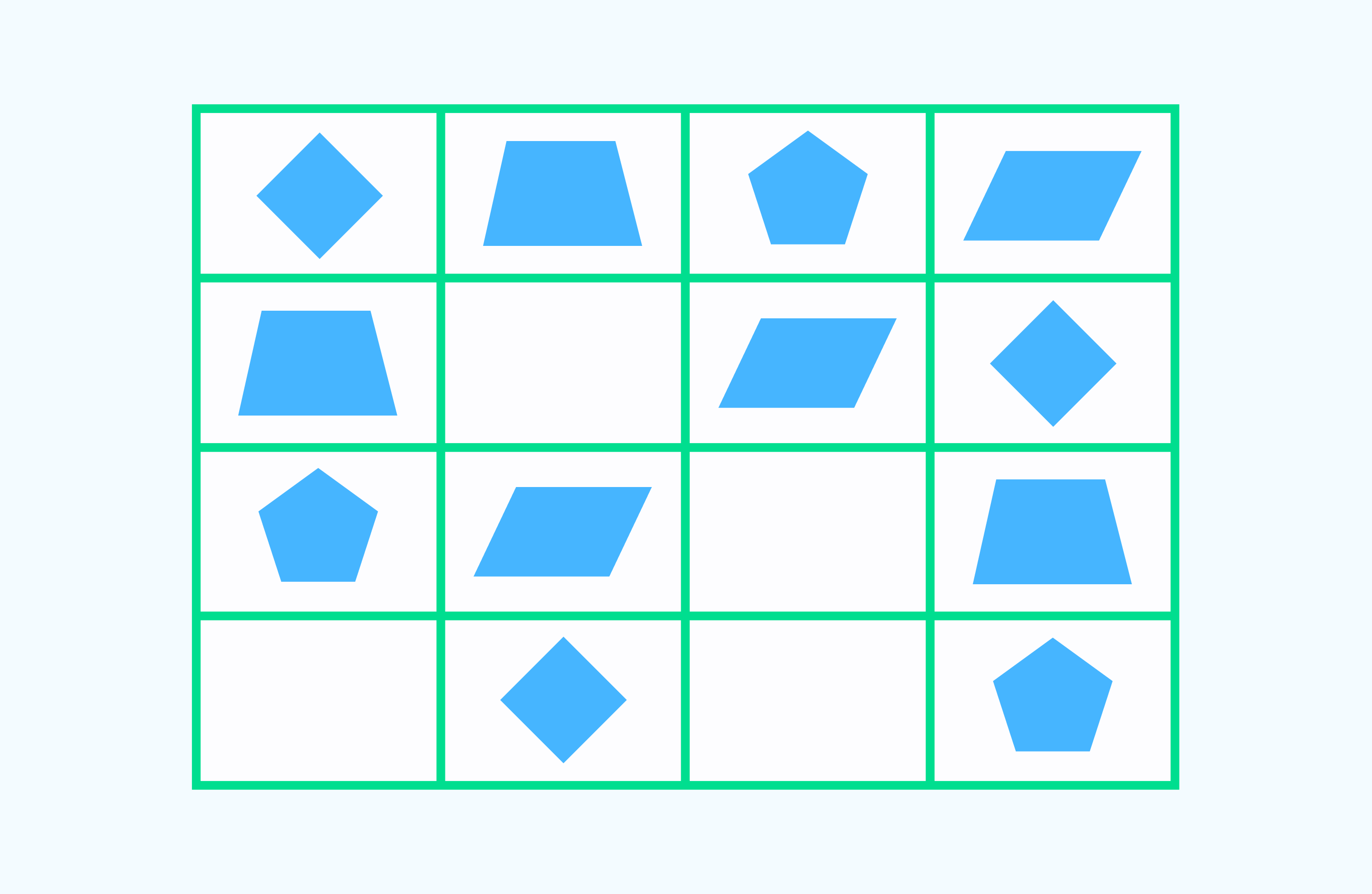
Решение: Определить, какой элемент изменился во втором и последующих рядах, можно, выделив последовательность: ромб, трапеция, шестиугольник и параллелограмм. Во втором ряду недостает шестиугольника, в третьем — ромба, в четвертом – параллелограмма и трапеции.


Математика и логика для детей 7-13 лет
Развиваем логическое мышление через решение сюжетных математических задач в интерактивном игровом формате
узнать подробнее
 Поэзия — та же добыча радия.
Поэзия — та же добыча радия.
В грамм добыча, в годы труды.
Изводишь единого слова ради
Тысячи тонн словесной руды.
Но как испепеляюще слов этих жжение
Рядом с тлением слова-сырца.
Эти слова приводят в движение
Тысячи лет миллионов сердца.
Владимир Маяковский
Напомню, что наша ближайшая задача — показать алгоритм универсального обобщения. Такое обобщение должно удовлетворять всем требованиям, сформулированным ранее в десятой части. Кроме того, оно должно быть свободно от традиционных для многих методов машинного обучения недостатков (комбинаторный взрыв, переобучение, схождение к локальному минимуму, дилемма стабильности-пластичности и тому подобное). При этом механизм такого обобщения должен не противоречить нашим знаниям о работе реальных нейронов живого мозга.
Сделаем еще один шаг в сторону универсального обобщения. Опишем идею комбинаторного пространства и то, как это пространство помогает искать закономерности и тем самым решать задачу обучения с учителем.
Задача контекстного сдвига текстовой строки
Сейчас мы покажем, как очень сложно решить очень простую задачу. Мы научимся сдвигать на одну позицию произвольную текстовую строку.
Предположим, что у нас есть длинный текст. Мы последовательно читаем его от начала к концу. За один шаг чтения мы смещаемся на один символ. Предположим, что у нас есть скользящее окно шириной N символов и в каждый момент времени нам доступен только фрагмент текста, помещающийся в это окно. Введем циклический идентификатор позиции (описан в конце четвертой части), указывающий на позицию символов в тексте. Период идентификатора обозначим K. Пример текста с наложенным идентификатором позиции и сканирующим окном приведен на рисунке ниже.

Фрагмент текста. Числами обозначен циклический идентификатор позиции. Период идентификатора K=10. Вертикальными линиями выделено одно из положений скользящего окна. Размер окна N=6
Основная идея такого представления в том, что если размер окна N меньше периода идентификатора K, то набор пар «буква — идентификатор позиции» позволяет однозначно записать строку внутри скользящего окна. Ранее похожий метод записи мы упоминали, когда говорили о том, как можно закодировать звуковую информацию. Подставьте вместо букв коды неких условных фонем, и вы получите запись звукового фрагмента.
Введем систему понятий, позволяющую описать все, что появляется в скользящем окне. Для простоты не будем делать разницы между заглавными и строчными буквами и не будем учитывать знаки препинания. Так как потенциально любая буква может встретиться нам в любой позиции, то нам понадобятся все возможные сочетания букв и позиций, то есть N x K понятий. Условно эти понятия можно обозначить как
{a0,a1⋯a(K-1),b0,b1⋯b(K-1),z0,z1⋯z(K-1)}
Мы можем записать любое состояние скользящего окна как перечисление советующих понятий. Так для окна, показанного на рисунке выше, это будет
{s1,w3,e4,d6}
Сопоставим каждому понятию некий разряженный бинарный код. Например, если взять длину кода в 256 бит и отвести 8 бит для кодирования одного понятия, то кодирование буквы «a» в различных позициях будет выглядеть как показано на рисунке ниже. Напомню, что коды выбираются случайным образом, и биты у них могут повторяться, то есть одни и те же биты могут быть общими для нескольких кодов.

Пример кодов буквы a в позициях от 0 до 9. Бинарные вектора показаны вертикально, единицы выделены горизонтальными светлыми линиями
Создадим бинарный код фрагмента логическим сложением кодов составляющих его понятий. Как уже писалось ранее, такой бинарный код фрагмента будет обладать свойствами фильтра Блума. Если разрядность бинарного массива достаточна высока, то с достаточно высокой точностью можно выполнить обратное преобразование и получить из кода фрагмента набор исходных понятий.
На рисунке ниже приведен пример того, как будут выглядеть коды понятий и суммарный код фрагмента для предыдущего примера.

Пример сложения бинарных кодов понятий в код фрагмента
Описание, составленное таким образом, хранит не только набор букв фрагмента текста, но и их последовательность. Однако и набор понятий, и суммарный код этой последовательности зависит от того, в какой позиции находился циклический идентификатор на момент, когда последовательность появилась в тексте. На рисунке ниже приведен пример того, как описание одного и того же фрагмента текста зависит от начального положения циклического идентификатора.

Изменение кодировки текста при разном начальном смещении
Первому случаю будет соответствовать описание
{s1,w3,e4,d6}
Второй случай будет записан, как
{s9,w1,e2,d4}
В результате текст один и тот же, но совсем другой набор понятий и, соответственно, совсем другой описывающий его бинарный код.
Тут мы приходим к тому, о чем так много говорили в предыдущих частях. Варианты, получаемые при смещении текста, – это возможные трактовки одной и той же информации. При этом контекстами выступают все возможные варианты смещения. И хотя суть информации неизменна, ее внешняя форма, то есть описание через набор понятий или через его бинарное представление, меняется от контекста к контексту, то есть, в нашем случае, при каждом изменении начальной позиции.
Чтобы иметь возможность сравнивать фрагменты текста инвариантно к их смещению, надо ввести пространство контекстов смещений. Для этого понадобится K контекстов. Каждый контекст будет соответствовать одному из вариантов возможного начального смещения.
Напомню, что контексты определяются правилами контекстных преобразований. В каждом контексте задается набор правил относительно того, как меняются понятия в этом контексте.
Контекстными преобразованиями в случае с текстом будут правила изменения понятий при переходе к соответствующему контексту смещению. Так, например, для контекста с нулевым смещением правила переходов будут переходами сами в себя
a0→a0, a2→a2⋯z(K-1)→z(K-1)
Для контекста со смещением на 8 позиций при длине кольцевого идентификатора K=10, что соответствует нижней строке примера с рисунка выше, правила будут иметь вид
a0→a8, a1→a9, a2→a0⋯z9→z7
При таких правилах в контексте со смещением 8 описание окна из первой строки примера перейдет в описание окна из второй строки, что, собственно, вполне очевидно и без долгих пояснений
{s1,w3,e4,d6}→{s9,w1,e2,d4}
В нашем случае контексты, по сути, выполняют вариацию смещения текстовой строки по всем возможным позициям кольцевого идентификатора. В результате если две строки совпадают или похожи друг на друга, но сдвинуты одна относительно другой, то всегда найдется контекст, который нивелирует это смещение.
Позже мы подробно разовьем мысль о контекстах, сейчас же нас будет интересовать один частный, но при этом очень важный вопрос: как изменяются бинарные коды описаний при переходе от одного контекста к другому?
В нашем примере мы имеем текст и знаем позиции букв. Задав требуемое смещение, мы всегда можем пересчитать позиции букв и получить новое описание. Не представляет труда вычислить бинарные коды для исходного и смещенного состояния. Например, на рисунке ниже показано, как будет выглядеть код строки «arkad» в нулевом смещении и код той же строки при смещении на одну позицию вправо.

Код исходной строки и ее смещения
Так как у нас есть алгоритм пересчета описаний, мы без труда можем для любой строки получить ее исходный бинарный код (в нулевом контексте) и код в смещении на одну позицию (в контексте «1»). Взяв длинный текст, мы можем создать сколь угодно много таких примеров, относящихся к одному смещению.
А теперь возьмем сгенерированные примеры и представим, что перед нами черный ящик. Есть бинарное описание на входе, есть бинарное описание на выходе, но нам ничего не известно ни про природу входного описания, ни про правила, по которым происходит преобразование. Можем ли мы воспроизвести работу этого черного ящика?
Мы пришли к классической задаче обучения с учителем. Есть обучающая выборка и по ней требуется воспроизвести внутреннюю логику, связывающую входные и выходные данные.
Такая постановка задачи типична для ситуаций, с которыми часто сталкивается мозг, решая вопросы контекстных преобразований. Например, в прошлой части было описано, как сетчатка глаза формирует бинарные коды, соответствующие зрительной картинке. Микродвижения глаз постоянно создают обучающие примеры. Так как движения очень быстрые, то можно считать, что мы видим одну и ту же сцену, но только в разных контекстах смещения. Таким образом мозг получает исходный код изображения и код, в который это изображение переходит в контексте проделанного глазом смещения. Задача обучения зрительных контекстов – это вычисление правил, которым подчиняются зрительные трансформации. Знание этих правил позволяет получать трактовки одного и того же изображения одновременно в различных вариантах смещений без необходимости глазу физически эти смещения совершать.
В чем сложность?
Когда я учился в институте, у нас была очень популярна игра «Быки и коровы». Один игрок загадывает четырехзначное число без повторов, другой пытается его угадать. Тот, кто пытается, называет некие числа, а загадавший сообщает, сколько в них быков, то есть угаданных цифр, стоящих на своем месте, и сколько коров, цифр, которые есть в загаданном числе, но стоят не там, где им положено. Вся соль игры в том, что ответы загадавшего не дают однозначной информации, а создают множество допустимых вариантов. Каждая попытка порождает такую неоднозначную информацию. Однако совокупность попыток позволяет найти единственно верный ответ.
Что-то похожее есть и в нашей задаче. Выходные биты не случайны, каждый из них зависит от определенного сочетания входных битов. Но так как во входном векторе может содержаться несколько понятий, то неизвестно, какие именно биты отвечают за срабатывание конкретного выходного бита.
Так как в кодах понятий биты могут повторяться, то один входной бит ничего не говорит о выходе. Чтобы судить о выходе, требуется анализировать сочетание нескольких входных битов.
Поскольку один и тот же выходной бит может относиться к кодам разным понятий, то срабатывание выходного бита еще не говорит о том, что на входе появилось то же сочетание бит, которое заставило этот выходной бит сработать ранее.
Иначе говоря, получается достаточно сильная неопределенность, как со стороны входа, так и со стороны выхода. Эта неопределенность оказывается серьезной помехой и затрудняет слишком простое решение. Одна неопределенность перемножается на другую неопределенность, что в результате приводит к комбинаторному взрыву.
Для борьбы с комбинаторным взрывом требуется «комбинаторный лом». Есть два инструмента, позволяющие на практике решать сложные комбинаторные задачи. Первый – это массовое распараллеливание вычислений. И тут важно не только иметь большое количество параллельных процессоров, но и подобрать такой алгоритм, который позволяет распараллелить задачу и загрузить все доступные вычислительные мощности.
Второй инструмент – это принцип ограниченности. Основной метод, использующий принцип ограниченности – это метод «случайных подпространств». Иногда комбинаторные задачи допускают сильное ограничение исходных условий и при этом сохраняют надежду, что и после этих ограничений в данных сохранится достаточно информации, чтобы можно было найти требуемое решение. Вариантов того, как можно ограничить исходные условия, может быть много. Не все из них могут быть удачными. Но если, все же, вероятность, что удачные варианты ограничений есть, то тогда сложная задача может быть разбита на большое количество ограниченных задач, каждая из которых решается значительно проще исходной.
Комбинируя эти два принципа, можно построить решение и нашей задачи.
Комбинаторное пространство
Возьмем входной битовый вектор и пронумеруем его биты. Создадим комбинаторные «точки». В каждую точку сведем несколько случайных битов входного вектора (рисунок ниже). Наблюдая за входом, каждая из этих точек будет видеть не всю картину, а только ее малую часть, определяемую тем, какие биты сошлись в выбранной точке. Так на рисунке ниже крайняя слева точка с индексом 0 следит только за битами 1, 6, 10 и 21 исходного входного сигнала. Создадим таких точек достаточно много и назовем их набор комбинаторным пространством.

Комбинаторное пространство
В чем смысл этого пространства? Мы предполагаем, что входной сигнал не случаен, а содержит определенные закономерности. Закономерности могут быть двух основных типов. Что-то во входном описании может появляться несколько чаще чем другое. Например, в нашем случае отдельные буквы появляются чаще чем их сочетания. При битовом кодировании это означает, что определенные комбинации битов встречаются, чаще чем другие.
Другой тип закономерностей – это когда кроме входного сигнала есть сопутствующий ему сигнал обучения и что-то, содержащееся во входном сигнале, оказывается связано с чем-то, что содержится в сигнале обучения. В нашем случае активные выходные биты – это реакция на комбинацию определенных входных битов.
Если искать закономерности «в лоб», то есть глядя на весь входной и весь выходной векторы, то не очень понятно, что делать и куда двигаться. Если начинать строить гипотезы на предмет того, что от чего может зависеть, то моментально наступает комбинаторный взрыв. Количество возможных гипотез оказывается чудовищно.
Классический метод, широко используемый в нейронных сетях, — градиентный спуск. Для него важно понять, в какую сторону двигаться. Обычно это несложно, когда выходная цель одна. Например, если мы хотим обучить нейронную сеть написанию цифр, мы показываем ей изображения цифр и указываем, что за цифру она при этом видит. Сети понятно «как и куда спускаться». Если мы будем показывать картинки сразу с несколькими цифрами и называть все эти цифры одновременно, не указывая, где что, то ситуация становится значительно сложнее.
Когда создаются точки комбинаторного пространства с сильно ограниченным «обзором» (случайные подпространства), то оказывается, что некоторым точкам может повезти и они увидят закономерность если не совсем чистой, то, по крайней мере, в значительно очищенном виде. Такой ограниченный взгляд позволит, например, провести градиентный спуск и получить уже чистую закономерность. Вероятность для отдельной точки наткнуться на закономерность может быть не очень высока, но всегда можно подобрать такое количество точек, чтобы гарантировать себе, что всякая закономерность «где-то да всплывет».
Конечно, если делать размеры точек слишком узкими, то есть количество битов в точках выбирать приблизительно равным тому, сколько битов ожидается в закономерности, то размеры комбинаторного пространства начнут стремиться к количеству вариантов полного перебора возможных гипотез, что возвращает нас к комбинаторному взрыву. Но, к счастью, можно увеличивать обзор точек, снижая их общее количество. Это снижение не дается бесплатно, комбинаторика «переносится в точки», но до определенного момента это не смертельно.
Создадим выходной вектор. Просто сведем в каждый бит выхода несколько точек комбинаторного пространства. Какие это будут точки выберем случайным образом. Количество точек, попадающих в один бит, будет соответствовать тому, во сколько раз мы хотим уменьшить комбинаторное пространство. Такой вектор выхода будет хэш-функцией для вектора состояния комбинаторного пространства. О том, как это состояние считается, мы поговорим чуть позже.
В общем случае, например, как показано на рисунке выше, размер входа и выхода могут быть различны. В нашем примере с перекодированием строк эти размеры совпадают.
Кластеры рецепторов
Как искать закономерности в комбинаторном пространстве? Каждая точка видит свой фрагмент входного вектора. Если в том, что она видит, оказывается достаточно много активных битов, то можно предположить, что то, что она видит, и есть какая-либо закономерность. То есть, набор активных битов, попадающий в точку, можно назвать гипотезой о наличии закономерности. Запомним такую гипотезу, то есть зафиксируем набор активных битов, видимых в точке. В ситуации, показанной на рисунке ниже, видно, что в точке 0 надо зафиксировать биты 1, 6 и 21.

Фиксация битов в кластере
Будем называть запись номера одного бита рецептором к этому биту. Это подразумевает, что рецептор следит за состоянием соответствующего бита входного вектора и реагирует, когда там появляется единица.
Набор рецепторов будем называть кластером рецепторов или рецептивным кластером. Когда предъявляется входной вектор, рецепторы кластера реагируют, если в советующих позициях вектора стоят единицы. Для кластера можно подсчитать количество сработавших рецепторов.
Так как информация у нас кодируется не отдельными битами, а кодом, то от того, сколько битов мы возьмем в кластер, зависит точность, с которой мы сформулируем гипотезу. К статье приложен текст программы, решающий задачу с перекодировкой строк. По умолчанию в программе заданы следующие настройки:
- длина входного вектора — 256 бит;
- длина выходного вектора – 256 бит;
- отдельная буква кодируется 8 битами;
- длина строки — 5 символов;
- количество контекстов смещения — 10;
- размер комбинаторного пространства – 60000;
- количество битов, пересекающихся в точке – 32;
- порог создания кластера – 6;
- порог частичной активации кластера — 4.
При таких настройках практически каждый бит, который есть в коде одной буквы, повторяется в коде другой буквы, а то и в кодах нескольких букв. Поэтому одиночный рецептор не может надежно указать на закономерность. Два рецептора указывают на букву значительно лучше, но и они могут указывать на сочетание совсем других букв. Можно ввести некий порог длины, начиная с которого можно достаточно достоверно судить о том, есть ли в кластере нужный нам фрагмент кода.
Введем минимальный порог по количеству рецепторов, необходимых для формирования гипотезы (в примере он равен 6). Приступим к обучению. Будем подавать исходный код и код, который мы хотим получить на выходе. Для исходного кода легко подсчитать, сколько активных битов попадает в каждую из точек комбинаторного пространства. Выберем только те точки, которые подключены к активным битам выходного кода и у которых количество попавших в нее активных битов входного кода окажется не меньше порога создания кластера. В таких точках создадим кластеры рецепторов с соответствующими наборами битов. Сохраним эти кластеры именно в тех точках, где они были созданы. Чтобы не создавать дубликаты, предварительно проверим, что эти кластеры уникальны для этих точек и точки еще не содержат точно таких же кластеров.
Скажем то же другими словами. По выходному вектору мы знаем, какие биты должны быть активны. Соответственно, мы можем выбрать связанные с ними точки комбинаторного пространства. Для каждой такой точки мы можем сформулировать гипотезу о том, что то, что она сейчас видит на входном векторе, – это и есть закономерность, которая отвечает за активность того бита, к которому эта точка подключена. Мы не можем сказать по одному примеру, верна или нет эта гипотеза, но выдвинуть предположение нам никто не мешает.
Обучение. Консолидация памяти
В процессе обучения каждый новый пример создает огромное количество гипотез, большинство из которых неверны. От нас требуется проверить все эти гипотезы и отсеять ложные. Это мы можем сделать, наблюдая за тем, подтвердятся ли эти гипотезы на последующих примерах. Кроме того, создавая новый кластер, мы запоминаем все биты, которые видит точка, а это, даже если там и содержится закономерность, еще и случайные биты, которые попали туда от других понятий, не влияющих на наш выход, и которые в нашем случае являются шумом. Соответственно, требуется не только подтвердить или опровергнуть, что в запомненной комбинации битов содержится нужная закономерность, но и очистить эту комбинацию от шума, оставив только «чистое» правило.
Возможны разные подходы к решению поставленной задачи. Опишу один из них, не утверждая, что он лучший. Я перебрал множество вариантов, этот подкупил меня качеством работы и простотой, но это не значит, что его нельзя улучшить.
Удобно воспринимать кластеры, как автономные вычислители. Если каждый кластер может проверять свою гипотезу и принимать решения независимо от остальных, то это очень хорошо для потенциального распараллеливания вычислений. Каждый кластер рецепторов после создания начинает самостоятельную жизнь. Он следит за поступающими сигналами, накапливает опыт, меняет себя и принимает если необходимо решение о самоликвидации.
Кластер – это набор битов, про который мы предположили, что внутри него сидит закономерность, связанная со срабатыванием того выходного бита, к которому подключена точка, содержащая этот кластер. Если закономерность есть, то скорее всего она затрагивает только часть битов, причем мы заранее не знаем, какую. Поэтому будем фиксировать все моменты, когда в кластере срабатывает существенное количество рецепторов (в примере не менее 4). Возможно, что в эти моменты закономерность, если она есть, проявляет себя. Когда накопится определенная статистика, мы сможем попробовать определить, есть ли в таких частичных срабатываниях кластера что-то закономерное или нет.
Пример статистики показан на рисунке ниже. Плюс в начале строки показывает, что в момент частичного срабатывания кластера выходной бит также был активен. Биты кластера сформированы из соответствующих битов входного вектора.

Хроника частичного срабатывания кластера рецепторов
Что нас должно интересовать в этой статистике? Нам важно, какие биты чаще других срабатывают совместно. Не спутайте это с самыми частыми битами. Если посчитать для каждого бита частоту его появления и взять самые распространенные биты, то это будет усреднение, которое совсем не то, что нам надо. Если в точке сошлись несколько устойчивых закономерностей, то при усреднении получится средняя между ними «не закономерность». В нашем примере, видно, что 1,2 и 4 строки похожи между собой, также похожи 3,4 и 6 строки. Нам надо выбрать одну из этих закономерностей, желательно самую сильную, и очистить ее от лишних битов.
Наиболее распространенная комбинация, которая проявляется как совместное срабатывание определенных битов, является для этой статистики первой главной компонентой. Чтобы вычислить главную компоненту, можно воспользоваться фильтром Хебба. Для этого можно задать вектор с единичными начальными весами. Затем получать активность кластера, перемножая вектор весов на текущее состояние кластера. А затем сдвигать веса в сторону текущего состояния тем сильнее, чем выше эта активность. Чтобы веса не росли бесконтрольно, после изменения весов их надо нормировать, например, на максимальное значение из вектора весов.
Такая процедура повторяется для всех имеющихся примеров. В результате вектор весов все больше приближается к главной компоненте. Если тех примеров, что есть, не хватает, чтобы сойтись, то можно несколько раз повторить процесс на тех же примерах, постепенно уменьшая скорость обучения.
Основная идея в том, что по мере приближения к главной компоненте кластер начинает все сильнее реагировать на образцы, похожие на нее и все меньше на остальные, за счет этого обучение в нужную сторону идет быстрее, чем «плохие» примеры пытаются его испортить. Результат работы такого алгоритма после нескольких итераций показан ниже.

Результат, полученный после нескольких итераций выделения первой главной компоненты
Если теперь подрезать кластер, то есть оставить только те рецепторы, у которых высокие веса (например, выше 0.75), то мы получим закономерность, очищенную от лишних шумовых битов. Эту процедуру можно повторить несколько раз по мере накопления статистики. В результате можно понять, есть ли в кластере какая-либо закономерность, или мы собрали вместе случайный набор битов. Если закономерности нет, то в результате подрезания кластера останется слишком короткий фрагмент. В этом случае такой кластер можно удалить как несостоявшуюся гипотезу.
Кроме подрезки кластера надо следить за тем, чтобы была поймана именно нужная закономерность. В исходной строке смешаны коды нескольких букв, каждый из них является закономерностью. Любой из этих кодов может быть «пойман» кластером. Но нас интересует код только той буквы, которая влияет на формирование выходного бита. По этой причине большинство гипотез будут ложными и их необходимо отвергнуть. Это можно сделать по тем критериям, что частичное или даже полное срабатывание кластера слишком часто будет не совпадать с активностью нужного выходного бита. Такие кластеры подлежат удалению. Процесс такого контроля и удаления лишних кластеров вместе с их «подрезкой» можно назвать консолидацией памяти.
Процесс накопления новых кластеров достаточно быстрый, каждый новый опыт формирует несколько тысяч новых кластеров-гипотез. Обучение целесообразно проводить этапами с перерывом на «сон». Когда кластеров создается критически много, требуется перейти в режим «холостой» работы. В этом режиме прокручивается ранее запомненный опыт. Но при этом не создается новых гипотез, а только идет проверка старых. В результате «сна» удается удалить огромный процент ложных гипотез и оставить только гипотезы, прошедшие проверку. После «сна» комбинаторное пространство не только оказывается очищено и готово к приему новой информации, но и гораздо увереннее ориентируется в том, что было выучено «вчера».
Выход комбинаторного пространства
По мере того, как кластеры будут накапливать статистику и проходить консолидацию, будут появляться кластеры, достаточно похожие на то, что их гипотеза либо верна, либо близка к истине. Будем брать такие кластеры и следить за тем, когда они будут полностью активироваться, то есть когда будут активны все рецепторы кластера.
Далее из этой активности сформируем выход как хеш комбинаторного пространства. При этом будем учитывать, что чем длиннее кластер, тем выше шанс, что мы поймали закономерность. Для коротких кластеров есть вероятность, что сочетание битов возникло случайно как комбинация других понятий. Для повышения помехоустойчивости воспользуемся идеей бустинга, то есть будем требовать, чтобы для коротких кластеров активация выходного бита происходила только когда таких срабатываний будет несколько. В случае же длинных кластеров будем считать, что достаточно и единичного срабатывания. Это можно представить через потенциал, который возникает при срабатывании кластеров. Этот потенциал тем выше, чем длиннее кластер. Потенциалы точек, подключенных к одному выходному биту, складываются. Если итоговый потенциал превышает определенный порог, то бит активируется.
После некоторого обучения на выходе начинает воспроизводиться часть, совпадающая с тем, что мы хотим получить (рисунок ниже).

Пример работы комбинаторного пространства в процессе обучения (порядка 200 шагов). Сверху исходный код, в середине требуемый код, снизу код, предсказанный комбинаторным пространством
Постепенно выход комбинаторного пространства начинает все лучше воспроизводить требуемый код выхода. После нескольких тысяч шагов обучения выход воспроизводится с достаточно высокой точностью (рисунок ниже).

Пример работы обученного комбинаторного пространства. Сверху исходный код, в середине требуемый код, снизу код, предсказанный комбинаторным пространством
Чтобы наглядно представить, как это все работает, я записал видео с процессом обучения. Кроме того, возможно, мои пояснения помогут лучше разобраться во всей этой кухне.
Усиление правил
Для выявления более сложных закономерностей можно использовать тормозные рецепторы. То есть вводить закономерности, блокирующие срабатывание некоторых утвердительных правил при появлении некой комбинации входных битов. Это выглядит как создание при определенных условиях кластера рецепторов с тормозными свойствами. При срабатывании такого кластера он будет не увеличивать, а уменьшать потенциал точки.
Несложно придумать правила проверки тормозных гипотез и запустить консолидацию тормозных рецептивных кластеров.
Так как тормозные кластеры создаются в конкретных точках, то они влияют не на блокировку выходного бита вообще, а на блокировку его срабатывания от правил, обнаруженных именно в этой точке. Можно усложнить архитектуру связей и ввести тормозные правила, общие для группы точек или для всех точек, подключенных к выходному биту. Похоже, что можно придумать еще много чего интересного, но пока остановимся на описанной простой модели.
Случайный лес
Описанный механизм позволяет найти закономерности, которые в Data Mining принято называть правилами типа «if-then». Соответственно, можно найти что-то общее между нашей моделью и всеми теми методами, что традиционно используются для решения таких задач. Пожалуй, наиболее близок к нам «random forest».
Этот метод начинается с идеи «случайных подпространств». Если в исходных данных слишком много переменных и эти переменные слабо, но коррелированы, то на полном объеме данных становится трудно вычленить отдельные закономерности. В таком случае можно создать подпространства, в которых будут ограничены как используемые переменные, так и обучающие примеры. То есть каждое подпространство будет содержать только часть входных данных, и эти данные будут представлены не всеми переменными, а их случайным ограниченным набором. Для некоторых из этих подпространств шансы обнаружить закономерность, плохо видимую на полном объеме данных, значительно повышаются.
Затем в каждом подпространстве на ограниченном наборе переменных и обучающих примеров производится обучение решающего дерева. Решающее дерево – это древовидная структура (рисунок ниже), в узлах которой происходит проверка входных переменных (атрибутов). По результатам проверки условий в узлах определяется путь от вершины к терминальному узлу, который принято называть листом дерева. В листе дерева находится результат, который может быть значением какой-либо величины или номером класса.

Пример дерева принятия решений
Для решающих деревьев существуют различные алгоритмы обучения, которые позволяют построить дерево с более-менее оптимальными атрибутами в его узлах.
На завершающем этапе применяется идея бустинга. Решающие деревья формируют комитет для голосования. На основании коллективного мнения создается наиболее правдоподобный ответ. Главное достоинство бустинга – это возможность при объединении множества «плохих» алгоритмов (результат которых лишь немного лучше случайного) получить сколь угодно «хороший» итоговый результат.
В нашем алгоритме, эксплуатирующем комбинаторное пространство и кластеры рецепторов, используются те же фундаментальные идеи, что и в методе случайного леса. Поэтому нет ничего удивительного, что наш алгоритм работает и выдает неплохой результат.
Биология обучения
Собственно, в этой статье описана программная реализация тех механизмов, которые были описаны в предыдущих частях цикла. Поэтому не будем повторять все с самого начала, отметим лишь основное. Если вы забыли о том, как работает нейрон, то можно перечитать вторую часть цикла.
На мембране нейрона располагается множество различных рецепторов. Большинство этих рецепторов находится в «свободном плавании». Мембрана создает для рецепторов среду, в которой они могут свободно перемещаться, легко меняя свое положение на поверхности нейрона (Sheng, M., Nakagawa, T., 2002) (Tovar K. R.,Westbrook G. L., 2002).

Мембрана и рецепторы
В классическом подходе на причинах такой «свободы» рецепторов обычно акцент не делается. Когда синапс усиливает свою чувствительность, это сопровождается перемещением рецепторов из внесинаптического пространства в синаптическую щель (Malenka R.C., Nicoll R.A., 1999). Этот факт негласно воспринимается как оправдание подвижности рецепторов.
В нашей модели можно предположить, что основная причина подвижности рецепторов – это необходимость «на лету» формировать из них кластеры. То есть картина выглядит следующим образом. По мембране свободно дрейфуют самые разные рецепторы, чувствительные к различным нейромедиаторам. Информационный сигнал, возникший в миниколонке, вызывает выброс нейромедиаторов аксонными окончаниями нейронов и астроцитами. В каждом синапсе, где испускается нейромедиаторы, кроме основного нейромедиатора присутствует своя уникальная добавка, которая идентифицирует именно этот синапс. Нейромедиаторы выплескиваются из синаптических щелей в окружающее пространство, за счет чего в каждом месте дендрита (точках комбинаторного пространства) возникает специфический коктейль нейромедиаторов (ингредиенты коктейля указывают на биты, попадающие в точку). Те свободно блуждающие рецепторы, которые находят в этот момент свой нейромедиатор в этом коктейле (рецепторы конкретных битов входного сигнала), переходят в новое состояние – состояние поиска. В этом состоянии у них есть небольшое время (до того момента, пока не наступит следующий такт), за которое они могут встретить другие «активные» рецепторы и создать общий кластер (кластер рецепторов, чувствительных к определенному сочетанию битов).
Метаботропные рецепторы, а речь идет о них, имеют достаточно сложную форму (рисунок ниже). Они состоят из семи трансмембранных доменов, которые соединены петлями. Кроме того, у них есть два свободных конца. За счет разных по знаку электростатических зарядов свободные концы могут через мембрану «залипать» друг на друга. За счет таких соединений рецепторы и объединяются в кластеры.

Одиночный метаботропный рецептор
После объединения начинается совместная жизнь рецепторов в кластере. Можно предположить, что положение рецепторов относительно друг друга может меняться в широких пределах и кластер может принимать причудливые формы. Если допустить, что рецепторы, срабатывающие совместно, будут стремиться занять место ближе друг к другу, например, за счет электростатических сил, то получится интересное следствие. Чем ближе будут оказываться такие «совместные» рецепторы, тем сильнее будет их совместное притяжение. Сблизившись они начнут усиливать влияние друг друга. Такое поведение воспроизводит поведение фильтра Хебба, который выделяет первую главную компоненту. Чем точнее фильтр настраивается на главную компоненту, тем сильнее оказывается его реакция, когда она появляется в примере. Таким образом, если после ряда итераций совместно срабатывающие рецепторы окажутся вместе в условном «центре» кластера, а «лишние» рецепторы на удалении, на его краях, то, в принципе, такие «лишние» рецепторы могут в какой-то момент самоликвидироваться, то есть просто оторваться от кластера. И тогда мы получим поведение кластера, аналогичное тому, что описано выше в нашей вычислительной модели.
Кластеры, которые прошли консолидацию, могут переместиться куда-нибудь «в тихую гавань», например, в синаптическую щель. Там существует постсинаптическое уплотнение, за которое кластеры рецепторов могут якориться, теряя уже ненужную им подвижность. Поблизости от них будут находиться ионные каналы, которыми они смогут управлять через G-белки. Теперь эти рецепторы начнут влиять на формирование локального постсинаптического потенциала (потенциала точки).
Локальный потенциал складывается из совместного влияния расположенных рядом активирующих и тормозящих рецепторов. В нашем подходе активирующие отвечают за узнавание закономерностей, призывающих активировать выходной бит, тормозящие за определение закономерностей, которые блокируют действие локальных правил.
Синапсы (точки) расположены на дендритном дереве. Если где-то на этом дереве находится место, где на небольшом участке срабатывает сразу несколько активирующих рецепторов и это не блокируется тормозными рецепторами, то возникает дендритный спайк, который распространяется до тела нейрона и, дойдя до аксонного холмика, вызывает спайк самого нейрона. Дендритное дерево объединяет множество синапсов, замыкая их на один нейрон, что очень похоже на формирование выходного бита комбинаторного пространства.
Объединение сигналов с разных синапсов одного дендритного дерева может быть не простым логическим сложением, а быть сложнее и реализовывать какой-нибудь алгоритм хитрого бусинга.
Напомню, что базовый элемент коры – это кортикальная миниколонка. В миниколонке около ста нейронов расположены друг под другом. При этом они плотно окутаны связями, которые гораздо обильнее внутри миниколонки, чем связи, идущие к соседним миниколонкам. Вся кора мозга – это пространство таких миниколонок. Один нейрон миниколонки может соответствовать одному выходному биту, все нейроны одной кортикальной миниколонки могут быть аналогом выходного бинарного вектора.
Кластеры рецепторов, описанные в этой главе, создают память, ответственную за поиск закономерностей. Ранее мы описывали, как с помощью кластеров рецепторов создать голографическую событийную память. Это два разных типа памяти, выполняющие разные функции, хотя и основанные на общих механизмах.
Сон
У здорового человека сон начинается с первой стадии медленного сна, которая длится 5-10 минут. Затем наступает вторая стадия, которая продолжается около 20 минут. Еще 30-45 минут приходится на периоды третей и четвертой стадий. После этого спящий снова возвращается во вторую стадию медленного сна, после которой возникает первый эпизод быстрого сна, который имеет короткую продолжительность — около 5 минут. Во время быстрого сна глазные яблоки очень часто и периодически совершают быстрые движения под сомкнутыми веками. Если в это время разбудить спящего, то в 90% случаев можно услышать рассказ о ярком сновидении. Вся эта последовательность называется циклом. Первый цикл имеет длительность 90-100 минут. Затем циклы повторяются, при этом уменьшается доля медленного сна и постепенно нарастает доля быстрого сна, последний эпизод которого в отдельных случаях может достигать 1 часа. В среднем при полноценном здоровом сне отмечается пять полных циклов.
Можно предположить, что во сне происходит основная работа по расчистке, накопившихся за день. В вычислительной модели мы описали процедуру «холостого» обучения. Старый опыт предъявляется мозгу, не вызывая формирования новых кластеров. Цель – проверка уже существующих гипотез. Такая проверка состоит из двух этапов. Первый — вычисление главной компоненты закономерности и проверка того, что количество битов, отвечающих за нее, достаточно для четкой идентификации. Второй – проверка истинности гипотезы, то есть того, что закономерность оказалась в нужной точке, связанной с нужным выходным битом. Можно предположить, что часть стадий ночного сна связана с такими процедурами.
Все процессы, связанные с изменениями в клетках, сопровождаются экспрессией определенных белков и транскрипционных факторов. Многочисленными экспериментами вычислены белки и факторы, участвующие в формировании нового опыта. Так вот, оказывается, что их количество сильно увеличивается во время бодрствования и резко уменьшается во время сна.
Увидеть и оценить концентрацию белков можно через окрашивание среза мозговой ткани красителем, избирательно реагирующим на требуемый белок. Подобные наблюдения показали, что наиболее масштабные изменения для белков, связанных с памятью, происходят именно во время сна (Chiara Cirelli, Giulio Tononi, 1998) (Cirelli, 2002) (рисунки ниже).

Распределение белка Arc в теменной коре крысы после трех часов сна (S) и после трех часов спонтанного бодрствования (W) (Cirelli, 2002)

Распределение транскрипционного фактора P-CREB в корональных участках теменной коры крысы после трех часов сна (S) и в случае лишения сна на три часа (SD) (Cirelli, 2002)
В такие рассуждения о роли сна хорошо укладывается известная каждому особенность – «утро вечера мудренее». Утром мы гораздо лучше ориентируемся в том, что еще вчера было не особо понятно. Все становится четче и очевиднее. Возможно, что этим мы обязаны именно масштабной расчистке кластеров рецепторов, произошедшей во время сна. Удаляются ложные и сомнительные гипотезы, достоверные проходят консолидацию и начинают активнее участвовать в информационных процессах.
При моделировании было видно, что количество ложных гипотез во многие тысячи раз превышает количество истинных. Так как отличить одни от других можно только временем и опытом, то мозгу не остается ничего другого, кроме как копить всю эту информационную руду в надежде найти в ней со временем граммы радия. При получении нового опыта количество кластеров с гипотезами, требующими проверки, постоянно растет. Количество кластеров, формирующихся за день и содержащих руду, которую еще предстоит обработать, может превышать количество кластеров, отвечающих за кодирование накопленного за всю предыдущую жизнь проверенного опыта. Ресурс мозга по хранению сырых гипотез, требующих проверки должен быть ограничен. Похоже, что за 16 часов дневного бодрствования кластерами рецепторов практически полностью забивается все доступное пространство. Когда наступает этот момент, мозг начинает принуждать нас перейти в режим сна, чтобы позволить ему выполнить консолидацию и расчистить свободное место. Видимо, процесс полной расчистки занимает около 8 часов. Если разбудить нас раньше, то часть кластеров останется необработанной. Отсюда происходит феномен того, что усталость накапливается. Если несколько дней недосыпать, то потом придется наверстывать упущенный сон. В противном случае мозг начинает «аварийно» удалять кластеры, что ни к чему хорошему не приводит, так как лишает нас возможности почерпнуть знания из полученного опыта. Событийная память скорее всего сохранится, но закономерности останутся невыявленными.
Кстати, мой личный совет: не пренебрегайте качественным сном, особенно если вы учитесь. Не пытайтесь сэкономить на сне, чтобы больше успеть. Сон не менее важен в обучении, чем посещение лекций и повтор материала на практических занятиях. Недаром дети в те периоды развития, когда накопление и обобщение информации идет наиболее активно, большую часть времени проводят во сне.
Быстродействие мозга
Предположение о роли рецептивных кластеров позволяет по-новому взглянуть на вопрос быстродействия мозга. Ранее мы говорили, что каждая миниколонка коры, состоящая из сотни нейронов – это самостоятельный вычислительный модуль, который рассматривает трактовку поступающей информации в отдельном контексте. Это позволяет одной зоне коры рассматривать до миллиона возможных вариантов трактовки одновременно.
Теперь можно предположить, что каждый кластер рецепторов может работать как автономный вычислительный элемент, выполняя весь цикл вычислений по проверке своей гипотезы. Таких кластеров в одной только кортикальной колонке может быть сотни миллионов. Это значит, что, хотя частоты, с которыми работает мозг, далеки от частот, на которых работают современные компьютеры, тревожиться о быстродействии мозга не стоит. Сотни миллионов кластеров рецепторов, работающих параллельно в каждой миниколонке коры, позволяют успешно решать сложные задачи, находящиеся на границе с комбинаторным взрывом. Чудес не бывет. Но можно научиться ходить по грани.
Текст приведенной программы доступен на GitHub. В коде оставлено достаточно много отладочных фрагментов, я не стал их удалять, а только закомментировал на случай, если кому-то захочется самостоятельно поэкспериментировать.
Алексей Редозубов
Логика сознания. Часть 1. Волны в клеточном автомате
Логика сознания. Часть 2. Дендритные волны
Логика сознания. Часть 3. Голографическая память в клеточном автомате
Логика сознания. Часть 4. Секрет памяти мозга
Логика сознания. Часть 5. Смысловой подход к анализу информации
Логика сознания. Часть 6. Кора мозга как пространство вычисления смыслов
Логика сознания. Часть 7. Самоорганизация пространства контекстов
Логика сознания. Пояснение «на пальцах»
Логика сознания. Часть 8. Пространственные карты коры мозга
Логика сознания. Часть 9. Искусственные нейронные сети и миниколонки реальной коры
Логика сознания. Часть 10. Задача обобщения
Логика сознания. Часть 11. Естественное кодирование зрительной и звуковой информации
Логика сознания. Часть 12. Поиск закономерностей. Комбинаторное пространство
Автор: Алексей Редозубов
Источник
js версия
var numerator = function(maxN){
var i = 0;
var result = [];
do{
result.push(i+3, i+6, i+9);
i += 10;
}while((i+9 <= maxN))
return result;
};
демо
а сама задача как я понял среднее арифметическое посчитать для данного ряда, если учесть Среднее арифметическое — сумма всех членов поделенное на количество, исходя из того, что мы определили что ряд комбинация 3 чисел, увеличивается по арифметической прогрессии шагом 10, мы можем далее 3,6,9,13,16,19,23,26,29 => 3,13,23,6,16,26,9,19,29 => вспоминаем математику S = S1 + S2 + S3 где S общая сумма элементов S1,S2,S3
если вспомним что Sn = ((2a1 + (n-1)d)/2 )n — где d шаг, а1 — первый член, n- количество элементов S1 = ((23 + (3-1)10)/2)*3 = 39 и т.д. для других таким образом функция для посчета среднего арифметического для данной последовательности (js)
var srSred = function(items){
var len = items.length / 3;
var result = 0;
for(i=0;i<=2;i++)
result += ((2 * items[0] + ((len - 1)* 10))/2)*len;
result = result / items.length;
return result;
}
демо
Если бы я хотел узнать о распознавании образов в целом, с чего бы начать (порекомендуйте книгу)?
Кроме того, есть ли у кого-нибудь опыт / знания о том, как применять эти алгоритмы для поиска шаблонов абстракции в программах? (повторяющийся код, фрагменты кода, которые делают то же самое, но немного по-разному и т. д.)
Благодарность
Изменить: я не возражаю против математически насыщенных книг. На самом деле, это было бы хорошо.
8 ответов
Лучший ответ
Если вы достаточно математически уверены, то для изучения распознавания образов очень хороши книги Криса Бишопа «Распознавание образов и машинное обучение» или «Нейронные сети для распознавания образов».
2
Ian G
10 Фев 2009 в 15:23
Это помогает, если у вас есть доступ к дереву синтаксического анализа, сгенерированному во время компиляции. Таким образом, вы можете искать похожие части дерева, игнорируя узлы, которые глубже того, на что вы смотрите, таким образом вы можете выбрать, например, узлы, которые умножают вместе два подвыражения, игнорируя содержимое подвыражений. Вы можете применить ту же логику к набору узлов, например вы хотите найти умножение двух подвыражений, где эти два подвыражения являются добавлением большего количества подвыражений. Сначала вы ищите умножения, затем проверяете, являются ли два узла под умножением сложениями, игнорируя все более глубокие.
1
jheriko
10 Фев 2009 в 15:17
Я бы посоветовал посмотреть код какого-нибудь проекта с открытым исходным кодом (например, FindBugs или SIM) это то, о чем вы говорите.
0
joel.neely
10 Фев 2009 в 15:13
Если вы работаете на одном из поддерживаемых языков, у IntelliJ idea есть действительно умный структурный поиск и замените в соответствии с вашей проблемой.
0
krosenvold
10 Фев 2009 в 15:17
Другие интересные проекты: PMD и Затмение.
Eclipse использует AST (абстрактные синтаксические деревья) для всего исходного кода в любом проекте. Затем инструменты могут регистрироваться для определенных типов AST (например, исходный код Java) и получать предварительно обработанное представление, в которое они могут добавлять дополнительную информацию (например, ссылки на документацию, маркеры ошибок и т. Д.).
0
Aaron Digulla
10 Фев 2009 в 15:17
Еще один проект, который вы можете изучить, — это Duplo — это проект с открытым исходным кодом / GPL, так что вы можете подробно изучить их подход, взяв код из SourceForge.
0
mskfisher
10 Фев 2009 в 15:31
Это характерно для .Net и Visual Studio, но обнаруживает повторяющийся код в вашем проекте. Он действительно сообщает о некоторых ложных срабатываниях, которые я обнаружил, но это может быть хорошим местом для начала.
Клон-детектив
0
TWith2Sugars
10 Фев 2009 в 16:01
Один из видов шаблона — это код, который был клонирован методами копирования и вставки. См. CloneDR для инструмента, который автоматически находит такой код, несмотря на различия в макете и даже изменения в тело клона, сравнивая абстрактные синтаксические деревья для рассматриваемого языка.
CloneDR работает с различными языками: C, C ++, C #, Java, JavaScript, PHP, COBOL, Python, … На веб-сайте представлены отчеты об обнаружении клонов для различных языков программирования.
0
Ira Baxter
24 Мар 2010 в 01:47