 Поэзия — та же добыча радия.
Поэзия — та же добыча радия.
В грамм добыча, в годы труды.
Изводишь единого слова ради
Тысячи тонн словесной руды.
Но как испепеляюще слов этих жжение
Рядом с тлением слова-сырца.
Эти слова приводят в движение
Тысячи лет миллионов сердца.
Владимир Маяковский
Напомню, что наша ближайшая задача — показать алгоритм универсального обобщения. Такое обобщение должно удовлетворять всем требованиям, сформулированным ранее в десятой части. Кроме того, оно должно быть свободно от традиционных для многих методов машинного обучения недостатков (комбинаторный взрыв, переобучение, схождение к локальному минимуму, дилемма стабильности-пластичности и тому подобное). При этом механизм такого обобщения должен не противоречить нашим знаниям о работе реальных нейронов живого мозга.
Сделаем еще один шаг в сторону универсального обобщения. Опишем идею комбинаторного пространства и то, как это пространство помогает искать закономерности и тем самым решать задачу обучения с учителем.
Задача контекстного сдвига текстовой строки
Сейчас мы покажем, как очень сложно решить очень простую задачу. Мы научимся сдвигать на одну позицию произвольную текстовую строку.
Предположим, что у нас есть длинный текст. Мы последовательно читаем его от начала к концу. За один шаг чтения мы смещаемся на один символ. Предположим, что у нас есть скользящее окно шириной N символов и в каждый момент времени нам доступен только фрагмент текста, помещающийся в это окно. Введем циклический идентификатор позиции (описан в конце четвертой части), указывающий на позицию символов в тексте. Период идентификатора обозначим K. Пример текста с наложенным идентификатором позиции и сканирующим окном приведен на рисунке ниже.

Фрагмент текста. Числами обозначен циклический идентификатор позиции. Период идентификатора K=10. Вертикальными линиями выделено одно из положений скользящего окна. Размер окна N=6
Основная идея такого представления в том, что если размер окна N меньше периода идентификатора K, то набор пар «буква — идентификатор позиции» позволяет однозначно записать строку внутри скользящего окна. Ранее похожий метод записи мы упоминали, когда говорили о том, как можно закодировать звуковую информацию. Подставьте вместо букв коды неких условных фонем, и вы получите запись звукового фрагмента.
Введем систему понятий, позволяющую описать все, что появляется в скользящем окне. Для простоты не будем делать разницы между заглавными и строчными буквами и не будем учитывать знаки препинания. Так как потенциально любая буква может встретиться нам в любой позиции, то нам понадобятся все возможные сочетания букв и позиций, то есть 26 x K понятий. Условно эти понятия можно обозначить как
{a0,a1⋯a(K-1),b0,b1⋯b(K-1),z0,z1⋯z(K-1)}
Мы можем записать любое состояние скользящего окна как перечисление соответствующих понятий. Так для окна, показанного на рисунке выше, это будет
{s1,w3,e4,d6}
Сопоставим каждому понятию некий разреженный бинарный код. Например, если взять длину кода в 256 бит и отвести 8 бит для кодирования одного понятия, то кодирование буквы «a» в различных позициях будет выглядеть как показано на рисунке ниже. Напомню, что коды выбираются случайным образом, и биты у них могут повторяться, то есть одни и те же биты могут быть общими для нескольких кодов.

Пример кодов буквы a в позициях от 0 до 9. Бинарные вектора показаны вертикально, единицы выделены горизонтальными светлыми линиями
Создадим бинарный код фрагмента логическим сложением кодов составляющих его понятий. Как уже писалось ранее, такой бинарный код фрагмента будет обладать свойствами фильтра Блума. Если разрядность бинарного массива достаточна высока, то с достаточно высокой точностью можно выполнить обратное преобразование и получить из кода фрагмента набор исходных понятий.
На рисунке ниже приведен пример того, как будут выглядеть коды понятий и суммарный код фрагмента для предыдущего примера.

Пример сложения бинарных кодов понятий в код фрагмента
Описание, составленное таким образом, хранит не только набор букв фрагмента текста, но и их последовательность. Однако и набор понятий, и суммарный код этой последовательности зависит от того, в какой позиции находился циклический идентификатор на момент, когда последовательность появилась в тексте. На рисунке ниже приведен пример того, как описание одного и того же фрагмента текста зависит от начального положения циклического идентификатора.

Изменение кодировки текста при разном начальном смещении
Первому случаю будет соответствовать описание
{s1,w3,e4,d6}
Второй случай будет записан, как
{s9,w1,e2,d4}
В результате текст один и тот же, но совсем другой набор понятий и, соответственно, совсем другой описывающий его бинарный код.
Тут мы приходим к тому, о чем так много говорили в предыдущих частях. Варианты, получаемые при смещении текста, – это возможные трактовки одной и той же информации. При этом контекстами выступают все возможные варианты смещения. И хотя суть информации неизменна, ее внешняя форма, то есть описание через набор понятий или через его бинарное представление, меняется от контекста к контексту, то есть, в нашем случае, при каждом изменении начальной позиции.
Чтобы иметь возможность сравнивать фрагменты текста инвариантно к их смещению, надо ввести пространство контекстов смещений. Для этого понадобится K контекстов. Каждый контекст будет соответствовать одному из вариантов возможного начального смещения.
Напомню, что контексты определяются правилами контекстных преобразований. В каждом контексте задается набор правил относительно того, как меняются понятия в этом контексте.
Контекстными преобразованиями в случае с текстом будут правила изменения понятий при переходе к соответствующему контексту смещению. Так, например, для контекста с нулевым смещением правила переходов будут переходами сами в себя
a0→a0, a2→a2⋯z(K-1)→z(K-1)
Для контекста со смещением на 8 позиций при длине кольцевого идентификатора K=10, что соответствует нижней строке примера с рисунка выше, правила будут иметь вид
a0→a8, a1→a9, a2→a0⋯z9→z7
При таких правилах в контексте со смещением 8 описание окна из первой строки примера перейдет в описание окна из второй строки, что, собственно, вполне очевидно и без долгих пояснений
{s1,w3,e4,d6}→{s9,w1,e2,d4}
В нашем случае контексты, по сути, выполняют вариацию смещения текстовой строки по всем возможным позициям кольцевого идентификатора. В результате если две строки совпадают или похожи друг на друга, но сдвинуты одна относительно другой, то всегда найдется контекст, который нивелирует это смещение.
Позже мы подробно разовьем мысль о контекстах, сейчас же нас будет интересовать один частный, но при этом очень важный вопрос: как изменяются бинарные коды описаний при переходе от одного контекста к другому?
В нашем примере мы имеем текст и знаем позиции букв. Задав требуемое смещение, мы всегда можем пересчитать позиции букв и получить новое описание. Не представляет труда вычислить бинарные коды для исходного и смещенного состояния. Например, на рисунке ниже показано, как будет выглядеть код строки «arkad» в нулевом смещении и код той же строки при смещении на одну позицию вправо.

Код исходной строки и ее смещения
Так как у нас есть алгоритм пересчета описаний, мы без труда можем для любой строки получить ее исходный бинарный код (в нулевом контексте) и код в смещении на одну позицию (в контексте «1»). Взяв длинный текст, мы можем создать сколь угодно много таких примеров, относящихся к одному смещению.
А теперь возьмем сгенерированные примеры и представим, что перед нами черный ящик. Есть бинарное описание на входе, есть бинарное описание на выходе, но нам ничего не известно ни про природу входного описания, ни про правила, по которым происходит преобразование. Можем ли мы воспроизвести работу этого черного ящика?
Мы пришли к классической задаче обучения с учителем. Есть обучающая выборка и по ней требуется воспроизвести внутреннюю логику, связывающую входные и выходные данные.
Такая постановка задачи типична для ситуаций, с которыми часто сталкивается мозг, решая вопросы контекстных преобразований. Например, в прошлой части было описано, как сетчатка глаза формирует бинарные коды, соответствующие зрительной картинке. Микродвижения глаз постоянно создают обучающие примеры. Так как движения очень быстрые, то можно считать, что мы видим одну и ту же сцену, но только в разных контекстах смещения. Таким образом мозг получает исходный код изображения и код, в который это изображение переходит в контексте проделанного глазом смещения. Задача обучения зрительных контекстов – это вычисление правил, которым подчиняются зрительные трансформации. Знание этих правил позволяет получать трактовки одного и того же изображения одновременно в различных вариантах смещений без необходимости глазу физически эти смещения совершать.
В чем сложность?
Когда я учился в институте, у нас была очень популярна игра «Быки и коровы». Один игрок загадывает четырехзначное число без повторов, другой пытается его угадать. Тот, кто пытается, называет некие числа, а загадавший сообщает, сколько в них быков, то есть угаданных цифр, стоящих на своем месте, и сколько коров, цифр, которые есть в загаданном числе, но стоят не там, где им положено. Вся соль игры в том, что ответы загадавшего не дают однозначной информации, а создают множество допустимых вариантов. Каждая попытка порождает такую неоднозначную информацию. Однако совокупность попыток позволяет найти единственно верный ответ.
Что-то похожее есть и в нашей задаче. Выходные биты не случайны, каждый из них зависит от определенного сочетания входных битов. Но так как во входном векторе может содержаться несколько понятий, то неизвестно, какие именно биты отвечают за срабатывание конкретного выходного бита.
Так как в кодах понятий биты могут повторяться, то один входной бит ничего не говорит о выходе. Чтобы судить о выходе, требуется анализировать сочетание нескольких входных битов.
Поскольку один и тот же выходной бит может относиться к кодам разным понятий, то срабатывание выходного бита еще не говорит о том, что на входе появилось то же сочетание бит, которое заставило этот выходной бит сработать ранее.
Иначе говоря, получается достаточно сильная неопределенность, как со стороны входа, так и со стороны выхода. Эта неопределенность оказывается серьезной помехой и затрудняет слишком простое решение. Одна неопределенность перемножается на другую неопределенность, что в результате приводит к комбинаторному взрыву.
Для борьбы с комбинаторным взрывом требуется «комбинаторный лом». Есть два инструмента, позволяющие на практике решать сложные комбинаторные задачи. Первый – это массовое распараллеливание вычислений. И тут важно не только иметь большое количество параллельных процессоров, но и подобрать такой алгоритм, который позволяет распараллелить задачу и загрузить все доступные вычислительные мощности.
Второй инструмент – это принцип ограниченности. Основной метод, использующий принцип ограниченности – это метод «случайных подпространств». Иногда комбинаторные задачи допускают сильное ограничение исходных условий и при этом сохраняют надежду, что и после этих ограничений в данных сохранится достаточно информации, чтобы можно было найти требуемое решение. Вариантов того, как можно ограничить исходные условия, может быть много. Не все из них могут быть удачными. Но если, все же, вероятность, что удачные варианты ограничений есть, то тогда сложная задача может быть разбита на большое количество ограниченных задач, каждая из которых решается значительно проще исходной.
Комбинируя эти два принципа, можно построить решение и нашей задачи.
Комбинаторное пространство
Возьмем входной битовый вектор и пронумеруем его биты. Создадим комбинаторные «точки». В каждую точку сведем несколько случайных битов входного вектора (рисунок ниже). Наблюдая за входом, каждая из этих точек будет видеть не всю картину, а только ее малую часть, определяемую тем, какие биты сошлись в выбранной точке. Так на рисунке ниже крайняя слева точка с индексом 0 следит только за битами 1, 6, 10 и 21 исходного входного сигнала. Создадим таких точек достаточно много и назовем их набор комбинаторным пространством.

Комбинаторное пространство
В чем смысл этого пространства? Мы предполагаем, что входной сигнал не случаен, а содержит определенные закономерности. Закономерности могут быть двух основных типов. Что-то во входном описании может появляться несколько чаще чем другое. Например, в нашем случае отдельные буквы появляются чаще чем их сочетания. При битовом кодировании это означает, что определенные комбинации битов встречаются, чаще чем другие.
Другой тип закономерностей – это когда кроме входного сигнала есть сопутствующий ему сигнал обучения и что-то, содержащееся во входном сигнале, оказывается связано с чем-то, что содержится в сигнале обучения. В нашем случае активные выходные биты – это реакция на комбинацию определенных входных битов.
Если искать закономерности «в лоб», то есть глядя на весь входной и весь выходной векторы, то не очень понятно, что делать и куда двигаться. Если начинать строить гипотезы на предмет того, что от чего может зависеть, то моментально наступает комбинаторный взрыв. Количество возможных гипотез оказывается чудовищно.
Классический метод, широко используемый в нейронных сетях, — градиентный спуск. Для него важно понять, в какую сторону двигаться. Обычно это несложно, когда выходная цель одна. Например, если мы хотим обучить нейронную сеть написанию цифр, мы показываем ей изображения цифр и указываем, что за цифру она при этом видит. Сети понятно «как и куда спускаться». Если мы будем показывать картинки сразу с несколькими цифрами и называть все эти цифры одновременно, не указывая, где что, то ситуация становится значительно сложнее.
Когда создаются точки комбинаторного пространства с сильно ограниченным «обзором» (случайные подпространства), то оказывается, что некоторым точкам может повезти и они увидят закономерность если не совсем чистой, то, по крайней мере, в значительно очищенном виде. Такой ограниченный взгляд позволит, например, провести градиентный спуск и получить уже чистую закономерность. Вероятность для отдельной точки наткнуться на закономерность может быть не очень высока, но всегда можно подобрать такое количество точек, чтобы гарантировать себе, что всякая закономерность «где-то да всплывет».
Конечно, если делать размеры точек слишком узкими, то есть количество битов в точках выбирать приблизительно равным тому, сколько битов ожидается в закономерности, то размеры комбинаторного пространства начнут стремиться к количеству вариантов полного перебора возможных гипотез, что возвращает нас к комбинаторному взрыву. Но, к счастью, можно увеличивать обзор точек, снижая их общее количество. Это снижение не дается бесплатно, комбинаторика «переносится в точки», но до определенного момента это не смертельно.
Создадим выходной вектор. Просто сведем в каждый бит выхода несколько точек комбинаторного пространства. Какие это будут точки выберем случайным образом. Количество точек, попадающих в один бит, будет соответствовать тому, во сколько раз мы хотим уменьшить комбинаторное пространство. Такой вектор выхода будет хэш-функцией для вектора состояния комбинаторного пространства. О том, как это состояние считается, мы поговорим чуть позже.
В общем случае, например, как показано на рисунке выше, размер входа и выхода могут быть различны. В нашем примере с перекодированием строк эти размеры совпадают.
Кластеры рецепторов
Как искать закономерности в комбинаторном пространстве? Каждая точка видит свой фрагмент входного вектора. Если в том, что она видит, оказывается достаточно много активных битов, то можно предположить, что то, что она видит, и есть какая-либо закономерность. То есть, набор активных битов, попадающий в точку, можно назвать гипотезой о наличии закономерности. Запомним такую гипотезу, то есть зафиксируем набор активных битов, видимых в точке. В ситуации, показанной на рисунке ниже, видно, что в точке 0 надо зафиксировать биты 1, 6 и 21.

Фиксация битов в кластере
Будем называть запись номера одного бита рецептором к этому биту. Это подразумевает, что рецептор следит за состоянием соответствующего бита входного вектора и реагирует, когда там появляется единица.
Набор рецепторов будем называть кластером рецепторов или рецептивным кластером. Когда предъявляется входной вектор, рецепторы кластера реагируют, если в соответствующих позициях вектора стоят единицы. Для кластера можно подсчитать количество сработавших рецепторов.
Так как информация у нас кодируется не отдельными битами, а кодом, то от того, сколько битов мы возьмем в кластер, зависит точность, с которой мы сформулируем гипотезу. К статье приложен текст программы, решающий задачу с перекодировкой строк. По умолчанию в программе заданы следующие настройки:
- длина входного вектора — 256 бит;
- длина выходного вектора – 256 бит;
- отдельная буква кодируется 8 битами;
- длина строки — 5 символов;
- количество контекстов смещения — 10;
- размер комбинаторного пространства – 60000;
- количество битов, пересекающихся в точке – 32;
- порог создания кластера – 6;
- порог частичной активации кластера — 4.
При таких настройках практически каждый бит, который есть в коде одной буквы, повторяется в коде другой буквы, а то и в кодах нескольких букв. Поэтому одиночный рецептор не может надежно указать на закономерность. Два рецептора указывают на букву значительно лучше, но и они могут указывать на сочетание совсем других букв. Можно ввести некий порог длины, начиная с которого можно достаточно достоверно судить о том, есть ли в кластере нужный нам фрагмент кода.
Введем минимальный порог по количеству рецепторов, необходимых для формирования гипотезы (в примере он равен 6). Приступим к обучению. Будем подавать исходный код и код, который мы хотим получить на выходе. Для исходного кода легко подсчитать, сколько активных битов попадает в каждую из точек комбинаторного пространства. Выберем только те точки, которые подключены к активным битам выходного кода и у которых количество попавших в нее активных битов входного кода окажется не меньше порога создания кластера. В таких точках создадим кластеры рецепторов с соответствующими наборами битов. Сохраним эти кластеры именно в тех точках, где они были созданы. Чтобы не создавать дубликаты, предварительно проверим, что эти кластеры уникальны для этих точек и точки еще не содержат точно таких же кластеров.
Скажем то же другими словами. По выходному вектору мы знаем, какие биты должны быть активны. Соответственно, мы можем выбрать связанные с ними точки комбинаторного пространства. Для каждой такой точки мы можем сформулировать гипотезу о том, что то, что она сейчас видит на входном векторе, – это и есть закономерность, которая отвечает за активность того бита, к которому эта точка подключена. Мы не можем сказать по одному примеру, верна или нет эта гипотеза, но выдвинуть предположение нам никто не мешает.
Обучение. Консолидация памяти
В процессе обучения каждый новый пример создает огромное количество гипотез, большинство из которых неверны. От нас требуется проверить все эти гипотезы и отсеять ложные. Это мы можем сделать, наблюдая за тем, подтвердятся ли эти гипотезы на последующих примерах. Кроме того, создавая новый кластер, мы запоминаем все биты, которые видит точка, а это, даже если там и содержится закономерность, еще и случайные биты, которые попали туда от других понятий, не влияющих на наш выход, и которые в нашем случае являются шумом. Соответственно, требуется не только подтвердить или опровергнуть, что в запомненной комбинации битов содержится нужная закономерность, но и очистить эту комбинацию от шума, оставив только «чистое» правило.
Возможны разные подходы к решению поставленной задачи. Опишу один из них, не утверждая, что он лучший. Я перебрал множество вариантов, этот подкупил меня качеством работы и простотой, но это не значит, что его нельзя улучшить.
Удобно воспринимать кластеры, как автономные вычислители. Если каждый кластер может проверять свою гипотезу и принимать решения независимо от остальных, то это очень хорошо для потенциального распараллеливания вычислений. Каждый кластер рецепторов после создания начинает самостоятельную жизнь. Он следит за поступающими сигналами, накапливает опыт, меняет себя и принимает если необходимо решение о самоликвидации.
Кластер – это набор битов, про который мы предположили, что внутри него сидит закономерность, связанная со срабатыванием того выходного бита, к которому подключена точка, содержащая этот кластер. Если закономерность есть, то скорее всего она затрагивает только часть битов, причем мы заранее не знаем, какую. Поэтому будем фиксировать все моменты, когда в кластере срабатывает существенное количество рецепторов (в примере не менее 4). Возможно, что в эти моменты закономерность, если она есть, проявляет себя. Когда накопится определенная статистика, мы сможем попробовать определить, есть ли в таких частичных срабатываниях кластера что-то закономерное или нет.
Пример статистики показан на рисунке ниже. Плюс в начале строки показывает, что в момент частичного срабатывания кластера выходной бит также был активен. Биты кластера сформированы из соответствующих битов входного вектора.
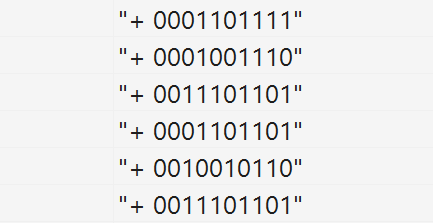
Хроника частичного срабатывания кластера рецепторов
Что нас должно интересовать в этой статистике? Нам важно, какие биты чаще других срабатывают совместно. Не спутайте это с самыми частыми битами. Если посчитать для каждого бита частоту его появления и взять самые распространенные биты, то это будет усреднение, которое совсем не то, что нам надо. Если в точке сошлись несколько устойчивых закономерностей, то при усреднении получится средняя между ними «не закономерность». В нашем примере, видно, что 1,2 и 4 строки похожи между собой, также похожи 3,4 и 6 строки. Нам надо выбрать одну из этих закономерностей, желательно самую сильную, и очистить ее от лишних битов.
Наиболее распространенная комбинация, которая проявляется как совместное срабатывание определенных битов, является для этой статистики первой главной компонентой. Чтобы вычислить главную компоненту, можно воспользоваться фильтром Хебба. Для этого можно задать вектор с единичными начальными весами. Затем получать активность кластера, перемножая вектор весов на текущее состояние кластера. А затем сдвигать веса в сторону текущего состояния тем сильнее, чем выше эта активность. Чтобы веса не росли бесконтрольно, после изменения весов их надо нормировать, например, на максимальное значение из вектора весов.
Такая процедура повторяется для всех имеющихся примеров. В результате вектор весов все больше приближается к главной компоненте. Если тех примеров, что есть, не хватает, чтобы сойтись, то можно несколько раз повторить процесс на тех же примерах, постепенно уменьшая скорость обучения.
Основная идея в том, что по мере приближения к главной компоненте кластер начинает все сильнее реагировать на образцы, похожие на нее и все меньше на остальные, за счет этого обучение в нужную сторону идет быстрее, чем «плохие» примеры пытаются его испортить. Результат работы такого алгоритма после нескольких итераций показан ниже.

Результат, полученный после нескольких итераций выделения первой главной компоненты
Если теперь подрезать кластер, то есть оставить только те рецепторы, у которых высокие веса (например, выше 0.75), то мы получим закономерность, очищенную от лишних шумовых битов. Эту процедуру можно повторить несколько раз по мере накопления статистики. В результате можно понять, есть ли в кластере какая-либо закономерность, или мы собрали вместе случайный набор битов. Если закономерности нет, то в результате подрезания кластера останется слишком короткий фрагмент. В этом случае такой кластер можно удалить как несостоявшуюся гипотезу.
Кроме подрезки кластера надо следить за тем, чтобы была поймана именно нужная закономерность. В исходной строке смешаны коды нескольких букв, каждый из них является закономерностью. Любой из этих кодов может быть «пойман» кластером. Но нас интересует код только той буквы, которая влияет на формирование выходного бита. По этой причине большинство гипотез будут ложными и их необходимо отвергнуть. Это можно сделать по тем критериям, что частичное или даже полное срабатывание кластера слишком часто будет не совпадать с активностью нужного выходного бита. Такие кластеры подлежат удалению. Процесс такого контроля и удаления лишних кластеров вместе с их «подрезкой» можно назвать консолидацией памяти.
Процесс накопления новых кластеров достаточно быстрый, каждый новый опыт формирует несколько тысяч новых кластеров-гипотез. Обучение целесообразно проводить этапами с перерывом на «сон». Когда кластеров создается критически много, требуется перейти в режим «холостой» работы. В этом режиме прокручивается ранее запомненный опыт. Но при этом не создается новых гипотез, а только идет проверка старых. В результате «сна» удается удалить огромный процент ложных гипотез и оставить только гипотезы, прошедшие проверку. После «сна» комбинаторное пространство не только оказывается очищено и готово к приему новой информации, но и гораздо увереннее ориентируется в том, что было выучено «вчера».
Выход комбинаторного пространства
По мере того, как кластеры будут накапливать статистику и проходить консолидацию, будут появляться кластеры, достаточно похожие на то, что их гипотеза либо верна, либо близка к истине. Будем брать такие кластеры и следить за тем, когда они будут полностью активироваться, то есть когда будут активны все рецепторы кластера.
Далее из этой активности сформируем выход как хеш комбинаторного пространства. При этом будем учитывать, что чем длиннее кластер, тем выше шанс, что мы поймали закономерность. Для коротких кластеров есть вероятность, что сочетание битов возникло случайно как комбинация других понятий. Для повышения помехоустойчивости воспользуемся идеей бустинга, то есть будем требовать, чтобы для коротких кластеров активация выходного бита происходила только когда таких срабатываний будет несколько. В случае же длинных кластеров будем считать, что достаточно и единичного срабатывания. Это можно представить через потенциал, который возникает при срабатывании кластеров. Этот потенциал тем выше, чем длиннее кластер. Потенциалы точек, подключенных к одному выходному биту, складываются. Если итоговый потенциал превышает определенный порог, то бит активируется.
После некоторого обучения на выходе начинает воспроизводиться часть, совпадающая с тем, что мы хотим получить (рисунок ниже).

Пример работы комбинаторного пространства в процессе обучения (порядка 200 шагов). Сверху исходный код, в середине требуемый код, снизу код, предсказанный комбинаторным пространством
Постепенно выход комбинаторного пространства начинает все лучше воспроизводить требуемый код выхода. После нескольких тысяч шагов обучения выход воспроизводится с достаточно высокой точностью (рисунок ниже).

Пример работы обученного комбинаторного пространства. Сверху исходный код, в середине требуемый код, снизу код, предсказанный комбинаторным пространством
Чтобы наглядно представить, как это все работает, я записал видео с процессом обучения. Кроме того, возможно, мои пояснения помогут лучше разобраться во всей этой кухне.
Усиление правил
Для выявления более сложных закономерностей можно использовать тормозные рецепторы. То есть вводить закономерности, блокирующие срабатывание некоторых утвердительных правил при появлении некой комбинации входных битов. Это выглядит как создание при определенных условиях кластера рецепторов с тормозными свойствами. При срабатывании такого кластера он будет не увеличивать, а уменьшать потенциал точки.
Несложно придумать правила проверки тормозных гипотез и запустить консолидацию тормозных рецептивных кластеров.
Так как тормозные кластеры создаются в конкретных точках, то они влияют не на блокировку выходного бита вообще, а на блокировку его срабатывания от правил, обнаруженных именно в этой точке. Можно усложнить архитектуру связей и ввести тормозные правила, общие для группы точек или для всех точек, подключенных к выходному биту. Похоже, что можно придумать еще много чего интересного, но пока остановимся на описанной простой модели.
Случайный лес
Описанный механизм позволяет найти закономерности, которые в Data Mining принято называть правилами типа «if-then». Соответственно, можно найти что-то общее между нашей моделью и всеми теми методами, что традиционно используются для решения таких задач. Пожалуй, наиболее близок к нам «random forest».
Этот метод начинается с идеи «случайных подпространств». Если в исходных данных слишком много переменных и эти переменные слабо, но коррелированы, то на полном объеме данных становится трудно вычленить отдельные закономерности. В таком случае можно создать подпространства, в которых будут ограничены как используемые переменные, так и обучающие примеры. То есть каждое подпространство будет содержать только часть входных данных, и эти данные будут представлены не всеми переменными, а их случайным ограниченным набором. Для некоторых из этих подпространств шансы обнаружить закономерность, плохо видимую на полном объеме данных, значительно повышаются.
Затем в каждом подпространстве на ограниченном наборе переменных и обучающих примеров производится обучение решающего дерева. Решающее дерево – это древовидная структура (рисунок ниже), в узлах которой происходит проверка входных переменных (атрибутов). По результатам проверки условий в узлах определяется путь от вершины к терминальному узлу, который принято называть листом дерева. В листе дерева находится результат, который может быть значением какой-либо величины или номером класса.

Пример дерева принятия решений
Для решающих деревьев существуют различные алгоритмы обучения, которые позволяют построить дерево с более-менее оптимальными атрибутами в его узлах.
На завершающем этапе применяется идея бустинга. Решающие деревья формируют комитет для голосования. На основании коллективного мнения создается наиболее правдоподобный ответ. Главное достоинство бустинга – это возможность при объединении множества «плохих» алгоритмов (результат которых лишь немного лучше случайного) получить сколь угодно «хороший» итоговый результат.
В нашем алгоритме, эксплуатирующем комбинаторное пространство и кластеры рецепторов, используются те же фундаментальные идеи, что и в методе случайного леса. Поэтому нет ничего удивительного, что наш алгоритм работает и выдает неплохой результат.
Биология обучения
Собственно, в этой статье описана программная реализация тех механизмов, которые были описаны в предыдущих частях цикла. Поэтому не будем повторять все с самого начала, отметим лишь основное. Если вы забыли о том, как работает нейрон, то можно перечитать вторую часть цикла.
На мембране нейрона располагается множество различных рецепторов. Большинство этих рецепторов находится в «свободном плавании». Мембрана создает для рецепторов среду, в которой они могут свободно перемещаться, легко меняя свое положение на поверхности нейрона (Sheng, M., Nakagawa, T., 2002) (Tovar K. R.,Westbrook G. L., 2002).
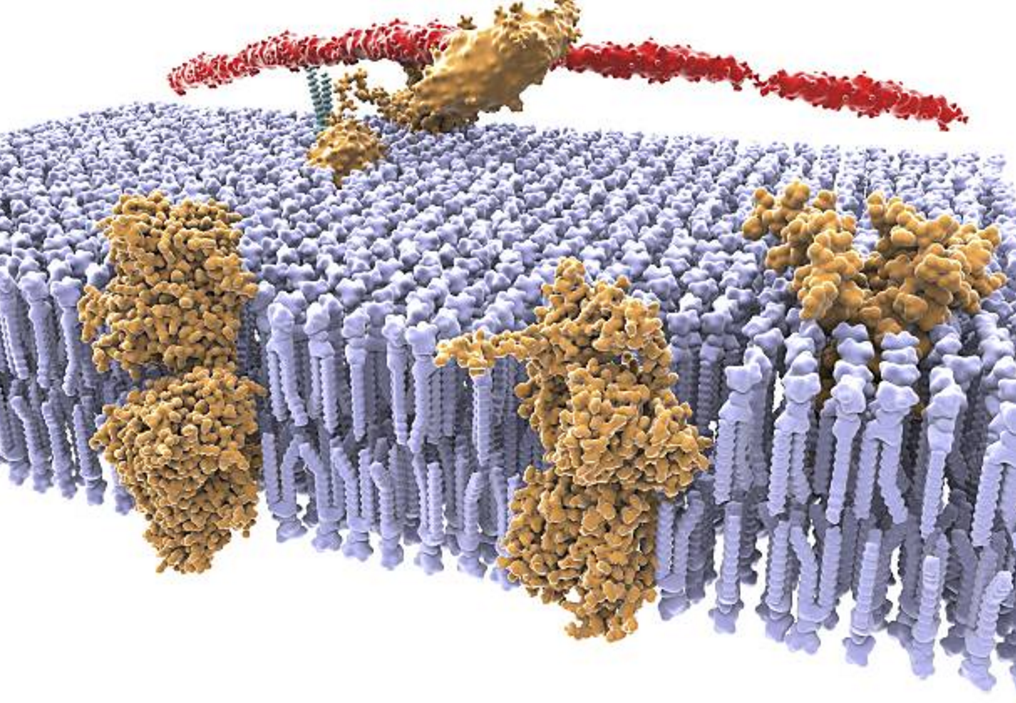
Мембрана и рецепторы
В классическом подходе на причинах такой «свободы» рецепторов обычно акцент не делается. Когда синапс усиливает свою чувствительность, это сопровождается перемещением рецепторов из внесинаптического пространства в синаптическую щель (Malenka R.C., Nicoll R.A., 1999). Этот факт негласно воспринимается как оправдание подвижности рецепторов.
В нашей модели можно предположить, что основная причина подвижности рецепторов – это необходимость «на лету» формировать из них кластеры. То есть картина выглядит следующим образом. По мембране свободно дрейфуют самые разные рецепторы, чувствительные к различным нейромедиаторам. Информационный сигнал, возникший в миниколонке, вызывает выброс нейромедиаторов аксонными окончаниями нейронов и астроцитами. В каждом синапсе, где испускаются нейромедиаторы, кроме основного нейромедиатора присутствует своя уникальная добавка, которая идентифицирует именно этот синапс. Нейромедиаторы выплескиваются из синаптических щелей в окружающее пространство, за счет чего в каждом месте дендрита (точках комбинаторного пространства) возникает специфический коктейль нейромедиаторов (ингредиенты коктейля указывают на биты, попадающие в точку). Те свободно блуждающие рецепторы, которые находят в этот момент свой нейромедиатор в этом коктейле (рецепторы конкретных битов входного сигнала), переходят в новое состояние – состояние поиска. В этом состоянии у них есть небольшое время (до того момента, пока не наступит следующий такт), за которое они могут встретить другие «активные» рецепторы и создать общий кластер (кластер рецепторов, чувствительных к определенному сочетанию битов).
Метаботропные рецепторы, а речь идет о них, имеют достаточно сложную форму (рисунок ниже). Они состоят из семи трансмембранных доменов, которые соединены петлями. Кроме того, у них есть два свободных конца. За счет разных по знаку электростатических зарядов свободные концы могут через мембрану «залипать» друг на друга. За счет таких соединений рецепторы и объединяются в кластеры.
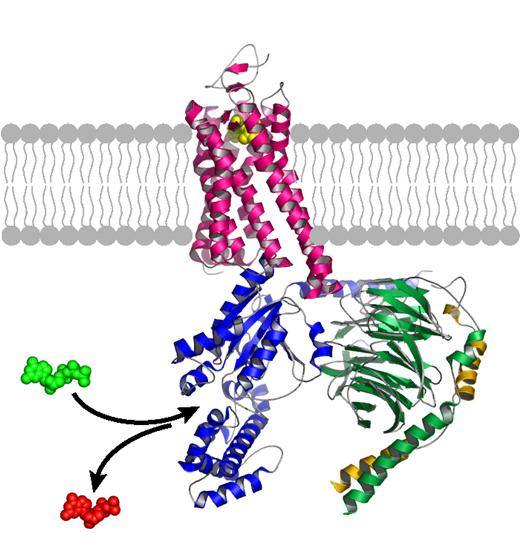
Одиночный метаботропный рецептор
После объединения начинается совместная жизнь рецепторов в кластере. Можно предположить, что положение рецепторов относительно друг друга может меняться в широких пределах и кластер может принимать причудливые формы. Если допустить, что рецепторы, срабатывающие совместно, будут стремиться занять место ближе друг к другу, например, за счет электростатических сил, то получится интересное следствие. Чем ближе будут оказываться такие «совместные» рецепторы, тем сильнее будет их совместное притяжение. Сблизившись они начнут усиливать влияние друг друга. Такое поведение воспроизводит поведение фильтра Хебба, который выделяет первую главную компоненту. Чем точнее фильтр настраивается на главную компоненту, тем сильнее оказывается его реакция, когда она появляется в примере. Таким образом, если после ряда итераций совместно срабатывающие рецепторы окажутся вместе в условном «центре» кластера, а «лишние» рецепторы на удалении, на его краях, то, в принципе, такие «лишние» рецепторы могут в какой-то момент самоликвидироваться, то есть просто оторваться от кластера. И тогда мы получим поведение кластера, аналогичное тому, что описано выше в нашей вычислительной модели.
Кластеры, которые прошли консолидацию, могут переместиться куда-нибудь «в тихую гавань», например, в синаптическую щель. Там существует постсинаптическое уплотнение, за которое кластеры рецепторов могут якориться, теряя уже ненужную им подвижность. Поблизости от них будут находиться ионные каналы, которыми они смогут управлять через G-белки. Теперь эти рецепторы начнут влиять на формирование локального постсинаптического потенциала (потенциала точки).
Локальный потенциал складывается из совместного влияния расположенных рядом активирующих и тормозящих рецепторов. В нашем подходе активирующие отвечают за узнавание закономерностей, призывающих активировать выходной бит, тормозящие за определение закономерностей, которые блокируют действие локальных правил.
Синапсы (точки) расположены на дендритном дереве. Если где-то на этом дереве находится место, где на небольшом участке срабатывает сразу несколько активирующих рецепторов и это не блокируется тормозными рецепторами, то возникает дендритный спайк, который распространяется до тела нейрона и, дойдя до аксонного холмика, вызывает спайк самого нейрона. Дендритное дерево объединяет множество синапсов, замыкая их на один нейрон, что очень похоже на формирование выходного бита комбинаторного пространства.
Объединение сигналов с разных синапсов одного дендритного дерева может быть не простым логическим сложением, а быть сложнее и реализовывать какой-нибудь алгоритм хитрого бустинга.
Напомню, что базовый элемент коры – это кортикальная миниколонка. В миниколонке около ста нейронов расположены друг под другом. При этом они плотно окутаны связями, которые гораздо обильнее внутри миниколонки, чем связи, идущие к соседним миниколонкам. Вся кора мозга – это пространство таких миниколонок. Один нейрон миниколонки может соответствовать одному выходному биту, все нейроны одной кортикальной миниколонки могут быть аналогом выходного бинарного вектора.
Кластеры рецепторов, описанные в этой главе, создают память, ответственную за поиск закономерностей. Ранее мы описывали, как с помощью кластеров рецепторов создать голографическую событийную память. Это два разных типа памяти, выполняющие разные функции, хотя и основанные на общих механизмах.
Сон
У здорового человека сон начинается с первой стадии медленного сна, которая длится 5-10 минут. Затем наступает вторая стадия, которая продолжается около 20 минут. Еще 30-45 минут приходится на периоды третей и четвертой стадий. После этого спящий снова возвращается во вторую стадию медленного сна, после которой возникает первый эпизод быстрого сна, который имеет короткую продолжительность — около 5 минут. Во время быстрого сна глазные яблоки очень часто и периодически совершают быстрые движения под сомкнутыми веками. Если в это время разбудить спящего, то в 90% случаев можно услышать рассказ о ярком сновидении. Вся эта последовательность называется циклом. Первый цикл имеет длительность 90-100 минут. Затем циклы повторяются, при этом уменьшается доля медленного сна и постепенно нарастает доля быстрого сна, последний эпизод которого в отдельных случаях может достигать 1 часа. В среднем при полноценном здоровом сне отмечается пять полных циклов.
Можно предположить, что во сне происходит основная работа по расчистке кластеров рецепторов, накопившихся за день. В вычислительной модели мы описали процедуру «холостого» обучения. Старый опыт предъявляется мозгу, не вызывая формирования новых кластеров. Цель – проверка уже существующих гипотез. Такая проверка состоит из двух этапов. Первый — вычисление главной компоненты закономерности и проверка того, что количество битов, отвечающих за нее, достаточно для четкой идентификации. Второй – проверка истинности гипотезы, то есть того, что закономерность оказалась в нужной точке, связанной с нужным выходным битом. Можно предположить, что часть стадий ночного сна связана с такими процедурами.
Все процессы, связанные с изменениями в клетках, сопровождаются экспрессией определенных белков и транскрипционных факторов. Есть белки и факторы про которые показано, что они участвут в формировании нового опыта. Так вот, оказывается, что их количество сильно увеличивается во время бодрствования и резко уменьшается во время сна.
Увидеть и оценить концентрацию белков можно через окрашивание среза мозговой ткани красителем, избирательно реагирующим на требуемый белок. Подобные наблюдения показали, что наиболее масштабные изменения для белков, связанных с памятью, происходят именно во время сна (Chiara Cirelli, Giulio Tononi, 1998) (Cirelli, 2002) (рисунки ниже).

Распределение белка Arc в теменной коре крысы после трех часов сна (S) и после трех часов спонтанного бодрствования (W) (Cirelli, 2002)

Распределение транскрипционного фактора P-CREB в корональных участках теменной коры крысы после трех часов сна (S) и в случае лишения сна на три часа (SD) (Cirelli, 2002)
В такие рассуждения о роли сна хорошо укладывается известная каждому особенность – «утро вечера мудренее». Утром мы гораздо лучше ориентируемся в том, что еще вчера было не особо понятно. Все становится четче и очевиднее. Возможно, что этим мы обязаны именно масштабной расчистке кластеров рецепторов, произошедшей во время сна. Удаляются ложные и сомнительные гипотезы, достоверные проходят консолидацию и начинают активнее участвовать в информационных процессах.
При моделировании было видно, что количество ложных гипотез во многие тысячи раз превышает количество истинных. Так как отличить одни от других можно только временем и опытом, то мозгу не остается ничего другого, кроме как копить всю эту информационную руду в надежде найти в ней со временем граммы радия. При получении нового опыта количество кластеров с гипотезами, требующими проверки, постоянно растет. Количество кластеров, формирующихся за день и содержащих руду, которую еще предстоит обработать, может превышать количество кластеров, отвечающих за кодирование накопленного за всю предыдущую жизнь проверенного опыта. Ресурс мозга по хранению сырых гипотез, требующих проверки должен быть ограничен. Похоже, что за 16 часов дневного бодрствования кластерами рецепторов практически полностью забивается все доступное пространство. Когда наступает этот момент, мозг начинает принуждать нас перейти в режим сна, чтобы позволить ему выполнить консолидацию и расчистить свободное место. Видимо, процесс полной расчистки занимает около 8 часов. Если разбудить нас раньше, то часть кластеров останется необработанной. Отсюда происходит феномен того, что усталость накапливается. Если несколько дней недосыпать, то потом придется наверстывать упущенный сон. В противном случае мозг начинает «аварийно» удалять кластеры, что ни к чему хорошему не приводит, так как лишает нас возможности почерпнуть знания из полученного опыта. Событийная память скорее всего сохранится, но закономерности останутся невыявленными.
Кстати, мой личный совет: не пренебрегайте качественным сном, особенно если вы учитесь. Не пытайтесь сэкономить на сне, чтобы больше успеть. Сон не менее важен в обучении, чем посещение лекций и повтор материала на практических занятиях. Недаром дети в те периоды развития, когда накопление и обобщение информации идет наиболее активно, большую часть времени проводят во сне.
Быстродействие мозга
Предположение о роли рецептивных кластеров позволяет по-новому взглянуть на вопрос быстродействия мозга. Ранее мы говорили, что каждая миниколонка коры, состоящая из сотни нейронов – это самостоятельный вычислительный модуль, который рассматривает трактовку поступающей информации в отдельном контексте. Это позволяет одной зоне коры рассматривать до миллиона возможных вариантов трактовки одновременно.
Теперь можно предположить, что каждый кластер рецепторов может работать как автономный вычислительный элемент, выполняя весь цикл вычислений по проверке своей гипотезы. Таких кластеров в одной только кортикальной колонке может быть сотни миллионов. Это значит, что, хотя частоты, с которыми работает мозг, далеки от частот, на которых работают современные компьютеры, тревожиться о быстродействии мозга не стоит. Сотни миллионов кластеров рецепторов, работающих параллельно в каждой миниколонке коры, позволяют успешно решать сложные задачи, находящиеся на границе с комбинаторным взрывом. Чудес не бывет. Но можно научиться ходить по грани.
Текст приведенной программы доступен на GitHub. В коде оставлено достаточно много отладочных фрагментов, я не стал их удалять, а только закомментировал на случай, если кому-то захочется самостоятельно поэкспериментировать.
Алексей Редозубов
Логика сознания. Часть 1. Волны в клеточном автомате
Логика сознания. Часть 2. Дендритные волны
Логика сознания. Часть 3. Голографическая память в клеточном автомате
Логика сознания. Часть 4. Секрет памяти мозга
Логика сознания. Часть 5. Смысловой подход к анализу информации
Логика сознания. Часть 6. Кора мозга как пространство вычисления смыслов
Логика сознания. Часть 7. Самоорганизация пространства контекстов
Логика сознания. Пояснение «на пальцах»
Логика сознания. Часть 8. Пространственные карты коры мозга
Логика сознания. Часть 9. Искусственные нейронные сети и миниколонки реальной коры
Логика сознания. Часть 10. Задача обобщения
Логика сознания. Часть 11. Естественное кодирование зрительной и звуковой информации
Логика сознания. Часть 12. Поиск закономерностей. Комбинаторное пространство
Логика сознания. Часть 13. Мозг, смысл и конец света
Поиск логических закономерностей в данных
Основное требование к математическому аппарату Data Minning заключается не только в эффективности классификаторов, но и в интерпретируемости результатов. Методы поиска логических закономерностей в бинарных матрицах наблюдений (как и в некоторых классических методах многомерного анализа) апеллируют к информации, заключенной не в отдельных признаках, а в различных сочетаниях их значений. Для признаков, измеренных в альтернативных шкалах, их значения (x_i = 0) или (x_i = 1) рассматриваются как элементарные события, что позволяет сформулировать решающие правила на простом и понятном человеку языке логических высказываний, таких как ЕСЛИ {(событие 1) и (событие 2) и ... и (событие N)} ТО ....
Так, классификация лиц в рассмотренном примере рис. 5.1 может быть произведена, например, с помощью логических высказываний 1 и 2:
ЕСЛИ {(голова овальная) и (есть носогубная складка) и (есть очки) и (есть трубка)} ИЛИ {(глаза круглые) и (лоб без морщин) и (есть борода) и (есть серьга)} ТО ("Патриот")ЕСЛИ {(нос круглый) и (лысый) и (есть усы) и (брови подняты кверху)} ИЛИ {(оттопыренные уши) и (толстые губы) и (нет родинки на щеке) и (есть бабочка)} ТО ("Демократ").
Математическая запись этих правил выглядит следующим образом:
[[(x_1=0) wedge (x_6=1) wedge (x_{11}=1) wedge (x_{16}=1)] vee \
[(x_{4}=1) wedge (x_{5}=0) wedge (x_{10}=1) wedge (x_{15}=1)] Rightarrow omega_1]
[[(x_3=1) wedge (x_8=0) wedge (x_9=1) wedge (x_{14}=1)] vee\
[(x_2=1) wedge (x_7=1) wedge (x_{12}=0) wedge (x_{13}=1)] Rightarrow omega_2.]
Здесь значки (vee) — конъюнкция (“и”), (wedge) — дизъюнкция (“или”), (Rightarrow) — импликация (“если, то”).
Будем использовать логический метод распознавания, известный под названием алгоритм “Кора”, который в свое время широко использовался в геологоразведочных работах и скрининге лекарственных препаратов (Бонгард, 1967; Вайнцвайг, 1973). В детерминистической версии алгоритма обучающая выборка (boldsymbol{x}), предварительно разделенная на два класса (1 и 2), многократно просматривается и из всего множества высказываний выделяются так называемые непротиворечивые логические высказывания (mathbf{Psi}(boldsymbol{x}, tau)), покрывающие все множество примеров. Непротиворечивым высказыванием для каждого класса считается конъюнкция, которая встречается с вероятностью не менее (tau) только в одном классе и ни разу не встречается в другом.
Представленный ниже скрипт выполняет перебор всех возможных комбинаций столбцов (x_i), (i = 1, dots, m = 16), по 2, 3 и maxKSize = 4 с использованием функции combn(). Для каждой комбинации столбцов перебираются все возможные варианты событий (x_i = 0 или x_i = 1). Для сокращения объема вычислений подмножества исходной матрицы трансформировались в векторы символьных бинарных переменных, а комбинации значений (x_i) выражались наборами “битовых масок” (например, "000", "001", "010", "011", "100", "101", "110", "111").
В ходе перебора конъюнкции, отобранные по совокупности условий, будем сохранять в трех глобальных объектах класса list, для чего используем оператор глобального присваивания <<-. Определим предварительно несколько функций:
# Преобразование числа в набор битов (5 -> "0101")
number2binchar <- function(number, nBits) {
paste(tail(rev(as.numeric(intToBits(number))), nBits),
collapse = "")
}
# Поиск конъюнкций по набору битовых масок
MaskCompare <- function(Nclass, KSize, BitMask,
vec_pos, vec_neg, ColCom) {
nK <- sapply(BitMask, function(x) {
if (sum(x == vec_neg) > 0) return (0)
if (minNum > (countK = sum(x == vec_pos))) return(0)
# Cохранение конъюнкции в трех объектах list
Value.list[[length(Value.list) + 1]] <<-
list(Nclass = Nclass, KSize = KSize,
countK = countK, Bits = x)
ColCom.list[[length(ColCom.list) + 1]] <<- list(ColCom)
RowList.list[[length(RowList.list) + 1]] <<-
list(which(vec_pos %in% x))
return(countK) } )
}Зададим минимальную частоту встречаемости конъюнкций minNum = 4 (т.е. (tau) = 50%) и выполним формирование всех логических правил для рассматриваемого примера:
DFace <- read.delim(file = "data/Faces.txt",
header = TRUE, row.names = 1)
maxKSize <- 4
minNum <- 4
# Списки для хранения результатов
Value.list <- list() # Nclass, KSize, BitMask, countK
ColCom.list <- list() # Наименования переменных ColCom
RowList.list <- list() # Номера индексов строк RowList
# Перебор конъюнкций разной длины
for (KSize in 2:maxKSize) {
BitMask <- sapply(0:(2^KSize - 1),
function(x) number2binchar(x, KSize))
cols <- combn(colnames(DFace[, -17]), KSize)
for (i in 1:ncol(cols)) {
SubArr <- DFace[, (names(DFace) %in% cols[, i])]
vec1 <- apply(SubArr[DFace$Class == 1, ],1,
function(x) paste(x, collapse = ""))
vec2 <- apply(SubArr[DFace$Class == 2,], 1,
function(x) paste(x, collapse = ""))
MaskCompare(1, KSize, BitMask, vec1, vec2, cols[, i])
MaskCompare(2, KSize, BitMask, vec2, vec1, cols[, i])
}
}
# Создание результирующей таблицы
DFval = do.call(rbind.data.frame, Value.list)
nrow = length(Value.list)
DFvar <- as.data.frame(matrix(NA, ncol = maxKSize + 1, nrow = nrow,
dimnames = list(1:nrow, c(
paste("L", 1:maxKSize, sep = ""),
"Объекты:"))))
for (i in 1:nrow) {
Varl <- unlist(ColCom.list[[i]])
DFvar[i, 1:length( Varl)] <- Varl
Objl <- unlist(RowList.list[[i]])
DFvar[i, maxKSize + 1] <- paste(Objl, collapse = " ")
}
DFvar[is.na(DFvar)] <- " "
DFout <- cbind(DFval, DFvar)
# Вывод результатов
print("Конъюнкции класса 1") ## [1] "Конъюнкции класса 1"DFout[DFout$Nclass == 1, ]## Nclass KSize countK Bits L1 L2 L3 L4 Объекты:
## 1 1 2 4 00 x2 x14 2 3 6 8
## 2 1 2 4 00 x3 x7 1 3 5 7
## 7 1 3 4 010 x2 x11 x14 2 3 6 8
## 10 1 3 4 111 x4 x10 x15 2 5 7 8
## 12 1 3 4 111 x6 x9 x11 1 3 6 8
## 13 1 3 4 111 x6 x11 x16 1 3 4 6
## 14 1 3 4 111 x9 x11 x13 1 3 6 8
## 16 1 4 4 0111 x1 x6 x9 x11 1 3 6 8
## 17 1 4 4 0111 x1 x6 x11 x16 1 3 4 6
## 18 1 4 4 0111 x1 x9 x11 x13 1 3 6 8
## 23 1 4 4 1011 x4 x5 x10 x15 2 5 7 8
## 25 1 4 4 1111 x6 x9 x11 x13 1 3 6 8
## 26 1 4 4 0101 x8 x9 x12 x13 1 6 7 8print("Конъюнкции класса 2")## [1] "Конъюнкции класса 2"DFout[DFout$Nclass == 2, ] ## Nclass KSize countK Bits L1 L2 L3 L4 Объекты:
## 3 2 2 4 00 x6 x10 4 5 6 8
## 4 2 2 4 00 x11 x15 1 3 5 7
## 5 2 3 4 111 x2 x4 x7 5 6 7 8
## 6 2 3 4 111 x2 x7 x13 2 5 7 8
## 8 2 3 4 111 x3 x9 x14 1 3 4 6
## 9 2 3 4 111 x4 x7 x16 5 6 7 8
## 11 2 3 4 010 x6 x7 x10 4 5 6 8
## 15 2 4 4 0101 x1 x4 x5 x16 1 6 7 8
## 19 2 4 4 1110 x2 x4 x7 x12 5 6 7 8
## 20 2 4 4 1111 x2 x4 x7 x16 5 6 7 8
## 21 2 4 4 1101 x2 x7 x12 x13 2 5 7 8
## 22 2 4 4 1011 x3 x8 x9 x14 1 3 4 6
## 24 2 4 4 1101 x4 x7 x12 x16 5 6 7 8Результат, содержащий логические высказывания для каждого класса (Nclass) будет выглядеть следующим образом, где KSize — длина коньюнкции, Bits — ее битовая маска, L1—L4 — наименования исходных переменных, countK — встречаемость конъюнкции на объектах своего класса.
Дальнейшая работа с выделенными логическими высказываниями сводится к следующему (реализация алгоритма в R находится в стадии доработки). Из генерируемого списка необходимо исключить подчиненные (или дочерние) конъюнкции, включающие более короткие претенденты: например, для класса 1 высказывание №7 является дочерним по отношению к конъюнкции №1 и должно было быть удалено. После такой операции поглощения ликвидируется избыточность решающего правила, в котором остаются конъюнкции минимального ранга, содержащие выделенные закономерности в концентрированной форме.
Хорошим правилом было бы также исключить высказывания, которые по определенным критериям считаются “предрассудками”. К ним относятся конъюнкции, не связанные с объективным правилом классификации, но, в силу ограниченности выборки, получившие хорошие оценки на обучении. Для выделения признаков, склонных к предрассудкам, выполняют бутстреп-процедуру, в которой обучающая выборка многократно случайным образом разбивается на классы. Разбитая таким образом выборка является тестом, позволяющим присвоить каждому исходному признаку штрафные баллы за склонность к предрассудкам. Конъюнкции, набравшие сверхнормативное количество штрафных очков, из решающего правила исключаются.
Описанием каждого класса является логическая сумма (дизъюнкция) некоторого количества непротиворечивых и продуктивных конъюнкций, прошедших описанные выше этапы отбора. Комбинация этих логических высказываний представляет собой своеобразную мозаично-фрагментарную разделяющую поверхность специального типа (в отличии, например, от линейной плоскости логита). Более общая версия алгоритма “Кора” предполагает выделение логических закономерностей для (K) классов, (K > 2). Среди конъюнкций выделяются те, которые верны на обучающей выборке чаще, чем некоторый порог (tau_1), для одного из классов и не характерны для любого другого (верны реже, чем в доле случаев (tau_2)).
Существует возможность использовать сгенерированные конъюнкции для экзамена тестируемых примеров по принципу голосования. Чтобы классифицировать новое наблюдение (boldsymbol{x}), подсчитывается число отобранных конъюнкций (L_k), характерных для каждого (k)-гo класса, которые верны для тестируемого бинарного вектора. Если (L_k) является максимальным из всех, то принимается решение о принадлежности объекта (k)-му классу.
Алгоритм “Кора”, как и другие логические методы распознавания образов, является достаточно трудоемким, поскольку при отборе конъюнкций необходим полный или частично направленный перебор. Здесь может быть полезно использование процедур эволюционного поиска: генетический алгоритм (genetic algorithm), случайный поиск с адаптацией (СПА — см. книгу Г. С. Лбова, 1981 на сайте math.nsc.ru) и др.
Из своего хз-сколько-летнего опыта интенсивного тестирования торговых алгоритмов выяснил следующее:
Если получил профит в бектесте, то первое, что нужно сделать — удвоить количество обсчитываемых событий (баров или тиков) или сместить тестируемые события во времени. Если после этого опять натестился профит, то нужно еще раз удвоить количество обсчитываемых событий или сместить события во времени. Как правило, после этого профит проходит. И вместе с ним проходит необоснованная радость.
Что такое «количество обсчитываемых событий»?
Это важнейший параметр алгоритма поиска закономерностей. Например, за 10 лет на часовом таймфрейме обсчитывается ~22 000 событий, каждое из которых описывается четырьмя точками — O, H, L и C. Итого ~88 000 точек. На минутном таймфрейме за 10 лет обсчитываается ~1 320 000 событий. Это ~5 280 000 точек.
Чем больше обсчитываемых точек в истории — тем выше вероятность, что найденная закономерность повторится в будущем.
Например, закономерности, найденные обсчетом 22 000 событий (88 000 точек) дают оконулевую вероятность повторения в будущем. Точнее — они дают переменный финансовый результат, стремящийся к нулю на длинной дистанции. Например, закономерность может давать профит какое-то время, а потом наоборот, а потом снова профит, а потом опять слив. Все это можно увидеть собственными глазами в тестах с помощью смещения точки начала торговли в прошлое:

Берем компьютер — и считаем. Быстро, просто, удобно. И никаких страданий.
Так вот… чтобы выявить более-менее устойчивые закономерности, нужно обсчитать не менее 1 000 000 точек. Такие расчеты можно проводить только на мелких таймфреймах ниже пяти минут, собирая (выкачивая) длинную историю.
Зачем так заморачиваться, если можно нарисовать на графике уровни/каналы и торговать в свое удовольствие?
Затем, что уровни на графике — это закономерность, выявленная на сверхмалом количестве событий. Если протестировать уровни/каналы на 1 000 000 точек, то результат получится примерно нулевой. А комиссии утащат в убытки. Не верь в это. Возьми компьютер, залей миллион точек и проверь.
На этом пока всё. Если что-то не понятно или просто интересно, пишите в комментах. Обсудим)
———————
Оригинал поста — в дзене с зеркалом в телеге
Информационные технологии поиска закономерностей в данных»
В том случае, когда
необходимо проводить многокритериальный
анализ, выявить закономерности в данных
и решать другие подобные задачи,
целесообразно использовать технологии
Data-Mining.
Эти технологии
включают в себя поиск корреляционных
зависимостей, тенденций, взаимосвязей
и закономерностей посредством различных
математических и статистических
алгоритмов: кластеризации, создания
подвыборок, регрессионного и корреляционного
анализа.
Основное отличие
Data-Mining от OLAP технологий заключается в
том, что технологии Data-Mining выявляют
закономерностей в данных, а технологии
OLAP
проверяют достоверность предлагаемых
гипотез. Качество результатов технологий
поиска закономерностей зависит от
полноты и достоверности данных.
Достоверность полученных результатов
проверяется путем использования не
одного, а нескольких алгоритмов обработки
одних и тех же данных и сравнения близости
результатов.
Традиционно
выделяют пять стандартных типов
закономерностей, выявляемых методами
Data Mining:
-
ассоциация
— высокая вероятность связи событий
друг с другом (например, один товар
часто приобретается вместе с другим), -
последовательность
— высокая вероятность цепочки связанных
во времени событий (например, в течение
определенного срока после приобретения
одного товара будет с высокой степенью
вероятности приобретен другой), -
классификация
— имеются признаки, характеризующие
группу, к которой принадлежит то или
иное событие или объект (обычно при
этом на основании анализа уже
классифицированных событий формулируются
некие правила), -
кластеризация
— закономерность, сходная с классификацией
и отличающаяся от нее тем, что сами
группы при этом не заданы — они выявляются
автоматически в процессе обработки
данных, -
временные
закономерности — наличие шаблонов в
динамике поведения тех или иных данных
(типичный пример — сезонные колебания
спроса на те или иные товары либо
услуги), используемых для прогнозирования.
Поиск закономерностей
в данных в настоящее время базируется
на довольно большом количестве
разнообразных методов исследования
данных, среди них можно выделить:
-
регрессионный,
дисперсионный и корреляционный анализ, -
методы
анализа в конкретной предметной области,
базирующиеся на эмпирических моделях, -
нейросетевые
алгоритмы, идея которых основана на
аналогии с функционированием нервной
ткани и заключается в том, что исходные
параметры рассматриваются как сигналы,
преобразующиеся в соответствии с
имеющимися связями между «нейронами»,
а в качестве ответа, являющегося
результатом анализа, рассматривается
отклик всей сети на исходные данные, -
деревья
решений, -
кластерные
модели, -
алгоритмы
ограниченного перебора, вычисляющие
частоты комбинаций простых логических
событий в подгруппах данных.
В
последнее время имеет место тенденция
снижения стоимости средств, использующих
технологию Data-Mining, что делает данную
технологию более массовой и дает
возможность среднему и малому бизнесу
оценить плюсы использования данной
технологии и внедрять ее использование
в повседневную практику.
Одним
из недостатков Data – Mining, как известно,
является жесткая зависимость результата
анализа от репрезентативности
первоначальной информации.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
УДК 519.854.33
Вестник СибГАУ Т. 16, № 1. С. 16-21
ОБНАРУЖЕНИЕ ЗАКОНОМЕРНОСТЕЙ В ДАННЫХ ДЛЯ РАСПОЗНАВАНИЯ ОБЪЕКТОВ КАК ЗАДАЧА УСЛОВНОЙ ПСЕВДОБУЛЕВОЙ ОПТИМИЗАЦИИ
А. Н. Антамошкин, И. С. Масич
Сибирский государственный аэрокосмический университет имени академика М. Ф. Решетнева Российская Федерация, 660014, г. Красноярск, просп. им. газ. «Красноярский рабочий», 31
E-mail: i-masich@yandex.ru
Создание и использование логических алгоритмов классификации основывается на выявлении в исходных данных закономерностей, из набора которых формируется решающая функция. Поиск закономерностей можно рассматривать как задачу комбинаторной оптимизации. Для получения более эффективного решения выбор алгоритма оптимизации следует производить исходя из характерных свойств, присущих рассматриваемой оптимизационной задаче. Рассматриваются некоторые свойства задач оптимизации, решаемых в ходе поиска логических закономерностей в данных.
Рассматривается задача распознавания объектов, описываемых бинарными признаками и разделенных на два класса. Закономерности являются элементарными блоками для построения логических алгоритмов распознавания.
Задачу нахождения максимальной закономерности можно записать в виде задачи условной псевдобулевой оптимизации. Проводится исследование свойств оптимизационной модели, описывающей поиск логических закономерностей в данных.
Результаты исследований показывают, что в пространстве поиска имеется множество постоянства целевой функции, которое затрудняет работу алгоритмов оптимизации, начинающих поиск из допустимой точки и ведущих его по соседним точкам, так как вычисление целевой функции в системе окрестностей, состоящей из соседних точек, не дает информации о наилучшем направлении поиска. При решении практических задач больших размерностей это множество постоянства может быть таким, что ему принадлежит большая часть точек допустимой области.
Рассматриваются возможности улучшения алгоритмов поиска закономерностей. Проводится экспериментальное исследование на практических задачах распознавания. Результаты экспериментов показывают, что использование информации о близости объектов выборки к закономерности позволяет преодолеть трудности, связанные с характерными особенностями решаемой задачи оптимизации и проявляющиеся в наличии множеств постоянства, и находить лучшие закономерности в данных для их использования в решении задач распознавания.
Ключевые слова: классификация, логические закономерности, псевдобулевая оптимизация.
Vestnik SibGAU Vol. 16, No. 1, P. 16-21
DETECTION OF PATTERNS IN DATA FOR RECOGNITION OF OBJECTS AS A CONDITIONAL PSEUDO-BOOLEAN OPTIMIZATION PROBLEM
A. N. Antamoshkin, I. S. Masich
Siberian State Aerospace University named after academician M. F. Reshetnev 31, Krasnoyarsky Rabochy Av., Krasnoyarsk, 660014, Russian Federation E-mail: i-masich@yandex.ru
Creating and using logical classification algorithms are based on revealing patterns in the input data, and a decision function is formed from a set of these patterns. Search for patterns can be viewed as a combinatorial optimization problem. To produce the most effective solutions, the choice of the optimization algorithm should be made on the basis of the characteristic properties inherent in the considered optimization problem. In this paper we consider some properties of optimization problems that are solved in the course offinding logical patterns in the data.
We consider the recognition problem for objects described by binary attributes and divided into two classes. Regularities are the elementary blocks for construction logical recognition algorithms.
The problem of finding the maximum patterns can be written in the form of a constrained pseudo-Boolean optimization problem. We study the properties of the optimization model, which describes the search for logical patterns in the data.
Research results show that in the search space there is a set of constancy of the objective function. This hampers performance of the optimization algorithms, which begin the search from a feasible point and leading it to neighboring points, since the calculation of the objective function in the system of neighborhoods consisting of neighboring points, gives no information on best search direction. While solving practical problems of large dimension, this set of constancy may own most of the points of the feasible region.
We consider the possibilities of improving algorithms of search for patterns. Experimental investigations were conducted on the real-world recognition problems. Experimental results show that the use of information about the proximity of the sample objects to patterns can overcome the difficulties associated with the characteristic features of optimization problem solved and manifested in the presence of constancy sets. And this allows finding the best patterns in the data to use them in solving the recognition problems.
Keywords: classification, logical patterns, pseudo-Boolean optimization
Введение. Среди множества подходов к распознаванию образов можно выделить группу методов, основанных на выявлении закономерностей в наборах исходных данных и использовании этих закономерностей для формирования решающих правил. Эти закономерности представляют собой логические условия, связывающие комбинации значений некоторых признаков, описывающих объекты распознавания, с определенным классом объектов. Описываемый и схожие подходы с успехом применяются для решения практических задач распознавания, в том числе и в аэрокосмической отрасли [1-4].
Создание и использование логических алгоритмов классификации основывается на выявлении в исходных данных закономерностей, из набора которых формируется решающая функция. Поиск закономерностей можно рассматривать как задачу комбинаторной оптимизации. Для получения более эффективного решения выбор алгоритма оптимизации следует производить исходя из характерных свойств, присущих рассматриваемой оптимизационной задаче. В данной работе рассматриваются некоторые свойства задач оптимизации, решаемых в ходе поиска логических закономерностей в данных.
Ограничимся рассмотрением задачи распознавания объектов, описываемых бинарными признаками и разделенных на два класса К = К+ и К~ с Б, , где Б, = {0,1}, Б, = Б2 х Б2 х • • • х Б2. При этом классы не
пересекаются: К+ п К~ = 0. Объект X е К описывается бинарным вектором X = (х1,х2, …,хп) и может быть представлен как точка в гиперкубе пространства бинарных признаков Б,. Объекты класса К+ будем
называть положительными точками выборки К, а объекты класса К- — отрицательными точками выборки.
Рассмотрим подмножество точек из Б,, у которых некоторые переменные фиксированы и одинаковы, а остальные принимают произвольное значение
Т = {х е Б, |хг- = 1 для V/ е А и х/ = 0 для V/ е Б}
для некоторых подмножеств А, Б с {1, 2, …, п}, А п Б = 0. Это множество может быть также определено в виде булевой функции, принимающей истинное значение для элементов множества:
t (х) = ( Л х/ ) Л ( Л х/ ) .
/еА /еБ
Этот терм выделяет подкуб в булевом гиперкубе Б,, число точек подкуба равно 2(п~|АНБ|).
Будем считать, что терм t покрывает точку а е Б, , если t(а) = 1, т. е. эта точка принадлежит соответствующему подкубу.
Под закономерностью Р (или правилом) в данном случае понимается терм, который покрывает хотя бы один объект некоторого класса и не покрывает ни одного объекта другого класса [5]. То есть закономерность соответствует подкубу, имеющему непустое пересечение с одним из множеств (К+ или К) и пустое пересечение с другим множеством (К- или К+ соответственно). Закономерность Р, которая не пересекается с К-, будем называть положительной, а закономерность Р’, которая не пересекается с К+, — отрицательной. В дальнейшем, для определенности, будем рассматривать только положительные закономерности.
Закономерности являются элементарными блоками для построения логических алгоритмов распознавания [6-8]. Наиболее полезными для этой цели являются закономерности с наибольшим покрытием (максимальные закономерности), т. е. такие, для которых | Р п К+ | максимально [9].
Один из путей в составлении набора закономерностей для алгоритма распознавания — это поиск закономерностей, опирающихся на значения признаков конкретных объектов.
Поиск максимальных закономерностей. Выделим некоторый объект а е К+. Обозначим Ра закономерность, покрывающую точку а. Те переменные, которые зафиксированы в Ра, равны соответствующим значениям признаков объекта а.
Для задания закономерности Ра введем бинарные переменные У = (ух,у2, …,уп):
11, если /-й признак фиксирован в Ра;
У/ |
[0, в противном случае.
Отметим, что если /-й признак фиксирован в Ра (т. е. у/ = 1), то он обязательно равен а/ (иначе эта закономерность не будет покрывать базовый объект а). При У = (1, 1, …, 1) закономерность покрывает лишь сам базовый объект а (и полностью совпадающие с ним объекты), но не покрывает ни один объект, отличающийся значением хотя бы одного признака.
Некоторая точка Ь е К будет покрываться закономерностью Ра только в том случае, если уг = 0 для всех 1, для которых Ьг Ф аг. С другой стороны, некоторая точка се К не будет покрываться закономерностью Ра в том случае, если у, = 1 хотя бы для одной переменной 1, для которой с, Ф а.
Таким образом, задачу нахождения максимальной закономерности можно записать в виде задачи поиска таких значений У = (у1, у2, …, уП), при которых получаемая закономерность Ра покрывает как можно больше точек Ь е К и не покрывает ни одной точки с е К- [10]:
_ П
Е П (1 — Уг ) ^ max,
ЬеК+ г =
Ь Фаг
П
Е уг ^ 1 для всех с е К- .
1=1 сг Фаг
Эта задача является задачей условной псевдобулевой оптимизации, т. е. задачей оптимизации, в которой целевая функция и функции, находящиеся в левой части ограничения, являются псевдобулевыми функциями — вещественными функциями булевых переменных.
Следует заметить, что любая точка У = (у1, у2, …, уП) соответствует подкубу в пространстве бинарных признаков X = (хьх2, …, хП), включающему в себя объект а. При У е Ок (У(т. е. У отличается от У1 значением к координат), где У1 = (1, 1, …, 1), число точек
этого подкуба равно 2к .
Основные понятия и свойства. Для исследования и описания свойств приведенной выше модели оптимизации изложим основные понятия и определения, связанные с построением алгоритмов псевдобулевой оптимизации [11]:
1. Точки X1, X2 е ВП назовем к-соседними, если они отличаются значением к координат, к = 1, п .
2. Множество Ок (X), к = 0, п , всех точек ВП, к-соседних к точке X, назовем к-м уровнем точки X.
3. Точку X е ВП назовем к-соседней множеству
А с В2П, если А пО^) Ф 0 и V/ = 0,к -1: А п О1 (X) = 0.
4. Точку X* е В2П , для которой / (X*) < /(X), VX е ), назовем локальным минимумом псевдобулевой функции /.
5. Псевдобулевую функцию, имеющую только один локальный минимум, будем называть унимодальной на В2П функцией.
6. Унимодальную функцию / назовем монотонной на В2П, если VXk е Ок (X*), к = 1П : /X-1) < /X), VXk-1 е Ок-1 (X*) п О1X).
7. Множество точек Щ.Ж0,X1) ={X0,X1, …,X1}сЩ назовем путем между точками X0 и X1, если V г = 1, …, 1 точка X1 является соседней к X1-1.
8. Путь Ж(X0,X1) с ВП между к-соседними точками X0 и X1 назовем кратчайшим, если 1 = к .
9. VX, У е ВП объединение всех кратчайших путей Ж(X, У) будем называть подкубом ВП и обозначать К (X, У).
Рассмотрим основные свойства множества допустимых решений задачи условной псевдобулевой оптимизации. Имеется задача следующего вида
C(X) ^ max
(1)
X eS с Б»
где С^) — монотонно возрастающая от X псевдо-булевая функция; £ с В2П — некоторая подобласть пространства булевых переменных, определяемая заданной системой ограничений, например:
A, (X) < H,, j = 1, m .
(2)
j v’ ~ j’
Введем ряд понятий для подмножества точек пространства булевых переменных [12]:
— точка Y e S является граничной точкой множества S, если существует X e O1 (Y), для которой
X g S;
— точку Y e Oi (X0) n S будем называть крайней точкой множества S с базовой точкой X0 e S , если VX e O (Y) П Oi +1 (X0) выполняется X g S;
— ограничение, определяющее подобласть пространства булевых переменных, будем называть активным, если оптимальное решение задачи условной оптимизации не совпадает с оптимальным решением соответствующей задачи оптимизации без учета ограничения.
Одно из свойств множества допустимых решений состоит в следующем: если целевая функция является монотонной унимодальной функцией, а ограничение активно, то оптимальным решением задачи (1) будет точка, принадлежащая подмножеству крайних точек множества допустимых решений S с базовой точкой X0, в которой целевая функция принимает наименьшее значение:
C (X0) = min C (X).
X eB»
Свойства множества допустимых решений. Рассмотрим отдельное ограничение
Aj (Y) > 1,
n
где Aj (Y) = £ y для всех С eKT, j = {1,2, …, |K-| }.
¿=1 cj *ai
Введем обозначение
11, если c- Ф ai; [0, если с/ = ai.
Aj (Y) = £ j.
Тогда
i=1
Функция Aj (Y) монотонно убывает от точки
Y1 = (1, 1, …, 1).
Крайними точками допустимой области являются точки Yk е On_1(Y1) (либо, что то же самое, Yk е O1(Y0)), причем такие, что Yk отличаются от Y0 = (0, 0, …, 0) значением k-й компоненты, при
которой zJk = 1.
Множеством допустимых решений является объединение подкубов, образуемых крайними точками допустимой области и точкой Y1:
U K (Yk, Y1).
t.zl =1
Теперь вернёмся ко всей системе ограничений
Aj (Y) > 1, для всех j = 1,2,…,| K_ |. Этой системе будут удовлетворять точки, принадлежащие множеству
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
П U K(Yk, Y1),
j=1 k :zk=1
которое, в конечном счете, является объединением конечного числа подкубов. Крайние точки допустимой области могут находиться на совершенно разных уровнях точки Y1. А их количество, в худшем случае, может достигать значения сПп/2], т. е. мощности срединного уровня.
«Двойственные» алгоритмы оптимизации, т. е. алгоритмы, начинающие поиск из недопустимой области (в данном случае, например, из точки Y0), приводят к поиску ближайших допустимых точек, которые зачастую имеют не очень высокие значения целевой функции, так как лучшие решения могут находиться на любом уровне Y0.
Свойства целевой функции. Рассмотрим целевую функцию
C (Y) = X П d _ Я)
beK+ i=1 bi *ai
для некоторого «базового» объекта а е K+. Либо можно записать
с (Y)=Хш (1 _ у,).
j=1 i=1
Функция C(X) монотонно возрастает от точки Y1 = (1, 1, …, 1), принимая в ней значение 1, что соответствует покрытию «базового» объекта а. Наибольшее значение, равное |k +1, функция C(X) принимает
в точке Y0 = (0, 0, …, 0).
Положим, что ближайший к объекту а объект b е K отличается значением s компонент:
п
s = min XI а, _ b, |.
beK + {a} ,=1
Во всех точках Y e Ok(Yk = 0, 1, …, s _ 1, значение целевой функции будет одинаковым и равным 1. Наличие такого множества постоянства затрудняет
работу алгоритмов оптимизации, начинающих поиск из допустимой точки У1 и ведущих его по соседним точкам, так как вычисление целевой функции в системе окрестностей, состоящей из соседних точек, не дает информации о наилучшем направлении поиска.
При решении практических задач больших размерностей это множество постоянства может быть таким, что ему принадлежит большая часть точек допустимой области. Это усложняет или делает невозможной работу таких алгоритмов, как генетический алгоритм, локальный поиск с мультистартом.
Поиск закономерностей по системе окрестностей. Некоторые алгоритмы поиска закономерностей путем решения задачи условной псевдобулевой оптимизации, приведенной выше, описаны в [13; 14]. Один из них — алгоритм поиска по соседним точкам -выглядит следующим образом.
Алгоритм 1.
1. Положим У = У1, г = 1.
2. Вычисляем С (У,) и А(Уу) для У, е 01(У) п Ог (У1), ] = 1, 2, …, п -1 +1.
3. Если нет Уj, для которых А (У,) = 1, то У * = У —
решение задачи.
4. Из тех У, , для которых A(Уj) = 1, находим
У = а^тш С (У,).
У ]
5. Положим г = г +1, перейти на шаг 2.
Обобщенная функция ограничения А (У) вычисляется следующим образом:
Ц если А, (У) > 1, для всех у = 1, 2, …, | К- |; А(У) = ‘ ■’ 1 1
[0, в другом случае.
Основная трудность, возникающая при наличии множеств постоянства, т. е. связанных множеств, в которых функция принимает одинаковое значение, состоит в отсутствии информации о том, в каком направлении следует вести поиск для получения оптимальных или субоптимальных решений. Это касается поведения функций С(У) и А(У) в пространстве бинарных переменных. Один из способов улучшить ситуацию — использовать информацию не только о покрытии закономерностью объектов выборки, но также использовать данные о расстоянии до непокрытых пока объектов.
Рассмотрим множество точек, задаваемое закономерностью Ра и некоторый объект Ь е К Ра. Естественный способ определить близость объекта Ь к Ра -это использовать номер уровня к, при котором
Ь е Ок (Ра). Величина г(Ра, Ь) = к определяет степень близости объекта Ь к множеству Ра .
Закономерность Ра, задаваемая переменными У = (у1, У2, •••, Уп), представляет собой подкуб в пространстве признаков X = (хь х2, • .., хп). Поэтому
величину г(Ра,Ь) можно вычислить как число фиксированных компонент в закономерности Ра, для которых значение соответствующего признака объекта Ь отличается от значения признака а:
r(pa, b) = £ у • | a, — ь, |.
Величина
Я + (Ра) = £ г (Ра, Ь)
ЬеК + Ра
показывает суммарную близость положительных объектов выборки, не покрывающихся закономерностью Ра к этой закономерности. Для множества объектов другого класса
Я — (Ра) = £ г (Ра, с).
е^К- Ра
Величины Я + (Ра) и Я — (Ра) могут использоваться при выборе направления при поиске. Например, последующую допустимую точку можно выбирать исходя из минимума отношения Я+ (Ра) / Я- (Ра).
Ниже приведен один из алгоритмов оптимизации, осуществляющий поиск по соседним точкам, который способен вести поиск во множестве постоянства целевой функции.
Алгоритм 2.
1. Положим У = У1, I = 1.
2. Вычисляем (У.)
Y. е Oi(Y) n O, (Yj = 1, 2,
и A(Yj)
n — i +1 .
для
3. Если нет Y:, для которых A(Yf) = 1, то Y = Y —
решение задачи.
4. Из тех , для которых Ау) = 1, находим
У = а^шш 5 (У,).
^ 3
5. Положим I = I +1, перейти на шаг 2. Здесь
если А,(У) > 1, для всех 3 = 1, 2, …, | К- |;
A(Y) =
10, в другом случае;
S (Y) =
R+ (Pa)
цательного) правила вычисляется как отношение числа покрываемых им положительных (отрицательных) объектов к общему числу положительных (отрицательных) объектов.
Сравнение правил
Задача Число Объем Покрытие Покрытие
переменных выборки правил, алгоритм 1 правил, алгоритм 2
breast- 9 / 80 699 0,5 0,65
cancer
wdbc 30 / 66 569 0,35 0,54
hepatitis 19 / 37 155 0,22 0,33
spect 22 / 22 80 0,14 0,16
infarction 112/216 338 0,04 0,12
R ‘ (Pa)
где P — закономерность, соответствующая Y.
Результаты. Проведено экспериментальное сравнение двух описанных выше алгоритмов поиска правил на ряде задач распознавания [15; 16]. Решались следующие задачи распознавания (в скобках приведено краткое обозначение задачи, используемое при описании результатов): диагностика рака молочной железы (breast-cancer, wdbc); диагностика наследственного гипатита (hepatitis); данные по сердечной компьютерной томографии (spect); диагностика осложнений инфаркта миокарда — фибрилляция предсердий (infarction).
Результаты получены с помощью разработанного авторами программного обеспечения [17; 18]. Результаты представлены в таблице. Для каждой задачи в таблице приведено число переменных (число исходных признаков / число переменных, полученное в результате бинаризации исходных признаков); объем выборки (число наблюдений); среднее покрытие правил, найденных алгоритмами (число правил равно объему выборки). Покрытие положительного (отри-
Заключение. Результаты экспериментов показывают, что использование близости объектов выборки к закономерности позволяет преодолеть трудности, связанные с характерными особенностями решаемой задачи оптимизации и проявляющиеся в наличии множеств постоянства, и находить лучшие закономерности в данных для их использования в решении задач распознавания.
Библиографические ссылки
1. Dupuis C., Gamache M., Page J. F. Logical analysis of data for estimating passenger show rates in the airline industry // Journal of Air Transport Management. 2012. № 18. P. 78-81.
2. Hammer P. L., Bonates T. O. Logical analysis of data — An overview: From combinatorial optimization to medical applications // Annals of Operations Research 2006. 148.
3. Esmaeili S. Development of equipment failure prognostic model based on logical analysis of data : Master of Applied Science Thesis. Dalhousie University, Halifax, Nova Scotia, 2012.
4. An implementation of logical analysis of data / E. Boros [et al.] // IEEE Trans. on Knowledge and Data Engineering. 2000. 12. P. 292-306.
5. Hammer P. L. The Logic of Cause-effect Relationships // Lecture at the International Conference on Multi-Attribute Decision via Operations Research-based Expert Systems. Passau, Germany : Universitat Passau, 1986.
6. Pareto-optimal patterns in logical analysis of data / P. L. Hammer [et al.] // Discrete Applied Mathematics. 2004. № 144(1). P. 79-102.
7. Alexe G., Hammer P. L. Spanned patterns for the logical analysis of data // Discrete Appl. Math. 2006. Т. 154. P. 1039-1049.
8. Guoa C., Ryoo H. S. Compact MILP models for optimal and Pareto-optimal LAD patterns // Discrete Applied Mathematics. 2012. Т. 160. P. 2339-2348.
9. The maximum box problem and its application to data analysis / J. Eckstein [et al.] // Computational Optimization and Applications. 2002. Т. 23. P. 285-298.
i=i
10. Bonates T. O., Hammer P. L., Kogan A. Maximum Patterns in Datasets // Discrete Applied Mathematics. 2008. Vol. 156. No. 6. P. 846-861.
11. Антамошкин А. Н. Регулярная оптимизация псевдобулевых функций. Красноярск : Изд-во Красноярского ун-та, 1989. 284 с.
12. Antamoshkin A. N., Masich I. S. Pseudo-Boolean optimization in case of unconnected feasible sets // Models and Algorithms for Global Optimization. Series: Springer Optimization and Its Applications. Springer. 2007. Vol. 4. P. 111-122.
13. Антамошкин А. Н., Масич И. С. Эффективные алгоритмы условной оптимизации монотонных псевдобулевых функций // Вестник СибГАУ. 2003. Вып. 4. С. 60-67.
14. Масич И. С. Приближенные алгоритмы поиска граничных точек для задачи условной псевдобулевой оптимизации // Вестник СибГАУ. 2006. Вып. 1(8). С. 39-43.
15. Bache K., Lichman M. UCI Machine Learning Repository. Irvine, CA : University of California, School of Information and Computer Science, 2013. URL: http://archive.ics.uci.edu/ml.
16. Осложнения инфаркта миокарда: база данных для апробации систем распознавания и прогноза / С. Е. Головенкин [и др.] // Препринт. 1997. № 6. Красноярск: Вычислительный центр СО РАН.
17. Модель логического анализа для решения задачи прогнозирования осложнений инфаркта миокарда / С. Е. Головенкин [и др.] // Вестник СибГАУ. 2010. Вып. 4(30). С. 68-73.
18. Логический анализ данных в задачах классификации : свидетельство о государственной регистрации программы для ЭВМ / И. С. Масич, Р. И. Кузьмич, Е. М. Краева. № 2011612265. 2011.
References
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
1. Dupuis C., Gamache M., Page J. F. Logical analysis of data for estimating passenger show rates in the airline industry, Journal of Air Transport Management 18, 2012. P. 78-81.
2. Hammer P. L., Bonates T. O. Logical analysis of data — An overview: From combinatorial optimization to medical applications. Annals of Operations Research 148, 2006.
3. Esmaeili S. Development of equipment failure prognostic model based on logical analysis of data, Master of Applied Science Thesis, Dalhousie University, Halifax, Nova Scotia, July 2012.
4. Boros E., Hammer P. L., Ibaraki T., Kogan A., Mayoraz E., Muchnik I. An implementation of logical analysis of data, IEEE Trans. on Knowledge and Data Engineering 12, 2000. P. 292-306.
5. Hammer P. L. The Logic of Cause-effect Relationships. Lecture at the International Conference on Multi-Attribute Decision via Operations Research-based Expert Systems. Passau, Germany : Universitat Passau, 1986.
6. Hammer P. L., Kogan A., Simeone B., Szedmak S. Pareto-optimal patterns in logical analysis of data.
Discrete Applied Mathematics, 2004, vol. 144, no. 1, p. 79-102.
7. Alexe G., Hammer P. L. Spanned patterns for the logical analysis of data, Discrete Appl. Math. 2006, vol. 154, p. 1039-1049.
8. Guoa C., Ryoo H. S. Compact MILP models for optimal and Pareto-optimal LAD patterns, Discrete Applied Mathematics, 2012, vol. 160, p. 2339-2348.
9. Eckstein J., Hammer P. L., Liu Y., Nediak M., Simeone B. The maximum box problem and its application to data analysis. Computational Optimization and Applications. 2002, vol. 23, p. 285-298.
10. Bonates T. O., Hammer P. L., Kogan A. Maximum Patterns in Datasets. Discrete Applied Mathematics, 2008, vol. 156, no. 6, p. 846-861.
11. Antamoshkin A. N. Regulyarnaya optimizatsiya psevdobulevykh funktsiy. [Regular optimization of pseudo-functions]. Krasnoyarsk, Izd-vo Krasnoyarskogo un-ta Publ., 1989, 284 p.
12. Antamoshkin A. N., Masich I. S. Pseudo-Boolean optimization in case of unconnected feasible sets. Models and Algorithms for Global Optimization. Series: Springer Optimization and Its Applications. Springer, 2007, vol. 4, p. 111-122.
13. Antamoshkin A. N., Masich I. S. [Efficient algorithms for constrained optimization pseudo-monotone functions]. Vestnik SibGAU. 2003, no. 4, p. 60-67 (In Russ.).
14. Masich I. S. [The heuristic algorithms of boundary points search for an constraint pseudo-boolean optimization problem.] Vestnik SibGAU. 2006, no. 1(8), p. 39-43. (In Russ.)
15. Bache K., Lichman M. UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science, 2013. Available at: http://archive.ics.uci.edu/ml.
16. Golovenkin S. Е. et al. Oslozhneniya infarkta miokarda: baza dannykh dlya aprobatsii sistem raspoznavaniya i prognoza [Complications of myocardial infarction: a database for testing recognition systems and forecasting]. Krasnoyarsk, Vychislitel’nyy tsentr SO RAN, Preprint no. 6, 1997 (In Russ.).
17. Golovenkin S. Е. et al. [Model of logical analysis for solving problem of prognosis of myocardial infarction complication]. Vestnik SibGAU. 2010, no. 4(30), p. 68-73 (In Russ.).
18. Masich I. S., Kuzmich R. I., Kraeva E. M.
Logicheskiy analiz dannykh v zadachakh klassifikatsii. Svidetel’stvo gosudarstvennoy registratsii programmy dlya EVM №2011612265 [Logical analysis of data in classification problems. Certificate of state registration of the computer № 2011612265]. SibGAU, 2011 (In Russ.).
© Антамошкин А. Н., Масич И. С., 2015