What Is the Coefficient of Determination?
The coefficient of determination is a statistical measurement that examines how differences in one variable can be explained by the difference in a second variable when predicting the outcome of a given event. In other words, this coefficient, more commonly known as r-squared (or r2), assesses how strong the linear relationship is between two variables and is heavily relied on by investors when conducting trend analysis.
This coefficient generally answers the following question: If a stock is listed on an index and experiences price movements, what percentage of its price movement is attributed to the index’s price movement?
Key Takeaways
- The coefficient of determination is a complex idea centered on statistical analysis of data and financial modeling.
- The coefficient of determination is used to explain the relationship between an independent and dependent variable.
- The coefficient of determination is commonly called r-squared (or r2) for the statistical value it represents.
- This measure is represented as a value between 0.0 and 1.0, where a value of 1.0 indicates a perfect correlation. Thus, it is a reliable model for future forecasts, while a value of 0.0 suggests that asset prices are not a function of dependency on the index.
R-Squared
Understanding the Coefficient of Determination
The coefficient of determination is a measurement used to explain how much the variability of one factor is caused by its relationship to another factor. This correlation is represented as a value between 0.0 and 1.0 (0% to 100%).
A value of 1.0 indicates a 100% price correlation and is thus a reliable model for future forecasts. A value of 0.0 suggests that the model shows that prices are not a function of dependency on the index.
So, a value of 0.20 suggests that 20% of an asset’s price movement can be explained by the index, while a value of 0.50 indicates that 50% of its price movement can be explained by it, and so on.
The coefficient of determination is the square of the correlation coefficient, also known as «r» in statistics. The value «r» can result in a negative number, but because r-squared is the result of «r» multiplied by itself (or squared), r2 cannot result in a negative number—regardless of what is found on the internet—the square of a negative number is always a positive value.
Calculating the Coefficient of Determination
To calculate the coefficient of determination. This is done by creating a scatter plot of the data and a trend line.
For instance, if you were to plot the closing prices for the S&P 500 and Apple stock (Apple is listed on the S&P 500) for trading days from Dec. 21, 2022, to Jan. 20, 2023, you’d collect the prices as shown in the table below.
| S&P Daily Close | APPL Daily Close | |
|---|---|---|
| Jan. 20 | $3,972.61 | $137.87 |
| 19 | $3,898.85 | $135.27 |
| 18 | $3,928.86 | $135.21 |
| 17 | $3,990.97 | $135.94 |
| 13 | $3,999.09 | $134.76 |
| 12 | $3,983.17 | $133.41 |
| 11 | $3,969.61 | $133.49 |
| 10 | $3,919.25 | $130.73 |
| 9 | $3,892.09 | $130.15 |
| 6 | $3,895.08 | $129.62 |
| 5 | $3,808.10 | $125.02 |
| 4 | $3,852.97 | $126.36 |
| 3 | $3,824.14 | $125.07 |
| Dec. 30 | $3,839.50 | $139.93 |
| 29 | $3,849.28 | $129.61 |
| 28 | $3,783.22 | $126.04 |
| 27 | $3,829.25 | $130.03 |
| 23 | $3,844.82 | $131.86 |
| 22 | $3,822.39 | $132.23 |
| 21 | $3,878.44 | $135.45 |
Then, you’d create a scatter plot. On a graph, how well the data fits the regression model is called the goodness of fit, which measures the distance between a trend line and all of the data points that are scattered throughout the diagram.
Spreadsheets
Most spreadsheets use the same formula to calculate the r2 of a dataset. So, if the data reside in columns A and B on your sheet:
= RSQ ( A1 : A10 , B1 : B10 )
Using this formula and highlighting the corresponding cells for the S&P 500 and Apple prices, you get an r2 of 0.347, suggesting that the two prices are less correlated than if the r2 was between 0.5 and 1.0.
Manual Calculation
Calculating the coefficient of determination by hand involves several steps. First, you gather the data as in the previous table. Second, you need to calculate all the values you need, as shown in this table, where:
- x= S&P 500 daily close
- y = APPL daily close
| x | x2 | y | y2 | xy | |
|---|---|---|---|---|---|
| Jan. 20 | $3,972.61 | $15,781,630.21 | $137.87 | $19,008.14 | $547,703.74 |
| 19 | $3,898.85 | $15,201,031.32 | $135.27 | $18,297.97 | $527,397.44 |
| 18 | $3,928.86 | $15,435,940.90 | $135.21 | $18,281.74 | $531,221.16 |
| 17 | $3,990.97 | $15,927,841.54 | $135.94 | $18,479.68 | $542,532.46 |
| 13 | $3,999.09 | $15,992,720.83 | $134.76 | $18,160.26 | $538,917.37 |
| 12 | $3,983.17 | $15,865,643.25 | $133.41 | $17,798.23 | $531,394.71 |
| 11 | $3,969.61 | $15,757,803.55 | $133.49 | $17,819.58 | $529,903.24 |
| 10 | $3,919.25 | $15,360,520.56 | $130.73 | $17,090.33 | $512,363.55 |
| 9 | $3,892.09 | $15,148,364.57 | $130.15 | $16,939.02 | $506,555.51 |
| 6 | $3,895.08 | $15,171,648.21 | $129.62 | $16,801.34 | $504,880.27 |
| 5 | $3,808.10 | $14,501,625.61 | $125.02 | $15,630.00 | $476,088.66 |
| 4 | $3,852.97 | $14,845,377.82 | $126.36 | $15,966.85 | $486,861.29 |
| 3 | $3,824.14 | $14,624,046.74 | $125.07 | $15,642.50 | $478,285.19 |
| Dec. 30 | $3,839.50 | $14,741,760.25 | $139.93 | $19,580.40 | $537,261.24 |
| 29 | $3,849.28 | $14,816,956.52 | $129.61 | $16,798.75 | $498,905.18 |
| 28 | $3,783.22 | $14,312,753.57 | $126.04 | $15,886.08 | $476,837.05 |
| 27 | $3,829.25 | $14,663,155.56 | $130.03 | $16,907.80 | $497,917.38 |
| 23 | $3,844.82 | $14,782,640.83 | $131.86 | $17,387.06 | $506,977.97 |
| 22 | $3,822.39 | $14,610,665.31 | $132.23 | $17,484.77 | $505,434.63 |
| 21 | $3,878.44 | $15,042,296.83 | $135.45 | $18,346.70 | $525,334.70 |
| Sum (Σ) | $77,781.69 | $302,584,424.00 | $2,638.05 | $348,307.23 | $10,262,772.73 |
Next, use this formula and substitute the values for each row of the table, where n equals the number of samples taken, in this case, 20:
r
2
=
(
n
(
∑
x
y
)
−
(
∑
x
)
(
∑
y
)
[
n
∑
x
2
−
(
∑
x
)
2
]
×
[
n
∑
y
2
−
(
∑
y
)
2
]
)
2
begin{aligned}&r ^ 2 = Big ( frac {n ( sum xy) — ( sum x )( sum y ) }{ sqrt { [ n sum x ^ 2 — ( sum x ) ^ 2 ] } times sqrt { [ n sum y ^ 2 — ( sum y ) ^ 2 ] } } Big ) ^ 2 \end{aligned}
r2=([n∑x2−(∑x)2]×[n∑y2−(∑y)2]n(∑xy)−(∑x)(∑y))2
Where √ represents the square root of the product in the brackets that follow it.
r
2
=
(
20
(
10
,
262
,
772.73
)
−
(
77
,
781.69
)
(
2
,
638.05
)
[
20
(
302
,
584
,
424
)
−
(
77
,
781.69
)
2
]
×
[
20
(
348
,
307.23
)
−
(
2
,
638.05
)
2
]
)
2
begin{aligned}&r ^ 2 = Big ( tiny { frac {20 ( 10,262,772.73) — ( 77,781.69 )( 2,638.05 ) }{ sqrt { [ 20 ( 302,584,424 ) — ( 77,781.69 ) ^ 2 ] } times sqrt { [ 20 ( 348,307.23 ) — ( 2,638.05 ) ^ 2 ] } } } Big ) ^ 2 \end{aligned}
r2=([20(302,584,424)−(77,781.69)2]×[20(348,307.23)−(2,638.05)2]20(10,262,772.73)−(77,781.69)(2,638.05))2
So you now have:
1.
(
20
×
10
,
262
,
772.73
)
−
(
77
,
781.69
×
2
,
638.05
)
=
63
,
467.32
2.
(
(
20
×
302
,
584
,
424
)
−
(
77
,
781.69
)
2
=
1
,
697
,
180.74
=
1
,
302.76
3.
(
(
20
×
10
,
262
,
772.73
)
−
(
2
,
638.05
)
2
=
6
,
836.85
=
82.69
begin{aligned}&1. tiny { ( 20 times 10,262,772.73 ) — ( 77,781.69 times 2,638.05 ) = 63,467.32 } \&2. tiny { (sqrt { ( 20 times 302,584,424 ) — ( 77,781.69 ) ^ 2 } = sqrt { 1,697,180.74 } = 1,302.76 } \&3. tiny { (sqrt { ( 20 times 10,262,772.73 ) — ( 2,638.05 ) ^ 2 } = sqrt { 6,836.85 } = 82.69 }\end{aligned}
1.(20×10,262,772.73)−(77,781.69×2,638.05)=63,467.322.((20×302,584,424)−(77,781.69)2=1,697,180.74=1,302.763.((20×10,262,772.73)−(2,638.05)2=6,836.85=82.69
Then, multiply steps two and three, divide step one by the result, and square it:
(
63
,
467.32
1
,
302.76
×
82.69
)
2
=
0.347
begin{aligned}&Big ( frac { 63,467.32 }{ 1,302.76 times 82.69 } Big ) ^ 2 = 0.347end{aligned}
(1,302.76×82.6963,467.32)2=0.347
You can see how this can become very tedious with lots of room for error, especially, if you’re using more than a few weeks of trading data.
Interpreting the Coefficient of Determination
Once you have the coefficient of determination, you use it to evaluate how closely the price movements of the asset you’re evaluating correspond to the price movements of an index or benchmark. In the Apple and S&P 500 example, the coefficient of determination for the period was 0.347.
Because 1.0 demonstrates a high correlation and 0.0 shows no correlation, 0.357 shows that Apple stock price movements are somewhat correlated to the index.
Apple is listed on many indexes, so you can calculate the r2 to determine if it corresponds to any other indexes’ price movements.
One aspect to consider is that r-squared doesn’t tell analysts whether the coefficient of determination value is intrinsically good or bad. It is their discretion to evaluate the meaning of this correlation and how it may be applied in future trend analyses.
How Do You Interpret a Coefficient of Determination?
The coefficient of determination shows how correlated one dependent and one independent variable are. Also called r2 (r-squared), the value should be between 0.0 and 1.0. The closer to 0.0, the less correlated the dependent value is. The closer to 1.0, the more correlated the value is.
What Does R-Squared Tell You in Regression?
It tells you whether there is a dependency between two values and how much dependency one value has on the other.
What If the Coefficient of Determination Is Greater Than 1?
The coefficient of determination cannot be more than one because the formula always results in a number between 0.0 and 1.0. If it is greater or less than these numbers, something is not correct.
The Bottom Line
The coefficient of determination is a ratio that shows how dependent one variable is on another variable. Investors use it to determine how correlated an asset’s price movements are with its listed index.
When an asset’s r2 is closer to zero, it does not demonstrate dependency on the index; if its r2 is closer to 1.0, it is more dependent on the price moves the index makes.
R-квадрат (R2 или Коэффициент детерминации) — это статистическая мера, которая показывает степень вариации зависимой переменной из-за независимой переменной. В инвестировании он действует как полезный инструмент для технического анализа. Он оценивает эффективность ценной бумаги или фонда (зависимая переменная) по отношению к заданному эталонному индексу (независимая переменная).

В отличие от корреляции (R), которая измеряет силу связи между двумя переменными, R-квадрат указывает на изменение данных, объясняемое связью между независимой переменной. Независимая переменная. Независимая переменная — это объект, период времени или входное значение, изменения которого используется для оценки влияния на выходное значение (т. е. конечную цель), которое измеряется в математическом, статистическом или финансовом моделировании. Подробнее и зависимая переменная. Значение R2 находится в диапазоне от 0 до 1 и выражается в процентах. В финансах он указывает процент, на который ценные бумаги перемещаются в ответ на движение индекса. Чем выше значение R-квадрата, тем синхроннее движение ценных бумаг с индексом и наоборот. В результате это помогает инвесторам отслеживать свои инвестиции.
Оглавление
- Значение R-квадрата
- Формула R-квадрата
- Примеры расчета
- Пример №1
- Пример #2
- Интерпретация R-квадрата
- R-квадрат против скорректированного R-квадрата
- R против R-квадрат
- Часто задаваемые вопросы (FAQ)
- Рекомендуемые статьи
- R-квадрат измеряет степень движения зависимой переменной (акции или фонды) по отношению к независимой переменной (эталонный индекс).
- Это помогает узнать производительность ценной бумаги по эталонному индексу.
- Чем выше значение R2, тем больше зависимость зависимой переменной от независимой переменной и наоборот.
- Значения R2 представлены в процентах в диапазоне от 1 до 100 процентов.
- R, R2 и скорректированный R2 — это разные термины в статистике. R представляет собой корреляцию между переменными, R2 указывает на изменение данных, объясняемое корреляцией, а скорректированный R2 учитывает другие переменные.
Формула R-квадрата
Чтобы добраться до R2, сделайте следующее:
1. Определите коэффициент корреляцииКоэффициент корреляцииКоэффициент корреляции, иногда называемый коэффициентом взаимной корреляции, представляет собой статистическую меру, используемую для оценки силы взаимосвязи между двумя переменными. Его значения варьируются от -1,0 (отрицательная корреляция) до +1,0 (положительная корреляция). читать дальше (р)

где,
- n = количество наблюдений
- Σx = общее значение независимой переменной
- Σy = общее значение зависимой переменной
- Σxy = сумма произведения независимой и зависимой переменных
- Σx2 = сумма квадратов значения независимой переменной
- Σy2 = сумма квадратов значения зависимой переменной
2. Возведите в квадрат коэффициент корреляции (R)

Значение R2 лежит в диапазоне от 0 до 1. Это означает, что если значение равно 0, независимая переменная не объясняет изменения зависимой переменной. Однако значение 1 показывает, что независимая переменная прекрасно объясняет изменение зависимой переменной. Обычно R2 выражается в процентах для удобства.
Примеры расчета
Вот несколько примеров, чтобы прояснить концепцию R-квадрата.
Пример №1
Выясним зависимость между количеством статей, написанных журналистами в месяц, и их многолетним стажем. Здесь зависимая переменная (y) — количество написанных статей, а независимая переменная (x) — количество лет опыта.
Сначала найдите коэффициент корреляции (R), а затем возведите его в квадрат, чтобы получить коэффициент детерминацииКоэффициент детерминацииКоэффициент детерминации, также известный как R в квадрате, определяет степень дисперсии зависимой переменной, которую можно объяснить независимой переменной. Следовательно, чем выше коэффициент, тем лучше уравнение регрессии, так как это означает, что независимая переменная выбрана с умом. Подробнее или R2. Вот данные.



R2 = 0,932 = 0,8649
Следовательно, коэффициент детерминации составляет 86%. Это означает, что 86% различий в количестве написанных статей объясняются многолетним опытом автора.
Пример #2
Предположим, инвестор хочет контролировать свой портфель, просматривая индекс S&P. Поэтому он хочет знать корреляцию между доходностью своего портфеля. Доходность портфеля. Формула доходности портфеля вычисляет доходность всего портфеля, состоящего из различных отдельных активов. Формула рассчитывается путем вычисления рентабельности инвестиций в отдельный актив, умноженной на соответствующую весовую категорию в общем портфеле, и сложения всех результатов вместе. Rp = ∑ni=1 wi riчитать далее и эталонный индекс. Итак, он вычисляет R и R-квадрат. Высокое значение R-квадрата указывает на то, что портфель движется подобно индексу.
Вот список доходности портфеля, представленной зависимой переменной (y), и доходности эталонного индекса, обозначенной независимой переменной (x).

Наконец, R2 рассчитывается по формуле:


Р2 = [0.8759 ]2
= 0,7672
Значение R2 подразумевает, что вариация доходности портфеля на 76,72% соответствует индексу S&P. Таким образом, инвестор может отслеживать движения своего портфеля, следя за индексом.
Интерпретация R-квадрата
R-квадрат измеряет влияние изменения независимой переменной на изменение зависимой переменной. На фондовых рынках это процент, на который ценные бумаги изменяются в ответ на движение эталонного индекса, такого как индекс S&P.
Если кто-то хочет, чтобы портфель ценных бумаг синхронизировался с эталонным индексом, он должен иметь высокое значение R2. Однако, если кто-то хочет, чтобы эталонный тест не влиял на производительность портфеля ценных бумаг, ему нужно искать портфель с низким значением R2.
Другими словами, если значение R2 находится в диапазоне:
- 70-100 %, тогда портфель ценных бумаг имеет наибольшую связь с движением и доходностью эталонных индексов.
- 40-70%, то соотношение между доходностью портфеля и доходностью эталонных индексов среднее
- 1-40%, то связь между доходностью портфеля и доходностью эталонного индекса очень мала или отсутствует.
R-квадрат против скорректированного R-квадрата
И R2, и скорректированный R2 используются для измерения корреляции между зависимой переменной и независимой переменной. С одной стороны, R2 представляет собой процент дисперсии зависимой переменной, описываемой независимой переменной. С другой стороны, скорректированный R2 представляет собой пересмотренную версию R-квадрата, скорректированную с учетом количества используемых независимых переменных.
Скорректированный R-квадрат Скорректированный R-квадрат Скорректированный R-квадрат относится к статистическому инструменту, который помогает инвесторам измерять степень дисперсии зависимой переменной, которая может быть объяснена независимой переменной, и учитывает влияние только тех независимых переменных, которые оказывают влияние на изменение зависимой переменной. Читать далее обеспечивает более точную корреляцию между переменными, учитывая влияние всех независимых переменных на функцию регрессии. В результате легко определить точные переменные, влияющие на корреляцию. Кроме того, это помогает узнать, какие переменные более важны, чем другие.
R-квадрат имеет тенденцию к увеличению при добавлении независимых переменных в набор данных. Однако скорректированный R2 может устранить этот недостаток. Следовательно, всякий раз, когда добавленные переменные несущественны или отрицательны, скорректированное значение R2 соответственно уменьшается или корректируется. Следовательно, можно сказать, что скорректированный R2 более надежен, чем R2.
R против R-квадрат
R или коэффициент корреляции — это термин, который передает прямую связь между любыми двумя переменными, такими как доходность и риск ценной бумаги. Диапазон R составляет от -1 до 1. Отрицательное значение указывает на обратную связь, а +1 указывает на прямую связь между переменными.
R2 используется в наборе данных, который содержит несколько переменных с различными свойствами, такими как риск, доходность, процентная ставка и срок погашения ценных бумаг. Диапазон R2 составляет от 0 до 1, где 0 — плохой показатель, а 1 — отличный.
Часто задаваемые вопросы (FAQ)
Что означает R-квадрат?
В функции регрессии R2 означает меру взаимосвязи между зависимой и независимой переменными. Его также называют коэффициентом детерминации в статистике. В финансовой терминологии R2 представляет отношение безопасности портфеля к эталонному индексу. Более высокое значение R2 означает, что эталонный индекс представляет производительность портфеля ценных бумаг и наоборот.
Что такое идеальное значение R-квадрата?
Значение R2 находится в диапазоне от 0 до 1 и выражается в процентах. Более высокий процент, близкий к 100%, указывает на то, что независимая переменная, выбранная для определения зависимой переменной, является идеальной, и наоборот. При инвестировании желательным считается значение R2 70% и более.
Как рассчитывается R-квадрат?
R2 можно рассчитать по следующей формуле:
где n — количество наблюдений, x — независимая переменная, а y — зависимая переменная.
Рекомендуемые статьи
Эта статья была руководством по R-Squared и его значению. Здесь мы обсуждаем формулу R-Squared, интерпретацию значений в регрессии, примеры и различия с R. Вы можете узнать больше об экономике из следующих статей:
- Эконометрика
- Формула множественной регрессии
- Нелинейная регрессия
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
- Среднеквадратичная ошибка (Mean Squared Error)
- Корень из среднеквадратичной ошибки (Root Mean Squared Error)
- Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error)
- Cредняя абсолютная ошибка (Mean Absolute Error)
- Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error)
- Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error)
- Средняя абсолютная масштабированная ошибка (Mean absolute scaled error)
- Средняя относительная ошибка (Mean Relative Error)
- Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error
- R-квадрат
- Скорректированный R-квадрат
- Сравнение метрик
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
frac{partial RMSE}{partial widehat{y}_{i}}=frac{1}{2sqrt{MSE}}frac{partial MSE}{partial widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=frac{100}{n}sumlimits_{i=1}^{n}left ( frac{y_{i}-widehat{y}_{i}}{y_{i}} right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=frac{1}{n}sumlimits_{i=1}^{n}left | y_{i}-widehat{y}_{i} right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{left | y_{i} right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{(left | y_{i} right |+left | widehat{y}_{i} right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=frac{1}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y}_{i}right |}{left | y_{i} right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(log(widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}/(n-k)}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
коэффициент детерминации (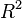 — R-квадрат) — это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости, то есть объясняющими переменными. Более точно — это единица минус доля необъясненной дисперсии (дисперсии случайной ошибки модели, или условной по факторам дисперсии зависимой переменной) в дисперсии зависимой переменной. Его рассматривают как универсальную меру зависимости одной случайной величины от множества других. В частном случае линейной зависимости является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели парной линейной регрессии коэффициент детерминации равен квадрату обычного коэффициента корреляции между y и x.
— R-квадрат) — это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости, то есть объясняющими переменными. Более точно — это единица минус доля необъясненной дисперсии (дисперсии случайной ошибки модели, или условной по факторам дисперсии зависимой переменной) в дисперсии зависимой переменной. Его рассматривают как универсальную меру зависимости одной случайной величины от множества других. В частном случае линейной зависимости является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели парной линейной регрессии коэффициент детерминации равен квадрату обычного коэффициента корреляции между y и x.
Содержание
- 1 Определение и формула
- 1.1 Интерпретация
- 2 Недостаток и альтернативные показатели
- 2.1 Скорректированный (adjusted)
- 2.2 Информационные критерии
- 2.3 -обобщенный (extended)
- 3 Замечание
- 4 Вау!! 😲 Ты еще не читал? Это зря!
- 5 Примечания
- 6 Ссылки
Определение и формула[править ]
Истинный коэффициент детерминации модели зависимости случайной величины y от факторов x определяется следующим образом:

где 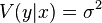 — условная (по факторам x) дисперсия зависимой переменной (дисперсия случайной ошибки модели).
— условная (по факторам x) дисперсия зависимой переменной (дисперсия случайной ошибки модели).
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):

где 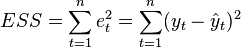 — сумма квадратов остатков регрессии,
— сумма квадратов остатков регрессии, 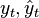 — фактические и расчетные значения объясняемой переменной.
— фактические и расчетные значения объясняемой переменной.
 — общая сумма квадратов.
— общая сумма квадратов.
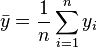
В случае линейной регрессии с константой 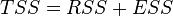 , где
, где 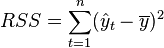 — объясненная сумма квадратов, поэтому получаем более простое определение в этом случае — коэффициент детерминации — это доля объясненной суммы квадратов в общей:
— объясненная сумма квадратов, поэтому получаем более простое определение в этом случае — коэффициент детерминации — это доля объясненной суммы квадратов в общей:
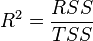
Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу.
Интерпретация[править ]
- Коэффициент детерминации для модели с константой принимает значения от 0 до 1 . Об этом говорит сайт https://intellect.icu . Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50 % (в этом случае коэффициент множественной корреляции превышает по модулю 70 %). Модели с коэффициентом детерминации выше 80 % можно признать достаточно хорошими (коэффициент корреляции превышает 90 %). Значение коэффициента детерминации 1 означает функциональную зависимость между переменными.
- При отсутствии статистической связи между объясняемой переменной и факторами, статистика
 для линейной регрессии имеет асимптотическое распределение , где — количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределенными случайными ошибками статистика имеет точное (для выборок любого объема) распределение Фишера (см. F- тест ). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
для линейной регрессии имеет асимптотическое распределение , где — количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределенными случайными ошибками статистика имеет точное (для выборок любого объема) распределение Фишера (см. F- тест ). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю. - В общем случае коэффициент детерминации может быть и отрицательным, это говорит о крайней неадекватности модели: простое среднее приближает лучше.
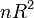 для линейной регрессии имеет асимптотическое распределение
для линейной регрессии имеет асимптотическое распределение 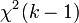 , где
, где 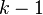 — количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределенными случайными ошибками статистика
— количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределенными случайными ошибками статистика 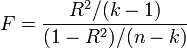 имеет точное (для выборок любого объема) распределение Фишера
имеет точное (для выборок любого объема) распределение Фишера 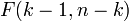 (см. F- тест ). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
(см. F- тест ). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.Недостаток и альтернативные показатели[править ]
Основная проблема применения (выборочного) заключается в том, что его значение увеличивается (не уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют! Поэтому сравнение моделей с разным количеством факторов с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели.
Скорректированный (adjusted) [править ]
Для того, чтобы была возможность сравнивать модели с разным числом факторов так, чтобы число регрессоров (факторов) не влияло на статистику обычно используется скорректированный коэффициент детерминации, в котором используются несмещенные оценки дисперсий:

который дает штраф за дополнительно включенные факторы, где n — количество наблюдений, а k — количество параметров.
Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве факторов). Поэтому теряется интерпретация показателя как «доли». Тем не менее, применение показателя в сравнении вполне обоснованно.
Для моделей с одинаковой зависимой переменной и одинаковым объемом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии 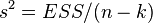 или стандартной ошибки модели
или стандартной ошибки модели  . Разница только в том, что последние критерии чем меньше, тем лучше.
. Разница только в том, что последние критерии чем меньше, тем лучше.
Информационные критерии[править ]
AIC — информационный критерий Акаике — применяется исключительно для сравнения моделей. Чем меньше значение, тем лучше. Часто используется для сравнения моделей временных рядов с разным количеством лагов.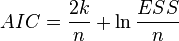 , где k— количество параметров модели.
, где k— количество параметров модели.
BIC или SC — байесовский информационный критерий Шварца — используется и интерпретируется аналогично AIC.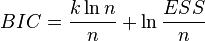 . Дает больший штраф за включение лишних лагов в модель , чем AIC.
. Дает больший штраф за включение лишних лагов в модель , чем AIC.
-обобщенный (extended)[править ]
В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной реализации. Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию . Эта проблема решается с помощью построения обобщенного коэффициента детерминации 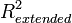 , который совпадает с исходным для случая МНК регрессии со свободным членом, и для которого выполняются четыре свойства, перечисленные выше. Суть этого метода заключается в рассмотрении проекции единичного вектора на плоскость объясняющих переменных.
, который совпадает с исходным для случая МНК регрессии со свободным членом, и для которого выполняются четыре свойства, перечисленные выше. Суть этого метода заключается в рассмотрении проекции единичного вектора на плоскость объясняющих переменных.
Для случая регрессии без свободного члена: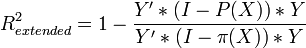 ,
,
где X — матрица nxk значений факторов, 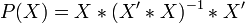 — проектор на плоскость X,
— проектор на плоскость X, 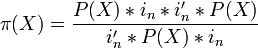 , где
, где 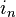 — единичный вектор nx1.
— единичный вектор nx1.
с условием небольшой модификации, также подходит для сравнения между собой регрессий, построенных с помощью: МНК, обобщенного метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщенно-условного метода наименьших квадратов (ОУМНК).
Замечание[править ]
Высокие значения коэффициента детерминации, вообще говоря, не свидетельствуют о наличии причинно-следственной зависимости между переменными (также как и в случае обычного коэффициента корреляции). Например, если объясняемая переменная и факторы, на самом деле не связанные с объясняемой переменой, имеют возрастающую динамику, то коэффициент детерминации будет достаточно высок. Поэтому логическая и смысловая адекватность модели имеют первостепенную важность. Кроме того, необходимо использовать критерии для всестороннего анализа качества модели .
Вау!! 😲 Ты еще не читал? Это зря![править ]
- Коэффициент корреляции
- Корреляция
- Мультиколлинеарность
- Дисперсия случайной величины
- Метод группового учета аргументов
- Регрессионный анализ
Примечания[править ]
Напиши свое отношение про коэффициент детерминации. Это меня вдохновит писать для тебя всё больше и больше интересного. Спасибо Надеюсь, что теперь ты понял что такое коэффициент детерминации
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Теория вероятностей. Математическая статистика и Стохастический анализ
Коэффициент детерминации (CoD) = r^2, где r = коэффициент корреляции
Инференциальная статистика измеряет вероятность наступления событий. Эта область математического анализа применима ко многим сферам деятельности, где профессионалы применяют статистический анализ для измерения вероятностей и корреляций. Коэффициент детерминации — это одно из статистических измерений, которое является неотъемлемой частью понимания вероятных корреляций между переменными. В этой статье мы обсудим, что такое коэффициент детерминации, как рассчитать коэффициент детерминации и к чему он применим, с примером для более глубокого понимания.
Что такое коэффициент детерминации?
Коэффициент детерминации — это статистическое измерение, которое оценивает, как изменения в одной переменной влияют на изменения в другой переменной. Это мера вариации, которая происходит в у, поскольку х изменяется в модели линейной регрессии. Математически, коэффициент детерминации — это квадрат коэффициента корреляции, который измеряет взаимосвязь или корреляцию двух переменных.
Коэффициент корреляции заменяет переменную r, а коэффициент детерминации — это квадрат r или r**2. Чтобы найти коэффициент детерминации, просто возведите в квадрат коэффициент корреляции. Полученное значение колеблется между нулем и единицей, которое вы преобразуете в процент, чтобы объяснить, какая часть изменений в y происходит из-за изменений в x.
Как рассчитать коэффициент детерминации
Используйте следующие шаги, чтобы найти коэффициент детерминации с помощью коэффициента корреляции:
1. Определите коэффициент корреляции
При оценке коэффициента детерминации определите коэффициент корреляции r. В большинстве случаев статистики и аналитики данных используют компьютерные расчеты для нахождения коэффициента корреляции при измерении вариаций в наборах данных. Если вы еще не знаете коэффициент корреляции, вы можете использовать следующую формулу для его расчета вручную:
r = [N?xy — (?x)(?y)] v[N?x2 — (?x)2] x [N?y2 — (?y)2]
2. Примените формулу коэффициента корреляции
Если вы используете формулу коэффициента корреляции, подставьте значения данных для переменных N, x и y, где N — количество пар значений данных, которые у вас есть, и ? переменная диктует функцию суммирования. Это означает ?xy — это сумма произведений значений x и y, ?x — сумма значений x и ?y — сумма значений y. Сайт ?Коэффициент x2 представляет собой сумму квадратов значений x, и ?y**2 — сумма квадратов значений y.
Например, предположим, аналитик данных рассчитывает коэффициент корреляции по формуле и получает r = (166) (346) = 0.39. Это означает, что коэффициент корреляции равен 0.39.
3. Возведение коэффициента корреляции в квадрат
Получив коэффициент корреляции, возведите результат в квадрат. Вы также можете оценить, насколько сильная связь существует между вашими переменными, взяв абсолютное значение r, где большие значения показывают более сильную корреляцию. Чтобы возвести r-значение в квадрат, умножьте его на себя. Например, если у вас есть коэффициент корреляции r = -0.35, возведение этого значения в квадрат дает коэффициент детерминации:
r2 = (-0.35)(-0.35) = 0.1225
4. Оценить результаты
Преобразуйте коэффициент детерминации в процент и оцените данные. Используя пример коэффициента 0.1225, переведите это в проценты, чтобы получить 12.25%. Анализ этого процента показывает, что 12.25% значений ваших данных появляются вдоль соответствующей линии регрессии, когда вы наносите данные на график. Более высокий коэффициент детерминации означает, что большее количество ваших данных собирается вдоль линии регрессии, что приводит к более сильной связи между вашими наблюдениями. Коэффициент, равный единице, означает, что линия регрессии содержит 100% данных, а нулевой коэффициент означает, что ни один из данных не отображается на линии.
Используется для коэффициента детерминации
Коэффициент детерминации является важным значением для построения графика линии регрессии, поскольку он показывает вероятность повторения значений данных в будущих измерениях. Он также указывает на силу корреляции между переменными, что может быть важно для целого ряда процессов обработки данных, в том числе:
Финансовый анализ
Коэффициент детерминации может быть незаменим при анализе корреляции между изменяющимися финансовыми показателями. Например, многие аналитики рассматривают корреляционные связи для определения вероятности будущих доходов, расходов и других инвестиционных показателей. Финансовое управление акциями часто зависит от анализа данных, который помогает специалистам оценить вероятные результаты при инвестировании в различные ценные бумаги.
Бизнес-анализ
Рост и развитие бизнеса — важные показатели, для отслеживания которых используется статистика. При измерении темпов роста, например, профессионалы бизнеса могут анализировать корреляционные связи между стратегиями и результатами, чтобы определить методы, которые приводят к процентному росту с течением времени. Расходы бизнеса — еще одно применение статистического анализа, которое может зависеть от корреляционных измерений, где коэффициент детерминации может показать бизнесу области, которые несут наибольшие затраты.
Медицинские исследования
Сферы здравоохранения и медицины часто полагаются на анализ данных в клинических исследованиях. Например, фармацевтические исследователи могут применять коэффициент детерминации для измерения различий в изменениях между дозировкой лекарства и реакцией пациента. Врачи также могут использовать информацию из коэффициента детерминации при применении новых методов лечения и составлении прогнозов. Хотя коэффициент может описать силу корреляции, для выявления причинно-следственной связи необходимы другие факторы.
Экономика
Статистика и анализ данных являются неотъемлемой частью экономических приложений, таких как измерение демографических показателей населения, экономических расходов и экономического роста. В этой области коэффициенты корреляции применяются для выявления закономерностей между переменными, а коэффициент детерминации может помочь экономистам измерить силу различных корреляций между видами экономической деятельности. Импорт и экспорт — одна из областей, где может применяться этот фактор вероятности, поскольку экономисты могут определить относительную корреляцию между увеличением и уменьшением доходов для импортируемых и экспортируемых товаров.
Технический анализ
Линейная регрессия и статистический анализ также важны в технических приложениях, таких как наука о данных, компьютерное программирование и машинное обучение. Например, специалисты по исследованию данных могут использовать статистику вероятности для построения алгоритмов, которые с наибольшей вероятностью приведут к желаемым результатам в системах машинного обучения. В данном случае коэффициент детерминации может помочь специалистам по исследованию данных оценить эффективность их моделей линейной регрессии. При более высоком коэффициенте системы машинного обучения с большей вероятностью будут иметь небольшую вариацию между желаемым выходом и начальным входом.
Пример коэффициента детерминации
Специалист по исследованию данных, рассчитывающий линейную регрессионную модель, хочет определить силу изменчивости между независимым входом и зависимым выходом. Используя коэффициент корреляции для определения r2, специалист по изучению данных использует формулу:
r = [N?xy — (?x)(?y)] v[N?x2 — (?x)2] x [N?y2 — (?y)2]
Чтобы найти r-значение, равное 0.79. Ученый возводит это значение в квадрат, используя нотацию CoD = r2, чтобы получить (0.79)(0.79) = 0.6241. Оценивая эту метрику, ученый определяет, что она учитывает 62.41% входных данных влияет на выход, в то время как 37.59% — нереализованные данные. В этом типе приложений специалист по исследованию данных может скорректировать параметры модели линейной регрессии для увеличения коэффициента корреляции, чтобы он был ближе к 1.00 или 100%.