Те, кто давно занимается поисковой оптимизацией, хорошо знают об операторах расширенного поиска Google. Например, почти все знают об операторе site:, который ограничивает поисковую выдачу одним сайтом.
Большинство операторов легко запомнить, это короткие команды. Но уметь эффективно их использовать — совсем другая история. Многие специалисты знают основы, но немногие по-настоящему овладели этими командами.
В этой статье я поделюсь советами, которые помогут освоить поисковые операторы для 15 конкретных задач.
- Поиск ошибок индексации
- Поиск незащищённых страниц (не https)
- Поиск дубликатов контента
- Поиск нежелательных файлов и страниц на своём сайте
- Поиск возможностей для гостевой публикации
- Поиск страниц со списками ресурсов
- Поиск сайтов с примерами инфографики… так что можно предложить свою
- Поиск сайтов для размещения своих ссылок… и проверки, насколько они подходят
- Поиск профилей в социальных сетях
- Поиск возможностей для внутренних ссылок
- Поиск упоминаний конкурентов для своего пиара
- Поиск возможностей для спонсорских постов
- Поиск тем Q+A, связанных с вашим контентом
- Проверка, как часто конкуренты публикуют новый контент
- Поиск сайтов со ссылками на конкурентов
Сначала полный список всех поисковых операторов Google и их функций.
Операторы поиска Google: полный список
Вы знали, что Google постоянно удаляет полезные операторы? Именно поэтому большинство существующих списков устарели и неточны. Для этой статьи я лично проверил каждый оператор, что смог найти.
Вот полный список всех рабочих, частично рабочих и сломанных операторов расширенного поиска Google по состоянию на 2018 год.
Рабочие операторы
“поисковый запрос”
Принудительный поиск точного совпадения. Используйте его для уточнения неоднозначных результатов поиска или исключения синонимов при поиске отдельных слов.
Пример: “steve jobs”
OR
Поиск по X или Y. Вернёт результаты, связанные с X или Y, или и то, и другое. Вместо него можно использовать оператор (|).
Примеры: jobs OR gates / jobs | gates
AND
Поиск по X и Y. Вернёт только результаты, связанные как с X, так и с Y. Примечание: в реальности не имеет значения для обычного поиска, потому что Google по умолчанию вставляет AND. Но очень полезен в сочетании с другими операторами.
Пример: jobs AND gates
—
Исключение термина или фразы. В нашем примере все страницы будут упоминать Джобса, но не с Apple (компанией).
Пример: jobs -apple
*
Действует как подстановочный знак для произвольного слова или фразы.
Пример: steve * apple
( )
Группировка нескольких терминов или операторов, чтобы контролировать выдачу.
Пример: (ipad OR iphone) apple
$
Поиск цен. Также работает для евро (€), но не для британского фунта (£).
Пример: ipad $329
define:
По сути, это встроенный в Google словарь. Показывает значение слова.
Пример: define:entrepreneur
cache:
Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно).
Пример: cache:apple.com
filetype:
Ограничивает результаты файлами определённого формата, например, pdf, docx, txt, ppt и т. д. Примечание: аналогично оператору “ext:”.
Пример: apple filetype:pdf / apple ext:pdf
site:
Результаты для определённого домена.
Пример: site:apple.com
related:
Поиск сайтов, связанных с данным доменом.
Пример: related:apple.com
intitle:
Найти страницы с определённым словом (или словами) в заголовке страницы. В нашем примере возвратятся все результаты со словом [apple] в теге title.
Пример: intitle:apple
allintitle:
Аналогично “intitle», но будут возвращает результаты, содержащие все указанные слова в теге title.
Пример: allintitle:apple iphone
inurl:
Найти страницы с определённым словом (или словами) в URL. В этом примере будут возвращены все результаты, содержащие слово [apple] в URL.
Пример: inurl:apple
allinurl:
Аналогично “inurl», но возвращает результаты со всеми указанными словами в URL.
Пример: allinurl:apple iphone
intext:
Найти страницы, содержащие определённое слово (или слова) где-то в содержании. В примере будут возвращены все результаты, содержащие слово [apple] на странице.
Пример: intext:apple
allintext:
Аналогично “intext», но возвращает результаты со всеми указанными словами на странице.
Пример: allintext:apple iphone
AROUND(X)
Поиск поблизости. Страницы, содержащие два слова или фразы на расстоянии X слов друг от друга. В этом примере слова [apple] и [iphone] должны присутствовать в тексте на расстоянии не более четырёх слов друг от друга.
Пример: apple AROUND(4) iphone
weather:
Найти погоду для конкретного места. Отображается в погодном сниппете, но также возвращает результаты с других метеорологических сайтов.
Пример: weather:san francisco
stocks:
Биржевая информация (т. е., цена и т. д.) для любой акции по биржевому тикеру.
Пример: stocks:aapl
map:
Результаты поиска по картам.
Пример: map:silicon valley
movie:
Найти информацию о конкретном фильме. Также находит расписание сеансов, если фильм сейчас показывают недалеко от вас.
Пример: movie:steve jobs
in
Преобразует одну единицы измерения в другую. Работает с валютами, весами, температурой, расстояниями и т. д.
Пример: $329 in GBP
source:
Найти новостные результаты из определённого источника в Google News.
Пример: apple source:the_verge
_
Не совсем оператор поиска, но действует как подстановочный знак для автодополнения.
Пример: apple CEO _ jobs
Частично рабочие операторы
Вот операторы, которые не всегда дают желательный результат:
#..#
Поиск диапазона чисел. В приведённом примере возвращаются результаты [видео WWDC] за 2010-2014 годы, но не за 2015 год и последующие годы.
Пример: wwdc video 2010..2014
inanchor:
Поиск страниц, связанных с определённым текстом в ссылке. В этом примере будут возвращены все страницы, на которые есть ссылки со словами [apple] или [iphone].
Пример: inanchor:apple iphone
allinanchor:
Аналогично inanchor, но возвращает результаты, содержащие все указанные слова во входящих ссылках.
Пример: allinanchor:apple iphone
blogurl:
Поиск URL блога в определённом домене. Использовался в поиске Google по блогам, но кое-как работает и в обычном поиске.
Пример: blogurl:microsoft.com
Примечание. Поиск Google по блогам закрыт в 2011 году.
loc:placename
Найти результаты из заданного места.
Пример: loc:”san francisco” apple
Примечание. Официально не закрыт, но результаты противоречивы.
location:
Найти результаты из заданного места в Google News.
Пример: location:”san francisco” apple
Примечание. Официально не закрыт, но результаты противоречивы.
Сломанные операторы
Операторы поиска Google, которые удалены и больше не работают.
+
Принудительный поиск по одному слову или фразе.
Пример: jobs +apple
Примечание. То же самое делается с помощью кавычек.
~
Включить синонимы. Не работает, потому что Google теперь включает синонимы по умолчанию. (Подсказка: для исключения синонимов используйте двойные кавычки).
Пример: ~apple
inpostauthor:
Найти сообщения в блоге, написанные конкретным автором. Работало только в поиске по блогам.
Пример: inpostauthor:”steve jobs”
Примечание. Поиск Google по блогам закрыт в 2011 году.
allinpostauthor:
Аналогично предыдущему, но устраняет необходимость в кавычках (если вы хотите найти конкретного автора, включая фамилию).
Пример: allinpostauthor:steve jobs
inposttitle:
Найти сообщения в блоге с конкретными словами в названии. Больше не работает, так как этот оператор был уникальным для поиска по блогам.
Пример: inposttitle:apple iphone
link:
Поиск страниц, которые ссылаются на определённый домен или URL. Google убила этот оператор в 2017 году, но он по-прежнему возвращает некоторые результаты — вероятно, не особо точные (поддержка прекращена в 2017 году)
Пример: link:apple.com
info:
Найти информацию о конкретной странице, включая время последнего кэширования, похожие страницы и т. д. (поддержка завершена в 2017 году). Примечание: идентичен оператору id:.
Примечание. Хотя изначальная функциональность этого оператора устарела, он по-прежнему полезен для поиска канонической индексированной версии. Благодарю @glenngabe за информацию!
Пример: info:apple.com / id:apple.com
daterange:
Найти результаты по определённому диапазону дат. Почему-то использует юлианский формат даты.
Пример: daterange:11278–13278
Примечание. Официально не закрыт, но, похоже, не работает.
phonebook:
Найди чей-то номер телефона (поддержка прекращена в 2010 году).
Пример: phonebook:tim cook
#
Поиск по хэштегу. Появился вместе с Google+, теперь устарел.
Пример: #apple
15 вариантов использования операторов поиска Google
Теперь рассмотрим несколько способов эффективного применения этих операторов, в том числе в сочетании друг с другом. Не стесняйтесь отклоняться от приведённых примеров, можете найти что-то новое.
Поехали!
1. Поиск ошибок индексации
На большинстве сайтов есть страницы, которые Google проиндексирвоал некорректно. Возможно, какой-то страницы нет в индексе или наоборот, там присутствует что-то лишнее. Воспользуемся оператором site:, чтобы узнать количество проиндексированных страниц на моём сайте.

Около 1040.
Примечание. Google здесь даёт примерное количество. Точную информацию см. в Google Search Console.
Но сколько из них являются статьями в блоге?
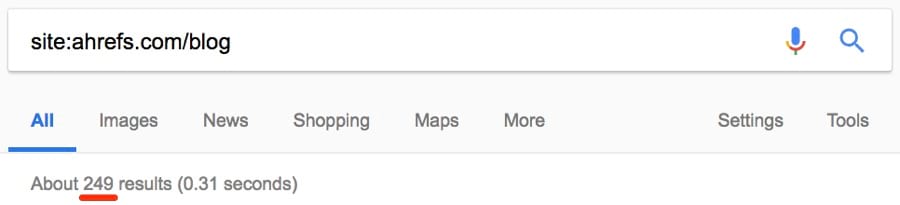
Примерно четверть: около 249.
Я отлично знаю свой блог, поэтому уверен, что у меня статей реально меньше.
Исследуем дальше.

Кажется, проиндексировано несколько странных страниц.
(Это даже не реальная страница — она выдаёт 404)
Такие страницы следует удалить из индекса. Сузим поиск до поддоменов и посмотрим, что получится.
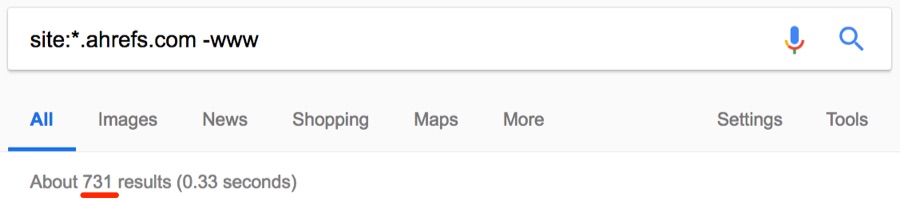
Примечание. Здесь мы используем подстановочный знак (*), чтобы найти все поддомены, принадлежащие домену, в сочетании с оператором исключения (-), чтобы исключить обычные результаты www.
Примерно 731 результат.
Вот страница на поддомене, которая определённо не должна индексироваться. Она сразу выдаёт 404.

Есть несколько других способов выявить ошибки индексации:
site:yourblog.com/category— найти страницы рубрик в блоге WordPress;site:yourblog.com inurl:tag— найти странице тегов в блоге WordPress.
2. Поиск незащищённых страниц (не https)
HTTPS в наше время стал обязательным требованием, особенно для сайтов электронной коммерции. Но вы знали, что с помощью оператора site: можно найти незащищённые страницы? Проверим на примере asos.com.
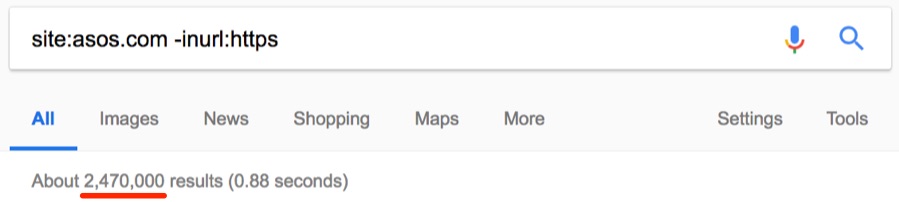
О боже, около 2,47 млн незащищённых страниц.
Похоже, что Asos вообще не используют SSL — невероятно для такого большого сайта.

Примечание. Клиентам Asos волноваться не стоит — страницы оформления заказа безопасны.
Но вот ещё одна вещь: Asos доступен в версиях https и http.
И мы узнали это с помощью простого оператора site:!
Примечание. Иногда страницы индексируются без https, но после перехода по ссылке происходит редирект на версию https.
3. Поиск дубликатов контента
Дубликаты — это плохо. Вот пара джинсов Abercrombie & Fitch на сайте Asos со стандартным описанием:

Стандартные описания сторонних брендов часто дублируются на других сайтах. Но интересно, сколько раз текст встречается на asos.com.
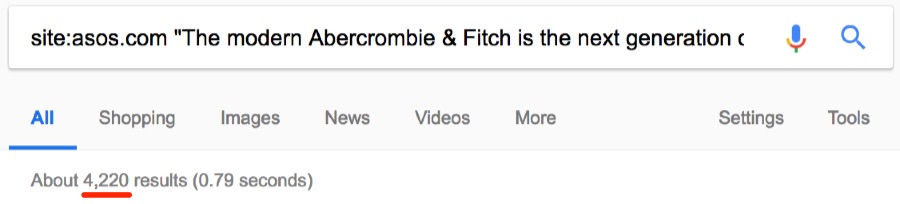
Примерно 4200 раз.
Теперь интересно, является ли текст уникальным для Asos. Проверим.

Нет, он не уникален. Есть 15 других сайтов с точно таким же текстом, то есть дублированным контентом. Иногда дубли присутствуют на страницах с похожими товарами. Например, аналогичные продукты или тот же товар в упаковках с разным количеством. Вот пример на сайте Asos:
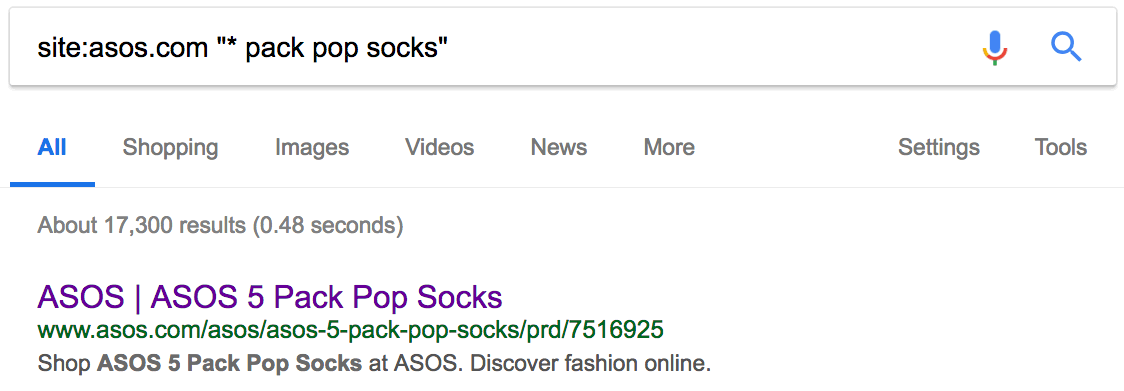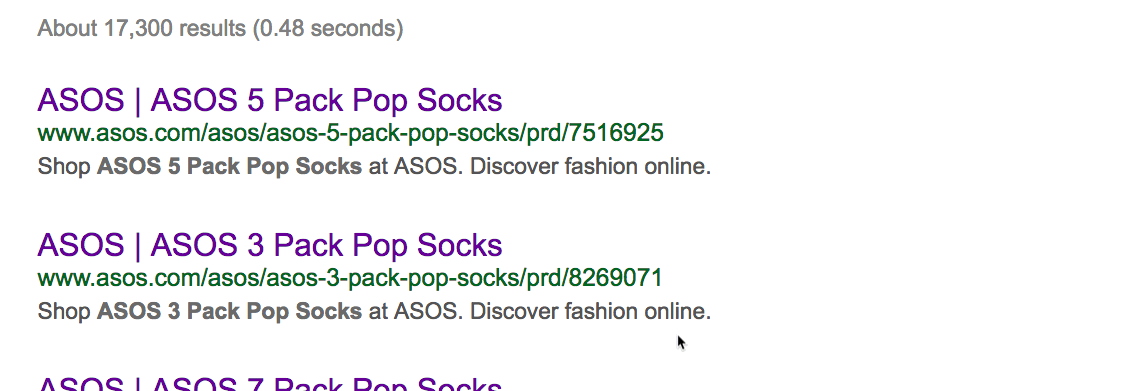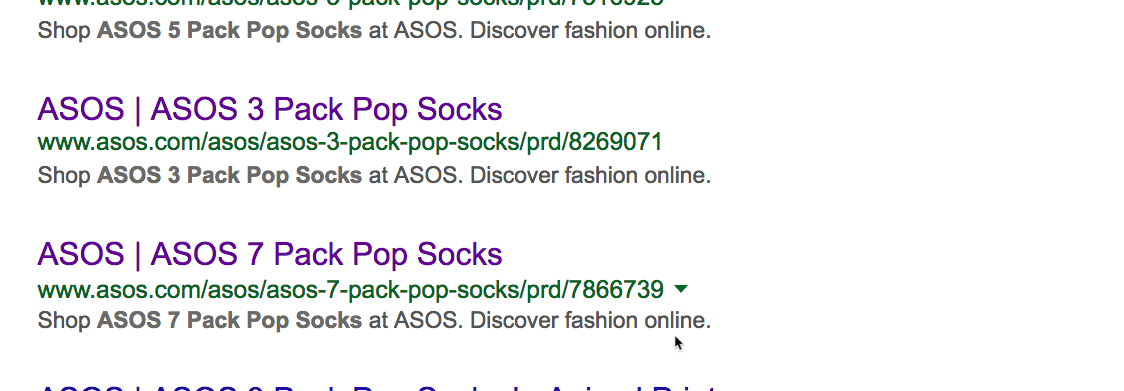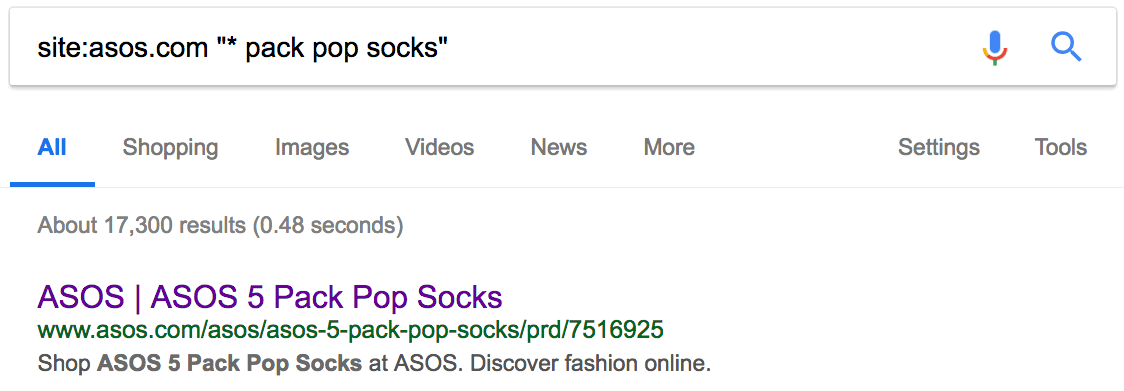
Как видим, за исключением количества, страницы одинаковые. Но дубликаты встречаются не только на сайтах электронной коммерции. Если у вас есть блог, то люди могут красть и публиковать ваш контент без надлежащей ссылки. Посмотрим, может кто-то украл и опубликовал наш список советов по SEO.
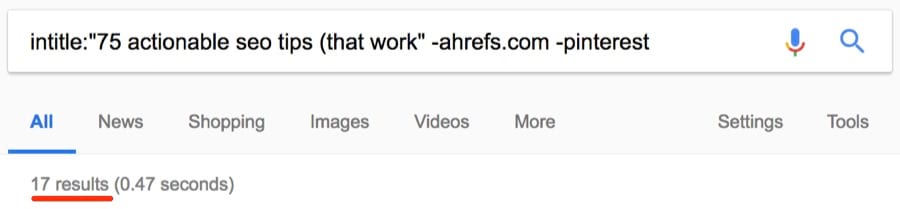
Около 17 результатов.
Примечание. Как видите, я исключил ahrefs.com из результатов с помощью оператора исключения (-), а также исключил слово [pinterest], потому что по запросу выдаётся много результатов с сайта Pinterest, которые не имеют отношения к нашей задаче. Можно было исключить только pinterest.com (-pinterest.com), но у него много доменов, так что это не особо поможет. Исключение слова [pinterest] оказалось лучшим способом очистки результатов.
Большинство страниц, наверное, созданы в результате синдикации. Всё-таки стоит проверить, что они ссылаются на вас.
4. Поиск нежелательных файлов и страниц на своём сайте (о которых вы могли забыть)
Трудно уследить за всем на большом сайте, поэтому легко забыть о каких-то старых загруженных файлах: PDF, документы Word, презентации PowerPoint, текстовые файлы и т. д. Оператор filetype: поможет их найти.
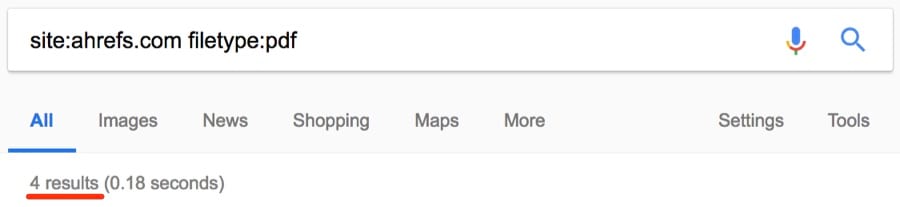
Примечание. Помните, что аналогичная функциональность у оператора ext:.
Вот одна находка:

Никогда раньше не видел этой статьи, а вы? Комбинируя несколько операторов, можно одновременно выводить результаты для разных типов файлов.

Примечание. Этот оператор также поддерживает .asp, .php, .html и др.
Важно удалить или деиндексировать их, чтобы они не попадались людям на глаза.
5. Поиск возможностей для гостевой публикации
Возможность публикации на других сайтах… есть много способов найти такие ресурсы:

Но вы уже знали об этом методе, верно!? 
Примечание. Этот метод находит страницы с предложением написать статью. Такие страницы создают многие сайты, которые ищут авторов.
Так что применим более творческий подход. Во-первых: не ограничивайтесь одной фразой. Также можете использовать такие поисковые запросы:
[become a contributor][contribute to][write for me](да, есть отдельные блогеры, которые тоже приглашают авторов!)[guest post guidelines]inurl:guest-postinurl:guest-contributor-guidelines- и др.
Многие забывают один классный совет: можно искать всё сразу.

Примечание. На этот раз я использую оператор (“|”) вместо AND, он делает то же самое.
Можно даже искать эти фразу с учётом тематики.

Нужна конкретная страна? Просто добавьте оператор site:.tld .

Вот ещё один метод: если знаете конкретного блоггера в своей нише, попробуйте такой способ:
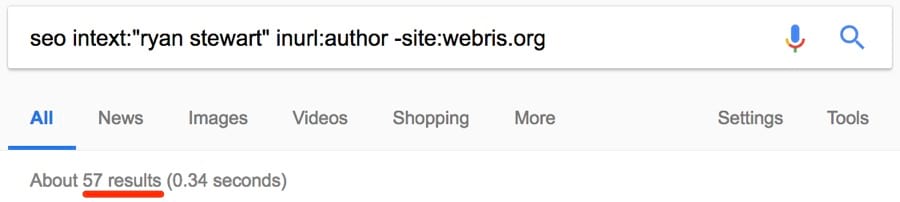
Так найдутся все сайты, где публиковался этот автор.
Примечание. Не забудьте исключить его сайт из выдачи, чтобы сохранить чистоту результатов!
Наконец, если вам интересно, принимает ли конкретный сайт статьи от сторонних авторов, попробуйте это:
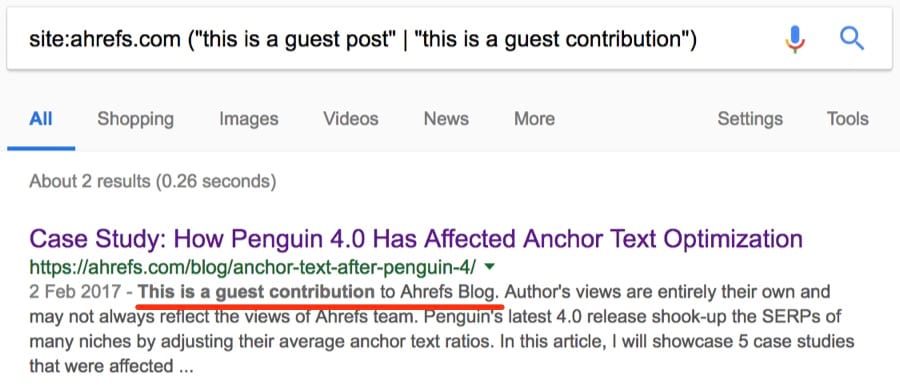
Примечание. В список можно добавить много других фраз.
6. Поиск страниц со списками ресурсов
Такие страницы собирают списки ресурсов по определённой теме.

Всё это — ссылки на сторонние ресурсы. По иронии, учитывая тему этой конкретной страницы — многие ссылки там не работают.
Так что если у вас есть крутой ресурс, можно найти соответствующие «ресурсные» страницы и подать заявку на добавление туда своей ссылки.
Вот один из способов найти их:

Но это может вернуть много мусора. Сужаем поиск:

Ещё больше сужаем:

Примечание. Здесь allintitle: гарантирует, что тег title содержит слова [fitness] и [resources], а также число от 5 до 15.
Примечание об операторе #..#
Я знаю, о чем вы думаете: почему бы вместо этой длинной последовательности чисел не использовать оператор
#..#. Хорошая мысль, попробуем:
Странно, да? Дело в том, что этот оператор плохо сочетается с большинством других операторов. Да и вообще не всегда работает. Поэтому я рекомендую использовать последовательность чисел с оператором OR или вертикальной чертой (“|”). Это немного трудоёмкая процедура, зато работает.
7. Поиск сайтов с примерами инфографики… так что можно предложить свою
У инфографики плохая репутация. Скорее всего, потому что многие создают некачественную, дешёвую инфографику, которая не служит никакой реальной цели… кроме как «привлекать ссылки». Но не вся инфографика такая.
Кому вы можете предложить свою инфографику? Любым известным сайтам в своей нише?
НЕТ.
Надо обратиться к сайтам, которые действительно захотят её опубликовать. Лучший способ — найти сайты, где уже публиковались такие материалы:

Примечание. Есть смысл поискать в пределах диапазона недавних дат, например, за последние три месяца. Если сайт публиковал инфографику два года назад, это не означает, что они таким занимаются до сих пор. Но если сайт публиковал её в последние несколько месяцев, то есть вероятность, что примет и вашу. Поскольку оператор daterange: больше не работает, придётся указать диапазон дат во встроенном фильтре поиска Google.
Но опять же, придётся отфильтровать мусор.
Вот быстрый трюк:
- использовать вышеуказанный запрос для поиска качественной инфографики по заданной теме;
- найти, где она размещалась.
Пример:

Нашлось два результата за последние три месяца. И более 450 результатов за всё время. Проведите такой поиск для нескольких конкретных иллюстраций — и получите хороший список.
8. Поиск сайтов для размещения своих ссылок… и проверки, насколько они подходят
Предположим, вы нашли сайт, где хотите разместить ссылку. Вручную проверили актуальность… всё выглядит хорошо. Вот как найти список похожих сайтов или страниц:

Получаем около 49 результатов, все похожие.
Примечание. В приведённом примере мы ищем сайты, похожие именно на блог Ahrefs, а не на весь сайт Ahrefs.
Вот один из результатов: yoast.com/seo-blog.
Я хорошо знаю Yoast, поэтому уверен, что это подходящий сайт для наших целей. Но предположим, что я ничего не знаю об этом сайте, Как проверить, что он подходит? Вот как:
- запустить
site:domain.comнайдите и записать количество результатов; - запустить
site:domain.com [niche], опять записать количество результатов; - делим второе число на первое: если оно выше 0,5, это подходящий вариант; если выше 0.75, то это просто супер.
Попробуем на примере yoast.com. Вот количество результатов для простого поиска:
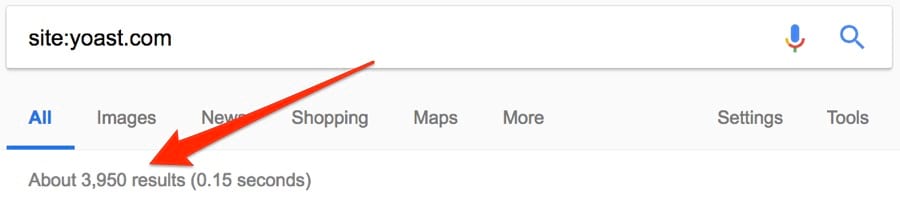
И site: [niche]:

Итак, 3950 / 3330 = ~0,84. Отличный результат.
Теперь проверим на сайтах, которые точно нам не подходят.
Количество результатов для поиска site:greatist.com: ~18,000
Количество результатов для поиска site:greatist.com SEO: ~7
(18000 / 7 = ~0,0004 = совершенно нерелевантный сайт)
Важно! Это отличный способ быстро устранить крайне нерелевантные результаты, но он не всегда надёжно работает. Конечно же, это не замена ручной проверке потенциального кандидата: их всегда следует просматривать вручную, прежде чем обращаться с предложением. Иначе вы начнёте генерировать спам.
9. Поиск профилей в социальных сетях
Хотите с кем-то связаться? Попробуйте найти контактную информацию таким способом:

Примечание. Имя человека обычно легко найти, а вот контактную информацию сложно.
Четыре лучших результата:
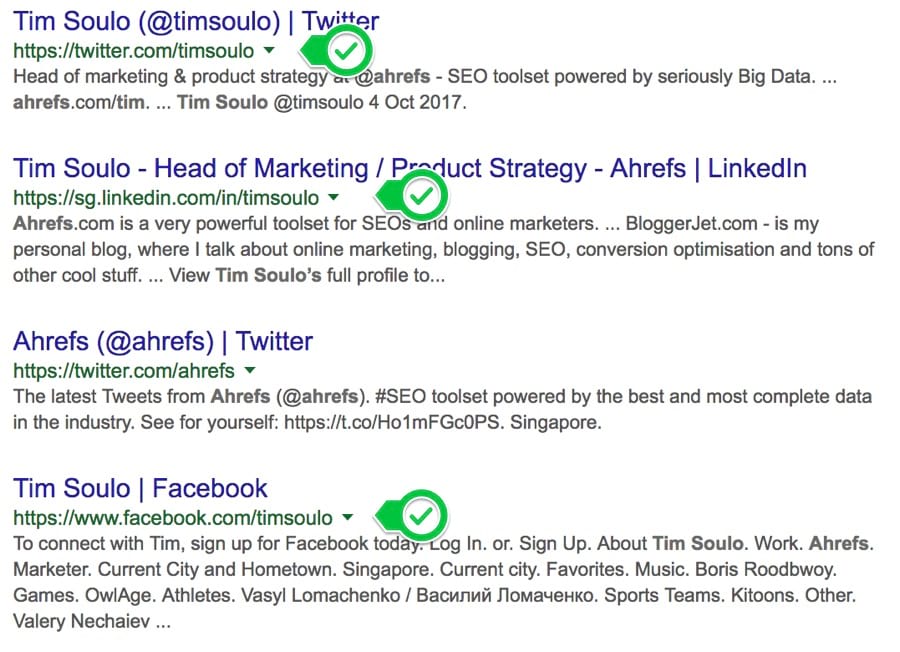
БИНГО.
Затем можете связаться с человеком напрямую через социальные медиа. Или воспользуйтесь советами 4 и 6 из этой статьи для поиска адреса электронной почты.
10. Поиск возможностей для внутренних ссылок
Внутренние ссылки очень важны. Они помогают в навигации посетителей по вашему сайту, а также полезны для SEO (при разумном использовании). Но нужно убедиться, что вы добавляете внутренние ссылки только там, где это уместно. Допустим, вы только опубликовали большой список советов по SEO. Разве не здорово добавить внутреннюю ссылку на эту статью со всех страниц, где упоминаются советы по SEO?
Определённо.
Но не так легко найти соответствующие места для добавления этих ссылок, особенно на больших сайтах. Вот быстрый трюк:

Для тех, кто ещё не освоил операторы поиска, здесь мы делаем следующее:
- Ограничиваем поиск определённым сайтом.
- Исключаем страницу/публикацию, на которую требуется создать внутренние ссылки.
- Ищем определённое слово или фразу в тексте.
Вот одна из подходящих страниц, которую я нашёл таким запросом:

Поиск занял три секунды.
11. Поиск упоминаний конкурентов для своего пиара
Вот страница, на которой упоминается наш конкурент — Moz.

Найдено с помощью такого расширенного поиска:

Но почему нет упоминания блогов Ahrefs? 
С помощью site: и intext: я вижу, что этот сайт раньше упоминал нас пару раз.
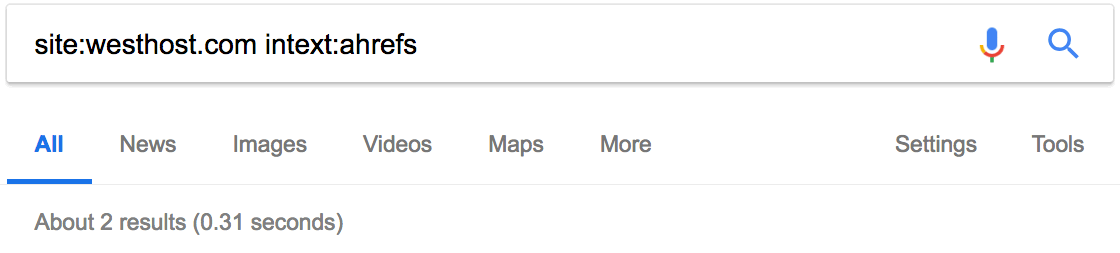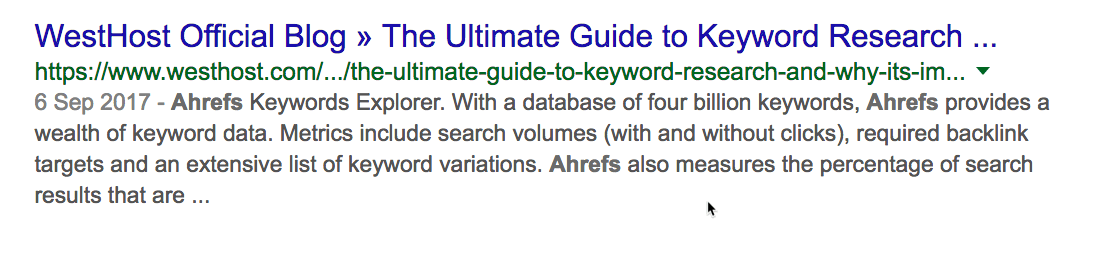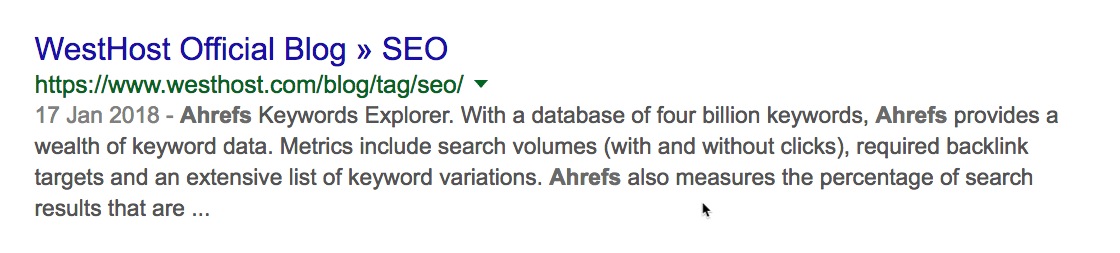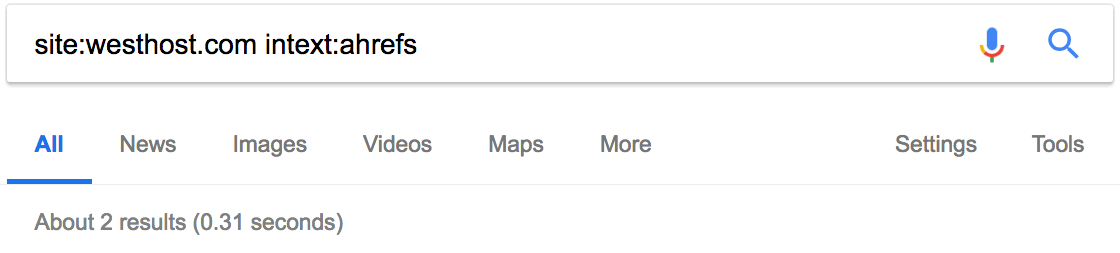
Но они не разместили никакой статьи с обзором наших инструментов, как в случае с Moz. Это даёт возможность. Свяжитесь с ними, пообщайтесь. Возможно, они напишут также про Ahrefs.
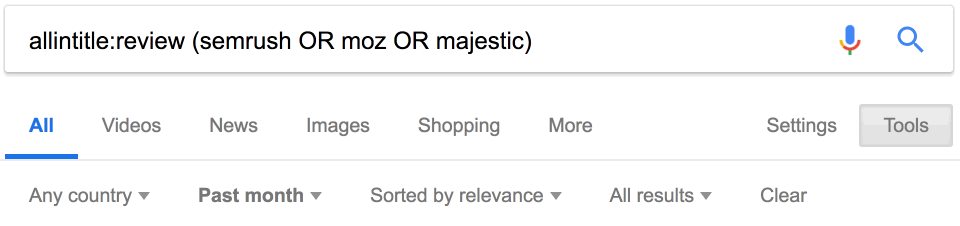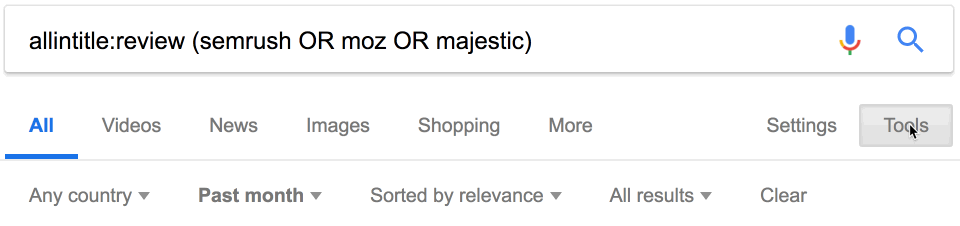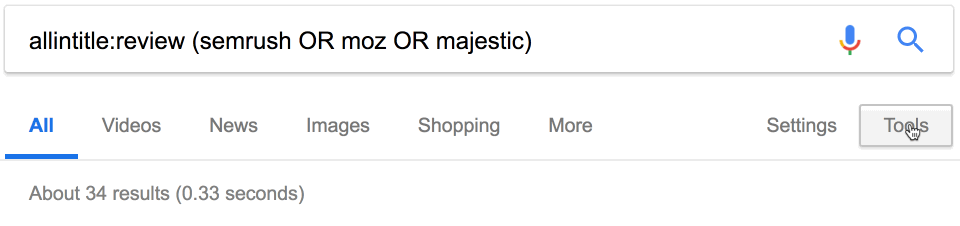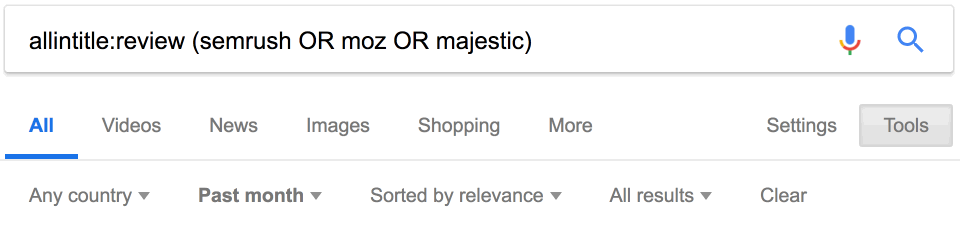
Вот ещё один классный запрос, который можно использовать для поиска отзывов о конкурентах:

Примечание. Поскольку мы используем [allintitle], а не [intitle], то получим результаты со словом [review] и названием одного из конкурентов в теге заголовка.
Можете пообщаться с этими людьми, чтобы они повторно рассмотрели ваш товар/услугу.
Вот ещё один совет. Оператор daterange: устарел, но на странице поиска можно добавить фильтр для дат, чтобы найти последние упоминания конкурентов. Просто используйте этот встроенный фильтр.
Похоже, за последний месяц опубликовано 34 отзыва о наших конкурентах.
12. Поиск возможностей для спонсорских постов
Спонсорские посты — это платные статьи, продвигающие ваш бренд, продукт или услугу. Такой вариант не предназначен для размещения ссылок.
В руководстве Google явно запрещено:
Покупка или продажа ссылок, которые передают PageRank. Это включает в себя передачу денег на ссылки или сообщения, содержащие ссылки; передачу товаров или услуг в обмен на ссылки; отправку кому-то «бесплатного» продукта в обмен на то, что они напишут о нём и поставят ссылку.
Вот почему вы всегда должны следить за ссылками в спонсорских статьях.
Но истинная ценность этих статей всё равно не сводится к ссылкам. Это пиар, то есть демонстрация свого бренда перед нужными людьми. Вот один из способов найти возможности для спонсорских публикаций с помощью операторов поиска Google:
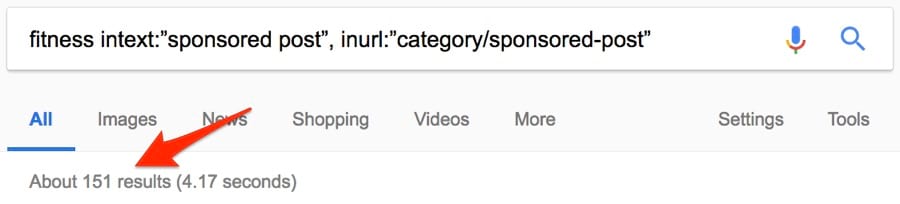
Примерно 151 результат. Неплохо.
Несколько других комбинаций операторов:
[niche] intext:”this is a sponsored post by”[niche] intext:”this post was sponsored by”[niche] intitle:”sponsored post”[niche] intitle:”sponsored post archives” inurl:”category/sponsored-post”“sponsored” AROUND(3) “post”
Примечание. Приведённые примеры — именно примеры. Почти наверняка эти сообщения можно найти по другим фразам. Не бойтесь проверять различные идеи.
13. Поиск тем Q+A, связанных с вашим контентом
Форумы, а также сайты с вопросами и ответами отлично подходят для продвижения контента.
Примечание. Продвижение != спам. Не заходите на эти сайты только для того, чтобы добавить свои ссылки. Публикуйте ценную информацию, а по ходу дела иногда — уместные ссылки.
На ум приходит Quora, которая разрешает публиковать в своих ответах релевантные ссылки.
Ответ в Quora со ссылкой на SEO-блог
Правда, этим ссылкам проставляется тег nofollow. Но мы не пытаемся здесь строить базу ссылок, это пиар! Вот один из способов найти подходящие темы:

Это можно сделать на любом форуме или сайте с вопросами и ответами. Такой же поиск для Warrior Forum:

Я знаю, что там есть раздел о поисковой оптимизации. У каждой темы в этом разделе в URL указано .com/search‐engine‐optimization/. Так что я могу ещё больше уточнить запрос с помощью оператора inurl:.

Такие операторы даже лучше находят темы на форуме, чем встроенный поиск на сайте.
14. Проверка, как часто конкуренты публикуют новый контент
Большинство блогов находятся в подпапке или поддомене, например:
ahrefs.com/blogblog.hubspot.comblog.kissmetrics.com
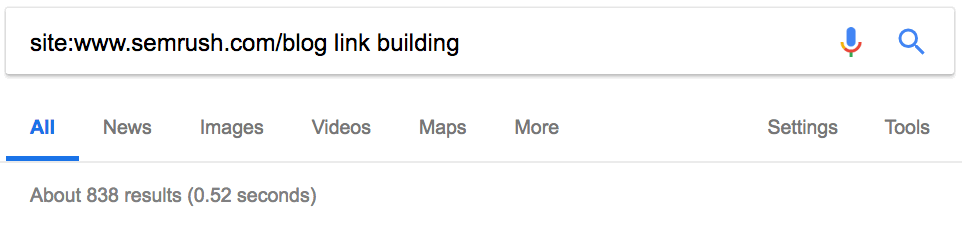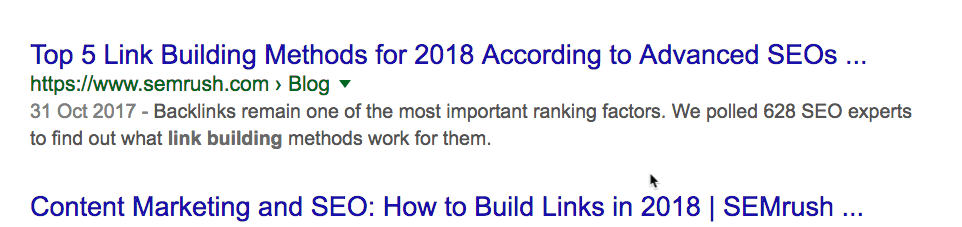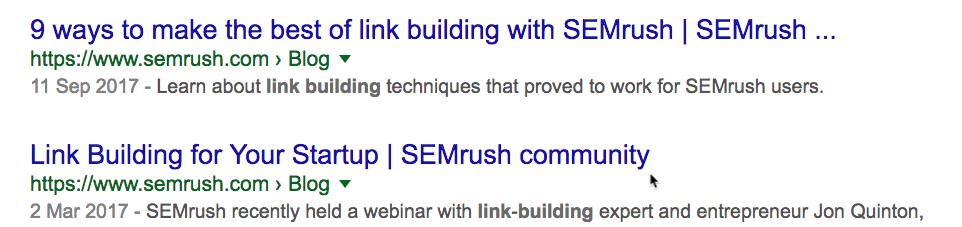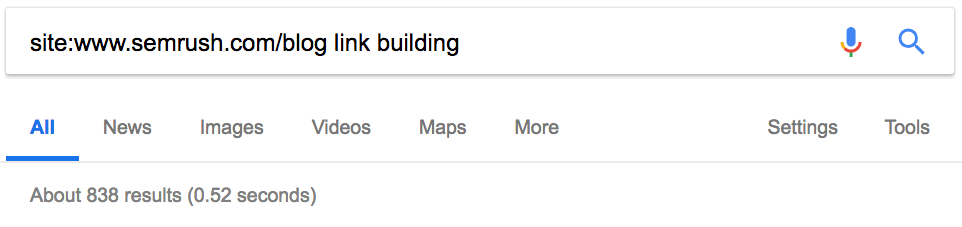
Это позволяет легко проверить, насколько регулярно конкуренты публикуют новый контент. Проверим на одном из наших конкурентов: SEMrush.
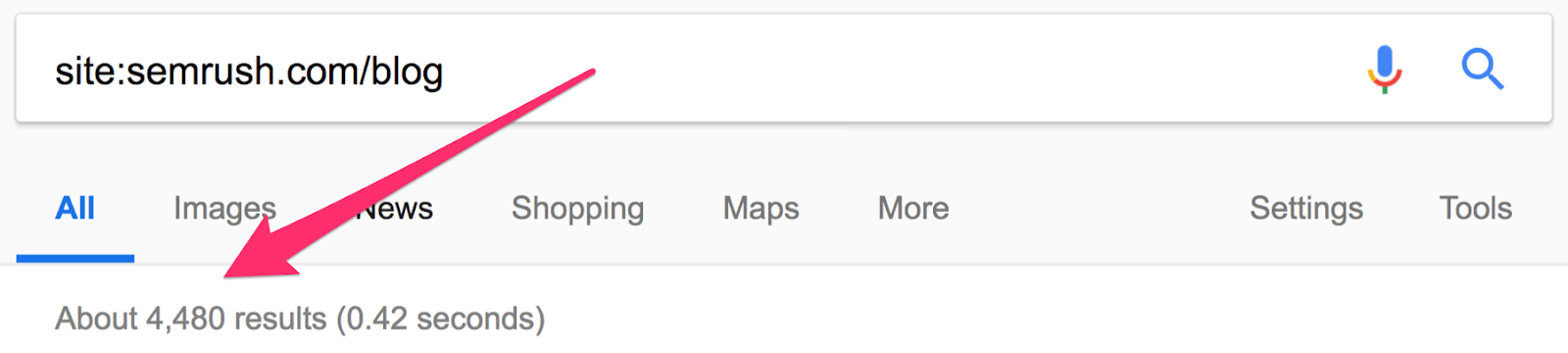
Похоже, у них уже около 4500 статей. Но это не совсем так. Сюда входят версии блога на разных языках, которые находятся на поддоменах.
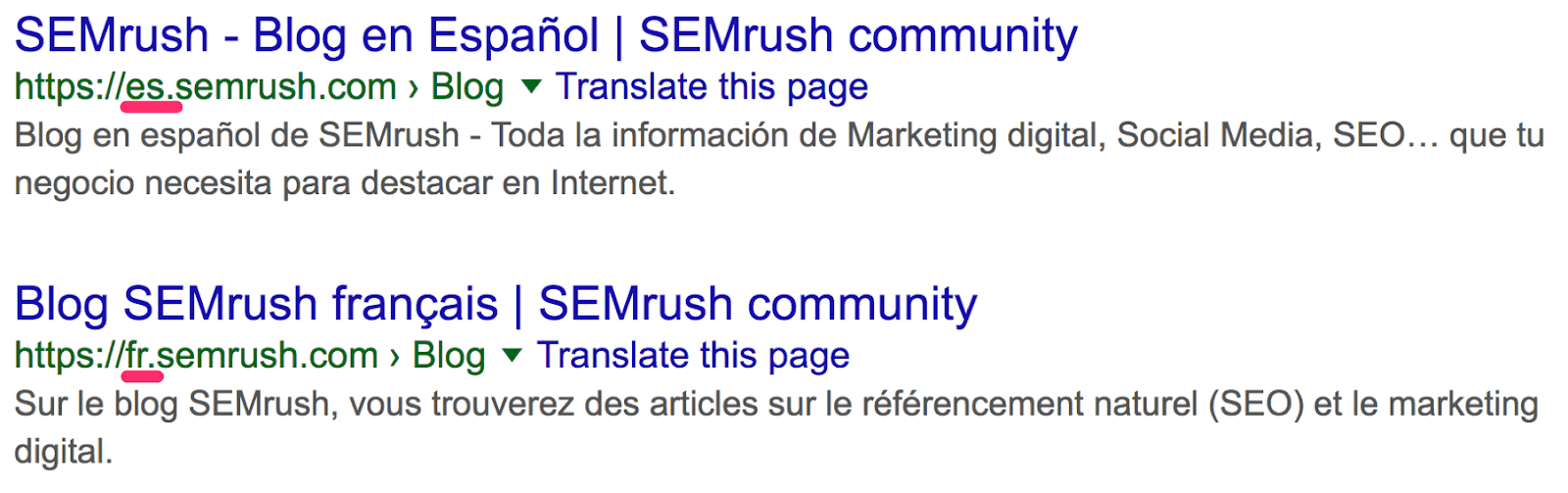
Отфильтруем их.
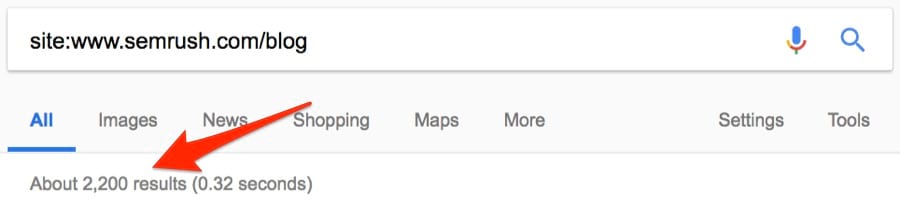
Это больше похоже на правду: около 2200 постов. Посмотрим, сколько опубликовано за последний месяц. Поскольку оператор daterange: больше не работает, используем встроенный фильтр Google.

Примечание. Можно указать любой диапазон дат. Просто выберите “Custom”.
Около 29 постов. Интересно. Это примерно вчетверо больше, чем у нас. И у них в целом примерно в 15 раз больше постов, чем у нас. Но мы всё равно получаем больше трафика… с двукратным превосходством по ценности.

Качество важнее количества, верно!?
Оператор site: в сочетании с поисковым запросом покажет, сколько статей конкурент опубликовал по определённой теме.
15. Поиск сайтов со ссылками на конкурентов
На конкурентов ставят ссылки? Может быть, мы тоже можем их получить? Google прекратил поддержку оператора link в 2017 году, но он по-прежнему возвращает некоторые результаты.
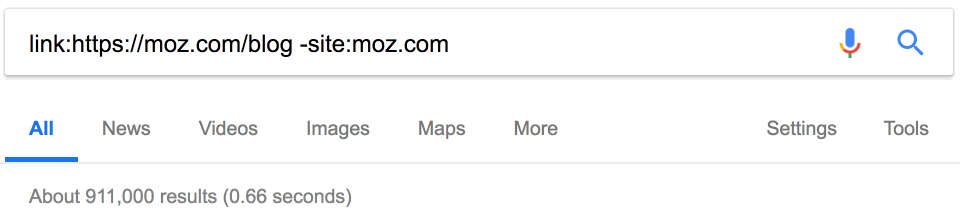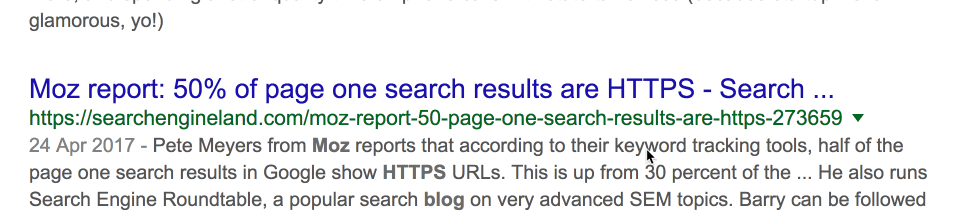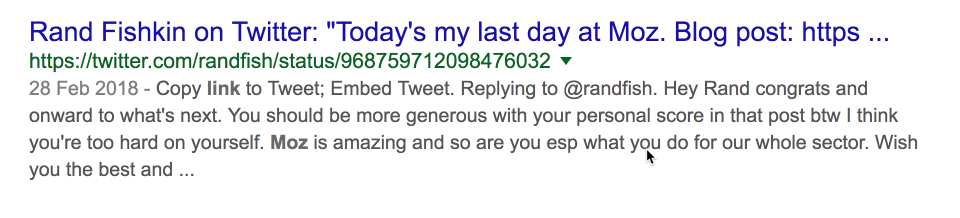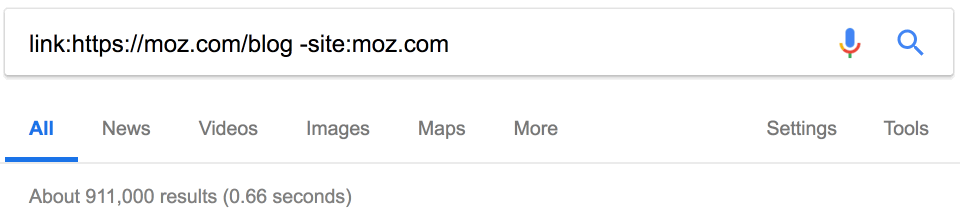
Примечание. Обязательно исключайте сайт конкурента, чтобы отфильтровать внутренние ссылки.
Около 900 тыс. ссылок. Здесь тоже пригодится фильтр по дате. Например, за последний месяц на Moz поставили 18 тыс. новых ссылок.
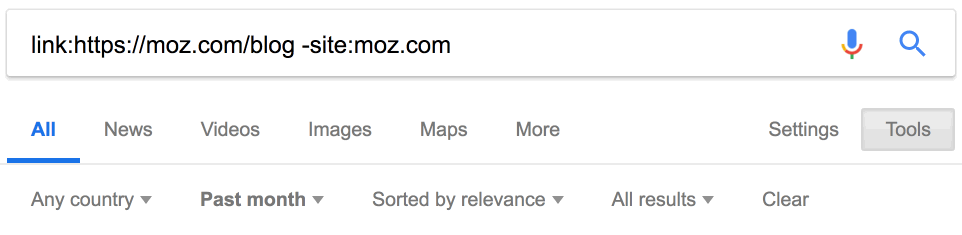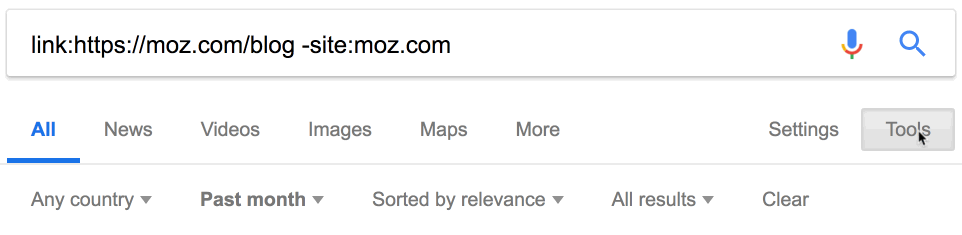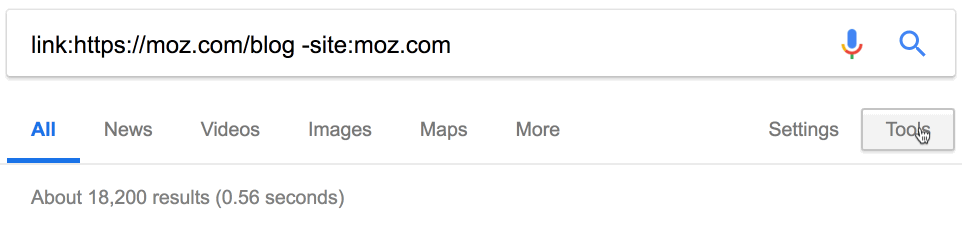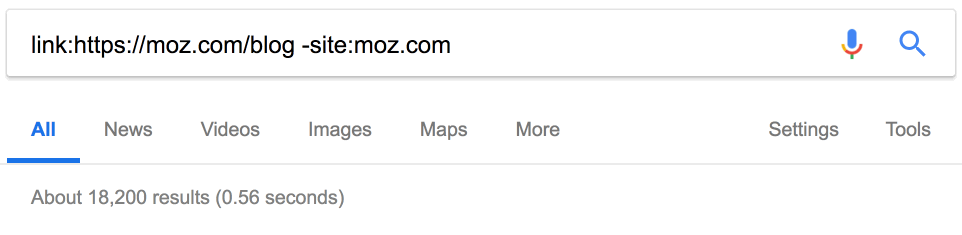
Очень полезная информация. Но эти данные тоже могут быть неточными.
Заключение
Операторы расширенного поиска Google безумно мощные. Просто надо знать, как их использовать. Но я должен признать, что некоторые полезнее других, особенно в поисковой оптимизации. Я практически ежедневно использую site:, intitle:, intext: и inurl:, но очень редко прибегаю к помощи AROUND(X), allintitle: и многих других более мутных операторов.
Я бы ещё добавил, что многие операторы бесполезны, если не применяются в сочетании с другим оператором… или двумя-тремя. Так что поиграйте с ними и напишите, как ещё их можно использовать. Я с радостью добавлю в статью любые полезные комбинации, какие вы найдёте.
Популярные операторы поисковой системы Google, а также полезные параметры адресной строки. Большинство из них доступны со страницы Advanced Search, но не все, да и смысл их не всем известен и не сразу понятен.
| Оператор | Пример запроса | Описание |
|---|---|---|
| filetype: | продвижение оптимизация filetype:doc | Искать файлы только указанного типа (по расширению файла) |
| site: | черный список site:searchengines.ru | Искать в пределах сайта или домена (с поддоменами) |
| inurl: | inurl:продвижение | Искать страницы со словом в адресе (URL), с русским языком работает нормально |
| allinurl: | allinurl: продвижение сайтов | Искать несколько слов в URL страницы |
| intext: | intext:раскрутка | Искать слово в тексте (<body>) страницы |
| allintext: | allintext: раскрутка бесплатно | Искать несколько слов в тексте (<body>) страницы |
| intitle: | intitle:»Бесплатное продвижение» | Искать слово или фразу (в кавычках) в заголовке (<title>) страницы |
| allintitle: | allintitle: Продвижение гарантии | Искать несколько слов в заголовке страницы (<title> в html и его аналоги в других типах документов) |
| inanchor: | inanchor:»SEO анализ» | Искать несколько слово или фразу в текстах ссылок (<a>) |
| allinanchor: | allinanchor: SEO продвижение | Искать несколько слов в анкорах (<a>) |
| daterange: | ePassporte daterange:2454833-2454863 | Искать в страницах, проиндексированных в указанный промежуток дней (указывать необходимо Юлианские даты) |
| related: | related:seo.ru | Найти похожие (по мнению Google) страницы |
| info: | info:seoninja.ru | Показать информацию о странице (если она проиндексирована) |
| link: | link:domain.com | Показать список страниц, ссылающихся на указанный документ (URL) |
| cache: | cache:domain.com/page.html | Показать версию документа, сохраненного в Google Cache |
| define: | define:идиосинкразия | Определение (значение) фразы или слова. |
Пояснения и комментарии
filetype:
Вы можете ограничить тип искомого документа, например filetype:doc для Word, filetype:xls для Excel, filetype:pdf для PDF, filetype:ppt для PowerPoint.
Удобный оператор, елси вы хотите найти образец какого-либо договора или презенации, чек-лист, заготовку для документа. Наоборот, если не хотите делиться со всем человечеством своими материалами — не вставляйте ссылки на свои документы, иначе они будут проиндексированы и доступны для поиска. Как вариант, закрывайте критичные типы файлов с помощью robots.txt (Disallow: /*.doc$).
Google ничего не знает о реальном типе документа, он ориентируется только на расширение файла/документа. У оператора есть синоним ext, то есть filetype:pdf и ext:pdf делают одно и то же. Важно: не ставьте пробел между двоеточием и расширением!
site:
С помощью этого оператора можно найти что-либо в пределах одного сайта, либо раздела сайта (google site:seoninja.ru/tag/). Если не указывать сам запрос, то Google покажет список всех проиндексированных страниц на сайте, либо домене с поддоменами, либоо в разделе сайта — что укажете в параметре site. В качестве области поиска можно использовать даже доменную зону (.ru, .co.uk, .gov и так далее). Пробел после двоеточия ставить тоже не надо.
inurl:
Поиск определенного слова в адресе страницы. Пригодно, например, для розыска однотипных приложений, например каталогов (inurl:addurl.pl) по заранее известному названию скрипта. Пробела тоже не надо.
allinurl:
Похоже на оператор inurl, но ищет страницы с несколькими словами в адресе. Как и предыдущий оператор, для осмысленного поиска по словам в рунете менее пригоден, чем для англоязычного сегмента — русский язык в адресах используется мало, а способов perevoda v latinicu больше, чем один, особенно для сложных слов.
intext:
Поиск слова в тексте документа, внутри тега body. Любопытен в комбинации с другими операторами, например intitle:seo -inbody:seo выдаст список страниц с плохой оптимизацией, по крайней мере по слову SEO.
allintext:
Поиск нескольких слов в текстах проиндексированных Гуглом страниц. Принцип тот же, что у allinurl, только область поиска иная.
intitle:
Поиск по заголовкам страниц. Принцип действия, полагаю, уже понятен. Любопытна возможность искать не только html по тегу title, но и по заголовку вордовского файла (intitle:bomb filetype:doc), который находится в свойствах документа (Файл — Свойства).
allintitle:
То же, что intitle, но ищет несколько слов. Например: allintitle:seo dumbest mistake.
inanchor:
Еще одна область для обнаружения искомого слова (или фразы, если в кавычках) — текст ссылки, он же якорь, он же анкор. Учитываются как исходящие ссылки, так и ссылки, ведущие на страницу.
allinanchor:
Тот же inanchor, только для нескольких слов. Поиск wordpress theme allinanchor: free download, теоретически, найдет нам страницу с бесплатными темами для WordPress.
daterange:
Оператор ограничивает область поиска только теми документами, которые были изменены или добавлены в индекс Google в течение указанного промежутка времени. Проблема в том, что промежуток надо указывать в Юлианских датах, например daterange:2455440-2455445 — это поиск с 1го по 6е сентября 2010 года. Перевести Грегорианские даты в Юлианские «дни с начала времен» можно здесь. Менее экзотический способ указать диапазон дат — выбрать ссылку ‘More search tools’ в результатах поиска, там есть набор популярных диапазонов, а также возможность указать свой.
related:
Поиск похожих страниц. Параметром к этому оператору будет адрес (URL) интересующей вас страницы, присутствующей в индексе. Результатом — список похожих страниц в индексе Google.
info:
Запрос info:site.com/path/page покажет, есть ли это страница в индексе, поможет узнать присутствует ли она в кеше Google, посмотреть список ссылающихся страниц и упоминаний — короче, это неплохой стартовый запрос, который несколько обесценивает операторы related, link, cache.
link:
Оператор link позволяет получить список страниц, ссылающихся на интересующую нас страницу, адрес которой необходимо указать после двоеточия. Проблема в том, что Google не позволяет отфильтровать ссылки с какого либо сайта, то есть link:seoninja.ru -site:seoninja.ru работать не будет, равно как и наоборот — нельзя посмотреть ссылки с какого-либо определенного сайта. Кроме этого, этот оператор показывает далеко не все проиндексированные ссылки.
cache:
Оператор cache показывает последнюю сохраненную в кеше Google копию страницы, а также показывает дату сохранения страницы.
define:
Учебно-развлекательный оператор, ищет значение, толкование, определение указанного в запросе слова или выражения. Полезно для устранения пробелов в эрудиции и образовании: define:smite
Параметры в строке запроса
Операторы можно использовать для создания эффективных запросов, но есть вещи, которые можно получить проще (или исключительно) путем подстановки параметров в строку с адресом выдачи Google.
Параметры передаются в виде пар переменная=значение, разделяются амперсандом (&) и начинаются после адреса страницы поиска, после знака вопроса. Порядок следования параметров не важен. Базовый адрес для поиска будет http://google.com/search или http://google.ru/search для рунета.
| Параметр в URL | Пример | Описание |
|---|---|---|
| q | http://google.com/search?q=путин+калина | Самый простой запрос, искомые слова перечислены через +. Это единственный необходимый параметр. |
| num | http://google.com/search?q=калина&num=100 | Установить количество результатов на страницу. По-умолчанию Google выдает только 10 результатов, то откровенно мало. |
| start | http://google.com/search?q=сухой&start=990 | Показать выдачу, начиная с указанной в параметре позиции |
| filter | http://google.com/search?q=мокрый&filter=0 | Включить отображение результатов поиска, которые Google по-умолчанию исключает, ввиду их сильной, по его мнению, похожести. Аналогично нажатию ссылки «repeat the search with the omitted results included» на последней странице выдачи. |
| pws | http://google.com/search?q=синий&pws=0 | Выключить «персонализированный поиск». Запрос с добавлением &pws=0 выключает всякую персонализацию и ищет одинаково для всех пользователей, без учета «шлейфа» посещенных сайтов, предыдущих запросов и т.п. |
| safe | http://google.com?q=зеленый&safe=off | Выключает (off) или включает (on) безопасный поиск Google. Фильтр убирает из результатов поиска «взрослые» страницы. Бывает любопытно, не попал ли сайт под него. |
| strip | http://google.com/search?q=cache:www.amazon.com&strip=1 | Параметр специфичен для запросов к Google Cache. Добавление &strip=1 убирает из отображения картинки, стили, скрипты, которые кеш не хранит, то есть без этого параметра браузер заново обращается за ничи непосредственно на сайт. |
| imgtype | http://google.com/images?q=cheese&imgtype=face | Работает только для поска картинок в Google Images. Варианты: face, photo, clipart, lineart, news. |
Это далеко не все параметры. Самый простой запрос к Google из браузера FireFox по ключу SEO, для примера:
http://www.google.cоm/search?q=seo&ie=utf-8&oe=utf-8&aq=t
&rls=org.mozilla:ru:official&client=firefox#hl=en&client=firefox&
hs=Emq&rls=org.mozilla%3Aru%3Aofficial&q=seo&aq=f&aqi=&
aql=&oq=seo&gs_rfai=&pbx=1&fp=d331bd8e2d0de10c
В 4 строки уместился, вроде, хотя даже первая строка уже избыточна.
Похожие записи
На чтение 6 мин. Просмотров 4.6k. Опубликовано 09.08.2021
Специалисты, работающие с Google Analytics, видели или знают, что в отчетах с параметром “Страница” (Page) одна и та же страница может дублироваться за счет добавления разных параметров.
В этой статье я расскажу, откуда берутся эти параметры, почему их наличие может мешать, а главное — что с ними делать.
Содержание
- Что такое параметры запроса URL
- Виды параметров
- Как посмотреть параметры запросов
- Что плохого в параметрах запросов
- Что делать с параметрами
- Какие параметры запросов исключать
- Инструмент сбора параметров URL запроса
Что такое параметры запроса URL
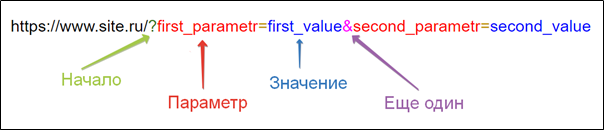
Параметры запроса URL (URL Query Parameters) — это дополнительная информация, которую можно добавить в URL-адрес. Состоит из двух обязательных элементов: из самого параметра и его значения, разделенных знаком равенства (=).
Параметры указываются в конце URL, отделяясь от основного адреса знаком вопроса (?). Можно указать более одного параметра, для этого каждый параметр со значениями отделяется от следующего знаком амперсанда (&).
Виды параметров
Есть параметры, которые влияют на страницу, к URL-адресу которой они добавлены.
Например:
- Параметры для перемещения между разными страницами постраничной навигации (пагинации).
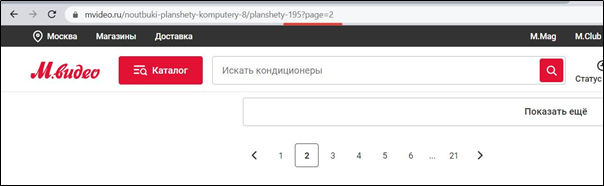
- Параметры для сортировки товаров в каталогах (по цене, популярности и т. п.), а также фильтрации по каким-то критериям.

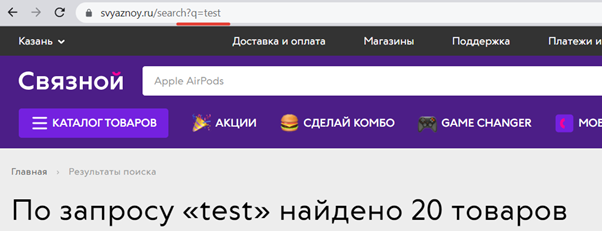
- Параметры запросов при поиске по сайту и пр.
И есть параметры, никак не влияющие на страницу, к URL-адресу которой они добавлены. Их обычно используются для передачи какой-то информации о посещении сайта.
Например:
- UTM-метки (например: utm_source_utm_medium и т.п.) — используются для отслеживания эффективности рекламных кампаний;
- _ga — параметр для настройки междоменного отслеживания;
- fbclid — параметр с информацией о рекламном переходе из Facebook и т. п.
Как посмотреть параметры запросов
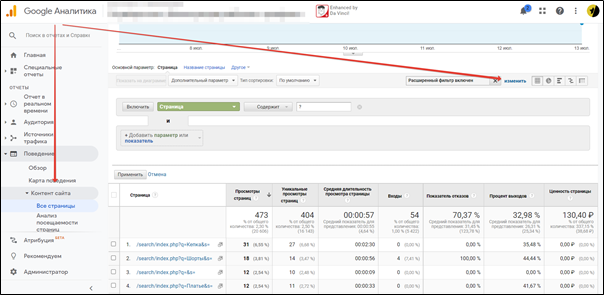
Чтобы увидеть все параметры запросов, с которыми взаимодействовали пользователи на сайте, в Google Analytics надо:
- Перейти в отчет “Поведение → Контент сайта → Все страницы”.
- Раскрыть фильтр (нажать кнопку “Ещё”).
- Выбрать параметр-фильтр: “Включить → Страница → Содержит → ?” и применить фильтр.
На многих сайтах можно увидеть большое количество страниц с разными параметрами.
Что плохого в параметрах запросов
Основная причина, по которой наличие большого количества параметров —плохо, это “размытие” данных о странице.
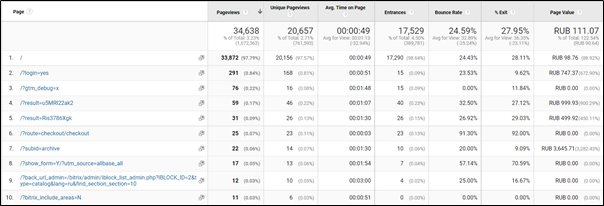
Посмотрите на отчет ниже. Это данные по взаимодействию с главной страницей и её параметрами за последние 6 месяцев.
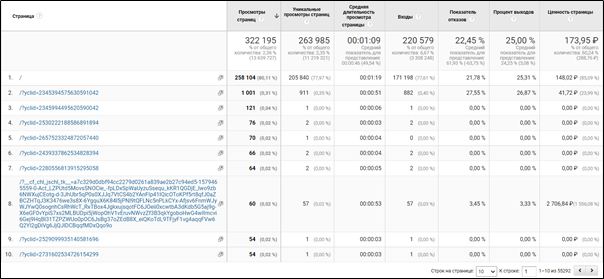
В нижнем правом углу показано количество строк в отчете. Более 55 тысяч уникальных параметров, на которые приходится около 20% от всех просмотров главной страницы.
При этом, если сравнить выведенные метрики качества основной главной страницы (/) и главной страницы с параметрами, мы видим существенные отличия.
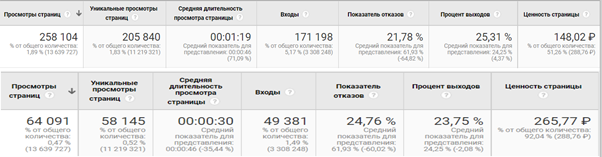
То есть неконтролируемые параметры могут сильно искажать данные о странице.
Что делать с параметрами
Самое просто решение — исключать их из отчетов Google Analytics. При этом исключаются не сами взаимодействия, а удаляются параметры из URL-адресов страниц, “приклеивая” оставшуюся информацию к основной странице. То есть, если в отчете есть информация о 10 взаимодействиях с основной страницей и информация о 10 взаимодействиях с параметрами этой страницы, после исключения параметров мы получим 20 взаимодействий с основной страницей.

Google Analytics по умолчанию сам умеет исключать параметры (_ga, UTM-метки). Для исключения других параметров в Google Analytics есть удобный встроенный инструмент исключения параметров запросов URL. Находится он в разделе “Администратор > Представление > Настройки представления”.
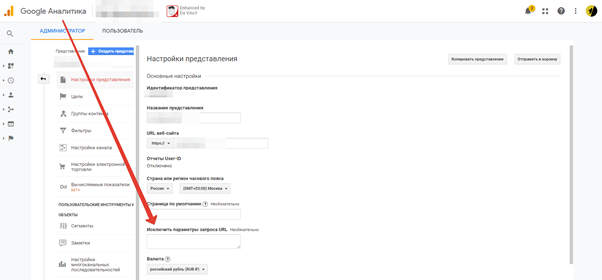
Достаточно указать в данном поле через запятую все параметры, которые надо исключать из отчетов, и в момент внесения изменений данные в представлении будут отображаться без параметров.
Тут стоит сделать две важные ремарки:
- Хорошим тоном для работы со счетчиками Google Analytics является создание двух представлений: чистое представление, данные в котором не меняются, и “рабочее” представление, в которое вносятся все правки. Это важно, так как изменение данных на уровне представления откатить нельзя, и, если появится какая-то ошибка, правильные данные можно извлечь из чистого представления.
- Иногда я слышу опасения, что исключение параметров может исказить отчетность. Этого можно не бояться, так как распределение данных по отчетам Google Analytics проводит на этапе обработки сырых данных. Сначала Google Analytics распределит данные по отчетам, а только потом исключит все указанные параметры.
Какие параметры запросов исключать
Из отчетов надо исключать параметры второго вида, то есть те, которые не влияют на работу сайта, но передают дополнительные параметры.
Но перед удалением параметров обязательно надо обсудить с командой проекта, не связан ли какой-нибудь отчет с этими параметрами.
Ниже пример параметров, которые мы обычно исключаем:
utm_banner,_openstat,mixid,field_city_tid,yclid,block,pos,utm_adid,field_,fb_comment_id,field_works_value,Firstname,utm_keyword,pm_source,pm_block,pm_position,roistat,roistat_referrer,roistat_pos,campaignid,adgroupid,loc_physical_ms,device,placement,phone,Phone,fmode,back_url_admin,pageurl,comment_id,type,url,cm_id,p,rb_clickid,type,source,added,block,pos,key,campaign,retargeting,ad,phrase,gbid,device,region,region_name,redir-setuniq,yclid,target_ref,turbo_url,mlid,msid,lr,t,stid,from,lang,target_ref
Без предварительной подготовки из отчетов не рекомендуется исключать параметры, которые влияют на работу сайта: пагинация, фильтрация, сортировка, действия пользователей. Так как эти параметры могут служить хорошим источником информации для разных исследований и гипотез. Например, какие фильтры с какими значениями предпочитают выбирать пользователи из разных рекламных кампаний.
Отойду от темы и скажу, что часть информации из параметров лучше отправлять в пользовательские параметры. Но это тема отдельной статьи.
Инструмент сбора параметров URL запроса
Раньше для сбора параметров из отчетов Google Analytics необходимо было выгрузить данные из отчетов, выделить параметры, подчистить их, проанализировать.
Но коллеги из 3whitehats разработали инструмент “Google Analytics Query Parameter Extractor”, который позволяет автоматизировать весь процесс, сведя его к нескольким простым шагам. Сам инструмент работает на базе Google Таблиц + расширения Google Analytics Spreadsheet Add-on.
Как пользоваться инструментом:
- Перейдите по ссылке и сохраните копию себе (Файл > Создать копию).
- Установите расширение Google Analytics Spreadsheet Add-on.
Все настройки проводятся на первом листе “Query Parameter Extractor”.
- В поле “Google Analytics View ID” укажите ID представления для анализа. Узнать его можно в разделе “Администратор > Представление > Настройки представления” в поле “Идентификатор представления”.
- В поле “Start Date” укажите дату, начиная с которой надо анализировать данные.
- В поле “End Date” укажите крайнюю дату сбора данных.
Данные в полях с датами необходимо указывать в формате YYYY-MM-DD.
- В поле “Row Limit (Optional)” указывается количество строк, которое будет запрошено через API Google Analytics. Чем больше данных в проекте, тем больше строк надо. С другой стороны, это поле можно оставить пустым, тогда будут получено максимальное количество строк из API.
- Запустите расширение “Дополнения > Google Analytics > Run Report” и дождитесь завершения формирования отчета.
- Нажмите кнопку “Analyze”, чтобы извлечь все уникальные параметры URL.
Может потребоваться авторизация скрипта.
В поле ниже будут собраны все найденные параметры, а в круговой диаграмме – частота появления этих параметров.
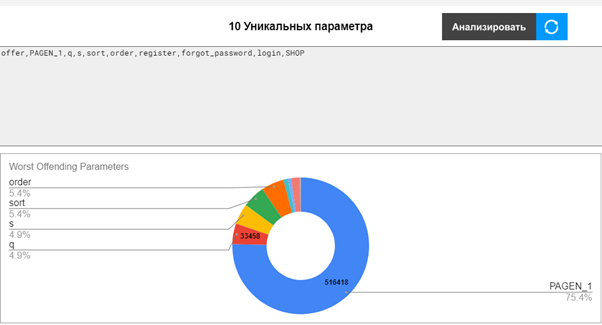
Надеюсь, эта статья поможет вам внести ясность в тему параметров URL-запросов, а инструмент позволит обрабатывать эти параметры эффективнее и быстрее.
Подпишитесь на рассылку новостей. Никакого спама!
Email*
Дубли страниц на сайте могут появиться в поиске вместо ценных страниц сайта или замедлить их обход и индексирование.
Вообще, дубли — это страницы сайта, содержание текста в которых полностью или практически совпадает. Страницы с GET-параметрами в URL тоже могут быть дублями. Если GET-параметр влияет на содержание страницы — это не дубль. А если GET-параметр не меняет контент страницы, то этот параметр называют незначащим и страницу стоит скрыть от поиска.
Расскажем подробнее, что такое незначащие GET-параметры, как найти дубли с такими параметрами и убрать их.
Что такое дубли страниц с незначащими GET-параметрами
GET-параметр — это параметр, который передается серверу в URL страницы. Он начинается с вопросительного знака. Если URL содержит более одного параметра, то эти параметры разделяются знаком «&». Самый частый случай появления дублей из-за незначащих параметров — метки для задач веб-аналитики. Например, utm_source, utm_medium, from. Такими метками владельцы сайтов привыкли помечать трафик. Фактически эти URL одинаковые, на них опубликован одинаковый контент. Но формально адреса разные, так как различаются GET-параметрами в URL. Соответственно, и поиск тоже может посчитать их разными. Такие страницы и называются дублями с незначащими GET-параметрами.
Наличие дублей страниц с незначащими GET-параметрами не приносит пользы и может негативно сказаться на взаимодействии сайта с поисковой системой.
Зачем отслеживать дубли
1) Скорость обхода. Когда на сайте много дублей, роботы тратят больше времени и ресурсов на их обход, вместо того, чтобы обходить ценный контент. А значит, ценные страницы вашего сайта будут медленнее попадать в поиск.
2) Неуправляемость. Так как поисковой робот произвольно выбирает, какой из дублей показывать в поиске, то на поиск могут попасть не те страницы, которые вам нужны.
3) Влияние на поиск. Если незначащие параметры не добавлены в clean-param, робот может обходить эти страницы и считать их разными, не объединяя их в поиске. Тогда поисковый робот будет получать разные неагрегируемые сигналы по каждой из них. Если бы все сигналы получала одна страница, то она имела бы шансы показываться выше в поиске.
4) Нагрузка на сайт. Лишний обход роботом также дает нагрузку на сайт.
Например, на сайте по продаже билетов есть форма заявки на обратный звонок. При ее заполнении в url передается GET-параметр?form=show1, — он сообщает информацию о том, какой спектакль с этой страницы выбрал пользователь в заявке, хотя контент самой страницы никак не меняется. Таким образом, поисковой робот будет тратить время на обход множества одинаковых страниц, различающихся только GET-параметрами в URL, а до ценных страниц сайта доберется значительно позже.
Для интернет-магазинов типичный пример — страницы с фильтрами. Например, если пользователь выбирает товары в дорогом ценовом диапазоне, изменяя значения в фильтре «Цена», то в большинстве случаев ему будет показана страница с одними и теми же товарами. Таким образом, поиск будет получать сигналы о множестве одинаковых страниц, отличающихся только GET-параметром price= в URL.
Как обнаружить дубли
Теперь находить одинаковые страницы стало проще: в разделе «Диагностика» появилось специальное уведомление, которое расскажет про дубли из-за GET-параметров. Алерт появляется с небольшой задержкой в 2-3 дня, поэтому если вы увидели в нем исправленные страницы, не пугайтесь — это может быть связано с задержкой обработки данных. Дубли с параметром amp, даже если они у вас есть, мы не сможем показать в алерте.

Подписываться на оповещения не нужно, уведомление появится само.
Как оставить в поиске нужную страницу
1. Добавьте в файл robots.txt директиву Clean-param, чтобы робот не учитывал незначащие GET-параметры в URL. Робот Яндекса, используя эту директиву, не будет много раз обходить повторяющийся контент. Значит, эффективность обхода повысится, а нагрузка на сайт снизится.
2. Если вы не можете добавить директиву Clean-param, укажите канонический адрес страницы, который будет участвовать в поиске. Это не уменьшит нагрузку на сайт: роботу Яндекса всё равно придётся обойти страницу, чтобы узнать о rel=canonical. Поэтому мы рекомендуем использовать Сlean-param как основной способ.
3. Если по каким-то причинам предыдущие пункты вам не подходят, закройте дубли от индексации при помощи директивы Disallow. Но в таком случае поиск Яндекса не будет получать никаких сигналов с запрещенных страниц. Поэтому мы рекомендуем использовать Сlean-param как основной способ.
Директива Clean-param — межсекционная, это означает, что она будет обрабатываться в любом месте файла robots.txt. Указывать ее для роботов Яндекса при помощи User-Agent: Yandex не требуется. Но если вы хотите указать директивы именно для наших роботов, убедитесь, что для User-Agent: Yandex указаны и все остальные директивы — Disallow и Allow. Если в robots.txt будет указана директива User-Agent: Yandex, наш робот будет следовать указаниям только для этой директивы, а User-Agent: * будет проигнорирован.
Подробнее о работе со страницами-дублями читайте в Справке.
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
Канал Яндекса о продвижении сайтов на YouTube
Канал для владельцев сайтов в Яндекс.Дзен
Автор: Джес Шольц (Jes Scholz), digital-директор, Ringier
Хотя веб-разработчики и поклонники аналитики любят параметры, для SEO-специалистов они часто являются кошмаром. Бесконечные комбинации параметров могут создавать из одного и того же контента тысячи вариантов URL.
Проблема в том, что мы не можем их игнорировать. Параметры
играют важную роль в пользовательском опыте. Поэтому необходимо понять, как
правильно обращаться с ними с точки зрения SEO.
Что такое параметры URL?
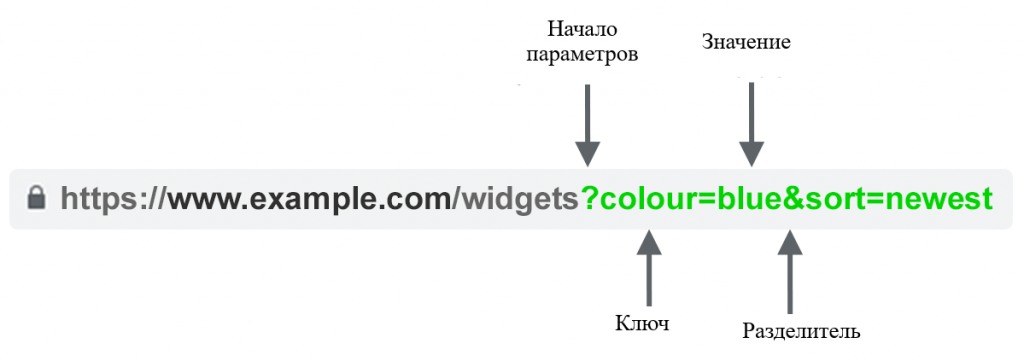
Параметры URL, также известные как строки запроса и переменные URL, представляют собой ту часть URL-адреса, которая идёт после знака вопроса.
Они состоят из пары «ключ + значение», разделённых знаком равенства (=). Используя амперсанд (знак &), можно добавить несколько параметров на одну страницу.
Самые распространённые варианты использования параметров:
- Отслеживание. Например: utm_medium=social, ?sessionid=123 или ?affiliateid=abc.
- Изменение порядка. Например: ?sort=lowest-price, ?order=highest-rated или ?so=newest.
- Фильтрация. Например: ?type=widget, colour=blue или ?price-range=20-50.
- Идентификация. Например: ?product=small-blue-widget, categoryid=124 или itemid=24AU.
- Пагинация. Например: ?page=2, ?p=2 или viewItems=10-30.
- Поиск. Например: ?query=users-query, ?q=users-query или ?search=drop-down-option.
- Смена языковой версии. Например: ?lang=fr, ?language=de.
SEO-проблемы при использовании
параметров URL
1. Параметры создают
дублированный контент
Зачастую параметры URL не вносят существенных изменений в содержимое страницы.
Переупорядоченная версия страницы часто не сильно отличается от оригинала, а URL страницы с тегами
отслеживания или идентификатором сеанса идентичен оригиналу.
Например, следующие URL-адреса все будут возвращать подборку виджетов:
- Статический URL: https://www.example.com/widgets
- Параметр отслеживания: https://www.example.com/widgets?sessionID=32764
- Параметр, меняющий порядок на странице: https://www.example.com/widgets?sort=newest
- Параметр идентификации: https://www.example.com?category=widgets
- Параметр поиска: https://www.example.com/products?search=widget
Таким образом, мы получаем несколько URL для, по сути, одного и того же
контента. Теперь представьте такую ситуацию для каждой категории на сайте.
Проблема в том, что поисковые системы обрабатывают каждый URL с параметрами как новую
страницу. Поэтому они видят несколько вариаций одной и той же страницы. При
этом все они содержат дублированный контент и нацелены на одну и ту же ключевую
фразу или тему.
Хотя дублирование такого рода вряд ли вызовет полное выпадение сайта из результатов поиска, оно приводит к каннибализации ключевых слов и может ухудшать представление Google об общем качестве сайта, поскольку эти дополнительные URL-адреса не приносят реальной пользы.
2. Параметры
расходуют бюджет сканирования
Сканирование страниц с большим количество параметров истощает
бюджет сканирования, снижая возможность индексирования важных для SEO страниц и повышая
нагрузку на сервер.
Google
описал эту проблему в Справке для
вебмастеров:
«Слишком сложные URL, особенно включающие несколько параметров,
могут затруднять работу поисковых роботов, так как создается чрезмерное
количество URL-адресов, указывающих на одно и то же или схожее содержание на
сайте. В результате робот Googlebot может использовать гораздо больше ресурсов
канала передачи данных, чем это необходимо. Кроме того, есть вероятность, что он
не сможет просканировать всё содержание сайта полностью».
3. Параметры
распыляют сигналы ранжирования страницы
Если у вас имеется несколько вариантов одного и того же содержимого страницы, то ссылки и репосты в социальных сетях могут поступать для разных его версий.
Это размывает сигналы ранжирования страницы. В такой
ситуации краулеру может быть сложно понять, какую версию страницы следует
индексировать для поискового запроса.
4. Параметры делают URL менее кликабельными

Давайте посмотрим правде в глаза: параметры
малопривлекательны. Их трудно читать. Они не вызывают доверия. Соответственно,
такие URL получают
меньше кликов. А это может отразиться на эффективности страницы в поиске.
Причём, не только потому, что CTR
может влиять на ранжирование, но также потому, что такие URL менее
кликабельны в социальных медиа, в email-сообщениях, при копировании на форумах и в других местах,
где может отображаться полный URL-адрес.
Каждый твит, лайк, репост, email,
ссылка и упоминание имеют значение для домена.
Плохая читабельность URL приводит к снижению вовлечённости во взаимодействие с
брендом.
Оцените масштабы проблемы с параметрами на сайте
SEO-специалисту важно знать о каждом параметре, используемом на его сайте. Однако отнюдь не факт, что разработчики будут обновлять этот список.
Как найти все параметры, используемые на сайте? Или понять,
как поисковые системы сканируют и индексируют такие страницы? Узнать, какую
ценность они несут для пользователей?
Выполните следующие пять шагов:
- Запустите краулер. С помощью такого инструмента, как Screaming Frog, можно искать «?» в URL.
- Проверьте данные в инструменте «Параметры URL» в Search Console: Google автоматически добавляет все строки запросов, которые он находит.
- Просмотрите лог-файлы: проверьте, сканирует ли Googlebot URL с параметрами.
- Выполните поиск по сайту. Используйте операторы поиска site: и inurl:. Узнать, как Google индексирует параметры, которые вы нашли, можно с помощью следующего запроса: [site: example.com inurl:ключ].
- Просмотрите отчёт «Все страницы» в Google Analytics. Ищите «?», чтобы увидеть, как каждый из найденных вами параметров используется пользователями. Проверьте, чтобы параметры URL не были исключены в настройках просмотра.
Вооружившись этими данными, вы сможете решить, как наилучшим
образом обойтись с каждым параметром вашего сайта.
SEO-решения для «укрощения» параметров URL
Для работы с параметрами URL на стратегическом уровне в арсенале SEO-специалиста есть 6 инструментов. Рассмотрим их подробнее.
Ограничьте количество
URL, основанных на параметрах
Простая проверка того, как и почему генерируются параметры,
может обеспечить быстрые выигрыши для SEO. Ниже – четыре частые проблемы, с которых стоит начать
работу.
1. Удалите ненужные параметры
Попросите своего программиста предоставить вам список всех параметров и их функций. Есть шансы, что вы обнаружите те параметры, которые больше не выполняют полезной функции. Так, пользователи могут быть лучше идентифицированы с помощью файлов cookies, а не идентификаторов сеансов. При этом параметр sessionID может по-прежнему присутствовать на сайте, поскольку он использовался ранее.
Или же вы можете обнаружить, что фильтр в фасетной навигации
редко применяется вашими пользователями.
Любые параметры, вызванные техническими недоработками
(незавершёнными изменениями в программном коде) должны быть немедленно
устранены.
2. Не допускайте появления пустых значений
Параметры должны добавляться к URL только в том случае, когда у них есть полезная функция. Не допускайте добавления ключей параметров, если у них пустое значение.
Так, на примере выше key2 и key3 не добавляют URL никакой ценности.
3. Используйте ключи только один раз
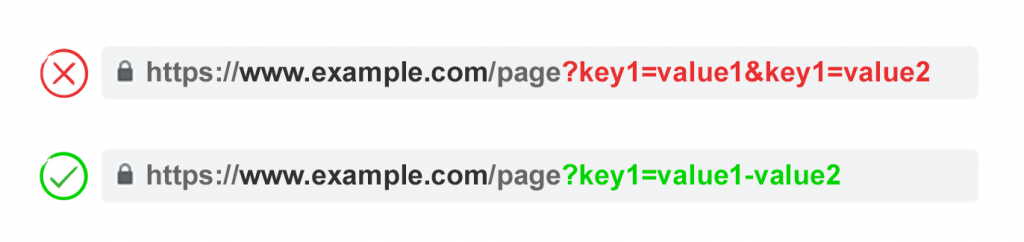
Избегайте применения нескольких параметров с одним и тем же
именем, но разным значением.
Для множественного выбора лучше объединять значения после ключа.
4. Очерёдность параметров
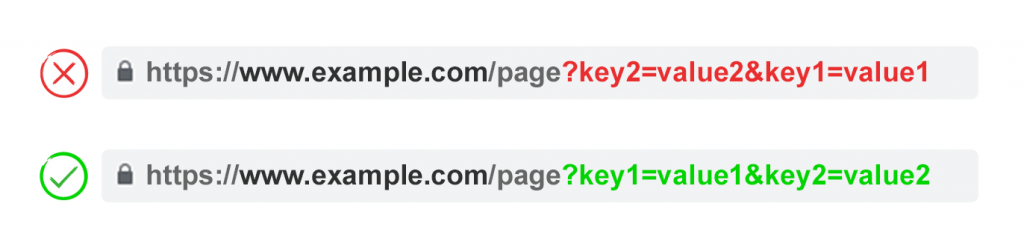
Если одни и те же параметры URL поменяны местами, то страницы
интерпретируются поисковыми системами как идентичные. Поэтому порядок параметров
не значим с точки зрения дублированного контента. Однако каждая из этих
комбинаций сжигает бюджет сканирования и рассеивает сигналы ранжирования.
Во избежание этих проблем, попросите своего разработчика написать скрипт, который будет гарантировать добавление параметров в определённом порядке – независимо от того, как пользователь будет их выбирать.
Мы рекомендуем начинать с параметров языка, затем добавлять
идентификацию, пагинацию, фильтрацию или поисковые параметры, а в самом конце –
отслеживание.
Плюсы:
- Более эффективное использование краулингового
бюджета; - Сокращение проблем с дублированным контентом;
- Консолидация сигналов ранжирования для
нескольких страниц; - Подходит для всех типов параметров.
Минусы:
- Требует времени на внедрение.
Атрибут rel=”canonical”
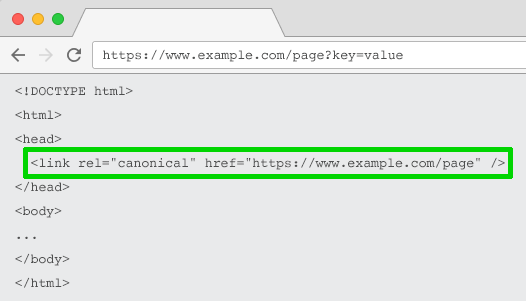
Атрибут rel=”canonical” указывает, что
содержимое страницы идентично или похоже не содержимое другой страницы. Это
побуждает поисковые системы объединять сигналы ранжирования по URL, указанному как
канонический (основной).
Таким образом, вы можете добавить этот атрибут на URL с параметрами, указав как канонический более оптимизированный с точки зрения SEO URL-адрес – для отслеживания, идентификации или переупорядочивания контента. Однако эта тактика не подойдёт в том случае, когда содержимое страницы с параметрами недостаточно похоже на содержимого канонического URL.
Плюсы:
- Относительно легко реализовать;
- Высокая вероятность защиты от проблем с
дублированным контентом; - Консолидирует сигналы ранжирования на
каноническом URL.
Минусы:
- Бюджет сканирования тратится на страницы с
параметрами; - Подходит не для всех типов параметров.
- Интерпретирует поисковыми системами как
подсказка, но не директива.
Директива noindex в метатеге robots
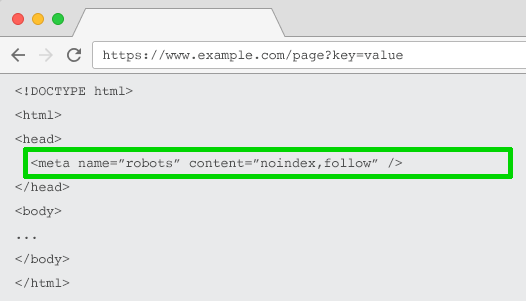
Настройте директиву noindex для любой страницы с параметрами, которая не имеет
ценности для SEO. В результате
поисковые системы не будут индексировать эти страницы.
Кроме того, такие URL реже сканируются, а директива noindex, follow со временем переходит в noindex, nofollow.
Плюсы:
- Относительно легко внедрить;
- Высокая вероятность защиты от проблем с
дублированным контентом; - Подходит для всех типов параметров, которые не
должны индексироваться; - Удаляет существующие URL с параметрами из индекса.
Минусы:
- Не запрещает поисковым системам сканировать URL, но побуждает их делать
это реже; - Не объединяет сигналы ранжирования;
- Интерпретируется поисковыми системами как намёк,
но не директива.
Директива Disallow в файле robots.txt
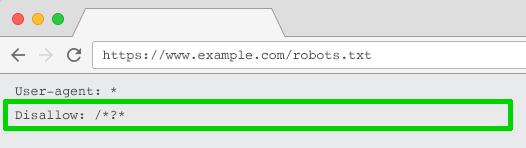
Файл robots.txt – это то, на что
поисковые системы смотрят в первую очередь, прежде чем сканировать сайт. Если
они увидят там запрет на что-либо, то на следующую стадию даже не перейдут.
Вы можете использовать этот файл, чтобы заблокировать
краулерам доступ к URL
с параметрами с помощью директивы Disallow: /*?* или указания конкретных строк запроса, которые не
должны индексироваться.
Плюсы:
- Просто внедрить.
- Позволяет более эффективно использовать бюджет
сканирования. - Позволяет избежать проблем с дублированием
контента. - Подходит для всех типов параметров, которые не
должны сканироваться.
Минусы:
- Не объединяет сигналы ранжирования.
- Не удаляет существующие URL из индекса.
Инструмент «Параметры
URL» в Google Search Console
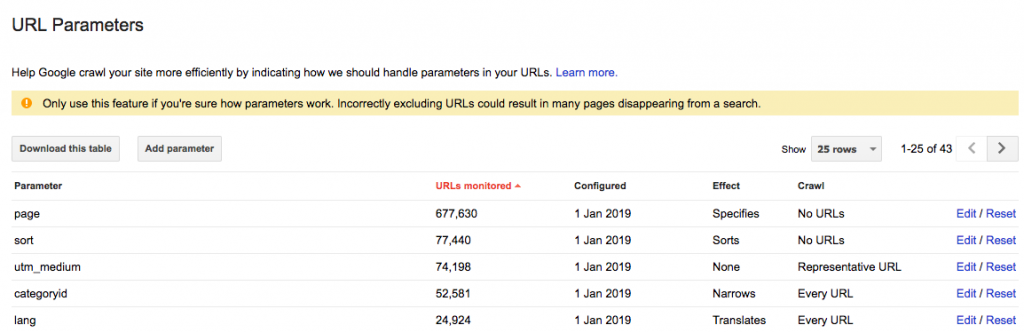
Настройте инструмент «Параметры URL» таким образом, чтобы он сообщал
краулерам назначение ваших параметров и то, как бы вы хотели, чтобы они
обрабатывались.
Google Search Console
предупреждает, что использование этого инструмента «может привести к
исчезновению многих страниц из поиска».
Это может звучать зловеще, но что ещё более пугающе, так это
тысячи дублированных страниц, которые вредят ранжированию вашего сайта.
Поэтому лучше узнать, как настроить параметры URL в Search Console, чем позволить решать
Googlebot.
Ключ в том, чтобы спросить себя, как каждый параметр влияет на содержимое страницы.
- Параметры отслеживания не меняют контент страницы. Настройте их как «основные URL» (representative URL).
- Параметры, которые меняют порядок отображения контента на странице, настройте как «сортирующие». Если они опционально добавляются пользователем, то выберите вариант сканирования «Никакие URL». Если параметр «sort» применяется по умолчанию, используйте настройку «Только URL со значением», введя значение по умолчанию.
- Параметры, которые фильтруют данные на странице, настройте как «ограничивающие». Если эти фильтры не релевантны для SEO, выберите вариант сканирования «Никаких URL». В противном случае – «Каждый URL».
- Параметры, которые показывают определённый фрагмент или группу контента, настройте как «указывающие». В идеале это должен быть статичный URL. Если это невозможно, выберите вариант «Каждый URL».
- Параметры, которые предоставляют посетителю страницу на определённом языке, настройте как «перевод». В идеале это должно быть реализовано через подпапки. Если это невозможно, выберите вариант сканирования «Каждый URL».
- Параметры, которые отображают конкретную страницу длинного списка или статьи, настройте как «разбивающие на страницы». Если вы добились эффективной индексации с помощью файлов Sitemap.xml, вы можете сэкономить краулинговый бюджет и выбрать вариант сканирования «Никакой URL». В противном случае выберите «Каждый URL», чтобы краулеры могли получить доступ ко всем элементам.
При выборе варианта «На усмотрение робота Googlebot» Google автоматически добавит параметры в список. Проблема в том, что удалить эти параметры не получится – даже если они больше не нужны. Поэтому, когда это возможно, лучше заранее добавить параметры самостоятельно. Тогда, если параметр перестанет использоваться, вы сможете удалить его из Search Console.
Плюсы:
- Не нужно привлекать разработчика.
- Позволяет более эффективно использовать бюджет
сканирования. - Помогает избежать проблем с дублированным
контентом. - Подходит для всех типов параметров.
Минусы:
- Не объединяет сигналы ранжирования.
- Интерпретируется Google как подсказка, а не директива.
- Работает только для Google.
Перейдите от
динамических URL к
статическим
Многие считают, что оптимальный способ обхождения с параметрами URL – это просто избегать их. В конце концов, подпапки лучше, чем параметры, помогают Google понять структуру сайта, а статические URL-адреса на основе ключевых слов всегда были краеугольным камнем on-page SEO.
Чтобы достичь этой цели, вы можете использовать перезапись URL-адресов на стороне сервера для преобразования параметров в URL-адреса подпапок.
Например, текущий URL:
www.example.com/view-product?id=482794
Станет:
www.example.com/widgets/blue
Этот подход хорошо работает для описательных параметров на основе ключевых слов — например, для тех, что определяют категории и товары. Он также эффективен для контента, переведённого на другие языки.
Однако его использование становится проблематичным для некоторых элементов фасетной навигации, таких как цена. Наличие такого фильтра в качестве статического индексируемого URL не несёт никакой ценности для SEO.
Это также проблема для поисковых параметров, поскольку
каждый сгенерированный пользователем запрос будет создавать статичную страницу,
которая будет соперничать за ранжирование с канонической. Или, что ещё хуже,
будет предоставлять краулерам страницы с низкокачественным контентом всякий
раз, когда пользователь будет искать товар, которого нет на сайте.
Этот подход также не очень применим к пагинации (хотя это не
редкость из-за WordPress),
поскольку в итоге он даст примерно такой URL:
www.example.com/widgets/blue/page2
Ещё более странно будет выглядеть URL при переупорядочивании контента:
www.example.com/widgets/blue/lowest-price
Кроме того, зачастую это неподходящий вариант для отслеживания. Google Analytics не признаёт статическую версию UTM.
Более того, замена динамических параметров на статические URL для таких вещей, как
пагинация, поиск на сайте или сортировка, не решает проблему дублированного
контента, расхода краулингового бюджета или рассеивания ссылочного веса.
При этом наличие всех комбинаций фильтров из фасетной
навигации в качестве индексируемых URL часто приводит к проблемам с так называемым «thin» контентом. Особенно в
том случае, если вы предлагаете фильтры с множественным выбором.
Многие SEO-специалисты
утверждают, что можно обеспечить такой же пользовательский опыт, не затрагивая URL. Например, используя POST-запросы вместо GET-запросов для изменения
содержимого страницы, что позволяет сохранить пользовательский опыт и избежать
проблем с SEO.
Однако удаление параметров таким способом лишит вашу
аудиторию возможности добавить страницу в закладки или поделиться ссылкой на
неё. И этот вариант явно не подходит для параметров отслеживания и не является
оптимальным для разбивки на страницы.
Суть в том, что для многих сайтов этот подход не приемлем,
если нужно обеспечить идеальный пользовательский опыт. Это также не является
лучшей практикой с точки зрения SEO.
Таким образом, те параметры, которые не должны индексироваться (пагинация, переупорядочивание, отслеживание и т.п.), реализуйте как строки запроса. А для тех параметров, которые должны индексироваться, используйте статические URL.
Плюсы:
- Смещает внимание краулеров с URL, основанных на параметрах, на
статические URL,
которые имеют больше шансов на ранжирование.
Минусы:
- Значительные затраты времени на переписывание URL и настройку 301 редиректов.
- Не предотвращает проблемы с дублированным контентом.
- Не объединяет сигналы ранжирования.
- Подходит не для всех типов параметров.
- Может приводить к появлению tnin-контента и соответствующих проблем.
- Не всегда предоставляет URL, которые можно добавить в закладки или использовать в качестве ссылки.
Какой подход выбрать?
Итак, какой же из этих шести подходов следует внедрить?
Выбрать все сразу нельзя. Это создаст ненужные сложности. Кроме того, разные SEO-решения нередко
конфликтуют друг с другом.
Например, если вы настраиваете директиву disallow в файле robots.txt, то Google не должен видеть метатеги noindex. Кроме того, метатег noindex не следует сочетать с атрибутом rel=canonical.
Ясно одно: идеального
решения нет.
Даже сотрудник Google Джон Мюллер не может определиться с подходом. Во время одной из
видеовстреч для вебмастеров он сначала посоветовал не запрещать параметры, но
когда его спросили об этом с точки зрения фасетной навигации, он ответил: «Здесь возможны варианты».
Есть случаи, когда эффективность сканирования более важна,
чем консолидация сигналов авторитетности. В конечном счёте, оптимальное решение
будет зависеть от ваших приоритетов.

Лично я не использую noindex и не блокирую доступ к
страницам с параметрами. Если Google не может сканировать и понимать все
переменные URL, то он не может объединить сигналы ранжирования на канонической
странице.
Оптимальное управление
параметрами для SEO
Мы рекомендуем придерживаться следующего плана:
- Проведите исследование ключевых слов, чтобы
понять, какие параметры должны быть представлены в виде дружественных к поисковым
системам статичных URL. - Корректно реализуйте пагинацию с помощью rel=”next” и rel=”prev”.
- Настройте обработку каждого параметра в Google и других поисковых
системах, чтобы помочь им понять их функции. - Убедитесь, что URL с параметрами не добавляются в файл Sitemap.xml.
Какую бы стратегию вы не выбрали, обязательно документируйте влияние своих действий на KPI.