Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
В статье:
-
Как поисковики сканируют страницу
-
Robots.txt для Яндекса и Google
-
Как составить robots.txt правильно
-
Инструменты для составления и проверки robots.txt
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено
краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта —
Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Как узнать, попала ли страница сайта в индекс Яндекса или Google
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки
инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью
анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt«, название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:

Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на
карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
User-agent: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел
http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам «site.com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123»
«www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123»
«www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123»
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123»
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243»
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311»
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже
не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке
http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:

Для
проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
{«id»:13960,»url»:»/distributions/13960/click?bit=1&hash=5a66902d4ef807c2f12c01d0517253c795e30ffb23e978780172082d6e405c9d»,»title»:»u0421u043eu0442u0440u0443u0434u043du0438u043au0438 u0432u0441u0451 u0435u0449u0451 u0438u0441u043fu043eu043bu044cu0437u0443u044eu0442 qwerty? u0415u0441u0442u044c u0440u0435u0448u0435u043du0438u0435 u0431u0435u0437u043eu043fu0430u0441u043du0435u0435″,»buttonText»:»u041au0430u043au043eu0435?»,»imageUuid»:»c04eba06-036a-5455-b12e-57035f11403c»}
Дмитрий Молодняков
RPA-разработчик компании NFP
Технология RPA с каждым днем набирает популярность. Сегодня фраза «написать робота» уже мало кого удивляет. Более того, для этой несложной задачи достаточно базовых навыков программирования. А в сочетании с хорошо выбранной платформой, дополненной машинным обучением, процесс создания робота будет состоять из набора последовательных шагов. Расскажу о них подробнее.
RPA — удобное и надежное решение для автоматизации процессов. В современных платформах с каждым обновлением увеличивается и модернизируется функционал. Для создания роботов требуется все меньше навыков программирования.
К примеру, ведущий российской разработчик программного обеспечения для роботизации бизнес-процессов, компания Pix Robotics, дополнила свою платформу PIX RPA модулем машинного обучения Machine Learning (ML). Machine Learning — класс методов искусственного интеллекта, характерной чертой которых является способность к самостоятельному обучению путем решения множества сходных задач. В нашем случае именно ML позволяет роботам самостоятельно работать с информацией, используя инструменты аналитики. Преимуществом использования ML является возможность написать робота, имея только входные данные.
5 шагов создания робота
Для того, чтобы получился «правильный» робот (оптимальный в плане выполнения задачи и затрат на разработку, корректный, долгосрочный) в большинстве случаев достаточно сделать 5 основных шагов:
Шаг 1
Выберите процесс, подходящий для автоматизации. Для этого есть ряд критериев. Рассмотрим основные:
- Процесс, основанный на правилах (алгоритмизируемый)
Процесс должен осуществляться в соответствии с заранее известной логикой.
- Регулярно повторяющийся процесс
Последовательность действий сотрудника, являющаяся процессом, должна систематически повторяться.
- Стандартизированные входные данные
Входные данные должны предоставляться в соответствии с единым шаблоном.
- Процесс, способный быть автономным
Автоматизируемый процесс должен быть способен выполняться без участия человека.
Шаг 2
Составьте схемы «Как есть» и «Как будет» для выбранного процесса. В схеме «Как есть» перечислите действия сотрудника на данный момент, т.е. до автоматизации. Например:
В схеме «Как будет» отобразите процесс после автоматизации. Блоков, где необходимо вмешательство человека, может не быть, но встречаются и случаи, когда участие сотрудника необходимо. Пример простейшей схемы «Как будет»:
Шаг 3
Составьте архитектуру робота. Лучше разбивать участки процесса на отдельные блоки, чтобы использовать их повторно вызовом этих блоков, а не копированием. Старайтесь, чтобы каждый блок выполнял свой функционал, не пересекаясь с функционалами других блоков. Благодаря такому подходу вы сможете видеть весь процесс и избежите ошибок, следствием которых могут стать неоптимальность, длительная разработка, переделывание, корректировки.
Шаг 4
Теперь можно смело приступать к разработке робота. Опираясь на архитектуру из 3 шага, начните с малых подпроцессов. Держите в голове участки, где возможны ошибки. Настройте оповещения об ошибках.
Шаг 5
Вы почти у цели! Заключительный этап включает в себя полный цикл тестирования робота. Для этого подавайте на него различные варианты входных данных. Не лишним будет и проверить работу робота, используя заведомо неверные данные.
Успехов вам!
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Зачем это нужно:
- уменьшить количество запросов к серверу;
- оптимизировать краулинговый бюджет сайта — общее количество страниц, которое за один раз может посетить поисковый бот;
- уменьшить шанс того, что в выдачу попадут страницы, которые там не нужны.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
 Главная страница сайта в выдаче, но описание бот составить не смог
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию <head> HTML-кода страницы:
<meta name="robots" content="noindex, nofollow"/>Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
- Формат — только txt.
- Вес — не превышающий 32 КБ.
- Название — строго строчными буквами «robots.txt». Никакие другие варианты, к примеру, с заглавной, боты не воспримут.
- Наполнение — строго латиница. Все записи должны быть на латинице, включая адрес сайта: если он кириллический, его нужно переконвертировать в punycode. Например, после конвертации запись сайта «окна.рф» будет выглядеть как «xn--80atjc.xn--p1ai». Ее и нужно использовать в командах.
- Исключение для предыдущего правила — комментарии вебмастера. Они могут быть на любом языке, поскольку специалист оставляет их для себя и коллег, а не для поисковых ботов. Для обозначения комментариев используют символ «#». Все, что указано после «#», роботы проигнорируют, поэтому следите, чтобы туда случайно не попали важные команды.
- Количество файлов robots.txt — должен быть один общий файл на весь сайт вместе с поддоменами.
- Местоположение — корневой каталог. У поддоменов файл должен быть таким же, только разместить его нужно в корневом каталоге каждого поддомена.
- Ссылка на файл — https://example.com/robots.txt (вместо https://example.com нужно указать адрес вашего сайта).
- Ссылка на robots.txt должна отдавать код ответа сервера 200 OK.
Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пример:
Disallow: /blog/page-2.html
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
User-agent: *
Disallow:
А эта запись запрещает всем роботом сканировать весь сайт:
User-agent: *
Disallow: /
Если речь идет о новом сайте, проследите, чтобы в файле robots.txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Disallow: /catalog/blog/photo/
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Disallow: /catalog/
Disallow: /blog/
Disallow: /photo/
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
User-agent: *
Allow: /album/photo1.html
Disallow: /album/
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
https://example.com/index.php?page=1&sid=2564126ebdec301c607e5df
https://example.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index.php» индексировать не нужно:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Sitemap: https://example.com/sitemap.xml
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
Disallow: /catalog/category1$
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
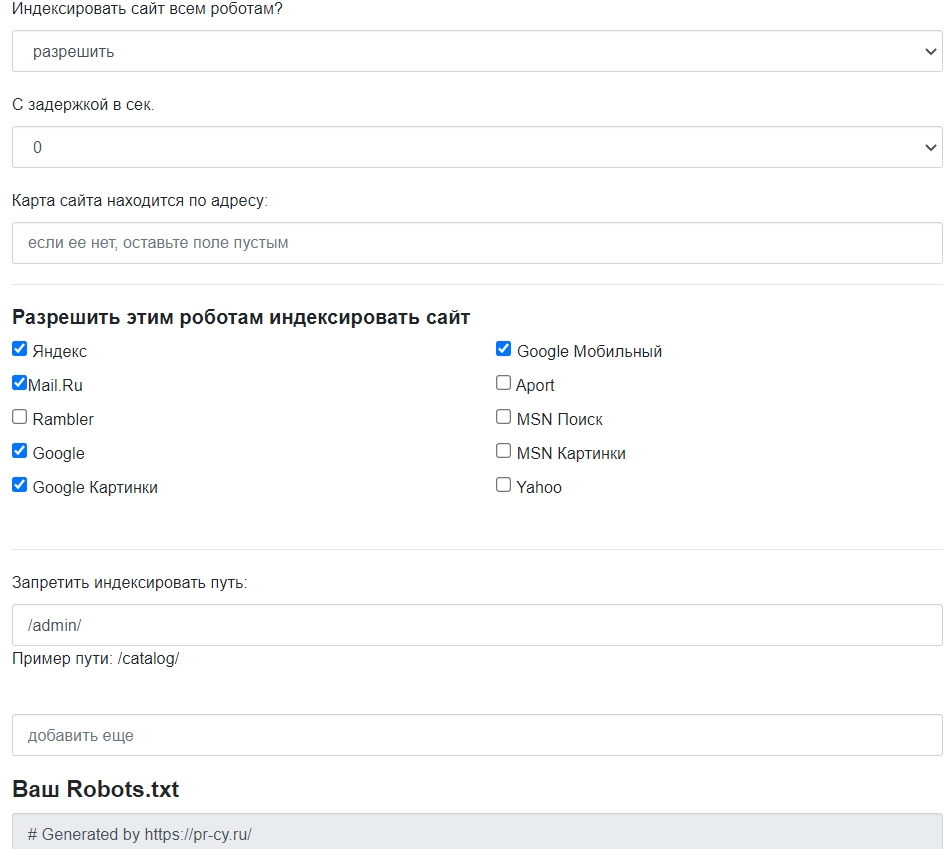 Настройки файла в инструменте
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
- Найти ошибки в заполнении robots — инструмент от Яндекса. Укажите сайт и введите содержимое файла в поле.
- Проверить доступность для ботов — инструмент от Google. Введите ссылку на URL с вашим robots.txt.
- Определить наличие файла robots.txt в корневом каталоге и доступность сайта для индексации — Анализ сайта от PR-CY. В сервисе есть еще 70+ тестов с проверкой SEO, технических параметров, ссылок и другого.
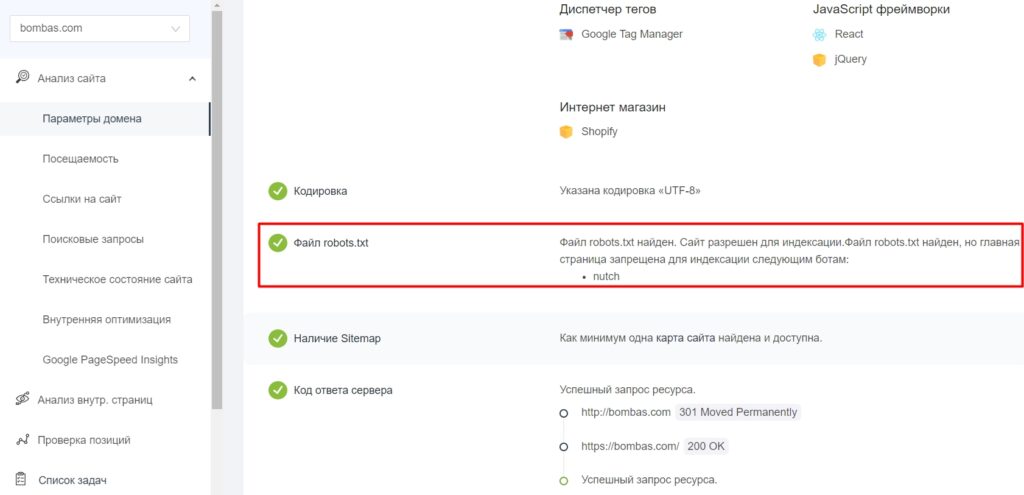 Фрагмент проверки сайта сервисом pr-cy.ru/analysis
Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
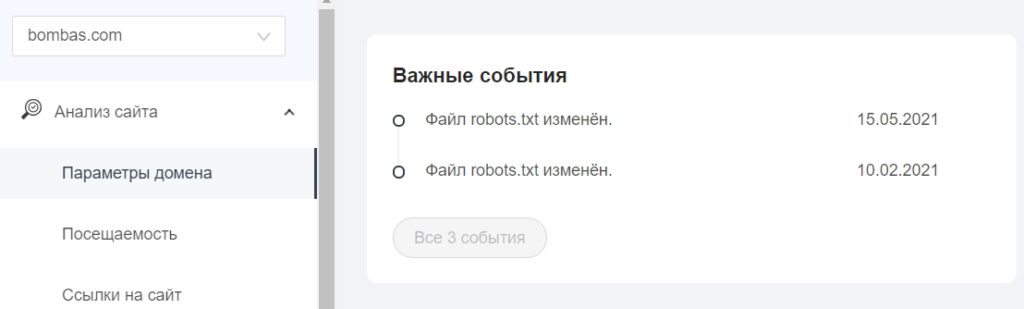 Оповещения в интерфейсе
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots.txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
- Robots.txt Editor,
- Virtual Robots.txt,
- WordPress Robots.txt optimization (+XML Sitemap).
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: *&s=
Disallow: /search/
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xml
1C-Битрикс
В модуле «Поисковая оптимизация» этой CMS начиная с версии 14.0.0 можно настроить управление файлом robots из административной панели сайта. Нужный раздел находится в меню Маркетинг > Поисковая оптимизация > Настройка robots.txt.
Пример robots.txt для сайта на Битрикс
Похожий набор рекомендаций с дополнениями, подразумевающими, что у сайта есть личный кабинет пользователя.
User-agent: *
Disallow: /cgi-bin # закрыли папку на хостинге
Disallow: /bitrix/ # закрыли папку с системными файлами Битрикс
Disallow: *bitrix_*= # GET-запросы Битрикс
Disallow: /local/ # другая папка с системными файлами Битрикс
Disallow: /*index.php$ # дубли страниц с index.php
Disallow: /auth/ # страница авторизации
Disallow: *auth=
Disallow: /personal/ # личный кабинет
Disallow: *register= # страница регистрации
Disallow: *forgot_password= # страница с функцией восстановления пароля
Disallow: *change_password= # страница с возможностью изменить пароль
Disallow: *login= # вход с логином
Disallow: *logout= # выход из кабинета
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url=
Disallow: *back_url_admin=
Disallow: *captcha # страница с прохождением капчи
Disallow: */feed # новостные ленты
Disallow: */rss # rss-фиды
Disallow: *?FILTER*= # несколько популярных параметров фильтров в каталоге
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # все ссылки, имеющие метки UTM
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открыли папку, где находятся файлы uploads
Allow: /bitrix/*.js # здесь и далее открыли скрипты js и css
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg # открыли доступ к картинкам в формате jpg и далее в других форматах
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
Sitemap: https://example.com/sitemap.xml
OpenCart
У этого движка есть официальный модуль Редактирование robots.txt Opencart для работы с файлом прямо из панели администратора.
Пример robots.txt для магазина на OpenCart
CMS OpenCart обычно используют в качестве базы для интернет-магазина, поэтому пример robots заточен под нужды e-commerce.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter=
Disallow: /*&filter=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: *page=*
Disallow: *search=*
Disallow: /cart/
Disallow: /forgot-password/
Disallow: /login/
Disallow: /compare-products/
Disallow: /add-return/
Disallow: /vouchers/
Sitemap: https://example.com/sitemap.xml
Joomla
Отдельных расширений, связанных с формированием файла robots.txt для этой CMS нет, система управления автоматически генерирует файл при установке, в нем содержатся все необходимые запреты.
Пример robots.txt для сайта на Joomla
В файле закрыты плагины, шаблоны и прочие системные решения.
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
Sitemap: https://example.com/sitemap.xml
Поисковые системы воспринимают директивы в robots.txt как рекомендации, которым можно следовать или не следовать. Тем не менее, если в файле не будет противоречий, а на закрытые страницы нет входящих ссылок — у ботов не будет причин игнорировать правила. Пользуйтесь нашими инструкциями и примерами, и пусть в выдаче появляются только действительно нужные пользователям страницы вашего сайта.
Пошаговое руководство по созданию торгового бота на любом языке программирования
Время на прочтение
14 мин
Количество просмотров 92K
У меня нет квалификации, позволяющей давать советы, касающиеся инвестиций, законов, или чего-то подобного. Я и не пытаюсь этого делать. Цель руководства заключается в том, чтобы, в учебных целях, рассказать о программировании торговых ботов. Вы должны понимать, что, создав бота, вы несёте ответственность за принимаемые им решения, за выполняемые им инвестиционные операции, за те риски, которые сопряжены с торговой деятельностью. Я не могу отвечать за те решения, которые вы примете после прочтения данного материала. Помните, что боты способны потерять большие деньги, поэтому используйте их с осторожностью.
Часто можно встретить статьи, которые называются примерно так: «10 проектов, которые нужно реализовать программисту». Часто в списки этих статей входят торговые боты. Я считаю, что разработка торгового бота — это достойное вложение сил. Поэтому я решил уделить некоторое время тому, чтобы написать учебное руководство об этом.
Но вместо того, чтобы устраивать тут построчный разбор некоего кода, я решил, что лучше будет разобрать те концепции, с которыми должен быть знаком тот, кто хочет создать собственного бота. Смысл моего материала заключается в том, чтобы, прочтя его, вы сами написали бы код.
Поэтом я расскажу о том, что полезно знать для разработки торгового бота, и о том, что для этого нужно (от работы с биржами до реализации простой торговой стратегии). Здесь же я коснусь вопросов, связанных с архитектурой и внутренним устройством простых торговых ботов, с идеями, которые лежат в их основе.

Я буду демонстрировать примеры, написанные на псевдокоде. Поэтому вы сможете читать это руководство и тут же писать собственного бота на выбранном вами языке программирования.
В результате вам будет комфортно, так как вы будете пользоваться инструментом, с которым вы хорошо знакомы. Сможете спокойно заниматься программированием, а не тратить время на настройку рабочей среды и на привыкание к новому языку.
Вы выберете оружие, а я научу вас владеть этим оружием.
Шаг 1. Выбираем оружие
На первом шаге этого руководства вы выберете язык программирования, которым будете пользоваться. Этот вопрос вы должны решить самостоятельно.
Некоторым языкам, вроде Python, можно отдать предпочтение в том случае, если вы планируете в будущем оснастить своего бота, например, механизмами машинного обучения. Но моя основная идея заключается в том, что вы можете выбрать тот язык, с которым вам удобнее всего работать.
Шаг 2. Ищем поле битвы

В руководствах по написанию торговых ботов часто упускают одну важную тему. Она касается выбора биржи. Дело в том, что для того чтобы бот смог бы заниматься тем, для чего он создан, ему нужен доступ к бирже, на которой можно чем-то торговать. Выбор биржи и умение ей пользоваться — это так же важно, как навыки программирования.
Итак, вашим первым шагом будет принятие решения о том, чем именно вы собираетесь торговать (акциями, валютами, криптовалютами), и решения о том, где именно вы будете торговать.
Если говорить о биржевых активах, то я посоветовал бы обратить внимание на криптовалюты. Причина такой рекомендации заключается не в том, что я являюсь сторонником блокчейн-технологий и криптовалют (я полностью открыт в этом вопросе), а всего лишь в том, что криптовалютные рынки работают круглые сутки 7 дней в неделю.
Более «традиционными» активами можно торговать только в определённые временные промежутки, и часто — только по будним дням. Рынки акций, например, обычно открыты с 9 утра до 4 вечера и по выходным они не работают. Рынки FOREX, хотя и могут работать круглосуточно, обычно закрыты в выходные.
В связи с этим нам лучше всего подойдут криптовалюты, так как выбор данного рынка позволит нашем боту работать без перерывов. Кроме того, криптовалюты известны высоким уровнем волатильности. А это значит, во-первых, то, что на торговле ими можно потерять большие деньги, и во-вторых, то, что они представляют собой отличный инструмент для изучения и тестирования торговых стратегий.
О биржевых активах мы уже поговорили. Давайте теперь обсудим требования, которые нужно учитывать при выборе биржи, для которой будет создаваться бот. А именно, я говорю о двух основных требованиях:
- У вас должна быть законная возможность торговать на выбранной бирже и работать с предлагаемыми ей торговыми инструментами. Если говорить о криптовалютах, то в некоторых странах торговля ими запрещена. Учитывайте это, выбирая инструменты и биржу.
- Биржа должна обладать API, который доступен её клиентам. Нельзя создать торгового бота, который не отправляет запросы к бирже и не получает от неё ответов.
После того, как оказалось, что некая биржа удовлетворяет этим двум основным требованиям, вы можете проанализировать её глубже. Например, оценить размер комиссий, оценить её надёжность и известность, взглянуть на качество документации к её API.
И ещё, что так же важно, как и всё остальное, я порекомендовал бы оценить объём торгов биржи. Биржи с низкими объёмами имеют свойство «отставать» от ценовых движений. На них, кроме того, сложнее бывает выполнять лимитные заявки (подробнее об этом мы поговорим ниже).
Если вы, в итоге, решили выбрать криптовалюты, то вот — хороший список ведущих бирж. Здесь вы можете найти различные сведения о них, которые помогут вам в выборе биржи.
Шаг 3. Строим лагерь

Если биржа — это поле битвы, то теперь мы поговорим о том месте, из которого будем отправлять на поле битвы свои войска. Кстати, мне, пожалуй, пора завязывать с такими аналогиями.
Здесь я говорю о сервере. Код бота должен выполняться на некоем сервере, что позволит боту отправлять запросы к API биржи.
Во время тестирования бота, естественно, в роли сервера может выступать ваш компьютер. Но если вам нужно, чтобы бот работал бы постоянно, обычный компьютер — это, определённо, не лучший выбор.
Тут у меня есть два предложения:
- Роль сервера может выполнять Raspberry Pi (этот подход интереснее).
- Сервером может быть некая облачная служба (а этот подход лучше).
Я так думаю, что организация деятельности бота на базе собственного Raspberry Pi-сервера — это интересная и современная идея, поэтому, если и вам эта идея нравится, вы можете претворить её в жизнь.
Но большинство создателей ботов, вероятно, остановят свой выбор на каком-нибудь провайдере облачных услуг вроде AWS, Azure, GCS или Digital Ocean.
Большинство крупных облачных провайдеров имеют хорошие бесплатные тарифные планы, поэтому вам, возможно, удастся хостить своего бота у такого провайдера бесплатно.
На этом я разговор о серверах завершаю. Вам стоит выбрать то, что лучше всего вам подходит. Для маленького проекта, вроде того, которым занимаемся мы, то, что именно будет выбрано, не особенно сильно повлияет на конечный результат работы.
Шаг 4. Создаём бота

А вот теперь начинается самое интересное. Но, прежде чем приступать к этой части нашего проекта, проверьте, выполнено ли следующее:
- Вы зарегистрировались на бирже и получили необходимые разрешения на работу с ней.
- У вас есть возможность работать с API биржи, у вас имеется ключ API.
- Вы выбрали хостинг для бота.
Если эти вопросы решены, это значит, что мы можем двигаться дальше.
▍Простейший бот
Моя цель заключается в том, чтобы помочь тому, кто до этого момента совершенно ничего не знал о ботах, подняться до уровня создания простого действующего бота. Поэтому я расскажу о том, как создать простого торгового бота, которого вы сможете, в соответствии с вашими нуждами, расширять и улучшать.
У нашего бота будут некоторые ограничения:
- Бот сможет пребывать лишь в одном из двух состояний: BUY (покупка) или SELL (продажа). Он не будет постоянно размещать заявки на покупку или на продажу по разным ценам. Если последней операцией была продажа, то следующей операцией, которую попытается выполнить бот, будет покупка.
- Бот будет использовать фиксированные пороговые значения для принятия решений о покупке и продаже. Более интеллектуальный бот может быть способен самостоятельно настраивать подобные значения, основываясь на различных индикаторах, но стратегия и ограничения нашего бота будут задаваться вручную.
- Он будет торговать только одной валютной парой. Например — BTC/USD.
Эти ограничения упрощают нашу задачу. Бот будет простым, а значит, его легче будет создать и поддерживать. Это же позволит нам очень быстро развёртывать его код на сервере. В целом, тут мы говорим о принципе KISS.
▍Механизм принятия решений
Вот простая диаграмма, дающая общий обзор функционирования нашего бота.
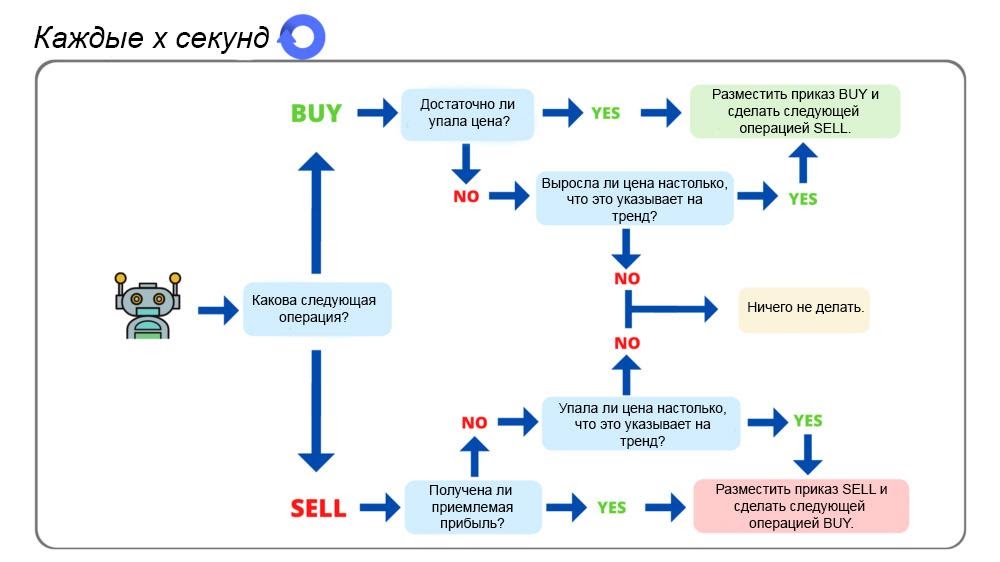
А теперь можно приступать к планированию архитектуры бота.
Нам, для начала, понадобится переменная, в которой будут храниться сведения о том, в каком именно состоянии находится бот в текущий момент. Это либо BUY, либо — SELL. Для хранения подобных сведений хорошо подойдёт логическая переменная или перечисление.
Затем нужно задать пороговые значения для операций покупки и продажи. Эти значения выражаются в процентах, они представляют собой увеличение или уменьшение цены актива с момента выполнения предыдущей операции.
Например, если я купил что-то по цене в $100, а в настоящий момент цена составляет $102, то мы имеем дело с увеличением цены на 2%. Если порог для операции SELL установлен на однопроцентное увеличение цены, то бот, увидев эти 2%, продаст актив, так как он уже получил прибыль, превышающую заданное нами пороговое значение.
В нашем случае подобные значения будут константами. Нам понадобится 4 таких значения — по 2 на каждое состояние бота.
▍Пороговые значения для выполнения операции BUY (если бот находится в состоянии SELL)
DIP_THRESHOLD: бот выполняет операцию покупки в том случае, если цена уменьшилась на значение, большее, чем заданоDIP_THRESHOLD. Смысл этого заключается в реализации стратегии «покупай дёшево, продавай дорого». То есть, бот будет пытаться купить актив по заниженной цене, ожидая роста цены и возможности выгодной продажи актива.UPWARD_TREND_THRESHOLD: бот покупает актив в том случае, если цена выросла на значение, превышающее то, что задано этой константой. Этот ход противоречит философии «покупай дёшево, продавай дорого». Его цель заключается в том, чтобы выявить восходящий тренд и не пропустить возможность покупки до ещё большего роста цены.
Вот иллюстрация, которая может помочь в понимании смысла этих констант.
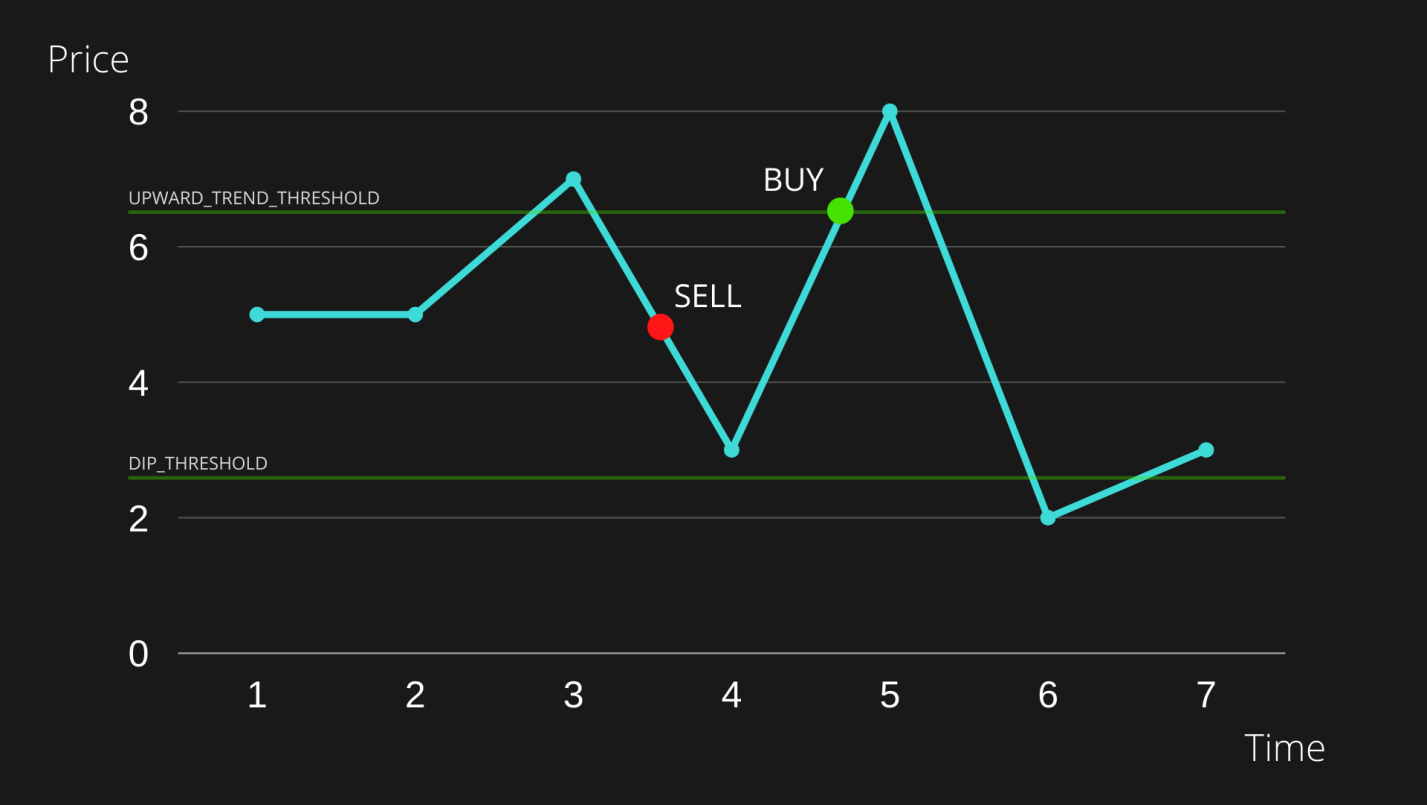
Если мы выполнили операцию SELL в момент, отмеченный на рисунке красным маркером SELL, то после этого бот, принимая решение о выполнении операции BUY, будет руководствоваться пороговыми значениями DIP_THRESHOLD и UPWARD_TREND_THRESHOLD.
Если цена уйдёт ниже нижней зелёной линии или выше верхней зелёной линии, мы выполним операцию BUY. В ситуации, показанной на рисунке, цена ушла выше верхнего предела. Поэтому мы, руководствуясь значением UPWARD_TREND_THRESHOLD, выполнили операцию BUY.
▍Пороговые значения для выполнения операции SELL (если бот находится в состоянии BUY)
PROFIT_THRESHOLD: бот продаёт актив в том случае, если цена стала выше цены, вычисленной на основе этого значения, так как ранее актив был куплен по более низкой цене. Именно так мы получаем прибыль. Мы продаём актив по цене, которая выше той, что была в момент его покупки.STOP_LOSS_THRESHOLD: в идеальной ситуации мы хотели бы, чтобы бот продавал бы активы только тогда, когда продажа приносит нам прибыль. Но, возможно, произошло сильное движение рынка вниз. В такой ситуации мы решим выйти из сделки до того, как понесём слишком большие убытки, и позже купить актив по более низкой цене. Это пороговое значение используется для закрытия позиции с убытком. Цель этой операции — предотвращение более сильных потерь.
Вот иллюстрация.
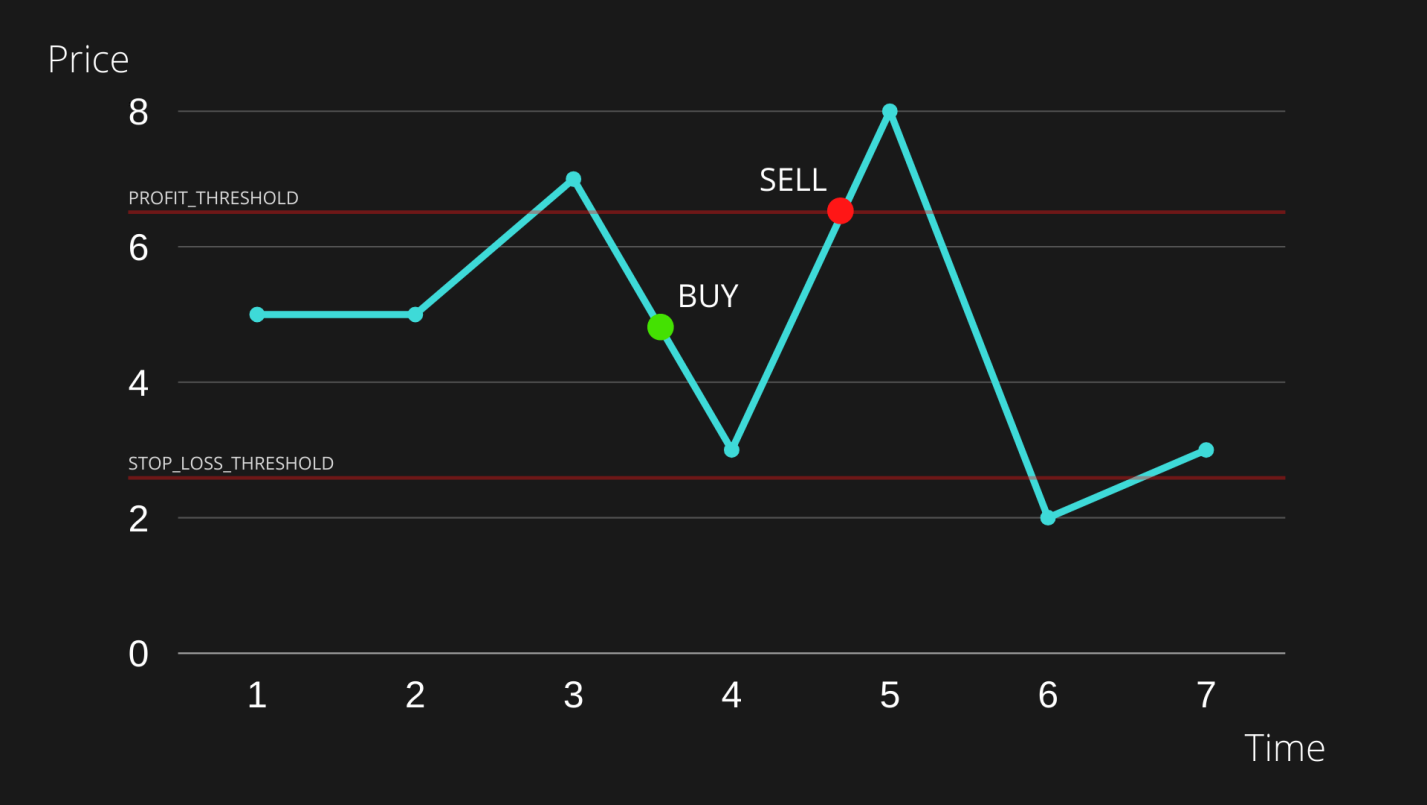
Тут показана ситуация, когда там, где стоит маркер BUY, была сделана покупка. После этого цена достигает предела, заданного PROFIT_THRESHOLD, и мы продаём актив с прибылью. Именно так боты зарабатывают.
Теперь, после того, как у нас сформировалось общее понимание того, как функционирует бот, пришло время рассмотреть псевдокод.
▍Вспомогательные функции для работы с API
Первое, что понадобится боту, это возможности обмена данными с API биржи. Эти возможности мы реализуем с помощью нескольких вспомогательных функций:
FUNCTION getBalances():
DO: Выполнить GET-запрос к API биржи для получения
сведений о балансах
RETURN: Сведения о балансах
FUNCTION getMarketPrices():
DO: Выполнить GET-запрос к API биржи для получение
текущей цены актива
RETURN: Текущая цена актива
FUNCTION placeSellOrder():
DO:
1. Вычислить количество актива для продажи (на основе
некоего заданного порогового значения, например,
50% общего баланса)
2. Отправить POST-запрос к API биржи для выполнения
операции SELL
RETURN: Цена совершения сделки
FUNCTION placeBuyOrder():
DO:
1. Вычислить количество актива для покупки (на основе
некоего заданного порогового значения, например,
50% общего баланса)
2. Отправить POST-запрос к API биржи для выполнения
операции BUY
RETURN: Цена совершения сделки
// Необязательная функция, которая предназначена для
// получения подтверждения выполнения операций
FUNCTION getOperationDetails():
DO: Выполнить GET-запрос к API биржи для получения
сведений об операции
RETURN: Сведения об операции
Вышеприведённый код должен быть понятен без особых объяснений. Но, реализуя этот функционал, вы должны точно знать о том, какие именно данные нужно передать API при выполнении POST-запросов, инициирующих покупку или продажу чего-либо.
Часто, например, когда торгуют парой XAU/USD (золото и доллары США), при выполнении запроса можно указать или то, сколько золота нужно купить, или то, сколько долларов нужно продать. При выполнении подобных запросов очень важно чётко понимать смысл производимых действий.
▍Главный цикл бота
Теперь, когда мы подготовили вспомогательные функции, приступим к описанию действий бота. Для начала нам нужно создать бесконечный цикл, выполняемый с некоторой периодичностью. Предположим, нам нужно, чтобы бот пытался бы выполнить некую операцию каждые 30 секунд. Вот как может выглядеть такой цикл:
FUNCTION startBot():
INFINITE LOOP:
attemptToMakeTrade()
sleep(30 seconds)
Далее — настроим переменные и константы, о которых мы говорили выше, и напишем логику бота, позволяющую ему принимать решения. В результате, помимо вспомогательных функций и главного цикла, основной код бота будет выглядеть так:
bool isNextOperationBuy = True
const UPWARD_TREND_THRESHOLD = 1.50
const DIP_THRESHOLD = -2.25
const PROFIT_THRESHOLD = 1.25
const STOP_LOSS_THRESHOLD = -2.00
float lastOpPrice = 100.00
FUNCTION attemptToMakeTrade():
float currentPrice = getMarketPrice()
float percentageDiff = (currentPrice - lastOpPrice)/lastOpPrice*100
IF isNextOperationBuy:
tryToBuy(percentageDiff)
ELSE:
tryToSell(percentageDiff)
FUNCTION tryToBuy(float percentageDiff):
IF percentageDiff >= UPWARD_TREND_THRESHOLD OR percentageDiff <= DIP_THRESHOLD:
lastOpPrice = placeBuyOrder()
isNextOperationBuy = False
FUNCTION tryToSell(float percentageDiff):
IF percentageDiff >= PROFIT_THRESHOLD OR percentageDiff <= STOP_LOSS_THRESHOLD:
lastOpPrice = placeSellOrder()
isNextOperationBuy = True
Обратите внимание на то, что пороговые значения в этом коде выбраны произвольным образом. Вам следует подобрать эти значения самостоятельно, в соответствии с применяемой вами торговой стратегией.
Если вышеприведённый код совместить со вспомогательными функциями и с главным циклом бота, который может быть представлен чем-то вроде функции main, это будет означать, что теперь в нашем распоряжении имеется очень простой работающий бот, обладающий основными возможностями, характерными для ботов.
На каждой итерации цикла бот будет проверять своё текущее состояние (BUY или SELL) и будет пытаться выполнить торговую операцию, используя при анализе текущей ситуации жёстко заданные в его коде пороговые значения. Затем, если операция будет выполнена, бот обновит сведения о своём текущем состоянии и данные о цене, по которой была совершена последняя операция.
Шаг 5. Улучшаем бота

Базовая архитектура нашего бота готова. Но мы, вероятно, можем его немного улучшить, оснастив его некоторыми дополнительными возможностями.
▍Журналы
Когда я приступил к созданию одного из вариантов этого бота, для меня было очень важно то, чтобы бот постоянно бы логировал сведения о своих действиях, выводя их в терминал и в отдельный файл журнала.
Каждый шаг работы программы должен был сопровождаться примерно такими записями:
[BALANCE] USD Balance = 22.15$
[BUY] Bought 0.002 BTC for 22.15 USD
[PRICE] Last Operation Price updated to 11,171.40 (BTC/USD)
[ERROR] Could not perform SELL operation - Insufficient balance
То, что попадает в файл журнала, снабжается отметками времени. В результате, если я подключаюсь к серверу раз в день, и вижу, например, сообщение об ошибке, я могу узнать о том, когда именно произошла ошибка, и о том, чем бот занимался всё это время.
Оснастить бота подобными возможностями — значит написать функцию, которую можно назвать createLog. Эта функция должна вызываться на каждом шаге главного цикла бота. Вот как может выглядеть эта функция:
FUNCTION createLog(string msg):
DO:
1. Вывести msg в терминал
2. Записать msg в файл журнала, добавив отметку времени
▍Идентификация трендов
Главная цель нашего бота заключается в том, чтобы дёшево покупать активы и продавать их, получая прибыль. Но в его коде есть две константы, символизирующие два пороговых значения, которые отчасти этой цели противоречат. Это UPWARD_TREND_THRESHOLD и STOP_LOSS_THRESHOLD.
Эти значения предназначены для ограничения убытков путём продажи актива при падении цены и для организации покупки актива при росте цены. Смысл тут в том, что с их помощью мы пытаемся предугадать тренды, цены при появлении которых выходят за пределы обычной стратегии, но могут либо нам навредить, либо дать нам заработать. И то и другое предусматривает некие действия с нашей стороны.
То, как сейчас устроен анализ цены, очень сильно нас ограничивает. Анализ цены, проводимый путём сравнения пары показателей, далёк от механизма, позволяющего выявлять тренды.
Но мы, к счастью, можем, без особенных проблем, сделать нашу систему определения трендов более надёжной.
Нам нужно лишь организовать наблюдение за большим количеством ценовых значений, чем раньше. А раньше мы хранили сведения лишь об одном ценовом показателе — о стоимости актива на момент последней операции (lastOpPrice). Можно, например, хранить сведения о ценах за 10 или 20 последних итераций цикла бота и сравнивать с текущей ценой их, а не только lastOpPrice. Это, вероятно, позволит лучше идентифицировать тренды, так как при таком подходе мы можем уловить краткосрочные колебания цены, а не колебания, происходящие за долгое время.
▍База данных?
Простому боту, на самом деле, база данных не нужна. Ведь он оперирует весьма небольшими объёмами данных и хранит всю необходимую ему информацию в памяти.
Но что произойдёт в том случае, если, например, бот будет аварийно остановлен? Как ему узнать, без вмешательства человека, о том, каким было значение lastOpPrice?
Для того чтобы исключить необходимость ручного вмешательства в код бота при его перезапуске нам может понадобиться некая простая база данных, в которой можно хранить какие-то показатели вроде lastOpPrice.
При таком подходе бот, запускаясь, может не использовать значения, жёстко заданные в коде. Вместо этого он обращается к сохранённым данным и продолжает работу с того места, где она была прервана.
В зависимости от того, насколько простой, по вашему мнению, должна быть эта «база данных», вы можете даже решить использовать в таком качестве обычные .txt- или .json-файлы, так как, в любом случае, речь идёт о хранении весьма ограниченного набора данных.
▍Панель управления

Если вы хотите организовать визуализацию деятельности бота, а так же управлять им, не редактируя его код, то вам может захотеться подключить бота к некоей панели управления.
Это потребует наличия у бота собственного серверного API, предназначенного для управления его функционалом.
Подобный подход, например, позволит легко менять пороговые значения.
Существует множество шаблонов панелей управления, а значит вам, если вы решите сделать что-то подобное, даже не придётся создавать такую панель с нуля. Взгляните, например, на Start Bootstrap и Creative Tim.
▍Тестирование стратегий на исторических данных
Многие биржи дают клиентам доступ к историческим ценовым данным. Кроме того, если вам нужны такие данные, их обычно несложно достать.
Их использование весьма полезно для тестирования торговых стратегий перед их реальным применением. Это позволяет запустить симуляцию, используя исторические данные и «ненастоящие» деньги. Благодаря этому можно узнать о том, насколько удачно показали бы себя пороговые значения, и, если нужно, поменять эти значения.
▍Дополнительные сведения о пороговых значениях и заявках
При размещении заявок нужно учитывать несколько моментов.
Во-первых, нужно знать о том, что существуют два типа заявок: лимитные и рыночные. Если вы совсем ничего об этом не знаете — вам, определённо, стоит почитать специальную литературу. Я тут объясню эти идеи буквально в двух словах.
Рыночные заявки — это заявки, которые исполняются по текущей рыночной цене. В большинстве случаев это означает их немедленное исполнение.
Лимитные заявки, с другой стороны, это заявки, которые размещают, указывая цену, которая ниже рынка (в случае с заявками на покупку), или выше рынка (в случае с заявками на продажу). При этом нет гарантии того, что эти заявки будут исполнены, так как цена может не достигнуть заданного значения.
Сильная сторона лимитных заявок заключается в том, что они позволяют, предугадывая движения рынка, размещать заявки там, где, по мнению трейдера, может оказаться цена.
Кроме того, к таким заявкам обычно применяются более низкие комиссии, чем к рыночным. Это так из-за того, что к рыночным заявкам обычно применимо то, что называется «taker fee» («комиссия получателя»), а к лимитным заявкам — то, что обычно называется «maker fee» («комиссия создателя»).
Причины, по которым эти комиссии называются именно так, заключаются в том, что тот, кто размещает рыночную заявку, просто принимает («taking») текущую рыночную цену. А лимитные заявки находятся за пределами рыночных цен, они добавляют рынку ликвидности и, в результате, «создают рынок», за что их создатели вознаграждаются более низкими комиссиями.
Обратите внимание на то, что бот, который мы тут рассматриваем, лучше всего подходит для работы с рыночными заявками.
И, завершая разговор о комиссиях, хочу отметить, что задавая значение PROFIT_THRESHOLD нужно учитывать и комиссии.
Для того чтобы получить прибыль, бот должен сначала выполнить операцию BUY, а потом — операцию SELL. А это значит, что комиссия будет взята два раза.
В результате бота нужно настроить так, чтобы прибыль, получаемая с продаж, по меньшей мере, покрывала бы комиссии. В противном случае бот будет торговать в убыток.
Поразмыслим об этом, исходя из предположения о применении комиссий, не зависящих от суммы заявки и от вида операции. Итак, комиссия за покупку актива на $100,00 составляет $0,50. Если этот актив будет продан за $100,75 и при этом будет взята такая же комиссия, то окажется, что валовая прибыль составляет 0,75%. Но, на самом деле, тут мы имеем дело с чистым убытком в 0,25%.
А теперь представьте себе, что ваш бот всегда закрывает сделки с чистым убытком. В такой ситуации можно довольно быстро потерять немалые деньги.
Итоги
Моей основной целью было раскрытие концепций, о которых нужно знать при разработке торговых ботов. Я старался описать всё так, чтобы это было понятно даже тем, кто раньше никогда не торговал на бирже. При этом я не привязывал повествование к какому-то конкретному языку программирования.
Я исходил из предположения о том, что читатели этого материала знают о том, как, пользуясь выбранным ими языком программирования, выполнять HTTP-запросы. Поэтому в детали программирования я не вдавался, сосредоточившись на других вещах.
Я рассказал вам о разработке торговых ботов всё, что хотел. Надеюсь, теперь вы сможете создать собственного бота.
А вы пользуетесь торговыми ботами?

На предыдущих уроках мы установили среду Кумир, настроили ее для дальнейшей работы и научились задавать стартовую обстановку Робота. Теперь перейдем непосредственно к составлению алгоритмов для Робота с использованием простых команд.
Если вам больше нравится информация в формате видеоуроков, то на сайте есть видеоурок Робот. Простые команды.
У любого исполнителя должна быть система команд (СКИ — система команд исполнителя). Система команд исполнителя — совокупность всех команд, которые может выполнить исполнитель. В качестве примера рассмотрим дрессированную собаку. Она умеет выполнять некоторые команды — «Сидеть», «Лежать», «Рядом» и т. п. Это и есть ее система команд.
Простые команды Робота
У нашего Робота тоже есть система команд. Сегодня мы рассмотрим простые команды Робота. Всего их 5:
- вверх
- вниз
- влево
- вправо
- закрасить
Результат выполнения этих команд понятен из их названия:
- вверх — переместить Робота на одну клетку вверх
- вниз — переместить Робота на одну клетку вниз
- влево — переместить Робота на одну клетку влево
- вправо — переместить Робота на одну клетку вправо
- закрасить — закрасить текущую клетку (клетку в которой находится Робот).
Эти команды можно писать с клавиатуры, а можно использовать горячие клавиши (нажав их команды будут вставляться автоматически):
- вверх — Escape, Up (стрелка вверх)
- вниз — Escape, Down (стрелка вниз)
- влево — Escape, Left (стрелка влево)
- вправо — Escape, Right (стрелка вправо)
- закрасить — Escape, Space (пробел)
Обратите внимание, что набирать нужную комбинацию горячих клавиш нужно не привычным нам способом! Мы привыкли нажимать клавиши одновременно, а здесь их нужно нажимать последовательно. К примеру, чтобы ввести команду вверх, нужно нажать Escape, отпустить ее и после этого нажать стрелку вверх. Это нужно помнить.
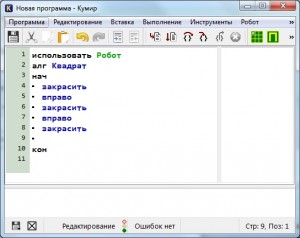
Теперь мы готовы написать первый алгоритм для Робота. Предлагаю начать с простого — нарисуем квадрат со стороной 3 клетки. Поехали!
Запускаем Кумир, настраиваем его. Можно начинать писать программу? Конечно нет! Мы же не задали стартовую обстановку! Делаем это. Предлагаю использовать вот такую:
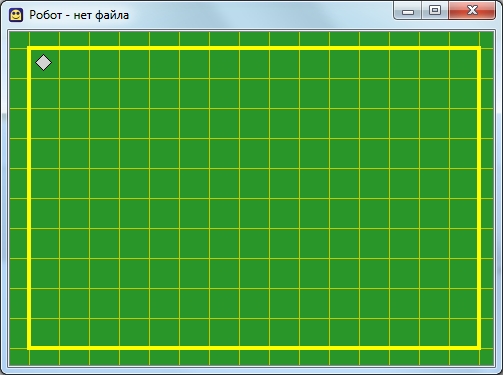
Стартовая обстановка Робота
Вот теперь все готово. Начинаем писать программу. Пока она выглядит так
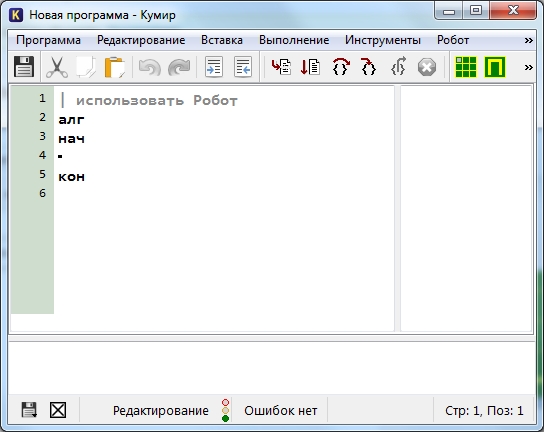
Первая программа для Робота
Удаляем символ «|» и называем наш алгоритм «Квадрат»
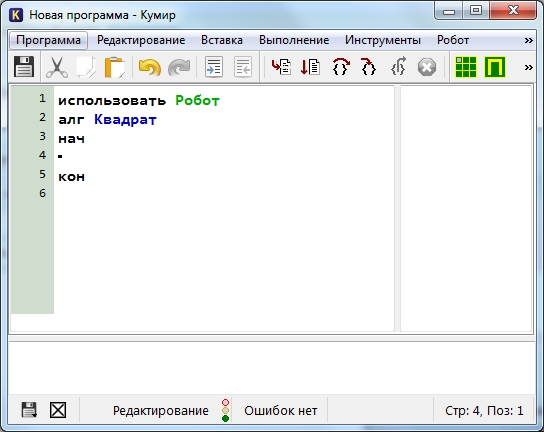
Алгоритм квадрат
Предлагаю рисовать квадрат, двигаясь по часовой стрелке. Для начала закрасим текущую клетку, дав команду закрасить. Потом делаем шаг вправо и опять закрашиваем клетку. И еще раз шаг вправо и закрасить.
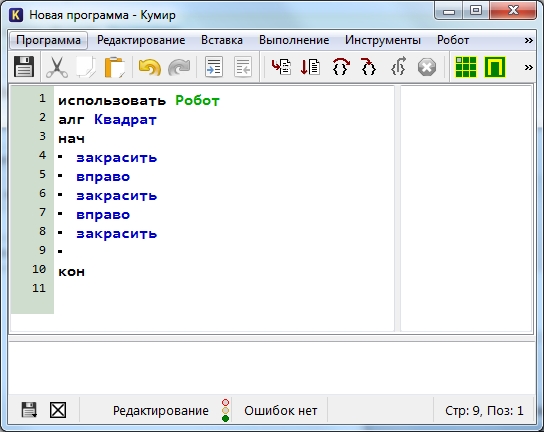
Первые шаги
Попробуем запустить программу и посмотреть что же получилось. Для запуска нажимаем F9 или же кнопку на панели инструментов
выполнить программу
В результате мы должны увидеть вот такую картину
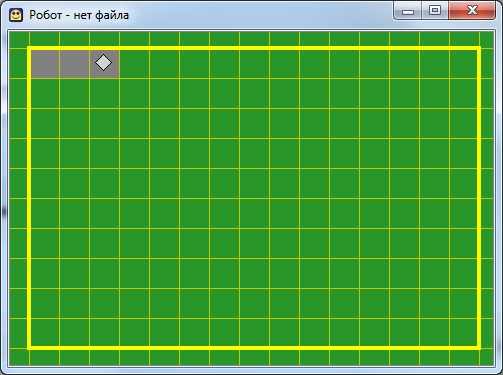
Первый результат
Если такое окно Робота у вас не появилось, то на панели инструментов щелкните «Показать окно Робота» или в меню Робот выберите пункт «Показать окно Робота«. Продолжаем дальше.
Теперь мы будем двигаться вниз и закрашивать правую сторону квадрата:
вниз
закрасить
вниз
закрасить
Потом пойдем влево, закрашивая нижнюю границу квадрата
влево
закрасить
влево
закрасить
У нас осталась одна незакрашенная клетка. Закрасим ее
вверх
закрасить
Все готово! В итоге наша программа выглядит так:
использовать Робот
алг Квадрат
нач
закрасить
вправо
закрасить
вправо
закрасить
вниз
закрасить
вниз
закрасить
влево
закрасить
влево
закрасить
вверх
закрасить
кон
А результат ее работы вот так
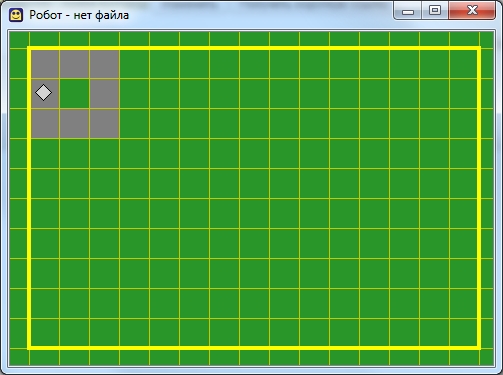
Результат работы программы
Итак, сегодня мы с вами написали программу, используя простые команды Робота. Рекомендую попрактиковаться самостоятельно — придумать себе задание и написать программу. Это могут быть самые различные фигуры, узоры, буквы. К примеру, попробуйте написать программу, рисующую букву П, Р, Ш, Щ, М. А если получится и захотите поделиться — комментируйте и прикрепляйте результат к комментарию.
Автор: