Tags:
Power BI
Агрегированные таблицы — это быстрое решение для огромных таблиц DirectQuery в Power BI. В предыдущем посте мы объяснили, что такое агрегация, и почему это важная часть реализации Power BI. Агрегации являются частью модели Composite в Power BI. Для настройки агрегации первым шагом будет создание агрегированной таблицы. Здесь мы расскажем, как можно реализовать этот шаг.
Пример набора данных
Если вы хотите следовать сценарию этого примера, вам понадобится база данных SQL Server с именем AdventureWorksDW. Мы внесли некоторые изменения в свой набор данных, чтобы он был немного больше по размеру его таблицы фактов, поэтому мы можем показать вам функциональность агрегатов. Вы можете скачать ссылку на базу данных здесь:
Download
Пример модели
В этом шаблоне модели мы будем анализировать данные FactInternetSales (которые мы считаем нашей большой таблицей фактов). Создайте отчет Power BI с подключением DirectQuery к SQL Server;
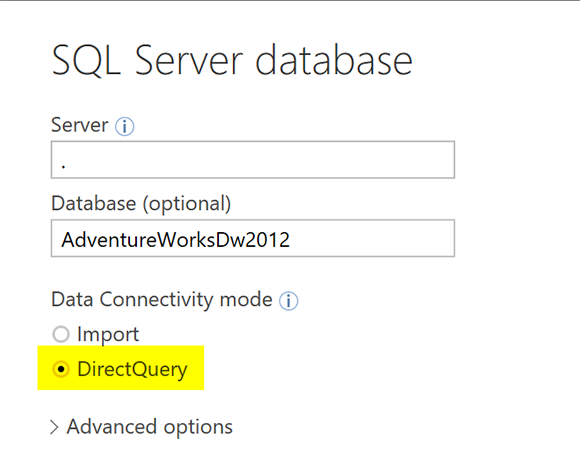
С помощью параметра DirectQuery выберите следующие таблицы:
FactInternetSales, DimCustomer, DimDate, DimProduct, DimProductCategory, DimProductSubCategory, DimPromotion и DimGeography.
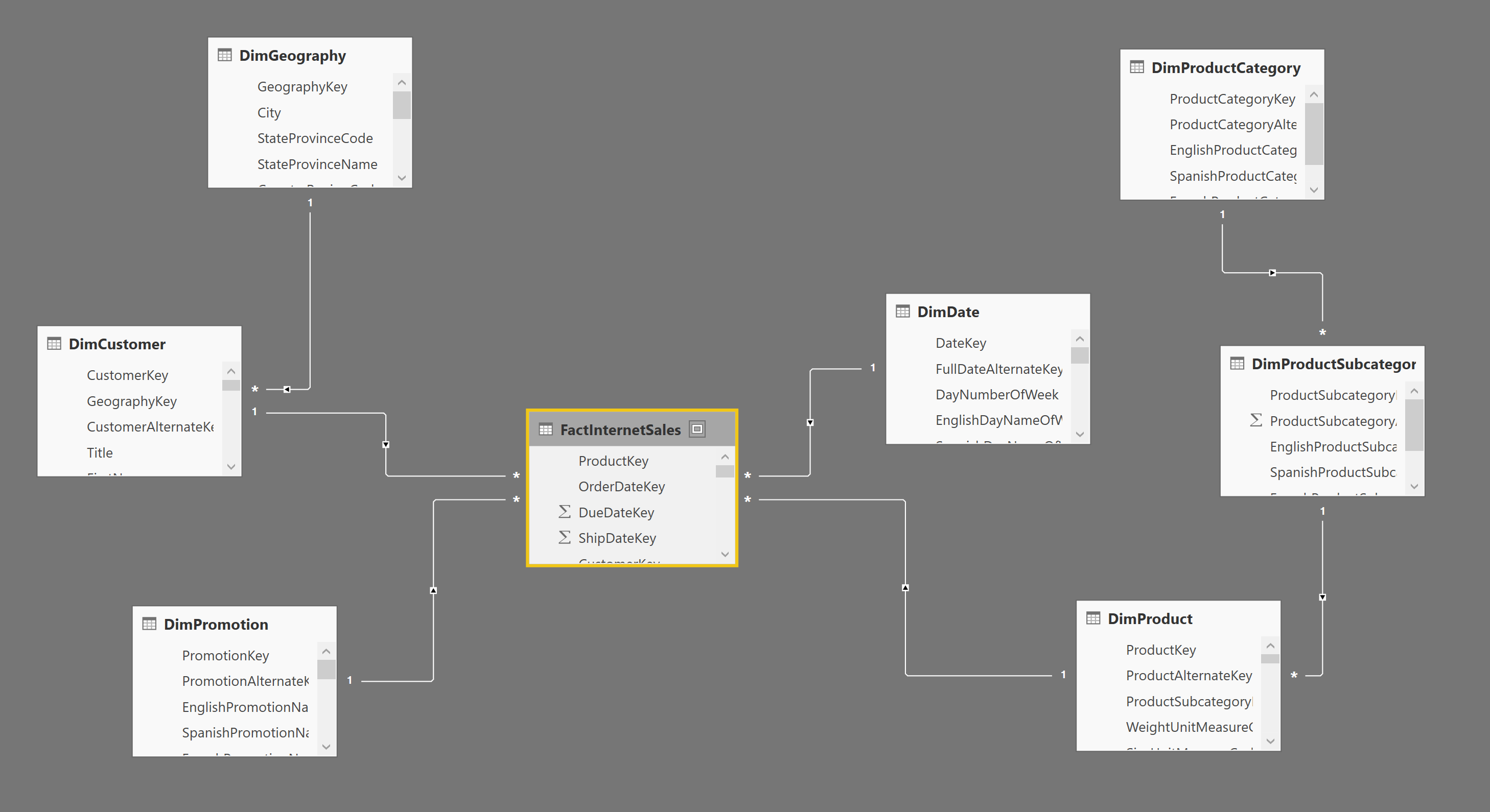
Таблицы, загруженные в Power BI, будут иметь совместные связи, мы просто ограничили связь между таблицей DimDate и FactInternetSales с одной активной связью, основанной на DateKey (в DimDate) и OrderDateKey (в FactInternetSales). Это диаграмма отношений.
Что такое агрегированная таблица
Агрегированная таблица представляет собой таблицу в Power BI, объединенную одним или несколькими полями из исходной таблицы DirectQuery. В нашем случае агрегированная таблица представляет собой сгруппированную таблицу по определенным полям из таблицы FactInternetSales. Совокупная таблица может быть создана всеми возможными способами. Вы можете создать агрегированную таблицу с операторами T-SQL из SQL Server. Или вы можете создать ее в Power Query. Вы можете создать его во всех других инструментах преобразования данных и языках запросов. Поскольку мы здесь делаем все с помощью Power BI, мы создадим агрегированную таблицу с Power Query.
Агрегированную таблицу можно создать в источнике данных с запросами T-SQL или в Power Query или в другом месте, где вы можете создать сгруппированную таблицу.
Создание агрегированной таблицы
Перейдите в Power Query Editor и выберите таблицу FactInternetSales. Агрегированная таблица, которую мы собираемся создать в этом примере, будет состоять из трех полей: OrderDateKey, CustomerKey и ProductSubCategoryKey. Первые два поля существуют в FactInternetSales, но не в третьем. Однако, используя столбцы связей, мы можем получить это.
Прокрутите направо в столбцах таблицы FactInternetSales, чтобы найти Product, затем нажмите Expand. В параметрах Expand просто выберите ProductSubCategoryKey.
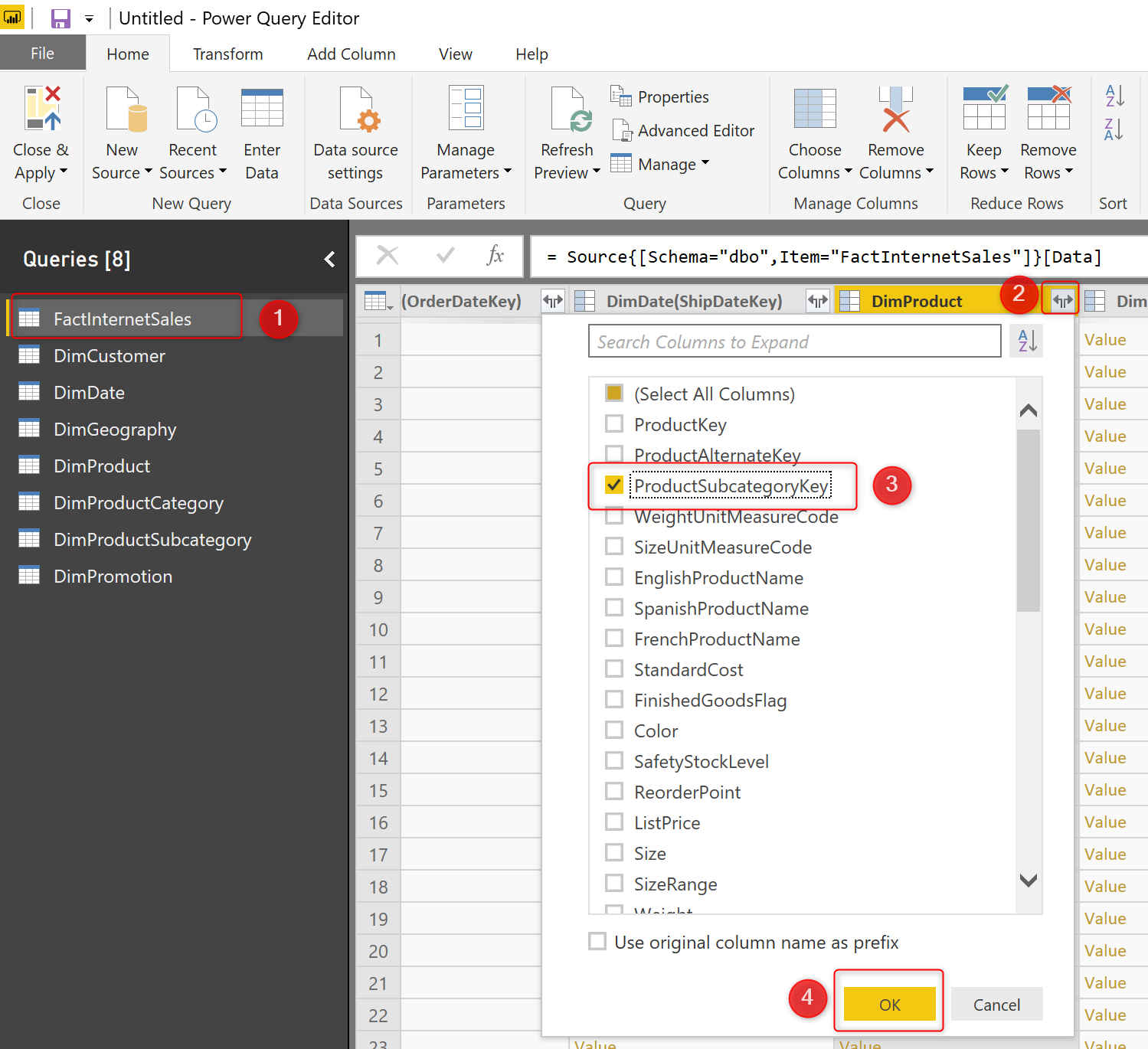
Теперь, когда вы получили ProductSubCategoryKey в таблице, вы можете применить Group By. На вкладке Transformation нажмите Group By;
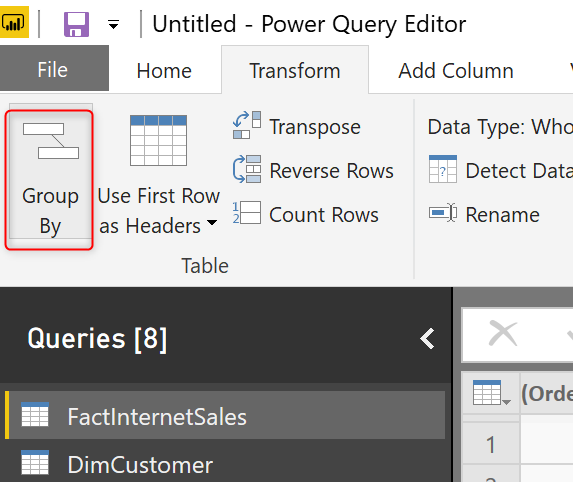
Когда появится диалоговое окно Group By, выберите Advanced
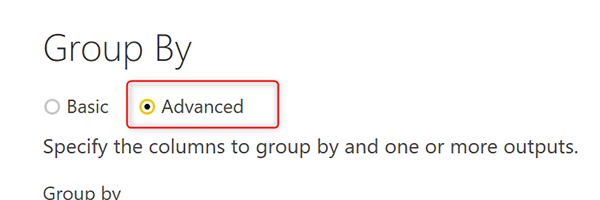
Выберите три поля OrderDateKey, CustomerKey и ProductSubcategoryKey в полях Group By
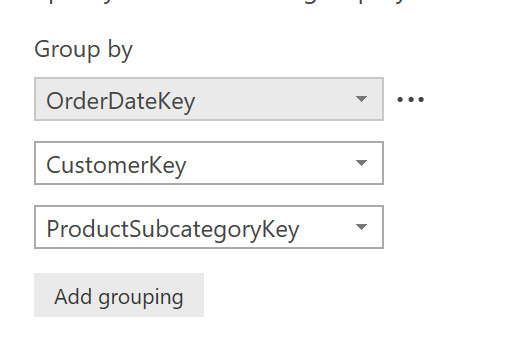
Затем добавьте четыре агрегации, как показано ниже:
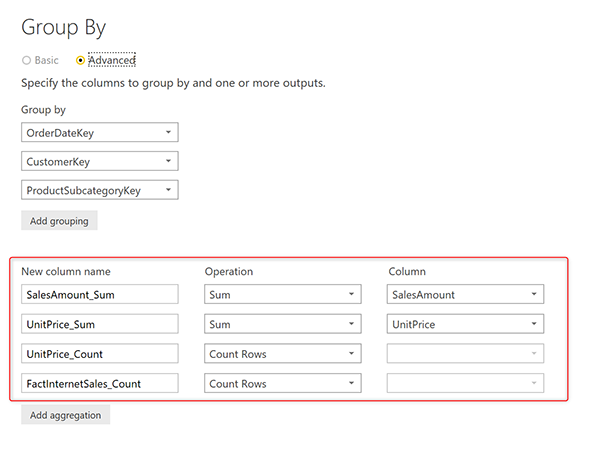
После построения этой таблицы назовем ее Sales Agg table. Вот скриншот этой таблицы.
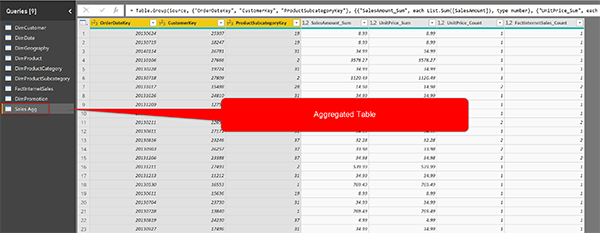
Ключевое рассмотрение предстоящих шагов
Агрегационные столбцы в агрегированной таблице должны соответствовать определенным правилам.
Правило № 1: точное соответствие для типов данных агрегации по Sum, Min, Max, Average
Столбцы, к которым применяется такая операция, как Sum, Average, Min или Max, должны иметь точно такой же тип данных, что и исходный столбец источника после агрегации. Если они этого не делают, убедитесь, что вы изменили типы данных, чтобы они были одинаковыми.
Поле SalesAmount в FactInternetSales имеет десятичный тип данных (если нет, измените его на это)
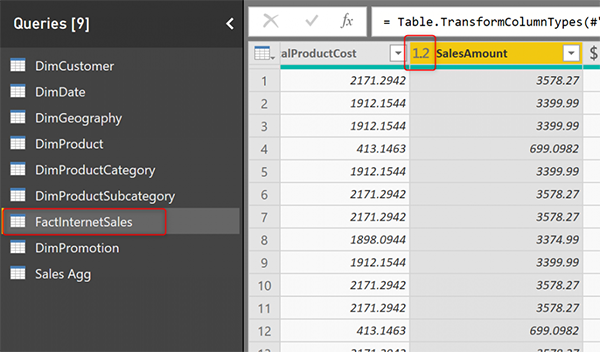
В столбце SalesAmount_Sum таблицы Sales Agg также должен быть одинаковый тип данных. В этом случае Decimal.
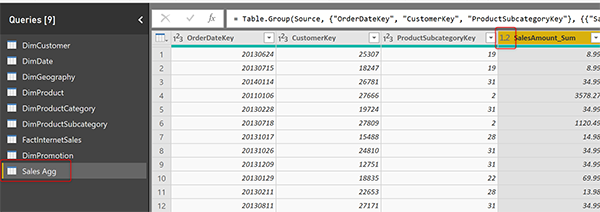
Обратите внимание, что наличие десятичного типа данных не является важной частью правила. Важно, чтобы оба типа данных точно соответствовали друг другу.
Этот процесс в нашем примере должен быть завершен для двух столбцов SalesAmount_Sum и UnitPrice_Sum.
Правило №2: Тип данных с полным номером является обязательным для агрегаций по Count
Любые агрегации, которые используют Count в качестве функции агрегации, должны иметь тип данных всего числа или, скажем, Integer. В нашей примерной таблице у нас есть два столбца с функцией Count:

Вы должны убедиться, что эти два столбца имеют тип данных целого числа после Group by transform;
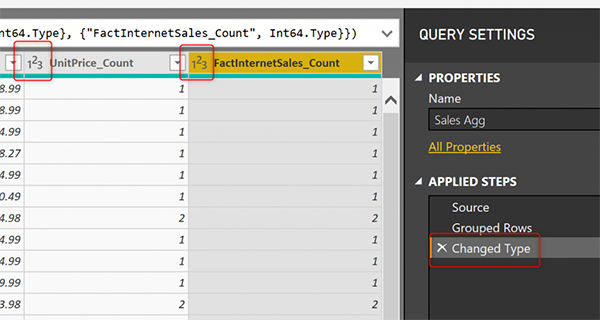
Два упомянутых выше правила будут важны в следующих статьях о шагах агрегации, когда мы будем выполнять настройку агрегации в Power BI.
Агрегированная таблица — это таблица импорта
Совокупная таблица, которую мы создали, называется Sales Agg. Поскольку эта таблица намного меньше, чем таблица FactInternetSales, ее можно сохранить в памяти. Таким образом, мы получаем максимальную производительность отклика запроса, когда мы запрашиваем что-то на агрегированном уровне.
Теперь ваша модель данных в Power BI должна иметь таблицы ниже, после завершения этого шага:
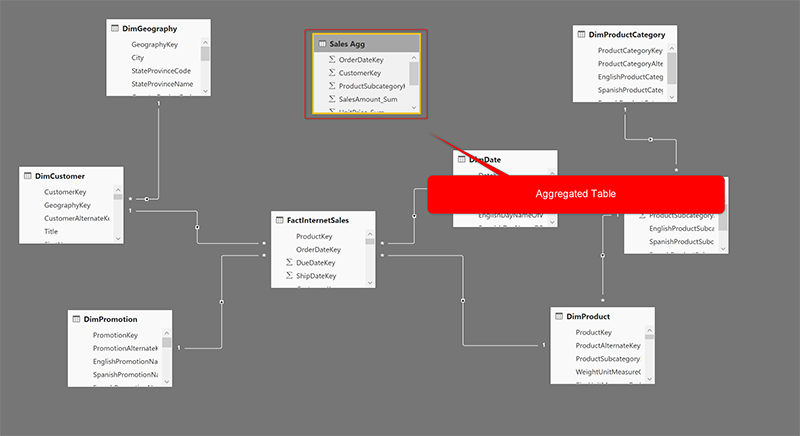
Поздравляем, вы создали сводную таблицу, и теперь вы можете создавать отношения между этой таблицей и тремя таблицами измерений: DimCustomer, DimDate и DimProductSubcategory. Вот диаграмма полной взаимосвязи;
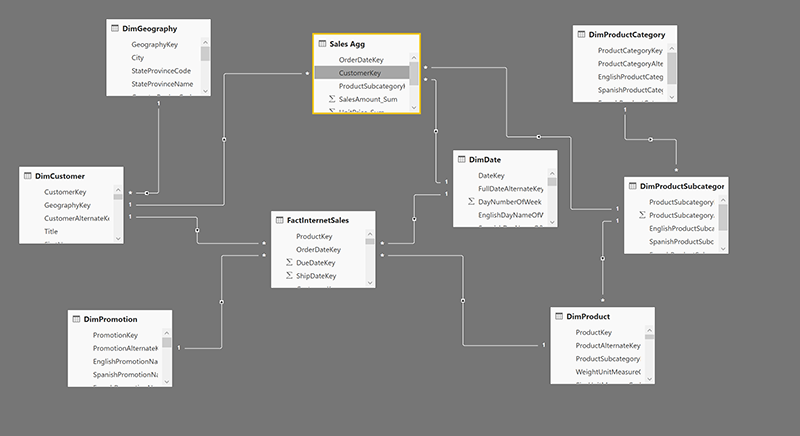
На следующем шаге мы объясним, что такое режим хранения, и насколько важна конфигурация модели Dual storage при использовании агрегаций.
Если вы хотите узнать, что такое агрегация, и как это может быть полезно, прочитайте предыдущий пост здесь.
Содержание
- Составить агрегированный баланс организации
- Агрегированный баланс – общее понятие и предназначение
- Степени агрегирования
- Составление и оформление баланса
- Пример статей и кодов строк
- Каким бывает анализ агрегированного баланса
- Статьи баланса
- Агрегирование баланса
- Тестовая база к разделу «Анализ финансовой отчетности»
- 3.Принадлежности капитала
Составить агрегированный баланс организации
Агрегирование баланса — это объединение однородных по экономическому содержанию статей баланса. При этом статьи актива баланса перегруппировываются по степени их ликвидности. Под ликвидностью активов понимают их способность превращения в денежную форму. Так, наиболее ликвидными являются денежные средства и ценные бумаги, а наименее ликвидными — основные средства. Текущие пассивы перегруппировываются по сроку погашения.
Таблица 1
Схема расчета укрупненных статей баланса
| Показатель | Код строки баланса |
| АКТИВ | |
| 1. Наиболее ликвидные активы (А1) (денежные средства и финансовые вложения) | 1240 + 1250 |
| 2. Быстрореализуемые активы (А2) (дебиторская задолженность до 1 года и прочие оборотные средства) | 1232 + 1260 |
| 3. Медленно реализуемые активы (А3) (запасы и затраты) | 1210 + 1220 |
| 4. Труднореализуемые активы (А4) (Внеоборотные активы и дебиторская задолженность свыше 1 года) | 1100 + 1231 |
| Итого активов (имущества), А | |
| ПАССИВ | |
| 1. Наиболее срочные обязательства (П1) (кредиторская задолженность и прочие обязательства) | 1520 + 1540 + 1550 |
| 2. Краткосрочные обязательства (П2) (краткосрочные займы) | |
| 3. Долгосрочные обязательства | |
| 4. Собственный капитал (капитал и резервы + доходы будущих периодов) | 1300 + 1530 |
| Итого пассивов (обязательств), П |
Для определения кредитоспособности заемщика проводится оценка его финансового состояния. Цель анализа — получение объективной оценки его финансового положения, способности заемщика своевременно и в полном объеме погасить задолженность по ссуде. Для оценки кредитоспособности заемщика с точки зрения банка предстоит рассчитать для нее коэффициенты ликвидности и финансовой устойчивости.
Банки оценивают финансовое состояние заемщиков по коэффициентам ликвидности (абсолютной, текущей и покрытия), финансового риска (соотношению собственных и заемных средств), а также рентабельности.
Показатели ликвидности характеризуют обеспеченность заемщика оборотными средствами. Первый из них, коэффициент абсолютной ликвидности, рассчитывается по формуле 1. Он показывает, насколько быстро компания в состоянии расплатиться по своим обязательствам, какая часть ее краткосрочных долгов может быть при необходимости погашена за счет имеющихся денежных средств и высоколиквидных краткосрочных ценных бумаг.
Формула 1. Расчет коэффициента абсолютной ликвидности
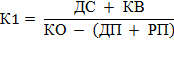
| Используемые обозначения | Расшифровка | Ед. измерения | Источник данных |
| К1 | Коэффициент абсолютной ликвидности | ед. | Результат расчета |
| ДС | Денежные средства | руб. | Баланс, стр. 1250 |
| КВ | Краткосрочные финансовые вложения | руб. | Баланс, стр. 1240 (только государственные ценные бумаги, ценные бумаги Сбербанка России и средства на депозитных счетах; если нет детальной информации по вложениям, этот показатель в расчетах не участвует) |
| КО | Краткосрочные обязательства | руб. | Баланс, стр. 1500 |
| ДП | Доходы будущих периодов | руб. | Баланс, стр. 1530 |
| РП | Резервы предстоящих расходов | руб. | Баланс, стр. 1540 (оценочные обязательства) |
Промежуточный коэффициент покрытия или критической (быстрой) ликвидности говорит о способности компании погасить свои текущие обязательства в критической ситуации только за счет дебиторской задолженности, денежных средств и ликвидных финансовых вложений. Предполагается, что ликвидационная стоимость запасов нулевая. Коэффициент определяется по формуле 2.
Формула 2. Расчет коэффициента критической ликвидности
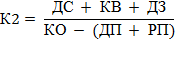
| Используемые обозначения | Расшифровка | Единицы измерения | Источник данных |
| К2 | Коэффициент критической (быстрой) ликвидности | ед. | Результат расчета |
| ДС | Денежные средства | руб. | Баланс, стр. 1250 |
| КВ | Краткосрочные финансовые вложения | руб. | Баланс, стр. 1240 (только государственные ценные бумаги, ценные бумаги Сбербанка России и средства на депозитных счетах; если нет детальной информации по вложениям, этот показатель в расчетах не участвует) |
| ДЗ | Дебиторская задолженность | руб. | Баланс, стр. 1230 |
| КО | Краткосрочные обязательства | руб. | Баланс, стр. 1500 |
| ДП | Доходы будущих периодов | руб. | Баланс, стр. 1530 |
| РП | Резервы предстоящих расходов | руб. | Баланс, стр. 1540 (оценочные обязательства) |
Общий коэффициент покрытия или текущей ликвидности свидетельствует о достаточности оборотного капитала для погашения краткосрочных обязательств компании. Вычисляется по формуле 3.
Формула 3. Расчет коэффициента текущей ликвидности
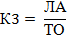
| Используемые обозначения | Расшифровка | Ед. измер. | Источник данных |
| К3 | Коэффициент текущей ликвидности | ед. | Результат расчета |
| ЛА | Ликвидные активы | руб. | Расчет по формуле |
| ТО | Текущие обязательства | руб. | Сумма краткосрочных заемных средств (баланс, раздел V, стр. 1510), кредиторской задолженности (баланс, раздел V, стр. 1520) и прочих обязательств (баланс, раздел V, стр. 1550) |
Коэффициент соотношения собственных и заемных средств или финансового риска показывает, сколько собственных средств компании приходится на рубль заемных. Для его расчета применяется формула 4.
Формула 4. Расчет коэффициента соотношения собственных и заемных средств
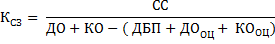
| Используемые обозначения | Расшифровка | Ед. изм. | Источник данных |
| К4 | Коэффициент соотношения собственных и заемных средств | ед. | Результат расчета |
| СС | Собственные средства | руб. | Сумма капитала и резервов (баланс, раздел III, стр. 1300), доходов будущих периодов (баланс, раздел V, стр. 1530), долгосрочных (баланс, раздел IV, стр. 1430) и краткосрочных (баланс, раздел V, стр. 1540) оценочных обязательств за минусом капитальных затрат по арендованному имуществу (отчет о финансовых результатах или прибылях и убытках, стр. 2350) и задолженности акционеров по взносу в уставный капитал (баланс, раздел II, стр. 1230, детальнее – счет 75 «Расчеты с учредителями») |
| ДО | Долгосрочные обязательства | руб. | Баланс, стр. 1400 |
| КО | Краткосрочные обязательства | руб. | Баланс, стр. 1500 |
| ДП | Доходы будущих периодов | руб. | Баланс, стр. 1530 |
| ДОоц | Долгосрочные оценочные обязательства | руб. | Баланс, стр. 1430 |
| КОоц | Краткосрочные оценочные обязательства | руб. | Баланс, стр. 1540 |
Кроме прочего, для анализа кредитоспособности рассчитываются два показателя рентабельности – продаж и деятельности в целом.
Формула 5. Расчет рентабельности продаж
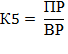
| Используемые обозначения | Расшифровка | Единицы измерения | Источник данных |
| К5 | Рентабельность продаж | ед. | Результат расчета |
| ПР | Прибыль от реализации | ед. | Отчет о финансовых результатах (о прибылях и убытках), стр. 2200 |
| ВР | Выручка от реализации | руб. | Отчет о финансовых результатах (о прибылях и убытках), стр. 2110 |
Формула 6. Расчет рентабельности деятельности
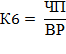
Агрегированный баланс – общее понятие и предназначение
Агрегированный баланс – это обобщенная (укрупненная) форма бухгалтерского баланса, благодаря использованию которой процедура проведения финансового анализа упрощается. вы узнаете, как правильно составить отчет о финансовых результатах фирмы.
Следует отметить, что даже стандартный бухгалтерский баланс в определенной степени является агрегированным из-за того, что некоторые приведенные в нем данные имеют схожий экономический смысл и объединяются в статьи. Об этом говорится в Приказе Минфина № 66н от 2 июля 2010 года.
Агрегированный баланс обладает рядом особенностей, а именно:
- Максимально упрощен, поэтому не вызывает сложностей при изучении и позволяет быстро выделить основные показатели, оказывающие влияние на экономическое положение организации;
- Содержит данные, предназначенные для расчета коэффициента финансовой устойчивости, индекса деловой активности, ликвидности;
- Формируется различными способами, ведь единого алгоритма укрупнения не существует;
- Имеет структуру стандартного баланса – преобразуются только статьи;
- Уровень достоверности проведенного анализа зависит от степени агрегирования информации: чем сильнее укрупнены данные, тем ниже качество оценки.
Как уже говорилось выше, агрегированный бухгалтерский баланс требуется при проведении анализа. На его основе производится оценка двух важных показателей, один из которых – ликвидность, второй – платежеспособность предприятия. Они взаимосвязаны друг с другом.
Так при расчете ликвидности сумма 3-х активов делится на сумму 2-х пассивов, а полученный результат позволяет установить, хватит ли организации денежных средств для покрытия имеющейся задолженности в текущем году.
Структуру и основные правила составления баланса можно посмотреть в этом видео:
Степени агрегирования
Общее количество степеней агрегирования бухгалтерского баланса назвать невозможно. Это связано с тем, что отчетный документ может быть составлен несколькими способами и предназначаться для проведения различного по глубине анализа.
Наиболее известны 2 степени агрегирования баланса – высшая и предшествующая ей. В первом случае данные максимально укрупнены и входят либо в раздел «Активы», либо в раздел «Пассивы», а единственным числовым показателем остается валюта.
Во втором случае упомянутые выше статьи детализированы. Так раздел «Активы» может включать в себя пункты «Внеоборотные активы» и «Оборотные активы», а в раздел «Пассивы» – подразделы «Капитал и резервы», «Долгосрочные обязательства», «Краткосрочные обязательства».
Составление и оформление баланса
Основой для формирования агрегированного баланса служит стандартный бухгалтерский баланс. В процессе укрупнения данных производится объединение статей, имеющих сходное экономическое содержание. Общая структура финансового документа остается нетронутой, поэтому сохраняется равенство активов и пассивов.
Чтобы сформировать агрегированный баланс, необходимо:
- Располагать оборотно-сальдовой ведомостью и стандартным бухгалтерским отчетом;
- Проанализировать содержание документов и выделить в них подразделы, которые можно объединить;
- Используя Microsoft Excel или аналогичную программу, составить отчет в виде таблицы, включающей в себя столбцы (их число зависит от степени агрегирования) с уже обобщенной информацией.
Это важно! Объединение разделов стандартного баланса должно иметь экономическое обоснование. В частности активы группируются по степени ликвидности, а пассивы – по срокам погашения.

Баланс для анализа финансовой устойчивости.
Пример статей и кодов строк
Готовый агрегированный баланс может выглядеть следующим образом:
| Статья | Коды строк стандартного баланса |
| Активы | |
| Постоянные активы: | |
| Нематериальные активы | 110 |
| Основные средства | 120+135 |
| Капиталовложения | 130 |
| Долгосрочные вложения | 140 |
| Прочие НМА | 150 |
| Дебиторская задолженность со сроком погашения более года | 230 |
| Итого постоянные активы: | 190+230 |
| Текущие активы | |
| НЗП | 213 |
| Авансы поставщикам | 245 |
| Запасы и МБП | 211 |
| Готовая продукция | 214 |
| Дебиторская задолженность со сроком погашения до года | 215+ |
| Денежные средства | 250+260 |
| Прочие текущие активы | +246+270 |
| Итого текущие активы: | 290-244-230 |
| БАЛАНС АКТИВОВ: | 300-244 |
| Пассивы | |
| Собственные средства: | |
| Уставной капитал | 410+420+244 |
| Накопленный капитал | |
| Итого собственные средства: | 490-244 |
| Заемные средства | |
| Долгосрочные обязательства | 590 |
| Краткосрочные кредиты | 610 |
| Кредиторская задолженность | 621+622+623 |
| Авансы покупателей | 627 |
| Расчеты с бюджетом и фондами | 625+626 |
| Расчеты по зарплате | 624 |
| Прочие пассивы | |
| Текущие пассивы | 690 |
| Итого заемные средства: | 590+690 |
| БАЛАНС ПАССИВОВ | 700-244 |
Каким бывает анализ агрегированного баланса
Агрегированная форма баланса используется для проведения двух видов анализа. Первый из них – вертикальный, а второй – горизонтальный. Краткие описания обоих приведены ниже.
Вертикальный анализ представляет собой эффективный способ оценки структуры и динамики всех расходов и прибылей в общей выручке предприятия. Его результаты позволяют определить тенденции, свойственные деятельности организации в заданном временном промежутке.
При проведении горизонтального анализа данные из агрегированного баланса сравниваются с аналогичными значениями, полученными ранее, например, месяц или год назад.
Одновременно с этим учитывается уровень инфляции, что дает возможность выявить определенные закономерности и сделать прогноз относительно будущих финансовых показателей предприятия.
Представленные виды анализа дополняют друг друга. Их единовременное проведение позволяет сформировать общее представление об экономическом положении организации.

Пример агрегированного баланса.
Статьи баланса
Количество статей в описываемой форме бухгалтерского баланса зависит от степени агрегирования. Если последняя является высшей, то документ имеет такую структуру, в которой есть всего 2 раздела: «Активы» и «Пассивы». Если баланс более развернут, то статей в нем гораздо больше.
вы узнаете, как правильно рассчитать и определить чистые активы в балансе.
Они формируются путем объединения схожих разделов стандартного бухгалтерского баланса. В приведенном выше примере статьи находятся в первом столбце. Это нематериальные активы, основные средства, долгосрочные вложения, уставной капитал и т.д.
Агрегированный баланс – важный финансовый документ. Он редко вызывает сложности в процессе составления, но при этом заметно облегчает аналитику. Отсюда следует, что использование укрупненной формы бухгалтерского баланса – залог проведения качественного экономического анализа.
Пример составления агрегированного баланса можно посмотреть тут:
Агрегирование баланса
Источником информации при проведении финансового анализа служит бухгалтерский баланс. Бухгалтерский баланс – это отчетный документ, представляющий собой детализированный перечень в стоимостной оценке имущества предприятия (активы) и источников их возникновения (пассивы).
Для удобства чтения данных и проведения анализа производят преобразование стандартной формы бухгалтерского баланса в укрупненную (агрегированную) форму.
Основным отличием агрегированного баланса от стандартного является перегруппировка статей бухгалтерского баланса, объединяющая статьи бухгалтерского баланса с одинаковым экономическим содержанием.
Форма агрегированного баланса более удобна для чтения и проведения анализа, она позволяет выделить ключевые элементы, характеризующие состояние компании. Кроме того, подобная форма представления информации близка (методологически и терминологически) к используемым в мировой практике формам балансовых отчетов. Корректное агрегирование статей бухгалтерского баланса является основой для проведения качественного финансового анализа.
На основании статей агрегированного баланса рассчитываются основные показателей, использующихся для характеристики финансового положения организации – коэффициенты ликвидности, финансовой устойчивости, оборачиваемости и т.п.
Агрегированный баланс предприятия, пример составления
При составлении агрегированного баланса сохраняется структура исходного баланса – выделение постоянных и текущих активов, собственного и заемного капитала, сохраняется равенство общих величин (сальдо) актива и пассива баланса. Однако внутри разделов осуществляется ряд преобразований.
Стоит отметить важную особенность агрегирования в финансовом анализе. Уровень укрупнения данных определяет уровень пригодности их для анализа. Чем больше данные агрегированы, тем менее качественный анализ можно провести. Следует подчеркнуть, что единого алгоритма агрегирования баланса для всех известных в практике форматов не существует. Проводя такое агрегирование, необходимо руководствоваться, прежде всего, здравым смыслом и логикой последующего анализа, в основе которой лежит подразделение активов и пассивов на долгосрочные и краткосрочные.
Тестовая база к разделу «Анализ финансовой отчетности»
(правильный вариант ответа выделен жирным шрифтом)
1. Понятие «ликвидность активов» означает:
1.Способность активов организации приносить доход, достаточный для покрытия всех расходов, связанных с производством и реализацией продукции, работ, услуг
2. Период, в течение которого имущество предприятия полностью изнашивается и подлежит ликвидации
3. Способность превращения активов в денежную форму в короткий срок и без существенного снижения их стоимости
4. Период ликвидации имущества предприятия при банкротстве
2. Агрегирование (уплотнение) баланса осуществляется:
1. Вычитанием средних арифметических сумм
2. Объединением в группы однородных статей
3. Исключением регулирующих статей
3. Ликвидность баланса отражает:
1. Состояние имущества и обязательств, при котором предприятие подлежит ликвидации
2. Степень покрытия обязательств предприятия его активами, срок превращения которых в денежную форму соответствует сроку погашения обязательств
3. Период утраты платежеспособности предприятия
4. В агрегированном балансе-нетто статьи актива баланса могут быть сгруппированы по:
1.Принадлежности капитала
2. Степени ликвидности
3. Продолжительности использования капитала
5. Статьи пассива агрегированного баланса могут быть сгруппированы по:
>1.Степени ликвидности
2.Срочности оплаты (степени востребования)
3.Принадлежности капитала
6. К внеоборотным активам относятся:
1. Расчеты по дивидендам
2. Основные средства
3. Краткосрочные финансовые вложения
7. К оборотным активам относятся:
1. Запасы
2. Долгосрочные финансовые вложения
3. Нематериальные активы
8. Эффективность использования оборотных активов характеризуется:
1. Рентабельностью оборотных активов
2. Структурой оборотных средств
3. Структурой капитала
9. Коэффициент текущей ликвидности характеризует:
1. Способность организации отвечать по своим долгосрочным обязательствам
2. Достаточность средств для погашения обязательств в случае его ликвидации
3. Способность отвечать по своим краткосрочным обязательствам в полном объеме и в надлежащие сроки, исходя из имеющихся оборотных активов
10. Чистые оборотные активы определяются так:
1. Активы — Обязательства
2. Собственный капитал — Обязательства
11. В величину стоимости чистых активов не включаются статьи:
1. Нематериальные активы
2. Прочие внеоборотные активы
3. Собственные акции, выкупленные у акционеров
12. В величину срочных обязательств, принимаемых в расчет коэффициентов ликвидности, не включается статья:
1. Расчеты по дивидендам
2. Прочие краткосрочные пассивы
3. Доходы будущих периодов
13. При расчете чистых активов в состав активов не включается статья:
1. Дебиторская задолженность, срок погашения которой превышает 12 месяцев
2. Прочие оборотные активы
3. Задолженность участников (учредителей) по взносам в уставный капитал
14. В величину стоимости чистых активов не включаются статьи:
1. Нематериальные активы
2. Прочие внеоборотные активы
3. Собственные акции, выкупленные у акционеров
15. В величину срочных обязательств, принимаемых в расчет коэффициентов ликвидности, не включается статья:
1. Расчеты по дивидендам
2. Прочие краткосрочные пассивы
3. Доходы от будущих периодов
16. При расчете чистых активов в состав активов не включается статья:
1. Дебиторская задолженность, срок погашения которой превышается 12 месяцев
2. Прочие оборотные активы
3. Задолженность участников (учредителей) по взносам в уставный капитал
17.В величину срочных обязательств, принимаемых в расчет коэффициентов ликвидности, не включается статья:
1. Расчеты по дивидендам
2. Прочие краткосрочные пассивы
3. Резерв по сомнительным долгам
18. При расчете чистых активов в состав активов не включается статья:
1. Дебиторская задолженность, срок погашения которой превышается 12 месяцев
2. Расходы будущих периодов
3. Задолженность участников (учредителей) по взносам в уставный капитал
19. В числитель коэффициента текущей ликвидности не включается:
1. Долгосрочная дебиторская задолженность
2. Прочие оборотные активы
3. Расходы в незавершенном производстве
20. В состав краткосрочных обязательств при расчете коэффициента абсолютной ликвидности не включаются:
1. Задолженность по выплате дивидендов
2. Доходы будущих периодов
3. Прочие краткосрочные пассивы
21. В числе коэффициента абсолютной ликвидности отражается:
1. Денежные средства
2. Денежные средства и их эквиваленты
3. Денежные средства и дебиторская задолженность покупателей с устойчивым финансовым положением
22. В величину срочных обязательств, принимаемых в расчет чистых оборотных активов, не включается статья:
1. Расчеты по дивидендам
2. Прочие краткосрочные пассивы
3. Резервы предстоящих расходов (или добавочный капитал)
23. К ликвидным активам 2 класса можно отнести:
1. Краткосрочная дебиторская задолженность (менее 12 месяцев)
2. Ценные бумаги, не имеющие рыночной котировки
3. Просроченная дебиторская задолженность
4. Готовая продукция, на которую заключены договора с покупателями
24. К ликвидным активам 3 класса можно отнести:
1. Товары, предназначенные для оптовой продажи на условиях предоплаты
2. Ценные бумаги, не имеющие рыночной котировки
3. Просроченная дебиторская задолженность
4. Непросроченная дебиторская задолженность
5. Готовая продукция
25. К ликвидным активам 2 класса можно отнести:
1. Краткосрочная дебиторская задолженность
2. Ценные бумаги со сроком реализации 3 банковских дня
3. Денежные средства на расчетном счете, блокированные в связи с выставлением аккредитива
4. Денежные средства в кассе
5. Готовая продукция, предназначенная к отгрузке в счет поступившей от покупателя предоплаты – если в вопросе будет 3 класса
26. К ликвидным активам 1 класса можно отнести:
1. Товары, предназначенные для оптовой продажи на условиях предоплаты
2. Ценные бумаги со сроком реализации 3 банковских дня и Денежные средства в кассе
3. Денежные средства на расчетном счете, блокированные в связи с выставлением аккредитива
4. Готовая продукция, предназначенная к отгрузке в счет поступившей от покупателя предоплаты
27. К ликвидным активам 1 класса нельзя отнести:
1.Товары, предназначенные для оптовой продажи на условиях предоплаты, денежные средства на расчетном счете, блокированные в связи с выставлением аккредитива, и готовую продукцию, предназначенную к отгрузке в счет поступившей от покупателя предоплаты
2. Ценные бумаги со сроком реализации 3 банковских дня и Денежные средства в кассе
28. Оборачиваемость готовой продукции рассчитывается исходя из:
1. Полная себестоимость произведенной продукции
2. Полная себестоимость реализованной продукции
3. Плановая производственная себестоимость продукции
4. Выручки от продаж
29. К ликвидным активам 3 класса можно отнести:
1. Запасы, дебиторы, готовая продукция
2. Запасы, НДС по приобретенным ценностям, авансы полученные
3. Материалы, незавершенное производство, готовая продукция, НДС по приобретенным ценностям, товары отгруженные
4. Запасы, НДС по приобретенным ценностям, дебиторская задолженность сроком погашения свыше 12 месяцев, авансы выданные
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Агрегации в аналитике
—
Аналитические задачи в бизнесе
Каждую минуту кто-то в мире совершает покупку или просто заходит на сайт интернет-магазина. Сегодня даже самые маленькие фирмы собирают большое количество данных о покупках, клиентах и партнерах. Данные такого объема бывает трудно помещать на один график и анализировать визуально, поэтому аналитикам нередко приходится прибегать к сжатию данных — агрегации.
В этом уроке вы узнаете, что такое агрегация и как работать с агрегированными данными. Мы изучим пять основных агрегаций и научимся построить их в Google Sheets.
Что такое агрегация
Агрегация данных — это способ преобразования набора данных в одно результирующее значение. Это значение описывает исходный набор данных с точки зрения того, какая именно агрегация была выбрана.
На схеме агрегацию данных можно изобразить так:

К основным агрегациям можно отнести:
- Количество данных
- Сумма значений
- Среднее значение
- Минимальное значение
- Максимальное значение
Агрегированные данные — это набор нескольких значений, описывающих исходные данные. Агрегированные данные позволяют охарактеризовать данные вне зависимости от их объема в наборе. Чем больше агрегаций, тем точнее.
Далее на примере аналитической задачи мы разберем основные функции агрегации и узнаем, как их реализовывать в Google Sheets.
Основные агрегации
Представим, что мы аналитики в интернет-магазине «Все для дома». Нам нужно предоставить руководителю отчет о покупках за прошедший месяц. Известно, что ему нужны ответы на следующие вопросы:
- Как часто клиенты покупали у нас?
- Сколько мы заработали денег на покупках?
- Какой средний чек покупки?
- Какая была максимальная покупка?
- Какая была минимальная покупка?
Для ответа на эти вопросы нам предоставили таблицу с суммами покупок за последний месяц. Задача — собрать агрегированные данные по информации о покупках.
Для удобства будем собирать эти данные в такую таблицу:

Количество данных: как часто клиенты покупали у нас?
Чтобы ответить на этот вопрос, можно посчитать количество всех совершенных покупок за месяц.
Нам нужно посчитать количество строк в таблице. В Google Sheets это можно сделать с помощью функции COUNT:
- Шаг 1. В нужной ячейке вводим
=COUNT - Шаг 2. Открываем скобки и указываем диапазон значений, для которых нужно посчитать агрегацию
- Шаг 3. Нажимаем Enter

Количество данных для этого набора — 181. Много это или мало? Мы не можем ответить, пока не сравним это количество покупок с той же метрикой за прошлые месяцы.
Сумма значений: cколько мы заработали денег на покупках?
Выручку от продаж можно получить, если сложить суммы всех покупок за месяц.
Посчитаем сумму всех значений столбца «Сумма покупки» в нашей таблице. В Google Sheets это можно сделать с помощью функции SUM.
- Шаг 1. В нужной ячейке вводим
=SUM - Шаг 2. Открываем скобки и указываем диапазон значений, для которых нужно посчитать агрегацию
- Шаг 3. Нажимаем Enter

Выручка интернет-магазина за этот месяц составила 848 855,7. На этом этапе мы выяснили, что в прошлом месяце 181 покупка принесла 848 855,7 рубля.
Среднее значение: какой средний чек покупки?
Средний чек покупки — это то же самое, что и среднее значение суммы всех покупок.
Посчитаем сумму всех значений и поделим ее на количество значений. В Google Sheets это можно сделать с помощью функции AVERAGE:
- Шаг 1. В нужной ячейке вводим
=AVERAGE - Шаг 2. Открываем скобки и указываем диапазон значений, для которых нужно посчитать агрегацию
- Шаг 3. Нажимаем Enter

Таким образом, средний чек за месяц составил 4 689,81 рубля. Другими словами, именно столько тратят покупатели в нашем интернет-магазине в среднем за одну покупку.
Минимальное значение: какая была минимальная покупка?
Чтобы рассчитать минимальную покупку, нужно найти минимальное значение всех покупок.
Можно отсортировать набор данных по возрастанию и взять самое первое значение. В Google Sheets это можно сделать с помощью функции MIN:
- Шаг 1. В нужной ячейке вводим
=MIN - Шаг 2. Открываем скобки и указываем диапазон значений, для которых нужно посчитать агрегацию
- Шаг 3. Нажимаем Enter

Минимальная сумма покупки месяца составила 1,25. Теперь мы знаем, что за месяц не было ни одной покупки ниже этой суммы. Возможно, за такую цену был приобретен пакет, что может указывать на самый дешевый товар в магазине.
Максимальное значение: какая была максимальная покупка?
Чтобы рассчитать самую дорогую покупку, нам нужно найти максимальное значение среди всех покупок.
Отсортируем набор данных по убыванию и возьмем первое значение. В Google Sheets это можно сделать с помощью функции MAX:
- Шаг 1. В нужной ячейке вводим
=MAX - Шаг 2. Открываем скобки и указываем диапазон значений, для которых нужно посчитать агрегацию
- Шаг 3. Нажимаем Enter

Самая дорогая покупка в прошлом месяце обошлась в 46 935 рублей. Это значение сильно выше среднего чека — значит оно могло сильно сместить расчет среднего чека. Мы можем сделать вывод, что в прогнозах не стоит полагаться на получившееся среднее значение.
В итоге у нас получилась вот такая таблица агрегированных данных:

Краткий отчет может выглядеть следующим образом:
«За прошлый месяц была совершена 181 покупка, что принесло фирме выручку в размере 848 855 рублей. Минимальное и максимальное значения покупок сильно далеки друг от друга, поэтому разброс между суммами покупок большой. Это означает, что средний чек может быть сильно смещен. Вероятно, расчеты среднего чека не показывают, какую сумму среднестатистический покупатель действительно тратит в магазине».
В дополнение скажем, что агрегации можно применять и к нечисловым данным. Например, мы хотим описать набор данных с именами наших клиентов. Тогда можно посчитать количество уникальных значений — количество уникальных имен. Так мы сможем посчитать самое распространенное имя среди наших клиентов — то есть самое часто встречающееся значение. В статистике его еще называют модой.
Выводы
В этом уроке мы узнали, что такое агрегация и для чего нужно агрегировать данные. Теперь вы умеете реализовать агрегацию в Google Sheets.
Напомним ключевые выводы урока:

Введение¶
Одна из базовых функций анализа данных — группировка и агрегирование. В некоторых случаях этого уровня анализа может быть достаточно, чтобы ответить на вопросы бизнеса. В других случаях — это может стать первым шагом в более сложном анализе.
В pandas функцию groupby можно комбинировать с одной или несколькими функциями агрегирования, чтобы быстро и легко обобщать данные. Эта концепция обманчиво проста и большинство новых пользователей pandas поймут ее. Однако они удивятся тому, насколько полезными могут стать функции агрегирования для проведения сложного анализа данных.
В этом Блокноте кратко изложены основные функции агрегирования pandas и показаны примеры более сложных настраиваемых агрегаций. Независимо от того, являетесь ли вы начинающим или опытным пользователем pandas, я думаю, вы узнаете что-то новое для себя.
Оригниал статьи Криса тут.
Агрегирование¶
В контексте даннной статьи функция агрегирования — это функция, которая принимает несколько отдельных значений и возвращает сводные данные. В большинстве случаев возвращаемые данные представляют собой одно значение.
Наиболее распространенные функции агрегирования — это простое среднее (simple average) или суммирование (summation) значений.
Далее представлен пример расчета суммарной и средней стоимости билетов для набора данных «Титаник», загруженного из пакета seaborn.
15 апреля 1912 года самый большой пассажирский лайнер в истории во время своего первого рейса столкнулся с айсбергом. Когда Титаник затонул, погибли 1502 из 2224 пассажиров и членов экипажа. Эта сенсационная трагедия потрясла международное сообщество и привела к улучшению правил безопасности для судов. Одна из причин, по которой кораблекрушение привело к гибели людей, заключалась в том, что не хватало спасательных шлюпок для пассажиров и экипажа. Несмотря на то, что в выживании после затопления была определенная доля удачи, некоторые группы людей имели больше шансов выжить, чем другие.
In [1]:
import pandas as pd import seaborn as sns df = sns.load_dataset('titanic')
Каждая строка набора данных представляет одного человека. Столбцы описывают различные атрибуты, включая то, выжили ли они (survived), их возраст (age), класс пассажира (pclass), пол (sex) и стоимость проезда (fare).
Out[2]:
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
In [3]:
df['fare'].agg(['sum', 'mean']) # сумма и среднее по столбцу стоимости билета, здесь передаем список агрегирующих функций
Out[3]:
sum 28693.949300 mean 32.204208 Name: fare, dtype: float64
Эта простая концепция — необходимый строительный блок для более сложного анализа.
Одна из областей, которую необходимо обсудить, — это то, что существует несколько способов вызова функции агрегирования. Как показано выше, вы можете передать список функций для применения к одному или нескольким столбцам данных.
Что, если вы хотите выполнить анализ только подмножества столбцов?
Есть два других варианта агрегирования: использование словаря и именованное агрегирование (named aggregation).
In [4]:
df.agg({'fare': ['sum', 'mean'], 'sex' : ['count']})
Out[4]:
| fare | sex | |
|---|---|---|
| count | NaN | 891.0 |
| mean | 32.204208 | NaN |
| sum | 28693.949300 | NaN |
Использование кортежей (именованное агрегирование):
In [5]:
df.agg(fare_sum=('fare', 'sum'), fare_mean=('fare', 'mean'), sex_count=('sex', 'count'))
Out[5]:
| fare | sex | |
|---|---|---|
| fare_sum | 28693.949300 | NaN |
| fare_mean | 32.204208 | NaN |
| sex_count | NaN | 891.0 |
Важно знать об этих параметрах и понимать, какой из них и когда использовать.
Я предпочитаю использовать словари для агрегирования.
Подход с кортежами ограничен возможностью применять только одно агрегирование за раз к определенному столбцу. Если мне нужно переименовать столбцы, я буду использовать функцию rename после завершения агрегации. В некоторых случаях подход со списком является более рациональным. Тем не менее, я повторю, что, на мой взгляд, словарный подход обеспечивает наиболее надежный способ для большинства ситуаций.
Groupby¶
Теперь, когда мы знаем, как использовать агрегацию, мы можем объединить это с groupby для резюмирования данных.
Основы математики¶
Наиболее распространенными встроенными функциями агрегирования являются базовые математические функции, включая сумму (sum), среднее значение (mean), медианное значение (median), минимум (minimum), максимум (maximum), стандартное отклонение (standard deviation), дисперсию (variance), среднее абсолютное отклонение (mean absolute deviation) и произведение (product).
Мы можем применить все эти функции к fare (стоимости проезда) при группировке по embark_town (городу посадки на корабль):
In [6]:
agg_func_math = { 'fare': ['sum', 'mean', 'median', 'min', 'max', 'std', 'var', 'mad', 'prod'] }
In [7]:
df.groupby(['embark_town']).agg(agg_func_math).round(2)
Out[7]:
| fare | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| sum | mean | median | min | max | std | var | mad | prod | |
| embark_town | |||||||||
| Cherbourg | 10072.30 | 59.95 | 29.70 | 4.01 | 512.33 | 83.91 | 7041.39 | 53.02 | 6.193716e+250 |
| Queenstown | 1022.25 | 13.28 | 7.75 | 6.75 | 90.00 | 14.19 | 201.30 | 7.87 | 6.458671e+78 |
| Southampton | 17439.40 | 27.08 | 13.00 | 0.00 | 263.00 | 35.89 | 1287.95 | 21.30 | 0.000000e+00 |
Это все относительно простая математика.
Кстати, я не нашел подходящего варианта использования функции prod, которая вычисляет произведение всех значений в группе, и включил ее для полноты картины.
Еще один полезный трюк — использовать describe для одновременного выполнения нескольких встроенных агрегаторов:
In [8]:
agg_func_describe = {'fare': ['describe']}
In [9]:
df.groupby(['embark_town']).agg(agg_func_describe).round(2)
Out[9]:
| fare | ||||||||
|---|---|---|---|---|---|---|---|---|
| describe | ||||||||
| count | mean | std | min | 25% | 50% | 75% | max | |
| embark_town | ||||||||
| Cherbourg | 168.0 | 59.95 | 83.91 | 4.01 | 13.70 | 29.70 | 78.5 | 512.33 |
| Queenstown | 77.0 | 13.28 | 14.19 | 6.75 | 7.75 | 7.75 | 15.5 | 90.00 |
| Southampton | 644.0 | 27.08 | 35.89 | 0.00 | 8.05 | 13.00 | 27.9 | 263.00 |
Подсчет¶
После базовой математики подсчет (counting) является следующим наиболее распространенным агрегированием, которое я выполняю для сгруппированных данных.
Он несколько сложнее, чем простая математика. Вот три примера подсчета:
In [10]:
agg_func_count = {'embark_town': ['count', 'nunique', 'size']}
In [11]:
df.groupby(['deck']).agg(agg_func_count) # статистика по палубам Титаника
Out[11]:
| embark_town | |||
|---|---|---|---|
| count | nunique | size | |
| deck | |||
| A | 15 | 2 | 15 |
| B | 45 | 2 | 47 |
| C | 59 | 3 | 59 |
| D | 33 | 2 | 33 |
| E | 32 | 3 | 32 |
| F | 13 | 3 | 13 |
| G | 4 | 1 | 4 |
Главное отличие, о котором следует помнить, заключается в том, что
countне включает значенияNaN, тогда какsizeих включает. В зависимости от набора данных это различие может оказаться полезным.
Кроме того, функция nunique исключит значения NaN из уникальных счетчиков.
Продолжайте читать, чтобы увидеть пример того, как включить NaN в подсчет уникальных значений.
Первый и последний¶
В следующем примере мы можем выбрать самую высокую и самую низкую стоимость билета в зависимости от города, в котором совершили посадку пассажиры Титаника.
Следует помнить один важный момент: вы должны сначала отсортировать данные, если хотите, чтобы в качестве first (первого) и last (последнего) были выбраны максимальное и минимальное значения.
In [12]:
agg_func_selection = {'fare': ['first', 'last']}
In [13]:
df.sort_values(by=['fare'], ascending=False).groupby(['embark_town']).agg(agg_func_selection)
Out[13]:
| fare | ||
|---|---|---|
| first | last | |
| embark_town | ||
| Cherbourg | 512.3292 | 4.0125 |
| Queenstown | 90.0000 | 6.7500 |
| Southampton | 263.0000 | 0.0000 |
В приведенном выше примере я бы рекомендовал использовать max и min, но для полноты картины включил first и last. В других приложениях (например, при анализе временных рядов) вы можете выбрать значения first и last для дальнейшего анализа.
Другой подход к выбору — использовать idxmax и idxmin для выбора значения индекса, соответствующего максимальному или минимальному значениям.
In [14]:
agg_func_max_min = {'fare': ['idxmax', 'idxmin']}
In [15]:
df.groupby(['embark_town']).agg(agg_func_max_min)
Out[15]:
| fare | ||
|---|---|---|
| idxmax | idxmin | |
| embark_town | ||
| Cherbourg | 258 | 378 |
| Queenstown | 245 | 143 |
| Southampton | 27 | 179 |
Можем проверить результаты:
Out[16]:
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 258 | 1 | 1 | female | 35.0 | 0 | 0 | 512.3292 | C | First | woman | False | NaN | Cherbourg | yes | True |
| 378 | 0 | 3 | male | 20.0 | 0 | 0 | 4.0125 | C | Third | man | True | NaN | Cherbourg | no | True |
Вот еще один трюк, который можно использовать для просмотра строк с максимальной стоимостью проезда (fare):
In [17]:
df.loc[df.groupby('class')['fare'].idxmax()]
Out[17]:
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 258 | 1 | 1 | female | 35.0 | 0 | 0 | 512.3292 | C | First | woman | False | NaN | Cherbourg | yes | True |
| 72 | 0 | 2 | male | 21.0 | 0 | 0 | 73.5000 | S | Second | man | True | NaN | Southampton | no | True |
| 159 | 0 | 3 | male | NaN | 8 | 2 | 69.5500 | S | Third | man | True | NaN | Southampton | no | False |
Приведенный выше пример — одно из тех мест, где агрегирование на основе списка является полезным.
Другие библиотеки¶
Вы не ограничены функциями агрегирования в pandas. К примеру, можно использовать функции статистики из scipy или numpy.
Вот пример расчета моды (mode) и асимметрии (skew) данных для стоимости проезда.
In [18]:
from scipy.stats import skew, mode
In [19]:
agg_func_stats = {'fare': [skew, mode, pd.Series.mode]}
In [20]:
df.groupby(['embark_town']).agg(agg_func_stats)
Out[20]:
| fare | |||
|---|---|---|---|
| skew | mode | mode | |
| embark_town | |||
| Cherbourg | 3.305112 | ([7.2292], [15]) | 7.2292 |
| Queenstown | 4.265111 | ([7.75], [30]) | 7.7500 |
| Southampton | 3.640276 | ([8.05], [43]) | 8.0500 |
Интересны результаты вычисления моды (mode). Функция mode из scipy.stats возвращает наиболее часто встречающееся значение, а также количество вхождений. Если вам просто нужно наиболее частое значение, то используйте pd.Series.mode.
Ключевым моментом является то, что вы можете использовать любую функцию, которую хотите, если она знает, как интерпретировать массив значений pandas и возвращает одно значение.
Работа с текстом¶
При работе с текстом функции подсчета будут работать должным образом. Вы также можете использовать функцию mode из scipy для текстовых данных.
Одно интересное приложение состоит в том, что если у вас небольшое количество различных значений, то можете использовать питоновскую функцию set для отображения списка уникальных значений.
Следующая краткая сводка для class (класса каюты) и deck (палубы) показывает, как данный подход можно использовать:
In [21]:
agg_func_text = {'deck': ['nunique', mode, set]}
In [22]:
df.groupby(['class']).agg(agg_func_text)
Out[22]:
| deck | |||
|---|---|---|---|
| nunique | mode | set | |
| class | |||
| First | 5 | ([C], [59]) | {C, nan, A, B, E, D} |
| Second | 3 | ([F], [8]) | {nan, D, F, E} |
| Third | 3 | ([F], [5]) | {nan, F, E, G} |
Пользовательские функции¶
Стандартные функции агрегирования pandas и функции из экосистемы Python удовлетворят многие ваши потребности в анализе данных. Однако вы, вероятно, захотите создать свои собственные пользовательские функции агрегирования. Есть четыре способа для создания собственных функций.
Чтобы проиллюстрировать различия, давайте вычислим 25-й процентиль данных (также называемый квантилью .25 или нижней квартилью), используя четыре подхода.
Во-первых, мы можем использовать функцию partial:
In [23]:
from functools import partial
In [24]:
q_25 = partial(pd.Series.quantile, q=0.25) # возвращает обортку над pd.Series.quantile()
In [25]:
q_25.__name__ = '25%' # пойдет в наименование будущего столбца
Затем мы определяем нашу собственную функцию (которая представляет собой небольшую обертку для quantile):
In [26]:
def percentile_25(x): return x.quantile(.25)
Далее определяем лямбда-функцию и даем ей имя:
In [27]:
lambda_25 = lambda x: x.quantile(.25)
In [28]:
lambda_25.__name__ = 'lambda_25%'
Затем задаем встроенную (inline) лямбду и формируем словарь:
In [29]:
agg_func = { 'fare': [q_25, percentile_25, lambda_25, lambda x: x.quantile(.25)] }
In [30]:
df.groupby(['embark_town']).agg(agg_func).round(2)
Out[30]:
| fare | ||||
|---|---|---|---|---|
| 25% | percentile_25 | lambda_25% | <lambda_0> | |
| embark_town | ||||
| Cherbourg | 13.70 | 13.70 | 13.70 | 13.70 |
| Queenstown | 7.75 | 7.75 | 7.75 | 7.75 |
| Southampton | 8.05 | 8.05 | 8.05 | 8.05 |
Как видите, результаты одинаковые, но названия столбцов немного отличаются. Это область предпочтений программистов, но я рекомендую ознакомиться с вариантами, поскольку вы встретите большинство из них в онлайн-решениях.
Я предпочитаю использовать собственные функции или встроенные (inline) лямбды.
Как и во многих других областях программирования — это элемент стиля и предпочтений, но я рекомендую вам выбрать один или два подхода и придерживаться их для единообразия.
Примеры пользовательских функций¶
Как показано выше, существует несколько подходов к разработке пользовательских функций агрегирования.
В большинстве случаев функции представляют собой легкие обертки (wrappers) для встроенных функций pandas. Они нужны, т.к. нет возможности передать аргументы в агрегаты (aggregations).
Следующие примеры должны пояснить этот момент.
Если вы хотите подсчитать количество нулевых значений, вы можете использовать эту функцию:
In [31]:
def count_nulls(s): return s.size - s.count()
Если вы хотите включить значения NaN в свои уникальные счетчики, вам необходимо указать параметр dropna=False у функции nunique.
In [32]:
def unique_nan(s): return s.nunique(dropna=False)
Вот результат применения всех функций:
In [33]:
agg_func_custom_count = { 'embark_town': ['count', 'nunique', 'size', unique_nan, count_nulls, set] }
In [34]:
df.groupby(['deck']).agg(agg_func_custom_count)
Out[34]:
| embark_town | ||||||
|---|---|---|---|---|---|---|
| count | nunique | size | unique_nan | count_nulls | set | |
| deck | ||||||
| A | 15 | 2 | 15 | 2 | 0 | {Cherbourg, Southampton} |
| B | 45 | 2 | 47 | 3 | 2 | {nan, Cherbourg, Southampton} |
| C | 59 | 3 | 59 | 3 | 0 | {Cherbourg, Southampton, Queenstown} |
| D | 33 | 2 | 33 | 2 | 0 | {Cherbourg, Southampton} |
| E | 32 | 3 | 32 | 3 | 0 | {Cherbourg, Southampton, Queenstown} |
| F | 13 | 3 | 13 | 3 | 0 | {Cherbourg, Southampton, Queenstown} |
| G | 4 | 1 | 4 | 1 | 0 | {Southampton} |
Если вы хотите рассчитать 90-й процентиль, используйте quantile:
In [35]:
def percentile_90(x): return x.quantile(.9)
Если вы хотите вычислить усеченное среднее (trimmed mean) значение, из которого исключен самый низкий 10-й процент, используйте функцию trim_mean из scipy:
In [36]:
from scipy.stats import trim_mean def trim_mean_10(x): return trim_mean(x, 0.1)
Если вы хотите получить наибольшее значение, независимо от порядка сортировки (см. ранее в этом Блокноте о first и last):
In [37]:
def largest(x): return x.nlargest(1)
Это эквивалентно max, но я приведу еще один пример с nlargest ниже, чтобы подчеркнуть разницу.
Ранее я уже писал о sparkline. Обратитесь к этой статье за инструкциями по установке.
Вот как включить их в агрегатную функцию для уникального представления данных:
In [38]:
#!pip3 install sparklines
In [39]:
from sparklines import sparklines
In [40]:
import numpy as np def sparkline_str(x): bins = np.histogram(x)[0] sl = ''.join(sparklines(bins)) return sl
In [41]:
agg_func_largest = { 'fare': [percentile_90, trim_mean_10, largest, sparkline_str] }
In [42]:
df.groupby(['class', 'embark_town']).agg(agg_func_largest)
Out[42]:
| fare | |||||
|---|---|---|---|---|---|
| percentile_90 | trim_mean_10 | largest | sparkline_str | ||
| class | embark_town | ||||
| First | Cherbourg | 227.5250 | 85.408335 | 512.3292 | █▇▂▁▃▁▁▁▁▂ |
| Queenstown | 90.0000 | 90.000000 | 90.0000 | ▁▁▁▁▁█▁▁▁▁ | |
| Southampton | 152.3150 | 60.500160 | 263.0000 | ▃█▄▃▂▂▁▁▂▂ | |
| Second | Cherbourg | 41.5792 | 25.167500 | 41.5792 | █▄▁▁▄▂▄▁▄▅ |
| Queenstown | 12.3500 | 12.350000 | 12.3500 | ▁▁▁▁▁█▁▁▁▁ | |
| Southampton | 31.7500 | 18.202273 | 73.5000 | ▂█▂▅▁▂▁▁▁▁ | |
| Third | Cherbourg | 19.0229 | 10.677941 | 22.3583 | ▁█▃▂▁▄▃▁▂▂ |
| Queenstown | 24.0600 | 9.670476 | 29.1250 | █▁▁▂▁▁▁▂▁▂ | |
| Southampton | 31.2750 | 11.501469 | 69.5500 | ▁█▂▂▂▁▁▁▁▁ |
Функции nlargest и nsmallest могут быть полезны для резюмирования данных в различных сценариях.
Следующий код показывает суммарную стоимость для 10 первых и 10 последних пассажиров:
In [43]:
def top_10_sum(x): return x.nlargest(10).sum()
In [44]:
def bottom_10_sum(x): return x.nsmallest(10).sum()
In [45]:
agg_func_top_bottom_sum = { 'fare': [top_10_sum, bottom_10_sum] }
In [46]:
df.groupby('class').agg(agg_func_top_bottom_sum)
Out[46]:
| fare | ||
|---|---|---|
| top_10_sum | bottom_10_sum | |
| class | ||
| First | 3361.2584 | 108.3709 |
| Second | 622.2376 | 42.0000 |
| Third | 656.3374 | 36.1291 |
Использование этого подхода может быть полезно для применения закона Парето к вашим собственным данным.
Пользовательские функции с несколькими столбцами¶
Если у вас есть сценарий, в котором небходимо запустить несколько агрегаций по столбцам, то вы можете использовать groupby в сочетании с apply, как описано в этом ответе на stack overflow.
Используя этот метод, вы получите доступ ко всем столбцам данных и сможете выбрать подходящий способ агрегирования для создания итогового DataFrame (включая наименование столбцов):
In [47]:
def summary(x): result = { 'fare_sum': x['fare'].sum(), 'fare_mean': x['fare'].mean(), 'fare_range': x['fare'].max() - x['fare'].min() } return pd.Series(result).round(0)
In [48]:
df.groupby(['class']).apply(summary)
Out[48]:
| fare_sum | fare_mean | fare_range | |
|---|---|---|---|
| class | |||
| First | 18177.0 | 84.0 | 512.0 |
| Second | 3802.0 | 21.0 | 74.0 |
| Third | 6715.0 | 14.0 | 70.0 |
Использование apply с groupby дает максимальную гибкость. Однако есть и обратная сторона. Функция apply работает медленно, поэтому этот подход следует использовать с осторожностью.
Работа с групповыми объектами¶
После группировки и агрегирования данных вы можете выполнять дополнительные вычисления для сгруппированных объектов.
В следующем примере определим, какой процент от общего количества проданных билетов можно отнести к каждой комбинации embark_town и class.
Мы используем метод assign() и лямбда-функцию для добавления столбца pct_total:
In [49]:
df.groupby(['embark_town', 'class']).agg({'fare': 'sum'}).assign(pct_total=lambda x: x / x.sum())
Out[49]:
| fare | pct_total | ||
|---|---|---|---|
| embark_town | class | ||
| Cherbourg | First | 8901.0750 | 0.311947 |
| Second | 431.0917 | 0.015108 | |
| Third | 740.1295 | 0.025939 | |
| Queenstown | First | 180.0000 | 0.006308 |
| Second | 37.0500 | 0.001298 | |
| Third | 805.2043 | 0.028219 | |
| Southampton | First | 8936.3375 | 0.313183 |
| Second | 3333.7000 | 0.116833 | |
| Third | 5169.3613 | 0.181165 |
Следует отметить, что можно сделать проще с использованием кросс-таблицы pd.crosstab, как описано в статье:
In [50]:
pd.crosstab(df['embark_town'], df['class'], values=df['fare'], aggfunc='sum', normalize=True)
Out[50]:
| class | First | Second | Third |
|---|---|---|---|
| embark_town | |||
| Cherbourg | 0.311947 | 0.015108 | 0.025939 |
| Queenstown | 0.006308 | 0.001298 | 0.028219 |
| Southampton | 0.313183 | 0.116833 | 0.181165 |
Пока мы говорим о crosstab (кросс-таблицах), полезно иметь в виду, что функции агрегации также можно комбинировать со сводными таблицами (pivot tables).
In [51]:
pd.pivot_table(data=df, index=['embark_town'], columns=['class'], aggfunc=agg_func_top_bottom_sum)
Out[51]:
| fare | ||||||
|---|---|---|---|---|---|---|
| bottom_10_sum | top_10_sum | |||||
| class | First | Second | Third | First | Second | Third |
| embark_town | ||||||
| Cherbourg | 282.9957 | 172.2041 | 68.2500 | 3239.3542 | 334.6084 | 196.7457 |
| Queenstown | 180.0000 | 37.0500 | 73.5916 | 180.0000 | 37.0500 | 264.5750 |
| Southampton | 108.3709 | 42.0000 | 39.6291 | 2237.5251 | 614.5000 | 656.3374 |
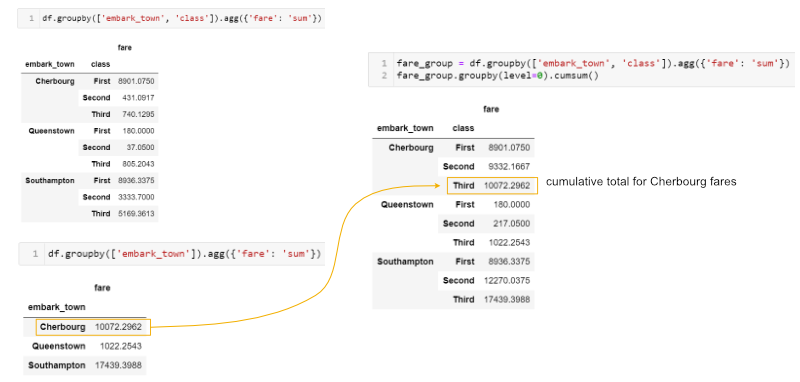
Иногда необходимо выполнить множество группировок (multiple groupby), чтобы ответить на вопрос. Например, если мы хотим увидеть кумулятивную сумму стоимости билетов, мы можем сгруппировать и агрегировать по городу (town) и классу (class), затем сгруппировать полученный объект и вычислить кумулятивную сумму (cumulative sum):
In [52]:
fare_group = df.groupby(['embark_town', 'class']).agg({'fare': 'sum'}) fare_group
Out[52]:
| fare | ||
|---|---|---|
| embark_town | class | |
| Cherbourg | First | 8901.0750 |
| Second | 431.0917 | |
| Third | 740.1295 | |
| Queenstown | First | 180.0000 |
| Second | 37.0500 | |
| Third | 805.2043 | |
| Southampton | First | 8936.3375 |
| Second | 3333.7000 | |
| Third | 5169.3613 |
In [53]:
fare_group.groupby(level=0).cumsum()
Out[53]:
| fare | ||
|---|---|---|
| embark_town | class | |
| Cherbourg | First | 8901.0750 |
| Second | 9332.1667 | |
| Third | 10072.2962 | |
| Queenstown | First | 180.0000 |
| Second | 217.0500 | |
| Third | 1022.2543 | |
| Southampton | First | 8936.3375 |
| Second | 12270.0375 | |
| Third | 17439.3988 |
Это может быть сложным для понимания. Вот краткое пояснение того, что мы делаем:
Пример с данными о продажах¶
В следующем примере резюмируем ежедневные данные о продажах и преобразуем их в совокупное ежедневное и ежеквартальное представление.
Обратитесь к статье о Grouper, если вы не знакомы с использованием метода pd.Grouper().
В этом примере мы хотим включить сумму ежедневных продаж, а также совокупную (cumulative) сумму за квартал:
In [54]:
sales = pd.read_excel('https://github.com/chris1610/pbpython/blob/master/data/2018_Sales_Total_v2.xlsx?raw=True') sales.head()
Out[54]:
| account number | name | sku | quantity | unit price | ext price | date | |
|---|---|---|---|---|---|---|---|
| 0 | 740150 | Barton LLC | B1-20000 | 39 | 86.69 | 3380.91 | 2018-01-01 07:21:51 |
| 1 | 714466 | Trantow-Barrows | S2-77896 | -1 | 63.16 | -63.16 | 2018-01-01 10:00:47 |
| 2 | 218895 | Kulas Inc | B1-69924 | 23 | 90.70 | 2086.10 | 2018-01-01 13:24:58 |
| 3 | 307599 | Kassulke, Ondricka and Metz | S1-65481 | 41 | 21.05 | 863.05 | 2018-01-01 15:05:22 |
| 4 | 412290 | Jerde-Hilpert | S2-34077 | 6 | 83.21 | 499.26 | 2018-01-01 23:26:55 |
In [55]:
daily_sales = sales.groupby([pd.Grouper(key='date', freq='D')]).agg(daily_sales=('ext price', 'sum')).reset_index() daily_sales.head()
Out[55]:
| date | daily_sales | |
|---|---|---|
| 0 | 2018-01-01 | 6766.16 |
| 1 | 2018-01-02 | 1551.91 |
| 2 | 2018-01-03 | 4278.96 |
| 3 | 2018-01-04 | 6044.10 |
| 4 | 2018-01-05 | 1971.94 |
In [56]:
daily_sales['quarter_sales'] = daily_sales.groupby(pd.Grouper(key='date', freq='Q')).agg({'daily_sales': 'cumsum'}) daily_sales.head()
Out[56]:
| date | daily_sales | quarter_sales | |
|---|---|---|---|
| 0 | 2018-01-01 | 6766.16 | 6766.16 |
| 1 | 2018-01-02 | 1551.91 | 8318.07 |
| 2 | 2018-01-03 | 4278.96 | 12597.03 |
| 3 | 2018-01-04 | 6044.10 | 18641.13 |
| 4 | 2018-01-05 | 1971.94 | 20613.07 |
Чтобы получить хорошее представление о том, что происходит, вам нужно взглянуть на границу квартала (с конца марта по начало апреля):
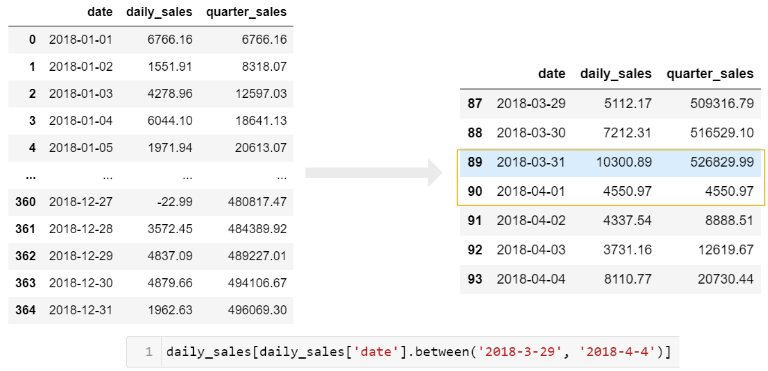
Если вы хотите просто получить совокупный (cumulative) квартальный итог, вы можете связать несколько функций groupby.
Сначала сгруппируйте ежедневные результаты, затем сгруппируйте эти результаты по кварталам и используйте кумулятивную сумму:
In [57]:
# веселый пример :) sales.groupby( [pd.Grouper(key='date', freq='D')]).agg( daily_sales=('ext price', 'sum')).groupby( pd.Grouper(freq='Q')).agg( {'daily_sales': 'cumsum'}).rename( columns={'daily_sales': 'quarterly_sales'})
Out[57]:
| quarterly_sales | |
|---|---|
| date | |
| 2018-01-01 | 6766.16 |
| 2018-01-02 | 8318.07 |
| 2018-01-03 | 12597.03 |
| 2018-01-04 | 18641.13 |
| 2018-01-05 | 20613.07 |
| … | … |
| 2018-12-27 | 480817.47 |
| 2018-12-28 | 484389.92 |
| 2018-12-29 | 489227.01 |
| 2018-12-30 | 494106.67 |
| 2018-12-31 | 496069.30 |
365 rows × 1 columns
В этом примере я включил именованный подход агрегации (named aggregation approach), чтобы переименовать переменную и уточнить, что теперь это ежедневные продажи. Затем я снова группирую и использую совокупную (cumulative) сумму, чтобы получить текущую сумму за квартал. Наконец, я переименовал столбец в квартальные продажи (quarterly sales).
По отзывам, на первый взгляд, это сложно понять. Однако, если выполните по шагам, т.е. построите функцию и будете проверять результаты на каждом шаге, то начнете понимать ее.
Не расстраивайтесь!
Сглаживание иерархических индексов столбцов¶
По умолчанию pandas в сводном DataFrame создает иерархический индекс у столбца:
In [58]:
df.groupby(['embark_town', 'class']).agg({'fare': ['sum', 'mean']}).round()
Out[58]:
| fare | |||
|---|---|---|---|
| sum | mean | ||
| embark_town | class | ||
| Cherbourg | First | 8901.0 | 105.0 |
| Second | 431.0 | 25.0 | |
| Third | 740.0 | 11.0 | |
| Queenstown | First | 180.0 | 90.0 |
| Second | 37.0 | 12.0 | |
| Third | 805.0 | 11.0 | |
| Southampton | First | 8936.0 | 70.0 |
| Second | 3334.0 | 20.0 | |
| Third | 5169.0 | 15.0 |
В какой-то момент в процессе анализа вы, вероятно, захотите «сгладить» (flatten) столбцы, чтобы получилась одна строка с именами.
Я обнаружил, что мне лучше всего подходит следующий подход.
Я использую параметр as_index=False при группировке, а затем создаю новое имя свернутого (collapsed) столбца.
Вот код:
In [59]:
multi_df = df.groupby(['embark_town', 'class'], as_index=False).agg({'fare': ['sum', 'mean']}) multi_df
Out[59]:
| embark_town | class | fare | ||
|---|---|---|---|---|
| sum | mean | |||
| 0 | Cherbourg | First | 8901.0750 | 104.718529 |
| 1 | Cherbourg | Second | 431.0917 | 25.358335 |
| 2 | Cherbourg | Third | 740.1295 | 11.214083 |
| 3 | Queenstown | First | 180.0000 | 90.000000 |
| 4 | Queenstown | Second | 37.0500 | 12.350000 |
| 5 | Queenstown | Third | 805.2043 | 11.183393 |
| 6 | Southampton | First | 8936.3375 | 70.364862 |
| 7 | Southampton | Second | 3333.7000 | 20.327439 |
| 8 | Southampton | Third | 5169.3613 | 14.644083 |
In [60]:
multi_df.columns = ['_'.join(col).rstrip('_') for col in multi_df.columns.values] multi_df.round(2)
Out[60]:
| embark_town | class | fare_sum | fare_mean | |
|---|---|---|---|---|
| 0 | Cherbourg | First | 8901.07 | 104.72 |
| 1 | Cherbourg | Second | 431.09 | 25.36 |
| 2 | Cherbourg | Third | 740.13 | 11.21 |
| 3 | Queenstown | First | 180.00 | 90.00 |
| 4 | Queenstown | Second | 37.05 | 12.35 |
| 5 | Queenstown | Third | 805.20 | 11.18 |
| 6 | Southampton | First | 8936.34 | 70.36 |
| 7 | Southampton | Second | 3333.70 | 20.33 |
| 8 | Southampton | Third | 5169.36 | 14.64 |
Вот изображение, показывающее, как выглядит сплющенный кадр данных:
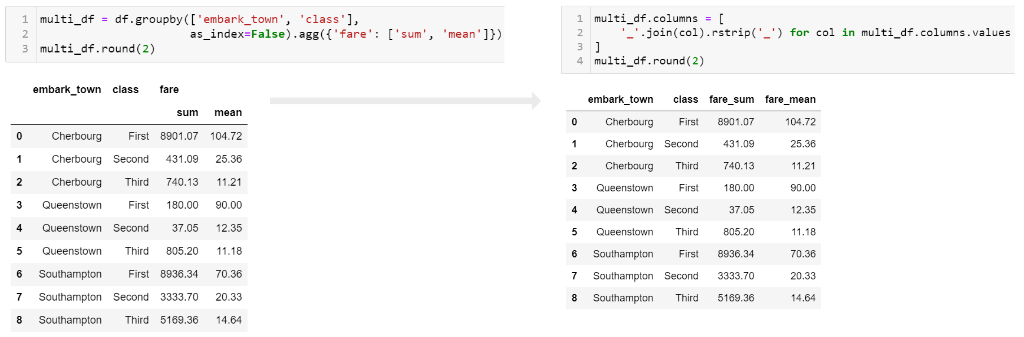
Я предпочитаю использовать _ в качестве разделителя, но вы можете использовать другие значения. Просто имейте в виду, что для последующего анализа будет проще, если в именах результирующих столбцов нет пробелов.
Промежуточные итоги¶
Если вы хотите добавить промежуточные итоги (subtotal), я рекомендую пакет sidetable.
Инструкция по работе с sidetable на русском языке тут.
Вот как вы можете суммировать fares по class, embark_town и sex с промежуточным итогом на каждом уровне, а также общим итогом внизу:
In [63]:
df.groupby(['class', 'embark_town', 'sex']).agg({'fare': 'sum'}).stb.subtotal()
Out[63]:
| fare | |||
|---|---|---|---|
| class | embark_town | sex | |
| First | Cherbourg | female | 4972.5333 |
| male | 3928.5417 | ||
| First | Cherbourg — subtotal | 8901.0750 | ||
| Queenstown | female | 90.0000 | |
| male | 90.0000 | ||
| First | Queenstown — subtotal | 180.0000 | ||
| Southampton | female | 4753.2917 | |
| male | 4183.0458 | ||
| First | Southampton — subtotal | 8936.3375 | ||
| First — subtotal | 18017.4125 | ||
| Second | Cherbourg | female | 176.8792 |
| male | 254.2125 | ||
| Second | Cherbourg — subtotal | 431.0917 | ||
| Queenstown | female | 24.7000 | |
| male | 12.3500 | ||
| Second | Queenstown — subtotal | 37.0500 | ||
| Southampton | female | 1468.1500 | |
| male | 1865.5500 | ||
| Second | Southampton — subtotal | 3333.7000 | ||
| Second — subtotal | 3801.8417 | ||
| Third | Cherbourg | female | 337.9833 |
| male | 402.1462 | ||
| Third | Cherbourg — subtotal | 740.1295 | ||
| Queenstown | female | 340.1585 | |
| male | 465.0458 | ||
| Third | Queenstown — subtotal | 805.2043 | ||
| Southampton | female | 1642.9668 | |
| male | 3526.3945 | ||
| Third | Southampton — subtotal | 5169.3613 | ||
| Third — subtotal | 6714.6951 | ||
| grand_total | 28533.9493 |
sidetable также позволяет настраивать уровни промежуточных итогов и итоговые метки. Обратитесь к документации пакета для получения дополнительных примеров того, как sidetable может резюмировать данные.
Резюме¶
Спасибо, что прочитали эту статью. Здесь много деталей, но это связано с тем, что существует множество различных применений для группировки и агрегирования данных с помощью pandas. Я надеюсь, что этот пост станет полезным ресурсом, который вы сможете добавить в закладки и вернуться к нему, когда столкнетесь с собственной сложной проблемой.
Если у вас есть другие распространенные техники, которые вы часто используете, дайте мне знать в комментариях к статье. Если я получу что-нибудь полезное, я включу его в этот пост или как обновленную статью.
Подписка на онлайн-обучение ![]()
Бухгалтерский баланс – основной источник данных при проведении финансово-экономического анализа. В процессе анализа чаще всего применяется его агрегированная форма. Привести стандартный, детализированный по статьям актива и пассива, баланс к агрегированному виду – значит, преобразовать его, суммируя экономически однородные балансовые показатели, представить их в укрупненном виде. Следует при этом иметь в виду, что единой методики агрегирования бухгалтерского баланса не существует.
Как определяются показатели агрегированного баланса?
Структура и использование агрегированного баланса
Строго говоря, сам по себе «стандартный» бухгалтерский баланс, составляемый по итогам года, является агрегированной формой отчетности. Аналитические, развернутые бухгалтерские данные группируются в нем по статьям, по признаку схожести экономического содержания: «Запасы», «Кредиторская задолженность» и пр.
Как балансовые счета соответствуют статьям агрегированного баланса?
Объединяя статьи далее, можно в итоге агрегировать баланс до формы, в которой будет лишь две сбалансированные по цифровому значению строки – актив и пассив. Агрегированный баланс можно получить, если привычный баланс по итогам года представить в виде разделов, без расшифровки. В левой части такой таблицы будут отражаться оборотные и внеоборотные активы, а в правой – капитал и резервы, долгосрочные и краткосрочные обязательства как отдельные статьи.
Очевидно, что чем более укрупненные показатели формируются в процессе агрегирования данных, тем менее точные данные в процессе анализа могут быть получены. При этом, какова бы ни была степень укрупнения данных, балансовое равенство должно соблюдаться.
Какова структура агрегированного баланса?
В практике анализа используют такую форму агрегированного баланса, данные которого позволяют учитывать ликвидность его активов.
На заметку! Ликвидность – способность перевода активов организации в денежную форму, без утраты балансовой стоимости. Ликвидность активов поддерживает необходимый уровень платежеспособности организации. Наивысшей ликвидностью обладают денежные средства, наиболее низкая активность у основных средств.
Агрегирование баланса в аналитических целях состоит не только в укрупнении показателей отчетного бухгалтерского баланса, но и в перегруппировке его отдельных статей. Как правило, группируют:
- актив – по степени ликвидности;
- пассив – по сроку погашения задолженностей.
Агрегированная форма баланса наиболее близка к мировой практике составления балансов и позволяет исчислить ряд важных экономических показателей: оборачиваемости, ликвидности, финансовой устойчивости, деловой активности предприятия и др. На основе полученных данных и проводится экономический анализ.
Агрегирование баланса и использование его показателей
Ранее говорилось, что единой методики агрегирования балансовых показателей не существует. Рассмотрим одну из наиболее распространенных в практике экономического анализа методику.
Группировка активов в общем случае делается указанным ниже способом:
- Имеющие наибольшую ликвидность (А1) — это финансовые средства и вложения краткосрочного характера, т.е. на срок менее года.
- Имеющие перспективы быстрой реализации (А2) — «дебиторка» и прочие активы.
- Медленно реализуемые — запасы, НДС, финансовые вложения на срок, превышающий один год (А3).
- Трудно реализуемые — основные средства и иные активы внеоборотного характера (А4).
Группировка пассивов также имеет свою последовательность:
- Пассивы наиболее срочные (П1) – кредиторская задолженность.
- Краткосрочные и долгосрочные обязательства соответственно (П2, П3).
- Пассивы, имеющие постоянный характер (П4), – собственный капитал, доходы будущих периодов.
На основе полученных данных можно провести анализ ликвидности. Так, если А1, А2, А3 соответственно больше П1, П2, П3, но А4 меньше П4, считается, что баланс имеет абсолютную ликвидность.
Текущую ликвидность исчисляют суммированием А1, А2, А3 и делением полученного результата на сумму П1, П2. Показатель характеризует способность фирмы покрыть свои долги в течение 12 месяцев за счет собственных средств.
Быстрая ликвидность, то есть отношение А1 сумме П1 и П2, характеризует степень покрытия задолженности посредством наиболее ликвидных активов.
На основе агрегированных балансовых данных исчисляют и другие аналитические показатели.
На заметку! Краткосрочные финансовые вложения в ценные бумаги в условиях нестабильности этого сегмента рынка могут на практике не обладать высокой степенью ликвидности. В этом случае имеет смысл рассматривать статьи денежных средств и краткосрочных финансовых вложений независимо друг от друга, а также учитывать указанное обстоятельство при анализе ликвидационных показателей, о которых шла речь выше.
Особенности агрегирования отдельных показателей баланса
Кроме методики группировки, опирающейся на ликвидность активов, и соответствующей группировки пассивов, существуют иные способы группировать данные. При этом следует помнить о ряде существенных моментов.
Группировка активов на постоянные (вне оборота) и текущие (в обороте) отчетном балансе отражается в р.1 и 2 актива, однако чтобы иметь корректные итоги указанных показателей, следует из р. 2 исключить дебиторскую задолженность по следующим причинам:
- платежи по ней ожидаются в срок более года;
- по этой строке может отражаться безнадежная задолженность, подлежащая списанию.
Ни то, ни другое не отвечает сущности оборотных активов, период оборота которых менее 12 месяцев. Дебиторская задолженность сроком более года может включаться в состав активов вне оборота как отдельная статья либо в составе прочих постоянных активов.
В статью «Запасы» агрегированного баланса правильным будет включить сумму расходов будущих периодов в той их части, которые по экономическому смыслу близки понятию запасов.
Пример: методическая литература, буклеты, прилагаемые к продукции, которая в будущем может быть реализована (например, при производстве сложной бытовой техники). Указанные затраты с течением времени будут включены в себестоимость продукции.
Раздел 3 пассива целесообразно сгруппировать по строкам, одна из которых будет показывать величину уставного капитала, а другая – накопленного капитала. Такая группировка наглядно демонстрирует, какова величина источников, образованных за счет приобретенных, заработанных в процессе деятельности, средств, а какая часть выражена собственно уставным капиталом (с учетом переоценки основных средств, вторичной эмиссии акций и пр.).
Из накопленного капитала вычитают величину непокрытых убытков минувших периодов и текущего года. Из уставного капитала вычитают задолженности участников по взносам в него.
Главное
В ходе экономического анализа деятельности организации применяются различные формы агрегированных (уплотненных) балансов. Суть агрегирования состоит в суммировании статей стандартного баланса, сходных по смыслу. На основе полученных данных рассчитывается ряд показателей, в том числе ликвидности организации.
При составлении агрегированного баланса используют гибкий, экономически выверенный подход, учитывают существенные нюансы экономической деятельности объекта анализа.