Рассказывает Юрий Дубровских
Экспертные системы — это вычислительные системы, способные в определённой предметной области принимать решения, схожие с решениями экспертов-людей.
Выглядит это примерно так: система задаёт ряд вопросов, причём последующие вопросы зависят от полученных ответов. Затем система делает вывод и показывает всю цепочку рассуждений, которая к нему привела. То есть знания и опыт эксперта тиражируются, а что не менее важно — тиражируется сам ход его рассуждений.
Кроме того, можно применить несколько интересных особенностей. Например, система может сделать не один вывод, а перечислить варианты с разной степенью вероятности. Можно учитывать различные виды нечётких данных — если пользователь не знает ответы на некоторые вопросы или что-то предполагает. Вместо пользователя система может опрашивать датчики или брать информацию из разных источников. Продвинутые системы могут самообучаться, то есть выявлять закономерности во время сеансов работы и генерировать новые знания.
Таким образом, экспертные системы могут применяться для довольно широкого круга задач:
- интерпретация, т. е. описание ситуации по наблюдаемым данным, определение смысла данных;
- диагностика — заключение о нарушениях в системе, составленное на основе наблюдений;
- отладка, исправление неисправностей — составление рекомендаций и выполнение последовательности действий по устранению неисправностей в системе;
- мониторинг — непрерывное сравнение результатов наблюдений с критическими точками плана;
- прогноз — предсказание будущих событий на основе анализа имеющихся данных о прошлом и настоящем;
- проектирование, конструирование — подготовка спецификаций для создания объектов с заранее определёнными свойствами;
- планирование — нахождение плана действий для достижения заранее поставленной цели;
- обучение какой-либо дисциплине или приёмам использования чего-либо;
- управление — решение задач проектирования и планирования, а также интерпретации и диагностики с корректировкой имеющихся планов;
- поддержка принятия решений — помощь в формировании или выборе варианта действий среди множества альтернатив.
Конечно, есть и ограничения. Во-первых, использовать экспертные системы есть смысл только в довольно узких предметных областях, где трудно найти экспертов и легче использовать компьютерную систему. Во-вторых, они не подходят для тех областей, в которых эксперты руководствуются не столько своими знаниями, сколько здравым смыслом, то есть сведениями из общей области знаний, не связанной с конкретным предметом. Также к недостаткам экспертных систем можно отнести то, что они плохо соотносятся с реляционными базами данных, к которым мы все так привыкли.
Тем не менее, в настоящее время существует и используется довольно много экспертных систем в сфере медицины, химии и военного дела. Вот некоторые примеры:
- Система по глобальной онтологии;
- Акинатор — система, которая отгадывает загаданного вами персонажа;
- MYCIN — выбор антимикробной терапии в условиях стационара;
- DENDRAL — химический анализ сложных молекул;
- поговаривают также, что отечественная система «Периметр», предназначенная для ответного удара в случае уничтожения командных пунктов, оснащена экспертной системой (которая и принимает решение о нанесении удара).
Попробуем создать небольшую экспертную систему. Для первого раза возьмём тренировочную предметную область. Хороший способ убедиться, что искусственный интеллект своими руками — это просто.
Не секрет, что в летний сезон в России ожидается резкий рост количества экспертов по приготовлению шашлыка. Думаю, многим знакома ситуация, когда кто-то один готовит шашлык а несколько людей стоят вокруг и дают советы и вообще высказывают своё экспертное мнение. Поведение таких шашлычных экспертов мы и попытаемся сымитировать.
Немного теории
Для начала разберёмся, что нам предстоит сделать.
Итак, экспертная система состоит из нескольких основных компонентов:
- база знаний;
- механизм логического вывода (МЛВ);
- компонента объяснения.
База знаний
База знаний — это, можно сказать, сердце экспертной системы. Знание — это информация вместе со способом её интерпретации, то есть это более высокий уровень информации. Система, обладающая знаниями, может не только выдавать информацию, но и объяснять её смысл и происхождение. Описание способа интерпретации называется метаданными.
Зачастую вся сложность создания экспертной системы заключается в формировании базы знаний. Этим занимаются специально обученные люди — инженеры по знаниям. Совместно с одним или несколькими экспертами они формулируют правила, имеющиеся в предметной области, и заносят их в определённом виде в базу знаний. В промышленных системах количество правил может исчисляться тысячами. При этом связи в предметной области могут быть такими запутанными и даже противоречивыми, что незначительная модификация базы знаний, например изменение порядка следования двух правил, может вызвать кардинальные изменения в работе всей системы.
Отдельная трудность заключается в самом общении с экспертами. Эксперты могут расходиться во мнениях и устраивать принципиальные споры. Кстати, поэтому предпочтительно использовать экспертные системы для тех областей знаний, которые уже устоялись. Кроме того, эксперты могут применять какие-то правила неосознанно или даже намеренно что-то скрывать. Остаётся только пожелать инженерам по знаниям, чтобы они держались.
Получаемая при этом база знаний может быть представлена в различных видах. Это может быть, к примеру, семантическая сеть. Но более классический вариант — набор продукционных правил (продукций). Продукционное правило — это правило вида ЕСЛИ <условие> ТО <действие>. Формулируя на естественном языке: если мясо жарится долго, оно приготовилось. Где же тут действие, спросите вы. Обо всём по порядку. Посмотрим на структуру правила более пристально.
И условие, и действие содержат в себе некие факты. Факт сам по себе может быть истинным или ложным, а также мы можем не иметь данных о его истинности. Факт может иметь определённую степень уверенности, например мы не знаем, что значит «долго» в контексте приготовления шашлыка, но кажется, что жарится уже довольно давно. Состоит факт из переменной и значения. Значение берётся из множества возможных значений — домена переменной. То есть наше условие «мясо жарится долго» можно переписать в виде: Время жарки = долго, где «время жарки» — переменная, а «долго» — значение. Если все возможные вопросы относительно времени жарки будут иметь ответ только «долго» и «недолго» — это и будет домен этой переменной.
Действие представляет собой присвоение истинности некоторому факту. То есть вместо человеческого «оно приготовилось», в ходе работы правила факт Мясо готово = да помечается как истинный.
Ещё раз посмотрим на то, что получилось из простого предложения эксперта. Из начального Если мясо жарится долго, оно приготовилось получается:
Переменные:
- Время жарки (домен: долго, недолго).
- Мясо готово (домен: да, нет).
Правило:
Если факт «время жарки = долго» — истинный, то факт «мясо готово = да» пометить как истинный.
Конечно, если мясо долго жарится, ещё нельзя уверенно утверждать, что оно готово, может быть, угли холодные. Но в нашем примере мы закроем на это глаза и не будем использовать степень уверенности в фактах.
Так, изучая высказывания экспертов, инженеры по знаниям выделяют имеющиеся в предметной области сущности и формируют правила. Что же с этими правилами происходит дальше?
Механизм логического вывода
После того как база знаний сформирована, можно задавать вопросы системе. Механизм логического вывода обеспечивает поиск ответов на эти вопросы. Вопрос задаёт цель консультации, в общем случае это определение значения какой-либо переменной. В нашем примере мы хотим понять, что же делать с шашлыком, то есть целью консультации будет значение переменной Действие с шашлыком. Возможными вариантами будут ждать, перевернуть или снимать.
На первом шаге механизм находит в базе знаний все правила, в которых переменная-цель присутствует в качестве вывода, не важно, с каким значением. Теперь каждое правило, если они нашлись, по очереди (именно поэтому важен порядок следования правил) проверяются до первого сработавшего. То есть до того, все условия которого окажутся истинными. Для проверки правила берутся все его условия и, опять же, по очереди проверяются — объявляются целью консультации, и алгоритм запускается для них с первого шага.
Не для всех переменных существуют правила, которые их определяют. Некоторые запрашиваются из внешних источников, в простейшем случае — у пользователя. Переменные, которые определяются правилами, называются выводимыми, а определяемые пользователем во время консультации — запрашиваемыми. Тип переменной определяется ещё на этапе формирования базы знаний, и для запрашиваемых должны быть заданы способы определения, например сформулирован вопрос для пользователя. Если пользователь не может ответить или для выводимой переменной не нашлось правил, или ни одно из правил не сработало — переменная остаётся без значения, а пользователь — без установленной истины.
Существуют ещё выводимо-запрашиваемые переменные. Для них существуют и правила вывода, и вопрос пользователю. Сначала механизм логического вывода пытается определить такие переменные с помощью правил, а если не получается — задаёт вопрос.
Компонента объяснения
Ещё одна немаловажная часть экспертной системы. Именно объяснение хода рассуждений и обоснование выводов выгодно отличают экспертную систему от других отраслей искусственного интеллекта.
На этапе формирования базы знаний в качестве метаданных к правилам прилагаются их объяснения на естественном языке. После консультации система может показать все сработавшие правила вместе с этими пояснениями. Комментарии можно также добавлять к отдельным фактам или переменным.
В итоге мы узнаём не только что надо перевернуть шашлык, но и почему нужно это сделать.
Это очень серьёзное преимущество для систем поддержки принятия решений и для других применений экспертных систем. Некоторые промышленные системы в качестве результата дают несколько ответов с пояснениями и степенями вероятности.
Переход к практике
Механизм логического вывода и компонента объяснения не относятся к конкретной экспертной системе. Они используют правила и метаданные базы знаний, но представляют собой скорее оболочку для экспертных систем. Имея такую оболочку, можно конструировать различные системы, создавая только базы знаний. Возможно, потребуются какие-то настройки в механизме логического вывода, но в целом оболочка может использоваться в любой предметной области.
Оболочка экспертной системы
Конечно, существует множество готовых оболочек. Они предоставляют различные возможности и различные способы формирования базы знаний. Однако, я достаточно жаден, чтобы не использовать платные решения и достаточно высокомерен, чтобы из бесплатных ни одно меня не устроило.
Ещё в студенческие годы мне довелось написать оболочку для экспертной системы. Конечно, она далеко не идеальна, ни с точки зрения кода, ни с точки зрения пользовательского интерфейса. Но во-первых, она работает. По крайней мере для небольших задач, как наша, она вполне годится для примера. Во-вторых, как ни странно, та же Википедия называет одним из основных недостатков экспертных систем отсутствие графического пользовательского интерфейса (взаимодействие обычно идёт через терминал). Так что наличие какого бы то ни было интерфейса (который у меня есть) — уже достаточный вклад в отрасль.
Далее я опишу схему данных и основной алгоритм работы механизма логического вывода в собственной оболочке, и дальнейшее создание экспертной системы буду показывать именно в ней. Вам же предлагаю на выбор — поискать оболочки в интернете (например можно взять эту в Википедии, а вот и ссылка на сам проект), воспользоваться моей.
Модель данных можно использовать самую простую, как в теории:
- Domain (Домен):
- Имя.
- Список значений.
- Variable:
- Имя.
- Домен.
- Тип (выводимая, запрашиваемая, выводимо-запрашиваемая).
- Вопрос для пользователя.
- Объяснение.
- Fact:
- Переменная.
- Значение.
- Истинность (неизвестно, истинный, ложный).
- Rule:
- Список фактов-условий.
- Факт-вывод.
- Результат (не сработало, сработало и вывод признан истинным, сработало и не привело к получению значения переменной).
В режиме проектирования базы знаний пользователь может завести все эти данные. Затем он переходит в режим консультации. Выбирается цель консультации, и запускается процедура GoConsult. Вот схема её работы:
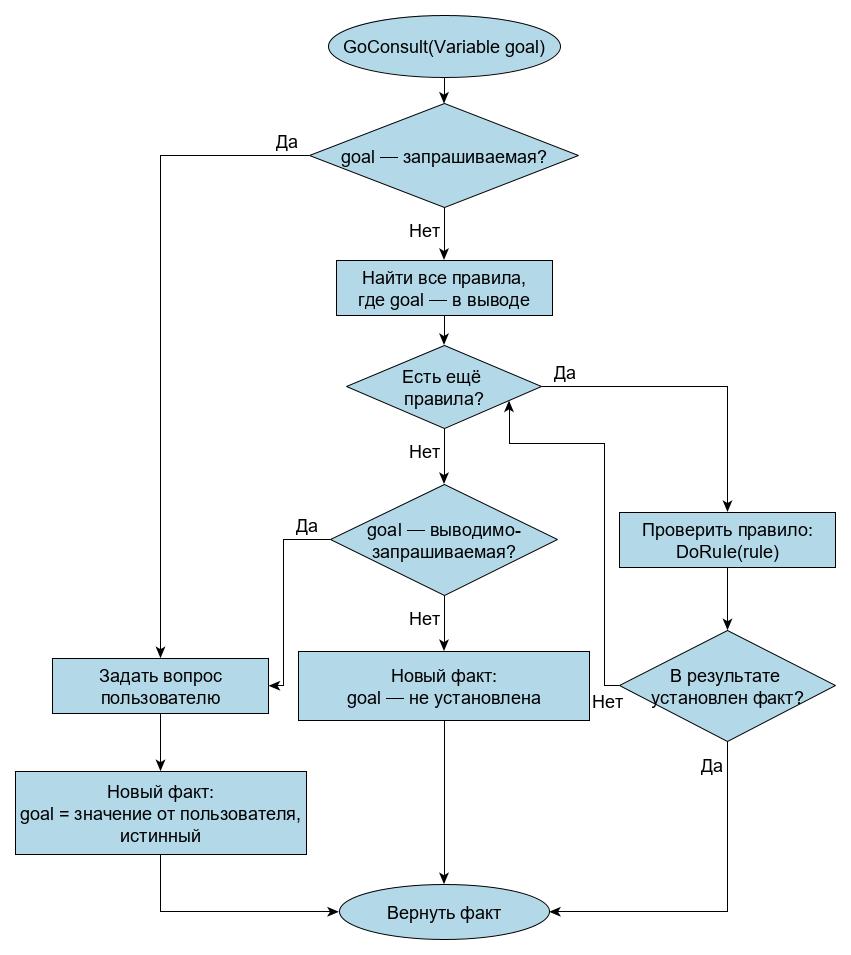
Как видно, эта процедура вызывает проверку правил DoRule, её тоже рассмотрим подробно:
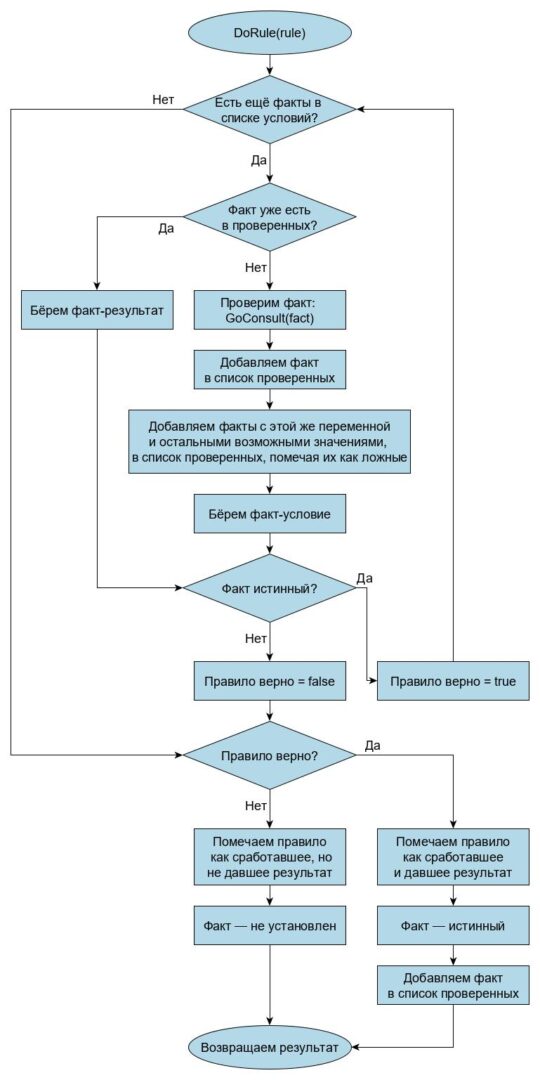
DoRule в свою очередь вызывает GoConsult, то есть алгоритм получается косвенно-рекурсивным. А в результате мы получаем факт — значение искомой переменной, которое введено пользователем или получено из базы знаний, или отсутствие значения, если истину определить не удалось.
Теперь, когда у нас есть модель данных и алгоритм, можем переходить к самому интересному — проектированию базы знаний.
База знаний
Что ж, начнём записывать в систему свои знания о шашлыке. При этом нужно помнить несколько вещей:
- Согласно алгоритму логического вывода, все условия в правиле объединены через И. Чтобы использовать ИЛИ, нужно создать несколько правил.
- Создать нужно не только подтверждающие что-то правила, но и противоположные. Например, если мы создаём правило ЕСЛИ Время жарки = Долго И Степень поджарки = Поджаристое, ТО Готово = Да, мы должны создать ещё такие правила: ЕСЛИ Время жарки = Только положили ТО Готово = Нет и ЕСЛИ Степень поджарки = Ещё сырое, ТО Готово = Нет.
- Важен порядок правил в базе знаний.
Нужно формализовать свои знания о шашлыке и представить в виде модели базы знаний, то есть выделить домены, переменные и правила. Чтобы было легче сформировать набор правил, да ещё и в нужном порядке, можно составить их графическое представление. У меня получилась довольно дикая, боюсь, понятная только мне схема:

Вершины определяют список переменных и возможных значений, а также какие переменные будут запрашиваемыми, а какие выводимыми. Дуги указывают на некоторые связи, из которых впоследствии получаются правила. Здесь я предположил, что мы будем жарить курицу или свинину, а система может подсказать три действия — ждать, перевернуть, снимать. Исходя из вашего опыта, вы можете сделать другие правила, расширить или переделать эту базу знаний. Вообще говоря, этим база знаний и хороша, что её ещё долго можно расширять, включая новые виды мяса, предполагаемые действия, обстоятельства и так далее. Пока же у меня получилось 27 правил:
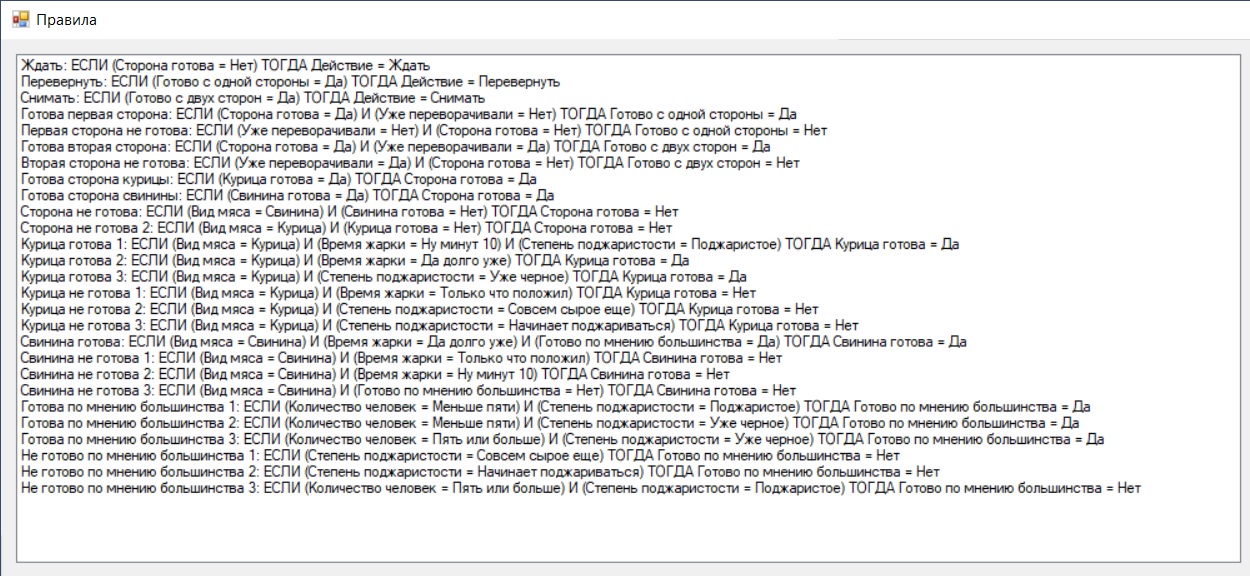
В промышленных системах количество правил может исчисляться тысячами. Для нашей тренировочной области пока попробуем чуть меньше. Итак, запустим консультацию и посмотрим, что нам посоветует система.
Я сказал, что жарю свинину минут 10, и система посоветовала подождать ещё, и вот почему:
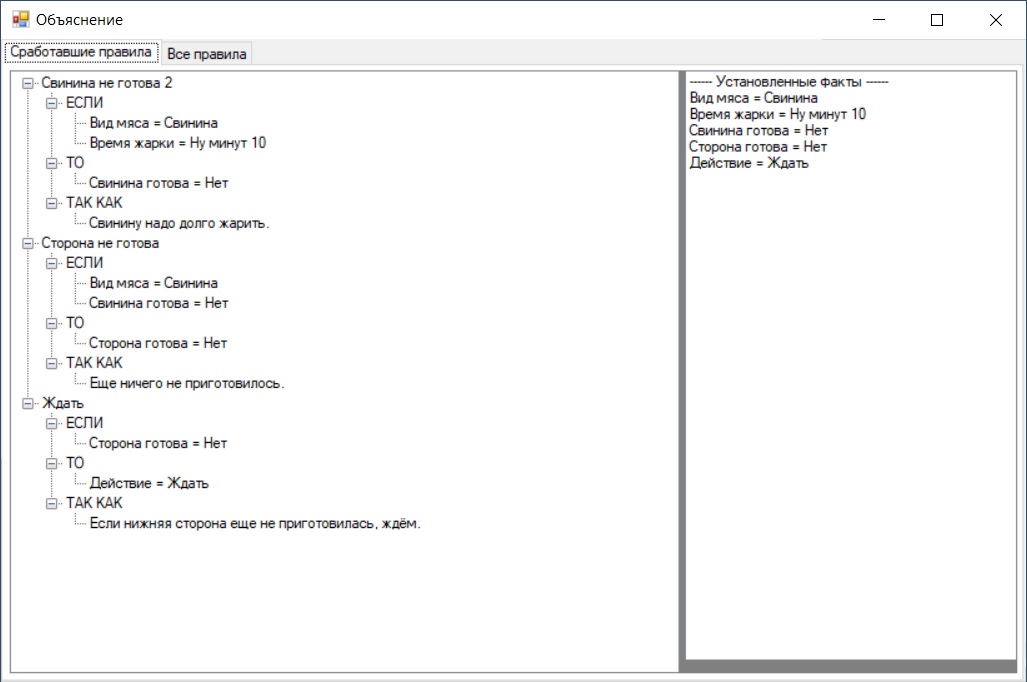
Когда смотришь на объяснение, как-то даже легче смириться с тем, что надо ещё ждать. Можно поэкспериментировать, запуская консультацию и по-разному отвечая на вопросы. Возможно, в каких-то случаях истина установлена не будет — значит, надо дополнить базу знаний новыми правилами.
Вот и всё, искусственный интеллект — система поддержки принятия решений в узкой предметной области — создан. Конечно, он не учитывает многие факторы, нечёткости и так далее. В базе знаний нет сведений о том, как захватить мир, и в отличие от некоторых промышленных систем, наша не способна анализировать консультации и сама генерировать новые правила. Но с шашлычными экспертами, которые будут кучковаться летом вокруг мангала, она уже вполне может поспорить.
Экспертная система — компьютерная программа, которая, как и любая другая программа, получает какие-то данные на вход и формирует другие данные на выходе. Особенность в том, что целью работы экспертной системы является замена эксперта (человека) в некоторой предметной области. Естественно, работают такие программы без магии, а по вполне определенному алгоритму. От некоторых других видов интеллектуальных систем они отличаются большим объемом знаний эксперта, необходимым для принятия решения. Например, система, которая контролирует температуру в мангале при жарке шашлыка не может называться экспертной системой.
Экспертные системы создаются для самых различных предметных областей, например:
- созданы системы медицинской диагностики, которые по набору симптомов назначают анализы, по результатам которых ставится диагноз и определяется курс лечения [1, 2];
- экспертные системы могут следить за соблюдением правил дорожного движения [3] и даже оценивать военную безопасность государства [4].
Так или иначе, в процессе использования в систему попадают факты пользователя, чаще всего это происходит в форме диалога, при этом система формирует вопросы исходя их данных в базе и данных ранее ответов. Например, система Akinator [5], угыдывающая задуманного пользователем персонажа мультфильма, может спросить «является ли ваш персонаж человеком?».
Важно, что все экспертные системы, вне зависимости от предметной области, имеют схожую структуру — на самом деле, какая разница «угадывает» система диагноз по симптомам или персонажа мультфильма по его параметрам? По этой причине для разработки часто используются специальные инструменты создания типовых систем или заготовки систем, в которые эксперту нужно лишь внести данные и правила, однако, в этой статье мы посмотрим как сделать простейшую экспертную систему на языке Prolog.
На рисунке ниже схематично приведена структура такой системы. В некоторых системах встречается модуль объяснения решения, который поясняет пользователю результаты работы (почему выставлен именно такой диагноз, например). Иногда, система обучается в процессе диалога с пользователем, при этом в базу данных заносятся новые факты.

Важно понимать, что база данных содержит факты, а база знаний — правила вывода решений на основе фактов и введенных пользователем данных. Правила представляют собой, по сути, исходный код программы, — именно поэтому для разработки экспертных систем удобно использовать языки типа SWI Prolog, ведь они позволяют добавлять новые правила в программу прямо во время ее исполнения. Чтобы понять как разработанная система работает и как запустить приведенный код стоит пройти по ссылкам [6, 7].
Ниже приведен пример разработки сильно упрощенной экспертной системы, помогающей студенту выбрать тему дипломной работы.
1 Обзор предметной области
Так как в основе любой экспертной системы находится база данных, то разработка начинается с анализа предметной области. Тут надо понять какие критерии стоит учитывать при подборе темы дипломной работы. Темы выпускных работ обычно формируют преподаватели исходя из своих интересов. Студент выбирает тему бакалаврской работы из набора имеющихся с учетом:
- желания работать с преподавателем, выдающим тему.
- своих интересов;
- сложности темы (по экспертной оценке руководителя темы);
- своих знаний по теме работы;
- владению необходимыми технологиями если они указаны руководителем как обязательные.
Например, если студент при обучении у преподавателя Пупкина с трудом получил тройку — маловероятно он пойдет к нему на дипломирование. Если студент ничего не знает в области блокчейна, но ему хотелось бы развиваться в этой сфере — возможно он выберет соответствующую тему. Тема работы «Разработка клиент-серверного приложения для игры в покер» может быть интересна студенту, но он не возьмет ее если руководитель требует писать сервер на Erlang, а студент не любит функциональное программирование.
Таким образом, предметная область задачи состоит из сущностей:
- руководитель ВКР;
- область интересов;
- тема ВКР;
- технология выполнения;
- студент.
Модель предметной области с использованием нотации диаграммы классов UML [8] приведена на рисунке:

2 Наполнение базы данных
Исходя из информации, изложенной в обзоре предметной области, ясно, что хранить программа должна темы и данные студента. Однако, данные студента вводятся в процессе диалога с ним и не должны храниться после чтобы не влиять на работу с системой следующего пользователя. Таким образом, в базе надо хранить лишь информацию о темах.
Для наполнения базы были найдены темы ВКР, по первому запросу поисковая система выдала информацию о темах Высшей школы экономики [9]. Однако, опубликованный список тем содержит лишь информацию о названии и руководителе, остальная информация была сформирована мной и не является точной — данные в базу данных экспертной системы должен вносить эксперт (руководитель ВКР).
В результате создана такая база данных:
theme('Повышение эффективности операций в цепях поставок',
'Бажина Д.Б.',
complex(70),
knowledge_areas(['экономика', 'управление', 'экономика', 'оптимизация']),
skills(['1C'])
).
theme('Повышение эффективности управления цепями поставок скоропортящихся товаров',
'Бажина Д.Б.',
complex(75),
knowledge_areas(['экономика', 'управление', 'законы', 'экономика', 'оптимизация']),
skills([])
).
theme('Разработка мероприятий по повышению лояльности потребителей транспортных услуг',
'Бородулина С.А.',
complex(85),
knowledge_areas(['транспорт', 'психология']),
skills([])
).
theme('Повышение эффективности управления материальными ресурсами транспортной компании',
'Бородулина С.А.',
complex(60),
knowledge_areas(['транспорт', 'управление', 'экономика', 'оптимизация']),
skills(['1C'])
).
theme('Разработка рекомендаций по применению геоинформационных технологий для повышения качества работы транспортной системы мегаполиса',
'Бочкарев А.А.',
complex(60),
knowledge_areas(['ГИС', 'транспорт', 'оптимизация']),
skills(['1C'])
).
theme('Применение аппарата теории массового обслуживания для повышения эффективности синтеза обслуживающих систем',
'Булатов М.А.',
complex(95),
knowledge_areas(['математика', 'оптимизация']),
skills(['теория массового обслуживания'])
).
На этом этапе можно лишь перебрать все записи базы и вывести их запросом:
?- theme(Theme, Name, Complex, knowledge_areas(Areas), skills(Skills)).
3 Алгоритмы работы экспертной системы (формирование базы знаний)
3.1 Выбор руководителей
Чтобы посоветовать тему, экспертная система должна получить информацию о студенте. Для начала можно узнать с какими преподавателями он готов работать. Для этого соберем список из всех преподавателей и выведем ему их под номерами. Пусть студент введет номера подходящих ему руководителей.
Собрать всех преподавателей можно так:
findall(Name, theme(_Theme, Name, _Complex, _Areas, _Skills), Names), list_to_set(Names, Set).
Встроенный предикат findall находит все решения предиката, переданного вторым аргументом и формирует из решений список. Однако, имена в таком списке могут повторяться — если у одного преподавателя было несколько тем то интерпретатор найдет его имя несколько раз. Поэтому следом вызывается предикат list_to_set, который убирает из списка повторы.

Теперь надо вывести эти имена списком так, чтобы к каждому имени был привязан номер. Это позволит пользователю не вводя имя (в котором легко сделать опечатку) выбрать нужные имена. Для этого описан предикат, принимающий на вход список и начальный номер и выводящий элементы списка в столбик так, что у каждого следующего элемента номер на единицу больше. Также написан предикат, выполняющий запрос всех имен (как показано выше) и выводящий их:
print_enumeration_list([], _Number):-!.
print_enumeration_list([Head|Tail], Number):-
write('t'), write(Number), write(' - '), write(Head), nl,
Next is Number+1,
print_enumeration_list(Tail, Next).
get_names(Names):-
findall(Name, theme(_Theme, Name, _Complex, _Areas, _Skills), Names),
list_to_set(Names, Set).
Результат выполнения запроса:

Теперь можно запросить у пользователя список имен и выбрать соответствующих номерам преподавателей:
nths_1(All, Indexes, Selected):-
Indexes = [], !, Selected = [];
Indexes = [HeadIndex|TailIndexes],
nth1(HeadIndex, All, HeadSelected),
nths_1(All, TailIndexes, TailSelected),
Selected = [HeadSelected|TailSelected].
select_names(SelectedNames):-
get_names(Names),
print_enumeration_list(Names, 1),
write('Введи подходящих преподавателей [номера через запятую]: '),
read(Numbers),
nths_1(Names, Numbers, SelectedNames), !;
% введены неверные данные:
write('Неправильный ввод, повторим...'), nl,
select_names(SelectedNames).
Тут предикат select_names после вывода списка преподавателей запрашивает список номеров и передает их в предикат nths_1, который выбирает элементы списка соответствующие списку номеров (нумерация начинается с единицы). если введены неверные данные — то выведется сообщение об ошибке и процесс повторится (рекурсивно):

3.2 Выбор области знаний
Теперь, когда выбраны предполагаемые — можно собрать список областей знаний в которых у них есть темы и выдать их в виде такого же списка.
Сначала можно получить список всех областей в которых есть темы у выбранных руководителей:
area_of_masters(Names, Area):-
member(Name, Names),
theme(_Theme, Name, _Complex, knowledge_areas(Areas), _Skills),
member(Area, Areas).
этот предикат сначала перебирает руководителей с помощью встроенного предиката member, затем перебирает все темы этого руководителя в базе, для каждой из них получает список областей. Искомая область принадлежит этому списку. Перебрать все области опять помогает member.
Теперь можно собрать все эти области в список и убрать из него повторы:
collect_areas(Names, Areas):-
findall(Area,
area_of_masters(Names, Area),
AreasList
),
list_to_set(AreasList, Areas).
Мы смогли получить по списку имен руководителей список областей в которых они работают без повторов, выведем этот список на экран чтобы студент смог выбрать интересующие его области:
select_areas(Names, SelectedAreas):-
collect_areas(Names, Areas),
print_enumeration_list(Areas, 1),
write('Введи подходящих области [номера через запятую]: '),
read(Numbers),
nths_1(Areas, Numbers, SelectedAreas), !;
write('Неправильный ввод, повторим...'), nl,
select_areas(Names, SelectedAreas).
В настоящий момент можно написать такую цель:
?- select_names(Names), select_areas(Names, Areas).
с ее помощью мы сначала просим выбрать имена, а затем области. Результат ее выполнения:

3.3 Указание компетенций студента
Аналогичным образом можно запросить у пользователя набор его компетенций. Для этого можно описать правила поиска всех компетенций, которые требуются в темах выбранных преподавателей по выбранным областям, примерно так:
skills_of_such_themes_that(Names, Areas, Skill):-
theme(_Theme, Name, _Complex, knowledge_areas(ThemeAreas), skills(Skills)),
member(Name, Names),
member(Area, Areas), member(Area, ThemeAreas),
member(Skill, Skills).
collect_skills(Names, Areas, Skills):-
findall(Skill,
skills_of_such_themes_that(Names, Areas, Skill),
SkillsList
),
list_to_set(SkillsList, Skills).
Дадим пользователю выбрать навыки из имеющегося списка:
select_skills(Names, Areas, SelectedSkills):-
collect_skills(Names, Areas, Skills),
print_enumeration_list(Skills, 1),
write('Введи имеющиеся компетенции [номера через запятую]: '),
read(Numbers),
nths_1(Skills, Numbers, SelectedSkills), !;
write('Неправильный ввод, повторим...'), nl,
select_skills(Names, Areas, SelectedSkills).
Дальше надо убрать из выдачи темы, для выполнения которых у студента не хватает компетенций…
3.4 Выбор темы
Для выбора тем, соответствующих всем выбранным критериям написан такой предикат:
matched_theme(Names, Areas, Skills, Theme):-
theme(Theme, Name, _Complex, knowledge_areas(ThemeAreas), skills(ThemeSkills)),
member(Name, Names),
member(Area, Areas), member(Area, ThemeAreas),
+ (
member(Skill, ThemeSkills),
+ member(Skill, Skills)
).
Итак, он перебирает все темы в базе данных и для каждой из них проверяет следующее:
- имя преподавателя есть в списке
Names; - среди областей знаний темы есть тема из выбранного пользователем списка (проверяется с помощью двух вызовов member — выбери такой
Areaв спискеAreas, что такой жеAreaесть в спискеThemeAreas); - проверяет что НЕТ такого навыка в теме, что им НЕ владеет студент.
Для реализации последней части используется два отрицания. Так:
+ member(Skill, Skills)
проверяет что навыка Skill нет в списке Skills. Список Skills — навыки студента.
А тут:
+ (
member(Skill, ThemeSkills),
+ member(Skill, Skills)
).
первый оператор + стоит перед группой (почти лямбда-функцией) и завершится успешно если вся группа «провалится». Группа провалится если среди навыков темы найдется такой Skill, что его нет у студента. Таким образом весь приведенный в последнем листинге фрагмент завершится если у студента есть все необходимые навыки для выполнения темы.
Все описанные выше предикаты собраны (вызываются) в предикате выбора темы так:
selected_theme(Theme):-
select_names(Names),
(
Names = [], write('Ничем не могу помочь');
select_areas(Names, Areas),
(
Areas = [], write('Ничем не могу помочь');
select_skills(Names, Areas, Skills),
matched_theme(Names, Areas, Skills, Theme)
)
).
То есть если на каком то этапе оказалось что система не может помочь — например, нет преподавателя, с которым хотел бы работать студент — то процесс подбора темы прерывается с сообщением о проблеме.
Результат подбора темы:

На приведенном рисунке видно, что одна и та же тема выведена дважды. Чтобы убрать это — все названия помещаются в список, который преобразуется во множество:
run(Theme):-
findall(T, selected_theme(T), Themes),
(
Themes = [], write('Нет подходящих тем');
list_to_set(Themes, ThemesSet),
member(Theme, ThemesSet)
).
4 Итоги
Видно, что для создания экспертной системы надо сначала проанализировать предметную область и понять какие данные стоит сохранять в системе, а также определиться с набором правил, по которым система может принимать решения. Затем, стоит описать данные и правила на языке программирования. В созданной тут системе нет никакого интерфейса для эксперта, таким образом система является статической.
Исходный код разработанной системы доступен в репозитории [10], пример ее использования:

Предлагаю посмотреть несколько похожих по структуре экспертных систем, написанных на других диалектах языка Prolog:
- Система подбора танцев (для Visual Prolog 5.2) [11];
- Система диагностики болезней (для Turbo Prolog) [12].
Список использованной литературы
- РОДИНА Р. В., СУЗДАЛЬЦЕВ В. А. Экспертная система прогнозирования медицинских диагнозов //Молодежь и системная модернизация страны. – 2018. – С. 137-141.
- Ле Н. В. Интеллектуальная медицинская система дифференциальной диагностики на основе экспертных систем // Вестник СГТУ. 2014. №1. URL: https://cyberleninka.ru/article/n/intellektualnaya-meditsinskaya-sistema-differentsialnoy-diagnostiki-na-osnove-ekspertnyh-sistem (дата обращения: 30.09.2021).
- Варламов О.О., Аладин Д.В. О СОЗДАНИИ МИВАРНЫХ СИСТЕМ КОНТРОЛЯ ЗА СОБЛЮДЕНИЕМ ПРАВИЛ ДОРОЖНОГО ДВИЖЕНИЯ НА ОСНОВЕ «РАЗУМАТОРОВ» И ЭКСПЕРТНЫХ СИСТЕМ. Радиопромышленность. 2018;28(2):25-35. https://doi.org/10.21778/2413-9599-2018-2-25-35
- Буравлев А. И., Чумичкин А. А. Формирование базы знаний экспертной системы оценки военной безопасности: методологический подход //Вооружение и экономика. – 2011. – №. 1. – С. 156-166.
- Akinator. URL: https://ru.akinator.com/game
- Введение в логическое программирование (Prolog) // Блог программиста. URL: https://pro-prof.com/archives/2362
- Как работать в SWI Prolog // Блог программиста. URL: https://pro-prof.com/forums/topic/work_in_swi-prolog
- Нотации модели сущность-связь (ER диаграммы) // Блог программиста. URL: https://pro-prof.com/archives/8126
- Темы ВКР // ВШЭ. URL: https://spb.hse.ru/data/2020/10/01/1369098873/Предлагаемые темы ВКР 2020-2021 учебный год.pdf
- Исходный код экспертной системы // Bitbucket. URL: https://bitbucket.org/rrrfer-admin/pro-prof.com-sources/branch/prolog_es
- Экспертная система Подбор танцев на Prolog // Блог программиста. URL: https://pro-prof.com/forums/topic/%d1%8d%d0%ba%d1%81%d0%bf%d0%b5%d1%80%d1%82%d0%bd%d0%b0%d1%8f-%d1%81%d0%b8%d1%81%d1%82%d0%b5%d0%bc%d0%b0-%d0%bf%d0%be%d0%b4%d0%b1%d0%be%d1%80-%d1%82%d0%b0%d0%bd%d1%86%d0%b5%d0%b2-%d0%bd%d0%b0-prolog
- Prolog — Экспертная система диагностики болезней // Блог программиста. URL: https://pro-prof.com/forums/topic/prolog-%d1%8d%d0%ba%d1%81%d0%bf%d0%b5%d1%80%d1%82%d0%bd%d0%b0%d1%8f-%d1%81%d0%b8%d1%81%d1%82%d0%b5%d0%bc%d0%b0-%d0%b4%d0%b8%d0%b0%d0%b3%d0%bd%d0%be%d1%81%d1%82%d0%b8%d0%ba%d0%b8-%d0%b1%d0%be%d0%bb
После
того, как на основе когнитивного анализа
выработаны предложения или приняты
решения о выполнении определенного
набора действий (операций), в базу данных
экспертной системы (или нескольких
экспертных систем) записываются условия,
при которых могут быть выполнены эти
действия и детали и выполнения в
соответствии с создавшимися условиями.
На основе этой информации, записанной
в базе знаний, экспертная система
соответствии с конкретной обстановкой,
генерирует решение о порядке выполнения
операций (действий).
3. Сценарий − последовательность действий, предпринимаемых для достижения цели
СППР
рассматривая набор операций, полученный
в результате когнитивного анализа или
формированных в экспертной системе как
исходные данные, система поддержки
принятия решений формирует возможные
сценарии −
последовательности выполнения таких
операций (действий). Сценарии могут
различаться не только последовательностью
действий, но и составом.
Сценарий может
быть создан и без формального выполнения
двух ранее указанных этапов.
При
создании СППР для различных приложений
могут быть использованы либо один из
этапов генерации решений, либо их
различные комбинации
Генерацию возможных
альтернатив решений можно реализовать
следующими формальными методами:
-
используя экспертные
системы; -
путем комбинации
различных операций, задаваемых экспертами
или взятых из базы данных.
Экспертная
система использует эвристические
знания, получаемые от специалистов в
данной предметной области. Для всех
наиболее успешных применений экспертных
систем характерна, по крайней мере, одна
общая черта − они работают в одной
ограниченной предметной области знаний.
Попытки расширить предметную область,
даже в пределах одной области знаний
(например, в медицине), в подавляющем
большинстве случаев успеха не давали.
При
возникновении нестандартной ситуации
предлагается набор возможных действий
(операций). Если такой набор не
предусматривается заранее, он может
быть создан экспертом. Лицо, принимающее
решение, или эксперт должен указать
возможную последовательность выполнения
операций, а также отметить, какие операции
могут выполняться параллельно. Эта
информация хранится в базе данных вместе
со списком операций. На основании этих
данных, а также времени выполнения
каждой операции могут порождаться
возможные последовательности операций
(варианты сценариев). Таким образом,
порождаются все возможные сценарии, и
в дальнейшем возникает задача выбора
наилучшего.
Оценка
возможных вариантов решений необходима
для всех типов задач и типов систем. Она
предшествует окончательному выбору
решения. Для анализа альтернатив могут
использоваться различные методы:
-
традиционные
(однокритериальные или балльные); -
многокритериальные;
-
методы нечеткой
логики.
3.2.4. Оценка вариантов решения по заданным критериям:
1.
Традиционные методы оценки возможных
решений.
В некоторых случаях можно дать оценку
каждого варианта решения, например, в
баллах. Однако очень часто однозначно
оценить предложенные варианты не
удается.
2.
Многокритериальные оценки.
Оценка варианта решения (сценария,
программы) по многим критериям означает,
что имеется более чем один показатель
качества принимаемого решения и
невозможно свести эти показатели
естественным образом к одному. В данном
случае могут применяться методы,
основанные на различных принципах,
например:
1.
Принцип свертки критериев.
Применяется при «оптимизации»
многих критериев одним координирующим
центром (задача многокритериальной
оптимизации). Для каждого из критериев
(целевых функций) f1
(x),…, fn
(x) экспертным путем назначаются «веса»
(числа)

причем
![]() показывает
показывает
«важность или значимость» критерия
fi.
Далее решение х* из множества допустимых
решений Х выбирается так, чтобы
максимизировать (или минимизировать)
свертку критериев:

2.
Принцип минимакса.
Применяется при столкновении интересов
противоборствующих сторон (антагонистический
конфликт). Каждое ЛПР сначала для каждой
своей стратегии (альтернативы) вычисляет
«гарантированный» результат, затем
окончательно выбирает ту стратегию,
для которой этот результат наибольший
по сравнению с другими его стратегиями.
Такое действие не дает ЛПР «максимального
выигрыша», однако является единственно
разумным принципом оптимальности в
условиях антагонистического конфликта.
В частности, исключен всякий риск.
3.
Принцип равновесия по Нэшу.
Это обобщение принципа минимакса, когда
во взаимодействии участвуют много
сторон, преследующий каждый свою цель
(прямого противостояния нет). Пусть
число ЛПР (участников неантагонистического
конфликта) есть n. Набор выбранных
стратегий (ситуация) (х1*
, х2*,…,
хn*)
называется равновесным, если одностороннее
отклонение любого ЛПР от этой ситуации
может привести разве лишь к уменьшению
его же «выигрыша». В ситуации
равновесия по Нэшу участники не получают
максимального «выигрыша», но они
вынуждены придерживаться ее.
4.
Принцип оптимальности по Парето.
Данный принцип предполагает в качестве
оптимальных те ситуации (наборы стратегий
(х1*
, х2*,…,
хn*)),
в которых улучшение «выигрыша»
отдельного участника невозможно без
ухудшения «выигрышей» остальных
участников. Этот принцип предъявляет
более слабые требования к понятию
оптимальности, чем принцип равновесия
по Нэшу. Поэтому Парето-оптимальные
ситуации существуют почти всегда.
3.2.5.
Использование нечеткой логики для
оценки возможных решений.
Необходимость применения нечеткой
логики вызвана тем, что по мере роста
сложности систем постоянно падает наша
способность делать точные и в то же
время значащие утверждения относительно
их поведения, пока не будет достигнут
порог, за которым точность и значимость
становятся почти взаимоисключающими
характеристиками.
После
того как процедура оценки вариантов
решений проведена, возможны три варианта:
-
переход к
согласованию критериев (если не удалось
ранжировать варианты); -
переход
к анализу последствий принятия решений
(если предложенные варианты удовлетворяют
экспертов или лиц, принимающих решения); -
если
не найдено ни одного удовлетворительного
решения, то производится уточнение
постановки задачи, выявление дополнительных
ресурсов, согласование целей с имеющимися
ресурсами, ограничениями и т. д.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Привет, мой друг, тебе интересно узнать все про моделирование экспертной системы, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое
моделирование экспертной системы , настоятельно рекомендую прочитать все из категории Экспертные системы.
Применение сетевой объектно-ориентированной базы знаний в моделировании экспертной системы на основе семантической нейронной сети
Описана реализация продукционной экспертной системы, база знаний которой выполнена на основе семантической нейронной сети. Описана реализация семантической нейронной сети на основе сетевой объектно-ориентированной базы данных. Описана реализация сетевой объектно-ориентированной базы данных в среде Microsoft .NET Framework 1.1
Возможности и архитектура системы
Основная цель данной разработки — создать виртуальную машину, поддерживающую нейронные сети со свободной топологией и числом нейронов до 2 млрд в одном хранилище. Данная возможность обеспечивается путем реализации системы управления сетевой объектно-ориентированной базы знаний (СООБЗ). Текущая версия СООБЗ Cerebrum представляет собой однопользовательскую файловую (desktop) базу. Поддерживаются однопользовательские одноуровневые транзакции. Во время транзакции файловое хранилище отключается, и все изменения объектов накапливаются в оперативной памяти. В будущем предполагается реализации поддержки иерархических транзакций, блокировок объектов, управление версиями (versioning) объектов, конкурентного доступа, многопользовательского режима и клиент-серверной архитектуры.
Система управления сетевой объектно-ориентированной базой знаний обладает следующими возможностями:
- Сохранять текущее состояние графа объектов или нейронной сети в СООБЗ между сеансами работы с пользователем. В том числе сохраняется текущая топология сети объектов. При повторном запуске приложения не понадобится создавать сеть объектов заново.
- При большем количестве экземпляров объектов ограничить объем памяти, используемый графом объектов или нейронной сетью. Наиболее часто используемые объекты остаются в оперативной памяти, остальные вытесняются в файловое хранилище и загружаются в оперативную память по мере необходимости. При загрузке экземпляра в оперативную память он вытесняет другие, редко используемые объекты.
- Ограничение объема памяти позволяет избавиться от использования файла подкачки операционной системы, что значительно повышает производительность моделирования сетей с большим количеством экземпляров объектов (при суммарном размере всех экземпляров большем, чем размер текущей свободной памяти в системе). В случае, если объем сети объектов меньше чем размер текущей свободной памяти в системе, вся сеть находится в оперативной памяти и потерь производительности, связанных с сериализацией-десериализацией .не возникает.
- Применение СООБЗ не накладывает никаких ограничений на используемую бизнес логику или математическую модель нейрона, которую можно реализовать как методы объектов, находящихся в СООБЗ. Основное требование — организовать связи между объектами в сети не с помощью указателей, а с помощью ID объектов.
Уровень ядра VNPI – хранение и управление временем жизни объектов
Ядро системы включает в себя уровень взаимодействия с операционной системой и уровень хранения и управления объектами. Уровень взаимодействия с операционной системой должен обеспечить адаптацию функций операционной системы к нуждам виртуальной машины, реализующей нейронную сеть. Уровень хранения объектов должен обеспечить хранение и быстрый доступ к объектам и их связям, а также управление временем жизни объектов. Совокупность API всех уровней виртуальной машины, для определенности, названа Virtual Neural Programming Interface, далее VNPI.
К эффективности языка реализации ядра виртуальной машины, эмулирующей нейронную сеть со многими миллионами эмулируемых нейронов, предъявляются повышенные требования. Ядро необходимо разработать учитывая современные компонентные технологии. Ядро VNPI предоставляет компоненты базового уровня для реализации объектно-сетевой базы. Оно включает в себя компоненты взаимодействия с операционной системой, управления памятью с подсистемой сборки мусора, управления структурированным хранилищем объектов, подсистему кэширования объектами и управления их временем жизни в оперативной памяти.
Уровень моста .NET-VNPI
Уровень реализации пользовательских объектов должен быть удобным для использования прикладными программистами. На данный момент этому требованию наиболее полно соответствует Microsoft .NET Framework. Для обеспечения интеграции .NET Framework и ядра VNPI необходим мост VNPI — .NET. Мост VNPI — .NET обеспечивает доступ к VNPI из среды .NET Framework. Он так же позволяет реализовывать объекты в среде .NET управляемые подсистемами ядра VNPI.
Учитывая различные цели и требования стоящие перед .NET Framework и VNPI идеология системы сборки мусора кардинально отличается. Так в .NET уничтожение объекта возможно только после того как не останется возможности его использования в текущем процессе. В отличие от этого в ядре VNPI сборка мусора осуществляется, когда исчерпана память допустимая для размещения объектов. В этом случае ненужные объекты вытесняются на устройство долговременного хранения. Уничтожение объектов является частью модели предметной области и поэтому выполняется только в ручную. Мост осуществляет подсчет ссылок на объекты ядра VNPI используемые .NET и препятствует вытеснению объектов, которые могут быть доступны через обращения из контекста .NET
В системе реализована собственная версия Garbage Collector с альтернативным алгоритмом выполнения. Когда память исчерпывается, самые старые объекты вытесняются на диск, освобождая место более нужным в данный момент. Таким образом, объекты, которые находятся в использовании, нужно защищать от принудительной выгрузки из оперативной памяти. Если не выполнить блокировку, то объект может быть разрушен в памяти еще до момента окончания его модификации . Об этом говорит сайт https://intellect.icu . Типичный прецедент вызова метода у пользовательского объекта выглядит следующим образом:
- NativeHandle someObjectHandle = …;
- IConnector someConnector = …;
- using(IContainer container = someConnector.GetContainer() as IContainer)
- {
- using(IConnector connector
- = container.AttachConnector(someObjectHandle))
- {
- (connector.Component as CMyType).MyMethod();
- }
- }
Система сама следит за временем жизни пользовательских объектов в памяти. Инициировать сохранение объектов в ручную не нужно. Наименее часто используемые объекты автоматически вытесняются на систему долговременного хранения, освобождая оперативную память. Поэтому в любой момент возможно что системе придется произвести вытеснение и разрушение какого то пользовательского объекта.
Уровень сетевой объектно-ориентированной базы
Уровень сетевой объектно-ориентированной базы отвечает за создание экземпляров пользовательских объектов, а так же за работу с атрибутами объектов. Каждый объект сетевой объектно-ориентированной базы может иметь несколько атрибутов. В качестве значений атрибутов могут выступать другие объекты или простейшие (скалярные) типы данных. Однотипные экземпляры объектов (с совместимыми наборами атрибутов) удобно представлять таблицами и управлять ими с помощью интерфейса пользователя ориентированного на обработку таблиц. Однотипные объекты имеют одинаковый набор атрибутов. Поэтому возможно представить коллекции однотипных объектов в виде таблицы, в которой сроки являются объектами, а колонки — атрибутами этих объектов.
Для создания объектов необходимо иметь информацию об их типах. Средствами сетевой объектно-ориентированной базы можно реализовать табличную структуру, близкую к структуре реляционной базы данных. Поэтому, для унификации информации о типах объектов, используемая этим уровнем, организованна в виде связанных друг с другом таблиц. Информация об объектах зарегистрированных в системе организована в виде нескольких таблиц Types, Attributes, Tables. Это позволяет определять в БД типы объектов .NET в унифицированном виде. Однако, свойства таблиц, строк и колонок в ОО базе отличаются от свойств, принятых в реляционных базах данных. Объектно-ориентированная база позволяет хранить не строки таблиц, как это принято в табличных базах данных, а экземпляры объектов. В пространстве имен Cerebrum.Reflection этим таблицам соответствуют классы TypeDescriptor, AttributeDescriptor, TableDescriptor. Класс MemberDescriptor представляет собой базовый класс, от которого унаследованы классы TypeDescriptor, AttributeDescriptor, TableDescriptor.
- public class MemberDescriptor : Cerebrum.Integrator.GenericComponent
- {
- public string Name
- public string DisplayName
- public string Description
- }
где Name — имя экземпляра; DisplayName — дружественное имя экземпляра предъявляемое пользователю; Description — описание данного экземпляра. MemberDescriptor — это базовый класс для классов которые обладают атрибутами имя, дружественное имя и описание. Многие объекты могут иметь такие атрибуты, поэтому удобно наследовать такие объекты от MemberDescriptor.
Колонка таблицы представляет собой сущность, отдельную и независимую от таблицы. Одна и та же колонка может принадлежать разным таблицам. Колонка таблицы описывает некоторый атрибут объекта. Таблица Attributes содержит информацию об атрибутах объектов, находящихся в сетевой объектно-ориентированной базе. Эта таблица содержит экземпляры класса AttributeDescriptor. Дескриптор атрибута описывает имя некоторого атрибута объекта. Он расширяет объект MemberDescriptor добавляя свойства AttributeType, AttributeTypeHandle а также метод GetTypeDescriptor().
- public class AttributeDescriptor : MemberDescriptor
- {
- public Cerebrum.Runtime.NativeHandle AttributeTypeHandle
- public System.Type AttributeType
- public Cerebrum.Runtime.IConnector GetTypeDescriptor()
- }
где AttributeType возвращает тип данного атрибута; AttributeTypeHandle возвращает handle типа; GetTypeDescriptor() возвращает объект-дескриптор типа данного атрибута. Если в базе находится несколько объектов, которые имеют атрибут имя, то значениями для этого атрибута (колонки) являются имена этих объектов. Атрибуты (колонки) так же являются объектами ООБД. Например, объект-атрибут «Object name» так же имеет имя, так как класс AttributeDescriptor унаследован от класса MemberDescriptor. Очевидно что, значением атрибута «Object Name» для экземпляра класса AttributeDescriptor, описывающего имя объекта является строка «Object name».
Рассмотрим пример. Для свойства Name объекта MemberDescriptor в ООБД создается экземпляр объекта AttributeDescriptor с значениями свойств соответственно:
- Name = “Name”;
- DisplayName = “Name”;
- Description = “Object name”;
- AttributeType = typeof(System.String);
- GetTypeDescriptor() = экземпляр TypeDescriptor описывающий System.String.
Таким образом экземпляры класса AttributeDescriptor описывают свойства объектов, хранимых в ООБД, в том числе и свойства собственно класса AttributeDescriptor. Таблица Types содержит описание типов данных (включая пользовательские), которые известны системе и на основе которых система создает экземпляры объектов, помещаемые в сетевую базу. Эта таблица содержит экземпляры классов TypeDescriptor.
- public class TypeDescriptor : MemberDescriptor
- {
- public string QualifiedTypeName
- public Cerebrum.Runtime.KernelObjectClass KernelObjectClass
- public System.Type ComponentType
- }
где QualifiedTypeName — возвращает имя .NET класса на основе которого создаются пользовательские объекты, например “System.String” ; KernelObjectClass — возвращает тип объекта ядра VNPI ассоциированного с экземплярами описываемого типа; ComponentType — возвращает typeof(QualifiedTypeName) тоесть .NET тип описываемый дескриптором. Свойства, унаследованные от MemberDescriptor были описаны ранее. Рассмотрим пример. Для свойства QualifiedTypeName создается экземпляр AttributeDescriptor у которого
- Name = “QualifiedTypeName”
- DisplayName = “Qualified Type Name”
- Description = “.NET Qualified Type Name”
- AttributeType = typeof(System.String)
- GetTypeDescriptor() = экземпляр TypeDescriptor описывающий System.String
Данная структура позволяет описывать типы классов объектов, содержащиеся в ООБД. Описатели типов также являются объектами, содержащимися в ООБД. Поэтому описатели типов описывают сами себя.
Каждая таблица имеет две коллекции указателей на объекты. Коллекцию атрибутов (колонок) и коллекцию компонентов (строк). Каждая строка любой таблицы это тоже объект. Если в коллекцию указателей на строки включить указатель на саму таблицу, то таблица станет собственной строкой. Таблица Tables содержит сама себя в качестве строки. И таблица Tables и строка Tables в таблице Tables — это один и тот же экземпляр одного и того же класса TableDescriptor. Этот экземпляр расположен по одному и тому же адресу в памяти. Значениями для колонок таблицы являются значения атрибутов объектов находящихся в строках таблицы. А значением ее колонки «SelectedAttributes» является коллекция колонок этой же таблицы. Хотя желательно держать в одной и той же таблице объекты одного и того же типа — это вовсе не обязательно. Главное чтоб у этих объектов были атрибуты, хотя бы частично совпадающие с колонками данной таблицы. Я рекомендую держать в одной таблице объекты, классы которых унаследованы от некоторого, базового класса, который содержит все колонки данной таблицы в качестве собственных атрибутов. Например колонка «Object name» имеет смыл практически в любой таблице. Объекты могут входить одновременно в разные таблицы как их строки. Дескрипторы атрибутов объектов сами являются объектами и зарегистрированы в таблице атрибутов. Класс TableDescriptor описывает таблицу из экземпляров некоторых объектов. Свойства, унаследованные от MemberDescriptor соответсвенно описывают имя, дружественное имя и описание данной таблицы.
- public class TableDescriptor : MemberDescriptor, System.ComponentModel.IListSource
- {
- public Cerebrum.Runtime.NativeVector GetSelectedAttributesVector()
- public Cerebrum.Runtime.NativeVector GetSelectedComponentsVector()
- public System.Type ComponentType
- }
где GetSelectedAttributesVector — метод возвращает коллекцию атрибутов таблицы; GetSelectedComponentsVector — метод возвращает коллекцию строк таблицы; ComponentType — свойство возвращает тип объектов содержащихся в строках таблицы.Методу GetSelectedAttributesVector соответствует экземпляр AttributeDescriptor укоторого
- Name = “SelectedAttributes”
- DisplayName = “SelectedAttributes”
- Description = “SelectedAttributes collection”
- AttributeType = typeof(System.ComponentModel.IBindingList)
Метод GetSelectedComponentsVector возвращает коллекцию объектов — строк, этомуметоду соответсвует экземпляр AttributeDescriptor у которого
- Name = “SelectedComponents”
- DisplayName = “SelectedComponents”
- Description = “SelectedComponentscollection”
- AttributeType = typeof(System.ComponentModel.IBindingList)
Все экземпляры AttributeDescriptor перечислинны в таблице TableDescriptor.Name = “Attributes”. Все экземпляры TypeDescriptor перечислинны в таблицеTableDescriptor.Name = “Types”. Все экземпляры TableDescriptor перечислинны втаблице TableDescriptor.Name = “Tables”. При этом экземпляр классаAttributeDescriptor.Name = “Name” содержится в коллекции строк таблицы Attributes, атак же в коллекциях атрибутов (колонок) таблиц “Attributes”, “Types” и “Tables”.Экземпляр класса TableDescriptor.Name = “Tables” хранится в своей же коллекции строктаблицы (SelectedComponents). Следовательно, применение тавтологии для эмуляции РБД на основе ООБД является оправданным и полезным. Надо заметить, что экземпляры объектов могут одновременно входить в разные таблицы при этом важно, чтоб они поддерживали все атрибуты, являющиеся колонками таблиц в которые они входят в качестве строк.
Пользователь имеет возможность создавать новые таблицы путем добавления новых записей в таблицу Tables. Созданные экземпляры таблиц, атрибутов и других объектов так же не обязательно регистрировать в соответствующих таблицах. Однако практика регистрации таких объектов в соответствующих таблицах является рекомендуемой, так как позволяет изменять их атрибуты через унифицированный интерфейс пользователя. Обязательным требованием является регистрация пользовательского типа в таблице Types. В этом случае Integrator.Acivator при необходимости автоматически произведет создание нового экземпляра. В противном случае программист будет обязан реализовать собственную версию интерфейса IActivator.
В ООБД поддерживаются полноценные C# объекты, у объектов поддерживаются методы, свойства, поля и события. В данной разработке статические методы классов — просто обычные статические методы в .NET а экземплярные методы — обычные методы объектов. Рекомендуется создавать свойства для поддерживаемых классом атрибутов. Механизм делегатов и событий не будет поддерживаться, в случае если связь реализуется между объектами, хранящимися в БД. Это связанно с ограничениями по времени жизни экземпляров. Во время, когда БД остановлена, все объекты хранятся в сериализированном (serialized) виде. Если время жизни у приемников или источников сообщений может быть изолированно от времени жизни объектов БД, то механизмы делегатов — сообщений работают в пределах подсети объектов развернутых в памяти .NET Framework. Система разрабатывается в первую очередь для поддержки нейронных сетей со свободной топологией и числом нейронов до 2 млрд в одном хранилище. Поэтому только часть ОО БД находится в данный момент в RAM. Большая часть объектов заморожена в файловом хранилище и десериализируется (deserializing) по мере необходимости.
Уровень семантической нейронной сети
Следующий логический уровень представляет собой нейронную сеть. Нейронная сеть реализована на основе ядра VNPI. Каждый нейрон представляет собой совокупность объектов более простых объектов. Нейроны могут быть различных типов. Наиболее интересными являются нейроны рецепторы, эффекторы и внутренние нейроны. Чтобы обеспечить эмуляцию одновременной параллельной работы множества нейронов на последовательной вычислительной машине, необходимо последовательно обрабатывать состояния всех нейронов в сети для каждого кванта времени. Рассмотрим реализацию квазипараллельного режима обработки нейронов в семантической нейронной сети, реализующей экспертную систему. Выполнение нейронов в нейронной сети производится тактами. Такты выполняются до момента, когда в сети не останется ни одного нейрона, требующего обработки. После завершения всех тактов на эффекторах выставляется текущее решение, принятое данным участком сети. При изменении информации на рецепторах запускаются новые такты, и по их окончании на эффекторах выставляется уточненное решение. Работа экспертной системы проходит либо в один такт, по выставлению всех входных нечетких данных на слое рецепторов, либо итерационно, по мере накопления этих данных. Каждый такт состоит из нескольких проходов. Проход представляет собой рассылку сообщений всем зарегистрированным нейронам. При этом для каждого нейрона выполняется специальная функция обработчик сообщения, соответствующая данному сообщению.
Как ты считаеешь, будет ли теория про моделирование экспертной системы улучшена в обозримом будующем? Надеюсь, что теперь ты понял что такое моделирование экспертной системы
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Экспертные системы
Представления знаний в интеллектуальных системах, экспертные системы
Время на прочтение
7 мин
Количество просмотров 72K
Введение
Экспертная система (далее по тексту — ЭС) — это информационная система, назначение которой частично или полностью заменить эксперта в той или иной предметной области. Подобные интеллектуальные системы эффективно применяются в таких областях, как логистика, управление воздушными полетами, управление театром военных действий. Основною направленной деятельностью предсказание, прогнозирование в рамках определенного аспекта в предметной области.
Экскурс в историю экспертных систем
История экспертных систем берет свое начало в 1965 году. Брюс Бучанан и Эдвард Фейгенбаум начали работу над созданием информационной системы для определения структуры химических соединений.
Результатом работы была система под названием Dendral. В основе системы формировалась последовательность правил подобных к «IF – THEN». Информационная система не перестала развиваться и получила множество наследников, таких как ONCOIN – информационная система для диагностики раковых заболеваний, MYCIN – информационная система для диагностики легочных инфекционных заболеваний.
Следующим этапом стали 70-е годы. Период не выделялся особыми разработками. Было создано множество разных прототипов системы Dendral. Примером служит система PROSPECTOR, областью деятельности которой являлась геологические ископаемые и их разведка.
В 80-ых годах появляются профессия – инженер по знаниям. Экспертные системы набирают популярность и выходят на новый этап эволюции интеллектуальных систем. Появились новые медицинские системы INTERNIS, CASNE.
С 90-ых годов развитие интеллектуальных систем приобретает новые и новые методы и особенности. Нововведением становится парадигма проектирования эффективных и перспективных систем. Гибкость, четкость решения поставленных задач дало новое название – мультиагентных систем. Агент – фоновый процесс который действует в целях пользователя. Каждый агент имеет свою цель, «разум» и отвечает за свою область деятельности. Все агенты в совокупности образуют некий интеллект. Агенты вступают в конкуренцию, настраивают отношения, кооперируются, все как у людей.
В 21 век, интеллектуальной системой уже не удивишь никого. Множество фирм внедряет экспертные системы в области своей деятельности.
Быстродействующая система OMEGAMON разрабатывается c 2004 года с IBM, цель которой отслеживание состояния корпоративной информационной сети. Служит для моментального принятия решений в критических или неблагоприятных ситуациях.
G2 – экспертная система от фирмы Gensym, направленная на работу с динамическими объектами. Особенность этой системы состоит в том, что в нее внедрили распараллеливание процессов мышления, что делает ее быстрее и эффективней.
Структура экспертной системы
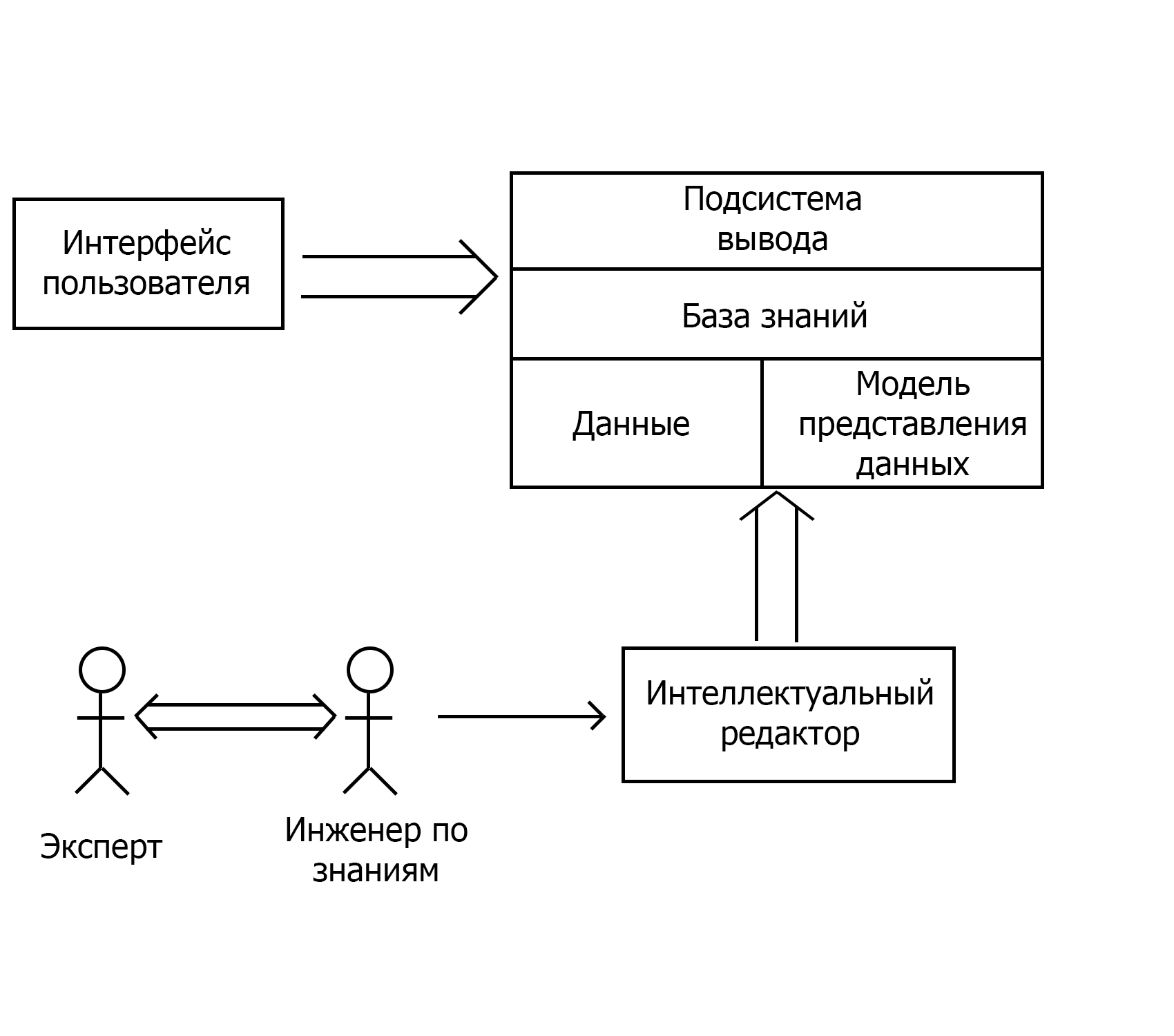
1. База знаний
Знания — это правила, законы, закономерности получены в результате профессиональной деятельности в пределах предметной области.
База знаний — база данных содержащая правила вывода и информацию о человеческом опыте и знаниях в некоторой предметной области. Другими словами, это набор таких закономерностей, которые устанавливают связи между вводимой и выводимой информацией.
2. Данные
Данные — это совокупность фактов и идей представленных в формализованном виде.
Собственно на данных основываются закономерности для предсказания, прогнозирования. Продвинутые интеллектуальные системы способные учиться на основе этих данных, добавляя новые знания в базу знаний.
3. Модель представления данных
Самая интересная часть экспертной системы.
Модель представления знаний (далее по тексту — МПЗ) — это способ задания знаний для хранения, удобного доступа и взаимодействия с ними, который подходит под задачу интеллектуальной системы.
4. Механизм логического вывода данных(Подсистема вывода)
Механизм логического вывода(далее по тексту — МЛВ) данных выполняет анализ и проделывает работу по получению новых знаний исходя из сопоставления исходных данных из базы данных и правил из базы знаний. Механизм логического вывода в структуре интеллектуальной системы занимает наиболее важное место.
Механизм логического вывода данных концептуально можно представить в виде <A,B,C,D>:
А — функция выбора из базы знаний и из базы данных закономерностей и фактов соответственно
B — функция проверки правил, результатом которой определяется множество фактов из базы данных к которым применимы правила
С — функция, которая определяет порядок применения правил, если в результате правила указаны одинаковые факты
D — функция, которая применяет действие.
Какие существуют модели представления знаний?
Распространены четыре основных МПЗ:
- Продукционная МПЗ
- Семантическая сеть МПЗ
- Фреймовая МПЗ
- Формально логическая МПЗ
Продукционная МПЗ
В основе продукционной модели представления знаний находится конструктивная часть, продукция(правило):
IF <условие>, THEN <действие>
Продукция состоит из двух частей: условие — антецендент, действие — консеквент. Условия можно сочетать с помощью логических функций AND, OR.
Антецеденты и консеквенты составленных правил формируются из атрибутов и значений. Пример: IF температура реактора подымается THEN добавить стержни в реактор
В базе данных продукционной системы хранятся правила, истинность которых установлена к за ранее при решении определенной задачи. Правило срабатывает, если при сопоставлении фактов, содержащихся в базе данных с антецедентом правила, которое подвергается проверке, имеет место совпадение. Результат работы правила заносится в базу данных.
Пример
| Диагноз | Температура | Давление | Кашель |
|---|---|---|---|
| Грипп | 39 | 100-120 | Есть |
| Бронхит | 40 | 110-130 | Есть |
| Аллергия | 38 | 120-130 | Нет |
Пример продукции:
IF Температура = 39 AND Кашель = Есть AND Давление = 110-130 THEN Бронхит
Продукционная модель представления знаний нашла широкое применение в АСУТП
Среды разработки продукционных систем(CLIPS)
CLIPS (C Language Integrated Production System) — среда разработки продукционной модели разработана NASA в 1984 году. Среда реализована на языке С, именно потому является быстрой и эффективной.
Пример:
(defrule bronchitis // deftule зарезервированное слово, которое вводит новое правило за ним следует название правила
(symptoms (temperature 39) (cough true)(pressure "110-130")) //симптом с температурой 39, наличием кашля, и давлением 110-130
=> (printout t "Диагноз - бронхит" crlf)) //это симптомы бронхитаПодобное правило будет активировано только тогда, когда в базе данных появится факт симптома с подобными параметрами.
Семантическая сеть МПЗ
В основе продукционной модели лежит ориентированный граф. Вершины графа — понятия, дуги — отношения между понятиями.
Особенностью является наличие трех типов отношений:
- класс — подкласс
- свойство — значение
- пример элемента класса
По количеству типов отношений выделяют однородные и неоднородные семантические сети. Однородные имею один тип отношения между всеми понятиями, следовательно, не однородные имею множество типов отношений.
Все типы отношений:
- часть — целое
- класс — подкласс
- элемент — количество
- атрибутивный
- логический
- лингвистический
Пример
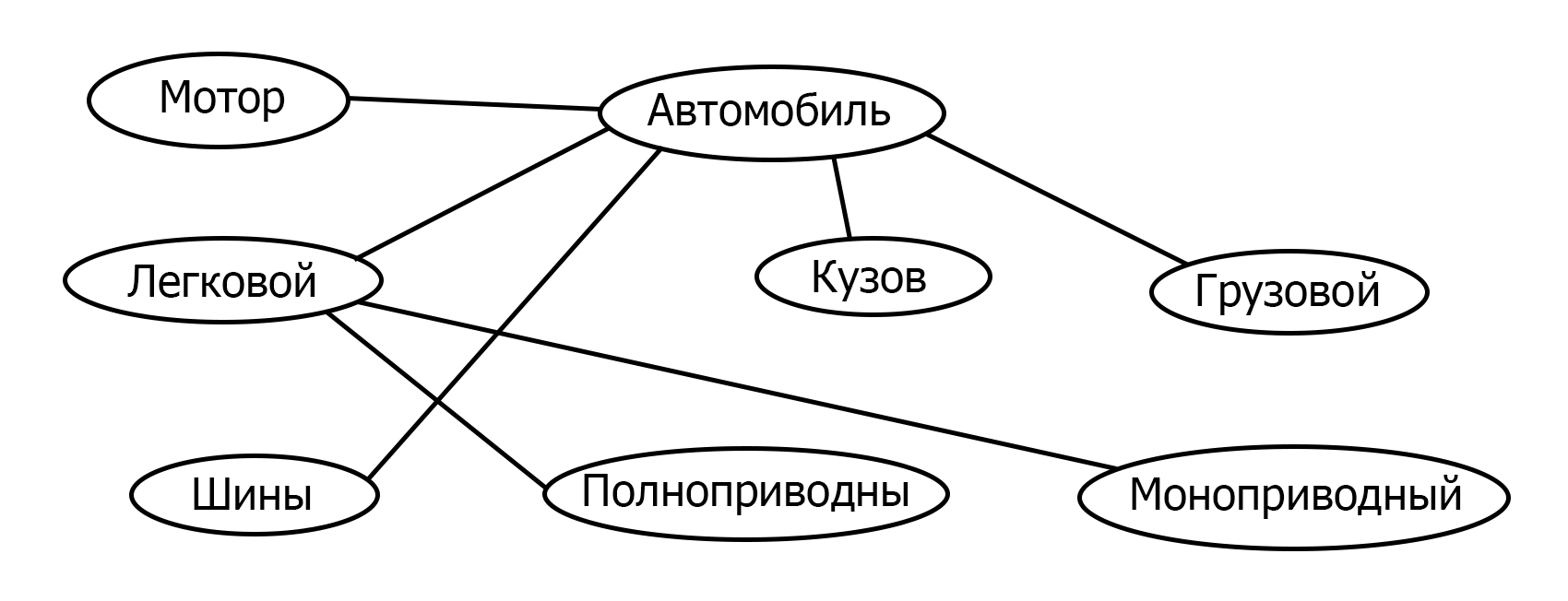
Недостатком МПЗ является сложность в извлечении знаний, особенно при большой сети, нужно обходить граф.
Фреймовая МПЗ
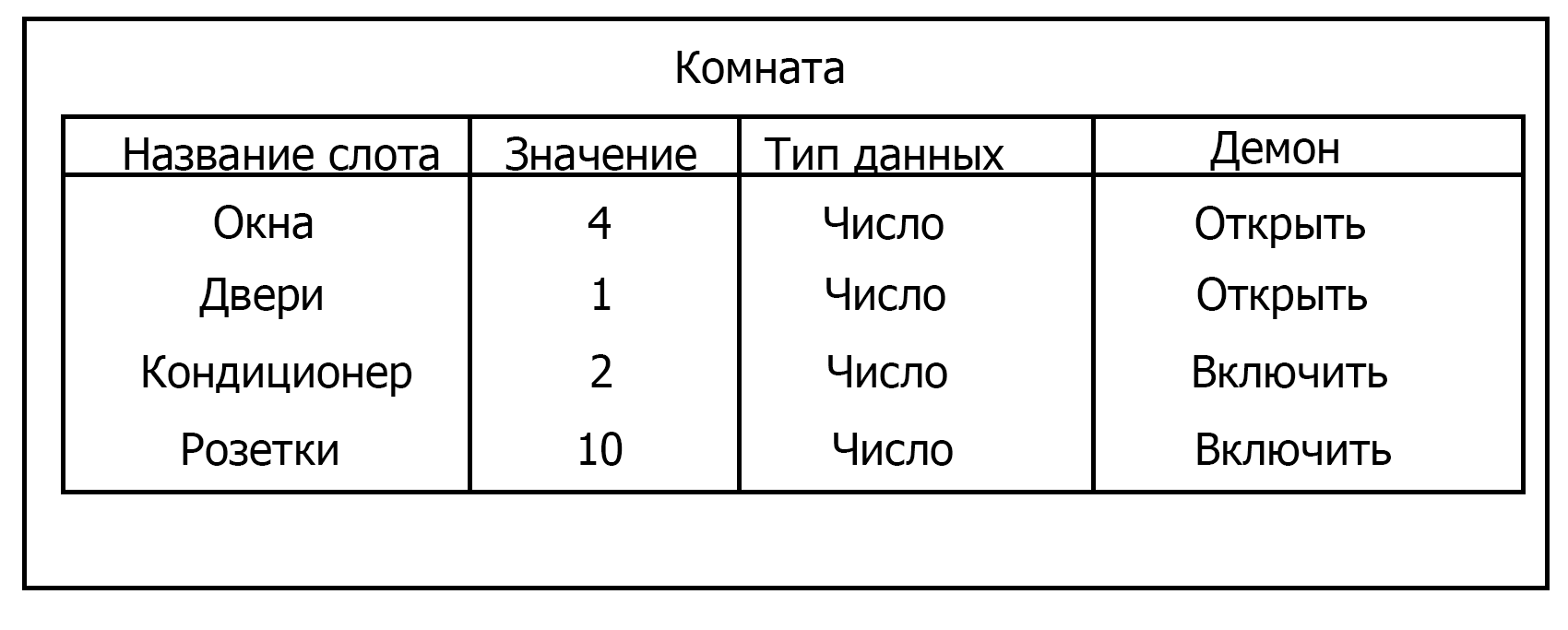
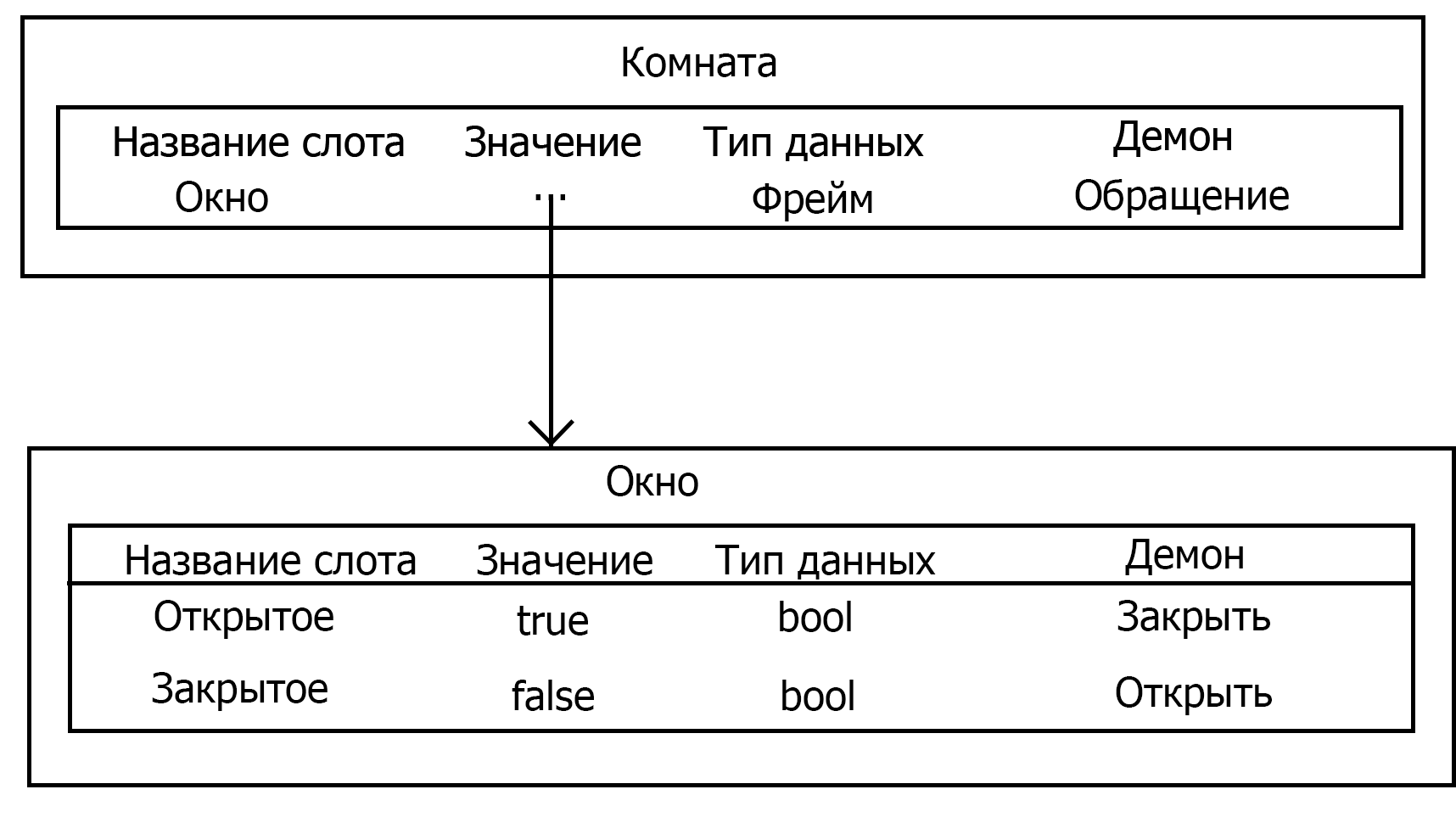
Предложил Марвин Мински в 1970 году. В основе фреймовой модели МПЗ лежит фрейм. Фрейм — это образ, рамка, шаблон, которая описывает объект предметной области, с помощью слотов. Слот — это атрибут объекта. Слот имеет имя, значение, тип хранимых данных, демон. Демон — процедура автоматически выполняющаяся при определенных условиях. Имя фрейма должно быть уникальным в пределах одной фреймовой модели. Имя слота должно быть уникальным в пределах одного фрейма.
Слот может хранить другой фрейм, тогда фреймовая модель вырождается в сеть фреймов.
Пример
Пример вырождающейся в сеть фреймов
На своей практике, мне доводилось встречать системы на основе фреймовой МПЗ. В университете в Финляндии была установлена система для управления электроэнергией во всем здании.
Языки разработки фреймовых моделей (Frame Representation Language)
FRL (Frame Representation Language) — технология создана для проектирования интеллектуальных систем на основе фреймовой модели представления знаний. В основном применяется для проектирования вырождающихся в сеть фреймовой модели.
Запись фрейма на языке FRL будет иметь вид:
(frame Room // вводим новый фрейм Room
(windows (value(4), demon(open))) //Слот windows со значением 4 и демоном open
(doors (value(1), demon(open))) //Слот doors со значением 1 и демоном open
(conditioners (value(2), demon(turn on))) //Слот conditioners со значением 2 и демоном turn on
(sokets (value(10), demon(turn on))) //Слот sokets со значением 10 и демоном turn on
)Существуют и другие среды: KRL (Knowledge Representation Language), фреймовая оболочка Kappa, PILOT/2.
Формально логическая МПЗ
В основе формально логической МПЗ лежит предикат первого порядка. Подразумевается, что существует конечное, не пустое множество объектов предметной области. На этом множестве с помощью функций интерпретаторов установлены связи между объектами. В свою очередь на основе этих связей строятся все закономерности и правила предметной области. Важное замечание: если представление предметной области не правильное, то есть связи между объектами настроены не верно или не в полной мере, то правильная работоспособность системы будет под угрозой.
Пример
A1 = <идет дождь> A2 = <небо в тучах> A3 = <солнечно>; IF A1 AND A2 THEN <взять зонтик>
Банальней примера и не придумаешь.
Важно: Стоит заметить, что формально логическая МПЗ схожа с продукционной. Частично это так, но они имеют огромную разницу. Разница состоит в том, что в продукционной МПЗ не определены никакие связи между хранимыми объектами предметной области.
Важно
Любая экспертная система должна иметь вывод данных и последовательность «мышления» системы. Это нужно для того чтобы увидеть дефекты в проектировании системы. Хорошая интеллектуальная система должна иметь право ввода данных, которое реализуется через интеллектуальный редактор, право редактора на перекрестное «мышление» представлений при проектировании системы и полноту баз знаний(реализуется при проектировки закономерностей предметной области между инженером по знаниям и экспертом).
Заключение
Экспертные системы действительно имеют широкое применение в нашей жизни. Они позволяют экономить время реальных экспертов в определенной предметной области. Модели представления знаний это неотъемлемая часть интеллектуальных систем любого уровня. Поэтому, я считаю, что каждый уважающий себя IT-специалист, должен иметь даже поверхностные знания в этих областях.
Спасибо за внимание!