Время на прочтение
15 мин
Количество просмотров 216K
кадр из фильма Миссия Невыполнима II
Эта история началась пару месяцев назад, в первый день рождения моего сына. На мой телефон пришло СМС-сообщение с поздравлением и пожеланиями от неизвестного номера. Думаю, если бы это был мой день рождения мне бы хватило наглости отправить в ответ, не совсем культурное, по моему мнению, «Спасибо, а Вы кто?». Однако день рождения не мой, а узнать кто передаёт поздравления было интересно.
Первый успех
Было решено попробовать следующий вариант:
- Добавить неизвестный номер в адресную книгу телефона;
- Зайти по очереди в приложения, привязанные к номеру (Viber, WhatsApp);
- Открыть новый чат с вновь созданным контактом и по фотографии определить отправителя.
Мне повезло и в моём случае в списке контактов Viber рядом с вновь созданным контактом появилась миниатюра фотографии, по которой я, не открывая её целиком, распознал отправителя и удовлетворенный проведенным «расследованием» написал смс с благодарностью за поздравления.
Сразу же за секундным промежутком эйфории от удачного поиска в голове появилась идея перебором по списку номеров мобильных операторов составить базу [номер_телефона => фото]. А еще через секунду идея пропустить эти фотографии через систему распознавания лиц и связать с другими открытыми данными, например, фотографиями из социальных сетей.
Естественно на пункте 3 (по фотографии определить отправителя) нас может настигнуть неудача и у этой неудачи есть 6 вариантов:
- Номер не привязан к WhatsApp или Viber
- Пользователь есть, но он не устанавливал себе Фото профиля
- Фото установлено, но настроены параметры «приватности» или «конфиденциальности» («Показывать фото только моим контактам», а Вас в этом списке нет)
- Вам доступно фото, но на нём изображён кот
- На фото человек, но черт лица и/или особенностей телосложения не разобрать (отсутствие резкости, маленькое разрешение, затемнённые очки, шляпы, кепки, грим)
- На фотографии владелец номера; анфас; высокая четкость, но вспомнить этого человека вы не можете
Четвертый пункт (на фото кот) имеет множество вариантов: это и фотографии знаменитостей, и персонажи мультфильмов, и фотографии еды, автомобилей, оружия и пр.
Испытания на малых порядках.
В качестве пробы пера было решено экспериментировать на своём списке контактов. На телефонах с ОС Android фотографии контактов Viber хранит в папке /sdcard/viber/media/User photos в виде [Хэш].jpg. Файлы сохраняются только при условии, что вы общались с данным контактом или хотя бы открывали его профиль и удаляются через некоторое время. Для эксперимента вручную откроем/закроем профили 20-ти пользователей.
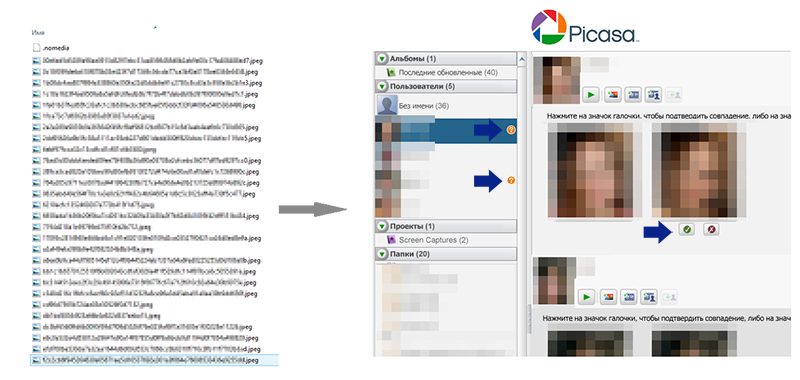
Часть знакомых, для которых были найдены файлы были также найдены в социальных сетях, загружены в программу Picasa с включенной опцией «Распознавать лица автоматически». Распознанные программой лица затем были названы соответственно их владельцам. На следующем шаге скармливаем Picas’e папку с фотографиями из Viber. Для схожих лиц в окне «Пользователи» появляются иконки с вопросительным знаком.
В моём случае для исходных 20 пользователей Viber Picasa обнаружила только два совпадения. Эти два случая при этом достаточно комично совпали: в каждой паре фотографии различались между собой, но были сняты в один и тот же день (для первого человека на двух фотографиях отличался поворот головы и наличие/отсутствие улыбки, для второго отличалась только улыбка).
Промежуточный итог довольно успешный:
Выборка из Viber: 20 (все подряд и с котами и с едой)
Выборка из VK: 5 (только если на фото можно кого-то распознать зрительно)
Совпадений верных: 2
Совпадений ложных: 0
Начинаем перебор
Попробуем получить данные с помощью телефона. Viber берёт контакты из телефонной книги, которая в свою очередь в ОС Android связана с Google Contacts, которые имеют ограничение в 25 000 номеров на аккаунт. На сегодняшний момент количество номеров мобильных операторов, закрепленных за г. Москва — 93 311 000. Так что идея получить базу таким вот «решением в лоб» отпадает. Тем более, что даже если Viber возьмет хотя бы первую пачку в 25 000 номеров, все равно в каждый профиль нужно зайти, а потом еще связать получившийся файл [Хэш].jpg с конкретным номером (что, наверное, можно отследить по дате создания файла, но это всё равно очень трудоёмко и долго).
Решение было найдено быстро: в сети есть программная реализация другого популярного сервиса — WhatsApp. Все вызовы идут через php. Есть готовый скрипт регистрации нового пользователя и собственно пример вызова getProfilePicture. Чтобы начать процесс нужен *nix сервер и нужно понять насколько можно обнаглеть с частотой и скоростью запросов. Для эксперимента был написан php код, который авторизуется в Whatsapp и в бесконечном цикле получает/не получает для номеров +7XXXXXXXXXX getProfilePicture и выдаёт на экран временную метку. Этот код при первом и последующих запусках доходил до 220-250 номеров и уходил в timeout — пробуем после каждого 200-го делать паузу sleep(5) — не помогает, всё равно timeout. Пробуем завершить процесс и сразу запустить заново — успех. Соответственно имеем дело либо с ограничением на сервере (необходимо после 200 запросов заново авторизоваться), либо с ошибкой в этой php реализации. Экспериментировать я не стал, а убил двух зайцев, переписав php скрипт, чтобы он обрабатывал только 200 номеров и добавив управляющий скрипт на Bash, который в цикле запускает php с параметром $startPhoneNumber и дожидается его завершения.
Таким образом получили работающую схему перебора со скоростью 5,7 номеров в секунду.
Для обработки всей московской ёмкости нам потребуется:
93 311 000 (номеров) / 5.7 (номеров в секунду) / 60 (секунд) / 60 (минут) / 24 (часа) ~ 190 дней.
Многопоточность
Авторизация в WhatsApp идет через связку
username — номера телефона в формате +7XXXXXXXXXX
password — полученный через скрипт регистрации (для регистрации нужна работающая симкарта для получения кода подтверждения)
nickname — может быть любым
WhatsApp запрещает >1 авторизации на один username одномоментно. В связи с чем в официальном магазине было закуплено три SIM-карты оператора Мегафон по 200р. каждая. С одного и того же сервера на ОС Centos все три номера были зарегистрированы в WhatsApp и на всех трёх было запущено по скрипту с кусочком емкости «Билайн Бизнес». Соотношение количества номеров к сохраненным фотографиям держалось в районе 10 к 1-му; потом разница увеличилась благодаря «сотням» и «тысячам», которые видимо еще не распределены и для всего диапазона не дают ни одного изображения.
Блокировка
В лицензионном соглашении WhatsApp (с которым я соглашаюсь, когда прохожу регистрацию) сказано:
Отрывок из соглашения ENG
C. You agree not to use or launch any automated system, including without limitation, «robots,» «spiders,» «offline readers,» etc. or «load testers» such as wget, apache bench, mswebstress, httpload, blitz, Xcode Automator, Android Monkey, etc., that accesses the Service in a manner that sends more request messages to the WhatsApp servers in a given period of time than a human can reasonably produce in the same period by using a WhatsApp application, and you are forbidden from ripping the content unless specifically allowed. Notwithstanding the foregoing, WhatsApp grants the operators of public search engines permission to use spiders to copy materials from the website for the sole purpose of creating publicly available searchable indices of the materials, but not caches or archives of such materials. WhatsApp reserves the right to revoke these exceptions either generally or in specific cases. While we don’t disallow the use of sniffers such as Ethereal, tcpdump or HTTPWatch in general, we do disallow any efforts to reverse-engineer our system, our protocols, or explore outside the boundaries of the normal requests made by WhatsApp clients. We have to disallow using request modification tools such as fiddler or whisker, or the like or any other such tools activities that are meant to explore or harm, penetrate or test the site. You must secure our permission before you measure, test, health check or otherwise monitor any network equipment, servers or assets hosted on our domain. You agree not to collect or harvest any personally identifiable information, including phone number, from the Service, nor to use the communication systems provided by the Service for any commercial solicitation or spam purposes. You agree not to spam, or solicit for commercial purposes, any users of the Service.
Отрывок из соглашения; примерный перевод
«Вы соглашаетесь не использовать или не запускать автоматизированные системы, которые посылают больше запросов на сервис WhatsApp, чем способен человек…»
Все мои SIM-карты заблокировали на третий день без объяснения причин. По логам видно, что отключение произошло в 00:22 по Москве по всем картам одновременно (карты успели обработать каждая около 500 000 номеров). Что интересно сервера WhatsApp сначала стали очень долго отвечать на запросы, а потом вообще перестали авторизовывать. На попытку зарегистрировать номер заново сервер отвечает «Failed; Reason: Blocked;«. При попытке зарегистрировать WhatsApp по-человечески с телефона выскакивает сообщение: «Извините, вы больше не можете пользоваться сервисом WhatsApp.»
Кроме того, что все три запущенных скрипта делали одно то же с одной и той же скоростью у них было много общего, чтобы заблокировать их одновременно, а именно: все логинились с одним и тем же nickname «V» и работали с одного и того же IP-адреса.
Усложняем схему

Считаем, что стали чуть-чуть (а именно на 600р. потраченные на те три SIM) умней. На этот раз покупаем 10 сим карт в «неофициальном магазине» у метро по 100р. за штуку. Усложняем скрипт, создаём массив симкарт и даём каждой свой nickname согласно списку актёров одного замечательного фильма:
Объявление массива
// username,"password","nickname"
$SIMDict = array( <br>
"SIM1" => array(7969XXXXXXX,"123123211231231231231231231=","Zooey"),
"SIM2" => array(7916XXXXXXX,"123123211231231231231231231=","Martin"),
"SIM3" => array(7985XXXXXXX,"123123211231231231231231231=","Sam"),
"SIM4" => array(7916XXXXXXX,"123123211231231231231231231=","Bill"),
"SIM5" => array(7985XXXXXXX,"123123211231231231231231231=","Mos"),
"SIM6" => array(7985XXXXXXX,"123123123211231231231231231=","Warwick"),
"SIM7" => array(7916XXXXXXX,"123123211231231231231231231=","Anna"),
"SIM8" => array(7985XXXXXXX,"123123123123123123123123121=","John"),
"SIM9" => array(7,"","Kelly"),
"SIM10" => array(7,"","Jason")
);
Заставляем каждую сим карту выходить через отдельный IP адрес
Наш Centos — виртуальный сервер, запущенный под гипервизором Hyper-V, что позволяет нам добавить в него еще 7 Ethernet адаптеров (ограничение Hyper-v: 8 Ethernet адаптеров + 4 legacy). Останется только заставить процессы php выходить в интернет каждый с разным ip адресом.
В системе по умолчанию есть подсистема ip namespaces (ip netns), которая позволяет полностью виртуализировать сетевой стек. Это означает что можно создавать так называемые namespac’ы (ns), и в рамках каждого отдельного ns будут свои адреса, маршруты, правила, dns и пр. В интернете не так много статей про ip netns, а те которые есть дают разные показания по использованию физических интерфейсов — некоторые пишут, что нельзя физический интерфейс добавить в namespace отличный от default, некоторые, что можно, но только связать через tap интерфейс, некоторые, что можно и без tap.
Создать семь secondary ip (alias) и раскидать их по разным namespace у меня не вышло, ни напрямую ни через tap интерфейсы. А вот вариант создать 7 namespace’ов и к каждому привязять отдельный физический интерфейс, несмотря на заверения интернет сообщества, удалось без проблем.
Команды настройки
LINUX
ip netns add net1 && ip link set netns net1 dev eth1
ip netns exec net1 ip addr add Y.Y.Y.71/24 dev eth1
ip netns exec net1 ip link set up dev eth1
ip netns exec net1 ip route add default via Y.Y.Y.1
ip netns add net2 && ip link set netns net2 dev eth2
ip netns exec net2 ip addr add Y.Y.Y.72/24 dev eth2
ip netns exec net2 ip link set up dev eth2
ip netns exec net2 ip route add default via Y.Y.Y.1
CISCO
ip nat inside source static Y.Y.Y.71 X.X.X.71
ip nat inside source static Y.Y.Y.72 X.X.X.72
Legacy adapter не заработал вообще, поэтому остановимся на 8-ми карточках.
Теперь скрипт Bash берёт на вход startNumber, endNumber, SIM, NS, где SIM имя симкарты в массиве, NS — имя namespace в котором запустить процесс php. Пример вызова:
./run.sh 79671380000 79671780000 SIM1 net1 &
Сам скрипт run.sh
...
start=$1
last=$2
net=$4
startParam="ip netns exec $net"
./pushme.sh "$3 $4" "$start begins"
while [ $start -lt $last ]
do
$startParam php ./getProfiles.php instance=$start prefix=$start count=50 sim=$3 net=$4
#> $3.log
start=$(( $start + 50 ))
done
...
Делим емкость на кусочки меньше 2 000 номеров. Также добавляем в Bash и php скрипты Push-уведомления через Pushover («7XXXXX start», «7XXXXX finish», «Houston we have a problem»)
Последнее отправляем при нестандартных ответах сервера WhatsApp, либо при очень долгом (>5 секунд) отсутствии ответа.
Забегая вперёд хочу сказать, что WhatsApp хитрее меня и все эти симкарты тоже были заблокированы через некоторое время и тоже почти одновременно. В любом случае 8 000 000 телефонных номеров скрипты всё-таки успешно проработали и у нас на руках 411 279 фотографий. Соотношение 20 к 1. Что уже вполне неплохо.

Выборка из результатов обработки по г. Москва
Ненецкий автономный округ
Долгое время не было возможности активировать оставшиеся сим-карты и запустить скрипты. Наконец свободная минута появилась, а вместе с ней силы признать, что начинать перебор с Москвы (население 12 197 596 человек) — это лихо. Поэтому прячем поглубже свой юношеский максимализм и берём менее населенный субъект, например, Ненецкий автономный округ. Почему бы и нет. Запускаем скрипт — и через 12 часов перебор всех емкостей Ненецкого округа завершен. Для 169 995 номеров было найдено всего 2 208 фотографий в WhatsApp. Переходим к следующему этапу.
ВКонтакте
Задача: получить все фотографии пользователей VK, у которых указан интересующий нас город.
Немалое количество времени ушло, чтобы разобраться с VK API. И оказалось, что запрос getuser выполнить можно без проблем, не имея access-token. А вот запрос search (чтобы взять только людей из конкретного города) сработает только с токеном, причём полученным на пользователя, а не на standalone приложение. В этом нам поможет статья Как я получал access token для взаимодействия с vk api. Но даже когда мы получили этот токен — мы утыкаемся в ограничение — получить можно только 1000 пользователей (не 1000 за один запрос, а 1000 всего), при том, что, например, город Нарьян-Мар (Ненецкий АО) указан у 15 660 человек.
Пробуем пойти через get_users перебором: перебираем всех пользователей вконтакте от $id = 1 до N следующим запросом:
response=$(curl --silent "https:// api.vk.com /method/users.get?user_id=$id&fields=photo_max_orig,country,city")
В сети вконтакте на момент написания этой статьи было N = 300 000 000 пользователей. На один такой запрос без скачивания фото уходила 1 секунда.
300 000 000 (пользователей) / 1 (в секунду) / 60 (секунд) / 60 (минут) / 24 (часа) ~ 3472 дней.
Итого около 3472 дней в одном потоке, при условии, что VK не будет блокировать наши IP-адреса. Вариант отбрасываем.
Возвращаемся к users.search с ограничением на количество в выдаче, но не на «качество» запроса. Поясняю. В запросе можно бесконечно уточнять параметры: например, взять только женщин или мужчин, уменьшив выдачу в два раза, или взять только тех, у кого есть фото, и что самое удобное — взять только людей конкретного возраста, естественно в цикле от $age = 14 до 80. Итого 66 прогонов по 1000, с замечанием, что, если для некоторых возрастов мы перевалим за 1000 — такие запросы мы повторим с дополнительным разделением по полу.
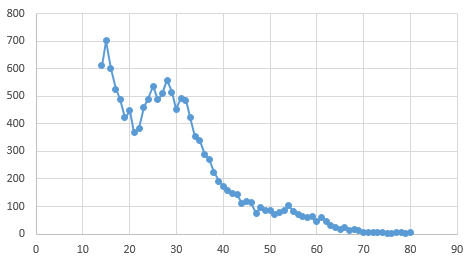
Распределение пользователей VK из г. Нарьян-Мар по возрасту
Скрипт постепенного скачивания из VK
01: acc_token="abc123abc123abc123abc123abc123abc123abc123abc123"
02: vk_url="api.vk.com/method/users.search?has_photo=1&count=1000&city=2487&country=1&access_token=$acc_token&fields=photo_max_orig"
03:
04: for age in {14..80}
05: do
06: echo -n $id " " >>vk.log
07: date +"%T" >>vk.log
08: mkdir photos/$id
09: list=$(curl --silent "$vk_url&age_from=$age&age_to=$age" | jq '.response | .[] | (.uid|tostring) + " " + .photo_max_orig' |
sed 's/^"(.*)"$/1/')
10: counter=0
11: while read -r line; do
12: let counter++
13: arr=($line)
14: echo -n "$counter." >>vk.log
15: photo=${arr[1]}
16: filename=${arr[0]}$(echo $photo | sed "s/.*(..*).*$/1/")
17: wget $photo -O photos/$id/$filename
18: done <<< "$list"
19:done
Собственно, скрипт, используя полученный заранее (с того же IP) access_token запрашивает через VK API в цикле список всех людей конкретного возраста из конкретного города (city=2487).
Самое интересное здесь — строчка № 9:
Она превращает JSON ответ от вконтакте вида ( {«response»:[COUNT,{«uid»:XXXXXXX,«first_name»:«Иван»,«last_name»:«Иванов»,«photo_max_orig»:«http://QQQ.vk.me/ZZZ/YYY.jpg»} ) в список
id photo_url (XXXXX http:// QQQ.vk.me /ZZZ/YYY и т.д.)
Способов это реализовать масса и наверняка есть более симпатичный вариант. Но в поисках как это сделать я наткнулся на так называемый «jq is a lightweight and flexible command-line JSON processor», синтаксис которого мне приглянулся:
jq ‘.response | .[] | (.uid|tostring) + » » + .photo_max_orig’
Если читать с конца, то: взять текстом id пользователя (.uid|tostring) с ссылкой на фото .photo_max_orig для всех элементов массива .[] в рамках объекта response
На 19 годах VK что-то заподозрили, и стали очень медленно отвечать на запросы. Через полтора часа было скачано 13 967 изображений. У остальных 1 700 человек возраст видимо не был указан вообще. Еще 400 скачанных изображений оказались, по каким-то причинам битыми, либо очень маленькими (<10 кб).
Распознавание и сравнение лиц
Как мы уже выяснили среди полученных изображений множество котов и автомобилей, поэтому для начала хочется их отфильтровать. Поможет нам с этим OpenCV (Open Source Computer Vision Library, библиотека компьютерного зрения с открытым исходным кодом).
Существует множество реализаций, на различных языках программирования, основанных на этой библиотеке. Например, facedetect, которая определяет координаты по которым находится лицо на фото. Она же вместе с ImageMagick вырежет по координатам распознанное лицо в отдельный файл.
По распознаванию лиц на фото, есть интересная реализация от компании Betaface. У них платное API для большого количества изображений, но есть отличная демо, которая распознает всех присутствующих на загруженном фото и кроме прочего определяет пол, наличие усов, очков, улыбки и (женщинам это не понравится) показывает предположительный возраст (мне даёт 27, плюшевому кролику на холодильнике — 42).

Мы же возьмем готовые скрипты на python от английского разработчика Terence Eden. Он написал их в рамках очень интересного проекта. В его задаче стояло: скачать открытую коллекцию картин Лондонского музея «Тейт Британия», и распознать на ней изображения людей. Затем с помощью получившейся базы лиц и своей фотографии можно найти картину, на которой изображен человек максимально похожий на тебя. Web API он, к сожалению, не даёт, но все исходники есть на github.
Корректируем скрипт Тэренса — выключаем скачивание из Британской галереи и удаляем обработку по папкам.
Скрипт на python
import sys, os
import cv2
import urllib
from urlparse import urlparse
def detect(path):
img = cv2.imread(path)
cascade = cv2.CascadeClassifier("haarcascade_frontalface_alt.xml")
rects = cascade.detectMultiScale(img, 1.3, 4, cv2.cv.CV_HAAR_SCALE_IMAGE, (20,20))
if len(rects) == 0:
return [], img
rects[:, 2:] += rects[:, :2]
return rects, img
def box(rects, img, file_name):
i = 0 # Track how many faces found
for x1, y1, x2, y2 in rects:
print "Found " + str(i) + " face!" # Tell us what's going on
cut = img[y1:y2, x1:x2] # Defines the rectangle containing a face
file_name = file_name.replace('.jpg','_') # Prepare the filename
file_name = file_name + str(i) + '.jpg'
file_name = file_name.replace('n','')
print 'Writing ' + file_name
cv2.imwrite('detected/' + str(file_name), cut) # Write the file
i += 1 # Increment the face counter
def main():
for filename in os.listdir('whphotos'):
print filename + " "
rects, img = detect("whphotos/" + filename)
box(rects, img, filename)
os.remove("whphotos/" + filename)
if __name__ == "__main__":
main()
Итог обработки:
13 500 изображений из VK => 6 427 / 5 446 лиц. (с учетом / без учёта случаев с несколькими лицами на одном фото)
2 208 из WhatsApp => 963 / 876 лиц
Проглядывается интересная закономерность — каждый второй пользователь не ставит фото на профиль.
Следом за распознанием идёт создание модели eigenfaces.xml. Скриптом предусмотрено по папке исходных фотографий сформировать XML файл, по которому в будущем будет производиться поиск. Поэтому по одному комплекту готовим такой файл, а из второго потом берём по одному элементу и ищем соответствие. Техника решила за меня какой из комплектов брать за основной: 6 400 фотографий из VK скрипт обработать не смог с ошибкой по памяти «Couldn’t allocate over 4GB«. Время — 11 ночи — разбираться не охота — пропускаем через скрипт 963 фото из WhatsApp и через 20 минут имеем eigenfaces.xml размером 1.6 ГБ. Можно представить какого бы размера он был в случае с VK. Позже оказалось, переделывая скрипт под себя, я случайно удалил строку идентификации в модели, вместо неё все элементы имели идентификатор «0». Смешно бы было прождать несколько дней выполнения скрипта и только потом это обнаружить. Исправляем ошибку и ждём еще 20 минут.
Затем для каждого файла из VK запускаем скрипт проверки.
find detectedVK/ -name *.jpg -exec ./myscript.sh {} ;
#myscript.sh
python recognise.py detectedWH $1 100000 >> result
`100000` здесь — точность совпадения, при 100 — идеальное совпадение.
На одно сравнение имеем 40 секунд. 6 400 * 40 ~ 3 дня на одном процессоре. Оставляем на ночь; идем спать — завтра понедельник.
Сразу скажу, что у меня были мысли, что для такой маленькой выборки совпадений будет ноль. Пока работали скрипты я периодически смотрел на совпадения. С указанной мною точностью результатов было много, но при ближайшем рассмотрении даже на совпадениях порядка `3500` было множество результатов мальчик-девочка. При том создавалось ощущение, что эти двое родственники. Результат интересный, но это не совсем то, что мы искали.
Первое попадание случилось к концу первой тысячи аккаунтов. Девушка Яна из города Нарьян-Мар поставила одинаковую фотографию и в WhatsApp и в VK. Несмотря на то, что фото одинаковые (отличается только разрешение) точность совпадения ~3 000. Для всех результатов с точностью <6000 с помощью convert объединяем совпавшие изображения, чтобы зрительно окончательно принять решение
...
if [ "$precise" -lt 6000 ]
then
echo $precise $whIMG $vkIMG
convert detectedWH.bak/$whIMG detectedVK.bak/$vkIMG -append convertResults/${precise}_$whIMG$vkIMG
fi
...

Итого к окончанию вторых суток успешно распознаны и привязаны к номеру телефона 25 аккаунтов VK.
Это 2% от числа найденных лиц WhatsApp, либо 1% от всех изображений.

Результаты анализа по г.Нарьян-Мар
Я верю, что это отличный результат, и вот почему:
- У нас маленькие выборки, с большой разницей между ними (16 600 VK против 2 000 WhatsApp);
- Для поиска совпадений мы использовали только алгоритм Eigenfaces, а можно добавить, например, Fisherfaces;
- Можно увеличить шансы на распознание добавив по аналогии перебор через Viber;
- Из VK можно брать не только последнее фото профиля, но и несколько предыдущих;
- Наконец, к списку социальных сетей можно добавить Facebook, Одноклассники и пр.
Тут сложно говорить о конкретных цифрах, но можно точно сказать, что процент успешных попаданий значительно увеличится, если соблюсти все пункты. Процессорные мощности для этого конечно тоже надо увеличить в несколько раз.
Заключение
К чему это всё. Полезного для общества практического применения полученных данных я пока не придумал. Получилось небольшое исследование ради исследования.
Библиотека OpenCV отличный инструмент, используя который на полученных данных, можно провести еще ряд интересных экспериментов.
В награду дочитавшим до конца, такой, например, весёлый вариант: Собрать модель eigenfaces.xml по фотографиям известных актрис, российских и зарубежных, и провести перебор на соответствие по полученной из WhatsApp базе москвичей (у нас их на данный момент ~400 000). Не беря во внимание моральную составляющую (а именно, вопрос: культурно ли звонить незнакомым людям), набираем номер и приглашаем в кино. Прикольно ведь пойти в кино с девушкой, которая с точностью 3000 к 100 похожа на главную героиню.

Еще в качестве вывода можно было бы сказать: «Не забывайте ставить галочки в настройках приватности». Но я не большой сторонник параноидальных настроений (» Они знают где я», «Интернет-провайдер знает обо мне всё», «Большой брат следит за нами» и пр.). Меня, например, веселит, когда моя жена выключает сбор анонимных геоданных на телефоне, со словами, что её «найдут» (кто, а главное зачем она пока не придумала).
Не знаю будет ли меня когда-нибудь кто-нибудь искать — я в своей жизни вроде бы ничего не нарушал (кроме лицензионного соглашения WhatsApp).

Из статьи вы узнаете, как за несколько шагов в LibreOffice создать простую базу данных на примере словаря терминов.
Статья написана для пользователей, которые ничего не знают о базах данных. Поэтому в тексте нет сложных терминов и определений, а в базе данных всего две таблицы и одна простая форма для ввода данных.
Базы данных разрабатываются не только программистами и не только для больших приложений. Например, в университетах создают базы данных для хранения научной и учебной информации, а затем регистрируют их в Роспатенте.
Свидетельства о госрегистрации баз данных приравниваются к научным публикациям (Постановление Правительства РФ от 24.09.2013 N 842 (ред. от 01.10.2018, с изм. от 26.05.2020) «О порядке присуждения ученых степеней»), поэтому на них ссылаются в диссертациях, отчётах, статьях, указывают в резюме и портфолио. Кроме того, свидетельство служит подтверждением квалификации сотрудника при проведении аттестации.
База данных: что это такое?
Когда информации много, то работать с ней трудно. Данные могут быть разбросаны по разным файлам и папкам, их легко потерять и сложно найти.
В базе данных весь материал систематизирован, структурирован и хранится в одном месте. С ним легко и удобно взаимодействовать. Вы можете искать и фильтровать информацию так, как это делается в интернет-магазинах и поисковых системах.
База данных — это одна или несколько таблиц, в которые заносится информация. Количество столбцов в таблицах и их тип определяется пользователем — автором базы данных.
Как можно создавать базы данных
Базы данных создаются в специальных программах, которые называются системами управления базами данных.
Систем управления базами данных много. Среди них: Microsoft SQL Server, Oracle Database, PostgreSQL, MySQL, SQLite. Для простых и небольших баз данных уровня лаборатории/кафедры/школы подойдут бесплатные OpenOffice.org Base или LibreOffice Base.
Как создать базу данных в LibreOffice Base
LibreOffice — бесплатный пакет офисных программ. Является альтернативой коммерческому Microsoft Office.
Мы создавали эту инструкцию для LibreOffice 6.4. Чтобы не было расхождений при создании базы данных по этому руководству, рекомендуем работать с LibreOffice версии 6.1 и выше.
Итак, давайте создадим простую базу данных «Словарь терминов», в которой будут храниться термины, их определения, а также разделы учебной дисциплины, к которым они относятся. В качестве примера мы взяли дисциплину «Базы данных».
Шаг 1. Запуск программы и подготовка
Запустите программу для создания баз данных LibreOffice Base.
В появившемся окне Мастера баз данных выберите Создать новую базу данных, укажите формат Firebird встроенная, нажмите Далее.
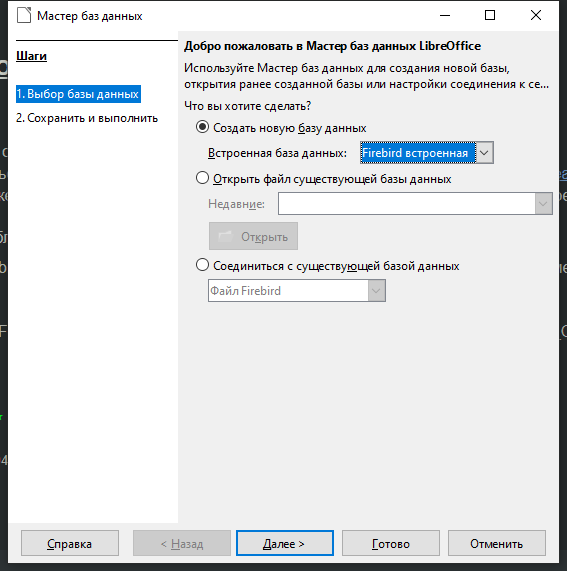
На втором шаге Мастера установите флажок в Открыть базу для редактирования, нажмите Готово.
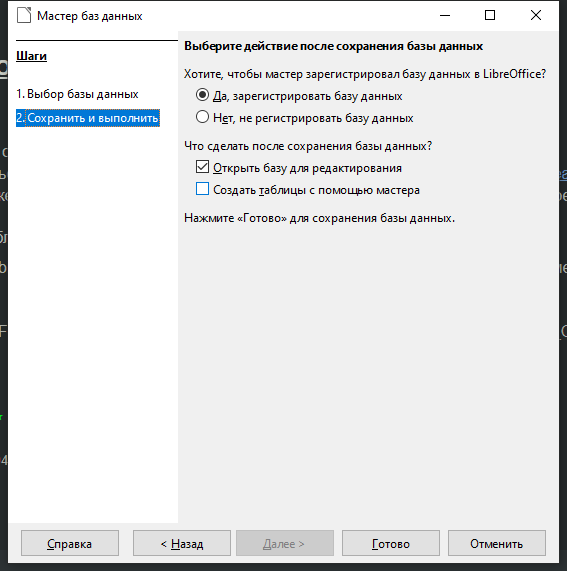
В появившемся окне выберите папку, в которой нужно сохранить базу данных, введите имя файла. Нажмите Сохранить.
Шаг 2. Создание таблиц
В базах данных принято хранить один вид информации в одной таблице. Например, информация о сотрудниках, информация о подразделениях, информация о проектах организации — всё это должно быть в разных таблицах. Чтобы база данных и пользователь понимали, в каком подразделении работает сотрудник, и какие проекты разрабатываются в подразделениях, создаются дополнительные столбцы или таблицы для хранения связей между записями. Так устраняется избыточность информации в базе данных.
Каждая строка в таблице должна быть уникальна, чтобы база данных понимала, какую запись следует удалить или отредактировать. Для этого создаётся первичный ключ в таблице — столбец, в котором значения встречаются ровно по одному разу. Это похоже на ситуацию, когда фамилия, имя, отчество и даже дата рождения у двух людей могут совпадать, но данные их паспортов обязательно будут отличаться. В случае с базой данных аналогом паспорта выступает столбец с первичным ключом.
В нашем примере два вида информации: термин и раздел дисциплины, для которой создаётся словарь. Каждый термин относится к определённому разделу дисциплины, поэтому надо установить связь между будущими таблицами.
В окне редактора базы данных кликните на Создать таблицу в режиме дизайна…
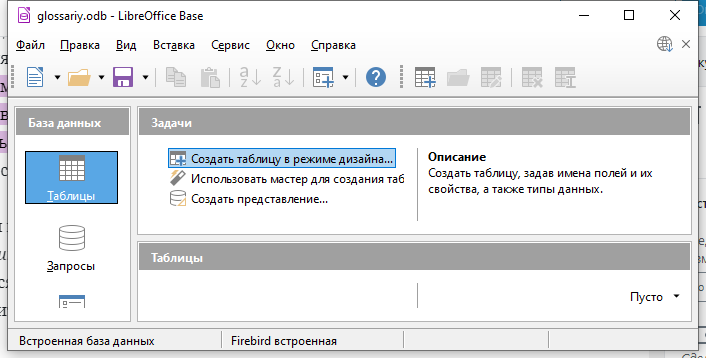
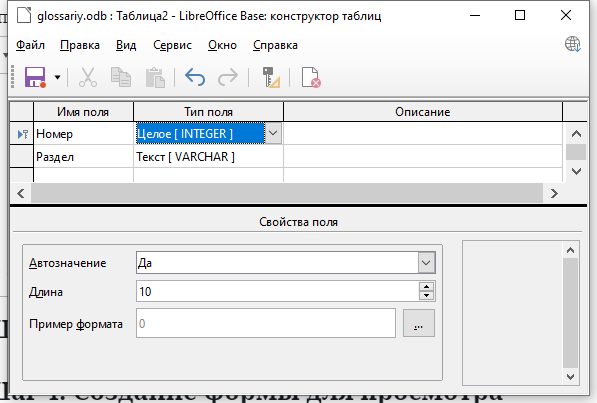
В появившемся окне добавьте характеристики столбцов таблицы для разделов дисциплины:
- Имя поля — Номер. Тип поля — Целое [INTEGER]. Автозначение — Да (будет автоматически наращивать значение поля при добавлении новой записи в таблицу: 1, 2, 3 и т.д.). Этот столбец будет первичным ключом таблицы, и база данных сама добавит этот признак (будет отображаться изображение ключика с левой стороны поля).
- Имя поля — Раздел. Тип поля — Текст [VARCHAR], длина 100. В этом столбце будут находиться названия разделов дисциплины.
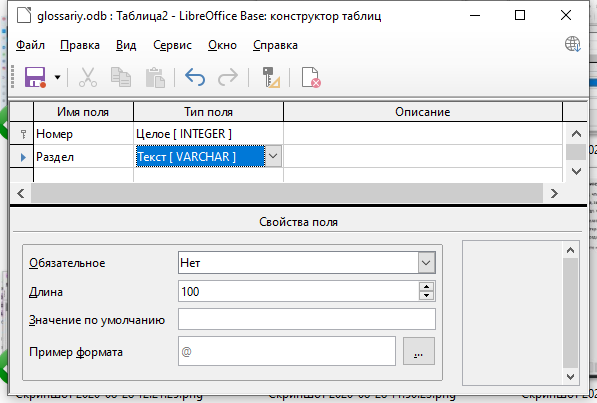
Для сохранения таблицы выберите пункт меню Файл — Сохранить. В диалоговом окне укажите название таблицы — Разделы, нажмите ОК.
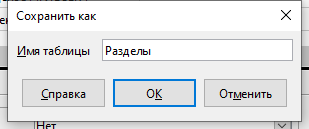
Закройте окно со структурой таблицы Разделы.
Сохраните базу данных (Файл — Сохранить).
Для создания второй таблицы с терминами опять кликните на Создать таблицу в режиме дизайна… и введите параметры столбцов таблицы:
- Имя поля — Номер. Тип поля — Целое [INTEGER]. Автозначение — Да. Столбец будет первичным ключом таблицы по аналогии с таблицей Разделы.
- Имя поля — Раздел. Тип поля — Целое [INTEGER]. Автозначение — Нет. Обязательное — Да. В данном столбце будут указываться значения первичного ключа таблицы Разделы для того, чтобы связать термины и разделы, к которым они относятся.
- Имя поля — Термин. Тип поля — Текст [VARCHAR], длина 100. Обязательное — Да. В этом столбце будут находиться термины.
- Имя поля — Определение. Тип поля — Текст [VARCHAR], длина 255. В этом столбце будут находиться определения терминов.
- Имя поля — Источник. Тип поля — Текст [VARCHAR], длина 255. В этом столбце будет указываться информация об источнике, из которого взята информация о термине. Например, ссылка на страницу сайта, библиографическая ссылка.
Проверьте указанную структуру с изображением ниже.
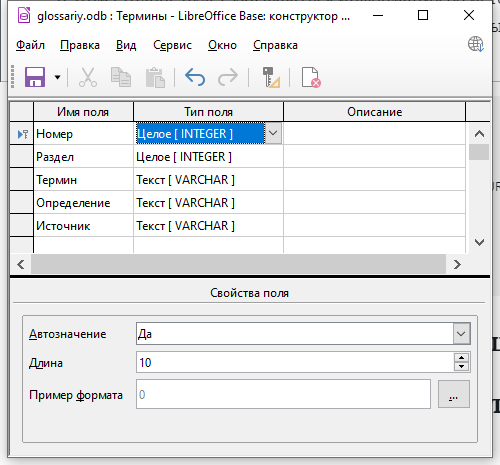
Сохраните таблицу под именем Термины, закройте окно структуры таблицы.
Сохраните базу данных.
Шаг 3. Создание связи между таблицами
В главном меню программы выберите пункт Сервис — Связи..
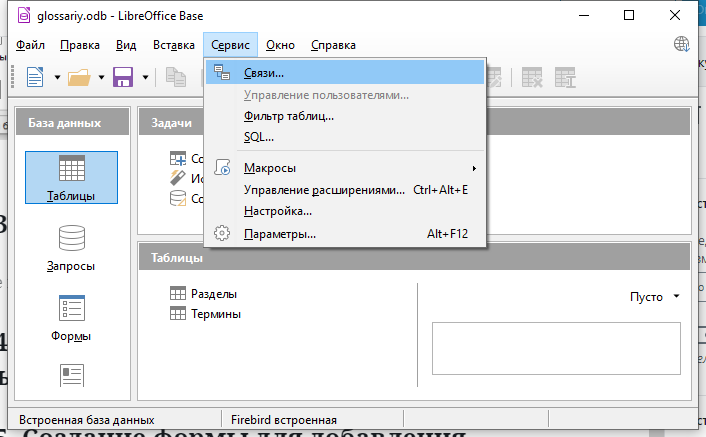
Далее с помощью окна добавьте обе таблицы для установления связей между ними.
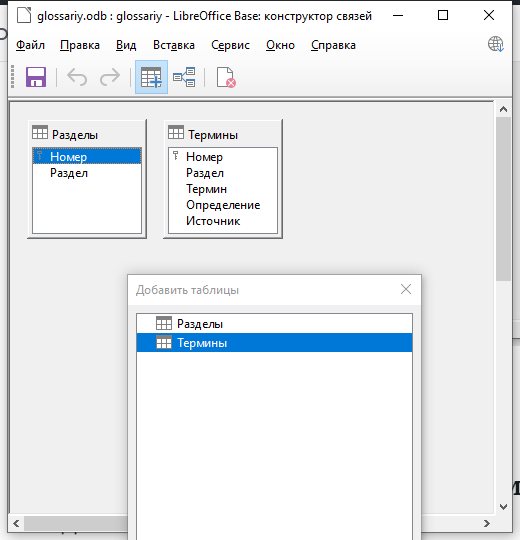
Так как столбец Раздел в таблице Термины создан для хранения ключа соответствующего термину раздела, то нам надо его связать со столбцом Номер таблицы Разделы.
Для этого левой кнопкой мыши установите курсор на столбце Номер таблицы Разделы и, не отпуская кнопки, ведите курсор к столбцу Раздел таблицы Термины. Отпустите кнопку мыши. В результате таблицы будут соединены ломаной линией. На одном конце линии будет 1, а на другом — n. Это указывает на тип связи один-ко-многим, что означает, что к одному разделу может относиться много терминов.
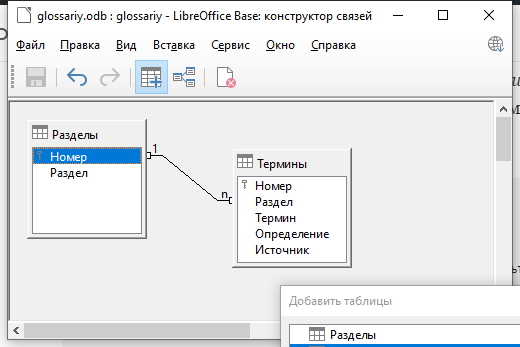
Сохраните образованную связь (Файл — Сохранить) и закройте окно.
Сохраните базу данных.
Шаг 4. Ввод данных в таблицы
Для добавления информации о разделах откройте одноимённую таблицу. Установите курсор мыши в первой строке в столбце Раздел и введите название. Нажмите клавишу Enter на клавиатуре и введите ещё одно название раздела в новой строке и опять нажмите на клавишу Enter. Обратите внимание, что столбец Номер заполняется автоматически, потому что мы указали в его настройках Автозначение.
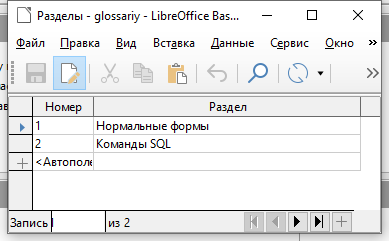
Теперь чтобы заполнить данные о терминах, откройте таблицу Термины. Введите данные, как показано на рисунке ниже. Обратите внимание: для указания раздела, к которому относится термин, нам надо знать его номер в таблице Разделы. Если разделов и терминов много, то вводить такую информацию становится неудобным, так как придётся подглядывать в таблицу Разделы.
На этом шаге, в принципе, уже можно завершить работу с базой данных, заполнив всею необходимую информацию о разделах и терминах.
Поздравляем — ваша первая база данных создана!
Чтобы вводить информацию о разделах и терминах с использованием удобного графического интерфейса и привычных пользователям элементов ввода (флажки, текстовые поля, выпадающие списки и пр.), в LibreOffice Base предусмотрены Формы.
Обратите внимание: не все системы управления базами данных поддерживают создание форм. Для большинства придётся программировать приложения, чтобы получить удобный пользовательский интерфейс.
Шаг 5. Создание формы для добавления и просмотра данных
Форма — это набор элементов для ввода информации в таблицы базы данных (текстовые поля, выпадающие списки, переключатели, навигатор по строкам и пр.).
В одной форме может быть сколько угодно главных и подчинённых форм. В нашем случае главной формой выступает форма с разделами, а подчинённой — форма с терминами. Перемещаясь по строкам таблицы главной формы, мы сможем видеть термины, которые относятся к текущему разделу. Теперь знать номер раздела для ввода термина нам не придётся: мы будем выбирать его из выпадающего списка.
Чтобы начать создание формы, в левой части окна базы данных выберите раздел Формы. Кликните на Создать форму в режиме дизайна…
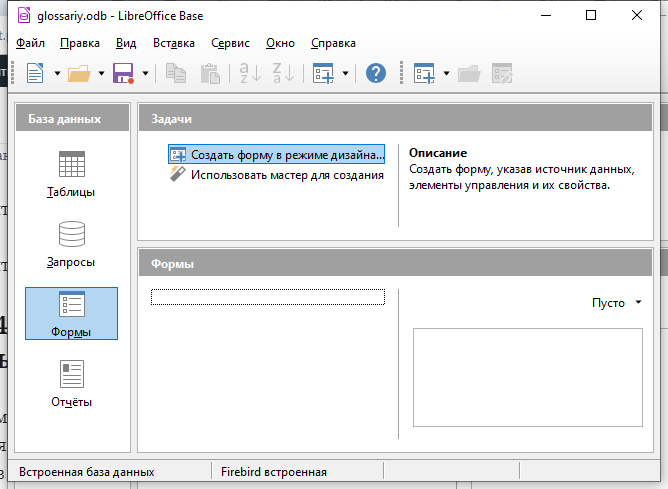
Выберите пункт меню Форма — Навигатор форм… В результате появится маленькое окно со списком форм.
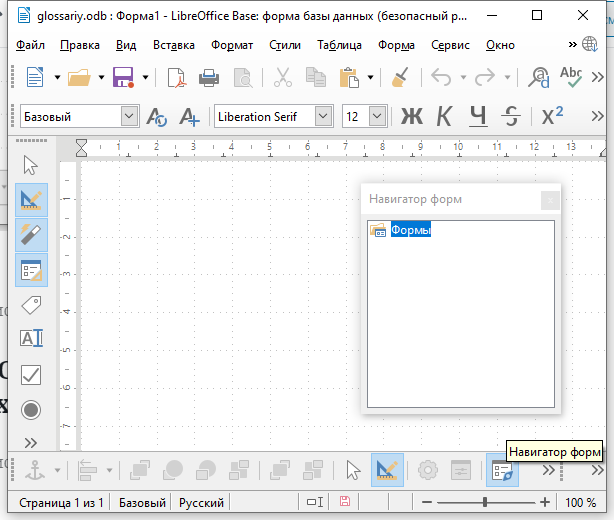
Создание главной формы для работы с разделами
Создайте главную форму для работы с разделами. Для этого правой кнопкой мыши щёлкните на пункте Формы и в контекстном меню выберите Создать — Форма.
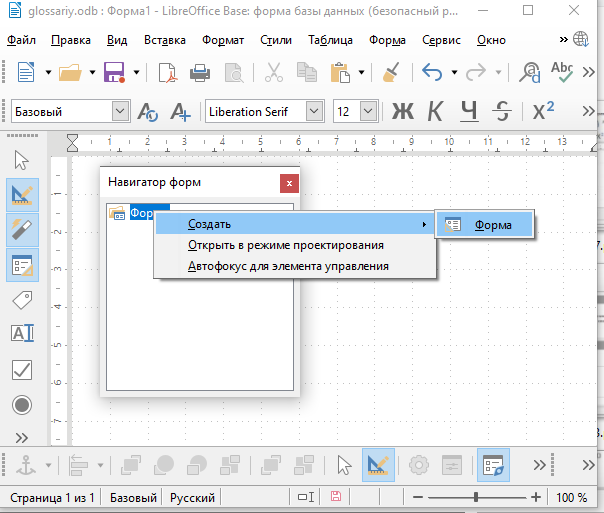
Правой кнопкой мыши кликните на созданной форме в Навигаторе форм. Далее в контекстном меню выберите Свойства.
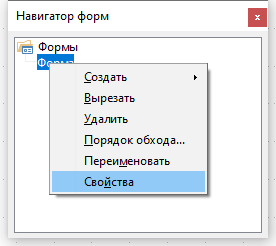
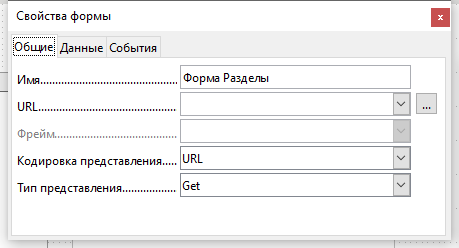
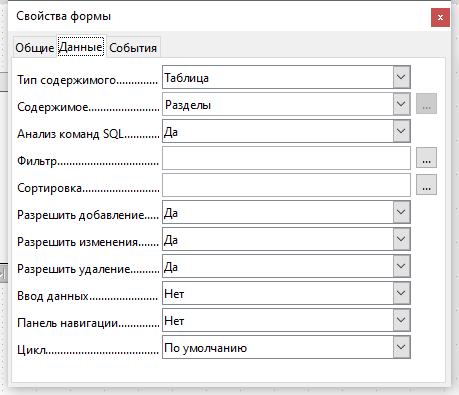
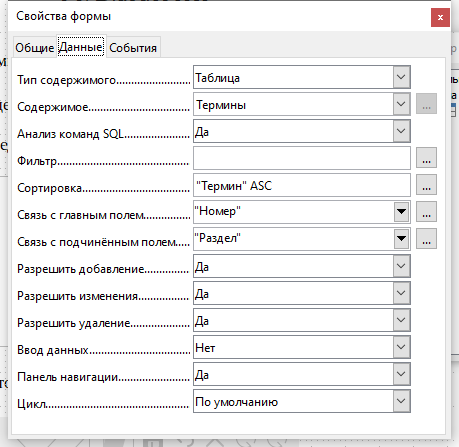
В окне свойств формы на вкладке Общие введите название формы «Форма Разделы». На вкладке Данные укажите Тип содержимого —Таблица, в поле Содержимое введите имя таблицы — Разделы, отключите Панель навигации. Остальные настройки не меняйте.
Сохраните форму базы данных (Файл — Сохранить), введите название формы.
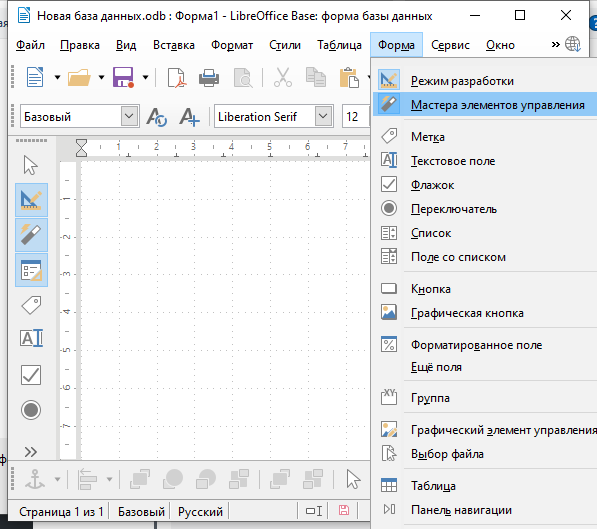
Проверьте активность Мастера элементов управления в меню Форма. Кликните на этом пункте, если он не активен.
В главную форму добавим таблицу для просмотра и редактирования разделов. Для этого установите курсор мыши на элементе Форма разделы в Навигаторе форм.
Выберите пункт главного меню Форма — Таблица. В левой части окна формы курсором мыши нарисуйте таблицу. В появившемся окне с помощью кнопки =>> добавьте все поля таблицы в созданный элемент управления.
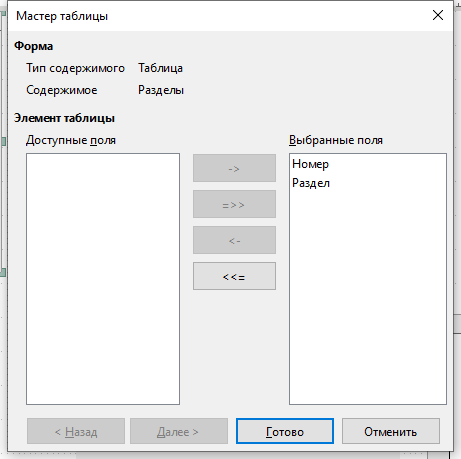
Поменяйте Привязку у таблицы с Как символ на К странице, чтобы можно было перемещать её в любое место формы.
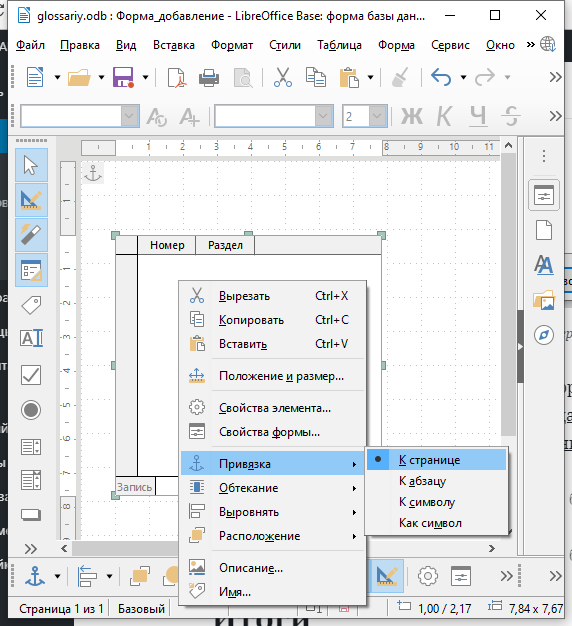
Столбец Раздел сделайте шире. На названии столбца Номер кликните правой кнопкой мыши и в контекстном меню выберите Столбец….
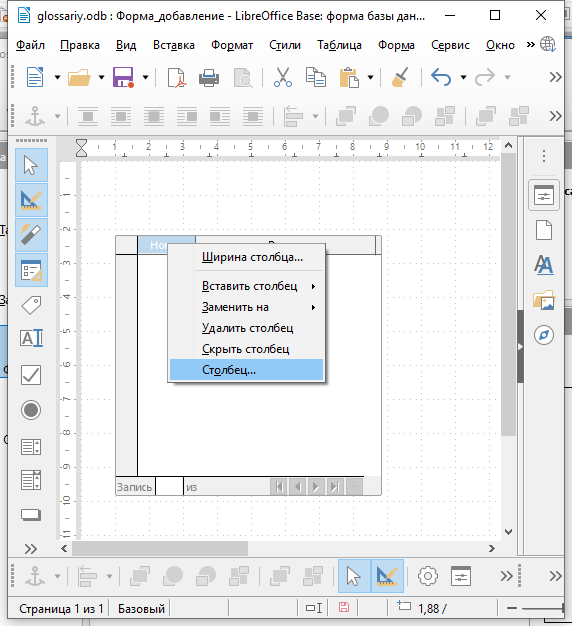
В появившемся окне настроек укажите 0 в пункте Точность, затем закройте окно.
С помощью Вставка — Текстовое поле добавьте на форму подпись с текстом РАЗДЕЛЫ и отформатируйте на свой вкус.
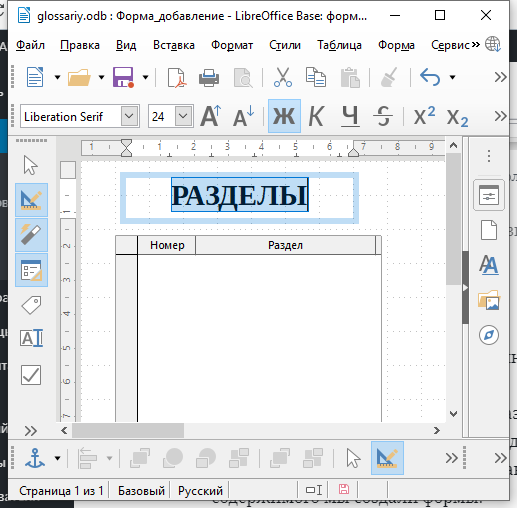
Чтобы посмотреть, как работает созданная форма, отключите Режим разработки в меню Форма.
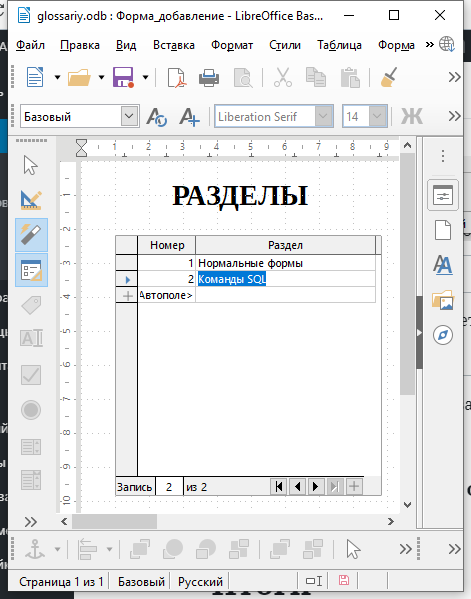
Чтобы вернуться к редактированию формы выберите пункт Режим разработки повторно.
Создание подчинённой формы для работы с терминами
Чтобы создать форму, подчинённую главной форме с разделами, кликните правой кнопкой мыши на Форма Разделы в Навигаторе форм, и выберите пункт Создать — Форма.
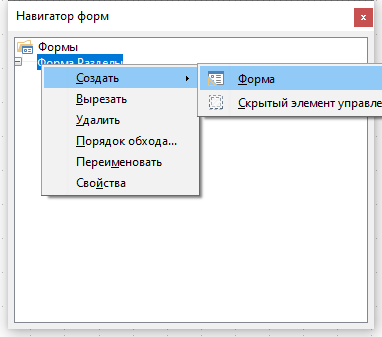
Кликните правой кнопкой мыши на появившейся в Навигаторе форм форме и в контекстном меню выберите Свойства. В окне свойств формы на вкладке Общие введите название Форма Термины. На вкладке Данные укажите Тип содержимого — Таблица, Содержимое — Термины. Отключите Панель навигации.
Нажмите на кнопку с тремя точками напротив пункта Связь с главным полем. В появившемся окне выберите поле Раздел для таблицы Термины и Номер для таблицы Разделы.
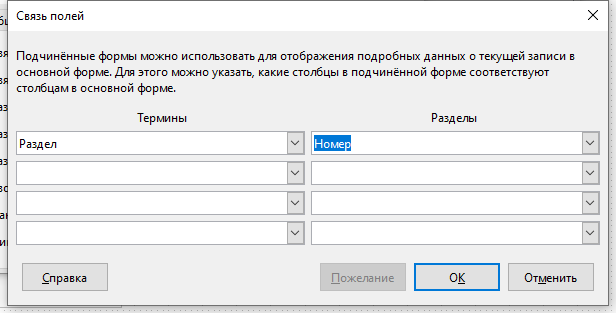
Напротив свойства Сортировка кликните на кнопке с тремя точками и в появившемся окне укажите Имя поля — Термин, а Порядок сортировки — по возрастанию.
С помощью Форма — Текстовое поле добавьте три новых элемента в подчинённую форму. Далее указаны свойства для каждого из них.
В свойствах первого текстового поля укажите Поле Термин в Имя. Во вкладке Данные выберите Термин в свойстве Поле данных. Укажите Нет в свойстве Пустая строка — NULL, чтобы программа не разрешала сохранять термины с пустыми названиями.
Выберите второе текстовое поле. Укажите Поле Определение в свойстве Имя. В свойстве Тип текста укажите Многострочный. Поле данных — Определение. Остальное не меняйте.
В свойстве Имя третьего текстового поля укажите Поле Источник. Поле данных — Источник. Остальное не меняйте.
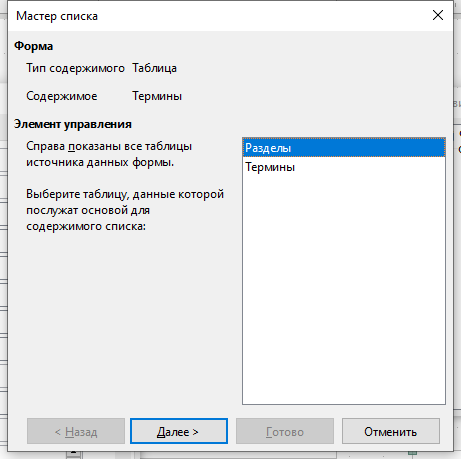
Выберите пункт меню Форма — Список и разместите на форме новый элемент управления. В появившемся диалоговом окне укажите таблицу Разделы в качестве источника данных для построения списка. Кликните Далее.
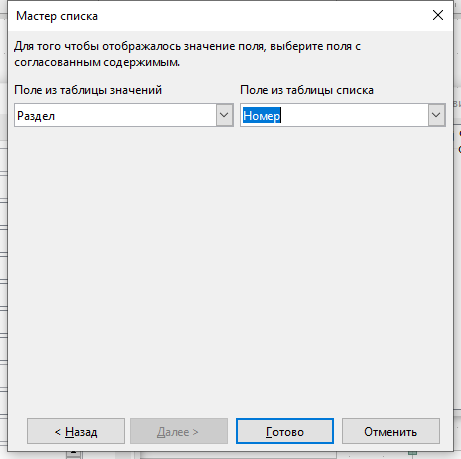
На следующем шаге укажите Раздел в качестве Отображаемого поля. Кликните Далее.
На последнем шаге Мастера укажите Раздел для Поле из таблицы значений и Номер для Поле из таблицы списка. Кликните Готово.
С помощью Форма — Панель навигации разместите на форме элемент, позволяющий перемещаться по записям таблицы с терминами.
Для всех элементов подчинённой формы добавьте подписи с использованием Вставка — Текстовое поле. Оформите на свой вкус.
Ваша форма должна выглядеть примерно так:
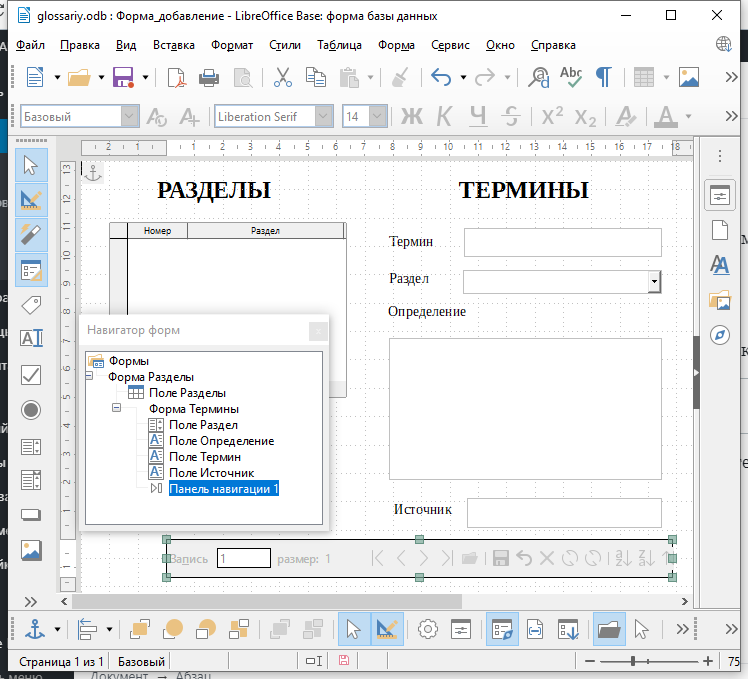
Сохраните форму с использованием Файл — Сохранить. Закройте окно редактирования формы.
Два раза кликните на созданной Форма добавление в разделе Формы базы данных. Так созданная форма откроется для работы с таблицами базы данных. Перемещаясь по строкам таблицы с разделами, вы делаете активным один из них.
Чтобы изменить форму, кликните правой кнопкой мыши на её названии и в контекстном меню выберите Правка…
Итоги
Мы рассмотрели, что такое базы данных и зачем они нужны.
Мы научились создавать простую базу данных в бесплатной программе LibreOffice Base. Создали две таблицы, установили между ними связь. Для наполнения базы данных и просмотра её содержимого мы создали форму.
Эту базу данных можно использовать в качестве основы для создания других баз данных с похожей структурой.
В статье рассказывается:
- Принцип работы базы данных и СУБД
- 10 популярных программ для создания и обработки базы данных
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Существуют различные программы для создания баз данных. Как правило, в таком ПО реализованы функции управления, редактирования, обработки информации. В зависимости от объема, типа данных, предпочтений компании, выбирается тот или иной софт.
Самое распространенное и знакомое всем решение, правда, не самое удобное для работы с большими массивами – это Excel. Если говорить о продуктах Microsoft, то непосредственно для работы с БД было создано приложение Access. Кроме нее есть не менее удобные варианты. В нашем материале вы найдете подборку наиболее популярных программ для работы с данными.
Принцип работы базы данных и СУБД
База данных представляет собранное множество записей различных сведений. Они необходимы, чтобы у пользователей была возможность сразу получить доступ к большому объему данных для выполнения разного рода операций.
В базе данных содержится абсолютно разная информация: это может быть семейная книга рецептов на все случаи жизни, книга доходов и расходов вашего отца, где видно передвижение денег в семье, или страница в социальных сетях, где можно изучить всех подписчиков владельца. Таким образом, можно сделать вывод, что вся информация в базе данных относится к какому-то конкретному типу.

С появлением баз данных пользователи получили доступ к множеству наборов информации. Как видно из вышеприведенных примеров, база данных может содержать записи с информацией похожего типа. Но, это понятие не устойчиво, так как с появлением NoSQL определение поменялось. Дело в том, что размеры веб-сайтов стали больше. Увеличилась их интерактивность, стало больше информации не только о пользователях, но и потенциальных клиентах, заявках, заказах и т.д.
Таким образом, базы данных превратились из простого источника информации в серьезный актив компаний, которые нуждаются различных базах данных с возможностью их масштабирования и в инженерах, которые умеют управлять этими базами.
Мы выяснили, что базы данных — это неотъемлемая часть современного мира. Теперь необходимо рассказать о программах для создания и обработки базы данных. Нужно понять, каким образом обрабатываются базы данных в компьютерных системах. Вот сейчас самое время рассказать о системе управления базами данных. СУБД — программное обеспечение, с помощью которого выполняют различные манипуляции с базами данных на компьютере.
Это может быть редактирование, создание, выполнение различных операций вроде вставки данных и т. д. Чтобы все эти операции были выполнимы, СУБД предоставляет необходимые API. Практически ни одна программа не обходится без использования СУБД при работе с данными, хранящимися на диске. Более того, СУБД отвечает за резервное копирование, проверяет, в каком состоянии находятся базы данных, осуществляют проверку доступов и т. д.
Скачать
файл
Именно по этой причине для работы с различными базами данных рекомендовано пользоваться СУБД.
Многие организации используют базы данных для стандартного учета информации. Для работы с такими системами разработаны специальные программы. Мы привели вашему вниманию несколько самых известных и качественных программ для создания и использования баз данных в целях пользователей.
- Microsoft Access
Одна из самых распространенных СУБД — Microsoft Access. Функционал и интуитивно понятный интерфейс делают инструмент доступным даже для начинающих пользователей. Microsoft Access подходит как для обучения, так и для решения конкретных задач. Инструмент содержит в себе функцию переключения между двумя режимами — таблицы и конструктора.
Примечательно и то, что внутри СУБД имеется много шаблонов самых разных баз, что дает возможность сэкономить время на выборе макета, а вместо этого подобрать нужный вариант из предложенных: «Контакты», «Отслеживание активов», «Пользовательское веб-приложение», «Управление проектами» и др.

Пользователь устанавливает тип данных для каждой из ячеек базы. Так, это может быть текстовая информация, число, время и дата, гиперссылка, логическое значение и т. д. Есть встроенный многофункциональный модуль с большим количеством изменяемых параметров. Он используется для составления отчетов, заполнения запросов и форм.
Чтобы разобраться в особенностях работы, пользователи могут изучить подробное руководство, где все процессы подробно описаны. Поддерживается интерфейс на русском языке. Программа для создания базы данных Access платная. Ее распространение возможно лишь в рамках офисного пакета Microsoft.


Читайте также
- LibreOffice
LibreOffice — аналог Microsoft Office и приложения Access в частности. Он может быть применен при работе с текстовыми документами, таблицами, презентациями, базами данных, графическими изображениями и даже математическими записями. Для работы необходимо установить на компьютере полный пакет и выбрать нужный модуль для запуска. Для БД необходим формат ODB.
LibreOffice содержит практически весь функционал Access. Кроме того, разработчики позаботились об удобном и понятном для пользователя интерфейсе, без загромождения разного рода кнопками и категориями. Главное окно содержит только основные возможности. Но есть нюанс — здесь нет мастера создания баз данных со встроенными шаблонами. Зато поддерживается интерфейс на русском языке, и есть открытый исходный код. Это одна из бесплатных программ для создания баз данных.
- Database.NET
Еще один продукт с открытым исходным кодом, который можно скачать бесплатно. В Database.NET пользователь может выполнять разные виды деятельности: редактировать и удалять базы данных, импортировать и экспортировать. Экспорт возможен в форматы CSV, XML и TXT, есть распечатка таблиц. Имеется консоль с подсветкой синтаксиса, что удобно для работы с SQL.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 21007 ![]()
Database.NET функционирует с любыми форматами баз данных и таблиц. Это и Access, Excel, Firebird, MySQL, SQL Server, SQL Azure, SQLCE, SQLite, PostgreSQL, Oracle, DB2, OLEDB, ODBC и OData. Интересно, что устанавливать это решение нет необходимости. Официальную версию можно просто записать на флешку и без проблем запустить на любое устройство. Есть бесплатная версия, есть расширенная — платная. Локализация на русском языке имеется.
- MySQL Workbench
Инструмент предназначен для работы с базами на основе технологии MySQL. Продукт разработан специалистами Workbench и содержит все инструменты для создания и администрирования баз данных, необходимых на практике. Интерфейс очень простой и удобный, справится даже начинающий пользователь. Отдельно стоит выделить возможность установки шаблона, предназначенного для автоматического индексирования ячеек, обработки запросов и смены сценариев SQL.

MySQL Workbench содержит модуль для визуального проектирования. Для формирования таблиц и установки связей между ними предусмотрены ER-диаграммы. Подсвечивается синтаксис SQL, в том числе все возможные ошибки как при наборе простого теста, так и кода. Интерфейс удобен и интуитивно понятен, но не поддерживает русского языка. Это, наверно, самый большой минус для русскоговорящих пользователей.
- Navicat
Navicat —полноценное хранилище программ, предназначенных для работы с СУБД. Сайт разработчика предлагает на выбор множество версий для установки: MySQL, PostgreSQL, MongoDB, MariaDB, SQL Server, Oracle, SQLite. Кроме того, инструмент полноценно функционирует и с облачными сервисами вроде AmazonAWS, Google Cloud и т. д. Чтобы подключиться, нужен логин, пароль, туннели SSL, SSH или HTTP.
Интерфейс Navicat состоит из 3 частей. Слева — список всех имеющихся БД пользователя. В центре — место, предназначенное для обработки таблиц, справа — информация по выделенным объектам. Для возможности проектирования имеются удобные ER-диаграммы. Интерфейс на русском языке отсутствует. Есть бесплатная ознакомительная версия. При необходимости можно приобрести подписку на базовую версию, стандартную и коммерческую.
- DataExpress
DataExpress — одна из популярных программ для создания и обработки баз данных клиентов. Это своеобразный конструктор, содержаний большое количество разнообразных приложений. У пользователя есть полноценная возможность создать персонализированную программу учета. Инструмент содержит все модули привычных СУБД: мастер ввода данных, опции фильтрации и поиска, шаблоны, автоматическая генерация значений и т. д.
Только до 1.06
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
 Тест на определение компетенций
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:

Уже скачали 7503
При создании системы за основу была взята технология RemObject Pascal Script, что сделало возможным реализацию любых логических алгоритмов. DataExpress отличается простым лаконичным интерфейсом. Это удобно для рядовых пользователей и дает им возможность создавать свои СУБД, не обладая навыками программирования. Для возможности работы в интернете есть движок Firebird. Кроме того, можно расширить функционал ПО, просто добавив ряд собственных расширений.
- dbForge Studio
Интерфейс этого решения удобный и приятный пользователю, подходит для осуществления запросов разного характера, а также для разработки и отладки объектов БД. dbForge Studio работает с системами MySQL и MariaDB, а проектирование происходит только на SQL. Встроенный редактор умеет подсвечивать синтаксис, допущенные ошибки, и может отладить хранимые процедуры. Имеется и визуальный редактор, что удобно для начинающих пользователей.
dbFogrge Studio содержит все необходимые инструменты для полноценного администрирования баз данных. Есть возможность открыть доступ для работы нескольких пользователей в рассматриваемой СУБД.
Пользователь может настроить автоматическое резервное копирование, осуществлять импорт и экспорт, копировать БД и т. д. Можно анализировать информацию в таблицах и составлять отчеты с помощью специального мастера с содержанием множества параметров. Продукт поддерживает русский язык. Бесплатной версии нет.
- Paradox Data Editor
Paradox Data Editor работает с таблицами баз данных на BDE. Считается, что интерфейс этой программы для создания локальных баз данных, морально устарел. Но пользователи отмечают его удобство и простоту взаимодействия. Имеет смысл отметить средство просмотра технологии BLOB. Можно устанавливать разные фильтры и инструменты поиска, вывести статистические данные по каждой колонке в таблице. И это далеко не весь список удобных возможностей, которые есть у данного решения.

На базу данных можно установить пароль. Также можно экспортировать данные в форматы HTML, CSV, Excel, RTF, SYLK, запускать печать на принтере. Интерфейс на русском языке не поддерживается, но зато Paradox Data Editor можно установить бесплатно.
- Reportizer
Это приложение создавалось не для администрирования баз данных, а для создания отчетности. После формирования отчета программа экспортирует их в специальный файл или выводит на печать. Reportizer свободно работает Oracle, Interbase, Access, Excel, SQL Server и HTML. При тестировании приложения на этих системах результаты были превосходными. Однако инструмент может работать и с другими форматами, однако нет гарантии стабильного результата.
Редактировать отчеты можно с помощью возможностей конструктора, расположенного на панели инструментов. Формировать отчеты можно в форматах: TXT, DB, DBF, CSV, ASC, XLS и HTML. Конструктор работает в двух режимах: визуальном и текстовом. С визуальным справятся даже неопытные пользователи, а вот текстовый предназначен лишь для тех, кто знаком с Delphi. Оценить возможности программы можно в течение ознакомительного 24-дневного периода. Русский интерфейс не поддерживается, но есть украинский.
- HeidiSQL
HeidiSQL — бесплатный инструмент для работы с базами данных, имеющий открытый исходный код. Работает с технологией SQL, а именно MySQL, Microsoft SQL и PostgreSQL. Содержит все инструменты, необходимые для проектирования, создания, редактирования баз данных. Содержит как графический интерфейс, так и командную строку.

Интерфейс довольно прост и понятен, но русский язык не поддерживает. Подключается к серверу по туннелям. Имеет возможность импортировать текстовые файлы. Программа не только мониторит, но и при необходимости ограничивает процессы клиента. Есть возможность добавления двоичных файлов и поиск сразу во всех таблицах базы данных.
Мы рассмотрели часть основных программ, предназначенных для создания и администрирования баз данных документов. Они поддерживают лишь часть форматов систем и подойдут только для решения определенных задач. Однако, вариантов много, поэтому каждый пользователь сможет подобрать для себя подходящий вариант.
Базы данных (БД) — набор упорядоченной информации, которая хранится в одном месте. Их создают, чтобы быстро находить, систематизировать и редактировать нужные данные, а при необходимости собирать их в отчёт или показывать в виде диаграммы.
Специализированных программ для формирования и ведения баз данных много. В том же MS Office для этого есть отдельное приложение — Microsoft Access. Но и в Excel достаточно возможностей для создания простых баз и удобного управления ими. Есть ограничение — количество строк базы данных в Excel не должно быть больше одного миллиона.
В статье разберёмся:
- как выглядит база данных в Excel;
- как её создать и настроить;
- как работать с готовой базой данных в Excel — фильтровать, сортировать и искать записи.
База данных в Excel — таблица с информацией. Она состоит из однотипных строк — записей базы данных. Записи распределены по столбцам — полям базы данных.
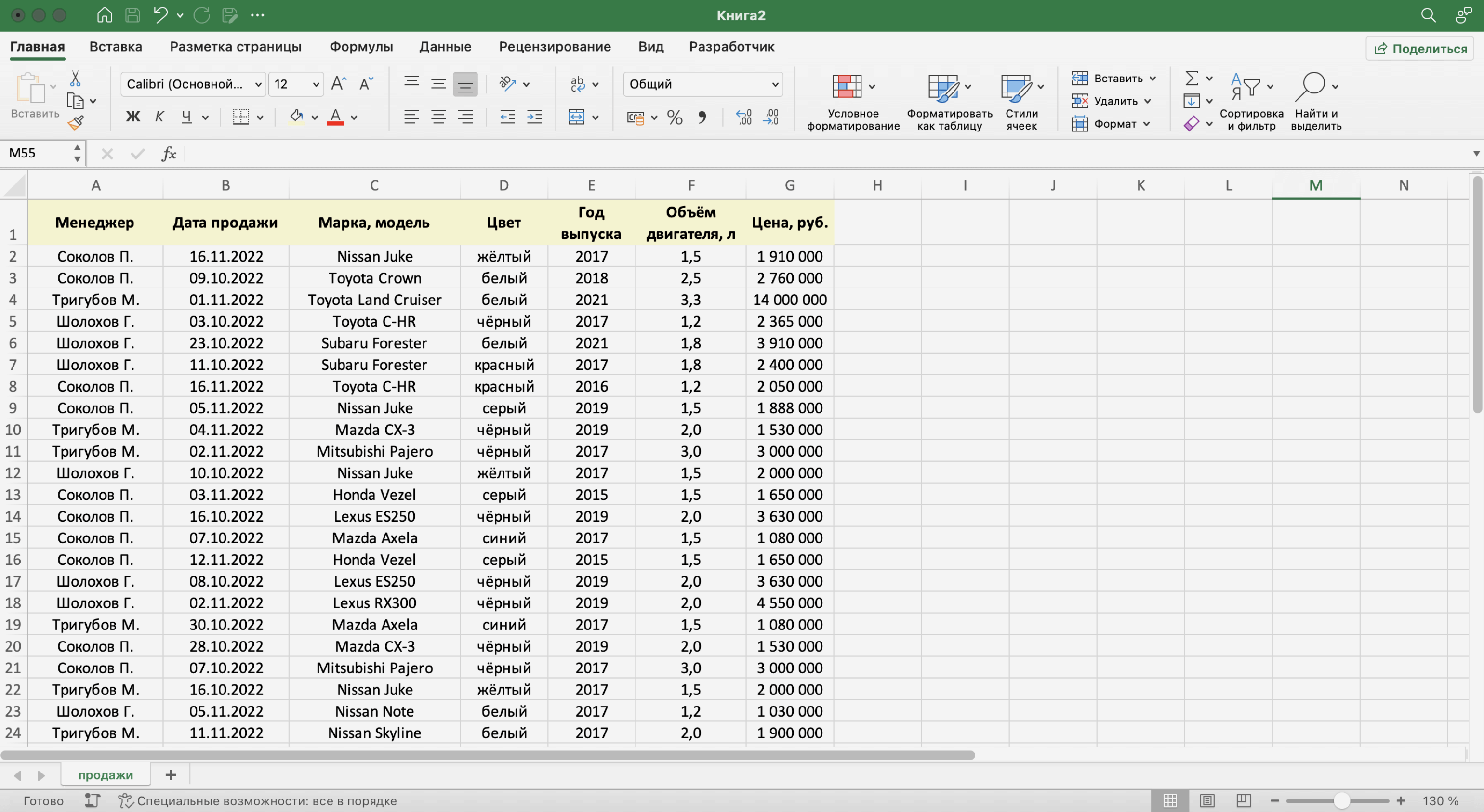
Скриншот: Excel / Skillbox Media
Названия полей — шапка таблицы — определяют структуру базы данных. Они показывают, какую информацию содержит база. В примере выше это имя менеджера автосалона, дата продажи, модель и характеристики автомобиля, который он продал.
Каждая запись — строка таблицы — относится к одному объекту базы данных и содержит информацию о нём. В нашем примере записи характеризуют продажи, совершённые менеджерами автосалона.
При создании базы данных нельзя оставлять промежуточные строки полностью пустыми, как на скриншоте ниже. Так база теряет свою целостность — в таком виде ей нельзя управлять как единым объектом.
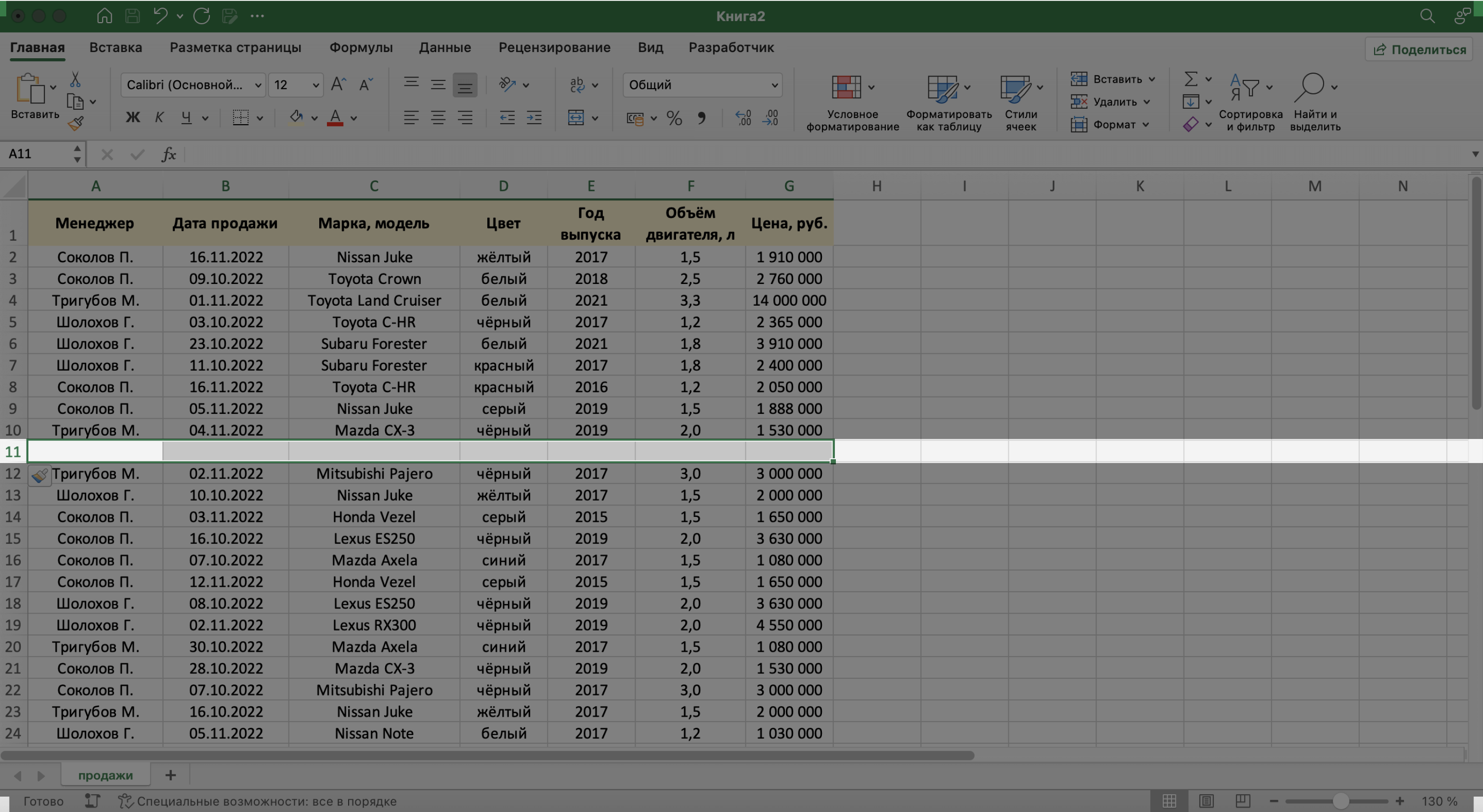
Скриншот: Excel / Skillbox Media
Разберём пошагово, как создать базу данных из примера выше и управлять ей.
Создаём структуру базы данных
Выше мы определили, что структуру базы данных определяют названия полей (шапка таблицы).
Задача для нашего примера — создать базу данных, в которой будут храниться все данные о продажах автомобилей менеджерами автосалона. Каждая запись базы — одна продажа, поэтому названия полей БД будут такими:
- «Менеджер»;
- «Дата продажи»;
- «Марка, модель»;
- «Цвет»;
- «Год выпуска»;
- «Объём двигателя, л»;
- «Цена, руб.».
Введём названия полей в качестве заголовков столбцов и отформатируем их так, чтобы они визуально отличались от дальнейших записей.
Скриншот: Excel / Skillbox Media
Создаём записи базы данных
В нашем примере запись базы данных — одна продажа. Перенесём в таблицу всю имеющуюся информацию о продажах.
При заполнении ячеек с записями важно придерживаться одного стиля написания. Например, Ф. И. О. менеджеров во всех строках вводить в виде «Иванов И. И.». Если где-то написать «Иван Иванов», то дальше в работе с БД будут возникать ошибки.
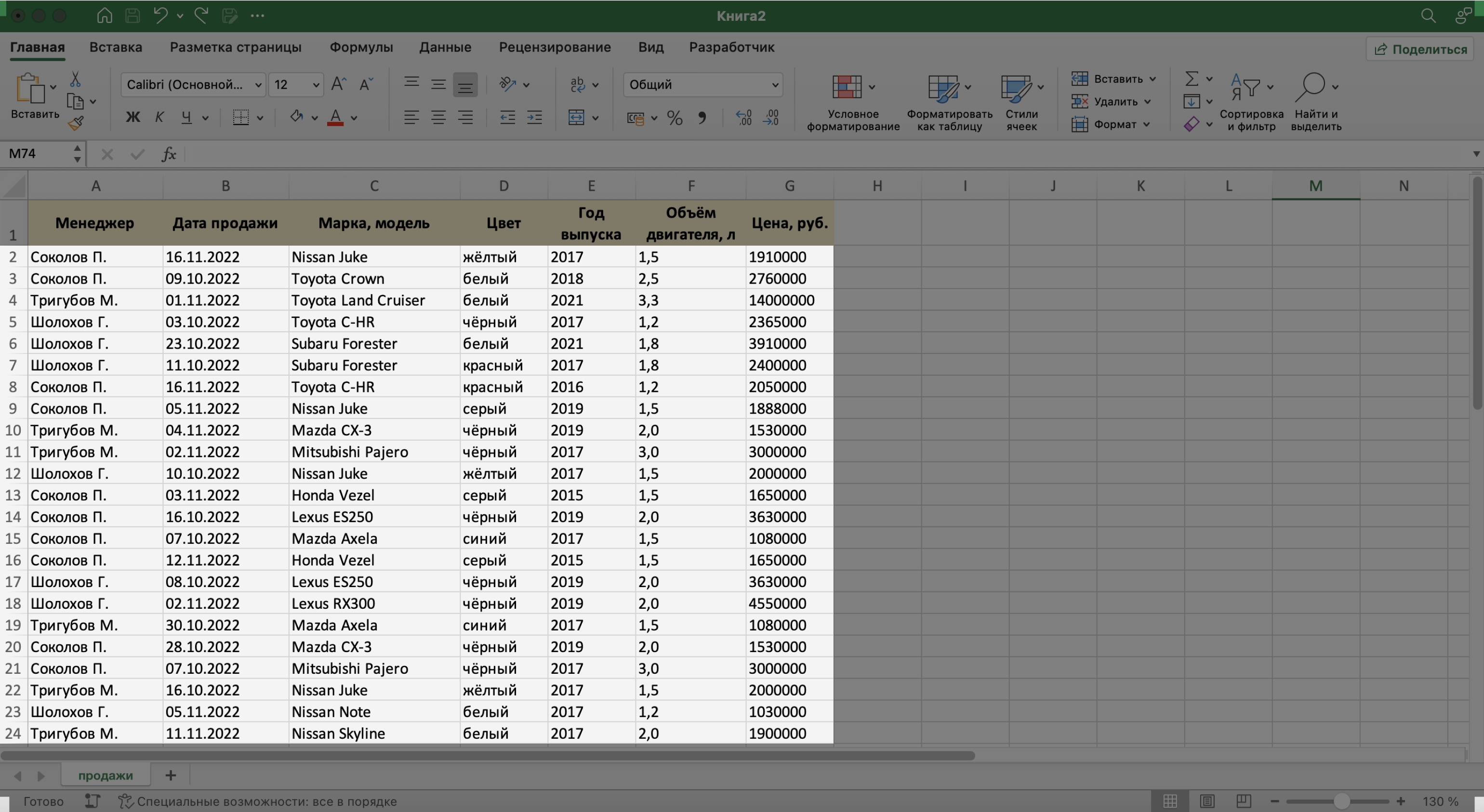
Скриншот: Excel / Skillbox Media
На этом же этапе важно проконтролировать, подходит ли формат ячеек данным в них. По умолчанию все ячейки получают общий формат. Чтобы в дальнейшем базой данных было удобнее пользоваться, можно изменить формат там, где это нужно.
В нашем примере данные в столбцах A, C и D должны быть в текстовом формате. Данные столбца B должны быть в формате даты — его Excel определил и присвоил автоматически. Данные столбцов E, F — в числовом формате, столбца G — в финансовом.
Чтобы изменить формат ячейки, выделим нужный столбец, кликнем правой кнопкой мыши и выберем «Формат ячеек».
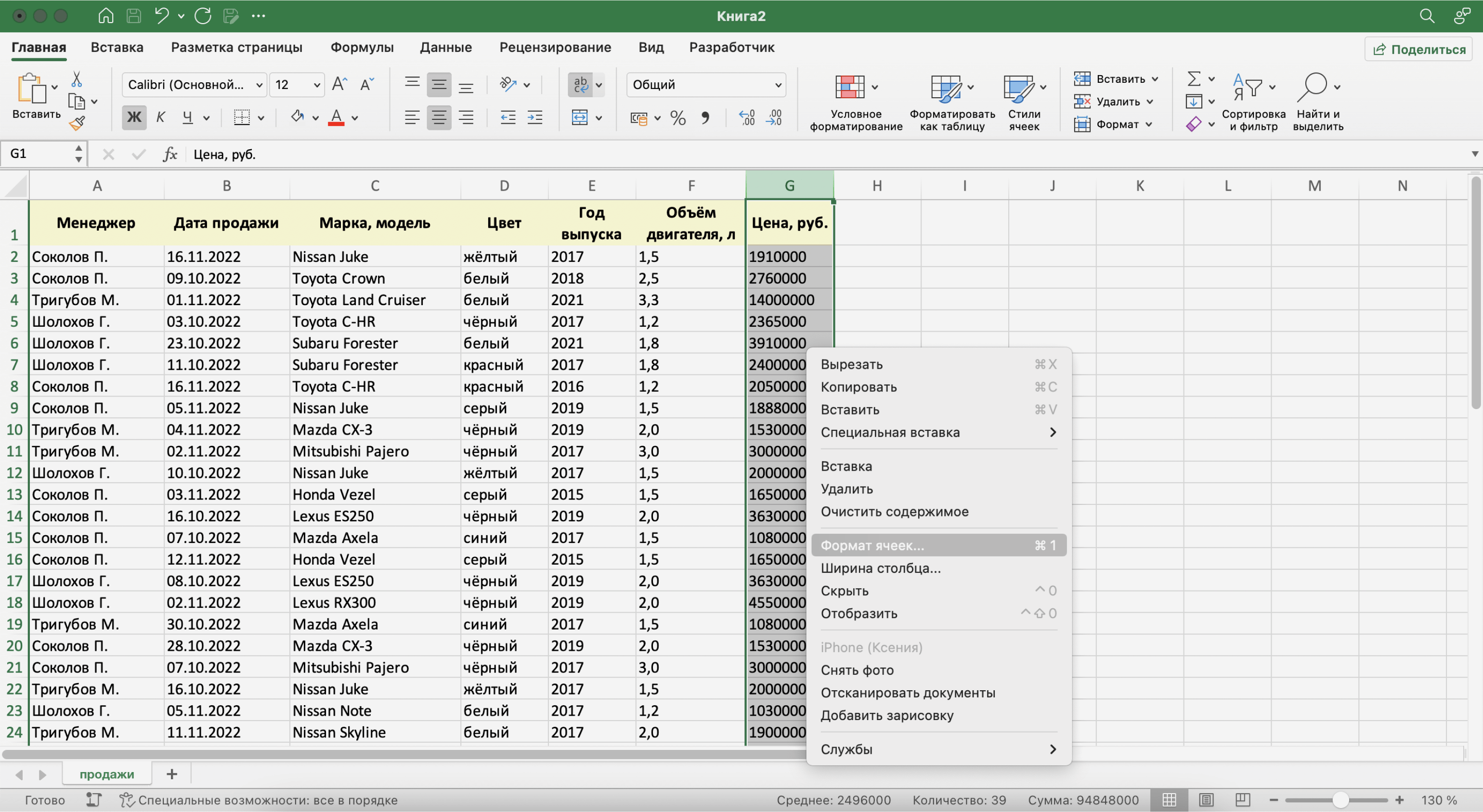
Скриншот: Excel / Skillbox Media
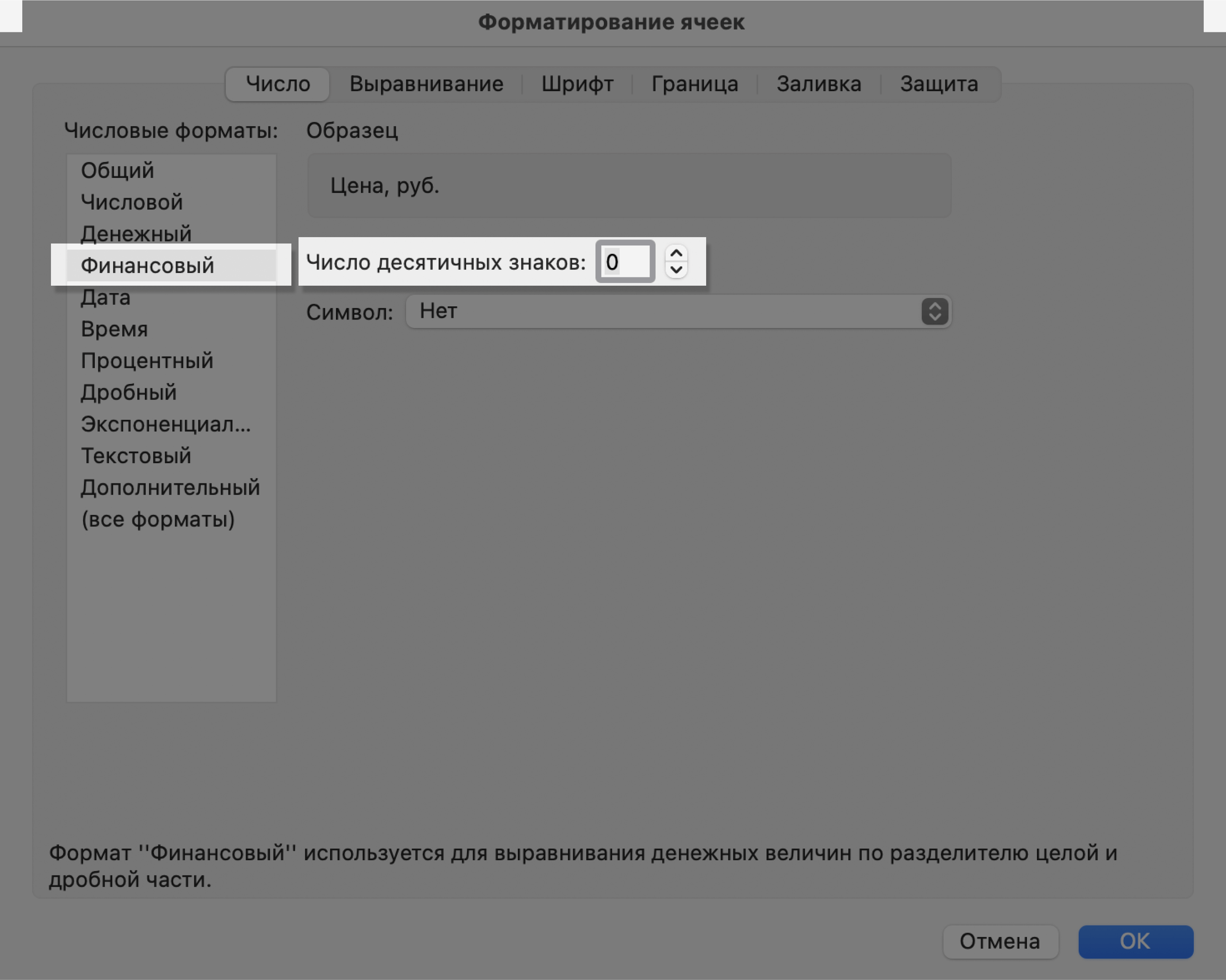
В появившемся меню выберем нужный формат и настроим его. В нашем примере для ячейки «Цена, руб.» выберем финансовый формат, уберём десятичные знаки (знаки после запятой) и выключим отображение символа ₽.
Скриншот: Excel / Skillbox Media
Также изменить формат можно на панели вкладки «Главная».
Скриншот: Excel / Skillbox Media
Присваиваем базе данных имя
Для этого выделим все поля и записи базы данных, включая шапку. Нажмём правой кнопкой мыши и выберем «Имя диапазона».
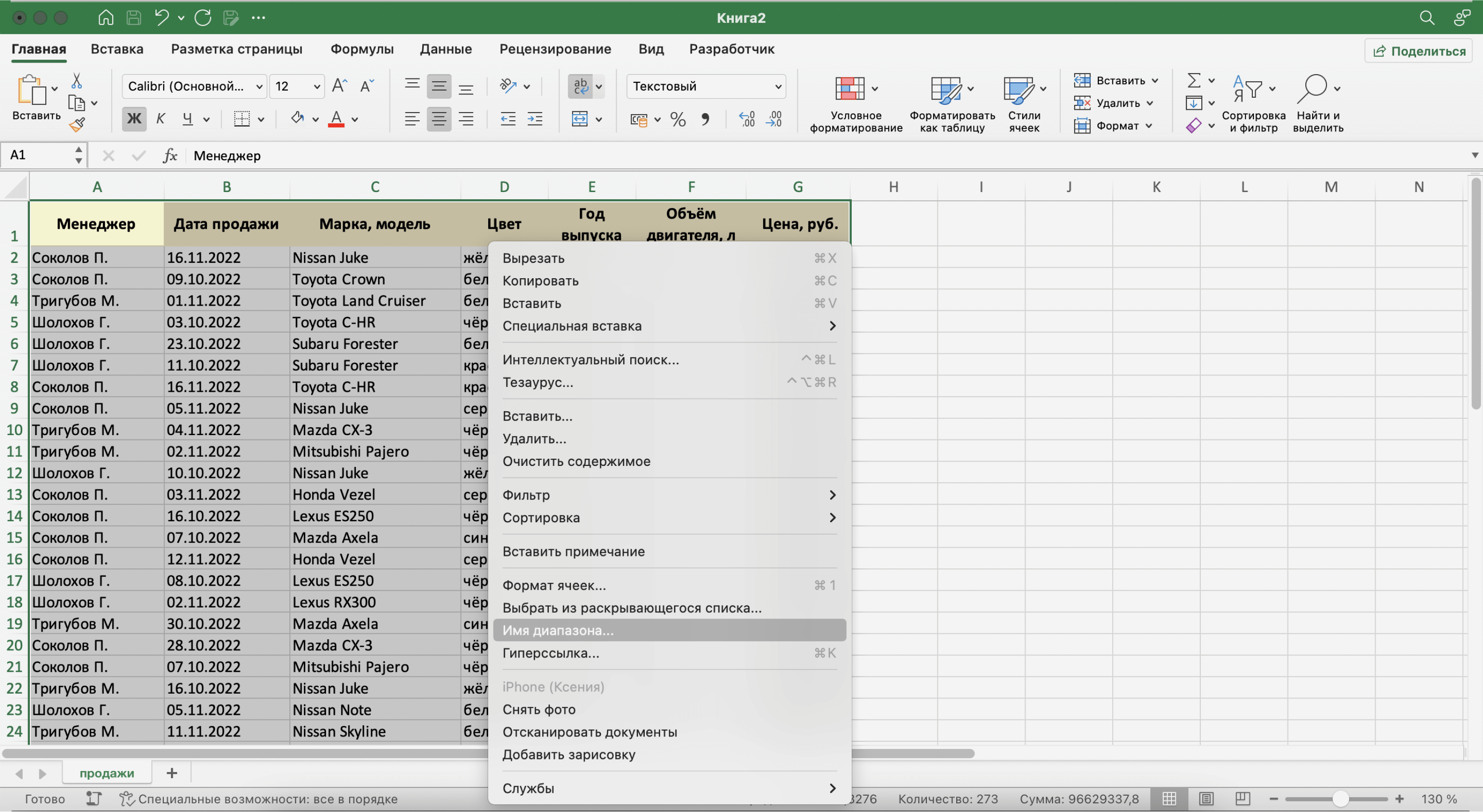
Скриншот: Excel / Skillbox Media
В появившемся окне вводим имя базы данных без пробелов.
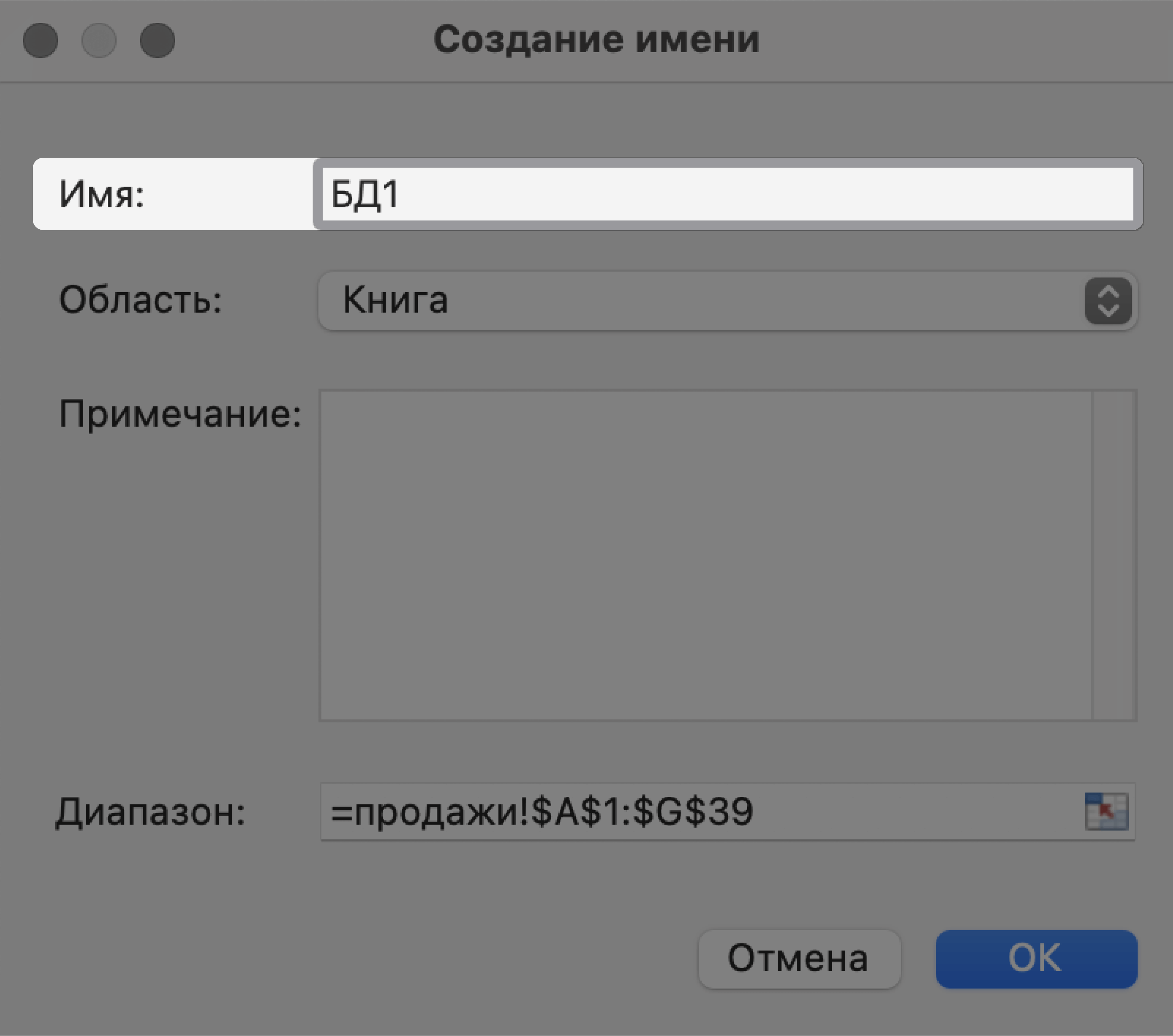
Скриншот: Excel / Skillbox Media
Готово — мы внесли в базу данных информацию о продажах и отформатировали её. В следующем разделе разберёмся, как с ней работать.
Скриншот: Excel / Skillbox Media
Сейчас в созданной базе данных все записи расположены хаотично — не упорядочены ни по датам, ни по фамилиям менеджеров. Разберёмся, как привести БД в более удобный для работы вид. Все необходимые для этого функции расположены на вкладке «Данные».
Скриншот: Excel / Skillbox Media
Для начала добавим фильтры. Это инструмент, с помощью которого из большого объёма информации выбирают и показывают только нужную в данный момент.
Подробнее о фильтрах в Excel говорили в этой статье Skillbox Media.
Выберем любую ячейку из базы данных и на вкладке «Данные» нажмём кнопку «Фильтры».
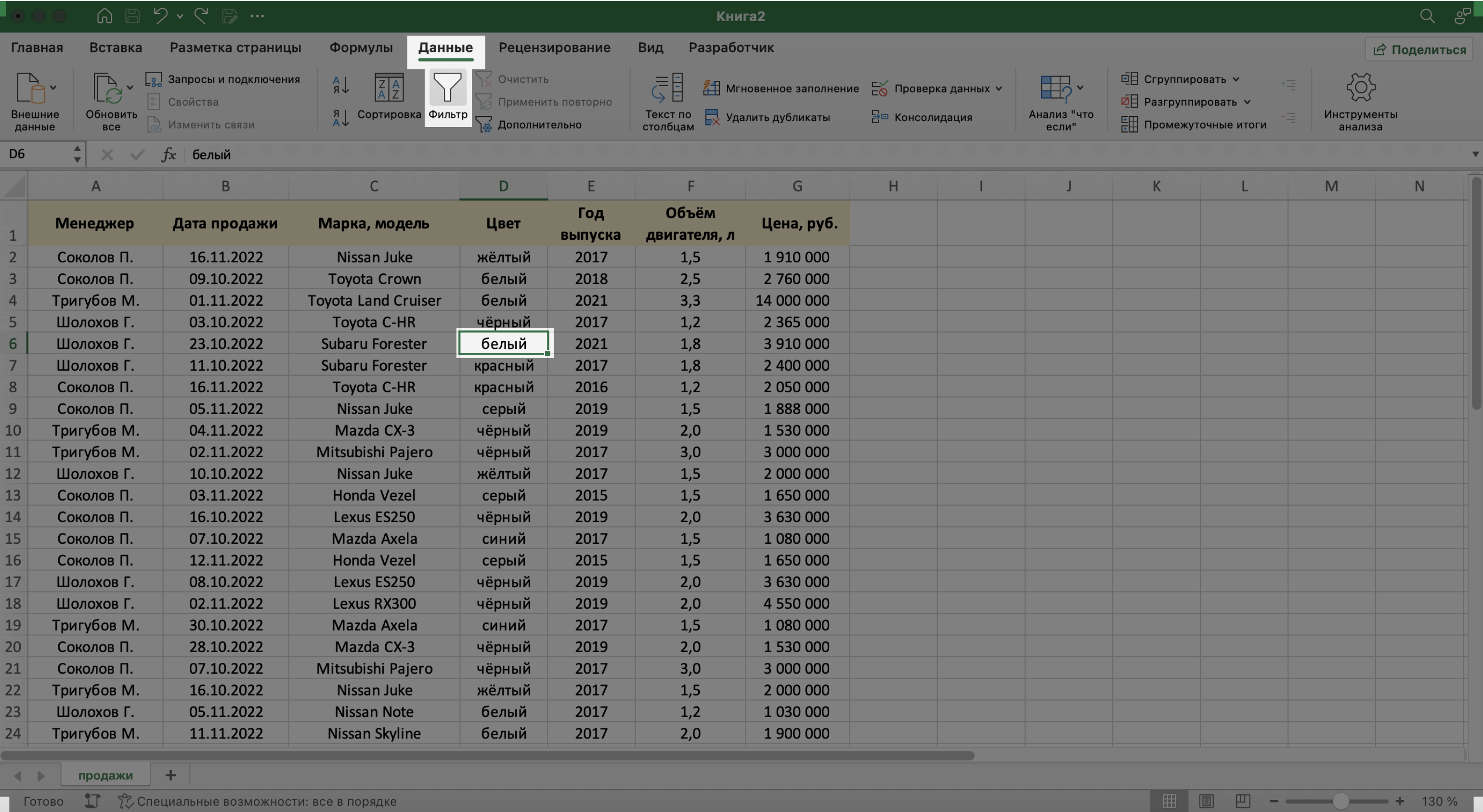
Скриншот: Excel / Skillbox Media
В каждой ячейке шапки таблицы появились кнопки со стрелками.
Предположим, нужно показать только сделки менеджера Тригубова М. — нажмём на стрелку поля «Менеджер» и оставим галочку только напротив него. Затем нажмём «Применить фильтр».
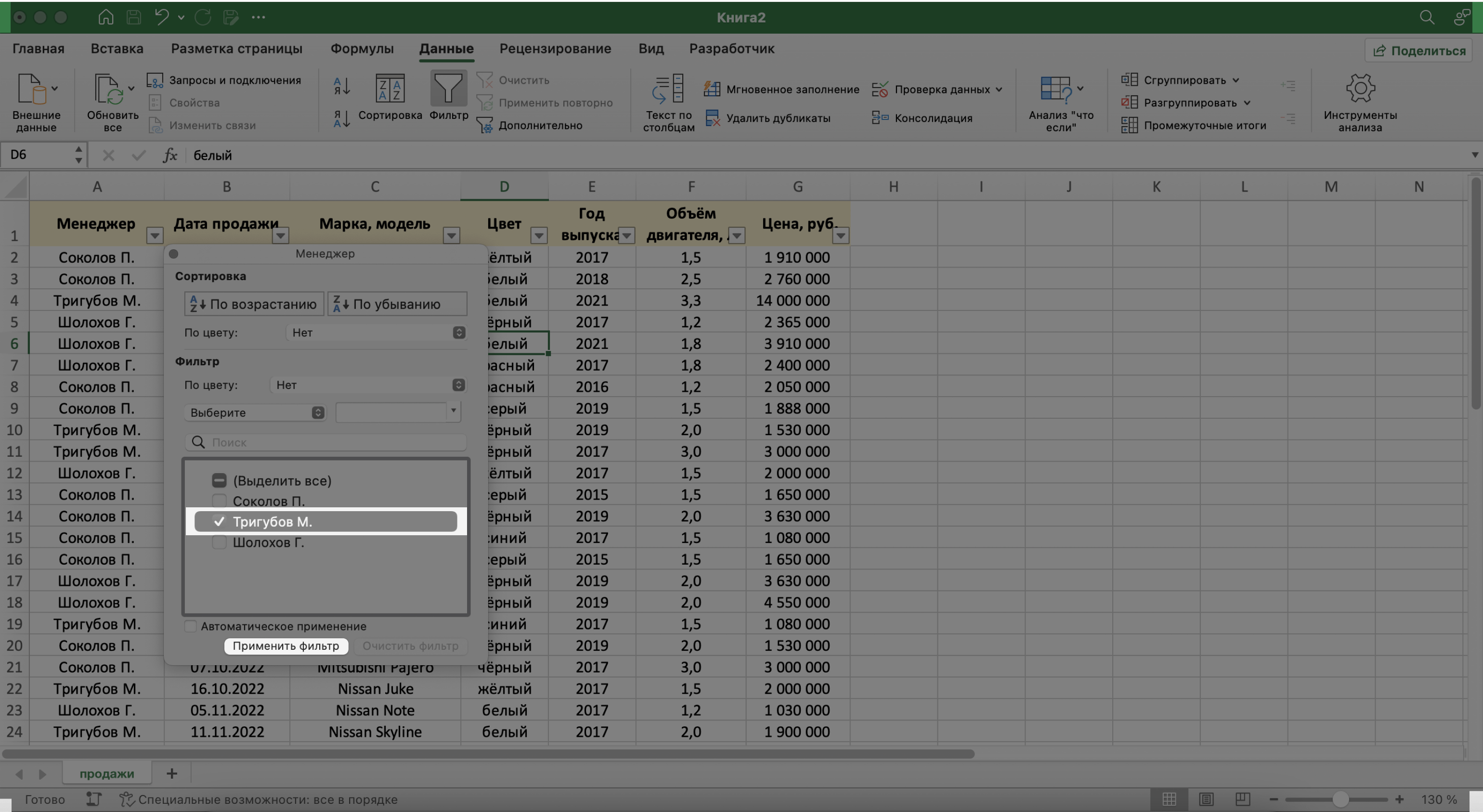
Скриншот: Excel / Skillbox Media
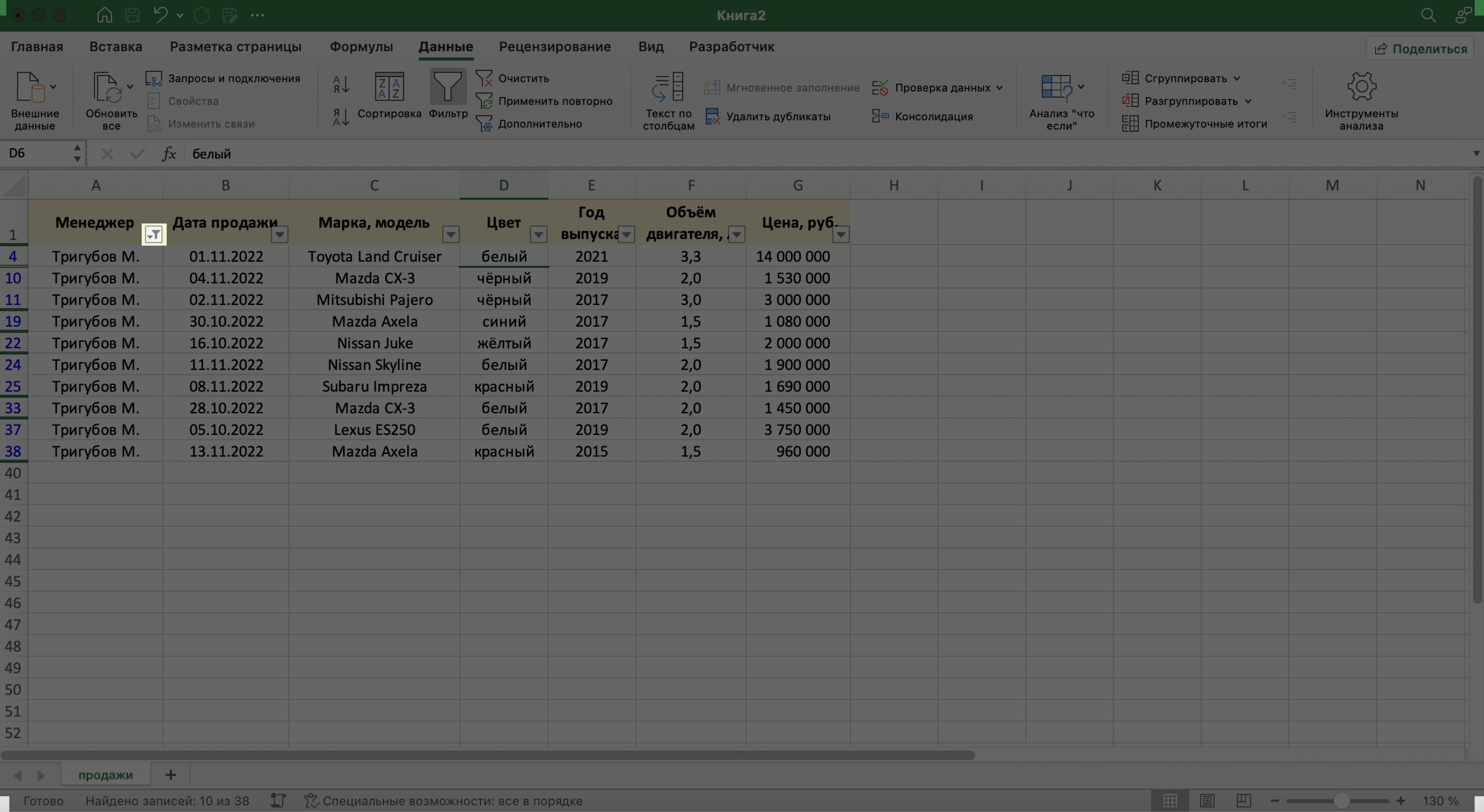
Готово — в базе отражены данные о продажах только одного менеджера. На кнопке со стрелкой появился дополнительный значок. Он означает, что в этом столбце настроена фильтрация. Чтобы её снять, нужно нажать на этот дополнительный значок и выбрать «Очистить фильтр».
Скриншот: Excel / Skillbox Media
Записи БД можно фильтровать по нескольким параметрам одновременно. Для примера покажем среди продаж Тригубова М. только автомобили дешевле 2 млн рублей.
Для этого в уже отфильтрованной таблице откроем меню фильтра для столбца «Цена, руб.» и нажмём на параметр «Выберите». В появившемся меню выберем параметр «Меньше».
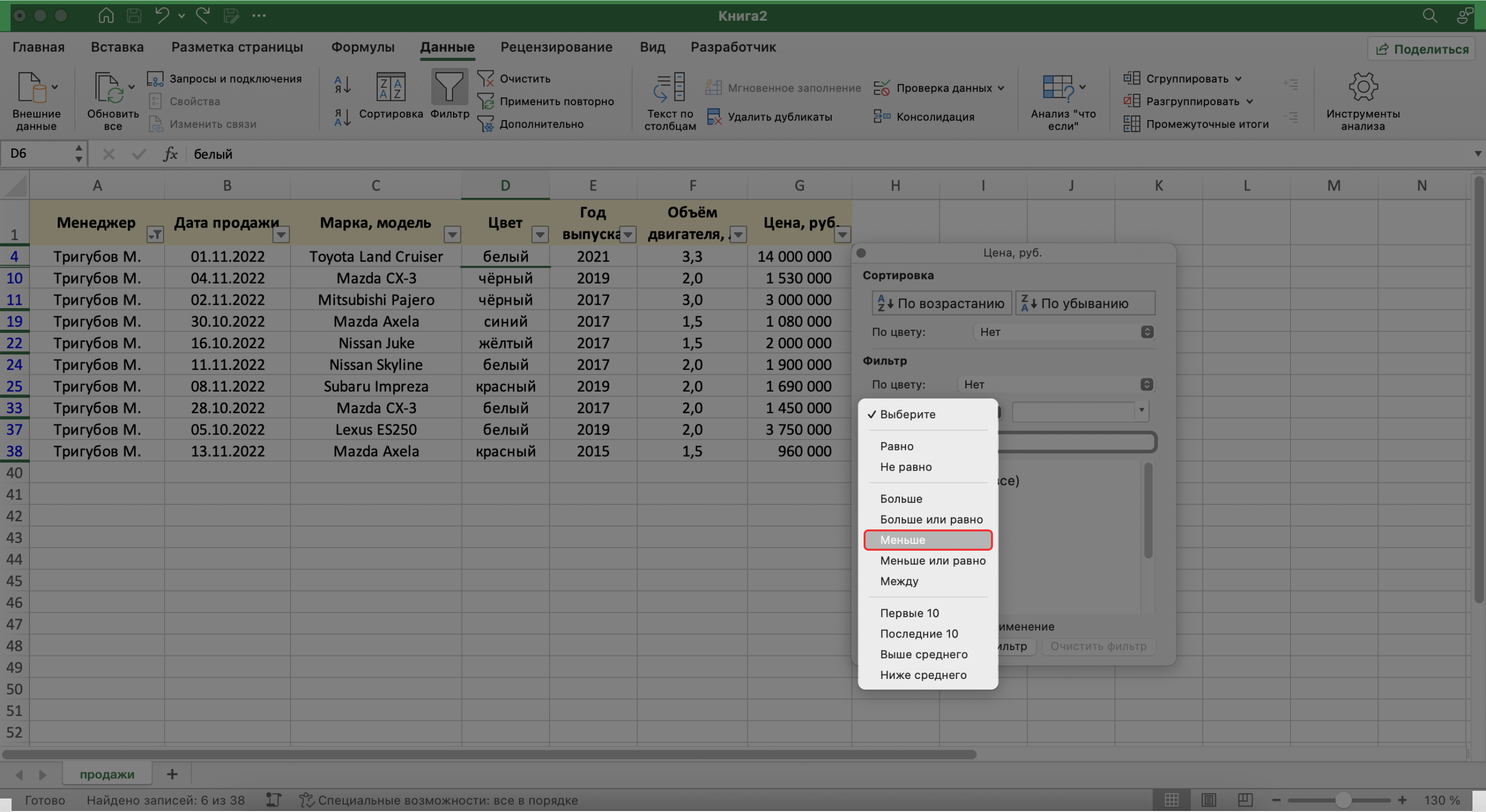
Скриншот: Excel / Skillbox Media
Затем в появившемся окне дополним условие фильтрации — в нашем случае «Меньше 2000000» — и нажмём «Применить фильтр».
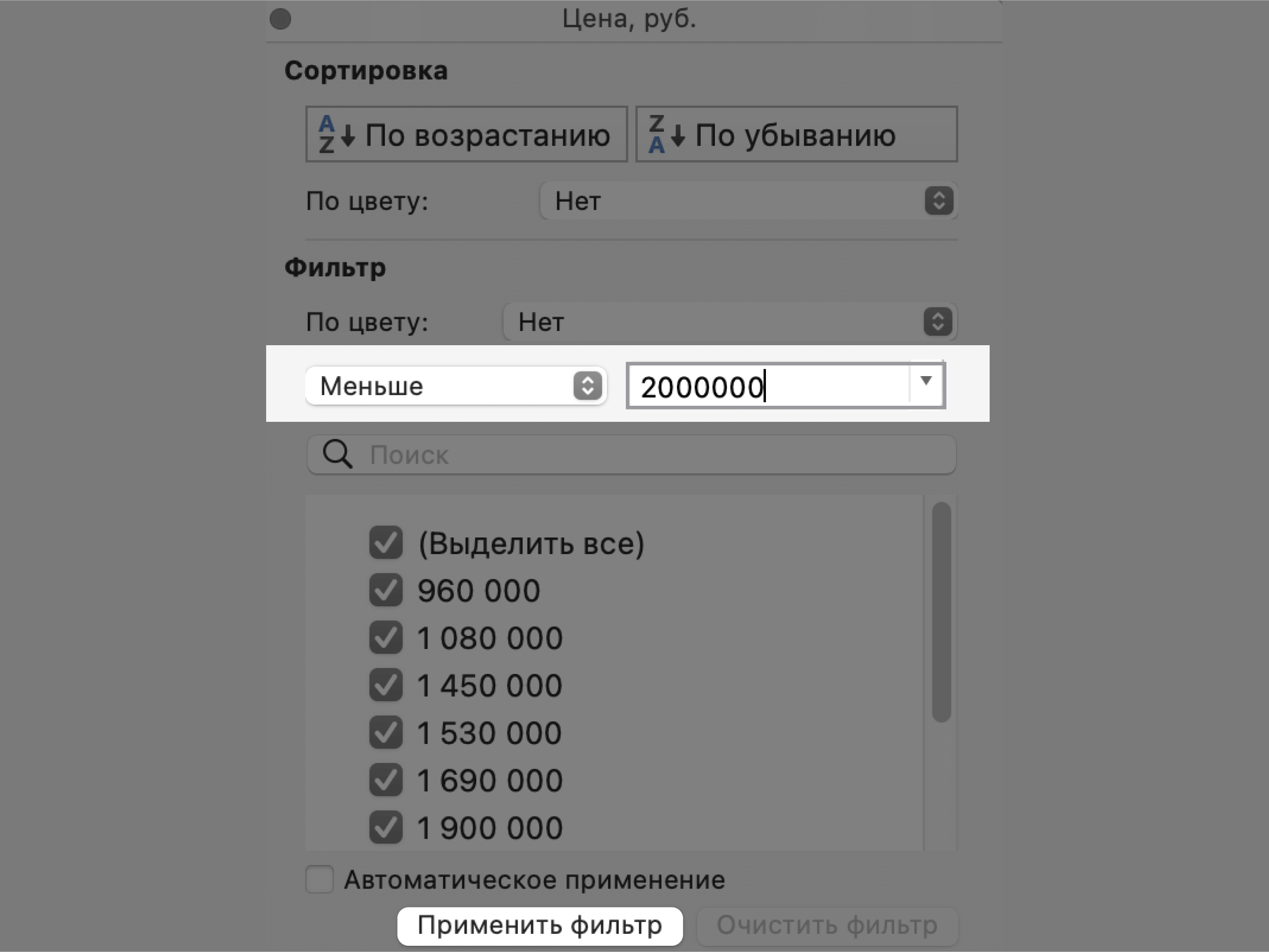
Скриншот: Excel / Skillbox Media
Готово — фильтрация сработала по двум параметрам. Теперь БД показывает только те проданные менеджером авто, цена которых ниже 2 млн рублей.
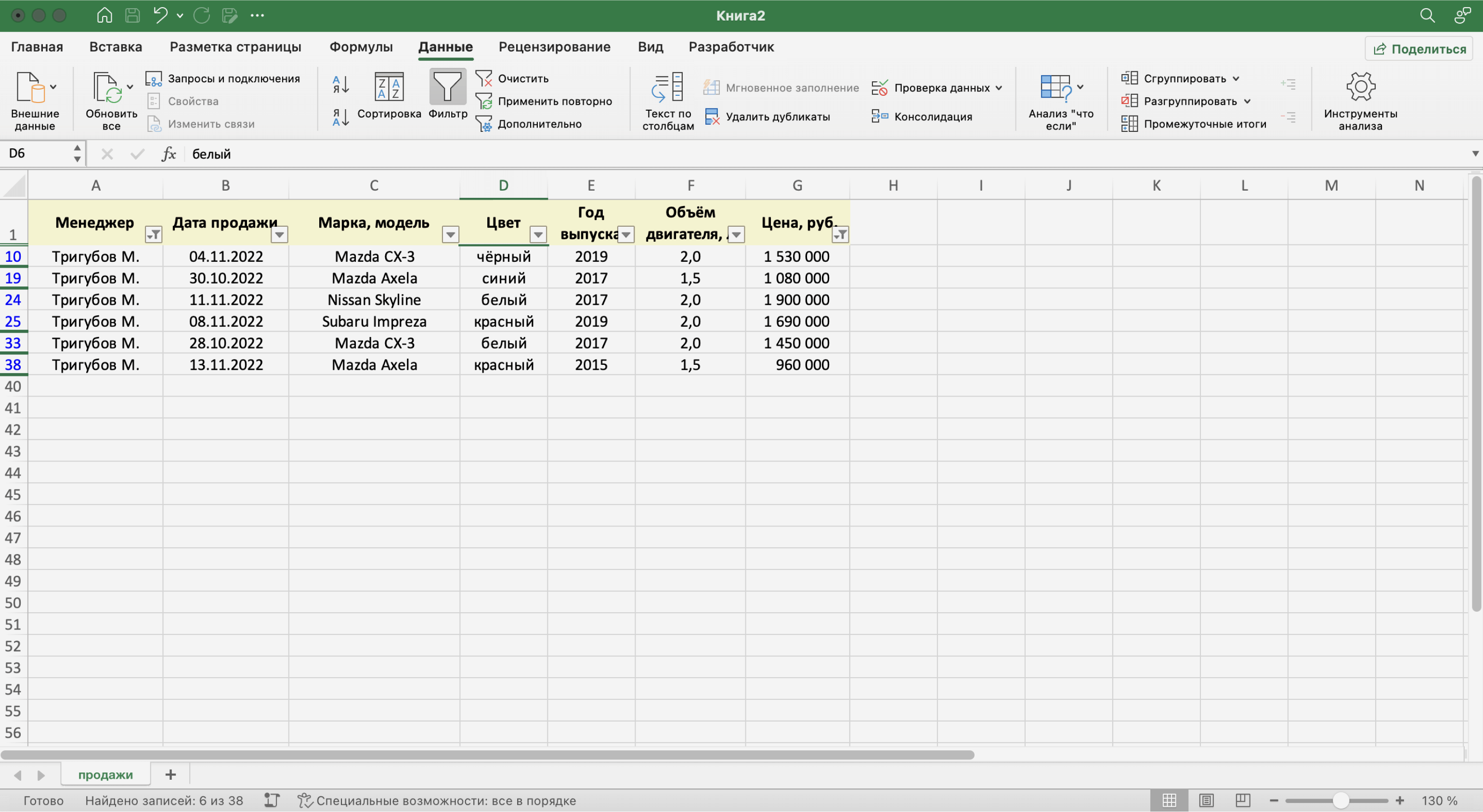
Скриншот: Excel / Skillbox Media
Кроме этого, в Excel можно установить расширенный фильтр. Он позволяет фильтровать БД по сложным критериям сразу в нескольких столбцах. Подробно о том, как настроить расширенный фильтр, говорили в статье.
Сортировка — инструмент, с помощью которого данные в БД организовывают в необходимом порядке. Их можно сортировать по алфавиту, по возрастанию и убыванию чисел, по дате.
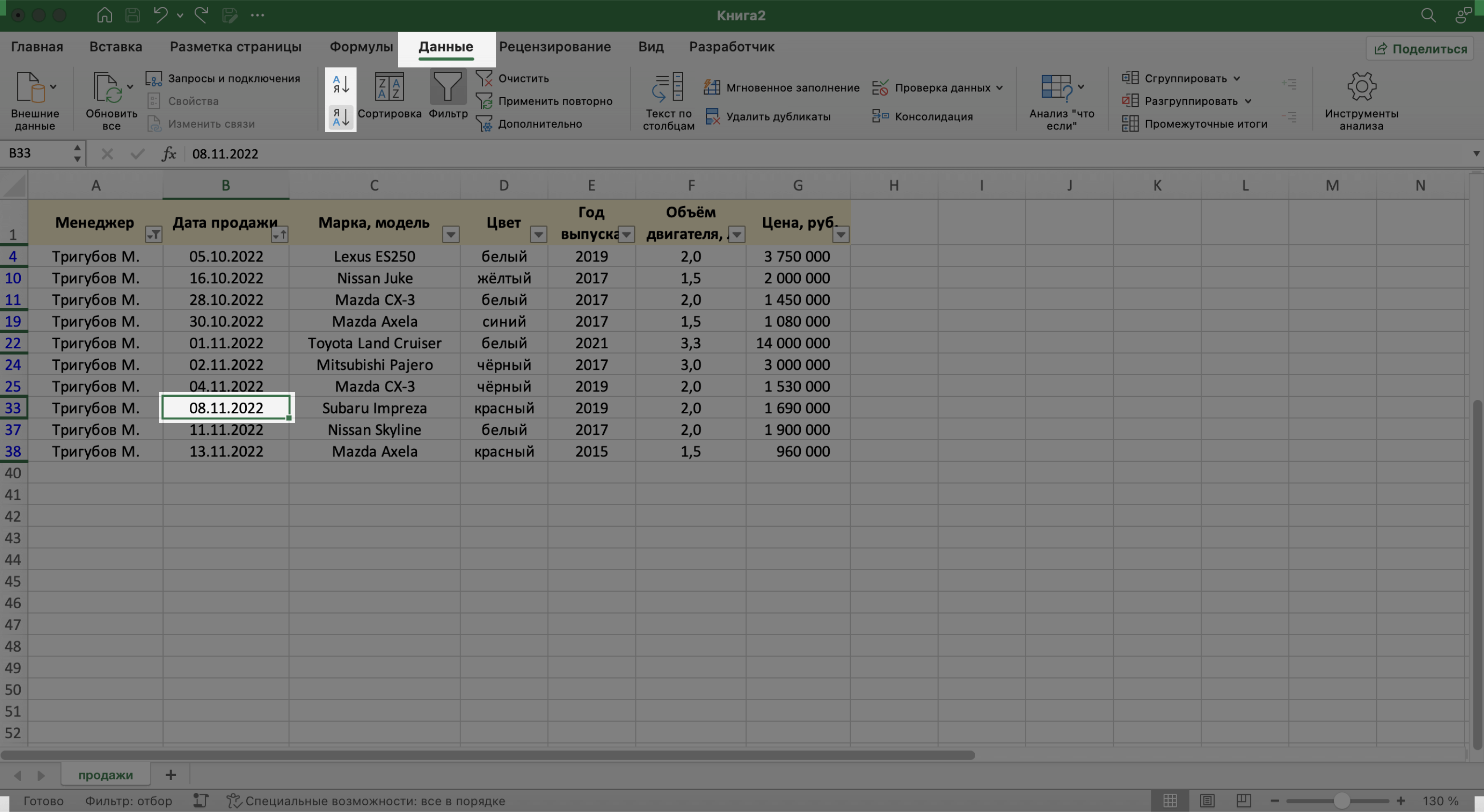
Для примера отсортируем сделки выбранного менеджера в хронологическом порядке — по датам. Для этого выделим любую ячейку в поле «Дата продажи» и нажмём кнопку «Сортировка».
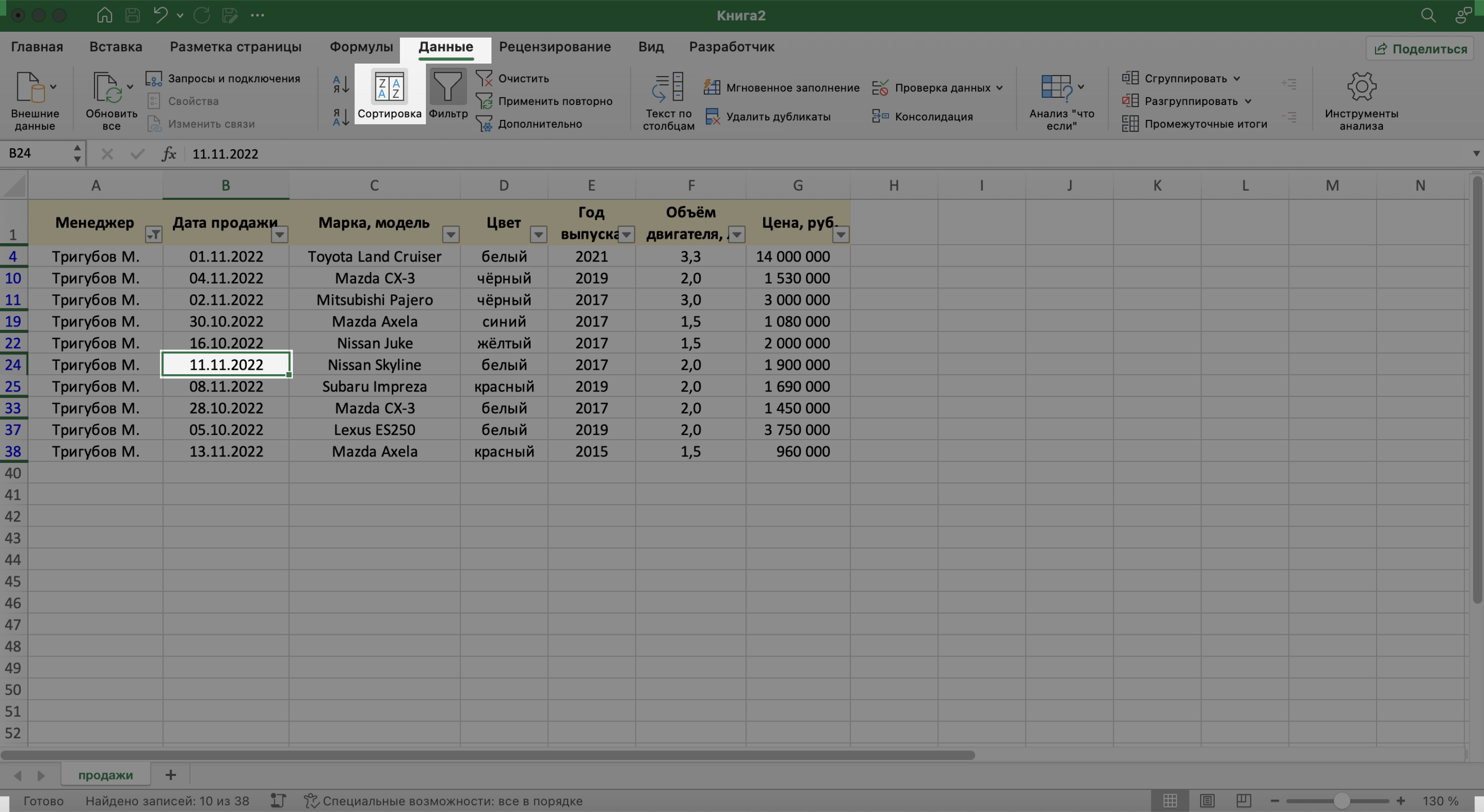
Скриншот: Excel / Skillbox Media
В появившемся окне выберем параметр сортировки «От старых к новым» и нажмём «ОК».
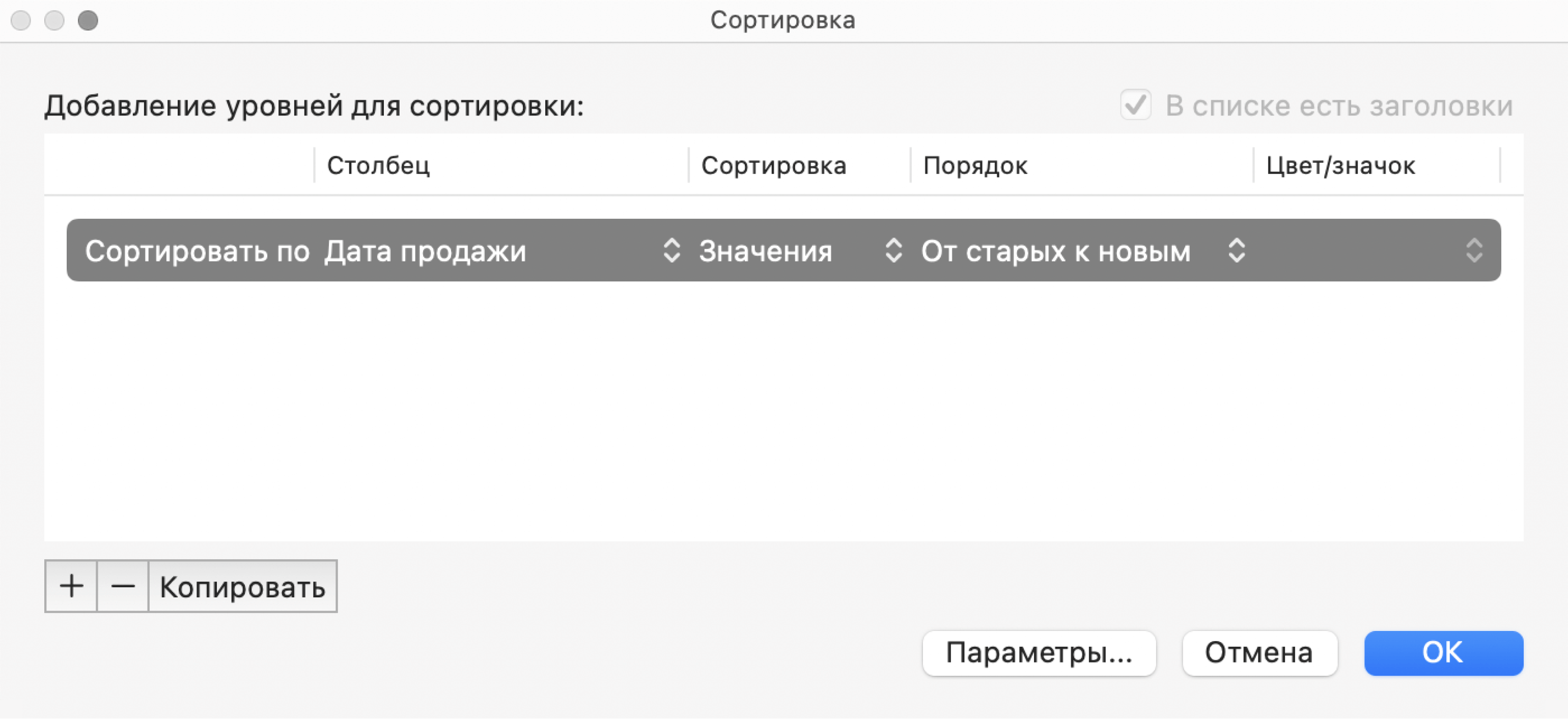
Скриншот: Excel / Skillbox Media
Готово — теперь все сделки менеджера даны в хронологическом порядке.
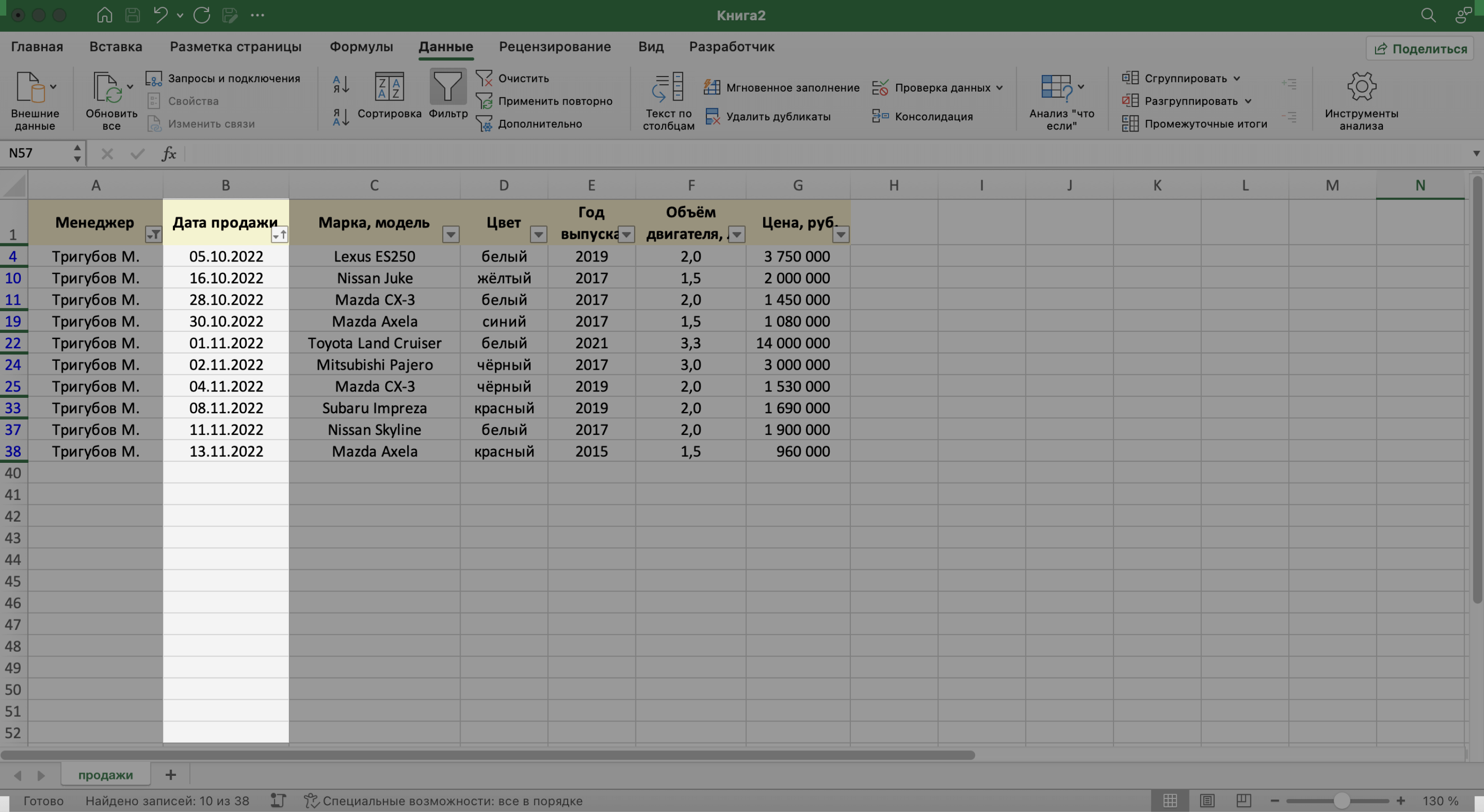
Скриншот: Excel / Skillbox Media
То же самое можно сделать другим способом — выбрать любую ячейку столбца, который нужно отсортировать, и нажать на одну из двух кнопок рядом с кнопкой «Сортировка»: «Сортировка от старых к новым» или «Сортировка от новых к старым». В этом случае данные отсортируются без вызова дополнительных окон.
Скриншот: Excel / Skillbox Media
Кроме стандартной сортировки в Excel, можно настроить сортировку по критериям, выбранным пользователем. Эта функция полезна, когда нужные критерии не предусмотрены стандартными настройками. Например, если требуется отсортировать данные по должностям сотрудников или по названиям отделов.
Подробнее о пользовательской сортировке в Excel говорили в этой статье Skillbox Media.
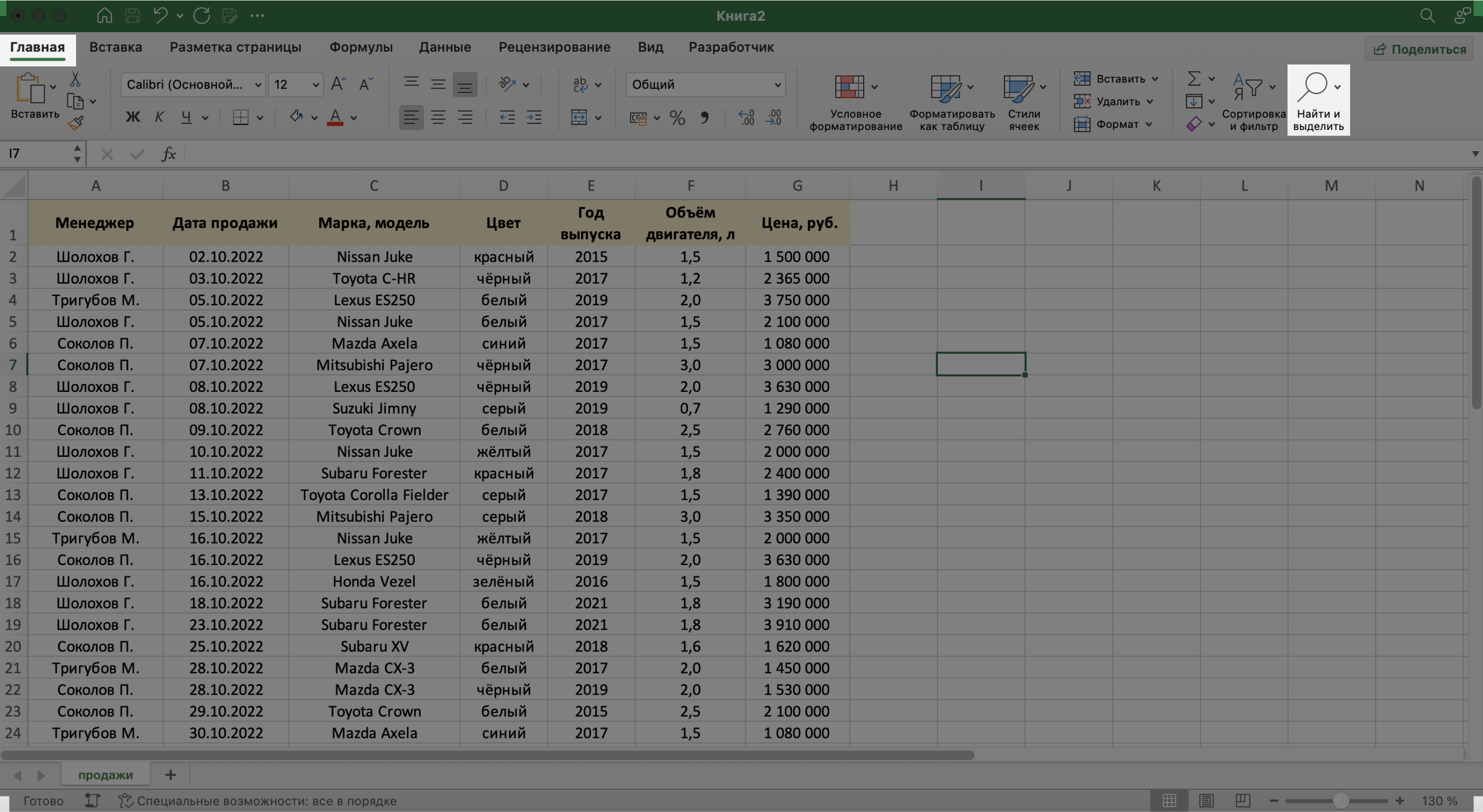
В процессе работы базы данных могут разрастись до миллиона строк — найти нужную информацию станет сложнее. Фильтрация и сортировка не всегда упрощают задачу. В этом случае для быстрого поиска нужной ячейки — текста или цифры — можно воспользоваться функцией поиска.
Предположим, нужно найти в БД автомобиль стоимостью 14 млн рублей. Перейдём на вкладку «Главная» и нажмём на кнопку «Найти и выделить». Также быстрый поиск можно задавать с любой вкладки Excel — через значок лупы в правом верхнем углу экрана.
Скриншот: Excel / Skillbox Media
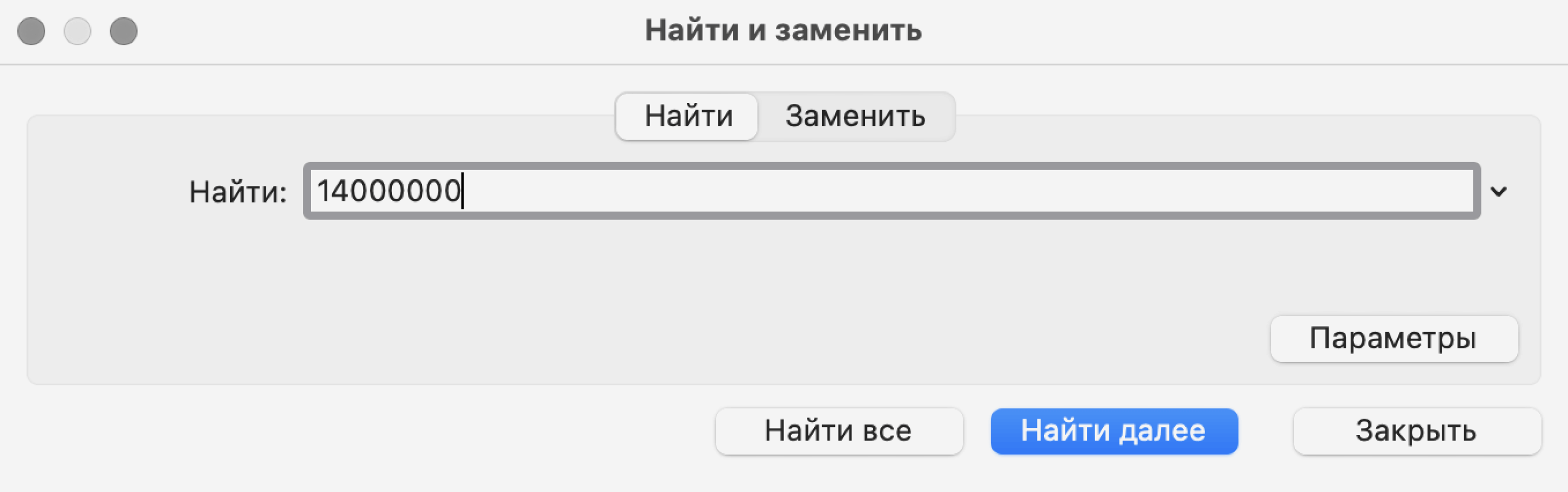
В появившемся окне введём значение, которое нужно найти, — 14000000 — и нажмём «Найти далее».
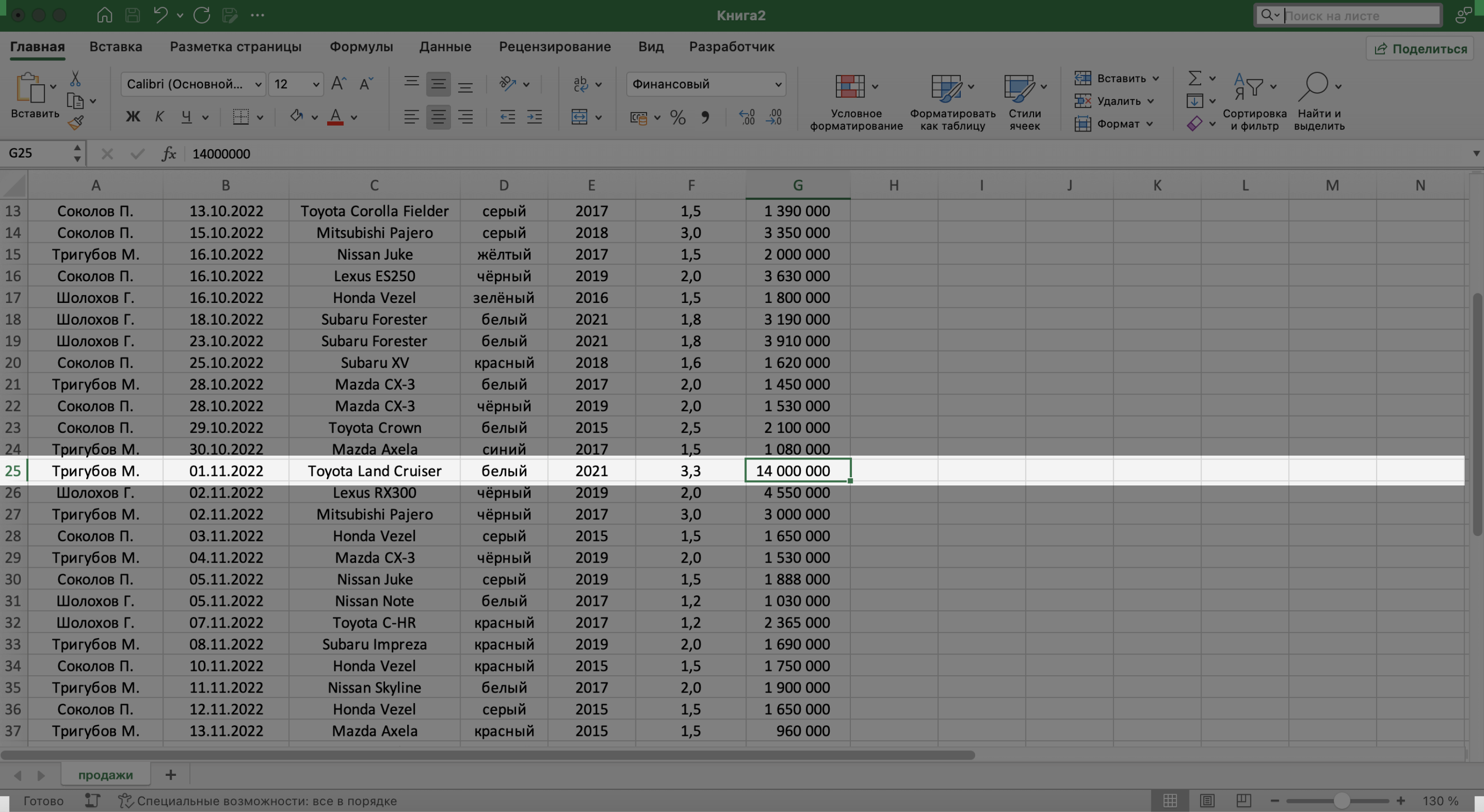
Скриншот: Excel / Skillbox Media
Готово — Excel нашёл ячейку с заданным значением и выделил её.
Скриншот: Excel / Skillbox Media
- В этой статье Skillbox Media собрали в одном месте 15 статей и видео об инструментах Excel, которые ускорят и упростят работу с электронными таблицами.
- Также в Skillbox есть курс «Excel + Google Таблицы с нуля до PRO». Он подойдёт как новичкам, которые хотят научиться работать в Excel с нуля, так и уверенным пользователям, которые хотят улучшить свои навыки. На курсе учат быстро делать сложные расчёты, визуализировать данные, строить прогнозы, работать с внешними источниками данных, создавать макросы и скрипты.
- Кроме того, Skillbox даёт бесплатный доступ к записи онлайн-интенсива «Экспресс-курс по Excel: осваиваем таблицы с нуля за 3 дня». Он подходит для начинающих пользователей. На нём можно научиться создавать и оформлять листы, вводить данные, использовать формулы и функции для базовых вычислений, настраивать пользовательские форматы и создавать формулы с абсолютными и относительными ссылками.
Другие материалы Skillbox Media по Excel
- Как сделать сортировку в Excel: детальная инструкция со скриншотами
- Как установить фильтр и расширенный фильтр в Excel: детальные инструкции со скриншотами
- Как сделать ВПР в Excel: пошаговая инструкция со скриншотами
- Основы Excel: работаем с выпадающим списком. Пошаговая инструкция со скриншотами
- Основы Excel: как использовать функцию ЕСЛИ
- Как сделать сводные таблицы в Excel: пошаговая инструкция со скриншотами
В современном мире нужны инструменты, которые бы позволяли хранить, систематизировать и обрабатывать большие объемы информации, с которыми сложно работать в Excel или Word.
Подобные хранилища используются для разработки информационных сайтов, интернет-магазинов и бухгалтерских дополнений. Основными средствами, реализующими данный подход, являются MS SQL и MySQL.
Продукт от Microsoft Office представляет собой упрощенную версию в функциональном плане и более понятную для неопытных пользователей. Давайте рассмотрим пошагово создание базы данных в Access 2007.

Microsoft Access 2007 – это система управления базами данных (СУБД), реализующая полноценный графический интерфейс пользователя, принцип создания сущностей и связей между ними, а также структурный язык запросов SQL. Единственный минус этой СУБД – невозможность работать в промышленных масштабах. Она не предназначена для хранения огромных объемов данных. Поэтому MS Access 2007 используется для небольших проектов и в личных некоммерческих целях.
Но прежде чем показывать пошагово создание БД, нужно ознакомиться с базовыми понятиями из теории баз данных.

Определения основных понятий
Без базовых знаний об элементах управления и объектах, использующихся при создании и конфигурации БД, нельзя успешно понять принцип и особенности настройки предметной области. Поэтому сейчас я постараюсь простым языком объяснить суть всех важных элементов. Итак, начнем:
- Предметная область – множество созданных таблиц в базе данных, которые связаны между собой с помощью первичных и вторичных ключей.
- Сущность – отдельная таблица базы данных.
- Атрибут – заголовок отдельного столбца в таблице.
- Кортеж – это строка, принимающая значение всех атрибутов.
- Первичный ключ – это уникальное значение (id), которое присваивается каждому кортежу.
- Вторичный ключ таблицы «Б» – это уникальное значение таблицы «А», использующееся в таблице «Б».
- SQL запрос – это специальное выражение, выполняющее определенное действие с базой данных: добавление, редактирование, удаление полей, создание выборок.
Теперь, когда в общих чертах есть представление о том, с чем мы будем работать, можно приступить к созданию БД.
Создание БД
Для наглядности всей теории создадим тренировочную базу данных «Студенты-Экзамены», которая будет содержать 2 таблицы: «Студенты» и «Экзамены». Главным ключом будет поле «Номер зачетки», т.к. данный параметр является уникальным для каждого студента. Остальные поля предназначены для более полной информации об учащихся.
Итак, выполните следующее:
- Запустите MS Access 2007.
- Нажмите на кнопку «Новая база данных».
- В появившемся окне введите название БД и выберите «Создать».

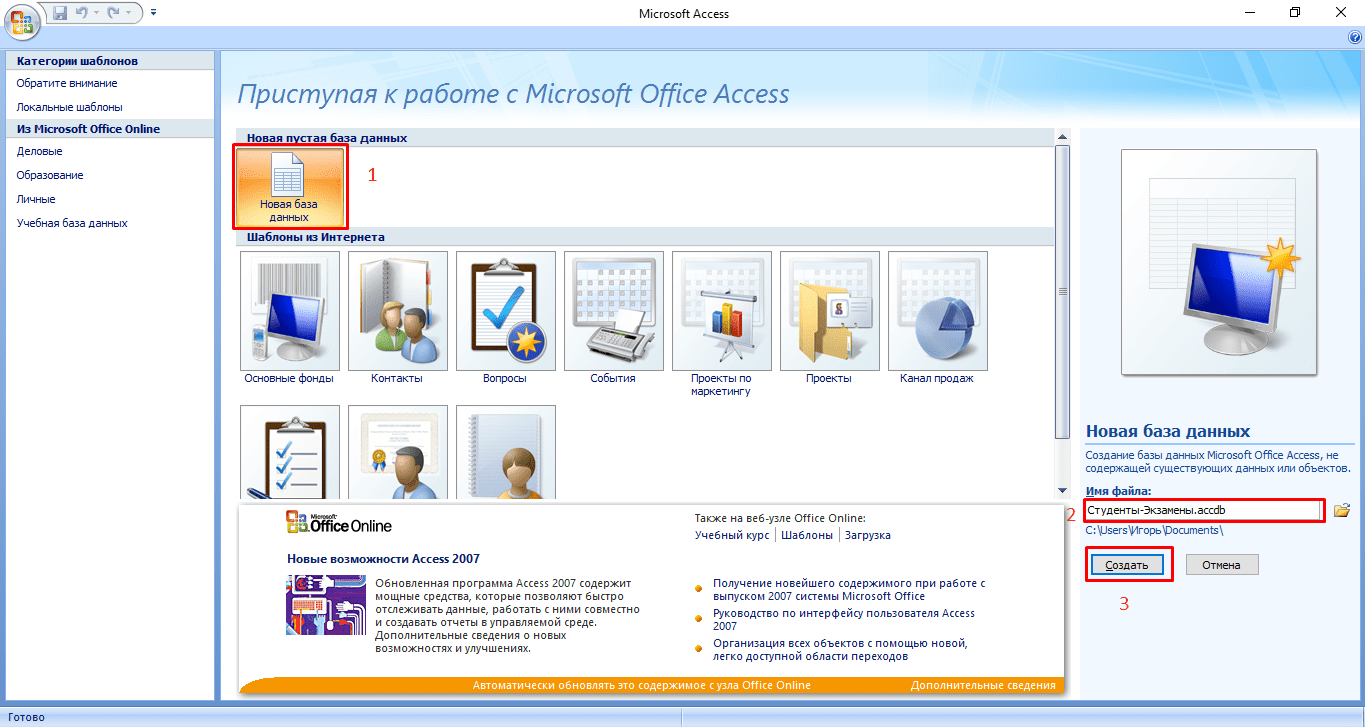
Все, теперь осталось только создать, заполнить и связать таблицы. Переходите к следующему пункту.
Создание и заполнение таблиц
После успешного создания БД на экране появится пустая таблица. Для формирования ее структуры и заполнения выполните следующее:
- Нажмите ПКМ по вкладке «Таблица1» и выберите «Конструктор».

- Теперь начинайте заполнять названия полей и соответствующий им тип данных, который будет использоваться.

Внимание! Первым полем принято устанавливать уникальное значение (первичный ключ). Для него предпочтительно числовое значение.
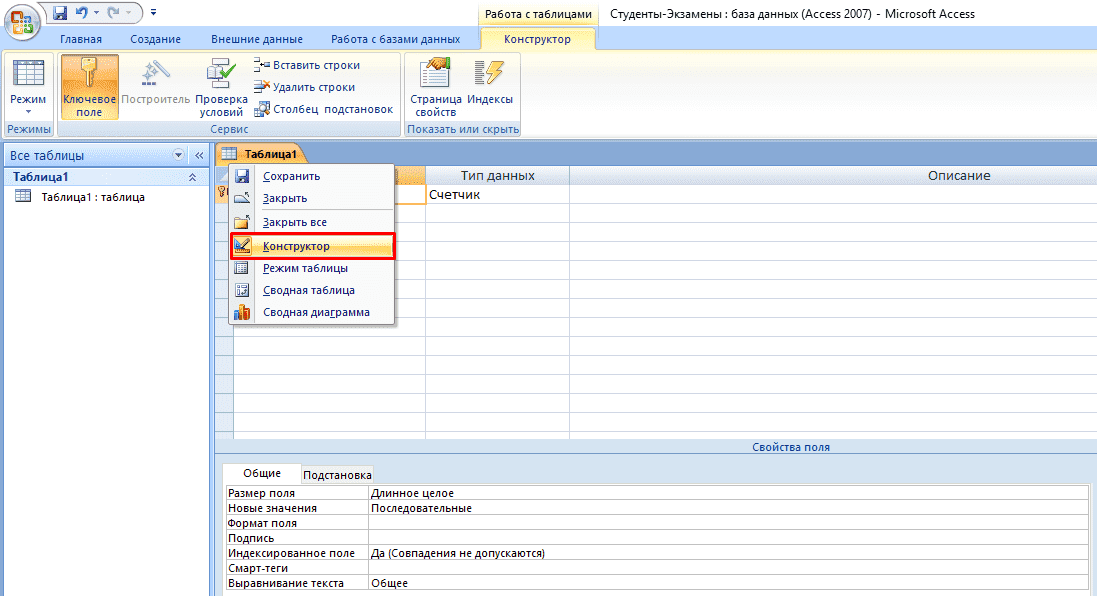
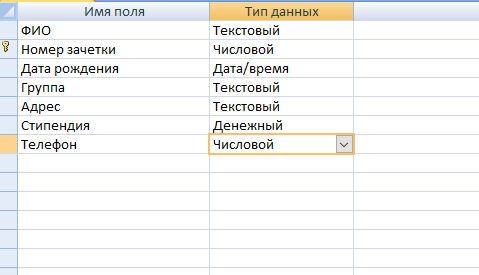
- После создания необходимых атрибутов сохраните таблицу и введите ее название.
- Снова нажмите ПКМ по вкладке с уже новым название и выберите «Режим таблицы».

- Заполните таблицу необходимыми значениями.

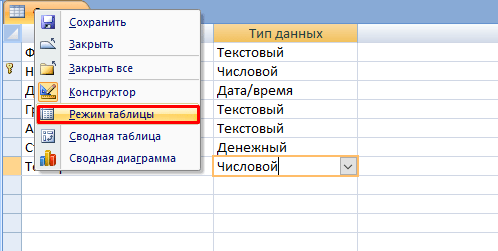

Совет! Для тонкой настройки формата данных перейдите на ленте во вкладку «Режим таблицы» и обратите внимание на блок «Форматирование и тип данных». Там можно кастомизировать формат отображаемых данных.
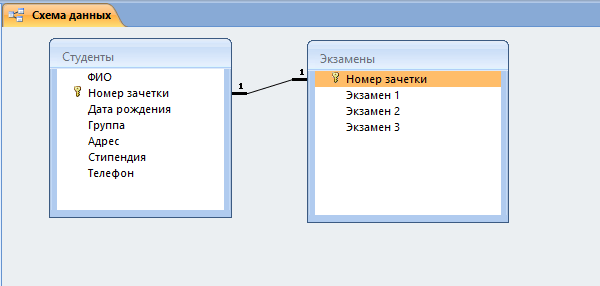
Создание и редактирование схем данных
Перед тем, как приступить к связыванию двух сущностей, по аналогии с предыдущим пунктом нужно создать и заполнить таблицу «Экзамены». Она имеет следующие атрибуты: «Номер зачетки», «Экзамен1», «Экзамен2», «Экзамен3».
Для выполнения запросов нужно связать наши таблицы. Иными словами, это некая зависимость, которая реализуется с помощью ключевых полей. Для этого нужно:
- Перейти во вкладку «Работа с базами данных».
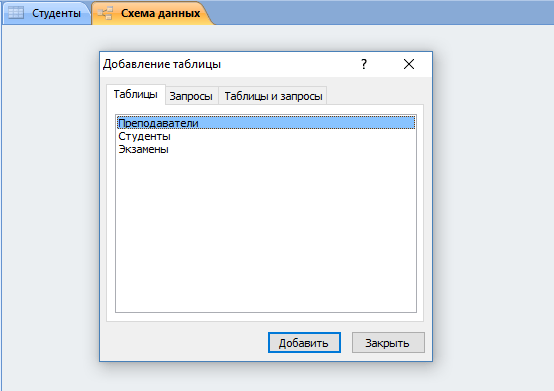
- Нажать на кнопку «Схема данных».
- Если схема не была создана автоматически, нужно нажать ПКМ на пустой области и выбрать «Добавить таблицы».

- Выберите каждую из сущностей, поочередно нажимая кнопку «Добавить».
- Нажмите кнопку «ОК».
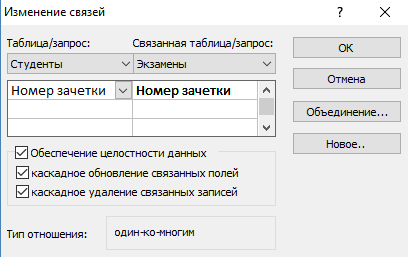
Конструктор должен автоматически создать связь, в зависимости от контекста. Если же этого не случилось, то:
- Перетащите общее поле из одной таблицы в другую.
- В появившемся окне выберите необходимы параметры и нажмите «ОК».

- Теперь в окне должны отобразиться миниатюры двух таблиц со связью (один к одному).

Выполнение запросов
Что же делать, если нам нужны студенты, которые учатся только в Москве? Да, в нашей БД только 6 человек, но что, если их будет 6000? Без дополнительных инструментов узнать это будет сложно.
Именно в этой ситуации к нам на помощь приходят SQL запросы, которые помогают изъять лишь необходимую информацию.
Виды запросов
SQL синтаксис реализует принцип CRUD (сокр. от англ. create, read, update, delete — «создать, прочесть, обновить, удалить»). Т.е. с помощью запросов вы сможете реализовать все эти функции.
На выборку
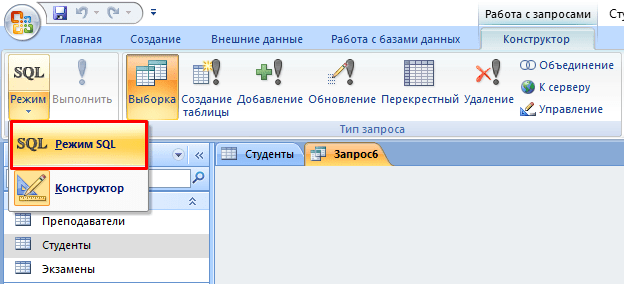
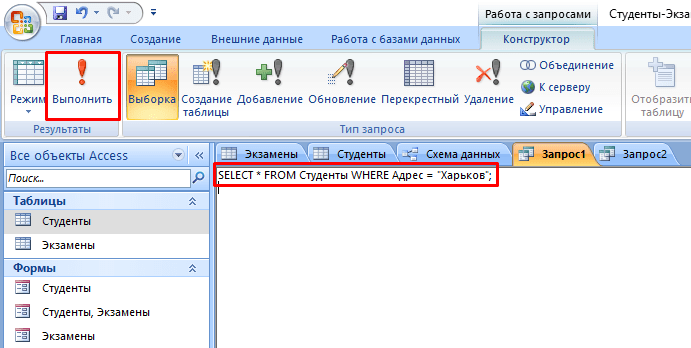
В этом случае в ход вступает принцип «прочесть». Например, нам нужно найти всех студентов, которые учатся в Харькове. Для этого нужно:
- Перейти во вкладку «Создание».
- Нажать кнопку «Конструктор запросов» в блоке «Другие».
- В новом окне нажмите на кнопку SQL.

- В текстовое поле введите команду: SELECT * FROM Студенты WHERE Адрес = “Харьков”; где «SELECT *» означает, что выбираются все студенты, «FROM Студенты» – из какой таблицы, «WHERE Адрес = “Харьков”» – условие, которое обязательно должно выполняться.
- Нажмите кнопку «Выполнить».

- На выходе мы получаем результирующую таблицу.

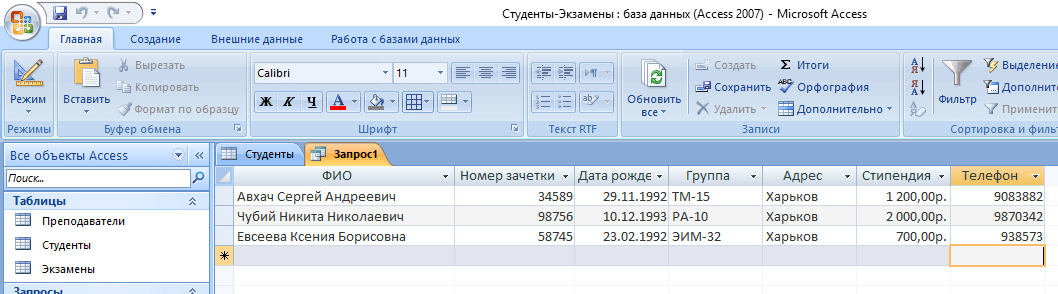
А что делать, если нас интересуют студенты из Харькова, стипендии у которых больше 1000? Тогда наш запрос будет выглядеть следующим образом:
SELECT * FROM Студенты WHERE Адрес = “Харьков” AND Стипендия > 1000;
а результирующая таблица примет следующий вид:

На создание сущности
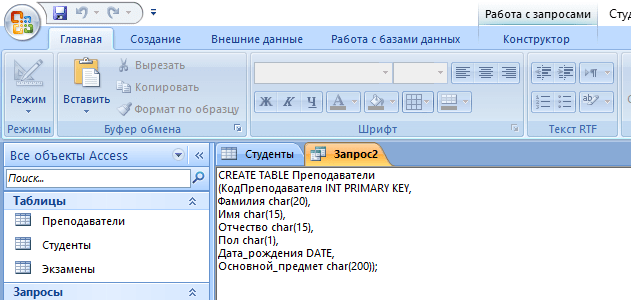
Кроме добавления таблицы с помощью встроенного конструктора, иногда может потребоваться выполнение этой операции с помощью SQL запроса. В большинстве случаев это нужно во время выполнения лабораторных или курсовых работ в рамках университетского курса, ведь в реальной жизни необходимости в этом нет. Если вы, конечно, не занимаетесь профессиональной разработкой приложений. Итак, для создания запроса нужно:
- Перейти во вкладку «Создание».
- Нажать кнопку «Конструктор запросов» в блоке «Другие».
- В новом окне нажмите на кнопку SQL, после чего в текстовое поле введите команду:
CREATE TABLE Преподаватели
(КодПреподавателя INT PRIMARY KEY,
Фамилия CHAR(20),
Имя CHAR (15),
Отчество CHAR (15),
Пол CHAR (1),
Дата_рождения DATE,
Основной_предмет CHAR (200));
где «CREATE TABLE» означает создание таблицы «Преподаватели», а «CHAR», «DATE» и «INT» – типы данных для соответствующих значений.
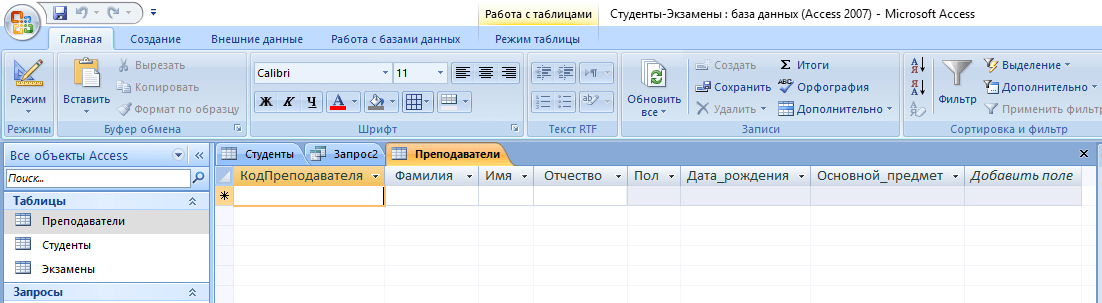
- Кликните по кнопке «Выполнить».
- Откройте созданную таблицу.

Внимание! В конце каждого запроса должен стоять символ «;». Без него выполнение скрипта приведет к ошибке.
На добавление, удаление, редактирование
Здесь все гораздо проще. Снова перейдите в поле для создания запроса и введите следующие команды:
Создание формы
При огромном количестве полей в таблице заполнять базу данных становится сложно. Можно случайно пропустить значение, ввести неверное или другого типа. В данной ситуации на помощь приходят формы, с помощью которых можно быстро заполнять сущности, а вероятность допустить ошибку минимизируется. Для этого потребуются следующие действия:
- Откройте интересующую таблицу.
- Перейдите во вкладку «Создание».
- Нажмите на необходимый формат формы из блока «Формы».

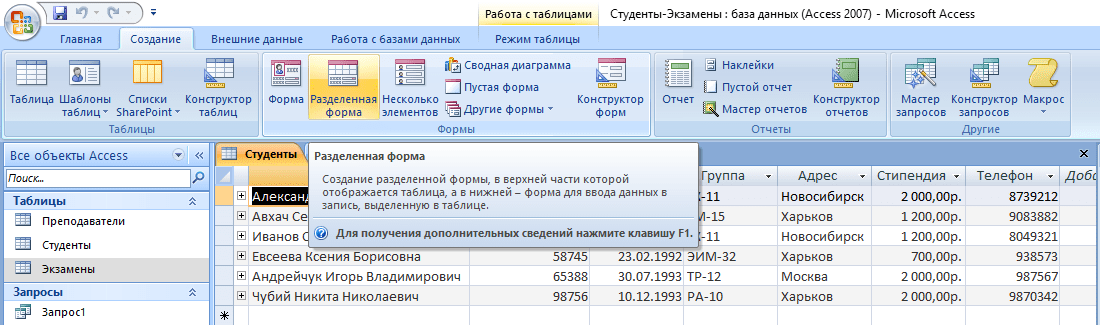
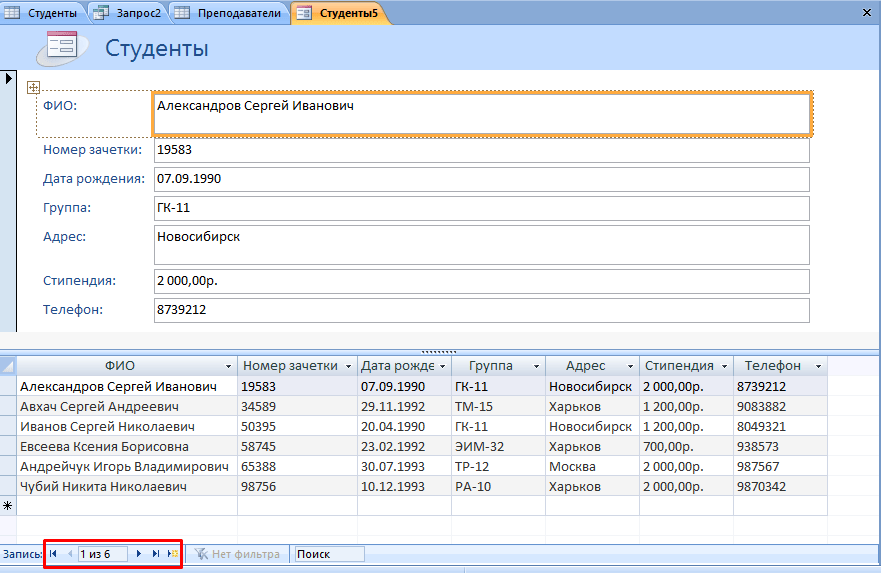
Совет! Рекомендуется использовать «Разделенную форму» – кроме самого шаблона, в нижней части будет отображаться миниатюра таблицы, которая сделает процесс редактирования еще более наглядным.
- С помощью навигационных кнопок переходите к следующей записи и вносите изменения.

Все базовые функции MS Access 2007 мы уже рассмотрели. Остался последний важный компонент – формирование отчета.
Формирование отчета
Отчет – это специальная функция MS Access, позволяющая оформить и подготовить для печати данные из базы данных. В основном это используется для создания товарных накладных, бухгалтерских отчетов и прочей офисной документации.
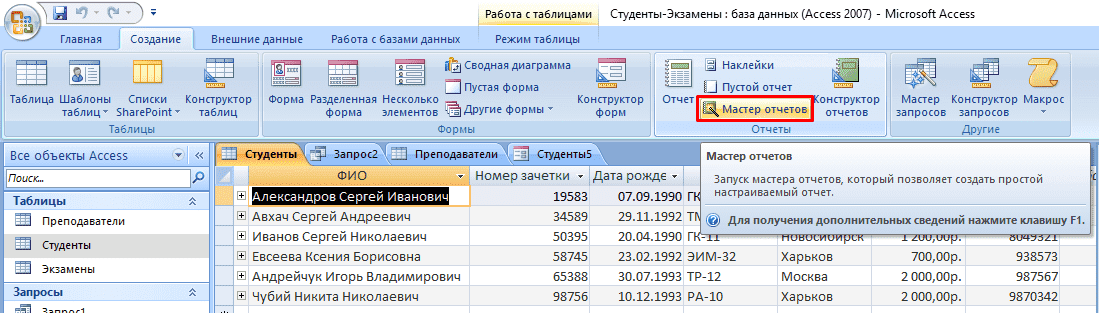
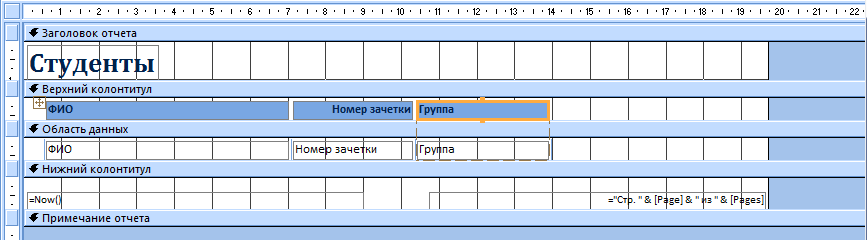
Если вы никогда не сталкивались с подобной функцией, рекомендуется воспользоваться встроенным «Мастером отчетов». Для этого сделайте следующее:
- Перейдите во вкладку «Создание».
- Нажмите на кнопку «Мастер отчетов» в блоке «Отчеты».

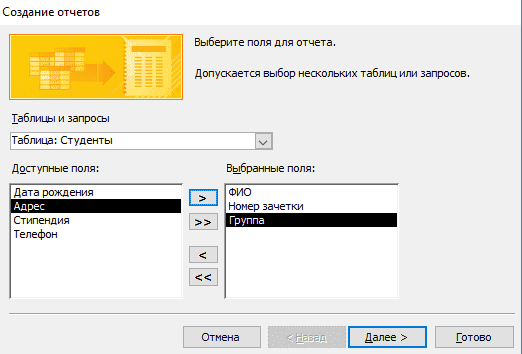
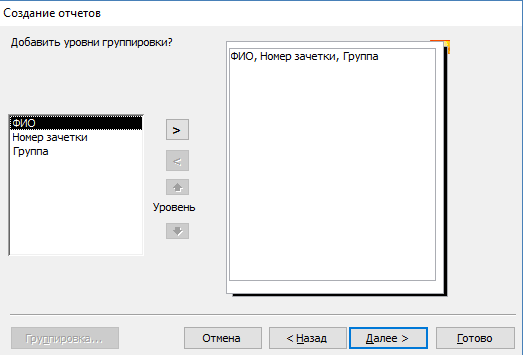
- Выберите интересующую таблицу и поля, нужные для печати.

- Добавьте необходимый уровень группировки.

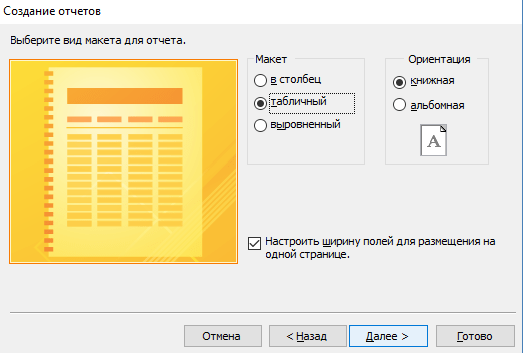
- Выберите тип сортировки каждого из полей.

- Настройте вид макета для отчета.

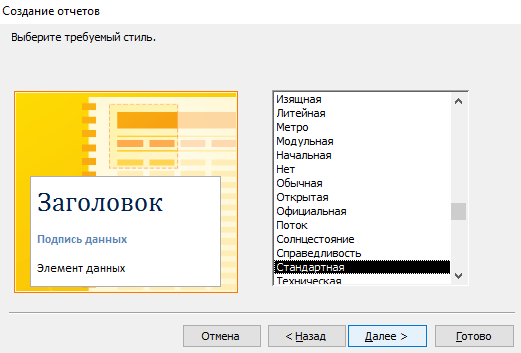
- Выберите подходящий стиль оформления.

Внимание! В официальных документах допускается только стандартный стиль оформления.
- Просмотрите созданный отчет.


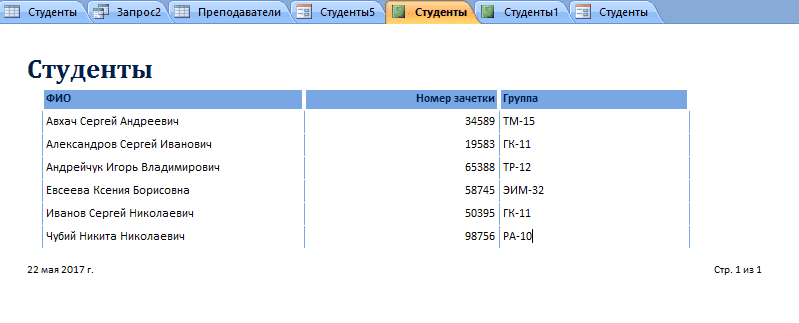
Если отображение вас не устраивает, его можно немного подкорректировать. Для этого:
- Нажмите ПКМ на вкладке отчета и выберите «Конструктор».
- Вручную расширьте интересующие столбцы.

- Сохраните изменения.
Вывод
Итак, с уверенностью можно заявить, что создание базы данных в MS Access 2007 мы разобрали полностью. Теперь вам известны все основные функции СУБД: от создания и заполнения таблиц до написания запросов на выборку и создания отчетов. Этих знаний хватит для выполнения несложных лабораторных работ в рамках университетской программы или использования в небольших личных проектах.
Для проектирования более сложных БД необходимо разбираться в объектно-ориентированном программировании и изучать такие СУБД, как MS SQL и MySQL. А для тех, кому нужна практика составления запросов, рекомендую посетить сайт SQL-EX, где вы найдете множество практических занимательных задачек.
Удачи в освоении нового материала и если есть какие-либо вопросы – милости прошу в комментарии!