Используем черную магию для создания быстрого кольцевого буфера
Время на прочтение
10 мин
Количество просмотров 20K

Вчера я заглянул на страницу Википедии, посвященную кольцевому буферу (circular buffer), и был заинтригован предполагаемой техникой оптимизации, с которой до этого не был знаком:
Реализация кольцевого буфера может быть оптимизирована путем отображения нижележащего буфера в двух смежных областях виртуальной памяти. (Естественно, длина нижележащего буфера должна в таком случае равняться некоторому размеру кратному размеру страницы системы.) Чтение и запись в кольцевой буфер могут выполняться в этой реализации с большей эффективностью посредством прямого доступа к памяти; те обращения, которые выходят за пределы первой области виртуальной памяти, автоматически переходят в начало нижележащего буфера. Когда смещение чтения продвигается во вторую область виртуальной памяти, оба смещения — чтения и записи — уменьшаются на длину нижележащего буфера.
В рамках реализации кольцевого буфера нам необходимо обработать случай, когда сообщение попадает на «разрыв» в очереди и должно быть перенесено (wrap around). Очевидная реализация записи в кольцевой буфер может полагаться на побайтовую запись и выглядеть примерно так:
void put(queue_t *q, uint8_t *data, size_t size) {
for(size_t i = 0; i < size; i++){
q->buffer[(q->tail + i) % q->buffer_size] = data[i];
}
q->tail = (q->tail + size) % q->buffer_size;
}Тот факт, что для индексации в массиве необходима операция деления, затрудняет (если не исключает) векторизацию этой функции и, следовательно, делает ее неоправданно медленной. Хотя есть и другие оптимизации, которые мы можем здесь применить, методика из Википедии, предложенная выше, превосходит аппаратно-независимые подходы в силу того факта, что блок управления памятью может справиться с львиной долей логики циклического переноса за нас. Я был так воодушевлен этой идеей, что не стал проводить никаких дополнительных исследований и реализовал ее, основываясь только на кратком описании, приведенном выше.
В следующих двух разделах рассматривается конструкция кольцевого буфера и логика работы виртуальной памяти соответственно. Если вы не нуждаетесь в освежении этой информации, можете смело пропустить их.
Кольцевой буфер
Кольцевой (циклический) буфер — это удобный подход к хранению потоковых данных, которые создаются в реальном времени и вскоре после этого потребляются. Он «закольцован» для того, чтобы новые данные могли постоянно перезанимать пространство, ранее занимаемое данными, которые с тех пор уже были использованы.
Кольцевой буфер обычно инкрементируется посредством сохранения двух указателей (или индексов): указателя чтения (я назову его head — голова) и указателя записи (или tail — хвост). Очевидно, мы записываем в буфер по tail, а читаем из head. Структура может быть определена следующим образом:
typedef struct {
uint8_t *buffer;
size_t buffer_size;
size_t head;
size_t tail;
size_t bytes_avail;
} queue_t;Учитывая это, мы можем написать простые методы чтения (get) и записи (put), используя побайтовый доступ:
bool put(queue_t *q, uint8_t *data, size_t size) {
if(q->buffer_size - q->bytes_avail < size){
return false;
}
for(size_t i = 0; i < size; i++){
q->buffer[(q->tail + i) % q->buffer_size] = data[i];
}
q->tail = (q->tail + size) % q->buffer_size;
q->bytes_avail += size;
return true;
}
bool get(queue_t *q, uint8_t *data, size_t size) {
if(q->bytes_avail < size){
return false;
}
for(size_t i = 0; i < size; i++){
data[i] = q->buffer[(q->head + i) % q->buffer_size];
}
q->head = (q->head + size) % q->buffer_size;
q->bytes_avail -= size;
return true;
}Обратите внимание, что этот метод put идентичен приведенной ранее варианту, за исключением того, что мы теперь проверяем, что свободного места достаточно прежде чем пытаться писать. Я также намеренно пренебрег логикой синхронизации (которая была бы абсолютно необходима для любого реального применения кольцевого буфера).
Побайтовый тип доступа и модульная арифметика, встроенные в каждую итерацию цикла, делают этот код ужасающе медленным. Вместо этого мы можем реализовать каждую операцию чтения или записи через два вызова memcpy, где один обрабатывает часть сообщения в конце буфера, а другой обрабатывает часть в начале, если мы закольцевались.
static inline off_t min(off_t a, off_t b) {
return a < b ? a : b;
}
bool put(queue_t *q, uint8_t *data, size_t size) {
if(q->buffer_size - q->bytes_avail < size){
return false;
}
const size_t part1 = min(size, q->;buffer_size - q->;tail);
const size_t part2 = size - part1;
memcpy(q->;buffer + q->;tail, data, part1);
memcpy(q->;buffer, data + part1, part2);
q->;tail = (q->;tail + size) % q->;buffer_size;
q->;bytes_avail += size;
return true;
}
bool get(queue_t *q, uint8_t *data, size_t size) {
if(q->bytes_avail < size){
return false;
}
const size_t part1 = min(size, q->;buffer_size - q->;head);
const size_t part2 = size - part1;
memcpy(data, q->;buffer + q->;head, part1);
memcpy(data + part1, q->;buffer, part2);
q->;head = (q->;head + size) % q->;buffer_size;
q->;bytes_avail -= size;
return true;
}А вот пример использования этого кольцевого буфера:
int main() {
queue_t queue;
queue.buffer = malloc(128);
queue.buffer_size = 128;
queue.head = 0;
queue.tail = 0;
queue.bytes_avail = 0;
put(&q, "hello ", 6);
put(&q, "worldn", 7);
char s[13];
get(&q, (uint8_t *) s, 13);
printf(s); // prints "hello world"
}Наш код прост и отлично работает. Но почему бы не усложнить его немного?
Встречайте таблицу страниц
На заре персональных компьютеров компьютеры могли одновременно запускать только одну программу. Какую бы программу мы ни запустили, она будет иметь полный прямой доступ к физической памяти. Оказывается, если мы хотим запустить несколько программ вместе, они будут бороться за то, какие области этой памяти они хотят использовать. Решением этого конфликта является виртуальная память, благодаря которой каждая программа считает, что она контролирует всю память, но на самом деле операционная система решает, кто какую память получает.
Ключом к виртуальной памяти является таблица страниц, с помощью которой операционная система сообщает ЦП о сопоставлениях между виртуальными и физическими страницами. Страница — это непрерывная выровненная область памяти (обычно) фиксированного размера, скажем, около 4 КиБ. Когда программе требуется доступ к некоторой (виртуальной) памяти, ЦП определяет, какой странице она принадлежит, а затем использует таблицу страниц для индексации в физической памяти.
Таблица страниц для некоторой программы А может выглядеть следующим:
|
Номер виртуальной страницы |
Номер физической страницы |
|
0 |
null |
|
1 |
25 |
|
2 |
12 |
|
3 |
null |
|
4 |
56 |
|
… |
… |
B то же время, для программы B она могла бы выглядеть следующим:
|
Номер виртуальной страницы |
Номер физической страницы |
|
0 |
11 |
|
1 |
null |
|
2 |
92 |
|
3 |
21 |
|
4 |
null |
|
… |
… |
Ключевой момент заключается в том, что нет никакой закономерности или скрытого смысла в том, как физические страницы назначены виртуальным страницам. Они могут быть не упорядочены по отношению к виртуальным страницам, а некоторым виртуальным страницам вообще не требуется назначенная им физическая память. Обе наши программы могут использовать один и тот же номер виртуальной страницы для ссылки на разные физические страницы, и поэтому им не нужно беспокоиться о конфликте с памятью друг друга.
Подробности определения номеров страниц, выделения памяти и индексации в таблице страниц выходят за рамки этой статьи, но не являются необходимыми для понимания того, что будет изложено дальше.
Несколько обычных системных вызовов и один, о котором glibc не хотел бы, чтобы вы знали
Прежде чем приступить к использованию таблицы страниц для оптимизации нашего кольцевого буфера, давайте рассмотрим некоторые стандартные системные вызовы Linux.
|
Системный вызов |
Описание |
|
|
Возвращает количество байтов в странице памяти. (Технически не всегда системный вызов, но в любом случае где-то рядом) |
|
|
Устанавливает размер файла равным length, используя его файловый дескриптор |
|
|
Отображает файл, описанный |
А теперь менее распространенный системный вызов, который glibc (наш дружественный пользовательский интерфейс ядра) не предоставляет нам:
|
System Call Системный вызов |
Description Описание |
|
|
Возвращает файловый дескриптор анонимного файла (anonymous file), который существует только в памяти. |
Интересно! Поскольку glibc его не реализует, нам нужно будет написать небольшую обертку, если мы захотим его использовать.
int memfd_create(const char *name, unsigned int flags) {
return syscall(__NR_memfd_create, name, flags);
}Отлично, теперь мы сможем вызывать ее, как любую другую функцию. Это позволит нам выделить память и манипулировать ей как файлом. Поскольку она ведет себя как файл, мы сможем разместить ее в любом месте (внимание спойлер).
Жуткая черная магия взлома таблицы
Ну что ж, перейдем к делу. Давайте сделаем то, что сказано в Википедии, и сделаем так, чтобы две соседние страницы указывали на одну и ту же память. Нам нужно будет изменить структуру нашей очереди и расширить ее API удобным методом инициализации.
typedef struct {
uint8_t *buffer;
size_t buffer_size;
int fd;
size_t head;
size_t tail;
} queue_t;
bool init(queue *q, size_t size){
// Для начала убедимся, что размер кратен размеру страницы
if(size % getpagesize() != 0){
return 0;
}
//Создаем анонимный файл и устанавливаем его размер
q->;fd = memfd_create("queue_buffer", 0);
ftruncate(q->;fd, size);
// Запрашиваем у mmap адрес локации, где мы можем отобразить обе виртуальные копии буфера
q->;buffer = mmap(NULL, 2 * size, PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// Отображаем буфер по этому адресу
mmap(q->;buffer, size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED, q->;fd, 0);
// Теперь снова отображаем его на следующей виртуальной странице
mmap(q->;buffer + size, size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_FIXED, q->;fd, 0);
// Инициализируем индексы нашего буфера
q->;head = 0;
q->;tail = 0;
}
Хорошо, что тут происходит? Что ж, сначала мы вызываем memfd_create, который делает именно то, что написано на этикетке. Мы находим место для двух копий буфера и сохраняем его как адрес нашего буфера. Затем мы отображаем виртуальный файл в память по адресу, который нам дал mmap. После этого в игру вступает наша черная магия.
Мы просим mmap снова отобразить наш файл по адресу в size байтах после его исходного местоположения. Теперь таблица страниц будет выглядеть следующим образом (предполагается, что size больше одной страницы):
|
Виртуальный адрес |
Физический адрес |
|
… |
… |
|
|
анонимный файл |
|
|
анонимным файл |
|
… |
… |
|
|
анонимным файл |
|
|
анонимный файл |
|
… |
… |
Да, тут у нас по две виртуальные страницы, которые указывают на одну и ту же физическую страницу для каждой страницы в нашем буфере. Посмотрим, как это повлияет на нашу логику кольцевого буфера:
bool put(queue_t *q, uint8_t *data, size_t size) {
if(q->buffer_size - (q->tail - q->head) < size){
return false;
}
memcpy(&q->buffer[q->tail], data, size);
q->tail += size;
return true;
}
bool get(queue_t *q, uint8_t *data, size_t size) {
if(q->tail - q->head < size){
return false;
}
memcpy(data, &q->buffer[q->head], size);
q->head += size;
if(q->head > q->buffer_size) {
q->head -= q->buffer_size;
q->tail -= q->buffer_size;
}
return true;
}
Мы позволяем нашему tail-смещению продвигаться во вторую область виртуальной памяти за пределы «реального» буфера. Однако он по-прежнему записывает в ту же физическую память. Точно так же мы можем читать за пределами первой области, а перейдя во вторую область, мы в конечном итоге читаем ту же физическую память, как если бы мы вручную закольцевали ее.
Обратите внимание, что нам нужно делать только один вызов memcpy вместо двух. После чтения данных мы проверяем, что указатель head не переместился во вторую виртуальную копию буфера. Если он все же переместился, мы можем уменьшить оба значения на размер буфера; они будут указывать на одну и ту же физическую память, хотя виртуальные адреса будут разными. API остался прежним.
Насколько это хорошо?
Ключевое отличие здесь в том, что мы можем всегда получить доступ к непрерывным блокам виртуальной памяти, вместо того, чтобы беспокоиться о переносе в середине сообщения. Мы можем написать простой микро-бенчмарк, который проверит эту логику следующим образом:
#include <stdio.h>
#include <string.h>
#include <stdint.h>
#include <sys/time.h>
#define BUFFER_SIZE (1024)
#define MESSAGE_SIZE (32)
#define NUMBER_RUNS (1000000)
static inline double microtime() {
struct timeval tv;
gettimeofday(&tv, NULL);
return 1e6 * tv.tv_sec + tv.tv_usec;
}
static inline off_t min(off_t a, off_t b) {
return a < b ? a : b;
}
int main() {
uint8_t message[MESSAGE_SIZE];
uint8_t buffer[2 * BUFFER_SIZE];
size_t offset;
double slow_start = microtime();
offset = 0;
for(int i = 0; i < NUMBER_RUNS; i++){
const size_t part1 = min(MESSAGE_SIZE, BUFFER_SIZE - offset);
const size_t part2 = MESSAGE_SIZE - part1;
memcpy(buffer + offset, message, part1);
memcpy(buffer, message + part1, part2);
offset = (offset + MESSAGE_SIZE) % BUFFER_SIZE;
}
double slow_stop = microtime();
double fast_start = microtime();
offset = 0;
for(int i = 0; i < NUMBER_RUNS; i++){
memcpy(&buffer[offset], message, MESSAGE_SIZE);
offset = (offset + MESSAGE_SIZE) % BUFFER_SIZE;
}
double fast_stop = microtime();
printf("slow: %f microseconds per writen", (slow_stop - slow_start) / NUMBER_RUNS);
printf("fast: %f microseconds per writen", (fast_stop - fast_start) / NUMBER_RUNS);
return 0;
}
На моем i5-6400 я получаю довольно единообразные результаты, выглядящие примерно так:
slow: 0.012196 microseconds per write
fast: 0.004024 microseconds per writeОбратите внимание, что код с одним memcpy примерно в три раза быстрее, чем код с двумя memcpy. У нас гораздо большее преимущество по сравнению с наивным побайтовым копированием, которое составило 0,104943 микросекунды на запись. Этот микро-бенчмарк не полностью отражает всю логику очереди (на которую могут влиять такие условия, как сбои страниц и промахи TLB), однако дает нам хорошее указание на то, что наша оптимизация была успешной.
Что только что произошло?
Судя по всему, этот трюк давно известен, но используется редко. Тем не менее, это отличный пример использования низкоуровневого поведения машины для оптимизации программного обеспечения.
Если вам интересно увидеть мою полную реализацию кольцевого буфера, вы можете найти ее на GitHub. В этой версии есть синхронизация, проверка ошибок и доступ к деталям сообщений произвольного размера.
В преддверии старта онлайн-курса «Программист С» приглашаем всех желающих на открытый демо-урок «Жизненный цикл программы на C под UNIX». На этом вебинаре мы рассмотрим полный жизненный цикл программы на языке C под UNIX-подобной ОС на примере системы из семейства BSD. Начнём с исходного кода и закончим загрузкой готового выполняемого файла. По ходу дела посмотрим «под капот» различным низкоуровневым механизмам операционной системы и тулчейна компиляции и познакомимся с инструментарием UNIX для анализа программ. Присоединяйтесь!
— Узнать подробнее о курсе «Программист С»
— Смотреть вебинар «Жизненный цикл программы на C под UNIX»
Делаем простой и универсальный кольцевой буфер.
Делаем простой кольцевой буфер
Постоянно приходится передавать и принимать данные из/в UART, SPI, I2C и др. Всё просто и понятно когда посылки идут редко и есть время на их обработку, а что же делать если посылки могут идти пачками за один раз, а потом долгое время отсутствовать и мы при обработке первой не успеваем обрабатывать остальные и они теряются или портятся. Значит нужно использовать какой-то буфер, откуда потом понемногу брать и обрабатывать данные, а что делать если мы уже заполнили буфер и нам уже некуда писать? Писать дальше начиная с первого (на самом деле с нулевого) элемента буфера, дополнительно нужно учитывать место с которого можно читать данные и место с которого можно писать. Вот мы и получаем наш кольцевой буфер.
И так, мы уже определились, что нам нужно для нашего буфера, поэтому создадим структуру и определим её поля в соответствии с их предназначением:
typedef struct
{
uint8_t buffer[SIZE];
uint16_t idxIn;
uint16_t idxOut;
} RING_buffer_t;Теперь появляется вопрос, а каким же размером должен быть наш буфер, ведь для одной задачи может хватить 10, а для другой и 256 не хватит, мы же хотим сделать себе простой и удобный буфер на все случаи жизни? Значит нужно определять размерность как-то иначе, пожалуй выделим память статически и отдадим указатель на неё, а саму нашу структуру немного изменим.
typedef struct
{
uint8_t *buffer;
uint16_t idxIn;
uint16_t idxOut;
uint16_t size;
} RING_buffer_t;Теперь buffer у нас стал указателем и добавилось новое поле size, пусть будет 16 разрядным, не думаю, что для простого обмена по UART может понадобиться буфер размером в 65 кбайт, а если понадобиться, значит стоит задуматься, возможно что-то делаем не так.
Теперь осталось определиться с функционалом нашего буфера, а именно, что мы можем с ним делать:
- Добавлять данные (побайтно);
- Забирать данные.
Еще хорошо бы иметь возможность:
- Узнать сколько у нас полезных даных;
- Подсмотреть какой-то байт в буфере;
- Очистить буфер;
- Инициализировать.
Описание функций
Пожалуй сразу сделаем прототипы наших функций:
void RING_Put(uint8_t symbol, RING_buffer_t* buf);
uint8_t RING_Pop(RING_buffer_t *buf);
uint16_t RING_GetCount(RING_buffer_t *buf);
int32_t RING_ShowSymbol(uint16_t symbolNumber ,RING_buffer_t *buf);
void RING_Clear(RING_buffer_t* buf);
RING_ErrorStatus_t RING_Init(RING_buffer_t *ring, uint8_t *buf, uint16_t size);Добавить данные.
Для добавления данных нужно сделать несколько действий. Само добавление и изменение поля idxIn, что бы значть куда писать в следующий раз, попутно исключить ситуазию выхода за границу массива (buf->idxIn >= buf->size). Код функции будет следующим:
void RING_Put(uint8_t symbol, RING_buffer_t* buf)
{
buf->buffer[buf->idxIn++] = symbol;
if (buf->idxIn >= buf->size) buf->idxIn = 0;
}Функция принимает два аргумента. Первый — само значние, второй указатель на переменную типа RING_buffer_t (типа нашей структуры). Второй аргумент добавлен для универсальности, очень часто, я бы сказал, что в более половины случаях необходим буфер и на приём и на передачу данных, иногда и на нескоько таких каналов приёма передачи.
Получить данные.
Объяснять лишнего не буду, смысл такой же, только данные не записываются, а читаются,и меняется другое поле idxOut. Соответственно обрабатывается выход его за границы массива.
uint8_t RING_Pop(RING_buffer_t *buf)
{
uint8_t retval = buf->buffer[buf->idxOut++];
if (buf->idxOut >= buf->size) buf->idxOut = 0;
return retval;
}Узнаём сколько у нас полезных данных.
Здесь на первый взгляд всё просто. Нужно из конца (место откуда пишем) вычесть начало (место откуда читаем), оно так только о одном случае, если у нас указатель на запись стоит после указателя на чтение. Если это не так, то мы получим не правильный ответ, тут логика немного сложнее, но не сильно. Предлагаю взглянуть на код и разобраться самостоятельно.
uint16_t RING_GetCount(RING_buffer_t *buf)
{
uint16_t retval = 0;
if (buf->idxIn < buf->idxOut) retval = buf->size + buf->idxIn - buf->idxOut;
else retval = buf->idxIn - buf->idxOut;
return retval;
}Подсматриваем байт.
Функция RING_Pop меняет указатель на место чтения, по сути удаляя прочитанный элемент, н оиногда требуется просто посмотреть значение без его удаления, тогда делаем так.
int32_t RING_ShowSymbol(uint16_t symbolNumber ,RING_buffer_t *buf)
{
uint32_t pointer = buf->idxOut + symbolNumber;
int32_t retval = -1;
if (symbolNumber < RING_GetCount(buf))
{
if (pointer > buf->size) pointer -= buf->size;
retval = buf->buffer[ pointer ] ;
}
return retval;
}Здесь symbolNumber — это смещение относительно начала буфера (точки для чтения). Если вы внимательно читали код, то заметили что эта функция в отличии от RING_Pop имеет знаковый 32-х битный тип данных (int32_t) это сделано для того, что бы мы в последствии могли определить, а не пытаемся ли мы подсмотреть ячейку которой не существует, если да, то функция вернёт -1, в случае правильного выбора номера элемента мы получим его значение.
Очистить буфер.
Нет, мы не будем забивать весь массив нулями или чем-либо ещё, это не нужно. Достаточно просто обнулить указатели на чтение и запись.
void RING_Clear(RING_buffer_t* buf)
{
buf->idxIn = 0;
buf->idxOut = 0;
}Инициализация буфера.
RING_ErrorStatus_t RING_Init(RING_buffer_t *ring, uint8_t *buf, uint16_t size)
{
ring->size = size;
ring->buffer = buf;
RING_Clear( ring );
return ( ring->buffer ? RING_SUCCESS : RING_ERROR ) ;
}Как этим пользоваться
Расположеный ниже код носит только ознакомитеьный характер
Шаг первый.
Необходимо определить переменную типа RING_buffer_t и инициализировать размер буфера.
RING_buffer_t ring_Rx;
int main( void )
{
RING_Init(&ring_Rx, 256); // Пусть будет 256 байт - 0..255!
}Шаг второй.
Добавляем элементы в буфер, например в прерывании от UART.
void USART2_IRQHandler(void)
{
USART_ClearITPendingBit(USART2, USART_IT_RXNE);
RING_Put(USART_ReceiveData(USART2), &ring_Rx);
data.flag_off = false;
}Шаг третий.
Обрабатываем полученные данные, тут позволю чистателю самому придумать реализацию.
Где взять исходнии? Или нужно самому всё писать?
Конечно же лучше написать всё самостоятельно, так можно и получше разобраться и возможно найти косяки в моём коде.
Особо ленивые могут заглянуть на gitlab или скачать мой пакет для keil, в котором есть этот модуль — devprodest.Lib.pack.
Ну и так, как я не считаю лень плохим качеством, по ссылкам можно получить бонус в виде вычисления CRC16 ccitt для кольцевого буфера.
А для совсем уж ленивых вот оно:
uint16_t RING_CRC16ccitt(RING_buffer_t *buf, uint16_t lenght, uint16_t position)
{
return RING_CRC16ccitt_Intermediate( buf, lenght, 0xFFFF, position);
}
uint16_t RING_CRC16ccitt_Intermediate(RING_buffer_t *buf, uint16_t lenght, uint16_t tmpCrc, uint16_t position)
{
uint16_t crc = tmpCrc;
uint16_t crctab;
uint8_t byte;
while (lenght--)
{
crctab = 0x0000;
byte = (RING_ShowSymbol(lenght + position, buf))^( crc >> 8 );
if( byte & 0x01 ) crctab ^= 0x1021;
if( byte & 0x02 ) crctab ^= 0x2042;
if( byte & 0x04 ) crctab ^= 0x4084;
if( byte & 0x08 ) crctab ^= 0x8108;
if( byte & 0x10 ) crctab ^= 0x1231;
if( byte & 0x20 ) crctab ^= 0x2462;
if( byte & 0x40 ) crctab ^= 0x48C4;
if( byte & 0x80 ) crctab ^= 0x9188;
crc = ( ( (crc & 0xFF)^(crctab >> 8) ) << 8 ) | ( crctab & 0xFF );
}
return crc;
}UPD Со времени публикации версия на gitlab изменилась, будьте внимательны.
Кольцевой буфер — это фиксированная очередь типа FIFO (акроним First In, First Out — «первым пришёл — первым ушёл»). Пространства в буфере можно рассматривать как связанные в кольцо. Элементы в буфере никогда не перемещаются. Вместо этого используются переменные указатели для идентификации головы и хвоста очереди.
Что такое кольцевой буфер?
Круговой буфер, также известный как круговая очередь или циркулярный буфер, представляет собой высокопроизводительную очередь FIFO. Как и в случае любого другого типа очереди, значения могут быть добавлены в конец очереди и извлечены с самого начала, так что элементы будут выгружены в том же порядке, в котором они были установлены в очередь.
В некоторых структурах очередей, когда элементы добавляются или удаляются, содержимое очереди физически перемещается в памяти. С круглым буфером позиции фиксированы. Голова и хвост очереди идентифицируются с помощью двух указателей, которые обновляются, когда элементы добавляются или удаляются. Кроме того, буферные пространства можно рассматривать как циклические. После использования последнего пробела в буфере, следующий элемент в очереди сохраняется в первом пространстве. На приведенной ниже диаграмме показана концептуальная модель кольцевого буфера.
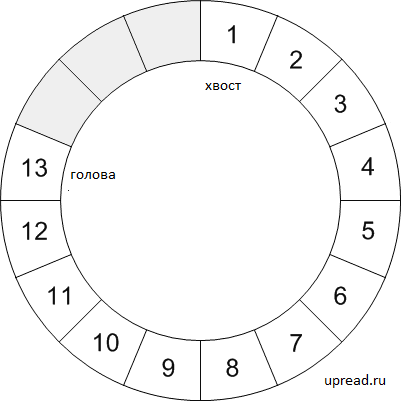
Диаграмма представляет собой круговой буфер с шестнадцатью пробелами, тринадцать из которых используются. В этом случае значения от одного до тринадцати были добавлены по порядку. Голова очереди указывает на последнее значение, тринадцать, а хвост находится в пространстве, содержащем номер один. Когда следующий элемент будет выставлен в очередь, он будет добавлен в следующее доступное пустое пространство после тринадцати, и указатель на голову будет смещен, чтобы указать на эту позицию. Когда будет выполняться следующая операция декомпрессии, номер один в указателе хвоста будет извлечен, а хвост будет перемещаться по часовой стрелке на одно место. При удалении объекта нет необходимости очищать старое буферное пространство, поскольку значение будет перезаписано в какой-то момент в будущем.
Природа кругового буфера такова, что голова очереди может поймать хвост. Когда следующий элемент, который должен быть установлен в очередь, перезаписывает элемент хвоста, есть несколько возможных действий. Наиболее распространенными являются:
- Разрешить новому элементу перезаписывать элемент хвоста, перемещая указатель хвоста вперед, чтобы указать на следующий самый старый предмет. Этот подход полезен для обработки сигналов в реальном времени. Например, при применении фильтра к видеопотоку. Если хвост очереди перезаписан, это может вызвать «блики» в видео или мгновенную потерю качества, но может позволить выходному видео продолжить воспроизведение без паузы или замедления.
- Выбросьте исключение при попытке добавить в полную очередь или прочитать из пустого буфера. Это гарантирует, что никакие данные не будут потеряны, но менее полезны для очередей в режиме реального времени или где скорость постановки в очередь и извлечение из очереди неодинаковы.
- Блокируйте поток при попытке добавить в полную очередь или прочитать из пустой очереди. Как и при ловле исключений, это гарантирует, что данные не будут потеряны. Это полезно в параллельных приложениях, когда отдельные потоки используются для очереди и деоккуляции. Только один из двух потоков может быть заблокирован в любое время, и исключений не будет, поэтому очередь может использоваться для обработки больших потоков данных без риска сбоя.
В этой статье мы реализуем первый вариант. При добавлении в полную очередь самый старый элемент в буфере будет перезаписан. При удалении из пустого буфера мы выставим исключение. Код может быть легко изменен для других сценариев.
Реализация кругового буфера
Мы можем начать с создания класса для кольцевого буфера. Чтобы позволить буферу хранить данные любого типа, мы объявим его как общий класс с параметром одного типа.
public class CircularBuffer<T>
{
}
Далее нам понадобятся несколько переменных уровня класса. Во-первых, нам нужно где-то хранить данные буфера. Для этого мы будем использовать массив типа, определенного в параметре type. Мы будем использовать два целых значения в качестве указателей на голову и хвост. Они будут содержать значения индекса для массива буфера. Два дополнительных целых числа будут содержать текущую длину очереди и размер буфера. Они будут использоваться при определении того, полностью ли заполнен или пуст буфер. Наконец, чтобы предотвратить ошибки синхронизации, если несколько потоков пытаются в очереди или деактивировать одновременно, мы создадим объект для управления блокировками.
Код для переменных уровня класса выглядит следующим образом:
T [] _buffer; Int _head; Int _tail; Int _length; Int _bufferSize; Object _lock = new object ();
Добавление конструктора
Когда экземпляр объекта CircularBuffer создается, мы инициализируем буфер и указатель на голову с помощью конструктора. Конструктор включает в себя единственный параметр, который позволяет указать размер буфера. Это сохраняется и используется для инициализации массива. Указатель на голове установлен на последний элемент массива. Когда первый элемент находится в очереди, указатель будет перемещен вперед к первому элементу перед сохранением, после чего значения головы и хвоста будут равны нулю.
public CircularBuffer(int bufferSize)
{
_buffer = new T[bufferSize];
_bufferSize = bufferSize;
_head = bufferSize - 1;
}
Добавление флагов статуса очереди
При работе с очередью нам нужно знать, когда буфер заполнен или пуст. Эта информация также может быть полезна для пользователей класса, поэтому мы создадим два булевых свойства, которые указывают эти статусы. Очередь пуста, когда текущая длина равна нулю и заполняется, когда текущая длина совпадает с размером буфера.
Код для этого выглядит следующим образом:
public bool IsEmpty
{
get { return _length == 0; }
}
public bool IsFull
{
get { return _length == _bufferSize; }
}
Извлекаемые значения
Теперь мы можем добавить метод Dequeue, который извлекает и возвращает самый старый элемент из буфера. Это простой процесс, который состоит из нескольких шагов. Во-первых, если очередь пуста, мы генерируем исключение. Это не позволяет потребителям загружать слишком много элементов, что может привести к возврату данных, которые были предварительно удалены или извлечены из пустых пространств буфера.
Затем мы получаем значение массива в позиции хвоста, которое будет возвращено в конце процесса. Далее мы продвигаем хвост на одно пространство, увеличивая значение индекса. Если указатель достигает размера буфера, мы возвращаем его в ноль, чтобы следить за циклическим характером структуры данных. В коде это достигается с помощью оператора модуля. Продвижение определяется в отдельном методе NextPosition, поскольку эта функциональность будет повторно использоваться. Поскольку количество элементов в буфере теперь меньше, мы уменьшаем переменную длины до правильного значения.
Код метода показан ниже. Обратите внимание, что добавлена блокировка, чтобы гарантировать, что указатели не могут быть изменены другим процессом.
public T Dequeue()
{
lock (_lock)
{
if (IsEmpty) throw new InvalidOperationException("Queue exhausted");
T dequeued = _buffer[_tail];
_tail = NextPosition(_tail);
_length--;
return dequeued;
}
}
private int NextPosition(int position)
{
return (position + 1) % _bufferSize;
}
Значения очереди
Последний способ реализации позволяет организовать очередность новых значений. Когда элемент добавляется в очередь, мы сначала указываем указатель на голову и сохраняем новое значение в новом индексе. Это означает, что указатель всегда указывает положение нового элемента в очереди. Если очередь уже заполнена, это перезапишет самое старое значение в буфере, чтобы мы продвинули позицию хвоста, чтобы указать на следующий элемент, который теперь является самым старым. Если буфер еще не заполнен, индекс хвоста остается неизменным, а текущая длина увеличивается.
public void Enqueue(T toAdd)
{
lock (_lock)
{
_head = NextPosition(_head);
_buffer[_head] = toAdd;
if (IsFull)
_tail = NextPosition(_tail);
else
_length++;
}
}
Использование кольцевого буфера
Теперь мы можем протестировать круговой буфер, запустив и сняв с охраны предметы. Для первого теста попробуйте код, показанный ниже. Он создает небольшой буфер с пятью целыми числами. Пять значений помещаются в очередь, а затем удаляются, показывая, что порядок элементов сохранен.
CircularBuffer<int> queue = new CircularBuffer<int>(5);
queue.Enqueue(1);
queue.Enqueue(2);
queue.Enqueue(3);
queue.Enqueue(4);
queue.Enqueue(5);
while (!queue.IsEmpty)
{
Console.WriteLine("Dequeued {0}", queue.Dequeue());
}
/*Вывод
Dequeued 1
Dequeued 2
Dequeued 3
Dequeued 4
Dequeued 5
*/
Второй пример показывает, что происходит, когда емкость очереди превышена. Здесь шесть элементов добавляются в очередь, которая может содержать только пять. При удалении мы видим, что самый старый элемент был отброшен.
CircularBuffer<int> queue = new CircularBuffer<int>(5);
queue.Enqueue(1);
queue.Enqueue(2);
queue.Enqueue(3);
queue.Enqueue(4);
queue.Enqueue(5);
queue.Enqueue(6);
queue.Enqueue(7);
while (!queue.IsEmpty)
{
Console.WriteLine("Dequeued {0}", queue.Dequeue());
}
/* Вывод
Dequeued 3
Dequeued 4
Dequeued 5
Dequeued 6
Dequeued 7
*/
Если статья оказалась вам полезна, то я не откажусь от благодарности в денежном эквиваленте.
Если вам что-то непонятно, то вы всегда можете написать мне на почту up777up@yandex.ru – за небольшую плату вам будет оказана квалифицированная помощь по алгоритмам, структурам данных или любым другим областям теоретического и практического программирования на C# (.NET). Также я могу предложить вам свои услуги по программированию и на других языках: C++, Java, PHP, JavaScript.

Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
![]() статьи IT, си шарп, стек, буфер, теория программирования
статьи IT, си шарп, стек, буфер, теория программирования
Простое FIFO
Столкнулся с интересной реализацией циклического буфера на Си, поначалу даже подумал, что этот код не работает, но разобравшись, решил использовать в своих проектах.
Весь код реализован в виде defin’ов и содержится в одном заголовочном файле fifo.h
#ifndef FIFO__H #define FIFO__H //размер должен быть степенью двойки: 4,8,16,32...128 #define FIFO( size ) struct { unsigned char buf[size]; unsigned char tail; unsigned char head; } //количество элементов в очереди #define FIFO_COUNT(fifo) (fifo.head-fifo.tail) //размер fifo #define FIFO_SIZE(fifo) ( sizeof(fifo.buf)/sizeof(fifo.buf[0]) ) //fifo заполнено? #define FIFO_IS_FULL(fifo) (FIFO_COUNT(fifo)==FIFO_SIZE(fifo)) //fifo пусто? #define FIFO_IS_EMPTY(fifo) (fifo.tail==fifo.head) //количество свободного места в fifo #define FIFO_SPACE(fifo) (FIFO_SIZE(fifo)-FIFO_COUNT(fifo)) //поместить элемент в fifo #define FIFO_PUSH(fifo, byte) { fifo.buf[fifo.head & (FIFO_SIZE(fifo)-1)]=byte; fifo.head++; } //взять первый элемент из fifo #define FIFO_FRONT(fifo) (fifo.buf[fifo.tail & (FIFO_SIZE(fifo)-1)]) //уменьшить количество элементов в очереди #define FIFO_POP(fifo) { fifo.tail++; } //очистить fifo #define FIFO_FLUSH(fifo) { fifo.tail=0; fifo.head=0; } #endif //FIFO__H
Update:
Что бы использовать этот код для fifo c размером 256 и более, надо для head и tail поменять тип c unsigned char на unsigned short.
Запись опубликована в рубрике Великий и могучий Си с метками fifo, Си. Добавьте в закладки постоянную ссылку.
Фундаментальная вещь организации любой цифровой системы — буферы. Они используются везде: память, шины, сети, алгоритмы. Рассмотрим реализацию такого буфера на языке Си для использования в своих проектах.

Function Reference
Как обычно, методы возвращают статусы:
typedef enum RINGBUF_STATUS {
RINGBUF_OK, ///< Успех
RINGBUF_ERR, ///< Ошибка
RINGBUF_PARAM_ERR, ///< Ошибка в аргументах
RINGBUF_OVERFLOW, ///< Попытка записи > буфера
} RINGBUF_STATUS;Сам буфер инициализируется через структуру:
typedef struct RINGBUF_t {
u8_t *buf; ///< Указатель на буфер
volatile size_t tail; ///< Точка чтения [ячейка]
volatile size_t head; ///< Точка записи [ячейка]
volatile size_t size; ///< Размер буфера [ячейка]
volatile size_t cell_size; ///< Размер одной ячейки [байт]
} RINGBUF_t;Описание методов:
(Описание аргументов представлено в DoxyGen-формате в .с-файле)
/* Главные методы */
// Инициализация буфера
RINGBUF_STATUS RingBuf_Init(void *buf, u16_t size, size_t cellsize, RINGBUF_t *rb);
// Очистка буфера
RINGBUF_STATUS RingBuf_Clear(RINGBUF_t *rb);
// Считать количество доступных для чтения ячеек
RINGBUF_STATUS RingBuf_Available(u16_t *len, RINGBUF_t *rb);
/* Запись */
// Записать 1 байт в буфер
RINGBUF_STATUS RingBuf_BytePut(const u8_t data, RINGBUF_t *rb);
// Записать 1 ячейку заданного размера в буфер
RINGBUF_STATUS RingBuf_CellPut(const void *data, RINGBUF_t *rb);
// Записать произвольное количество данных в буфер
RINGBUF_STATUS RingBuf_DataPut(const void *data, u16_t len, RINGBUF_t *rb);
/* Чтение (Считывание и очистка) */
// Прочесть 1 байт
RINGBUF_STATUS RingBuf_ByteRead(u8_t *data, RINGBUF_t *rb);
// Прочесть 1 ячейку заданного размера
RINGBUF_STATUS RingBuf_CellRead(void *data, RINGBUF_t *rb);
// Прочесть произвольное количество данных
RINGBUF_STATUS RingBuf_DataRead(void *data, u16_t len, RINGBUF_t *rb);
/* Просмотр (Считывание без очистки) */
// Подсмотреть 1 байт
RINGBUF_STATUS RingBuf_ByteWatch(u8_t *data, RINGBUF_t *rb);
// Подсмотреть 1 ячейку заданного размера
RINGBUF_STATUS RingBuf_CellWatch(void *data, RINGBUF_t *rb);
// Подсмотреть произвольное количество данных
RINGBUF_STATUS RingBuf_DataWatch(void *data, u16_t len, RINGBUF_t *rb);Принцип кольцевого буфера
Кольцевые буферы по умолчанию строятся по топологии “FIFO”.
Это один из способов организации данных. Ещё он называется очередью.
FIFO расшифровывается как “First Input — First Output”. Первым вошёл — первым вышел.
Другой способ — “LIFO” или стек. Last input, first output — последним вошёл — первым вышел.
Практически применение закольцованности для LIFO бессмысленно, по крайней мере я ни разу такого не встречал.
LIFO применяется в алгоритмах, например DFS.
Также стек применяется для низкоуровневых задач, таких как стек вызовов подпрограмм или прерываний.
Гипотетически, все нижеописанные выкладки и рассуждения подходят для реализации LIFO.
Суть FIFO в том, что те данные, которые первыми записали, первыми и должны быть считаны.
Проще представить это схематично.
Представим себе мусоропровод. Это такая труба для мусора в многоквартирных домах, с люками на каждом этаже.
(Такую аналогию я в сети ещё не встречал)
В начальный момент времени он пуст. Мы кинули туда мешок, то есть некоторый пакет данных.

Остальные жильцы в течение дня накидали ещё мусора. Образовалась горочка. Ну, предположим, 5 пакетов. Пришла уборщица, открыла люк, мешки посыпались. Какой мешок выпадет первым? Правильно. Наш первый. Далее вывалится мешок жильца №2, затем жильца №3, и так далее…

А теперь представим, что уборщица вовремя не собирает мусор, труба мусоропровода забилась. Вызвали аварийную бригаду из ЖЭКа, доблестный Жека прочистил трубу, она вновь доступна для жильцов.
Это и есть закольцованность FIFO буфера. Некоторое допущение, которое позволяет потеряться данным, но которое всегда оставляет возможность для записи новых, релевантных данных.
FIFO блокируется при переполнении, в отличие от кольцевого буфера
Какое этому применение?
В любых асинхронных процессах, например для шины USB, или для приёма данных по UART, требуется своевременно обрабатывать принятые данные.
Так как посылки могут прийти в любой момент, а контроллер в это время может заниматься более приоритетными задачами, вызывается быстрое прерывание, которое лишь перекладывает данные из одного буфера в другой.
Таким образом, когда придёт время обработать шину, программа обратится к долгосрочному буферу, который обеспечит обработку данных так, как будто они были получены в реальном времени.
Реализация в языке
Читатель может задаться вопросом: зачем же прописывать всё это руками, если это есть почти в любом языке?
Ответ прост: в языке Си, основном для разработки для микроконтроллеров, всего этого нет.
На мой взгляд, для создания высокоэффективных систем, в целях максимальной оптимизации, разработчик обязан “прощупать” всё своими руками. Тем более, что подобные вещи пишутся один раз, и применяются во всех последующих проектах.
Это есть в том же C++, но там подобные структуры — динамические. Для нашей крохотной относительно ПК ОЗУ динамическая память — зло злющее.
Сначала поймём, как представить эту очередь в памяти. Естественно, делать это будем с помощью массива. Он будет хранилищем данных. Создадим ещё 2 переменные — некоторые счётчики. В них будут лежать индексы чтения и записи.

Создадим также методы. Основные:
- Чтение
- Запись
- Размер (ячеек для чтения)
- Очистка
Так как буферов может использоваться несколько, используем структурный подход. В структуре будут лежать:
- Массив данных — а лучше указатель на выделенное пространство памяти
- Размер этого массива
- Точка записи или head
- Точка чтения или tail
В каждый метод будем передавать указатель на instance структуры. То есть сами методы будут реализовывать лишь логику.
Начнём с размера. Количество доступных для чтения ячеек считается так: tail-head. Всё просто. Самое главное — проверить, если tail > head, то нужно учесть ещё и размер всего буфера.

Операция записи: положили данные, начиная с head, прибавили head.

Операция чтения: считали данные, начиная с tail, прибавили tail.

Теперь можно писать саму реализацию. Пример можно найти на GitHub.
В своём фирменном стиле я использовал ещё и статусы, но в вашем коде это совершенно необязательно.
Благодарность можно оставить тут.
Ссылки
- https://www.geeksforgeeks.org/fifo-first-in-first-out-approach-in-programming/
- https://cdeblog.ru/simple-ring-buffer
- https://livepcwiki.ru/wiki/Circular_buffer