Время на прочтение
21 мин
Количество просмотров 32K
Привет всем!
Я учу английский и всячески упрощаю этот процесс. Как-то мне потребовалось получить список слов вместе с переводом и транскрипцией для определенного текста. Задача не была сложной, и я принялась за дело. Чуть позднее был написан скрипт на python, все это умеющий, и даже умеющий чуть больше, поскольку мне захотелось получить еще и частотный словарь из всех файлов с английским текстом внутри. Так вышел маленький набор скриптов, о котором я и хотела бы рассказать.
Работа скрипта заключается в распарсивании файлов, выделении английских слов, нормализации их, подсчете и выдачи первыx countWord слов из всего получившегося списка английских слов.
В итоговом файле слово записывается в виде:
[число повторений] [само слово] [перевод слова]
О чем будет дальше:
- Мы начнем с получения списка английских слов из файла (используя регулярные выражения);
- Дальше начнем нормализовывать слова, то есть приводить их с естественной формы в тот вид, в котором они хранятся в словарях (тут мы немного изучим формат WordNet);
- Затем мы подсчитаем количество вхождений у всех нормализованных слов (это быстро и просто);
- Дальше мы углубимся в формат StarDict, потому что именно с помощью него получим переводы и транскрипцию.
- Ну и в самом конце мы куда-нибудь запишем результат (я выбрала файл формата Excel).
Я использовала python 3.3 и надо сказать не один раз пожалела, что не пишу на python 2.7, поскольку часто не хватало нужных модулей.
Частотный анализатор.
Итак, начнем с простого, получим файлы, распарсим их на слова, подсчитаем, отсортируем, и выдадим результат.
Для начала составим регулярное выражение для поиска английских слов в тексте.
Регулярное выражение для поиска английских слов
Простое английское слово, например «over», можно найти, используя выражение «([a-zA-Z]+)» — здесь ищется одна или более букв английского алфавита.
Составное слово, к примеру «commander-in-chief», найти несколько сложнее, нам нужно искать идущие друг за другом подвыражения вида «commander-», «in-», после которых идет слово «chief». Регулярное выражение примет вид «(([a-zA-Z]+-?)*[a-zA-Z]+)».
Если в выражении присутсвует промежуточное подвыражение, оно тоже включается в результат. Так, в наш результат попадает не только слово «commander-in-chief», но также и все найденные подвыражения, Чтобы их исключить, добавим в начале подвыражеения ‘?:‘ стразу после открывающейся круглой скобки. Тогда регулярное выражение примет вид «((?:[a-zA-Z]+-?)*[a-zA-Z]+)». Нам еще осталось включить в выражения слова с апострофом вида «didn’t». Для этого заменим в первом подвыражении «-?» на «[-‘]?».
Все, на этом закончим улучшения регулярного выражения, его можно было бы улучшать и дальше, но остановимся на таком:
«((?:[a-zA-Z]+[-‘]?)*[a-zA-Z]+)»
Реализация частотного анализатора английских слов
Напишем маленький класс, умеющий извлекать английские слова, считать их и выдавать результат.
# -*- coding: utf-8 -*-
import re
import os
from collections import Counter
class FrequencyDict:
def __init__():
# Определяем регулярное выражение для поиска английских слов
self.wordPattern = re.compile("((?:[a-zA-Z]+[-']?)*[a-zA-Z]+)")
# Частотный словарь(использум класс collections.Counter для поддержки подсчёта уникальных элементов в последовательностях)
self.frequencyDict = Counter()
# Метод парсит файл, получает из него слова
def ParseBook(self, file):
if file.endswith(".txt"):
self.__ParseTxtFile(file, self.__FindWordsFromContent)
else:
print('Warning: The file format is not supported: "%s"' %file)
# Метод парсит файл в формате txt
def __ParseTxtFile(self, txtFile, contentHandler):
try:
with open(txtFile, 'rU') as file:
for line in file: # Читаем файл построчно
contentHandler(line) # Для каждой строки вызываем обработчик контента
except Exception as e:
print('Error parsing "%s"' % txtFile, e)
# Метод находит в строке слова согласно своим правилам и затем добавляет в частотный словарь
def __FindWordsFromContent(self, content):
result = self.wordPattern.findall(content) # В строке найдем список английских слов
for word in result:
word = word.lower() # Приводим слово к нижнему регистру
self.frequencyDict[word] += 1 # Добавляем в счетчик частотного словаря не нормализованное слово
# Метод отдает первые countWord слов частотного словаря, отсортированные по ключу и значению
def FindMostCommonElements(self, countWord):
dict = list(self.frequencyDict.items())
dict.sort(key=lambda t: t[0])
dict.sort(key=lambda t: t[1], reverse = True)
return dict[0 : int(countWord)]
На этом, в сущности, работа с частотным словарем могла бы быть и закончена, но наша работа только начинается. Все дело в том, что слова в тексте пишутся с учетом грамматических правил, а это значит, что в тексте могут встретиться слова с окончаниями ed, ing и тд. По сути, даже формы глагола to be ( am, is, are) будут засчитываться за разные слова.
Значит до того, как слово будет добавлено в счетчик слов, нужно привести его к правильной форме.
Переходим ко второй части — написанию нормализатора английских слов.
Лемматизатор английских слов
Существуют два алгоритма — стемминг и лемматизация. Стемминг относится к эвристическому анализу, в нем не используются какие-либо базы. При лемматизации используются различные базы слов, а также применяются преобразования согласно грамматическим правилам. Мы для наших целей будем использовать лемматизацию, поскольку погрешность результата намного меньше, чем при стемминге.
Про лемматизацию уже было несколько статей на хабре, например вот и вот. Они используют базы aot. Мне не хотелось повторяться, а также было интересно поискать какие-нибудь другие базы для лемматизации. Я хотела бы рассказать про WordNet, на нем лемматизатор мы и построим. Начну с того, что на официальном сайте WordNet можно скачать исходники программы и сами базы данных. WordNet умеет очень много, но нам потребуется лишь малая часть его возможностей — нормализация слов.
Нам понадобятся только базы данных. В исходниках WordNet (на си) описан сам процесс нормализации, в сущности сам алгоритм я взяла оттуда, переписав на python. Ах да, разумеется для WordNet существует библиотека для python — nltk, но во-первых, она работает только на python 2.7, а во-вторых, насколько бегло я смотрела, при нормализации всего лишь посылаются запросы на сервер WordNet.
Общая диаграмма классов для лемматизатора:
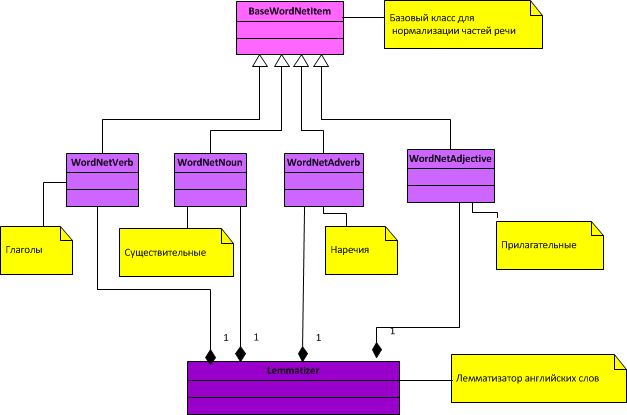
Как видно из диаграммы, нормализуются только 4 части речи (существительные, глаголы, прилагательные и наречия).
Если кратко описать процесс нормализации, то он заключается в следующем:
1. Для каждой части речи загружаются из WordNet по 2 файла — индексный словарь (имеет название index и расширение согласно части речи, например index.adv для наречий) и файл исключений ( имеет расширение exc и название согласно части речи, например adv.exc для наречий).
2. При нормализации сперва проверяется массив исключений, если слово там есть, возвращается его нормализованная форма. Если слово не является исключением, то начинается привидение слова по грамматическим правилам, то есть отсекается окончание, приклеивается новое окончание, затем слово ищется в индексном массиве, и если оно там есть, то слово считается нормализованным. Иначе применяется следующее правило и тд, пока правила не закончатся или слово не будет нормализовано раньше.
Классы для леммализатора:
Базовый класс для частей речи BaseWordNetItem.py
# -*- coding: utf-8 -*-
import os
class BaseWordNetItem:
# Конструктор
def __init__(self, pathWordNetDict, excFile, indexFile):
self.rule=() # Правила замены окончаний при нормализации слова по правилам.
self.wordNetExcDict={} # Словарь исключений
self.wordNetIndexDict=[] # Индексный массив
self.excFile = os.path.join(pathWordNetDict, excFile) # Получим путь до файла исключений
self.indexFile = os.path.join(pathWordNetDict, indexFile) # Получим путь до индексного словаря
self.__ParseFile(self.excFile, self.__AppendExcDict) # Заполним словарь исключений
self.__ParseFile(self.indexFile, self.__AppendIndexDict) # Заполним индексный массив
self.cacheWords={} # Немного оптимизации. Кэш для уже нормализованных слов, ключ - ненормализованное слово, значение - нормализованное слово
# Метод добавляет в словарь исключений одно значение.
# Файл исключений представлен в формате: [слово-исключение][пробел][лемма]
def __AppendExcDict(self, line):
# При разборе строки из файла, каждую строку разделяем на 2 слова и заносим слова в словарь(первое слово - ключ, второе - значение). При этом не забываем убрать с концов пробелы
group = [item.strip() for item in line.replace("n","").split(" ")]
self.wordNetExcDict[group[0]] = group[1]
# Метод добавляет в индексный массив одно значение.
def __AppendIndexDict(self, line):
# На каждой строке берем только первое слово
group = [item.strip() for item in line.split(" ")]
self.wordNetIndexDict.append(group[0])
# Метод открывает файл на чтение, читает по одной строке и вызывает для каждой строки функцию, переданную в аргументе
def __ParseFile(self, file, contentHandler):
try:
with open(file, 'r') as openFile:
for line in openFile:
contentHandler(line) # Для каждой строки вызываем обработчик контента
except Exception as e:
raise Exception('File does not load: "%s"' %file)
# Метод возвращает значение ключа в словаре. Если такого ключа в словаре нет, возвращается пустое значение.
# Под словарем здесь подразумевается просто структура данных
def _GetDictValue(self, dict, key):
try:
return dict[key]
except KeyError:
return None
# Метод проверяет слово на существование, и возвращает либо True, либо False.
# Для того, чтобы понять, существует ли слово, проверяется индексный массив(там хранится весь список слов данной части речи).
def _IsDefined(self, word):
if word in self.wordNetIndexDict:
return True
return False
# Метод возвращает лемму(нормализованную форму слова)
def GetLemma(self, word):
word = word.strip().lower()
# Пустое слово возвращаем обратно
if word == None:
return None
# Пройдемся по кэшу, возможно слово уже нормализовывалось раньше и результат сохранился в кэше
lemma = self._GetDictValue(self.cacheWords, word)
if lemma != None:
return lemma
# Проверим, если слово уже в нормализованном виде, вернем его же
if self._IsDefined(word):
return word
# Пройдемся по исключениям, если слово из исключений, вернем его нормализованную форму
lemma = self._GetDictValue(self.wordNetExcDict, word)
if lemma != None:
return lemma
# На этом шаге понимаем, что слово не является исключением и оно не нормализовано, значит начинаем нормализовывать его по правилам.
lemma = self._RuleNormalization(word)
if lemma != None:
self.cacheWords[word] = lemma # Предварительно добавим нормализованное слово в кэш
return lemma
return None
# Нормализация слова по правилам (согласно грамматическим правилам, слово приводится к нормальной форме)
def _RuleNormalization(self, word):
# Бежим по всем правилам, смотрим совпадает ли окончание слова с каким либо правилом, если совпадает, то заменяем окончние.
for replGroup in self.rule:
endWord = replGroup[0]
if word.endswith(endWord):
lemma = word # Копируем во временную переменную
lemma = lemma.rstrip(endWord) # Отрезаем старое окончание
lemma += replGroup[1] # Приклеиваем новое окончание
if self._IsDefined(lemma): # Проверим, что получившееся новое слово имеет право на существование, и если это так, то вернем его
return lemma
return None
Класс для нормализации глаголов WordNetVerb.py
# -*- coding: utf-8 -*-
from WordNet.BaseWordNetItem import BaseWordNetItem
# Класс для нормализации глаголов
# Класс наследуется от BaseWordNetItem
class WordNetVerb(BaseWordNetItem):
def __init__(self, pathToWordNetDict):
# Конструктор родителя (BaseWordNetItem)
BaseWordNetItem.__init__(self, pathToWordNetDict, 'verb.exc', 'index.verb')
# Правила замены окончаний при нормализации слова по правилам. К примеру, окончание "s" заменяется на "" , "ies" на и "y" тд.
self.rule = (
["s" , "" ],
["ies" , "y" ],
["es" , "e" ],
["es" , "" ],
["ed" , "e" ],
["ed" , "" ],
["ing" , "e" ],
["ing" , "" ]
)
# Метод получения нормализованной формы слова GetLemma(word) определен в базовом классе BaseWordNetItem
Класс для нормализации существительных WordNetNoun.py
# -*- coding: utf-8 -*-
from WordNet.BaseWordNetItem import BaseWordNetItem
# Класс для работы с нормализацией существительных
# Класс наследуется от BaseWordNetItem
class WordNetNoun(BaseWordNetItem):
def __init__(self, pathToWordNetDict):
# Конструктор родителя (BaseWordNetItem)
BaseWordNetItem.__init__(self, pathToWordNetDict, 'noun.exc', 'index.noun')
# Правила замены окончаний при нормализации слова по правилам. К примеру, окончание "s" заменяется на "", "ses" заменяется на "s" и тд.
self.rule = (
["s" , "" ],
["’s" , "" ],
["’" , "" ],
["ses" , "s" ],
["xes" , "x" ],
["zes" , "z" ],
["ches" , "ch" ],
["shes" , "sh" ],
["men" , "man" ],
["ies" , "y" ]
)
# Метод возвращает лемму сушествительного(нормализованную форму слова)
# Этот метод есть в базовом классе BaseWordNetItem, но нормализация существительных несколько отличается от нормализации других частей речи,
# поэтому метод в наследнике переопределен
def GetLemma(self, word):
word = word.strip().lower()
# Если существительное слишком короткое, то к нормализованному виду мы его не приводим
if len(word) <= 2:
return None
# Если существительное заканчивается на "ss", то к нормализованному виду мы его не приводим
if word.endswith("ss"):
return None
# Пройдемся по кэшу, возможно слово уже нормализовывалось раньше и результат сохранился в кэше
lemma = self._GetDictValue(self.cacheWords, word)
if lemma != None:
return lemma
# Проверим, если слово уже в нормализованном виде, вернем его же
if self._IsDefined(word):
return word
# Пройдемся по исключениям, если слово из исключений, вернем его нормализованную форму
lemma = self._GetDictValue(self.wordNetExcDict, word)
if (lemma != None):
return lemma
# Если существительное заканчивается на "ful", значит отбрасываем "ful", нормализуем оставшееся слово, а потом суффикс приклеиваем назад.
# Таким образом, к примеру, из слова "spoonsful" после нормализации получится "spoonful"
suff = ""
if word.endswith("ful"):
word = word[:-3] # Отрезаем суффикс "ful"
suff = "ful" # Отрезаем суффикс "ful", чтобы потом приклеить назад
# На этом шаге понимаем, что слово не является исключением и оно не нормализовано, значит начинаем нормализовывать его по правилам.
lemma = self._RuleNormalization(word)
if (lemma != None):
lemma += suff # Не забываем добавить суффикс "ful", если он был
self.cacheWords[word] = lemma # Предварительно добавим нормализованное слово в кэш
return lemma
return None
Класс для нормализации наречий WordNetAdverb.py
# -*- coding: utf-8 -*-
from WordNet.BaseWordNetItem import BaseWordNetItem
# Класс для нормалзации наречий
# Класс наследуется от BaseWordNetItem
class WordNetAdverb(BaseWordNetItem):
def __init__(self, pathToWordNetDict):
# Конструктор родителя (BaseWordNetItem)
BaseWordNetItem.__init__(self, pathToWordNetDict, 'adv.exc', 'index.adv')
# У наречий есть только списки исключений(adv.exc) и итоговый список слов(index.adv).
# Правила замены окончаний при нормализации слова по правилам у наречий нет.
Класс для нормализации прилагательных WordNetAdjective.py
# -*- coding: utf-8 -*-
from WordNet.BaseWordNetItem import BaseWordNetItem
# Класс для работы с нормализацией прилагательных
# Класс наследуется от BaseWordNetItem
class WordNetAdjective(BaseWordNetItem):
def __init__(self, pathToWordNetDict):
# Конструктор родителя (BaseWordNetItem)
BaseWordNetItem.__init__(self, pathToWordNetDict, 'adj.exc', 'index.adj')
# Правила замены окончаний при нормализации слова по правилам. К примеру, окончание "er" заменяется на "" или "e" и тд.
self.rule = (
["er" , "" ],
["er" , "e"],
["est" , "" ],
["est" , "e"]
)
# Метод получения нормализованной формы слова GetLemma(word) определен в базовом классе BaseWordNetItem
Класс для лемматизатора Lemmatizer.py
# -*- coding: utf-8 -*-
from WordNet.WordNetAdjective import WordNetAdjective
from WordNet.WordNetAdverb import WordNetAdverb
from WordNet.WordNetNoun import WordNetNoun
from WordNet.WordNetVerb import WordNetVerb
class Lemmatizer:
def __init__(self, pathToWordNetDict):
# Разделитель составных слов
self.splitter = "-"
# Инициализируем объекты с частям речи
adj = WordNetAdjective(pathToWordNetDict) # Прилагательные
noun = WordNetNoun(pathToWordNetDict) # Существительные
adverb = WordNetAdverb(pathToWordNetDict) # Наречия
verb = WordNetVerb(pathToWordNetDict) # Глаголы
self.wordNet = [verb, noun, adj, adverb]
# Метод возвращает лемму слова (возможно, составного)
def GetLemma(self, word):
# Если в слове есть тире, разделим слово на части, нормализуем каждую часть(каждое слово) по отдельности, а потом соединим
wordArr = word.split(self.splitter)
resultWord = []
for word in wordArr:
lemma = self.__GetLemmaWord(word)
if (lemma != None):
resultWord.append(lemma)
if (resultWord != None):
return self.splitter.join(resultWord)
return None
# Метод возвращает лемму(нормализованную форму слова)
def __GetLemmaWord(self, word):
for item in self.wordNet:
lemma = item.GetLemma(word)
if (lemma != None):
return lemma
return None
Ну вот, с нормализацией закончили. Теперь частотный анализатор умеет нормализовывать слова. Переходим к последней части нашей задачи — получение переводов и транскрипции для английских слов.
Переводчик иностранных слов, использующий словари StarDict
Про StarDict можно писать долго, но основное преимущество этого формата то, что для него есть очень много словарных баз, практически на всех языках. На хабре еще не было статей на тему StarDict и пора восполнить это пробел. Файл, описывающий формат StarDict, обычно расположен рядом с самими исходниками.
Если отбросить все дополнения, то самый минимальный набор знаний по этому формату будет следующим:
Каждый словарь должен содержать в себе 3 обязательных файла:
1. Файл с расширением ifo — содержит непротиворечивое описание самого словаря;
2. Файл с расширением idx . Каждая запись внутри idx файла состоит из 3-х полей, идущих друг за другом:
- word_str — Строка в формате utf-8, заканчивающаяся »;
- word_data_offset -Смещение до записи в файле .dict (размер числа 32 или 64 бита);
- word_data_size — Размер всей записи в файле .dict.
3. Файл с расширением dict — содержит сами переводы, добраться до которых можно зная смещение до перевода (смещение записано в файле idx ).
Не долго размышляя над тем, какие классы в итоге должны получиться, я создала по одному классу для каждого из файлов, и один общий класс StarDict, объединяющий их.
Получившаяся диаграмма классов:

Классы для перводчика StarDict:
Базовый класс для элементов словаря BaseStarDictItem.py
# -*- coding: utf-8 -*-
import os
class BaseStarDictItem:
def __init__(self, pathToDict, exp):
# Определяем переменную с кодировкой
self.encoding = "utf-8"
# Получаем полный путь до файла
self.dictionaryFile = self.__PathToFileInDirByExp(pathToDict, exp)
# Получаем размер файла
self.realFileSize = os.path.getsize(self.dictionaryFile)
# Метод ищет в папке path первый попапвшийся файл с расширением exp
def __PathToFileInDirByExp(self, path, exp):
if not os.path.exists(path):
raise Exception('Path "%s" does not exists' % path)
end = '.%s'%(exp)
list = [f for f in os.listdir(path) if f.endswith(end)]
if list:
return os.path.join(path, list[0]) # Возвращаем первый попавшийся
else:
raise Exception('File does not exist: "*.%s"' % exp)
Класс Ifo.py
# -*- coding: utf-8 -*-
from StarDict.BaseStarDictItem import BaseStarDictItem
from Frequency.IniParser import IniParser
class Ifo(BaseStarDictItem):
def __init__(self, pathToDict):
# Конструктор родителя (BaseStarDictItem)
BaseStarDictItem.__init__(self, pathToDict, 'ifo')
# Создаем и инициализируем парсер
self.iniParser = IniParser(self.dictionaryFile)
# Считаем из ifo файла параметры
# Если хотя бы одно из обязательных полей отсутствует, вызовется исключение и словарь не будет загружен
self.bookName = self.__getParameterValue("bookname", None) # Название словаря [Обязательное поле]
self.wordCount = self.__getParameterValue("wordcount", None) # Количество слов в ".idx" файле [Обязательное поле]
self.synWordCount = self.__getParameterValue("synwordcount", "") # Количество слов в ".syn" файле синонимов [Обязательное поле, если есть файл ".syn"]
self.idxFileSize = self.__getParameterValue("idxfilesize", None) # Размер (в байтах) ".idx" файла. Если файл сжат архиватором, то здесь указывается размер исходного несжатого файла [Обязательное поле]
self.idxOffsetBits = self.__getParameterValue("idxoffsetbits", 32) # Размер числа в битах(32 или 64), содержащего внутри себя смещение до записи в файле .dict. Поле пояилось начиная с версии 3.0.0, до этого оно всегда было 32 [Необязательное поле]
self.author = self.__getParameterValue("author", "") # Автор словаря [Необязательное поле]
self.email = self.__getParameterValue("email", "") # Почта [Необязательное поле]
self.description = self.__getParameterValue("description", "") # Описание словаря [Необязательное поле]
self.date = self.__getParameterValue("date", "") # Дата создания словаря [Необязательное поле]
self.sameTypeSequence = self.__getParameterValue("sametypesequence", None) # Маркер, определяющий форматирование словарной статьи[Обязательное поле]
self.dictType = self.__getParameterValue("dicttype", "") # Параметр используется некоторыми словарными плагинами, например WordNet[Необязательное поле]
def __getParameterValue(self, key, defaultValue):
try:
return self.iniParser.GetValue(key)
except:
if defaultValue != None:
return defaultValue
raise Exception('n"%s" has invalid format (missing parameter: "%s")' % (self.dictionaryFile, key))
Класс Idx.py
# -*- coding: utf-8 -*-
from struct import unpack
from StarDict.BaseStarDictItem import BaseStarDictItem
class Idx(BaseStarDictItem):
# Конструктор
def __init__(self, pathToDict, wordCount, idxFileSize, idxOffsetBits):
# Конструктор родителя (BaseStarDictItem)
BaseStarDictItem.__init__(self, pathToDict, 'idx')
self.idxDict ={} # Словарь, self.idxDict = {'иностр.слово': [Смещение_до_записи_в_файле_dict, Размер_всей_записи_в_файле_dict], ...}
self.idxFileSize = int(idxFileSize) # Размер файла .idx, записанный в .ifo файле
self.idxOffsetBytes = int(idxOffsetBits/8) # Размер числа, содержащего внутри себя смещение до записи в файле .dict. Переводим в байты и приводим к числу
self.wordCount = int(wordCount) # Количество слов в ".idx" файле
# Проверяем целостность словаря (информация в .ifo файле о размере .idx файла [idxfilesize] должна совпадать с его реальным размером)
self.__CheckRealFileSize()
# Заполняем словарь self.idxDict данными из файла .idx
self.__FillIdxDict()
# Проверяем целостность словаря (информация в .ifo файле о количестве слов [wordcount] должна совпадать с реальным количеством записей в .idx файле)
self.__CheckRealWordCount()
# Функция сверяет размер файла, записанный в .ifo файле, с ее реальным размером и в случае расхождений генерирует исключение
def __CheckRealFileSize(self):
if self.realFileSize != self.idxFileSize:
raise Exception('size of the "%s" is incorrect' %self.dictionaryFile)
# Функция сверяет количестве слов, записанное в .ifo файле, с реальным количеством записей в файле .idx и в случае расхождений генерирует исключение
def __CheckRealWordCount(self):
realWordCount = len(self.idxDict)
if realWordCount != self.wordCount:
raise Exception('word count of the "%s" is incorrect' %self.dictionaryFile)
# Функция считывает из потока данных массив байтов заданной длины, затем преобазует байткод в число
def __getIntFromByteArray(self, sizeInt, stream):
byteArray = stream.read(sizeInt) # Получили массив байтов, отведенных под число
# Определим формат пробразования в числовой формат
formatCharacter = 'L' # Формат означает "unsigned long" (для sizeInt = 4)
if sizeInt == 8:
formatCharacter = 'Q' # Формат означает "unsigned long long" (для sizeInt = 8)
format = '>' + formatCharacter # Общий формат будет состоять из: "направление порядка байтов" + "формат числа"
# Строка '>' - означает, что мы распаковываем байткод в число int(размера formatCharacter) от старшего бита к младшему.
integer = (unpack(format, byteArray))[0] # Распаковываем массив байтов в заданном формате
return int(integer)
# Функция разделяет файл .idx на отдельные записи (запись состоит из 3-х полей) и каждую запись добавляет в словарь self.idxDict
def __FillIdxDict(self):
languageWord = ""
with open(self.dictionaryFile, 'rb') as stream:
while True:
byte = stream.read(1) # Читаем один байт
if not byte: break # Если байтов больше нет, то выходим из цикла
if byte != b'': # Если байт не является символом окончания строки '', то прибавляем его к слову
languageWord += byte.decode("utf-8")
else:
# Если дошли до '', то считаем, что слово закончилось и дальше идут два числа ("Смещение до записи в файле dict" и "Размер всей записи в файле dict")
wordDataOffset = self.__getIntFromByteArray(self.idxOffsetBytes, stream) # Получили первое число "Смещение до записи в файле dict"
wordDataSize = self.__getIntFromByteArray(4, stream) # Получили второе число "Размер всей записи в файле dict"
self.idxDict[languageWord] = [wordDataOffset, wordDataSize] # Добавим в словарь self.idxDict запись: иностранное слово + смещение + размер данных
languageWord = "" # Обнуляем переменную, поскольку начинается следующая струтура
# Функция возвращает расположение слова в файле .dict ("Смещение до записи в файле dict" и "Размер всей записи в файле dict").
# Если такого слова в словаре нет, функция возвращает None
def GetLocationWord(self, word):
try:
return self.idxDict[word]
except KeyError:
return [None, None]
Класс Dict.py
# -*- coding: utf-8 -*-
from StarDict.BaseStarDictItem import BaseStarDictItem
# Маркер может быть составным (к примеру, sametypesequence = tm).
# Виды одно-символьныx идентификаторов словарных статей (для всех строчных идентификаторов текст в формате utf-8, заканчивается ''):
# 'm' - просто текст в кодировке utf-8, заканчивается ''
# 'l' - просто текст в НЕ в кодировке utf-8, заканчивается ''
# 'g' - текст размечен с помощью языка разметки текста Pango
# 't' - транскрипция в кодировке utf-8, заканчивается ''
# 'x' - текст в кодировке utf-8, размечен с помощью xdxf
# 'y' - текст в кодировке utf-8, содержит китайские(YinBiao) или японские (KANA) символы
# 'k' - текст в кодировке utf-8, размечен с помощью KingSoft PowerWord XML
# 'w' - текст размечен с помощью MediaWiki
# 'h' - текст размечен с помощью Html
# 'n' - текст размечен формате для WordNet
# 'r' - текст содержит список ресурсов. Ресурсами могут быть файлы картинки (jpg), звуковые (wav), видео (avi), вложенные(bin) файлы и др.
# 'W' - wav файл
# 'P' - картинка
# 'X' - этот тип зарезервирован для экспериментальных расширений
class Dict(BaseStarDictItem):
def __init__(self, pathToDict, sameTypeSequence):
# Конструктор родителя (BaseStarDictItem)
BaseStarDictItem.__init__(self, pathToDict, 'dict')
# Маркер, определяющий форматирование словарной статьи
self.sameTypeSequence = sameTypeSequence
def GetTranslation(self, wordDataOffset, wordDataSize):
try:
# Убеждаемся что смещение и размер данных неотрицательны и находятся в пределах размера файла .dict
self.__CheckValidArguments(wordDataOffset, wordDataSize)
# Открываем файл .dict как бинарный
with open(self.dictionaryFile, 'rb') as file: # менеджер контекста
file.seek(wordDataOffset) # Смешаемся внутри файла до начала текста, относящегося к переводу слова
byteArray = file.read(wordDataSize) # Читаем часть файла, относящегося к переводу слова
return byteArray.decode(self.encoding) # Вернем раскодированный в юникодную строку набор байтoв (self.encoding определен в базовом классе BaseDictionaryItem)
except Exception:
return None
def __CheckValidArguments(self, wordDataOffset, wordDataSize):
if wordDataOffset is None:
pass
if wordDataOffset < 0:
pass
endDataSize = wordDataOffset + wordDataSize
if wordDataOffset < 0 or wordDataSize < 0 or endDataSize > self.realFileSize:
raise Exception
Ну вот, переводчик готов. Теперь нам осталось только объединить вместе частотный анализатор, нормализатор слов и переводчик. Создадим главный файл main.py и файл настроек Settings.ini.
Главный файл main.py
# -*- coding: utf-8 -*-
import os
import xlwt3 as xlwt
from Frequency.IniParser import IniParser
from Frequency.FrequencyDict import FrequencyDict
from StarDict.StarDict import StarDict
ConfigFileName="Settings.ini"
class Main:
def __init__(self):
self.listLanguageDict = [] # В этом массиве сохраним словари StarDict
self.result = [] # В этом массиве сохраним результат (само слово, частота, его перевод)
try:
# Создаем и инициализируем конфиг-парсер
config = IniParser(ConfigFileName)
self.pathToBooks = config.GetValue("PathToBooks") # Считываем из ini файла переменную PathToBooks, которая содержит путь до файлов(книг, документов и тд), из которых будут браться слова
self.pathResult = config.GetValue("PathToResult") # Считываем из ini файла переменную PathToResult, которая содержит путь для сохранения результата
self.countWord = config.GetValue("CountWord") # Считываем из ini файла переменную CountWord, которая содержит количество первых слов частотного словаря, которые нужно получить
self.pathToWordNetDict = config.GetValue("PathToWordNetDict") # Считываем из ini файла переменную PathToWordNetDict, которая содержит путь до словаря WordNet
self.pathToStarDict = config.GetValue("PathToStarDict") # Считываем из ini файла переменную PathToStarDict, которая содержит путь до словарей в формате StarDict
# Отделяем пути словарей StarDict друг от друга и удаляем пробелы с начала и конца пути. Все пути заносим в список listPathToStarDict
listPathToStarDict = [item.strip() for item in self.pathToStarDict.split(";")]
# Для каждого из путей до словарей StarDict создаем свой языковый словарь
for path in listPathToStarDict:
languageDict = StarDict(path)
self.listLanguageDict.append(languageDict)
# Получаем список книг, из которых будем получать слова
self.listBooks = self.__GetAllFiles(self.pathToBooks)
# Создаем частотный словарь
self.frequencyDict = FrequencyDict(self.pathToWordNetDict)
# Подготовка закончена, загружены словари StarDict и WordNet. Запускаем задачу на выполнение, то есть начинаем парсить текстовые файл, нормализовывать и считать слова
self.__Run()
except Exception as e:
print('Error: "%s"' %e)
# Метод создает список файлов, расположенных в папке path
def __GetAllFiles(self, path):
try:
return [os.path.join(path, file) for file in os.listdir(path)]
except Exception:
raise Exception('Path "%s" does not exists' % path)
# Метод бежит по всем словарям, и возвращает перевод из ближайшего словаря. Если перевода нет ни в одном из словарей, возвращается пустая строка
def __GetTranslate(self, word):
valueWord = ""
for dict in self.listLanguageDict:
valueWord = dict.Translate(word)
if valueWord != "":
return valueWord
return valueWord
# Метод сохраняет результат(само слово, частота, его перевод) по первым countWord словам в файл формата Excel
def __SaveResultToExcel(self):
try:
if not os.path.exists(self.pathResult):
raise Exception('No such directory: "%s"' %self.pathResult)
if self.result:
description = 'Frequency Dictionary'
style = xlwt.easyxf('font: name Times New Roman')
wb = xlwt.Workbook()
ws = wb.add_sheet(description + ' ' + self.countWord)
nRow = 0
for item in self.result:
ws.write(nRow, 0, item[0], style)
ws.write(nRow, 1, item[1], style)
ws.write(nRow, 2, item[2], style)
nRow +=1
wb.save(os.path.join(self.pathResult, description +'.xls'))
except Exception as e:
print(e)
# Метод запускает задачу на выполнение
def __Run(self):
# Отдаем частотному словарю по одной книге
for book in self.listBooks:
self.frequencyDict.ParseBook(book)
# Получаем первые countWord слов из всего получившегося списка английских слов
mostCommonElements = self.frequencyDict.FindMostCommonElements(self.countWord)
# Получаем переводы для всех слов
for item in mostCommonElements:
word = item[0]
counterWord = item[1]
valueWord = self.__GetTranslate(word)
self.result.append([counterWord, word, valueWord])
# Запишем результат в файл формата Excel
self.__SaveResultToExcel()
if __name__ == "__main__":
main = Main()
Файл настроек Settings.ini
; Путь до файлов(книг, документов и тд), из которых будут браться слова
PathToBooks = e:BienneFrequencyBooks
; Путь до словаря WordNet(он нужен для нормализации слов)
PathToWordNetDict = e:BienneFrequencyWordNetwn3.1.dict
; Путь до словарей в формате StarDict(нужны для перевода слов)
PathToStarDict = e:BienneFrequencyDictstardict-comn_dictd04_korolew
; Количество первых слов частотного словаря, которые будут записаны в файл в формате Excel
CountWord = 100
; Путь, куда сохранить результат (файл в формате Excel с тремя заполненными колонками - само слово, частота, его перевод)
PathToResult = e:BienneFrequencyBooks
Единственной сторонней библиотекой, которую нужно скачать и поставить дополнительно, является xlwt, она потребуется для создания файла в формате Excel (туда записывается результат).
В файле настроек Settings.ini для переменной PathToStarDict можно писать несколько словарей через «;». В этом случае слова будут искаться в порядке очередности словарей — если слово найдено в первом словаре, поиск заканчивается, иначе перебираются все остальные словари StarDict.
Послесловие
Все исходники, описанные в этой статье, можно скачать на github.
Напоминание:
- Скрипты писались под windows;
- Использовался python 3.3;
- Дополнительно нужно будет поставить библиотеку xlwt для работы с Excel;
- Отдельно нужно скачать словарные базы для WordNet и StarDict (у словарей StarDict нужно будет дополнительно распаковать запакованные в архив файлы с расширением dict);
- В файле Settings.ini нужно прописать пути для словарей и куда сохранить результат.
- Отдельно хотелось бы сказать про транскрипцию, она есть не во всех словарных базах StarDict, но найти словарь с транскрипцией по поиску в гугле не составит труда (во всяком случае я их легко находила).
- Главная
- Английский алфавит
Частота встречаемости букв
Частота встречаемости букв в английском языке
Как известно, самая часто встречаемая буква — E, редко встречаемая — Z.
Вот наглядная таблица английского алфавита
| Буква | Частота встречаемости |
| Aa | 8,17 % |
| Bb | 1,49 % |
| Cc | 2,78 % |
| Dd | 4,25 % |
| Ee | 12,70 % |
| Ff | 2,23 % |
| Gg | 2,02 % |
| Hh | 6,09 % |
| Ii | 6,97 % |
| Jj | 0,15 % |
| Kk | 0,77 % |
| Ll | 4,03 % |
| Mm | 2,41 % |
| Nn | 6,75 % |
| Oo | 7,51 % |
| Pp | 1,93 % |
| 0,10 % | |
| Rr | 5,99 % |
| Ss | 6,33 % |
| Tt | 9,06 % |
| Uu | 2,76 % |
| Vv | 0,98 % |
| Ww | 2,36 % |
| Xx | 0,15 % |
| Yy | 1,97 % |
| Zz | 0,07 % |
| Всего | 100,02 %* |
* Сумма показана с погрешностью округления
Частотный
словарь (1001 — 2000) ·
Частотный словарь (2001 — 3000)
· Озвученный
словарь
Английские слова, расположенные в порядке встречаемости в
речи. Первая тысяча слов.
1
—
a —
неопределенный артикль
2
—
the —
определенный артикль
3
—
be —
быть
4
—
of —
предлог родительного падежа
5
—
and —
и
6
—
in —
в; через (о времени)
7
—
to —
к; в
8
—
have —
иметь
9
—
it —
это; он, она, оно (для неодуш.сущ.)
10
—
for —
для; ибо
11
—
I —
я
12
—
that —
тот; что
13
—
you —
ты, вы
14
—
he —
он
15
—
on —
на
16
—
with —
с
17
—
do —
делать
18
—
at —
у
19
—
by —
к; предлог творительного падежа
20
—
not —
не
21
—
this —
это
22
—
but —
но, кроме
23
—
from —
от
24
—
they —
они
25
—
his —
его
26
—
she —
она
27
—
or —
или
28
—
which —
который
29
—
as —
как; так как
30
—
we —
мы
31
—
say —
сказать
32
—
will —
вспом.глагол буд.вр.; воля
33
—
would —
бы
34
—
can —
уметь, мочь
35
—
if —
если
36
—
their —
их
37
—
go —
ходить, идти
38
—
what —
что
39
—
there —
там
40
—
all —
все
41
—
get —
получать
42
—
her —
ее
43
—
make —
делать
44
—
who —
кто
45
—
out —
вне
46
—
up —
вверх
47
—
see —
видеть
48
—
know —
знать
49
—
time —
время; раз
50
—
take —
брать
51
—
them —
им
52
—
some —
несколько, какой-то
53
—
could —
мог
54
—
so —
такой, поэтому
55
—
him —
ему
56
—
year —
год
57
—
into —
в
58
—
its —
его
59
—
then —
затем
60
—
think —
думать
61
—
my —
мой
62
—
come —
приходить
63
—
than —
чем
64
—
more —
больше
65
—
about —
о; около
66
—
now —
сейчас
67
—
last —
прошлый, продолжаться
68
—
your —
твой, ваш
69
—
me —
мне
70
—
no —
нет
71
—
other —
другой
72
—
give —
дать
73
—
just —
только что; справедливый
74
—
should —
следует
75
—
these —
эти
76
—
people —
люди
77
—
also —
также
78
—
well —
хорошо
79
—
any —
любой
80
—
only —
только; единственный
81
—
new —
новый
82
—
very —
очень; тот самый
83
—
when —
когда (вопросительное слово)
84
—
may —
мочь
85
—
way —
путь, способ
86
—
look —
смотреть, выглядеть; взгляд
87
—
like —
любить, нравиться; как
88
—
use —
использовать; применение
89
—
such —
такой
90
—
how —
как
91
—
because —
потому что
92
—
good —
хороший
93
—
find —
найти
94
—
man —
человек, мужчина
95
—
our —
наш
96
—
want —
хотеть
97
—
day —
день
98
—
between —
между
99
—
even —
даже
100
—
many —
много (для исчисляемых)
101
—
those —
те
102
—
after —
после
103
—
down —
внизу
104
—
yeah —
да
105
—
thing —
вещь
106
—
tell —
сказать (кому-то)
107
—
through —
сквозь
108
—
back —
назад; спина
109
—
still —
все еще; тихий
110
—
must —
должен
111
—
child —
ребенок
112
—
here —
здесь
113
—
over —
над, выше (предлог); пере-; движение через (наречие)
114
—
too —
тоже; слишком
115
—
put —
положить
116
—
own —
собственный
117
—
work —
работа, работать
118
—
become —
становиться
119
—
old —
старый
120
—
government —
правительство
121
—
mean —
иметь в виду
122
—
part —
часть
123
—
leave —
покинуть
124
—
life —
жизнь
125
—
great —
великий, великолепный
126
—
where —
где
127
—
case —
случай, коробка
128
—
woman —
женщина
129
—
seem —
казаться
130
—
same —
тот же самый
131
—
us —
нас
132
—
need —
нужда; нужно
133
—
feel —
чувствовать
134
—
each —
каждый
135
—
might —
(пр.вр. от may может быть)
136
—
much —
много (для неисчисл.), очень
137
—
ask —
спрашивать, задавать
138
—
group —
группа
139
—
number —
число, номер
140
—
yes —
да
141
—
however —
однако
142
—
another —
другой
143
—
again —
снова
144
—
world —
мир
145
—
area —
территория, площадь
146
—
show —
шоу, показывать
147
—
course —
курс
148
—
shall —
«вспом.глагол буд.вр.
149
—
under —
под
150
—
problem —
проблема
151
—
against —
против
152
—
never —
никогда
153
—
most —
самый
154
—
service —
служба
155
—
try —
стараться
156
—
call —
звонок; звать, звонить, называться
157
—
hand —
рука
158
—
party —
вечеринка; партия
159
—
high —
высоко, высокий
160
—
something —
что-то
161
—
school —
школа
162
—
small —
маленький
163
—
place —
место, размещать
164
—
before —
до
165
—
why —
почему
166
—
while —
в то время как, пока; промежуток времени
167
—
away —
вне
168
—
keep —
хранить, держать, продолжать
169
—
point —
точка; смысл; указывать
170
—
house —
дом
171
—
different —
различный
172
—
country —
страна; сельская местность
173
—
really —
в самом деле
174
—
provide —
обеспечить
175
—
week —
неделя
176
—
hold —
держать, проводить
177
—
large —
большой
178
—
member —
член
179
—
off —
от
180
—
always —
всегда
181
—
next —
следующий
182
—
follow —
следовать
183
—
without —
без
184
—
turn —
очередность; поворачивать
185
—
end —
конец, заканчивать
186
—
local —
местный
187
—
during —
в течение
188
—
bring —
нести
189
—
word —
слово
190
—
begin —
начинать
191
—
although —
хотя
192
—
example —
пример
193
—
family —
семья
194
—
rather —
скорее
195
—
fact —
факт
196
—
social —
общественный
197
—
write —
писать
198
—
state —
государство, штат; утверждать
199
—
percent —
процент
200
—
quite —
довольно
201
—
both —
оба
202
—
start —
старт; начинать
203
—
run —
бег, бежать
204
—
long —
длинный
205
—
right —
правый; право
206
—
set —
набор; установить
207
—
help —
помогать, помощь
208
—
every —
каждый
209
—
home —
дом, домашний
210
—
month —
месяц
211
—
side —
сторона
212
—
night —
ночь
213
—
important —
важный
214
—
eye —
глаз
215
—
head —
возглавлять; голова
216
—
question —
вопрос; сомневаться
217
—
play —
играть, пьеса
218
—
power —
власть, сила
219
—
money —
деньги
220
—
change —
изменение; сдача; менять
221
—
move —
двигаться
222
—
interest —
интерес; процент прибыли
223
—
order —
приказ; порядок; заказывать
224
—
book —
книга; заказать
225
—
often —
часто
226
—
young —
молодой
227
—
national —
национальный
228
—
pay —
платить
229
—
hear —
слышать
230
—
room —
комната
231
—
whether —
ли
232
—
water —
вода
233
—
form —
форма; бланк; формировать
234
—
car —
автомобиль
235
—
others —
другие
236
—
yet —
еще (не); однако
237
—
perhaps —
возможно
238
—
meet —
встретить, познакомиться
239
—
till —
до
240
—
though —
хотя
241
—
policy —
политика
242
—
include —
включать (в себя)
243
—
believe —
верить
244
—
already —
уже
245
—
possible —
возможный
246
—
nothing —
ничего
247
—
line —
линия
248
—
allow —
позволять
249
—
effect —
эффект
250
—
big —
большой
251
—
late —
поздний
252
—
lead —
руководство; вести
253
—
stand —
стоять; стойка
254
—
idea —
идея
255
—
study —
учеба; кабинет; учиться
256
—
lot —
много (в выраженииa lot)
257
—
live —
жить
258
—
job —
работа
259
—
since —
с (тех пор как)
260
—
name —
имя, называть
261
—
result —
результат
262
—
body —
тело
263
—
happen —
случаться
264
—
friend —
друг
265
—
least —
наименьший
266
—
almost —
почти
267
—
carry —
нести
268
—
authority —
власть
269
—
early —
рано
270
—
view —
взгляд; обозревать
271
—
himself —
(он) сам
272
—
public —
общественный; народ, публика
273
—
usually —
обычно
274
—
together —
вместе
275
—
talk —
беседа, беседовать
276
—
report —
доклад; сообщать
277
—
face —
лицо; стоять лицом к
278
—
sit —
сидеть
279
—
appear —
появляться
280
—
continue —
продолжать
281
—
able —
способный
282
—
political —
политический
283
—
hour —
час
284
—
rate —
пропорция; ставка
285
—
law —
закон
286
—
door —
дверь
287
—
company —
компания
288
—
court —
суд
289
—
fuck —
трахаться
290
—
little —
маленький, немного
291
—
because of —
из-за
292
—
office —
офис
293
—
let —
позволить
294
—
war —
война
295
—
reason —
причина
296
—
less —
менее
297
—
subject —
предмет
298
—
person —
лицо; человек
299
—
term —
термин; срок
300
—
full —
полный
301
—
sort —
сорт, вид; сортировать
302
—
require —
требовать
303
—
suggest —
предлагать, предполагать
304
—
far —
далеко
305
—
towards —
к
306
—
anything —
ничего
307
—
period —
период
308
—
read —
читать
309
—
society —
общество
310
—
process —
процесс
311
—
mother —
мать
312
—
offer —
предложение, предлагать
313
—
voice —
голос
314
—
once —
как только; однажды
315
—
police —
полиция
316
—
lose —
терять
317
—
add —
добавлять
318
—
probably —
вероятно
319
—
expect —
ожидать
320
—
ever —
коогда-нибудь
321
—
price —
цена
322
—
action —
действие
323
—
issue —
выпуск
324
—
remember —
помнить
325
—
position —
позиция
326
—
low —
низкий
327
—
matter —
дело, вопрос, факты; иметь значение
328
—
community —
община
329
—
remain —
оставаться
330
—
figure —
цифра
331
—
type —
тип
332
—
actually —
вообще-то
333
—
education —
образование
334
—
fall —
падать; упадок; осень (ам.)
335
—
speak —
говорить
336
—
few —
мало
337
—
today —
сегодня
338
—
enough —
достаточно
339
—
open —
открытый, открывать
340
—
bad —
плохой
341
—
buy —
покупать
342
—
minute —
минута
343
—
moment —
момент
344
—
girl —
девочка, девушка
345
—
age —
возраст
346
—
centre —
центр
347
—
stop —
остановка; остановить(-ся)
348
—
control —
контроль, контролировать
349
—
send —
посылать
350
—
health —
здоровье
351
—
decide —
решать
352
—
main —
главный
353
—
win —
победить; победа
354
—
wound —
рана; ранить
355
—
understand —
понимать
356
—
develop —
развивать
357
—
class —
класс
358
—
industry —
промышленность
359
—
receive —
получать
360
—
several —
несколько
361
—
return —
возвращение, возвращаться
362
—
build —
строить
363
—
spend —
проводить (время)
364
—
force —
сила, принуждать
365
—
condition —
условие
366
—
itself —
(он) сам
367
—
paper —
бумага; газета
368
—
themselves —
(они) сами
369
—
major —
главный
370
—
describe —
описывать
371
—
agree —
соглашаться
372
—
economic —
экономический
373
—
upon —
на
374
—
learn —
учить
375
—
general —
генерал; общий
376
—
century —
век
377
—
therefore —
поэтому
378
—
father —
отец
379
—
section —
раздел
380
—
patient —
терпеливый; пациент
381
—
around —
вокруг
382
—
activity —
мероприятие
383
—
road —
дорога
384
—
table —
стол
385
—
cow —
корова
386
—
including —
включающий
387
—
church —
церковь
388
—
reach —
достигать
389
—
real —
реальный
390
—
lie —
лгать
391
—
mind —
ум; возражать
392
—
likely —
вероятный
393
—
among —
среди
394
—
team —
команда
395
—
death —
смерть
396
—
soon —
скоро
397
—
act —
акт, действие; действовать
398
—
sense —
смысл; чувство; чувствовать
399
—
staff —
персонал
400
—
certain —
определенный
401
—
student —
студент
402
—
half —
половина
403
—
language —
язык
404
—
walk —
прогулка; ходить (пешком)
405
—
die —
умереть
406
—
special —
особый
407
—
difficult —
трудный
408
—
international —
международный
409
—
department —
отделение
410
—
management —
управление
411
—
morning —
утро
412
—
draw —
рисовать (карандашом)
413
—
hope —
надежда; надеяться
414
—
across —
через
415
—
plan —
план, планировать
416
—
product —
продукт
417
—
city —
город
418
—
committee —
комитет
419
—
ground —
земля
420
—
letter —
письмо; буква
421
—
create —
создавать
422
—
evidence —
свидетельство
423
—
foot —
нога
424
—
clear —
ясный, очищать
425
—
boy —
мальчик
426
—
game —
игра
427
—
food —
еда
428
—
role —
роль
429
—
practice —
практика
430
—
bank —
банк; берег
431
—
else —
еще
432
—
support —
поддержка, поддерживать
433
—
sell —
продавать
434
—
event —
событие
435
—
building —
здание
436
—
behind —
за, сзади
437
—
sure —
уверенный
438
—
pass —
передавать, проходить
439
—
black —
черный
440
—
stage —
стадия
441
—
meeting —
встреча
442
—
hi —
привет
443
—
sometimes —
иногда
444
—
thus —
таким образом
445
—
accept —
допускать
446
—
available —
наличный
447
—
town —
город
448
—
art —
искусство
449
—
further —
дальнейший
450
—
club —
клуб
451
—
arm —
рука
452
—
history —
история
453
—
parent —
родитель
454
—
land —
земля; приземляться
455
—
trade —
торговля, торговать
456
—
watch —
часы; наблюдать
457
—
white —
белый
458
—
situation —
ситуация
459
—
whose —
чей
460
—
ago —
назад
461
—
teacher —
учитель
462
—
record —
запись; записывать
463
—
manager —
управляющий, менеджер
464
—
relation —
связь, отношение
465
—
common —
общий
466
—
system —
система
467
—
strong —
сильный
468
—
whole —
целый
469
—
field —
поле
470
—
free —
свободный
471
—
break —
ломать; перерыв
472
—
yesterday —
вчера
473
—
window —
окно
474
—
account —
счет
475
—
explain —
объяснять
476
—
stay —
остановиться
477
—
wait —
ждать
478
—
material —
материал
479
—
air —
воздух
480
—
wife —
жена
481
—
cover —
крышка, покрывать
482
—
apply —
обращаться
483
—
love —
любить, любовь
484
—
project —
проект
485
—
raise —
поднимать
486
—
sale —
продажа
487
—
relationship —
отношение
488
—
indeed —
в самом деле
489
—
please —
пожалуйста
490
—
light —
светлый; легкий; свет
491
—
claim —
требование, требовать
492
—
base —
основа, база;базироваться
493
—
care —
заботиться; забота, осторожность
494
—
someone —
кто-то
495
—
everything —
всё
496
—
certainly —
конечно
497
—
rule —
правило; управлять
498
—
cut —
резать
499
—
grow —
расти, выращивать
500
—
similar —
подобный
501
—
story —
история, рассказ
502
—
quality —
качество
503
—
tax —
налог
504
—
worker —
рабочий
505
—
nature —
природа
506
—
structure —
структура
507
—
necessary —
необходимый
508
—
pound —
фунт
509
—
method —
метод
510
—
unit —
часть
511
—
central —
центральный
512
—
bed —
кровать
513
—
union —
союз
514
—
movement —
движение
515
—
board —
доска; совет
516
—
true —
правдивый
517
—
especially —
особенно
518
—
short —
короткий
519
—
personal —
личный
520
—
detail —
деталь
521
—
model —
модель
522
—
bear —
медведь;носить; рождать
523
—
single —
одинокий
524
—
join —
присоединяться
525
—
reduce —
сокращать
526
—
establish —
учреждать
527
—
herself —
(она) сама
528
—
wall —
стена
529
—
easy —
легкий
530
—
private —
частный
531
—
computer —
компьютер
532
—
former —
бывший
533
—
hospital —
больница
534
—
chapter —
глава
535
—
scheme —
схема, план
536
—
bye —
пока
537
—
consider —
полагать
538
—
council —
совет
539
—
development —
развитие
540
—
experience —
опыт
541
—
information —
информация
542
—
involve —
вовлекать
543
—
theory —
теория
544
—
within —
в
545
—
choose —
выбирать
546
—
wish —
желать; желание
547
—
property —
собственность
548
—
achieve —
достигать
549
—
financial —
финансовый
550
—
poor —
бедный
551
—
blow —
дуть
552
—
charge —
ответственность; загружать
553
—
director —
директор
554
—
drive —
водить (машину); катание, езда
555
—
approach —
подход, приближаться
556
—
chance —
шанс
557
—
application —
приложение
558
—
seek —
искать
559
—
cool —
крутой; прохладный
560
—
foreign —
иностранный
561
—
along —
вдоль
562
—
top —
верхний, верх
563
—
amount —
количество
564
—
son —
сын
565
—
operation —
операция
566
—
fail —
потерпеть неудачу
567
—
human —
человеческий,человек
568
—
opportunity —
возможность
569
—
simple —
простой
570
—
leader —
лидер
571
—
level —
уровень
572
—
production —
продукция
573
—
value —
стоимость
574
—
firm —
крепкий; фирма
575
—
picture —
картина
576
—
source —
источник
577
—
security —
безопасность
578
—
serve —
служить
579
—
according —
соответствие
580
—
business —
дело
581
—
decision —
решение
582
—
contract —
контакт
583
—
wide —
широкий
584
—
agreement —
соглашение
585
—
kill —
убивать
586
—
site —
место
587
—
either —
один из двух; тоже (не)
588
—
various —
разнообразный
589
—
screw —
закручивать
590
—
test —
тест; проверять
591
—
eat —
кушать
592
—
close —
близкий;закрывать
593
—
represent —
представлять
594
—
colour —
цвет
595
—
shop —
магазин
596
—
benefit —
выгода
597
—
animal —
животное
598
—
heart —
сердце
599
—
election —
выборы
600
—
purpose —
цель
601
—
due —
обязанный
602
—
secretary —
секретарь
603
—
rise —
восход; подниматься
604
—
date —
дата, датировать
605
—
hard —
упорно; тяжелый, упорный
606
—
music —
музыка
607
—
hair —
волосы
608
—
prepare —
приготовить
609
—
anyone —
кто-нибудь
610
—
pattern —
модель
611
—
manage —
управлять
612
—
piece —
кусок
613
—
discuss —
обсуждать
614
—
prove —
даказывать
615
—
front —
передняя часть, передний
616
—
evening —
вечер
617
—
royal —
королевский
618
—
tree —
дерево
619
—
population —
население
620
—
fine —
прекрасный
621
—
plant —
растение; завод; сажать
622
—
pressure —
давление
623
—
response —
ответ
624
—
catch —
хватать
625
—
street —
улица
626
—
knowledge —
знание
627
—
despite —
несмотря на
628
—
design —
дизайн, разрабатывать
629
—
kind —
вид; тип; добрый
630
—
page —
страница
631
—
enjoy —
наслаждаться
632
—
individual —
личный;частное лицо
633
—
rest —
остаток; отдых; отдыхать
634
—
instead —
вместо
635
—
wear —
носить
636
—
basis —
базис
637
—
size —
размер
638
—
fire —
огонь, пожар; поджигать
639
—
series —
ряд, серия
640
—
success —
успех
641
—
natural —
естественный
642
—
wrong —
неправильный
643
—
near —
около
644
—
round —
вокруг; круглый; круг
645
—
thought —
мысль
646
—
list —
список
647
—
argue —
спорить
648
—
final —
окончательный
649
—
future —
будущее
650
—
introduce —
знакомить
651
—
enter —
входить
652
—
space —
космос; место
653
—
arrive —
прибывать
654
—
ensure —
обеспечивать
655
—
statement —
утверждение
656
—
balcony —
балкон
657
—
attention —
внимание
658
—
principle —
принцип
659
—
pull —
тянуть
660
—
doctor —
доктор
661
—
choice —
выбор
662
—
refer —
ссылаться
663
—
feature —
особенность, функция
664
—
couple —
пара
665
—
step —
шаг; шагать
666
—
following —
следующий
667
—
thank —
благодарить
668
—
machine —
машина
669
—
income —
доход
670
—
training —
тренировка
671
—
present —
подарок; дарить; настоящий
672
—
association —
ассоциация
673
—
film —
фильм; пленка
674
—
difference —
различие
675
—
fucking —
проклятый
676
—
region —
регион
677
—
effort —
усилие
678
—
player —
игрок
679
—
everyone —
каждый
680
—
village —
деревня
681
—
organisation —
организация
682
—
whatever —
что бы ни было
683
—
news —
новости
684
—
nice —
замечательный
685
—
modern —
современный
686
—
cell —
ячейка; камера
687
—
current —
текущий
688
—
legal —
законный
689
—
energy —
энергия
690
—
finally —
окончательно
691
—
degree —
степень
692
—
mile —
миля
693
—
means —
средство
694
—
whom —
кем
695
—
treatment —
лечение
696
—
sound —
звук, звучать
697
—
above —
над
698
—
task —
задание
699
—
red —
красный
700
—
happy —
счастливый
701
—
behaviour —
поведение
702
—
identify —
распознавать
703
—
resource —
ресурс; источник
704
—
defence —
защита
705
—
garden —
сад
706
—
floor —
пол; этаж
707
—
technology —
технология
708
—
style —
стиль
709
—
feeling —
чувство
710
—
science —
наука
711
—
relate —
быть родственным
712
—
doubt —
сомнение, сомневаться
713
—
ok —
хорошо
714
—
produce —
производить
715
—
horse —
лошадь
716
—
answer —
ответ
717
—
compare —
сравнить
718
—
suffer —
страдать
719
—
forward —
вперед
720
—
announce —
объявлять
721
—
user —
пользователь
722
—
character —
герой
723
—
risk —
риск; рисковать
724
—
normal —
обычный
725
—
myself —
(я) сам
726
—
dog —
собака
727
—
obtain —
приобретать
728
—
quickly —
быстро
729
—
army —
армия
730
—
forget —
забывать
731
—
ill —
больной
732
—
station —
станция, участок
733
—
glass —
стекло; стакан
734
—
cup —
кружка
735
—
previous —
предыдущий
736
—
husband —
муж
737
—
recently —
недавно
738
—
publish —
публиковать
739
—
serious —
серьезный
740
—
anyway —
в любом случае
741
—
visit —
приходить в гости
742
—
capital —
столица
743
—
sock —
носок
744
—
note —
заметка, отмечать
745
—
season —
сезон; время года
746
—
argument —
спор
747
—
listen —
слушать
748
—
responsibility —
ответственность
749
—
significant —
значительный
750
—
deal —
некоторое количество; иметь дело
751
—
prime —
первичный
752
—
economy —
экономика
753
—
finish —
закончить
754
—
duty —
долг
755
—
fight —
бой, драка; сражаться
756
—
train —
поезд;тренировать
757
—
maintain —
обеспечивать
758
—
attempt —
попытка
759
—
leg —
нога
760
—
save —
беречь
761
—
suddenly —
вдруг
762
—
brother —
брат
763
—
improve —
улучшать
764
—
avoid —
избегать
765
—
teenager —
подросток
766
—
wonder —
хотеть знать; удивление
767
—
fun —
забава
768
—
title —
название
769
—
post —
почта; должность
770
—
hotel —
гостиница
771
—
aspect —
сторона, аспект
772
—
increase —
увеличивать
773
—
surname —
фамилия
774 — industrial — промышленный
775
—
express —
выражать
776
—
summer —
лето
777
—
determine —
определять
778
—
generally —
в общем
779
—
daughter —
дочь
780
—
exist —
существовать
781
—
used to —
бывало
782
—
share —
делить; акция
783
—
baby —
дитя
784
—
nearly —
около
785
—
smile —
улыбка, улыбаться
786
—
sorry —
извини
787
—
sea —
море
788
—
skill —
навык
789
—
treat —
лечить
790
—
remove —
удалить
791
—
concern —
забота, заботиться
792
—
university —
университет
793
—
left —
левый
794
—
dead —
мертвый
795
—
discussion —
обсуждение
796
—
specific —
особый
797
—
box —
ящик
798
—
outside —
вне
799
—
total —
всеобщий
800
—
bit —
немного
801
—
cost —
стоимость, стоить
802
—
girlfriend —
подружка
803
—
market —
рынок, купить или продать на рынке
804
—
occur —
иметь место
805
—
research —
исследование; исследовать
806
—
wonderful —
чудесный
807
—
division —
подразделение
808
—
throw —
выбрасывать
809
—
officer —
служащий
810
—
procedure —
процедура
811
—
fill —
вставлять
812
—
king —
король
813
—
assume —
допускать
814
—
image —
образ
815
—
oil —
нефть, масло
816
—
obviously —
очевидно
817
—
unless —
до тех пор пока не
818
—
appropriate —
подходящий
819
—
military —
военный
820
—
proposal —
предложение
821
—
mention —
упоминать
822
—
client —
клиент
823
—
sector —
сектор
824
—
direction —
направление
825
—
admit —
допускать
826
—
basic —
основной
827
—
instance —
пример
828
—
sign —
знак; подписывать
829
—
original —
оригинальный
830
—
successful —
успешный
831
—
reflect —
отражать
832
—
aware —
осознавать
833
—
pardon —
извините
834
—
measure —
мера, измерять
835
—
attitude —
отношение
836
—
yourself —
(тебя) самого
837
—
exactly —
точно
838
—
commission —
комиссия
839
—
beyond —
за пределами
840
—
seat —
сидение
841
—
president —
президент
842
—
encourage —
воодушевлять
843
—
addition —
дополнение
844
—
goal —
цель
845
—
miss —
скучать
846
—
popular —
популярный
847
—
affair —
дело
848
—
technique —
техника
849
—
respect —
уважение; уважать
850
—
drop —
капля, капать
851
—
professional —
профессиональный; профессионал
852
—
fly —
летать; муха
853
—
version —
версия
854
—
maybe —
может быть
855
—
ability —
способность
856
—
operate —
действовать
857
—
goods —
товар
858
—
campaign —
кампания
859
—
heavy —
тяжелый
860
—
advice —
совет
861
—
institution —
институт
862
—
discover —
открывать
863
—
surface —
поверхность
864
—
library —
библиотека
865
—
pupil —
ученик
866
—
refuse —
отказывать
867
—
prevent —
предотвращать
868
—
tasty —
вкусный
869
—
dark —
темный
870
—
teach —
учить (кого-либо)
871
—
memory —
память
872
—
culture —
культура
873
—
blood —
кровь
874
—
majority —
большинство
875
—
insane —
сумасшедший
876
—
variety —
разнообразие
877
—
depend —
зависеть
878
—
bill —
банкнота
879
—
competition —
соревнование
880
—
ready —
готовый
881
—
access —
доступ
882
—
hit —
ударить, толчок; нагревать
883
—
stone —
камень
884
—
useful —
полезный
885
—
extent —
расширение
886
—
employment —
занятость
887
—
regard —
внимание; принимать во внимание
888
—
apart —
отдельно
889
—
besides —
кроме того
890
—
shit —
дерьмо
891
—
text —
текст
892
—
parliament —
парламент
893
—
recent —
недавний
894
—
article —
статья
895
—
object —
предмет, объект
896
—
context —
контекст
897
—
notice —
извещение, заметить
898
—
complete —
полный; заполнить
899
—
direct —
прямой, управлять
900
—
immediately —
немедленно
901
—
collection —
коллекция
902
—
card —
карточка
903
—
interesting —
интересный
904
—
considerable —
значительный
905
—
television —
телевидение
906
—
agency —
агентство
907
—
except —
кроме
908
—
physical —
физический
909
—
check —
проверять, проверка
910
—
sun —
солнце
911
—
possibility —
возможность
912
—
species —
вид
913
—
speaker —
спикер, выступающий
914
—
second —
секунда
915
—
laugh —
смеяться
916
—
weight —
вес; авторитет
917
—
responsible —
ответственный
918
—
document —
документ
919
—
solution —
решение
920
—
medical —
медицинский
921
—
hot —
горячий, жаркий
922
—
budget —
бюджет
923
—
river —
река
924
—
fit —
подходящий
925
—
push —
толкать
926
—
tomorrow —
завтра
927
—
requirement —
требование
928
—
cold —
холодный; простуда
929
—
opposition —
оппозиция
930
—
opinion —
мнение
931
—
drug —
наркотик
932
—
quarter —
четверть, квартал
933
—
option —
опция, вариант
934
—
worth —
стоящий
935
—
define —
определять
936
—
influence —
влияние, влиять
937
—
occasion —
случай
938
—
software —
программное обеспечение
939
—
highly —
высоко
940
—
exchange —
обмен
941
—
lack —
отсутствие, недостаток; испытывать недостаток
942
—
concept —
понятие, концепция
943
—
blue —
синий
944
—
star —
звезда; играть главную роль
945
—
radio —
радио
946
—
arrangement —
приведение в порядок
947
—
examine —
проверять
948
—
bird —
птица
949
—
busy —
занятый, многолюдный
950
—
chair —
кресло
951
—
green —
зеленый
952
—
band —
(музыкальная) группа
953
—
sex —
пол
954
—
finger —
палец
955
—
independent —
независимый
956
—
equipment —
оборудование
957
—
north —
север
958
—
message —
послание
959
—
afternoon —
время после полудня
960
—
fear —
страх, бояться
961
—
drink —
пить; спиртной напиток
962
—
fully —
полностью
963
—
race —
раса; гонка
964
—
strategy —
стратегия
965
—
extra —
дополнительный
966
—
scene —
сцена
967
—
slightly —
слегка
968
—
kitchen —
кухня
969
—
arise —
подниматься
970
—
speech —
речь
971
—
network —
сеть
972
—
tea —
чай
973
—
peace —
мир
974
—
failure —
провал
975
—
employee —
работник
976
—
ahead —
вперед
977
—
scale —
шкала
978
—
attend —
посещать
979
—
hardly —
едва
980
—
shoulder —
плечо
981
—
otherwise —
по-другому
982
—
railway —
железная дорога
983
—
supply —
запас; снабжать
984
—
owner —
собственник
985
—
associate —
общаться
986
—
corner —
угол
987
—
past —
прошлый
988
—
match —
матч; спичка; соответствовать
989
—
sport —
спорт
990
—
beautiful —
красивый
991
—
hang —
висеть
992
—
marriage —
свадьба
993
—
civil —
гражданский
994
—
sentence —
предложение
995
—
crime —
преступление
996
—
ball —
мяч
997
—
marry —
жениться
998
—
wind —
ветер
999
—
truth —
правда
1000
—
protect —
защищать
Частотный словарь (1001 — 2000)
· Частотный
словарь (2001 — 3000) ·
Словари
Библиографическое описание:
Ржеуцкая, С. Ю. Программное обеспечение для формирования частотных словарей в процессе обучения английскому языку в техническом вузе / С. Ю. Ржеуцкая, Т. В. Мальцева. — Текст : непосредственный // Современные тенденции технических наук : материалы II Междунар. науч. конф. (г. Уфа, май 2013 г.). — Т. 0. — Уфа : Лето, 2013. — С. 14-16. — URL: https://moluch.ru/conf/tech/archive/74/3835/ (дата обращения: 24.05.2023).
Изучение иностранных языков — труд нелегкий, независимо от того, самостоятельно ли учится человек или под руководством преподавателя. Последний вариант, безусловно, представляется более предпочтительным, поскольку преподаватель, даже не являясь носителем языка, является носителем культуры изучения языков (или какого-либо конкретного иностранного языка), отражающей громадный опыт предыдущих поколений, тщательно выбиравших наиболее оптимальный путь для достижения поставленной цели. Тем не менее, современные информационные технологии способны внести определенные новшества, оптимизирующие процессы запоминания иностранных слов, чтения оригинальных текстов в определенной предметной области.
Интересным и сравнительно новым средством обучения, которое может помочь в освоении англоязычной профессионально-ориентированной лексики, являются частотные словари. Частотные словари отражают относительную частоту использования слов в каком-либо тексте, коллекции текстов определенной тематики или в разговорной практике.
Чем же может помочь частотный словарь преподавателю, студенту технического вуза? Прежде всего, частотный словарь, полученный путем анализа достаточно большого текстового фрагмента на английском языке (например, подборка англоязычных материалов из Интернета по теме «Databases»), демонстрирует богатство используемых англоязычных технических терминов. Также преподаватель, используя частотный словарь, может определить необходимый словарный запас своих студентов для успешного чтения того или иного текста. При этом, если текст достаточно большой, студенту в первую очередь необходимо изучить слова и сочетания слов, наиболее часто встречающиеся в нем (например, более двух-трех раз). Выделить такие слова и сочетания можно автоматически, сформировав частотный словарь на основе изучаемого текста или коллекции текстов по определенной теме. Таким образом, частотные словари позволяют оптимизировать процесс освоения англоязычной лексики, соответствующей будущей профессии студентов.
В реалиях современного мира существует множество частотных словарей общеупотребительного английского языка. Однако словари по узким предметным областям найти достаточно сложно, да и самому преподавателю английского языка сложно составить подобный словарь или выбрать термины, которые необходимы для изучения студентами какой-то конкретной специальности. Ведь, как известно, профессиональная терминология студента-экономиста и студента-программиста сильно различается и для успешного делового общения в будущем таких студентов необходимо обучать разным нюансам языка, что позволит рационализировать процесс обучения. В связи с этим актуальной является задача построения частотных словарей для различных предметных областей с целью повышения качества профессионально-ориентированного обучения английскому языку.
Целью работы, представленной в докладе, являетсяразработка программного обеспечения, которое будет анализировать коллекцию технических текстов определенной тематики на английском языке и автоматически формировать частотный словарь используемых слов или сочетаний слов, включая также и их перевод. Наличие такого словаря позволяет студенту быстрее изучить тему и запомнить сложные профессиональные термины вместе с их англоязычными эквивалентами.
Итак, функционально, разрабатываемая система должна позволять преподавателю английского языка выбрать тексты для частотного анализа, выбрать слова, которые следует исключить из частотного словаря, провести частотный анализ, просмотреть и сохранить частотный словарь, выбрать параметры для формирования словаря, исключить уже изученные слова из словаря.
В процессе выполнения данного проекта была подобрана коллекция профессионально-ориентированных аутентичных текстов на английском языке по теме «Информационные технологии». Следует учитывать, что чем больше коллекция, тем более предметно-ориентированным получается частотный словарь.
При реализации проекта была выработана следующая стратегия обработки текстов:
1. Не учитываются слова, длина которых меньше трех букв.
2. Проводится процедура исключения словоформ (ведется поиск форм слов таких как: множественное/единственное число существительного, настоящее/прошедшее время глаголов)
3. Обрабатываются окончания –ing
4. Пропускаются слова из списка исключаемых слов (артикли, предлоги, союзы, а также слова, которые изучаются еще в школе).
5. Для словаря также исключаются слова, которые выбрал преподаватель, например, слова, которые студенты уже изучили.
При выборе методики решения были рассмотрены два способа представления данных: двоичные деревья и хэш-таблица. Приведем некоторые результаты сравнения:
1. Сортировка результата. Если результат должен быть отсортирован, хеш-таблицы представляются не вполне подходящими, поскольку их элементы заносятся в таблицу в порядке, определяемом только их хеш-значениями. При проходе дерева в обратном порядке получаем отсортированный список.
2. Память. Минимизация памяти, которая уходит на «накладные расходы», особенно важна, когда нужно хранить много маленьких узлов. Для хеш-таблиц требуется только один указатель на узел. Кроме того, требуется память под саму таблицу. Для двоичных деревьев необходимо хранить значения ключа, указатели на левое и правое поддерево.
3. Время. Алгоритм должен быть эффективным. Это особенно важно, когда ожидаются большие объемы данных. Хеш-таблица работает быстрее.
По результатам сравнения для реализации был выбран метод на основе построения хеш-таблицы как наиболее оптимальный для решения данной задачи. С учетом вышеизложенного было разработано программное обеспечение для формирования частотных словарей в среде Visual C++ (Microsoft Visual Studio).
Перечислим основные результаты выполненного проекта:
1. Выявлены требования к разрабатываемому программному обеспечению, определены функциональные особенности системы, выбрана методика решения.
2. Разработано программное обеспечение, которое будет анализировать коллекцию текстов на английском языке и автоматически формировать частотный словарь.
3. Подобрана коллекция профессионально-ориентированных аутентичных текстов по теме «Информационные технологии».
В будущем планируется доработка, включающая реализацию словаря по заданным преподавателем параметрам, доработка интерфейса с целью повышения эргономики программного продукта.
Применение разработанного программного обеспечения дает возможность повысить эффективность и качество обучения студентов технических вузов английскому языку, а также сделать это обучение профессионально-ориентированным и коммуникативно-направленным.
Литература:
1. Алексеев П. М. Частотные словари: Учебное пособие. — СПб.: Изд-во С.-Петерб. Ун-та, 2001–156 с.
2. Ахо, А. Структуры данных и алгоритмы/ А.Ахо, Д. Хопкрофт, Д. Ульман; пер. с англ. — М.: Вильямс, 2000. — 384 с.
Основные термины (генерируются автоматически): частотный словарь, английский язык, слово, коллекция текстов, программное обеспечение, словарь, текст, результат сравнения, сочетание слов, частотный анализ.
|
0 / 0 / 0 Регистрация: 02.04.2013 Сообщений: 7 |
|
|
1 |
|
Вывести частотный словарь введенного текста14.10.2013, 18:53. Показов 8983. Ответов 1
Помогите,Плиз. Пользователь вводит n предложений на латинице. Вывести частотный словарь введенного текста. Регистр символов учитывать. Использовать Dictionary для подсчета слов. Ключ – слово, значение – количество повторений. Критерий: введенная информация содержит только символы латиницы
0 |

|
Courage 145 / 45 / 16 Регистрация: 10.10.2013 Сообщений: 110 |
||||
|
14.10.2013, 19:51 |
2 |
|||
|
Решение держи
2 |
 Сообщение было отмечено romanch как решение
Сообщение было отмечено romanch как решение
")