«Дерево продукта» — это творческий и наглядный инструмент, который помогает найти и организовать направления развития продукта и его концепции, а также увидеть его слабые и сильные стороны через визуализацию образа и процесса роста обычного дерева.
Шаг №1. Визуализируйте продукт в дерево
Продакт-менеджер представляет свой продукт как дерево, где:
- Ствол дерева – основная функция продукта, на которой держится ваш продукт.
- Ветки дерева – доп. функции продукта, растущие из его ствола, которые реализуют эту функцию.
- Листья – идеи/гипотезы по текущим и новым функциям. Листья, расположенные ближе к стволу, являются краткосрочными, а листья, расположенные ближе к кроне дерева, указывают на долгосрочный рост.
- Корни дерева — инфраструктура продукта (его технологии), способные обеспечить рост ствола, веток и листьев. Как и в случае с любым деревом, чем больше оно становится, тем больше поддержки ему требуется от его корней.
Цель вас и команды – заполнить это дерево новыми листьями (мелкими функциями) или даже ветками (новыми гипотезами и направлениями для дальнейшего роста), не забывая оглядываться вниз на корни.
Запишите на стикеры все функции, которые у вас уже есть в вашем продукте (сплошной обводкой) или которые вы хотите добавить к нему (можно обводить пунктирной линией). Далее начните обсуждать и приклеивать каждый стикер (листок) по одному к соответствующим веткам.
Шаг №2. Оцените ваше дерево/продукт
Форма, которую принимает дерево, также должна дать ценную информацию. Предложите участникам прокомментировать то, что они заметили. Например, кажется ли рост сбалансированным или он сильно сгруппирован по одной ветви?
- Если вы видите очевидный дисбаланс на одной из веток (много листьев на одной ветке), то очевидный факт того, что развитие продукта глобально смещается в определенную сторону (ваш КО).
- Достаточно ли эффективно растёт ваш продукт? Если рядом со стволом много листьев (а не веток), то, возможно, что вы недостаточно быстро находите новые «больные места» пользователей и не закрываете их доп. функционалом, вместо чего выпускаете обилие улучшений основной функции (что в том числе, может быть правильным решением).
- Множество веток с малым количеством листьев говорят о том, что вы распыляете фокус и вовремя не отказываетесь от невостребованного функционала (или не развиваете его должным образом).
После этого, перед вами предстанет полноценный образ вашего продукта со всеми его возможностями и решениями.
Шаг №3. Подстригите ваше дерево
Какие функции обрезать в первую очередь? Как и садовники – мертвые ветки, на которых не вырастут новые листья. Либо большие и не нужные пользователям листья, которые забирают все полезные вещества из корней и не дают расти соседним веткам.
Дополнительные советы для командной работы:
- Поощряйте всех задавать вопросы и обсуждать – в ходе этого процесса генерируется ещё больше идей.
- Для формирования нескольких стратегий и «будущего», можно разработать сразу несколько деревьев, которые впоследствии можно сравнить между собой.
- Помните, какое значение имеет расположение листьев. Определите для себя что есть краткосрочное, а что есть долгосрочное видение.
- Не стесняйтесь использовать доп. обозначения: линии для отображения зависимостей между функциями, пунктирные и сплошные линии для текущих и будущих фич (листьев). Участники могут даже ставить плюсы или score рядом с листьями/ветками.
- Не забывайте оценивать текущие возможности и потенциал корневой системы. От неё зависит сможет ли дерево быстро расти (масштабироваться).
Product Tree — отличный способ разобраться в приоритизации функций.
Задача продакта сводится к структурированию всего, что есть в продукте для того, чтобы понять, какие новые фичи из раздела идей могут стать листьями на ветках дерева, а какие новыми ветками, либо вообще обзавестить полноценными стволовыми ответвлениями.
P.S. Шаблон «Дерево продукта» в Miro (на примере приложения для метеозависимых МетеоАгент). Оригинал картинки для печати.
Дерево метрик — как построить, с чего начать?
Время на прочтение
3 мин
Количество просмотров 5.2K


Автор статьи: Кристина Курдюмова
product marketing manager (stream B2B) в Rutube
Самый популярный вопрос у моих учеников — «как построить дерево метрик и с чего начать?», а следом за ним — можно ли сформировать бэклог продукта без дерева метрик.
Дерево метрик — это декомпозированная цель компании.
Зачем строить дерево метрик?
-
помогает фокусироваться на ключевых метриках;
-
обнаружить точки роста;
-
помогает при приоритизации бэклога.
Допустим, цель компании — заработать 10 млн. (Revenue). Сложно сразу сказать, как можно повлиять экспериментом напрямую на цель компании. Поэтому необходимо декомпозировать, чтобы выявить «прокси» метрики. Прокси метрики наиболее чувствительны к экспериментам и
«Сложная рабочая система неизменно получается из простой рабочей системы.
Сложная система, разработанная с нуля, никогда не работает.
И никакие улучшения не заставят ее работать.
Начинать следует с простой рабочей системы»— закон Голла, 1986
Разложим дерево метрик на примере пошагово.
-
Ставим ключевую метрику вашей компании, например Выручка (Revenue).
-
Определяем ключевую метрику вашего продукта, которая “бьет” в ключевую метрику вашей компании.
-
Раскладываем метрику Выручку на прокси метрики 1 уровня.
Например,
-
число активных пользователей
-
% платящих пользователей
-
частота покупок
-
средний чек
-
Каждую метрику 1 уровня раскладываем на подметрики 2 уровня.
Например,
-
число активных пользователей: % пользователей, прошедших онбординг и Retention 1, 7 или 30 дня (в зависимости от вашего продукта).
-
% платящих пользователей: все пользователи и платящие пользователи.
-
частота покупок: количество активных пользователей и количество покупок.
-
средний чек: среднее число товаров в заказе и средняя стоимость товара.
5. То же самое проделываем с каждым следующим уровнем. Каждую метрику 2 уровня раскладываем на подметрики 3 уровня.
-
средний чек: среднее число товаров в заказе и средняя стоимость товара;
-
среднее число товаров в заказе: среднее число товаров в избранном и среднее число товаров в корзине.
В итоге у вас получится примерно такая иерархия:

После декомпозиции необходимо узнать состояние метрик в настоящий момент, посчитать конверсии уровней. Как только вы подпишите метрики:
-
Вы увидите, над каким шагом или какой метрикой стоит поработать в первую очередь (где отток?)
-
Попробуйте прибавить к метрике +1% и посмотреть, как этот условный 1% может повлиять на вашу цель.
Конечно, стоит учитывать ещё некоторый коэффициент “плеча” изменения метрики — то есть если вы супер-сильно измените метрику IV-уровня, то это опередит по полезности слабое изменение метрики II-го уровня).
Изучить метрики I-го и II-го уровня, сфокусироваться на них и провести брейншторм, определить какие новые фичи могут забустить данные фокусные метрики — затем включить фичи в бэклог вашего продукта
Пошаговый план работы с деревом метрик:
Удобно визуализировать на MindMap (например, MindMeister, Mind42, Miro), либо на обычном листе, доске маркерной.
-
Напишите цель компании, поставьте ее во главу дерева.
-
Последовательно определяйте, на что раскладывается метрика выше? Как можно ее рассчитать? Добавляйте новые ответвления вашего дерева, определяя метрики.
-
Узнайте во внутренних отчетах или дашбордах компании значения метрик за последний месяц.
-
Проанализируйте дерево: выявите его слабые места (метрика или конверсия, которая ниже средних показателей в вашей компании). Определите максимальный потенциал метрики.
-
Сгенерируйте гипотезы, которые, по вашему мнению, вырастят метрику.
-
Приоритезируйте гипотезы.
-
Сделайте расчет импакта для ТОП 3 гипотез.
Немного про метрики.
-
Какие метрики могут быть в дереве метрик?
Ответ: любые.
Метрики можно разделить на такие группы:
-
маркетинговые (CPV, CTR, Open Rate и т.д.)
-
бизнес-метрики (LTV, GMV и т.д.)
-
продуктовые (RR, CR и т.д.)
-
метрики привлечения (CPI или Cost Per Install)
-
метрики удержания (Retention, LT и т.д.)
-
метрики допродажи (upsell, cross sell и т.д.)
-
метрики оттока (Retention rate и т.д.)
-
управленческие метрики
-
метрики для пресс-релизов
-
опережающие и запаздывающие метрики
Совершенно нормально, что метрики вашей компании могут быть иными. Их не стоит искать в интернете, а логически стараться понять, как данную метрику можно посчитать. На что она распадается?
Предупреждение от автора: дерево метрик — это инструмент визуализации. После его выполнения не стоит ожидать сразу роста метрик, потому что для этого нужны действия и эксперименты.
Статья подготовлена в преддверии старта курса «Продуктовая аналитика».
В больших и сложных продуктах с разными целевыми аудиториями, бизнес-моделями и несколькими продуктовыми командами есть много типичных проблем: как проверять гипотезы, которые ведут продукт к общей цели, как не развивать свою часть продукта в изоляции от всего продукта и не потерять его консистентность, как проверять гипотезы на адекватность и встраивать их в чёткую, понятную логическую иерархию.
Андрей Шапиро, арт-директор и партнер в Byndyusoft рассказал о том, что такое дерево продуктовых гипотез, как его создавать и ухаживать за ним, а также как эффективно использовать принципы рационального мышления и научные методы при проектировании и запуске цифровых продуктов.
Как и почему появился метод
Однажды я развивал продукт с зашкаливающим уровнем неопределенности и сложной структурой. Это был сервис мелкооптовой продажи автозапчастей. Бизнес состоял из двух логистических (сортировка и транспортировка) и IT (разработка платформы) компаний, а наша ecommerce-платформа должна была эффективно работать сразу на несколько целевых аудиторий с разными бизнес-моделями и конфликтом интересов в некоторых деталях.
Мы пишем о менеджменте продуктов и развитии в телеграм-каналах ProductSense и Продуктовое мышление.
Чтобы работать было удобнее, мы явно выделили несколько подпродуктов, в каждом из которых были свои системы приоритизации. При этом общего бэклога не было, и появился риск, что развиваться эти подпродукты будут вразнобой, без целостного видения. В итоге каждая команда могла свалиться в локальную оптимизацию и просто долбить изолированно одну, важную для нее, метрику.
И нам понадобился способ который помог бы командам не потерять большую цель в процессе локальных улучшений и заставить улучшения вести продукт к той самой большой цели, а не в противоположную сторону.
Логика, текстовые модели и отражение действительности
В 1958 году в «Логико-философском трактате» Лев Витгештейн сформулировал принцип: текст, если подойти к его формулированию достаточно строго, становится инструментом для точного описания мира — то есть создаёт некую зеркальную пару с миром, отражает его. Проще говоря, если что-то существует в действительности, это можно описать с помощью языковой конструкции. А значит, язык становится средством конструирования моделей мира.
Например, фраза «разница в давлении воздушных масс вызывает ветер, а ветер колышет деревья» отражает реальные природные процессы. При этом мы можем расшифровать и понятие «ветер», чтобы уточнить эту текстовую формулу. Например: «ветер — это движение воздушных масс в определенном направлении с определенной скоростью». Получается, что можно рекурсивно уточнять формулировку настолько, насколько нам это необходимо — то есть пока мы не объясним всё, что кажется неочевидным.
Однако есть важный момент: необходимо тщательно следить, чтобы наши языковые конструкции были адекватными — то есть отражали действительность максимально точно, с минимальными расхождениями. Хотя, конечно, какой-то зазор между реальностью и описывающей её моделью всегда останется, ведь язык — это неидеальное средство описания и он отражает мир только с определенной степенью точности. Причем разные языки могут лучше или хуже подходить для описания разных сущностей — например, есть знаменитый пример с эскимосскими языками, в которых существует множество слов для разных типов снега.
Модели мира в тексте как правило помогают объяснять, как устроено и работает то, что уже существует. Однако они становятся крайне важны, когда надо создать новые искусственные системы и встроить их в уже известные и привычные для нас системы. Причем системы эти должны быть максимально согласованными, чтобы не конфликтовать, а сосуществовать и развиваться гармонично. Например, техническая система типа Яндекс.Услуг или Профи, где независимые специалисты помогают людям решать разные задачи, должна объединить следующие принципы:
- как работают сообщества,
- как создаётся и поддерживается доверие между людьми,
- как люди проявляют коварство и обманывают друг друга,
- какие особенности есть в разных услугах, с которыми работает сервис (например, обучение иностранному языку вполне может работать удалённо, а аренда квартиры обязательно привязана к географии).
Вернёмся к примеру с ветром. У нас есть определение ветра и сформулированный принцип о том, что ветер возникает из-за разницы в давлении и качает кроны деревьев. Теперь мы можем добавить к этой текстовой модели еще один элемент: «в этой местности ветры особенно сильны в феврале и апреле». И вот уже у нас появилась конструкция для прогнозирования возможности или невозможности некоторой деятельности. Если мы знаем, что в определённое время ветры в какой-то местности сильны, то несколько раз подумаем, прежде чем ставить в таких условиях шатер.
Далее мы можем углубить и уточнить модель, задавшись вопросом, насколько сильны ветры. А получив ответ мы можем пойти дальше и задать новый вопрос — а какая несущая способность должна быть у конструкции при этой ветровой нагрузке. Таким образом, имея точные текстовые модели мы получаем инструмент для прогнозирования будущего.
Кому-то может показаться странным, что тщательно формулируемые фразы похожи на заклинания или что от них зависит, как работает действительность. Но всё устроено ровно наоборот: текстовые конструкции, строго сформулированные и адекватно уложенные во взаимосвязи причин и следствий, отражают закономерности реального мира.
Итак, чтобы подытожить, соберем цепочку из текстовых конструкций о сказанном выше.
- Логические построения помогают отразить взаимосвязи в мире.
- Чётко построенные взаимосвязи дают шанс иметь адекватную модель для более точного прогноза.
- Более точный прогноз даёт большие шансы на выживание и процветание.
В итоге, если мы действительно понимаем важность создания адекватных текстовых моделей и осознанно обращаем внимание на их точность, то шансы получить на выходе желаемый результат увеличиваются.
Научный метод и гипотезы в продуктовой разработке
Итак, перед нами стоит задача: необходимо создать новую систему, которая как минимум не будет отторгнута уже существующими системами, а в идеале будет процветать и гармонировать с ними. Перед запуском такой новой системы я рекомендую представить, смоделировать, как она работает в контуре ближайших систем и сред. В этом помогут гипотезы и эксперименты — артефакты научного подхода.
Гипотеза — это текстовое утверждение в виде логической цепочки, которая моделирует какую-то закономерность этого мира (уже существующую или будущую) и которую необходимо проверить.
Пример гипотезы:
Если покупателям предложить самостоятельно собирать купленную мебель, то покупатели охотно этим воспользуются и будут покупать больше, потому что:
- упростится и удешевится транспортировка,
- уменьшится итоговая стоимость,
- проявится эмоциональная сопричастность и удовлетворенность покупателя («я сам собрал»).
Если изучить нашу гипотезу про мебель, то мы увидим, что у неё трехчастный каркас: если X то Y, потому что R. Или немного иначе если X, то R, а значит Y. Часть с R нужна для того, чтобы раскрыть причинно-следственные связи. В добротных размышлениях таких цепочек между X и Y (то есть причинно-следственных связей) может быть множество — они как раз-таки помогают более тщательно выстроить и проверить взаимосвязи в модели.
Когда у нас есть гипотеза, мы обращаемся ко второй части научного подхода — эксперименту. В большинстве случаев невозможно или бесконечно трудно на 100% доказать, что одно явление повлияло на другое, то есть что между ними есть причинно-следственная связь. А потому для выявления взаимосвязей используют метод индукции.
В чем его суть: мы принимаем на веру существование взаимосвязи, которая постоянно подтверждается на некотором объеме экспериментов (например, отражением этого метода является понятие статистической значимости — когда мы с некоторой долей вероятности утверждаем, что результат нашего эксперимента не случаен).
И тут становится интересно: начинали мы с разговора о рациональности и вдруг пришли к вере. Поясню на примере цвета лебедей. До того, как западная цивилизация «открыла» Австралию, людям европейской цивилизации встречались исключительно белые лебеди. Так в ходе наблюдений и практического опыта учёные установили чёткую связь между сущностью «лебедь» и возможными значениями её признака «цвет»: если лебедь, то белый. А когда в Австралии обнаружили чёрных лебедей, знание об этом мире изменилось, прежняя модель была отвергнута и заменена новой.
Именно поэтому в индуктивном подходе даже бесконечного количества экспериментов не будет хватать для окончательного выявления и установления взаимосвязи. Вместо этого учёные с помощью достаточного количества экспериментов пытаются опровергнуть обратное утверждение. Так проще и быстрее получать новые знания, двигаясь циклически и уточняя модель мира.
В итоге такие взаимосвязи имеют вероятностную природу, то есть всегда есть шанс встретить исключения или новые экземпляры какой-то сущности, которые разрушат прежнюю структуру знаний. Однако пока этого не произошло, в качестве рабочего варианта используют наиболее адекватное приближение.
Но вернёмся к структуре гипотезы. Ниже приведён обобщенный каркас для продуктовой гипотезы, который я использую сам:
Если сделаем X,
то произойдёт Y (
это решит проблему P;
это может опровергнуть такую-то часть прежней модели;
<тут может быть что-то еще>
),
потому что R (
причинно-следственная связь — тест, эксперимент, мостик между X и Y
),
и за время эксперимента T
это изменит метрики A1 и A2 таким-то образом.
Чтобы понять, хороша ваша гипотеза или нет, достаточно проверить строгость утверждения и наличие структуры, с помощью которых вы будете принимать или отвергать итоговое знание по результатам эксперимента.
Вот как П. Г. Щедровицкий определяет критерии пригодности гипотезы: «Не стоит в рефлексии рассчитывать, что ваша исходная гипотеза имеет (сразу имеет — примечание автора статьи) хоть какое-то отношение к реальности, но она должна быть, и она должна быть достаточно артикулирована, чтобы вы потом могли подвергнуть ее критике и изменить. Карл Поппер, австрийский и британский философ и социолог, выражает ту же самую мысль в своём определении знания: знание — это то, от чего мы отказываемся, то, что фальсифицируется, то есть имеет такую структуру, в которой присутствует то, от чего мы отказываемся и то, что сохраняем. Если такой структуры нет, то это не гипотеза».
В цитате выше прозвучал главный принцип научного подхода: ничего нельзя экспериментально доказать, зато можно со 100-процентной точностью опровергнуть. Следовательно, мы получаем новое знание только через попытки отрицания гипотез (или другого знания). Если мы провели много экспериментов и не смогли опровергнуть свою гипотезу, значит, на некоторое время она становится частью нового знания.
Однако надо понимать — чтобы обоснованно отвергнуть какое-то утверждение, необходимо провести много экспериментов. За «достаточность» количества экспериментов при заданной строгости (то есть желаемой точности) отвечает критерий статистической значимости. И если использовать методы математической статистики при проверке гипотез, он не даст раньше времени принять неверную гипотезу.
Правда, применяя научный метод в современной продуктовой разработке, необходимо помнить об одной опасности. Научный подход создавался для описания фундаментальных закономерностей мира — например, таких как законы электромагнетизма и гидродинамики. Такие закономерности, в отличие от закономерностей в человеческих сообществах (мода, тренды, этика, стандарты красоты и поведения и т.п.) не изменяются на протяжении миллионов лет.
Следовательно, анализируя результаты продуктовых экспериментов, надо понимать: как стабильное отсутствие связи, так и стабильное его наличие может отражать временные явления. Если рынок изменится, то и открытые ранее закономерности «поплывут», станут некорректными и непрактичными, а то, что сегодня никому не нужно, может стать хитом и must have через 5 или 10 лет.
Деревья гипотез и бесконечные «почему»
Как мы видим из структуры выше, каждая из гипотез имеет цепочку из двух-трёх утверждений, связанных логикой причин и следствий. Гипотезы в формулировках, приведенных выше, удобны тем, что они могут проверяться изолированно. Например, можно разделить работу над двумя гипотезами между двумя разными командами — и они не будут зависеть от результатов друг друга.
Вместе с тем, гипотезы могут зацепляться друг за друга связями между тезисом-причиной и тезисом-следствием и создавать тем самым как более длинные цепочки, так и ветвления. Цепочки, в свою очередь, можно стыковывать друг с другом, получая ветви дерева.
Пример ветвления
- Если я буду поливать дерево в моменты засухи, дерево проживёт дольше.
- Если я буду уничтожать древесных вредителей, дерево проживёт дольше.
Это две равноправные гипотезы, которые будут выходить из ствола/ветки «дерево проживёт дольше».

Пример последовательной (составной) цепочки
- Если я обеспечу минимальную влажность стволу и кроне, то вредителей будет меньше.
- Если вредителей будет меньше, дерево проживёт дольше.

Существует несколько инструментов, которые помогают упорядочить процесс обдумывания и решения проблем и в основе которых лежат логические цепочки, организованные в виде деревьев. Например, в Теории решения изобретательских задач (ТРИЗ) это причинно-следственный анализ (ПСА), а в ТОС — дерево текущей реальности. Оба метода помогают «разматывать» текущую проблемную ситуацию, последовательно задавая вопрос «Почему» на каждом из звеньев дерева.
Процесс такой. Сначала мы записываем некоторое текстовое утверждение, которое отражает и описывает нежелательное явление, с которым мы столкнулись. Потом задаем к этому утверждению вопрос «Почему» и пытаемся на него ответить. С каждым новым уровнем ответов на вопрос «Почему» исследователь всё больше смещается от анализа следствий к анализу причин, соединяя звенья дерева.
С помощью цепочки причинно-следственных связей можно не только анализировать имеющуюся ситуацию, но и синтезировать логические связи для какой-то будущей ситуации. Например, я уже упоминал инструмент Дерево будущей реальности, в котором за счёт звеньев-инъекций, вносящих изменения в дерево текущей реальности, можно создавать модель взаимосвязей будущей системы (то есть новой системы, которой ещё не существует).
А имея модель взаимосвязей будущей системы, мы ещё до её создания сможем принимать осмысленные решения о том, как усилить или ослабить её отдельные звенья и оптимизировать отдельный показатель или группу показателей.
Метод дерева продуктовых гипотез
Сам метод заключается в том, что мы создаём логическую диаграмму, которая отражает структуру будущего продукта — а потом на основе этой диаграммы принимаем решения. Структура эта изначально строится так, чтобы все инициативы (гипотезы), которые в неё закладываются, улучшали продукт. Чем более строго мы подойдем к составлению дерева, тем меньший зазор будет между нашей моделью и будущей реальностью.
Вот набор тезисов, на основе которых строится дерево гипотез:
- В качестве структуры, формирующей ствол и ветви дерева, удобно использовать структуру потоков бизнес-ценности в продукте. В коммерческих системах это чаще всего логистические потоки товаров или услуг, потоки потребителей и их покупок и денежные потоки.
- Корень дерева строится на основе текстовых утверждений вида «Действующий бизнес успешен, если…» или «доходность бизнеса растёт, когда…». От этого корня пойдут утверждения, описывающие, когда именно и при каких условиях это может быть правдой. Так формируется ствол и ветви дерева.
- В качестве «двигателя» улучшений в продукте принимается принцип максимизации потоков. В коммерческих продуктах это максимизация выгоды и минимизация расходов. В обобщённом варианте — максимизация ширины каналов и количества полезного вещества или информации в каналах и минимизация количества вредного.
- Следуя принятому принципу максимизации потоков, в дерево складываются утверждения двух видов:
- улучшения (или «прорыв» в ТОС) — например, «потребитель заранее оповещен о корректном сроке возврата товара»;
- нежелательные эффекты в форме отрицания — например, «нет помех в процессе подбора товара», «технологии компании не устаревают».
- Текстовые формулировки всех идей улучшений и проблемных ситуаций должны укладываться в согласованную логическую цепочку. То есть каждая ветка-потомок должна быть связана с веткой-родителем отношением «если — то» (помните X и Y из начала статьи?).
Если реализовать «суждение-потомок»,
то получим «суждение-родитель»
- Каждую связь при работе с деревом необходимо проверять на валидность и состоятельность. Под валидностью мы понимаем адекватность логической связи: например, связь «если прошёл дождь, то земля под открытым небом мокрая» — валидна, а связь «если земля мокрая, значит шёл дождь» — нет, потому что на степень сухости земли могло повлиять что-то ещё, кто-то мог плеснуть воды из стаканчика. Под состоятельностью мы понимаем правдоподобность, реалистичность связи, которую мы заявляем. Например, связь «если долго сидеть и ждать, то однажды увидишь инопланетян» не проходит тест на состоятельность.
Если построить дерево согласно этим тезисам, то мы получим целостный план инициатив и их связей с коммерческими целями в корне дерева. Кроме того, процесс построения дерева помогает участникам прокачать интуицию о продукте и лучше изучить взаимосвязи в нём, благодаря тщательному и вдумчивому отбору адекватных связей и отбрасыванию заблуждений.
Как применять дерево продуктовых гипотез
Я выделяю несколько принципиальных фаз в работе с деревом:
- Генерация первоначального дерева.
- Выращивание: размещение в дереве новых элементов и проверка новой гипотезы.
- Уход за деревом: чистка и проверка дерева с перемещением ветвей по его структуре.
- Принятие стратегических и тактических решений с использованием дерева: оценка вклада в потоки отдельных ветвей и лепестков, выбор мероприятий по реализации.
Разберём подробнее каждую фазу.
1. Генерация первоначального дерева
Для начала надо установить, какие потоки ценности существуют в бизнесе и как они увязаны друг с другом. Такой анализ лучше всего провести с помощью схемы или визуализации связей потоков в виде графа. В процессе важно сразу оцифровывать и ширину каналов (русел, в которых течет вещество потока), и текущую скорость потоков. Без этих данных будет трудно принимать решения.
На изображении ниже можно увидеть структуру потоков действий потребителей, которые они совершают, проходя несколько экранных форм типичного ecom-продукта в сфере автозапчастей.
Мы взяли такой фрагмент сценария: проверка наличия товаров → поисковые запросы → просмотру вариантов поставки → добавление товара в корзину.
И несколько важных для анализа срезов:
- какая запчасть рассматривалась: искомая или заменитель;
- когда она была в наличии: сегодня или завтра;
- привозили ли её сторонние поставщики или справлялись собственные склады;
- добавили ли её в итоге в корзину.
По всем величинам у нас были данные, благодаря которым мы смогли визуализировать сценарии и провести первичный анализ.
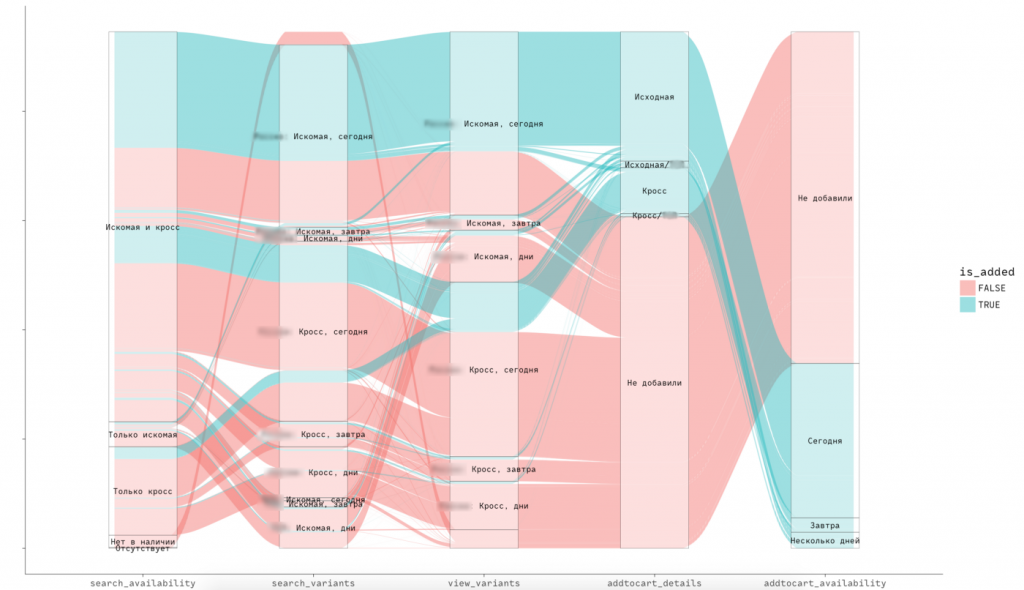
Может оказаться, что у нас не будет точной численной информации о потоках — однако это не должно вас останавливать. Самое важное — понимание процессов: как всё происходит, откуда и куда «текут» основные ценности.
К примеру, ниже показана принципиальная схема для маркетплейса запчастей. В «котёл» подбора вариантов и принятия решения попадают потоки потребителей и поток предложений от поставщиков и продавцов. На каждый из каналов, приводящий часть потока, можно воздействовать. Наша задача на этом этапе — вычленить каналы и перенести их на дерево в виде словесных формулировок.
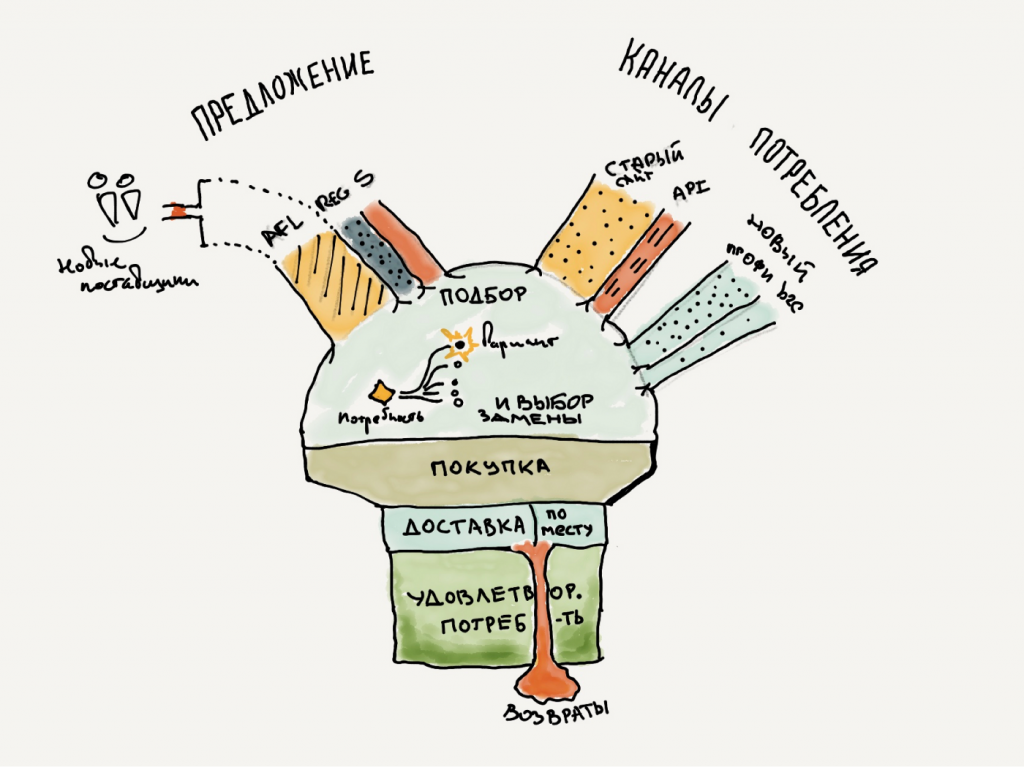
Вот пример записи корня дерева и его первых мощных ветвей на основе этой принципиальной схемы.

Эту запись следует читать так: «Действующий операционный бизнес максимизирует выгоду тогда, когда все ниже перечисленные условия одновременно (логическое И) выполняются. А именно: организован сбор товарного предложения, организован информационный доступ потребителей, …».
Пока текстовые формулировки описывают организацию базовых компонентов бизнеса — на этапе запуска это нормально. Но со временем просто организовать что-то с нуля будет уже недостаточно и придётся перейти к формулировкам оптимизационным. Например, сейчас в этой связке нет требований к тому как организована работа по возврату товаров, а в будущем мы можем заложить требования к минимизации возврата и искать подходящие решения.
Рассмотрим ещё один пример — гипотетическое дерево гипотез для предприятия летнего киоска с мороженым с несколькими ветвями.

Генерировать дерево лучше всей продуктовой командой, чтобы все «схватили» и усвоили, как устроена та часть бизнеса, для которой составляется дерево. Встречи по генерации лучше делать с минимальными перерывами, чтобы участники не забывали контекст. Каждую из встреч лучше ограничить полутора часами и внутри такого блока делать один небольшой перерыв. Нагрузка на мозг при построении логических схем очень высокая, поэтому лучше организовать работу так, чтобы когнитивный ресурс расходовался бережно.
2. Выращивание дерева
Следующая фаза работы с деревом растянута по всему времени существования продукта. К этой фазе необходимо возвращаться каждый раз, когда требуется приземлить в дерево новую гипотезу. Основными процессами на этом этапе являются добавление гипотезы и верификация её встройки в дерево.
Добавление гипотезы
Существует два типа гипотез — гипотезы улучшений и гипотезы проблем.
Гипотезы улучшений формулируются как утверждения в настоящем времени, как неоспоримый факт, в формате «мама моет раму», то есть они содержат три компонента:
- субъект, оказывающий воздействие;
- само воздействие;
- объект, испытывающий воздействие.
Например, «отходы увеличивают количество выпускаемой продукции».
Гипотезы проблем формулируются в виде отрицания. Например, «конечные устройства системы не становятся заложниками устаревающей платформы». Конечные устройства здесь — это мобильник, планшет, десктоп, терминал сбора данных (ТСД). Если ОС устарела или ушла с рынка, а ты к ней привязан, твой планшет или ТСД превращается в тыкву. Задача бизнеса — не оказаться заложником подобной ситуации.
Возьмём дерево гипотез продукта для продавцов на том же маркетплейсе автозапчастей и попробуем добавить в него новую гипотезу.
Гипотеза улучшений, которую мы хотим добавить, связана с повышением прозрачности в системе и звучит так:
Если Продавец увидит статистику оценок Покупателями качества его работы с разрезом по типичным проблемам, то он вероятно повысит качество своей работы.
Пробуем приземлить гипотезу в следующую ветку дерева:

До этого в дереве не было ветки с улучшением качества работы продавца, мы добавили её только что — чтобы было куда поместить лепесток с нашей гипотезой улучшения. Теперь необходимо проверить новую ветку на валидность и состоятельность.
Развернём её мысленно в логическую цепочку:
- ЕСЛИ Продавец увидит статистику оценок Покупателями качества его работы с разрезом по типичным проблемам, ТО есть шанс, что Продавец улучшит качество своей работы, (1)
- ЕСЛИ качество возрастёт, ТО придёт больше Покупателей, (2)
- ЕСЛИ придёт больше Покупателей, ТО они сделают больше покупок, (3)
- ЕСЛИ вырастет число покупок, ТО вырастет выручка в канале Продавцов. (4)
Легко обнаружить проблемы с валидностью утверждений 2 и 3. Не факт, что если на платформе появится больше покупателей, то они совершат больше покупок. И не факт, что при возрастании качества придёт больше покупателей. Вероятно, по задумке авторов гипотезы речь здесь идёт о повторных покупках, о возврате (retention) действующих покупателей — если они будут довольны качеством, то процент таких вернувшихся покупателей вырастет. Но зазор с реальность здесь слишком большой, поэтому уточним формулировку 2 в цепочке, чтобы сделать её более аккуратной.
- ЕСЛИ качество возрастёт, ТО часть Покупателей вернётся и купит повторно (2)
Теперь поправим эту часть в дереве. А чтобы дерево осталось логически корректным, придётся добавить ещё одну промежуточную ветвь — на иллюстрации она отмечена курсивом — и поместить гипотезу в неё:

Теперь, если проверить цепочку, прочитав записи от лепестка (крайнее в ветке утверждение) в направлении к корню (то есть к верхнему, самому первому, утверждению), всё будет корректным.
Конечно, у нас могут быть вопросы к состоятельности самой гипотезы. Никто не знает насколько правдоподобно утверждение 1 — разрешить эту коллизию поможет только эксперимент. А на текущем этапе мы можем лишь мысленно проверить гипотезу на состоятельность, уповая на интуицию и способность участников команды делать более-менее корректные прогнозы. Хотя, конечно, такие мысленные эксперименты могут загубить хорошую идею — или наоборот, дать ход идее довольно посредственной.
Но как бы то ни было, мы всё равно используем интуицию продуктовой команды — она помогает ускорить процесс отбора идей и проверки гипотез. Да, степень уверенности в успехе гипотезы входит в некоторые системы оценки — например, в RICE, однако главным критерием истинности могут служить только реальные испытания. А доводить до них все подряд гипотезы очень нерационально и дорого, всё равно необходим предварительный отбор.
Попробуем приземлить в наше дерево ещё три утверждения:
- «80% посетителей сайта не удовлетворяют свою потребность» (5)
- «Профессиональным участникам не нравится новый сайт. Они не торопятся перейти со старого сайта на новый» (6)
- «У компании есть возможность беспрепятственно и бесперебойно запускать до 10 A/B-тестов в месяц и получать достоверные данные по их результатам» (7)
Утверждения 5 и 6 в такой формулировке не готовы для погружения в дерево — они лишь констатируют некоторые наблюдения. Однако если эти факты являются для нас нежелательными, мы можем попытаться внести их в дерево через отрицание. Например, «80% посетителей сайта удовлетворяют свою потребность». Такая ветка будет формулировать промежуточную цель, желаемый результат.
Однако с подобной верхнеуровневой формулировкой у команды вряд ли появятся конкретные идеи о том, как достигать результата, и лучше будет исследовать факты более детально. Например, проанализировать их с помощью причинно-следственного анализа, атаковать найденные во время анализа корневые причины и предлагать идеи исправлению вредного влияния.
А вот в утверждении 7 довольно чётко сформулирована задача. Можно погрузить её в дерево и предлагать в качестве потомков к ней идеи с решением. Вот пример ветки, в которую можно погрузить такое утверждение.

3. Уход за деревом
Дерево реального продукта, скорее всего, будет большим и развесистым. Если за ним не ухаживать, в разных частях могут появиться схожие по идеям ветки. Всё это будет затруднять работу с деревом — вплоть до того, что будет непонятно, куда именно добавить новую идею, и появится немало противоречий. Чтобы такого не происходило, полезно время от времени пересматривать формулировки, «пересаживать» ветки с одних мест в другие и находить между ними противоречия.
К сожалению, в самом методе дерева продуктовых гипотез нет встроенного механизма, который бы гарантировал, что вы, будучи даже единственным автором, не создадите противоречащие друг другу ветки. Поэтому в работе с деревом необходимы внимательность и дисциплина. А если над деревом работает команда, то критичность ухода за деревом возрастает ещё больше — придётся регулярно договариваться и пересматривать дерево, оповещать коллег о нововведениях.
Итак, что делать, когда на дереве появляются противоречащие ветви. Если такие ветви ещё не вылились в реальные действия и не стали частью бизнеса, то проще всего отказаться от одной из ветвей. Лучше, конечно, отказываться от той из них, которая приносит меньше выгод или требует больше усилий на проверку и реализацию. Если же обе противоречащие ветки уже стали частью вашей системы, я рекомендую добавить в дерево ещё одну ветку — ветку по избавлению от противоречия. Я делаю это следующим образом.

Важно следить, чтобы в дереве не было веток, жадно оптимизирующих какой-то из параметров внутри себя. Такая локальная оптимизация может привести к падению результатов в соседних ветках и эффективности предприятия в целом. Поэтому формулировки по основным потокам лучше записывать в связке, чтобы они учитывали влияние друг друга. Будет отлично, если дерево подкреплено схемами или даже визуализациями потоков и их взаимосвязью — это даёт интуицию для более аккуратного его построения.
4. Принятие решений
Теперь самое интересное. Ведь мы создавали дерево не ради него самого, а для того, чтобы получить инструмент для принятия решений. И если у вас есть оцифровка потоков, то, скорее всего, уже есть и понимание приоритетов — какую из ветвей бизнеса пускать в работу первой.
Обычно это ветка с наивысшим ROI, которая легче всего может максимизировать выгоду. Однако это может быть и что-то связанное с самым большим стратегическим риском, зафиксированном в дереве как отрицание его нежелательного эффекта.
Алгоритм работы с деревом на этой фазе такой:
- Выбрать ветвь с наибольшим потенциалом. Для этого надо оцифровать вклад каждого из потоков.
- Выдвинуть идеи, максимизирующие полезное действие в этой ветке.
- Проверить идеи на адекватность (валидность и состоятельность), невалидные отбросить.
- Оцифровать ценность валидных идей, если это возможно.
- Вычленять задачи на базе этих идей, если они встроились в дерево.
- Запустить в работу задачи с максимальным вкладом в ценность, организовав эксперимент по контролю за результатом.
- Повторить весь процесс, начиная с первого шага.
Результатом эксперимента может быть и отсутствие ожидаемого в гипотезе результата. В этих случаях мы фиксируем лишь полученное знание и двигаемся дальше.
Сильные и слабые стороны метода
Этот метод подойдёт не всем — он требует дисциплины и опыта рационального мышления, чем попросту отпугивает людей. Вместе с тем, в методе нет ничего, кроме движения к чистому мышлению, и автор, если бы увидел для этого возможность, с радостью перевёл бы его в символически более строгое пространство, чем естественный язык.
Сильные стороны метода
- Структурирует знания. Помогает осознать взаимосвязи в создаваемой системе.
- Даёт опору для генерации идей, благодаря обретенной ясной структуре взаимосвязей.
- Является лакмусовой бумажкой для проверки пригодности идей по инициативам. Хорошо составленное дерево не впустит ерунды в себя.
Слабые стороны
- Требует опыта рационального мышление.
- Требует жёсткой дисциплины.
Видео доклада автора о методике построения и использования деревьев гипотез на конференции «Бизнес-ТРИЗ Онлайн»
Материалы
- Лев Витгенштейн, «Логико-философский трактат», 1958
- Уильям Детмер, Теория ограничений Голдратта. Системный подход к непрерывному совершенствованию, — Альпина Паблишер, М.: 2015, 443 стр.
- Анатолий Карпов, Идея статистического вывода. Из курса «Основы статистики. Часть 1»
- Юрий Окуловский, Гипотезы в научном методе. Из курса «Научное мышление»
- Арсений Ольховский, Как формулировать продуктовые гипотезы, подкаст make sense
- Бертран Рассел, «Лекция 2. Искусство делать выводы» // «Искусство мыслить»
- Презентация https://speakerdeck.com/byndyusoft/produktovyie-instrumienty-ghipotiezy-ekspierimienty-dieriev-ia-rosta-i-probliematiki
Практические руководства
Алгоритм FP Growth
Использование алгоритма роста FP в Python для частого интеллектуального анализа наборов элементов для анализа корзины

В этой статье вы познакомитесь с алгоритмом роста FP. Это один из самых современных алгоритмов для частого анализа наборов элементов (также называемого интеллектуальным анализом правил ассоциации) и анализа корзины.
Частый поиск наборов товаров и анализ корзины
Начнем с введения в анализ часто используемых наборов товаров и анализ корзины.
Анализ корзины
Анализ корзины — это исследование корзин в покупках. Это могут быть покупки онлайн или офлайн, если вы можете получать данные, отслеживающие товары для каждой транзакции.
Часто изучаемый вариант использования анализа корзины — это изучение продуктов, которые часто покупаются вместе. Этот тип понимания может быть использован для того, чтобы дать покупателю рекомендации по совершению покупок в Интернете или для перегруппировки продуктов в обычном магазине, чтобы покупателям было легче добавить их в свою корзину.
Частый майнинг наборов предметов
Частый поиск наборов предметов — это технический термин для поиска комбинаций продуктов, которые часто покупаются вместе. Обычно вы начинаете со списка транзакций, в котором каждая транзакция представлена в виде списка продуктов.
Целью анализа часто встречающихся наборов элементов является выявление часто встречающихся комбинаций продуктов с помощью быстрого и эффективного алгоритма. Для этого есть разные алгоритмы. Одним из основополагающих алгоритмов является алгоритм априори.
Алгоритм FP Growth можно рассматривать как современную версию Apriori, поскольку он быстрее и эффективнее при достижении той же цели.
Кстати, алгоритмы анализа часто используемых наборов элементов не зависят от предметной области: вы можете использовать частый анализ наборов элементов для других полей, кроме анализа корзины.
Пример использования алгоритма роста FP
Давайте воспользуемся примером набора данных, который содержит список транзакций ночного магазина. Для каждой транзакции у нас есть список продуктов, которые были куплены во время транзакции. Этот пример также используется в этой статье об алгоритме априори, так что это даст нам интересный тест для сравнения производительности двух алгоритмов.
Вы можете увидеть таблицу со списком транзакций ниже. Это довольно небольшая база данных, так как это позволит легко отследить шаги алгоритма FP Growth вручную, прежде чем погрузиться в реализацию Python.

Как работает алгоритм роста FP?
Идея алгоритма FP Growth состоит в том, чтобы найти наиболее часто встречающиеся наборы элементов в наборе данных, будучи быстрее, чем алгоритм Apriori. Алгоритм Apriori в основном обращается к набору данных и проверяет совпадение продуктов в наборе данных.
Для получения более подробной информации о тесте, который мы должны пройти, в этой статье подробно перечислены этапы алгоритма априори.
Чтобы быть быстрее, алгоритм FP изменил организацию данных в виде дерева, а не наборов. Эта древовидная структура данных позволяет ускорить сканирование, и именно здесь алгоритм выигрывает время.
Шаги алгоритма роста FP
Давайте теперь посмотрим, как составить дерево из наборов продуктов, используя данные транзакции из приведенного выше примера.
Шаг 1. Подсчет количества экземпляров отдельных элементов
Первым шагом алгоритма роста FP является подсчет вхождений отдельных элементов. В таблице ниже показано количество каждого элемента:

Шаг 2. Отфильтруйте нечастые товары с минимальной поддержкой
Вам необходимо выбрать значение для минимальной поддержки: каждый элемент или набор элементов с меньшим количеством вхождений, чем минимальная поддержка, будет исключен.
В нашем примере давайте выберем минимальную поддержку 7. Это означает, что мы собираемся отказаться от предметов «Мука» и «Масло».
Шаг 3. Упорядочите наборы элементов по индивидуальным случаям
Для остальных позиций создадим упорядоченную таблицу. Эта таблица будет содержать элементы, которые еще не были отклонены, а элементы внутри транзакции будут упорядочены в зависимости от наличия отдельного продукта.

Шаг 4. Создайте дерево и добавьте транзакции одну за другой
Теперь мы можем создать дерево, начиная с первой транзакции. Каждый продукт представляет собой узел в дереве, как показано ниже:

Обратите внимание, что мы также добавляем счетчик к каждому продукту, который мы будем использовать для подсчета позже.
Теперь мы можем перейти ко второй транзакции:

Давайте теперь посмотрим, что произойдет, когда мы добавим третью транзакцию:

Третья транзакция не содержала пива, в отличие от двух первых транзакций. Следовательно, было невозможно связать его напрямую с первым деревом. У него есть отдельный начальный узел, к которому вы можете добраться через главный узел сыра.
После того, как это дерево FP построено, гораздо быстрее будет пройти по нему и найти информацию о наиболее часто встречающихся наборах элементов. Дополнительные технические подробности и эталон скорости обхода вы можете найти в этой статье, которая мне кажется довольно ясной. В оставшейся части статьи перейдем к примеру использования алгоритма FP Growth в Python.
Пример роста FP на Python
Давайте теперь начнем с алгоритма FP Growth в Python. Для этого мы воспользуемся пакетом mlxtend, который можно установить с помощью приведенного ниже кода:
Как указано в коде, вам необходимо обновить пакет, если вы работаете в Google Colab, так как это позволяет избежать ошибки в дальнейшем.
Теперь вам нужно ввести данные в виде списка транзакций. Каждая транзакция представляет собой список предметов. Внимание: вы не можете использовать кортежи элементов, как в других реализациях, потому что это приведет к ошибке.
Невозможно вписать алгоритм роста FP непосредственно в список транзакций. Сначала вам нужно закодировать его с помощью кодировщика, сопоставимого с One-Hot Encoder. TransactionEncoder предоставляется пакетом mlxtend, и вы можете использовать следующий код для создания закодированного фрейма данных:
Полученный фрейм данных должен выглядеть следующим образом:

Следующим шагом является вычисление частых наборов элементов. Вы можете использовать функцию fpgrowth из mlxtend, как показано ниже:
Вы увидите поддержку для каждого из наборов элементов. Элементы, которых здесь нет, отфильтровываются, потому что они не достигают минимального уровня поддержки. Кстати, обратите внимание, что минимальный уровень поддержки здесь выражен в процентах, тогда как в ручном примере он был выражен целым числом.

В качестве последнего шага нам нужно использовать функцию association_rules для преобразования этих частых наборов элементов в правила ассоциации. Это можно сделать с помощью следующего кода:
Окончательные правила ассоциации, вычисленные с использованием FP Growth, выглядят следующим образом:

Интерпретация результатов алгоритма FP Growth
Теперь мы переходим к заключительной части этой статьи: интерпретации правил и показателей, которые были сгенерированы алгоритмом роста FP.
Правила
Во-первых, можно сделать вывод, что существует две комбинации продуктов, и обе ассоциации двунаправленные. Люди, которые покупают сыр, также покупают вино, а люди, которые покупают вино, также покупают сыр. Отдельно мы видим, что люди, покупающие пиво, также покупают картофельные чипсы и наоборот.
Метрики правил
Вторая вещь, на которую интересно взглянуть, — это показатели правил. Вместе они кое-что говорят нам о надежности правил. Важно обратить внимание на следующие три показателя:
- Поддержка сообщает нам, сколько раз или процент совпадений продуктов
- Достоверность сообщает нам, сколько раз срабатывает правило. Это можно сформулировать иначе, как условную вероятность правой части с учетом левой части
- Лифт дает нам силу ассоциации
Заключение по метрикам
Не обязательно есть одна общая метрика, которую мы можем использовать, чтобы решить, какие правила «официально» принять или отклонить. В конце концов, метод — это скорее инструмент исследования, чем инструмент подтверждения.
В нашем текущем случае мы получаем два двунаправленных правила, которые кажутся очень действительными на основе данных. Если бы у нас было больше, например слишком много, чтобы посмотреть, мы могли бы использовать метрики, чтобы создать подмножество правил, которые будут наиболее полезны для нас. Затем мы могли бы также изменить минимальную поддержку.
В конце концов, важно помнить о том, чтобы адаптировать модель к вашему конкретному варианту использования.
Заключение
В этой статье вы открыли для себя алгоритм роста FP. Вы видели пошаговое описание алгоритма вместе с примером использования, реализованным с помощью Python.
Надеюсь, эта статья была для вас полезной. А пока, пожалуйста, следите за обновлениями, чтобы получать больше математических данных, статистики и данных!
![]()
Дерево продуктов/услуг
Дерево продуктов/услуг
(Product/Service tree) –
предназначено для структурирования продуктов/услуг в виде составляющих их частей.
Эта диаграмма существует в двух видах: графическом и пиктографическом

Объекты дерева продуктов/услуг
|
Service |
|
|
Product |
Услуга |
|
Продукт |
 Objective
Objective
Цель
Function
(Manufacturing)
Функция
(производственная)
Information
service
Информационная
услуга
 Person (m)
Person (m)
Персона
Function
(Office)
Функция
(офисная)

Дерево продуктов/услуг
Продукты
|
Продукты |
Продукты |
Продукты |
Продукты |
Продукты |
Продукты |
Продукты |
||
|
бокситовых |
||||||||
|
глиноземных |
алюминиевых |
предприятий |
предприятий |
предприятий |
предприятий |
|||
|
и нифелиновых |
||||||||
|
предприятий |
предприятий |
Прокатного дивизионаТарного дивизионадивизиона АСКУпаковочного дивизиона |
||||||
|
производств |
||||||||
|
Глинозем |
Чистый |
|||||||
|
алюминий |
||||||||
|
Вспомогательная |
||||||||
|
продукция |
Сплавы |
|||||||
|
глиноземных |
||||||||
|
предприя |
||||||||
|
тий |
||||||||
|
Кремний |
||||||||
|
Германий |
||||||||
|
Каустическая |
Продукция |
|||||||
|
сода |
компании |
|||||||
|
Шламы |
|
Ножницы |
Укладки для |
Термоконтейнеры |
Пинцеты Укладки для бригад |
Укладки |
Штативы |
|
медицинских |
медицинские |
скорой медицинской |
для ампул |
медицинские |
|
|
работников |
переносные |
помощи |

Диаграмма движения продукта/услуги
Диаграмма движения продукта/услуги (Product/Service exchange diagram)
—
предназначена для описания процесса создания продуктов и услуг, а также их передвижения в масштабах организации. Эта диаграмма существует в двух видах: графическом и пиктографическом

Диаграмма движения продукта/услуги
|
Упаковочный |
Электро- |
Медный |
Изоляционные |
|
|
техническая |
||||
|
материал |
провод |
материалы |
||
|
сталь |
||||
|
Штамповоч- |
Каркасная |
|||
|
ный цех |
группа |
|||
|
Сердечник |
Намоточный |
Каркас |
||
|
трансформатора |
провод |
трансформатора |
Участок
сборки
|
Ящик |
Ящик |
Трансформатор |
Трансфор- |
|
|
готов |
матор готов |
|||
Участок
упаковки
Упакованный Трансфор- трансформатор матор готов к отгрузке

Диаграмма движения продукта/услуги
Отдел
сбыта
|
Звонки по |
Рекламма |
Личные |
|
телефону |
в Интернете |
контакты |
|
Сообщения |
Рекламма |
|
|
по E-mail |
в печати |
|
|
Расширять |
||
|
сбыт продукции |

Диаграмма потоков материалов
Диаграмма материальных потоков
(Material Flow Diagram)
отображает поток материалов между функциями.

Диаграмма потоков материалов
|
Закупать |
sends |
is received from |
||
|
сталь |
Электротехническая |
|||
|
сталь |
||||
|
Закупать |
Хранить |
|||
|
изоляционные |
||||
|
материалы |
||||
|
материалы |
Изоляционные |
|||
|
материалы |
||||
|
Закупать |
||||
|
медные |
||||
|
провода |
Медный |
executes |
||
|
провод |
||||
|
Отдел |
||||
|
Склад |
||||
|
снабжения |
||||
Цех
штамповки
Производить
магнито- 

Электротехническая проводы Магнитопроводы сталь
|
Производить |
|
|
Изоляционные |
каркасы |
|
Каркасы |
|
|
материалы |
Собирать |
|
трансфор- |
|
|
Медный |
маторы |
|
провод |
Сборочный |
|
цех |

Диаграмма взаимодействий
Диаграмма взаимодействий
(Communication Diagram) –
позволяет представить процессы взаимодействия организационных единиц

Пример диаграммы взаимодействий
Поставшик
оборудования
Прием продукции у поставщиков
Поставщик
комплектующих
Заказ у поставщиков
Прием
заказов
Потребитель 

Отгрузка
продукции
Склад
входящей
продукции
Отдел
снабжения
Отдел
сбыта
Склад
готовой
продукции
Передача
материалов
Согласование по объемам
Плановый
отдел Согласование 
поставок
|
Формирование |
Планирование |
|
заказа |
производства |
|
Производство |
|
|
Передача |
|
|
продукции |
Соседние файлы в папке Prezentaciya_Lekciya_4_5_6_7_8
- #
22.08.2013122 б31.listing
- #
- #