Цифровой словарь от А до Я
Время на прочтение
5 мин
Количество просмотров 13K
Одной из самых полезных программ на ПК и смартфоне в моем понимании является электронный словарь. В те стародавние времена, когда я учил иностранный язык, каждое слово приходилось искать в бумажном словаре. Эту тривиальную операцию я проделывал сотни раз, а некоторые зловредные слова приходилось смотреть снова и снова, так как я успевал забыть их значение. Как это было обидно! То ли дело сейчас, вжух и перевод перед глазами на экране монитора. История поиска, на случай, если искомое слово не перешло из области кратковременной памяти в долгосрочную.
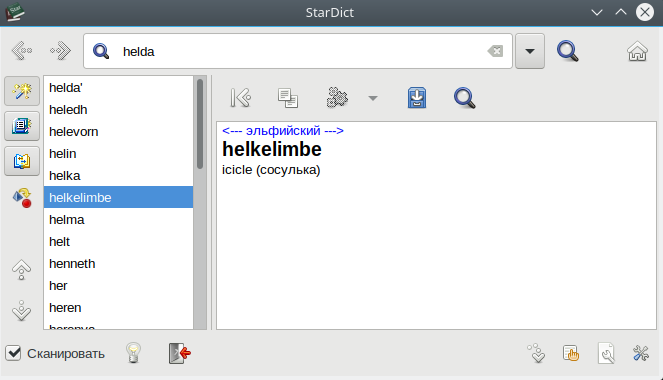
Давайте своими силами создадим электронный словарь для программ StarDict / GoldenDict. Для этого может понадобится много, или мало человеко-часов, в зависимости от качества исходного материала.
Шаг первый: OCR
В отличие от альпинизма при оцифровке словаря самый тяжелый шаг, не последний а первый. Если вам придется проводить OCR бумажного словаря с выцветшими страницами, напечатанного слишком мелко, с различными артефактами небрежного использования, или на экзотическом языке, то даже FineReader не сильно поможет. На некоторых страницах разница в длительности времени между ручным набором текста и OCR с корректировкой ошибок ничтожна.
Советую сохранять все в простых текстовых файлах, так как продвинутый поиск и исправление ошибок, расстановка тэгов, преобразование сортировки и прочие операции с текстовым массивом невообразимо осуществлять с бинарным фалом.
На этом шаге важно определиться со структурой словарных статей. В самом простом случае будет всего два поля: ключ и значение. Этого достаточно, но если нужна подсветка различных элементов статей, то тогда потребуется все такие элементы определенным образом маркировать.
Самое время немного поговорить о форматах. Существует много форматов электронных словарей, вот их список.
Все форматы мы здесь разбирать не будем, так как большинство из них проприетарные. Нас интересуют открытые стандарты и открытое ПО.
Dictd
Возникший в эпоху, когда сетевые TCP/IP протоколы беспрепятственно плодились и размножались dictd сейчас представляет лишь археологический интерес. Это клиент серверный протокол, использующий TCP порт 2628, определен в RFC 2229.
Исходный файл для словаря форматируется следующим образом.
:статья: объяснениеНапример, такой словарик
:catalysis: "increase in the rate of a chemical reaction due to the participation of an additional substance called a catalyst, which is not consumed in the catalyzed reaction and can continue to act repeatedly.
" <a href="is.gd/v6a22Q">ref</a>.
:deconstruction:
:rendered: eg. "rendered irrelevant."
:reading: cf. 'reading of'
:minor: a minor reading.Готовый файл для словаря создается командой dictfmt.
dictfmt --utf8 -s "Длинное имя словаря" -j dict-name < mydict.txtВ результате образуются 2 файла: dict-name.index и dict-name.dict. Из них первый очевидно индексный файл, с ним ничего делать не нужно, а второй можно сжать командой dictzip. Данная команда сжимает *.dict файл с помощью утилиты gzip. Сразу же возникает вопрос: а зачем оно тогда нужно, если есть обычный gzip?
Дело в том, что dictzip использует добавочные байты в заголовке архивного файлы для обеспечения псевдо-произвольного доступа к файлу.
Наконец файлы помещаются в профильные каталоги, т. к. /usr/lib/dict, перезагружаем службу dictd и вуаля. Синтаксис поиска прост, достаточно набрать
dict СЛОВО.
Пробежка по dictd ссылкам напоминает сафари по интернет сети 90-х, жив и еще лягается!
Sdict
Дерзкая попытка Алексея Семенова изменить мир к лучшему с помощью магии Perl в ту пору, когда Microsoft еще не крутил шашни с Linux и сообществом открытого ПО, а основной источник словарей были пиратки ABBYY Lingvo.
Заголовок исходного файла словаря.
<header>
title = Sample 1 test dictionary - dictionary name;
copyright = GNU Public License - copyright information;
version = 0.1 - version;
w_lang = en - language for words;
a_lang = fi - language for articles. For further information
about language codes refer 'C:Sdictsharedociso639.htm' file;
# charset = ... - use if your source file is not in UTF-8 encoding.
</header>Тело форматировано следующим образом:
word___articleМожно качнуть версию для ОС Symbian, если что. Проект более не жив, и даже сами словари можно почерпнуть лишь с Машины Времени.
XDXF
Ну все, завязываем с археологией и переходим к словарным форматам и программам годным для использования IRL.
XDXF имеет все преимущества и недостатки XML формата, каковым и является. Весь синтаксис формата и примеры можно обозреть тут.
Скелет словарного файла выгладит следующим образом, состоит из 2-х частей: meta_info и lexicon.
<xdxf ...>
<meta_info>
Вся информация про словарь: название, автор и пр.
</meta_info>
<lexicon>
<ar>статья 1</ar>
<ar>статья 2</ar>
<ar>статья 3</ar>
<ar>статья 4</ar>
...
</lexicon>
</xdxf>Есть огромное количество словарей в этом формате. Большим достоинством формата является то, что далее нет надобности ничего конвертировать. Программа GoldenDict распознает XDXF файлы наряду с большим количеством других поддерживаемых форматов.
TSV / StarDict
StarDict и клоны его это не столько про формат электронного словаря, сколько про качественное ПО просмотра, конвертации и создания таковых.
Для создания электронного словаря с помощью StarDict достаточно TSV файла, что я и выбрал для цифровой копии армяно-русского словаря.
Тем не менее возможно и кое-какое форматирования и разметка файла словаря, однако не идет ни в какое сравнение с XDXF.
a 1n2n3
b 4\5n6
c 789Формат определяет символ переноса строки n, в том случае, когда статья разбита на параграфы.
Шаг второй: корректировка
После первого шага скорее всего будут десятки, а то и сотни орфографических, грамматических и всяких прочих ошибок, странных символов и прочих артефактов OCR.
Особенность словарей в том, что проверка орфографии нужна одновременно по двум языкам. Даже сейчас в 2018-м удивительно мало текстовых редакторов и даже офисных пакетов умеют это нехитрое действие выполнять.
Не холивара для, рекомендую обработку теска производить с Vim. Если ваш любимый текстовый редактор справляется с этим не хуже, то и славно. С Vim достаточно команды.
:setlocal spell spelllang=en,ruдля проверки орфографии по двум словарям, в данном случае русском и английском. Далее список граблей.
- Сортировка текста работает абы как для не латинских локалей, особенно плохо там, где написание буквы требует более одного символа, как армянская
ու = ո + ւ. Необходимо в таких случаях самостоятельно сортировать список слов с помощью простенького Perl, или иного скрипта. - Поиск по шаблону также может работать неожиданно для некоторых локалей, даже если сам текст и консоль в UTF-8.
- При оцифровке печатного словаря нужно быть готовым не только к ошибкам оцифровки, но и ошибкам в самом печатном словаре. Их там может содержаться немало!
- Если название статьи пишется заглавными, то возможно следует перевести при оцифровке в нижний регистр. Не все буквы имеют символы в верхнем регистре, собственно не для всех локалей даже есть верхний регистр.
Шаг третий: компиляция словаря
Для формата XDXF, как уже было сказано, этот шаг не требуется. Просто запихнуть файл в папку /usr/share/goldendict, где программа подхватит его.
Для TSV файла, используется утилита stardict-editor, поставляемого с набором инструментов StarDict.

На выходе программа создает следующие файлы, наподобие древнего Dict.
- somedict.ifo
- somedict.idx либо somedict.idx.gz
- somedict.dict либо somedict.dict.dz
- somedict.syn (optional)
Файлы копируются в каталог /ysr/share/stardict/dic и на этом все.
P. S. Для мобильной платформы Android программа GoldenDict внезапно стал платной, однако в интернет сети все еще можно найти последнюю бесплатную версию программы.
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
Введение
В последнее время, как в отечественной, так и в зарубежной лингвистике большое внимание уделяется вопросам всестороннего изучения проблем терминологии, которое ведётся на базе различных языков и различных предметных областей. Усиление социальной роли науки и увеличение объема информации влекут за собой систематическое исследование терминосистем, повышение интереса к таким областям человеческого знания, как терминоведение, информатизация знаний, автоматическая обработка информации. Количество электронных документов, которые использует в своей ежедневной деятельности современная компания, стремительно возрастает. При этом данные хранятся в различных хранилищах, каждое из которых имеет собственную структуру (базы данных, информационные порталы, электронные библиотеки и т.д.) либо хранилище документов вообще неструктурированно (файлы на жестком диске пользователя).
Поэтому для обеспечения жизнедеятельности крупных государственных структур и частных корпораций необходимым условием является использование локальных поисковых систем для осуществления поиска по внутренним информационным ресурсам.
Именно для этого используются электронные словари, информационно-поисковые тезаурусы и онтологии.
Объект исследования – электронные словари, информационно-поисковые тезаурусы и онтологии.
Предмет исследования – средства разработки электронных словарей, информационно-поисковых тезаурусов и онтологий.
Цель курсовой работы – на основе средств разработки электронных словарей и информационно-поисковых тезаурусов разработать двуязычный электронный словарь и тезаурус терминов предметной области.
Задачи курсовой работы:
-
Рассмотреть понятия электронных словарей, информационно-поисковых тезаурусов и онтологий.
-
Проанализировать средства разработки электронных словарей, информационно-поисковых тезаурусов и онтологий.
-
Разработать электронный двуязычный словарь и тезаурус предметной области «Информатика и ИКТ».
§1.Понятия электронных словарей, тезаурусов и онтологий
С появлением компьютерной техники, создатели программного обеспечения создали новый тип словарей — электронный.
Электронный словарь — это словарь в компьютере или другом электронном устройстве. Позволяет быстро найти нужное слово, часто с учётом морфологии и возможностью поиска словосочетаний, а также с возможностью изменения направления перевода[4]. Такой тип словаря — абсолютно новое слово в истории лексикографии, отметившее новую качественную ступень ее развития. Именно сейчас электронные словари вышли из тени бумажных и становятся самостоятельными игроками на языковой площадке, причем игроками, которые, похоже, в ближайшее время сделают остальных действующих лиц экспонатами Музея книги. Ведь электронные словари обладают рядом очевидных и существенных преимуществ по сравнению со словарями традиционными. Единственным же их недостатком является привязанность к персональному компьютеру и, следовательно, ограниченная доступность. Однако этот недостаток будет достаточно скоро устранен если не полностью, то, по крайней мере, большей частью, вследствие все возрастающих темпов компьютеризации, в том числе и растущей доступностью переносным компьютеров типа Laptop.
Электронных словарей сейчас выпущено довольно много, поэтому остановимся только на двуязычных англо-русских и русско-английских словарях. Для примера возьмем два самых известных: Lingvo компании Abbyy и МультиЛекс, разработанный фирмой МедиаЛингва. Эти словари были выбраны благодаря такими преимуществам между остальными электронными словарями, как многофункциональность, количество встроенных словарей и простота использования.
Компания МедиаЛингва придерживается при создании словарей МультиЛекс довольно простой стратегии. Она создает цифровую копию известных книжных изданий. На сайте фирмы можно найти формулировку этого принципа: «В основу электронных словарей заложены словарные базы книжных изданий, уже завоевавших популярность и признание среди переводчиков, преподавателей иностранных языков, студентов и школьников». Некоторые эксперты считают, что такая политика покоится на эксклюзивном договоре МедиаЛингва с «естественным монополистом» рынка российских словарей, издательством «Русский язык». С точки зрения МедиаЛингва, задача электронной лексикографии — как можно точнее перевести традиционный словарь в электронную форму.
За основу словаря МультиЛекс взят «Новый большой англо-русский словарь» под редакцией А.Д. Апресяна. Есть и расширенная версия, где к основному словарю добавлены экономико-финансовый, юридический, строительный, политехнический словари и словарь по полиграфии и издательскому делу.
Конечно, словарь Апресяна — выдающееся достижение лексикографии, но подход МедиаЛингва имеет и недостатки. Первое, традиционные словари довольно серьезно отстают от языковой реальности. Обычно это не менее десяти лет. А электронные словари можно пополнять чуть ли не ежедневно. Второе, словари, содержащие сотни тысяч словарных статей, какими бы квалифицированными лексикографами они не составлялись, всегда содержат ошибки и неточности, не говоря уже о возникновении дополнительных значений слов. Жесткая привязка к бумажному прототипу не дает возможности исправлять и дополнять электронный, тем более изменять структуру построения словарной статьи.
По другому и, вероятно, более перспективному пути пошла компания Abbyy. Конечно, и в их большом электронном словаре Lingvo7.0 есть переведенные в цифровой вид лицензированные бумажные словари — это политехнический, юридический, экономический, финансовый, медицинский и — что очень своевременно — динамично пополняемый компьютерный словарь. Но основу Lingvo, по словам руководителя лингвистического отдела фирмы Владимира Селегея, составляет электронный словарь собственной разработки. Каждая новая версия Lingvo дополняется актуальной лексикой, и в ней исправляются найденные ошибки и неточности. Таким образом, благодаря лексикографическим исследованиям англо-русский словарь фирмы Abbyy близок к языковой практике.
Удачной находкой Abbyy выглядит приглашение всем желающим размещать на их Интернет-узле словари собственного изготовления. Такое вовлечение пользователей в лексикографическую работу вполне соответствует духу открытых Интернет-сообществ. Дополнительных словарей на сайте уже набралось 23 штуки. Причем всякий желающий может скачать их из Интернета и присоединить хоть все к уже имеющимся в базовой версии. Надо сказать, что базовая версия Lingvo-7.0 содержит миллион двести тысяч словарных статей. Причем основные статьи тщательно проработаны. Первое, что бросается в глаза, когда мы говорим об электронных словарях — это резкое сокращение объема. На десятиграммовом компакт-диске помещается целая полка толстых словарей общим весом в двадцать пять килограмм. Но, естественно, не это главное. Важно, что электронный словарь принципиально может обойти ключевое противоречие книжной лексикографии: чем больше информации предлагает словарь, чем развитее его научный аппарат, тем сложнее им пользоваться. Поэтому классические словари разделяется на две категории. Первая — популярные, относительно удобные, но довольно простые. Вторая — обстоятельные академические издания, не позволяющие быстро получить искомую информацию.
Современные электронные словари не только значительно превосходят по объему книжные, но и находят искомое слово или словосочетание за несколько секунд. Причем искать можно в любой форме. Некоторые, например Lingvo, встраиваются во все основные офисные приложения и выделенное слово можно переводить нажатием нескольких клавиш. Рассмотрим преимущества электронных словарей.
При традиционном подходе минимальной единицей доступа является лексема (имя словарной статьи): нужно прочесть всю статью, чтобы определить, содержится ли в ней ответ на наш запрос. Для таких словарей, как оксфордский, это представляет серьезную проблему. Пользователь хотел бы, чтобы словарь максимально локализовал релевантную информацию. При этом речь не идет об автоматическом выборе переводного эквивалента (если мы говорим о переводном словаре). Специфика словарного ответа в том, что он дает весьма разнообразную информацию о слове или словосочетании, а не просто переводное соответствие, предполагает активный выбор пользователя из нескольких возможных хорошо обоснованных альтернатив.
Однако попытка решить проблему адекватной реакции словаря на запрос неизбежно наталкивается на сопротивление самого словарного материала, перенесенного из бумажного словаря.
Электронные словари не только содержат транскрипцию, но и могут произносить слова. Здесь тоже существует два подхода. В МультиЛекс встроен синтезатор звука и произносятся все слова. Однако полностью доверять такому подходу, не контролируя его по транскрипции, опасно. Синтезатор может неправильно поставить ударение или вообще исказить произношение слова. В Abbyy Lingvo основную лексику озвучивает диктор с оксфордским произношением.
Но, конечно, самое главное преимущество хороших электронных словарей — одновременный поиск не только по названию словарной статьи, но и по всему огромному объему словарей, что просто нереально в бумажном варианте. Такой поиск создает многомерный портрет слова, при этом извлекаются из глубин словарной статьи не только конкретные примеры его использования и устойчивые выражения, в которых слово встречается, но и обнажаются, становятся явными языковые законы, которым подчиняются правила словообразования. Даже мобильный электронный словарь не может отразить все сиюминутные движения языка, но он может дать ключ для расшифровки и понимания этих изменений, делая пользователя соавтором лексикографа. Что очень важно, когда требуется точный смысловой перевод, ведь это не задача подбора подходящего выражения, а в широком смысле отображение одной культуры с помощью языка другой. Поэтому в Lingvo можно строить и свой собственный словарь под общей оболочкой.
Язык — отражение реальной жизни. А жизнь не стоит на месте: появляются новые отрасли производства, науки, бизнеса, культуры. В обычную разговорную речь приходят новые слова, термины, устойчивые словосочетания. Можно ли представить в речи наших сограждан лет десять назад такие слова, как «холдинг», «транш»? Выражение «конечный пользователь» вызвало бы у них недоумение, и никто не мог бы предположить, что слово «мыло» будет означать на компьютерном жаргоне электронную почту (вольная русская транскрипция английского слова «e-mail»).
Вся эта лексика не может быть адекватно отражена в «бумажных» словарях по той простой причине, что они слишком долго готовятся. Так, известный англо-русский словарь Мюллера, сочетающий относительную простоту пользования (один том, хотя и тяжелый!) и полноту содержания, был издан в 1960 году и с тех пор претерпел лишь косметические изменения в 1978 и 1994 годах.
Фактически многие словари, которые сформировались в языковой атмосфере середины века, сильно устарели. В них не указаны современные значения старых слов, а многие новые слова просто отсутствуют. Буквальное перенесение таких словарей на компьютеры бесперспективно. Это стало особенно очевидно в связи с развитием Интернета: большая часть Веб-страниц состоит из английских текстов, написанных живым современным языком, обильно использующим разговорную лексику и сленг. Вряд ли какой-либо из существующих англо-русских словарей может ответить на этот вызов. Решить данную задачу под силу лишь электронным словарям. Большинство «бумажных» словарей ориентировано на человека, читающего на иностранном языке, то есть человека, который в непонятном ему тексте находит «опорные» слова, помогающие выстроить общую смысловую картину. Человек «пишущий», кроме знания всех используемых слов, должен четко представлять, как эти слова сочетаются друг с другом, какие предлоги при этом используются, есть ли устойчивые выражения, передающие необходимый смысл.
Увы, если «бумажный» словарь и удовлетворяет нужды Читателя, то уж интересы Писателя на неродном языке он чаще всего попросту игнорирует. А ведь в наш век электронных коммуникаций Писателем стал практически каждый пользователь Интернета.
И здесь электронный словарь оказывается намного полезнее «бумажного». Даже буквальное воспроизведение приличного «бумажного» словаря на компьютере дает возможность извлечь из него столь необходимую Писателю информацию, похороненную в глубинах словарных статей. Например, пользователь может открыть на экране сразу несколько словарных статей, характеризующих все значения слова «достать» (брать, получать, надоесть и т. д.) как на одном языке, так и на другом, и, таким образом, изучить все нюансы использования слова.
Однако более правильный путь — подумать о Писателе заранее, при составлении словаря. Чтобы учесть его интересы, надо уметь описывать способы образования сложных словосочетаний. Например, как передать по-английски смысл «подтасовать или фальсифицировать результаты выборов»? Это выражение не относится к идиоматическим, потому его не следует искать в словнике целиком. С другой стороны, оно не может быть правильно переведено и по частям. Логичнее всего искать это выражение в статье «election» (выборы). Однако, чтобы оно там оказалось, нужно желание разработчиков словаря его туда поместить.
Чтобы Писатель смог почувствовать оттенки слова, необходимо привести в словаре максимально возможное количество синонимов — слов, близких по смыслу. Например, английский глагол break означает, в частности: 1) ломать, разрушать, разбивать и 2) рвать, разрывать, отрывать. Для первого случая синонимами будут слова crush (давить, дробить) и smash (разбиваться вдребезги). Второму значению близки слова separate (отделять, разделять — более деликатный смысл) и tear off (отрывать, срывать). Через общую «карту» синонимов становится яснее, как перевести на иностранный язык слово с тем или иным смысловым оттенком. Очень полезны иллюстрирующие примеры, особенно на использование слов с предлогами или в устойчивых словосочетаниях. Например: «уехать отсюда», «уехать куда-то», «уехать за чем-то», «уехать» в значении «отсутствовать».
Информацию о синонимах, словосочетаниях и случаях употребления правильнее всего предоставить на родном языке пишущего: если Писатель русский — то в русско-английском словаре, если он англичанин — то в англо-русском. Ни для кого не секрет, насколько лучше помогают толковые английские словари при решении мучительной проблемы, какое слово употребить. А вот жесткая ориентация словаря на перевод, а не на описание языка делает его использование Писателем непростым и неочевидным. Таким образом, в современных электронных словарях отражено пионерское достижение российской лексикографии — двуязычный словарь во многом становится толковым. Кроме того, такой электронный словарь, как Lingvo, строит нажатием нужной клавиши парадигму, то есть совокупность всех форм слова.
Перейдем к рассмотрению понятия электронно-поискового тезауруса.
Информационно-поисковый тезаурус (ИПТ) — это контролируемый словарь терминов на естественном языке, явно указывающий отношения между терминами и предназначенный для информационного поиска[5].
Разработка ИПТ предполагает следующие цели:
-
обеспечение перевода естественного языка документов и пользователей на контролируемый словарь, применяемый для индексирования и поиска;
-
обеспечение последовательного использования единиц индексирования;
-
описание отношений между терминами;
-
использование как поискового средства при поиске документов;
Основной единицей тезаурусов являются термины, которые разделяются на дескрипторы (авторизованные термины) и недескрипторы (аскрипторы). Большинство версий стандартов по ИПТ указывают на связь терминов с понятиями предметной области. По американскому стандарту термин — это слово либо словосочетание, обозначающее понятие. Стандарт ISO подчеркивает, что индексирующий термин — это представление понятия предпочтительно в форме существительного или именной группы. При этом понятие рассматривается как единица мысли, которая формируется мысленно для отражения всех или некоторых свойств конкретного или абстрактного, реально существующего или мысленного объекта. Понятия существуют как абстрактные сущности, независимо от терминов, которые их выражают. Стоит отметить, что не все разработчики тезаурусов четко разделяли понятия и термины. Так, разработчики тезауруса AGROVOC определили его как термино-ориентированный (term-oriented), что находит свое проявление в том, что к термину невозможно добавить синонимы. Эта особенность тезауруса рассматривается авторами как недостаток, который необходимо исправить. Таким образом, разработчики тезаурусов предполагают, что понятие предметной области обычно имеет несколько возможных вариантов лексического представления в тексте, которые рассматриваются как синонимы. Среди таких синонимов выбирается дескриптор — термин, который рассматривается как основной способ ссылки на понятие в рамках тезауруса. Другие термины из синонимического ряда, включенные в тезаурус, называются аскрипторами или недескрипторами. Они используются как вспомогательные элементы, текстовые входы, помогающие найти подходящие дескрипторы. Дескрипторы тезауруса должны соответствовать выбранной предметной области тезауруса. Каждый дескриптор, внесенный в тезаурус, должен представлять отдельное понятие данной области. Дескриптор может быть однословным или многословным. Поскольку часто бывает достаточно трудно понять, представляет ли отдельное понятие многословное словосочетание, многие тезаурусы и руководства уделяют особое внимание основным принципам включения в тезаурус в качестве дескрипторов многословных терминов.
Переходя к онтологиям, для начала рассмотрим их определение и предназначение.
Неформально онтология представляет собой некоторое описание взгляда на мир применительно к конкретной области интересов. Это описание состоит из терминов и правил использования этих терминов, ограничивающих их значения в рамках конкретной области.
На формальном уровне онтология — это система, состоящая из набора понятий и набора утверждений об этих понятиях, на основе которых можно описывать классы, отношения, функции и индивиды[16].
В последние годы разработка онтологий — явное формальное описание терминов предметной области и отношений между ними — переходит из мира лабораторий по искусственному интеллекту на рабочие столы экспертов по предметным областям. Во всемирной паутине онтологии стали обычным явлением. Онтологии в сети варьируются от больших таксономий, категоризирующих веб, до категоризаций продаваемых товаров и их характеристик. Во многих дисциплинах сейчас разрабатываются стандартные онтологии, которые могут использоваться экспертами по предметным областям для совместного использования и аннотирования информации в своей области.
Онтология определяет общий словарь для ученых, которым нужно совместно использовать информацию в предметной области. Она включает машинно-интерпретируемые формулировки основных понятий предметной области и отношения между ними.
Совместное использование людьми или программными агентами общего понимания структуры информации является одной из наиболее общих целей разработки онтологий. К примеру, пусть несколько различных веб-сайтов содержат информацию по медицине или предоставляют информацию о платных медицинских услугах, оплачиваемых через Интернет. Если эти веб-сайты совместно используют и публикуют одну и ту же базовую онтологию терминов, которыми они все пользуются, то компьютерные агенты могут извлекать информацию из этих различных сайтов и накапливать ее. Агенты могут использовать накопленную информацию для ответов на запросы пользователей или как входные данные для других приложений.
Обеспечение возможности использования знаний предметной области стало одной из движущих сил недавнего всплеска в изучении онтологий. Например, для моделей многих различных предметных областей необходимо сформулировать понятие времени. Это представление включает понятие временных интервалов, моментов времени, относительных мер времени и т.д. Если одна группа ученых детально разработает такую онтологию, то другие могут просто повторно использовать ее в своих предметных областях. Кроме того, если нам нужно создать большую онтологию, мы можем интегрировать несколько существующих онтологий, описывающих части большой предметной области. Мы также можем повторно использовать основную онтологию, такую как UNSPSC, и расширить ее для описания интересующей нас предметной области.
Создание явных допущений в предметной области, лежащих в основе реализации, дает возможность легко изменить эти допущения при изменении наших знаний о предметной области. Жесткое кодирование предположений о мире на языке программирования приводит к тому, что эти предположения не только сложно найти и понять, но и также сложно изменить, особенно непрограммисту. Кроме того, явные спецификации знаний в предметной области полезны для новых пользователей, которые должны узнать значения терминов предметной области.
Отделение знаний предметной области от оперативных знаний — это еще один вариант общего применения онтологий. Мы можем описать задачу конфигурирования продукта из его компонентов в соответствии с требуемой спецификацией и внедрить программу, которая делает эту конфигурацию независимой от продукта и самих компонентов. После этого мы можем разработать онтологию компонентов и характеристик ЭВМ и применить этот алгоритм для конфигурирования нестандартных ЭВМ. Мы также можем использовать тот же алгоритм для конфигурирования лифтов, если мы предоставим ему онтологию компонентов лифта.
Анализ знаний в предметной области возможен, когда имеется декларативная спецификация терминов. Формальный анализ терминов чрезвычайно ценен как при попытке повторного использования существующих онтологий, так и при их расширении.
Часто онтология предметной области сама по себе не является целью. Разработка онтологии сродни определению набора данных и их структуры для использования другими программами. Методы решения задач, доменно-независимые приложения и программные агенты используют в качестве данных онтологии и базы знаний, построенные на основе этих онтологий.
В проектировании онтологий условно можно выделить два направления, до некоторого времени развивавшихся отдельно. Первое связано с представлением онтологии как формальной системы, основанной на математически точных аксиомах. Второе направление развивалось в рамках компьютерной лингвистики и когнитивной науки. Там онтология понималась как система абстрактных понятий, существующих только в сознании человека, которая может быть выражена на естественном языке (или средствами какой-то другой системы символов). При этом обычно не делается предположений о точности или непротиворечивости такой системы.
Таким образом, существует два альтернативных подхода к созданию и исследованию онтологий. Первый (формальный) основан на логике (предикатов первого порядка, дескриптивной, модальной и т.п.). Второй (лингвистический) основан на изучении естественного языка (в частности, семантики) и построении онтологий на больших текстовых массивах, так называемых корпусах.
В настоящее время данные подходы тесно взаимодействуют. Идет поиск связей, позволяющих комбинировать соответствующие методы. Поэтому иногда бывает сложно отделить лексические онтологии с элементами формальных аксиоматик от логических систем с включениями лингвистических знаний.
Общие онтологии описывают наиболее общие концепты (пространство, время, материя, объект, событие, действие и т.д.), которые независимы от конкретной проблемы или области. В эту категорию попадают и онтологии представления, и онтологии верхнего уровня.
Онтология, ориентированная на задачу — это онтология, используемая конкретной прикладной программой и содержащая термины, которые используются при разработке ПО, выполняющего конкретную задачу. Она отражает специфику приложения, но может также содержать некоторые общие термины (например, в графическом редакторе будут и специфические термины — палитра, тип заливки, наложение слоев и т.д., и общие — сохранить и загрузить файл). Задачи, которым может быть посвящена онтология, могут быть самыми разнообразными: составления расписания, определение целей, диагностика, продажа, разработка ПО, построение классификации. При этом онтология задачи использует специализацию терминов, представленных в онтологиях верхнего уровня (общих онтологиях).
Предметная онтология (или онтология предметов ) описывает реальные предметы, участвующие в какой-либо деятельности (производстве). Например, это может быть онтология всех частей и компонентов самолетов определененной марки (Boeing) и сведения об их поставщиках, характеристиках, способе соединения друг с другом и т.п.
§2. Методы разработки электронных словарей, тезаурусов и онтологий
В предыдущее параграфе были рассмотрены двуязычные электронные словари Lingvo и Мультилекс. Теперь определим необходимые методы для разработки собственного словаря на основе работы электронного программы «Мультилекс». Данный словарь был выбран по таким основным преимуществам, как передовой программный функционал, 7 видов поиска и перевода, в том числе моментальный всплывающий перевод при наведении курсора мыши, перевод словосочетаний и поиск слов с неизвестным написанием.
Интерфейс программы в основном режиме работы («Со статьей») представляет собой окно, состоящее из окна списка слов словаря и окна статьи, содержимое которого меняется при выделении другого слова в соседнем окне. Над этими окнами расположена панель инструментов, в которой представлены кнопки Копировать, Вырезать, Вставить, Печать и 4 закладки, позволяющие активизировать панели инструментов Перевод, Словари, Настройки, Справка.
На панели инструментов «Перевод» расположены следующие кнопки:
-
Направление перевода;
-
Поиск по шаблону;
-
Варианты написания;
-
Начать тест;
-
Неправильные глаголы;
-
Словоформы;
-
Добавить в карточки;
-
Добавить закладку;
-
Найти в статье.
В режиме словаря «без статьи» в главном окне 4 последние пункта отсутствуют, но они появляются при переводе в отдельных окнах со словарными статьями.На панели инструментов «Словари» расположены кнопки:
-
Управление словарями;
-
Каталог;
-
Создать статью.
На панели инструментов «Настройки» расположены кнопки:
-
Размер шрифта;
-
Всплывающий перевод;
-
Общие настройки.
На панели инструментов «Справка» расположены следующие кнопки:
-
Справка;
-
Установленные словари;
-
Регистрация;
-
Обновление;
-
О программе.
Ниже панели инструментов над окном списка слов расположена строка ввода и кнопки:
-
Вперед;
-
Назад;
-
Поиск;
-
Виртуальная Клавиатура.
Ввод данных может осуществляться при помощи:
-
Стандартной клавиатуры;
-
Виртуальной клавиатуры словаря;
-
Операций копирования и вставки;
-
Системы рукописного ввода (например, программой PenReader).
С помощью функции интеллектуального ввода, Можно печатать слова, не переключая направление перевода каждый раз – оно будет определено автоматически в соответствии с языком ввода.
К тому же модуль морфологии новой версии программы позволяет вводить слова в произвольной форме. И даже если нет уверенности как пишется слово, в данной программе предусмотрены функции поиск по шаблону или поиск вариантов написания, которые помогут без труда найти нужное слово.
Перед тем как начать работу со словарем, необходимо выбрать направление перевода. Это можно осуществить через вызов меню словаря в области уведомлений панели задач Windows. Если в словаре установлено несколько словарных баз, нужно нажать на стрелку кнопки смены направления перевода, и появится список доступных направлений перевода. Также новая версия программы позволяет менять направление перевода путем переключения раскладок на клавиатуре.
Когда было введено необходимое слово в строку перевода, нужно нажать клавишу ENTER и программа автоматически начнет поиск, в результате чего Вы увидите список слов.
К тому же, в процессе ввода слова список слов автоматически перемещается к нужной букве, и можно выбрать слово из списка, даже не закончив ввод.
Полнотекстовый поиск — это поиск слов или словосочетаний по всему содержимому словарных статей всех словарей активного направления (заголовку, переводу и примерам употребления).
Чтобы выполнить такой поиск нужно просто ввести слово в строку перевода и нажать на кнопку «Поиск» или Enter на клавиатуре.
В случае если в строку был ввод словосочетания, а полнотекстовый поиск не дал результатов, программа автоматически начинает процедуру пословного перевода. Это означает, что поиск ведется по всем доступным словарным базам для каждого слова в отдельности. При этом, как правило, задействован и морфологический модуль, так как в результате всех поисков программа показывает базовые формы каждого из искомых слов.
Если заинтересовало какое-либо слово из открывшейся словарной статьи, то, дважды щелкнув левой кнопкой мыши по нему, программа найдет соответствующий перевод. Эта функция особенно актуальна при прочтении примеров использования слова, для которого открылась статья. Если столкнулись с незнакомым словом, и это вызвало затруднения целостного понимания фразы можно просто перевести его.
Благодаря функции поиска внутри статьи, легко можно найти любое нужное слово даже в самой подробной и длинной статье перевода. Для этого, нужно нажать на кнопку «Найти в статье» и ввести слово в открывшееся поле ввода. Если введенное слово в данной статье присутствует, то оно автоматически будет выделено.
Через менеджер словарей можно создавать свои собственные словари и постоянно пополнять их новыми статьями. Это функция особенно важна, если находиться в языковой среде и нужно непрерывно обогащать свой словарный запас разговорными фразами. Теперь, чтобы не забыть ни одного ценного слова, нужно просто создать для него отдельную статью в собственном словаре
Таким образом, можно создавать множество собственных словарей дополнительно к уже установленным и постоянно пополнять их новыми статьями.
Кроме того, возможно самостоятельно форматировать текст созданной статьи. Для этого вверху редактора статьи предусмотрены следующие стили шрифта:
-
Заголовок;
-
Перевод;
-
Пример;
-
Комментарий;
-
Транскрипция;
-
Число;
-
Другой Стиль.
При наличии уже созданных ранее пользовательских словарей, можно использовать их вне оболочки данной программы. Просто нужно выбрать и выделить нужный словарь и экспортировать его, следуя команде Словари>Управление словарями>Экспортировать.Экспортированный таким образом файл будет сохранен в формате HTML.С помощью данной программной оболочки появилась возможность использовать словари, созданные в других программных продуктах. Чтобы импортировать словарь, в менеджере словарей нужно нажать «Импортировать» и выбрать файл для импорта. В настоящий момент для импорта поддерживаются MLX, HTML и DSL файлов.
В окне «Управление словарями» можно управлять своими словарями, и расставлять между ними приоритет, пользуясь кнопками «Выше»/«Ниже». Причем словарь, занимающий более высокую позицию в этом списке, имеет более высокий приоритет. Таким образом, программа будет выполнять поиск, в первую очередь, по словарям с более высоким приоритетом, и в результате в окне перевода, статьи будут расположены в соответствующем порядке.
В окне «Управление словарями» можно включать новые или отключать ненужные словари. Для этого просто следует отметить словарь рядом с его названием, если нужно включить его; или снять метку, если необходимо его выключить. Также можно установить приоритет для только что выбранных словарей
Удаление словарей производится в окне Менеджера словарей (Словари> Управление словарями) с помощью кнопки «Удалить». Так же можно удалять собственные словарные статьи при помощи кнопки удаления, расположенной в окне конкретной статьи.
На панели инструментов «Настройки» расположены 3 кнопки, позволяющие настраивать словарь для максимально удобной, быстрой и эффективной работы:
-
Размер Шрифта;
-
Всплывающий перевод;
-
Общие настройки.
Кнопка «Размер Шрифта» представляет собой ползунок, двигая который можно подбирать наиболее подходящий размер шрифта в словарной статье. Всего доступно 5 различных размеров шрифта:
-
Очень маленький;
-
Маленький;
-
Средний;
-
Большой;
-
Очень большой.
Далее рассмотрим принципы автоматического построения списка возможных терминов программе «Конспект». Данное средство разработки терминов предметной области, было выбрано по таким главным алгоритмическим особенностям системы, как использование в целях отбора текстов средств семантического анализа и генерация по результатам семантического анализа заданного числа вторичных ключей, использование которых в циклическом режиме позволяет углубить раскрытие темы в формируемых конспектах.
При наличии тезауруса терминов предметной области, пользователю в поисковом запросе достаточно ввести только один термин. Если в тезаурусе есть список синонимов к введенному слову, то в результатах поиска будут присутствовать как документы, которые содержат слово, введенное пользователем, так и документы, содержащие слова-синонимы.
К сожалению, из-за отсутствия формализованных словарей терминов для конкретных предметных областей, автоматическое создание тезауруса невозможно. Ручное составление тезауруса является весьма трудоемкой задачей, так как требует экспертного анализа значительного количества документов организации (корпорации) для выделения списка терминов предметной области, при этом достаточно трудно оценить полноту полученного списка. Для решения такой задачи необходимо использовать автоматизированное создание списка терминов предметной области.
Для построения понятийного аппарата из текстов предметной области используется поиск и выделение субстантивных именных словосочетаний, выражаемых схемой: согласуемое слово + существительное. В этой модели существительное является главным словом, а согласуемое слово — зависимым и может выражаться как прилагательным, так и существительным. Словосочетания могут включать в свой состав также предлоги и сочинительные союзы. Количество слов в именных словосочетаниях колеблется от двух до пятнадцати и в среднем составляет три слова. В работе приводится 9 шаблонов именных словосочетаний, используемых для выделения терминов предметной области. В русском языке синтаксическая структура терминов предметной области более чем в 90 процентов случаев соответствует следующим пяти шаблонам:
-
одиночные существительные, прилагательные, и сокращения;
-
существительное + существительное в родительном падеже;
-
прилагательное + существительное;
-
прилагательное + прилагательное + существительное;
-
существительное + прилагательное + существительное в родительном падеже[9].
Вместе с тем существуют сложные словосочетания, используемые для обозначения понятий и терминов, состоящих из трех и более значимых слов. Выражение понятий и терминов словосочетаниями в пять и более слов, с использованием союзов и предлогов встречается редко, особенно такими словосочетаниями, в которых части речи не чередуются (например, прилагательное + прилагательное + прилагательное + существительное + существительное в родительном падеже).
Словосочетания длиной пять и более слов используются в наименованиях организаций, в определении понятий относящихся к финансово-экономической сфере деятельности организаций. Шаблоны именных словосочетаний, используемых для поиска терминов, приведены в Таблице 1.
Таблица 1. Шаблоны именных словосочетаний
|
№ |
Структура шаблона |
Пример термина |
|
1 |
Аббревиатура |
ИКТ, ИТ |
|
2 |
Существительное |
Партнер, Доход |
|
3 |
Существительное + существительное_в_родительном_падеже |
Директор компании, Бюджет расходов |
|
4 |
Прилагательное + существительное |
Экономический рост |
|
5 |
Существительное + существительное_в_родительном_падеже + существительное_в_родительном_падеже |
Указ президента России |
|
6 |
Прилагательное + существительное + существительное_в_родительном_падеже |
Корпоративная сеть компании |
|
7 |
Существительное + прилагательное_в_родительном_падеже + существительное_в_родительном_падеже |
Сотрудники финансового отдела |
|
8 |
Прилагательное + прилагательное + существительное |
Всемирная мультимедийная среда |
|
9 |
Существительное + существительное_в_родительном_падеже + существительное_в_родительном_падеже + существительное_в_родительном_падеже |
Угроза защиты информации компании |
Автоматическое выделение однословных и многословных терминов, кроме шаблонов, использует результаты синтактико-семантического анализа текста. Распознание поверхностных семантических отношений осуществляется с помощью анализа флексий полнозначных слов, учитывая предлоги и союзы, без предварительного полного грамматического разбора и построения синтаксических отношений, которые используется в традиционной грамматике.
Процедура выделения терминов из текста включает два основных этапа. На первом этапе происходит непосредственный поиск в тексте слов и словосочетаний – кандидатов в термины. В качестве однословных терминов выбираются существительные и аббревиатуры. Многословные термины формируются с помощью определенных типов отношений между словами предложения, путем постепенного присоединения слов к однословному термину-существительному. Для терминов – именных словосочетаний используются следующие основные типы отношений между словами: объектное, принадлежность (между двумя существительными), определительное (между прилагательным и существительным), однородные слова (между двумя существительными или двумя прилагательными). Выделенные группы слов проверяются на соответствие заданным шаблонам. Порядок расположения в предложении слов, образующих термин, может точно не соответствовать заданному шаблону, но обязательным условием выделения термина является соответствие отношений между словами определенным типам отношений. Это позволяет, например, из предложения «Построение онтологии указанной предметной области» выделить термин «онтология предметной области».
На втором этапе список кандидатов в термины фильтруется: учитывается значимость выделенных словосочетаний (приближенность в дереве разбора к подлежащему или сказуемому предложения) и частота, с которой они встречаются в тексте.
Рассмотрим средства и этапы разработки онтологий. При создании онтологий (как и при проектировании программного обеспечения или написании электронного документа) целесообразно пользоваться подходящими инструментами. Будем называть инструментальные программные средства, созданные специально для проектирования, редактирования и анализа онтологий, редакторами онтологий.
Основная функция любого редактора онтологий состоит в поддержке процесса формализации знаний и представлении онтологии как спецификации (точного и полного описания).
В большинстве своем современные редакторы онтологий предоставляют средства «кодирования» (в смысле «описания») формальной модели в том или ином виде. Некоторые дают дополнительные возможности по анализу онтологии, используют механизм логического вывода.
В этой части будут описаны наиболее общие характеристики редакторов и проведен их сравнительный анализ. Подробно рассматривается редактор Protege. Данная платформа была благодаря таким преимуществам, как открытая, легко расширяемая архитектура за счет поддержки модулей расширений функциональности и поддержки значительно сообщества, состоящих из разработчиков и ученых, правительственных и корпоративных пользователей, использующие его для решения различных задач.
Рассмотрим поддерживаемые редактором формализмы и форматы представления. Подформализмомпонимается теоретический базис, лежащий в основе способа представления онтологических знаний. Примерами формализмов могут служить логика предикатов (FirstOrder Logic- FOL),дескриптивная логика,фреймовые модели(Frames), концептуальные графы и т.п. Формализм, используемый редактором, может не только существенно влиять на внутренние структуры данных, но и определять формат представления или даже пользовательский интерфейс.
Формат представления онтологии задает вид хранения и способ передачи онтологических описаний. Под форматами подразумеваются языки представления онтологий: RDF, OWL, KIF, SCL.
Таким образом, некоторая формальная модель представляется в формализме FOL и может быть выражена средствами языка KIF.
Редакторы онтологий обычно поддерживают работу с несколькими формализмами и форматами представления, но часто только один формализм является «родным» (native) для данного редактора.
Функциональность редактора онтологий
Важной характеристикой является функциональность редактора, т.е. множество сценариев его использования.
К дополнительным возможностям редакторов относят поддержку языка запросов (для поиска нетривиальных утверждений), анализ целостности, использование механизма логического вывода, поддержку многопользовательского режима, поддержку удаленного доступа через Интернет.
Инструментальные средства для создания онтологий нужны для того, чтобы не только вводить и редактировать онтологическую информацию, но и анализировать ее, выполняя типичные операции над онтологиями, например:
-
выравнивание (alignment) онтологий — установка различного вида соответствий между двумя онтологиями для того, чтобы они могли использовать информацию друг друга;
-
отображение (mapping) одной онтологии на другую — нахождение семантических связей между подобными элементами разных онтологий;
-
объединение (merging) онтологий — операция, которая по двум онтологиям генерирует третью, объединяющую информацию из первых двух.
Этапы создания онтологий:
-
определение классов в онтологии;
-
расположение классов в таксономическую иерархию;
-
определение слотов и описание их допустимых значений;
-
заполнение значений слотов экземпляров.
После этого можно создать базу знаний, определив отдельные экземпляры этих классов, введя в определенный слот значение и дополнительные ограничения для слота:
Выделим некоторые фундаментальные правила разработки онтологии. Они выглядят довольно категоричными, но во многих случаях помогут принять верные проектные решения.
-
Не существует единственно правильного способа моделирования предметной области — всегда существуют жизнеспособные альтернативы. Лучшее решение почти всегда зависит от предполагаемого приложения и ожидаемых расширений.
-
Разработка онтологии — это обязательно итеративный процесс.
-
Понятия в онтологии должны быть близки к объектам (физическим или логическим) и отношениям в интересующей предметной области. Скорее всего, это существительные (объекты) или глаголы (отношения) в предложениях, которые описывают предметную область[8].
Знание того, для чего предполагается использовать онтологию, и того, насколько детальной или общей она будет, может повлиять на многие решения, касающиеся моделирования. Нужно определить, какая из альтернатив поможет лучше решить поставленную задачу и будет более наглядной, более расширяемой и более простой в обслуживании. Следует помнить, что онтология — это модель реального мира, и понятия в онтологии должны отражать эту реальность.
После того как определена начальная версия онтологии, мы можем оценить и отладить ее, используя ее в каких-то приложениях и/или обсудив ее с экспертами предметной области. В результате начальную онтологию скорее всего нужно будет пересмотреть. И этот процесс итеративного проектирования будет продолжаться в течение всего жизненного цикла онтологии.
Повторное использование существующих онтологий может быть необходимым, если системе нужно взаимодействовать с другими приложениями, которые уже вошли в отдельные онтологии или контролируемые словари. Многие полезные онтологии уже доступны в электронном виде и могут быть импортированы. Существуют библиотеки повторно используемых онтологий, например,Ontolingua или DAML.
§3 Разработка Электронного словаря и тезауруса
По описанным рекомендациям в предыдущем параграфе, создадим собственный электронный словарь в программе «Мультилекс»
На рис.1. показан общий вид электронного словаря
Рис.1. Общий вид словаря «Мультилекс»
Для создания пользовательского словаря откроем меню «Управление словарями» на панели управления «Словари» и выберем в открывшемся окне менеджера кнопку «Создать»
Далее вводим название словаря, выбираем язык статьи и перевода и нажимаем на «ОК», как показано на Рис. 2.
Теперь двуязычный словарь «Рынки ИКТ» создан и отправлен в список словарей. Данным образом можно создавать множество собственных словарей дополнительно к уже установленным и постоянно пополнять их новыми статьями, для этого на панели инструментов «Словари» нажмем на кнопку «Создать статью» См. Рис.3.
Подобным образом создадим еще несколько статей и добавим их в наш словарь. После этого, найдем их по поиску слов, но для начала мы расстановим приоритеты по словарям так, чтобы программа при поиске выводила словарь «Рынок ИКТ» в первую очередь. Для этого воспользуемся в окне «Управление словарями» кнопками «Выше»/»Ниже», как показано на Рис.4.
Теперь введем слово «Прибыль» и попробуем найти его перевод. После запроса словарь «Рынки ИКТ» опередил это слово и вывел на экран. Посмотрим это на Рис.5.
Таким образом, мы разработали собственный двуязычный словарь «Рынки ИКТ», добавили в него статьи и воспользовались им.
Теперь подойдем к разработке электронно-поискового тезауруса в программе «Конспект» на основе рекомендаций, представленных в предыдущем параграфе.
Полученный предварительный список терминов редактируется вручную с помощью утилиты – редактора тезауруса терминов предметной области. Общий вид окна редактора изображен на Рис. 6.
Входными данными для утилиты является список терминов, сформированный программой. Мы вручную добавляем и связываем термины, являющиеся синонимами для заданной предметной области. Полученные кортежи синонимов терминов сохраняются в XML-файл заданной структуры, который может использоваться поисковой системой среды Microsoft Office SharePoint Server 2007 в качестве тезауруса (списка расширений).
В общем виде процесс автоматизированного построения тезауруса терминов предметной области изображен на Рис.7.
Рис.7. Схема процесса автоматизированного построения тезауруса
Рассмотренный метод автоматизированного создания тезауруса терминов предметной области был использован для обработки текстов на русском языке, относящихся к сфере рынков информационно-коммуникационных технологий.
Из сформированного списка для дальнейшего ручного редактирования терминов было оставлено 66 слов и словосочетаний. Термины, не имеющие синонимов, были исключены из тезауруса. От общего количества терминов в тезаурусе однословные термины составили 76%, двухсловные – 21%, термины, состоящие из трех и более слов– 3%.
Заключение
В данной курсовой работе были рассмотрены понятия и электронных словарей, информационно-поисковых тезаурусов, онтологий и их средства для разработки. В программе «Мультилекс» был разработан англоязычный словарь «Рынки ИКТ» на основе рекомендаций по созданию электронных словарей, а же был создан тезаурус терминов предметной области в программе «Конспект».
Список литературы:
-
Агеев М., Кураленок И., Некрестьянов И. Официальные метрики РОМИП’2007. // Российскийсеминар по Оценке Методов Информационного Поиска. Труды РОМИП 2007-2008. Санкт-Петербург: НУ ЦСИ, 2008.
-
Алексеев, А.А. Лингвистическая онтология – тезаурус РуТез // Материалы международной научно-технической конференции Открытые семантические технологии проектирования интеллектуальных систем 2013 г.
-
Бименова Ж.Б., Разработка методов автоматического извлечения тезаурусных отношений из текста на основе лексических шаблонов //Материалы 50-й юбилейной международной научной студенческой конференции / Новосибирск, 2012 г.
-
Браславский, П.И Автоматическое извлечение терминологии с использованием поисковых машин интернета // Компьютерная лингвистика и интеллектуальные технологии: Труды Междунар. конф. Диалог’2008. / Браславский П.И., Соколов Е.А. // М.: Изд-во РГГУ, 2008 г.
-
Гендина, Н. И., Информационно-поисковые тезаурусы: основные виды и области применения // Научные и технические библиотеки. – М.: Государственная публичная научно-техническая библиотека России, 2008
- ГОСТ 7.25-2001 «СИБИД. Тезаурус информационно-поисковый одноязычный. Правила разработки, структура, состав и форма представления»
-
Добров Б. В., Иванов В.В., Лукашевич Н.В., Соловьев В.Д. Онтологии и тезаурусы: модели, инструменты, приложения. — М.: Бином. Лаборатория знаний, 2009 г.
-
Добров, Б.В. Лингвистическая онтология по естественным наукам и технологиям для приложений в сфере информационного поиска // Добров Б.В., Лукашевич Н.В. / Ученые записки Казанского Государственного Университета. Серия Физико-математические науки. 2008
-
Загорулько, Ю.А. Подход к разработке русско-английского тезауруса по компьютерной лингвистике. Издательско-полиграфический центр Воронежского государственного университета, 2011.
-
Информационно-поисковые тезаурусы и онтологии. Разработка. [Электронный ресурс] / Режим доступа: http://www.intuit.ru/studies/courses/1078.htm
-
Лапшин В. А. Онтологии в компьютерных системах. — М.: Научный мир, 2010 г.
-
Лукашевич, Н.В. Тезаурусы в задачах информационного поиска. – М.: Изд-во МГУ, 2011.
-
Мозжерина, Е. С. Автоматическое построение онтологии по коллекции текстовых документов. // Труды 13й Всероссийской научной конференции «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» — RCDL’2011, Воронеж, Россия, 2011.
-
П.Жмайло С. В. Анализ массива публикаций по теме «Тезаурус» в базе данных «Информатика» ВИНИТИ. // НТИ. Сер. 1. – 2008 г.
-
Рабчевский, Е.А. Автоматическое построение онтологий на основе лексико-синтаксических шаблонов для информационного поиска // Труды 11-й Всероссийской научной конференции RCDL’2009 «Электронные библиотеки: перспективные методы и технологии, электронные коллекции». Петрозаводск, Россия, 2009 г.
-
Саломатина, Н.В. О возможностях автоматического выявления связей между терминами предметной области (на примере катализа). Саломатина Н.В., Гусев В.Д., Ильина Л.Ю., Кузьмин А.О., Пармон В.Н // М.: Изд-во РГГУ, 2010.
-
Сидорова, Е.А. Программный инструментарий разработки лингвистических ресурсов // Труды III Международной научно-технической конференции «Открытые 37 семантические технологии проектирования интеллектуальных систем» OSTIS-2013. Сидорова Е.А., Загорулько М.Ю. / Минск: БГУИР, 2013.
42
Балалаева Елена Юрьевна
Национальный университет биоресурсов и природопользования Украины
кандидат педагогических наук, доцент кафедры журналистики и языковой коммуникации
Аннотация
Статья посвящена анализу концептуального этапа проектирования электронного словаря, на котором разрабатывают общую концепцию словаря: определяют его тип и назначение, устанавливают принципы описания лексикографического материала, проектирует функции, макро- и микроструктуру словаря, осуществляют отбор материала для него.
Balalajeva Olena Yurievna
National University of Life and Environmental Sciences of Ukraine
PhD in Pedagogy, Associate Professor
Abstract
The article is devoted to the analysis of the conceptual stage of designing an electronic dictionary, at which the general concept of the dictionary is developed: its type and purpose are determined, the principles for describing lexicographic material are established, the functions, macrostructure and microstructure of the dictionary are designed, and material is selected for it.
Библиографическая ссылка на статью:
Балалаева Е.Ю. Концептуальный этап создания электронного словаря // Гуманитарные научные исследования. 2021. № 3 [Электронный ресурс]. URL: https://human.snauka.ru/2021/03/42058 (дата обращения: 10.05.2023).
Несмотря на безусловную популярность электронных словарей в самых широких кругах пользователей, среди ученых нет единой точки зрения в отношении стадий проектирования этого лексикографического продукта. Более детально расписаны этапы создания словарей, предполагающие конкретные технические решения. Зачастую создание словаря движется не от концепции, а от имеющейся программной оболочки. Вместе с тем процедурам реализации словаря предшествуют весьма важные этапы. В частности, создание любого словаря должно начинаться с аналитического этапа, который предполагает анализ реальной ситуации на рынке лексикографической продукции в конкретной области и реальных потребностей пользователей, определение актуальности и целесообразности создания нового словаря, исследование факторов, влияющих на выбор его параметров.
Среди факторов, влияющих на параметры словаря и процесс его создания, различают собственно лексикографические и внешние. Первые связаны с удовлетворением потребностей пользователей словаря, вторые – корректируют проект словаря соответствии с реальными условиями [1, с. 66-70].
К лексикографическим относятся следующие факторы: пользователи, материал, с которым оперируют пользователи, характер этих операций, информационные потребности пользователей и потребности, связанные с особенностями поиска и восприятия информации. Внешними факторами считают ресурсы, требования сторон, предоставляющих эти ресурсы, ограничения, связанные с носителем информации.
На выбор предметной области словаря могут влиять: социальный заказ, уровень предметной компетенции составителя, наличие доступа к материалам, специфика выбранной отрасли.
На концептуальном этапе на основе анализа данных, полученных в ходе предварительного этапа, разрабатывают общую концепцию словаря: определяют его тип и назначение, устанавливают принципы описания лексикографического материала, проектирует функции, макро- и микроструктуру словаря, осуществляют отбор материала для него (первоисточники, печатные лексикографические работы, кодексы номенклатур, авторские наработки и т.д.).
Как замечает В. Широков, важным понятием для определения структуры словарных систем является предложенное Ю. Карауловым понятие лексикографического параметра – некоего «кванта» лингвистической информации, которая может иметь самостоятельный интерес для пользователя, но, как правило, выступает в комбинации с другими параметрами и находит свое специфическое выражение в словарях. Лексикографическим параметрам присущи определенные свойства, которые имеют универсальный характер и не зависят от типа словаря, а их значения характеризуются определенной спецификой конкретного языка. Количество лексикографических параметров в словарях варьируется от одного до нескольких десятков, причем эти колебания определяются не только целевой направленностью словаря, но и его ориентацией на пользователя [2, c. 13-15].
Словари в электронной форме, адресованные человеку, отличаются от бумажных словарей наличием в них технического инструмента, который позволяет предоставлять пользователю словарный контент, релевантный его запросу: морфологический и синтаксический анализ, полнотекстовый поиск, гипертекст, распознавание и синтез звука, а также позволяет предоставлять этот содержание различными способами: аудио, графические средства, последовательность предоставленного содержания. Поэтому в проектировании словарей, ориентированных на человека как конечного пользователя, необходимо учитывать и некоторые неинформационных потребности (эргономичную, экономическую и эстетическую) [1].
С одной стороны, электронный словарь является лексикографическим объектом, поэтому его создание может осуществляться на основе общих принципов описания лексикографических единиц [3]. В частности, В. Дубичинский называет пять основных принципов лексикографического описания:
1) преемственность лексикографических произведений – описание определенного словарного материала всегда опирается на имеющиеся лексикографические традиции;
2) значительная роль субъективного фактора в создании словарей;
3) обусловленность жестким прагматизмом;
4) нормативность в отборе лексики;
5) теоретическая и практическая многоплановость лексикографических произведений [4, с. 5].
С другой стороны, учитывая новую специфическую форму существования, электронные словари потребу формулировки новых принципов создания, к которым Л. Беляева относит модульность, динамичность, гибкость, сбалансированность и дружественность [5].
Важным типологическим параметром в проектировании любого словаря является функциональная обусловленность. По мнению В. Табанаковой, М. Ковязиной, доминантный параметр словаря отражают четыре универсальные функции: справочная (информативная), систематизирующая, учебная и нормативная [6].
Организация массива информации в словаре может иметь разнообразную и сложную структуру, единой общепринятой терминологии по структуре электронного словаря нет.
В. Широков отмечает, что традиционно словарную статью считают, как минимум, двухкомпонентной – в ней выделяют реестровую (левую) и интерпретационную (правую) части. Левая или реестровая, лексикографическая часть – это, как правило, любая единица языка, являющегося объектом лексикографирования. Множество таких единиц словаря определяет его реестр. Структура и содержание правой части словарной статьи зависит от типа словаря; здесь приводится лингвистическое описание соответствующей реестровая единицы (ее значение, перевод на другие языки, ударение, лексические, грамматические характеристики и др.) или содержится разнообразная информация о том, что она обозначает [2, с. 12].
Реестровые единицы в словаре связаны между собой многочисленными структурно-семантическими связями и в своей совокупности образуют определенную систему, которая реализует замыслы и цели его составителей. Кроме того, словарные статьи любого словаря должны иметь тождественные схемы описания однотипных элементов лексикографических структур. Совокупность правил, приемов и средств описания реестровых единиц создают метаязык словаря. Вместе с тем, В. Широков отмечает, что термины «левая» и «правая» части словарной статьи являются условными, поскольку в некоторых типах словарей наблюдается «чередования» или «смешения» элементов структур реестровой и интерпретационной частей [2, с. 13].
Этого же мнения придерживается И. Кудашев, который не только подчеркивает условность такого деления, но и замечает, что традиционная трактовка «левой» части как совокупности заглавных единиц и «правой» как совокупности словарных статей порождает ряд теоретических проблем [1, c. 32]. Левая часть словаря – это перечень определенных единиц: слова, термины, морфемы, словосочетания и пр. Эти единицы связаны между собой системными отношениями, а их перечень сортируются определенным образом (например, по алфавиту). Правая часть словаря содержит информацию о единицах левой части, а именно: толкование (значение), написание, произношение, грамматические и производные формы, функции, синонимы, этимологию, идиоматику, употребление, иноязычные соответствия, энциклопедическую информацию, справочные данные, систематическое описание и т.д. Исследователь предлагает рассматривать как «левую» часть любые единицы, о которых автор словаря сообщает релевантную при назначении словаря информацию, а как «правую» собственно эту информацию независимо от места расположения ее в словаре [там же, с. 33].
Ученые отмечают, что с развитием компьютерных технологий вопрос об упорядочении единиц словаря частично утратил актуальность [7], ведь в памяти компьютера словарь сохраняется в специфическом машинном представлении, а «вход» в словарь становится возможен практически через любой параметр или сочетание параметров. Н. Сивакова считает, что гипертекстовая структура электронного словаря заставляет переосмыслить традиционное понимание термина «композиция». В контексте электронного словаря композицией можно было бы назвать его меню или интерфейс. Но это лишь «внешнее» выявления композиции. Пользователь может создавать собственное композиционное решение, активизируя информационные зоны словаря в соответствии с личным запросом [8, c. 15].
По мнению И. Кудашева, проектирование структуры словаря целесообразно начинать с проектирования структуры микростатей – единиц словаря или единиц правой части информации о них. Прежде составляют классификацию микростатей, проектирует их наполнения и структуру, а затем объединяют. Микростатья единицы словаря с переводными соответствиями образует в многоязычном словаре самый тип словарной статьи [1, c. 364].
Лексикограф В. Дубичинский также считает словарную статью важнейшей частью словаря. микроструктура словаря, или модель комплексной словарной статьи может содержать следующие компоненты: заглавную единицу (слово, словосочетание, морфема, фразеологизм и т.д.), грамматическую характеристику (часть речи, род, число и т.д.), фонетическую характеристику (транскрипция, ударение, интонация), семантизацию заглавной единицы (толкование, дефиниция, переводной эквивалент, синонимы), сочетаемых информацию (словосочетания с заглавной единицей), фразеологические обороты, словообразовательную характеристику, этимологическую и историческую характеристики, иллюстрации по употреблению (словосочетания, предложения, цитаты), лексикографические отметки (грамматические, семантические, стилистические, специальные, эмоционально-экспрессивные, хронологические и т.д.), ссылки, энциклопедическую информацию [4, c. 4].
Форматом статьи электронного (компьютерного) словаря Е. Карпиловская считает модель организации, размещения и графического представления в словаре информации об описываемых в нем языковых объектах. Зонный принцип записи языковой информации является гибкой моделью, в которой каждому типу информации отведено отдельную зону и значимой является само наличие / отсутствие таких зон. Выработка такого формата составляет вместе с созданием базы данных и лексикографического процессора является неотъемлемой составляющей процесса создания электронного словаря [9, с. 49].
Л. Беляева рассматривает электронный словарь как базу данных, в которой каждая статья представлена как зонированный текст. Такой словарь должен иметь жесткую организацию и высокий уровень формализации представления данных [5].
Итак, создание электронного словаря предусматривает проектирование сложной системы в совокупности внутренних и внешних связей, организации ее компонентов. Единой жесткой схемы этапов проектирования электронного словаря не существует. Вместе с тем, важными этапами его создания, предшествующими технологическому, являются аналитический и концептуальный, пренебрежение которыми может привести к созданию продукта, не отвечающего требованиям современной лексикографии. Особенно тщательно следует подходить к разработке электронных словарей, предназначенных для использования в учебном процессе – игнорирование аналитического и концептуального этапов создания образовательного ресурса повышает дидактические риски его использования [10].
Библиографический список
- Кудашев И. С. Проектирование переводческих словарей специальной лексики. Helsinki: HU Print, 2007. 443 с.
- Лінгвістично-інформаційні студії: Праці Українського мовно-інформаційного фонду НАН України : у 5 т. . Т. 3 : Тлумачна лексикографія. Кн. 1. К.: Український мовно-інформаційний фонд, 2018. 276 с.
- Балалаєва О. Ю. Аналіз сутності поняття «електронний навчальний словник» // Проблеми сучасного підручника. 2014. Вип. 14. С. 26-33.
- Дубічинський В.В. Лексикографія: навч.-метод. посіб. Харків: НТУ «ХПІ», 2012. 66 с.
- Беляева Л. Н. Потенциал автоматизированной лексикографии и прикладная лингвистика // Известия РГПУ им. А.И. Герцена. 2010. № 134. С. 70-79.
- Табанакова В. Д., Ковязина М. А. Функциональная модель переводного специального словаря // Вестник ТюмГУ. 2006. № 4. С. 158–165.
- Лейчик В.М. Типология словарей на пороге XXI века. Вестник международного славянского университета. Харьков, 1999. Т. 2. № 4. С. 7–9.
- Сивакова Н. А. Лексикографическое описание английских и русских фитонимов в электронном глоссарии: автореф. дис. … канд. филол. наук. Тюмень, 2004.25 с.
- Карпіловська Є. А. Вступ до прикладної лінгвістики: комп’ютерна лінгвістика : підручник. Донецьк : Юго-Восток, 2006. 188 с.
- Балалаева Е.Ю. Дидактические риски использования электронных средств обучения // Непрерывное образование: XXI век. 2016. Вып. 4 (16) [Электронный ресурс]. URL: http://lll21.petrsu.ru/journal/article.php?id=3326
Количество просмотров публикации: Please wait
Все статьи автора «Балалаева Елена Юрьевна»
Данная статья посвящена созданию простого глоссария (словаря терминов) без плагинов на базе функционала меток (тегов) WordPress. Это некий аналог Википедии, с помощью которого ваш контент может быть более понятным для посетителей вашего ресурса.
Зачем нужен глоссарий для сайта WordPress?
Все просто — данный раздел будет помогать не только в навигации по сайту, но так же будет помогать пользователю вашего сайта ориентироваться в терминах, объясняя те или иные определения, встречающиеся на вашем сайте. При использовании seo разметки или плагинов для seo оптимизации, то можно привлечь на свой сайт дополнительный трафик.
Если говорить еще проще, то нам предстоит создать страницу в WordPress с выводом всех тегов сайта, сортированных в алфавитном порядке.
Наполнение тегов
Каждый тег необходимо заполнять как мини-статью, которая будет описывать определенный термин и давать общее представление о метке или теге, как о подразделе вашего сайта. Пример того, что получилось на данном ресурсе: https://nikonorow.ru/tag-glossary/
Создание раздела глоссария
Первым делом, мы создадим пустой файл шаблона с расширением .php с любым названием (в моем случае это gloss.php). В нем пропишем комментарий Template name, который затем поможет нам выбрать нужный шаблон при создании страницы.
<?php /* Template name: Глоссарий */ ?>Сохраняем и загружаем данный файл в папку, где лежит ваша тема WordPress (путь: /wp-content/themes/имя вашей темы).
Как создать страницу WordPress?
Затем, мы создадим страницу для нашего словаря терминов. Переходим в админ-панель вордпресс, выбираем в левом меню пункт «Страницы» (1) и нажимаем «Добавить новую.» (2):

Заполняем заголовок (1), описание раздела (2), уникальный URL-адрес (3). Выбираем файл нашего будущего шаблона (4), в открывшемся списке выбираем нужный шаблон (5) и нажимаем опубликовать (6).

Пишем код шаблона на PHP:
Верстку я буду использовать с данного ресурса. Возвращаемся к нашему шаблону и в него вставляем код приведенный ниже:
<?php /* Template name: Глоссарий тегов */ ?>
<?php get_header(); //выводим шапку сайта (header.php из вашего шаблона)
?>
<div class="main-content">
<div class="container">
<div class="wlatest">
<div class="wtopics" id="portfolio">
<div class="block-title">
<?php the_title('<h1><span class="white">#</span>', '</h1>'); //выводим заголовок страницы
?>
</div>
<?php the_content(); //выводим текст или контент страницы
?>
</div>
<div class="wposts">
<?php
$tags = get_tags(); // записываем в переменную $tags список тегов
if ($tags_list) {
$all = ''; // переменная для всех тегов
foreach ($tags as $tag) { // запускем цикл и обращаемся к каждому объекту массива тегов
$letter = mb_substr($tag->name, 0, 1, 'utf-8'); //выводим первую букву тега - UTF-8 нужен для корректного отображения кириллицы
$pos = strpos($all, $letter); // Ищем первую букву в переменной all
if ($pos === false) { // если не нашли, показываем букву
$all .= $letter; // и добавляем ее в переменную.
?>
<div class="npost">
<div class="textpost">
<?php
echo '<h3 class="yellow">' . $letter . '</h3>'; // выводим заголовок letter
$tags_list = get_tags(); // записываем в переменную $tag_list список тегов
foreach ($tag_list as $t) { //запускем цикл и обращаемся к каждому объекту массива тегов
if ($letter == mb_substr($t->name, 0, 1, 'utf-8')) { //если первая буква тега равна заголовку letter
echo '<p><a href="' . get_tag_link($t->term_id) . '" class="tag mons-up white">' . $t->name . '</a></p>'; // то выводим ссылку на данный тег, внутри которой будет само название тега
}
}
?>
</div>
</div>
<?php
}
}
}
?>
</div>
</div>
</div>
</div>
</body>
<?php get_footer(); // выводим подвал сайта (footer.php из вашего шаблона)> Не забудьте переписать верстку под ваш шаблон (об обновлении шаблона и верстки данного сайта — смотрите здесь), либо используйте данные html-фрагменты, но в style.css вашей темы пропишите парараметры классов. После того вы как во всем разобрались, рекомендую удалить комментарии из кода, чтобы ускорить его. И, в дальнейшем, не комментируйте так много и таким образом. Данные пояснения необходимы только для данной статьи, чтобы максимально разжевать суть происходящего.
Итог
Вот мы и написали простой раздел, который выводит все метки сайта и служит в качестве глоссария. Еще раз повторю пример того, что получилось на данном ресурсе: https://nikonorow.ru/tag-glossary/
Дополнять и переделывать данный функционал можно как угодно:
- В идеале, в данный раздел можно добавить простую навигацию по алфавиту (вывести уникальные значения всех первых букв, например: появится алфавитная полоса и нажимая на букву «А» — пользователю отображается только блок терминов, начинающихся с данной буквы.
- Второй вариант — сделать поиск, который будет отображать термины, введенные пользователем в строке поиска. Данный функционал можно реализовать с помощью javascript.
Можно использовать оба варианта одновременно, это лишь идея по поводу того, как можно улучшить данный раздел.
Рубрика: Веб-разработка
Муниципальная общеобразовательная бюджетная школа
средняя общеобразовательная школа №12 города Якутска.
Разработка электронного терминологического словаря справочника
по информатике.

Якутск 2021 год.
СОДЕРЖАНИЕ
Цель и задачи……………………………………………………………………3
Введение …………………………………………………………………………5
Этапы процесса разработки ……………………………………………………7
Схема алгоритма ………………………………………………………………..8
Технические характеристики ………………………..…………………….….10
Заключение …………………………………………………………..…………14
Список использованных источников ………………………..………………..15
Приложение ………………………………………………………….…………16
Цель:
Необходимо разработать программу для перевода слова. Требуется создать программу переводчик. В первую текстовую форму вводится переводимое слово, по нажатию на кнопку переведенное слово отображается во второй текстовой форме.
Задачи:
1) Изучение предметной области.
2) Изучение алгоритма перевода.
3) Разработка программы
Актуальность:
Человечество вступило в новую эру — век информации. Новейшие информационные технологии вносят радикальные изменения во все сферы деятельности человека: образование, медицину, промышленное производство, научные исследования, домашний быт. Информация уже сегодня в решающей степени определяет уровень цивилизации общества. Ведь для того, чтобы двигаться вперед, расширять технические возможности производства, повышать уровень материальной и культурной жизни общества, необходимо в кратчайшие сроки получать информацию, обрабатывать и использовать ее для решения тех или иных задач.
Объект изучения:
Термины и понятия, с которыми можно встретиться при изучении информатики, вычислительной техники, алгоритмизации и программирования.
Предметом исследования:
Является значение, происхождение и история образования терминов в информатике. Сопоставление смысла современного понятия термина с первоначальным значением.
Введение.
Под компьютерным справочным пособием понимается электронное пособие, поддерживающее компьютерную технологию создания и обучения, где основным инструментом является компьютер. По своим функциональным возможностям компьютер уже сегодня стал практически идеальным средством работы в сфере обучения, поэтому возникает необходимость создания таких программных продуктов, с которыми работать удобно и легко.
У таких пособий (источников информации) множество преимуществ по сравнению, например, с печатными: размещение в сети Интернет, быстрый и лёгкий обмен информацией, возможность печати любой части пособия, возможность редактирования и дополнения, более долгое время хранения, физически требует для хранения объект малого размера.
Разработка компьютерного пособия включает в себя множество этапов: разработка сценария, поиск материала, способ структурирования материала, разработка дизайна и интерфейса, кодирование. Поэтому создание справочного пособия является многопрофильной задачей, при реализации которой необходимо обладать знаниями в разных областях. В функциональный состав группы разработчиков должны входить: преподаватель – предметник, специалист по компьютерным методикам обучения и компьютерной интерпретации учебных материалов, а также программист.
Бурное развитие информационных технологий в настоящее время сопровождается лавинообразным увеличением информации, в результате чего возникает непростая задача по выбору актуальной информации (особенно это касается именно информатики), при этом необходимо отсекать второстепенную информацию и не перегружать справочное пособие частными подробностями.
В данном справочнике представлен интересный материал для наблюдения и познания. Словарь-справочник содержит основные термины и определения по информатике школьного курса общеобразовательных учреждений. Он может быть полезным ученику и учителю при подготовке к экзаменам, ЕГЭ, для составления тестовых заданий и для самостоятельной работы. Материал справочника может быть использован в качестве дополнительного источника информации. Все термины и определения разбиты на две большие группы по русскому и английскому алфавитам.
Для создания пособия использовался объектно-ориентированный язык программирования дельфи, краткий курс которого преподается в школе. Реализация проекта стала реальной в связи с наличием кружка «Юный программист», на котором даются более глубокие знания в сфере программирования.
В процессе создания пособия я реализовал процесс организации профессиональной подготовки будущего специалиста в сфере компьютерных технологий, что является весьма актуальным в настоящее время.
Словари являются сокровищницами языка, в них сосредоточено его лексическое богатство. Словари дают возможность рассмотреть каждое слово как особый микромир в своей системе, формируется языковая картина мира.
Как справедливо отметили З. А. Потиха и Д. Е. Розенталь «словарная работа способствует развивающему обучению в школе».
Работа со словарем, создание и использование в учебном процессе собственных словарей становится эффективным средством формирования и развития лингвистической, языковой и коммуникативной компетенции. Включившись в сопоставительный анализ фактов языка, учащийся более сознательно выделяет свои речевые ошибки, в том числе и лингвокультурологического характера, определяет их причины и, следовательно, быстрее от них избавляется.
По мнению французского писателя Анатоля Франса, словарь – это вселенная расположенная в алфавитном порядке. Словари необходимы не только, когда не знаешь написания того или иного слова. Но и являются важной единицей национальной культуры.
Назначения и область применения.
Формулировка задачи и её роль
Для разработки программы требуется понять принцип самого машинного перевода. Задачей является разработка программы, предназначенной для перевода слова.
Изучение предметной области
Целесообразность поставленной задачи
Этапы процесса разработки
Проектирование разработки
В программе реализован алгоритм перевода, по сути, она является двухоконным редактором с функцией перевода, что даёт возможность редактирования текста прямо в окне программы переводчика. Программа позволяет получить приемлемый не подстрочный.
Алгоритм перевода представлена на рис 1.

Рис 1 Схема алгоритма перевода
Технологии разработки
Разрабатываемое приложение является программой терминологического словаря по информатике. Для реализации программы использовались ниже перечисленные средства.
Delphi
В связи с тем, что на момент начала создания программы – переводчика имелись некоторые наработки, написанные на языке программирования Pascal, было принято решение для реализации задачи выбрать близкий к Pascal, язык программирования Delphi.
Преимущества Delphi:
- быстрота разработки приложения;
- высокая оптимизация при компиляции программы, в результате чего производительность разработанного приложения не уступает, а иногда превосходит программы, написанные на других языках;
- настоящий 32-битный код, полученный в результате компиляции оптимизирующим компилятором;
- возможность полного доступа к функциям операционных систем Windows9x и Windows NT;
- наращиваемость за счет встраивания новых компонент и инструментов в среду Delphi;
- возможность разработки новых компонент и инструментов собственными средствами Delphi (существующие компоненты и инструменты доступны в исходных текстах);
- удачная проработка иерархии объектов;
- Программа была написана на языке Delphi c использованием 32-x разрядного компилятора Delphi 2006.
Результаты разработки
Результатом выполнения проектирования, является программа словарь по информатике.
На рисунке 2 представлен конечный вид разрабатываемой программы.

Рис.2 Программа словарь по информатике
Технические характеристики разработки
Общие сведения о разработке
Наименование программы
Электронный терминологический словарь по информатике
Языки программирования
Программа выполнялась с использования языка программирования Delphi6.
Назначение и функции, выполняемые программой
Данная программа предназначена для выполнения перевода терминологических слов по информатике.
Основные характеристики
Необходимо следующее программное обеспечение:
- Операционная система Windows XP;
- локальный диск с файловой системой Fat32 или NTFS.
Для работы программы предоставлено программно-аппаратное обеспечение следующей конфигурации:
- Компьютер Pentium IV и выше;
- оперативная память 512Мб;
- 5 Мб свободного места на жестком диске;
Сведения о входных и выходных данных
Структура входных данных
Входными данными является переводимое слово.
Рис.3 Входные данные
Структура выходных данных
Переведенное слово является выходным данным и выводится в диалоговое окно.

Рис.4 Выходные данные
Описание логической структуры
Лингвистическая трех уровневая модель системы перевода.
Структура программы
Программа состоит из двух блоков. В первый блок входит текстовое поле, куда вводится переводимое слово, рядом с которым находится кнопка, по нажатию на которую выполняется перевод.
Во втором блоке отображается переведенный текст.
Описание выполняемых функций
Программа выполняет функцию перевода слова.
Отладка и тестирование программы
Вызов программы осуществляется непосредственно из проекта, созданного в Delphi6, как показано на рисунке 5

Рис.5 Запуск проекта.
Слово для перевода введем в первое текстовое поле, как показано на рисунке 6

Рис. 6 Ввод слова в первое поле.
Перевод слова осуществляется по нажатию на кнопку «Искать в словаре». Переведенное слово отображается в правом текстовом поле.
Рис.7 Переведенное слово.
Режимы работы программы
Данная программа использует интерактивный режим работы. Запрос отправляемый пользователем обрабатывается немедленно после принятия решения. Программа так же умеет добавлять новые слова в словарь и удалять например неправильно введенные слова.
Завершение выполнения программы
Завершение программы происходит путём нажатия на кнопку закрытия в правом верхнем углу программы.
Заключение
«Электронный словарь терминов по информатике» не только является достаточно надежным справочником, помогающим осмыслить терминологию, которая используется в информатике и вычислительной технике, но и дополняет, расширяет материалы учебников, помогает более четко воспринять значение терминов и терминологических сочетаний, учит правильно использовать их в речи. Словарь является пособием справочного характера для всех учащихся, интересующихся информатикой, может оказать неоценимую помощь учителю, каждому, изучающему этот предмет.
Программа предназначено для широкого круга пользователей: преподавателей, школьников, переводчиков, филологов, лингвистов.
В результате выполнения проекта «Разработка электронного словаря» были решены следующие задачи:
- разработана программа «электронный словарь»;
- обоснован выбор технических и программных средств, необходимых для решения поставленной задачи;
- реализована задача в соответствии с требованиями.
Таким образом, задача проекта выполнена в полном объеме.
Список использованных источников
- Delphi 7. Основы программирования. Решение типовых задач — М.: Издательско-торговый дом «Русская Редакция», 2000. — 576 стр.: ил.
- Графика в проектах Delphi. –Символ-Петербург.2009. – 628 с.: ил.
- Рабинер Л.Р, Шафер Р.В. Создание Windows-приложений в среде Delphi // Москва, Изд-во » Солон-пресс «, 2007.
- Тюкачев Н.А.. Программирование графики в Delphi. // – СПб.: БХВ-Петербург, 2008.
- Программирование в Delphi: процедурное, объектно-ориентированное, визуальное. СПБ.: Питер, 2002.
- Солонина А. И., Улахович Д. А., Арбузов С. М. и др. Delphi 7. Основы программирования. Решение типовых задач / СПБ.: Петербург, 2003.
Приложение
(исходный код программы)
unit tyldyt;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, ExtCtrls;
type
TForm1 = class(TForm)
Button1: TButton;
ListBox1: TListBox;
Edit1: TEdit;
Button2: TButton;
Edit2: TEdit;
Memo1: TMemo;
Edit3: TEdit;
Label1: TLabel;
Label2: TLabel;
Image1: TImage;
Label3: TLabel;
Label4: TLabel;
Label5: TLabel;
Label6: TLabel;
Button3: TButton;
Label7: TLabel;
Label8: TLabel;
Label9: TLabel;
Label10: TLabel;
procedure Button1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure onclose(Sender: TObject; var Action: TCloseAction);
procedure Button3Click(Sender: TObject);
procedure ListBox1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
j,h2:integer;
implementation
{$R *.dfm}
procedure TForm1.FormCreate(Sender: TObject);
begin
ListBox1.Items.LoadFromFile(‘tyldyt.crc’);
j:=-1;
memo1.Clear;
end;
procedure TForm1.Button1Click(Sender: TObject);
var
p: integer;
begin
While j< ListBox1.Items.Count-1 Do
begin
j:=j+1;
p:=Pos(‘ ‘+Edit2.Text+’ ‘, ListBox1.Items[j]);
if p>0 then
begin
Memo1.Lines.Clear;
Memo1.Lines.Add(ListBox1.Items[j]);
break;
end;
if j=ListBox1.Items.Count-1 then
begin
if p=0 then
ShowMessage(‘Не найдено’);
end;
end;
ListBox1.ItemIndex:=J;
if j= ListBox1.Items.Count-1 then j:=-1;
end;
procedure TForm1.Button2Click(Sender: TObject);
begin
h2:=h2+1;
if (edit1.Text<>») and (edit3.Text<>») then begin
ListBox1.Items.Add(‘ ‘+Edit1.Text+’ — ‘+edit3.Text+’ ‘);
end else showmessage(‘поля не заполнены’);
edit1.Clear; edit3.clear;
end;
procedure TForm1.onclose(Sender: TObject; var Action: TCloseAction);
begin
begin
{h2:=ListBox1.Items.Count;}
if h2>0 then
begin
if MessageDlg(‘Внесены новые слова. Сохранить ли их?’,
mtConfirmation, [mbYes, mbNo], 0) = mrYes
then
begin
ListBox1.Items.SaveToFile(‘tyldyt.crc’);
ShowMessage(‘Изменения сохранены’);
end;
end;
end;
end;
procedure TForm1.Button3Click(Sender: TObject);
begin
h2:=h2+1;
ListBox1.DeleteSelected;
end;
procedure TForm1.ListBox1Click(Sender: TObject);
begin
memo1.Clear;
Memo1.Lines.Add(ListBox1.Items[ListBox1.ItemIndex]);
end;
end.