Продолжая насыщать курс Аналитика больших данных для руководителей важными понятиями системного анализа, сегодня мы рассмотрим, что такое дерево решений (Decision Tree). А также расскажем, как этот метод Data Mining и предиктивной аналитики используется в машинном обучении, экономике, менеджменте, бизнес-анализе и аналитике больших данных.
Как растут деревья решений: базовые основы
Начнем с определения: дерево решений – это математическая модель в виде графа, которая отображает точки принятия решений, предшествующие им события и последствия. Этот метод Data Mining широко используется в машинном обучении, позволяя решать задачи классификации и регрессии [1].
Аналитические модели в виде деревьев решений более вербализуемы, интерпретируемы и понятны человеку, чем другие методы Machine Learning, например, нейронные сети. Дополнительное достоинство Decision Tree – это быстрота за счет отсутствия этапа подготовки данных (Data Preparation), поскольку не нужно очищать и нормализовать датасет [2].
В бизнес-анализе, менеджменте и экономике Decision Tree – это отличный инструмент для наглядного отображения всех возможных альтернатив (сценариев), прогнозирования будущих событий, а также оценки их потенциальной выгоды и рисков. Для этого дерево решений представляют в виде графической схемы, чтобы его проще воспринимать и анализировать. Данный граф состоит из следующих элементов [3]:
- вершины, от которых возможно несколько вариантов, называют узлами. Они показывают возможные ситуации (точки принятия решений);
- конечные узлы (листья) представляют результат (значение целевой функции);
- ребра (ветви), соединяющие узлы, описывают вероятности развития событий по этому сценарию.
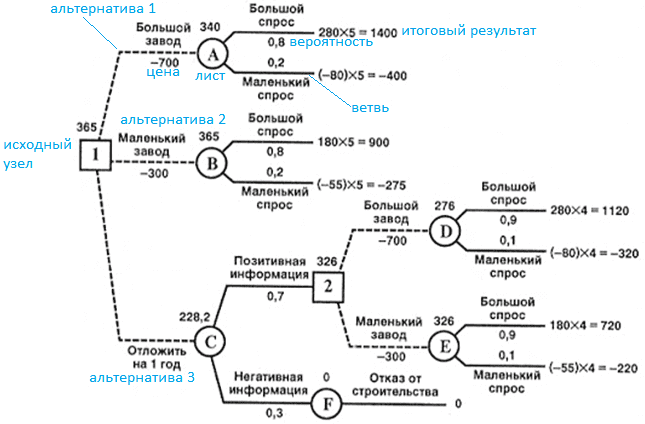
Обычно многоузловые деревья решений строятся с помощью специального программного обеспечения. Но граф с ограниченным числом вершин можно построить в табличном редакторе или даже вручную. Как это сделать самостоятельно, мы рассмотрим далее на простом примере из управленческой практики.
Строим дерево решений на примере обучения Big Data
Итак, проанализируем кейс построения дерева решений на примере расчета выгоды от обучения сотрудников новой Big Data технологии с целью быстрого выпуска продукта ценой X. При этом возможны следующие альтернативные сценарии:
- поручить каждому сотруднику самостоятельно освоить нужные подходы, фреймворки и языки программирования в свободное от работы время. Фактические затраты на реализацию такого решения равны нулю, а вероятность успешного освоения технологии для быстрого выпуска продукта оценивается на уровне 30%.
- выделить w рабочих дней на самостоятельное обучение каждого сотрудника на его рабочем месте. Фактические затраты на реализацию такого решения составляют стоимость рабочего дня каждого сотрудника в день (Z), умноженное на количество дней (w) и число сотрудников (k). Успех ожидается в 50% случаев.
- организовать корпоративное обучение всех сотрудников в специализированном учебном центре в течении n дней. Затраты на обучения составят совокупную стоимость курсов (Y), а также цену рабочего дня каждого сотрудника в день (Z)*количество дней (n)*число сотрудников (k). При этом сотрудники освоят технологию с вероятностью 98% за n дней (n<w).
|
Решение |
Затраты на реализацию решения |
Вероятность успешного освоения технологии для быстрого выпуска продукта ценой X |
Выгода |
|
Самостоятельное обучение каждого сотрудника вне работы |
0 |
0,3 |
X*0,3 |
|
Самостоятельное обучение каждого сотрудника на работе |
стоимость рабочего дня каждого сотрудника в день (Z)*количество дней (w)*число сотрудников (k) |
0,5 |
X*0,5 – Z*w*k |
|
Организованные курсы для всех сотрудников в учебном центре |
цена обучения (Y) + стоимость рабочего дня каждого сотрудника в день (Z)*количество дней (n)*число сотрудников (k) |
0,98 |
X*0,98 – (Y+Z*n*k) |
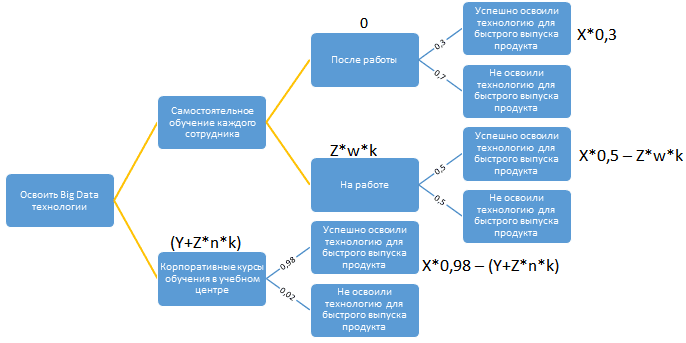
Сравнив в абсолютных числах выражения 0,3X, (X*0,5 – Z*w*k) и (X*0,98 – Y – Z*n*k), можно выбрать наиболее выгодный вариант. Таким образом, дерево решений позволяет количественно оценить риски, затраты и выгоды возможных альтернатив и выработать оптимальную управленческую стратегию. Не случайно профессиональный стандарт бизнес-аналитика, руководство BABOK, о котором мы рассказывали здесь, включило дерево решений в набор наиболее часто используемых техник [4]. В следующей статье мы расскажем, как деревья решений и другие методы интеллектуального анализа данных реализуются в новом тренде аналитики больших данных — Augmented Analytics.
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
28 июня, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
66 000 руб.
Другие прикладные понятия системного и бизнес-анализа, важные для принятия управленческих решений, цифровизации бизнеса и аналитики больших данных разбираются на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Аналитика больших данных для руководителей
- ТОП-10 инструментов бизнес-анализа для предпринимателя и менеджера
Источники
- https://loginom.ru/blog/decision-tree-p1
- https://ru.wikipedia.org/wiki/Дерево_решений
- http://datareview.info/article/derevya-resheniy-i-algoritmyi-ih-postroeniya/
- https://www.skylinetechnologies.com/Blog/Skyline-Blog/May_2019/how-to-use-decision-modeling-bi-requirements
по объему ТС, в которых общее число вариантов задания ус ловий выбора решений может достигать десятков, сотен ты сяч и даже миллионов.
Наиболее удобным математическим аппаратом для ана лиза и оптимизации связей, для выявления и устранения пе речисленных выше недостатков исходных ТС являются ме тоды теории графов [93], используя которые строят и анали зируют граф-схемы алгоритмов выбора решений.
Поясним сущность и применение граф-схем, пользуясь терминологией теории графов.
Граф-схема представляет собой геометрическое построе ние в виде расширяющегося книзу дерева, состоящего из вер шин и соединяющих их линий, называемых дугами (рис. 10). Из каждой вершины графа исходит вниз не менее двух дуг. На чальная (верхняя) вершина графа называется его корнем. Вер шины, находящиеся на оконечностях ветвей дерева, называются конечными, а часть графа, не имеющая промежуточных вер шин, — кустом. Путь в графе — это последовательность дуг, в которой начальная вершина последующей дуги совпадает с конечной вершиной предыдущей дуги.
Рис. 10. Общий вид граф-схемы: Х — корень (начальная вершина); Х г X i0, Х„, Х„2 — промежуточные вершины; у + у 4; у„, — конечные вершины
Процесс построения граф-схем называется синтезом. По форме синтез граф-схемы состоит в ее пошаговом наращива нии, начиная от начальной вершины (корня) графа. На каж дом шаге производится отождествление добавляемого эле мента графа —вершины или дуги — с определенными элемен тами базовой таблицы соответствий. Вершины графа отожде ствляют с параметрами ТС, а дуги —со значениями парамет ров. Процесс построения заканчивают, когда каждой конеч ной вершине граф-схемы будут приписаны некоторые реше ния из области прибытия ТС или решение у = 0, что означает отсутствие решения. Применяются определенные правила отождествления элементов, графического изображения вер шин и идентификации, то есть присвоения названий или ко дов вершинам и дугам на граф-схеме.
Методика синтеза граф-схем алгоритмов выбора решений была опубликована в 60-70-х годах прошлого века в научных трудах Г.К. Горанского и его сотрудников из Института техни ческой кибернетики АН Белоруссии [2, 19, 20, 88], в учебной литературе не дублировалась и знакома только узкому кругу специалистов. Поэтому целесообразно изложить ее с подробно стями, достаточными для практического применения.
Рассмотрим пример, в котором за исходную базовую модель принята таблица соответствий (табл. 8).
Процесс построения граф-схемы можно представить
ввиде ряда процедур:
—отождествление начальной вершины граф-схемы с об ластью прибытия ТС и ее идентификация;
—выбор параметра для построения куста граф-схемы;
—построение куста-распознавателя;
—отождествление конечных вершин куста с подмноже ствами решений области прибытия ТС и их идентификация;
Таблица 8 Таблица соответствий для построения граф-схемы
|
Y |
X , |
Х 2 |
X ] |
Х 4 |
Х 6 |
х 7 |
|||||||||
|
1 |
2 |
1 |
2 |
1 |
2 |
3 |
4 |
1 |
2 |
3 |
1 |
2 |
1 |
2 |
|
|
V) |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
Уг |
1 |
1 |
1 |
1 |
1 |
||||||||||
|
У.1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||||||
|
У4 |
1 |
1 |
1 |
||||||||||||
|
.У|5 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|||||||
|
Уь |
1 |
t |
1 |
1 |
1 |
1 |
|||||||||
|
2 L |
1 |
1 |
1 |
1 |
1 |
—составление частичных таблиц, соответствующих по лученным конечным вершинам куста;
—окончание построений;
—идентификация конечных вершин граф-схемы.
Процедура 1. Отождествление начальной вершины с областью прибытия ТС н ее идентификация. Построение граф-схемы алгоритма выбора решений на основе таблицы соответствий начинают с начальной вершины, которую ото ждествляют со всей областью прибытия ТС. Это единствен ная из вышеперечисленных процедур, выполняемая фор мально и один раз для каждой граф-схемы.
Графически это изображают в виде прямоугольника с соответствующей записью, варианты которой показаны на рис. 11.
Рис. 11. Варианты записи идентификаторов начальной вершины на граф-схеме: а — полная запись; б, в — сокращенная запись; Х п — параметр, с которого начинается построение куста
Процедура 2. Выбор параметра для построения куста граф-схемы. Напомним, что в теории графов кустом назы вают граф или часть графа, состоящую из вершин, соединен ных ребрами (дугами), и не имеющую промежуточных вер шин. В рассматриваемых граф-схемах кусты имеют как ми нимум три вершины, из них одна начальная, остальные ко нечные (термины «начальная», «конечные» относятся только к данному кусту). Начальная вершина соединена с конечны ми дугами.
В данной процедуре речь идет о выборе параметра для начальной вершины куста. На граф-схеме алгоритма выбора решений вершины графа изображают с помощью двух фигур: прямоугольника и примыкающего к нему кружка. В прямо угольнике, как об этом сказано в описании процедуры 1, по мещают приписанные коды соответствующего множества решений, а в кружке — один из параметров области отправле ния ТС. Какой именно? В принципе можно взять любой из параметров. Однако от выбора параметра будут зависеть компактность всей граф-схемы и качество составленной по ней машинной программы для ЭВМ. Минимизацию графсхемы можно обеспечить на основе знания так называемой информативности параметров.
Информативностью параметра Хк называют его харак
|
теристику р*, подсчитанную по формуле |
||
|
рк = гпк +Рк-Як, |
(Ю) |
|
|
где тк — |
число столбцов параметра^ в таблице; |
|
|
рк — |
суммарное число решений в тк столбцах нормали |
|
|
зованной таблицы (число единиц в этих столбцах); |
||
|
qk — |
принимает значение 1 или 0 в зависимости от того, |
существуют или нет неопределенные значения параметра Хк
(есть ли у него столбцы с одними нулями).
Подсчитаем, к примеру, информативность параметров нормализованной таблицы (см. табл. 8).
Для параметра Х информативность pi = 2 + 8 — 0 = 1 0
|
и далее соответственно: |
|
|
р2 = 2 + 7 — 0 = 9; |
р4 = 3 + 7 — 0 = 10; |
|
р3 = 4 + 9 — 1= 12; |
Р5 = 2 + 7 — 0 = 9. |
Для транзитного параметра Х6 информативность не под считывается. В целом к транзитным параметрам проявляется особый подход. Они не являются параметрами-разделителями (то есть не разделяют область прибытия на части), но участ вуют в построении граф-схемы. Если в ТС есть транзитный параметр, его ставят в начале графа (на место Х„ на рис. 11).
Из числа параметров-разделителей для построения оче редного куста (после транзитных кустов) выбирают параметр с наименьшей информативностью. В результате обеспечива ется тенденция строить куст с минимальным числом дуг.
В дальнейшем указанная процедура выбора параметра применяется для построения всех кустов граф-схемы, а не только корня дерева: рассматриваемой вершине графа при писывают транзитный параметр, а если его нет, то параметр с наименьшей информативностью. Если имеется несколько параметров с наименьшей информативностью, то для по строения куста из них выбирают параметр с наименьшим числом безразличных значений (столбцов, полностью за полненных единицами). Если и таких параметров окажется несколько, то выбирают параметр с наименьшим индексом.
Процедура 3. Построение куста-распознавателя. Оп ределение куста графа дано в предыдущем параграфе. Кус том-распознавателем в граф-схеме алгоритмов выбора ре шений называют такой куст, из начальной вершины которого исходит две или более дуг.
Построение какого-либо куста граф-схемы заключается в том, что из имеющейся начальной вершины вниз выводят столько дуг, сколько столбцов содержит выбранный для по строения куста параметр. Каждой дуге приписывается значе ние параметра, относящееся к тому столбцу, которому соот ветствует дуга. Затем на концах дуг строят вершины, анало гичные начальной вершине графа, как это описано выше в процедурах 1 и 2. С чем отождествляются полученные ко нечные вершины куста-распознавателя, объяснено в сле дующей процедуре.
Процедура 4. Отождествление конечных вершин куста с подмножествами решений области прибытия ТС и их идентификация. Из самого названия процедуры следу ет, что каждую полученную конечную вершину куста ото ждествляют не со всей областью прибытия ТС, как это имеет место для начальной вершины графа, а только с определен ным подмножеством (частью) области прибытия. Для этого по исходной при построении куста таблице определяют, с какими решениями из области отправления имеет соответ ствие каждое значение параметра, приписанного вершине куста (для каких решений в столбце проставлены единицы) и отождествляют каждую соответствующую конечную вер шину только с этими решениями. Формальная запись этого производится аналогично записи для начальной вершины гра фа: на конце каждой дуги строится прямоугольник, в котором записывается соответствующее подмножество решений.
Поясним процедуры 3 и 4 на примере с исходной ТС (см. табл. 8). Начало построения граф-схемы показано на рис. 12.
Начинается построение с процедуры 1, то есть отожде ствляем начальную вершину графа со всей областью прибы тия ТС. Показываем это записью в прямоугольнике: 1 7.
Затем выбираем параметр для построения куста (процедура 2). Так как в исходной ТС имеется транзитный параметр Хь, ставим его в начале графа и записываем Х6 в кружке при начальной вершине. Первая вершина — корень графа — по строена.
Рис. 12. Построение транзитного куста и куста-распознавателя
Транзитный параметр Х6 имеет в ТС два столбца, соответ ствующие его значениям 1 и 2, поэтому на схеме проводим две линии — дуги и обозначаем их цифрами 1 и 2. Значение 1 пара метра Х6имеет соответствие со всеми решениями области при бытия ТС, значение 2 соответствий не имеет ни с одним из ре шений. В связи с этим с конечной вершиной дуги 1 отождеств ляем всю область прибытия (снова записываем в прямоуголь нике 1 -г- 7), а конечной вершине дуги 2 приписываем отсутст вие решения. В итоге получился транзитный куст.
Далее построение граф-схемы продолжается только по одной ветви. Выбираем параметр для построения куста (проце дура 2). Выше для параметров Х +Х5была подсчитана инфор мативность. Наименьшую информативность (р* = 9) имеют па раметры Х2 и Х$). Приписываем параметр Х2 вершине графа,
отождествленной с областью прибытия, и строим кустраспознаватель (процедура 3). В исходной ТС параметр Х2име ет два значения (два столбца). Проводим из вершины две дуги, приписывая им значения параметра 1 и 2. Значение 1 согласно таблице имеет соответствие с решениями у9у3, у4 и уъ значение 2- с решениямиу2,ys иув. Производим на граф-схеме соответст вующие записи у конечных вершин куста (процедура 4).
Таким образом, в результате построения куста-распоз навателя число ветвей на граф-схеме увеличилось. В даль нейшем процедуры 2-4 повторяют для каждой ветви в отде льности до тех пор, пока не будут получены определенные ре шения. О некоторых дополнительных условиях построения и окончания построений на граф-схеме будет сказано ниже.
Процедура 5. Построение частичных таблиц. Обратим внимание на то, что в рассмотренном примере конечные вершины куста-распознавателя отождествлены не со всей областью отправления ТС, а только с ее определенными ре шениями (подмножествами решений). Естественно, что при продолжении построений от каждой ветви граф-схемы в ка честве исходной принимается не вся ТС, а только выборка из нее — частичная таблица.
Частичную таблицу получают из исходной с помощью следующих приемов:
1) из исходной таблицы удаляют все столбцы парамет ров, уже использованных для построения ветви граф-схемы до данного куста. В рассматриваемом примере (см. рис. 12) это будут параметры Хв и Х2;
2) в таблице оставляют только те строки (решения), с которыми оставшиеся параметры Х9Х3, Х4, Х5 имеют соот ветствия, остальные строки удаляют. В рассматриваемом примере оставляют в таблице строки для решений {уи Уз, Уа, у7} или {у2,Уъ,Уб}, в зависимости оттого, для какой из конеч ных вершин куста строится частичная таблица;
3) при необходимости производят нормализацию полу ченной частичной таблицы, после чего ее принимают за ис ходную для построения следующего куста. Конкретно, час тичная таблица используется для оценки информативности параметров и выбора одного из них по процедуре 2.
Частичные таблицы, построенные для конечных вершин куста параметра Х2, приведены на рис. 13 и 14. Там же даны расчеты информативности параметров.
|
Л’1 |
Л’5 |
Р1 = 2 + 4 —0 = 6 |
|||||||
|
1 |
2 1 2 3 4 I 2 3 1 |
2 |
|||||||
|
У |
рз = 4 -f-6 — 1 ~9 |
||||||||
|
У |
1 |
1 |
1 |
1 |
1 |
р4 = 3 + 4 — 1 6 |
|||
|
1 |
1 |
1 |
1 |
Р5 = 2 + 4 —0 —6 |
|||||
|
Уз |
б |
||||||||
|
У4 |
1 |
1 |
1 |
1 |
1 |
||||
|
У7 |
1 |
1 |
1 |
1 |
а
Рис. 13. Частичная таблица для вершины {1, 3,4, 7} (см.рис. 12): а — таблица; б — расчет информативности параметров
а
|
А’| |
*3 |
*4 |
XS |
Pl = 2 + А — |
0 |
— 6 |
|||||
|
Y |
1 |
2 |
1,3 2 4 |
1 |
2 3 |
1 |
2 |
рэ = 3 + 3 — |
1= 5 |
||
|
У2 |
1 |
1 |
1 |
1 |
р.1= 3 |
+ 3 — |
I |
= ? |
|||
|
Р5 = 2 |
3 — 0 |
||||||||||
|
У* |
1 |
1 |
1 |
1 |
1 |
в |
|||||
|
Уб |
1 |
1 |
1 |
1 |
|||||||
|
б |
Рис. 14. Частичная таблица для вершины {2, 5, 6} (см. рис. 12): а — таблица до нормализации; б — нормализованная таблица; в — расчет информативности параметров
Процедура 6. Окончание построений и идентифика ция конечных вершин граф-схемы. Процедуры 2-5 про должают выполнять до тех пор, пока не наступит одна из сле дующих ситуаций, приводящих к окончанию построений на определенных ветвях граф-схемы (см. рис. 12):
1. В частичной таблице, построенной для конечной вер шины куста, имеется только один параметр (см. рис. 15, а).
В этом случае строится последний куст по процедурам 3 и 4. Решения, приписываемые конечным вершинам куста, счита ются окончательными независимо от того, являются ли они единственными или множественными.
2. Дуге куста приписано неопределенное значение пара метра (примером может служить значение 3 параметра Х2 на рис. 15, б). В этом случае конечной вершине дуги приписы вается отсутствие решения, то есть пустое множество 0. Не определенное значение, в частности, всегда имеет транзит ный параметр (см. рис. 12).
Рис. 15. Идентификация конечных вершин для случаев: а — в таблице один параметр; б — значения параметра х 2и * 2 2 имеют соответствия с единственными решениями, значение х 2з неоп ределенное; в — в частичной таблице все параметры безразличные (после нормализации X = 0)
3. В частичной таблице у параметра с наименьшей и формативностью все или некоторые значения имеют соот ветствия с единственными решениями из области прибытия. Например, значения 1 и 2 параметра Х2 на рис. 15, б имеют соответствия с решениями у2 и ys. В этом случае строится куст с конечными вершинами для всех значений параметра, дальнейшие построения от упомянутых ветвей прекращают ся, несмотря на наличие в частичной таблице еще одного па раметра (Х+).
Рис. 16. Минимизированная граф-схема алгоритма выбора решений, построенная на основании исходной ТС (см. табл. 
4. Все параметры построенной для какой-либо вершины частичной таблицы являются безразличными (см. рис. 15, в), то есть при любом значении каждого из параметров могут существовать все решения области прибытия Y частичной таблицы. Как указывалось выше, безразличные параметры исключаются из таблицы и, следовательно, после нормализа
ции множество параметров X = 0. В этом случае вершине приписывается множество решений Y.
Минимизированная граф-схема алгоритма, построенная в соответствии с изложенными правилами для исходной таб лицы соответствий (см. табл. 8), приведена на рис. 16..
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
15.11.202220.05 Mб1Теория механизмов и механика систем машин учебное пособие..pdf
Понятие графа
Кроме таблиц, удобным инструментом для перебора и подсчёта различных комбинаций является граф.
Граф – это абстрактный математический объект, представляющий собой множество вершин графа и набор рёбер, то есть соединений между парами вершин.

Граф из 6 вершин и 7 ребёр.
Например:
Сколько различных трёхзначных чисел можно написать с помощью цифр 0 и 1?

Получаем 4 числа: 100,101,110 и 111
Полный граф в комбинаторике
Полный граф– это граф со всеми возможными ребрами.

С помощью полного графа удобно решать задачи полного перебора про «всех со всеми».
Например:
5 школьных команд по волейболу сыграли серию игр. Каждая команда провела с другими командами по одному матчу. Сколько всего матчей было сыграно?
Изобразим полный граф с 5-ю вершинами и посчитаем количество ребёр.

N = 10. Значит, было сыграно 10 матчей.
Граф-дерево
Дерево – это граф без циклов, у которого между парами вершин имеется только одно ребро.

Граф-дерево с 9 узлами и 8 ребрами.
Из каждого узла выходит не более 2 ребер.
Такое дерево называют бинарным.
С помощью дерева удобно составлять упорядоченные комбинации элементов.
Например:
На столе стоит три стакана сока – апельсиновый, виноградный и яблочный. Можно взять только два стакана. Сколько есть возможных вариантов и каких?
По правилу произведения число возможных вариантов: $3 cdot 2 = 6$. Поскольку, порядок выбора неважен, остаётся $frac{6}{2} = 3$ варианта. Построим граф:

3 варианта: 1) апельсиновый + яблочный, 2)апельсиновый + виноградный, 3) виноградный + яблочный.
Примеры
Пример 1. Вася, Петя, Коля и Толя хотят быть дежурными в столовой. Но можно выбрать только троих. Сколько вариантов выбора есть?
Построим полный граф.

Каждая тройка ребят соответствует треугольнику в этом графе.
Например, Вася образует три треугольника с оставшимися тремя ребятами:
$ frac{3cdot 2}{2} = 3$ — ВПК, ВТК и ВТП
Без Васи есть только один треугольник – ПКТ
Общее количество треугольников 3+1=4
Ответ: 4 варианта
Пример 2. Под рукой есть 6 видов овощей (капуста, морковь, лук, помидоры, огурцы и перец). Для салата нужно 3 вида овощей. Сколько всего различных салатов можно приготовить?
Построим полный граф.

Каждые три овоща на полном графе образуют треугольник.
Например, капуста образует треугольники с оставшимися 5 овощами. Таких треугольников $ frac{5cdot 4}{2} = 10$, где деление на 2 учитывает повторение ребра в каждой паре («лук-огурец» = «огурец-лук» и т.д.).
Количество треугольников, в которые не входит капуста: $ frac{4cdot 3}{2} = 6$
Количество треугольников, в которые не входят капуста и морковь: $ frac{3cdot 2}{2} = 3$
Количество треугольников, в которые не входят капуста, морковь и перец: $ frac{2cdot 1}{2} = 1$
Итого 10+6+3+1 = 20 различных треугольников.
Ответ: 20 салатов
Примечание: по расчетной формуле $C_6^3 = frac{6cdot 5 cdot 4}{1cdot 2 cdot 3} = 20$ — ответ правильный.
Пример 3*. Сколько существует способов занять 1,2 и 3 места на чемпионате, в котором участвуют 11 команд? Решите задачу с помощью полного графа.
Если построить полный граф с 11-ю вершинами, каждая тройка команд в нём образует треугольник.

По аналогии с примерами 1 и 2, общее количество треугольников:
$$N = left(frac{10cdot 9}{2} + frac{9cdot 8}{2}right) + left(frac{8cdot 7}{2} + frac{7cdot 6}{2}right) + left(frac{6cdot 5}{2} + frac{5cdot 4}{2}right) + left(frac{4cdot 3}{2} + frac{3cdot 2}{2}right) + frac{2cdot 1}{2} = $$
$$ = 9 frac{(10+8)}{2} + 7 frac{(8+6)}{2} + 5 frac{(6+4)}{2} + 3 frac{(4+2)}{2} +1 = $$
$$ = 9^2+7^2+5^2+3^2+1 = 165 $$
Так, как порядок мест важен, в каждом треугольнике $– 3cdot2 = 6$ вариантов распределения медалей.
По правилу произведения: $6cdot165 = 990$ — общее количество способов.
Ответ: 990 вариантов
Примечание: по расчетной формуле $A_3^{11} = 11cdot10cdot9 = 990 $ — ответ правильный.
Пример 4. В столовой есть на выбор
- два первых блюда: щи (Щ) и борщ (Б)
- три вторых блюда: мясо (М), рыба (Р), блинчики с творогом (Т)
- два напитка: компот (К) и сок (С)
Сколько вариантов обедов можно составить из этих блюд и каких?
По правилу произведения общее количество вариантов обедов: $2cdot3cdot2 = 12$
Построим дерево для перечисления вариантов:

Ответ: 12 вариантов
Построение графов для чайников: пошаговый гайд
Время на прочтение
7 мин
Количество просмотров 54K
Ранее мы публиковали пост, где с помощью графов проводили анализ сообществ в Точках кипения из разных городов России. Теперь хотим рассказать, как строить такие графы и проводить их анализ.

Под катом — пошаговая инструкция для тех, кто давно хотел разобраться с визуализацией графов и ждал подходящего случая.
1. Выбор гипотезы
Если попытаться визуализировать хотя бы что-то, бездумно загрузив данные в программу построения графов, результат вас не порадует. Поэтому сначала сформулируйте для себя, что хотите узнать с помощью графов, и придумайте жизнеспособную гипотезу.
Для этого разберитесь, какие данные у вас уже есть, что из них можно представить «объектами», а что – «связями» между ними. Обычно объектов значительно меньше, чем связей — можно таким образом проверять себя.
Наш тестовый пример мы готовили совместно с командой Точки кипения из Томска. Соответственно, все данные для анализа по мероприятиям и их участникам у нас будут именно оттуда. Нам стало интересно, сформировалось ли из участников этих мероприятий сообщество и как оно выглядит с точки зрения принадлежности участников к бизнесу, университетам и власти.
Мы предположили, что люди, которые посетили одно и то же мероприятие, связаны друг с другом. Причем чем чаще они присутствовали на мероприятиях совместно, тем сильнее связь.
Во втором случае мы решили узнать, как соотносится принадлежность участников к одному из «нетов» (наших ключевых направлений) с интересующими их сквозными технологиями. Равномерно ли распределение, есть ли «горячие темы»? Для этого анализа мы взяли данные по участникам мероприятий из 200 томских технологических компаний.
В принципе, даже таких первичных формулировок гипотез достаточно, чтобы перейти ко второму шагу.
2. Подготовка данных
Теперь, когда вы определились с тем, что хотите узнать, возьмите весь массив данных, посмотрите, какая информация об «объектах» хранится, выкиньте все лишнее и добавьте недостающее. Если данные распределены по нескольким источникам, предварительно соберите все в одну кучу, убрав дубли.
Поясню на примере. У нас были данные об участниках 650 мероприятий. Это, условно говоря, 650 эксель-таблиц с ~23000 записей в них, содержащих поля «Leader ID», «Должность», «Организация». Для постройки графа достаточно одного уникального идентификатора (тут, к счастью, такой есть – это Leader ID) и признака, привязывающего каждого участника к одной из трех рассматриваемых сфер: власти, бизнесу или университетам. И этой информации у нас еще нет.
Чтобы получить ее, можно пойти напролом: в каждом из 650 файлов убрать лишние столбцы и добавить новое поле, заполнить его значениями для каждой строки, например: «1» для власти, «2» для бизнеса и «3» для образования и науки. А можно сначала объединить все 650 файлов в один большой список, убрать дубли и только после этого добавлять новые значения. В первом случае такая работа займет 1-2 месяца. Во втором — 1-2 недели.
Вообще при добавлении новых атрибутов старайтесь предварительно группировать данные. Например, можно отсортировать участников по компаниям/организациям и скопом выставлять признак.
Готовим данные дальше. Для их загрузки в большинство программ визуализации потребуется создать два файла: один — с перечнем вершин, второй — со списком ребер.
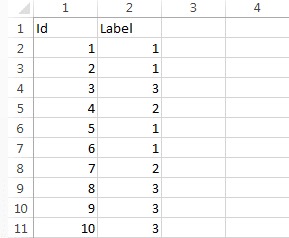
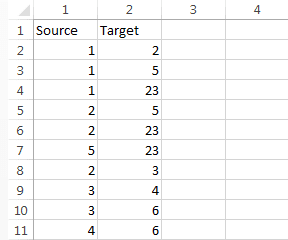
Файл вершин в нашем случае содержал два столбца: Id — номер вершины и Label — тип. Файл ребер содержал также два столбца: Source — id начальной вершины, Target — id конечной вершины.
Как превратить данные о том, что участники 1, 2, 5 и 23 посетили одно мероприятие, в ребра? Необходимо создать шесть строк и отметить связь каждого участника с каждым: 1 и 2, 1 и 5, 1 и 23, 2 и 5, 2 и 23, 5 и 23.
Во втором нашем примере таблицы выглядели так:
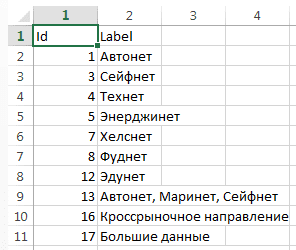
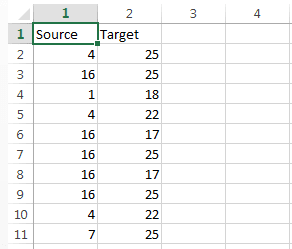
В качестве вершин перечислены как рынки, так и сквозные технологии. Если, скажем, представитель компании, относящейся к рынку «Технет» (ID=4), посетил мероприятие по теме «Большие данные и ИИ» (ID=17), в таблицу ребер заносим ребро (строку), соединяющее эти вершины (Source=4, Target=17).
Этап подготовки данных – это самая трудоемкая часть процесса, но наберитесь терпения.
3. Визуализация графа
Итак, таблицы с данными подготовлены, можно искать средство для их представления в виде графа. Для визуализации мы использовали программу Gephi — мощный опенсорсный инструмент, способный обрабатывать графы с сотнями тысяч вершин и связей. Скачать его можно с официального сайта.
Скриншоты я буду делать со второго проекта, в котором было небольшое число вершин и связей, чтобы все было максимально понятно.
Первым делом нам надо загрузить таблицы с вершинами и ребрами. Для этого выбираем пункт «Импортировать из CSV» из меню раздела «Лаборатория данных».
Сначала грузим файл с вершинами. На первом экране формы указываем, что импортируем именно вершины, и проверяем, чтобы программа правильно определила кодировку подписей.
На третьей форме «Отчет об импорте» важно указать тип графа. У нас он не ориентирован.
Похожим образом грузим ребра. В первом окне указываем, что это файл с ребрами, и также проверяем кодировку.
Важный момент ждет нас в третьем окне «Отчет об импорте». Тут важно указать не только то, что граф не ориентирован, но и подгрузить ребра в то же рабочее пространство, что и вершины. Поэтому выбираем пункт «Append to existing workplace».

В результате перед нами предстанет граф примерно вот в таком виде (закладка «Обработка»):
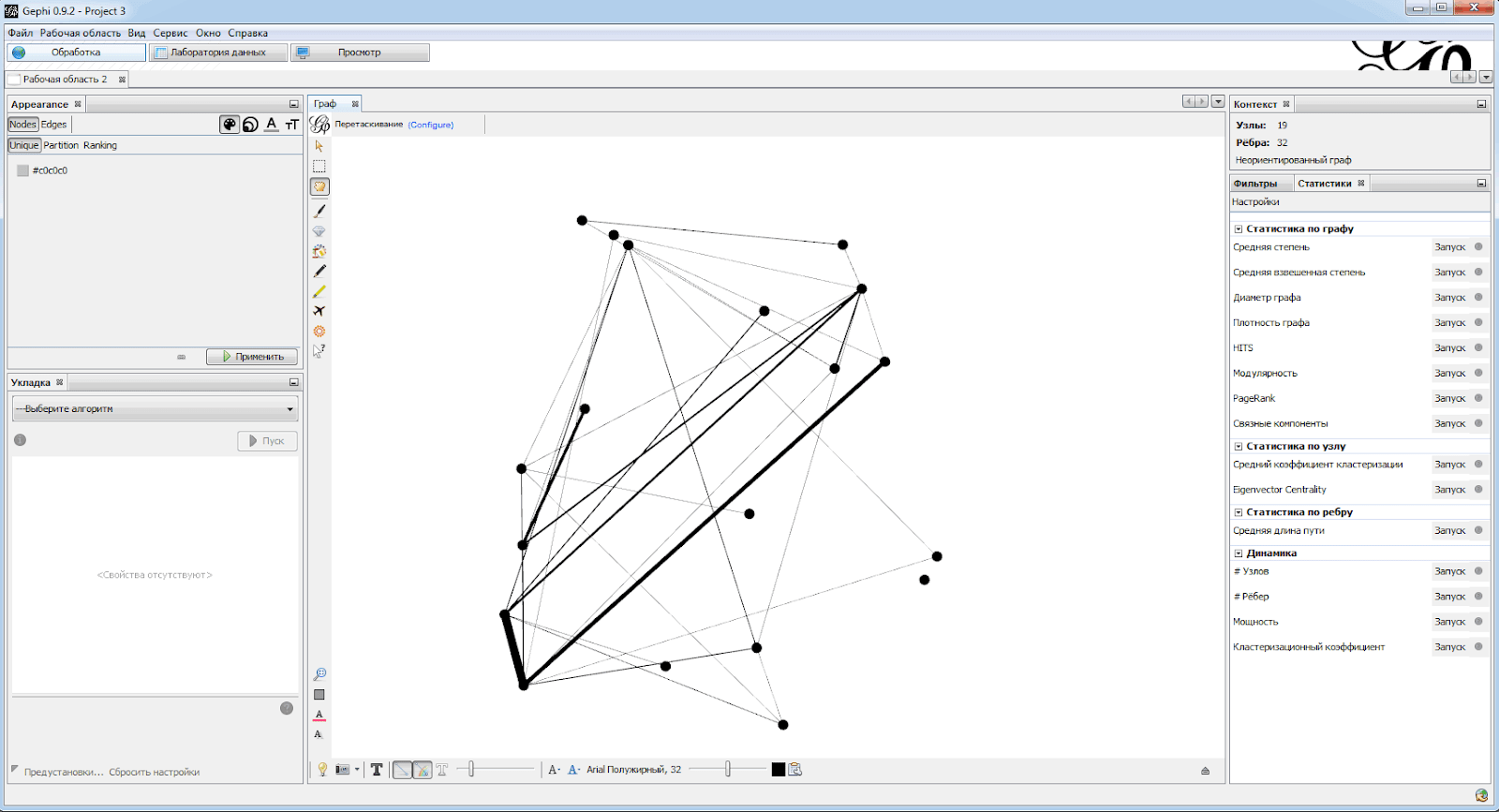
Итак, ребра имеют разную толщину в зависимости от количества связей между вершинами. Посмотреть, какой вес стал у каждого ребра, можно на закладке «Лаборатория данных» в свойствах ребер в столбце Weight.
Что здесь плохо: все вершины имеют один размер и расположены абсолютно произвольно. На закладке «Обработка» мы это исправим. Сначала в верхнем левом окне выбираем Nodes и жмем на пиктограммку с кругами («Размер»). Далее выбираем пункт Ranking — он позволяет задать размер вершины в зависимости от какого-либо параметра. У нас есть возможность выбрать только один параметр — Degree (степень), который показывает, сколько ребер выходят из вершины. Выбираем минимальный и максимальный размер кружочка и жмем кнопку «Применить». Здесь же, если выбрать другие пиктограммки, можно настроить цвет маркера вершины и цвет ребер. Теперь граф уже более нагляден.

Следующее, что нужно сделать, — распутать граф. Это можно сделать вручную, двигая вершины, а можно использовать алгоритмы укладки, которые реализованы в Gephi.
Чего мы добиваемся правильной укладкой? Максимальной наглядности. Чем меньше на графе наложений вершин и ребер, чем меньше пересечений ребер, тем лучше. Также неплохо было бы, чтобы смежные вершины были расположены поближе друг к другу, а несмежные —подальше друг от друга. Ну и все было распределено по видимой области, а не сжато в одну кучу.
Как это сделать в Gephi? Левое нижнее окно «Укладка» содержит самые популярные алгоритмы укладки, построенные на силовых аналогиях. Представьте, что вершины — это заряженные шарики, который отталкиваются друг от друга, но при этом некоторые скреплены чем-то, похожим на пружинки. Если задать соответствующие силы и «отпустить» граф, вершины разбегутся на максимально допустимые пружинками расстояния.
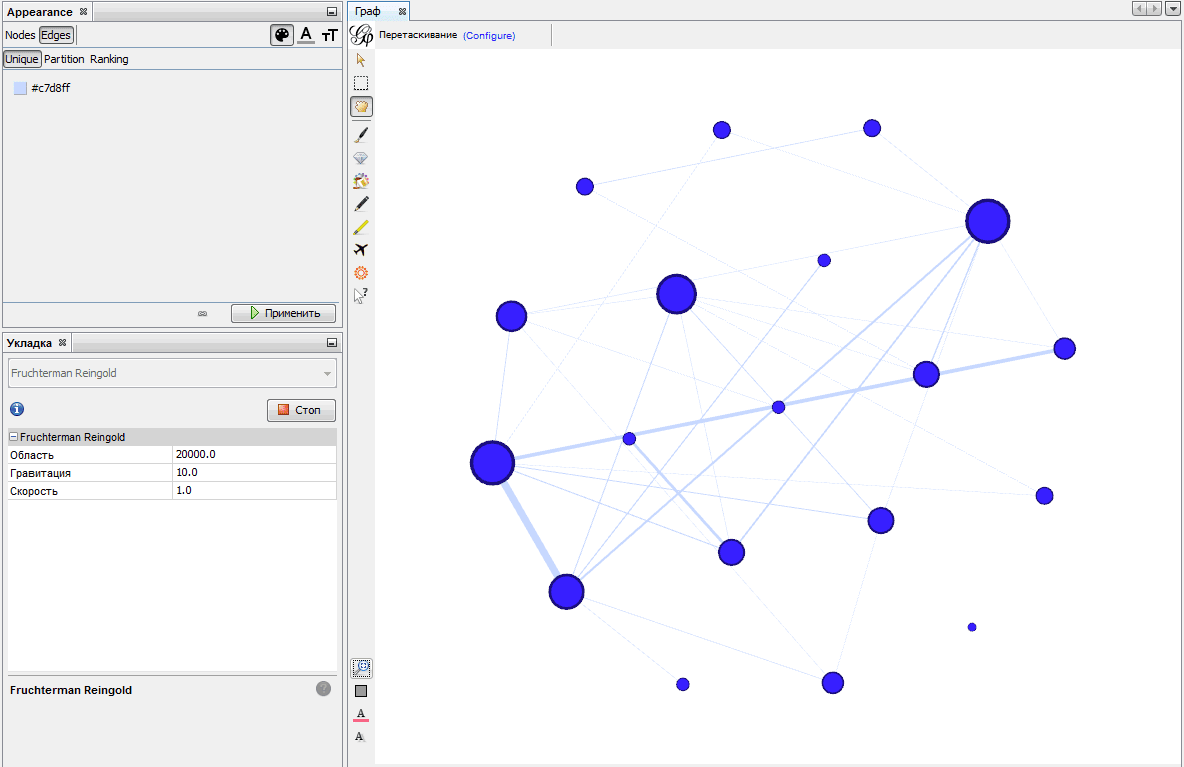
Наиболее равномерную картину дает алгоритм Фрюхтермана и Рейнгольда. Выберите Fruchterman Reingold из выпадающего меню и задайте размер области построения. Нажмите кнопку «Исполнить». Получится что-то вроде этого:
Можно помочь алгоритму и, не останавливая его, поперетаскивать некоторые вершины, стараясь распутать граф. Но помните, что здесь нет кнопки «Отменить», вернуться к прежнему расположению вершин уже не удастся. Поэтому сохраняйте новые версии проекта перед каждым рискованным изменением.
Еще один полезный алгоритм — Force Atlas 2. Он представляет граф в виде металлических колец, связанных между собой пружинами. Деформированные пружины приводят систему в движение, она колеблется и в конце концов принимает устойчивое положение. Этот алгоритм хорош для визуализаций, подчеркивающих структуру группы и выделяющих подмножества с высокой степенью взаимодействия.
Этот алгоритм имеет большое количество настроек. Рассмотрим наиболее важные. «Запрет перекрытия» запрещает вершинам перекрывать друг друга. Разреженность увеличивает расстояние между вершинами, делая граф более читаемым. Также более воздушным граф делает уменьшение влияния весов ребер на взаимное расположение вершин.
Поигравшись с настройками, получим такой граф:
Получив граф в том виде, который вас устраивает, переходите к финальной обработке. Это закладка «Просмотр». Здесь мы можем задать, например, отрисовку графа кривыми ребрами, которая минимизирует наложение вершин на чужие ребра. Можем включить подписи вершин, задав размер и цвет шрифта. Наконец, поменять фон подложки. Например, так:
Для того чтобы сохранить получившийся рисунок, нажмите на надпись «Экспорт SVG/PDF/PNG в левом нижнем углу окна. Также отдельно не забудьте сохранить сам проект через верхнее меню «Файл» — «Сохранить проект».
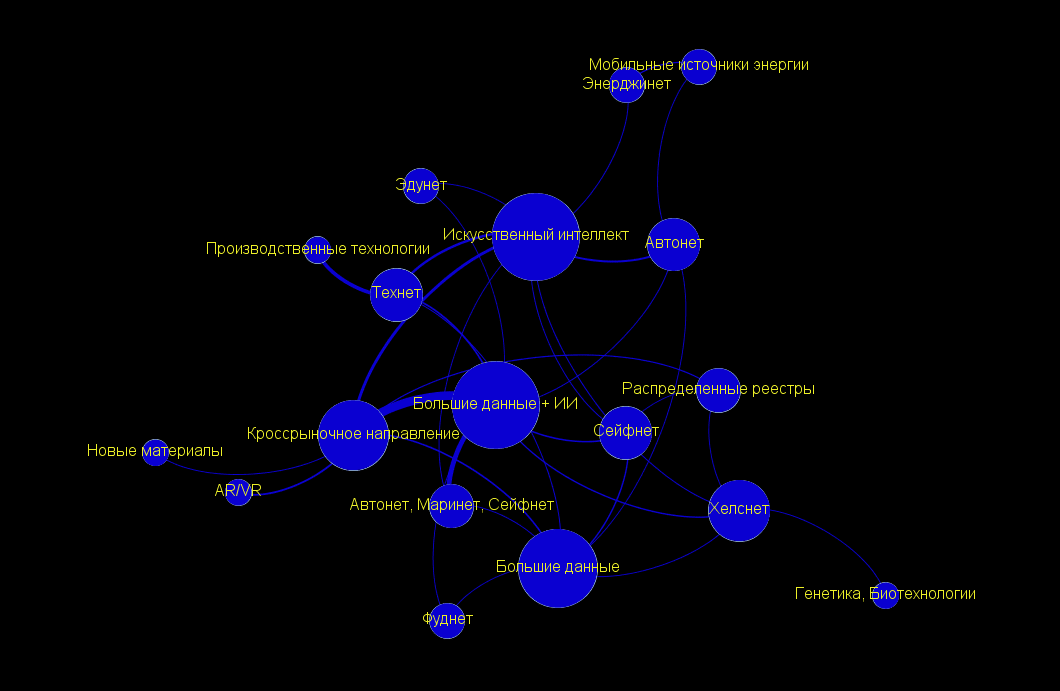
В нашем случае принципиально было выделить взаимосвязь сквозных технологий с рынками НТИ, для чего мы вручную выстроили все рынки в одну линию в центре и разместили все остальное сверху и снизу. Получился вот такой граф. Все-таки для решения конкретных задач без ручной расстановки вершин обойтись не удалось.
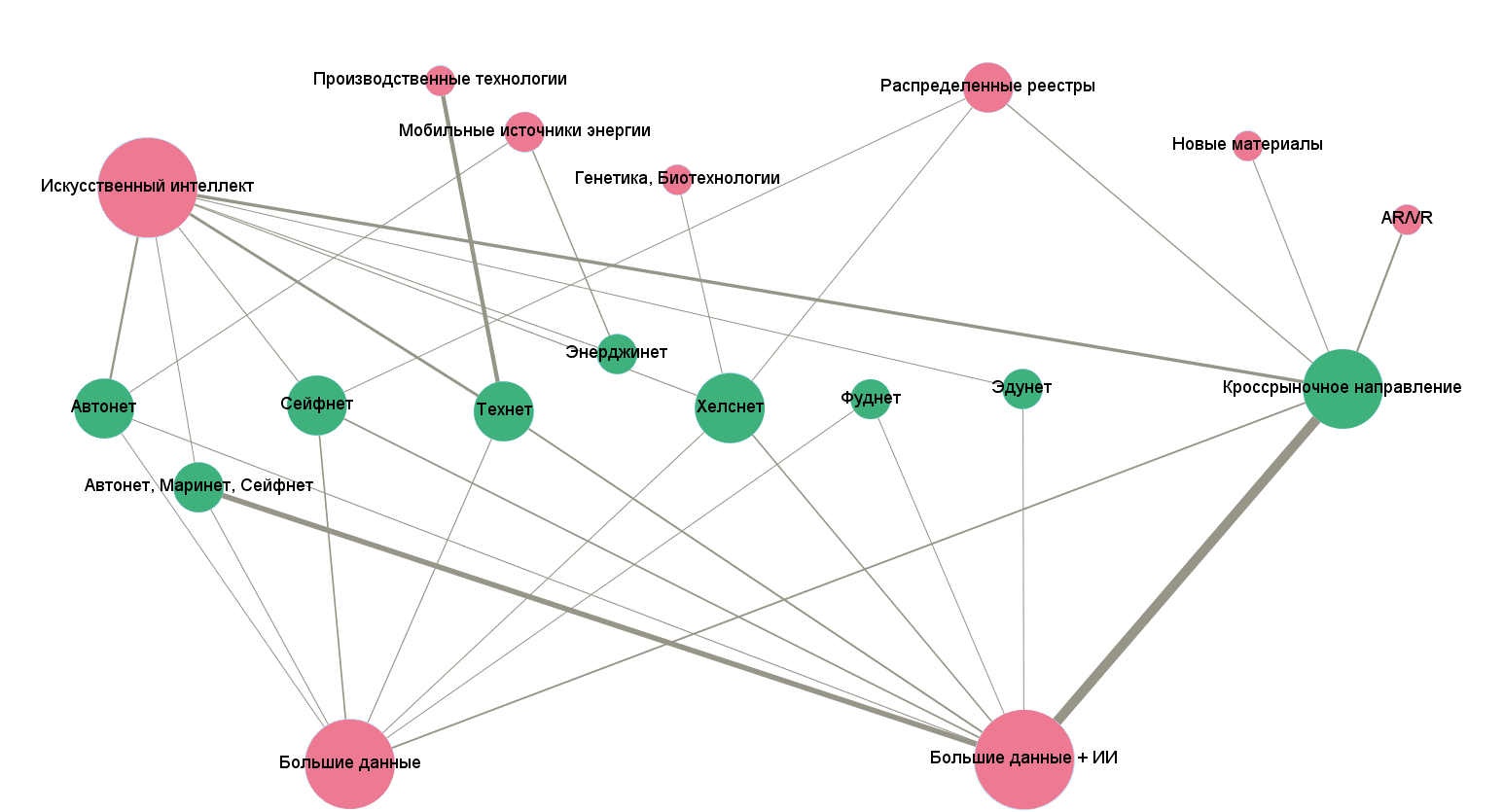
Вы, наверное, думаете, как нам удалось раскрасить вершины в разный цвет? Есть одна хитрость. Можно перейти в закладку «Лаборатория данных», создать там новый столбец в вершинах, назвав его «Market». И заполнить для каждой вершины значениями: 1 если это рынок НТИ, 0 — если сквозная технология. Затем достаточно перейти в «Обработку», выбрать пиктограммку в виде палитры, Nodes — Partition, а в качестве разделителя — наш новый атрибут Market.
Для более сложных построений, когда требуется выделить кластеры и закрасить их разными цветами, в Gephi используется богатый арсенал статистических расчетов, результаты которых можно использовать для раздельной окраски. Находятся эти расчеты в правом столбце вкладки «Обработка».

Например, нажав кнопку «Запуск» возле расчета «Модулярность», вы узнаете оценку уровня кластеризации вашего графа. Если после этого выставить цвет вершин в зависимости от Modularity Class, появится симпатичная картинка наподобие такой:
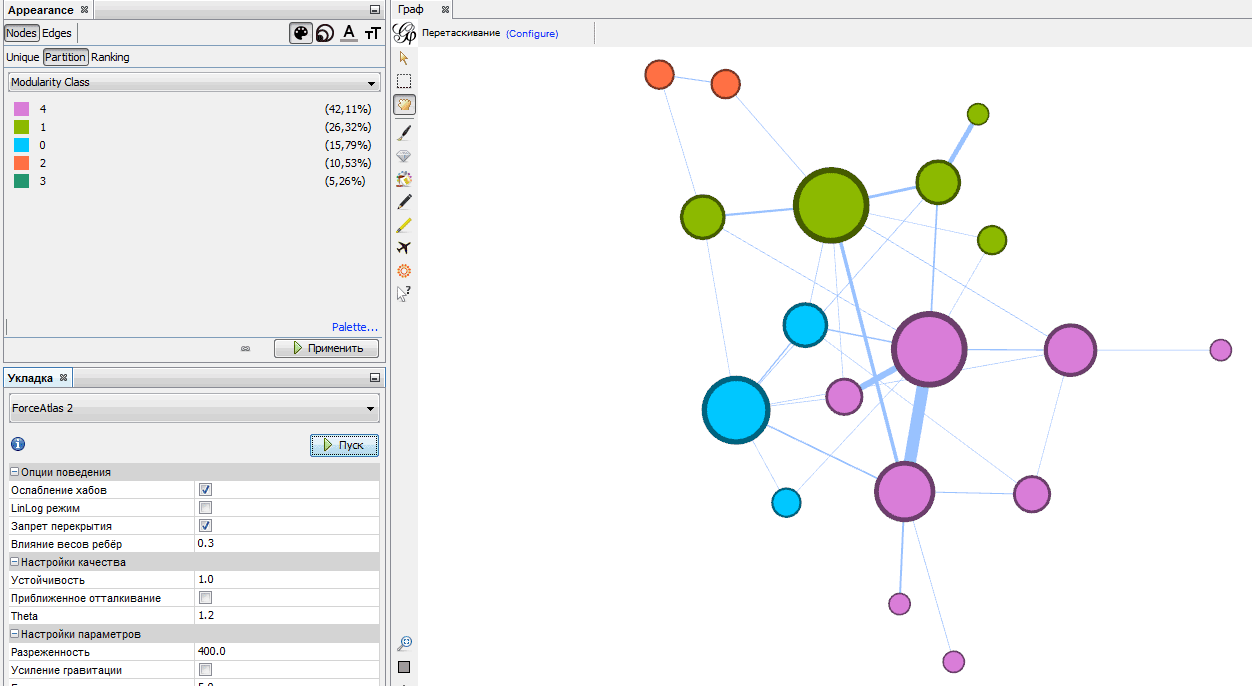
Если вы хотите еще больше узнать о возможностях Gephi, стоит почитать руководство по работе с программой от Мартина Гранджина http://www.martingrandjean.ch/gephi-introduction/.
4. Анализ результата
Итак, вы получили итоговую визуализацию графа. Что она вам дает? Во-первых, это красиво, ее можно вставить в презентацию, показать знакомым или сделать заставкой на рабочем столе. Во-вторых, по ней вы можете понять, насколько сложной и многокластерной структурой является рассматриваемая вами предметная область. В-третьих, обратите внимание на самые крупные вершины и на самые жирные связи. Это особенные элементы, на которых все держится.
Так, построив граф экспертного сообщества, посещающего мероприятия в Точке кипения, мы сразу обнаружили участников, которые с наибольшей вероятностью выполняют роль суперконнекторов. Они являлись «вершинами», через которые кластеры объединялись в единое целое. А во втором случае мы увидели, как выглядит концентрация специалистов из томских компаний с точки зрения их принадлежности к рынку и сквозной цифровой технологии, на которую они делают ставку. Это косвенно говорит об уровне технологических компетенций и экспертизы региона.
Помощь графов в понимании окружающей действительности реально велика, так что не поленитесь и попробуйте создать собственную визуализацию данных. Это совсем не сложно, но порой трудозатратно.
Некоторые техники BABOK®Guide имеют похожие названия и рекомендуются для решения одних и тех же задач. Это может слегка запутать даже опытного бизнес-аналитика, который готовится к сертификационному экзамену по этому руководству к своду знаний от международного института IIBA®. Чтобы помочь вам в подготовке к сертификации CBAP, CCBA или ECBA, сегодня я на практических примерах расскажу про технику «Анализ решений» и кратко отмечу, чем она отличается от их моделирования.
Что такое анализ решений (Decision Analysis)
Начнем с определения: анализ решений – это техника для формальной оценки проблемы и потенциальных вариантов ее решения с определением полезной ценности альтернативных исходов в условиях неопределенности. Это определение хорошо коррелирует с формулировкой практической миссии аналитика в любом проекте – снизить уровень неопределенности.
Суть техники «Анализ решений» из BABOK®Guide сводится к следующим вопросам:
- Что за проблема? – четкое определение проблемы, которую требуется решить. Причем проблема должна быть действительно проблемой, т.е. свершившимся фактом, который уже стал причиной финансовых потерь или иных убытков в других измеримых показателях. Этим проблема отличается от риска – потенциально возможного события, которое еще не свершилось, но может произойти в будущем и негативно повлиять на бизнес.
- Каковы возможные решения? – определение альтернативных вариантов совокупности действий и инструментов, которые помогут устранить обозначенную проблему.
- Насколько хороши возможные решения? – оценка предложенных альтернатив по ряду критериев, например, ожидаемая выгода, стоимость реализации, длительность развертывания, сложность внедрения и пр. Критерии могут иметь различные весовые коэффициенты для выставления оценок в баллах.
- Выбор альтернативы, когда лица, принимающие решения, определяют наилучший вариант устранения проблемы на основе проранжированных результатов оценки.
Управление бизнес-анализом — курс для руководителей
Код курса
BAMP
Ближайшая дата курса
27 июля, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
BABOK рекомендует использовать технику анализа решений в 11 задачах из 4-х областей знаний бизнес-анализа:
- приоритизация требований;
- оценка изменений требований;
- утверждение требований;
- определение будущего состояния;
- оценка рисков;
- определение стратегии изменения;
- анализ потенциальной ценности и рекомендация решения;
- измерение эффективности решения;
- оценка ограничений решения;
- оценка ограничений предприятия;
- рекомендация действий по увеличению ценности решения.
В каждой из этих задач техника «Анализ решений» помогает бизнес-аналитику снизить уровень неопределенности через исследование и моделирование ограниченного множества последствий от применения разных решений для конкретной проблемы. Инструментально это реализовать можно сразу несколькими методами: сравнительный анализ, метод анализа иерархий, многокритериальный анализ, в т.ч. с использованием сложных математических моделей и нелинейных алгоритмов. Однако, на практике чаще всего используются таблицы и деревья решений.
Например, с помощью простой матрицы решений бизнес-аналитик проверяет, как каждая предлагаемая альтернатива соответствует взвешенным критериям оценки, проставляет баллы и суммирует их количество. Наилучшей альтернативой считается та, которая набрала максимум баллов. Чтобы показать, как работает эта техника BABOK®Guide, рассмотрим простой кейс.
Как составить таблицу решений: практический пример
Проблемой является ежедневная недостача товаров в магазине, т.е. воровство продукции на сумму в размере 10% дневной выручки. Решить эту проблему, т.е. устранить воровство можно следующими способами:
- промаркировать каждый товар так, чтобы его невозможно было незаметно вынести с территории магазина без покупки. К примеру, внедрить систему отслеживания товаров на базе RFID-меток.
- вручную досматривать каждого покупателя и посетителя магазина, а также сотрудников и партнеров на выходе с помощью штатных охранников или вневедомственной охраны;
- выборочно досматривать каждого покупателя и посетителя магазина, а также сотрудников и партнеров на выходе с помощью штатных охранников или вневедомственной охраны;
- организовать непрерывное видеонаблюдение за людьми на входе и выходе из магазина, а также внутри торгового зала и служебных помещений с оперативным реагированием штатных охранников или вневедомственной охраны на случаи хищения товаров. Система будет включать модуль распознавания лиц, чтобы сообщать о подозрительных действиях и входе неблагонадежных посетителей в торговый зал или служебные помещения.
- имитировать непрерывное видеонаблюдение, развесив камеры и информационные плакаты об административной и уголовной ответственности за воровство на входе и выходе из магазина, а также внутри торгового зала и служебных помещений.
Оценим все эти альтернативы по следующим критериям:
- эффективность – как основная ценность (полезность) решения, показывающая насколько % альтернатива сможет уменьшить случаи воровства. Для оценки эффективности будем использовать следующую шкалу:
- 5 баллов – снижение объема воровства на 80% и более;
- 4 балла – снижение объема воровства на 60-79%;
- 3 балла – снижение объема воровства на 40-59%;
- 2 балла – снижение объема воровства на 20-39%;
- 1 балла – снижение объема воровства на 10-19%;
- 0 баллов – объемы воровства остались прежними.
- быстрота реализации – насколько быстро можно запустить решение в работу. Для оценки быстроты реализации будем использовать следующую шкалу:
- 5 баллов – можно запустить в работу за 1 неделю или меньше;
- 4 балла – на запуск в работу потребуется не более 1 месяца;
- 3 балла – на запуск в работу потребуется 1-3 месяца;
- 2 балла – на запуск в работу потребуется 3-6 месяцев;
- 1 балла – на запуск в работу потребуется 6-12 месяцев;
- 0 баллов – на запуск в работу потребуется более 1 года;
- стоимость реализации – затраты на внедрение и сопровождение в эксплуатации. Для оценки стоимости реализации будем использовать следующую шкалу:
- 5 баллов – инвестиции в решение не превышают месячного объема потерь из-за воровства в денежном выражении;
- 4 балла – инвестиции в решение не превысят 3 месячных объема потерь из-за воровства в денежном выражении;
- 3 балла – инвестиции в решение не превысят 6 месячных объемов потерь из-за воровства в денежном выражении;
- 2 балла – инвестиции в решение не превысят 12 месячных объемов потерь из-за воровства в денежном выражении;
- 1 балла – инвестиции в решение не превысят 18 месячных объемов потерь из-за воровства в денежном выражении;
- 0 баллов – инвестиции в решение составят более 18 месячных объемов потерь из-за воровства в денежном выражении;
- сложность внедрения – насколько сложно внедрить решение в работу с учетом изменения бизнес-процессов, организационных структур и других ограничений предприятия, таких как особенности помещений, ИТ-инфраструктура и пр. Для оценки сложности внедрения будем использовать следующую шкалу:
- 5 баллов – внедрение не изменит текущие бизнес-процессы, организационные структуры, ИТ-комплекс и инфраструктуру помещений;
- 4 балла – внедрение требует небольшого изменения текущих бизнес-процессов;
- 3 балла – внедрение требует значительного изменения текущих бизнес-процессов;
- 2 балла – внедрение требует значительного изменения текущих бизнес-процессов и организационных структур, включая найм дополнительных сотрудников;
- 1 балла – внедрение требует значительного изменения текущих бизнес-процессов и организационных структур, а также затрагивает ИТ-комплекс;
- 0 баллов – внедрение требует значительного изменения текущих бизнес-процессов и организационных структур, а также затрагивает ИТ-комплекс и инфраструктуру помещений.
- долгосрочность эксплуатации – насколько долго решение будет эффективным и не потребует замены. Для оценки долгосрочности эксплуатации будем использовать следующую шкалу:
- 5 баллов – решение будет работоспособным и эффективным без каких-либо инвестиций (денег и трудозатрат) не менее 3 лет;
- 4 балла – решение будет работоспособным и эффективным без каких-либо вложений не менее 2 лет;
- 3 балла – решение будет работоспособным и эффективным без каких-либо вложений не менее 1 года;
- 2 балла – решение будет работоспособным и эффективным без каких-либо вложений не менее 6 месяцев;
- 1 балла – решение будет работоспособным и эффективным без каких-либо вложений не менее 3 месяцев;
- 0 баллов – решение будет работоспособным и эффективным без каких-либо вложений не более месяца.
Составим таблицу решений для рассматриваемой проблемы:
| Решение | Эффективность | Быстрота | Стоимость | Сложность | Долгосрочность | Итог |
| RFID-метки | 5 | 2 | 1 | 3 | 5 | 16 |
| Тотальный ручной досмотр | 5 | 2 | 2 | 2 | 0 | 11 |
| Выборочный досмотр | 1 | 4 | 4 | 3 | 3 | 15 |
| Видеонаблюдение | 4 | 3 | 1 | 4 | 5 | 17 |
| Имитация видеонаблюдения | 1 | 5 | 5 | 5 | 0 | 16 |
Максимальную сумму баллов получил вариант с тотальным видеонаблюдением на базе интеллектуальной системы распознавания лиц.
Лучшее из BABOK®Guide: ТОП-10 задач и 20+ техник для аналитика
Код курса
EXBAB
Ближайшая дата курса
3 июля, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
45 000 руб.
Дерево решений (Decision Tree): еще один метод техники BABOK®Guide
Если требуется более наглядная визуализация движения от проблемы к результатам, которые принесут различные варианты решения, вместо таблицы можно использовать дерево решений. Это математическая модель в виде направленного взвешенного графа, которая отображает точки принятия решений, предшествующие им события и последствия. Деревья решений наглядны, интерпретируемы и понятны человеку как отличный инструмент отображения всех возможных сценариев, прогнозирования будущих событий, а также оценки их потенциальной выгоды и рисков. Граф дерева решений состоит из следующих элементов:
- вершины, от которых возможно несколько вариантов (сценариев). Эти узлы показывают возможные ситуации и называются точками принятия решений.
- конечные узлы (листья) – результат как значение целевой функции;
- ребра (ветви), которые соединяют узлы и имеют вес, равный вероятности развития событий по этому сценарию.
Обычно многоузловые деревья решений строятся с помощью специального ПО. Но граф с ограниченным числом вершин можно просто построить в табличном редакторе или даже нарисовать вручную. В отличие от таблицы решений, деревья решений больше подходят для оценки вероятностных сценариев развития ситуации и предоставляют результат только по одному критерию, а не по нескольким.
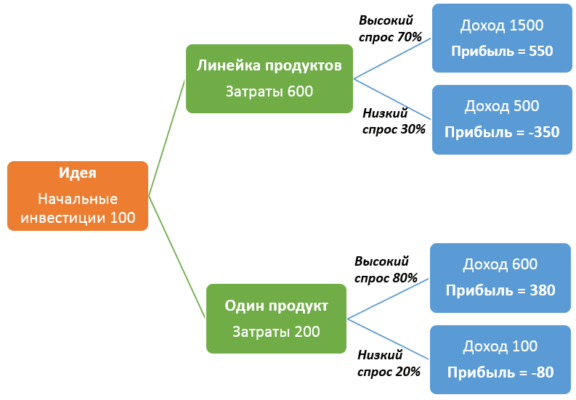
Чтобы понять, как работают деревья решений, рассмотрим простой пример с запуском нового продукта. Пусть начальные инвестиции составляют 100 условных единиц. Если запускать сразу целый ассортимент (продуктовую линейку), на это уйдет 600 у.е. При высоком спросе, вероятность которого оценивается в 70%, ожидаемый доход от продажи продуктов из новой линейки составит 1500 у.е. В этом случае ожидаемая прибыль равна 1500*0,7-600+100=550. При низком спросе с вероятностью 30%, ожидаемый доход будет 500 у.е. В этом случае ожидаемая прибыль равна 500*0,3-600+100=-350 у.е., что означает фактический убыток.
При запуске одного продукта затраты составят 200 у.е. При высоком спросе с вероятностью 80%, ожидаемый доход равен 600 у.е. В этом случае ожидаемая прибыль равна 600*0,8-200+100=380. При низком спросе, вероятность которого составляет 20%, ожидаемый доход составит 100 у.е. Здесь ожидаемая прибыль равна 100*0,2-200+100=-80 у.е., что означает фактический убыток.
Примечательно, что таблицы и деревья решений также применяются в рамках другой техники BABOK®Guide с похожим названием «Моделирование решений» (Decision Modelling), которая показывает, как принимаются повторяемые бизнес-решения, описывая используемые при этом данные и бизнес-знания. Как выглядят модели решений, рассмотрим в следующий раз, а пока предлагаю вам проверить знание некоторых концепций BABOK. Мы подготовили для вас серию бесплатных интерактивных тестов по терминам и содержанию этого руководства к своду знаний по бизнес-анализу, включая кейсы, похожие на вопросы сертификационных экзаменов ECBA, CCBA и CBAP:
- тест по техникам руководства BABOK;
- тест по терминологии BABOK на русском языке;
- примеры ситуационных задач (case study) для сертификации CBAP на английском языке;
- примеры тестовых вопросов для сертификаций CBAP, CCBA и ECBA на английском языке.
Управление бизнес-анализом — курс для руководителей
Код курса
BAMP
Ближайшая дата курса
27 июля, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
А детально разобраться с содержанием BABOK®Guide на практических примерах вам помогут курсы нашей Школы прикладного бизнес-анализа в лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Лучшее из BABOK®Guide: ТОП-10 задач и техник для аналитика
- Управление бизнес-анализом – курс для руководителей