Note
Click here
to download the full example code
This tutorial covers some basic usage patterns and best practices to
help you get started with Matplotlib.
import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np
A simple example#
Matplotlib graphs your data on Figures (e.g., windows, Jupyter
widgets, etc.), each of which can contain one or more Axes, an
area where points can be specified in terms of x-y coordinates (or theta-r
in a polar plot, x-y-z in a 3D plot, etc.). The simplest way of
creating a Figure with an Axes is using pyplot.subplots. We can then use
Axes.plot to draw some data on the Axes:
fig, ax = plt.subplots() # Create a figure containing a single axes. ax.plot([1, 2, 3, 4], [1, 4, 2, 3]) # Plot some data on the axes.
Note that to get this Figure to display, you may have to call plt.show(),
depending on your backend. For more details of Figures and backends, see
Creating, viewing, and saving Matplotlib Figures.
Parts of a Figure#
Here are the components of a Matplotlib Figure.
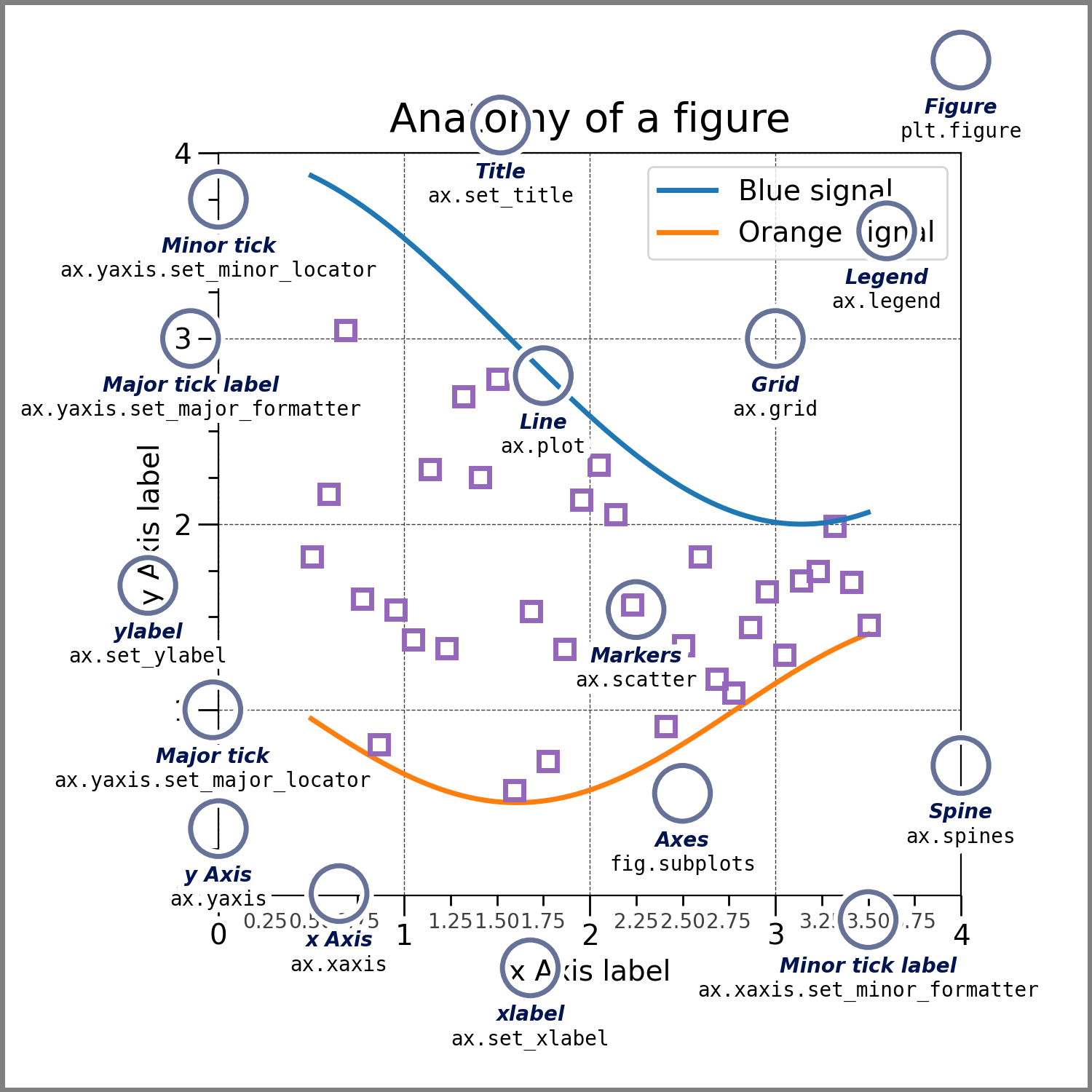
Figure#
The whole figure. The Figure keeps
track of all the child Axes, a group of
‘special’ Artists (titles, figure legends, colorbars, etc), and
even nested subfigures.
The easiest way to create a new Figure is with pyplot:
It is often convenient to create the Axes together with the Figure, but you
can also manually add Axes later on. Note that many
Matplotlib backends support zooming and
panning on figure windows.
For more on Figures, see Creating, viewing, and saving Matplotlib Figures.
Axes#
An Axes is an Artist attached to a Figure that contains a region for
plotting data, and usually includes two (or three in the case of 3D)
Axis objects (be aware of the difference
between Axes and Axis) that provide ticks and tick labels to
provide scales for the data in the Axes. Each Axes also
has a title
(set via set_title()), an x-label (set via
set_xlabel()), and a y-label set via
set_ylabel()).
The Axes class and its member functions are the primary
entry point to working with the OOP interface, and have most of the
plotting methods defined on them (e.g. ax.plot(), shown above, uses
the plot method)
Axis#
These objects set the scale and limits and generate ticks (the marks
on the Axis) and ticklabels (strings labeling the ticks). The location
of the ticks is determined by a Locator object and the
ticklabel strings are formatted by a Formatter. The
combination of the correct Locator and Formatter gives very fine
control over the tick locations and labels.
Artist#
Basically, everything visible on the Figure is an Artist (even
Figure, Axes, and Axis objects). This includes
Text objects, Line2D objects, collections objects, Patch
objects, etc. When the Figure is rendered, all of the
Artists are drawn to the canvas. Most Artists are tied to an Axes; such
an Artist cannot be shared by multiple Axes, or moved from one to another.
Types of inputs to plotting functions#
Plotting functions expect numpy.array or numpy.ma.masked_array as
input, or objects that can be passed to numpy.asarray.
Classes that are similar to arrays (‘array-like’) such as pandas
data objects and numpy.matrix may not work as intended. Common convention
is to convert these to numpy.array objects prior to plotting.
For example, to convert a numpy.matrix
b = np.matrix([[1, 2], [3, 4]]) b_asarray = np.asarray(b)
Most methods will also parse an addressable object like a dict, a
numpy.recarray, or a pandas.DataFrame. Matplotlib allows you to
provide the data keyword argument and generate plots passing the
strings corresponding to the x and y variables.
np.random.seed(19680801) # seed the random number generator. data = {'a': np.arange(50), 'c': np.random.randint(0, 50, 50), 'd': np.random.randn(50)} data['b'] = data['a'] + 10 * np.random.randn(50) data['d'] = np.abs(data['d']) * 100 fig, ax = plt.subplots(figsize=(5, 2.7), layout='constrained') ax.scatter('a', 'b', c='c', s='d', data=data) ax.set_xlabel('entry a') ax.set_ylabel('entry b')
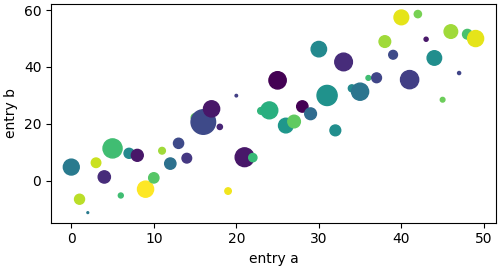
Coding styles#
The explicit and the implicit interfaces#
As noted above, there are essentially two ways to use Matplotlib:
-
Explicitly create Figures and Axes, and call methods on them (the
«object-oriented (OO) style»). -
Rely on pyplot to implicitly create and manage the Figures and Axes, and
use pyplot functions for plotting.
See Matplotlib Application Interfaces (APIs) for an explanation of the tradeoffs between the
implicit and explicit interfaces.
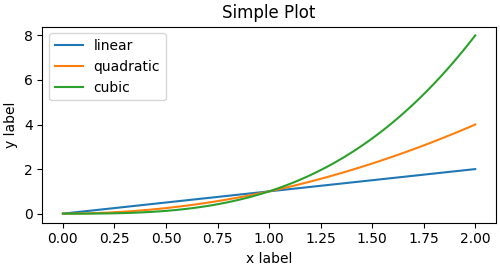
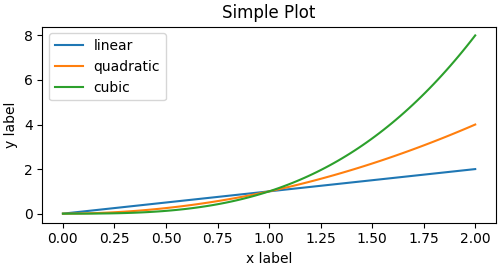
So one can use the OO-style
x = np.linspace(0, 2, 100) # Sample data. # Note that even in the OO-style, we use `.pyplot.figure` to create the Figure. fig, ax = plt.subplots(figsize=(5, 2.7), layout='constrained') ax.plot(x, x, label='linear') # Plot some data on the axes. ax.plot(x, x**2, label='quadratic') # Plot more data on the axes... ax.plot(x, x**3, label='cubic') # ... and some more. ax.set_xlabel('x label') # Add an x-label to the axes. ax.set_ylabel('y label') # Add a y-label to the axes. ax.set_title("Simple Plot") # Add a title to the axes. ax.legend() # Add a legend.
or the pyplot-style:
x = np.linspace(0, 2, 100) # Sample data. plt.figure(figsize=(5, 2.7), layout='constrained') plt.plot(x, x, label='linear') # Plot some data on the (implicit) axes. plt.plot(x, x**2, label='quadratic') # etc. plt.plot(x, x**3, label='cubic') plt.xlabel('x label') plt.ylabel('y label') plt.title("Simple Plot") plt.legend()
(In addition, there is a third approach, for the case when embedding
Matplotlib in a GUI application, which completely drops pyplot, even for
figure creation. See the corresponding section in the gallery for more info:
Embedding Matplotlib in graphical user interfaces.)
Matplotlib’s documentation and examples use both the OO and the pyplot
styles. In general, we suggest using the OO style, particularly for
complicated plots, and functions and scripts that are intended to be reused
as part of a larger project. However, the pyplot style can be very convenient
for quick interactive work.
Note
You may find older examples that use the pylab interface,
via from pylab import *. This approach is strongly deprecated.
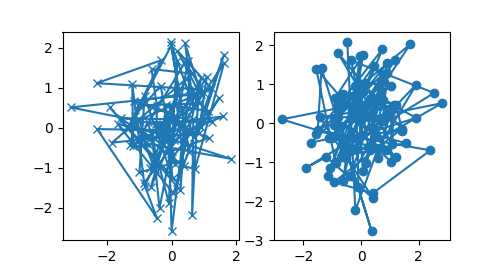
Making a helper functions#
If you need to make the same plots over and over again with different data
sets, or want to easily wrap Matplotlib methods, use the recommended
signature function below.
which you would then use twice to populate two subplots:
data1, data2, data3, data4 = np.random.randn(4, 100) # make 4 random data sets fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(5, 2.7)) my_plotter(ax1, data1, data2, {'marker': 'x'}) my_plotter(ax2, data3, data4, {'marker': 'o'})
Note that if you want to install these as a python package, or any other
customizations you could use one of the many templates on the web;
Matplotlib has one at mpl-cookiecutter
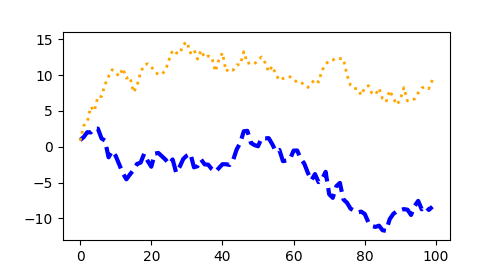
Styling Artists#
Most plotting methods have styling options for the Artists, accessible either
when a plotting method is called, or from a «setter» on the Artist. In the
plot below we manually set the color, linewidth, and linestyle of the
Artists created by plot, and we set the linestyle of the second line
after the fact with set_linestyle.
fig, ax = plt.subplots(figsize=(5, 2.7)) x = np.arange(len(data1)) ax.plot(x, np.cumsum(data1), color='blue', linewidth=3, linestyle='--') l, = ax.plot(x, np.cumsum(data2), color='orange', linewidth=2) l.set_linestyle(':')
Colors#
Matplotlib has a very flexible array of colors that are accepted for most
Artists; see the colors tutorial for a
list of specifications. Some Artists will take multiple colors. i.e. for
a scatter plot, the edge of the markers can be different colors
from the interior:
Linewidths, linestyles, and markersizes#
Line widths are typically in typographic points (1 pt = 1/72 inch) and
available for Artists that have stroked lines. Similarly, stroked lines
can have a linestyle. See the linestyles example.
Marker size depends on the method being used. plot specifies
markersize in points, and is generally the «diameter» or width of the
marker. scatter specifies markersize as approximately
proportional to the visual area of the marker. There is an array of
markerstyles available as string codes (see markers), or
users can define their own MarkerStyle (see
Marker reference):
fig, ax = plt.subplots(figsize=(5, 2.7)) ax.plot(data1, 'o', label='data1') ax.plot(data2, 'd', label='data2') ax.plot(data3, 'v', label='data3') ax.plot(data4, 's', label='data4') ax.legend()
Labelling plots#
Axes labels and text#
set_xlabel, set_ylabel, and set_title are used to
add text in the indicated locations (see Text in Matplotlib Plots
for more discussion). Text can also be directly added to plots using
text:
mu, sigma = 115, 15 x = mu + sigma * np.random.randn(10000) fig, ax = plt.subplots(figsize=(5, 2.7), layout='constrained') # the histogram of the data n, bins, patches = ax.hist(x, 50, density=True, facecolor='C0', alpha=0.75) ax.set_xlabel('Length [cm]') ax.set_ylabel('Probability') ax.set_title('Aardvark lengthsn (not really)') ax.text(75, .025, r'$mu=115, sigma=15$') ax.axis([55, 175, 0, 0.03]) ax.grid(True)
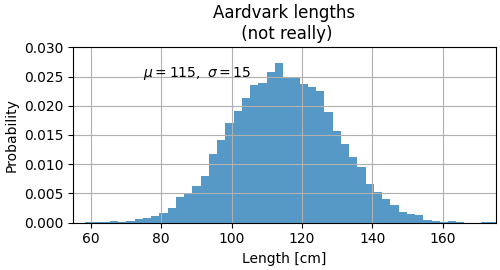
All of the text functions return a matplotlib.text.Text
instance. Just as with lines above, you can customize the properties by
passing keyword arguments into the text functions:
These properties are covered in more detail in
Text properties and layout.
Using mathematical expressions in text#
Matplotlib accepts TeX equation expressions in any text expression.
For example to write the expression (sigma_i=15) in the title,
you can write a TeX expression surrounded by dollar signs:
where the r preceding the title string signifies that the string is a
raw string and not to treat backslashes as python escapes.
Matplotlib has a built-in TeX expression parser and
layout engine, and ships its own math fonts – for details see
Writing mathematical expressions. You can also use LaTeX directly to format
your text and incorporate the output directly into your display figures or
saved postscript – see Text rendering with LaTeX.
Annotations#
We can also annotate points on a plot, often by connecting an arrow pointing
to xy, to a piece of text at xytext:
fig, ax = plt.subplots(figsize=(5, 2.7)) t = np.arange(0.0, 5.0, 0.01) s = np.cos(2 * np.pi * t) line, = ax.plot(t, s, lw=2) ax.annotate('local max', xy=(2, 1), xytext=(3, 1.5), arrowprops=dict(facecolor='black', shrink=0.05)) ax.set_ylim(-2, 2)
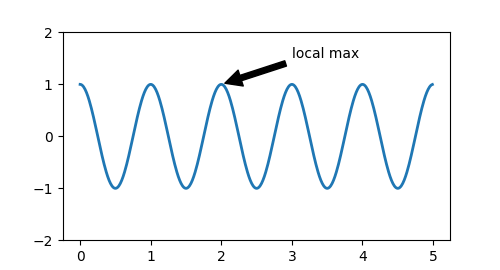
In this basic example, both xy and xytext are in data coordinates.
There are a variety of other coordinate systems one can choose — see
Basic annotation and Advanced annotation for
details. More examples also can be found in
Annotating Plots.
Axis scales and ticks#
Each Axes has two (or three) Axis objects representing the x- and
y-axis. These control the scale of the Axis, the tick locators and the
tick formatters. Additional Axes can be attached to display further Axis
objects.
Scales#
In addition to the linear scale, Matplotlib supplies non-linear scales,
such as a log-scale. Since log-scales are used so much there are also
direct methods like loglog, semilogx, and
semilogy. There are a number of scales (see
Scales for other examples). Here we set the scale
manually:
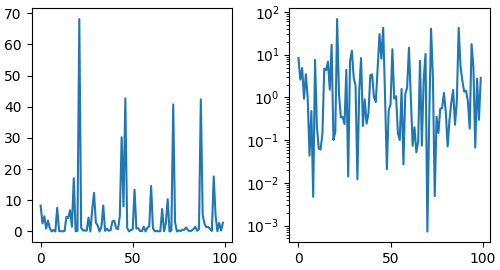
The scale sets the mapping from data values to spacing along the Axis. This
happens in both directions, and gets combined into a transform, which
is the way that Matplotlib maps from data coordinates to Axes, Figure, or
screen coordinates. See Transformations Tutorial.
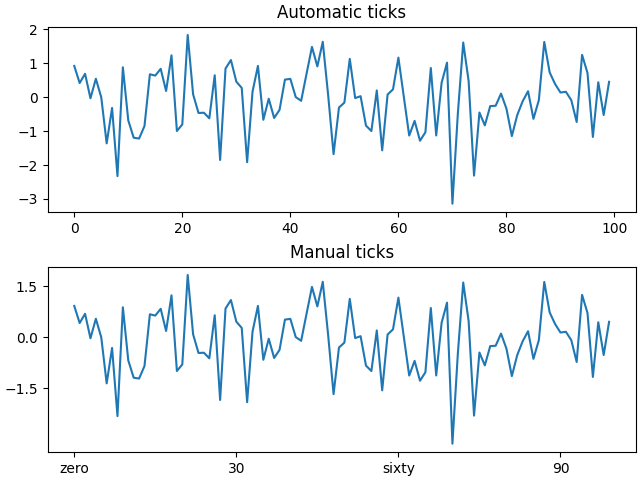
Tick locators and formatters#
Each Axis has a tick locator and formatter that choose where along the
Axis objects to put tick marks. A simple interface to this is
set_xticks:
fig, axs = plt.subplots(2, 1, layout='constrained') axs[0].plot(xdata, data1) axs[0].set_title('Automatic ticks') axs[1].plot(xdata, data1) axs[1].set_xticks(np.arange(0, 100, 30), ['zero', '30', 'sixty', '90']) axs[1].set_yticks([-1.5, 0, 1.5]) # note that we don't need to specify labels axs[1].set_title('Manual ticks')
Different scales can have different locators and formatters; for instance
the log-scale above uses LogLocator and LogFormatter. See
Tick locators and
Tick formatters for other formatters and
locators and information for writing your own.
Plotting dates and strings#
Matplotlib can handle plotting arrays of dates and arrays of strings, as
well as floating point numbers. These get special locators and formatters
as appropriate. For dates:
For more information see the date examples
(e.g. Date tick labels)
For strings, we get categorical plotting (see:
Plotting categorical variables).
One caveat about categorical plotting is that some methods of parsing
text files return a list of strings, even if the strings all represent
numbers or dates. If you pass 1000 strings, Matplotlib will think you
meant 1000 categories and will add 1000 ticks to your plot!
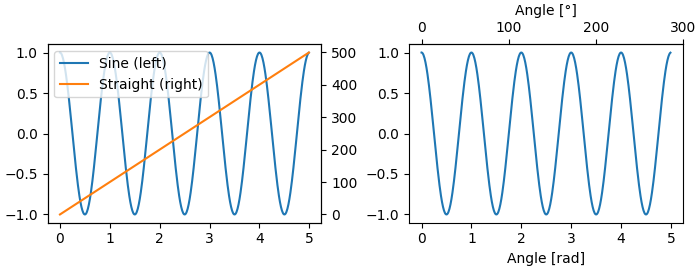
Additional Axis objects#
Plotting data of different magnitude in one chart may require
an additional y-axis. Such an Axis can be created by using
twinx to add a new Axes with an invisible x-axis and a y-axis
positioned at the right (analogously for twiny). See
Plots with different scales for another example.
Similarly, you can add a secondary_xaxis or
secondary_yaxis having a different scale than the main Axis to
represent the data in different scales or units. See
Secondary Axis for further
examples.
fig, (ax1, ax3) = plt.subplots(1, 2, figsize=(7, 2.7), layout='constrained') l1, = ax1.plot(t, s) ax2 = ax1.twinx() l2, = ax2.plot(t, range(len(t)), 'C1') ax2.legend([l1, l2], ['Sine (left)', 'Straight (right)']) ax3.plot(t, s) ax3.set_xlabel('Angle [rad]') ax4 = ax3.secondary_xaxis('top', functions=(np.rad2deg, np.deg2rad)) ax4.set_xlabel('Angle [°]')
Color mapped data#
Often we want to have a third dimension in a plot represented by a colors in
a colormap. Matplotlib has a number of plot types that do this:
X, Y = np.meshgrid(np.linspace(-3, 3, 128), np.linspace(-3, 3, 128)) Z = (1 - X/2 + X**5 + Y**3) * np.exp(-X**2 - Y**2) fig, axs = plt.subplots(2, 2, layout='constrained') pc = axs[0, 0].pcolormesh(X, Y, Z, vmin=-1, vmax=1, cmap='RdBu_r') fig.colorbar(pc, ax=axs[0, 0]) axs[0, 0].set_title('pcolormesh()') co = axs[0, 1].contourf(X, Y, Z, levels=np.linspace(-1.25, 1.25, 11)) fig.colorbar(co, ax=axs[0, 1]) axs[0, 1].set_title('contourf()') pc = axs[1, 0].imshow(Z**2 * 100, cmap='plasma', norm=mpl.colors.LogNorm(vmin=0.01, vmax=100)) fig.colorbar(pc, ax=axs[1, 0], extend='both') axs[1, 0].set_title('imshow() with LogNorm()') pc = axs[1, 1].scatter(data1, data2, c=data3, cmap='RdBu_r') fig.colorbar(pc, ax=axs[1, 1], extend='both') axs[1, 1].set_title('scatter()')
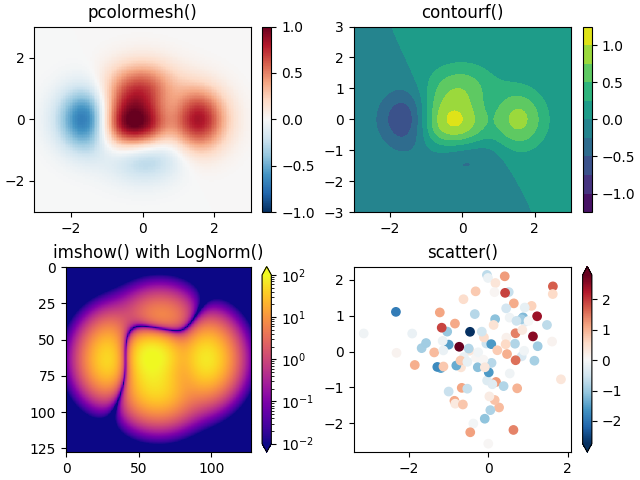
Colormaps#
These are all examples of Artists that derive from ScalarMappable
objects. They all can set a linear mapping between vmin and vmax into
the colormap specified by cmap. Matplotlib has many colormaps to choose
from (Choosing Colormaps in Matplotlib) you can make your
own (Creating Colormaps in Matplotlib) or download as
third-party packages.
Normalizations#
Sometimes we want a non-linear mapping of the data to the colormap, as
in the LogNorm example above. We do this by supplying the
ScalarMappable with the norm argument instead of vmin and vmax.
More normalizations are shown at Colormap Normalization.
Colorbars#
Adding a colorbar gives a key to relate the color back to the
underlying data. Colorbars are figure-level Artists, and are attached to
a ScalarMappable (where they get their information about the norm and
colormap) and usually steal space from a parent Axes. Placement of
colorbars can be complex: see
Placing Colorbars for
details. You can also change the appearance of colorbars with the
extend keyword to add arrows to the ends, and shrink and aspect to
control the size. Finally, the colorbar will have default locators
and formatters appropriate to the norm. These can be changed as for
other Axis objects.
Working with multiple Figures and Axes#
You can open multiple Figures with multiple calls to
fig = plt.figure() or fig2, ax = plt.subplots(). By keeping the
object references you can add Artists to either Figure.
Multiple Axes can be added a number of ways, but the most basic is
plt.subplots() as used above. One can achieve more complex layouts,
with Axes objects spanning columns or rows, using subplot_mosaic.
fig, axd = plt.subplot_mosaic([['upleft', 'right'], ['lowleft', 'right']], layout='constrained') axd['upleft'].set_title('upleft') axd['lowleft'].set_title('lowleft') axd['right'].set_title('right')
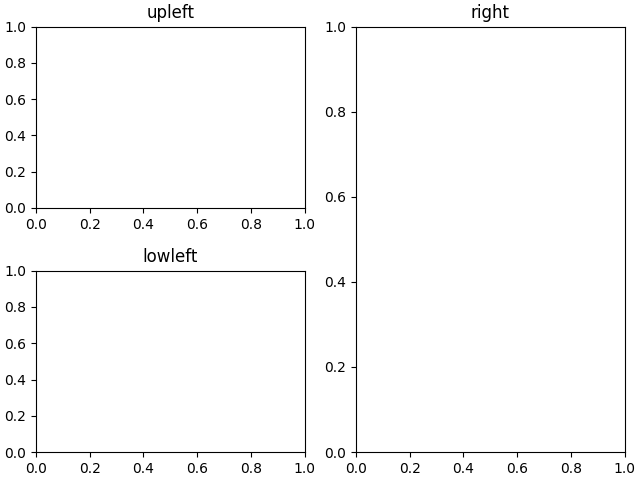
Matplotlib has quite sophisticated tools for arranging Axes: See
Arranging multiple Axes in a Figure and
Complex and semantic figure composition (subplot_mosaic).
More reading#
For more plot types see Plot types and the
API reference, in particular the
Axes API.
Total running time of the script: ( 0 minutes 8.602 seconds)
Gallery generated by Sphinx-Gallery
Время на прочтение
39 мин
Количество просмотров 297K
Те, кто работает с данными, отлично знают, что не в нейросетке счастье — а в том, как правильно обработать данные. Но чтобы их обработать, необходимо сначала проанализировать корреляции, выбрать нужные данные, выкинуть ненужные и так далее. Для подобных целей часто используется визуализация с помощью библиотеки matplotlib.

Встретимся «внутри»!
Настройка
Запустите следующий код для настройки. Отдельные диаграммы, впрочем, переопределяют свои настройки сами.
# !pip install brewer2mpl
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings; warnings.filterwarnings(action='once')
large = 22; med = 16; small = 12
params = {'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
%matplotlib inline
# Version
print(mpl.__version__) #> 3.0.0
print(sns.__version__) #> 0.9.0
Корреляция
Графики корреляции используются для визуализации взаимосвязи между 2 или более переменными. То есть, как одна переменная изменяется по отношению к другой.
1. Точечный график
Scatteplot — это классический и фундаментальный вид диаграммы, используемый для изучения взаимосвязи между двумя переменными. Если у вас есть несколько групп в ваших данных, вы можете визуализировать каждую группу в другом цвете. В matplotlib вы можете легко сделать это, используя plt.scatterplot().
Показать код
# Import dataset
midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")
# Prepare Data
# Create as many colors as there are unique midwest['category']
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
# Draw Plot for Each Category
plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal',
data=midwest.loc[midwest.category==category, :],
s=20, c=colors[i], label=str(category))
# Decorations
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Scatterplot of Midwest Area vs Population", fontsize=22)
plt.legend(fontsize=12)
plt.show()

2. Пузырьковая диаграмма с захватом группы
Иногда хочется показать группу точек внутри границы, чтобы подчеркнуть их важность. В этом примере мы получаем записи из фрейма данных, которые должны быть выделены, и передаем их в encircle() описанный в приведенном ниже коде.
Показать код
from matplotlib import patches
from scipy.spatial import ConvexHull
import warnings; warnings.simplefilter('ignore')
sns.set_style("white")
# Step 1: Prepare Data
midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")
# As many colors as there are unique midwest['category']
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
# Step 2: Draw Scatterplot with unique color for each category
fig = plt.figure(figsize=(16, 10), dpi= 80, facecolor='w', edgecolor='k')
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :], s='dot_size', c=colors[i], label=str(category), edgecolors='black', linewidths=.5)
# Step 3: Encircling
# https://stackoverflow.com/questions/44575681/how-do-i-encircle-different-data-sets-in-scatter-plot
def encircle(x,y, ax=None, **kw):
if not ax: ax=plt.gca()
p = np.c_[x,y]
hull = ConvexHull(p)
poly = plt.Polygon(p[hull.vertices,:], **kw)
ax.add_patch(poly)
# Select data to be encircled
midwest_encircle_data = midwest.loc[midwest.state=='IN', :]
# Draw polygon surrounding vertices
encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="k", fc="gold", alpha=0.1)
encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="firebrick", fc="none", linewidth=1.5)
# Step 4: Decorations
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Bubble Plot with Encircling", fontsize=22)
plt.legend(fontsize=12)
plt.show()
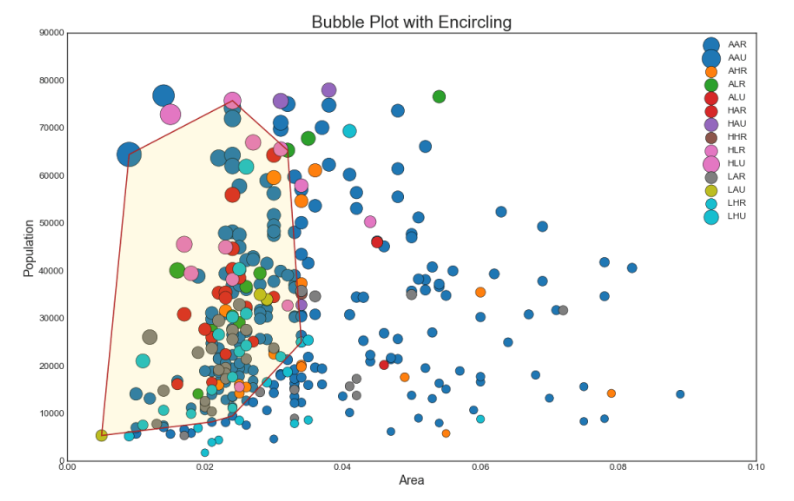
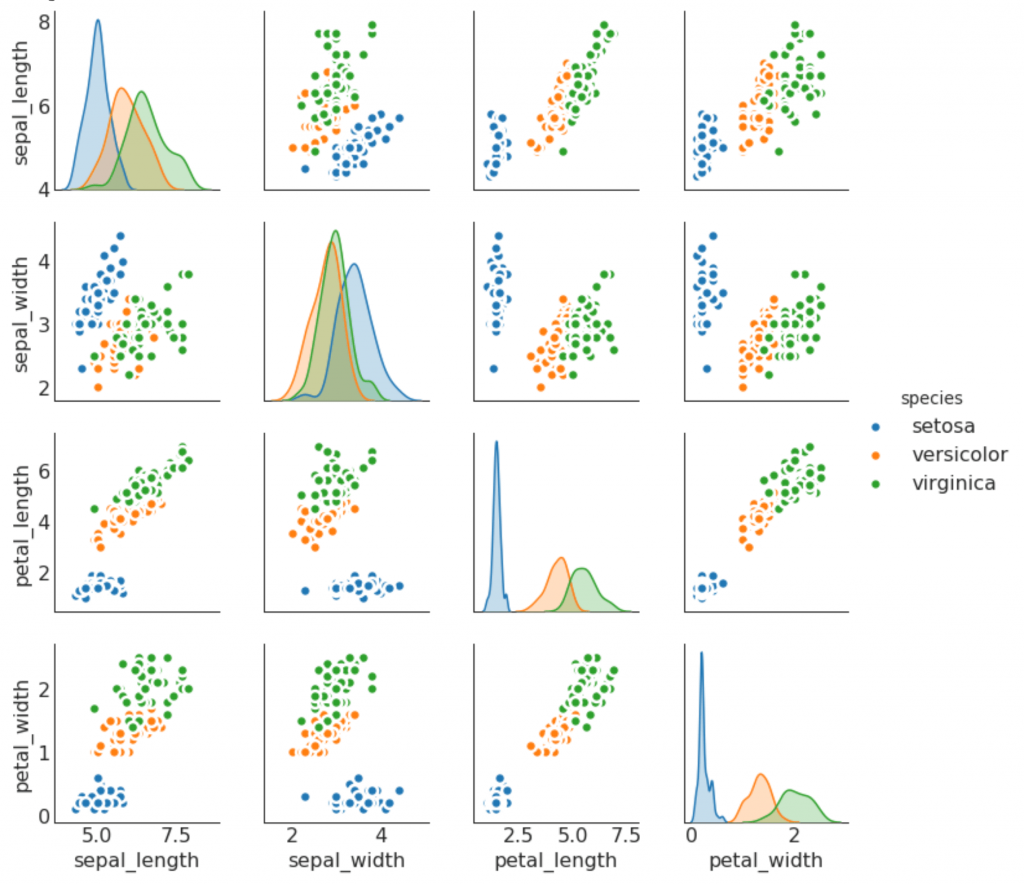
3. График линейной регрессии best fit
Если вы хотите понять, как две переменные изменяются по отношению друг к другу, лучше всего подойдет линия best fit. На графике ниже показано, как best fit отличается среди различных групп данных. Чтобы отключить группировки и просто нарисовать одну линию best fit для всего набора данных, удалите параметр hue=’cyl’ из sns.lmplot() ниже.
Показать код
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_select = df.loc[df.cyl.isin([4,8]), :]
# Plot
sns.set_style("white")
gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select,
height=7, aspect=1.6, robust=True, palette='tab10',
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
# Decorations
gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
plt.title("Scatterplot with line of best fit grouped by number of cylinders", fontsize=20)
plt.show()

Каждая строка регрессии в своем собственном столбце
Кроме того, вы можете показать линию best fit для каждой группы в отдельном столбце. Вы хотите сделать это, установив параметр col=groupingcolumn внутри sns.lmplot().
Показать код
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_select = df.loc[df.cyl.isin([4,8]), :]
# Each line in its own column
sns.set_style("white")
gridobj = sns.lmplot(x="displ", y="hwy",
data=df_select,
height=7,
robust=True,
palette='Set1',
col="cyl",
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
# Decorations
gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
plt.show()
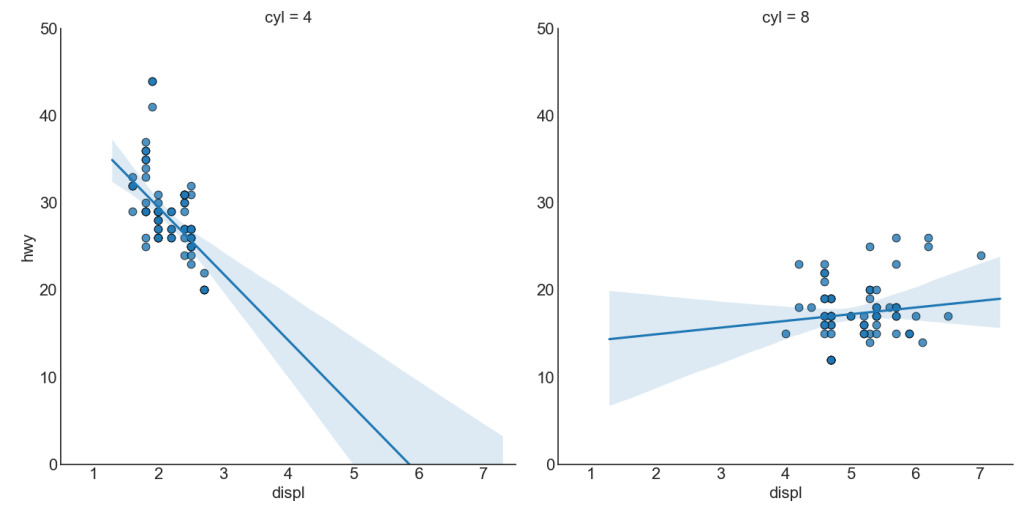
4. Stripplot
Часто несколько точек данных имеют одинаковые значения X и Y. В результате несколько точек наносятся друг на друга и скрываются. Чтобы избежать этого, слегка раздвиньте точки, чтобы вы могли видеть их визуально. Это удобно делать с помощью стрипплота stripplot().
Показать код
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# Draw Stripplot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
sns.stripplot(df.cty, df.hwy, jitter=0.25, size=8, ax=ax, linewidth=.5)
# Decorations
plt.title('Use jittered plots to avoid overlapping of points', fontsize=22)
plt.show()
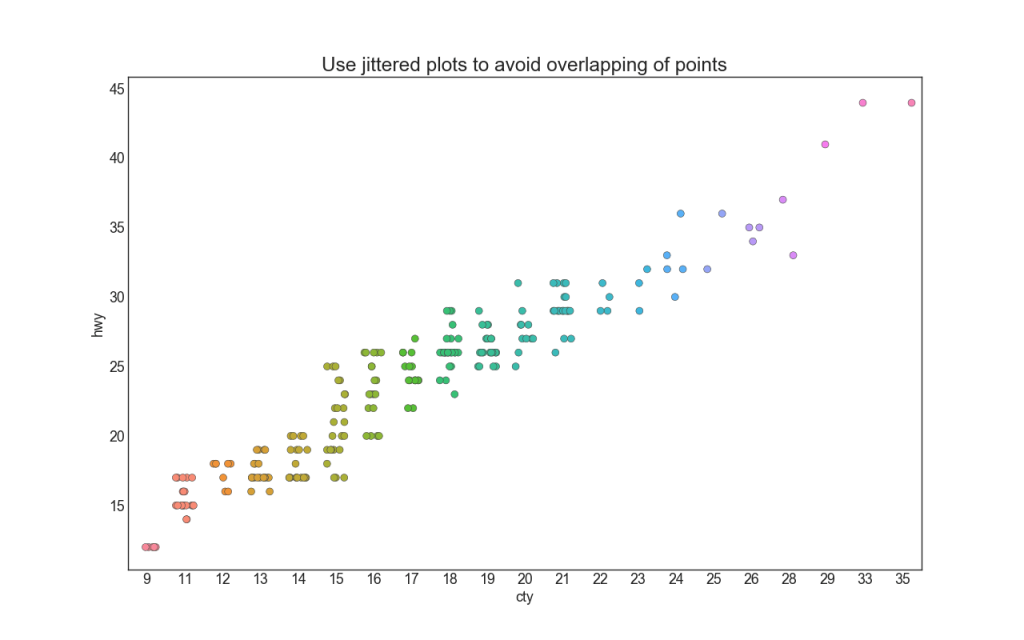
5. График подсчета (Counts Plot)
Другим вариантом, позволяющим избежать проблемы наложения точек, является увеличение размера точки в зависимости от того, сколько точек лежит в этом месте. Таким образом, чем больше размер точки, тем больше концентрация точек вокруг нее.
Показать код
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_counts = df.groupby(['hwy', 'cty']).size().reset_index(name='counts')
# Draw Stripplot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
sns.scatterplot(df_counts.cty, df_counts.hwy, size=df_counts.counts*2, ax=ax)
# Decorations
plt.title('Counts Plot - Size of circle is bigger as more points overlap', fontsize=22)
plt.show()

6. Построчная гистограмма
Построчные гистограммы имеют гистограмму вдоль переменных оси X и Y. Это используется для визуализации отношений между X и Y вместе с одномерным распределением X и Y по отдельности. Этот график часто используется в анализе данных (EDA).
Показать код
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# Create Fig and gridspec
fig = plt.figure(figsize=(16, 10), dpi= 80)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)
# Define the axes
ax_main = fig.add_subplot(grid[:-1, :-1])
ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])
# Scatterplot on main ax
ax_main.scatter('displ', 'hwy', s=df.cty*4, c=df.manufacturer.astype('category').cat.codes, alpha=.9, data=df, cmap="tab10", edgecolors='gray', linewidths=.5)
# histogram on the right
ax_bottom.hist(df.displ, 40, histtype='stepfilled', orientation='vertical', color='deeppink')
ax_bottom.invert_yaxis()
# histogram in the bottom
ax_right.hist(df.hwy, 40, histtype='stepfilled', orientation='horizontal', color='deeppink')
# Decorations
ax_main.set(title='Scatterplot with Histograms n displ vs hwy', xlabel='displ', ylabel='hwy')
ax_main.title.set_fontsize(20)
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()):
item.set_fontsize(14)
xlabels = ax_main.get_xticks().tolist()
ax_main.set_xticklabels(xlabels)
plt.show()
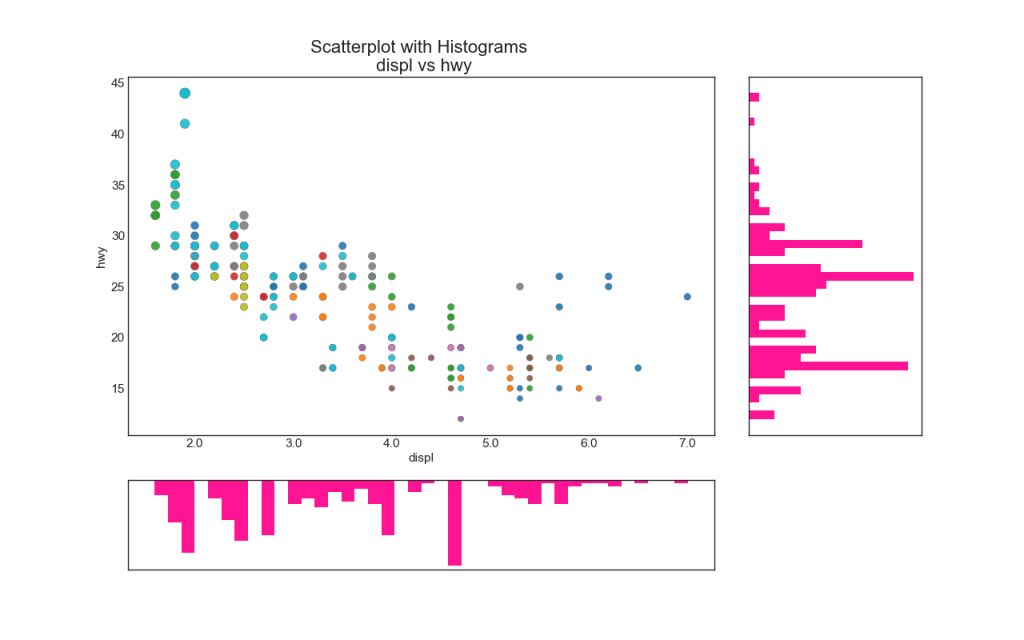
7. Boxplot
Boxplot служит той же цели, что и построчная гистограмма. Тем не менее, этот график помогает точно определить медиану, 25-й и 75-й персентили X и Y.
Показать код
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# Create Fig and gridspec
fig = plt.figure(figsize=(16, 10), dpi= 80)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)
# Define the axes
ax_main = fig.add_subplot(grid[:-1, :-1])
ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])
# Scatterplot on main ax
ax_main.scatter('displ', 'hwy', s=df.cty*5, c=df.manufacturer.astype('category').cat.codes, alpha=.9, data=df, cmap="Set1", edgecolors='black', linewidths=.5)
# Add a graph in each part
sns.boxplot(df.hwy, ax=ax_right, orient="v")
sns.boxplot(df.displ, ax=ax_bottom, orient="h")
# Decorations ------------------
# Remove x axis name for the boxplot
ax_bottom.set(xlabel='')
ax_right.set(ylabel='')
# Main Title, Xlabel and YLabel
ax_main.set(title='Scatterplot with Histograms n displ vs hwy', xlabel='displ', ylabel='hwy')
# Set font size of different components
ax_main.title.set_fontsize(20)
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()):
item.set_fontsize(14)
plt.show()
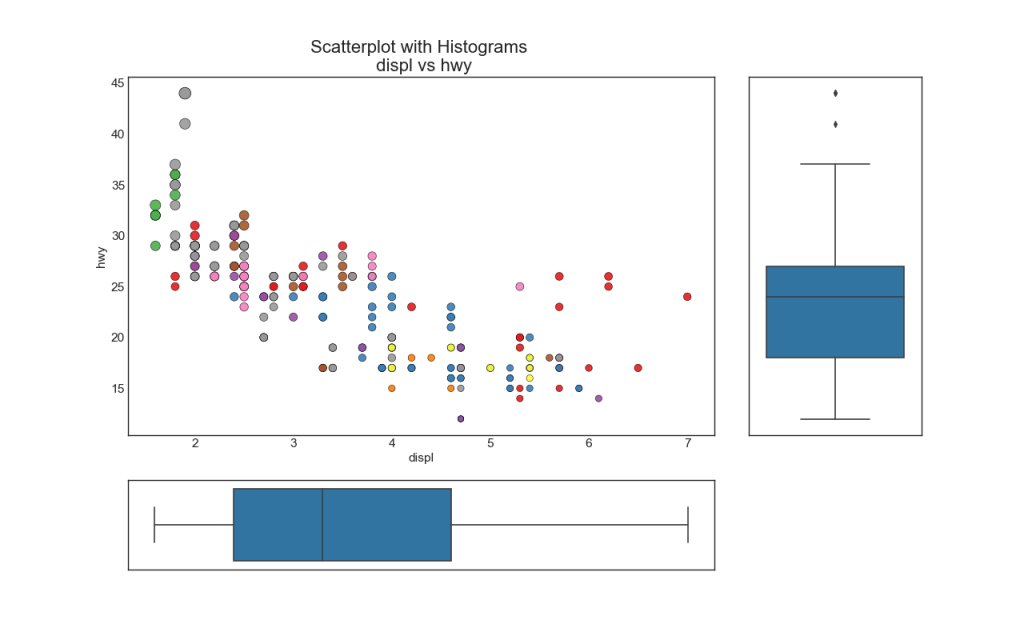
8. Диаграмма корреляции
Диаграмма корреляции используется для визуального просмотра метрики корреляции между всеми возможными парами числовых переменных в данном наборе данных (или двумерном массиве).
Показать код
# Import Dataset
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
# Plot
plt.figure(figsize=(12,10), dpi= 80)
sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True)
# Decorations
plt.title('Correlogram of mtcars', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
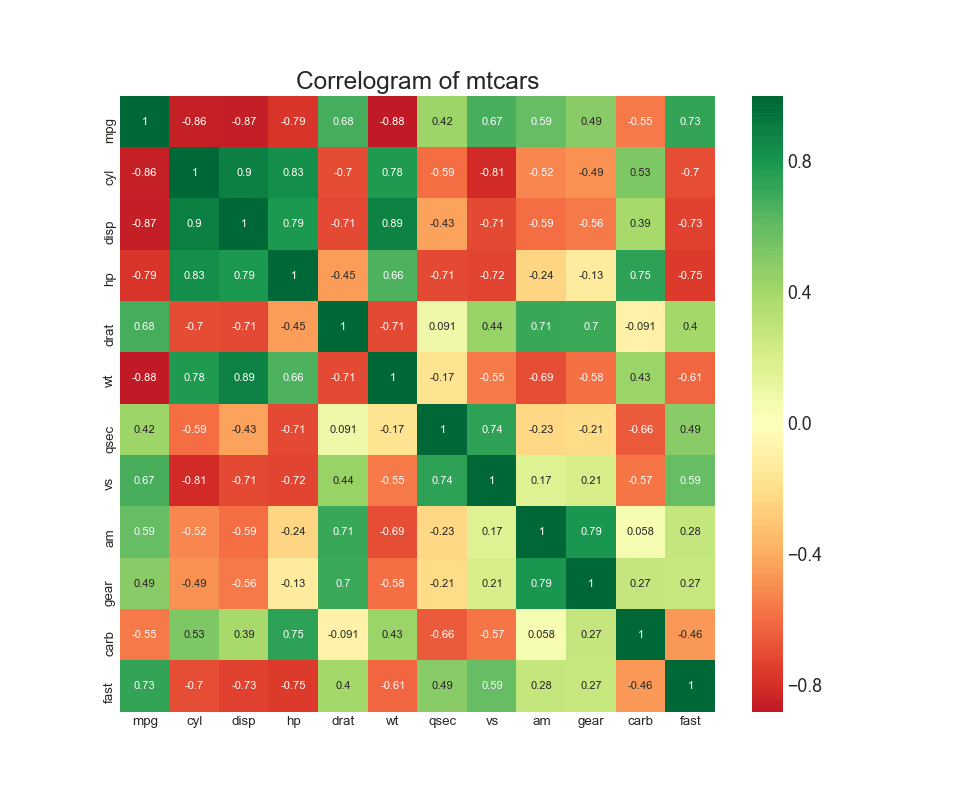
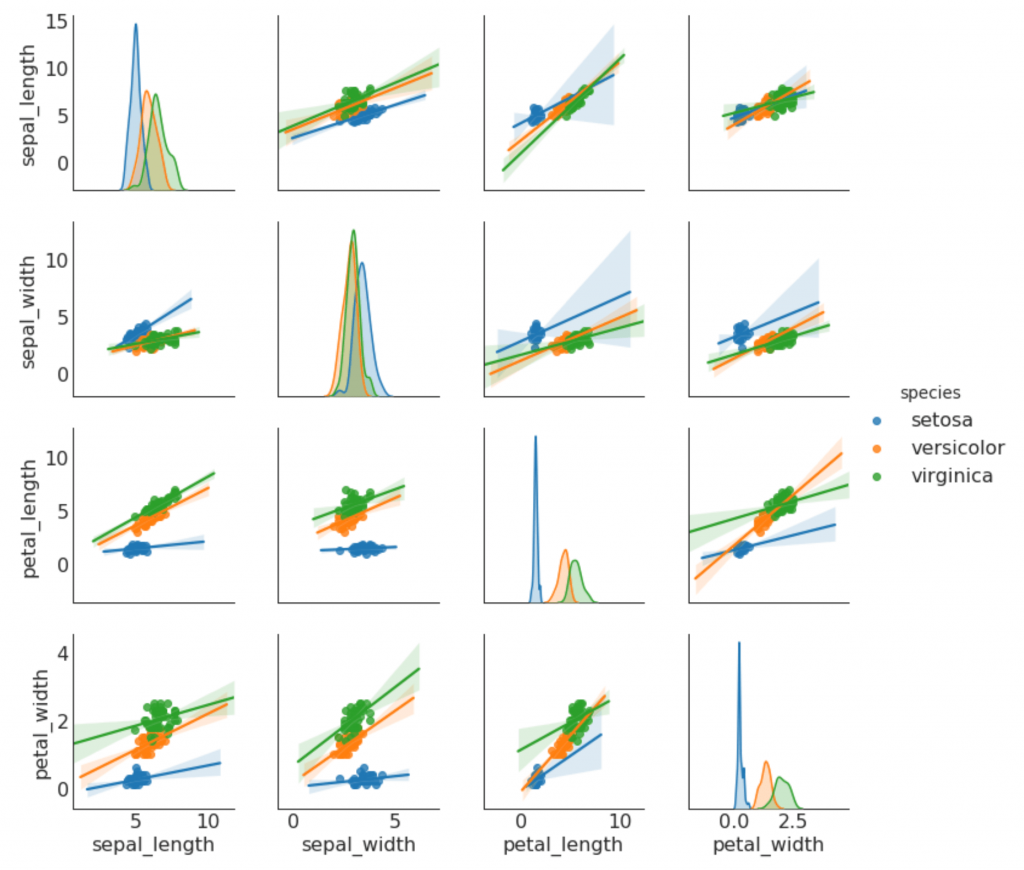
9. Парный график
Часто используется в исследовательском анализе, чтобы понять взаимосвязь между всеми возможными парами числовых переменных. Это обязательный инструмент для двумерного анализа.
Показать код
# Load Dataset
df = sns.load_dataset('iris')
# Plot
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df, kind="scatter", hue="species", plot_kws=dict(s=80, edgecolor="white", linewidth=2.5))
plt.show()
Показать код
# Load Dataset
df = sns.load_dataset('iris')
# Plot
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df, kind="reg", hue="species")
plt.show()
Отклонение
10. Расходящиеся стобцы
Если вы хотите увидеть, как элементы меняются в зависимости от одной метрики, и визуализировать порядок и величину этой дисперсии, расходящиеся стобцы — отличный инструмент. Он помогает быстро дифференцировать производительность групп в ваших данных, является достаточно интуитивным и мгновенно передает смысл.
Показать код
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
# Draw plot
plt.figure(figsize=(14,10), dpi= 80)
plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z, color=df.colors, alpha=0.4, linewidth=5)
# Decorations
plt.gca().set(ylabel='$Model$', xlabel='$Mileage$')
plt.yticks(df.index, df.cars, fontsize=12)
plt.title('Diverging Bars of Car Mileage', fontdict={'size':20})
plt.grid(linestyle='--', alpha=0.5)
plt.show()

11. Расходящиеся стобцы с текстом
— похожи на расходящиеся столбцы, и это предпочтительнее, если вы хотите показать значимость каждого элемента в диаграмме в хорошем и презентабельном виде.
Показать код
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
# Draw plot
plt.figure(figsize=(14,14), dpi= 80)
plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z)
for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z):
t = plt.text(x, y, round(tex, 2), horizontalalignment='right' if x < 0 else 'left',
verticalalignment='center', fontdict={'color':'red' if x < 0 else 'green', 'size':14})
# Decorations
plt.yticks(df.index, df.cars, fontsize=12)
plt.title('Diverging Text Bars of Car Mileage', fontdict={'size':20})
plt.grid(linestyle='--', alpha=0.5)
plt.xlim(-2.5, 2.5)
plt.show()
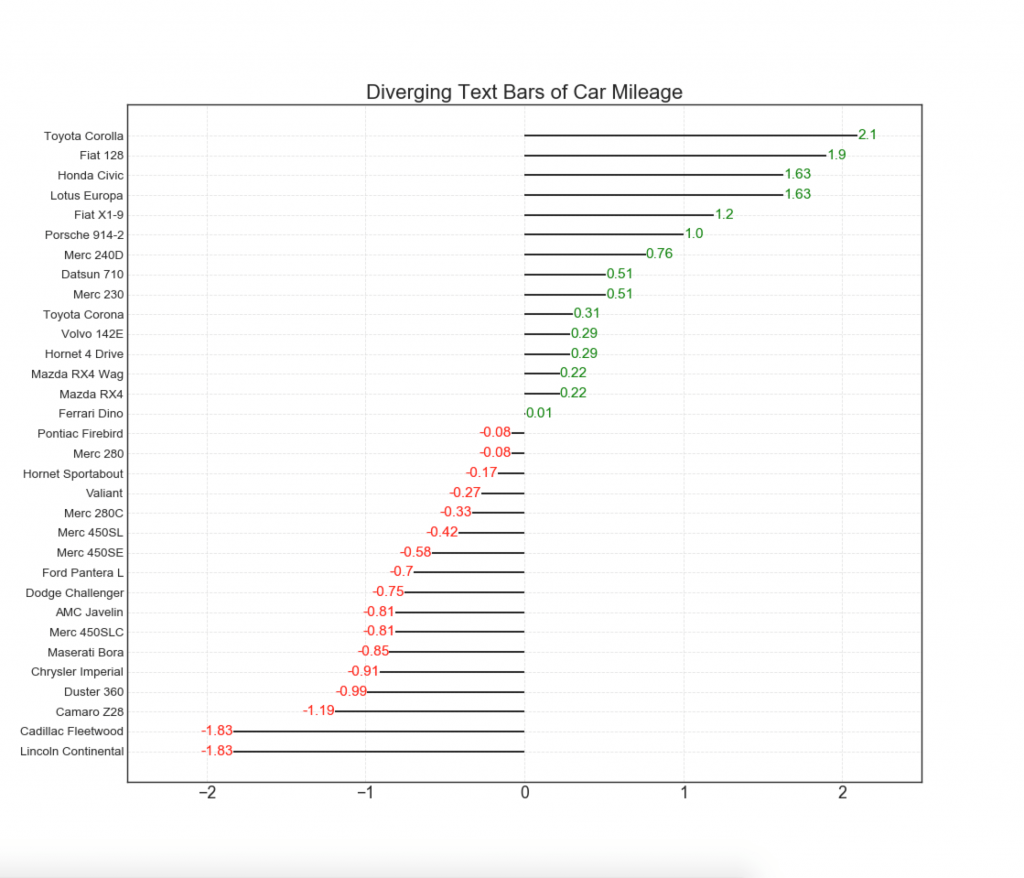
12. Расходящиеся точки
График расходящихся точек также похож на расходящиеся столбцы. Однако по сравнению с расходящимися столбиками, отсутствие столбцов уменьшает степень контрастности и несоответствия между группами.
Показать код
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'darkgreen' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
# Draw plot
plt.figure(figsize=(14,16), dpi= 80)
plt.scatter(df.mpg_z, df.index, s=450, alpha=.6, color=df.colors)
for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z):
t = plt.text(x, y, round(tex, 1), horizontalalignment='center',
verticalalignment='center', fontdict={'color':'white'})
# Decorations
# Lighten borders
plt.gca().spines["top"].set_alpha(.3)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(.3)
plt.gca().spines["left"].set_alpha(.3)
plt.yticks(df.index, df.cars)
plt.title('Diverging Dotplot of Car Mileage', fontdict={'size':20})
plt.xlabel('$Mileage$')
plt.grid(linestyle='--', alpha=0.5)
plt.xlim(-2.5, 2.5)
plt.show()
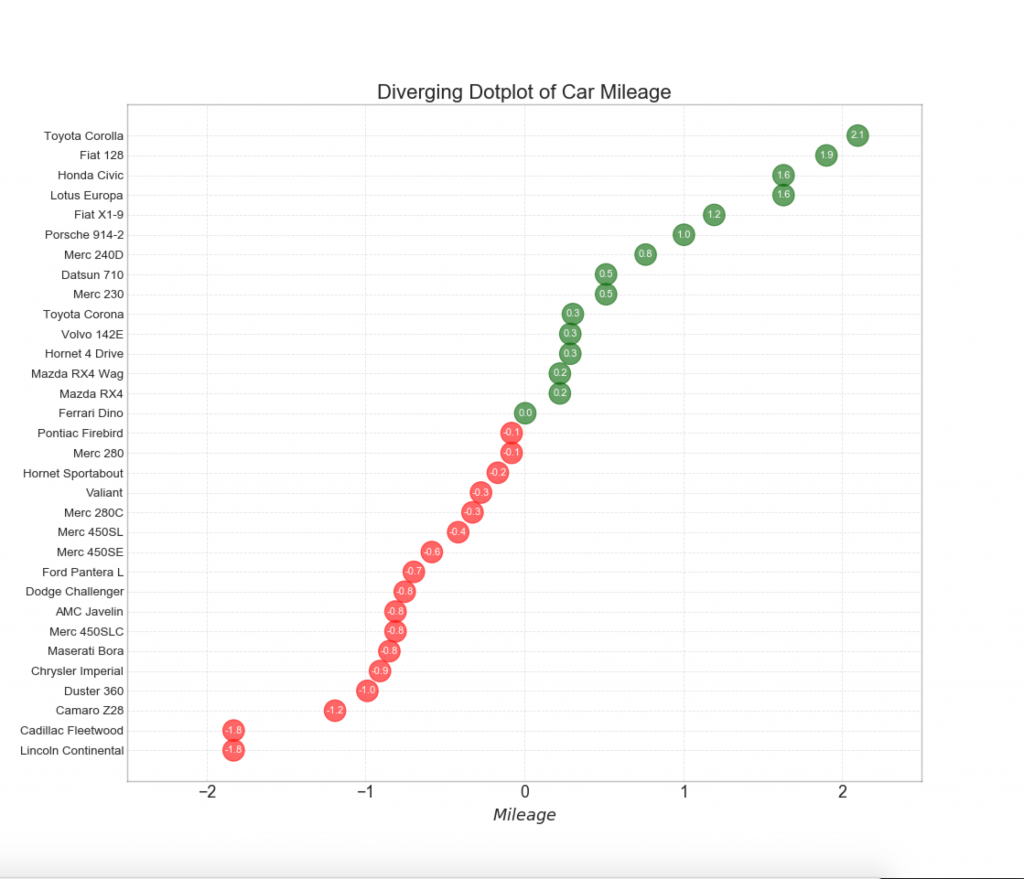
13. Расходящаяся диаграмма Lollipop с маркерами
Lollipop обеспечивает гибкий способ визуализации расхождения, делая акцент на любых значимых точках данных, на которые вы хотите обратить внимание.
Показать код
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = 'black'
# color fiat differently
df.loc[df.cars == 'Fiat X1-9', 'colors'] = 'darkorange'
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
# Draw plot
import matplotlib.patches as patches
plt.figure(figsize=(14,16), dpi= 80)
plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z, color=df.colors, alpha=0.4, linewidth=1)
plt.scatter(df.mpg_z, df.index, color=df.colors, s=[600 if x == 'Fiat X1-9' else 300 for x in df.cars], alpha=0.6)
plt.yticks(df.index, df.cars)
plt.xticks(fontsize=12)
# Annotate
plt.annotate('Mercedes Models', xy=(0.0, 11.0), xytext=(1.0, 11), xycoords='data',
fontsize=15, ha='center', va='center',
bbox=dict(boxstyle='square', fc='firebrick'),
arrowprops=dict(arrowstyle='-[, widthB=2.0, lengthB=1.5', lw=2.0, color='steelblue'), color='white')
# Add Patches
p1 = patches.Rectangle((-2.0, -1), width=.3, height=3, alpha=.2, facecolor='red')
p2 = patches.Rectangle((1.5, 27), width=.8, height=5, alpha=.2, facecolor='green')
plt.gca().add_patch(p1)
plt.gca().add_patch(p2)
# Decorate
plt.title('Diverging Bars of Car Mileage', fontdict={'size':20})
plt.grid(linestyle='--', alpha=0.5)
plt.show()
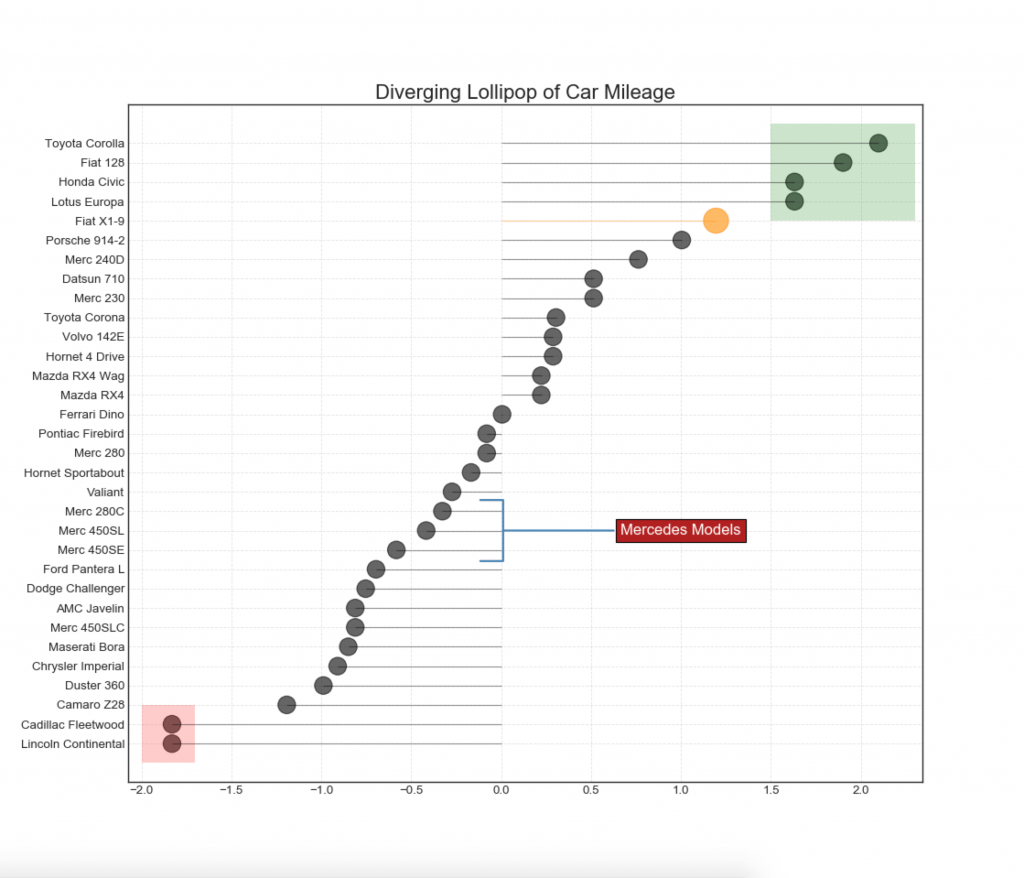
14. Диаграмма площади
Раскрашивая область между осью и линиями, диаграмма площади подчеркивает пики и впадины, но и на продолжительности максимумов и минимумов. Чем больше продолжительность максимумов, тем больше площадь под линией.
Показать код
import numpy as np
import pandas as pd
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv", parse_dates=['date']).head(100)
x = np.arange(df.shape[0])
y_returns = (df.psavert.diff().fillna(0)/df.psavert.shift(1)).fillna(0) * 100
# Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] >= 0, facecolor='green', interpolate=True, alpha=0.7)
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] <= 0, facecolor='red', interpolate=True, alpha=0.7)
# Annotate
plt.annotate('Peak n1975', xy=(94.0, 21.0), xytext=(88.0, 28),
bbox=dict(boxstyle='square', fc='firebrick'),
arrowprops=dict(facecolor='steelblue', shrink=0.05), fontsize=15, color='white')
# Decorations
xtickvals = [str(m)[:3].upper()+"-"+str(y) for y,m in zip(df.date.dt.year, df.date.dt.month_name())]
plt.gca().set_xticks(x[::6])
plt.gca().set_xticklabels(xtickvals[::6], rotation=90, fontdict={'horizontalalignment': 'center', 'verticalalignment': 'center_baseline'})
plt.ylim(-35,35)
plt.xlim(1,100)
plt.title("Month Economics Return %", fontsize=22)
plt.ylabel('Monthly returns %')
plt.grid(alpha=0.5)
plt.show()
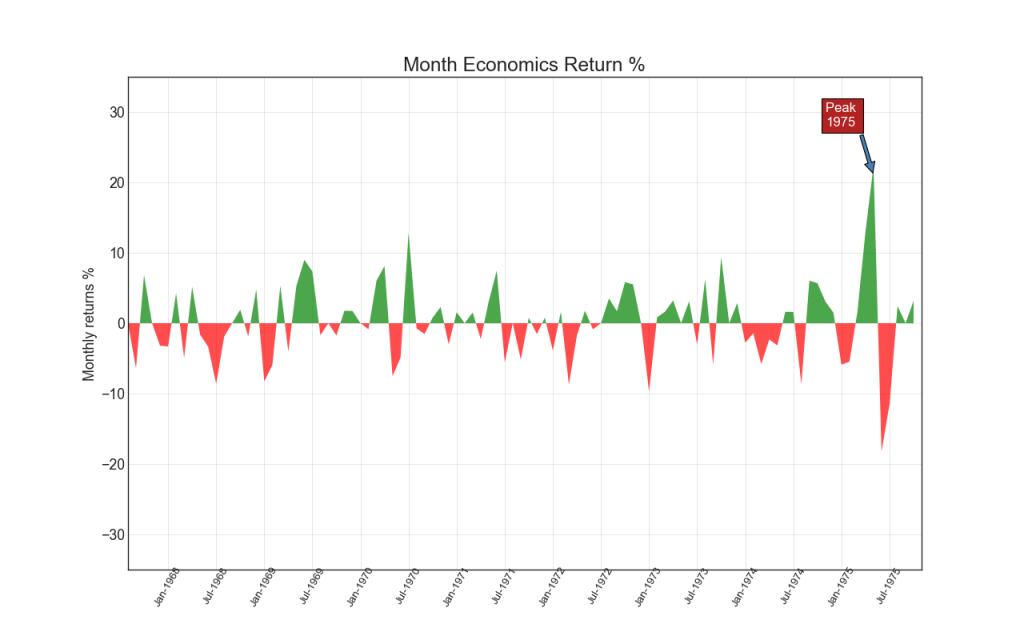
Ранжирование
15. Упорядоченная гистограмма
Упорядоченная гистограмма эффективно передает порядок ранжирования элементов. Но, добавив значение показателя над диаграммой, пользователь получает точную информацию от самой диаграммы.
Показать код
# Prepare Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())
df.sort_values('cty', inplace=True)
df.reset_index(inplace=True)
# Draw plot
import matplotlib.patches as patches
fig, ax = plt.subplots(figsize=(16,10), facecolor='white', dpi= 80)
ax.vlines(x=df.index, ymin=0, ymax=df.cty, color='firebrick', alpha=0.7, linewidth=20)
# Annotate Text
for i, cty in enumerate(df.cty):
ax.text(i, cty+0.5, round(cty, 1), horizontalalignment='center')
# Title, Label, Ticks and Ylim
ax.set_title('Bar Chart for Highway Mileage', fontdict={'size':22})
ax.set(ylabel='Miles Per Gallon', ylim=(0, 30))
plt.xticks(df.index, df.manufacturer.str.upper(), rotation=60, horizontalalignment='right', fontsize=12)
# Add patches to color the X axis labels
p1 = patches.Rectangle((.57, -0.005), width=.33, height=.13, alpha=.1, facecolor='green', transform=fig.transFigure)
p2 = patches.Rectangle((.124, -0.005), width=.446, height=.13, alpha=.1, facecolor='red', transform=fig.transFigure)
fig.add_artist(p1)
fig.add_artist(p2)
plt.show()
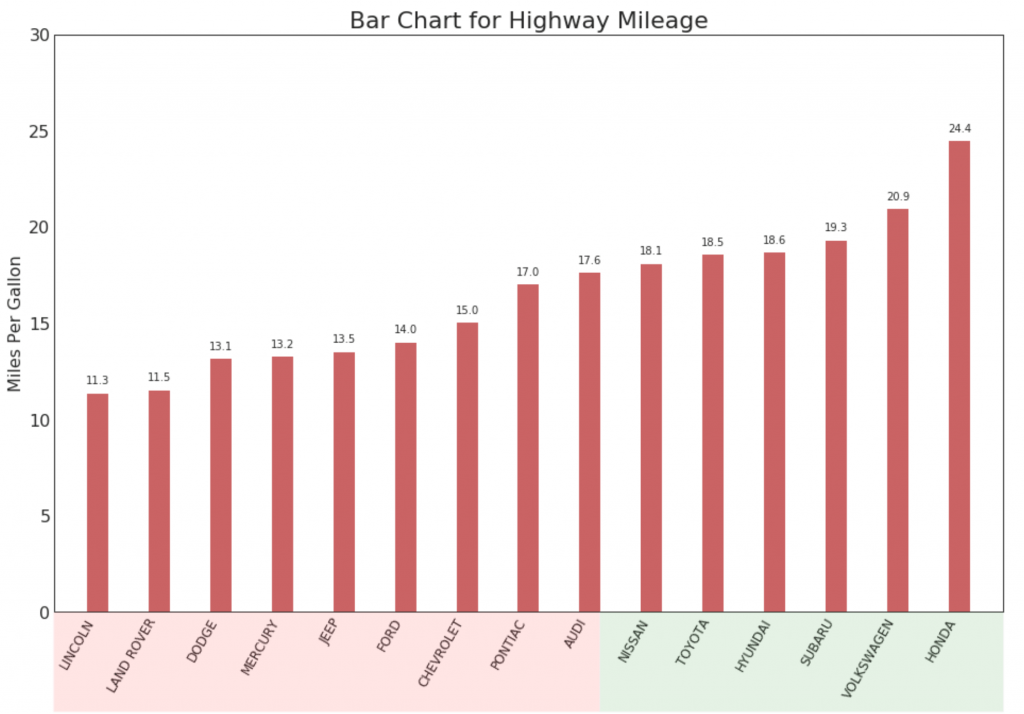
16. Диаграмма Lollipop
Диаграмма Lollipop служит аналогичной цели как упорядоченная гистограмма визуально приятным способом.
Показать код
# Prepare Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())
df.sort_values('cty', inplace=True)
df.reset_index(inplace=True)
# Draw plot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
ax.vlines(x=df.index, ymin=0, ymax=df.cty, color='firebrick', alpha=0.7, linewidth=2)
ax.scatter(x=df.index, y=df.cty, s=75, color='firebrick', alpha=0.7)
# Title, Label, Ticks and Ylim
ax.set_title('Lollipop Chart for Highway Mileage', fontdict={'size':22})
ax.set_ylabel('Miles Per Gallon')
ax.set_xticks(df.index)
ax.set_xticklabels(df.manufacturer.str.upper(), rotation=60, fontdict={'horizontalalignment': 'right', 'size':12})
ax.set_ylim(0, 30)
# Annotate
for row in df.itertuples():
ax.text(row.Index, row.cty+.5, s=round(row.cty, 2), horizontalalignment= 'center', verticalalignment='bottom', fontsize=14)
plt.show()
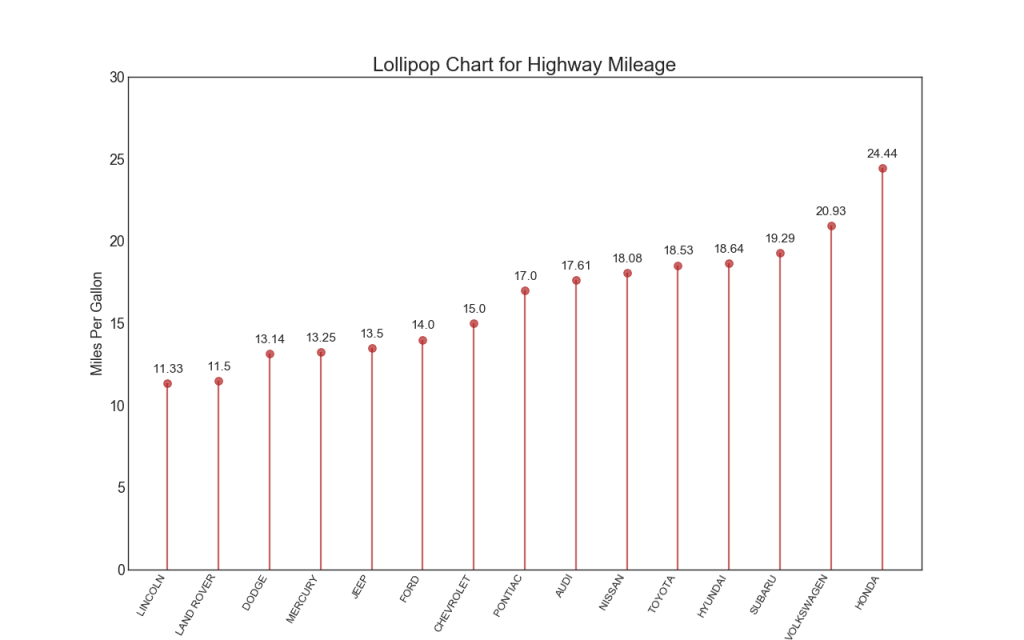
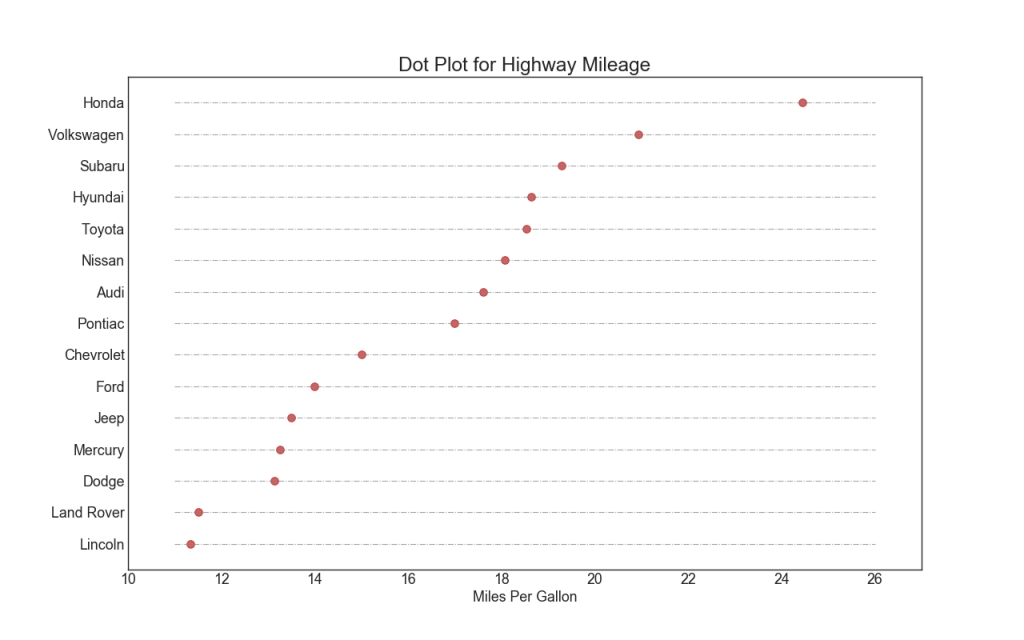
17. Поточечный график с подписями
Точечный график передает порядок ранжирования предметов. А поскольку он выровнен вдоль горизонтальной оси, вы можете визуально оценить, как далеко точки находятся друг от друга.
Показать код
# Prepare Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())
df.sort_values('cty', inplace=True)
df.reset_index(inplace=True)
# Draw plot
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
ax.hlines(y=df.index, xmin=11, xmax=26, color='gray', alpha=0.7, linewidth=1, linestyles='dashdot')
ax.scatter(y=df.index, x=df.cty, s=75, color='firebrick', alpha=0.7)
# Title, Label, Ticks and Ylim
ax.set_title('Dot Plot for Highway Mileage', fontdict={'size':22})
ax.set_xlabel('Miles Per Gallon')
ax.set_yticks(df.index)
ax.set_yticklabels(df.manufacturer.str.title(), fontdict={'horizontalalignment': 'right'})
ax.set_xlim(10, 27)
plt.show()
18. Наклонная карта
Диаграмма уклона наиболее подходит для сравнения позиций «До» и «После» данного человека / предмета.
Показать код
import matplotlib.lines as mlines
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/gdppercap.csv")
left_label = [str(c) + ', '+ str(round(y)) for c, y in zip(df.continent, df['1952'])]
right_label = [str(c) + ', '+ str(round(y)) for c, y in zip(df.continent, df['1957'])]
klass = ['red' if (y1-y2) < 0 else 'green' for y1, y2 in zip(df['1952'], df['1957'])]
# draw line
# https://stackoverflow.com/questions/36470343/how-to-draw-a-line-with-matplotlib/36479941
def newline(p1, p2, color='black'):
ax = plt.gca()
l = mlines.Line2D([p1[0],p2[0]], [p1[1],p2[1]], color='red' if p1[1]-p2[1] > 0 else 'green', marker='o', markersize=6)
ax.add_line(l)
return l
fig, ax = plt.subplots(1,1,figsize=(14,14), dpi= 80)
# Vertical Lines
ax.vlines(x=1, ymin=500, ymax=13000, color='black', alpha=0.7, linewidth=1, linestyles='dotted')
ax.vlines(x=3, ymin=500, ymax=13000, color='black', alpha=0.7, linewidth=1, linestyles='dotted')
# Points
ax.scatter(y=df['1952'], x=np.repeat(1, df.shape[0]), s=10, color='black', alpha=0.7)
ax.scatter(y=df['1957'], x=np.repeat(3, df.shape[0]), s=10, color='black', alpha=0.7)
# Line Segmentsand Annotation
for p1, p2, c in zip(df['1952'], df['1957'], df['continent']):
newline([1,p1], [3,p2])
ax.text(1-0.05, p1, c + ', ' + str(round(p1)), horizontalalignment='right', verticalalignment='center', fontdict={'size':14})
ax.text(3+0.05, p2, c + ', ' + str(round(p2)), horizontalalignment='left', verticalalignment='center', fontdict={'size':14})
# 'Before' and 'After' Annotations
ax.text(1-0.05, 13000, 'BEFORE', horizontalalignment='right', verticalalignment='center', fontdict={'size':18, 'weight':700})
ax.text(3+0.05, 13000, 'AFTER', horizontalalignment='left', verticalalignment='center', fontdict={'size':18, 'weight':700})
# Decoration
ax.set_title("Slopechart: Comparing GDP Per Capita between 1952 vs 1957", fontdict={'size':22})
ax.set(xlim=(0,4), ylim=(0,14000), ylabel='Mean GDP Per Capita')
ax.set_xticks([1,3])
ax.set_xticklabels(["1952", "1957"])
plt.yticks(np.arange(500, 13000, 2000), fontsize=12)
# Lighten borders
plt.gca().spines["top"].set_alpha(.0)
plt.gca().spines["bottom"].set_alpha(.0)
plt.gca().spines["right"].set_alpha(.0)
plt.gca().spines["left"].set_alpha(.0)
plt.show()

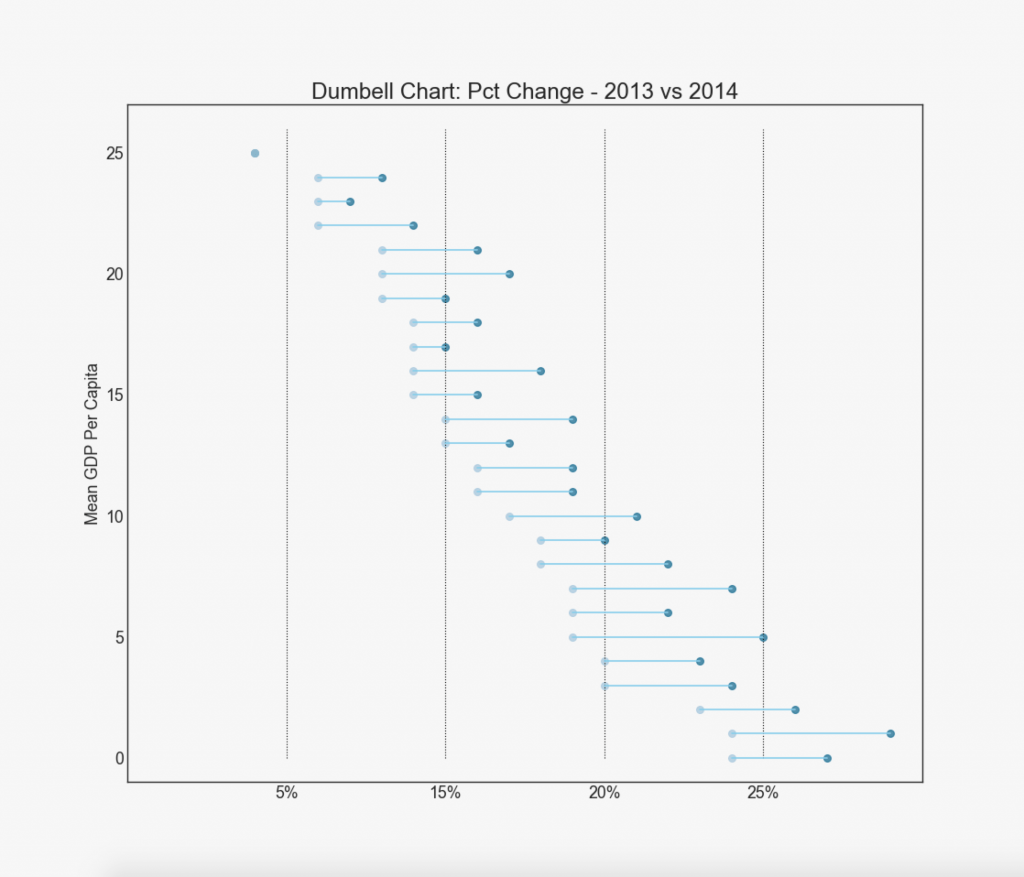
19. «Гантели»
График «Гантели» передает позиции «до» и «после» различных влияний, а также порядок ранжирования предметов. Это очень полезно, если вы хотите визуализировать влияние чего-либо на разные объекты.
Показать код
import matplotlib.lines as mlines
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/health.csv")
df.sort_values('pct_2014', inplace=True)
df.reset_index(inplace=True)
# Func to draw line segment
def newline(p1, p2, color='black'):
ax = plt.gca()
l = mlines.Line2D([p1[0],p2[0]], [p1[1],p2[1]], color='skyblue')
ax.add_line(l)
return l
# Figure and Axes
fig, ax = plt.subplots(1,1,figsize=(14,14), facecolor='#f7f7f7', dpi= 80)
# Vertical Lines
ax.vlines(x=.05, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.10, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.15, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.20, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
# Points
ax.scatter(y=df['index'], x=df['pct_2013'], s=50, color='#0e668b', alpha=0.7)
ax.scatter(y=df['index'], x=df['pct_2014'], s=50, color='#a3c4dc', alpha=0.7)
# Line Segments
for i, p1, p2 in zip(df['index'], df['pct_2013'], df['pct_2014']):
newline([p1, i], [p2, i])
# Decoration
ax.set_facecolor('#f7f7f7')
ax.set_title("Dumbell Chart: Pct Change - 2013 vs 2014", fontdict={'size':22})
ax.set(xlim=(0,.25), ylim=(-1, 27), ylabel='Mean GDP Per Capita')
ax.set_xticks([.05, .1, .15, .20])
ax.set_xticklabels(['5%', '15%', '20%', '25%'])
ax.set_xticklabels(['5%', '15%', '20%', '25%'])
plt.show()
Распределение
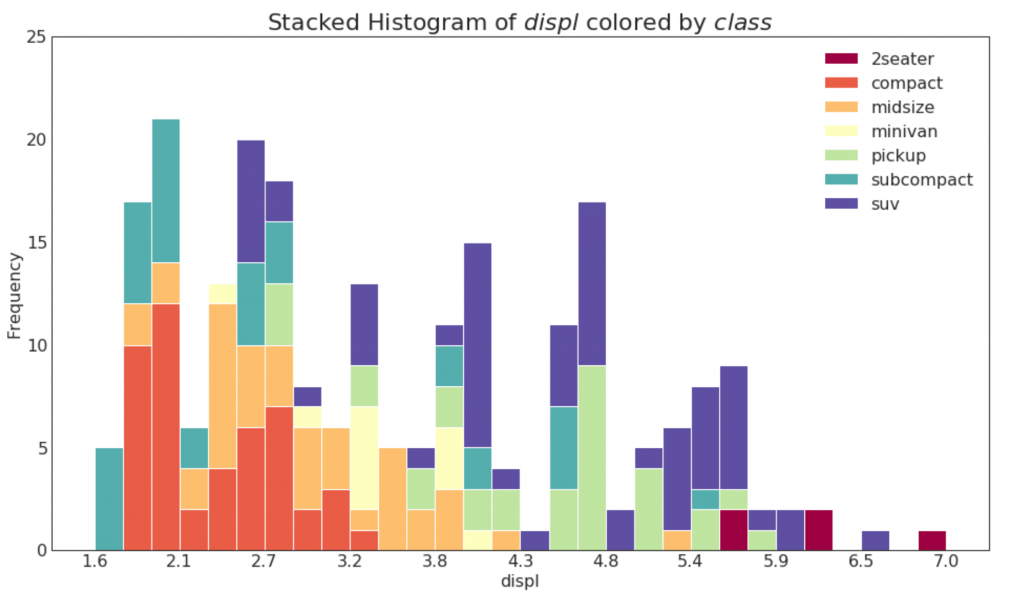
20. Гистограмма для непрерывной переменной
Гистограмма показывает распределение частот данной переменной. Приведенное ниже представление группирует полосы частот на основе категориальной переменной.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare data
x_var = 'displ'
groupby_var = 'class'
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df[x_var].values.tolist() for i, df in df_agg]
# Draw
plt.figure(figsize=(16,9), dpi= 80)
colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]
n, bins, patches = plt.hist(vals, 30, stacked=True, density=False, color=colors[:len(vals)])
# Decoration
plt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})
plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)
plt.xlabel(x_var)
plt.ylabel("Frequency")
plt.ylim(0, 25)
plt.xticks(ticks=bins[::3], labels=[round(b,1) for b in bins[::3]])
plt.show()
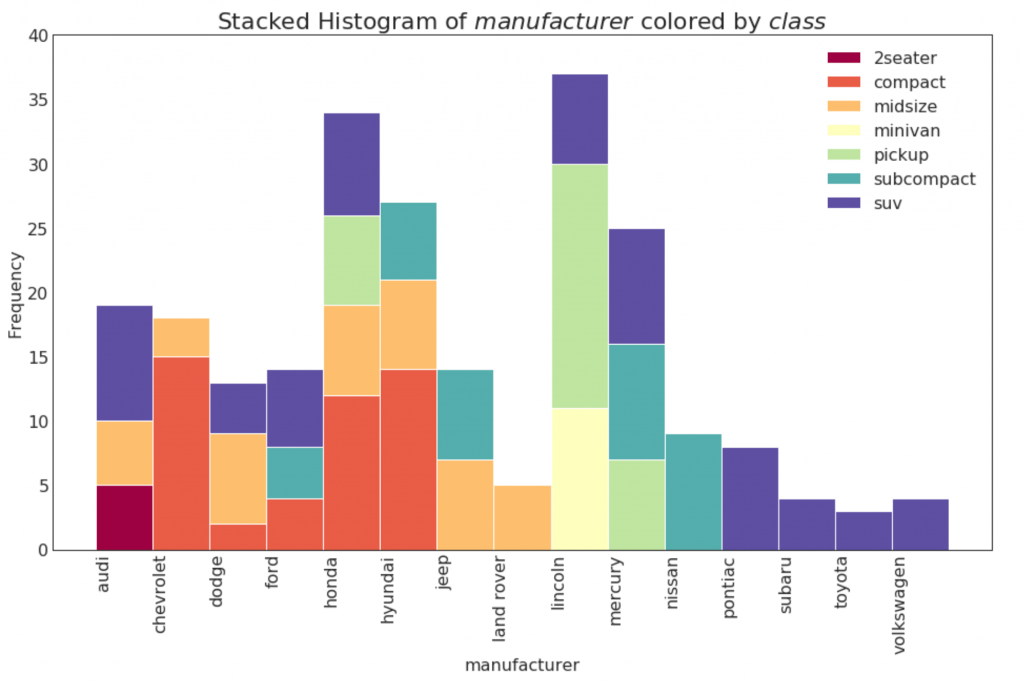
21. Гистограмма для категориальной переменной
Гистограмма категориальной переменной показывает распределение частоты этой переменной. Раскрашивая столбцы, вы можете визуализировать распределение в связи с другой категориальной переменной, представляющей цвета.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare data
x_var = 'manufacturer'
groupby_var = 'class'
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df[x_var].values.tolist() for i, df in df_agg]
# Draw
plt.figure(figsize=(16,9), dpi= 80)
colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]
n, bins, patches = plt.hist(vals, df[x_var].unique().__len__(), stacked=True, density=False, color=colors[:len(vals)])
# Decoration
plt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})
plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)
plt.xlabel(x_var)
plt.ylabel("Frequency")
plt.ylim(0, 40)
plt.xticks(ticks=bins, labels=np.unique(df[x_var]).tolist(), rotation=90, horizontalalignment='left')
plt.show()
22. График плотности
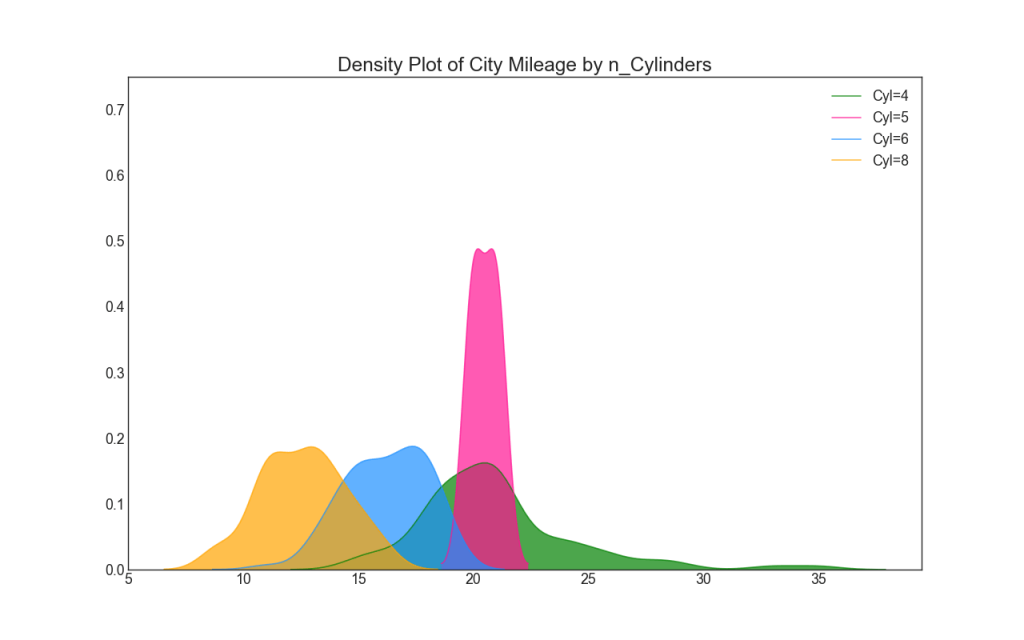
Графики плотности являются широко используемым инструментом для визуализации распределения непрерывной переменной. Сгруппировав их по переменной «response», вы можете проверить взаимосвязь между X и Y. Ниже представлен пример, если для наглядности описать, как распределение пробега по городу меняется в зависимости от количества цилиндров.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(16,10), dpi= 80)
sns.kdeplot(df.loc[df['cyl'] == 4, "cty"], shade=True, color="g", label="Cyl=4", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 5, "cty"], shade=True, color="deeppink", label="Cyl=5", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 6, "cty"], shade=True, color="dodgerblue", label="Cyl=6", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 8, "cty"], shade=True, color="orange", label="Cyl=8", alpha=.7)
# Decoration
plt.title('Density Plot of City Mileage by n_Cylinders', fontsize=22)
plt.legend()
plt.show()
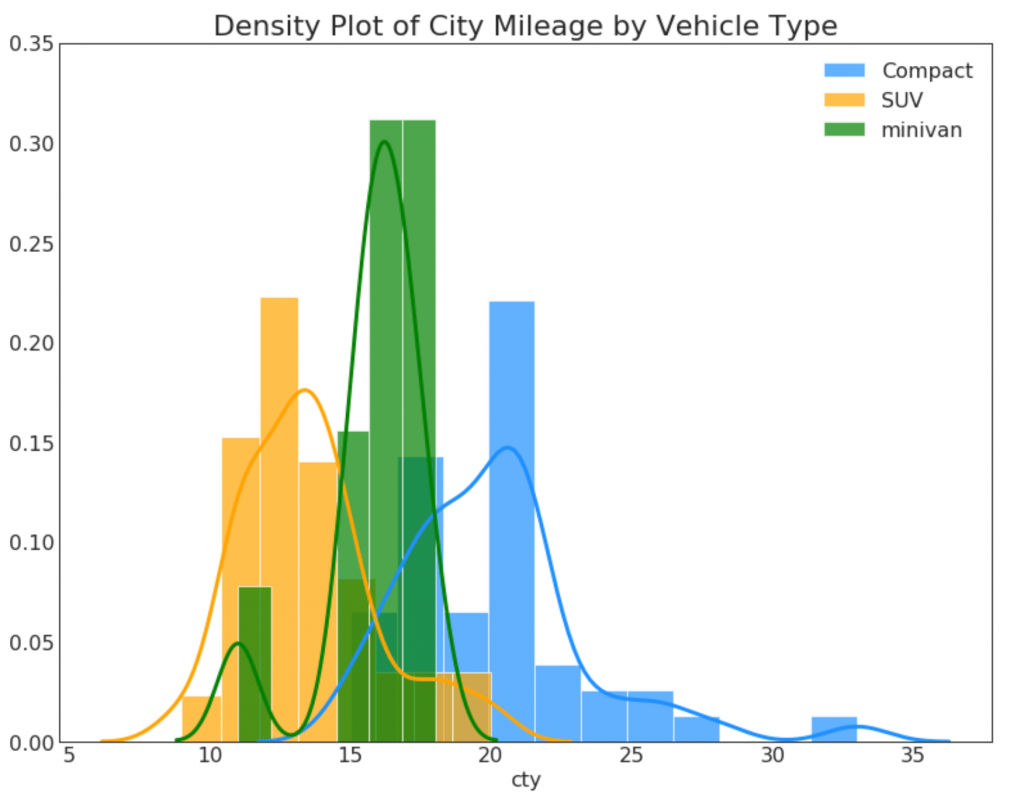
23. Кривые плотности с гистограммой
Кривая плотности с гистограммой объединяет сводную информацию, передаваемую двумя графиками, так что вы можете видеть оба в одном месте.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.distplot(df.loc[df['class'] == 'compact', "cty"], color="dodgerblue", label="Compact", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'suv', "cty"], color="orange", label="SUV", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'minivan', "cty"], color="g", label="minivan", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
plt.ylim(0, 0.35)
# Decoration
plt.title('Density Plot of City Mileage by Vehicle Type', fontsize=22)
plt.legend()
plt.show()
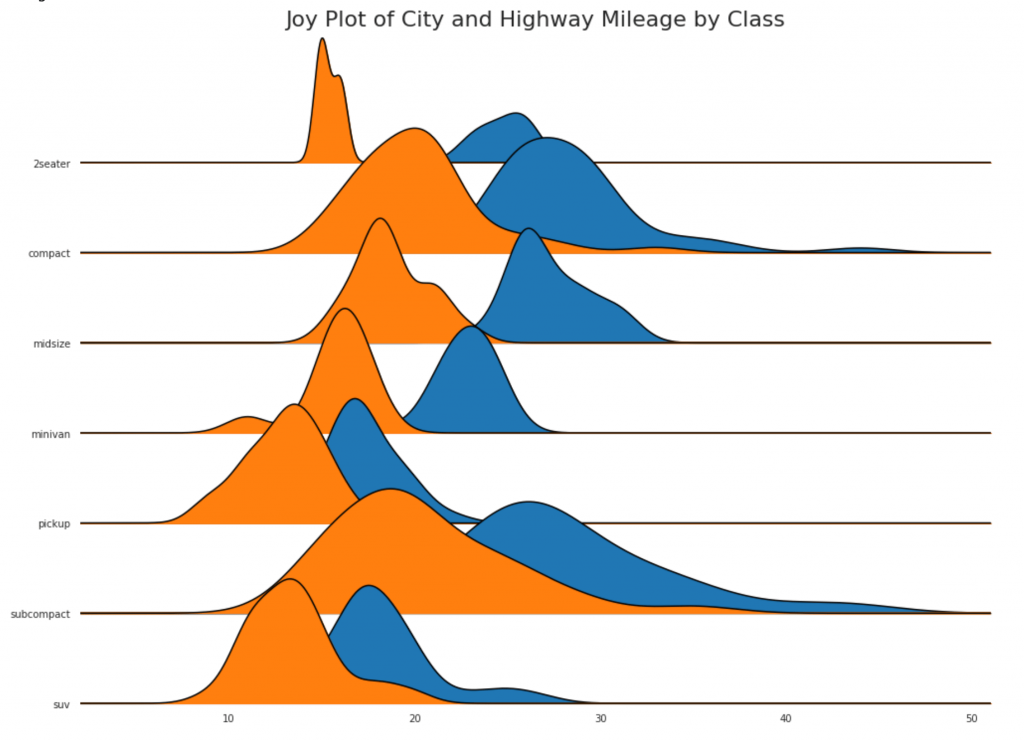
24. График Joy
График Joy позволяет перекрывать кривые плотности разных групп, это отличный способ визуализировать распределение большого числа групп по отношению друг к другу. Это выглядит приятным для глаз и четко передает только правильную информацию.
Показать код
# !pip install joypy
# Import Data
mpg = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(16,10), dpi= 80)
fig, axes = joypy.joyplot(mpg, column=['hwy', 'cty'], by="class", ylim='own', figsize=(14,10))
# Decoration
plt.title('Joy Plot of City and Highway Mileage by Class', fontsize=22)
plt.show()
25. Распределенная точечная диаграмма
Распределенная точечная диаграмма показывает одномерное распределение точек, сегментированных по группам. Чем темнее точки, тем больше концентрация точек данных в этом регионе. По-разному окрашивая медиану, реальное расположение групп становится очевидным мгновенно.
Показать код
import matplotlib.patches as mpatches
# Prepare Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
cyl_colors = {4:'tab:red', 5:'tab:green', 6:'tab:blue', 8:'tab:orange'}
df_raw['cyl_color'] = df_raw.cyl.map(cyl_colors)
# Mean and Median city mileage by make
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.mean())
df.sort_values('cty', ascending=False, inplace=True)
df.reset_index(inplace=True)
df_median = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(lambda x: x.median())
# Draw horizontal lines
fig, ax = plt.subplots(figsize=(16,10), dpi= 80)
ax.hlines(y=df.index, xmin=0, xmax=40, color='gray', alpha=0.5, linewidth=.5, linestyles='dashdot')
# Draw the Dots
for i, make in enumerate(df.manufacturer):
df_make = df_raw.loc[df_raw.manufacturer==make, :]
ax.scatter(y=np.repeat(i, df_make.shape[0]), x='cty', data=df_make, s=75, edgecolors='gray', c='w', alpha=0.5)
ax.scatter(y=i, x='cty', data=df_median.loc[df_median.index==make, :], s=75, c='firebrick')
# Annotate
ax.text(33, 13, "$red ; dots ; are ; the : median$", fontdict={'size':12}, color='firebrick')
# Decorations
red_patch = plt.plot([],[], marker="o", ms=10, ls="", mec=None, color='firebrick', label="Median")
plt.legend(handles=red_patch)
ax.set_title('Distribution of City Mileage by Make', fontdict={'size':22})
ax.set_xlabel('Miles Per Gallon (City)', alpha=0.7)
ax.set_yticks(df.index)
ax.set_yticklabels(df.manufacturer.str.title(), fontdict={'horizontalalignment': 'right'}, alpha=0.7)
ax.set_xlim(1, 40)
plt.xticks(alpha=0.7)
plt.gca().spines["top"].set_visible(False)
plt.gca().spines["bottom"].set_visible(False)
plt.gca().spines["right"].set_visible(False)
plt.gca().spines["left"].set_visible(False)
plt.grid(axis='both', alpha=.4, linewidth=.1)
plt.show()

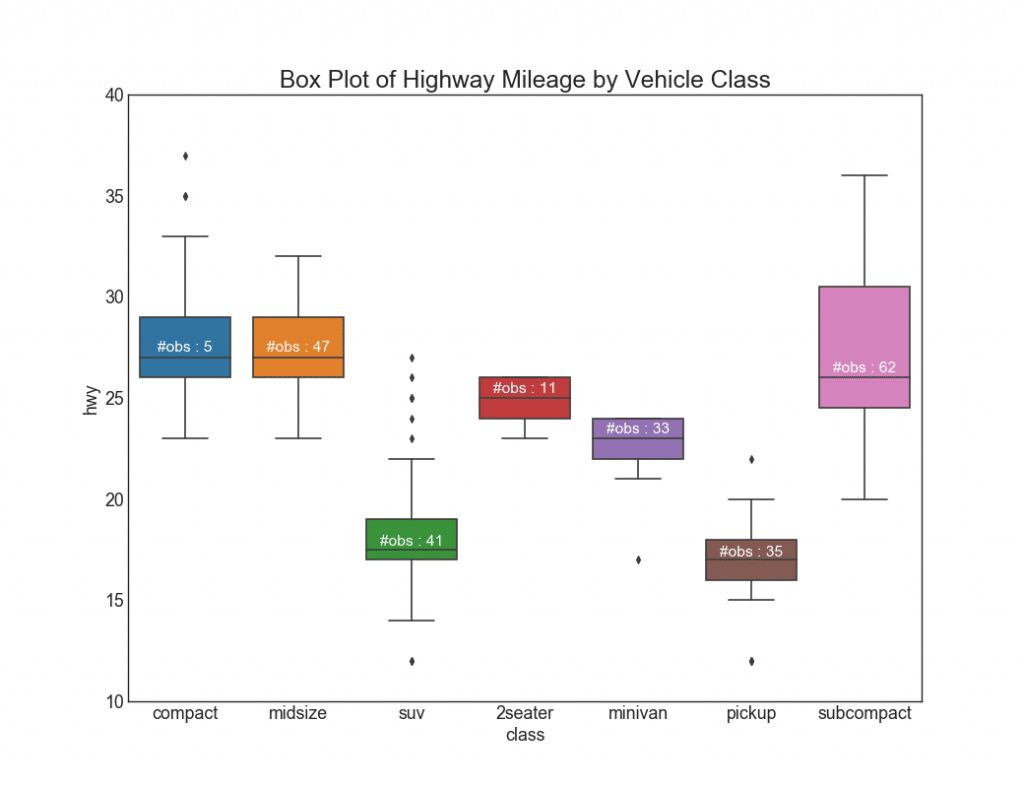
26. Графики с прямоугольниками
Такие графики — отличный способ визуализировать распределение, зная медиану, 25-й, 75-й квартили и максимумы с минимумами. Однако вы должны быть осторожны при интерпретации размера полей, которые могут потенциально исказить количество точек, содержащихся в этой группе. Таким образом, ручное указание количества наблюдений в каждой ячейке поможет преодолеть этот недостаток.
Например, первые два прямоугольника слева одинакового размера, хотя они имеют 5 и 47 элементов данных соответственно. Поэтому необходимо отмечать количество наблюдений.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.boxplot(x='class', y='hwy', data=df, notch=False)
# Add N Obs inside boxplot (optional)
def add_n_obs(df,group_col,y):
medians_dict = {grp[0]:grp[1][y].median() for grp in df.groupby(group_col)}
xticklabels = [x.get_text() for x in plt.gca().get_xticklabels()]
n_obs = df.groupby(group_col)[y].size().values
for (x, xticklabel), n_ob in zip(enumerate(xticklabels), n_obs):
plt.text(x, medians_dict[xticklabel]*1.01, "#obs : "+str(n_ob), horizontalalignment='center', fontdict={'size':14}, color='white')
add_n_obs(df,group_col='class',y='hwy')
# Decoration
plt.title('Box Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.ylim(10, 40)
plt.show()
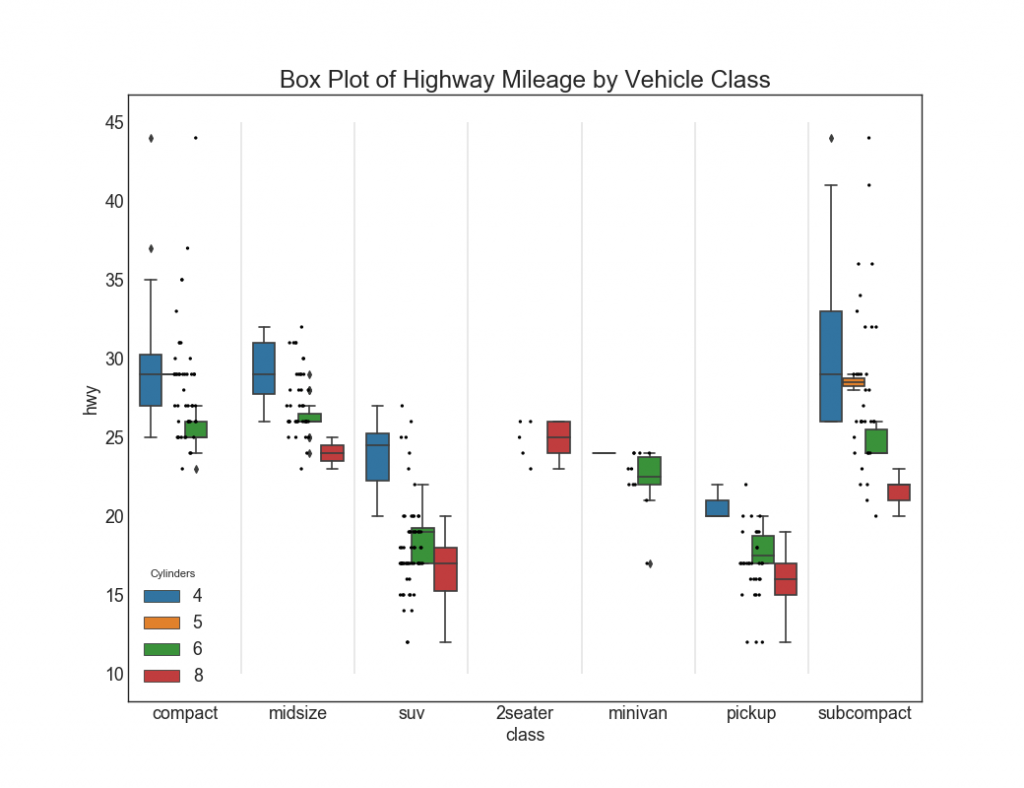
27. Графики с прямоугольниками и точками
Dot + Box plot передает аналогичную информацию, как boxplot, разбитый на группы. Кроме того, точки дают представление о количестве элементов данных в каждой группе.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.boxplot(x='class', y='hwy', data=df, hue='cyl')
sns.stripplot(x='class', y='hwy', data=df, color='black', size=3, jitter=1)
for i in range(len(df['class'].unique())-1):
plt.vlines(i+.5, 10, 45, linestyles='solid', colors='gray', alpha=0.2)
# Decoration
plt.title('Box Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.legend(title='Cylinders')
plt.show()
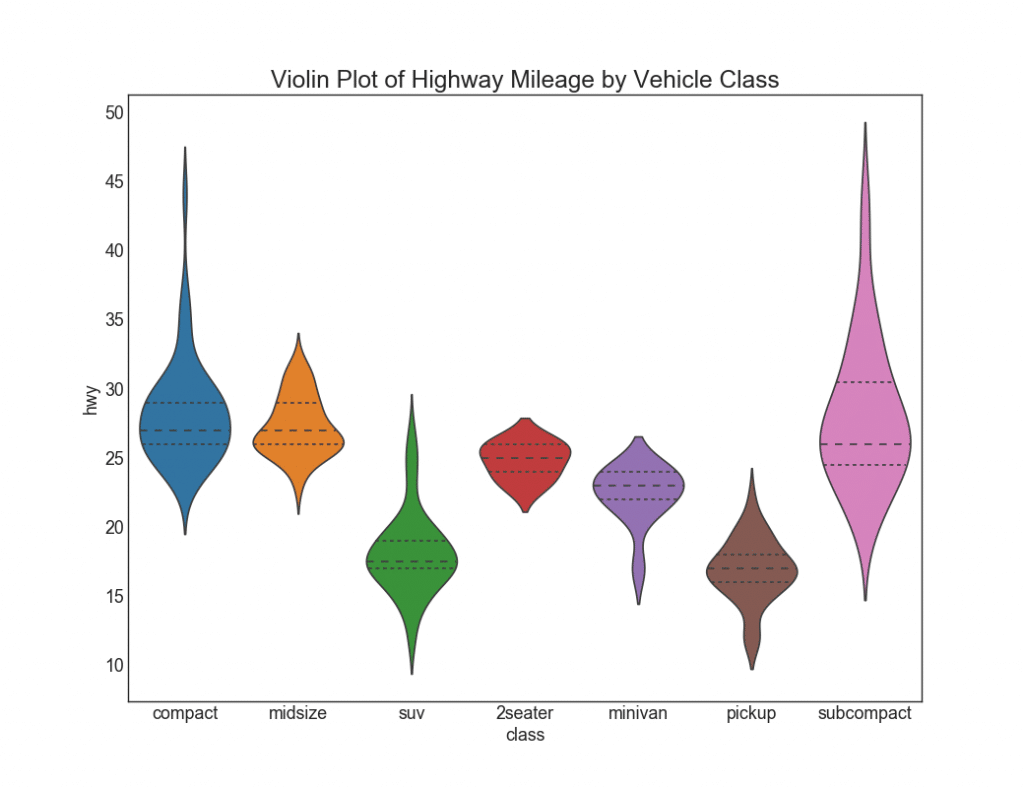
28. График «скрипками»
Такой график — это визуально приятная альтернатива boxplot. Форма или площадь «скрипки» зависит от количества данных в этой группе. Тем не менее, такие графики могут быть сложнее для чтения, и они обычно не используются в профессиональных условиях.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
sns.violinplot(x='class', y='hwy', data=df, scale='width', inner='quartile')
# Decoration
plt.title('Violin Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.show()
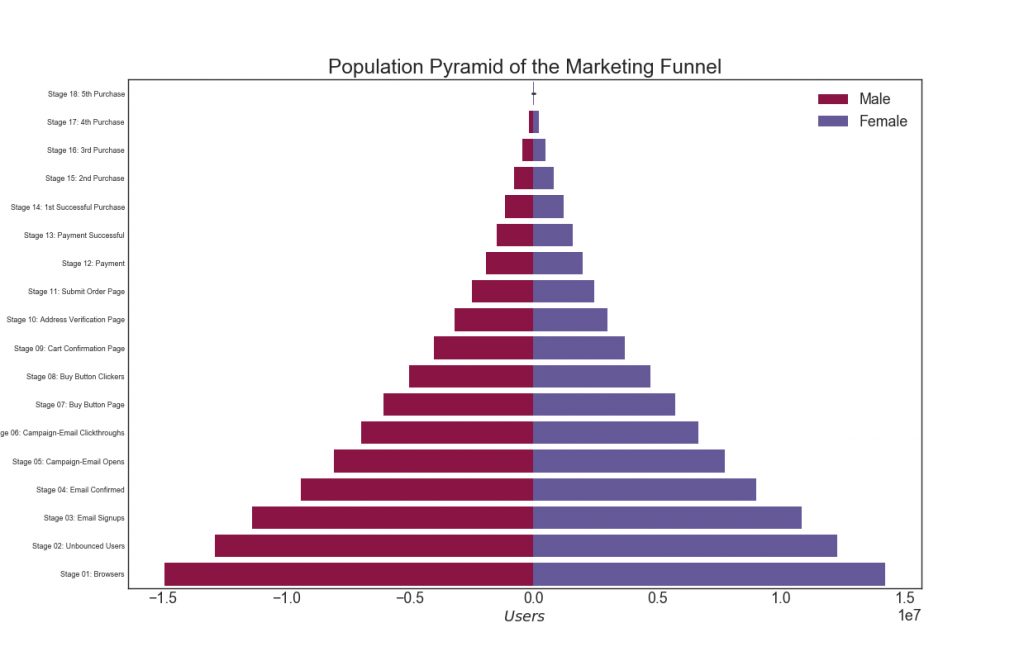
29. Пирамида населенности
Популяционная пирамида может использоваться, чтобы показать распределение групп, упорядоченных по объему, или для показа поэтапной фильтрации населения, как это показано ниже, чтобы визуализировать, сколько людей проходит через каждую стадию воронки маркетинга.
Показать код
# Read data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/email_campaign_funnel.csv")
# Draw Plot
plt.figure(figsize=(13,10), dpi= 80)
group_col = 'Gender'
order_of_bars = df.Stage.unique()[::-1]
colors = [plt.cm.Spectral(i/float(len(df[group_col].unique())-1)) for i in range(len(df[group_col].unique()))]
for c, group in zip(colors, df[group_col].unique()):
sns.barplot(x='Users', y='Stage', data=df.loc[df[group_col]==group, :], order=order_of_bars, color=c, label=group)
# Decorations
plt.xlabel("$Users$")
plt.ylabel("Stage of Purchase")
plt.yticks(fontsize=12)
plt.title("Population Pyramid of the Marketing Funnel", fontsize=22)
plt.legend()
plt.show()
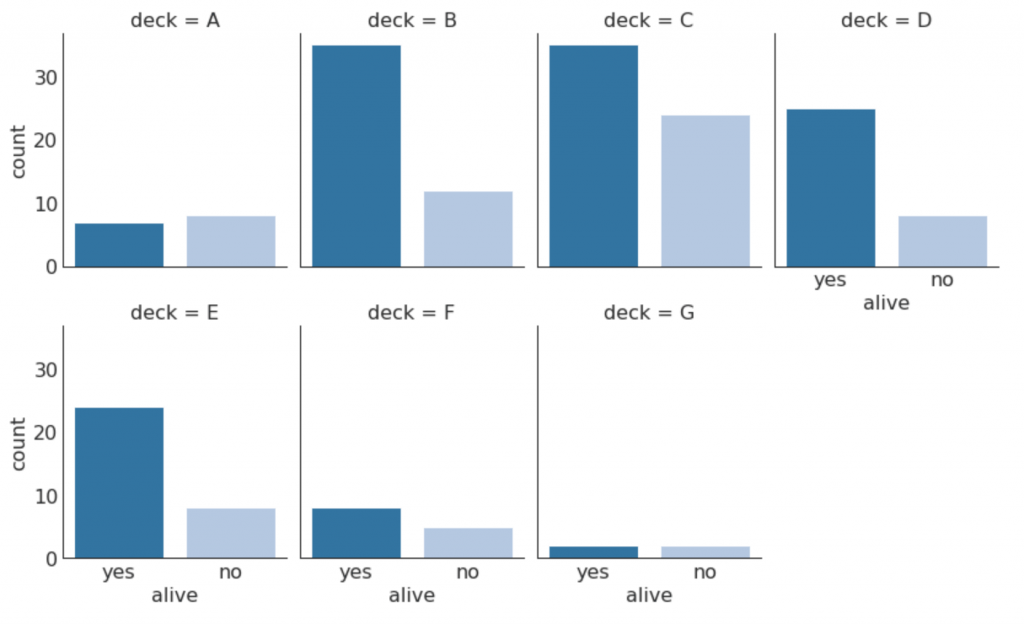
30. Категориальные графики
Категориальные графики, предоставленные библиотекой seaborn, можно использовать для визуализации распределения количества двух или более категориальных переменных по отношению друг к другу.
Показать код
# Load Dataset
titanic = sns.load_dataset("titanic")
# Plot
g = sns.catplot("alive", col="deck", col_wrap=4,
data=titanic[titanic.deck.notnull()],
kind="count", height=3.5, aspect=.8,
palette='tab20')
fig.suptitle('sf')
plt.show()
Показать код
# Load Dataset
titanic = sns.load_dataset("titanic")
# Plot
sns.catplot(x="age", y="embark_town",
hue="sex", col="class",
data=titanic[titanic.embark_town.notnull()],
orient="h", height=5, aspect=1, palette="tab10",
kind="violin", dodge=True, cut=0, bw=.2)
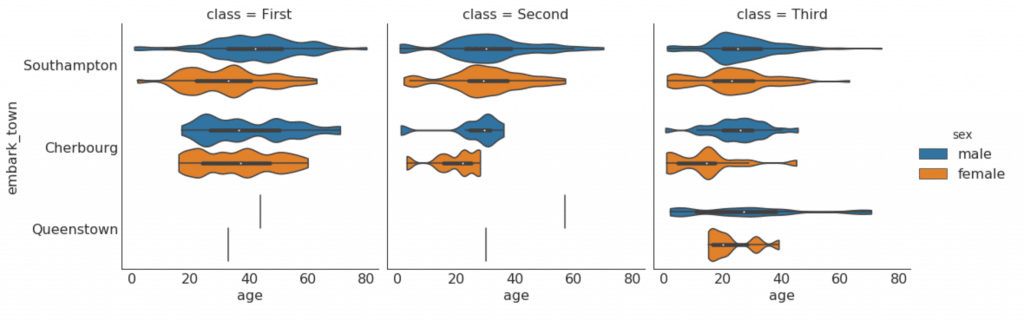
Сборка, композиция
31. Вафельная диаграмма
waffle график может быть создан с помощью pywaffle пакета и используется для отображения композиций групп в большей части населения.
Показать код
#! pip install pywaffle
# Reference: https://stackoverflow.com/questions/41400136/how-to-do-waffle-charts-in-python-square-piechart
from pywaffle import Waffle
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
n_categories = df.shape[0]
colors = [plt.cm.inferno_r(i/float(n_categories)) for i in range(n_categories)]
# Draw Plot and Decorate
fig = plt.figure(
FigureClass=Waffle,
plots={
'111': {
'values': df['counts'],
'labels': ["{0} ({1})".format(n[0], n[1]) for n in df[['class', 'counts']].itertuples()],
'legend': {'loc': 'upper left', 'bbox_to_anchor': (1.05, 1), 'fontsize': 12},
'title': {'label': '# Vehicles by Class', 'loc': 'center', 'fontsize':18}
},
},
rows=7,
colors=colors,
figsize=(16, 9)
)
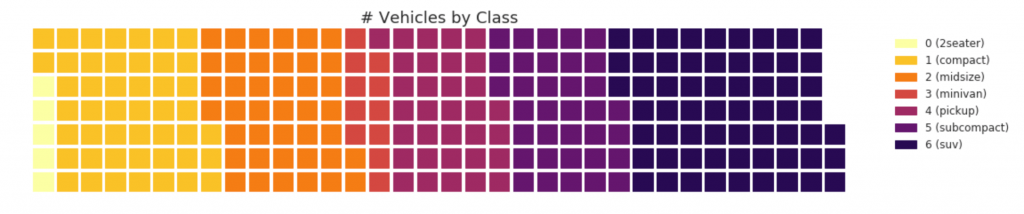
Показать код
#! pip install pywaffle
from pywaffle import Waffle
# Import
# df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
# By Class Data
df_class = df_raw.groupby('class').size().reset_index(name='counts_class')
n_categories = df_class.shape[0]
colors_class = [plt.cm.Set3(i/float(n_categories)) for i in range(n_categories)]
# By Cylinders Data
df_cyl = df_raw.groupby('cyl').size().reset_index(name='counts_cyl')
n_categories = df_cyl.shape[0]
colors_cyl = [plt.cm.Spectral(i/float(n_categories)) for i in range(n_categories)]
# By Make Data
df_make = df_raw.groupby('manufacturer').size().reset_index(name='counts_make')
n_categories = df_make.shape[0]
colors_make = [plt.cm.tab20b(i/float(n_categories)) for i in range(n_categories)]
# Draw Plot and Decorate
fig = plt.figure(
FigureClass=Waffle,
plots={
'311': {
'values': df_class['counts_class'],
'labels': ["{1}".format(n[0], n[1]) for n in df_class[['class', 'counts_class']].itertuples()],
'legend': {'loc': 'upper left', 'bbox_to_anchor': (1.05, 1), 'fontsize': 12, 'title':'Class'},
'title': {'label': '# Vehicles by Class', 'loc': 'center', 'fontsize':18},
'colors': colors_class
},
'312': {
'values': df_cyl['counts_cyl'],
'labels': ["{1}".format(n[0], n[1]) for n in df_cyl[['cyl', 'counts_cyl']].itertuples()],
'legend': {'loc': 'upper left', 'bbox_to_anchor': (1.05, 1), 'fontsize': 12, 'title':'Cyl'},
'title': {'label': '# Vehicles by Cyl', 'loc': 'center', 'fontsize':18},
'colors': colors_cyl
},
'313': {
'values': df_make['counts_make'],
'labels': ["{1}".format(n[0], n[1]) for n in df_make[['manufacturer', 'counts_make']].itertuples()],
'legend': {'loc': 'upper left', 'bbox_to_anchor': (1.05, 1), 'fontsize': 12, 'title':'Manufacturer'},
'title': {'label': '# Vehicles by Make', 'loc': 'center', 'fontsize':18},
'colors': colors_make
}
},
rows=9,
figsize=(16, 14)
)
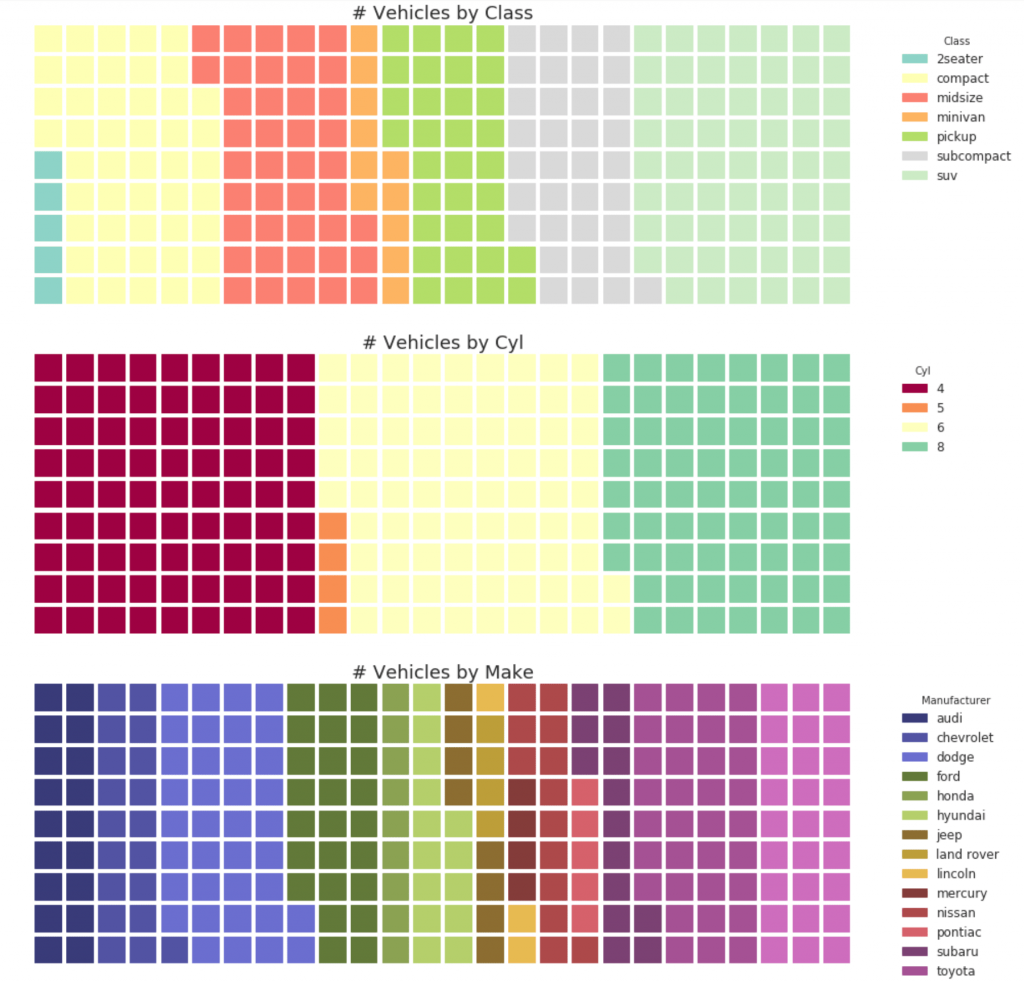
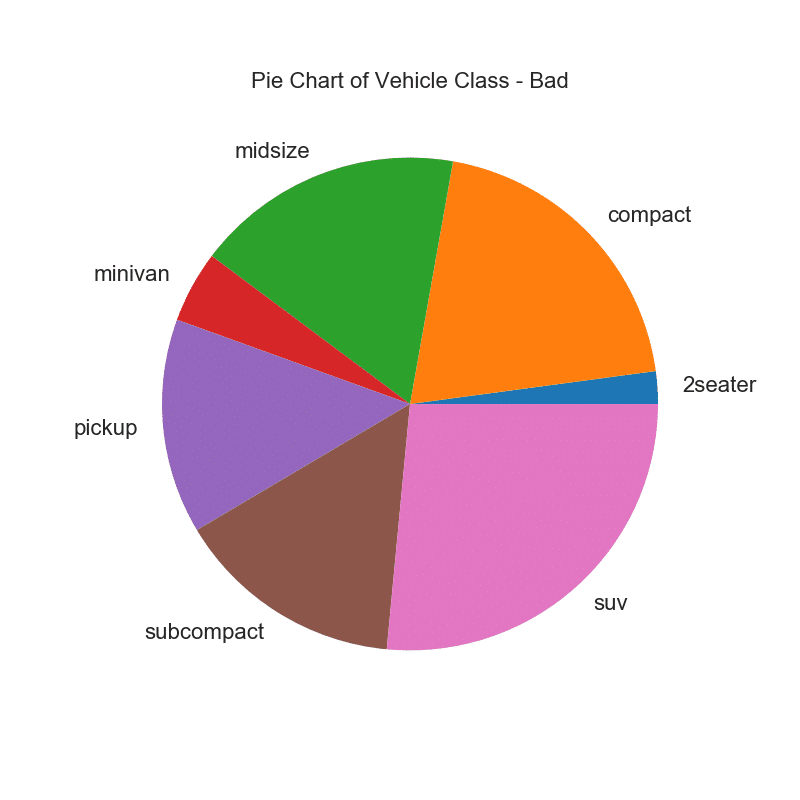
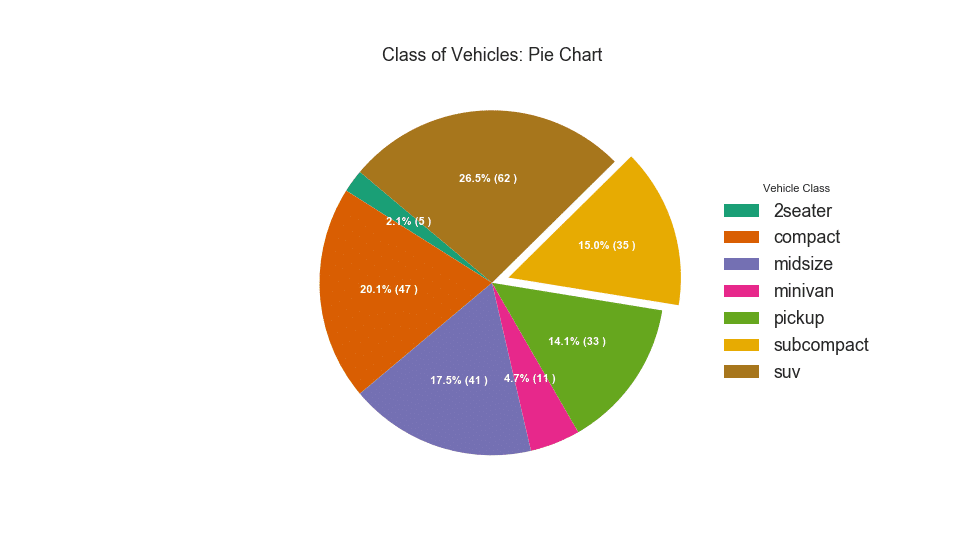
32. Круговая диаграмма
Круговая диаграмма — это классический способ показать состав групп. Тем не менее, в настоящее время, как правило, не рекомендуется использовать этот график, потому что площадь сегментов может иногда вводить в заблуждение. Поэтому, если вы хотите использовать круговую диаграмму, настоятельно рекомендуется явно записать процент или число для каждой части круговой диаграммы.
Показать код
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size()
# Make the plot with pandas
df.plot(kind='pie', subplots=True, figsize=(8, 8), dpi= 80)
plt.title("Pie Chart of Vehicle Class - Bad")
plt.ylabel("")
plt.show()
Показать код
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
# Draw Plot
fig, ax = plt.subplots(figsize=(12, 7), subplot_kw=dict(aspect="equal"), dpi= 80)
data = df['counts']
categories = df['class']
explode = [0,0,0,0,0,0.1,0]
def func(pct, allvals):
absolute = int(pct/100.*np.sum(allvals))
return "{:.1f}% ({:d} )".format(pct, absolute)
wedges, texts, autotexts = ax.pie(data,
autopct=lambda pct: func(pct, data),
textprops=dict(color="w"),
colors=plt.cm.Dark2.colors,
startangle=140,
explode=explode)
# Decoration
ax.legend(wedges, categories, title="Vehicle Class", loc="center left", bbox_to_anchor=(1, 0, 0.5, 1))
plt.setp(autotexts, size=10, weight=700)
ax.set_title("Class of Vehicles: Pie Chart")
plt.show()
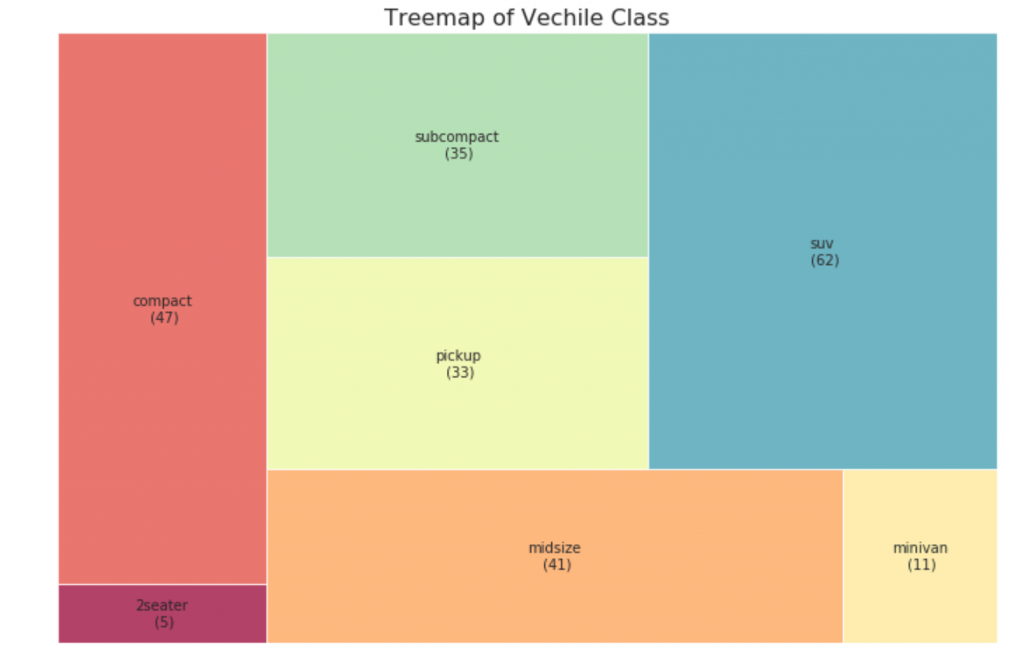
33. Древовидная карта
Древовидная карта похожа на круговую диаграмму и работает лучше, не вводя в заблуждение долю каждой группы.
Показать код
# pip install squarify
import squarify
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
labels = df.apply(lambda x: str(x[0]) + "n (" + str(x[1]) + ")", axis=1)
sizes = df['counts'].values.tolist()
colors = [plt.cm.Spectral(i/float(len(labels))) for i in range(len(labels))]
# Draw Plot
plt.figure(figsize=(12,8), dpi= 80)
squarify.plot(sizes=sizes, label=labels, color=colors, alpha=.8)
# Decorate
plt.title('Treemap of Vechile Class')
plt.axis('off')
plt.show()
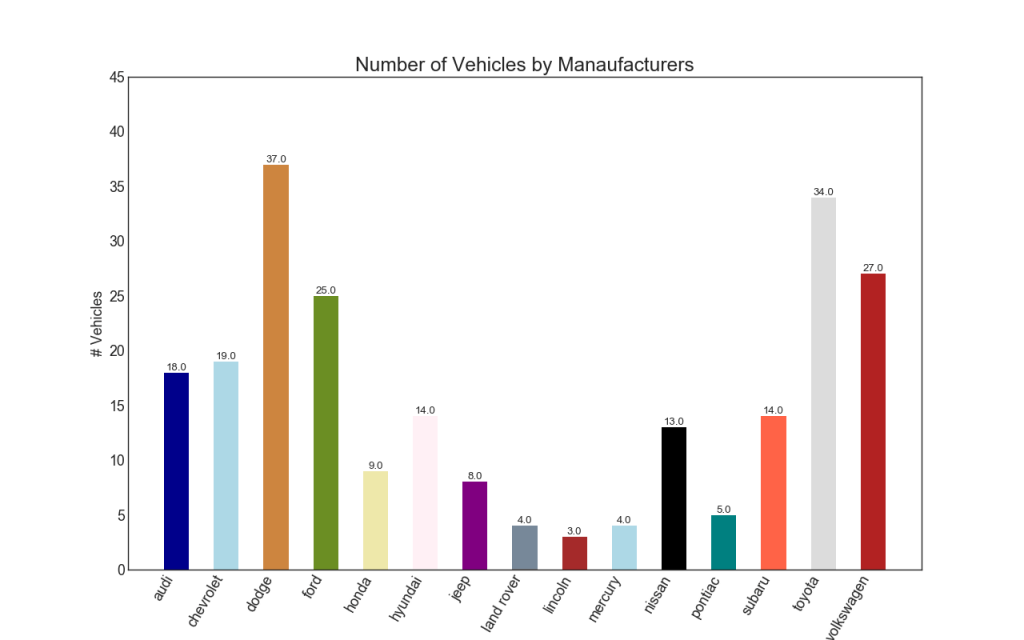
34. Гистограмма
Гистограмма — это классический способ визуализации элементов на основе количества или любой заданной метрики. На приведенной ниже диаграмме я использовал разные цвета для каждого элемента, но вы можете выбрать один цвет для всех элементов, если вы не хотите раскрашивать их по группам. Имена цветов хранятся внутри all_colors в коде ниже. Вы можете изменить цвет полос, установив параметр color в .plt.plot()
Показать код
import random
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('manufacturer').size().reset_index(name='counts')
n = df['manufacturer'].unique().__len__()+1
all_colors = list(plt.cm.colors.cnames.keys())
random.seed(100)
c = random.choices(all_colors, k=n)
# Plot Bars
plt.figure(figsize=(16,10), dpi= 80)
plt.bar(df['manufacturer'], df['counts'], color=c, width=.5)
for i, val in enumerate(df['counts'].values):
plt.text(i, val, float(val), horizontalalignment='center', verticalalignment='bottom', fontdict={'fontweight':500, 'size':12})
# Decoration
plt.gca().set_xticklabels(df['manufacturer'], rotation=60, horizontalalignment= 'right')
plt.title("Number of Vehicles by Manaufacturers", fontsize=22)
plt.ylabel('# Vehicles')
plt.ylim(0, 45)
plt.show()
Отслеживание изменений
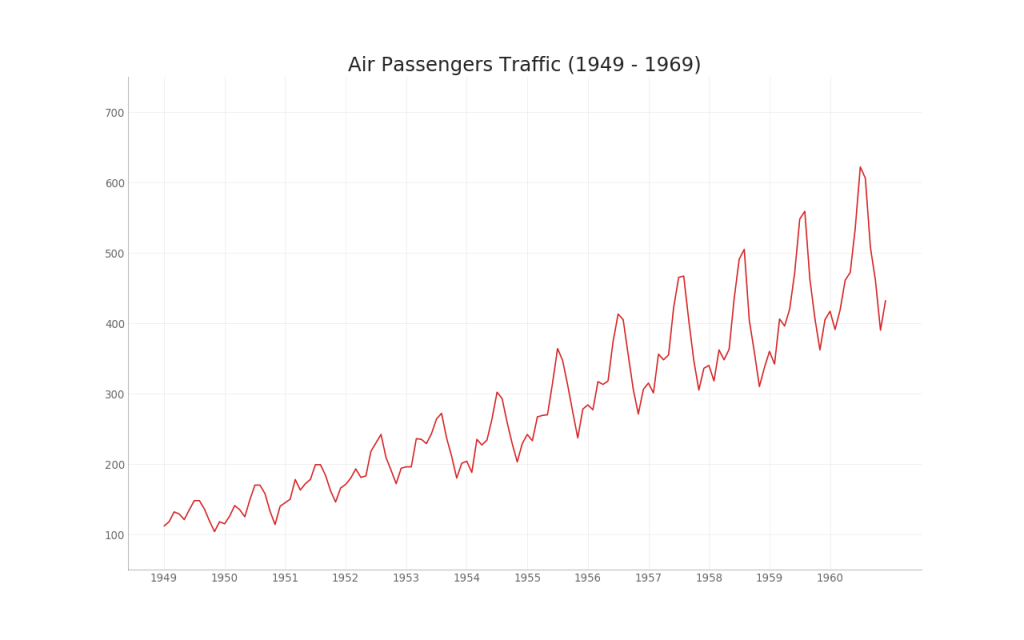
35. График временного ряда
График временных рядов используется для визуализации того, как данный показатель изменяется со временем. Здесь вы можете увидеть, как пассажиропоток изменился с 1949 по 1969 год.
Показать код
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
# Draw Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.plot('date', 'traffic', data=df, color='tab:red')
# Decoration
plt.ylim(50, 750)
xtick_location = df.index.tolist()[::12]
xtick_labels = [x[-4:] for x in df.date.tolist()[::12]]
plt.xticks(ticks=xtick_location, labels=xtick_labels, rotation=0, fontsize=12, horizontalalignment='center', alpha=.7)
plt.yticks(fontsize=12, alpha=.7)
plt.title("Air Passengers Traffic (1949 - 1969)", fontsize=22)
plt.grid(axis='both', alpha=.3)
# Remove borders
plt.gca().spines["top"].set_alpha(0.0)
plt.gca().spines["bottom"].set_alpha(0.3)
plt.gca().spines["right"].set_alpha(0.0)
plt.gca().spines["left"].set_alpha(0.3)
plt.show()
36. Временные ряды с пиками и впадинами
Приведенный ниже временной ряд отображает все пики и впадины и отмечает возникновение отдельных особых событий.
Показать код
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
# Get the Peaks and Troughs
data = df['traffic'].values
doublediff = np.diff(np.sign(np.diff(data)))
peak_locations = np.where(doublediff == -2)[0] + 1
doublediff2 = np.diff(np.sign(np.diff(-1*data)))
trough_locations = np.where(doublediff2 == -2)[0] + 1
# Draw Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.plot('date', 'traffic', data=df, color='tab:blue', label='Air Traffic')
plt.scatter(df.date[peak_locations], df.traffic[peak_locations], marker=mpl.markers.CARETUPBASE, color='tab:green', s=100, label='Peaks')
plt.scatter(df.date[trough_locations], df.traffic[trough_locations], marker=mpl.markers.CARETDOWNBASE, color='tab:red', s=100, label='Troughs')
# Annotate
for t, p in zip(trough_locations[1::5], peak_locations[::3]):
plt.text(df.date[p], df.traffic[p]+15, df.date[p], horizontalalignment='center', color='darkgreen')
plt.text(df.date[t], df.traffic[t]-35, df.date[t], horizontalalignment='center', color='darkred')
# Decoration
plt.ylim(50,750)
xtick_location = df.index.tolist()[::6]
xtick_labels = df.date.tolist()[::6]
plt.xticks(ticks=xtick_location, labels=xtick_labels, rotation=90, fontsize=12, alpha=.7)
plt.title("Peak and Troughs of Air Passengers Traffic (1949 - 1969)", fontsize=22)
plt.yticks(fontsize=12, alpha=.7)
# Lighten borders
plt.gca().spines["top"].set_alpha(.0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(.0)
plt.gca().spines["left"].set_alpha(.3)
plt.legend(loc='upper left')
plt.grid(axis='y', alpha=.3)
plt.show()
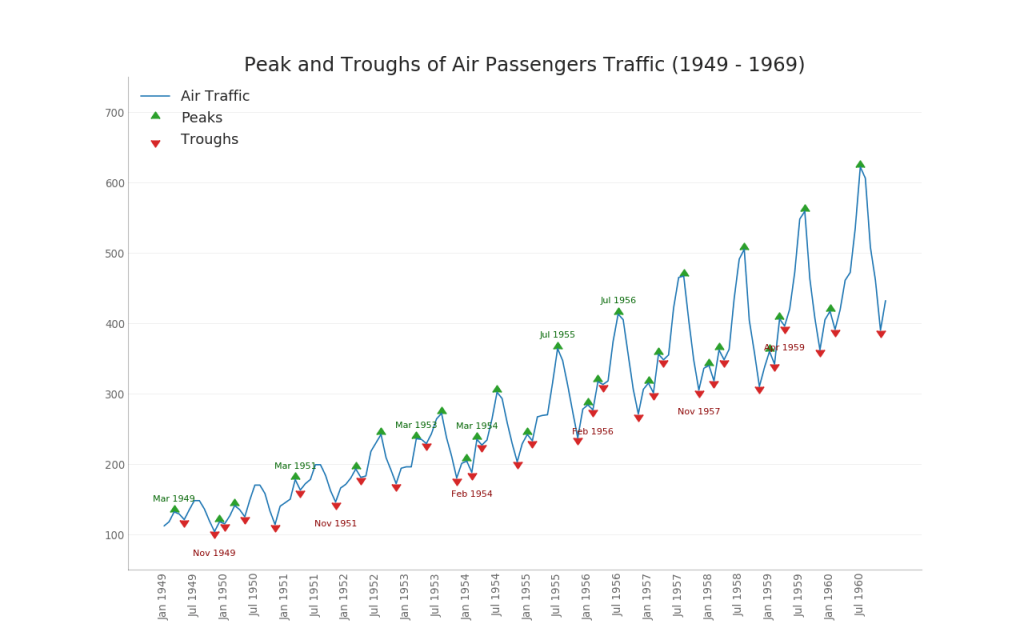
37. График автокорреляции (ACF) и частичной автокорреляции (PACF)
График ACF показывает корреляцию временного ряда с его собственным временем. Каждая вертикальная линия (на графике автокорреляции) представляет корреляцию между рядом и его временем, начиная с времени 0. Синяя заштрихованная область на графике является уровнем значимости. Те моменты, которые лежат выше синей линии, являются существенными.
Так как же это интерпретировать?
Для AirPassengers мы видим, что в x=14 «леденцы» пересекли синюю линию и, таким образом, имеют большое значение. Это означает, что пассажиропоток, наблюдавшийся до 14 лет назад, оказывает влияние на движение, наблюдаемое сегодня.
PACF, с другой стороны, показывает автокорреляцию любого заданного времени (временного ряда) с текущим рядом, но с удалением влияний между ними.
Показать код
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
# Draw Plot
fig, (ax1, ax2) = plt.subplots(1, 2,figsize=(16,6), dpi= 80)
plot_acf(df.traffic.tolist(), ax=ax1, lags=50)
plot_pacf(df.traffic.tolist(), ax=ax2, lags=20)
# Decorate
# lighten the borders
ax1.spines["top"].set_alpha(.3); ax2.spines["top"].set_alpha(.3)
ax1.spines["bottom"].set_alpha(.3); ax2.spines["bottom"].set_alpha(.3)
ax1.spines["right"].set_alpha(.3); ax2.spines["right"].set_alpha(.3)
ax1.spines["left"].set_alpha(.3); ax2.spines["left"].set_alpha(.3)
# font size of tick labels
ax1.tick_params(axis='both', labelsize=12)
ax2.tick_params(axis='both', labelsize=12)
plt.show()
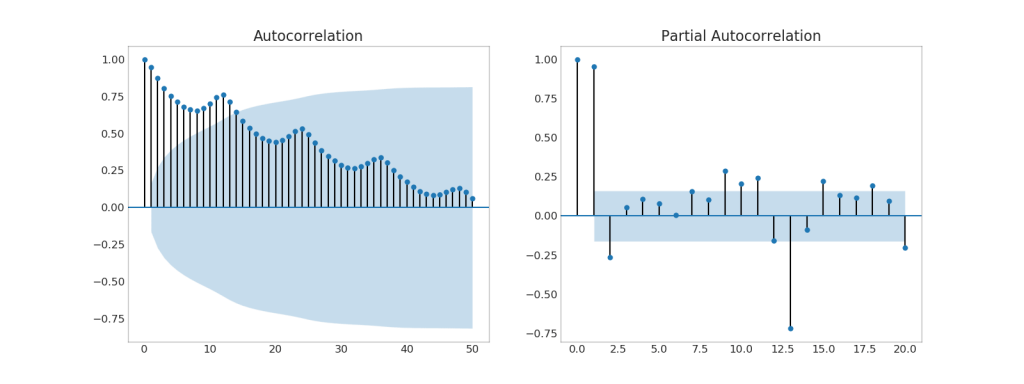
38. Кросс-корреляционный график
График взаимной корреляции показывает задержки двух временных рядов друг с другом.
Показать код
import statsmodels.tsa.stattools as stattools
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/mortality.csv')
x = df['mdeaths']
y = df['fdeaths']
# Compute Cross Correlations
ccs = stattools.ccf(x, y)[:100]
nlags = len(ccs)
# Compute the Significance level
# ref: https://stats.stackexchange.com/questions/3115/cross-correlation-significance-in-r/3128#3128
conf_level = 2 / np.sqrt(nlags)
# Draw Plot
plt.figure(figsize=(12,7), dpi= 80)
plt.hlines(0, xmin=0, xmax=100, color='gray') # 0 axis
plt.hlines(conf_level, xmin=0, xmax=100, color='gray')
plt.hlines(-conf_level, xmin=0, xmax=100, color='gray')
plt.bar(x=np.arange(len(ccs)), height=ccs, width=.3)
# Decoration
plt.title('$Cross; Correlation; Plot:; mdeaths; vs; fdeaths$', fontsize=22)
plt.xlim(0,len(ccs))
plt.show()
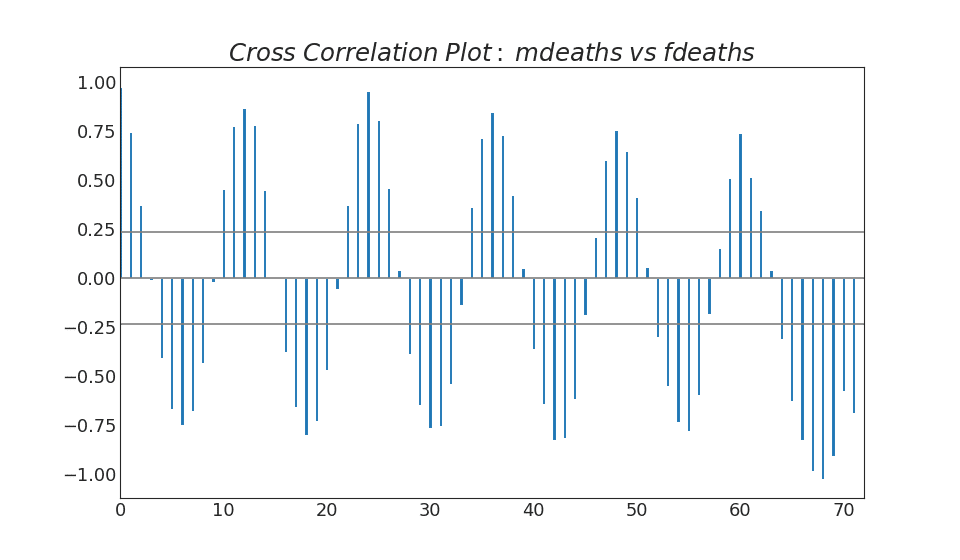
39. Разложение временных рядов
График разложения временных рядов показывает разбивку временных рядов на трендовую, сезонную и остаточную составляющие.
Показать код
from statsmodels.tsa.seasonal import seasonal_decompose
from dateutil.parser import parse
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
dates = pd.DatetimeIndex([parse(d).strftime('%Y-%m-01') for d in df['date']])
df.set_index(dates, inplace=True)
# Decompose
result = seasonal_decompose(df['traffic'], model='multiplicative')
# Plot
plt.rcParams.update({'figure.figsize': (10,10)})
result.plot().suptitle('Time Series Decomposition of Air Passengers')
plt.show()
40. Несколько временных рядов
Вы можете построить несколько временных рядов, которые измеряют одно и то же значение на одном графике, как показано ниже.
Показать код
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/mortality.csv')
# Define the upper limit, lower limit, interval of Y axis and colors
y_LL = 100
y_UL = int(df.iloc[:, 1:].max().max()*1.1)
y_interval = 400
mycolors = ['tab:red', 'tab:blue', 'tab:green', 'tab:orange']
# Draw Plot and Annotate
fig, ax = plt.subplots(1,1,figsize=(16, 9), dpi= 80)
columns = df.columns[1:]
for i, column in enumerate(columns):
plt.plot(df.date.values, df
.values, lw=1.5, color=mycolors[i])
plt.text(df.shape[0]+1, df
.values[-1], column, fontsize=14, color=mycolors[i])
# Draw Tick lines
for y in range(y_LL, y_UL, y_interval):
plt.hlines(y, xmin=0, xmax=71, colors='black', alpha=0.3, linestyles="--", lw=0.5)
# Decorations
plt.tick_params(axis="both", which="both", bottom=False, top=False,
labelbottom=True, left=False, right=False, labelleft=True)
# Lighten borders
plt.gca().spines["top"].set_alpha(.3)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(.3)
plt.gca().spines["left"].set_alpha(.3)
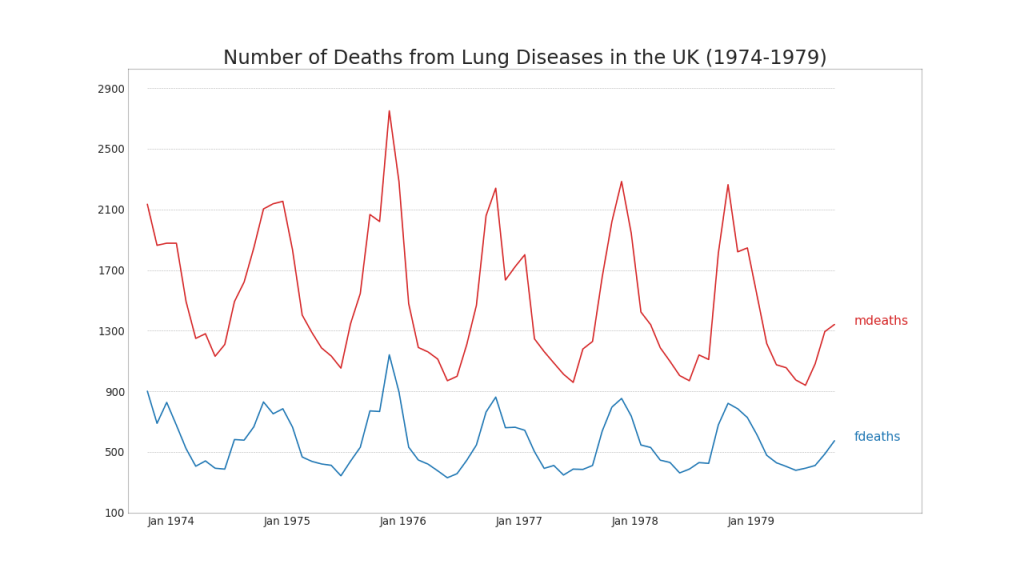
plt.title('Number of Deaths from Lung Diseases in the UK (1974-1979)', fontsize=22)
plt.yticks(range(y_LL, y_UL, y_interval), [str(y) for y in range(y_LL, y_UL, y_interval)], fontsize=12)
plt.xticks(range(0, df.shape[0], 12), df.date.values[::12], horizontalalignment='left', fontsize=12)
plt.ylim(y_LL, y_UL)
plt.xlim(-2, 80)
plt.show()
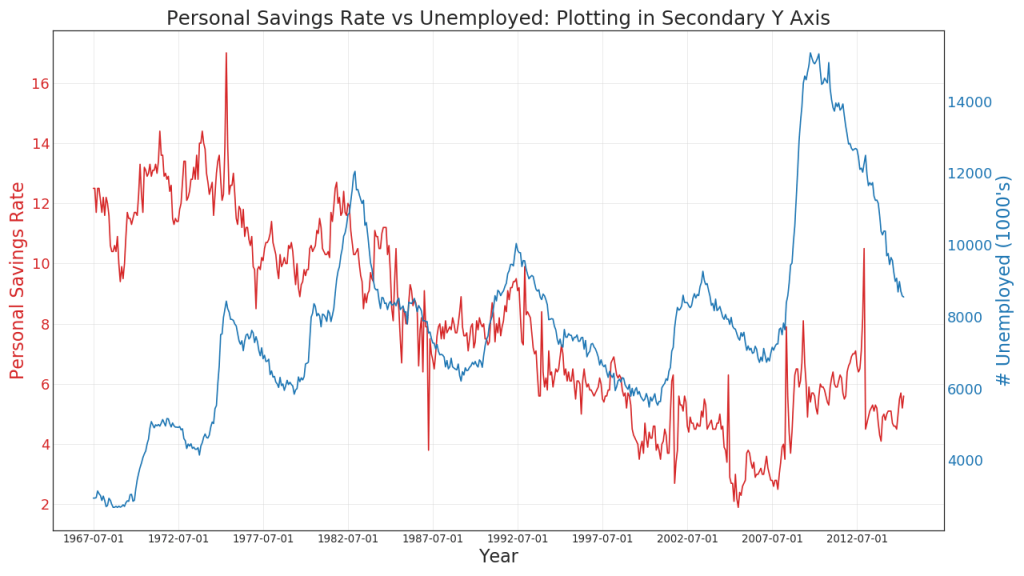
41. Построение в разных масштабах с использованием вторичной оси Y
Если вы хотите показать два временных ряда, которые измеряют две разные величины в один и тот же момент времени, вы можете построить второй ряд снова на вторичной оси Y справа.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv")
x = df['date']
y1 = df['psavert']
y2 = df['unemploy']
# Plot Line1 (Left Y Axis)
fig, ax1 = plt.subplots(1,1,figsize=(16,9), dpi= 80)
ax1.plot(x, y1, color='tab:red')
# Plot Line2 (Right Y Axis)
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
ax2.plot(x, y2, color='tab:blue')
# Decorations
# ax1 (left Y axis)
ax1.set_xlabel('Year', fontsize=20)
ax1.tick_params(axis='x', rotation=0, labelsize=12)
ax1.set_ylabel('Personal Savings Rate', color='tab:red', fontsize=20)
ax1.tick_params(axis='y', rotation=0, labelcolor='tab:red' )
ax1.grid(alpha=.4)
# ax2 (right Y axis)
ax2.set_ylabel("# Unemployed (1000's)", color='tab:blue', fontsize=20)
ax2.tick_params(axis='y', labelcolor='tab:blue')
ax2.set_xticks(np.arange(0, len(x), 60))
ax2.set_xticklabels(x[::60], rotation=90, fontdict={'fontsize':10})
ax2.set_title("Personal Savings Rate vs Unemployed: Plotting in Secondary Y Axis", fontsize=22)
fig.tight_layout()
plt.show()
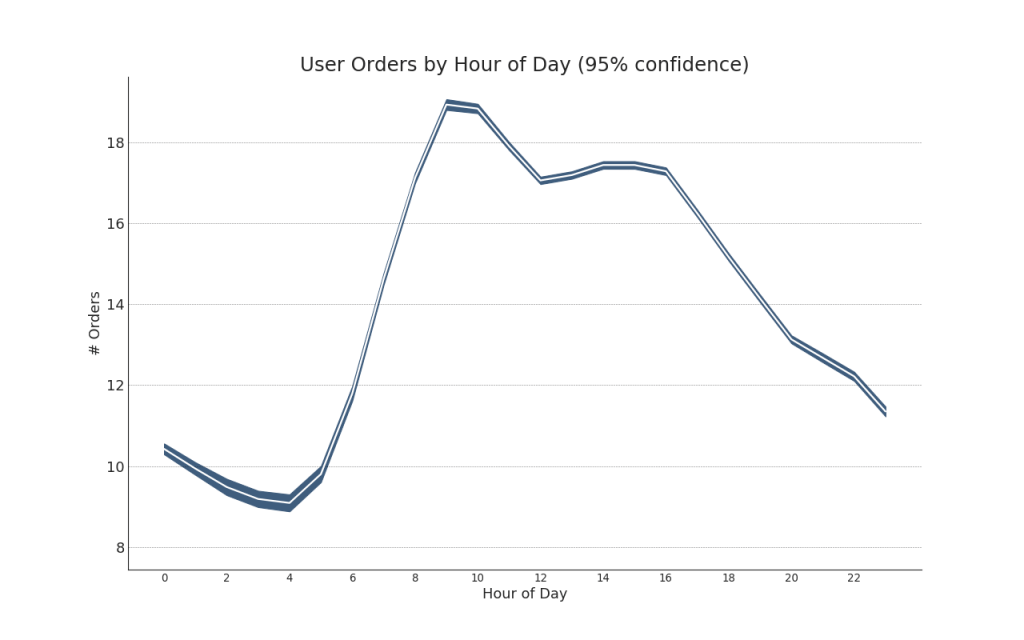
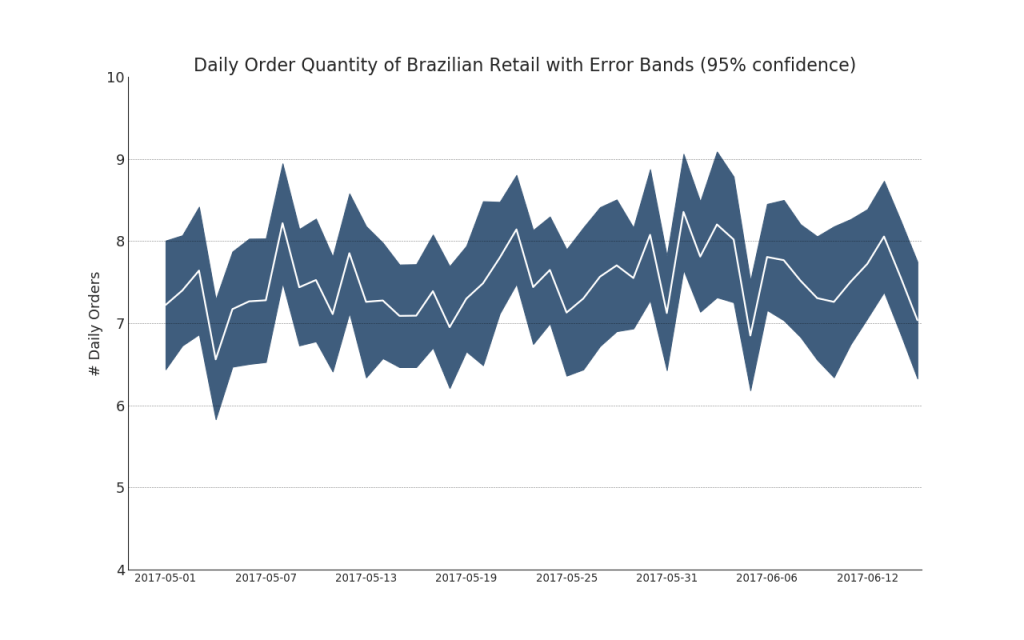
42. Временные ряды с полосами ошибок
Временные ряды с полосами ошибок могут быть построены, если у вас есть набор данных временных рядов с несколькими наблюдениями для каждой временной точки (дата / временная метка). Ниже вы можете увидеть несколько примеров, основанных на поступлении заказов в разное время дня. И еще один пример количества заказов, поступивших в течение 45 дней.
При таком подходе среднее количество заказов обозначается белой линией. И 95% -ые интервалы вычисляются и строятся вокруг среднего значения.
Показать код
from scipy.stats import sem
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/user_orders_hourofday.csv")
df_mean = df.groupby('order_hour_of_day').quantity.mean()
df_se = df.groupby('order_hour_of_day').quantity.apply(sem).mul(1.96)
# Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.ylabel("# Orders", fontsize=16)
x = df_mean.index
plt.plot(x, df_mean, color="white", lw=2)
plt.fill_between(x, df_mean - df_se, df_mean + df_se, color="#3F5D7D")
# Decorations
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(1)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(1)
plt.xticks(x[::2], [str(d) for d in x[::2]] , fontsize=12)
plt.title("User Orders by Hour of Day (95% confidence)", fontsize=22)
plt.xlabel("Hour of Day")
s, e = plt.gca().get_xlim()
plt.xlim(s, e)
# Draw Horizontal Tick lines
for y in range(8, 20, 2):
plt.hlines(y, xmin=s, xmax=e, colors='black', alpha=0.5, linestyles="--", lw=0.5)
plt.show()
Показать код
"Data Source: https://www.kaggle.com/olistbr/brazilian-ecommerce#olist_orders_dataset.csv"
from dateutil.parser import parse
from scipy.stats import sem
# Import Data
df_raw = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/orders_45d.csv',
parse_dates=['purchase_time', 'purchase_date'])
# Prepare Data: Daily Mean and SE Bands
df_mean = df_raw.groupby('purchase_date').quantity.mean()
df_se = df_raw.groupby('purchase_date').quantity.apply(sem).mul(1.96)
# Plot
plt.figure(figsize=(16,10), dpi= 80)
plt.ylabel("# Daily Orders", fontsize=16)
x = [d.date().strftime('%Y-%m-%d') for d in df_mean.index]
plt.plot(x, df_mean, color="white", lw=2)
plt.fill_between(x, df_mean - df_se, df_mean + df_se, color="#3F5D7D")
# Decorations
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(1)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(1)
plt.xticks(x[::6], [str(d) for d in x[::6]] , fontsize=12)
plt.title("Daily Order Quantity of Brazilian Retail with Error Bands (95% confidence)", fontsize=20)
# Axis limits
s, e = plt.gca().get_xlim()
plt.xlim(s, e-2)
plt.ylim(4, 10)
# Draw Horizontal Tick lines
for y in range(5, 10, 1):
plt.hlines(y, xmin=s, xmax=e, colors='black', alpha=0.5, linestyles="--", lw=0.5)
plt.show()
43. Диаграмма с накоплением
Диаграмма с областями с накоплением дает визуальное представление степени вклада от нескольких временных рядов.
Показать код
# Import Data
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/nightvisitors.csv')
# Decide Colors
mycolors = ['tab:red', 'tab:blue', 'tab:green', 'tab:orange', 'tab:brown', 'tab:grey', 'tab:pink', 'tab:olive']
# Draw Plot and Annotate
fig, ax = plt.subplots(1,1,figsize=(16, 9), dpi= 80)
columns = df.columns[1:]
labs = columns.values.tolist()
# Prepare data
x = df['yearmon'].values.tolist()
y0 = df[columns[0]].values.tolist()
y1 = df[columns[1]].values.tolist()
y2 = df[columns[2]].values.tolist()
y3 = df[columns[3]].values.tolist()
y4 = df[columns[4]].values.tolist()
y5 = df[columns[5]].values.tolist()
y6 = df[columns[6]].values.tolist()
y7 = df[columns[7]].values.tolist()
y = np.vstack([y0, y2, y4, y6, y7, y5, y1, y3])
# Plot for each column
labs = columns.values.tolist()
ax = plt.gca()
ax.stackplot(x, y, labels=labs, colors=mycolors, alpha=0.8)
# Decorations
ax.set_title('Night Visitors in Australian Regions', fontsize=18)
ax.set(ylim=[0, 100000])
ax.legend(fontsize=10, ncol=4)
plt.xticks(x[::5], fontsize=10, horizontalalignment='center')
plt.yticks(np.arange(10000, 100000, 20000), fontsize=10)
plt.xlim(x[0], x[-1])
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.show()
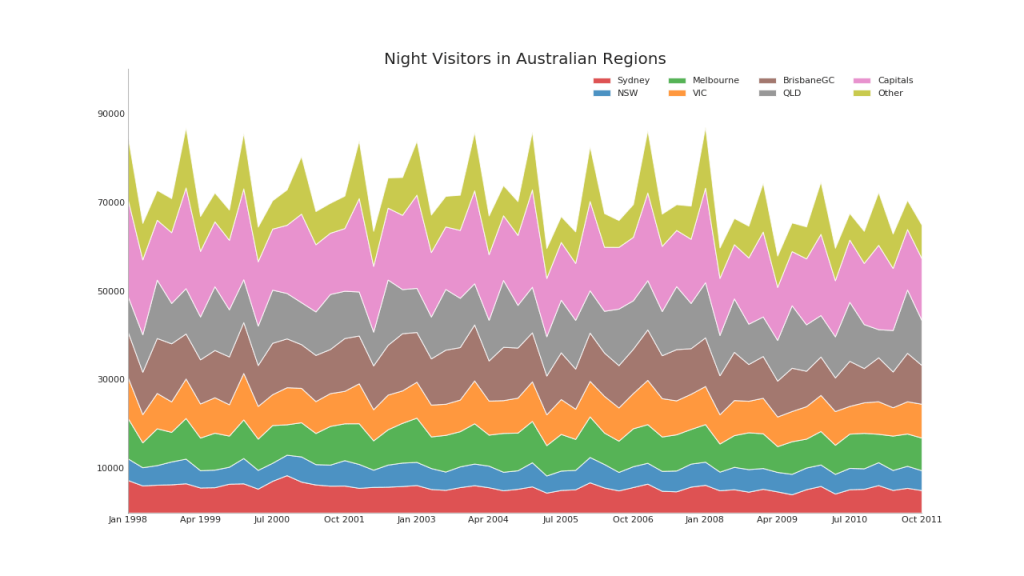
44. Диаграмма площади Unstacked
Диаграмма незакрытой области используется для визуализации прогресса (взлеты и падения) двух или более рядов относительно друг друга. На приведенной ниже диаграмме вы можете четко увидеть, как норма личных сбережений снижается при увеличении средней продолжительности безработицы. Диаграмма с незакрытыми участками хорошо показывает это явление.
Показать код
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv")
# Prepare Data
x = df['date'].values.tolist()
y1 = df['psavert'].values.tolist()
y2 = df['uempmed'].values.tolist()
mycolors = ['tab:red', 'tab:blue', 'tab:green', 'tab:orange', 'tab:brown', 'tab:grey', 'tab:pink', 'tab:olive']
columns = ['psavert', 'uempmed']
# Draw Plot
fig, ax = plt.subplots(1, 1, figsize=(16,9), dpi= 80)
ax.fill_between(x, y1=y1, y2=0, label=columns[1], alpha=0.5, color=mycolors[1], linewidth=2)
ax.fill_between(x, y1=y2, y2=0, label=columns[0], alpha=0.5, color=mycolors[0], linewidth=2)
# Decorations
ax.set_title('Personal Savings Rate vs Median Duration of Unemployment', fontsize=18)
ax.set(ylim=[0, 30])
ax.legend(loc='best', fontsize=12)
plt.xticks(x[::50], fontsize=10, horizontalalignment='center')
plt.yticks(np.arange(2.5, 30.0, 2.5), fontsize=10)
plt.xlim(-10, x[-1])
# Draw Tick lines
for y in np.arange(2.5, 30.0, 2.5):
plt.hlines(y, xmin=0, xmax=len(x), colors='black', alpha=0.3, linestyles="--", lw=0.5)
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.show()
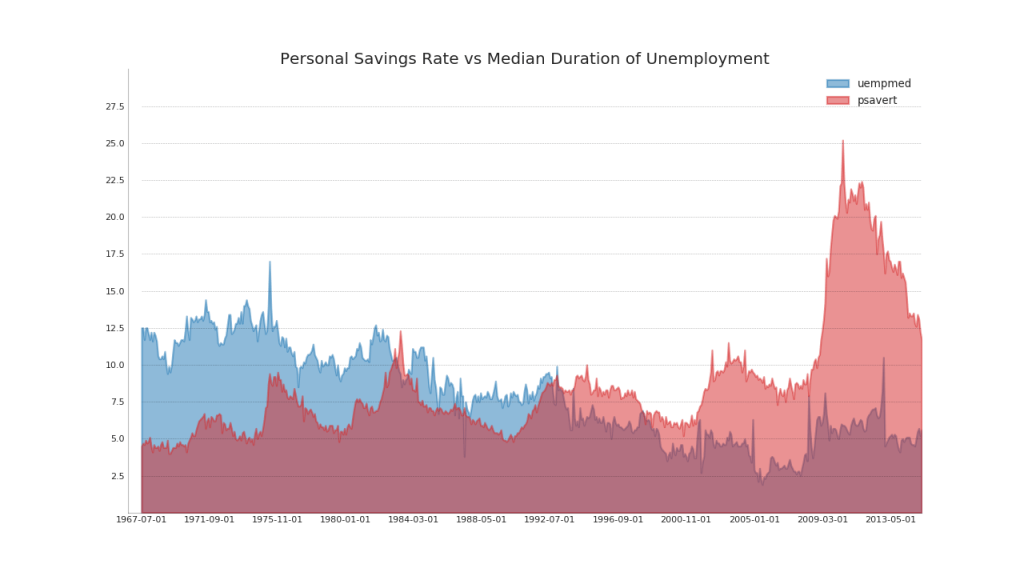
45. Календарная тепловая карта
Календарная карта является альтернативным и менее предпочтительным вариантом для визуализации данных на основе времени по сравнению с временным рядом. Хотя они могут быть визуально привлекательными, числовые значения не совсем очевидны.
Показать код
import matplotlib as mpl
import calmap
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/yahoo.csv", parse_dates=['date'])
df.set_index('date', inplace=True)
# Plot
plt.figure(figsize=(16,10), dpi= 80)
calmap.calendarplot(df['2014']['VIX.Close'], fig_kws={'figsize': (16,10)}, yearlabel_kws={'color':'black', 'fontsize':14}, subplot_kws={'title':'Yahoo Stock Prices'})
plt.show()

46. График сезонов
Сезонный график может использоваться для сравнения временных рядов, выполненных в тот же день в предыдущем сезоне (год / месяц / неделя и т. д.).
Показать код
from dateutil.parser import parse
# Import Data
df = pd.read_csv('https://github.com/selva86/datasets/raw/master/AirPassengers.csv')
# Prepare data
df['year'] = [parse(d).year for d in df.date]
df['month'] = [parse(d).strftime('%b') for d in df.date]
years = df['year'].unique()
# Draw Plot
mycolors = ['tab:red', 'tab:blue', 'tab:green', 'tab:orange', 'tab:brown', 'tab:grey', 'tab:pink', 'tab:olive', 'deeppink', 'steelblue', 'firebrick', 'mediumseagreen']
plt.figure(figsize=(16,10), dpi= 80)
for i, y in enumerate(years):
plt.plot('month', 'traffic', data=df.loc[df.year==y, :], color=mycolors[i], label=y)
plt.text(df.loc[df.year==y, :].shape[0]-.9, df.loc[df.year==y, 'traffic'][-1:].values[0], y, fontsize=12, color=mycolors[i])
# Decoration
plt.ylim(50,750)
plt.xlim(-0.3, 11)
plt.ylabel('$Air Traffic$')
plt.yticks(fontsize=12, alpha=.7)
plt.title("Monthly Seasonal Plot: Air Passengers Traffic (1949 - 1969)", fontsize=22)
plt.grid(axis='y', alpha=.3)
# Remove borders
plt.gca().spines["top"].set_alpha(0.0)
plt.gca().spines["bottom"].set_alpha(0.5)
plt.gca().spines["right"].set_alpha(0.0)
plt.gca().spines["left"].set_alpha(0.5)
# plt.legend(loc='upper right', ncol=2, fontsize=12)
plt.show()
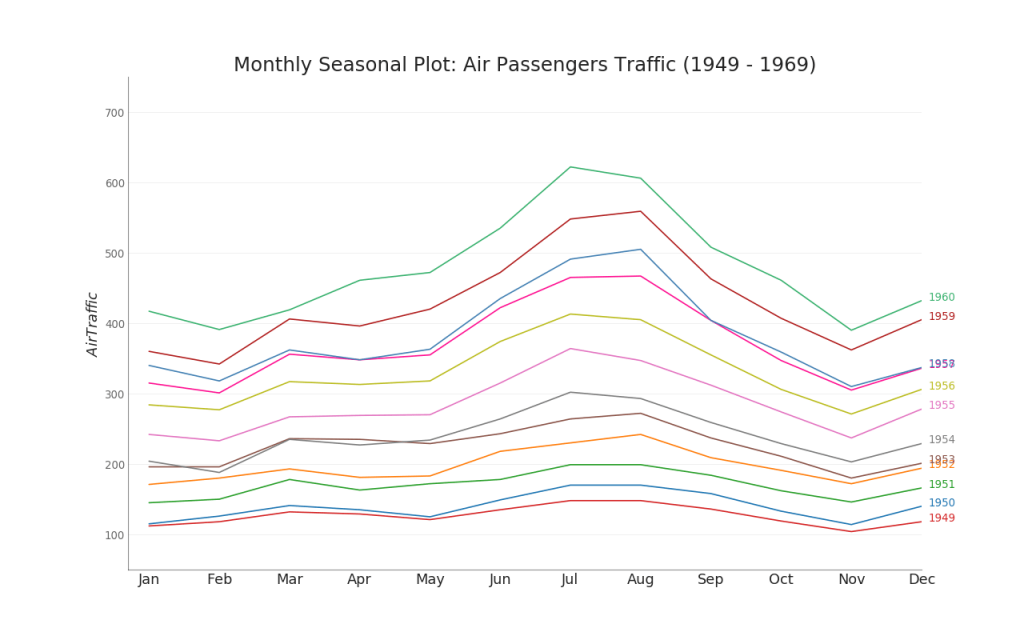
Группы
47. Дендрограмма
Дендрограмма группирует сходные точки на основе заданной метрики расстояния и упорядочивает их в виде древовидных связей на основе сходства точек.
Показать код
import scipy.cluster.hierarchy as shc
# Import Data
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/USArrests.csv')
# Plot
plt.figure(figsize=(16, 10), dpi= 80)
plt.title("USArrests Dendograms", fontsize=22)
dend = shc.dendrogram(shc.linkage(df[['Murder', 'Assault', 'UrbanPop', 'Rape']], method='ward'), labels=df.State.values, color_threshold=100)
plt.xticks(fontsize=12)
plt.show()
48. Кластерная диаграмма
График кластера может использоваться для разграничения точек, принадлежащих одному кластеру. Ниже приведен иллюстративный пример группировки штатов США в 5 групп на основе набора данных USArrests. Этот кластерный график использует столбцы «убийство» и «нападение» в качестве оси X и Y. В качестве альтернативы вы можете использовать компоненты от первого до главного в качестве осей X и Y.
Показать код
from sklearn.cluster import AgglomerativeClustering
from scipy.spatial import ConvexHull
# Import Data
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/USArrests.csv')
# Agglomerative Clustering
cluster = AgglomerativeClustering(n_clusters=5, affinity='euclidean', linkage='ward')
cluster.fit_predict(df[['Murder', 'Assault', 'UrbanPop', 'Rape']])
# Plot
plt.figure(figsize=(14, 10), dpi= 80)
plt.scatter(df.iloc[:,0], df.iloc[:,1], c=cluster.labels_, cmap='tab10')
# Encircle
def encircle(x,y, ax=None, **kw):
if not ax: ax=plt.gca()
p = np.c_[x,y]
hull = ConvexHull(p)
poly = plt.Polygon(p[hull.vertices,:], **kw)
ax.add_patch(poly)
# Draw polygon surrounding vertices
encircle(df.loc[cluster.labels_ == 0, 'Murder'], df.loc[cluster.labels_ == 0, 'Assault'], ec="k", fc="gold", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 1, 'Murder'], df.loc[cluster.labels_ == 1, 'Assault'], ec="k", fc="tab:blue", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 2, 'Murder'], df.loc[cluster.labels_ == 2, 'Assault'], ec="k", fc="tab:red", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 3, 'Murder'], df.loc[cluster.labels_ == 3, 'Assault'], ec="k", fc="tab:green", alpha=0.2, linewidth=0)
encircle(df.loc[cluster.labels_ == 4, 'Murder'], df.loc[cluster.labels_ == 4, 'Assault'], ec="k", fc="tab:orange", alpha=0.2, linewidth=0)
# Decorations
plt.xlabel('Murder'); plt.xticks(fontsize=12)
plt.ylabel('Assault'); plt.yticks(fontsize=12)
plt.title('Agglomerative Clustering of USArrests (5 Groups)', fontsize=22)
plt.show()
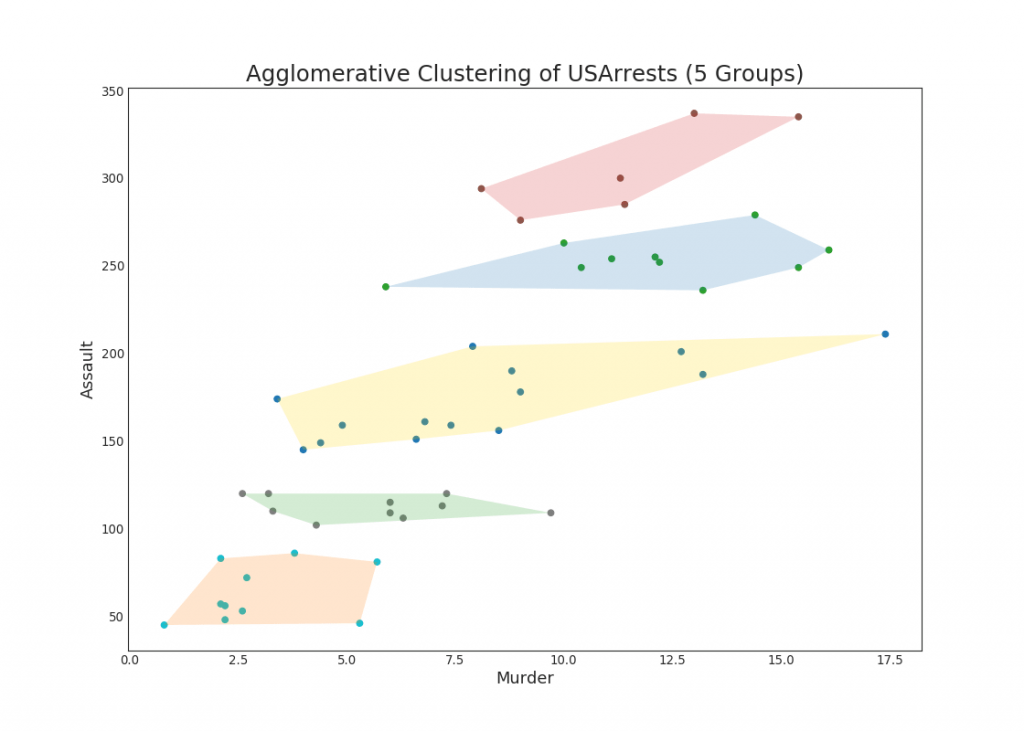
49. Кривая Эндрюса
Кривая Эндрюса помогает визуализировать, существуют ли присущие группировке числовые особенности, основанные на данной группировке. Если объекты (столбцы в наборе данных) не помогают различить группу, то линии не будут хорошо разделены, как показано ниже
Показать код
from pandas.plotting import andrews_curves
# Import
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
df.drop(['cars', 'carname'], axis=1, inplace=True)
# Plot
plt.figure(figsize=(12,9), dpi= 80)
andrews_curves(df, 'cyl', colormap='Set1')
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.title('Andrews Curves of mtcars', fontsize=22)
plt.xlim(-3,3)
plt.grid(alpha=0.3)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
50. Параллельные координаты
Параллельные координаты помогают визуализировать, помогает ли функция эффективно разделять группы. Если происходит сегрегация, эта функция, вероятно, будет очень полезна для прогнозирования этой группы.
Показать код
from pandas.plotting import parallel_coordinates
# Import Data
df_final = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/diamonds_filter.csv")
# Plot
plt.figure(figsize=(12,9), dpi= 80)
parallel_coordinates(df_final, 'cut', colormap='Dark2')
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.title('Parallel Coordinated of Diamonds', fontsize=22)
plt.grid(alpha=0.3)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
Бонус, код в юпитере
Гусь, ты же обещал флюиды!
В статье я сказал, что думаю сделать симуляцию жидкости. Но вероятно ее будет писать мой коллега, и, если его статья выберется из песочницы, я поделюсь ссылкой на нее с отписавшимися в комментарии или диалоги.
Картиной можно выразить тысячу слов. В случае с библиотекой Python matplotlib, к счастью, понадобится намного меньше слов в коде для создания качественных графиков.
Однако, matplotlib это еще и массивная библиотека, и создание графика, который будет выглядеть «просто, нормально» обычно проходит через путь проб и ошибок. Использование однострочных линий для создания базовых графиков в matplotlib – весьма просто, но умело пользоваться остальными 98% библиотеки может быть сложно.
Содержание:
- Почему Matplotlib может быть сложным?
- Pylab: что это и нужно ли мне это?
- Иерархия объектов Matplotlib
- Структурированные и неструктурированные подходы
- Понимание нотации plt.subplots()
- «Фигуры» за кулисами
- Игра красок: imshow() и matshow()
- Построение графиков в Pandas
- Подведение итогов
- Дополнительные ресурсы
- Приложение А: Конфигурация и стилизация
- Приложение Б: Интерактивный режим
Эта статья – руководство для пользователей Python на начальном-среднем уровне по matplotlib, с использованием как теории, так и практических примеров. Обучение по практическим примерам может быть очень продуктивным, и дает возможность получить представление даже на поверхностном уровне понимания внутренней работы и макета библиотеки.
Что мы рассмотрим?
- Pylab и pyplot: кто есть кто?
- Ключевые концепции дизайна matplotlib;
- Понимание plt.subplots();
- Визуализация массивов при помощи matplotlib;
- Построение графиков с комбинацией pandas и matplotlib.
Эта статья подразумевает, что пользователь имеет хотя-бы минимальное представление о NumPy. Мы в основном будем пользоваться модулем numpy.random для создания «игрушечных» данных, рисовать примеры из различных статистических источников.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Если у вас еще не установлен matplotlib, рекомендуем ознакомиться с руководством по установке, перед тем как продолжить.
|
python —mpip install —U pip python —mpip install —U matplotlib |
Изучение matplotlib временами может быть тяжелым процессом. Проблема не в нехватке документации (которая весьма обширная, между прочим). Сложности могут возникнуть со следующим:
- Размер библиотеки огромный сам по себе, около 70 000 строк кода;
- Matplotlib содержит несколько разных интерфейсов (способов построения фигуры) и может взаимодействовать с большим количеством бекендов. (Бекенды отвечают за то, как по факту будут отображаться диаграммы, не только за внутреннюю структуру);
- Несмотря на обширность, часть собственной документации matplotlib серьезно устарела. Библиотека все еще развивается, и множество старых примеров в сети могут включать на 70% меньше кода, чем в их современной версии;
Так что, перед тем как мы перейдем к сложным примерам, не помешает освоить корневые концепции дизайна matplotlib.
Pylab: что это и нужно ли мне это?
Немножко истории: Нейробиолог Джон Д. Хантер начал разрабатывать matplotlib в 2003 году, в основном вдохновляясь эмуляцией команд программного обеспечения Mathworks MATLAB. Джон отошел в мир иной трагически рано, в возрасте 44 лет в 2012 году, и matplotlib на сегодняшний день является целиком и полностью продуктом сообщества: развивается и поддерживается множеством людей. (Джон говорил об эволюции matplotlib на конференции SciPy в 2012, которую однозначно стоит посмотреть.)
Одной из важных особенностей MATLAB является его глобальный стиль. Концепция импорта Python не сильно используется в MATLAB, и большинство функций MATLAB легко доступны для пользователя на верхнем уровне.
Заказать свой собственный уникальный номер можно от Сим-Трейд.ру. Быстрая доставка в день заказа и красивые номера начиная от 300 руб. с выгодным тарифным планом. Свой уникальный номер это хороший признак для введения бизнеса с момента первого звонка.
Понимание того, что корни matplotlib растут из MATLAB, помогает объяснить существование pylab. pylab – это модуль внутри библиотеки matplotlib, который был встроен для подражания общего стиля MATLAB. Он существует только для внесения ряда функций классов из NumPy и matplotlib в пространство имен, что упрощает переход пользователей MATLAB, которые не сталкивались с необходимостью в операторах импорта. Бывшие пользователи MATLAB (которые очень хорошие люди, обещаем!) полюбили его функционал, потому что при помощи from pylab import * они могут просто вызывать plot() или array() напрямую также, как они это делали в MATLAB.
Проблема здесь может быть очевидной для некоторых пользователей Python: использование from pylab import * в сессии или скрипте – как правило, плохая идея. Matplotlib сегодня прямым текстом рекомендуют не делать этого в своих руководствах:
[pylab] все еще существует по историческим причинам, но его использование не рекомендуется. Он перегружает пространства имен функциями, которые оттеняют надстройки Python и может привести к скрытым багам. Для получения интеграции IPython без использования импортов, рекомендуется использовать %matplotlib.
В глубине своей, существует целая тонна потенциально конфликтных импортов, замаскированных в коротком источнике pylab. Фактически, использование ipython —pylab (из терминала или командной строки) или %pylab (из инструментов IPython/Jupyter) легко вызывает from pylab import *
Суть в том, что matplotlib забросили этот удобный модуль и рекомендуют не использовать pylab, подтверждая ключевое правило Python – явное лучше, чем неявное.
Без необходимости в использовании pylab, мы всегда можем обойтись всего одним каноничным импортом:
|
import matplotlib.pyplot as plt |
Кстати, давайте импортируем NumPy, пока мы здесь. Мы используем его для генерации данных в будущем и вызовем np.random.seed() для решения примеров со (псевдо) случайными воспроизводимыми данными:
|
import numpy as np np.random.seed(444) |
Иерархия объектов в Matplotlib
Одной из визитных карточек matplotlib является иерархия его объектов.
Если вы уже работали с вводным руководством matplotlib, вы, возможно, уже проводили вызов чего-то на подобии plt.plot([1, 2, 3]). Одна эта строка указывает на то, что график, на самом деле – это иерархия объектов Python. Под «иерархией» мы имеем ввиду, что каждый график основывается на древоподобной структуре объектов matplotlib.
Объект Figure – это самый важный внешний контейнер для графики matplotlib, который может включать в себя несколько объектов Axes. Причиной сложности в понимании может быть название: Axes (оси), на самом деле, превращаются в то, что мы подразумеваем под индивидуальным графиком или диаграммой (а не множественное число «оси», как вы можете ожидать).
Вы можете рассматривать объект Figure как похожий на ящик контейнер, содержащий один или несколько объектов Axes (настоящих графиков). Под объектами Axes, в порядке иерархии расположены меньшие объекты, такие как индивидуальные линии, отметки, легенды и текстовые боксы. Практически каждый «элемент» диаграммы – это собственный манипулируемый объект Python, вплоть до ярлыков и отметок:
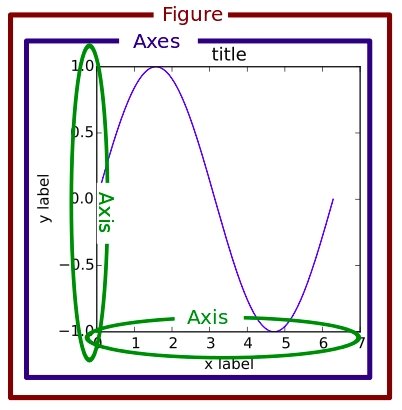
Это изображение данной иерархии в действии. Не беспокойтесь о том, что вы не совсем понимаете эту часть, мы рассмотрим ее подробнее в дальнейшем.
|
fig, _ = plt.subplots() print(type(fig)) # <class ‘matplotlib.figure.Figure’> |
Мы создали две переменные с plt.subplots(). Первый объект – это верхний объект Figure, второй – это второстепенная подчеркиваемая переменная, которая нам в данный момент не нужна. Использование нотации атрибута упрощает переход к иерархии фигур и позволяет увидеть, что первая отметка оси y – это первый объект Axes:
|
one_tick = fig.axes[0].yaxis.get_major_ticks()[0] print(type(one_tick)) # <class ‘matplotlib.axis.YTick’> |
Вверху наш fig (экземпляр класса Figure) содержит множество объектов Axes (список, для которого мы берем первый элемент). Каждый объект Axes имеет ось х и ось у (xaxis и yaxis соответственно), каждая из которых имеет набор «основных отметок», и мы возьмем самую первую. Matplotlib представляет это как анатомию фигуры, а не явную иерархию:
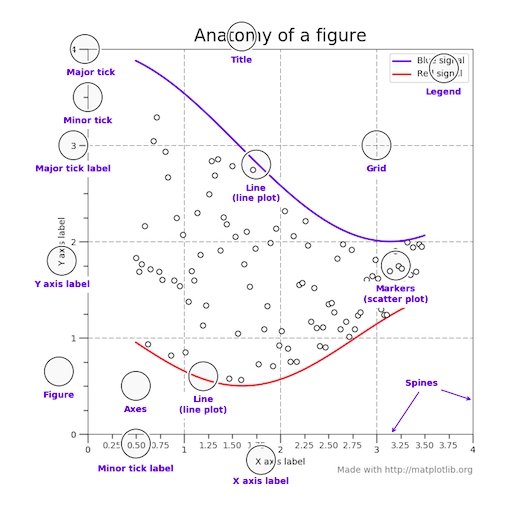
(В родной стилистике matplotlib, фигура выше создана в документации matplotlib)
Структурированные и неструктурированные подходы
Что-ж, сейчас нам необходим еще один кусок теории, перед тем как мы приступим к созданию различных визуализаций – разница между структурированными (ориентированными на структуру) и неструктурированными (ориентированными на объект) интерфейсами.
Ранее, мы использовали import matplotlib.pyplot as plt для импорта модуля pyplot из matplotlib и назвали его plt.
Практически все функции pyplot, такие как plt.plot(), так или иначе, ссылаются на нынешний существующий объект Figure и нынешний объект Axes, или создают их, если какой-либо из них не существует. Рассмотрим полезный фрагмент, скрытый в документации matplotlib:
[pyplot], простые функции используются для добавления элементов графика (линии, изображения, текста, и т.д.) в текущие оси в нашей фигуре.
Хардкорные бывшие пользователи MATLAB могут определить это как: «plt.plot() — это интерфейс структурной машины, который неявно отслеживает текущую фигуру!». По-русски это будет звучать так:
- Структурный интерфейс делает свои вызовы с plt.plot() и другими высшими функциями pyplot. Существует только один объект Figure или Axes, который вы используете за данное время, и вам не нужна явная ссылка на этот объект;
- Модификация изложенных ниже объектов напрямую – это объектно-ориентированный подход. Обычно, мы делаем это, вызывая методы объекта Axes, который является объектом, который отображает целостный график.
Поток этих процессов на высшем уровне выглядит следующим образом:

Связав все это в месте, большая часть функций из pyplot также существует в качестве методов класса matplotlib.axes.Axes.
Для простоты понимания, мы можем взглянуть под капот. plt.plot() может быть сокращен до пяти строк кода:
|
def plot(*args, **kwargs): «»»An abridged version of plt.plot().»»» ax = plt.gca() return ax.plot(*args, **kwargs) def gca(**kwargs): «»»Get the current Axes of the current Figure.»»» return plt.gcf().gca(**kwargs) |
И это все. Вызов plt.plot() – это удобный способ получения текущего объекта Axes текущего объекта Figure и вызвать его метод plot(). Это тот случай, когда утверждается, что структурированный интерфейс всегда «неявно отслеживает» график, на который он хочет ссылаться.
pyplot содержит ряд функций, которые просто являются обертками объектно-ориентированного интерфейса. Например, при использовании plt.title() в рамках объектно-ориентированного подхода (далее ОО), существуют соответствующие методы получения данных и настроек: ax.set_title() и ax.get_title(). (Использование геттеров и сеттеров распространено в таких языках, как Java. Тем не менее, это основная функция ОО подхода matplotlib).
Вызов plt.title() преобразуется в одну следующую строку: gca().set_title(s, *args, **kwargs). Что она делает?
- gca() захватывает текущую ось и возвращает её
- set_title() – это метод сеттер, который указывает заголовок для отдельного объекта Axes. «Удобство» в данном случае заключается в том, что нам не нужно определять прозрачность объекта Axes при помощи plt.title().
Соответственно, если вы уделите немного времени, чтобы взглянуть на источник функций верхнего уровня, таких как plt.grid(), plt.legend(), и plt.ylabels(), вы увидите, что все они следуют общей структуре делегирования текущим объектам Axes с gca(), после чего вызывают определенный метод для текущего объекта Axes. (Это основа объектно-ориентированного подхода!).
Понимание нотации plt.subplots()
Ну что же, достаточно теории. Сейчас мы готовы к тому, чтобы связать все вместе и перейти к графикам. Начиная с этого момента, мы (по большому счету) будем ссылаться на неструктурированный (объектно-ориентированный) подход, который более гибкий и становится удобным, в то время как графики становятся все сложнее.
Предпочтительный способ создания объекта Figure с одним объектом Axes под ОО-подходом (не самый интуитивный способ) – это использовать plt.subplots(). (Это единственный раз, когда ОО — подход использует pyplot для создания объектов Figure и Axes).
Только что мы воспользовались итерируемой распаковкой для назначения отдельной переменной к каждому из двух результатов plt.subplots(). Обратите внимание на то, что мы не передали аргументы к subplots() в данном случае. Вызов по умолчанию – это subplots(nrows=1, ncols=1). В результате, ax является единственным объектом AxesSubplot:
|
print(type(ax)) # <class ‘matplotlib.axes._subplots.AxesSubplot’> |
Мы можем вызывать методы экземпляра для управления графиком так же, как когда мы вызываем функции pyplots. Давайте изобразим график с разбивкой по областям трех временных столбцов:
|
import numpy as np import matplotlib.pyplot as plt rng = np.arange(50) rnd = np.random.randint(0, 10, size=(3, rng.size)) yrs = 1950 + rng fig, ax = plt.subplots(figsize=(5, 3)) ax.stackplot(yrs, rng + rnd, labels=[‘Eastasia’, ‘Eurasia’, ‘Oceania’]) ax.set_title(‘Combined debt growth over time’) ax.legend(loc=‘upper left’) ax.set_ylabel(‘Total debt’) ax.set_xlim(xmin=yrs[0], xmax=yrs[—1]) fig.tight_layout() plt.show() |
Что здесь происходит?
- После создания трех временных столбцов (рядов), мы определили одну фигуру (fig), содержащую один объект Axes (plot, ax);
- Мы вызываем методы ax напрямую для создания диаграммы с разбивкой по областям и добавлением легенды, заголовка и ярлыка оси y. С ОО-подходом, становится ясно, что все это – атрибуты ах;
- tight_layout() применяется к объекту Figure в целом для очистки пробелов;
Давайте рассмотрим пример, в котором содержится несколько малых графиков (Axes) внутри одного объекта Figure, формирующих два коррелированных массива, выводящихся из дискретного равномерного распределения:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import numpy as np import matplotlib.pyplot as plt x = np.random.randint(low=1, high=11, size=50) y = x + np.random.randint(1, 5, size=x.size) data = np.column_stack((x, y)) fig, (ax1, ax2) = plt.subplots( nrows=1, ncols=2, figsize=(8, 4) ) ax1.scatter(x=x, y=y, marker=‘o’, c=‘r’, edgecolor=‘b’) ax1.set_title(‘Scatter: $x$ versus $y$’) ax1.set_xlabel(‘$x$’) ax1.set_ylabel(‘$y$’) ax2.hist( data, bins=np.arange(data.min(), data.max()), label=(‘x’, ‘y’) ) ax2.legend(loc=(0.65, 0.8)) ax2.set_title(‘Frequencies of $x$ and $y$’) ax2.yaxis.tick_right() plt.show() |
В данном примере происходит больше, чем на первый взгляд:
- Так как мы создаем фигуру «1×2», полученный результат от plt.subplots(1, 2) теперь является объектом Figure и массивом NumPy объектов Axes. (Вы можете проверить это при помощи fig, axs = plt.subplots(1, 2), и взглянуть на оси);
- Мы имеем дело с ax1 и ax2 индивидуально. (Случай, когда использование объектно-ориентированного подхода будет весьма трудным.) Последняя строка – это хорошее изображение иерархии объектов, где мы модифицируем принадлежащую второму объекту Axes ось y, разместив галочки и отметки справа;
- Текст внутри знака доллара использует разметку TeX для выделения переменных курсивом.
Обратите внимание на то, что несколько объектов Axes могут «принадлежать» или быть переданными данной фигуре. В данном примере (строчные, а не прописные объекты Axes – не спорим, терминология здесь слегка запутанная), дает нам список всех объектов Axes:
|
(fig.axes[0] is ax1, fig.axes[1] is ax2) # (True, True) |
Сделав еще один шаг вглубь, мы можем создать фигуру, которая содержит сетку объектов Axes 2х2 в качестве альтернативы:
|
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(7, 7)) |
Так, а это за «ax»? Теперь это не одиночный объект Axes, но их двухмерный массив NumPy:
|
print(type(ax)) # numpy.ndarray print(ax) |
Результат:
|
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x1106daf98>, <matplotlib.axes._subplots.AxesSubplot object at 0x113045c88>], [<matplotlib.axes._subplots.AxesSubplot object at 0x11d573cf8>, <matplotlib.axes._subplots.AxesSubplot object at 0x1130117f0>]], dtype=object) |
Это подтверждается в документации:
«ax» может быть как одним объектом matplotlib.axes.Axes, так и массивом объектов Axes в более чем одном созданном малом графике.
Сейчас нам нужно вызвать методы создания графиков для каждого из этих объектов Axes (не массива NumPy, который является просто контейнером). Простой способ передать эти объекты, это использовать итеративную распаковку после выравнивания массива как одномерного:
|
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(7, 7)) ax1, ax2, ax3, ax4 = ax.flatten() |
Мы также могли бы выполнить это при помощи ((ax1, ax2), (ax3, ax4)) = ax, но первый подход более гибкий.
Для демонстрации более продвинутых функций меньших графиков, давайте добавим немного данных о макроэкономике недвижимости в Калифорнии, извлеченной из сжатого архива tar, пользуясь io, tarfile, и urllib из стандартной библиотеки Python.
|
from io import BytesIO import tarfile from urllib.request import urlopen url = ‘http://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.tgz’ b = BytesIO(urlopen(url).read()) fpath = ‘CaliforniaHousing/cal_housing.data’ with tarfile.open(mode=‘r’, fileobj=b) as archive: housing = np.loadtxt(archive.extractfile(fpath), delimiter=‘,’) |
Переменная «response» оси y, указанная ниже, использует термин из статистики: среднюю стоимость недвижимости. pop и age обозначают население и средний возраст недвижимости, соответственно.
|
y = housing[:, —1] pop, age = housing[:, [4, 7]].T |
Далее, давайте определим «вспомогательную функцию», которая размещает текстовый бокс внутри графика и выполняет функцию «заголовка внутри графика»:
|
def add_titlebox(ax, text): ax.text(.55, .8, text, horizontalalignment=‘center’, transform=ax.transAxes, bbox=dict(facecolor=‘white’, alpha=0.6), fontsize=12.5) return ax |
Теперь мы готовы к тому, чтобы сделать реальный график. Модуль gridspec нашей библиотеки matplotlib открывает расширенные возможности для настройки объектов под графиком. subplot2grid() отлично взаимодействует с этим модулем. Скажем, мы хотим создать такой макет:
Выше, у нас есть сетка 3х2. ax1 в два раза выше и шире ax2 и ax3. Это значит, что она занимает два ряда и две строки.
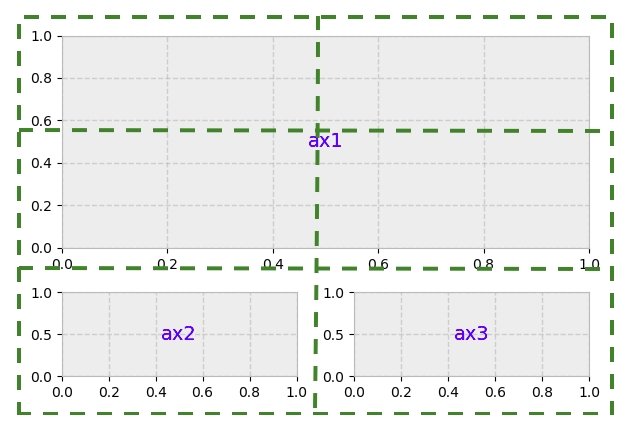
Второй аргумент, принадлежащий subplot2grid() – это (ряд, строка) локация объекта Axes со следующей сеткой:
|
import matplotlib.pyplot as plt gridsize = (3, 2) fig = plt.figure(figsize=(12, 8)) ax1 = plt.subplot2grid(gridsize, (0, 0), colspan=2, rowspan=2) ax2 = plt.subplot2grid(gridsize, (2, 0)) ax3 = plt.subplot2grid(gridsize, (2, 1)) plt.show() |
Теперь мы можем перейти к привычному режиму, настраивая каждый объект Axes индивидуально:
|
ax1.set_title( ‘Home value as a function of home age & area population’, fontsize=14 ) sctr = ax1.scatter(x=age, y=pop, c=y, cmap=‘RdYlGn’) plt.colorbar(sctr, ax=ax1, format=‘$%d’) ax1.set_yscale(‘log’) ax2.hist(age, bins=‘auto’) ax3.hist(pop, bins=‘auto’, log=True) add_titlebox(ax2, ‘Histogram: home age’) add_titlebox(ax3, ‘Histogram: area population (log scl.)’) |
Выше, colorbar() (который отличается от ColorMap) вызывается напрямую к объекту Figure, а не к Axes. Его первый аргумент – это результат ax1.scatter(), который выполняет функцию отображения переменных оси y в ColorMap.
Визуально, разница в цветах незначительна, если мы двигаемся по оси y вверх-вниз, похоже, что возраст дома сильнее определяет его стоимость.
«Фигуры» за кулисами
Каждый раз, когда вы вызываете plt.subplots(), или реже используемую plt.figure() (которая создает объект Figure без объектов Axes), вы создаете новый объект Figure, который matplotlib по хитрому хранит в памяти. Ранее, мы упоминали концепцию текущего объекта Figure и Axes. По умолчанию, такие объекты Figure и Axes создаются чаще всего, это мы можем продемонстрировать при помощи встроенной функции id(), чтобы показать адрес объекта в памяти:
|
import matplotlib.pyplot as plt fig1, ax1 = plt.subplots() # fig1– это текущая фигура. print(id(fig1)) # 4525567840 print(id(plt.gcf())) # 4525567840 # текущая фигура была изменена на fig2. fig2, ax2 = plt.subplots() print(id(fig2) == id(plt.gcf())) # True |
(Мы также можем использовать встроенный оператор is в этом коде)
После показанной только что рутины, текущая фигура называется fig2, и является фигурой, которая создается чаще всего. Однако, обе фигуры висят в памяти, и обе носят соответствующий номер ID (с одним индексом, в духе MATLAB):
|
print(plt.get_fignums()) # [1, 2] |
|
def get_all_figures(): return [plt.figure(i) for i in plt.get_fignums()] print(get_all_figures()) |
Результат:
|
[<matplotlib.figure.Figure at 0x10dbeaf60>, <matplotlib.figure.Figure at 0x1234cb6d8>] |
Небольшая сноска: убедитесь в том, что используете скрипт, где вы создаете группу фигур. Вам нужно будет явно закрыть каждый из них, во избежание ошибки MemoryError. plt.close(), сам по себе, закрывает текущую фигуру, plt.close(num) закрывает фигуру под номером num, а plt.close(‘all’) закрывает все окна фигур.
|
plt.close(‘all’) print(get_all_figures()) # [] |
Игра красок: imshow() и matshow()
В то время, как ax.plot() является одним из основных методов построения графиков на объектах Axes, существует целый ряд других (Мы использовали ax.stackplot() ранее, со списком остальных вы можете ознакомиться здесь).
Одна группа популярных использовании методов – это imshow() and matshow(), причем последний используется в качестве обертки первого. Они полезны в тех случаях, когда необработанный численный массив будет визуализирован как цветная таблица.
Для начала, давайте создадим две отдельные таблицы с какой-нибудь миловидной индексацией NumPy используя arange:
|
import numpy as np x = np.diag(np.arange(2, 12))[::—1] x[np.diag_indices_from(x[::—1])] = np.arange(2, 12) x2 = np.arange(x.size).reshape(x.shape) |
Далее, мы можем сопоставить их с собственными изображениями. В конкретном данном случае, мы выключаем (нажав “off”) все метки и штрихи осей, пользуясь пониманием словаря и передаем результат к ax.tick_params():
|
sides = (‘left’, ‘right’, ‘top’, ‘bottom’) nolabels = {s: False for s in sides} nolabels.update({‘label%s’ % s: False for s in sides}) print(nolabels) |
Результат:
|
{‘left’: False, ‘right’: False, ‘top’: False, ‘bottom’: False, ‘labelleft’: False, ‘labelright’: False, ‘labeltop’: False, ‘labelbottom’: False} |
Далее, мы можем использовать контекстный менеджер для отключения таблицы и вызвать matshow() в каждом объекте Axes. Наконец, нам нужно добавить цветную панель, в том, что технически является новым объектом Axes в fig. Для этого мы можем использовать одну специфическую функцию из глубин matplotlib:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable x = np.diag(np.arange(2, 12))[::—1] x[np.diag_indices_from(x[::—1])] = np.arange(2, 12) x2 = np.arange(x.size).reshape(x.shape) sides = (‘left’, ‘right’, ‘top’, ‘bottom’) nolabels = {s: False for s in sides} nolabels.update({‘label%s’ % s: False for s in sides}) with plt.rc_context(rc={‘axes.grid’: False}): fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4)) ax1.matshow(x) img2 = ax2.matshow(x2, cmap=‘RdYlGn_r’) for ax in (ax1, ax2): ax.tick_params(axis=‘both’, which=‘both’, **nolabels) for i, j in zip(*x.nonzero()): ax1.text(j, i, x[i, j], color=‘white’, ha=‘center’, va=‘center’) divider = make_axes_locatable(ax2) cax = divider.append_axes(«right», size=‘5%’, pad=0) plt.colorbar(img2, cax=cax, ax=[ax1, ax2]) fig.suptitle(‘Heatmaps with `Axes.matshow`’, fontsize=16) plt.show() |
Построение графиков в Pandas
Библиотека pandas стала популярной не только благодаря обеспечению мощным анализом данных, но и благодаря удобным методам построения графиков. Это интересно тем, что методы построения графиков pandas – это просто удобные обертки существующих вызовов matplotlib.
Таким образом, метод plot() в Series и DataFrame pandas – это обертка для plt.plot(). Удобство заключается в том, что если индекс DataFrame состоит из дат, gcf().autofmt_xdate() вызывается pandas изнутри для получения текущего объекта Figure и красивого форматирования оси х в автоматическом режиме.
Помните о том, что plt.plot() (структурированный подход) неявно имеет представление о текущем объекте Figure и Axes, так что pandas следует структурированному подходу путем расширения.
Мы можем подтвердить эту «цепочку» вызовов функций при помощи небольшой внутренней проверки. Для начала, давайте создадим ванильную Series в pandas, предположив, что мы создаем свежую сессию интерпретатора:
|
import pandas as pd s = pd.Series(np.arange(5), index=list(‘abcde’)) ax = s.plot() print(type(ax)) # <matplotlib.axes._subplots.AxesSubplot at 0x121083eb8> print(id(plt.gca()) == id(ax)) # True |
Такая внутренняя архитектура весьма полезна для понимания того, когда вы смешиваете методы построения графиков pandas с традиционными вызовами matplotlib. Что и продемонстрированно ниже в построении графика смещения среднего показателя широко просматриваемых финансовых временных отрезков. ma – это Series нашей библиотеки pandas, для которой мы можем вызвать ma.plot() (метод pandas) и затем провести настройку, извлекая объект Axes, который был создан этим вызовом (plt.gca()) для matplotlib для ссылки.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
import numpy as np import matplotlib.pyplot as plt import pandas as pd import matplotlib.transforms as mtransforms url = ‘https://fred.stlouisfed.org/graph/fredgraph.csv?id=VIXCLS’ vix = pd.read_csv(url, index_col=0, parse_dates=True, na_values=‘.’, infer_datetime_format=True, squeeze=True).dropna() ma = vix.rolling(’90d’).mean() state = pd.cut( ma, bins=[—np.inf, 14, 18, 24, np.inf], labels=range(4) ) cmap = plt.get_cmap(‘RdYlGn_r’) ma.plot( color=‘black’, linewidth=1.5, marker=», figsize=(8, 4), label=‘VIX 90d MA’ ) ax = plt.gca() # получаем текущий объект Axes, на который ссылается ma.plot() ax.set_xlabel(») ax.set_ylabel(’90d moving average: CBOE VIX’) ax.set_title(‘Volatility Regime State’) ax.grid(False) ax.legend(loc=‘upper center’) ax.set_xlim(xmin=ma.index[0], xmax=ma.index[—1]) trans = mtransforms.blended_transform_factory(ax.transData, ax.transAxes) for i, color in enumerate(cmap([0.2, 0.4, 0.6, 0.8])): ax.fill_between(ma.index, 0, 1, where=state == i, facecolor=color, transform=trans) ax.axhline( vix.mean(), linestyle=‘dashed’, color=‘xkcd:dark grey’, alpha=0.6, label=‘Full-period mean’, marker=» ) plt.show() |
В этом коде происходит много чего:
- ma – это 90-дневное скользящее среднее число индекса VIX, который является показателем рыночных ожиданий в краткосрочной волатильности акций. state – это группирование скользящего среднего числа в разных состояниях режима. Высокий индекс VIX виден как сигнал о повышенном уровне страха на рынке.
- cmap (ColorMap) – объект matplotlib, который по сути своей, является отображением поплавков в цветах RGBA. Любая цветовая палитра может быть перевернута добавлением ‘_r’, где ‘RdYlGn_r‘ – перевернутая цветовая гамма красного, желтого и синего. Matplotlib поддерживает удобное справочное руководство по цветовым гаммам в своей документации.
- Единственный вызов pandas, который мы делаем в данном примере — это ma.plot(). Который проводит внутренний вызов plt.plot(), так что для интеграции объектно-ориентированного подхода нам нужно получить явную отсылку к текущему объекту Axes при помощи ax = plt.gca().
- Второй кусок кода создает закрашенные блоки, которые соответствуют всем регистрам state. cmap([0.2, 0.4, 0.6, 0.8]) как бы говорит нам: «Дайте нам последовательность RGBA в 20-х, 40-х, 60-х и 80-х «перцентилях» в спектре цветовой гаммы». Мы используем enumerate(), так как нам нужно сопоставить каждый цвет RGBA с состоянием.
Pandas также предоставляет небольшое количество более продвинутых графиков (обзор которых может представлять собой целое отдельное руководство). Однако, все они (включая их упрощенные аналоги) полагаются на внутренние механизмы matplotlib.
Подведем итоги
Как было показано в некоторых примерах, становится ясно, что matplotlib может быть технически и синтаксически сложной библиотекой. Чтобы создать готовую диаграмму, может уйти полчаса на один только поиск в Гугле и комбинирование всей этой мешанины для точной настройки графика.
Однако, понимание того, как интерфейсы matplotlib взаимодействуют друг с другом – это инвестиция, которая может окупиться. Совет Дэна Бадера (владельца Real Python):
Уделив время на анализ кода, а не на то, чтобы просто копипастить его, вы совершаете разумное решение с долгосрочной перспективой. Придерживаясь объектно-ориентированного подхода, вы можете сэкономить несколько часов страданий, делая свой график произведением искусства.
Дополнительные ресурсы
Из документации matplotlib:
- Примеры matplotlib;
- Часто задаваемые вопросы FAQ;
- Страница руководств, разбитая на начальный, средний и продвинутый уровни;
- Жизненный цикл графика, где затрагивается соотношение объектно-ориентированного и структурно-ориентированного подходов;
- Библиотека math которая предоставляет полный набор необходимых математических функций в Питоне.
Сторонние ресурсы
- Шпаргалка DataCamp в matplotlib;
- Вычислительная биология ПНБ (публичной научной библиотеки): десять простых правил для хороших фигур;
- Глава 9 (Построение графиков и Визуализация) из книги Python for Data Analysis (Python для анализа данных) Уеса МакКинни, второе издание;
- Глава 11 (Визуализация с Matplotlib, Pandas и Seaborn), Pandas Cookbook (Кулинарная книга Pandas) автора Теда Петроу;
- Раздел 1.4 (Matplotlib: Построение графиков) Scipy Lecture Notes;
- Цветовая палитра xkcd;
- Страница внешних ресурсов matplotlib;
- queirozf.com: Matplotlib, Pylab, Pyplot, и т.д.: Какая разница между ними и когда пользоваться каждым из них?;
- Страница визуализации в документации pandas.
Прочие библиотеки для построения графиков
- Библиотека seaborn, созданная на основе matplotlib и разработана для продвинутых статистических графиков, описание которой может стоить отдельного целого руководства;
- Datashader, графическая библиотека, ориентированная на большие наборы данных;
- Список всех остальных сторонних пакетов из документации matplotlib.
Приложение А: Конфигурация и стилизация
Если вы внимательно читали эту статью, то заметили, что различные графики отличаются стилистически от тех, что были предоставлены здесь.
Matplotlib предоставляет два способа индивидуальной настройки стиля в различных графиках:
- При помощи настройки файла matplotlibrc;
- Путем интерактивного изменения ваших параметров настройки или из скрипта .py.
Файл matplotlibrc (вариант №1) – это текстовый файл, определяющий пользовательские настройки, которые сохраняются между сессиями Python. В MacOSX он, как правило, находится в ~/.matplotlib/matplotlibrc.
Небольшой совет: GitHub – это отличное место для хранения файлов настроек. Только убедитесь в том, что они не содержат приватные данные, такие как пароли или ключи SSH!
В качестве альтернативы, вы можете изменить свои параметры настроек интерактивно (вариант №2). Когда вы импортируете import matplotlib.pyplot as plt, вы получаете доступ к объекту rcParams, который похож на словарь настроек Python. Все объекты модуля, названия которых начинаются с «rc» используются для взаимодействия со стилями вашего графика и настроек:
|
data = [attr for attr in dir(plt) if attr.startswith(‘rc’)] print(data) # [‘rc’, ‘rcParams’, ‘rcParamsDefault’, ‘rc_context’, ‘rcdefaults’] |
Из этого следует, что:
- plt.rcdefaults() восстанавливает параметры rc из внутренних настроек по умолчанию Matplotlib, которые находятся в списке plt.rcParamsDefault. Это вернет (перезапишет) что-либо из того, что вы уже настроили в файле matplotlibrc;
- plt.rc() используется для интерактивной настройки параметров;
- plt.rcParams – это словароподобный (изменяемый) объект, который позволяет вам управлять настройками напрямую. Если у вас есть измененные настройки в файле matplotlibrc, это отразится в данном словаре.
plt.rc() и plt.rcParams — два синтаксиса, которые являются эквивалентами для настройки параметров:
|
plt.rc(‘lines’, linewidth=2, color=‘r’) # Синтакс 1 plt.rcParams[‘lines.linewidth’] = 2 # Синтакс 2 plt.rcParams[‘lines.color’] = ‘r’ |
Обратите внимание на то, что класс Figure после этого использует некоторые из них в качестве своих аргументов по умолчанию.
Соответственно, стиль – это просто предопределенный кластер пользовательских настроек. Чтобы увидеть доступные стили, используйте:
|
import matplotlib.pyplot as plt print(plt.style.available) |
Результат:
|
[‘seaborn-dark’, ‘seaborn-darkgrid’, ‘seaborn-ticks’, ‘fivethirtyeight’, ‘seaborn-whitegrid’, ‘classic’, ‘_classic_test’, ‘fast’, ‘seaborn-talk’, ‘seaborn-dark-palette’, ‘seaborn-bright’, ‘seaborn-pastel’, ‘grayscale’, ‘seaborn-notebook’, ‘ggplot’, ‘seaborn-colorblind’, ‘seaborn-muted’, ‘seaborn’, ‘Solarize_Light2’, ‘seaborn-paper’, ‘bmh’, ‘seaborn-white’, ‘dark_background’, ‘seaborn-poster’, ‘seaborn-deep’] |
Чтобы настроить стиль, вызовите:
|
plt.style.use(‘fivethirtyeight’) |
Ваши графики теперь будут выглядеть по-новому:
Для вдохновения, в Matplotlib содержится несколько таблиц стилей для справки.
Приложение Б: Интерактивный режим
За кулисами, matplotlib также взаимодействует с различными бэкендами. Бэкенд – это рабочая лошадка фактического рендеринга диаграммы. (К примеру, в популярном дистрибутиве Anaconda бэкенд – это Qt5Agg). Некоторые бэкенды интерактивны, это значит, что они обновляются динамически и «выскакивают» перед пользователем, когда меняются.
Несмотря на то, что интерактивный режим по умолчанию отключен, вы можете проверить его статус при помощи plt.rcParams[‘interactive’] или plt.isinteractive и включать или выключать его при помощи plt.ion() и plt.ioff(), соответственно:
|
plt.rcParams[‘interactive’] # или: plt.isinteractive() |
|
plt.ioff() print(plt.rcParams[‘interactive’]) # False |
В некоторых примерах вы можете заметить наличие plt.show() в последней части кода. Основная задача plt.show(), о чем и говорит название, это показывать (открывать) фигуру, когда вы работаете с отключенным интерактивным режимом. Иными словами:
- Если интерактивный режим включен, вам не нужен plt.show(), а изображения будут автоматически выскакивать перед пользователем и обновляться, когда вы ссылаетесь на них;
- Если интерактивный режим отключен, plt.show() нужен вам для показа фигуры и plt.draw() для обновления графика.
Ниже, мы отключаем интерактивный режим, что влечет за собой необходимость вызова plt.show() после построения графика.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import numpy as np import matplotlib.pyplot as plt plt.ioff() x = np.arange(—4, 5) y1 = x ** 2 y2 = 10 / (x ** 2 + 1) fig, ax = plt.subplots() ax.plot(x, y1, ‘rx’, x, y2, ‘b+’, linestyle=‘solid’) ax.fill_between(x, y1, y2, where=y2>y1, interpolate=True, color=‘green’, alpha=0.3) lgnd = ax.legend([‘y1’, ‘y2’], loc=‘upper center’, shadow=True) lgnd.get_frame().set_facecolor(‘#ffb19a’) plt.show() |
Стоит отметить, что интерактивный режим не имеет ничего общего с используемой вами средой разработки, или если вы подключили встроенное построение графика при помощи: jupyter notebook —matplotlib inline или %matplotlib.
Оригинал статьи: https://realpython.com/python-matplotlib-guide/
Автор: Brad Solomon

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
#статьи
- 13 фев 2023
-

0
Разбираемся в том, как работает библиотека Matplotlib, и строим первые графики.
Иллюстрация: Оля Ежак для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Matplotlib — популярная Python-библиотека для визуализации данных. Она используется для создания любых видов графиков: линейных, круговых диаграмм, построчных гистограмм и других — в зависимости от задач.
В этой статье научимся импортировать библиотеку и на примерах разберём основные способы визуализации данных.
Библиотека Matplotlib — пакет для визуализации данных в Python, который позволяет работать с данными на нескольких уровнях:
- с помощью модуля Pyplot, который рассматривает график как единое целое;
- через объектно-ориентированный интерфейс, когда каждая фигура или её часть является отдельным объектом, — это позволяет выборочно менять их свойства и отображение.
В этой статье мы будем работать с модулем Pyplot, которого достаточно для построения графиков.
Matplotlib используют для визуализации данных любой сложности. Библиотека позволяет строить разные варианты графиков: линейные, трёхмерные, диаграммы рассеяния и другие, а также комбинировать их.
Дополнительные библиотеки позволяют расширить возможности анализа данных. Например, модуль Cartopy добавляет возможность работать с картографической информацией. Подробно про Matplotlib можно узнать из официальной документации.
Инфографика: Matplotlib
Изображение: Cartopy / SciTools
Сама Matplotlib является основой для других библиотек — например, Seaborn позволяет проще создавать графики и имеет больше возможностей для косметического улучшения их внешнего вида. Но Matplotlib — это базовая библиотека для визуализации данных, незаменимая в анализе данных.
При погружении в Matplotlib можно встретить упоминание двух модулей — Pyplot и Pylab. Важно понимать, какой из них использовать в работе и почему они появились. Разберёмся в терминологии.
Библиотека Matplotlib — это пакет для визуализации данных в Python. Pyplot — это модуль в пакете Matplotlib. Его вы часто будете видеть в коде как matplotlib.pyplot. Модуль помогает автоматически создавать оси, фигуры и другие компоненты, не задумываясь о том, как это происходит. Именно Pyplot используется в большинстве случаев.
Pylab — это ещё один модуль, который устанавливается вместе с пакетом Matplotlib. Он одновременно импортирует Pyplot и библиотеку NumPy для работы с массивами в интерактивном режиме или для доступа к функциям черчения при работе с данными.
Сейчас Pylab имеет только историческое значение — он облегчал переход с MATLAB на Matplotlib, так как позволял обходиться без операторов импорта (а именно так привыкли работать пользователи MATLAB). Вы можете встретиться с Pylab в примерах кода на разных сайтах, но на практике использовать модуль не придётся.
Matplotlib — универсальная библиотека, которая работает в Python на Windows, macOS и Linux. При работе с Google Colab или Jupyter Notebook устанавливать Python и Matplotlib не понадобится — язык программирования и библиотека уже доступны «из коробки». Но если вы решили писать код в другой IDE, например в Visual Studio Code, то сначала установите Python, а затем библиотеку Learn через терминал:
pip3 install matplotlib
Теперь можно переходить к импорту библиотеки:
import matplotlib.pyplot as plt
Сокращение plt для библиотеки — общепринятое. Вы встретите его в официальной документации, книгах и в ноутбуках других людей. Так что используйте его.
Для начала создадим две переменные — x и y, которые будут содержать координаты точек по осям х и у:
x = [1, 2, 3, 4, 5] y = [25, 32, 34, 20, 25]
Теперь построим график, который соединит эти точки:
plt.plot(x, y) plt.show()
Мы получили обычный линейный график. Разберём каждую команду:
- plt.plot() — стандартная функция, которая строит график в соответствии со значениями, которые ей были переданы. Мы передали в неё координаты точек;
- plt.show() — функция, которая отвечает за вывод визуализированных данных на экран. Её можно и не указывать, но тогда, помимо красивой картинки, мы увидим разную техническую информацию.
Дополним наш первый график заголовком и подписями осей:
plt.plot(x, y) plt.xlabel('Ось х') #Подпись для оси х plt.ylabel('Ось y') #Подпись для оси y plt.title('Первый график') #Название plt.show()
Смотрим на результат:
С помощью Matplotlib можно настроить отображение любого графика. Например, мы можем изменить цвет линии, а также выделить точки, координаты которых задаём в переменных:
plt.plot(x, y, color='green', marker='o', markersize=7)
Теперь точки хорошо видны, а цвет точек и линии изменился на зелёный:
Подробно про настройку параметров функции plt.plot() можно прочесть в официальной документации.
Диаграмма рассеяния используется для оценки взаимосвязи двух переменных, значения которых откладываются по разным осям. Для её построения используется функция plt.scatter(), аргументами которой выступают переменные с дискретными значениями:
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [25, 32, 34, 20, 25, 23, 21, 33, 19, 28] plt.scatter(x, y) plt.show()
Диаграмма рассеяния выглядит как множество отдельных точек:
Такой тип визуализации позволяет удобно сравнивать значения отдельных переменных. В столбчатой диаграмме длина столбцов пропорциональна показателям, которые они отображают. Как правило, одна из осей соответствует одной категории, а вторая — её дискретному значению.
Например, столбчатая диаграмма позволяет наглядно показать величину прибыли по месяцам. Построим следующий график:
x = ['Январь', 'Февраль', 'Март', 'Апрель', 'Май'] y = [2, 4, 3, 1, 7] plt.bar(x, y, label='Величина прибыли') #Параметр label позволяет задать название величины для легенды plt.xlabel('Месяц года') plt.ylabel('Прибыль, в млн руб.') plt.title('Пример столбчатой диаграммы') plt.legend() plt.show()
Столбчатая диаграмма позволяет увидеть динамику изменения прибыли по месяцам:
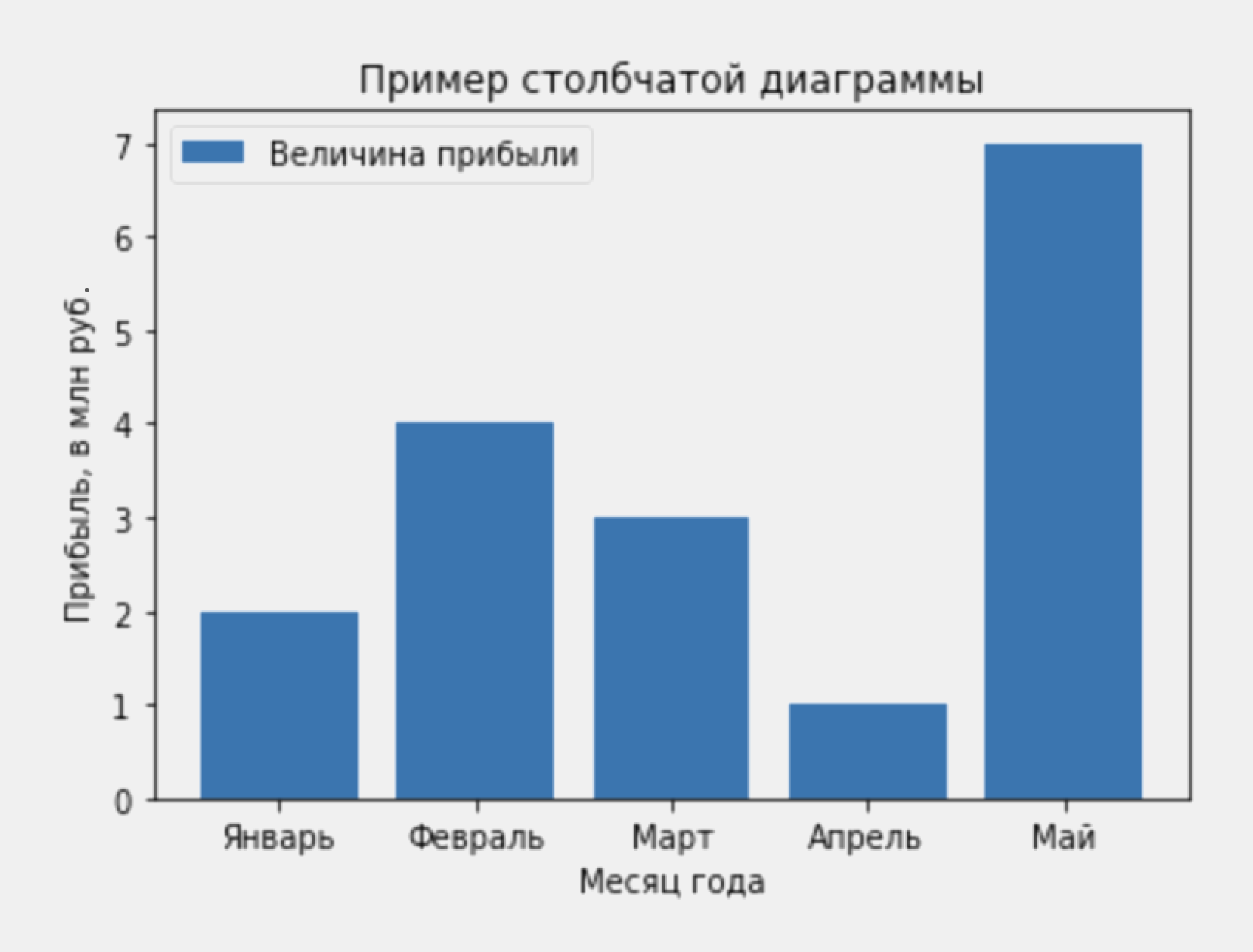
Для некоторых задач полезно объединить несколько типов графиков, например столбчатую диаграмму и линейный график. Доработаем его, добавив к столбцам точки со значениями прибыли, и соединим их:
x = ['Январь', 'Февраль', 'Март', 'Апрель', 'Май'] y = [2, 4, 3, 1, 7] plt.bar(x, y, label='Величина прибыли') #Параметр label позволяет задать название величины для легенды plt.plot(x, y, color='green', marker='o', markersize=7) plt.xlabel('Месяц года') plt.ylabel('Прибыль, в млн руб.') plt.title('Комбинирование графиков') plt.legend() plt.show()
Теперь на одном экране мы видим сразу оба типа:
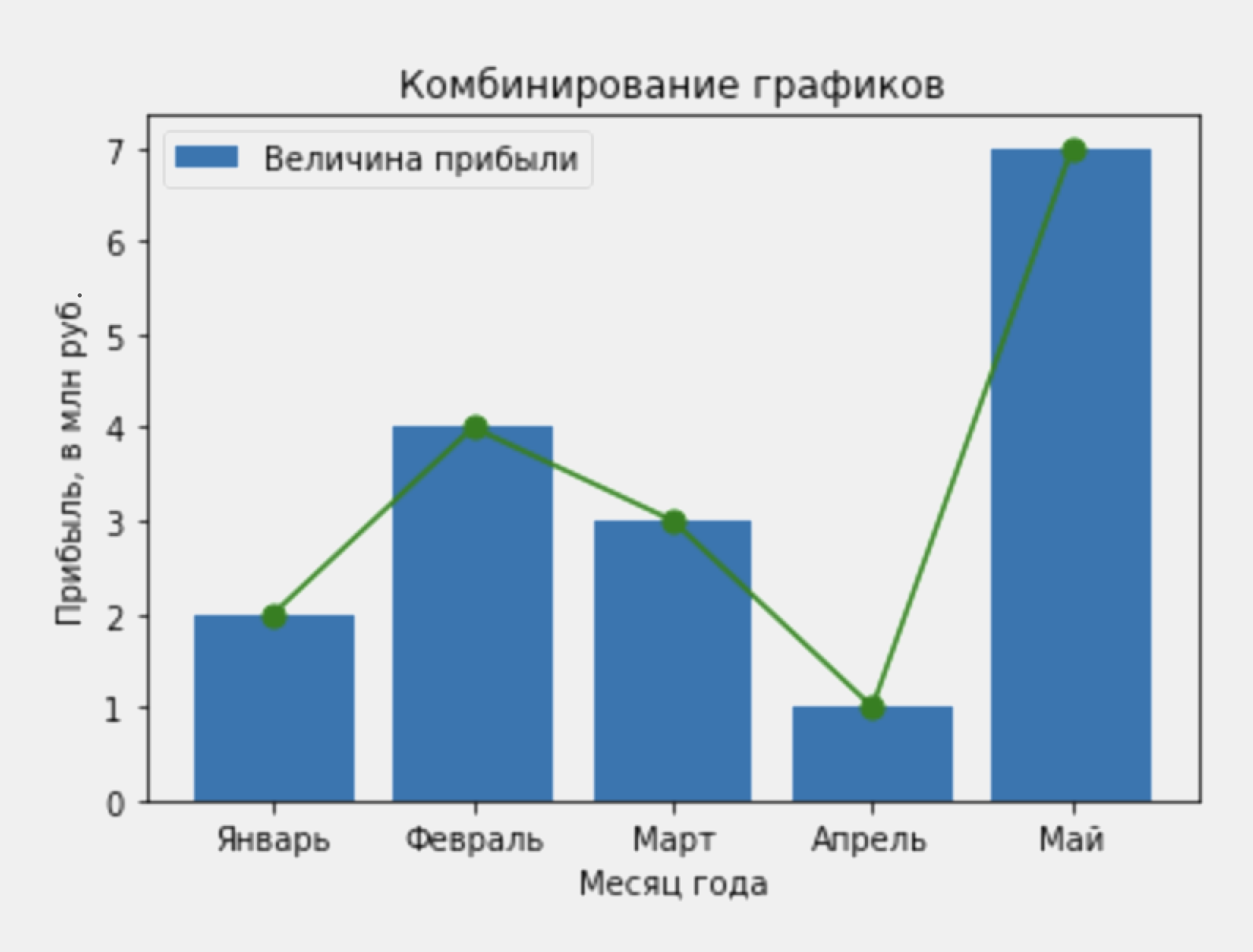
Всё получилось. Но сейчас линейный график видно плохо — он просто теряется на синем фоне столбцов. Увеличим прозрачность столбчатой диаграммы с помощью параметра alpha:
plt.bar(x, y, label='Величина прибыли', alpha=0.5)
Параметр alpha может принимать значения от 0 до 1, где 0 — полная прозрачность, а 1 — отсутствие прозрачности. Посмотрим на результат:
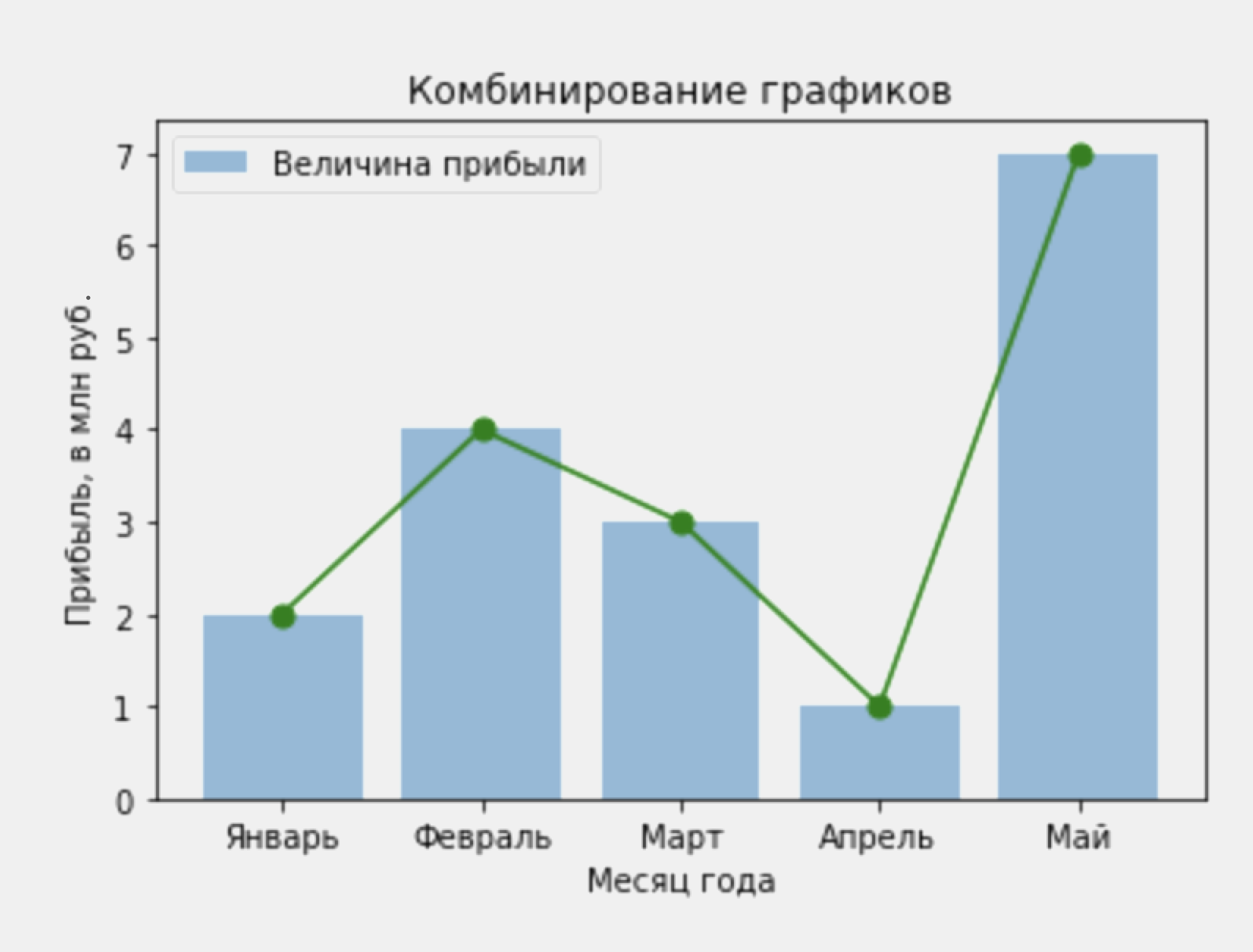
Теперь линейный график хорошо виден и мы можем оценивать динамику изменения прибыли.
Круговую диаграмму используют для отображения состава групп. Например, мы можем наглядно показать, какие марки автомобилей преобладают на дорогах города:
vals = [24, 17, 53, 21, 35] labels = ["Ford", "Toyota", "BMW", "Audi", "Jaguar"] plt.pie(vals, labels=labels) plt.title("Распределение марок автомобилей на дороге") plt.show()
Результат:
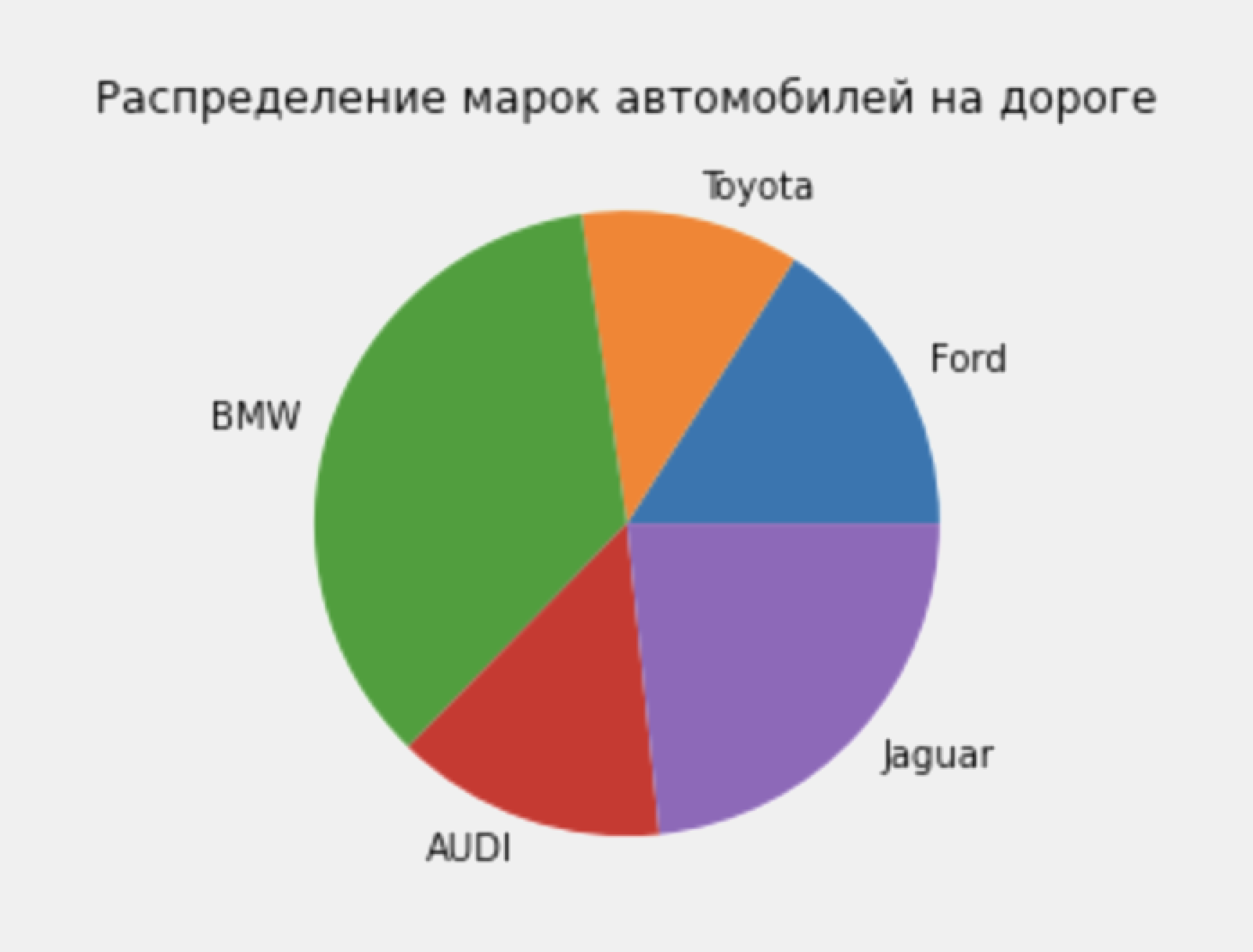
Так информация нагляднее, но непонятно, какая именно доля приходится на каждую марку автомобиля. Поэтому круговые диаграммы всегда лучше дополнять значениями в процентах. Отредактируем наш код, добавив к функции pie параметр autopct:
vals = [24, 17, 53, 21, 35] labels = ["Ford", "Toyota", "BMW", "Audi", "Jaguar"] plt.pie(vals, labels=labels, autopct='%1.1f%%') plt.title("Распределение марок автомобилей на дороге") plt.show()
В параметр мы передаём формат отображения числа. В нашем случае это будет целое число с одним знаком после запятой. Запустим код и посмотрим на результат:
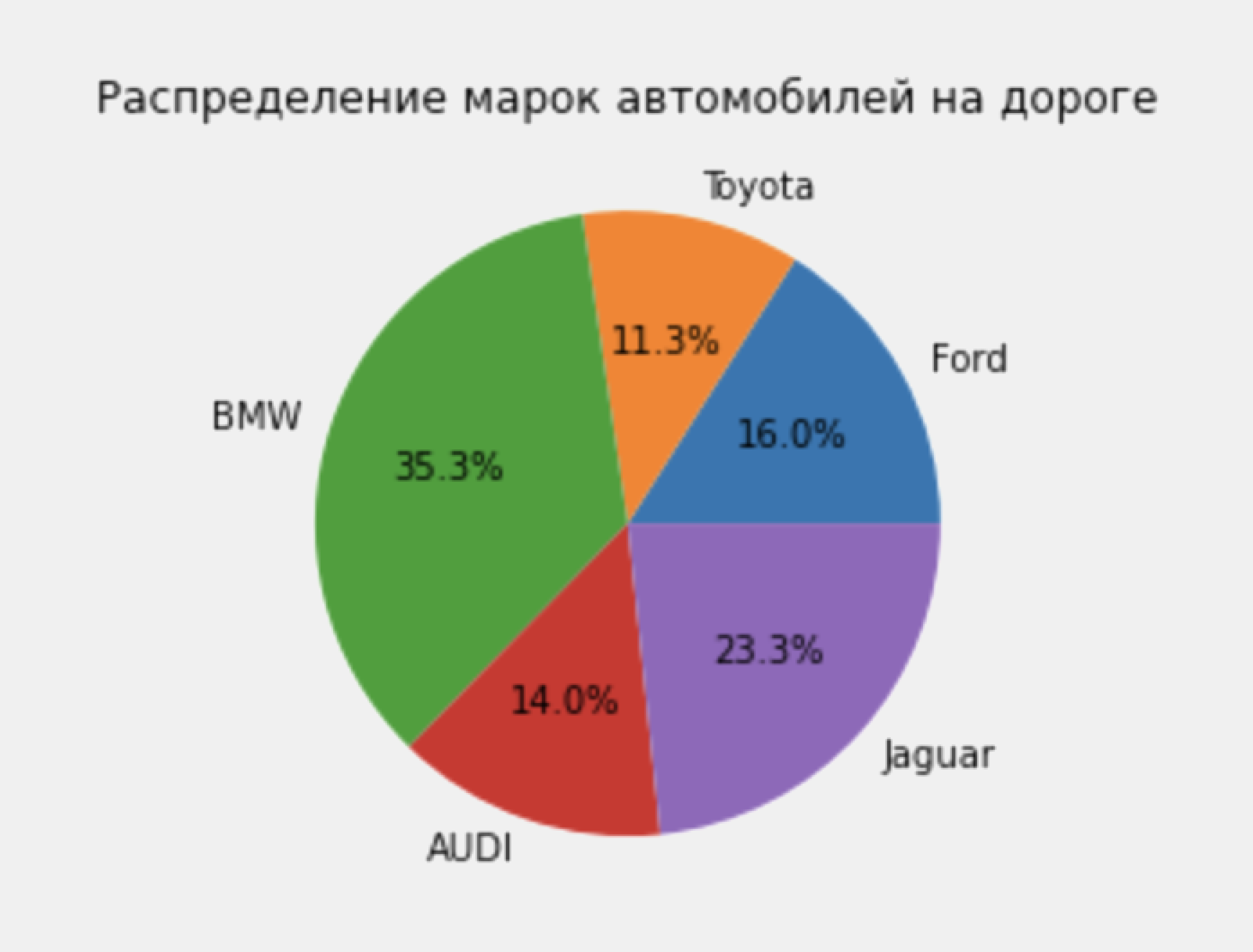
Теперь сравнить категории проще, так как мы видим числовые значения.
Построим столбчатый график с накоплением. Он позволяет оценить динамику соотношения значений одной переменной. Попробуем показать, как соотносится количество устройств на Android и iOS в разные годы:
labels = ['2017', '2018', '2019', '2020', '2021'] android_users = [85, 85.1, 86, 86.2, 86] ios_users = [14.5, 14.8, 13, 13.8, 14.0] width = 0.35 #Задаём ширину столбцов fig, ax = plt.subplots() ax.bar(labels, android_users, width, label='Android') ax.bar(labels, ios_users, width, bottom=android_users, label='iOS') #Указываем с помощью параметра bottom, что значения в столбце должны быть выше значений переменной android_users ax.set_ylabel('Соотношение, в %') ax.set_title('Распределение устройств на Android и iOS') ax.legend(loc='lower left', title='Устройства') #Сдвигаем легенду в нижний левый угол, чтобы она не перекрывала часть графика plt.show()
Смотрим на результат:
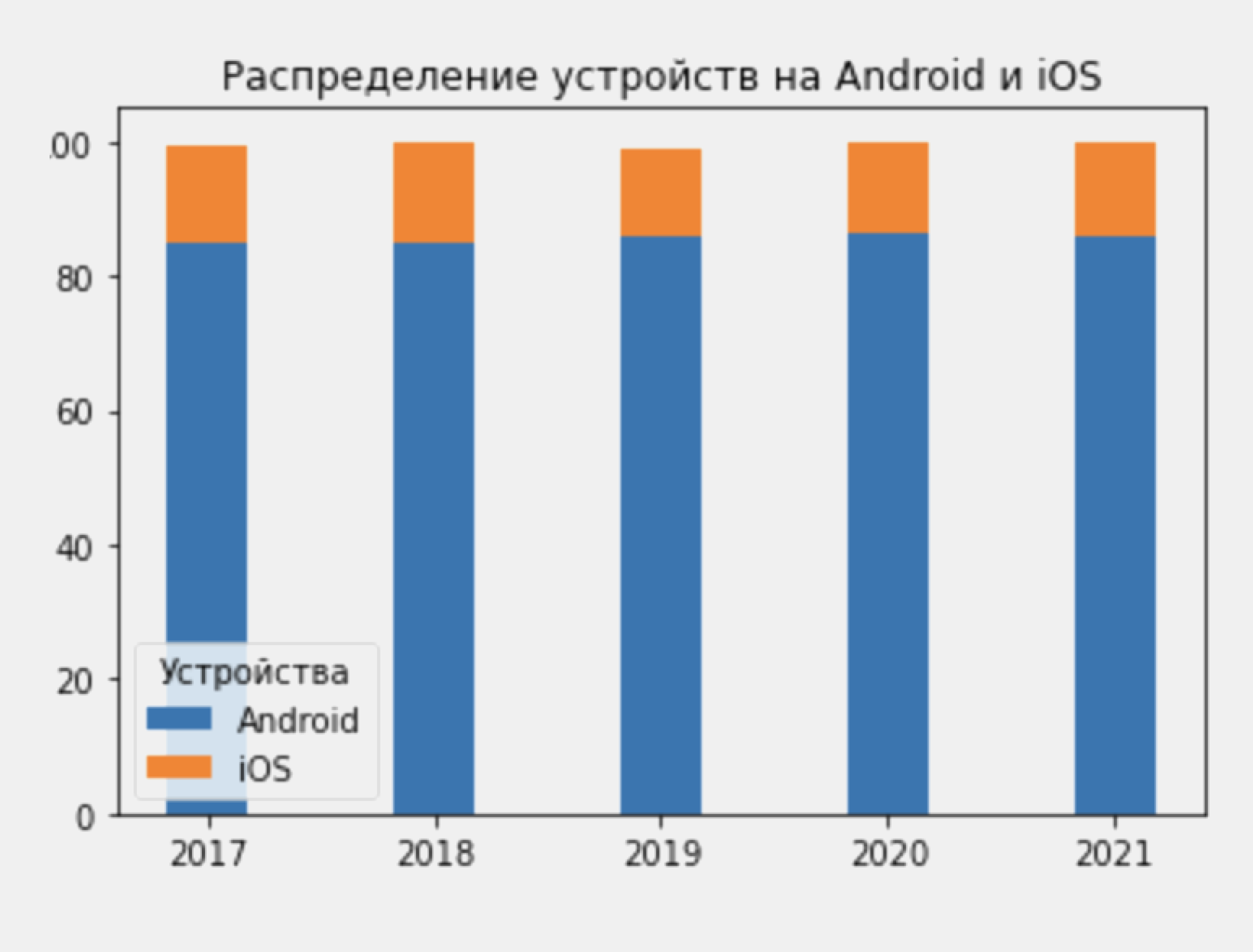
График позволяет увидеть, что соотношение устройств, работающих на Android и iOS, постепенно меняется — устройств на Android становится больше.
Matplotlib — мощная библиотека для визуализации данных в Python. В этой статье мы познакомились только с самыми основами. Ещё много полезной информации можно найти в официальной документации.
Но если вы решили действительно углубиться в возможности библиотеки и визуализацию данных, то здесь помогут книги:
- Mastering matplotlib Дункана Макгреггора;
- Hands-on Matplotlib: Learn Plotting and Visualizations with Python 3 Ашвина Паянкара;
- Matplotlib 3.0 Cookbook: Over 150 recipes to create highly detailed interactive visualizations using Python Рао Полади.

Научитесь: Профессия Python-разработчик
Узнать больше
Библиотека matplotlib содержит большой набор инструментов для двумерной графики. Она проста в использовании и позволяет получать графики высокого качества. В этом разделе мы рассмотрим наиболее распространенные типы диаграмм и различные настройки их отображения.
Модуль matplotlib.pyplot предоставляет процедурный интерфейс к (объектно-ориентированной) библиотеке matplotlib, который во многом копирует инструменты пакета MATLAB. Инструменты модуля pyplot де-факто являются стандартным способом работы с библиотекой matplotlib, поэтому мы органичимся рассмотрением этого пакета.
Двумерные графики
pyplot.plot
Нарисовать графики функций sin и cos с matplotlib.pyplot можно следующим образом:
import numpy as np
import matplotlib.pyplot as plt
phi = np.linspace(0, 2.*np.pi, 100)
plt.plot(phi, np.sin(phi))
plt.plot(phi, np.cos(phi))
plt.show()
В результате получаем
Мы использовали функцию plot, которой передали два параметра — списки значений по горизонтальной и вертикальной осям. При последовательных вызовах функции plot графики строятся в одних осях, при этом происходит автоматическое переключение цвета.
Строковый параметр
fmt = '[marker][line][color]'
функции plot позволяет задавать тип маркера, тип линии и цвет. Приведем несколько примеров:
x = np.linspace(0, 1, 100)
f1 = 0.25 - (x - 0.5)**2
f2 = x**3
plt.plot(x, f1, ':b') # пунктирная синяя линия
plt.plot(x, f2, '--r') # штрихованная красная линия
plt.plot(x, f1+f2, 'k') # черная непрерывная линия
plt.show()
rg = np.random.Generator(np.random.PCG64())
plt.plot(rg.binomial(10, 0.3, 6), 'ob') # синие круги
plt.plot(rg.poisson(7, 6), 'vr') # красные треугольники
plt.plot(rg.integers(0, 10, 6), 'Dk') # черные ромбы
plt.show()
Из последнего примера видно, что если в функцию plot передать только один список y, то он будет использован для значений по вертикальной оси. В качестве значений по горизонтальной оси будет использован range(len(y)).
Более тонкую настройку параметров можно выполнить, передавая различные именованные аргументы, например:
marker:str— тип маркераmarkersize:float— размер маркераlinestyle:str— тип линииlinewidth:float— толщина линииcolor:str— цвет
Полный список доступных параметров можно найти в документации.
pyplot.errorbar
Результаты измерений в физике чаще всего представлены в виде величин с ошибками. Функция plt.errorbar позволяет отображать такие данные:
rg = np.random.Generator(np.random.PCG64(5))
x = np.arange(6)
y = rg.poisson(149, x.size)
plt.errorbar(x, y, yerr=np.sqrt(y), marker='o', linestyle='none')
plt.show()
Ошибки можно задавать и для значений по горизонтальной оси:
rg = np.random.Generator(np.random.PCG64(5))
N = 6
x = rg.poisson(169, N)
y = rg.poisson(149, N)
plt.errorbar(x, y, xerr=np.sqrt(x), yerr=np.sqrt(y), marker='o', linestyle='none')
plt.show()
Ошибки измерений могут быть асимметричными. Для их отображения в качестве параметра yerr (или xerr) необходимо передать кортеж из двух списков:
rg = np.random.Generator(np.random.PCG64(11))
N = 6
x = np.arange(N)
y = rg.poisson(149, N)
yerr = [
0.7*np.sqrt(y),
1.2*np.sqrt(y)
]
plt.errorbar(x, y, yerr=yerr, marker='o', linestyle='none')
plt.show()
Функция pyplot.errorbar поддерживает настройку отображения графика с помощью параметра fmt и всех именованных параметров, которые доступны в функции pyplot. Кроме того, здесь появляются параметры для настройки отображения линий ошибок (“усов”):
ecolor:str— цвет линий ошибокelinewidth:float— ширина линий ошибокcapsize:float— длина “колпачков” на концах линий ошибокcapthick:float— толщина “колпачков” на концах линий ошибок
и некоторые другие. Изменим параметры отрисовки данных из предыдущего примера:
# ...
plt.errorbar(x, y, yerr=yerr, marker='o', linestyle='none',
ecolor='k', elinewidth=0.8, capsize=4, capthick=1)
plt.show()
Настройки отображения
Наши графики все еще выглядят довольно наивно. В этой части мы рассмотрим различные настройки, которые позволят достичь качества оформления диаграмм, соответствующего, например, публикациям в рецензируемых журналах.
Диапазон значений осей
Задавать диапазон значений осей в matplotlib можно несколькими способами. Например, так:
pyplot.xlim([0, 200]) # диапазон горизонтальной оси от 0 до 200
pyplot.xlim([0, 1]) # диапазон вертикальной оси от 0 до 1
Размер шрифта
Размер и другие свойства шрифта, который используется в matplotlib по умолчанию, можно изменить с помощью объекта matplotlib.rcParams:
matplotlib.rcParams.update({'font.size': 14})
Объект matplotlib.rcParams хранит множество настроек, изменяя которые, можно управлять поведением по умолчанию. Смотрите подробнее в документации.
Подписи осей
Подписи к осям задаются следующим образом:
plt.xlabel('run number', fontsize=16)
plt.ylabel(r'average current ($mu A$)', fontsize=16)
В подписях к осям (и вообще в любом тексте в matplotlib) можно использовать инструменты текстовой разметки TeX, позволяющие отрисовывать различные математические выражения. TeX-выражения должны быть внутри пары символов $, кроме того, их следует помещать в r-строки, чтобы избежать неправильной обработки.
Заголовок
Функция pyplot.title задает заголовок диаграммы. Применим наши новые знания:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# задаем размер шрифта
matplotlib.rcParams.update({'font.size': 12})
rg = np.random.Generator(np.random.PCG64(11))
x = np.arange(6)
y = rg.poisson(149, x.size)
yerr = [
0.7*np.sqrt(y),
1.2*np.sqrt(y)
]
plt.errorbar(x, y, yerr=yerr, marker='o', linestyle='none',
ecolor='k', elinewidth=0.8, capsize=4, capthick=1)
# добавляем подписи к осям и заголовок диаграммы
plt.xlabel('run number', fontsize=16)
plt.ylabel(r'average current ($mu A$)', fontsize=16)
plt.title(r'The $alpha^prime$ experiment. Season 2020-2021')
# задаем диапазон значений оси y
plt.ylim([0, 200])
# оптимизируем поля и расположение объектов
plt.tight_layout()
plt.show()
В этом примере мы использовали функцию pyplot.tight_layout, которая автоматически подбирает параметры отображения так, чтобы различные элементы не пересекались.
Легенда
При построении нескольких графиков в одних осях полезно добавлять легенду — пояснения к каждой линии. Следующий пример показывает, как это делается с помощью аргументов label и функции pyplot.legend:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams.update({'font.size': 12})
x = np.linspace(0, 1, 100)
f1 = 0.25 - (x - 0.5)**2
f2 = x**3
# указываем в аргументе label содержание легенды
plt.plot(x, f1, ':b', label='1st component')
plt.plot(x, f2, '--r', label='2nd component')
plt.plot(x, f1+f2, 'k', label='total')
plt.xlabel(r'$x$', fontsize=16)
plt.ylabel(r'$f(x)$', fontsize=16)
plt.xlim([0, 1])
plt.ylim([0, 1])
# выводим легенду
plt.legend(fontsize=14)
plt.tight_layout()
plt.show()
Функция pyplot.legend старается расположить легенду так, чтобы она не пересекала графики. Аргумент loc позволяет задать расположение легенды вручную. В большинстве случаев расположение по умолчанию получается удачным. Детали и описание других аргументов смотрите в документации.
Сетка
Сетка во многих случаях облегчает анализ графиков. Включить отображение сетки можно с помощью функции pyplot.grid. Аргумент axis этой функции имеет три возможных значения: x, y и both и определяет оси, вдоль которых будут проведены линии сетки. Управлять свойствами линии сетки можно с помощью именованных аргументов, которые мы рассматривали выше при обсуждении функции pyplot.plot.
В matplotlib поддерживается два типа сеток: основная и дополнительная. Выбор типа сетки выполняется с помощью аргумента which, который может принимать три значения: major, minor и both. По умолчанию используется основная сетка.
Линии сетки привязаны к отметкам на осях. Чтобы работать с дополнительной сеткой необходимо сначала включить вспомогательные отметки на осях (которые по умолчанию отключены и к которым привязаны линии дополнительной сетки) с помощью функции pyplot.minorticks_on. Приведем пример:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams.update({'font.size': 12})
x = np.linspace(-1, 1, 250)
plt.plot(x, x, label=r'$x$')
plt.plot(x, x**2, label=r'$x^2$')
plt.plot(x, x**3, label=r'$x^3$')
plt.plot(x, np.cbrt(x), label=r'$x^{1/3}$')
plt.legend(fontsize=16)
# включаем дополнительные отметки на осях
plt.minorticks_on()
plt.xlabel(r'$x$', fontsize=16)
plt.xlim([-1., 1.])
plt.ylim([-1., 1.])
# включаем основную сетку
plt.grid(which='major')
# включаем дополнительную сетку
plt.grid(which='minor', linestyle=':')
plt.tight_layout()
plt.show()
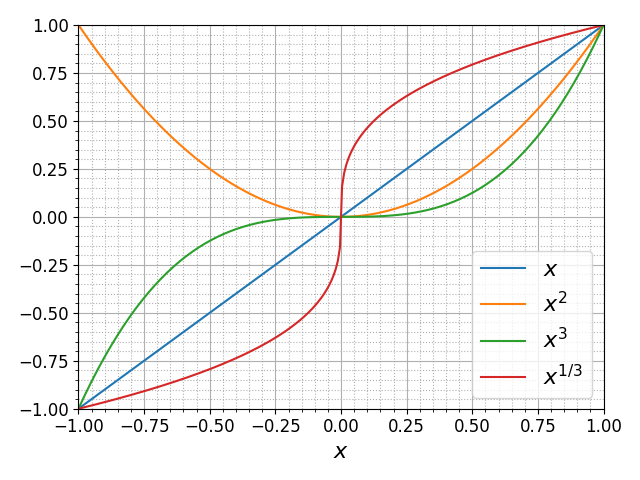
Логарифмический масштаб
Функции pyplot.semilogy и pyplot.semilogx выполняют переключение между линейным и логарифмическим масштабами осей. В некоторых случаях логарифмический масштаб позволяет отобразить особенности зависимостей, которые не видны в линейном масштабе. Вот так выглядят графики экспоненциальных функций в линейном масштабе:
Добавление строки
делает график гораздо более информативным:
Теперь мы видим поведение функций во всем динамическом диапазоне, занимающем 12 порядков.
Произвольные отметки на осях
Вернемся к первому примеру, в котором мы строили графики синуса и косинуса. Сделаем так, чтобы на горизонтальной оси отметки соответствовали различным долям числа pi и имели соответствующие подписи:
Метки на горизонтальной оси были заданы с помощью функции pyplot.xticks:
plt.xticks(
np.linspace(-np.pi, np.pi, 9),
[r'$-pi$', r'$-3pi/4$', r'$-pi/2$', r'$-pi/4$', r'$0$',
r'$pi/4$', r'$+pi/2$', r'$3pi/4$', r'$+pi$'])
Модуль pyplot.ticker содержит более продвинутые инструменты для управления отметками на осях. Подробности смотрите в документации.
Размер изображения
До сих пор мы строили графики в одном окне, размер которого был задан по умолчанию. За кадром matplotlib создавал объект типа Figure, который определяет размер окна и содержит все остальные элементы. Кроме того, автоматически создавался объект типа Axis. Подробнее работа с этими объектами будет рассмотрена ниже. Сейчас же мы рассмотрим функцию pyplot.figure, которая позволяет создавать новые объекты типа Figure и переключаться между уже созданными объектами.
Функция pyplot.figure может принимать множество аргументов. Вот основные:
num:intилиstr— уникальный идентификатор объекта типа. Если задан новый идентификатор, то создается новый объект и он становится активным. В случае, если передан идентификатор уже существующего объекта, то этот объект возвращается и становится активнымfigsize:(float, float)— размер изображения в дюймахdpi:float— разрешение в количестве точек на дюйм
Описание других параметров функции pyplot.figure можно найти в документации. Используем эту функцию и функцию pyplot.axis чтобы улучшить наш пример с построением степенных функций:
Мы добавили две строки по сравнению с прошлой версией:
fig = plt.figure(figsize=(6, 6))
# ...
plt.axis('equal')
Функция pyplot.axis позволяет задавать некоторые свойства осей. Ее вызов с параметром 'equal' делает одинаковыми масштабы вертикальной и горизонтальной осей, что кажется хорошей идеей в этом примере. Функция pyplot.axis возвращает кортеж из четырех значений xmin, xmax, ymin, ymax, соответствующих границам диапазонов значений осей.
Некоторые другие способы использования функции pyplot.axis:
- Кортеж из четырех
floatзадаст новые границы диапазонов значений осей - Строка
'off'выключит отображение линий и меток осей
Гистограммы
Обратимся теперь к другим типам диаграмм. Функция pyplot.hist строит гистограмму по набору значений:
import numpy as np
import matplotlib.pyplot as plt
rg = np.random.Generator(np.random.PCG64(5))
data = rg.poisson(145, 10000)
plt.hist(data, bins=40)
# для краткости мы опускаем код для настройки осей, сетки и т.д.
Аргумент bins задает количество бинов гистограммы. По умолчанию используется значение 10. Если вместо целого числа в аргумент bins передать кортеж значений, то они будут использованы для задания границ бинов. Таким образом можно построить гистограмму с произвольным разбиением.
Некоторые другие аргументы функции pyplot.hist:
range:(float, float)— диапазон значений, в котором строится гистограмма. Значения за пределами заданного диапазона игнорируются.density:bool. При значенииTrueбудет построена гистограмма, соответствующая плотности вероятности, так что площадь гистограммы будет равна единице.weights: списокfloatзначений того же размера, что и набор данных. Определяет вес каждого значения при построении гистограммы.histtype:str. может принимать значения{'bar', 'barstacked', 'step', 'stepfilled'}. Определяет тип отрисовки гистограммы.
В качестве первого аргумента можно передать кортеж наборов значений. Для каждого из них будет построена гистограмма. Аргумент stacked со значением True позволяет строить сумму гистограмм для кортежа наборов. Покажем несколько примеров:
rg = np.random.Generator(np.random.PCG64(5))
data1 = rg.poisson(145, 10000)
data2 = rg.poisson(140, 2000)
# левая гистограмма
plt.hist([data1, data2], bins=40)
# центральная гистограмма
plt.hist([data1, data2], bins=40, histtype='step')
# правая гистограмма
plt.hist([data1, data2], bins=40, stacked=True)
В физике гистограммы часто представляют в виде набора значений с ошибками, предполагая при этом, что количество событий в каждом бине является случайной величиной, подчиняющейся биномиальному распределению. В пределе больших значений флуктуации количества событий в бине могут быть описаны распределением Пуассона, так что характерная величина флуктуации определяется корнем из числа событий. Библиотека matplotlib не имеет инструмента для такого представления данных, однако его легко получить с помощью комбинации numpy.histogram и pyplot.errorbar:
def poisson_hist(data, bins=60, lims=None):
""" Гистограмма в виде набора значений с ошибками """
hist, bins = np.histogram(data, bins=bins, range=lims)
bins = 0.5 * (bins[1:] + bins[:-1])
return (bins, hist, np.sqrt(hist))
rg = np.random.Generator(np.random.PCG64(5))
data = rg.poisson(145, 10000)
x, y, yerr = poisson_hist(data, bins=40, lims=(100, 190))
plt.errorbar(x, y, yerr=yerr, marker='o', markersize=4,
linestyle='none', ecolor='k', elinewidth=0.8,
capsize=3, capthick=1)
Диаграммы рассеяния
Распределение событий по двум измерениям удобно визуализировать с помощью диаграммы рассеяния:
rg = np.random.Generator(np.random.PCG64(5))
means = (0.5, 0.9)
covar = [
[1., 0.6],
[0.6, 1.]
]
data = rg.multivariate_normal(means, covar, 5000)
plt.scatter(data[:,0], data[:,1], marker='o', s=1)
Каждой паре значений в наборе данных соответствует одна точка на диаграмме. Несмотря на свою простоту, диаграмма рассеяния позволяет во многих случаях наглядно представлять двумерные данные. Функция pyplot.scatter позволяет визуализировать и данные более высокой размерности: размер и цвет маркера могут быть заданы для каждой точки отдельно:
rg = np.random.Generator(np.random.PCG64(4))
data = rg.uniform(-1, 1, (50, 2))
col = np.arctan2(data[:, 1], data[:, 0])
size = 100*np.sum(data**2, axis=1)
plt.scatter(data[:,0], data[:,1], marker='o', s=size, c=col)
Цветовую палитру можно задать с помощью аргумента cmap. Подробности и описание других аргументов функции pyplot.scatter можно найти в документации.
Контурные диаграммы
Контурные диаграммы позволяют визуализировать функции двух переменных:
from scipy import stats
means = (0.5, 0.9)
covar = [
[1., 0.6],
[0.6, 1.]
]
mvn = stats.multivariate_normal(means, covar)
x, y = np.meshgrid(
np.linspace(-3, 3, 80),
np.linspace(-2, 4, 80)
)
data = np.dstack((x, y))
# левая диаграмма — без заливки цветом
plt.contour(x, y, mvn.pdf(data), levels=10)
# правая диаграмма — с заливкой цветом
plt.contourf(x, y, mvn.pdf(data), levels=10)
Аргумент levels задает количество контуров. По умолчанию контуры отрисовываются равномерно между максимальным и минимальным значениями. В аргумент levels также можно передать список уровней, на которых следует провести контуры.
Обратите внимание на использование функций numpy.meshgrid и numpy.dstack в этом примере.
Контурную диаграмму можно дополнить цветовой полосой colorbar, вызвав функцию pyplot.colorbar:
cs = plt.contourf(x, y, mvn.pdf(data), levels=15,
cmap=matplotlib.cm.magma_r)
cbar = plt.colorbar(cs)
Более подробное описание функций plt.contour и plt.contourf смотрите в документации.
Расположение нескольких осей в одном окне
В одном окне (объекте Figure) можно разместить несколько осей (объектов axis.Axis). Функция pyplot.subplots создает объект Figure, содержащий регулярную сетку объектов axis.Axis:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(12, 8))
x = np.linspace(0.01, 25, 250)
for idx, row in enumerate(axes):
for jdx, ax in enumerate(row):
ndf = idx * 3 + jdx + 1
y = stats.chi2.pdf(x, ndf)
ax.plot(x, y, label=fr'$chi^2_{{ndf={ndf}}}(x)$')
ax.set_xlabel(r'$x$', fontsize=16)
ax.set_ylim([0, 1.05*y.max()])
ax.minorticks_on()
ax.legend(fontsize=16)
ax.grid(which='major')
ax.grid(which='minor', linestyle=':')
fig.tight_layout()
plt.show()
Количество строк и столбцов, по которым располагаются различные оси, задаются с помощью параметров nrows и ncols, соответственно. Функция pyplot.subplots возвращает объект Figure и двумерный список осей axis.Axis. Обратите внимание на то, что вместо вызовов функций модуля pyplot в этом примере использовались вызовы методов классов Figure и axis.Axis.
В последнем примере горизонтальная ось во всех графиках имеет один и тот же диапазон. Аргумент sharex функции pyplot.subplots позволяет убрать дублирование отрисовки осей в таких случаях:
fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(12, 8),
sharex=True)
# ...
for idx, row in enumerate(axes):
for jdx, ax in enumerate(row):
# ...
if idx:
ax.set_xlabel(r'$x$', fontsize=16)
Существует аналогичный параметр sharey для вертикальной оси.
Более гибкие возможности регулярного расположения осей предоставляет функция pyplot.subplot. Мы не будем рассматривать эту функцию и ограничимся лишь ее упоминанием.
Функция pyplot.axes позволяет добавлять новые оси в текущем окне в произвольном месте:
import numpy as np
import matplotlib.pyplot as plt
exno = 26
rg = np.random.Generator(np.random.PCG64(5))
x1 = rg.exponential(10, 5000)
x2 = rg.normal(10, 0.1, 100)
# Строим основную гистограмму
plt.hist([x1, x2], bins=150, range=(0, 60), stacked=True)
plt.minorticks_on()
plt.xlim((0, 60))
plt.grid(which='major')
plt.grid(which='minor', linestyle=':')
# Строим вторую гистограмму в отдельных осях
plt.axes([.5, .5, .4, .4])
plt.hist([x1, x2], bins=100, stacked=True, range=(9, 11))
plt.grid(which='major')
plt.tight_layout()
# сохраняем диаграмму в файл
plt.savefig('histograms.png')
plt.show()
В этом примере была использована функция pyplot.savefig, сохраняющая содержимое текущего окна в файл в векторном или растровом формате. Формат задается с помощью аргумента format или автоматически определяется из имени файла (как в примере выше). Набор доступных форматов зависит от окружения, однако в большинстве случаев можно использовать такие форматы как png, jpeg, pdf, svg и eps.
Резюме
Предметом изучения в этом разделе был модуль pyplot библиотеки matplotlib, содержащий инструменты для построения различных диаграмм. Были рассмотрены:
- функции для построения диаграмм
pyplot.plot,pyplot.errorbar.pyplot.hist,pyplot.scatter,pyplot.contourиpyplot.contourf; - средства настройки свойств линий и маркеров;
- средства настройки координатных осей: подписи, размер шрифта, координатная сетка, произвольные метки др.;
- инструмены для расположения нескольких координатных осей в одном окне.
Рассмотренные инструменты далеко не исчерпывают возможности библиотеки matplotlib, однако их должно быть достаточно в большинстве случаев для визуализации данных. Мы рекомендуем заинтересованному читалелю изучить список источников, в которых можно найти много дополнительной информации.
Источники
- matplotlib.pyplot
- Pyplot tutorial
- Colormaps
- Scipy Lecture Notes