Алгоритм Хаффмана на пальцах
Время на прочтение
5 мин
Количество просмотров 499K
Вы вероятно слышали о Дэвиде Хаффмане и его популярном алгоритме сжатия. Если нет, то поищите информацию в интернете — в этой статье я не буду вас грузить историей или математикой. Сегодня я хочу просто попытаться показать вам практический пример применения алгоритма к символьной строке.
Примечание переводчика: под символом автор подразумевает некий повторяющийся элемент исходной строки — это может быть как печатный знак (character), так и любая битовая последовательность. Под кодом подразумевается не ASCII или UTF-8 код символа, а кодирующая последовательность битов.
К статье прикреплён исходный код, который наглядно демонстрирует, как работает алгоритм Хаффмана — он предназначен для людей, которые плохо понимают математику процесса. В будущем (я надеюсь) я напишу статью, в которой мы поговорим о применении алгоритма к любым файлам для их сжатия (то есть, сделаем простой архиватор типа WinRAR или WinZIP).
Идея, положенная в основу кодировании Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код. Это нужно, так как мы хотим, чтобы, когда мы обработали весь ввод, самые частотные символы заняли меньше всего места (и меньше, чем они занимали в оригинале), а самые редкие — побольше (но так как они редкие, это не имеет значения). Для нашей программы я решил, что символ будет иметь длину 8 бит, то есть, будет соответствовать печатному знаку.
Мы могли бы с той же простотой взять символ длиной в 16 бит (то есть, состоящий из двух печатных знаков), равно как и 10 бит, 20 и так далее. Размер символа выбирается, исходя из строки ввода, которую мы ожидаем встретить. Например, если бы я собрался кодировать сырые видеофайлы, я бы приравнял размер символа к размеру пикселя. Помните, что при уменьшении или увеличении размера символа меняется и размер кода для каждого символа, потому что чем больше размер, тем больше символов можно закодировать этим размером кода. Комбинаций нулей и единичек, подходящих для восьми бит, меньше, чем для шестнадцати. Поэтому вы должны подобрать размер символа, исходя из того по какому принципу данные повторяются в вашей последовательности.
Для этого алгоритма вам потребуется минимальное понимание устройства бинарного дерева и очереди с приоритетами. В исходном коде я использовал код очереди с приоритетами из моей предыдущей статьи.
Предположим, у нас есть строка «beep boop beer!», для которой, в её текущем виде, на каждый знак тратится по одному байту. Это означает, что вся строка целиком занимает 15*8 = 120 бит памяти. После кодирования строка займёт 40 бит (на практике, в нашей программе мы выведем на консоль последовательность из 40 нулей и единиц, представляющих собой биты кодированного текста. Чтобы получить из них настоящую строку размером 40 бит, нужно применять битовую арифметику, поэтому мы сегодня не будем этого делать).
Чтобы лучше понять пример, мы для начала сделаем всё вручную. Строка «beep boop beer!» для этого очень хорошо подойдёт. Чтобы получить код для каждого символа на основе его частотности, нам надо построить бинарное дерево, такое, что каждый лист этого дерева будет содержать символ (печатный знак из строки). Дерево будет строиться от листьев к корню, в том смысле, что символы с меньшей частотой будут дальше от корня, чем символы с большей. Скоро вы увидите, для чего это нужно.
Чтобы построить дерево, мы воспользуемся слегка модифицированной очередью с приоритетами — первыми из неё будут извлекаться элементы с наименьшим приоритетом, а не наибольшим. Это нужно, чтобы строить дерево от листьев к корню.
Для начала посчитаем частоты всех символов:
| Символ | Частота |
|---|---|
| ‘b’ | 3 |
| ‘e’ | 4 |
| ‘p’ | 2 |
| ‘ ‘ | 2 |
| ‘o’ | 2 |
| ‘r’ | 1 |
| ‘!’ | 1 |
После вычисления частот мы создадим узлы бинарного дерева для каждого знака и добавим их в очередь, используя частоту в качестве приоритета:

Теперь мы достаём два первых элемента из очереди и связываем их, создавая новый узел дерева, в котором они оба будут потомками, а приоритет нового узла будет равен сумме их приоритетов. После этого мы добавим получившийся новый узел обратно в очередь.
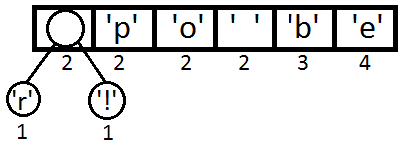
Повторим те же шаги и получим последовательно:
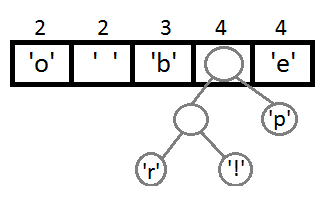
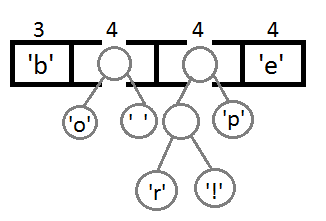
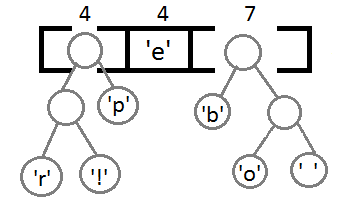
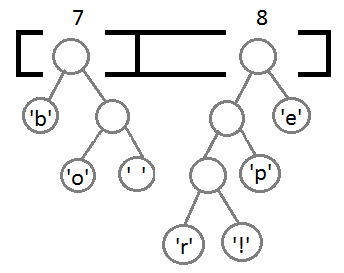
Ну и после того, как мы свяжем два последних элемента, получится итоговое дерево:
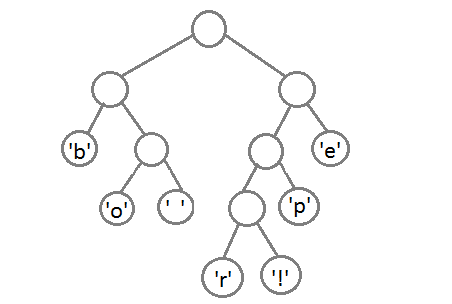
Теперь, чтобы получить код для каждого символа, надо просто пройтись по дереву, и для каждого перехода добавлять 0, если мы идём влево, и 1 — если направо:
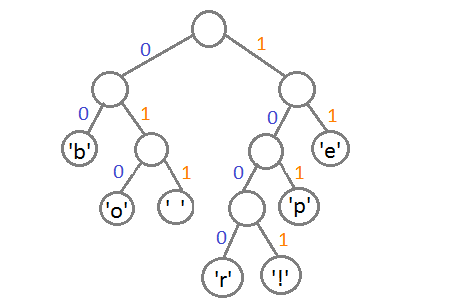
Если мы так сделаем, то получим следующие коды для символов:
| Символ | Код |
|---|---|
| ‘b’ | 00 |
| ‘e’ | 11 |
| ‘p’ | 101 |
| ‘ ‘ | 011 |
| ‘o’ | 010 |
| ‘r’ | 1000 |
| ‘!’ | 1001 |
Чтобы расшифровать закодированную строку, нам надо, соответственно, просто идти по дереву, сворачивая в соответствующую каждому биту сторону до тех пор, пока мы не достигнем листа. Например, если есть строка «101 11 101 11» и наше дерево, то мы получим строку «pepe».
Важно иметь в виду, что каждый код не является префиксом для кода другого символа. В нашем примере, если 00 — это код для ‘b’, то 000 не может оказаться чьим-либо кодом, потому что иначе мы получим конфликт. Мы никогда не достигли бы этого символа в дереве, так как останавливались бы ещё на ‘b’.
На практике, при реализации данного алгоритма сразу после построения дерева строится таблица Хаффмана. Данная таблица — это по сути связный список или массив, который содержит каждый символ и его код, потому что это делает кодирование более эффективным. Довольно затратно каждый раз искать символ и одновременно вычислять его код, так как мы не знаем, где он находится, и придётся обходить всё дерево целиком. Как правило, для кодирования используется таблица Хаффмана, а для декодирования — дерево Хаффмана.
Входная строка: «beep boop beer!»
Входная строка в бинарном виде: «0110 0010 0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111 0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 000»
Закодированная строка: «0011 1110 1011 0001 0010 1010 1100 1111 1000 1001»
Как вы можете заметить, между ASCII-версией строки и закодированной версией существует большая разница.
Приложенный исходный код работает по тому же принципу, что и описан выше. В коде можно найти больше деталей и комментариев.
Все исходники были откомпилированы и проверены с использованием стандарта C99. Удачного программирования!
Скачать исходный код
Чтобы прояснить ситуацию: данная статья только иллюстрирует работу алгоритма. Чтобы использовать это в реальной жизни, вам надо будет поместить созданное вами дерево Хаффмана в закодированную строку, а получатель должен будет знать, как его интерпретировать, чтобы раскодировать сообщение. Хорошим способом сделать это, является проход по дереву в любом порядке, который вам нравится (я предпочитаю обход в глубину) и конкатенировать 0 для каждого узла и 1 для листа с битами, представляющими оригинальный символ (в нашем случае, 8 бит, представляющие ASCII-код знака). Идеальным было бы добавить это представление в самое начало закодированной строки. Как только получатель построит дерево, он будет знать, как декодировать сообщение, чтобы прочесть оригинал.
Алгоритм Хаффмана (англ. Huffman’s algorithm) — алгоритм оптимального префиксного кодирования алфавита. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. Используется во многих программах сжатия данных, например, PKZIP 2, LZH и др.
Содержание
- 1 Определение
- 2 Алгоритм построения бинарного кода Хаффмана
- 2.1 Время работы
- 2.2 Пример
- 3 Корректность алгоритма Хаффмана
- 4 См. также
- 5 Источники информации
Определение
| Определение: |
Пусть — алфавит из различных символов, — соответствующий ему набор положительных целых весов. Тогда набор бинарных кодов , где является кодом для символа , такой, что:
называется кодом Хаффмана. |
Алгоритм построения бинарного кода Хаффмана
Построение кода Хаффмана сводится к построению соответствующего бинарного дерева по следующему алгоритму:
- Составим список кодируемых символов, при этом будем рассматривать один символ как дерево, состоящее из одного элемента c весом, равным частоте появления символа в строке.
- Из списка выберем два узла с наименьшим весом.
- Сформируем новый узел с весом, равным сумме весов выбранных узлов, и присоединим к нему два выбранных узла в качестве детей.
- Добавим к списку только что сформированный узел вместо двух объединенных узлов.
- Если в списке больше одного узла, то повторим пункты со второго по пятый.
Время работы
Если сортировать элементы после каждого суммирования или использовать приоритетную очередь, то алгоритм будет работать за время .Такую асимптотику можно улучшить до , используя обычные массивы.
Пример
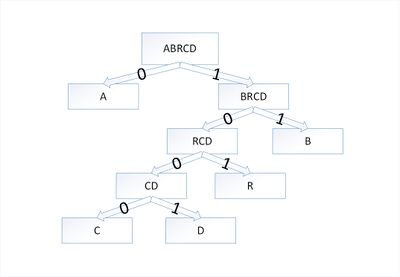
Дерево Хаффмана для слова
Закодируем слово . Тогда алфавит будет , а набор весов (частота появления символов алфавита в кодируемом слове) :
В дереве Хаффмана будет узлов:
| Узел | a | b | r | с | d |
|---|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 1 | 1 |
По алгоритму возьмем два символа с наименьшей частотой — это и . Сформируем из них новый узел весом и добавим его к списку узлов:
| Узел | a | b | r | cd |
|---|---|---|---|---|
| Вес | 5 | 2 | 2 | 2 |
Затем опять объединим в один узел два минимальных по весу узла — и :
| Узел | a | rcd | b |
|---|---|---|---|
| Вес | 5 | 4 | 2 |
Еще раз повторим эту же операцию, но для узлов и :
| Узел | brcd | a |
|---|---|---|
| Вес | 6 | 5 |
На последнем шаге объединим два узла — и :
| Узел | abrcd |
|---|---|
| Вес | 11 |
Остался один узел, значит, мы пришли к корню дерева Хаффмана (смотри рисунок). Теперь для каждого символа выберем кодовое слово (бинарная последовательность, обозначающая путь по дереву к этому символу от корня):
| Символ | a | b | r | с | d |
|---|---|---|---|---|---|
| Код | 0 | 11 | 101 | 1000 | 1001 |
Таким образом, закодированное слово будет выглядеть как . Длина закодированного слова — бита. Стоит заметить, что если бы мы использовали алгоритм кодирования с одинаковой длиной всех кодовых слов, то закодированное слово заняло бы бита, что существенно больше.
Корректность алгоритма Хаффмана
Чтобы доказать корректность алгоритма Хаффмана, покажем, что в задаче о построении оптимального префиксного кода проявляются свойства жадного выбора и оптимальной подструктуры. В сформулированной ниже лемме показано соблюдение свойства жадного выбора.
| Лемма (1): |
|
Пусть — алфавит, каждый символ которого встречается с частотой . Пусть и — два символа алфавита с самыми низкими частотами. |
| Доказательство: |
|
Возьмем дерево , представляющее произвольный оптимальный префиксный код для алфавита . Преобразуем его в дерево, представляющее другой оптимальный префиксный код, в котором символы и — листья с общим родительским узлом, находящиеся на максимальной глубине. Пусть символы и имеют общий родительский узел и находятся на максимальной глубине дерева . Предположим, что и . Так как и — две наименьшие частоты, а и — две произвольные частоты, то выполняются отношения и . Пусть дерево — дерево, полученное из путем перестановки листьев и , а дерево — дерево полученное из перестановкой листьев и . Разность стоимостей деревьев и равна: что больше либо равно , так как величины и неотрицательны. Величина неотрицательна, потому что — лист с минимальной частотой, а величина является неотрицательной, так как лист находится на максимальной глубине в дереве . Точно так же перестановка листьев и не будет приводить к увеличению стоимости. Таким образом, разность тоже будет неотрицательной. Таким образом, выполняется неравенство . С другой стороны, — оптимальное дерево, поэтому должно выполняться неравенство . Отсюда следует, что . Значит, — дерево, представляющее оптимальный префиксный код, в котором символы и имеют одинаковую максимальную длину, что и доказывает лемму. |
| Лемма (2): |
|
Пусть дан алфавит , в котором для каждого символа определены частоты . Пусть и — два символа из алфавита с минимальными частотами. Пусть — алфавит, полученный из алфавита путем удаления символов и и добавления нового символа , так что . По определению частоты в алфавите совпадают с частотами в алфавите , за исключением частоты . Пусть — произвольное дерево, представляющее оптимальный префиксный код для алфавита Тогда дерево , полученное из дерева путем замены листа внутренним узлом с дочерними элементами и , представляет оптимальный префиксный код для алфавита . |
| Доказательство: |
|
Сначала покажем, что стоимость дерева может быть выражена через стоимость дерева . Для каждого символа верно , значит, . Так как , то из чего следует, что или Докажем лемму от противного. Предположим, что дерево не представляет оптимальный префиксный код для алфавита . Тогда существует дерево такое, что . Согласно лемме (1), элементы и можно считать дочерними элементами одного узла. Пусть дерево получено из дерева заменой элементов и листом с частотой . Тогда , что противоречит предположению о том, что дерево представляет оптимальный префиксный код для алфавита . Значит, наше предположение о том, что дерево не представляет оптимальный префиксный код для алфавита , неверно, что и доказывает лемму. |
| Теорема: |
|
Алгоритм Хаффмана дает оптимальный префиксный код. |
| Доказательство: |
| Справедливость теоремы непосредственно следует из лемм (1) и (2) |
См. также
- Оптимальное хранение словаря в алгоритме Хаффмана
Источники информации
- Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн. Алгоритмы: построение и анализ — 2-е изд. — М.: «Вильямс», 2007. — с. 459. — ISBN 5-8489-0857-4
- Wikipedia — Huffman coding
- Википедия — Бинарное дерево
- Википедия — Префиксный код
Кодирование Хаффмана (также известное как кодирование Хаффмана) — это алгоритм сжатия данных, который формирует основную идею сжатия файлов. В этом посте рассказывается о кодировании с фиксированной и переменной длиной, уникально декодируемых кодах, правилах префиксов и построении дерева Хаффмана.
Обзор
Мы уже знаем, что каждый символ представляет собой последовательность 0's а также 1's и хранится с использованием 8-бит. Это известно как “кодирование с фиксированной длиной”, так как каждый символ использует одинаковое количество фиксированных битов памяти.
Учитывая текст, как уменьшить количество места, необходимое для хранения символа?
Идея состоит в том, чтобы использовать “кодирование переменной длины”. Мы можем использовать тот факт, что одни символы встречаются в тексте чаще, чем другие (см. это) для разработки алгоритма, который может представлять тот же фрагмент текста, используя меньшее количество битов. При кодировании с переменной длиной мы присваиваем символам переменное количество битов в зависимости от их частоты в данном тексте. Таким образом, некоторые символы могут в конечном итоге занимать один бит, а некоторые — два бита, некоторые могут быть закодированы с использованием трех битов и так далее. Проблема с кодированием переменной длины заключается в его декодировании.
Учитывая последовательность битов, как ее однозначно декодировать?
Рассмотрим строку aabacdab. Оно имеет 8 символов в нем и использует 64-битное хранилище (с использованием кодирования фиксированной длины). Если принять во внимание, что частота символов a, b, c а также d находятся 4, 2, 1, 1, соответственно. Попробуем представить aabacdab используя меньшее количество битов, используя тот факт, что a встречается чаще, чем b, а также b встречается чаще, чем c а также d. Начнем со случайного присвоения однобитового кода 0 к a, 2-битный код 11 к b, и 3-битный код 100 а также 011 к персонажам c а также d, соответственно.
a 0
b 11
c 100
d 011
Итак, строка aabacdab будет закодирован в 00110100011011 (0|0|11|0|100|011|0|11) используя приведенные выше коды. Но настоящая проблема заключается в расшифровке. Если мы попытаемся декодировать строку 00110100011011, это приведет к неоднозначности, так как его можно декодировать,
0|011|0|100|011|0|11 adacdab
0|0|11|0|100|0|11|011 aabacabd
0|011|0|100|0|11|0|11 adacabab
…
and so on
Чтобы предотвратить двусмысленность при декодировании, мы обеспечим соответствие нашего кодирования “правилу префикса”, что приведет к “уникально декодируемым кодам”. Правило префикса гласит, что ни один код не является префиксом другого кода. Под кодом мы подразумеваем биты, используемые для определенного символа. В приведенном выше примере 0 является префиксом 011, что нарушает правило префикса. Если наши коды удовлетворяют префиксному правилу, декодирование будет однозначным (и наоборот).
Давайте снова рассмотрим приведенный выше пример. На этот раз мы присваиваем символам коды, удовлетворяющие правилу префикса. 'a', 'b', 'c', а также 'd'.
a 0
b 10
c 110
d 111
Используя приведенные выше коды, строка aabacdab будет закодирован в 00100110111010 (0|0|10|0|110|111|0|10). Теперь мы можем однозначно декодировать 00100110111010 вернуться к нашей исходной строке aabacdab.
Теперь, когда мы разобрались с кодированием переменной длины и правилом префиксов, давайте поговорим о кодировании Хаффмана.
Кодирование Хаффмана
Техника работает, создавая бинарное дерево узлов. Узел может быть листовым узлом или внутренним узлом. Изначально все узлы являются листовыми узлами, которые содержат сам персонаж, вес (частоту появления) персонажа. Внутренние узлы содержат вес символов и ссылки на два дочерних узла. По общему соглашению, бит 0 представляет следующий левый дочерний элемент, и немного 1 представляет следующий правильный ребенок. Готовое дерево имеет n листовые узлы и n-1 внутренние узлы. Рекомендуется, чтобы дерево Хаффмана отбрасывало неиспользуемые символы в тексте, чтобы получить наиболее оптимальную длину кода.
Мы будем использовать приоритетная очередь для построения дерева Хаффмана, где узел с наименьшей частотой имеет наивысший приоритет. Ниже приведены полные шаги:
1. Создайте конечный узел для каждого символа и добавьте их в очередь приоритетов.
2. Пока в queue больше одного узла:
- Удалите из queue два узла с наивысшим приоритетом (самой низкой частотой).
- Создайте новый внутренний узел с этими двумя узлами в качестве дочерних элементов и частотой, равной сумме частот обоих узлов.
- Добавьте новый узел в очередь приоритетов.
3. Оставшийся узел является корневым узлом, и дерево завершено.
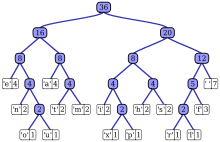
Рассмотрим некоторый текст, состоящий только из 'A', 'B', 'C', 'D', а также 'E' символов, а их частота 15, 7, 6, 6, 5, соответственно. Следующие рисунки иллюстрируют шаги, за которыми следует алгоритм:
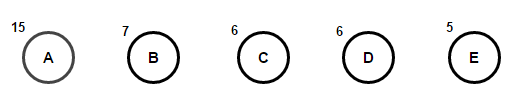
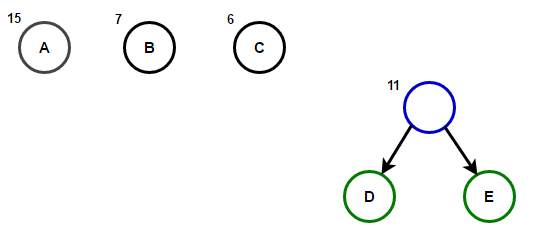
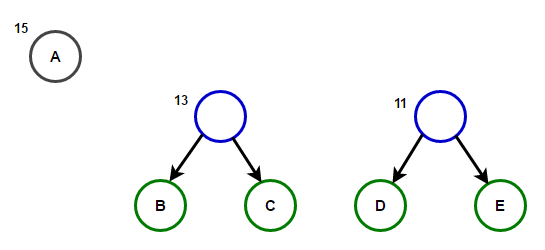

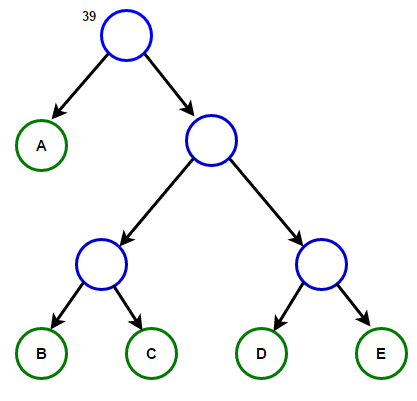
Путь от корня к любому конечному узлу хранит оптимальный код префикса (также называемый кодом Хаффмана), соответствующий символу, связанному с этим конечным узлом.
Реализация
Ниже приведена реализация алгоритма сжатия кода Хаффмана на C++, Java и Python:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 |
#include <iostream> #include <string> #include <queue> #include <unordered_map> using namespace std; #define EMPTY_STRING «» // Узел дерева struct Node { char ch; int freq; Node *left, *right; }; // Функция для выделения нового узла дерева Node* getNode(char ch, int freq, Node* left, Node* right) { Node* node = new Node(); node->ch = ch; node->freq = freq; node->left = left; node->right = right; return node; } // Объект сравнения, который будет использоваться для упорядочивания кучи struct comp { bool operator()(const Node* l, const Node* r) const { // элемент с наивысшим приоритетом имеет наименьшую частоту return l->freq > r->freq; } }; // Вспомогательная функция для проверки, содержит ли дерево Хаффмана только один узел bool isLeaf(Node* root) { return root->left == nullptr && root->right == nullptr; } // Проходим по дереву Хаффмана и сохраняем коды Хаффмана на карте. void encode(Node* root, string str, unordered_map<char, string> &huffmanCode) { if (root == nullptr) { return; } // найден листовой узел if (isLeaf(root)) { huffmanCode[root->ch] = (str != EMPTY_STRING) ? str : «1»; } encode(root->left, str + «0», huffmanCode); encode(root->right, str + «1», huffmanCode); } // Проходим по дереву Хаффмана и декодируем закодированную строку void decode(Node* root, int &index, string str) { if (root == nullptr) { return; } // найден листовой узел if (isLeaf(root)) { cout << root->ch; return; } index++; if (str[index] == ‘0’) { decode(root->left, index, str); } else { decode(root->right, index, str); } } // Строит дерево Хаффмана и декодирует заданный входной текст void buildHuffmanTree(string text) { // базовый случай: пустая строка if (text == EMPTY_STRING) { return; } // подсчитываем частоту появления каждого символа // и сохранить его на карте unordered_map<char, int> freq; for (char ch: text) { freq[ch]++; } // Создаем приоритетную очередь для хранения активных узлов дерева Хаффмана priority_queue<Node*, vector<Node*>, comp> pq; // Создаем конечный узел для каждого символа и добавляем его // в приоритетную очередь. for (auto pair: freq) { pq.push(getNode(pair.first, pair.second, nullptr, nullptr)); } // делаем до тех пор, пока в queue не окажется более одного узла while (pq.size() != 1) { // Удаляем два узла с наивысшим приоритетом // (самая низкая частота) из queue Node* left = pq.top(); pq.pop(); Node* right = pq.top(); pq.pop(); // создаем новый внутренний узел с этими двумя узлами в качестве дочерних и // с частотой, равной сумме частот двух узлов. // Добавляем новый узел в приоритетную очередь. int sum = left->freq + right->freq; pq.push(getNode(», sum, left, right)); } // `root` хранит указатель на корень дерева Хаффмана Node* root = pq.top(); // Проходим по дереву Хаффмана и сохраняем коды Хаффмана // на карте. Кроме того, распечатайте их unordered_map<char, string> huffmanCode; encode(root, EMPTY_STRING, huffmanCode); cout << «Huffman Codes are:n» << endl; for (auto pair: huffmanCode) { cout << pair.first << » « << pair.second << endl; } cout << «nThe original string is:n» << text << endl; // Печатаем закодированную строку string str; for (char ch: text) { str += huffmanCode[ch]; } cout << «nThe encoded string is:n» << str << endl; cout << «nThe decoded string is:n»; if (isLeaf(root)) { // Особый случай: для ввода типа a, aa, aaa и т. д. while (root->freq—) { cout << root->ch; } } else { // Снова проходим по дереву Хаффмана и на этот раз // декодируем закодированную строку int index = —1; while (index < (int)str.size() — 1) { decode(root, index, str); } } } // Реализация алгоритма кодирования Хаффмана на C++ int main() { string text = «Huffman coding is a data compression algorithm.»; buildHuffmanTree(text); return 0; } |
Скачать Выполнить код
результат:
Huffman Codes are:
c 11111
h 111100
f 11101
r 11100
t 11011
p 110101
i 1100
g 0011
l 00101
a 010
o 000
d 10011
H 00100
. 111101
s 0110
m 0111
e 110100
101
n 1000
u 10010
The original string is:
Huffman coding is a data compression algorithm.
The encoded string is:
00100100101110111101011101010001011111100010011110010000011101110001101010101011001101011011010101111110000111110101111001101000110011011000001000101010001010011000111001100110111111000111111101
The decoded string is:
Huffman coding is a data compression algorithm.
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 |
import java.util.Comparator; import java.util.HashMap; import java.util.Map; import java.util.PriorityQueue; // Узел дерева class Node { Character ch; Integer freq; Node left = null, right = null; Node(Character ch, Integer freq) { this.ch = ch; this.freq = freq; } public Node(Character ch, Integer freq, Node left, Node right) { this.ch = ch; this.freq = freq; this.left = left; this.right = right; } } class Main { // Проходим по дереву Хаффмана и сохраняем коды Хаффмана на карте. public static void encode(Node root, String str, Map<Character, String> huffmanCode) { if (root == null) { return; } // Найден листовой узел if (isLeaf(root)) { huffmanCode.put(root.ch, str.length() > 0 ? str : «1»); } encode(root.left, str + ‘0’, huffmanCode); encode(root.right, str + ‘1’, huffmanCode); } // Проходим по дереву Хаффмана и декодируем закодированную строку public static int decode(Node root, int index, StringBuilder sb) { if (root == null) { return index; } // Найден листовой узел if (isLeaf(root)) { System.out.print(root.ch); return index; } index++; root = (sb.charAt(index) == ‘0’) ? root.left : root.right; index = decode(root, index, sb); return index; } // Вспомогательная функция для проверки, содержит ли дерево Хаффмана только один узел public static boolean isLeaf(Node root) { return root.left == null && root.right == null; } // Строит дерево Хаффмана и декодирует заданный входной текст public static void buildHuffmanTree(String text) { // Базовый случай: пустая строка if (text == null || text.length() == 0) { return; } // Подсчитаем частоту появления каждого символа // и сохранить его на карте Map<Character, Integer> freq = new HashMap<>(); for (char c: text.toCharArray()) { freq.put(c, freq.getOrDefault(c, 0) + 1); } // создаем приоритетную очередь для хранения живых узлов дерева Хаффмана. // Обратите внимание, что элемент с наивысшим приоритетом имеет наименьшую частоту PriorityQueue<Node> pq; pq = new PriorityQueue<>(Comparator.comparingInt(l -> l.freq)); // создаем конечный узел для каждого символа и добавляем его // в приоритетную очередь. for (var entry: freq.entrySet()) { pq.add(new Node(entry.getKey(), entry.getValue())); } // делаем до тех пор, пока в queue не окажется более одного узла while (pq.size() != 1) { // Удаляем два узла с наивысшим приоритетом // (самая низкая частота) из queue Node left = pq.poll(); Node right = pq.poll(); // создаем новый внутренний узел с этими двумя узлами в качестве дочерних // и с частотой равной сумме обоих узлов // частоты. Добавьте новый узел в очередь приоритетов. int sum = left.freq + right.freq; pq.add(new Node(null, sum, left, right)); } // `root` хранит указатель на корень дерева Хаффмана Node root = pq.peek(); // Проходим по дереву Хаффмана и сохраняем коды Хаффмана на карте Map<Character, String> huffmanCode = new HashMap<>(); encode(root, «», huffmanCode); // Выводим коды Хаффмана System.out.println(«Huffman Codes are: « + huffmanCode); System.out.println(«The original string is: « + text); // Печатаем закодированную строку StringBuilder sb = new StringBuilder(); for (char c: text.toCharArray()) { sb.append(huffmanCode.get(c)); } System.out.println(«The encoded string is: « + sb); System.out.print(«The decoded string is: «); if (isLeaf(root)) { // Особый случай: для ввода типа a, aa, aaa и т. д. while (root.freq— > 0) { System.out.print(root.ch); } } else { // Снова проходим по дереву Хаффмана и на этот раз // декодируем закодированную строку int index = —1; while (index < sb.length() — 1) { index = decode(root, index, sb); } } } // Реализация алгоритма кодирования Хаффмана на Java public static void main(String[] args) { String text = «Huffman coding is a data compression algorithm.»; buildHuffmanTree(text); } } |
Скачать Выполнить код
результат:
Huffman Codes are: { =100, a=010, c=0011, d=11001, e=110000, f=0000, g=0001, H=110001, h=110100, i=1111, l=101010, m=0110, n=0111, .=10100, o=1110, p=110101, r=0010, s=1011, t=11011, u=101011}
The original string is: Huffman coding is a data compression algorithm.
The encoded string is: 11000110101100000000011001001111000011111011001111101110001100111110111000101001100101011011010100001111100110110101001011000010111011111111100111100010101010000111100010111111011110100011010100
The decoded string is: Huffman coding is a data compression algorithm.
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
import heapq from heapq import heappop, heappush def isLeaf(root): return root.left is None and root.right is None # Узел дерева class Node: def __init__(self, ch, freq, left=None, right=None): self.ch = ch self.freq = freq self.left = left self.right = right # Переопределить функцию `__lt__()`, чтобы заставить класс `Node` работать с приоритетной очередью. # таким образом, что элемент с наивысшим приоритетом имеет наименьшую частоту def __lt__(self, other): return self.freq < other.freq # Пройти по дереву Хаффмана и сохранить коды Хаффмана в словаре def encode(root, s, huffman_code): if root is None: return # обнаружил листовой узел if isLeaf(root): huffman_code[root.ch] = s if len(s) > 0 else ‘1’ encode(root.left, s + ‘0’, huffman_code) encode(root.right, s + ‘1’, huffman_code) # Пройти по дереву Хаффмана и декодировать закодированную строку def decode(root, index, s): if root is None: return index # обнаружил листовой узел if isLeaf(root): print(root.ch, end=») return index index = index + 1 root = root.left if s[index] == ‘0’ else root.right return decode(root, index, s) # строит дерево Хаффмана и декодирует заданный входной текст def buildHuffmanTree(text): # Базовый случай: пустая строка if len(text) == 0: return # подсчитывает частоту появления каждого символа # и сохраните его в словаре freq = {i: text.count(i) for i in set(text)} # Создайте приоритетную очередь для хранения активных узлов дерева Хаффмана. pq = [Node(k, v) for k, v in freq.items()] heapq.heapify(pq) # делать до тех пор, пока в queue не окажется более одного узла while len(pq) != 1: # Удалить два узла с наивысшим приоритетом # (самая низкая частота) из queue left = heappop(pq) right = heappop(pq) # создает новый внутренний узел с этими двумя узлами в качестве дочерних и # с частотой, равной сумме частот двух узлов. # Добавьте новый узел в приоритетную очередь. total = left.freq + right.freq heappush(pq, Node(None, total, left, right)) # `root` хранит указатель на корень дерева Хаффмана. root = pq[0] # проходит по дереву Хаффмана и сохраняет коды Хаффмана в словаре. huffmanCode = {} encode(root, », huffmanCode) # распечатать коды Хаффмана print(‘Huffman Codes are:’, huffmanCode) print(‘The original string is:’, text) # распечатать закодированную строку s = » for c in text: s += huffmanCode.get(c) print(‘The encoded string is:’, s) print(‘The decoded string is:’, end=‘ ‘) if isLeaf(root): # Особый случай: для ввода типа a, aa, aaa и т. д. while root.freq > 0: print(root.ch, end=») root.freq = root.freq — 1 else: # снова пересекают дерево Хаффмана, и на этот раз # декодирует закодированную строку index = —1 while index < len(s) — 1: index = decode(root, index, s) # Реализация алгоритма кодирования # Хаффмана на Python if __name__ == ‘__main__’: text = ‘Huffman coding is a data compression algorithm.’ buildHuffmanTree(text) |
Скачать Выполнить код
результат:
Huffman Codes are: {‘l’: ‘00000’, ‘p’: ‘00001’, ‘t’: ‘0001’, ‘h’: ‘00100’, ‘e’: ‘00101’, ‘g’: ‘0011’, ‘a’: ‘010’, ‘m’: ‘0110’, ‘.’: ‘01110’, ‘r’: ‘01111’, ‘ ‘: ‘100’, ‘n’: ‘1010’, ‘s’: ‘1011’, ‘c’: ‘11000’, ‘f’: ‘11001’, ‘i’: ‘1101’, ‘o’: ‘1110’, ‘d’: ‘11110’, ‘u’: ‘111110’, ‘H’: ‘111111’}
The original string is: Huffman coding is a data compression algorithm.
The encoded string is: 11111111111011001110010110010101010011000111011110110110100011100110110111000101001111001000010101001100011100110000010111100101101110111101111010101000100000000111110011111101000100100011001110
The decoded string is: Huffman coding is a data compression algorithm.
Обратите внимание, что размер входной строки составляет 47×8 = 376 бит, но наша закодированная строка занимает всего 194 бита, т. е. примерно 48% сжатия данных. Чтобы сделать программу читабельной, мы использовали класс string для хранения закодированной строки вышеуказанной программы.
Поскольку эффективные структуры данных очереди приоритетов требуют O(log(n)) время на вставку и полное бинарное дерево с n листья имеют 2n-1 узлов, а дерево кодирования Хаффмана является полным бинарным деревом, этот алгоритм работает в O(n.log(n)) время, где n это общее количество символов.
Использованная литература:
https://en.wikipedia.org/wiki/Huffman_coding
https://en.wikipedia.org/wiki/Variable-length_code
Д-р Навин Гарг, IIT – D (Лекция – 19 Сжатие данных)
Huffman tree generated from the exact frequencies of the text «this is an example of a huffman tree». The frequencies and codes of each character are below. Encoding the sentence with this code requires 135 (or 147) bits, as opposed to 288 (or 180) bits if 36 characters of 8 (or 5) bits were used. (This assumes that the code tree structure is known to the decoder and thus does not need to be counted as part of the transmitted information.)
| Char | Freq | Code |
|---|---|---|
| space | 7 | 111 |
| a | 4 | 010 |
| e | 4 | 000 |
| f | 3 | 1101 |
| h | 2 | 1010 |
| i | 2 | 1000 |
| m | 2 | 0111 |
| n | 2 | 0010 |
| s | 2 | 1011 |
| t | 2 | 0110 |
| l | 1 | 11001 |
| o | 1 | 00110 |
| p | 1 | 10011 |
| r | 1 | 11000 |
| u | 1 | 00111 |
| x | 1 | 10010 |
In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code proceeds by means of Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper «A Method for the Construction of Minimum-Redundancy Codes».[1]
The output from Huffman’s algorithm can be viewed as a variable-length code table for encoding a source symbol (such as a character in a file). The algorithm derives this table from the estimated probability or frequency of occurrence (weight) for each possible value of the source symbol. As in other entropy encoding methods, more common symbols are generally represented using fewer bits than less common symbols. Huffman’s method can be efficiently implemented, finding a code in time linear to the number of input weights if these weights are sorted.[2] However, although optimal among methods encoding symbols separately, Huffman coding is not always optimal among all compression methods — it is replaced with arithmetic coding[3] or asymmetric numeral systems[4] if a better compression ratio is required.
History[edit]
In 1951, David A. Huffman and his MIT information theory classmates were given the choice of a term paper or a final exam. The professor, Robert M. Fano, assigned a term paper on the problem of finding the most efficient binary code. Huffman, unable to prove any codes were the most efficient, was about to give up and start studying for the final when he hit upon the idea of using a frequency-sorted binary tree and quickly proved this method the most efficient.[5]
In doing so, Huffman outdid Fano, who had worked with Claude Shannon to develop a similar code. Building the tree from the bottom up guaranteed optimality, unlike the top-down approach of Shannon–Fano coding.
Terminology[edit]
Huffman coding uses a specific method for choosing the representation for each symbol, resulting in a prefix code (sometimes called «prefix-free codes», that is, the bit string representing some particular symbol is never a prefix of the bit string representing any other symbol). Huffman coding is such a widespread method for creating prefix codes that the term «Huffman code» is widely used as a synonym for «prefix code» even when such a code is not produced by Huffman’s algorithm.
Problem definition[edit]

Constructing a Huffman Tree
Informal description[edit]
- Given
- A set of symbols and their weights (usually proportional to probabilities).
- Find
- A prefix-free binary code (a set of codewords) with minimum expected codeword length (equivalently, a tree with minimum weighted path length from the root).
Formalized description[edit]
Example[edit]
We give an example of the result of Huffman coding for a code with five characters and given weights. We will not verify that it minimizes L over all codes, but we will compute L and compare it to the Shannon entropy H of the given set of weights; the result is nearly optimal.
| Input (A, W) | Symbol (ai) | a | b | c | d | e | Sum |
|---|---|---|---|---|---|---|---|
| Weights (wi) | 0.10 | 0.15 | 0.30 | 0.16 | 0.29 | = 1 | |
| Output C | Codewords (ci) | 010
|
011
|
11
|
00
|
10
|
|
| Codeword length (in bits) (li) |
3 | 3 | 2 | 2 | 2 | ||
| Contribution to weighted path length (li wi ) |
0.30 | 0.45 | 0.60 | 0.32 | 0.58 | L(C) = 2.25 | |
| Optimality | Probability budget (2−li) |
1/8 | 1/8 | 1/4 | 1/4 | 1/4 | = 1.00 |
| Information content (in bits) (−log2 wi) ≈ |
3.32 | 2.74 | 1.74 | 2.64 | 1.79 | ||
| Contribution to entropy (—wi log2 wi) |
0.332 | 0.411 | 0.521 | 0.423 | 0.518 | H(A) = 2.205 |
For any code that is biunique, meaning that the code is uniquely decodeable, the sum of the probability budgets across all symbols is always less than or equal to one. In this example, the sum is strictly equal to one; as a result, the code is termed a complete code. If this is not the case, one can always derive an equivalent code by adding extra symbols (with associated null probabilities), to make the code complete while keeping it biunique.
As defined by Shannon (1948), the information content h (in bits) of each symbol ai with non-null probability is

The entropy H (in bits) is the weighted sum, across all symbols ai with non-zero probability wi, of the information content of each symbol:

(Note: A symbol with zero probability has zero contribution to the entropy, since  . So for simplicity, symbols with zero probability can be left out of the formula above.)
. So for simplicity, symbols with zero probability can be left out of the formula above.)
As a consequence of Shannon’s source coding theorem, the entropy is a measure of the smallest codeword length that is theoretically possible for the given alphabet with associated weights. In this example, the weighted average codeword length is 2.25 bits per symbol, only slightly larger than the calculated entropy of 2.205 bits per symbol. So not only is this code optimal in the sense that no other feasible code performs better, but it is very close to the theoretical limit established by Shannon.
In general, a Huffman code need not be unique. Thus the set of Huffman codes for a given probability distribution is a non-empty subset of the codes minimizing  for that probability distribution. (However, for each minimizing codeword length assignment, there exists at least one Huffman code with those lengths.)
for that probability distribution. (However, for each minimizing codeword length assignment, there exists at least one Huffman code with those lengths.)
Basic technique[edit]
Compression[edit]
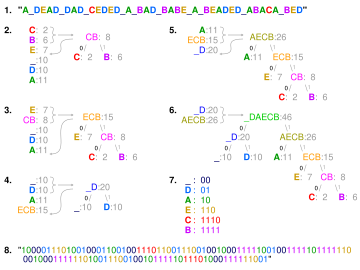
Visualisation of the use of Huffman coding to encode the message «A_DEAD_DAD_CEDED_A_BAD_BABE_A_BEADED_ABACA_
BED». In steps 2 to 6, the letters are sorted by increasing frequency, and the least frequent two at each step are combined and reinserted into the list, and a partial tree is constructed. The final tree in step 6 is traversed to generate the dictionary in step 7. Step 8 uses it to encode the message.

A source generates 4 different symbols  with probability
with probability  . A binary tree is generated from left to right taking the two least probable symbols and putting them together to form another equivalent symbol having a probability that equals the sum of the two symbols. The process is repeated until there is just one symbol. The tree can then be read backwards, from right to left, assigning different bits to different branches. The final Huffman code is:
. A binary tree is generated from left to right taking the two least probable symbols and putting them together to form another equivalent symbol having a probability that equals the sum of the two symbols. The process is repeated until there is just one symbol. The tree can then be read backwards, from right to left, assigning different bits to different branches. The final Huffman code is:
| Symbol | Code |
|---|---|
| a1 | 0 |
| a2 | 10 |
| a3 | 110 |
| a4 | 111 |
The standard way to represent a signal made of 4 symbols is by using 2 bits/symbol, but the entropy of the source is 1.74 bits/symbol. If this Huffman code is used to represent the signal, then the average length is lowered to 1.85 bits/symbol; it is still far from the theoretical limit because the probabilities of the symbols are different from negative powers of two.
The technique works by creating a binary tree of nodes. These can be stored in a regular array, the size of which depends on the number of symbols,  . A node can be either a leaf node or an internal node. Initially, all nodes are leaf nodes, which contain the symbol itself, the weight (frequency of appearance) of the symbol and optionally, a link to a parent node which makes it easy to read the code (in reverse) starting from a leaf node. Internal nodes contain a weight, links to two child nodes and an optional link to a parent node. As a common convention, bit ‘0’ represents following the left child and bit ‘1’ represents following the right child. A finished tree has up to leaf nodes and
. A node can be either a leaf node or an internal node. Initially, all nodes are leaf nodes, which contain the symbol itself, the weight (frequency of appearance) of the symbol and optionally, a link to a parent node which makes it easy to read the code (in reverse) starting from a leaf node. Internal nodes contain a weight, links to two child nodes and an optional link to a parent node. As a common convention, bit ‘0’ represents following the left child and bit ‘1’ represents following the right child. A finished tree has up to leaf nodes and  internal nodes. A Huffman tree that omits unused symbols produces the most optimal code lengths.
internal nodes. A Huffman tree that omits unused symbols produces the most optimal code lengths.
The process begins with the leaf nodes containing the probabilities of the symbol they represent. Then, the process takes the two nodes with smallest probability, and creates a new internal node having these two nodes as children. The weight of the new node is set to the sum of the weight of the children. We then apply the process again, on the new internal node and on the remaining nodes (i.e., we exclude the two leaf nodes), we repeat this process until only one node remains, which is the root of the Huffman tree.
The simplest construction algorithm uses a priority queue where the node with lowest probability is given highest priority:
- Create a leaf node for each symbol and add it to the priority queue.
- While there is more than one node in the queue:
- Remove the two nodes of highest priority (lowest probability) from the queue
- Create a new internal node with these two nodes as children and with probability equal to the sum of the two nodes’ probabilities.
- Add the new node to the queue.
- The remaining node is the root node and the tree is complete.
Since efficient priority queue data structures require O(log n) time per insertion, and a tree with n leaves has 2n−1 nodes, this algorithm operates in O(n log n) time, where n is the number of symbols.
If the symbols are sorted by probability, there is a linear-time (O(n)) method to create a Huffman tree using two queues, the first one containing the initial weights (along with pointers to the associated leaves), and combined weights (along with pointers to the trees) being put in the back of the second queue. This assures that the lowest weight is always kept at the front of one of the two queues:
- Start with as many leaves as there are symbols.
- Enqueue all leaf nodes into the first queue (by probability in increasing order so that the least likely item is in the head of the queue).
- While there is more than one node in the queues:
- Dequeue the two nodes with the lowest weight by examining the fronts of both queues.
- Create a new internal node, with the two just-removed nodes as children (either node can be either child) and the sum of their weights as the new weight.
- Enqueue the new node into the rear of the second queue.
- The remaining node is the root node; the tree has now been generated.
Once the Huffman tree has been generated, it is traversed to generate a dictionary which maps the symbols to binary codes as follows:
- Start with current node set to the root.
- If node is not a leaf node, label the edge to the left child as 0 and the edge to the right child as 1. Repeat the process at both the left child and the right child.
The final encoding of any symbol is then read by a concatenation of the labels on the edges along the path from the root node to the symbol.
In many cases, time complexity is not very important in the choice of algorithm here, since n here is the number of symbols in the alphabet, which is typically a very small number (compared to the length of the message to be encoded); whereas complexity analysis concerns the behavior when n grows to be very large.
It is generally beneficial to minimize the variance of codeword length. For example, a communication buffer receiving Huffman-encoded data may need to be larger to deal with especially long symbols if the tree is especially unbalanced. To minimize variance, simply break ties between queues by choosing the item in the first queue. This modification will retain the mathematical optimality of the Huffman coding while both minimizing variance and minimizing the length of the longest character code.
Decompression[edit]
Generally speaking, the process of decompression is simply a matter of translating the stream of prefix codes to individual byte values, usually by traversing the Huffman tree node by node as each bit is read from the input stream (reaching a leaf node necessarily terminates the search for that particular byte value). Before this can take place, however, the Huffman tree must be somehow reconstructed. In the simplest case, where character frequencies are fairly predictable, the tree can be preconstructed (and even statistically adjusted on each compression cycle) and thus reused every time, at the expense of at least some measure of compression efficiency. Otherwise, the information to reconstruct the tree must be sent a priori. A naive approach might be to prepend the frequency count of each character to the compression stream. Unfortunately, the overhead in such a case could amount to several kilobytes, so this method has little practical use. If the data is compressed using canonical encoding, the compression model can be precisely reconstructed with just  bits of information (where B is the number of bits per symbol). Another method is to simply prepend the Huffman tree, bit by bit, to the output stream. For example, assuming that the value of 0 represents a parent node and 1 a leaf node, whenever the latter is encountered the tree building routine simply reads the next 8 bits to determine the character value of that particular leaf. The process continues recursively until the last leaf node is reached; at that point, the Huffman tree will thus be faithfully reconstructed. The overhead using such a method ranges from roughly 2 to 320 bytes (assuming an 8-bit alphabet). Many other techniques are possible as well. In any case, since the compressed data can include unused «trailing bits» the decompressor must be able to determine when to stop producing output. This can be accomplished by either transmitting the length of the decompressed data along with the compression model or by defining a special code symbol to signify the end of input (the latter method can adversely affect code length optimality, however).
bits of information (where B is the number of bits per symbol). Another method is to simply prepend the Huffman tree, bit by bit, to the output stream. For example, assuming that the value of 0 represents a parent node and 1 a leaf node, whenever the latter is encountered the tree building routine simply reads the next 8 bits to determine the character value of that particular leaf. The process continues recursively until the last leaf node is reached; at that point, the Huffman tree will thus be faithfully reconstructed. The overhead using such a method ranges from roughly 2 to 320 bytes (assuming an 8-bit alphabet). Many other techniques are possible as well. In any case, since the compressed data can include unused «trailing bits» the decompressor must be able to determine when to stop producing output. This can be accomplished by either transmitting the length of the decompressed data along with the compression model or by defining a special code symbol to signify the end of input (the latter method can adversely affect code length optimality, however).
Main properties[edit]
The probabilities used can be generic ones for the application domain that are based on average experience, or they can be the actual frequencies found in the text being compressed.
This requires that a frequency table must be stored with the compressed text. See the Decompression section above for more information about the various techniques employed for this purpose.
Optimality[edit]
Huffman’s original algorithm is optimal for a symbol-by-symbol coding with a known input probability distribution, i.e., separately encoding unrelated symbols in such a data stream. However, it is not optimal when the symbol-by-symbol restriction is dropped, or when the probability mass functions are unknown. Also, if symbols are not independent and identically distributed, a single code may be insufficient for optimality. Other methods such as arithmetic coding often have better compression capability.
Although both aforementioned methods can combine an arbitrary number of symbols for more efficient coding and generally adapt to the actual input statistics, arithmetic coding does so without significantly increasing its computational or algorithmic complexities (though the simplest version is slower and more complex than Huffman coding). Such flexibility is especially useful when input probabilities are not precisely known or vary significantly within the stream. However, Huffman coding is usually faster and arithmetic coding was historically a subject of some concern over patent issues. Thus many technologies have historically avoided arithmetic coding in favor of Huffman and other prefix coding techniques. As of mid-2010, the most commonly used techniques for this alternative to Huffman coding have passed into the public domain as the early patents have expired.
For a set of symbols with a uniform probability distribution and a number of members which is a power of two, Huffman coding is equivalent to simple binary block encoding, e.g., ASCII coding. This reflects the fact that compression is not possible with such an input, no matter what the compression method, i.e., doing nothing to the data is the optimal thing to do.
Huffman coding is optimal among all methods in any case where each input symbol is a known independent and identically distributed random variable having a probability that is dyadic. Prefix codes, and thus Huffman coding in particular, tend to have inefficiency on small alphabets, where probabilities often fall between these optimal (dyadic) points. The worst case for Huffman coding can happen when the probability of the most likely symbol far exceeds 2−1 = 0.5, making the upper limit of inefficiency unbounded.
There are two related approaches for getting around this particular inefficiency while still using Huffman coding. Combining a fixed number of symbols together («blocking») often increases (and never decreases) compression. As the size of the block approaches infinity, Huffman coding theoretically approaches the entropy limit, i.e., optimal compression.[6] However, blocking arbitrarily large groups of symbols is impractical, as the complexity of a Huffman code is linear in the number of possibilities to be encoded, a number that is exponential in the size of a block. This limits the amount of blocking that is done in practice.
A practical alternative, in widespread use, is run-length encoding. This technique adds one step in advance of entropy coding, specifically counting (runs) of repeated symbols, which are then encoded. For the simple case of Bernoulli processes, Golomb coding is optimal among prefix codes for coding run length, a fact proved via the techniques of Huffman coding.[7] A similar approach is taken by fax machines using modified Huffman coding. However, run-length coding is not as adaptable to as many input types as other compression technologies.
Variations[edit]
Many variations of Huffman coding exist,[8] some of which use a Huffman-like algorithm, and others of which find optimal prefix codes (while, for example, putting different restrictions on the output). Note that, in the latter case, the method need not be Huffman-like, and, indeed, need not even be polynomial time.
n-ary Huffman coding[edit]
The n-ary Huffman algorithm uses the {0, 1,…, n − 1} alphabet to encode message and build an n-ary tree. This approach was considered by Huffman in his original paper. The same algorithm applies as for binary ( ) codes, except that the n least probable symbols are taken together, instead of just the 2 least probable. Note that for n greater than 2, not all sets of source words can properly form an n-ary tree for Huffman coding. In these cases, additional 0-probability place holders must be added. This is because the tree must form an n to 1 contractor; for binary coding, this is a 2 to 1 contractor, and any sized set can form such a contractor. If the number of source words is congruent to 1 modulo n−1, then the set of source words will form a proper Huffman tree.
) codes, except that the n least probable symbols are taken together, instead of just the 2 least probable. Note that for n greater than 2, not all sets of source words can properly form an n-ary tree for Huffman coding. In these cases, additional 0-probability place holders must be added. This is because the tree must form an n to 1 contractor; for binary coding, this is a 2 to 1 contractor, and any sized set can form such a contractor. If the number of source words is congruent to 1 modulo n−1, then the set of source words will form a proper Huffman tree.
Adaptive Huffman coding[edit]
A variation called adaptive Huffman coding involves calculating the probabilities dynamically based on recent actual frequencies in the sequence of source symbols, and changing the coding tree structure to match the updated probability estimates. It is used rarely in practice, since the cost of updating the tree makes it slower than optimized adaptive arithmetic coding, which is more flexible and has better compression.
Huffman template algorithm[edit]
Most often, the weights used in implementations of Huffman coding represent numeric probabilities, but the algorithm given above does not require this; it requires only that the weights form a totally ordered commutative monoid, meaning a way to order weights and to add them. The Huffman template algorithm enables one to use any kind of weights (costs, frequencies, pairs of weights, non-numerical weights) and one of many combining methods (not just addition). Such algorithms can solve other minimization problems, such as minimizing ![max _{i}left[w_{i}+mathrm {length} left(c_{i}right)right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/1a80c0b460cf854976824c251037db43d7ed1810) , a problem first applied to circuit design.
, a problem first applied to circuit design.
Length-limited Huffman coding/minimum variance Huffman coding[edit]
Length-limited Huffman coding is a variant where the goal is still to achieve a minimum weighted path length, but there is an additional restriction that the length of each codeword must be less than a given constant. The package-merge algorithm solves this problem with a simple greedy approach very similar to that used by Huffman’s algorithm. Its time complexity is  , where
, where  is the maximum length of a codeword. No algorithm is known to solve this problem in
is the maximum length of a codeword. No algorithm is known to solve this problem in  or
or  time, unlike the presorted and unsorted conventional Huffman problems, respectively.
time, unlike the presorted and unsorted conventional Huffman problems, respectively.
Huffman coding with unequal letter costs[edit]
In the standard Huffman coding problem, it is assumed that each symbol in the set that the code words are constructed from has an equal cost to transmit: a code word whose length is N digits will always have a cost of N, no matter how many of those digits are 0s, how many are 1s, etc. When working under this assumption, minimizing the total cost of the message and minimizing the total number of digits are the same thing.
Huffman coding with unequal letter costs is the generalization without this assumption: the letters of the encoding alphabet may have non-uniform lengths, due to characteristics of the transmission medium. An example is the encoding alphabet of Morse code, where a ‘dash’ takes longer to send than a ‘dot’, and therefore the cost of a dash in transmission time is higher. The goal is still to minimize the weighted average codeword length, but it is no longer sufficient just to minimize the number of symbols used by the message. No algorithm is known to solve this in the same manner or with the same efficiency as conventional Huffman coding, though it has been solved by Karp whose solution has been refined for the case of integer costs by Golin.
Optimal alphabetic binary trees (Hu–Tucker coding)[edit]
In the standard Huffman coding problem, it is assumed that any codeword can correspond to any input symbol. In the alphabetic version, the alphabetic order of inputs and outputs must be identical. Thus, for example,  could not be assigned code
could not be assigned code  , but instead should be assigned either
, but instead should be assigned either  or
or  . This is also known as the Hu–Tucker problem, after T. C. Hu and Alan Tucker, the authors of the paper presenting the first -time solution to this optimal binary alphabetic problem,[9] which has some similarities to Huffman algorithm, but is not a variation of this algorithm. A later method, the Garsia–Wachs algorithm of Adriano Garsia and Michelle L. Wachs (1977), uses simpler logic to perform the same comparisons in the same total time bound. These optimal alphabetic binary trees are often used as binary search trees.[10]
. This is also known as the Hu–Tucker problem, after T. C. Hu and Alan Tucker, the authors of the paper presenting the first -time solution to this optimal binary alphabetic problem,[9] which has some similarities to Huffman algorithm, but is not a variation of this algorithm. A later method, the Garsia–Wachs algorithm of Adriano Garsia and Michelle L. Wachs (1977), uses simpler logic to perform the same comparisons in the same total time bound. These optimal alphabetic binary trees are often used as binary search trees.[10]
The canonical Huffman code[edit]
If weights corresponding to the alphabetically ordered inputs are in numerical order, the Huffman code has the same lengths as the optimal alphabetic code, which can be found from calculating these lengths, rendering Hu–Tucker coding unnecessary. The code resulting from numerically (re-)ordered input is sometimes called the canonical Huffman code and is often the code used in practice, due to ease of encoding/decoding. The technique for finding this code is sometimes called Huffman–Shannon–Fano coding, since it is optimal like Huffman coding, but alphabetic in weight probability, like Shannon–Fano coding. The Huffman–Shannon–Fano code corresponding to the example is  , which, having the same codeword lengths as the original solution, is also optimal. But in canonical Huffman code, the result is
, which, having the same codeword lengths as the original solution, is also optimal. But in canonical Huffman code, the result is  .
.
Applications[edit]
Arithmetic coding and Huffman coding produce equivalent results — achieving entropy — when every symbol has a probability of the form 1/2k. In other circumstances, arithmetic coding can offer better compression than Huffman coding because — intuitively — its «code words» can have effectively non-integer bit lengths, whereas code words in prefix codes such as Huffman codes can only have an integer number of bits. Therefore, a code word of length k only optimally matches a symbol of probability 1/2k and other probabilities are not represented optimally; whereas the code word length in arithmetic coding can be made to exactly match the true probability of the symbol. This difference is especially striking for small alphabet sizes.[citation needed]
Prefix codes nevertheless remain in wide use because of their simplicity, high speed, and lack of patent coverage. They are often used as a «back-end» to other compression methods. Deflate (PKZIP’s algorithm) and multimedia codecs such as JPEG and MP3 have a front-end model and quantization followed by the use of prefix codes; these are often called «Huffman codes» even though most applications use pre-defined variable-length codes rather than codes designed using Huffman’s algorithm.
References[edit]
- ^ Huffman, D. (1952). «A Method for the Construction of Minimum-Redundancy Codes» (PDF). Proceedings of the IRE. 40 (9): 1098–1101. doi:10.1109/JRPROC.1952.273898.
- ^ Van Leeuwen, Jan (1976). «On the construction of Huffman trees» (PDF). ICALP: 382–410. Retrieved 2014-02-20.
- ^ Ze-Nian Li; Mark S. Drew; Jiangchuan Liu (2014-04-09). Fundamentals of Multimedia. Springer Science & Business Media. ISBN 978-3-319-05290-8.
- ^ J. Duda, K. Tahboub, N. J. Gadil, E. J. Delp, The use of asymmetric numeral systems as an accurate replacement for Huffman coding, Picture Coding Symposium, 2015.
- ^ Huffman, Ken (1991). «Profile: David A. Huffman: Encoding the «Neatness» of Ones and Zeroes». Scientific American: 54–58.
- ^ Gribov, Alexander (2017-04-10). «Optimal Compression of a Polyline with Segments and Arcs». arXiv:1604.07476 [cs.CG].
- ^ Gallager, R.G.; van Voorhis, D.C. (1975). «Optimal source codes for geometrically distributed integer alphabets». IEEE Transactions on Information Theory. 21 (2): 228–230. doi:10.1109/TIT.1975.1055357.
- ^ Abrahams, J. (1997-06-11). Written at Arlington, VA, USA. Division of Mathematics, Computer & Information Sciences, Office of Naval Research (ONR). «Code and Parse Trees for Lossless Source Encoding». Compression and Complexity of Sequences 1997 Proceedings. Salerno: IEEE: 145–171. CiteSeerX 10.1.1.589.4726. doi:10.1109/SEQUEN.1997.666911. ISBN 0-8186-8132-2. S2CID 124587565.
- ^ Hu, T. C.; Tucker, A. C. (1971). «Optimal Computer Search Trees and Variable-Length Alphabetical Codes». SIAM Journal on Applied Mathematics. 21 (4): 514. doi:10.1137/0121057. JSTOR 2099603.
- ^ Knuth, Donald E. (1998), «Algorithm G (Garsia–Wachs algorithm for optimum binary trees)», The Art of Computer Programming, Vol. 3: Sorting and Searching (2nd ed.), Addison–Wesley, pp. 451–453. See also History and bibliography, pp. 453–454.
Bibliography[edit]
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 16.3, pp. 385–392.
External links[edit]
- Huffman coding in various languages on Rosetta Code
- Huffman codes (python implementation)
- A visualization of Huffman coding
In this tutorial, you will learn how Huffman Coding works. Also, you will find working examples of Huffman Coding in C, C++, Java and Python.
Huffman Coding is a technique of compressing data to reduce its size without losing any of the details. It was first developed by David Huffman.
Huffman Coding is generally useful to compress the data in which there are frequently occurring characters.
How Huffman Coding works?
Suppose the string below is to be sent over a network.

Each character occupies 8 bits. There are a total of 15 characters in the above string. Thus, a total of 8 * 15 = 120 bits are required to send this string.
Using the Huffman Coding technique, we can compress the string to a smaller size.
Huffman coding first creates a tree using the frequencies of the character and then generates code for each character.
Once the data is encoded, it has to be decoded. Decoding is done using the same tree.
Huffman Coding prevents any ambiguity in the decoding process using the concept of prefix code ie. a code associated with a character should not be present in the prefix of any other code. The tree created above helps in maintaining the property.
Huffman coding is done with the help of the following steps.
- Calculate the frequency of each character in the string.

Frequency of string - Sort the characters in increasing order of the frequency. These are stored in a priority queue Q.
Characters sorted according to the frequency - Make each unique character as a leaf node.
- Create an empty node z. Assign the minimum frequency to the left child of z and assign the second minimum frequency to the right child of z. Set the value of the z as the sum of the above two minimum frequencies.

Getting the sum of the least numbers - Remove these two minimum frequencies from Q and add the sum into the list of frequencies (* denote the internal nodes in the figure above).
- Insert node z into the tree.
- Repeat steps 3 to 5 for all the characters.

Repeat steps 3 to 5 for all the characters. 
Repeat steps 3 to 5 for all the characters. - For each non-leaf node, assign 0 to the left edge and 1 to the right edge.

Assign 0 to the left edge and 1 to the right edge






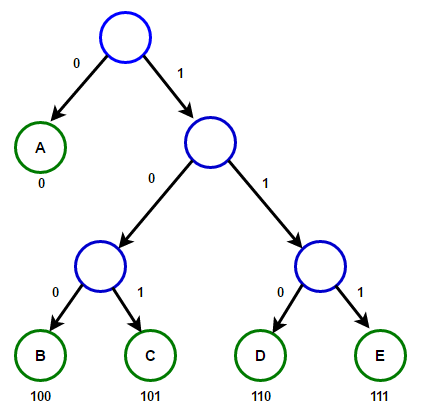
For sending the above string over a network, we have to send the tree as well as the above compressed-code. The total size is given by the table below.
| Character | Frequency | Code | Size |
|---|---|---|---|
| A | 5 | 11 | 5*2 = 10 |
| B | 1 | 100 | 1*3 = 3 |
| C | 6 | 0 | 6*1 = 6 |
| D | 3 | 101 | 3*3 = 9 |
| 4 * 8 = 32 bits | 15 bits | 28 bits |
Without encoding, the total size of the string was 120 bits. After encoding the size is reduced to 32 + 15 + 28 = 75.
Decoding the code
For decoding the code, we can take the code and traverse through the tree to find the character.
Let 101 is to be decoded, we can traverse from the root as in the figure below.

Huffman Coding Algorithm
create a priority queue Q consisting of each unique character.
sort then in ascending order of their frequencies.
for all the unique characters:
create a newNode
extract minimum value from Q and assign it to leftChild of newNode
extract minimum value from Q and assign it to rightChild of newNode
calculate the sum of these two minimum values and assign it to the value of newNode
insert this newNode into the tree
return rootNode
Python, Java and C/C++ Examples
# Huffman Coding in python
string = 'BCAADDDCCACACAC'
# Creating tree nodes
class NodeTree(object):
def __init__(self, left=None, right=None):
self.left = left
self.right = right
def children(self):
return (self.left, self.right)
def nodes(self):
return (self.left, self.right)
def __str__(self):
return '%s_%s' % (self.left, self.right)
# Main function implementing huffman coding
def huffman_code_tree(node, left=True, binString=''):
if type(node) is str:
return {node: binString}
(l, r) = node.children()
d = dict()
d.update(huffman_code_tree(l, True, binString + '0'))
d.update(huffman_code_tree(r, False, binString + '1'))
return d
# Calculating frequency
freq = {}
for c in string:
if c in freq:
freq[c] += 1
else:
freq[c] = 1
freq = sorted(freq.items(), key=lambda x: x[1], reverse=True)
nodes = freq
while len(nodes) > 1:
(key1, c1) = nodes[-1]
(key2, c2) = nodes[-2]
nodes = nodes[:-2]
node = NodeTree(key1, key2)
nodes.append((node, c1 + c2))
nodes = sorted(nodes, key=lambda x: x[1], reverse=True)
huffmanCode = huffman_code_tree(nodes[0][0])
print(' Char | Huffman code ')
print('----------------------')
for (char, frequency) in freq:
print(' %-4r |%12s' % (char, huffmanCode[char]))// Huffman Coding in Java
import java.util.PriorityQueue;
import java.util.Comparator;
class HuffmanNode {
int item;
char c;
HuffmanNode left;
HuffmanNode right;
}
// For comparing the nodes
class ImplementComparator implements Comparator<HuffmanNode> {
public int compare(HuffmanNode x, HuffmanNode y) {
return x.item - y.item;
}
}
// IMplementing the huffman algorithm
public class Huffman {
public static void printCode(HuffmanNode root, String s) {
if (root.left == null && root.right == null && Character.isLetter(root.c)) {
System.out.println(root.c + " | " + s);
return;
}
printCode(root.left, s + "0");
printCode(root.right, s + "1");
}
public static void main(String[] args) {
int n = 4;
char[] charArray = { 'A', 'B', 'C', 'D' };
int[] charfreq = { 5, 1, 6, 3 };
PriorityQueue<HuffmanNode> q = new PriorityQueue<HuffmanNode>(n, new ImplementComparator());
for (int i = 0; i < n; i++) {
HuffmanNode hn = new HuffmanNode();
hn.c = charArray[i];
hn.item = charfreq[i];
hn.left = null;
hn.right = null;
q.add(hn);
}
HuffmanNode root = null;
while (q.size() > 1) {
HuffmanNode x = q.peek();
q.poll();
HuffmanNode y = q.peek();
q.poll();
HuffmanNode f = new HuffmanNode();
f.item = x.item + y.item;
f.c = '-';
f.left = x;
f.right = y;
root = f;
q.add(f);
}
System.out.println(" Char | Huffman code ");
System.out.println("--------------------");
printCode(root, "");
}
}// Huffman Coding in C
#include <stdio.h>
#include <stdlib.h>
#define MAX_TREE_HT 50
struct MinHNode {
char item;
unsigned freq;
struct MinHNode *left, *right;
};
struct MinHeap {
unsigned size;
unsigned capacity;
struct MinHNode **array;
};
// Create nodes
struct MinHNode *newNode(char item, unsigned freq) {
struct MinHNode *temp = (struct MinHNode *)malloc(sizeof(struct MinHNode));
temp->left = temp->right = NULL;
temp->item = item;
temp->freq = freq;
return temp;
}
// Create min heap
struct MinHeap *createMinH(unsigned capacity) {
struct MinHeap *minHeap = (struct MinHeap *)malloc(sizeof(struct MinHeap));
minHeap->size = 0;
minHeap->capacity = capacity;
minHeap->array = (struct MinHNode **)malloc(minHeap->capacity * sizeof(struct MinHNode *));
return minHeap;
}
// Function to swap
void swapMinHNode(struct MinHNode **a, struct MinHNode **b) {
struct MinHNode *t = *a;
*a = *b;
*b = t;
}
// Heapify
void minHeapify(struct MinHeap *minHeap, int idx) {
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 * idx + 2;
if (left < minHeap->size && minHeap->array[left]->freq < minHeap->array[smallest]->freq)
smallest = left;
if (right < minHeap->size && minHeap->array[right]->freq < minHeap->array[smallest]->freq)
smallest = right;
if (smallest != idx) {
swapMinHNode(&minHeap->array[smallest], &minHeap->array[idx]);
minHeapify(minHeap, smallest);
}
}
// Check if size if 1
int checkSizeOne(struct MinHeap *minHeap) {
return (minHeap->size == 1);
}
// Extract min
struct MinHNode *extractMin(struct MinHeap *minHeap) {
struct MinHNode *temp = minHeap->array[0];
minHeap->array[0] = minHeap->array[minHeap->size - 1];
--minHeap->size;
minHeapify(minHeap, 0);
return temp;
}
// Insertion function
void insertMinHeap(struct MinHeap *minHeap, struct MinHNode *minHeapNode) {
++minHeap->size;
int i = minHeap->size - 1;
while (i && minHeapNode->freq < minHeap->array[(i - 1) / 2]->freq) {
minHeap->array[i] = minHeap->array[(i - 1) / 2];
i = (i - 1) / 2;
}
minHeap->array[i] = minHeapNode;
}
void buildMinHeap(struct MinHeap *minHeap) {
int n = minHeap->size - 1;
int i;
for (i = (n - 1) / 2; i >= 0; --i)
minHeapify(minHeap, i);
}
int isLeaf(struct MinHNode *root) {
return !(root->left) && !(root->right);
}
struct MinHeap *createAndBuildMinHeap(char item[], int freq[], int size) {
struct MinHeap *minHeap = createMinH(size);
for (int i = 0; i < size; ++i)
minHeap->array[i] = newNode(item[i], freq[i]);
minHeap->size = size;
buildMinHeap(minHeap);
return minHeap;
}
struct MinHNode *buildHuffmanTree(char item[], int freq[], int size) {
struct MinHNode *left, *right, *top;
struct MinHeap *minHeap = createAndBuildMinHeap(item, freq, size);
while (!checkSizeOne(minHeap)) {
left = extractMin(minHeap);
right = extractMin(minHeap);
top = newNode('$', left->freq + right->freq);
top->left = left;
top->right = right;
insertMinHeap(minHeap, top);
}
return extractMin(minHeap);
}
void printHCodes(struct MinHNode *root, int arr[], int top) {
if (root->left) {
arr[top] = 0;
printHCodes(root->left, arr, top + 1);
}
if (root->right) {
arr[top] = 1;
printHCodes(root->right, arr, top + 1);
}
if (isLeaf(root)) {
printf(" %c | ", root->item);
printArray(arr, top);
}
}
// Wrapper function
void HuffmanCodes(char item[], int freq[], int size) {
struct MinHNode *root = buildHuffmanTree(item, freq, size);
int arr[MAX_TREE_HT], top = 0;
printHCodes(root, arr, top);
}
// Print the array
void printArray(int arr[], int n) {
int i;
for (i = 0; i < n; ++i)
printf("%d", arr[i]);
printf("n");
}
int main() {
char arr[] = {'A', 'B', 'C', 'D'};
int freq[] = {5, 1, 6, 3};
int size = sizeof(arr) / sizeof(arr[0]);
printf(" Char | Huffman code ");
printf("n--------------------n");
HuffmanCodes(arr, freq, size);
}// Huffman Coding in C++
#include <iostream>
using namespace std;
#define MAX_TREE_HT 50
struct MinHNode {
unsigned freq;
char item;
struct MinHNode *left, *right;
};
struct MinH {
unsigned size;
unsigned capacity;
struct MinHNode **array;
};
// Creating Huffman tree node
struct MinHNode *newNode(char item, unsigned freq) {
struct MinHNode *temp = (struct MinHNode *)malloc(sizeof(struct MinHNode));
temp->left = temp->right = NULL;
temp->item = item;
temp->freq = freq;
return temp;
}
// Create min heap using given capacity
struct MinH *createMinH(unsigned capacity) {
struct MinH *minHeap = (struct MinH *)malloc(sizeof(struct MinH));
minHeap->size = 0;
minHeap->capacity = capacity;
minHeap->array = (struct MinHNode **)malloc(minHeap->capacity * sizeof(struct MinHNode *));
return minHeap;
}
// Print the array
void printArray(int arr[], int n) {
int i;
for (i = 0; i < n; ++i)
cout << arr[i];
cout << "n";
}
// Swap function
void swapMinHNode(struct MinHNode **a, struct MinHNode **b) {
struct MinHNode *t = *a;
*a = *b;
*b = t;
}
// Heapify
void minHeapify(struct MinH *minHeap, int idx) {
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 * idx + 2;
if (left < minHeap->size && minHeap->array[left]->freq < minHeap->array[smallest]->freq)
smallest = left;
if (right < minHeap->size && minHeap->array[right]->freq < minHeap->array[smallest]->freq)
smallest = right;
if (smallest != idx) {
swapMinHNode(&minHeap->array[smallest],
&minHeap->array[idx]);
minHeapify(minHeap, smallest);
}
}
// Check if size if 1
int checkSizeOne(struct MinH *minHeap) {
return (minHeap->size == 1);
}
// Extract the min
struct MinHNode *extractMin(struct MinH *minHeap) {
struct MinHNode *temp = minHeap->array[0];
minHeap->array[0] = minHeap->array[minHeap->size - 1];
--minHeap->size;
minHeapify(minHeap, 0);
return temp;
}
// Insertion
void insertMinHeap(struct MinH *minHeap, struct MinHNode *minHeapNode) {
++minHeap->size;
int i = minHeap->size - 1;
while (i && minHeapNode->freq < minHeap->array[(i - 1) / 2]->freq) {
minHeap->array[i] = minHeap->array[(i - 1) / 2];
i = (i - 1) / 2;
}
minHeap->array[i] = minHeapNode;
}
// BUild min heap
void buildMinHeap(struct MinH *minHeap) {
int n = minHeap->size - 1;
int i;
for (i = (n - 1) / 2; i >= 0; --i)
minHeapify(minHeap, i);
}
int isLeaf(struct MinHNode *root) {
return !(root->left) && !(root->right);
}
struct MinH *createAndBuildMinHeap(char item[], int freq[], int size) {
struct MinH *minHeap = createMinH(size);
for (int i = 0; i < size; ++i)
minHeap->array[i] = newNode(item[i], freq[i]);
minHeap->size = size;
buildMinHeap(minHeap);
return minHeap;
}
struct MinHNode *buildHfTree(char item[], int freq[], int size) {
struct MinHNode *left, *right, *top;
struct MinH *minHeap = createAndBuildMinHeap(item, freq, size);
while (!checkSizeOne(minHeap)) {
left = extractMin(minHeap);
right = extractMin(minHeap);
top = newNode('$', left->freq + right->freq);
top->left = left;
top->right = right;
insertMinHeap(minHeap, top);
}
return extractMin(minHeap);
}
void printHCodes(struct MinHNode *root, int arr[], int top) {
if (root->left) {
arr[top] = 0;
printHCodes(root->left, arr, top + 1);
}
if (root->right) {
arr[top] = 1;
printHCodes(root->right, arr, top + 1);
}
if (isLeaf(root)) {
cout << root->item << " | ";
printArray(arr, top);
}
}
// Wrapper function
void HuffmanCodes(char item[], int freq[], int size) {
struct MinHNode *root = buildHfTree(item, freq, size);
int arr[MAX_TREE_HT], top = 0;
printHCodes(root, arr, top);
}
int main() {
char arr[] = {'A', 'B', 'C', 'D'};
int freq[] = {5, 1, 6, 3};
int size = sizeof(arr) / sizeof(arr[0]);
cout << "Char | Huffman code ";
cout << "n----------------------n";
HuffmanCodes(arr, freq, size);
}Huffman Coding Complexity
The time complexity for encoding each unique character based on its frequency is O(nlog n).
Extracting minimum frequency from the priority queue takes place 2*(n-1) times and its complexity is O(log n). Thus the overall complexity is O(nlog n).
Huffman Coding Applications
- Huffman coding is used in conventional compression formats like GZIP, BZIP2, PKZIP, etc.
- For text and fax transmissions.
Table of Contents
- Definition
- How Huffman Coding works?
- Decoding the code
- Huffman Coding Algorithm
- Python, Java and C/C++ Examples
- Huffman Coding Complexity
- Huffman Coding Applications