Алгоритм Шеннона-Фано
Время на прочтение
2 мин
Количество просмотров 92K
Алгоритм метода Шеннона-Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано, и он имеет большое сходство с алгоритмом Хаффмана. Алгоритм основан на частоте повторения. Так, часто встречающийся символ кодируется кодом меньшей длины, а редко встречающийся — кодом большей длины.
В свою очередь, коды, полученные при кодировании, префиксные. Это и позволяет однозначно декодировать любую последовательность кодовых слов. Но все это вступление.
Для работы оба алгоритма должны иметь таблицу частот элементов алфавита.
Итак, алгоритм Хаффмана работает следующим образом:
- На вход приходят упорядоченные по невозрастанию частот данные.
- Выбираются две наименьших по частоте буквы алфавита, и создается родитель (сумма двух частот этих «листков»).
- Потомки удаляются и вместо них записывается родитель, «ветви» родителя нумеруются: левой ветви ставится в соответствие «1», правой «0».
- Шаг два повторяется до тех пор, пока не будет найден главный родитель — «корень».

Алгоритм Шеннона-Фано работает следующим образом:
- На вход приходят упорядоченные по невозрастанию частот данные.
- Находится середина, которая делит алфавит примерно на две части. Эти части (суммы частот алфавита) примерно равны. Для левой части присваивается «1», для правой «0», таким образом мы получим листья дерева
- Шаг 2 повторяется до тех пор, пока мы не получим единственный элемент последовательности, т.е. листок

Таким образом, видно, что алгоритм Хаффмана как бы движется от листьев к корню, а алгоритм Шеннона-Фано, используя деление, движется от корня к листям.
Ну вот, быстро осмыслив информацию, можно написать код алгоритма Шеннона-Фано на паскале. Попросили именно на нем написать. Поэтому приведу листинг вместе с комментариями.
program ShennonFano;
uses crt;
const
a :array[1..6] of char = ('a','b','c','d','e','f'); { символы }
af:array[1..6] of integer = (10, 8, 6, 5, 4, 3); { частота символов }
{ Процедура для поиска кода каждой буквы }
procedure SearchTree(branch:char; full_branch:string; start_pos:integer; end_pos:integer);
var
dS:real; { Среднее значение массива }
i, m, S:integer; { m - номер средней буквы в последовательности, S - сумма чисел, левой ветки }
c_branch:string; { текущая история поворотов по веткам }
begin
{ проверка если это вход нулевой то очистить историю }
if (a<>' ') then c_branch := full_branch + branch
else c_branch := '';
{ Критерий выхода: если позиции символов совпали, то это конец }
if (start_pos = end_pos) then
begin
WriteLn(a[start_pos], ' = ', c_branch);
exit;
end;
{ Подсчет среднего значения частоты в последовательности }
dS := 0;
for i:=start_pos to end_pos do dS:= dS + af[i];
dS := dS/2;
{ Тут какой угодно можно цикл for, while, repeat поиск середины }
S := 0;
i := start_pos;
m := i;
while ((S+af[i]<dS) and (i<end_pos)) do
begin
S := S + af[i];
inc(i); inc(m);
end;
{ Рекурсия левая ветка дерева }
SearchTree('1', c_branch, start_pos, m);
{ Правая ветка дерева }
SearchTree('0', c_branch, m+1, end_pos);
end;
begin
WriteLn('Press <enter> to show');
ReadLn;
ClrScr;
{ Поиск кода Фано, входные параметры начало и конец последовательности }
SearchTree(' ',' ', 1, 6);
ReadLn;
end;
Ну вот собственно и все, о чем я хотел рассказать. Всю информацию можно взять из википедии. На рисунках приведены частоты сверху.
Спасибо за внимание!
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
DATA COMPRESSION AND ITS TYPES
Data Compression, also known as source coding, is the process of encoding or converting data in such a way that it consumes less memory space. Data compression reduces the number of resources required to store and transmit data.
It can be done in two ways- lossless compression and lossy compression. Lossy compression reduces the size of data by removing unnecessary information, while there is no data loss in lossless compression.
WHAT IS SHANNON FANO CODING?
Shannon Fano Algorithm is an entropy encoding technique for lossless data compression of multimedia. Named after Claude Shannon and Robert Fano, it assigns a code to each symbol based on their probabilities of occurrence. It is a variable-length encoding scheme, that is, the codes assigned to the symbols will be of varying lengths.
HOW DOES IT WORK?
The steps of the algorithm are as follows:
- Create a list of probabilities or frequency counts for the given set of symbols so that the relative frequency of occurrence of each symbol is known.
- Sort the list of symbols in decreasing order of probability, the most probable ones to the left and the least probable ones to the right.
- Split the list into two parts, with the total probability of both parts being as close to each other as possible.
- Assign the value 0 to the left part and 1 to the right part.
- Repeat steps 3 and 4 for each part until all the symbols are split into individual subgroups.
The Shannon codes are considered accurate if the code of each symbol is unique.
EXAMPLE:
The given task is to construct Shannon codes for the given set of symbols using the Shannon-Fano lossless compression technique.
Step:

Tree:
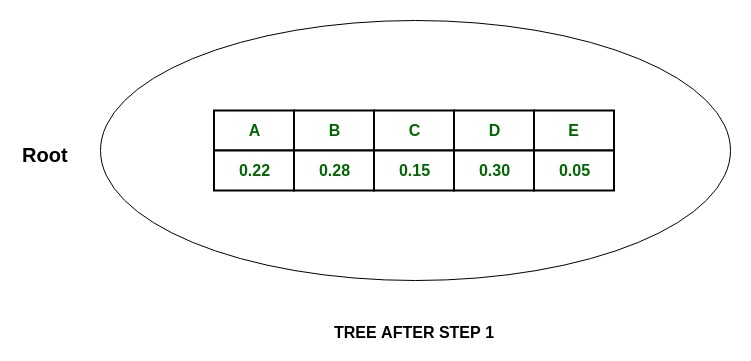
Solution:
1. Upon arranging the symbols in decreasing order of probability:
P(D) + P(B) = 0.30 + 0.2 = 0.58
and,
P(A) + P(C) + P(E) = 0.22 + 0.15 + 0.05 = 0.42
And since they almost equally split the table, the most is divided it the blockquote table isblockquotento
{D, B} and {A, C, E}
and assign them the values 0 and 1 respectively.
Step:
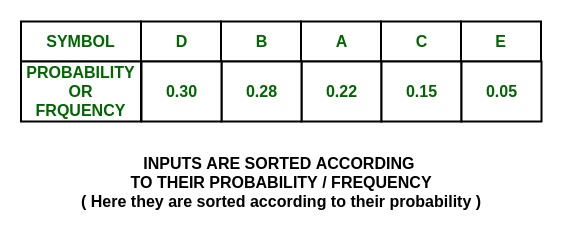
Tree:
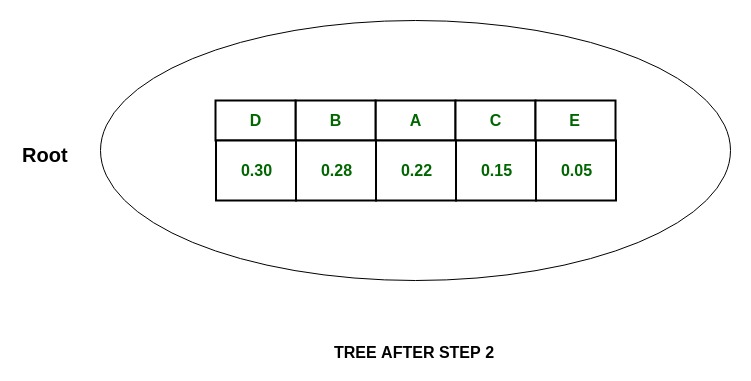
2. Now, in {D, B} group,
P(D) = 0.30 and P(B) = 0.28
which means that P(D)~P(B), so divide {D, B} into {D} and {B} and assign 0 to D and 1 to B.
Step:
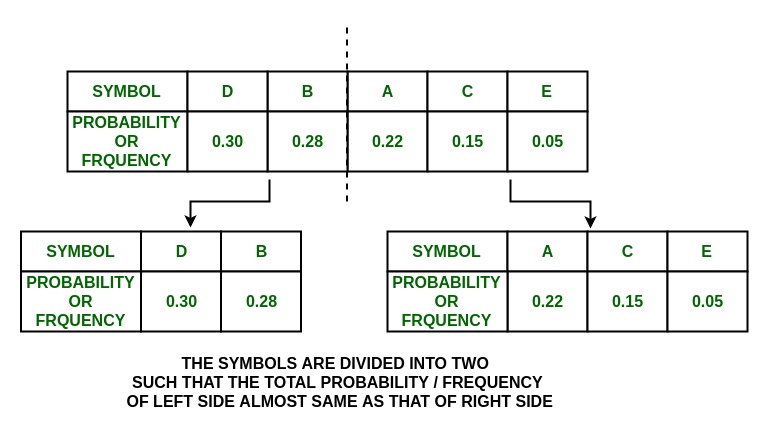
Tree:
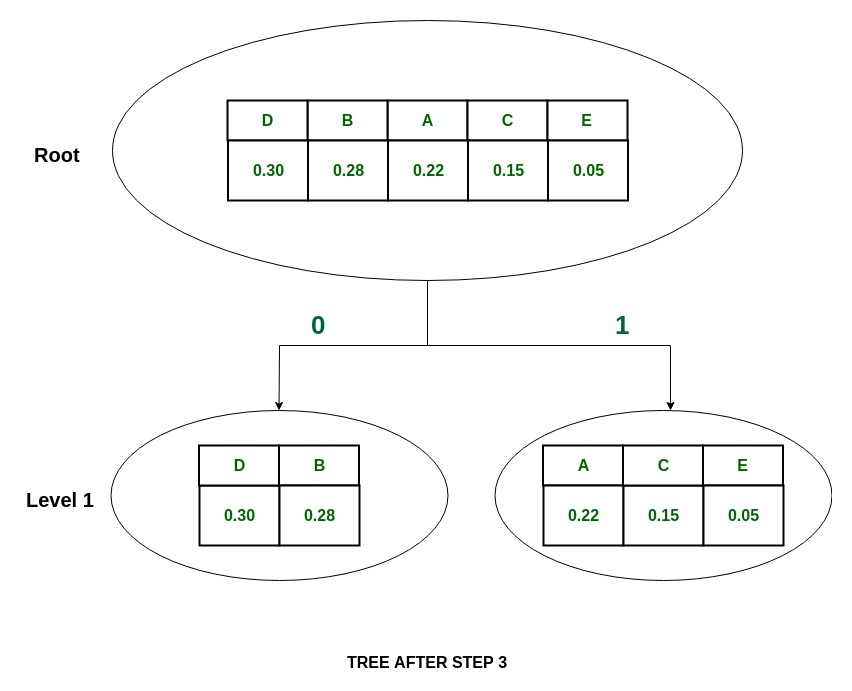
3. In {A, C, E} group,
P(A) = 0.22 and P(C) + P(E) = 0.20
So the group is divided into
{A} and {C, E}
and they are assigned values 0 and 1 respectively.
4. In {C, E} group,
P(C) = 0.15 and P(E) = 0.05
So divide them into {C} and {E} and assign 0 to {C} and 1 to {E}
Step:
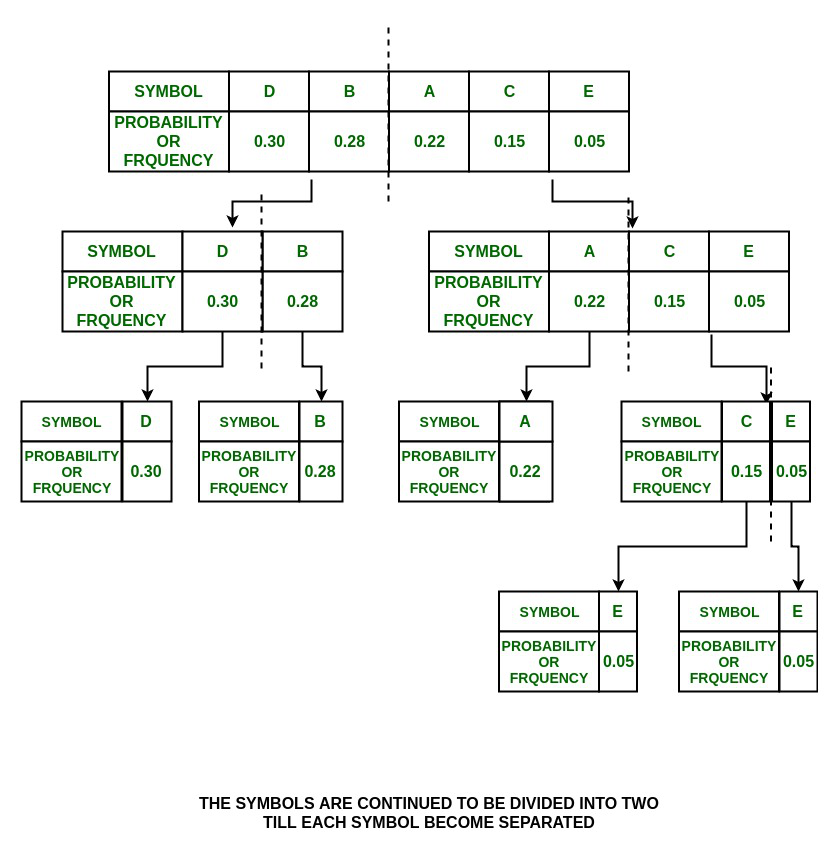
Tree:
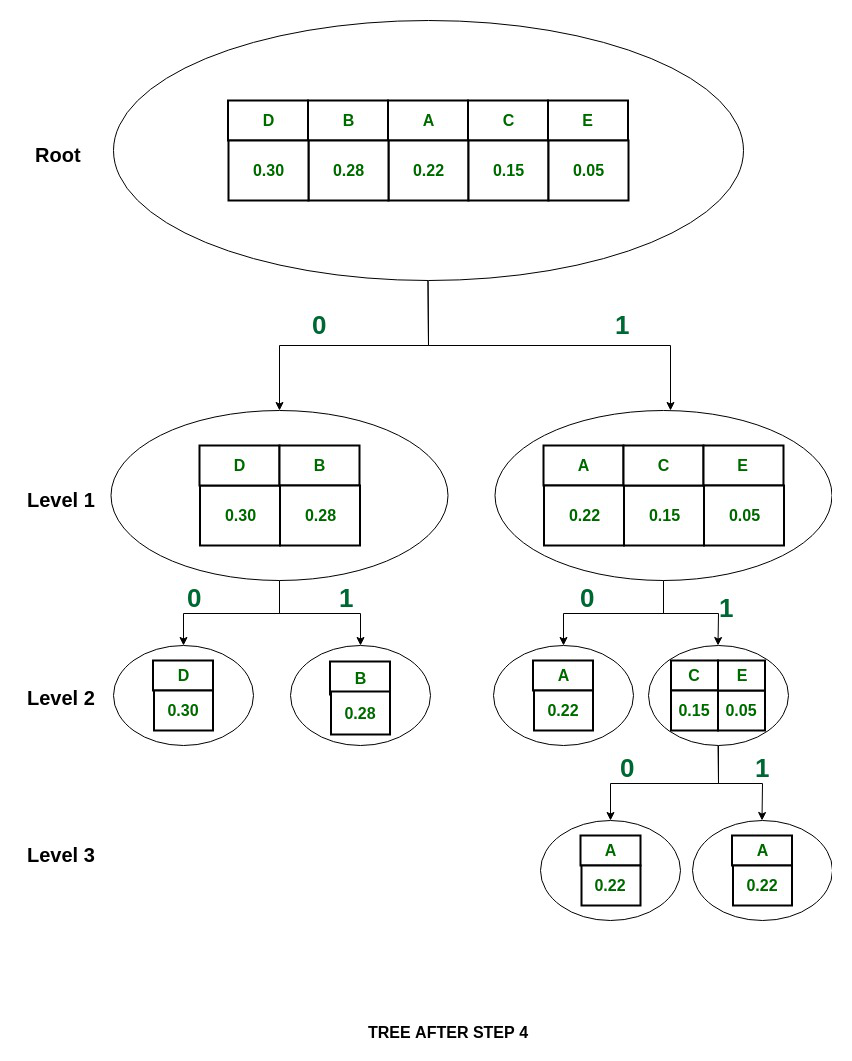
Note: The splitting is now stopped as each symbol is separated now.
The Shannon codes for the set of symbols are:
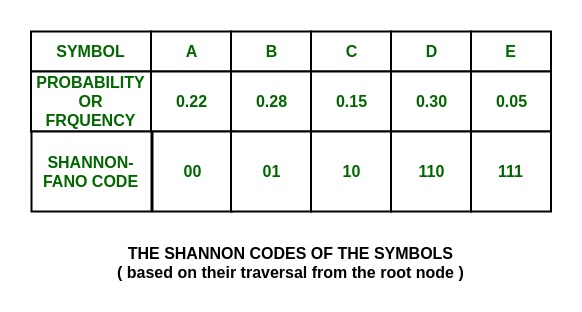
As it can be seen, these are all unique and of varying lengths.
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
struct node {
string sym;
float pro;
int arr[20];
int top;
} p[20];
typedef struct node node;
void shannon(int l, int h, node p[])
{
float pack1 = 0, pack2 = 0, diff1 = 0, diff2 = 0;
int i, d, k, j;
if ((l + 1) == h || l == h || l > h) {
if (l == h || l > h)
return;
p[h].arr[++(p[h].top)] = 0;
p[l].arr[++(p[l].top)] = 1;
return;
}
else {
for (i = l; i <= h - 1; i++)
pack1 = pack1 + p[i].pro;
pack2 = pack2 + p[h].pro;
diff1 = pack1 - pack2;
if (diff1 < 0)
diff1 = diff1 * -1;
j = 2;
while (j != h - l + 1) {
k = h - j;
pack1 = pack2 = 0;
for (i = l; i <= k; i++)
pack1 = pack1 + p[i].pro;
for (i = h; i > k; i--)
pack2 = pack2 + p[i].pro;
diff2 = pack1 - pack2;
if (diff2 < 0)
diff2 = diff2 * -1;
if (diff2 >= diff1)
break;
diff1 = diff2;
j++;
}
k++;
for (i = l; i <= k; i++)
p[i].arr[++(p[i].top)] = 1;
for (i = k + 1; i <= h; i++)
p[i].arr[++(p[i].top)] = 0;
shannon(l, k, p);
shannon(k + 1, h, p);
}
}
void sortByProbability(int n, node p[])
{
int i, j;
node temp;
for (j = 1; j <= n - 1; j++) {
for (i = 0; i < n - 1; i++) {
if ((p[i].pro) > (p[i + 1].pro)) {
temp.pro = p[i].pro;
temp.sym = p[i].sym;
p[i].pro = p[i + 1].pro;
p[i].sym = p[i + 1].sym;
p[i + 1].pro = temp.pro;
p[i + 1].sym = temp.sym;
}
}
}
}
void display(int n, node p[])
{
int i, j;
cout << "nnntSymboltProbabilitytCode";
for (i = n - 1; i >= 0; i--) {
cout << "nt" << p[i].sym << "tt" << p[i].pro << "t";
for (j = 0; j <= p[i].top; j++)
cout << p[i].arr[j];
}
}
int main()
{
int n, i, j;
float total = 0;
string ch;
node temp;
cout << "Enter number of symbolst: ";
n = 5;
cout << n << endl;
for (i = 0; i < n; i++) {
cout << "Enter symbol " << i + 1 << " : ";
ch = (char)(65 + i);
cout << ch << endl;
p[i].sym += ch;
}
float x[] = { 0.22, 0.28, 0.15, 0.30, 0.05 };
for (i = 0; i < n; i++) {
cout << "nEnter probability of " << p[i].sym << " : ";
cout << x[i] << endl;
p[i].pro = x[i];
total = total + p[i].pro;
if (total > 1) {
cout << "Invalid. Enter new values";
total = total - p[i].pro;
i--;
}
}
p[i].pro = 1 - total;
sortByProbability(n, p);
for (i = 0; i < n; i++)
p[i].top = -1;
shannon(0, n - 1, p);
display(n, p);
return 0;
}
Python3
class node :
def __init__(self) -> None:
self.sym=''
self.pro=0.0
self.arr=[0]*20
self.top=0
p=[node() for _ in range(20)]
def shannon(l, h, p):
pack1 = 0; pack2 = 0; diff1 = 0; diff2 = 0
if ((l + 1) == h or l == h or l > h) :
if (l == h or l > h):
return
p[h].top+=1
p[h].arr[(p[h].top)] = 0
p[l].top+=1
p[l].arr[(p[l].top)] = 1
return
else :
for i in range(l,h):
pack1 = pack1 + p[i].pro
pack2 = pack2 + p[h].pro
diff1 = pack1 - pack2
if (diff1 < 0):
diff1 = diff1 * -1
j = 2
while (j != h - l + 1) :
k = h - j
pack1 = pack2 = 0
for i in range(l, k+1):
pack1 = pack1 + p[i].pro
for i in range(h,k,-1):
pack2 = pack2 + p[i].pro
diff2 = pack1 - pack2
if (diff2 < 0):
diff2 = diff2 * -1
if (diff2 >= diff1):
break
diff1 = diff2
j+=1
k+=1
for i in range(l,k+1):
p[i].top+=1
p[i].arr[(p[i].top)] = 1
for i in range(k + 1,h+1):
p[i].top+=1
p[i].arr[(p[i].top)] = 0
shannon(l, k, p)
shannon(k + 1, h, p)
def sortByProbability(n, p):
temp=node()
for j in range(1,n) :
for i in range(n - 1) :
if ((p[i].pro) > (p[i + 1].pro)) :
temp.pro = p[i].pro
temp.sym = p[i].sym
p[i].pro = p[i + 1].pro
p[i].sym = p[i + 1].sym
p[i + 1].pro = temp.pro
p[i + 1].sym = temp.sym
def display(n, p):
print("nnntSymboltProbabilitytCode",end='')
for i in range(n - 1,-1,-1):
print("nt", p[i].sym, "tt", p[i].pro,"t",end='')
for j in range(p[i].top+1):
print(p[i].arr[j],end='')
if __name__ == '__main__':
total = 0
print("Enter number of symbolst: ",end='')
n = 5
print(n)
i=0
for i in range(n):
print("Enter symbol", i + 1," : ",end="")
ch = chr(65 + i)
print(ch)
p[i].sym += ch
x = [0.22, 0.28, 0.15, 0.30, 0.05]
for i in range(n):
print("nEnter probability of", p[i].sym, ": ",end="")
print(x[i])
p[i].pro = x[i]
total = total + p[i].pro
if (total > 1) :
print("Invalid. Enter new values")
total = total - p[i].pro
i-=1
i+=1
p[i].pro = 1 - total
sortByProbability(n, p)
for i in range(n):
p[i].top = -1
shannon(0, n - 1, p)
display(n, p)
Javascript
<script>
function shannon(l, h, p) {
let pack1 = 0, pack2 = 0, diff1 = 0, diff2 = 0;
let i, d, k, j;
if ((l + 1) == h || l == h || l > h) {
if (l == h || l > h) return;
p[h].arr[++(p[h].top)] = 0;
p[l].arr[++(p[l].top)] = 1;
return;
} else {
for (i = l; i <= h - 1; i++) pack1 = pack1 + p[i].pro;
pack2 = pack2 + p[h].pro;
diff1 = pack1 - pack2;
if (diff1 < 0) diff1 = diff1 * -1;
j = 2;
while (j != h - l + 1) {
k = h - j;
pack1 = pack2 = 0;
for (i = l; i <= k; i++) pack1 = pack1 + p[i].pro;
for (i = h; i > k; i--) pack2 = pack2 + p[i].pro;
diff2 = pack1 - pack2;
if (diff2 < 0) diff2 = diff2 * -1;
if (diff2 >= diff1) break;
diff1 = diff2;
j++;
}
k++;
for (i = l; i <= k; i++) p[i].arr[++(p[i].top)] = 1;
for (i = k + 1; i <= h; i++) p[i].arr[++(p[i].top)] = 0;
shannon(l, k, p);
shannon(k + 1, h, p);
}
}
function sortByProbability(n, p) {
let i, j;
let temp;
for (j = 1; j <= n - 1; j++) {
for (i = 0; i < n - 1; i++) {
if ((p[i].pro) > (p[i + 1].pro)) {
temp = p[i];
p[i] = p[i + 1];
p[i + 1] = temp;
}
}
}
}
function display(n, p) {
let i, j;
document.write("nnn Symbol Probability Code" + "<br>");
for (i = n - 1; i >= 0; i--) {
document.write(`${p[i].sym} ${p[i].pro} `);
for (j = 0; j <= p[i].top; j++) document.write(p[i].arr[j]);
document.write("<br>")
}
}
document.write("Enter number of symbols : ");
let n = 5;
document.write(n + "<br>")
let p = [];
let total = 0;
for (let i = 0; i < n; i++) {
document.write(" Enter symbol " + (i + 1) + " : ");
let ch = String.fromCharCode(65 + i);
document.write(ch + "<br>")
p.push({ sym: ch, pro: 0, arr: [], top: -1 });
}
let x = [0.22, 0.28, 0.15, 0.30, 0.05];
for (let i = 0; i < n; i++) {
document.write("Enter probability of " + p[i].sym + " : ");
document.write(x[i] + "<br>")
p[i].pro = x[i];
total = total + p[i].pro;
if (total > 1) {
document.write("Invalid. Enter new values");
total = total - p[i].pro;
i--;
}
}
p[n - 1].pro = 1 - total;
sortByProbability(n, p);
for (let i = 0; i < n; i++) p[i].top = -1;
shannon(0, n - 1, p);
display(n, p);
</script>
Output
Enter number of symbols : 5
Enter symbol 1 : A
Enter symbol 2 : B
Enter symbol 3 : C
Enter symbol 4 : D
Enter symbol 5 : E
Enter probability of A : 0.22
Enter probability of B : 0.28
Enter probability of C : 0.15
Enter probability of D : 0.3
Enter probability of E : 0.05
Symbol Probability Code
D 0.3 00
B 0.28 01
A 0.22 10
C 0.15 110
E 0.05 111
Last Updated :
24 Jan, 2023
Like Article
Save Article
Vote for difficulty
Current difficulty :
Medium

Indian Technical Authorship Contest starts on 1st July 2023. Stay tuned.
In this article we are going to talk about the classic data compression algorithm called «Shannon-Fano code.»
Table of contents:
- What is a Shannon-Fano code?
- How Shannon-Fano encoding works? (includes Algorithm and Example)
- Implementing the Solution (Python code)
- Implementing the Solution (C++ code)
- How the Code works?
- Purpose of Shannon Fano coding
- Advantages and Disadvantages of Shannon Fano coding
What is a Shannon-Fano code?
A Shannon-Fano code is simply a method of encoding information.
Q.)So, how do we encode it?
Ans.) By using probabilities.
So we can define Shannon Fano Algorithm as a data compression «method of obtaining codes using probability.«
The Shannon-Fano code was discovered almost simultaneously by Shannon and Fano around 1948. Also, the code created by the Shannon-Fano code is an instantaneous code . However, unlike the Huffman code , it is not necessarily a compact code.
How Shannon-Fano encoding works?
probability of occurrence
Occurrence probability is the probability that the symbol appears in the symbol string .
In this example,
aabbcddddd
Now let’s see how the encoding actually works:
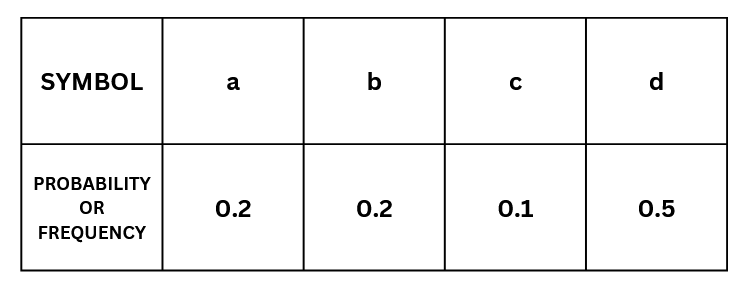
Step 1 Sort in descending order of probability of occurrence
First, sort the probabilities of each event in descending order .
In our example it would look like this:
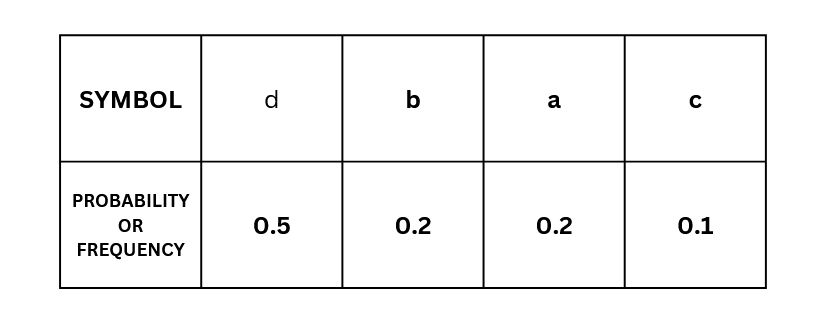
Here,
s1=d,
s2=b,
s3=a,
s4=c.
Step 2 Determine code length
The code length of each codeword using the formula we will continue to seek:
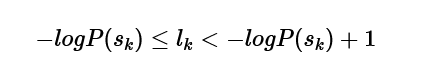
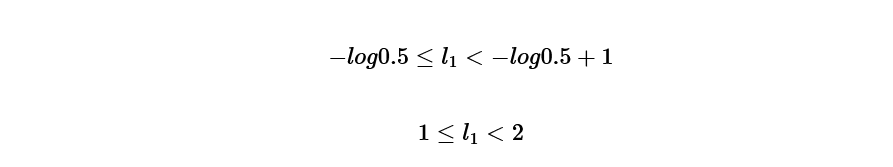
and from this formula called Kraft’s inequality,
l(1)=1
Doing the same calculation for s2=b, s3=a, s4=c.

l2=3, l3=3, l4=4.
With this we obtained, d is one digit, b is 3 digits, a is 3 digits, c is 4 digits.
Step 3 Find the probability that is the basis of the code
Now that the code length has been determined, the next step is to determine the specific code.
first, P(1)=0, it is calculated as follows:
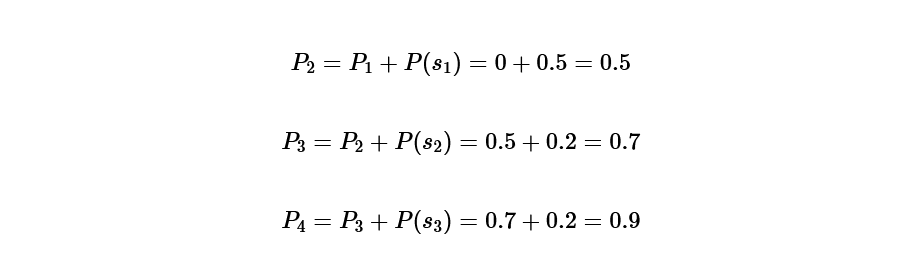
P(1)=0,
P(2)=0.5,
P(3)=0.7,
P(4)=0.9.
Step 4 Convert the probability obtained in step 3 into a binary number
Convert the calculated probabilities to binary.
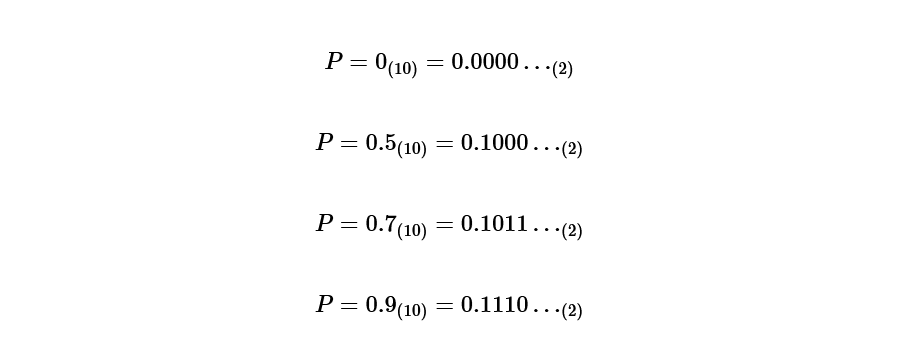
Step 5 Determine the code according to the code length
Pay attention only to the binary number after the decimal point obtained in step 4, and match it with the length of the code length.
d is one digit,
b is 3 digits,
a is 3 digits,
c is 4 digits, so
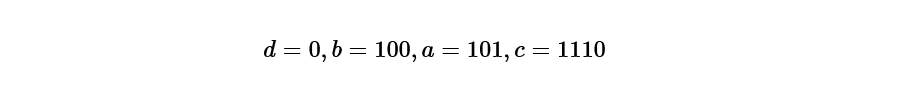
Conclusion
The higher the probability of occurrence, the shorter the code length.
If a code with a high probability of occurrence is associated with a code with a long code length, the data will be unnecessarily large.
Therefore, by associating a code with a shorter code length with a symbol with a higher probability of occurrence, communication can be performed efficiently.
Python Code — Shannon-Fano
class compress:
# Compress class for storing different parameters of string
def __init__(self, correspond):
self.original = correspond
self.count = 0
self.code = ""
self.probability = 0
class shannon_fennon_compression:
# Shannon Compression Class for compressing data using shannon fennon encoding
def __getProbability(self, compressor):
return compressor.probability
def compress_data(self, data):
'''
1- Process String and find probability of all the unique occurences of characters in String
2- Using processed list to store elements which are been processed ie... probability is been found
3- probability list consists of probability of each characters
'''
processed = []
compressor = []
total_length = len(data)
for i in range(len(data)):
if data[i] not in processed:
processed.append(data[i])
count = data.count(data[i])
# Finding probability of unique characters in data
var = count/total_length
comp = compress(data[i])
comp.count = count
comp.probability = var
compressor.append(comp)
# sorting probability in descending order
sorted_compressor = sorted(
compressor, key=self.__getProbability, reverse=True)
split = self.__splitter(
probability=[i.probability for i in sorted_compressor], pointer=0)
self.__encoder(sorted_compressor, split)
return sorted_compressor
# split probabilities in order used in shannon encoding
def __splitter(self, probability, pointer):
diff = sum(probability[:pointer+1]) -
sum(probability[pointer+1:len(probability)])
if diff < 0:
point = self.__splitter(probability, pointer+1)
diff_1 = sum(probability[:point]) -
sum(probability[point:len(probability)])
diff_2 = sum(probability[:point+1]) -
sum(probability[point+1:len(probability)])
if abs(diff_1) < abs(diff_2):
return point-1
return point
else:
return pointer
# Encode string to compressed version of string data in binary
def __encoder(self, compressor, split):
if split > 0:
part_1 = compressor[:split+1]
for i in part_1:
i.code += '0'
if len(part_1) <= 1:
return
self.__encoder(part_1, self.__splitter(
probability=[i.probability for i in part_1], pointer=0))
part_2 = compressor[split+1:len(compressor)]
for i in part_2:
i.code += '1'
if len(part_2) <= 1:
return
self.__encoder(part_2, self.__splitter(
probability=[i.probability for i in part_2], pointer=0))
elif split == 0:
part_1 = compressor[:split+1]
for i in part_1:
i.code += '0'
part_2 = compressor[split+1:len(compressor)]
for i in part_2:
i.code += '1'
# Main Function
if __name__ == '__main__':
print("Data--- malyalam madman")
compressor = shannon_fennon_compression()
compressed_data = compressor.compress_data("malyalam madman")
for i in compressed_data:
print(
f"Character-- {i.original}:: Code-- {i.code} :: Probability-- {i.probability}")
print("")
print("Data--- shannon")
compressed_data = compressor.compress_data("shannon")
for i in compressed_data:
print(
f"Character-- {i.original}:: Code-- {i.code} :: Probability-- {i.probability}")
print("")
print("Data--- fennon")
compressed_data = compressor.compress_data("fennon")
for i in compressed_data:
print(
f"Character-- {i.original}:: Code-- {i.code} :: Probability-- {i.probability}")
C++ Code — Shannon-Fano
#include<iostream>
#include<bits/stdc++.h>
#include<vector>
#include<stdlib.h>
#include<math.h>
#include<fstream>
#include<windows.h>
using namespace std;
int actual;
class OP{
public:
int freq;
char ch;
string codw;
void getd()
{
cout<<"Enter Character:";cin>>ch;
cout<<"Enter Frequency:";cin>>freq;
this->codw="";
}
void getd(char dh,int preq)
{
this->ch=dh;
this->freq=preq;
this->codw="";
}
void display()
{
cout<<"Character:"<<ch<<" Frequency:"<<freq<<endl;
}
void cop()
{
cout<<"Code of "<<ch<<"="<<codw<<endl;
}
};
OP pi[127];
class chunks{
public:
string b8;
char d8;
int i8;
};
chunks cnks[500];
void shan(int s,int e)
{
if(s<e)
{
int sum_1=0,sum_2=0;
int mind=10000;
int t=0;
int diff=0;
int pt;
int i,j,k,cmp;
for(cmp=0;cmp<(e-s);cmp++)
{
for(k=s;k<=s+cmp;k++)
{
sum_1=sum_1+pi[k].freq;
}
for(j=s+cmp+1;j<=e;j++)
{
sum_2=sum_2+pi[j].freq;
}
diff=abs(sum_2-sum_1);
if(diff<=mind)
{
mind=diff;
pt=cmp+s;
}
sum_1=0;
sum_2=0;
}
for(i=s;i<=pt;i++)
{
pi[i].codw=pi[i].codw+"1";
}
cout<<endl;
for(i=pt+1;i<=e;i++)
{
pi[i].codw=pi[i].codw+"0";
}
int tmpp=pt;
shan(tmpp+1,e);
shan(s,tmpp);
}
}
void rdfile()
{
ifstream inFile;
char ch;
cout<<"Reading file = ab.txt";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
inFile.open("ab.txt");
if (!inFile)
{
cout << "The input file could not be opened."<<endl;
exit(0);
}
for(int i=0;i<127;i++)
{
cout<<"Char("<<i<<")="<<char(i)<<endl;
pi[i].getd(char(i),0);
}
ch = inFile.get();
while (ch != EOF)
{
pi[int(ch)].freq++;
ch = inFile.get();
}
}
void wtfile(int h)
{
ifstream inFile;
ofstream outfile;
outfile.open("1_Codeword.txt");
char ch;
cout<<endl;
cout<<"Reading file = ab.txt"<<endl;
cout<<"Generating 1_Codeword.txt file";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
inFile.open("ab.txt");
if (!inFile)
{
cout << "The input file could not be opened."<<endl;
exit(0);
}
ch = inFile.get();
int i;
while (ch != EOF)
{
i=h;
while(pi[i].ch!=ch)
{
i++;
}
outfile<<pi[i].codw;
ch = inFile.get();
}
outfile.close();
cout<<"File Generated!"<<endl;
}
int binTOdec(string binaryString)
{
int value = 0;
int indexCounter = 0;
for(int i=binaryString.length()-1;i>=0;i--)
{
if(binaryString[i]=='1'){
value += pow(2, indexCounter);
}
indexCounter++;
}
return value;
}
void dcp()
{
ifstream inFile;
ofstream outfile;
outfile.open("2_compressed.txt");
char ch;
cout<<"Reading 1_Codeword.txt file"<<endl;
cout<<"Generating 2_compressed.txt file.";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
inFile.open("1_codeword.txt");
if (!inFile)
{
cout << "The input file could not be opened."<<endl;
exit(0);
}
ch = inFile.get();
int i=0,lmt=0;
cout<<"tCHARtINTtBINARYtCint"<<endl;
while (ch != EOF)
{
cnks[i].b8=cnks[i].b8+ch;
while(cnks[i].b8.length()!=8)
{
ch = inFile.get();
if(ch == EOF)
{
lmt++;
ch = '0';
}
cnks[i].b8=cnks[i].b8+ch;
}
// cnks[i].i8 = binTOdec(cnks[i].b8);
// cnks[i].d8 = char(cnks[i].i8);
cnks[i].d8 = char(binTOdec(cnks[i].b8));
cnks[i].i8 = int(cnks[i].d8);
cout<<"t"<<cnks[i].d8<<"t"<<cnks[i].i8<<"t"<<cnks[i].b8<<"t"<<int(cnks[i].d8)<<endl;
outfile<<cnks[i].d8;
ch = inFile.get();
i++;
}
actual = (i*8)-lmt;
outfile.close();
cout<<"nFile 2_compressed.txt Generated!"<<endl;
Sleep(100);
}
void fina()
{
ifstream inFile; // input file
ofstream outfile; //output file
outfile.open("3_BinaryOfCompressed.txt");
char ch;
cout<<"Reading file = 2_Compressed.txt"<<endl;
cout<<"Generating 3_BinaryOfCompressed.txt file.";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
inFile.open("2_compressed.txt");
if (!inFile)
{
cout << "The input file could not be opened."<<endl;
exit(0);
}
ch = inFile.get();
int i=0;
cout<<"Results In 3_BinaryOfCompressed"<<endl;
cout<<"CharactertBinary"<<endl;
while(ch != EOF)
{
while (ch != EOF)
{
cout <<"t"<< ch<<"t"<<int(ch)<<"t";
bitset<8> bin_x(ch);
outfile<<bin_x;
cout<<"binary ="<<bin_x<<endl;
ch = inFile.get();
cout<<"CHAR"<<ch<<"t"<<int(ch)<<"tt";
}
ch = inFile.get();
}
cout<<"nGenerated 3_BinaryOfCompressed.txt file!"<<endl;
Sleep(1000);
outfile.close();
}
void las(int h)
{
ifstream inFile;
ofstream outfile;
inFile.open("3_BinaryOfCompressed.txt");
outfile.open("4_Finalizedfile.txt");
cout<<"Reading file = 3_BinaryOfCompressed.txt"<<endl;
cout<<"Generating 4_Finalizedfile.txt file.";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
Sleep(500);
cout<<".";
if(!inFile)
{
cout << "The input file could not be opened."<<endl;
exit(0);
}
char ch;
ch = inFile.get();
string str="";
for(int i=0;i<actual;i++)
{
str=str+ch;
for(int k=h;k<127;k++)
{
if(pi[k].codw==str)
{
outfile<<pi[k].ch;
str="";
}
}
ch = inFile.get();
}
outfile.close();
cout<<"nGenerated 4_Finalizedfile.txt file!"<<endl;
}
void deta()
{
ifstream iff;
iff.open("ab.txt"); //enter Your input file path with name
iff >> std::noskipws;
char ch;
int siz=0;
while(iff>>ch)
{
siz++;
}
cout<<"ntFile Namet|tSize";
cout<<"nt ab.txt||t"<<siz<<"bytes";
iff.close();
iff >> std::noskipws;
iff.open("2_compressed.txt"); //enter Your input file path with name
siz=0;
while(iff>>ch)
{
siz++;
}
cout<<"nt2_compressed.txt||t"<<siz<<"bytes";
iff.close();
}
int main()
{
int i,j,k,n;
int sum_1=0,sum_2=0;
int mind=10000;
int t=0;
int diff=0;
int pt;
n=127;
rdfile();
for(i=0;i<n-1;i++)
{
for(j=0;j<n-i-1;j++)
{
if(pi[j].freq>pi[j+1].freq)
{
OP tmp;
tmp=pi[j];
pi[j]=pi[j+1];
pi[j+1]=tmp;
}
}
}
int h;
for(i=0;i<n;i++)
{
if(pi[i].freq!=0)
{
h=i;
break;
}
}
for(i=h;i<n;i++)
{
cout<<i;
pi[i].display();
}
shan(h,n-1);
ofstream codfile;//codeword file
codfile.open("codfile.txt");
for(i=h;i<n;i++)
{
codfile<<pi[i].ch<<" || Freq="<<pi[i].freq<<" || Codeword="<<pi[i].codw<<endl;
pi[i].cop();
}
codfile.close();
wtfile(h);
dcp();
cout<<"ACTUAL==================================================="<<actual<<endl;
fina();
las(h);
deta();
return 0;
}
The following codes helps us to fully implement implement Shannon Fano coding Algorithm.
How the Code works?
Idea implemented :
- Count the number of each symbol and make a frequency table.
- Sort the table in descending order of appearance frequency.
- Split the table vertically. At this time, the sum of appearance frequencies should be equalized as much as possible.
- Assign code 0 to the upper half symbol and code 1 to the lower half symbol.
- Apply steps 3 and 4 again to the two split parts and assign the next code. Repeat this operation until there is only one element in the table.
Purpose of Shannon Fano coding
Therefore, by associating a code with a shorter code length with a symbol with a higher probability of occurrence, communication can be performed efficiently .
Advantages and Disadvantages of Shannon Fano coding
Advantages :
-
Shannon-Fano codes are easy to implement using recursion.
-
Higher the probability of occurrence, the shorter the code length in Shannon Fano Coding.
-
For Shannon Fano coding we do not need to build the entire codeblock again and again. Instead, we simply obtain the code for the tag corresponding to a given sequence.
Disadvantages :
-
Shannon-Fano codes are not compact codes.
-
In Shannon-Fano coding, we cannot be sure about the codes generated. There may be two different codes for the same symbol depending on the way we build our tree.
-
Shannon Fanon coding is not a unique code. So in case of errors or loss during data transmission, we have to start from the beginning.
With this article at OpenGenus, you must have the complete idea of Shannon Fano coding.
При ответе на данный вопрос необходимо
привести пример построения префиксного
кода Шеннона-Фано для заданного начального
алфавита и известных частот использования
символов этого алфавита с помощью
таблицы и графа.
В 1948-1949 гг. Клод Шеннон
(Claude
Elwood
Shannon)
и Роберт Фано (Robert
Mario Fano) независимо
друг от друга предложили префиксный
код, названный в последствие в их честь.
Алгоритм Шеннона — Фано использует
избыточность сообщения, заключённую в
неоднородном распределении частот
символов его первичного алфавита, то
есть заменяет коды более частых
символов короткими
двоичными последовательностями, а коды
более редких
символов — более длинными
двоичными последовательностями.
Рассмотрим этот префиксный код на
примере. Пусть имеется первичный алфавит,
состоящий из шести символов: {A; B; C; D; E;
F}, также известны вероятности появления
этих символов в сообщении соответственно
{0,15; 0,2; 0,1; 0,3; 0,2; 0,05}. Расположим эти символы
в таблице в порядке убывания их
вероятностей.
|
Первичный алфавит |
Вероятности |
|
D |
0,3 |
|
B |
0,2 |
|
E |
0,2 |
|
A |
0,15 |
|
C |
0,1 |
|
F |
0,05 |
Кодирование осуществляется
следующим образом. Все знаки делятся
на две группы с
сохранением порядка следования
(по убыванию вероятностей появления),
так чтобы суммы вероятностей в каждой
группе были приблизительно равны. В
нашем примере в первую группу попадают
символы D и B, все остальные буквы попадают
во вторую группу. Поставим ноль в первый
знак кодов для всех символов из первой
группы, а первый знак кодов символов
второй группы установим равным единице.
Продолжим деление каждой группы. В
первой группе два элемента, и деление
на подгруппы здесь однозначно: в первой
подгруппе будет символ D, а во второй —
символ B. Во второй группе теоретически
возможны три способа деления на подгруппы:
{E} и {A, C, F}, {E, A} и {C, F}, {E, A, C} и {F}. Но в первом
случае абсолютная разность суммарных
вероятностей будет |0,2 — (0,15 + 0,1 + 0,05)| =
0,1. Во втором и третьем варианте деления
аналогичные величины будут 0,2 и 0,4
соответственно. Согласно алгоритму
необходимо выбрать тот способ деления,
при котором суммы вероятностей в каждой
подгруппе были примерно одинаковыми,
а, следовательно, вычисленная разность
минимальна. Соответственно наилучшим
способом деления будет следующий
вариант: {E} в первой подгруппе и {A, C, F}
во второй. Далее по имеющемуся алгоритму
распределим нули и единицы в соответствующие
знаки кода каждой подгруппы.
Осуществляем деление на подгруппы по
той же схеме до тех пор, пока не получим
группы, состоящие из одного элемента.
Процедура деления изображена в таблице
(символ Х означает, что данный знак кода
отсутствует):
|
Первичный алфавит |
Вероятности |
Знаки кода символа |
Код символа |
Длина кода |
|||
|
I |
II |
III |
IV |
||||
|
D |
0,3 |
0 |
0 |
Х |
Х |
00 |
2 |
|
B |
0,2 |
0 |
1 |
Х |
Х |
01 |
2 |
|
E |
0,2 |
1 |
0 |
Х |
Х |
10 |
2 |
|
A |
0,15 |
1 |
1 |
0 |
Х |
110 |
3 |
|
C |
0,1 |
1 |
1 |
1 |
0 |
1110 |
4 |
|
F |
0,05 |
1 |
1 |
1 |
1 |
1111 |
4 |
Данный код может быть построен и с
помощью графа. Распределим символы
алфавита в порядке убывания вероятностей
— это будут концевые вершины (листья)
будущего двоичного дерева (нижние
индексы соответствуют вероятностям
появления символов):
|
D 0,3 |
B 0,2 |
E 0,2 |
A 0,15 |
C 0,1 |
F 0,05 |
Согласно алгоритму построения кода
Шеннона-Фано разобьем эти символы на
две группы с приблизительно равными
суммарными вероятностями появления и
соединим первые символы каждой группы
с корнем дерева:
|
D 0,3 |
B 0,2 |
E 0,2 |
A 0,15 |
C 0,1 |
F 0,05 |
|


Продолжаем построение графа по
приведенному алгоритму, соединяя первые
символы получающихся подгрупп с узлами
ветвления более высоких уровней. Таким
образом, на следующих этапах построения
получим:
|
D 0,3 |
B 0,2 |
E 0,2 |
A 0,15 |
C 0,1 |
F 0,05 |
|




Далее:
|
D 0,3 |
B 0,2 |
E 0,2 |
A 0,15 |
C 0,1 |
F 0,05 |
|





Окончательно имеем следующий граф:
|
D 0,3 |
B 0,2 |
E 0,2 |
A 0,15 |
C 0,1 |
F 0,05 |




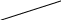

Теперь для каждого узла ветвления
обозначим каждую левую исходящую дугу
цифрой 0, а каждую правую исходящую дугу
цифрой 1:
|
1
1 0 0 D 0,3 |
B 0,2 |
E 0,2 |
A 0,15 |
C 0 0,1 |
F 0,05 |
|
0 |
1 |
||||
|
1 |
|||||
|
1 |
|||||
|
0 |
Для получения кода символа достаточно
пройти по дугам полученного дерева от
корня к соответствующей вершине и
записать номера дуг, по которым
осуществляется движение. Например, для
символа A, двигаясь от корня дерева,
проходим дуги с номерами 1, 1 и 0,
следовательно код символа A — 110.
Аналогично могут быть получены коды
других символов.
Полученный код удовлетворяет условию
Фано, следовательно он является
префиксным. Средняя длина этого кода
равна (см. формулу на стр.13):
К(Шеннона-Фано, А, Binary) = 0,3*2+0,2*2+0.2*2+0,15*3
+0,1*4+0.05*4 = 2,45 символа.
Среднее количество информации на один
символ первичного алфавита равно:
IA=
— (0,3* log20,3
+ 0,2* log20,2
+ 0,2* log20,2
+ 0,15* log20,15
+ + 0,1* log20,1
+ 0,05* log20,05)
= 2,41 бит.
Теперь по известной нам формуле найдем
избыточность кода Шеннона –Фано:
Q(Шеннона—Фано,
A, Binary) = 2,45/2,41 – 1 = 0,01659751.
То есть избыточность кода Шеннона-Фано
для нашего шестибуквенного алфавита
составляет всего около 1,7 %. Для русского
алфавита этот избыточность кодирования
кодом Шеннона-Фано составила бы примерно
1,47%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Привет, Вы узнаете про задачи кодирования сообщений код шеннона-фэно алгоритм шеннона — фано, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
задачи кодирования сообщений код шеннона-фэно алгоритм шеннона — фано , настоятельно рекомендую прочитать все из категории Теория информации и кодирования.
При передаче сообщений по линиям связи всегда приходится пользоваться тем или иным кодом, т. е. представлением сообщения в виде ряда сигналов. Общеизвестным примером кода может служить принятая в телеграфии для передачи словесных сообщений азбука Морзе. С помощью этой азбуки любое сообщение представляется в виде комбинации элементарных сигналов: точка, тире, пауза (пробел между буквами), длинная пауза (пробел между словами).
Алгоритм Шеннона — Фано
Алгоритм Шеннона — Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские ученые Шеннон и Роберт Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже и является логическим продолжением алгоритма Шеннона. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся — кодом большей длины. Коды Шеннона — Фано префиксные, то есть никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Кодирование Шеннона — Фано (англ. Shannon–Fano coding) — алгоритм префиксного неоднородного кодирования. Относится к вероятностным методам сжатия (точнее, методам контекстного моделирования нулевого порядка). Подобно алгоритму Хаффмана, алгоритм Шеннона — Фано использует избыточность сообщения, заключенную в неоднородном распределении частот символов его (первичного) алфавита, то есть заменяет коды более частых символов короткими двоичными последовательностями, а коды более редких символов — более длинными двоичными последовательностями.
Алгоритм был независимо друг от друга разработан Шенноном (публикация «Математическая теория связи», 1948 год) и, позже, Фано (опубликовано как технический отчет). подобнее будет рассмотрено ниже в этой статье.
Задачи кодирования сообщений
Вообще кодированием называется отображение состояния одной физической системы с помощью состояния некоторой другой. Например, при телефонном разговоре звуковые сигналы кодируются в виде электромагнитных колебаний, а затем снова декодируются, превращаясь в звуковые сигналы на другом конце линии. Наиболее простым случаем кодирования является случай, когда обе системы  и
и 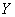 (отображаемая и отображающая) имеют конечное число возможных состояний. Так обстоит дело при передаче записанных буквами сообщений, например, при телеграфировании. Мы ограничимся рассмотрением этого простейшего случая кодирования.
(отображаемая и отображающая) имеют конечное число возможных состояний. Так обстоит дело при передаче записанных буквами сообщений, например, при телеграфировании. Мы ограничимся рассмотрением этого простейшего случая кодирования.
Пусть имеется некоторая система (например, буква русского алфавита), которая может случайным образом принять одно из состояний  . Мы хотим отобразить ее (закодировать) с помощью другой системы , возможные состояния которой
. Мы хотим отобразить ее (закодировать) с помощью другой системы , возможные состояния которой 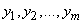 . Если
. Если 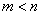 (число состояний системы меньше числа состояний системы ), то нельзя каждое состояние системы закодировать с помощью одного-единственного состояния системы . В таких случаях одно состояние системы приходится отображать с помощью определенной комбинации (последовательности) состояний системы . Так, в азбуке Морзе буквы отображаются различными комбинациями элементарных символов (точка, тире). Выбор таких комбинаций и установление соответствия между передаваемым сообщением и этими комбинациями и называется «кодированием» в узком смысле слова.
(число состояний системы меньше числа состояний системы ), то нельзя каждое состояние системы закодировать с помощью одного-единственного состояния системы . В таких случаях одно состояние системы приходится отображать с помощью определенной комбинации (последовательности) состояний системы . Так, в азбуке Морзе буквы отображаются различными комбинациями элементарных символов (точка, тире). Выбор таких комбинаций и установление соответствия между передаваемым сообщением и этими комбинациями и называется «кодированием» в узком смысле слова.
Коды различаются по числу элементарных символов (сигналов), из которых формируются комбинации, иными словами — по числу возможных состояний системы . В азбуке Морзе таких элементарных символов четыре (точка, тире, короткая пауза, длинная пауза). Передача сигналов может осуществляться в различной форме: световые вспышки, посылки электрического тока различной длительности, звуковые сигналы и т. п. Код с двумя элементарными символами (0 и 1) называется двоичным. Двоичные коды широко применяются на практике, особенно при вводе информации в электронные цифровые вычислительные машины, работающие по двоичной системе счисления.
Одно и то же сообщение можно закодировать различными способами. Возникает вопрос об оптимальных (наивыгоднейших) способах кодирования. Естественно считать наивыгоднейшим такой код, при котором на передачу сообщений затрачивается минимальное время. Если на передачу каждого элементарного символа (например 0 или 1) тратится одно и то же время, то оптимальным будет такой код, при котором на передачу сообщения заданной длины будет затрачено минимальное количество элементарных символов.
Предположим, что перед нами поставлена задача: закодировать двоичным кодом буквы русской азбуки так, чтобы каждой букве соответствовала определенная комбинация элементарных символов 0 и 1 и чтобы среднее число этих символов на букву текста было минимальным.
Рассмотрим 32 буквы русской азбуки: а, б, в, г, д, е, ж, з, и, й, к, л, м, н, о, п, р, с, т, у, ф, х, ц, ч, ш, щ, ъ, ы, ь, э, ю, я плюс промежуток между словами, который мы будем обозначать «–». Если, как принято в телеграфии, не различать букв ъ и ь (это не приводит к разночтениям), то получится 32 буквы: а, б, в, г, д, е, ж. з, и, й, к, л, м, н, о, п, р, с, т, у. ф, х, ц, ч, ш, щ, (ъ, ь). ы. э, ю, я, «–».
Первое, что приходит в голову — это, не меняя порядка букв, занумеровать их подряд, приписав им номера от 0 до 31, и затем перевести нумерацию в двоичную систему счисления. Двоичная система — это такая, в которой единицы разных разрядов представляют собой разные степени двух. Например, десятичное число 12 изобразится в виде

и в двоичной системе запишется как 1100.
Десятичное число 25 —
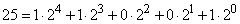
— запишется в двоичной системе как 11001.
Каждое из чисел 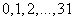 может быть изображено пятизначным двоичным числом. Тогда получим следующий код:
может быть изображено пятизначным двоичным числом. Тогда получим следующий код:
а – 00000
б – 00001
в – 00010
г – 00011
………
я – 11110
«-» – 11111
В этом коде на изображение каждой буквы тратится ровно 5 элементарных символов. Возникает вопрос, является ли этот простейший код оптимальным и нельзя ли составить другой код, в котором на одну букву будет в среднем приходиться меньше элементарных символов?
Действительно, в нашем коде на изображение каждой буквы — часто встречающихся «а», «е», «о» или редко встречающихся «щ», «э», «ф» — тратится одно и то же число элементарных символов. Очевидно, разумнее было бы, чтобы часто встречающиеся буквы были закодированы меньшим числом символов, а реже встречающиеся — большим.
Чтобы составить такой код, очевидно, нужно знать частоты букв в русском тексте. Эти частоты приведены в таблице 18.8.1. Буквы в таблице расположены в порядке убывания частот.
Таблица 18.8.1.
|
Буква |
Частота |
Буква |
Частота |
Буква |
Частота |
Буква |
Частота |
|
«-» |
0,145 |
р |
0,041 |
я |
0,019 |
х |
0,009 |
|
о |
0,095 |
в |
0,039 |
ы |
0,016 |
ж |
0,008 |
|
е |
0,074 |
л |
0,036 |
з |
0,015 |
ю |
0,007 |
|
а |
0,064 |
к |
0,029 |
ъ,ь |
0,015 |
ш |
0,006 |
|
и |
0,064 |
м |
0,026 |
б |
0,015 |
ц |
0,004 |
|
т |
0,056 |
д |
0,026 |
г |
0,014 |
щ |
0,003 |
|
н |
0,056 |
п |
0,024 |
ч |
0,013 |
э |
0,003 |
|
с |
0,047 |
у |
0,021 |
й |
0,010 |
ф |
0,002 |
Пользуясь такой таблицей, можно составить наиболее экономичный код на основе соображений, связанных с количеством информации . Об этом говорит сайт https://intellect.icu . Очевидно, код будет самым экономичным, когда каждый элементарный символ будет передавать максимальную информацию. Рассмотрим элементарный символ (т. е. изображающий его сигнал) как физическую систему с двумя возможными состояниями: 0 и 1.
Информация, которую дает этот символ, равна энтропии системы и максимальна в случае, когда оба состояния равновероятны; в этом случае элементарный символ передает информацию 1 (дв. ед.). Поэтому основой оптимального кодирования будет требование, чтобы элементарные символы в закодированном тексте встречались в среднем одинаково часто.
Изложим здесь способ построения кода, удовлетворяющего поставленному условию; этот способ известен под названием «кода Шеннона — Фэно». Идея его состоит в том, что кодируемые символы (буквы или комбинации букв) разделяются на две приблизительно равновероятные группы: для первой группы символов на первом месте комбинации ставится 0 (первый знак двоичного числа, изображающего символ); для второй группы — 1. Далее каждая группа снова делится на две приблизительно равновероятные подгруппы; для символов первой подгруппы на втором месте ставится нуль; для второй подгруппы — единица и т. д.
Продемонстрируем принцип построения кода Шеннона — Фэно на материале русского алфавита (табл. 18.8.1). Отсчитаем первые шесть букв (от «-» до «т»); суммируя их вероятности (частоты), получим 0,498; на все остальные буквы (от «н» до «сф») придется приблизительно такая же вероятность 0,502. Первые шесть букв (от «-» до «т») будут иметь на первом месте двоичный знак 0. Остальные буквы (от «н» до «ф») будут иметь на первом месте единицу. Далее снова разделим первую группу на две приблизительно равновероятные подгруппы: от «-» до «о» и от «е» до «т»; для всех букв первой подгруппы на втором месте поставим нуль, а второй подгруппы»- единицу. Процесс будем продолжать до тех пор, пока в каждом подразделении не останется ровно одна буква, которая и будет закодирована определенным двоичным числом. Механизм построения кода показан на таблице 18.8.2, а сам код приведен в таблице 18.8.3.
Таблица 18.8.2.
|
Двоичные знаки |
|||||||||
|
Буквы |
1-й |
2-й |
3-й |
4-й |
5-й |
6-й |
7-й |
8-й |
9-й |
|
— |
0 |
0 |
0 |
||||||
|
о |
1 |
||||||||
|
е |
1 |
0 |
0 |
||||||
|
а |
1 |
||||||||
|
и |
1 |
0 |
|||||||
|
т |
1 |
||||||||
|
н |
1 |
0 |
0 |
0 |
|||||
|
с |
1 |
||||||||
|
р |
1 |
0 |
0 |
||||||
|
в |
1 |
||||||||
|
л |
1 |
0 |
|||||||
|
к |
1 |
||||||||
|
м |
1 |
0 |
0 |
0 |
|||||
|
д |
1 |
0 |
|||||||
|
п |
1 |
||||||||
|
у |
1 |
0 |
|||||||
|
я |
1 |
0 |
|||||||
|
ы |
1 |
||||||||
|
з |
1 |
0 |
0 |
0 |
|||||
|
ъ,ь |
1 |
||||||||
|
б |
1 |
0 |
|||||||
|
г |
1 |
||||||||
|
ч |
1 |
0 |
0 |
||||||
|
й |
1 |
0 |
|||||||
|
х |
1 |
||||||||
|
ж |
0 |
0 |
|||||||
|
ю |
1 |
||||||||
|
ш |
1 |
0 |
0 |
||||||
|
ц |
1 |
||||||||
|
щ |
1 |
0 |
|||||||
|
э |
1 |
0 |
|||||||
|
ф |
1 |
Таблица 18.8.3
|
Буква |
Двоичное число |
Буква |
Двоичное число |
Буква |
Двоичное число |
Буква |
Двоичное число |
|
«-» |
000 |
р |
10100 |
я |
110110 |
х |
1111011 |
|
о |
001 |
в |
10101 |
ы |
110111 |
ж |
1111100 |
|
е |
0100 |
л |
10110 |
з |
111000 |
ю |
1111101 |
|
а |
0101 |
к |
10111 |
ъ,ь |
111001 |
ш |
11111100 |
|
и |
0110 |
м |
11000 |
б |
111010 |
ц |
11111101 |
|
т |
0111 |
д |
110010 |
г |
111011 |
щ |
11111110 |
|
н |
1000 |
п |
110011 |
ч |
111100 |
э |
111111110 |
|
с |
1001 |
у |
110100 |
й |
1111010 |
ф |
111111111 |
С помощью таблицы 18.8.3 можно закодировать и декодировать любое сообщение.
В виде примера запишем двоичным кодом фразу: «теория информации»
01110100001101000110110110000
0110100011111111100110100
1100001011111110101100110
Заметим, что здесь нет необходимости отделять друг от друга буквы специальным знаком, так как и без этого декодирование выполняется однозначно. В этом можно убедиться, декодируя с помощью таблицы 18.8.2 следующую фразу:
10011100110011001001111010000
1011100111001001101010000110101
010110000110110110
(«способ кодирования»).
Однако необходимо отметить, что любая ошибка при кодировании (случайное перепутывание знаков 0 и 1) при таком коде губительна, так как декодирование всего следующего за ошибкой текста становится невозможным. Поэтому данный принцип кодирования может быть рекомендован только в случае, когда ошибки при кодировании и передаче сообщения практически исключены.
Возникает естественный вопрос: а является ли составленный нами код при отсутствии ошибок действительно оптимальным? Для того чтобы ответить на этот вопрос, найдем среднюю информацию, приходящуюся на один элементарный символ (0 или 1), и сравним ее с максимально возможной информацией, которая равна одной двоичной единице. Для этого найдем сначала среднюю информацию, содержащуюся в одной букве передаваемого текста, т. е. энтропию на одну букву:
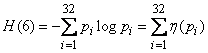 ,
,
где 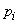 — вероятность того, что буква примет определенное состояние («-», о, е, а,…, ф).
— вероятность того, что буква примет определенное состояние («-», о, е, а,…, ф).
Из табл. 18.8.1 имеем

(дв. единиц на букву текста).
По таблице 18.8.2 определяем среднее число элементарных символов на букву
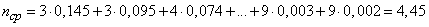 .
.
Деля энтропию 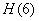 на
на 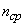 , получаем информацию на один элементарный символ
, получаем информацию на один элементарный символ
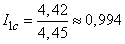 (дв. ед.).
(дв. ед.).
Таким образом, информация на один символ весьма близка к своему верхнему пределу 1, а выбранный нами код весьма близок к оптимальному. Оставаясь в пределах задачи кодирования по буквам, мы ничего лучшего получить не сможем.
Заметим, что в случае кодирования просто двоичных номеров букв мы имели бы изображение каждой буквы пятью двоичными знаками и информация на один символ была бы
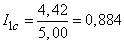 (дв. ед.),
(дв. ед.),
т. е. заметно меньше, чем при оптимальном буквенном кодировании.
Однако надо заметить, что кодирование «по буквам» вообще не является экономичным. Дело в том, что между соседними буквами любого осмысленного текста всегда имеется зависимость. Например, после гласной буквы в русском языке не может стоять «ъ» или «ь»; после шипящих не могут стоять «я» или «ю»; после нескольких согласных подряд увеличивается вероятность гласной и т. д.
Мы знаем, что при объединении зависимых систем суммарная энтропия меньше суммы энтропий отдельных систем; следовательно, информация, передаваемая отрезком связного текста, всегда меньше, чем информация на один символ, умноженная на число символов. С учетом этого обстоятельства более экономный код можно построить, если кодировать не каждую букву в отдельности, а целые «блоки» из букв. Например, в русском тексте имеет смысл кодировать целиком некоторые часто встречающиеся комбинации букв, как «тся», «ает», «ние» и т. п. Кодируемые блоки располагаются в порядке убывания частот, как буквы в табл. 18.8.1, а двоичное кодирование осуществляется по тому же принципу.
В ряде случаев оказывается разумным кодировать даже не блоки из букв, а целые осмысленные куски текста. Например, для разгрузки телеграфа в предпраздничные дни целесообразно кодировать условными номерами целые стандартные тексты, вроде:
«поздравляю новым годом желаю здоровья успехов работе».
Не останавливаясь специально на методах кодирования блоками, ограничимся тем, что сформулируем относящуюся сюда теорему Шеннона.
Пусть имеется источник информации и приемник , связанные каналом связи 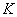 (рис. 18.8.1).
(рис. 18.8.1).

Рис. 18.8.1.
Известна производительность источника информации 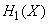 , т. е. среднее количество двоичных единиц информации, поступающее от источника в единицу времени (численно оно равно средней энтропии сообщения, производимого источникам в единицу времени). Пусть, кроме того, известна пропускная способность канала
, т. е. среднее количество двоичных единиц информации, поступающее от источника в единицу времени (численно оно равно средней энтропии сообщения, производимого источникам в единицу времени). Пусть, кроме того, известна пропускная способность канала 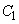 , т. е. максимальное количество информации (например, двоичных знаков 0 или 1), которое способен передать канал в ту же единицу времени. Возникает вопрос: какова должна быть пропускная способность канала, чтобы он «справлялся» со своей задачей, т. е. чтобы информация от источника к приемнику поступала без задержки?
, т. е. максимальное количество информации (например, двоичных знаков 0 или 1), которое способен передать канал в ту же единицу времени. Возникает вопрос: какова должна быть пропускная способность канала, чтобы он «справлялся» со своей задачей, т. е. чтобы информация от источника к приемнику поступала без задержки?
Ответ на этот вопрос дает первая теорема Шеннона. Сформулируем ее здесь без доказательства.
1-я теорема Шеннона
Если пропускная способность канала связи больше энтропии источника информации в единицу времени
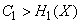 ,
,
то всегда можно закодировать достаточно длинное сообщение так, чтобы оно передавалось каналом связи без задержки. Если же, напротив,
 ,
,
то передача информации без задержек невозможна
Основные этапы Алгоритма Шеннона — Фано
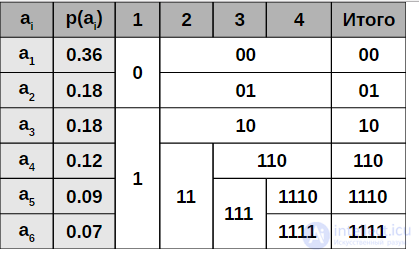
Пример построения кодовой схемы для шести символов a1 — a6 и вероятностей pi
- Символы первичного алфавита m1 выписывают по убыванию вероятностей.
- Символы полученного алфавита делят на две части, суммарные вероятности символов которых максимально близки друг другу.
- В префиксном коде для первой части алфавита присваивается двоичная цифра «0», второй части — «1».
- Полученные части рекурсивно делятся и их частям назначаются соответствующие двоичные цифры в префиксном коде.
Когда размер подалфавита становится равен нулю или единице, то дальнейшего удлинения префиксного кода для соответствующих ему символов первичного алфавита не происходит, таким образом, алгоритм присваивает различным символам префиксные коды разной длины. На шаге деления алфавита существует неоднозначность, так как разность суммарных вероятностей p0-p1 может быть одинакова для двух вариантов разделения (учитывая, что все символы первичного алфавита имеют вероятность больше нуля).
Алгоритм вычисления кодов Шеннона — Фано
Код Шеннона — Фано строится с помощью дерева. Построение этого дерева начинается от корня. Все множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона — Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути еще не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона — Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона — Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона — Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
- A (частота встречаемости 50)
- B (частота встречаемости 39)
- C (частота встречаемости 18)
- D (частота встречаемости 49)
- E (частота встречаемости 35)
- F (частота встречаемости 24)
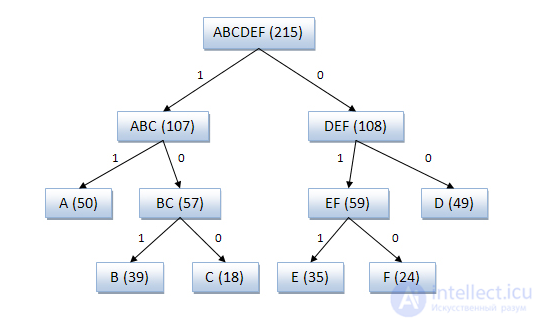
Кодовое дерево
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона — Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона — Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Вау!! 😲 Ты еще не читал? Это зря!
- Арифметическое кодирование
- кодирование Хаффмана
- Методы сжатия информации
- Энтропийное сжатие информации
- Словарные методы сжатия информации
- Сжатие информации с потерями
Надеюсь, эта статья про задачи кодирования сообщений код шеннона-фэно алгоритм шеннона — фано, была вам полезна,счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое задачи кодирования сообщений код шеннона-фэно алгоритм шеннона — фано
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Теория информации и кодирования